
端侧 AI 与机器人技术雷达|2026-07-31
今日必看 VisionPsy-Nano 把小型 VLM 的竞争压到视觉 token 预算 Tether AI Research 在 2026 年 7 月 29 日发布 VisionPsy-Nano 系列:VisionPsy-Nano-460M 主打质量,VisionPsy-Nano-460M-Flash 主打延迟,二
今日必看 VisionPsy-Nano 把小型 VLM 的竞争压到视觉 token 预算 Tether AI Research 在 2026 年 7 月 29 日发布 VisionPsy-Nano 系列:VisionPsy-Nano-460M 主打质量,VisionPsy-Nano-460M-Flash 主打延迟,二
本文记录第一次在 Isaac Lab 中完成强化学习训练、查看训练曲线、加载 checkpoint 推理、观察仿真效果,以及修改奖励函数做对照实验的完整过程。 这次学习的重点不是背诵算法公式,而是先打通以下闭环: 理解任务 →

世界模型:让机器人先在“脑内”试一遍 什么是世界模型,它和机器人有什么关系,以及截至 2026 年 7 月有哪些值得关注的开源选择。 图 1:世界模型的直觉——机器人不必把每个动作都拿到现实里试,而是
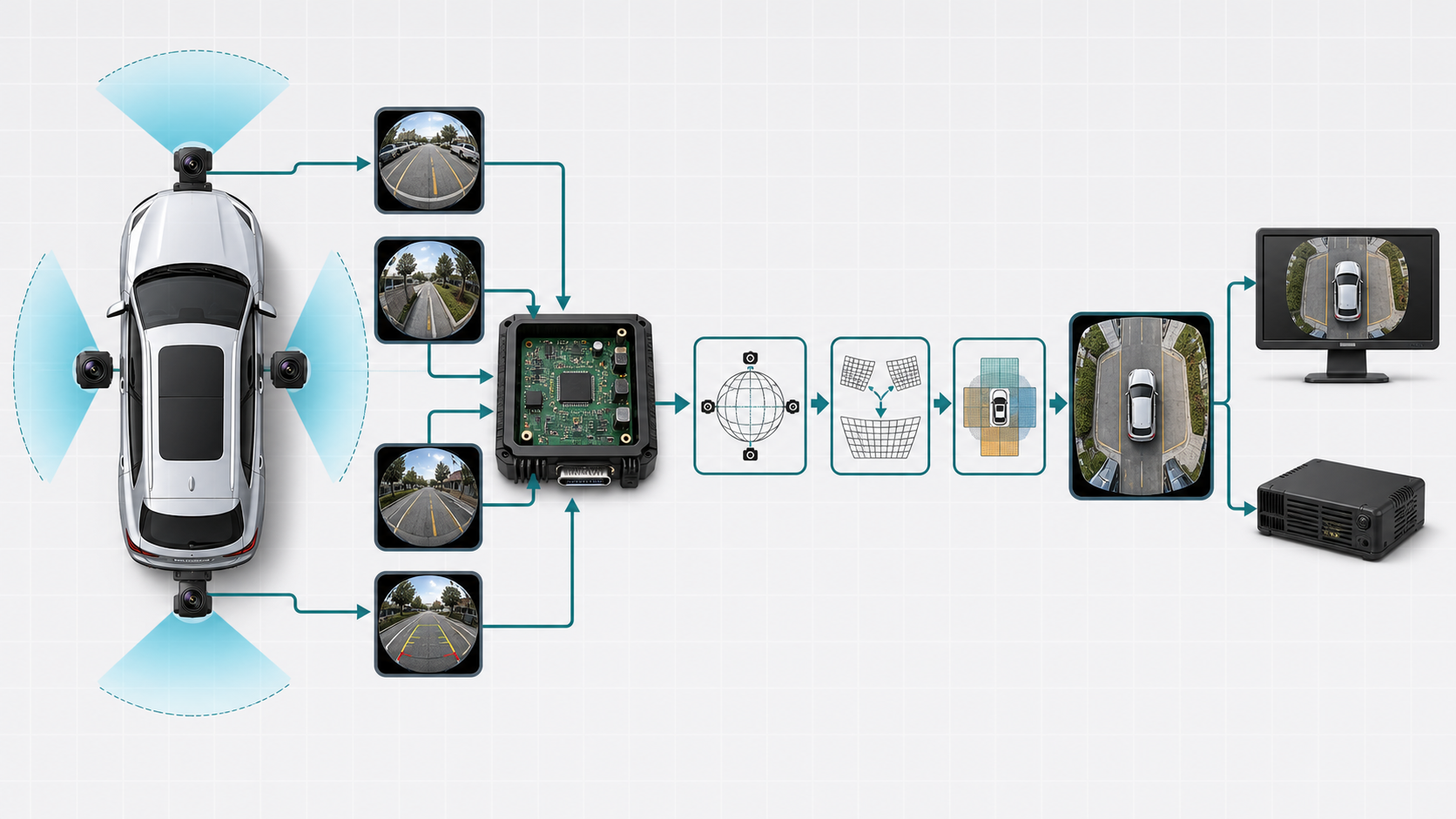
这篇笔记梳理 360 全景拼接,也就是 AVM(Around View Monitor)/环视鸟瞰系统的原理、整条视频通路,以及它对芯片的真实需求。 先把结论说清楚:车载 360 拼接通常不是做“球形全景照片”
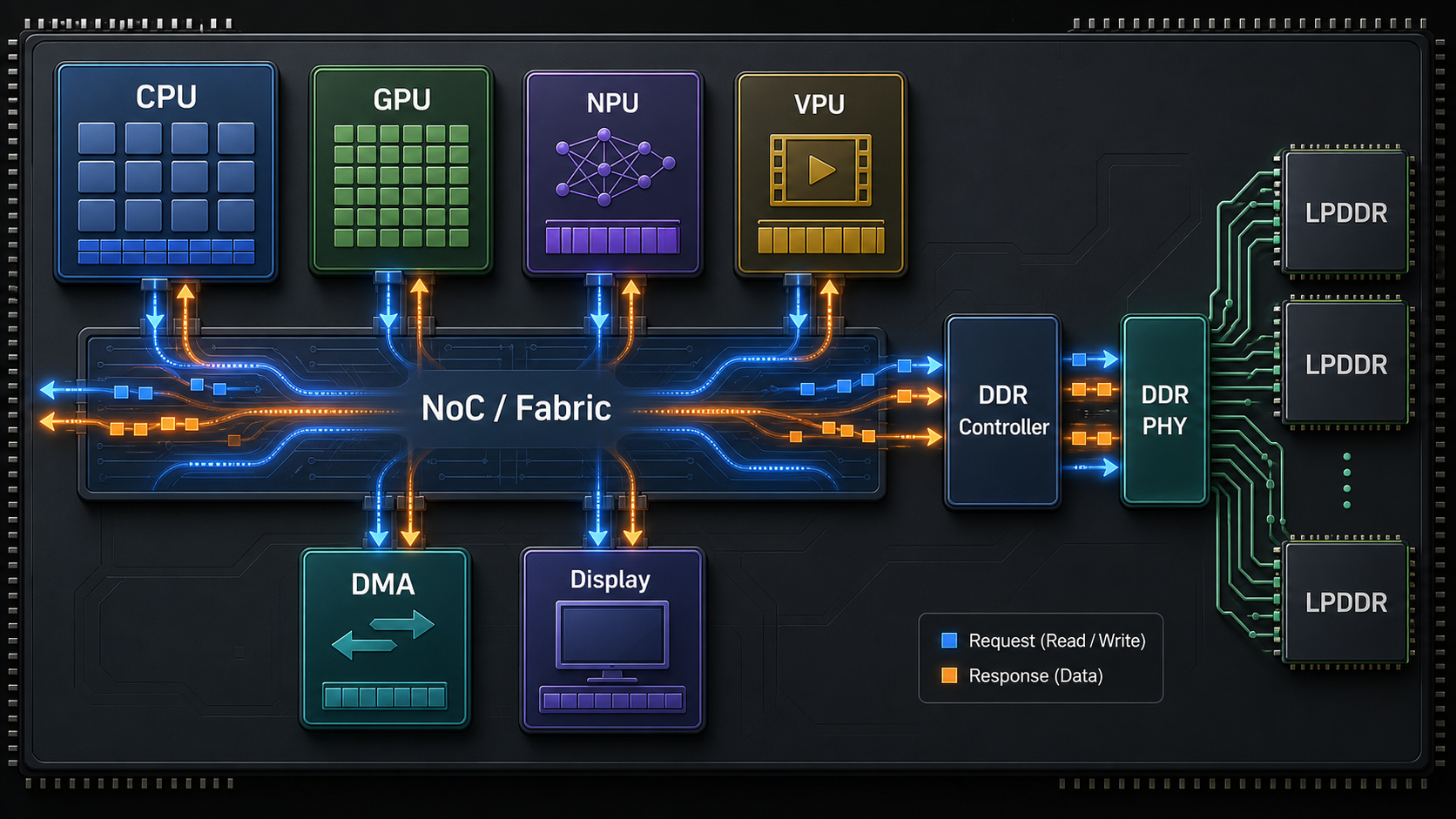
学习 SoC 架构时,最容易混淆的是几个词:Bus、AXI、NoC、DDR、QoS。