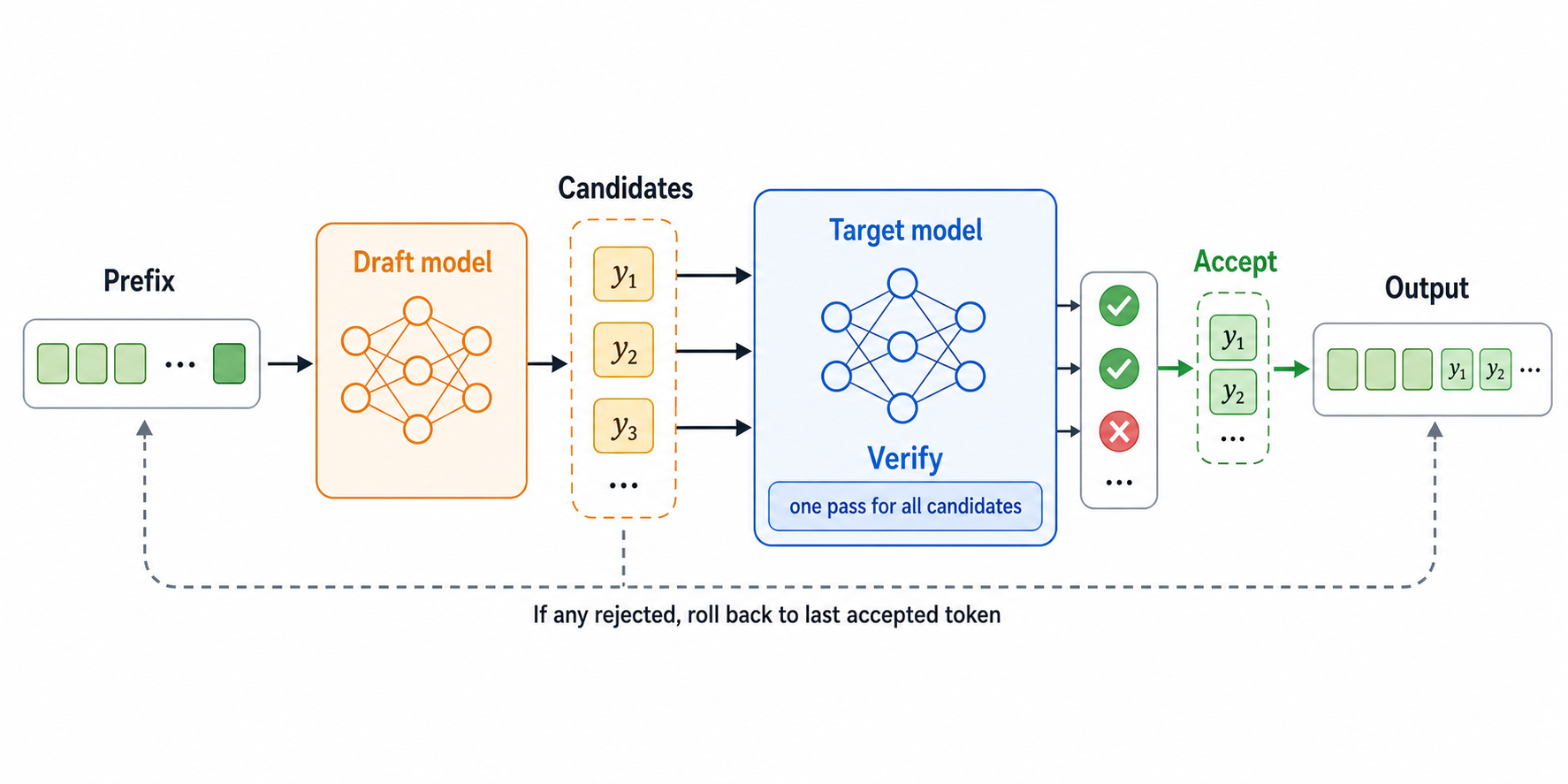
投机解码原理:用草稿模型加速大模型生成
概述 大语言模型生成文本时,本质上是一个自回归过程:先根据已有上下文预测下一个token,再把这个token拼回上下文里,继续预测下一个token。也就是说,如果要生成100个tok
概述 大语言模型生成文本时,本质上是一个自回归过程:先根据已有上下文预测下一个token,再把这个token拼回上下文里,继续预测下一个token。也就是说,如果要生成100个tok
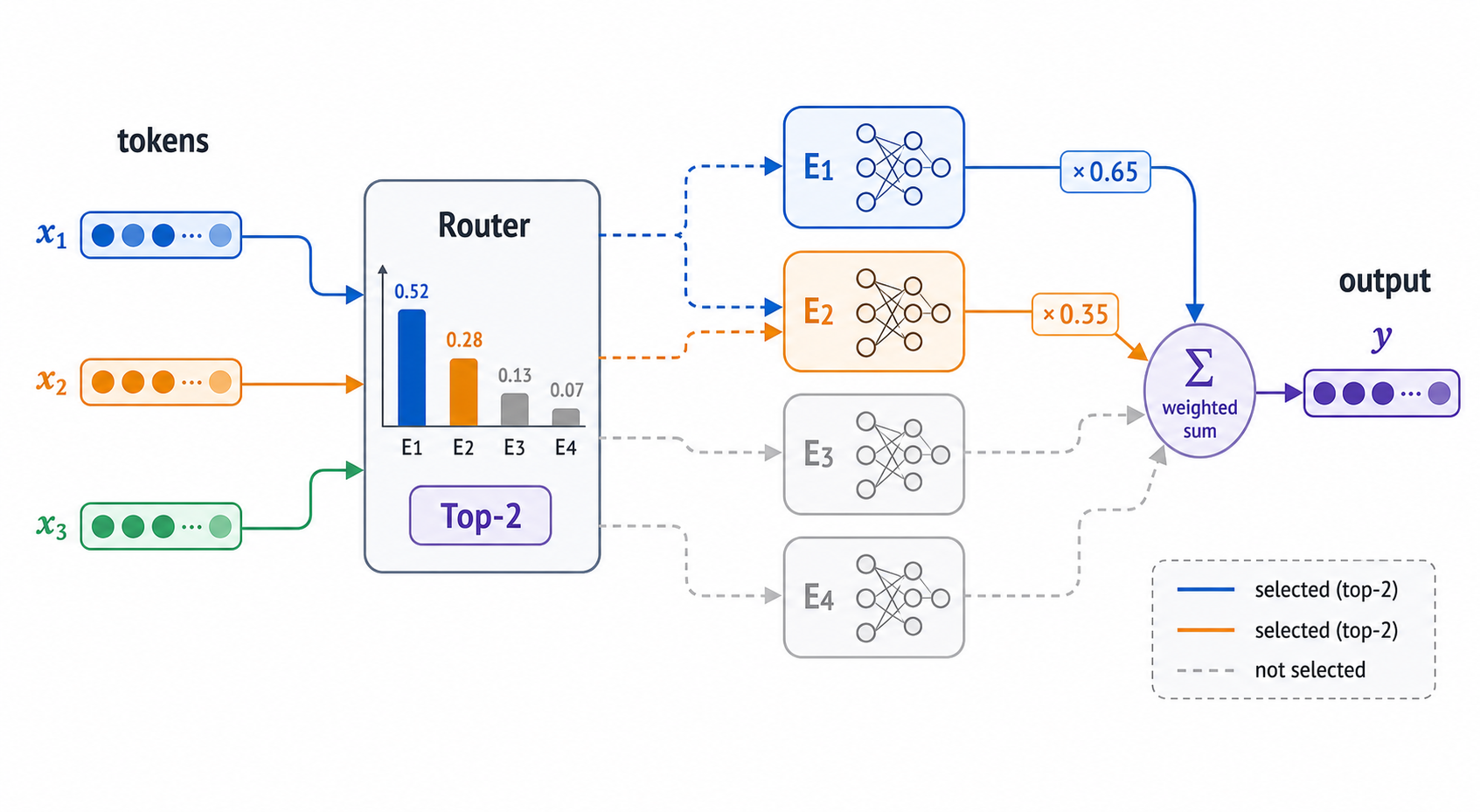
