内存管理
-

内存测量
系统占用内存 free 旧版本free $ free total used free shared buffers cached Mem: 65960636 63933576 2027060 73392 1602076 32628548 -/+ buffers/cache: 29702952 36257684 Swap: 0 0 0 (1)第一行Mem:内存的使用情况,默认单位是Kb。 - total:系统总共的内存。total=used+free - used:已经被使用的内存。 - free:剩余还没有被使用的物理内存。 - shared: 多个进程共享的内存。 - buffers:块设备所占的缓存页,包括直接读写块设备、文件系统元数据(metadata)、SupperBlock所使用的缓存页等。 - cached:普通文件数据所占用的缓存页。 (2)第二行-/+ buffers/cache:物理内存缓存统计。 -buffers/cache(used列):29702952,被程序正在使用的缓存内存,等于used-buffers-cached +buffers/cache(used列):36257684,还可以挪用使用的缓存内存,等于free+buffers+cached (3)第三行:交换区空间的统计。 新版本free root@TinaLinux:/# free total used free shared buff/cache available Mem: 2022788 98876 1818264 84 105648 1898696 Swap: 0 0 0 第一行Mem:内存的使用情况,默认单位是Kb。 第二行Swap:交换空间的使用情况。 - total:系统总共的内存。total = used+free+buff/cache - used:已经被使用的内存。 - free:剩余还没有被使用的物理内存。 - shared: 多个进程共享的内存。 - buff:块设备所占的缓存页。 - cache:普通文件数据所占用的缓存页。 - available:还可以被应用程序使用的物理内存大小。available=free+可回收利用的buff/cache 在系统中available才是系统真正可还能申请到的内存。 /proc/meminfo # cat /proc/meminfo MemTotal: 2022788 kB MemFree: 1818376 kB MemAvailable: 1898700 kB Buffers: 436 kB Cached: 20352 kB SwapCached: 0 kB Active: 5104 kB Inactive: 31432 kB Active(anon): 116 kB Inactive(anon): 15716 kB Active(file): 4988 kB Inactive(file): 15716 kB Unevictable: 0 kB Mlocked: 0 kB SwapTotal: 0 kB SwapFree: 0 kB Dirty: 0 kB Writeback: 0 kB AnonPages: 15792 kB Mapped: 5156 kB Shmem: 84 kB KReclaimable: 84752 kB Slab: 148640 kB SReclaimable: 84752 kB SUnreclaim: 63888 kB KernelStack: 2144 kB PageTables: 620 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 1011392 kB Committed_AS: 93972 kB VmallocTotal: 259653632 kB VmallocUsed: 4820 kB VmallocChunk: 0 kB Percpu: 768 kB CmaTotal: 65536 kB CmaFree: 48764 kB MemTotal: 系统当前可用物理内存总量,除去了reserved的内存。 MemFree:系统当前剩余空闲物理内存。 MemAvailable:系统中可使用的物理内存,包含了可以回收的内存。 Buffers:块设备缓存。 Cached:普通文件页的缓存。 SwapCached:系统有多少匿名页面曾经被交换到交换区过。 Active:活动的匿名页面和活动的文件映射页面内存,=Active(anon)+Active(file)。 Inactive:不活跃的匿名页面和文件页面。=Inactive(anon)+Inactive(file)。 Active(anon):活跃的匿名页面。 Inactive(anon): 不活跃的匿名页面。 Active(file):活跃的文件页面。 Inactive(file): 不活跃的文件页面。 Unevictable: 不能回收的页面(LRU_UNEVICTABLE)。 Mlocked: 不能被交换(swap)出去的页面。 SwapTotal:交换分区的大小。 SwapFree: 交换分区空闲的大小。 Dirty: 脏页的数量。 Writeback: 正在回写的也买你数量。 AnonPages:有反向映射的页面,通常是匿名页面并且被映射到用户空间的。 Mapped:所有映射到用户地址空间的内容缓存页面。 Shmem: 共享内存(tmpfs事先的shmem/devtmpfs等)。 KReclaimable: 内核可回收内存,包括可回收的slab和其他可回收的内核页面。 Slab:所有slab页面,包括可回收和不可回收。 SReclaimable:可回收的slab页面。 SUnreclaim: 不可回收的slab页面。 KernelStack: 所有进程的内核栈总大小。 PageTables: 用于存储页表的页面数量。 NFS_Unstable:NFS中,发给服务器但是还没有写入磁盘的页面。 Bounce: 针对智能访问低端内存的设备,当DMA分配到高端内存时,分配要给低端临时buffer用于复制处理。 WritebackTmp:回写过程中使用的临时缓存 CommitLimit: Committed_AS: VmallocTotal:vmalloc区域总大小。 VmallocUsed:vmalloc区域使用的内存大小。 VmallocChunk:vmalloc可用的连续最大块大小。 Percpu:percpu机制使用的页面。 CmaTotal:CMA机制使用的总内存。 CmaFree:CMA机制剩余空用内存。 1.Linux内核的内存用了多少?Slab+VmallocUsed+PageTables+KernelStack+Bounce。 2.用户内存用了多少内存? (1)LRU视角:active+inactive+unevicatable = 5104+31432+0= 36536KB (2)缓存视角(swapcache=0):Cached+Buffers +AnonPages= 20352+436+15792=36580KB,cached和buffers内存并不是都使用完成了,这种统计方式往往大于实际使用内存。 观察内存泄露的时候重点看:Memfree、Slab的变化。 /proc/zoneinfo zoneinfo显示了当前系统所有内存管理区的信息,可以分为以下几个部分。 1.当前内存节点的内存统计信息 Node 0,zone DMA:第0个节点,DMA区域的总体信息。 2.当前内存管理区的总信息 节点0,zone区域。 - pages free:内存管理区中空闲的页面数量。 - min:警戒水位的页面数量。 - low:低水位的页面数量。 - high:高水位的页面数量。 - spanned:内存管理区总的页面数量,包含空洞。 - present:内存管理区总的可用页面数量,不包含空洞。 - managed:被伙伴系统管理的页面数量。 - protection:管理区中预留内存的页面数量。分别是预留给DMA,DMA32,NORMAL,HIGH。 3.每个CPU内存分配器的信息per_cpu_pageset pagesets:表示每个CPU内存分配器中每个CPU缓存的页面信息。 - count: 在该CPU内存区域上已经分配的页面数量。 - high:页面回收的空闲页面数量的水位线,如果cpu上的页面数量超过该值,需要退还给zone。 - batch:如果缓存中没有页面了,一次性中zone中获取batch个页面。。 - vm stats threshold: 某个进程虚拟内存使用量超过该阈值时,内核将在/proc/PID/smaps打印进程的详细内存映射信息。 zoneinfo节点重点可以看一下各区域min/low/high的水位值,可以通过/proc/sys/vm/min_free_kbytes调整min值。 用户进程占用内存 /proc/pid/status # cat /proc/1151/status Name: wifi_daemon Umask: 0022 State: S (sleeping) Tgid: 1151 Ngid: 0 Pid: 1151 PPid: 1 TracerPid: 0 Uid: 0 0 0 0 Gid: 0 0 0 0 FDSize: 64 Groups: VmPeak: 239316 kB VmSize: 239316 kB VmLck: 0 kB VmPin: 0 kB VmHWM: 1172 kB VmRSS: 1172 kB RssAnon: 532 kB RssFile: 640 kB RssShmem: 0 kB VmData: 33540 kB VmStk: 132 kB VmExe: 36 kB VmLib: 7560 kB VmPTE: 76 kB VmSwap: 0 kB CoreDumping: 0 THP_enabled: 0 Threads: 3 SigQ: 0/7639 SigPnd: 0000000000000000 ShdPnd: 0000000000000000 SigBlk: 0000000000000000 SigIgn: 0000000000001000 SigCgt: 0000000180000000 CapInh: 0000000000000000 CapPrm: 000001ffffffffff CapEff: 000001ffffffffff CapBnd: 000001ffffffffff CapAmb: 0000000000000000 NoNewPrivs: 0 Seccomp: 0 Seccomp_filters: 0 Speculation_Store_Bypass: not vulnerable SpeculationIndirectBranch: unknown Cpus_allowed: ff Cpus_allowed_list: 0-7 voluntary_ctxt_switches: 12 nonvoluntary_ctxt_switches: 0 VmPeak: 进程使用的最大虚拟内存,通常等于进程内存描述符号mm->total_vm。 VmSize:进程使用的虚拟内存,等于mm->total_vm。 VmLck:记录所有用户或内核锁定的内存,主要是mlock的内存,系统回收内存时,不会优先回收这部分内存。 VmPin:进程固定在内存的虚拟地址空间大小,记录了无法被换出到磁盘的页面数量。 VmHWM:进程使用的最大物理内存,包括进程使用的匿名页面、文件映射页面以及共享内存页面大小总和。 VmRSS: 进程使用的最大物理内存,通常等于VmHMM。 RssAnon: 进程使用的匿名页面大小。 RssFile: 进程使用的文件页面大小。 RssShmem: 进程使用的共享内存页面大小。 VmData:进程私有数据段占用内存大小。 VmStk:进程用户栈占用内存大小。 VmExe:进程代码段占用大小。 VmLib:进程共享库占用大小。 VmPTE:进程占用的页表大小。 VmSwap: 进程使用巨型页的大小。 /proc/pid/smaps 7fac964000-7fac9b8000 r-xp 00000000 b3:07 403 /lib/libwifimg-v2.0.so Size: 336 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Rss: 240 kB Pss: 240 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 240 kB Private_Dirty: 0 kB Referenced: 136 kB Anonymous: 0 kB LazyFree: 0 kB AnonHugePages: 0 kB ShmemPmdMapped: 0 kB FilePmdMapped: 0 kB Shared_Hugetlb: 0 kB Private_Hugetlb: 0 kB Swap: 0 kB SwapPss: 0 kB Locked: 0 kB THPeligible: 0 VmFlags: rd ex mr mw me 7fac964000-7fac9b8000 r-xp 00000000 b3:07 403 /lib/libwifimg-v2.0.so: 7fac964000-7fac9b8000虚拟内存段的开始和结束位置,表示一个VMA。 r-xp表示该VMA是可读、可执行、私有。00000000虚拟内存段其实地址对应映射文件中以页为单位的偏移量。 size:虚拟内存空间大小。不是实际物理内存的分配大小,对应的是VMA的内存大小,内存总是会延迟分配。 Rss:实际分配的内存,包括其他进程的共享内存Rss=Shared_Clean+Shared_Dirty+Private_Clean+Private_Dirty。 Pss:平摊计算后的实际物理内存使用。共享部分按比例均分+Private_xx部分。 Private_Dirty:进程独占的脏页面大小。 Private_Clean:进程独占干净页面大小。 USS:等于Private_Dirty+Private_Clean,通常用来表示进程独占的物理内存大小,去掉与其他共享内存部分。 Rss计算: cat /proc/pid/smaps | awk '/^Rss/ {sum += $2} END {print sum}' Pss计算 cat /proc/pid/smaps | awk '/^Pss/ {sum += $2} END {print sum}' Uss计算 cat /proc/pid/smaps | awk '/^Pss/ {sum += $2} END {print sum}' 进程1001: VSS=1+2+3 RSS=4+5+6 PSS=4/2+5+6 USS=5+6 看进程是否有内存泄露,可以优先看USS(Private_Dirty+Private_Clean)是否有增长。 pmap -x [pid] - Address:虚拟地址起始地址 - Kbytes:内存块占用虚拟内存大小,单位KB。 - PSS:进程使用的物理内存大小(贡献内存按比例分配的大小),单位KB。 - Dirty:脏内存大小,指进程修改过的页面大小,单位KB。 - Swap:被交换到磁盘上的内存大小,单位KB。 - Mode:显示内存段的权限属性。 - Mapping:显示内存段对应的文件或库名。 - Total:汇总内存区域的虚拟内存大小,单位KB。 在linux物理内存中,每个页面有一个dirty的标志,如果该页面被改写了,我们称之位dirty page。总的来说,所有非dirty page的物理页面都可以被回收。进程中各个段的dirty page情况。 内核占用内存 /proc/meminfo 内核占用内存:Slab+VmallocUsed+PageTables+KernelStack+Bounce。 /proc/pagetypeinfo Page block order:10,支持最高阶order,这里是10,表示内存大小一块为2^10页面。 Pages per block:最高阶一块内存需要的页面数量,等于2^10=1024,即page block大小为1024*4K=4MB。 Unmovable order=1的数量有87个,也就是2^1个页面组成的内存块有87个。 Movable 454:表示在DMA区域,movable类型的page block的数量为454。(按照最高阶计算oder = 2^10的页面组成的内存块)。 小结 内存统计 #!/bin/sh while true; do #1计算系统总共内存及剩余内存 TOTAL_MEM=$(grep MemTotal /proc/meminfo | awk '{print $2}') FREE_MEM=$(grep MemFree /proc/meminfo | awk '{print $2}') #2计算内核占用内存 SLAB=$(grep Slab /proc/meminfo | awk '{print $2}') VMALLOC=$(grep VmallocUsed /proc/meminfo | awk '{print $2}') PAGETABLE=$(grep PageTables /proc/meminfo | awk '{print $2}') KERNELSTACK=$(grep KernelStack /proc/meminfo | awk '{print $2}') KERNEL_MEM=$((SLAB + VMALLOC + PAGETABLE + KERNELSTACK)) #3计算用户USS/PSS/RSS占用内存 CURRENT_USER=$(id -u) TOTAL_USS=0 TOTAL_PSS=0 TOTAL_RSS=0 for pid in $(ls /proc/ | grep "^[0-9]*$"); do if [ -f "/proc/${pid}/status" ]; then username=$(awk '/^Uid:/{printf $2}' "/proc/${pid}/status") if [ "$username" = "$CURRENT_USER" ]; then name=$(awk '/^Name:/{print $2}' "/proc/${pid}/status") mem1=0 mem1=$(cat /proc/${pid}/smaps | awk '/^Private/ {sum += $2} END {print sum}') mem2=0 mem2=$(cat /proc/${pid}/smaps | awk '/^Pss/ {sum += $2} END {print sum}') mem3=0 mem3=$(cat /proc/${pid}/smaps | awk '/^Rss/ {sum += $2} END {print sum}') fi TOTAL_USS=$((TOTAL_USS + mem1)) TOTAL_PSS=$((TOTAL_PSS + mem2)) TOTAL_RSS=$((TOTAL_RSS + mem3)) fi done echo "total_mem:$TOTAL_MEM KB, free_mem:$FREE_MEM KB" echo "slab:$SLAB KB, vmalloc:$VMALLOC KB, pagetable:$PAGETABLE KB, kernel_stack:$KERNELSTACK KB" echo "Kernel_mem:$KERNEL_MEM KB, USS:$TOTAL_USS KB, PSS:$TOTAL_PSS KB, RSS:$TOTAL_RSS KB" sleep 1 done 查询占用较多内存的进程 #!/bin/sh CURRENT_USER=$(id -u) TOTAL_USS=0 TOTAL_PSS=0 TOTAL_RSS=0 for pid in $(ls /proc/ | grep "^[0-9]*$"); do if [ -f "/proc/${pid}/status" ]; then username=$(awk '/^Uid:/{printf $2}' "/proc/${pid}/status") if [ "$username" = "$CURRENT_USER" ]; then name=$(awk '/^Name:/{print $2}' "/proc/${pid}/status") mem1=0 mem1=$(cat /proc/${pid}/smaps | awk '/^Private/ {sum += $2} END {print sum}') mem2=0 mem2=$(cat /proc/${pid}/smaps | awk '/^Pss/ {sum += $2} END {print sum}') mem3=0 mem3=$(cat /proc/${pid}/smaps | awk '/^Rss/ {sum += $2} END {print sum}') echo "$pid USS:$mem1, PSS:$mem2, RSS:$mem3" fi fi done 进程内存监测 #!