语音识别模型:SenseVoice入门实践
是什么
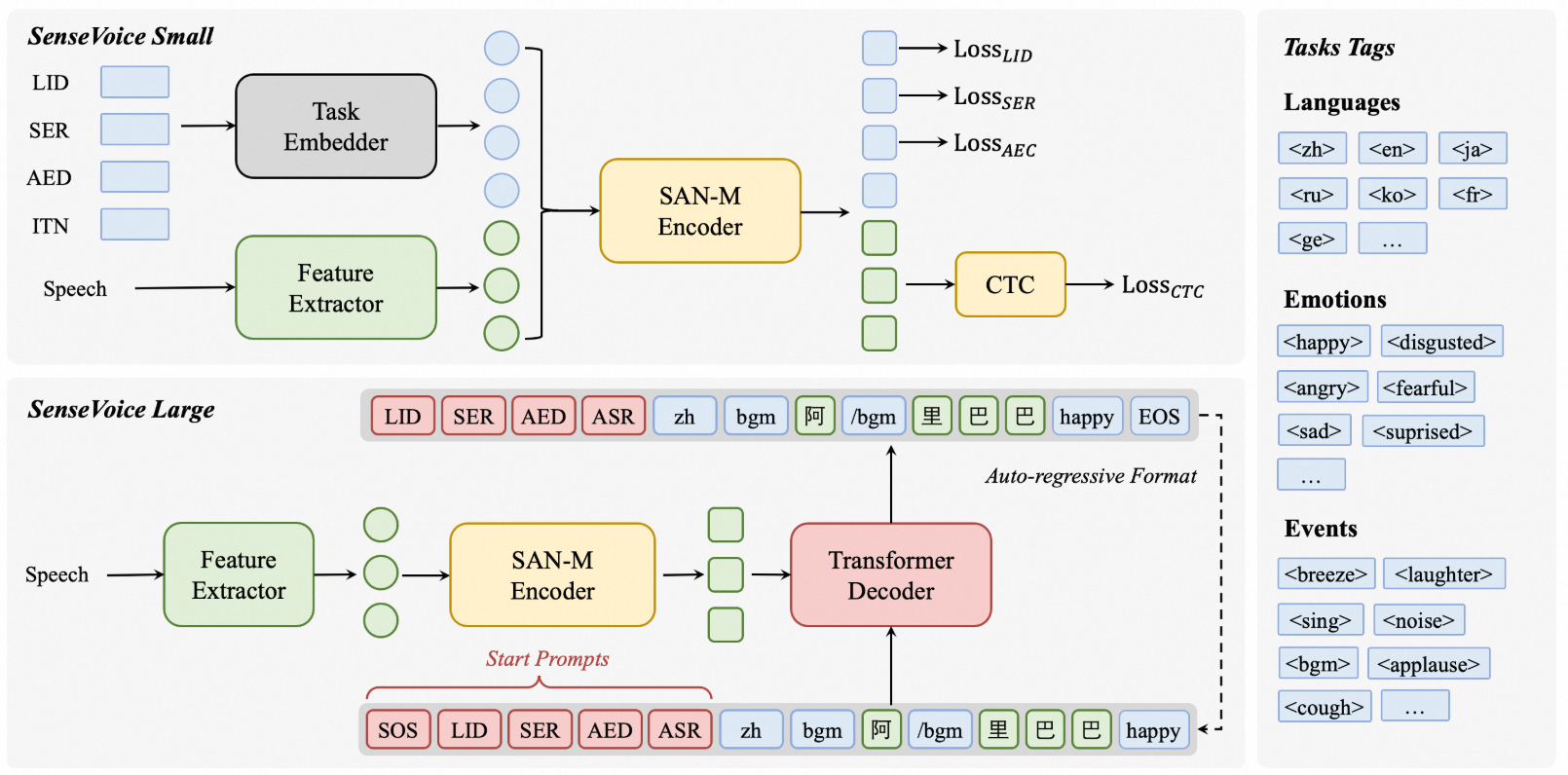
SenseVoice是多语言识别的模型,支持语音转文字(ASR, Automatic Speech Recognition,自动语音识别),语种识别(LID, Language Identification),语音情感识别(SER, Speech Emotion Recognition),音频事件检测 / 声学事件分类(AED/AEC, Audio Event Detection / Classification),逆文本正则化 / 标点 / 富文本转写等。
怎么用
配置环境
配置一个conda sensevoice环境并且激活。
conda create -n sensevoice python=3.10
