CFS调度实现
时间计算
vruntime与runtime
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
//实际运行时间 = 当前时刻 减去上次执行时刻
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
//重新更新开始执行时刻
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
//累计进程实际运行的时间
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq->exec_clock, delta_exec);
//累计计算进程的虚拟时间,公式vruntime = delta_exec*(nice_0_weight/weight)
curr->vruntime += calc_delta_fair(delta_exec, curr);
//更新min_vruntime
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cgroup_account_cputime(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
schduer_tick最终会update_curr来个更新当前进程的相关时间信息,包括进程实际运行的时间runtime,虚拟时间vruntime一级min_vruntime。
ideal_runtime
在Linux系统中,为了保证每个进程在一段时间内至少能够运行的机会,系统使用sched_period来表示系统周期,也就是将时间划分成n个sched_period,通常值时6ms,用户可以进行修改。而在这个period周期内,根据各进程的权重来进行瓜分。
Idea_runtime表示每个进程在这个period周期内,可以调度的执行的最长时间,但并不是累计值,比如在period=15ms,进程A的ideal_runtime=6ms,当进程A运行了4ms由于等待某个资源让出了调度,后续获得资源继续运行并不是说进程A只能再运行2ms了,而是运行不超过6ms就行,也就是说ideal_runtime限制的是每次运行不超过的时间,并不算累计值。
在计算ideal_runtime的时候,需要考虑当前进程是否处于任务组内,处于任务组内的进程ideal_runtime相当于是在组内进行按权重划分。在引入任务组后,进程的组织方式可以按照层次来划分,调度实体分为任务调度实体和组调度实体,当然都是使用struct sched_entity来描述。按照层次来划分后,无论调度实体处理哪一个层次,其调度实体ideal_runtime的时间在其平行层次的树中按比例来计算获取,可以简计为
A.ideal_runtime = A.weight / cfs_rqX.load,其中cfs_rqX.load为调度实体所处层级所有进程权重之和。
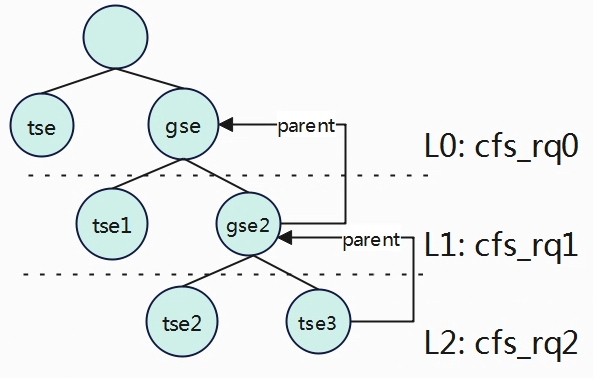
tse.ideal_runtime = tse.weight / cfs_rq.load = tse.weight / (tse.weight + gse.weight)。
tse3.ideal_runtime= gse2.ideal_runtime * tse3.weight / cfs_rq2.load
gse2.ideal_runtime = gse.ideal_runtime * gse2.weight / cfs_rq1.load
gse.ideal_runtime = period * gse.weight / cfs_rq0.load
tse3.ideal_runtime = period *
gse.weight / cfs_rq0.load *
gse2.weight / cfs_rq1.load *
tse3.weight / cfs_rq2.load
由上公式,period表示当前的运行周期的总时间,根据以上公式,因为都是相乘(ABC与CBA一样),所以计算调度实体的ideal_runtime可以从下往上进计算。
对于tse3处于最底层级L2,所以其权重先计算period * tse3.weight / cfs_rq2.load得到C,然后计算Cgse2.weight / cfs_rq1.load得到B,最后再计算Bgse.weight / cfs_rq0.load得到最终tse3的ideal_runtime。
对于tse处于最高层级L0,也可以从下往上计算,只不过上面没有了,因此就只遍历一次得到结果ideal_runtime = gse.weight / cfs_rq0.load。
在软件上的实现也就变得简单很多了,调度实体se中有一个成员parent指向其父实体,如果parent为空表示没有父实体,也就处于最高层级,不存在任务组内,因此在代码中只要根据se从下往上遍历即可。
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
unsigned int nr_running = cfs_rq->nr_running;
u64 slice;
if (sched_feat(ALT_PERIOD))
nr_running = rq_of(cfs_rq)->cfs.h_nr_running; 当前层级tse与gse个数之和
slice = __sched_period(nr_running + !se->on_rq); 一个周期的运行时间period
for_each_sched_entity(se) {
struct load_weight *load;
struct load_weight lw;
cfs_rq = cfs_rq_of(se);
load = &cfs_rq->load;
if (unlikely(!se->on_rq)) {
lw = cfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
}
//slice=slice * (se->load.weight / se->cfs_rq->load.weight)
//根据权重比例逐级往上计算分配到的物理时间。如果不是属于组任务,则只有一级。
slice = __calc_delta(slice, se->load.weight, load);
}
if (sched_feat(BASE_SLICE))
slice = max(slice, (u64)sysctl_sched_min_granularity);
return slice;
}
在设置抢占调度标志章节系统会调用scheduler_tick周期性的检测任务是否超过运行时间,如果超过了就会设置抢占标志位,让出调度权。
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
bool skip_preempt = false;
ideal_runtime = sched_slice(cfs_rq, curr); 计算当前进程一个周期内可以运行的时间。
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime; 实际运行时间。
如果运行时间超过了一个周期内可调度的时间,则设置可抢占标志。
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
clear_buddies(cfs_rq, curr);
return;
}
......
