概述
大语言模型生成文本时,本质上是一个自回归过程:先根据已有上下文预测下一个token,再把这个token拼回上下文里,继续预测下一个token。也就是说,如果要生成100个token,普通解码通常需要让大模型顺序跑100次前向。
这个过程慢的原因不是模型不知道后面可能会生成什么,而是自回归约束要求一个token一个token确认。第10个token必须依赖前9个token,第11个token又必须依赖前10个token,所以看起来很难并行。
投机解码(Speculative Decoding)解决的是这个问题:先让一个更便宜的草稿模型(Draft Model)快速猜出后面几个token,再让原来的大模型(Target Model)一次性验证这些token。如果猜得对,就一次接受多个token;如果猜错,就从第一个错误位置开始修正。
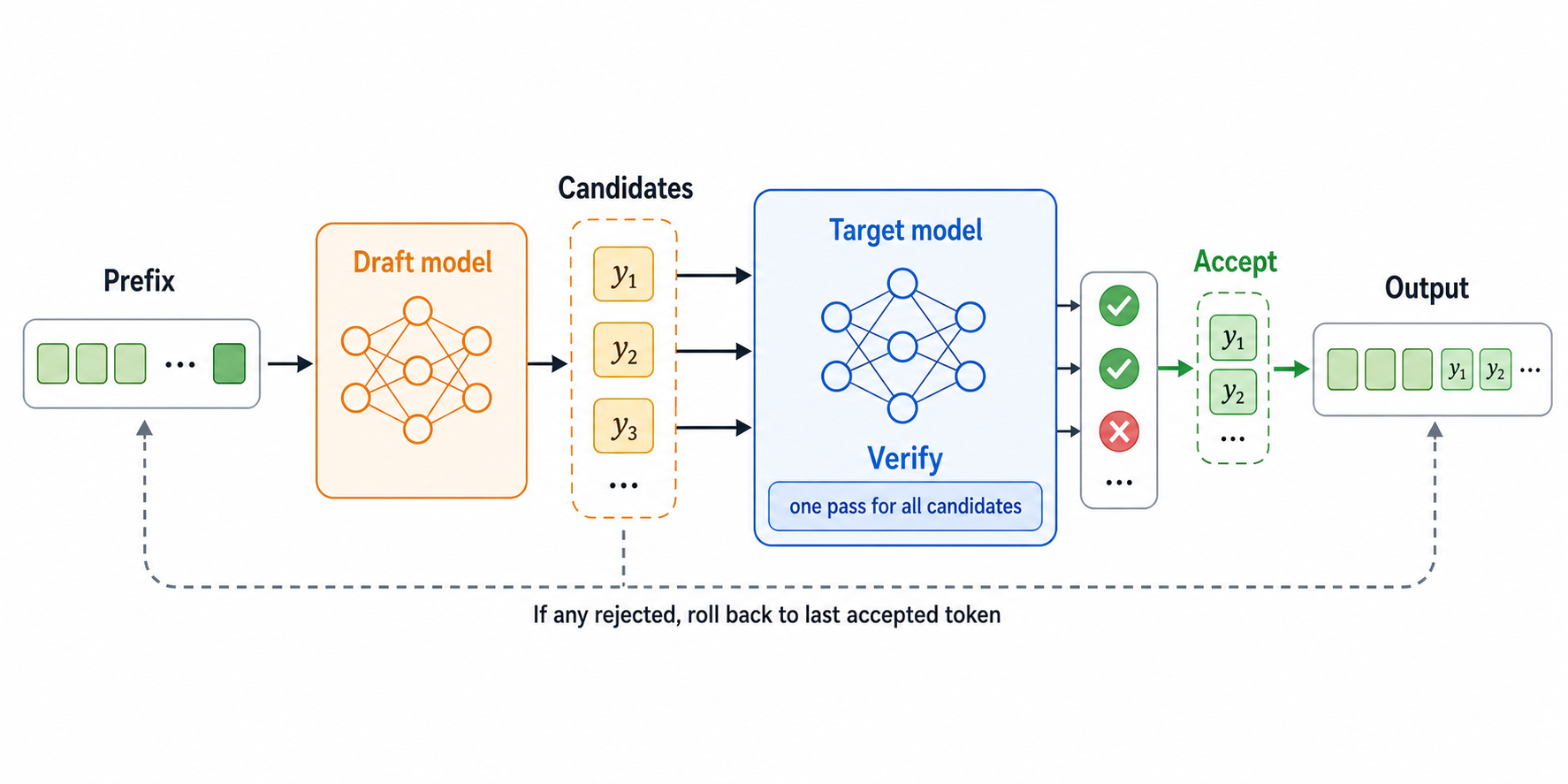
上图是投机解码的核心流程。草稿模型负责“先猜”,目标模型负责“验收”。只要草稿模型猜得足够准,并且草稿模型足够便宜,就可以把多次大模型前向压缩成更少轮目标模型验证。
这里要注意一点:投机解码不是用小模型替代大模型。最终输出仍然由目标模型分布控制。对于标准的采样版投机解码,只要接受/拒绝步骤实现正确,理论上可以保持与目标模型直接采样相同的分布。
普通解码为什么慢
自回归生成的串行瓶颈
普通大模型生成时,每一步大致如下:
- 输入当前上下文。
- 目标模型前向计算,得到下一个token的概率分布。
- 根据贪心、采样、Top-k、Top-p等策略选出一个token。
- 把这个token加入上下文,进入下一步。
如果把目标模型记为$p$,当前上下文为$x_{1:t}$,那么下一步预测为:
$$ p(x_{t+1}\mid x_{1:t}) $$
生成第$t+1$个token以后,才能继续生成第$t+2$个token:
$$ p(x_{t+2}\mid x_{1:t},x_{t+1}) $$
这个依赖关系导致生成阶段天然串行。即使GPU很强,也很难直接把“未来token”全部并行算出来,因为未来token本身还没有确定。
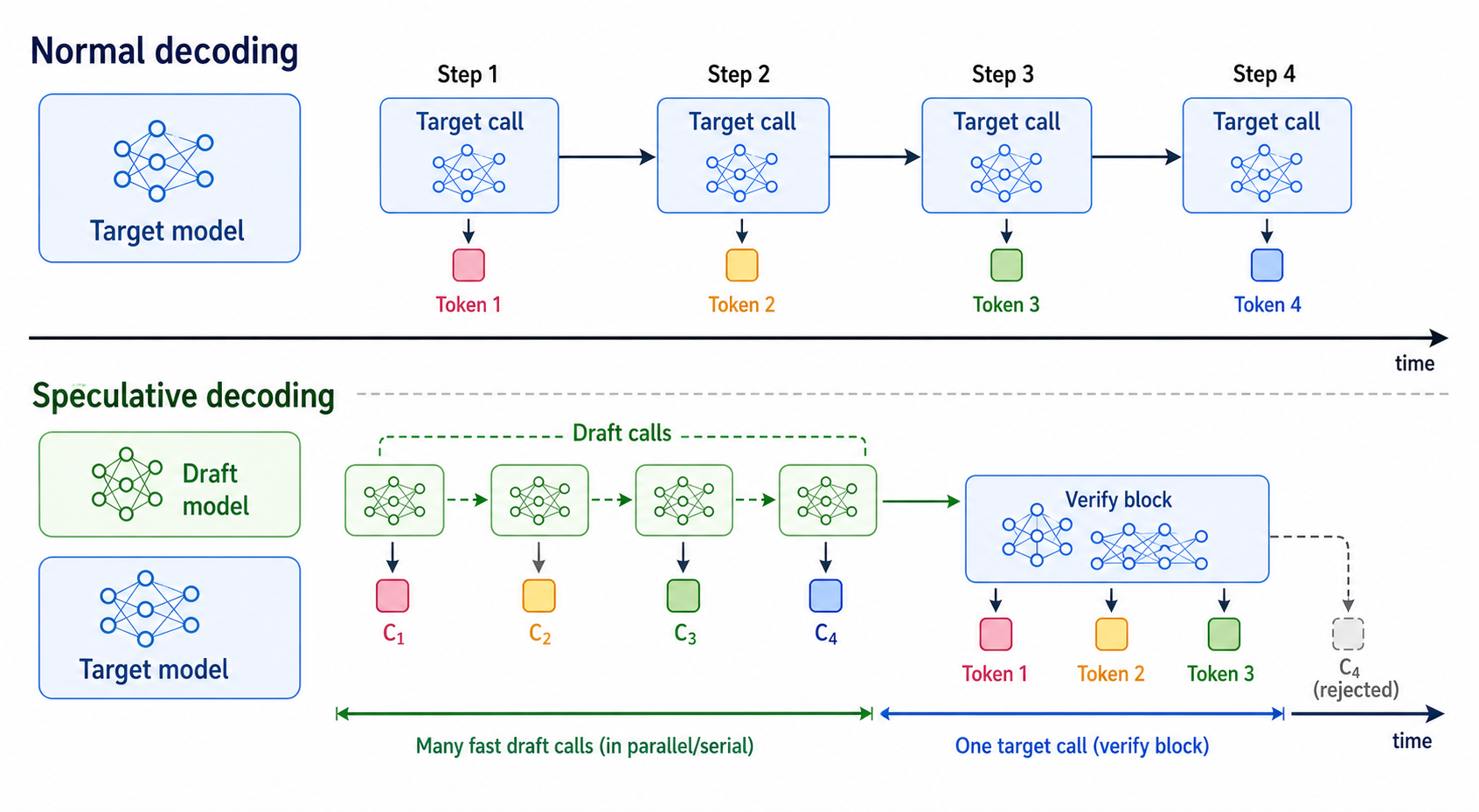
上图对比了普通解码和投机解码的时间线。普通解码中目标模型每次调用只确认一个token;投机解码先用草稿模型快速提出多个候选token,再让目标模型用一次验证确认一段候选。
目标模型验证为什么可以并行
虽然生成token是串行的,但验证一段已经给定的token可以并行。假设草稿模型已经猜出:
$$ y_1,y_2,y_3 $$
那么目标模型可以一次输入“原上下文 + 草稿token序列”,并在一次前向里得到多个位置的分布:
$$ p(y_1\mid x),\quad p(y_2\mid x,y_1),\quad p(y_3\mid x,y_1,y_2) $$
Transformer的因果掩码仍然存在,每个位置只能看它左边的token。但是由于这些草稿token已经被放进输入序列里,模型可以在一次前向中并行计算这些位置的logits。这就是投机解码能成立的关键。
也就是说,普通解码慢在“每次只能确认一个新token”,投机解码利用草稿模型提前给出候选序列,让目标模型从“逐个生成”变成“批量验证”。
投机解码基本流程
草稿模型先生成候选token
投机解码通常有两个模型:
- 目标模型:最终希望保持输出质量的大模型,记为$p$。
- 草稿模型:速度更快的小模型或轻量模块,记为$q$。
在每一轮中,草稿模型先自回归生成$K$个候选token:
$$ y_1,y_2,\dots,y_K $$
这里的$K$也叫投机长度,表示一轮最多尝试提前生成多少个token。$K$越大,理论上单轮可能接受更多token,但草稿模型要多跑几步,而且越往后猜错概率越大。
目标模型一次验证多个token
草稿模型生成候选token以后,目标模型一次性验证整个候选序列。对于候选token $y_i$,目标模型计算它在对应前缀下的概率$p_i(y_i)$,草稿模型生成它时也有自己的概率$q_i(y_i)$。
如果是贪心解码,可以用一个简单直觉理解:目标模型如果也认为这些token是正确的,就连续接受;一旦某个位置不一致,就停止本轮,使用目标模型的结果修正。
如果是采样解码,就不能简单比较argmax,因为目标模型本来就是按概率采样。此时需要用接受/拒绝规则来保证最后分布仍然等价于目标模型直接采样。
接受前缀并进入下一轮
投机解码每一轮不是必须接受全部草稿token,而是接受一段连续前缀。假设草稿模型生成了3个token:
$$ y_1,y_2,y_3 $$
如果$y_1$和$y_2$被接受,而$y_3$被拒绝,那么本轮输出就是:
$$ y_1,y_2,z $$
其中$z$是根据目标模型分布修正后采样得到的token。$y_3$以及它之后的草稿token都会被丢弃。然后模型基于新的上下文进入下一轮。
接受与拒绝机制
贪心解码的直观版本
先看最简单的贪心版本。假设目标模型每一步都选择概率最大的token,草稿模型也生成了一段候选序列。目标模型验证时,也能得到每个位置自己认为最应该输出的token。
如果目标模型在第1、第2个位置的预测和草稿一致,但第3个位置不一致,那么就接受前两个token,然后用目标模型第3个位置的token替换草稿第3个token。
这种方式很好理解,但它只适合解释贪心场景。真实模型经常会使用temperature、Top-p等采样策略,采样场景下不能只比较“是否同一个最大概率token”,否则会改变原本的采样分布。
采样解码的接受概率
采样版投机解码需要保证:最终生成结果的分布和直接从目标模型$p$采样一致。其核心是一个接受概率:
$$ \alpha_i=\min\left(1,\frac{p_i(y_i)}{q_i(y_i)}\right) $$
其中:
- $y_i$:草稿模型在第$i$个位置提出的token。
- $q_i(y_i)$:草稿模型生成$y_i$的概率。
- $p_i(y_i)$:目标模型在相同前缀下生成$y_i$的概率。
- $\alpha_i$:接受这个草稿token的概率。
如果草稿模型给出的token在目标模型那里概率也很高,那么$p_i(y_i)$接近或大于$q_i(y_i)$,这个token就容易被接受。如果目标模型认为这个token概率很低,那么它被接受的概率就会下降。
拒绝后如何修正
如果第$i$个草稿token被拒绝,不能随便从目标模型$p_i$直接采样一个token,因为前面“接受/拒绝”已经改变了概率质量。标准做法是从下面这个正残差分布中采样:
$$ \frac{(p_i-q_i)+}{\sum_v (p_i(v)-q_i(v))+} $$
其中$(p_i-q_i)_+$表示只保留$p_i(v)-q_i(v)$大于0的部分。直觉上可以理解为:草稿模型已经覆盖了一部分概率质量,拒绝发生后,需要从目标模型还没有被草稿模型覆盖好的那部分概率里补回来。
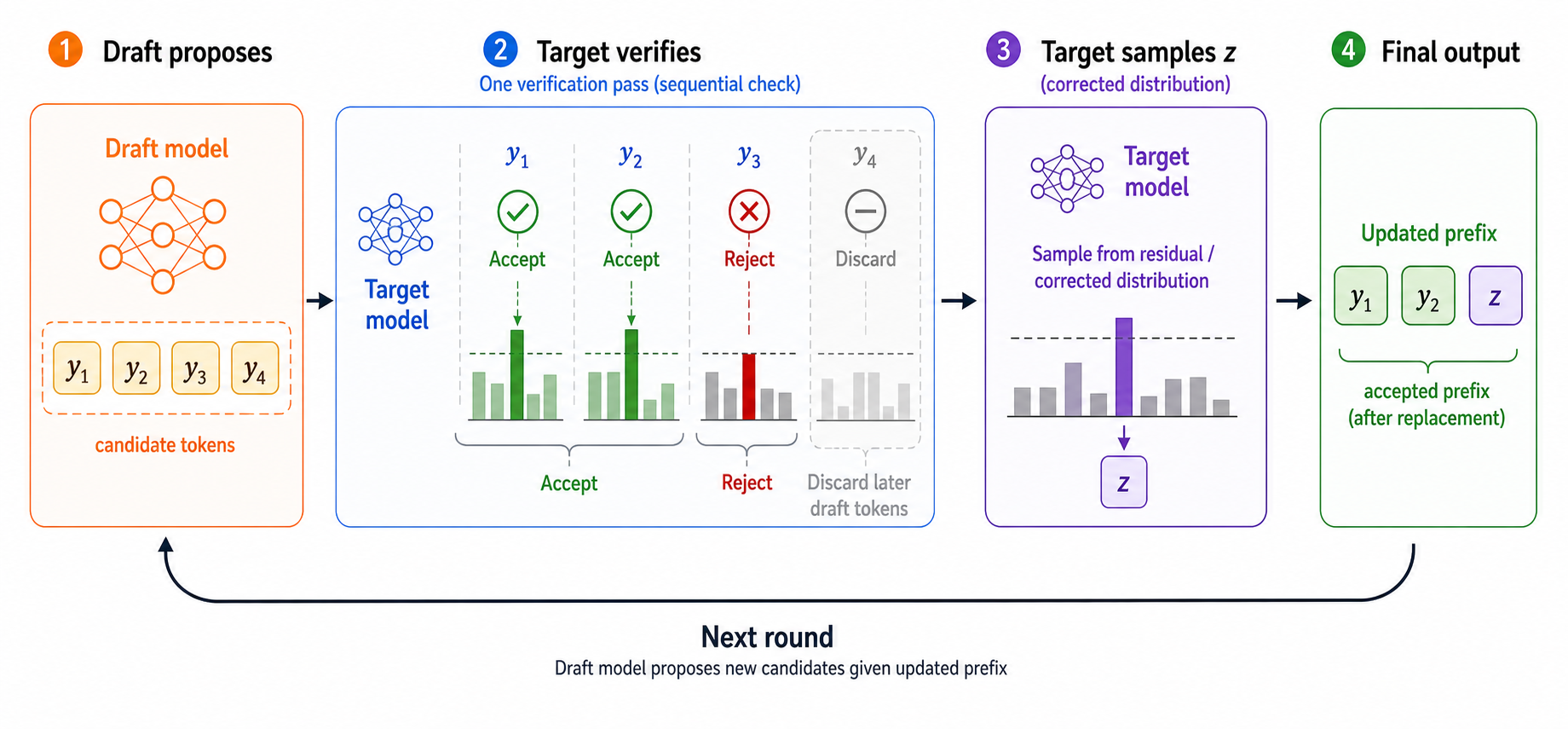
上图展示了接受/拒绝过程。目标模型从左到右检查草稿token,前面通过的token直接加入输出;第一个拒绝位置会触发目标模型从修正分布中采样替代token,后面的草稿token全部丢弃。也就是说,被拒绝的位置不是draft重新生成,而是由目标模型修正;draft只会在下一轮基于新的上下文继续提出候选。这个设计保证了采样版投机解码不会因为用了小草稿模型而改变目标模型的输出分布。
为什么能加速
一次目标前向换多个token
普通解码中,目标模型每前向一次通常只确认一个token。投机解码中,目标模型每前向一次可能确认多个token。假设一轮草稿长度为$K$,其中平均能接受$A$个token,那么一轮目标模型验证大约可以输出$A$个或更多token。
可以粗略写成:
$$ \text{Speedup}\approx \frac{\mathbb{E}[\text{本轮输出token数}]\cdot C_{target}}{C_{target}+K\cdot C_{draft}} $$
其中:
- $C_{target}$:目标模型一次前向成本。
- $C_{draft}$:草稿模型一次前向成本。
- $K$:草稿长度。
这个公式不是严格性能模型,只是帮助理解加速来源:如果草稿模型很便宜,并且目标模型能接受较多草稿token,那么收益就明显;反过来,如果草稿模型很慢或者经常猜错,投机解码反而可能没有收益。
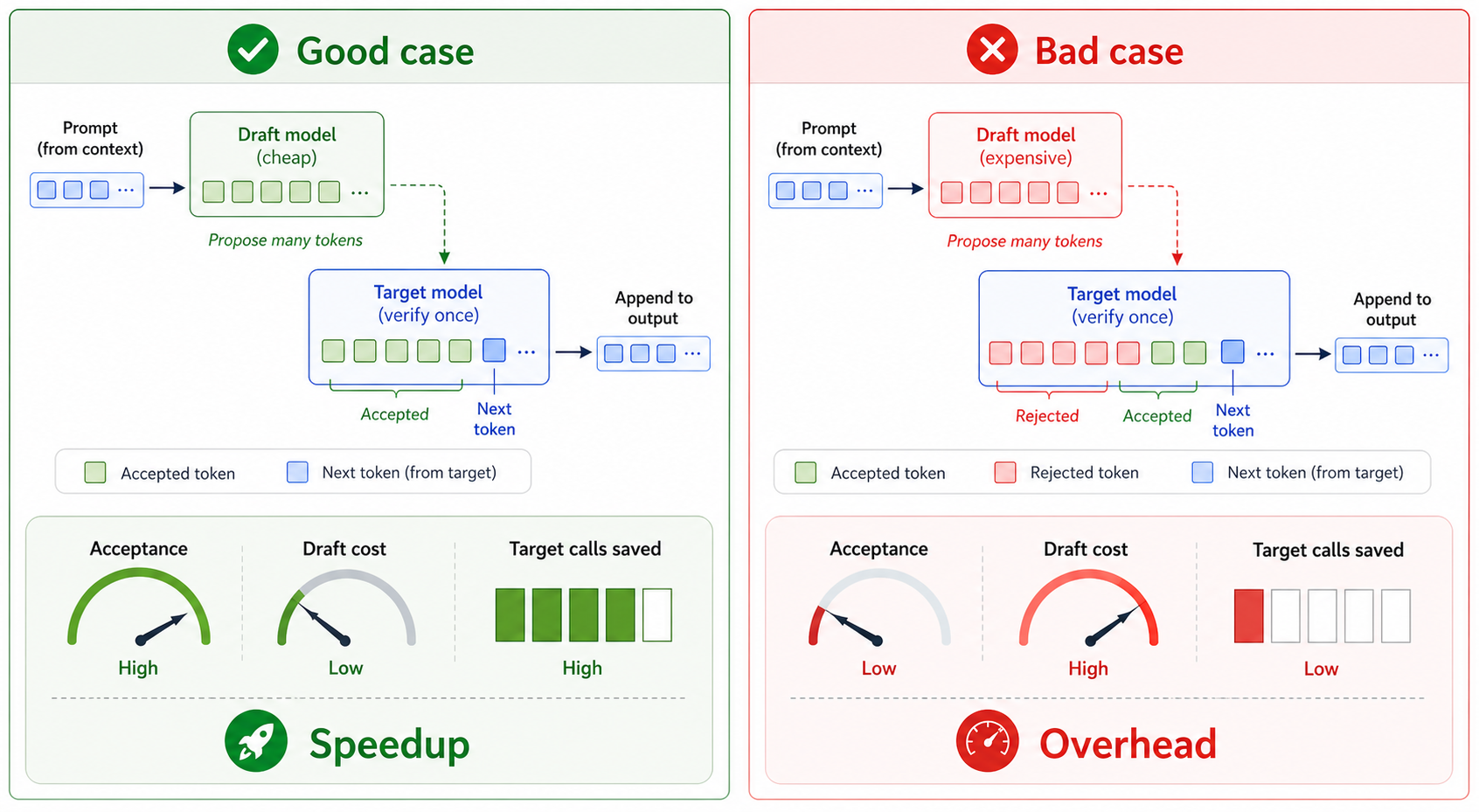
接受率决定收益上限
投机解码的核心指标是接受率。接受率越高,说明草稿模型和目标模型越一致,一轮能接受的token越多。
接受率受几个因素影响:
- 草稿模型能力:草稿模型越接近目标模型,候选token越容易被接受。
- 任务难度:格式化文本、重复模式、代码补全这类局部可预测性高的任务,通常更容易接受多个token。
- 采样参数:temperature越高,输出随机性越强,草稿模型更难准确跟上目标模型分布。
- 投机长度:$K$越大,后面token越依赖前面预测,越容易累积误差。
因此投机解码不是简单把$K$设得越大越好。太短,单轮收益不明显;太长,草稿开销上升,后面token又容易被拒绝。
草稿成本不能太高
草稿模型必须足够便宜。如果草稿模型本身也很大,那么每轮都要先跑$K$次草稿,再跑一次目标验证,最终可能只是把目标模型的一部分成本换成草稿模型成本,并没有真实加速。
所以投机解码通常要求草稿模型满足两个条件:
- 速度快:单步前向成本明显低于目标模型。
