SmolVLA 异步推理:远程 Policy Server 与本地 Client 实操
概述
本文记录lerobot smolvla异步推理实践,将SmolVLA的策略server部署到AutoDL上,真机client在本地笔记本上运行。
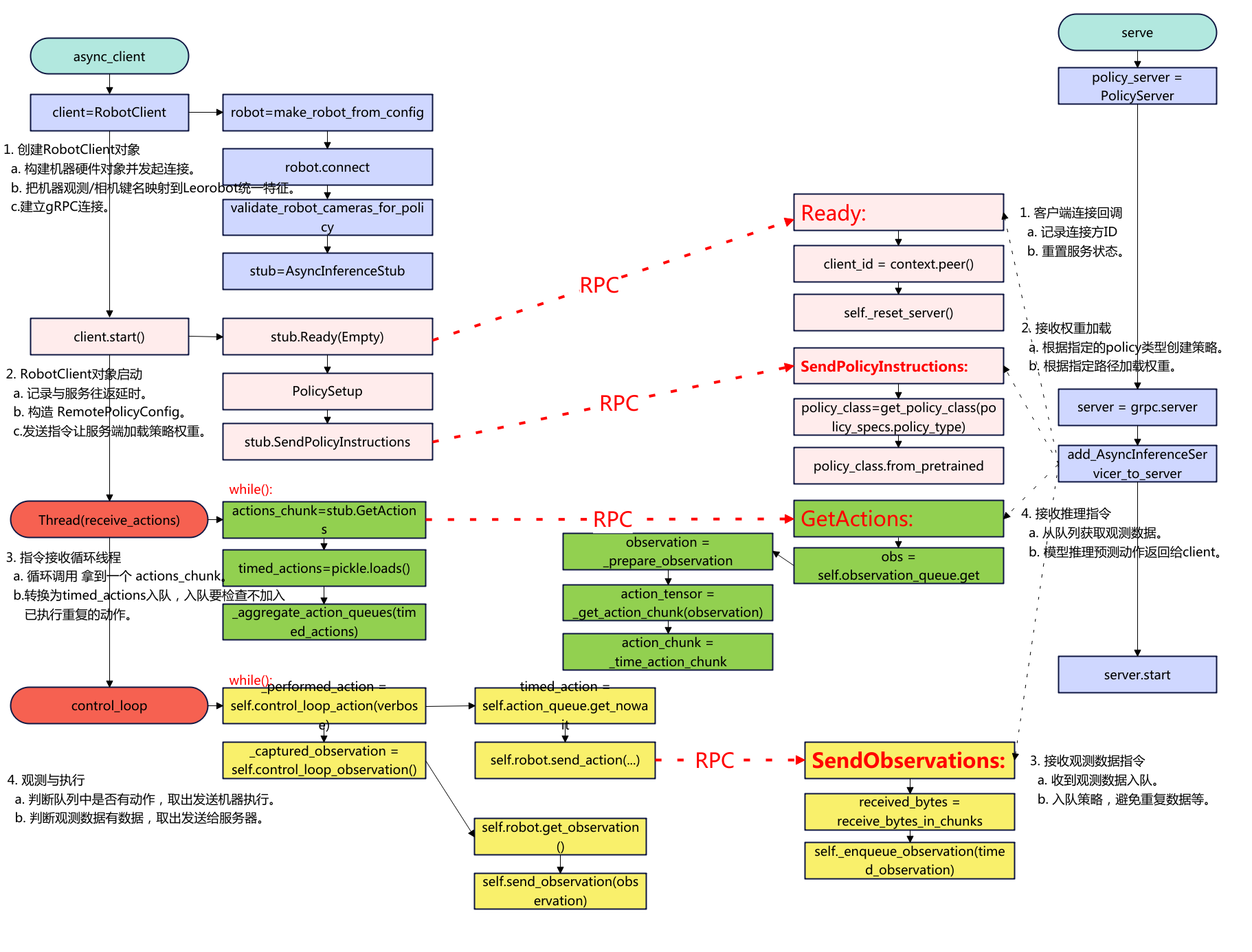
下面是代码的流程图:
环境准备
先登录AutoDL事先搭建好lerobot的环境,这里就不再重复了,参考往期文章。lerobot环境搭建好后,需要先安装smolvla和gRPC。
# 建议先升级打包工具
python -m pip install -U pip setuptools wheel
pip install -e ".[smolvla]"
# 安装 gRPC 及相关
python -m pip install grpcio grpcio-tools protobuf
服务器
python src/lerobot/scripts/server/policy_server.py
--host=127.0.0.1
--port=8080
--fps=30
--inference_latency=0.033
--obs_queue_timeout=2
启动成功后的日志如下:
python src/lerobot/scripts/server/policy_server.py --host=127.0.0.1 --port=8080 --fps=30 --inference_latency=0 --obs_queue_timeout=2
INFO 2025-08-28 10:33:07 y_server.py:384 {'fps': 30,
'host': '127.0.0.1',
'inference_latency': 0.0,
'obs_queue_timeout': 2.0,
'port': 8080}
INFO 2025-08-28 10:33:07 y_server.py:394 PolicyServer started on 127.0.0.1:8080
被客户端连接后的日志:
INFO 2025-08-28 10:40:42 y_server.py:104 Client ipv4:127.0.0.1:45038 connected and ready
INFO 2025-08-28 10:40:42 y_server.py:130 Receiving policy instructions from ipv4:127.0.0.1:45038 | Policy type: smolvla | Pretrained name or path: outputs/smolvla_weigh_08181710/pretrained_model | Actions per chunk: 50 | Device: cuda
Loading HuggingFaceTB/SmolVLM2-500M-Video-Instruct weights ...
INFO 2025-08-28 10:40:54 odeling.py:1004 We will use 90% of the memory on device 0 for storing the model, and 10% for the buffer to avoid OOM. You can set `max_memory` in to a higher value to use more memory (at your own risk).
