概述
大模型推理服务的核心问题不是“单个请求能不能跑”,而是“很多请求同时进来时,GPU能不能一直忙,并且用户等待时间不要太长”。这里会遇到两个层面的调度问题。
- 请求层面:不同用户请求长度不同,有的很快结束,有的还在继续生成,如何让GPU batch不要出现大量空槽。
- MoE专家层面:一个batch里的token会被Router分配到不同专家,如何把分散的小计算合并成更高效的专家计算。
Continuous Batching解决的是第一个问题,它把batch从“固定一批请求跑到底”改成“每个decode step都可以动态加入和移除请求”。Expert Grouping解决的是第二个问题,它把MoE路由后的token按专家重新分组,让每个专家一次处理一组token,而不是零散地一个个算。
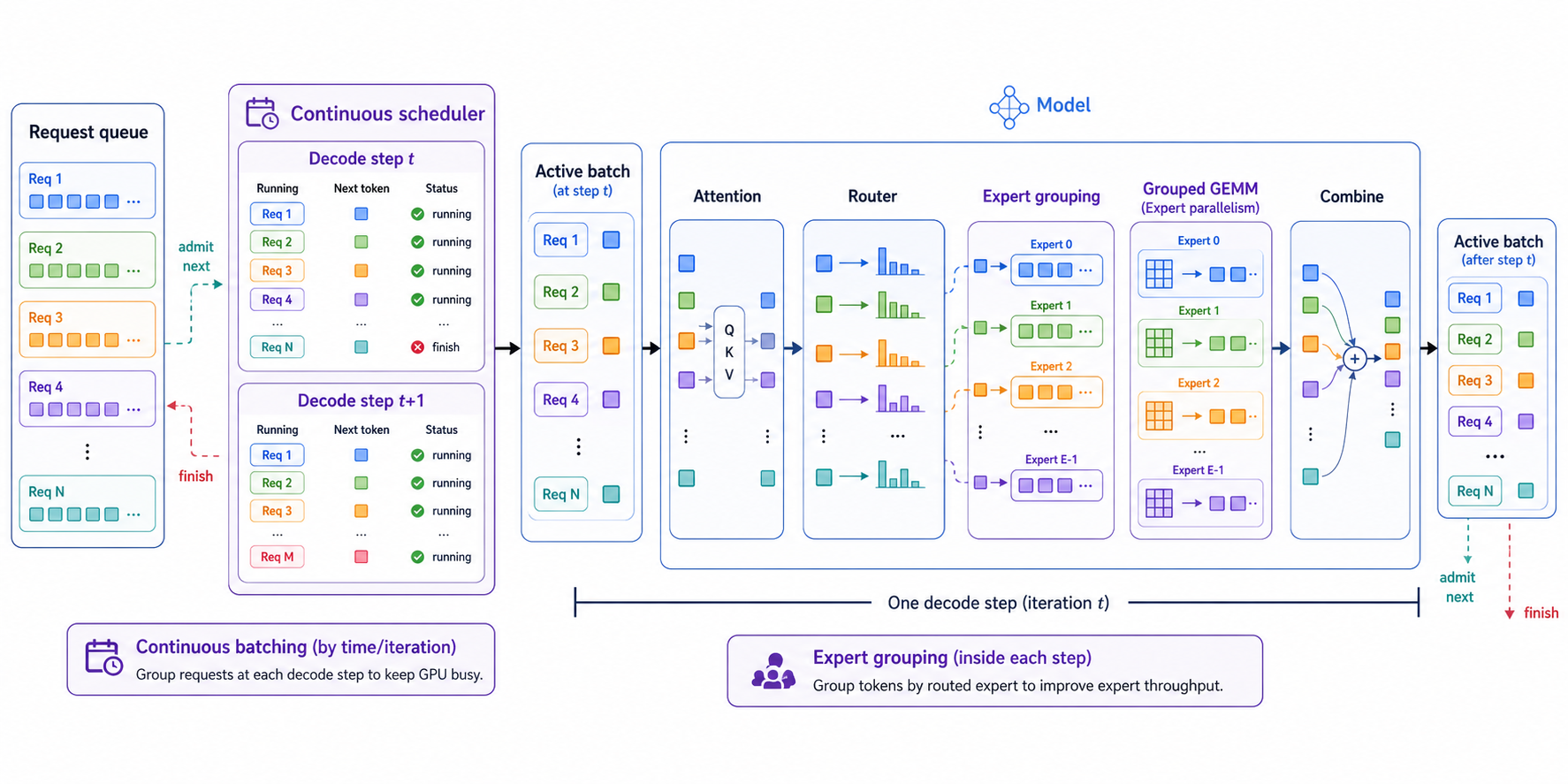
上图可以先建立一个整体位置关系:Continuous Batching发生在推理服务调度层,决定这一轮decode step有哪些请求进入active batch;Expert Grouping发生在MoE层内部,决定这一轮active tokens被Router分配后如何按专家重排、计算和合并。
如果用一句话总结:Continuous Batching是按时间/请求维度组batch,Expert Grouping是按专家/计算维度组token。
Continuous Batching
静态批处理的问题
传统静态批处理(Static Batching)的做法比较简单:攒够一批请求,然后一起跑。问题是大模型生成长度不固定,请求之间差异很大。
假设一个batch里有4个请求:
- R1要生成100个token。
- R2只生成30个token。
- R3只生成20个token。
- R4要生成120个token。
如果按静态批处理,R2、R3很早就结束了,但batch仍然要等R1、R4继续跑。此时R2、R3对应的batch slot就空着,GPU实际利用率下降。更糟糕的是,新请求来了也不能立刻插进这个batch,只能等整批结束。
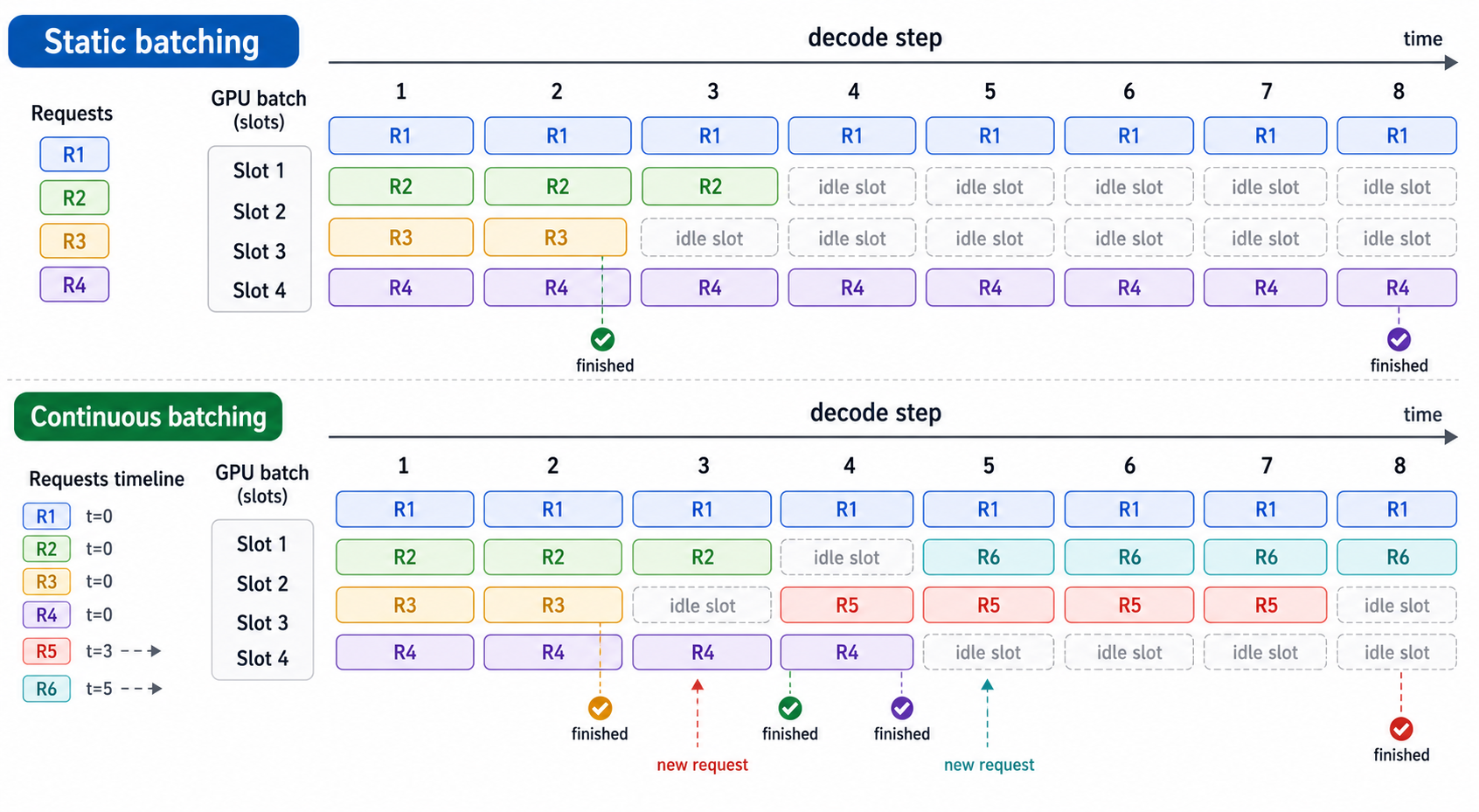
上图上半部分是静态批处理:短请求结束后,空槽会一直闲置。下半部分是连续批处理:某个请求完成后,下一个decode step就可以把新请求放进空槽,让batch长期保持较高利用率。
