
linux 实时性能测试
使能方法 在linux 6.12版本之后原生SDK就支持了PREEMPT_RT,使能方式如下: make kernel_menuconfig General setup ---> <*> Fully Preemptible Kernel (Real-Time) 或者直接搜索CONFIG_PREEMPT_RT=y 确认是否已经打开 zcat …
使能方法 在linux 6.12版本之后原生SDK就支持了PREEMPT_RT,使能方式如下: make kernel_menuconfig General setup ---> <*> Fully Preemptible Kernel (Real-Time) 或者直接搜索CONFIG_PREEMPT_RT=y 确认是否已经打开 zcat …
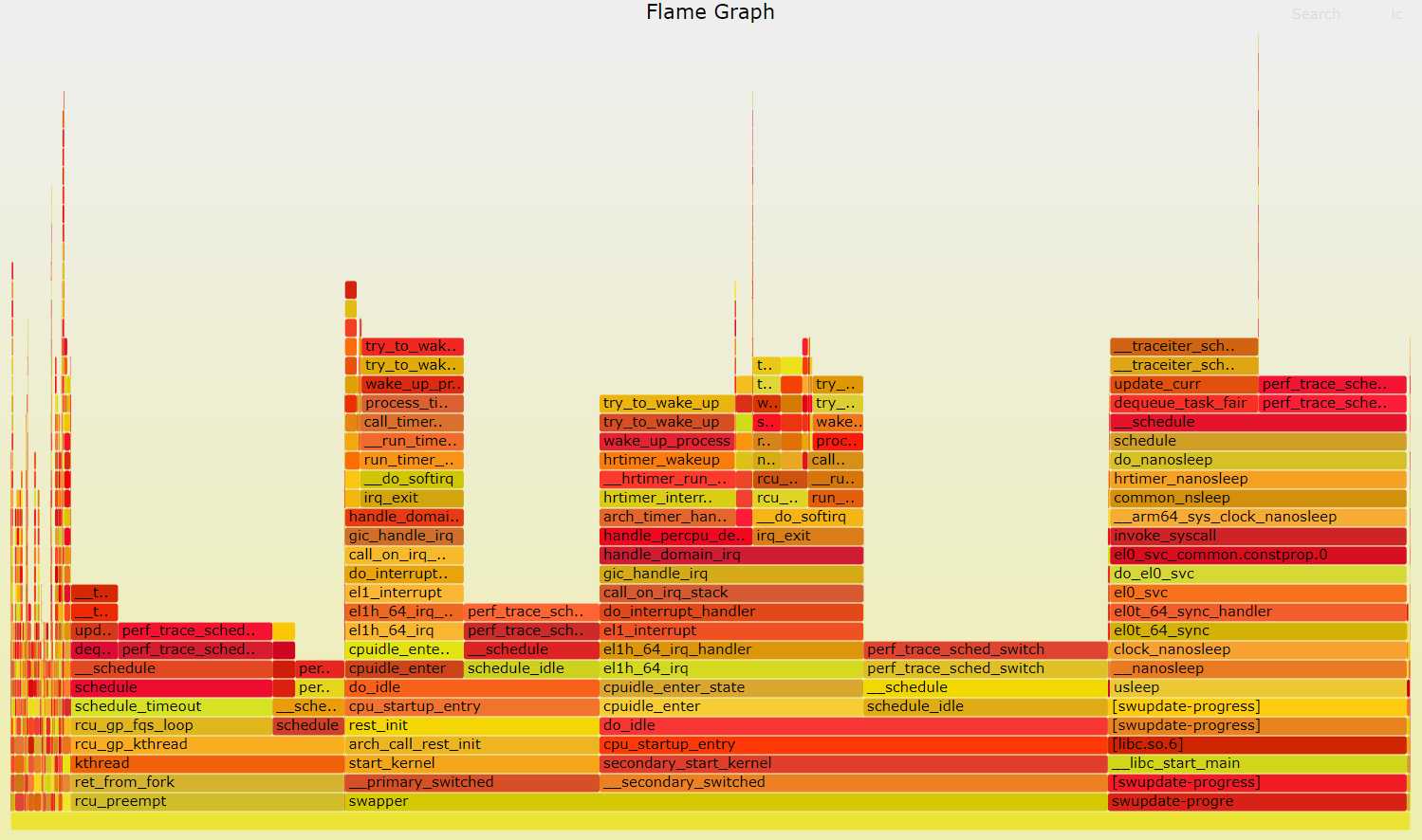
perf介绍 perf 是一个强大的 Linux 性能分析工具,广泛用于分析程序的性能瓶颈,帮助开发者进行调优。perf 工具能够收集并分析多种硬件和软件事件,包括 CPU 的指令执行、缓存命中与失误、上下文切换
此文章需要密码访问。
此文章需要密码访问。
此文章需要密码访问。
此文章需要密码访问。
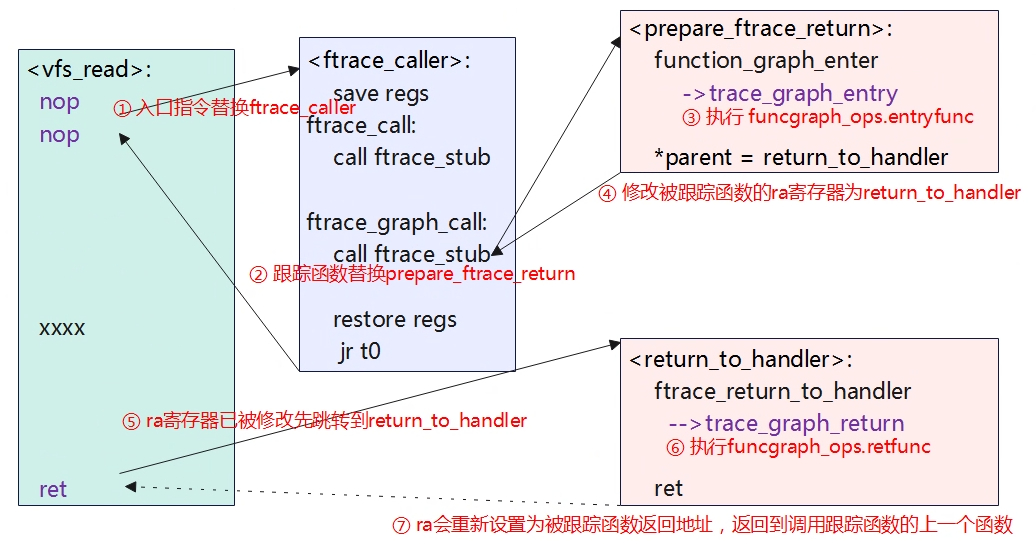
概述 Function graph相对function trace的不同点是,在函数入口会trace,在函数出口也会trace。 ksys_read ->vfs_read ->ftrace_caller ->prepare_ftrace_return ->function_graph_enter …
此文章需要密码访问。
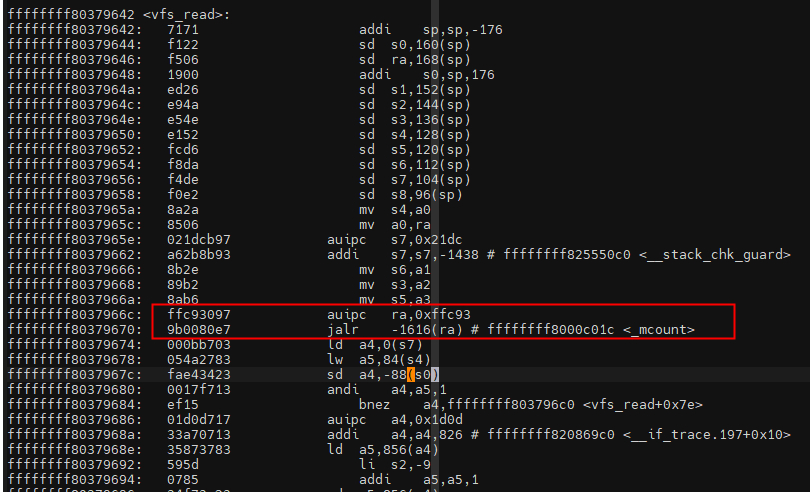
上面章节主要描述的是动态ftrace,在早期还有静态ftrace。区别主要如下: - 动态ftrace与静态ftrace在编译参数方面静态编译使用的是参数“-pg”,而动态使用的是fp
