具身智能ACT算法
基本原理
简单总结一下什么是ACT算法。传统的机器算法过程是观测关节位置J1经过模型预测动作A2然后执行,观测到J2预测数A3,观测到J3遇到A4依次类推,这样就有一个问题,假设预测出的A2跟实际相比偏差就比较大那么对应的观测到的J2就偏离比较大。如果要连续预测K步,就要连续采集K步,缺点就是误差会累积同时预测效率也比较低。那么对于ACT算法是怎么进行优化的了?
ACT算法是一下观测连续的K个动作,然后预测出K个动作,这样相对于传统算法效率就提升了K倍。同时也可以解决累积误差,计时K个连续的动作中,有某个动作偏差比较大,但是整体经过模型就会弱化不至于累积。假设K是10 ,简单举个例子理解过程,T0时刻观测到J1数据(开始时只有一个数据),模型直接预测数10个动作序列,等机器按顺序依次执行完这10个动作后,模型下一次就直接把这10个动作当做输入然后预测下一批的10个动作,依次类推。
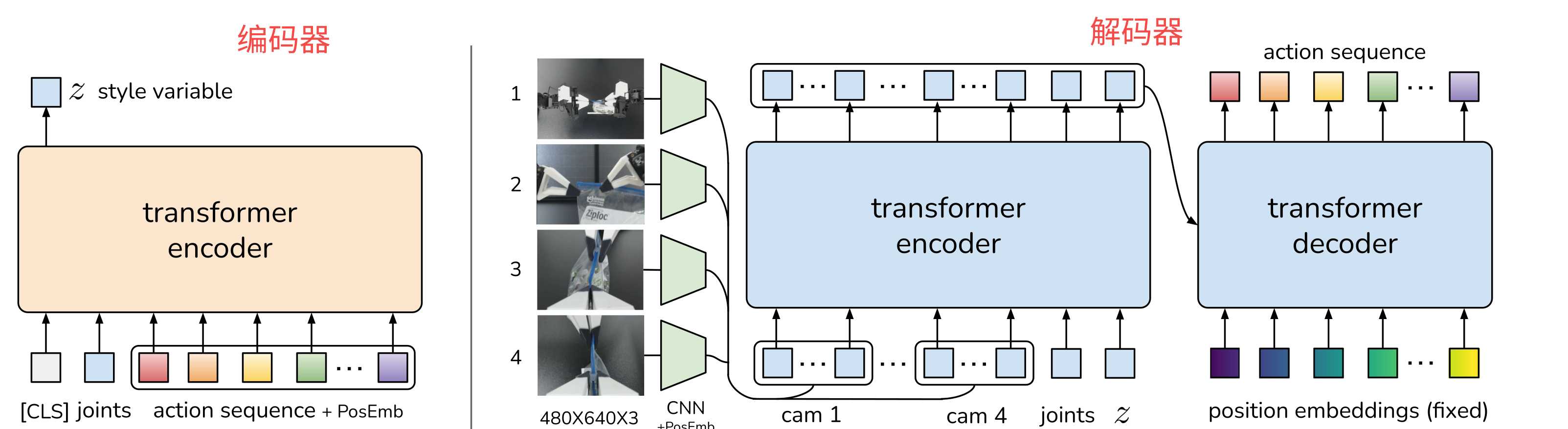
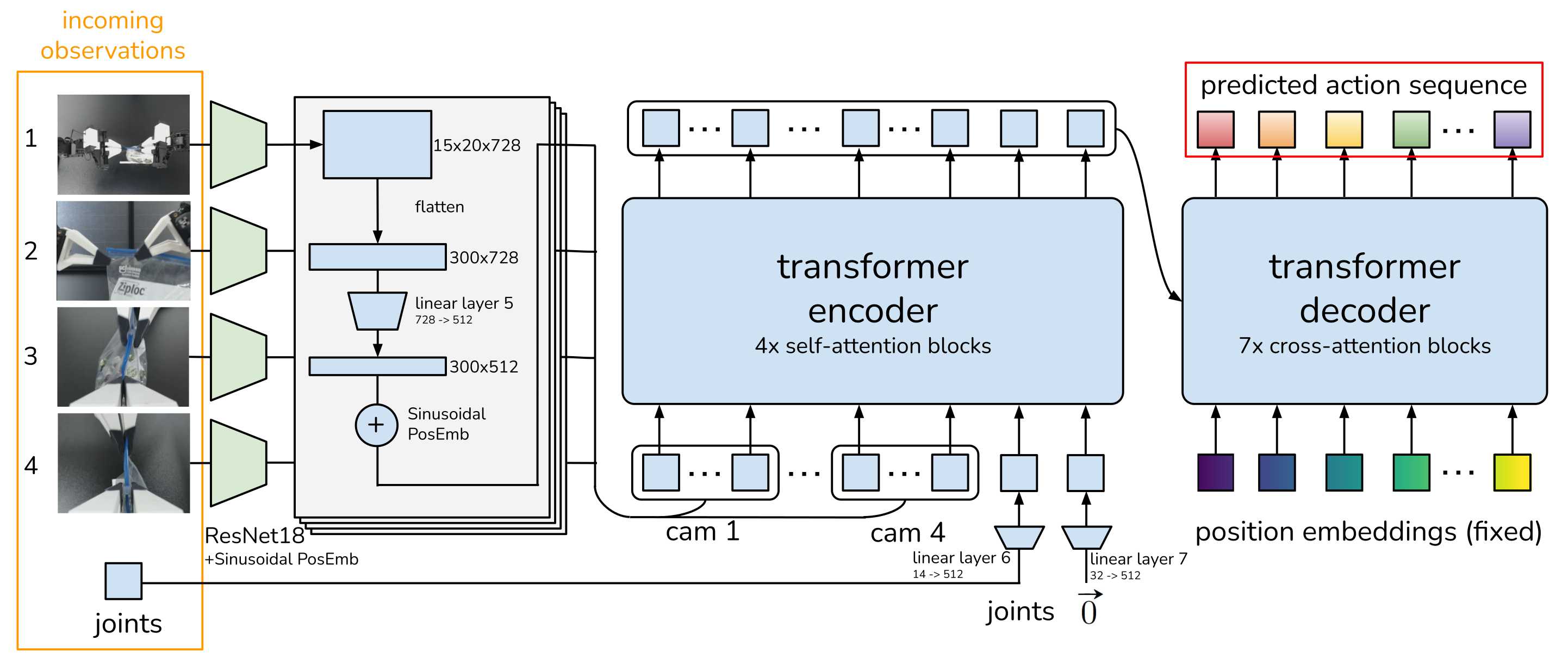
