解构LLM: 以llama.cpp分析模型推理过程
大模型推理的”第一性原理”
从Deepseek V3到Kimi K2
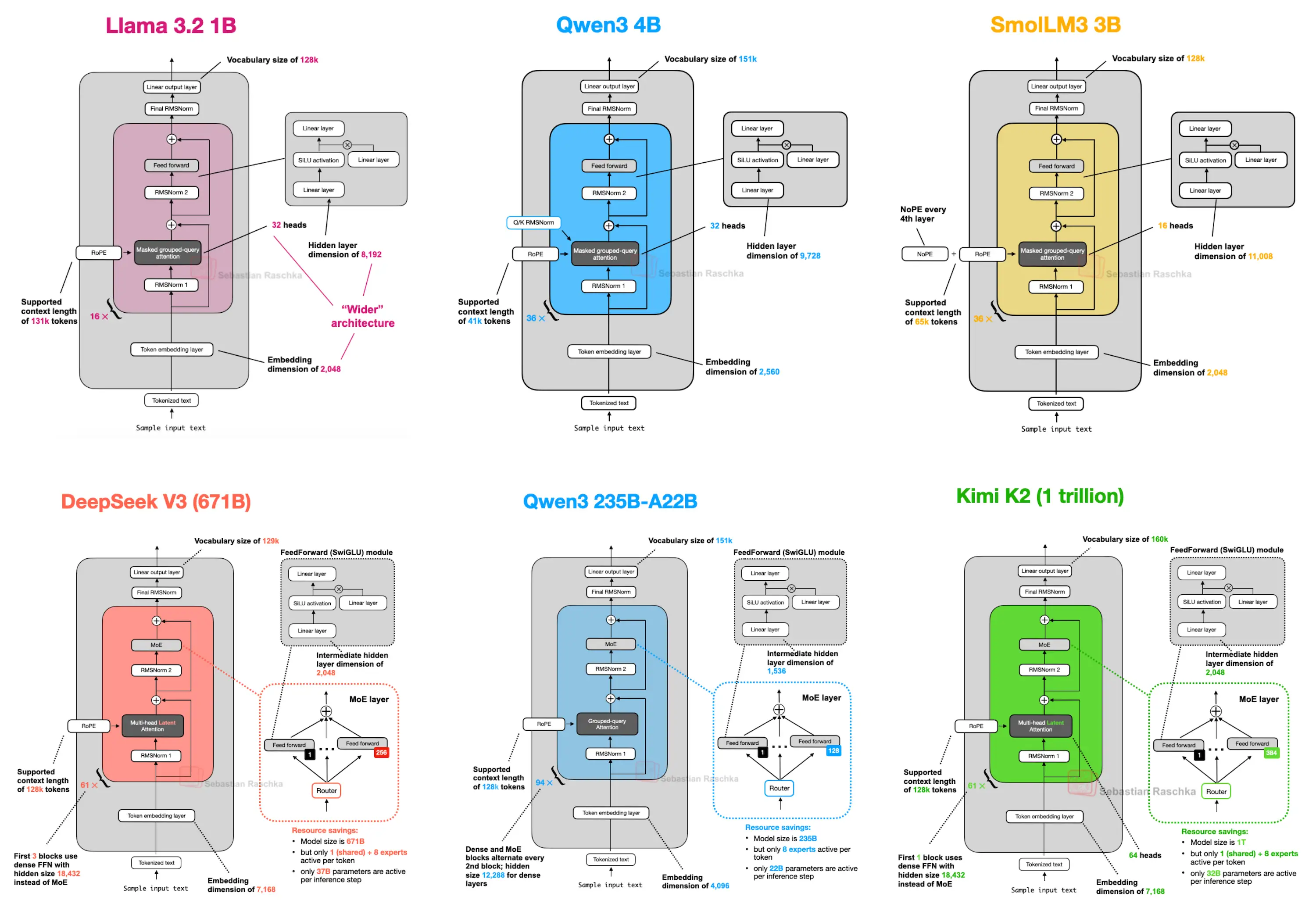
无论模型如何变化,当前主流大模型的核心架构都是基于transformer。其本质是一个由多层相同结构堆叠而成的序列到序列的模型,每一层中有一个最核心的模块:Self-Attention(自注意力),让模型理解“哪些词和那些词相关”。
核心:Self-Attention直观理解
Self-Attention本质上就是回答一个问题:让计算机能够理解这些词的含义,对于当前这个词,序列里其他哪些词对它最重要?重要多少?(在一个句子中,根据上下文来进行理解每个词的含义)
直观理解,“苹果公司发布了一款新的手机,它的股价可能也会随之上涨”。
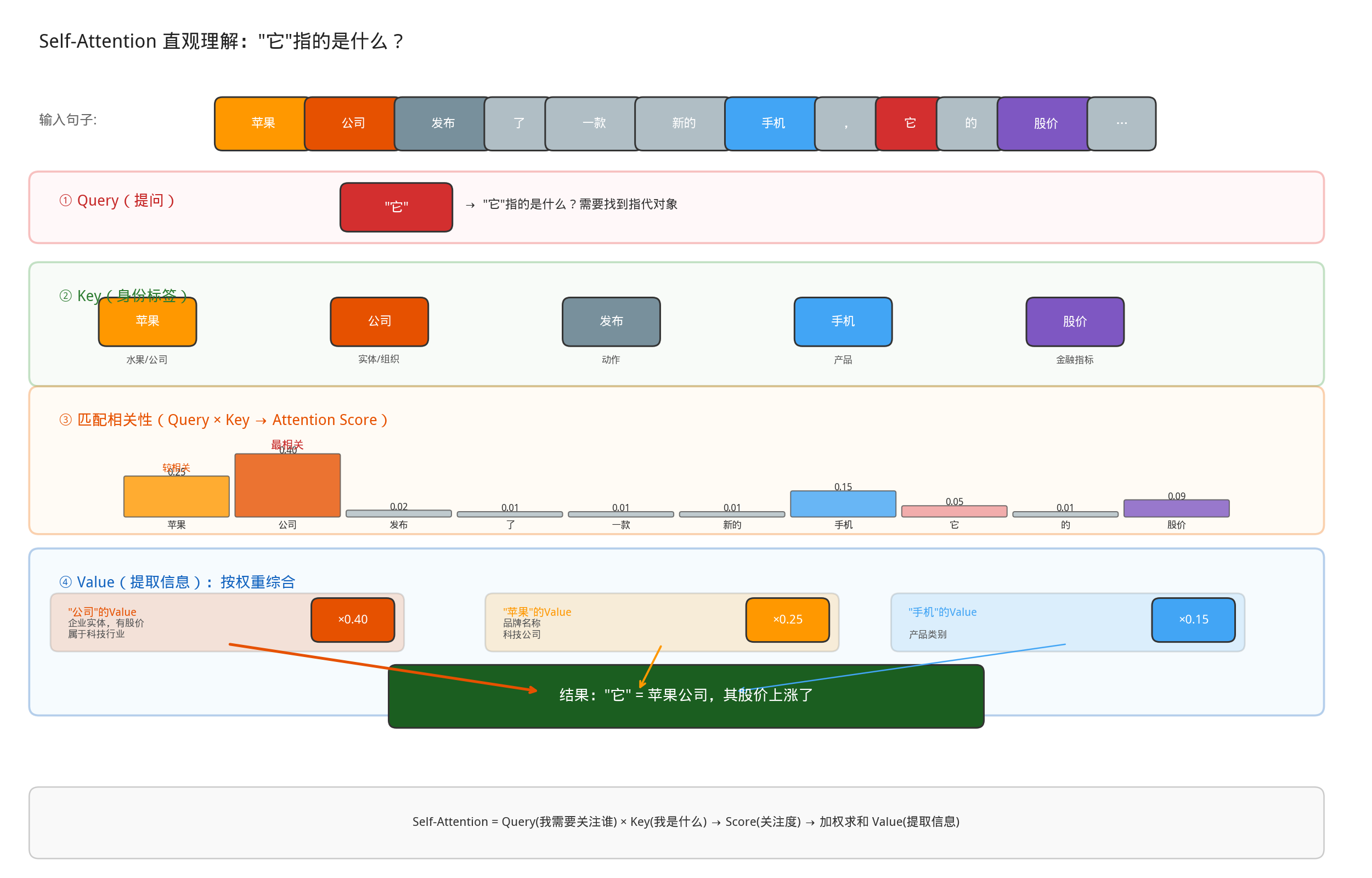
- 提问(Query):“它”,指的是什么?
- 关键词(Key): 在上下文中扫描关键信息,每个词都自带一个“身份标签”(Key),比如“苹果”可能是水果或公司,“公司”是实体,“手机”是产品。
匹配相关性,将你的问题(Query)和每个词的“身份标签”(Key)比对:“它”指代物 -> 和“公司”“手机”更相关,和“发布”(动作)不太相关。“股价”通常属于公司 ->所以“公司”的标签最匹配。匹配度越高,你分配的关注度(Attention Score)就越大。
- 提取信息(Value):确定“它”指“苹果公司”后,你从“公司”这个词背后提取的信息(Value)是:这是一个企业实体,有股价,属于科技行业……,最终,你综合所有词的信息(但主要权重给了“公司”),得出理解:“它” = 苹果公司,其股价上涨了。
总结一下:计算机怎么理解每个词的意思?词跟句子中的每个词去做相关性计算(矩阵相乘)得到一个注意力分数,然后通过这个分数再去跟句子的中每个词做提取信息,最后得到的一个归一信息就是计算机对该词的理解。
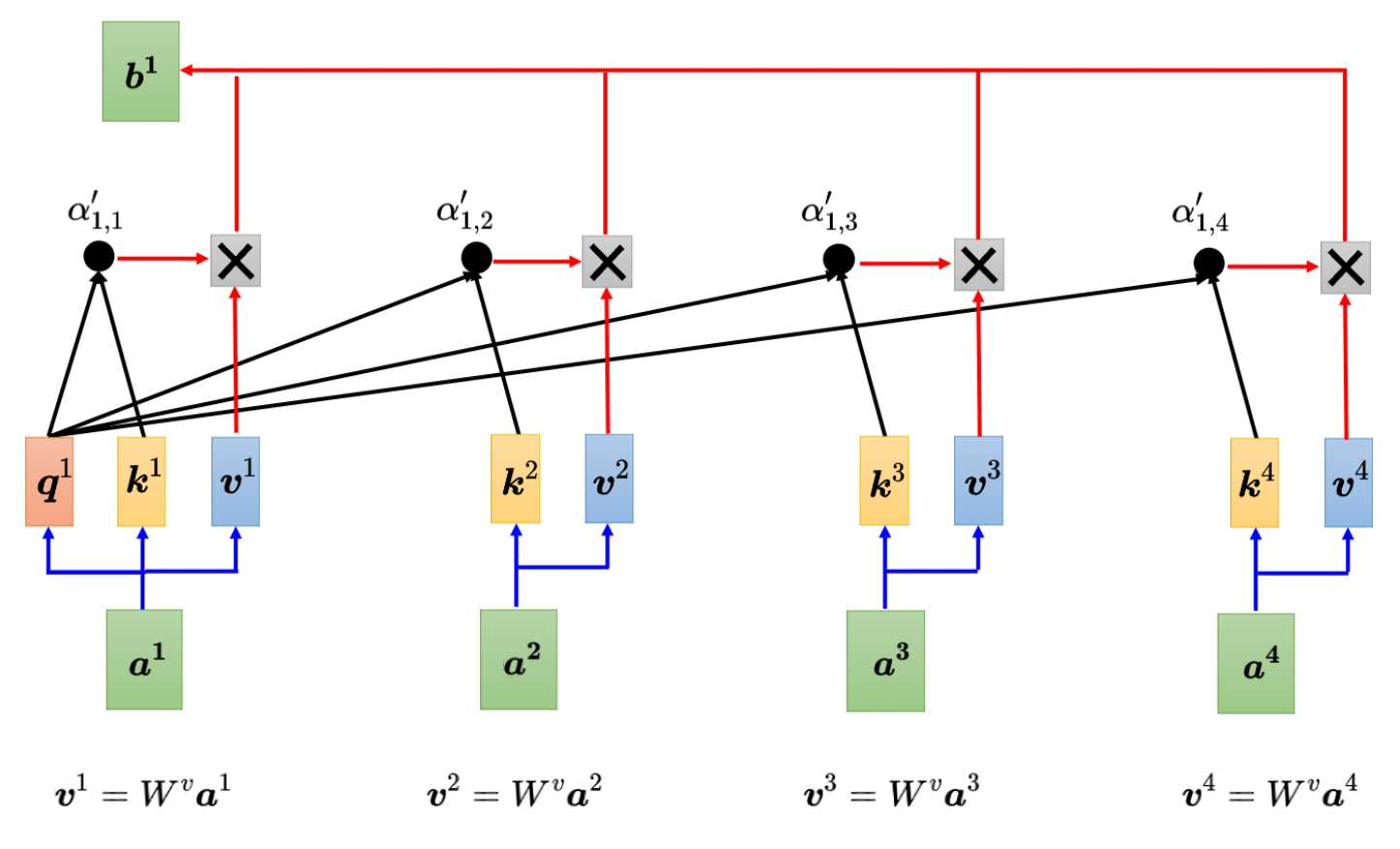
Attention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right) V
其中:
- Q (Query):当前位置的”提问”向量,代表”我在找什么”
- K (Key):所有位置的”标签”向量,代表”我是什么”
- V (Value):所有位置的”内容”向量,代表”我能提供什么”
- d_k:Key 向量的维度,用于缩放防止点积过大
步骤1: 线性投影
Q = X × Wq # [seq_len, d_model] × [d_model, d_k] → [seq_len, d_k]
K = X × Wk # 同上
V = X × Wv # 同上
步骤2: 计算注意力分数
S = Q × K^T # [seq_len, d_k] × [d_k, seq_len] → [seq_len, seq_len]
# ⚠ 这个 N×N 矩阵是内存瓶颈的根源
步骤3: 缩放 + Softmax
P = softmax(S / √d_k) # 每行归一化为概率分布
步骤4: 加权求和
O = P × V # [seq_len, seq_len] × [seq_len, d_v] → [seq_len, d_v]
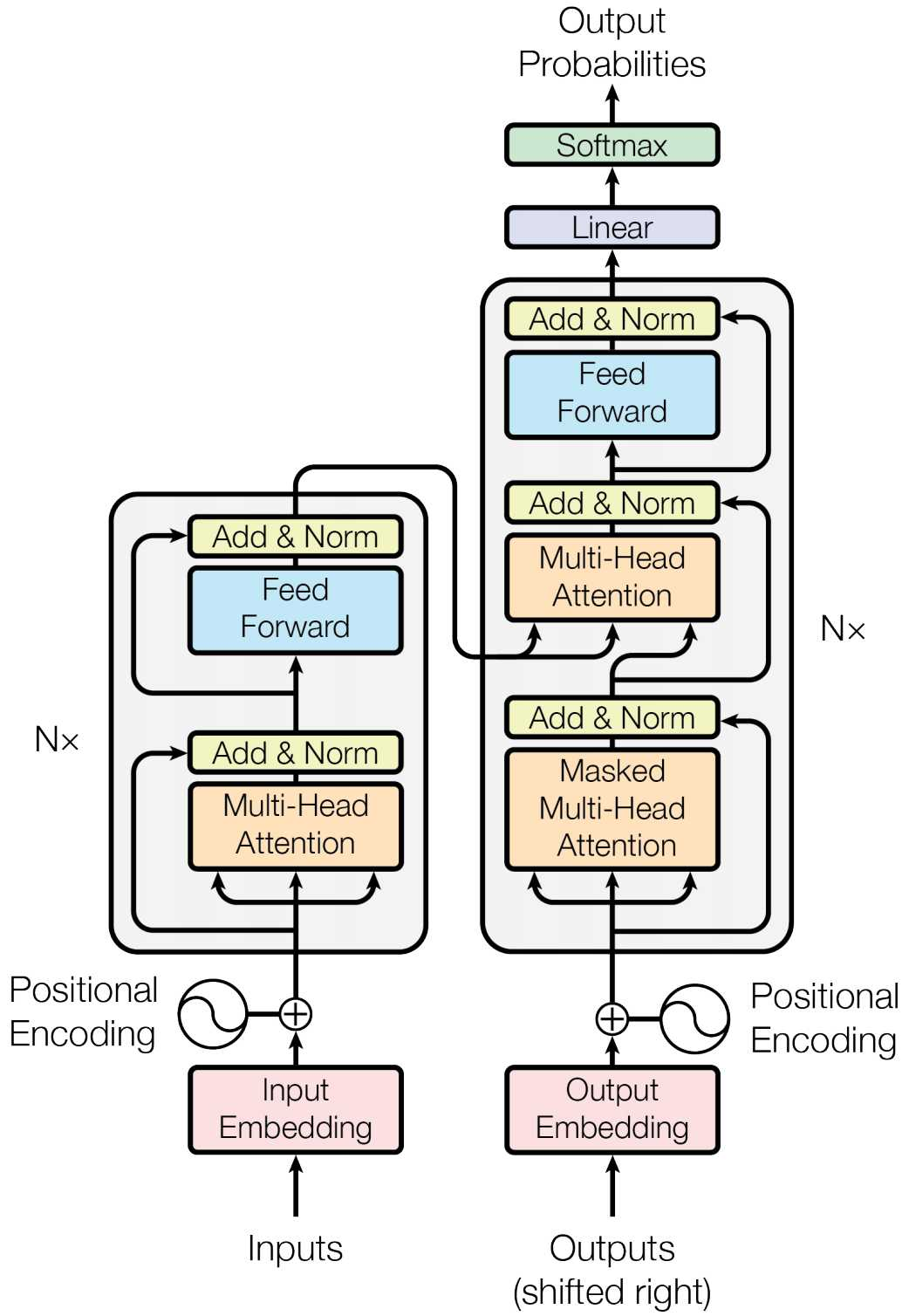
transformer架构
Multi-Head Attention
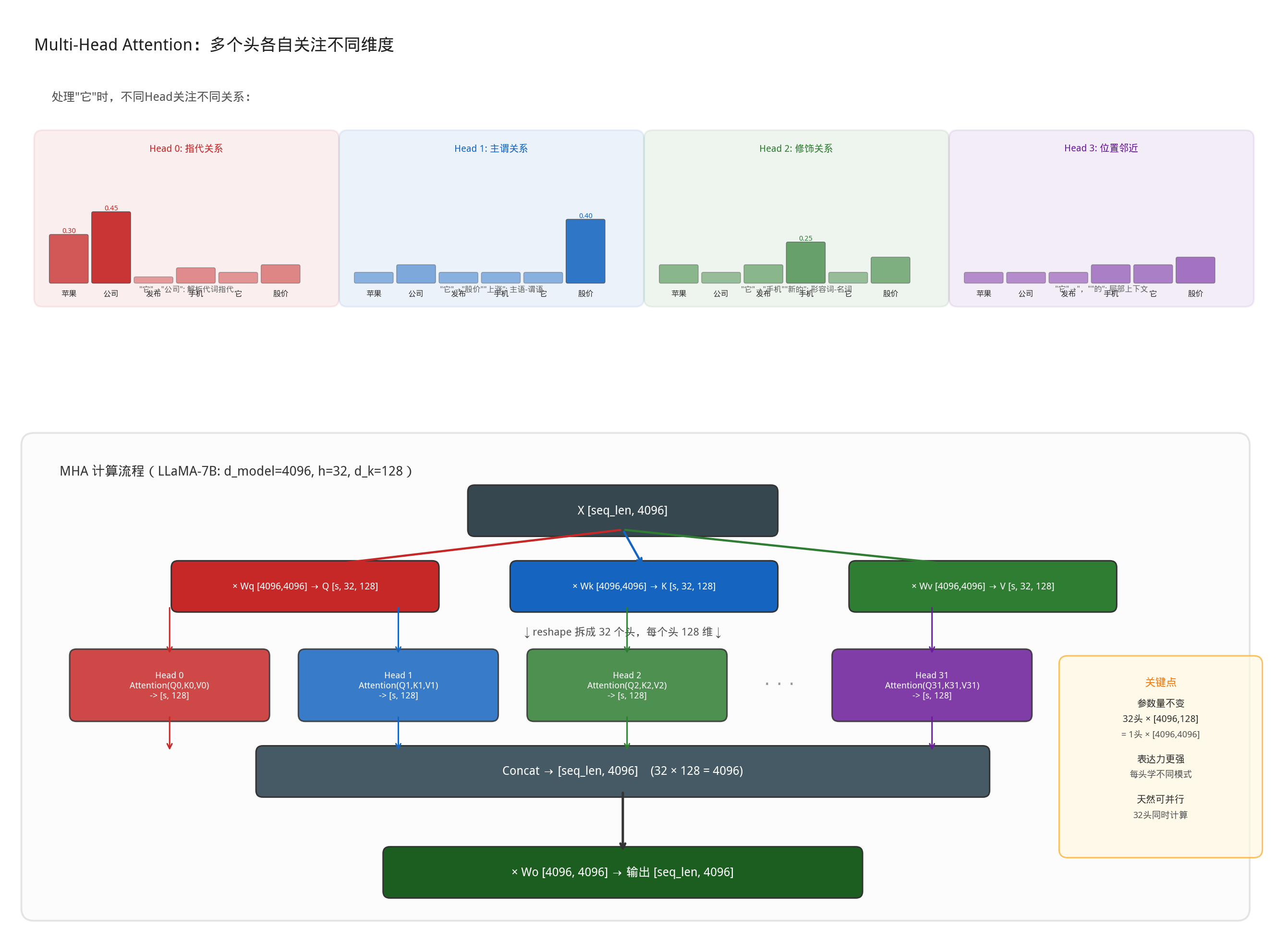
单组Q/K/V只能捕获一种“关注模式”。但语言中的关系是多维度的,同一个词可能同时需要关注语法结构,语义关联,位置关系等不同维度的信息。而Multi-Head Attention的做法就是:把一个大的注意力拆成多个小的”头”(head),每个头独立学习一种关注模式,最多把所有的结果拼接起来。还是以“苹果公司发布了一款新的手机,它的股价可能也会随之上涨”为例,当模型处理”它”时,不同的头可能各自关注不同的维度:
Head 0 (指代关系): "它" → 重点关注 "公司"(0.45) "苹果"(0.30) → 解析代词指代
Head 1 (主谓关系): "它" → 重点关注 "股价"(0.40) "上涨"(0.35) → 理解主语-谓语
Head 2 (修饰关系): "它" → 重点关注 "新的"(0.30) "手机"(0.25) → 捕捉形容词-名词
Head 3 (位置邻近): "它" → 重点关注 ","(0.35) "的"(0.30) → 关注局部上下文
每个头只看 d_dmole / h 维的子空间(如 4096/32 = 128 维),计算量和单头 Attention 一样,但能并行捕捉多种关系。
MultiHead(Q, K, V) = Concat(head₁, head₂, ..., headₕ) × Wo
其中 headᵢ = Attention(X × Wqᵢ, X × Wkᵢ, X × Wvᵢ)
Attention变体演进
随着模型规模的增长和序列变长,标准的MHA面临两大瓶颈:KV Cache(下文会阐述)显存占用和N * N注意力矩阵的计算/内存开销。为此,业界提出了多种优化方案。
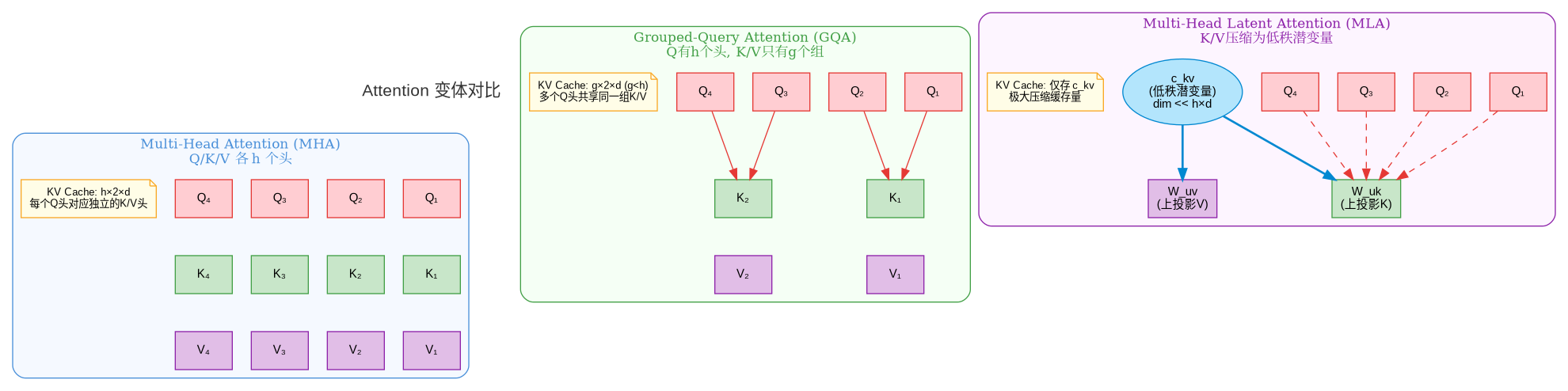
- GQA 由 Google 在 2023 年提出(论文:GQA: Training Generalized Multi-Query Attention),核心思想是让多个 Query 头共享同一组 Key/Value 头,从而减少 KV Cache 的大小。GQA 是 MHA 和 MQA 的折中——既显著减少了 KV Cache(LLaMA 3 使用 8 组 GQA,缓存压缩 4 倍),又保持了接近 MHA 的模型质量。LLaMA 2 70B、LLaMA 3、Mistral 等主流模型均采用 GQA。
- MLA 由 DeepSeek 在 DeepSeek-V2(2024)中提出,是目前 KV Cache 压缩最激进的方案。核心思想:不再缓存完整的 K 和 V,而是将它们压缩为一个低维的潜变量(latent variable) ckvckv,推理时再通过上投影矩阵恢复。KV Cache 只需存储 ckvckv(维度 d_c),而非完整的 K 和 V(维度 h×d_k + h×d_v)。DeepSeek-V2 中 d_c=512,而 h×d_k=12288,压缩比高达 24 倍。
Flash Attention(Tri Dao, 2022)解决的不是”用更少的头”,而是”如何高效计算注意力本身”。标准 Attention 需要在 GPU 显存(HBM)中存储完整的 N×N 注意力矩阵,当序列长度 N 很大时,显存和带宽都成为瓶颈。而flash attention解决的是”单次Attention计算中的N x N矩阵太大”的问题,分块计算,不存完整的注意力矩阵,这样可以省显存带宽不改变计算量。类比:一次性搬运10吨大石头过桥(承重桥不够,还慢),分20次搬运20公斤,反而更快。
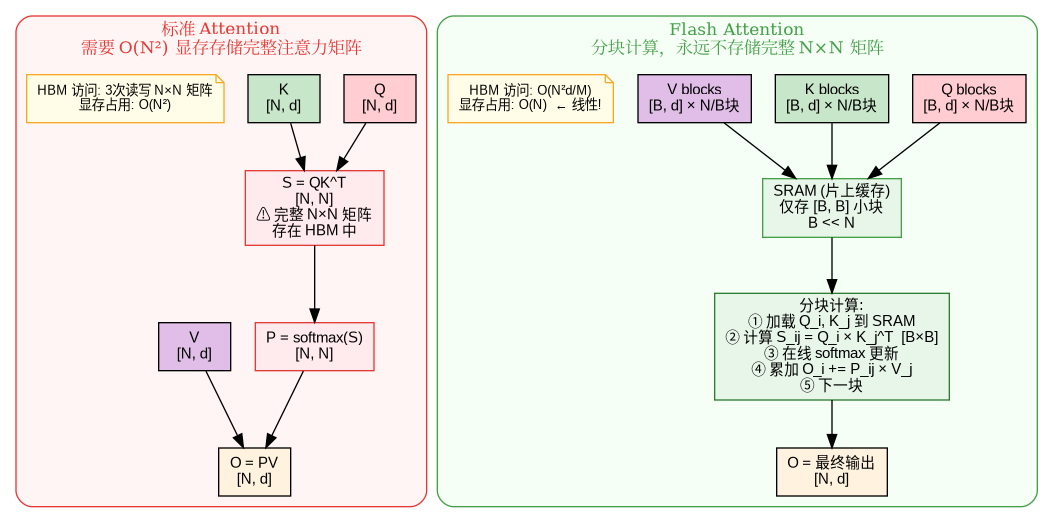
Flash Attention 的核心技巧是分块计算(tiling), 不改变模型结构,是纯粹的工程优化,可以和 MHA/GQA/MLA 任意组合使用。llama.cpp 中通过 llama_set_flash_attn()启用。
- 将 Q/K/V 分成小块,每次只在 GPU 的片上缓存(SRAM)中计算一个小块的注意力
- 使用在线 softmax 算法(Milakov & Gimelshein, 2018),无需看到完整的一行就能增量更新 softmax
- 永远不在 HBM 中存储完整的 N×N 矩阵
应用示例: 翻译英文
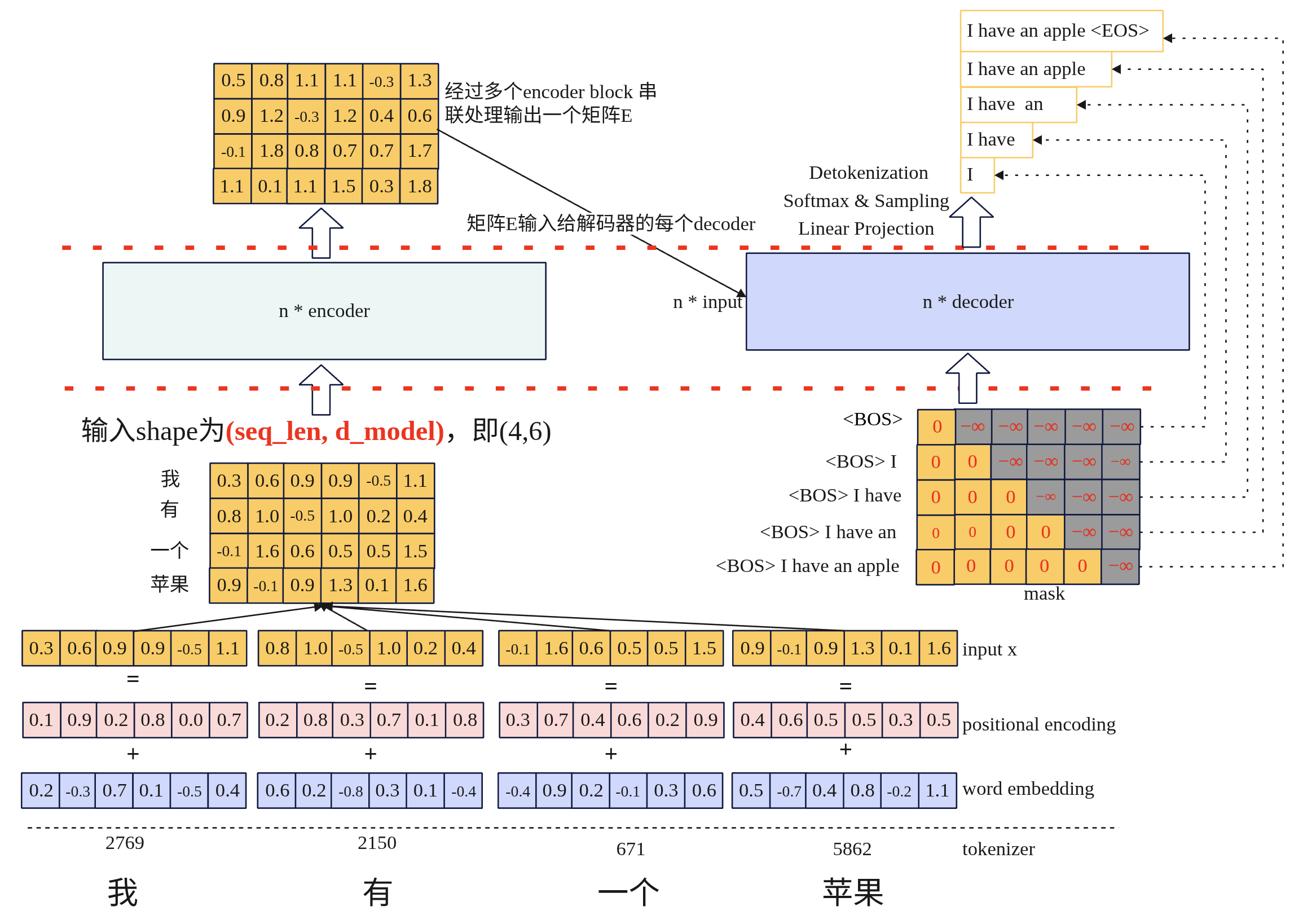
- Tokenization(分词):将原始文本(我有一个苹果)切分成模型可识别的词元(如[“我”, “有”, “一”, “个”, “苹”, “果”]),并映射为Token ID(如[2769, 2150, 671, …])。这是文本进入模型的第一步。