/bin/sh count=0 pid=$1 while true; do let "count++" #计算USS,RSS,PSS mem1=$(cat /proc/$pid/smaps | awk '/^Private/ {sum += $2} END {print sum}') mem2=$(cat /proc/$pid/smaps | awk '/^Rss/ {sum += $2} END {print sum}') mem3=$(cat /proc/$pid/smaps | awk '/^Pss/ {sum += $2} END {print sum}') #计算Dirty,进程虚拟内存 Dirty=$(pmap -x $pid | awk '/^total/{dirty=$4}END{print dirty}') VSS=$(pmap -x $pid | awk '/^total/{VSS=$2}END{print VSS}') #计算系统使用内存,剩余内存 used=$(free | awk '/^Mem/{used=$3}END{print used}') free=$(free | awk '/^Mem/{free=$4}END{print free}') #计算堆空间虚拟内存 start_addr=$(cat /proc/$pid/maps | grep "\\[heap\\]" | awk '{print $1}' | cut -d'-' -f1) end_addr=$(cat /proc/$pid/maps | grep "\\[heap\\]" | awk '{print $1}' | cut -d'-' -f2) start_addr=$(printf "%d" "0x$start_addr") end_addr=$(printf "%d" "0x$end_addr") heap_vs=$(expr $end_addr - $start_addr) heap_vs=$(expr $heap_vs / 1024) #计算栈空间虚拟内存 start_addr=$(cat /proc/$pid/maps | grep "\\[stack\\]" | awk '{print $1}' | cut -d'-' -f1) end_addr=$(cat /proc/$pid/maps | grep "\\[stack\\]" | awk '{print $1}' | cut -d'-' -f2) start_addr=$(printf "%d" "0x$start_addr") end_addr=$(printf "%d" "0x$end_addr") stack_vs=$(expr $end_addr - $start_addr) stack_vs=$(expr $stack_vs / 1024) echo "count:$count,USS:$mem1 KB,VSS:$VSS KB, RSS:$mem2 KB,PSS:$mem3 KB,Dirty:$Dirty KB,heapvs:$heap_vs KB,stackvs:$stack_vs KB,used:$used KB,free:$free KB" sleep 1 done 测试代码,可配合脚本观察 int main(int argc, char *argv[]) { char *ptr1; char *ptr2; char *ptr3; char *ptr4; char *ptr5; struct mallinfo m_info; int size_kb = 65; getchar(); mallopt(M_TRIM_THRESHOLD, 1024 * 128); printf("malloc ptr[0] %dkb\\n", size_kb); ptr1 = (char *)malloc(1048 * size_kb); //memset(ptr1,24,1048 * size_kb); //memset不会导致USS增加,可能是由于值是一样的. //memset(ptr1,25,1048 * size_kb); 即使用两次memset设置不同值也不会增加USS for (int i = 0; i < 1048 * size_kb; i++) { ptr1[i] = i % 255; } getchar(); printf("malloc ptr[1] %dkb\\n", size_kb); ptr2 = (char *)malloc(1048 * size_kb); //memset(ptr2,25,1048 * size_kb); for (int i = 0; i < 1048 * size_kb; i++) { ptr2[i] = i % 255; } getchar(); printf("malloc ptr[2] %dkb\\n", size_kb); ptr3 = (char *)malloc(1048 * size_kb); //memset(ptr3,26,1048 * size_kb); for (int i = 0; i < 1048 * size_kb; i++) { ptr3[i] = i % 255; } getchar(); printf("malloc ptr[3] %dkb\\n", size_kb); ptr4 = (char *)malloc(1048 * size_kb); //memset(ptr4,27,1048 * size_kb); for (int i = 0; i < 1048 * size_kb; i++) { ptr4[i] = i % 255; } getchar(); printf("malloc ptr[4] %dkb\\n", size_kb); ptr5 = (char *)malloc(1048 * size_kb); //memset(ptr5,28,1048 * size_kb); for (int i = 0; i < 1048 * size_kb; i++) { ptr5[i] = i % 255; } getchar(); printf("free ptr[0] %dkb\\n", size_kb); free(ptr1); getchar(); printf("free ptr[1] %dkb\\n", size_kb); free(ptr2); getchar(); printf("free ptr[2] %dkb\\n", size_kb); free(ptr3); getchar(); printf("free ptr[3] %dkb\\n", size_kb); free(ptr4); getchar(); printf("free ptr[4] %dkb\\n", size_kb); free(ptr5); getchar(); return 0; } 操作系统对于小块内存的管理方式,如 Linux 内核中的延迟映射(Lazy Mapping)或零页复制(Zero Page COW)等技术所导致的。在某些情况下,操作系统可能会推迟实际的物理页面映射,直到首次访问相应的内存位置。这意味着即使您访问和修改了分配的内存,实际的物理页面映射可能仍然被推迟。即使使用memset修改了内存,但是可能也不会进行映射,通常可能只有在内存被修改为不同内容时,才会进行实际物理页面映射。而只有做了物理页面映射,进程的USS才会增加。 -

进程虚拟内存
进程虚拟地址空间 Executable and Linkable Format(ELF) 上图是可执行文件的内容结构图,由ELF header、program headers、各section、sections headers组成。 - ELF header:描述整个文件的基本属性,如文件版本号、目标机器型号、程序入口地址等。 - program headers:描述ELF文件该如何被操作系统映射到进程的虚拟地址空间,对于LOAD类型的Segment,每个Segment对应一个VMA。对于操作系统来说,并不关心各个section所包含的内容,它只关心跟装载相关的问题,最主要的是section的权限(可读,可写,可执行),所以对于相同类型的section,将会被合并成要给Segment进行映射,如init/text/rodata,这些都是可读可执行所以合并成一个Segment来描述。对于.o文件是没有program heades的。 - sections:代码经过编译之后,将会分类链接多个section,如init/text/data/bss。 - sections headers:用于ELF文件中各sections的。 ELF header 描述ELF header的结构体 typedef struct { unsigned char e_ident[EI_NIDENT]; /* 16 bytes */ Elf64_Half e_type; /* File type */ .... Elf64_Addr e_entry; /* Entry point virtual address */ Elf64_Off e_phoff; /* Prog headers file offset */ Elf64_Off e_shoff; /* Sec headers file offset */ .... Elf64_Half e_phentsize; /* Prog headers entry size */ Elf64_Half e_phnum; /* Prog headers entry count */ Elf64_Half e_shentsize; /* Sec headers entry size */ Elf64_Half e_shnum; /* Sec headers entry count */ Elf64_Half e_shstrndx; /* Sec string table index */ } Elf64_Ehdr; 可以通过readelf -h 来获取ELF的header信息。 $ readelf -h wifi_daemon ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: EXEC (Executable file) Machine: AArch64 Version: 0x1 Entry point address: 0x401c00 Start of program headers: 64 (bytes into file) Start of section headers: 44568 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 56 (bytes) Number of program headers: 9 Size of section headers: 64 (bytes) Number of section headers: 29 Section header string table index: 28 program headers 描述Program header的结构体。 // Program header for ELF64. typedef struct { Elf64_Word p_type; // Type of segment Elf64_Word p_flags; // Segment flags Elf64_Off p_offset; // File offset where segment is located, in bytes Elf64_Addr p_vaddr; // Virtual address of beginning of segment Elf64_Addr p_paddr; // Physical addr of beginning of segment (OS-specific) Elf64_Xword p_filesz; // Num. of bytes in file image of segment (may be zero) Elf64_Xword p_memsz; // Num. of bytes in mem image of segment (may be zero) Elf64_Xword p_align; // Segment alignment constraint } Elf64_Phdr; 可以通过readelf -l []来获取ELF的pragram header信息。 $ readelf -l wifi_daemon Elf file type is EXEC (Executable file) Entry point 0x401c00 There are 9 program headers, starting at offset 64 Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flags Align PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040 0x00000000000001f8 0x00000000000001f8 R 8 INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238 0x000000000000001b 0x000000000000001b R 1 [Requesting program interpreter: /lib/ld-linux-aarch64.so.1] LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000 0x000000000000899c 0x000000000000899c R E 10000 LOAD 0x0000000000008b60 0x0000000000418b60 0x0000000000418b60 0x00000000000005b4 0x00000000000005e0 RW 10000 DYNAMIC 0x0000000000008b68 0x0000000000418b68 0x0000000000418b68 0x0000000000000270 0x0000000000000270 RW 8 NOTE 0x0000000000000254 0x0000000000400254 0x0000000000400254 0x0000000000000020 0x0000000000000020 R 4 GNU_EH_FRAME 0x0000000000008628 0x0000000000408628 0x0000000000408628 0x000000000000008c 0x000000000000008c R 4 GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 RW 10 GNU_RELRO 0x0000000000008b60 0x0000000000418b60 0x0000000000418b60 0x00000000000004a0 0x00000000000004a0 R 1 Section to Segment mapping: Segment Sections... 00 01 .interp 02 .interp .note.ABI-tag .hash .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame 03 .init_array .fini_array .data.rel.ro .dynamic .got .data .bss 04 .dynamic 05 .note.ABI-tag 06 .eh_frame_hdr 07 08 .init_array .fini_array .data.rel.ro .dynamic .got 从上可以看出一共有9各segment,与前面elf header信息中的Number of program headers:9对应。这里我们重点关注02和03的segment即可,因为这两个segment的类型是LOAD类型,每个segment就对应一个VMA,与我们后面关于虚拟地址到物理地址的映射有着非常重要的联系。 操作系统只关心段的权限(可读、可写、可执行),所以对于相同类型权限段可以合并到一起当作一个段来映射,所以通常的分类有一下三种: - 可读可执行:代码块为代表 - 可读可写:data块和BSS块为代表 - 只读:rodata块为代表 sections 下面是描述sections headers的结构体。 // Section header. struct Elf32_Shdr { Elf32_Word sh_name; // Section name (index into string table) Elf32_Word sh_type; // Section type (SHT_*) Elf32_Word sh_flags; // Section flags (SHF_*) Elf32_Addr sh_addr; // Address where section is to be loaded Elf32_Off sh_offset; // File offset of section data, in bytes Elf32_Word sh_size; // Size of section, in bytes Elf32_Word sh_link; // Section type-specific header table index link Elf32_Word sh_info; // Section type-specific extra information Elf32_Word sh_addralign; // Section address alignment Elf32_Word sh_entsize; // Size of records contained within the section }; 可以通过readelf -S []来读取ELF的section header的信息。 $ readelf -S wifi_daemon There are 29 section headers, starting at offset 0xae18: Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 [ 1] .interp PROGBITS 0000000000400238 00000238 000000000000001b 0000000000000000 A 0 0 1 [ 2] .note.ABI-tag NOTE 0000000000400254 00000254 0000000000000020 0000000000000000 A 0 0 4 [ 3] .hash HASH 0000000000400278 00000278 00000000000001a0 0000000000000004 A 5 0 8 [ 4] .gnu.hash GNU_HASH 0000000000400418 00000418 0000000000000024 0000000000000000 A 5 0 8 [ 5] .dynsym DYNSYM 0000000000400440 00000440 0000000000000618 0000000000000018 A 6 1 8 [ 6] .dynstr STRTAB 0000000000400a58 00000a58 00000000000003b8 0000000000000000 A 0 0 1 [ 7] .gnu.version VERSYM 0000000000400e10 00000e10 0000000000000082 0000000000000002 A 5 0 2 [ 8] .gnu.version_r VERNEED 0000000000400e98 00000e98 0000000000000060 0000000000000000 A 6 3 8 [ 9] .rela.dyn RELA 0000000000400ef8 00000ef8 0000000000000030 0000000000000018 A 5 0 8 [10] .rela.plt RELA 0000000000400f28 00000f28 00000000000005e8 0000000000000018 AI 5 22 8 [11] .init PROGBITS 0000000000401510 00001510 0000000000000018 0000000000000000 AX 0 0 4 [12] .plt PROGBITS 0000000000401530 00001530 0000000000000410 0000000000000000 AX 0 0 16 [13] .text PROGBITS 0000000000401940 00001940 00000000000038e4 0000000000000000 AX 0 0 64 [14] .fini PROGBITS 0000000000405224 00005224 0000000000000014 0000000000000000 AX 0 0 4 [15] .rodata PROGBITS 0000000000405238 00005238 00000000000033f0 0000000000000000 A 0 0 8 [16] .eh_frame_hdr