- 分布近:生成的token和目标模型足够一致。
这两个条件有天然矛盾。草稿模型越小越快,但越小可能越不准;草稿模型越接近目标模型越准,但成本也越高。投机解码的工程优化,本质上就是在这两者之间找平衡。
工程实现要点
KV Cache如何处理
投机解码仍然需要KV Cache。目标模型验证一段草稿token时,会为这些候选token产生对应的KV Cache。被接受的token可以保留到目标模型缓存中;被拒绝位置之后的候选token不能进入最终上下文,因此对应缓存也需要丢弃。
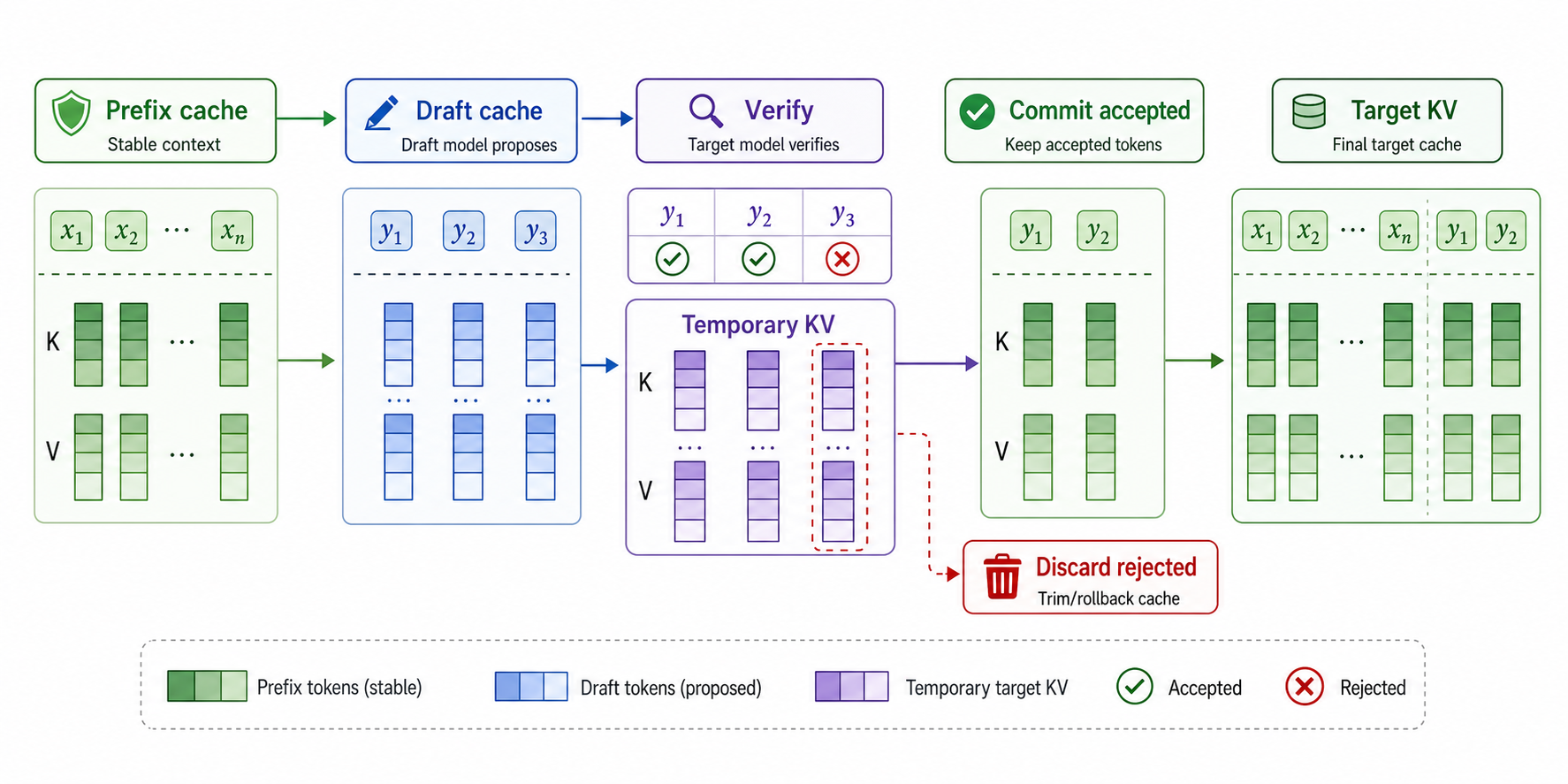
上图展示了缓存处理的关键边界:已经稳定的prefix cache会保留;草稿token经过目标模型验证后,只有被接受的部分会提交到Target KV;被拒绝位置及其后面的临时KV需要丢弃或回滚。
草稿模型也有自己的缓存。每一轮草稿生成时,草稿模型要基于当前已接受上下文继续往后猜。目标模型接受或拒绝以后,草稿模型缓存也要和最终上下文对齐,否则下一轮会从错误上下文继续生成。
因此投机解码不仅是算法问题,也是缓存管理问题。实现中要处理:
- 目标模型缓存只保留已接受token。
- 草稿模型缓存要跟随最终上下文更新。
- 拒绝以后要丢弃无效候选token对应缓存。
- 流式输出时要等token被目标模型验证后再稳定输出。
批处理和并发的影响
投机解码对小batch、低延迟场景通常更有吸引力。原因是自回归逐token生成时,小batch很容易让GPU吃不满;如果一次验证多个候选token,就能提高单轮目标模型前向的有效工作量。
但在大batch服务场景下,情况会复杂很多。连续批处理已经能把多个请求拼在一起提高GPU利用率,此时投机解码带来的额外收益可能下降,甚至因为动态接受长度不同,让调度更复杂。
所以是否使用投机解码,需要看具体服务场景:
| 场景 | 投机解码收益 |