- Word Embedding(词嵌入):将每个Token ID转换为一个稠密的、可学习的向量,这个向量能捕捉词语的语义信息。
- Positional Encoding(位置编码):为词嵌入向量添加位置信息,让模型知道单词的顺序(因为Self-Attention本身是顺序无关的)。
- Encoder Stack(编码器堆叠):由N个相同的Encoder层堆叠而成。每层通过自注意力(Self-Attention) 和前馈网络(FFN),让输入序列的每个词元都能充分“看到”并融合其他所有词元的信息,最终输出包含完整上下文语义的编码表示。
- Decoder Stack(解码器堆栈):由N个相同的Decoder层堆叠而成。除了自注意力和FFN,它还包含交叉注意力,用于“聚焦”Encoder的输出,从而基于源语言信息生成目标语言。推理时采用自回归方式,逐个生成Token。
- Linear Projection(线性投影):将Decoder顶层的输出向量(维度d_model)映射到词表大小的向量。这一步通常在图中Decoder之后,用“Linear + Softmax”表示。
- Softmax & Sampling(概率化与采样):对上一步的输出做Softmax,得到每个词元在词表中的概率分布。然后根据策略(贪心、束搜索、采样等)选择下一个Token。
- Detokenization(反分词):将生成的Token ID序列转换回人类可读的文本。这是模型输出的最后一步。
大模型推理的软件实现
llama.cpp的软件框架图
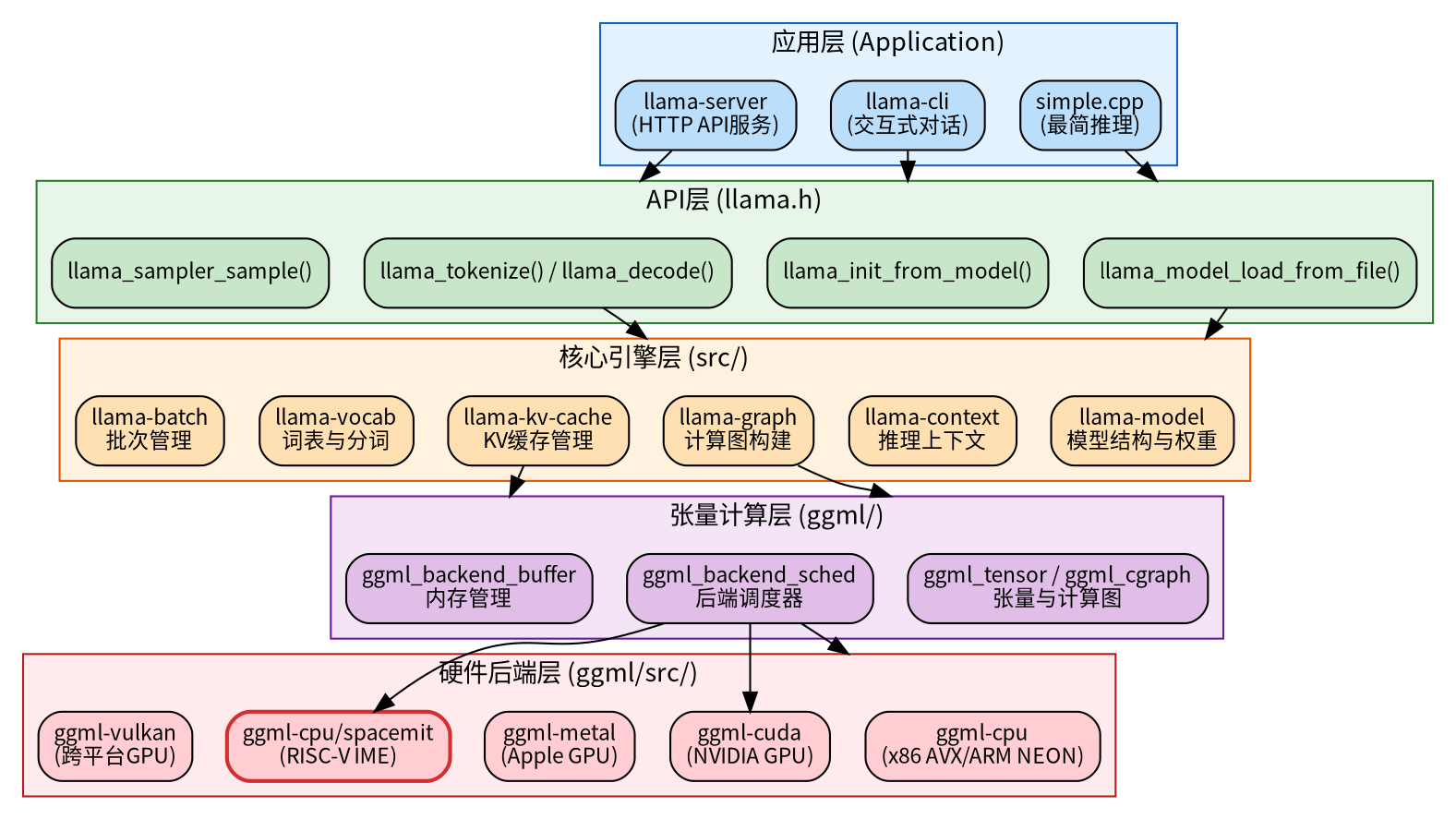
simple.cpp为例:推理流程
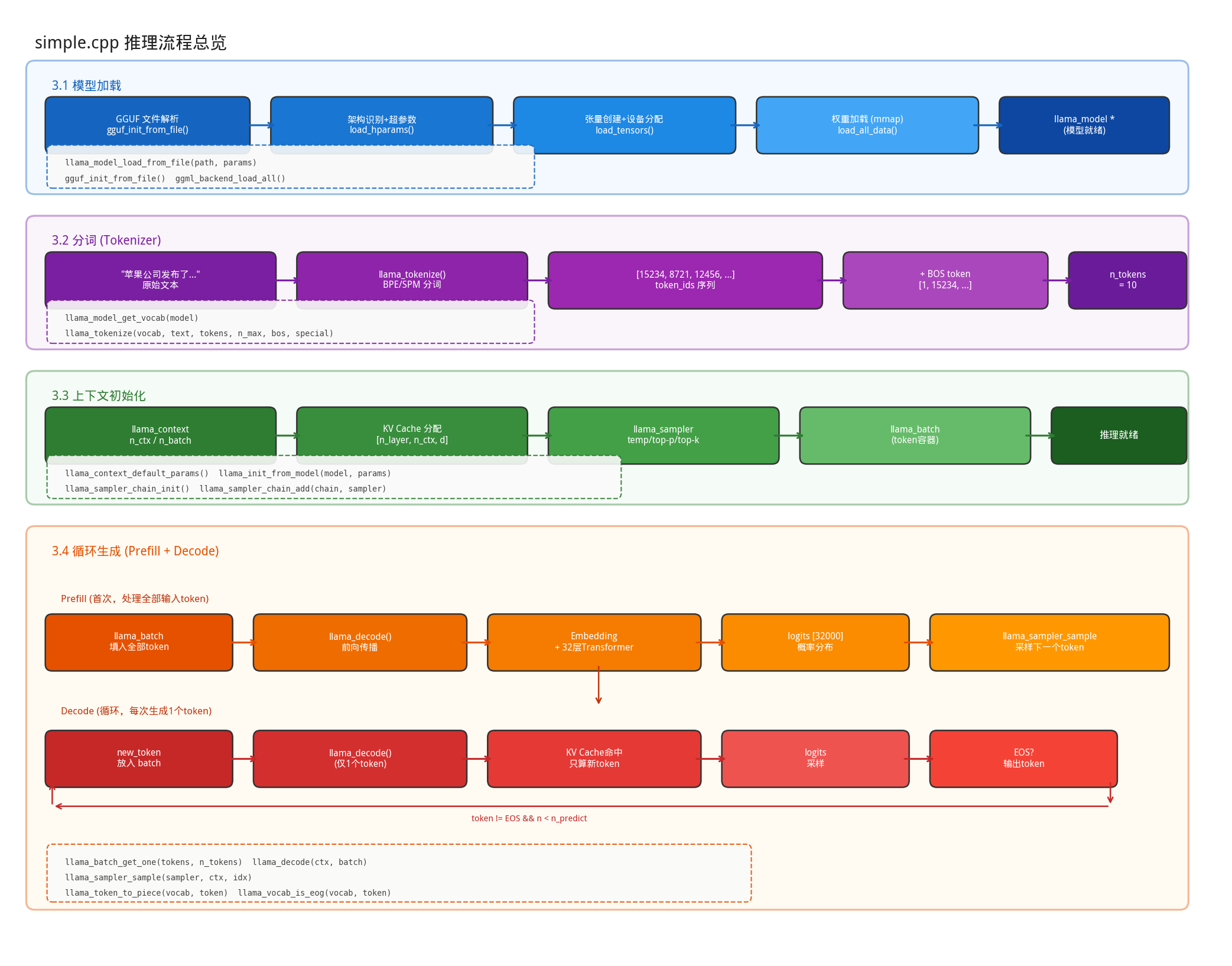
模型加载:不只是读取,更是映射
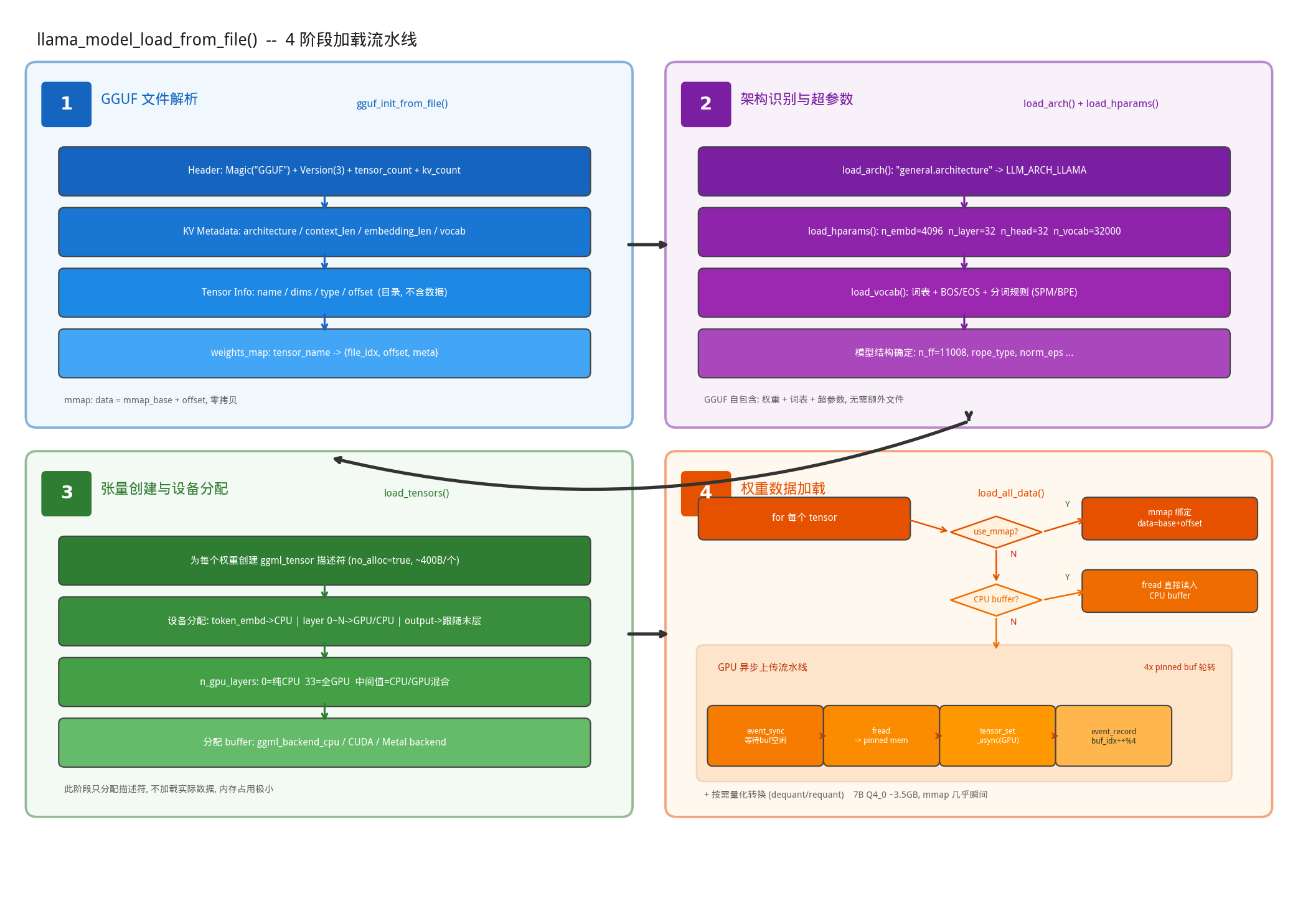
模型加载可以分为4个阶段:GGUF文件解析、架构识别与超参数、张量创建与设备分配、权重数据加载。
阶段一:GGUF文件解析

GGUF(GGML Universal Format)是 llama.cpp 的模型文件格式。gguf_init_from_file()按顺序解析其二进制结构。上图展示了 GGUF 文件的二进制布局,从上到下依次是:
- Header:Magic Number(”GGUF”)、版本号、张量数量、KV 元数据数量。
- KV Metadata:模型超参数(架构类型、embedding 维度、层数、注意力头数等)和完整的词表信息(分词算法、token 列表、合并规则、特殊 token ID 等),每个 KV 对由 key + value type + value data 组成
- Tensor Info:每个权重张量的”目录”——包含张量名称(如 blk.0.attn_q.weight)、维度数组(如 [4096, 4096])、数据类型(Q4_0/Q8_0/F16/F32 等)以及该张量在数据区中的字节偏移量。这里只记录元信息,不含实际权重数据,类似于书的目录页。
- Alignment Padding:填充到 16 字节边界,确保数据区内存对齐。
- Tensor Data:所有权重的实际二进制数据,按偏移量排列。
GGUF 文件只存储数据,不存储计算逻辑。矩阵乘法、softmax、残差连接等计算图操作并不在文件中,而是由 llama.cpp 代码根据模型架构(general.architecture)在推理时动态构建(详见下文)。换句话说,GGUF 回答的是”参数是什么”,代码回答的是”怎么算”。
阶段二:架构识别与超参数加载
阶段一解析出的KV元数据是”原始数据”,阶段二的任务是将这些原始数据转换为代码可以直接使用的结构化参数(填充到结构体中),主要分为以下3步。
// src/llama-model.cpp — 调用链
model.load_arch(ml); // 从 "general.architecture" 识别模型类型
model.load_hparams(ml); // 提取 n_embd, n_layer, n_head, n_vocab 等
model.load_vocab(ml); // 加载词表和特殊 Token (BOS/EOS/PAD)
- load_arch():读取 general.architecture字段(如 “llama”),映射到内部枚举 LLM_ARCH_LLAMA。这个枚举决定了后续推理时使用哪套计算图构建逻辑——不同架构(LLaMA、GPT-2、Falcon 等)的注意力机制、归一化方式、FFN 结构各不相同,代码需要知道”这是什么模型”才能正确计算。
- load_hparams():根据架构类型,从 KV 元数据中提取对应的超参数。
| 参数 | KV Key | 值 | 含义 |
|---|---|---|---|
| n_embd | llama.embedding_length | 4096 | 隐藏层维度 |
| n_layer | llama.block_count | 32 | Transformer 层数 |
| n_head | llama.attention.head_count | 32 | 注意力头数 |
| n_head_kv | llama.attention.head_count_kv | 32 | KV 头数(GQA 时可能更少) |
| n_vocab | llama.vocab_size | 32000 | 词表大小 |
| n_ff | llama.feed_forward_length | 11008 | FFN 中间层维度 |
| n_ctx_train | llama.context_length | 4096 | 训练时的上下文长度 |
这些参数直接决定了每个权重张量的形状。例如 attn_q.weight 的形状是 [n_embd, n_embd] = [4096, 4096],ffn_gate.weight 的形状是 [n_embd, n_ff] = [4096, 11008]。此外还会解析 RoPE 相关参数(rope_type、rope_freq_base)和归一化参数(norm_eps)等。
- load_vocab():从 KV 元数据中加载完整的词表信息,包括 token 字符串列表、分数/优先级、BPE 合并规则、特殊 token ID(BOS/EOS/PAD/UNK)等。这些信息在后续的分词阶段(下文)会被直接使用。
阶段三:张量创建与设备分配
load_tensors()(src/llama-model.cpp:2576)是整个加载过程中最精巧的阶段。它的核心任务是:根据阶段二确定的模型结构,为每个权重创建 ggml_tensor 描述符,并决定每个张量应该放在哪个计算设备上。
load_tensors()(src/llama-model.cpp:2576)是整个加载过程中最精巧的阶段。它的核心任务是:根据阶段二确定的模型结构,为每个权重创建 ggml_tensor 描述符,并决定每个张量应该放在哪个计算设备上。
- 张量描述符创建:对于 LLaMA-7B,需要创建约 290+ 个张量描述符(1 个 token embedding + 32 层 × 9 个权重/层 + 输出层)。每个描述符只是一个轻量级的元数据结构(约 400 字节),记录张量的名称、形状、数据类型和设备归属,不包含实际的权重数据。这里使用了 no_alloc = true 策略——先规划,后分配,避免在设备分配确定之前浪费内存。
-
设备分配策略:n_gpu_layers 参数控制了 CPU/GPU 的分工:
| 层类型 | 设备分配策略 |
|---|---|
| 输入层(token_embd) | 始终在 CPU(embedding 查表操作 CPU 更高效) |
| 中间层 0 ~ N-1 | 根据 n_gpu_layers 从第 0 层开始依次分配到 GPU |