它们不是同一层面的概念。 Bus、Crossbar、Fabric、NoC:描述片上模块之间怎么连接。 AXI
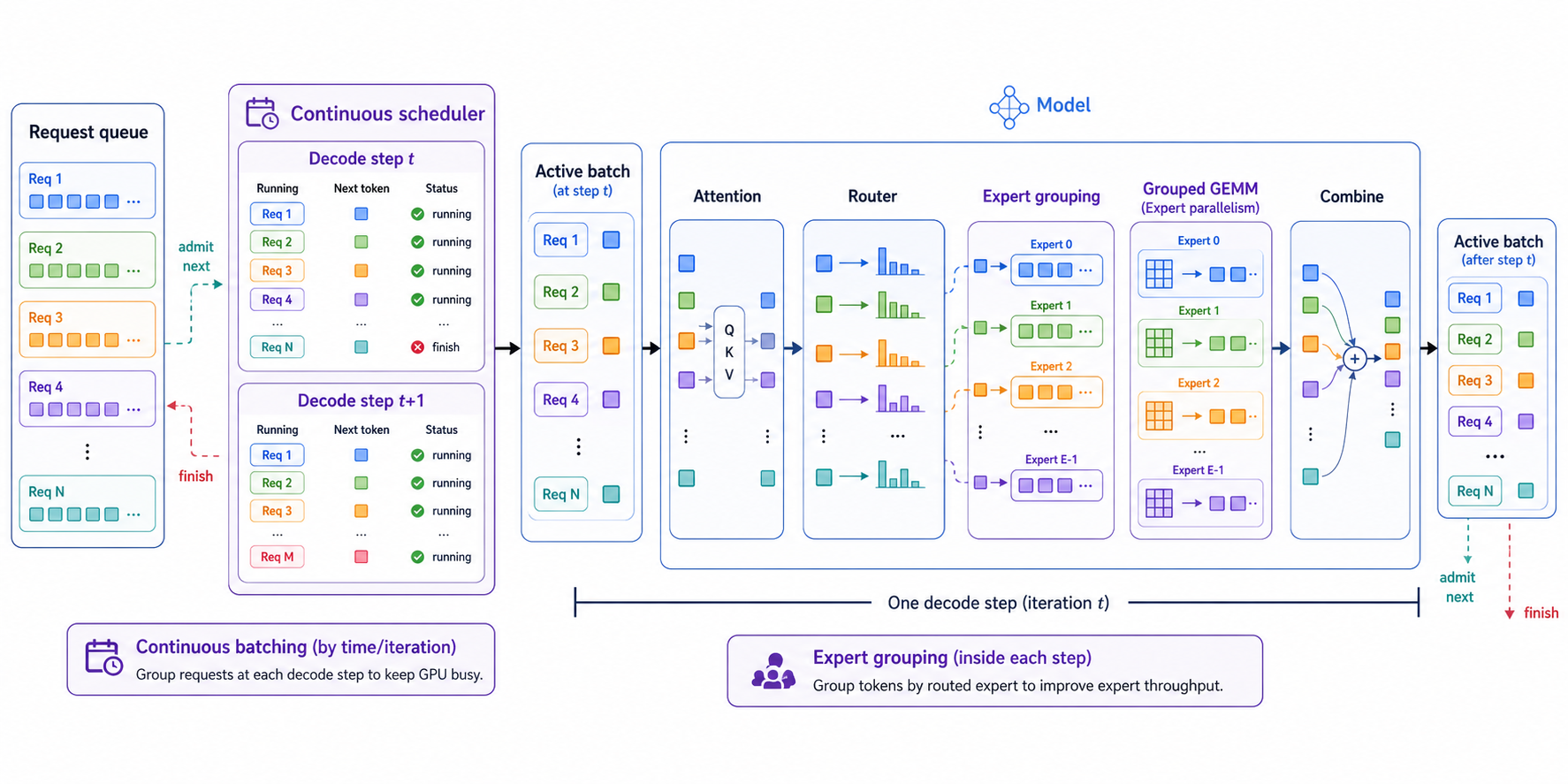
概述 大模型推理服务的核心问题不是“单个请求能不能跑”,而是“很多请求同时进来时,GPU能不能一直忙,并且用户等待时间不要太长”。这里会遇到两个层面的调度问题。 请求层面:不同用户请求
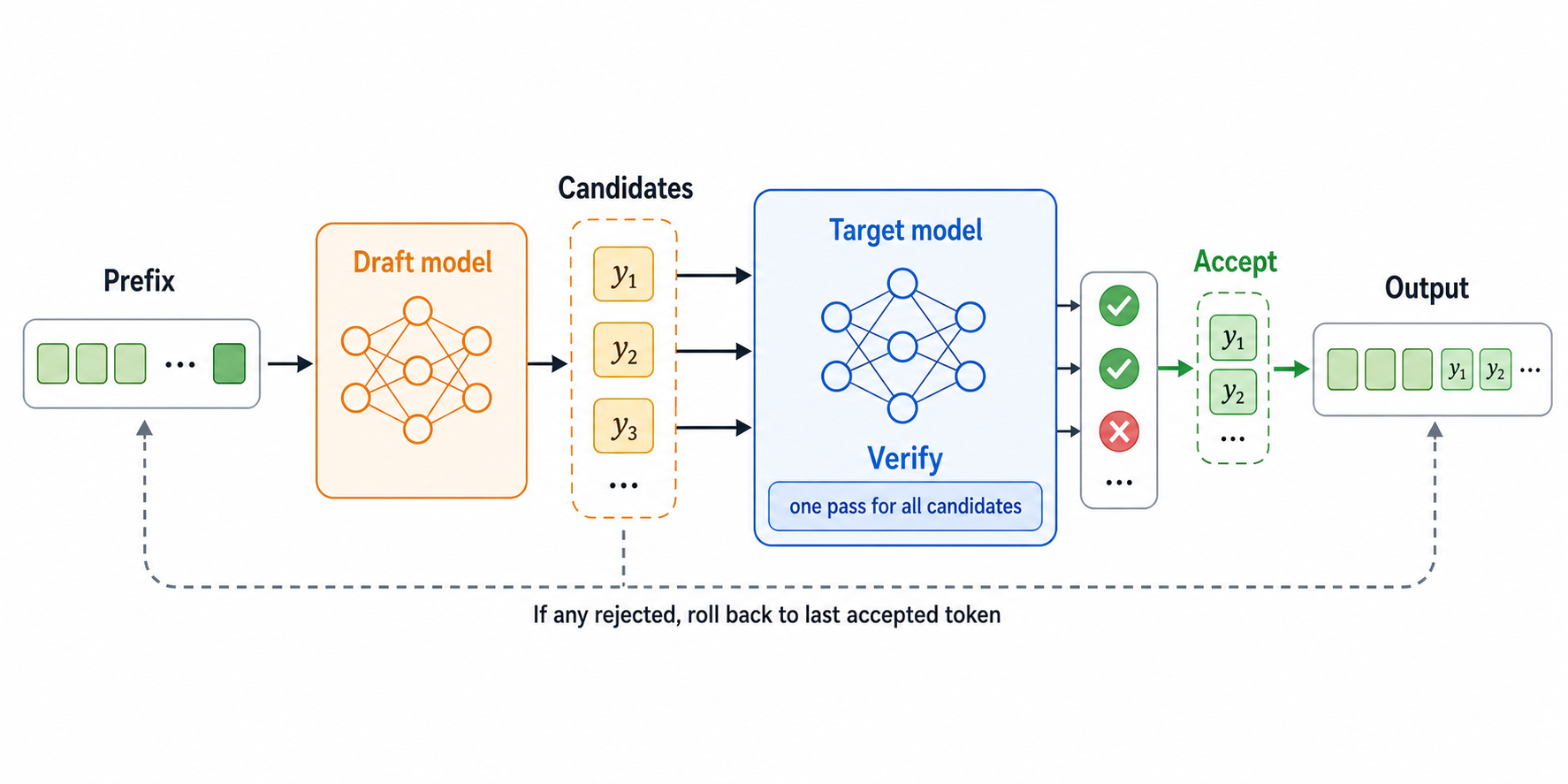