概述 大模型能力提升通常依赖两个方向:模型参数变多、训练数据变多。Dense模型的做法比较直接,每一层的参数都会参与每个token的计算,模型越大,单次前向计算也越重。这样虽然简单,

强化学习简介 什么是强化学习 以直升机控制飞行的程序来举例。 自动驾驶的直升机配备了机载计算机、GPS、加速度计、陀螺仪和磁罗盘,我们可以实时确定的知道直升机的位置。如何使用强化学习来让
概念 WBC(Whole-Body Control,全身控制)是什么?机器人是由“各关节”组成的,其不是“各关节各玩各的”而是一个耦合的整体。在某个时刻可能要做很多事情,比如保持平衡(
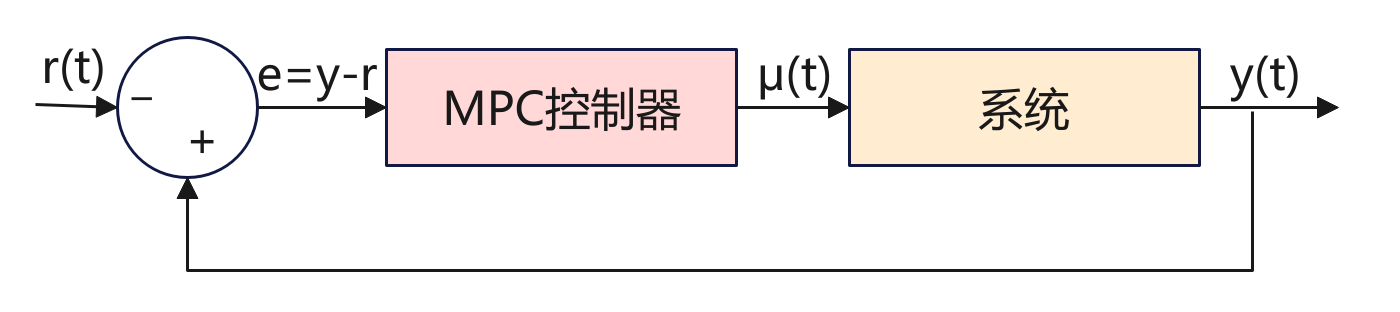