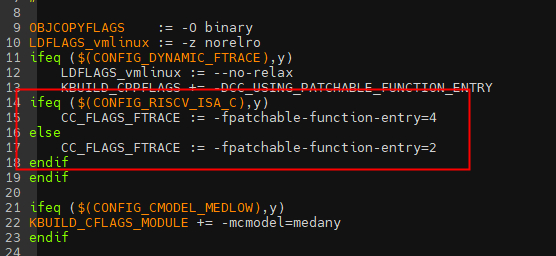
fpatchable-function-entry选项 编译时指定-fpatchable-function-entry=N[,M],①会在函数入口第一个指令之前插入N个nop,但是会
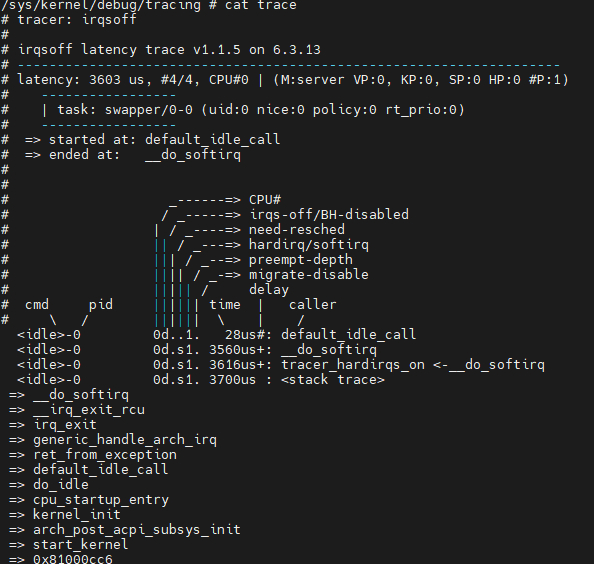
tracer irqsoff 当关闭中断时,CPU就无法响应中断了(NMI和SMI除外),无法响应外部事件做出反应。这会阻止定时器触发或鼠标中断触发,导致系统延迟。 irqsoff跟踪器跟踪中断被禁用的时间,
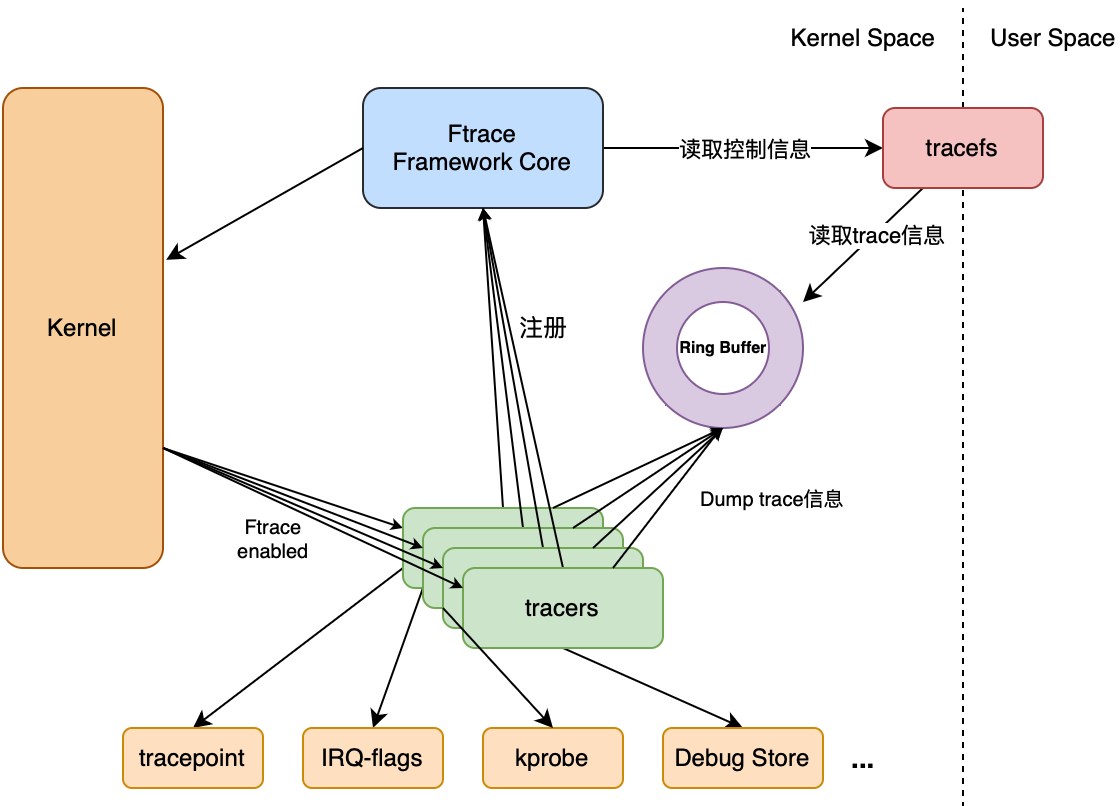
ftrace是一个内部跟踪器,用于帮助开发人员查找内核正在发生的事情,它可用于调试或分析用户空间之外发生的延迟和性能问题。ftrace从名称上看是function trace,函数跟
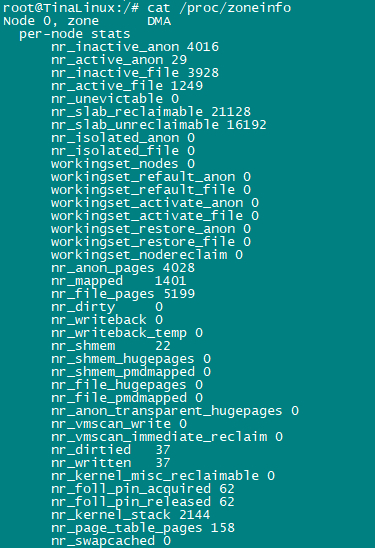
系统占用内存 free 旧版本free $ free total used free shared buffers cached Mem: 65960636 63933576 2027060 73392 1602076 32628548 -/+ buffers/cache: 29702952 36257684 Swap: 0 0 0 (1)第一行Mem:内存 …
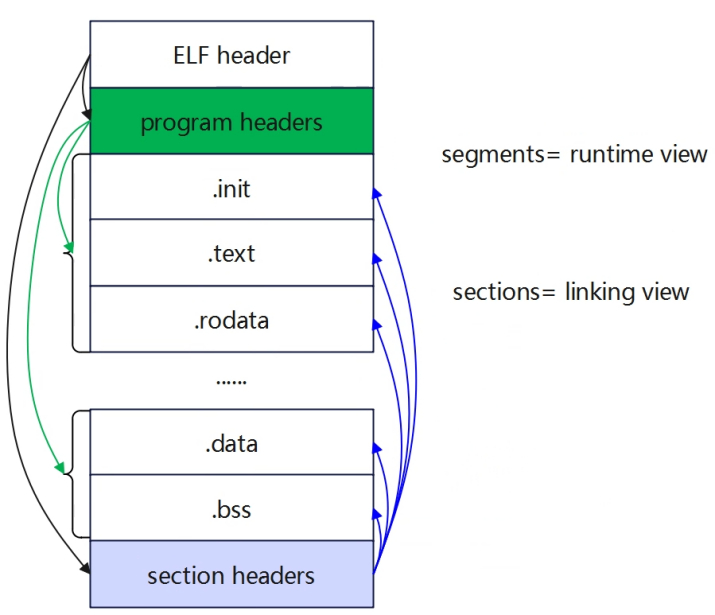
进程虚拟地址空间 Executable and Linkable Format(ELF) 上图是可执行文件的内容结构图,由ELF header、program headers、各section、sections headers组成。
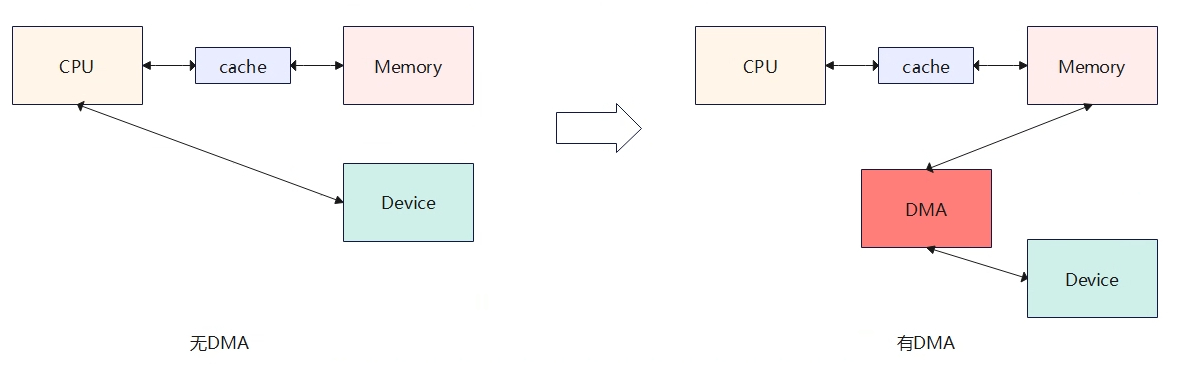
无DMA时:设备与内存之间数据搬运需要依靠CPU来完成。 有DMA时:DMA可以直接完成设备与内存直接的数据搬运,不需要cpu介入。 DMA的引入,优点是数据在内存和设备之间的搬运不需
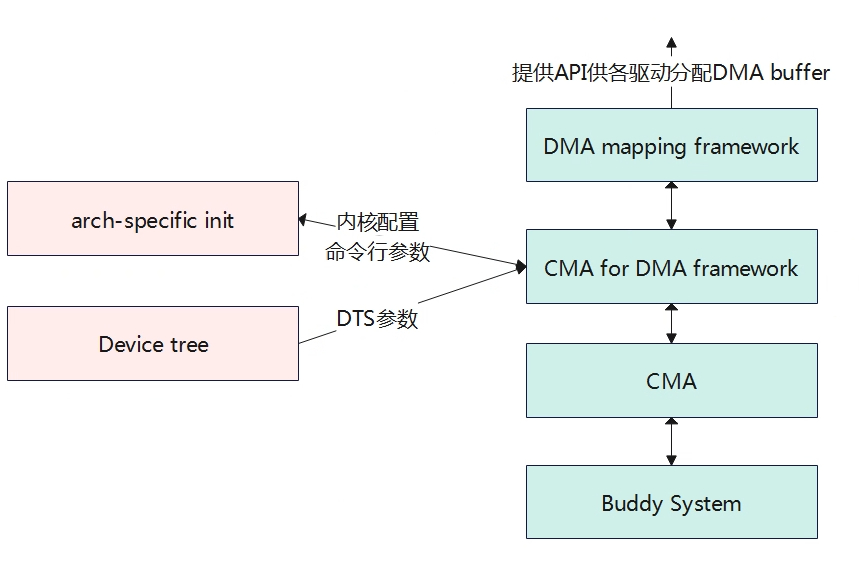
CMA,contiguous memory allocator是内存管理子系统的一个模块,其主要为了解决分配连续的物理内存。尽管有了伙伴系统、slab分配器以及相关的内存回收机制,但是对于一些驱动如camera、disp
伙伴系统内存分配是以物理页面4KB为单位,但是实际使用的时候不会一下使用到4KB。实际使用中很多情况会以字节为单位。因此为了更精确的划分使用内存,linux内核在伙伴系统之上使用s
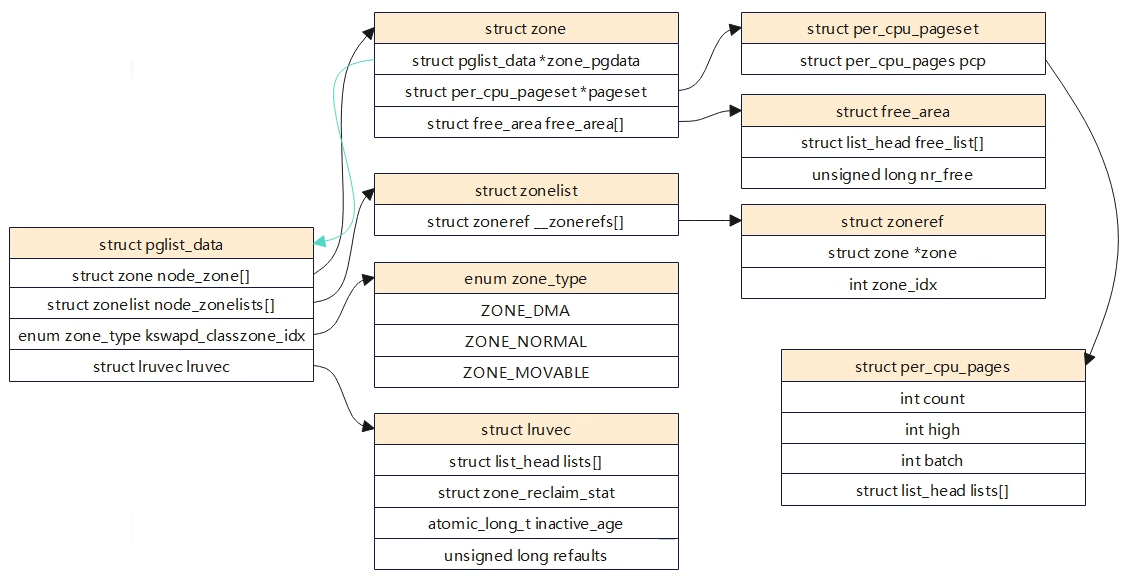
相关结构体 核心结构体 struct pglist_data: 节点的描述,arm64 UMA架构中,只有一个节点。 struct zone node_zone[]:是一个数组,每个元素表示一个内存区域所对应的 struct zone 结构体。从名字可以看出,此数组
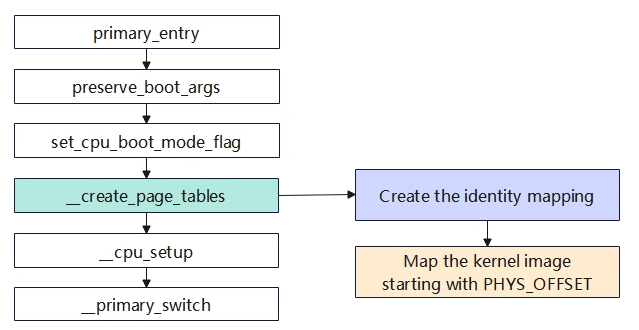
恒等映射与内核镜像映射__create_page_tables preserve_boot_args:保持启动参数到boot_args[]数组 set_cpu_boot_maode_f
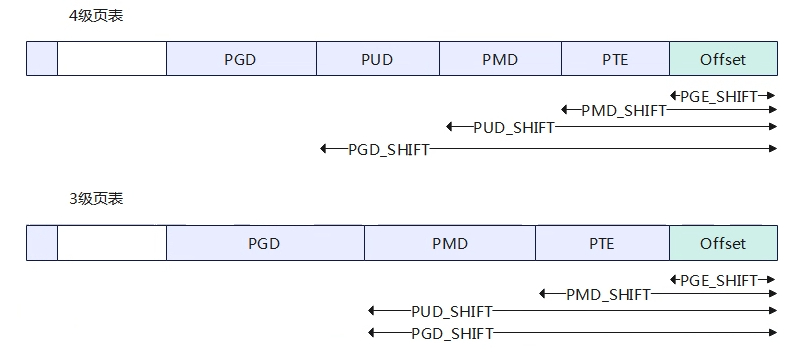
页表级数 如何确定page table level?确定了VABITS和PAGES size之后,页表级数也可确定,根据内核的配置如下: config PGTABLE_LEVELS int default 2 if ARM64_16K_PAGES && ARM64_VA_BITS_36 default 2 if ARM64_64K_PAGES && …
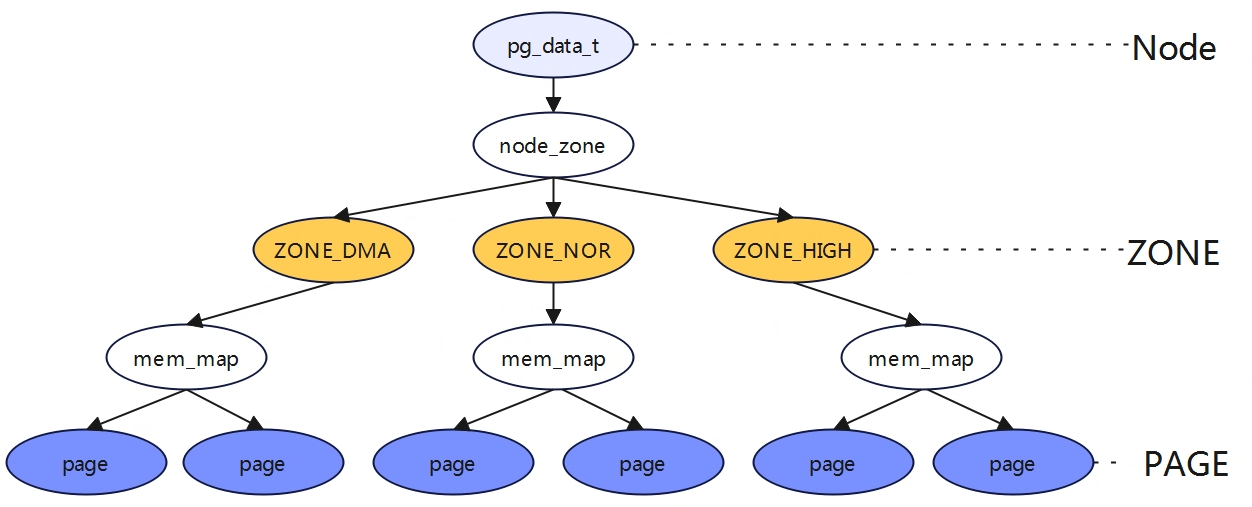
三级结构Node、Zone、Page Node与内存架构UMA、NUMA UMA架构(uniform memory acces) 一致内存访问,所有CPU访问内存都需要过总线,距离都是一样的,所以每个

#To free pagecache echo 1 > /proc/sys/vm/drop_caches #To free dentry and inode cache echo 2 > /proc/sys/vm/drop_caches #To free pagecache,dentry cache,inode cache echo 3 > …
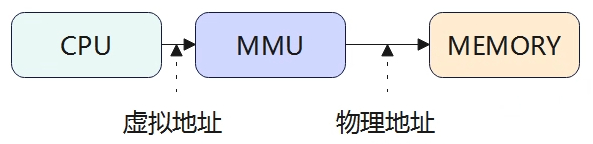
地址空间 虚拟地址:程序使用的内存地址;物理地址:硬件的地址空间。虚拟地址通过MMU转化为物理地址,虚拟地址的长度与实际的物理内存容量没有关系,从系统中每个进程的角度看,地址空间的进
实验环境 准备 kernel version: linux 5.15 kernel module: 块设备:simpleblk.ko 文件系统:simplefs.ko application: 制作文件系统:mkfs.simplefs 步骤 1.加载块设备驱动:in
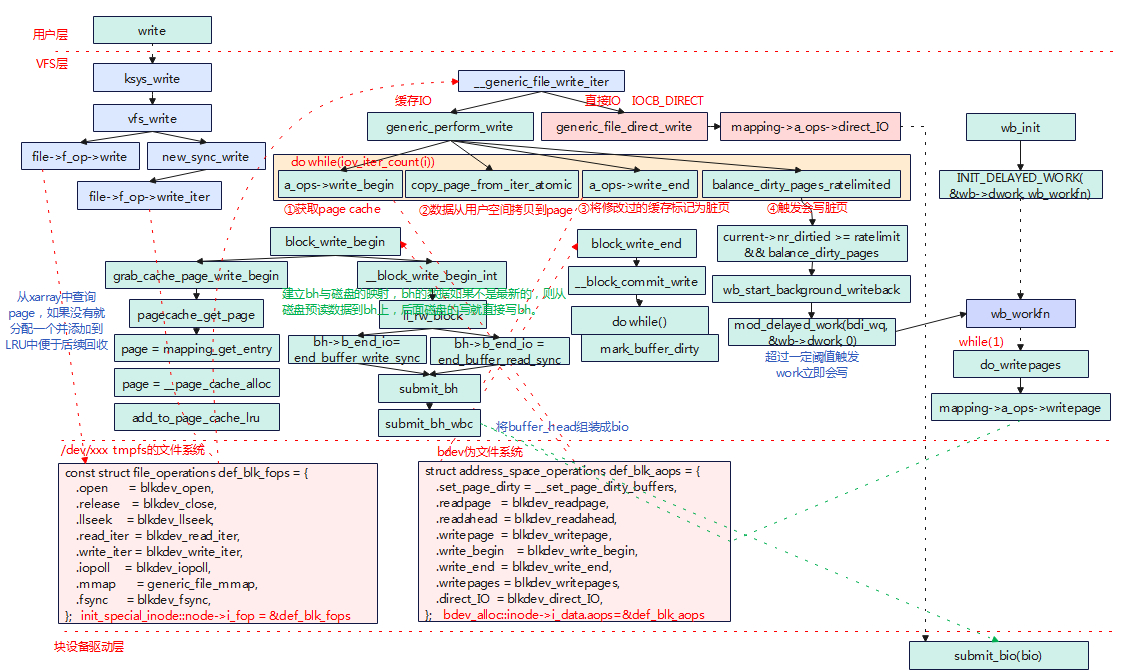
实验环境 kernel version: linux 5.15 kernel module: simpleblk.ko 参考上一章节 application:app_test 参考上一章节 块设备无文件系统方式读写 写数据 存储设备没有格式化挂载文件系统,那么对磁盘设备的操作会经过/de
块设备驱动示例 #include <linux/blk_types.h> #include <linux/blkdev.h> #include <linux/device.h> #include <linux/blk-mq.h> #include <linux/list.h> #include <linux/module.h> #include …
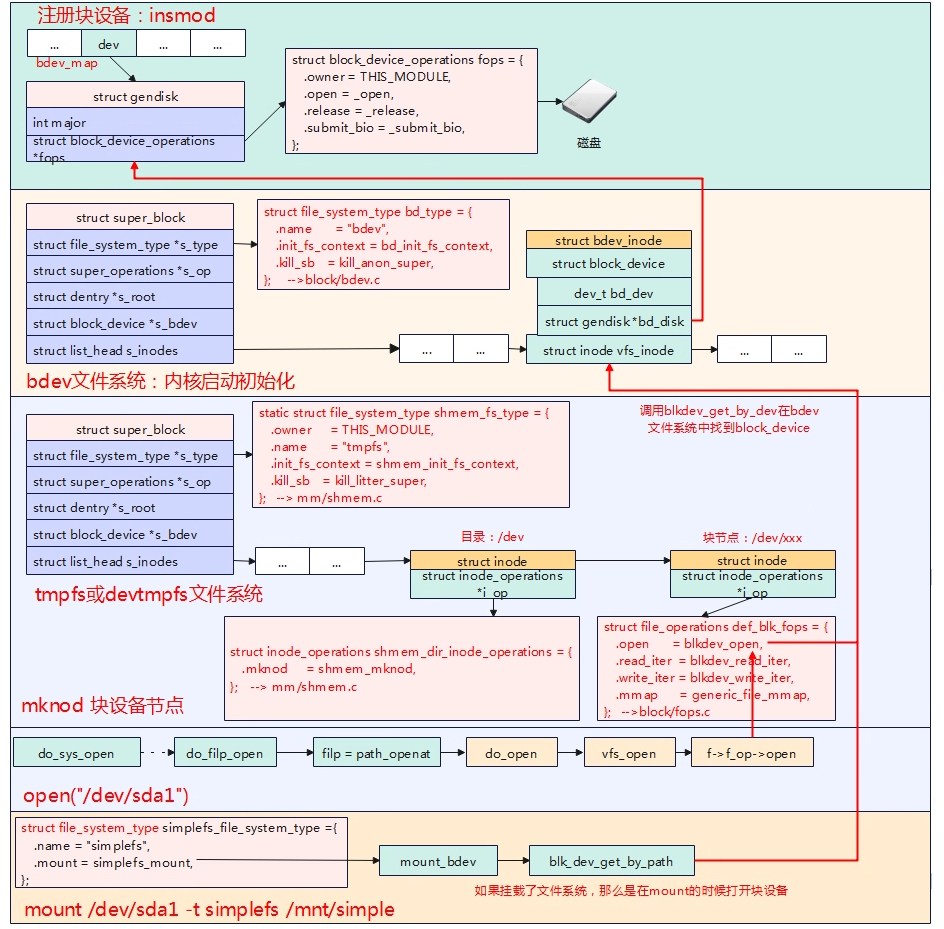
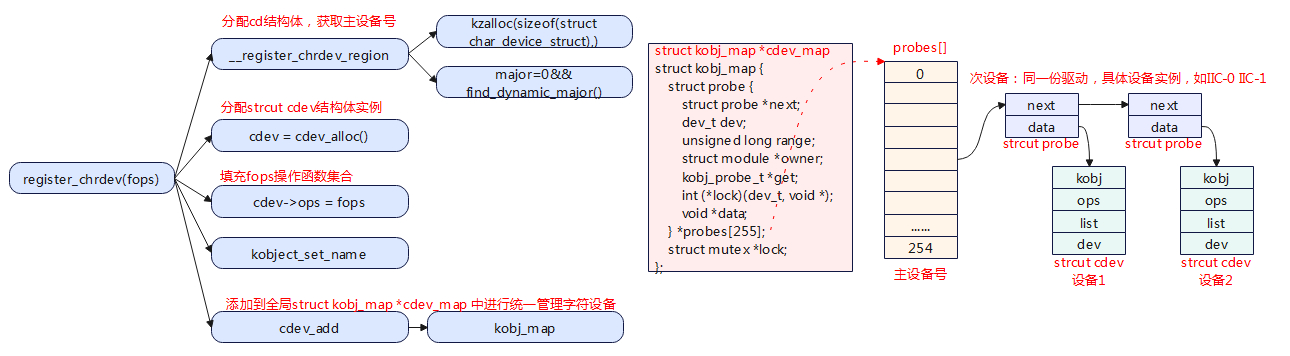
打开块设备 mknod 块设备同样要使用mknod创建设备节点,这与字符设备一样。会调用到init_special_inode填充inode的file_operations,只不过块设备注册的
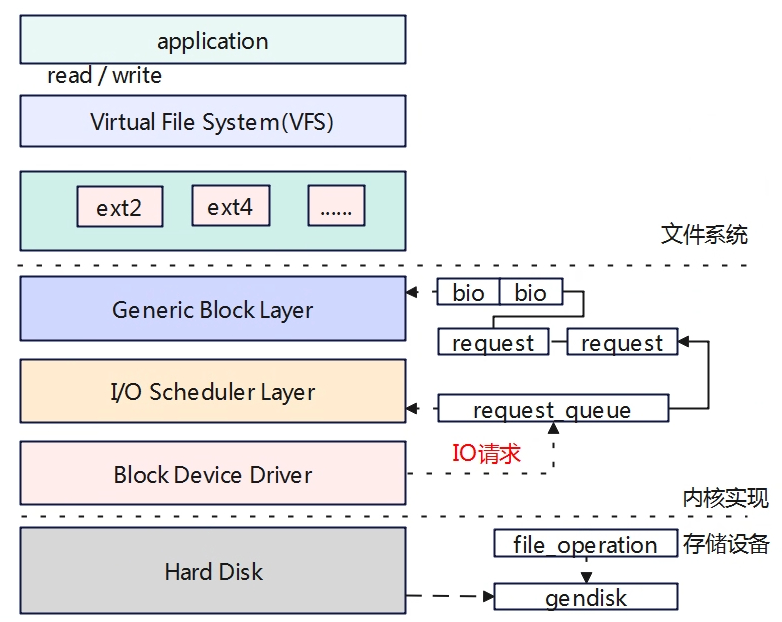
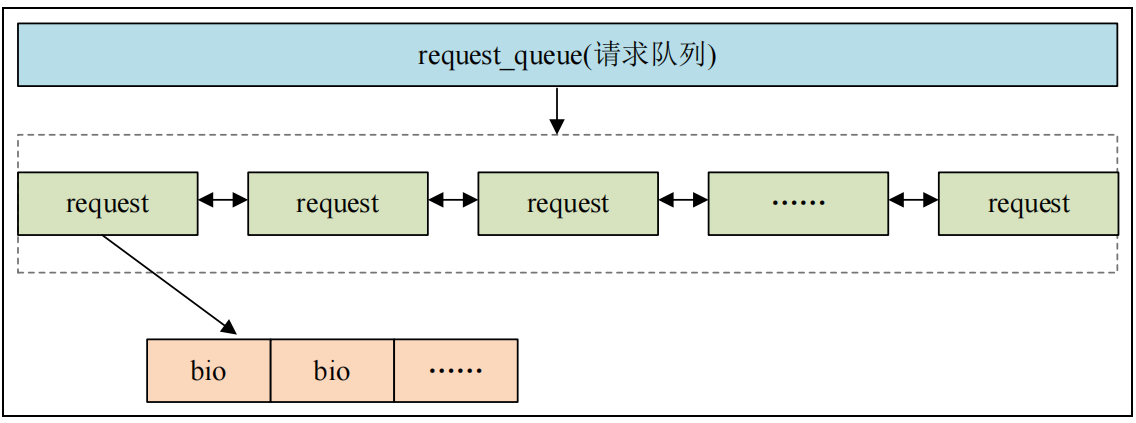
块设备驱动简介 在linux系统中,有3大驱动类型,分别是:字符设备驱动、块设备驱动、网络设备驱动。块设备驱动与文件系统有着密不可分的关系,块设备是文件系统实际的数据传输单位,通常存
#include <linux/module.h> #include <linux/fs.h> #include <linux/uaccess.h> #define DEVICE_NAME "mychardev" #define BUFFER_SIZE 1024 static char device_buffer[BUFFER_SIZE]; static …
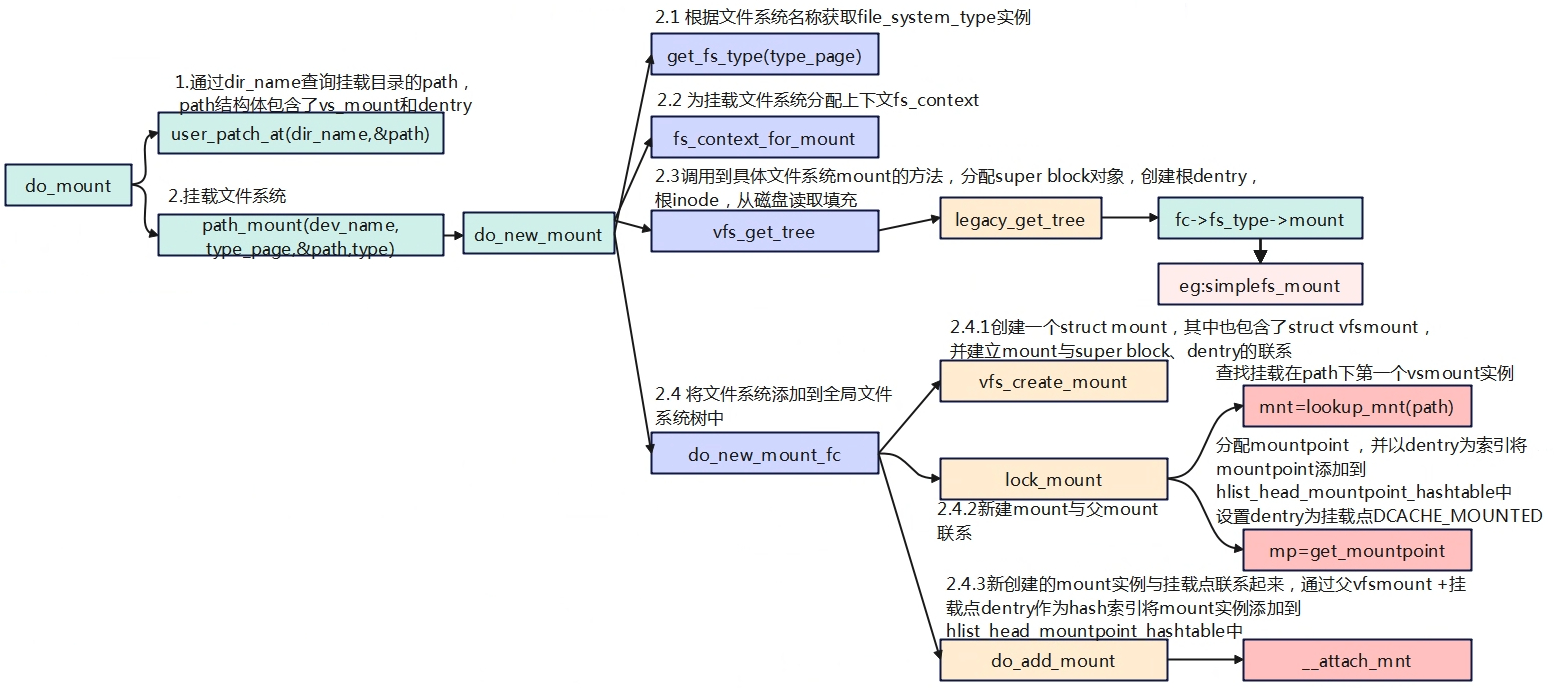
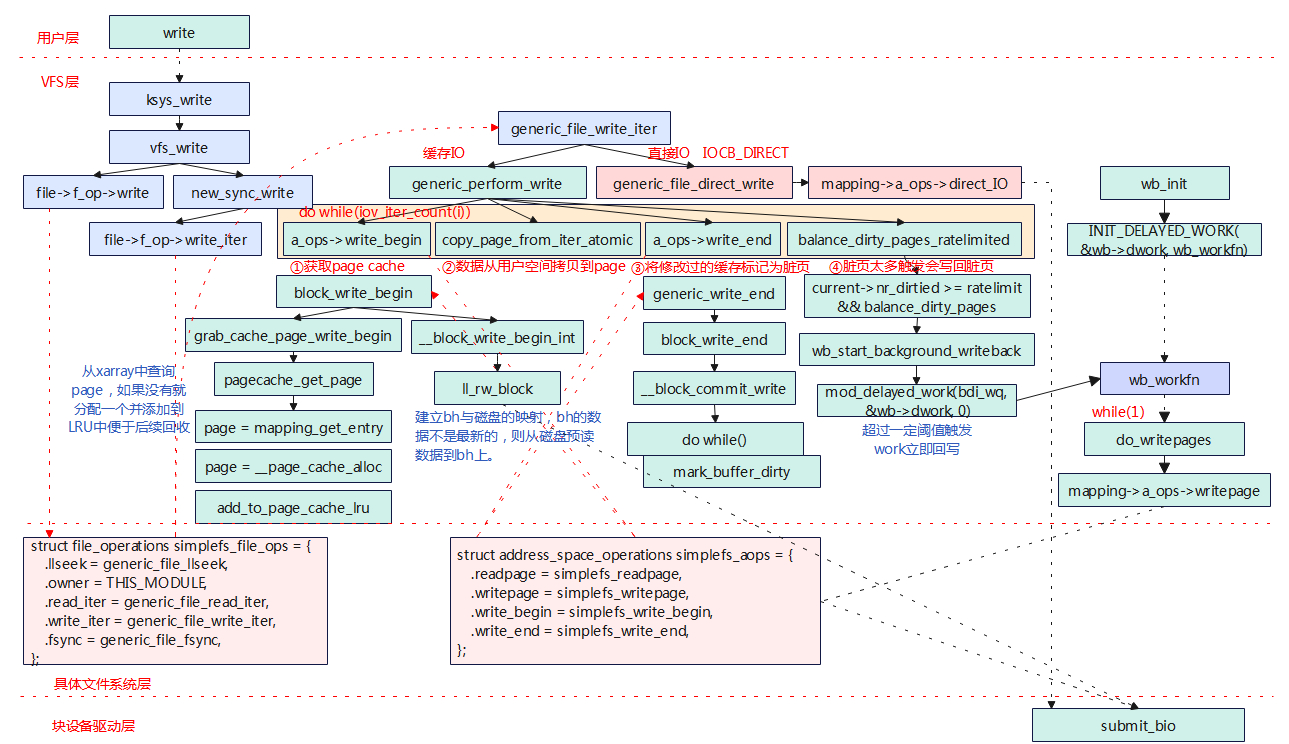
上一章节中,我们编写了没有带磁盘设备的文件系统,了解了文件系统操作的大致流程,本章节我们继续在上一章节的基础上完善文件系统,并梳理从用户空间到内核空间大致的调用流程。实验的代码我们
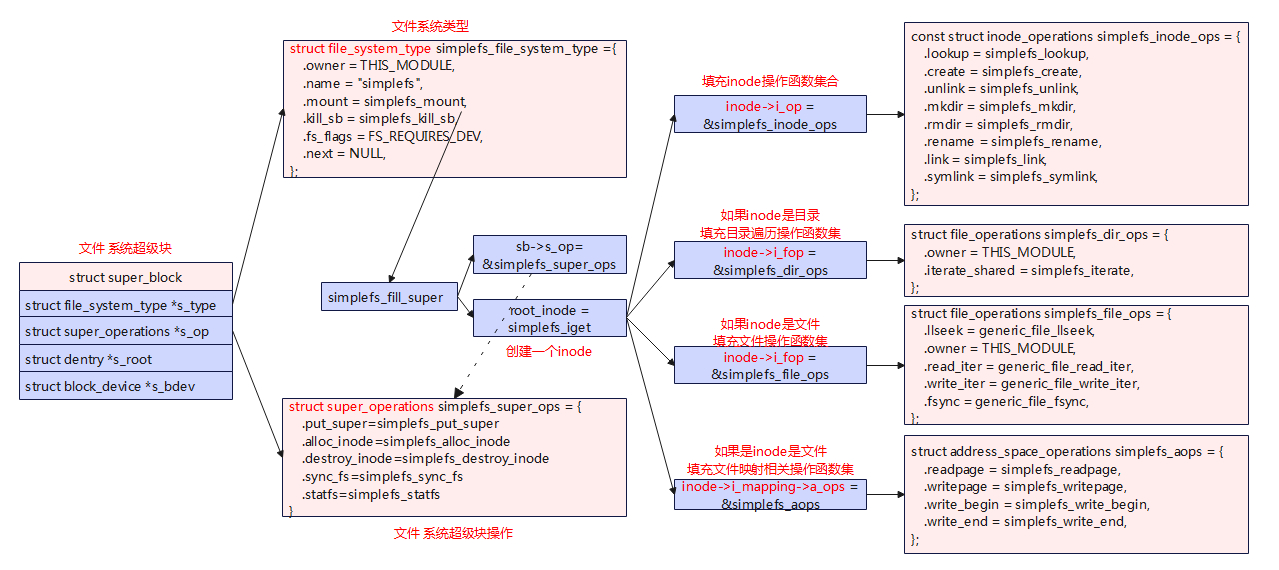
文件系统注册与挂载 static struct file_system_type simplefs_fs_type = { .owner = THIS_MODULE, .name = "simplefs", .mount = simplefs_mount, .kill_sb = simplefs_kill_sb, }; static int __init …
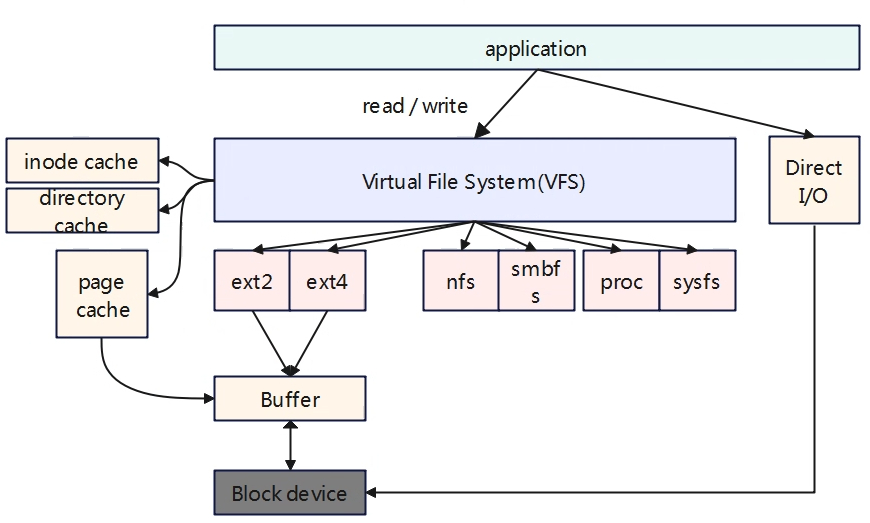
Linux系统中支持多种不同的文件系统,为了是用户可以通过一个文件系统操作界面,对各种不同的文件系统进行操作,在具体的文件系统(ext2/ext4等)之上增加了一层抽象一个统一的虚
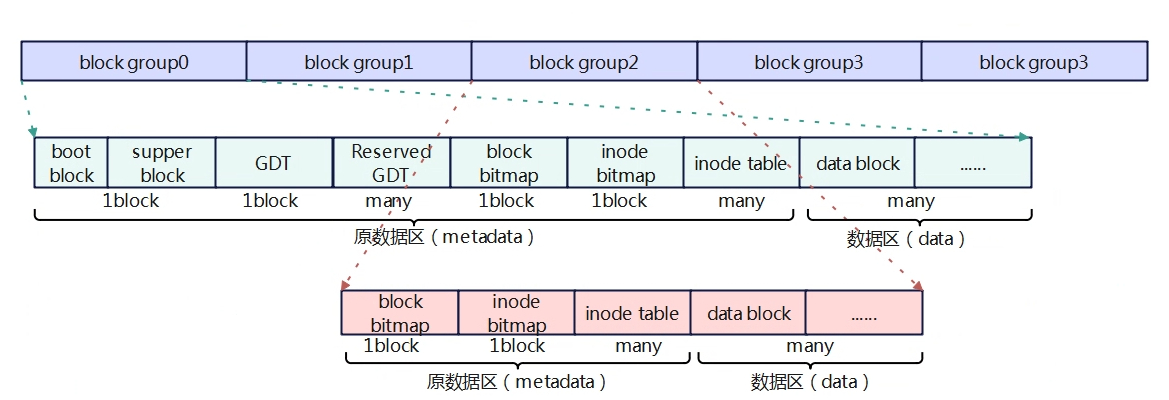
磁盘空间布局 Extx将磁盘划分为等份的若干区域(最后一个区域可能会小一些),这些区域称为块组(block group)。磁盘以块组为单位进行管理。每个块组再划分为相同大小的block
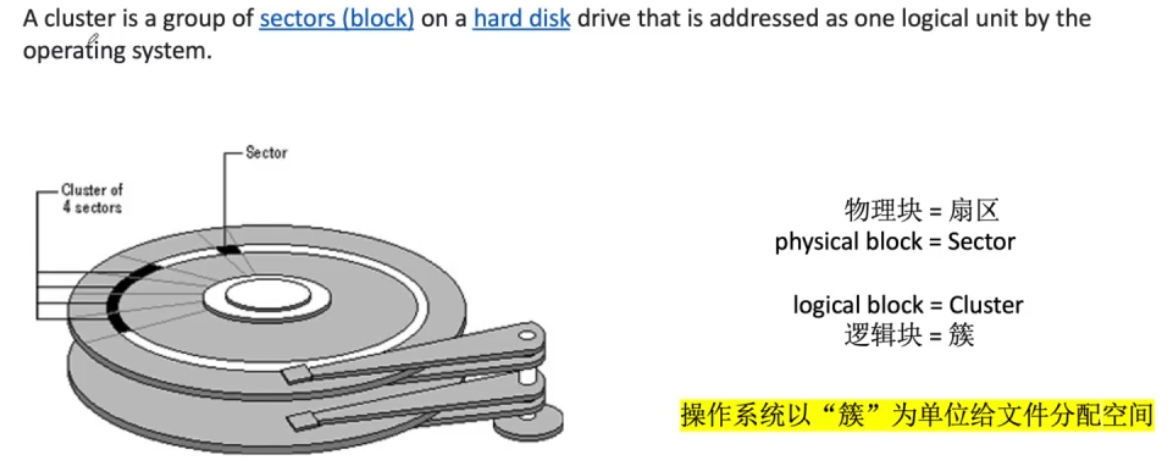
mount的机制是如何实现的? inode是如何分配的。磁盘inode和内存inode有什么区别? dentry缓存是怎么回事?如何管理? free命令中Cache和buff有什么区别?
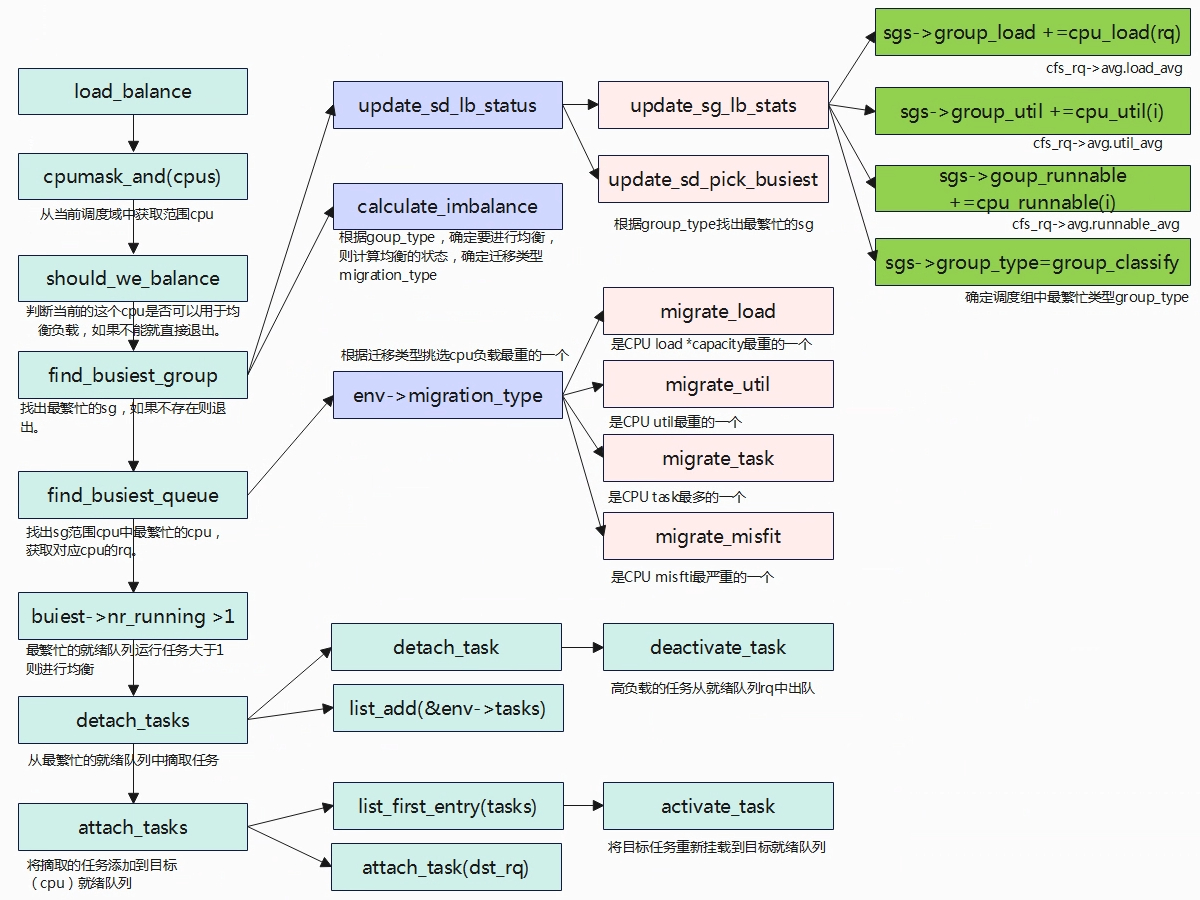
何时均衡 在linux内核中,有一些场景会触发任务均衡的分布在系统的各个cpu上,可以分为以下几个场景: 任务放置:task placement,fork创建的任务、sched_exec
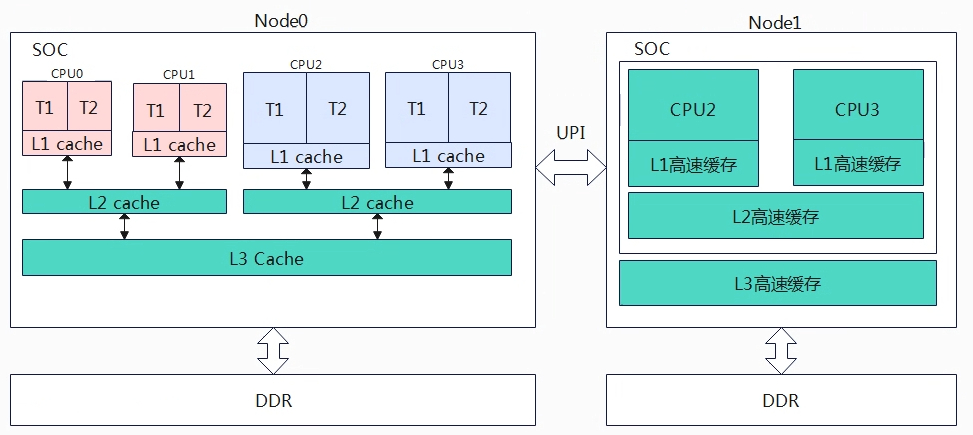
概述 从上一章节大概应该能够理解负载和利用率的区别了,当一个进程正在运行或者即使没有在cpu上运行,而在就绪队列中等待运行,那么他依旧消耗cpu的负载。这是合理的,因为cpu的就绪队
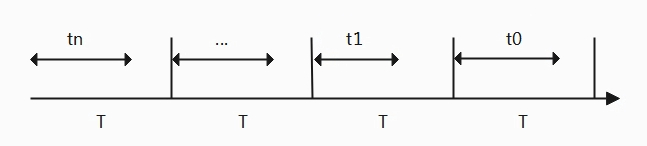
各任务负载、各cpu的算力(频率+架构)、任务迁移开销(调度域,调度组)。 root@Linux:/# cat /proc/loadavg 3.49 3.43 3.54 4/131 3065 cat /proc/loadavg可以获取CPU全局平均负载,前面的三个值分别表示为1分钟、5分
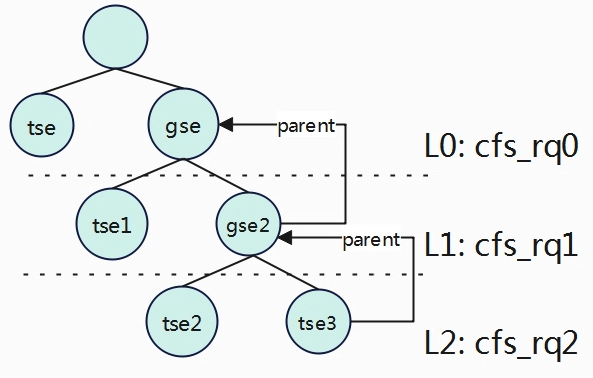
时间计算 vruntime与runtime static void update_curr(struct cfs_rq *cfs_rq) { struct sched_entity *curr = cfs_rq->curr; u64 now = rq_clock_task(rq_of(cfs_rq)); u64 delta_exec; if …
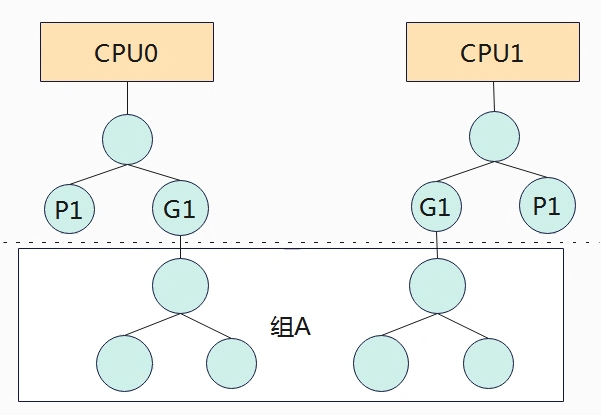
Linux系统都是支持多用户登录,如果一个Linux系统两个用户存在不同的数量的进程,假设A用户有10个进程,B用户有20个进程,如果系统对这30个进程进行平分CPU,实际上是不公

上一章节中描述了Linux系统中支持多种调度,不同的调度有不同的优先级范围。对于普通进程使用的CFS调度(Completely Fair Scheduler,CFS)。完全公平调度主要核心思

调度类别 进程调度依赖于调度策略(schedule policy),linux内核把相同的调度策略抽象成调度类(schedule class)。不同类型的进程采用不同的调度策略,目前Li
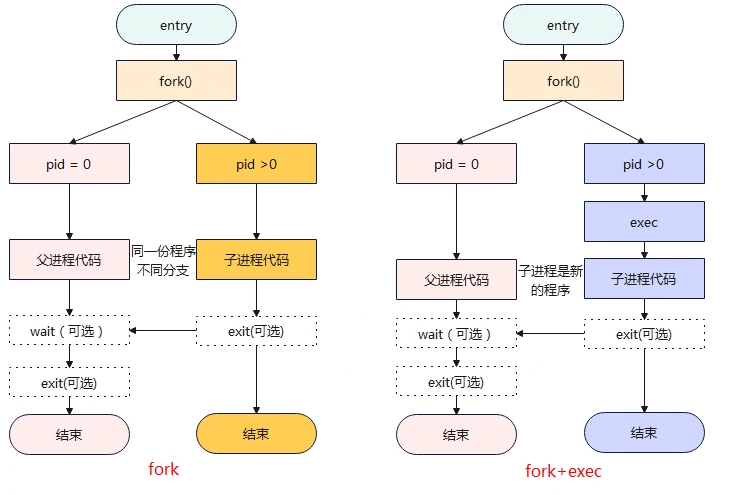
fork创建了一个新的进程,也就是fork执行后就会返回两次,分别是父进程返回和子进程返回。 exec可以加载新的程序运行(原程序是A,可以在A中运行后加载可执行程序B,B是A的子进
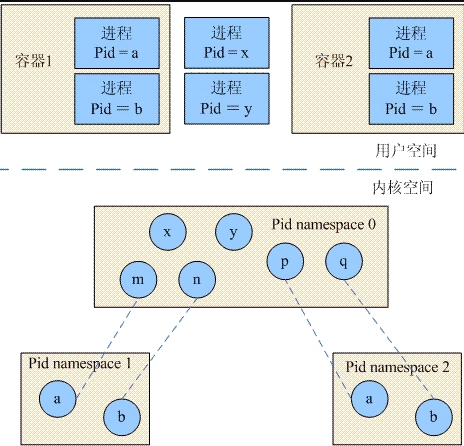
进程标识 进程是程序加载到内存的执行过程。进程与程序相比用于操作系统的资源如内存空间、文件、signal等。对于进程的标识我们使用process id来标识(PID)。 线程是进程中活跃
上下文 是否抢占 顶半部 中断 否 Softirq/tasklet 软中断 是 workqueue 进程 是 threaded_irq 进程 是 Tasklet:底半部,优先级比较高,处理函数中不能睡眠。 workqueue:底半部,处理函数可以睡眠,也可以执行比较长的应用。
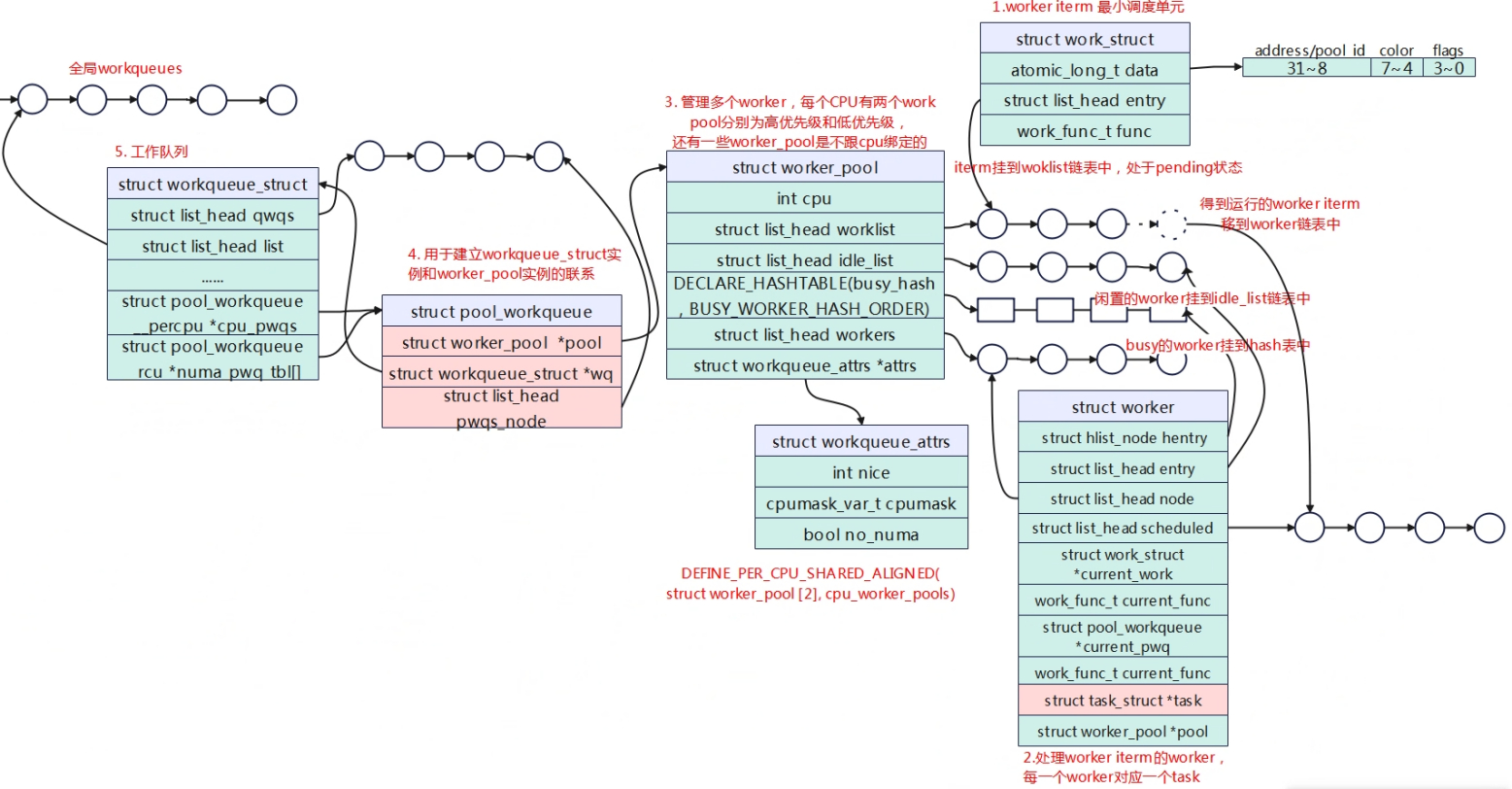
API接口 初始化 函数 说明 DECLARE_WORK(n, f) 静态定义一个work,实际就是定义一个struct work_struct的全局变量。 DECLARE_DELAYED_WORK(_work, _func) 静态定义一个work,与上面的区别就是work可以在指定时间之后
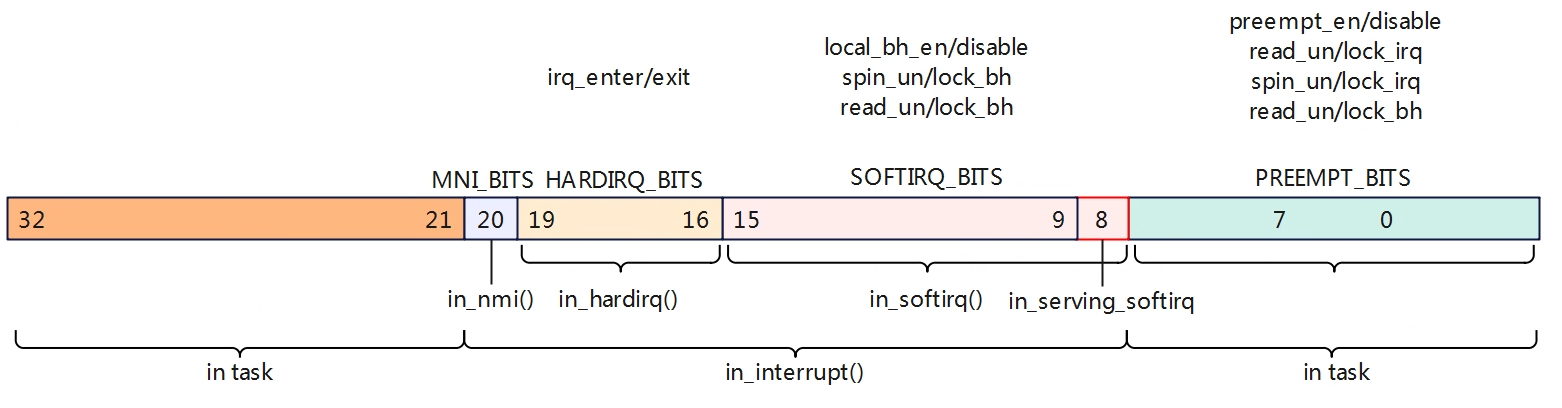
Linux的中断分为上下部机制,上半部在中断上下文中关闭了本地CPU中断响应,下半部是在中断线程中处理。在Linux系统没有引入中断线程化机制之前,就已经出现了一些下半部的机制,如
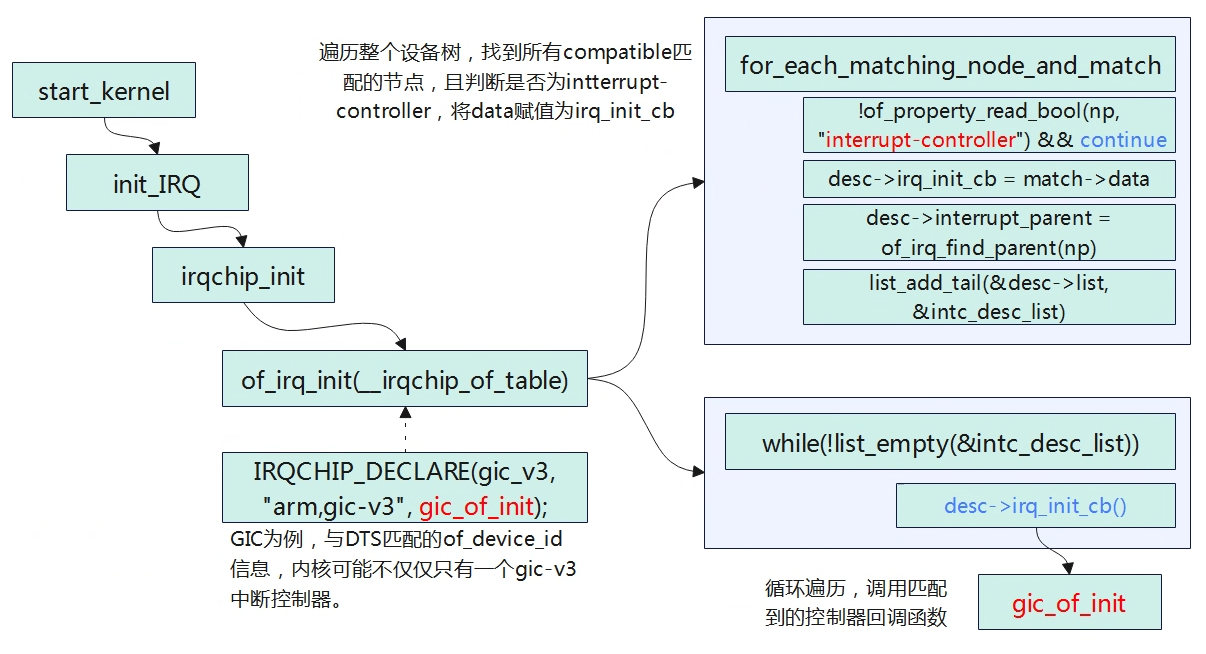
interrupt controller初始化 设备树中对gic-v3的描述如下,其中interrupt-controller标识了该设备是一个中断控制器。 interrupt-controller@3400000 { compatible = "arm,gic-v3"; #interrupt-cells = <0x03>; #address-cells = …
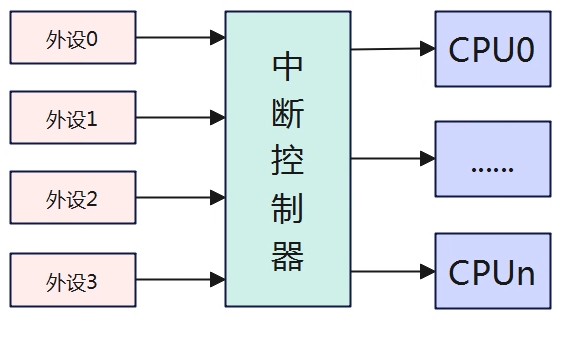
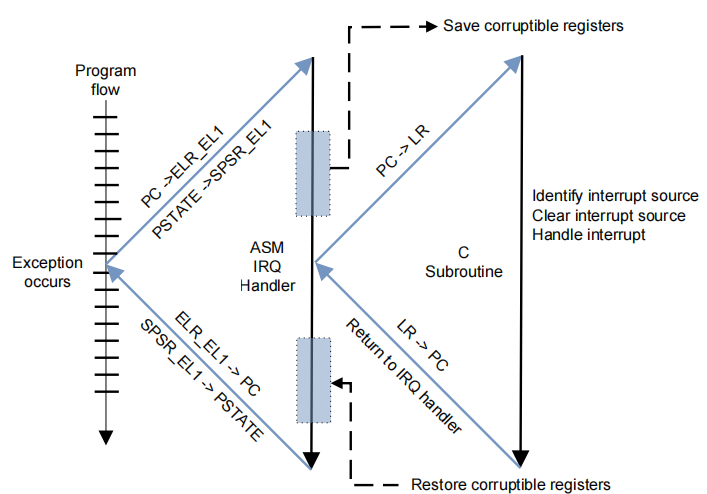
在现代嵌入式系统中,处理器上会挂接很多个外设,CPU在执行任务的时候,可能会同时由多个中断发生,那么中断必要要进行响应处理并维护一个队列一一运行,这样自然会影响CPU的效率,为了让

ARM简介 ARM版本 典型处理器 主要特性 v1 26位地址空间 v2 增加乘法、乘加法、支持协处理指令等 v3 地址空间扩展到32位,增加SPSP和CPSR等 v4 ARM7TDMI/ARM920T 增加Thumb指令等 v5 ARM926EJ-S 增加Jazel