| 输出层(output) | 跟随最后一个中间层的设备 |
以 LLaMA-7B(32 层)为例:
-
- n_gpu_layers=0:纯 CPU 推理,所有层在 CPU
-
- n_gpu_layers=20:layer 0~19 在 GPU,layer 20~31 在 CPU(混合推理)
-
- n_gpu_layers=33:全部 32 层 + 输出层都在 GPU(全 GPU 推理)
- Buffer 分配:设备分配确定后,为每个设备创建对应的 ggml_backend_buffer。CPU 使用 ggml_backend_cpu_buffer,GPU 使用对应的 CUDA/Metal buffer。Buffer 是一块连续的设备内存,同一设备上的所有张量共享同一个 buffer,每个张量在 buffer 中占据一段连续区域。这种设计减少了内存碎片,也方便后续的批量数据传输。
阶段四:权重数据的加载
ml.load_all_data()(src/llama-model-loader.cpp:1359)是最后一步——将 GGUF 文件中的实际权重数据填充到阶段三创建的张量描述符中。这个阶段遍历每个张量,根据其目标设备和系统能力,选择三条加载路径之一。
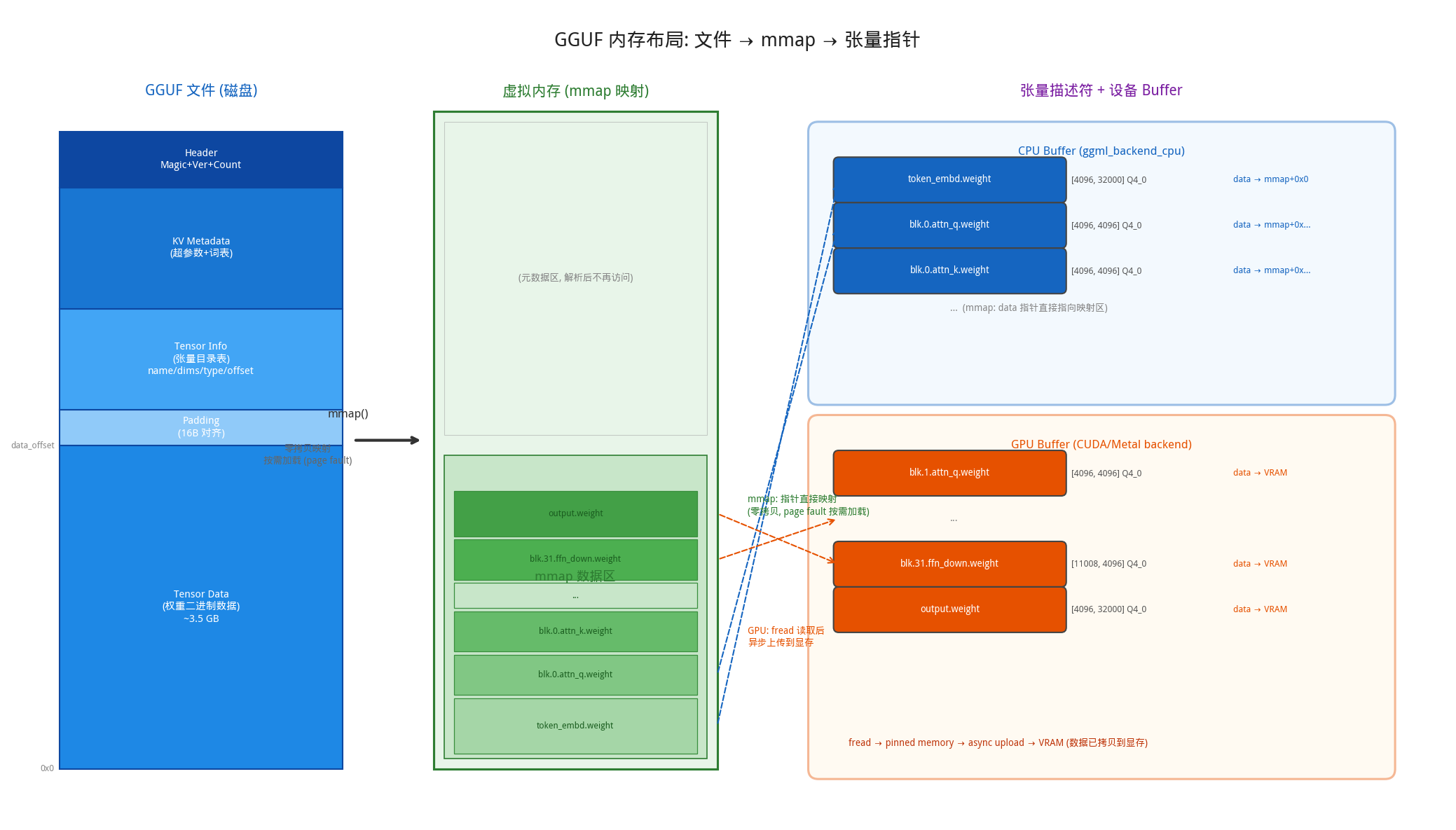
- 路径 A — mmap 绑定(零拷贝,默认):直接将张量的 data 指针指向 mmap_base + offset,不发生任何数据拷贝。操作系统通过虚拟内存机制,在首次访问时才从磁盘读取对应的页面(4KB/页)。这是最快的”加载”方式——对于 3.5GB 的模型,mmap 映射本身只需不到 0.1 秒。
- 路径 B — fread 文件读取(备选):通过 fread() 将权重数据直接读入 CPU buffer。用于不支持 mmap 的平台(如某些嵌入式系统),或用户显式禁用 mmap 的场景。这种方式启动较慢(需要实际读取全部数据),但首次推理不会有 page fault 开销。
- 路径 C — GPU 异步上传:对于分配到 GPU 的张量,先通过 fread 读入 CPU 端的 pinned memory(页锁定内存),然后通过 GPU backend 的异步传输接口上传到显存。llama.cpp 使用 event 机制实现流水线化——在上传第 N 个张量的同时,可以并行读取第 N+1 个张量的数据,最大化 PCIe 带宽利用率。
此外,加载过程中还可能发生量化转换:如果目标设备要求的数据类型与文件中存储的不同(例如某些 backend 不支持 Q4_0 但支持 Q8_0),会在加载时自动进行 dequant/requant 转换。mmap 是默认且推荐的方式——一个 7B Q4_0 模型约 3.5GB,mmap 让进程几乎瞬间”加载”完毕,实际的磁盘读取延迟到首次访问时由操作系统透明处理。
语言转数字:Tokenizer 的实现逻辑
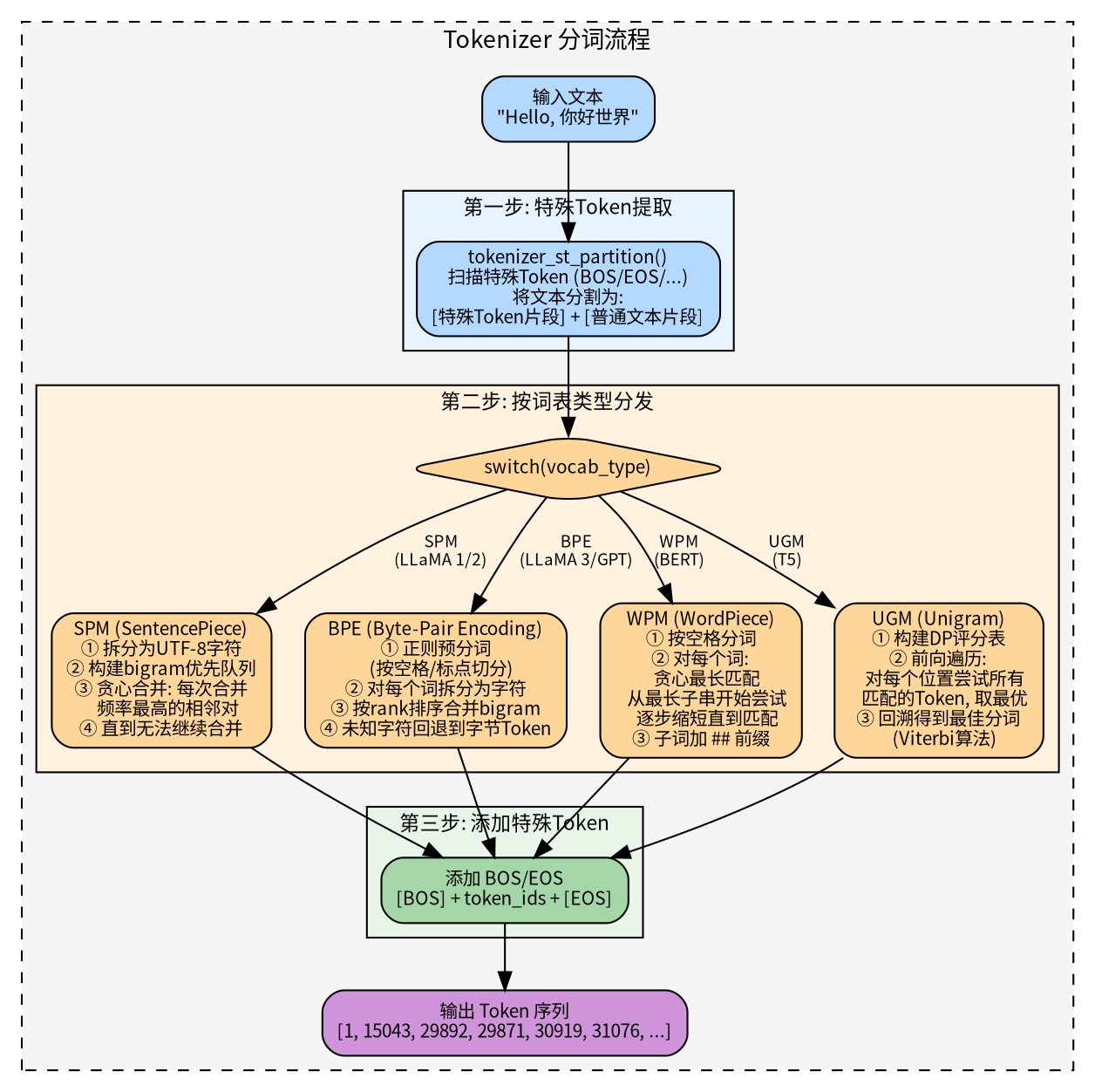
llama.cpp 支持四种主流分词算法,具体使用哪种取决于模型的词表类型,无论哪种算法,流程都是三步:先提取特殊 Token(BOS/EOS 等),再对普通文本执行分词算法,最后在序列首尾添加特殊 Token。
| 算法 | 代表模型 | 核心思想 |
|---|---|---|
| SPM (SentencePiece) | LLaMA 1/2 | 将文本拆为字符,贪心合并频率最高的相邻对 |
| BPE (Byte-Pair Encoding) | LLaMA 3, GPT | 正则预分词后,按 rank 排序合并 bigram |
| WPM (WordPiece) | BERT | 按空格分词,对每个词做贪心最长子串匹配 |
| UGM (Unigram) | T5 | Viterbi 动态规划,选择全局概率最优的分词方案 |
上下文初始化:llama_model与llama_conext
到目前为止,我们完成了两件事:加载模型权重(3.1 节)和将用户输入转化为 token 序列(3.2 节)。但要真正开始推理,还缺少一个关键角色——推理上下文。
模型权重是”知识”,token 序列是”问题”,而推理上下文就是”工作台”:它提供了推理过程中所需的全部运行时资源,包括 KV Cache(存储注意力历史)、计算图缓冲区(存放中间计算结果)、后端调度器(管理 CPU/GPU 协作)等。没有这个工作台,模型虽然”知道”所有知识,却没有地方展开计算。
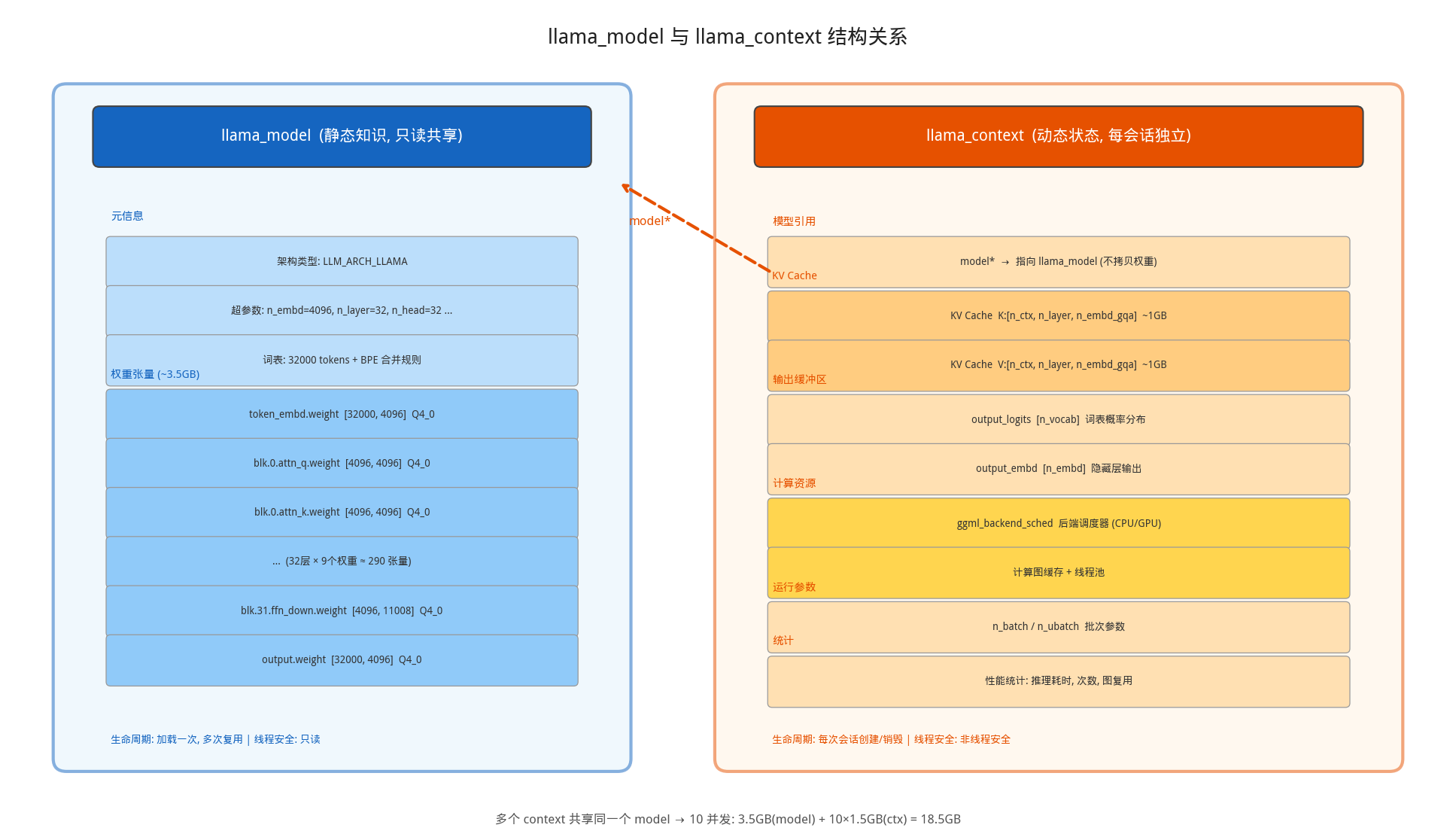
llama.cpp 将这个工作台抽象为两个核心结构体:llama_model(模型本身)和 llama_context(推理上下文)。这种分离设计是整个推理框架的架构基石——理解它们的关系,是理解后续所有推理步骤的前提。
Model contex的关系
llama_model 和 llama_context 的关系类似于”类”和”实例”——model 是只读的共享知识库,context 是每次推理会话的独立工作空间:
| 概念 | llama_model | llama_context |
|---|---|---|
| 生命周期 | 加载一次,多次复用 | 每次会话创建 |
| 包含内容 | 权重张量、架构参数、词表 | KV Cache、计算图、后端调度器 |
| 内存占用 | 大(模型权重 ~3.5GB) | 中(KV Cache + 计算缓冲区 ~1-2GB) |
| 线程安全 | 只读,可多线程共享 | 非线程安全,每线程一个 |
这种分离允许一个模型服务多个并发请求。想象一个 API 服务器:模型权重只加载一次(3.5GB)常驻内存,每个用户请求创建独立的 context(~1.5GB),10 个并发请求只需 3.5GB + 10×1.5GB = 18.5GB,而不是 10×5GB = 50GB。同时,model 只读可安全共享,context 包含可变状态各自独立,多线程实现更简单。
Context 创建过程
llama_context_params ctx_params = llama_context_default_params();
ctx_params.n_ctx = n_prompt + n_predict - 1; // 上下文窗口大小
ctx_params.n_batch = n_prompt; // 单次 decode 最大 token 数
ctx_params.no_perf = false; // 启用性能计数
llama_context * ctx = llama_init_from_model(model, ctx_params);
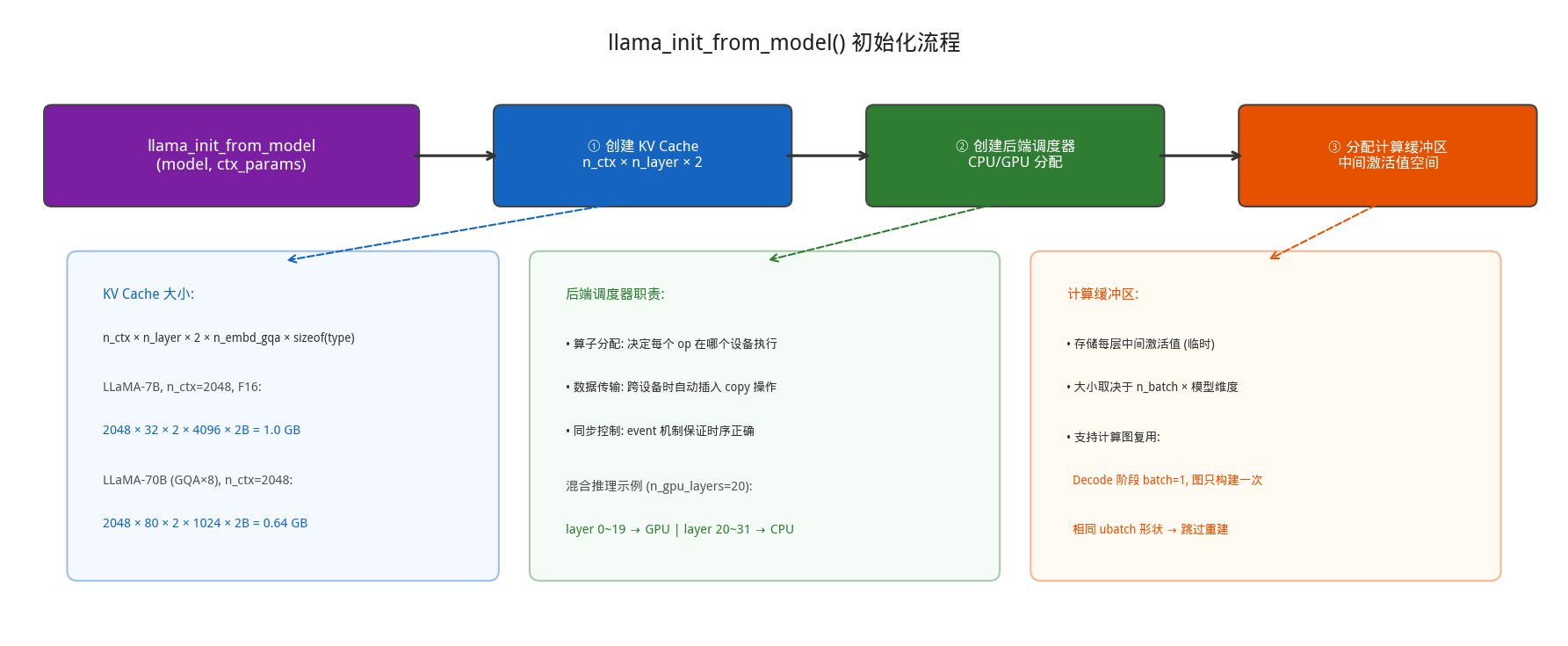
llama_init_from_model() 内部会依次创建三个核心组件:
KV cache:缓存历史Key和Value
KV Cache 是 Transformer 推理加速的关键——没有它,每生成一个新 token 都要重新计算所有历史 token 的 K/V,复杂度从 O(n) 变成 O(n²)。它的大小由 n_ctx 参数决定:
KV Cache 大小 = n_ctx × n_layer × 2 × n_embd_gqa × sizeof(type)
各参数含义:n_ctx 是上下文窗口大小(用户指定),n_layer 是模型层数,2 代表 K 和 V 各一份,n_embd_gqa 是每层 KV 的维度(GQA 模型会压缩),sizeof(type) 是数据类型大小(F16 为 2 字节)。
| 模型 | n_ctx | n_layer | n_embd_gqa | type | KV Cache 大小 |
|---|---|---|---|---|---|
| LLaMA-7B | 2048 | 32 | 4096 | F16 | 2048×32×2×4096×2 = 1.0 GB |
| LLaMA-7B | 4096 | 32 | 4096 | F16 | 4096×32×2×4096×2 = 2.0 GB |