概述 大语言模型生成文本时,本质上是一个自回归过程:先根据已有上下文预测下一个token,再把这个token拼回上下文里,继续预测下一个token。也就是说,如果要生成100个tok
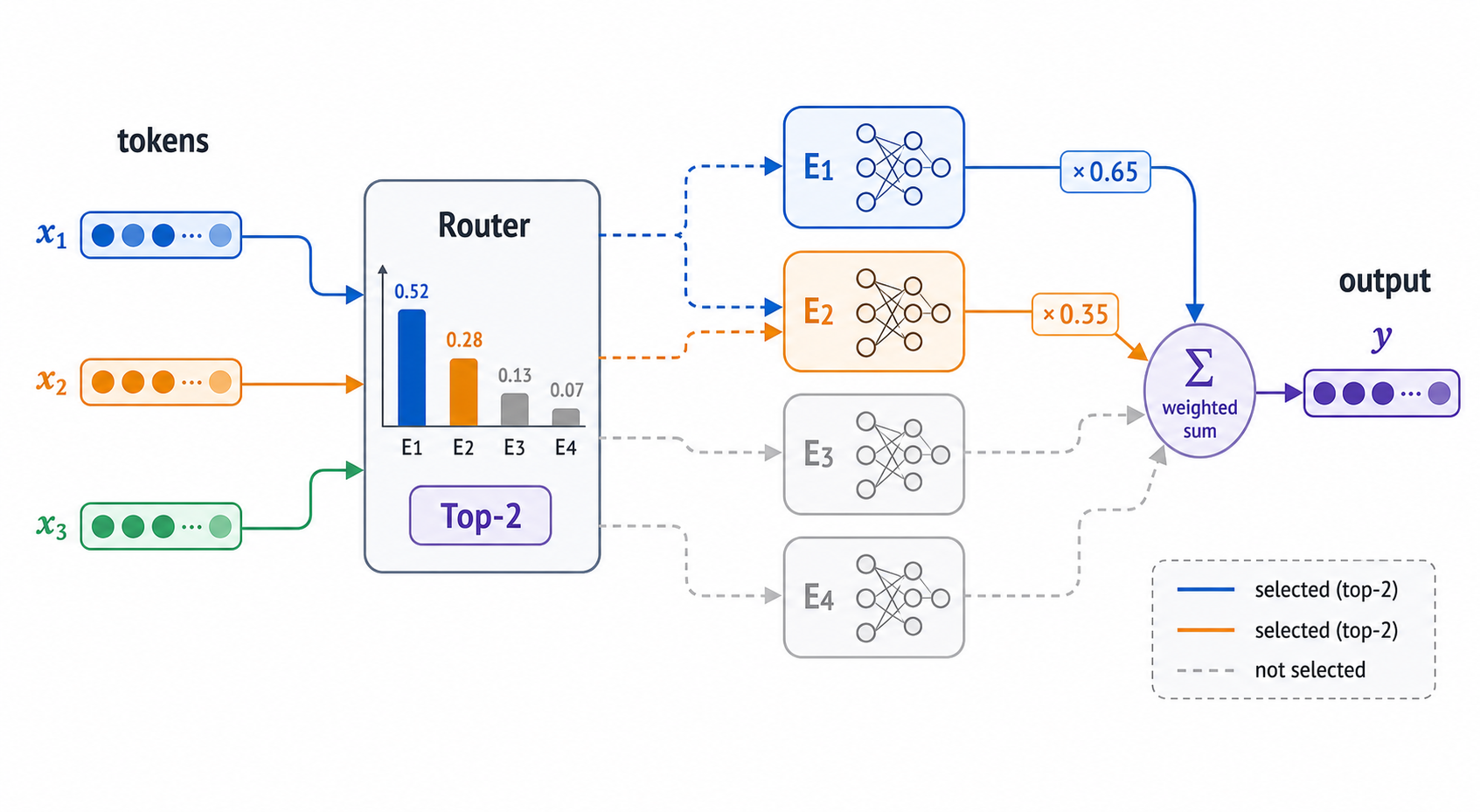
概述 大模型能力提升通常依赖两个方向:模型参数变多、训练数据变多。Dense模型的做法比较直接,每一层的参数都会参与每个token的计算,模型越大,单次前向计算也越重。这样虽然简单,

这篇文章把 ISP Pipeline 中常见缩写按数据流阶段串起来。看 ISP 文档时,不建议孤立记缩写,而是先判断它处在输入接收、RAW 前处理、HDR/3A、RGB/YUV 后处理、几何校正、输出,还是 AI/CV 支路。 完