迭代级调度
Continuous Batching也常被称为迭代级调度(iteration-level scheduling)。这里的“迭代”通常指一次decode step:每个活跃序列生成一个新token。
普通静态batch的边界是“请求批次”,而Continuous Batching的边界是“decode迭代”。每一轮decode结束后,调度器都会做几件事:
- 把已经生成EOS或达到长度上限的请求移出active batch。
- 回收这些请求占用的KV Cache。
- 从等待队列中选择新请求进入。
- 对新请求先做prefill,然后进入后续decode。
- 组成下一轮active batch继续推理。
所以Continuous Batching不是在一个Transformer层中途随便插请求,而是在每次decode step之间调整batch成员。它的核心价值是减少空槽,让GPU持续有活干。
Prefill与Decode的差异
大模型请求通常分为两个阶段:
- Prefill:处理用户输入prompt,一次性计算整段prompt的KV Cache。
- Decode:在已有KV Cache基础上,每轮生成一个新token。
这两个阶段的计算形态不同。Prefill一次处理很多prompt token,矩阵计算更大,通常更容易吃满GPU;Decode每个请求每轮只生成一个token,更容易受batch大小、KV Cache读取、调度开销影响。

上图中,等待队列里的请求prompt长度不同。调度器需要决定哪些请求先做prefill,哪些请求进入decode。Continuous Batching主要让decode阶段的active batch动态变化,但prefill请求插入太多也会影响正在decode的请求延迟,因此服务系统通常还会做prefill/decode分离、chunked prefill或优先级控制。
Expert Grouping
MoE推理中的碎片化计算
在Dense模型中,每个token都会走同一个FFN,所以一个batch里的token天然可以组成一个大的矩阵乘法。但MoE模型不一样,每个token会先经过Router,再被分配到Top-1或Top-2专家。