| LLaMA-70B | 2048 | 80 | 1024 | F16 | 2048×80×2×1024×2 = 0.64 GB |
注意 LLaMA-70B 使用了 GQA(8 组),n_embd_gqa = 8192/8 = 1024,KV Cache 反而比 7B 小。n_ctx 的选择需要权衡:太小无法处理长文本,太大浪费内存且注意力计算复杂度是 O(n_ctx²)。
后端调度器与计算缓冲
- 后端调度器(ggml_backend_sched)是多设备协作的核心,负责三件事:根据算子类型和输入张量的设备决定在哪个后端执行(CPU/CUDA/Metal);当算子输入在不同设备时自动插入数据传输操作;通过 event 机制确保跨设备操作的正确时序。例如在 CPU+GPU 混合推理中(n_gpu_layers=20),前 20 层在 GPU 执行,后 12 层在 CPU,调度器在边界自动插入 GPU→CPU 数据搬运。
- 计算缓冲区存储推理过程中每层的中间激活值,大小取决于 n_batch 和模型的中间层维度。llama.cpp 支持计算图复用——如果连续两次推理的 batch 形状相同(如 Decode 阶段每次都是 1 个 token),可以跳过重新构建计算图,直接复用上次的图结构。
n_batch和n_ubatch:批次拆分
代码中设置的 n_batch 是用户指定的批次大小(Prefill 阶段等于 prompt 长度,Decode 阶段为 1),但 llama.cpp 内部会进一步拆分为微批次(ubatch,默认 512)。例如 n_batch=1024 会被拆成 2 个 ubatch 分别处理。
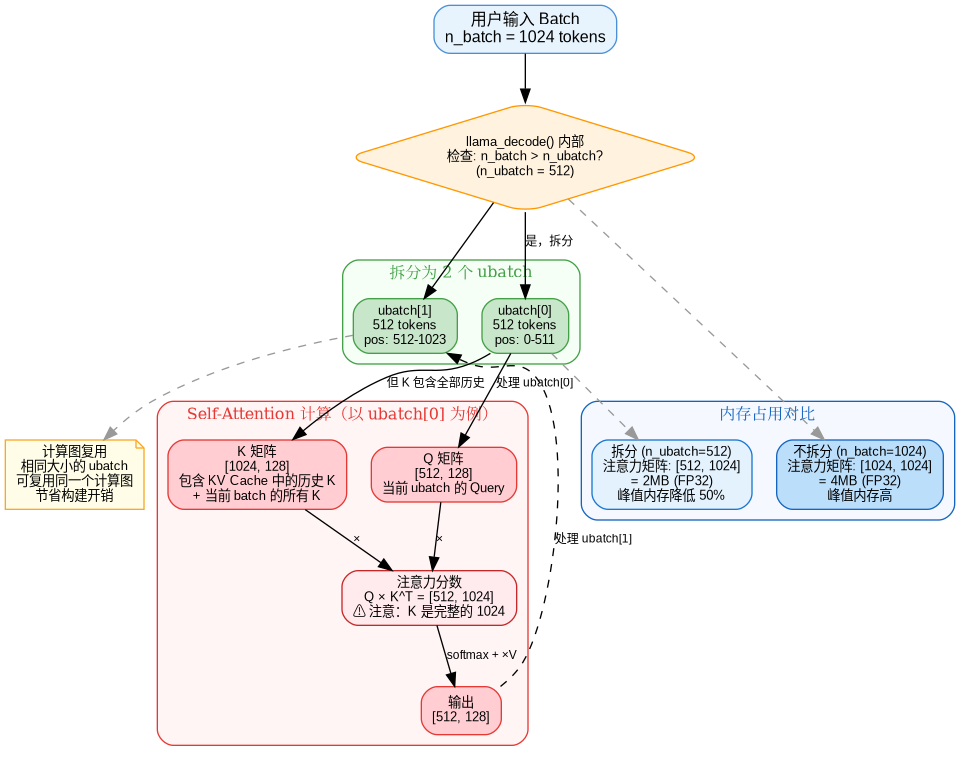
拆分的核心动机是控制 Self-Attention 的内存峰值。计算 Q×K^T 时,Q 矩阵大小取决于当前处理的 token 数,而 K 矩阵始终是完整的(包含所有历史 token)。拆分 ubatch 只缩小 Q,不影响 K:
| 场景 | Q 矩阵大小 | K 矩阵大小 | 注意力矩阵大小 | 内存占用 (FP32) |
|---|---|---|---|---|
| 不拆分 (n_batch=1024) | [1024, 128] | [1536, 128] | [1024, 1536] | 6 MB |
| 拆分 ubatch[0] | [512, 128] | [1536, 128] | [512, 1536] | 3 MB |
| 拆分 ubatch[1] | [512, 128] | [1536, 128] | [512, 1536] | 3 MB |
拆分后峰值内存降低 50%。此外,相同大小的 ubatch 可以复用计算图结构(Decode 阶段每次 1 个 token,图只需构建一次),也能避免显存不足时的 OOM。默认值 512 是内存与性能的经验折中,可通ctx_params.n_ubatch 调整。
循环生成:Token的”轮回”
// examples/simple/simple.cpp:149-203
llama_batch batch = llama_batch_get_one(prompt_tokens.data(), prompt_tokens.size());
for (int n_pos = 0; n_pos + batch.n_tokens < n_prompt + n_predict; ) {
// 核心:将 batch 送入模型计算
llama_decode(ctx, batch);
n_pos += batch.n_tokens;
// 从 logits 中采样下一个 token
new_token_id = llama_sampler_sample(smpl, ctx, -1);
// 检查是否生成了结束符
if (llama_vocab_is_eog(vocab, new_token_id)) break;
// 输出文本
char buf[128];
int n = llama_token_to_piece(vocab, new_token_id, buf, sizeof(buf), 0, true);
printf("%s", std::string(buf, n).c_str());
// 用新 token 构建下一轮的 batch
batch = llama_batch_get_one(&new_token_id, 1);
}
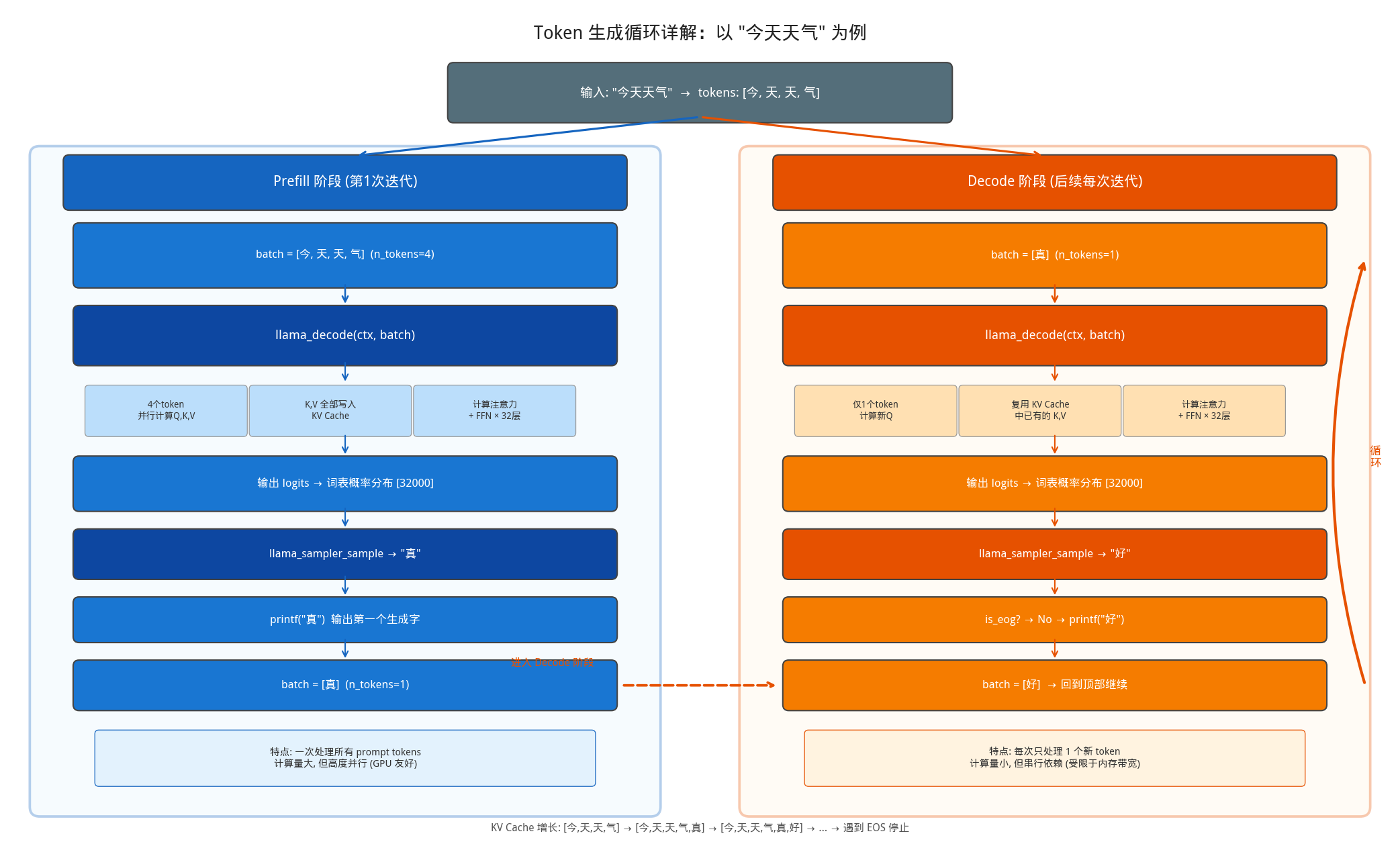
- prefill阶段:第一次迭代,Prefill 就是把整个 prompt(比如 “今天天气”)一次性送进 Decoder-only 模型,每个 token 都走完完整的decode (Attention + FFN × 32 层)。它的产出是两个东西:所有 prompt token 的 K、V 向量,写入 KV Cache(这是最重要的产出,后续 Decode 阶段要复用)最后一个 token 位置的 logits,用于采样第一个生成字。
- decode阶段:每次只送入 1 个新 token(上一步刚生成的),同样走完 32 层 Transformer。区别是 Self-Attention计算时,只需要为这 1 个 token 算新的 Q,而 K 和 V 直接从 KV Cache中读取历史的,不用重算。算完后把这个新 token 的 K、V 追加到 KV Cache,采样出下一个token,循环往复直到遇到 EOS。
推理引擎基础:GGML
前面第3章从用户视角看了推理流程:加载模型 ->分词 -> 初始化 context -> 循环生成。但这些高层 API 背后,GGML 引擎是如何组织数据和计算的?
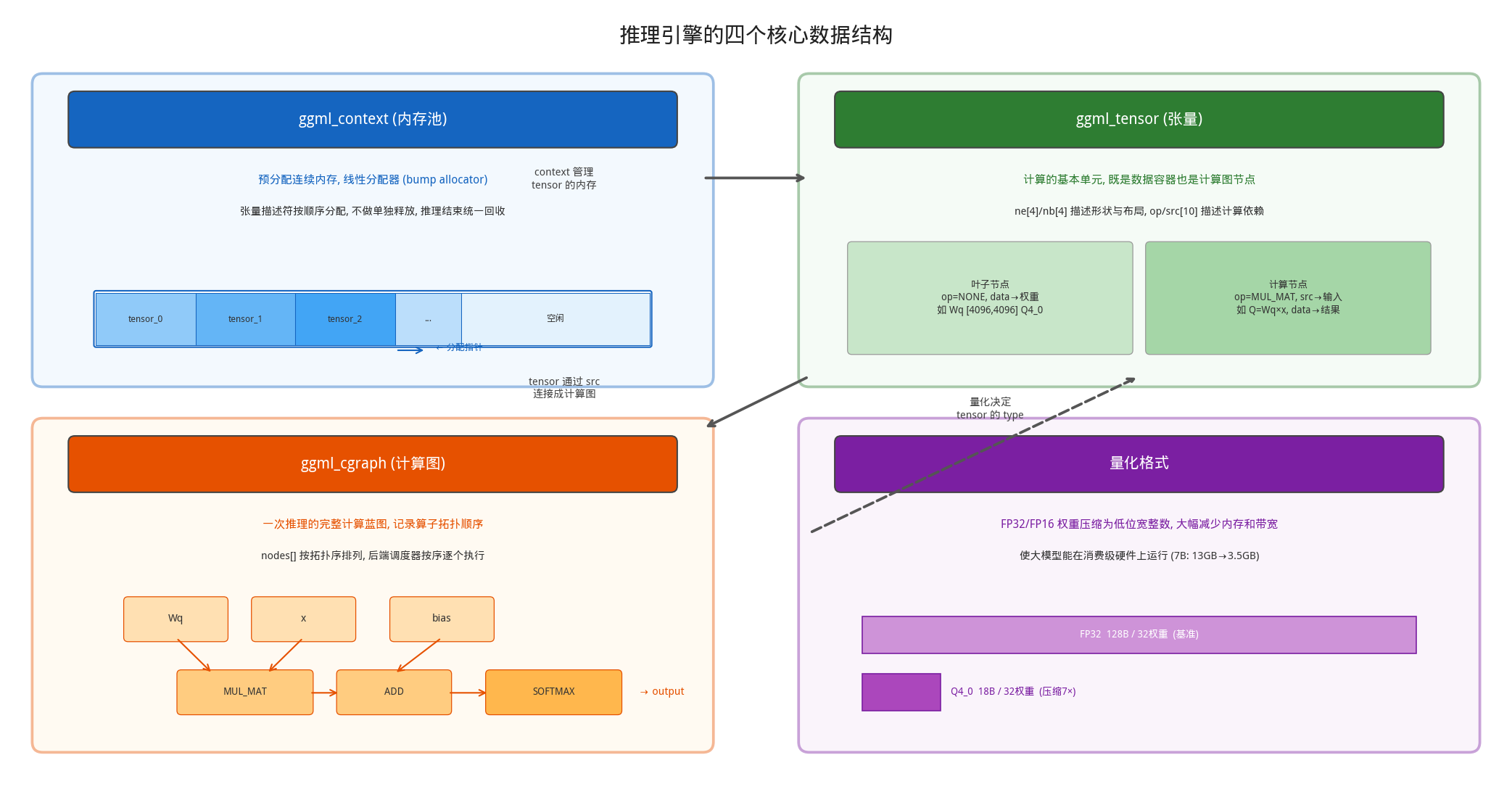
想象一家餐厅要做一道”Transformer炒饭”:需要工作台(内存池)、食材(张量)、菜谱(计算图)、预处理食材包(量化)。理解这些数据结构,才能真正看懂 llama.cpp 的推理引擎。
内存池:静态内存规划
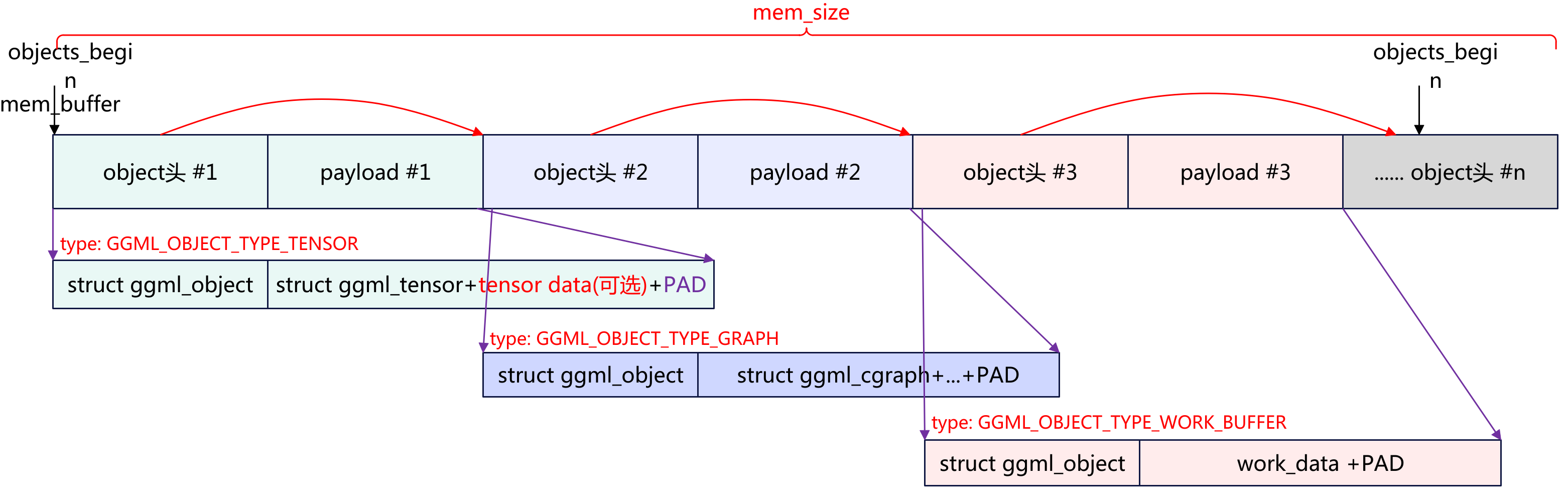
推理过程中需要创建大量张量描述符(一个 7B 模型约 290+ 个权重张量,加上每次推理的中间结果张量)。如果每个张量都单独 malloc/free,不仅有分配开销,还会产生内存碎片。ggml_context 的解决方案是:预分配一块连续内存,所有张量从中顺序分配。
struct ggml_context {
size_t mem_size; // 内存池总大小
void * mem_buffer; // 内存池起始地址
bool mem_buffer_owned; // 是否由 context 自己分配
bool no_alloc; // true = 只分配描述符,不分配数据
int n_objects; // 对象数量
struct ggml_object * objects_begin; // 对象链表头
struct ggml_object * objects_end; // 对象链表尾
};
ggml_context 采用线性分配器(bump allocator)模式:
- 内存池在创建时一次性分配,之后只做指针递增,不做单独释放
- no_alloc = true 时只分配 tensor 描述符(约 400 字节/个),数据由后端 buffer 管理
- 这种设计避免了频繁的 malloc/free,对推理场景的确定性内存需求非常友好
张量:计算的原子
ggml_tensor 是 GGML 中最核心的数据结构,既描述数据的形状和类型,也记录了计算图中的依赖关系。每个张量同时扮演两个角色:数据容器(通过 type/data 存储实际数值)和计算图节点(通过 op/src 描述运算和输入依赖)。
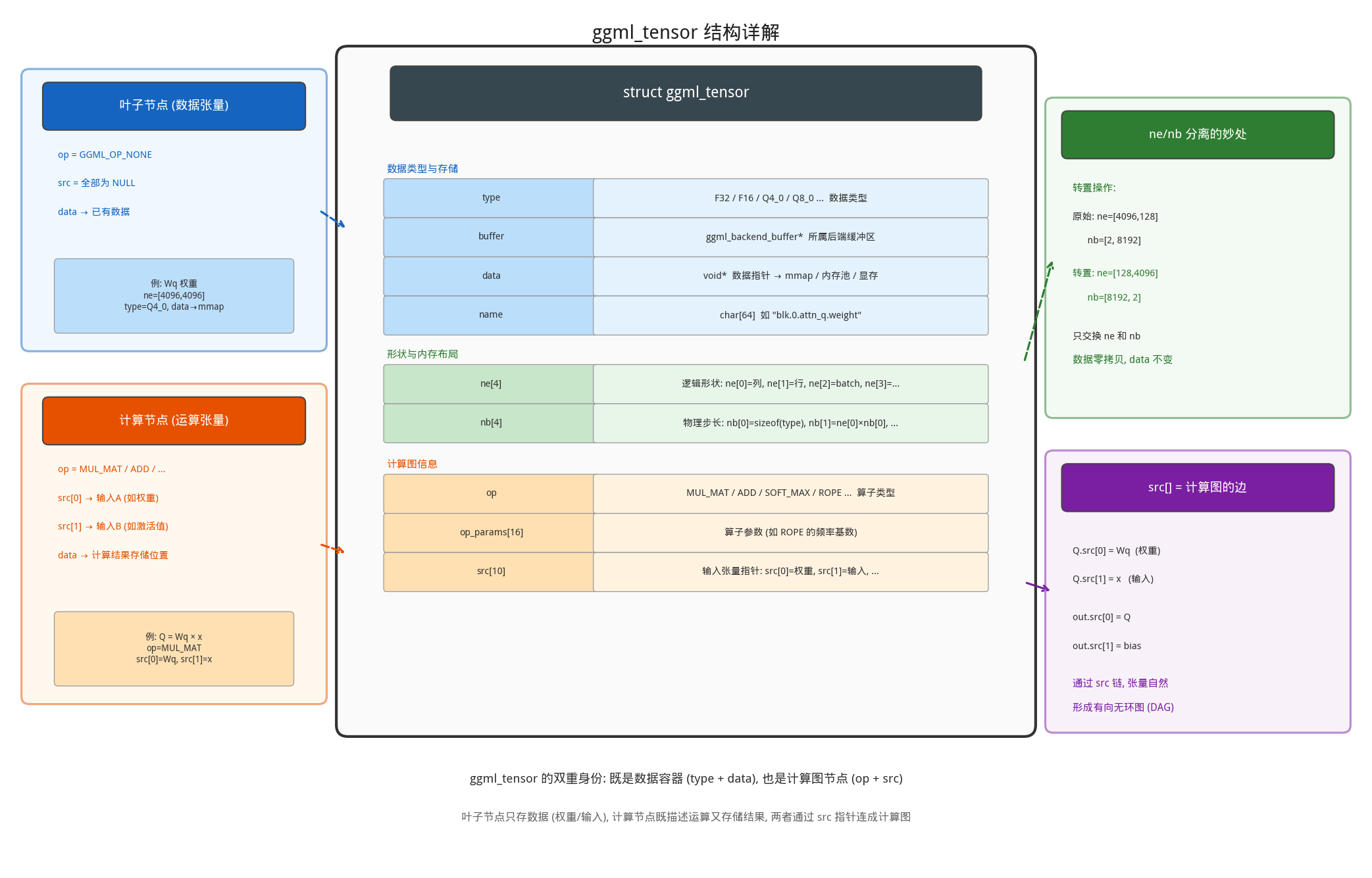
struct ggml_tensor {
enum ggml_type type; // 数据类型:F32, F16, Q4_0, Q8_0...