|---|---|
| 单请求、低延迟 | 通常更容易受益 |
| 小batch在线服务 | 常见适用场景 |
| 大batch高吞吐 | 收益不一定明显,调度成本更高 |
| 高随机采样 | 接受率可能下降 |
| 格式化输出/代码补全 | 局部可预测性强,可能更适合 |
什么时候不会更快
投机解码不是无条件加速。下面几种情况收益可能不明显:
- 草稿模型太慢,抵消了目标模型验证节省的时间。
- 草稿模型和目标模型差异太大,接受率低。
- 采样温度较高,输出随机性大。
- batch很大,目标模型本来已经能充分利用GPU。
- 系统实现中KV Cache拷贝、token分发、动态调度开销过高。
因此,投机解码的效果不能只看算法步骤,还要看模型大小、草稿质量、采样参数、batch形态和推理框架实现。
常见变体
双模型投机解码
最经典的投机解码是双模型结构:一个小草稿模型$q$,一个大目标模型$p$。草稿模型提出候选token,目标模型验证并修正。
这种方式的优点是目标模型不需要改结构,只要找到一个合适的小模型作为草稿模型即可。缺点是需要同时加载两个模型,并且草稿模型和目标模型的tokenizer、词表、分布差异都会影响实现复杂度。
Self-Speculative Decoding
Self-Speculative Decoding不使用外部小模型,而是在同一个模型内部构造草稿路径。常见做法是跳过部分层、使用浅层输出或轻量分支先生成候选token,再用完整模型验证。
这种方式的优点是不用额外加载一个完整草稿模型,词表和模型分布天然更接近。缺点是需要对模型结构或推理过程做更多改造,实现难度和适配成本更高。
Medusa、EAGLE与树状候选
Medusa的思路是在模型上增加多个解码头,让这些头并行预测未来多个位置的token。它不再依赖一个独立小模型逐步生成草稿,而是通过多头一次产生多个候选。
EAGLE则从特征层面进行投机生成,核心动机是直接预测未来token不稳定,而在更规则的中间特征空间做预测可能更高效。
还有一些方法会构造树状候选,一次提出多条可能路径,再用目标模型批量验证。树状候选可以提高命中概率,但也会带来更复杂的候选组织、attention mask和缓存管理。
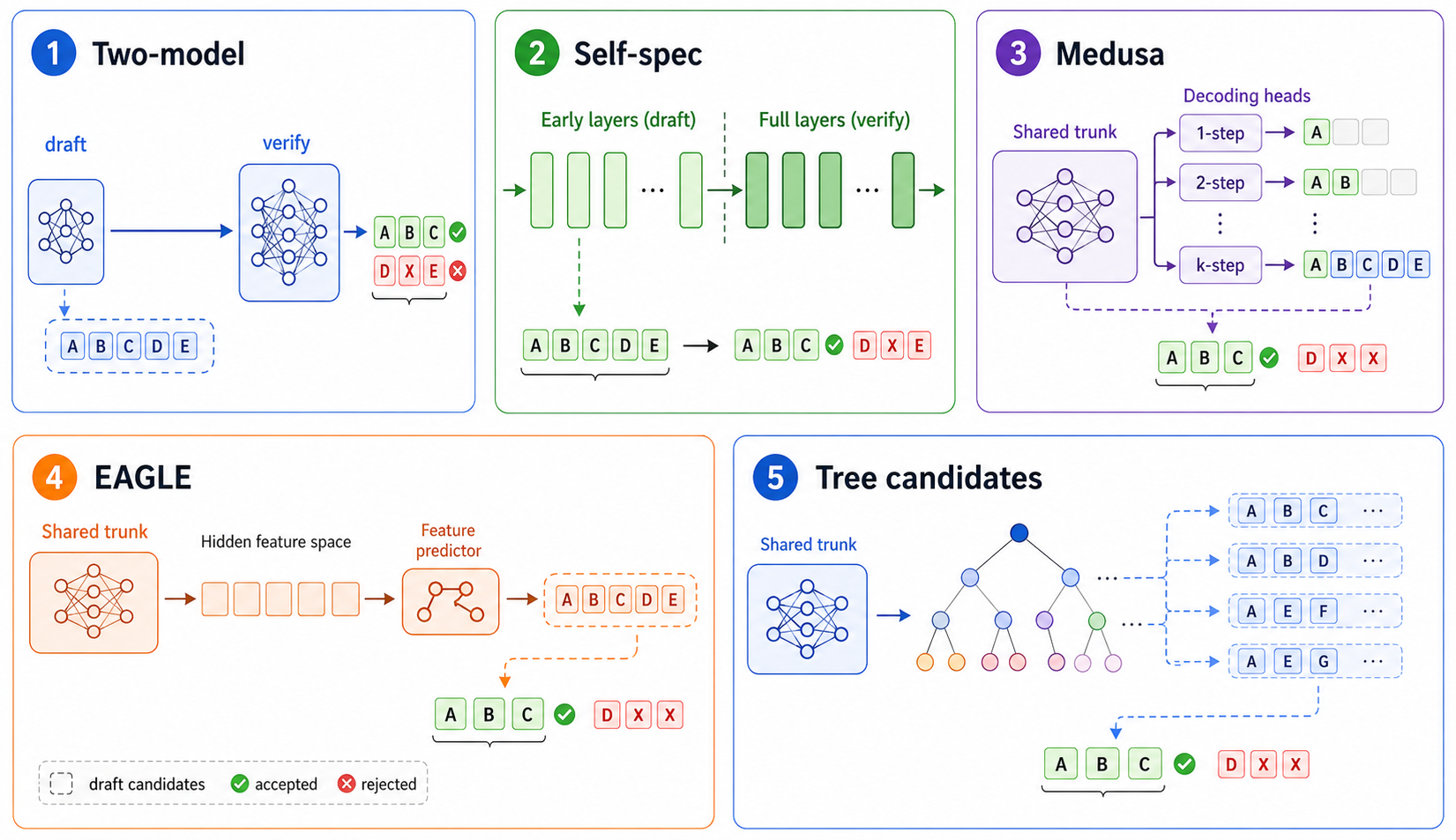
上图把几类常见变体放在一起对比。它们的共同点都是“先提出候选,再用目标模型或完整路径验证”,差异主要在草稿候选来自哪里:外部小模型、模型内部浅层、多解码头、中间特征预测,或树状多分支候选。
| 方法 | 草稿来源 | 特点 |
|---|---|---|
| 双模型投机解码 | 小草稿模型 | 目标模型无需改结构,依赖草稿质量 |
| Self-Speculative | 目标模型内部浅层/跳层 | 不需要外部模型,但需要改推理流程 |
| Medusa | 多个额外解码头 | 并行预测多个未来token |
| EAGLE | 中间特征预测 | 在特征空间做草稿生成 |
| 树状候选 | 多分支候选序列 | 提高候选覆盖率,但调度复杂 |
小结
投机解码的核心不是让小模型替代大模型,而是让小模型先提出草稿,再让大模型批量验证。它利用了一个关键事实:自回归生成必须逐个确认token,但Transformer可以并行验证一段已经给定的候选token。
从流程上看,投机解码主要包含三步:
- 草稿模型快速生成多个候选token。
- 目标模型一次前向验证这些候选token。
- 接受连续前缀,拒绝后用目标模型分布修正,再进入下一轮。
从落地上看,投机解码能不能加速,取决于草稿模型是否足够便宜、接受率是否足够高、目标模型验证是否能高效执行,以及KV Cache和批处理调度是否处理得好。它是一种很典型的“算法 + 推理系统”结合的优化,不是单纯换一个解码参数就能稳定提速。
参考:
评论