背景 MPC(Model Predictive Control)模型预测控制,是一种控制方法,广泛应用在机器人、无人驾驶、过程控制、能源系统等领域。它的核心思想用一句话来总结:利用系统模型预测未来,并通过
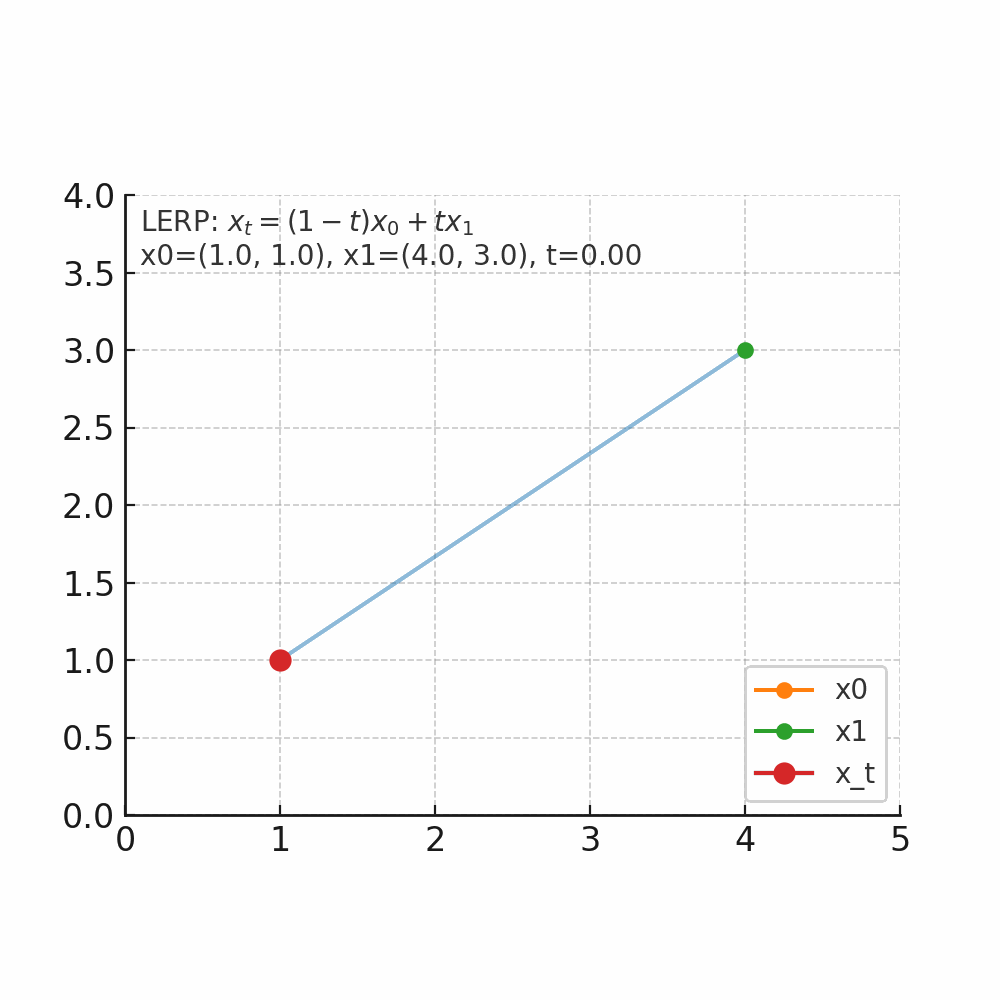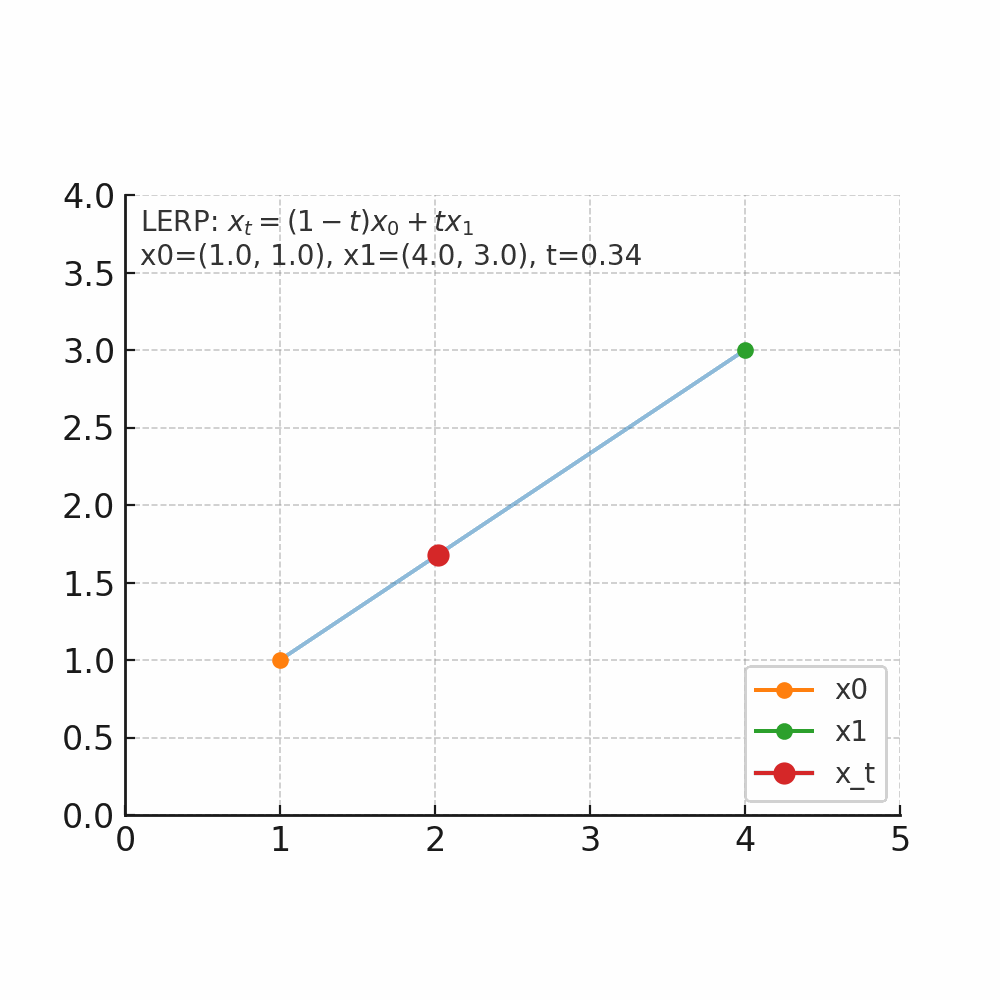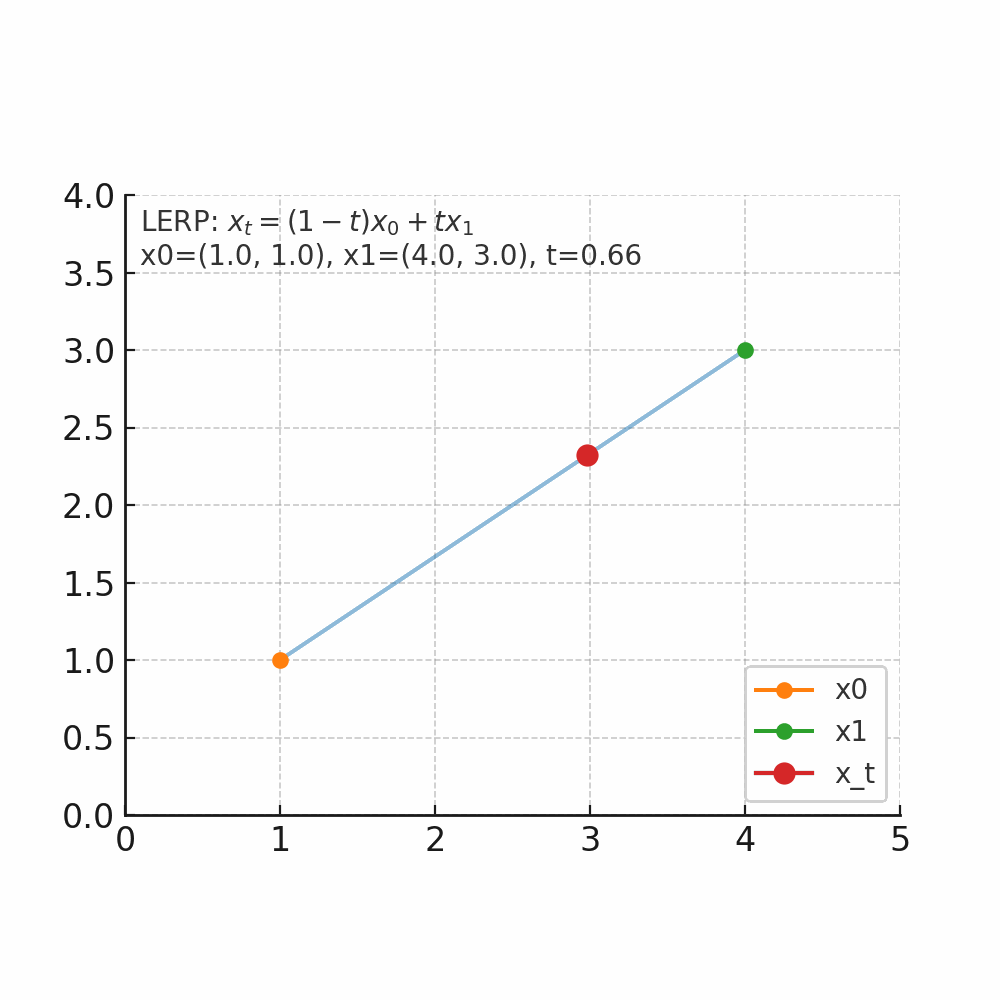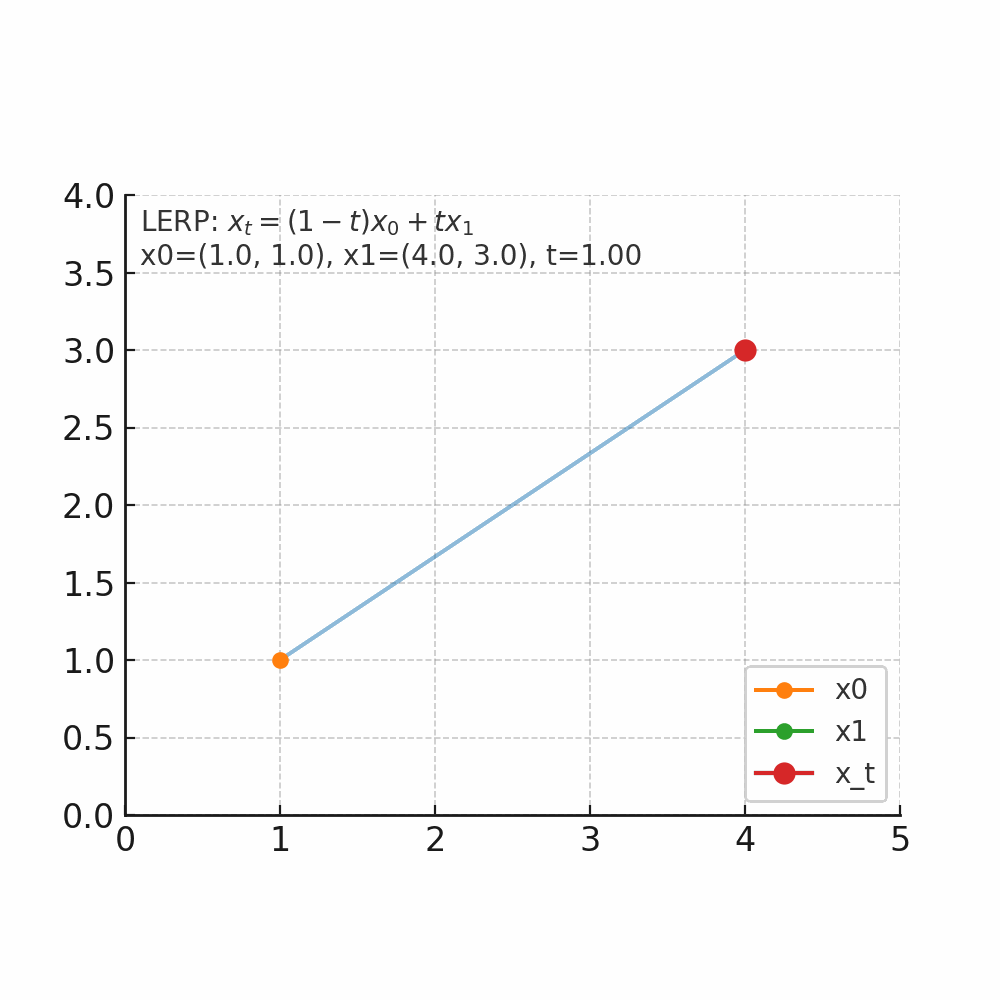
什么是插值 插值的核心问题是:在已知两个点的情况下,如何找到它们之间的中间点。 举个人走路的例子,起点在家门口(A点),终点在公司(B点),总的路程为1000米,假设人是匀速移动,如果