struct ggml_backend_buffer * buffer; // 所属的后端缓冲区
int64_t ne[4]; // 各维度元素数: ne[0]=列, ne[1]=行, ne[2]=batch...
size_t nb[4]; // 各维度步长(字节): nb[0]=sizeof(type), nb[1]=ne[0]*nb[0]...
enum ggml_op op; // 算子类型: MUL_MAT, ADD, SOFT_MAX...
int32_t op_params[16]; // 算子参数
struct ggml_tensor * src[10]; // 输入张量(计算图的边)
void * data; // 数据指针(指向 buffer 中的实际数据)
char name[64]; // 张量名称,如 "blk.0.attn_q.weight"
};
- ne/nb 分离:ne 描述逻辑形状,nb 描述物理布局。这使得转置、切片等操作只需修改 nb 而无需拷贝数据(零拷贝视图)
- src 数组:最多 10 个输入,构成计算图的有向边。例如 MUL_MAT 操作的 src[0] 是权重,src[1] 是输入
- op + data 双重身份:一个 tensor 既是数据容器(通过 data 指针),也是计算图中的节点(通过 op 和 src)
计算图:指令的蓝图
struct ggml_tensor * ggml_mul_mat(
struct ggml_context * ctx,
struct ggml_tensor * a,
struct ggml_tensor * b) {
GGML_ASSERT(ggml_can_mul_mat(a, b));
GGML_ASSERT(!ggml_is_transposed(a));
const int64_t ne[4] = { a->ne[1], b->ne[1], b->ne[2], b->ne[3] };
struct ggml_tensor * result = ggml_new_tensor(ctx, GGML_TYPE_F32, 4, ne);
result->op = GGML_OP_MUL_MAT;
result->src[0] = a;
result->src[1] = b;
return result;
}
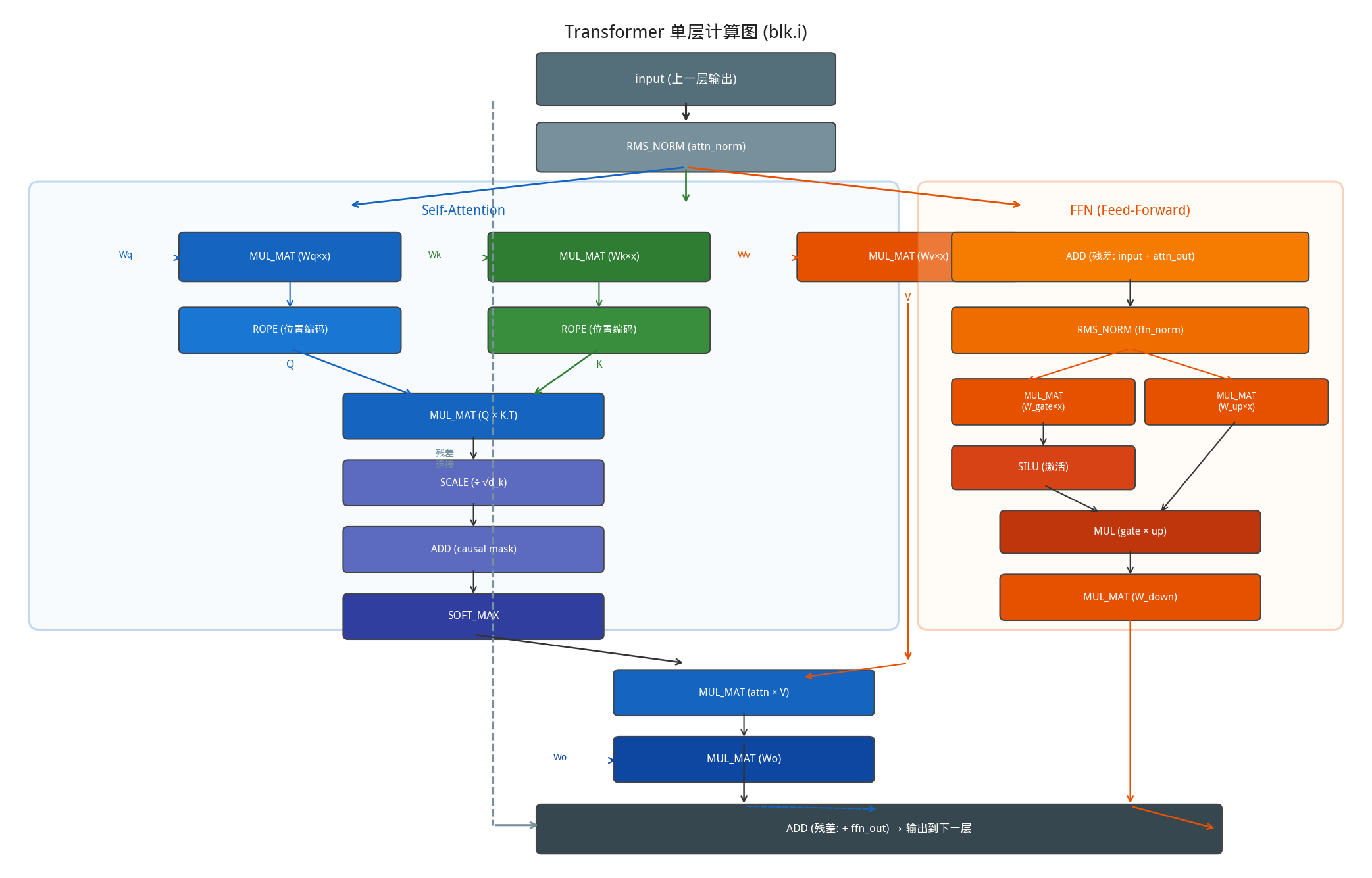
上图展示了 Transformer 单层的计算图结构。计算图是如何构建和执行的了?
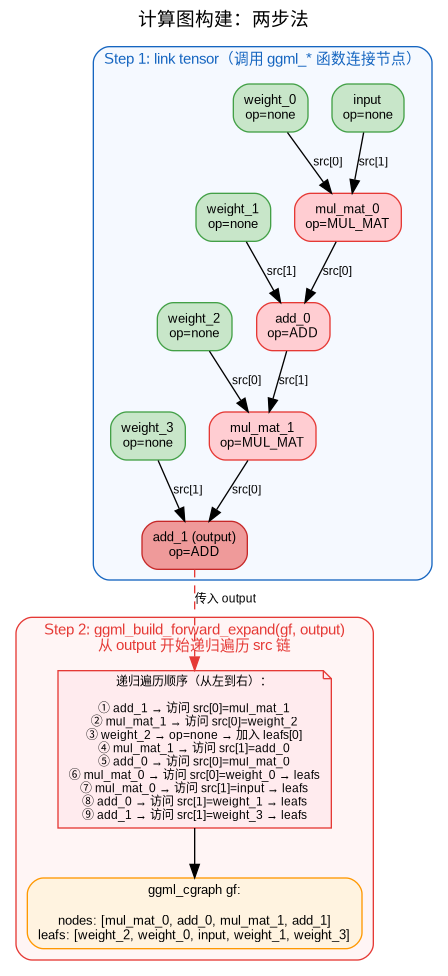
计算图的构建,nodes 数组天然满足拓扑序:每个节点的依赖一定排在它前面。
遇到 op ≠ 无 的张量 → 加入 nodes 数组(计算节点)
遇到 op = 无 的张量 → 加入 leafs 数组(叶子节点)
使用 visited_hash_set 去重,防止同一个张量被重复添加
递归顺序:先访问 src[0],再访问 src[1](从左到右)
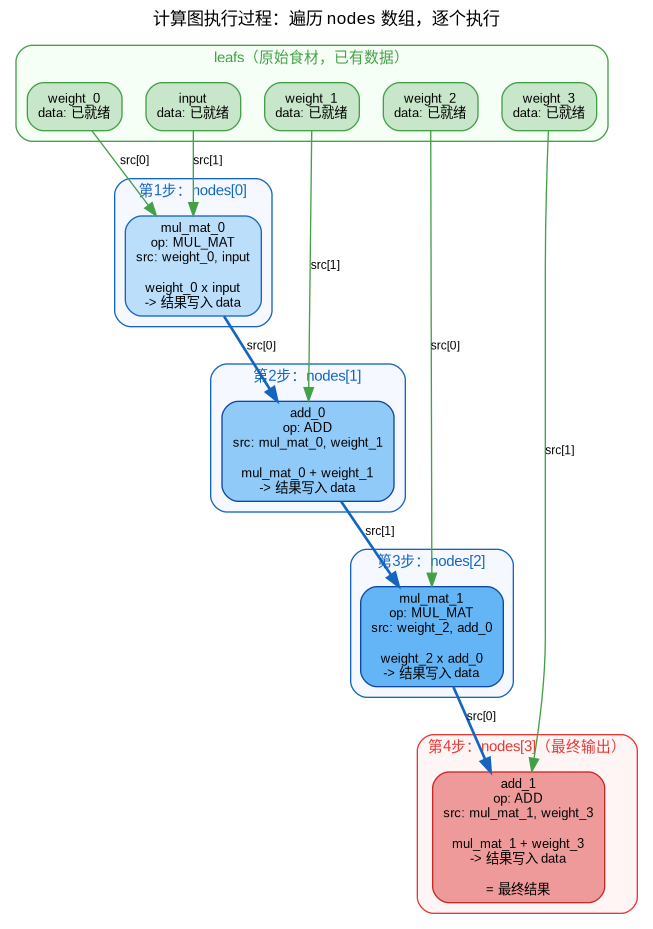
计算图的运行:
第1步:执行 nodes[0] = mul_mat_0
├─ 看 op:MUL_MAT(矩阵乘法)
├─ 看 src:src[0]=weight_0(已有数据),src[1]=input(已有数据)
└─ 执行:weight_0 × input → 结果写入 mul_mat_0->data
第2步:执行 nodes[1] = add_0
├─ 看 op:ADD(加法)
├─ 看 src:src[0]=mul_mat_0(第1步刚算好),src[1]=weight_1(已有数据)
└─ 执行:mul_mat_0 + weight_1 → 结果写入 add_0->data
... 后续节点同理,直到 add_1(最终输出)完成
量化格式:用更少的位数表示权重
量化就像把高清菜谱照片压缩成缩略图。原图(FP32)每个像素都精确记录,文件很大;缩略图(Q4_0)只保留大致的色块信息,文件小了 7 倍,远看效果差不多,但放大就能看到模糊和色差。量化也是一样——用更少的位数近似表示权重,省了内存、算得更快,但每个权重值都不再精确,会引入误差。位数越少(Q8->Q4 ->Q2),压缩越狠,误差越大,模型输出质量也会逐渐下降。
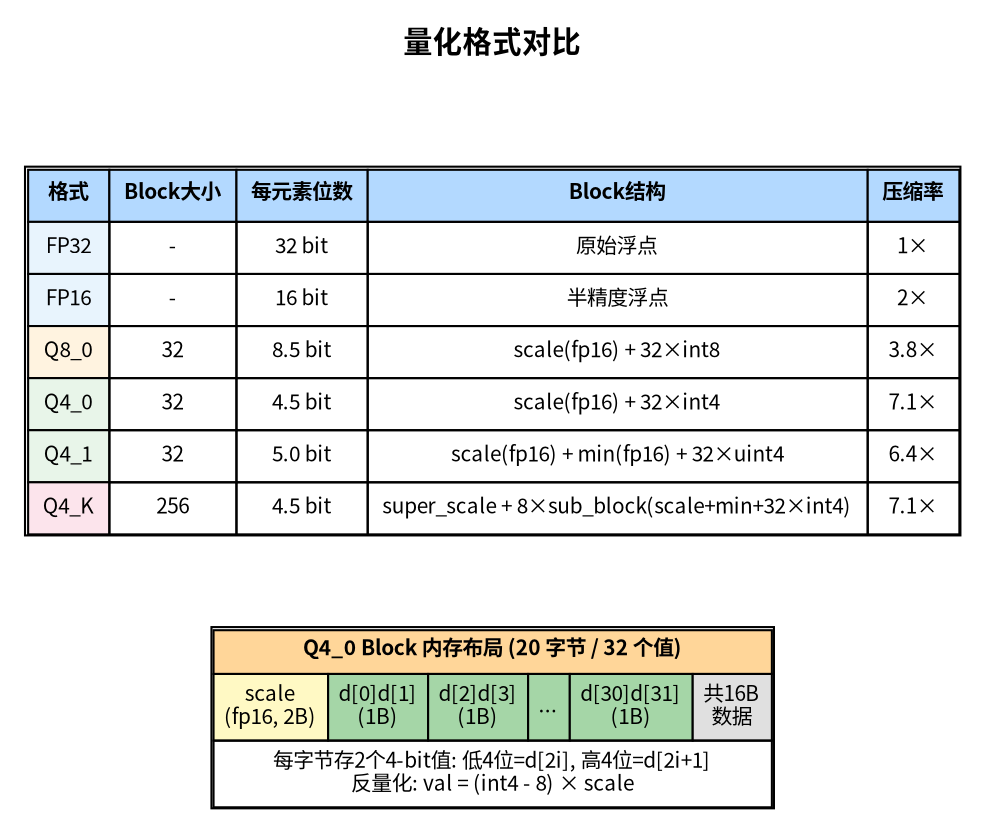
量化是 llama.cpp 能在消费级硬件上运行大模型的关键技术。核心思想是将 FP32/FP16 权重压缩为更低位宽的整数表示。
以最常用的 Q4_0 为例,每 32 个权重值组成一个 block:
- 计算这 32 个值的最大绝对值,得到 scale = max_abs / 7
- 每个值量化为 4-bit 整数:q = round(val / scale) + 8
- 反量化:val = (q – 8) × scale
一个 Q4_0 block 只占 18 字节(2B scale + 16B data),而 FP32 需要 128 字节,压缩率约 7 倍。
llama.cpp 支持多种量化格式,精度和压缩率各有取舍:
| 格式 | 位宽 | 每32权重占用 | 压缩率(vs FP32) | 精度损失 | 适用场景 |
|---|---|---|---|---|---|
| F32 | 32-bit | 128 B | 1× | 无 | 调试/基准 |
| F16 | 16-bit | 64 B | 2× | 极小 | GPU 推理 |
| Q8_0 | 8-bit | 34 B | 3.8× | 很小 | 精度敏感场景 |
| Q5_K_M | 5-bit | ~22 B | 5.8× | 小 | 精度与大小的平衡点 |
| Q4_0 | 4-bit | 18 B | 7.1× | 中等 | 最常用,性价比高 |
| Q4_K_M | 4-bit | ~20 B | 6.4× | 较小 | Q4 中精度最好 |
| Q2_K | 2-bit | ~12 B | 10.7× | 大 | 极端内存受限 |
其中 K 系列(Q4_K_M、Q5_K_M 等)是改进版量化,对不同层使用不同的量化精度——注意力层用更高精度,FFN 层用更低精度,在相同位宽下获得更好的输出质量。量化对实际推理的影响:
- 内存:LLaMA-7B 从 FP16 的 13GB 降到 Q4_0 的 3.5GB,可以在 8GB 显存的消费级 GPU 上运行
- 速度:量化权重更小,内存带宽占用更低,Decode 阶段(内存带宽瓶颈)速度反而更快
- 质量:Q8_0 几乎无损,Q4_K_M 在大多数任务上表现接近 FP16,Q2_K 在复杂推理任务上会有明显退化
llama.cpp关键技术补充
计算图的构建:llm_build_graph如何动态生成算子依赖
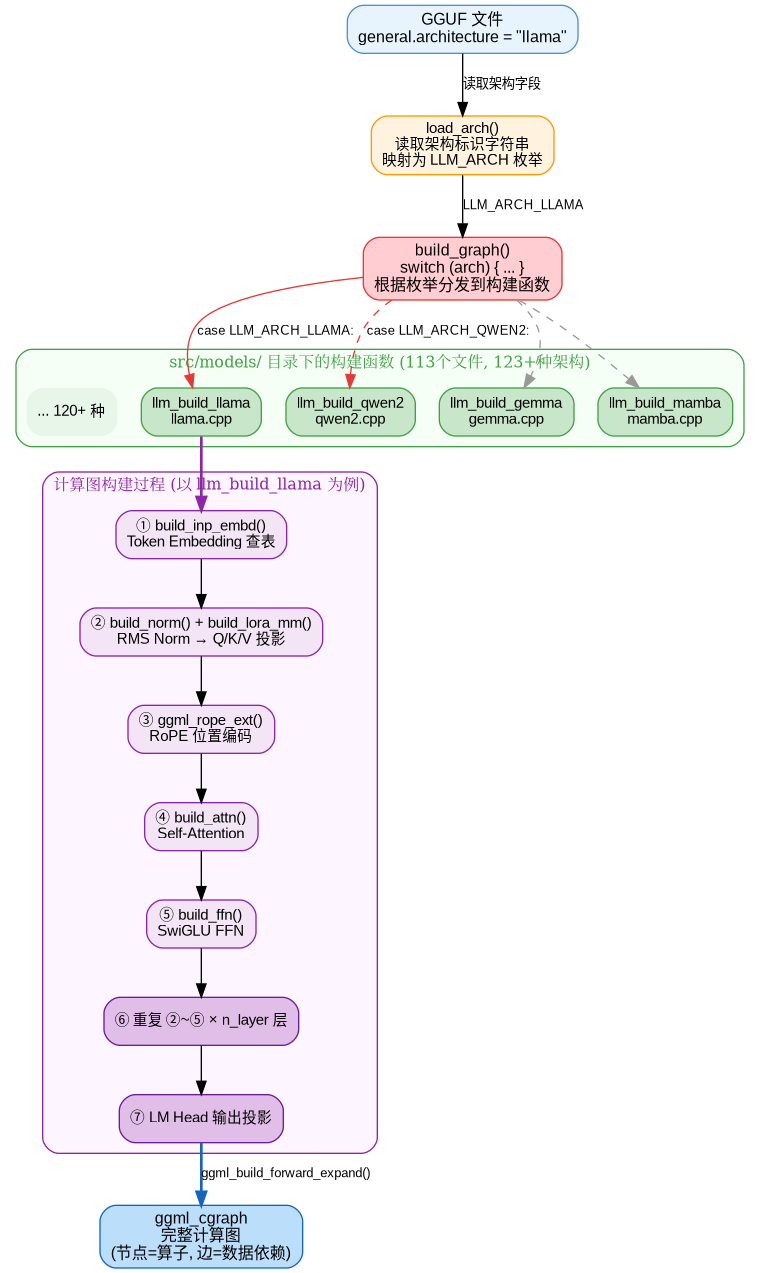
整个流程可以分为3步:架构识别、构建函数分发,逐层构建计算图。
- 架构识别:模型加载时,load_arch()(src/llama-model.cpp)从 GGUF 的 KV 元数据中读取 general.architecture 字段(如 “llama”),并映射为枚举值 LLM_ARCH_LLAMA。llama.cpp 在 src/llama-arch.h 中定义了 123+ 种架构枚举,涵盖主流的开源模型。
| 架构家族 | 代表枚举 | 说明 |
|---|---|---|
| LLaMA 系列 | LLM_ARCH_LLAMA, LLM_ARCH_LLAMA4 | Meta LLaMA 1/2/3/4 |
| Qwen 系列 | LLM_ARCH_QWEN2, LLM_ARCH_QWEN3, LLM_ARCH_QWEN35MOE | 阿里通义千问 |
| Gemma 系列 | LLM_ARCH_GEMMA, LLM_ARCH_GEMMA2, LLM_ARCH_GEMMA3 | Google Gemma |
| 状态空间模型 | LLM_ARCH_MAMBA, LLM_ARCH_MAMBA2, LLM_ARCH_RWKV6 | 非 Transformer 架构 |
| BERT 系列 | LLM_ARCH_BERT, LLM_ARCH_MODERN_BERT | 编码器模型 |
| 其他 | LLM_ARCH_FALCON, LLM_ARCH_BAICHUAN, LLM_ARCH_DEEPSEEK_V2 | 60+ 种其他架构 |
- 构建函数分发:推理时,build_graph()(src/llama-model.cpp:8134)根据架构枚举,通过一个巨大的 switch 语句(500+ 行)分发到对应的构建函数
ggml_cgraph * llama_model::build_graph(const llm_graph_params & params) const {
std::unique_ptr<llm_graph_context> llm;
switch (arch) {
case LLM_ARCH_LLAMA:
llm = std::make_unique<llm_build_llama<false>>(*this, params);
break;
case LLM_ARCH_QWEN2:
llm = std::make_unique<llm_build_qwen2>(*this, params);
break;
case LLM_ARCH_GEMMA:
llm = std::make_unique<llm_build_gemma>(*this, params);
break;
// ... 120+ 个 case
default:
GGML_ABORT("fatal error");
}
llm->build_pooling(...); // 后处理:池化、采样、输出层
llm->build_sampling();
llm->build_dense_out(...);
return llm->res->get_gf(); // 返回完整计算图
}
每个架构对应一个独立的构建类(如 llm_build_llama),实现在 src/models/ 目录下(共 113 个文件)。这些类都继承自 llm_graph_context 基类,在构造函数中完成计算图的构建。
- 逐层构建计算图:以 LLaMA 架构为例,llm_build_llama 的构造函数按照 Transformer 的标准流程,逐层调用 GGML 的算子创建函数。
// src/models/llama.cpp — llm_build_llama 构造函数(简化)
struct llm_build_llama : public llm_graph_context {
llm_build_llama(const llama_model & model, const llm_graph_params & params) {
// 1. 输入 embedding
ggml_tensor * inpL = build_inp_embd(model.tok_embd);
ggml_tensor * inp_pos = build_inp_pos();
// 2. 逐层构建
for (int il = 0; il < n_layer; ++il) {
ggml_tensor * cur;
// Attention 子图
cur = build_norm(inpL, model.layers[il].attn_norm, LLM_NORM_RMS, il);
ggml_tensor * Qcur = build_lora_mm(model.layers[il].wq, cur); // Q = Wq × x
ggml_tensor * Kcur = build_lora_mm(model.layers[il].wk, cur); // K = Wk × x
ggml_tensor * Vcur = build_lora_mm(model.layers[il].wv, cur); // V = Wv × x
Qcur = ggml_rope_ext(ctx0, Qcur, inp_pos, ...); // RoPE 位置编码
Kcur = ggml_rope_ext(ctx0, Kcur, inp_pos, ...);
cur = build_attn(inp_attn, Qcur, Kcur, Vcur, ...); // Self-Attention
cur = build_lora_mm(model.layers[il].wo, cur); // 输出投影
// 残差连接 + FFN
cur = ggml_add(ctx0, cur, inpL); // 残差①
ggml_tensor * ffn_inp = cur;
cur = build_norm(cur, model.layers[il].ffn_norm, LLM_NORM_RMS, il);
cur = build_ffn(cur, ...); // SwiGLU FFN
inpL = ggml_add(ctx0, cur, ffn_inp); // 残差②
}
// 3. 最终输出
cur = build_norm(inpL, model.output_norm, LLM_NORM_RMS, -1);
cur = build_lora_mm(model.output, cur); // LM Head: [n_vocab, n_embd] × [n_embd, 1]
ggml_build_forward_expand(gf, cur); // 展开为完整计算图
}
};
每个 build_* / ggml_* 调用并不立即执行计算,而是创建一个新的 ggml_tensor 节点并记录其 op 和 src 依赖。最终 ggml_build_forward_expand() 从输出节点反向遍历,将所有依赖的节点按拓扑序收集到 ggml_cgraph 中。
问题1:为什么不把计算图存入GGUF文件中?