PROGBITS 0000000000408628 00008628 000000000000008c 0000000000000000 A 0 0 4 [17] .eh_frame PROGBITS 00000000004086b8 000086b8 00000000000002e4 0000000000000000 A 0 0 8 [18] .init_array INIT_ARRAY 0000000000418b60 00008b60 0000000000000000 0000000000000008 WA 0 0 1 [19] .fini_array FINI_ARRAY 0000000000418b60 00008b60 0000000000000000 0000000000000008 WA 0 0 1 [20] .data.rel.ro PROGBITS 0000000000418b60 00008b60 0000000000000008 0000000000000000 WA 0 0 8 [21] .dynamic DYNAMIC 0000000000418b68 00008b68 0000000000000270 0000000000000010 WA 6 0 8 [22] .got PROGBITS 0000000000418dd8 00008dd8 0000000000000228 0000000000000008 WA 0 0 8 [23] .data PROGBITS 0000000000419000 00009000 0000000000000114 0000000000000000 WA 0 0 8 [24] .bss NOBITS 0000000000419118 00009114 0000000000000028 0000000000000000 WA 0 0 8 [25] .comment PROGBITS 0000000000000000 00009114 0000000000000033 0000000000000001 MS 0 0 1 [26] .symtab SYMTAB 0000000000000000 00009148 00000000000011a0 0000000000000018 27 103 8 [27] .strtab STRTAB 0000000000000000 0000a2e8 0000000000000a38 0000000000000000 0 0 1 [28] .shstrtab STRTAB 0000000000000000 0000ad20 00000000000000f4 0000000000000000 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings) I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown) O (extra OS processing required) o (OS specific), p (processor specific) 可以看出wifi_daemon中一共有29个section,与ELF header描述内容中的Number of section headers:29是匹配的。 进程虚拟地址空间布局 系统对虚拟地址空间进行布局,在2.3章节中描述了内核空间的划分,同样针对用户空间也有进行了划分。可以分为4类: - 栈:用于维护函数调用的上下文,栈在用户空间的最高地址处分配,地址是向下增长。 - 堆:用户程序动态分配内存的区域,当使用malloc分配内存时,虚拟地址空间将在这个范围,地址向上增长。 - MMAP:在栈和堆空间有一个MMAP区域,主要用于mmap系统调用的映射。包括文件映射(包含动态库、文件IO)和匿名映射。 - 可执行文件映像:存储可执行文件在内存的映像,装载器会将ELF内容读取或映射到这里。 可执行文件映像可再进行分类,前面章节描述了,程序最终编译临界成各个sections,如text,data,bss等等,但对于系统来说关注的是加载的方式,如读写执行权限,因此可执行文件映像的分类是按照权限划分的。如上分为只读权限(对应init,text等section),读写权限(对应.data,bss等)。 虚拟地址空间描述 Linux系统操作的是虚拟地址,访问实际内存需要将虚拟地址通过MMU查询页表,转化为物理地址。用户空间的虚拟地址可以按照如上图进行分为几个segment,每个segment都对应一个VMA。虚拟地址到物理地址的映射,是每个VMA到物理地址的映射。 VMA作为进程地址空间一块连续区域,使用struct vm_area_struct结构体进行描述。该结构体中描述了连续区域的起始地址和地址。 VMA之间通过双向链接连接在一起,在struct vm_area_struct中vm_next,vm_prev分别指向下一个VMA和上一个VMA,使用双向链表来组织VMA,便于进程虚拟地址对VMA的插入。 VMA同时又被加入到一棵红黑树中,在struct vm_area_struct中的vm_rb描述红黑树的节点,根节点在struct mm_struct mm_rb来描述,既然VMA通过链表串一起了,为什么再使用红黑树来组织,主要是使用红黑树能够加快进程搜索VMA的速度。 mm_struct数据结构中的pgd指向了该进程的页表页目录,每个进程都有自己一份独立的页表,当CPU第一次访问虚拟地址空间时,如果查询页表找不到对应的物理页,将会发生缺页异常,在缺页异常中,进行分配物理页面,当然如果页表没有创建,需要先申请物理页面创建页表,最后将物理页面填充到页表中,完成虚拟地址到物理地址的映射关系。 上图中数据结构的层级关系struct task_struct->struct mm_struct->struct vm_area_struct。 可以通过节点/proc/[pid]/maps来查看内存mappings,下面例子中每一行都表示一个VMA。可以man proc来查看各项参数意义。 address perms offset dev inode pathname 00400000-00452000 r-xp 00000000 08:02 173521 /usr/bin/dbus-daemon 00651000-00652000 r--p 00051000 08:02 173521 /usr/bin/dbus-daemon 00652000-00655000 rw-p 00052000 08:02 173521 /usr/bin/dbus-daemon 00e03000-00e24000 rw-p 00000000 00:00 0 [heap] ... 35b1800000-35b1820000 r-xp 00000000 08:02 135522 /usr/lib64/ld-2.15.so 35b1a1f000-35b1a20000 r--p 0001f000 08:02 135522 /usr/lib64/ld-2.15.so 35b1a20000-35b1a21000 rw-p 00020000 08:02 135522 /usr/lib64/ld-2.15.so 35b1a21000-35b1a22000 rw-p 00000000 00:00 0 35b1c00000-35b1dac000 r-xp 00000000 08:02 135870 /usr/lib64/libc-2.15.so 35b1dac000-35b1fac000 ---p 001ac000 08:02 135870 /usr/lib64/libc-2.15.so 35b1fac000-35b1fb0000 r--p 001ac000 08:02 135870 /usr/lib64/libc-2.15.so 35b1fb0000-35b1fb2000 rw-p 001b0000 08:02 135870 /usr/lib64/libc-2.15.so .. 7fffb2c0d000-7fffb2c2e000 rw-p 00000000 00:00 0 [stack] address: VMA对应的起始地址,对应struct vm_area_struct中的vm_start,vm_end。 perms:VMA的权限,r=read,w=write,x=execute,s=shared,p=private。s和p二选一,主要是判断当前的地址空间是进程私有,还是共享。 offset: 文件映射,表示此段虚拟内存起始地址在文件中以页为单位的偏移,匿名映射为0。 dev:所映射文件所属的设备号,匿名映射为0。 inode:映射文所属节点节点号,匿名映射为0。 pathname:文件映射,对应的就是映射的文件名。匿名映射,是此段虚拟内存在进程的角色,如heap,stack等。 是否可以查看进程虚拟内存都被谁占用了,对应的VMA的大小是否有增大趋势,可以用于判断内存泄露? 操作系统角度看可执行文件的装载运行 从操作系统角度看,一个进程最关键的特征是它拥有独立的虚拟地址空间,这使得它跟别的进程有差别。下面来看一个程序被执行比较通用的情形,流程如下: - 创建一个独立的虚拟地址空间。 - 建立执行程序虚拟空间与可执行文件的映射关系。 - 将CPU的指令寄存器设置成可执行文件的入口函数,启动运行。 - 运行过程中,通过缺页异常将指令、数据装载进内存。 (1)创建独立的虚拟地址空间 系统访问使用的是虚拟地址,虚拟地址通过查询页表找到对应的物理内存,因此最开始是创建好虚拟地址空间,而创建虚拟地址空间实际上并不是创建空间直接建立好跟物理内存的连续,而是先创建映射函数所需要的相应数据结构,比如task_struct,mm_struct等。对应页表的创建,实际上只分配了一个页目录就可以了,不需要设置页的映射关系,等实际程序访问的时候通过缺页异常才进行设置。 (2)建立执行程序虚拟空间与可执行文件的映射关系 上一个步骤建立了虚拟地址空间,这一步所做的建立虚拟空间与可执行文件的映射关系,因为程序执行时发生缺页异常,系统会从物理内存分配一块内存,然后将缺页从磁盘读取到内存中,再设置缺页的虚拟页和物理页的映射关系,这样程序就可以运行了。因此,当程序发生缺页异常时,需要知道程序当前的页在磁盘的那一个位置。 Linux系统将进程虚拟地址空间分配成多个段,这个段叫做虚拟内存区域(VMA,Virtual Memory Area)。如系统创建进程后,会设置一个.text段(原则上应该时多个sections的合并)的VMA。 (3)将CPU的指令寄存器设置可执行程序文件的入口函数 这一步就是将ELF文件头中保存的入口地址赋值为PC,然后启动运行。 (4)缺页异常 在上述步骤执行后,实际可执行文件的指令和数据都还没有装入到内存中,操作系统只是通过该可执行文件头部信息建立起可执行文件和进程虚拟内存空间直接的映射关系,当程序启动运行时,执行相关的虚拟地址,当发现这虚拟地址对应的物理页面为空,将会发生缺页异常,缺页异常会分配一块内存,然后将可执行文件的指令和数据从磁盘加载到内存中,后续就可以直接访问内存进行读写访问执行了。 VMA的操作函数 VMA查找 VMA插入 VMA合并与拆分 malloc函数 用户空间分配内存,不会每次申请都向linux内核做一个系统调用进行分配获取内存,而是在用户空间维持着一个缓冲池,这个缓冲池有自己的内存管理算法。当用户进行malloc时候,如果缓存池中有内存,就直接获取返回,如果缓存池中没有内存,就会下陷做系统调用到linux内核中获取内存。 用户空间通过系统调用向内核获取内存时分为两种情况:当分配的内存小于M_MMAP_THRESHOLD阈值时会使用brk系统调用来扩展堆空间,当分配内存大于M_MMAP_THRESHOLD阈值时,会使用mmap进行映射分配。M_MMAP_THRESHOLD通常为128K,用户可以通过调用mallopt函数来修改该阈值。 malloc通过brk方式申请的内存,free释放内存时,并不会归还给系统,而是缓存到malloc内存池中,待下次使用。 malloc通过mmap申请到的内存,free释放内存时,会把内存归还给系统,内存得到真正释放。 与malloc相关的函数 malloc系统调用流程 待补充 mmap函数 基本概念 mmap用于内存映射,将一段区域映射到自己的进程地址空间中。这段区域可以是文件页属性也可以是物理页属性,所以分为两种: - 文件映射:将文件映射到进程空间,文件存放在存储设备上(文件内容会以page cache缓存到物理内存中)。 - 匿名映射:没有文件对应的区域,内容在物理内存上。 mmap用于文件映射能提高读写效率,主要的差异点是常规的文件操作需要从磁盘到页缓存拷贝,然后内核空间到用户空间还有拷贝,有两次数据拷贝动作;而mmap操控文件,只需要从磁盘到用户主存一次拷贝,后续的读写直接对主存读写,相当于少了依次内核到用户空间的拷贝。 mmap针对进程是否可见,有分为两种: - 私有映射:数据源拷贝一次副本,进程之间互不影响。 - 共享映射:共享的进程都能看到。 根据排列组合就有4中映射情况: - 私有匿名映射:可以用于分配大的内存,如malloc堆空间。 - 共享匿名隐射:可用于父子进程间通信,在内存文件系统中创建/dev/zero设备。 - 私有文件映射:常用于动态库的加载,如代码段,数据段等。 - 共享文件映射:非父子之间的进程间通信,文件读写等。 实现原理 do_mmap函数调用流程待补充..... 举例mmap文件内存映射的实现过程,可以分为三个阶段: - 1.创建mmap虚拟地址空间VMA 如果mmap没有指定虚拟地址空间区域,则搜索一段空闲的连续虚拟地址空间,并分配一个vm_area_struct实例添加到红黑树和链表中。 - 2.建立VMA与文件物理地址(在磁盘那个位置)的映射关系 通过虚拟文件系统inode模块定位到文件在磁盘的位置,建立VMA与文件的联系。 call_mmap->file->f_op->mmap? - 3.访问文件对应的虚拟地址,引发缺页异常,将文件内容加载到内存 前面阶段,并没有将文件的数据拷贝到内存中,真正的文件读取是进程发起读写操作时。进程在读货写操作访问映射的虚拟地址空间,通过查询页表,发现这一段地址并不再物理页面上,引发缺页异常,于是先从磁盘加载数据到内存中。后续堆文件的读写,直接就对对应的物理内存读写,当改变了内容,系统会自动将脏页面写回到磁盘上,当前也可以强行同步(msync) 缺页异常 Linux系统有一个重要的特性就是用户“欺骗性”,如通过malloc申请了内存,但是实际上并没有分配内存给你,等实际访问内存的时候才会分配给你。用户很多重要的初始化操作只是针对虚拟内存的,虚拟内存实际对应的物理内存空间并没有分配,等实际需要访问的时候才会进行分配,因此当进程访问虚拟地址空间,发现虚拟地址空间没有与物理内存建立映射关系,处理器就会自动触发缺页异常(缺页中断)。下面是触发缺页异常的一些场景情形: 缺页异常会执行到对应的中断函数,会跟实际的处理器架构有些关系,在实际中缺页异常最终会调用到do_page_fault(arch/arm64/mm/fault.c)函数,接下来将会从这个函数进行重点分析。 do_page_fault 匿名页面 发生匿名页缺页异常,一般是①malloc/mmap分配进程地址空间区域,没有对应的物理内存将会触发分配。② 用户栈不够时,进行栈区的扩大处理。 匿名页面分配时,会判断页面是否可写,如果是只读权限,那么系统会分配一个zero page。Zero page是一个特殊的物理页(实际没有使用物理内存空间),里面值全部为0,zero page针对匿名页场景专门进行的优化,主要是节省内存和对性能的一定优化。当malloc或者mmap分配内存仅仅是进程地址空间中的虚拟内存,如果用程序需要读这个malloc分配的虚拟内存,那么系统会返回全0的数据,因此linux内核不必为这种情况单独分配物理内存,而是使用系统零页,当程序需要写入这个页面时就会触发一个缺页异常,于是缺页异常变成写时复制的缺页异常。malloc分配虚拟内存,有以下几种情况。 - malloc分配后,直接读内存,这时缺页异常,分配到的是zero page,PTE的属性是read only。 - malloc分配后,先读后写,先读的时候缺页异常分配的是系统零页,再写再触发缺页异常触发写时复制。 - malloc分配后,直接写内存,触发缺页异常,使用alloc_zerod_user_highpage_movable分配新页面。 文件页面 文件页面异常分为读文件异常,写私有文件异常,写共享文件异常。总体的思路是没有分配物理页面,就进行分配物理页面,然后将内容从文件中拷贝到物理页面中,再建立好页表。 - 读文件异常:会尝试多映射数据周围的内容,因为周围数据再次被命中的概率比较高,这样减少缺页异常次数。 - 写私有文件:写私有文件会发生写时复制,会先分配一块物理页面cow_page,先将文件内容读取文件缓存页(page cache),然后再将其内容复制到cow_page中。 - 写共享文件:写共享文件不会发生写时复制,如果mkwrite函数不为空,将会通知进程页面变成可写。同时会将页设置为脏页。 swap页面换入 当内存不足时,会把页面交换到磁盘swap分区中,当再次访问这块内存时会发生缺页异常,大致的流程就是搜索swap cache看页面是否在内存中,如果不在说明被交换出去了,那就需要从磁盘里面读出来,然后重新刷新页表,重新建立虚拟地址和物理页面的映射关系。 页面写时复制COW 通常有以下两种情况会触发写时复制(Copy on write,CoW)。 (1)父进程创建一个子进程,为了避免复制物理页,子进程和父进程以只读方式共享的匿名页和文件页,当有一个进程需要写只读页时,将会触发页错误异常,进程会拷贝一份新的物理页进行写。 (2)进程创建了一个私有文件映射,当进行读访问时,缺页异常将文件内容读取到page cache中,并将以只读方式跟虚拟页建立映射关系。当进程再对改内容进行写时,缺页异常会触发写时复制,为page cache创建一个副本,新建一个虚拟页与复制的物理页建立联系。 vm_normal_page从页表项得到页帧号,如果返回值为NULL,表示这是一个特殊的页映射,这种特殊的页映射只有页帧号,没有对应实际的物理页,具体是什么用途,需要再研究? 如上图,写时复制一共有四种情形。 - 写时复制:wp_page_copy - 可写且共享的特殊映射页面:wp_pfn_shared - 可写且共享的普通页面:wp_page_shared - KSM匿名页面(复用的页面):wp_page_reuse 下面重点看看wp_page_copy的流程: 1.为什么会产生page fault? Page fault是硬件提供的特性,由硬件触发,触发条件为CPU访问某线性地址时,如果没有找到对应可访问页表项,则由硬件直接触发page fault。 2.发生缺页的地址是否可以位于内核态地址空间? 有可能,内核地址空间发生缺页异常仅可能在vmalloc区,线性映射区域对应的页表在内核初始化就已经建立好了,所以这部分内存对应的虚拟地址空间不可能产生page fault。 RMAP 反向映射是物理页面page可以寻找到其对应的虚拟地址空间VMA。当进行页面回收的时候,就需要利用反向映射技术找到其对应的进程VMA,然后将VMA与当前页面断开映射关系,即可进行回收当前页面。 一个物理页面是可以同时被多个进程的虚拟页面映射的,但是一个虚拟页面只能映射一个物理页面。不同虚拟页面映射到同一物理页面的场景主要有子进程复制了父进程的VMA以及KSM机制的存在。 关键数据结构 基本原理 映射到一个进程的反向映射 static vm_fault_t do_anonymous_page(struct vm_fault *vmf) { ...... __anon_vma_prepare(vma) page = alloc_zeroed_user_highpage_movable(vma, vmf->address); page_add_new_anon_rmap(page, vma, vmf->address, false); ...... } 以匿名映射为例说明: 在缺页异常分配物理页时,会调用两个函数做RAMP相关的处理:__anon_vma_prepare,以及page_add_new_anon_rmap。 创建过程: (1)分配页面的时候,为每个VMA创建一个AVC,然后再创建一个AV。 (2)AVC->vma指向VMA,AVC->AV指向AV。 (3)将AVC添加到VMA->anon_vma_chain链表中。 (4)将AVC添加到AV->rb_root红黑树中。 (5)将page->mapping指向av。 反向映射过程: (1)通过page->mapping找到av。 (2)在av->rb_root红黑树中从根节点进行遍历avc。 (3)从avc中avc->vma找到vma。 void page_add_new_anon_rmap(struct page *page, struct vm_area_struct *vma, unsigned long address, bool compound) { int nr = compound ? thp_nr_pages(page) : 1; VM_BUG_ON_VMA(address < vma->vm_start || address >= vma->vm_end, vma); __SetPageSwapBacked(page); 设置page的标志位位PG_swapbacked,表示页面可以交换到磁盘。 if (compound) { VM_BUG_ON_PAGE(!PageTransHuge(page), page); /* increment count (starts at -1) */ atomic_set(compound_mapcount_ptr(page), 0); if (hpage_pincount_available(page)) atomic_set(compound_pincount_ptr(page), 0); __mod_lruvec_page_state(page, NR_ANON_THPS, nr); } else { /* Anon THP always mapped first with PMD */ VM_BUG_ON_PAGE(PageTransCompound(page), page); /* increment count (starts at -1) */ atomic_set(&page->_mapcount, 0); } __mod_lruvec_page_state(page, NR_ANON_MAPPED, nr); __page_set_anon_rmap(page, vma, address, 1); 设置页面位匿名映射 } static void __page_set_anon_rmap(struct page *page, struct vm_area_struct *vma, unsigned long address, int exclusive) { struct anon_vma *anon_vma = vma->anon_vma; anon_vma = (void *) anon_vma + PAGE_MAPPING_ANON; WRITE_ONCE(page->mapping, (struct address_space *) anon_vma); Page中的mapping指向anon_vma page->index = linear_page_index(vma, address); } 映射到多个进程的反向映射 未发生写时复制 父进程创建子进程时,如果没有还没有进行写操作只有读操作,为了节省内存,父子是共享物理页面的,只有当父子进程需要修改页面内容是,才会发生写时复制一份。 - 遍历父进程的VMA,子进程进行复制一份VMA。 - 每复制一份VMA,就创建一个AVC(下图的AVC_c),用于建立父子之间的桥梁联系。AVC_c(AVC_c->anon_vma)指向父AV并添加到父AV(AV->rb_root)红黑树中,同时AVC_c(AVC_c->vma)又指向子进程的VMA。这样在遍历父AV的红黑树,就能通过AVC_c找到子进程的VMA。 - 子进程创建属于自己的AVC/AV,并建立VMA,AVC,AV的联系。 - 子进程复制了父进程的pte,所以子进程的vma对应虚拟页面也父进程的虚拟页面同时指向物理页面page(二对一的情况)。 物理页面page寻找虚拟页面过程: - 通过page->mapping找到父进程的AV,如上图AV0。 - 遍历AV0的红黑树,这里找到两个AVC节点,分别是父AVC0节点以及父子进程桥梁节点AVC_c。 - 通过父AVC0找到父进程的VMA0(AVC0->vma指向父VMA0)。 - 通过桥梁AVC_c找到子进程的VMA1(AVC_c-vma指向子VMA1) 经过上述过程,物理页面page就可以找到与其对应的两个虚拟页面了。 发生写时复制 当父子进程的某一方出现写页面操作时,将会触发写时复制复制一份自己的物理页面,如上图,VMA1的pte指向复制的新物理页,同时物理页page->mapping指向AV1,这样copy page就能够通过AV1遍历其红黑树找到AVC1,进而通过AVC1找到VMA1。 疑问:上图中AVC_c依旧在AV0的红黑树中,所以父进程的物理页page依旧通过AV0找到子进程的VMA1,但是子进程实际的pte已经指向copy page了,跟父进程的page没有关系了。网上看到的说法是,为了解决这个问题,即使page找到了对应的VMA,会检查vma的页表是否确实映射到了此页,进而解决这个问题,需要进一步研究代码求证。 反向映射的应用 反向映射主要的应用场景如下: - Kswapd回收页面是,需要断开映射到物理页面的PTE。 - 页面迁移时,需要断开所有映射到页面的PTE。 -
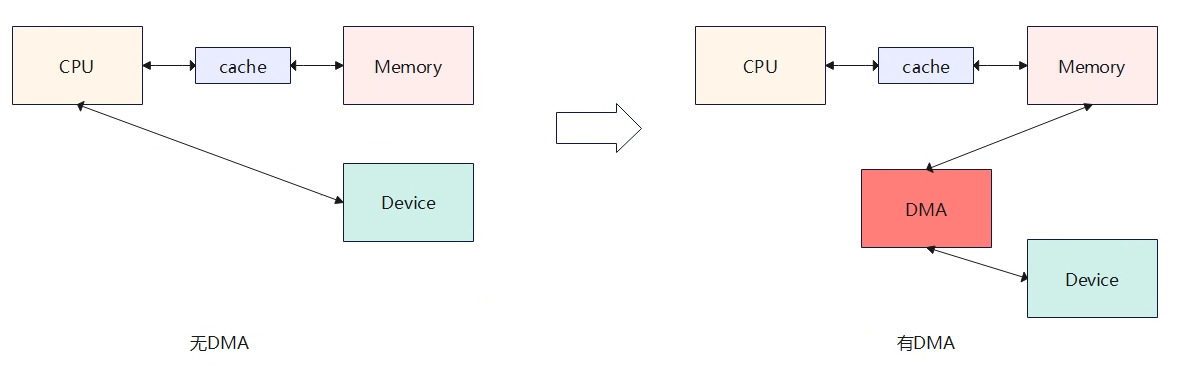
DMA与cache一致性
无DMA时:设备与内存之间数据搬运需要依靠CPU来完成。 有DMA时:DMA可以直接完成设备与内存直接的数据搬运,不需要cpu介入。 DMA的引入,优点是数据在内存和设备之间的搬运不需要CPU参与,这极大降低了CPU的负荷。但是也引入了新的问题,即cpu读取到的数据不一定是最新的,是因为中间cache的存在(如上图有DMA的情况),具体表现为当DMA修改从Device读取数据写入到memory后,即这块memory就被更新了,而此时cpu想要读取内存数据时,会先判断对应内存是否被cache命中,如果命中将直接读取cache中的数据内容不会经过内存,但是了cache中的数据并不是最新内存的数据,最新内存的数据已经被dma修改了。 为了解决上述DMA与Cache不一致的问题,引入了两种dma机制来处理:一致性DMA(Consistent mapping)和流式DMA(Stream mapping)。 (1)一致性DMA:可以认为是同步的(数据在搬运的时候就已经同步好了,没什么延时),也就是DMA和CPU之间看到的物理内存是一样的。DMA操作和CPU之间的主要隔阂主要是CPU会先访问cache,而DMA只操作物理内存,不会动cache。早期一致性DMA的实现主要就是让DMA处理的这段内存uncache,这样cpu和dma对内存的操作就是一致的,cpu每次访问都不会经过cache了,直接访问内存,这样导致的问题就是降低效率(相当于没有cache了),以至后来随着SOC的发展,SOC可以用硬件来做到CPU和外设的cache一致,简单来说就是DMA在处理设备和物理内存的搬运是,硬件会同时把cache也更新了。一致性DMA通常在驱动初始化的时候进行mapping一块内存,在驱动卸载时再进行unmapping掉。 (2)流式DMA:可以认为是异步的(数据搬运完成,需要进行刷一下cache相关的操作)。流式DMA没做一次DMA传输就需要mapping一次操作的内存,传输结束后进行unmapping。流式DMA之所以是异步,是因为等DMA搬运设备和内存的数据后,需要进行刷cache,刷cache需要根据方向来判断是clean cache还是invaild cache,当DMA将内存数据搬运到设备,则需要clean cache(清除cache数据,防止写回到内存);当DMA将设备数据搬运到内存,则需要invalid cache(使cpu获取的cache数据无效)。 与DMA相关的概念 DMA mapping 在早期,linux内核使用DMA操作的直接是物理地址,即利用phys_to_virt/virt_to_phys在CPU/memory/device直接处理DMA传输,这种代码不具备较好的移植性,随着硬件的发展,DMA地址和物理地址空间发生了变化,DMA地址空间已经不在等同于物理地址空间了,DMA地址空间到物理地址也需要转化,设备不能直接通过物理地址的方式访问物理内存,而需要通过IOMMU进行转化才能访问物理内存(Z->Y的变化,类似与虚拟地址到物理地址的变化)。 从CPU角度看到的地址是虚拟地址,要访问对应的物理地址需要页表将虚拟地址与物理地址映射起来。 从DMA角度看到的地址是总线地址,DMA的主要工作是负责设备与物理内存数据的搬运。当数据需要从物理内存搬运到设备时,物理地址B会通过host brigde转化为总线地址A,即可访问到设备。当数据从设备到物理内存搬运,总线地址Z会通过IOMMU转为为物理地址Y,即可访问物理内存。当CPU要访问设备时,虚拟地址与物理地址B通过ioremap进行映射,再通过host bridge访问到总线地址A,这样就建立起C->B->A的访问。 IOMMU 通过MMU的引入,Linux内存管理子系统解决了CPU内存离散的访问问题,对应用户空间,虚拟地址是连续的,但是对应的物理地址页帧确实可以离散的,对用户是屏蔽的,毫无感知的。但是在内核空间如外设(类DMA设备,不具MMU功能)想要访问内存,一般需要连续的物理内存地址,而连续的大块内存对长期允许的系统来说是奢侈的存在,因此引入了IOMMU,专门用于解决外设(DMA)无法访问连续物理内存的问题,对应外设角色来看,相当于也引入了虚拟地址的概念,IOMMU的用途就是将外设角度访问的虚拟地址转化为物理地址,这样即便物理内存不是连续的也没关系,虚拟地址连续就行,IOMMU会负责将外设访问的虚拟地址转化成物理地址,这样就解决了外设需要分配大块连续内存的问题,分配离散的物理内存也能满足要求了。 DMA传输方向 DMA_TO_DEVICE: 从内存到设备。 DMA_FROM_DEVICE:从设备到内存。 DMA_BIDIRECTIONAL:双向传输。 流式DMA需要指定方向,一致性DMA具有隐式的方向属性为双向(DMA_BIDIRECTIONAL),在方向属性性,如果不明确方向,可以使用DMA_BIDIRECTIONAL,由平台来保证,但这样会引入性能的额外开销。 cache的工作模式 Write-back:回写模式,cache内容更改不需要每次写回内存,直到新的cache要刷新或软件要求刷新才会写回 Write-through:写直通,每次强制将内容写回内存主要时为了内存与cache相一致。 Prefectching:一些cache允许处理器对cache line进行预取,以响应读请求,读取的相邻内容同时被读处理。 DMA 访问系统内存的限制 DMA负责设备与物理内存的数据搬运,那么DMA是否对系统内存访问无限制?DMA访问的内存还是有一些特点和要求的。 - 伙伴系统分配的内存:如kmalloc、kmem_cache_alloc分配的接口可以直接用于DMA mapping接口的API。 - vmalloc/kmap: 由于分配的内存是不联系的,对于DMA来使用比较麻烦。 - 全局变量(数组):一般可以用于DMA操作,但需要注意cacheline对齐,避免chache coherence问题。 DMA寻址范围限制 不同的硬件平台,器DMA的寻址范围可能会有限制,如系统总线寻址是64bit,但是设备的DMA驱动访问的只有24bit,也就只能访问16M以下的系统内存,因此系统提供了接口,用于确定设备DMA寻址访问声明。 int dma_set_mask_and_coherent(struct device *dev, u64 mask); 上面的接口同时设置一致性和流式DMA寻址范围。如果一致性和流式DMA的地址掩码不同,还可以分别设定,如下: int dma_set_mask(struct device *dev, u64 mask); //用于流式DMA地址掩码 int dma_set_coherent_mask(struct device *dev, u64 mask); //用于一致性DMA地址掩码 一致性DMA映射 一致性DMA映射,也称为静态映射,与dma_map_xxx函数的差异就是会分配好物理内存并建立好映射,内存是长期存在。 使用dma_alloc_coherent分配内存,一共有3种方式,①依次为先从设备驱动预留的内存进行分配,驱动预留的内存为在设备树中事先从物理内存预留了一块内存,该内存看起来不会加入到伙伴系统,专门留给驱动的dma分配。②如果驱动预留内存分配失败,则系统管理的物理内存中分配,这里会先从CMA中申请,CMA申请不到再从伙伴系统中获取。③最后从IOMMU的方式中分配内存。 流式DMA映射 与dma_alloc_coherent相比,dma_map_xxx该函数不会分配内存,只是建立好虚拟地址到DMA的映射关系(将分配好的内存转化成设备/DMA可访问的地址)。调用者必须保证虚地址的物理内存时连续的,且物理地址范围必须满足device中的dma_mask限制,dma_map_xxx调用等dma传输完成后,需要马上调用dma_unmap_xxx。dma_map_xxx有三个函数,区别主要表现在物理内存组织上,dma_map_sg将多个物理内存进行映射成一块连续内存,dma_map_single将一块连续物理内存进行映射;dma_map_page将一个物理页进行映射。 一块联系内存映射dma_map_single 多个连续物理内存映射dma_ma_sg 一个物理页映射dma_map_page -
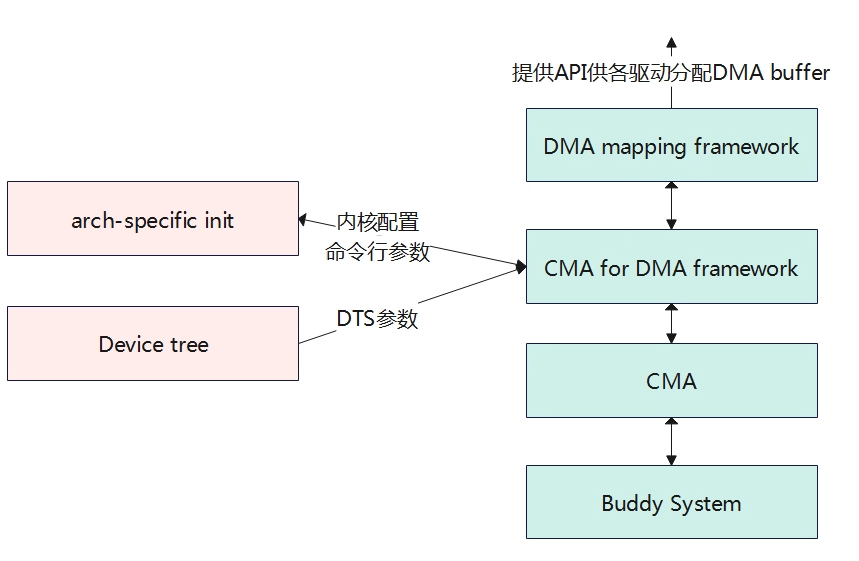
连续内存分配器CMA
CMA,contiguous memory allocator是内存管理子系统的一个模块,其主要为了解决分配连续的物理内存。尽管有了伙伴系统、slab分配器以及相关的内存回收机制,但是对于一些驱动如camera、display等模块一下需要分配比较大的一块连续物理内存,随着系统运行久之后,碎片化严重,分配较大的连续内存会变得困难,而同时又不能直接预留一块大的连续内存只用于连续物理内存分配,因为当模块不使用这些内存时,内存就浪费掉了。因此为解决这个问题,提出了CMA机制,先预留一部分内存出来专门用于CMA内存,当驱动没有分配使用的时候,这些memory可以给伙伴系统供其他模块正常使用,当需要分配连续的大内存时,就回收回来形成物理地址连续的大块内存。 上图可以看出CMA所处的位置,CMA向下是基于伙伴系统,向上是提供给DMA的封装接口,最终用户通过操作DMA buffer来分配和释放内存。CMA的区域有两种方式可以进行配置,分别是内核命令行参数配置和DTS设备树的方式配置。 struct cma { unsigned long base_pfn; 物理地址起始页帧号 unsigned long count; 区域的总页数 unsigned long *bitmap; 页的分配情况0表示free,1表示已分配。 unsigned int order_per_bit; 每次分配/释放对应的2^order 页,与bitmap的bit对应 struct mutex lock; #ifdef CONFIG_CMA_DEBUGFS struct hlist_head mem_head; spinlock_t mem_head_lock; #endif const char *name; }; extern struct cma cma_areas[MAX_CMA_AREAS]; extern unsigned cma_area_count; 内核使用struct cma结构体来描述cma区域,系统中可能有多个cma区域,使用一个全局的数组来描述所有的cma区域struct cma cma_areas[MAX_CMA_AREAS]; 如上图,cma_areas 0号区域,物理页号从0开始,每块内存由4页物理帧组成,目前只分配了第0块。 CMA区域创建 创建CMA区域有两种方式:第一种方式是通过设备树DTS的配置方式,另一种是根据命令行或宏配置方式。 设备数的方式创建 /* global autoconfigured region for contiguous allocations */ linux,cma { compatible = "shared-dma-pool"; reusable; size = <0x4000000>; alignment = <0x2000>; linux,cma-default; }; CMA的内存区域通过以上设备树信息来进行描述,对节点的解析在rmem_cma_setup函数中进行。 static int __init rmem_cma_setup(struct reserved_mem *rmem) { phys_addr_t align = PAGE_SIZE << max(MAX_ORDER - 1, pageblock_order); phys_addr_t mask = align - 1; unsigned long node = rmem->fdt_node; bool default_cma = of_get_flat_dt_prop(node, "linux,cma-default", NULL); (1)解析linux,cma-default节点。 struct cma *cma; int err; if (size_cmdline != -1 && default_cma) { pr_info("Reserved memory: bypass %s node, using cmdline CMA params instead\\n", rmem->name); return -EBUSY; } (2)CMA对应的reserved memory节点必须有reusable属性,不能有no-map属性。 reusable属性才能被伙伴系统回收使用。 if (!of_get_flat_dt_prop(node, "reusable", NULL) || of_get_flat_dt_prop(node, "no-map", NULL)) return -EINVAL; if ((rmem->base & mask) || (rmem->size & mask)) { pr_err("Reserved memory: incorrect alignment of CMA region\\n"); return -EINVAL; } (3)解析出来的参数进行初始化CMA区域 err = cma_init_reserved_mem(rmem->base, rmem->size, 0, rmem->name, &cma); if (err) { pr_err("Reserved memory: unable to setup CMA region\\n"); return err; } /* Architecture specific contiguous memory fixup. */ dma_contiguous_early_fixup(rmem->base, rmem->size); if (default_cma) dma_contiguous_default_area = cma; rmem->ops = &rmem_cma_ops; rmem->priv = cma; pr_info("Reserved memory: created CMA memory pool at %pa, size %ld MiB\\n", &rmem->base, (unsigned long)rmem->size / SZ_1M); return 0; } RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup); rmem_cma_setup函数主要解析设备树,获取cma区域的地址及大小,然后调用cma_init_reserved_mem函数从全局数组struct cma cma_areas[MAX_CMA_AREAS]获取一个cma进行初始化设置。 int __init cma_init_reserved_mem(phys_addr_t base, phys_addr_t size, unsigned int order_per_bit, const char *name, struct cma **res_cma) { struct cma *cma; phys_addr_t alignment; /* Sanity checks */ if (cma_area_count == ARRAY_SIZE(cma_areas)) { pr_err("Not enough slots for CMA reserved regions!\\n"); return -ENOSPC; } if (!size || !memblock_is_region_reserved(base, size)) return -EINVAL; /* ensure minimal alignment required by mm core */ alignment = PAGE_SIZE << max_t(unsigned long, MAX_ORDER - 1, pageblock_order); /* alignment should be aligned with order_per_bit */ if (!IS_ALIGNED(alignment >> PAGE_SHIFT, 1 << order_per_bit)) return -EINVAL; if (ALIGN(base, alignment) != base || ALIGN(size, alignment) != size) return -EINVAL; /* * Each reserved area must be initialised later, when more kernel * subsystems (like slab allocator) are available. */ cma = &cma_areas[cma_area_count]; (1)从全局数组中获取一个cma if (name) snprintf(cma->name, CMA_MAX_NAME, name); else snprintf(cma->name, CMA_MAX_NAME, "cma%d\\n", cma_area_count); (2)设置cma相关的参数 cma->base_pfn = PFN_DOWN(base); cma->count = size >> PAGE_SHIFT; cma->order_per_bit = order_per_bit; *res_cma = cma; cma_area_count++; totalcma_pages += (size / PAGE_SIZE); return 0; } 命令行或宏方式创建 内核还提供通过内核启动参数或宏的方式来进行配置,本章节重点描述内核启动参数的方式,这里的启动参数一般是uboot传递过来的参数。 env.cfg earlycon=uart8250,mmio32,0x02500000 initcall_debug=0 console=ttyAS0,115200 nand_root=/dev/nand0p4 mmc_root=/dev/mmcblk0p4 nor_root=/dev/mtdblock4 init=/init loglevel=8 selinux=0 cma=64M mac= wifi_mac= bt_mac= specialstr= keybox_list=hdcpkey,widevine 笔者系统中内核的启动参数配置在env.cfg中,如下cma的大小配置为64M。内核代码中通过函数dma_contiguous_reserve进行获取cmdline或宏配置的cma大小。 void __init dma_contiguous_reserve(phys_addr_t limit) { phys_addr_t selected_size = 0; phys_addr_t selected_base = 0; phys_addr_t selected_limit = limit; bool fixed = false; pr_debug("%s(limit %08lx)\\n", __func__, (unsigned long)limit); (1)获取cmdline中传入的cma size大小和地址。 if (size_cmdline != -1) { selected_size = size_cmdline; selected_base = base_cmdline; selected_limit = min_not_zero(limit_cmdline, limit); if (base_cmdline + size_cmdline == limit_cmdline) fixed = true; } else { 这里是宏定义的方式 #ifdef CONFIG_CMA_SIZE_SEL_MBYTES selected_size = size_bytes; #elif defined(CONFIG_CMA_SIZE_SEL_PERCENTAGE) selected_size = cma_early_percent_memory(); #elif defined(CONFIG_CMA_SIZE_SEL_MIN) selected_size = min(size_bytes, cma_early_percent_memory()); #elif defined(CONFIG_CMA_SIZE_SEL_MAX) selected_size = max(size_bytes, cma_early_percent_memory()); #endif } if (selected_size && !dma_contiguous_default_area) { pr_debug("%s: reserving %ld MiB for global area\\n", __func__, (unsigned long)selected_size / SZ_1M); (2)获取到cma区域后,进行初始化 dma_contiguous_reserve_area(selected_size, selected_base, selected_limit, &dma_contiguous_default_area, fixed); } } dma_contiguous_reserve_area函数最终还是会调用到cma_init_reserved_mem,进而获取一个cma实例,然后进行初始化cma结构体。 CMA初始化 static int __init cma_init_reserved_areas(void) { int i; 遍历CMA数组,进行初始化 for (i = 0; i < cma_area_count; i++) cma_activate_area(&cma_areas[i]); return 0; } core_initcall(cma_init_reserved_areas); 主要是遍历cma_areas数组,进行初始化。 static void __init cma_activate_area(struct cma *cma) { unsigned long base_pfn = cma->base_pfn, pfn; struct zone *zone; (1)计算需要的bitmap大小,然后进行分配。主要受count和bit的影响。 cma->bitmap = bitmap_zalloc(cma_bitmap_maxno(cma), GFP_KERNEL); if (!cma->bitmap) goto out_error; /* * alloc_contig_range() requires the pfn range specified to be in the * same zone. Simplify by forcing the entire CMA resv range to be in the * same zone. */ WARN_ON_ONCE(!pfn_valid(base_pfn)); (2)判断物理页是否都在一个zone区,需要在同一个zone区。 zone = page_zone(pfn_to_page(base_pfn)); for (pfn = base_pfn + 1; pfn < base_pfn + cma->count; pfn++) { WARN_ON_ONCE(!pfn_valid(pfn)); if (page_zone(pfn_to_page(pfn)) != zone) goto not_in_zone; } (3)将物理页释放到伙伴系统中去。 for (pfn = base_pfn; pfn < base_pfn + cma->count; pfn += pageblock_nr_pages) init_cma_reserved_pageblock(pfn_to_page(pfn)); spin_lock_init(&cma->lock); #ifdef CONFIG_CMA_DEBUGFS INIT_HLIST_HEAD(&cma->mem_head); spin_lock_init(&cma->mem_head_lock); #endif return; not_in_zone: bitmap_free(cma->bitmap); out_error: /* Expose all pages to the buddy, they are useless for CMA. */ for (pfn = base_pfn; pfn < base_pfn + cma->count; pfn++) free_reserved_page(pfn_to_page(pfn)); totalcma_pages -= cma->count; cma->count = 0; pr_err("CMA area %s could not be activated\\n", cma->name); return; } CMA应用 DMA的申请 struct page *dma_alloc_from_contiguous(struct device *dev, size_t count, unsigned int align, bool no_warn) { if (align > CONFIG_CMA_ALIGNMENT) align = CONFIG_CMA_ALIGNMENT; return cma_alloc(dev_get_cma_area(dev), count, align, no_warn); } DMA的释放 bool dma_release_from_contiguous(struct device *dev, struct page *pages, int count) { return cma_release(dev_get_cma_area(dev), pages, count); } 对内核的申请和释放提供给用户使用的分配是dma_alloc_from_contiguous和dma_release_from_contiguous,其调用的是cma_alloc和cma_release来实现的。 cma_alloc指定CMA areas上分配count个连续的page frame,具体就是遍历bitmap看是否有可用内存,如果有就向伙伴系统申请内存,如果伙伴系统将对应的内存挪给其他应用了,那么需要进行页面迁移、页面回收等操作回收回来。 ION 待补充 -

slub分配器
伙伴系统内存分配是以物理页面4KB为单位,但是实际使用的时候不会一下使用到4KB。实际使用中很多情况会以字节为单位。因此为了更精确的划分使用内存,linux内核在伙伴系统之上使用slab分配器来进行管理。截止目前linux内核中从最初slab发展到现在,衍生了slub,slob三种方式。Linux内核通过配置,选择其中一种。本章节主要围绕slub分配器进行说明。 乒乓球的管理 某公司的组织架构如上,公司划分为多个中心(事业部),各事业部再划分为多个二级部门,员工所在的部门就在各二级部门。 公司有一批数量有限的乒乓球作为全公司的公有资产,提供给员工用于日常借用。乒乓球以盒装为单位,每盒有4个,并对盒和球都进行了编号,球归还是也要与盒子对应。为了有限管理这批乒乓球,假设有如下规定: - 兵乓球被借出去需要明确知道谁借出去了,便于兵乓球资产追溯管理。 - 闲置的球能尽快收回,以便其他人能够使用,使兵乓球利用最大化。 - 员工在借用乒乓球时需要经过部门->中心->公司各级领导的审批。 当前出现一个问题,就是员工想打球的时候,每次都要跨多级走流程,时间周期比较长。好不容易有个空闲个时间想打个球,等漫长的流程走完活又来了,没时间打了,但是也不能提前先把球借了,闲置屯着,这样别人想打也打不了,每个人都这样,那实际想打球的也无球可打。 为了解决这个问题,小明同学于是设计了这么一套方案,让员工想打球的时候能够快速获得兵乓球,也让公司的球能够利用最大化。 借球 部门主管向公司申请一盒的球(每盒有4个),然后将球分给D同学。并将该盒乒乓球做标记,在部门内部宣导,此后谁要是向借用球,可直接从该盒从获取,自觉做好登记皆可(不再需要走漫长流程)。 有一天部门集体运动,一下子需要多个球,部门主管发现原来的一盒已经不够了,所以又向公司再借了3盒(公司以盒为单位借出,方便管理)。 1、2、3号盒球已经全部借出,所以部门没有再管理了(盒子没啥好管理的,由对应借出的同学共同保管盒子,盒子变成没人要的“孩子”),部门当前管理的是4号盒子(盒子里面还有球,如果还有谁要借,自己拿并自觉做好登记就行)。 还球 借球人借球时需记住自己从那个盒子里面拿的球,还球时需要找到对应的盒子还球。1号、2号、3号盒分别有人归还了球,但是还没有还满,此前的空盒子是不需要管理的,但是现在盒子里面现在有球了,那必须得管理起来了(一旦盒子非空,就需要管理起来了),直接退还给公司也不行啊,一个是盒子没还满,另外一个就是下次又有大需求量还得走流程申请慢。 所以索性部门先将这些盒子管理起来,当前部门累计球数有9个球,闲置在二级部门太多球,也不行,每个二级部门都闲置很多球,球总有耗尽的时候,就有可能其他二级部门的员工没法获得球了,于是公司做了规定,每个部门闲置的球数不能大于4个,因此只有1号和2号盒子可以继续由部门管理,而3号盒子可以不归还公司,但可以由中心先保管。 当盒子不再为空时,先由部门进行管理,当部门的球数闲置超过一定数量后,需要交给由中心管理,交给中心管理的单位也是以盒子为单位(还球的人是根据盒子编号找还球的),这样的好处就是,当有该中心的其他二级部门需要借用球是,发现部门没球了,可以先中心是否有球,如果中心有,那就从中心拿就行,不用从公司申请,这样流程虽然没这么快,但相比跟公司申请的流程也有些优化。 长期进行下去,中心可能会很多个盒子,同时有些盒子是满的(球都还完了),中心也不能由太多闲置球,否则其他中心就可能没法从公司申请到球了,所以公司规定,对中心管理的盒子数量进行了闲置,如盒子数量不能超过10个,当超过10个时,满盒子的球需要归还给公司。 再论借球 当二级部门员工进行借球时,可以从4号盒子免报备申请直接登记拿球就好,这样的借球周期是最短的。而1号和2号盒子虽也归部门管理,但是员工不能从这些盒子里面拿,为了管理效率,二级部门只开个了一个盒子的权限(免报备直接登记即可获取),所以借球只能先从4号盒子拿,当4号盒子被拿完了之后,就需要跟主管报备,看部门还没有备用,发现还有,那就将1号盒子再拿出去,此后大家就又可以从1号盒子免报备借球。当部门没有备用球了,就先问中心有没有,如果中心有,那就将先用中心的,从中心拿到的盒子就归部门管理了。如果中心也没有了,那就只能走流程从公司申请了。 slub 基本原理 一块缓存 = nslab,slab = m * obj,slab = k page。系统从伙伴系统中分配一个或多个连续的物理页组成一个slab,然后将slab切分为n个相同大小的内存(obj),提供给linux内核系统使用,这些相同obj大小组成一个集合。 可以通过cat /proc/slabinfo查看系统中slab的信息。 actives_objs:已经分配出去的对象数量 num_objs:一共有多少个对象,包含使用的和未使用的。 objsize:每个对象的大小是多少,单位是字节 objperslab:每个slab中的对象数量是多少。 pagesperslab:每个slab对应的page数量 limit/batchcount/sharedfactor:这些是可调整的参数,使用slub分配器没有使用 actives_slabs: 非游离状态的slab数量 nums_slabs:一共有多少slab sharedavail:待记录 slub函数接口 关键数据结构 设计思想 为什么kmem_cache中分为每个cpu分配对应有缓存池,每个节点有对应的缓存池。每个cpu分配的缓存池又再划分为当前正在使用的缓存slab,以及备用缓存slab(Per-CPU partial)? 访问Per-CPU slab是不需要加锁的,所以获取速度很快。访问node slab是需要加锁的,因为这是多个cpu共享的slab,访问速度慢。 而中间的Partial slab是方便Current slab的,系统分配slab必须要从current slab中分区对象,当current slab对象使用完时,就会从依次L2从L3中获取新的slab变成Per-CPU current。因为L3是需要加锁,为了进一步解决这速率问题,中间加了Per-CPU partial slab,当Per-CPU current slab中的所有对象被分配完后将会被移除变成游离状态,而当系统释放当前处理游离状态的full slab中对象时其就会变成部分full 对象的slab,其会被再次从游离状态添加到链表中等待系统从中分配,因此这个slab就会被添加到Partial slab链表中,当下次current slab中没有可用对象时,再将其Partial 链表中的slab置为current slab,这样就不用从Node Partial slab中获取,减少锁的使用,提高系统使用率。 kmem_cache struct kmem_cache是管理slub分配器的的基础数据结构。 struct kmem_cache { struct kmem_cache_cpu __percpu *cpu_slab; 一个cpu对应一个本地内存缓存池 slab_flags_t flags; unsigned long min_partial; 限制struct kmem_cache_node中partial链表slab的数量,如果slab数量超过这个值,那么多余的slab需要被释放会伙伴系统。 unsigned int size; 分配object的大小,包含一些管理数据。 unsigned int object_size; object对象的内存大小,用户层每次分配大小。 struct reciprocal_value reciprocal_size; unsigned int offset; 用于寻找object的地址 #ifdef CONFIG_SLUB_CPU_PARTIAL /* Number of per cpu partial objects to keep around */ unsigned int cpu_partial; 每CPU中slab的空闲对象最大值,当超过这个值,需要将slab转移到kmem_cache_node的partial链表 #endif struct kmem_cache_order_objects oo; 低16代表一个slab中的object数量,高16代表一个slab需要多个page数量。 /* Allocation and freeing of slabs */ struct kmem_cache_order_objects max; struct kmem_cache_order_objects min; gfp_t allocflags; /* gfp flags to use on each alloc */ int refcount; /* Refcount for slab cache destroy */ void (*ctor)(void *); unsigned int inuse; /* Offset to metadata */ unsigned int align; /* Alignment */ unsigned int red_left_pad; /* Left redzone padding size */ const char *name; /* Name (only for display!) */ struct list_head list; /* List of slab caches */ #ifdef CONFIG_SYSFS struct kobject kobj; /* For sysfs */ #endif #ifdef CONFIG_SLAB_FREELIST_HARDENED unsigned long random; #endif #ifdef CONFIG_NUMA /* * Defragmentation by allocating from a remote node. */ unsigned int remote_node_defrag_ratio; #endif #ifdef CONFIG_SLAB_FREELIST_RANDOM unsigned int *random_seq; #endif #ifdef CONFIG_KASAN struct kasan_cache kasan_info; #endif unsigned int useroffset; /* Usercopy region offset */ unsigned int usersize; /* Usercopy region size */ struct kmem_cache_node *node[MAX_NUMNODES];NUMA系统中,每个node都有一个slab缓存池。 }; kmem_cache_cpu 每个cpu都有个自己的slab缓存池,使用struct kmem_cache_cpu来描述每个cpu自己所属的缓存池. struct kmem_cache_cpu { void **freelist; 指向下一个可用的object地址 unsigned long tid; /* Globally unique transaction id */ struct page *page; 指向当前正在使用的slab地址,只有一个slab。复用struct page来描述一个slab #ifdef CONFIG_SLUB_CPU_PARTIAL struct page *partial; 指向slab中只有一部分空闲object的地址,可能存在多个部分空闲对象的slab,slab直接通过struct page中的next链表进行串联起来。 与上一个的区别:这是一个slab集合,而上一个只有一个slab,表示正在使用的slab ,当正在使用的slab中object对象全部用完后,就会变成一个full slab将会被游离出去,而当slab中某个object被释放后,就变成了存在部分空闲对象的slab,这个slab将会被重新被添加到partial中去。 #endif local_lock_t lock; /* Protects the fields above */ #ifdef CONFIG_SLUB_STATS unsigned stat[NR_SLUB_STAT_ITEMS]; #endif }; kmem_cache_node struct kmem_cache_node { spinlock_t list_lock; #ifdef CONFIG_SLUB unsigned long nr_partial; 节点中slab的数量 struct list_head partial; 用于将各个slab串起来的链表 #ifdef CONFIG_SLUB_DEBUG atomic_long_t nr_slabs; atomic_long_t total_objects; struct list_head full; #endif #endif }; struct page 复用struct page结构体来描述slub。 struct page { unsigned long flags; 设置标志位,PG_slab,表示页属于SLUB内存管理器 union { struct { /* slab, slob and slub */ union { struct list_head slab_list; 用于将slab添加到partial部分空闲链表 struct { /* Partial pages */ struct page *next; int pages; /* Nr of pages left */ int pobjects; /* Approximate count */ }; }; struct kmem_cache *slab_cache; /* not slob */索引page所所属的kmem_cache void *freelist; /* first free object */ 指向slab中第一个空闲对象 union { void *s_mem; /* slab: first object */ unsigned long counters; /* SLUB */ struct { /* SLUB */ unsigned inuse:16; 当前slab已分配对象的数量 unsigned objects:15; 当slab所包含对象的总数 unsigned frozen:1; slab是否缓存到Per-CPU缓存池(冻结), }; }; }; } _struct_page_alignment; slub重要概念 内核中通过一下配置来使能SLUB内存管理。 CONFIG_SLUB_DEBUG=y CONFIG_SLUB=y CONFIG_SLAB_MERGE_DEFAULT=y CONFIG_SLUB_CPU_PARTIAL=y CONFIG_MEMCG_KMEM=y # CONFIG_SLAB_FREELIST_RANDOM is not set # CONFIG_SLAB_FREELIST_HARDENED is not set 对象内存组织 对象的内部组织如上,有两种布局方式,主要区别是指向下一个空闲对象的指针存储方式不同。当flags设置了SLAB_TYPESAFE_BY_RCU/SLAB_POISON/ctor构造函数不为空则使用第一种方式,即下一个空闲对象的指针放到当前空闲对象的末端,占据8个字节(64bit)空间;反之使用第二种方式,复用当前对象的空间,存放下一个对象的地址再起始地址。 同时如果使能了CONFIG_SLUB_DEBUG,对象内部的布局会新增用于跟踪分配/释放的用户,便于调试。下面是4个对象的示意图。 struct kmem_cache_cpu::freelist和struct page::freelist这两个都是用于指向第一个空闲对象的地址,其中struct page * page->freelist指向内存节点空闲链表slab中的第一个空闲对象,当这个slab被设置为活动slab后,表示当前该slab正在被使用,page->frozen=1,表示已经处于冻结,那么page->freelist=NULL,slab中第一个空闲对象地址被存放到cpu_slab->freelist中。在分配对象时,值需要将当前freelist地址返回,让后将freelist地址更新到下一个空闲对象的起始地址即可。 slub的挂载和活动的slub 系统中的Slub的可以认为被挂载在4个地方: - 正在使用的slub(只有一个slub):cpu_slab->page指向的slub。 - Per-CPU partial上的slub:cpu_slab->partial指向的slub,用链表组织起来,可以存在多个。 - Node节点partial的slub:node->partial指向的slub,用链表组织起来,每个节点对应一个链表,每个链表有可以多个slub。 - 游离状态的slub:前三种slub中的至少还有有部分对象未被使用,处于空闲,当slub中所有对象都被用完时,将会移除,相当于游离状态,如果打开了SLUB_DEBUG,这些slub会被串到链表上。 分配内存对象,都是从kmem_cache中cpu_slab->freelist上获取,该slub为正在使用的slub,也称为活动的slub(自己命名的),即使当cpu_slab->freelist为空或者cpu_slab->page为空,从Per-CPU partial或者Node partial中获取slub时,其就会被设置为活动的slub。 创建kmem_cache 分配slub cache 第一次分配 Slub刚创建的时候并没有实际分配内存,所以kmem_cache中无论时cpu_slab还是node节点中,都没有slab缓存,第一次申请的时候会从伙伴系统分配页面生成一个slab,然后取其中一个object返回给系统。此后,在没有分配完成当前slab中的object时,分配内存直接返回freelist就是对应的空闲object内存。 从Per CPU partial中分配获取 从当前活动的slab中无法分配到object,那就从Per CPU partial上进行获取一个slab进行分配,设置为活动的slab,此前的活动的slab就会被游离出去(full slab,如果开了SLUB DEBUG,会添加到这个debug链表中,如果没有开,就相当于没有要的孩子,当释放对象的时候会通过对应的slab描述符号相关成员找出来。)。 从Node Partial中获取 如果从Per CPU partial中依旧没法后去到slab,就会从node partial中获取slab,然后将其设置为活动的slab,此前活动的slab设置为游离状态。 释放slub cache Slab中对象部分被使用(非游离):① ② ③场景 (1)释放了obj后,slab中还存在部分obj未释放:直接释放,建立好空闲obj之间的联系即可。 (2)释放了obj后,slab所有的obj都为空闲:如果在node partial上,nr_partial>min_partial,表明节点上存在的slab数量超过上限,空闲的slab会回收到伙伴系统中;如果是在Per-CPU partial上,管理的slab中空闲object数量大于cpu_partial(kmem_cache成员),将该slab移动到node partial链表上管理。 Slab中对象全部被使用(游离):④⑤场景 释放了obj之后,slab变成部分空闲的slab,由于此前是处于游离状态,没有添加到对应链表管理(未开SLUB DEBUG),当变成部分空闲是,就需要将其进行管理。首先尝试将slab添加到Per-CPU partial中,如果Per-CPU超过阈值没法管理了,就添加到Node parital中。 kmalloc 函数接口 kmalloc实现 static __always_inline void *kmalloc(size_t size, gfp_t flags) { 1.判断参数是否为常数 if (__builtin_constant_p(size)) { #ifndef CONFIG_SLOB unsigned int index; #endif if (size > KMALLOC_MAX_CACHE_SIZE) return kmalloc_large(size, flags); #ifndef CONFIG_SLOB index = kmalloc_index(size); if (!index) return ZERO_SIZE_PTR; return kmem_cache_alloc_trace( kmalloc_caches[kmalloc_type(flags)][index], flags, size); #endif } return __kmalloc(size, flags); 2.直接走这里 } void *__kmalloc(size_t size, gfp_t flags) { struct kmem_cache *s; void *ret; 1.如果分配空间大于KMALLOC_MAX_CACHE_SIZE,直接从伙伴系统进行分配 if (unlikely(size > KMALLOC_MAX_CACHE_SIZE)) return kmalloc_large(size, flags); 2.创建slab的数据结构,实际上建立的是全局kmem_cache s = kmalloc_slab(size, flags); if (unlikely(ZERO_OR_NULL_PTR(s))) return s; 3.slab分配器 ret = slab_alloc(s, flags, _RET_IP_, size); trace_kmalloc(_RET_IP_, ret, size, s->size, flags); ret = kasan_kmalloc(s, ret, size, flags); return ret; } struct kmem_cache *kmalloc_slab(size_t size, gfp_t flags) { unsigned int index; struct kmem_cache *s = NULL; if (size KMALLOC_MAX_CACHE_SIZE)) return NULL; index = fls(size - 1); } trace_android_vh_kmalloc_slab(index, flags, &s); if (s) return s; 2.在全局kmalloc_caches数组中找到对应的kmem_cache示例返回。 return kmalloc_caches[kmalloc_type(flags)][index]; } static u8 size_index[24] __ro_after_init = { 3, /* 8 */ 4, /* 16 */ 5, /* 24 */ 5, /* 32 */ 6, /* 40 */ 6, /* 48 */ 6, /* 56 */ 6, /* 64 */ 1, /* 72 */ 1, /* 80 */ 1, /* 88 */ 1, /* 96 */ 7, /* 104 */ 7, /* 112 */ 7, /* 120 */ 7, /* 128 */ 2, /* 136 */ 2, /* 144 */ 2, /* 152 */ 2, /* 160 */ 2, /* 168 */ 2, /* 176 */ 2, /* 184 */ 2 /* 192 */ }; 启动阶段创建kmem_cache 系统启动初期调用create_kmalloc_caches创建多个管理不同大小对应的kmem_cache,最大的size一般是8K,也就是对应的是kmalloc-8192,当系统通过kmalloc申请内存时,会直接从其中获取。 void __init create_kmalloc_caches(slab_flags_t flags) { int i; enum kmalloc_cache_type type; if (android_kmalloc_64_create) for (type = KMALLOC_NORMAL; type -
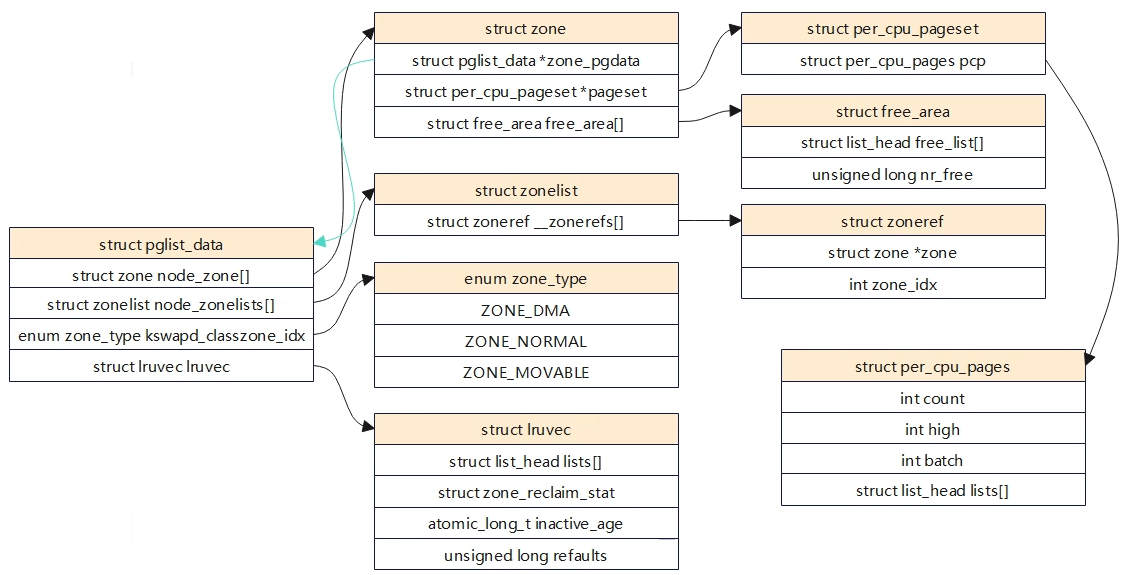
伙伴系统
相关结构体 核心结构体 struct pglist_data: 节点的描述,arm64 UMA架构中,只有一个节点。 struct zone node_zone[]:是一个数组,每个元素表示一个内存区域所对应的 struct zone 结构体。从名字可以看出,此数组的长度为 MAX_NR_ZONES,即它最多可以包含 MAX_NR_ZONES 个元素,因此,此数组通常用于描述系统所能支持的所有内存区域。这些内存区域可能包括不同类型(例如,DMA、普通或高端)和大小的内存区域。 struct zonelist node_zonelists[]:仅在 NUMA 架构系统中使用。它也是一个数组,每个元素表示一个 NUMA 节点所对应的内存区域所组成的链表。它是为了支持 NUMA 系统中的内存分配而设计的。在 NUMA 系统中,每个节点只能访问一部分物理内存,因此需要将所有可访问的内存区域组成一个链表供内存分配器使用。从名字可以看出,此数组的长度为 MAX_ZONELISTS,即它最多可以包含 MAX_ZONELISTS 个元素,因此,此数组通常用于描述系统所支持的所有 NUMA 节点。 struct lruvec lruvec:用于处理该节点的页面回收 struct per_cpu_pageset: pageset用于实现冷热分配器,内核页时热的意味着页已经加载到CPU高速缓存,与在内存中的页相比,其数据能够更快地访问。相反,冷页则不再高速缓存中,在多处理器系统上,每个CPU都有一个或多个高速缓存。 free_area:用于实现伙伴系统,每个数组元素都表示某中固定长度的一些连续内存区。对于包含在每个区域的空闲内存页的管理。 free_area 上图描述出了Node->zone->free_area->page之间的关系。 struct zone { ...... struct free_area free_area[MAX_ORDER]; //存储着不同长度的空闲区域 ...... } 伙伴系统中是以2^n次方来对内存进行分配的,因此系统中是以2^n次方来组织链表结构的。例如struct free_area[2]对应的就是2^n个page内存块链表。 struct free_area { struct list_head free_list[MIGRATE_TYPES]; unsigned long nr_free; } nr_free指定了当前内存区中空闲页块的数目。 free_list用于连接空闲页的链表,每种迁移类型都对应于一个空闲列表。 free_area[]确定连续内存的级数后,还会根据其MIGRATE类型来进行分类。这样做是为了便更好的管理内存,以减少内存碎片。 基本原理 为了解决内存碎片的问题,linux内核使用的伙伴系统算法。伙伴系统算法是一个高效且简单的内存分配策略,当我们找到待分配内存的zone后,内核将从对应zone的空闲链表中去分配内存。在释放内存是,内核将相应的内存还回相应的内存还回对应的zone空闲内存链表中。 如上图所示free_area数组大小为MAX_ORDER,也就是free_area数组存放着MAX_ORDER个链表,每个链表的元素存放的页块大小为2的n次幂,其中n为该链表在free_area数组中的索引位置。在同一个order内存块中,有根据MIGRATE类型将page存放在不同的链表中。 伙伴系统内存块分配 如果内核要分配2^n个页内存大小,伙伴系统处理方式如下: (1)检查对应的free_area[n]索引(如果是3,则是free_area[3])的数组,如果在其索引下的链表有空闲内存块,则返回。 (2)如果没有找到满足要求的内存块,则查找n+1数组索引(free_area[4]),若存在空闲内存块,将n+1索引的内存块拆分成大小相等且连续的两块内存,将一块内存返回给内核使用,另外一块内存添加到n的数组索引链表中。 (3)若n+1数组索引中依旧没有找到,则继续向n+2数组索引寻找,再依次向下拆分,直至满足要求位置。 伙伴系统内存块合并 当系统中存在两块大小一样,内存物理地址连续将会试图合并添加到上一阶。上图中在free_area[2]中有5个空闲内存块,当非空闲内存块PFN=6即将释放是,伙伴系统将会进行检查,发现PFN=6与PFN=1内存块大小一样且连续,则进行合并添加到order=3的上一阶连续内存块中,同时在order=3中会继续搜索,看是否满足可以合并添加到order=4中,直到不能合并为止。struct page中有几个成员变量与伙伴系统有关系。 __mapcount:标记page是否在伙伴系统中 private:页块中的第一页private字段存放了内存块的order值 index:存放MIFRATE的类型 __refcount:用户使用计数 内存块迁移 伙伴系统能一定程度解决内存碎片问题,但是系统运行久之后,内核会大量的进行内存的分配和释放工作,这依旧会导致内存碎片。 如上图,假定内存由60页组成,左侧的地址空间散布着空闲页,尽管25%的物理内存仍然未分配,但最大的连续空闲区只有一页。这对用户空间应用程序是没问题(其内存通过页表映射,即使空闲页在物理内存中分布如何,应用程序看到的内存是连续的)。右图给出的情形中,空闲页和使用页的数目与作图相同,但所有空闲页都位于一个连续区中。为了缓解这种内存碎片问题,内核伙伴系统引入了MIGRATE。下面是Linux内核中用于描述不同内存区域的迁移类型常量,表示对应区域中页面的可移动性和重要性等属性。 MIGRATE_ISOLATE:表示这个内存区域的页面不可移动,并且需要独立出来,例如用于设备DMA。 MIGRATE_CMA:表示这个内存区域的页面被保留用于连续内存分配(CMA),通常用于一些嵌入系统中。 MIGRATE_HIGHATOMIC:表示这个内存区域的页面被预期会经常进行搞优先级内存操作,例如解锁页需要使用硬件原子操作。 MIGRATE_MOVABLE:表示这个内存区域的页面可以自由被迁移,通常用于用户空间的虚拟内存或者支持虚拟机的内存管理场景。 MIGRATE_RECALAIMABLE:表示这个内存区域的页面可以被回收,例如包含缓存页,匿名页等。 MIGRATE_UNMOVABLE:表示这个内存区域的页面不可移动,例如内核代码,内核数据等。 在伙伴系统分配连续内存块是,当一个指定迁移类型所对应的链表中没有空闲内存块时,内核将会按照静态定义的顺序在其他迁移类型的链表中进行寻找。 static int fallbacks[MIGRATE_TYPES][3] = { [MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, [MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES }, [MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, #ifdef CONFIG_CMA [MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */ #endif #ifdef CONFIG_MEMORY_ISOLATION [MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */ #endif }; 初始化 初始化相关数据结构 伙伴系统相关数据结构主要在zone_sizes_init中完成,主要的几点如下: (1)为每个zone区域的free_area[]数组中的MIGRATE free list链表初始化。 (2)为每个zone区域所有的页框描述符struct page(分配)初始化。 (3)为每个zone区域中所有的pageblock设定迁移类型。 (4)为每个内存节点初始化可使用的备用内存node_zonelists。 为每个zone区域的每cpu成员pageset初始化。 memblock内存释放到伙伴系统 页面分配器 分配器API 就伙伴系统接口而言,与c库中的malloc函数不同的是,这里分配的参数是以分配阶为参数,即伙伴系统将在内存中分配2^order页。 分配接口 分配掩码 区域修饰符 移动修饰符 水线修饰符 回收修饰符 alloc_pages alloc_pages最终会调用到__alloc_pages,分配物理页面首先会先尝试从伙伴系统中进行快速分配,如果快速分配不成功会进入慢速分配。快速分配和慢速分配的区别? prepare_alloc_pages 用于初始化页面分配器中用到的参数,确定首选的zone等。在页面分配器中,使用alloc_context数据结构来用于各函数之间的参数传递。 #include “mm/internal.h” struct alloc_context { struct zonelist *zonelist; nodemask_t *nodemask; struct zoneref *preferred_zoneref; int migratetype; enum zone_type highest_zoneidx; bool spread_dirty_pages; }; zonelist: 分配页面的区域列表 nodemask:指定的node,如果没有指定则在所有节点中进行分配 prefered_zoneref:指定首先分配的区域 migratetype:要分配的迁移类型 highest_zoneidx:将分配限制为小于区域列表中指定的高区域 spread_dirty_pages:脏区平衡相关 static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask, struct alloc_context *ac, gfp_t *alloc_gfp, unsigned int *alloc_flags) { ac->highest_zoneidx = gfp_zone(gfp_mask); ac->zonelist = node_zonelist(preferred_nid, gfp_mask); //(1)确定首选内存节点的zonelist,一个内存节点包含两个zonelist,一个是本地的,另外一个是远端的,对于arm64架构只有一个。 ac->nodemask = nodemask; ac->migratetype = gfp_migratetype(gfp_mask); //(2)根因分配掩码来确定获取内存的迁移类型 if (cpusets_enabled()) { *alloc_gfp |= __GFP_HARDWALL; /* * When we are in the interrupt context, it is irrelevant * to the current task context. It means that any node ok. */ if (in_task() && !ac->nodemask) ac->nodemask = &cpuset_current_mems_allowed; else *alloc_flags |= ALLOC_CPUSET; } fs_reclaim_acquire(gfp_mask); fs_reclaim_release(gfp_mask); might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM); if (should_fail_alloc_page(gfp_mask, order)) return false; *alloc_flags = gfp_to_alloc_flags_cma(gfp_mask, *alloc_flags); /* Dirty zone balancing only done in the fast path */ ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE); /* * The preferred zone is used for statistics but crucially it is * also used as the starting point for the zonelist iterator. It * may get reset for allocations that ignore memory policies. */ ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask); //(3)确定首选的zone return true; } 快速路径分配 遍历zonelist中的zone,扫描zone的方向是从高端zone到低端zone,大部分情况不一定扫描zonelist中所有的zone,而是从首选zone(prefered_zone)开始扫描,首选zone是通过gfp_mask换算。 alloc_context是一个非常重要的参数,其存储了zone从哪里开始扫描,内存分配的迁移类型等。zone_watermark_ok将会检测在分配内存时需要判断zone的水位情况以及是否满足分配连续大内存块的需求,如果不符合则分配失败。 rmqueue会从伙伴系统中获取内存,如果对应的order不满足,就会从高一阶的内存块区获取。在调用requeue分配内存时,当分配的时单个物理页面(order=0),将会调用rmqueue_pcplist函数,从Per-CPU变量per_cpu_pages中分配页面。per_cpu_pages是一个Per-CPU变量,即每个CPU都由一个本地的per_cpu_pages变量,这个per_cpu_pages数据结构理由一个单页面链表,里面存放一小部分单个物理页面,当系统需要单个物理页面是,就从本地CPU的Per-CPU变量链表中直接获取物理页面,这样就可以快速分配内存,减少zone中相关锁的操作(在多个节点中访问内存会有锁保护)。 慢速路径分配 水位管理 水位管理的设置主要在init_per_zone_wmark_min函数中实现,如下: int __meminit init_per_zone_wmark_min(void) { (1)计算min_free_kbytes值 calculate_min_free_kbytes(); (2)设置各zone的水位值 setup_per_zone_wmarks(); (3)zone状体阈值,用于内存压缩,Per-CPU相关? refresh_zone_stat_thresholds(); (4)设置各zone区预留内存 setup_per_zone_lowmem_reserve(); #ifdef CONFIG_NUMA setup_min_unmapped_ratio(); setup_min_slab_ratio(); #endif khugepaged_min_free_kbytes_update(); return 0; } 相关数据结构 #include "common/framework/platform_init.h" struct zone { ...... unsigned long _watermark[NR_WMARK]; unsigned long nr_reserved_highatomic; long lowmem_reserve[MAX_NR_ZONES]; atomic_long_t managed_pages; unsinged long spanned_pages; unsinged long present_pages; ...... }; enum zone_wtermarks { WMARK_MIN, WMARK_LOW, WMARK_HIGH, NR_WMARK, }; #define min_wmark_pages(z) (z->watermark[WMARK_MIN]) #define low_wmark_pages(z) (z->watermark[WMARK_LOW]) #define high_wmark_pages(z) (z->watermark[WMARK_HIGH]) _watermark[NR_WMARK]:存储水位等级对应的内存容量 nr_reserved_highatomic:该内存区域内预留内存的大小,其大小=watermark[WMARK_MIN]? lowmem_reserve[MAX_NR_ZONES]:每个区域必须为自己保留一定的物理页数量,防止高位内存区域对自己内存空间进行过多的挤压。如当NORMAL区域分配不到内存是,会往下分配DMA区域,DMA区域要保留一定空间不能让NORMAL区域的挤压。 managed_pages: 通过buddy伙伴系统管理的所有可用页,=present_pages-reserved_pages spanned_pages:zone区域所有的物理页,包含空洞,=zone_end_pfn-zone_start_pfn present_pages:zone区域可用的所有物理页,包含reserved_pages,=spanned_pages-hole_pages WMARK_HIGH:当物理内存区域的剩余内存容量高于_watermark[WMARK_HIGH]时,说明物理内存区域中的内存容量非常充足,内存分配没有压力 WMARK_LOW:当剩余内存容量介于_watermark[WMARK_LOW]与_watermark[WMARK_HIGH]之间时,说明此时内容容量有点危险了,内存分配面临一定压力,但是还可以满足进程的内存分配要求,当给进程分配完内存之后,就会唤醒kswapd进程开始进行内存回收,知道剩余内存高于_watermark[WMARK_HIGH]为止。分配内存时会触发内存回收,但是分配的进程本身不会被阻塞,属于异步回收内存。 WMARK_MIN:当剩余内存容量低于_watermark[WMARK_MIN]时,说明此时的内容容量非常危险了,如果进程再此时请求分配内存,内核会进行阻塞式直接内存回收,直到内存容量大于_watermark[WMARK_LOW]给予分配。_watermark[WMARK_MIN]以下的内存容量时预留给内核在紧急情况下使用的,这部分内存对应的时nr_reserved_highatomic。 水位线的计算概述 WMARK_HIGH,WMARK_LOW,WMARK_MIN这个三个水位线的数值是通过内核参数/proc/sys/vm/min_free_kbytes为基准分别计算处理的,单位是KB。min_free_kbytes是系统保留空闲内存的最低限,_watermark[WMARK_MIN]的是通过min_free_kbytes计算出来的。 _watermark[WMARK_MIN]=f(min_free_kbytes) _watermark[WMARK_LOW]=1.25*_watermark[WMARK_MIN] _watermark[WMARK_HIGH]=1.5*[WMARK_LOW] min_free_kbytes计算 在函数calculate_min_free_kbytes用于计算min_free_kbytes的值,接下来线看看min_free_kbytes内核是如何计算出来的。如下(如果有DMA32也需要包含进去),初始化时high=0,所以实际等于ZONE_DMA+ZONE_NORMAL中managed_pages的和。 static unsigned long nr_free_zone_pages(int offset) { struct zoneref *z; struct zone *zone; /* Just pick one node, since fallback list is circular */ unsigned long sum = 0; struct zonelist *zonelist = node_zonelist(numa_node_id(), GFP_KERNEL); (1)对每个zone做计算,将每个zone中低于high水位的可用内存做累加,得到如上图的A+B。初始化时,high_pages实际=0. for_each_zone_zonelist(zone, z, zonelist, offset) { unsigned long size = zone_managed_pages(zone); unsigned long high = high_wmark_pages(zone); if (size > high) sum += size - high; return sum; } unsigned long nr_free_buffer_pages(void) { return nr_free_zone_pages(gfp_zone(GFP_USER)); } void calculate_min_free_kbytes(void) { unsigned long lowmem_kbytes; int new_min_free_kbytes; (2)低位内存区域(非HIGH_MEM,实际上64没有HIGH_MEM)总容量有页数转为KB。 lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10); (3)对lowmem_kbytes*16再进行开方 new_min_free_kbytes = int_sqrt(lowmem_kbytes * 16); (4)user_min_free_kbytes是用户设置的值(/proc/sys/vm/min_free_kbytes),算出来的值与用户设置的值进行比较取大值,但是最终范围需要介于128~262144KB之间 if (new_min_free_kbytes > user_min_free_kbytes) { min_free_kbytes = new_min_free_kbytes; if (min_free_kbytes < 128) min_free_kbytes = 128; if (min_free_kbytes > 262144) min_free_kbytes = 262144; } else { pr_warn(\"min_free_kbytes is not updated to %d because user defined value %d is preferred\\n\", new_min_free_kbytes, user_min_free_kbytes); } } 水位线设置 函数setup_per_zone_wmarks用于计算watermark[min,low,high]的值。 static void __setup_per_zone_wmarks(void) { (1)将min_free_kbytes转为page为单位 unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10); unsigned long lowmem_pages = 0; struct zone *zone; unsigned long flags; /* Calculate total number of !ZONE_HIGHMEM pages */ for_each_zone(zone) { if (!is_highmem(zone)) lowmem_pages += zone_managed_pages(zone); } for_each_zone(zone) { u64 tmp; (2)计算出水线挡位基础值tmp= (u64)min_free_kbytes/ 4 * zone_managed_pages(zone) / lowmem_pages 如果只有一个zone的话,tmp= min_free_kbytes / 4 spin_lock_irqsave(&zone->lock, flags); tmp = (u64)pages_min * zone_managed_pages(zone); do_div(tmp, lowmem_pages); (3)HIGHMEM_ZONE水线挡位计算 if (is_highmem(zone)) { /* * __GFP_HIGH and PF_MEMALLOC allocations usually don\'t * need highmem pages, so cap pages_min to a small * value here. * * The WMARK_HIGH-WMARK_LOW and (WMARK_LOW-WMARK_MIN) * deltas control async page reclaim, and so should * not be capped for highmem. */ unsigned long min_pages; min_pages = zone_managed_pages(zone) / 1024; min_pages = clamp(min_pages, SWAP_CLUSTER_MAX, 128UL); zone->_watermark[WMARK_MIN] = min_pages; } else { /* * If it\'s a lowmem zone, reserve a number of pages * proportionate to the zone\'s size. */ zone->_watermark[WMARK_MIN] = tmp; (4)非HIGHMEM_ZONE 水位线min挡位的计算 } /* * Set the kswapd watermarks distance according to the * scale factor in proportion to available memory, but * ensure a minimum size on small systems. */ (5)计算各个zone的low和hig挡位的值,挡位值tmp会受用户节点/proc/sys/vm/watermark_scale_factor的影响,让用户可调节min到low和high间的比例关系。tmp为min与low和high之间的差值,mult_frac(zone_managed_pages(zone),watermark_scale_factor, 10000)=zone_managed_pages(zone)* (watermark_scale_factor/10000),即总内存大小*(watermark_scale_factor/10000),因此tmp取的是 tmp >> 2和(watermark_scale_factor/10000)的最大值,意思就是即使用户通过节点修改,但是值算出来小,还是会选择原计算出来的差值。 tmp = max_t(u64, tmp >> 2, mult_frac(zone_managed_pages(zone), watermark_scale_factor, 10000)); zone->watermark_boost = 0; zone->_watermark[WMARK_LOW] = min_wmark_pages(zone) + tmp; zone->_watermark[WMARK_HIGH] = min_wmark_pages(zone) + tmp * 2; spin_unlock_irqrestore(&zone->lock, flags); } /* update totalreserve_pages */ calculate_totalreserve_pages(); } watermark_scale_factor min水位到low和high水位之间的距离,可以通过调节节点/proc/sys/vm/watermark_scale_factor来控制,内存占比计算方式为范围为watermark_scale_factor/10000,意思是min与low的差值为总内存大小*。 (watermark_scale_factor/10000),watermark_scale_factor取值范围10~1000,所以占比范围0.1%~10%(10/10000~1000/10000)。因此min和low的差值为总内存大小*(0.1%~10%)。 小结,对应水线的low和high为止分两种情况: - 若min_free_kbytes偏大,则水线low到high区间长度由min_free_kbytes决定, - 若min_free_kbytes偏小,则水线low到high区间长度由watermark_scale_factor决定。 当分配内存发现剩余空间低于低水位,将会唤醒kswpad内核线程进行内存回收,回收过程是异步的,如果low与min水位差值较小,即使kswpad启动,但是回收过程是缓慢,当出现突发大内存分配时,可能直接触发到min水位,这时候就会触发阻塞式内存回收(Direct Reclaim),所以需要进行合理的调整low和min之间的差值,因此引入了watermark_scale_factor,该值就是进行人为调整low和min之间的差值,当差值较大时,中间空余空间较大,也能使kswpad提前进行唤醒回收内存。 可以观察/proc/vmstat中的allocstall计数,当进程频繁发生allocstall或者kswapd过早进入休眠状体,说明min和low水位差值太小,无法应对突发内存分配。即可通过watermark_scale_factor用于调整kspwad的激进程度。 cat /proc/vmstat |grep -E 'allocstall|kswapd_low_wmark_hit_quickly' allocstall_dma 0 allocstall_dma32 0 allocstall_normal 4 allocstall_movable 11 kswapd_low_wmark_hit_quickly 611 如上,如果这些数值在短时间内是否有增加,如果是,则说明频繁发生Direct Recleam,需要调大watermark_scale_factor。 思考:如果min和low水位线差值很大,又有什么坏处? watermark判断 在快速路径分配章节中,内存分配会进行水位的检测,其中__zone_watermark_ok用于检测内存水位情况。 预留内存 根据物理内存地址高低,低位内存到高位内存区域的顺序一次:ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM。当高位内存区域不够用时,内存就会向下挤压其他内存区域物理内存来满足内存分配需求。如从ZONE_NORMAL中分配内存,当分配完是会从ZONE_DMA中进行分配。但是内核不允许高位内存无限制的挤压低位内存区域,因为低位内存有着特定的用途,比如ZONE_DMA区域满足特定设备的寻址(ISA)。