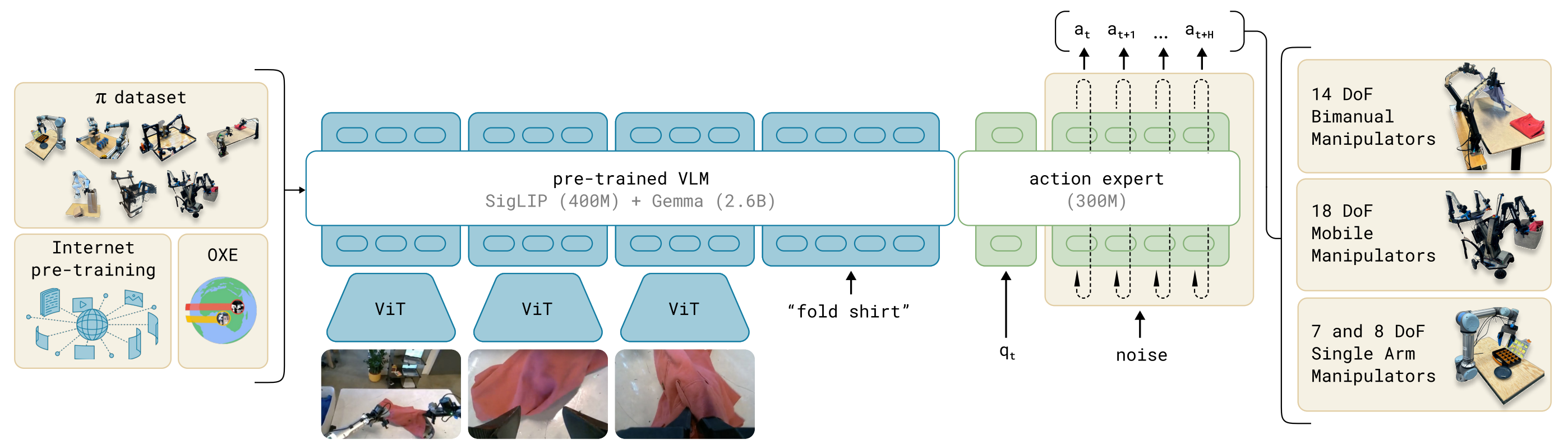
概述 SmolVLA 是一套轻量级视觉-语言-行动(VLA)策略:前端用小型 VLM(视觉 SigLIP + 语言 SmolLM2)做感知与理解;后端用一个“动作专家”专门预测一段连续的低层控制。它与Pi0相比,参数
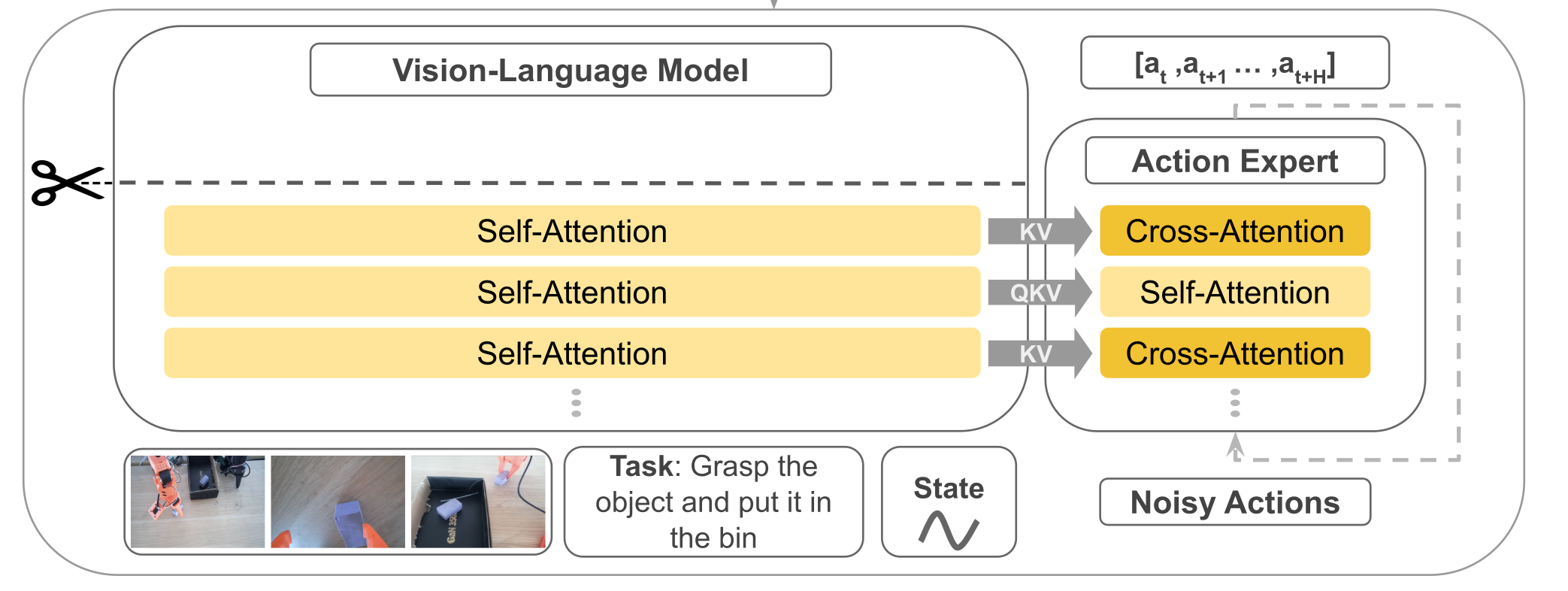
概述 传统机器人策略模型往往局限在单一任务或平台,难以跨场景泛化。与此同时,大规模 视觉-语言模型(VLM) 已展现出卓越的语义理解与任务指令解析能力。如果能将 VLM 的语义理解能力 与 Flow Matching 的连
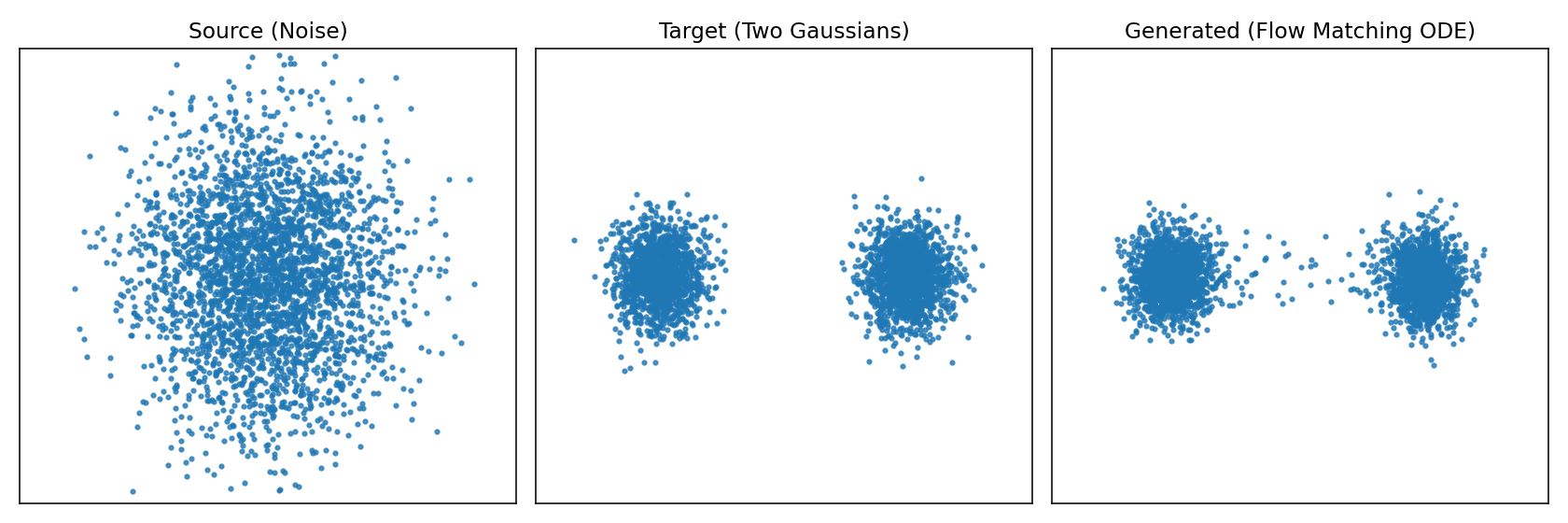