牺牲通用性,换取极致的简单和快速。可以做到代码随时优化,无需重新转换模型,方便更新计算图。
问题2:权重张量如何与计算图关联?
答案是张量命名规范。GGUF文件通过张量名称提供权重数据,代码逻辑通过构建函数定义计算图结构。两者在load_tensors中通过名称匹配”焊接”在一起。
GGUF 文件中: "blk.0.attn_q.weight" → offset=0x1A00, dims=[4096,4096], type=Q4_0
↓ load_tensors() 按名称匹配
代码中: model.layers[0].wq → tensor.data = mmap_base + 0x1A00
↓ build_graph() 构建计算图
计算图: ggml_mul_mat(wq, cur)
src[0] = wq (权重, 来自GGUF)
src[1] = cur (激活值, 来自上一步计算)
↓ graph_compute() 执行
结果: Qcur = Wq × cur
KV cache的管理:逻辑槽位分配、物理内存复用
KV Cache 是推理性能的关键。它缓存了已计算的 Key 和 Value 向量,避免 Decode 阶段的重复计算。llama.cpp 的 KV Cache 采用 Ring Buffer(环形缓冲区) 设计。
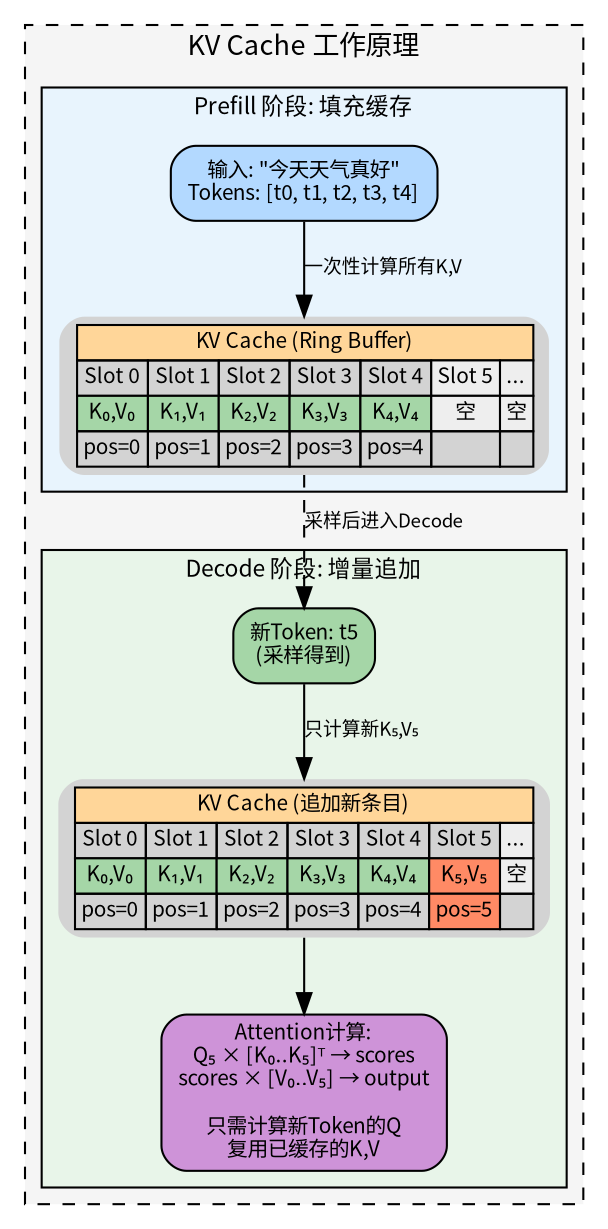
槽位分配流程(find_slot(),src/llama-kv-cache.cpp:704):
- 从 head 位置开始扫描空闲槽位
- 如果 head 已经远超已用区域,重置到 0(环形复用)
- 对每个 token 分配一个槽位,记录其 pos(位置)和 seq_id(序列ID)
- 分配失败时回滚所有修改(事务性设计)
// src/llama-kv-cache.h — 核心数据结构(简化)
struct llama_kv_cache {
// 每层的 K、V 张量
struct kv_layer {
ggml_tensor * k; // [n_embd_k_gqa, kv_size]
ggml_tensor * v; // [n_embd_v_gqa, kv_size]
};
std::vector<kv_layer> layers;
// 槽位管理
std::vector<llama_kv_cells> v_cells; // 每个槽位的状态(pos, seq_id)
std::vector<int32_t> v_heads; // 环形缓冲区头指针
};
算子是如何跑到硬件上的
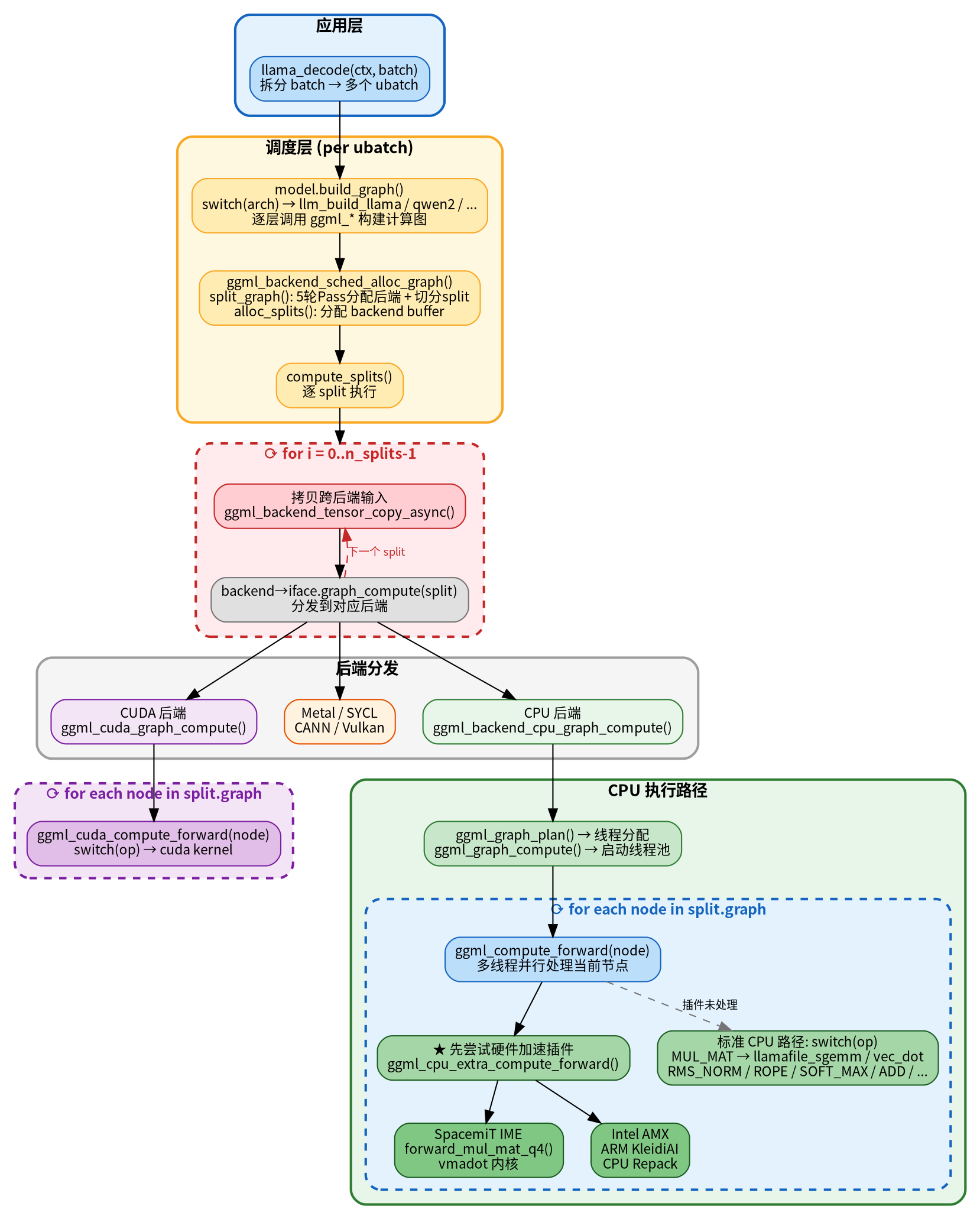
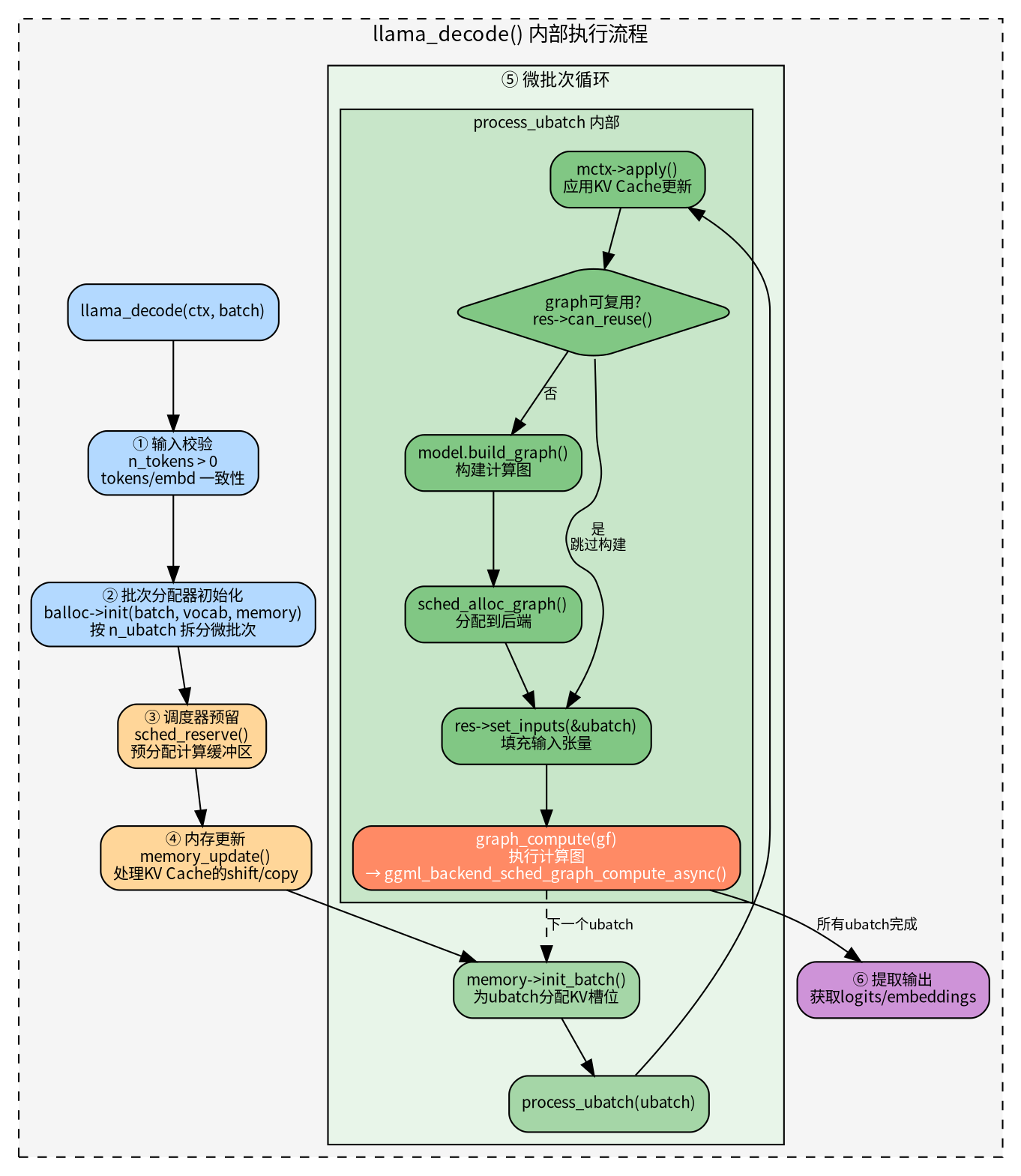
调用llama_decode调用链如下,具体代码的调用链路:
llama_decode(ctx, batch) // [src/llama-context.cpp] 应用入口
└→ llama_context::decode(batch) // [src/llama-context.cpp:1511] 拆分 batch 为多个 ubatch
└→ process_ubatch(ubatch) // [src/llama-context.cpp:1159] 处理每个微批次
│
├→ model.build_graph(params) // [src/llama-model.cpp:8134] Step 1: 构建计算图
│ └→ switch(arch) // 根据模型架构分发(500+ 行 switch)
│ ├→ llm_build_llama(model, params) // [src/models/llama.cpp] 逐层调用 ggml_*
│ ├→ llm_build_qwen2(model, params) // [src/models/qwen2.cpp]
│ └→ ...(113种架构,113个文件)
│
├→ ggml_backend_sched_alloc_graph(sched,gf) // [ggml/src/ggml-backend.cpp] 分配张量内存
│
└→ graph_compute(gf) // [src/llama-context.cpp:2145] Step 2: 执行计算图
└→ ggml_backend_sched_graph_compute_async(sched, gf) // [ggml/src/ggml-backend.cpp:1797]
├→ 绑定 backend_id // 遍历节点,根据 supports_op() 分配后端
├→ 分割子图 (splits) // 相同后端的连续节点归为一组
└→ ggml_backend_sched_compute_splits(sched) // [ggml/src/ggml-backend.cpp:1445]
└→ for each split: // --->逐个子图执行(确定后端)
└→ backend->iface.graph_compute(split) // [ggml/src/ggml-backend.cpp:364]
│
├→ CUDA 后端: ggml_cuda_graph_compute() // [ggml/src/ggml-cuda/ggml-cuda.cu]
│ └→ for each node:
│ ggml_cuda_compute_forward(node) // switch(op) → ggml_cuda_mul_mat() 等
│
├→ Metal / SYCL / CANN / Vulkan / ... // 各自的 graph_compute()
│
└→ CPU 后端(下面展开)
CPU 后端的执行路径(以 SpacemiT RISC-V 为例):
backend->iface.graph_compute(split)
└→ ggml_backend_cpu_graph_compute() // [ggml/src/ggml-cpu/ggml-cpu.cpp:170]
├→ ggml_graph_plan(cgraph, n_threads) // 计算工作缓冲区大小、线程分配
└→ ggml_graph_compute(cgraph, &cplan) // [ggml/src/ggml-cpu/ggml-cpu.c:3223]
└→ ggml_graph_compute_thread() // 多线程,每个线程遍历 nodes
└→ for each node:
ggml_compute_forward(params, node) // [ggml/src/ggml-cpu/ggml-cpu.c:1694]
│
│ //关键分叉点:先尝试硬件加速插件
├→ ggml_cpu_extra_compute_forward(params, node) // [ggml/src/ggml-cpu/traits.cpp:12]
│ └→ 遍历注册的 extra_buffer_types:
│ ├→ SpacemiT IME (GGML_USE_CPU_RISCV64_SPACEMIT)
│ │ └→ tensor_traits::compute_forward()
│ │ └→ forward_mul_mat_q4() // [spacemit/ime.cpp]
│ │ └→ IME 内核 (vmadot) // [spacemit/ime1_kernels.cpp]
│ ├→ Intel AMX (__AMX_INT8__)
│ ├→ ARM KleidiAI (GGML_USE_CPU_KLEIDIAI)
│ └→ CPU Repack (GGML_USE_CPU_REPACK)
│
│ // 如果没有插件处理,走标准 CPU 路径
└→ switch (node->op)
├→ MUL_MAT: ggml_compute_forward_mul_mat() // 标准 GEMM
│ └→ llamafile_sgemm() 或 vec_dot // SIMD 加速
├→ RMS_NORM: ggml_compute_forward_rms_norm()
├→ ROPE: ggml_compute_forward_rope()
├→ SOFT_MAX: ggml_compute_forward_soft_max()
├→ ADD: ggml_compute_forward_add()
└→ ...(100+ 种算子)
核心思路:构建计算图 → 调度器分配后端 → 遍历节点逐个执行算子。CPU 后端有一个插件机制(extra_buffer_type),允许各硬件平台(SpacemiT、AMX、KleidiAI)注册自己的加速实现,优先于标准 CPU 路径执行。
LLM 推理的核心算子与加速策略
ggml 定义了 100+ 种算子(enum ggml_op,见 ggml/include/ggml.h),但跑一个 Transformer 大语言模型,真正用到的只有十几种。按计算量排序如下。MUL_MAT 一个算子就占了 90% 以上的计算量。这就是为什么各硬件平台的加速工作几乎都集中在矩阵乘法上。
| 算子 | 作用 | 计算量占比 | 说明 |
|---|---|---|---|
| MUL_MAT | 矩阵乘法 | ~90% | Q/K/V 投影、FFN、LM Head,几乎所有”权重 x 输入”都是它 |
| FLASH_ATTN_EXT | 融合注意力 | ~5% | 将 QK^T、softmax、V 融合为一个算子,减少显存访问 |
| ROPE | 旋转位置编码 | <1% | 给 Q、K 注入位置信息 |
| RMS_NORM | RMS 归一化 | <1% | 每层 Attention 和 FFN 前的归一化 |
| SOFT_MAX | Softmax | <1% | 注意力分数归一化(未融合时使用) |
| ADD | 逐元素加法 | <1% | 残差连接 |
| MUL | 逐元素乘法 | <1% | SwiGLU 中的门控乘法 |
| SILU / GELU | 激活函数 | <1% | FFN 中的非线性激活 |
| GET_ROWS | 行查找 | <1% | Embedding 查表:token_id → 向量 |
| CPY / CONT / VIEW / PERMUTE | 数据搬运/变形 | ~0% | 不做计算,只改变数据的排列方式 |
llama.cpp 通过后端接口对接了 10+ 种硬件平台,每个平台重点加速的算子不同:
| 平台 | 后端文件 | 重点加速算子 | 加速手段 |
|---|---|---|---|
| x86 CPU | ggml-cpu/arch/x86/ | MUL_MAT | AVX2/AVX-512 SIMD,量化内核 |
| ARM CPU | ggml-cpu/arch/arm/ | MUL_MAT | NEON/SVE 向量指令 |
| RISC-V CPU (SpacemiT) | ggml-cpu/spacemit/ | MUL_MAT, NORM, RMS_NORM | IME 矩阵扩展(Q4_0/Q4_1/Q4_K),向量扩展 (RVV) |
| NVIDIA GPU | ggml-cuda/ (61个.cu文件) | MUL_MAT, FLASH_ATTN, ROPE, SOFT_MAX 等 | CUDA Kernel,Tensor Core,cuBLAS |
| Apple GPU | ggml-metal/ | MUL_MAT, FLASH_ATTN 等 | Metal Shader |
| Intel GPU | ggml-sycl/ | MUL_MAT 等 | SYCL/oneAPI |
| 华为 NPU | ggml-cann/ | MUL_MAT 等 | CANN 算子库 |
| 通用 GPU | ggml-vulkan/ | MUL_MAT 等 | Vulkan Compute Shader |
CPU 后端通常只加速 MUL_MAT(因为其他算子计算量太小,优化收益不大),但 SpacemiT 是个例外——除了 MUL_MAT,还通过 IME 加速了 NORM 和 RMS_NORM。GPU 后端则会加速更多算子,原因不是这些小算子在GPU 上跑得更快,而是为了避免来回搬运:如果 GPU 只加速 MUL_MAT,一个 Transformer 层的执行路径会变成 GPU 做矩阵乘->搬到 CPU 做 RMS_NORM ->搬回 GPU 做矩阵乘 ->搬到 CPU 做 ROPE ->搬回 GPU…每次搬运都要走 PCIe 总线,延迟高、带宽有限。把小算子也留在 GPU 上,整层计算都在显存里完成,省掉的搬运开销远大于小算子本身的计算开销。这也是调度器 Pass 2 让 GPU “吞噬”相邻节点的原因——尽量减少 split 数量和跨设备传输。