假设一个decode step里有8个token,Router结果如下:
| token | Top-2专家 |
|---|---|
| t1 | E1, E3 |
| t2 | E2, E4 |
| t3 | E1, E2 |
| t4 | E3, E4 |
| t5 | E2, E1 |
| t6 | E4, E2 |
如果不做分组,token会以很零散的方式调用专家,计算颗粒度太小,GPU矩阵乘法效率很差。Expert Grouping的做法是:把所有路由到同一个专家的token收集起来,形成专家队列,然后每个专家一次做一个批量计算。
按专家重排token
Expert Grouping可以拆成4步:
- Router计算每个token要去哪些专家。
- Dispatcher按照专家编号重排token,把同一专家的token放到一起。
- 每个专家对自己的token队列做batched GEMM或grouped GEMM。
- Scatter回原始token顺序,并按Router权重做加权合并。
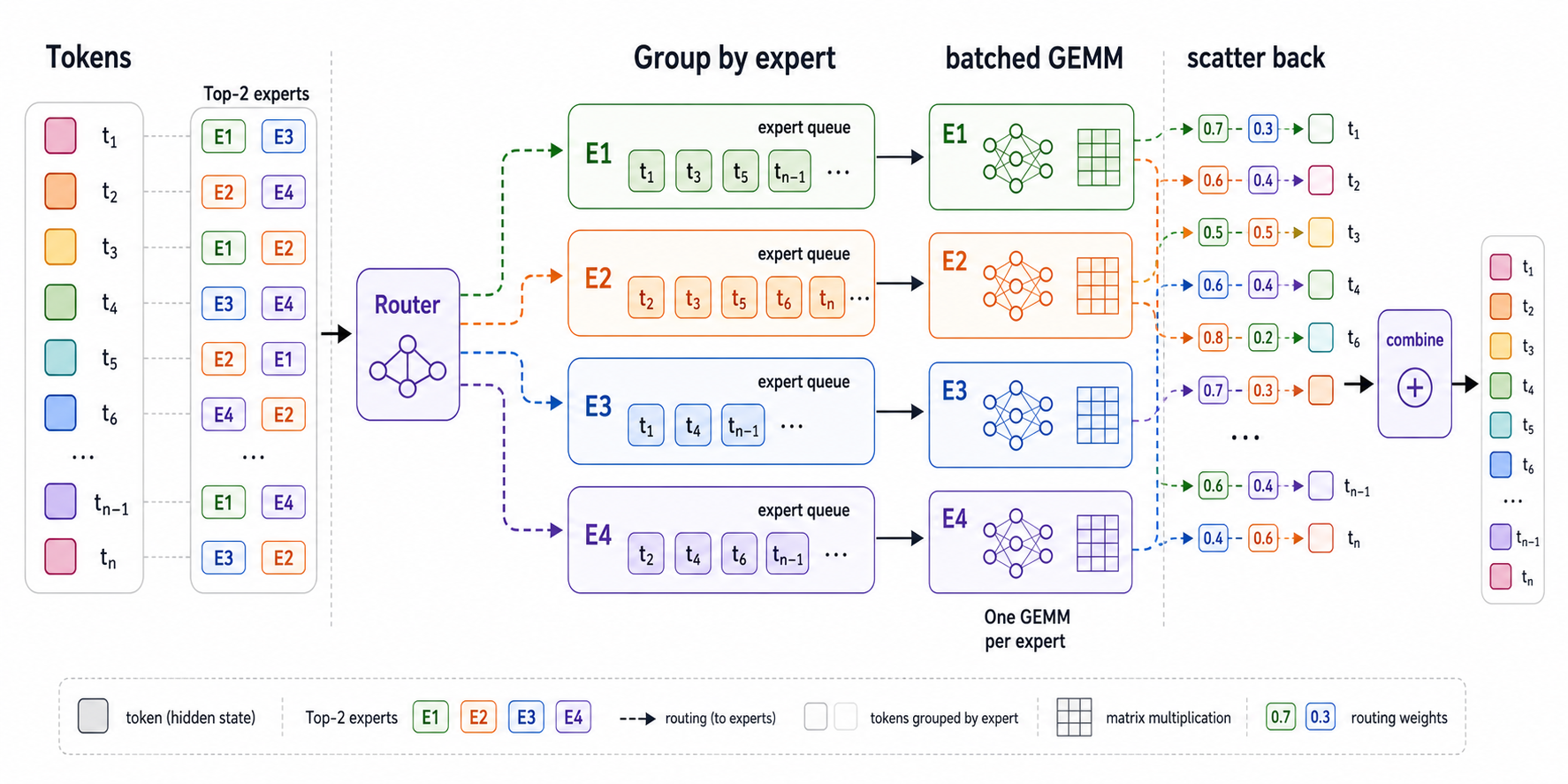
上图展示了这个过程。左边token来自同一个active batch,但它们的Top-2专家不同;中间先按E1、E2、E3、E4重排成专家队列;右边每个专家做一次批量矩阵乘法,最后再scatter back回原始token位置。
这里的关键点是:Expert Grouping不是改变MoE数学结果,而是改变计算组织方式。原来零散的小专家调用被合并成更大的专家批处理,从而提高GPU利用率。
Expert Parallel与All-to-All
如果MoE专家都在同一张GPU上,Expert Grouping主要是本地重排和批量GEMM。但大模型服务中,专家通常会被切到不同GPU上,这就是Expert Parallel。
此时流程会变成:
- 每张GPU上都有一部分token隐藏状态。
- Router决定这些token要去哪些专家。
- 如果目标专家在其他GPU,需要通过All-to-All通信发送过去。
- 各GPU上的专家处理收到的token。
- 专家输出再通过All-to-All发回原token所在位置。