Reducing the number of VLM layers to 16 ...
Loading weights from local directory
INFO 2025-08-28 10:41:14 y_server.py:150 Time taken to put policy on cuda: 32.3950 seconds
INFO 2025-08-28 10:41:14 ort/utils.py:74 <Logger policy_server (NOTSET)> Starting receiver
INFO 2025-08-28 10:41:14 y_server.py:175 Received observation #0 | Avg FPS: 3.45 | Target: 30.00 | One-way latency: -9.22ms
INFO 2025-08-28 10:41:14 y_server.py:205 Running inference for observation #0 (must_go: True)
INFO 2025-08-28 10:41:15 ort/utils.py:74 <Logger policy_server (NOTSET)> Starting receiver
INFO 2025-08-28 10:41:15 y_server.py:175 Received observation #0 | Avg FPS: 3.45 | Target: 30.00 | One-way latency: -9.58ms
服务器仅本地监听(12.0.0.1),这样不暴露公网,客户端通过SSH隧道安全转发。
nohup python src/lerobot/scripts/server/policy_server.py
--host=127.0.0.1 --port=8080 --fps=30 --inference_latency=0.033 --obs_queue_timeout=2
>/tmp/policy_server.log 2>&1 &
也可以选择后台运行。
客户端
建立SSH转发
在本地客户端线建立SSH本地端口转发(隧道)
ssh -p <服务器ssh的port> -fN -L 8080:127.0.0.1:8080 <用户名@服务器ssh的ip或域名>
如:ssh -p 20567 -fN -L 8080:127.0.0.1:8080 root@connect.xx.xxx.com
如果不想后台运行,运行在前台(Crtl+C结束)
ssh -p 20567 -N -L 8080:127.0.0.1:8080 root@connect.xx.xxx.com
本地运行
python src/lerobot/scripts/server/robot_client.py \
--robot.type=so101_follower --robot.port=/dev/ttyACM0 --robot.id=R12252801 \
--robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}}" \
--policy_type=smolvla \