背景 上一篇文章分析了diffusion扩散模型。diffusion扩散模型做法是加噪声、再一步步去噪,训练过程复杂,还需要 carefully 设计噪声调度。 Flow Matching提出了更直接的方式:与其
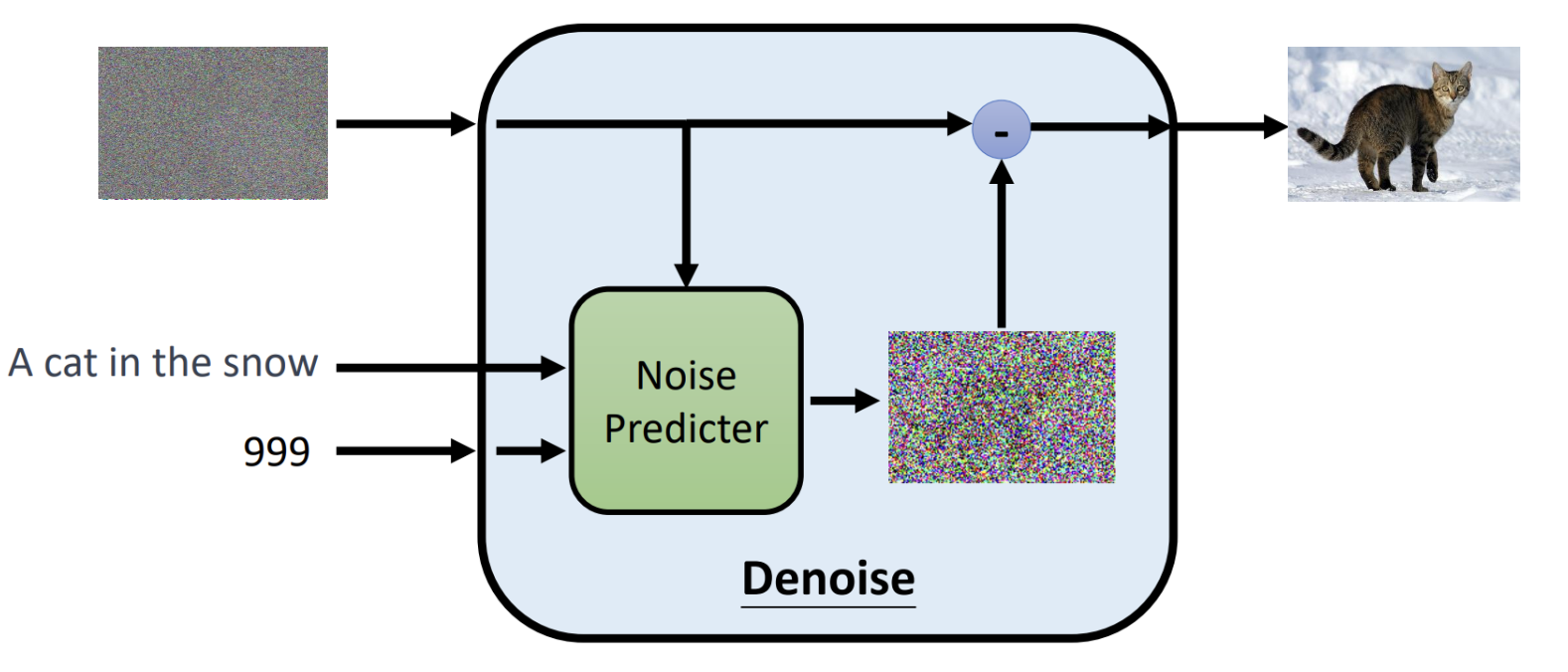
概述 图像生成是当下研究的热点,diffusion是一种人工智能领域图像生成的基础模型,当下Stable diffusion、DALL·E、MidJourney文生图模型的基座都使用了
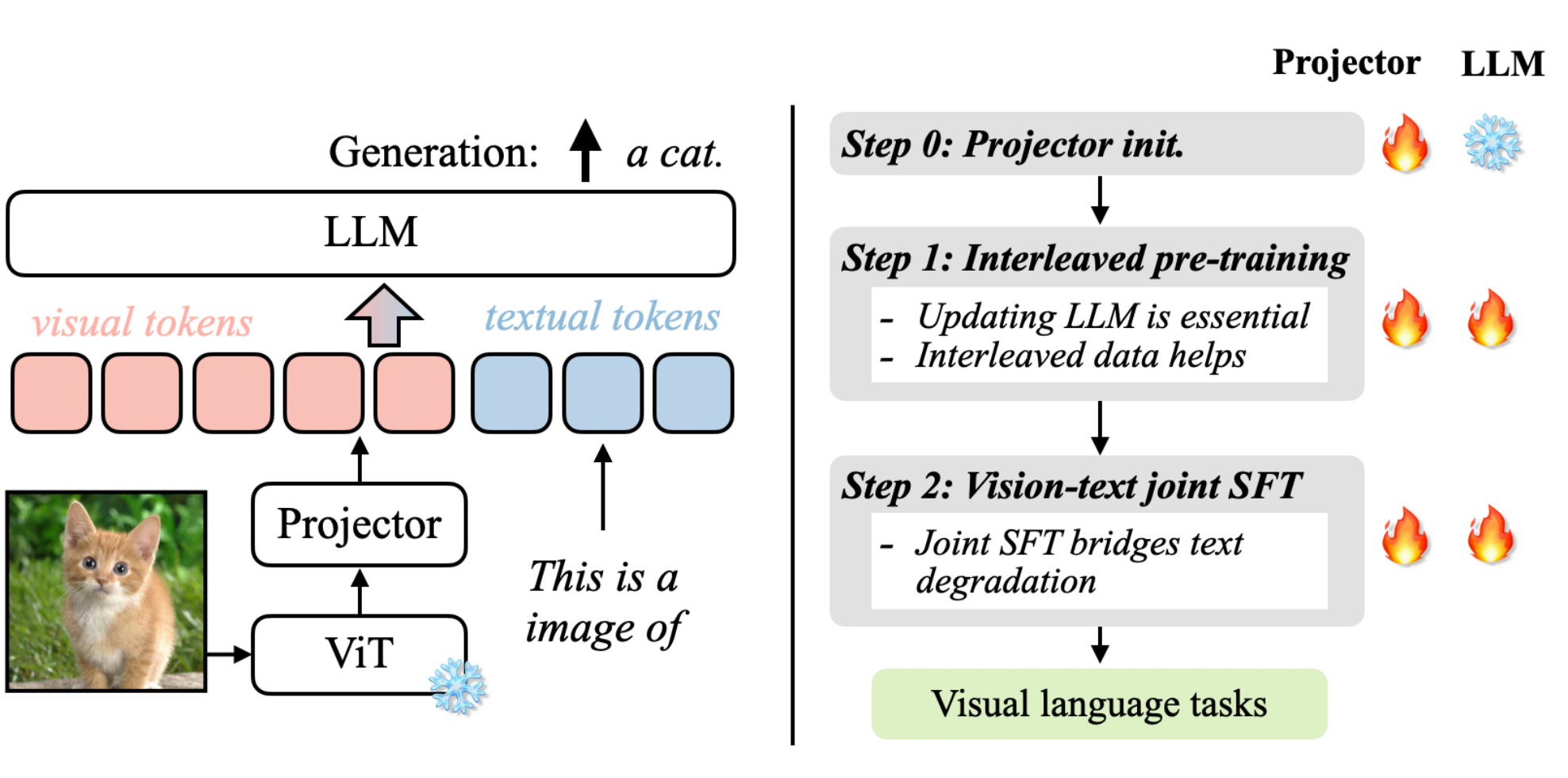
VLM与LLM 如果说我们有一张图片、一个图表想让大模型来帮忙理解那应该要怎么实现了? 标准的LLM语言大模型只能处理文本序列,是不能够读取图像的,如果没有办法将视觉的数据转换为LLM
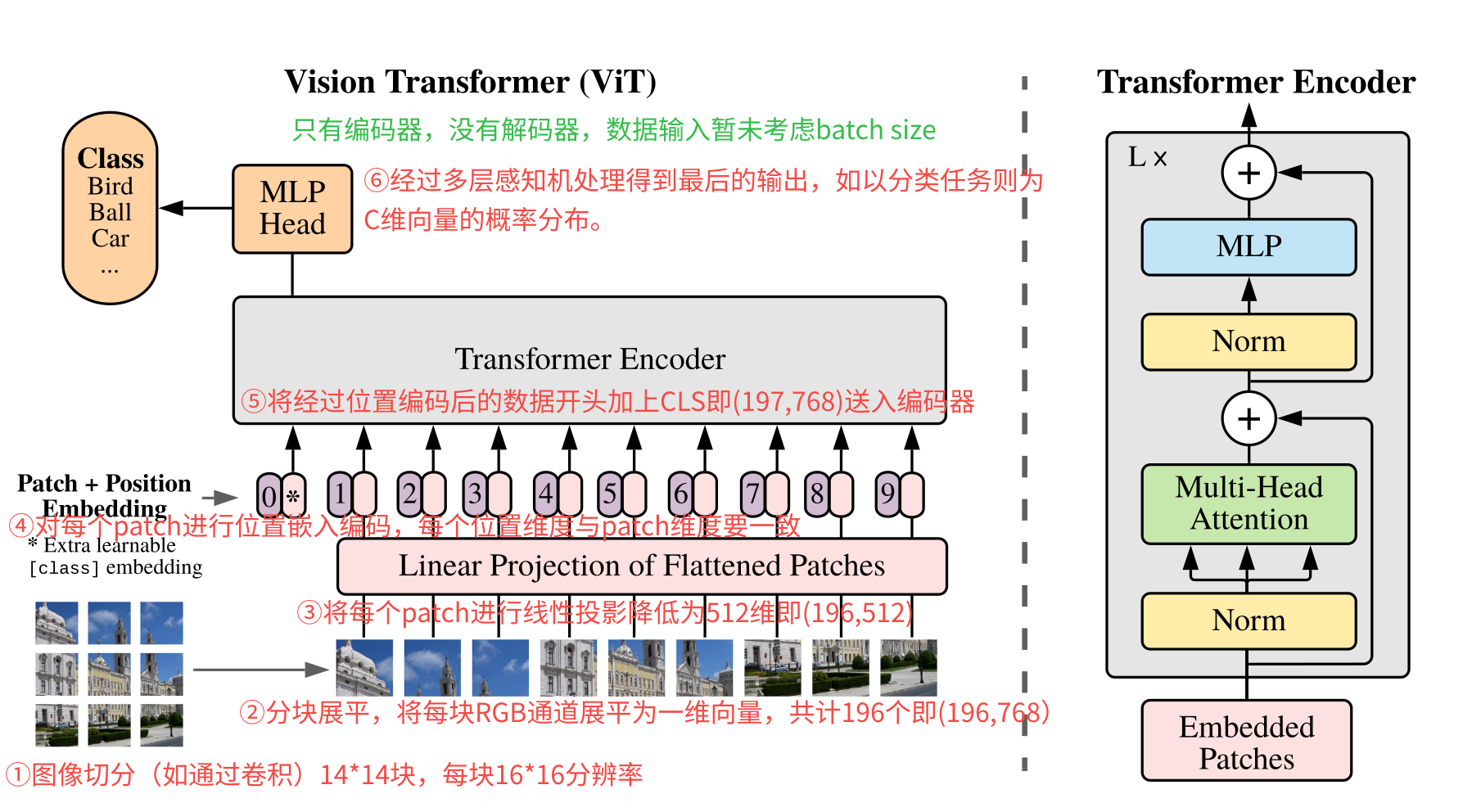
背景 计算机视觉领域,一直都是卷积天下。传统的卷积神经网络(CNN)依赖于卷积核提取局部特征,效果很好,但是也有一些不足,如需要人工设计卷积结构包括卷积核大小和层数,另外就是难以捕捉

概述 框架 以翻译作为例子,从宏观角度理解大模型,可以把大模型视为一个黑匣子,它可以输入一种语言然后输出另外一种翻译语言,如下图所示。 如果将模型稍微展开一下,模型分为encoders和
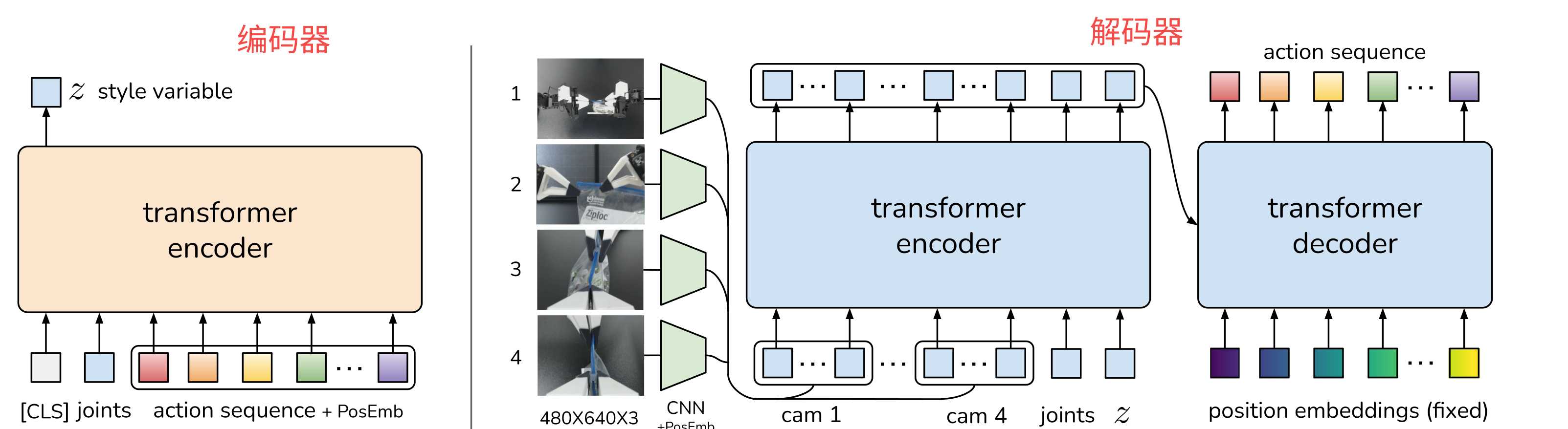
基本原理 简单总结一下什么是ACT算法。传统的机器算法过程是观测关节位置J1经过模型预测动作A2然后执行,观测到J2预测数A3,观测到J3遇到A4依次类推,这样就有一个问题,假设预测
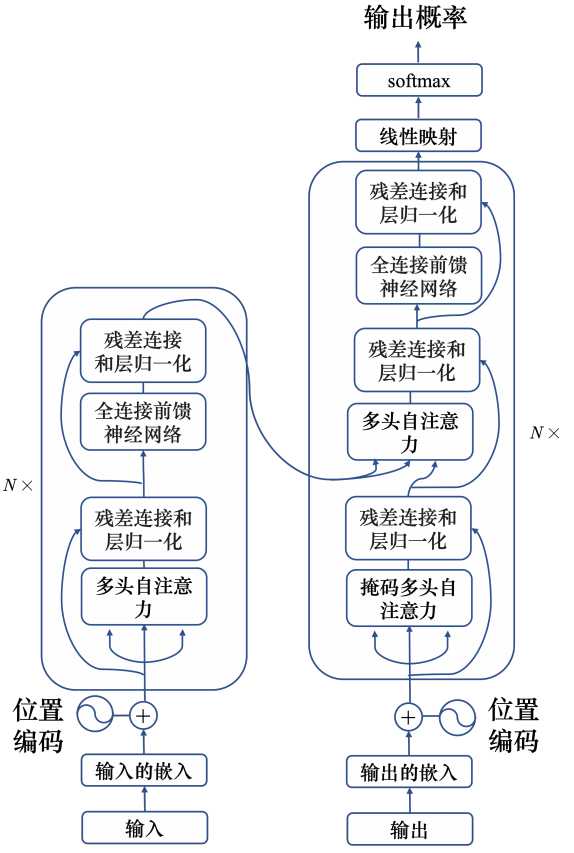
模型结构 transform使用了自注意力机制,由编码器和解码器组成。 编码器 transformer的编码器输入一排向量,输出另外一排同样长度的向量。transformer的编码中加入
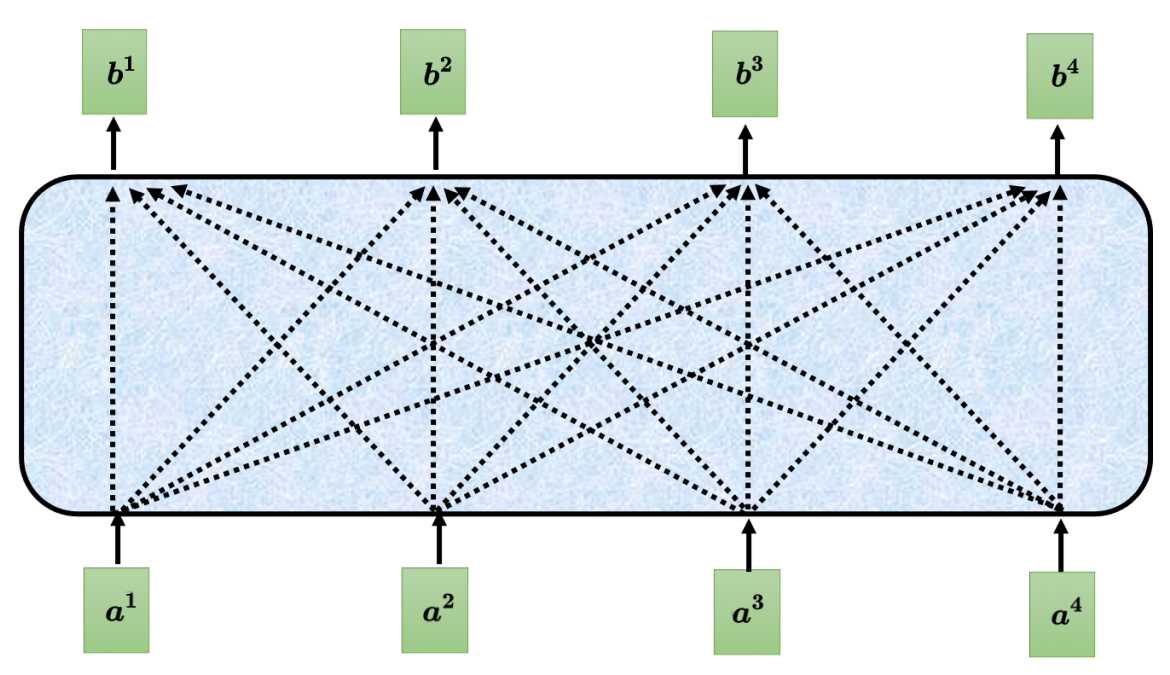
