学习 SoC 架构时,最容易混淆的是几个词:Bus、AXI、NoC、DDR、QoS。它们不是同一层面的概念。
- Bus、Crossbar、Fabric、NoC:描述片上模块之间怎么连接。
- AXI、AHB、APB、ACE、CHI:描述模块之间用什么协议通信。
- DDR Controller、DDR PHY、LPDDR/DDR:描述外部内存如何接入 SoC。
- QoS:描述多个模块同时抢 NoC、DDR 时如何调度。
更准确地说,这些概念应该分层理解:
业务模块层:CPU / GPU / NPU / VPU / Display / DMA / I/O
协议层 :AXI / AHB / APB / ACE / CHI
互连层 :Bus / Crossbar / Fabric / NoC
存储层 :SRAM / ROM / DDR Controller / DDR PHY / LPDDR
调度层 :QoS / priority / bandwidth limit / urgent / aging
一句话总结:
AXI/CHI 是语言,Bus/NoC 是道路,DDR Controller 是内存调度站,
DDR PHY 是电气接口,LPDDR/DDR 是真正保存数据的仓库,QoS 是竞争规则。
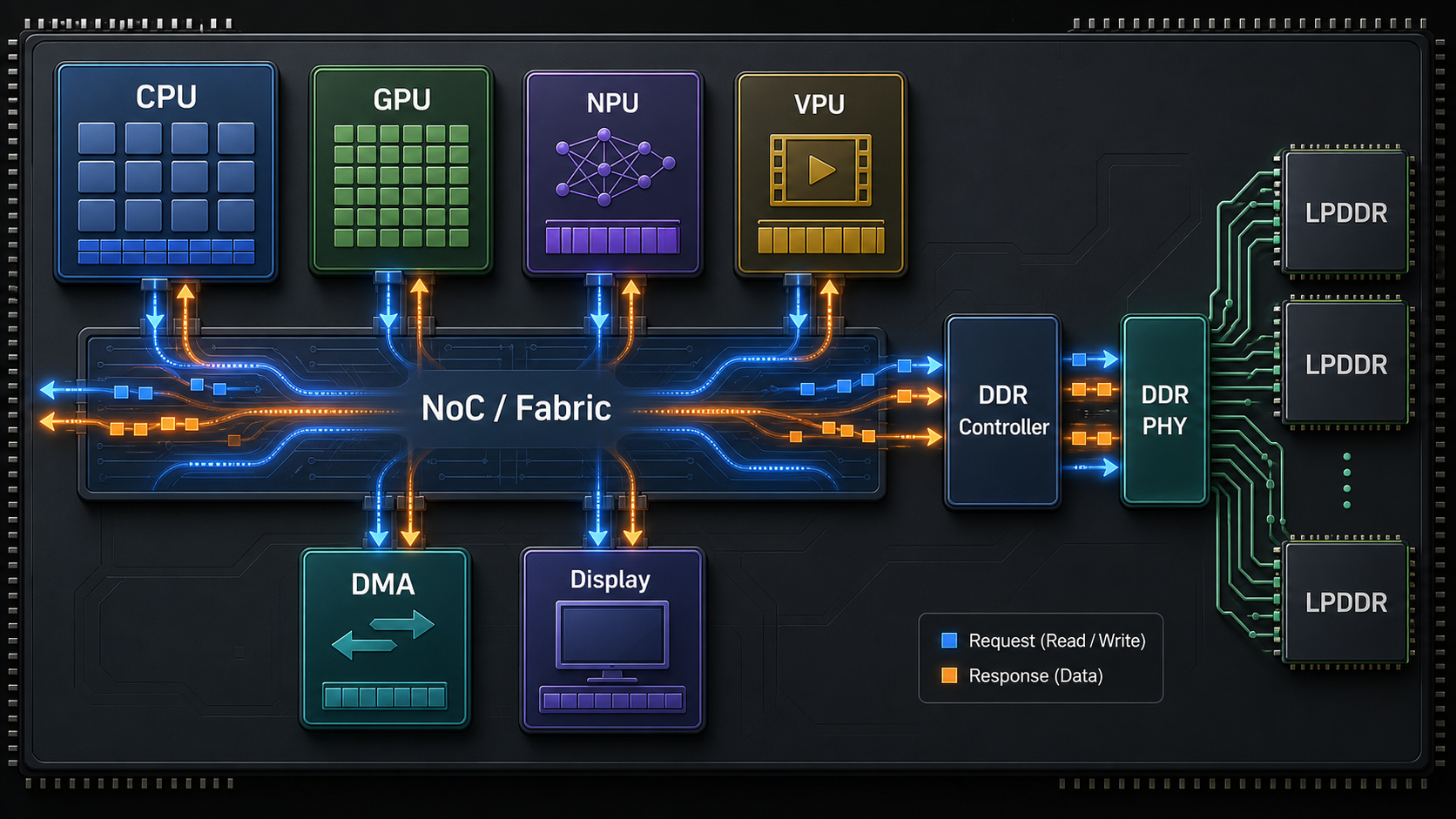
上图展示了现代 SoC 中常见的数据通路:CPU、GPU、NPU、VPU、Display、DMA 等模块先进入片上互连 Fabric/NoC,再访问 DDR Controller,最后通过 DDR PHY 访问片外 LPDDR/DDR 颗粒。蓝色和橙色箭头可以理解为请求与数据返回。
1. 为什么 SoC 需要互连
SoC 不是一个 CPU 加一块内存这么简单,而是很多硬件模块组成的系统。
常见模块包括:
- CPU cluster:运行操作系统和应用。
- GPU:图形渲染和通用计算。
- NPU/AI core:神经网络推理。
- VPU:视频编解码。
- ISP/Camera:摄像头图像处理。
- Display Controller:从 DDR 读取 framebuffer 并输出到屏幕。
- DMA:做大块数据搬运。
- PCIe、USB、UFS、Ethernet:高速 I/O。
- UART、SPI、I2C、GPIO:低速外设。
- DDR Controller:访问外部内存。
- SRAM、ROM:片上存储。
这些模块之间需要互相访问。例如:
CPU -> UART 寄存器
CPU -> DDR
