Ai
-
语音生成模型:CosyVoice入门实践
是什么 CosyVoice是阿里开源的一款文字转语音的开源模型,可以支持音色复刻。 怎么用 环境安装 (1)代码下载 git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git cd CosyVoice git submodule update --init --recursive 因为CosyVoice仓库中还依赖了第三方的Matcha-TTS,所以克隆本地仓库后,还需要下载第三方的。 (2)创建conda环境 conda create -n cosyvoice -y python=3.10 conda activate cosyvoice pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com 创建conda环境并安装依赖。如果没有安装cuda工具的话,还需要执行下面命令安装。 sudo apt install nvidia-cuda-toolkit (3)下载预训练模型 sudo apt update && sudo apt install git-lfs -y mkdir -p pretrained_models git clone https://www.modelscope.cn/iic/CosyVoice2-0.5B.git pretrained_models/CosyVoice2-0.5B git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct git clone https://www.modelscope.cn/iic/CosyVoice-ttsfrd.git pretrained_models/CosyVoice-ttsfrd 上面的模型文件选择一个即可,需要注意的是因为模型比较大,所以要在本地安装git-lfs才能下载大文件。 测试 python3 webui.py --port 50000 --model_dir pretrained_models/CosyVoice-300M 执行上面命令后,就可以登录网页输入http://127.0.0.1:50000/进行测试了。 -
语音识别模型:SenseVoice入门实践
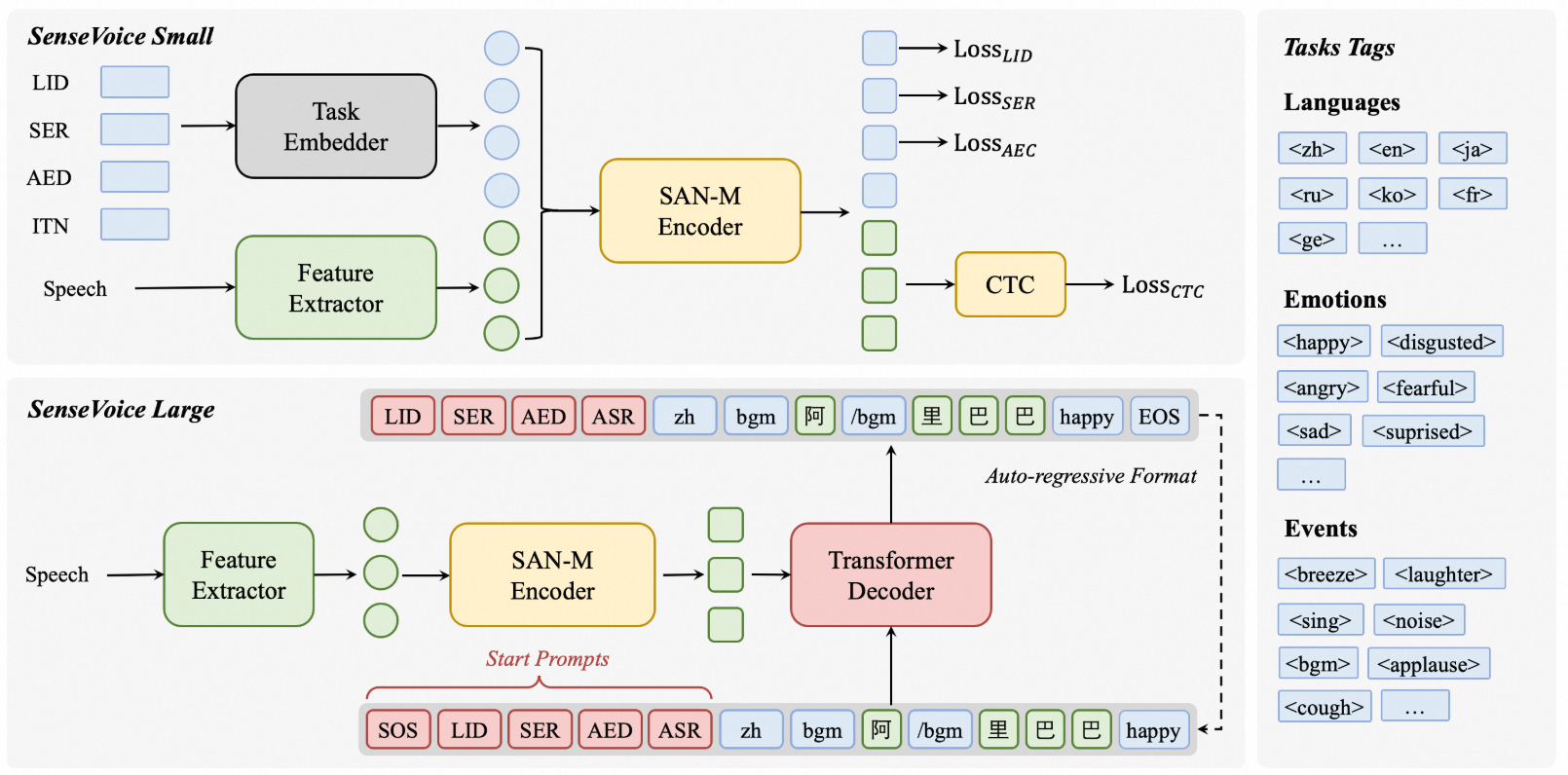
是什么 SenseVoice是多语言识别的模型,支持语音转文字(ASR, Automatic Speech Recognition,自动语音识别),语种识别(LID, Language Identification),语音情感识别(SER, Speech Emotion Recognition),音频事件检测 / 声学事件分类(AED/AEC, Audio Event Detection / Classification),逆文本正则化 / 标点 / 富文本转写等。 怎么用 配置环境 配置一个conda sensevoice环境并且激活。 conda create -n sensevoice python=3.10 conda activate sensevoice 拉取代码,安装依赖 git clone https://github.com/FunAudioLLM/SenseVoice.git cd SenseVoice/ pip install -r requirements.txt 示例测试 代码中有两个示例分别是demo1.py和demo2.py,执行后可以看看效果。 python demo1.py 执行后会自动从modelscope上下载模型和相关配置到本地。 下载到本地后有模型和相关的配置文件以及示例音频。 (sensevoice) laumy@ThinkBook-14-G7-IAH:~/.cache/modelscope/hub/models/iic$ tree . ├── SenseVoiceSmall │ ├── am.mvn │ ├── chn_jpn_yue_eng_ko_spectok.bpe.model │ ├── configuration.json │ ├── config.yaml │ ├── example │ │ ├── en.mp3 │ │ ├── ja.mp3 │ │ ├── ko.mp3 │ │ ├── yue.mp3 │ │ └── zh.mp3 │ ├── fig │ │ ├── aed_figure.png │ │ ├── asr_results.png │ │ ├── inference.png │ │ ├── sensevoice.png │ │ ├── ser_figure.png │ │ └── ser_table.png │ ├── model.pt │ ├── README.md │ └── tokens.json └── speech_fsmn_vad_zh-cn-16k-common-pytorch ├── am.mvn ├── configuration.json ├── config.yaml ├── example │ └── vad_example.wav ├── fig │ └── struct.png ├── model.pt └── README.md 7 directories, 25 files 最后的识别效果为 还可以测试webui版本 python webui.py 然后网址输入:http://127.0.0.1:7860, 注意不能开代理否则会启动失败。 接口调用 主要简要分析一下使用funASR调用示例。 (1)模型加载 model = AutoModel(model=[str], device=[str], ncpu=[int], output_dir=[str], batch_size=[int], hub=[str], **kwargs) model:模型仓库中的名称 device:推理的设备,如gpu ncpu:cpu并行线程。 output_dir:输出结果的输出路径 batch_size:解码时的批处理,样本个数 hub:从modelscope下载模型。如果为hf,从huggingface下载模型。 (2)推理 res = model.generate(input=[str], output_dir=[str]) input:要解码的输入可以是wav文件路径, 例如: asr_example.wav。 output_dir: 输出结果的输出路径。 实时识别 编写一个示例实时识别 #!/usr/bin/env python3 # -*- encoding: utf-8 -*- # Real-time microphone transcription (pure memory) using ALSA (pyalsaaudio) + numpy import argparse import os import signal import sys import time from pathlib import Path from typing import Optional import numpy as np def _safe_imports() -> None: try: import alsaaudio # noqa: F401 except Exception: print( "缺少 pyalsaaudio,请先安装:\n pip install pyalsaaudio\nUbuntu 可能需要:sudo apt-get install -y python3-alsaaudio 或 alsa-utils", file=sys.stderr, ) raise def _safe_import_model(): try: from funasr import AutoModel from funasr.utils.postprocess_utils import rich_transcription_postprocess except Exception: print( "导入 funasr 失败。如果仓库根目录存在本地 'funasr.py',请重命名(如 'funasr_demo.py')以避免遮蔽外部库。", file=sys.stderr, ) raise return AutoModel, rich_transcription_postprocess def int16_to_float32(audio_int16: np.ndarray) -> np.ndarray: if audio_int16.dtype != np.int16: audio_int16 = audio_int16.astype(np.int16, copy=False) return (audio_int16.astype(np.float32) / 32768.0).clip(-1.0, 1.0) def resample_to_16k(audio_f32: np.ndarray, orig_sr: int) -> tuple[np.ndarray, int]: if orig_sr == 16000: return audio_f32, 16000 backend = os.environ.get("SV_RESAMPLE", "poly").lower() # poly|librosa|linear # 优先使用更快的 poly(scipy),其次 librosa,最后线性插值兜底 if backend in ("poly", "auto"): try: from scipy.signal import resample_poly # type: ignore y = resample_poly(audio_f32, 16000, orig_sr) return y.astype(np.float32, copy=False), 16000 except Exception: pass if backend in ("librosa", "auto"): try: import librosa # type: ignore y = librosa.resample(audio_f32, orig_sr=orig_sr, target_sr=16000) return y.astype(np.float32, copy=False), 16000 except Exception: pass # 线性插值兜底(最慢但零依赖) x = np.arange(audio_f32.size, dtype=np.float32) new_n = int(round(audio_f32.size * 16000.0 / float(orig_sr))) if new_n <= 1: return audio_f32, orig_sr new_x = np.linspace(0.0, x[-1] if x.size > 0 else 0.0, new_n, dtype=np.float32) y = np.interp(new_x, x, audio_f32).astype(np.float32) return y, 16000 def _build_cfg_from_env() -> dict: cfg = {} # runtime knobs try: cfg["min_rms"] = float(os.environ.get("SV_MIN_RMS", "0.003")) except Exception: cfg["min_rms"] = 0.003 try: cfg["overlap_sec"] = float(os.environ.get("SV_OVERLAP_SEC", "0.3")) except Exception: cfg["overlap_sec"] = 0.3 cfg["merge_vad"] = os.environ.get("SV_MERGE_VAD", "0") == "1" try: cfg["merge_len"] = float(os.environ.get("SV_MERGE_LEN", "2.0")) except Exception: cfg["merge_len"] = 2.0 cfg["debug"] = os.environ.get("SV_DEBUG") == "1" cfg["resample_backend"] = os.environ.get("SV_RESAMPLE", "poly").lower() cfg["dump_wav_path"] = os.environ.get("SV_DUMP_WAV") return cfg def _select_strong_channel(frame_any: np.ndarray, channels: int, debug: bool) -> np.ndarray: if channels <= 1: return frame_any frame_mat = frame_any.reshape(-1, channels) ch_rms = np.sqrt(np.mean(frame_mat.astype(np.float32) ** 2, axis=0)) sel = int(np.argmax(ch_rms)) if debug: print(f"[debug] multi-channel rms={ch_rms.tolist()}, select ch={sel}", flush=True) return frame_mat[:, sel] def _ensure_pcm_open(alsa_audio, device: str | None, samplerate: int, channels: int, period_frames: int) -> tuple[object, int, str, str]: tried: list[tuple[str, str, str]] = [] for dev in [device or "default", f"plughw:{(device or 'default').split(':')[-1]}" if (device and not device.startswith('plughw')) else None]: if not dev: continue for fmt in (alsa_audio.PCM_FORMAT_S16_LE, alsa_audio.PCM_FORMAT_S32_LE): try: p = alsa_audio.PCM(type=alsa_audio.PCM_CAPTURE, mode=alsa_audio.PCM_NORMAL, device=dev) p.setchannels(channels) p.setrate(samplerate) p.setformat(fmt) p.setperiodsize(period_frames) dtype = np.int16 if fmt == alsa_audio.PCM_FORMAT_S16_LE else np.int32 sample_bytes = 2 if dtype == np.int16 else 4 fmt_name = "S16_LE" if dtype == np.int16 else "S32_LE" return p, sample_bytes, fmt_name, dev except Exception as e: # noqa: BLE001 tried.append((dev, "S16_LE" if fmt == alsa_audio.PCM_FORMAT_S16_LE else "S32_LE", str(e))) continue raise RuntimeError(f"打开 ALSA 设备失败,尝试: {tried}") def _to_int16_mono(raw_bytes: bytes, sample_bytes: int, channels: int, debug: bool) -> np.ndarray: if sample_bytes == 2: frame_any = np.frombuffer(raw_bytes, dtype=np.int16) else: frame_any = np.frombuffer(raw_bytes, dtype=np.int32) frame_any = (frame_any.astype(np.int32) >> 16).astype(np.int16) if channels > 1: frame_any = _select_strong_channel(frame_any, channels, debug) return frame_any.astype(np.int16, copy=False) def _should_infer(audio_f32: np.ndarray, min_rms: float, debug: bool, frames_count: int) -> bool: if audio_f32.size == 0: return False rms = float(np.sqrt(np.mean(np.square(audio_f32)))) if rms < min_rms: if debug: print(f"[debug] frames={frames_count}, rms={rms:.4f} < min_rms={min_rms:.4f}, skip", flush=True) return False return True def _infer_block(model, arr: np.ndarray, sr: int, cfg: dict, language: str, running_cache: dict) -> str: prefer = os.environ.get("SV_INPUT_FORMAT", "f32") # candidate arrays f32 = arr.astype(np.float32, copy=False) i16 = (np.clip(f32, -1.0, 1.0) * 32767.0).astype(np.int16) candidates: list[tuple[np.ndarray, bool]] if prefer == "i16": candidates = [(i16, False), (f32, False), (i16[None, :], True), (f32[None, :], True)] elif prefer == "f32_2d": candidates = [(f32[None, :], True), (f32, False), (i16[None, :], True), (i16, False)] elif prefer == "i16_2d": candidates = [(i16[None, :], True), (i16, False), (f32[None, :], True), (f32, False)] else: candidates = [(f32, False), (i16, False), (f32[None, :], True), (i16[None, :], True)] res = None for cand, _is2d in candidates: try: try: res = model.generate( input=cand, input_fs=sr, cache=running_cache, language=language, use_itn=True, batch_size_s=60, merge_vad=cfg["merge_vad"], merge_length_s=cfg["merge_len"], ) except TypeError: res = model.generate( input=cand, fs=sr, cache=running_cache, language=language, use_itn=True, batch_size_s=60, merge_vad=cfg["merge_vad"], merge_length_s=cfg["merge_len"], ) break except Exception: continue if not res: return "" out = res[0].get("text", "") return out def run_in_memory( model_dir: str, device: str, language: str, samplerate: int, channels: int, block_seconds: float, alsa_device: Optional[str], ) -> None: _safe_imports() AutoModel, rich_post = _safe_import_model() # 关闭底层 tqdm 进度条等多余输出 os.environ.setdefault("TQDM_DISABLE", "1") print("加载模型...", flush=True) model = AutoModel( model=model_dir, trust_remote_code=True, remote_code="./model.py", vad_model="fsmn-vad", vad_kwargs={"max_single_segment_time": 30000}, device=device, disable_update=True, ) import alsaaudio # 更小的 periodsize,降低 I/O 错误概率;推理聚合由 block_seconds 控制 period_frames = max(256, int(0.1 * samplerate)) cfg = _build_cfg_from_env() # 打开设备,尝试 S16 -> S32;必要时切换 plughw 以启用自动重采样/重格式化 pcm, sample_bytes, fmt_name, open_dev = _ensure_pcm_open(alsaaudio, alsa_device, samplerate, channels, period_frames) if cfg["debug"]: print(f"[debug] opened ALSA device {open_dev} fmt={fmt_name} period={period_frames}", flush=True) print( f"开始录音(纯内存采集),设备={alsa_device or 'default'}, sr={samplerate}, ch={channels}, period={period_frames},按 Ctrl+C 停止。\n", flush=True, ) running_cache: dict = {} printed_text = "" # 聚合到这一帧阈值后才调用一次模型,降低调用频率与输出 min_frames = max(1, int(block_seconds * samplerate)) # 重叠帧数,减少句首/句尾丢失 overlap_frames = int(max(0, cfg["overlap_sec"]) * samplerate) block_buf: list[np.ndarray] = [] buf_frames = 0 stop_flag = False def handle_sigint(signum, frame): # noqa: ANN001 nonlocal stop_flag stop_flag = True signal.signal(signal.SIGINT, handle_sigint) # 连续读取 PCM,并聚合达到阈值后执行一次增量推理 while not stop_flag: try: length, data = pcm.read() except Exception as e: # noqa: BLE001 # 读失败时尝试重建(常见于某些 DMIC Raw) if cfg["debug"]: print(f"[debug] pcm.read error: {e}, reopen stream", flush=True) # 尝试使用 plughw 以获得自动格式/采样率适配 dev = alsa_device or "default" if not dev.startswith("plughw") and dev != "default": dev = f"plughw:{dev.split(':')[-1]}" pcm, sample_bytes, fmt_name, open_dev = _ensure_pcm_open(alsaaudio, dev, samplerate, channels, period_frames) length, data = pcm.read() if length <= 0: time.sleep(0.005) continue # 根据实际格式解析 bytes pcm_int16 = _to_int16_mono(data, sample_bytes, channels, cfg["debug"]) block_buf.append(pcm_int16) buf_frames += pcm_int16.size if buf_frames < min_frames: continue # 达到阈值,拼接并转换为 float32 [-1, 1] joined = np.concatenate(block_buf, axis=0) # 为下一个块保留尾部重叠 if overlap_frames > 0 and joined.size > overlap_frames: tail = joined[-overlap_frames:] block_buf = [tail.astype(np.int16, copy=False)] buf_frames = tail.size else: block_buf.clear() buf_frames = 0 audio_block_f32 = int16_to_float32(joined) # 若采样率不是 16k,重采样到 16k audio_block_f32, eff_sr = resample_to_16k(audio_block_f32, samplerate) if not _should_infer(audio_block_f32, cfg["min_rms"], cfg["debug"], joined.size): continue if cfg["debug"]: rms = float(np.sqrt(np.mean(np.square(audio_block_f32)))) print(f"[debug] frames={joined.size}, eff_sr={eff_sr}, rms={rms:.4f}, infer", flush=True) # 可选:调试时将当前块写到一个覆盖的临时 WAV(重采样后,单声道16k),方便用 aplay 检查采音 if cfg["dump_wav_path"]: import wave, tempfile dump_path = cfg["dump_wav_path"] or str( Path(tempfile.gettempdir()) / "sv_debug_block.wav" ) with wave.open(dump_path, "wb") as wf: wf.setnchannels(1) wf.setsampwidth(2) wf.setframerate(eff_sr) dump_i16 = (np.clip(audio_block_f32, -1.0, 1.0) * 32767.0).astype(np.int16) wf.writeframes(dump_i16.tobytes()) # 执行推理 res_text = _infer_block(model, audio_block_f32, eff_sr, cfg, language, running_cache) if not res_text: continue text = rich_post(res_text) if text.startswith(printed_text): new_part = text[len(printed_text) :] else: new_part = text if new_part: print(new_part, end="", flush=True) printed_text += new_part # 停止前做一次 flush:如果还有残留缓冲,强制推理,避免句尾丢失 if block_buf: try: joined = np.concatenate(block_buf, axis=0) audio_block_f32 = int16_to_float32(joined) audio_block_f32, eff_sr = resample_to_16k(audio_block_f32, samplerate) text = _infer_block(model, audio_block_f32, eff_sr, cfg, language, running_cache) text = rich_post(text) if text: print(text[len(printed_text):], end="", flush=True) except Exception: pass print("\n已停止。") def main() -> None: parser = argparse.ArgumentParser(description="Real-time mic transcription (in-memory ALSA)") parser.add_argument("--model", default="iic/SenseVoiceSmall", help="模型仓库或本地路径") parser.add_argument("--device", default="cuda:0", help="设备,如 cuda:0 或 cpu") parser.add_argument("--language", default="auto", help="语言代码或 'auto'") parser.add_argument("--samplerate", type=int, default=16000, help="采样率") parser.add_argument("--channels", type=int, default=1, help="通道数") parser.add_argument("--block-seconds", type=float, default=1.0, help="每次推理块时长(秒)") parser.add_argument("--min-rms", type=float, default=0.003, help="触发推理的最小能量阈值(0-1)") parser.add_argument("--overlap-seconds", type=float, default=0.3, help="块间重叠时长(秒),减少句首/句尾丢失") parser.add_argument("--merge-vad", action="store_true", help="启用 VAD 合并(默认关闭以获得更快输出)") parser.add_argument("--merge-length", type=float, default=2.0, help="VAD 合并的最大分段时长(秒)") parser.add_argument("--debug", action="store_true", help="打印调试信息(RMS、帧数等)") parser.add_argument("--alsa-device", default=None, help="ALSA 设备名(如 hw:0,0 或 default)") args = parser.parse_args() # 将 CLI 设置传入环境变量,供运行体内读取 if args.debug: os.environ["SV_DEBUG"] = "1" os.environ["SV_MIN_RMS"] = str(args.min_rms) os.environ["SV_MERGE_VAD"] = "1" if args.merge_vad else "0" os.environ["SV_MERGE_LEN"] = str(args.merge_length) os.environ["SV_OVERLAP_SEC"] = str(args.overlap_seconds) run_in_memory( model_dir=args.model, device=args.device, language=args.language, samplerate=args.samplerate, channels=args.channels, block_seconds=args.block_seconds, alsa_device=args.alsa_device, ) if __name__ == "__main__": main() 执行前先安装一下模块组件 pip install pyalsaaudio 接着运行,就可以实时说话转换为文字了。 python demo_realtime_memory.py --alsa-device plughw:0,6 --samplerate 48000 --channels 2 --block-seconds 1.0 --language zh --device cuda:0 参考:https://github.com/FunAudioLLM/SenseVoice -
Isaac Sim 快速入门:三种工作流程示例
简介 如果是NVIDIA Isaac Sim的新用户,可以按照本文的两个示例来体验Isaac Sim。本文主要提供Isaac Sim基础使用教程、机器人基础教程。 在快速入门教程中,所有可通过 GUI 执行的操作同样也能用 Python 实现。您可以在 GUI 操作与 Python 脚本之间自由切换。您在 GUI 中创建的所有内容都能保存为 USD 文件的一部分。 例如,您可以通过图形界面创建世界,并为机器人添加所需动作。随后将整个 USD 文件导入独立的 Python 脚本中,根据需求系统性地修改属性。 基础使用教程 本教程涵盖 Isaac Sim 的基础操作,包括界面导航、场景对象添加、查看对象基本属性以及运行模拟等内容。 通过本教程,您将从空白场景开始,根据三种不同工作流程的选择,最终实现机器人运动控制。提供三种不同工作流程的目的是展示 Isaac Sim 可根据需求以多种方式灵活使用。 可以查看两种工作流中的脚本以了解它们的差异。通过对比分析,有助于掌握如何执行完全相同的任务: 扩展脚本可在Window > Examples > Robotics Examples中找到,然后单击浏览器右上角的**Open Script **按钮。 独立脚本位于 \<isaac-sim-root-dir>/standalone_examples/tutorials/ 文件夹内。 可以通过编辑扩展示例中的任意脚本来体验"hot-reloading"功能。保存文件后,无需关闭模拟器即可立即看到变更生效。 在官方教程中有3个标签页,三个标签页执行相同操作并达成相同结果。 GUI: 图形用户界面 Extensions:扩展功能 Standalone Python:独立Python环境 GUI方式 步骤1:启动Isaac Sim linux:cd ~/isaacsim && ./isaac-sim.selector.sh windows:双击isaac-sim.selector.bat 模拟器完全加载后,创建新场景: 从顶部菜单栏点击File > New。首次启动 Isaac Sim 时,可能需要 5-10 分钟完成初始化。 步骤2: 添加地平面 为场景添加地平面:从顶部菜单栏点击Create > Physics > Ground Plane。 步骤3:添加光源 可以为场景添加光源以照亮其中的物体。如果场景中有光源但没有物体反射光线,场景仍会显得昏暗。 在顶部菜单栏中,点击Create > Lights > Distant Light。 步骤4:添加视觉立方体 "视觉"立方体是指没有附加物理属性的立方体,例如没有质量、没有碰撞体积。这种立方体不会受重力影响下落,也不会与其他物体发生碰撞。 从顶部菜单栏中,依次点击Create > Shape > Cube. 在用户界面最左侧找到箭头图标并点击Play。运行模拟时立方体不会有任何动作。 步骤5:移动、旋转与缩放立方体 使用左侧工具栏上的各种操控工具来操作立方体。 按下"W"键或点击移动工具即可拖拽移动立方体。通过点击箭头并拖拽可单轴移动,点击彩色方块并拖拽可双轴移动,点击工具中心的圆点并拖拽则可三轴自由移动。 按下“E”键或点击旋转控制器来旋转立方体。 按下“R”键或点击缩放控制器来调整立方体大小。点击箭头并拖动可单维度缩放,点击彩色方块并拖动可双维度缩放,点击控制器中心的圆圈并拖动则可实现三维同步缩放。 按下“esc”键取消选中立方体。 对于“移动”和“旋转”操作,可选择基于局部坐标系或世界坐标系进行操作。长按控制器即可查看选项。 可以通过立方体的Property属性面板进行更精确的修改,只需在对应输入框中输入具体数值即可。点击输入框旁的蓝色方块可将数值重置为默认值。 步骤6:添加物理与碰撞属性 常见的物理属性包括质量和惯性矩阵,这些属性使物体能够在重力作用下下落。碰撞属性则决定了物体能否与其他物体发生碰撞。 物理和碰撞属性可以分别添加,因此你可以创建一个能与其他物体碰撞但不受重力影响的物体,或是受重力影响但不会与其他物体碰撞的物体。但在多数情况下,这两个属性会同时添加。 为立方体添加物理和碰撞属性: 在场景树中找到对象("/World/Cube")并高亮显示它。 从工作区右下角的Property属性面板中,点击"Add"按钮并在下拉菜单中选择Physics。这将显示可添加到对象的一系列属性选项。 选择Rigid Body with Colliders Preset“带碰撞器的刚体预设”可为对象同时添加物理和碰撞网格。 按下播放Play按钮,观察立方体在重力作用下坠落并与地平面发生碰撞。 教程结束,记得保存你的工作。 扩展功能方式 通过一个名为"脚本编辑器"的现有扩展模块来演示扩展工作流的特性。脚本编辑器允许用户通过 Python 与场景进行交互。主要使用与独立 Python 工作流相同的 Python API。当我们开始与模拟时间轴交互时,特别是下一个教程中,这两种工作流的区别将变得清晰。 步骤1:启动 启动一个新的 Isaac Sim 实例,转到顶部菜单栏并点击Window > Script Editor。 步骤2:添加地平面 要通过交互式 Python 添加地平面,请将以下代码片段复制粘贴到脚本编辑器中,然后点击底部的运行Run按钮执行。 from isaacsim.core.api.objects.ground_plane import GroundPlane GroundPlane(prim_path="/World/GroundPlane", z_position=0) 步骤3:添加光源 可以为场景添加光源以照亮其中的物体。如果场景中有光源但没有物体反射光线,场景仍会显得昏暗。 在脚本编辑器中新建一个标签页(Tab > Add Tab)。 在脚本编辑器中复制粘贴以下代码片段并运行,即可添加光源。 import omni.usd from pxr import Sdf, UsdLux stage = omni.usd.get_context().get_stage() distantLight = UsdLux.DistantLight.Define(stage, Sdf.Path("/DistantLight")) distantLight.CreateIntensityAttr(300) 步骤4:添加视觉立方体 在脚本编辑器中新建一个标签页 (Tab > Add Tab)。 在脚本编辑器中复制粘贴以下代码片段并运行,即可添加两个立方体。我们将保留其中一个作为纯视觉对象,同时为另一个添加物理和碰撞属性以便对比。 import numpy as np from isaacsim.core.api.objects import VisualCuboid VisualCuboid( prim_path="/visual_cube", name="visual_cube", position=np.array([0, 0.5, 0.5]), size=0.3, color=np.array([255, 255, 0]), ) VisualCuboid( prim_path="/test_cube", name="test_cube", position=np.array([0, -0.5, 0.5]), size=0.3, color=np.array([0, 255, 255]), ) Isaac Sim 核心 API 是对原生 USD 和物理引擎 API 的封装。您可以使用原生 USD API 添加一个视觉立方体(不含物理和颜色属性)。请注意原生 USD API 更为冗长,但能提供对每个属性的更精细控制。 from pxr import UsdPhysics, PhysxSchema, Gf, PhysicsSchemaTools, UsdGeom import omni # USD api for getting the stage stage = omni.usd.get_context().get_stage() # Adding a Cube path = "/visual_cube_usd" cubeGeom = UsdGeom.Cube.Define(stage, path) cubePrim = stage.GetPrimAtPath(path) size = 0.5 offset = Gf.Vec3f(1.5,-0.2,1.0) cubeGeom.CreateSizeAttr(size) if not cubePrim.HasAttribute("xformOp:translate"): UsdGeom.Xformable(cubePrim).AddTranslateOp().Set(offset) else: cubePrim.GetAttribute("xformOp:translate").Set(offset) 步骤5:添加物理与碰撞属性 在 Isaac Sim 核心 API 中,我们为常用对象编写了封装器,这些封装器附带所有物理和碰撞属性。您可以通过以下代码片段添加一个具有物理和碰撞属性的立方体。 import numpy as np from isaacsim.core.api.objects import DynamicCuboid DynamicCuboid( prim_path="/dynamic_cube", name="dynamic_cube", position=np.array([0, -1.0, 1.0]), scale=np.array([0.6, 0.5, 0.2]), size=1.0, color=np.array([255, 0, 0]), ) 另外,如果想修改现有对象使其具备物理和碰撞属性,可以使用以下代码片段。 from isaacsim.core.prims import RigidPrim RigidPrim("/test_cube") from isaacsim.core.prims import GeometryPrim prim = GeometryPrim("/test_cube") prim.apply_collision_apis() 点击播放Play按钮,观察立方体在重力作用下坠落并与地平面碰撞。 步骤6: 移动、旋转与缩放立方体 使用核心 API 移动物体: import numpy as np from isaacsim.core.prims import XFormPrim translate_offset = np.array([[1.5,1.2,1.0]]) orientation_offset = np.array([[0.7,0.7,0,1]]) # note this is in radians scale = np.array([[1,1.5,0.2]]) stage = omni.usd.get_context().get_stage() cube_in_coreapi = XFormPrim(prim_paths_expr="/test_cube") cube_in_coreapi.set_world_poses(translate_offset, orientation_offset) cube_in_coreapi.set_local_scales(scale) 使用原始 USD API 移动物体: from pxr import UsdGeom, Gf import omni.usd stage = omni.usd.get_context().get_stage() cube_prim = stage.GetPrimAtPath("/visual_cube_usd") translate_offset = Gf.Vec3f(1.5,-0.2,1.0) rotate_offset = Gf.Vec3f(90,-90,180) # note this is in degrees scale = Gf.Vec3f(1,1.5,0.2) # translation if not cube_prim.HasAttribute("xformOp:translate"): UsdGeom.Xformable(cube_prim).AddTranslateOp().Set(translate_offset) else: cube_prim.GetAttribute("xformOp:translate").Set(translate_offset) # rotation if not cube_prim.HasAttribute("xformOp:rotateXYZ"): # there are also "xformOp:orient" for quaternion rotation, as well as "xformOp:rotateX", "xformOp:rotateY", "xformOp:rotateZ" for individual axis rotation UsdGeom.Xformable(cube_prim).AddRotateXYZOp().Set(rotate_offset) else: cube_prim.GetAttribute("xformOp:rotateXYZ").Set(rotate_offset) # scale if not cube_prim.HasAttribute("xformOp:scale"): UsdGeom.Xformable(cube_prim).AddScaleOp().Set(scale) else: cube_prim.GetAttribute("xformOp:scale").Set(scale) 独立python环境方式 脚本位于standalone_examples/tutorials/getting_started.py,要运行该脚本,请打开终端,导航至 Isaac Sim 安装根目录,并执行以下命令: ./python.sh standalone_examples/tutorials/getting_started.py 机器人基础教程 本小节介绍如何将机器人添加到场景中、移动机器人以及检查机器人状态。在开始教程前,请确保已经完成了上一章节isaac sim基础使用教程。 GUI方式 步骤1:向场景中添加机器人 新建场景:通过File > New Stage.。 添加机器人:向场景添加机器人,从顶部菜单栏点击Create > Robots > Franka Emika Panda Arm。 步骤2:检查机器人 使用物理检查器查看机器人关节属性。 前往Tools > Physics > Physics Inspector.。右侧将打开一个窗口。 选择 Franka 进行检查。窗口默认会显示关节信息,例如上下限位及默认位置。 点击右上角的三横线图标可查看更多选项,例如关节刚度和阻尼系数。 可选)修改这些数值,观察舞台上机器人随参数变化的运动。修改成功后会出现绿色对勾标记。 点击绿色对勾按钮,将当前参数设为机器人新的默认值。 步骤3:控制机器人 基于图形界面的机器人控制器位于 Omniverse 可视化编程工具 OmniGraphs 中。OmniGraph 相关章节提供了更深入的教程指导。本教程将通过快捷工具生成控制图,然后在 OmniGraph 编辑器中查看该控制图。 通过菜单栏选择 Tools > Robotics > Omnigraph Controllers > Joint Position.来打开控制图生成器。。 在新弹出的关节位置控制器**Articulation Position Controller Inputs **输入窗口中,点击 Robot Prim 字段旁的添加"Add"按钮。 选择 Franka 作为目标对象。 点击确定生成图表。 要移动机器人的话按照下面步骤 在右上角的“舞台”选项卡中,选择Graph > Position_Controller.。 选择 JointCommandArray 节点。您可以通过在舞台树中选择该节点,或在图表编辑器中选择该节点来完成此操作。 在右下角的Property选项卡中,可以看到关节命令值。构造数组节点Construct Array Node下的输入Inputs项对应机器人上的关节,从基座关节开始。 点击+按住+拖动不同的数值字段,或输入不同的值,可以看到机械臂位置发生变化。 点击Play开始模拟。 要生成可视化的图标 打开图表编辑器窗口:**Window > Graph Editors > Action Graph. **。该编辑器窗口会在包含机器人的视口选项卡下方以新选项卡形式打开。 调出新打开的浏览器标签页。 点击位于图形编辑器窗口中央的Edit Action Graph选项。 从列表中选择唯一存在的图形。 选择一个数组并查看Stage和Property选项卡,以了解每个数组节点关联的值。 在图形中选择"关节控制器"Articulation Controller对象以查看其属性。 Extension方式 步骤1:向场景添加机器人 新建一个场景(File > New)。要将机器人添加到场景中,请将以下代码片段复制粘贴到脚本编辑器中并运行。 import carb from isaacsim.core.prims import Articulation from isaacsim.core.utils.stage import add_reference_to_stage from isaacsim.storage.native import get_assets_root_path import numpy as np assets_root_path = get_assets_root_path() if assets_root_path is None: carb.log_error("Could not find Isaac Sim assets folder") usd_path = assets_root_path + "/Isaac/Robots/FrankaRobotics/FrankaPanda/franka.usd" prim_path = "/World/Arm" add_reference_to_stage(usd_path=usd_path, prim_path=prim_path) arm_handle = Articulation(prim_paths_expr=prim_path, name="Arm") arm_handle.set_world_poses(positions=np.array([[0, -1, 0]])) 步骤2:检查机器人 Isaac Sim 核心 API 提供了许多函数调用来获取机器人相关信息。以下是查询关节数量与名称、各类关节属性以及关节状态的示例代码。 在脚本编辑器中新建标签页,复制粘贴以下代码片段。该操作需在上一步添加机器人完成后执行(此时 arm_handle 已创建)。运行代码前需先点击播放Play按钮,这些命令需在物理引擎运行状态下才能生效。 # Get the number of joints num_joints = arm_handle.num_joints print("Number of joints: ", num_joints) # Get joint names joint_names = arm_handle.joint_names print("Joint names: ", joint_names) # Get joint limits joint_limits = arm_handle.get_dof_limits() print("Joint limits: ", joint_limits) # Get joint positions joint_positions = arm_handle.get_joint_positions() print("Joint positions: ", joint_positions) 请注意,点击"运行"时仅会打印一次状态信息,即使模拟正在持续运行。如需查看最新状态,需反复点击"运行"按钮。若希望在每个物理步长都打印信息,需要将这些命令插入到每个物理步长都会执行的回调函数中。在章节"工作流程"中详细讲解时间步进机制。 要将命令插入物理回调中,请在脚本编辑器的单独标签页中运行以下代码片段。 import asyncio from isaacsim.core.api.simulation_context import SimulationContext async def test(): def print_state(dt): joint_positions = arm_handle.get_joint_positions() print("Joint positions: ", joint_positions) simulation_context = SimulationContext() await simulation_context.initialize_simulation_context_async() await simulation_context.reset_async() simulation_context.add_physics_callback("printing_state", print_state) asyncio.ensure_future(test()) 按下播放键启动模拟,然后运行该代码片段。您将看到终端在每个物理步骤打印出的信息。 如果不再需要每个物理步骤都打印信息,可以通过运行以下代码片段来移除物理回调。 simulation_context = SimulationContext() simulation_context.remove_physics_callback("printing_state") 步骤3:控制机器人 在 Isaac Sim 中有多种控制机器人的方式。最底层是直接发送关节指令来设置位置、速度和力矩。以下是通过关节层级的 Articulation API 控制机器人的示例。 在脚本编辑器中新建一个标签页,复制粘贴以下代码片段。该代码需在前述添加机器人步骤完成后运行(此时 arm_handle 已建立)。运行代码片段前请先点击播放键Play。这些指令需在物理引擎运行状态下生效。我们将提供两个位置供您切换。若您已将上述打印状态代码片段添加至每个物理步骤,当机器人移动时您应能看到打印的关节编号发生变化。 # Set joint position randomly arm_handle.set_joint_positions([[-1.5, 0.0, 0.0, -1.5, 0.0, 1.5, 0.5, 0.04, 0.04]]) # Set all joints to 0 arm_handle.set_joint_positions([[0.0, 0.0, 0.0 , 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]]) 与前述 get_joint_positions 功能类似,此处的 set_joint_positions 仅在您点击"运行"时执行一次。若您希望在每个物理步骤发送指令,则需将这些命令插入到每个物理步骤都会执行的物理回调函数中。 独立Python方式 脚本位于 standalone_examples/tutorials/getting_started_robot.py 。要运行该脚本,请打开终端,导航至 Isaac Sim 安装的根目录,并执行以下命令: ./python.sh standalone_examples/tutorials/getting_started_robot.py 到此就完成了基本的操作了,接下来就是一系列的教程可以参考:《机器人设置教程系列》。 -
Isaac Sim v5.0.0:探索AI 机器人仿真平台
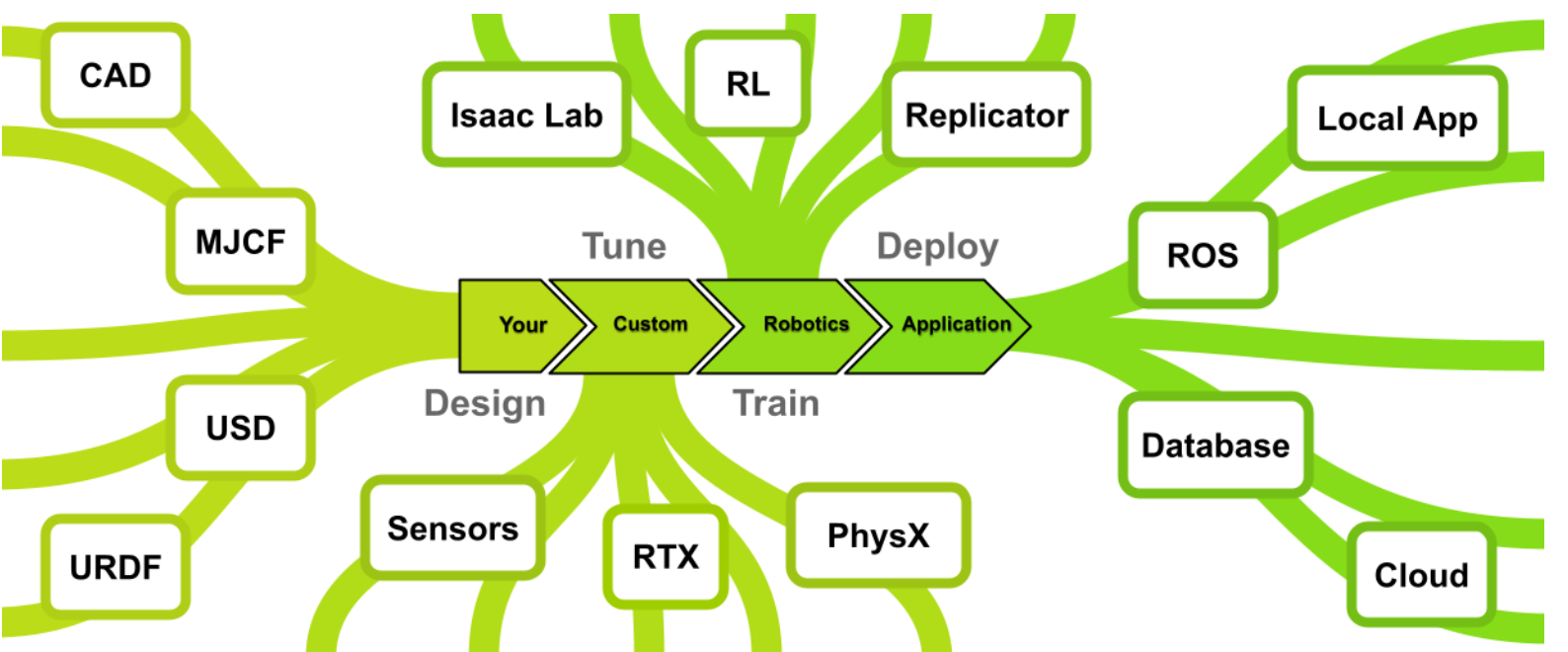
什么是isaac sim NVIDIA Issac Sim是一款基于NVIDIA omniverse构建的参考应用应用程序,使开发人员能够在基于物理的虚拟环境开发、模拟和测试AI机器人。 设计 Isaac Sim提供了一系列工作流程,用于导入和调整最常见格式(包括Onshape、统一机器人描述格式URDF和MuJoco XML格式MJCF)设计的机械系统。这通过使用通用常见描述USD实现,该开源3D常见描述API具有高度可扩展性,是Isaac Sim核心的统一数据交换格式。 微调与训练 Isaac Sim的核心功能在与其仿真能力本身:这是一个基于GPU的高保真physX物理引擎,能够支持工业规模的传感器PTX渲染。该平台通过直接调用GPU,实现了对各类传感器(包括摄像头、激光雷达和接触式传感器)的仿真模拟。这种能力进而支持数字孪生技术的实现,让您的端到端流程在真实机器人启动前就能完成测试运行。Isaac Sim提供了一整套工具链:通过Replicator生成合成数据,利用Omnigraph编程仿真环境,调整PhysX参数以匹配实现物理特性,最终通过强化学习RL等多样化方法训练控制智能体。 部署 Isaac Sim预先配备了所有必要组建,不仅能将智能体部署到真实机器人,还能构建与这类系统完全集成的应用程序。Omniverse提供了应用基础设施API,包括图形界面和文件管理功能。该平台还提供了与ROS 2桥接API,实现真实机器人与仿真的直接通信,同时搭建NVIDIA Isaac ROS:一套高性能硬件加速的ROS 2工具包,专为打造自主机器人而设计。 快速入门 快速安装:一小时内完成安装并开始使用。 Isaac Sim基础教程:助您快速上手 NVIDIA Isaac 仿真平台 工作站安装:本地工作站安装指南。 容器安装:远程桌面服务器安装指南。 开发工具:用于调试和开发的工具与环境。 python脚本与教程:使用 NVIDIA Isaac Sim 核心 Python API 构建环境、机器人和任务的工具与教程。 图形用户界面参考:通过图形用户界面了解 NVIDIA Isaac Sim 中的机器人基础概念。 导入与导出功能:支持多种文件格式的机器人及资产导入导出功能。 机器人设置:Isaac Sim 提供的机器人修改工具集。 机器人设置教程系列:关于机器人配置工具及工作流程的系列教学。 机器人仿真:用于模拟机器人的控制器与运动生成工具。 ROS2:ROS2桥接与接口。 Isaac Lab:强化学习框架与克隆器API。 合成数据生成:用于生成合成书记的工具集与工作流程。 数字孪生::用于构建和操作数字孪生的工具,如仓库物流、Cortex 和地图绘制。 系统架构 Isaac Sim旨在支持新型机器人工具的创建,并增强现有工具的功能。该平台为为C++和Python提供了灵活的API,可根据需求以不同深度集成到项目中。平台目标并非与现有软件竞争,而是与之协调并提升其能力。为此,Isaac Sim的许多组建都是开源的,可自由独立使用。可以在Onshape中设计机器人,用Isaac Sim模拟传感器,并通过ROS或其他消息系统控制场景。同样,也可以完全基于isaac sim提供的ingt构建完整的独立应用程序。 Omniverse Kit Isaac Sim基于Omniverse Kit构建,这是一个用于开发原生Omniverse应用和微服务的工具包。Omniverse Kit通过一系列轻量级插件提供多样化功能。这些插件采样C语言接口开发以确保API持久兼容性,同时提供python解释器以便进行便捷的脚本编写和定制。 通过 Python API 可以为 Omniverse Kit 编写新扩展,或为 Omniverse 创建新体验。 开发工作流 Isaac Sim基于C++和Python构建,通常分别通过编译插件和绑定进行操作。这意味着该平台能够支持多种工作流程,拥有构建和交互利用Isaac Sim项目。Isaac Sim提供完整的OMniverse应用程序,拥有与机器人交互和仿真,虽然这是用户与平台互动的最常见方式,但绝非唯一途径。Isaac Sim还以VS code和Jupyter Notebook扩展形式提供直接python开发支持。此外Isaac Sim不仅限与同步操作,还能通过ROS2实现硬件在环运行,从而促进仿真到现实的迁移以及数字孪生应用。 USD格式 NVIDIA Isaac Sim采用USD通过常见描述文件格式呈现常见。Universal Scene Description(USD)是由皮克斯开发的一种易于扩展的开源 3D 场景描述文件格式,专为内容创作和不同工具间的交互而设计。凭借其强大功能和通用性,USD 不仅被视觉特效领域广泛采用,还应用于建筑、设计、机器人、制造等多个学科领域。 安装指南 Isaac Sim支持windows和Linux系统安装。可通过容器( container)、工作站(workstation)、云端(in the cloud)、直播流(livestream)或者python环境进行部署,根据使用场景,还可以自定义硬件配置。 快速安装 快速安装适用于演示场景,可让您了解完整产品的功能概览。完成快速安装后,您能创建包含机器人的虚拟房间,这将更全面的展示产品能力。该只能面向具备基础计算机知识的安装人员。 windows或linux系统快速安装步骤: (1)下载以下任意安装包 windows: windows系统兼容性检查工具 linux:linux系统兼容性检查工具 (2)将安装包解压至制定文件夹 (3)运行脚本检查 window:请双击 omni.isaac.sim.compatibility_check.bat。 linux:./omni.isaac.sim.compatibility_check.sh 更多信息参阅:Isaac Sim兼容性检查 (4)下载任意一个安装包 window:https://download.isaacsim.omniverse.nvidia.com/isaac-sim-standalone-5.0.0-windows-x86_64.zip linux:https://download.isaacsim.omniverse.nvidia.com/isaac-sim-standalone-5.0.0-linux-x86_64.zip (5)创建一个isaac-sim的文件夹 在windows的C:/或linux根目录下直接创建一个名为isaac-sim的文件夹。然后将下载的文件解压到文件夹中去。 (6)在isaac-sim文件夹中,执行操作 window:请双击 isaac-sim.selector.bat linux:命令窗口中运行 ./post_install.sh ,然后运行 ./isaac-sim.selector.sh。 (7)在issac应用选择起窗口,选择"start" 有关应用选择器的详细信息,请参阅《Isaac Sim 应用选择器》。随后将打开另一个命令窗口并运行脚本,此过程可能比预期耗时更长。在此期间由于会出现空白窗口,可能看似安装失败。请继续等待。 (8)issac启动成功 (9)选择 选择创建一个房间 Create > Environment > Simple Room. (10)选择创建一个机械臂 Create > Robots > Franka Emika Panda Arm. (11)点击运行模拟 在屏幕最左侧寻找箭头按钮,点击它来运行一段简短模拟。 isaac 系统需求 对操作系统需求如下 对驱动的要求如下 工作站安装 工作站安装方式是在本地允许模拟器,需要对本地电脑有较高的要求,官方要求最低的配置要为RTX4080的显卡。因此若本地配置了GPU的windows或linux系统上以GUI应用程序允许isaac sim,推荐采用工作站安装方式。下面是安装步骤 (1)isaac Sim兼容性检查工具 Isaac 兼容性检查工具是一款轻量级应用程序,可通过编程方式检查本地的软硬件要求,会给出运行NVIDIA isaac sim时那些要求满足或不满足。 下载工具:Latest Release兼容性工具 解压:将压缩包解压到指定文件夹。 运行:在Linux系统上云霄omni.isaac.sim.compatibility_check.sh脚本,在windows系统上运行omni.isaac.sim.compatibility_check.bat文件。 点击工具的"Test Kit"按钮就会显示测试结果。 应用程序会以不同颜色高亮显示以下状态: 绿色:表示优秀 浅绿色:表示良好 橙色:表示基本满足,建议更高配置 红色:不足/不支持 应用程序检查维度为: NVIDIA GPU:驱动程序版本、支持RTX功能的GPU、显存容量。 CPU、内存和存储:CPU处理器、CPU核心数量、运行内存、可用存储空间。 others:操作系统、显示设备。 对于操作系统如果ubuntu大于版本号也会变成红色,可先测试是否可运行,实测是可以,但不排除有兼容性问题。 (2)下载软件包 下载链接:Latest Release,根据自己的系统选择软件包下载的本地。 在本地创建一个isaacsim文件夹,然后将压缩包解压到文件夹。 (3)运行启动 先创建extension_examples 的符号链接,请运行 post_install 脚本。 linux:./post_install.sh windows:双击 post_install.bat 文件 然后就可以启动应用程序 linux: 执行 ./isaac-sim.selector.sh windows:双击isaac-sim.selector.bat 文件 启动后会弹出以下界面 在弹出的窗口中选择isaac Sim Full,然后点击START就可以运行。启动过程中可能要一点时间,如果期间弹出“程序无法响应”,可以选择等待,以免被误杀。 启动后就可以开始第一个基础教程了:基础教程。 总结一下命令执行的实例: linux系统 mkdir ~/isaacsim cd ~/Downloads unzip "isaac-sim-standalone-5.0.0-linux-x86_64.zip" -d ~/isaacsim cd ~/isaacsim ./post_install.sh ./isaac-sim.selector.sh window系统 mkdir C:\isaacsim cd %USERPROFILE%/Downloads tar -xvzf "isaac-sim-standalone-5.0.0-windows-x86_64.zip" -C C:\isaacsim cd C:\isaacsim post_install.bat isaac-sim.selector.bat Docker容器安装 在远程服务器或者云端部署isaac sim建议使用docker容器的方式。 (1)检查系统是否满足需求 首先先确保系统满足运行NVIDIA isaac Sim所需的系统要求和驱动程序要求。 (2)安装docker Docker installation using the convenience script curl -fsSL https://get.docker.com -o get-docker.sh sudo sh get-docker.sh Post-install steps for Docker sudo groupadd docker sudo usermod -aG docker $USER newgrp docker Verify Docker docker run hello-world 详细的docker安装步骤见docker安装,安装后的配置步骤见配置步骤。 (3)安装NVIDIA容器工具包 Configure the repository curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list \ && \ sudo apt-get update Install the NVIDIA Container Toolkit packages sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker Configure the container runtime sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker Verify NVIDIA Container Toolkit docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi 安装最新版本的 NVIDIA 容器工具包以获取安全补丁。 (4)容器部署 docker pull nvcr.io/nvidia/isaac-sim:5.0.0 拉取isaac sim容器。 然后以交互式bash会话运行isaac sim容器。 docker run --name isaac-sim --entrypoint bash -it --runtime=nvidia --gpus all -e "ACCEPT_EULA=Y" --rm --network=host \ -e "PRIVACY_CONSENT=Y" \ -v ~/docker/isaac-sim/cache/kit:/isaac-sim/kit/cache:rw \ -v ~/docker/isaac-sim/cache/ov:/root/.cache/ov:rw \ -v ~/docker/isaac-sim/cache/pip:/root/.cache/pip:rw \ -v ~/docker/isaac-sim/cache/glcache:/root/.cache/nvidia/GLCache:rw \ -v ~/docker/isaac-sim/cache/computecache:/root/.nv/ComputeCache:rw \ -v ~/docker/isaac-sim/logs:/root/.nvidia-omniverse/logs:rw \ -v ~/docker/isaac-sim/data:/root/.local/share/ov/data:rw \ -v ~/docker/isaac-sim/documents:/root/Documents:rw \ nvcr.io/nvidia/isaac-sim:5.0.0 使用 -e "ACCEPT_EULA=Y" 标志即表示您接受 NVIDIA Omniverse 许可协议中规定的镜像许可协议。 使用 -e "PRIVACY_CONSENT=Y" 标志即表示您同意数据收集与使用协议中的条款。不设置此标志即可选择退出数据收集。 使用-e "PRIVACY_USERID=\<emai\l>" 标志可选择性地设置用于标记会话日志。 最后以原生直播模式启动 isaac sim ./runheadless.sh -v 运行直播客户端前,必须确保 Isaac Sim 应用已加载就绪。Isaac Sim 可能需要几分钟才能完全加载。-v 标志用于在着色器缓存预热时显示额外日志。要确认这一点,请留意控制台或日志中的这一行:Isaac Sim Full Streaming App is loaded。 首次加载 Isaac Sim 时,着色器缓存需要较长时间。后续运行 Isaac Sim 会更快,因为着色器已被缓存,且容器运行时缓存会被挂载。 (5)安装isaac sim WebRTC流媒体客户端 见后续章节。输入运行 Isaac Sim 容器的机器或实例的 IP 地址,点击连接按钮开始实时流传输。 云部署 Isaac Sim以容器形式提供,可在本地运行,也可在配备NVIDIA RTX的亚马逊云服务、微软、谷歌云平台、腾讯云或阿里云上运行,并支持将应用程序直接流式传输到您的桌面。这种基于云的交付方式能为任何桌面系统提供最新的RTX图像处理能力与性能,无需本地配置NVIDIA RTX GPU。 根据选择的云服务提供商,提供以下可选方案。 NVIDIA Brev:NVIDIA Brev Instructions AWS:Amazon Web Instructions Azure:Microsoft Cloud Instructions GCP:Google Cloud Instructions Tencent:Tencent Cloud Instructions Alibaba:Alibaba Cloud Instructions Volcano Engine:Volcano Engine Instructions Remote:Remote Workstation Instructions 上述链接提供了云端部署指南,包含通过 SSIsaac Automator 是一款高级工具,可帮助将自定义 Isaac Sim 部署自动化至公有云平台。该工具支持通过 SSH、基于网页的 VNC 客户端以及远程桌面客户端访问 Isaac Sim 实例,兼容 AWS、Azure、GCP 和阿里云等主流云服务商。H 和远程桌面客户端访问实例的操作说明。 直播客户端 本节将介绍如何以无界面模式直播运行 Isaac Sim 实例。需要注意的是每个 Isaac Sim 实例同一时间只能采用一种直播方式。同一时间仅允许一个客户端访问单个 Isaac Sim 实例。要远程退出 Isaac Sim 应用程序:点击文件菜单,然后在流式传输的 Isaac Sim 应用中选择退出。接着关闭 Isaac Sim WebRTC 流媒体客户端应用。当 Isaac Sim 运行在 A100 GPU 上时不支持直播功能。直播需要 NVENC(NVIDIA 编码器)支持,而 A100 GPU 不包含该编码器。 Isaac Sim WebRTC流媒体客户端是推荐的远程查看工具,可让您在桌面或工作站以无需配置高性能GPU可以查看Isaac Sim画面。 (1)服务端的启动 要使用Isaac Sim WebRTC流媒体客户端,需要先在远程运行isaac Sim。 linux:cd ~/isaacsim && ./isaac-sim.streaming.sh windows:双击isaac-sim.streaming.bat Docker:./runheadless.sh PIP:isaacsim isaacsim.exp.full.streaming --no-window Python sample:./python.sh standalone_examples/api/isaacsim.simulation_app/livestream.py 要可以通过互联网连接远程实例运行isaac sim,需要添加以下标志:--/app/livestream/publicEndpointAddress= --/app/livestream/port=49100。如在docker容器示例中: PUBLIC_IP=$(curl -s ifconfig.me) && ./runheadless.sh --/app/livestream/publicEndpointAddress=$PUBLIC_IP --/app/livestream/port=49100 然后在 Isaac Sim WebRTC 流媒体客户端应用中使用相同的公共 IP。运行 Isaac Sim 的主机必须开放UDP port 47998和TCP port 49100。 确保 Isaac Sim 应用已加载就绪。首次启动时,Isaac Sim 可能需要数分钟才能完全加载完成。 为确认加载状态,请在终端/控制台输出或应用日志中查找以下信息。使用 PIP 或 Python Sample 运行时可能不会显示该行信息。Isaac Sim Full Streaming App is loaded. (2)客户端的启动 请根据您的平台,从最新发布版块下载 Isaac Sim WebRTC 流媒体客户端。 运行 Isaac Sim WebRTC 流媒体客户端应用程序。 使用默认的 127.0.0.1 IP 地址作为服务器,连接到本地 Isaac Sim 实例。点击"连接"。连接过程可能需要一些时间。连接成功后,您将在客户端窗口中看到 Isaac Sim 界面。 需要注意的是建议在与 Isaac Sim 无头实例相同的网络中使用 WebRTC 流媒体客户端。连接到同一网络中无头模式的 Isaac Sim 实例时,请将 127.0.0.1 替换为运行 Isaac Sim 的计算机 IP 地址。 linux系统:在终端中运行 chmod +x xx.AppImage 命令,使应用程序获得可执行权限。双击 AppImage 文件即可运行 Isaac Sim WebRTC 流媒体客户端。重要提示:在 Ubuntu 22.04 或更高版本上运行需安装 libfuse2。具体安装方法请参阅《安装 FUSE 2》指南。 windows:若在连接本地或远程 Isaac Sim 实例时遇到问题,请确保 Windows 防火墙允许列表中已添加/kit/kit.exe 及 Isaac Sim WebRTC 流媒体客户端应用。 macbook:打开 DMG 文件后,点击并拖拽 Isaac Sim WebRTC 流媒体客户端应用程序至"应用程序"文件夹图标完成安装。 要重新加载连接,请在视图菜单中点击“重新加载”。如果一段时间后出现空白屏幕,此操作可能会有所帮助。 Python环境安装 主要是在python虚拟环境中通过PIP安装Isaac Sim和使用isaac Sim默认python环境。这里就不展开了,具体参考链接:python环境安装 Isaac Sim 资源库 isaac Sim提供多种资源与机器人模型,助您构建虚拟世界。部分资源专为isaac Sim及机器人应用打造,另一些则适用于其他基于NVIDIA Omniverse的应用程序。默认提供的资源均可在Window > Browsers选项卡中找到。 内容浏览器集中管理所有isaac Sim资源与文件,包含下来全部资源清单,以及URDF文件、配置文件、策略二进制等。Window > Browsers > Content。 isaac Sim最新版本提供示例资源包可供下载。使用这些资源时,需将文件下载至本地磁盘或Nucleus服务器。下文中所有资源路径均默认相对于 persistent.isaac.asset_root.default 设置中的默认资源根目录。详见本地资源包章节。 首次加载资源时耗时较长:机器人模型可能需要数分钟加载,大型环境场景的加载时间可能长达十分钟以上 资源分类如下: 机器人资产 相机与深度传感器 非视觉传感器 道具 环境 精选资源 Neural Volume渲染 机器人 NVIDIA Isaac Sim 支持多种具有不同底盘、外形和功能的机器人。这些机器人可分为轮式机器人、全向移动机器人、四足机器人、机械臂和空中机器人(无人机),它们位于内容浏览器的 Isaac Sim/Robots 文件夹中。 (1)轮式机器人 Limo是NVIDIA Isaac Sim 支持集成 ROS 系统的 AgileX Limo 差速驱动底盘机器人。Robots/AgilexRobotics/Limo/limo.usd NVIDIA 卡特机器人专为导航相关应用提供差速移动底盘。新一代 Nova 卡特机器人基于 Nova Orin 计算与传感器平台打造。 NVIDIA Isaac Sim 支持 Clearpath 移动机器人,包括 Dingo 和 Jackal。Clearpath 机器人位于 Robots/Clearpath 中。 Evobot 是一款采用两轮驱动的自平衡机器人,专为抓取和运输物体设计。该机器人由德国多特蒙德弗劳恩霍夫研究所开发。 Forklift 叉车模型采用单枢轴轮和滚轮设计,通过连接至关节动作的棱柱关节来控制升降操作。 JetBot是开源 NVIDIA JetBot 人工智能机器人平台为创客、学生和爱好者提供了构建创意趣味 AI 应用所需的一切。 Idealworks iw.hub 是一款配备激光雷达和摄像头的移动底盘,搭载 NVIDIA AGX GPU 实现自主导航。该平台负载能力达 1000 公斤,最高行驶速度 2.2 米/秒。 iRobot 公司推出的 Create3 机器人是一款先进的差速驱动机器人,专为多种教育应用场景设计。其圆形底盘集成了多种传感器和先进控制功能,特别适合室内导航、环境建图等任务。NVIDIA Isaac Sim 中的 Create3 机器人配备了差速驱动系统和各类传感器,可实现高度逼真的仿真效果。Create 3 机器人可在 Robots/iRobot/Create3/create_3.usd - 基础版本中找到。已配置移动底盘物理系统。更多信息参阅 iRobot Create 3 。 Leatherback 是 NVIDIA 用于自动驾驶的研究平台。皮背甲机器人位于 Robots/NVIDIA/Leatherback/leatherback.usd (2)全向移动机器人 Kaya机器人是一个展示 Isaac 机器人引擎在 NVIDIA Jetson Nano™平台上运行能力与灵活性的演示平台。该平台采用 3D 打印部件和爱好者级组件设计,力求实现最大程度的可及性,并配备三轮全向驱动系统,使其能够朝任意方向移动。 Robots/NVIDIA/Kaya/kaya.usd :基础版本 Robots/NVIDIA/Kaya/kaya_ogn_gamepad.usd:基础版本,外加使用全向控制器实现的游戏手柄操控功能。 O3dyn 是由多特蒙德弗劳恩霍夫研究所开发的自主全向运输机器人。凭借其全向轮,该机器人可实现任意方向移动,并通过四个杠杆抓取托盘,进而抬升托盘进行运输。 Robots/Fraunhofer/O3dyn/o3dyn.usd: 基础版本。包含移动底盘、夹具与升降机构的物理绑定,以及传感器定位功能。 Robots/Fraunhofer/O3dyn/o3dyn_controller.usd :基础版本,外加使用全向控制器实现的游戏手柄操控功能。 (3)四足机器人 Ant蚂蚁是一种基础四足机器人,腿部采用旋转关节设计,其原型源自 OpenAI Gym 中的 Ant 机器人。 Robots/IsaacSim/Ant/ant.usd :基础版本。可通过菜单栏中 Create>Robots>Ant 选项创建。 Robots/IsaacSim/Ant/ant_instanceable.usd :可实例化版本,专为强化学习场景配置以创建多个高效克隆体。 ANYmal 机器人是由 ANYbotics 开发的自主四足机器人。Isaac Sim 支持 B、C、D 三种型号。 Boston Dynamics Spot 波士顿动力 Spot 机器人位于 Robots/BostonDynamics/spot Unitree Quadruped Robots 宇树四足机器人A1、B2、Go1 和 Go2 是 Unitree Robotics 研发的四足机器人,在 Isaac Sim 中进行仿真。四足示例中使用的是 A1 型号。 关于四组机器人控制示例,请参阅:Isaac Sim 中的强化学习策略示例 (4)机械臂机器人 Denso Cobotta 包含以下 Denso 型号:Cobotta Pro 900、Cobotta Pro 1300。位于 Robots/Denso/Cobotta。 Fanuc CRX10iA/L 是一款 6 轴机器人,有效载荷为 10 公斤。 Festo费斯托协作机器人是一款六轴气动机械臂。 Flexiv Rizon 4 是一款 7 轴自适应机械臂。 RobotStudio是lerobot机械臂,包含以下 RobotStudio 模型:SO-100、SO-101。RobotStudio 机器人位于 Robots/RobotStudio。 太多了,只列出部分。 (5)空中机器人 Crazyflie 2.X 微型四轴飞行器机器人 Ingenuity火星直升机"机智号" (6)人形机器人 Fourier Intelligence GR1 傅里叶智能 GR1 Unitree Humanoids 宇树人形机器人,位于 Robots/Unitree Xiao Peng PX5 小鹏 PX5机器人位于 Robots/XiaoPeng/PX5 (7)移动式机械臂 Clearpath Ridgeback提供两种 Clearpath Ridgeback 型号配置:一种配备 Emika Franka Panda 机械臂,另一种配备 Universal Robots UR5 机械臂。位于 Robots>Clearpath 目录下。 Boston Dynamics Spot 波士顿动力 Spot 机器人,带机械臂的 Spot 机器人位于 Robots>BostonDynamics>spot 路径下 相机与深度传感器 Isaac Sim 支持相机和深度传感器,其数字孪生体可在内容浏览器中找到,位于 Isaac Sim/Sensors 目录下,并按制造商分类存放于子文件夹中。这里就不过多阐述。 非视觉传感器 Isaac Sim 模拟了多种类型的非视觉传感器模型,其数字孪生体可在内容浏览器的 Isaac Sim/Sensors 路径下找到,并按制造商分类存放于子文件夹中。 部分非视觉传感器类型尚未提供数字孪生体。有关这些传感器的详细信息(包括如何通过图形界面创建它们),请点击下方链接: 接触传感器 惯性测量单元传感器 光束传感器 激光雷达 雷达 道具 道具主要是一些角色人物如警察、医生、工人,以及杂项资产。 环境资产 环境资产提供如网格、房间、仓库、医院、办公室、赛道、小型仓库数字孪生 (1)简单网格 这个简易环境包含一块带有网格纹理的平坦地面和围边。系统提供了三种配置:前两种为直角转角,第三种则为圆角设计。 (2)简单房间 包含一张桌子的简易房间 在内容浏览器中搜索 simple_room.usd 或通过创建菜单:Create>Environments>Simple Room (3)仓库 一个包含货架及可放置物品的仓库环境。提供四种配置方案: (4)医院 医院环境,包含多个房间和空间。 (5)办公室 一个办公环境,包含多个房间和开放式平面布局。 (6)赛道 地面上勾勒出的 Jetracer 赛道轮廓。 (7)小型仓库数字孪生 一个小型仓库的数字孪生,可以使用。 精选资产 Nova Carter 搭载 Nova Orin™传感器与计算架构,是一套完整的机器人开发平台,可加速新一代自主移动机器人(AMR)的开发和部署。 Nova Carter 目前作为 Isaac AMR 和 Isaac ROS 软件的双重参考平台,支持真实场景与仿真环境下的开发工作。用户可通过赛格威机器人公司购买 Nova Carter 机器人。 关于功能完整的 Nova Carter Isaac Sim 资产详情,请参阅Nova Carter 文档页面。 注意Nova Carter 机器人在首次加载时可能需要数分钟时间。 Neural Volume渲染 NuRec(神经重建)技术能够利用源自真实世界图像的神经体积数据,在 Omniverse 中进行场景渲染。这些基于 3D 高斯模型的场景可作为标准 USD 资产加载至 Isaac Sim,用于可视化与仿真。 有关 NuRec 在 Omniverse 中的详细工作原理(包括数据准备、渲染设置及已知限制),请参阅NuRec 文档。要生成兼容场景,可使用开源项目3DGruT——该项目提供从图像集合训练 3D 高斯模型的工具,并能导出适用于 Omniverse 应用的 USDZ 格式数据。 示例展示了如何将 NuRec 场景加载到 Isaac Sim 中并运行模拟。该代码片段遍历提供的示例,首先加载指定的舞台,随后加载 carter 导航资源并设置起始位置。接着检查是否需要在生成位置创建碰撞地平面,若需要,则创建一个应用了碰撞 API 的平面基元。然后设置 carter 导航目标基元位置,并运行指定步数的模拟。在模拟过程中,轮式机器人将朝目标位置行进。 import asyncio import os import omni.kit.commands import omni.kit.app import omni.usd import omni.timeline from isaacsim.storage.native import get_assets_root_path_async from isaacsim.core.utils.stage import add_reference_to_stage from pxr import PhysxSchema, UsdGeom, UsdPhysics # User path of the HF NuRec dataset USER_PATH = "/home/user/PhysicalAI-Robotics-NuRec" # Paths for loading and placing the Nova Carter navigation asset and its target. NOVA_CARTER_NAV_URL = "/Isaac/Samples/Replicator/OmniGraph/nova_carter_nav_only.usd" NOVA_CARTER_NAV_USD_PATH = "/World/NovaCarterNav" NOVA_CARTER_NAV_TARGET_PATH = f"{NOVA_CARTER_NAV_USD_PATH}/targetXform" # Scenarios for testing navigation in the environments EXAMPLE_CONFIGS = [ { "name": "Voyager Cafe", "stage_url": f"{USER_PATH}/nova_carter-cafe/stage.usdz", "nav_start_loc": (0, 0, 0), "nav_relative_target_loc": (-3, -1.5, 0), "create_collision_ground_plane": False, "num_simulation_steps": 500, }, { "name": "Galileo Lab", "stage_url": f"{USER_PATH}/nova_carter-galileo/stage.usdz", "nav_start_loc": (3.5, 2.5, 0), "nav_relative_target_loc": (4, 0, 0), "create_collision_ground_plane": False, "num_simulation_steps": 500, }, { "name": "Wormhole", "stage_url": f"{USER_PATH}/nova_carter-wormhole/stage.usdz", "nav_start_loc": (0, 0, 0), "nav_relative_target_loc": (5, 0, 0), "create_collision_ground_plane": False, "num_simulation_steps": 500, }, { "name": "ZH Lounge", "stage_url": f"{USER_PATH}/zh_lounge/usd/zh_lounge.usda", "nav_start_loc": (-1.5, -3, -1.6), "nav_relative_target_loc": (-0.5, 5, -1.6), "create_collision_ground_plane": True, "num_simulation_steps": 500, }, ] async def run_example_async(example_config): example_name = example_config.get("name") print(f"Running example: '{example_name}'") # Open the stage stage_url = example_config.get("stage_url") if not stage_url: print(f"Stage URL not provided, exiting") return if not os.path.exists(stage_url): print(f"Stage URL does not exist: '{stage_url}', exiting") return print(f"Opening stage: '{stage_url}'") await omni.usd.get_context().open_stage_async(stage_url) stage = omni.usd.get_context().get_stage() # Make sure the physics scene is set to synchronous for the navigation to work for prim in stage.Traverse(): if prim.IsA(UsdPhysics.Scene): physx_scene = PhysxSchema.PhysxSceneAPI.Apply(prim) physx_scene.GetUpdateTypeAttr().Set("Synchronous") break # Load the carter navigation asset assets_root_path = await get_assets_root_path_async() carter_nav_path = assets_root_path + NOVA_CARTER_NAV_URL print(f"Loading carter nova asset: '{carter_nav_path}'") carter_nav_prim = add_reference_to_stage(usd_path=carter_nav_path, prim_path=NOVA_CARTER_NAV_USD_PATH) # Set the carter navigation start location nav_start_loc = example_config.get("nav_start_loc") if not nav_start_loc: print(f"Navigation start location not provided, exiting") return print(f"Setting carter navigation start location to: {nav_start_loc}") if not carter_nav_prim.GetAttribute("xformOp:translate"): UsdGeom.Xformable(carter_nav_prim).AddTranslateOp() carter_nav_prim.GetAttribute("xformOp:translate").Set(nav_start_loc) # Check if a collision ground plane needs to be created at the spawn location if example_config.get("create_collision_ground_plane"): plane_path = "/World/CollisionPlane" print(f"Creating collision ground plane {plane_path} at {nav_start_loc}") omni.kit.commands.execute("CreateMeshPrimWithDefaultXform", prim_path=plane_path, prim_type="Plane") plane_prim = stage.GetPrimAtPath(plane_path) plane_prim.GetAttribute("xformOp:scale").Set((10, 10, 1)) plane_prim.GetAttribute("xformOp:translate").Set(nav_start_loc) if not plane_prim.HasAPI(UsdPhysics.CollisionAPI): collision_api = UsdPhysics.CollisionAPI.Apply(plane_prim) else: collision_api = UsdPhysics.CollisionAPI(plane_prim) collision_api.CreateCollisionEnabledAttr(True) plane_prim.GetAttribute("visibility").Set("invisible") # Set the carter navigation target prim location nav_relative_target_loc = example_config.get("nav_relative_target_loc") if not nav_relative_target_loc: print(f"Navigation relative target location not provided, exiting") return print(f"Setting carter navigation target location to: {nav_relative_target_loc}") carter_navigation_target_prim = stage.GetPrimAtPath(NOVA_CARTER_NAV_TARGET_PATH) if not carter_navigation_target_prim.IsValid(): print(f"Carter navigation target prim not found at path: '{NOVA_CARTER_NAV_TARGET_PATH}', exiting") return if not carter_navigation_target_prim.GetAttribute("xformOp:translate"): UsdGeom.Xformable(carter_navigation_target_prim).AddTranslateOp() carter_navigation_target_prim.GetAttribute("xformOp:translate").Set(nav_relative_target_loc) # Run the simulation for the given number of steps num_simulation_steps = example_config.get("num_simulation_steps") if not num_simulation_steps: print(f"Number of simulation steps not provided, exiting") return print(f"Running {num_simulation_steps} simulation steps") timeline = omni.timeline.get_timeline_interface() timeline.play() for i in range(num_simulation_steps): if i % 10 == 0: print(f"Step {i}, time: {timeline.get_current_time():.4f}") await omni.kit.app.get_app().next_update_async() print(f"Simulation complete, pausing timeline") timeline.pause() async def run_examples_async(): for example_config in EXAMPLE_CONFIGS: await run_example_async(example_config) asyncio.ensure_future(run_examples_async()) 从 Hugging Face 下载 NVIDIA NuRec 数据集。更新脚本中的 USER_PATH 变量: USER_PATH = "/home/user/PhysicalAI-Robotics-NuRec"。 本文主要来自Isaac Sim Documentation V5.0.0的翻译。 -
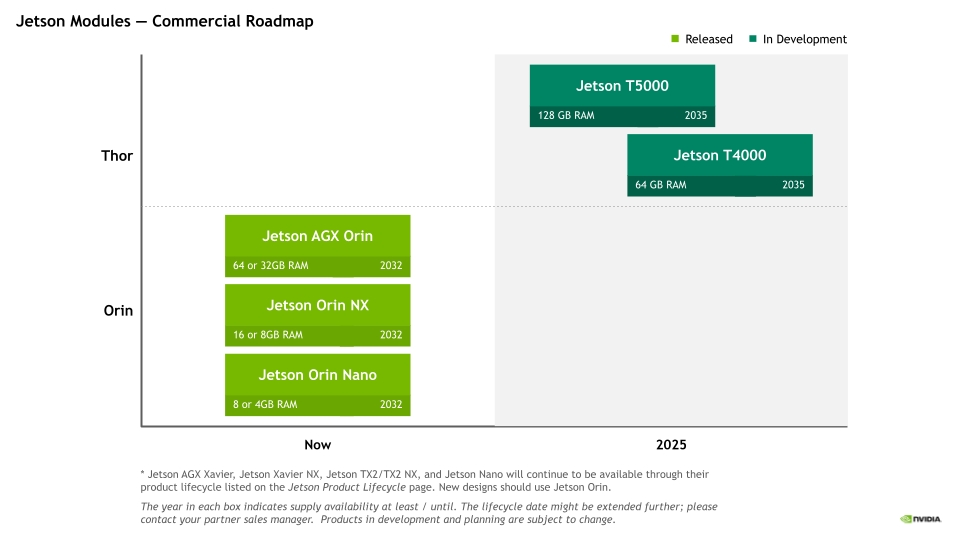
NVIDIA Jetson平台简介:机器人和边缘AI
简介 NVIDIA Jetson平台提供用于开发和部署AI赋能机器人、无人机、IVA(Intelligent Video Analytics,智能视频)应用和自主机器的工具。在边缘生成式AI、NVIDIA Metropolis和Isaac平台支持下,Jetson提供可拓展得软件、现代AI堆栈、灵活的微服务和API、生成就绪型ROS软件包以及特定于应用程序的AI工作流。 Jetson 硬件Roadmap,分为商业方向和工业方向。 上图是商业硬件roadmap,主要分为orin(欧林)和thor(雷神)两个系列。 而工业方向roadmap主要是entry、mainstream、perfromance三个方向。 在软件方面,jetson提供JetPack软件包,截止目前最新的发布版本是JetPack 7.0,主要是基于ubuntu 24.04,集成了CUDA 13.0以及holoscan sensor bride支持。 硬件 NVIDIA Jetson 模组可提供适合各种性能水平和价位的加速计算功能,从而能够满足各种自主应用的需求。从制造业到建筑业,从医疗健康到物流行业,Jetson 平台都能提供出色的性能、卓越的能效和无比轻松的开发体验。下面是jetson系列提供的模组规格简要对比。 上面是NVIDIAjetson系列的模组从最小0.5TFLOPS算力到最大2070 TOPS算力的平台矩阵。 Nano:四核A57@1.43G CPU+128核Maxwell架构GPU+4GB LPDDR内存,可提供472 FGLOP的AI算力;并行运行多个神经网络并同时处理多个高分辨率传感器,其功耗仅需5~10W;应用在网络硬盘录像机(NVR)、家用机器人以及具备全面分析功能的智能网关上面。 TX2:双核NVIDIA Denver™@1.95G+四核Arm® Cortex®-A57@1.92G CPU+256核 Pascal GPU+4GB/8GB LPDDR内存,可提供1.3TFLOPS的AI算力;计算性能翻倍,功耗仅7.5W。可应用在工厂机器人、商用无人机、便携式医疗设备和企业协作设备中。 Xavier NX:6核NVIDIA Carmel ARM®v8.2 64 位 CPU + 48 个 Tensor Core 的 384 核 NVIDIA Volta™ GPU+8/16GB LPDDR4x内存;可提供14TOPS+功耗10W~21TOPS+功耗20W的AI算力;应用在 适用于无人机、便携式医疗设备、小型商业机器人、智能摄像头、高分辨率传感器、自动光学检测、智能工厂和其他 IoT 嵌入式系统等高性能 AI 系统。 AGX Xavier:8 核 NVIDIA Carmel Armv8.2 64 位 CPU+512 个 NVIDIA CUDA Core 和 64 个 Tensor Core Volta 架构GPU+32/64GB内存,提供32TOPS的AI算力,功耗在10W~40W;非常适用于配送和物流机器人、工厂系统和大型工业UAV等自主机器。 Orin Nano、NX、AGX:6\~12核 Arm® Cortex® A78AE v8.2@1.7G\~2.2G +(32\~64)x (1024\~2048)核Ampere 架构 GPU+4G\~64G LPDDR5内存;功耗满足7\~60W,提供算力34 TOPS\~275 TOPS的AI算力;Orin系列是包含7个相同架构的模组其性能是上一代AI推理的8倍并支持高速接口;强大的软件堆栈包含预训练的 AI 模型、参考 AI 工作流和垂直应用框架,可加速生成性 AI 的端到端开发,以及边缘 AI 和机器人应用。 Thor:12\~14核 Arm® Neoverse®-V3AE 64 位 CPU@2.6G+(64\~96)X(1536\~2560)核Blackwell 架构 GPU+128G LPDDR5X内存,提供1200~2070TFLOPS(FP4)算力;功耗在40~75W,与AGX Orin相比,Jetson Thor 系列模组的 AI 计算性能提高至 7.5 倍以上,能效提高至 3.5 倍。应用在人形机器人、空间智能、多传感器处理、生成式AI等多个场景。 软件 NVIDIA Jetson软件是永远边缘构建、部署和扩展人形机器人及生成式AI应用的旗舰平台。它支持全系列Jetson模块,为从原型开发到量产提供统一且可扩展的基础。NVIDIA JetPack SDK赋能实时传感处理、多摄像头追踪,以及如操作和导航等先进机器人功能,集成于强大的AI生态之中。开发者可借助诸如NVIDIA Holoscan(传感器流式处理)和Metropolis VSS(视频分析)等集成框架。通过NVIDIA Isaac机器人工作流程,包括想NVIDIA GROOT N1等基础生成式AI模型,Jetson软件为机器人实现快速、精准、变革性的AI赋能和规模化部署提供支持。 JetPack SDK:是一套完整的软件套件,用于NVIDIA Jetson平台上开发和部署AI驱动的边缘应用。 Holoscan传感器桥接器:将边缘传感器连接到AI工作流,以实现实时、高性能的传感器数据处理。 Jetson AI Lab:由NVIDIA工具和社区项目提供支持,激发机器人和生成式AI领域的创新和动手探索。 NVIDIA Isaac:提供NVIDIA CUDA加速库、框架和AI模型,用一个构建自主机器人,包括ARM、机械臂和人形机器人。 NVIDIA Metropolis:为智慧城市、工业和零售业开发和部署视觉AI应用,并在边缘进行实时视频分析。 JetPack SDK JetPack是NVIDIA Jetson平台官方软件套件,涵盖丰富的工具和库,可用于大招AI赋能边缘应用。目前最新的版本是JetPack7,采用Linux kernel 6.8及ubuntu 24.04 LTS,模块化云原生架构,结合最新的NVIDIA计算堆栈,无缝衔接NVIDIA AI工作流。 JetPack组件由AI计算堆栈、AI框架、Linux组件几个部分组成。 AI计算堆栈:由CUDA、cuDNN、TensorRT组成;用于提供硬件GPU的加速底层接口;CUDA提供NVIDIA GPU 上编写和运行通用计算程序的能力;cuDNN在CUDA之上的深度神经网络算子库,提供高度优化的深度学习核心算子(卷积、池化、激活函数、RNN/LSTM、注意力等)。Pytorch/TensorFlow调用cuDNN中的Conv2d、RNN等。TensorRT推理优化器,只负责推理不负责训练,把训练好的模型转换成高效的 GPU 可执行引擎底层依赖CUDA/cuDNN。与pytorch、TensorFlow不同其即是训练+推理框架。但相对pytorch、TensorFlow的推理,TensorRT性能效率更高。 AI框架:由pytorch、vLLM、SGLang、Triton推理服务器等部分组成。vLLM是便捷、快速的大型语言模型推理与服务库,SGLang 是专为大语言模型及视觉语言模型打造的高效推理框架。 Linux组件:主要是基础系统组件,基于ubuntu系统构建,提供刷机、安全、OTA、图形库(OpenGL、Vulkan、EGL等)、多媒体API、计算机视觉库(OpenCV、VisionWorks)等。 其他组件:Jetson平台服务、云原生设计、Nsight开发工具组成;平台服务提供预构建和可定制的云原生软件服务;云原生设计师提供容器化开发、kubernetes和微服务;Nsight提供强大的分析、调试、性能分析功能,在AI、图形和计算工作负载中优化GPU加速应用。 在JetPack SDK上各种应用SDK,如提供NVIDIA DeepStream SDK、NVIDIA Isaac ROS、NVIDIA Holoscan SDK。 Metropolis VIDIA Metropolis 是一个视觉 AI 应用平台和合作伙伴生态系统,可简化从边缘到云端的视觉 AI 智能体的开发、部署和可扩展性。可以做自动化视觉检查、智能交通系统、工业自动化、智能零售商店等等。 模型:可访问各种先进的AI模型,构建视觉AI应用,支持VLM等;提供TAO工具套件。对模型训练、适应和优化上手简单,不需要专业的AI知识或大型训练数据集,使用自己的数据微调即可完成。 工具:提供AI智能体Blueprints,借助大模型构建智能体,分析、解释和处理大量视频数据,以提供关键见解,帮助各行各业优化流程、提高安全性并降低成本。提供NVIDIA NIM一套易于使用的推理微服务,NIM 支持各种 AI 模型 (包括基础模型、LLM、VLM 等) ,可确保使用行业标准 API 在本地或云端进行无缝、可扩展的 AI 推理。提供DeepStream SDK,是基于 GStreamer 的完整流分析工具包。 数据:Omniverse集成 OpenUSDNVIDIA RTX™ 渲染技术,以及 物理 AI 集成到现有软件工具和仿真工作流中进行开发和测试 。NVIDIA Cosmos™ 是一个先进的生成式AI平台世界基础模型( WFM) 、高级标记器、护栏以及加速数据处理和管护流程,旨在加速物理 AI系统。NVIDIA Isaac SIM开发者在物理精准的虚拟环境中生成合成图像和视频数据,以训练自定义视觉AI模型。 Isaac NVIDIA Isaac AI机器人开发平台有NVIDIA CUDA加速库、应用框架和AI模型组成,可加速自主移动机器人、手臂和操作器以及人形机器人等。 NVIDIA Robotis提供了全栈、加速库和优化的AI模型,能够高效开发、训练、仿真、部署机器人系统。 Isaac ROS:机器人操作系统,是基于开源ROS2构建,包含了NVIDIA CUDA加速计算包的集合,便于简化和加速高级AI机器人应用开发。 Isaac Manipulator:基于Isaac ROS构建,支持开发AI驱动的机械臂,这些机械臂可以无缝感知和理解环境并与环境进行交互。 Isaac Perceptor:基于Isaac ROS构建,支持开发先进的自主移动机器人,能够在仓库货工厂等非结构化环境中进行感知和定位。 Isaac GR00T:用于通用机器人基础模型和数据流水线,以加速人形机器人的开发。 还提供了基于物理的虚拟环境中设计、仿真、测试和训练的框架。NVIDIA Isaac Sim和NVIDIA Isaac Lab。 NVIDIA Isaac Sim:是一款基于 NVIDIA Omniverse 构建的开源参考应用,使开发者能够在基于物理的虚拟环境中模拟和测试 AI 驱动的机器人开发解决方案。 NVIDIA Isaac Lab:Isaac Lab 基于 NVIDIA Isaac Sim™ 开发,使用 NVIDIA®PhysX® 以及基于物理性质的 NVIDIA RTX™ 渲染提供高保真物理仿真。 Holoscan SDK NVIDIA Holoscan 将传感器数据传输到 GPU 进行实时推理,从而加速边缘 AI 开发。 Holoscan 传感器桥接器:可在高吞吐量传感器数据与 GPU 之间提供关键链接,从而无缝集成异构传感器数据。它可标准化并管理从各种传感器接口 (如摄像头输入、超声波或内窥镜视频) 中的数据提取,确保以低延迟、同步和可靠的方式传输数据,从而实现实时 AI 处理。 NVIDIA IGX ORIN:是一个结合了企业级硬件、软件和支持的工业级平台,可在生产就绪型硬件上进行部署。虽然 Holoscan SDK 可在您的目标设备上灵活部署,但 IGX 使公司能够专注于应用开发,并更快地实现 AI 的优势。 Jetson AI Lab Jetson AI Lab 由 NVIDIA 工具和社区项目提供支持,其提供了各种大模型的快速部署示例,如大语言模型LLM/SLM、视觉语言大模型VLM、Web UI等等。 如上图,如果要运行一个模型,就可以通过如上图示例直接获取到运行命令,还可以调整参数。更详细的教程参考:https://www.jetson-ai-lab.com/tutorial-intro.html 参考:https://www.nvidia.cn/autonomous-machines/ -
Jetson nano平台随记
环境准备 烧录镜像 下载NVIDIA jetson nano镜像,其镜像是基于ubuntu18.04修改。使用开源的balenaEtcher烧录器写到SD卡上,然后插卡启动 网络准备 买一个无线网卡然后安装好驱动配置好wifi连接。 远程访问 方法1: 在nano上安装xrdp的方式,window就可以远程桌面访问。 方法2:在nano上安装VNC,远程访问设备需要下载VNC客户端,支持ubuntu系统。 pyhton独立环境 类型conda activate的环境 sudo apt-get install python3-pip pip3 install virturalenv 创建一个环境 python3 -m virtualenv -p python3 env --system-site-packages 激活环境 source env/bin/activate 图像和视频 主要是https://github.com/thehapyone/NanoCamera 安装opencv 创建一个swap空间,否则内存可能不够。 在安装opencv前,还要准备一下环境 使用wget下载opencv的包。 wget -O opencv_contrib.zip https://github.com/openc/opencv_corntrib/archive/4.5.1.1.zip 使用cmake进行编译。 使用jtop可以查看系统统计信息,前提是要按照pip install -U jeston-stats 硬件接上CSI的摄像头,接上之后可以在/dev/videox 看到节点。可以使用下面的命令测试就可以看到图像。 nvgstcaptrue-1.0 --orientation=2 --cap-dev-node=1指定节点如/dev/video1 读取显示 import cv2 img = cv2.imread('/assets/a.jpg') cv2.imshow("Output",img) cv2.waitkey(0) 对于平台CSI摄像头需要import nanocamera import nanocamera as nano camera = nano.Camera(flip=2, width=640,height=480,fps=30) -
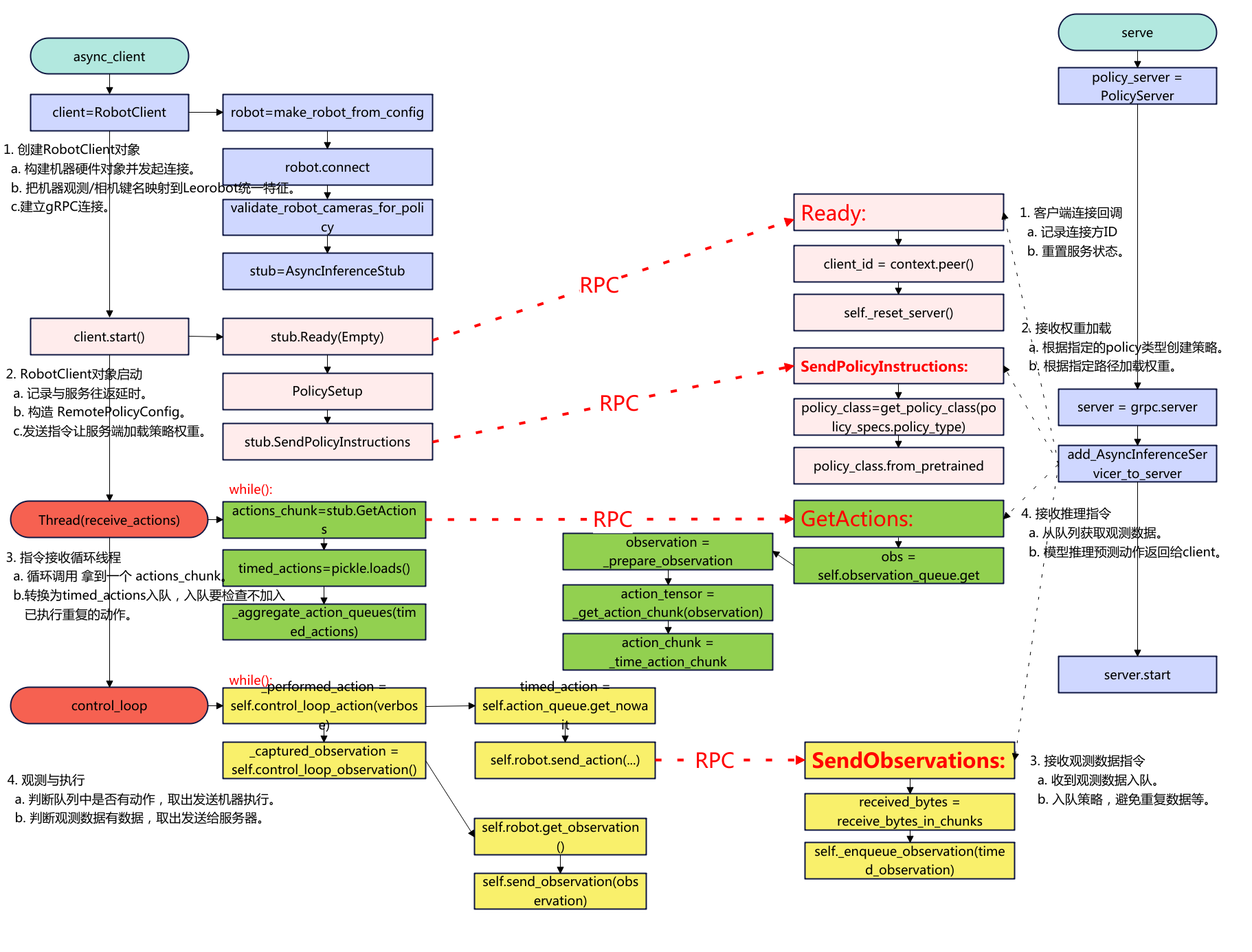
SmolVLA 异步推理:远程 Policy Server 与本地 Client 实操
概述 本文记录lerobot smolvla异步推理实践,将SmolVLA的策略server部署到AutoDL上,真机client在本地笔记本上运行。 下面是代码的流程图: 环境准备 先登录AutoDL事先搭建好lerobot的环境,这里就不再重复了,参考往期文章。lerobot环境搭建好后,需要先安装smolvla和gRPC。 # 建议先升级打包工具 python -m pip install -U pip setuptools wheel pip install -e ".[smolvla]" # 安装 gRPC 及相关 python -m pip install grpcio grpcio-tools protobuf 服务器 python src/lerobot/scripts/server/policy_server.py --host=127.0.0.1 --port=8080 --fps=30 --inference_latency=0.033 --obs_queue_timeout=2 启动成功后的日志如下: python src/lerobot/scripts/server/policy_server.py --host=127.0.0.1 --port=8080 --fps=30 --inference_latency=0 --obs_queue_timeout=2 INFO 2025-08-28 10:33:07 y_server.py:384 {'fps': 30, 'host': '127.0.0.1', 'inference_latency': 0.0, 'obs_queue_timeout': 2.0, 'port': 8080} INFO 2025-08-28 10:33:07 y_server.py:394 PolicyServer started on 127.0.0.1:8080 被客户端连接后的日志: INFO 2025-08-28 10:40:42 y_server.py:104 Client ipv4:127.0.0.1:45038 connected and ready INFO 2025-08-28 10:40:42 y_server.py:130 Receiving policy instructions from ipv4:127.0.0.1:45038 | Policy type: smolvla | Pretrained name or path: outputs/smolvla_weigh_08181710/pretrained_model | Actions per chunk: 50 | Device: cuda Loading HuggingFaceTB/SmolVLM2-500M-Video-Instruct weights ... INFO 2025-08-28 10:40:54 odeling.py:1004 We will use 90% of the memory on device 0 for storing the model, and 10% for the buffer to avoid OOM. You can set `max_memory` in to a higher value to use more memory (at your own risk). Reducing the number of VLM layers to 16 ... Loading weights from local directory INFO 2025-08-28 10:41:14 y_server.py:150 Time taken to put policy on cuda: 32.3950 seconds INFO 2025-08-28 10:41:14 ort/utils.py:74 <Logger policy_server (NOTSET)> Starting receiver INFO 2025-08-28 10:41:14 y_server.py:175 Received observation #0 | Avg FPS: 3.45 | Target: 30.00 | One-way latency: -9.22ms INFO 2025-08-28 10:41:14 y_server.py:205 Running inference for observation #0 (must_go: True) INFO 2025-08-28 10:41:15 ort/utils.py:74 <Logger policy_server (NOTSET)> Starting receiver INFO 2025-08-28 10:41:15 y_server.py:175 Received observation #0 | Avg FPS: 3.45 | Target: 30.00 | One-way latency: -9.58ms 服务器仅本地监听(12.0.0.1),这样不暴露公网,客户端通过SSH隧道安全转发。 nohup python src/lerobot/scripts/server/policy_server.py --host=127.0.0.1 --port=8080 --fps=30 --inference_latency=0.033 --obs_queue_timeout=2 >/tmp/policy_server.log 2>&1 & 也可以选择后台运行。 客户端 建立SSH转发 在本地客户端线建立SSH本地端口转发(隧道) ssh -p <服务器ssh的port> -fN -L 8080:127.0.0.1:8080 <用户名@服务器ssh的ip或域名> 如:ssh -p 20567 -fN -L 8080:127.0.0.1:8080 root@connect.xx.xxx.com 如果不想后台运行,运行在前台(Crtl+C结束) ssh -p 20567 -N -L 8080:127.0.0.1:8080 root@connect.xx.xxx.com 本地运行 python src/lerobot/scripts/server/robot_client.py \ --robot.type=so101_follower --robot.port=/dev/ttyACM0 --robot.id=R12252801 \ --robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}}" \ --policy_type=smolvla \ --pretrained_name_or_path=outputs/smolvla_weigh_08181710/pretrained_model \ --policy_device=cuda \ --actions_per_chunk=50 \ --fps=30 \ --server_address=localhost:8080 \ --chunk_size_threshold=0.8 \ --debug_visualize_queue_size=True 其他参数 --debug_visualize_queue_size=True: 执行结束后可视化队列情况。 需要安装 pip install matplotlib。 --aggregate_fn_name=conservative:当新动作到达时,如果队列中已经存在相同时间步的动作,系统会使用聚合函数来合并它们。如果为latest_only(默认),只用最新动作,这样可能会抖动剧烈。 --pretrained_name_or_path 会在“服务器上”加载。需要确保服务器上outputs/smolvla_weigh_08181710路径有权重文件。 连接执行的日志如下: python src/lerobot/scripts/server/robot_client.py --robot.type=so101_follower --robot.port=/dev/ttyACM0 --robot.id=R12252801 --robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 320, height: 240, fps: 25}, fixed: {type: opencv, index_or_path: 0, width: 320, height: 240, fps: 25}}" --policy_type=smolvla --pretrained_name_or_path=outputs/smolvla_weigh_08181710/pretrained_model --policy_device=cuda --actions_per_chunk=50 --chunk_size_threshold=0.8 --fps=30 --server_address=localhost:8080 --aggregate_fn_name=average INFO 2025-08-28 10:40:38 t_client.py:478 {'actions_per_chunk': 50, 'aggregate_fn_name': 'average', 'chunk_size_threshold': 0.8, 'debug_visualize_queue_size': False, 'fps': 30, 'policy_device': 'cuda', 'policy_type': 'smolvla', 'pretrained_name_or_path': 'outputs/smolvla_weigh_08181710/pretrained_model', 'robot': {'calibration_dir': None, 'cameras': {'fixed': {'color_mode': <ColorMode.RGB: 'rgb'>, 'fps': 25, 'height': 240, 'index_or_path': 0, 'rotation': <Cv2Rotation.NO_ROTATION: 0>, 'warmup_s': 1, 'width': 320}, 'handeye': {'color_mode': <ColorMode.RGB: 'rgb'>, 'fps': 25, 'height': 240, 'index_or_path': 6, 'rotation': <Cv2Rotation.NO_ROTATION: 0>, 'warmup_s': 1, 'width': 320}}, 'disable_torque_on_disconnect': True, 'id': 'R12252801', 'max_relative_target': None, 'port': '/dev/ttyACM0', 'use_degrees': False}, 'server_address': 'localhost:8080', 'task': '', 'verify_robot_cameras': True} INFO 2025-08-28 10:40:40 a_opencv.py:179 OpenCVCamera(6) connected. INFO 2025-08-28 10:40:41 a_opencv.py:179 OpenCVCamera(0) connected. INFO 2025-08-28 10:40:41 follower.py:104 R12252801 SO101Follower connected. WARNING 2025-08-28 10:40:42 ils/utils.py:54 No accelerated backend detected. Using default cpu, this will be slow. WARNING 2025-08-28 10:40:42 /policies.py:80 Device 'cuda' is not available. Switching to 'cpu'. WARNING 2025-08-28 10:40:42 ils/utils.py:54 No accelerated backend detected. Using default cpu, this will be slow. WARNING 2025-08-28 10:40:42 /policies.py:80 Device 'cuda' is not available. Switching to 'cpu'. INFO 2025-08-28 10:40:42 t_client.py:121 Initializing client to connect to server at localhost:8080 INFO 2025-08-28 10:40:42 t_client.py:140 Robot connected and ready INFO 2025-08-28 10:40:42 t_client.py:163 Sending policy instructions to policy server INFO 2025-08-28 10:41:14 t_client.py:486 Starting action receiver thread... INFO 2025-08-28 10:41:14 t_client.py:454 Control loop thread starting INFO 2025-08-28 10:41:14 t_client.py:280 Action receiving thread starting INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 | INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 288.72 INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 | INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 132.22 INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 | INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 127.84 INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 | INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 123.95 INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 | INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 140.21 INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 0.54 INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 0.42 如果使用ACT策略,对于ACT来说chunk_size_threshold不要设置太大,实测发现不然一个chunk到下一个chunk抖动比较严重 python src/lerobot/scripts/server/robot_client.py \ --robot.type=so101_follower \ --robot.port=/dev/ttyACM0 \ --robot.id=R12252801 \ --robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}}" \ --policy_type=act \ --pretrained_name_or_path=outputs/act_weigh_07271539/pretrained_model \ --policy_device=cuda \ --actions_per_chunk=100 \ --fps=30 \ --server_address=localhost:8080 \ --chunk_size_threshold=0.1 以上就是用SSH隧道的方式实现异步推理的过程。 参考:https://hugging-face.cn/docs/lerobot/async 常见问题 (0)服务器监控日志分析 Received observation #136:服务器接收到第136个观察数据 Avg FPS: 11.52:实际观测数据帧率,根据客户端每秒采样时间计算,跟服务端没有关系。 Target:目标设置的观测数据帧率,如15帧/s。 One-way latency: 客户端到服务器的单向网络延迟为1.71ms。 inference time: 模型推理耗时时长为1667ms。 action chunk #136:生成了第136个动作块。 Total time: 推理+序列化总处理时长。 (1)服务端实际的观测帧率低 INFO 2025-08-29 09:47:05 y_server.py:175 Received observation #573 | Avg FPS: 1.20 | Target: 30.00 | One-way latency: 35.78ms 可以看到上面的收到的观测帧率平均只有1.2,看看服务端计算FPS的逻辑。 # 每次接收观测时调用 self.total_obs_count += 1 # 包括所有接收的观测(包括被过滤的) total_duration = current_timestamp - self.first_timestamp avg_fps = (self.total_obs_count - 1) / total_duration 影响服务端的接受观测帧帧率的有客户端观测发送频率低,服务端观测被过滤,推理时间长间接影响 关于客户端观测数据的发送限制如下: # 只有当队列大小/动作块大小 <= 阈值时才发送观测 if queue_size / action_chunk_size <= chunk_size_threshold: send_observation() 可以看到只有满足上面的小于动作阈值才会发送,所以要加大发送的帧率需要改大阈值chunk_size_threshold,减少actions_per_chunk,减少queue_size。 对于ACT策略的FPS 低可能不是问题,这是观察发送频率,不是控制频率,因为ACT 策略就是低频观察,高频执行,主要看机器是不是以30FPS动作执行就好。smolvla也是同样的。因此有时候不要过于误解这个观测帧率,太高的观测帧率也不一定是好事。 (2)观测数据被过滤 y_server.py:191 Observation #510 has been filtered out 服务端会根据这次和上次的关节角度计算欧拉来判断相似性,默认的阈值参数是1,可以改小一点,对相似性的判断严苛一下。 def observations_similar( obs1: TimedObservation, obs2: TimedObservation, lerobot_features: dict[str, dict], atol: float = 1 ) -> bool: ...... return bool(torch.linalg.norm(obs1_state - obs2_state) < atol) 如上修改atol的值,可以改小为如0.5。 总结一下: 对于分布式推理不要过于去纠结实际的观测帧率,而是应该看控制的实际帧率,只要控制动作的帧率(如下的延时,大概就是30fps)是满足的就是可以的,也就是说动作队列中动作不要去获取的时候是空。 对于参数优化重点看服务端的推理延时和客户端的队列管理。 服务端是可以设置推理延时的 # 推理延迟控制 --inference_latency=0.033 # 模型推理延迟(秒) # 观察队列管理 --obs_queue_timeout=2 # 获取观测队列超时时间(秒) 客户端动作管理 --actions_per_chunk=100 # 一个动作块的序列大小,越大推理负载就重 --chunk_size_threshold=0.5 # 队列阈值,越大缓存的动作序列越多,越小实时性越好。 --fps=30 # 控制频率 如果要低延时那么就需要把fps提高,也就是服务端的推理时间设置小,客户端的chunk、threshold要小,fps要高。 -
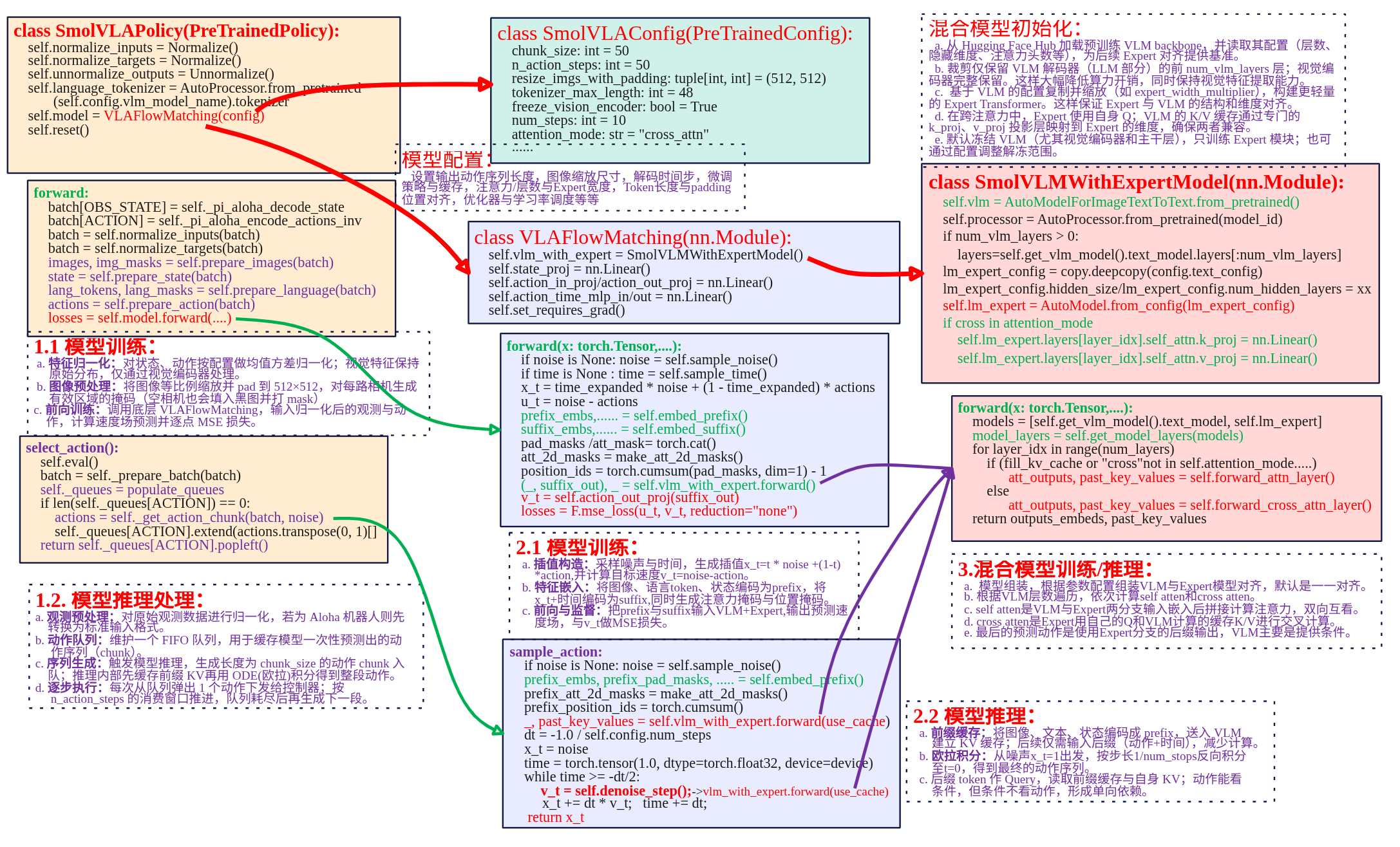
LeRobot SmolVLA:从训练到推理链路剖析
框架 本文主要对lerobot SmolVLA策略代码进行分析,下面是策略实现关键部分框图。 SmolVLAPolicay类封装向上提供策略的调用。SmolVLAConfig是对SmolVLA策略的配置,用于配置输出动作序列长度、观测图像输入后到模型的缩放尺寸以及微调策略等等。SmolVLAPolicay类中关键的成员是VLAFlowMatching类,是实现SmolVLA模型flow matching机制训练、推理的核心。在VLAFlowMatching类中关系成员是SmolVLMWithExpertModel类,其定义了VLM+Expert模型具体实现。 SmolVLA策略实现主要涉及SmolVLAPolicy、VLAFlowMatching 、SmolVLMWithExperModel三个类来实现。就以模型训练、模型推理两条主线来进行总结。 训练 训练过程可以分为一下几个核心部分: 数据输入处理:图像、文本和状态通过各自处理方法嵌入并标准化,合并成统一的输入,供后续层次处理。 VLM与专家模型交互前向传播:图像、文本和状态数据通过VLM和专家模型进行多层次的自注意力和交叉注意力计算,得到联合特征表示。 损失计算与优化:通过计算预测动作和目标动作之间的损失,具体是速度场的损失,使用反向传播更新参数。 模型参数冻结与训练策略:通过冻结不必要的模型部分(VLM),专注优化重要部分,减少计算的开销。 输入处理 SmolVLA模型分为前缀prefix、后缀suffix输入。前缀主要是观测端数据由图像、文本和机器的状态嵌入构成,提供给VLM处理,目的是为模型提供上下文信息,理解任务的背景。后缀是用于生成过程中,输入的是噪声动作+时间步,经过Expert模型处理输出具体的预测动作。 (1)前缀prefix嵌入 def embed_prefix(self, images, img_masks, lang_tokens, lang_masks, state: torch.Tensor = None): embs = [] pad_masks = [] att_masks = [] # 处理图像 for _img_idx, (img, img_mask) in enumerate(zip(images, img_masks)): img_emb = self.vlm_with_expert.embed_image(img) embs.append(img_emb) pad_masks.append(img_mask) # 处理语言 lang_emb = self.vlm_with_expert.embed_language_tokens(lang_tokens) embs.append(lang_emb) pad_masks.append(lang_masks) # 处理状态 state_emb = self.state_proj(state) embs.append(state_emb) state_mask = torch.ones_like(state_emb) pad_masks.append(state_mask) # 合并所有嵌入 embs = torch.cat(embs, dim=1) pad_masks = torch.cat(pad_masks, dim=1) att_masks = torch.cat(att_masks, dim=1) return embs, pad_masks, att_masks 代码的流程是依次对输入图像、语言、机器状态进行分别做embedding,然后进行按列合并为一个前缀输入。 图像嵌入:通过embed_image方法转换为嵌入表示,每个图像的嵌入被添加到embs列表中,img_mask则记录图像的有效区域。 文本嵌入:通过embed_language_tokens() 被转换为嵌入表示,lang_emb 是语言的嵌入,包含了语言的语法和语义信息。 状态嵌入:状态信息通过 state_proj() 映射到与图像和文本相同维度的空间,得到 state_emb。 最终图像嵌入、文本嵌入和状态嵌入通过 torch.cat() 方法按列合并成一个大的 前缀输入(Prefix)。pad_masks 和 att_masks 也被合并成一个统一的输入,确保每个模态的信息能够与其他模态的输入一起传递。 图像和文本嵌入调用已经隐式包含了位置编码,状态信息state_proj 转换为嵌入,尽管没有显式的位置信息,但会在模型中通过与其他模态嵌入的融合获取上下文信息。 (2)后缀Suffix嵌入 def embed_suffix(self, noisy_actions, timestep): embs = [] pad_masks = [] att_masks = [] # 使用 MLP 融合时间步长和动作信息 action_emb = self.action_in_proj(noisy_actions) device = action_emb.device bsize = action_emb.shape[0] dtype = action_emb.dtype # 使用正弦-余弦位置编码生成时间嵌入 time_emb = create_sinusoidal_pos_embedding( timestep, self.vlm_with_expert.expert_hidden_size, self.config.min_period, self.config.max_period, device=device, ) time_emb = time_emb.type(dtype=dtype) # 将时间嵌入和动作嵌入结合 time_emb = time_emb[:, None, :].expand_as(action_emb) action_time_emb = torch.cat([action_emb, time_emb], dim=2) action_time_emb = self.action_time_mlp_in(action_time_emb) action_time_emb = F.silu(action_time_emb) # swish == silu action_time_emb = self.action_time_mlp_out(action_time_emb) # 将生成的动作嵌入加入到输入中 embs.append(action_time_emb) bsize, action_time_dim = action_time_emb.shape[:2] action_time_mask = torch.ones(bsize, action_time_dim, dtype=torch.bool, device=device) pad_masks.append(action_time_mask) # 设置注意力掩码,防止图像、语言和状态的输入与动作输入相互影响 att_masks += [1] * self.config.chunk_size embs = torch.cat(embs, dim=1) pad_masks = torch.cat(pad_masks, dim=1) att_masks = torch.tensor(att_masks, dtype=embs.dtype, device=embs.device) att_masks = att_masks[None, :].expand(bsize, len(att_masks)) return embs, pad_masks, att_masks 后缀的输入主要是提供给Expert专家模型用于flow matching预测出输出,输入是噪声动作(noisy actions)+时间步长(timestep)。上述代码可以分为以下几个部分: 时间步长嵌入:时间步长(timestep)用于表示当前的生成步骤,生成一个正弦-余弦位置编码(Sine-Cosine Positional Embedding)。create_sinusoidal_pos_embedding() 使用正弦和余弦函数生成时间嵌入,增强模型对时序的理解。 动作嵌入:动作通过 action_in_proj 进行嵌入,得到 action_emb。这一步是将生成的动作(采样的噪声动作)转化为嵌入表示。 融合时间和动作:动作嵌入与时间嵌入(time_emb)通过 torch.cat() 进行拼接,形成一个新的包含时间信息的动作嵌入。这样,生成的动作不仅包含来自环境的信息,还加入了时间步长的变化。 MLP处理:合并后的动作嵌入通过 action_time_mlp_in 和 action_time_mlp_out 层进行处理。这个过程是对动作嵌入进行进一步的处理,确保其能够适应后续的生成任务。 最终,生成的动作嵌入被加入到 embs 列表中,并通过 torch.cat() 合并为一个统一的后缀输入。这个后缀输入将与前缀输入一起通过 Transformer 层进行处理。 前向传播 forward是整个前向传播的核心,将将输入组合后通过模型计算输出。 def forward( self, images, img_masks, lang_tokens, lang_masks, state, actions, noise=None, time=None ): # 1. 前缀输入的生成 prefix_embs, prefix_pad_masks, prefix_att_masks = self.embed_prefix( images, img_masks, lang_tokens, lang_masks, state ) # 2. 后缀输入的生成 suffix_embs, suffix_pad_masks, suffix_att_masks = self.embed_suffix(actions, time) # 3. 拼接前缀和后缀的嵌入 pad_masks = torch.cat([prefix_pad_masks, suffix_pad_masks], dim=1) att_masks = torch.cat([prefix_att_masks, suffix_att_masks], dim=1) # 4. 计算注意力掩码 att_2d_masks = make_att_2d_masks(pad_masks, att_masks) position_ids = torch.cumsum(pad_masks, dim=1) - 1 # 5. 前向计算 (_, suffix_out), _ = self.vlm_with_expert.forward( attention_mask=att_2d_masks, position_ids=position_ids, past_key_values=None, inputs_embeds=[prefix_embs, suffix_embs], use_cache=False, fill_kv_cache=False, ) # 6. 速度场预测计算损失 suffix_out = suffix_out[:, -self.config.chunk_size :] suffix_out = suffix_out.to(dtype=torch.float32) v_t = self.action_out_proj(suffix_out) losses = F.mse_loss(v_t, actions, reduction="none") return losses 代码调用前缀、后缀输入然后进行拼接得到inputs_embeds,然后再计算注意力的掩码就可以调用VLM+Expert模型进行前向计算。在前向计算中有两个参数use_cache 和 fill_kv_cache 参数,这两个参数的设置控制 key-value 缓存 的使用。 (1)模型组合 models = [self.get_vlm_model().text_model, self.lm_expert] model_layers = self.get_model_layers(models) def get_model_layers(self, models: list) -> list: vlm_layers = [] expert_layers = [] multiple_of = self.num_vlm_layers // self.num_expert_layers for i in range(self.num_vlm_layers): if multiple_of > 0 and i > 0 and i % multiple_of != 0: expert_layer = None else: expert_layer_index = i // multiple_of if multiple_of > 0 else i expert_layer = models[1].layers[expert_layer_index] vlm_layers.append(models[0].layers[i]) expert_layers.append(expert_layer) return [vlm_layers, expert_layers] 模型混合主要是生成一个混合的模型层列表,通过get_model_layers函数计算并返回 VLM 层和 Expert 层的对齐关系,VLM层和Expert层对齐是基于multiple_of来进行层级分配的。如果某些 VLM 层 没有对应的 Expert 层,则设置为 None,仅由 VLM 层处理。默认情况下VLM和Expert的层数一样都为16,下图看看VLM=8,Expert=4的示例。 因此最终对于SmolVLA来说,模型是一个混合的模型层列表model_layers。可以通过model_layers[i][layer_idx]来访问具体的模型,model_layers[0][x]为VLM模型,model_layers[1][x]为Expert模型。如model_layers[0][2]为第二层的VLM,model_layers[1][2]为第二层的Expert,model_layers[1][1]为None。 (2)处理输入嵌入 for hidden_states in inputs_embeds: if hidden_states is None: continue batch_size = hidden_states.shape[0] 遍历输入嵌入(inputs_embeds),检查是否有无效的输入(即 None),并获取当前批次的大小batch_size。 inputs_embeds:模型的输入嵌入数据,可能包含多种模态的输入(例如,图像嵌入、文本嵌入等)。 hidden_states.shape[0]:获取当前输入数据的批次大小。 (3)自注意力与交叉注意力 num_layers = self.num_vlm_layers head_dim = self.vlm.config.text_config.head_dim for layer_idx in range(num_layers): if ( fill_kv_cache or "cross" not in self.attention_mode or (self.self_attn_every_n_layers > 0 and layer_idx % self.self_attn_every_n_layers == 0) ): att_outputs, past_key_values = self.forward_attn_layer() else: att_outputs, past_key_values = self.forward_cross_attn_layer() 使用VLM层数来进行遍历,因为VLM侧的层数是Expert的一倍。进行如循环根据条件来判断是进行自注意力计算还是交叉注意力计算。 判断使用自注意力的条件是有3种情况(其中一种满足即可): fill_kv_cache:如果需要填充 键值缓存(key-value cache),则使用自注意力计算。 "cross" not in self.attention_mode:如果当前没有启用交叉注意力模式,则使用自注意力。 self_attn_every_n_layers:在每隔 n 层计算自注意力时,执行该条件。通常用于启用跨层的自注意力机制。 具体关于自注意力与交叉注意力计算的细节见后续章节。 (4)残差连接与前馈网络 out_emb += hidden_states after_first_residual = out_emb.clone() out_emb = layer.post_attention_layernorm(out_emb) out_emb = layer.mlp(out_emb) out_emb += after_first_residual 残差连接:每一层都使用残差连接,将当前层的输出与原始输入相加,防止深层网络的梯度消失问题。 前馈网络(MLP):通过前馈神经网络(通常包括一个隐藏层和激活函数)进行处理,进一步捕捉输入的非线性关系。 (5)输出处理 outputs_embeds = [] for i, hidden_states in enumerate(inputs_embeds): if hidden_states is not None: out_emb = models[i].norm(hidden_states) outputs_embeds.append(out_emb) else: outputs_embeds.append(None) return outputs_embeds, past_key_values 遍历输入嵌入(inputs_embeds),对每个有效的 hidden_states 进行 归一化处理(models[i].norm())。如果嵌入无效(即 None),则直接将 None 放入输出列表中,以保持输入结构的对齐。最终返回 处理后的嵌入 和 past_key_values(如果有的话)。 归一化(通常是层归一化)确保嵌入在后续计算中具有更好的数值稳定性,帮助模型学习。对缺失的嵌入(None)进行特殊处理,主要是VLM+Expert对齐时,Expert通常为VLM的一半,而模型遍历是时按照VLM层次来遍历的,所以有一半的Expert是None,但是这部的None不能在处理VLM层的时候断掉Expert的输入,否则Expert模型梯度链就断了。 损失计算 SmolVLAPolicy.forward(...) ...... 调 VLAFlowMatching 计算逐样本/逐步/逐维损失(不聚合) losses = self.model.forward(images, img_masks, lang_tokens, lang_masks, state, actions, noise, time) if actions_is_pad is not None: in_episode_bound = ~actions_is_pad losses = losses * in_episode_bound.unsqueeze(-1) # 去掉为对齐而pad出的 action 维度 losses = losses[:, :, : self.config.max_action_dim] # 聚合为标量 loss(反向传播用) loss = losses.mean() return loss, {"loss": loss.item()} 在SmolVLAPolicy.forward(...)调用VLAFlowMatching.forward计算返回损失,下面直接来看VLAFlowMatching.forward。 def forward(self, images, img_masks, lang_tokens, lang_masks, state, actions, noise=None, time=None) -> Tensor: # ① 采样噪声与时间 if noise is None: noise = self.sample_noise(actions.shape, actions.device) # ~N(0,1) if time is None: time = self.sample_time(actions.shape[0], actions.device) # Beta(1.5,1.0)→偏向 t≈1 # ② 合成中间点 x_t 与“真向量场” u_t time_expanded = time[:, None, None] # [B,1,1] x_t = time_expanded * noise + (1 - time_expanded) * actions # convex组合 u_t = noise - actions # ③ 前缀/后缀嵌入(图像+文本+状态 | 动作+时间),拼注意力mask/位置id prefix_embs, prefix_pad_masks, prefix_att_masks = self.embed_prefix(images, img_masks, lang_tokens, lang_masks, state) suffix_embs, suffix_pad_masks, suffix_att_masks = self.embed_suffix(x_t, time) pad_masks = torch.cat([prefix_pad_masks, suffix_pad_masks], dim=1) att_masks = torch.cat([prefix_att_masks, suffix_att_masks], dim=1) att_2d_masks = make_att_2d_masks(pad_masks, att_masks) position_ids = torch.cumsum(pad_masks, dim=1) - 1 # ④ 走双塔文本Transformer:prefix + suffix(训练时不建缓存) (_, suffix_out), _ = self.vlm_with_expert.forward( attention_mask=att_2d_masks, position_ids=position_ids, past_key_values=None, inputs_embeds=[prefix_embs, suffix_embs], use_cache=False, fill_kv_cache=False, ) suffix_out = suffix_out[:, -self.config.chunk_size :] # 取后缀对应的输出token # ⑤ Expert头→动作向量场 v_t,并与 u_t 做逐元素 MSE suffix_out = suffix_out.to(dtype=torch.float32) # 数值稳定 v_t = self.action_out_proj(suffix_out) losses = F.mse_loss(u_t, v_t, reduction="none") # [B, T, A] 不聚合 return losses 核心思想还是学习一个向量场 $v_{\theta}(x_t,t)$ 去逼近真实向量场 $u_t = \epsilon - a$,其中 $$ x_t = t \cdot \epsilon + (1 - t) \cdot a, \quad \epsilon \sim \mathcal{N}(0,I) $$ $a$ 是机器真实的动作如舵机的角度,对应上述代码的action;$\epsilon$是noisy action,最开始随机生成采样而来,对应上述的noise。 模型参数 模型参数冻结主要是以下两个方法决定 SmolVLMWithExpertModel.set_requires_grad(管 VLM/Expert的大部分参数); VLAFlowMatching.set_requires_grad(只管 state 的投影头)。 (1)VLM/Expert大部分参数 def set_requires_grad(self): # 1) 冻结视觉编码器(可选) if self.freeze_vision_encoder: self.get_vlm_model().vision_model.eval() for p in self.get_vlm_model().vision_model.parameters(): p.requires_grad = False # 2) 只训练 Expert(常见默认) if self.train_expert_only: self.vlm.eval() for p in self.vlm.parameters(): p.requires_grad = False else: # 3) 非“只训 Expert”时,VLM 只冻结一小部分层,避免 DDP unused params last_layers = [self.num_vlm_layers - 1] if (self.num_vlm_layers != self.num_expert_layers and self.num_vlm_layers % self.num_expert_layers == 0): last_layers.append(self.num_vlm_layers - 2) frozen = ["lm_head", "text_model.model.norm.weight"] for L in last_layers: frozen.append(f"text_model.model.layers.{L}.") for name, p in self.vlm.named_parameters(): if any(k in name for k in frozen): p.requires_grad = False # 4) Expert 侧不训练 lm_head(没用到 LM 头) for name, p in self.lm_expert.named_parameters(): if "lm_head" in name: p.requires_grad = False 冻结视觉编码器:把 VLM 的 vision encoder 切到 eval(),并把其所有参数 requires_grad=False。对于VLM视觉部分已经比较稳定了,若下游数据量不大,继续训练易带来不稳定与显存开销;冻结能省资源并保持视觉表征稳定。 只训练 Expert:把VLM的(视觉编码+LLM)都起到eval且全部冻结。这是一种轻量微调策略——只训练 Expert+ 动作/时间/状态投影头,能在小数据上快速稳定收敛,避免对大模型语义分布造成破坏。 非“只训 Expert”时,VLM 只冻结一小部分层:永远冻结 VLM 的 lm_head(语言模型头,动作任务用不到),冻结text_model.model.norm.weight,降低训练不稳定,冻结最后 1 层; 总结一下: 目标 典型设置 实际可训练部分 轻量微调(默认/推荐起步) freeze_vision_encoder=True + train_expert_only=True Expert 全部层(除 lm_head) + 动作/时间/状态头(VLAFlowMatching 里的 action_in/out_proj、action_time_mlp_、state_proj) 加强表达(部分放开 VLM) freeze_vision_encoder=True/False + train_expert_only=False Expert 全部层 + 大多数 VLM 文本层(但冻结 lm_head、末尾 norm、最后 1–2 层) + 动作/时间/状态头 除了上面的参数之外在 SmolVLMWithExpertModel.train 中又做了一层保险: def train(self, mode=True): super().train(mode) if self.freeze_vision_encoder: self.get_vlm_model().vision_model.eval() if self.train_expert_only: self.vlm.eval() 即使外部调用了 model.train(),被冻的模块仍保持 eval(),避免 Dropout/BN 等训练态行为干扰。是否参与反向仍由 requires_grad 决定;两者配合保证“真冻结”。 (2)state 的投影头 class VLAFlowMatching(nn.Module): def __init__(self, config): super().__init__() self.config = config self.vlm_with_expert = SmolVLMWithExpertModel( ... ) # —— 与动作/状态/时间相关的投影头 —— self.state_proj = nn.Linear( self.config.max_state_dim, self.vlm_with_expert.config.text_config.hidden_size ) self.action_in_proj = nn.Linear(self.config.max_action_dim, self.vlm_with_expert.expert_hidden_size) self.action_out_proj = nn.Linear(self.vlm_with_expert.expert_hidden_size, self.config.max_action_dim) self.action_time_mlp_in = nn.Linear(self.vlm_with_expert.expert_hidden_size * 2, self.vlm_with_expert.expert_hidden_size) self.action_time_mlp_out = nn.Linear(self.vlm_with_expert.expert_hidden_size, self.vlm_with_expert.expert_hidden_size) self.set_requires_grad() # ← 这里调用 ... def set_requires_grad(self): for params in self.state_proj.parameters(): params.requires_grad = self.config.train_state_proj 根据 config.train_state_proj(布尔值)开/关状态投影层 state_proj 的可训练性。这里只对state_proj做控制,这个是把机器人状态(关节角、抓取开合等)映射到 VLM 文本编码器的隐藏维度。不同机器人/任务,状态分布差异很大(量纲、范围、相关性);是否需要学习这个映射,取决于你的数据规模与分布,所以可以根据train_state_proj=True/False来决定是否要训练或冻结。其它头(action_in/out_proj、action_time_mlp_*)对动作/时间更直接,通常都需要学习,因此默认不在这里冻结。 推理 推理的入口函数入口:SmolVLAPolicy.predict_action_chunk ->select_action-> VLAFlowMatching.sample_actions(...),推理跟训练流程大致相同,这里只简单总结一下不同点。 前缀缓存 prefix_embs, prefix_pad_masks, prefix_att_masks = self.embed_prefix(...) prefix_att_2d_masks = make_att_2d_masks(prefix_pad_masks, prefix_att_masks) prefix_position_ids = torch.cumsum(prefix_pad_masks, dim=1) - 1 # 只喂前缀,构建 KV cache _, past_key_values = self.vlm_with_expert.forward( attention_mask=prefix_att_2d_masks, position_ids=prefix_position_ids, past_key_values=None, inputs_embeds=[prefix_embs, None], # ★ 只有前缀 use_cache=self.config.use_cache, # 通常 True fill_kv_cache=True, # ★ 建缓存 ) 与训练的差别是训练不建缓存,推理先把 VLM 的 Q/K/V(更准确:K/V)算出来并存起来(past_key_values),这步只走 self-attn 分支(因为 fill_kv_cache=True),Expert 不参与。另外需要注意的时传递的输入只有prefix_embs而训练是inputs_embeds=[prefix_embs, suffix_embs]既要传递prefix_embs也有传递suffix_embs,这里的后缀编码为插值点的嵌入,即x_t = time_expanded * noise + (1 - time_expanded) * actions。因为没有Expert的输入,所以自注意力算的也只有VLM的输入。 后缀循环 dt = -1.0 / self.config.num_steps x_t = noise # 初始噪声 time = torch.tensor(1.0, ...) while time >= -dt/2: v_t = self.denoise_step(prefix_pad_masks, past_key_values, x_t, time) x_t += dt * v_t # Euler 更新 time += dt return x_t # 作为动作 做 ODE 去噪循环(Euler),每一步只算后缀。与训练的差别是“采一个随机 t 直接监督向量场”,推理是“从 t=1 积分到 t=0”(ODE 解)。这里的 num_steps 控制积分步数(精度/速度权衡)。 denoise_step(...)----> suffix_embs, suffix_pad_masks, suffix_att_masks = self.embed_suffix(x_t, timestep) # 组装 prefix/suffix 的联合注意力掩码(prefix 只提供 pad_2d 以允许被看) full_att_2d_masks = torch.cat([prefix_pad_2d_masks, suffix_att_2d_masks], dim=2) position_ids = prefix_offsets + torch.cumsum(suffix_pad_masks, dim=1) - 1 outputs_embeds, _ = self.vlm_with_expert.forward( attention_mask=full_att_2d_masks, position_ids=position_ids, past_key_values=past_key_values, # ★ 复用 prefix KV inputs_embeds=[None, suffix_embs],# ★ 只有后缀 use_cache=self.config.use_cache, # True fill_kv_cache=False, # ★ 不再建缓存 ) suffix_out = outputs_embeds[1][:, -chunk_size:] v_t = self.action_out_proj(suffix_out) denoise_step(...)拿缓存 + 只喂后缀(前缀为None),分层走 cross/self。VLM 不再重算 Q/K/V,层内 cross-attn 时,Expert 的 Query 去看 prefix 的 K/V 缓存;若该层被 self_attn_every_n_layers 强制 self,则只做 Expert 自注意(VLM 旁路,因为没有输入前缀)。与训练的差别是训练时两侧一起算(inputs_embeds=[prefix, suffix]),且无缓存。 训练 vs 推理 维度 训练(VLAFlowMatching.forward) 推理(sample_actions + denoise_step) 是否用真动作 用,参与构造 x_t,t 与 u_t=noise-actions,形成监督 不用(没有 label),从噪声解 ODE 得动作 时间使用 随机采样 t~Beta(1.5,1.0),单步监督 从 t=1 到 t=0 迭代(步长 dt=-1/num_steps) 是否建 KV Cache 否(use_cache=False, fill_kv_cache=False) 是:先prefix-only 建缓存;循环中 suffix-only 复用缓存 两塔前向喂法 一次性 inputs_embeds=[prefix, suffix] 两段:① [prefix, None](建缓存);② [None, suffix](复用缓存) 层内注意力路由 由 attention_mode / self_attn_every_n_layers 决定,但无缓存上下文 相同路由;cross 时 Expert-Q × cached VLM-KV;self 时只 Expert 自注意 位置编码(RoPE) 每层对参与计算的 Q/K 应用 同上;prefix 的位置在建缓存时用过;suffix 在每步都重算 损失/梯度 MSE(u_t, v_t) → 反向 无损失、无反向 输出后处理 返回标量 loss(policy 中聚合/掩码后) x_t 作为动作 → unnormalize →(可选)Aloha 映射;支持 n-step 队列 注意力 注意力的计算是模型训练和推理的核心,主要涉及自注意力和交叉注意力,这里单独总结一章节进行梳理分析。 自注意力 自注意力的代码注意在forward_attn_layer函数中,接下来根据代码来进行分析。 (1)自注意力QKV计算 query_states = [] key_states = [] value_states = [] 首先定义了Self-Attention 中的 Query、Key 和 Value。这些将用于计算注意力权重。 for i, hidden_states in enumerate(inputs_embeds): layer = model_layers[i][layer_idx] if hidden_states is None or layer is None: continue hidden_states = layer.input_layernorm(hidden_states) inputs_embeds 是一个包含不同模态输入的列表或张量。例如,它可能包含 VLM 的前缀输入(图像、文本、状态)和 Expert 的后缀输入(动作、时间)。enumerate(inputs_embeds) 会遍历 inputs_embeds 中的每个元素,并返回 i(当前元素的索引)和 hidden_states(对应的输入嵌入)。通过 enumerate 我们可以分别处理每个输入模态,i 用来区分是处理 VLM 还是 Expert。i=0 对应 VLM 的输入,i=1 对应 Expert 的输入。 因此model_layers[i][layer_idx]根据 i 来选择当前是处理 VLM 层还是 Expert 层。如果 i=0,则选择 VLM 的层;如果 i=1,则选择 Expert 的层。layer_idx是当前处理的层的索引,指定当前模型中的哪一层进行处理。 当判断hidden_states is None或layer is None是则跳过不处理,对于Expert侧来说会为空,因为外层是按照VLM层数来遍历的,Expert只有VLM的一半,因此每隔VLM一层就会有一个Expert为空。 先使用input_layernorm对当前输入hidden_states进行归一化。然后就各自进行Q/K/V计算。 hidden_states = hidden_states.to(dtype=layer.self_attn.q_proj.weight.dtype) query_state = layer.self_attn.q_proj(hidden_states).view(hidden_shape) key_state = layer.self_attn.k_proj(hidden_states).view(hidden_shape) value_state = layer.self_attn.v_proj(hidden_states).view(hidden_shape) query_states.append(query_state) key_states.append(key_state) value_states.append(value_state) 在for循环中,遍历VLM和Expert各自计算Q/K/V,然后把VLM和Expert计算的Q/K/V都分类各自加入到相同的列表中,如VLM和Expert的Q加入列表query_states.append。 (2)拼接QKV query_states = torch.cat(query_states, dim=1) key_states = torch.cat(key_states, dim=1) value_states = torch.cat(value_states, dim=1) 将VLM和Expert计算出来的Query、Key、Value各自拼接成一个大的张量,用于后续的注意力计算,从这里可以看出。VLM和Expert的注意力计算是使用一个transformer同时对VLM+Expert的输入拼接输入计算的。相当于VLM和Expert的输入可以双向注意力。 (3)EoPE编码 seq_len = query_states.shape[1] if seq_len < position_ids.shape[1]: _position_ids = position_ids[:, :seq_len] _attention_mask = attention_mask[:, :seq_len, :seq_len] else: _position_ids = position_ids _attention_mask = attention_mask attention_mask_ = _attention_mask position_ids_ = _position_ids query_states = apply_rope(query_states, position_ids_) key_states = apply_rope(key_states, position_ids_) 这段代码主要处理的是位置编码和注意力掩码,这里主要是引入了RoPE编码,计算两个位置之间的相对距离来构造编码,而不是仅仅依赖于绝对位置,提高增强模型的泛化能力。 (4)缓存机制 if use_cache: if fill_kv_cache: past_key_values[layer_idx] = { "key_states": key_states, "value_states": value_states, } else: # TODO here, some optimization can be done - similar to a `StaticCache` we can declare the `max_len` before. # so we create an empty cache, with just one cuda malloc, and if (in autoregressive case) we reach # the max len, then we (for instance) double the cache size. This implementation already exists # in `transformers`. (molbap) key_states = torch.cat([past_key_values[layer_idx]["key_states"], key_states], dim=1) value_states = torch.cat([past_key_values[layer_idx]["value_states"], value_states], dim=1) 将每一层的Key和Value缓存到past_key_values[layer_idx]中,模型训练时这里的use_cache设置为0,当模型是推理时use_cache设置为1,fill_kv_cache设置为1。主要是在推理阶段,会先调用VLM+Expert模型推理一次将Key、Value进行缓存保存起来,后续就只是推理Expert了,VLM将不再计算了,通过这样的方式以提高计算效率。 (5)注意力输出 att_output = attention_interface( attention_mask_, batch_size, head_dim, query_states, key_states, value_states ) return [att_output], past_key_values 注意力计算时会把可用来源(VLM 前缀、Expert 后缀)各自算出的 Q/K/V在序列维度拼接后统一做一次注意力,但掩码保证了“单向可见”,即VLM 与 Expert 的 Q/K/V都参与拼接,但二维掩码使 VLM 基本不看 Expert,Expert 能看 VLM。 交叉注意力 交叉注意力在forward_cross_attn_layer中实现。下面来进行分析。 (1)前缀自注意力 if len(inputs_embeds) == 2 and not past_key_values: seq_len = inputs_embeds[0].shape[1] position_id, expert_position_id = position_ids[:, :seq_len], position_ids[:, seq_len:] prefix_attention_mask = attention_mask[:, :seq_len, :seq_len] layer = model_layers[0][layer_idx] # 选 VLM 的第 layer_idx 层 hidden_states = layer.input_layernorm(inputs_embeds[0]) # 投影出 VLM 的 Q/K/V query_state = layer.self_attn.q_proj(hidden_states).view(B, Lp, H, Dh) key_state = layer.self_attn.k_proj(hidden_states).view(B, Lp, H, Dh) value_state = layer.self_attn.v_proj(hidden_states).view(B, Lp, H, Dh) # 对 Q/K 施加 RoPE(相对位置编码) query_states = apply_rope(query_state, position_id) key_states = apply_rope(key_state, position_id) # 只在 prefix 上自注意力(用 prefix 的方阵 mask) att_output = attention_interface(prefix_attention_mask, batch_size, head_dim, query_states, key_states, value_state) att_outputs.append(att_output) else: expert_position_id = position_ids 当满足inputs_embeds有前缀+后缀的数据且没有缓存的时,只取VLM的输入prefix用于计算自注意力,输出结果为att_outputs。同时如果这层是Expert的交叉注意力,那么VLM计算出来的K/V后面要给到后面Expert用作cross的K/V。 上面前缀自注意力只有只有训练的模型的时候进入交叉注意力每次都会跑,在推理阶段时每次推理只会跑一次。 (2)K/V cache缓存处理 if use_cache and past_key_values is None: past_key_values = {} if use_cache: if fill_kv_cache: past_key_values[layer_idx] = {"key_states": key_states, "value_states": value_states} else: key_states = past_key_values[layer_idx]["key_states"] value_states = past_key_values[layer_idx]["value_states"] 推理的时候会用到缓存,在推理时会调用两次forward。 建缓存阶段(prefix-only):外层会先单独跑一遍,只给 inputs_embeds=[prefix_embs, None],fill_kv_cache=True,把 VLM prefix 的 K/V 存到 past_key_values[layer_idx]。 后缀阶段(真正 cross):用 inputs_embeds=[prefix_embs, suffix_embs] 或者只给 suffix,fill_kv_cache=False,此时直接复用缓存里的 prefix K/V,不用再算。 (3)Expert的交叉注意力 expert_layer = model_layers[1][layer_idx] # 取 Expert 的第 layer_idx 层(可能是 None) if expert_layer is not None: expert_hidden_states = expert_layer.input_layernorm(inputs_embeds[1]) expert_layer is None 的出现是由 get_model_layers 对齐规则决定的,multiple_of = num_vlm_layers // num_expert_layers。Expert要能够计算交叉注意力也要满足当前层是否有Expert层。因为VLM和Expert是对齐的,不一定每一层都有Expert,而当self_attn_every_n_layers设置为2时,相当于是奇数层才会自注意力,而当VLM为16,Expert为8,那么正好Expert都在偶数层基数层没有,所以整个模型都没有注意力机制计算。 expert_query_state = expert_layer.self_attn.q_proj(expert_hidden_states) \ .view(B, Ls, He, Dhe) # 先把 VLM 的 K/V 合并 head 维,变为 [B, Lp, H*Dh] _key_states = key_states.to(dtype=expert_layer.self_attn.k_proj.weight.dtype).view(*key_states.shape[:2], -1) _value_states = value_states.to(dtype=expert_layer.self_attn.v_proj.weight.dtype).view(*value_states.shape[:2], -1) # 再喂给 Expert 自己的 k_proj/v_proj,把维度映射到 Expert 的头数与 head_dim expert_key_states = expert_layer.self_attn.k_proj(_key_states) \ .view(*_key_states.shape[:-1], -1, expert_layer.self_attn.head_dim) # [B, Lp, He, Dhe] expert_value_states = expert_layer.self_attn.v_proj(_value_states) \ .view(*_value_states.shape[:-1], -1, expert_layer.self_attn.head_dim) Expert的expert_query_state来自自己的输入,而expert_key_states、expert_value_states来之与key_states、value_states即为VLM计算过来的缓存K/V。也就是Expert计算注意力是Q使用自己的,而K/V使用的是VLM的。但是需要注意的是可能两边的模型VLM和Expert的hidden宽度、KV头数/维度不一样,先把 VLM K/V 的多头维合并(view(*, H*Dh)),再用 Expert 自己的 k_proj/v_proj 做一次线性变换,映射到 Expert 的多头维度。这就是代码里 “cross K/V 适配层” 的作用;对应到 init,当 attention_mode 包含 "cross" 时,会把 Expert 的 k_proj/v_proj 重定义成输入维=VLM 的 kv_heads x head_dim,输出维=Expert 的。 # 让 Expert 的 token 位置从 0 开始(RoPE 需要相对位置) expert_position_id = expert_position_id - torch.min(expert_position_id, dim=1, keepdim=True).values # 行选择 Expert 的 queries(后缀那段),列只到 prefix 的 K/V 长度(严格 cross,不看自己) expert_attention_mask = attention_mask[:, -inputs_embeds[1].shape[1]:, : expert_key_states.shape[1] ] # 对 Expert 的 Query 施加 RoPE expert_query_states = apply_rope(expert_query_state, expert_position_id) att_output = attention_interface(expert_attention_mask, batch_size, head_dim, expert_query_states, expert_key_states, expert_value_states) att_outputs.append(att_output) 接下来就是计算mask,确保Expert计算cross时只看到前缀(纯cross-attn),不能自回看(不看后缀自身)。再计算RoPE的位置编码,最后调用attention_interface计算交叉注意力得到结果输出。 return att_outputs, past_key_values 最终返回的是两个流对应的自注意力输出,att_outputs 的 长度与 inputs_embeds 对齐,索引0代表VLM 流的输出(前面 prefix 自注意力的结果);索引 1 代表Expert 流的输出(本层 cross 的结果;没有 Expert 就是 None)。外层主循环会据此对两个流分别过 o_proj + 残差 + MLP 等,继续下一层。 总结一下:cross-attn 分支“不拼接 Expert 的 K/V”:Expert 的 Q 只对 VLM 的 K/V(经投影到 Expert 维度)做注意。训练时VLM K/V现场算出并可选择写入缓存;Expert Q 只看这份 VLM K/V。推理时先用前缀阶段填好 VLM KV 缓存;去噪时 Expert Q 直接用缓存的 VLM K/V。VLM 不产生 Q,不会“看”Expert。 Expert要计算交叉注意力需要满足什么条件? 主要看3个参数 L = num_vlm_layers:VLM 总层数 E = num_expert_layers:Expert 总层数(必须 > 0 且能整除 L) S = self_attn_every_n_layers:每隔 S 层强制走一次自注意力(=这层不做 cross) 某层做 cross 的条件 : i % M 0 且(S = 0 或 i % S != 0) 举例1:L=16, E=8;有Expert的层是{0,2,4,6,8,10,12,14},若S=2这些层全是S的倍数,那么没有一层做cross。若S=3,做cross的为{2,4,8,10,14}。 总结一下就是能做cross的,先看每隔几层做cross(间接有self_attn_every_n_layers决定)同时要满足能做cross的这几层有没有Expert。一般情况下,当VLM和Expert具有相同层数是,奇数层做Cross,如果Expert为VLM的一半是需要设置self_attn_every_n_layers设置大于2以上的奇数才能做cross。 层类型 训练时 推理时 Self-Attn VLM & Expert 各自算 QKV → 拼接 → 双向注意 → 切分结果 同训练,但 prefix KV 在首轮缓存,后续复用;双向依旧存在,但 VLM 冻结 Cross-Attn VLM 自注意更新自身 KV;Expert 只算 Q,从 VLM KV(线性投影后)读条件 prefix KV 已缓存;Expert 只算 Q,直接读缓存的 VLM KV;无需重复计算 模型配置 SmolVLAConfig 模型配置主要是SmolVLAConfig类,其决定了训练/推理是模型结构、预处理、优化器/调度器、以及VLM骨干选择与冻结策略。 class SmolVLAConfig(PreTrainedConfig): # Input / output structure. n_obs_steps: int = 1 chunk_size: int = 50 n_action_steps: int = 50 normalization_mapping: dict[str, NormalizationMode] = field( default_factory=lambda: { "VISUAL": NormalizationMode.IDENTITY, "STATE": NormalizationMode.MEAN_STD, "ACTION": NormalizationMode.MEAN_STD, } ) # Shorter state and action vectors will be padded max_state_dim: int = 32 max_action_dim: int = 32 # Image preprocessing resize_imgs_with_padding: tuple[int, int] = (512, 512) # Add empty images. Used by smolvla_aloha_sim which adds the empty # left and right wrist cameras in addition to the top camera. empty_cameras: int = 0 # Converts the joint and gripper values from the standard Aloha space to # the space used by the pi internal runtime which was used to train the base model. adapt_to_pi_aloha: bool = False # Converts joint dimensions to deltas with respect to the current state before passing to the model. # Gripper dimensions will remain in absolute values. use_delta_joint_actions_aloha: bool = False # Tokenizer tokenizer_max_length: int = 48 # Decoding num_steps: int = 10 # Attention utils use_cache: bool = True # Finetuning settings freeze_vision_encoder: bool = True train_expert_only: bool = True train_state_proj: bool = True # Training presets optimizer_lr: float = 1e-4 optimizer_betas: tuple[float, float] = (0.9, 0.95) optimizer_eps: float = 1e-8 optimizer_weight_decay: float = 1e-10 optimizer_grad_clip_norm: float = 10 scheduler_warmup_steps: int = 1_000 scheduler_decay_steps: int = 30_000 scheduler_decay_lr: float = 2.5e-6 vlm_model_name: str = "HuggingFaceTB/SmolVLM2-500M-Video-Instruct" # Select the VLM backbone. load_vlm_weights: bool = False # Set to True in case of training the expert from scratch. True when init from pretrained SmolVLA weights add_image_special_tokens: bool = False # Whether to use special image tokens around image features. attention_mode: str = "cross_attn" prefix_length: int = -1 pad_language_to: str = "longest" # "max_length" num_expert_layers: int = 8 # Less or equal to 0 is the default where the action expert has the same number of layers of VLM. Otherwise the expert have less layers. num_vlm_layers: int = 16 # Number of layers used in the VLM (first num_vlm_layers layers) self_attn_every_n_layers: int = 2 # Interleave SA layers each self_attn_every_n_layers expert_width_multiplier: float = 0.75 # The action expert hidden size (wrt to the VLM) min_period: float = 4e-3 # sensitivity range for the timestep used in sine-cosine positional encoding max_period: float = 4.0 可以分为几个部分 (1)输入输出与时序 n_obs_steps: 输入观测的历史步数,默认为1。 chunk_size:每次模型生成的动作序列长度(后缀序列长度)。 n_action_steps:外部消费的动作步数,需要满足n_action_steps <= chunk_size(代码中已校验)。 采样与训练的后缀长度在 VLAFlowMatching.sample_actions/forward 中使用,动作队列在 SmolVLAPolicy 中按 n_action_steps 出队。 (2)归一化与特征维度 normalization_mapping:各模态的标准化策略,视觉默认 Identity,状态与动作 MeanStd。 max_state_dim/max_action_dim:状态、动作向量的固定上限维度;短向量会 pad 到该维度(pad_vector)。 Normalize/Unnormalize 与 state_proj/action_ x _proj 的投影维度。 (3)图像预处理与空相机 resize_imgs_with_padding=(512,512):视觉输入 pad-resize 到固定分辨率,然后再做 [-1,1] 归一化(SigLIP 习惯)。 empty_cameras:允许在 batch 缺少图像时补空相机占位(用于多摄像头但部分缺失的场景)。 (4)Aloha 相关开关 adapt_to_pi_aloha:状态/动作与 Aloha 空间的双向转换(关节翻转、夹爪角度/线性空间互转)。 use_delta_joint_actions_aloha:将关节维度转为相对量(目前未在 LeRobot 中实现,置 True 会报错)。 (5)文本与采样步数 tokenizer_max_length=48:语言 token 最大长度。 num_steps=10:Flow Matching 反推理的 Euler 步数(越大越精细,越慢)。 prepare_language、sample_actions 的迭代去噪循环。 (6)缓存与注意力 use_cache=True:是否使用 KV-Cache(前缀只算一次,后续重复用)。 attention_mode="cross_attn":与 SmolVLMWithExpertModel 的交叉注意力对齐策略。 prefix_length=-1/pad_language_to="longest":前缀长度/语言 padding 策略;用于构造 attention_mask 与 position_ids。 (7)微调的策略 freeze_vision_encoder=True:冻结 VLM 视觉编码器。 train_expert_only=True:只训练动作 expert(VLM 其它部分冻结)。 train_state_proj=True:是否训练状态投影层。 影响SmolVLMWithExpertModel.set_requires_grad 以及 VLM 参数的 requires_grad 设置。 (8)优化器与调度器 optimizer_* 与 scheduler_*:在训练入口 TrainPipelineConfig.validate() 使用,生成默认的 AdamW + 余弦退火带预热调度。 可被 CLI 覆写(如 --optimizer.lr 等)。 (9)VLM骨干与权重加载 vlm_model_name="HuggingFaceTB/SmolVLM2-500M-Video-Instruct":指定用哪个 VLM 仓库(用于取 tokenizer/processor,和构建骨干结构)。 load_vlm_weights=False:是否直接从该 VLM 仓库下载骨干权重。为 False时只拿 AutoConfig 构结构,权重随机初始化,随后通常被策略检查点覆盖。为 True时用 AutoModelForImageTextToText.from_pretrained 加载骨干权重(仅在 --policy.type=smolvla 路线下常用)。 与 --policy.path 的关系为用 --policy.path=lerobot/smolvla_base 时,实际权重来自本地/Hub 的策略检查点(包含 VLM+expert),不会使用骨干权重,但仍会用 vlm_model_name 主要是加载 tokenizer/processor。用 --policy.type=smolvla 时,vlm_model_name 决定骨干结构,load_vlm_weights 决定是否拉骨干权重,expert 按本地配置新建训练。 (10)层数与宽度对齐 num_vlm_layers:把 VLM 的文本层裁剪为前 N 层再用。裁剪层数后设为 self.num_vlm_layers。 num_expert_layers:专家 expert 模型的层数;若 ≤0 则默认与 VLM 层数相同。决定 expert 与 VLM 的层对齐步长 multiple_of = num_vlm_layers // num_expert_layers。只有在 i % multiple_of = 0 的 VLM 层位点才映射到一个 expert 层用于交叉注意力;其他层的 expert_layer 为空。 self_attn_every_n_layers:每隔 n 层强制走“仅自注意力”而不是交叉注意力。当 attention_mode 含 “cross” 且 fill_kv_cache=False 时,如果 layer_idx % n = 0 则走 self-attn 分支,否则走 cross-attn 分支。例如n=2 → 偶数层自注意、奇数层尝试交叉注意,但还需该层“有映射到的 expert 层”(见 multiple_of)才真正执行 cross-attn。 expert_width_multiplier:expert 的隐藏维度 = VLM 隐藏维度 × multiplier(同时重设 FFN 的 intermediate_size)。expert 更窄以降算力;但会改动线性层形状,需与加载的检查点一致,否则会维度不匹配。为实现 cross-attn,代码会按 VLM hidden 尺寸重建部分 q/k/v 投影,使其能接收来自 VLM 的输入(跳过“只自注意”层)。 在SmolVLAConfig配置集中定义了 SmolVLA 的“结构与训练/推理开关”。训练微调常用 --policy.path=lerobot/smolvla_base,此时多数结构参数不宜修改,微调时从smolvla_base中加载config.json配置;而从骨干自建训练时才需要精细调 num_expert_layers/num_vlm_layers/expert_width_multiplier/load_vlm_weights 等,并确保与骨干 hidden_size/层数一致。 加载流程 策略的加载主要分为两条入口路径,两者互斥,通过启动时参数指定。 (1)--policy.path=....方式 用 --policy.path=.....:指定一个已存在的策略checkpoint(Hub 上或本地目录)。如训练时微调可以指定lerobot/smolvla_base,推理时指定output/train/pretrained_model。会从 path/config.json 里反序列化成 SmolVLAConfig;会加载同目录下的 model.safetensors(整个策略权重:VLM骨干 + 动作专家 + 投影层等);训练开始时,模型已经有了一套完整的初始化参数(通常是预训练好的)。 python -m lerobot.scripts.train \ --policy.path=lerobot/smolvla_base \ --dataset.repo_id=xxx \ --batch_size=64 --steps=200000 这里会拿 Hugging Face Hub 上的 lerobot/smolvla_base(含 config.json + model.safetensors,整个策略权重:VLM骨干 + 动作专家 + 投影层等)来初始化。 (2)--policy.type=smolvla方式 指定一个 策略类别(由 @PreTrainedConfig.register_subclass("smolvla") 注册)。会创建一个全新的 SmolVLAConfig 对象(带默认超参),而不是加载 checkpoint。没有预训练权重,除非配合 load_vlm_weights=True,这时只会拉取纯VLM背骨的预训练权重(而动作专家层仍然是随机初始化)。可以用命令行参数覆盖任意超参(比如 --policy.num_expert_layers=4)。 python -m lerobot.scripts.train \ --policy.type=smolvla \ --dataset.repo_id=xxx \ --batch_size=64 --steps=200000 \ --policy.load_vlm_weights=True 从零(或仅用 VLM 预训练骨干)开始训练一个新策略。 下面以推理和训练举例说明其调用流程。 (1)训练使用policy.path方式 在 validate() 中读取 path,并把所有 --policy.xxx 作为“同层覆写”传入配置加载。 policy_path = parser.get_path_arg("policy") self.policy = PreTrainedConfig.from_pretrained(policy_path, cli_overrides=cli_overrides) self.policy.pretrained_path = policy_path 判断是从本地目录还是Hub下载获取配置文件,然后应用得到 SmolVLAConfig。只加载“配置”(config.json),不加载模型权重。权重加载发生在后续 policy_cls.from_pretrained(...)(另一个类,见 policies/pretrained.py)。 @classmethod def from_pretrained(cls, pretrained_name_or_path, *, ..., **policy_kwargs) -> T: model_id = str(pretrained_name_or_path) # 1) 决定从本地目录还是Hub取配置文件(只取config,不取权重) if Path(model_id).is_dir(): if CONFIG_NAME in os.listdir(model_id): config_file = os.path.join(model_id, CONFIG_NAME) else: print(f"{CONFIG_NAME} not found in {Path(model_id).resolve()}") else: try: config_file = hf_hub_download(repo_id=model_id, filename=CONFIG_NAME, ...) except HfHubHTTPError as e: raise FileNotFoundError(...) from e # 2) 应用CLI覆写(如 --policy.xxx=...) cli_overrides = policy_kwargs.pop("cli_overrides", []) with draccus.config_type("json"): return draccus.parse(cls, config_file, args=cli_overrides) 构建策略,注入数据集特征与统计,若存在 pretrained_path 则连同权重加载。 cfg.input_features/output_features = ... if cfg.pretrained_path: policy = policy_cls.from_pretrained(**kwargs) else: policy = policy_cls(**kwargs) 加载权重(目录或 Hub 的 model.safetensors),随后迁移到 device、设 eval()(训练循环里会再切回 train())。 if os.path.isdir(model_id): policy = cls._load_as_safetensor(...) policy.to(config.device); policy.eval() SmolVLA 特定初始化,即使走 path,仍按 vlm_model_name 加载 tokenizer/processor(非权重),并实例化骨干+expert。 self.language_tokenizer = AutoProcessor.from_pretrained(self.config.vlm_model_name).tokenizer self.model = VLAFlowMatching(config) (2)训练使用policy.type方式 draccus 按类型直接实例化 SmolVLAConfig(该类已注册)并解析 --policy.xxx。 @PreTrainedConfig.register_subclass("smolvla") class SmolVLAConfig(PreTrainedConfig): make_policy 同上;因无 pretrained_path,默认从零构建。若配置 load_vlm_weights=true,才会把骨干权重从 vlm_model_name 拉下来(expert 仍需训练)。 if load_vlm_weights: self.vlm = AutoModelForImageTextToText.from_pretrained(model_id, ...) else: config = AutoConfig.from_pretrained(model_id) self.vlm = SmolVLMForConditionalGeneration(config=config) (3)推理模式只能使用policy.path方式 policy_path = parser.get_path_arg("policy") self.policy = PreTrainedConfig.from_pretrained(policy_path, cli_overrides=cli_overrides) self.policy.pretrained_path = policy_path record 的配置按policy.path加载训练的模型,随后通过 predict_action/select_action 使用策略进行推理。 policy.path 对比 policy.type 维度 policy.path=... policy.type=smolvla 配置来源 从 checkpoint 目录/Hub 仓库里的 config.json 反序列化成 SmolVLAConfig 通过 @PreTrainedConfig.register_subclass("smolvla") 新建一个默认 SmolVLAConfig,命令行可覆写 权重来源 从 checkpoint 里的 model.safetensors 加载完整策略权重(VLM骨干 + 动作专家 + 投影层) 默认全随机;若 load_vlm_weights=True,则只加载 VLM骨干权重(SmolVLM2),动作专家仍随机 归一化统计 不从 checkpoint 恢复,而是来自数据集 dataset_stats(normalize_inputs/targets在加载时被忽略) 同左 Tokenizer/Processor 仍然会用 config.vlm_model_name(默认 HuggingFaceTB/SmolVLM2)加载 tokenizer/processor 同左 常见场景 - 直接推理- 微调已有策略 - 从零开始训练新策略- 换结构做实验(改 num_expert_layers、expert_width_multiplier等) 推理可用性 一键可用(权重完整) 不可直接用(专家没训练,输出无意义),除非后续手动加载你自己训练好的权重 是否需要 HuggingFaceTB/SmolVLM2 权重 不需要(只用到它的 processor/tokenizer) 如果 load_vlm_weights=True → 需要拉骨干权重;否则全随机 -
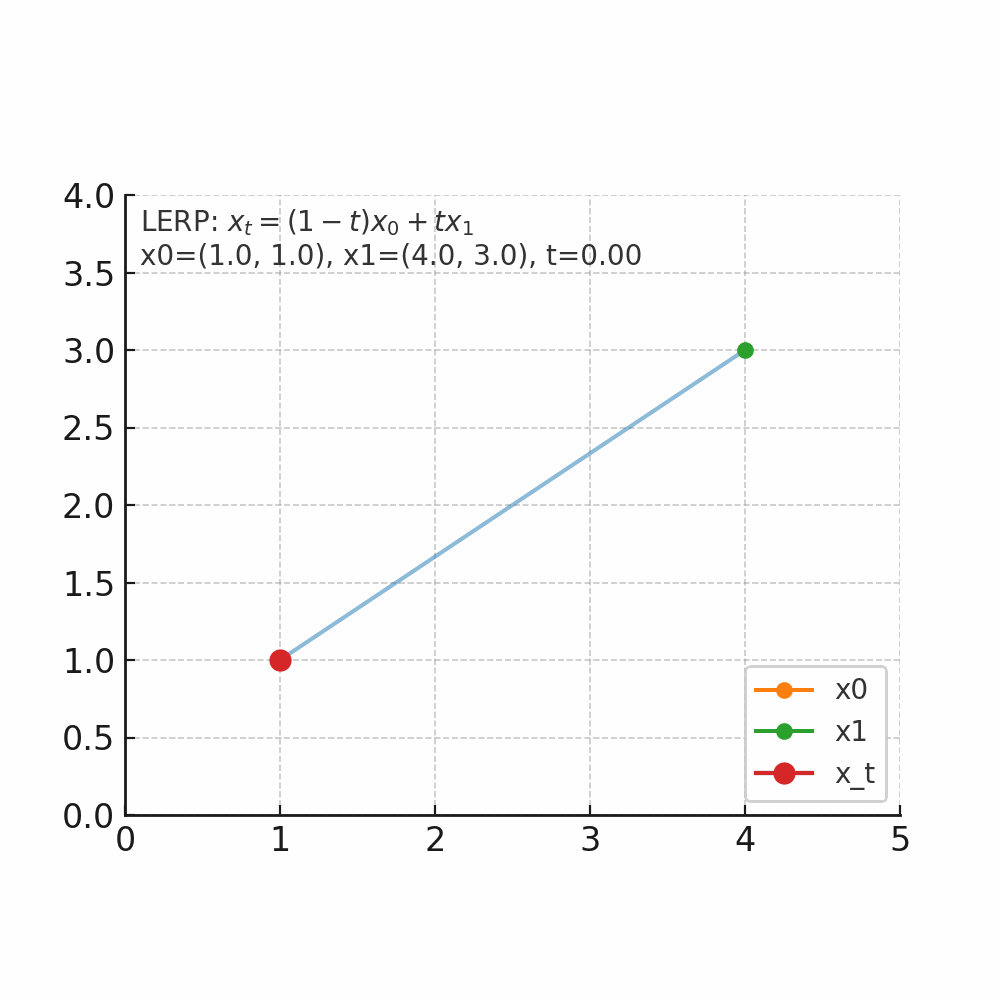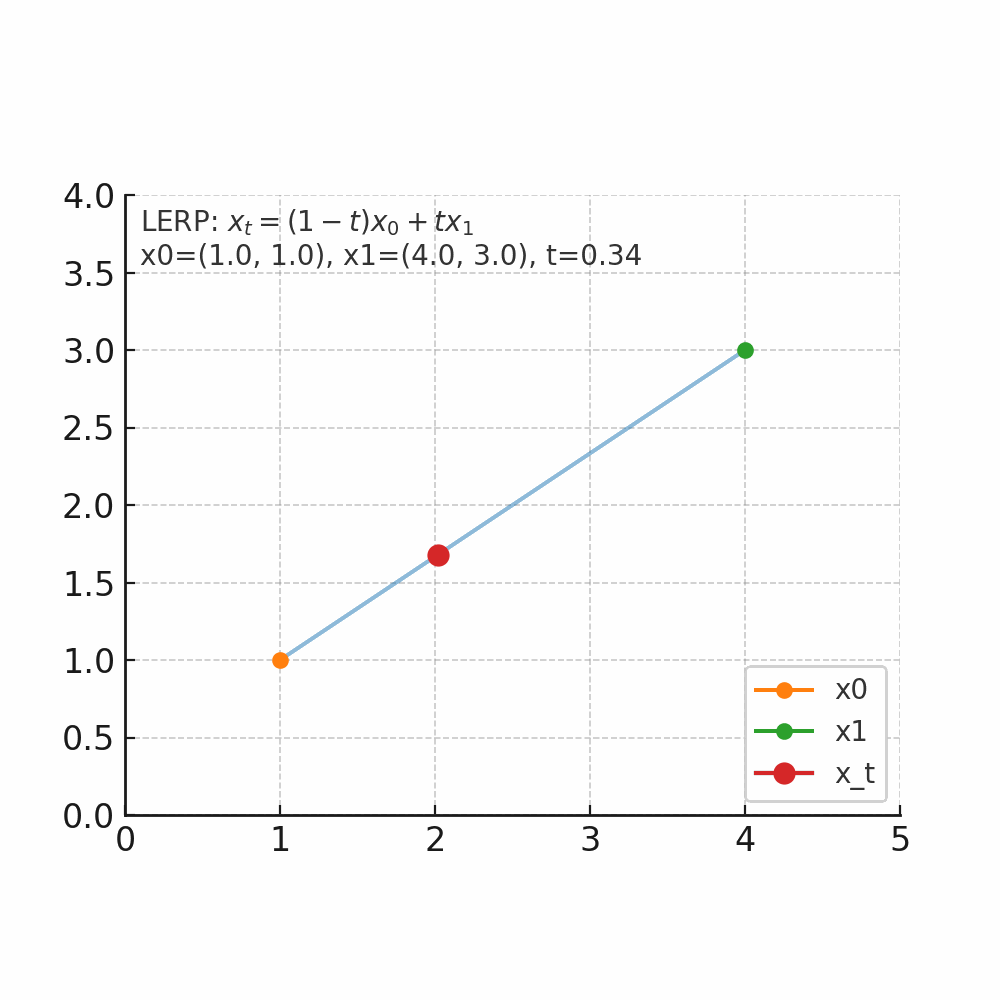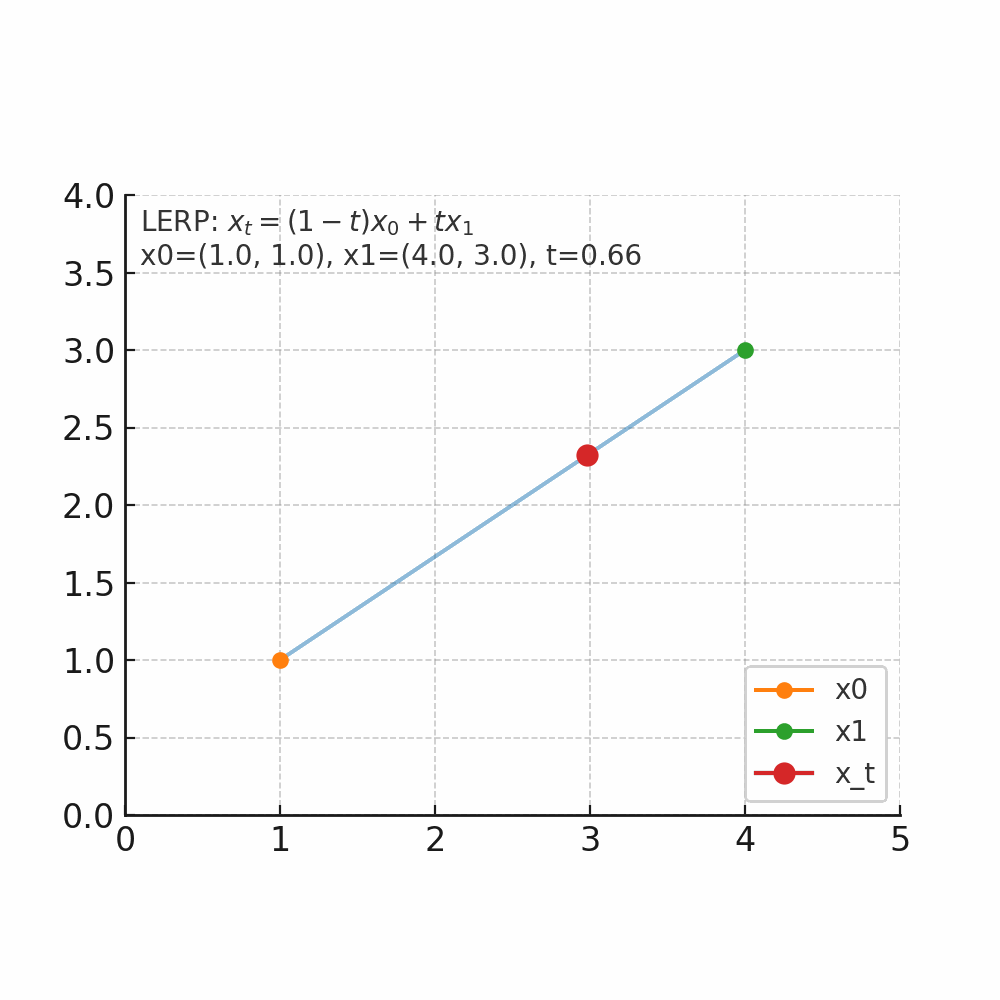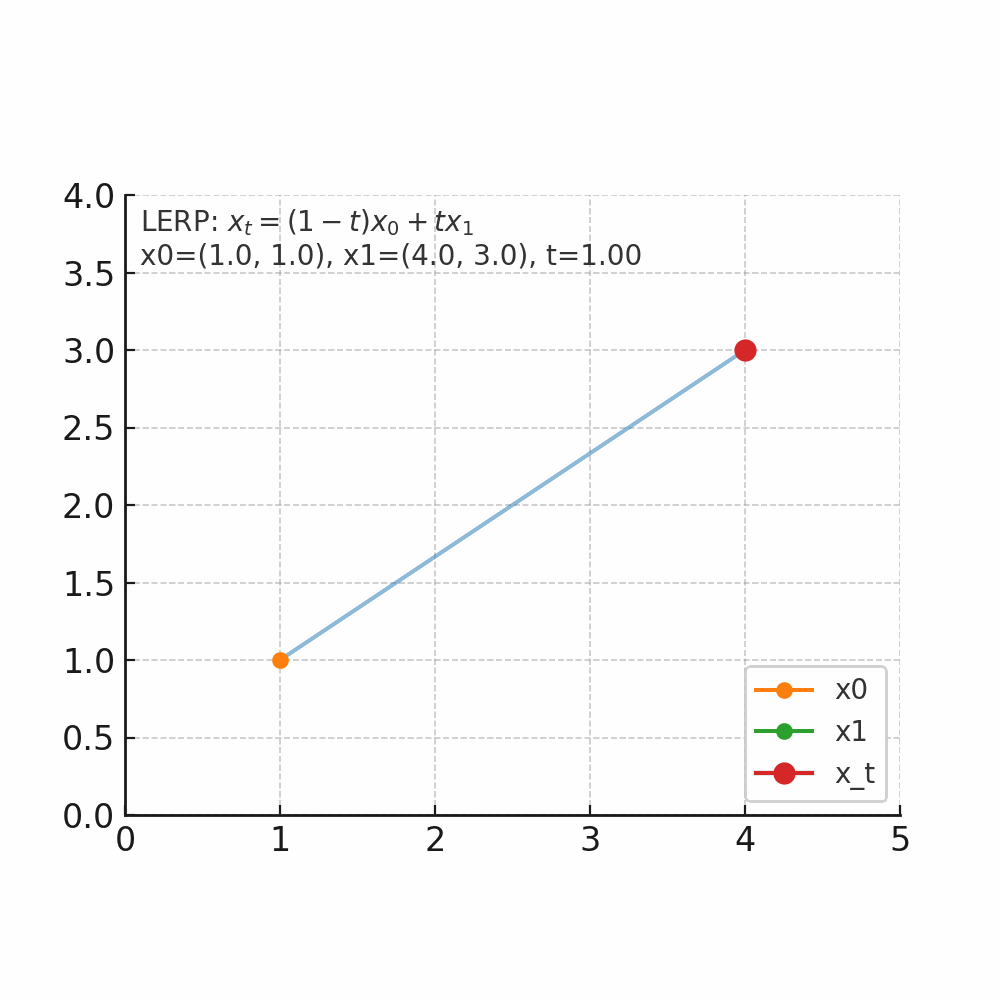
从数学角度理解flow matching中的线性插值
什么是插值 插值的核心问题是:在已知两个点的情况下,如何找到它们之间的中间点。 举个人走路的例子,起点在家门口(A点),终点在公司(B点),总的路程为1000米,假设人是匀速移动,如果走到一半(t=0.5),那么人就在家和公司的正中间,如果走到四分之一(t=0.25),那么离家250米,离公司750米。 线性插值(LERP) 是最简单的一种:它假设两个点之间的变化是“直线型、匀速”的。 公式 $$ x_t = (1-t)x_0 + t x_1, \quad t \in [0,1] $$ 把两个量$x_0$和$x_1$按加权$1-t$与$t$做加权平均,得到他们之间的线性过渡点。$x_0$是起点,$x_1$是终点,$t$是插值因子,控制起点与重点的位置。当 $t=0$,结果是 $x_0$;当 $t=1$,结果是 $x_1$;当 $t=0.5$,结果是中点;$t$从0到1连续变化时,$x_t$沿着二者之间等速变化(为什么是等速,待会解释)。 先上个图看看直观体会一下。 如图所示起点$x_0$为坐标(1,1),终点$x_1$(4,3),当$t$从0开始连续变化是,$x_t$的位置会朝着$x_1$的方向变化。 当$t=0$时,坐标为(1 - 0) x (1, 1) + 0 x (4, 3) = (1, 1)。 当$t=0.2$时,坐标为(1 - 0.2) x (1, 1) + 0.2 x (4, 3) = (1.6, 1.4)。 当$t=0.5$时,坐标为(1 - 0.5) x (1, 1) + 0.5 x (4, 3) = (2.5, 2)。 当$t=1$时,坐标为(1 - 01) x (1, 1) + 1 x (4, 3) = (4, 3)。 通过公式可以算出每个时间的位置,但是如果要知道每个位置变化的速度/趋势我们应该怎么来衡量了? 那自然就是要求导数了。 $$ \frac{d}{dt}x_t = x_1 - x_0 $$ 可以看到其倒数是一个常数,那就意味着变化是匀速的,以上图为例,都是朝着(4,3)-(1,1)=(3,2)的向量方向去变化。 有了这个变化量,假设我们时间步$\Delta t=0.1$,那么意味着每次变化的位置是0.1 x (3,2) = (0.3, 0.2);假设当前位置是(1,1)那么就可以计算出下一个时间步的位置为$(1,1)+(0.3,0.2)=(1.3,0.2)$。这就与我们此前flow matching里面的公式$x_{k+1} = x_k + v_\theta(x_k, t_k)\Delta t$。 -
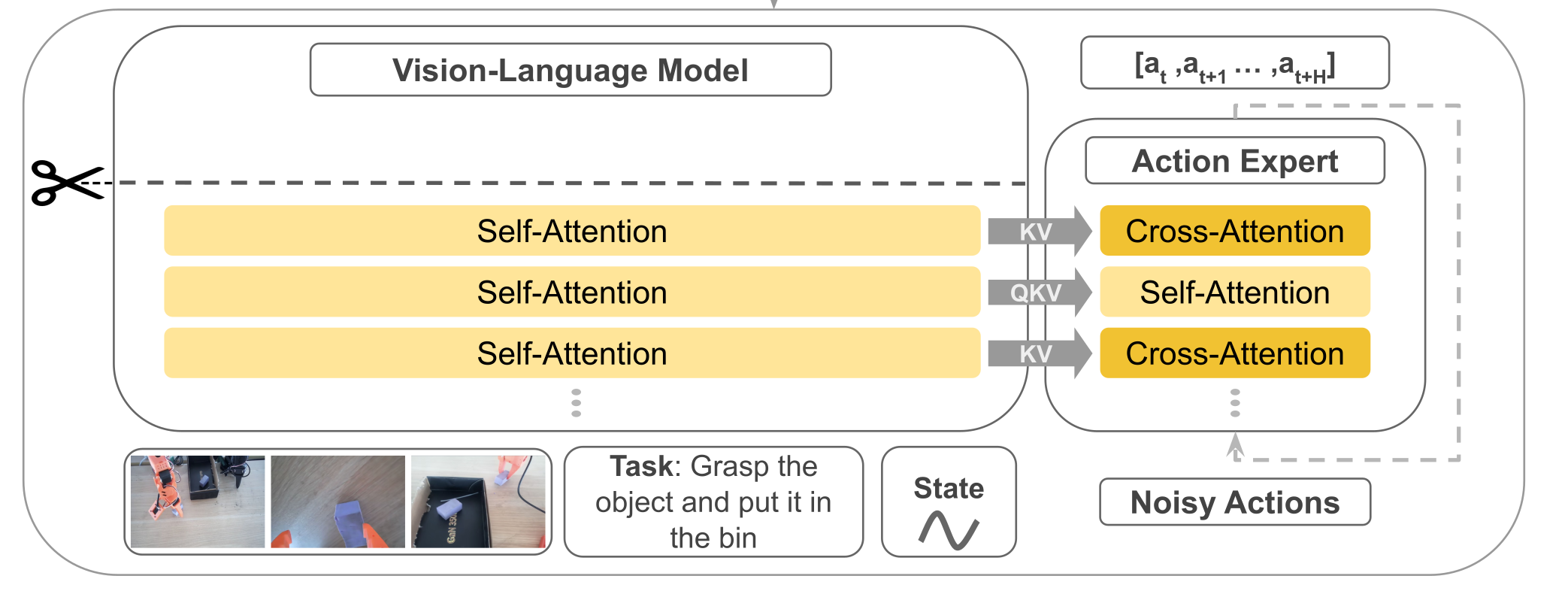
轻量SmolVLA:半层VLM、视觉压缩与异步推理赋能具身智能
概述 SmolVLA 是一套轻量级视觉-语言-行动(VLA)策略:前端用小型 VLM(视觉 SigLIP + 语言 SmolLM2)做感知与理解;后端用一个“动作专家”专门预测一段连续的低层控制。它与Pi0相比,参数规模少了将近10倍只有约0.45B(450M)。它的目标是在低算力下也能稳定执行多任务机器人控制,并保持接近甚至超过更大模型的效果。 SmolVLA 通过冻结 VLM、只训练动作专家(Action Expert),再配上四件“硬核小技巧”——取 VLM 的前半层、把每帧视觉 token 压到 64、以及Self-Attn—>Cross-Attn交替方式、异步推理;在大幅降算力与时延的同时,保持/逼近甚至超过更大模型的性能;注意力计算交替方式让动作专家既能不断获取外部视觉/语言指导,又能在内部序列里建立自己的时序与物理一致性,从而在算力可控的前提下提升稳定性和表现;提供异步执行,把“算下一段动作”和“执行当前动作”并行起来,显著减少空窗时间。 原理 结构 其模型结构主要有前端的VLM+后端的动作专家Action Expert组成,结构组成与Pi基本一致但实现方式有很大差异不同。先总结一下组件,稍后我们在稍作展开补充。 输入:文本指令token+视觉token(多摄像头采集的图像)+机器的状态(关节角、传感器)。 VLM(感知端):采用SmolVLM-2,VLM共有L层,但是只N=⌊L/2⌋层隐藏表示喂给动作专家。 Action Expert(控制端):一个Flow Matching Transformer,以以Cross → Causal Self → Cross 的“三明治”层为基本单元,按块预测n步动作序列。 输出:一次预测长度为n的动作块,对应机器的控制指令。 SmolVLA与Pi0有很多相似之处,不过其背后有四个关键设计,分别是Layer Skipping(层跳过)、Visual tokens reduction(视觉token压缩)、动作专家交替Self-Attn与Cross-Attn、异步推理。本小节先围绕前面3部分进行解析,异步推理于后续章节展开。 (1)Layer Skipping 层跳过就是把感知端的VLM(视觉+语言)的解码器中间层拿来当条件特征,而不是等它把整个层都计算完再输出;具体的做法就是只去$N=L/2$层的隐藏层表示送给动作专家,VLM权重冻结不训练。之所以要这样做经验规律表示(论文中作者提到)深层 LLM 层更偏“词级生成/长链路语义”,而中层已经集中了“指令 + 视觉”的对齐语义,对控制足够;继续往后让语言头生成 token 既耗算,又不是控制必须。前半层就停下,少算一半的自注意 + MLP,显存开销也随之下降。 大概得实现是把“文本指令 token、图像 token、状态 token”拼接,送入解码器;在第$N$层获取特征信息H然后用一个线性投影到Action expert所需的维度$d_a$作为$K/V$。如果在长时、极强推理型任务(需要深层语言生成)时可以适当调大N。 (2)视觉token压缩 在transformer里面,“token”就是序列里的一个位置。对图像来说,我们把一张图拆成很多小块(patch)或网格上的特征点,每个块/点用一个向量表示,这个向量就是视觉 token(不明白的可以看看ViT原理解析介绍)。视觉token压缩具体的做法是保整图、不裁块,把空间上密的token折叠到通道里,从而让token数变少。 设 ViT patch 后得到的特征图大小为 $\frac{H}{p} \times \frac{W}{p} \times d$,选一个下采样因子 $r$ (整数),做 space-to-depth: $$ \underbrace{\frac{H}{p} \times \frac{W}{p}}{\text{原网格}} \xrightarrow{\div r} \underbrace{\frac{H}{pr} \times \frac{W}{pr}}{\text{更稀疏的网格}}, \quad \underbrace{d}{\text{通道}} \xrightarrow{\times r^2} \underbrace{d \cdot r^2}{\text{更厚的通道}} $$ 计算示例: 输入尺寸:$512 \times 512$ 图像 Patch大小 $p=16$ ⇒ $32 \times 32$ token网格 选$r=4$ ⇒ $\frac{32}{4} \times \frac{32}{4} = 8 \times 8$ 网格 Token数:$8 \times 8 = 64$(减少$4^2=16$倍) 通道维度:$d=3 \rightarrow d=3 \times 16=48$ 可以看到如果是按照ViT的默认方式patch数量为32x32=1024,每个patch的维度为3x16x16=768,然后如果输入编码的$d_mode=512$那么经过线性投影变成矩阵(1024,512),即1024个token数量,每个token维度是512;而如果进行压缩后patch数量为8x8=64,每个patch的维度为48x16x16=12288,经过线性投影后变成(64,512)即64个token,每个维度是512。这里也可以看到原来是768降为到512,压缩的是从12288降维到512,降得比较猛,效果真的没有衰减吗? 总结一下smolvla在视觉token上进行了压缩,使用space-to-depth,对于512X512的图每帧token从1024降低到了64帧,如ViT的patch操作后得到的特征图维度为$\mathbb{R}^{\frac{H}{p} \times \frac{W}{p} \times d}$,选择下采样因子 $r$(整数)进行space-to-depth操作: $$ \mathbb{R}^{\frac{H}{p}\times\frac{W}{p}\times d} \xrightarrow{\text{S2D}_{r}} \mathbb{R}^{\frac{H}{pr}\times\frac{W}{pr}\times(d\cdot r^{2})} $$ 这样token数减少$r^{2}$倍,把细节挪到通道数去。 (3)动作专家交替Self-Attn与Cross-Attn 在动作专家中使用了交叉注意力机制,具体的排布可以配置。VLM的每一层与右边的Expert是一一对齐的,当然也可以配置Expert模型只有VLM层数的一半,每两层VLM才有一层Expert,那么其中VLM对齐层将为NONE,下图以VLM和Expert都为4层来示例交替注意力的实现。 Self-Attn(管自己,守时序):只允许第 i 步看 ≤i 的历史步(因果掩码),在动作序列内部传播动力学与约束,做轨迹的时间一致性与平滑。这一步相当于“内化刚才读到的证据”并让各步动作彼此协调。在计算注意力时,会将VLM的QKV与Expert的QKV进行拼接起来一起送入transformer计算,但通过掩码保证 VLM 的Q只看自己(不去读 Expert),而 Expert 的 Q 可以访问 VLM 的 K/V(即“读”VLM 语义),这样既提供了计算效率也提升了Expert的语义丰富性。 Cross-Attn(看环境,取证):看环境取证,让每个动作 token 先从条件特征里“读”一遍(条件=VLM中间层输出,含文本指令+多路视觉+状态)。这样动作表示一开始就被场景锚定,知道当下该关注哪里/哪件物体。具体是交叉注意力计算Q来自Expert Action自己,而K/V 来自 VLM 对应层的输出缓存。 训练 目标让动作专家 在观测条件 $o_t$ 下输出$v_\theta$速度场,把“噪声动作”沿路径推向真实动作块 $A_t$。这里跟Pi0和Flow Matching是一样大同小异,就简要说明一下。 观测条件:$o_t=H^{(N)}\in\mathbb{R}^{T\times d_o}\ \xrightarrow{\text{proj}}\ O_N\in\mathbb{R}^{T\times d_a}$(VLM 冻结;$O_N$ 作为 Cross-Attn 的 K/V)。 真实动作块:$A_t\in\mathbb{R}^{n\times d_{\text{act}}}$(建议标准化/白化)。 噪声:$\varepsilon\sim\mathcal N(0,I)$(同形)。 路径时间:$\tau\sim\mathrm{Beta}(\alpha,\beta)$。这里与Pi0不同。 路径与目标速度场: $$ A_t^{\tau}=\tau A_t+(1-\tau)\varepsilon,\left(A_t^{\tau}\mid A_t\right)=\varepsilon-A_t $$ 计算损失函数: $$ \mathcal{L}^{\tau}(\theta) = \mathbb{E}{p\left(\mathbf{A}{t} \mid \mathbf{o}{t}\right), q\left(\mathbf{A}{t}^{\tau} \mid \mathbf{A}{t}\right)} \left[ \left|| \mathbf{v}{\theta}\left(\mathbf{A}{t}^{\tau}, \mathbf{o}{t}\right) - \mathbf{u}\left(\mathbf{A}{t}^{\tau} \mid \mathbf{A}{t}\right) \right||^{2} \right] $$ 这里 $||\cdot||^{2}$ 表示欧氏范数平方;实现即逐元素 MSE。 为提升推理效率,动作专家隐藏宽度取 $d_a=0.75\times d$($d$ 为 VLM 的隐藏宽度)。 以下是一个简单的示例,可看看过程理解一下。 # 条件:取 VLM 第 N 层隐藏(冻结) with torch.no_grad(): H = vlm_hidden_at_layer_N(obs_tokens) # [T, d_o] KV = proj(H) # [T, d_a] 供 Cross-Attn 作 K/V(可缓存) # 构造路径与目标速度 A = sample_action_chunk() # [n, d_act] (已标准化) eps = torch.randn_like(A) # [n, d_act] tau = Beta(alpha, beta).sample(()).to(A.device) A_tau = tau * A + (1 - tau) * eps u = eps - A # 前向与损失 pred = v_theta(A_tau, KV) # 与 u 同形 loss = F.mse_loss(pred, u) # 对应 ||·||^2 loss.backward(); optimizer.step(); optimizer.zero_grad() 推理 在SmolVLA提到了异步推理,先来看看同步推理。 取最新观测 → 得到 $O_N$; 以噪声初始化,做 $K\approx10$ 步显式积分(Euler/Heun)得到一个动作块 $[a_t,\dots,a_{t+n-1}]$; 执行动作块 → 重复。 同步(sync)推理一次性生成长度为 $n$ 的动作队列(chunk)$A_t=\big[a_t,\dots,a_{t+n-1}\big]$,执行完再用新观测预测下一段。执行与推理串行,会产生“空窗”(执行停下等待推理)。而异步(async)推理是解耦“动作执行”和“动作预测”。机器人端持续消费现有队列;当队列余额低于阈值就异步把当前观测发给策略端预测“下一段”,回来后与旧队列重叠拼接。这样执行与推理并行,显著降低总时延,同时仍保持接近的成功率。 异步推理在架构上可以分为两个部分: RobotClient(机器人端):以控制周期 $\Delta t$ 持续下发队列头部动作;本地维护动作队列 $A_t$ 与触发逻辑;可做相似度过滤(见下节)。 PolicyServer(策略端):接收观测 $o_t$,运行策略 $\pi$ 预测新队列 $\tilde A_{t+1}$ 后返回;可放在更强的远端算力(GPU/工作站/云)。 看看论文中给出的算法实现: 设时域 $T$、段长 $n$、触发阈值 $g\in[0,1]$。 初始化:采集 $o_0$,发送到策略端,得到首段 $A_0\leftarrow\pi(o_0)$。 主循环 对 $t=0\dots T$:取出并执行一步 $a_t\leftarrow\text{PopFront}(A_t)$;若 队列余额占比 $\dfrac{|A_t|}{n}<g$,采集新观测 $o_{t+1}$;若 NeedsProcessing$(o_{t+1})$ 为真(见“相似度过滤”),则异步触发:①发送 $o_{t+1}$ 到策略端,得到新段 $\tilde A_{t+1}\leftarrow\pi(o_{t+1})$(异步返回);②用重叠拼接函数 $f(\cdot)$ 合并:$A_{t+1}\leftarrow f(A_t,\tilde A_{t+1})$;若本轮异步推理尚未结束:$A_{t+1}\leftarrow A_t$(继续消费旧队列)。 论文中的 NeedsProcessing 用于避免重复观测触发;$f$ 表示对重叠步的拼接(线性渐入/平滑器等,见下重叠拼接(Overlap & Merge))。 关键触发量,队列余额阈值 $g$: 触发条件:当 $\dfrac{|A_t|}{n}<g$ 时触发一次异步预测。 直觉:$g$ 越大,越提前触发,越不容易见底;但也会更频繁地调用策略端(算力/网络开销更高)。 论文的三个代表场景:$g=0$(顺序极限):耗尽队列才发起新预测 → 一定出现空窗等待;$g=0.7$(典型异步):每段大约消耗 $1-g=0.3$ 的比例就触发,计算摊在执行过程中,队列不见底;$g=1$(计算密集极限):步步都发观测 → 几乎“满队列”,反应最快但计算最贵(等同每个 tick 都前向一次)。 对于相似性过滤做法:主要动机是观测几乎不变时没必要反复调用服务器 → 降低抖动与无效请求。具体做法(论文)是用关节空间距离作为近似(例如欧式距离),若两次观测间距离 $<\varepsilon$(阈值,$\varepsilon\in\mathbb{R}^+$)则丢弃本次请求。兜底做法是若队列真的耗尽,则无论相似度如何都要处理最近的观测,以防停摆。 重叠拼接(Overlap & Merge):核心思想通过重叠区域平滑过渡避免硬切抖动,数学上实现是设旧队列尾部与新队列头部重叠 $w$ 步,对第 $k=0,\dots,w-1$ 步做线性渐入融合: $$ a_{t+k}^{\text{merge}} = \alpha_k \tilde{a}{t+1+k} + (1-\alpha_k) a{t+k}, \quad \alpha_k = \frac{k+1}{w} $$ 也可用余弦窗、Slerp 或在位姿/速度层加滤波器;关键是重叠 + 平滑避免硬切抖动。 总结一下对于异步并发处理有优势,但是需要处理其中的细节主要是: 维护动作队列。前台执行当前队列,后台异步预测下一段;在重叠窗口内平滑拼接新旧段。 避免队列见底的解析下界,设控制周期为 $\Delta t$,则避免队列耗尽的充分条件为 $$ g\ \ge\ \frac{\mathbb E[\ell_S]/\Delta t}{n} $$ 其中 $\ell_S$ 为一次(本地/远端)推理延迟,$\Delta t$ 控制周期,$n$ 为动作块长度。从触发到返回的时间内(平均 $\mathbb{E}[\ell_S]$ 秒)你还要有足够的剩余动作可执行(约 $\mathbb{E}[\ell_S]/\Delta t$ 个),所以触发点的剩余比例至少为这部分占 $n$ 的比值。论文配合给出真实控制频率示例(如 $30$ FPS $\to \Delta t=33,$ms),并分析了不同 $g$ 对队列曲线的影响(下图)。 数据 论文中提到的复现配置如下: 模型与输入:冻结 VLM,仅训动作专家;取 前半层 $N=\lfloor L/2\rfloor$ 的 $H^{(N)}$ → 投影成 $O_N$。图像 512×512;64 视觉 token/帧;状态→1 token;bfloat16。 动作块与解算: 每段 $n=50$;推理 10 步 Flow-Matching 积分。 优化:训练 200k step;global batch 256;AdamW($\beta_1=0.9,\ \beta_2=0.95$);余弦退火学习率 $1\times10^{-4}\to2.5\times10^{-6}$。 参数量: 总计 ≈450M;动作专家 ≈100M;若 VLM 有 32 层,取前 16 层。 论文中提到需要关注的信息: 模拟(LIBERO/Meta-World):中等规模(~0.45B)已对标/超过若干更大基线;放大到 ~2.25B 继续提升。 真实机器人(SO100/101):多任务平均成功率 ≈78%,优于 π0 与 ACT。 异步 vs 同步:成功率相近,但异步平均完成时间缩短 ~30%,固定窗口内完成次数显著更多。 论文中提到的落地经验: 形状与缓存:把 $H^{(N)}(T\times d_o)$ 投到 $d_a$ 后当 K/V;两次 Cross 复用 KV 缓存。 因果掩码:Self-Attn 必须用因果掩码(第 $i$ 步不可看未来)。 视觉压缩:优先用 space-to-depth 固定 64/帧;任务特别细腻时用 $r=2$(256 token)或多尺度/ROI 方案。 起步超参:$n=50$、积分步数 10、$N=\lfloor L/2\rfloor$、$d_a=0.75d$。 异步阈值:按 $g\ge\frac{\ell_S/\Delta t}{n}$ 设定,取略高于下界更稳;配合相似度过滤与重叠拼接。 动作归一化:对不同量纲(角/位移/速度)做标准化,训练更稳、积分不发散。 交替注意力有效:Cross + 因果 Self 明显优于单一注意力;“用前半层”普遍优于“直接换小 VLM”。 参考:https://arxiv.org/abs/2506.01844 -
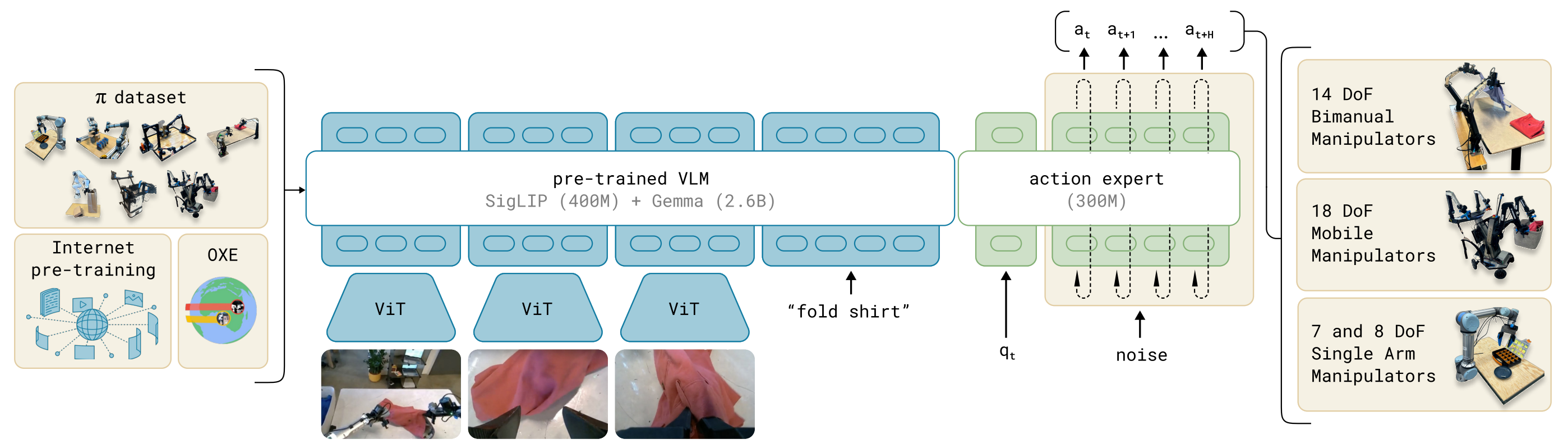
浅析Pi0 :VLM 与 Flow Matching 的结合之道
概述 传统机器人策略模型往往局限在单一任务或平台,难以跨场景泛化。与此同时,大规模 视觉-语言模型(VLM) 已展现出卓越的语义理解与任务指令解析能力。如果能将 VLM 的语义理解能力 与 Flow Matching 的连续动作建模能力 结合,有望构建具备泛化与实时性的机器人通用控制器。 Pi0 (π0)正是这样一个探索:基于 PaliGemma(3B 参数 VLM) 作为感知与语义主干,结合 Flow Matching 动作生成器,实现语言到多机器人动作的端到端建模。它借鉴了大语言模型的“预训练 + 微调”范式,把互联网级别的语义知识和机器人操控数据结合起来,从而实现跨平台、跨任务的通用机器人控制。 我们此前分析了VLM、Flow Matching原理,掌握这些之后理解Pi0是非常简单的。 原理 结构 模型结构主要有VLM主干+ Action Expert动作专家构成。 VLM主干:基于 PaliGemma(一个 3B 参数的 VLM),继承互联网规模的图像+语言知识。 Action Expert(动作专家):额外的子网络,负责用 Flow Matching 方法预测连续动作向量。 模型的输入包括观测的多视角RGB图像、语言指令、机器人自身状态(关节角、传感器),经过模型处理后输出为高频动作序列(每秒50HZ动作chunk),这些动作控制单臂、双臂、移动操作臂等多类机器人。 训练 我们训练的目标是让$A_t^0 \sim \mathcal{N}(0, I)$ ——>$A_t$(真实动作),希望模型学会如何把一个“噪声动作”流动成一个真实的动作。就像扩散模型是“噪声 → 图像”,这里是“噪声动作 → 专家动作”。 在训练的时候要让噪声动作流向真实动作,我们需要构建一个路径,这里依旧使用的是直线路径。 $$ A_t^\tau = \tau A_t + (1-\tau)\epsilon, \quad \epsilon \sim \mathcal{N}(0,I) $$ 这个公式跟我们在Flow Matching文章中的训练公式是不是一样的。我们在噪声动作$\epsilon$和真实动作$A_t$之间,采样一个"插值点"。$\tau $表示时间的进度,当$\tau = 0$时完全是噪声,当$\tau = 1$时完全是真实动作,这个就构造了一条噪声到动作的直线路径。 我们的目标是要让模型告诉我们"从当前点$A_t$应该往哪个方向移动,才能逐渐靠近真实动作",因此就是在计算在每个时间速度。 $$ u(A_t^\tau \mid A_t) \triangleq \frac{d}{d\tau} A_t^\tau $$ 代入公式可得: $$ \frac{d}{d\tau} A_t^\tau = A_t - \epsilon $$ 而论文中成$u(A_t^\tau \mid A_t) = \epsilon - A_t$,只是方向约定相反,本质上没有差异。上面的公式,目标速度就是噪声 - 动作,它定义了“流动的方向”。就像在地图上,目标向量场就是指路的“箭头”。这样得到了真实的速度场,我们就可以在训练的时候计算损失了。 $$ L(\theta) = \mathbb{E}\big[ | v_\theta(A_t^\tau, o_t) - u(A_t^\tau \mid A_t) |^2 \big] $$ $v_\theta$是神经网络(Action Expert),输入 当前 noisy action + 观察$o_t$,输出预测的速度场。损失函数就是 预测的速度场 vs 真实的目标速度场 的均方误差 (MSE)。训练目标:让模型学会在任意中间点给出正确的“流动方向”。 推理 $$ A_t^{\tau+\delta} = A_t^\tau + \delta v_\theta(A_t^\tau, o_t) $$ 推理生成也比较简单,从噪声动作$A_t$开始,每次迭代一步:输入当前的$A_t^\tau $和观察的$o_t$,接着模型给出速度场,就沿着这个方向走一步(步长$\delta$),然后按照这个步骤重复迭代,最终得到真实的动作$A_t$。和扩散模型不同:这里不需要几十/上百步,只要 ~10 步 ODE 积分,就能得到高质量动作,适合机器人实时控制。 参考: https://arxiv.org/abs/2410.24164 -
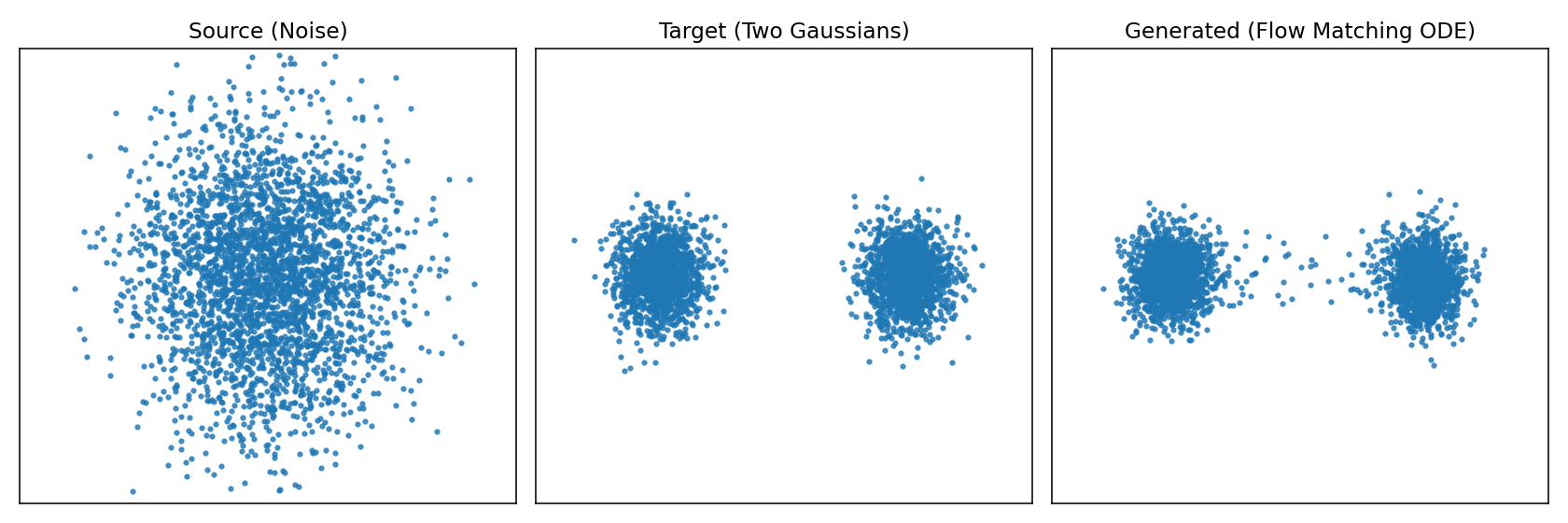
Flow Matching:让生成模型“流动”起来
背景 上一篇文章分析了diffusion扩散模型。diffusion扩散模型做法是加噪声、再一步步去噪,训练过程复杂,还需要 carefully 设计噪声调度。 Flow Matching提出了更直接的方式:与其通过一大堆离散的“加噪/去噪”步骤,不如直接学习一个连续的流动 (flow),让点从噪声“顺滑地流动”到目标数据。 原理 把生成过程看作流体运动,想象有一堆水滴(噪声),通过一个力场,它们会被推动、流动,最后聚集成目标形状(真实分布的数据)。Flow Matching从物理学角度学一个"速度场",让数据点从"源分布(噪声)"流动到"目标分布(真实数据)"。 如图所示左边是源随机点云,中间是目标形状,右边是实际使用模型生成的形状。为了更直观的体会再来看下图从源分布逼近目标分布的过程。 左图就是源分布的点在不同时间应该朝那个方向运动直到最终的目标分布,右图是不同时刻让这些点应该往哪个方向进行流动速度场。 接下来看看数学怎么表示,我们希望从源分布$p_{src}$(比如高斯分布)按照流动的方式到目标分布$p_{data}$,那么方式就是在每个时间$t$为每个点$x$都指定一个速度$v_\theta(x,t)$,这样在不同时间就知道点该往哪里动,那么点的轨迹就完全确定了。在数学上点的位置$x(t)$随着时间变化,那就是速度场向量,即常微分方程 $$ \frac{dx}{dt} = v_\theta(x, t) $$ 左边的$\frac{dx}{dt}$描述的是随时间的变化率,右边$v_\theta(x, t)$就是我们要学习的"速度场",它给出"$t$时刻,位置$x$应该往哪里动"。 总结一下Flow Matching 里速度场写成 ODE,是因为它给出“点的位置随时间的变化率”,这正是常微分方程的定义,生成过程就是解 ODE,从噪声轨迹流到数据。 推理 模型要做的事情就是要预测出下一个时间刻应该往哪里走,输出是一个速度场;推理的过程就是解常微分方程ODE。 输入:当前位置$x \in \mathbb{R}^d$,当前时间$t \in [0,1]$。 输出:模型计算输出当前的速度向量,即$\frac{dx}{dt} = v_\theta(x,t)$。 更新:根据速度向量$v_\theta(x,t)$通过积分公式把所有时间段速度累积起来得到最终点$x(1)$。 $$ x(1) = x(0) + \int_{0}^{1} v_\theta(x(t),t)\,dt $$ 直观理解就是神经网络提供"切线方向",积分就是"把所有切线拼起来",形成完整的轨迹,从噪声走到目标分布。 但实际过程中我们用离散的数值方式,比如欧拉法,如下: 时间从$t$=$0$到$t$=$1$,分成若干小步(比如50或100步),在每一步按照上面公式更新。 输入:当前的位置$x_k$和当前时间步$t_k$。 输出: 模型预测计算速度向量场$v_\theta(x_k, t_k)$。 更新:通过欧拉法更新公式更新下一步位置$x_{k+1} = x_k + v_\theta(x_k, t_k)\Delta t$ 每一步模型计算出速度向量$v_\theta(x_k, t_k)$然后根据公式进行更新下一步的位置,新位置=旧位置+速度x时间步长;$v_\theta(x_k, t_k)\Delta t$计算每次迭代的移动距离(速度x时间),这就是基本的欧拉积分法,直观的意义是在短时间$\Delta t$内,点会沿着速度场方向前进一点。不断的进行多步迭代,从$x_0$出发,逐步得到$x_1$,$x_1$,$x_2$,$x_3$,....,$x_k$,当$k$=$K$时,$t_K$=$1$,就得到最终的$x(1)$。 怎么理解$t_k$、$x_k$、$\Delta t$? $t_k$是第$k$步对应的时间点,如果flow matching的时间区间是[0,1],我们把它切成$K$个小步(如50或100步),每个时间点就是$t0$=$0.00$,$t1$=$0.01$;$\Delta t$是时间步长如把时间区间[0,1]均匀分成100步,那么$\Delta t$=$1/100$=$0.01$;$x_k$是表示在$t_k$时的点(或点云),初始时从高斯噪音采样到。 下面再来一个直观图展示了Flow Matching推理的过程。 灰色箭头:代表速度场$v_\theta(x_k, t_k)$,告诉每个位置的点应该往哪里走。上图设定的目标是(2,2)。 绿色点:初始$x(0)$来自噪声分布即源分布。 红色叉:表示目标位置,代表数据分布的一个样本区域。 蓝色折现轨迹:数值积分结果,点一步一步验证速度场北推向目标。 训练 我们希望模型学会把源分布$p_{src}$流动到目标分布$p_{data}$;换句话说就是有$x_0 \sim p_{\text{src}}$,输出目标点$x_1 \sim p_{\text{data}}$我们要训练一个速度场网络$v_\theta(x_k, t_k)$,让它指导点$x_t$沿正确的路径从$x_0$——>$x_1$。 要训练行动轨迹需要知道真实轨迹这样才能和实际预测值做比较求损失,而训练的关键却正好是不知道真实的速度场。那如何构建训练的目标了?可以设计一个简单的"参考轨迹",如直线路径$x_0$——>$x_1$。 $$ x_t = (1 - t)x_0 + tx_1 $$ 给定输入样本$(x_0 \sim p_{\text{src}},x_1 \sim p_{\text{data}})$,其中$x_0$是源随机位置,$x_1$是目标位置。在训练的时候我们自己定义一条直线路径$x_0$——>$x_1$,我们不能一步到位,而是要有一个流动的过程。 这条直线路径上的真实速度公式对$t$求偏导,而恰巧速度是一个常数(始终指向目标点$x_1$)。 $$ u^\star = \frac{dx_t}{dt} = x_1 - x_0 $$ 既然速度方向就是一个常数$x1-x0$,为什么不直接一步把$x1$变成$x0$,而要搞成连续流动了? 如果一步到位公式就变成$x_1 = x_0 + (x_1 - x_0)$,相当于直接跳到目标点,完全不需要ODE、积分、网络。但问题在于训练时我们有配对的$(x_0, x_1)$,所以能写下$(x_1-x_0)$,而推理时了我们只有$x_0 \sim p_{\text{src}}$,并不知道该对应那个$x1$,因此不能一步到位,因为没有$x_1$可直接计算。 最后我们训练目标就是网络预测的速度$v_\theta(x_k, t_k)$,损失就网络预测的速度$v_\theta(x_k, t_k)$与真实的速度$x_1-x_0$的均方误差。训练完成之后,网络就学会了在任何位置$x_t$、时间$t$给出正确的速度场。 $$ \mathbb{E}\Big[ || v_\theta(x_t, t) - (x_1 - x_0) ||^2 \Big] $$ 源码示例 为了加深理解,程序实现一个最小的 Conditional Flow Matching(直线路径的 Rectified Flow)示例,学习时间条件速度场 vθ(x,t),把二维标准高斯源分布推到左右两个高斯簇的目标分布。训练后输出两张图:训练损失曲线 cfm_loss.png,以及三联静态图 cfm_overview.png(源/目标/生成)。 # -*- coding: utf-8 -*- # Flow Matching demo: source N(0,I) -> target: Two Gaussians (left & right) # 输出: # 1) cfm_loss.png(训练损失) # 2) cfm_overview.png(三联图:Source / Target / Generated) # 依赖:pip install torch matplotlib import time, warnings warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib") import numpy as np import torch, torch.nn as nn, torch.optim as optim import matplotlib matplotlib.use("Agg") import matplotlib.pyplot as plt # ------------------------- 配置 ------------------------- device = torch.device("cuda" if torch.cuda.is_available() else "cpu") torch.manual_seed(0) XLIM = (-4.0, 4.0) YLIM = (-3.0, 3.0) # ------------------------- 数据分布 ------------------------- def sample_source(n): return torch.randn(n, 2, device=device) def sample_target(n): sigma = 0.35 means = torch.tensor([[-2.0, 0.0], [2.0, 0.0]], device=device) idx = torch.randint(0, 2, (n,), device=device) mu = means[idx] return mu + sigma * torch.randn(n, 2, device=device) # ------------------------- 模型:速度场 v_theta(x,t) ------------------------- class VelocityNet(nn.Module): def __init__(self, h=64): super().__init__() self.net = nn.Sequential( nn.Linear(3, h), nn.ReLU(), nn.Linear(h, h), nn.ReLU(), nn.Linear(h, 2), ) def forward(self, x, t): return self.net(torch.cat([x, t], -1)) # ------------------------- 训练(CFM,直线路径) ------------------------- def train_cfm(steps=2000, batch=512, lr=1e-3): net = VelocityNet().to(device) opt = optim.Adam(net.parameters(), lr=lr) loss_hist = [] t0 = time.time() for s in range(1, steps + 1): x0 = sample_source(batch) x1 = sample_target(batch) t = torch.rand(batch, 1, device=device) xt = (1 - t) * x0 + t * x1 u = x1 - x0 pred = net(xt, t) loss = ((pred - u)**2).mean() opt.zero_grad(set_to_none=True) loss.backward(); opt.step() loss_hist.append(float(loss)) if s % 200 == 0: print(f"[{s}/{steps}] loss={loss:.4f}") print(f"Train time: {time.time() - t0:.2f}s") return net, loss_hist # ------------------------- 采样(生成轨迹) ------------------------- @torch.no_grad() def generate_traj(net, n=3000, steps=60): x = sample_source(n) dt = 1.0 / steps traj = [x.cpu().numpy()] for k in range(steps): t = torch.full((n,1), (k + 0.5) * dt, device=device) x = x + net(x, t) * dt traj.append(x.cpu().numpy()) return traj # ------------------------- Matplotlib 工具 ------------------------- def save_loss(loss_hist, path): plt.figure(figsize=(6, 3.6)) plt.plot(loss_hist) plt.title("Training Loss (CFM)") plt.xlabel("step"); plt.ylabel("MSE") plt.tight_layout(); plt.savefig(path, dpi=140); plt.close() print(f"Saved {path}") def save_overview(src, tgt, gen, path): fig, axes = plt.subplots(1, 3, figsize=(12, 4)) titles = ["Source (Noise)", "Target (Two Gaussians)", "Generated (Flow Matching ODE)"] for ax, title, pts in zip(axes, titles, [src, tgt, gen]): ax.scatter(pts[:, 0], pts[:, 1], s=5, alpha=0.75) ax.set_title(title) ax.set_xlim(*XLIM); ax.set_ylim(*YLIM) ax.set_xticks([]); ax.set_yticks([]) plt.tight_layout(); plt.savefig(path, dpi=140); plt.close() print(f"Saved {path}") # (已移除 GIF 相关工具与依赖) # ------------------------- 主程序 ------------------------- if __name__ == "__main__": # 训练 net, loss_hist = train_cfm(steps=2000, batch=512, lr=1e-3) save_loss(loss_hist, "cfm_loss.png") # 数据与生成 src = sample_source(3000).cpu().numpy() tgt = sample_target(3000).cpu().numpy() traj = generate_traj(net, n=3000, steps=60) gen = traj[-1] # 三联静态图 save_overview(src, tgt, gen, "cfm_overview.png") # (已移除 GIF 生成步骤) print("All done.") (1)模型结构 模型结构为VelocityNet,使用了一个小型 MLP,输入 3 维(x 的 2 维 + t 的 1 维),输出 2 维速度向量。结构为Linear(3,64) → ReLU → Linear(64,64) → ReLU → Linear(64,2)。forward(x,t) 直接拼接 [x, t] 后送入网络。这里没有使用时间位置编码。 (2)训练过程 训练函数为train_cfm(steps=2000, batch=512, lr=1e-3),具体过程如下: 1) 每步采样源 x0 ~ source 和目标 x1 ~ target,独立均匀采样 t~U(0,1)。 2) 构造直线桥接点 xt = (1 - t)x0 + tx1。 3) 定义理想恒定速度 u = x1 - x0(常速,不依赖 t)。 4) 让网络在 (xt, t) 上预测 pred = vθ(xt,t),用 MSE(pred, u) 作为损失。 5) Adam 更新一次;每 200 步打印当前损失。 6) 返回训练好的 net 与 loss_hist。 直观理解,虽然 u 依赖 (x0, x1),但模型只观察 (xt,t)。训练学到的是条件期望 E[x1 - x0 | xt, t],也就是让网络在直线路径上学会把点往“正确方向”推的平均速度。这是直线路径 CFM 的核心思想。 (3)采样 采样函数为generate_traj,从源分布采样 n 个起点,设步长 dt=1/steps。用无梯度模式按欧拉法更新:对每步 k,用中点时间 t=(k+0.5)dt 预测速度 vθ(x,t),然后 x ← x + vθ(x,t)dt。记录每一步的点云到列表,返回整个轨迹(列表元素是 numpy 数组)。主程序中只使用最后一步作为“生成结果”。 (4)主流程 最后就是主流程先调 train_cfm 进行训练,保存 cfm_loss.png。分别采样 3000 个源样本 src 与目标样本 tgt。生成 n=3000、steps=60 的轨迹 traj,并取 gen = traj[-1] 作为最终生成样本。保存 cfm_overview.png,展示源/目标/生成的对比。 整体主要的实现点为 目标路径:x_t = (1 - t) x0 + t x1,直线连接源与目标。 理想速度:dx/dt = x1 - x0,使点沿直线以恒定速度匀速前进。 学习目标:在 (xt,t) 上回归 u = x1 - x0 的条件期望;推断时只需网络与当前状态,无需知道具体的 x0 或 x1。 数值积分:使用欧拉法简单高效;采用中点时间能略微减小离散误差。 -
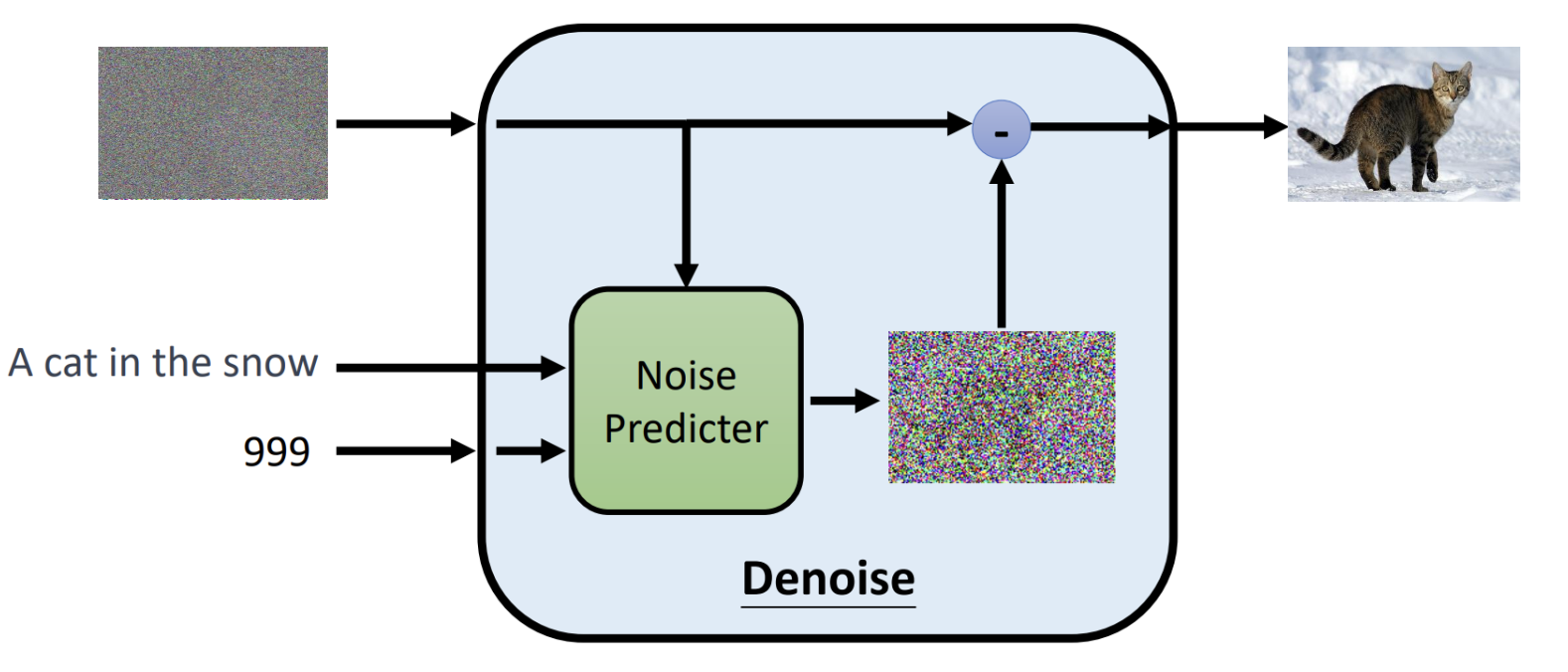
Diffusion:如何从噪声中生成清晰图像
概述 图像生成是当下研究的热点,diffusion是一种人工智能领域图像生成的基础模型,当下Stable diffusion、DALL·E、MidJourney文生图模型的基座都使用了diffusion。 diffusion扩散模型属于生成式模型,生成图像不是正向从0到1构成图像而是反向的预先生成一个随机的噪声图中然后根据文本提示词逐渐的去噪"扣"出图像。主要思想是先训练一个权重模型,把一张清晰照片弄得越来越模糊(加入噪声),然后把模糊的图片融合文本提示词作为输入去训练一个模型学会“擦亮它”,反向恢复成清晰图像。训练完成后,就得到了模型的权重,那么使用这个权重模型只要给一副完全随机的“噪点图”和要生成图片的提示词,它就能一步步去掉噪声,变出一幅崭新、逼真的图片。 借用米开朗基罗雕刻"大卫像"时说的"我在大理石中看见天使,于是我不停地雕刻,直至使他自由”。而diffusion也是这样的原理,通过随机生成的一个噪声图片,结合输入的文字去掉噪音恢复到你想象的照片样子。 工作原理 推理 (1)输入阶段 输入阶段有3个输入信息,分别是随机噪声图像、文本提示、时间步。 随机噪声图像:最开始随机生成一个高斯噪声的图片。 文本提示:告诉模型,想要生成的内容是什么。 时间步:指明当前是去噪第几步,模型是一个多步迭代去噪的过程。按照数字依次递减进行迭代,数值越小去噪强度越弱。 (2)模型处理 核心组件是Noise Predictor(一般是一个U-Net结构神经网络),输入的带噪图像$X_{t}$、时间步$t$、以及提示文本通过Noise Predictor预测出这张图里有多少噪声,生成一张噪声图片$\epsilon^\theta(x_t, t, c)$。 (3)输出阶段 将输入-减去预测出的噪声图片就得到最后的去噪图片了,$x_{t-1} = x_t - \epsilon^\theta(x_t, t, c)$。 (4)迭代 迭代一轮得到一个降噪图片之后,接着将输出的降噪图片作为输入的带噪图片按照之前的步骤进行重复,直至$t$=$T$(比如$1000$)一直迭代到$t$=$0$得到最终的图像。当所有步骤完成后,随机噪声逐渐被“洗掉”,生成的就是一张符合条件描述的清晰图像。 下面是推理过程的算法伪代码 初始化:$x_T \sim \mathcal{N}(0, I)$从标准高斯分布中采样一个随机噪声向量(或噪声图像),作为生成过程的起点。 迭代循环:从$t$=$T$到$t$=$1$逐步迭代,每次去掉一部分噪声。如果$t$>$1$,额外采样一个噪声向量$z\sim \mathcal{N}(0, I)$。如果$t$=$1$,则$z$=$0$,即最后一步不加噪声。 核心公式:先去掉预测的噪声(括号里面的部分)得到更接近干净数据的样子,接着在进行缩放调整(除以$\sqrt{\alpha_t}$),最后加一点随机噪声$\sigma_t z$来保持生成的多样性。 输出:当循环结束时,最终的$x_0$就是最终生成的清晰图像了。 对于核心公式的参数这里稍微补充一下 参数 $\epsilon_\theta(x_t, t)$是预测的噪声; 参数$\alpha_t$取值范围是$0$~$1$,控制在第$t$步中保留多少原始图像信息加入多少噪声,当$\alpha_t$接近$1$时几乎保留全部信息,噪声小;当值趋于0时,原始信号衰减就大,噪声比例高; 参数$\bar{\alpha}_t$累积乘积参数,表示从第$1$步到$t$步累积保留原始信息的比例。 参数$\sigma_t z$随机扰动项,保持采样的多样性。 训练 训练模型我们需要把模型的输出结果和真实值进行比较才能进行梯度下降找到网络权重,那该如何设计准备训练结果和真实值的数据? diffusion模型的核心是要预测出图片的噪声分布然后减去预测的噪声得到真实的输出照片。以上图第一步进行说明,使用原始的图片,通过随机生成一个噪声图($x_{1}$)迭加作用到原始图片上这样就得到了模型的带噪声的输入图像,然后融合文本、时间步模型前向计算得到噪声图($x_2$)。已经知道了真实的噪声图是$x_{1}$,那么计算$x_{1}$和$x_{2}$的相似性就可以计算出损失了。 训练过程中关于图片-文本可以从Lion平台上获取,通过上面步骤取样照片然后不断加强噪声得到越来越模糊的图片送入模型预测进行计算迭代权重,让模型学会真正准确预测每一步中"加进去的噪声",训练完成之后,模型学会了如何"识别噪声",在推理时就从纯随机噪声$x_T$出发,通过文本提示词反向迭代去噪得到最终的想要的照片。 论文中的伪代码如下: repeat:表示循环执行训练过程。 采样数据:$x_0 \sim q(x_0)$从真实数据分布$q(x_0)$中采样一个训练样本比如一张猫。 随机采样时间步:$t \sim \text{Uniform}({1, \dots, T})$随机挑选一个扩散的时间步$t$,确保模型能在不同噪声水平都学会去噪。 采样噪声:$\epsilon \sim \mathcal{N}(0, I)$从标准的高斯分布中采样一份噪声,用于后续得到到原始图片上。 梯度下降更新参数:计算预测噪声和真实噪声$\epsilon$的均方误差。 模型 本章节简要说一下业界文生图模型,其结构可以总结为以上3个部分,文本编码器、生成式模型、解码器。 文本编码器:将用户输入的文本提示通过预训练的文本编码器如CLIP Text Encoder将自然语言转化为向量表示。 生成式模型:将编码的文本向量和噪声图像noisy latent作为输入,然后逐步迭代去噪。这里的模型如有diffusion、autoregressive等。输出是压缩到更低维的"潜在空间"。 解码器:将生成式模型的输入Latten Representation通过解码器还原最终生成清晰图像。生成式模型一般输出的是压缩的低维潜在空间,这样可以降低每一步迭代的计算量,最终加一个解码器来将其还原。 下面是stable diffusion、DALL-E、Imagen的模型结构图,核心组成都是上面3个部分,这里就不过多阐述了。 stable diffusion DALL-E Imagen 本文主要来自李宏毅Diffusion Model原理解析的笔记。 -
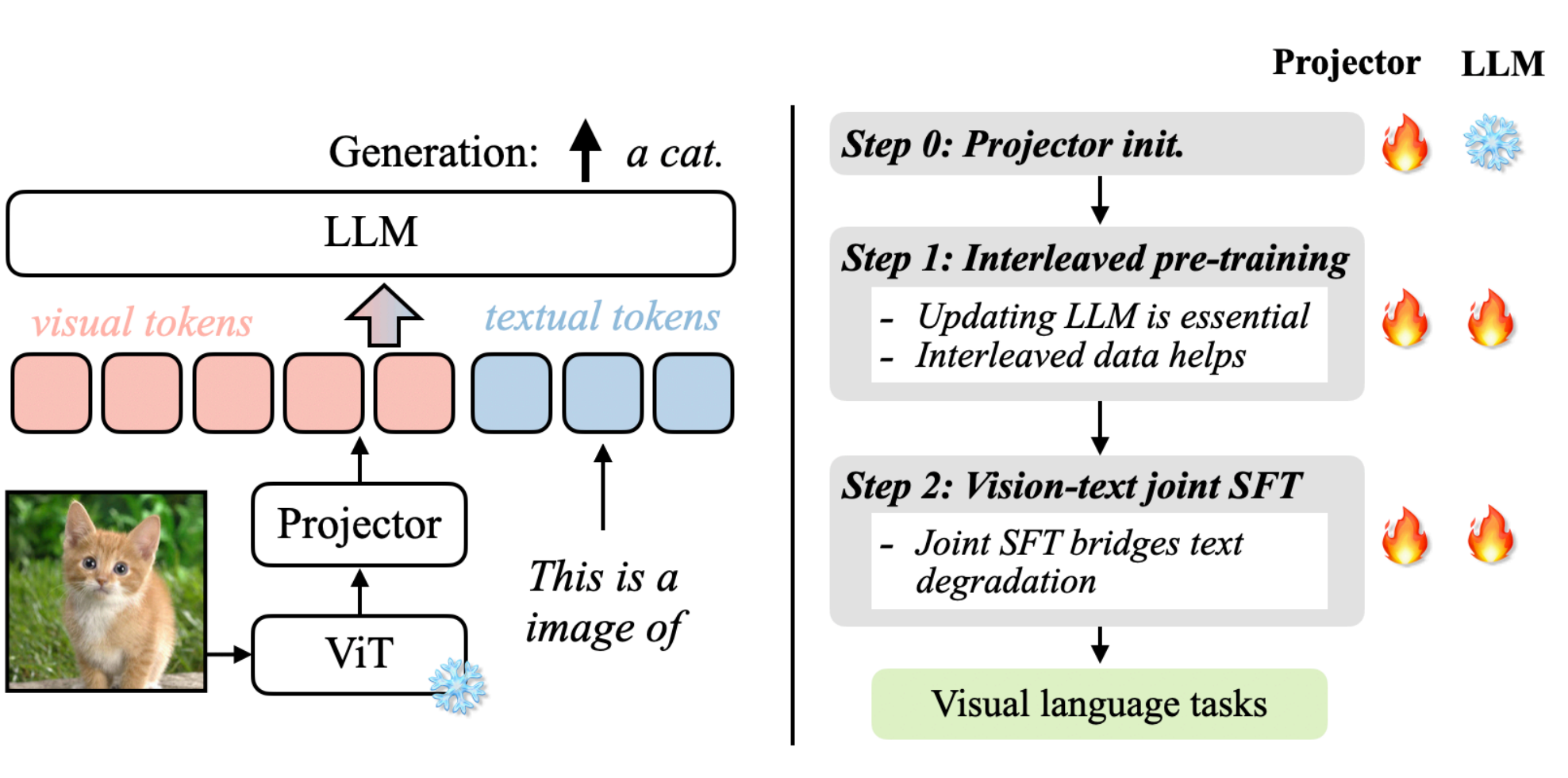
视觉 Token 如何注入语言模型?VLM拆解
VLM与LLM 如果说我们有一张图片、一个图表想让大模型来帮忙理解那应该要怎么实现了? 标准的LLM语言大模型只能处理文本序列,是不能够读取图像的,如果没有办法将视觉的数据转换为LLM能够理解的形式,那么LLM是无法处理的。需要注意的是我们这里说的LLM并不是transformer,LLM指的是大语言模型如DeepSeek,GPT,Qwen,其是使用了transformer架构应用,而transformer是一种神经网络架构。LLM的token专门指的是文本token来自Tokennizer其输入是字节流,而transformer不一定是文本单位,可以是任何序列元素如词、图像(上节说的ViT)等。 要解决语言大模型理解图片,那么这就是视觉-语言大模派上用场了。回顾一下我们此前说的ViT视觉大模型,是不是就是用提取图像特征的,因此本章节我们要介绍的正是视觉大模型与语言大模型的融合:vision language model,即视觉-语言大模型。 视觉-语言大模型是视觉大模型+语言大模型的结合,其主要有哪些用途?核心用处是让 AI 能够“读图如读文”,在多模态场景下实现理解、生成和交互,如下示例: 内容理解:多模态的问答VQA,比如给一张图让大模型理解图片里面描述了什么,让其识别图片里物体、动作、关系,自动生成图片说明(Image Captioning)等等。 信息获取与搜索:给一张图找对应的描述,或给一句话找到相关图片(比如电商商品搜索)以及搜索引擎文字搜图或图搜文字等。 模型结构 发展到今天有很多的视觉-语言大模型,各自都有自己的架构实现。我们先以VILA为例来说明一下视觉-语言大模型的关键组件,上图来自论文:VILA: On Pre-training for Visual Language Models。 上图我们先来分析一下其运作流程,可以分为左右两部分:左图可以看成是怎么跑起来的(数据流推理/前向),右图是如何训练的步骤。 数据流 左图:数据流推理 ViT: 首先将图像送入ViT视觉编码器,提取出视觉特征。 Projector:因为ViT输出的特征维度可能与LLM词嵌入维度不一致,所以这里也需要通过一个线性层/小MLP做映射,把视觉特征空间转换为LLM的嵌入空间为,为上图的visual tokens。 token融合:文本提示经过tokenizer转换为text tual tokens与visu tokens在同一序列中进行拼接或交错输入到LLM。 LLM生成:进入LLM后,视觉与文本已在同一token流中就可以共同参与计算注意力,最后输出最后的结果a cat。 训练策略 右图:训练策略 训练主要分为3个阶段,projector初始化,交错式预训练、监督微调,主要涉及projector和LLM模型参数更新,火焰代表参数会被更新,雪花代表冻结不更新。 Step 0 Projector初始化:只训Projector,LLM冻结,通常ViT也冻结,目的是先把视觉特征大致对齐到LLM词向量空间,避免一上来就动LLM破坏语言能力。 Step 1 交错式预训练:同时更新Projector与LLM,在包含图像-文本交错(图像token混在文本序列里)的数据上做自回归训练。更新LLM才参数才能让LLM学会"在文本上下文中使用视觉特征";图像和文本的输入进行交错能够教会模型跨模态对齐与引用。 Step2 监督微调:联合微调projector与LLM,输入数据是指令时的多模态问答/对话。这样可以把能力对齐到agent任务上,同时避免LLM文本能力退化。 小结 通过VILA架构为例,我们大概了解了VLM视觉-语言大模型的架构,我们总结下VLM模型架构主要可以分为三大部分: 视觉编码器:将视觉输入转换为结构化的数值表示,提取语义信息。如基于transformer架构的ViT,将图像分割成小块,通过transformer编码全局和局部特征;如传统基于CNN卷积神经网络ResNet,擅长提取局部纹理特征。 投影器:视觉和文本嵌入必须对齐到一个共享的多模态嵌入空间。通常由一个较小的模块完成,称为投影层或融合层:常见的实现方式有MLP通过全连接层转化维度(如DeepSeek-VL);交叉注意力机制通过动态关联图像区域与文本token(如llama 3.2 vision),增强空间理解。 LLM:接收图像+文本融合后的多模态输入,生成自然语言响应(如描述、答案、推理)。 QA1:这里的投影器projector与此前我们分析ViT中的projection线性投影有什么不一样? ViT中的projection作用是将图像分割后的每个小块线性映射为固定维度向量(token)作为transformer编码器的输入;而VLM的projector是将视觉编码器(如ViT)输出特征映射到语言大模型(LLM)的文本嵌入空间,解决跨模态语义鸿沟。一个是作用在ViT的输入映射为transformer的标准输入另外是一个作用再ViT的输出映射为LLM的标准输入。 QA2:为什么要将图像和文本进行融合多模态嵌入空间? 多模态嵌入空间是VLM具备推理能力的关键,通过在同一潜在空间表示视觉和文本信息,主要有以下优势: 上下文感知:使不同模态之间能够进行丰富的交互,这意味着模型能够将文本概念(例如,“公交车”、“十字路口”)准确地与视觉特征信息(公交车位置、颜色、十字路口)连续起来。 语义连接:将抽象的文本概念与具体的视觉示例进行对齐。例如模型不仅将“行人”理解为单词,还将其视为图像中可视觉识别的实体。 跨模态推理:允许模型在不同模态之间进行推理,回答复杂的视觉问题,进行逻辑推断,或检测微妙的视觉-文本差异。 模型预训练 训练史 先来看看视觉识别训练的发展,可以划分为5个阶段:传统机器学习与预测,深度学习从零训练与预测,监督式预训练、微调与预测,无监督预训练、微调与预测,视觉语言模型预训练与零样本预测。稍微总结一下各自特点。 传统机器学习与预测:需要人工设计学习特征。 深度学习从零训练与预测:从零自己标注大量数据(因为没法迁移),从零训练。 监督式预训练、微调与预测:预训练复用公开标注好的海量数据(可以迁移,所以可用公开别人标注好的海量数据),从零标注一些少量数进行微调。 无监督预训练、微调与预测:预训练数据集再扩大了,可以直接爬取互联网的数据进行训练,但还是需要从零标注一些少量数据进行微调。 视觉语言模型预训练与零样本预测:不需要进行微调了,那么也不需要标注的数据集了,做到零样本。 VLM的预训练与零样本预测方式与过往的相比,对下游视觉识别任务上实现零样本,去掉了微调的过程,那么这种方式就可以有效利用大规模的网络数据。 预训练架构 因为VLM有很多种模型架构,因此预训练的架构也有区别,下面列出常见的几种。 双塔式架构:视觉和文本模态分别通过独立的编码器处理(如ViT处理图像、BERT处理文本),模态交互仅发生在编码后的特征层面,在最后进行融合,典型的模型有CLIP、ALIGN等。 双分支架构:在独立编码器基础上引入动态交互模块,支持灵活切换双塔或单塔模式,实现任务自适应融合如VLMo、Mini-Gemini等。 单塔式架构:像和文本输入共享同一Transformer编码器,通过交叉注意力机制实现早期深度融合,典型的模型如ViLT,FLAVA等。 预训练目标 前面阐述了当前视觉-语言大模型通常采用预训练与零样本预测的方式。那么在视觉语言大模型(Vision-Language Models, VLM)中我们的预训练目标是什么了?所谓预训练目标(Pre-training Objectives)是让模型从海量无标注图文对中自动学习跨模态关联的核心机制。这些目标的目的建立视觉与语言模态的语义对齐,为下游任务(如视觉问答、图像描述)提供通用表征基础。而当前的训练目标大致可以分为3类:对比目标、生成目标、对齐目标。 对比目标:让模型学会"配对"正确的图文,并区分错误的组合,比如正样本匹配的图文对(如猫图 + “一只猫”),模型需让它们的特征向量高度相似;负样本不匹配的图文对(如猫图 + “一辆汽车”),模型需让它们的特征向量差异巨大。计算的损失函数为所有配对的相似度误差(如 InfoNCE损失),指导模型调整参数,代表模型有CLIP、ALIGN等,该方式一般适用于零样本分类、图文检索的模型。 生成目标:让模型“填空”或“创作”,通过预测缺失内容学习深层语义。具体输入通过mask遮住文本或图像,训练模型让其复原得到网络权重。该方式一般应用与图像描述、视觉问答(VQA)的模型。 对齐目标:让模型能够把句子的词精准对应到图中位置,要求最高。比如用目标检测框出识别图中的物体(如汽车),与文本中的词精确关联。该方式一般用于目标检测、语义分割等场景。 VLM模型 当前已经出现了很多视觉语言模型,各自的模型都具有独特的功能,在视觉语言研究领域和实际应用上扮演着重要的贡献,除了在第2章节我们介绍的VILA外,这里我们在本章节再补充举例几个进行简要说明一下。 CLIP 上图是CLIP模型,是一个典型的双塔式视觉-语言模型,由视觉编码器(ViT)和文本编码器(Transformer)等核心组件构成。通过预训练对比目标的方式学习实现图像与文本的跨膜态对齐,其核心创新点在于无需任务特定训练,直接利用自然语言提示(Pormt)完成零样本预测,支持识别训练数据中为出现的新类别。 从图中我们可以看成可以分为3个阶段,对比预训练、创建零样本分类器、零样本预测。 (1)对比预训练阶段 输入是海量的图文对,如图片输入狗+文本输入"pepper the aussie pup"。 编码:文本编码器(如transformer)将文本嵌入向量,图像编码器(如ViT/ResNet)将图像嵌入向量。 目标:图文预文本嵌入向量的点积度量图文相似性。通过对比损失(infoNCE)计算图文相似度矩阵。拉近匹配对(如对角线深蓝块,如狗图与"狗"文本),推远不匹配对(非对角线浅色块,如狗图与“汽车”文本)。 (2)创建零样本分类器 输入:新任务的类别标签(如 "dog", "bird", "car")。 处理:将标签转化为提示文本(如 "a photo of a {label}"),文本编码器生成所有标签的文本嵌入向量。 输出:得到一组文本嵌入,构成无需训练的分类器权重(传统模型需图像数据训练分类头) (3)零样本预测 输入:一张新图像(如鸟的图片)。 处理:图像编码器生成图像嵌入向量(左侧绿色向量),计算该向量与所有类别文本嵌入相似度。 输出:选择相似度最高的文本标签作为预测结果(如输出 "a photo of a bird")。 总结一下就是,通过上面的预训练,将配对的图文靠近,非配对的原理,学到语义对齐的公共空间,这样在在推理时把“类别标签”也写成一句话,当作“文本查询”;用这句“查询”去和图像向量比相似度,谁最像选谁。 LLaVA LLaVA是把视觉模型提取的图像特征通过一个映射层转成语言模型能理解的 token,然后和用户的语言指令一起输入到大语言模型(LLM),从而实现图像理解与多模态对话。其架构主要由Vision Encoder(视觉编码器)、Projector(视觉特征投影)、Language Instruction(语言指令输入)、LLM大模型几个组件构成,跟我们前面第2章节总结的结构类似,这里就不过多阐述了。下面简要说一下流程: 输入图像:输入的图像通过Vision Encoder提取特征$Z_{v}$。具体来说,预训练用的是CLIP模型的视觉编码器ViT-L/14。 特征投影:通过projector W提取的图像特征$Z_{v}$转换成LLM能够处理的token表示$H_{v}$。 输入指令:用户文本$X_{q}$转换为token表示$H_{q}$。 拼接输入:将[$H_{v}$,$H_{q}$]拼接一起送入LLM。 语言生成:LLM输出语言响应$X_{a}$,完成图像理解+问答。 LLaVA 是一个用于对齐视觉和语言数据以处理复杂多模态任务的复杂模型。它采用独特的方法,将图像处理与大型语言模型融合,以增强其解释和响应图像相关查询的能力。通过利用文本和视觉表示,LLaVA 在视觉问答、交互式图像生成以及涉及图像的基于对话的任务中表现出色。其与强大语言模型的集成使其能够生成详细描述,并协助实时视觉语言交互。 参考: 1. An Introduction to Vision-Language Modeling 2. Vision Language Transformers: A Survey 3. Understanding Vision-Language Models (VLMs): A Practical Guide 4. Guide to Vision-Language Models (VLMs) -
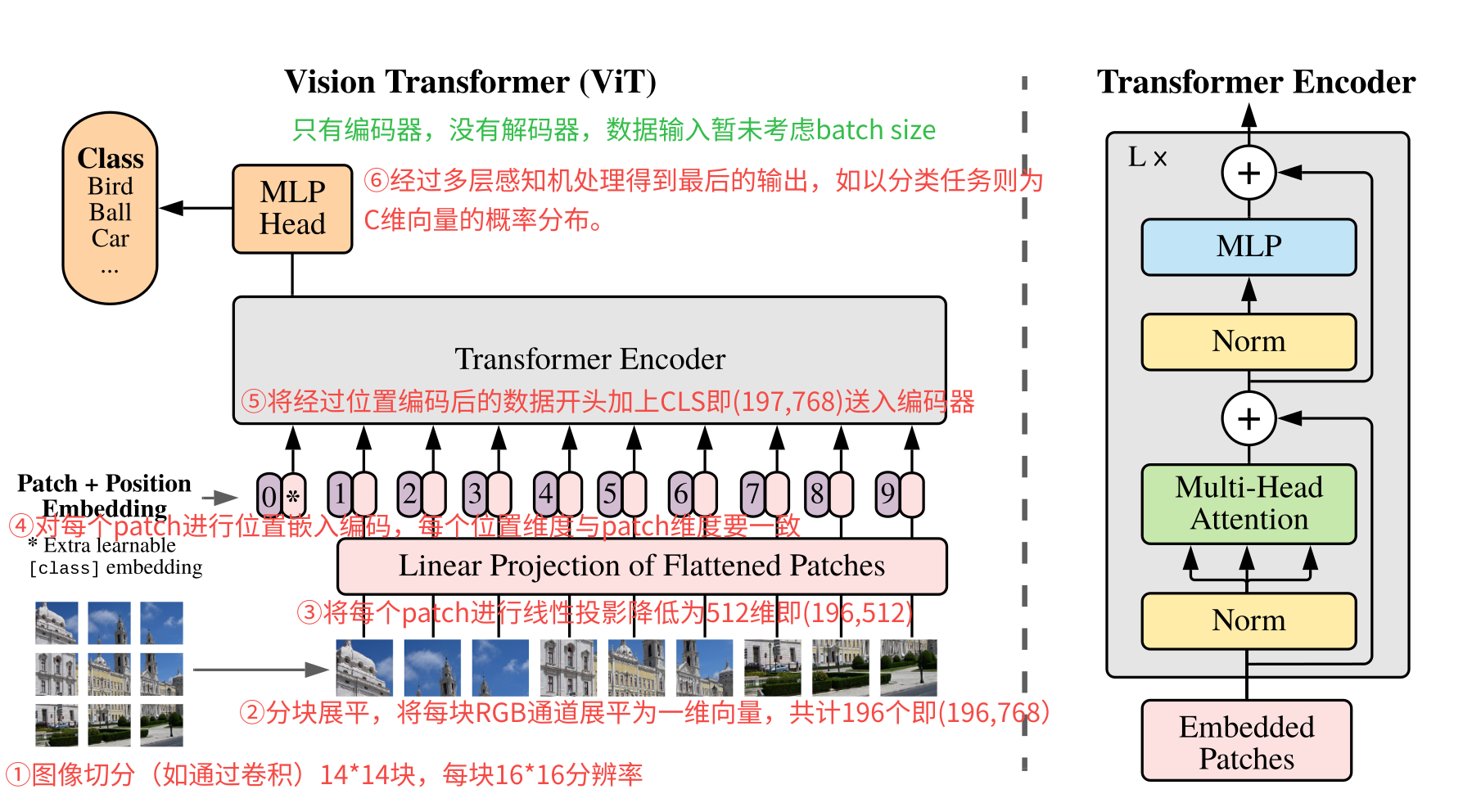
解读ViT:Transformer 在视觉领域如何落地
背景 计算机视觉领域,一直都是卷积天下。传统的卷积神经网络(CNN)依赖于卷积核提取局部特征,效果很好,但是也有一些不足,如需要人工设计卷积结构包括卷积核大小和层数,另外就是难以捕捉全局的依赖关系。 transformer最早更多的是应用在NLP领域的架构,用注意力机制来捕捉长距离的依赖。那把transformer应用在视觉领域了,会有什么效果吗?而在2021年发表的https://arxiv.org/abs/2010.11929这篇论文就是使用transformer应用在图像识别的领域。 论文中提到基于transformer使用监督学习方式训练模型进行图像分类时,在中等规模数据集(如ImageNet)上如果没有使用强正则化其准确率略低于同等规模的ResNet。但是当加大数据集(1400W至3亿张图像)训练时,发现其识别水平超越了现有技术。 模型概览 上图就是整个ViT模型结构了,对transformer比较熟悉的,整个结构就很简单了。可以发现只有transformer encoder没有transformer decoder。 这里先整体看看其流程步骤: 图像切块:原图输入为224x224分辨率的图像,将其切分为14x14共196块的(如使用卷积),每块大小的分辨率为16x16。 分块展平:将每块为16x16分辨率的patch展平为一维向量,共计有196个这样的向量。由于每块是RGB 3通道图像,因此向量维度为16x16x3= 768,按照RGB排布进行展开为一维向量。因此最后的数据形状为(196,768)。 线性投影:对每个patch的向量乘以一个权重矩阵,映射到D维的embedding空间,这个D维跟transformer输入维度一致(默认是512)。因此经过转换后的数据就变成了(196,768)->(196,512)。 位置编码:对经过线性映射的patch加上位置编码,每个patch一个位置向量,其向量的维度与patch维度一致,总的位置编码矩阵为(196,512)。将这个位置编码与经过线性映射的进行相加得到输入。 编码输入:经过位置编码后的输入然后在最开始加上了[CLS]向量送入编码器。因此输入的数据为(197,512)。如果算上批量数据最后就是(B,197,768)。B为batch size,197为patch数,512为embedding维度。 编码输出:最后经过多层感知机MLP得到最后的输出,如果是分类任务的话,就是(B,C)结果,B为batch size,C为类别数。也就是结果每行就是一个概率分布。 常见问题 (1)图像是如何切分展平的? 以输入尺寸3x224x224的RGB图像为例,块大小为16x16,因此块的数量为14x14=196个块。每个块3x16x16被拉成一维向量长度为16x16x3=768,也就是每个块被展平为768维向量,一共有196个块,也就是说转换为(196,768)的矩阵。 (2)每个patch为什么要展平? 主要是transformer的输入要求,因为transformer是序列处理器,其输入必现是一维的向量序列,而图像分块后得到的每个块是二维矩阵。还记得在transformer实现文章中吗?输入的是(seq,d_model),seq为token的数量,而d_model为每个token嵌入的向量。当然这里的图像最后还需要经过映射降维跟这里的d_model保持一致,这样才能输入到transformer的编码器中。 (3)线性投影有什么作用? 主要有两个作用,其一是图像分块展平后得到的是高维稀疏向量(如16163=768),包含了大量冗余信息如局部宽高、噪声等,缺乏高层语义表达,数据量大,计算量也大,线性投影是一个可训练全连接权重矩阵,可以提取保留关键局部特征;其二是为了适配transformer输入结构,Transformer要求输入为固定维度向量序列(如 D=512)。线性投影统一所有图像块的输出维度,确保自注意力机制可计算。 (4)这里的位置编码与transformer的有什么不同吗? ViT中的位置编码使用的是自适应位置编码,transformer中用的是正余弦固定公式,因为ViT中的输入序列位置一般都有限,因此用1D的可学习的位置编码即可,这个位置编码是一个可学习的参数矩阵,初始化为全0,在训练过程中通过反向传播自动优化。 (5)输出的MLP与transformer FFN有什么不同吗? 基本一样的,FFN是前馈神经网络的统称,MLP是具体的前馈神经网络具体实现特指全连接网络。 (6)最后的输出是什么样的? ViT最后的输出结构根据实际任务需求有关,如果是图像分类任务,在最终输出是[CLS] token向量经 MLP Head映射后的logits(未归一化的类别分数),形状为 [B, K](K为类别数); (7)整个处理流程数据变化是怎么样的? 处理阶段 输入形状 操作 输出形状 示例值(B=64) 原始输入 [B, C, H, W] — [64, 3, 224, 224] Patch分块 + 展平 [B, C, H, W] 卷积核尺寸=步长=P(如 16×16) [B, N, P²·C] [64, 196, 768] 线性投影(Patch Embedding) [B, N, P²·C] 全连接层映射至目标维度 D=512 [B, N, D] [64, 196, 512] 添加 Class Token [B, N, D] 序列前拼接可学习的 [CLS] 向量 [B, N+1, D] [64, 197, 512] 位置编码叠加 [B, N+1, D] 加可学习位置编码 E_{pos} ∈ ℝ^{1×(N+1)×D} [B, N+1, D] [64, 197, 512] Transformer 编码器 [B, N+1, D] 多头自注意力(MSA) + MLP 前馈网络 [B, N+1, D] [64, 197, 512] 分类头输出 [B, D](仅取 [CLS]) 全连接层映射至类别数 K [B, K] [64, 1000] -

lerobot之smolvla体验
环境安装 pip install -e ".[smolvla]" 在原来lerobot的环境基础上。 启动训练 本文主要是记录复现lerobot smolvla策略的效果,为了快速看到效果,这里不进行采集数据了,直接用此前ACT采集的数据,将数据打包放到autodl云服务器上进行训练。 python src/lerobot/scripts/train.py \ --dataset.root=/root/autodl-tmp/lerobot/data/record-07271539 \ --dataset.repo_id=laumy/record-07271539 \ --policy.push_to_hub=false \ --policy.path=lerobot/smolvla_base \ --policy.device=cuda \ --output_dir=outputs/train/smolvla_test \ --job_name=smolvla_test --batch_size=64 \ --steps=20000 --wandb.enable=false 或者 python -m lerobot.scripts.train \ --policy.type=smolvla \ --policy.vlm_model_name=HuggingFaceTB/SmolVLM2-500M-Video-Instruct \ --policy.load_vlm_weights=true \ --policy.num_vlm_layers=16 \ --policy.num_expert_layers=8 \ --dataset.repo_id=laumy/record-07271539 \ --output_dir=outputs/train/smolvla_test2 \ --job_name=smolvla_test \ --batch_size=64 --steps=20000 --wandb.enable=false 如果数据集在huggingface上面,则需要先登陆hugging face huggingface-cli login 填写token. python src/lerobot/scripts/train.py \ --dataset.repo_id=laumy0929/grab_candy_or_lemon \ --policy.path=lerobot/smolvla_base \ --policy.device=cuda \ --policy.repo_id=laumy0929/smolvla_test \ --output_dir=outputs/train/smolvla_test \ --job_name=smolvla_test --batch_size=64 \ --steps=20000 --wandb.enable=false 关于数据集的获取取决于两个参数,一个是repo_id另外一个是dataset.root。 repo_id: 必填字段,是在 Hugging Face Hub 上的数据集标识(datasets 仓库名)。 dataset.root :选填字段,是本地数据集所在目录。 训练首先从 dataset.root 读取本地数据;如果本地缺失需要的文件,才会用 repo_id 到 Hub 拉取缺的内容到这个 root 目录里。 下面有几个场景。 如果同时给定了dataset.root和dataset.repo_id 如果 root 目录已经是规范的 LeRobot v2 数据集结构(有 meta/info.json、data/.parquet、可选 videos/.mp4),会直接用本地文件,不会下载。 如果本地缺少 meta(或部分 data 文件),代码会用 repo_id 从 Hub 把缺的部分同步到你指定的 root 目录后再加载。 如果只传dataset.repo_id 会把本地根目录设为默认缓存:~/.cache/huggingface/lerobot/{repo_id}(若设置了环境变量 LEROBOT_HOME,则用 $LEROBOT_HOME/{repo_id}),如果本地缓存里已经有完整数据,则直接用本地文件,不再下载。如果本地没有缓存,远端也没有数据,就会报错。 推理验证 python -m lerobot.record \ --robot.type=so101_follower \ --robot.disable_torque_on_disconnect=true \ --robot.port=/dev/ttyACM0 --robot.cameras="{ handeye: {type: opencv, index_or_path: 4, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}}" \ --robot.id=R12252801 \ --display_data=false \ --dataset.single_task="Grab the cube" \ --policy.path=outputs/smolvla_weigh_08181710/pretrained_model \ --dataset.episode_time_s=240 \ --dataset.repo_id=laumy/eval_smolvla_08181710 常见问题 训练报错如下: Traceback (most recent call last): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connection.py", line 198, in _new_conn sock = connection.create_connection( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/util/connection.py", line 85, in create_connection raise err File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/util/connection.py", line 73, in create_connection sock.connect(sa) TimeoutError: [Errno 110] Connection timed out The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 787, in urlopen response = self._make_request( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 488, in _make_request raise new_e File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 464, in _make_request self._validate_conn(conn) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 1093, in _validate_conn conn.connect() File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connection.py", line 753, in connect self.sock = sock = self._new_conn() File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connection.py", line 207, in _new_conn raise ConnectTimeoutError( urllib3.exceptions.ConnectTimeoutError: (<urllib3.connection.HTTPSConnection object at 0x7fe651566380>, 'Connection to huggingface.co timed out. (connect timeout=None)') The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/adapters.py", line 667, in send resp = conn.urlopen( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 841, in urlopen retries = retries.increment( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/util/retry.py", line 519, in increment raise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type] urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/HuggingFaceTB/SmolVLM2-500M-Video-Instruct/tree/main/additional_chat_templates?recursive=False&expand=False (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7fe651566380>, 'Connection to huggingface.co timed out. (connect timeout=None)')) During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/root/autodl-tmp/lerobot/src/lerobot/scripts/train.py", line 291, in <module> train() File "/root/autodl-tmp/lerobot/src/lerobot/configs/parser.py", line 226, in wrapper_inner response = fn(cfg, *args, **kwargs) File "/root/autodl-tmp/lerobot/src/lerobot/scripts/train.py", line 139, in train policy = make_policy( File "/root/autodl-tmp/lerobot/src/lerobot/policies/factory.py", line 168, in make_policy policy = policy_cls.from_pretrained(**kwargs) File "/root/autodl-tmp/lerobot/src/lerobot/policies/pretrained.py", line 101, in from_pretrained instance = cls(config, **kwargs) File "/root/autodl-tmp/lerobot/src/lerobot/policies/smolvla/modeling_smolvla.py", line 356, in __init__ self.language_tokenizer = AutoProcessor.from_pretrained(self.config.vlm_model_name).tokenizer File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/models/auto/processing_auto.py", line 288, in from_pretrained config_dict, _ = ProcessorMixin.get_processor_dict(pretrained_model_name_or_path, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/processing_utils.py", line 873, in get_processor_dict for template in list_repo_templates( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/utils/hub.py", line 161, in list_repo_templates return [ File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/utils/hub.py", line 161, in <listcomp> return [ File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 3168, in list_repo_tree for path_info in paginate(path=tree_url, headers=headers, params={"recursive": recursive, "expand": expand}): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/huggingface_hub/utils/_pagination.py", line 36, in paginate r = session.get(path, params=params, headers=headers) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/sessions.py", line 602, in get return self.request("GET", url, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/sessions.py", line 589, in request resp = self.send(prep, **send_kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/sessions.py", line 703, in send r = adapter.send(request, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/huggingface_hub/utils/_http.py", line 96, in send return super().send(request, *args, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/adapters.py", line 688, in send raise ConnectTimeout(e, request=request) requests.exceptions.ConnectTimeout: (MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/HuggingFaceTB/SmolVLM2-500M-Video-Instruct/tree/main/additional_chat_templates?recursive=False&expand=False (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7fe651566380>, 'Connection to huggingface.co timed out. (connect timeout=None)'))"), '(Request ID: 7f4d5747-ec95-47cc-a55f-cb3e230c52e2)') 原因是训练在初始化 SmolVLA 的 VLM 时需要从 Hugging Face Hub 拉取资源(AutoProcessor.from_pretrained 默认用 vlm_model_name=HuggingFaceTB/SmolVLM2-500M-Video-Instruct)。你的机器连到 huggingface.co 超时,导致下载失败并报 ConnectTimeout。 解决办法:export HF_ENDPOINT=https://hf-mirror.com 把原本指向 https://huggingface.co 的所有 Hub 请求(模型/数据集下载、API 调用)改走 https://hf-mirror.com。作用范围仅当前这个终端会话。关闭终端或开新终端就失效。 训练过程过程中警告 huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) TOKENIZERS_PARALLELISM是分词器在一次调用会开多线程并行处理文本。分词器库是hugging Face的分词器库,负责把文本指令变成模型可用的token id序列,也能把id还原会文本,跟我们此前在一步步实现transformer 的词表类型。出现这样的警告是tokenizers它开了多线程并发,而 DataLoader 再 fork 出子进程并发(本身DataLoader是可以并发),这样容易有死锁风险,为安全起见,库检测到这种顺序就自动把自己的多线程并行关掉,并给出提示。如果要关掉tokenizers的多线程并发,export TOKENIZERS_PARALLELISM=false。 -
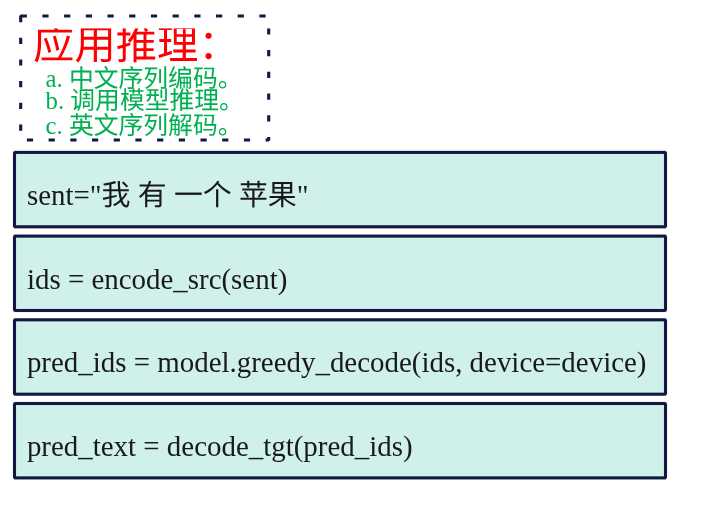
从零实现 Transformer:中英文翻译实例
概述 在http://www.laumy.tech/2458.html#h37章节中,介绍了transformer的原理,本章用pytorch来实现一个将"我有一个苹果"翻译为英文"I have an apple"的模型,直观体会transformer原理实现。 接下来先上图看看整体的代码流程。 推理 训练 模型 编解码器 到这里就涵盖了整个transformer模型翻译的例子了,下面的章节只是对图中的代码进行展开说明,如果不想陷入细节,可以直接跳转到最后一节获取源码运行实验一下。 数据预处理 数据准备 (1) 准备原始文本对 既然要做翻译那得先有数据用于模型训练,因此需要先准备原始的中文->英文的文本对,下面是使用python列表(List)准备中英匹配语料,List中包含的是元组(Tuple)。 pairs = [ ("我 有 一个 苹果", "i have an apple"), ("我 有 一本 书", "i have a book"), ("你 有 一个 苹果", "you have an apple"), ("他 有 一个 苹果", "he has an apple"), ("她 有 一个 苹果", "she has an apple"), ("我们 有 一个 苹果", "we have an apple"), ("我 喜欢 苹果", "i like apples"), ("我 吃 苹果", "i eat apples"), ("你 喜欢 书", "you like books"), ("我 喜欢 书", "i like books"), ("我 有 两个 苹果", "i have two apples"), ("我 有 红色 苹果", "i have red apples"), ] 为了方便,在构建原始文本对时,中英文的分词就以空格划分,这样接下来就可以根据空格来进行构建词表。 (2)构建词表 因为神经网络不能直接处理文本,模型只能处理数字,比如不能直接处理"我"、"有","I"等中英文词,对于计算机来讲都是数字,所以需要把文字转换为对应的映射表。 所以词表就是一个"字典",把每个词映射到一个唯一的数字ID上,所有的文本都需要转换为数字序列。 如下示例,中英文的编号。 # 中文词表示例 SRC_STOI = { "我": 1, "有": 2, "一个": 3, "苹果": 4, "书": 5, "喜欢": 6, # ... 更多词 } # 英文词表示例 TGT_STOI = { "i": 1, "have": 2, "an": 3, "apple": 4, "a": 5, "book": 6, # ... 更多词 } 如何构建词表了。既然中文、英文都需要各自编号,那么得先把此前准备的原始文本队中文、英文各自拆出来,然后我们使用python的set集合,将中文、英文分别添加到set集合中,使用set集合的好处是可以自动去重,添加了重复元素,set就不会添加,这样就得到了各自的中文、英文词表。最后再对这些词表进行依次编号即可。 下面就看看使用python代码怎么实现,首先是将原始文本对拆解,把中文放一起,英文放一起。 src_texts = [p[0] for p in pairs] tgt_texts = [p[1] for p in pairs] print(src_texts) print(tgt_texts) src_texts ['我 有 一个 苹果', '我 有 一本 书', '你 有 一个 苹果', '他 有 一个 苹果', '她 有 一个 苹果', '我们 有 一个 苹果', '我 喜欢 苹果', '我 吃 苹果', '你 喜欢 书', '我 喜欢 书', '我 有 两个 苹果', '我 有 红色 苹果'] tgt_texts ['i have an apple', 'i have a book', 'you have an apple', 'he has an apple', 'she has an apple', 'we have an apple', 'i like apples', 'i eat apples', 'you like books', 'i like books', 'i have two apples', 'i have red apples'] 接下来实现一个build_vocab函数,主要的思路就是句子先按照空格进行分好词,接着将所有词添加到set集合中,set集合会自动去重,这里需要注意的时,需要再加上3个特殊的词,分别是pad、bos、eos分别表示填充、开始、结束。填充是因为输入句子是不定长的,但是对于transformer来说所有的输入矩阵处理都是固定长度,所以不够的需要补齐,而bos和eos是用于transformer解码的,便于开始和结束翻译过程,最后构建好词表后就按照词表中进行变化,3个特殊词分为为1、2、3其他的词依次编号。 def build_vocab(examples: List[str]): """构建词表(字符串→索引 与 索引→字符串) - 输入示例为用空格分词后的句子列表 - 加入特殊符号 `<pad>`, `<bos>`, `<eos>` 并将其它 token 排序,保证可复现 返回: stoi: dict[token->id] itos: List[id->token] """ tokens = set() # 建立一个集合,用于存储所有的词表(不重复的词) for s in examples: # 依次遍历获得每个句子 for t in s.split(): # 通过空格划分,依次遍历句子中的每个词, tokens.add(t.lower()) # 将词添加到set中,这里为了方便统一转换小写 itos = ["<pad>", "<bos>", "<eos>"] + sorted(tokens) # 加入3个特殊的词,同时对set中的词进行排序。 stoi = {t: i for i, t in enumerate(itos)} # 对词表中的词按照顺序依次编号 return stoi, itos SRC_STOI, SRC_ITOS = build_vocab(src_texts) TGT_STOI, TGT_ITOS = build_vocab(tgt_texts) build_vocab最终返回是一个字典和列表,字典是词:编号的映射,列表是存放的是词表。列表是按照编号顺序依次排布,这样我们可以通过编号定位到时那个词。 为什么要一个字典和列表了?因为transformer输入是词->编号(转换为编码数字给计算机处理),输出是编号->词过程(转化为句子给人看)。通过字典我们可以查询词对应的编号[key:value],而通过列表的索引(编号)我们可以查询到对应的词。 中文和英文分别各自对应一个字典和词表。 SRC_STOI {'<pad>': 0, '<bos>': 1, '<eos>': 2, '一个': 3, '一本': 4, '两个': 5, '书': 6, '他': 7, '你': 8, '吃': 9, '喜欢': 10, '她': 11, '我': 12, '我们': 13, '有': 14, '红色': 15, '苹果': 16} SRC_ITOS ['<pad>', '<bos>', '<eos>', '一个', '一本', '两个', '书', '他', '你', '吃', '喜欢', '她', '我', '我们', '有', '红色', '苹果'] TGT_STOI {'<pad>': 0, '<bos>': 1, '<eos>': 2, 'a': 3, 'an': 4, 'apple': 5, 'apples': 6, 'book': 7, 'books': 8, 'eat': 9, 'has': 10, 'have': 11, 'he': 12, 'i': 13, 'like': 14, 'red': 15, 'she': 16, 'two': 17, 'we': 18, 'you': 19} TGT_ITOS ['<pad>', '<bos>', '<eos>', 'a', 'an', 'apple', 'apples', 'book', 'books', 'eat', 'has', 'have', 'he', 'i', 'like', 'red', 'she', 'two', 'we', 'you'] 这样我们就给中文和英文的所有词都编好号了,同时通过列表也可以通过编号查询到词。 数据加载器 在pytorch中模型训练那必然少不了DataLoader和Dataset,关于这两个类的介绍在http://www.laumy.tech/2491.html#h23中有简要说明,这里就不阐述了。注意本小节说明的数据的批量处理都适用于训练准备,主要是实现Dataset和Dataloader用于pytorch模型的训练,如果只是推理则是不需要的。 (1)Dataset继承类实现 首先要实现DataLoader中关键的输入类Dataset继承类,用于产出“单个样本”,怎么按索引取到一个样本,以及总共有多少个样本。每个样本是中文句子->英文句子。样本集为此前定义pairs,但是要把pairs中句子转换为编号,词表在前面我们已经构建好了,直接查询就行,那这里我们定义一个Example用于定义样本,src是中文句子的编号列表,tgt是对于英文句子的编号列表。 @dataclass class Example: """单条并行样本 - src: 源语言索引序列(不含 BOS/EOS) - tgt: 目标语言索引序列(含 BOS/EOS) """ src: List[int] tgt: List[int] 接下来就是实现Dataset的继承类ToyDataset,返回有多少个样本,以及通过编号获取指定的样本。 class ToyDataset(Dataset): """语料数据集,用于快速过拟合演示。""" def __init__(self, pairs: List[Tuple[str, str]]): self.data = [Example(encode_src(s), encode_tgt(t)) for s, t in pairs] def __len__(self): return len(self.data) def __getitem__(self, idx): return self.data[idx] 需要把pairs句子中词列表编码为数字列表,这里实现encode_src用于将输入(即pairs中的中文)编号为列表,再实现encode_tgt将输出(即pairs中的英文)编号为列表。使用for列表推导式从pairs列表中获取到s(中文句子)和t(英文句子)然后传入encode_src和encoder_tgt进而构建一个新的列表元素Example。这样就组建样本的self.data的样本列表,元素为Example类型,可以通过idx获取到指定的样本。 def encode_src(s: str) -> List[int]: """将原语句(已空格分词)编码为索引序列(不含 BOS/EOS)。""" return [SRC_STOI[w.lower()] for w in s.split()] def encode_tgt(s: str) -> List[int]: """将目标语句编码为索引序列,并在首尾添加 BOS/EOS。""" return [BOS_IDX] + [TGT_STOI[w.lower()] for w in s.split()] + [EOS_IDX] 上面就是输入句子编码为编号向量的实现了,也很简单,通过此前构建的词表字典,通过词就可以搜索到对应编号了。这里需要注意的是编码的源句子(输入)是没有包含BOS和EOS的,因为transformer的编码器不需要BOS和EOS,而编码的目标句子(输出)需要在句子前加上BOS,句子结尾加上EOS,因为transformer的解码器输入需要通过BOS来翻译第一个词,通过EOS来结束一个句子的翻译,要是不明白为什么了可以看看前面transformer原理的文章。 (2)Dataload DataLoader 负责“成批取样”,模型训练输入数据不是一个样本一个样本的送入训练,而是按照批次(多个样本合成一个批次)进行训练,这样训练效率才高。DataLoader决定批大小、是否打乱、多进程加载,返回的是一个可迭代的对象。 DataLoader重点是要实现 collate_fn回调,也就是怎么把一个批里的样本“拼起来”。 loader = DataLoader(dataset, batch_size=8, shuffle=True, collate_fn=collate_fn) 训练transformer,准备数据。我们的目的是要能够返回批量数据,批量数据也有好几个类型。 输入给encoder批量数据:输入矩阵类型(B,S),包含补齐的padding。 输入给decoder的批量数据:输入给decoder的矩阵类型(B,T),包含BOS以及右对齐的padding。不能加EOS,因为EOS是预测的结果,防止模型训练作弊。 decoder输出的批量数据:解码器的监督目标,主要用于预测数据与实际的结果比较计算损失,矩阵类型(B,T),不含BOS但是包含EOS。 encoder输入的pad掩码数据:因为输入给encoder的数据有padding,所以要告诉transformer哪些做了补齐,后续计算的时候要处理。 decoder输入的pad掩码数据:同上。 def collate_fn(batch: List[Example]): """将一个 batch 的样本对齐为等长张量,并构造 teacher forcing 所需的输入/输出。 返回: - src: (B,S) 源序列,已 padding - tgt_in: (B,T) 解码器输入(含 BOS,右对齐 padding) - tgt_out: (B,T) 解码器监督目标(对 tgt_in 右移一位,含 EOS) - src_pad_mask: (B,S) 源端 padding 掩码,True 表示 padding 位置 - tgt_pad_mask: (B,T) 目标端 padding 掩码(针对输入序列) """ # padding to max length in batch src_max = max(len(b.src) for b in batch) tgt_max = max(len(b.tgt) for b in batch) src_batch = [] tgt_in_batch = [] tgt_out_batch = [] for ex in batch: src = ex.src + [PAD_IDX] * (src_max - len(ex.src)) # Teacher forcing: shift-in, shift-out tgt_in = ex.tgt[:-1] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[:-1])) tgt_out = ex.tgt[1:] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[1:])) src_batch.append(src) tgt_in_batch.append(tgt_in) tgt_out_batch.append(tgt_out) src = torch.tensor(src_batch, dtype=torch.long) # (B, S) tgt_in = torch.tensor(tgt_in_batch, dtype=torch.long) # (B, T_in) tgt_out = torch.tensor(tgt_out_batch, dtype=torch.long) # (B, T_out) src_pad_mask = src.eq(PAD_IDX) # (B, S) tgt_pad_mask = tgt_in.eq(PAD_IDX) # (B, T) return src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask 上面就是Dataloader回调函数如何获取批量数据的实现了,输入为一个列表(包含所有样本的列表)。输出为5个2维向量,分别对应的就是上面说的5个批量数据。 首先计算样本列表中最长的源序列长度src_max和目标序列长度tgt_max,为后续的不足长度的句子进行padding操作,提供基准的长度。 其次使用for循环遍历每个样本(Example),将源序列src(encoder的输入)使用PAD_IDX填充到相同长度,保持做对齐;将目标序列输入(tgt_in)去掉最后一个token(EOS)作为decoder的输入,目标序列输出比对样本tgb_out去掉第一个tokenBOS作为监督目标,使用的teacher Forcing机制,这样就是实现了输入预测下一个的训练模式数据准备。 最后就是准备src和tgt_in的mask矩阵,形状跟src和tgt_in一样,使用python的eq比对如果对应的位置是padding就是true,不是就是false。 模型架构 数据准备好了,接下来就是设计我们的模型了。我们的模型是一个翻译模型可以分为两个路径,一个是编码路径和解码路径。 编码路径:词嵌入->位置编码->编码器。 解码路径:词嵌入->位置编码->解码器->生成器。 Class Seq2SeqTransformer(nn.Module): def __init__(self, src_vocab_size, tgt_vocab_size, d_model=128, nhead=4, num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1): super().__init__() self.d_model = d_model # 编码路径 # 1.词嵌入层,将tokenID转换为密集向量 self.src_tok = nn.Embedding(src_vocab_size, d_model, padding_idx=PAD_IDX) self.tgt_tok = nn.Embedding(tgt_vocab_size, d_model, padding_idx=PAD_IDX) # 2. 对输入添加位置信息 self.pos_enc = PositionalEncoding(d_model, dropout=dropout) # 3. 源序列的编码 self.encoder = Encoder(d_model, nhead, dim_ff, num_encoder_layers, dropout) # 解码路径 # 1. 解码生成目标序列 self.decoder = Decoder(d_model, nhead, dim_ff, num_decoder_layers, dropout) # 2. 将解码器输出转换为词表概率 self.generator = nn.Linear(d_model, tgt_vocab_size) 词嵌入直接调用的是神经网络的库nn.Embedding,其他部分都要自己实现,接下来我们会一一展开。下面我们需要先实现模型Seq2SeqTransformer的方法,主要包括如下: make_subsequent_mask:解码器因果掩码,不允许解码器看到未来。 forward: 模型前向传播的方法,pytorch训练的时候自动调用。 greedy_decode:模型推理方法,用于推理的应用。 因果掩码 为什么需要掩码了?主要是让模型不能看到未来的词。 推理阶段虽然是自回归一个一个输入然后一个一个迭代输出,但是在训练阶段,我们解码器的样本是全部一次性输入的。如下的步骤,我们虽然给到模型输入为:"BOS i have an apple ",但是每个步骤给到模型看到的不能是全部,否则给模型都看到输入结果了,那还谈啥预测,模型会偷懒直接就照搬就是一个映射过程了。如当输入BOS i 期望预测输出i have,如果没有掩码模型都看到全部的"BOS i have an apple ",就不是预测了,模型的参数也没法迭代了。 # 步骤1: 输入BOS → 期望输出i # 步骤2: 输入BOS i → 期望输出i have # 步骤3: 输入BOS i have → 期望输出i have an # 步骤4: 输入BOS i have an → 期望输出 i have an apple # 步骤5: 输入BOS i have an apple → 期望输出i have an apple EOS 哪有个问题,为什么我们输入的时候不按照要多少输入多少,为啥要全部一下给到输入?输入倒是可以要多少输入多少,但是要要考虑模型的并行训练,实际上上面的5个步骤在模型训练时是并行进行的,模型训练要的是训练参数,在某个阶段看到什么输入遇到什么输出,都分好类了自然可以并行的,所以这就需要结合掩码了,告诉模型那个步骤你能看到哪些? 总结一下mask的作用就是让模型不能看到未来的词,同时也是让模型不要对padding位进行误预测。 def make_subsequent_mask(self, sz: int) -> torch.Tensor: """构造大小为 (sz, sz) 的下三角因果掩码;True 为屏蔽(不允许看未来)。""" return torch.triu(torch.ones(sz, sz, dtype=torch.bool), diagonal=1) mask是要生成一个下三角形状,示例如下: # 对于序列长度4 mask = make_subsequent_mask(4) # 结果: # [[False, True, True, True], # 位置0: 只能看位置0 # [False, False, True, True], # 位置1: 能看位置0,1 # [False, False, False, True], # 位置2: 能看位置0,1,2 # [False, False, False, False]] # 位置3: 能看所有位置 前向传播 def forward(self, src, tgt_in, src_pad_mask, tgt_pad_mask): """训练/教师强制阶段的前向。 参数: - src: (B, S) 源 token id - tgt_in: (B, T) 目标端输入(以 BOS 开头) - src_pad_mask: (B, S) True 为 padding - tgt_pad_mask: (B, T) True 为 padding(针对 tgt_in) 返回: - logits: (B, T, V) 词表维度的分类分布 """ # 1) 词嵌入 + 位置编码 src_emb = self.pos_enc(self.src_tok(src)) # (B,S,C) tgt_emb = self.pos_enc(self.tgt_tok(tgt_in)) # (B,T,C) # 2) 编码:仅使用 key_padding_mask 屏蔽 padding memory = self.encoder(src_emb, src_key_padding_mask=src_pad_mask) # (B,S,C) # 3) 解码:自注意力需要因果掩码 + padding 掩码;交叉注意力需要 memory 的 padding 掩码 tgt_mask = self.make_subsequent_mask(tgt_in.size(1)).to(src.device) # (T,T) out = self.decoder( tgt_emb, memory, tgt_mask=tgt_mask, tgt_key_padding_mask=tgt_pad_mask, memory_key_padding_mask=src_pad_mask, ) # (B,T,C) logits = self.generator(out) return logits 上面就是模型的训练了,也比较简单,就是对输入词进行词嵌入+位置编码计算,然后送入编码器得到输出特征矩阵memory;给编码器输入的只是padding的掩码,因为不要提取padding的词; 其次生成因果掩码,将编码器的的特征矩阵输出结果memory以及解码器侧自身的输入给到解码器最终得到(B,T,C)的输出矩阵,其包含了最终输出结果词位置的隐藏信息; 最后调用self.generator(out)即线性变化得到输出目标词表的概率分布(B,T,V);后面就可以用其使用交叉熵跟目标结果进行比对计算损失了。 解码推理 @torch.no_grad() def greedy_decode(self, src_ids: List[int], max_len=20, device="cpu"): """在推理阶段进行贪心解码。 参数: - src_ids: 源端 token id 序列(不含 BOS/EOS) - max_len: 最大生成长度(含 BOS/EOS) - device: 运行设备 返回: - 生成的目标端 id 序列(含 BOS/EOS) """ #切换为评估模式,关闭dropout/batchnorm等随机性 self.eval() # 将源端token id序列转换为张量,并添加一个维度,如[1, 2, 3, 4] -> [[1, 2, 3, 4]] # 变为批维度的 (1, S);dtype 为 long 主要是以适配 nn.Embedding的输入格式。 src = torch.tensor(src_ids, dtype=torch.long, device=device).unsqueeze(0) # 生成一个跟src相同形状的mask矩阵,让编码器不要计算提取pandding的位置信息。 #按元素判断 src 是否等于 PAD_IDX,等于的位置为 True,不等的位置为 False。 src_pad_mask = src.eq(PAD_IDX) # 计算src_tok= src 经过词嵌入+位置编码后的结果 src_tok = self.src_tok(src) src_pos = self.pos_enc(src_tok) # 将该结果送入编码器,返回的memory就是编码器提取的特征向量。 # 输入编码器,即使没有填充(pandding)的token,也需要传入src_key_padding_mask。 memory = self.encoder(src_pos, src_key_padding_mask=src_pad_mask) # 初始化目标端token id序列,维度为(1,1),初始值为BOS_IDX # 表示目标端序列的开始,BOS_IDX=1 # 推理时输入是没有PAD,但是仍然需要tgt_pad_mask. ys = torch.tensor([[BOS_IDX]], dtype=torch.long, device=device) for _ in range(max_len - 1): #计算本次解码的Mask,跟ys形状一样。 tgt_pad_mask = ys.eq(PAD_IDX) # 计算本次因果掩码,把未来看到的token都屏蔽。 tgt_mask = self.make_subsequent_mask(ys.size(1)).to(device) # 可以看到当推理模式时,解码器输入token数量依次是1,2,3,4..... out = self.decoder( self.pos_enc(self.tgt_tok(ys)), memory, tgt_key_padding_mask=tgt_pad_mask, memory_key_padding_mask=src_pad_mask, ) # 转化为预测词的概率分布 logits = self.generator(out[:, -1:, :]) # 使用贪心选择概率最大的作为本次预测的目标 next_token = logits.argmax(-1) next_id = next_token.item() # 显示选择的token token_text = TGT_ITOS[next_id] if next_id < len(TGT_ITOS) else f"ID_{next_id}" print(f"选择: {token_text}({next_id})") ys = torch.cat([ys, next_token], dim=1) # 当下一个输出为EOS时表示结束,则退出。 if next_id == EOS_IDX: break return ys.squeeze(0).tolist() 上面代码的设计要点主要为几个部分: 编码信息提取:将要翻译的句子进行词嵌入,位置编码,然后送入编码器计算提出特征信息memory,最终给到解码器作为输入。 自回归生成:最开始使用BOS一个token+编码器此前计算的输出memory、掩码等信息输入给解码器,解码器预测得到一个输出,然后将输出拼接会此前BOS的后面形成解码器新的输入,以此循环进行预测,直至遇到EOS结束。解侧输入序列长度逐步增长:1 → 2 → 3 → 4 → ...,最开始的序列为BOS表示开始。 掩码生成:使用了因果掩码和padding掩码;虽然推理阶段没有对输入数据进行padding操作,但是依旧需要这两个掩码,主要的考量是保持接口的一致性(原来的接口需要传递这个参数)。 贪心策略:解码器的输出进行线性变化得到词表的概率分布后,然后挑选概率最高的token。 结束循环:当判断到模型预测出EOS时,模式则结束,整个预测完成。 位置编码 class PositionalEncoding(nn.Module): """经典正弦/余弦位置编码。 给定嵌入 `x (B,L,C)`,按长度切片并与位置编码相加,再做 dropout。 """ def __init__(self, d_model: int, max_len: int = 5000, dropout: float = 0.1): super().__init__() self.dropout = nn.Dropout(dropout) # 创建一个形状为 (max_len, d_model) 的零张量,用于存储位置编码 pe = torch.zeros(max_len, d_model) # (L, C) # 创建一个形状为 (max_len, 1) 的张量,用于存储位置索引 position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (L, 1) # 创建一个形状为 (d_model//2,) 的张量,用于存储位置编码的缩放因子 div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # sin, cos 交错 pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0) # (1, L, C) self.register_buffer("pe", pe) def forward(self, x: torch.Tensor): # (B, L, C) """为输入嵌入添加位置编码并做 dropout。 参数: - x: (B, L, C) 返回: - (B, L, C) """ x = x + self.pe[:, : x.size(1)] return self.dropout(x) # 对于位置 pos 和维度 i: # 偶数维度: PE(pos, 2i) = sin(pos / 10000^(2i/d_model)) # 奇数维度: PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model)) # pe[:, 0::2]: 选择所有行的偶数列 (0, 2, 4, ...) # pe[:, 1::2]: 选择所有行的奇数列 (1, 3, 5, ...) # 计算过程: # 位置0: sin(0 * div_term), cos(0 * div_term), sin(0 * div_term), ... # 位置1: sin(1 * div_term), cos(1 * div_term), sin(1 * div_term), ... # 位置2: sin(2 * div_term), cos(2 * div_term), sin(2 * div_term), ... 位置编码比较简单,就是按照sin和cos按公式计算生成向量,最终返回词嵌入向量+位置编码向量。 编码器 class Encoder(nn.Module): def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1): super().__init__() self.layers = nn.ModuleList([ EncoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers) ]) def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor: """堆叠若干编码层。 参数: - x: (B, S, C) - src_key_padding_mask: (B, S) True 为 padding 返回: - (B, S, C) """ for layer in self.layers: x = layer(x, src_key_padding_mask=src_key_padding_mask) return x 编码器框架就是若干个编码层堆叠起来,但是每层的都有自己的参数,主要调用的是nn.ModuleList进行注册子模块,确保参数都能够被优化器找到,num_layers控制了编码器的深度。 前向传播函数也很简单,输入一次通过每一个编码层,得到的输出结果给到下一个编码层,以此循环最终经过最后一层编码器得得到的特征信息,给后续解码器使用。 class EncoderLayer(nn.Module): """Transformer 编码层(后归一化 post-norm 版本) 子层:自注意力 + 前馈;均带残差连接与 LayerNorm。 """ def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.self_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm1 = nn.LayerNorm(d_model) self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout) self.norm2 = nn.LayerNorm(d_model) def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor: """单层编码层前向。 参数: - x: (B, S, C) - src_key_padding_mask: (B, S) True 为 padding 返回: - (B, S, C) """ # 自注意力子层 attn_out = self.self_attn(x, x, x, attn_mask=None, key_padding_mask=src_key_padding_mask) x = self.norm1(x + attn_out) # 前馈子层 ff_out = self.ff(x) x = self.norm2(x + ff_out) return x 编码层的组件为MultiHeadAttention、LayerNorm、PositionwiseFeedForward这与我们此前介绍的transformer原理一致。 其前向传播过程,首先输入X(查询),X(键),X(值),qkv都是一样的;注意力计算时,把attn_mask=None,因为编码器不需要因果掩码,但是需要padding mask。其次进行残差连接计算x+attn_out,再调用norml进行层归一化,最后是计算前馈网络,再进行归一化就得到一层的输出结果了。 class PositionwiseFeedForward(nn.Module): """前馈网络:逐位置的两层 MLP(含激活与 dropout)""" def __init__(self, d_model: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.fc1 = nn.Linear(d_model, dim_ff) self.fc2 = nn.Linear(dim_ff, d_model) self.act = nn.ReLU() self.dropout = nn.Dropout(dropout) def forward(self, x: torch.Tensor) -> torch.Tensor: """两层逐位置前馈网络。 参数: - x: (B, L, C) 返回: - (B, L, C) """ x = self.fc2(self.dropout(self.act(self.fc1(x)))) x = self.dropout(x) return x 前馈网络主要两层: 第一层:d_model → dim_ff (通常 dim_ff = 4 * d_model) 激活函数:ReLU。 第二层:dim_ff → d_model 就是对输入进行升维然后非线性变化再降维,提取更多的信息。两层都使用了dropout,展开就是如下。 # 1. 第一层线性变换 x = self.fc1(x) # (B, L, C) → (B, L, dim_ff) # 2. 激活函数 x = self.act(x) # 应用ReLU # 3. 第一个dropout x = self.dropout(x) # 随机置零部分神经元 # 4. 第二层线性变换 x = self.fc2(x) # (B, L, dim_ff) → (B, L, C) # 5. 第二个dropout x = self.dropout(x) # 最终dropout 解码器 class Decoder(nn.Module): def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1): super().__init__() self.layers = nn.ModuleList([ DecoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers) ]) def forward( self, x: torch.Tensor, memory: torch.Tensor, tgt_mask: torch.Tensor | None = None, tgt_key_padding_mask: torch.Tensor | None = None, memory_key_padding_mask: torch.Tensor | None = None, ) -> torch.Tensor: """堆叠若干解码层。 参数: - x: (B, T, C) 目标端嵌入 - memory: (B, S, C) 编码器输出 - tgt_mask: (T, T) 因果掩码,True 为屏蔽 - tgt_key_padding_mask: (B, T) 目标端 padding 掩码 - memory_key_padding_mask: (B, S) 源端 padding 掩码 返回: - (B, T, C) """ for layer in self.layers: x = layer( x, memory, tgt_mask=tgt_mask, tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=memory_key_padding_mask, ) return x 与编码器类似,使用nn.ModuleList创建多个解码层,每个解码层都是独立的DecoderLayer实例;解码器的输入数据有两个,一个是解码器侧自己的输入序列,另外一个是编码器计算得到的特征信息。解码器的每一层都需要输入编码器给的特征序列,但是都是一样的;解码器层计算得到的输出将传递给下一层解码器层,循环得到最后的输出。 Decoder (解码器) ├── DecoderLayer 1 (解码层1) │ ├── MultiHeadAttention (自注意力) │ ├── LayerNorm1 + 残差连接 │ ├── MultiHeadAttention (交叉注意力) │ ├── LayerNorm2 + 残差连接 │ ├── PositionwiseFeedForward (前馈网络) │ └── LayerNorm3 + 残差连接 ├── DecoderLayer 2 (解码层2) │ └── ... (同上结构) └── ... (重复 num_layers 次) 输入: x (B, T, C) + memory (B, S, C) → DecoderLayer 1 → DecoderLayer 2 → ... → DecoderLayer N → 输出: (B, T, C) 其前向传播也大同小异,与编码器不同的是需要传递因果掩码,tgt_mask,防止看到未来信息,同时还传入了源序列的pandding掩码,跟输入给编码器的mask是一样的。 class DecoderLayer(nn.Module): """Transformer 解码层(自注意力 + 交叉注意力 + 前馈)""" def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.self_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm1 = nn.LayerNorm(d_model) self.cross_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm2 = nn.LayerNorm(d_model) self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout) self.norm3 = nn.LayerNorm(d_model) def forward( self, x: torch.Tensor, memory: torch.Tensor, tgt_mask: torch.Tensor | None = None, tgt_key_padding_mask: torch.Tensor | None = None, memory_key_padding_mask: torch.Tensor | None = None, ) -> torch.Tensor: """单层解码层前向。 参数: - x: (B, T, C) 解码器输入 - memory: (B, S, C) 编码器输出 - tgt_mask: (T, T) 因果掩码,true为屏蔽 - tgt_key_padding_mask: (B, T) - memory_key_padding_mask: (B, S) 返回: - (B, T, C) """ # 1) 解码器自注意力(带因果掩码 tgt_mask) sa = self.self_attn(x, x, x, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask) x = self.norm1(x + sa) # 2) 交叉注意力:Q 来自解码器,K/V 来自编码器 memory ca = self.cross_attn(x, memory, memory, attn_mask=None, key_padding_mask=memory_key_padding_mask) x = self.norm2(x + ca) # 3) 前馈 ff = self.ff(x) x = self.norm3(x + ff) return x 解码器层比编码器层多了一个cross_attn交叉注意力。除了输入数据有些不同,其他都基本类似,下面按前向传播的流程来分析一下。 首先是第一个子层自注意力的计算,输入X(q),X(k),X(v)来自解码器侧路径的输入,推理模式则是由自己预测自回归的输入,训练模式是给定的。自注意力传入了因果掩码attn_mask和屏蔽pandding mask。 其次就是计算残差和层归一化,与编码器类似。 接着就是计算交叉注意力了,核心的注意力类还是MultiHeadAttention,跟编码器和解码器的都来自一个。唯一的区别就是传入的参数不一样,其中查询Q来自于解码器当前的状态X即解码器上一个自注意力的的输出,特征路径是解码器给的信息。而键值K,V则使用的是编码器的输出memory,不使用因果掩码,因为因果掩码前面已经处理了。 最后就是前馈网络的升维和降维处理等了,跟编码器就一样了,就不阐述了。 三个子层的不同作用: 自注意力层:处理目标序列内部的关系,生成"i have an apple"时,"have"应该关注"i","an"应该关注"i have",通过因果掩码确保只能看到历史信息。 交叉注意力层:让解码器"看到"编码器的信息,翻译成英文时,需要参考中文源序列,通过交叉注意力,解码器可以访问编码器的完整表示。 前馈网络则层:增加非线性表达能力,每个位置独立计算,不涉及位置间的关系。 注意力 接下来就是核心MultiHeadAttention。 MultiHeadAttention class MultiHeadAttention(nn.Module): """多头注意力(Batch-first) - 输入输出为 (B, L, C) - 内部将通道 C 切分到 H 个头,每头维度 Dh=C/H - 支持两类掩码: 1) attn_mask: (Lq, Lk) 下三角等自回归掩码 2) key_padding_mask: (B, Lk) 序列 padding 掩码 两者会在内部合并为可广播到 (B,H,Lq,Lk) 的布尔张量。 """ def __init__(self, d_model: int, nhead: int, dropout: float = 0.1): super().__init__() assert d_model % nhead == 0, "d_model 必须能被 nhead 整除" self.d_model = d_model self.nhead = nhead self.d_head = d_model // nhead self.w_q = nn.Linear(d_model, d_model) self.w_k = nn.Linear(d_model, d_model) self.w_v = nn.Linear(d_model, d_model) self.attn = ScaledDotProductAttention(dropout) self.proj = nn.Linear(d_model, d_model) self.dropout = nn.Dropout(dropout) # 将 (B, L, C) 重塑为 (B, L, H, Dh),原来的数据都不会变化,只是形状改变了 # 加了一个维,然后交换了张量维度顺序。 def _shape(self, x: torch.Tensor) -> torch.Tensor: """(B, L, C) 切分重排为 (B, H, L, Dh)。""" B, L, C = x.shape # 第一步:将 (B, L, C) 重塑为 (B, L, H, Dh) x_reshaped = x.view(B, L, self.nhead, self.d_head) #x.view不复制数据,只是改变数据的"视角",数据在内存中存储顺序不变 # 第二步:交换维度 1 和 2,从 (B, L, H, Dh) 变为 (B, H, L, Dh) x_transposed = x_reshaped.transpose(1, 2) return x_transposed def _merge(self, x: torch.Tensor) -> torch.Tensor: """(B, H, L, Dh) 合并重排回 (B, L, C)。""" B, H, L, Dh = x.shape # 第一步:交换维度 1 和 2,从 (B, H, L, Dh) 变为 (B, L, H, Dh) x_transposed = x.transpose(1, 2) # 第二步:确保内存连续,然后重塑为 (B, L, H*Dh) x_contiguous = x_transposed.contiguous() # 第三步:重塑为 (B, L, C) 其中 C = H * Dh x_reshaped = x_contiguous.view(B, L, H * Dh) return x_reshaped # 因为QKV算的是矩阵,在transformer中涉及到两个mask # 一个是attn_mask控制哪些位置可以相互关注,如因果掩码防止看未来 # 一个是key_padding_mask控制哪些位置是有效的,如填充token不应该被关注 # 因为都要计算所以把这两个使用|合并起来,一起跟QKV计算即可,否则得计算两次。 # 对于encode来说传参只会穿key_pandding_mask,另外一个没有 # 对于decoder来说,两个都会传递。 def _build_attn_mask( self, Lq: int, Lk: int, attn_mask: torch.Tensor | None, key_padding_mask: torch.Tensor | None, device: torch.device, ) -> torch.Tensor | None: """将两类掩码合并成 (1/ B, 1/ H, Lq, Lk) 可广播布尔张量。True 表示屏蔽。""" mask = None if attn_mask is not None: # (Lq, Lk) -> (1,1,Lq,Lk) m1 = attn_mask.to(device).unsqueeze(0).unsqueeze(0) mask = m1 if mask is None else (mask | m1) if key_padding_mask is not None: # (B, Lk) -> (B,1,1,Lk) m2 = key_padding_mask.to(device).unsqueeze(1).unsqueeze(1) mask = m2 if mask is None else (mask | m2) return mask (0)网络层定义 self.w_q = nn.Linear(d_model, d_model) # 查询线性变换 self.w_k = nn.Linear(d_model, d_model) # 键线性变换 self.w_v = nn.Linear(d_model, d_model) # 值线性变换 self.attn = ScaledDotProductAttention(dropout) # 缩放点积注意力 self.proj = nn.Linear(d_model, d_model) # 输出投影 self.dropout = nn.Dropout(dropout) # 输出dropout w_q, w_k, w_v: 将输入转换为查询、键、值表示,attn为计算注意力权重和加权求和,proj将多头结果投影会原始维度,dropout是防止过拟合。 (1)将输入分成多个头 对输入按照head划分为多份,所以这里需要注意的是d_model必现要能被nhead整除,确保每个头有相同的维度。如原来的输入为(B,L,C)切分后变成(B, H, L, Dh),Dh=d_model/nhead。 第一步先使用view重塑为(B, H, L, Dh),然后第二步进行重排。举个例子输入为(B, L, C) = (1, 4, 6)重塑为(B, L, H, Dh) = (1, 4, 2, 3),重塑后的内存布局,[word1_head1_3, word1_head2_3, word2_head1_3, word2_head2_3, ...]每个词的头是交错存储的,为了适应多头注意力的并行计算还要重排一下,让每个头的数据连续存储。 (2)掩码合并 将key_padding_mask和attn_mask(因果)进行合并,这样后续计算就不用计算两次了。 # 使用逻辑或运算 | 合并 # True | True = True (屏蔽) # True | False = True (屏蔽) # False | False = False (不屏蔽) # 最终掩码形状: (B, H, Lq, Lk) 或 (1, H, Lq, Lk) # 可以广播到注意力计算的形状 (3)每个头计算注意力 Q = self._shape(self.w_q(query)) # (B,H,Lq,Dh) K = self._shape(self.w_k(key)) # (B,H,Lk,Dh) V = self._shape(self.w_v(value)) # (B,H,Lk,Dh) mask = self._build_attn_mask(Lq, Lk, attn_mask, key_padding_mask, device) out = self.attn(Q, K, V, mask) # (B,H,Lq,Dh) 计算注意力时,首先对输入分别进行计算线性变换(如QxWq,这样就有参数了)然后重排分别得到QKV,对于编码器来说输入的query、key、value都是一样的,计算QKV的方式也是一样的,都是进行线性nn.Linear层然后再进行重排,但是各自有各自参数,这就是要训练的参数。经过线性层的结果后都需要调用_shape进行重排划分为多个头的数据,便于输入给多头注意力;构建好合并后的掩码之后,就传递到attn中计算注意力。计算出的多头的注意力,需要合并为原来的形状,最后再通过一个线性变化得到最后的结果输出。 完整的数据流示例: # 输入: query (1, 4, 6), key (1, 4, 6), value (1, 4, 6) # 参数: d_model=6, nhead=2, d_head=3 # 步骤1: 线性变换 (保持形状) # w_q(query): (1, 4, 6) -> (1, 4, 6) # w_k(key): (1, 4, 6) -> (1, 4, 6) # w_v(value): (1, 4, 6) -> (1, 4, 6) # 每个词从6维变换到6维 # 学习查询、键、值的表示 # 步骤2: 分头 # _shape(w_q(query)): (1, 4, 6) -> (1, 2, 4, 3) # _shape(w_k(key)): (1, 4, 6) -> (1, 2, 4, 3) # _shape(w_v(value)): (1, 4, 6) -> (1, 2, 4, 3) # 将6维分成2个头,每个头3维 # 头1: 3维表示 # 头2: 3维表示 # 步骤3: 注意力计算 # attn(Q, K, V, mask): (1, 2, 4, 3) -> (1, 2, 4, 3) # 每个头独立计算注意力: # 头1: 计算4个位置之间的注意力,每个位置3维 # 头2: 计算4个位置之间的注意力,每个位置3维 # 步骤4: 合并头 # _merge(out): (1, 2, 4, 3) -> (1, 4, 6) # 将2个头的3维表示合并回6维 # 每个位置现在包含所有头的信息 # 步骤5: 输出变换 # proj(out): (1, 4, 6) -> (1, 4, 6) # dropout(out): (1, 4, 6) -> (1, 4, 6) # 最终输出: (1, 4, 6) ScaledDotProductAttention class ScaledDotProductAttention(nn.Module): """缩放点积注意力(单头) 给定 Q(查询)、K(键)、V(值) 与掩码,计算注意力加权输出。 形状约定: - Q: (B, H, Lq, Dh) - K: (B, H, Lk, Dh) - V: (B, H, Lk, Dh) - mask: 可广播到 (B, H, Lq, Lk),True 表示屏蔽。 """ def __init__(self, dropout: float = 0.1): super().__init__() self.dropout = nn.Dropout(dropout) def forward(self, Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor, mask: torch.Tensor | None = None): """计算缩放点积注意力。 参数: - Q: (B, H, Lq, Dh) - K: (B, H, Lk, Dh) - V: (B, H, Lk, Dh) - mask: 可广播到 (B, H, Lq, Lk) 的布尔掩码,True 表示屏蔽 返回: - (B, H, Lq, Dh) """ d_k = Q.size(-1) # 注意力分数 = QK^T / sqrt(dk) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # (B,H,Lq,Lk) if mask is not None: # 对被屏蔽位置填充一个极小值,softmax 后 ~0 scores = scores.masked_fill(mask, float("-inf")) attn = torch.softmax(scores, dim=-1) # (B,H,Lq,Lk) attn = self.dropout(attn) out = torch.matmul(attn, V) # (B,H,Lq,Dh) return out 这里就是实现缩放点积注意力机制了,Q.transpose(-2, -1)将K的最后两个维度转置,torch.matmul(Q, K^T): 计算Q和K的点积,再math.sqrt(d_k): 缩放因子,防止分数过大。 可以看到会根据传入的mask进行处理,让mask=True的位置会被填充为-inf,这样经过softmax之后,这些位置就接近0,从而实现了屏蔽某位位置的效果。 softmax是将分数转换为概率分布,所有位置的权重和为1,分数越高的位置,权重越大,也就是跟词相关性越大提取的值越丰富,如果是0那基本不相关,掩码为true的位置就是0,也就是基本不提取信息。 总结一下,核心就是公式Attention(Q,K,V) = softmax(QK^T/√d_k)V计算。 应用 接下来就是调用应用了 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") dataset = ToyDataset(pairs) loader = DataLoader(dataset, batch_size=8, shuffle=True, collate_fn=collate_fn) model = Seq2SeqTransformer( src_vocab_size=len(SRC_ITOS), tgt_vocab_size=len(TGT_ITOS), d_model=6, nhead=3, num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1 ).to(device) criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX) optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4) 定义dataset、loader准备数据,然后定义模型model,损失函数定义以及优化方法。 def evaluate_sample(sent="我 有 一个 苹果"): """辅助函数:对输入中文句子进行编码→推理→解码并打印结果。""" ids = encode_src(sent) print("ids",ids) pred_ids = model.greedy_decode(ids, device=device) pred_text = decode_tgt(pred_ids) print(f'INPUT : {sent}') print(f'OUTPUT: {pred_text}\n') print("Before training:") evaluate_sample("我 有 一个 苹果") 上面是整个应用翻译应用,在没有训练出参数,自然预测出的结果是不对的。 EPOCHS = 800 # 小步数即可过拟合玩具数据 for epoch in range(1, EPOCHS + 1): model.train() total_loss = 0.0 for src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask in loader: src = src.to(device) tgt_in = tgt_in.to(device) tgt_out = tgt_out.to(device) src_pad_mask = src_pad_mask.to(device) tgt_pad_mask = tgt_pad_mask.to(device) logits = model(src, tgt_in, src_pad_mask, tgt_pad_mask) # (B, T, V) loss = criterion(logits.reshape(-1, logits.size(-1)), tgt_out.reshape(-1)) optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() total_loss += loss.item() if epoch % 5 == 0 or epoch == 1: print(f"Epoch {epoch:02d} | loss={total_loss/len(loader):.4f}") evaluate_sample("我 有 一个 苹果") 上面是训练过程。 常见问题 (1) 解码器训练时的输入和推理时的输入有什么不同? 训练模式是固定长度输入,例如(2,5),所有样本都padding到相同长度,批次内所有样本的长度一致。 # 使用教师强制,目标序列已知 tgt_in = [BOS, i, have, an, apple,PAD] # 完整的输入序列 tgt_out = [i, have, an, apple, EOS] # 完整的监督目标 而推理模式序列长度随着时间步逐步增长,例如# 例如: (1, 1) → (1, 2) → (1, 3) → ...,每次生成后长度+1。 # 逐步生成,每次只预测下一个token ys = [[BOS_ID]] # 第1步 ys = [[BOS_ID, i]] # 第2步 ys = [[BOS_ID, i, have]] # 第3步 ys = [[BOS_ID, i, have, an]] # 第4步 ys = [[BOS_ID, i, have, an,apple]] # 第5步 之所以有这样的差异是训练时用的是Teacher Forcing优势,使用了并行计算让所有位置可以同时计算预测,提高效率快速收敛。而推理时是自回归模式,每个token的生成只能基于之前输出的信息。 (2)什么情况下输入数据需要PAD? 通常无论是编码器的输入还是解码器的输入如果不是批量并行计算都可以不用PAD,但如果是批量并行都需要PAD MASK。 在训练模式下,为了提高效率需要批量并行计算,所以无论编码器还是解码器的输入都是需要PAD,在本文中要不要PAD动作是在DataLoader的回调函数中collate_fn进行的,会对编码器和解码器的输入都会pad对齐到一样的长度。 因此最主要的考量是否要批量并行计算,因为并行计算如果长度不同,无法并行处理,无论是自注意力分数、前馈网络、还是残差连接,只有长度一致,才能并行一下处理多个样本。而往往训练模型基本都是批量处理。 总之只处理一个样本时可以不需要PAD,如果要批量都一定需要PAD。而只处理一个样本,往往是推理模式场景。 (3)既然推理模式的编码器和解码器输入没有进行PAD到一定长度,那为什么无论编码器和解码器都依旧还需要传入PAD mask? 需要PAD mask我认为本质上有两点原因:其一用于告知模型输入序列的长度,其二为了接口的一致性,因为transformer最核心的是无论编码器还是解码器最终的核心是Scaled Dot-Product Attetion,可以理解为这是一个共有底层函数,都要调用,做兼容了所以一定要传这个参数。 (3)推理模式的解码器既然是一个一个token往后生成的然后依次拼接回给到输入,未来的词其实根本就没有输入,为什么还需要下三角度的因果mask? 本质上还是保证接口的兼容性,这块都无论是推理还是训练模式都需要传入这个因果mask。 首先在实现层面让训练模式和推理模式代码能够兼容,训练模式使用的是teacher forcing把整个目标序列一次性喂进去,那自然不能让模型看到未来token。推理模式严格上如果一次一个token,每次只输入已经生成的部分,在这种最简单的视线下,确实不需要再加下三角mask,因为未来token不存在,自然无法attend到。但是大多数框架都选择统一接口,无论训练还是推理都传causal mask,避免在不同模式下切换逻辑。 其次从推理模式的多样性考虑,即使是推理阶段,也有可能遇到这种情况,也就是批量生成,一次生成多个序列,每个序列长度不同。 下三角是一个通用的"未来屏蔽"机制,不只是为了防止模型看见未来token,也是为了让实现和训练推理保持一致,并支持批量/并行推理优化。 附:完整源码 # toy_transformer_translation.py # A tiny, runnable Transformer seq2seq example to translate Chinese->English on a toy dataset. # PyTorch >= 2.0 recommended. import math import random from dataclasses import dataclass from typing import List, Tuple import torch import torch.nn as nn from torch.utils.data import DataLoader, Dataset random.seed(0) torch.manual_seed(0) # -------------------------- # 1) Toy parallel corpus # -------------------------- pairs = [ # 基本陈述 ("我 有 一个 苹果", "i have an apple"), ("我 有 一本 书", "i have a book"), ("你 有 一个 苹果", "you have an apple"), ("他 有 一个 苹果", "he has an apple"), ("她 有 一个 苹果", "she has an apple"), ("我们 有 一个 苹果", "we have an apple"), ("我 喜欢 苹果", "i like apples"), ("我 吃 苹果", "i eat apples"), ("你 喜欢 书", "you like books"), ("我 喜欢 书", "i like books"), # 稍作扩展 ("我 有 两个 苹果", "i have two apples"), ("我 有 红色 苹果", "i have red apples"), ] # 中文使用"空格分词(简化)",英文用空格分词 def build_vocab(examples: List[str]): """构建词表(字符串→索引 与 索引→字符串) - 输入示例为用空格分词后的句子列表 - 加入特殊符号 `<pad>`, `<bos>`, `<eos>` 并将其它 token 排序,保证可复现 返回: stoi: dict[token->id] itos: List[id->token] """ tokens = set() # 建立一个集合,用于存储所有不同的token for s in examples: # 遍历所有句子,s是句子,如我 有 一个 苹果 for t in s.split(): # 遍历句子中的每个token,t是token,如我 tokens.add(t.lower()) # 将token添加到集合中,并转换为小写,如我 # 特殊符号 itos = ["<pad>", "<bos>", "<eos>"] + sorted(tokens) # 将特殊符号和所有不同的token排序 # print(itos) stoi = {t: i for i, t in enumerate(itos)} # 将token和索引建立映射关系 # print(stoi) return stoi, itos src_texts = [p[0] for p in pairs] tgt_texts = [p[1] for p in pairs] print("src_texts",src_texts) print("tgt_texts",tgt_texts) SRC_STOI, SRC_ITOS = build_vocab(src_texts) print("SRC_STOI",SRC_STOI) print("SRC_ITOS",SRC_ITOS) TGT_STOI, TGT_ITOS = build_vocab(tgt_texts) print("TGT_STOI",TGT_STOI) print("TGT_ITOS",TGT_ITOS) PAD_IDX, BOS_IDX, EOS_IDX = 0, 1, 2 #将源语句编码为索引序列(不含 BOS/EOS),如我 有 一个 苹果 -> [1, 2, 3, 4] def encode_src(s: str) -> List[int]: """将原语句(已空格分词)编码为索引序列(不含 BOS/EOS)。""" return [SRC_STOI[w.lower()] for w in s.split()] def encode_tgt(s: str) -> List[int]: """将目标语句编码为索引序列,并在首尾添加 BOS/EOS。""" return [BOS_IDX] + [TGT_STOI[w.lower()] for w in s.split()] + [EOS_IDX] def decode_tgt(ids: List[int]) -> str: """将目标端索引序列解码回字符串(忽略 PAD/BOS,遇到 EOS 停止)。""" words = [] for i in ids: if i == EOS_IDX: break if i in (PAD_IDX, BOS_IDX): continue words.append(TGT_ITOS[i]) return " ".join(words) @dataclass class Example: """单条并行样本 - src: 源语言索引序列(不含 BOS/EOS) - tgt: 目标语言索引序列(含 BOS/EOS) """ src: List[int] tgt: List[int] class ToyDataset(Dataset): """极小玩具平行语料数据集,用于快速过拟合演示。""" def __init__(self, pairs: List[Tuple[str, str]]): self.data = [Example(encode_src(s), encode_tgt(t)) for s, t in pairs] def __len__(self): return len(self.data) def __getitem__(self, idx): return self.data[idx] def collate_fn(batch: List[Example]): """将一个 batch 的样本对齐为等长张量,并构造 teacher forcing 所需的输入/输出。 返回: - src: (B,S) 源序列,已 padding - tgt_in: (B,T) 解码器输入(含 BOS,右对齐 padding) - tgt_out: (B,T) 解码器监督目标(对 tgt_in 右移一位,含 EOS) - src_pad_mask: (B,S) 源端 padding 掩码,True 表示 padding 位置 - tgt_pad_mask: (B,T) 目标端 padding 掩码(针对输入序列) """ # padding to max length in batch src_max = max(len(b.src) for b in batch) tgt_max = max(len(b.tgt) for b in batch) src_batch = [] tgt_in_batch = [] tgt_out_batch = [] for ex in batch: src = ex.src + [PAD_IDX] * (src_max - len(ex.src)) # Teacher forcing: shift-in, shift-out tgt_in = ex.tgt[:-1] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[:-1])) tgt_out = ex.tgt[1:] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[1:])) src_batch.append(src) tgt_in_batch.append(tgt_in) tgt_out_batch.append(tgt_out) src = torch.tensor(src_batch, dtype=torch.long) # (B, S) tgt_in = torch.tensor(tgt_in_batch, dtype=torch.long) # (B, T_in) tgt_out = torch.tensor(tgt_out_batch, dtype=torch.long) # (B, T_out) src_pad_mask = src.eq(PAD_IDX) # (B, S) tgt_pad_mask = tgt_in.eq(PAD_IDX) # (B, T) return src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask # -------------------------- # 2) Positional encoding # -------------------------- class PositionalEncoding(nn.Module): """经典正弦/余弦位置编码。 给定嵌入 `x (B,L,C)`,按长度切片并与位置编码相加,再做 dropout。 """ def __init__(self, d_model: int, max_len: int = 5000, dropout: float = 0.1): super().__init__() self.dropout = nn.Dropout(dropout) # 创建一个形状为 (max_len, d_model) 的零张量,用于存储位置编码 pe = torch.zeros(max_len, d_model) # (L, C) # 创建一个形状为 (max_len, 1) 的张量,用于存储位置索引 position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (L, 1) # 创建一个形状为 (d_model//2,) 的张量,用于存储位置编码的缩放因子 div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # sin, cos 交错 pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0) # (1, L, C) self.register_buffer("pe", pe) def forward(self, x: torch.Tensor): # (B, L, C) """为输入嵌入添加位置编码并做 dropout。 参数: - x: (B, L, C) 返回: - (B, L, C) """ x = x + self.pe[:, : x.size(1)] return self.dropout(x) # -------------------------- # 3) 手写 Transformer 编码/解码层(含详细注释) # -------------------------- class ScaledDotProductAttention(nn.Module): """缩放点积注意力(单头) 给定 Q(查询)、K(键)、V(值) 与掩码,计算注意力加权输出。 形状约定: - Q: (B, H, Lq, Dh) - K: (B, H, Lk, Dh) - V: (B, H, Lk, Dh) - mask: 可广播到 (B, H, Lq, Lk),True 表示屏蔽。 """ def __init__(self, dropout: float = 0.1): super().__init__() self.dropout = nn.Dropout(dropout) def forward(self, Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor, mask: torch.Tensor | None = None): """计算缩放点积注意力。 参数: - Q: (B, H, Lq, Dh) - K: (B, H, Lk, Dh) - V: (B, H, Lk, Dh) - mask: 可广播到 (B, H, Lq, Lk) 的布尔掩码,True 表示屏蔽 返回: - (B, H, Lq, Dh) """ d_k = Q.size(-1) # 注意力分数 = QK^T / sqrt(dk) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # (B,H,Lq,Lk) if mask is not None: # 对被屏蔽位置填充一个极小值,softmax 后 ~0 scores = scores.masked_fill(mask, float("-inf")) attn = torch.softmax(scores, dim=-1) # (B,H,Lq,Lk) attn = self.dropout(attn) out = torch.matmul(attn, V) # (B,H,Lq,Dh) return out class MultiHeadAttention(nn.Module): """多头注意力(Batch-first) - 输入输出为 (B, L, C) - 内部将通道 C 切分到 H 个头,每头维度 Dh=C/H - 支持两类掩码: 1) attn_mask: (Lq, Lk) 下三角等自回归掩码 2) key_padding_mask: (B, Lk) 序列 padding 掩码 两者会在内部合并为可广播到 (B,H,Lq,Lk) 的布尔张量。 """ def __init__(self, d_model: int, nhead: int, dropout: float = 0.1): super().__init__() assert d_model % nhead == 0, "d_model 必须能被 nhead 整除" self.d_model = d_model self.nhead = nhead self.d_head = d_model // nhead self.w_q = nn.Linear(d_model, d_model) self.w_k = nn.Linear(d_model, d_model) self.w_v = nn.Linear(d_model, d_model) self.attn = ScaledDotProductAttention(dropout) self.proj = nn.Linear(d_model, d_model) self.dropout = nn.Dropout(dropout) # 将 (B, L, C) 重塑为 (B, L, H, Dh),原来的数据都不会变化,只是形状改变了 # 加了一个维,然后交换了张量维度顺序。 def _shape(self, x: torch.Tensor) -> torch.Tensor: """(B, L, C) 切分重排为 (B, H, L, Dh)。""" B, L, C = x.shape # 第一步:将 (B, L, C) 重塑为 (B, L, H, Dh) x_reshaped = x.view(B, L, self.nhead, self.d_head) #x.view不复制数据,只是改变数据的"视角",数据在内存中存储顺序不变 # 第二步:交换维度 1 和 2,从 (B, L, H, Dh) 变为 (B, H, L, Dh) x_transposed = x_reshaped.transpose(1, 2) return x_transposed def _merge(self, x: torch.Tensor) -> torch.Tensor: """(B, H, L, Dh) 合并重排回 (B, L, C)。""" B, H, L, Dh = x.shape # 第一步:交换维度 1 和 2,从 (B, H, L, Dh) 变为 (B, L, H, Dh) x_transposed = x.transpose(1, 2) # 第二步:确保内存连续,然后重塑为 (B, L, H*Dh) x_contiguous = x_transposed.contiguous() # 第三步:重塑为 (B, L, C) 其中 C = H * Dh x_reshaped = x_contiguous.view(B, L, H * Dh) return x_reshaped # 因为QKV算的是矩阵,在transformer中涉及到两个mask # 一个是attn_mask控制哪些位置可以相互关注,如因果掩码防止看未来 # 一个是key_padding_mask控制哪些位置是有效的,如填充token不应该被关注 # 因为都要计算所以把这两个使用|合并起来,一起跟QKV计算即可,否则得计算两次。 # 对于encode来说传参只会穿key_pandding_mask,另外一个没有 # 对于decoder来说,两个都会传递。 def _build_attn_mask( self, Lq: int, Lk: int, attn_mask: torch.Tensor | None, key_padding_mask: torch.Tensor | None, device: torch.device, ) -> torch.Tensor | None: """将两类掩码合并成 (1/ B, 1/ H, Lq, Lk) 可广播布尔张量。True 表示屏蔽。""" mask = None if attn_mask is not None: # (Lq, Lk) -> (1,1,Lq,Lk) m1 = attn_mask.to(device).unsqueeze(0).unsqueeze(0) mask = m1 if mask is None else (mask | m1) if key_padding_mask is not None: # (B, Lk) -> (B,1,1,Lk) m2 = key_padding_mask.to(device).unsqueeze(1).unsqueeze(1) mask = m2 if mask is None else (mask | m2) return mask def forward( self, query: torch.Tensor, key: torch.Tensor, value: torch.Tensor, attn_mask: torch.Tensor | None = None, key_padding_mask: torch.Tensor | None = None, ) -> torch.Tensor: """多头注意力前向。 参数: - query, key, value: (B, L, C) - attn_mask: (Lq, Lk) 因果/结构掩码,True 为屏蔽 - key_padding_mask: (B, Lk) padding 掩码,True 为 padding 返回: - (B, Lq, C) """ # 输入均为 (B, L, C) B, Lq, _ = query.shape _, Lk, _ = key.shape device = query.device Q = self._shape(self.w_q(query)) # (B,H,Lq,Dh) K = self._shape(self.w_k(key)) # (B,H,Lk,Dh) V = self._shape(self.w_v(value)) # (B,H,Lk,Dh) mask = self._build_attn_mask(Lq, Lk, attn_mask, key_padding_mask, device) out = self.attn(Q, K, V, mask) # (B,H,Lq,Dh) out = self._merge(out) # (B,Lq,C) out = self.proj(out) out = self.dropout(out) return out class PositionwiseFeedForward(nn.Module): """前馈网络:逐位置的两层 MLP(含激活与 dropout)""" def __init__(self, d_model: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.fc1 = nn.Linear(d_model, dim_ff) self.fc2 = nn.Linear(dim_ff, d_model) self.act = nn.ReLU() self.dropout = nn.Dropout(dropout) def forward(self, x: torch.Tensor) -> torch.Tensor: """两层逐位置前馈网络。 参数: - x: (B, L, C) 返回: - (B, L, C) """ x = self.fc2(self.dropout(self.act(self.fc1(x)))) x = self.dropout(x) return x class EncoderLayer(nn.Module): """Transformer 编码层(后归一化 post-norm 版本) 子层:自注意力 + 前馈;均带残差连接与 LayerNorm。 """ def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.self_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm1 = nn.LayerNorm(d_model) self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout) self.norm2 = nn.LayerNorm(d_model) def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor: """单层编码层前向。 参数: - x: (B, S, C) - src_key_padding_mask: (B, S) True 为 padding 返回: - (B, S, C) """ # 自注意力子层 attn_out = self.self_attn(x, x, x, attn_mask=None, key_padding_mask=src_key_padding_mask) x = self.norm1(x + attn_out) # 前馈子层 ff_out = self.ff(x) x = self.norm2(x + ff_out) return x class DecoderLayer(nn.Module): """Transformer 解码层(自注意力 + 交叉注意力 + 前馈)""" def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.self_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm1 = nn.LayerNorm(d_model) self.cross_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm2 = nn.LayerNorm(d_model) self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout) self.norm3 = nn.LayerNorm(d_model) def forward( self, x: torch.Tensor, memory: torch.Tensor, tgt_mask: torch.Tensor | None = None, tgt_key_padding_mask: torch.Tensor | None = None, memory_key_padding_mask: torch.Tensor | None = None, ) -> torch.Tensor: """单层解码层前向。 参数: - x: (B, T, C) 解码器输入 - memory: (B, S, C) 编码器输出 - tgt_mask: (T, T) 因果掩码,true为屏蔽 - tgt_key_padding_mask: (B, T) - memory_key_padding_mask: (B, S) 返回: - (B, T, C) """ # 1) 解码器自注意力(带因果掩码 tgt_mask) sa = self.self_attn(x, x, x, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask) x = self.norm1(x + sa) # 2) 交叉注意力:Q 来自解码器,K/V 来自编码器 memory ca = self.cross_attn(x, memory, memory, attn_mask=None, key_padding_mask=memory_key_padding_mask) x = self.norm2(x + ca) # 3) 前馈 ff = self.ff(x) x = self.norm3(x + ff) return x class Encoder(nn.Module): def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1): super().__init__() self.layers = nn.ModuleList([ EncoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers) ]) def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor: """堆叠若干编码层。 参数: - x: (B, S, C) - src_key_padding_mask: (B, S) True 为 padding 返回: - (B, S, C) """ for layer in self.layers: x = layer(x, src_key_padding_mask=src_key_padding_mask) return x class Decoder(nn.Module): def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1): super().__init__() self.layers = nn.ModuleList([ DecoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers) ]) def forward( self, x: torch.Tensor, memory: torch.Tensor, tgt_mask: torch.Tensor | None = None, tgt_key_padding_mask: torch.Tensor | None = None, memory_key_padding_mask: torch.Tensor | None = None, ) -> torch.Tensor: """堆叠若干解码层。 参数: - x: (B, T, C) 目标端嵌入 - memory: (B, S, C) 编码器输出 - tgt_mask: (T, T) 因果掩码,True 为屏蔽 - tgt_key_padding_mask: (B, T) 目标端 padding 掩码 - memory_key_padding_mask: (B, S) 源端 padding 掩码 返回: - (B, T, C) """ for layer in self.layers: x = layer( x, memory, tgt_mask=tgt_mask, tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=memory_key_padding_mask, ) return x class Seq2SeqTransformer(nn.Module): """最小可运行的手写 Transformer 序列到序列模型 - 使用我们实现的 Encoder/Decoder/MHA/FFN - 仍保持与上文训练/解码接口一致 """ def __init__(self, src_vocab_size, tgt_vocab_size, d_model=128, nhead=4, num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1): super().__init__() self.d_model = d_model self.src_tok = nn.Embedding(src_vocab_size, d_model, padding_idx=PAD_IDX) self.tgt_tok = nn.Embedding(tgt_vocab_size, d_model, padding_idx=PAD_IDX) self.pos_enc = PositionalEncoding(d_model, dropout=dropout) self.encoder = Encoder(d_model, nhead, dim_ff, num_encoder_layers, dropout) self.decoder = Decoder(d_model, nhead, dim_ff, num_decoder_layers, dropout) self.generator = nn.Linear(d_model, tgt_vocab_size) def make_subsequent_mask(self, sz: int) -> torch.Tensor: """构造大小为 (sz, sz) 的下三角因果掩码;True 为屏蔽(不允许看未来)。""" return torch.triu(torch.ones(sz, sz, dtype=torch.bool), diagonal=1) def forward(self, src, tgt_in, src_pad_mask, tgt_pad_mask): """训练/教师强制阶段的前向。 参数: - src: (B, S) 源 token id - tgt_in: (B, T) 目标端输入(以 BOS 开头) - src_pad_mask: (B, S) True 为 padding - tgt_pad_mask: (B, T) True 为 padding(针对 tgt_in) 返回: - logits: (B, T, V) 词表维度的分类分布 """ # 1) 词嵌入 + 位置编码 src_emb = self.pos_enc(self.src_tok(src)) # (B,S,C) tgt_emb = self.pos_enc(self.tgt_tok(tgt_in)) # (B,T,C) # 2) 编码:仅使用 key_padding_mask 屏蔽 padding memory = self.encoder(src_emb, src_key_padding_mask=src_pad_mask) # (B,S,C) # 3) 解码:自注意力需要因果掩码 + padding 掩码;交叉注意力需要 memory 的 padding 掩码 tgt_mask = self.make_subsequent_mask(tgt_in.size(1)).to(src.device) # (T,T) out = self.decoder( tgt_emb, memory, tgt_mask=tgt_mask, tgt_key_padding_mask=tgt_pad_mask, memory_key_padding_mask=src_pad_mask, ) # (B,T,C) logits = self.generator(out) return logits @torch.no_grad() def greedy_decode(self, src_ids: List[int], max_len=20, device="cpu"): """在推理阶段进行贪心解码。 参数: - src_ids: 源端 token id 序列(不含 BOS/EOS) - max_len: 最大生成长度(含 BOS/EOS) - device: 运行设备 返回: - 生成的目标端 id 序列(含 BOS/EOS) """ #切换为评估模式,关闭dropout/batchnorm等随机性 self.eval() # 将源端token id序列转换为张量,并添加一个维度,如[1, 2, 3, 4] -> [[1, 2, 3, 4]] # 变为批维度的 (1, S);dtype 为 long 主要是以适配 nn.Embedding的输入格式。 src = torch.tensor(src_ids, dtype=torch.long, device=device).unsqueeze(0) # 生成一个跟src相同形状的mask矩阵,让编码器不要计算提取pandding的位置信息。 #按元素判断 src 是否等于 PAD_IDX,等于的位置为 True,不等的位置为 False。 src_pad_mask = src.eq(PAD_IDX) # 计算src_tok= src 经过词嵌入+位置编码后的结果 src_tok = self.src_tok(src) src_pos = self.pos_enc(src_tok) # 将该结果送入编码器,返回的memory就是编码器提取的特征向量。 # 输入编码器,即使没有填充(pandding)的token,也需要传入src_key_padding_mask。 memory = self.encoder(src_pos, src_key_padding_mask=src_pad_mask) # 初始化目标端token id序列,维度为(1,1),初始值为BOS_IDX # 表示目标端序列的开始,BOS_IDX=1 # 推理时输入是没有PAD,但是仍然需要tgt_pad_mask. ys = torch.tensor([[BOS_IDX]], dtype=torch.long, device=device) for _ in range(max_len - 1): #计算本次解码的Mask,跟ys形状一样。 tgt_pad_mask = ys.eq(PAD_IDX) # 计算本次因果掩码,把未来看到的token都屏蔽。 tgt_mask = self.make_subsequent_mask(ys.size(1)).to(device) # 可以看到当推理模式时,解码器输入token数量依次是1,2,3,4..... out = self.decoder( self.pos_enc(self.tgt_tok(ys)), memory, tgt_key_padding_mask=tgt_pad_mask, memory_key_padding_mask=src_pad_mask, ) # 转化为预测词的概率分布 logits = self.generator(out[:, -1:, :]) # 使用贪心选择概率最大的作为本次预测的目标 next_token = logits.argmax(-1) next_id = next_token.item() # 显示选择的token token_text = TGT_ITOS[next_id] if next_id < len(TGT_ITOS) else f"ID_{next_id}" print(f"选择: {token_text}({next_id})") ys = torch.cat([ys, next_token], dim=1) if next_id == EOS_IDX: break return ys.squeeze(0).tolist() # -------------------------- # 4) Train # -------------------------- device = torch.device("cuda" if torch.cuda.is_available() else "cpu") dataset = ToyDataset(pairs) loader = DataLoader(dataset, batch_size=8, shuffle=True, collate_fn=collate_fn) model = Seq2SeqTransformer( src_vocab_size=len(SRC_ITOS), tgt_vocab_size=len(TGT_ITOS), d_model=6, nhead=3, num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1 ).to(device) criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX) optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4) def evaluate_sample(sent="我 有 一个 苹果"): """辅助函数:对输入中文句子进行编码→推理→解码并打印结果。""" ids = encode_src(sent) print("ids",ids) pred_ids = model.greedy_decode(ids, device=device) pred_text = decode_tgt(pred_ids) print(f'INPUT : {sent}') print(f'OUTPUT: {pred_text}\n') print("Before training:") evaluate_sample("我 有 一个 苹果") EPOCHS = 80 # 小步数即可过拟合玩具数据 for epoch in range(1, EPOCHS + 1): model.train() total_loss = 0.0 for src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask in loader: src = src.to(device) tgt_in = tgt_in.to(device) tgt_out = tgt_out.to(device) src_pad_mask = src_pad_mask.to(device) tgt_pad_mask = tgt_pad_mask.to(device) logits = model(src, tgt_in, src_pad_mask, tgt_pad_mask) # (B, T, V) loss = criterion(logits.reshape(-1, logits.size(-1)), tgt_out.reshape(-1)) optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() total_loss += loss.item() if epoch % 5 == 0 or epoch == 1: print(f"Epoch {epoch:02d} | loss={total_loss/len(loader):.4f}") evaluate_sample("我 有 一个 苹果") print("After training:") evaluate_sample("我 有 一个 苹果") evaluate_sample("我 有 一本 书") evaluate_sample("你 有 一个 苹果") -
dataset和DataLoader
简介 Dataset和DataLoader在pytorch中主要用于数据的组织。这两个类通常一起搭配处理深度学习中的数据流。 Dataset 用于产出“单个样本”:定义怎么按索引取到一个样本,以及总共有多少个样本。 DataLoader 负责“成批取样”:决定批大小、是否打乱、多进程加载、并用 collate_fn 把一个批里的样本“拼起来”(对齐、padding、mask、teacher forcing 等)。 一句话记忆:Dataset 只管“单条样本”;DataLoader 负责“多条怎么一起、怎么并行、怎么对齐”。变长就写 collate_fn,性能就调 workers/pin_memory/分桶。 Dataset Dataset类作用:定义数据集的统一接口,支持自定义数据加载逻辑。 关键方法: init:初始化数据路径、预处理函数等。 len:返回数据集样本总数。 getitem:根据索引返回单个样本(数据+标签)。 通常情况下用户都会有自己的数据集,所以定义的数据集类继承dataset。 #准备一个数据集 pairs: List[Tuple[str, str]] = [ ("我 有 一个 苹果", "i have an apple"), ("我 有 一本 书", "i have a book"), ("你 喜欢 书", "you like books"), ("我 吃 苹果", "i eat apples"), ] def build_vocab(texts: List[str]): tokens = set() for s in texts: tokens.update([w.lower() for w in s.split()]) itos = ["<pad>", "<bos>", "<eos>"] + sorted(tokens) stoi = {t: i for i, t in enumerate(itos)} return stoi, itos src_texts = [s for s, _ in pairs] tgt_texts = [t for _, t in pairs] SRC_STOI, SRC_ITOS = build_vocab(src_texts) TGT_STOI, TGT_ITOS = build_vocab(tgt_texts) PAD_IDX, BOS_IDX, EOS_IDX = 0, 1, 2 def encode_src(s: str) -> List[int]: return [SRC_STOI[w.lower()] for w in s.split()] def encode_tgt(s: str) -> List[int]: return [BOS_IDX] + [TGT_STOI[w.lower()] for w in s.split()] + [EOS_IDX] # Dataset:定义“单样本怎么取” @dataclass class Example: src: List[int] tgt: List[int] class ToyDataset(Dataset): def __init__(self, pairs: List[Tuple[str, str]]): for s, t in pairs: print("encode_src(s)",encode_src(s)) print("encode_tgt(t)",encode_tgt(t)) self.data = [Example(encode_src(s), encode_tgt(t)) for s, t in pairs] def __len__(self) -> int: return len(self.data) def __getitem__(self, idx: int) -> Example: return self.data[idx] 样本结构:用 Example(src: List[int], tgt: List[int]) 表示一条样本的源序列与目标序列(都是 token id 列表)。 词表与编码:源序列仅分词并映射到 id。目标序列前加 bos、后加 eos,便于自回归训练。 协议:实现 len 和 getitem 两个方法即可被 DataLoader 使用。 DataLoader class torch.utils.data.DataLoader(Data[T_co]): def __init__( self, dataset, batch_size: int = 1, shuffle: bool | None = None, sampler = None, batch_sampler = None, num_workers: int = 0, collate_fn = None, pin_memory: bool = False, drop_last: bool = False, timeout: float = 0, worker_init_fn = None, multiprocessing_context = None, generator = None, prefetch_factor: int = 2, persistent_workers: bool = False, pin_memory_device: str = "" ): ... dataset: Dataset 或 IterableDataset 实例。 batch_size: 每批样本数。 shuffle: 是否在每个 epoch 打乱索引(Map-style 且未显式传 sampler 时有效)。 sampler: 自定义样本采样器(与 shuffle 互斥;指定它就不要再用 shuffle)。 batch_sampler: 一次直接产出“一个 batch 的索引列表”(与 batch_size、shuffle、sampler 互斥)。 num_workers: 进程数(0 为主进程;>0 开多进程并行加载)。 collate_fn(samples_list) -> batch: 批内拼接函数;变长序列需要自定义(默认会尝试堆叠等长 tensor)。 pin_memory: 将 batch 固定到页锁内存,配合 CUDA 加速 H2D 拷贝。 drop_last: 数据量不是 batch_size 整数倍时,是否丢弃最后不满的一批。 timeout: 从 worker 等待数据的秒数(>0 时生效)。 worker_init_fn(worker_id): 每个 worker 的初始化回调(设随机种子、打开文件等)。 multiprocessing_context: 指定多进程上下文(spawn/forkserver 等)。 generator: 控制随机性(打乱、采样)用的随机数生成器。 prefetch_factor: 每个 worker 预取多少个 batch(num_workers > 0 时有效)。 persistent_workers: True 时 DataLoader 第一次迭代后保持 worker 不销毁,提高多轮迭代性能。 pin_memory_device: 当 pin_memory=True 时,指定固定内存的设备标签(一般留空即可)。 DataLoader返回是一个可迭代的对象,每次迭代产出一个批次的样本。一个批次的内容就是把当批样本列表交给 collate_fn 的返回值(若未自定义,则用 PyTorch 的默认 default_collate)。而类型取决于两点Dataset.getitem 返回什么(tensor/数值/dict/tuple…)和collate_fn 如何把一批“样本列表”拼成“批次”。 这里重点阐述一下collate_fn是一个用户需要注册的回调函数,目的是要把一个批的样本拼接起来。同时对于输入样本如果张量的形状不一致如变长序列,进行padding、对齐、mask等动作。 def collate_fn(batch: List[Example]): src_max = max(len(b.src) for b in batch) tgt_max = max(len(b.tgt) for b in batch) src_batch: List[List[int]] = [] tgt_in_batch: List[List[int]] = [] tgt_out_batch: List[List[int]] = [] for ex in batch: src = ex.src + [PAD_IDX] * (src_max - len(ex.src)) # teacher forcing:输入去掉最后一个、输出去掉第一个 tgt_in = ex.tgt[:-1] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[:-1])) tgt_out = ex.tgt[1:] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[1:])) src_batch.append(src) tgt_in_batch.append(tgt_in) tgt_out_batch.append(tgt_out) src = torch.tensor(src_batch, dtype=torch.long) # (B,S) tgt_in = torch.tensor(tgt_in_batch, dtype=torch.long) # (B,T) tgt_out = torch.tensor(tgt_out_batch, dtype=torch.long) # (B,T) src_pad_mask = src.eq(PAD_IDX) # (B,S) True=PAD tgt_pad_mask = tgt_in.eq(PAD_IDX) # (B,T) True=PAD return src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask 输入:batch 是若干个 Example,每个包含 src: List[int] 与 tgt: List[int](目标序列已含 bos/eos)。 核心:对齐变长序列(右侧 padding),构造 teacher forcing 的 (tgt_in, tgt_out),并生成 padding 掩码。 输出: src: (B, S) tgt_in: (B, T) tgt_out: (B, T) src_pad_mask: (B, S);True=PAD tgt_pad_mask: (B, T);True=PAD 首先使用src_max/tgt_max计算批内最长长度,这样能够将所有样本右侧补到同一长度,方便堆叠为矩阵。 接着定义批内累积的容器src_batch,tgt_in_batch,tgt_out_batch。 src_batch: 编码器输入样本的批次。 tgt_in_batch:解码器输入样本的批次。 tgt_out_batch:解码器输出样本的批次。 其次使用for循环对每个样本进行补齐,使其跟src_max、tgt_max长度一致,[PAD_IDX] * (src_max - len(ex.src))的意思是将[PAD_IDX]的单元素列表重复src_max - len(ex.src)用于拼接追加到ex.src后,使其对齐。tgt_in和tgt_out同理。 在对tgt_in和tgt_out做样本补齐时,因为输入ex.tgt是包含了bos和eos目标序列,对于tgt_in输入需要去掉最后一个token bos,tgt_out输出需要去掉第一个token eos。 然后就是将补齐的序列依次添加到src_batch,tgt_in_batch,tgt_out_batch。这样就对输入的数据进行了分类,把编码器的输入整合了在一起,解码器的输入和输出整合了一起。 最后就是将批内对齐后的源序列列表转换为张量,同时计算src和tag_in的mask,也就是说对数据哪些位置添加了pad。 下面是collate_fn相关的打印数据,便于理解。 batch [Example(src=[9, 10, 3, 11], tgt=[1, 11, 10, 4, 5, 2]), Example(src=[6, 8, 5], tgt=[1, 13, 12, 8, 2])] src [9, 10, 3, 11] tgt_in [1, 11, 10, 4, 5] tgt_out [11, 10, 4, 5, 2] src [6, 8, 5, 0] tgt_in [1, 13, 12, 8, 0] tgt_out [13, 12, 8, 2, 0] src_batch [[9, 10, 3, 11], [6, 8, 5, 0]] tgt_in_batch [[1, 11, 10, 4, 5], [1, 13, 12, 8, 0]] tgt_out_batch [[11, 10, 4, 5, 2], [13, 12, 8, 2, 0]] src tensor([[ 9, 10, 3, 11], [ 6, 8, 5, 0]]) tgt_in tensor([[ 1, 11, 10, 4, 5], [ 1, 13, 12, 8, 0]]) tgt_out tensor([[11, 10, 4, 5, 2], [13, 12, 8, 2, 0]]) src_pad_mask tensor([[False, False, False, False], [False, False, False, True]]) tgt_pad_mask tensor([[False, False, False, False, False], [False, False, False, False, True]]) src tensor([[ 9, 10, 3, 11], [ 6, 8, 5, 0]]) tgt_in tensor([[ 1, 11, 10, 4, 5], [ 1, 13, 12, 8, 0]]) tgt_out tensor([[11, 10, 4, 5, 2], [13, 12, 8, 2, 0]]) src_mask tensor([[False, False, False, False], [False, False, False, True]]) tgt_mask tensor([[False, False, False, False, False], [False, False, False, False, True]]) 最后完整的示例代码 #!/usr/bin/env python3 """ 最小可运行示例:用 Dataset + DataLoader(含 collate_fn)演示变长序列如何拼批并生成 padding 掩码。 运行: python3 dataloader_demo.py """ from dataclasses import dataclass from typing import List, Tuple import torch from torch.utils.data import Dataset, DataLoader # -------------------------- # 1) 准备一点语料(空格分词) # -------------------------- pairs: List[Tuple[str, str]] = [ ("我 有 一个 苹果", "i have an apple"), ("我 有 一本 书", "i have a book"), ("你 喜欢 书", "you like books"), ("我 吃 苹果", "i eat apples"), ] def build_vocab(texts: List[str]): tokens = set() for s in texts: tokens.update([w.lower() for w in s.split()]) itos = ["<pad>", "<bos>", "<eos>"] + sorted(tokens) stoi = {t: i for i, t in enumerate(itos)} return stoi, itos src_texts = [s for s, _ in pairs] tgt_texts = [t for _, t in pairs] SRC_STOI, SRC_ITOS = build_vocab(src_texts) TGT_STOI, TGT_ITOS = build_vocab(tgt_texts) PAD_IDX, BOS_IDX, EOS_IDX = 0, 1, 2 def encode_src(s: str) -> List[int]: return [SRC_STOI[w.lower()] for w in s.split()] def encode_tgt(s: str) -> List[int]: return [BOS_IDX] + [TGT_STOI[w.lower()] for w in s.split()] + [EOS_IDX] # -------------------------- # 2) Dataset:定义“单样本怎么取” # -------------------------- @dataclass class Example: src: List[int] tgt: List[int] class ToyDataset(Dataset): def __init__(self, pairs: List[Tuple[str, str]]): for s, t in pairs: print("encode_src(s)",encode_src(s)) print("encode_tgt(t)",encode_tgt(t)) self.data = [Example(encode_src(s), encode_tgt(t)) for s, t in pairs] def __len__(self) -> int: return len(self.data) def __getitem__(self, idx: int) -> Example: return self.data[idx] # -------------------------- # 3) collate_fn:把“样本列表”拼成一批(对齐 padding + 生成 mask + teacher forcing) # -------------------------- def collate_fn(batch: List[Example]): src_max = max(len(b.src) for b in batch) #计算批次内最长长度,这样能将样本右侧补齐到同一长度,方便堆叠矩阵 tgt_max = max(len(b.tgt) for b in batch) src_batch: List[List[int]] = [] tgt_in_batch: List[List[int]] = [] tgt_out_batch: List[List[int]] = [] print("batch",batch) for ex in batch: src = ex.src + [PAD_IDX] * (src_max - len(ex.src)) # teacher forcing:输入去掉最后一个、输出去掉第一个 tgt_in = ex.tgt[:-1] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[:-1])) tgt_out = ex.tgt[1:] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[1:])) print("src",src) print("tgt_in",tgt_in) print("tgt_out",tgt_out) src_batch.append(src) tgt_in_batch.append(tgt_in) tgt_out_batch.append(tgt_out) print("src_batch",src_batch) print("tgt_in_batch",tgt_in_batch) print("tgt_out_batch",tgt_out_batch) src = torch.tensor(src_batch, dtype=torch.long) # (B,S) tgt_in = torch.tensor(tgt_in_batch, dtype=torch.long) # (B,T) tgt_out = torch.tensor(tgt_out_batch, dtype=torch.long) # (B,T) src_pad_mask = src.eq(PAD_IDX) # (B,S) True=PAD tgt_pad_mask = tgt_in.eq(PAD_IDX) # (B,T) True=PAD print("src",src) print("tgt_in",tgt_in) print("tgt_out",tgt_out) print("src_pad_mask",src_pad_mask) print("tgt_pad_mask",tgt_pad_mask) return src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask # -------------------------- # 4) DataLoader:定义“如何按批取样本”并演示输出 # -------------------------- def main(): dataset = ToyDataset(pairs) for i in range(len(dataset)): print("dataset",dataset.__getitem__(i)) loader = DataLoader( dataset, batch_size=2, shuffle=True, num_workers=0, # 跨平台演示,用 0;Linux 可调大 collate_fn=collate_fn, pin_memory=False, ) # EPOCH=40 # for epoch in range(EPOCH): # for src, tgt_in, tgt_out, src_mask, tgt_mask in loader: # 前向、loss、反传、优化 total_steps = 1000 data_iter = iter(loader) for step in range(total_steps): try: src, tgt_in, tgt_out, src_mask, tgt_mask = next(data_iter) except StopIteration: # 当前迭代器用尽,重建一个新的(相当于进入新一轮) data_iter = iter(loader) src, tgt_in, tgt_out, src_mask, tgt_mask = next(data_iter) print("src",src) print("tgt_in",tgt_in) print("tgt_out",tgt_out) print("src_mask",src_mask) print("tgt_mask",tgt_mask) if __name__ == "__main__": main() iter(loader): 把可迭代的 DataLoader 变成“批次迭代器”。 next(iterator): 从该迭代器中取“下一个批次”。第一次调用就是“第一个 batch”。 it = iter(loader) batch1 = next(it) batch2 = next(it) 在 shuffle=True 时,每次 iter(loader) 相当于开始“新的一轮遍历”,顺序会重新洗牌;drop_last、num_workers、pin_memory 等参数会影响批次数量、并行加载与传输性能。 当然除了用next迭代,还是用for循环的方式,如下: for epoch in range(EPOCH): for src, tgt_in, tgt_out, src_mask, tgt_mask in loader: print("src", src) print("tgt_in", tgt_in) print("tgt_out", tgt_out) print("src_mask", src_mask) print("tgt_mask", tgt_mask) -

数据维度
维度是什么 维度=数据需要“几个”索引才能定位到一个元素,也叫做轴数(axis)或阶(rank)。 可以看成"套盒子"的层数,盒子里面装盒子,再装数字。每多一层外括号/分类,就多一维。 0维=一个数;1维=一排数;2维=表格;3维=一摞表格;更高维=外面再套一层一层分类; 判断有几个维度的方法: 获取一个元素需要几个索引才能定位到。 多一层外括号=多一维;形状从外到内写“有多少个”。(外层是更粗粒度的分类,写在前面,如小批量彩色图像 (B, C, H, W);批次B、通道C、高H、宽W) 1D: ──●──●──●── 一条线 2D: 行×列 一张表 ┌───────┐ │● ● ● │ │● ● ● │ └───────┘ 3D: 多张2D表叠成“砖块” 从0到多维的例子 0维(标量):单个数 42 标量 shape:(), 只要“指它自己”就能找到,例:体温36.5。 1维(向量):一排数 [3, 5, 8] 向量shape:(N),需要1个索引(第几个)才能定位。 2维(矩阵/表格):多排多列 [ [1, 2, 3], [4, 5, 6] [7, 8, 9]] 矩阵shape:(R,C),需要2个索引(第几行,第几列)才能定位到。 3维度(立体):多张矩阵堆叠 [ [[1,2,3], [4,5,6]], [[7,8,9], [11,12,13]] ] 或 层0: [ [...], [...], ... ] 层1: [ [...], [...], ... ] ... 立体shape:(D,R,C),需要3个索引(第几层、第几行、第几列)才能定位到。 n维(张量):继续外面套一层索引 如4维度,小批量彩色图像 (B, C, H, W);批次B、通道C、高H、宽W 深度学习场景维度含义 图像/CNN:(B,C,H,W),B为batch个数,C为图像通道,H为图像高度,W为图像宽度。 文本/transformer:(B,S,C),Batch size,批大小。一次前向里同时处理的样本数。S有时也写作L,Sequence length,序列长度/时间步数(NLP 的 token 数、语音/时序的帧数)。在图像等场景里,若把二维特征展平成序列,也可表示展平后的步数。Channels/Features,特征维度。NLP 里常指 embedding 或 d_model;CV 里指通道数;时序里指每步的特征维度。[B, S, C] 通常表示“B 个样本,每个样本有 S 个时间步/位置,每个时间步有 C 维特征”。 怎么理解C(特征维/通道数)? 在一个张量形状 [B, S, C] 中,C 表示“每个位置(序列中的每个 token/时间步)所携带的特征向量维度”。也就是“描述一个位置所需的数值属性个数”。 表达能力上限: C 越大,单个位置能承载的信息越丰富(更“宽”的向量空间),可拟合更复杂的模式。 稳定性与信息瓶颈: 太小的 C 可能造成信息瓶颈,难以表达远距离依赖或复杂结构。 计算与显存代价: 层内线性/注意力的主计算大多与 C^2 成正比,激活占用与 BLC 成正比。增大 C 会显著提高计算/显存成本。 x.dim() # 轴数,也就是多少个维度。 x.shape # 形状,如 (B,L,C) x.size(-1) # 最后一维长度 -

Transformer 原理解析:从注意力机制到自回归生成
概述 框架 以翻译作为例子,从宏观角度理解大模型,可以把大模型视为一个黑匣子,它可以输入一种语言然后输出另外一种翻译语言,如下图所示。 如果将模型稍微展开一下,模型分为encoders和decoders两部分。为什么要分为编码器和解码器了?主要是从以下动机考量。 条件生成需求:在机器翻译、摘要、对话等条件文本生成任务重,需要读懂输入再逐步输出目标序列这两个事情的约束不同。读懂输入需要双上下文(每个词即要看到左也要右),也就是说要在上下文中去理解,没有因果约束。而生成输出需要的是自回归,因为是预测,只需要看历史不能偷看未来,这就需要因果掩码的自注意力。 结构解耦:把理解和生成拆开,分别最优各自的注意力、掩码和结构,这样更清晰也更高效。 encoders是有多个相同的encoder堆叠在一起形成,decoders也是一样。 encoder和decoder在结构上都是相同的,但是他们不共享权重。下图是encoder和decoder微观结构。 编码器将输入的序列X=(x1,......,xn)映射到连续表示序列Z=(z1,.....zn),然后将Z给到解码器。解码器每次生成一个元素的符号输出序列(y1,......yn)。解码器在每一步都是自回归的,在生成下一步时将先前生成的符号作为额外输入。 编码器:编码器由N=6个相同层堆叠组成。每层都有两个子层,第一个子层是多头注意力(Multi-Head Attention),第二个是简单的按位置完全连接的前馈网络(Feed Forward)。在两个子层的周围分别采用残差连接(Add),然后再进行层正则化(Norm)。每个子层的输出是LayerNorm(X+Sublayer(X)),其中Sublayer(X)是由子层本身实现的函数。为了促进这些残差连接,模型中所有子层以及嵌入层都产生维度为$d_{model}$=512的输出。 解码器:解码器也是由N=6个相同层堆栈组成,除了每个解码器层中的两个子层之外,解码器还插入了第三个子层Masked Multi-Head Attention,该子层对编码堆栈的输出执行多头注意。与编码器类似,在每个子层周围采用残差连接然后正则化。与编码器不同的是,这里增加了Masked Multi-Head Attention修改于Multi-Head Attention,防止当前的输入元素关注到后续的位置元素,这种掩码加上输出嵌入偏移一个位置,确保位置i的预测只能依赖小于i的位置的已知输出。 流程 下面以一个中文句子翻译为英文为例,简要说明步骤。 word embedding: 输入的句子分词得到["我", "有", "一个", "苹果"],然后将每个词进行词嵌入(算法这里不阐述)转换为6维的向量。 positional encoding:每个词进行位置编码,生成相关的位置信息。每个词的向量维度与词embedding维度一致。 transformer输入X: X=embedding + positional embedding,shape形状为(seq_len,d_model),其中seq_len为输入token数量,这里为4,d_model为词embedding向量维度。 编码输出矩阵E:输入X经过编码器后,经过自注意力分数等计算最后输出矩阵E将作为解码器的输入。矩阵E与输入的X形状一致。 解码输出:解码器的输出根据输入一个一个产生的,最开始的时候输入"BOS"代表开始将输出"I",输入"BOS I"输出I have,输入"BOS I have"输出"I have an".......。 mask:在解码器内部有一个mask,其主要的作用是让生成步骤仅以来历史信息,不能访问未来的词。因为decoder是一个一个词生成的,自注意力层天然会计算序列中所有位置间的关联,若不施加约束,模型可能尝试为当前未生成的空白位置分配权重,生成第3个词时,模型默认会为第4、5等未来位置计算注意力权重(尽管这些位置尚无实际内容)。 输入 transformer的输入是一个多阶段的过程,核心的目标是将原始序列的数据转换为包含语义和位置信息的向量表示,这里重点分为word embedding和positional encoding。 word embedding 在进行word embedding之前,需要先把输入句子进行分词,得到离散的序列。如"我有一个苹果" → ["我", "有", "一个", "苹果"]。 所谓word embedding词嵌入,就是将句子拆分的每个词映射到固定维度的向量,transformer论文中默认的向量维度为512,本文的示例是6维。如下: 我:[0.2, -0.3, 0.7, 0.1, -0.5, 0.4] 有:[0.6, 0.2, -0.8, 0.3, 0.1, -0.4] 一个:[-0.4, 0.9, 0.2, -0.1, 0.3, 0.6] 苹果:[0.5, -0.7, 0.4, 0.8, -0.2, 1.1] 关于转换映射的有很多方式,如随机初始化+训练学习的方式,或者word2vec,Glove等外部嵌入算法,这里就先不研究了。 positional encoding 自注意力机制本身不具备序列顺序的感知能力,而自然语言的语义高度以来次序,比如"猫爪老鼠"和"老鼠抓猫"含义就完全相反。因此需要显性的为每个词助于顺序信息,通过给每个位置进行编号,让模型感知词序。 而在transformer中,使用是的正弦函数和余弦函数给每个词生成唯一向量,其中偶数的向量维度使用正弦函数计算得到,基数使用余弦函数计算得到。其公式如下: 变量说明 变量$pos$:词在序列中的位置(从0或1开始,示例中为1~4,如"我"是1,"有"是2,“一个”是3,"苹果"是4) 变量$i$:向量维度索引(从0开始,文档示例中$d_{\text{model}}=6$,故$i=0,1,2$) 变量$d_{\text{model}}$:模型隐藏层维度,也是word embedding向量维度(示例中为6,原始论文中为512) 下面基于d_mode=6说明计算过程,以第一个词"我"为例,计算其过程。 已知条件 变量$pos=1$(第1个词的位置) 变量$d_{\text{model}}=6$(向量维度为6) 变量$i=0,1,2$(对应3对奇偶维度) 维度0(偶数位,$2i=0$):$PE_{(1,0)} = \sin\left(\frac{1}{10000^{2×0/6}}\right) \approx 0.8 \quad $ 维度1(奇数位,$2i+1=1$):$PE_{(1,1)} = \cos\left(\frac{1}{10000^{2×0/6}}\right) \approx 0.5 \quad $ 维度2(偶数位,$2i=2$):$PE_{(1,2)} = \sin\left(\frac{1}{10000^{2×1/6}}\right) \approx 0.1 \quad$ 维度3(奇数位,$2i+1=3$):$PE_{(1,3)} = \cos\left(\frac{1}{10000^{2×1/6}}\right) \approx 1.0 \quad $ 维度4(偶数位,$2i=4$):$PE_{(1,4)} = \sin\left(\frac{1}{10000^{2×2/6}}\right) = \approx 0.0 \quad$ 维度5(奇数位,$2i+1=5$):$PE_{(1,5)} = \cos\left(\frac{1}{10000^{2×2/6}}\right) \quad 1.0 $ 最后得到"我"的positional encoding为[0.8,0.5,0.1,1.0.0.0,1.0]。 使用正弦函数、余弦函数进行编码有以下好处。 相对位置可学习:对于任意位置偏移$k$,$PE_{pos+k}$可表示为$PE_{pos}$的线性组合(利用三角函数的和角公式),使模型能轻松学习相对位置关系。 无界序列适应:公式基于指数函数衰减,对任意长度的序列(远超训练时的最大长度)均能生成有效编码,避免了学习型位置编码的泛化性问题。 数值稳定性:正弦/余弦函数的值域固定在$[-1,1]$,与词嵌入向量相加后不会导致数值范围剧烈波动,有利于模型训练稳定。 注意力机制 在transformer中最关键的就是Multi-Head Attention,本小节先来重点分析其实现原理。Multi-Head Attention由多个Scaled Dot-Product Attention组成。 注意力函数可以描述为将查询(Query)和一组键值对(Key-Value)映射到输出,其中查询、键、值和输出都是向量,输出计算为加权和。 Scaled Dot-Product Attetion 其核心的公式就是如下: $$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$ 对于Scaled Dot-Product Attention自下而上计算的流程如下: MatMul:输入查询矩阵 Q(目标序列)与键矩阵 K(源序列)进行矩阵乘法,主要用于计算原始相关性的分数。$\text{Scores} = QK^T$ Scale:缩放的目的是防止计算的分数导致softmax梯度消失,因此对结果进行缩放。$\text{Scaled Scores} = \frac{\text{Scores}}{\sqrt{d_k}}$。 Optional Mask:mask用于遮挡无效位置(如未来词或填充符),训练是设置-inf,只有在解码器的时候用。 SoftMax:对计算分数进行归一化,输出注意力权重权重概率分布。$\text{Weights} = \text{softmax}(\text{Masked Scores})$ MatMul:前面的QK计算得出了目标词在句子中的哪些词相关性比较大,也就是得到一个注意力分数,最后根据注意力分数做加权求和到最后的目标词上下文信息向量。$ \text{Output} = \text{Weights} \cdot V$ 接下来我们展开按照流程来分析一下。 计算QKV Transformer中引入Q(Query)、K(Key)、V(Value)三元组的设计是注意力机制的核心创新,使用QKV本质是实现动态语义的聚集。传统的传统RNN/CNN在长距离建模时存在固有缺陷,CNN依赖局部卷积核,RNN受制于顺序编码,无法动态关注全局关键信息。而使用QKV三元组模拟"信息检索系统" Query(查询):表示当前需要关注的内容,需要“寻找什么信息”(如翻译中"apple"要找出"苹果"的语义需求)。 Key(键):描述源信息的特征标签(如中文词"苹果"的语义属性)。 Value(值):存储实际待提取的信息本体(如"苹果"的词嵌入向量)。 自注意力机制就是用q去找相关的k,得到注意力分数,然后通过注意力分数去从v中提取信息。 如翻译“I have an apple”时,生成“apple”的Query会去找跟(“苹果”)相关的key计算高相似度,然后用得到的K取提取Value(“苹果”的语义向量),实现精准跨语言对齐。 使用Q MatMul K的方式可以量化查询的需求与源特征的匹配程度,最后在MatMul上V是因为做最终的提取。 既然Q MatMul K是量化查询需求与源特征的匹配程度,那么每个词一般都是在句子中去理解的,所以每个词都需要去计算在句子中其他词的关联。 每个都需要与句子中的其他进行相关性计算,各自得到一个输出。如a1最终计算出得到b1,a2计算得到b2......。 (1)以单个词为例说明运作流程 下面以a1为例: 首先a1先自己计算出q1,q1=Wq a1,其中Wq为权重参数。 其次句子中所有词a1,a2,a3,a4分别乘Wk计算各自得到k1,k2,k3,k4。 接着q1分别与k1,k2,k3,k4分别做点积计算得到a11,a12,a13,a14。 最后在对a11,a12,a13,a14做softmax得到最终的结果。a'11,a'12,a'13,a'14。 为什么要做softmax了? 归一化概率:将原始分数(可能为任意实数)转换为概率分布,使得所有权重和为1,便于后续的加权求和操作(即用这些权重来加权值向量)。 增强区分度:softmax 的指数运算会放大高分数的影响,同时抑制低分数。这样,模型可以更加关注最相关的键,而忽略不相关的键。在图中,如果某个 α{1,i} 较大,经过 softmax 后其对应的 α'{1,i} 会远大于其他较小的分数对应的权重,从而实现选择性聚焦。 在对softmax之前还要进行一次scale这里就不周赘述了。 a'11,a'12,a'13,a'14即为a1对句子中每个词的注意力分数,计算出值后就可以根据其值从序列里面抽取出了重要的信息,根据a'11,a'12,a'13,a'14可知输入的词向量哪些跟与a1相关性大,接下来即可根据关联性(即注意力分数)抽取重要的信息。 将向量a1~a4分别乘以Wv权重得到新的向量v1,v2,v3,v4,将其中的每一个向量分别乘以注意力分数a'xx,再把结果加起来。 $$ b_1 = \sum_{i} \alpha'_{1,i} v_i $$ 如果a1和a2关联性强,即a'12的值就很大,那么在做加权和以后,得到的b1就越接近与v2,所以谁的注意力分数越大,谁的v就会主导抽取结果。同理可以计算出b2,b3,b4。 (2)以矩阵乘法角度说明运作流程 上面的过程是单个词的计算过程,但是实际在自注意力模型的运作过程中,是通过矩阵乘法的方式计算的,这样效率才高,接下来看看从矩阵乘法的角度理解运行过程。 因为每个词都要产生qkv,即每个ai都要乘以权重参数Wq得到qi,那么可以把这些ai合并起来当做一个矩阵,即把a1到a4拼接起来,看成一个矩阵I,矩阵I有4列,其中每一列都是自注意力模型的输入。把矩阵I乘以矩阵Wq,就可以得到Q。其中Wq则是权重参数,Q则可以看成q1~q4的拼接。 同理产生k和v的操作跟q一模一样,计算得到K,V矩阵。 通过两个Q与K转置相乘就可以得到注意力分数的矩阵A,然后将A经过softmax得到A'。 最后使用注意力分数A'提出V,得到最终的输出矩阵O,即b1~b4的拼接。 最后总结下,自注意力模型输入是一组向量,将这些向量拼接起来得到I,让后将I分别乘以三个矩阵Wq,Wk,Wq,得到另外三个矩阵QKV,将Q乘以K的转置得到A,然后对A在做一些处理得到A',A'为注意力分数矩阵,将A'乘以V提取出特征,最后得到自注意力的输出O。 Multi-Head Attention 论文中阐述,与其使用一套维度为$d_{model}$的单头注意力,还不如把输入的Query、Key、Value各自用不同的、可学习的线性投影经过注意力机制映射出$h$份版本,每份的维度更小,计为$d_{k}$和$d_{v}$。 在每一份(也就是每个头)上各自并行计算注意力,得到$d_{v}-$维的输出,然后再把所有头的输出沿特征维度拼接,再做一次线性投影到得到最终的输出。 为什么要做多头?多头可以“同时在不同表示子空间里看信息”。一个头往往只能聚焦一种关系(比如短距依赖),多个头能并行关注不同关系(长距、句法、语义等)。如果只有单头,容易把多种关系“平均混在一起”,表达力受限。 多头注意力会把输入进行降维值C/h,这样每个头的输入维度就为C/h。为什么使用"多头+降维"而不是"多头不降维",主要会是考虑如果每个头都保持默认的输入C维,h个头拼接后会是[B, L, h·C],参数量与计算复杂度都膨胀 h 倍,不经济。标准做法让每头维度变为 C/h,拼接回到 C,因此总计算/参数量与单头同量级,但表达力更强(多视角、子空间解耦)。 下面是来说明一下多头注意力机制是如何计算的,下面省略了输入降维的过程。 如上图,先把a乘以一个矩阵得到q,然后再把q乘以另外两个矩阵得到q1,q2。qi1和qi2代表的有两个头,表示要查询两种不同的相关性,那么既然有两个q,k,v也得需要两个,同理得到各自的两个k,v。 关于多头注意力机制的计算跟上一节的计算类似,各自的头计算各自的,如上图是计算头1,下图是计算头2。 通过各自头的计算,那么将会得到各自头的一个输出bi1,bi2,最后需要将bi1和bi2拼起来,先乘以一个矩阵进行变换得到bi,再送到下下一层。 encoder 编码器有多个相同的子编码器叠加而成,最小单元的子编码器由Multil-Head Aattention、Add & Norm、Feed Forward这几个组件构成,Multil-head Attention前面已经解释了,接下来重点分析剩余模块的流程。为表述方便后面的编码器都默认指最小单元的编码器。 Add & Norm Add & Norm在编码器一个block中出现了两次,首次出现是位于 Multi-Head Attention(橙色模块)的输出端,再次出现是位于 Feed Forward(蓝色模块)的输出端。如下图: (1)残差连接 残差连接的作用是在深层网络中,梯度在反向传播时可能会消失或爆炸。残差连接通过将输入直接加到函数输出上(即 F(x) + x),提供了一个恒等映射的路径。这使得梯度在反向传播时可以直接流过,从而缓解了梯度消失的问题,使深层网络训练成为可能。 Add操作是残差连接(Resudual Connection),其公式 $$ \mathbf{y} = \mathcal{F}(\mathbf{x}, {\mathbf{W}_i}) + \mathbf{x} $$ (2)层归一化 层归一化的作用是在残差连接之后,数据的分布可能会发生变化,可能会导致后续层的学习变得困难,使用层归一化能够重新调整数据分布(如将每一层的输出归一化为均值为0,方差为1),从而加速训练并提高模型的泛化能力。 层归一化计算公式步骤如下: 这里使用的是层归一化而非批归一化,主要是可以独立处理每个样本,应对变长序列输入,同时对小批量训练不依赖批量统计量。 为什么Add&Norm要成对使用? 每个主要计算层后面都有Add & Norm,形成了一种模式:计算层 -> Add & Norm。这样,每个计算层的输出在传递给下一层之前都会被重新调整,使得模型在训练过程中保持稳定。如果只有残差连接而没有归一化,那么随着层数的增加,输出的尺度可能会不断增长,导致训练不稳定;如果只有归一化而没有残差连接,则可能无法解决深层网络中的梯度消失问题。 Feed Forward 先来看看什么是Feed Forward,前馈神经有两层全连接神经网络组成,中间使用非线性激活函数(通常是ReLU),数学表达式如下: $$ FFN(x) = \text{ReLU}(xW_1 + b_1)W_2 + b_2 $$ (1)特征扩展,将特征维度从512扩展至2048 $$ \boxed{ h_i = \text{ReLU}( \underbrace{x_i}{1 \times 512} \underbrace{W_1}{512 \times 2048} + b_1 )} $$ $x_i$:位置$i$的输入向量($1 \times 512$) $W_1$:扩展层权重矩阵($512 \times 2048$) 前面输入attention结果本质上计算是加权平均,都是线性操作,这里引入ReLu非线性变化,使模型能学习更复杂的函数映射。同时升维可以在高维空间捕捉更细微模式。 (2)进行特征压缩,将特征从2048压缩回512 $$ \boxed{ y_i = \underbrace{h_i}{1 \times 2048} \underbrace{W_2}{2048 \times 512} + b_2 } $$ $h_i$:ReLU激活后的特征向量($1 \times 2048$) $W_2$:压缩层权重矩阵($2048 \times 512$) 最后再从高维进行降维,保持与后续模块的兼容性。 总结一下FFN的作用有如下: 高纬投影:将输入映射到高维空间(如512→2048),捕获更复杂的特征组合。 非线性激活:引入非线性(如ReLU),打破线性变换限制,增强模型表达能力。 低维还原:将特征压缩回原始维度,保持与后续模块兼容性。 encoder block Multi-Head Attention、Add & Norm、Feed Ward构成了一个encoder block。 每个encoder block接入输入矩阵Xnd,并输出一个矩阵Ond,再把输出的O当做输入传递给下一个encoder,通过多个encoder的叠加,最后一个encoder block输出的就是编码信息矩阵E,用于送入到解码器中,就完成transformer的Encoder。 decoder decoder与encoder大致的结构类似,但是也有差别主要由Masked Multi-head Attention、Multi-head Attention、Add & Norm、Feed Forward组成,这里唯一不一样的是Masked Multi-head Attention,接下来分模块介绍一下关键流程。 Masked Multi-head Attention Masked Multi-head Attention通过一个掩码来阻止每个位置选择器后面的输入信息。 Multi-head Attention自注意力输入一排向量,自己输出另一排向量,这一排向量中的每个项链都要看过完整的输入后才能决定。如上图必现根据a1,a2,a3,a4的所有信息来输出b1。 而掩码多头注意力则不再看右边的部分,如下图。 在产生b1的时候,只考虑a1的信息,不再考虑a2,a3,a4的信息。在产生b2的时候,只考虑a1,a2的信息,不再考虑a3,a4的信息,在产生b3的时候,只考虑a1,a2,a3的信息,不再考虑a4的信息,只有在阐述b4的时候,才考虑整个输入序列的信息。 下面是Multi-head Attention产生b2的过程,b2需要和a1,a2,a2,a3的qkv信息计算得到b2。 而如果是Masked Multi-head Attention,b2只需要拿q2和k1、k2计算注意力,最后只计算v1和v2的加权和,不管a2右边的部分,则计算过下。 为什么在注意力机制中加上掩码了? 因为解码器的输出是一个一个产生的,只能考虑左边已经生成的部分,而没有办法考虑未生成的右边部分。举个例子,先有得a1,再有a2,接下来是a3,然后是a4。这个跟编码器中的self-attention不一样,编码器中的是a1,a2,a3,a4一次性输入模型,编码器一次性处理输出。正因为解码器这个特性,现有a1,才能预测输出a2,再有后面的a3,a4,所以当我们在计算b2时,a3,a4实际是还没输出的,所以没有办法考虑a3,a4。 Multi-head Attention 第二个Mult-head Attention也称为交叉注意力,结构组成与编码器没什么差别。主要的差异点计算输入,解码器的第二个Multi-head Attention(交叉注意力)输入,这个注意力层的Query来自解码器前一层(通常是解码器的第一个Masked Self-Attention层)的输出,而Key和Value则来自编码器的最终输出(即最后一个编码器层的输出)。因此,该注意力层的目的是让解码器在生成当前输出时能够关注到输入序列的相关部分。 输出 transformer最后的输出层是linear层和softmax层。 linear层:将解码器输出的高维语义向量映射到词汇表空间,输入为(batch_size, seq_len, d_model),输出为(batch_size, seq_len, vocab_size),主要的作用是将抽象语义转换为具体词汇的匹配分数(Logits)。 softmax层:将Logits转换为概率分布,输入为Logits矩阵,输出为(batch_size, seq_len, vocab_size)的概率张量,满足概率约束(和为1),支持损失计算与生成任务。 Linear层 Linear层主要作用是计算解码器向量与每个词嵌入的点积,得到词汇表中每个词的原始匹配分数,计算公式为。 $$Logits = X \cdot W^{T} + b$$ X:解码器最后一层输出(形状 [batch_size, seq_len, d_model],例:[1, 4, 6]) W:权重矩阵(形状 [vocab_size, d_model],例:50000×6) b:偏置项(可选) 最终的输出是词汇表中每个词的概率(形状 [batch_size, seq_len, vocab_size],例:[1, 5, 10000]),假设这里的词库为10000个。 如下: logits = [ "I": 8.76, "have": 7.23, "a": 5.89, "an": 6.54, "apple": 7.91, ... # 其他99995个词 ] softmax层 $$P(\text{word}i) = \frac{e^{\text{logits}_i}}{\sum{j=1}^{V} e^{\text{logits}_j}}$$ V: 词汇表的大小 指数运算:放大高分优势。 如下 "I": 0.38, "have": 0.22, "an": 0.18, "apple": 0.15, "a": 0.04, ... # 其他词概率极小 总结一下: 时间步 解码器输入 Linear层Logits示例 Softmax后概率 选定词 1 <bos> I=9.8, He=1.2,... I=0.99,He=0.03,... I 2 <bos> I have=8.5, has=0.5,... have=0.97,has=0.02,.... have 3 <bos> I have an=7.9, a=2.1,... an=0.95,a=0.04 an 4 <bos> I have an apple=9.5, app=3.2,... apple=0.99,app=0.03,.... apple 到这里,transformer的原理就分析完了。 参考如下: 书籍:深度学习详解 https://arxiv.org/abs/1706.03762 https://jalammar.github.io/illustrated-transformer/ https://zhuanlan.zhihu.com/p/338817680