文件系统缓存
#To free pagecache
echo 1 > /proc/sys/vm/drop_caches
#To free dentry and inode cache
echo 2 > /proc/sys/vm/drop_caches
#To free pagecache,dentry cache,inode cache
echo 3 > /proc/sys/vm/drop_caches
dentry cache
struct dentry反映的是文件系统对象(包括目录、文件)在内核中所在文件系统树的位置,在文件系统对文件的操作中inode是对应文件处理的核心对象,而要找到inode就需要先找到dentry,dentry对象内容指向了inode。因此在文件系统做dentry的搜索效率也一定程度上决定着文件系统操作效率,在linux系统中为了提高dentry的处理效率,实现了dentry高速缓存,dentry cache简称dcache。
在3.1.3章节中我们列出了dentry的数据结构组成,其中对于搜索的提升有两个关键数据结构。
struct dentry {
struct hlist_bl_node d_hash;
strcut list_head d_lru;
}
在文件系统初始化时,调用vfs_caches_init->dcache_init为对dcache进行初始化,先创建一个dentry的slab,用于后续dentry对象的分配,同时还分配了一个dentry_hashtable用于管理dentry的全局hash表。
static void __init dcache_init(void)
{
/*
* A constructor could be added for stable state like the lists,
* but it is probably not worth it because of the cache nature
* of the dcache.
*/
dentry_cache = KMEM_CACHE_USERCOPY(dentry,
SLAB_RECLAIM_ACCOUNT|SLAB_PANIC|SLAB_MEM_SPREAD|SLAB_ACCOUNT,
d_iname);
/* Hash may have been set up in dcache_init_early */
if (!hashdist)
return;
dentry_hashtable =
alloc_large_system_hash("Dentry cache",
sizeof(struct hlist_bl_head),
dhash_entries,
13,
HASH_ZERO,
&d_hash_shift,
NULL,
0,
0);
d_hash_shift = 32 - d_hash_shift;
}
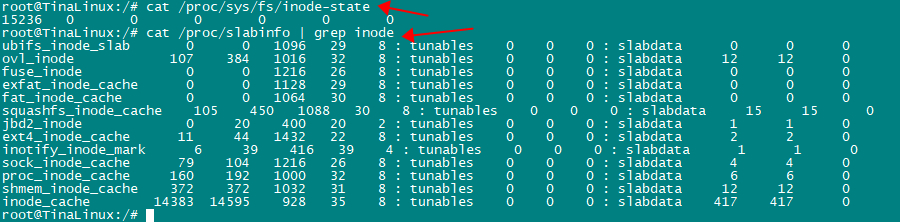
可以cat /proc/slabinfo | grep dentry查看dentry的情况。

dcache在kmem_cache_alloc的基础上定义了两个高层分配接口:d_alloc和d_alloc_root函数,用来从dentry_cache slab中分配dentry对象。d_alloc_root时用来为文件系统跟目录分配dentry对象的。
dentry释放后并不会马上清除掉,而是不缓存起来,所以通常有3种状态,而其中unused和negative是可以在主动触发释放是可以进行回收的。
- inuse:正在被使用,引用技术d_lockref>0。
- unused:未被内核使用,引用技术d_lockref为0,d_inode为空。
- negative:相应的磁盘inode已经被删除,d_inode为空。
- dentry结构通常在路径查找被创建,常用的有以下2种管理方式
- 哈希链表:static struct hlist_bl_head *dentry_hashtable __read_mostly,以dentry->name作为索引在dentry全局hash表中管理,用于提高路径查找效率。
- LRU链表:处于unused和negative状态不再使用的dentry都通过其dentry->d_lru指针链接到super_block->s_dentry_lru中,当需要内存回收时,由prune_dcache_sb回收使用较少的dentry。
在linux系统中定义了dentry_stat_t数据结构来统计dcache信息。
struct dentry_stat_t {
int nr_dentry; dentry的数量
int nr_unused; dentry为使用的数量
int age_limit;/* age in seconds */
int want_pages;/* pages requested by system */
int dummy[2];
};
extern struct dentry_stat_t dentry_stat;
可以通过节点/proc/sys/fs/dentry-state来获取,可以发现dentry-state的nr_dentry:15227与slab info中已经分配出去的对象15229差不多,16957表示当前dentry cache中一共还有多少个对象包括使用和为使用的,528表示每个对象的大小,单位是字节,可以看出一个对象是528字节,对应struct dentry数据结构的大小。

当系统使用echo 2 > /proc/sys/vm/drop_caches可以释放dentry和inode的缓存。
#To free dentry and inode cache
echo 2 > /proc/sys/vm/drop_caches
执行上面的命令后,可以查看节点/proc/sys/fs/dentry-state或cat /proc/slabinfo | grep dentry可以看出dentry的数量变少了,系统回收了。
inode cache
Inode是用于描述一个文件的,通常有一个或多个dentry与之对应,dentry已经描述了系统的目录树,提供了路径查找的方法,所以inode就不需要在搜索查询上处理复杂关系,管理方式也相对简单不少。
struct inode {
...
/* Stat data, not accessed from path walking */
unsigned long i_ino; //与其i_sb一起计算hash作为在inode_hashtable中的索引
struct hlist_node i_hash; //inode_hashtable全局hash表中的节点
struct list_head i_lru; /* inode LRU list */ //其i_sb->s_inode_lru中的节点
...
}
与dentry类似,在内核初始化阶段,会调用inode_init初始化一个inode_cache的slab对象,用于inode的分配。同时还创建了一个用于管理inode的全局哈希表inode_hashtable。
void __init inode_init(void)
{
/* inode slab cache */
inode_cachep = kmem_cache_create("inode_cache",
sizeof(struct inode),
0,
(SLAB_RECLAIM_ACCOUNT|SLAB_PANIC|
SLAB_MEM_SPREAD|SLAB_ACCOUNT),
init_once);
/* Hash may have been set up in inode_init_early */
if (!hashdist)
return;
inode_hashtable =
alloc_large_system_hash("Inode-cache",
sizeof(struct hlist_head),
ihash_entries,
14,
HASH_ZERO,
&i_hash_shift,
&i_hash_mask,
0,
0);
}
Inode结构主要涉及两种管理方式
- inode哈希表:inode_hashtable, super_block和i_ino作为索引在inode在全局inode_hashtable中管理,主要通过i_ino查找到inode。
- LRU链表:通过inode->i_lru链接到super_block->s_inode_lru上,表示不再使用的空闲inode,当需要内存回收是,从中选取最少使用的inode进行回收。
struct inodes_stat_t {
long nr_inodes;
long nr_unused;
long dummy[5]; /* padding for sysctl ABI compatibility */
};
struct inodes_stat_t inodes_stat;
与dentry类似,inode也定义了一个inodes_stat用于统计inode信息,可以通过cat /proc/sys/fs/inode-state来查询。
page cache
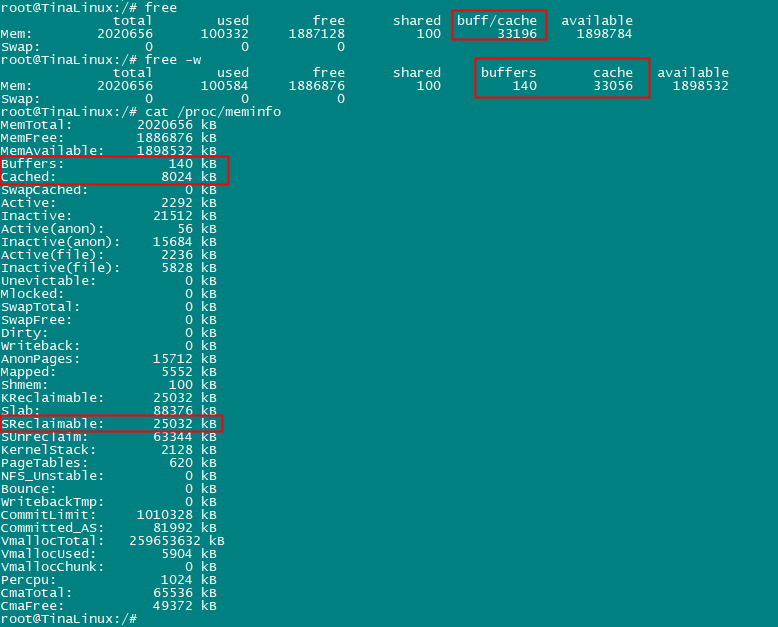
free显示中的buff和cache怎么理解,使用free -w会将buff和cache分开,字面上buffer缓冲,而cache是缓存。
free的数据来源与/proc/meminfo之间的关系。
- buffers:内核缓冲区的内存,对应的是/proc/meminfo中的Buffers
- cache:是内核页缓存和slab用到的内存,对应的是/proc/meminfo中cached+SReclainmable之和。
- buff/cache:则是buffers和cache之和。
所以要理解free中buff/cache的关键是要理解buffers、cached、SReclaimable三个的概念,下面是man proc的意思。
Buffers %lu
Relatively temporary storage for raw disk blocks that shouldn't get tremendously large (20MB or so).
Cached %lu
In-memory cache for files read from the disk (the page cache). Doesn't include SwapCached.
SReclaimable %lu (since Linux 2.6.19)
Part of Slab, that might be reclaimed, such as caches.
- Buffers:是对原始磁盘块的零时存储,用于缓存磁盘的数据,通常不会特别大(20MB左右),因为对应用户来说读写数据可能是几个字节,但是对应磁盘来说是按block来操作的,这样内核就可以把分散写集中起来,如把多次小的写集合并成单次大的写。
- Cached:是磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据,这样下次访问这些文件数据时,旧可以直接从内存快速获取,而不需要再次访问缓慢的磁盘,但是不包括交互到swap分区的。
- SReclaimable:是slab的一部分。Slab包含可回收和不可回收两部分,可回收的用SReclaimable记录(dentry cache、inode cache属于slab的一部分),不可回收的用SUnrecalaim记录。
从上面buffers和cached的来看,buffer是对磁盘的,而cache是针对文件页缓存读的,看起来是分开的,但实际上buffers和cached并没有分开,都是page cache,下面将来进行阐述。
CPU的读写速度与磁盘的读写速度是有很大差距的,因此文件系统在访问磁盘时,并不会直接与磁盘进行交互,而是在具体的文件系统与磁盘之间申请一段缓冲buffer,这段缓冲buffer实际就是申请了一块内存,将磁盘的数据缓存到这块内存中,具体的文件系统对磁盘的读写就转换为对缓冲buffer的读写这样就可以提高处理的速度,系统负责定期的将缓冲buff与磁盘进行数据同步,当然也可以手动sync的方式进行同步。
早期linux0.11阶段,buffer cache在linux中对应的数据结构是struct buffer_head,简称bh,顾名思义,表示缓冲区头部,这个缓冲区缓冲的是磁盘块设备数据,早期阶段为了提高磁盘的读写消息,在磁盘之上增加了一个缓冲,磁盘的读写单位是block,一般block的大小是1KB,每个block就对应一个bh,而bh的内存申请是以原始的内存分配方式,还没有基于page来分配内存。
strcut buffer_head {
char *b_data; /* pointer to data block (1024 bytes) *///指针。
unsigned long b_blocknr; /* block number */// 块号。
unsigned short b_dev; /* device (0 = free) */// 数据源的设备号。
unsigned char b_uptodate; // 更新标志:表示数据是否已更新。
unsigned char b_dirt; /* 0-clean,1-dirty *///修改标志:0 未修改,1 已修改.
unsigned char b_count; /* users using this block */// 使用的用户数。
unsigned char b_lock; /* 0 - ok, 1 -locked */// 缓冲区是否被锁定。
struct task_struct *b_wait; // 指向等待该缓冲区解锁的任务。
struct buffer_head *b_prev; // hash 队列上前一块(这四个指针用于缓冲区的管理)。
struct buffer_head *b_next; // hash 队列上下一块。
struct buffer_head *b_prev_free; // 空闲表上前一块。
struct buffer_head *b_next_free; // 空闲表上下一块。
};
发展到中间阶段时linux2.2版本,buffer 就基于page来分配内存,但是page cache和buffer没有什么直接连续,是各自独立的作用,page cache只用于负责mmap的部分处理,buffer 依旧负责对磁盘IO的访问缓冲,如下图。但这样就会出现一个问题,由于read/write是绕过了page cache,就会导致mmap和read/write操作同步问题,磁盘的同一份数据在page cache中有一份,在buffer中也有一份,这样分离的设计还会导致浪费内存。
struct buffer_head {
/* First cache line: */
struct buffer_head * b_next; /* Hash queue list */
unsigned long b_blocknr; /* block number */
unsigned long b_size; /* block size */
kdev_t b_dev; /* device (B_FREE = free) */
kdev_t b_rdev; /* Real device */
unsigned long b_rsector; /* Real buffer location on disk */
struct buffer_head * b_this_page; /* circular list of buffers in one page */
unsigned long b_state; /* buffer state bitmap (see above) */
struct buffer_head * b_next_free;
unsigned int b_count; /* users using this block */
/* Non-performance-critical data follows. */
char * b_data; /* pointer to data block (1024 bytes) */
unsigned int b_list; /* List that this buffer appears */
unsigned long b_flushtime; /* Time when this (dirty) buffer
* should be written */
struct wait_queue * b_wait;
struct buffer_head ** b_pprev; /* doubly linked list of hash-queue */
struct buffer_head * b_prev_free; /* doubly linked list of buffers */
struct buffer_head * b_reqnext; /* request queue */
/*
* I/O completion
*/
void (*b_end_io)(struct buffer_head *bh, int uptodate);
void *b_dev_id;
};
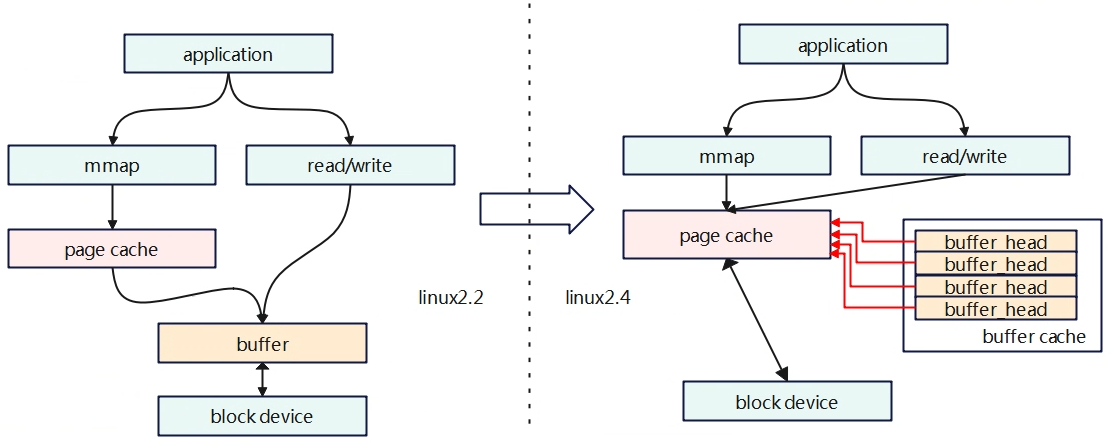
发展到第三阶段linux 2.4版本,对cache和buffer进行了融合,因为buffer的申请也是基于page的,那这两个为什么不融合在一起了,融合后buffer cache就直接存储在page cache中,但是依旧保留了buffer cache的描述。
struct buffer_head {
unsigned long b_state; /* buffer state bitmap (see above) */
struct buffer_head *b_this_page;/* circular list of page's buffers */
struct page *b_page; /* the page this bh is mapped to */
sector_t b_blocknr; /* start block number */
size_t b_size; /* size of mapping */
char *b_data; /* pointer to data within the page */
struct block_device *b_bdev;
bh_end_io_t *b_end_io; /* I/O completion */
void *b_private; /* reserved for b_end_io */
struct list_head b_assoc_buffers; /* associated with another mapping */
struct address_space *b_assoc_map; /* mapping this buffer is
associated with */
atomic_t b_count; /* users using this buffer_head */
spinlock_t b_uptodate_lock; /* Used by the first bh in a page, to
* serialise IO completion of other
* buffers in the page */
};
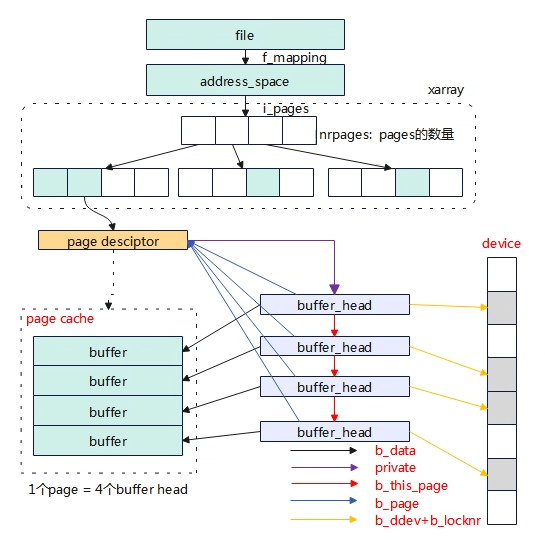
至此page cache和buffer 两者的关系融合了。磁盘的读写是按block为单位操作,一个block对应一个buffer_head缓冲,如块单位是1KB,那么1个page cache就有4个buffer_head。
对于文件系统的操作来说,buffer和cache都是page cache,对应的是进程打开文件内存的缓存,缓存在address_space::i_pages的xarray上,缓存的数量为address_space::nrpages。
Buffer_head的原义是与block对应,按照磁盘的布局分为元数据区和数据区域,元数据是用于管理磁盘的如supper_block、inode等,数据区域才是正在的对应文件系统操作的数据。所以的对于cache和buffer的区别,buffer还存储了对磁盘管理的元数据缓存,这部分
再后来在linux2.4版本之后,新的文件系统开始引入了bio结构来替换buffer_head,但是原有的一些文件系统并没有完全替换使用bio,所以了就需要做bio兼容buffer_head,在磁盘操作前会调用到submit_bh_wbc函数,该函数会将buffer_head组装成bio,因此最终对磁盘的操作都会转为bio的方式,新的文件系统就直接使用bio。
static int submit_bh_wbc(int op, int op_flags, struct buffer_head *bh,
enum rw_hint write_hint, struct writeback_control *wbc)
{
struct bio *bio;
BUG_ON(!buffer_locked(bh));
BUG_ON(!buffer_mapped(bh));
BUG_ON(!bh->b_end_io);
BUG_ON(buffer_delay(bh));
BUG_ON(buffer_unwritten(bh));
/*
* Only clear out a write error when rewriting
*/
if (test_set_buffer_req(bh) && (op == REQ_OP_WRITE))
clear_buffer_write_io_error(bh);
bio = bio_alloc(GFP_NOIO, 1);
fscrypt_set_bio_crypt_ctx_bh(bio, bh, GFP_NOIO);
bio->bi_iter.bi_sector = bh->b_blocknr * (bh->b_size >> 9);
bio_set_dev(bio, bh->b_bdev);
bio->bi_write_hint = write_hint;
bio_add_page(bio, bh->b_page, bh->b_size, bh_offset(bh));
BUG_ON(bio->bi_iter.bi_size != bh->b_size);
bio->bi_end_io = end_bio_bh_io_sync;
bio->bi_private = bh;
if (buffer_meta(bh))
op_flags |= REQ_META;
if (buffer_prio(bh))
op_flags |= REQ_PRIO;
bio_set_op_attrs(bio, op, op_flags);
/* Take care of bh's that straddle the end of the device */
guard_bio_eod(bio);
if (wbc) {
wbc_init_bio(wbc, bio);
wbc_account_cgroup_owner(wbc, bh->b_page, bh->b_size);
}
submit_bio(bio);
return 0;
}
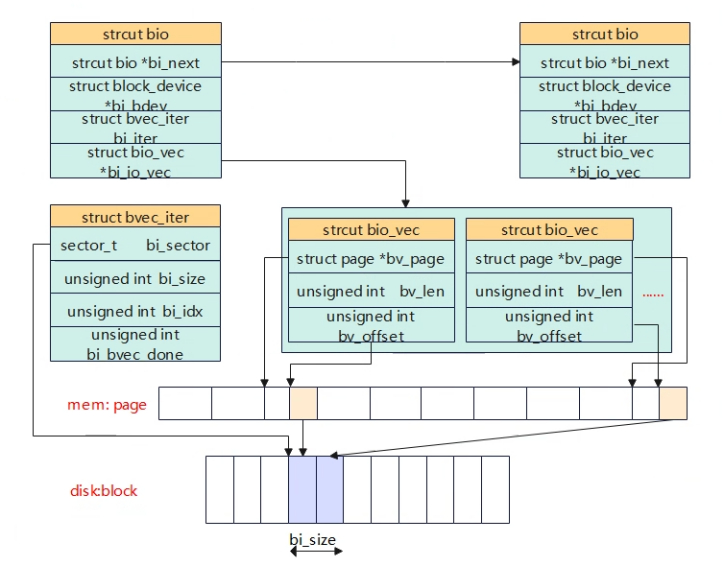
以上的page cache和buffer cache的融合是针对使用文件系统的方式访问块设备的场景。但是如果以下的两个方式访问磁盘①使用文件②使用块设备节点,这两种方式对应的page cache是不同的,文件的方式是buff/cache,而块设备节点是buff(实际也是page cache分配),这种情况下一个物理磁盘的block数据仍然对应linux内核的两份page,一个是通过通用文件层访问的文件page cache(page cache),另一个是通过块设备节点访问的page cache(buffer cache)。另外需要注意的是,如果通过块设备节点访问声明了O_DIRECT,将会直接访问磁盘不会经过buff。
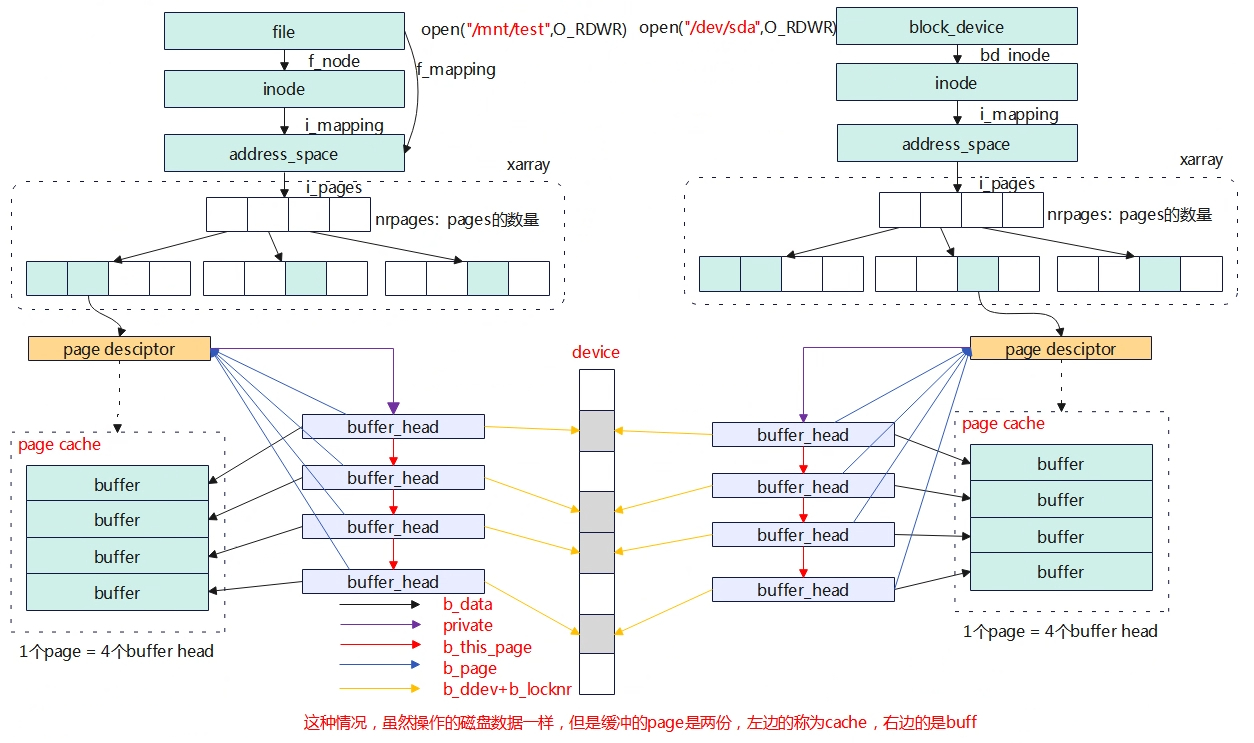
上图如果分别使用文件系统方式/mnt/test的方式或者裸设备/dev/sda的方式去写磁盘,即使是一个位置,但是将会有两份page cache,前者的page cache对应的就是free中的cache,而后边的page cache对应的是free中的buff。
可以从/proc/meminfo的实现来研究一下buff和cache的区别。
static int meminfo_proc_show(struct seq_file *m, void *v)
{
struct sysinfo i;
unsigned long committed;
long cached;
long available;
unsigned long pages[NR_LRU_LISTS];
unsigned long sreclaimable, sunreclaim;
int lru;
si_meminfo(&i);
si_swapinfo(&i);
committed = vm_memory_committed();
cached = global_node_page_state(NR_FILE_PAGES) -
total_swapcache_pages() - i.bufferram;
if (cached < 0)
cached = 0;
for (lru = LRU_BASE; lru < NR_LRU_LISTS; lru++)
pages[lru] = global_node_page_state(NR_LRU_BASE + lru);
available = si_mem_available();
sreclaimable = global_node_page_state_pages(NR_SLAB_RECLAIMABLE_B);
sunreclaim = global_node_page_state_pages(NR_SLAB_UNRECLAIMABLE_B);
show_val_kb(m, "MemTotal: ", i.totalram);
show_val_kb(m, "MemFree: ", i.freeram);
show_val_kb(m, "MemAvailable: ", available);
show_val_kb(m, "Buffers: ", i.bufferram); //show_val_kb会将page数量转化为kb。
show_val_kb(m, "Cached: ", cached);
show_val_kb(m, "SwapCached: ", total_swapcache_pages());
......
}
先来看看buff,buffers为i.bufferram,而该值在si_meminfo(&i)中计算而来,在该函数中调用nr_blockdev_pages计算而来。
void si_meminfo(struct sysinfo *val)
{
val->totalram = totalram_pages();
val->sharedram = global_node_page_state(NR_SHMEM);
val->freeram = global_zone_page_state(NR_FREE_PAGES);
val->bufferram = nr_blockdev_pages();
val->totalhigh = totalhigh_pages();
val->freehigh = nr_free_highpages();
val->mem_unit = PAGE_SIZE;
}
再看看下面的函数调用,buffers是遍历所有的块设备,累加address->i_mapping上nrpages值,该值就是xarray树上对应的page数量,对应上图中直接操作磁盘节点读写的方式 “open /dev/sda”。
long nr_blockdev_pages(void)
{
struct inode *inode;
long ret = 0;
spin_lock(&blockdev_superblock->s_inode_list_lock);
list_for_each_entry(inode, &blockdev_superblock->s_inodes, i_sb_list)
ret += inode->i_mapping->nrpages;
spin_unlock(&blockdev_superblock->s_inode_list_lock);
return ret;
}
再来看看cached的计算cached = global_node_page_state(NR_FILE_PAGES) -total_swapcache_pages() – i.bufferram,其中 global_node_page_state(NR_FILE_PAGES) 为vm_node_stat[NR_FILE_PAGES]的值。内核中定义了一个全局变量atomic_long_t vm_node_stat[],用于统计全局内存的信息,搜索内核中关于NR_FILE_PAGES的标志,主要有以下三个函数修改。
__mod_lruvec_page_state(item,val) //对全局变量vm_node_stat[item]增加val
__dec_lruvec_page_state()//对全局变量vm_node_stat[item]减1
__inc_lruvec_page_state()//对全局变量vm_node_stat[item]加1
示例
__mod_lruvec_page_state(page, NR_FILE_PAGES, -nr)
__mod_node_page_state(page_pgdat(page), idx, val)
node_page_state_add(delta, pgdat, item) //delta=-nr
atomic_long_add(x, &pgdat->vm_stat[item]);
atomic_long_add(x, &vm_node_stat[item]);
从上面的函数调用,__mod_lruvec_page_state(struct page *page,enum node_stat_item idx, int val)的作用就是根据item类型(这里是NR_FILE_PAGES)对全局变量vm_node_stat[item]增加val。

从上的函数调用流程可知,无论是文件系统的写还是读,当分配新的page时,会调用add_to_page_cache_lru将page添加到xarray树上,并调用__inc_lruvec_page_state增加page计数,同时会添加到LRU链表用于后续回收。除了调用generic_file_read/write读写文件系统会修改vm_node_stat[NR_FILE_PAGES]外,还有不少操作也会让vm_node_stat[NR_FILE_PAGES]会增加,如通过dev节点直接对磁盘的操作(buffers),以及匿名页交换到swap分区的也会修改。因此vm_node_stat[NR_FILE_PAGES]是一个总的值,实际在计算cached的时候会把交换到swap分区、以及buffers的值减去。cached = global_node_page_state(NR_FILE_PAGES) -total_swapcache_pages() – i.bufferram。
总结下:
- 对于文件系统的操作方式来说(如/mnt/UDISK/test),大部分是cached(buffers和cached以及合并了),会占用少部分的buffer,主要是存储一些元数据的存储是划到buffer中。
- 对于磁盘的操作方式来说(如/dev/sda),只有buffers。
可以使用测试使用vmstat观察buff和cache的变化情况。
通过文件系统的方式
写入到文件系统中
echo 3 > /proc/sys/vm/drop_caches
dd if=/dev/urandom of=/mnt/UDISK/test bs=1M count=5
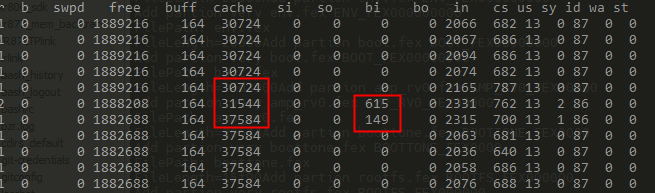
从文件系统中读
echo 3 > /proc/sys/vm/drop_caches
dd if=/mnt/UDISK/test4 of=/tmp/test bs=1M count=10
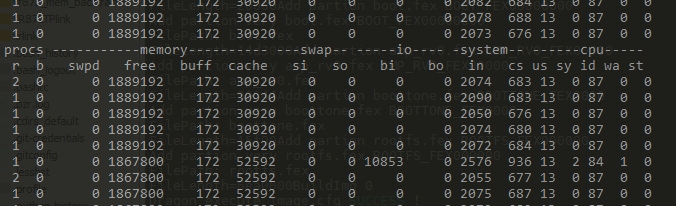
通过vmstat统计来看,写入到文件系统ext4上或从文件系统读,基本都是cache在变化。
通过磁盘的方式操作
echo 3 > /proc/sys/vm/drop_caches
dd if=/dev/urandom of=/dev/mmcblk0p9 bs=1M count=8
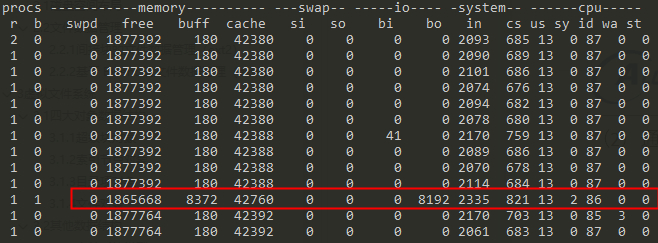
echo 3 > /proc/sys/vm/drop_caches
dd if=/dev/mmcblk0p9 of=/dev/null bs=1M count=8
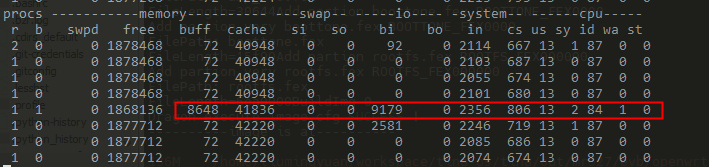
通过磁盘的方式操作,可以发现buff和cache都有变化(这里的cache还包括了slab可以回收部分,如果查询/proc/meminfo下的cached变化会更少些),但是buff变化更大些,然后突然又降回去了(被系统回收了)读磁盘数据会缓存到buffer中。
Direct IO写
dd if=/dev/urandom of=/dev/mmcblk0p9 bs=1M count=10 oflag=direct
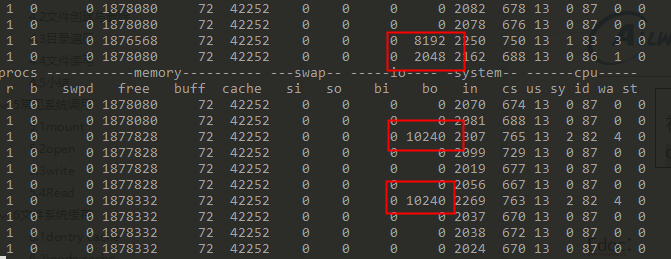
可以发现buff,cache基本没变化。