GPU -> DDR
VPU -> DDR
Display -> DDR framebuffer
PCIe DMA -> DDR
Camera -> DDR image buffer
所以 SoC 内部必须有一套互连系统,负责把访问请求从发起者送到目标模块。
在硬件里通常有两个角色:
Master / Initiator:发起访问的一方,例如 CPU、DMA、GPU、VPU
Slave / Target :响应访问的一方,例如 DDR Controller、SRAM、外设寄存器
软件看到的是统一物理地址空间:
0x0000_0000 ROM / SRAM
0x1000_0000 外设寄存器
0x8000_0000 DDR
CPU 访问某个地址时,互连系统根据地址译码,把请求路由到对应目标。
这里有一个容易忽略的点:CPU 访问外设寄存器和访问 DDR,在软件上都可能只是普通 load/store,但在硬件路径上差异很大。
CPU 访问 UART 寄存器:通常走低速寄存器总线,目标是外设控制寄存器
CPU 访问 DDR :通常走高性能互连,目标是 DDR Controller
Display 读取帧缓存 :通常是硬件 master 主动从 DDR 发起读请求
DMA 搬运数据 :通常是硬件 master 主动读一个地址、写另一个地址
所以“总线”不是只服务 CPU,很多硬件模块本身也是 master。
2. 从 Bus 到 Crossbar 再到 NoC
片上互连的发展,基本是从简单到复杂、从低并发到高并发的过程。
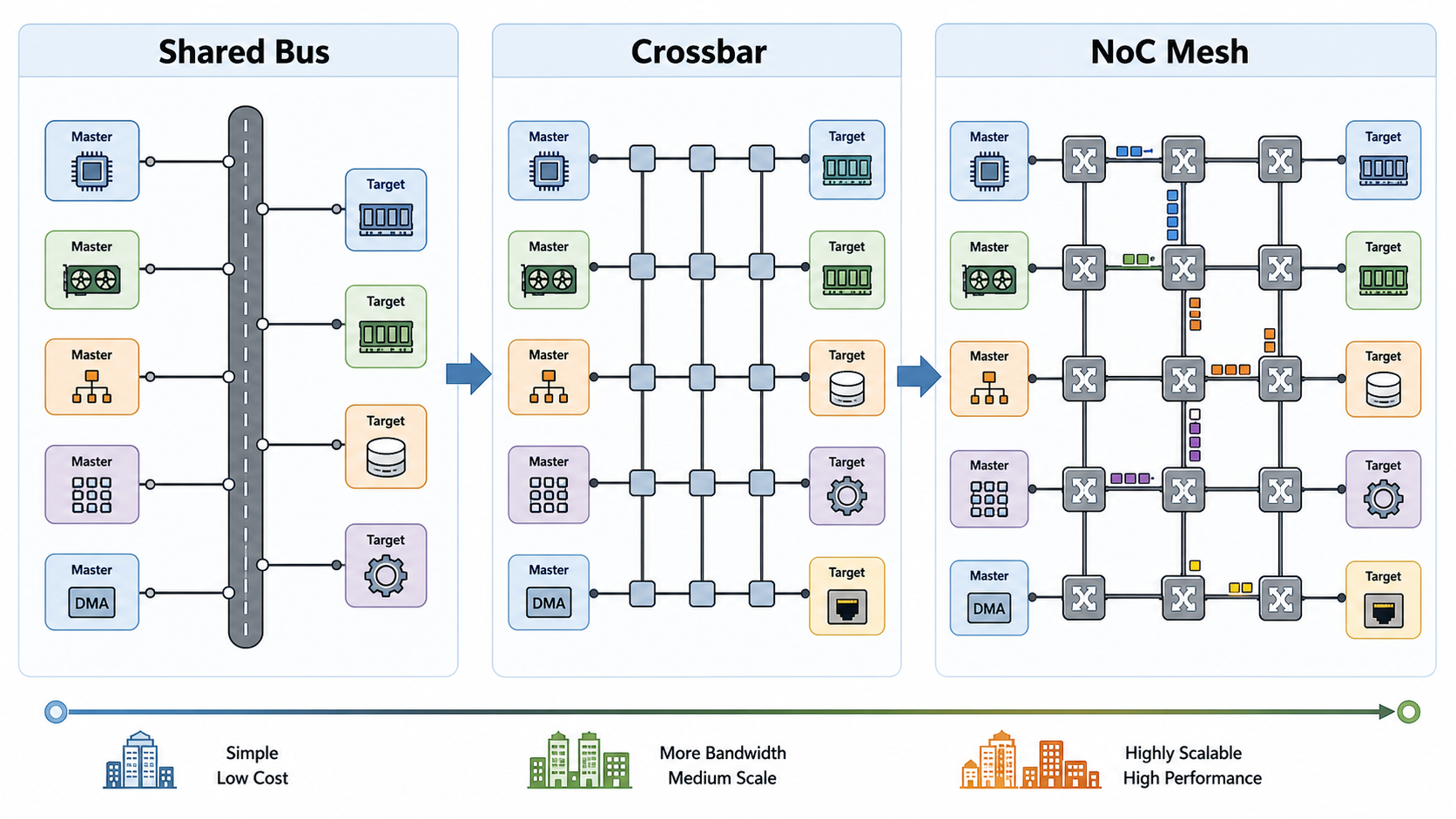
2.1 Shared Bus
最早的片上互连可以理解成一条共享总线。
CPU ----+
DMA ----+---- Shared Bus ---- SRAM / DDR / Peripheral
USB ----+
它的优点是简单,面积小,控制容易,适合 MCU 或低速控制系统。
缺点也明显:
- 同一时间通常只有一个 master 使用总线。
- master 变多后,仲裁压力变大。
- 带宽容易被某个模块占满。
- 总线线长变长后,时序难收敛。
- 不适合高带宽、多并发场景。
所以今天的复杂 SoC 不会只靠一条传统共享总线支撑全系统。
2.2 Crossbar
Crossbar 是共享总线的增强版。它允许多个 master 同时访问不同 target。
CPU ----\
GPU ----- Crossbar ---- DDR
DMA ----/ \- SRAM
\- Peripheral
例如 CPU 访问 SRAM,DMA 同时访问 DDR,这两个访问可以并行。
Crossbar 的问题是规模扩展性。它的连接复杂度接近:
master 数量 * target 数量
当 master 和 target 数量变多时,crossbar 的面积、功耗、布线、时序都会变得很难控制。
2.3 NoC
NoC 是 Network on Chip,片上网络。它把互连做成类似网络的结构。
典型组成:
- NIU:Network Interface Unit,把 AXI/CHI 等协议请求接入 NoC。
- Router/Switch:负责转发 packet/flit。
- Link:router 之间的连接。
- Buffer/Queue:缓存请求,吸收突发流量。
- Arbiter:多个请求竞争时决定谁先过。
- QoS/Regulator:优先级、限速、带宽保证。
抽象结构如下:
CPU -- NIU -- Router -- Router -- DDRC
GPU -- NIU ----/ |
NPU -- NIU -- Router -----+
VPU -- NIU ----/
NoC 的优势是可扩展:
- 可以把大芯片拆成多个物理区域。
- 可以用多个 router 分散布线压力。
- 可以支持多个时钟域、电源域。
- 可以做流量分类、QoS、带宽限制。
- 可以支持多 DDR Controller、多路径、多 master 并发。
它的代价是复杂度更高:
- router、buffer、queue 会增加面积和功耗。
- packet 化和排队会引入额外延迟。
- QoS、路由、监控寄存器需要系统级调试。
- 性能问题不再只看一个 master,而要看整条路径上的拥塞点。
所以关系可以这样理解:
Bus:简单共享道路
Crossbar:多入口多出口交换矩阵
NoC:片上分布式网络
3. Bus、Fabric、NoC、AXI 到底是什么关系
这里要区分两个层次:
协议层:AXI、AHB、APB、ACE、CHI
结构层:Bus、Crossbar、Fabric、NoC
协议层回答“怎么说话”,结构层回答“路怎么修”。
3.1 AMBA 协议族
Arm AMBA 是 SoC 里非常常见的一组片上通信协议。即使是 RISC-V SoC,也经常使用 AXI、AHB、APB 这类协议作为 IP 连接接口。
常见协议包括:
| 协议 | 典型用途 | 特点 |
|---|---|---|
| APB | UART、SPI、I2C、GPIO 等低速外设 | 简单、低功耗、无复杂流水 |
| AHB | 较早期的片上高性能总线 | 比 APB 强,但扩展性有限 |
| AXI | 高性能 master/slave 访问 | 支持 burst、outstanding、ID、乱序、QoS |
| ACE | AXI 加缓存一致性扩展 | 用于 cache coherent 系统 |
| CHI | 更大规模一致性互连 | 面向复杂多核和高性能 SoC |
AXI 常见 5 个通道:
AW:写地址
W :写数据
B :写响应
AR:读地址
R :读数据
一次读访问可能携带:
ARADDR:读地址
ARLEN :burst 长度
ARSIZE:每拍大小
ARID :事务 ID
ARQOS :QoS 标记
这里说的 AXI 主要是 AXI memory-mapped,用于访问地址空间里的 DDR、SRAM、寄存器窗口。还有一种常见协议叫 AXI-Stream,它没有地址通道,更像连续数据流,常用于视频、网络、音频、加速器流水线之间的数据传输。
AXI memory-mapped:有地址,适合“读写某个地址”
AXI-Stream :无地址,适合“连续推送一串数据”
讨论 NoC、DDR、QoS 时,默认通常指 AXI memory-mapped 路径。
3.2 AXI 不是 NoC
AXI 是协议,不是互连结构。
NoC 可以承载 AXI 请求:
AXI Master
|
v
NoC NIU:AXI transaction -> NoC packet
|
v
NoC routers
|
v
NoC NIU:NoC packet -> AXI transaction
|
v
AXI Slave
所以文档里看到“AXI NoC”,通常意思是:
NoC 的入口/出口是 AXI 协议,NoC 内部可能是厂商自己的 packet/flit 格式。
3.3 Fabric 是更泛的名字
很多芯片架构图会写 Main Fabric Bus、System Fabric、Interconnect Fabric。
这里的 Fabric 一般是泛称,表示全芯片互连主干。它内部可能由以下东西组合而成:
- AXI interconnect
- Crossbar
- NoC
- Bridge
- Clock domain crossing
- Power domain isolation
- QoS regulator
- Address decoder
- Security firewall
所以看到架构图上写 Bus,不要立刻理解成传统共享总线。现代 SoC 图里的 Bus 经常只是系统级抽象名。
判断它更接近传统 bus、crossbar 还是 NoC,不能只看方框图上的名字,而要看寄存器手册和互连文档里有没有这些线索:
- 是否有多个 initiator/target port。
- 是否有 route ID、node ID、traffic class。
- 是否有带宽监控和 QoS 配置寄存器。
- 是否支持 outstanding、urgent、bandwidth limiter。
- 是否有 clock domain / power domain bridge。
4. DDR 是什么
DDR 是 Double Data Rate DRAM,是 SoC 最主要的外部运行内存。
从软件角度看,DDR 是一大段物理内存。从硬件角度看,DDR 是有严格组织结构和时序约束的存储阵列。
DDR 和 LPDDR 都是 DRAM 家族。服务器、PC、部分工控板常见 DDR3/DDR4/DDR5;手机、平板、端侧 AI SoC 更常见 LPDDR4x/LPDDR5/LPDDR5x。LPDDR 的重点是低功耗和移动场景封装,协议和电气细节与普通 DDR 不完全一样,但系统结构上仍然可以按“Controller + PHY + DRAM 颗粒”理解。
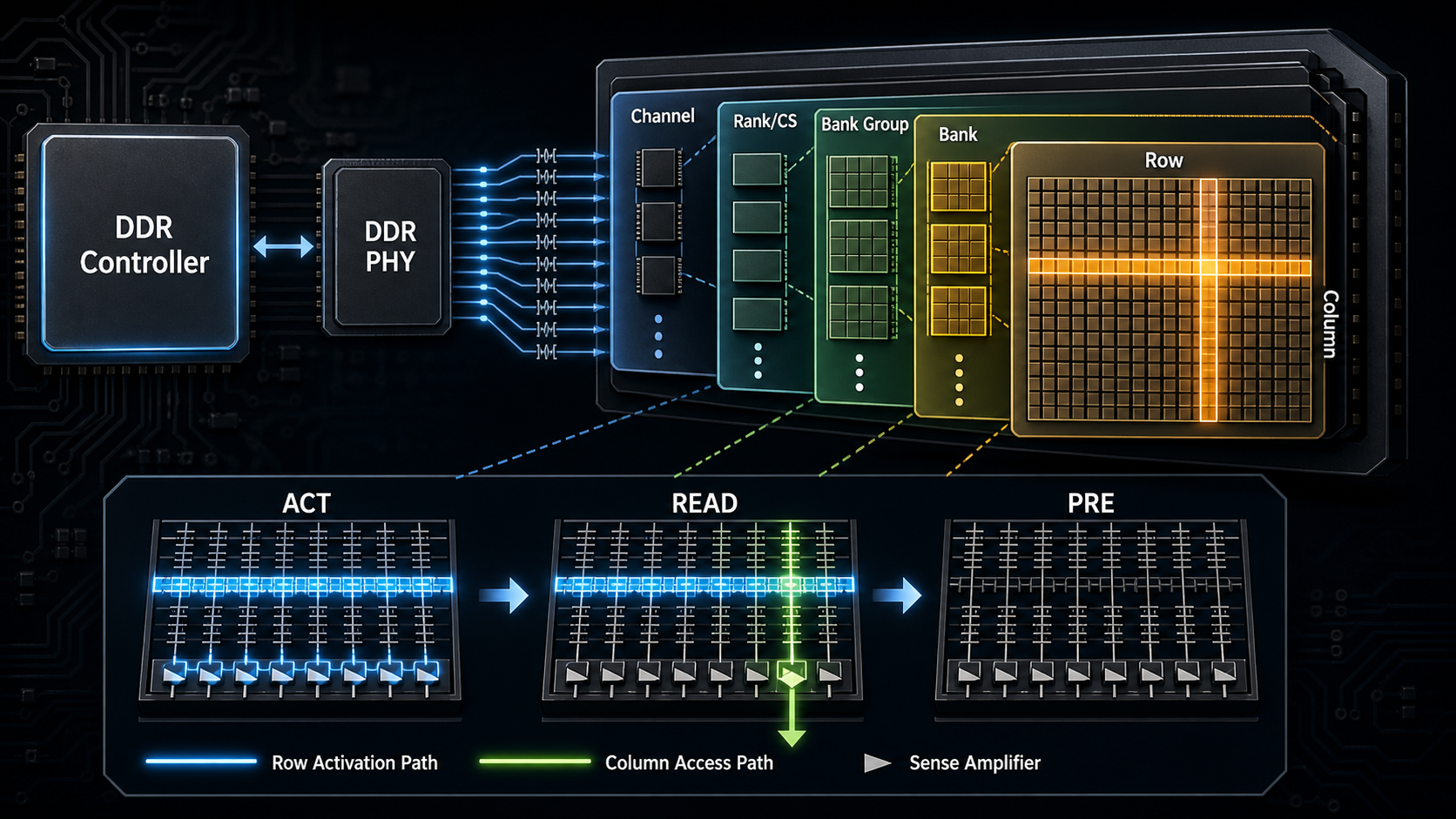
DDR 访问链路一般是:
CPU/GPU/NPU/VPU/DMA
|
v
NoC / Fabric
|
v
DDR Controller
|
v
DDR PHY
|
v
LPDDR / DDR DRAM
4.1 DDR 的内部层级
常见层级可以这样理解:
Channel
-> Rank / CS
-> Bank Group
-> Bank
-> Row
-> Column
通俗理解:
- Channel:一组独立的数据通道。
- Rank/CS:由片选控制的一组 DRAM 颗粒。
- Bank Group:多个 bank 的分组,用于提高并行性。
- Bank:可以独立打开 row 的存储阵列。
- Row:一整行存储单元。
- Column:行里的列地址。
DDR 并不是“给一个地址就立即读出一个字节”。一次访问通常涉及:
ACTIVATE:打开某个 bank 的某一行 row
READ/WRITE:访问这个 row 里的 column
PRECHARGE:关闭当前 row,准备打开其他 row
如果下一次访问还在同一个已打开 row,叫 row hit,效率高。
如果要切换到另一个 row,叫 row miss 或 row conflict,需要 precharge 和 activate,延迟更高。
4.2 DDR Controller
DDR Controller 位于 SoC 内部,负责把来自 NoC/Fabric 的访问请求变成 DDR 命令。
它主要做:
- 接收 AXI/NoC 读写请求。
- 按地址映射到 channel/rank/bank/row/column。
- 维护读写队列。
- 决定哪个请求先访问 DDR。
- 处理 refresh。
- 控制读写切换。
- 做 DDR QoS 调度。
DDR Controller 很关键,因为 DDR 本身有复杂时序限制。为了性能,它不能简单按请求到达顺序执行,而要综合考虑:
- QoS 优先级。
- 请求等待时间。
- row hit 机会。
- bank 并行性。
- 读写切换成本。
- refresh 时机。
4.3 DDR PHY
DDR PHY 负责电气层。
它把 Controller 的数字命令转换成 LPDDR/DDR 颗粒能识别的电气信号,包括:
- DQ/DQS/CLK/CA 信号。
- 读写时序对齐。
- training 和校准。
- delay line 调整。
- 电压、阻抗、采样窗口控制。
可以这样区分:
DDR Controller:协议、队列、调度、命令
DDR PHY :电气、时序、训练、信号完整性
4.4 DDR 带宽怎么估算
理论带宽公式:
带宽 = data rate * bus width / 8 * channel 数
例如 6400MT/s、64-bit 总线:
6400M * 64 / 8 = 51.2GB/s
这里的 6400MT/s 是传输速率,不是普通意义上的核心时钟频率。DDR 的名字来自 Double Data Rate,即一个时钟周期的上升沿和下降沿都传数据,所以数据传输率会高于时钟频率。资料里常见的 Mbps、MT/s、Gbps 要结合总线位宽一起看,不能只看单个数字。
但理论带宽不等于实际可用带宽。实际效率会被这些因素影响:
- row miss。
- refresh。
- 读写切换。
- bank 冲突。
- 命令时序约束。
- NoC 拥塞。
- DDR Controller 调度策略。
- QoS 限速。
5. 一次内存访问完整发生什么
以 VPU 读取 DDR 中的视频码流为例:
1. VPU 发起 AXI read 请求。
2. 请求带上地址、burst 长度、ID、ARQOS 等信息。
3. NoC/Fabric 的入口 NIU 接收请求。
4. NoC 根据地址判断目标是 DDR Controller。
5. 请求在 NoC router/link 中传输,中途可能和其他流量竞争。
6. NoC QoS 决定它什么时候能通过拥塞点。
7. 如果路径上有 IOMMU、IOPMP 或 firewall,还会做地址转换、权限检查或访问过滤。
8. 请求到达 DDR Controller。
9. DDR Controller 把请求放入读队列。
10. DDR Controller 根据 QoS、等待时间、bank/row 状态选择下一个请求。
11. DDR PHY 发出 ACT/READ/PRE 等电气时序。
12. DDR DRAM 返回数据。
13. 数据经 DDR PHY、Controller、NoC 返回 VPU。
所以一次 DDR 访问跨越了多层:
模块接口 -> 协议 -> NoC/Fabric -> DDR Controller -> DDR PHY -> DDR DRAM
任何一层出问题,都可能表现为“DDR 慢”。
常见瓶颈判断:
| 现象 | 可能原因 |
|---|---|
| 总吞吐上不去 | DDR 带宽满、NoC 链路满、outstanding 太少 |
| 延迟很高 | NoC 拥塞、DDR row miss 多、QoS 优先级低 |
| Display 花屏/underflow | 实时读流量没有得到最低带宽或 urgent 保护 |
| CPU 变卡 | 后台 DMA/GPU/NPU 抢占 DDR,CPU 读延迟升高 |
| VPU 解码超时 | 码流读或帧写被其他高带宽 master 挤压 |
6. QoS 为什么必须存在
现代 SoC 中,所有高性能模块最终都会争抢共享资源,尤其是 NoC 和 DDR。
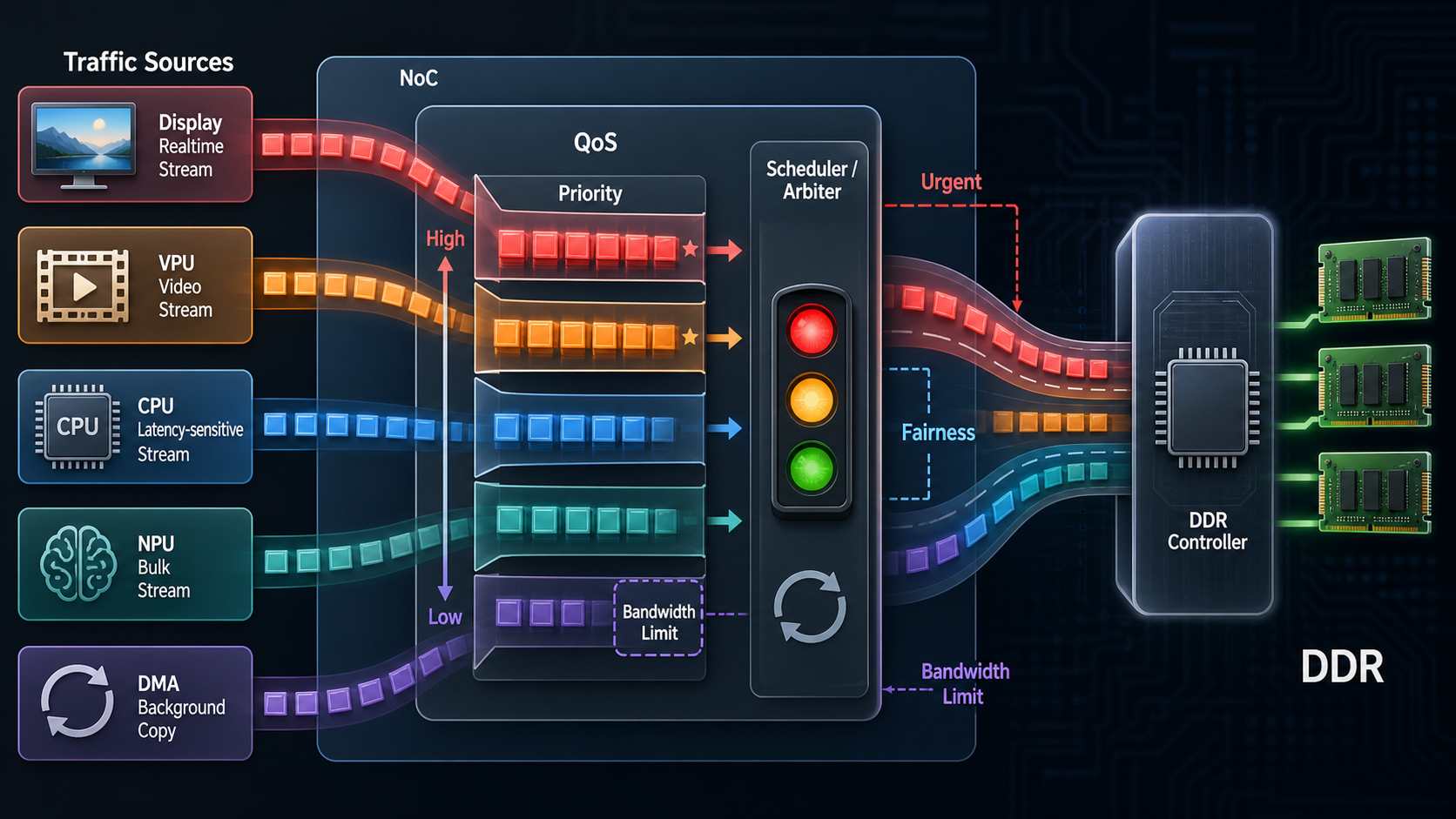
典型并发场景:
CPU 正在跑系统和应用
NPU 正在读权重和 feature map
GPU 正在渲染
VPU 正在编解码 4K 视频
Display 正在稳定读取 framebuffer
Camera 正在写图像 buffer
PCIe/USB/UFS 正在 DMA
如果没有 QoS,一个后台 DMA 或 NPU 可能把 DDR 打满,导致 Display 读不到数据,屏幕出现 underflow;或者 VPU 拿不到数据,视频卡顿;或者 CPU load 不高但交互很慢。
QoS 要解决的问题是:
- 谁优先?
- 谁最低带宽必须保证?
- 谁最大带宽要限制?
- 谁等待太久需要提权?
- 谁对延迟敏感?
- 谁只是后台吞吐?
注意,QoS 通常不是“绝对保证”。AXI 的 ARQOS/AWQOS 这类信号更像给互连和 DDR Controller 的调度提示,最终效果取决于芯片内部 QoS 寄存器、仲裁策略、限速器、队列深度和 DDR 当前状态。
6.1 NoC QoS
NoC QoS 管的是“路上怎么走”。
常见配置对象:
- master port priority。
- read/write traffic class。
- virtual channel。
- bandwidth limiter。
- outstanding 限制。
- urgent 信号。
- router 仲裁权重。
- NoC monitor 统计。
例如:
Display 读 framebuffer:实时流量,优先级高,需要防止 FIFO underflow。
DMA 后台搬运:吞吐流量,优先级低,可以限速。
CPU 请求:通常带宽不一定大,但延迟敏感。
NPU/GPU:带宽很大,需要限制 burst 对其他模块的影响。
6.2 DDR QoS
DDR QoS 管的是“到了 DDR Controller 后谁先进内存”。
常见机制:
- read/write 队列优先级。
- port priority。
- aging,等待时间过长自动提权。
- urgent threshold。
- read/write switch 策略。
- bank/row scheduler。
- bandwidth guarantee。
- bandwidth cap。
DDR Controller 的调度比较特殊,它不只看优先级,还要看 DDR 效率。
例如:
请求 A:高优先级,但访问另一个 row,需要 precharge + activate
请求 B:低优先级,但刚好 row hit
Controller 可能需要在“QoS 公平性”和“DDR 效率”之间取平衡。
NoC QoS 和 DDR QoS 的分工可以这样区分:
| 类型 | 关注点 | 典型问题 |
|---|---|---|
| NoC QoS | 片上路径、router、link、端口竞争 | 某段 fabric 被 NPU/DMA 打满,Display 请求过不去 |
| DDR QoS | DDR Controller 队列和 DRAM 命令调度 | 请求到了 DDRC,但排队太久或被读写切换、row miss 拖慢 |
实际调性能时,要尽量同时看 NoC 监控和 DDR 监控。只看 DDR utilization,可能漏掉 NoC 某个端口已经拥塞;只看 NoC 带宽,也可能漏掉 DDR row conflict 和 read/write switch 的损耗。
6.3 QoS 不是增加总带宽
QoS 不会凭空增加 DDR 带宽。
它做的是资源分配:
把有限带宽和有限低延迟机会,分配给更需要的模块。
所以 QoS 配置不当也会出问题:
- 所有模块都设最高优先级,等于没有优先级。
- 实时模块保护过强,后台吞吐下降明显。
- 最小带宽配置总和超过 DDR 实际能力,系统仍然会抖。
- CPU 优先级过低,系统交互变慢。
- DMA 没有限速,会冲击视频、显示、AI 任务。
7. Coherent 和 Non-Coherent
CPU 有 cache,多核之间共享内存时,需要缓存一致性。
例如:
CPU0 修改地址 A
CPU1 也缓存了地址 A
CPU1 不能继续读到旧值
这就需要 coherent interconnect。
一致性系统会处理:
- cache line 状态。
- snoop。
- ownership。
- shared/exclusive/modified 状态。
- 多 cluster 之间的数据可见性。
常见协议概念包括 MESI、MOESI、ACE、CHI。
但很多外设不需要硬件缓存一致性。例如 UART、SPI、普通 DMA 通常可以走 non-coherent fabric。它们和 CPU 共享 buffer 时,需要软件配合 cache flush/invalidate,或者通过 IOMMU/一致性端口访问。
要注意,IOMMU 主要解决地址转换和访问权限问题,不天然等于缓存一致性。一个设备经过 IOMMU 访问 DDR,仍然可能是 non-coherent 的;是否 coherent 取决于设备接入的端口、互连协议和 SoC 的一致性设计。
Coherent 也不等于一定更快。它解决的是“多个带 cache 的主体共享数据时是否正确”的问题,代价是 snoop、状态维护和一致性流量。对大吞吐、顺序访问、很少共享的数据流,non-coherent DMA 加上正确的 cache 管理反而更简单。
现代 SoC 常见结构是:
CPU cluster / cache coherent accelerator
|
Coherent Interconnect
|
Main Fabric / NoC
|
DDR / SRAM / I/O / Peripheral
这也是为什么一些芯片图里会同时出现:
Coherent Interconnect Bus
Main Fabric Bus
DDR Controller
DDR PHY
前者偏 CPU/多核一致性域,后者偏全芯片主干互连。
参考资料
- Arm AMBA specifications: https://www.arm.com/architecture/system-architectures/amba/amba-specifications
- Arm AXI channel signals: https://developer.arm.com/documentation/102202/0300/Channel-signals
- Dally and Towles, Route Packets, Not Wires: https://cva.stanford.edu/publications/2001/onchip_dac01.pdf
- Benini and De Micheli, Networks on Chips: A New SoC Paradigm: https://infoscience.epfl.ch/bitstreams/9d299acb-f8dc-497a-8877-c72790f3d7bf/download
- Micron DDR5 SDRAM overview: https://www.micron.com/products/memory/dram-components/ddr5-sdram
- SpacemiT K3 documentation: https://github.com/spacemit-com/docs-chip/blob/main/en/key_stone/k3/k3_docs/k3_ds.md
评论