--pretrained_name_or_path=outputs/smolvla_weigh_08181710/pretrained_model \
--policy_device=cuda \
--actions_per_chunk=50 \
--fps=30 \
--server_address=localhost:8080 \
--chunk_size_threshold=0.8 \
--debug_visualize_queue_size=True
其他参数
–debug_visualize_queue_size=True: 执行结束后可视化队列情况。 需要安装 pip install matplotlib。
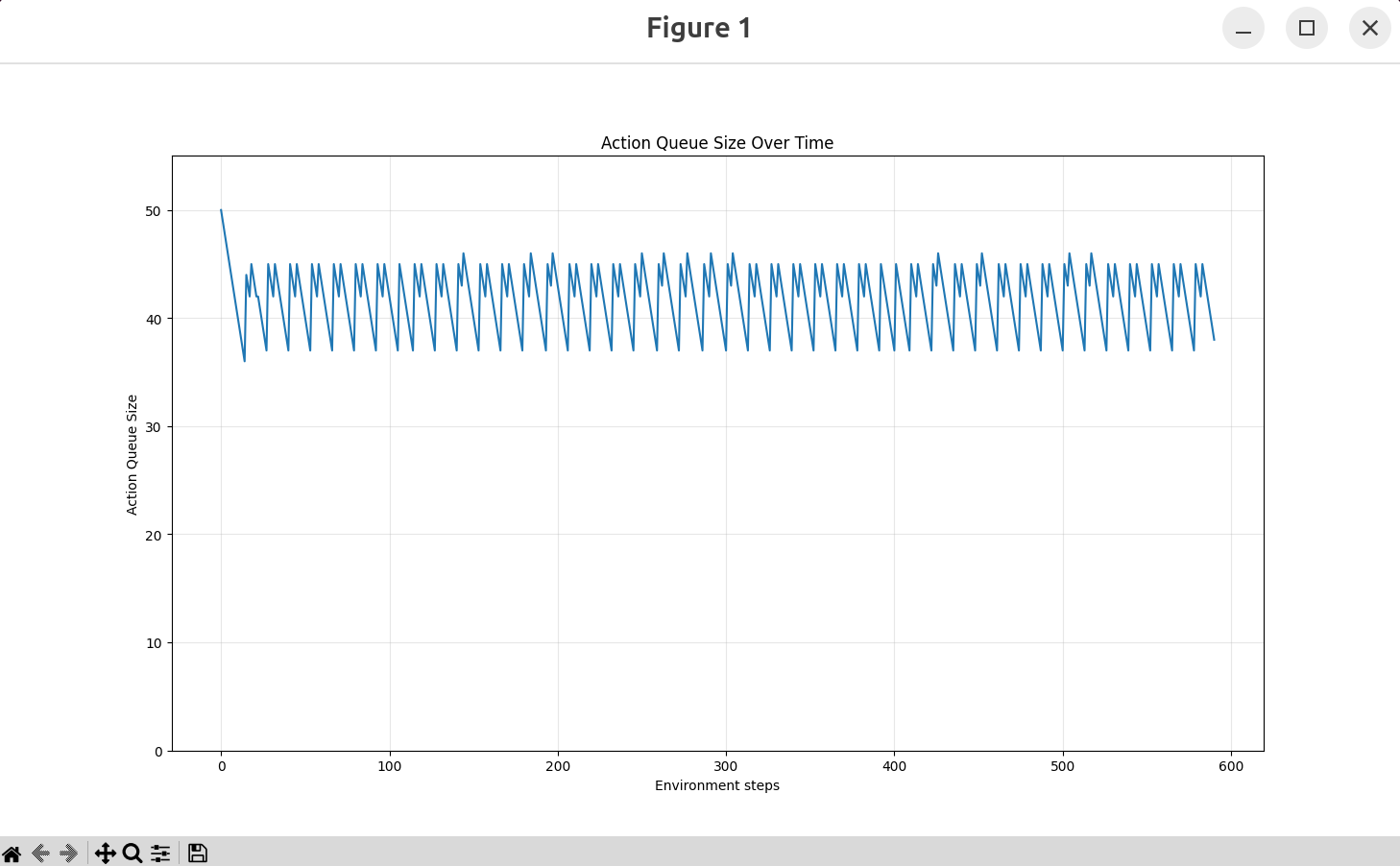
–aggregate_fn_name=conservative:当新动作到达时,如果队列中已经存在相同时间步的动作,系统会使用聚合函数来合并它们。如果为latest_only(默认),只用最新动作,这样可能会抖动剧烈。
–pretrained_name_or_path 会在“服务器上”加载。需要确保服务器上outputs/smolvla_weigh_08181710路径有权重文件。
连接执行的日志如下:
python src/lerobot/scripts/server/robot_client.py --robot.type=so101_follower --robot.port=/dev/ttyACM0 --robot.id=R12252801 --robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 320, height: 240, fps: 25}, fixed: {type: opencv, index_or_path: 0, width: 320, height: 240, fps: 25}}" --policy_type=smolvla --pretrained_name_or_path=outputs/smolvla_weigh_08181710/pretrained_model --policy_device=cuda --actions_per_chunk=50 --chunk_size_threshold=0.8 --fps=30 --server_address=localhost:8080 --aggregate_fn_name=average
INFO 2025-08-28 10:40:38 t_client.py:478 {'actions_per_chunk': 50,
'aggregate_fn_name': 'average',
'chunk_size_threshold': 0.8,
'debug_visualize_queue_size': False,
'fps': 30,
'policy_device': 'cuda',
'policy_type': 'smolvla',
'pretrained_name_or_path': 'outputs/smolvla_weigh_08181710/pretrained_model',
'robot': {'calibration_dir': None,
'cameras': {'fixed': {'color_mode': <ColorMode.RGB: 'rgb'>,
'fps': 25,
'height': 240,
'index_or_path': 0,
'rotation': <Cv2Rotation.NO_ROTATION: 0>,
'warmup_s': 1,
'width': 320},
'handeye': {'color_mode': <ColorMode.RGB: 'rgb'>,
'fps': 25,
'height': 240,
'index_or_path': 6,
'rotation': <Cv2Rotation.NO_ROTATION: 0>,
'warmup_s': 1,
'width': 320}},
'disable_torque_on_disconnect': True,
'id': 'R12252801',
'max_relative_target': None,
'port': '/dev/ttyACM0',
'use_degrees': False},
'server_address': 'localhost:8080',
'task': '',
'verify_robot_cameras': True}
INFO 2025-08-28 10:40:40 a_opencv.py:179 OpenCVCamera(6) connected.
INFO 2025-08-28 10:40:41 a_opencv.py:179 OpenCVCamera(0) connected.
INFO 2025-08-28 10:40:41 follower.py:104 R12252801 SO101Follower connected.
WARNING 2025-08-28 10:40:42 ils/utils.py:54 No accelerated backend detected. Using default cpu, this will be slow.
WARNING 2025-08-28 10:40:42 /policies.py:80 Device 'cuda' is not available. Switching to 'cpu'.
WARNING 2025-08-28 10:40:42 ils/utils.py:54 No accelerated backend detected. Using default cpu, this will be slow.
WARNING 2025-08-28 10:40:42 /policies.py:80 Device 'cuda' is not available. Switching to 'cpu'.
INFO 2025-08-28 10:40:42 t_client.py:121 Initializing client to connect to server at localhost:8080
INFO 2025-08-28 10:40:42 t_client.py:140 Robot connected and ready
INFO 2025-08-28 10:40:42 t_client.py:163 Sending policy instructions to policy server
INFO 2025-08-28 10:41:14 t_client.py:486 Starting action receiver thread...
INFO 2025-08-28 10:41:14 t_client.py:454 Control loop thread starting
INFO 2025-08-28 10:41:14 t_client.py:280 Action receiving thread starting
INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 |
INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 288.72
INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 |
INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 132.22
INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 |
INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 127.84
INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 |
INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 123.95
INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 |
INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 140.21
INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 0.54
INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 0.42
如果使用ACT策略,对于ACT来说chunk_size_threshold不要设置太大,实测发现不然一个chunk到下一个chunk抖动比较严重
python src/lerobot/scripts/server/robot_client.py \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=R12252801 \
--robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}}" \
--policy_type=act \
--pretrained_name_or_path=outputs/act_weigh_07271539/pretrained_model \
--policy_device=cuda \
--actions_per_chunk=100 \
--fps=30 \
--server_address=localhost:8080 \
--chunk_size_threshold=0.1
以上就是用SSH隧道的方式实现异步推理的过程。
参考:https://hugging-face.cn/docs/lerobot/async
常见问题
(0)服务器监控日志分析
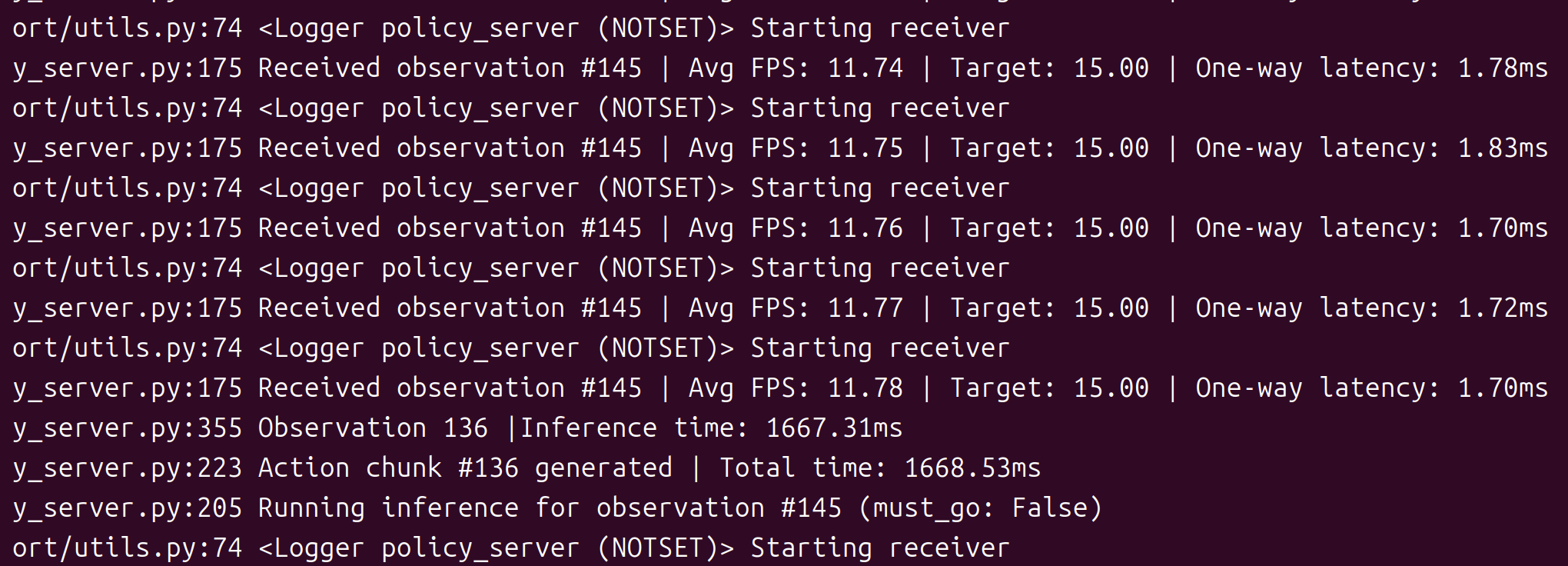
- Received observation #136:服务器接收到第136个观察数据
- Avg FPS: 11.52:实际观测数据帧率,根据客户端每秒采样时间计算,跟服务端没有关系。
- Target:目标设置的观测数据帧率,如15帧/s。
- One-way latency: 客户端到服务器的单向网络延迟为1.71ms。
- inference time: 模型推理耗时时长为1667ms。
- action chunk #136:生成了第136个动作块。
- Total time: 推理+序列化总处理时长。
(1)服务端实际的观测帧率低
INFO 2025-08-29 09:47:05 y_server.py:175 Received observation #573 | Avg FPS: 1.20 | Target: 30.00 | One-way latency: 35.78ms
可以看到上面的收到的观测帧率平均只有1.2,看看服务端计算FPS的逻辑。
# 每次接收观测时调用
self.total_obs_count += 1 # 包括所有接收的观测(包括被过滤的)
total_duration = current_timestamp - self.first_timestamp
avg_fps = (self.total_obs_count - 1) / total_duration
影响服务端的接受观测帧帧率的有客户端观测发送频率低,服务端观测被过滤,推理时间长间接影响
关于客户端观测数据的发送限制如下:
# 只有当队列大小/动作块大小 <= 阈值时才发送观测
if queue_size / action_chunk_size <= chunk_size_threshold:
send_observation()
可以看到只有满足上面的小于动作阈值才会发送,所以要加大发送的帧率需要改大阈值chunk_size_threshold,减少actions_per_chunk,减少queue_size。
对于ACT策略的FPS 低可能不是问题,这是观察发送频率,不是控制频率,因为ACT 策略就是低频观察,高频执行,主要看机器是不是以30FPS动作执行就好。smolvla也是同样的。因此有时候不要过于误解这个观测帧率,太高的观测帧率也不一定是好事。
(2)观测数据被过滤
y_server.py:191 Observation #510 has been filtered out
服务端会根据这次和上次的关节角度计算欧拉来判断相似性,默认的阈值参数是1,可以改小一点,对相似性的判断严苛一下。
def observations_similar(
obs1: TimedObservation, obs2: TimedObservation, lerobot_features: dict[str, dict], atol: float = 1
) -> bool:
......
return bool(torch.linalg.norm(obs1_state - obs2_state) < atol)
如上修改atol的值,可以改小为如0.5。
总结一下:
对于分布式推理不要过于去纠结实际的观测帧率,而是应该看控制的实际帧率,只要控制动作的帧率(如下的延时,大概就是30fps)是满足的就是可以的,也就是说动作队列中动作不要去获取的时候是空。
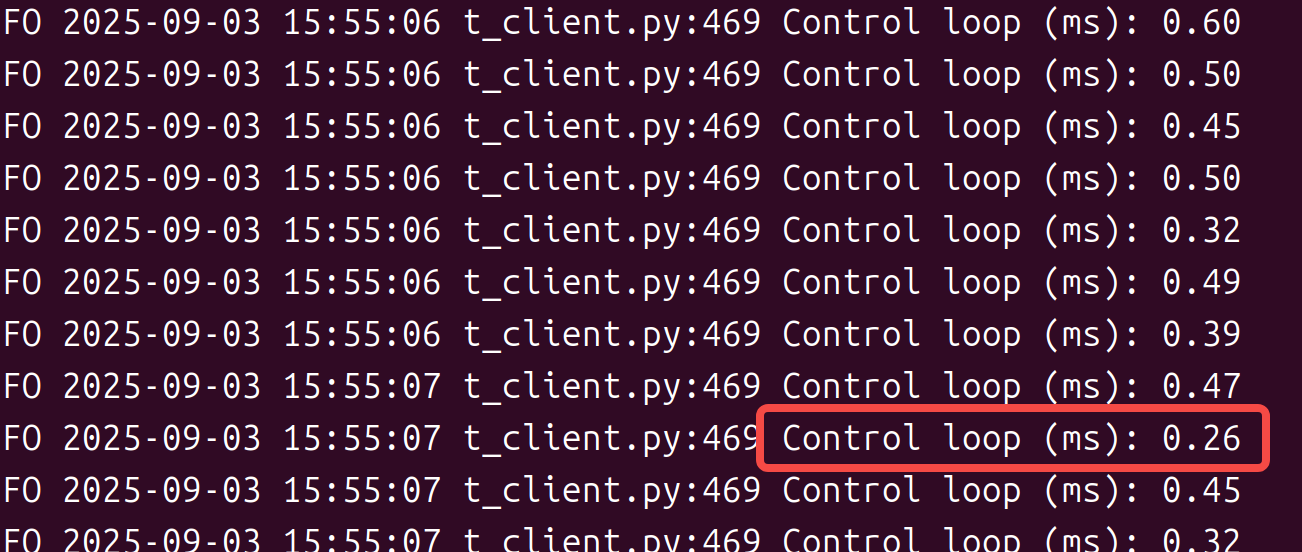
对于参数优化重点看服务端的推理延时和客户端的队列管理。
服务端是可以设置推理延时的
# 推理延迟控制
--inference_latency=0.033 # 模型推理延迟(秒)
# 观察队列管理
--obs_queue_timeout=2 # 获取观测队列超时时间(秒)
客户端动作管理
--actions_per_chunk=100 # 一个动作块的序列大小,越大推理负载就重
--chunk_size_threshold=0.5 # 队列阈值,越大缓存的动作序列越多,越小实时性越好。
--fps=30 # 控制频率
如果要低延时那么就需要把fps提高,也就是服务端的推理时间设置小,客户端的chunk、threshold要小,fps要高。
请问作者有遇到推理端反序列化耗时太长的问题吗