为什么AlphaGo能自学围棋?强化学习基本概念
强化学习简介
什么是强化学习
以直升机控制飞行的程序来举例。

自动驾驶的直升机配备了机载计算机、GPS、加速度计、陀螺仪和磁罗盘,我们可以实时确定的知道直升机的位置。如何使用强化学习来让直升机飞行了?
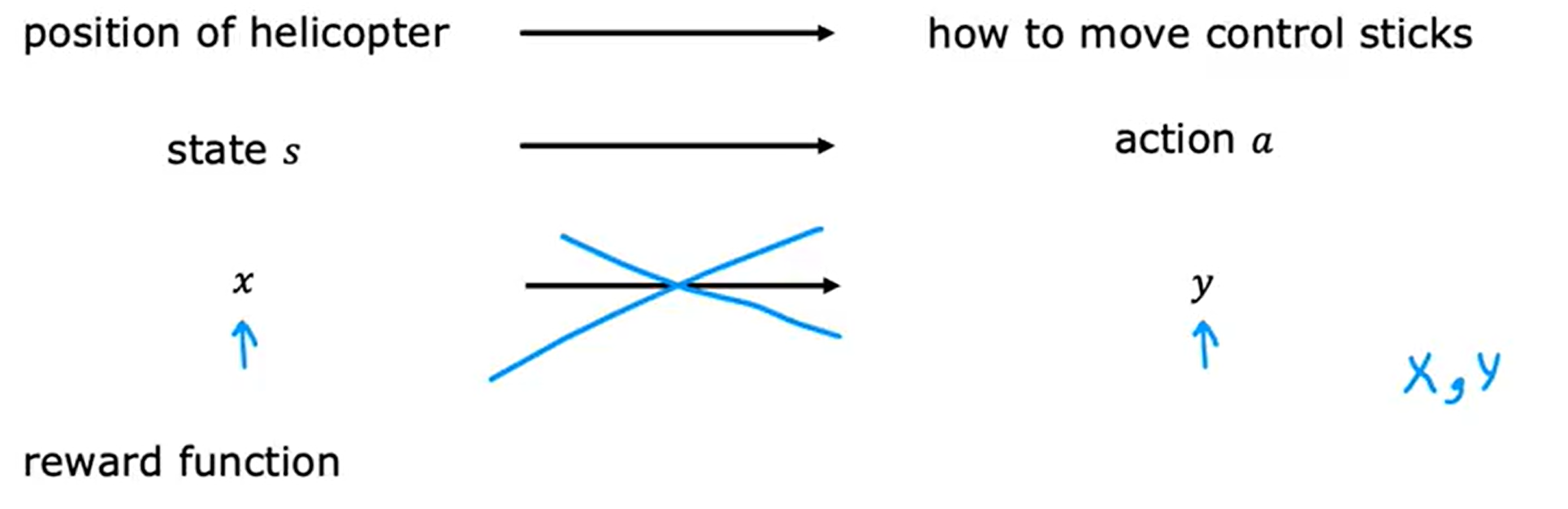
在强化学习中,将直升机的位置、方向和速度等称为状态s,因此我们的目标或任务就是从直升机的状态映射到动作a的函数,意思是将两根控制杆推多远才能保持直升机在空中平衡、飞行而不坠毁。
要获取到动作a可以使用监督学习来训练神经网络,直接学习从x(状态a)到y(动作a)的映射,但事实证明直升机在控制移动时实际上时摸棱两可的,不好判断正确的行动是什么?是向做倾斜一点还是倾斜很多,还是稍微增加直升机的压力?要获得x的数据集和理想的动作y实际上是很困难的。因此对于控制直升机和其他机器人的许多任务,监督学习方法效果不佳,我们改用强化学习。
强化学习的关键输入称为reward(奖励),它告诉直升机何时表现良好,何时表现不佳。强化学习就像是在训练狗,你不知道狗会做出什么行为?但是我们可以判断狗行为的好坏,如果狗的行为是好的我们就就认为他是一个好狗给予奖励,如果它做出的行为不达我们的预期我们认为就是一个坏狗给予惩罚。我们期望它能自己学会如何做出好的动作行为而少做坏的动作行为。