运作原理 自注意力机制要解决的是让机器根据输入序列能根据上下文来理解。举个例子,输入句子为"我有一个苹果手机",对于机器来说这里的"苹果"应该
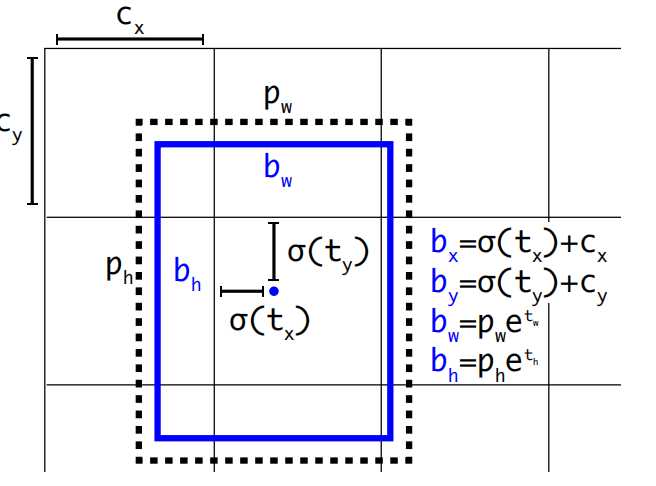
YOLOv2 回顾一下YOLOv1有哪些缺陷? 边界框训练时回归不稳定,导致定位误差大。 每个网格只能预测两个边界框且只能识别一类目标。 小目标检测效果差。 针对以上的问题,YOLOv2进行了改进,下
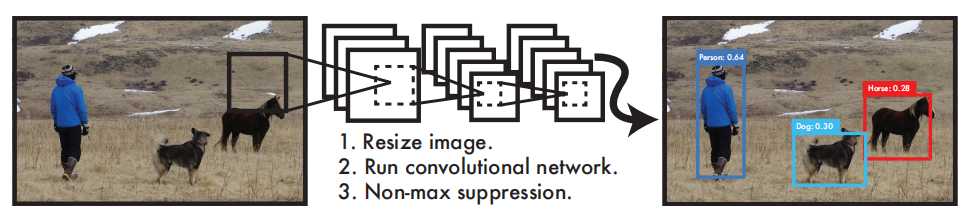
介绍 YOLO在目标视觉检测应用广泛,You Only Look Once的简称。作者期望YOLO能像人一样只需要看一眼就能够立即识别其中的物体、位置及交互关系。能够达到快速、实时检测的效果。 YOLO