基于transformer的动作分块(ACT)架构。分为训练模式和测试模式。
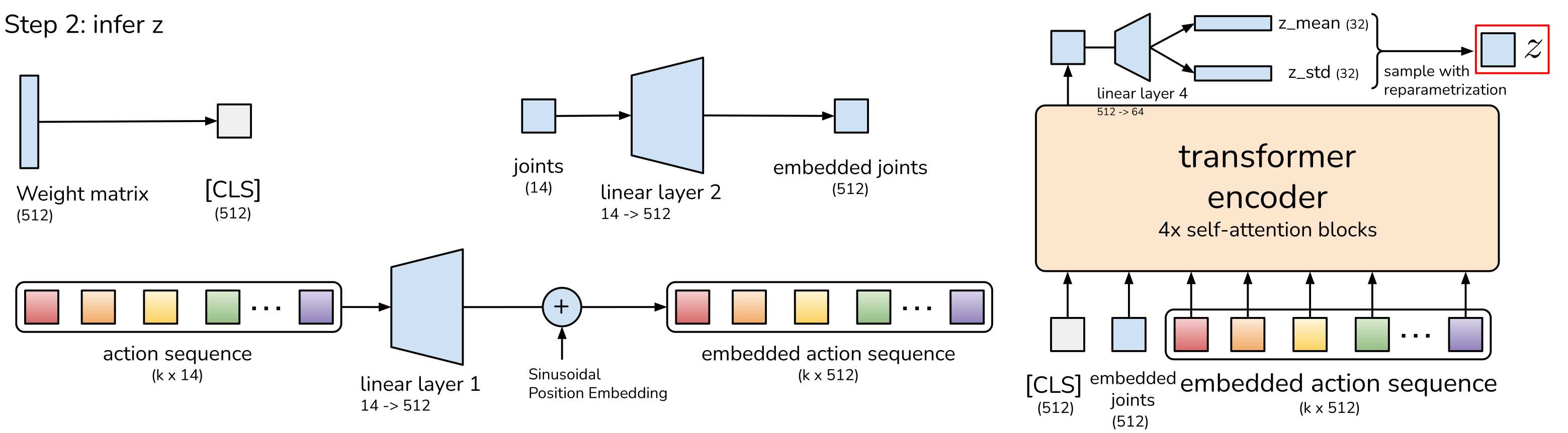
当为训练模式是,ACT为左图的编码器+右图的解码器。左图可以理解为一个CVAE的编码器,将关节序列、动作序列、CLS经过transformer编码压缩为风格变量Z。然后将Z再加上采集的摄像头数据、关节序列作为输入给到右边的解码器最终输出动作序列。
当为测试模式时,左图丢弃不再,只需要使用右图的部分,输入为摄像头数据、关节序列、Z(被简单设置为0,表示先验的平均值)。可以这么理解Z为CVAE模型中的风格,经过训练后,Z已经让模型的参数定型,在后续的测试过程中就不需要了,因为参数已经固定了就不用了。
以lerobot的机械臂为例,个人理解关节序列指的是从臂的舵机位置,而动作序列是主臂的舵机位置。
动作分块
动作分块Action Chunking机制,传统机器人每执行一步都要重新观测环境(如拍摄一张照片),走一步采集一步预测一步,而ACT采用的是”分块执行”策略。
具体就是累积到每K步观测一次(如K=100),然后一次性输出K个动作序列,执行这就可以按顺序执行这组K个动作序列。
动作分块也可以理解为决策频率进行了压缩,传统的单步策略需每一步观测环境并生成动作(如T次决策),而ACT是每K步观测一次,一次性生成后续K个动作序列(决策点将至T/K个),例如若K=10,1000步的任务仅需100次决策,效率提升了10倍。
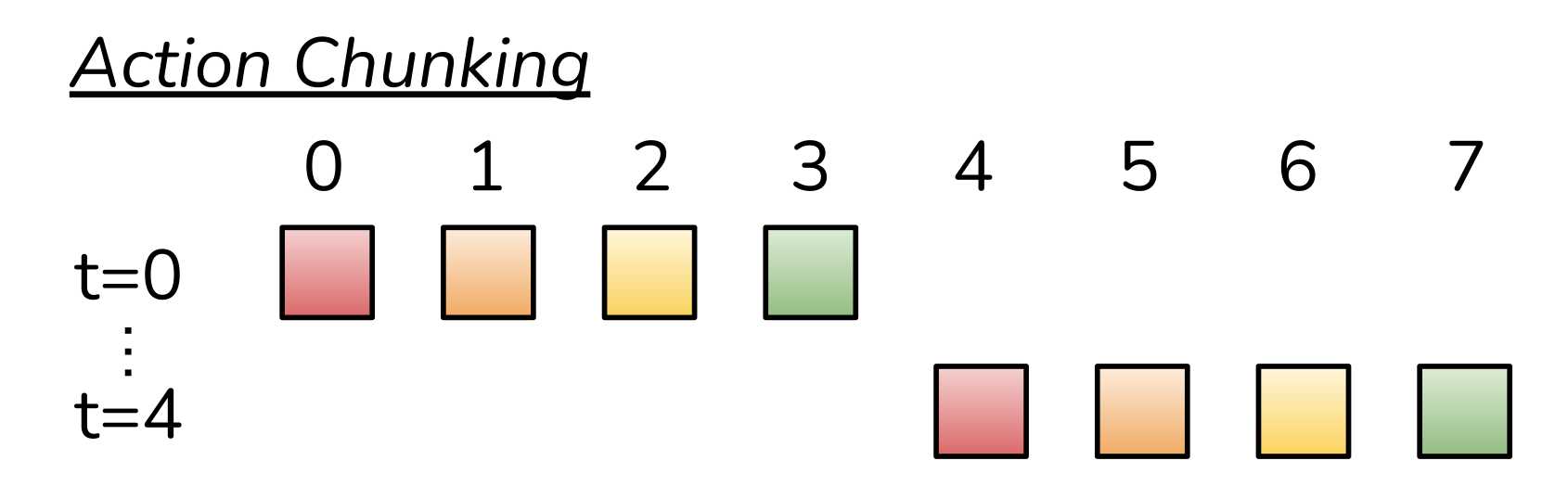
将各个动作组合在一起并作为一个单元的执行,从而使起存储和执行更有效率,直观地讲一组动作可以对应抓住糖果包装纸的一角或将电池插入插槽,在实现中将块大小固定为K,每K步agent会收到一次观测然后预测生成K个动作然后机器按顺序执行。如上图所示假设K为4,t=0时刻策略观测到4个动作,然后就会生成4个动作序列,让机器按顺序执行;紧接着到t=4这个时刻,策略又观测到4个动作,生成4个预测动作机器按这个4个动作顺序执行。
分块的还可以帮助模拟人类演示中的非马尔可夫行为,具体来说是单步策略会难以应对时间相关的混杂因素,例如在采集演示过程中的停顿,会让模型这时候不知道该如何做,因为这些行为不仅仅取决于状态,还取决于时间步长,而动作分块就可以缓解当混杂因素位于一个块内是,不会引入历史条件策略的因果混淆问题。
时间集成
仅仅简单的是用动作分块实现还有一个问题,那就是每K步突然合并一个新的环境观测,可能会导致机器人运动不平稳,也就是说执行完一系列动作后,再到下一个序列动作时,可能差异比较大会导致机器抽搐。如下图中t0时刻开始执行的0~3序列切到t4时刻执行的4~7训练,这个切换过程可能会导致机器运动不平稳。
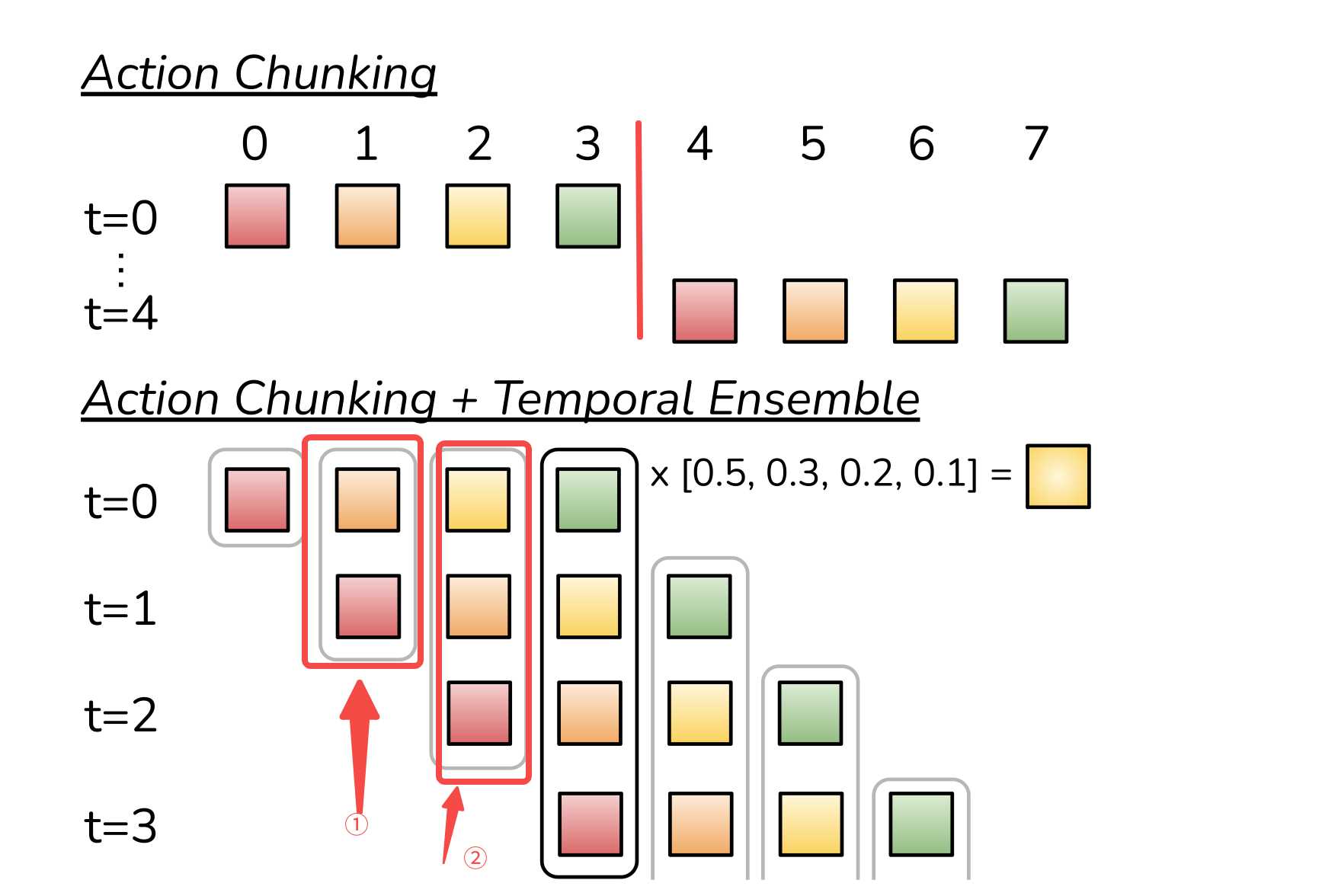
为了解决这个问题,提出了时间步查询策略。假设动作分块为K,那么每个时间刻都预测了K个序列,如上图t0时刻预测了0~3,t1时刻预测了1~4,t2时刻预测了2~5。然后每个时间刻真正要执行的序列为该时间集成加权平均,加权方案为wi = exp(−m ∗ i),其中w0是最早的动作权重,合并新的观测速度由m控制,其中m越小表示合并越快。如上图1位置实际执行的动作为t0时刻预测的第2个动作与t1时刻预测的第1个动作加权平均,2位置实际执行的动作是t0时刻第3个预测动作、t1时刻第2个预测动作、t2时刻第1个预测动作加权平均,以此类推。靠得越紧的预测动作权重值越大,靠得远的权重值越小。