CUDA 后端是最完整的,61 个 .cu 文件覆盖了几乎所有算子。其他后端通常只实现高频算子,不支持的算子会自动 fallback 到 CPU 执行。
了解了整体架构和各平台的加速策略后,接下来深入调度层的工作机制。计算图构建完毕后,调度器通过四个阶段将其送上硬件:
后端抽象层:屏蔽硬件差异的接口
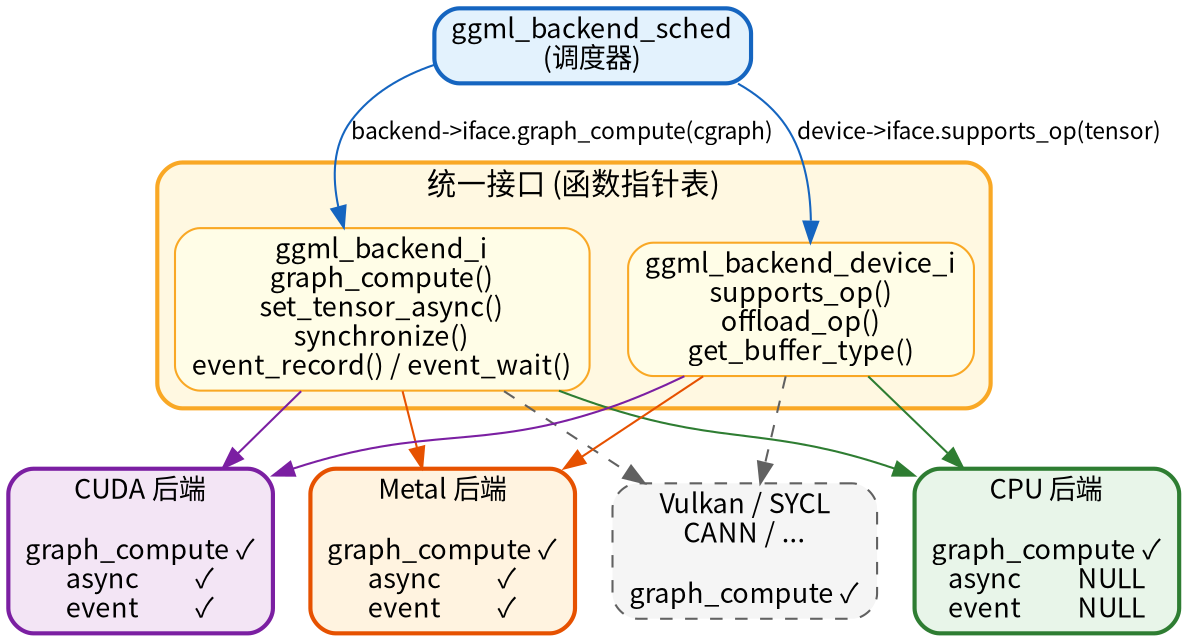
GGML 通过一套 C 接口(虚函数表)将硬件差异封装在后端实现中,上层代码完全不感知底层是 CPU、CUDA 还是 Metal。
// ggml/src/ggml-backend-impl.h:87 — 后端接口
struct ggml_backend_i {
const char * (*get_name)(ggml_backend_t backend);
void (*free)(ggml_backend_t backend);
// 异步数据传输
void (*set_tensor_async)(ggml_backend_t, ggml_tensor *, const void *, size_t, size_t);
void (*get_tensor_async)(ggml_backend_t, const ggml_tensor *, void *, size_t, size_t);
bool (*cpy_tensor_async)(ggml_backend_t src, ggml_backend_t dst, const ggml_tensor *, ggml_tensor *);
void (*synchronize)(ggml_backend_t);
// 核心:计算图执行
enum ggml_status (*graph_compute)(ggml_backend_t, struct ggml_cgraph *);
// 事件同步(流水线并行)
void (*event_record)(ggml_backend_t backend, ggml_backend_event_t event);
void (*event_wait)(ggml_backend_t backend, ggml_backend_event_t event);
};
// 后端实例
struct ggml_backend {
ggml_guid_t guid;
struct ggml_backend_i iface; // ★ 函数指针表(C语言的"虚函数")
ggml_backend_dev_t device; // 所属设备
void * context; // 后端私有数据(如 CUDA stream)
};
这是经典的 C 语言多态模式:通过函数指针表实现接口抽象。上层代码调用 backend->iface.graph_compute(backend, cgraph) 时,实际执行的是 CPU/CUDA/Metal 各自的实现。不同后端填入各自的函数指针:
// CPU后端 — ggml/src/ggml-cpu/ggml-cpu.cpp:193
static const struct ggml_backend_i ggml_backend_cpu_i = {
/* .graph_compute = */ ggml_backend_cpu_graph_compute, // ★ 核心
/* .set_tensor_async = */ NULL, // CPU不需要异步传输
/* .synchronize = */ NULL, // CPU不需要同步
/* .event_record = */ NULL, // CPU不支持事件
};
// CUDA后端(对比)
static const struct ggml_backend_i ggml_backend_cuda_i = {
/* .graph_compute = */ ggml_cuda_graph_compute,
/* .event_record = */ ggml_backend_cuda_event_record, // GPU支持事件
/* .event_wait = */ ggml_backend_cuda_event_wait,
// ... 支持异步传输等
};
CPU 后端的大部分可选接口都是 NULL——因为 CPU 上所有操作天然是同步的,不需要异步传输和事件机制。每个后端还需要实现设备接口,声明自己支持哪些操作。supports_op 和 offload_op 是调度决策的基础——调度器通过询问每个后端”是否能跑这个算子?
struct ggml_backend_device_i {
const char * (*get_name)(ggml_backend_dev_t dev);
void (*get_memory)(ggml_backend_dev_t dev, size_t * free, size_t * total);
// ★ 调度器用这两个方法决定算子分配
bool (*supports_op)(ggml_backend_dev_t, const struct ggml_tensor * op); // 是否支持该算子
bool (*offload_op)(ggml_backend_dev_t, const struct ggml_tensor * op); // 是否建议卸载到此设备
ggml_backend_buffer_type_t (*get_buffer_type)(ggml_backend_dev_t); // 获取缓冲区类型
};
子图分割与后端调度
ggml_backend_sched 是多后端协作的核心调度器。它的职责是:将计算图中的每个算子分配到最合适的后端,按后端边界切分子图,并处理跨后端的数据搬运。
一个计算图里可能混合了不同后端的算子——前20层权重在 GPU,后12层在 CPU。但每个后端的 graph_compute() 只能执行自己设备上的节点,不能跨设备访问。所以在执行之前,必须把一张大图按后端边界切分成多个子图(split),每个 split 内的节点都在同一个后端上,跨 split 的数据通过拷贝节点搬运。这就是 ggml_backend_sched(调度器)的核心工作:先决定每个节点跑在哪个后端(调度),再按后端边界切分子图(分割),最后为跨后端的张量插入拷贝节点。整个过程通过5轮 Pass 完成。
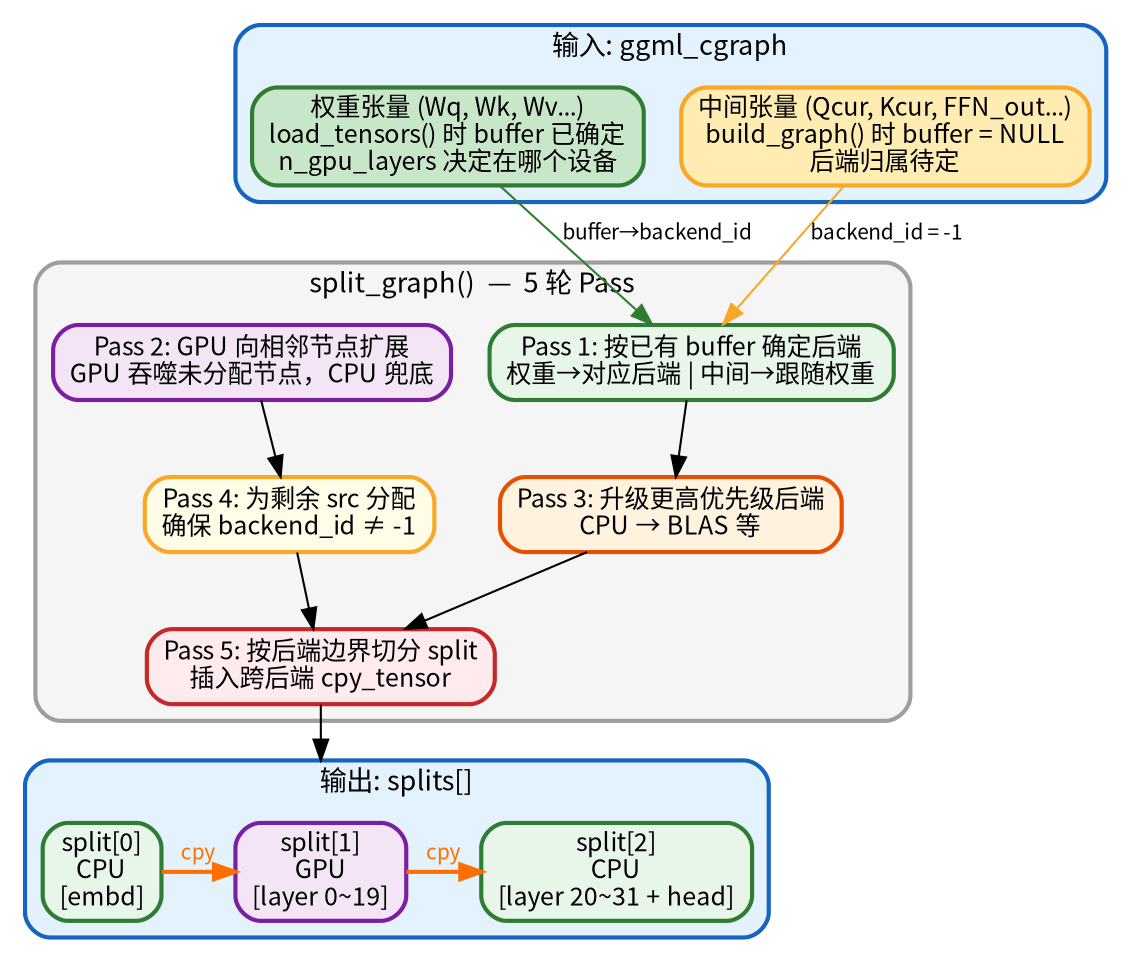
- 顶层:顶部是计算图中的两类张量:权重张量(Wq、Wk 等)在 load_tensors() 阶段已有确定的 buffer,n_gpu_layers决定了它们的设备归属;中间张量(Qcur、FFN_out 等)在 build_graph() 时创建,buffer 为 NULL,后端待定。
- 中间:中间是 split_graph() 的5轮 Pass:Pass 1 根据已有 buffer 确定后端,中间张量跟随权重;Pass 2 让 GPU 向相邻未分配节点扩展,CPU 兜底;Pass 3 尝试升级到更高优先级后端;Pass 4 确保无遗漏;Pass 5 按后端边界切分 split 并插入跨后端的 cpy_tensor。
- 底层:底部是输出的 splits 数组——以 n_gpu_layers=20 的32层模型为例,切出3个 split,相邻 split 之间通过 cpy 完成跨设备数据搬运。

以 n_gpu_layers=20、模型32层为例:
Pass 1-4 后的 nodes 后端分配:
[embd(CPU), layer0_norm(GPU), layer0_attn(GPU), ..., layer19_ffn(GPU), layer20_norm(CPU), ..., lm_head(CPU)]
Pass 5 遍历 nodes:
i=0: embd → backend=CPU, cur=CPU → split[0] 开始
i=1: layer0_norm → backend=GPU, cur=CPU → ★ 后端变了! 切分!
split[0].i_end=1, split[1] 开始, inputs=[embd]
i=2~N: layer0~19 → 全是GPU → 不切
i=N+1: layer20_norm → backend=CPU → ★ 后端变了! 切分!
split[1].i_end=N+1, split[2] 开始, inputs=[layer19_output]
...直到结束
结果: 3个splits
split[0]: CPU [embd] inputs=[]
split[1]: GPU [layer0~19] inputs=[embd]
split[2]: CPU [layer20~31 + lm_head] inputs=[layer19_output]
对于跨后端的输入张量,Pass 5 会创建拷贝张量并替换原始图中的 src 指针:
Pass 4 后的后端分配:
nodes: [A, B, C, D, E, F, G]
后端ID: [GPU,GPU,GPU,CPU,CPU,GPU,GPU]
Pass 5 切分结果:
split[0]: backend=GPU, nodes=[A, B, C]
inputs: [] (无跨后端输入)
split[1]: backend=CPU, nodes=[D, E]
inputs: [C_output] ← 需要从GPU拷贝到CPU
操作: D.src[0] 被替换为 C_output 的CPU拷贝
split[2]: backend=GPU, nodes=[F, G]
inputs: [E_output] ← 需要从CPU拷贝到GPU
操作: F.src[0] 被替换为 E_output 的GPU拷贝
切分的目的是让每个 split 内部的所有节点都在同一个后端上执行,避免单个 graph_compute调用中出现跨设备访问。
CPU后端执行模型:节点间串行、节点内并行
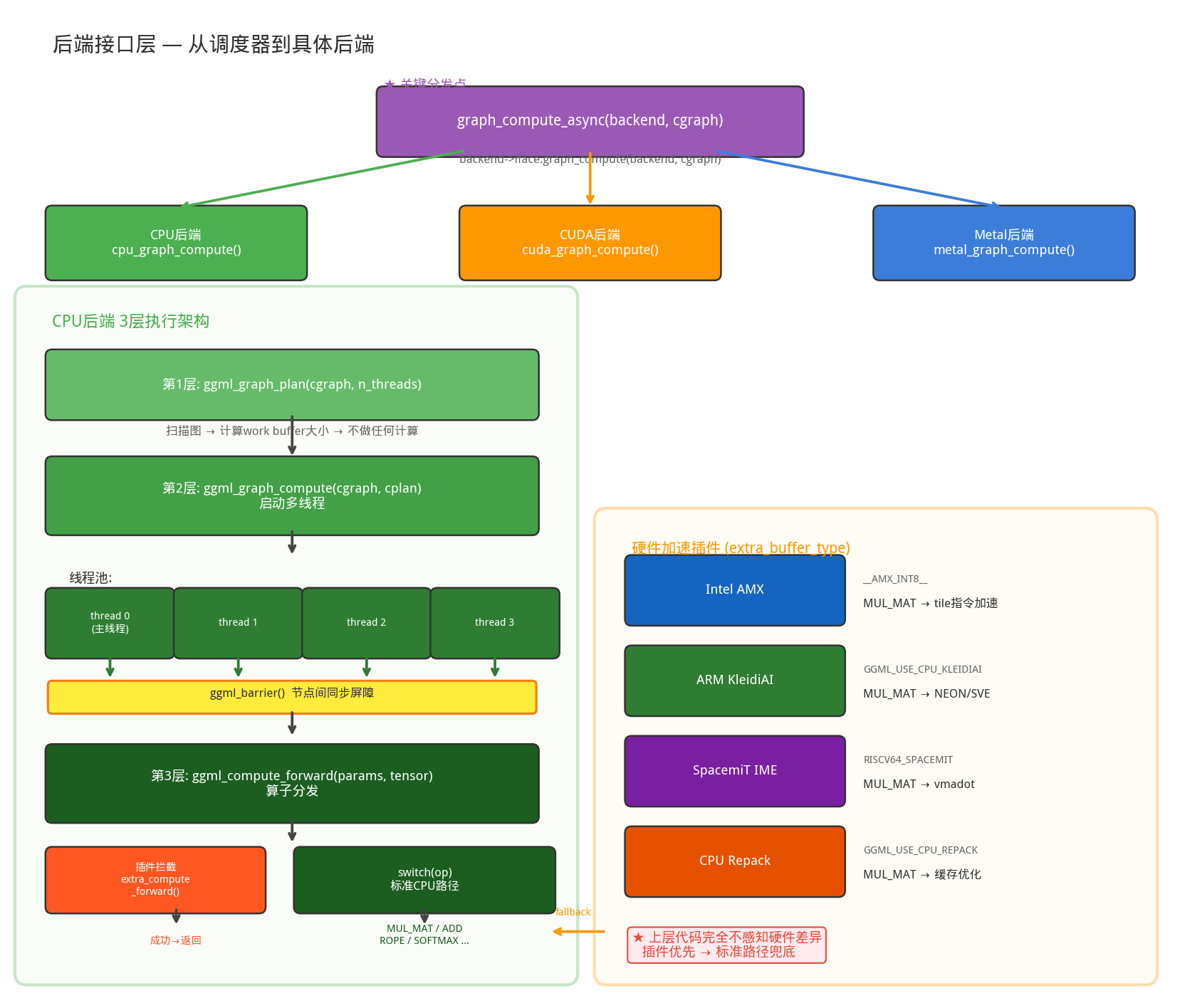
当 compute_splits() 调用 backend->iface.graph_compute() 进入 CPU 后端时,执行分为三层:
ggml_backend_cpu_graph_compute(backend, cgraph) // 后端入口
├→ ggml_graph_plan(cgraph, n_threads, threadpool) // 规划:计算work buffer大小
└→ ggml_graph_compute(cgraph, &cplan) // 执行:启动多线程
└→ ggml_graph_compute_thread(worker) // 每个线程
└→ for each node:
ggml_compute_forward(params, node) // 算子分发
ggml_barrier(threadpool) // 线程同步屏障
多线程执行
CPU 后端启动 N 个线程,每个线程执行相同的 ggml_graph_compute_thread() 函数:
// ggml/src/ggml-cpu/ggml-cpu.c:2948
static thread_ret_t ggml_graph_compute_thread(void * data) {
struct ggml_compute_params params = {
.ith = state->ith, // 我是第几个线程
.nth = n_threads, // 总共几个线程
.wdata = cplan->work_data, // 共享work buffer指针
};
// ★ 所有线程遍历相同的节点序列
for (int node_n = 0; node_n < cgraph->n_nodes; node_n++) {
struct ggml_tensor * node = cgraph->nodes[node_n];
// 每个线程都调用同一个算子,内部根据 ith/nth 分工
ggml_compute_forward(¶ms, node);
// ★ 节点间屏障:所有线程必须完成当前节点才能进入下一个
ggml_barrier(state->threadpool);