conda activate sensevoice
拉取代码,安装依赖
git clone https://github.com/FunAudioLLM/SenseVoice.git
cd SenseVoice/
pip install -r requirements.txt
示例测试
代码中有两个示例分别是demo1.py和demo2.py,执行后可以看看效果。
python demo1.py
执行后会自动从modelscope上下载模型和相关配置到本地。
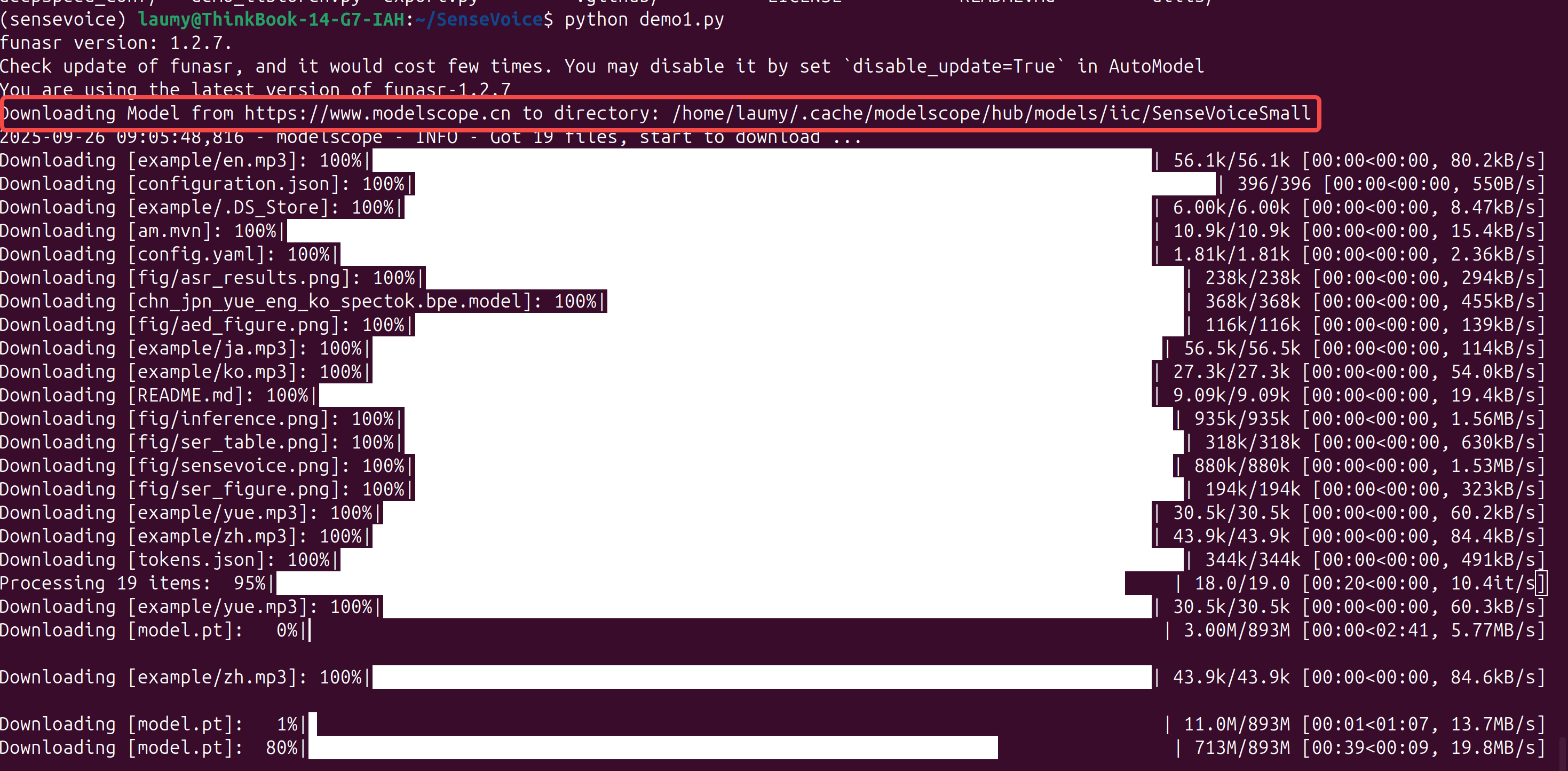
下载到本地后有模型和相关的配置文件以及示例音频。
(sensevoice) laumy@ThinkBook-14-G7-IAH:~/.cache/modelscope/hub/models/iic$ tree
.
├── SenseVoiceSmall
│ ├── am.mvn
│ ├── chn_jpn_yue_eng_ko_spectok.bpe.model
│ ├── configuration.json
│ ├── config.yaml
│ ├── example
│ │ ├── en.mp3
│ │ ├── ja.mp3
│ │ ├── ko.mp3
│ │ ├── yue.mp3
│ │ └── zh.mp3
│ ├── fig
│ │ ├── aed_figure.png
│ │ ├── asr_results.png
│ │ ├── inference.png
│ │ ├── sensevoice.png
│ │ ├── ser_figure.png
│ │ └── ser_table.png
│ ├── model.pt
│ ├── README.md
│ └── tokens.json
└── speech_fsmn_vad_zh-cn-16k-common-pytorch
├── am.mvn
├── configuration.json
├── config.yaml
├── example
│ └── vad_example.wav
├── fig
│ └── struct.png
├── model.pt
└── README.md
7 directories, 25 files
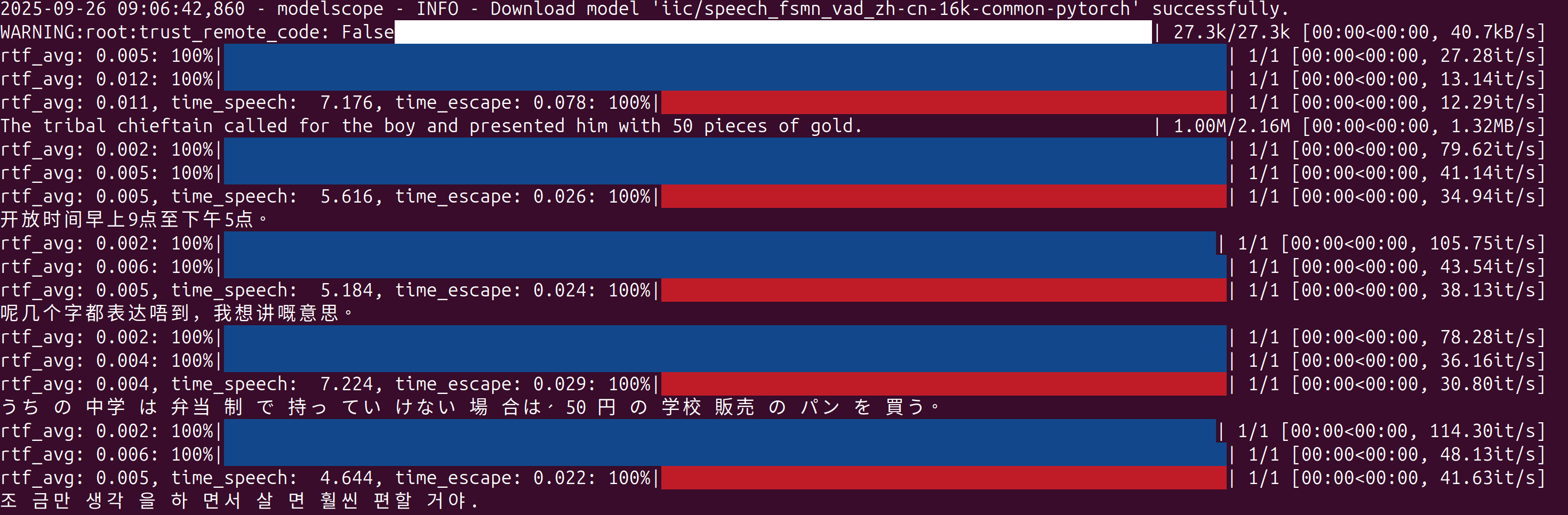
最后的识别效果为
还可以测试webui版本
python webui.py
然后网址输入:http://127.0.0.1:7860, 注意不能开代理否则会启动失败。
接口调用
主要简要分析一下使用funASR调用示例。
(1)模型加载
model = AutoModel(model=[str], device=[str], ncpu=[int], output_dir=[str], batch_size=[int], hub=[str], **kwargs)
- model:模型仓库中的名称
- device:推理的设备,如gpu
- ncpu:cpu并行线程。
- output_dir:输出结果的输出路径
- batch_size:解码时的批处理,样本个数
- hub:从modelscope下载模型。如果为hf,从huggingface下载模型。
(2)推理
res = model.generate(input=[str], output_dir=[str])
- input:要解码的输入可以是wav文件路径, 例如: asr_example.wav。
- output_dir: 输出结果的输出路径。
实时识别
编写一个示例实时识别
#!/usr/bin/env python3
# -*- encoding: utf-8 -*-
# Real-time microphone transcription (pure memory) using ALSA (pyalsaaudio) + numpy
import argparse
import os
import signal
import sys
import time
from pathlib import Path
from typing import Optional
import numpy as np
def _safe_imports() -> None:
try:
import alsaaudio # noqa: F401
except Exception:
print(
"缺少 pyalsaaudio,请先安装:\n pip install pyalsaaudio\nUbuntu 可能需要:sudo apt-get install -y python3-alsaaudio 或 alsa-utils",
file=sys.stderr,
)
raise
def _safe_import_model():
try:
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
except Exception:
print(
"导入 funasr 失败。如果仓库根目录存在本地 'funasr.py',请重命名(如 'funasr_demo.py')以避免遮蔽外部库。",
file=sys.stderr,
)
raise
return AutoModel, rich_transcription_postprocess
def int16_to_float32(audio_int16: np.ndarray) -> np.ndarray:
if audio_int16.dtype != np.int16:
audio_int16 = audio_int16.astype(np.int16, copy=False)
return (audio_int16.astype(np.float32) / 32768.0).clip(-1.0, 1.0)
def resample_to_16k(audio_f32: np.ndarray, orig_sr: int) -> tuple[np.ndarray, int]:
if orig_sr == 16000:
return audio_f32, 16000
backend = os.environ.get("SV_RESAMPLE", "poly").lower() # poly|librosa|linear
# 优先使用更快的 poly(scipy),其次 librosa,最后线性插值兜底
if backend in ("poly", "auto"):
try:
from scipy.signal import resample_poly # type: ignore
y = resample_poly(audio_f32, 16000, orig_sr)
return y.astype(np.float32, copy=False), 16000
except Exception:
pass
if backend in ("librosa", "auto"):
try:
import librosa # type: ignore
y = librosa.resample(audio_f32, orig_sr=orig_sr, target_sr=16000)
return y.astype(np.float32, copy=False), 16000
except Exception:
pass
# 线性插值兜底(最慢但零依赖)
x = np.arange(audio_f32.size, dtype=np.float32)
new_n = int(round(audio_f32.size * 16000.0 / float(orig_sr)))
if new_n <= 1:
return audio_f32, orig_sr
new_x = np.linspace(0.0, x[-1] if x.size > 0 else 0.0, new_n, dtype=np.float32)
y = np.interp(new_x, x, audio_f32).astype(np.float32)
return y, 16000
def _build_cfg_from_env() -> dict:
cfg = {}
# runtime knobs
try:
cfg["min_rms"] = float(os.environ.get("SV_MIN_RMS", "0.003"))
except Exception:
cfg["min_rms"] = 0.003
try:
cfg["overlap_sec"] = float(os.environ.get("SV_OVERLAP_SEC", "0.3"))
except Exception:
cfg["overlap_sec"] = 0.3
cfg["merge_vad"] = os.environ.get("SV_MERGE_VAD", "0") == "1"
try:
cfg["merge_len"] = float(os.environ.get("SV_MERGE_LEN", "2.0"))
except Exception:
cfg["merge_len"] = 2.0
cfg["debug"] = os.environ.get("SV_DEBUG") == "1"
cfg["resample_backend"] = os.environ.get("SV_RESAMPLE", "poly").lower()
cfg["dump_wav_path"] = os.environ.get("SV_DUMP_WAV")
return cfg
def _select_strong_channel(frame_any: np.ndarray, channels: int, debug: bool) -> np.ndarray:
if channels <= 1:
return frame_any
frame_mat = frame_any.reshape(-1, channels)
ch_rms = np.sqrt(np.mean(frame_mat.astype(np.float32) ** 2, axis=0))
sel = int(np.argmax(ch_rms))
if debug:
print(f"[debug] multi-channel rms={ch_rms.tolist()}, select ch={sel}", flush=True)
return frame_mat[:, sel]
def _ensure_pcm_open(alsa_audio, device: str | None, samplerate: int, channels: int, period_frames: int) -> tuple[object, int, str, str]:
tried: list[tuple[str, str, str]] = []
for dev in [device or "default", f"plughw:{(device or 'default').split(':')[-1]}" if (device and not device.startswith('plughw')) else None]:
if not dev:
continue
for fmt in (alsa_audio.PCM_FORMAT_S16_LE, alsa_audio.PCM_FORMAT_S32_LE):
try:
p = alsa_audio.PCM(type=alsa_audio.PCM_CAPTURE, mode=alsa_audio.PCM_NORMAL, device=dev)
p.setchannels(channels)
p.setrate(samplerate)
p.setformat(fmt)
p.setperiodsize(period_frames)
dtype = np.int16 if fmt == alsa_audio.PCM_FORMAT_S16_LE else np.int32
sample_bytes = 2 if dtype == np.int16 else 4
fmt_name = "S16_LE" if dtype == np.int16 else "S32_LE"
return p, sample_bytes, fmt_name, dev
except Exception as e: # noqa: BLE001
tried.append((dev, "S16_LE" if fmt == alsa_audio.PCM_FORMAT_S16_LE else "S32_LE", str(e)))
continue
raise RuntimeError(f"打开 ALSA 设备失败,尝试: {tried}")