因此Expert Grouping能提高专家计算效率,但也可能引入通信瓶颈。如果专家负载不均衡,某些GPU上的专家收到大量token,其他GPU专家很空,那么整个step仍然要等最慢的专家完成。
两者如何组合
两个分组维度
Continuous Batching和Expert Grouping经常一起出现在MoE推理服务中,但它们解决的问题不一样。
| 机制 | 分组对象 | 分组维度 | 目标 |
|---|---|---|---|
| Continuous Batching | 请求/序列 | 时间、decode step | 让active batch保持饱满,提高请求吞吐 |
| Expert Grouping | token隐藏状态 | Router选中的专家 | 合并专家计算,提高MoE层吞吐 |
可以理解为两层调度:
- 第一层:服务调度器决定这一轮有哪些请求进入active batch。
- 第二层:MoE层内部决定这些token分别去哪些专家,并按专家重排计算。
第一层解决“谁进入这一轮推理”,第二层解决“进入这一轮的token如何高效执行专家计算”。
一次Decode Step的流程
以一个MoE模型的decode step为例,二者组合后的流程大致如下:
- Continuous Scheduler从等待队列和运行中请求里形成active batch。
- 模型执行Embedding、Attention等Dense部分。
- 到MoE层时,Router为active tokens选择Top-K专家。
- Expert Grouping把token按专家分桶。
- 如果使用Expert Parallel,先做All-to-All分发。
- 每个专家对自己的token组做grouped GEMM。
- 专家输出scatter back,并按路由权重合并。
- 本轮decode得到每个序列的新token。
- 完成的请求移出,新的请求在下一轮加入。
这个流程里,Continuous Batching发生在step与step之间;Expert Grouping发生在每个step内部的MoE层里。
Prefill和Decode混合调度
真实服务中还有一个复杂点:新请求进入active batch之前,必须先做prefill。Prefill通常是长prompt的大块计算,而decode是短小但延迟敏感的一步步计算。