详细架构
训练
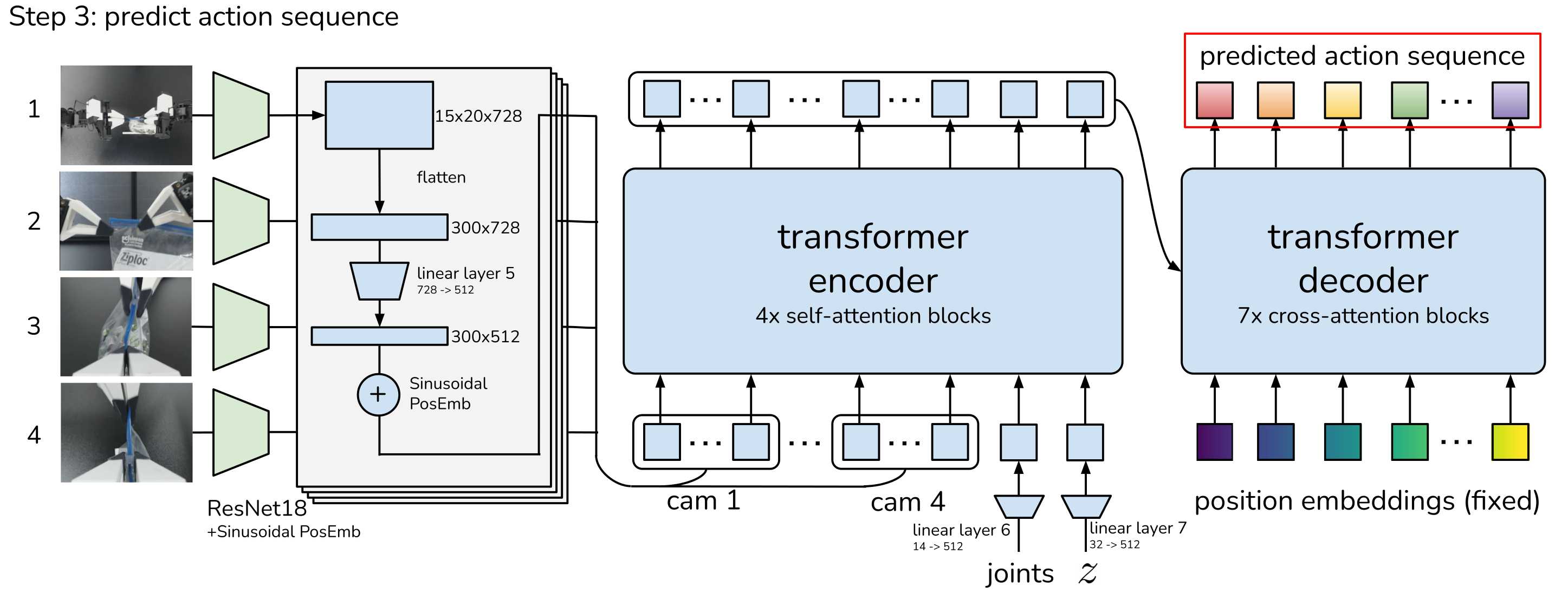
步骤1 采样数据

准备好采样数据:
- images:对应的4组RGB图像。
- joints:2个机器,每个机器有7个自由度,那么对应14个关节位置信息。
- action sequence:演示数据集长度为K组的目标动作序列,每组14个关节位置信息。
怎么理解joints和action sequence了?
假设当前是T0时刻,采样到机器4组摄像头数据得到4 * (4806403)的图像数据,然后也采样到当前时刻机器的关节位置信息(14,)。那么action sequence数据怎么来了,要从T0时刻开始计时,到T0+K时刻进行记录K组(每组14关节位置信息)关节位置信息,然后将这些信息组合得到一组完整的数据。但一般采样的这K组数据一般使用领导臂,不使用机器的,作者在论文中提到主要是考虑因为机器是通过低级PID控制器来转换执行的,采用机器的记录数据可能会导致符合误差。
步骤2 推理Z
步骤3 预测动作
推理