def _to_int16_mono(raw_bytes: bytes, sample_bytes: int, channels: int, debug: bool) -> np.ndarray:
if sample_bytes == 2:
frame_any = np.frombuffer(raw_bytes, dtype=np.int16)
else:
frame_any = np.frombuffer(raw_bytes, dtype=np.int32)
frame_any = (frame_any.astype(np.int32) >> 16).astype(np.int16)
if channels > 1:
frame_any = _select_strong_channel(frame_any, channels, debug)
return frame_any.astype(np.int16, copy=False)
def _should_infer(audio_f32: np.ndarray, min_rms: float, debug: bool, frames_count: int) -> bool:
if audio_f32.size == 0:
return False
rms = float(np.sqrt(np.mean(np.square(audio_f32))))
if rms < min_rms:
if debug:
print(f"[debug] frames={frames_count}, rms={rms:.4f} < min_rms={min_rms:.4f}, skip", flush=True)
return False
return True
def _infer_block(model, arr: np.ndarray, sr: int, cfg: dict, language: str, running_cache: dict) -> str:
prefer = os.environ.get("SV_INPUT_FORMAT", "f32")
# candidate arrays
f32 = arr.astype(np.float32, copy=False)
i16 = (np.clip(f32, -1.0, 1.0) * 32767.0).astype(np.int16)
candidates: list[tuple[np.ndarray, bool]]
if prefer == "i16":
candidates = [(i16, False), (f32, False), (i16[None, :], True), (f32[None, :], True)]
elif prefer == "f32_2d":
candidates = [(f32[None, :], True), (f32, False), (i16[None, :], True), (i16, False)]
elif prefer == "i16_2d":
candidates = [(i16[None, :], True), (i16, False), (f32[None, :], True), (f32, False)]
else:
candidates = [(f32, False), (i16, False), (f32[None, :], True), (i16[None, :], True)]
res = None
for cand, _is2d in candidates:
try:
try:
res = model.generate(
input=cand,
input_fs=sr,
cache=running_cache,
language=language,
use_itn=True,
batch_size_s=60,
merge_vad=cfg["merge_vad"],
merge_length_s=cfg["merge_len"],
)
except TypeError:
res = model.generate(
input=cand,
fs=sr,
cache=running_cache,
language=language,
use_itn=True,
batch_size_s=60,
merge_vad=cfg["merge_vad"],
merge_length_s=cfg["merge_len"],
)
break
except Exception:
continue
if not res:
return ""
out = res[0].get("text", "")
return out
def run_in_memory(
model_dir: str,
device: str,
language: str,
samplerate: int,
channels: int,
block_seconds: float,
alsa_device: Optional[str],
) -> None:
_safe_imports()
AutoModel, rich_post = _safe_import_model()
# 关闭底层 tqdm 进度条等多余输出
os.environ.setdefault("TQDM_DISABLE", "1")
print("加载模型...", flush=True)
model = AutoModel(
model=model_dir,
trust_remote_code=True,
remote_code="./model.py",
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device=device,
disable_update=True,
)
import alsaaudio
# 更小的 periodsize,降低 I/O 错误概率;推理聚合由 block_seconds 控制
period_frames = max(256, int(0.1 * samplerate))
cfg = _build_cfg_from_env()
# 打开设备,尝试 S16 -> S32;必要时切换 plughw 以启用自动重采样/重格式化
pcm, sample_bytes, fmt_name, open_dev = _ensure_pcm_open(alsaaudio, alsa_device, samplerate, channels, period_frames)
if cfg["debug"]:
print(f"[debug] opened ALSA device {open_dev} fmt={fmt_name} period={period_frames}", flush=True)
print(
f"开始录音(纯内存采集),设备={alsa_device or 'default'}, sr={samplerate}, ch={channels}, period={period_frames},按 Ctrl+C 停止。\n",
flush=True,
)
running_cache: dict = {}
printed_text = ""
# 聚合到这一帧阈值后才调用一次模型,降低调用频率与输出
min_frames = max(1, int(block_seconds * samplerate))
# 重叠帧数,减少句首/句尾丢失
overlap_frames = int(max(0, cfg["overlap_sec"]) * samplerate)
block_buf: list[np.ndarray] = []
buf_frames = 0
stop_flag = False
def handle_sigint(signum, frame): # noqa: ANN001
nonlocal stop_flag
stop_flag = True
signal.signal(signal.SIGINT, handle_sigint)
# 连续读取 PCM,并聚合达到阈值后执行一次增量推理
while not stop_flag:
try:
length, data = pcm.read()
except Exception as e: # noqa: BLE001
# 读失败时尝试重建(常见于某些 DMIC Raw)
if cfg["debug"]:
print(f"[debug] pcm.read error: {e}, reopen stream", flush=True)
# 尝试使用 plughw 以获得自动格式/采样率适配
dev = alsa_device or "default"
if not dev.startswith("plughw") and dev != "default":
dev = f"plughw:{dev.split(':')[-1]}"
pcm, sample_bytes, fmt_name, open_dev = _ensure_pcm_open(alsaaudio, dev, samplerate, channels, period_frames)
length, data = pcm.read()
if length <= 0:
time.sleep(0.005)
continue
# 根据实际格式解析 bytes
pcm_int16 = _to_int16_mono(data, sample_bytes, channels, cfg["debug"])
block_buf.append(pcm_int16)
buf_frames += pcm_int16.size
if buf_frames < min_frames:
continue
# 达到阈值,拼接并转换为 float32 [-1, 1]
joined = np.concatenate(block_buf, axis=0)
# 为下一个块保留尾部重叠
if overlap_frames > 0 and joined.size > overlap_frames:
tail = joined[-overlap_frames:]
block_buf = [tail.astype(np.int16, copy=False)]
buf_frames = tail.size
else:
block_buf.clear()
buf_frames = 0
audio_block_f32 = int16_to_float32(joined)
# 若采样率不是 16k,重采样到 16k
audio_block_f32, eff_sr = resample_to_16k(audio_block_f32, samplerate)
if not _should_infer(audio_block_f32, cfg["min_rms"], cfg["debug"], joined.size):
continue
if cfg["debug"]:
rms = float(np.sqrt(np.mean(np.square(audio_block_f32))))
print(f"[debug] frames={joined.size}, eff_sr={eff_sr}, rms={rms:.4f}, infer", flush=True)
# 可选:调试时将当前块写到一个覆盖的临时 WAV(重采样后,单声道16k),方便用 aplay 检查采音
if cfg["dump_wav_path"]:
import wave, tempfile
dump_path = cfg["dump_wav_path"] or str(
Path(tempfile.gettempdir()) / "sv_debug_block.wav"
)
with wave.open(dump_path, "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(eff_sr)
dump_i16 = (np.clip(audio_block_f32, -1.0, 1.0) * 32767.0).astype(np.int16)