火星探测器
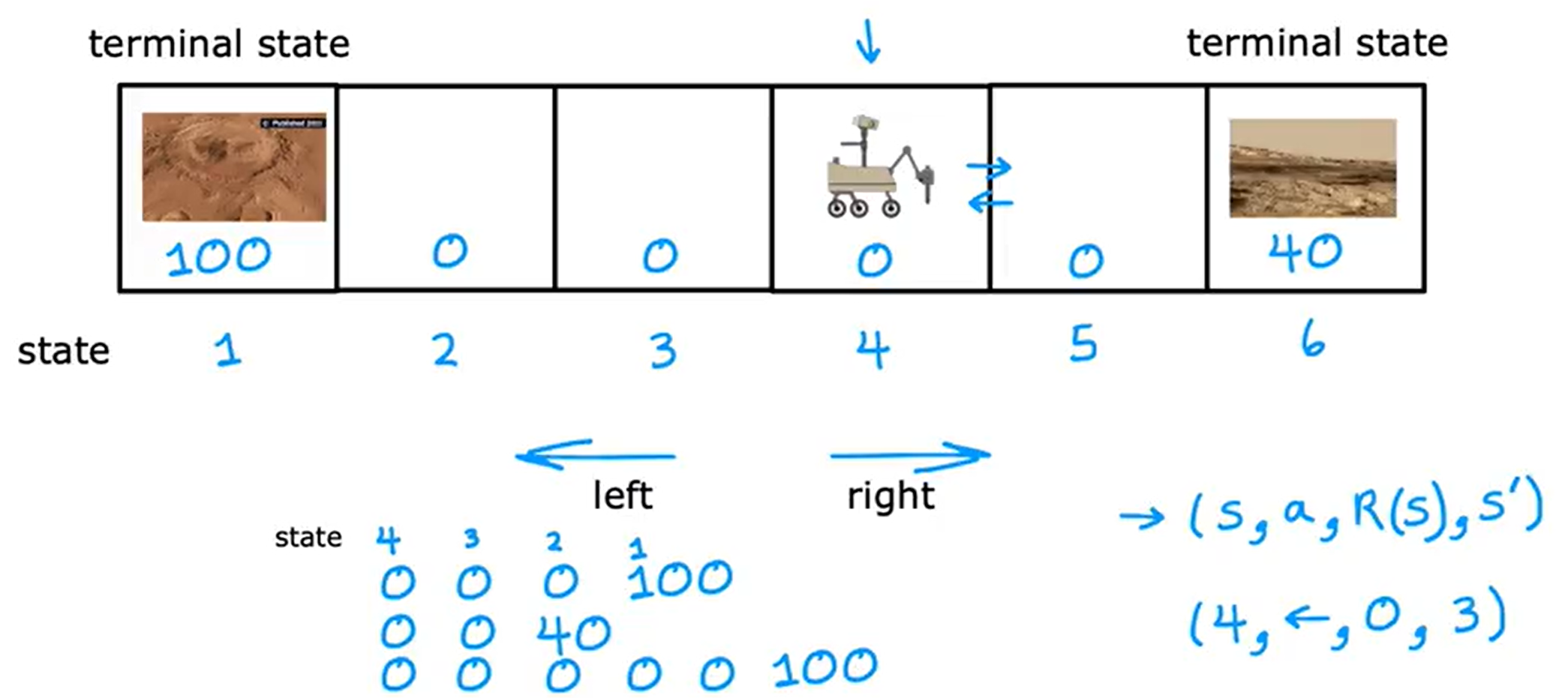
火星探测器从初始状态运动到最终状态(terminal state),最终会得到一个累计的分数(return),每运动一次都会有相应的奖励reward。
当前火星探测器的初始位置在state 4,它可以向左也可以向右。
- 场景1:state 4(初始)(获得0)->state 3(获得0)->state 2(获得0)->state 1(获得100);最终得100。
- 场景2:state 4(初始)(获得0)->state 5(获得0)->state 6(获得40);最终得40。
- 场景3:state 4(初始)(获得0)->state 4(获得0)->state 4(获得0)->state 3(获得0)->state 2(获得0)->state 1(获得100);最终得100。
在每个时间步长上,机器人处于某种状态,我们称为S,它开始选择一个动作a,然后就获得一些奖励(reward),奖励值它从该状态获取,同时了它会切换为一个新的状态S’。