如果prefill占用太多GPU时间,正在decode的请求会等待,用户看到的生成速度会变差。如果完全优先decode,新请求的首token延迟又会变高。因此推理系统通常需要在两者之间做平衡:
- 限制每轮允许插入的prefill token数量。
- 把长prompt切成多个chunk做chunked prefill。
- 给decode更高优先级,保证正在生成的请求不卡顿。
- 根据KV Cache容量决定是否接纳新请求。
对于MoE模型,这个调度还要叠加Expert Grouping。Prefill阶段token多,专家队列更容易形成大batch;Decode阶段每个请求只有一个新token,更依赖Continuous Batching把更多请求聚在一起,才能让每个专家有足够token可算。
性能收益与瓶颈
吞吐和延迟的取舍
Continuous Batching通常能提高吞吐,因为它减少了空槽,让GPU持续处理更多活跃请求。但它也可能增加等待时间:为了组成更大的batch,调度器可能会让请求多等一点。
Expert Grouping通常能提高MoE专家计算效率,因为它把路由到同一专家的token合并起来做批量计算。但如果batch太小、路由太分散,每个专家拿到的token仍然很少,grouped GEMM的收益就有限。
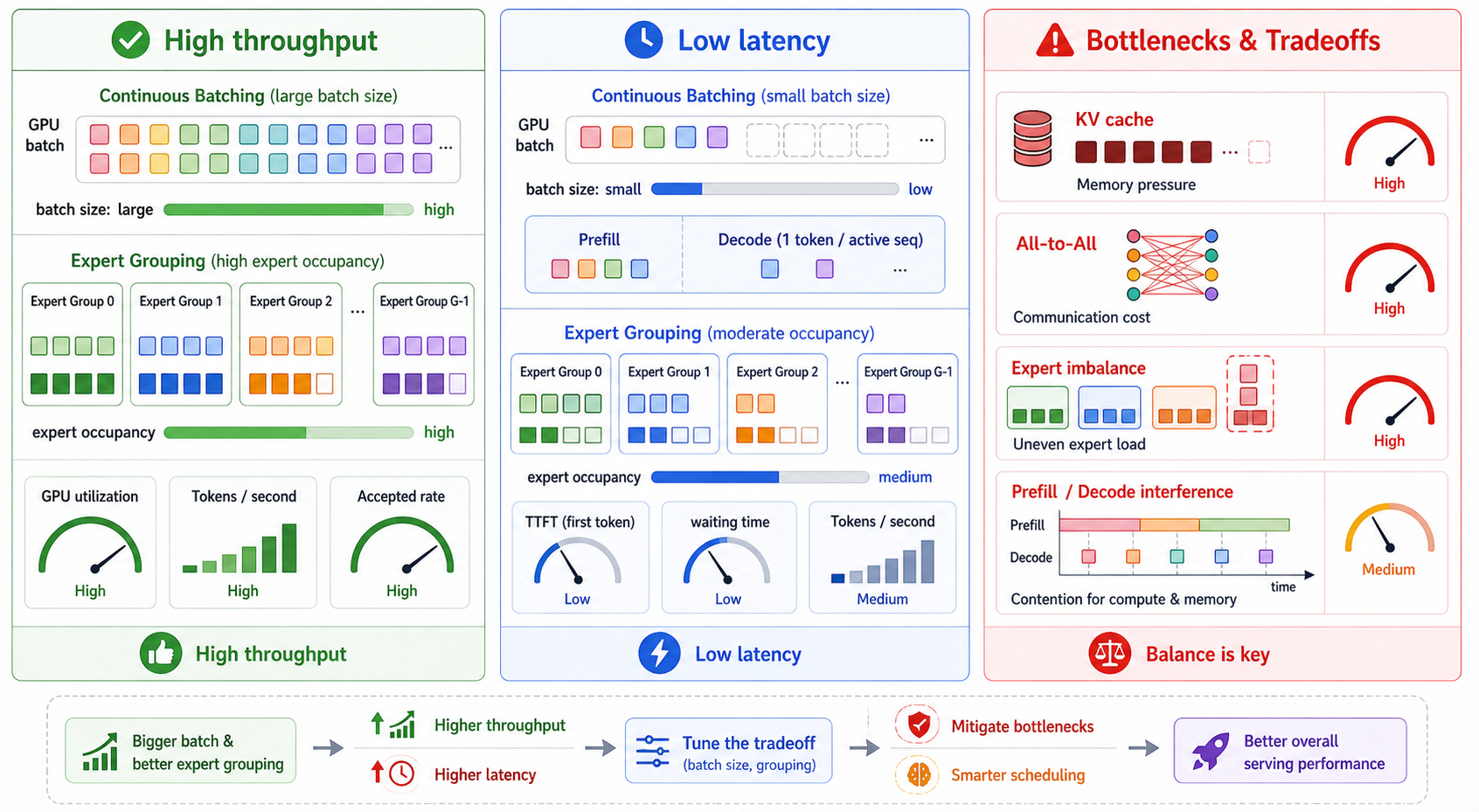
上图可以看到几个核心取舍:更大的batch通常带来更高吞吐,但也可能增加排队等待;专家分组能提高专家占用率,但会受到KV Cache、All-to-All通信、专家负载不均衡、prefill/decode互相干扰的限制。
KV Cache容量限制
Continuous Batching能动态加入请求,但不是想加多少就加多少。每个活跃请求都要占用KV Cache,而且上下文越长,占用越大。
如果KV Cache不足,调度器就需要:
- 暂停接纳新请求。
- 抢占低优先级请求。
- 把部分KV Cache换出到CPU内存。
- 使用分页式KV Cache管理减少碎片。
这也是vLLM这类推理框架强调PagedAttention和KV Cache管理的原因。Continuous Batching要真正稳定运行,必须有高效的KV Cache分配、回收和复用机制。
专家负载不均衡
Expert Grouping依赖Router输出。如果大量token都路由到同一个专家,那么这个专家会成为瓶颈。尤其在Expert Parallel场景中,专家分布在不同GPU上,某个GPU专家负载过高会拖慢整个step。
常见缓解方式包括:
- 训练时使用负载均衡损失,让专家分配更均匀。
- 推理时对专家容量做限制或使用更好的路由策略。
- 使用更高效的Grouped GEMM和All-to-All通信实现。
- 根据实际负载调整专家放置和并行策略。
这里要注意,Expert Grouping只能把“已经路由到同一专家的token”组织得更高效,它不能从根本上保证Router一定均衡。路由均衡仍然是模型训练和推理系统共同决定的。
小结
Continuous Batching和Expert Grouping都是为了提高大模型推理服务吞吐,但它们处在不同层次。
- Continuous Batching:在请求调度层,把不同请求动态组合成active batch,减少decode过程中的空槽。
- Expert Grouping:在MoE层内部,把路由到同一专家的token重排成专家队列,提高专家GEMM效率。
二者组合后,一次MoE decode step可以理解为:先按时间把请求组成batch,再按专家把token重新分组计算。前者让GPU有足够请求可处理,后者让MoE专家有足够token可批量计算。
从落地角度看,这不是一个单纯算法开关,而是推理系统的综合调度问题。要同时关注请求到达模式、prefill/decode比例、KV Cache容量、专家路由分布、All-to-All通信和GPU kernel效率。只有这些条件配合起来,Continuous Batching + Expert Grouping才能真正带来稳定收益。
参考:
- Orca: A Distributed Serving System for Transformer-Based Generative Models
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- MegaBlocks: Efficient Sparse Training with Mixture-of-Experts
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
评论