Ai
-

llama.cpp 模型加载机制深度解析
概述 llama.cpp 的模型加载系统是一个高度优化的、支持多后端、多设备的模型权重加载框架。它通过精心设计的数据结构和加载流程,实现了: 零拷贝加载:通过内存映射(mmap)实现模型文件的零拷贝加载 多设备支持:自动发现和分配GPU、CPU等设备,支持模型分层加载到不同设备 架构无关:通过统一的抽象支持Llama、Qwen、DeepSeek、Mamba、RWKV等多种架构 高性能I/O:支持直接I/O、异步上传、预取等优化策略 本文将从数据结构、加载流程、I/O机制、设备管理等多个维度深入解析模型加载的实现细节。 关键数据结构 llama_model - 核心模型容器 llama_model 是模型加载后的核心容器,它持有模型的所有权重指针、元数据和设备信息。 结构定义 struct llama_model { llm_type type = LLM_TYPE_UNKNOWN; // 模型规模(如3B、7B) llm_arch arch = LLM_ARCH_UNKNOWN; // 模型架构(如Llama、Qwen) std::string name = "n/a"; // 模型名称 llama_hparams hparams = {}; // 超参数 llama_vocab vocab; // 词表 // 全局权重张量 struct ggml_tensor * tok_embd = nullptr; // Token Embeddings struct ggml_tensor * output = nullptr; // Output weights struct ggml_tensor * output_norm = nullptr; // Output normalization // 分类器相关(用于分类模型) struct ggml_tensor * cls = nullptr; // 层权重数组 std::vector<llama_layer> layers; // GGUF元数据 std::unordered_map<std::string, std::string> gguf_kv; // 设备列表 std::vector<ggml_backend_dev_t> devices; // LoRA适配器 std::unordered_set<llama_adapter_lora *> loras; // 性能统计 int64_t t_load_us = 0; int64_t t_start_us = 0; // Pimpl模式隐藏实现细节 private: struct impl; std::unique_ptr<impl> pimpl; }; 核心设计点 结构化抽象 - layers数组 std::vector layers 是核心设计 将重复的层权重封装到 llama_layer 中 支持动态层数,无需修改结构体定义 设备管理 devices 向量记录所有使用的后端设备 dev_layer(int il) 返回第 il 层所在的设备 dev_output() 返回输出层所在的设备 支持多GPU分层加载 Pimpl模式 隐藏底层实现细节(mmap管理、内存映射句柄等) 保持API稳定性,修改实现不影响头文件 权重指针而非数据 llama_model 不存储实际权重数据 只存储指向权重数据的指针(ggml_tensor *) 实际数据通过mmap映射或buffer管理 关键方法 load_arch(): 从loader加载架构信息 load_hparams(): 加载超参数 load_vocab(): 加载词表 load_tensors(): 创建张量并分配设备 build_graph(): 构建计算图 create_memory(): 创建KV Cache内存 llama_layer - 单层权重抽象 llama_layer 封装了Transformer单层的所有权重张量,支持多种架构变体。 结构定义(部分) struct llama_layer { // 归一化层 struct ggml_tensor * attn_norm = nullptr; struct ggml_tensor * attn_norm_b = nullptr; struct ggml_tensor * attn_q_norm = nullptr; // Gemma 2 struct ggml_tensor * attn_k_norm = nullptr; struct ggml_tensor * ssm_norm = nullptr; // Mamba // 注意力机制 struct ggml_tensor * wq = nullptr; // Query投影 struct ggml_tensor * wk = nullptr; // Key投影 struct ggml_tensor * wv = nullptr; // Value投影 struct ggml_tensor * wo = nullptr; // Output投影 struct ggml_tensor * wqkv = nullptr; // 合并QKV(某些架构) // 注意力偏置 struct ggml_tensor * bq = nullptr; struct ggml_tensor * bk = nullptr; struct ggml_tensor * bv = nullptr; struct ggml_tensor * bo = nullptr; // Feed-Forward网络 struct ggml_tensor * ffn_norm = nullptr; struct ggml_tensor * ffn_gate = nullptr; struct ggml_tensor * ffn_up = nullptr; struct ggml_tensor * ffn_down = nullptr; // 混合专家系统(MoE) struct ggml_tensor * ffn_gate_inp = nullptr; // 门控输入 struct ggml_tensor * ffn_gate_exps = nullptr; // 专家门控权重 struct ggml_tensor * ffn_up_exps = nullptr; // 专家上投影 struct ggml_tensor * ffn_down_exps = nullptr; // 专家下投影 // RoPE相关 struct ggml_tensor * rope_freqs = nullptr; struct ggml_tensor * rope_long = nullptr; // LongRoPE struct ggml_tensor * rope_short = nullptr; // ... 更多架构特定张量 }; 设计特点 通用层抽象 合并了对Gemma、Mixtral、Mamba、RWKV、DeepSeek等模型的支持 通过指针是否为nullptr判断架构是否使用该张量 架构变体支持 归一化变体:支持RMSNorm、LayerNorm、Gemma 2的特殊归一化 注意力变体:标准QKV、合并QKV、分组查询注意力(GQA) MoE支持:专家门控、共享专家(Shared Experts) 非Transformer:Mamba的SSM层、RWKV的循环层 加载流程 预分配:model.layers.resize(n_layer) 创建N个空层 点对点赋值:loader解析GGUF,将张量地址赋给对应层的指针 后端绑定:根据设备分配策略,将指针指向CPU或GPU内存 llama_model_loader - 权重加载器 llama_model_loader 是模型加载的"施工队",负责GGUF文件解析、权重索引、内存映射和数据搬运。 核心成员 struct llama_model_loader { // GGUF元数据 gguf_context_ptr meta; // GGUF解析器上下文 // 文件管理 llama_files files; // 主文件+分片文件句柄 llama_mmaps mappings; // 内存映射句柄 // 权重索引表(核心数据结构) std::map<std::string, llama_tensor_weight, weight_name_comparer> weights_map; // KV覆盖 std::unordered_map<std::string, llama_model_kv_override> kv_overrides; // 张量Buffer类型覆盖 const llama_model_tensor_buft_override * tensor_buft_overrides; // I/O配置 bool use_mmap; bool use_direct_io; bool check_tensors; }; 权重索引表:weights_map 这是loader最核心的数据结构,充当"权重目录": // Key: tensor名称,如 "tok_embeddings.weight", "blk.0.attn_q.weight" // Value: llama_tensor_weight(定位信息) struct llama_tensor_weight { uint16_t idx; // 文件分片索引(主文件=0,split可能是1、2...) size_t offs; // 在文件中的字节偏移 ggml_tensor * tensor; // 张量元数据(shape/type/name) }; weight_name_comparer:自定义排序规则 解析层索引(如 blk.5 → 5) 按层号排序,而非纯字符串排序 优化磁盘读取顺序,利用预读缓存 关键流程 构造函数:初始化GGUF解析 llama_model_loader::llama_model_loader(...) { // 1. 调用gguf_init_from_file解析文件头 meta.reset(gguf_init_from_file(fname.c_str(), params)); // 2. 识别架构 get_key(LLM_KV_GENERAL_ARCHITECTURE, arch_name, false); llm_kv = LLM_KV(llm_arch_from_string(arch_name)); // 3. 打开文件句柄 files.emplace_back(new llama_file(fname.c_str(), "rb", use_direct_io)); // 4. 构建weights_map索引表 for (ggml_tensor * cur = ggml_get_first_tensor(ctx); cur; ...) { weights_map.emplace(tensor_name, llama_tensor_weight(...)); } // 5. 处理分片文件(如果有) // ... } init_mappings:初始化内存映射 void llama_model_loader::init_mappings(bool prefetch, llama_mlocks * mlock_mmaps) { if (use_mmap) { for (const auto & file : files) { // 创建mmap映射 std::unique_ptr<llama_mmap> mapping = std::make_unique<llama_mmap>(file.get(), prefetch ? -1 : 0, is_numa); mappings.emplace_back(std::move(mapping)); // 可选:内存锁定 if (mlock_mmaps) { std::unique_ptr<llama_mlock> mlock_mmap(new llama_mlock()); mlock_mmap->init(mapping->addr()); mlock_mmaps->emplace_back(std::move(mlock_mmap)); } } } } create_tensor:创建张量对象(空壳) 从weights_map查找元数据 在指定的ggml_context中创建tensor对象 此时tensor->data仍为nullptr load_all_data:加载实际数据 遍历所有tensor 根据use_mmap选择路径: mmap路径:ggml_backend_tensor_alloc(buf_mmap, cur, data) 绑定mmap地址 文件读取路径:file->read_raw(cur->data, n_size) 读取到内存 GPU异步上传:分块读取+异步上传到GPU llama_hparams - 超参数蓝图 llama_hparams 存储模型的数学参数,决定计算图的形状和逻辑。 核心参数分类 基础架构参数 n_embd: 隐藏层维度(如4096) n_layer: 总层数 n_ctx_train: 训练时上下文长度 n_head_arr[]: 每层注意力头数(数组支持每层不同) n_head_kv_arr[]: 每层KV头数(GQA支持) 注意力机制变体 n_embd_head_k_mla: MLA压缩后的KV维度(DeepSeek-V2/V3) n_swa: 滑动窗口大小(Mistral) swa_layers[]: 哪些层启用滑动窗口 位置编码(RoPE & YaRN) rope_freq_base_train: RoPE基础频率 rope_freq_scale_train: RoPE缩放因子 rope_scaling_type_train: 缩放类型(linear/yarn/longrope) yarn_ext_factor: YaRN扩展因子 rope_sections[]: 部分维度旋转(Partial RoPE) 混合专家模型(MoE) n_expert: 总专家数 n_expert_used: 每个token激活的专家数(如8选2) n_ff_exp: 专家FFN维度 n_ff_shexp: 共享专家维度(DeepSeek) expert_gating_func: 门控函数类型 状态空间模型(SSM/Mamba) ssm_d_conv: 卷积维度 ssm_d_inner: 内部维度 ssm_d_state: 状态维度 recurrent_layer_arr[]: 哪些层是循环层(混合架构) 归一化与数值稳定性 f_norm_rms_eps: RMSNorm的epsilon f_attn_logit_softcapping: Gemma 2的注意力分数软上限 f_residual_scale: 残差连接缩放(Granite) 加载流程 void llama_model::load_hparams(llama_model_loader & ml) { const gguf_context * ctx = ml.meta.get(); // 1. 保存所有KV对到gguf_kv(用于元数据查询) for (int i = 0; i < gguf_get_n_kv(ctx); i++) { const char * name = gguf_get_key(ctx, i); const std::string value = gguf_kv_to_str(ctx, i); gguf_kv.emplace(name, value); } // 2. 读取基础参数 ml.get_key(LLM_KV_CONTEXT_LENGTH, hparams.n_ctx_train); ml.get_key(LLM_KV_EMBEDDING_LENGTH, hparams.n_embd); ml.get_key(LLM_KV_BLOCK_COUNT, hparams.n_layer); // 3. 读取数组参数(支持每层不同) ml.get_key_or_arr(LLM_KV_FEED_FORWARD_LENGTH, hparams.n_ff_arr, hparams.n_layer, false); ml.get_key_or_arr(LLM_KV_ATTENTION_HEAD_COUNT, hparams.n_head_arr, hparams.n_layer, false); // 4. 架构特定参数(根据arch分支) switch (arch) { case LLM_ARCH_LLAMA: /* ... */ break; case LLM_ARCH_DEEPSEEK: /* ... */ break; // ... } // 5. 参数校验与推导 // 如果某些参数缺失,根据架构进行推导 } 为什么hparams要独立出来? 多版本适配:不同架构可能完全没有某些参数(如Mamba没有n_head),但都有n_embd KV Cache管理:hparams决定KV Cache的内存布局和大小 计算图构建:推理时算子需要从hparams读取数学常数 GGML相关结构 gguf_context GGUF文件的内存映射索引,存储所有KV对和张量元信息。 struct gguf_context { uint32_t version; // GGUF协议版本 // KV键值对存储 std::vector<gguf_kv> kv; // 所有元数据KV对 // 张量信息 std::vector<gguf_tensor_info> info; // 所有权重的"档案" // 物理布局 size_t alignment; size_t offset; // 数据区偏移 void * data; // 数据区指针(如果已映射) }; ggml_backend_buffer 张量真实的"物理房产",解决跨设备内存管理问题。 struct ggml_backend_buffer { struct ggml_backend_buffer_i iface; // 函数指针接口 ggml_backend_buffer_type_t buft; // Buffer类型(CPU/CUDA/Metal等) void * context; // 后端内部状态 size_t size; // 大小 enum ggml_backend_buffer_usage usage; // 用途 }; 关键设计: iface 定义了如何操作这块内存(分配、释放、拷贝等) buft 标识内存由哪个后端分配 支持CPU、CUDA、Metal、Vulkan等多种后端 模型加载完整流程 入口函数:llama_model_load_from_file_impl 这是模型加载的入口点,负责设备发现、模型对象创建和错误处理。 static struct llama_model * llama_model_load_from_file_impl( const std::string & path_model, std::vector<std::string> & splits, struct llama_model_params params) { // 1. 初始化时间统计 ggml_time_init(); // 2. 检查后端是否已加载 if (!params.vocab_only && ggml_backend_reg_count() == 0) { LLAMA_LOG_ERROR("no backends are loaded\n"); return nullptr; } // 3. 设置默认进度回调(如果未提供) if (params.progress_callback == NULL) { params.progress_callback = [](float progress, void * ctx) { // 打印进度点 return true; }; } // 4. 创建模型对象 llama_model * model = new llama_model(params); // 5. 设备发现与选择(详见"设备管理"章节) if (params.devices) { // 使用用户指定的设备 for (ggml_backend_dev_t * dev = params.devices; *dev; ++dev) { model->devices.push_back(*dev); } } else { // 自动发现设备 // - 收集所有GPU设备 // - 收集集成GPU(iGPU) // - 收集RPC服务器 // - 按优先级排序 } // 6. 单GPU模式处理 if (params.split_mode == LLAMA_SPLIT_MODE_NONE) { if (params.main_gpu < 0) { model->devices.clear(); // 只用CPU } else { // 只保留指定的GPU model->devices = {model->devices[params.main_gpu]}; } } // 7. 打印设备信息 for (auto * dev : model->devices) { ggml_backend_dev_props props; ggml_backend_dev_get_props(dev, &props); LLAMA_LOG_INFO("using device %s - %zu MiB free\n", ggml_backend_dev_name(dev), props.memory_free/1024/1024); } // 8. 调用核心加载函数 const int status = llama_model_load(path_model, splits, *model, params); // 9. 错误处理 if (status < 0) { if (status == -1) { LLAMA_LOG_ERROR("failed to load model\n"); } else if (status == -2) { LLAMA_LOG_INFO("cancelled model load\n"); } llama_model_free(model); return nullptr; } return model; } 核心加载函数:llama_model_load 这是模型加载的核心流程,按顺序执行各个加载阶段。 static int llama_model_load( const std::string & fname, std::vector<std::string> & splits, llama_model & model, llama_model_params & params) { // 初始化时间统计 model.t_load_us = 0; time_meas tm(model.t_load_us); model.t_start_us = tm.t_start_us; try { // ========== 阶段0:创建Loader ========== llama_model_loader ml(fname, splits, params.use_mmap, params.use_direct_io, params.check_tensors, params.no_alloc, params.kv_overrides, params.tensor_buft_overrides); ml.print_info(); // 打印模型基本信息 model.hparams.vocab_only = params.vocab_only; model.hparams.no_alloc = params.no_alloc; // ========== 阶段1:架构识别 ========== try { model.load_arch(ml); } catch(const std::exception & e) { throw std::runtime_error("error loading model architecture: " + std::string(e.what())); } // ========== 阶段2:超参数加载 ========== try { model.load_hparams(ml); } catch(const std::exception & e) { throw std::runtime_error("error loading model hyperparameters: " + std::string(e.what())); } // CLIP模型特殊处理 if (model.arch == LLM_ARCH_CLIP) { throw std::runtime_error("CLIP cannot be used as main model"); } // ========== 阶段3:词表加载 ========== try { model.load_vocab(ml); } catch(const std::exception & e) { throw std::runtime_error("error loading model vocabulary: " + std::string(e.what())); } // ========== 阶段4:统计信息 ========== model.load_stats(ml); model.print_info(); // 打印完整模型信息 // ========== 早期退出:仅词表模式 ========== if (params.vocab_only) { LLAMA_LOG_INFO("vocab only - skipping tensors\n"); return 0; } // ========== 阶段5:张量创建与加载 ========== if (!model.load_tensors(ml)) { return -2; // 被进度回调取消 } } catch (const std::exception & err) { LLAMA_LOG_ERROR("error loading model: %s\n", err.what()); return -1; } return 0; } 阶段一:架构识别与元数据解析 load_arch实现 void llama_model::load_arch(llama_model_loader & ml) { arch = ml.get_arch(); // 从loader获取架构枚举 if (arch == LLM_ARCH_UNKNOWN) { throw std::runtime_error("unknown model architecture: '" + ml.get_arch_name() + "'"); } } loader中的架构识别 // llama_model_loader构造函数中 llama_model_loader::llama_model_loader(...) { // 1. 解析GGUF文件头 meta.reset(gguf_init_from_file(fname.c_str(), params)); // 2. 读取架构名称 std::string arch_name; get_key(llm_kv(LLM_KV_GENERAL_ARCHITECTURE), arch_name, false); // 3. 转换为枚举 llm_kv = LLM_KV(llm_arch_from_string(arch_name)); // llm_arch_from_string("llama") -> LLM_ARCH_LLAMA } 架构识别流程: GGUF文件头包含 general.architecture KV对 读取字符串值(如"llama"、"qwen"、"deepseek") 通过 llm_arch_from_string() 转换为枚举 如果无法识别,抛出异常 阶段二:超参数加载 详见 llama_hparams - 超参数蓝图 章节。 关键点: 从GGUF的KV对中读取所有超参数 支持数组参数(每层不同) 架构特定参数根据arch分支处理 参数校验与默认值推导 阶段三:词表加载 void llama_model::load_vocab(llama_model_loader & ml) { const auto kv = LLM_KV(arch); // 获取架构特定的KV键前缀 vocab.load(ml, kv); // 加载词表 } 词表加载包括: Token ID到字符串的映射 Token类型(普通/BOS/EOS/等) 特殊Token(如<|im_start|>) 子词合并规则(BPE/SPM等) 阶段四:张量创建与设备分配 这是最复杂的阶段,涉及张量创建、设备分配、Buffer类型选择等。 load_tensors流程概览 bool llama_model::load_tensors(llama_model_loader & ml) { const int n_layer = hparams.n_layer; const int n_gpu_layers = this->n_gpu_layers(); // ========== 步骤1:构建Buffer类型列表 ========== pimpl->cpu_buft_list = make_cpu_buft_list(devices, ...); for (auto * dev : devices) { buft_list_t buft_list = make_gpu_buft_list(dev, split_mode, tensor_split); buft_list.insert(buft_list.end(), pimpl->cpu_buft_list.begin(), pimpl->cpu_buft_list.end()); pimpl->gpu_buft_list.emplace(dev, std::move(buft_list)); } // ========== 步骤2:计算设备分割点 ========== std::vector<float> splits(n_devices()); // 根据tensor_split参数或默认策略(按显存)分配 // ========== 步骤3:分配层到设备 ========== auto get_layer_buft_list = [&](int il) -> layer_dev { if (il < i_gpu_start || (il - i_gpu_start) >= act_gpu_layers) { return {cpu_dev, &pimpl->cpu_buft_list}; } const int layer_gpu = /* 根据splits计算 */; return {devices.at(layer_gpu), &pimpl->gpu_buft_list.at(devices.at(layer_gpu))}; }; pimpl->dev_input = {cpu_dev, &pimpl->cpu_buft_list}; pimpl->dev_layer.resize(n_layer); for (int il = 0; il < n_layer; ++il) { pimpl->dev_layer[il] = get_layer_buft_list(il); } pimpl->dev_output = get_layer_buft_list(n_layer); // ========== 步骤4:创建GGML Context ========== // 为每个Buffer类型创建独立的context std::map<ggml_backend_buffer_type_t, ggml_context_ptr> ctx_map; auto ctx_for_buft = [&](ggml_backend_buffer_type_t buft) -> ggml_context * { // 查找或创建context }; // ========== 步骤5:创建张量对象(架构特定) ========== layers.resize(n_layer); auto create_tensor = [&](const LLM_TN_IMPL & tn, const std::initializer_list<int64_t> & ne, int flags) -> ggml_tensor * { // 1. 从weights_map查找元数据 ggml_tensor * t_meta = ml.get_tensor_meta(tn.str().c_str()); // 2. 选择Buffer类型 buft_list_t * buft_list = /* 根据tensor层级选择 */; ggml_backend_buffer_type_t buft = select_weight_buft(hparams, t_meta, op, *buft_list); // 3. 检查覆盖规则 if (ml.tensor_buft_overrides) { // 应用用户指定的覆盖 } // 4. 获取或创建context ggml_context * ctx = ctx_for_buft(buft); // 5. 创建tensor对象(此时data仍为nullptr) return ml.create_tensor(ctx, tn, ne, flags); }; // 架构特定的张量创建 switch (arch) { case LLM_ARCH_LLAMA: tok_embd = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, 0); output_norm = create_tensor(tn(LLM_TENSOR_OUTPUT_NORM, "weight"), {n_embd}, 0); output = create_tensor(tn(LLM_TENSOR_OUTPUT, "weight"), {n_embd, n_vocab}, TENSOR_NOT_REQUIRED); for (int i = 0; i < n_layer; ++i) { auto & layer = layers[i]; layer.attn_norm = create_tensor(tn(LLM_TENSOR_ATTN_NORM, "weight", i), {n_embd}, 0); layer.wq = create_tensor(tn(LLM_TENSOR_ATTN_Q, "weight", i), {n_embd, n_embd_head_k * n_head}, 0); // ... 更多张量 } break; // ... 其他架构 } // ========== 步骤6:初始化内存映射 ========== ml.init_mappings(params.prefetch, &pimpl->mlock_mmaps); // ========== 步骤7:加载实际数据 ========== if (!ml.load_all_data(ctxs_bufs, params.progress_callback, params.progress_callback_user_data)) { return false; // 被取消 } // ========== 步骤8:保存Context和Buffer ========== for (auto & [buft, ctx] : ctx_map) { std::vector<ggml_backend_buffer_ptr> bufs; // 收集该context下的所有buffer pimpl->ctxs_bufs.emplace_back(ctx, std::move(bufs)); } return true; } 设备分配策略 输入层:始终在CPU(dev_input = cpu_dev) 中间层:根据n_gpu_layers和tensor_split分配 输出层:与最后一层相同设备 分割计算: // 默认分割:按显存比例 if (all_zero) { for (size_t i = 0; i < n_devices(); ++i) { ggml_backend_dev_props props; ggml_backend_dev_get_props(devices[i], &props); total_free += props.memory_free; } float acc = 0.0f; for (size_t i = 0; i < n_devices(); ++i) { ggml_backend_dev_props props; ggml_backend_dev_get_props(devices[i], &props); acc += props.memory_free / total_free; splits[i] = acc; } } 阶段五:权重数据加载 load_all_data实现 bool llama_model_loader::load_all_data( std::vector<std::pair<ggml_context_ptr, std::vector<ggml_backend_buffer_ptr>>> & ctxs_bufs, llama_progress_callback progress_callback, void * progress_callback_user_data) { // ========== 准备异步上传(如果支持) ========== ggml_backend_t upload_backend = /* 检查是否支持异步上传 */; std::vector<ggml_backend_buffer_ptr> host_buffers; std::vector<void *> host_ptrs; std::vector<ggml_backend_event_ptr> events; // ========== 遍历所有tensor ========== for (struct ggml_tensor * cur = ggml_get_first_tensor(ctx); cur != NULL; cur = ggml_get_next_tensor(ctx, cur)) { const auto * weight = get_weight(ggml_get_name(cur)); if (weight == nullptr) continue; // 进度回调 if (progress_callback) { if (!progress_callback((float) size_done / size_data, progress_callback_user_data)) { return false; // 用户取消 } } size_t n_size = ggml_nbytes(cur); // ========== 路径A:mmap模式(零拷贝) ========== if (use_mmap) { const auto & mapping = mappings.at(weight->idx); uint8_t * data = (uint8_t *) mapping->addr() + weight->offs; // 验证数据(如果启用) if (check_tensors) { validation_result.emplace_back(std::async(std::launch::async, [cur, data, n_size] { return std::make_pair(cur, ggml_validate_row_data(cur->type, data, n_size)); })); } // 绑定到mmap内存 ggml_backend_buffer_t buf_mmap = bufs.at(weight->idx); if (buf_mmap && cur->data == nullptr) { ggml_backend_tensor_alloc(buf_mmap, cur, data); // tensor->buffer = buf_mmap // tensor->data = data (指向mmap地址) } else { // 拷贝数据(如果tensor已有buffer) ggml_backend_tensor_set(cur, data, 0, n_size); } } // ========== 路径B:文件读取模式 ========== else { const auto & file = files.at(weight->idx); // CPU buffer:直接读取 if (ggml_backend_buffer_is_host(cur->buffer)) { file->seek(weight->offs, SEEK_SET); file->read_raw(cur->data, n_size); if (check_tensors) { validation_result.emplace_back(std::async(std::launch::async, [cur, n_size] { return std::make_pair(cur, ggml_validate_row_data(cur->type, cur->data, n_size)); })); } } // GPU buffer:异步上传 else { if (upload_backend) { // 分块读取+异步上传 size_t offset = weight->offs; size_t aligned_offset = offset & ~(alignment - 1); // ... 对齐读取边界 while (bytes_read < read_end - read_start) { // 等待上一个上传完成 ggml_backend_event_synchronize(events[buffer_idx]); // 读取对齐块 file->read_raw_unsafe(host_ptrs[buffer_idx], read_size); // 异步上传到GPU ggml_backend_tensor_set_async(upload_backend, cur, host_ptrs[buffer_idx], data_read, data_to_copy); ggml_backend_event_record(events[buffer_idx], upload_backend); buffer_idx = (buffer_idx + 1) % n_buffers; // 轮转缓冲区 } } else { // 同步上传 read_buf.resize(n_size); file->seek(weight->offs, SEEK_SET); file->read_raw(read_buf.data(), n_size); ggml_backend_tensor_set(cur, read_buf.data(), 0, n_size); } } } size_done += n_size; } // ========== 验证结果 ========== if (check_tensors) { for (auto & future : validation_result) { auto [tensor, valid] = future.get(); if (!valid) { throw std::runtime_error(format("tensor '%s' has invalid data", ggml_get_name(tensor))); } } } return true; } 三种数据加载路径对比 路径 适用场景 性能 内存占用 mmap绑定 CPU推理,mmap可用 最快(零拷贝) 最小(共享文件页) 文件读取+CPU CPU推理,mmap不可用 中等 中等(需要内存拷贝) 异步上传 GPU推理,支持异步 快(重叠I/O和计算) 中等(需要pinned memory) 同步上传 GPU推理,不支持异步 慢 中等 GGUF协议与I/O抽象 GGUF文件格式解析 GGUF(GPT-Generated Unified Format)是llama.cpp使用的二进制模型格式。 文件结构 ┌─────────────────────────────────────┐ │ Magic Number (4 bytes) │ "GGUF" ├─────────────────────────────────────┤ │ Version (4 bytes) │ 协议版本 ├─────────────────────────────────────┤ │ n_kv (8 bytes) │ KV对数量 ├─────────────────────────────────────┤ │ KV Pairs (变长) │ │ - Key: 字符串长度 + 字符串 │ │ - Type: 类型枚举 │ │ - Value: 根据类型存储 │ ├─────────────────────────────────────┤ │ n_tensors (8 bytes) │ 张量数量 ├─────────────────────────────────────┤ │ Tensor Info Array (变长) │ │ - Name: 字符串长度 + 字符串 │ │ - n_dims: 维度数 │ │ - dims[]: 各维度大小 │ │ - type: 数据类型 │ │ - offset: 数据偏移(相对数据区) │ ├─────────────────────────────────────┤ │ Alignment Padding │ 对齐到16字节 ├─────────────────────────────────────┤ │ Tensor Data (变长) │ 实际权重数据 └─────────────────────────────────────┘ 解析流程 struct gguf_context * gguf_init_from_file_impl(FILE * file, ...) { const struct gguf_reader gr(file); struct gguf_context * ctx = new gguf_context; // 1. 校验Magic Number uint32_t magic = gr.read_u32(); if (magic != GGUF_MAGIC) { throw std::runtime_error("invalid GGUF magic"); } // 2. 读取版本 ctx->version = gr.read_u32(); // 3. 读取KV对数量 int64_t n_kv = gr.read_u64(); // 4. 循环读取所有KV对 for (int64_t i = 0; i < n_kv; ++i) { std::string key = gr.read_string(); gguf_type type = (gguf_type)gr.read_u32(); switch (type) { case GGUF_TYPE_UINT8: ctx->kv.emplace_back(key, gr.read_u8()); break; case GGUF_TYPE_INT32: ctx->kv.emplace_back(key, gr.read_i32()); break; case GGUF_TYPE_FLOAT32: ctx->kv.emplace_back(key, gr.read_f32()); break; case GGUF_TYPE_STRING: ctx->kv.emplace_back(key, gr.read_string()); break; // ... 更多类型 } } // 5. 读取张量数量 int64_t n_tensors = gr.read_u64(); // 6. 循环读取所有张量信息 for (int64_t i = 0; i < n_tensors; ++i) { struct gguf_tensor_info info; info.name = gr.read_string(); info.n_dims = gr.read_u32(); for (uint32_t j = 0; j < info.n_dims; ++j) { info.dims[j] = gr.read_u64(); } info.type = (ggml_type)gr.read_u32(); info.offset = gr.read_u64(); // 相对数据区的偏移 ctx->info.push_back(info); } // 7. 计算数据区偏移 ctx->offset = gr.tell(); // 当前位置就是数据区开始 return ctx; } 内存映射(mmap)机制 mmap是llama.cpp实现零拷贝加载的核心技术。 mmap初始化 llama_mmap::llama_mmap(struct llama_file * file, size_t prefetch, bool numa) { size = file->size(); int fd = file->file_id(); #ifdef _POSIX_MAPPED_FILES int flags = MAP_SHARED; // Linux优化:预读建议 if (posix_fadvise(fd, 0, 0, POSIX_FADV_SEQUENTIAL)) { LLAMA_LOG_WARN("posix_fadvise failed\n"); } // 预填充页面(如果启用) if (prefetch) { flags |= MAP_POPULATE; } // 执行mmap addr = mmap(NULL, file->size(), PROT_READ, flags, fd, 0); if (addr == MAP_FAILED) { throw std::runtime_error(format("mmap failed: %s", strerror(errno))); } // 预取建议(如果启用) if (prefetch > 0) { posix_madvise(addr, std::min(file->size(), prefetch), POSIX_MADV_WILLNEED); } // NUMA优化 if (numa) { posix_madvise(addr, file->size(), POSIX_MADV_RANDOM); } #endif } mmap优势 零拷贝:文件数据直接映射到虚拟地址空间,无需拷贝 延迟加载:页面在首次访问时才从磁盘读取(按需分页) 内存共享:多个进程可以共享同一份映射,节省内存 操作系统优化:OS可以预读、缓存页面 mmap绑定tensor // 在load_all_data中 if (use_mmap) { const auto & mapping = mappings.at(weight->idx); uint8_t * data = (uint8_t *) mapping->addr() + weight->offs; // 关键:将tensor的data指针直接指向mmap地址 ggml_backend_tensor_alloc(buf_mmap, cur, data); // 执行后: // cur->buffer = buf_mmap // cur->data = data (指向mmap虚拟地址) } 注意:mmap地址是虚拟地址,实际数据仍在文件页中,由OS管理。 权重索引表构建 weights_map构建流程 llama_model_loader::llama_model_loader(...) { // 1. 解析GGUF元数据 meta.reset(gguf_init_from_file(fname.c_str(), params)); ggml_context * ctx = contexts[0]; // 2. 遍历GGML context中的所有tensor元数据 for (ggml_tensor * cur = ggml_get_first_tensor(ctx); cur; cur = ggml_get_next_tensor(ctx, cur)) { std::string tensor_name = std::string(cur->name); // 3. 计算文件偏移 size_t offs = gguf_get_data_offset(gguf_ctx) + gguf_get_tensor_offset(gguf_ctx, tensor_idx); // 4. 插入索引表(使用自定义排序) weights_map.emplace(tensor_name, llama_tensor_weight(files[0].get(), 0, meta.get(), cur)); } // 5. 处理分片文件(如果有) for (const auto & split : splits) { // 解析分片GGUF // 合并tensor到weights_map(idx递增) } } weight_name_comparer排序规则 struct weight_name_comparer { bool operator()(const std::string & a, const std::string & b) const { int bid_a = -1, bid_b = -1; // 解析层号(如 "blk.5.attn_q.weight" -> 5) sscanf(a.c_str(), "blk.%d.", &bid_a); sscanf(b.c_str(), "blk.%d.", &bid_b); // 按层号排序 if (bid_a != bid_b) { return bid_a < bid_b; } // 同层按名称排序 return a < b; } }; 排序目的:优化磁盘读取顺序,利用OS预读缓存。 数据加载路径 详见 阶段五:权重数据加载 章节。 设备管理与多GPU支持 设备发现与选择 自动设备发现 // 在llama_model_load_from_file_impl中 std::vector<ggml_backend_dev_t> gpus; std::vector<ggml_backend_dev_t> igpus; // 集成GPU std::vector<ggml_backend_dev_t> rpc_servers; // RPC服务器 for (size_t i = 0; i < ggml_backend_dev_count(); ++i) { ggml_backend_dev_t dev = ggml_backend_dev_get(i); switch (ggml_backend_dev_type(dev)) { case GGML_BACKEND_DEVICE_TYPE_GPU: { // 检查设备ID是否重复 ggml_backend_dev_props props; ggml_backend_dev_get_props(dev, &props); auto it = std::find_if(gpus.begin(), gpus.end(), [&props](ggml_backend_dev_t d) { // 比较device_id return /* 相同ID */; }); if (it == gpus.end()) { gpus.push_back(dev); } break; } case GGML_BACKEND_DEVICE_TYPE_IGPU: igpus.push_back(dev); break; } } // 优先级:RPC服务器 > 独立GPU > 集成GPU(仅当无其他设备时) model->devices.insert(model->devices.begin(), rpc_servers.begin(), rpc_servers.end()); model->devices.insert(model->devices.end(), gpus.begin(), gpus.end()); if (model->devices.empty()) { model->devices.insert(model->devices.end(), igpus.begin(), igpus.end()); } 单GPU模式 if (params.split_mode == LLAMA_SPLIT_MODE_NONE) { if (params.main_gpu < 0) { model->devices.clear(); // 只用CPU } else { // 只保留指定的GPU ggml_backend_dev_t main_gpu = model->devices[params.main_gpu]; model->devices.clear(); model->devices.push_back(main_gpu); } } 层到设备的映射策略 分割点计算 // 默认:按显存比例 std::vector<float> splits(n_devices()); if (all_zero) { // tensor_split全为0 size_t total_free = 0; for (size_t i = 0; i < n_devices(); ++i) { ggml_backend_dev_props props; ggml_backend_dev_get_props(devices[i], &props); total_free += props.memory_free; } float acc = 0.0f; for (size_t i = 0; i < n_devices(); ++i) { ggml_backend_dev_props props; ggml_backend_dev_get_props(devices[i], &props); acc += props.memory_free / total_free; splits[i] = acc; // 累积比例 } } else { // 使用用户指定的tensor_split float acc = 0.0f; for (size_t i = 0; i < n_devices(); ++i) { acc += tensor_split[i]; splits[i] = acc; } } 层分配函数 auto get_layer_buft_list = [&](int il) -> layer_dev { const bool is_swa = il < int(hparams.n_layer) && hparams.is_swa(il); // CPU层 if (il < i_gpu_start || (il - i_gpu_start) >= act_gpu_layers) { return {cpu_dev, &pimpl->cpu_buft_list}; } // GPU层:根据splits查找 float layer_ratio = float(il - i_gpu_start) / act_gpu_layers; const int layer_gpu = std::upper_bound(splits.begin(), splits.begin() + n_devices(), layer_ratio) - splits.begin(); auto * dev = devices.at(layer_gpu); return {dev, &pimpl->gpu_buft_list.at(dev)}; }; 示例:3个GPU,splits = [0.33, 0.67, 1.0] 层0-10 → GPU 0 层11-21 → GPU 1 层22-32 → GPU 2 Buffer类型选择 Buffer类型列表构建 // CPU Buffer类型列表 buft_list_t make_cpu_buft_list(...) { buft_list_t buft_list; // 1. Split buffer(如果启用) if (tensor_split && n_devices() > 1) { // 添加split buffer类型 } // 2. 默认CPU buffer buft_list.emplace_back(cpu_dev, ggml_backend_dev_buffer_type(cpu_dev)); // 3. Extra buffer类型(如果启用) if (use_extra_bufts) { auto * extra_bufts = ggml_backend_dev_get_extra_bufts(cpu_dev); // 添加extra buffer } return buft_list; } // GPU Buffer类型列表 buft_list_t make_gpu_buft_list(ggml_backend_dev_t dev, ...) { buft_list_t buft_list; // 1. Split buffer(如果启用) if (split_mode == LLAMA_SPLIT_MODE_LAYER) { // 添加split buffer } // 2. 默认GPU buffer buft_list.emplace_back(dev, ggml_backend_dev_buffer_type(dev)); // 3. Host buffer(用于CPU-GPU传输) auto * host_buft = ggml_backend_dev_host_buffer_type(dev); if (host_buft) { buft_list.emplace_back(dev, host_buft); } // 4. CPU buffer作为fallback buft_list.insert(buft_list.end(), cpu_buft_list.begin(), cpu_buft_list.end()); return buft_list; } 权重Buffer类型选择 ggml_backend_buffer_type_t select_weight_buft( const llama_hparams & hparams, ggml_tensor * w, ggml_op op, const buft_list_t & buft_list) { // 1. 检查权重是否支持该buffer类型 for (const auto & [dev, buft] : buft_list) { if (weight_buft_supported(hparams, w, op, buft, dev)) { return buft; } } // 2. 回退到CPU return ggml_backend_cpu_buffer_type(); } 选择策略: 优先选择GPU buffer(如果支持该操作) 回退到Host buffer(用于传输) 最后回退到CPU buffer 异步上传机制 异步上传初始化 ggml_backend_t upload_backend = [&]() -> ggml_backend_t { if (use_mmap || check_tensors) { return nullptr; // mmap或验证模式下不使用异步上传 } // 检查backend是否支持异步上传 auto * buf = bufs.count(0) ? bufs.at(0) : nullptr; if (!buf) return nullptr; auto * buft = ggml_backend_buffer_get_type(buf); auto * dev = ggml_backend_buft_get_device(buft); if (!dev) return nullptr; // 检查能力 ggml_backend_dev_props props; ggml_backend_dev_get_props(dev, &props); if (!props.caps.async || !props.caps.host_buffer || !props.caps.events) { return nullptr; } // 创建pinned memory buffers auto * host_buft = ggml_backend_dev_host_buffer_type(dev); for (size_t idx = 0; idx < n_buffers; ++idx) { auto * buf = ggml_backend_buft_alloc_buffer(host_buft, buffer_size); host_buffers.emplace_back(buf); host_ptrs.emplace_back(ggml_backend_buffer_get_base(buf)); auto * event = ggml_backend_event_new(dev); events.emplace_back(event); } return ggml_backend_dev_init(dev, nullptr); }(); 异步上传流程 // 在load_all_data中 if (upload_backend) { size_t offset = weight->offs; size_t aligned_offset = offset & ~(alignment - 1); size_t offset_from_alignment = offset - aligned_offset; file->seek(aligned_offset, SEEK_SET); size_t bytes_read = 0; size_t data_read = 0; while (bytes_read < read_end - read_start) { size_t read_size = std::min<size_t>(buffer_size, read_end - read_start - bytes_read); // 等待上一个上传完成(避免覆盖) ggml_backend_event_synchronize(events[buffer_idx]); // 读取对齐块到pinned memory file->read_raw_unsafe(host_ptrs[buffer_idx], read_size); // 计算实际数据部分(排除对齐填充) uintptr_t ptr_data = /* 对齐后的指针 */; size_t data_to_copy = read_size; if (bytes_read == 0) { ptr_data += offset_from_alignment; data_to_copy -= offset_from_alignment; } // 异步上传到GPU(不阻塞) ggml_backend_tensor_set_async(upload_backend, cur, reinterpret_cast<void *>(ptr_data), data_read, data_to_copy); // 记录事件(用于后续同步) ggml_backend_event_record(events[buffer_idx], upload_backend); data_read += data_to_copy; bytes_read += read_size; buffer_idx = (buffer_idx + 1) % n_buffers; // 轮转缓冲区 } } 优势: 重叠I/O和计算:读取下一块数据时,上一块正在上传 多缓冲区轮转:避免等待上传完成 对齐读取:提高I/O效率 内存管理优化 内存映射(mmap)优化 详见 内存映射(mmap)机制 章节。 补充优化点: 预填充页面:MAP_POPULATE标志立即读取所有页面(适用于小模型) 预读建议:POSIX_MADV_WILLNEED告诉OS预读页面 NUMA感知:POSIX_MADV_RANDOM优化NUMA系统访问模式 内存锁定(mlock)机制 mlock将内存页面锁定在RAM中,防止被swap到磁盘。 struct llama_mlock { void init(void * ptr) { // 初始化mlock } void grow_to(size_t target_size) { // 扩展锁定区域 #ifdef _POSIX_MEMLOCK_RANGE if (mlock(ptr, target_size) != 0) { // 处理错误(可能需要root权限) } #endif } }; 使用场景: 实时推理系统(避免swap延迟) 需要root权限或CAP_IPC_LOCK能力 NUMA感知 NUMA(Non-Uniform Memory Access)系统需要优化内存访问模式。 // 在init_mappings中 bool is_numa = false; auto * dev = ggml_backend_dev_by_type(GGML_BACKEND_DEVICE_TYPE_CPU); if (dev) { auto * reg = ggml_backend_dev_backend_reg(dev); auto * is_numa_fn = (decltype(ggml_is_numa) *) ggml_backend_reg_get_proc_address(reg, "ggml_backend_cpu_is_numa"); if (is_numa_fn) { is_numa = is_numa_fn(); } } // 创建mmap时传递NUMA标志 std::unique_ptr<llama_mmap> mapping = std::make_unique<llama_mmap>(file.get(), prefetch ? -1 : 0, is_numa); NUMA优化: 使用POSIX_MADV_RANDOM提示OS随机访问模式 避免跨NUMA节点访问(如果可能) 内存碎片管理 llama.cpp通过以下策略减少内存碎片: 按Buffer类型分组:相同类型的tensor使用同一个context 对齐分配:tensor数据按16字节对齐 mmap零拷贝:避免额外分配 架构特定加载逻辑 架构识别流程 // 1. 从GGUF读取架构名称 std::string arch_name; ml.get_key(LLM_KV_GENERAL_ARCHITECTURE, arch_name, false); // 2. 转换为枚举 llm_arch arch = llm_arch_from_string(arch_name); // "llama" -> LLM_ARCH_LLAMA // "qwen" -> LLM_ARCH_QWEN // ... // 3. 设置模型架构 model.arch = arch; 张量命名约定 llama.cpp使用统一的张量命名约定: {prefix}.{layer_idx}.{tensor_name}.{suffix} 示例: - tok_embeddings.weight (输入层) - blk.0.attn_norm.weight (第0层,注意力归一化) - blk.0.attn_q.weight (第0层,Query投影) - blk.0.ffn_gate.weight (第0层,FFN门控) - output_norm.weight (输出层) - output.weight (输出权重) 架构特定前缀: Llama: blk.{i} Qwen: blk.{i} DeepSeek: blk.{i} Mamba: blk.{i} (但使用SSM层) 特殊架构处理 MoE架构(Mixtral/DeepSeek) if (n_expert > 0) { // 门控输入 layer.ffn_gate_inp = create_tensor( tn(LLM_TENSOR_FFN_GATE_INP, "weight", i), {n_embd, n_expert}, 0); // 专家权重(3D张量:n_embd x n_ff x n_expert) layer.ffn_gate_exps = create_tensor( tn(LLM_TENSOR_FFN_GATE_EXPS, "weight", i), {n_embd, n_ff, n_expert}, TENSOR_NOT_REQUIRED); layer.ffn_up_exps = create_tensor( tn(LLM_TENSOR_FFN_UP_EXPS, "weight", i), {n_embd, n_ff, n_expert}, 0); layer.ffn_down_exps = create_tensor( tn(LLM_TENSOR_FFN_DOWN_EXPS, "weight", i), {n_ff, n_embd, n_expert}, 0); // 共享专家(DeepSeek) if (hparams.n_ff_shexp > 0) { layer.ffn_gate_shexp = create_tensor(...); layer.ffn_up_shexp = create_tensor(...); layer.ffn_down_shexp = create_tensor(...); } } Mamba架构 case LLM_ARCH_MAMBA: case LLM_ARCH_MAMBA2: // SSM归一化 layer.ssm_norm = create_tensor( tn(LLM_TENSOR_SSM_NORM, "weight", i), {n_embd}, 0); // SSM参数 layer.ssm_dt_rank = create_tensor(...); layer.ssm_in = create_tensor(...); layer.ssm_out = create_tensor(...); // ... break; RWKV架构 case LLM_ARCH_RWKV6: case LLM_ARCH_RWKV7: // RWKV使用循环层,不使用标准注意力 // 特殊的time_mix参数 layer.time_mix_k = create_tensor(...); layer.time_mix_v = create_tensor(...); // ... break; 错误处理与进度跟踪 异常处理机制 try { llama_model_loader ml(...); model.load_arch(ml); model.load_hparams(ml); model.load_vocab(ml); model.load_tensors(ml); } catch (const std::exception & err) { LLAMA_LOG_ERROR("error loading model: %s\n", err.what()); return -1; } 常见错误: 文件不存在或格式错误 架构不支持 超参数缺失或无效 张量缺失或形状不匹配 内存不足 进度回调系统 typedef bool (*llama_progress_callback)(float progress, void * ctx); // 在load_all_data中 if (progress_callback) { float progress = (float) size_done / size_data; if (!progress_callback(progress, progress_callback_user_data)) { return false; // 用户取消 } } 使用示例: bool my_progress(float progress, void * ctx) { printf("Loading: %.1f%%\r", progress * 100); fflush(stdout); return true; // 返回false可取消加载 } llama_model_params params = llama_model_default_params(); params.progress_callback = my_progress; params.progress_callback_user_data = nullptr; 取消加载机制 进度回调返回false时,加载会立即停止: // 在load_all_data中 if (progress_callback) { if (!progress_callback((float) size_done / size_data, progress_callback_user_data)) { return false; // 取消加载 } } // 在llama_model_load中 if (!model.load_tensors(ml)) { return -2; // 返回-2表示取消 } 数据结构关联关系总结 加载链路关联 ┌─────────────────────────────────────────────────────────────┐ │ 阶段 1: GGUF 读取 │ │ │ │ gguf_init_from_file() │ │ ↓ │ │ 解析所有 KV 对 → 存储在 gguf_context->kv 中 │ │ - "general.architecture" = "llama" │ │ - "llama.context_length" = 4096 │ │ - "llama.embedding_length" = 4096 │ │ - "llama.block_count" = 32 │ │ │ │ 结果:ml.meta (gguf_context_ptr) 持有所有 KV 对 │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 阶段 2: 架构识别 │ │ │ │ model.load_arch(ml) │ │ ↓ │ │ ml.get_arch() → 从gguf_context读取架构名称 │ │ ↓ │ │ model.arch = LLM_ARCH_LLAMA │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 阶段 3: 超参数加载 │ │ │ │ model.load_hparams(ml) │ │ ↓ │ │ ml.get_key(LLM_KV_CONTEXT_LENGTH, hparams.n_ctx_train) │ │ ↓ │ │ 从gguf_context->kv查找并填充hparams │ │ │ │ 结果:model.hparams 包含所有数学参数 │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 阶段 4: 张量创建 │ │ │ │ model.load_tensors(ml) │ │ ↓ │ │ 1. 根据hparams.n_layer创建layers数组 │ │ layers.resize(n_layer) │ │ │ │ 2. 从weights_map查找张量元数据 │ │ weight = ml.get_weight("blk.0.attn_q.weight") │ │ │ │ 3. 创建tensor对象(空壳) │ │ layer.wq = ml.create_tensor(ctx, tn, {n_embd, ...}, 0) │ │ │ │ 4. 分配设备 │ │ pimpl->dev_layer[0] = get_layer_buft_list(0) │ │ │ │ 结果:所有tensor对象已创建,但data仍为nullptr │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 阶段 5: 数据加载 │ │ │ │ ml.load_all_data() │ │ ↓ │ │ 遍历所有tensor: │ │ for (tensor in ctx) { │ │ weight = get_weight(tensor->name) │ │ if (use_mmap) { │ │ data = mapping->addr() + weight->offs │ │ ggml_backend_tensor_alloc(buf, tensor, data) │ │ // tensor->data = data (指向mmap地址) │ │ } else { │ │ file->read_raw(tensor->data, n_size) │ │ } │ │ } │ │ │ │ 结果:tensor->data指向实际权重数据 │ └─────────────────────────────────────────────────────────────┘ 数据结构职责划分 数据结构 职责 生命周期 gguf_context GGUF文件元数据存储 加载期间 llama_model_loader 权重索引、文件管理、数据加载 加载期间 llama_hparams 数学参数存储 模型生命周期 llama_model 权重指针、设备管理、元数据 模型生命周期 llama_layer 单层权重指针 模型生命周期 ggml_tensor 张量元数据+数据指针 模型生命周期 ggml_backend_buffer 物理内存管理 模型生命周期 关键设计模式 Pimpl模式:隐藏实现细节,保持API稳定 索引表模式:weights_map作为"目录",快速定位权重 策略模式:设备分配、Buffer选择通过策略函数实现 工厂模式:create_tensor根据架构创建不同张量 总结 GGUF读取的调用链 GGUF文件的读取在llama.cpp中遵循以下调用链: llama_model_load_from_file_impl() ↓ llama_model_load() ↓ llama_model_loader::llama_model_loader() // 构造函数 ↓ gguf_init_from_file() // 打开文件并调用解析函数 ↓ gguf_init_from_file_impl() // 实际解析函数 ↓ gguf_reader // 文件读取器 关键调用点: // 在 llama_model_loader 构造函数中(llama-model-loader.cpp:531) struct gguf_init_params params = { /*.no_alloc = */ true, // 只读取元数据,不分配tensor数据 /*.ctx = */ &ctx, // 返回ggml_context用于存储tensor元数据 }; meta.reset(gguf_init_from_file(fname.c_str(), params)); // meta 是 gguf_context_ptr,持有解析后的GGUF元数据 GGUF解析的详细流程 gguf_init_from_file_impl 按以下顺序解析文件: 步骤1:校验Magic Number std::vector<char> magic; gr.read(magic, 4); // 读取4字节 // 验证是否为 "GGUF" 步骤2:读取文件头 gr.read(ctx->version); // 读取版本号(4字节) gr.read(n_kv); // 读取KV对数量(8字节) gr.read(n_tensors); // 读取张量数量(8字节) 步骤3:解析所有KV对 for (int64_t i = 0; i < n_kv; ++i) { std::string key = gr.read_string(); // 读取键名 gguf_type type = (gguf_type)gr.read_u32(); // 读取类型 // 根据类型读取值 switch (type) { case GGUF_TYPE_UINT8: ctx->kv.emplace_back(key, gr.read_u8()); break; case GGUF_TYPE_INT32: ctx->kv.emplace_back(key, gr.read_i32()); break; case GGUF_TYPE_FLOAT32: ctx->kv.emplace_back(key, gr.read_f32()); break; case GGUF_TYPE_STRING: ctx->kv.emplace_back(key, gr.read_string()); break; // ... 更多类型 } } // 结果:所有KV对存储在 ctx->kv 向量中 步骤4:解析所有张量信息 for (int64_t i = 0; i < n_tensors; ++i) { struct gguf_tensor_info info; info.name = gr.read_string(); // 张量名称 info.n_dims = gr.read_u32(); // 维度数 for (uint32_t j = 0; j < info.n_dims; ++j) { info.dims[j] = gr.read_u64(); // 各维度大小 } info.type = (ggml_type)gr.read_u32(); // 数据类型 info.offset = gr.read_u64(); // 数据偏移(相对数据区) ctx->info.push_back(info); } // 结果:所有张量信息存储在 ctx->info 向量中 步骤5:计算数据区偏移 ctx->offset = gr.tell(); // 当前位置就是数据区开始位置 // 此时文件指针已跳过所有元数据,指向实际权重数据 步骤6:创建GGML Context和Tensor元数据(如果no_alloc=false) if (params.ctx && !params.no_alloc) { // 创建ggml_context ggml_context * ctx_data = ggml_init({...}); // 为每个tensor创建ggml_tensor对象 for (size_t i = 0; i < ctx->info.size(); ++i) { struct ggml_tensor * cur = ggml_new_tensor(ctx_data, ...); ggml_set_name(cur, info.t.name); // 如果no_alloc=false,将data指针指向文件中的数据位置 cur->data = (char *) data->data + info.offset; } } 读取后存储的数据结构 GGUF解析后的数据存储在以下结构中: gguf_context(核心存储结构) struct gguf_context { uint32_t version; // GGUF版本 std::vector<gguf_kv> kv; // 所有KV对 // 例如: // kv[0] = {"general.architecture", "llama"} // kv[1] = {"llama.context_length", 4096} // kv[2] = {"llama.embedding_length", 4096} // ... std::vector<gguf_tensor_info> info; // 所有张量信息 // 例如: // info[0] = {name: "tok_embeddings.weight", dims: [4096, 32000], type: F16, offset: 0} // info[1] = {name: "blk.0.attn_q.weight", dims: [4096, 4096], type: F16, offset: 131072000} // ... size_t alignment; // 对齐字节数(通常16或32) size_t offset; // 数据区在文件中的偏移 void * data; // 数据区指针(如果已映射) }; llama_model_loader中的存储 struct llama_model_loader { gguf_context_ptr meta; // 持有gguf_context // meta.get() 返回 gguf_context*,包含所有KV对和张量信息 llama_files files; // 文件句柄列表 // files[0] = 主文件 // files[1..n] = 分片文件(如果有) std::map<std::string, llama_tensor_weight> weights_map; // 权重索引表,Key是tensor名称,Value包含: // - idx: 文件索引(0=主文件,1..n=分片) // - offs: 在文件中的字节偏移 // - tensor: 指向ggml_tensor元数据 }; 在llama.cpp中的调用流程 完整调用链: // 1. 用户调用入口 llama_model * model = llama_model_load_from_file("model.gguf", params); // 2. 内部调用链 llama_model_load_from_file_impl() → llama_model_load() → llama_model_loader ml(fname, ...) // 构造函数开始解析GGUF → gguf_init_from_file(fname, params) → gguf_init_from_file_impl(file, params) // 解析文件头、KV对、张量信息 // 返回 gguf_context* → meta.reset(gguf_context*) // 保存到loader中 → 遍历ctx中的tensor,构建weights_map → 处理分片文件(如果有) // 3. 后续使用 model.load_arch(ml) // 从meta读取架构名称 model.load_hparams(ml) // 从meta读取超参数 model.load_vocab(ml) // 从meta读取词表 model.load_tensors(ml) // 从weights_map定位权重,从文件读取数据 关键访问接口: // 在 llama_model_loader 中访问KV对 ml.get_key(LLM_KV_CONTEXT_LENGTH, hparams.n_ctx_train); // 内部调用: // gguf_find_key(meta.get(), "llama.context_length") // gguf_get_val_u32(meta.get(), key_id) // 访问张量元数据 ggml_tensor * t_meta = ml.get_tensor_meta("blk.0.attn_q.weight"); // 内部从weights_map查找,返回ggml_tensor*(只有元数据,data为nullptr) // 访问权重位置 const auto * weight = ml.get_weight("blk.0.attn_q.weight"); // 返回 llama_tensor_weight,包含: // weight->idx = 0(主文件) // weight->offs = 131072000(文件偏移) // weight->tensor = ggml_tensor*(元数据) 数据流转图 ┌───────────────────────────────────────────────┐ │ GGUF文件(磁盘) │ │ ┌─────────┬─────────┬─────────┬─────────┐ │ │ │ Magic │ Version │ n_kv │ KV Pairs │ │ │ └─────────┴─────────┴─────────┴─────────┘ │ │ ┌─────────┬─────────────────────────────┐ │ │ │n_tensors │ Tensor Info Array │ │ │ └─────────┴─────────────────────────────┘ │ │ ┌───────────────────────────────────────┐ │ │ │ Tensor Data (实际权重) │ │ │ └───────────────────────────────────────┘ │ └──────────────────────────────────────────────┘ ↓ gguf_init_from_file() ┌────────────────────────────────────────────┐ │ gguf_context(内存) │ │ │ │ ctx->kv[]: │ │ [0] = {"general.architecture", "llama"} │ │ [1] = {"llama.context_length", 4096} │ │ [2] = {"llama.embedding_length", 4096} │ │ ... │ │ │ │ ctx->info[]: │ │ [0] = {name: "tok_embeddings.weight", offset: 0, ...} │ │ [1] = {name: "blk.0.attn_q.weight", offset: 131072000,...} │ │ ... │ │ │ │ ctx->offset = 数据区偏移 │ └────────────────────────────────────────────┘ ↓ 存储到 llama_model_loader ┌────────────────────────────────────────────┐ │ llama_model_loader │ │ │ │ meta: gguf_context_ptr → 持有所有KV和tensor信息 │ │ │ │ weights_map: │ │ "tok_embeddings.weight" → {idx:0, offs:0, tensor:...} │ │ "blk.0.attn_q.weight" → {idx:0, offs:131072000, tensor:...} │ │ ... │ │ │ │ files: [主文件句柄, 分片1句柄, ...] │ └────────────────────────── ─────────────────┘ ↓ 使用 ┌───────────────────────────────────────────┐ │ 模型加载各阶段 │ │ │ │ load_arch(): 从 meta->kv 读取架构名称 │ │ load_hparams(): 从 meta->kv 读取超参数 │ │ load_vocab(): 从 meta->kv 读取词表 │ │ load_tensors(): 从 weights_map 定位权重,从文件读取数据 │ └───────────────────────────────────────────┘ -
ggml后端架构简要分析
后端系统概述 GGML后端系统主要提供如下功能: 统一接口: 不同硬件平台使用相关的API。 自动选择:根据硬件自动选择最优后端。 灵活切换:可以在运行时切换后端。 扩展性:易于添加的新后端。 后端主要涉及如下概念: Backend:执行计算的抽象层(CPU,CUDA, Metal等) Buffer:后端管理的内存缓冲区。 Buffer Type:缓冲区的类型(主机内存、GPU内存等) Graph Plan:计算图的执行。 Devcice:物理设备(CPU,GPU等) 后端接口 核心类型 typedef struct ggml_backend * ggml_backend_t; // 后端句柄 typedef struct ggml_backend_buffer * ggml_backend_buffer_t; // 缓冲区句柄 typedef struct ggml_backend_buffer_type * ggml_backend_buffer_type_t; // 缓冲区类型 主要的API (1)后端管理 // 获取后端名称 const char * ggml_backend_name(ggml_backend_t backend); // 释放后端 void ggml_backend_free(ggml_backend_t backend); // 获取默认缓冲区类型 ggml_backend_buffer_type_t ggml_backend_get_default_buffer_type(ggml_backend_t backend); (2)缓冲区的操作 // 分配缓冲区 ggml_backend_buffer_t ggml_backend_alloc_buffer(ggml_backend_t backend, size_t size); // 释放缓冲区 void ggml_backend_buffer_free(ggml_backend_buffer_t buffer); // 获取缓冲区基址 void * ggml_backend_buffer_get_base(ggml_backend_buffer_t buffer); (3)Tensor操作 // 设置 tensor 数据 void ggml_backend_tensor_set(struct ggml_tensor * tensor, const void * data, size_t offset, size_t size); // 获取 tensor 数据 void ggml_backend_tensor_get(const struct ggml_tensor * tensor, void * data, size_t offset, size_t size); (4)计算图执行 // 同步执行 enum ggml_status ggml_backend_graph_compute(ggml_backend_t backend, struct ggml_cgraph * cgraph); // 异步执行 enum ggml_status ggml_backend_graph_compute_async(ggml_backend_t backend, struct ggml_cgraph * cgraph); 后端注册机制 注册流程 位置: src/ggml-backend-reg.cpp 初始化时注册: struct ggml_backend_registry { std::vector<ggml_backend_reg_entry> backends; ggml_backend_registry() { #ifdef GGML_USE_CUDA register_backend(ggml_backend_cuda_reg()); #endif #ifdef GGML_USE_METAL register_backend(ggml_backend_metal_reg()); #endif #ifdef GGML_USE_CPU register_backend(ggml_backend_cpu_reg()); #endif // ... 其他后端 } }; 后端注册结构 struct ggml_backend_reg { const char * name; // 后端名称 ggml_backend_t (*init_fn)(void); // 初始化函数 size_t (*dev_count_fn)(void); // 设备数量 // ... 其他函数指针 }; 动态加载 支持从动态库加载后端 ggml_backend_reg_t ggml_backend_load(const char * path); 4. demo.c vs demo_backend.c 对比 demo.c (传统模式) (1)特点 使用 ggml_init()直接分配内存 所有 tensor 从 context 分配 使用 ggml_graph_compute_with_ctx()执行 简单直接,适合 CPU 计算 (2)代码流程 // 1. 初始化 context ctx = ggml_init(params); // 2. 创建 tensor (从 context 分配) tensor = ggml_new_tensor_2d(ctx, ...); // 3. 构建计算图 gf = ggml_new_graph(ctx); ggml_build_forward_expand(gf, result); // 4. 执行 (使用 context 的工作内存) ggml_graph_compute_with_ctx(ctx, gf, n_threads); (3)内存管理 Context 管理所有内存 预分配内存池 运行时不再分配 demo_backend.c (后端模式) (1)特点 使用后端系统管理内存 支持 GPU 等后端 使用 ggml_gallocr 分配内存 更灵活,适合生产环境 (2)代码流程 // 1. 初始化后端 backend = ggml_backend_cpu_init(); // 或 CUDA, Metal 等 // 2. 初始化 context (no_alloc = true) ctx = ggml_init(params_no_alloc); // 3. 创建 tensor (不分配内存) tensor = ggml_new_tensor_2d(ctx, ...); // 4. 后端分配内存 buffer = ggml_backend_alloc_ctx_tensors(ctx, backend); // 5. 设置数据 ggml_backend_tensor_set(tensor, data, ...); // 6. 构建计算图 gf = ggml_new_graph(ctx_cgraph); ggml_build_forward_expand(gf, result); // 7. 分配计算图内存 allocr = ggml_gallocr_new(...); ggml_gallocr_alloc_graph(allocr, gf); // 8. 后端执行 ggml_backend_graph_compute(backend, gf); (3)内存管理 后端管理内存分配 支持不同内存类型 (主机内存、GPU 内存) 使用 ggml_gallocr优化分配 关键差异 特性 demo.c demo_backend.c 内存管理 Context 直接管理 后端系统管理 GPU 支持 否 是 内存类型 仅主机内存 支持多种类型 5. 内存分配器 ggml_gallocr (Graph Allocator) 用于 优化计算图的内存分配 减少内存碎片 支持内存复用 Tensor分配 适用场景:你希望某些 tensor 放到特定的内存/设备(比如 Spacemit/特殊 CPU buffer),而另一些 tensor 仍放在默认 CPU buffer。核心 API 是: ggml_backend_buft_get_alloc_size():算出某个 buft 下该 tensor 需要的实际分配大小 ggml_backend_buft_alloc_buffer():分配一块后端 buffer ggml_backend_buffer_get_base():拿到 buffer 的 base 地址 ggml_backend_tensor_alloc(buffer, tensor, base + offset):把 tensor “绑定”到这块 buffer 的地址上 典型流程(精简版): // 0) 构建 tensor 时建议 ctx.no_alloc = true(只建元数据,不在 ctx 内部分配) struct ggml_tensor * a = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_A, rows_A); struct ggml_tensor * b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_B, rows_B); // 1) 为 a 选择特殊 buft(如 Spacemit),为 b 选择默认 CPU buft ggml_backend_buffer_type_t a_buft = ggml_backend_cpu_riscv64_spacemit_buffer_type(); ggml_backend_buffer_type_t cpu_buft = ggml_backend_get_default_buffer_type(backend); // 2) 分配 buffer 并把 tensor 绑定进去 size_t a_size = ggml_backend_buft_get_alloc_size(a_buft, a); ggml_backend_buffer_t a_buf = ggml_backend_buft_alloc_buffer(a_buft, a_size); ggml_backend_tensor_alloc(a_buf, a, ggml_backend_buffer_get_base(a_buf)); size_t b_size = ggml_backend_buft_get_alloc_size(cpu_buft, b); ggml_backend_buffer_t b_buf = ggml_backend_buft_alloc_buffer(cpu_buft, b_size); ggml_backend_tensor_alloc(b_buf, b, ggml_backend_buffer_get_base(b_buf)); // 3) 写入/读取 tensor 数据(后端负责必要的数据搬运) ggml_backend_tensor_set(a, host_ptr_A, 0, ggml_nbytes(a)); ggml_backend_tensor_set(b, host_ptr_B, 0, ggml_nbytes(b)); // ... graph compute ... ggml_backend_tensor_get(out, host_ptr_out, 0, ggml_nbytes(out)); 要点: buffer 的生命周期必须覆盖计算阶段(结束后再 ggml_backend_buffer_free())。 这种方式本质上是“你负责 placement”,适合做 demo/异构内存验证/特殊平台适配。 Graph分配 适用场景:你希望把“中间 tensor + 输出 tensor”的内存分配交给 allocator 统一规划,减少碎片、提升复用率。前提通常是: 用于建图的 ctx 设置.no_alloc = true(tensor 先不分配) 图 gf 已经 ggml_build_forward_expand()完整展开 典型流程: // 1) 创建分配器:通常用 backend 的默认 buffer type ggml_gallocr_t allocr = ggml_gallocr_new( ggml_backend_get_default_buffer_type(backend) ); // 2) 为计算图分配内存(会给图里需要的 tensor 规划并分配后端 buffer) ggml_gallocr_alloc_graph(allocr, gf); // 3) 执行计算图 ggml_backend_graph_compute(backend, gf); // 4) 释放分配器(以及其内部持有的资源) ggml_gallocr_free(allocr); 可选优化(大模型/多次重复执行同结构图时更常见): ggml_gallocr_reserve(allocr, gf):先“规划/预留”一次,再根据 ggml_gallocr_get_buffer_size()观察峰值需求(见一些大 example 的用法)。 Workflow分配 适用场景:你有多个后端(例如主后端 + CPU fallback),希望由 scheduler/allocator 完成: 图的 tensor 分配 跨后端的 placement/拷贝(如果需要) simple/simple-backend.cpp 的核心思路是: 建图时 .no_alloc = true 每次计算前调用 ggml_backend_sched_alloc_graph()触发分配 用 ggml_backend_tensor_set/get在 host 与后端 tensor 之间传数据 典型流程(精简版): // 1) 初始化多个 backend,并创建 sched ggml_backend_t backend = ggml_backend_init_best(); ggml_backend_t cpu_backend = ggml_backend_init_by_type(GGML_BACKEND_DEVICE_TYPE_CPU, NULL); ggml_backend_t backends[] = { backend, cpu_backend }; ggml_backend_sched_t sched = ggml_backend_sched_new(backends, NULL, 2, GGML_DEFAULT_GRAPH_SIZE, /*pipeline_parallel=*/false, /*graph_copy=*/true); // 2) 建图(ctx.no_alloc=true;图结构固定后可重复执行) struct ggml_cgraph * gf = ...; // ggml_new_graph + ggml_build_forward_expand // 3) 分配 + 执行 ggml_backend_sched_reset(sched); ggml_backend_sched_alloc_graph(sched, gf); ggml_backend_tensor_set(a, host_ptr_A, 0, ggml_nbytes(a)); ggml_backend_tensor_set(b, host_ptr_B, 0, ggml_nbytes(b)); ggml_backend_sched_graph_compute(sched, gf); struct ggml_tensor * out = ggml_graph_node(gf, -1); ggml_backend_tensor_get(out, host_ptr_out, 0, ggml_nbytes(out)); 要点: 这条路线更接近“生产用法”:分配/拷贝/执行由 backend 系统统一处理,你只维护图和输入输出。 如果你需要“像 demo_spacemit.c 那样手动把某个输入 tensor 固定到特定 buft”,就不要完全依赖 scheduler 的自动分配;通常应采用tensor 级手动分配或者在更高层做 placement 策略(取决于后端能力)。 -

llama.cpp初探:simple示例代码简要分析
加载后端 void ggml_backend_load_all() { ggml_backend_load_all_from_path(nullptr); } void ggml_backend_load_all_from_path(const char * dir_path) { #ifdef NDEBUG bool silent = true; #else bool silent = false; #endif ggml_backend_load_best("blas", silent, dir_path); ggml_backend_load_best("zendnn", silent, dir_path); ggml_backend_load_best("cann", silent, dir_path); ggml_backend_load_best("cuda", silent, dir_path); ggml_backend_load_best("hip", silent, dir_path); ggml_backend_load_best("metal", silent, dir_path); ggml_backend_load_best("rpc", silent, dir_path); ggml_backend_load_best("sycl", silent, dir_path); ggml_backend_load_best("vulkan", silent, dir_path); ggml_backend_load_best("opencl", silent, dir_path); ggml_backend_load_best("hexagon", silent, dir_path); ggml_backend_load_best("musa", silent, dir_path); ggml_backend_load_best("cpu", silent, dir_path); // check the environment variable GGML_BACKEND_PATH to load an out-of-tree backend const char * backend_path = std::getenv("GGML_BACKEND_PATH"); if (backend_path) { ggml_backend_load(backend_path); } } 动态加载所有可用的计算后端(CPU、CUDA、Metal 等),让 llama.cpp 能在不同硬件上运行。通过评分机制选择最适合的后端进行注册。每个后端会提供一个获取评分的函数,使用该函数进行计算得到分值,比如使用位运算累加看看性能。注册后端注释是加载其对应后端的动态库,将后端添加到backends向量。 加载模型 先看看看GGUF的模型文件。 (1)文件头: 位于文件的最开始位置,用于快速校验文件是否合法。 Magic Number (4 bytes): 0x47 0x47 0x55 0x46,对应的 ASCII 码就是 "GGUF"。加载器首先读取这4个字节,如果不对,直接报错。 Version (4 bytes): 版本号(图中是 3)。这允许加载器处理不同版本的格式变化(向后兼容)。 Tensor Count (8 bytes, UINT64): 模型中包含的张量(权重矩阵)总数。比如一个 7B 模型可能有几百个 Tensor。 Metadata KV Count (8 bytes, UINT64): 元数据键值对的数量。这是 GGUF 最核心的改进点。 (2)元数据键值对:接在头部之后,这部分定义了模型的所有非权重信息 以前的格式(如 GGML)通常把超参数(层数、维度等)写死在代码或特定的结构体里。GGUF 改用 Key-Value 映射。 架构信息: general.architecture = "llama"(告诉加载器用哪套逻辑加载)。 模型参数: llama.context_length = 4096, llama.embedding_length = 4096 等。 Tokenizer (词表): 这一点非常重要。GGUF 将词表(tokenizer.ggml.tokens)直接打包在文件里,不再需要额外的 tokenizer.json 或 vocab.model 文件。这实现了真正的“单文件发布”。 其他: 作者信息、量化方法描述等。 (3)张量信息表:索引目录 在读取完所有元数据后,就是 Tensor 的索引列表。这里不包含实际的权重数据,只是数据的“描述”和“指针”。对于每一个 Tensor(共 tensor_count 个),包含以下字段: Name: 字符串,例如 blk.0.ffn_gate.weight。这对应了模型层中的具体权重名称。 n_dimensions: 维度数量(例如 2 表示矩阵,1 表示向量)。 dimensions: 具体的形状数组,例如 [4096, 32000]。 Type: 数据类型,例如 GGML_TYPE_Q2_K(2-bit 量化)、F16 等。 Offset (8 bytes, UINT64): 这是最关键的字段。它是一个指针(偏移量),告诉程序:“这个张量的实际二进制数据,位于文件数据区的第 X 个字节处”。 (4)数据区:图中右侧箭头指向的 10110... 部分。 这是文件体积最大的部分,包含所有权重矩阵的实际二进制数据。内存映射 (mmap) 的奥秘,因为有了上面的 Offset,llama_model_load_from_file 不需要把整个几 GB 的文件一次性读入 RAM。 它只需要调用系统级 API mmap,将文件映射到虚拟内存。当模型推理需要用到 blk.0 的权重时,CPU/GPU 根据 Offset 直接去磁盘(或文件系统缓存)里拿数据。这就是为什么 GGUF 模型启动速度极快且内存占用低的原因。 模型加载主要是将GGUF加载进来,主要的流程是先检查是否有注册后端,然后选择对应的设备,接着解析GGUF元信息包括KV/张量表,接着按照n_gpu_layers/tensor_split分配层与buffer,再者就是读取/映射/上传权重数据,返回llama_model对象指针。 其中最核心的函数就是llama_mode_load,这个函数主要的作用如下: load_arch:先知道是什么架构,后面的 KV key 解释/张量命名规则才对。 load_hparams:读 GGUF KV 填充超参。 load_vocab:构建 tokenizer/vocab。 load_tensors:决定设备/缓冲区并实际装载权重数据。 load_arch load_arch加载的是模型的架构类型,比如LLaMA、Falcon、Qwen、CLIP等大类,存储到llama_mode::arch字段里面,这个来源是GGUF的metadata key。 get_key(llm_kv(LLM_KV_GENERAL_ARCHITECTURE), arch_name, false); llm_kv = LLM_KV(llm_arch_from_string(arch_name)); load_arch本身只是把loader里解析好的枚举出来。 void llama_model::load_arch(llama_model_loader & ml) { arch = ml.get_arch(); if (arch == LLM_ARCH_UNKNOWN) { throw std::runtime_error("unknown model architecture: '" + ml.get_arch_name() + "'"); } } 之所以要解析加载arch是因为后面所以得操作都依赖着arch,比如怎么解释GGUF、怎么建张量的逻辑依赖arch。l oad_hparams 需要 arch 才知道该读哪些 KV、如何解释超参,而且它还用 arch 做特殊分支(例如 CLIP 直接跳过 hparams)。 load_vocab 会用 arch 构造 LLM_KV(arch),影响 vocab/tokenizer 的加载规则。 load_tensors 更是直接 switch (arch) 来决定要创建哪些权重张量、张量命名/shape/op 映射等。 load_hparams struct llama_hparams { bool vocab_only; bool no_alloc; bool rope_finetuned; bool use_par_res; bool swin_norm; uint32_t n_ctx_train; // context size the model was trained on uint32_t n_embd; uint32_t n_embd_features = 0; uint32_t n_layer; // ... uint32_t n_rot; uint32_t n_embd_head_k; uint32_t n_embd_head_v; uint32_t n_expert = 0; uint32_t n_expert_used = 0; // ... }; 这里的 hparams 指的是 llama_model 里的 模型超参数/结构参数(hyper-parameters):决定模型“长什么样”(层数、隐藏维度、头数、RoPE/ALiBi/SWA/MoE 等配置)。它对应的结构体是 struct llama_hparams llama_model::load_hparams(ml) 会从 GGUF 的 KV(metadata)里读取并填充 model.hparams(以及一些辅助状态,比如 gguf_kv 字符串表、type 等) 模型结构: 训练时的context长度、embedding/hidden size、transformer block 数、MoE等。 注意力/FFN:支持 KV 是标量或数组:有些模型每层不同。 RoPE相关:rope_finetuned / rope_freq_base_train / rope_freq_scale_train / rope_scaling_type_train / n_rot / n_embd_head_k/v 等 架构特化项:比如 LLM_ARCH_WAVTOKENIZER_DEC 会额外读 posnet/convnext 参数。 load_vocab load_vocab 加载的是 模型的词表/分词器(tokenizer + vocab):包括每个 token 的文本、score、属性(normal/control/user_defined/unknown/byte 等),以及各种 special token(BOS/EOS/EOT/PAD/…)和不同 tokenizer(SPM/BPE/WPM/UGM/RWKV/…)所需的附加数据(如 BPE merges、charsmap 等)。 struct llama_vocab { struct token_data { std::string text; float score; llama_token_attr attr; }; void load(llama_model_loader & ml, const LLM_KV & kv); std::string get_tokenizer_model() const; std::string get_tokenizer_pre() const; enum llama_vocab_type get_type() const; enum llama_vocab_pre_type get_pre_type() const; uint32_t n_tokens() const; uint32_t n_token_types() const; // ... }; 模型的推理需要做文本到token id的双向转换,输入的prompt必须先tokenize 才能喂给llama_decode,输出的token id必须detokenize 才能打印成字符串。不同模型(LLaMA / Falcon / ChatGLM / …)的 tokenizer 规则不同(SPM/BPE/WPM/UGM…,以及 pre-tokenization 规则),如果 vocab 没加载或加载错,模型就“无法正确理解输入/输出” load_tensor 这里的tensor是指模型推理所需的所有权重张量(weghts),比如: token embedding:tok_embd 每层 attention 的 Wq/Wk/Wv/Wo(以及可选 bias、norm 权重等) 每层 FFN 的 Wgate/Wup/Wdown(MoE 还会有专家张量、router 等) 输出层/输出 embedding(有些模型与 tok_embd 共享,需要 duplicated 处理) 在load tensors会按arch分支创建这些张量,比如已LLAMA类分支片段。 tok_embd = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, 0); // output output_norm = create_tensor(tn(LLM_TENSOR_OUTPUT_NORM, "weight"), {n_embd}, 0); output = create_tensor(tn(LLM_TENSOR_OUTPUT, "weight"), {n_embd, n_vocab}, TENSOR_NOT_REQUIRED); if (output == NULL) { output = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, TENSOR_DUPLICATED); } for (int i = 0; i < n_layer; ++i) { auto & layer = layers[i]; layer.attn_norm = create_tensor(tn(LLM_TENSOR_ATTN_NORM, "weight", i), {n_embd}, 0); layer.wq = create_tensor(tn(LLM_TENSOR_ATTN_Q, "weight", i), {n_embd, n_embd_head_k * n_head}, 0); layer.wk = create_tensor(tn(LLM_TENSOR_ATTN_K, "weight", i), {n_embd, n_embd_k_gqa}, 0); layer.wv = create_tensor(tn(LLM_TENSOR_ATTN_V, "weight", i), {n_embd, n_embd_v_gqa}, 0); layer.wo = create_tensor(tn(LLM_TENSOR_ATTN_OUT, "weight", i), {n_embd_head_k * n_head, n_embd}, 0); } (1)tensor对象(ggml_tensor *)存在哪里? 按语义分组存到 llama_model 的成员里:比如 tok_embd / output_norm / output,以及每层的 layers[i].wq/wk/wv/... 等(这些都是 ggml_tensor * 指针)。 struct llama_model { // ... struct ggml_tensor * tok_embd = nullptr; // ... struct ggml_tensor * output_norm = nullptr; struct ggml_tensor * output = nullptr; // ... std::vector<llama_layer> layers; // ... std::vector<std::pair<std::string, struct ggml_tensor *>> tensors_by_name; // ... }; 按名字查 tensor:load_tensors() 完成后会把每个 ggml_context 里的 tensor 都放进 tensors_by_name(主要用于内部/统计与 get_tensor(name) 这种按名访问)。 // populate tensors_by_name for (auto & [ctx, _] : pimpl->ctxs_bufs) { for (auto * cur = ggml_get_first_tensor(ctx.get()); cur != NULL; cur = ggml_get_next_tensor(ctx.get(), cur)) { tensors_by_name.emplace_back(ggml_get_name(cur), cur); } } 对应按名取 const ggml_tensor * llama_model::get_tensor(const char * name) const { auto it = std::find_if(tensors_by_name.begin(), tensors_by_name.end(), [name](const std::pair<std::string, ggml_tensor *> & it) { return it.first == name; }); if (it == tensors_by_name.end()) { return nullptr; } return it->second; } (2)tensor数据(权重内容)存在哪里? ggml_tensor 自身只是一个“描述 + 指针”,真正的权重数据会落在三类地方之一: CPU/GPU 后端 buffer 里:load_tensors() 会为不同 buffer type 创建对应的 backend buffer,并把它们与承载 tensor metadata 的 ggml_context 绑在一起。这些 buffer 句柄被保存在:pimpl->ctxs_bufs struct llama_model::impl { // contexts where the model tensors metadata is stored as well as the corresponding buffers: std::vector<std::pair<ggml_context_ptr, std::vector<ggml_backend_buffer_ptr>>> ctxs_bufs; // ... }; mmap 映射区域(文件映射内存):如果启用 mmap,loader 会把模型文件映射进内存,某些 tensor 的 data 会直接指向映射区域,或者后端 buffer 会通过 buffer_from_host_ptr 包装映射内存。映射对象被保存在loader侧:ml.mappings,model侧:pimpl->mappings。 no_alloc 模式:ml.no_alloc 时只是创建 tensor 元信息与“dummy buffer”,不装载数据,用于某些统计/规划场景。 (3)tensor是怎么分配到那个设备上的? 在GPU上还是CPU上,决策分为两层: 层级/设备选择(dev):决定每一层(input/repeating/output)用哪个 ggml_backend_dev_t(CPU / GPU / RPC / IGPU…)。 buffer type 选择(buft):在选定设备后,再决定该 tensor 用哪个 ggml_backend_buffer_type_t(同一设备也可能有多种 buffer type;并且还会把 CPU buffer type 作为 fallback)。 流程梳理(从“设备列表”到“权重进后端 buffer”)如下: ┌──────────────────────────────────────────────────────────────┐ │ llama_model_load_from_file_impl(path, params) │ │ - 选择/构建 model->devices (GPU/RPC/IGPU...) │ └───────────────┬──────────────────────────────────────────────┘ │ v ┌──────────────────────────────────────────────────────────────┐ │ llama_model_load(...) │ │ - llama_model_loader ml(...) 读取 GGUF 元信息、索引 tensors │ │ - model.load_arch/load_hparams/load_vocab │ │ - model.load_tensors(ml) ← 重点 │ └───────────────┬──────────────────────────────────────────────┘ │ v ┌──────────────────────────────────────────────────────────────┐ │ llama_model::load_tensors(ml) │ │ A) 构建候选 buft 列表 │ │ cpu_buft_list = make_cpu_buft_list(...) │ │ gpu_buft_list[dev] = make_gpu_buft_list(dev,...) + CPU fb │ │ │ │ B) 决定每层放哪台设备(层→dev) │ │ splits = tensor_split 或按 dev free-mem 默认计算 │ │ i_gpu_start = (n_layer+1 - n_gpu_layers) │ │ dev_input=CPU, dev_layer[il]=CPU/GPU..., dev_output=... │ │ │ │ C) 决定每个 tensor 用哪个 buft,并创建 ggml_tensor 元信息 │ │ 对每个权重 tensor: │ │ - 根据层(input/repeating/output)选 buft_list │ │ - buft = select_weight_buft(...) (考虑 op/type/override) │ │ - ctx = ctx_map[buft] (同 buft 归到同 ggml_context) │ │ - ml.create_tensor(ctx, ...) (创建 tensor meta) │ │ ml.done_getting_tensors() 校验数量 │ └───────────────┬──────────────────────────────────────────────┘ │ v ┌──────────────────────────────────────────────────────────────┐ │ D) 分配后端 buffer(真正“存储权重”的地方) │ │ ml.init_mappings(...) (mmap 时建立映射、算 size_data) │ │ 对每个 (buft -> ctx): │ │ - 若满足条件: ggml_backend_dev_buffer_from_host_ptr(...) │ │ (把 mmap 的区间包装成后端 buffer,少拷贝) │ │ - 否则: ggml_backend_alloc_ctx_tensors_from_buft(ctx,buft)│ │ - 结果保存到 model.pimpl->ctxs_bufs 维持生命周期 │ │ - 标记 buffer usage = WEIGHTS (帮助调度) │ └───────────────┬──────────────────────────────────────────────┘ │ v ┌──────────────────────────────────────────────────────────────┐ │ E) 装载权重数据到后端(mmap/读文件/异步上传) │ │ 对每个 ctx: ml.load_all_data(ctx, buf_map, progress_cb) │ │ - progress_cb 返回 false => 取消 => load_tensors 返回 false│ │ 若 use_mmap_buffer: model.pimpl->mappings 接管 ml.mappings │ │ 同时填充 model.tensors_by_name 供按名查询/统计 │ └──────────────────────────────────────────────────────────────┘ │ v ┌──────────────────────────────────────────────────────────────┐ │ 推理阶段 build_graph / llama_decode │ │ - 直接引用 model.tok_embd / model.layers[i].wq... 等 ggml_tensor│ │ - 后端根据 tensor 绑定的 buffer 决定在 CPU/GPU 执行与取数 │ └──────────────────────────────────────────────────────────────┘ buft 是什么? buft 是 ggml_backend_buffer_type_t(backend buffer type),可以理解为“某个后端设备上,用哪一种内存/分配方式来存放 tensor 数据”的类型句柄。 在 load_tensors() 里它的作用是:给每个权重 tensor 选择一个合适的 buffer type,并据此把 tensor 归到对应的 ggml_context,最终用该 buft 去创建真实的后端 buffer(CPU RAM / GPU VRAM / 远端 RPC buffer / host pinned buffer 等)。 load_tensors() 里按 tensor 所在层选一个 buft_list,再用 select_weight_buft(...) 选出最终 buft: if (!buft) { buft = select_weight_buft(hparams, t_meta, op, *buft_list); if (!buft) { throw std::runtime_error(format("failed to find a compatible buffer type for tensor %s", tn.str().c_str())); } } 随后用 buft 决定该 tensor 属于哪个 ggml_context(ctx_for_buft(buft)),并最终分配后端 buffer(例如 ggml_backend_alloc_ctx_tensors_from_buft(ctx, buft) 或 mmap 的 ggml_backend_dev_buffer_from_host_ptr(...))。 buft 和 dev(device)的区别 - dev(ggml_backend_dev_t):是哪块设备(CPU / 某张 GPU / RPC 设备…) - buft(ggml_backend_buffer_type_t):在这块设备上“用哪种 buffer 类型/内存形式”来存 tensor(默认 device buffer、host buffer、特殊优化 buffer 等) (4)推理阶段如何使用这些权重 后续推理构图时(model.build_graph(...) ——>各 src/models/xx.cpp),会直接用 llama_model 里的这些 ggml_tensor x 作为权重输入,和激活值做 ggml 运算(matmul/add/norm/rope…)。例如 src/models/stablelm.cpp 在构图时直接用: model.tok_embd 做输入 embedding - model.layers[il].wq/wk/wv 做 Q/K/V 投影 - model.layers[il].bq/bk/bv(可选)加 bias - ggml_rope_ext 用 rope 参数对 Q/K 做 RoPE Tokenization const llama_vocab * vocab = llama_model_get_vocab(model); // tokenize the prompt // find the number of tokens in the prompt const int n_prompt = -llama_tokenize(vocab, prompt.c_str(), prompt.size(), NULL, 0, true, true); // allocate space for the tokens and tokenize the prompt std::vector<llama_token> prompt_tokens(n_prompt); if (llama_tokenize(vocab, prompt.c_str(), prompt.size(), prompt_tokens.data(), prompt_tokens.size(), true, true) < 0) { fprintf(stderr, "%s: error: failed to tokenize the prompt\n", __func__); return 1; } 这段代码主要的作用是做文本->token ID的转换。整段的流程可以总结一下。 拿vocab:llama_model_get_vocab(model) 获取 tokenizer/词表句柄; 预估token数:第一次 llama_tokenize(..., NULL, 0, ...),只算需要多少 token,返回负数取反得到 n_prompt; 分配缓存:std::vector prompt_tokens(n_prompt); 为 prompt 分配精确长度的 token 缓冲区; 真正 tokenize:第二次 llama_tokenize 把 token id 写进 prompt_tokens,如果失败或容量不够返回 < 0 则报错退出。 llama_tokenize() tokenize 的对象是 一段输入文本(UTF-8 字符串),输出是 token id 序列(llama_token):也就是模型能直接消费的离散符号编号。它依赖 llama_vocab(模型绑定的 tokenizer + 词表 + special token 规则),把文本切分/编码成 token ids。 llama_tokenize会转发到vocab->tokenize,先做 special token 分段,再按 vocab type 分发到具体 tokenizer session。 std::vector<llama_token> llama_vocab::impl::tokenize(const std::string & raw_text, bool add_special, bool parse_special) const { // 1) special token partition(把 raw_text 切成「普通文本片段」和「已识别的特殊 token」) tokenizer_st_partition(fragment_buffer, parse_special); // 2) 按 vocab type 分发到具体 tokenizer session switch (get_type()) { case LLAMA_VOCAB_TYPE_SPM: llm_tokenizer_spm_session(...).tokenize(...); break; case LLAMA_VOCAB_TYPE_BPE: llm_tokenizer_bpe_session(...).tokenize(...); break; case LLAMA_VOCAB_TYPE_WPM: llm_tokenizer_wpm_session(...).tokenize(...); break; case LLAMA_VOCAB_TYPE_UGM: llm_tokenizer_ugm_session(...).tokenize(...); break; case LLAMA_VOCAB_TYPE_RWKV: llm_tokenizer_rwkv_session(...).tokenize(...); break; case LLAMA_VOCAB_TYPE_PLAMO2: llm_tokenizer_plamo2_session(...).tokenize(...); break; default: GGML_ABORT(...); } return output; } SPM SentencePiece BPE-ish 合并,项目里叫 SPM tokenizer,入口类是llm_tokenizer_spm_session,其核心思路是把文本先按 UTF-8 字符拆成链表 symbol,然后不断从优先队列取“得分最高”的可合并 bigram,做合并,最后把每个合并后的片段映射为 token。 struct llm_tokenizer_spm_session { void tokenize(const std::string & text, std::vector<llama_token> & output) { // split into utf8 chars -> symbols // seed work_queue with all 2-char tokens -> try_add_bigram // pop highest score, merge, and push new bigrams // resegment each final symbol into token ids / byte tokens } } 在 impl::tokenize 的 SPM 分支里,会先把空格转义成 “▁”(U+2581),并处理 add_space_prefix、BOS/EOS: if (add_space_prefix && is_prev_special) { text = ' '; } text += fragment... llama_escape_whitespace(text); // ' ' -> ▁ llm_tokenizer_spm_session session(vocab); session.tokenize(text, output); BEP Byte Pair Encoding,入口类:llm_tokenizer_bpe_session,其核心思路是 1) 用“pre-tokenizer regex”(不同模型 pre_type 不同)把文本切成词片段(word_collection)。 2) 每个词片段再按 UTF-8 拆成 symbols。 3) 用 vocab.find_bpe_rank(left,right) 查 merges rank(越小越优先),不断合并。 4) 合并结束后把每个最终 symbol 映射为 token(找不到就回退到逐字节 token)。 WPM WordPiece,入口类:llm_tokenizer_wpm_session,核心思路是: 先做 NFD 归一化 + 按 whitespace/标点切词(preprocess) 每个词前加 “▁” 对每个词做 最长匹配(从当前位置往后尽量取最长、且在 vocab 中存在的 token) 若某个词无法完全分解,回退整个词为unk UGM 入口类:llm_tokenizer_ugm_session,核心思路:典型 unigram LM 的 Viterbi 最优切分: 先 normalize 输入 每个位置沿 trie 找所有可能 token,做动态规划选择 “累计得分最大”的路径 走不通就用 unknown token + penalty 最后从末尾回溯得到 token 序列 初始化上下文 llama_context_params ctx_params = llama_context_default_params(); // n_ctx is the context size ctx_params.n_ctx = n_prompt + n_predict - 1; // n_batch is the maximum number of tokens that can be processed in a single call to llama_decode ctx_params.n_batch = n_prompt; // enable performance counters ctx_params.no_perf = false; llama_context * ctx = llama_init_from_model(model, ctx_params); if (ctx == NULL) { fprintf(stderr , "%s: error: failed to create the llama_context\n" , __func__); return 1; } 这段代码主要的作用是创建llama_context,用于管理推理的状态KV cache、batch 分配器、backend 调度器等)。 配置上下文参数、batch大小、性能统计。创建llama_context包括初始化计算后端,分配KV cache内存,创建batch分配器和调度器,预留计算图内存。llama_context是推理的核心对象,后续的llama_decode调用都会使用它来管理状态和执行计算。 初始化采样器 auto sparams = llama_sampler_chain_default_params(); sparams.no_perf = false; llama_sampler * smpl = llama_sampler_chain_init(sparams); llama_sampler_chain_add(smpl, llama_sampler_init_greedy()); 构造一个“采样器链”(sampler chain),并在其中添加一个贪心采样器(greedy sampler),后面主循环用它从 logits 里选下一个 token。下面按调用顺序拆开。采样器接收一个 llama_token_data_array(包含所有候选 token 的 id、logit、概率),经过处理(过滤、排序、选择等),最终确定一个 token。 处理提示词 // print the prompt token-by-token for (auto id : prompt_tokens) { char buf[128]; int n = llama_token_to_piece(vocab, id, buf, sizeof(buf), 0, true); if (n < 0) { fprintf(stderr, "%s: error: failed to convert token to piece\n", __func__); return 1; } std::string s(buf, n); printf("%s", s.c_str()); } // prepare a batch for the prompt llama_batch batch = llama_batch_get_one(prompt_tokens.data(), prompt_tokens.size()); if (llama_model_has_encoder(model)) { if (llama_encode(ctx, batch)) { fprintf(stderr, "%s : failed to eval\n", __func__); return 1; } llama_token decoder_start_token_id = llama_model_decoder_start_token(model); if (decoder_start_token_id == LLAMA_TOKEN_NULL) { decoder_start_token_id = llama_vocab_bos(vocab); } batch = llama_batch_get_one(&decoder_start_token_id, 1); } llama_token_to_piece是将token ID转换为文本并输出,llama_batch_get_one是为prompt创建batch结构。通过llama_model_has_encoder检查模型是不是编码-解码模型,如果是先进行prompt,在准备decoder的起始batch。 总结一下就是先调用llama_encode编码prompt的token,做完这一步,encoder部分就结束了,接着让decoder开始工作,我们知道大模型是一个自回归模型,需要有第一个token作为起点,类似机器翻译里的 BOS。 最后的llama_batch_get_one这里就是准备decoder起始batch。 llama_encode llama_decode 生成循环 for (int n_pos = 0; n_pos + batch.n_tokens < n_prompt + n_predict; ) { // evaluate the current batch with the transformer model if (llama_decode(ctx, batch)) { fprintf(stderr, "%s : failed to eval, return code %d\n", __func__, 1); return 1; } n_pos += batch.n_tokens; // sample the next token { new_token_id = llama_sampler_sample(smpl, ctx, -1); // is it an end of generation? if (llama_vocab_is_eog(vocab, new_token_id)) { break; } char buf[128]; int n = llama_token_to_piece(vocab, new_token_id, buf, sizeof(buf), 0, true); if (n < 0) { fprintf(stderr, "%s: error: failed to convert token to piece\n", __func__); return 1; } std::string s(buf, n); printf("%s", s.c_str()); fflush(stdout); // prepare the next batch with the sampled token batch = llama_batch_get_one(&new_token_id, 1); n_decode += 1; } } 这段代码是自回归文本生成的核心循环,实现decoder->sample->print的循环。llama_decode进行decoder,然后调用llamap_sampler_sample采样下一个token,获取对应的token ID,通过调用llama_vocab_is_eog来检查结束条件,判断采样到的token是否为结束token,是则退出循环。最后调用llama_token_to_piece将token ID转换为文本并打印。 核心的思想其实跟之前写的:从零实现 Transformer:中英文翻译实例文章是一样的。 -
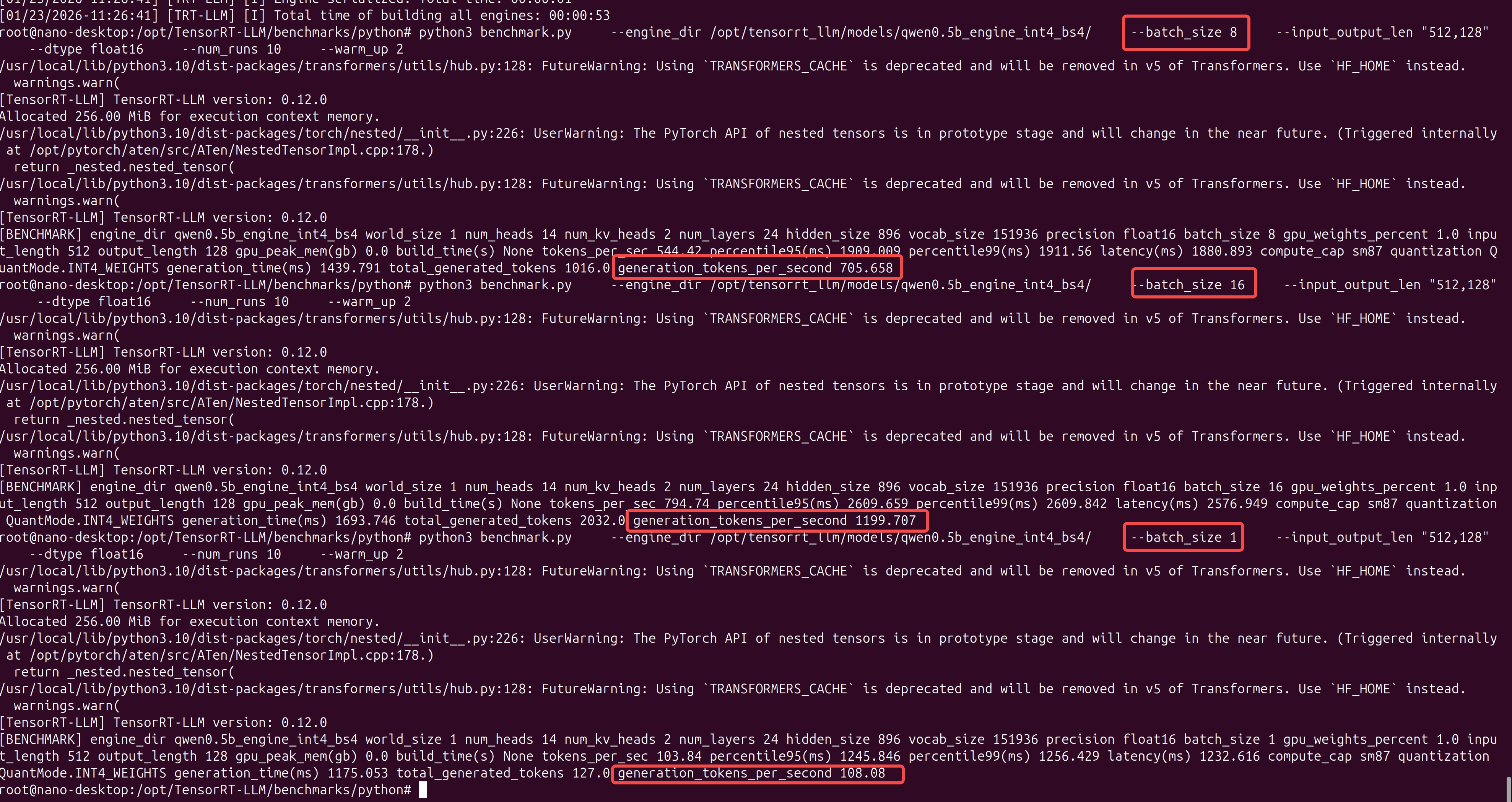
jetson orin nano使用TensorRT-LLM跑大模型
准备 硬件信息 硬件信息如下: sudo cat /proc/device-tree/model NVIDIA Jetson Orin NX Enginejetson_releasee Developer Kit(base) nano@nano-desktop:~$ jetson_release Software part of jetson-stats 4.3.2 - (c) 2024, Raffaello Bonghi Model: NVIDIA Jetson Orin NX Engineering Reference Developer Kit - Jetpack 6.2 [L4T 36.4.3] NV Power Mode[0]: 15W Serial Number: [XXX Show with: jetson_release -s XXX] Hardware: - P-Number: p3767-0003 - Module: NVIDIA Jetson Orin Nano (8GB ram) Platform: - Distribution: Ubuntu 22.04 Jammy Jellyfish - Release: 5.15.148-tegra jtop: - Version: 4.3.2 - Service: Active 超级模式 设置电源为超级性能模式,点击 Ubuntu 桌面顶部栏右侧的 NVIDIA 图标 Power mode 0: 15W 1: 25W 2: MAXN SUPER 如果没有MAXN SUPER,执行下面的命令安装。 sudo apt remove nvidia-l4t-bootloader sudo apt install nvidia-l4t-bootloader sudo reboot 如果还是无法配置的话,参考下:super mode 安装docker 本文主要使用https://github.com/dusty-nv/jetson-containers docker来进行部署测试,免去不少的环境搭建过程。 如果设备没有安装docker,执行下面命令进行安装docker。 sudo apt-get update sudo apt-get install -y docker.io nvidia-container-toolkit sudo usermod -aG docker $USER sudo systemctl daemon-reload sudo systemctl restart docker 接着容器启动拉取代码,然后拉取docker镜像: git clone https://github.com/dusty-nv/jetson-containers.git ./jetson-containers/run.sh -v $(pwd)/model_zoo:/opt/tensorrt_llm/models $(autotag tensorrt_llm) 下载模型 先下载一个模型 # Qwen 1.5B modelscope download --model Qwen/Qwen2.5-1.5B-Instruct --local_dir model_zoo/Qwen2.5-1.5B-Instruct # Qwen 0.5B modelscope download --model Qwen/Qwen2.5-0.5B-Instruct --local_dir model_zoo/Qwen2.5-0.5B-Instruct #DeepSeek 1.5B modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local_dir model_zoo/DeepSeek-R1-Distill-Qwen-1.5B qwen2.5-0.5B INT4 启动容器 ./jetson-containers/run.sh -v $(pwd)/model_zoo:/opt/tensorrt_llm/models $(autotag tensorrt_llm) 转换模型 使用TensorRT-LLM提供的工具进行量化 cd /opt/TensorRT-LLM/examples/qwen python3 convert_checkpoint.py \ --model_dir /opt/tensorrt_llm/models/Qwen2.5-0.5B-Instruct/ \ --output_dir /opt/tensorrt_llm/models/qwen0.5b_ckpt_int4/ \ --dtype float16 \ --use_weight_only \ --weight_only_precision int4 参数,作用说明 model_dir:源模型路径,指向原始 Qwen2.5-1.5B-Instruct的文件夹。 output_dir:输出路径,转换后的 TensorRT-LLM 格式权重将保存在此目录下。 dtype float16:计算精度,设置模型在推理时的基础数据类型为 float16(半精度)。 use_weight_only:启用仅权重处理,告诉脚本不要修改激活值(Activations),只处理权重部分。 weight_only_precision int4:量化等级,将权重从 FP16 压缩到 INT4。这意味着权重占用的空间将缩小为原来的约 1/4。 weight_only_precision和dtype的区别是,前者模型权重以 INT4 格式存放在显存里(非常省空间)。后者了是实际运算用的精度,动态解压 (Dequantization),当 GPU 准备计算某一层的矩阵乘法时,它会实时地将这一层的 INT4 权重“恢复”成 float16。 构建引擎 构建引擎 trtllm-build --checkpoint_dir /opt/tensorrt_llm/models/qwen0.5b_ckpt_int4/ \ --output_dir /opt/tensorrt_llm/models/qwen0.5b_engine_int4_bs4/ \ --gemm_plugin float16 \ --gpt_attention_plugin float16 \ --max_batch_size 4 \ --max_input_len 1024 \ --max_seq_len 1024 \ --workers 1 测试性能 压力测试 cd /opt/TensorRT-LLM/benchmarks/python # 运行 Batch Size 4 的测试 python3 benchmark.py \ --engine_dir /opt/tensorrt_llm/models/qwen0.5b_engine_int4_bs4/ \ --batch_size 4 \ --input_output_len "512,128" \ --dtype float16 \ --num_runs 10 \ --warm_up 2 engine_dir:指定 Engine 路径,指向已编译好的 TensorRT-LLM Engine。从路径名 qwen0.5b_engine_int4_bs4 可以推断,这个模型是 Qwen-0.5B,采用了 INT4 量化,且构建时设定的最大 Batch Size 为 4。 batch_size: 4,推理并发数,本次测试同时处理 4 个请求。这会直接测试芯片在满载(Full Load)状态下的性能。由于你的 Engine 编译时 max_batch_size 可能是 4,所以这里设置 4 是为了榨干该 Engine 的性能。 input_output_len: "512,128"",输入输出长度,512:输入 Prompt 的长度(影响 PP 阶段)。128:生成 Token 的长度(影响 TG 阶段)。这是一个非常标准的测试组合,模拟了“中等长度提问 + 短回答”的场景。 dtype: float16,计算精度,即使权重是 INT4 存储,实际矩阵运算(Activation)依然使用 FP16。这能保证在利用 INT4 节省显存的同时,推理精度不崩溃。 num_runs: 10,循环次数,连续运行 10 次。取平均值可以消除系统波动(如 CPU 调度、瞬时过热降频)带来的误差,使测试结果更具统计学意义。 warm_up: 2,预热次数,忽略前 2 次的成绩。GPU 在刚开始跑的时候需要进行内存申请、显存对齐等操作,通常第一遍会非常慢。预热可以确保获取的是稳定状态(Steady State)下的真实性能。 qwen2.5-1.5B INT4 启动容器 ./jetson-containers/run.sh -v $(pwd)/model_zoo:/opt/tensorrt_llm/models $(autotag tensorrt_llm) 转换模型 使用TensorRT-LLM提供的工具进行量化,如果内存不够就到PC上去做量化,见下。 cd /opt/TensorRT-LLM/examples/qwen python3 convert_checkpoint.py \ --model_dir /opt/tensorrt_llm/models/Qwen2.5-1.5B-Instruct/ \ --output_dir /opt/tensorrt_llm/models/qwen1.5b_ckpt_int4/ \ --dtype float16 \ --use_weight_only \ --weight_only_precision int4 构建引擎 构建引擎 trtllm-build \ --checkpoint_dir /opt/tensorrt_llm/models/qwen3b_ckpt_int4 \ --output_dir /opt/tensorrt_llm/models/qwen3b_int4_bs1_engine \ --gemm_plugin float16 \ --gpt_attention_plugin float16 \ --max_batch_size 1 \ --max_input_len 1024 \ --max_seq_len 1024 \ --workers 1 如果内存不够的话就把max_batch_size改小一点。 测试对话 python3 ../run.py \ --engine_dir /opt/tensorrt_llm/models/qwen1.5b_int4_bs1_engine/ \ --tokenizer_dir /opt/tensorrt_llm/models/Qwen2.5-3B-Instruct/ \ --max_output_len 128 \ --input_text "你好,请介绍一下你自己,并讲一个关于芯片工程师的冷笑话。" 测试性能 压力测试 cd /opt/TensorRT-LLM/benchmarks/python # 运行 Batch Size 1 的测试 python3 benchmark.py \ --engine_dir /opt/tensorrt_llm/models/qwen1.5b_engine_int4_bs4/ \ --batch_size 1 \ --input_output_len "128,128" \ --dtype float16 \ --num_runs 10 \ --warm_up 2 qwen2.5-3B INT4 启动容器 ./jetson-containers/run.sh -v $(pwd)/model_zoo:/opt/tensorrt_llm/models $(autotag tensorrt_llm) 转换模型 使用TensorRT-LLM提供的工具进行量化,如果内存不够就到PC上去做量化,见下。 python3 convert_checkpoint.py \ --model_dir /data/Qwen2.5-3B-Instruct/ \ --output_dir /data/qwen3b_ckpt_int4 \ --dtype float16 \ --use_weight_only \ --weight_only_precision int4 构建引擎 构建引擎 base) nano@nano-desktop:~$ docker run --runtime nvidia -it --rm \ --network host \ --shm-size=8g \ --volume /home/nano/model_zoo:/opt/tensorrt_llm/models \ --workdir /opt/tensorrt_llm/examples/qwen \ dustynv/tensorrt_llm:0.12-r36.4.0 \ /bin/bash -c "export TRT_MAX_WORKSPACE_SIZE=1073741824 && \ trtllm-build \ --checkpoint_dir /opt/tensorrt_llm/models/qwen3b_ckpt_int4 \ --output_dir /opt/tensorrt_llm/models/qwen3b_int4_bs1_engine \ --gemm_plugin float16 \ --gpt_attention_plugin float16 \ --max_batch_size 1 \ --max_seq_len 1024 \ --workers 1 \ --builder_opt 1" /usr/local/lib/python3.10/dist-packages/transformers/utils/hub.py:128: FutureWarning: Using `TRANSFORMERS_CACHE` is deprecated and will be removed in v5 of Transformers. Use `HF_HOME` instead. warnings.warn( [TensorRT-LLM] TensorRT-LLM version: 0.12.0 [01/24/2026-04:10:02] [TRT-LLM] [I] Set bert_attention_plugin to auto. [01/24/2026-04:10:02] [TRT-LLM] [I] Set gpt_attention_plugin to float16. [01/24/2026-04:10:02] [TRT-LLM] [I] Set gemm_plugin to float16. [01/24/2026-04:10:02] [TRT-LLM] [I] Set gemm_swiglu_plugin to None. [01/24/2026-04:10:02] [TRT-LLM] [I] Set fp8_rowwise_gemm_plugin to None. [01/24/2026-04:10:02] [TRT-LLM] [I] Set nccl_plugin to auto. [01/24/2026-04:10:02] [TRT-LLM] [I] Set lookup_plugin to None. [01/24/2026-04:10:02] [TRT-LLM] [I] Set lora_plugin to None. [01/24/2026-04:10:02] [TRT-LLM] [I] Set moe_plugin to auto. [01/24/2026-04:10:02] [TRT-LLM] [I] Set mamba_conv1d_plugin to auto. [01/24/2026-04:10:02] [TRT-LLM] [I] Set context_fmha to True. [01/24/2026-04:10:02] [TRT-LLM] [I] Set bert_context_fmha_fp32_acc to False. [01/24/2026-04:10:02] [TRT-LLM] [I] Set paged_kv_cache to True. [01/24/2026-04:10:02] [TRT-LLM] [I] Set remove_input_padding to True. [01/24/2026-04:10:02] [TRT-LLM] [I] Set reduce_fusion to False. [01/24/2026-04:10:02] [TRT-LLM] [I] Set enable_xqa to True. [01/24/2026-04:10:02] [TRT-LLM] [I] Set tokens_per_block to 64. [01/24/2026-04:10:02] [TRT-LLM] [I] Set use_paged_context_fmha to False. [01/24/2026-04:10:02] [TRT-LLM] [I] Set use_fp8_context_fmha to False. [01/24/2026-04:10:02] [TRT-LLM] [I] Set multiple_profiles to False. [01/24/2026-04:10:02] [TRT-LLM] [I] Set paged_state to True. [01/24/2026-04:10:02] [TRT-LLM] [I] Set streamingllm to False. [01/24/2026-04:10:02] [TRT-LLM] [W] Implicitly setting QWenConfig.qwen_type = qwen2 [01/24/2026-04:10:02] [TRT-LLM] [W] Implicitly setting QWenConfig.moe_intermediate_size = 0 [01/24/2026-04:10:02] [TRT-LLM] [W] Implicitly setting QWenConfig.moe_shared_expert_intermediate_size = 0 [01/24/2026-04:10:02] [TRT-LLM] [I] Set dtype to float16. [01/24/2026-04:10:02] [TRT-LLM] [W] remove_input_padding is enabled, while opt_num_tokens is not set, setting to max_batch_size*max_beam_width. [01/24/2026-04:10:02] [TRT-LLM] [W] max_num_tokens (1024) shouldn't be greater than max_seq_len * max_batch_size (1024), specifying to max_seq_len * max_batch_size (1024). [01/24/2026-04:10:02] [TRT-LLM] [W] padding removal and fMHA are both enabled, max_input_len is not required and will be ignored [01/24/2026-04:10:02] [TRT] [I] [MemUsageChange] Init CUDA: CPU +12, GPU +0, now: CPU 164, GPU 1447 (MiB) [01/24/2026-04:10:05] [TRT] [I] [MemUsageChange] Init builder kernel library: CPU +947, GPU +1133, now: CPU 1154, GPU 2594 (MiB) [01/24/2026-04:10:05] [TRT] [W] profileSharing0806 is on by default in TensorRT 10.0. This flag is deprecated and has no effect. [01/24/2026-04:10:05] [TRT-LLM] [I] Set weight_only_quant_matmul_plugin to float16. [01/24/2026-04:10:05] [TRT-LLM] [I] Set nccl_plugin to None. [01/24/2026-04:10:06] [TRT-LLM] [I] Total optimization profiles added: 1 [01/24/2026-04:10:06] [TRT-LLM] [I] Build TensorRT engine Unnamed Network 0 [01/24/2026-04:10:06] [TRT] [W] DLA requests all profiles have same min, max, and opt value. All dla layers are falling back to GPU [01/24/2026-04:10:06] [TRT] [W] Unused Input: position_ids [01/24/2026-04:10:06] [TRT] [W] [RemoveDeadLayers] Input Tensor position_ids is unused or used only at compile-time, but is not being removed. [01/24/2026-04:10:06] [TRT] [I] Global timing cache in use. Profiling results in this builder pass will be stored. [01/24/2026-04:10:06] [TRT] [I] Compiler backend is used during engine build. [01/24/2026-04:10:11] [TRT] [I] [GraphReduction] The approximate region cut reduction algorithm is called. [01/24/2026-04:10:11] [TRT] [I] Detected 15 inputs and 1 output network tensors. NvMapMemAllocInternalTagged: 1075072515 error 12 NvMapMemHandleAlloc: error 0 NvMapMemAllocInternalTagged: 1075072515 error 12 NvMapMemHandleAlloc: error 0 [01/24/2026-04:10:20] [TRT] [E] [resizingAllocator.cpp::allocate::74] Error Code 1: Cuda Runtime (out of memory) [01/24/2026-04:10:20] [TRT] [W] Requested amount of GPU memory (1514557910 bytes) could not be allocated. There may not be enough free memory for allocation to succeed. [01/24/2026-04:10:20] [TRT] [E] [globWriter.cpp::makeResizableGpuMemory::433] Error Code 2: OutOfMemory (Requested size was 1514557910 bytes.) Traceback (most recent call last): File "/usr/local/bin/trtllm-build", line 8, in <module> sys.exit(main()) File "/usr/local/lib/python3.10/dist-packages/tensorrt_llm/commands/build.py", line 500, in main parallel_build(model_config, ckpt_dir, build_config, args.output_dir, File "/usr/local/lib/python3.10/dist-packages/tensorrt_llm/commands/build.py", line 377, in parallel_build passed = build_and_save(rank, rank % workers, ckpt_dir, File "/usr/local/lib/python3.10/dist-packages/tensorrt_llm/commands/build.py", line 344, in build_and_save engine = build_model(build_config, File "/usr/local/lib/python3.10/dist-packages/tensorrt_llm/commands/build.py", line 337, in build_model return build(model, build_config) File "/usr/local/lib/python3.10/dist-packages/tensorrt_llm/builder.py", line 1060, in build engine = None if build_config.dry_run else builder.build_engine( File "/usr/local/lib/python3.10/dist-packages/tensorrt_llm/_common.py", line 204, in decorated return f(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/tensorrt_llm/builder.py", line 411, in build_engine assert engine is not None, 'Engine building failed, please check the error log.' AssertionError: Engine building failed, please check the error log. 内存不够,测不了了...... DeepSeek R1-1.5B 启动容器 ./jetson-containers/run.sh -v $(pwd)/model_zoo:/opt/tensorrt_llm/models $(autotag tensorrt_llm) 转换模型 使用TensorRT-LLM提供的工具进行量化,如果内存不够就到PC上去做量化,见下。 cd /opt/TensorRT-LLM/examples/qwen python3 convert_checkpoint.py \ --model_dir /data/DeepSeek-R1-Distill-Qwen-1.5B/ \ --output_dir /data/deepseek_r1_1.5b_ckpt_int4 \ --dtype float16 \ --use_weight_only \ --weight_only_precision int4 构建引擎 构建引擎 trtllm-build \ --checkpoint_dir /opt/tensorrt_llm/models/deepseek_r1_1.5b_ckpt_int4 \ --output_dir /opt/tensorrt_llm/models/deepseek_r1_1.5b_int4_bs1_engine \ --gemm_plugin float16 \ --gpt_attention_plugin float16 \ --max_batch_size 1 \ --max_input_len 1024 \ --max_seq_len 1024 \ --workers 1 如果内存不够的话就把max_batch_size改小一点。 测试对话 cd /opt/TensorRT-LLM/examples/qwen python3 ../run.py \ --engine_dir /opt/tensorrt_llm/models/deepseek_r1_1.5b_int4_bs1_engine/ \ --tokenizer_dir /opt/tensorrt_llm/models/DeepSeek-R1-Distill-Qwen-1.5B/ \ --max_output_len 128 \ --input_text "你好,请介绍一下你自己,并讲一个关于芯片工程师的冷笑话。" 测试性能 压力测试 cd /opt/TensorRT-LLM/benchmarks/python # 运行 Batch Size 1 的测试 python3 benchmark.py \ --engine_dir /opt/tensorrt_llm/models/deepseek_r1_1.5b_int4_bs1_engine/ \ --batch_size 1 \ --input_output_len "512,128" \ --dtype float16 \ --num_runs 10 \ --warm_up 2 在PC上做量化 由于在jetson nano上做量化,内存不足,可以考虑在PC上做量化,然后把模型拷贝到设备中去。由于容器内使用的python是3.12,所以我们安装一个PyTorch 24.02的容器。 安装量化环境 (1)启动容器 # 注意:镜像换成了 pytorch:24.02-py3,它是 Python 3.10 环境 docker run --rm -it --ipc=host --gpus all \ -v ~/model_zoo:/data \ -v ~/TensorRT-LLM:/code \ -w /code/examples/qwen \ nvcr.io/nvidia/pytorch:24.02-py3 bash (2)安装TensorRT-LLM 0.12.0 # 这一步会下载约 1GB 的包,请耐心等待 pip install tensorrt_llm==0.12.0 --extra-index-url https://pypi.nvidia.com (3)安装脚本依赖 pip install "transformers==4.38.2" safetensors accelerate (4)验证安装 python3 -c "import tensorrt_llm; print(tensorrt_llm.__version__)" # 输出应该是 0.12.0 过程中如果遇到问题,可以按照下面的办法处理 # 强制重装 TensorRT 相关的核心包 pip install --force-reinstall \ tensorrt==10.3.0 \ tensorrt-cu12==10.3.0 \ tensorrt-cu12-bindings==10.3.0 \ tensorrt-cu12-libs==10.3.0 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib/python3.10/dist-packages/tensorrt_libs #卸载捣乱的 Flash Attention,不需要这个 pip uninstall -y flash-attn # 1. 卸载可能存在的冲突包 pip uninstall -y pynvml nvidia-ml-py # 2. 安装旧版 pynvml (11.4.1 是最稳定的旧版,完美兼容 0.12.0) pip install pynvml==11.4.1 转换模型 python3 convert_checkpoint.py \ --model_dir /data/Qwen2.5-1.5B-Instruct/ \ --output_dir /data/qwen1.5b_ckpt_int4 \ --dtype float16 \ --use_weight_only \ --weight_only_precision int4 然后可以拷贝到设备上。 # 确保 Jetson 上有这个目录 ssh nano@10.0.91.125 "mkdir -p ~/model_zoo" # 开始传输 (PC -> Jetson) rsync -avP ~/model_zoo/qwen1.5b_ckpt_int4 nano@10.0.91.125:~/model_zoo/ 常见问题 找不到库 如果在模型转换的时候出现下面报错,先退出docker容器,安装下面的库 ImportError: libnvdla_compiler.so: cannot open shared object file: No such file or directory wget -O - https://repo.download.nvidia.com/jetson/common/pool/main/n/nvidia-l4t-dla-compiler/nvidia-l4t-dla-compiler_36.4.1-20241119120551_arm64.deb | dpkg-deb --fsys-tarfile - | sudo tar xv --strip-components=5 --directory=/usr/lib/aarch64-linux-gnu/nvidia/ ./usr/lib/aarch64-linux-gnu/nvidia/libnvdla_compiler.so 内存不足 禁用桌面图像界面,暂时禁用 $ sudo init 3 # stop the desktop # log your user back into the console (Ctrl+Alt+F1, F2, ect) $ sudo init 5 # restart the desktop 如果想重启也禁用 #禁用 sudo systemctl set-default multi-user.target #启用 sudo systemctl set-default graphical.target # 强行同步并释放缓存 sudo sh -c 'sync; echo 3 > /proc/sys/vm/drop_caches' 参考资料: jetson SDK jetson-ai-lab jetson官方数据 -
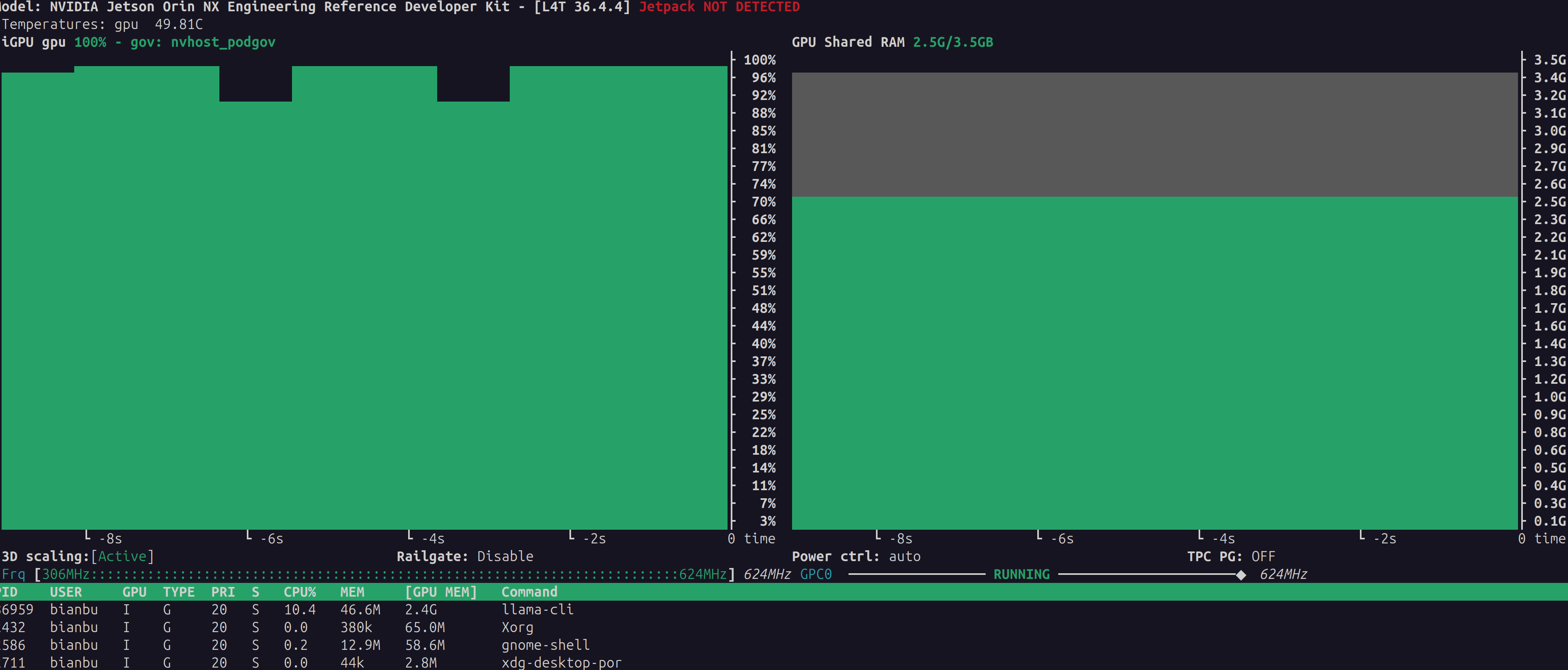
jetson orin nano使用llamap.cpp跑大模型
安装 确认一下是否有/usr/local/cuda/bin/nvcc,有就配置一下环境。 # 临时在当前终端生效 export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH # 验证 nvcc 是否能找到 nvcc --version 如果没有就安装 sudo -E apt install cuda-toolkit 下载代码 git clone https://github.com/ggerganov/llama.cpp cd llama.cpp 安装魔塔下载工具 pip install modelscope -i https://mirrors.aliyun.com/pypi/simple/ 编译 mkdir build cmake .. -DGGML_CUDA=ON cmake --build . --config Release -j $(nproc) 跑模型 低功耗模式 下载模型 mkdir model_zoo modelscope download --model Qwen/Qwen2.5-1.5B-Instruct-GGUF qwen2.5-1.5b-instruct-q4_0.gguf --local_dir ./model_zoo 测试模型 ./build/bin/llama-cli -m ../model_zoo/qwen2.5-1.5b-instruct-q4_0.gguf --perf --show-timings -lv 3 换个笑话 |slot get_availabl: id 0 | task -1 | selected slot by LCP similarity, sim_best = 0.952 (> 0.100 thold), f_keep = 1.000 slot launch_slot_: id 0 | task -1 | sampler chain: logits -> ?penalties -> ?dry -> ?top-n-sigma -> top-k -> ?typical -> top-p -> min-p -> ?xtc -> temp-ext -> dist slot launch_slot_: id 0 | task 184 | processing task, is_child = 0 slot update_slots: id 0 | task 184 | new prompt, n_ctx_slot = 4096, n_keep = 0, task.n_tokens = 248 slot update_slots: id 0 | task 184 | n_tokens = 236, memory_seq_rm [236, end) slot update_slots: id 0 | task 184 | prompt processing progress, n_tokens = 248, batch.n_tokens = 12, progress = 1.000000 slot update_slots: id 0 | task 184 | prompt done, n_tokens = 248, batch.n_tokens = 12 slot init_sampler: id 0 | task 184 | init sampler, took 0.11 ms, tokens: text = 248, total = 248 好的,以下是一个不同的笑话: 为什么电脑没有呼吸? 因为它只有一个输入口,一个输出口。slot print_timing: id 0 | task 184 | prompt eval time = 214.26 ms / 12 tokens ( 17.85 ms per token, 56.01 tokens per second) eval time = 1691.48 ms / 22 tokens ( 76.89 ms per token, 13.01 tokens per second) total time = 1905.74 ms / 34 tokens slot release: id 0 | task 184 | stop processing: n_tokens = 269, truncated = 0 srv update_slots: all slots are idle [ Prompt: 56.0 t/s | Generation: 13.0 t/s ] 看起来速度不是很快。 再跑一个3B的试试看。 ./build/bin/llama-cli -m ../model_zoo/qwen2.5-3b-instruct-q4_0.gguf --perf --show-timings -lv 3 prompt eval time = 1412.32 ms / 15 tokens ( 94.15 ms per token, 10.62 tokens per second) eval time = 48064.10 ms / 244 tokens ( 196.98 ms per token, 5.08 tokens per second) total time = 49476.41 ms / 259 tokens slot release: id 0 | task 148 | stop processing: n_tokens = 469, truncated = 0 srv update_slots: all slots are idle [ Prompt: 10.6 t/s | Generation: 5.1 t/s ] 看起来不太行。 加上个参数重新编译试试,针对CUDA的能力计算数值,加这个参数,llama.cpp 的 cmake 默认可能不会启用针对特定 GPU 架构的深度优化 rm -rf build && mkdir build && cd build cmake .. -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=87 #或者cmake .. -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=native cmake --build . --config Release -j$(nproc) 再测试执行: ./build/bin/llama-cli -m ../model_zoo/qwen2.5-3b-instruct-q4_0.gguf --perf --show-timings -lv 3 -ngl 99 prompt eval time = 201.92 ms / 13 tokens ( 15.53 ms per token, 64.38 tokens per second) eval time = 39903.36 ms / 386 tokens ( 103.38 ms per token, 9.67 tokens per second) total time = 40105.28 ms / 399 tokens slot release: id 0 | task 159 | stop processing: n_tokens = 598, truncated = 0 srv update_slots: all slots are idle [ Prompt: 64.4 t/s | Generation: 9.7 t/s ] 推理速度上来了,稳定在10 token/s。 再跑跑bench ./build/bin/llama-bench -m ../model_zoo/qwen2.5-3b-instruct-q4_0.gguf -ngl 99 ggml_cuda_init: found 1 CUDA devices: Device 0: Orin, compute capability 8.7, VMM: yes | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: | | qwen2 3B Q4_0 | 1.86 GiB | 3.40 B | CUDA | 99 | pp512 | 259.35 ± 0.46 | | qwen2 3B Q4_0 | 1.86 GiB | 3.40 B | CUDA | 99 | tg128 | 8.98 ± 0.03 | build: 37c35f0e1 (7787) (base) bianbu@ubuntu:~/llama.cpp$ sudo nvpmodel -m 0 # 开启最大功率模式 sudo jetson_clocks # 锁定 CPU/GPU/内存频率到最高 (base) bianbu@ubuntu:~/llama.cpp$ ./build/bin/llama-bench -m ../model_zoo/qwen2.5-3b-instruct-q4_0.gguf -ngl 99 ggml_cuda_init: found 1 CUDA devices: Device 0: Orin, compute capability 8.7, VMM: yes | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: | | qwen2 3B Q4_0 | 1.86 GiB | 3.40 B | CUDA | 99 | pp512 | 264.42 ± 0.27 | | qwen2 3B Q4_0 | 1.86 GiB | 3.40 B | CUDA | 99 | tg128 | 9.17 ± 0.01 | build: 37c35f0e1 (7787) 超级性能模式 上面跑了一下看起来还是很慢,看了一下jetson官网,要跑性能,需要设置电源为超级性能模式,点击 Ubuntu 桌面顶部栏右侧的 NVIDIA 图标 Power mode 0: 15W 1: 25W 2: MAXN SUPER 如果没有MAXN SUPER,执行下面的命令安装。 sudo apt remove nvidia-l4t-bootloader sudo apt install nvidia-l4t-bootloader sudo reboot 如果还是无法配置的话,参考下:super mode 接下来,接着跑。 ./build/bin/llama-cli -m ../model_zoo_gguf/model_zoo/qwen2.5-1.5b-instruct-q4_0.gguf --perf --show-timings -lv 3 -ngl 99 ./build/bin/llama-bench -m ../model_zoo_gguf/model_zoo/qwen2.5-1.5b-instruct-q4_0.gguf -ngl 99 在跑个3B的 ./build/bin/llama-bench -m ../model_zoo_gguf/model_zoo/qwen2.5-3b-instruct-q4_0.gguf -ngl 99 ./build/bin/llama-cli -m ../model_zoo_gguf/model_zoo/qwen2.5-3b-instruct-q4_0.gguf -ngl 99 --perf -lv 3 -
GGML的CPU算子解读:矩阵乘法
算子实现 调用流程 主要是ggml_compute_forward_mul_mat函数,该函数把任务拆分,最终计算执行调用ggml_compute_forward_mul_mat_one_chunk实现。 任务拆分 void ggml_compute_forward_mul_mat( const struct ggml_compute_params * params, struct ggml_tensor * dst) { // 1. 获取输入和输出张量的指针 const struct ggml_tensor * src0 = dst->src[0]; const struct ggml_tensor * src1 = dst->src[1]; // 2. 初始化一堆本地变量 (ne0, nb0 等),方便后面写公式 GGML_TENSOR_BINARY_OP_LOCALS // 3. 获取当前线程的信息 const int ith = params->ith; // 我是第几个线程? const int nth = params->nth; // 总共有几个线程? // 4. 获取src0(权重)的数据类型,用于后续查询src1(输入/激活值)必须转换为什么类型才能进行计算。 //在大语言模型中,为了省内存,src0(权重矩阵)通常是经过量化的比如Q4_0,Q5_1,Q8_0等格式。 enum ggml_type const vec_dot_type = type_traits_cpu[src0->type].vec_dot_type; // ... (省略一堆 GGML_ASSERT 检查,确保维度合法,比如 src0 和 src1 能不能相乘) ... #if GGML_USE_LLAMAFILE // 5. 【极速通道】如果系统支持 llamafile 的手写汇编优化,直接丢给它算,算完直接返回。 // 这比下面的 C 代码快得多。 if (src1_cont) { // ... 尝试调用 llamafile_sgemm ... if (!llamafile_sgemm(...)) goto UseGgmlGemm1; // 如果失败,就跳回下面的普通通道 return; } UseGgmlGemm1:; #endif // 6. 如果src1的类型与src0的类型不匹配,需要将src1转换成vec_dot_type类型。 if (src1->type != vec_dot_type) { char * wdata = params->wdata; // ... (循环遍历 src1,把数据解压并复制到 wdata) ... // 这里用了 from_float 函数进行转换 } // 7. 【同步】确保所有线程都知道数据准备好了 //只让线程0做一次初始化,把 current_chunk 设为 nth:因为每个线程先从 current_chunk = ith //开始领一个“私有起始 chunk”,所以下一个“公共可抢”的 chunk 从 nth 开始。 if (ith == 0) { atomic_store_explicit(¶ms->threadpool->current_chunk, nth, memory_order_relaxed); } ggml_barrier(params->threadpool); // barrier 等待:确保所有线程都完成了“src1 预处理/计数器初始化”,再进入真正的 chunk 计算阶段。 // ... (再次尝试 llamafile 优化,省略) ... // 8. 【切蛋糕】决定每个任务块 (chunk) 有多大 // nr0 是结果矩阵的行数,nr1 是其余维度的大小 const int64_t nr0 = ne0; //nr0 代表结果矩阵在“第一维”的长度(可以理解为输出的行数/一个主维度)。 const int64_t nr1 = ne1 * ne2 * ne3; //nr1 把其余维度展平成第二维(把 ne1*ne2*ne3 看成“列块/批次展平后的列方向”)。 int chunk_size = 16; // 默认每块按 16 规模做分块(和 one_chunk 内的 16×16 tiling 呼应)。 if (nr0 == 1 || nr1 == 1) { chunk_size = 64; } // 如果矩阵很细长,就切大一点 // 算出总共有多少块蛋糕 (nchunk0 * nchunk1) int64_t nchunk0 = (nr0 + chunk_size - 1) / chunk_size; int64_t nchunk1 = (nr1 + chunk_size - 1) / chunk_size; // 9. 【NUMA 优化】如果是多路 CPU 服务器,或者切得太碎了,就改用保守策略 if (nchunk0 * nchunk1 < nth * 4 || ggml_is_numa()) { nchunk0 = nr0 > nr1 ? nth : 1; nchunk1 = nr0 > nr1 ? 1 : nth; } // 计算每个块实际包含多少行/列 (dr0, dr1) //把 nr0/nr1 平均分给 nchunk0/nchunk1,得到每块在两维上的跨度 dr0/dr1。 const int64_t dr0 = (nr0 + nchunk0 - 1) / nchunk0; const int64_t dr1 = (nr1 + nchunk1 - 1) / nchunk1; // 10. 【开始干活】线程开始领任务 // 一开始,第 ith 个线程领第 ith 块蛋糕 //每个线程先从 current_chunk = ith 开始,保证一开始每个线程都有活(减少原子争用)。 int current_chunk = ith; while (current_chunk < nchunk0 * nchunk1) { // 算出当前蛋糕块在矩阵的哪个位置 (start 到 end) const int64_t ith0 = current_chunk % nchunk0; const int64_t ith1 = current_chunk / nchunk0; const int64_t ir0_start = dr0 * ith0; const int64_t ir0_end = MIN(ir0_start + dr0, nr0); // ... (同理算出 ir1 的范围) ... // 11. 【核心调用】把这一小块任务交给工人去算 // num_rows_per_vec_dot 是看 CPU 是否支持一次算两行 (MMLA 指令) ggml_compute_forward_mul_mat_one_chunk(..., ir0_start, ir0_end, ir1_start, ir1_end); // 如果线程数比蛋糕块还多,干完这一块就可以下班了 if (nth >= nchunk0 * nchunk1) { break; } // 12. 【抢任务】否则,去原子计数器里“取号”,领下一块没人干的蛋糕 current_chunk = atomic_fetch_add_explicit(¶ms->threadpool->current_chunk, 1, memory_order_relaxed); } } 计算执行 static void ggml_compute_forward_mul_mat_one_chunk( // ... 参数省略,主要是范围 ir0_start 等 ... ) { // 1. 获取数据指针 const struct ggml_tensor * src0 = dst->src[0]; const struct ggml_tensor * src1 = dst->src[1]; // ... 初始化本地变量 ... // 2. 准备点积函数 (vec_dot) // type_traits_cpu 是一张表,根据数据类型查到最优的计算函数 ggml_vec_dot_t const vec_dot = type_traits_cpu[type].vec_dot; // 3. 【广播因子】计算 src1 比 src0 大多少倍 // 比如 src1 有 2 个头,src0 只有 1 个头,那 r2 就是 2。计算时 src0 要重复用。 const int64_t r2 = ne12 / ne02; const int64_t r3 = ne13 / ne03; // 如果任务范围是空的,直接返回 if (ir0_start >= ir0_end || ir1_start >= ir1_end) { return; } // 4. 【Tiling 分块参数】 // 即使是这一小块任务,也要再切碎,为了放进 CPU 缓存 (L1 Cache) const int64_t blck_0 = 16; const int64_t blck_1 = 16; // 5. 定义临时缓冲区,防止多个线程写内存冲突 (False Sharing) float tmp[32]; // 6. 【双重 Tiling 循环】开始遍历任务块 // iir1 每次跳 16 行 for (int64_t iir1 = ir1_start; iir1 < ir1_end; iir1 += blck_1) { // iir0 每次跳 16 列 for (int64_t iir0 = ir0_start; iir0 < ir0_end; iir0 += blck_0) { // 7. 【处理块内的每一行】 for (int64_t ir1 = iir1; ir1 < iir1 + blck_1 && ir1 < ir1_end; ir1 += num_rows_per_vec_dot) { // 8. 【计算索引】这部分数学很绕,简单说就是: // 根据当前的行号 ir1,反推出它在 src1 的第几层、第几页 (i13, i12, i11) const int64_t i13 = (ir1 / (ne12 * ne1)); const int64_t i12 = (ir1 - i13 * ne12 * ne1) / ne1; const int64_t i11 = (ir1 - i13 * ne12 * ne1 - i12 * ne1); // 9. 【应用广播】算出对应的 src0 的位置 // 如果 src0 比较小,就除以倍率 r2, r3 来复用数据 const int64_t i03 = i13 / r3; const int64_t i02 = i12 / r2; // 拿到 src0 这一行的内存地址 const char * src0_row = (const char*)src0->data + (0 + i02 * nb02 + i03 * nb03); // 拿到 src1 这一列的内存地址 (wdata 是之前解压好的数据) const char * src1_col = (const char*)wdata + ...; // (省略复杂的偏移量计算) // 拿到 结果 dst 的写入地址 float * dst_col = (float*)((char*)dst->data + ...); // 10. 【核心计算循环】 // 遍历 src0 的行 (分块内),调用 SIMD 指令进行计算 for (int64_t ir0 = iir0; ir0 < iir0 + blck_0 && ir0 < ir0_end; ir0 += num_rows_per_vec_dot) { // vec_dot:一次性计算 ne00 个元素的点积 // 结果先存在 tmp 数组里,而不是直接写回 dst vec_dot(ne00, &tmp[ir0 - iir0], ..., src0_row + ir0 * nb01, ..., src1_col, ...); } // 11. 【写回结果】 // 把算好的 tmp 里的数据,一次性拷贝 (memcpy) 到最终的目标 dst_col for (int cn = 0; cn < num_rows_per_vec_dot; ++cn) { memcpy(&dst_col[iir0 + ...], tmp + ..., ...); } } } } } 以一个例子来总结一下。 void ggml_compute_forward_mul_mat( const struct ggml_compute_params * params, // 计算参数(包含线程信息) struct ggml_tensor * dst // 结果矩阵 C = A × B ) 功能是矩阵乘法:结果矩阵C=矩阵A x 矩阵B。其并行的策略如下: 切分对象: 结果矩阵C(不是A和B) 并行方式:2D切分+work_stealing(工作窃取) 写入方式:每个线程直接写入结果矩阵的不同位置。 矩阵A (m×k) × 矩阵B (k×n) = 结果矩阵C (m×n) ↑ ↑ ↑ 只读 只读 切分这个! 如上,矩阵A和B是只读的,所有线程都需要读取完整的A和B,结果矩阵C需要写入,每个线程写入不同的位置,切分C可以让多个线程并行计算不同的部分,互不干扰。 示例演示 输入数据 矩阵A (4行×3列): ┌─────────┐ │ 1 2 3 │ │ 4 5 6 │ │ 7 8 9 │ │ 10 11 12│ └─────────┘ 矩阵B (3行×4列): ┌─────────────┐ │ 1 2 3 4 │ │ 5 6 7 8 │ │ 9 10 11 12 │ └─────────────┘ 要计算:结果矩阵C = A × B (4行×4列) 分配结果矩阵 结果矩阵C(内存已分配,4×4 = 16个float): ┌─────────────────────┐ │ ? ? ? ? │ ← 行0 │ ? ? ? ? │ ← 行1 │ ? ? ? ? │ ← 行2 │ ? ? ? ? │ ← 行3 └─────────────────────┘ 列0 列1 列2 列3 计算切分参数 假设:2个线程,chunk_size = 2 nr0 = 4, nr1 = 4 nchunk0 = (4 + 2 - 1) / 2 = 3 nchunk1 = (4 + 2 - 1) / 2 = 3 总块数 = 3 × 3 = 9 检查:9 < 2 * 4 = 8? 不,9 >= 8 -> 不触发优化,保持3×3切分 dr0 = (4 + 3 - 1) / 3 = 2 // 每个块2行 dr1 = (4 + 3 - 1) / 3 = 2 // 每个块2列 切分结果矩阵 结果矩阵C (4×4) 被切分成9个块: ┌──────┬──────┬──────┐ │ 块0 │ 块1 │ 块2 │ ← 行块0(行0-1) │[0,0] │[0,1] │[0,2] │ │[1,0] │[1,1] │[1,2] │ ├──────┼──────┼──────┤ │ 块3 │ 块4 │ 块5 │ ← 行块1(行2-3) │[2,0] │[2,1] │[2,2] │ │[3,0] │[3,1] │[3,2] │ ├──────┼──────┼──────┤ │ 块6 │ 块7 │ 块8 │ ← 行块2(超出边界) │[0,3] │[1,3] │[2,3] │ │[1,3] │[2,3] │[3,3] │ └──────┴──────┴──────┘ 映射表 列0 列1 列2 列3 ┌────┬────┬────┬────┐ │块0 │块0 │块3 │块3 │ ← 行0 │ │ │ │ │ ├────┼────┼────┼────┤ │块0 │块0 │块3 │块3 │ ← 行1 │ │ │ │ │ ├────┼────┼────┼────┤ │块1 │块1 │块4 │块4 │ ← 行2 │ │ │ │ │ ├────┼────┼────┼────┤ │块1 │块1 │块4 │块4 │ ← 行3 └────┴────┴────┴────┘ 块0: ith0=0, ith1=0 → C[0:2, 0:2] → 左上角 2×2 块1: ith0=1, ith1=0 → C[2:4, 0:2] → 左下角 2×2 块3: ith0=0, ith1=1 → C[0:2, 2:4] → 右上角 2×2 块4: ith0=1, ith1=1 → C[2:4, 2:4] → 右下角 2×2 转换的过程 // 步骤1:块编号 → 块坐标 current_chunk = 3 ith0 = 3 % 3 = 0 // 块在第0行(行方向的第0个块) ith1 = 3 / 3 = 1 // 块在第1列(列方向的第1个块) // 步骤2:块坐标 → 实际位置 ir0_start = dr0 * ith0 = 2 * 0 = 0 // 从第0行开始 ir0_end = MIN(0 + 2, 4) = 2 // 到第2行结束(不包括2,实际是0-1行) ir1_start = dr1 * ith1 = 2 * 1 = 2 // 从第2列开始 ir1_end = MIN(2 + 2, 4) = 4 // 到第4列结束(不包括4,实际是2-3列) // 步骤3:实际位置 → 结果矩阵元素 块3 = C[0:2, 2:4] = { C[0][2], C[0][3], C[1][2], C[1][3] } 之所以要做一个映射,是因为work-stealing需要一维的变化,原子操作只能操作一个整数,线程并发是以块为最小运算单位。也是为了方便后面做负载均衡。 并行运算 (1)线程0的工作 current_chunk = 0 // 从块0开始 // 处理块0 ith0 = 0 % 3 = 0, ith1 = 0 / 3 = 0 ir0_start = 0, ir0_end = 2 // 行0-1 ir1_start = 0, ir1_end = 2 // 列0-1 计算: C[0][0] = A[0行] · B[第0列] = [1,2,3]·[1,5,9] = 38 C[0][1] = A[0行] · B[第1列] = [1,2,3]·[2,6,10] = 44 C[1][0] = A[1行] · B[第0列] = [4,5,6]·[1,5,9] = 83 C[1][1] = A[1行] · B[第1列] = [4,5,6]·[2,6,10] = 98 直接写入结果矩阵: dst->data[0*4 + 0] = 38 // C[0][0] dst->data[0*4 + 1] = 44 // C[0][1] dst->data[1*4 + 0] = 83 // C[1][0] dst->data[1*4 + 1] = 98 // C[1][1] // 完成后,抢下一个块 current_chunk = atomic_fetch_add(¤t_chunk, 1) = 2 // 处理块2(无效,会被跳过) ir0_start = 4, ir0_end = 4 // 空 → 跳过 // 继续抢下一个块 current_chunk = atomic_fetch_add(¤t_chunk, 1) = 3 // 处理块3 (2)线程1的工作 current_chunk = 1 // 从块1开始 // 处理块1 ith0 = 1 % 3 = 1, ith1 = 1 / 3 = 0 ir0_start = 2, ir0_end = 4 // 行2-3 ir1_start = 0, ir1_end = 2 // 列0-1 计算并写入 C[2:4, 0:2]... // 完成后,抢下一个块 current_chunk = atomic_fetch_add(¤t_chunk, 1) = 4 // 处理块4 (3)最终的结果 所有线程完成后,结果矩阵C: ┌─────────────────────┐ │ 38 44 50 56 │ ← 所有元素都已计算并写入 │ 83 98 113 128 │ │ 128 152 176 200 │ │ 173 206 239 272 │ └─────────────────────┘ -
GGML计算基础:矩阵的基本运算
矩阵相乘 是神经网络中算力消耗最大的部分,通常占据 LLM 推理计算量的 95% 以上。 矩阵乘法 (Matrix Multiplication / GEMM) 这是最通用的矩阵运算形式,也是 AI 芯片中 Tensor Core 或 MAC 阵列的主要工作内容。 定义: 设矩阵 $A$ 的形状为 $(M \times K)$,矩阵 $B$ 的形状为 $(K \times N)$,则它们的乘积 $C = A \times B$ 的形状为 $(M \times N)$。 计算公式: 目标矩阵中第 $i$ 行第 $j$ 列的元素,等于 $A$ 的第 $i$ 行与 $B$ 的第 $j$ 列的对应元素乘积之和: $$ C_{ij} = \sum_{k=1}^{K} A_{ik} \cdot B_{kj} $$ 工程视角: 维度约束:左矩阵的列数 ($K$) 必须等于右矩阵的行数 ($K$)。这个 $K$ 维度在运算中会被“消掉”(Reduction)。 LLM 应用:全连接层 (Linear Layers)、注意力机制中的 $Q/K/V$ 投影。 硬件特性:典型的计算密集型算子。优化的核心在于提高数据复用率(Data Reuse),减少从 HBM/DRAM 读取数据的次数。 向量点积 (Vector Dot Product) 在数学上,点积是矩阵乘法的一种特例;在物理意义上,它是衡量相似度的工具。 定义:两个同维度向量 $\vec{a}$ 和 $\vec{b}$ 的运算。 计算公式: $$ \vec{a} \cdot \vec{b} = \sum_{i=1}^{n} a_i b_i $$ 结果:结果是一个标量 (Scalar),即一个单纯的数值。 工程视角: 几何意义:反映两个向量方向的一致性。方向越接近,点积越大。 LLM 应用:Self-Attention 的核心逻辑。虽然代码实现通常是批量矩阵乘法 ($Q \times K^T$),但其数学本质是计算 Query 向量与 Key 向量的点积来获得注意力分数。 逐元素运算 (Element-wise Operations) 这类运算的特点是不改变矩阵形状,且计算之间互不依赖。它们通常对算力要求不高,但对显存带宽极其敏感。 逐元累积 (Hadamard Product) 常被称为 "Element-wise Product"。 定义: 两个形状完全相同的矩阵 $A$ 和 $B$ 进行运算。 计算公式: $$ (A \odot B){ij} = A{ij} \times B_{ij} $$ 工程视角: LLM 应用: 门控 (Gating):如 LLaMA 使用的 SwiGLU 激活函数,通过逐元素相乘来控制信息通过量。 掩码 (Masking):在 Attention 矩阵中,将不需要关注的位置乘以 0(或加负无穷)。 加法与减法 定义: 两个形状相同的矩阵对应位置相加或相减。 计算公式: $$(A \pm B){ij} = A{ij} \pm B_{ij}$$ 工程视角: LLM 应用: 残差连接 (Residual Connection):$X + \text{Layer}(X)$。这是深层网络能够训练的关键。 偏置 (Bias):$Y = XW + b$。 硬件特性:典型的 Memory Bound 操作。因为每个数据读进来只做一次简单的加法就写回去了,算术强度(Arithmetic Intensity)极低。 标量乘法 (Scalar Multiplication) 定义: 一个单独的数值 $\lambda$ 乘以矩阵中的每一个元素。 计算公式: $$ (\lambda A){ij} = \lambda \cdot A{ij} $$ 工程视角: LLM 应用: 缩放 (Scaling):Attention 中的 $\frac{QK^T}{\sqrt{d_k}}$,防止点积数值过大导致 Softmax 梯度消失。 归一化 (Normalization):LayerNorm 中的 $\gamma$ 参数本质上也是一种特定维度的缩放。 结构变换 (Structural Transformations) 这类操作通常不涉及数值的改变,而是改变数据的排列方式或索引方式。 转置 (Transpose) 定义: 将矩阵的行和列互换。 公式: $$(A^T){ij} = A{ji}$$ 工程视角: LLM 应用:多头注意力机制 (Multi-Head Attention) 中,为了并行计算多个头,需要频繁进行 (Batch, Seq, Head, Dim) 到(Batch, Head, Seq, Dim) 的维度置换(Permute,广义的转置)。 硬件挑战:转置意味着非连续的内存访问。在硬件设计中,通常需要专门的 Transpose Engine 或者利用 SRAM/寄存器文件进行巧妙的数据混洗,否则会严重导致 Cache Miss。 广播 (Broadcasting) 这是工程实现中极为重要的机制,允许不同形状的张量进行算术运算。 定义: 当两个矩阵形状不匹配时,自动将较小的矩阵在特定维度上进行逻辑上的复制,使其与大矩阵形状一致,再进行运算。 规则: 从最后面的维度开始对齐。 如果某个维度大小为 1,则可以扩展到任意大小。 工程视角: 例子:矩阵 $A(100 \times 256)$ 加上向量 $b(1 \times 256)$。系统会将 $b$ 在第 0 维复制 100 次。 硬件优势:优秀的 SDK 或 NPU 设计支持“隐式广播”,即不需要真的在内存中复制数据,只需利用 Stride(步长)为 0 的寻址方式重复读取同一个数据,从而节省大量的显存带宽。 -
GGML多线程计算:OpenMP简介
OpenMP是什么 OpenMP是一套用于共享内存并行系统的多线程程序设计标准。通俗的将,它允许通过简单的编译器指令(#pragma)将原本串行执行的C/C++ for循环瞬间变成多线程并发执行,而不需要手动的调用pthread_create的创建、销毁和同步。 核心模型:Fork-Join模型是理解OpenMP的关键。 Fork:主线程运行到并行区,Fork出一组线程。 Join:任务完成后,线程组同步并合并,只剩下主线程继续执行。 核心语法:从串行到并行 并行循环 这是最常用的指令。它告诉编译器:“把下面这个 for 循环的迭代次数拆分,分配给不同的线程同时跑”。 void add_arrays(float* a, float* b, float* c, int n) { for (int i = 0; i < n; i++) { c[i] = a[i] + b[i]; } } 要让他在多核CPU上并行,只需要加上一行: void add_arrays(float* a, float* b, float* c, int n) { // 自动将 n 次循环拆分给当前可用的线程 #pragma omp parallel for for (int i = 0; i < n; i++) { c[i] = a[i] + b[i]; // 每个线程处理一部分 i } } 数据作用域 写并发最怕数据竞争(Data Race)。OpenMP 必须明确变量是“大家共用”还是“每人一份”。 shared(x): 默认属性。所有线程读写同一个内存地址 x。比如输入的大矩阵。 private(i): 每个线程都有自己独立的变量 i 副本,互不干扰。比如循环计数器。 #pragma omp parallel for private(i, j) shared(A, B, C) for (int i = 0; i < rows; i++) { // ... } 规约 是计算“点积”(Dot Product)或“求和”时的神器。如果多个线程同时往同一个变量 sum 里加值,会冲突。 解决:使用 reduction(+:sum)。每个线程并在本地算自己的小 sum,最后 OpenMP 自动把所有线程的小 sum 加在一起。 float dot_product(float* a, float* b, int n) { float sum = 0.0; // 告诉编译器:sum 是归约变量,操作是加法 #pragma omp parallel for reduction(+:sum) for (int i = 0; i < n; i++) { sum += a[i] * b[i]; } return sum; } 循环是如何被切分的? 初学者最大的疑问通常是:多线程并发执行循环时,i 变量不会冲突吗?大家都执行 i++ 岂不是乱套了?答案是:不会。OpenMP 做的是“分地盘”,而不是“抢地盘”。 (1)空间划分 当编译器看到 #pragma omp parallel for 时,它并没有让多个线程去争夺同一个全局 i。相反,它把 0 到 n 这个迭代范围(Iteration Space)切成了若干块(Chunks),分给了不同的线程。 假设 n = 100,且有 4 个线程,默认调度下: 线程 0 负责 i 属于 [0, 24] 线程 1 负责 i 属于 [25, 49] 线程 2 负责 i 属于 [50, 74] 线程 3 负责 i 属于 [75, 99] (2)变量私有化 在生成的底层代码中,循环变量 i 被自动标记为线程私有(Private)。 线程 1 里的 i 实际上是一个局部变量,它从 25 开始,自己累加到 49。 它完全看不到线程 0 的 i 是多少。 结论:所谓的并发,是大家在各自划定的跑道上同时跑,互不干扰。 -
GGML 入门:搞懂张量、内存池与计算图
ggml是什么 ggml是用于transformer架构推理的机器学习库,类似于pytorch、TensorFlow等机器学习库。ggml不需要第三方库的依赖,目前兼容X86、ARM、Apple Silicon、CUDA等。 小demo开始 int main(void) { #define rows_A 4 #define cols_A 2 float matrix_A[rows_A * cols_A] = { 2, 8, 5, 1, 4, 2, 8, 6 }; #define rows_B 3 #define cols_B 2 float matrix_B[rows_B * cols_B] = { 10, 5, 9, 9, 5, 4 }; size_t ctx_size = 0; ctx_size += rows_A * cols_A * ggml_type_size(GGML_TYPE_F32); ctx_size += rows_B * cols_B * ggml_type_size(GGML_TYPE_F32); ctx_size += 2 * ggml_tensor_overhead(); ctx_size += ggml_graph_overhead(); ctx_size += 1024; struct ggml_init_params params = { .mem_size = ctx_size, .mem_buffer = NULL, .no_alloc = false, }; struct ggml_context * ctx = ggml_init(params); struct ggml_tensor * tensor_a = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_A, rows_A); struct ggml_tensor * tensor_b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_B, rows_B); memcpy(tensor_a->data, matrix_A, ggml_nbytes(tensor_a)); memcpy(tensor_b->data, matrix_B, ggml_nbytes(tensor_b)); struct ggml_cgraph * gf = ggml_new_graph(ctx); struct ggml_tensor *result = ggml_mul_mat(ctx, tensor_a, tensor_b); ggml_build_forward_expand(gf, result); int n_threads = 1; ggml_graph_compute_with_ctx(ctx, gf, n_threads); float *result_data = (float *)result->data; printf("mul mat (%d x %d) (transposed result):\n[", (int) result->ne[0], (int) result->ne[1]); for (int j = 0; j < result->ne[1]; j++) { if (j > 0) { printf("\n"); } for (int i = 0; i < result->ne[0]; i++) { printf(" %.2f", result_data[j * result->ne[0] + i]); } } printf(" ]\n"); ggml_free(ctx); return 0; } 下面以一个最小demo开始串起全流程,顺序是: 估算内存池需要的大小ctx_size。 ggml_init创建context内存池。 ggml_new_tensor_2d创建tensor,并把原始数组memcpy到tensor->data。 ggml_new_graph创建graph。 ggml_mul_mat创建一个“矩阵乘”节点(这里只是描述,还没算) ggml_build_forward_expand从result往回收集依赖,填充graph。 ggml_graph_compute_with_ctx执行graph,结果写到result->data。 关键数据结构 本章节中涉及到一些关键的数据结构,理解这些数据结构对于整个架构至关重要。主要的ggml_context、ggml_tensor、ggml_cgraph。 ggml_context:内存池管理器,用于存储张量、计算图等信息。 ggml_tensor:计算的元数据,但不仅仅是存储tensor,还存储的tensor操作。 ggml_cgraph:计算图的表示,用于传给后端的“计算执行顺序”。 内存池ggml_context struct ggml_context { size_t mem_size; void * mem_buffer; bool mem_buffer_owned; bool no_alloc; int n_objects; struct ggml_object * objects_begin; struct ggml_object * objects_end; }; ggml_context从命名看是上下文,从编码上来看是用于存储的全局信息,一个装载各类对象 (如张量、计算图、其他数据) 的“容器”。 内存池布局 ggml_context就是ggml的内存池管理器,它管理一块连续的大内存mem_buffer,并在其中按顺序分配"对象"(tensor、graph、work_buffer),最后用ggml_free(ctx)一次性释放。 mem_size:内存池的总大小。 mem_buffer:内存池的基址地址,一整块连续内存的起点。 mem_buffer_owned:这块mem_buffer由ggml拥有(负责释放)。 no_alloc:是否禁止ggml自动为tensor分配tensor->data。 n_objects:已经在ctx内存池里分配了多少个对象块(tensor/graph/work_buffer等)。 objects_begin/end:ctx内存池里对象链表的头/尾。 内存池中可以存储不同的对象,对象的类型主要分为3种。 GGML_OBJECT_TYPE_TENSOR:存储张量+计算的节点。 GGML_OBJECT_TYPE_GRAPH:一次执行要跑那些节点 GGML_OBJECT_TYPE_WORK_BUFFER:执行过程中临时scratch内存。 每一类的存储类型内存布局都是先以struct ggml_object开头,然后是对应的类型数据。而具体的类型数据前面又存储个其内存数据的描述结构。(这种类型结构很经典,跟蓝牙的广播AD type一样,也跟之前设计的眼镜方案消息传输方案一样)。 struct ggml_object { size_t offs; size_t size; struct ggml_object * next; enum ggml_object_type type; char padding[4]; }; ggml_object可以理解为header,其描述了存储数据的类型type,实际数据起始偏移(相对ctx->mem_buffer),实际的数据长度size,以及指向下一个类型的指针next。而padding是用于填充,保持对齐要求。 在ggml_object后面就是实际类型的数据,以tensor类型为例,同样开始存储的是struct ggml_tensor结构体,后面是实际的tensor数据以及padding,这里需要注意的是tensor的数据并不一定会存储在内存池中,主要根据struct ggml_context中的no_alloc来判断是否要为tensor分配空间,如果不需要那么这里只会存储的是描述tensor的数据结构即struct ggml_tensor+padding,在ggml_tensor中data指向的实际的tensor存储位置起始地址。 ctx->mem_buffer + (某个位置) ┌───────────────┬───────────────────┬──────────────────────┬──────┐ │ ggml_object头 │ ggml_tensor结构体 │ tensor data (bytes) │ PAD │ └───────────────┴───────────────────┴──────────────────────┴──────┘ ↑ tensor 指针(result) ↑ tensor->data 指针 内存池是先预分配,后续实际需要多少就从内存池中获取多少。这就LwIP网络协议栈中的实现原理是一样的,类似先分配一块内存池MEM_POOL,这样的话就不用反复的申请提高计算效率。 关键API 这里总结一下跟ggml_context相关的关键API。 创建: ggml_init(params),创建一份ggml_context。 释放:ggml_free。 查询: ggml_used_mem(ctx):当前已用到的内存池在哪里。 ggml_get_mem_size(ctx)/ggml_get_mem_buffer(ctx) ggml_get_no_alloc(ctx) / ggml_set_no_alloc(ctx) 下面我们重点分析一下ggml_init的实现。 分配内存池 ggml_init的实现其实非常简单,就是先使用malloc分配struct ggml_context数据结构,其次就是分配一块虚拟地址连续的mem_buffer。这里需要注意的是ggml_context和mem_buffer不要搞混了,ggml_context可不再内存池中,ggml_contexth是单独的一块数据结构用来管理内存池的,内存池的虚拟地址的连续的。 struct ggml_context * ggml_init(struct ggml_init_params params) { static bool is_first_call = true; ggml_critical_section_start(); if (is_first_call) { // initialize time system (required on Windows) ggml_time_init(); is_first_call = false; } ggml_critical_section_end(); struct ggml_context * ctx = GGML_MALLOC(sizeof(struct ggml_context)); // allow to call ggml_init with 0 size if (params.mem_size == 0) { params.mem_size = GGML_MEM_ALIGN; } const size_t mem_size = params.mem_buffer ? params.mem_size : GGML_PAD(params.mem_size, GGML_MEM_ALIGN); *ctx = (struct ggml_context) { /*.mem_size =*/ mem_size, /*.mem_buffer =*/ params.mem_buffer ? params.mem_buffer : ggml_aligned_malloc(mem_size), /*.mem_buffer_owned =*/ params.mem_buffer ? false : true, /*.no_alloc =*/ params.no_alloc, /*.n_objects =*/ 0, /*.objects_begin =*/ NULL, /*.objects_end =*/ NULL, }; GGML_ASSERT(ctx->mem_buffer != NULL); GGML_ASSERT_ALIGNED(ctx->mem_buffer); GGML_PRINT_DEBUG("%s: context initialized\n", __func__); return ctx; } 从上面的代码可以看出主要是调用GGML_MALLOC分配struct ggml_context本体,接着判断用户是否传入mem_buffer,如果没有传递同时mem_size有设置就会在内部分配一块。 张量ggml_tensor 数据结构 struct ggml_tensor { enum ggml_type type; struct ggml_backend_buffer * buffer; int64_t ne[GGML_MAX_DIMS]; // number of elements size_t nb[GGML_MAX_DIMS]; // stride in bytes: // nb[0] = ggml_type_size(type) // nb[1] = nb[0] * (ne[0] / ggml_blck_size(type)) + padding // nb[i] = nb[i-1] * ne[i-1] // compute data enum ggml_op op; // op params - allocated as int32_t for alignment int32_t op_params[GGML_MAX_OP_PARAMS / sizeof(int32_t)]; int32_t flags; struct ggml_tensor * src[GGML_MAX_SRC]; // source tensor and offset for views struct ggml_tensor * view_src; size_t view_offs; void * data; char name[GGML_MAX_NAME]; void * extra; // extra things e.g. for ggml-cuda.cu char padding[8]; }; 上面是ggml_tensor的结构体,ggml_tensor是ggml的核心对象,既是一个多维数组的描述符(type/shape/stride/data),也是计算图里的一个节点(op/src/params/flags)。 ggml_tensor代表了两种类型,理解这两类类型十分关键: 数据张量:张量持有实际的数据,包含一个多维数组的数组。 运算张量:这个张量表示的是有多个输入张量的运算结果,只有实际运算时才会有数据。 主要是通过数据结构中的op来判断,如果op为GGML_OP_NONE则表示的是张量数据,如果op为操作符如GGML_OP_MUL_MAT则表示张量不含数据,而是表示两个张量矩阵乘法的结果。 (1)作为数组的字段 type:元素的类型(F32/F16/量化类型),决定元素/块大小,行大小。 ne[]:每维有多少个元素,ggml默认最多4维。 nb[]:描述每个维度步长。 (2)作为计算节点的字段 op: 这个tensor通过那个算子得到。如果维GGML_OP_NONE表示不是算子输出而是输入张量。 src[]: 算子节点输入张量的指针数组,如对于mul_mat来说src[0]=a,src[1]=b。这决定后续计算graph的根本。 op_prarams:算子的额外参数。 (3)View/切片/共享数据 view_src+view_offs表示这个tensor是另一个tensor的视图(共享data,不重新分配),data通常等于view_src->data+view_offs。 (4)与后端/设备相关字段 buffer:指向ggml_backend_buffer(后端的内存抽象),CPU简单路径下很多时候是NULL或默认。 extra:给特定后端/实现放额外信息的扩展指针。 总结一下ggml_tensor承担的两件事情,一是存储张量/数组的描述,而是用于计算计算节点。 分配张量 分配张量就是调用ggml_new_tensor_xx,如下: struct ggml_tensor * ggml_new_tensor_1d:分配1维的张量。 struct ggml_tensor * ggml_new_tensor_2d: 分配2维的张量。 struct ggml_tensor * ggml_new_tensor_3d:分配3维的张量。 struct ggml_tensor * ggml_new_tensor_4d:分配4维的张量。 最终张量的分配都会调用ggml_new_tensor来实现。下面以ggml_new_tensor_2d为例。 ggml_new_tensor_2d最终会调用内部的ggml_new_tensor_impl来实现,主要的流程就是先试用ggml_new_object从内存池中分配一个头节点,然后在分配payload也就是再从内存池分配ensor的结构体,接着根据no_alloc来判断是否要为tensor的data从内存池分配空间,最后就是填充好ggml_object和ggml_tensor。 创建的tensor主要有两部分组成 tensor结构体本身:shape、stride、op、src等信息。 可选的数据区:紧跟在结构体后面((result + 1)),只有在 view_src NULL && ctx->no_alloc false 时才会在 ctx 内存池里实际分配。 这是ggml核心设计之一,ctx是一个arean/内存池,所有对象顺序追加,没有逐个free;ggml_free一次性释放整个池。 计算图ggml_cgraph 关键数据结构 struct ggml_cgraph { int size; // maximum number of nodes/leafs/grads/grad_accs int n_nodes; // number of nodes currently in use int n_leafs; // number of leafs currently in use struct ggml_tensor ** nodes; // tensors with data that can change if the graph is evaluated struct ggml_tensor ** grads; // the outputs of these tensors are the gradients of the nodes struct ggml_tensor ** grad_accs; // accumulators for node gradients struct ggml_tensor ** leafs; // tensors with constant data int32_t * use_counts;// number of uses of each tensor, indexed by hash table slot struct ggml_hash_set visited_hash_set; enum ggml_cgraph_eval_order order; }; nodes[]:真正要执行的算子节点(有op,或是参数param)。 leafs[]:常量/叶子(op=NONE且不是param),例如常量张量。 在ggml中理解叶子(leaf)和节点(node)十分关键。 这两个都是用struct ggml_tensor来表示的,leaf是没有算子的(op=NONE),leaf可以理解为是输入/常量,他不需要通过执行算子来产生数据,数据已经在tensor->data中了,通过前面的memcpy进来或者后端的buffer提供,也不会前向执行中被计算出来;而node是需要再图执行是被处理的,包括两类 真正的算子输出:它的值来之执行的op,由tensor->src[]通过tensor->op计算而来。 参数:这个 tensor 是训练里要被当作变量去优化更新的参数(比如权重参数),既是op=NONE,但是也会放进node。 针对我们的demo,tensor_a、tensor_b是由ggml_new_tensor_2d创建的默认op=NONE,也不是PARAM这个就是leaf。而result=ggml_mul_mat(ctx, tensor_a, tensor_b)会设置result->op=GGML_OP_MUL_MAT且src[0]=tensor_a,src[1]=tensor_b,这个就是node。 再总结一下leafs就是图的“外部给定值”(常量/输入),不由 op 产生;nodes是图的“计算产生值”(算子输出)+ “训练参数(PARAM)”。 分配计算图 分配计算图是在ctx的内存池里一次性分配并初始化一张计算图ggml_cgraph,同时把图需要的数组nodes/leafs/use_counts/hash_keys/(可选)grads/grad_accs/hash_used)都放在同一个对象内存块里,并把这些指针指向那块内存。 struct ggml_cgraph * ggml_new_graph_custom(struct ggml_context * ctx, size_t size, bool grads) { const size_t obj_size = ggml_graph_nbytes(size, grads); struct ggml_object * obj = ggml_new_object(ctx, GGML_OBJECT_TYPE_GRAPH, obj_size); struct ggml_cgraph * cgraph = (struct ggml_cgraph *) ((char *) ctx->mem_buffer + obj->offs); // the size of the hash table is doubled since it needs to hold both nodes and leafs size_t hash_size = ggml_hash_size(size * 2); void * p = cgraph + 1; struct ggml_tensor ** nodes_ptr = incr_ptr_aligned(&p, size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)); struct ggml_tensor ** leafs_ptr = incr_ptr_aligned(&p, size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)); int32_t * use_counts_ptr = incr_ptr_aligned(&p, hash_size * sizeof(int32_t), sizeof(int32_t)); struct ggml_tensor ** hash_keys_ptr = incr_ptr_aligned(&p, hash_size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)); struct ggml_tensor ** grads_ptr = grads ? incr_ptr_aligned(&p, hash_size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)) : NULL; struct ggml_tensor ** grad_accs_ptr = grads ? incr_ptr_aligned(&p, hash_size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)) : NULL; ggml_bitset_t * hash_used = incr_ptr_aligned(&p, ggml_bitset_size(hash_size) * sizeof(ggml_bitset_t), sizeof(ggml_bitset_t)); // check that we allocated the correct amount of memory assert(obj_size == (size_t)((char *)p - (char *)cgraph)); *cgraph = (struct ggml_cgraph) { /*.size =*/ size, /*.n_nodes =*/ 0, /*.n_leafs =*/ 0, /*.nodes =*/ nodes_ptr, /*.grads =*/ grads_ptr, /*.grad_accs =*/ grad_accs_ptr, /*.leafs =*/ leafs_ptr, /*.use_counts =*/ use_counts_ptr, /*.hash_table =*/ { hash_size, hash_used, hash_keys_ptr }, /*.order =*/ GGML_CGRAPH_EVAL_ORDER_LEFT_TO_RIGHT, }; ggml_hash_set_reset(&cgraph->visited_hash_set); if (grads) { memset(cgraph->grads, 0, hash_size*sizeof(struct ggml_tensor *)); memset(cgraph->grad_accs, 0, hash_size*sizeof(struct ggml_tensor *)); } return cgraph; } 如果grads=false,表示是这是推理/前向图,内存布局如下: graph payload (obj->offs 指向起点) +------------------------------+ | struct ggml_cgraph | <- cgraph 指向这里 | - nodes -> nodes_ptr | | - leafs -> leafs_ptr | | - visited_hash_set.size | | - visited_hash_set.used -> hash_used | - visited_hash_set.keys -> hash_keys_ptr | - use_counts -> use_counts_ptr | - grads/grad_accs == NULL | +------------------------------+ | (对齐到 sizeof(ptr)) | +------------------------------+ | nodes_ptr[size] | array of struct ggml_tensor* +------------------------------+ | leafs_ptr[size] | array of struct ggml_tensor* +------------------------------+ | use_counts_ptr[hash_size] | array of int32_t (按 hash slot) +------------------------------+ | hash_keys_ptr[hash_size] | array of struct ggml_tensor* (hash keys) +------------------------------+ | hash_used bitset | ggml_bitset_t[bitset_size(hash_size)] +------------------------------+ | (尾部 padding 到 GGML_MEM_ALIGN) | +------------------------------+ 如果grads=true,对应的就是训练图/反向图,在hash_keys_ptr后面多两段。 ... hash_keys_ptr[hash_size] +------------------------------+ | grads_ptr[hash_size] | struct ggml_tensor* (每个被访问 tensor 的 grad 输出) +------------------------------+ | grad_accs_ptr[hash_size] | struct ggml_tensor* (grad accumulator) +------------------------------+ | hash_used bitset ... 我们重点看推理这部分,在graph payload中,前面部门存储的是ggml_cgraph结构体,后面紧跟的就是ggml_cgraph结构的内容。其中就最关键的是nodes[]和leafs[],前者存储是指向node类型tensor的指针,后者存储的指向leafs类型tensor的指针。 计算图构建 计算节点 在ggml中创建一个算子节点,就是调用类似ggml_mul_mat的函数。 struct ggml_tensor * ggml_mul_mat( struct ggml_context * ctx, struct ggml_tensor * a, struct ggml_tensor * b) { GGML_ASSERT(ggml_can_mul_mat(a, b)); GGML_ASSERT(!ggml_is_transposed(a)); const int64_t ne[4] = { a->ne[1], b->ne[1], b->ne[2], b->ne[3] }; struct ggml_tensor * result = ggml_new_tensor(ctx, GGML_TYPE_F32, 4, ne); result->op = GGML_OP_MUL_MAT; result->src[0] = a; result->src[1] = b; return result; } 上面的代码其实很简单,就是创建一个ggml_tensor,然后赋值op和要操作的src[0]和src[1],最后返回的也是ggml_tensor。 所以了ggml_mul_mat并不会立刻进行做矩阵乘法运算,它只是创建了一个"算子节点",把算子类型和输入依赖挂上去,等后面ggml_build_forward_expand+ggml_graph_compute_with_ctx才正在执行。 计算图 ggml_build_forward_expand是GGML计算图构建最关键的一部,核心任务是执行拓扑排序,从一个目标节点开始(通常是Loss或输出张量),递归的遍历所有依赖项(源张量src[0],src[1]),并将它们按照"先输入后输出"的顺序填入计算图的执行队列中nodes数组。 static size_t ggml_visit_parents(struct ggml_cgraph * cgraph, struct ggml_tensor * node) { // 1) 用 visited_hash_set 去重:同一个 tensor 只处理一次 size_t node_hash_pos = ggml_hash_find(&cgraph->visited_hash_set, node); if (!ggml_bitset_get(cgraph->visited_hash_set.used, node_hash_pos)) { cgraph->visited_hash_set.keys[node_hash_pos] = node; ggml_bitset_set(cgraph->visited_hash_set.used, node_hash_pos); cgraph->use_counts[node_hash_pos] = 0; } else { return node_hash_pos; } // 2) 递归访问 node->src[k],同时对每个 src 做 use_counts++ for (int i = 0; i < GGML_MAX_SRC; ++i) { struct ggml_tensor * src = node->src[k]; if (src) { size_t src_hash_pos = ggml_visit_parents(cgraph, src); cgraph->use_counts[src_hash_pos]++; } } // 3) 分类:leaf vs node(leaf 是 op==NONE 且不是 PARAM) if (node->op == GGML_OP_NONE && !(node->flags & GGML_TENSOR_FLAG_PARAM)) { cgraph->leafs[cgraph->n_leafs++] = node; } else { cgraph->nodes[cgraph->n_nodes++] = node; } return node_hash_pos; } 核心在这个ggml_visit_parents函数中,核心原理是从results开始往上遍历,把tensor为leafs类型的添加到leafs[]中,把tensor为node类型的添加到nodes[]中。 (1)去重 在ggml_visit_parents中会去重,同一个tensor可能会被多个算子引用,但是只希望他在图中出现一次,通过使用 visited_hash_set(key 是 tensor 指针地址)记录“见没见过”。见过就直接返回,不再 DFS,不再追加 nodes/leafs。 (2)递归遍历DFS 先递归访问 node->src[],再把 node 自己追加到 nodes/leafs。这天然形成一种顺序:后序遍历(post-order),直觉上就是:先把依赖(输入、上游算子)放进图,再放当前算子输出,这就是为什么 build 结束后,nodes[] 基本满足“依赖在前,使用在后”,便于执行。 (3)use_count使用次数统计 cgraph->use_counts[src_hash_pos]++ 表示:这个 src tensor 被作为某个 node 的输入用了一次。 它按 “hash slot” 存(不是按 nodes[] 下标),原因是:去重后每个 tensor 都能在 hash 表里找到一个稳定位置,方便后续用同一套索引关联其它数组(例如 grads/grad_accs 在训练图里也是按 hash slot 对齐)。 if (node->op == GGML_OP_NONE && !(node->flags & GGML_TENSOR_FLAG_PARAM)) { cgraph->leafs[cgraph->n_leafs] = node; cgraph->n_leafs++; } else { cgraph->nodes[cgraph->n_nodes] = node; cgraph->n_nodes++; } 从这个代码中也可以看到对于ggml_tensor,是怎么区分leaf和node的。 leaf:op为NONE 且不是 PARAM ->通常代表“常量/输入常量”(不需要通过执行算子得到) node:其它情况 ->需要在图执行时被处理的东西(算子输出 or 训练参数) 下面以简单的图来说明一下,我们的示例小demo的表达式如下: result (MUL_MAT) / \ tensor_a tensor_b (op NONE) (op NONE) 调用 ggml_build_forward_expand(gf, result) 的 DFS(后序)大致是: visit(result) visit(tensor_a) -> leafs += tensor_a visit(tensor_b) -> leafs += tensor_b nodes += result 得到的结构就是 cgraph->leafs: [ tensor_a, tensor_b ] 如果图更复杂,有共享子图(DAG),去重就很关键: z = add(x, x) // x 被用两次 / \ x x visit(z): visit(x): 第一次见到 -> leafs += x visit(x): 第二次见到 -> 直接 return(不重复加入) use_counts[x] 会被 ++ 两次 nodes += z 计算结果就是 leafs: [x] nodes: [z] use_counts[x] == 2 执行计算 ggml_graph_cmpute会先调用ggml_graph_plan算出需要多大的临时buffer,然后把这个work buffer直接从ctx的内存池分配出来,最后在启动图的计算。 图规划 ggml_graph_plan(cgraph, n_threads, NULL)的目标是决定实际用多少线程+估算整张图执行所需的最大临时内存work_size。plan会编译cgraph->nodes[],对每个node 计算 n_tasks = ggml_get_n_tasks(node, n_threads)(这个 op 适合拆多少任务) 估算该 op 需要的额外临时空间 cur 全图取 work_size = max(work_size, cur)(注意是 max,不是 sum,因为 work buffer 复用) for (int i = 0; i < cgraph->n_nodes; i++) { struct ggml_tensor * node = cgraph->nodes[i]; const int n_tasks = ggml_get_n_tasks(node, n_threads); max_tasks = MAX(max_tasks, n_tasks); size_t cur = 0; // ... switch(node->op) 估算 cur ... work_size = MAX(work_size, cur); } if (work_size > 0) { work_size += CACHE_LINE_SIZE*(n_threads); } cplan.threadpool = threadpool; cplan.n_threads = MIN(max_tasks, n_threads); cplan.work_size = work_size; cplan.work_data = NULL; return cplan; 很多 op 需要一块临时空间(例如把 src1 转换/pack 成适合 vec-dot 的布局),但这些临时空间可以在不同节点之间复用,所以用 “最大需求” 的单一 work buffer 就够。struct ggml_cplan 如下 struct ggml_cplan { size_t work_size; uint8_t * work_data; int n_threads; struct ggml_threadpool * threadpool; ggml_abort_callback abort_callback; void * abort_callback_data; }; work_size:执行改图所需的临时工作区大小。 work_data:指向调用方分配的临时工作区内存。 n_threads:希望永远执行图的线程数(影响并行度、某些kernel的分块方式等)。 threadpool:可选的线程池句柄。 分配work buffer 主要的目的就是在ctx的内存池里分配一块连续的内存作为work buffer,并把指针协会cplan.work_data。 cplan.work_data = (uint8_t *)ggml_new_buffer(ctx, cplan.work_size); return ggml_graph_compute(cgraph, &cplan); 为什么放 ctx 里,主要是避免每次 compute 时 malloc/free,并且生命周期跟 ctx 同步;缺点是 ctx 必须预留足够大(demo 里看到加了 ggml_graph_overhead() 和额外 1024,就是类似目的)。 执行 ggml_graph_compute就是执行了 (1)首先是先启动线程池 初始化计算后端如 cpu backend。 根据 cplan->threadpool 是否为空,创建一个临时 threadpool 或复用传入的 threadpool。 并行运行 ggml_graph_compute_thread enum ggml_status ggml_graph_compute(struct ggml_cgraph * cgraph, struct ggml_cplan * cplan) { ggml_cpu_init(); GGML_ASSERT(cplan); GGML_ASSERT(cplan->n_threads > 0); GGML_ASSERT(cplan->work_size == 0 || cplan->work_data != NULL); int n_threads = cplan->n_threads; struct ggml_threadpool * threadpool = cplan->threadpool; if (threadpool == NULL) { disposable_threadpool = true; // 创建 threadpool threadpool = ggml_threadpool_new_impl(&ttp, cgraph, cplan); } else { // 复用 threadpool:设置当前要跑的 cgraph/cplan 等 threadpool->cgraph = cgraph; threadpool->cplan = cplan; // ... } // 然后让各线程进入 ggml_graph_compute_thread(...) } 启动线程池后每个线程跑 ggml_graph_compute_thread,按 node 顺序执行 op,每个线程会构造一个ggml_compute_params,里面包含线程编号和线程数,全局work buffer,同步/屏障等信息。 struct ggml_compute_params { int ith, nth; size_t wsize; void * wdata; struct ggml_threadpool * threadpool; }; (2)线程执行的主流程 static thread_ret_t ggml_graph_compute_thread(void * data) { const struct ggml_cgraph * cgraph = tp->cgraph; const struct ggml_cplan * cplan = tp->cplan; struct ggml_compute_params params = { .ith = state->ith, .nth = ..., .wsize = cplan->work_size, .wdata = cplan->work_data, .threadpool= tp, }; for (int node_n = 0; node_n < cgraph->n_nodes && ...; node_n++) { struct ggml_tensor * node = cgraph->nodes[node_n]; if (ggml_op_is_empty(node->op)) { continue; } ggml_compute_forward(¶ms, node); if (node_n + 1 < cgraph->n_nodes) { ggml_barrier(state->threadpool); // 每个 node 结束后做一次全线程同步 } } ggml_barrier(state->threadpool); return 0; } 上面的ggml_graph_compute_thread是OpenMP模式。有有个多个线程同时执行ggml_graph_compute_thread。 #pragma omp parallel num_threads(n_threads) // 8 个线程 { int ith = omp_get_thread_num(); // 0, 1, 2, ..., 7 ggml_graph_compute_thread(&threadpool->workers[ith]); // 8 个线程都调用 } 执行模式是,节点内并行,节点间串行。 所有线程都执行相同的循环: for (int node_n = 0; node_n < cgraph->n_nodes; node_n++) { ggml_compute_forward(¶ms, node); // ← 这里并行! ggml_barrier(...); // ← 这里同步! } 每个线程遍历相同的节点序列,但是调用ggml_compute_forward内部不同线程处理不同的数据部分。但是需要注意的是并行的是在节点内部,不是节点之间。 计算图:节点0 → 节点1 → 节点2 线程执行流程: ┌─────────────────────────────────────────┐ │ 线程 0: for (node_n=0; node_n<3; node_n++) │ │ 线程 1: for (node_n=0; node_n<3; node_n++) │ │ 线程 2: for (node_n=0; node_n<3; node_n++) │ │ ... │ │ 线程 7: for (node_n=0; node_n<3; node_n++) │ └─────────────────────────────────────────┘ 所有线程都遍历所有节点,但在每个节点内部,它们处理不同的数据部分。节点内部的数据会切分,以矩阵加法为例。 // 节点 0: A + B → C (假设 C 是 1024x1024 的矩阵) // 线程 0: 计算 C[0:128, :] ← 只处理这部分 // 线程 1: 计算 C[128:256, :] ← 只处理这部分 // 线程 2: 计算 C[256:384, :] ← 只处理这部分 // ... // 线程 7: 计算 C[896:1024, :] ← 只处理这部分 // 所有线程同时计算,没有重复! ggml_compute_forward 里会根据 node->op 分发到具体 kernel。比如 MUL_MAT: case GGML_OP_MUL_MAT: { ggml_compute_forward_mul_mat(params, tensor); } break; (3)以一个例子来理解哪里串行,哪里并行 W (leaf) x (leaf) \ / \ / y = MUL_MAT b (leaf) | | +-----> y2 = ADD | v o = RELU 经过DFS后续遍历后,结果是: cgraph->nodes[0] = y (MUL_MAT) cgraph->nodes[1] = y2 (ADD) cgraph->nodes[2] = o (RELU) 因为各个node的计算是有前后依赖的,因此不行并行,也就是说node0 -> node1 -> node2 是串行推进,不能乱序并发(因为 node1 依赖 node0 输出,node2 依赖 node1 输出)。 for node_n in [0..n_nodes): 所有线程一起执行 nodes[node_n] barrier 等齐 而并行多线程计算你的是单个node的内部,每个node内部数据量很大,通常会拆快让多个线程并行计算。 时间 → thread0: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B| thread1: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B| thread2: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B| thread3: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B| 其中竖线|B|就是ggml_barrier,所有线程必须等到这一个node全部完成,才能进入到下一个node,而有4个线程同时干一个算子的事情。在一个node算子内,数据量通常是一个多维的矩阵,那么对数据可以做拆分tile分发到多个线程并发执行,这样就可以提高速度。 -
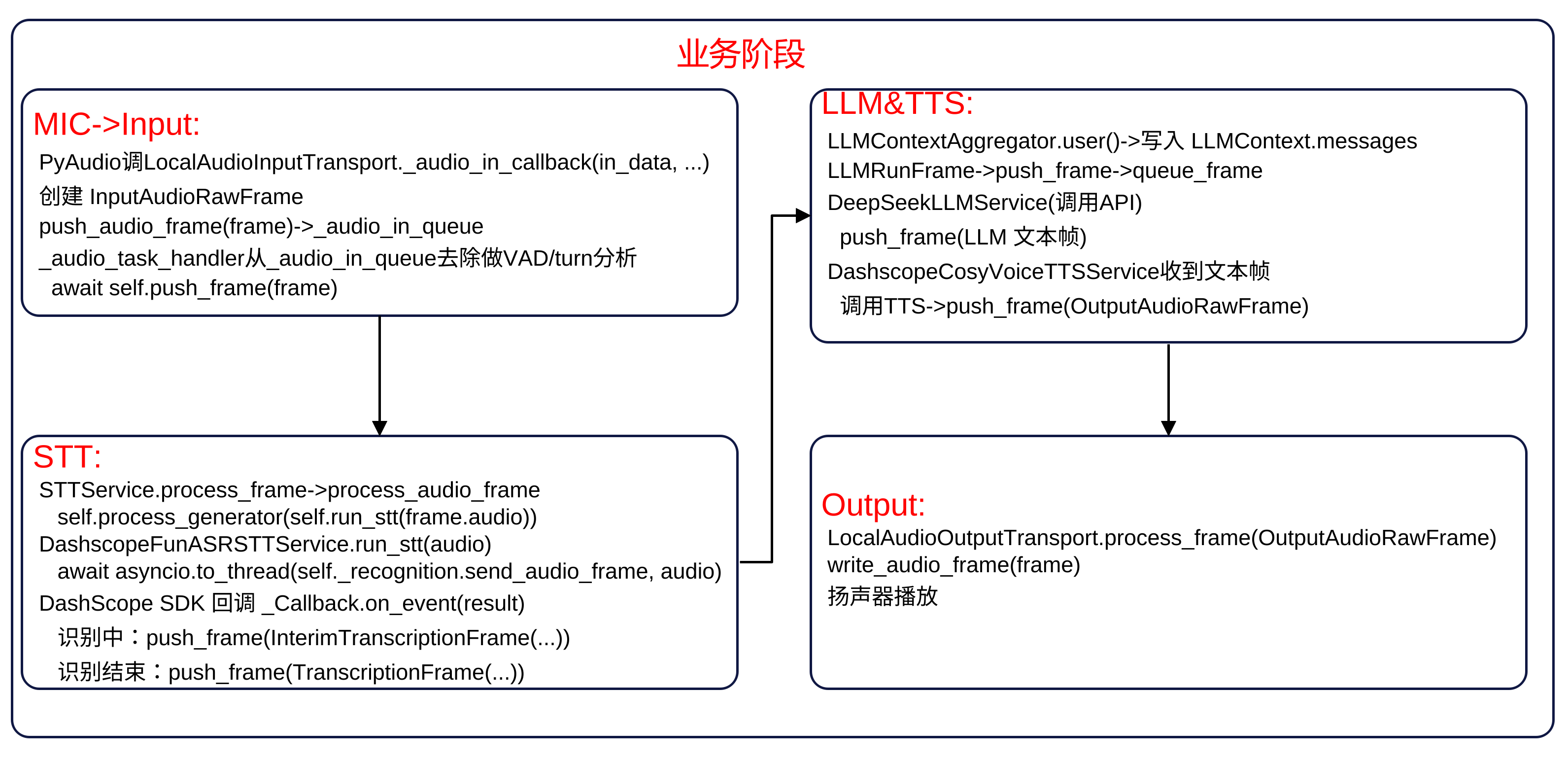
pipecat关键调用流程
业务流 启动阶段 帧处理 -
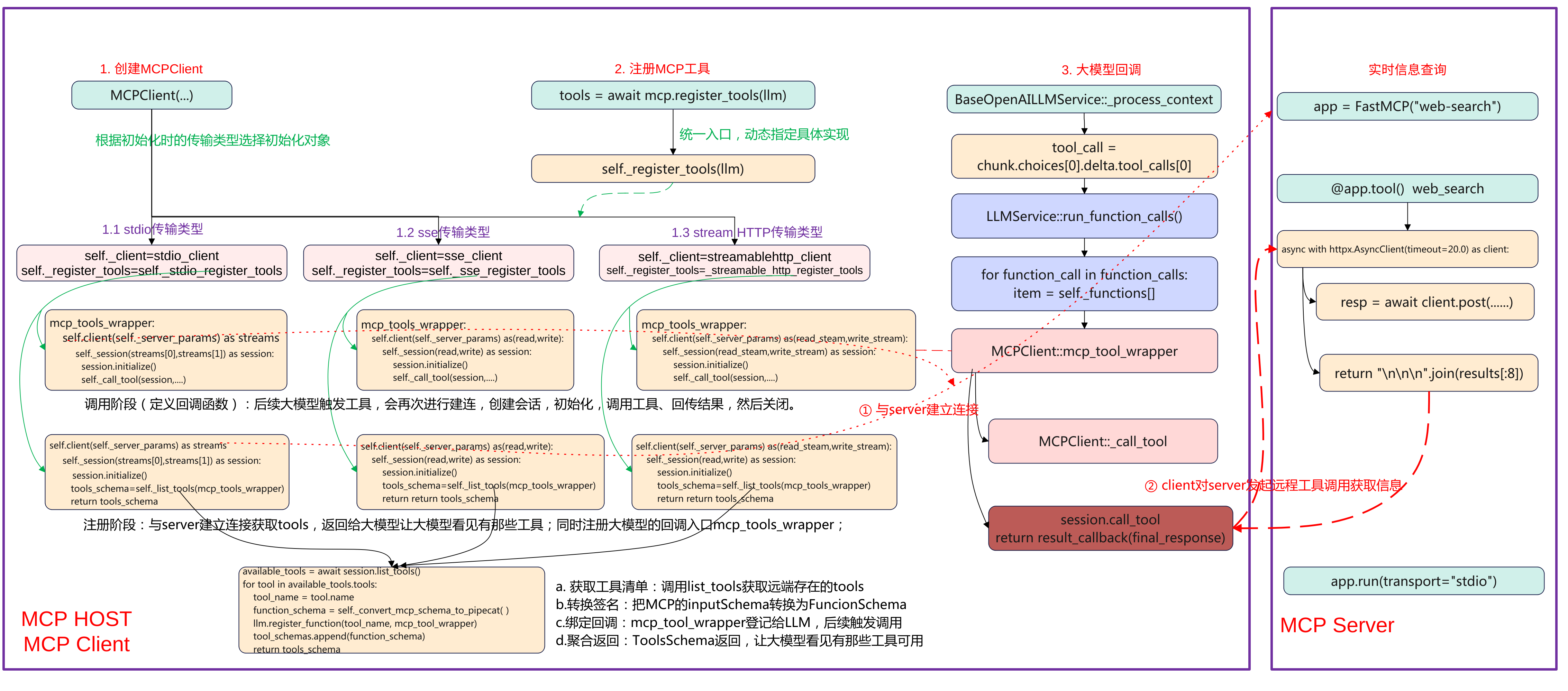
Pipecat MCP 实战流程分析:从 Client 到 Server
简介 本文主要基于Pipecat实现一个MCP stdio传输方式调用的示例。基于智谱Web-Search-Pro实现一个MCP Server,然后在Pipecat应用基础上实现MCP Client,实现可以实时查询天气等功能。通过这个示例来理解pipecat的mcp调用流程。 先上一张完整流程图,本文将重点围绕MCP Host、MCP Client端的创建MCP Client、注册MCP工具、以及大模型回调来展开说明pipecat上MCP的调用流程。 Pipecat MCP client端 下面pipecat应用MCP Host的关键代码: # STT: DashScope FunASR (realtime) stt = DashscopeFunASRSTTService(api_key=os.getenv("DASHSCOPE_API_KEY")) # TTS: DashScope CosyVoice v2 (streaming) tts = DashscopeCosyVoiceTTSService( api_key=os.getenv("DASHSCOPE_API_KEY"), voice="longxiaochun_v2", ) # LLM: Qwen (DashScope OpenAI compatible) llm = QwenLLMService( api_key=os.getenv("DASHSCOPE_API_KEY"), # Mainland China endpoint for OpenAI-compatible API: base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-plus", ) server_script = os.path.join(os.path.dirname(__file__), "mcp", "web_search_mcp.py") mcp = MCPClient( server_params=StdioServerParameters( command=sys.executable, args=[server_script], env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")}, ) ) tools = await mcp.register_tools(llm) system = f""" 你是一个在 WebRTC 通话里的中文助手。 - 回答尽量简洁,必要时可调用 MCP 工具完成查询/检索/图片等任务。 - 输出会被转换为语音,避免使用过多特殊字符。 - 工具调用时少解释过程,直接给出关键结论。 """ messages = [{"role": "system", "content": system}] context = LLMContext(messages, tools) if tools else LLMContext(messages) context_aggregator = LLMContextAggregatorPair(context) pipeline = Pipeline( [ transport.input(), # Transport user input stt, context_aggregator.user(), # User spoken responses llm, # LLM tts, # TTS transport.output(), # Transport bot output context_aggregator.assistant(), # Assistant spoken responses and tool context ] ) task = PipelineTask( pipeline, params=PipelineParams( enable_metrics=True, enable_usage_metrics=True, ), idle_timeout_secs=runner_args.pipeline_idle_timeout_secs, ) (1)语音识别 stt = DashscopeFunASRSTTService(api_key=os.getenv("DASHSCOPE_API_KEY")) 使用了DashScope提供的FunASR实时语音识别服务,输入音频流来自WebRTC,输出为识别的文字,这这是整个pipeline的第一个处理单元。 (2)语音合成 tts = DashscopeCosyVoiceTTSService( api_key=os.getenv("DASHSCOPE_API_KEY"), voice="longxiaochun_v2", ) 使用DataScope的CosyVoice2模型,将LLM输出的文本转为语音,参数Voice为"龙小纯"音色,支持流式输出,边生成边播放。 (3)大语言模型 llm = QwenLLMService( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-plus", ) 使用DashSCcope的Qwen plus模型,其兼容OpenAI接口模式,通过统一的LLMService封装,可以插拔替换,接收来自STT的文字输入,并可调用MCP工具。 (4)MCP工具客户端 mcp = MCPClient( server_params=StdioServerParameters( command=sys.executable, args=[server_script], env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")}, ) ) tools = await mcp.register_tools(llm) MCPClient启动一个外部MCP工具进程web_search_mcp.py,MCP是一个工具协议层,让LLM可以调用外部函数。register_tools会把MCP提供的工具注册进LLM,使其可以向OpenAI Function Call一样调用。例如查询天气、搜索网页、生成图片等。 (5)系统提示词system prompt system = """ 你是一个在 WebRTC 通话里的中文助手。 - 回答尽量简洁,必要时可调用 MCP 工具完成查询/检索/图片等任务。 - 输出会被转换为语音,避免使用过多特殊字符。 - 工具调用时少解释过程,直接给出关键结论。 """ LLMContex保持当前对话上下文、系统提示与工具注册,LLMContextAggregatorPair维护用户与助手的历史消息流(多轮对话记忆),这让语音交互能记住上下文内容,而非每轮都从0开始。 (6)pipeline定义语言交互主流程 pipeline = Pipeline([ transport.input(), # 用户语音输入流 stt, # 语音转文字 context_aggregator.user(),# 更新用户对话上下文 llm, # 调用大模型 tts, # 文本转语音 transport.output(), # 输出音频到客户端 context_aggregator.assistant(), # 保存助手回答上下文 ]) 顺序 模块 输入 输出 1 transport.input() 麦克风语音 音频流 2 stt 音频流 用户文字 3 context_aggregator.user() 用户文字 更新上下文 4 llm 上下文 模型回答文本 5 tts 回答文本 音频流 6 transport.output() 音频流 扬声器播放 7 context_aggregator.assistant() 模型回答 保存为记忆 (7)pipeline任务封装 task = PipelineTask( pipeline, params=PipelineParams( enable_metrics=True, enable_usage_metrics=True, ), idle_timeout_secs=runner_args.pipeline_idle_timeout_secs, ) 封装为可执行任务,支持性能监控与使用统计,可设置空闲超时自动关闭。 MCP Server工具端 (1)导入依赖与初始化 import os, asyncio, sys import httpx from mcp.server import FastMCP app = FastMCP("web-search") FastMCP("web-search") 表示这是一个名为 "web-search" 的 MCP 工具服务,CP 协议使用 JSON-RPC over stdio。httpx是异步HTTP客户端,用于调用外部搜索接口,如果httpx缺失,本地按照pip install httpx。 @app.tool() async def web_search(query: str) -> str: """ 搜索互联网内容 Args: query: 要搜索的内容 Returns: 搜索结果的简要总结 """ _log(f"tool called: web_search(query={repr(query)[:120]})") api_key = os.getenv("BIGMODEL_API_KEY") if not api_key: _log("Missing BIGMODEL_API_KEY") return "Missing BIGMODEL_API_KEY" # Some endpoints accept raw key; others require Bearer. Try raw first to match user sample. headers = {"Authorization": api_key} payload = { "tool": "web-search-pro", "messages": [{"role": "user", "content": query}], "stream": False, } async with httpx.AsyncClient(timeout=20.0) as client: try: _log("sending request to BigModel web-search-pro") resp = await client.post( "https://open.bigmodel.cn/api/paas/v4/tools", headers=headers, json=payload ) _log(f"received response status={resp.status_code}") resp.raise_for_status() data = resp.json() except Exception as e: _log(f"request error: {e}") return f"Web search error: {e}" results = [] try: for choice in data.get("choices", []): message = choice.get("message", {}) for tool_call in message.get("tool_calls", []): for item in tool_call.get("search_result", []) or []: content = item.get("content") if content: results.append(content) except Exception: # Fallback to raw body _log("unexpected response structure; returning raw JSON snippet") return str(data)[:2000] if not results: _log("no results") return "No results." _log(f"returning {len(results)} result chunks") return "\n\n\n".join(results[:8]) 使用@app.tool定义工具的接口,其会注册一个工具到MCP Server,工具名称默认为函数名web_search。最终这个工具会暴露给MCP Client,LLM调用时就像function call一样。 函数中具体的实现是构造一个请求体并调用BigModel API。输入为query表示要查询的内容,最终返回查询到的JSON格式结果,将结果进行解析返回结构类似OpenAI格式。 MCP Client初始化 创建MCPClient类 if StdioServerParameters is None: raise ImportError( "StdioServerParameters not available in your MCP package. " "Upgrade MCP: `pip install -U mcp`." ) server_script = os.path.join(os.path.dirname(__file__), "mcp", "web_search_mcp.py") mcp = MCPClient( server_params=StdioServerParameters( command=sys.executable, args=[server_script], env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")}, ) ) 首先检查StdioServerParameters是否可用,不可用的haul则升级mcp包。接着计算server_script路径,指向FastMCP服务脚本(实现@app.tool)的web_search,构造MCPClient,传入stdio参数,参数如下: command=sys.executable 确保用当前虚拟环境的 Python 启动子进程(依赖一致)。 args=[server_script] 启动该脚本。 env={"BIGMODEL_API_KEY": ...} 把 BigModel 的 API Key 传给子进程(工具内部要用)。 server_script 指向真正提供工具的 MCP 服务器(定义了 @app.tool() 的 web_search)。 MCPClient构造 class MCPClient(BaseObject): def __init__( self, server_params: ServerParameters, **kwargs, ): """Initialize the MCP client with server parameters. Args: server_params: Server connection parameters (stdio or SSE). **kwargs: Additional arguments passed to the parent BaseObject. """ super().__init__(**kwargs) self._server_params = server_params self._session = ClientSession self._needs_alternate_schema = False if isinstance(server_params, StdioServerParameters): self._client = stdio_client self._register_tools = self._stdio_register_tools elif isinstance(server_params, SseServerParameters): self._client = sse_client self._register_tools = self._sse_register_tools elif isinstance(server_params, StreamableHttpParameters): self._client = streamablehttp_client self._register_tools = self._streamable_http_register_tools else: raise TypeError( f"{self} invalid argument type: `server_params` must be either StdioServerParameters, SseServerParameters, or StreamableHttpParameters." ) 构造时“按参数类型选策略”。把同一套“注册逻辑”与不同“传输后端”(stdio/SSE/HTTP)解耦,延后到运行时绑定。具体的关键步骤如下: 保存参数与会话类:self._server_params = server_params:记录连接配置(命令/URL/headers/env 等)。self._session = ClientSession:后续用读写流构建 MCP 会话(initialize/list_tools/call_tool)。self._needs_alternate_schema = False:是否需要“严格 schema 清洗”留给后续判定。 选择传输实现与注册函数:根据传参来选择实际的client和注册函数,选择的类型为MCP的传输类型stdio类型、sse类型、streamhttp类型。 self._client 是“连接工厂”(异步上下文管理器),进入后产出读/写流(stdio 为子进程 stdin/stdout,SSE/HTTP 为对应流)。self._register_tools 是对应后端的“注册流程实现”,register_tools(llm) 会调用它去建连→初始化→列工具→注册“工具名→回调”。 这个设计要点是典型的Strategy + Factory:构造时完成“策略绑定”,后续使用统一入口(register_tools)。 MCP工具注册 mcp = MCPClient( server_params=StdioServerParameters( command=sys.executable, args=[server_script], env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")}, ) ) tools = await mcp.register_tools(llm) 创建完MCPClient对象后,就进行注册tools,调用到MCPClient::register_tools函数。 async def register_tools(self, llm) -> ToolsSchema: """Register all available MCP tools with an LLM service. Connects to the MCP server, discovers available tools, converts their schemas to Pipecat format, and registers them with the LLM service. Args: llm: The Pipecat LLM service to register tools with. Returns: A ToolsSchema containing all successfully registered tools. """ # Check once if the LLM needs alternate strict schema self._needs_alternate_schema = llm and llm.needs_mcp_alternate_schema() tools_schema = await self._register_tools(llm) return tools_schema 统一入口,完成连接MCP——>获取工具列表——>转换schema——>注册到LLM并返回ToolsSchema的过程。 self._needs_alternate_schema:询问当前 LLM 是否需要“严格 schema”兼容(有些 LLM 对 JSON Schema 更严格)。若为 True,后续在 schema 转换时会移除/调整如 additionalProperties 等字段。 tools_schema = await self._register_tools(llm):这里的 _register_tools 是构造函数里根据 server_params 绑定的具体实现(stdio/SSE/HTTP 之一)。内部会实际建连、session.initialize()、session.list_tools()、把每个工具注册为 “工具名 → 回调(mcp_tool_wrapper)”,并组装 ToolsSchema。 ToolsSchema(standard_tools=[FunctionSchema...]),供上层塞进 LLMContext(messages, tools),让大模型“看见”可用工具,同时建立调用时的回调映射。 xxx_register_tools 根据参数传入的类型stdio、sse、streamable_http选择注册的工具,分别会调用如下: stdio类型:调用_stdio_register_tools sse类型:调用_sse_register_tools streamable类型:调用_streamable_http_register_tools 这里以stdio类型为例分析, async def _stdio_register_tools(self, llm) -> ToolsSchema: """Register all available mcp tools with the LLM service. Args: llm: The Pipecat LLM service to register tools with Returns: A ToolsSchema containing all registered tools """ async def mcp_tool_wrapper(params: FunctionCallParams) -> None: """Wrapper for mcp tool calls to match Pipecat's function call interface.""" logger.debug( f"Executing tool '{params.function_name}' with call ID: {params.tool_call_id}" ) logger.trace(f"Tool arguments: {json.dumps(params.arguments, indent=2)}") try: async with self._client(self._server_params) as streams: async with self._session(streams[0], streams[1]) as session: await session.initialize() await self._call_tool( session, params.function_name, params.arguments, params.result_callback ) except Exception as e: error_msg = f"Error calling mcp tool {params.function_name}: {str(e)}" logger.error(error_msg) logger.exception("Full exception details:") await params.result_callback(error_msg) logger.debug("Starting registration of mcp tools") async with self._client(self._server_params) as streams: async with self._session(streams[0], streams[1]) as session: await session.initialize() tools_schema = await self._list_tools(session, mcp_tool_wrapper, llm) return tools_schema (1)定义回调mcp_tool_wrapper(未来执行) 定义回调 mcp_tool_wrapper(未来每次工具调用时执行),这个是要注册进llm大模型的,用于后续大模型触发的回调。具体的步骤如下: 记录日志 → 建立到 MCP 的 stdio 连接:self._client(self._server_params)。 取到读写流 streams[0]/streams[1] → 构建 ClientSession → initialize()。 调用 _call_tool(session, name, args, result_callback) 执行工具;异常则通过 result_callback 把错误文本回传。 (2)注册阶段(当前执行) 再开一次短连接并 initialize() 调用 _list_tools(session, mcp_tool_wrapper, llm),获取远端工具清单,转为 FunctionSchema 并用 llm.register_function(tool_name, mcp_tool_wrapper) 将“工具名→回调”登记到 LLM;聚合为 ToolsSchema 返回。 _list_tools async def _list_tools(self, session, mcp_tool_wrapper, llm): available_tools = await session.list_tools() tool_schemas: List[FunctionSchema] = [] try: logger.debug(f"Found {len(available_tools)} available tools") except: pass for tool in available_tools.tools: tool_name = tool.name logger.debug(f"Processing tool: {tool_name}") logger.debug(f"Tool description: {tool.description}") try: # Convert the schema function_schema = self._convert_mcp_schema_to_pipecat( tool_name, {"description": tool.description, "input_schema": tool.inputSchema}, ) # Register the wrapped function logger.debug(f"Registering function handler for '{tool_name}'") llm.register_function(tool_name, mcp_tool_wrapper) # Add to list of schemas tool_schemas.append(function_schema) logger.debug(f"Successfully registered tool '{tool_name}'") except Exception as e: logger.error(f"Failed to register tool '{tool_name}': {str(e)}") logger.exception("Full exception details:") continue logger.debug(f"Completed registration of {len(tool_schemas)} tools") tools_schema = ToolsSchema(standard_tools=tool_schemas) return tools_schema _list_tools是用当前MCP会话把远端工具同步到LLM,具体的步骤如下: list_tools() 获取远端工具清单。 遍历每个工具,inputSchema 转为 Pipecat 的 FunctionSchema(name/description/properties/required)。 调用 llm.register_function(tool_name, mcp_tool_wrapper) 把“工具名→回调”登记到 LLM(回调负责后续真实调用)。 把 FunctionSchema 累加到列表。 组装 ToolsSchema(standard_tools=...) 返回。 其目的是让大模型“看见”有哪些工具(用于决策),建立从“工具名”到“实际执行逻辑(mcp_tool_wrapper)”的映射,确保 tool_call 能打到 MCP。 大模型工具调用 触发tool_call @traced_llm async def _process_context(self, context: OpenAILLMContext | LLMContext): if chunk.choices[0].delta.tool_calls: tool_call = chunk.choices[0].delta.tool_calls[0] ... if tool_call.function and tool_call.function.name: function_name += tool_call.function.name tool_call_id = tool_call.id if tool_call.function and tool_call.function.arguments: arguments += tool_call.function.arguments 在_process_context中解析,大模型产生tool_call,接着组装函数调用并交给执行器。 function_calls.append( FunctionCallFromLLM(context=context, tool_call_id=tool_id, function_name=function_name, arguments=json.loads(arguments)) ) await self.run_function_calls(function_calls) 查表命中回调 async def run_function_calls(self, function_calls: Sequence[FunctionCallFromLLM]): if function_call.function_name in self._functions.keys(): item = self._functions[function_call.function_name] elif None in self._functions.keys(): item = self._functions[None] 在类LLMService中,LLM层查表命中"工具名-回调"。接着下发"调用进行时"帧并准备结果回调。 progress_frame = FunctionCallInProgressFrame(...) await self.push_frame(progress_frame, FrameDirection.DOWNSTREAM) await self.push_frame(progress_frame, FrameDirection.UPSTREAM) ..... async def function_call_result_callback(result: Any, *, properties: ...): result_frame = FunctionCallResultFrame(..., result=result, ...) await self.push_frame(result_frame, FrameDirection.DOWNSTREAM) await self.push_frame(result_frame, FrameDirection.UPSTREAM) MCP调用 以stdio为例最后触发已注册的回调。 async def _stdio_register_tools(self, llm) -> ToolsSchema: async with self._client(self._server_params) as streams: async with self._session(streams[0], streams[1]) as session: await session.initialize() await self._call_tool(session, params.function_name, params.arguments, params.result_callback) 真正调用MCP工具并聚合结果。 results = await session.call_tool(function_name, arguments=arguments) response = "" if results and hasattr(results, "content"): for i, content in enumerate(results.content): if hasattr(content, "text") and content.text: response += content.text await result_callback(response if response else "Sorry, could not call the mcp tool") -
MCP 协议:AI 应用连接外部系统的标准化接口
简介 什么是MCP MCP是Model Context Protocol模型上下文的一个开源标准,用于连接人工智能应用程序到外部系统。使用MCP,让Claude、ChatGPT这样的AI application可以连接到数据源(例如本地文件、数据库)、工具(例如搜索引擎、计算器)和工作流(例如专业提示),从而能够访问关键信息并执行任务。 可以把MCP类比是AI application的USB-C接口,USB-C为电子设备提供了一种标准化的连接方式,MCP也为Ai application连接到外部系统提供了一种标准化的方式。 具体MCP能够实现什么了? Agents可以访问Google日历和Notion,充当更个性化的AI助手。 Claude code可以使用Figma设计生成整个网络应用程序。 企业聊天机器人可以连接到组织内部的多个数据库,使用户能够通过聊天分析数据。 AI模型可以在Blendoer中创建3D设计,并使用3D打印机将其打印出来。 MCP为什么重要? 根据生态系统的位置不同,MCP可以带来一些列的好处。 开发者:MCP在构建或集成AI应用程序或代理是,可以减少开发时间和复杂性。 AI应用或智能体:MCP提供对数据源、工具和应用程序系统的访问,这将增强能力并改善最终用户体验。 最终用户:MCP导致更强大的AI应用或智能体,它们可以访问您的数据并在必要时代表您采取行动。 MCP架构 模型上下文包括以下项目: MCP 规范:概述客户端和服务器实现要求的MCP规范。 MCP SDKs:实现MCP不同的编程语言SDK。 MCP开发工具:用于开发MCP服务器和客户端的工具。 MCP参考服务器实现:MCP服务端的参考代码。 MCP的概念 Participants参与者 MCP遵循客户端-服务端架构,其中MCP Host(如Claude Code或Claude Desktop等AI应用)建立与一个或多个MCP服务器的链接。MCP Host通过为每个MCP server创建一个MCP Client来实现这一点。每个MCP Client与其对一个的MCP Server保持一对一的专用连接。 在MCP架构中,关键参与者可以分为如下: MCP Host:协调和管理一个或多个MCP Client的AI应用。 MCP Client:一个维护与MCP Server连接的组件,并从MCP 服务器获取上下文供MCP主机使用。 MCP Server:一个想MCP 客户端提供上下文的程序。 下面来举个例子,Visual studio Code作为MCP Host。当Visual Studio Code与MCP Server建立连接时,Visual Studio Code运行时会实例化一个MCP Client对象,该对象维护与Sentry MCP服务的连接。当Visual Studio Code随后连接到另一个MCP Server时,Visual Studio Code运行时会实例化另一个MCP Client对象以维护此连接,从而保持MCP客户端与MCP服务器的一对一关系。 需要注意的是,MCP server指的是提供上下文数据的程序,无论他运行在哪里。MCP服务器可以子啊本地或远程运行。例如,当Claude桌面启动文件系统服务器时,服务器在同一个机器上本地运行,因为他使用STDIO传输。这通常被成为本地MCP server,而官方Sentry MCP服务器在Sentry平台运行,并使用Streamable HTTP传输,这通常被称为远程MCP服务器。 MCP的层次 MCP有两层组成: data layer:定义JSION-RPC的客户端-服务端通信协议,包括生命周期管理,以及核心原语,如工具、资源、提示和通知。 transport layer:定义使客户端和服务器之间能够进行数据交换的通信机制和通道,包括特定于传输的连接建立、信息帧和授权。 从概念上将,数据层是内层,而传输层是外层。 Data layer 数据层实现了一个基于JSON-RPC 2.0的交互协议,该协议定义了消息结构和语义。该层包括。 Lifecycle management:处理客户端和服务器之间的连接初始化、能力协商和连接终止。 Server features:使服务器能够提供核心功能,包括用于AI操作的工具、用于上下文数据的资源以及从客户端接收和发送交互。 Client features:使服务器能够请求客户端从主机LLM采样、从用户获取输入以及向客户端记录消息。 Utility features:支持实时更新通知和长时间运行操作的进度跟踪等附加功能。 Transport layer 传输层管理客户端和服务器之间的通信通道和身份验证,它处理连接建立、消息帧处理以及MCP参与之间的安全通信。 MCP 支持两种传输机制: stdio transport:使用标准输入/输出流,在本地同一台机器上的进程之间进行直接进程通信,提供最佳性能且无网络开销。 Streamable HTTP transport: 使用HTTP POST传输客户端到服务器的消息,并可选的使用服务器发送事件(Server-Sent Events)实现流式传输功能。这种传输方式支持远程服务器通信,并支持标准HTTP认证方法,包括令牌、API密钥和自定义头信息。 传输层将通信细节抽象化,与协议层分离,使得 JSON-RPC 2.0 消息格式在所有传输机制中保持一致。 Data Layer Protocol MCP的核心部分之一是定义MCP client与MCP server之间的模式和语义。开发者可以会发现数据层特别是基本数据类型集合,这是MCP中最有趣的部分。他是定义开发者如何从MCP服务器共享上下文到MCP客户端的部分。 MCP 使用JSION-RPC 2.0作为其底层的RPC协议,客户端和服务器相互发送请求并做出相应的会议,当无需响应时,可以使用通知。 MCP定义了服务器可以公开的3个核心基本概念: Tools:AI应用程序可以调用执行操作的可执行函数(例如,文件操作、API调用、数据库查询) Rresources:为AI应用程序提供上下文信息的数据源(例如,文件内容、数据库记录、API响应) Prompts:可重复使用的模版,有助于构建与语言模型交互(例如系统提示、少量样本示例) 每种原始类型都有与之关联的发现方法(/list)、检索方法(/get),在某些情况下还有执行方法(tools/call)。在MCP客户端将使用*/list方法发现可用的原始类型。例如,客户端可以先列出所有可用的工具(tools/list),然后执行他们。 MCP还定义了客户端可以公开的原语,这些原语允许MCP服务器构建更丰富的交互。 Sampling:采样,允许server从client的ai应用程序请求语音模型补全,当server希望访问语言模型,但希望保持模型独立且不在其MCP server中包含语音模型SDK时,这很有用。他们可以使用sampling/comlete方法从客户端的AI应用程序请求语音模型补全。 Elicitation:提取,允许server从用户哪里请求额外信息,当server希望从用户获取更多信息,或请求确认某个操作时,这很有用,使用elicitation/request方法从用户哪里请求额外信息。 logging:日志记录,允许server向client发送日志信息,用于调试和监控目的。 Notifications该协议支持实时通知,以实现server与client之间的动态更新,例如,当server可用工具发生变化是,比如新功能可用或现有工具被修改,服务器可以向连接的客户端发送工具更新通知,告知这些变化,通知以JSON-RPC 2.0通知消息的形式发送,并使用MCP server能够向连接的client提供实时更新。 协议交互Example 初始化(生命周期管理) MCP通过能力协商握手开始生命周期管理,如生命周期管理部分所述,客户端发送initialize请求以建立连接并协商支持的功能。 initialize request { "jsonrpc": "2.0", "id": 1, "method": "initialize", "params": { "protocolVersion": "2025-06-18", "capabilities": { "elicitation": {} }, "clientInfo": { "name": "example-client", "version": "1.0.0" } } } initialize response { "jsonrpc": "2.0", "id": 1, "result": { "protocolVersion": "2025-06-18", "capabilities": { "tools": { "listChanged": true }, "resources": {} }, "serverInfo": { "name": "example-server", "version": "1.0.0" } } } 这段是典型的JSON-RPC协议交互过程,用于客户端和服务端建立连接时的初始化握手。客户端发送initialize方法,服务端results回复确定版本和返回支持的功能。初始化过程是MCP生命周期管理的关键部分,其服务有几个目的: 协议版本协商:protocolVersion字段确保客户端和服务端使用兼容的协议版本,可以防止不同版本尝试交互是可能发生通信错误,如果未能协商出相互兼容的版本,则应该终止连接。 能力发现:capabilities对象允许每一方声明他们支持的功能,包括他们可以处理的基元(工具、资源、提示)以及是否支持通知等特性。通过避免不支持的操作来实现高效通信。 身份交换:clientInfo和serverInfo对象提供用于调试和兼容性目的的识别和版本信息。 上面的示例中能力协商展示了如何声明MCP原语: 客户端的功能 "elicitation": {} - 客户端声明可以处理用户交互请求(可以接收 elicitation/create 方法调用) 服务端的功能: "tools": {"listChanged": true} - 服务器支持工具原语,并且在其工具列表发生变化时可以发送 tools/list_changed 通知 "resources": {} - 服务器也支持资源原语(可以处理 resources/list 和 resources/read 方法) 最后初始化成功后,客户端再发送同志表示已准备就绪 { "jsonrpc": "2.0", "method": "notifications/initialized" } 在初始化过程中,AI application的MCP client管理器连接到server后,并将它们的能力存储起来以供后续使用。应用程序使用这些信息来确定那些server可以提供特定类型的功能(tools、resource、prompts),以及它们是否支持实时更新。下面是AI application初始化伪代码。 # Pseudo Code async with stdio_client(server_config) as (read, write): async with ClientSession(read, write) as session: init_response = await session.initialize() if init_response.capabilities.tools: app.register_mcp_server(session, supports_tools=True) app.set_server_ready(session) 工具发现 连接建立成功后,client可以通过发送tools/list请求发现可用的工具。这个请求是MCP工具发现机制的基础,他允许client在尝试使用工具之前了解server有那些可用的工具。 工具列表请求: { "jsonrpc": "2.0", "id": 2, "method": "tools/list" } 工具列表请求很简单,tools/list的方法,不包含任何参数。 工具列表回复 { "jsonrpc": "2.0", "id": 2, "result": { "tools": [ { "name": "calculator_arithmetic", "title": "Calculator", "description": "Perform mathematical calculations including basic arithmetic, trigonometric functions, and algebraic operations", "inputSchema": { "type": "object", "properties": { "expression": { "type": "string", "description": "Mathematical expression to evaluate (e.g., '2 + 3 * 4', 'sin(30)', 'sqrt(16)')" } }, "required": ["expression"] } }, { "name": "weather_current", "title": "Weather Information", "description": "Get current weather information for any location worldwide", "inputSchema": { "type": "object", "properties": { "location": { "type": "string", "description": "City name, address, or coordinates (latitude,longitude)" }, "units": { "type": "string", "enum": ["metric", "imperial", "kelvin"], "description": "Temperature units to use in response", "default": "metric" } }, "required": ["location"] } } ] } } 响应包含一个tools数组,该数组提供了关于每个可用的工具全面元数据。这种基于数组的结构允许服务端同时暴露多个工具,同时保持不同功能之间的清晰界限。 响应中给每个工具对象包含几个关键字段: name: 服务器命名空间内工具的唯一标识符。这作为工具执行的主键,应遵循清晰的命名模式(例如, calculator_arithmetic 而不是仅仅 calculate )。 title : 客户端可以向用户展示的工具的可读显示名称。 description : 该工具的作用是什么以及何时使用它的详细说明。 inputSchema : 一个 JSON Schema,定义了预期的输入参数,支持类型验证并提供关于必需和可选参数的清晰文档。 inputSchema是描述tool需要的输入参数的规范,告诉LLM参数叫什么、类型是什么,有那些枚举、那些字段是必填,是否有默认值。结构如下: inputSchema └── type: object ← 输入是一个对象 └── properties ← 参数的列表(有那些参数) ├── expression ← 参数1,不要被expression迷惑只是一个参数的命名。 └── location ← 参数2 └── units ← 参数3 └── required ← 哪些字段必须提供 AI application从所有连接的MCP server获取可用的tools,并将它们组合成一个语言模型可以访问的统一工具注册表。这使得LLM能够了解他可以执行那些操作,并在对话期间自动生成相应的工具调用。下面是python tools发现的伪代码。 # Pseudo-code using MCP Python SDK patterns available_tools = [] for session in app.mcp_server_sessions(): tools_response = await session.list_tools() available_tools.extend(tools_response.tools) conversation.register_available_tools(available_tools) 工具执行 客户端现在可以使用tools/call的方法执行一个tool,这展示了MCP 原语在实际中的使用方式:在发现可用工具后,客户端可以用适当的参数调用它们。 理解工具执行的请求 tools/call请求遵循结构化格式,确保客户端和服务端之间的类型安全和清晰通信,请注意,我们使用的是发现响应中的正确工具名称,而不是简化名称。 工具调用请求: { "jsonrpc": "2.0", "id": 3, "method": "tools/call", "params": { "name": "weather_current", "arguments": { "location": "San Francisco", "units": "imperial" } } } 请求结构包含几个重要的组件: name:必须与发现响应中的工具名称( weather_current )完全匹配。这确保服务器能够正确识别要执行哪个工具。 arguments : 包含工具的 inputSchema 定义的输入参数。 JSON-RPC 结构:使用标准的 JSON-RPC 2.0 格式,并使用独特的 id 进行请求-响应关联。 工具调用响应: { "jsonrpc": "2.0", "id": 3, "result": { "content": [ { "type": "text", "text": "Current weather in San Francisco: 68°F, partly cloudy with light winds from the west at 8 mph. Humidity: 65%" } ] } } content 数组:工具响应返回一个内容对象数组,允许进行丰富、多格式的响应(文本、图像、资源等)。 Content Types:每个内容对象都有一个 type 字段。在这个例子中, "type": "text" 表示纯文本内容,但 MCP 支持多种内容类型以适应不同的使用场景。 Structured Output:结构化输出,该响应提供可操作的资讯,供 AI 应用作为语言模型交互的上下文使用。 当语言模型在对话中决定使用工具时,AI application会拦截工具调用,将其路由到适当的MCP服务器执行该调用,并将结果作为对话流程的一部分返回给LLM。这使LLM能够访问实时数据并在外部世界执行操作。下面是工具调用的是示例操作: # Pseudo-code for AI application tool execution async def handle_tool_call(conversation, tool_name, arguments): session = app.find_mcp_session_for_tool(tool_name) result = await session.call_tool(tool_name, arguments) conversation.add_tool_result(result.content) 实时更新 MCP支持实时通知,使server能够在未被明确请求的情况下通知客户端有关变更,这展示了通知系统,这是一个关键特性,它使MCP连接保持同步和响应。 当服务器的可用tool发生变化时,例如新功能可用、现有工具被修改或工具暂时不可用,服务端可以主动通知连接的客户端。 { "jsonrpc": "2.0", "method": "notifications/tools/list_changed" } notifications有关键的特性 No Response Required: 请注意通知中没有 id 字段。这遵循 JSON-RPC 2.0 通知的语义,即不期望或发送响应。 Capability-Based:此通知仅由在初始化期间(如步骤 1 所示)在其工具能力中声明了 "listChanged": true 的服务器发送。 Event-Driven:服务器根据内部状态变化决定何时发送通知,使 MCP 连接动态且响应迅速。 客户端收到notification后,客户端通常会通过请求更新的工具列表做出反应,这会形成一个刷新周期,使客户端对可用工具的理解保持最新: { "jsonrpc": "2.0", "id": 4, "method": "tools/list" } 当ai application收到关于tools变更的通知时,它会理解刷新其工具注册表并更新LLM的可用功能。这确保了正在进行的对话始终能够访问最新的一套工具,并LLM可以随着新功能的可用而动态适应。 # Pseudo-code for AI application notification handling async def handle_tools_changed_notification(session): tools_response = await session.list_tools() app.update_available_tools(session, tools_response.tools) if app.conversation.is_active(): app.conversation.notify_llm_of_new_capabilities() MCP Server MCP Server是通过标准协议接口向AI applicant提供功能的应用程序,常见例子包括文档访问的文件系统服务器、用于数据查询的数据库服务器、用于代码管理的Github服务器、用于团队沟通的slack服务器以及用于日程安排的日历服务器。 服务器通过3个构建模块提供功能: tools:LLM可以主动调用的功能,并根据用户请求决定何时使用它们。工具可以写入数据库、调用外部API、修改文件或触发其他逻辑。比如搜索航班、发送消息、创建日历事件。由模型来控制。 resources:提供只读访问权限以获取上下文信息的被动数据源,例如文件内容、数据库模式或API文档。比如检索文档、访问知识库、读取日历等。由application来控制。 prompts:预构建的指令模版,告诉模型如何使用特定的工具和资源。比如计划假期、总结我的会议、起草一封电子邮件等。由用户来控制。 下面假设一个场景来展示每个工具的作用,并介绍如何协同工作。 tools 工具使AI模型能够执行操作,每个tool定义了具有类型输入和输出的特定操作,模型根据上下文请求工具执行。 (1)tools如何工作的 具体的工作原理是LLMs可以调用的模式定义接口,MCP使用JSON Schema进行验证。每个工具执行一个具有明确定义的输入和输出的单一操作。tools在执行前可能需要用户同意,这有助于确保用户对模型采取的操作保持控制。 协议的操作: tools/list: 目的是发现可用工具,返回的是包含模式定义的工具数组。 tools/call:目的是执行特定的工具,返回的是工具执行的结果。 下面是示例工具的定义: { name: "searchFlights", description: "Search for available flights", inputSchema: { type: "object", properties: { origin: { type: "string", description: "Departure city" }, destination: { type: "string", description: "Arrival city" }, date: { type: "string", format: "date", description: "Travel date" } }, required: ["origin", "destination", "date"] } } (2)示例:旅行预定 tools使ai applicantion能够udaibiao用户执行操作,在旅行规划场景中,AI应用程序可能会使用多个工具来帮助预定假期。 航班的搜索:查询多个航班公司并返回结构化的航班选型。 searchFlights(origin: "NYC", destination: "Barcelona", date: "2024-06-15") 日历的阻止:在用户的日历中标记旅行日期。 createCalendarEvent(title: "Barcelona Trip", startDate: "2024-06-15", endDate: "2024-06-22") 邮件的通知:向同事发送自动的离境邮件。 sendEmail(to: "team@work.com", subject: "Out of Office", body: "...") (3)用户交互模型 工具由模型控制,这意味着AI模型可以自动的发型和调用它们。然而,MCP通过多种机制强调人工监督。 为了信任和安全,应用程序可以通过各种机制实现用户控制,例如: 在 UI 中显示可用工具,使用户能够定义工具是否应在特定交互中可用 单个工具执行的审批对话框 预先批准某些安全操作的权限设置 显示所有工具执行及其结果的活动日志 resources 资源为AI应用程序提供结构化访问信息,这些信息可以被应用程序检索并提供给模型作为上下文。 (1)resources如何工作的 资源从文件、API、数据库或其他AI需要理解上下文的任何来源中暴露数据。应用程序可以直接访问这些信息并决定如何使用它,无论是选择相关的部分、使用嵌入进行搜索,还是将所有信息传递给模型。 每个资源都有一个唯一的URI(例如, file:///path/to/document.md),并声明其MIME类型以进行适当的内容处理。 resources支持两种发现模式: Direct Resources: 指向特定数据的固定 URI。示例: calendar://events/2024 - 返回 2024 年的日历可用性。 Resource Templates:带参数的动态 URI,用于灵活查询。 资源模板包含标题、描述和预期 MIME 类型等元数据,使其可发现且自描述。下面是协议操作: resources/list:目的是列出可用的直接资源,返回的是资源描述符数组。 resources/templates/list:目的是发现资源的模版,返回的是资源模版定义数组。 resources/read:目的是获取资源内容,返回的是带元数据的资源数据。 resources/subscribe:目的是监控资源变化,返回的是订阅确认。 (2)示例:获取旅行规划上下文 继续以旅行规划为例,resources为AI application提供访问相关信息的方式: Calendar data:calendar://events/2024,日历数据,检查用户可用性。 Travel documents :file:///Documents/Travel/passport.pdf,访问重要文件。 Previous itineraries:trips://history/barcelona-2023,参考过去的旅行和偏好。 AI应用检索这些资源,并决定如何处理它们,无论是使用嵌入或关键词搜索选择数据子集,还是将原始数据直接传递给模型。在这种情况下,它向模型提供日历数据、天气信息和旅行偏好,使模型能够检查可用性、查询天气模式并参考过去的旅行偏好。 下面是resource模版示例: { "uriTemplate": "weather://forecast/{city}/{date}", "name": "weather-forecast", "title": "Weather Forecast", "description": "Get weather forecast for any city and date", "mimeType": "application/json" } { "uriTemplate": "travel://flights/{origin}/{destination}", "name": "flight-search", "title": "Flight Search", "description": "Search available flights between cities", "mimeType": "application/json" } 这些模版支持灵活的查询,对于天气数据,用户可以访问任何城市/日期组合的预报。对于航班,它们可以搜索任意两个机场之间的航线。当用户输入NYC作为origin机场,并开始输入Bar作为destination机场时,系统可以建议BCN或BGI。 (3)用户交互模型 resources有营养程序驱动,使其在获取、处理和呈现可用上下文方面具有灵活性,常见的交互模式包括: 用于在熟悉的类似文件夹的结构中浏览资源的树形或列表视图。 用于查找特定资源的搜索和筛选界面 基于启发式或 AI 选择的自动上下文包含或智能建议 用于包含单个或多个资源的手动或批量选择界面 Prompts 提示提供可重用的模版,它们允许MCP服务器为特定领域提供参数化提示,或展示如何最佳使用MCP服务器。 (1)Prompts如何工作的 提示是定义预期输入和交互模式的结构化模版。它们由用户控制,需要显示调用而非自动触发。提示可以感知上下文,引用可用的资源和工具来创建全面的流程。下面是协议的操作: prompts/list:目的是发现可用提示,返回的是提示描述符数组。 prompts/get:目的是检索提示详情,返回的是带参数的完整提示定义。 (2)示例 提示为场景任务提供结构化的模版。 { "name": "plan-vacation", "title": "Plan a vacation", "description": "Guide through vacation planning process", "arguments": [ { "name": "destination", "type": "string", "required": true }, { "name": "duration", "type": "number", "description": "days" }, { "name": "budget", "type": "number", "required": false }, { "name": "interests", "type": "array", "items": { "type": "string" } } ] } MCP Client MCP client由主机应用程序实例化,用于与特定的MCP server进行通信。主机应用程序,如claude.ai或集成开发环境IDE,管理整体用户体验并协调多个客户端。每个客户端负责与一个server进行直接通信。host是用户交互的应用程序,而client是使能server连接的协议级组件。 除了利用server提供上下文外,client还可以向server提供多种功能。这些client功能使server开发能够构建更丰富的交互。 sampling:采样允许server通过client请求LLM补全,从实现代理式工作流程。这种方法将用户权限和安全措施完全至于客户端的控制之下。比如一个用于预定旅行的服务器可以向LLM发送航班列表,并请求LLM为用户挑选最佳航班。 Roots:Roots允许客户端指定服务器应关注的目录,通过协调机制传达预期的范围。比如一个用于预定旅行的服务器可能会被授予特定目录的权限,从中可以读取用户的日历。 Elicitaion:交互式信息提取使服务器能够在交互过程中请求的特定信息,为服务器按需收集信息提供了一种结构化的方式。比如预定旅行的服务器可能会询问用户对飞机座位、房间类型或联系方式的偏好。 Elicitaion 交互式信息提取使server能够在交互过程中请求特定信息,创建更动态和响应迅速的工作流程。 (1)概述 Elicitaion提供了一种结构化的方式,让server按需收集必要信息。server不再需要一开始就获取所有信息或在数据缺失时失败,而是可以暂停操作,向用户请求特定的输入。者创造了更灵活的交互方式,server能够根据用户需求进行调整,而不是遵循僵化的模式。下面提取的流程: 该流程支持动态信息收集,server在需要时可以请求特定的数据,用户通过合适的界面提供信息,server则继续使用新获取的上下文进行后续处理。 (2)示例 提取组件的示例如下: { method: "elicitation/requestInput", params: { message: "Please confirm your Barcelona vacation booking details:", schema: { type: "object", properties: { confirmBooking: { type: "boolean", description: "Confirm the booking (Flights + Hotel = $3,000)" }, seatPreference: { type: "string", enum: ["window", "aisle", "no preference"], description: "Preferred seat type for flights" }, roomType: { type: "string", enum: ["sea view", "city view", "garden view"], description: "Preferred room type at hotel" }, travelInsurance: { type: "boolean", default: false, description: "Add travel insurance ($150)" } }, required: ["confirmBooking"] } } } Roots roots定义服务器操作的文件系统边界,允许客户端指定服务器应关注的目录。 roots是client向server传到文件系统访问边界的机制,它们由指示服务器可以操作的目录文件URI组成,帮助server理解可用文件和文件夹的范围。虽然roots传到了预期的边界,但他们并不强制执行安全显示。实际的安全必须在操作系统级别通过文件权限或沙盒机制来强制执行。 下面是roots结构 { "uri": "file:///Users/agent/travel-planning", "name": "Travel Planning Workspace" } roots是专有的文件系统路径,始终使用file:// 的URL方案,它们帮助server理解项目边界、工作空间组织和可访问的目录。根列表可以根据用户在不同项目或文件夹中工作动态更新,当边界发生变化时,服务器通过roots/list_changed接收通知。 sampling 采样允许server通过client请求语言模型补全,在保持安全性和用户控制的同时,实现代理行为。 采样使server能够在不直接继承或支付AI模型费用的情况下执行依赖AI的任务。相反,服务器可以请求已经具有AI模型访问权限的客户代表它们处理这些任务。这种方法将用户权限和安全措施完全置于客户控制之下。由于采样请求发生在其他操作的上下文中,并且作为单独的模型调用进行处理,它们在不同上下文之间保持清晰的界限,从而能够更有效地使用上下文窗口。 该流程通过多个人工审核环境确保安全性。用户可以在响应返回server之前,审查并修改初始请求和生成的响应。 { messages: [ { role: "user", content: "Analyze these flight options and recommend the best choice:\n" + "[47 flights with prices, times, airlines, and layovers]\n" + "User preferences: morning departure, max 1 layover" } ], modelPreferences: { hints: [{ name: "claude-sonnet-4-20250514" // Suggested model }], costPriority: 0.3, // Less concerned about API cost speedPriority: 0.2, // Can wait for thorough analysis intelligencePriority: 0.9 // Need complex trade-off evaluation }, systemPrompt: "You are a travel expert helping users find the best flights based on their preferences", maxTokens: 1500 } 本文主要来自官方文档的翻译:https://modelcontextprotocol.io/docs/getting-started/intro -
lekiwi录制训练推理流程实践
录制 设备端 先确定一下相机编号 cd ~/lerobot/ lerobot-find-cameras 生成路径:outputs/captured_images 然后修改uart的权限 sudo chmod 666 /dev/ttyACM0 启动等待连接 python -m lerobot.robots.lekiwi.lekiwi_host \ --robot.id=R1225280 \ --robot.cameras='{ "front": {"type":"opencv","index_or_path":"/dev/video2","width":640,"height":480,"fps":30}, "wrist": {"type":"opencv","index_or_path":"/dev/video0","width":480,"height":640,"fps":30,"rotation":"ROTATE_90"} }' \ --host.connection_time_s=300 如果分辨率跑不上去,就让相机用motion-JPEG传输帧,很多UVC相机默认YUYV在640x480只能到25fps。 python -m lerobot.robots.lekiwi.lekiwi_host \ --robot.id=R1225280 \ --robot.cameras='{ "front": {"type":"opencv","index_or_path":"/dev/video2","width":640,"height":480,"fps":30,"fourcc":"MJPG"}, "wrist": {"type":"opencv","index_or_path":"/dev/video0","width":480,"height":640,"fps":30,"rotation":"ROTATE_90","fourcc":"MJPG"} }' \ --host.connection_time_s=300 遥控端 启动前,需要配置一下,主要修改lekiwi/record.py。 主臂型号SO101:将SO100修改为SO101型号。 网络配置remote_ip:配置连接设备的ip地址,remote_ip:LeKiwi机器人主机的IP地址。id:机器人实例标识符。 机械臂配置port:配置领航臂的串口和标定参数文件,port="/dev/ttyACM0", id="R07252801"。 数据集路径HF_REPO_ID:配置录制数据集上传到的Hugging Face仓库,格式为用户名/仓库名,会存储到~/.cache/xxx路径下。 任务配置:配置采集回合数NUM_EPISODES,每个回合的时间EPISODE_TIME_SEC(单位秒),重置环境时间RESET_TIME_SEC(秒),任务描述信息TASK_DESCRIPTION。录制帧率FPS。 diff --git a/examples/lekiwi/record.py b/examples/lekiwi/record.py --- a/examples/lekiwi/record.py +++ b/examples/lekiwi/record.py -from lerobot.teleoperators.so100_leader import SO100Leader, SO100LeaderConfig +from lerobot.teleoperators.so101_leader import SO101Leader, SO101LeaderConfig EPISODE_TIME_SEC = 30 RESET_TIME_SEC = 10 TASK_DESCRIPTION = "My task description" -HF_REPO_ID = "<hf_username>/<dataset_repo_id>" +HF_REPO_ID = "laumy/lekiwi" -robot_config = LeKiwiClientConfig(remote_ip="172.18.134.136", id="lekiwi") -leader_arm_config = SO100LeaderConfig(port="/dev/tty.usbmodem585A0077581", id="my_awesome_leader_arm") +robot_config = LeKiwiClientConfig(remote_ip="10.0.90.31", id="lekiwi") +leader_arm_config = SO101LeaderConfig(port="/dev/ttyACM0", id="R07252801") keyboard_config = KeyboardTeleopConfig() -leader_arm = SO100Leader(leader_arm_config) +leader_arm = SO101Leader(leader_arm_config) 配置好后启动脚本进行采集数据,采集完成后数据存储在~/.cache/huggingface/lerobot/laumy/lekiwi/ python examples/lekiwi/record.py 训练 lerobot-train \ --dataset.repo_id=laumy/lekiwi \ --policy.type=act \ --output_dir=outputs/train/act_lekiwi_test \ --job_name=act_lekiwi_test \ --policy.device=cpu \ --policy.push_to_hub=false \ --wandb.enable=false \ --batch_size=8 --steps=10000 --policy.push_to_hub=false:训练的模型是否上传hugging face。 --policy.repo_id=your_username/your_model_name:指定推送的路径名称。 --wandb.enable=false:是否启用Weights & Biases (W&B) 实验跟踪。 推理 设备端 python -m lerobot.robots.lekiwi.lekiwi_host \ --robot.id=R1225280 \ --robot.cameras='{ "front": {"type":"opencv","index_or_path":"/dev/video2","width":640,"height":480,"fps":30,"fourcc":"MJPG"}, "wrist": {"type":"opencv","index_or_path":"/dev/video0","width":480,"height":640,"fps":30,"rotation":"ROTATE_90","fourcc":"MJPG"} }' \ --host.connection_time_s=300 PC端 启动前先修改配置,这里跟record.py修改差不多。 模型路径HF_MODEL_ID:如果不是本地目录则尝试从hugging face上下载。 数据集路径HF_DATASET_ID:推理还需要数据集主要是用于输入数据的归一化和策略输出反归一化。 设备remote_ip:配置设备端的ip地址。 index 4501008d..f508d448 100644 --- a/examples/lekiwi/evaluate.py +++ b/examples/lekiwi/evaluate.py @@ -29,12 +29,12 @@ from lerobot.utils.visualization_utils import init_rerun NUM_EPISODES = 2 FPS = 30 EPISODE_TIME_SEC = 60 -TASK_DESCRIPTION = "My task description" -HF_MODEL_ID = "<hf_username>/<model_repo_id>" -HF_DATASET_ID = "<hf_username>/<eval_dataset_repo_id>" +TASK_DESCRIPTION = "Move to grab block" +HF_MODEL_ID = "output/act" +HF_DATASET_ID = "laumy/lekiwi" # Create the robot configuration & robot -robot_config = LeKiwiClientConfig(remote_ip="172.18.134.136", id="lekiwi") +robot_config = LeKiwiClientConfig(remote_ip="10.0.90.31", id="lekiwi") 改完之后启动运行 python examples/lekiwi/evaluate.py -
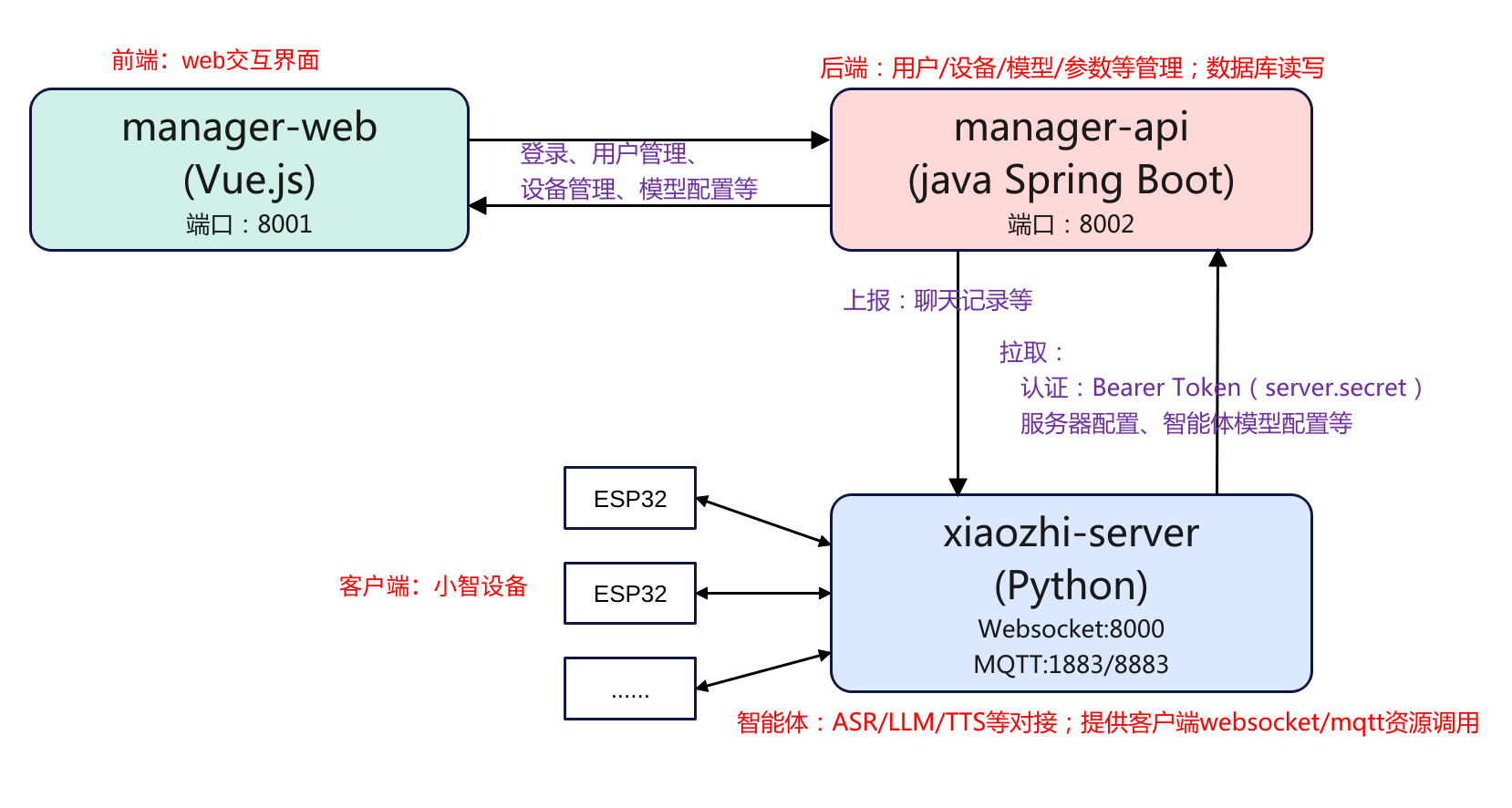
ubuntu系统xiaozhi server本地部署
简介 本文主要是记录在ubuntu系统从零源码的方式本地部署小智Ai服务端的过程,项目的地址为:xiaozhi-server。在部署之前简单了解一下其项目框架,这里总结可以分为3部分:manager-web、manager-api、xiaozhi-server,这3部分的运行是互相独立的,相互之间通过http rest api的方式进行访问,如下图: manager-web: 前端控制台(Vue)。管理员用浏览器操作;调用后端接口,不直接连设备。 manager-api: 后端管理服务(Java Spring Boot)。负责用户/设备/模型/参数/OTA/激活等业务,对外提供 REST API;对数据库(MySQL)与缓存(Redis)读写。 xiaozhi-server: 实时语音与智能体服务(Python)。负责 WebSocket 连接、ASR/LLM/TTS、工具/视觉接口;启动时向 manager-api 拉取配置、运行时上报对话。 3个组件分别使用了不用的语言环境,其中manager-web使用的是Vue.js,而manager-api使用的是java spring boot,xiaozhi-server使用的是python。因此需要装3个不同的语言环境。同时对于后端manager-api需要对数据进行存储,因此还需要安装mysql、redis。下面就围绕这3部分进行展开。 先在本地拉取一份代码: git clone https://github.com/xinnan-tech/xiaozhi-esp32-server.git 值得注意的时,xiaozhi server最简化版本安装,只需要安装xiaozhi-server即可,简化版部署见后续章节。 manager-api安装 数据库安装 由于后端的数据管理需要用到数据库,因此需要安装mysql、redis。 (1)mysql安装 # 安装MySQL sudo apt update sudo apt install -y mysql-server # 启动MySQL服务 sudo systemctl start mysql sudo systemctl enable mysql # 创建数据库 sudo mysql -e "CREATE DATABASE xiaozhi_esp32_server CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;" # 创建用户并指定认证方式(关键改动) sudo mysql -e "CREATE USER 'xiaozhi'@'localhost' IDENTIFIED WITH mysql_native_password BY 'xiaozhi123';" # 授权 sudo mysql -e "GRANT ALL PRIVILEGES ON xiaozhi_esp32_server.* TO 'xiaozhi'@'localhost';" sudo mysql -e "FLUSH PRIVILEGES;" mysql数据库安装后,同时也创建了用户和密码,分别是xiaozhi和xiaozhi123,这个后续需要填充到manaer-api的配置文件中,以便manager-api可以访问。 (2)安装Redis # 安装Redis sudo apt install -y redis-server # 启动Redis服务 sudo systemctl start redis-server sudo systemctl enable redis-server # 检查Redis状态 redis-cli ping Spring boot环境安装 因为后端程序manager-api使用的是java spring boot,因此需要安装java的运行环境。官方提示安装JDK21和Maven,前者是java的运行环境,后者是java项目管理工具。 # 安装JDK 21 sudo apt install -y openjdk-21-jdk # 设置JAVA_HOME环境变量 echo 'export JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64' >> ~/.bashrc echo 'export PATH=$JAVA_HOME/bin:$PATH' >> ~/.bashrc source ~/.bashrc # 验证Java安装 java -version # 安装Maven sudo apt install -y maven # 验证Maven安装 mvn -version 配置数据库 数据库和java环境安装好后,就可以配置java spring boot与数据库的连接了。 在xiaozhi-esp32-server/main/manager-api/src/main/resources/application-dev.yml中配置数据库连接信息 @@ -13,8 +13,8 @@ spring: #MySQL driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/xiaozhi_esp32_server?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true - username: root - password: 123456 + username: xiaozhi + password: xiaozhi123 initial-size: 10 max-active: 100 min-idle: 10 在xiaozhi-esp32-server/main/src/main/resources/application-dev.yml中配置Redis连接信息(redis默认配置好了,不用改) spring: data: redis: host: localhost port: 6379 password: database: 0 编译运行 配置好对数据库的连接后,就可以进行编译了。 # 进入manager-api目录 cd xiaozhi-esp32-server/main/manager-api # 编译项目 mvn clean package -DskipTests # 编译完成后的jar包位置 ls -lh target/*.jar 编译完成之后,就可以运行项目了。 java -jar target/xiaozhi-esp32-api.jar --spring.profiles.active=dev 运行如果没有什么报错就说明启动成功了。 manager-web安装 安装node.js 由于前端使用的的是vue.js,所以需要安装node.js环境。 # 安装Node.js 20 curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash - sudo apt install -y nodejs # 验证Node.js安装 node -v npm -v 安装依赖 node.js环境安装好后,就可以安装manager-web的依赖了。 # 进入manager-web目录 cd xiaozhi-esp32-server/main/manager-web # 安装依赖 npm install 启动 切换到manager-web路径下,就可以运行服务程序了。 cd xiaozhi-esp32-server/main/manager-web npm run serve 启动成功之后,就可以访问后台了。登陆地址:http://127.0.0.1:8001,登陆后进行注册一个用户就可以进入到后台进行配置了。 配置模型api key 要让设备能够访问,需要配置模型的api key,登陆到智普的后台,注册获取一个api key。 这里使用的是智谱ai,注册一个账户,然后申请一个api key 然后登陆智控台配置密钥。 xiaozhi-server安装 conda python环境 # 下载并安装miniconda wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh bash Miniconda3-latest-Linux-x86_64.sh -b -p $HOME/miniconda3 # 初始化conda $HOME/miniconda3/bin/conda init bash source ~/.bashrc # 创建Python环境 conda remove -n xiaozhi-esp32-server --all -y conda create -n xiaozhi-esp32-server python=3.10 -y # 激活环境 conda activate xiaozhi-esp32-server # 添加清华源 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge # 安装必要的系统库 conda install -y libopus ffmpeg libiconv python依赖包 # 进入xiaozhi-server目录 cd xiaozhi-esp32-server/main/xiaozhi-server # 设置pip镜像源 pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ # 安装Python依赖 pip install -r requirements.txt 下载语音模型 # 进入models目录 cd xiaozhi-esp32-server/main/xiaozhi-server/models # 下载模型文件(推荐阿里云镜像) cd SenseVoiceSmall wget https://modelscope.cn/models/iic/SenseVoiceSmall/resolve/master/model.pt # 验证文件 ls -lh model.pt 配置密钥 配置密钥主要是xiaozhi-server与manager-api交互时需要进行认证,因此需要先获取密钥。 (1)先在本地创建配置文件 # 创建data目录 cd xiaozhi-esp32-server/main/xiaozhi-server mkdir -p data # 复制配置文件 cp config_from_api.yaml data/.config.yaml # 编辑配置文件 vim data/.config.yaml 配置.config.yaml: manager-api: url: http://127.0.0.1:8002/xiaozhi secret: 待会从智控台获取 server: websocket: ws://你的IP:8000/xiaozhi/v1/ (2)然后登陆智控台获取密钥 访问智控台:http://127.0.0.1:8001 注册账号(第一个为超级管理员) 登录 → 参数管理 → 找到 server.secret 并复制 回到xiaozhi-server配置: vim xiaozhi-esp32-server/main/xiaozhi-server/data/.config.yaml 设置为 manager-api: url: http://127.0.0.1:8002/xiaozhi secret: 你刚才复制的server.secret值 启动服务 cd xiaozhi-esp32-server/main/xiaozhi-server conda activate xiaozhi-esp32-server python app.py 执行成功的话应该是下面这样 (xiaozhi-esp32-server) liumingyuan@HP-ProBook:~/xiaozhi-esp32-server/main/xiaozhi-server$ python app.py 从API读取配置 251029 20:47:34[0.8.5-00000000000000][core.providers.vad.silero]-INFO-SileroVAD 251029 20:47:34[0.8.5-00000000000000][core.utils.modules_initialize]-INFO-初始化组件: vad成功 VAD_SileroVAD 251029 20:47:38[0.8.5-00000000000000][core.providers.asr.fun_local]-INFO-funasr version: 1.2.3. 251029 20:47:38[0.8.5-00000000000000][core.utils.modules_initialize]-INFO-ASR模块初始化完成 251029 20:47:38[0.8.5-00000000000000][core.utils.modules_initialize]-INFO-初始化组件: asr成功 ASR_FunASR 251029 20:47:38[0.8.5-00000000000000][__main__]-INFO-视觉分析接口是 http://10.0.90.104:8003/mcp/vision/explain 251029 20:47:38[0.8.5-00000000000000][__main__]-INFO-Websocket地址是 ws://10.0.90.104:8000/xiaozhi/v1/ 251029 20:47:38[0.8.5-00000000000000][__main__]-INFO-=======上面的地址是websocket协议地址,请勿用浏览器访问======= 251029 20:47:38[0.8.5-00000000000000][__main__]-INFO-如想测试websocket请用谷歌浏览器打开test目录下的test_page.html 251029 20:47:38[0.8.5-00000000000000][__main__]-INFO-============================================================= 服务访问地址: 智控台:http://127.0.0.1:8001 API文档:http://127.0.0.1:8002/xiaozhi/doc.html WebSocket:ws://127.0.0.1:8000/xiaozhi/v1/ OTA接口:http://127.0.0.1:8002/xiaozhi/ota/ 配置websocket和OTA 由于是全模块部署,所以需要登陆智能控台,设置ota和websocket的接口,需要注意的是weboscket的启动必须是要等xiaozhi-server app启动才能设置。 OTA接口:http://你电脑局域网的ip:8002/xiaozhi/ota/ Websocket接口:ws://你电脑局域网的ip:8000/xiaozhi/v1/ 请你务必把以上两个接口地址写入到智控台中:他们将会影响websocket地址发放和自动升级功能。 1、使用超级管理员账号,登录智控台,在顶部菜单找到参数管理,找到参数编码是server.websocket,输入你的Websocket接口。 2、使用超级管理员账号,登录智控台,在顶部菜单找到参数管理,找到数编码是server.ota,输入你的OTA接口。 简化部署 所谓简化部署就是只跑xiaozhi-server,前后端都不跑。简化部署先参考"xiaozhi-server安装"章节,然后再次基础上进行配置文件即可。与完整部署xiaozhi-server部分唯一的区别就是配置文件不一样。如果要对接前后端使用的默认文件是config_from_api.yaml而如果是简化部署使用的默认文件是config.yaml。 下面是配置步骤。 cd xiaozhi-esp32-server/main/xiaozhi-server/data cp .config.yaml .config.yaml_back #对云端的配置作个备份 cp ../config.yaml .config.yaml #拷贝默认的配置 设置API key 测试 本地服务搭建好好后可以进行测试验证,可以使用xiaozhi-server自带的test程序,也可以使用开源的客户端py-xiaozhi,或者直接搭建esp32的设备接入。这里先用前面两者方式。 xiaozhi-server test cd xiaozhi-esp32-server/main/xiaozhi-server/test python -m http.server 8006 然后网页登陆:http://localhost:8006/test_page.html py-xiaozhi git clone https://github.com/huangjunsen0406/py-xiaozhi.git sudo apt-get update && sudo apt-get install -y portaudio19-dev libportaudio2 conda create -n py-xiaozhi-client python=3.10 conda activate py-xiaozhi-client 配置完成之后就可以执行应用获取到设备验证码之后,登陆绑定即可进行对话。 python main.py --protocol websocket -

Lekiwi驱动链路分析
系统架构 硬件组成 Lekiwi是一个底盘+机械臂的结构。 机械臂: 6个自由度(shoulder_pan, shoulder_lift, elbow_flex, wrist_flex, wrist_roll, gripper) 移动底盘:3个全向轮,三轮全向移动(left_wheel, back_wheel, right_wheel) github官网Lekiwi使用 Koch v1.1 机械臂、U2D2 电机控制器和 Dynamixel XL430 电机作为移动基座。我这里买到的使用的是feetech电机,机械臂和底盘一共9个motor接入到一个串口总线上,对于机械臂和底盘移动只需要通过一个串口总线进行。 软件架构 我这里将软件架构分为3层。 应用层:对设备的操作,实例化设备一个设备后,对设备进行连接,移动控制,观测数据获取。 总线层:实现一个MotorBus基类,对设备的一些操作进行统一定义、约束。实现操作的逻辑,具体的实现由继承设备来实现。 设备层:具体设备的实现,继承与MotorBus,实现对电机底层通信接口。 感觉这个框架不是很合理,主要的框架设计是设备层继承总线层的基类,继承相当于是扩展,应用层没有起到屏蔽设备的作用。在应用层要创建一个设备实例如self.bus = FeetechMotorsBus(),而FeetechMotorsBus继承MotorsBus,应用层直接操作FeetechMotorsBus实例,没有达到屏蔽底层的效果。可以完全借鉴Linux设备驱动模型,分为设备、总线、驱动(应用),设备注册后,总线负责匹配设备和驱动,完全隔离,不用关系底层的设备是什么。 驱动链路 初始化 class LeKiwi(Robot): config_class = LeKiwiConfig name = "lekiwi" def __init__(self, config: LeKiwiConfig): super().__init__(config) self.config = config norm_mode_body = MotorNormMode.DEGREES if config.use_degrees else MotorNormMode.RANGE_M100_100 self.bus = FeetechMotorsBus( port=self.config.port, motors={ # arm "arm_shoulder_pan": Motor(1, "sts3215", norm_mode_body), "arm_shoulder_lift": Motor(2, "sts3215", norm_mode_body), "arm_elbow_flex": Motor(3, "sts3215", norm_mode_body), "arm_wrist_flex": Motor(4, "sts3215", norm_mode_body), "arm_wrist_roll": Motor(5, "sts3215", norm_mode_body), "arm_gripper": Motor(6, "sts3215", MotorNormMode.RANGE_0_100), # base "base_left_wheel": Motor(7, "sts3215", MotorNormMode.RANGE_M100_100), "base_back_wheel": Motor(8, "sts3215", MotorNormMode.RANGE_M100_100), "base_right_wheel": Motor(9, "sts3215", MotorNormMode.RANGE_M100_100), }, calibration=self.calibration, ) self.arm_motors = [motor for motor in self.bus.motors if motor.startswith("arm")] self.base_motors = [motor for motor in self.bus.motors if motor.startswith("base")] self.cameras = make_cameras_from_configs(config.cameras) 继承Robot,指定了配置类为LeKiwiConfig其定义了uart的端口、相机的编号等信息。将角度统一归一化到[-100,100],创建Feetech电机总线实例,创建Feetech电机型号sts3215,配置了机械臂电机ID为1至6,底盘编号为7至9编号。同时对相机也进行了初始化,用于后续的视觉观测。 连接 robot.connect()————> def connect(self, calibrate: bool = True) -> None: if self.is_connected: raise DeviceAlreadyConnectedError(f"{self} already connected") self.bus.connect() if not self.is_calibrated and calibrate: logger.info( "Mismatch between calibration values in the motor and the calibration file or no calibration file found" ) self.calibrate() for cam in self.cameras.values(): cam.connect() self.configure() logger.info(f"{self} connected.") 初始化完成之后即可进行发起连接,连接主要是根据指定的串口好进行打开,然后进行握手验证,ping所有配置的电机,检查校准文件与电机的状态,并设置PID、加速度等参数。 校准 def calibrate(self) -> None: if self.calibration: # Calibration file exists, ask user whether to use it or run new calibration user_input = input( f"Press ENTER to use provided calibration file associated with the id {self.id}, or type 'c' and press ENTER to run calibration: " ) if user_input.strip().lower() != "c": logger.info(f"Writing calibration file associated with the id {self.id} to the motors") self.bus.write_calibration(self.calibration) return logger.info(f"\nRunning calibration of {self}") motors = self.arm_motors + self.base_motors self.bus.disable_torque(self.arm_motors) for name in self.arm_motors: self.bus.write("Operating_Mode", name, OperatingMode.POSITION.value) input("Move robot to the middle of its range of motion and press ENTER....") homing_offsets = self.bus.set_half_turn_homings(self.arm_motors) homing_offsets.update(dict.fromkeys(self.base_motors, 0)) full_turn_motor = [ motor for motor in motors if any(keyword in motor for keyword in ["wheel", "wrist_roll"]) ] unknown_range_motors = [motor for motor in motors if motor not in full_turn_motor] print( f"Move all arm joints except '{full_turn_motor}' sequentially through their " "entire ranges of motion.\nRecording positions. Press ENTER to stop..." ) range_mins, range_maxes = self.bus.record_ranges_of_motion(unknown_range_motors) for name in full_turn_motor: range_mins[name] = 0 range_maxes[name] = 4095 self.calibration = {} for name, motor in self.bus.motors.items(): self.calibration[name] = MotorCalibration( id=motor.id, drive_mode=0, homing_offset=homing_offsets[name], range_min=range_mins[name], range_max=range_maxes[name], ) self.bus.write_calibration(self.calibration) self._save_calibration() print("Calibration saved to", self.calibration_fpath) 首次校准,从归零到测量范围,生成并保存文件流程,后续使用按回车复用已有校准;输入 'c' 重新校准。可以总结为如下: LeKiwi.calibrate() → 用户选择(使用已有/重新校准) → 归零设置 → 运动范围测量 → 校准参数构建 → FeetechMotorsBus.write_calibration() → MotorsBus.write_calibration() → 逐个写入电机寄存器 校准主要是限定几个参数,如归零偏移、运动范围、驱动模式。校准的流程是由用户选择使用已经有的校准文件直接写入校准还是进行重新启动校准流程校准。 动作执行 def send_action(self, action: dict[str, Any]) -> dict[str, Any]: if not self.is_connected: raise DeviceNotConnectedError(f"{self} is not connected.") arm_goal_pos = {k: v for k, v in action.items() if k.endswith(".pos")} base_goal_vel = {k: v for k, v in action.items() if k.endswith(".vel")} base_wheel_goal_vel = self._body_to_wheel_raw( base_goal_vel["x.vel"], base_goal_vel["y.vel"], base_goal_vel["theta.vel"] ) # Cap goal position when too far away from present position. # /!\ Slower fps expected due to reading from the follower. if self.config.max_relative_target is not None: present_pos = self.bus.sync_read("Present_Position", self.arm_motors) goal_present_pos = {key: (g_pos, present_pos[key]) for key, g_pos in arm_goal_pos.items()} arm_safe_goal_pos = ensure_safe_goal_position(goal_present_pos, self.config.max_relative_target) arm_goal_pos = arm_safe_goal_pos # Send goal position to the actuators arm_goal_pos_raw = {k.replace(".pos", ""): v for k, v in arm_goal_pos.items()} self.bus.sync_write("Goal_Position", arm_goal_pos_raw) self.bus.sync_write("Goal_Velocity", base_wheel_goal_vel) return {**arm_goal_pos, **base_goal_vel} 输入为动作的序列,输出为实际发送的动作。首先将机械臂(后缀.pos)目标位置和底盘目标速度(后缀.vel)进行分离,如下: # 分离前 action = { "arm_shoulder_pan.pos": 45.0, # 机械臂位置 "arm_elbow_flex.pos": -30.0, "x.vel": 0.1, # 底盘速度 "y.vel": 0.0, "theta.vel": 0.05 } # 分离后 arm_goal_pos = { "arm_shoulder_pan.pos": 45.0, "arm_elbow_flex.pos": -30.0 } base_goal_vel = { "x.vel": 0.1, "y.vel": 0.0, "theta.vel": 0.05 } 然后调用_body_to_wheel_raw进行底盘运动学转换,输入为底盘坐标系速度 (x, y, θ),输出为三轮电机速度指令。转换的时候需要进行安全限制,实际获取机械臂的关节位置,然后计算步幅(目标位置-当前位置),超过max_relative_target 则裁剪使用安全的目标位置。 最后就是调用sync_write分别写入控制机械臂和底盘。下面总结一下流程: LeKiwi.send_action(action) → 动作分离(机械臂位置 + 底盘速度) → 底盘运动学转换 → 安全限制检查 → FeetechMotorsBus.sync_write() → MotorsBus._sync_write() → 批量写入电机寄存器 对Lekiwi的控制,由于底盘是3个万向轮,所以需要进行运动学转换,现将机械臂和底盘进行分离,计算之处底盘坐标系转换的3轮速度,在确保安全限制的条件下,调用sync_write进行写入,sync_write是同时写入多个电机。 状态读取 def get_observation(self) -> dict[str, Any]: if not self.is_connected: raise DeviceNotConnectedError(f"{self} is not connected.") # Read actuators position for arm and vel for base start = time.perf_counter() arm_pos = self.bus.sync_read("Present_Position", self.arm_motors) base_wheel_vel = self.bus.sync_read("Present_Velocity", self.base_motors) base_vel = self._wheel_raw_to_body( base_wheel_vel["base_left_wheel"], base_wheel_vel["base_back_wheel"], base_wheel_vel["base_right_wheel"], ) arm_state = {f"{k}.pos": v for k, v in arm_pos.items()} obs_dict = {**arm_state, **base_vel} dt_ms = (time.perf_counter() - start) * 1e3 logger.debug(f"{self} read state: {dt_ms:.1f}ms") # Capture images from cameras for cam_key, cam in self.cameras.items(): start = time.perf_counter() obs_dict[cam_key] = cam.async_read() dt_ms = (time.perf_counter() - start) * 1e3 logger.debug(f"{self} read {cam_key}: {dt_ms:.1f}ms") return obs_dict 首先调用sync_read分别读取机械臂位置和底盘的当前速度,然后调用底盘速度逆运动学转换(三轮电机->底盘坐标系速度(x, y, θ)),接着将机械臂位置和底盘转换的坐标系速度整合,再次就是对相机图像的待机,先遍历所有配置相机,将图像的数据添加到观测字段,最终再进行整合得到观测字典。 obs_dict = { # 机械臂位置 "arm_shoulder_pan.pos": 45.2, "arm_shoulder_lift.pos": -12.8, # ... 其他关节 # 底盘速度 "x.vel": 0.15, "y.vel": -0.08, "theta.vel": 0.12, # 相机图像 "camera_1": numpy_array, # (H, W, 3) "camera_2": numpy_array, # (H, W, 3) } 下面是总结流程 LeKiwi.get_observation() → FeetechMotorsBus.sync_read() → MotorsBus._sync_read() → 批量读取电机状态 → 底盘速度逆运动学 → 相机图像采集 获取状态与动作执行相反,首先读取到电机的状态,然后通过逆运动学,将底盘的速度转换为坐标系。 -

lekiwi+Orin Nano环境搭建
环境准备 简要记录在Orin nano平台搭建lekiwi环境,可以远程遥控底盘移动和机械臂示教的过程,需要的硬件如下: - NVIDIA Jetson Orin Nano开发板 - Lekiwi套件(底盘、主从机械臂) - PC,预装好Ubuntu系统 组装硬件 将底盘、主从机械臂、Orin nano组装好,需要注意的是由于官方默认使用的计算平台是树莓派,所以默认提供的供电接口是USB 5V。我们这里使用的Orin Nano平台,使用的是DC5525电源接口,因此需要提前购买准备DC5521 to DC5525的转接线。 详细组装可以参考 (1)https://github.com/SIGRobotics-UIUC/LeKiwi/blob/main/Assembly.md (2)https://huggingface.co/docs/lerobot/so101#step-by-step-assembly-instructions Orin nano 首先,首次启动先接上键盘、鼠标、显示器登录配置好网络和VNC。 sudo apt update sudo apt install vino # 设置vino开机自启 mkdir -p ~/.config/autostart cp /usr/share/applications/vino-server.desktop ~/.config/autostart/. cd /usr/lib/systemd/user/graphical-session.target.wants sudo ln -s ../vino-server.service ./. # 调整共享/认证设置 gsettings set org.gnome.Vino prompt-enabled false gsettings set org.gnome.Vino require-encryption false # 设置密码,默认thepassword gsettings set org.gnome.Vino authentication-methods "['vnc']" gsettings set org.gnome.Vino vnc-password $(echo -n 'thepassword'|base64) # 然后重启就可以使用VNC viewer访问了 sudo reboot 其次,安装conda 环境,由于Jetson架构是aarch64,所以下载miniconda aarch64的版本。 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh sh Miniconda3-latest-Linux-x86_64.sh source ~/.bashrc PC ubunut 同理安装conda环境,与jetson不一样的是,PC是X86架构。 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh sh Miniconda3-latest-Linux-x86_64.sh source ~/.bashrc 软件安装 代码下载 在Orin nano和PC ubuntu上各自从github上克隆开源代码。 git clone https://github.com/huggingface/lerobot.git 配置安装 首先,在Orin nano和PC ubuntu上各自创建lekiwi的环境。 conda create -n lekiwi python=3.10 conda activate lekiwi 其次,切到lerobot环境下进行安装 cd lerobot pip install -e ".[feetech]" conda install -c conda-forge ffmpeg=7.1.1 遥操作 标定 需要给主臂、从臂进行标定,以限制关节的最大运动范围。在标定前,可以先看看视频怎么操作机械臂https://huggingface.co/docs/lerobot/so101#calibrate (1)从臂的运行命令如下 lerobot-calibrate \ --robot.type=lekiwi \ --robot.id=R1225280 \ --robot.cameras='{handeye: {type: opencv, index_or_path: 0, width: 640, height: 360, fps: 30}}' 标定的文件 (2)主臂的运行命令如下: lerobot-calibrate \ --teleop.type=so101_leader \ --teleop.port=/dev/ttyACM0 \ --teleop.id=R07252801 (3)标定好后会在下面路径存储标定的参数 # orin nano平台 ~/.cache/huggingface/lerobot/calibration/robots/lekiwi/R1225280.json # ubuntu平台 ~/.cache/huggingface/lerobot/calibration/teleoperators/so101_leader/R07252801.json 遥控 (1)由于PC和lekiwi之前的遥控使用的是gRPC,所以需要先安装zmq,否则会报错。 pip install zmq (2)orin nano启动命令,host.connection_time_s设置的是时间(单位是秒),超过这个时间会自动断开。 python -m lerobot.robots.lekiwi.lekiwi_host \ --robot.id=R1225280 \ --robot.cameras='{handeye: {type: opencv, index_or_path: 0, width: 640, height: 360, fps: 30}}' \ --host.connection_time_s=300 (3)PC ubuntu需要修改示例代码,修改点如下: diff --git a/examples/lekiwi/teleoperate.py b/examples/lekiwi/teleoperate.py index 6b430df4..cb4ad415 100644 --- a/examples/lekiwi/teleoperate.py +++ b/examples/lekiwi/teleoperate.py @@ -18,20 +18,20 @@ import time from lerobot.robots.lekiwi import LeKiwiClient, LeKiwiClientConfig from lerobot.teleoperators.keyboard.teleop_keyboard import KeyboardTeleop, KeyboardTeleopConfig -from lerobot.teleoperators.so100_leader import SO100Leader, SO100LeaderConfig +from lerobot.teleoperators.so101_leader import SO101Leader, SO101LeaderConfig from lerobot.utils.robot_utils import busy_wait from lerobot.utils.visualization_utils import init_rerun, log_rerun_data FPS = 30 # Create the robot and teleoperator configurations -robot_config = LeKiwiClientConfig(remote_ip="172.18.134.136", id="my_lekiwi") -teleop_arm_config = SO100LeaderConfig(port="/dev/tty.usbmodem585A0077581", id="my_awesome_leader_arm") +robot_config = LeKiwiClientConfig(remote_ip="192.168.0.33", id="my_lekiwi") +teleop_arm_config = SO101LeaderConfig(port="/dev/ttyACM0", id="R07252801") keyboard_config = KeyboardTeleopConfig(id="my_laptop_keyboard") # Initialize the robot and teleoperator robot = LeKiwiClient(robot_config) -leader_arm = SO100Leader(teleop_arm_config) +leader_arm = SO101Leader(teleop_arm_config) keyboard = KeyboardTeleop(keyboard_config) 将SO100改成SO101,因为我们的主臂使用的是SO101 将remote_ip改成jetson nano的ip 配置好SO101的uart端口和标定的文件 (4)PC ubunut执行命令 python examples/lekiwi/teleoperate.py 之后就可以使用键盘和主臂进行遥控操作了。 Key Action W 前进 S 后退 A 左移 D 右移 Z 左转(逆时针) X 右转(顺时针) R 加速一档 F 减速一档 -
Jetson Orin Nano环境搭建
安装浏览器 sudo apt update sudo apt install chromium-browser -y 安装后发现点击浏览器会没反应。按照下面方法配置。 snap download snapd --revision=24724 sudo snap ack snapd_24724.assert sudo snap install snapd_24724.snap sudo sudo snap refresh --hold snapd 配置VNC sudo apt update sudo apt install vino 然后配置 步骤1: 设置开机自启 对于 LXDE 桌面(例如 2 GB 版本的 Jetson Nano) mkdir -p ~/.config/autostart cp /usr/share/applications/vino-server.desktop ~/.config/autostart/. 对于 GNOME 桌面: cd /usr/lib/systemd/user/graphical-session.target.wants sudo ln -s ../vino-server.service ./. 步骤2:调整共享/认证设置 gsettings set org.gnome.Vino prompt-enabled false gsettings set org.gnome.Vino require-encryption false 步骤3:然后设置密码 # Replace thepassword with your desired password gsettings set org.gnome.Vino authentication-methods "['vnc']" gsettings set org.gnome.Vino vnc-password $(echo -n 'thepassword'|base64) 上面登录密码设置的是thepassword 步骤4: Reboot the system so that the settings take effect sudo reboot SSH ssh user@ip 输入密码就可以登录进去了。 conda环境 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh sh Miniconda3-latest-Linux-x86_64.sh source ~/.bashrc 注意这里是aarch64 -

为什么AlphaGo能自学围棋?强化学习基本概念
强化学习简介 什么是强化学习 以直升机控制飞行的程序来举例。 自动驾驶的直升机配备了机载计算机、GPS、加速度计、陀螺仪和磁罗盘,我们可以实时确定的知道直升机的位置。如何使用强化学习来让直升机飞行了? 在强化学习中,将直升机的位置、方向和速度等称为状态s,因此我们的目标或任务就是从直升机的状态映射到动作a的函数,意思是将两根控制杆推多远才能保持直升机在空中平衡、飞行而不坠毁。 要获取到动作a可以使用监督学习来训练神经网络,直接学习从x(状态a)到y(动作a)的映射,但事实证明直升机在控制移动时实际上时摸棱两可的,不好判断正确的行动是什么?是向做倾斜一点还是倾斜很多,还是稍微增加直升机的压力?要获得x的数据集和理想的动作y实际上是很困难的。因此对于控制直升机和其他机器人的许多任务,监督学习方法效果不佳,我们改用强化学习。 强化学习的关键输入称为reward(奖励),它告诉直升机何时表现良好,何时表现不佳。强化学习就像是在训练狗,你不知道狗会做出什么行为?但是我们可以判断狗行为的好坏,如果狗的行为是好的我们就就认为他是一个好狗给予奖励,如果它做出的行为不达我们的预期我们认为就是一个坏狗给予惩罚。我们期望它能自己学会如何做出好的动作行为而少做坏的动作行为。 火星探测器 火星探测器从初始状态运动到最终状态(terminal state),最终会得到一个累计的分数(return),每运动一次都会有相应的奖励reward。 当前火星探测器的初始位置在state 4,它可以向左也可以向右。 场景1:state 4(初始)(获得0)->state 3(获得0)->state 2(获得0)->state 1(获得100);最终得100。 场景2:state 4(初始)(获得0)->state 5(获得0)->state 6(获得40);最终得40。 场景3:state 4(初始)(获得0)->state 4(获得0)->state 4(获得0)->state 3(获得0)->state 2(获得0)->state 1(获得100);最终得100。 在每个时间步长上,机器人处于某种状态,我们称为S,它开始选择一个动作a,然后就获得一些奖励(reward),奖励值它从该状态获取,同时了它会切换为一个新的状态S’。公示表示为$(s,a,R(s),s')$,举个具体的例子,机器人处于状态4并采取行动时往左边走没有获得奖励(4,<-,0,3)。核心点就是状态(state)、动作(action)、奖励(reward)、下一个状态(next state),基本上就是每采取新动时都会发生情况,这就是强化学习算法要决定如何采取行动考虑的核心要素。 回报return 采取的行动会经历不同的状态以及如何享受不同的奖励,但是怎么去衡量一组特定的奖励比另外一组奖励好还是差了? 打个比方炒股方案1是你今天买入一支股票A然后后天就卖出了赚了1000块,而方案2你今天买入一支股票但是后天你亏了500,但是到第三天你赚了6000,那你更愿意追求那种方案了?虽然是第三天才显示有收益,但是第三天收益很高,显然会选择方案2。 为了计算这个回报分数,我们对动作后的奖励进行累加,但是了随着越往后的动作,我们需要添加一个折扣因子,也就是说越往前的比例系数越高,但是越往后所占的比例折扣就越大。如上图假设折扣因子(discount factor)为0.9,那么R1的折扣因子是1,R2的折扣因子就是0.9,R3的折扣因子就是0.9的平方依此类推。 最终获得的回报(return)取决于奖励(reward),而奖励取决于你采取的行动,因此回报取决于你采取的行动。 如折扣因子是0.5,如果从状态5向左走回报是6.25,如果是状态4向左走回报是12.5,而如果你状态就在6那么回报就是60。 总结一下强化学习的回报是系统获得的奖励总和,但需要加上折扣系数,每一个时间步的权重不一样,时间步越大奖励的系数结果就越小。 Policy 在强化学习中,可以通过很多不同的方式采取行动,比如我们可以决定始终选择更接近的奖励,如果最左边的奖励更接近则向左走,如果最右边的奖励更接近则向右走。当然我们也可以换种策略,始终追求更大的奖励等等。 策略Pi就是希望我们在那种状态下采取什么样的行动。state———>action。强化学习的目标就是要找到一个策略Pi,告诉在什么状态应该采取什么行动,执行每个状态以最大化回报。 小结 上面涉及到的概念,状态、动作、奖励、折扣因子、回报、策略。强化学习的目标就是让策略选择一个好的行动以获取最大的回报,这个决策过程被称为马尔可夫决策过程(MDP)。MDP指的是未来仅取决于当前的状态,而不取决于进入当前状态之前可能发生的任何事情,换句话说在马尔可夫决策过程中,未来取决于你现在所处的位置,而不取决于你是如何达到这里的;再换一种就是MDP是我们有一个机器人,我们要做的是选择动作a,根据这些动作、环境中发生的事情执行科学的任务。 State-action value funciton 状态动作函数Q 表示在状态s下,执行 动作a后,智能体所能获得的期望累计回报(Expected Return)。换句话说Q值衡量的是:"如果我在当前状态下做这个动作,长期来看能赚多少奖励?"。 计算$Q(s,a)$是强化学习算法的重要组成部分。也就是i说有办法计算s的Q,a,对于每个状态和每个动作,那么当你处于某个状态时,你所要做的就是看看不同的动作A,然后选择动作A,那就最大化s的Q,a。求Q的最大值。 贝尔曼方程 如何计算状态动作价值函数Q of S,A了? 在强化学习中有一个名为贝尔曼方程帮助我们解决计算状态动作值函数。下面来看看示例。 上图中有两个示例当在状态2,向右移动时,那么Q(2,->)=R(2)+0.5 max Q(3,a'0)=0+(0.5)25=12.5。当在状态4,向左移动时,那么Q(4,<-)=R(4)+0.5max Q(3,a')=0+(0.5)25=12.5。 贝尔曼方程体现的核心思想是:"一个状态的价值 = 即时奖励 + 后续状态的折扣价值"。也就是说,当前决策的好坏取决于当下奖励 + 未来的期望收益。 Continuous State Space continuous state space示例 对于火星车可能只有一个单一的状态1~6,对于下面的卡车来说有很多个状态,比如x,y,角度等等。而对于直升机来说又有更多参数集合的状态。 因此状态不仅仅是少数可能离散值的一个,它可以是一个数字向量。 月球着陆器 月球着陆车有很多状态变量,如上图所示。奖励函数我们可以设计成下面这样。 对于月球着陆器要学习的策略pi就是输入s,通过策略得到a,然后计算出最大的return。 学习Q 在状态s处,使用神经网络来计算4个动作中,那个动作的Q(s,nothing),Q(s,left),Q(s,main),Q(s,right)最大,然后选择那个最大值的动作。 那如何获得一个包含X和Y值的训练集,可以进行训练神经网络了?这就需要用到贝尔曼方程如上图,我们可以把贝尔曼方程的左边命名为X,右边命名为Y,神经网络的输入是一个状态和动作对。而输出Y就是就是Q。神经网络学习的就是X到Y的映射。 改进的神经网络架构 对于火星车前面的神经网络对应需要推理4次,即Q(s,nothing),Q(s,left),Q(s,main),Q(s,right),这样效率比较低,那么可以对算法进行改进推理一次直接输出4个动作的对应的Q。下面就是修改后的神经网络架构。 算法改进:ϵ贪婪策略 总结 学习流程 智能体观察当前状态 $s_t$ 根据策略 $\pi(a|s_t)$ 选择动作 $a_t$ 环境返回奖励 $r_t$ 和下一状态 $s_{t+1}$ 智能体根据反馈更新策略或价值函数 这一过程可用 马尔可夫决策过程(MDP) 表示: $$ [ \text{MDP} = (S, A, P, R, \gamma) ] $$ 其中: - 参数$S$:状态集合 - 参数$A$:动作集合 - 参数$P(s'|s,a)$:状态转移概率 - 参数$R(s,a)$:奖励函数 - 参数$\gamma$:折扣因子(0~1) 算法 (1)算法分类 类别 特征 代表算法 基于价值(Value-based) 学习 Q 值,间接得到策略 Q-learning、DQN 基于策略(Policy-based) 直接优化策略函数 REINFORCE、PPO Actor-Critic 混合 同时学习策略(Actor)和值函数(Critic) A2C、A3C、DDPG、SAC 基于模型(Model-based) 显式学习环境动态模型 Dyna-Q、Dreamer、MuZero (2)算法演进 阶段 特征 代表算法 传统表格法(Tabular RL) 离散状态空间,值表更新 Q-Learning, SARSA 深度强化学习(Deep RL) 神经网络逼近 Q 函数 DQN, Double DQN, Dueling DQN 连续动作控制(Continuous Control) 针对机械臂、无人车等连续控制问题 DDPG, TD3, SAC 策略梯度类(Policy Gradient) 直接优化策略参数 REINFORCE, PPO, TRPO 基于模型的RL(Model-based RL) 同时学习环境模型 + 策略 MuZero, DreamerV3 模仿学习 / 具身智能结合 利用演示或视觉模仿学习 GAIL, BC, VLA, RT系列 参考:本文主要来之吴恩达强化学习笔记 -
机器人全身控制浅谈:理解 WBC 的原理
概念 WBC(Whole-Body Control,全身控制)是什么?机器人是由“各关节”组成的,其不是“各关节各玩各的”而是一个耦合的整体。在某个时刻可能要做很多事情,比如保持平衡(重心别出圈)、手/脚要动作到目标位置、躯干姿态不能乱、关节不能超限、脚下不能打滑。这些都是一系列任务的组合。 WBC的核心就是把这些任务(目标)和约束(物理/安全)写进一个小型优化问题,在每个控制周期(几百hz~1Khz)求解,得到“当下这毫秒,各关节应该怎么动/用多大力”。 一句话总结就是WBC就是用优化的方法求解出要给“关节多少力“”以便让机器的各个关节一起配合完成多个目标,且不违反物理与安全约束。 原理 动力学方程 要解释WBC的原理,那必须绕不开动力学方程,这里就先对动力学方程做个简单介绍。 $$ M(q)\dot{v} + h(q,v) = S^T \tau + J_c^T \lambda $$ 配合接触约束: $$ J_c v = 0,\quad \lambda \in \text{摩擦锥} $$ 通俗理解公式就是:“惯性 × 加速度 + 自然出现的力 = 电机能给的力 + 地面/物体的反力” 公式左边:机器人自身的自然物理 变量$M(q)\dot{v}$:惯性项。$M(q)$是质量矩阵,描述机器人在不同姿态下的惯性特性。$\dot{v} $是广义加速度(关节加速度或身体的加速度);其意义就像$F=ma$里面的$ma$,表示加速一个有惯性的物体需要的力 变量$h(q,v)$:重力+速度相关项(科氏力、离心力)。如果机器人静止,这里主要就是重力。如果在运动,这里就会出现"速度带来的额外力",类似开车转弯时身体被甩出去的感觉。 公式右边:外界能提供的“驱动力” 变量$S^T \tau$:电机能施加的关节力矩。$\tau$电机产生的力矩(控制器的输出),$S^T$选择矩阵,把电机力矩映射到广义坐标系中。 变量$J_c^T \lambda$:接触点反力。$\lambda$来自地面或物体的力(约束反作用力),$J_c$接触点的雅可比,把关节速度映射到接触点速度。$J_c^T \lambda$把“地面推脚的力”转换回“关节的力”。 直观记忆就是类比现实生活中的推车子: 你推车:电机力矩$\tau$。 地面支撑车子:接触反力$\lambda$。 车子有质量,要加速就得克服惯性:$M(q)\dot{v}$。 重力和转弯的惯性: $h(q,v)$。 接触力约束 还要满足接触力约束$J_c v = 0,\quad \lambda \in \text{摩擦锥}$,其中$J_c v = 0$意义是接触点速度为0,比如机器人脚贴在地上不滑、不穿透;$\quad \lambda \in \text{摩擦锥}$意义是接触力必须满足摩擦模型,脚不会不穷大摩擦,力要在摩擦椎范围内。 公式中涉及到一个雅可比,什么是雅可比$Jc$? 假设有一个机械臂: 关节角度:就像是控制的"按钮"。 手末端的位置:就是最终关心的"结果"。 那么问题就是关节角度动一动,末端的位置会怎么动了?这个"关节空间的微小变化"影响到“末端空间的微小变化”。这样一个映射关系,就是雅可比矩阵$J$。 图中红色箭头表示关节角度的小变化$\Delta \theta_1 , \Delta \theta_2$。红色箭头的变换导致绿色箭头末端位置的变化:$ \Delta x , \Delta y$。雅可比矩阵 $J$ 就是把 $$ \begin{bmatrix}\Delta \theta_1 \ \Delta \theta_2\end{bmatrix} \longrightarrow \begin{bmatrix}\Delta x \ \Delta y\end{bmatrix} $$ 因此如果想要末端动多少就用$J$,想算末端力传回关节多少就用$J^T$。 总结一下雅可比$J$就是关节空间和任务空间的桥梁,作用就是我们关节动多少,末端/接触点动多少。 动力学方程在WBC中的用处? 动力学方程是机器人身体运动的"牛顿定律",我们来看看WBC的目标是什么?WBC不只是让机器人"走"或"站",而是要全身协调,比如要去抓杯子,脚要保持不滑,躯干要保持平衡,关节力矩不能超过电机限制。所以WBC的本质是解一个优化问题,找出一组关节力矩$\tau$,既能完成任务目标,又满足动力学方程和约束。 优化问题 WBC的核心思路是把机器人全身的目标任务转化为优化问题,在满足物理规律和约束条件的前提下,求出最合适的一组关节力矩$\tau$。 具体一点在WBC中求解的决策变量通常是如下三个: 最优的关节力矩$\tau$。 接触点反力$\lambda$。 机器人下一步的加速度$\dot{v} $。 优化问题转换为数学的目标函数如下: $$ \min_{x} | J_{\text{task}} \dot{v} - \dot{v}_{\text{des}} |^2 + | \tau |^2 + | \lambda |^2 $$ 公式中$J_{\text{task}}\dot{v} - \dot{v}{\text{des}}$表示实际加速度与期望加速度的误差,$J{\text{task}} \dot{v}$是在当前关节加速度下,末端/任务空的实际加速度,而$\dot{v}_{\text{des}}$是我们期望任务空间实现的期望加速度(比如手往前加速 0.5 m/s²,质心保持 0 加速度)。 同时优化问题还要满足以下约束条件: 动力学约束:$M(q)\dot{v} + h(q,v) = S^T \tau + J_c^T \lambda$。这是硬约束,控制器必须遵守。 接触约束:$J_c v = 0$,接触点不能乱动(不滑、不穿透)。 摩擦约束:$\lambda \in \mathcal{K}_{\text{fric}}$,接触力必须符合摩擦模型(不能无限大)。 力矩限制:$\tau_{\min} \leq \tau \leq \tau_{\max}$。 总结一下优化问题的目标函数意思就是要满足任务误差最小化(手/身体/质心的加速度跟踪目标),同时要满足能量或力矩最小化(不能浪费力),同时满足接触力正则化(力要稳定不能乱跳)。 方程有了,怎么求解了? 这个目标函数是一个二次型,符合QP,所以可以用现成的QP求解器来解,例如:OSQP、qpOASES、Gurobi(商业求解器)、CPLEX(商业求解器)、CVXPy(Python 封装,常用于原型),这里就不过多阐述了。 总结一下WBC核心就是要解决一个优化问题:二次目标(误差最小 + 力矩正则) + 动力学/接触/摩擦/限幅约束。其求解的方式通常使用QP 求解器(实时、高效、全局最优)。求解的结果是关节力矩$\tau$(给电机执行),同时还得到加速度$\dot{v}$和接触力$\lambda$。 示例 接下来我们调用cvxpy库看看示例,直观体验一下。 import cvxpy as cp import numpy as np # ---- 机械臂参数 ---- l1, l2 = 1.0, 1.0 m1, m2 = 1.0, 1.0 theta1, theta2 = np.deg2rad(45), np.deg2rad(30) # ---- 雅可比(末端位置对关节的导数)---- J_task = np.array([ [-l1*np.sin(theta1) - l2*np.sin(theta1+theta2), -l2*np.sin(theta1+theta2)], [ l1*np.cos(theta1) + l2*np.cos(theta1+theta2), l2*np.cos(theta1+theta2)] ]) # ---- 动力学质量矩阵 M(简化版)---- M = np.array([ [m1*l1**2 + m2*(l1**2 + l2**2 + 2*l1*l2*np.cos(theta2)), m2*(l2**2 + l1*l2*np.cos(theta2))], [m2*(l2**2 + l1*l2*np.cos(theta2)), m2*l2**2] ]) h = np.zeros(2) # 忽略重力/科氏项 # ---- 接触约束:假设末端y方向不能动(竖直方向约束)---- Jc = np.array([[0, 1]]) @ J_task # 取末端y方向的行 # ---- 变量 ---- ddq = cp.Variable(2) # 关节加速度 tau = cp.Variable(2) # 力矩 lam = cp.Variable(1) # 接触力 (竖直反作用力) # ---- 期望任务加速度(末端x方向=1.0, y方向=0.0)---- xddot_des = np.array([1.0, 0.0]) # ---- 目标函数:末端任务 + 力矩/接触力正则 ---- objective = cp.Minimize( cp.sum_squares(J_task @ ddq - xddot_des) + 0.01*cp.sum_squares(tau) + 0.01*cp.sum_squares(lam) ) # ---- 约束 ---- constraints = [ M @ ddq + h == tau + Jc.T @ lam, # 动力学方程 Jc @ ddq == 0, # 接触点不加速 tau >= -10, tau <= 10, lam >= 0 # 接触力必须向上推 ] # ---- 求解 ---- prob = cp.Problem(objective, constraints) prob.solve() print("Optimal joint accelerations:", ddq.value) print("Optimal torques:", tau.value) print("Optimal contact force λ:", lam.value) print("End-effector acc achieved:", J_task @ ddq.value) print("Desired end-effector acc :", xddot_des) 上面的示例中可以分为几部分: (1)任务 末端(手)在水平 $x$ 方向产生 $1.0 \text{m/s}^2$ 的加速度。在垂直 $y$ 方向不要加速(因为手撑在桌子上,不应该离开桌面)。 数学写法: $$ \ddot{x}_{des} = [1.0,0.0]^T $$ (2)决策变量 优化器要决定的量是 $$ \ddot{q} = [\ddot{\theta}_1,\ddot{\theta}_2]^T, \quad \tau = [\tau_1,\tau_2]^T, \quad \lambda $$ (3)要优化的目标函数 最小化 $$ \min_{\ddot{q},\;\tau,\;\lambda}| J_{\text{task}} \ddot{q} - \ddot{x}_{des} |^2+ 0.01 |\tau|^2+ 0.01 |\lambda|^2 $$ (4)约束条件 动力学约束:$M(q)\ddot{q} + h(q,\dot{q}) = \tau + J_c^T \lambda$ 接触约束:$J_c \ddot{q} = 0$ 力矩范围:$-10 \leq \tau_i \leq 10$ 接触力非负:$\lambda \geq 0$ (5)输出结果 最后调用 prob = cp.Problem(objective, constraints) prob.solve() 求解得出结果: Optimal joint accelerations: [ 0.50615867 -1.88900987] Optimal torques: [-1.12977187 -0.94450493] Optimal contact force λ: [1.29515155e-23] End-effector acc achieved: [ 9.77823461e-01 -5.00938335e-17] Desired end-effector acc : [1. 0.] QP 解出来的就是 最优关节加速度:$\ddot{q}$ 最优关节力矩:$\tau$ 接触反力:$\lambda$ 实际末端加速度:$\ddot{x} = J_{\text{task}} \ddot{q}$ 并与期望值 $\ddot{x}_{des}$ 对比。 上面的代码中只截取了关键部分,下面是绘制图像的效果如下,可以直观体会看看: WBC与MPC 上一篇文章我们分析了MPC,那么MPC与WBC什么关系了? MPC在WBC之上,MPC作为决策层做"未来几步的规划",比如预测未来1S内,质心应该怎么移动,脚该放哪里,其输出的是期望的任务轨迹。WBC是在下层,拿到MPC给的任务(目标加速度/姿态/接触序列)在动力学和接触约束下,求解QP得到当下这一瞬间的关节力矩$\tau$。简而言之MPC决定“机器人未来要往哪走”,WBC决定“当前每个关节该怎么出力”。 举个例子:双足机器人走路 MPC:优化未来 1 秒的 质心轨迹、摆腿位置、支撑相切换。输出:期望的 $\ddot{x}_{des}$(质心加速度)、脚的落点计划。 WBC:把这些期望当作任务输入,解 QP ,输出关节力矩 $\tau$,同时计算接触力 $\lambda$,保证机器人在每一步不摔倒。 -
机器人控制利器:MPC入门与实践解析
背景 MPC(Model Predictive Control)模型预测控制,是一种控制方法,广泛应用在机器人、无人驾驶、过程控制、能源系统等领域。它的核心思想用一句话来总结:利用系统模型预测未来,并通过优化选择当前最优的控制输入。 如上图是一个MPC应用框图,先来看看框图中的各个变量。 r(t):参考输入,系统希望达到的目标(设定值/reference signal),例如机器人要达到的位置、温度控制的目标值、车辆期望的速度等等。 e:误差e(t) = y(t) – r(t),用来计算实际的输出期望值的差距。 μ(t):控制输入,由MPC控制器计算出来,施加在系统上的控制量。 y(t):系统实际输出,比如位置、速度、温度等。 系统的目标是由MPC控制器计算输出一个μ(t)控制量,然后作用到系统,让系统的输出能够达到期望值。其中有一个反馈回路,形成一个闭环系统,实际的输出y(t)会反馈给比较器,与目标值对比,当未达到目标时,系统自动修正直到达到目标。 原理 系统模型 为了简单,我们先令系统的实际输出$y=x$,下面用数学建模来描述系统状态模型是 $$ x_{k+1} = A x_k + B u_k $$ 参数$x_k$:系统在时刻$k$的状态,比如汽车的位置和速度[p,v]。 参数$u_k$:系统在时刻$k$的控制输入,比如油门大小、方向盘角度、电机电压等。 A:状态的转移矩阵,决定了系统状态的演化方式。 B:输入矩阵,描述了控制输入如何影响状态的变换。 参数$x_{k+1}$:系统在下一时刻$k+1$的状态。 A和B是两个矩阵,A决定系统 在没有控制输入时,状态如何随时间演化。B决定控制输入$u_k$如何影响的状态。 上面的模型是线性模型,本文以此来进行分析。但是在实际场景中根据实际问题进行建模,模型可能是非线性的如下,这里就过多解释。 $$ x_{k+1} = f(x_k,u_k) $$ 预测未来 MPC原理就是从当前状态$x+k$出发,用模型递推,预测出未来的N步(如果看过之前关于ACT原理,其实MPC有很多类似之处): $$ x_{k+1},x_{k+2},x_{k+3},......,x_{k+N} $$ 目标函数 工程中我们最主要的目标是要求出控制量$u_t$以便让系统最终调整到我们预期的状态。 那如何来设计这个系统了? 前面我们建模了$k$时刻的状态$x_t$,那么这个状态+动作需要满足什么样的数学关系了? 与深度学习类似,我们要对状态+动作的数学关系求一个最小值的表达式。看公式: $$ J = \sum_{i=0}^{N-1} \Big[ (x_{k+i} - x_{k+i}^{\text{ref}})^T Q (x_{k+i} - x_{k+i}^{\text{ref}}) + u_{k+i}^T R u_{k+i} \Big] $$ 上面的公式可以分为两部分,前面部分代表的是k时刻输出状态与目标状态误差值,后面部分是控制的动作。也就是说我们最核心的是要误差越小越好,同时控制的动作不要太大。误差小好理解,动作变化不要太大是因为要保证控制动作要平滑。两部分都是求平方$e^2$和$u^2$放大比例(跟深度学习中的损失差不多),同时各自有一个权重Q和R,这两个参数是权重参数可调,Q用来平衡快速到目标,R用来调节平衡动作要平稳。 公式中$x$和$J$可以说是已知的,那么就可以求出$u$控制量了。 对于求解$u$,需要根据实际的模型,如果模型是线性模型+二次目标函数这样就比较简单使用二次规划QP可以快速解析或数值求解。如果是非线性模型,那么就变成非线性规划NLP,需要迭代求解器(如SQP、IPOPT)。当然如果是简单还可以使用穷举控制序列$U$,直接算$J$取最小。 约束条件 约束条件是在求解代价函数最小值过程中,显示的对控制量$u$、$x_k$做约束。这样的目的是比如对于车来说油门不能超过100%,速度不能超速,机械臂必能超过关节限位等。 因此在求救$J$时,可以添加约束条件,如下: $$ u_{\min} \leq u_k \leq u_{\max};x_{\min} \leq x_k \leq x_{\max} $$ 第一个是 控制输入约束(油门、方向盘角度不能无限大)。第二个是 状态约束(位置、速度等不能超过物理限制)。 工作流程 MPC控制系统中,其工作流程最核心的滚动时域控制,其核心点是每次预测出N步,但是并不是一下就全部执行完N步,因为预测也是有偏差同时在执行过程中会有变化。而是每次预测N步,但是只取第一步进行执行,然后根据新的输出结果重新预测下一个N步。这个其实跟ACT的时间集成有点类似,也就是在每个时间刻都会预测N步,而MPC是取第一步执行,而ACT是取k时刻和此前时刻的加权平均。 下面来看看具体的执行流程: 当前时刻$K$:系统处于某个状态如蓝线上面的红点,控制器采集到当前状态作为优化的起点。 预测未来N步:橙色窗口覆盖未来N步的时间区;红色虚线显示预测的未来轨迹,如果采用这一串控制动作$U=[u_k,u_{k+1}...]$系统怎么走。 优化并得到最优控制序列:在预测窗口里,MPC通过解$J$(误差+控制代价)最小值得到结果一整串最优控制动作序列$U$。 只执行一步:红色箭头指向当前窗口里的第一个控制输入$u_k$,下方蓝色阶梯控制曲线更新,系统真是状态推进到下一个时刻;上方状态曲线的红点更新到新的位置。 丢弃其余动作:窗口里的控制动作$(u_{k+1},u_{k+2}...)$丢弃,因为下一时刻会重新优化得到新的控制动作。 窗口前移,重复循环:橙色预测窗口右移一格$(k->k+1->k+2)$,控制器基于新状态重新预测、重新优化,再次执行第一步,丢弃其余周而复始直到达到目标。 因此整个过程核心就是MPC的滚动时域机制:预测未来——>优化整串动作——>执行第一步——>丢弃其余——>窗口前移——>重新计算。 示例程序 下面是一个简单的示例加深对MPC的认识。场景是一个一维的小车: 状态$x=[位置,速度]$,控制输入$u=加速度$。 小车从0开始,目标位置在10米,并希望最后速度接近0. 用MPC做控制,预测N步,计算代价,找到最优控制序列,但只执行第一个动作然后滚动。 求解$u$这里直接使用的是穷举法。 import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation # --- 系统模型 (离散时间) --- dt = 0.2 # 状态空间模型: x_{k+1} = A x_k + B u_k # x = [位置, 速度],u = 加速度 A = np.array([[1, dt], [0, 1]]) B = np.array([[0.5*dt**2], [dt]]) # 初始状态: 位置=0, 速度=0 x = np.array([0.0, 0.0]) # 目标状态: 位置=10, 速度=0 (停在10米处) target = np.array([10.0, 0.0]) # --- MPC 参数 --- N = 5 # 预测时域长度 (未来看5步) U_candidates = [-1, 0, 1] # 控制输入候选集合 (加速度: -1=刹车, 0=不动, 1=加速) def simulate(x0, u_seq): """ 给定初始状态 x0 和一段控制序列 u_seq, 用系统模型递推未来轨迹,并计算代价 J """ x = x0.copy() cost = 0.0 traj = [x.copy()] # 保存预测轨迹 (用于可视化) for u in u_seq: # 状态更新 (预测未来) x = A @ x + B.flatten()*u traj.append(x.copy()) # 代价函数 J = 误差项 + 控制代价 err = x - target cost += err[0]**2 + 0.3*err[1]**2 + 0.1*(u**2) # 位置误差^2 + 速度误差^2(权重0.3) + 控制输入^2(权重0.1) return cost, np.array(traj) # --- MPC 主循环 (滚动时域控制) --- history_x = [] # 真实执行的状态轨迹 history_u = [] # 实际执行的控制输入 (只取最优序列的第一步) pred_trajs = [] # 每次优化得到的预测轨迹 (整串) for step in range(60): best_cost = 1e9 best_seq = None best_traj = None # 穷举所有可能的控制序列 U = [u_k, u_{k+1}, ..., u_{k+N-1}] for U in np.array(np.meshgrid(*[U_candidates]*N)).T.reshape(-1,N): cost, traj = simulate(x, U) if cost < best_cost: best_cost = cost best_seq = U # 当前最优控制序列 best_traj = traj # 当前最优预测轨迹 # 保存数据 (真实轨迹、控制输入、预测轨迹) history_x.append(x.copy()) history_u.append(best_seq[0]) # 只执行第一步 u_k* pred_trajs.append(best_traj) # 保存整条预测轨迹用于画红虚线 # 执行第一步 (滚动时域控制的核心:只执行u_k) u = best_seq[0] x = A @ x + B.flatten()*u # 收敛条件 (位置接近10, 速度≈0) if abs(x[0]-target[0]) < 0.1 and abs(x[1]-target[1]) < 0.1: history_x.append(x.copy()) history_u.append(0) # 终端时控制输入设为0 break history_x = np.array(history_x) # --- 动态可视化 --- fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(8, 6)) # 上图:位置随时间 ax1.axhline(target[0], color="green", linestyle="--", label="Target position") (line_real,) = ax1.plot([], [], "bo-", label="Real trajectory") # 蓝点=真实轨迹 (line_pred,) = ax1.plot([], [], "r--", label="Predicted trajectory") # 红虚线=预测轨迹 (point_exec,) = ax1.plot([], [], "ro", markersize=8, label="Execute point") # 红点=执行点 ax1.set_xlim(0, len(history_x)+N) ax1.set_ylim(0, target[0]+5) ax1.set_ylabel("Position") ax1.legend() # 下图:控制输入 (line_u,) = ax2.step([], [], where="post", label="Control input u") ax2.set_xlim(0, len(history_u)) ax2.set_ylim(min(U_candidates)-0.5, max(U_candidates)+0.5) ax2.set_xlabel("Time step") ax2.set_ylabel("u") ax2.legend() # --- 动画更新函数 --- def update(frame): # 蓝线:实际轨迹 line_real.set_data(np.arange(frame+1), history_x[:frame+1,0]) # 红虚线:预测轨迹 (窗口内) pred = pred_trajs[frame] line_pred.set_data(np.arange(frame, frame+len(pred)), pred[:,0]) # 红点:当前执行点 point_exec.set_data([frame], [history_x[frame,0]]) # 阶梯:控制输入 line_u.set_data(np.arange(frame+1), history_u[:frame+1]) return line_real, line_pred, point_exec, line_u # 动画循环:frames=len(pred_trajs),表示每个MPC优化时刻 ani = animation.FuncAnimation(fig, update, frames=len(pred_trajs), interval=800, blit=True, repeat=False) plt.show()