}
任务创建
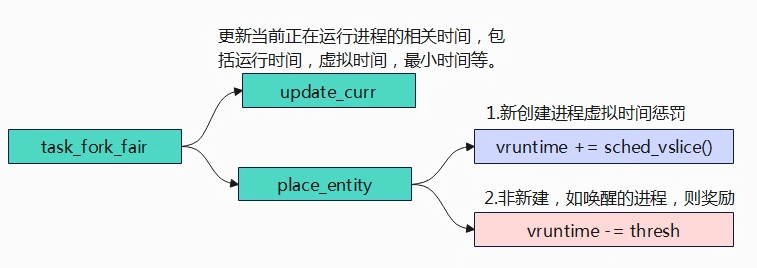
任务出入列
入就绪队列

出就绪队列
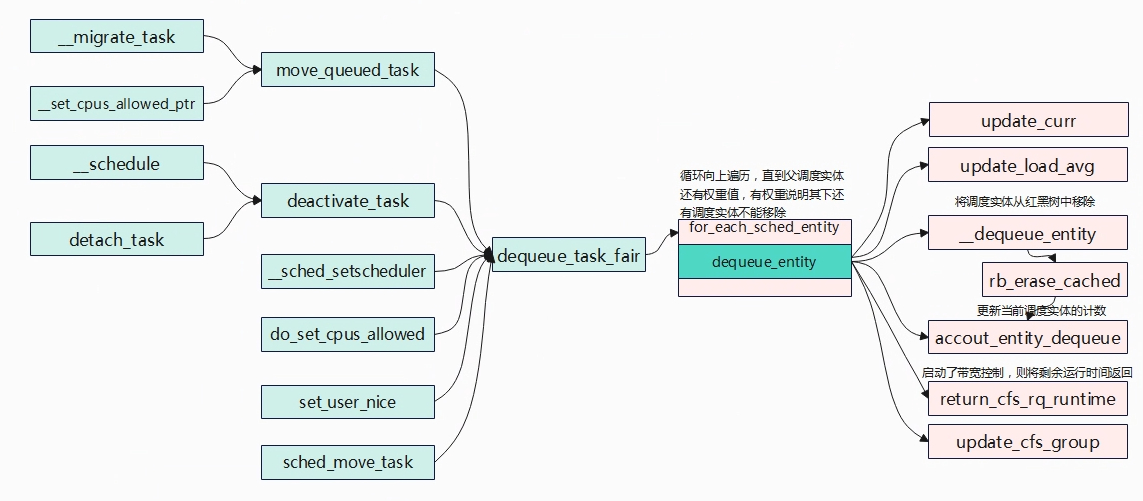
static void dequeue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
int task_sleep = flags & DEQUEUE_SLEEP;
int idle_h_nr_running = task_has_idle_policy(p);
bool was_sched_idle = sched_idle_rq(rq);
util_est_dequeue(&rq->cfs, p);
//迭代遍历每个调度实体,其中se是当前迭代的调度实体
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se); //获取se所属的CFS实时队列cfs_rq
dequeue_entity(cfs_rq, se, flags); //从CFS队列中取出当前的调度实体。
cfs_rq->h_nr_running--; //减少实时队列正在运行的任务数量
cfs_rq->idle_h_nr_running -= idle_h_nr_running; //减少空闲空闲状态下的任务数量
if (cfs_rq_is_idle(cfs_rq)) //如果实时队列变为空闲状态
idle_h_nr_running = 1;
/* end evaluation on encountering a throttled cfs_rq */
if (cfs_rq_throttled(cfs_rq)) //如果实时队列被限制,则直接结束处理。
goto dequeue_throttle;
//如果实时队列的负载权重大于0,则说明实时队列还有其他调度实体,将调度实体
//更新为其父调度实体,并设置接下来任务选择偏向于从当前实时队列中选择任务。
/* Don't dequeue parent if it has other entities besides us */
if (cfs_rq->load.weight) {
/* Avoid re-evaluating load for this entity: */
se = parent_entity(se); //获取父调度实体
/*
* Bias pick_next to pick a task from this cfs_rq, as
* p is sleeping when it is within its sched_slice.
*/
if (task_sleep && se && !throttled_hierarchy(cfs_rq))
set_next_buddy(se); //设置下一个调度实体
break;
}
flags |= DEQUEUE_SLEEP;
}
trace_android_rvh_dequeue_task_fair(rq, p, flags);
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
//更新CFS实时队列的负载平均值
update_load_avg(cfs_rq, se, UPDATE_TG);
se_update_runnable(se);//更新调度实体的可运行状态
update_cfs_group(se);//更新CFS调度组的信息
cfs_rq->h_nr_running--;
cfs_rq->idle_h_nr_running -= idle_h_nr_running;
if (cfs_rq_is_idle(cfs_rq))
idle_h_nr_running = 1;
/* end evaluation on encountering a throttled cfs_rq */
if (cfs_rq_throttled(cfs_rq))
goto dequeue_throttle;
}
/* At this point se is NULL and we are at root level*/
sub_nr_running(rq, 1);
/* balance early to pull high priority tasks */
if (unlikely(!was_sched_idle && sched_idle_rq(rq)))
rq->next_balance = jiffies;
dequeue_throttle:
util_est_update(&rq->cfs, p, task_sleep);
hrtick_update(rq);
}
任务选择
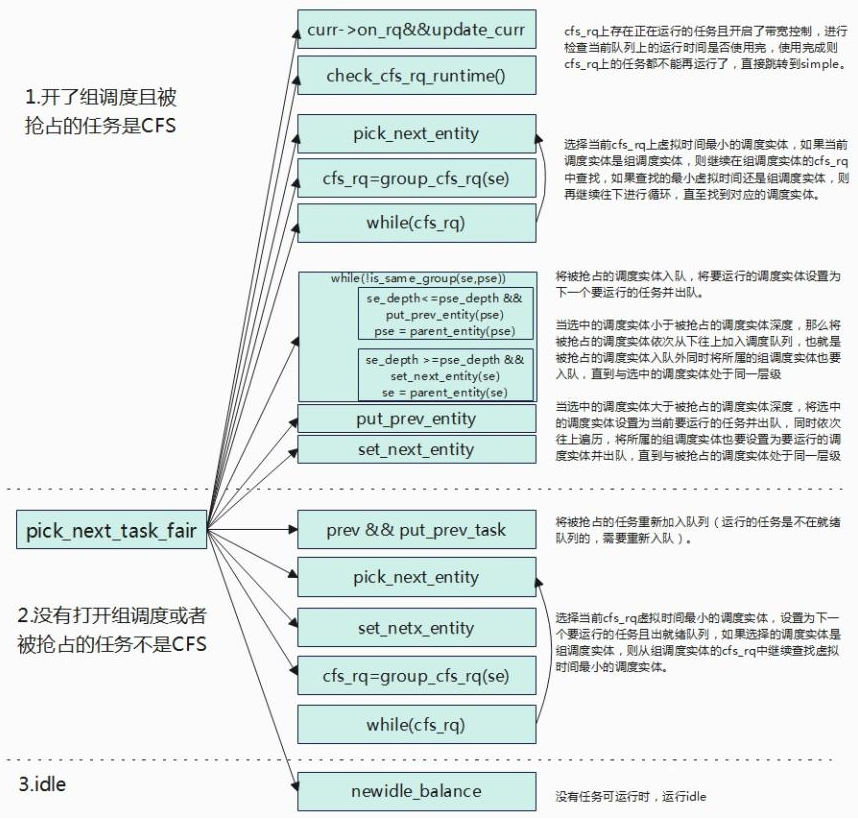
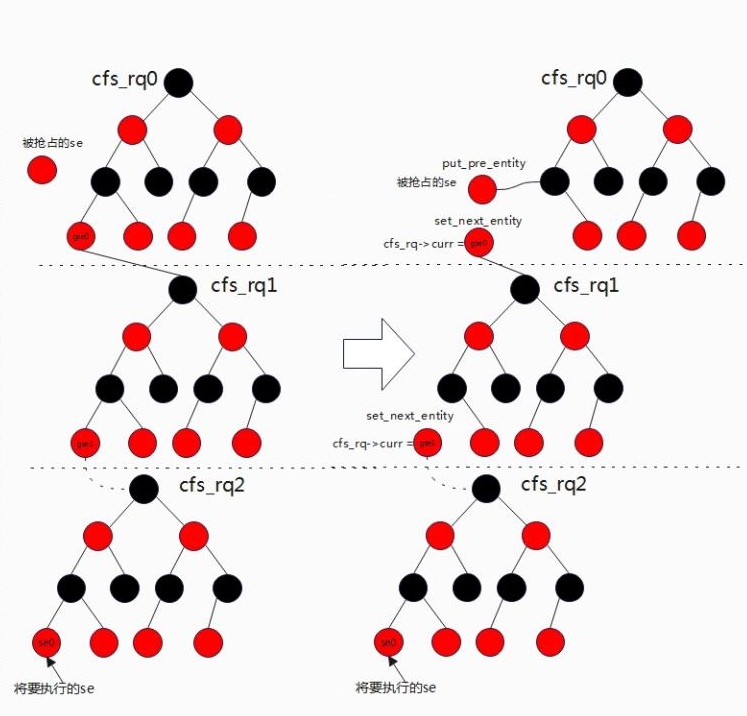
开启CFS组调度且被抢占的任务是CFS类
struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
//prev表示当前rq上正在运行的,被抢占的task。
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se = NULL;
struct task_struct *p = NULL;
int new_tasks;
bool repick = false;
again:
if (!sched_fair_runnable(rq))
goto idle;
#ifdef CONFIG_FAIR_GROUP_SCHED //组调度处理
if (!prev || prev->sched_class != &fair_sched_class)
goto simple;
//如果被抢占task不属于cfs,则跳转到simple处理。