wf.writeframes(dump_i16.tobytes())
# 执行推理
res_text = _infer_block(model, audio_block_f32, eff_sr, cfg, language, running_cache)
if not res_text:
continue
text = rich_post(res_text)
if text.startswith(printed_text):
new_part = text[len(printed_text) :]
else:
new_part = text
if new_part:
print(new_part, end="", flush=True)
printed_text += new_part
# 停止前做一次 flush:如果还有残留缓冲,强制推理,避免句尾丢失
if block_buf:
try:
joined = np.concatenate(block_buf, axis=0)
audio_block_f32 = int16_to_float32(joined)
audio_block_f32, eff_sr = resample_to_16k(audio_block_f32, samplerate)
text = _infer_block(model, audio_block_f32, eff_sr, cfg, language, running_cache)
text = rich_post(text)
if text:
print(text[len(printed_text):], end="", flush=True)
except Exception:
pass
print("\n已停止。")
def main() -> None:
parser = argparse.ArgumentParser(description="Real-time mic transcription (in-memory ALSA)")
parser.add_argument("--model", default="iic/SenseVoiceSmall", help="模型仓库或本地路径")
parser.add_argument("--device", default="cuda:0", help="设备,如 cuda:0 或 cpu")
parser.add_argument("--language", default="auto", help="语言代码或 'auto'")
parser.add_argument("--samplerate", type=int, default=16000, help="采样率")
parser.add_argument("--channels", type=int, default=1, help="通道数")
parser.add_argument("--block-seconds", type=float, default=1.0, help="每次推理块时长(秒)")
parser.add_argument("--min-rms", type=float, default=0.003, help="触发推理的最小能量阈值(0-1)")
parser.add_argument("--overlap-seconds", type=float, default=0.3, help="块间重叠时长(秒),减少句首/句尾丢失")
parser.add_argument("--merge-vad", action="store_true", help="启用 VAD 合并(默认关闭以获得更快输出)")
parser.add_argument("--merge-length", type=float, default=2.0, help="VAD 合并的最大分段时长(秒)")
parser.add_argument("--debug", action="store_true", help="打印调试信息(RMS、帧数等)")
parser.add_argument("--alsa-device", default=None, help="ALSA 设备名(如 hw:0,0 或 default)")
args = parser.parse_args()
# 将 CLI 设置传入环境变量,供运行体内读取
if args.debug:
os.environ["SV_DEBUG"] = "1"
os.environ["SV_MIN_RMS"] = str(args.min_rms)
os.environ["SV_MERGE_VAD"] = "1" if args.merge_vad else "0"
os.environ["SV_MERGE_LEN"] = str(args.merge_length)
os.environ["SV_OVERLAP_SEC"] = str(args.overlap_seconds)
run_in_memory(
model_dir=args.model,
device=args.device,
language=args.language,
samplerate=args.samplerate,
channels=args.channels,
block_seconds=args.block_seconds,
alsa_device=args.alsa_device,
)
if __name__ == "__main__":
main()
执行前先安装一下模块组件
pip install pyalsaaudio
接着运行,就可以实时说话转换为文字了。
python demo_realtime_memory.py --alsa-device plughw:0,6 --samplerate 48000 --channels 2 --block-seconds 1.0 --language zh --device cuda:0