}
}
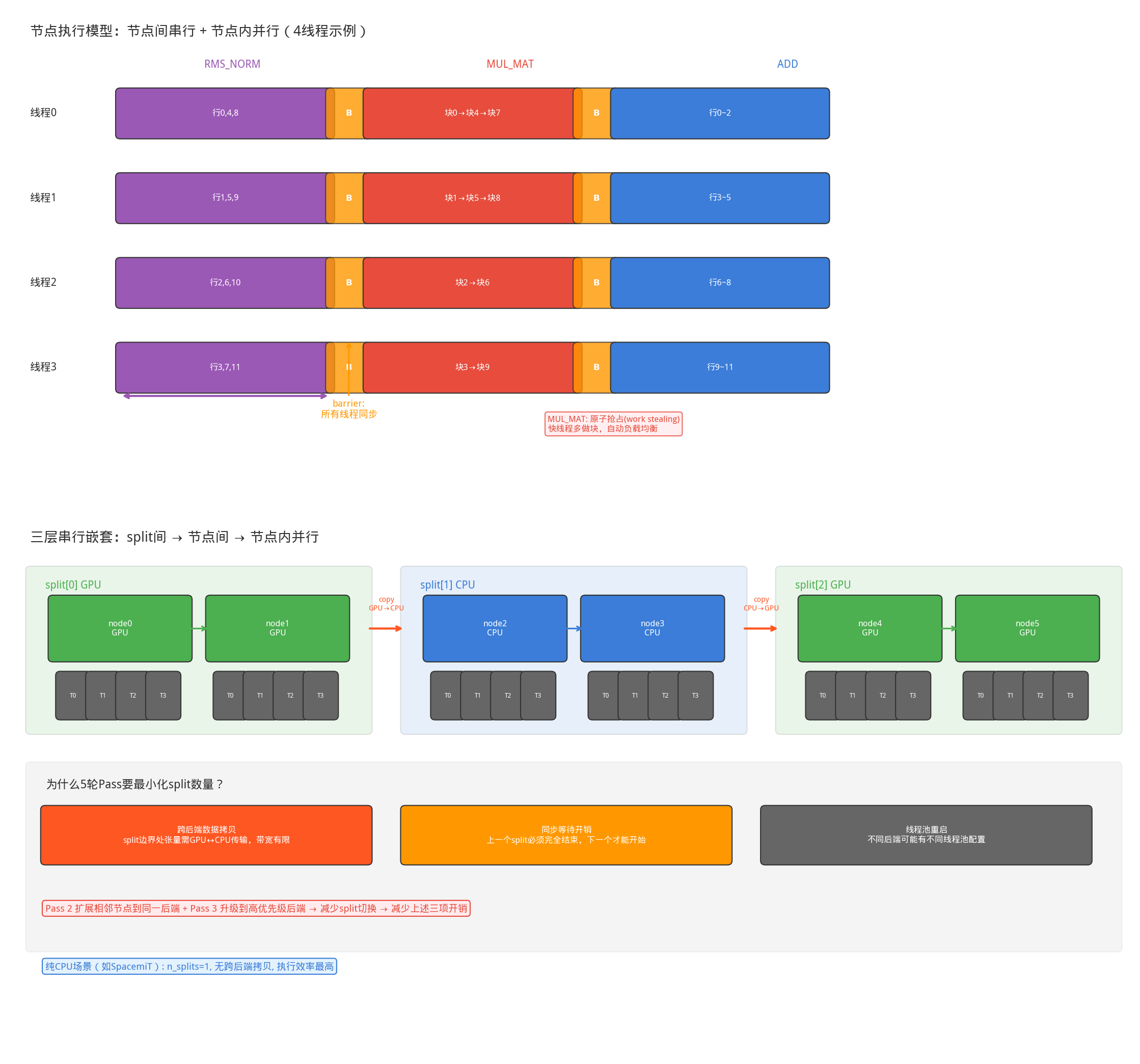
理解了”节点间串行、节点内并行”的执行模型后,就能理解图分割调度的设计逻辑:
- 节点间串行意味着:一个 split 内的所有节点必须在同一个后端上顺序执行。如果计算图中的节点分属不同后端(如 GPU 和 CPU),就必须把图切成多个 split,每个 split 内部是同一后端的连续节点序列。
原始计算图(拓扑序):
node0[GPU] → node1[GPU] → node2[CPU] → node3[CPU] → node4[GPU] → node5[GPU]
分割后:
split[0]: backend=GPU, nodes=[node0, node1]
split[1]: backend=CPU, nodes=[node2, node3] ← node1→node2 需要 GPU→CPU 拷贝
split[2]: backend=GPU, nodes=[node4, node5] ← node3→node4 需要 CPU→GPU 拷贝
- split 之间也是串行的。compute_splits() 逐个执行 split,每个 split 完成后才执行下一个:
// ggml/src/ggml-cpu/ggml-cpu.c (简化)
for (int i = 0; i < sched->n_splits; i++) {
// 1. 拷贝跨后端输入
for (int j = 0; j < split->n_inputs; j++) {
ggml_backend_tensor_copy_async(input_backend, split_backend, input, copy);
}
// 2. 在该后端上执行整个子图(节点间串行、节点内并行)
ggml_backend_graph_compute_async(split_backend, &split->graph);
// 3. 记录事件(用于流水线优化)
ggml_backend_event_record(split->event, split_backend);
}
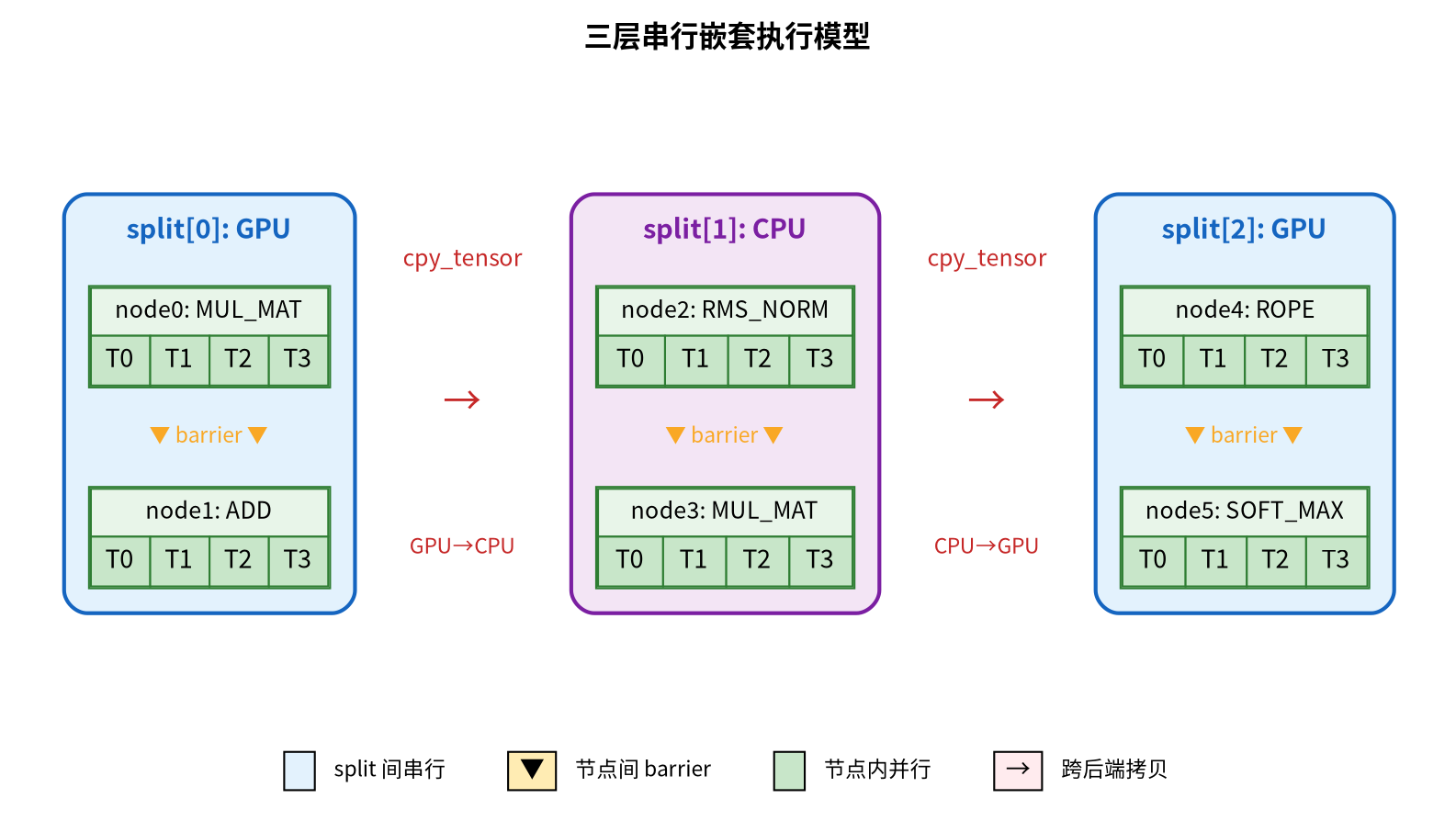
因此,整体执行模型是三层串行嵌套:
[图片]
每次 split 切换都有代价:跨后端数据拷贝(split 边界处的张量需要从一个后端搬到另一个)、同步开销(上一个 split 必须完全结束下一个才能开始)、线程池重启(不同后端可能有不同的线程池配置)。这就是 Pass 2(扩展相邻节点到同一后端)和 Pass 3(升级到更高优先级后端)的核心动机——让尽可能多的连续节点在同一后端执行,减少 split 切换。
节点内并行的3种模式
不同算子采用不同的并行策略:
模式一:行交错(Stride) — SOFT_MAX、RMS_NORM 等使用。每个线程处理第 ith, ith+nth, ith+2*nth, … 行:
4线程处理12行:
线程0: 行0, 行4, 行8
线程1: 行1, 行5, 行9
线程2: 行2, 行6, 行10
线程3: 行3, 行7, 行11
模式二:行分块(Block) — ADD、MUL 等使用。每个线程处理连续的一段行,有利于内存局部性:
4线程处理12行:
线程0: 行0, 行1, 行2
线程1: 行3, 行4, 行5
线程2: 行6, 行7, 行8
线程3: 行9, 行10, 行11
模式三:原子抢占(Work Stealing) — MUL_MAT 使用。将输出矩阵切成小块,线程通过原子操作抢占下一个可用块:这种模式的优势:自动负载均衡。快的线程多做几块,慢的线程少做几块,避免木桶效应。
// ggml/src/ggml-cpu/ggml-cpu.c:1235
while (true) {
int current_chunk = atomic_fetch_add(&tp->current_chunk, 1);
if (current_chunk >= nchunk0 * nchunk1) break; // 没有更多块了
// 计算该块的行列范围,执行矩阵乘法
}
算子分发
ggml_compute_forward() 是从后端到具体算子的最后一跳:
// ggml/src/ggml-cpu/ggml-cpu.c:1686
static void ggml_compute_forward(struct ggml_compute_params * params, struct ggml_tensor * tensor) {
// ★ 优先尝试硬件加速插件
if (ggml_cpu_extra_compute_forward(params, tensor)) {
return; // 插件处理了,直接返回
}
// 标准CPU路径:大switch分发
switch (tensor->op) {
case GGML_OP_MUL_MAT: ggml_compute_forward_mul_mat(params, tensor); break;
case GGML_OP_ADD: ggml_compute_forward_add(params, tensor); break;
case GGML_OP_ROPE: ggml_compute_forward_rope(params, tensor); break;
case GGML_OP_RMS_NORM: ggml_compute_forward_rms_norm(params, tensor); break;
case GGML_OP_SOFT_MAX: ggml_compute_forward_soft_max(params, tensor); break;
// ... 100+ 种算子
}
}
插件注册机制
ggml_backend_cpu_get_extra_buffer_types() 返回的插件列表:
├→ SpacemiT IME (GGML_USE_CPU_RISCV64_SPACEMIT)
│ └→ MUL_MAT + Q4_0/Q4_1/Q4_K → IME内核
│ └→ RMS_NORM/NORM → RVV实现
├→ Intel AMX (__AMX_INT8__)
│ └→ MUL_MAT + 量化类型 → AMX tile指令加速
├→ ARM KleidiAI (GGML_USE_CPU_KLEIDIAI)
│ └→ MUL_MAT → NEON/SVE优化内核
└→ CPU Repack (GGML_USE_CPU_REPACK)
└→ MUL_MAT → 重排权重布局以优化缓存访问
上层代码完全不感知硬件差异。无论是 x86 的 AMX、ARM 的 KleidiAI 还是 RISC-V 的 IME,都通过同一个插件接口注入,标准 CPU 路径作为通用 fallback 始终可用。
CPU后端加速算子:以SpacemiT IME(K1)为例
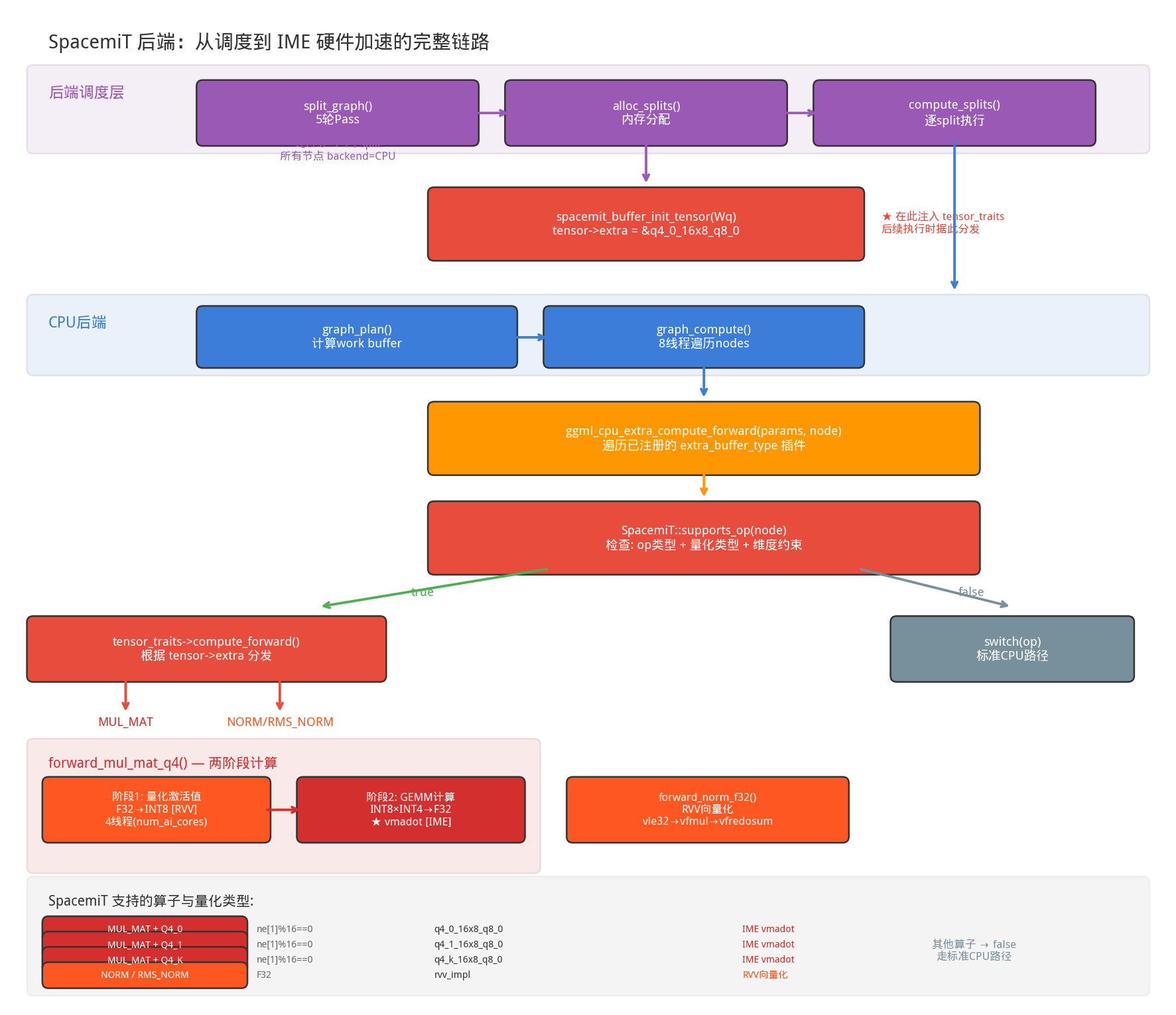
前面介绍了 CPU 后端的通用执行模型和插件机制。本节以 SpacemiT IME 为具体案例,展示一个硬件加速插件如何实现矩阵乘法的全流程优化。
SpacemiT 支持的算子总览
SpacemiT 后端通过 extra_buffer_type 插件机制注册(ggml-cpu/spacemit/ime.cpp),目前支持 3 个算子:
| 算子 | 加速方式 | 支持的权重类型 (src[0]) | 输入类型 (src[1]) | 额外条件 |
|---|---|---|---|---|
| MUL_MAT | IME 硬件矩阵引擎 | Q4_0, Q4_1, Q4_K | F32 | src[0] 为 2D,ne[1] % 16 0 |
| NORM | RVV 向量指令 | — | F32 | 无 |
| RMS_NORM | RVV 向量指令 | — | F32 | 无 |
分发逻辑(ime.cpp 中的 get_tensor_traits()):
// MUL_MAT → 根据量化类型选择对应的 IME tensor_traits
static const tensor_traits<block_q4_0, 8, 16> q4_0_16x8_q8_0; // Q4_0 → IME 内核
static const tensor_traits<block_q4_1, 8, 16> q4_1_16x8_q8_0; // Q4_1 → IME 内核
static const tensor_traits<block_q4_K, 8, 16> q4_k_16x8_q8_0; // Q4_K → IME 内核
// NORM / RMS_NORM → 走 RVV 向量实现
static const tensor_traits_common rvv_impl;
IME矩阵乘法执行流程
IME(Integer Matrix Extension) 是进迭时空 K1/K1X RISC-V 处理器的硬件加速指令集,专门用于量化整数矩阵乘法。其核心指令是 vmadot(向量乘累加点积)。
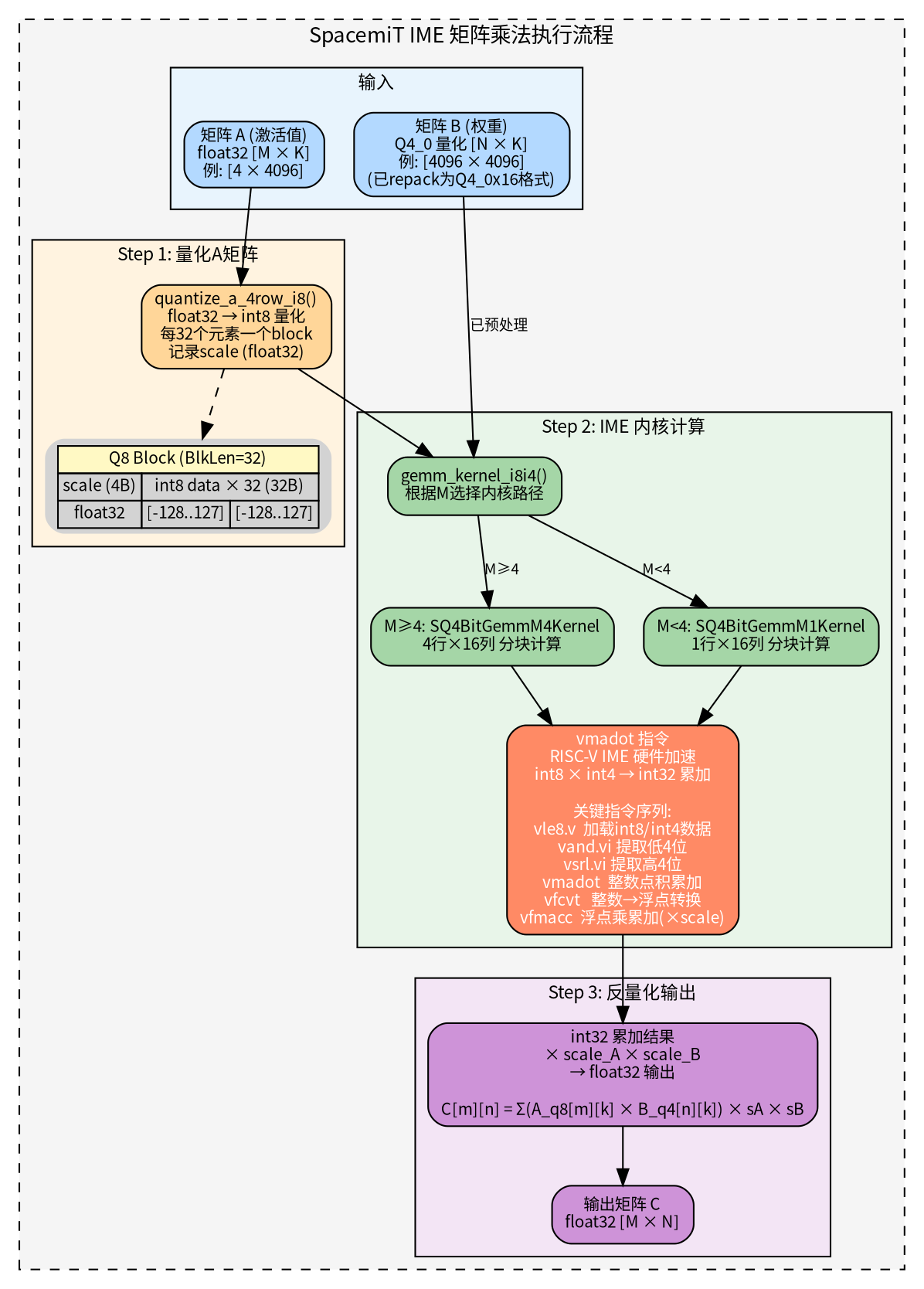
整个矩阵乘法分为三个阶段:
- 阶段一:权重预处理(Repack):模型加载时,权重从标准 Q4_0 格式重排为 IME 友好的 Q4_0x16 交错格式:
// ggml-cpu/spacemit/ime.cpp:230 — Q4_0 重排
// 标准布局: [block0][block1]...[block15]
// 交错布局: [scale0..scale15][data0..data15]
// 16 个 block 的 scale 连续存放,data 连续存放
// 这样 RISC-V 向量指令可以一次加载 16 个 block 的数据
void repack_q4_0_to_q4_0_16_bl(const block_q4_0 * src, block_q4_0x16 * dst, int64_t n);
- 阶段二:激活值量化(Runtime):每次推理时,将 float32 的激活值(A 矩阵)在线量化为 int8:
// ggml-cpu/spacemit/ime1_kernels.cpp:79 — 4行同时量化
// 使用 RISC-V 向量指令加速:
// vle32.v 加载 float32 数据
// vfabs.v 取绝对值,求 scale
// vfdiv.vf 除以 scale
// vfcvt.x.f 浮点转整数
// vse8.v 存储 int8 结果
void quantize_a_4row_i8(const float * src, int8_t * dst, float * scales,
int64_t K, int64_t lda, int blk_len);
- 阶段三:IME 内核计算:核心计算由 gemm_kernel_i8i4() 完成(ime1_kernels.cpp:3157),根据 M 的大小选择不同路径:
// M >= 4 时使用 4 行内核,M < 4 时使用单行内核
if (CountM >= 4) {
SQ4BitGemmM4Kernel_CompInt8(...) // 4行×16列 分块
return 4;
} else {
SQ4BitGemmM1Kernel_CompInt8(...) // 1行×16列 分块
return 1;
}
内核中的关键 RISC-V 汇编指令序列:
# ime1_kernels.cpp:1171 — 核心计算宏
vle8.v v4, (s1) # 加载 Q4 量化数据
vand.vi v0, v4, 15 # 提取低 4 位 (值 0-15)
vsrl.vi v4, v4, 4 # 提取高 4 位
vmadot v16, v10, v2 # IME 核心指令!int8 × int4 → int32 累加
# 硬件在一个周期内完成多个乘累加
vfcvt.f.x.v v16, v16 # int32 → float32
vfmacc.vv v28, v16, v24 # float 乘累加: result += int_result × scale_A × scale_B
vmadot 是 IME 的核心,它在硬件层面实现了 int8 × int4 的点积累加,这就是SpacemiT K1大模型加速的关键。
参考:
- https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison