概述
大模型能力提升通常依赖两个方向:模型参数变多、训练数据变多。Dense模型的做法比较直接,每一层的参数都会参与每个token的计算,模型越大,单次前向计算也越重。这样虽然简单,但是当参数规模继续增大时,训练和推理成本会快速上升。
MoE(Mixture of Experts,混合专家模型)的核心思路是:模型可以拥有很多参数,但每个token只激活其中一小部分参数。也就是说,不是每次都让所有参数一起工作,而是先用一个路由器判断当前token应该交给哪些专家处理,然后只调用这些专家。
这里要先注意一点,MoE不是把多个完整大模型放在一起做投票。现在大语言模型里的MoE,通常是把Transformer Block中的FFN/MLP层替换成多个专家,每个专家本质上是一个小的前馈网络。Attention、LayerNorm、残差连接等结构仍然存在,变化最大的地方是FFN层。
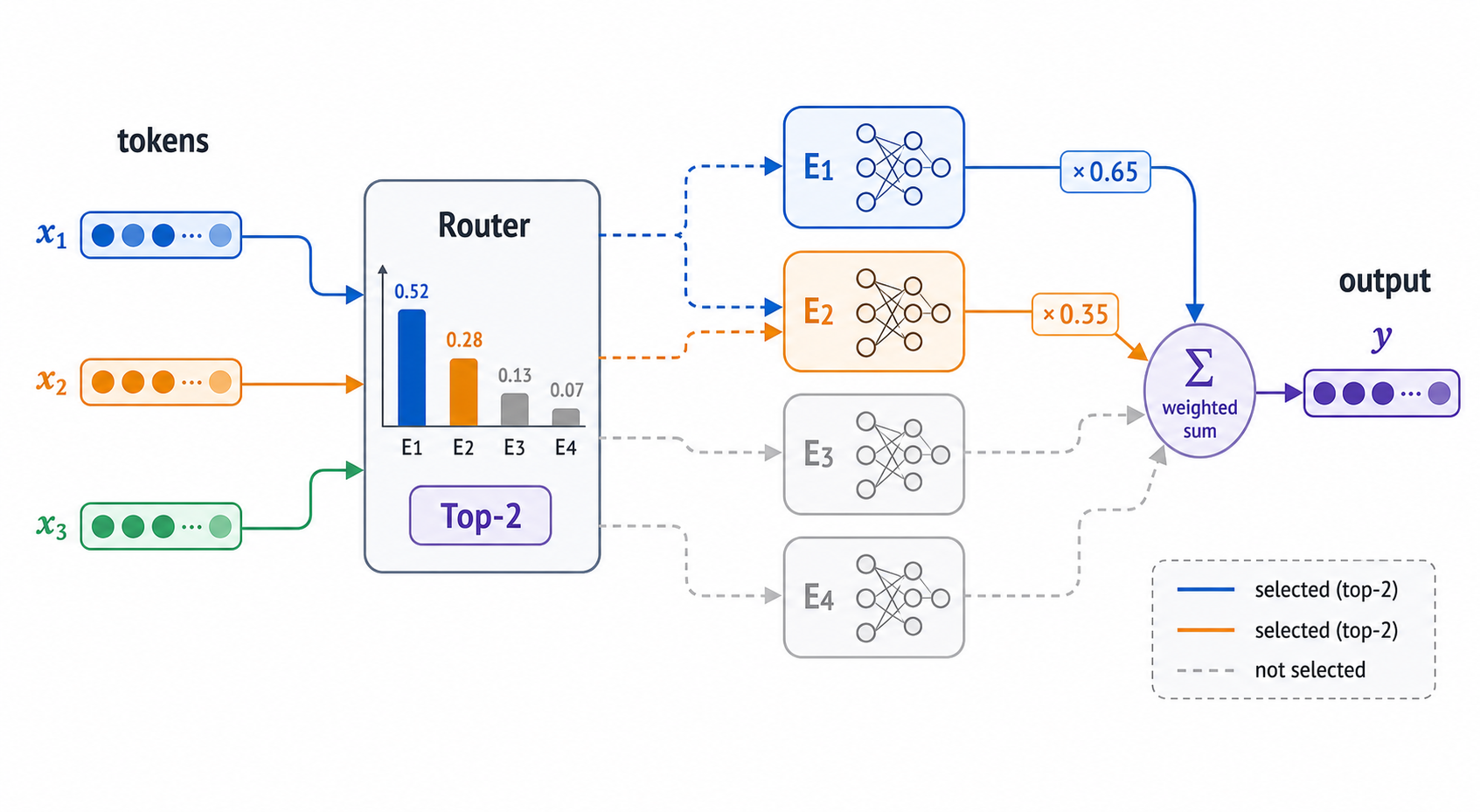
上图可以理解为一个MoE层的核心流程:token进入Router,Router选出Top-2专家,未选中的专家路径变灰,最后把选中专家的输出按权重合并。图中Router柱状图里的概率是对所有专家的打分,而右侧合并时的权重通常会在Top-K内部重新归一化。
| 对比项 | Dense模型 | MoE模型 |
|---|---|---|
| 计算路径 | 每个token走同一个FFN | 每个token按Router选择少量专家 |
| 参数使用 | 总参数和激活参数基本一致 | 总参数可以远大于激活参数 |
| 优势 | 结构简单,训练稳定 | 模型容量更大,按需激活专家 |
| 代价 | 扩参会直接增加计算量 | 路由、负载均衡、通信调度更复杂 |
如果用一句话总结MoE:它是一种条件计算结构,条件是当前token的隐藏状态,计算路径是路由器选出来的少量专家。
MoE基本结构
Dense模型的问题
Dense和MoE最大的差异是计算路径。Dense模型中,每个token都会经过同一个完整FFN;MoE模型中,token会先经过Router,再被分配给少量专家。
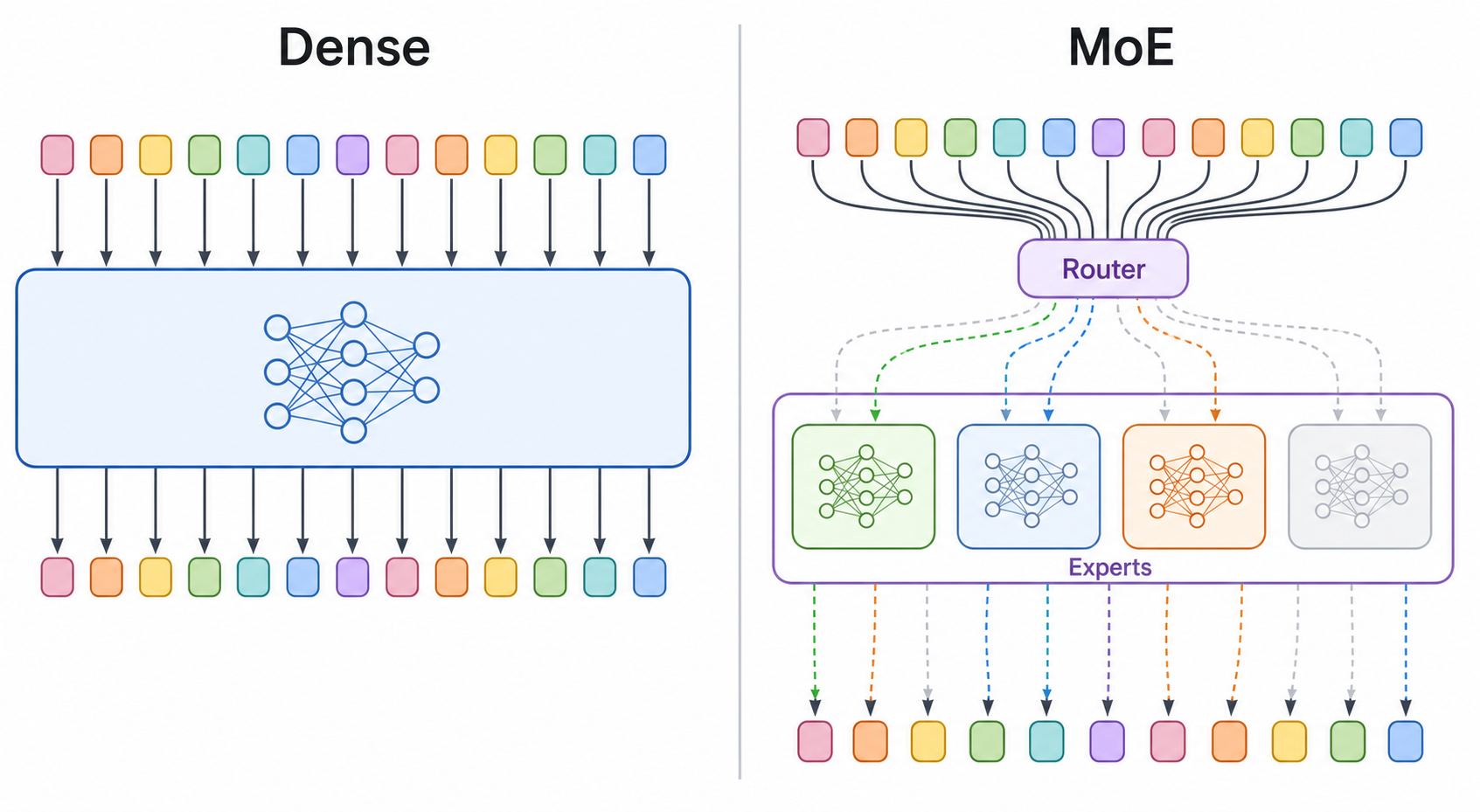
先回顾一下普通Transformer Block的结构。对于一个decoder-only语言模型,单层大致可以看成下面这样:
- 输入token隐藏状态 $x$
- 经过Self-Attention,建立token之间的上下文关系
- 经过FFN/MLP,对每个token的位置单独做非线性变换
- 残差连接与归一化,输出给下一层
其中FFN层通常占用了Transformer中相当大一部分参数。以常见的两层FFN为例:
$$ FFN(x)=W_2\sigma(W_1x+b_1)+b_2 $$
如果模型隐藏维度为$d_{model}$,FFN中间维度为$d_{ff}$,那么一个FFN大致有:
$$ 2 \times d_{model} \times d_{ff} $$
个权重参数。对于每个token来说,这些FFN参数都会被完整计算一遍。Dense模型的问题也就在这里:参数越大,所有token都要跟着付出完整计算成本。
MoE层的核心流程
MoE的改造位置通常就在FFN层。原来每层只有一个FFN:
$$ y=FFN(x) $$
换成MoE以后,一层中会有多个FFN专家:
$$ E_1(x),E_2(x),…,E_N(x) $$
但是每个token不会经过全部专家,而是先经过Router计算路由分数,然后选择Top-K个专家。假设Top-K选出来的专家集合为$S_K(x)$,那么常见MoE层输出为:
$$ MoE(x)=\sum_{e\in S_K(x)}\tilde{g}_e(x)E_e(x) $$
其中:
- $x$:当前token的隐藏状态。
- $E_e(x)$:第$e$个专家对当前token的计算结果。
- $S_K(x)$:当前token被分配到的Top-K专家集合。
- $\tilde{g}_e(x)$:Top-K内部重新归一化后的专家权重。
如果Router对所有专家输出概率$p_e(x)$,常见做法是对Top-K内部的概率重新归一化:
$$ \tilde{g}e(x)=\frac{p_e(x)}{\sum{j\in S_K(x)}p_j(x)},\quad e\in S_K(x) $$
这样就把“所有token都走同一个大FFN”变成了“不同token按需走不同专家”。总参数量可以随着专家数量增加而变大,但每个token实际激活的专家数量仍然很少。
Expert到底是什么
很多人第一次听到“专家”容易理解成多个完整模型,其实在Transformer MoE里,专家通常只是FFN/MLP层。也就是说,每个专家只负责对单个token隐藏状态做非线性变换,并不单独维护完整上下文。
普通FFN专家可以写成:
$$ E_e(x)=W_{2,e}\sigma(W_{1,e}x) $$
如果使用SwiGLU结构,则常见形式类似:
$$ E_e(x)=W_{2,e}\left(\text{SiLU}(W_{1,e}x)\odot W_{3,e}x\right) $$
不同专家拥有不同参数,因此同一个token送到不同专家会得到不同变换结果。至于哪个专家擅长代码、哪个专家擅长数学、哪个专家擅长语言,这不是人工提前规定的,而是在训练过程中由数据和路由共同形成的。
MoE的直觉是“不同专家处理不同类型token”,但专家分工不是天然就会稳定出现。模型训练时可能出现两种情况:
- 专家分化:不同专家逐渐处理不同分布的数据,比如某些专家更常处理代码、数学符号、多语言token等。
- 专家坍缩:Router总是把大量token分给少数专家,其他专家很少被使用,最后变成“名义上有很多专家,实际只有少数专家在工作”。
因此MoE训练中不能只看主任务损失,还要额外处理负载均衡问题。
Router如何选择专家
路由计算过程
Router也叫Gate,它的输入是token隐藏状态,输出是每个专家的选择概率。假设有$N$个专家,Router可以看成一个线性分类器:
$$ s=xW_g $$
其中:
- $x$:token隐藏状态,形状为$[d_{model}]$。
- $W_g$:路由器权重,形状为$[d_{model},N]$。
- $s$:当前token对所有专家的打分,形状为$[N]$。
接着对分数做softmax:
$$ p=\text{softmax}(s) $$
$p_i$就表示当前token分配给第$i$个专家的概率。最后从$p$里面选出概率最高的Top-K个专家参与计算。
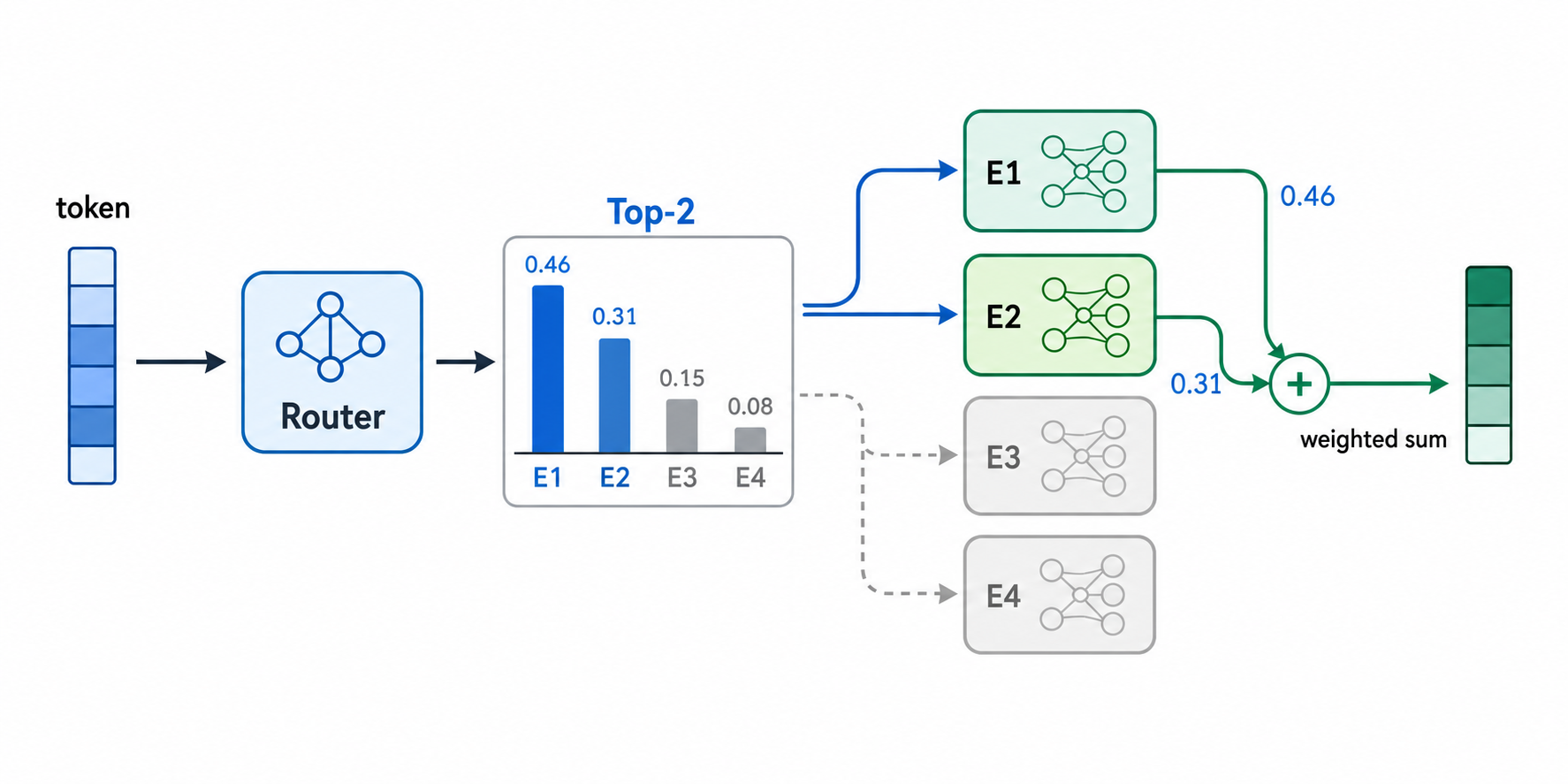
举个例子,假设当前token经过Router后得到4个专家的概率:
| 专家 | 概率 |
|---|---|
| Expert 1 | 0.55 |
| Expert 2 | 0.30 |
| Expert 3 | 0.10 |
| Expert 4 | 0.05 |
如果是Top-1路由,只会选择Expert 1。如果是Top-2路由,会选择Expert 1和Expert 2,并按照对应权重合并两个专家的输出。很多实现会对Top-K内部的权重再做一次归一化,比如这里会把0.55和0.30重新归一化为两者之和为1的权重。
Top-1、Top-2与Top-K
不同MoE模型会选择不同的路由方式。选择几个专家,不只是模型能力问题,也直接决定计算量、通信量和训练稳定性。
| 路由方式 | 含义 | 优点 | 代价 |
|---|---|---|---|
| Top-1 | 每个token只进入1个专家 | 计算最省,结构简单 | 路由错误时没有第二专家补充,训练更依赖负载均衡 |
| Top-2 | 每个token进入2个专家 | 更平滑,专家组合能力更强 | 专家计算和通信量更高 |
| Top-K | 每个token进入K个专家 | 表达能力更强 | K越大越接近Dense,效率下降 |
Switch Transformer是典型的Top-1路由,GShard和Mixtral这类模型常见Top-2设计。Top-1和Top-2没有绝对优劣,关键看目标是什么。如果追求训练和推理效率,Top-1更直接;如果希望路由更稳、专家之间组合能力更强,Top-2会更常见。
Token级路由的特点
MoE通常是token级路由,不是句子级路由,也不是请求级路由。也就是说,同一句话里的不同token可能会走不同专家,同一个token在不同MoE层里也可能走不同专家。
举个例子,输入一句包含自然语言、数学符号和代码片段的提示词时,不一定是整句话都交给“代码专家”或“数学专家”。更常见的情况是:每一层的Router根据当前token隐藏状态,为每个token分别选择专家。经过前面Attention层以后,token隐藏状态已经包含上下文信息,所以Router看到的不是孤立词,而是带上下文语义的表示。
这个特点带来两个影响:
- 优点:路由粒度细,不同类型token可以走不同计算路径。
- 代价:每一层、每个batch都要动态分发token,系统实现比Dense模型复杂。
负载均衡与专家容量
为什么会出现专家负载不均衡
假设一个MoE层有8个专家,理论上希望不同专家都能被充分使用。但如果Router训练早期偏向某几个专家,就会出现下面的问题:
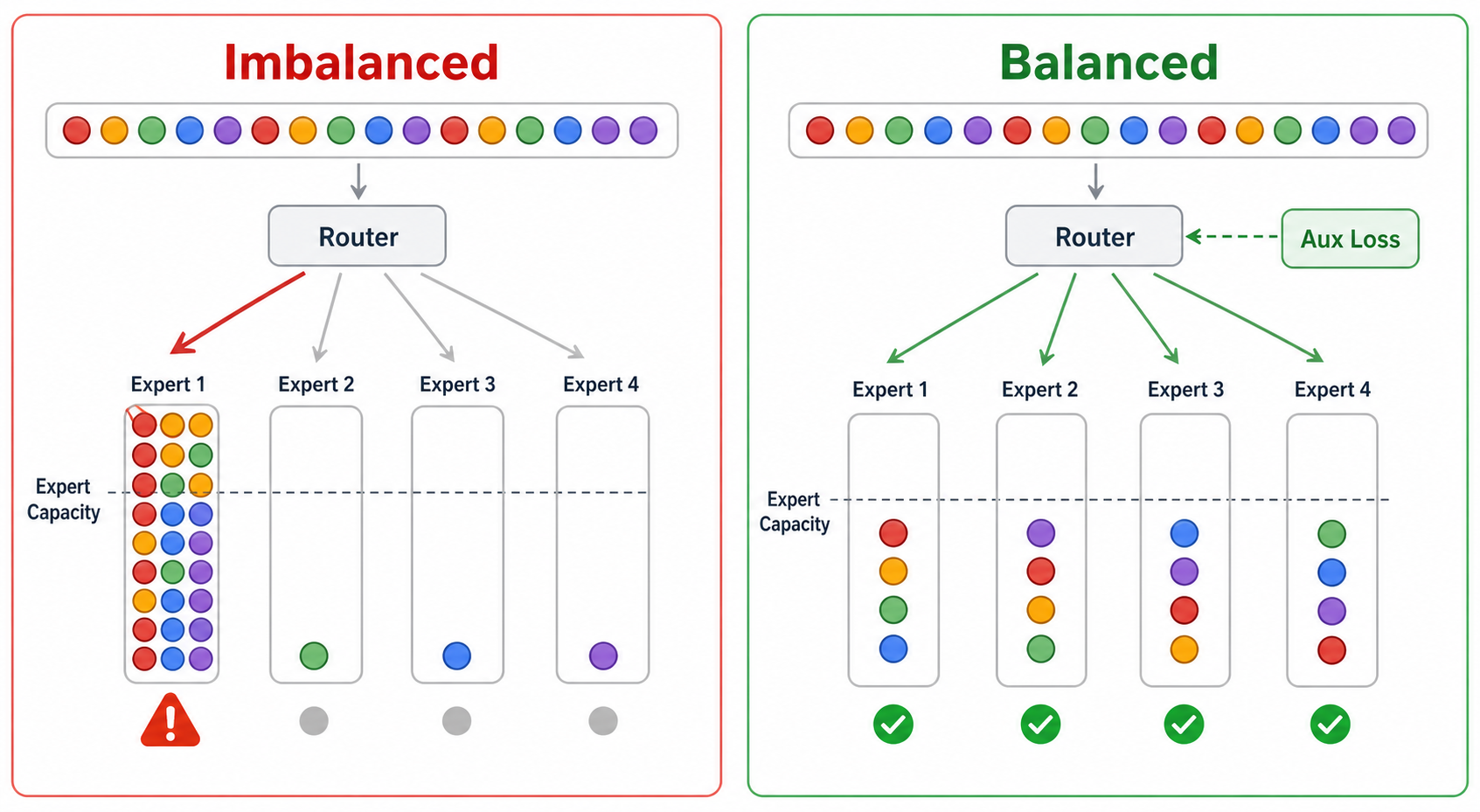
- 热门专家负载过高,计算和显存压力集中。
- 冷门专家拿不到足够训练样本,参数更新不足。
- 多卡训练时某些GPU特别忙,其他GPU空等,整体吞吐下降。
- 专家没有形成有效分工,MoE退化成低效Dense模型。
所以MoE一般会引入负载均衡损失,让Router不要把所有token都塞给少数专家。负载均衡不是为了让路由完全随机,而是让专家都有足够训练机会,同时保留内容相关的选择能力。
辅助损失如何约束Router
常见做法是统计一个batch中每个专家实际接收了多少token,以及Router给每个专家分配了多少概率质量。可以定义:
- $f_e$:第$e$个专家实际接收token的比例。
- $P_e$:Router给第$e$个专家的平均概率。
- $N$:专家数量。
一种典型的负载均衡损失可以写成:
$$ L_{balance}=\lambda \cdot N\sum_{e=1}^{N}f_eP_e $$
这里需要注意,这只是Switch Transformer一类方法中常见的辅助损失形式,不是所有MoE模型都完全这么写。后续很多模型会调整负载均衡目标,比如按sequence统计、按device统计,或者弱化辅助损失,改用更稳定的路由策略。
这个损失的目标不是让所有token随机分配,而是避免所有token长期集中到少数专家。比较理想的状态是:不同专家都有稳定流量,同时Router仍然可以根据token内容做有意义的选择。
专家容量与token溢出
除了辅助损失,MoE还会设置专家容量(Expert Capacity)。因为一个batch里面可能很多token都选中了同一个专家,如果不限制容量,这个专家的计算量会突然变得很大。
假设batch中有$T$个token、$N$个专家、每个token选择$K$个专家,那么平均每个专家接收:
$$ \frac{T \times K}{N} $$
个token。实际实现中会乘上一个容量因子$c$:
$$ C=\left\lceil c\cdot \frac{T\times K}{N}\right\rceil $$
$C$就是每个专家最多处理的token数。如果超过这个容量,超出的token可能会被丢弃、跳过专家计算、交给备用专家,或者通过其他策略重新路由。不同框架实现会有差异,但目的都是避免局部专家过载。
容量因子$c$太小,容易出现token溢出,影响训练信号和生成质量;容量因子太大,又会让显存和计算预留变多,降低MoE稀疏计算的收益。后来也有dropless MoE这类实现,尽量不丢token,而是通过更好的调度和kernel实现来处理不均衡负载。
训练与推理过程
MoE层的前向与反向传播
MoE层的前向过程可以拆成4步:
- Router为每个token计算专家概率。
- 选择Top-K专家,并生成对应权重。
- 将token按照专家编号重新分组,同一个专家处理分给自己的token。
- 将专家输出按照原始token位置散回去,再按Router权重加权合并。
从张量操作角度看,MoE层的核心不是单纯的矩阵乘法,而是“路由、分发、专家计算、合并”。这也是MoE实现比Dense FFN复杂很多的原因。
MoE可以端到端训练。专家参数通过主任务损失更新,Router参数也会根据被选中专家的输出效果更新。但由于Top-K选择是离散操作,没有被选中的专家通常拿不到当前token的梯度。因此训练时会有几个重点:
- Router不能过早坍缩到少数专家。
- 每个专家要拿到足够多样的数据。
- 负载均衡损失不能太大,否则会破坏内容相关的路由。
- batch要足够大,否则每个专家拿到的token太少,计算效率和训练稳定性都会受影响。
一些实现还会给Router加入噪声或扰动,让早期路由有更多探索,避免一开始就固定到少数专家。
激活参数与总参数
MoE经常会说“总参数很大,激活参数较小”。这句话要分清楚两个概念:
- 总参数:模型文件里所有专家、Attention、Embedding等参数总和。
- 激活参数:某个token在一次前向中实际参与计算的参数。
假设一个MoE层有8个专家,每个token只选择2个专家,那么这一层的专家参数总量是8份,但单个token只计算其中2份。这样激活参数小于总参数,计算量也不会随着专家总数线性增长。
但这不代表部署时只需要存放激活专家的权重。推理时不同token可能路由到不同专家,所以通常仍然需要把所有专家权重放在显存中,或者通过多卡/多机切分存放。MoE省的是每个token的计算,不一定省模型权重显存。
多GPU通信开销
在多GPU训练或推理时,专家通常会被分布到不同GPU上。Router选完专家后,token需要被发送到对应专家所在的GPU,专家算完以后再把结果发回来。这类操作一般称为All-to-All通信。
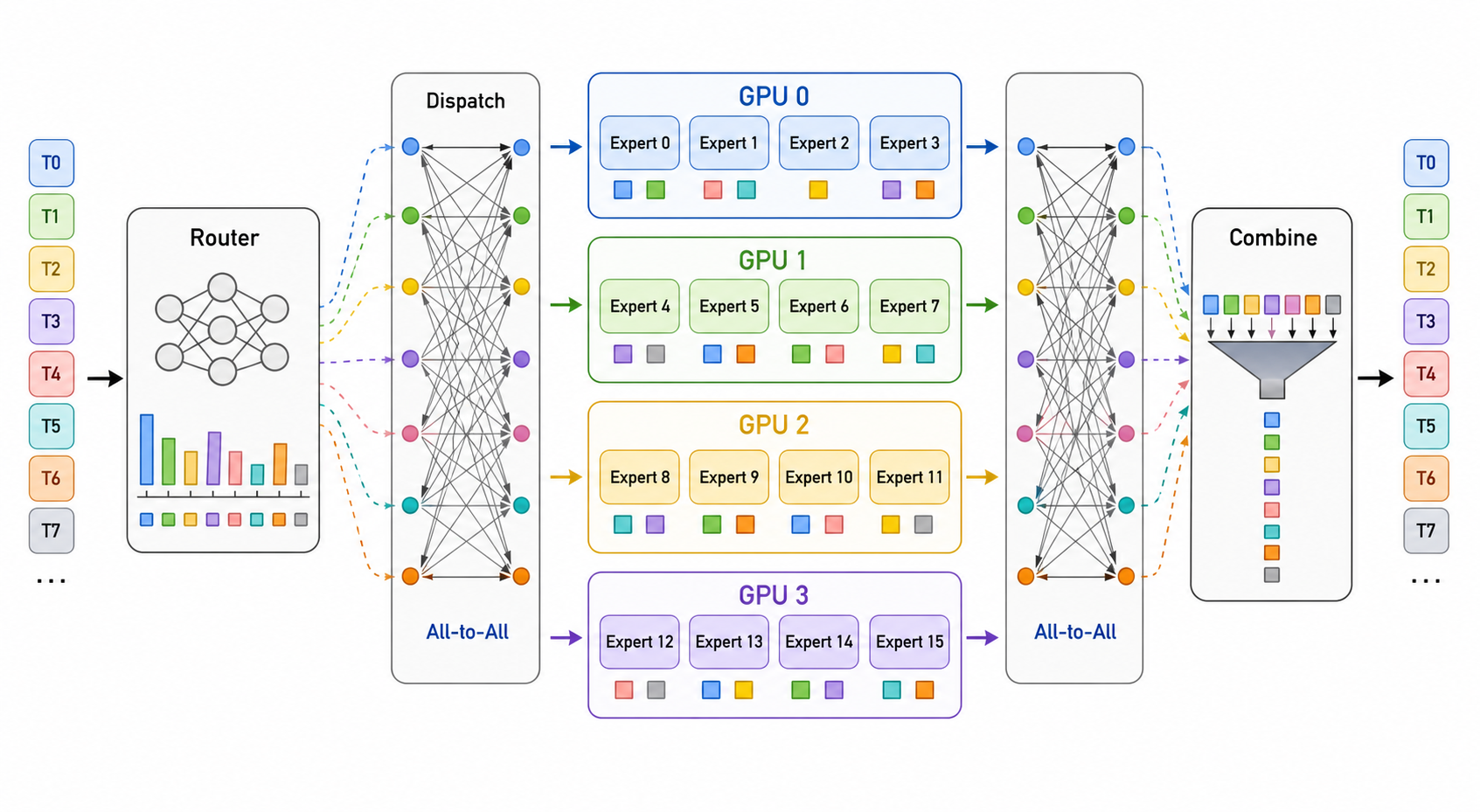
上图中Router先决定每个token要去哪几个专家,然后通过Dispatch发送到不同GPU上的专家,专家计算完以后再通过Combine恢复原始token顺序。这里的瓶颈不只是矩阵计算,还包括通信和调度:
- batch太小,专家计算不饱满,通信开销反而明显。
- 路由不均衡,某些GPU上的专家成为瓶颈。
- token分发和回收需要额外内存搬运。
这也是为什么MoE在训练吞吐上很依赖系统实现。理论上MoE能扩大参数规模,但落地时必须把路由、负载均衡、专家并行和通信效率一起考虑。
KV Cache为什么不会变小
对于自回归大模型推理,KV Cache来自Attention层,用于缓存历史token的Key和Value。MoE主要改造的是FFN层,不会直接减少Attention层的KV Cache。
所以长上下文推理时,MoE能降低部分FFN计算,但KV Cache显存压力仍然存在。如果上下文很长,Attention和KV Cache依旧可能是主要瓶颈。
换句话说,MoE不是一种“显存万能优化”。它主要降低的是每个token在专家FFN部分的计算,而不是让上下文缓存、Embedding、Attention参数自动变小。
参数计算与模型变体
参数量和计算量示例
假设某层Dense FFN参数规模为:
$$ 2\times d_{model}\times d_{ff} $$
如果把它换成8个同样大小的专家,那么专家总参数变成:
$$ 8\times 2\times d_{model}\times d_{ff} $$
如果Top-2路由,每个token只激活其中2个专家,那么该token在专家部分实际计算约为:
$$ 2\times 2\times d_{model}\times d_{ff} $$
可以用一个简化表来理解:
| 配置 | 专家总参数 | 单token专家计算 | 说明 |
|---|---|---|---|
| Dense FFN | 1份 | 1份 | 所有token都走同一个FFN |
| 8专家Top-1 | 8份 | 1份 | 容量扩大,专家计算接近原FFN |
| 8专家Top-2 | 8份 | 2份 | 容量扩大,单token专家计算约为2倍 |
| 8专家全激活 | 8份 | 8份 | 退化成Dense式全计算,不再稀疏 |
这说明一个关键点:MoE不是“免费把模型变大”。如果每个专家都和原Dense FFN一样大,Top-2的专家计算会比原单个FFN更高;但相比“把8个专家全部算一遍”的Dense扩容方式,Top-2只算其中2个,计算增长远小于总参数增长。
也就是说,MoE真正解决的问题是:在不让每个token承担全部参数计算的情况下,提高模型总容量。
Sparse MoE、Shared Expert与Expert Choice
MoE有很多变体,不同变体主要是在路由方式、专家组织方式和负载均衡方式上做权衡。
| 变体 | 核心思路 | 作用 |
|---|---|---|
| Sparse MoE | 每个token只选择少量专家 | 当前大语言模型中最常见,计算效率高,但训练和系统实现更复杂 |
| Shared Expert | 增加所有token都会经过的共享专家 | 承接通用能力,减少不同路由专家重复学习相同基础知识 |
| Expert Choice | 专家反过来选择token | 更直接控制每个专家容量,缓解负载不均衡 |
共享专家不需要Router选择,而是所有token都会经过它。路由专家负责处理更细分的模式,共享专家负责承接通用知识和公共能力。这种设计的直觉是:不是所有信息都需要被分流,有些基础能力每个token都可能需要。
Expert Choice则把普通Token Choice路由反过来。普通路由是“token选择专家”,Expert Choice是“专家选择token”。这样可以更直接控制每个专家的容量,不过也会改变token和专家之间的匹配方式,工程实现和训练目标都会更复杂。
代表模型对比
下面列几个典型模型,方便把前面概念和实际模型对应起来。
| 模型 | 路由/专家特点 | 主要意义 |
|---|---|---|
| Sparsely-Gated MoE | 稀疏门控、多专家FFN | 早期将条件计算用于超大规模神经网络 |
| GShard | Top-2路由、自动分片 | 将MoE扩展到大规模Transformer训练 |
| Switch Transformer | Top-1路由 | 用更简单的路由方式降低MoE训练复杂度 |
| Mixtral | 8专家Top-2 | 让开源LLM中MoE结构被广泛关注 |
| DeepSeekMoE | 细粒度专家、共享专家 | 强调专家专门化与共享通用能力的结合 |
这些模型并不是简单地“专家越多越好”。专家数量、每个专家大小、Top-K大小、共享专家比例、负载均衡方式都会影响最终效果。MoE的难点不只是把FFN复制成多个专家,而是让这些专家在训练和推理时都能高效、稳定地工作。
小结
MoE的核心不是“多个模型投票”,而是把Transformer里的FFN层拆成多个专家,再通过Router为每个token选择少量专家。这样模型可以拥有更大的总参数容量,但每个token只承担部分专家计算。
从原理上看,MoE主要由三部分组成:
- Router:决定每个token走哪些专家。
- Expert:通常是多个独立FFN/MLP。
- Dispatch/Combine:负责把token分发到专家,再把结果按权重合并回来。
从落地上看,MoE的难点也很明确:路由要均衡、专家要充分训练、多卡通信要高效、推理时还要处理动态路由带来的调度开销。因此MoE更像是一种“模型结构 + 系统工程”结合的方案,而不只是简单替换一层网络。
参考:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- Mixtral of Experts
- DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
评论