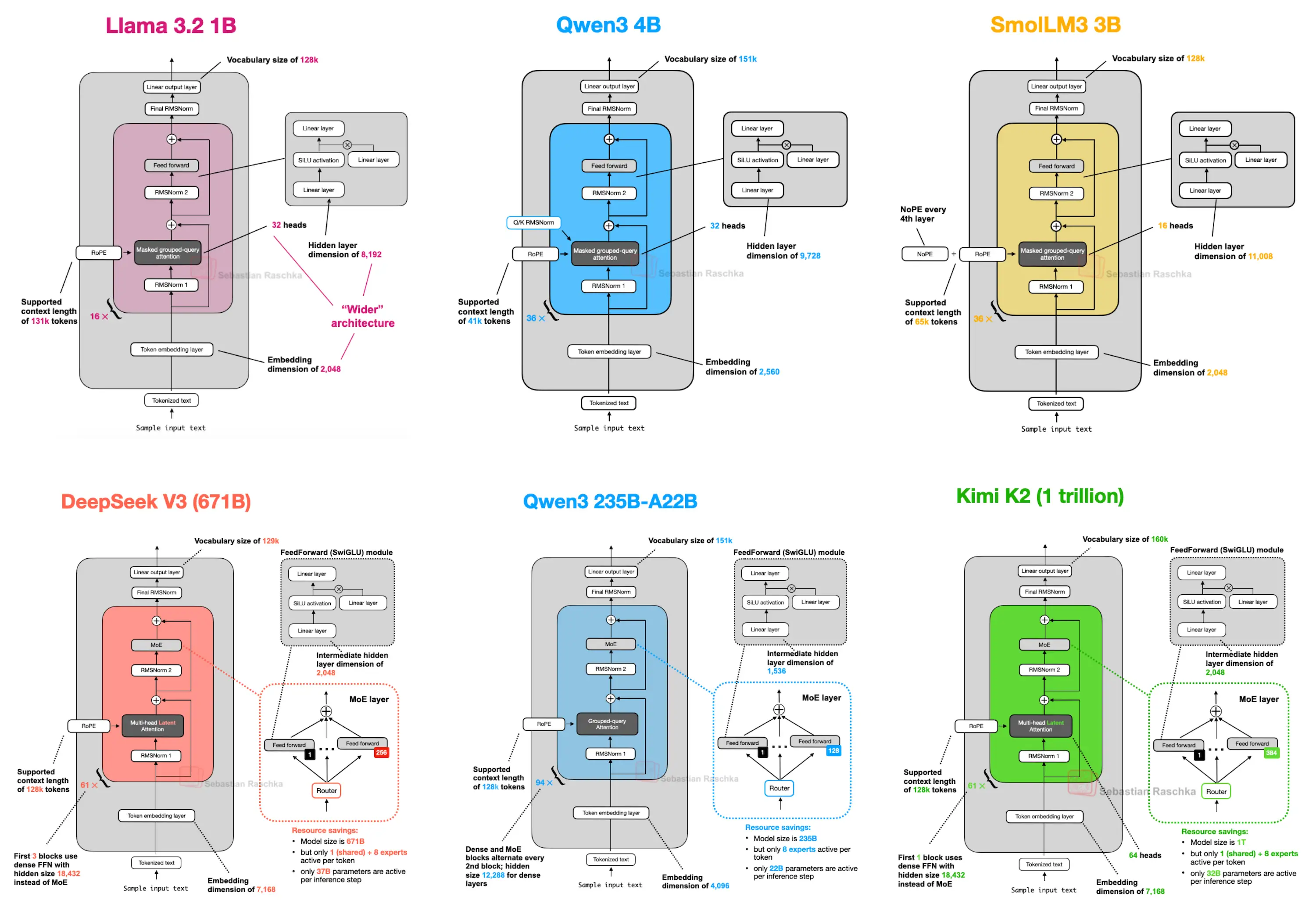
大模型推理的"第一性原理" 从Deepseek V3到Kimi K2 无论模型如何变化,当前主流大模型的核心架构都是基于transformer。其本质是一个由多层相同结构
概述 llama.cpp 的模型加载系统是一个高度优化的、支持多后端、多设备的模型权重加载框架。它通过精心设计的数据结构和加载流程,实现了: 零拷贝加载:通过内存映射(mmap)实现模型文件的零拷贝加载