/*
* Because of the set_next_buddy() in dequeue_task_fair() it is rather
* likely that a next task is from the same cgroup as the current.
*
* Therefore attempt to avoid putting and setting the entire cgroup
* hierarchy, only change the part that actually changes.
*/
do {
struct sched_entity *curr = cfs_rq->curr;
/*
* Since we got here without doing put_prev_entity() we also
* have to consider cfs_rq->curr. If it is still a runnable
* entity, update_curr() will update its vruntime, otherwise
* forget we've ever seen it.
*/
//如果当前cfs_rq队列中存在正在运行的调度实体,则需要更新时间,并检查当前
//cfs_rq上的时间片是否使用完(开启带宽控制),如果使用完,那么cfs_rq上所有的//任务都不能再调度,跳转simple处理。
if (curr) {
if (curr->on_rq)
update_curr(cfs_rq); //更新时间
else
curr = NULL;
//检查当前cfs_rq队列runtime是否还有剩余(cfs_rq->runtime_remaining>0)
//3.4.4.1描述,如果没有剩余,那么cfs_rq下所有的任务将不再允许调度。
if (unlikely(check_cfs_rq_runtime(cfs_rq))) {
cfs_rq = &rq->cfs;
if (!cfs_rq->nr_running)
goto idle;
goto simple;
}
}
//挑选下一个调度实体,选择红黑树最左边的
se = pick_next_entity(cfs_rq, curr);
cfs_rq = group_cfs_rq(se); //当前的调度实体是一个任务组,se->my_q !=NULL
} while (cfs_rq); //如果是一个任务组,则继续从该任务组从挑选合适的任务
p = task_of(se); //获取当前调度实体对应的task_struct。
trace_android_rvh_replace_next_task_fair(rq, &p, &se, &repick, false, prev);
/*
* Since we haven't yet done put_prev_entity and if the selected task
* is a different task than we started out with, try and touch the
* least amount of cfs_rqs.
*/
if (prev != p) { //被抢占的任务与当前挑选要允许的任务不同。
struct sched_entity *pse = &prev->se; //获取被抢占任务的调度实体。
//循环遍历,直到将要运行的调度实体与被抢占的调度实体或父实体在同一级
while (!(cfs_rq = is_same_group(se, pse))) {
int se_depth = se->depth; //获取将要运行的调度实体所在层次
int pse_depth = pse->depth;//获取将被抢占任务调度实体所在层次
if (se_depth <= pse_depth) { //要运行的调度实体层次比被抢占的要浅(在上一级)
put_prev_entity(cfs_rq_of(pse), pse);
//将其调度实体调整重新入队(运行的时候是不在就绪队列上的,不能调度了,//因此需要加入到就绪队列)
pse = parent_entity(pse);
//找到其父调度实体,继续循环跟当前要运行的调度实体在同一级
}
if (se_depth >= pse_depth) { //要运行的调度实体层次比被抢占的要深(在下一级)
set_next_entity(cfs_rq_of(se), se);
//设置将要执行的调度实体,主要动作是将当前将要调度的实体出队,要调度的实//体不应该在保存在就绪队列上,而是存储在cfs->curr上。
se = parent_entity(se); //指向其父调度实体
}
}
//到此时,已经找到将要调度的实体与被抢占的调度实体同一级的父调度实体
//为什么要找将要调度实体与被抢占的实体的父/祖所在同一层级的了,是因为
//调度是从上往下的,其任务组中的任务实体要能够被调度,那必须要让其父
//拿到调度权。
put_prev_entity(cfs_rq, pse); //将被抢占的调度实体(可能是父)重新入队
set_next_entity(cfs_rq, se);//设置当前的调度实体为下一个将要运行调度实体。
}
goto done;
未开启CFS组调度或被抢占的任务不是CFS调度类
simple:
#endif
if (prev)
put_prev_task(rq, prev);
//将被抢占的进程重新放回就绪队列中,运行的进程是放在cfs_rq->curr上,不在就绪队列上。
trace_android_rvh_replace_next_task_fair(rq, &p, &se, &repick, true, prev);
if (repick)
goto done;
do {
//从cfs_rq中重新挑选下一个调度实体
se = pick_next_entity(cfs_rq, NULL);
//将挑选的调度实体设置未将要运行的进程并移除就绪队列
set_next_entity(cfs_rq, se);
//判断当前的调度实体是任务组调度实体,如果是则在任务组cfs_rq查找调度实体。
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
done: __maybe_unused;
#ifdef CONFIG_SMP
/*
* Move the next running task to the front of
* the list, so our cfs_tasks list becomes MRU
* one.
*/
list_move(&p->se.group_node, &rq->cfs_tasks);
#endif
if (hrtick_enabled_fair(rq))
hrtick_start_fair(rq, p);
update_misfit_status(p, rq);
return p;
没有要运行的任务
idle:
if (!rf)
return NULL;
new_tasks = newidle_balance(rq, rf);
/*
* Because newidle_balance() releases (and re-acquires) rq->lock, it is
* possible for any higher priority task to appear. In that case we
* must re-start the pick_next_entity() loop.
*/
if (new_tasks < 0)
return RETRY_TASK;
if (new_tasks > 0)
goto again;
/*
* rq is about to be idle, check if we need to update the
* lost_idle_time of clock_pelt
*/
update_idle_rq_clock_pelt(rq);
return NULL;
}
小结
任务的选择分为三种情况:开了组调度且被抢占的任务是CFS类,未开组调度或被抢占的任务不是CFS类,没有任务可运行。
挑选了下一个要运行的任务调用set_next_entity来设置并且把被抢占的任务调用put_prev_entity重新入队。set_next_entity和put_prev_entity两个函数可以看出是一对,当设置要运行的运行时,任务将会从就绪队列出队,用cfs_rq->curr来指向当前正在运行的任务,但是这里需要注意的时出队调用的时__dequeue_entity直接从红黑树中移除,而不是调用dequeue_entity,再去更新时间、计算负载贡献等等,这里尤其要注意的是se->on_rq这个变量,在dequeue_entity该变量se->on_rq=0,表示任务出队,而set_next_entity直接调用__dequeue_entity该值se->on_rq不会变,而是se->on_rq=1,当前正在运行的任务即使从红黑树中被移除的,但是se->on_rq依旧是1,所以该任务并不是完全意义的出队列,因此se->on_rq=1意味着任务是runnable+running(runnable表示任务处于就绪队列中,running表示任务正在运行),这对于后续负载计算的时候影响较大。put_per_entity要做的时候就是将被抢占的任务再次入队与set_next_entity所做事情相对应。