公示表示为(s,a,R(s),s’),举个具体的例子,机器人处于状态4并采取行动时往左边走没有获得奖励(4,<-,0,3)。核心点就是状态(state)、动作(action)、奖励(reward)、下一个状态(next state),基本上就是每采取新动时都会发生情况,这就是强化学习算法要决定如何采取行动考虑的核心要素。
回报return
采取的行动会经历不同的状态以及如何享受不同的奖励,但是怎么去衡量一组特定的奖励比另外一组奖励好还是差了?
打个比方炒股方案1是你今天买入一支股票A然后后天就卖出了赚了1000块,而方案2你今天买入一支股票但是后天你亏了500,但是到第三天你赚了6000,那你更愿意追求那种方案了?虽然是第三天才显示有收益,但是第三天收益很高,显然会选择方案2。
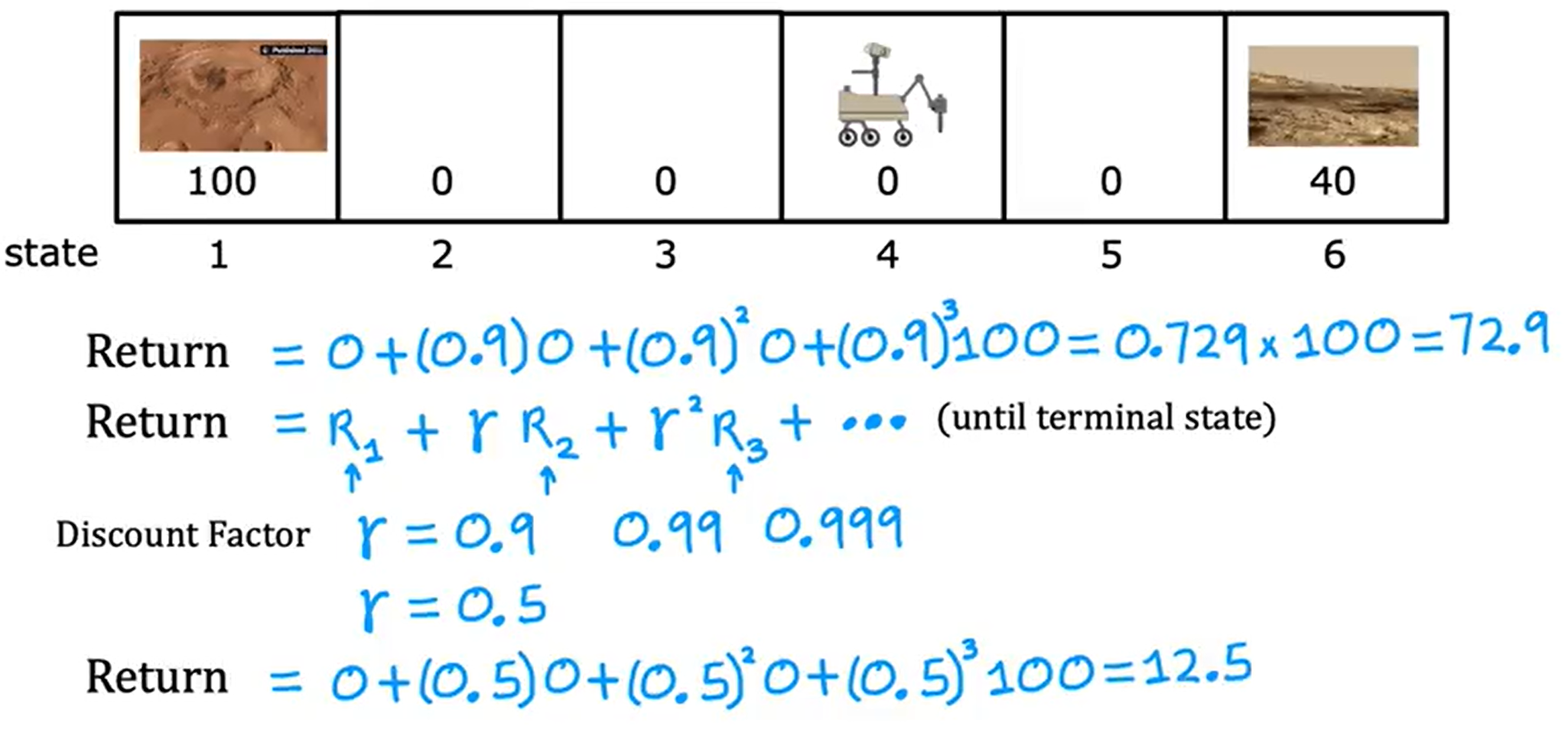
为了计算这个回报分数,我们对动作后的奖励进行累加,但是了随着越往后的动作,我们需要添加一个折扣因子,也就是说越往前的比例系数越高,但是越往后所占的比例折扣就越大。如上图假设折扣因子(discount factor)为0.9,那么R1的折扣因子是1,R2的折扣因子就是0.9,R3的折扣因子就是0.9的平方依此类推。
最终获得的回报(return)取决于奖励(reward),而奖励取决于你采取的行动,因此回报取决于你采取的行动。
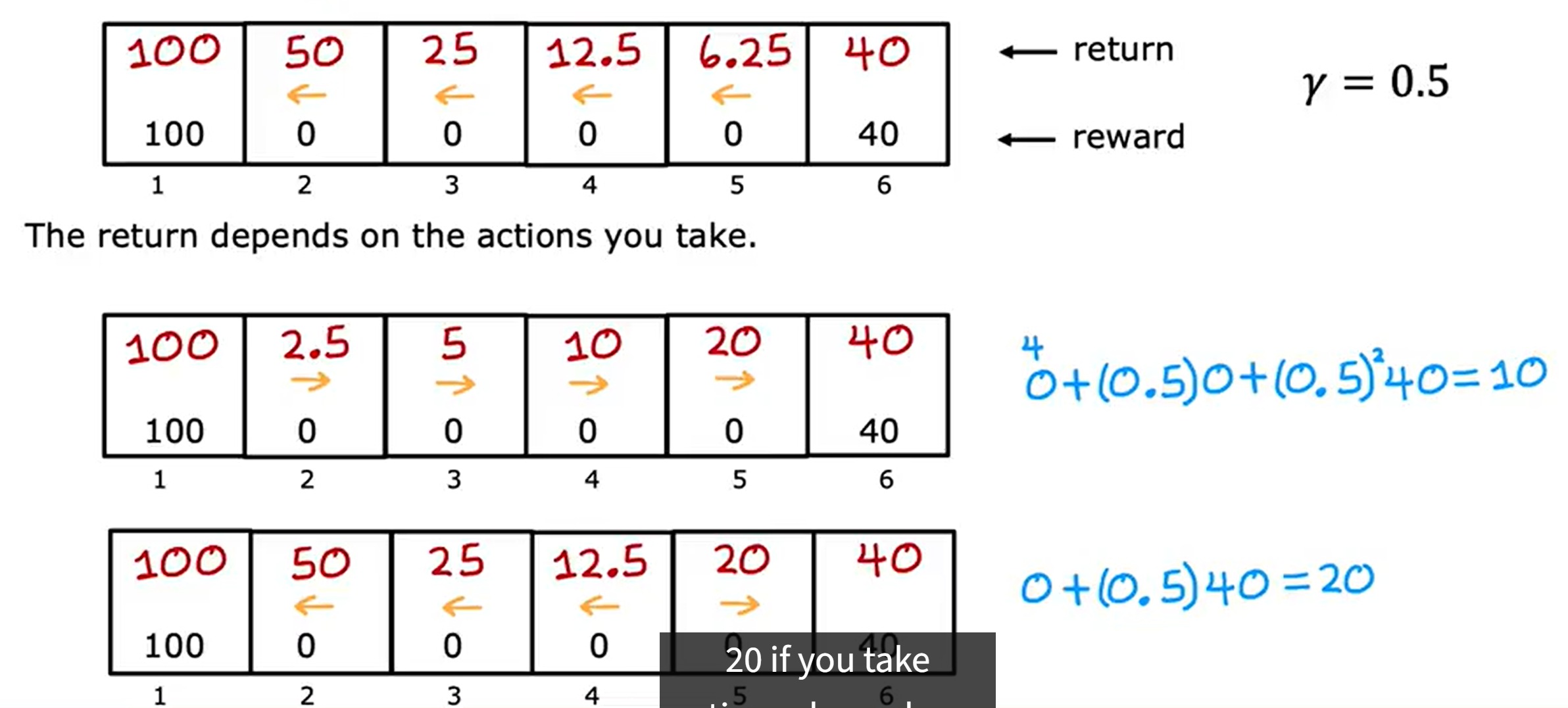
如折扣因子是0.5,如果从状态5向左走回报是6.25,如果是状态4向左走回报是12.5,而如果你状态就在6那么回报就是60。
总结一下强化学习的回报是系统获得的奖励总和,但需要加上折扣系数,每一个时间步的权重不一样,时间步越大奖励的系数结果就越小。
Policy
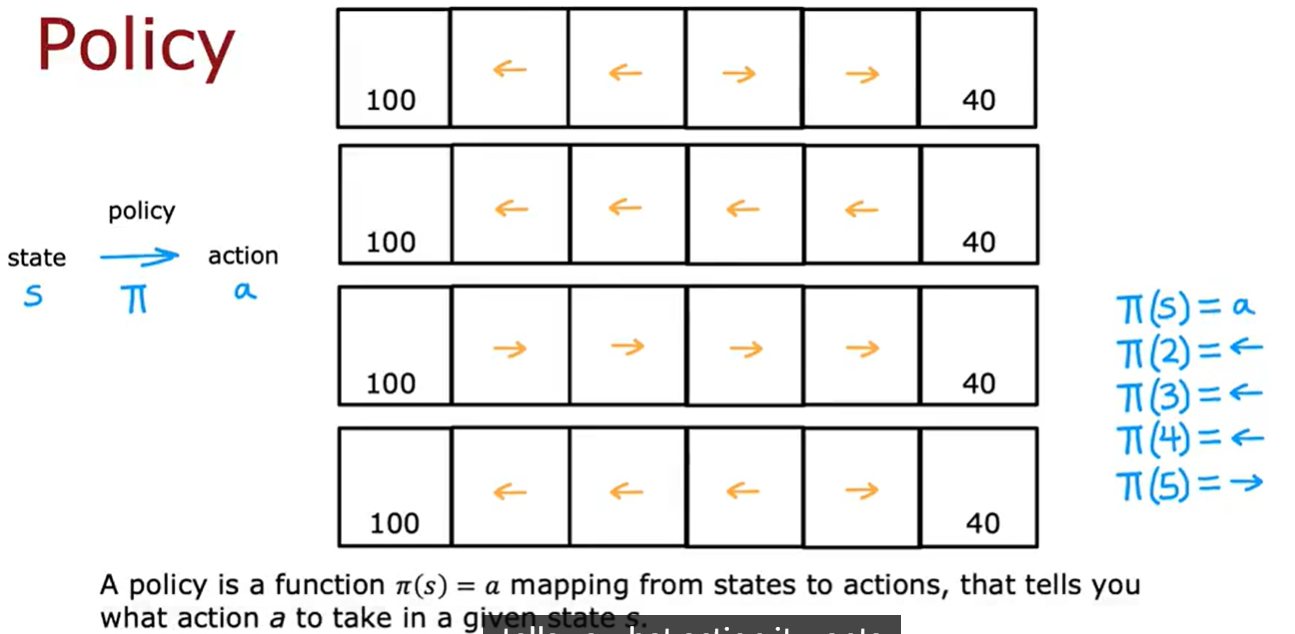
在强化学习中,可以通过很多不同的方式采取行动,比如我们可以决定始终选择更接近的奖励,如果最左边的奖励更接近则向左走,如果最右边的奖励更接近则向右走。当然我们也可以换种策略,始终追求更大的奖励等等。

策略Pi就是希望我们在那种状态下采取什么样的行动。state———>action。强化学习的目标就是要找到一个策略Pi,告诉在什么状态应该采取什么行动,执行每个状态以最大化回报。
小结
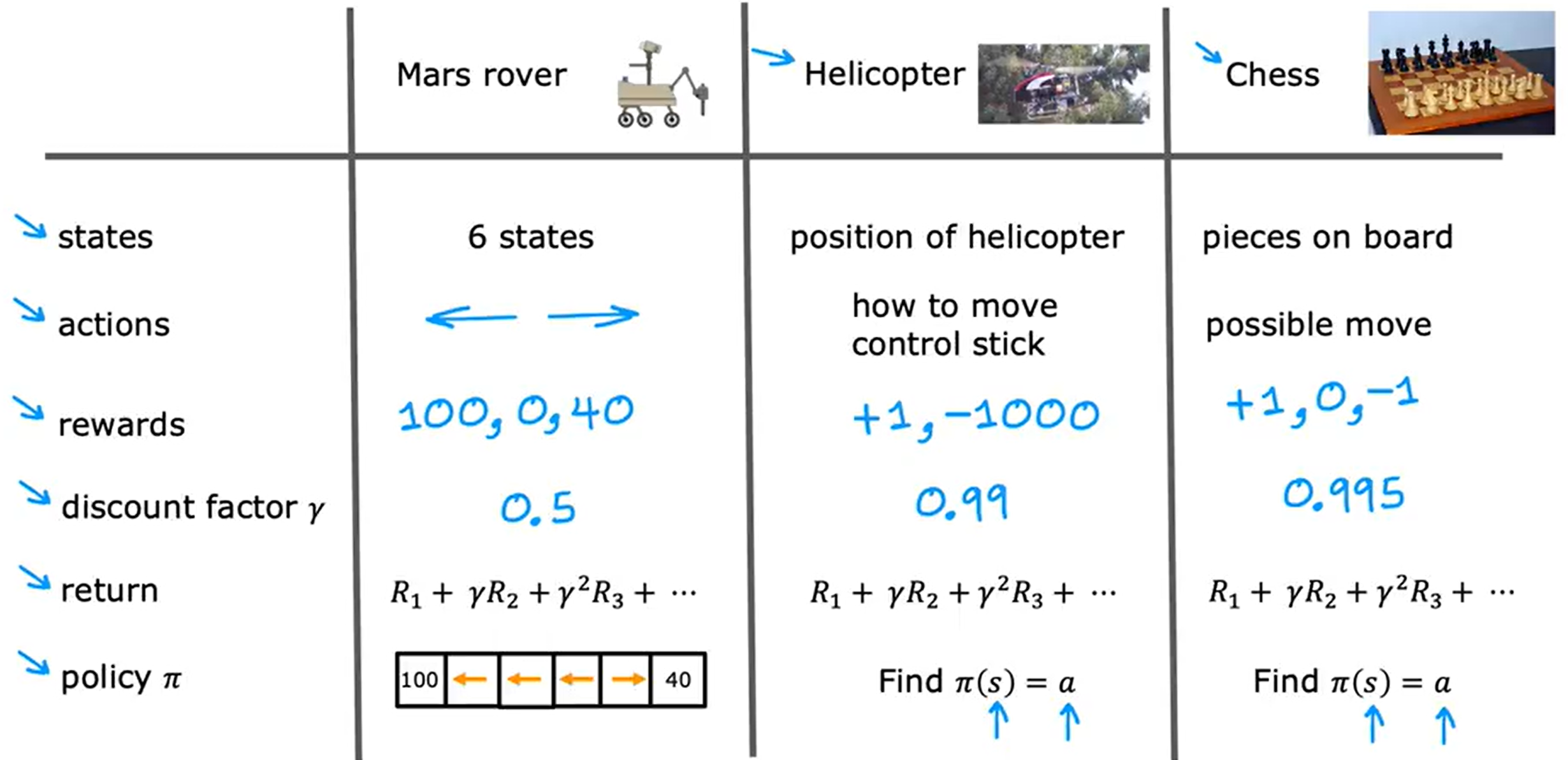
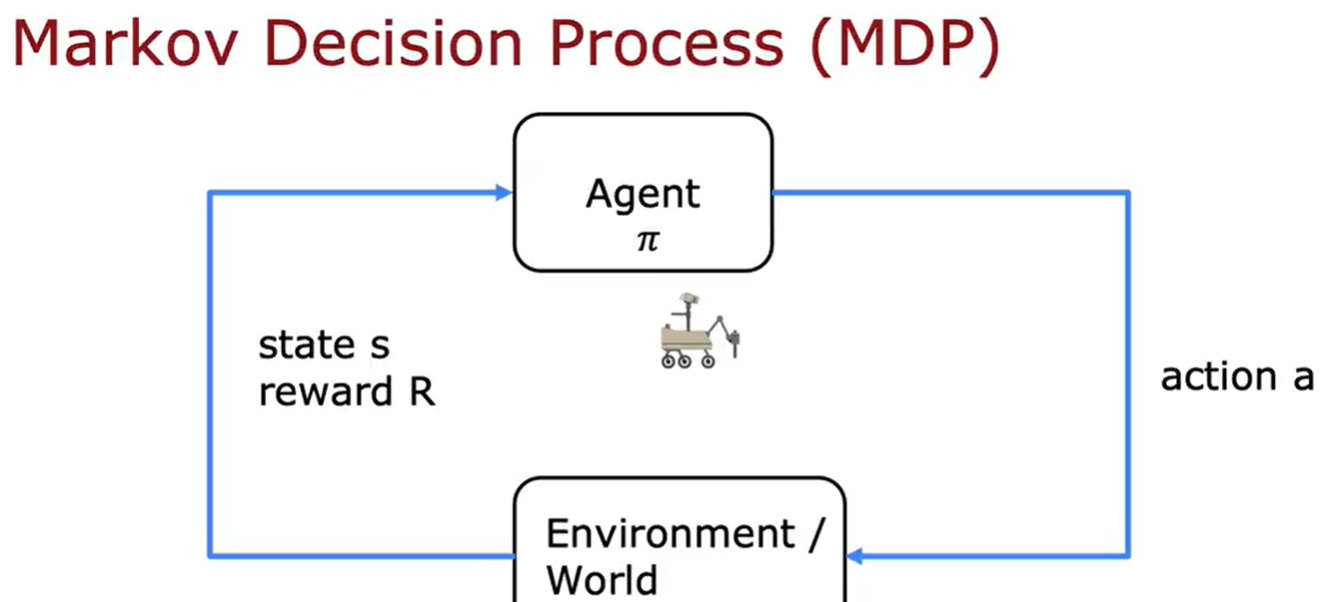
上面涉及到的概念,状态、动作、奖励、折扣因子、回报、策略。强化学习的目标就是让策略选择一个好的行动以获取最大的回报,这个决策过程被称为马尔可夫决策过程(MDP)。MDP指的是未来仅取决于当前的状态,而不取决于进入当前状态之前可能发生的任何事情,换句话说在马尔可夫决策过程中,未来取决于你现在所处的位置,而不取决于你是如何达到这里的;再换一种就是MDP是我们有一个机器人,我们要做的是选择动作a,根据这些动作、环境中发生的事情执行科学的任务。
State-action value funciton
状态动作函数Q

表示在状态s下,执行 动作a后,智能体所能获得的期望累计回报(Expected Return)。换句话说Q值衡量的是:”如果我在当前状态下做这个动作,长期来看能赚多少奖励?”。
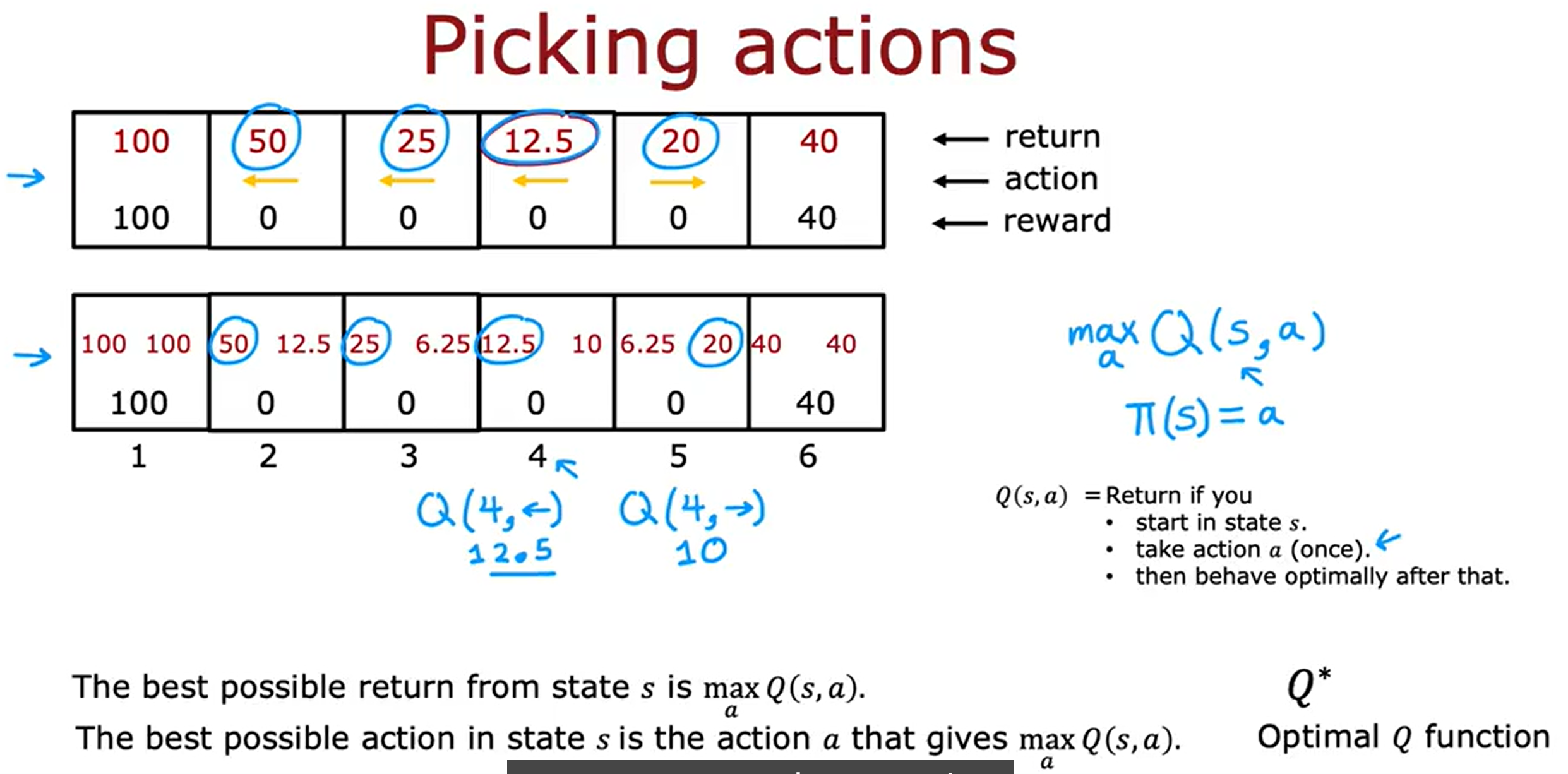
计算Q(s,a)是强化学习算法的重要组成部分。也就是i说有办法计算s的Q,a,对于每个状态和每个动作,那么当你处于某个状态时,你所要做的就是看看不同的动作A,然后选择动作A,那就最大化s的Q,a。求Q的最大值。
贝尔曼方程
如何计算状态动作价值函数Q of S,A了?
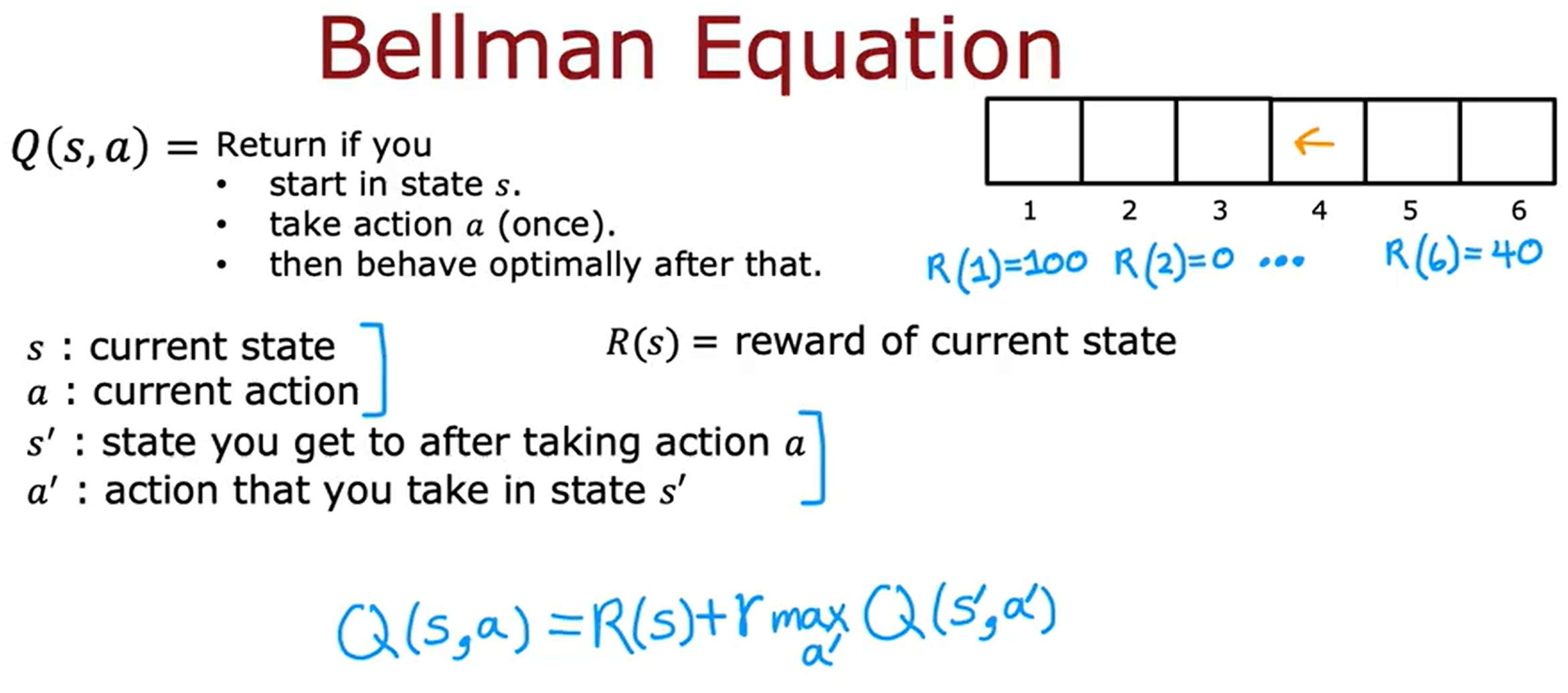
在强化学习中有一个名为贝尔曼方程帮助我们解决计算状态动作值函数。下面来看看示例。

上图中有两个示例当在状态2,向右移动时,那么Q(2,->)=R(2)+0.5 max Q(3,a’0)=0+(0.5)25=12.5。当在状态4,向左移动时,那么Q(4,<-)=R(4)+0.5max Q(3,a’)=0+(0.5)25=12.5。

贝尔曼方程体现的核心思想是:”一个状态的价值 = 即时奖励 + 后续状态的折扣价值”。也就是说,当前决策的好坏取决于当下奖励 + 未来的期望收益。
Continuous State Space
continuous state space示例
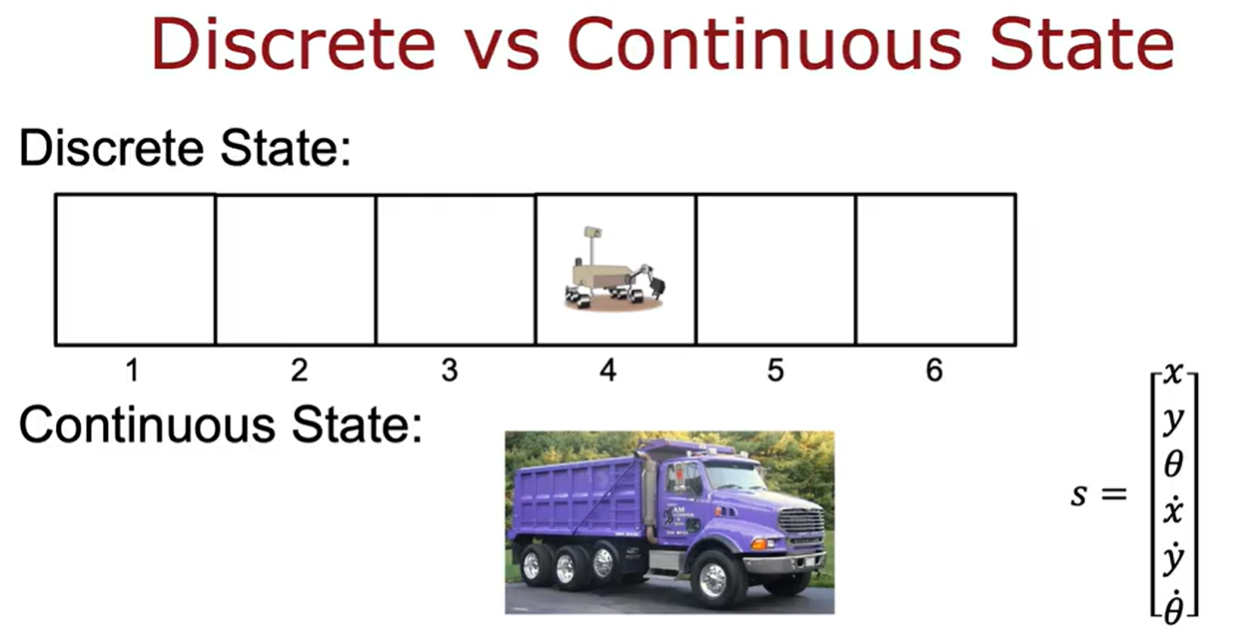
对于火星车可能只有一个单一的状态1~6,对于下面的卡车来说有很多个状态,比如x,y,角度等等。而对于直升机来说又有更多参数集合的状态。

因此状态不仅仅是少数可能离散值的一个,它可以是一个数字向量。
月球着陆器
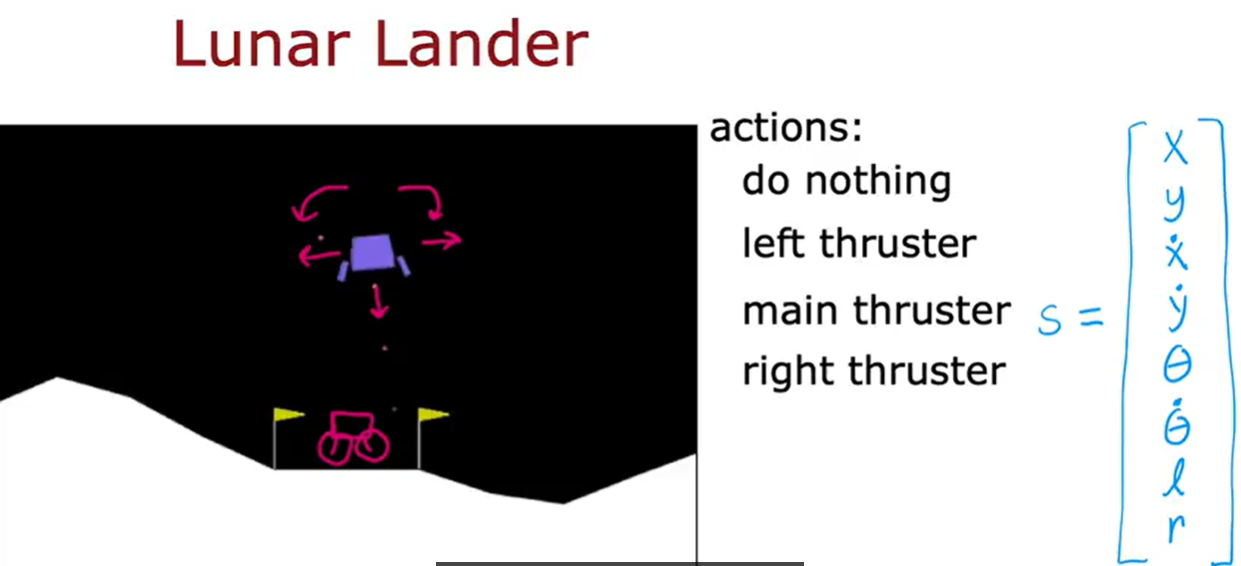
月球着陆车有很多状态变量,如上图所示。奖励函数我们可以设计成下面这样。

对于月球着陆器要学习的策略pi就是输入s,通过策略得到a,然后计算出最大的return。
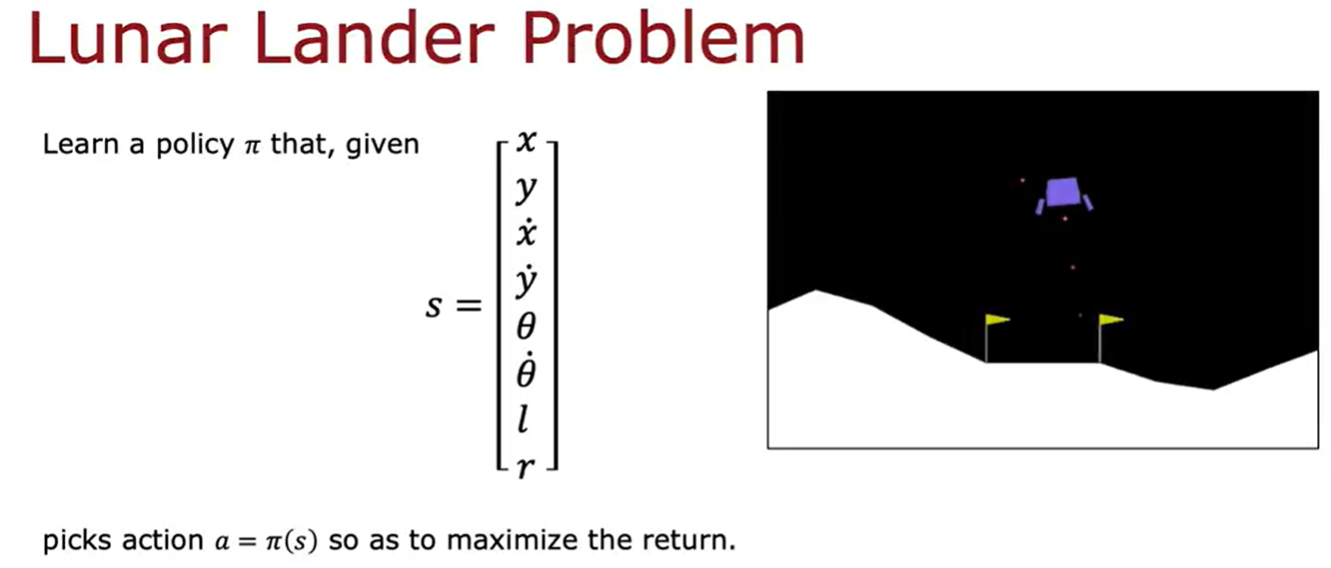
学习Q
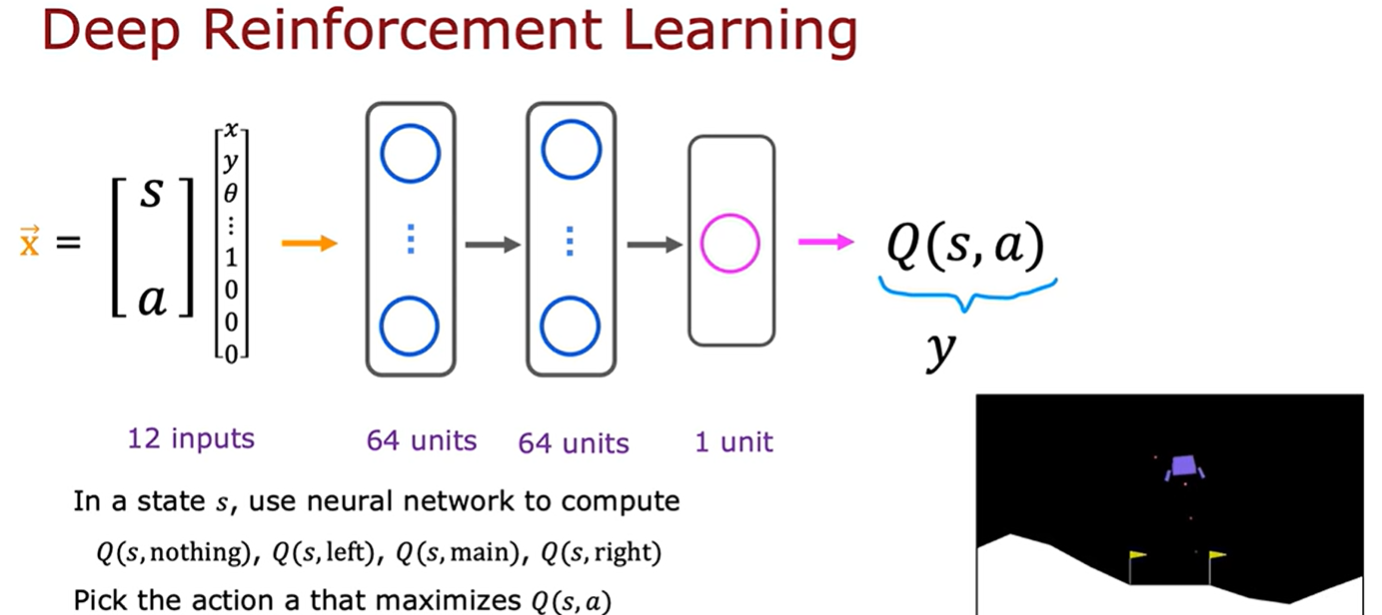
在状态s处,使用神经网络来计算4个动作中,那个动作的Q(s,nothing),Q(s,left),Q(s,main),Q(s,right)最大,然后选择那个最大值的动作。

那如何获得一个包含X和Y值的训练集,可以进行训练神经网络了?这就需要用到贝尔曼方程如上图,我们可以把贝尔曼方程的左边命名为X,右边命名为Y,神经网络的输入是一个状态和动作对。而输出Y就是就是Q。神经网络学习的就是X到Y的映射。

改进的神经网络架构
对于火星车前面的神经网络对应需要推理4次,即Q(s,nothing),Q(s,left),Q(s,main),Q(s,right),这样效率比较低,那么可以对算法进行改进推理一次直接输出4个动作的对应的Q。下面就是修改后的神经网络架构。
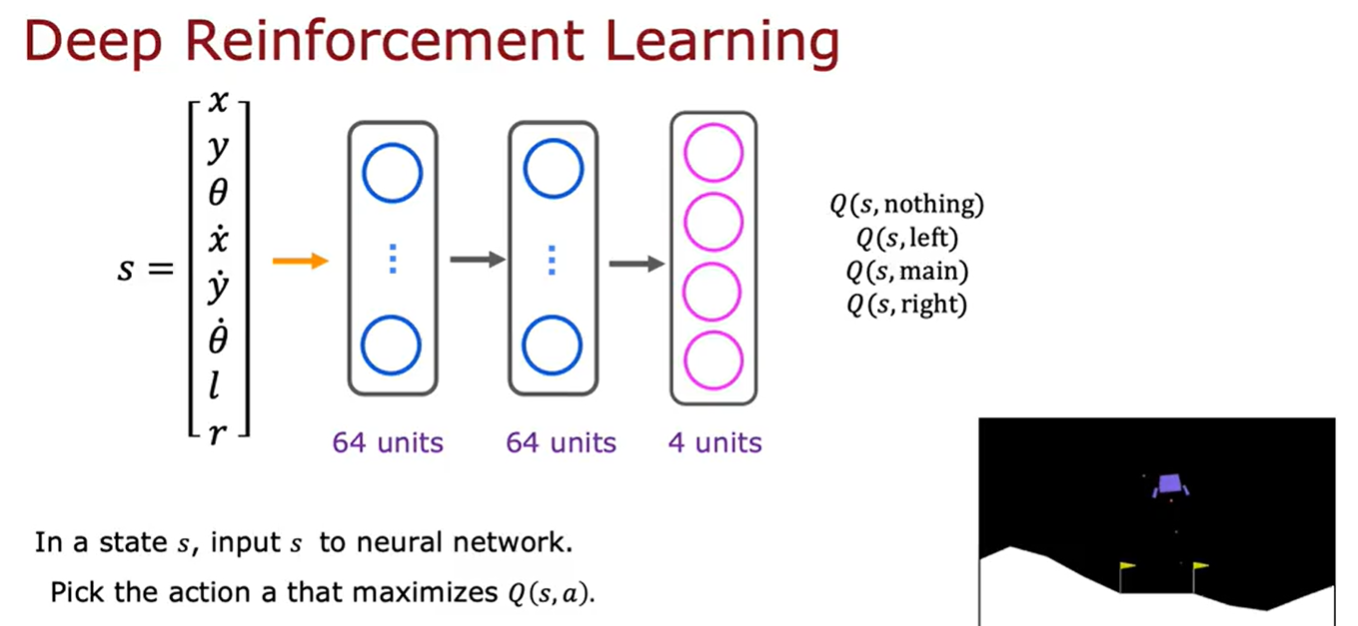
算法改进:ϵ贪婪策略

总结
学习流程
- 智能体观察当前状态 s_t
- 根据策略 \pi(a|s_t) 选择动作 a_t
- 环境返回奖励 r_t 和下一状态 s_{t+1}
- 智能体根据反馈更新策略或价值函数
这一过程可用 马尔可夫决策过程(MDP) 表示:
[
\text{MDP} = (S, A, P, R, \gamma)
]
其中:
– 参数S:状态集合
– 参数A:动作集合
– 参数P(s’|s,a):状态转移概率
– 参数R(s,a):奖励函数
– 参数\gamma:折扣因子(0~1)
算法
(1)算法分类
| 类别 | 特征 | 代表算法 |
|---|---|---|
| 基于价值(Value-based) | 学习 Q 值,间接得到策略 | Q-learning、DQN |
| 基于策略(Policy-based) | 直接优化策略函数 | REINFORCE、PPO |
| Actor-Critic 混合 | 同时学习策略(Actor)和值函数(Critic) | A2C、A3C、DDPG、SAC |
| 基于模型(Model-based) | 显式学习环境动态模型 | Dyna-Q、Dreamer、MuZero |
(2)算法演进
| 阶段 | 特征 | 代表算法 |
|---|---|---|
| 传统表格法(Tabular RL) | 离散状态空间,值表更新 | Q-Learning, SARSA |
| 深度强化学习(Deep RL) | 神经网络逼近 Q 函数 | DQN, Double DQN, Dueling DQN |
| 连续动作控制(Continuous Control) | 针对机械臂、无人车等连续控制问题 | DDPG, TD3, SAC |
| 策略梯度类(Policy Gradient) | 直接优化策略参数 | REINFORCE, PPO, TRPO |
| 基于模型的RL(Model-based RL) | 同时学习环境模型 + 策略 | MuZero, DreamerV3 |
| 模仿学习 / 具身智能结合 | 利用演示或视觉模仿学习 | GAIL, BC, VLA, RT系列 |
参考:本文主要来之吴恩达强化学习笔记