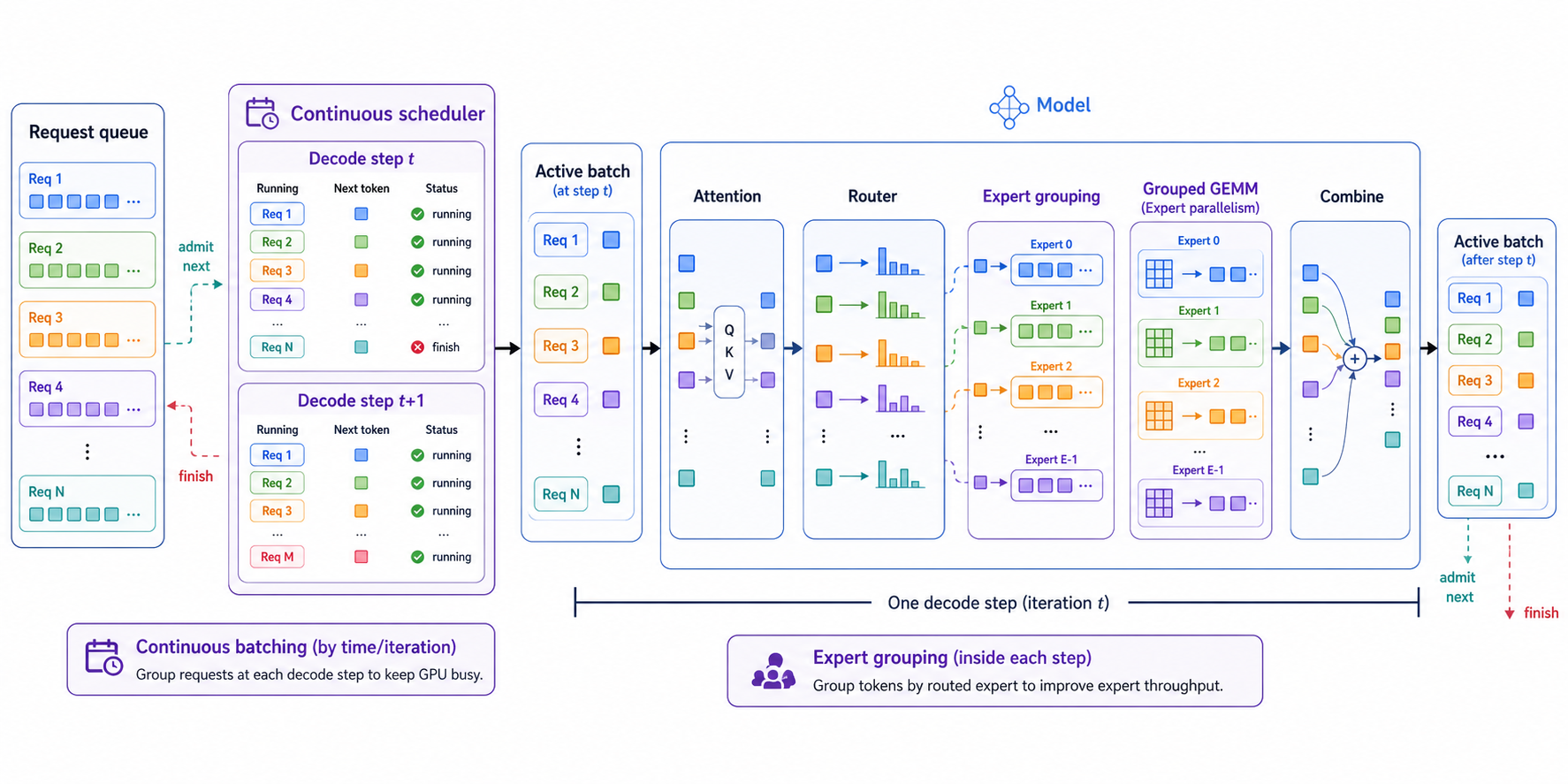
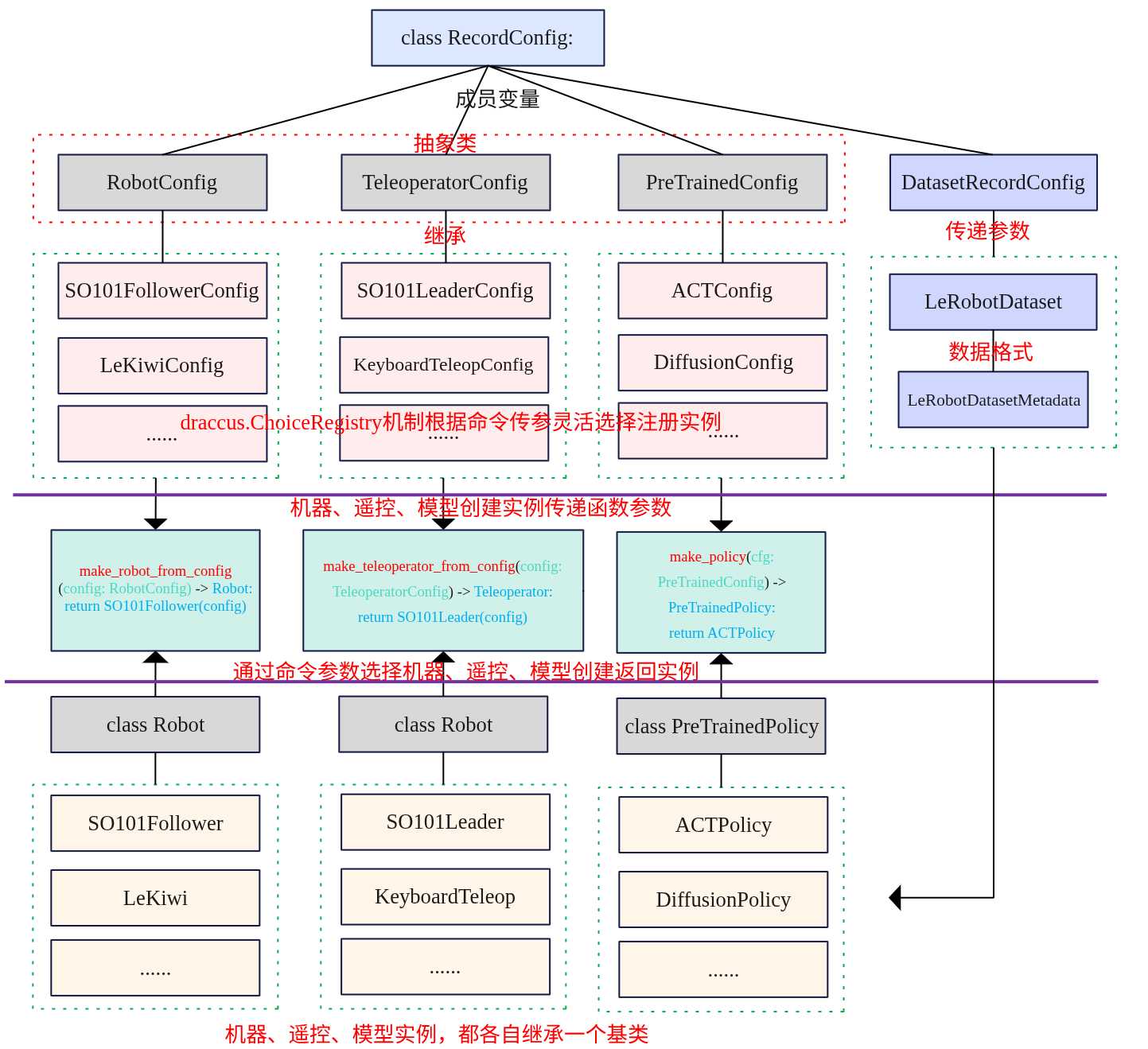
Continuous Batching与Expert Grouping:大模型推理服务优化原理
概述 大模型推理服务的核心问题不是“单个请求能不能跑”,而是“很多请求同时进来时,GPU能不能一直忙,并且用户等待时间不要太长”。这里会遇到两个层面的调度问题。 请求层面:不同用户请求
概述 大模型推理服务的核心问题不是“单个请求能不能跑”,而是“很多请求同时进来时,GPU能不能一直忙,并且用户等待时间不要太长”。这里会遇到两个层面的调度问题。 请求层面:不同用户请求
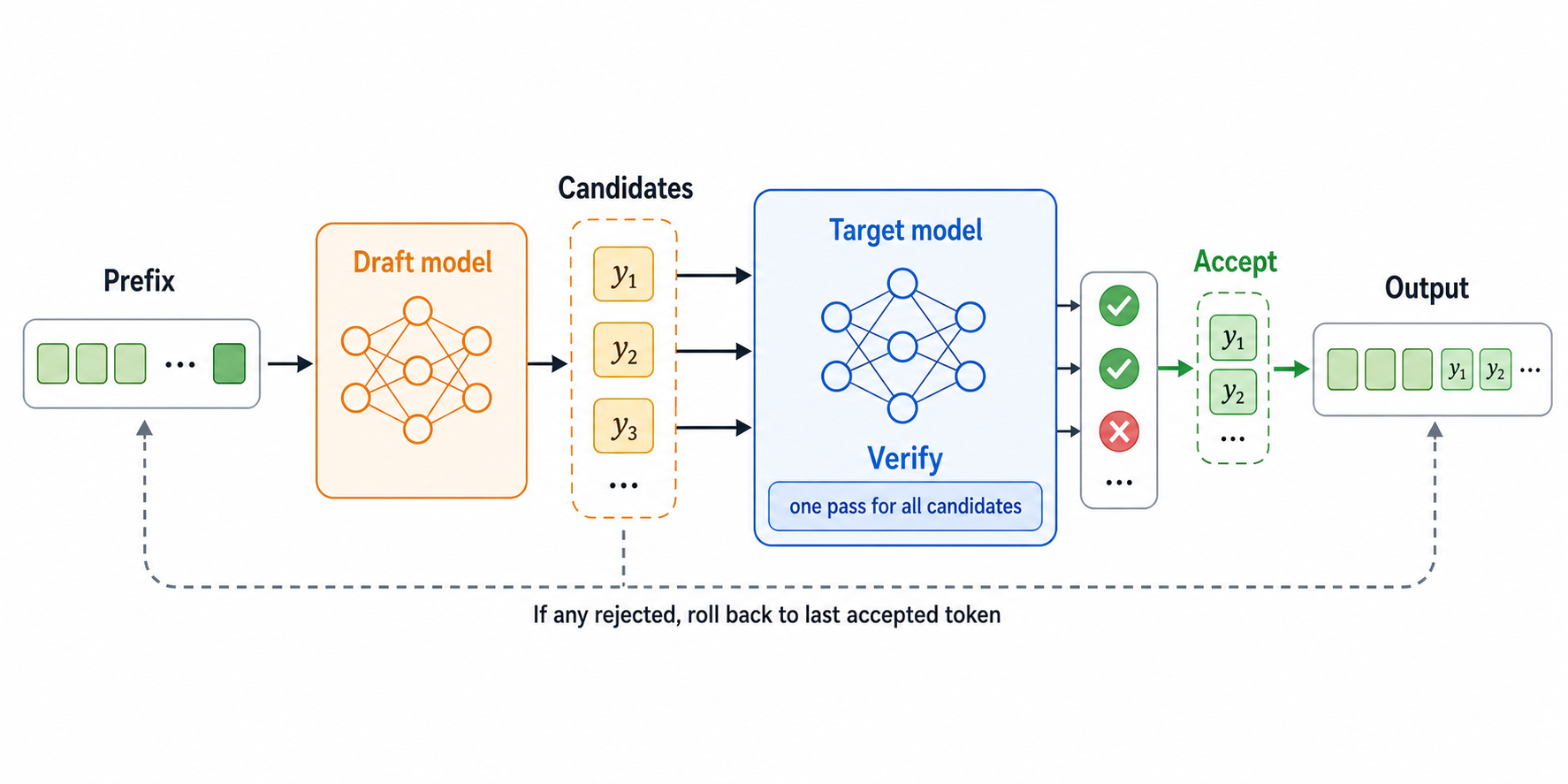
概述 大语言模型生成文本时,本质上是一个自回归过程:先根据已有上下文预测下一个token,再把这个token拼回上下文里,继续预测下一个token。也就是说,如果要生成100个tok
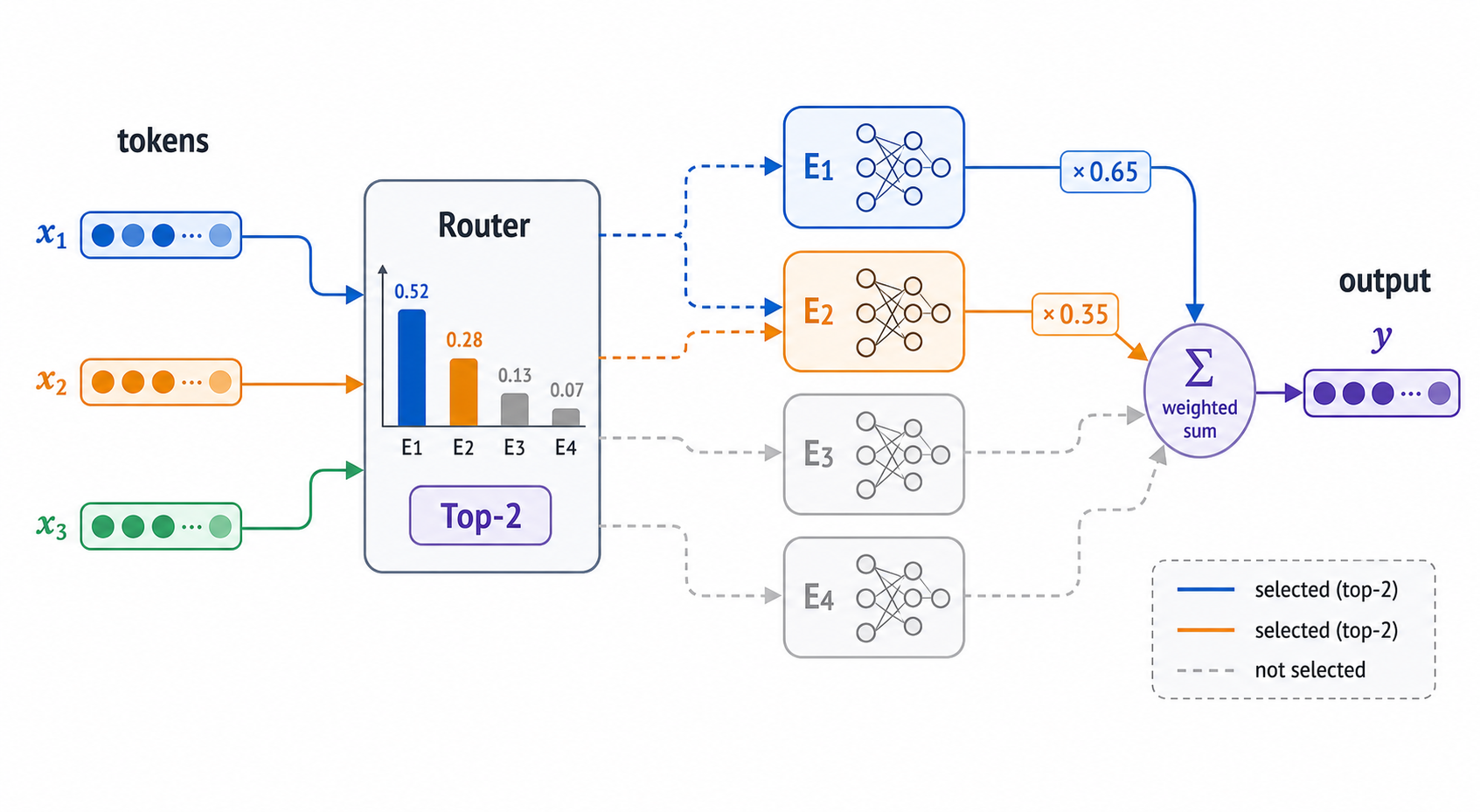
概述 大模型能力提升通常依赖两个方向:模型参数变多、训练数据变多。Dense模型的做法比较直接,每一层的参数都会参与每个token的计算,模型越大,单次前向计算也越重。这样虽然简单,
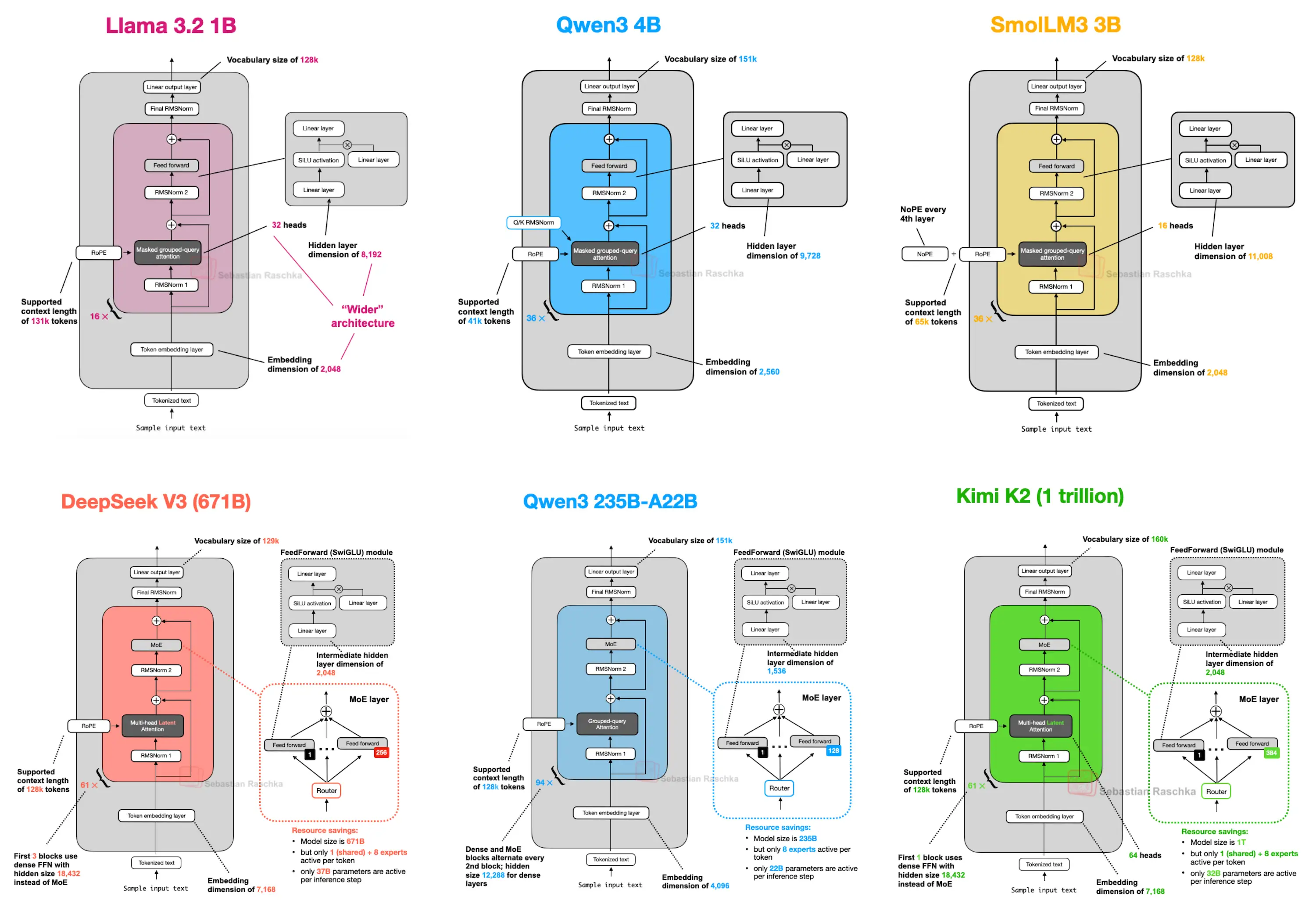
大模型推理的"第一性原理" 从Deepseek V3到Kimi K2 无论模型如何变化,当前主流大模型的核心架构都是基于transformer。其本质是一个由多层相同结构

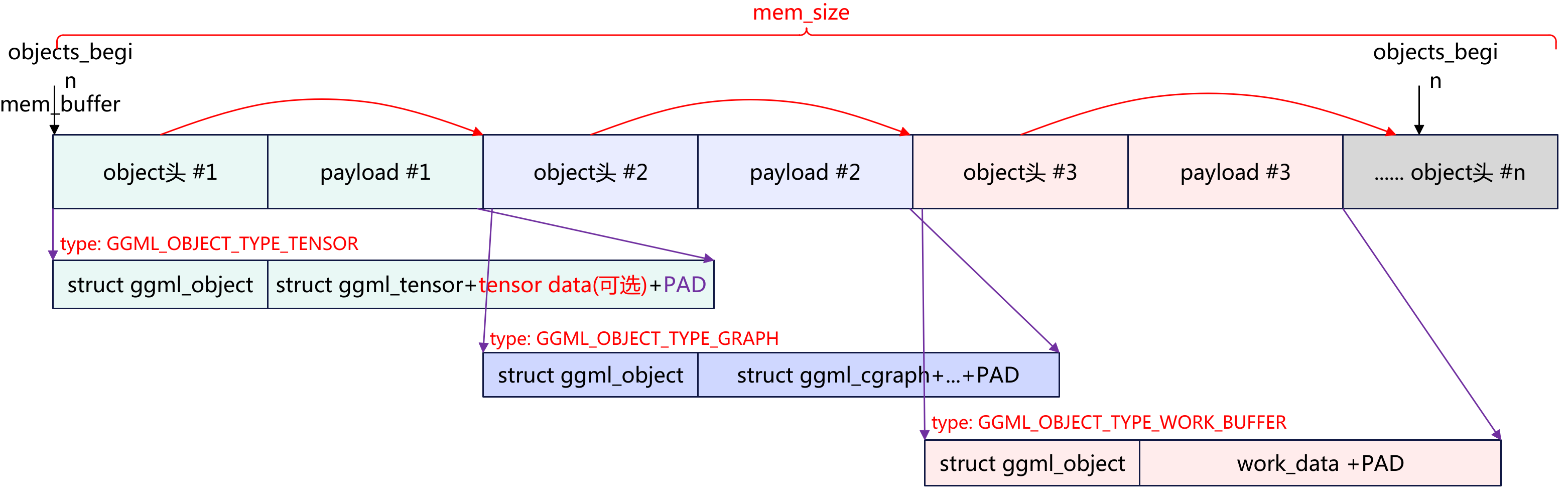
概述 llama.cpp 的模型加载系统是一个高度优化的、支持多后端、多设备的模型权重加载框架。它通过精心设计的数据结构和加载流程,实现了: 零拷贝加载:通过内存映射(mmap)实现模型文件的零拷贝加载
后端系统概述 GGML后端系统主要提供如下功能: 统一接口: 不同硬件平台使用相关的API。 自动选择:根据硬件自动选择最优后端。 灵活切换:可以在运行时切换后端。 扩展性:易于添加的新后端。

加载后端 void ggml_backend_load_all() { ggml_backend_load_all_from_path(nullptr); } void ggml_backend_load_all_from_path(const char * dir_path) { #ifdef NDEBUG bool silent = true; …
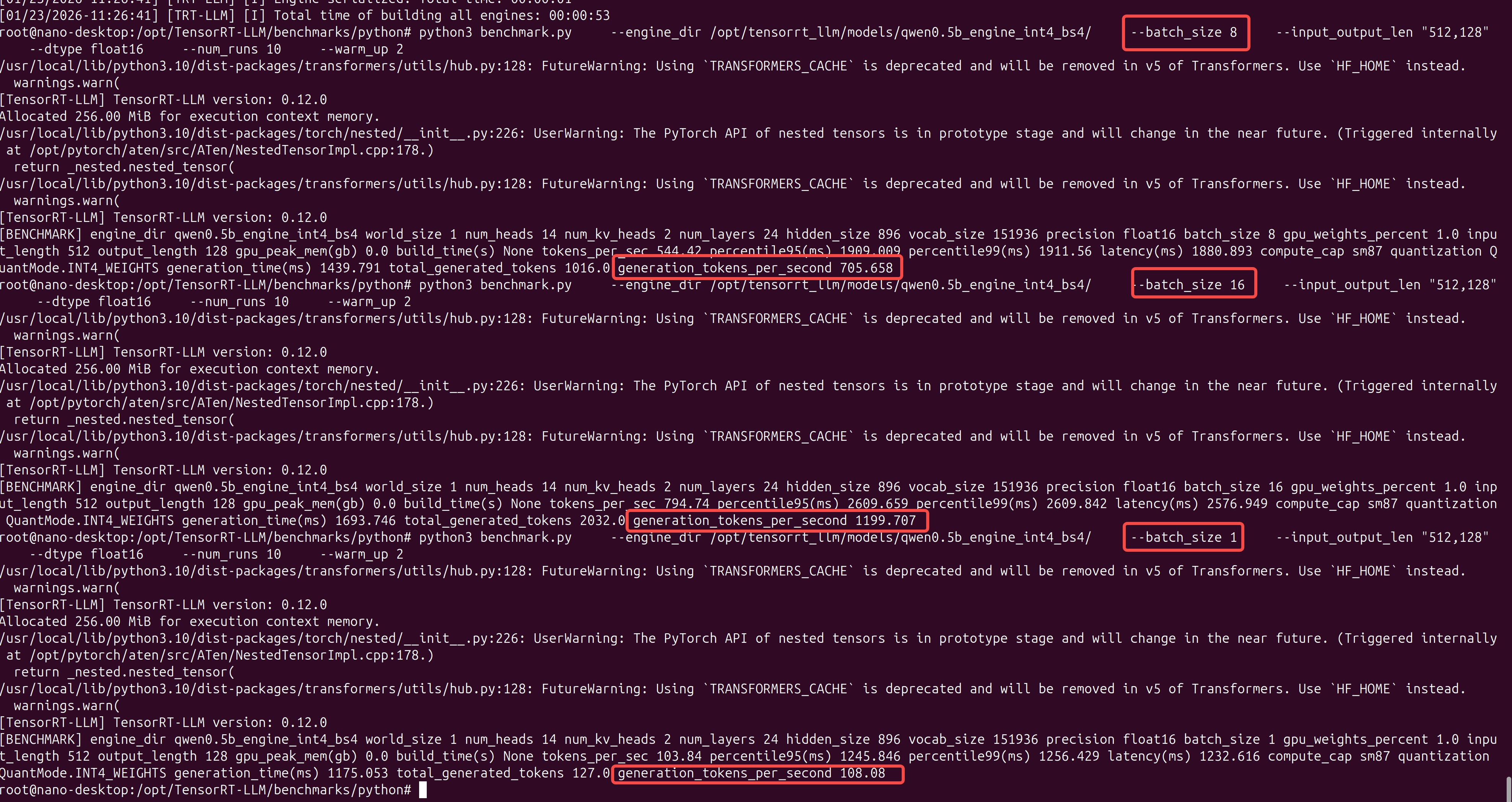
准备 硬件信息 硬件信息如下: sudo cat /proc/device-tree/model NVIDIA Jetson Orin NX Enginejetson_releasee Developer Kit(base) nano@nano-desktop:~$ jetson_release Software part of jetson-stats …
安全说明:本文是本地 AI 推理开发笔记,只记录 Jetson Orin Nano 上的 CUDA 环境检查、llama.cpp 官方源码编译、开源 GGUF 模型测试和性能观察。页面不提供可执行安装包,不要求输入账号、密码、支付信息或任
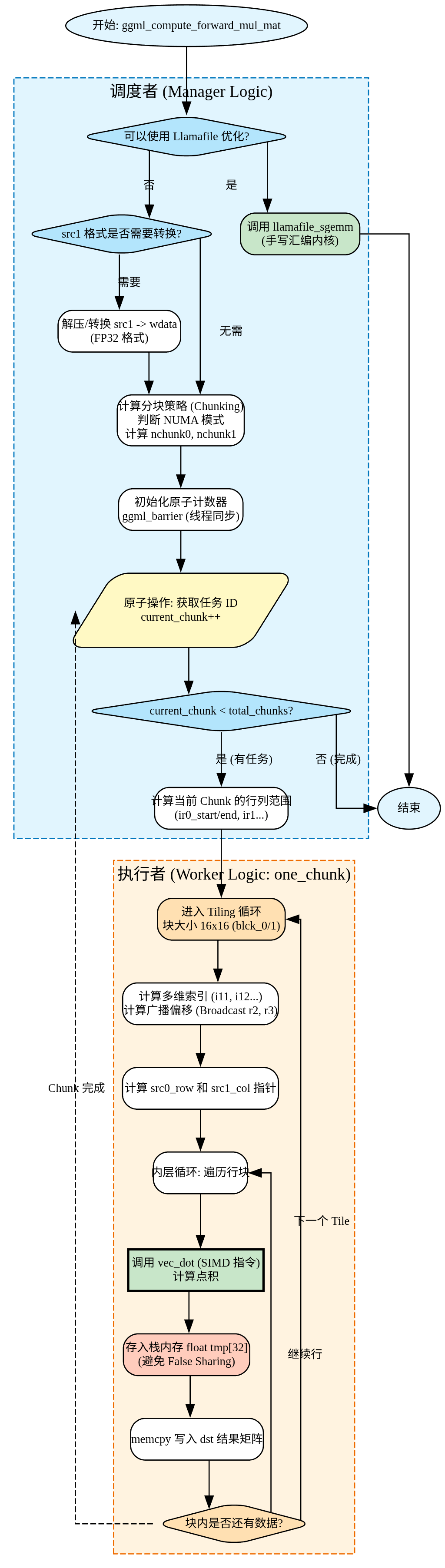
算子实现 调用流程 主要是ggml_compute_forward_mul_mat函数,该函数把任务拆分,最终计算执行调用ggml_compute_forward_mul_mat_on
矩阵相乘 是神经网络中算力消耗最大的部分,通常占据 LLM 推理计算量的 95% 以上。 矩阵乘法 (Matrix Multiplication / GEMM) 这是最通用的矩阵运算形式,也是 AI 芯片中 Tensor Core 或 MAC 阵列的主要工作内容。 定义: 设矩阵 $A$ 的形状为 $(M \times K
OpenMP是什么 OpenMP是一套用于共享内存并行系统的多线程程序设计标准。通俗的将,它允许通过简单的编译器指令(#pragma)将原本串行执行的C/C++ for循环瞬间变成多线
ggml是什么 ggml是用于transformer架构推理的机器学习库,类似于pytorch、TensorFlow等机器学习库。ggml不需要第三方库的依赖,目前兼容X86、ARM
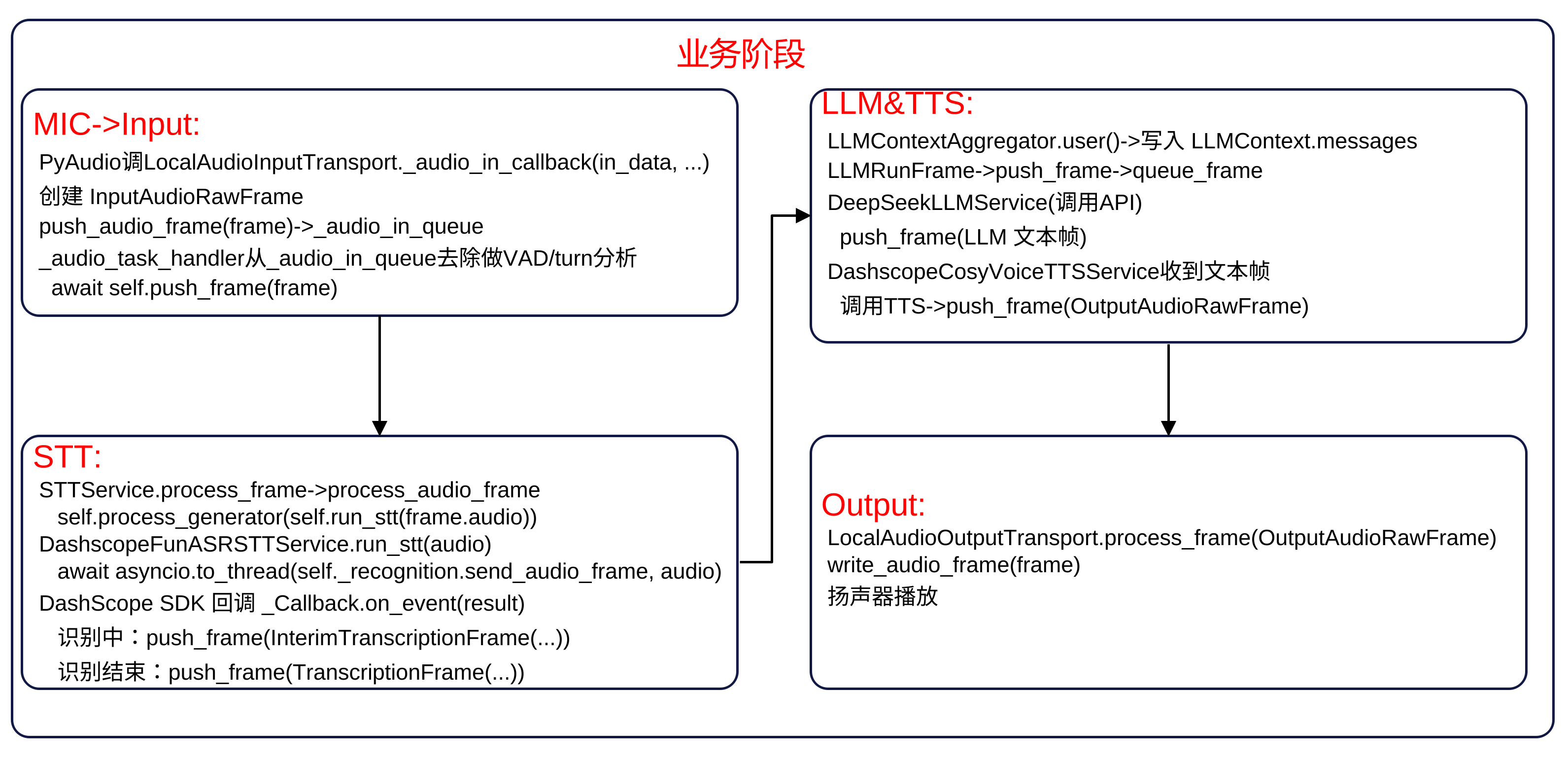
业务流 启动阶段 帧处理
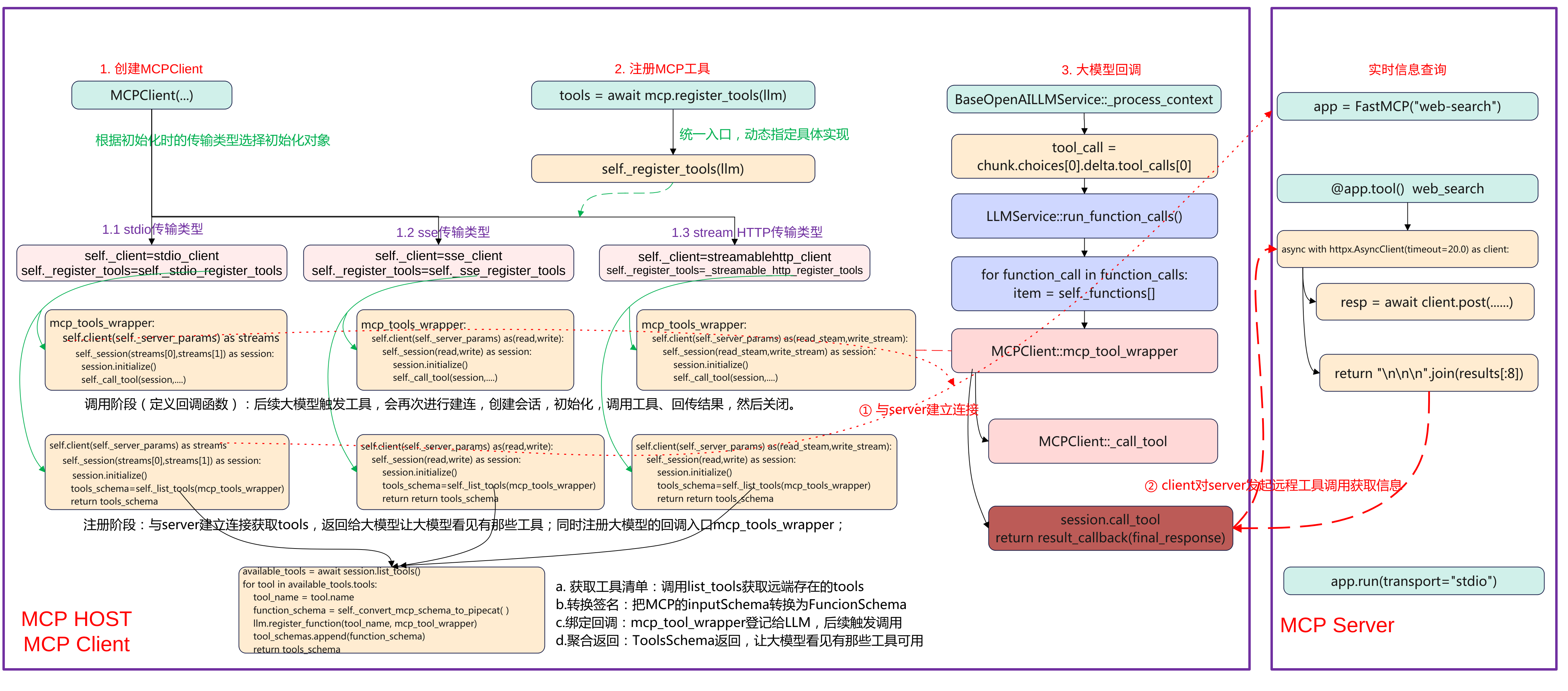
简介 本文主要基于Pipecat实现一个MCP stdio传输方式调用的示例。基于智谱Web-Search-Pro实现一个MCP Server,然后在Pipecat应用基础上实现MCP C
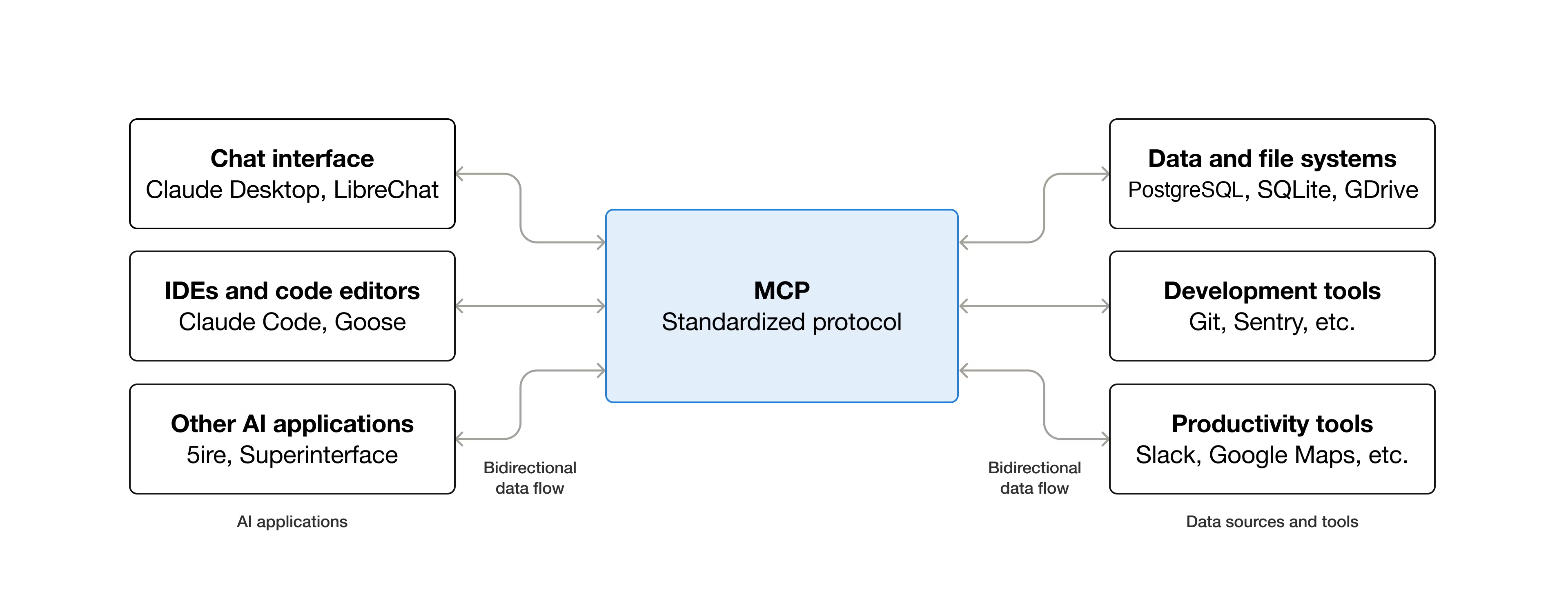
简介 什么是MCP MCP是Model Context Protocol模型上下文的一个开源标准,用于连接人工智能应用程序到外部系统。使用MCP,让Claude、ChatGPT这样的AI applica
录制 设备端 先确定一下相机编号 cd ~/lerobot/ lerobot-find-cameras 生成路径:outputs/captured_images 然后修改uart的权限 sudo chmod 666 /dev/ttyACM0 启动等待连接 python -m lerobot.robots.lekiwi.lekiwi_host \ …
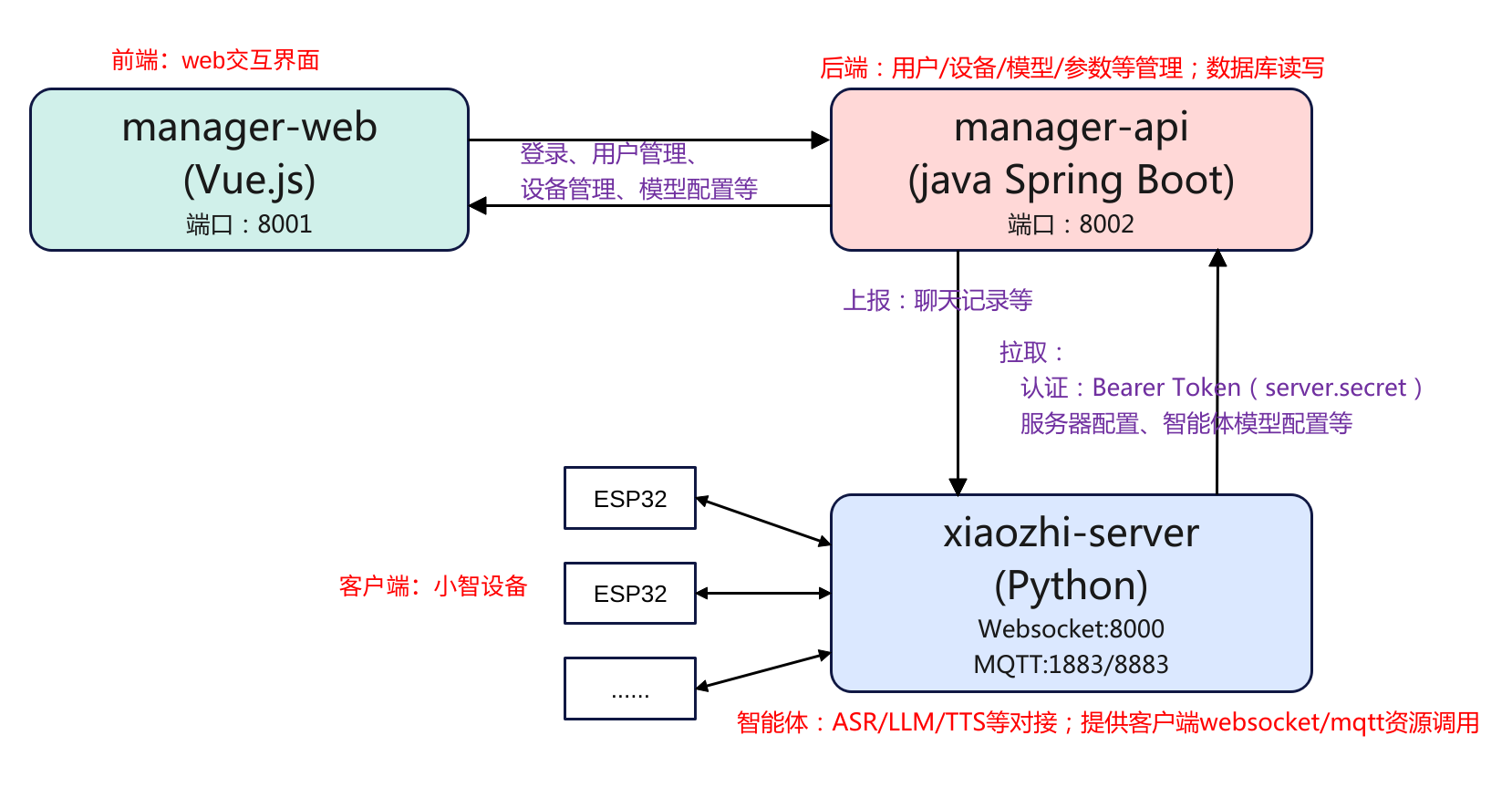
简介 本文主要是记录在ubuntu系统从零源码的方式本地部署小智Ai服务端的过程,项目的地址为:xiaozhi-server。在部署之前简单了解一下其项目框架,这里总结可以分为3部分

系统架构 硬件组成 Lekiwi是一个底盘+机械臂的结构。 机械臂: 6个自由度(shoulder_pan, shoulder_lift, elbow_flex, wrist_flex, wrist_roll, gripper) 移动底盘:3个全向轮,三轮全向移动(left_wheel

环境准备 简要记录在Orin nano平台搭建lekiwi环境,可以远程遥控底盘移动和机械臂示教的过程,需要的硬件如下: - NVIDIA Jetson Orin Nano开发板 - Lekiwi套件(底盘、主从机械臂) - P
安装浏览器 sudo apt update sudo apt install chromium-browser -y 安装后发现点击浏览器会没反应。按照下面方法配置。 snap download snapd --revision=24724 sudo snap ack snapd_24724.assert sudo snap install …

强化学习简介 什么是强化学习 以直升机控制飞行的程序来举例。 自动驾驶的直升机配备了机载计算机、GPS、加速度计、陀螺仪和磁罗盘,我们可以实时确定的知道直升机的位置。如何使用强化学习来让
概念 WBC(Whole-Body Control,全身控制)是什么?机器人是由“各关节”组成的,其不是“各关节各玩各的”而是一个耦合的整体。在某个时刻可能要做很多事情,比如保持平衡(
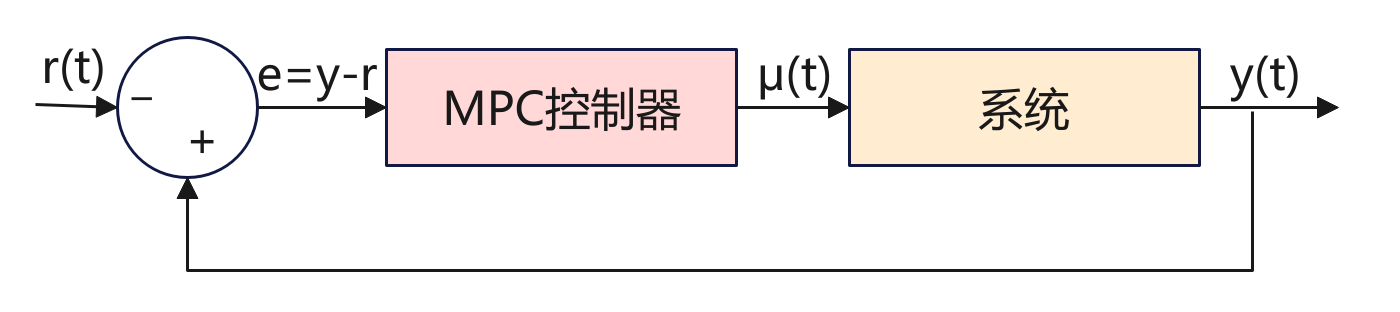
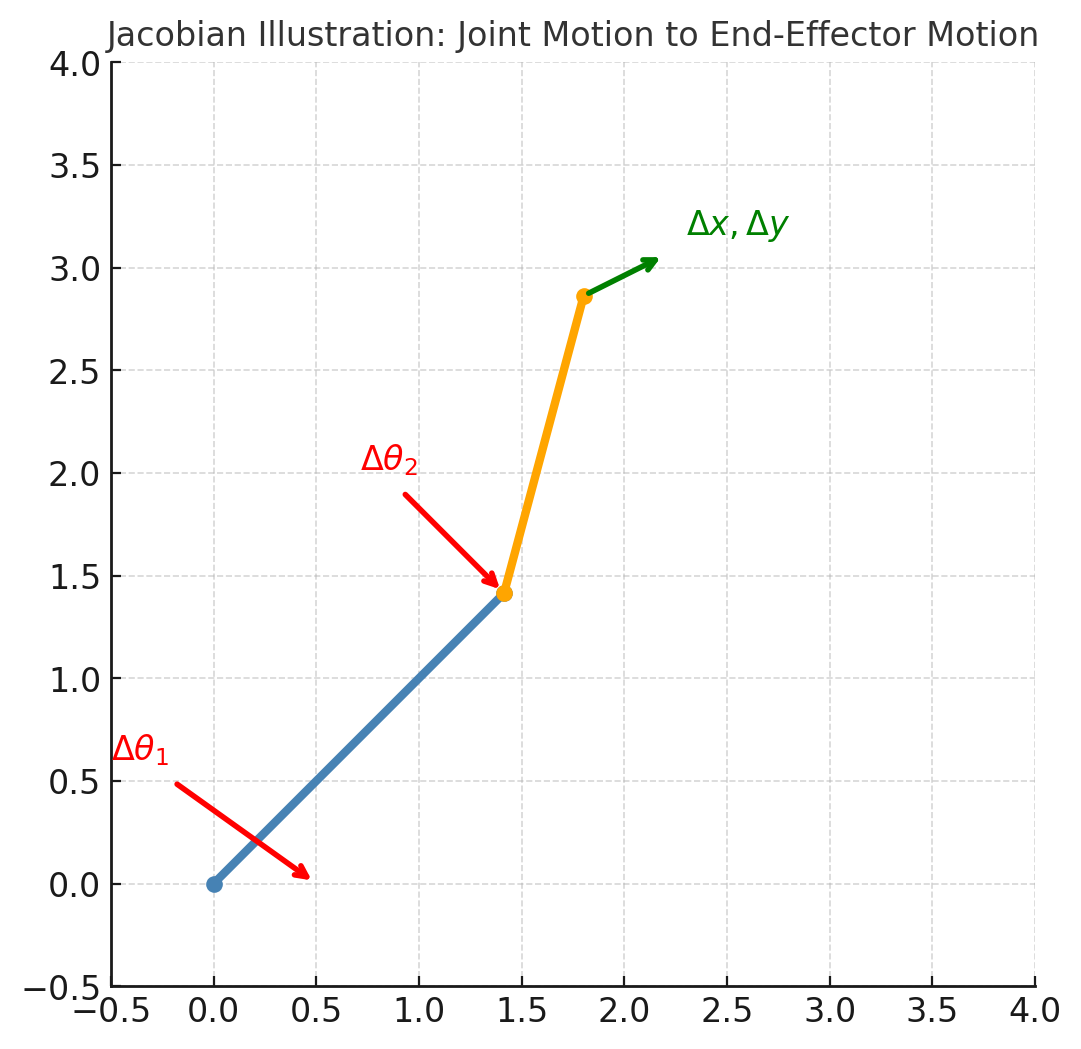
背景 MPC(Model Predictive Control)模型预测控制,是一种控制方法,广泛应用在机器人、无人驾驶、过程控制、能源系统等领域。它的核心思想用一句话来总结:利用系统模型预测未来,并通过
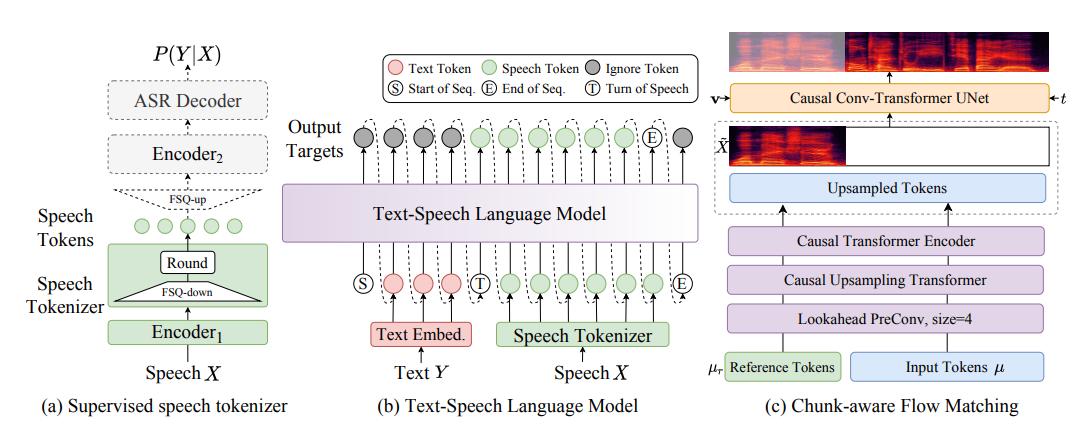
是什么 CosyVoice是阿里开源的一款文字转语音的开源模型,可以支持音色复刻。 怎么用 环境安装 (1)代码下载 git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git cd CosyVoice git submodule update --init --recursive 因 …
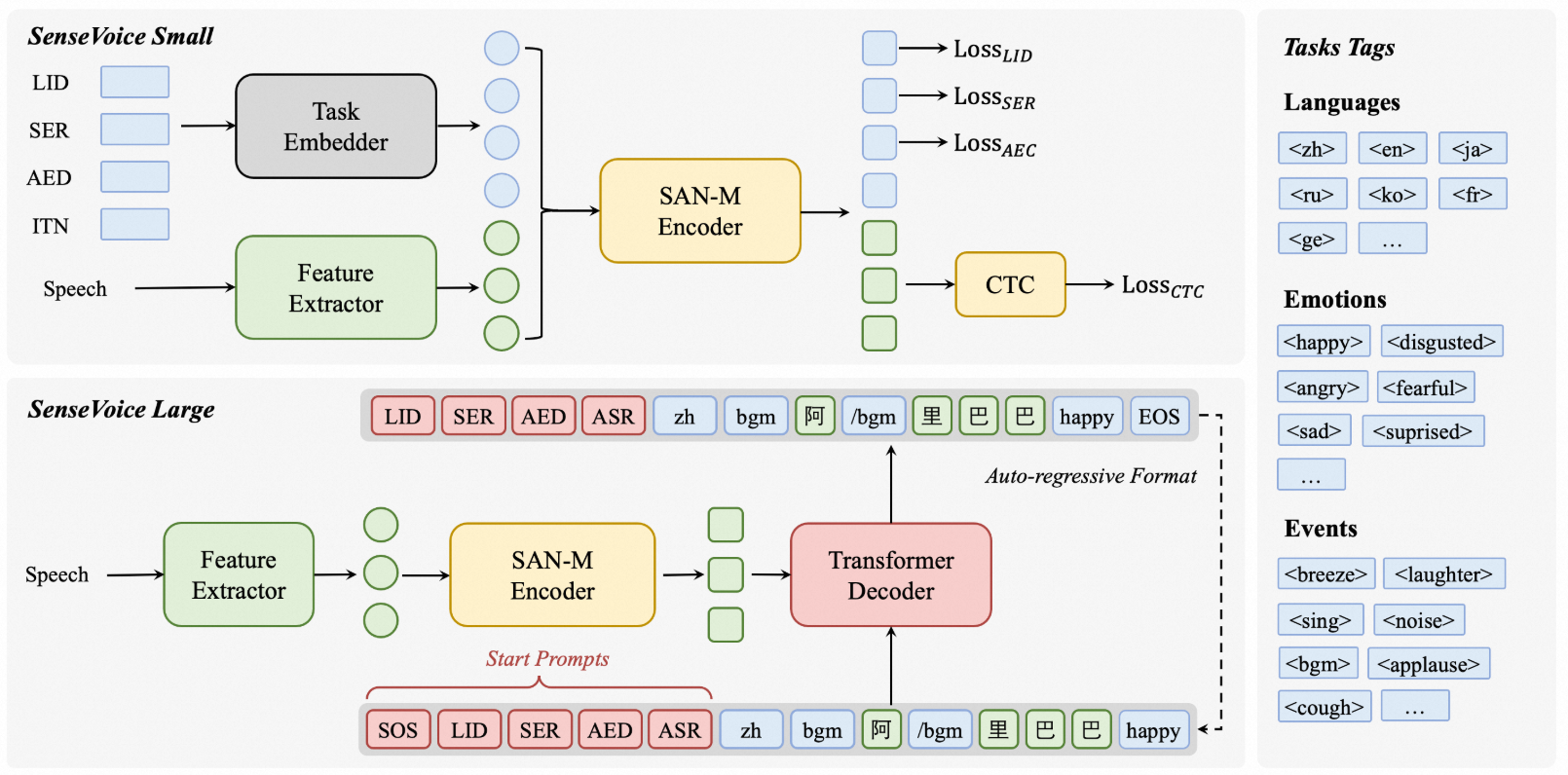
是什么 SenseVoice是多语言识别的模型,支持语音转文字(ASR, Automatic Speech Recognition,自动语音识别),语种识别(LID, Language Identification),语音情感识别(
简介 如果是NVIDIA Isaac Sim的新用户,可以按照本文的两个示例来体验Isaac Sim。本文主要提供Isaac Sim基础使用教程、机器人基础教程。 在快速入门教程中,所有可通过 GUI 执行的
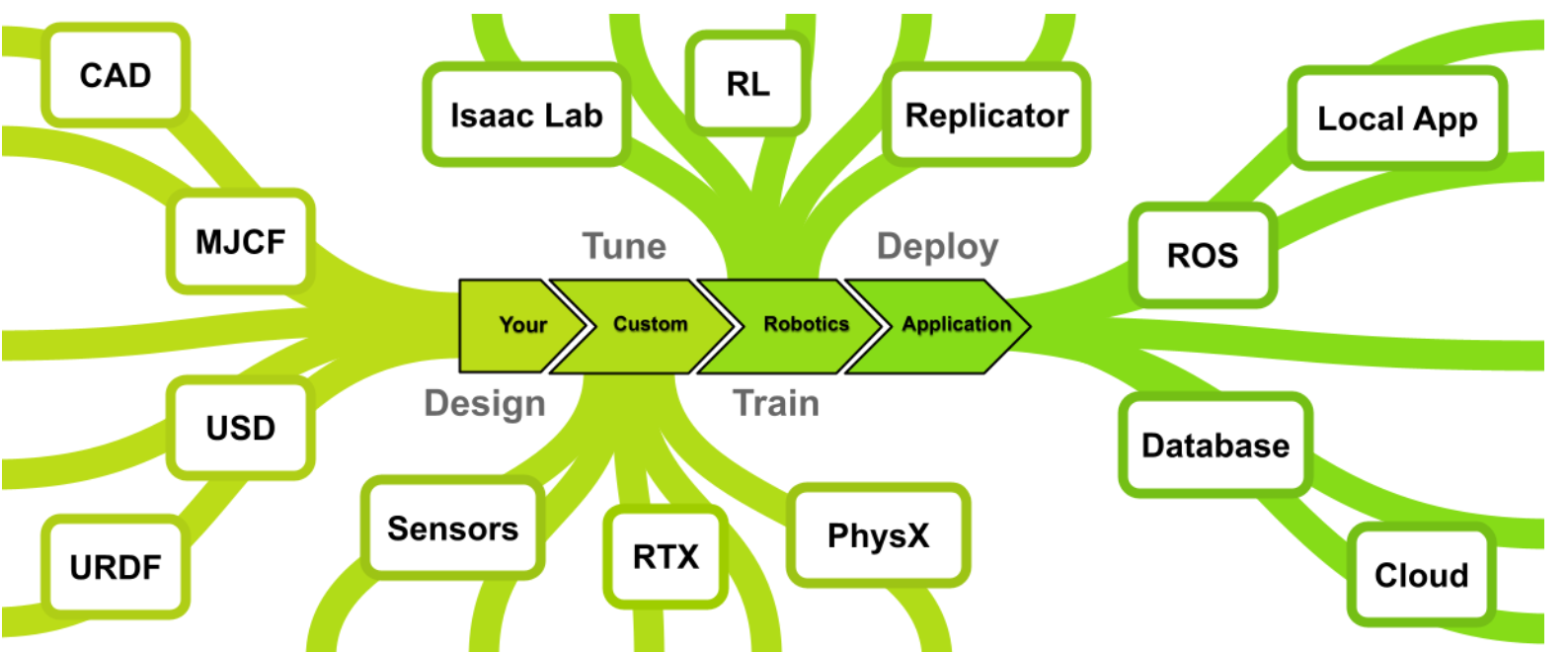
什么是isaac sim NVIDIA Issac Sim是一款基于NVIDIA omniverse构建的参考应用应用程序,使开发人员能够在基于物理的虚拟环境开发、模拟和测试AI机器人。 设计 Isaac Sim提供了一系列工
简介 NVIDIA Jetson平台提供用于开发和部署AI赋能机器人、无人机、IVA(Intelligent Video Analytics,智能视频)应用和自主机器的工具。在边缘生成式AI、NVIDIA M
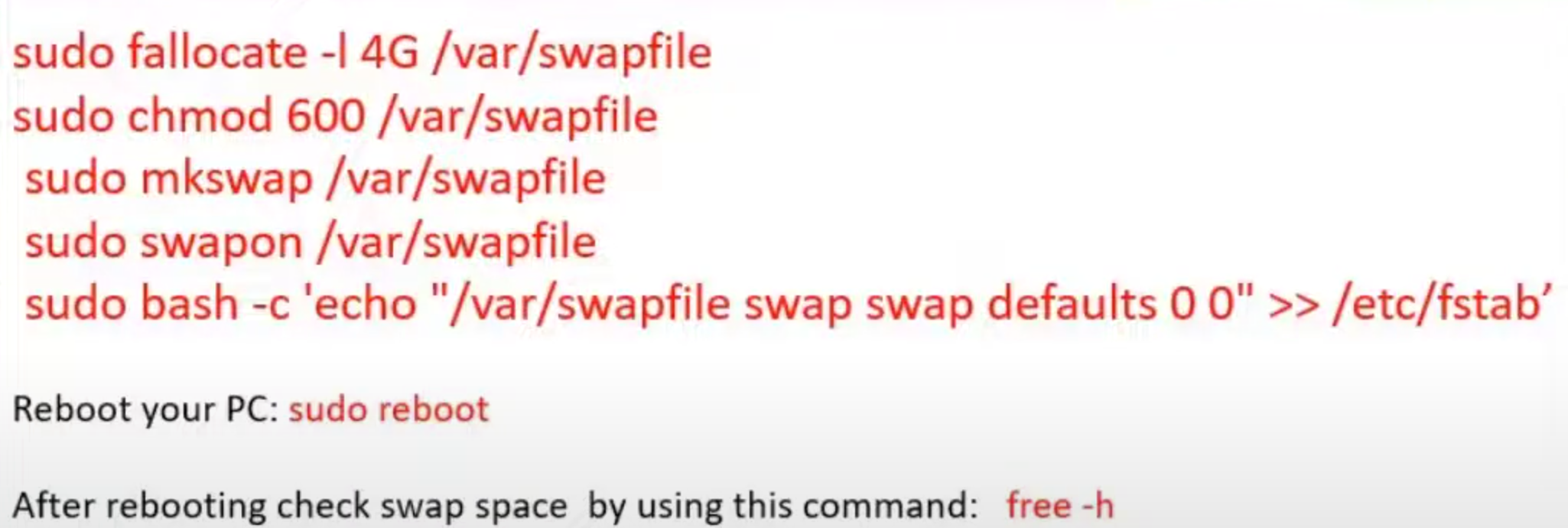
环境准备 烧录镜像 下载NVIDIA jetson nano镜像,其镜像是基于ubuntu18.04修改。使用开源的balenaEtcher烧录器写到SD卡上,然后插卡启动 网络准备 买一个无线网卡然后
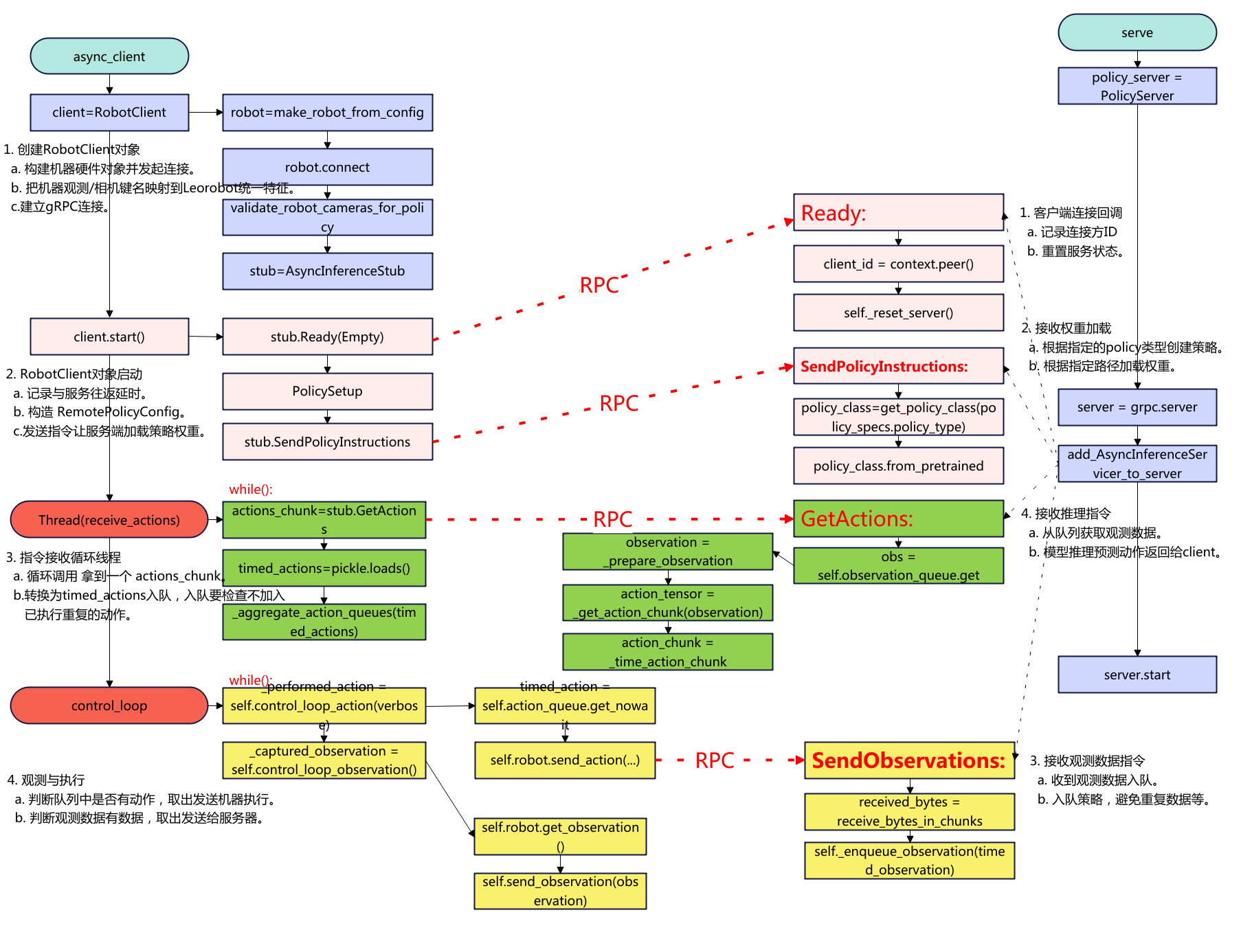
概述 本文记录lerobot smolvla异步推理实践,将SmolVLA的策略server部署到AutoDL上,真机client在本地笔记本上运行。 下面是代码的流程图: 环境准备 先登录
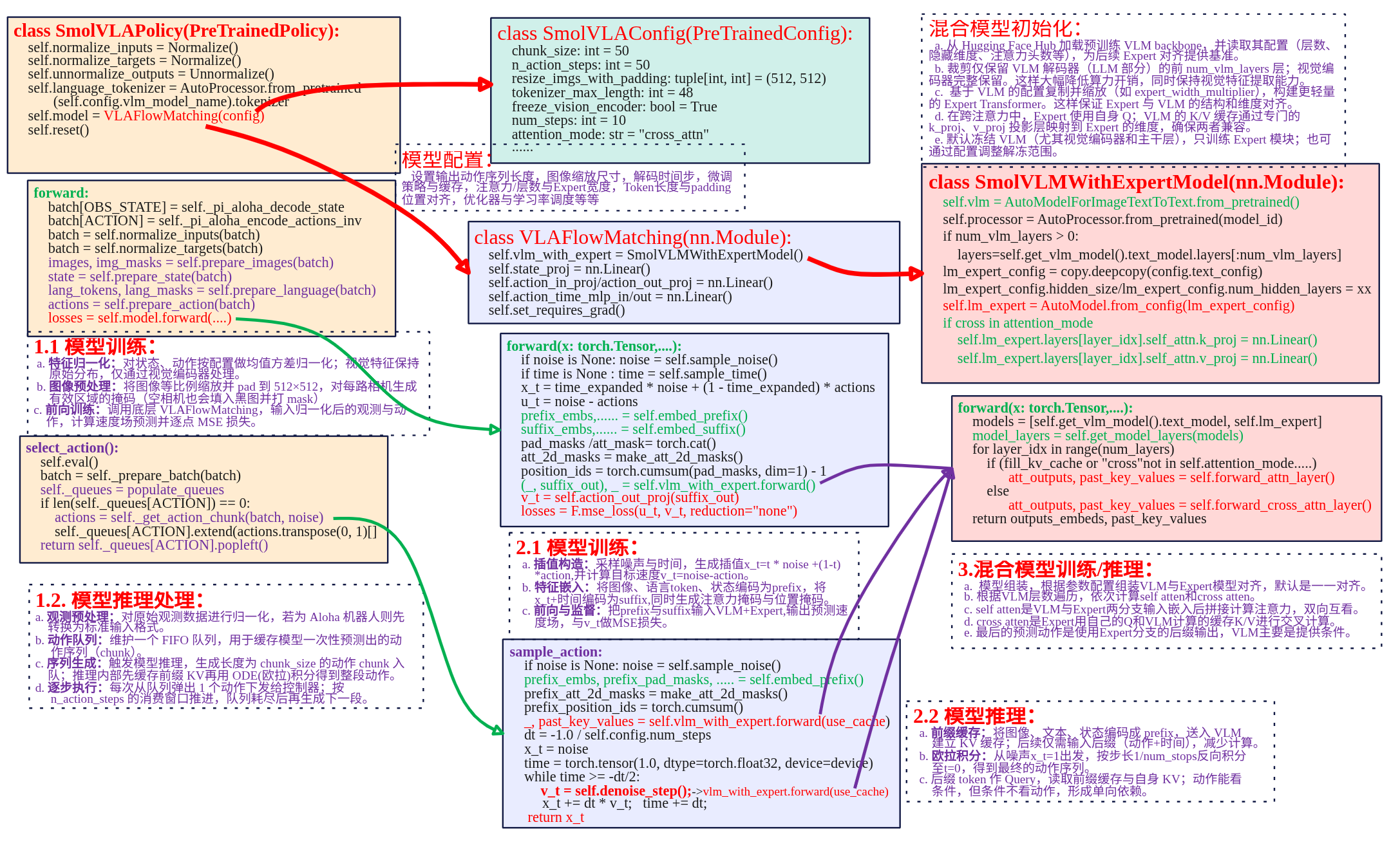
框架 本文主要对lerobot SmolVLA策略代码进行分析,下面是策略实现关键部分框图。 SmolVLAPolicay类封装向上提供策略的调用。SmolVLAConfig是对Smol
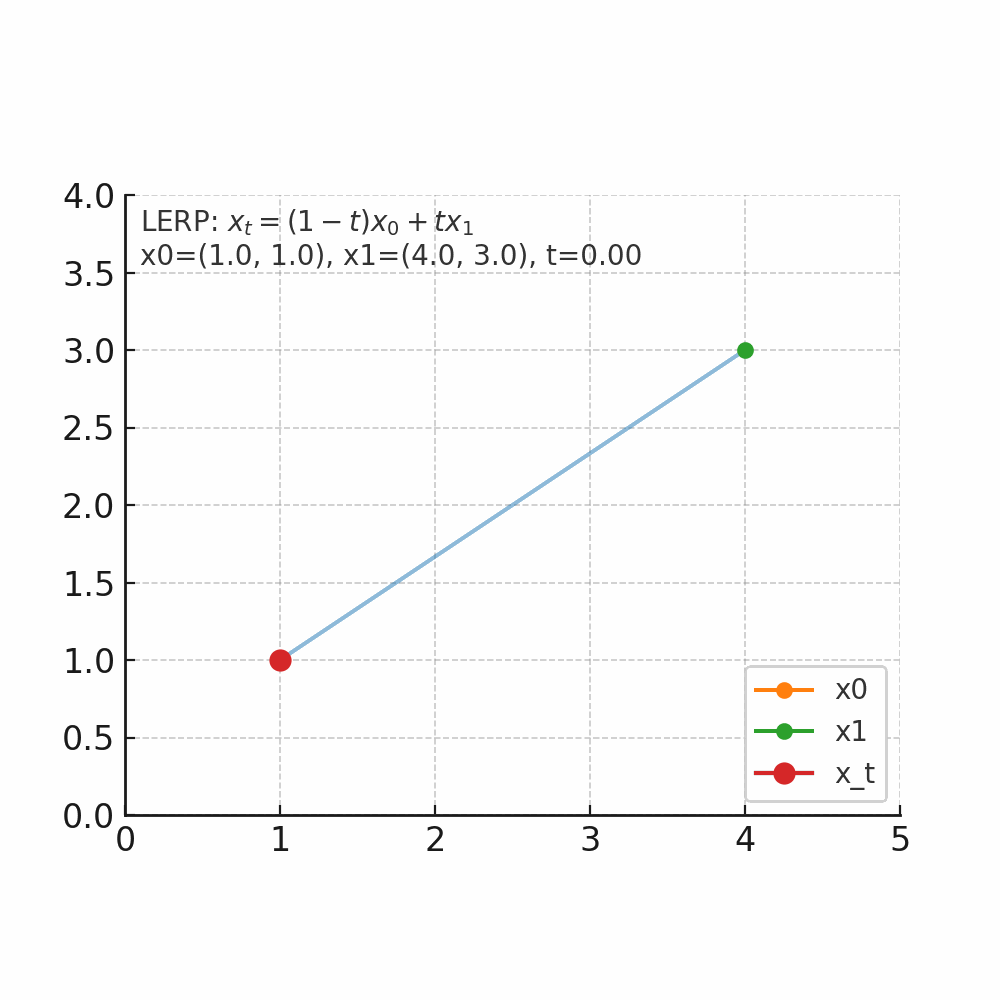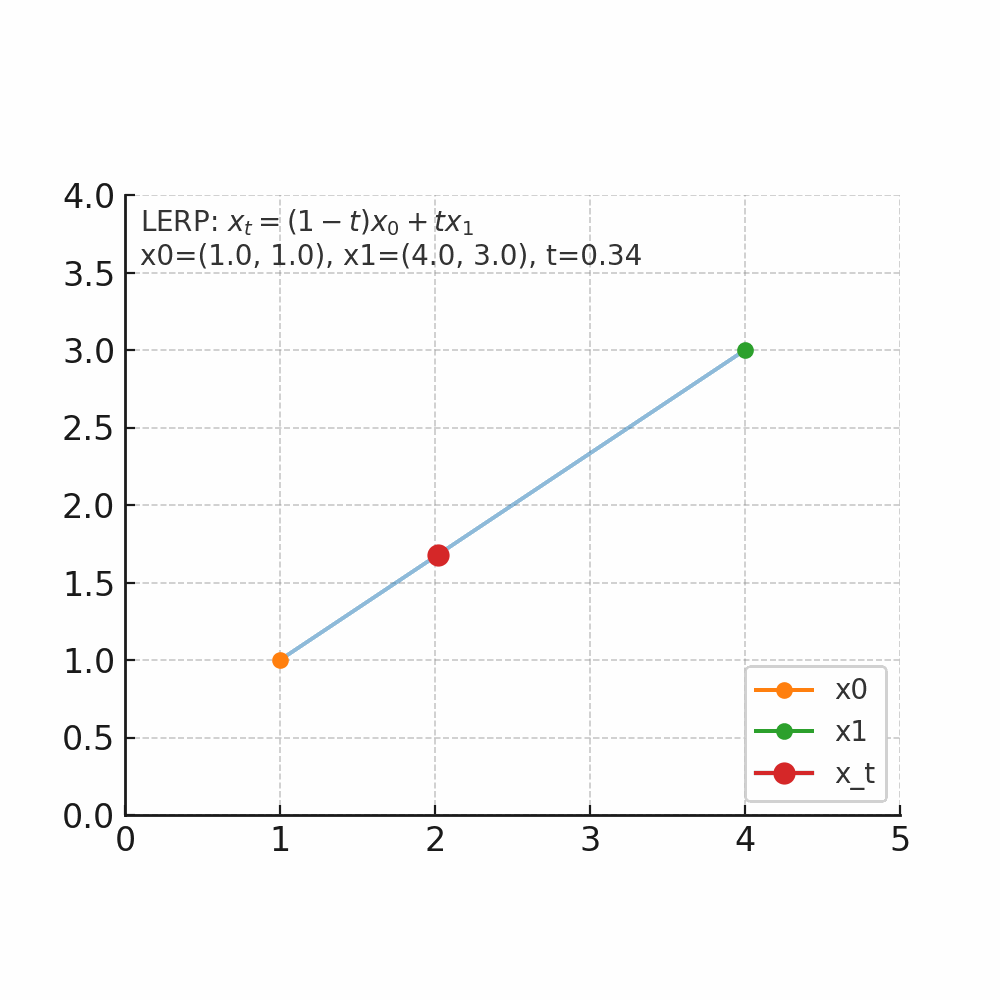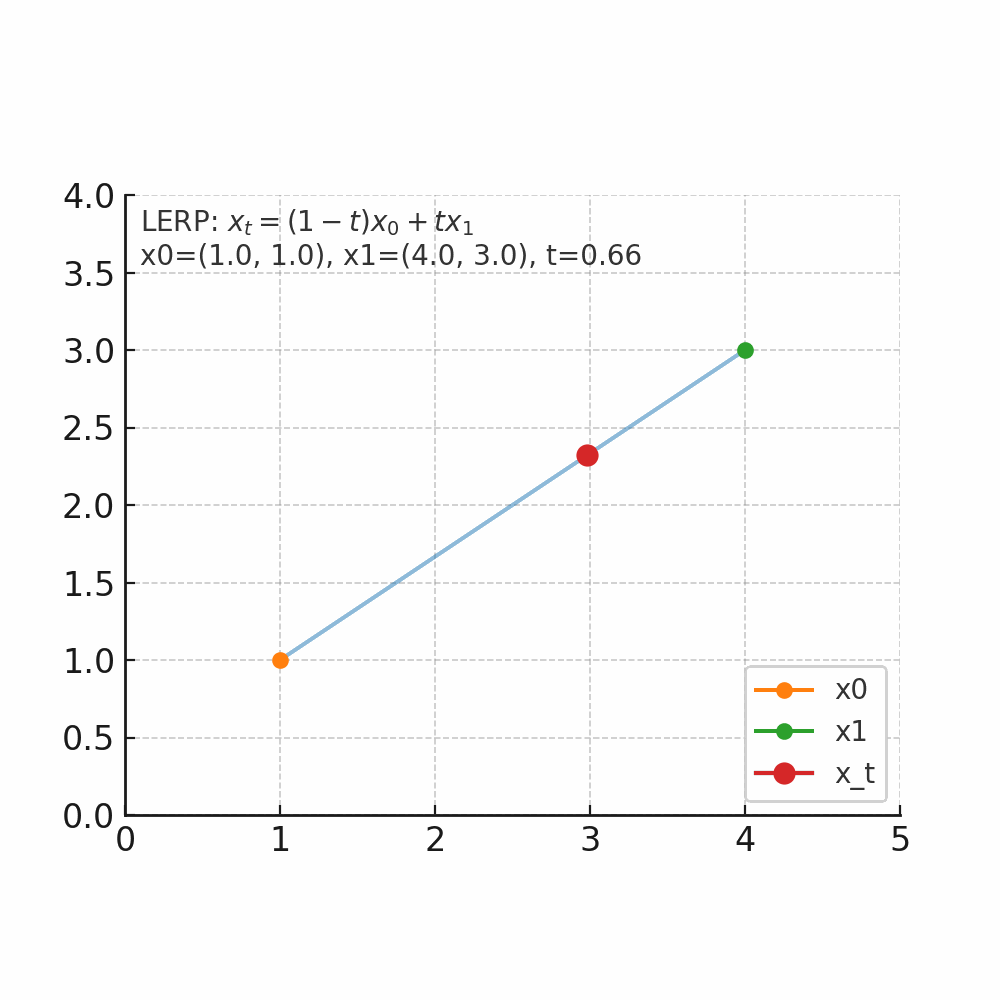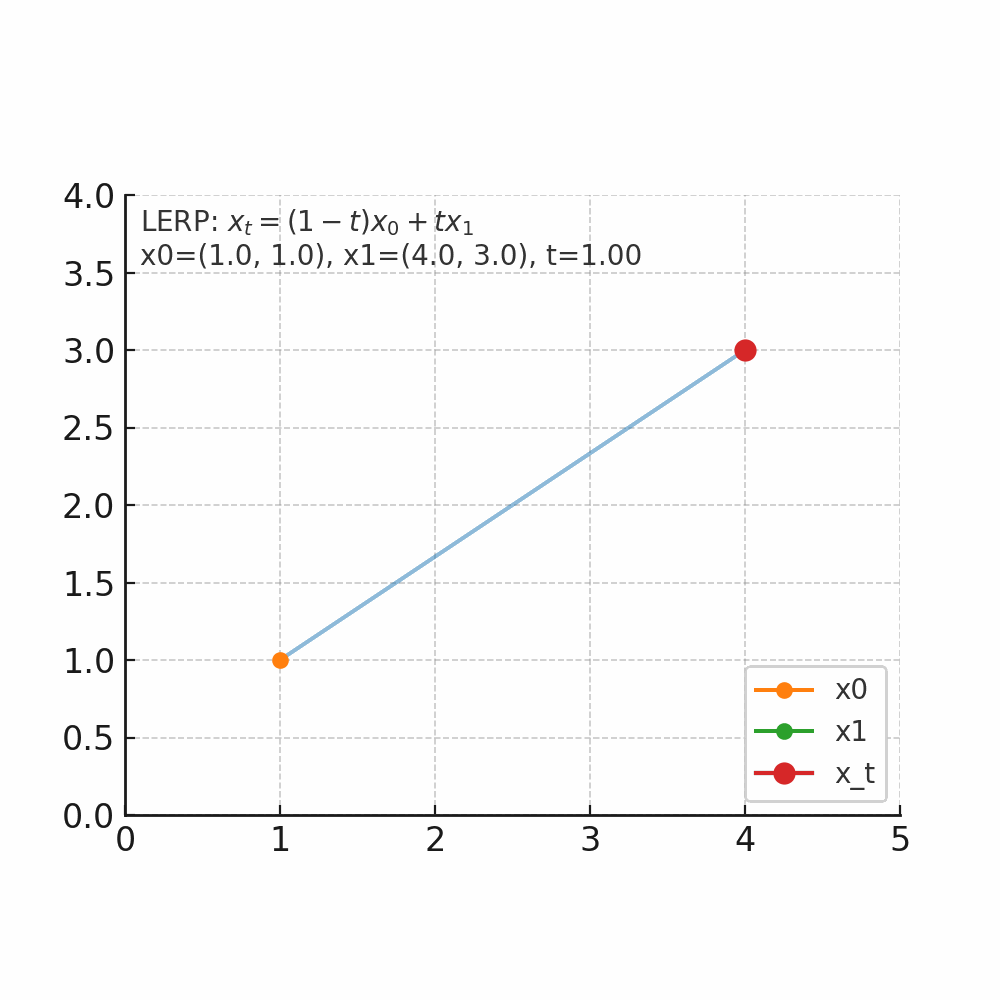
什么是插值 插值的核心问题是:在已知两个点的情况下,如何找到它们之间的中间点。 举个人走路的例子,起点在家门口(A点),终点在公司(B点),总的路程为1000米,假设人是匀速移动,如果
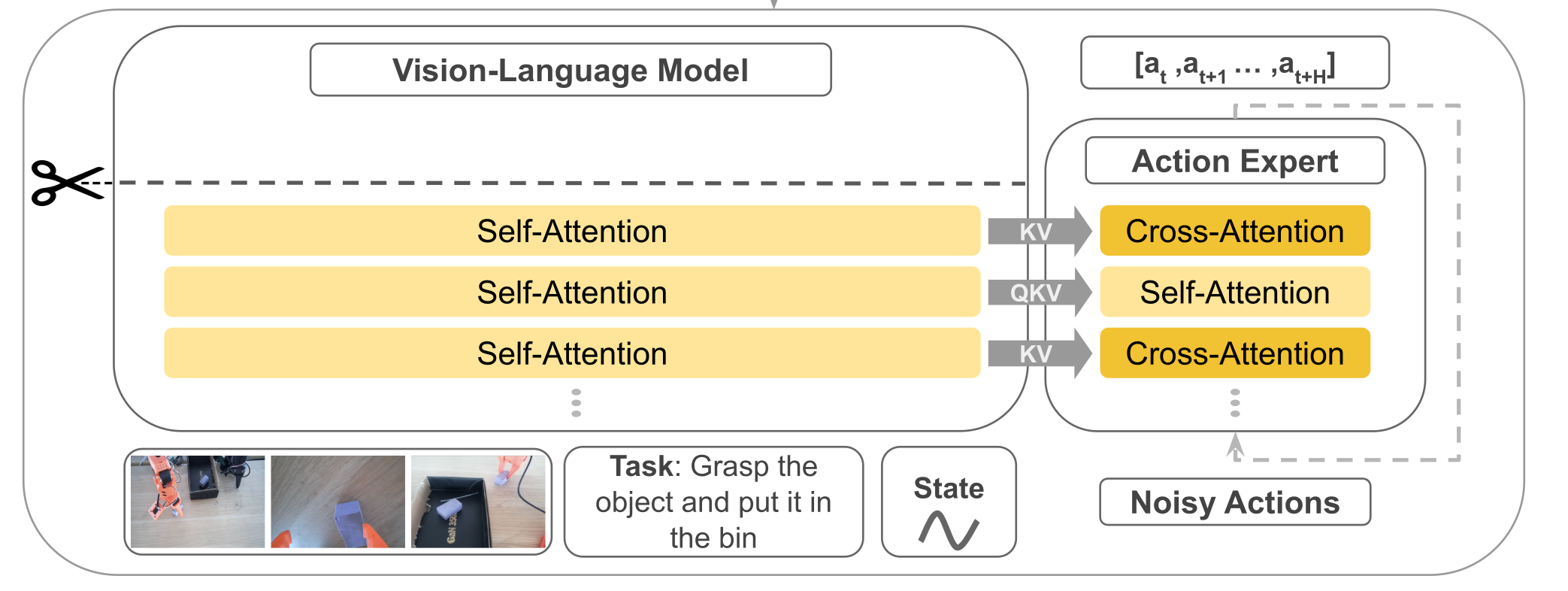
概述 SmolVLA 是一套轻量级视觉-语言-行动(VLA)策略:前端用小型 VLM(视觉 SigLIP + 语言 SmolLM2)做感知与理解;后端用一个“动作专家”专门预测一段连续的低层控制。它与Pi0相比,参数
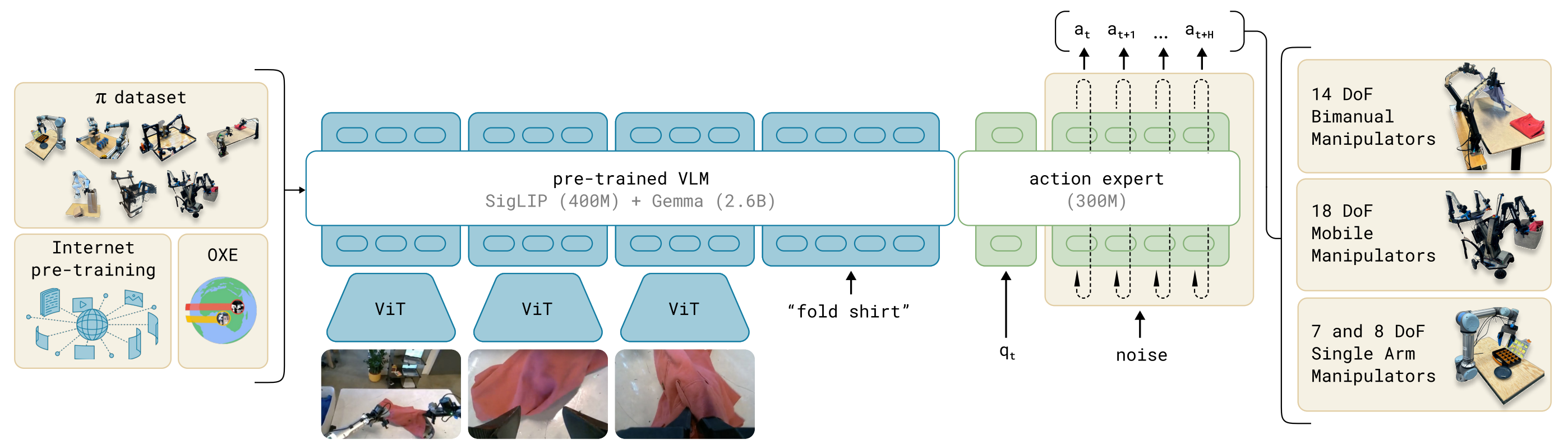
概述 传统机器人策略模型往往局限在单一任务或平台,难以跨场景泛化。与此同时,大规模 视觉-语言模型(VLM) 已展现出卓越的语义理解与任务指令解析能力。如果能将 VLM 的语义理解能力 与 Flow Matching 的连
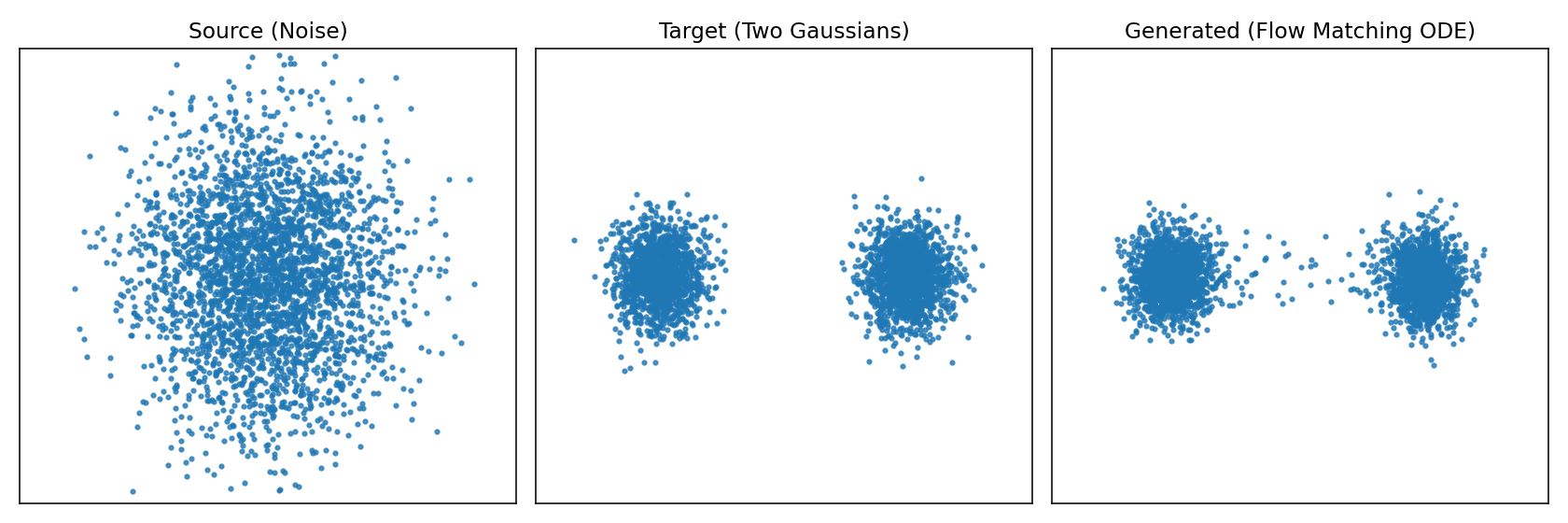
背景 上一篇文章分析了diffusion扩散模型。diffusion扩散模型做法是加噪声、再一步步去噪,训练过程复杂,还需要 carefully 设计噪声调度。 Flow Matching提出了更直接的方式:与其
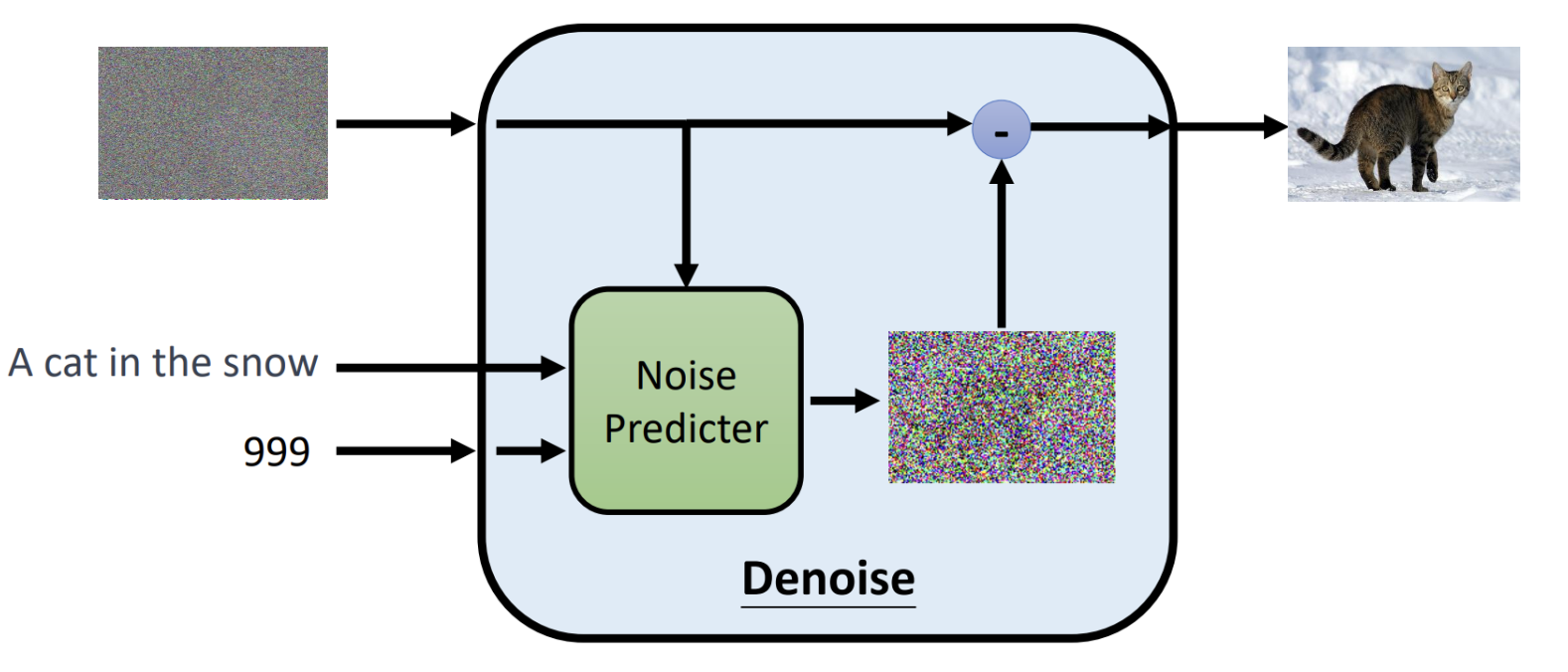
概述 图像生成是当下研究的热点,diffusion是一种人工智能领域图像生成的基础模型,当下Stable diffusion、DALL·E、MidJourney文生图模型的基座都使用了
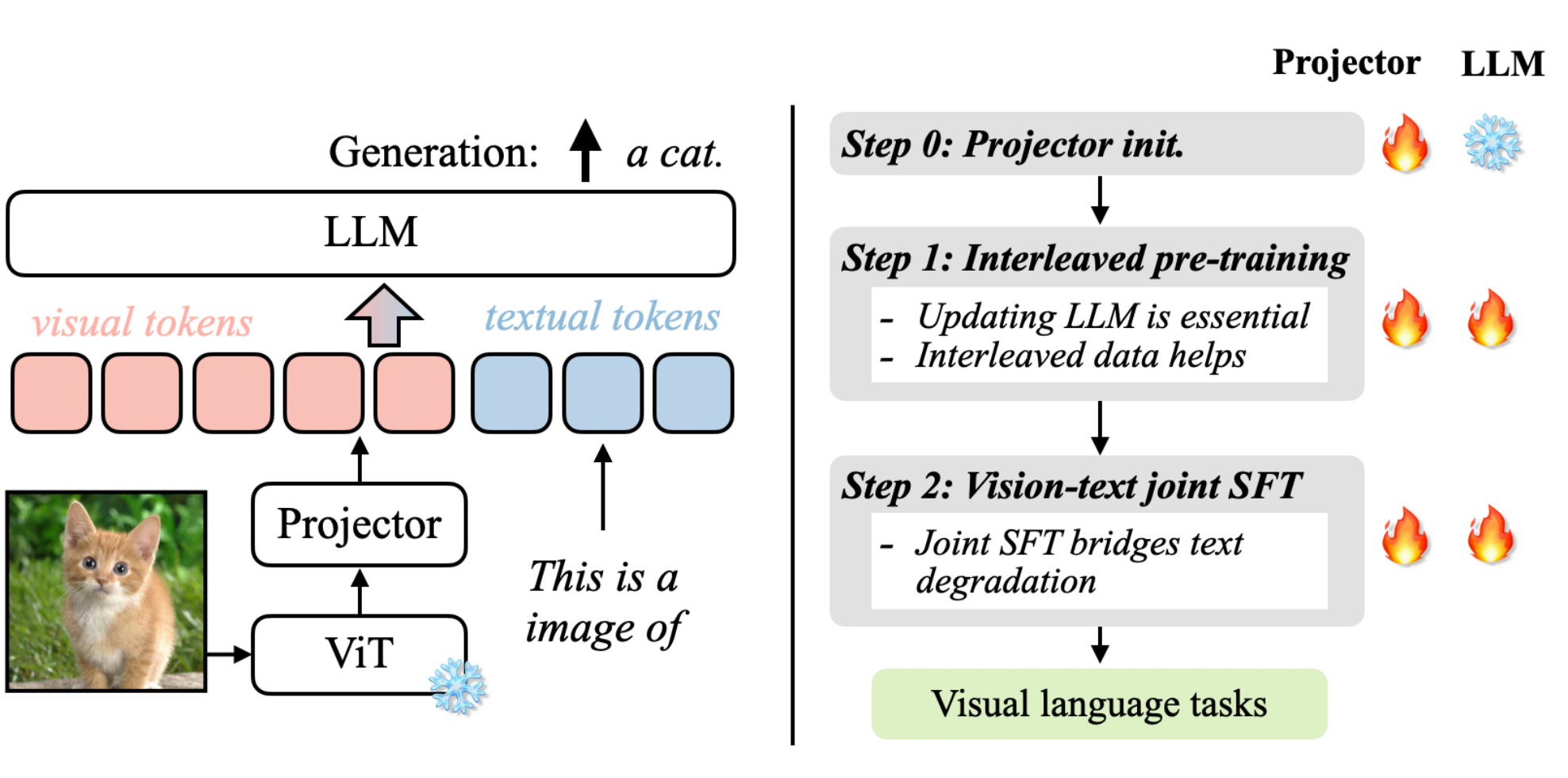
VLM与LLM 如果说我们有一张图片、一个图表想让大模型来帮忙理解那应该要怎么实现了? 标准的LLM语言大模型只能处理文本序列,是不能够读取图像的,如果没有办法将视觉的数据转换为LLM
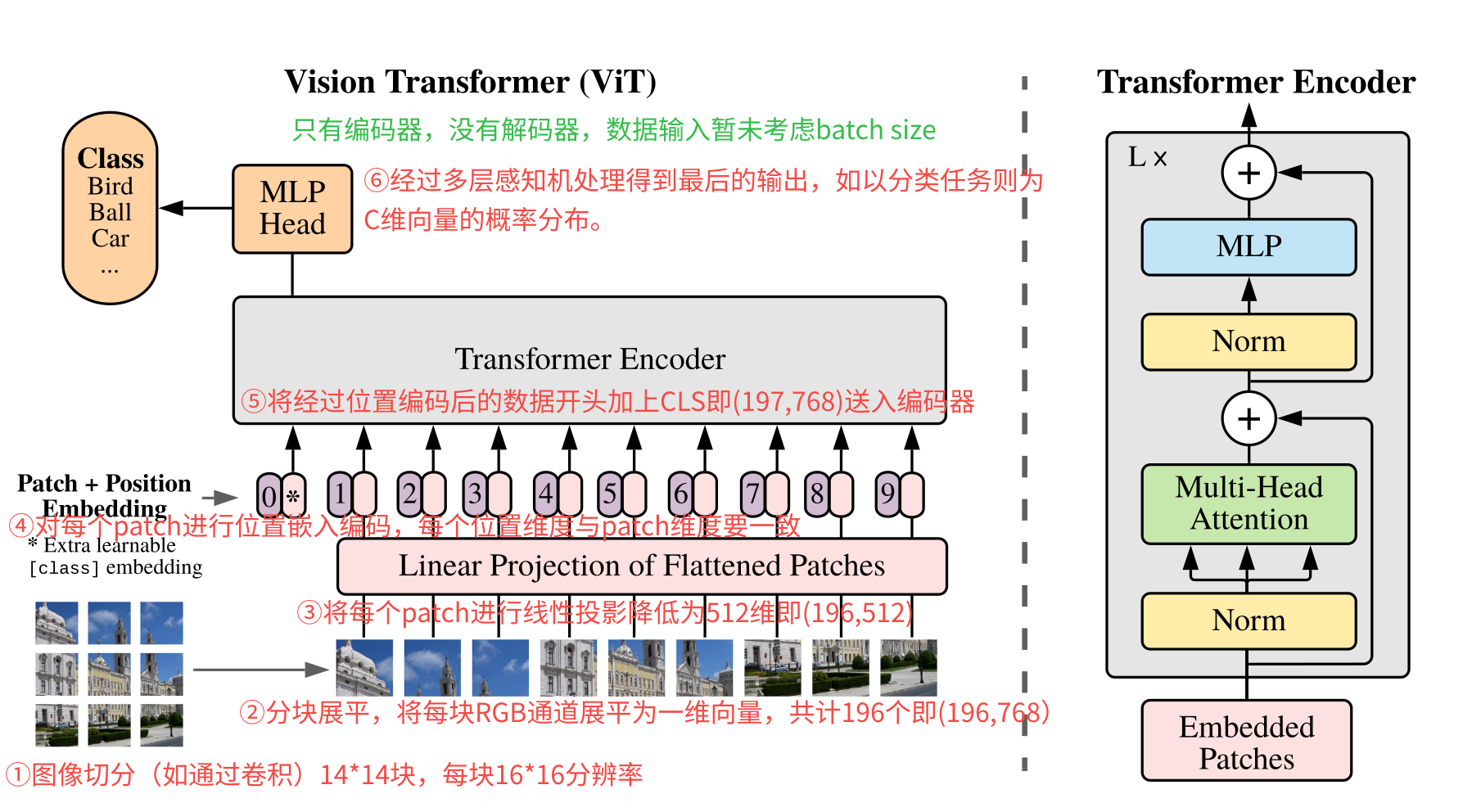
背景 计算机视觉领域,一直都是卷积天下。传统的卷积神经网络(CNN)依赖于卷积核提取局部特征,效果很好,但是也有一些不足,如需要人工设计卷积结构包括卷积核大小和层数,另外就是难以捕捉
环境安装 pip install -e ".[smolvla]" 在原来lerobot的环境基础上。 启动训练 本文主要是记录复现lerobot smolvla策略的效果,为了快速看到效果,这里不进行采集数据了,直接用此前ACT采集的数
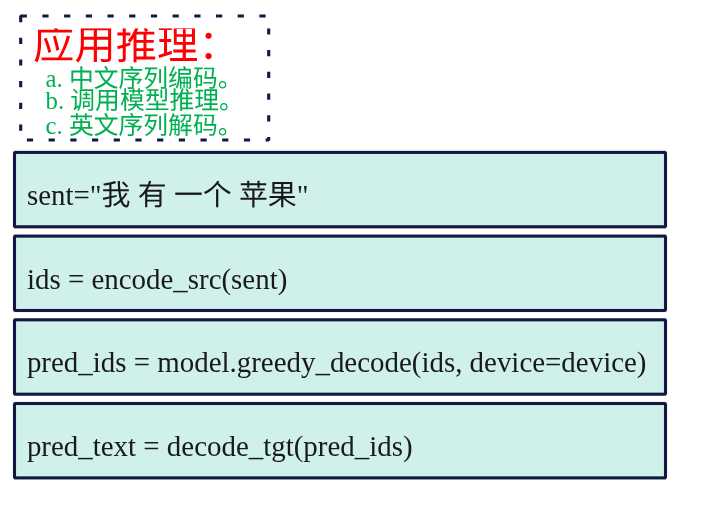
概述 在http://www.laumy.tech/2458.html#h37章节中,介绍了transformer的原理,本章用pytorch来实现一个将"我有一个苹果&q
简介 Dataset和DataLoader在pytorch中主要用于数据的组织。这两个类通常一起搭配处理深度学习中的数据流。 Dataset 用于产出“单个样本”:定义怎么按索引取到一个样本,以及总
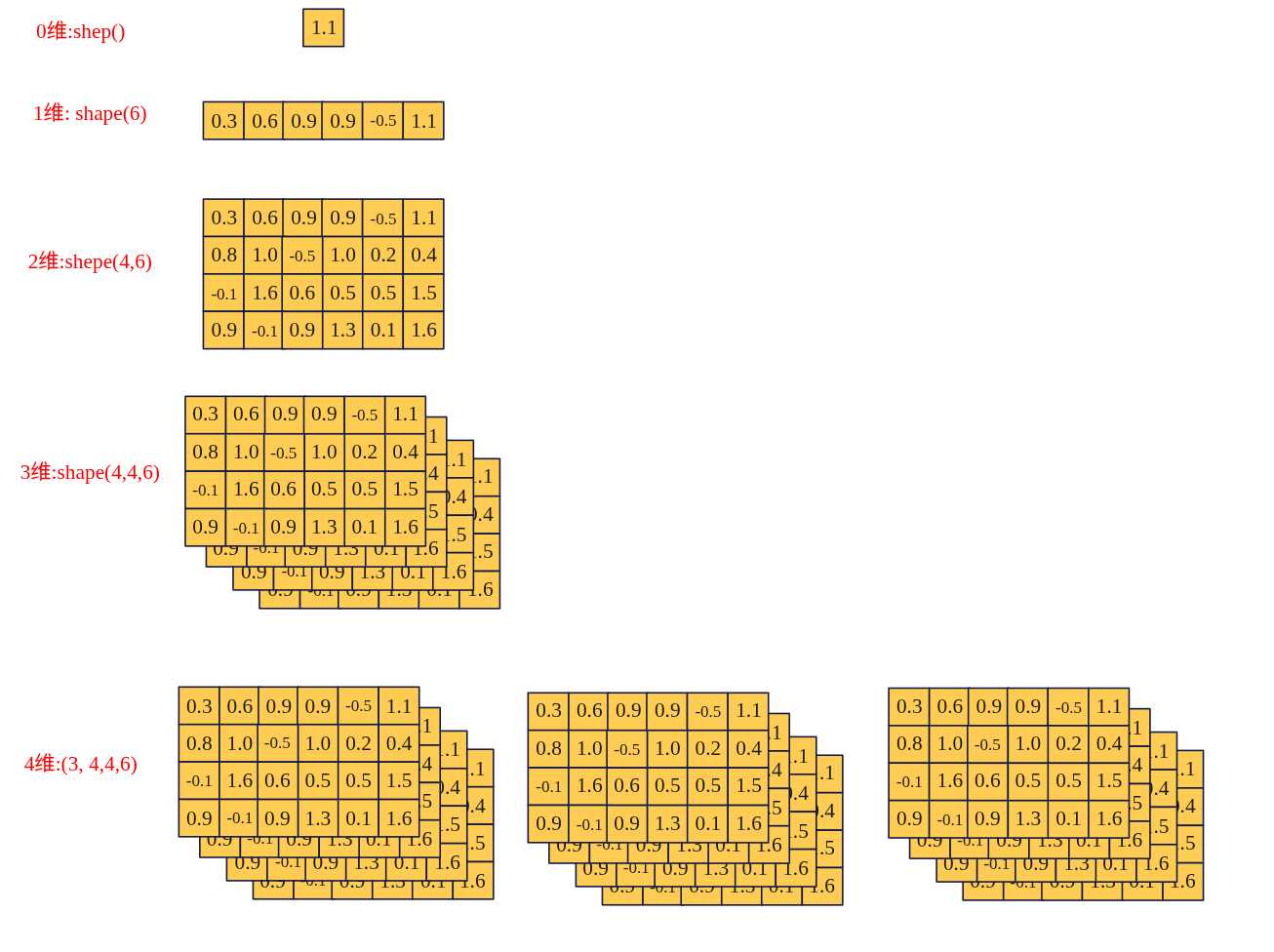
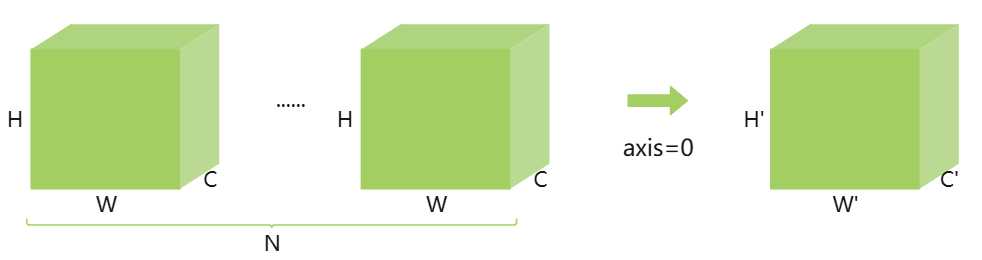
维度是什么 维度=数据需要“几个”索引才能定位到一个元素,也叫做轴数(axis)或阶(rank)。 可以看成"套盒子"的层数,盒子里面装盒子,再装数字。每多一层外括

概述 框架 以翻译作为例子,从宏观角度理解大模型,可以把大模型视为一个黑匣子,它可以输入一种语言然后输出另外一种翻译语言,如下图所示。 如果将模型稍微展开一下,模型分为encoders和
配置类ACTConfig @PreTrainedConfig.register_subclass("act") @dataclass class ACTConfig(PreTrainedConfig): # 输入/输出结构 chunk_size: int = 100 # 动作块长度(每次预测的动作序列长度) n_action_steps: int = 100 …
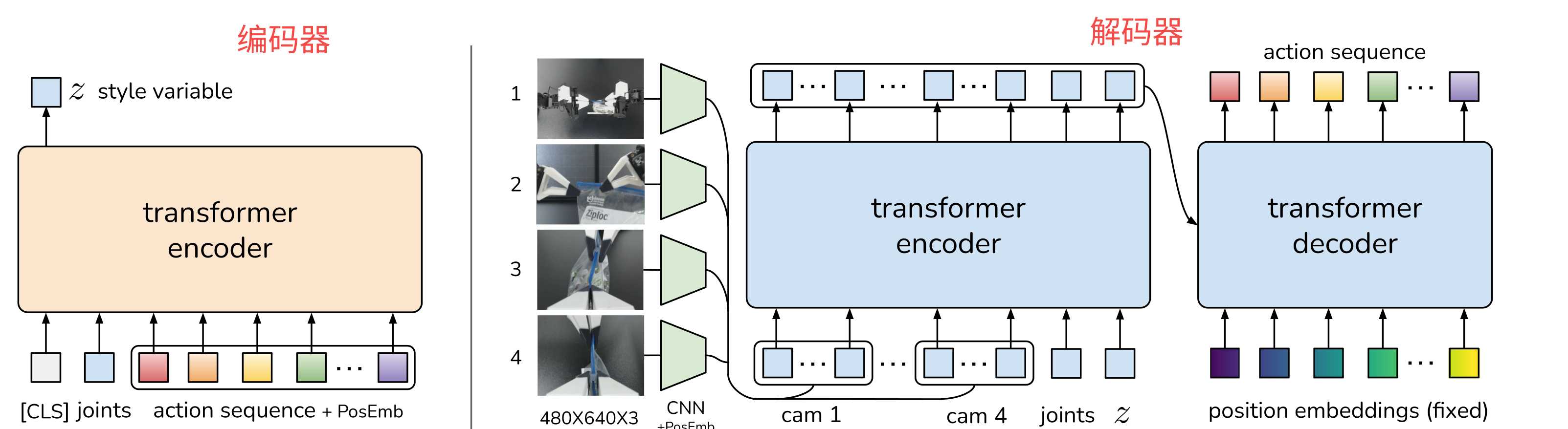
基本原理 简单总结一下什么是ACT算法。传统的机器算法过程是观测关节位置J1经过模型预测动作A2然后执行,观测到J2预测数A3,观测到J3遇到A4依次类推,这样就有一个问题,假设预测
学习率调度器简介 是什么 学习率调度器(Learning Rate Scheduler)是深度学习训练中动态调整优化器学习率的工具(注意是在优化器的基础上动态调整学习率),通过优化收敛过程提升模
torch.optim简介 在学校lerobot的策略优化器前,我们先再复习一下什么是优化器。 什么优化器 优化器官方解释就是在深度学习中让损失函数通过梯度下降思想逐步调整参数以达到最小
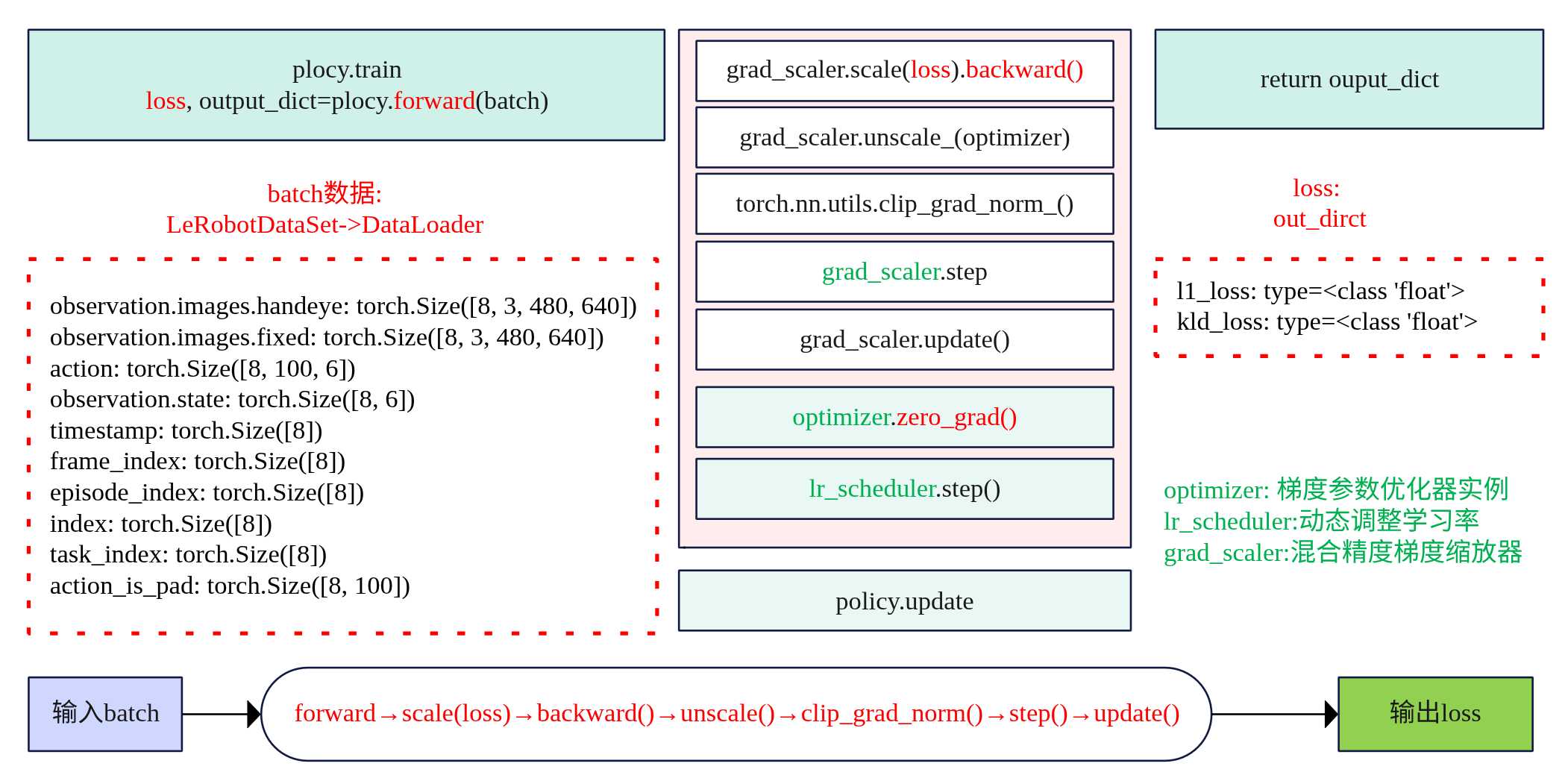
初始化 @parser.wrap() def train(cfg: TrainPipelineConfig): cfg.validate() # 验证配置合法性(如路径、超参数范围) init_logging() # 初始化日志系统(本地文件+控制台输出) if cfg.seed is not None: set_seed(cfg.seed) # 固定随机种 …
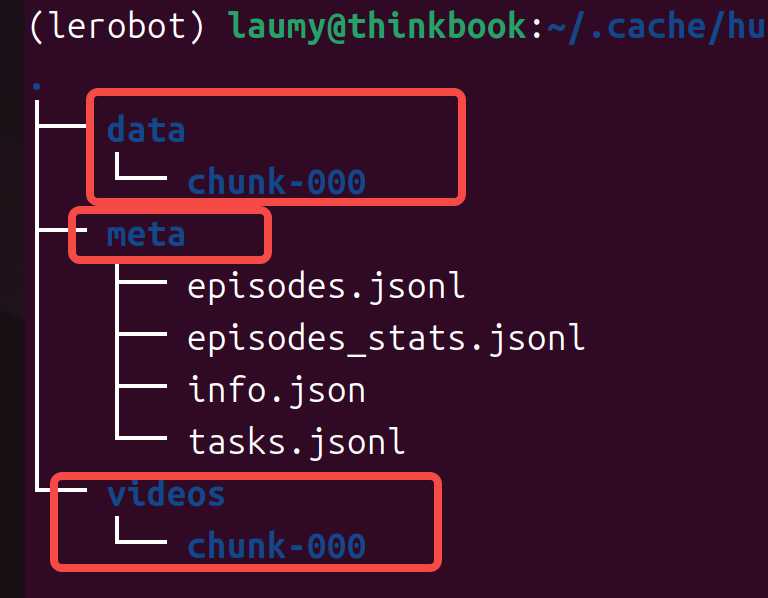
简介 lerobot record是关键核心流程,其包括了数据的采集和模型推理两部分。 如果是数据采集模式,命令启动如下 python -m lerobot.record \ --robot.disable_torque_on_disconnect=true \ --robot.type=so101_follower \ …
启动 示教的功能主要是主臂控制,从臂跟随,在数据采集是非常的一环。下面是模块启动的执行命令: python -m lerobot.teleoperate \ --robot.type=so101_follower \ --robot.port=/dev/ttyACM0 \ --robot.id=R12252801 \ …
why calibrate 先来看看标定后的数据 { "shoulder_pan": { #肩部旋转关节 "id": 1, "drive_mode": 0, "homing_offset": -1620, "range_min": 1142, "range_max": 2931 }, "shoulder_lift": { #肩部升降关节 "id": 2, …
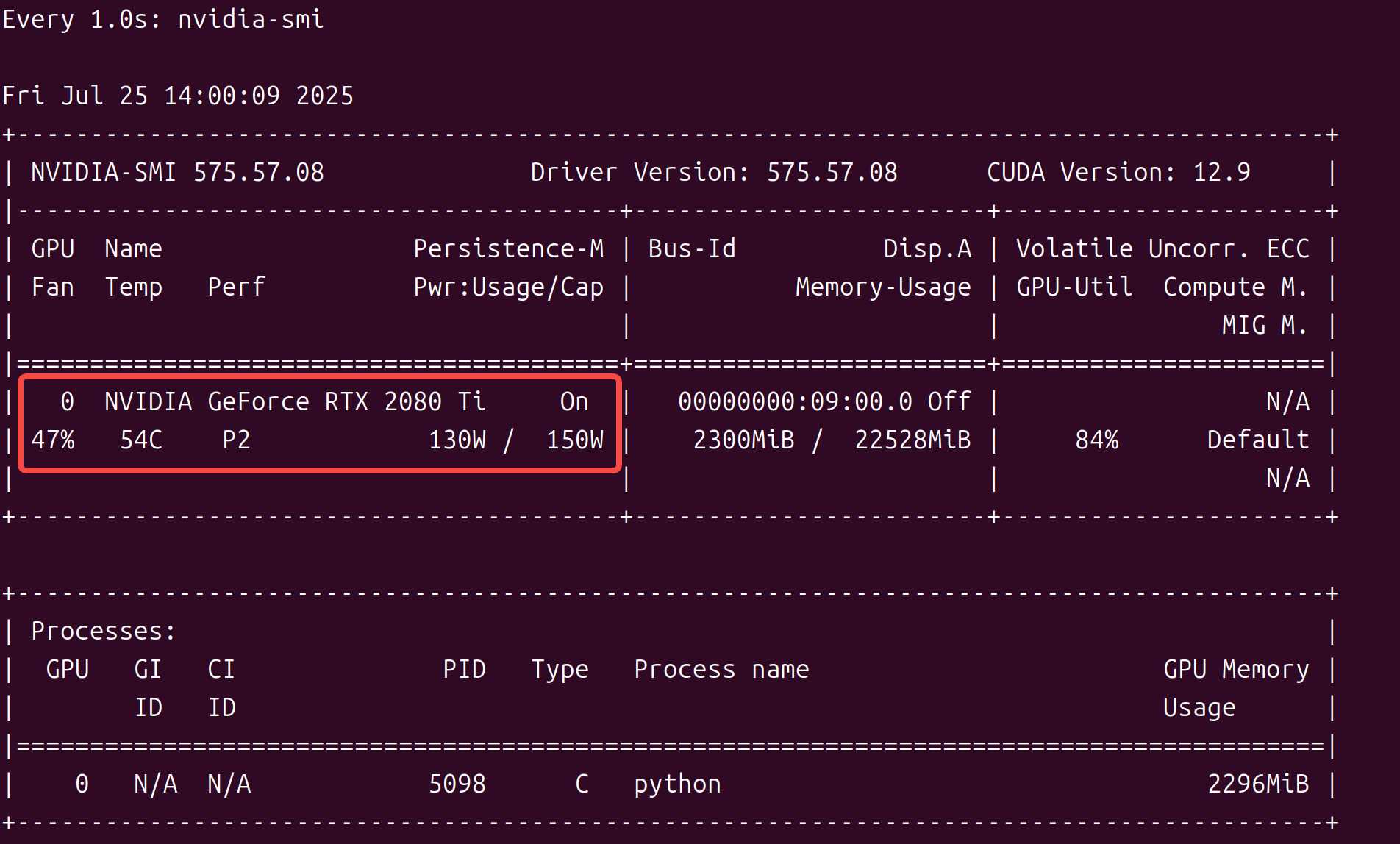
问题 当前使用的是魔改版的NVIDIA 2080 Ti 22G显卡,发现在模型训练过程中,跑着跑着就报错了,具体如下: raceback (most recent call last): File "/home/laumy/lerobot/./src/lerobot/scripts/train.py", line 291, in <module> …
设备查询 本文是记录ubuntu系统lerobot试验的快捷命令,方便开始负责执行设备,不会介绍为什么? python -m lerobot.find_port sudo chmod +666 /dev/ttyACM0 /dev/ttyACM1 python -m lerobot.find_cameras 机器标定 从臂标定 python -m …
加载准备 初始化ONNXRuntime环境 Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "YOLOv5Inference"); Ort::Env 是 ONNX Runtime C++ API 中用于初始化运行环境的类,有多个重载的构造函数,下面是一个构造函数原型及参数作用如下。 Ort::Env( …
是什么 pip install 是python包管理器,用于python软件包的下载、安装、卸载等功能。 怎么用 在线安装 pip install 软件包名 pip install 软件包名==版本号 例如pip install requests,或pip install reque
ONNX Runtime介绍 ONNX Runtime不依赖于Pytorch、tensorflow等机器学习训练模型框架。他提供了一种简单的方法,可以在CPU、GPU、NPU上运行模型。通常ONNX
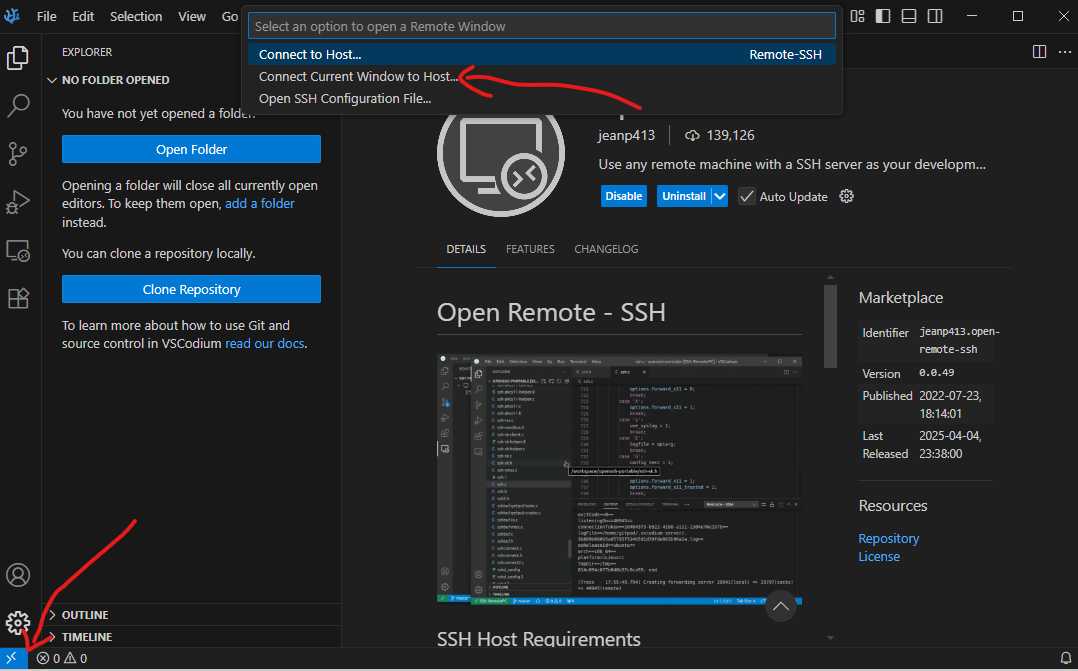
PC上安装vscodium 下载安装vscodium,https://vscodium.com/ 安装Open Remote - SSH插件。 可能要等等比较久,跟网络有关系,如果还是安装不了,可以参考
安装llama.cpp 从GitHub上下载官方的源码。 git clone https://github.com/ggml-org/llama.cpp.git cd llama.cpp 使用camke进行编译,先创建build环境 cmake -B build 发现有报错curl没有安装。 -- The C compiler identification …
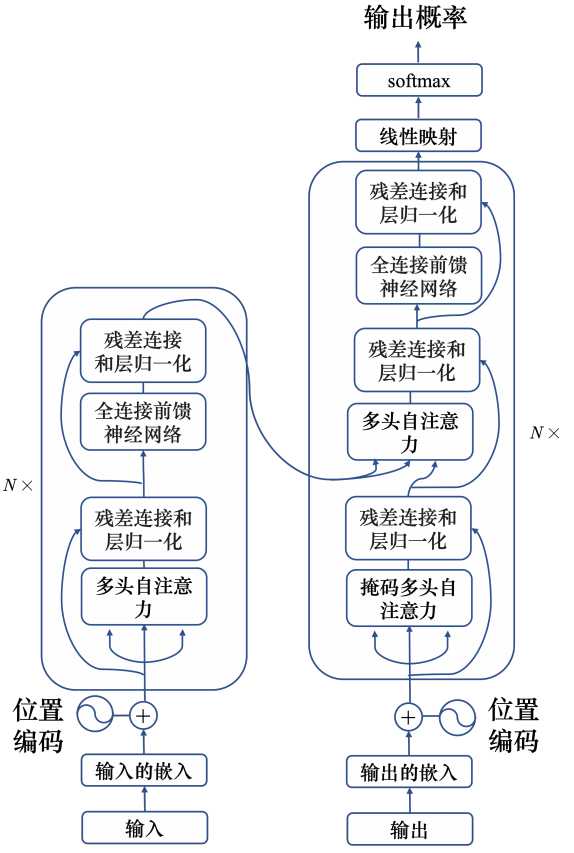
模型结构 transform使用了自注意力机制,由编码器和解码器组成。 编码器 transformer的编码器输入一排向量,输出另外一排同样长度的向量。transformer的编码中加入
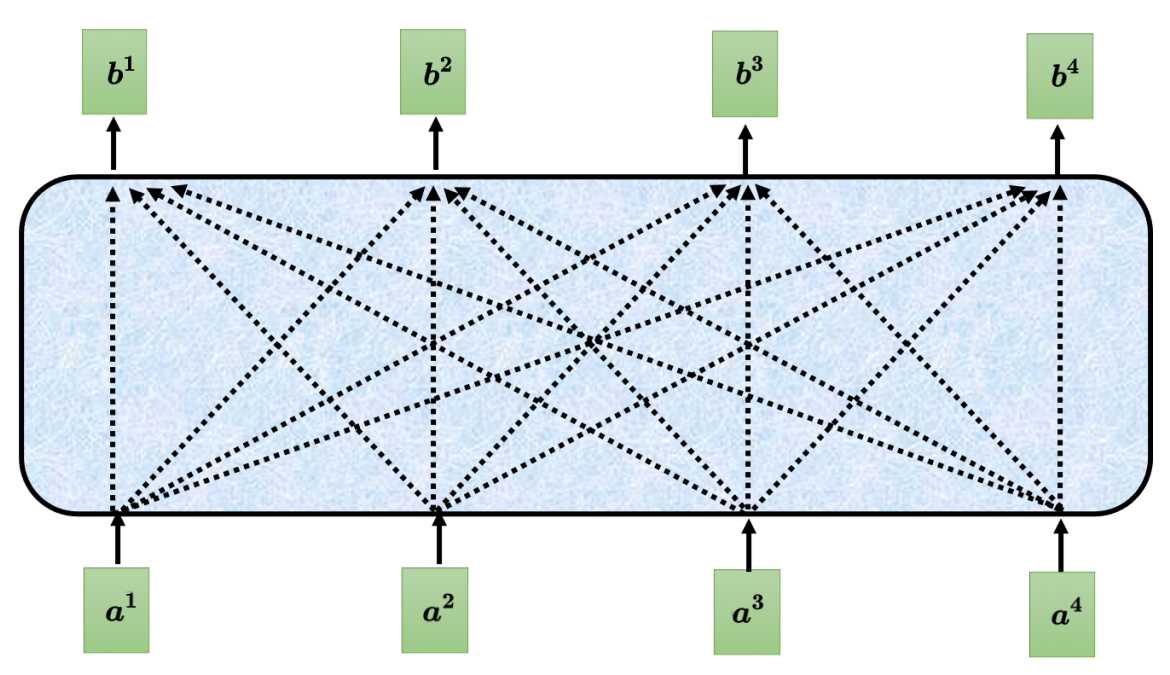
运作原理 自注意力机制要解决的是让机器根据输入序列能根据上下文来理解。举个例子,输入句子为"我有一个苹果手机",对于机器来说这里的"苹果"应该

模型流程 1. NPU初始化 NpuUint npu_uint; int ret = npu_uint.npu_init(); 2.根据传入的模型文件,创建网络 NetworkItem yolov5; status = yolov5.network_create(model_file, network_id); vip_create_network() …
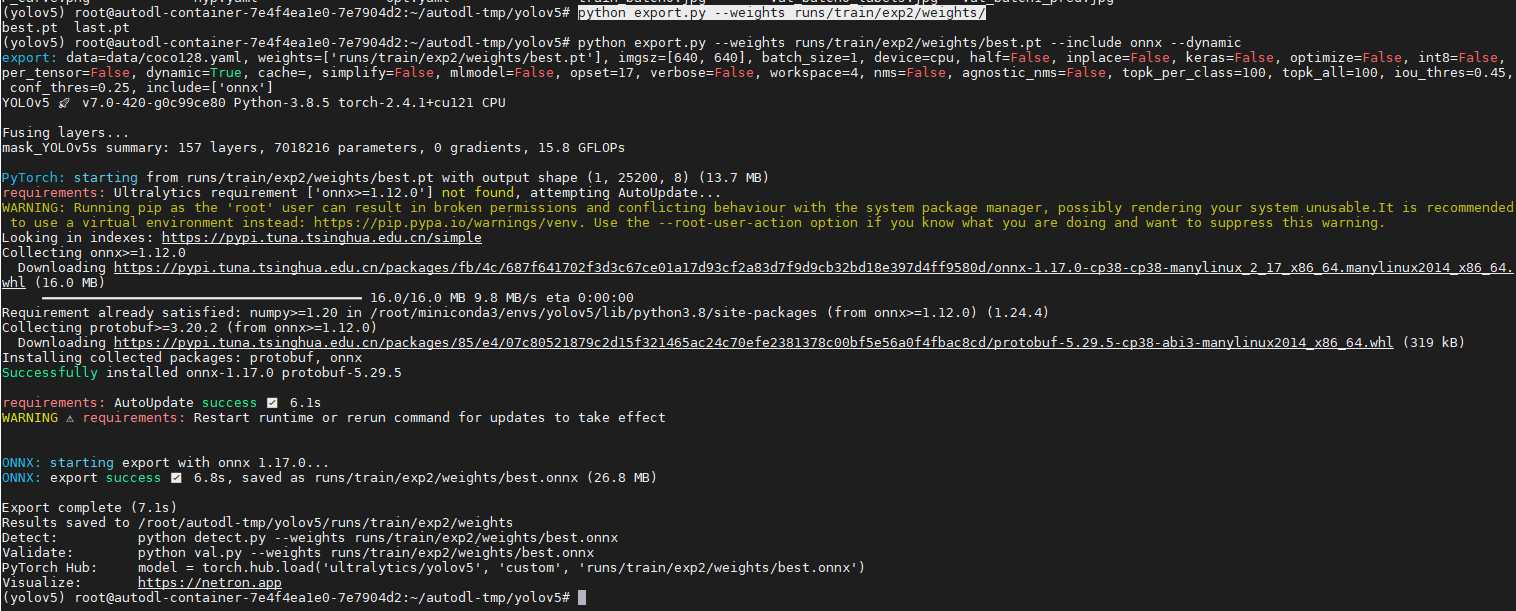
导出 ONNX模型 python export.py --weights runs/train/exp2/weights/ NPU不支持动态输入,使用onnxim工具进行转换为固定输入,先安装onnxsim工具。 pip install onnxsim -i https://pypi.doubanio.com/simple/ 接着进行转换 python -m …
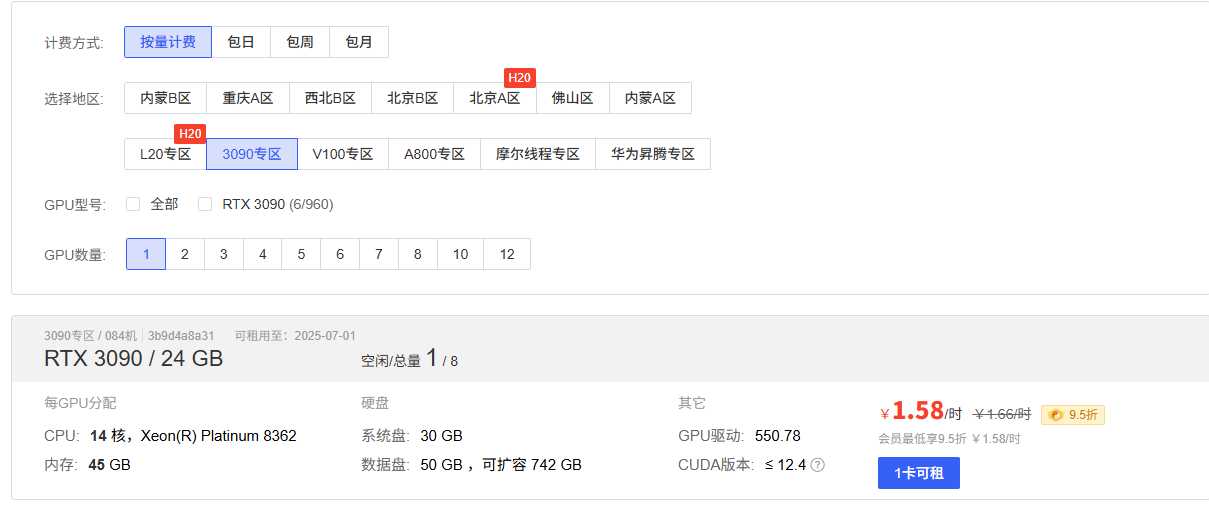
介绍 本文使用AutoDL云服务搭建YOLOv5的运行环境。 获取云服务器 在这个链接上https://www.autodl.com/home订阅服务,这里选择的是按量计费。 镜像选择基础
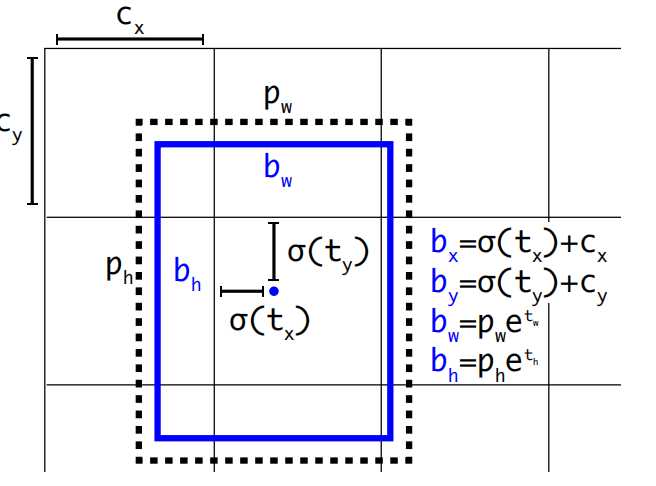
YOLOv2 回顾一下YOLOv1有哪些缺陷? 边界框训练时回归不稳定,导致定位误差大。 每个网格只能预测两个边界框且只能识别一类目标。 小目标检测效果差。 针对以上的问题,YOLOv2进行了改进,下
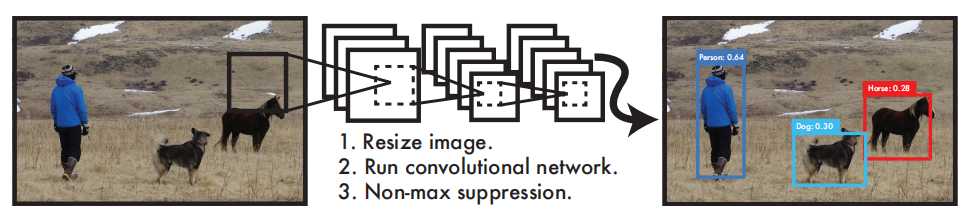
介绍 YOLO在目标视觉检测应用广泛,You Only Look Once的简称。作者期望YOLO能像人一样只需要看一眼就能够立即识别其中的物体、位置及交互关系。能够达到快速、实时检测的效果。 YOLO
环境准备 本文通过采集USB摄像头来示例说明 export LD_LIBRARY_PATH=/mnt/extsd/usr/lib:$LD_LIBRARY_PATH #指定库的路径 cat /sys/devices/platform/soc/usbc0/usb_host #激活USB host 摄像头采集 摄像头相关的主要使用的是VideoCapture类。 …
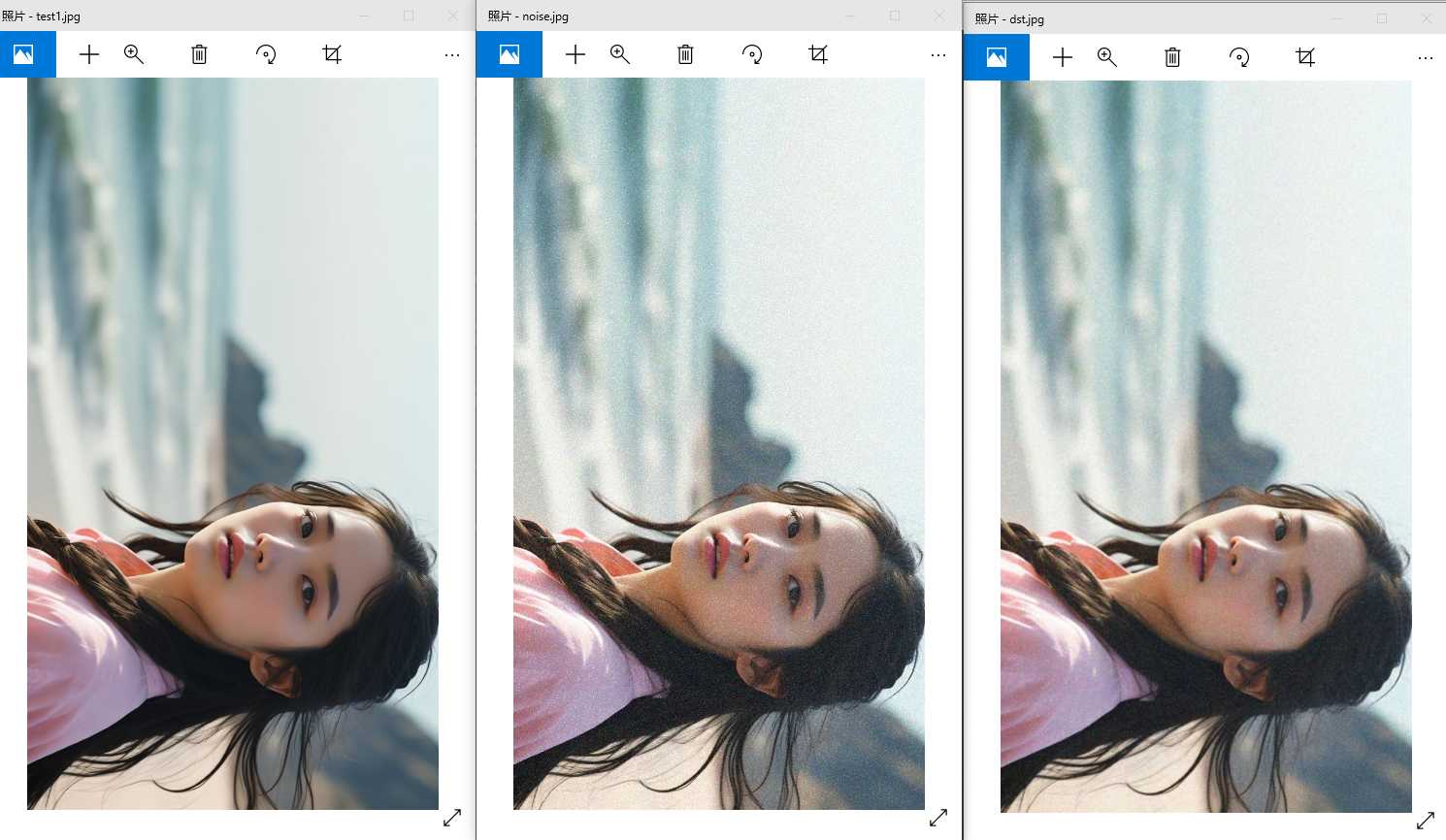
图像滤波 图像的滤波核心是使用一个小的矩阵(滤波器或卷积核)在图像上进行滑动卷积,将计算得到的结果作为目标像素的值。 均值滤波 cv::blur(InputArray src, OutputArray dst, Size ksize, Point anchor = Point(-1,-1), int borderType = BORDER_DEFAULT); …
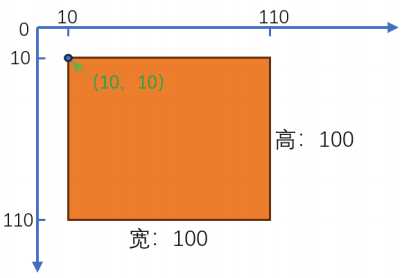
图像的读取和显示 读写图像 cv::Mat image = cv::imread("image.jpg", cv::IMREAD_COLOR); 使用imread函数读取图像,第一个参数是图像文件的路径,第二个参数是解释图像的颜色和格式(如彩色图像、灰度图像等)。第二个参数可省略,默认是cv
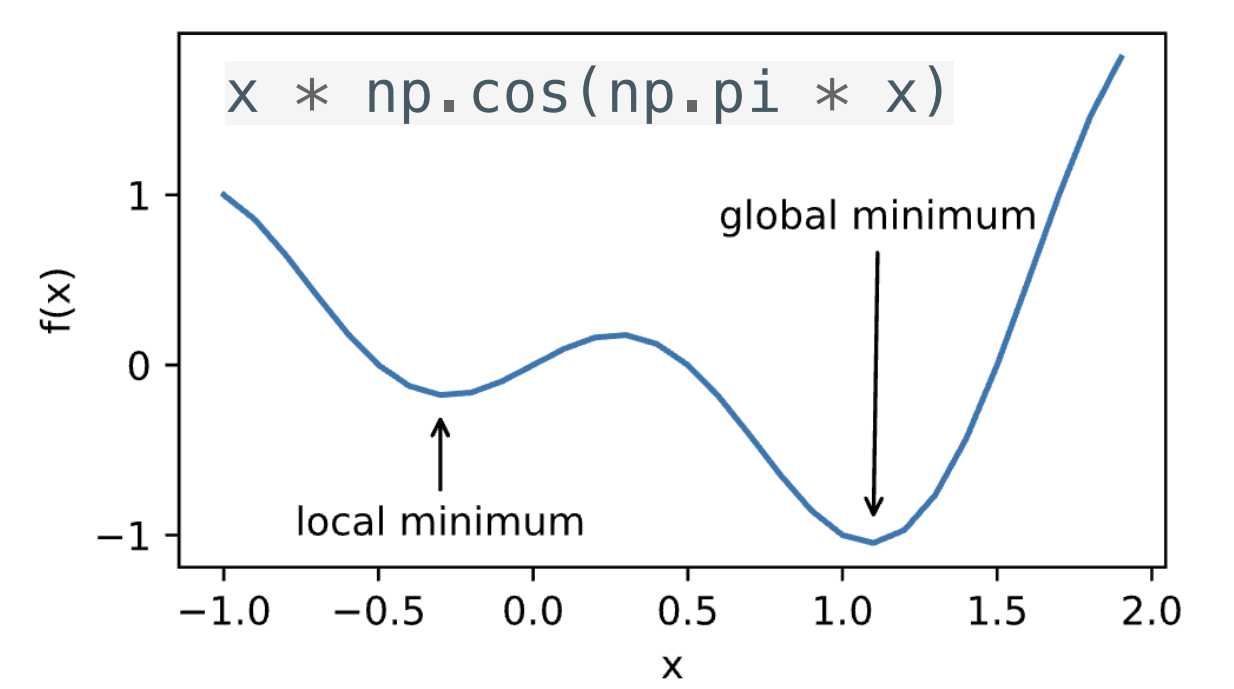
局部最小与全局最小 对应任何目标函数f(x),当然这里的目标函数可以是损失函数。如果在x处对应的f(x)小于x附近任意点的f(x),那么f(x)是局部最小的。如果f(x)在x处的值是
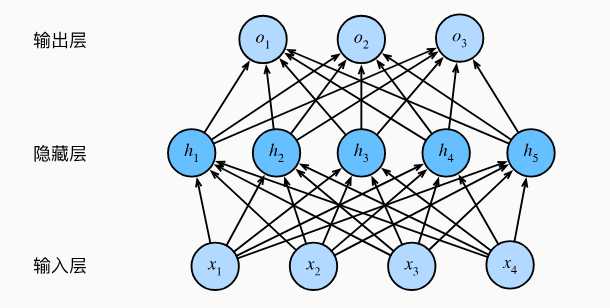
层的概念 在前面http://www.laumy.tech/2013.html有说明"层与块"概念,为了加深影响,本章再简要概括一下深度学习中常见的层。 在深度学习

图像增广 什么是图像增广?图像增广(Image Augmentation)是通过对原始图像进行一系列随机变换(如旋转、裁剪、颜色调整等)生成多样化样本的数据增强技术,旨在扩充训练数据集
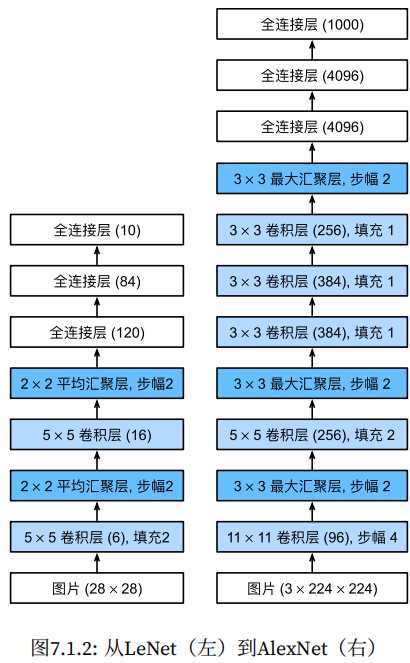
深度卷积神经网络AlexNet AlexNet相对LeNet的特点就是层数变得更深了,参数变得更多了。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。Ale
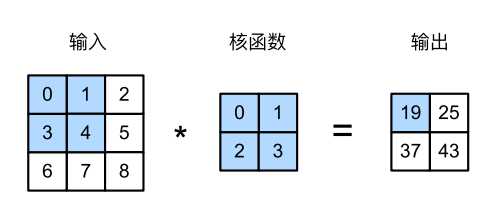
图像卷积 图像卷积是有一个卷积核,这个卷积核对输入做相关运算。卷积核从输入的张量左上角开始、从左到右、从上到下进行滑动,每到一个位置时,在该窗口的部分张量与卷积核做点积得到一个输出。
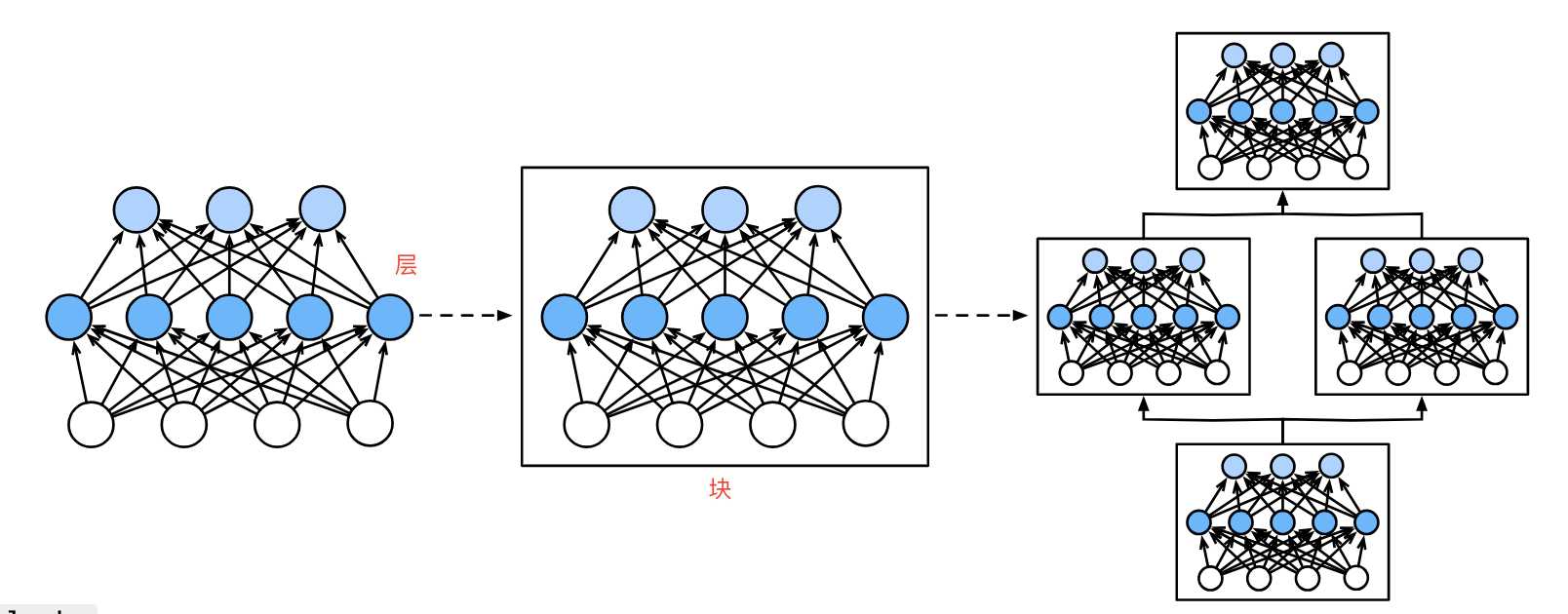
简单来说,如下图,第一个图中间5个神经元组成了一个层。第二图3个层组成了块。第三个图中3个块组成了整个模型。 层 层是神经网络的基本计算单元,负责对输入数据进行特定形式的变换,如线性映
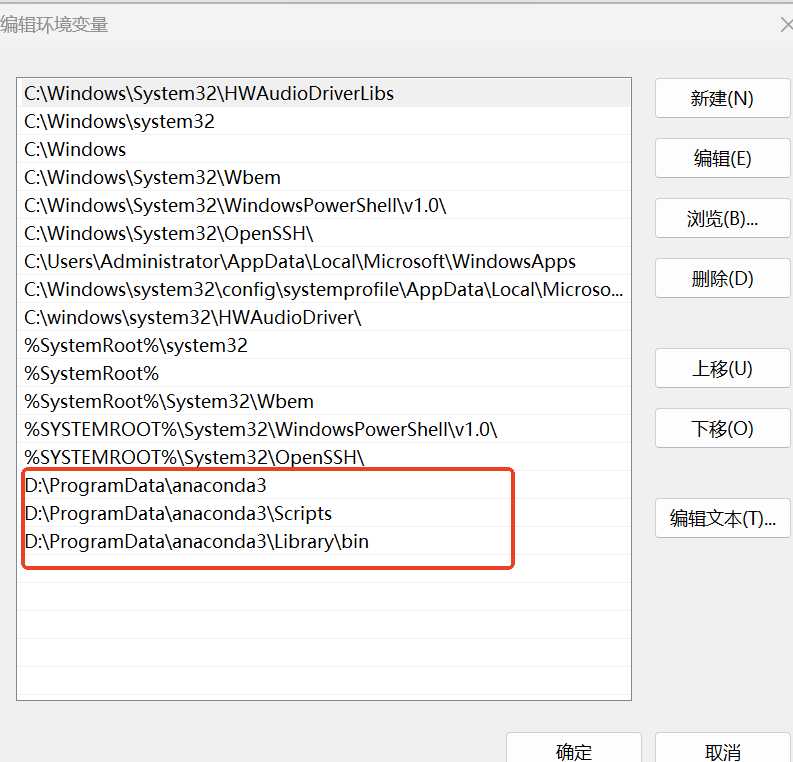
annaconda可以理解为ai环境可以创建很多个房间,比如允许多个不同版本的python。每个房间可以保存不同的环境变量。 步骤1:下载安装包,安装anaconda,https:/
前向传播(Forward Propagation) 前向传播是神经网络中从输入数据到输出预测值的计算过程。它通过逐层应用权重(W)和偏置(b),最终生成预测值 $y’ $,并计算损失函数$L $
什么是梯度 梯度(Gradient)是用于描述多元函数在某一点的变化率最大的方向及其大小。在深度学习中,梯度被广泛用于优化模型参数(如神经网络的权重和偏置),通过梯度下降等算法最小化
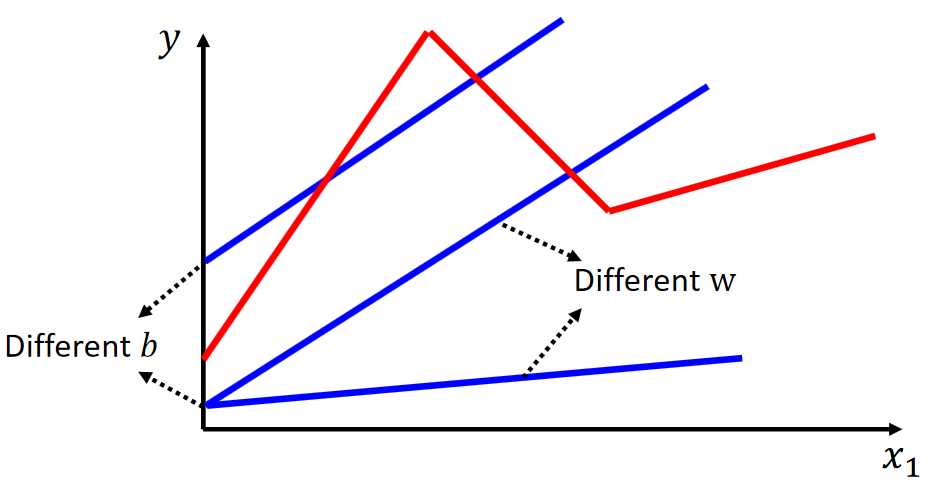
概念 前面我们主要使用的是线性模型,但是线性模型有很多局限性,因为我们要建模的问题并不能单纯使用线性模型就能够拟合的,如下示例。 我们要拟合红色部分的函数,使用线性模型即使在怎么调整W
什么是sotfmax回归 Softmax回归(Softmax Regression),也叫多项逻辑回归,是一种用于多分类问题的分类算法。它是对逻辑回归(Logistic Regressi
线性回归 线性回归模型根据给定的数据集和对应的标签,通过一个函数模型来拟合数据集以及对应标签的映射关系。而这个模型可以设置为y=wx+b的一个函数,其中x和w是一个向量。目标就是找出
app start 主要是初始化板级、显示、WiFi连接、音频codec、编解码、协议、音效、唤醒几个环节。 auto& board = Board::GetInstance(); //获取板级实例 SetDeviceState(kDeviceStateStart
环境是centos,下面是部署步骤。 命令1: 安装ollama 安装命令:curl -fsSL https://ollama.com/install.sh | sh 安装日志: >>> Cleaning up old version at /usr/local/lib/ollama >>> Installing ollama to /usr/local …
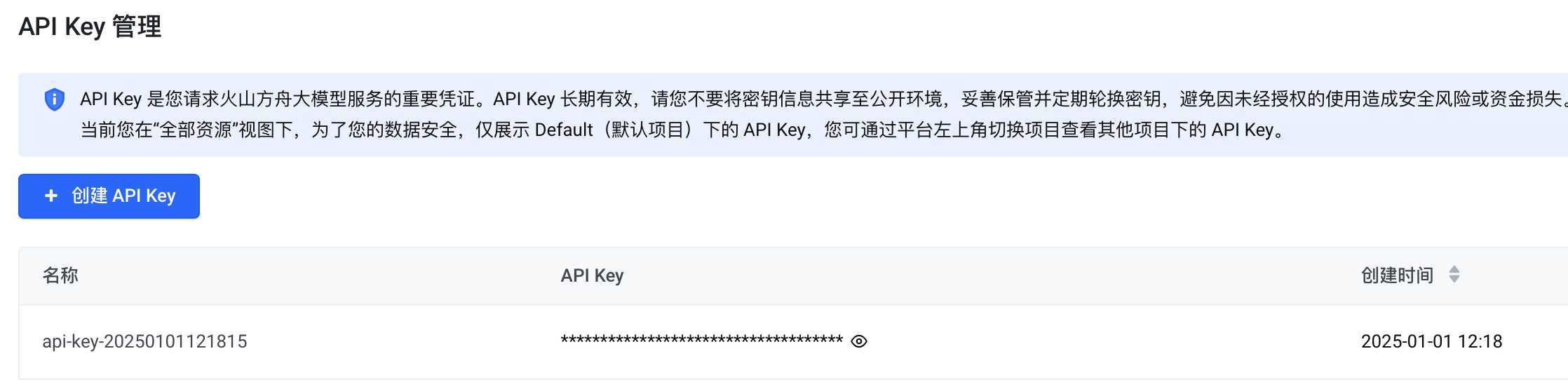
前置条件 需要先创建获得API key和创建推理接入点。 API key获取 https://www.volcengine.com/docs/82379/1361424#f79da451 创建推理接入点 https://www.volcengine.com/docs/82379/1099522 安装python环境 python版本需要安装到Python …