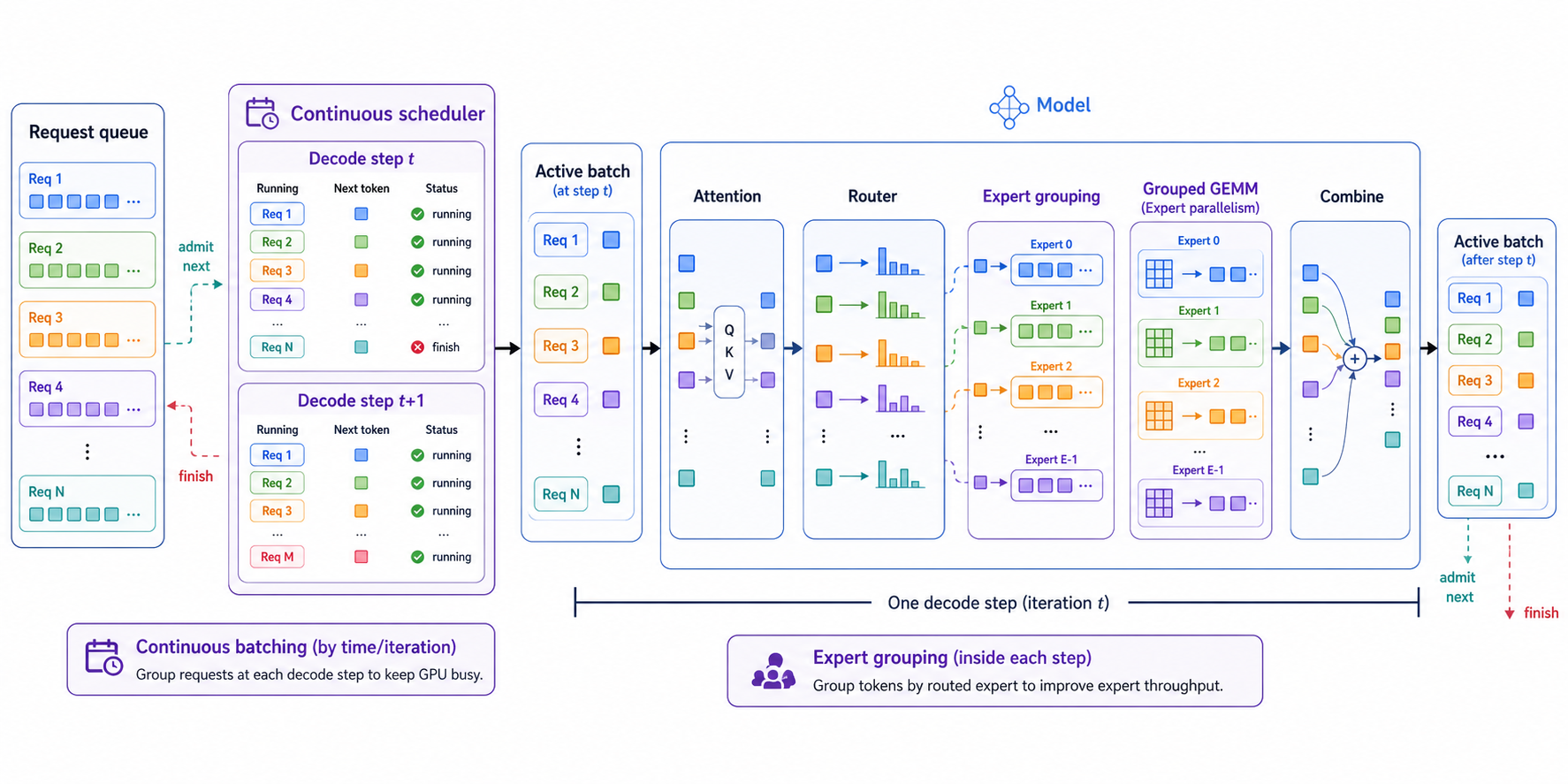
Continuous Batching与Expert Grouping:大模型推理服务优化原理
概述 大模型推理服务的核心问题不是“单个请求能不能跑”,而是“很多请求同时进来时,GPU能不能一直忙,并且用户等待时间不要太长”。这里会遇到两个层面的调度问题。 请求层面:不同用户请求
概述 大模型推理服务的核心问题不是“单个请求能不能跑”,而是“很多请求同时进来时,GPU能不能一直忙,并且用户等待时间不要太长”。这里会遇到两个层面的调度问题。 请求层面:不同用户请求
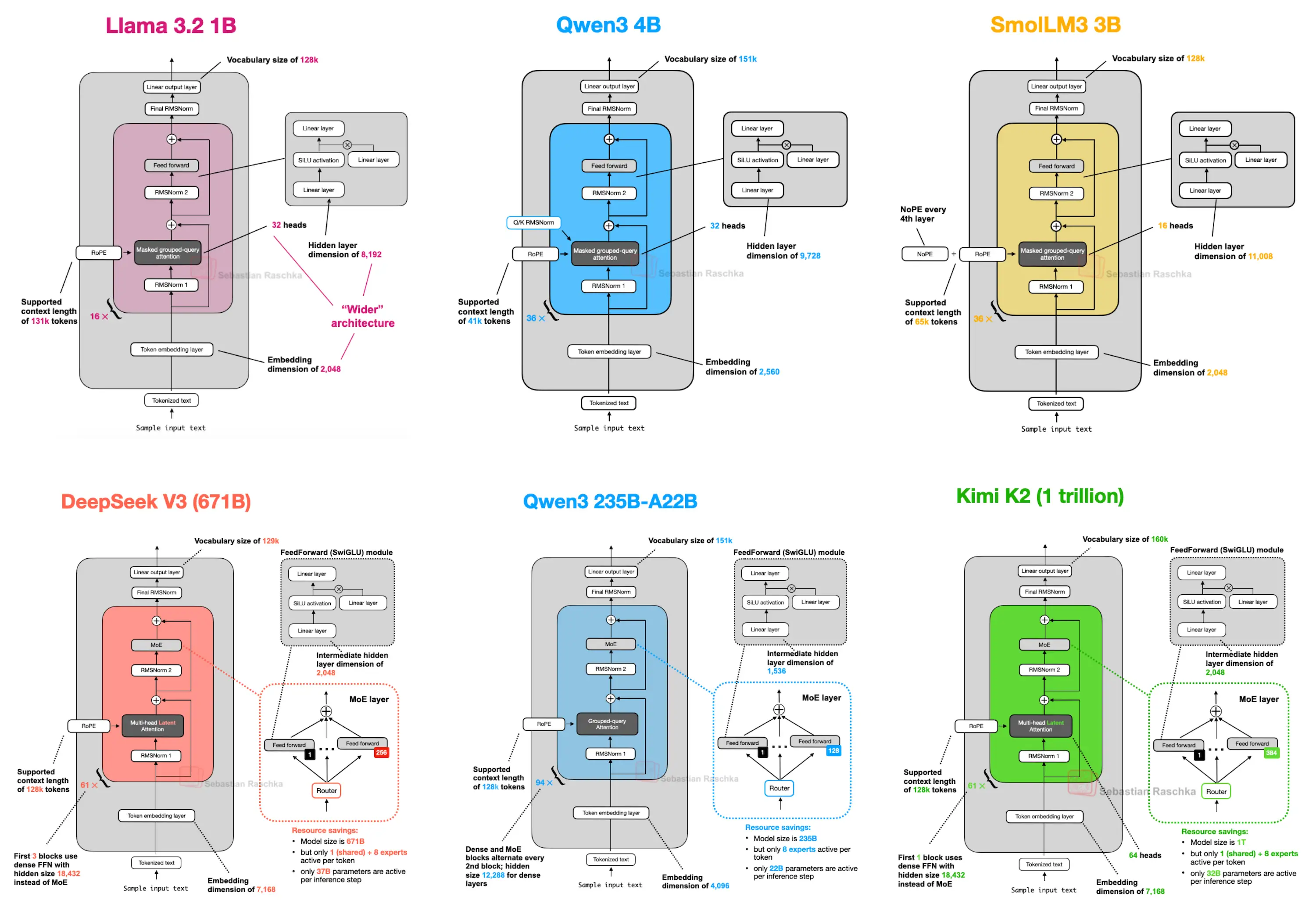
大模型推理的"第一性原理" 从Deepseek V3到Kimi K2 无论模型如何变化,当前主流大模型的核心架构都是基于transformer。其本质是一个由多层相同结构

概述 llama.cpp 的模型加载系统是一个高度优化的、支持多后端、多设备的模型权重加载框架。它通过精心设计的数据结构和加载流程,实现了: 零拷贝加载:通过内存映射(mmap)实现模型文件的零拷贝加载
后端系统概述 GGML后端系统主要提供如下功能: 统一接口: 不同硬件平台使用相关的API。 自动选择:根据硬件自动选择最优后端。 灵活切换:可以在运行时切换后端。 扩展性:易于添加的新后端。

加载后端 void ggml_backend_load_all() { ggml_backend_load_all_from_path(nullptr); } void ggml_backend_load_all_from_path(const char * dir_path) { #ifdef NDEBUG bool silent = true; …
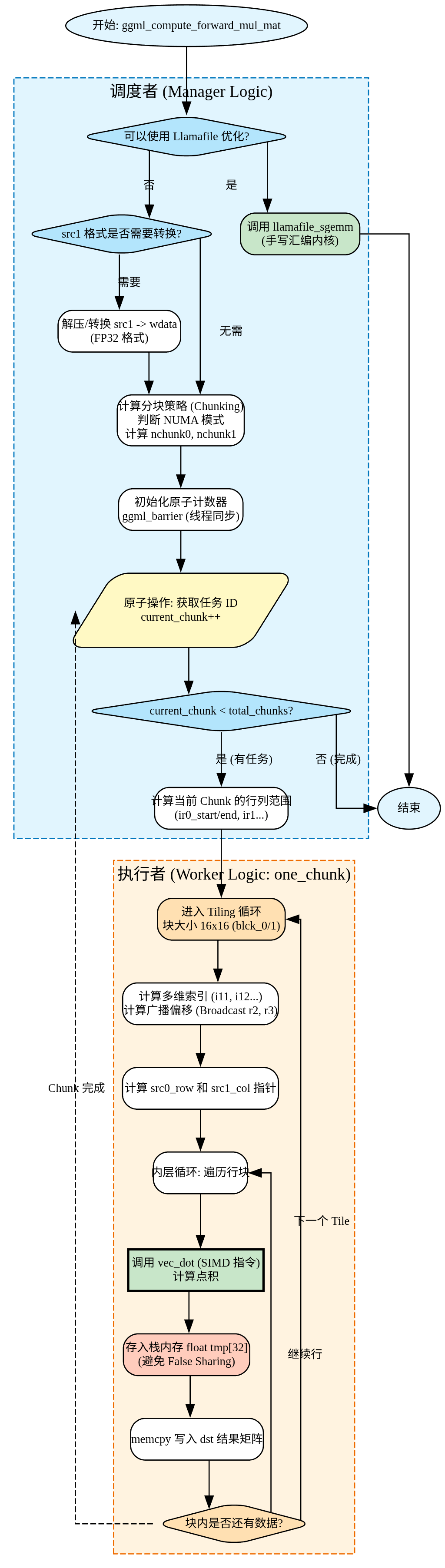
算子实现 调用流程 主要是ggml_compute_forward_mul_mat函数,该函数把任务拆分,最终计算执行调用ggml_compute_forward_mul_mat_on
矩阵相乘 是神经网络中算力消耗最大的部分,通常占据 LLM 推理计算量的 95% 以上。 矩阵乘法 (Matrix Multiplication / GEMM) 这是最通用的矩阵运算形式,也是 AI 芯片中 Tensor Core 或 MAC 阵列的主要工作内容。 定义: 设矩阵 $A$ 的形状为 $(M \times K
OpenMP是什么 OpenMP是一套用于共享内存并行系统的多线程程序设计标准。通俗的将,它允许通过简单的编译器指令(#pragma)将原本串行执行的C/C++ for循环瞬间变成多线
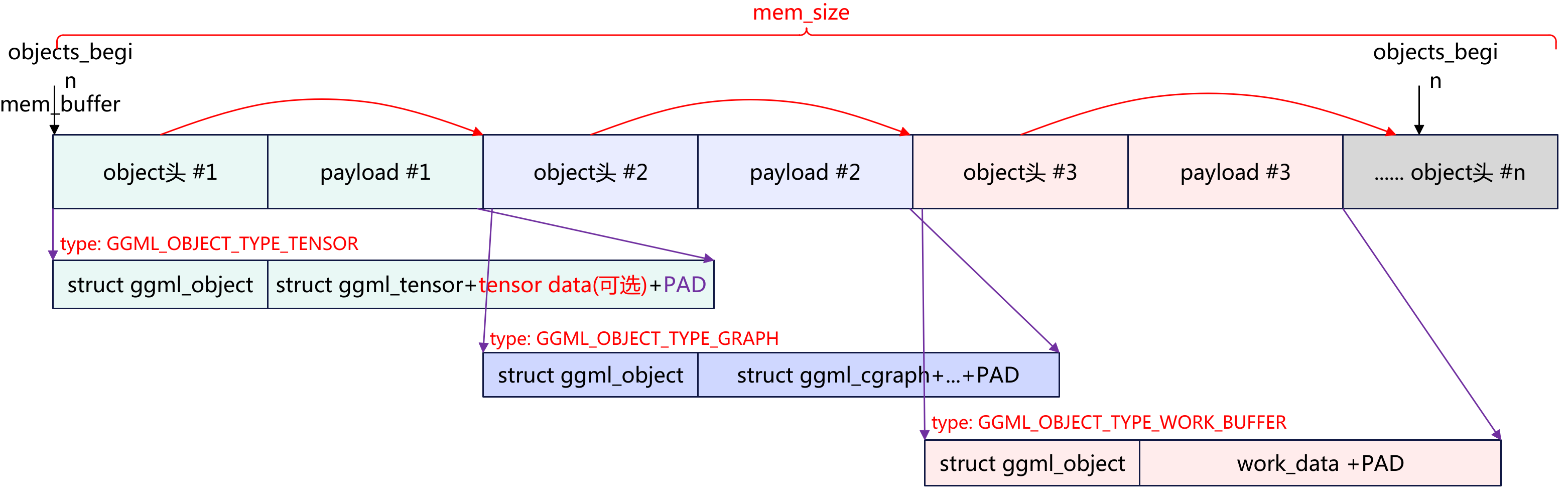
ggml是什么 ggml是用于transformer架构推理的机器学习库,类似于pytorch、TensorFlow等机器学习库。ggml不需要第三方库的依赖,目前兼容X86、ARM