因此每个内存区域会给自己预留一定的内存,防止被高位内存区域挤压占用。每个内存区域位自己预留的这部分内存就存储在lowmem_reserve数组中。 struct zone { ...... unsigned long nr_reserved_highatomic; long lowmem_reserve[MAX_NR_ZONES]; ...... } nr_reserved_highatomic:该节点内存区域一共预留的内存大小? lowmem_reserve:用于规定每个内存区域为自己预留的物理页面数量,防止高位内存区域挤压。 预留内存与lowmem_reserve_ratio值有关。 int sysctl_lowmem_reserve_ratio[MAX_NR_ZONES] = { #ifdef CONFIG_ZONE_DMA [ZONE_DMA] = 256, #endif #ifdef CONFIG_ZONE_DMA32 [ZONE_DMA32] = 256, #endif [ZONE_NORMAL] = 32, #ifdef CONFIG_HIGHMEM [ZONE_HIGHMEM] = 0, #endif [ZONE_MOVABLE] = 0, }; 系统通过读取节点也能够获取其值(如下,没有HIGHMEM) root@TinaLinux:/# cat /proc/sys/vm/lowmem_reserve_ratio 256 256 32 0 假设ZONE_DMA32,ZONE_NORMAL,ZONE_MOVABLE的内存大小分别是B,C,D,则预留内存的计算方式如下: - ZONE_DMA: B/256 + (B+C)/256 + (B+C+D)/256 - ZONE_DMA32: C/256 + (C+D)/256 - ZONE_NORMAL:D/32 - ZONE_MOVABLE:0 static void setup_per_zone_lowmem_reserve(void) { struct pglist_data *pgdat; enum zone_type i, j; for_each_online_pgdat(pgdat) { for (i = 0; i < MAX_NR_ZONES - 1; i++) { struct zone *zone = &pgdat->node_zones[i]; int ratio = sysctl_lowmem_reserve_ratio[i]; bool clear = !ratio || !zone_managed_pages(zone); unsigned long managed_pages = 0; for (j = i + 1; j < MAX_NR_ZONES; j++) { struct zone *upper_zone = &pgdat->node_zones[j]; (1)往上计算zone区总内存大小 managed_pages += zone_managed_pages(upper_zone); if (clear) zone->lowmem_reserve[j] = 0; else zone->lowmem_reserve[j] = managed_pages / ratio; (2)预留内存等于总内存/ratio } } } /* update totalreserve_pages */ calculate_totalreserve_pages(); } 计算方式图举例,如下: 图来源于网络 可以通过/proc/zoneinfo节点查看各个内存区域预留内存大小,参数protection读取的就是内存管理区中lowmem_reserve[]数组的值,lowmem_reserve[]数组的单位是页面。设置lowmem_reserved是为了防止页面分配器过度低从低端内存管理区中分配内存。下图中,ZONE_DMA32,ZONE_NORMAL对应的protection都为0,说明不需要做保护。 在内存管理中,判断是否满足这次分配任务是通过__zone_watermark_ok来判断。 bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark, int highest_zoneidx, unsigned int alloc_flags, long free_pages) { ...... if (free_pages <= min + z->lowmem_reserve[highest_zoneidx]) return false; ...... } z表示当前扫描的内存管理分区,highest_zoneidx表示这次分配请求首选的内存管理区,min为当前管理区的最低水位值,因此当发现剩余内存小于低水位+当前分区的预留内存,那么分配失败。 每个内存管理区的lowmem_reserve[]可以通过调整lowmem_reserve_ratio节点的值来修改,最终还是通过该调用setup_per_zone_lowmem_reserve来实现。 冷热页 待补充 内存规整 伙伴系统以页的方式来管理物理内存,随着系统不断的运行,系统就会产生碎片,一旦形成大片的碎片,系统就无法分配连续的物理内存(对用户空间的进程无影响?),因此linux内核引入的内存规整技术,来处理内存碎片的问题。内存碎片可以分配内碎片和外碎片。 内碎片:物理内存页里面的碎片。 外碎片:物理内存页之间的碎片,造成无法分配连续物理页。 基本原理 在内存卡迁移章节中,内核定义了migrate_type用于描述迁移类型,主要有 - MIGRATE_MOVABLE:可移动,表示这个内存区域的页面可以自由被迁移,通常用于用户空间的虚拟内存或者支持虚拟机的内存管理场景。 - MIGRATE_RECALAIMABLE:不可移动,但页面可以被回收,例如包含缓存页,匿名页等。 - MIGRATE_UNMOVABLE:不可移动,例如内核代码,内核数据等。 T0时刻:处于迁移前,此时物理内存中有空闲内存,但是并不连续。 T1时刻:启动迁移,迁移分两个方向对zone分区进行遍历扫描,zone区域低地址往高地址扫描空闲的物理页,zone区域高地址到地址扫描可移动已分配的物理页,两个扫描器在中间相遇时结束,将可移动已分配的物理页迁移(拷贝)到空闲页中,释放原内存。 T2时刻:迁移后,脏页被集中到一起,空闲页被集中到一起。 Linux内核触发内存规整有3个途径 - 手动触发:echo 1 > proc/sys/vm/compact_memory,会触发内存规整。 - kcompactd内核线程:每个内存节点会创建一个kcompactd内核线程,名称为kcompactd0、kcompactd1等等。内存水位不够时,kcompactd守护线程会在后台唤醒,与kswapd线程类似。 - 直接内存规整:在内存分配不足时,直接触发compact。 内存页面回收 Linux系统会将内存尽可能的都使用起来,如将剩余的内存作为文件缓存(page cache)从而提高系统的性能。当有更高优先级的任务需要分配内存发现内存不足时,会进行内存进行回收,将不常用的内存进行回收。内存回收不是简单的回收页面越多越好,因为系统中很多地方都是用空间换时间,如尽可能的使用内存作为设备交换的缓存,这样可以极大的提高系统运行效率。因此内存回收是系统在分配内存不足时,才会触发回收。 对于用户空间来说,页可以分为匿名页分为文件页和匿名页,对于内核空间申请的内存来说,没有匿名页和文件页的划分,所以本章节描述的页面回收,回收的都是用户空间的内存。 - 文件页(磁盘缓存页):与磁盘存在映射关系的内存页(文件背景),如进程代码段、文件映射页等,他们有对应的磁盘进行存储,要回收此类页面时,可将页面直接丢弃(回收),数据还能从磁盘中读取,这部分称为page cache。 - 匿名页:没有与磁盘存在映射关系(无文件背景),如堆、栈、数据段等,如果将此类数据直接丢弃将无法找回,因此要回收此类页面,需要将数据交换到指定磁盘空间存储(swap分区)。 磁盘高速缓存的页面都是可以直接被丢弃回收的,但当磁盘缓存页是脏页面时,在丢弃回收前需要将其写回到磁盘中。 匿名页是不可以丢弃的,因为磁盘中是没有对应的存储,因此要想回收这种类型的页面,需要将该页面的数据转储到指定磁盘空间中(称为swap分区),这个过程页称为页面交换(swap),显然这种交换的代价是相对较高一些。 Linux内核中除非页面被保留或上锁(特殊处理,避免回收),所有的磁盘高速缓存页面都可以回收,所有的匿名页面页可以被交换出去而回收。 LRU机制 对于linux内存回收来说,LRU链表是关键,因为内存回收的整个过程都是处理LRU链表的收缩。LRU链表主要是堆页进行排序,将使用频率低的页放到链表尾部,使用频率高的放到链表头部;而内存回收就是将LRU链表中最近很少访问的尾部页框内容从内存转储到磁盘中(分为匿名页和文件页),然后将其页框释放到伙伴系统作为空闲内存使用。 LRU算法认为过去一段时间频繁使用的页面,在不久的将来可能会在此访问到,而很久没有使用的页面在未来短时间内也不会被访问到,因此在物理内存不够用的情况下,这样的页面成为被换出的最佳候选者。 LRU的基本原理是为每个物理页面绑定一个计数器,用以表示该页面的访问频度。操作系统内核进行页面回收是就根据页面的计数器值来确定要回收那些页面。 Linux内核对于LRU的实现主要是基于一对双向链表:active和inactive两类链表。经常被访问处于活跃状态的页面会被放在active链表上,不常使用的页面被放到inactive链表上。系统在执行过程中,页面会在active链表和inactive链表之间转移,在active链表中使用频率最低的将会移到链表尾部,再转移到不活跃链表中,最后换出页面。 第二次机会法是在经典LRU链表算法基础上做了一些改进,在经典LRU链表算法中,新产生的页面被添加到LRU链表的开发,将LRU链表中现存的页面向后移动一个位置。当系统内存出现短缺是,LRU链表尾部的页面将会离开并经历换出。当系统再需要这些页面是,这些页面会重新置于LRU链表的开头,这样的设计只考虑的时间的先后顺序而没有考虑到页面是否频繁使用,而第二次机会法的改进就是避免经常使用的页面不会被置换出去,第二次机会法给页面设置一个访问状态位,在进行淘汰选择是,会先判断该状态是位为1,如果是则给他第二次机会,并清空该位,选择其他页面判断换出。 LRU链表 内核中一共有5条LRU链表,如下: - LRU_INACTIVE_ANON:不活跃匿名页面链表 - LRU_ACTIVE_ANON:活跃匿名页面链表 - LRU_INACTIVE_FILE:不活跃文件映射页面链表 - LRU_ACTIVE_FILE:活跃文件映射页面链表 - LRU_UNEVICTABLE:不可回收页面链表 Linux内核分成5条链表,主要是当内存出现紧缺时优先换出文件映射的文件换出页面,因为文件页可能不需要重新刷回磁盘而直接进行回收,而匿名页是必须要写入交换区才能回收。Linux每个内存节点都维护一整套LRU链表,存储在pglist_data中。 typedef struct pglist_data { ..... struct lruvec __lruvec; ...... }; 5种不同类型的LRU链表 enum lru_list { LRU_INACTIVE_ANON = LRU_BASE, LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE, LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE, LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE, LRU_UNEVICTABLE, NR_LRU_LISTS }; struct lruvec { struct list_head lists[NR_LRU_LISTS]; /* per lruvec lru_lock for memcg */ spinlock_t lru_lock; /* * These track the cost of reclaiming one LRU - file or anon - * over the other. As the observed cost of reclaiming one LRU * increases, the reclaim scan balance tips toward the other. */ unsigned long anon_cost; unsigned long file_cost; /* Non-resident age, driven by LRU movement */ atomic_long_t nonresident_age; /* Refaults at the time of last reclaim cycle */ unsigned long refaults[ANON_AND_FILE]; /* Various lruvec state flags (enum lruvec_flags) */ unsigned long flags; #ifdef CONFIG_LRU_GEN /* evictable pages divided into generations */ struct lru_gen_struct lrugen; /* to concurrently iterate lru_gen_mm_list */ struct lru_gen_mm_state mm_state; #endif #ifdef CONFIG_MEMCG struct pglist_data *pgdat; #endif ANDROID_VENDOR_DATA(1); }; 内存节点的描述数据结构种有一个成员变量lruvec指向这些链表,枚举类型变量lru_list列举出上述各种LRU链表类型,lruvec数据结构中定义了上述各种LRU类型链表。 linux内核使用有两个标志位来用于LRU机制的判断,分别是PG_active和PG_referenced, - PG_active:标志位指示了该页块应该在那个LRU链表,为1在active链表,0在inactive链表。 - PG_referenced:指示页框是否被使用,当页框被访问是,会置为1。 Linux中实现LRU链表之间的移动页面使用如下关键函数: - mark_page_accessed():访问一个页面时,调用该函数修改PG_active和PG_refenrenced - page_refenrenced():系统在进行扫描页面时,调用该函数判断PG_referenced位,如果该位被置位但是长时间没有被再次访问,该位就会被清除。 - active_page():将页面放到active链表上去。 shrink_active_list():将页面移动到inactive链表上去。 LRU缓存 系统内核根据其活跃程度将页面来active和inactive链表之间来回移动,随着当前的硬件系统大多都是多cpu处理器,所以需要保证多核之间的并发访问,因此需要通过自旋锁来防止并发操作。由于自旋锁会导致系统性能下降,为了减少其影响,于是内核引入了LRU缓存,每次处理页面移动时,进行批量处理,当累计到一定数量后才会统一迁移,这样就能降低锁的竞争,提升系统的性能。LRU缓存使用的时struct pagevec结构。 include/linux/pagevec.h #define PAGEVEC_SIZE 15 struct pagevec { unsigned char nr; bool percpu_pvec_drained; struct page *pages[PAGEVEC_SIZE]; //存放14个page }; 页面批量最终通过list_add函数添加到LRU链表中,list_add会将成员添加到链表头。 页面回收时机 系统中通常以下3种机制会触发进行页面回收(实际上与水位有关系,见2.4.2.4)三种方式触发页面回收,最终都会调用shrink_node: - 快速回收:快速路径做内存分配时失败,调用node_reclaim进行页面回收,这个时候不回收脏文件页,加速内存分配速度,避免回写磁盘耗时的IO操作。 - 异步回收(Kswapd内核线程):慢速路径内存分配时,会唤醒内核线程,该线程就会在后台进行页面回收处理。 直接回收:慢速路径内存分配时,经过多轮尝试依旧无法分配内存(水位低于min区),就会触发进行直接回收。(同步) 回收策略 内存的回收并不是回收的越多越好,系统中很多都会用到物理内存,系统尽可能的用空间换时间最大化提高运行速率,比如对磁盘IO的读写使用物理内存缓存。各个页面的回收效率是不一样的,比如回收干净的文件页效率是最高的,匿名页和脏文件夹都需要刷写数据到磁盘。综上,系统需要确定一下回收的策略。如要回收多少页面合适?回收匿名页面还是文件页面等等。 struct scan_control 该结构体描述了与页面相关的信息struct scan_control。 struct scan_control { unsigned long nr_to_reclaim; 需要回收的页面数量 nodemask_t *nodemask; 内存节点掩码(确定回收的节点),如果为NULL,则是所有节点 struct mem_cgroup *target_mem_cgroup;目标memcg,如果针对整个zone进行,则为NULL unsigned int may_writepage:1;允许文件脏页写回磁盘的方式回收 unsigned int may_unmap:1;允许取消页面映射的方式回收 unsigned int may_swap:1;允许使用匿名页交换swap分区方式回收 s8 order;申请分配内存的阶 s8 priority;扫描LRU的优先级,用于计算每次扫描页面的数量 s8 reclaim_idx; gfp_t gfp_mask; unsigned long nr_scanned;统计扫描过的非活动页面总数 unsigned long nr_reclaimed;统计回收了页面的总数 }; scan_balance 回收的页要么是文件页要么是匿名页,系统中对于页面回收的类型有四种基本策略。 enum scan_balance { SCAN_EQUAL, 计算出扫描值原样使用 SCAN_FRACT, 按分数的应用计算扫描值 SCAN_ANON, 只回收匿名页 SCAN_FILE, 只回收文件页 }; scan_control只是一个需求,真正要怎么回收还要综合考虑,根据get_scan_count来把控。 /* * Determine how aggressively the anon and file LRU lists should be * scanned. The relative value of each set of LRU lists is determined * by looking at the fraction of the pages scanned we did rotate back * onto the active list instead of evict. * * nr[0] = anon inactive pages to scan; nr[1] = anon active pages to scan * nr[2] = file inactive pages to scan; nr[3] = file active pages to scan */ static void get_scan_count(struct lruvec *lruvec, struct scan_control *sc, unsigned long *nr) 在确定每个LRU链表的扫描力度之前,get_scan_count根据scan_control参数以及其他参数综合判断决定扫描的策略,从上可知unsigned long *nr数组分别表示每个LRU链表的扫描力度,get_scan_count就是用于填充nr的数组。那其策略还会受什么影响了?会受swappiness影响。 swappiness:决定着匿名页交换到swap分区的频率,值的范围0~100(默认值一般60)。值越高,则匿名页交换到swap分区的概率就越高。 当值为0时,那就表示不扫描回收匿名页,只回收文件页(当然不绝对,当系统确实已经分配不到内存了,就不会再管swappiness值)。当值为100时,匿名页的回收优先级就等于文件页的优先级的。 系统默认设置的值为60,所以系统更倾向与回收文件页。前面说了回收文件页的代价更更低,因为文件页大部分页都是干净页,可直接释放内存,不需要刷回到磁盘。 可以通过节点/proc/sys/vm/swappiness获取或调节swappiness值。 root@TinaLinux:/# cat /proc/sys/vm/swappiness 60 快速页面回收 static int __node_reclaim(struct pglist_data *pgdat, gfp_t gfp_mask, unsigned int order) { /* Minimum pages needed in order to stay on node */ const unsigned long nr_pages = 1 << order; struct task_struct *p = current; unsigned int noreclaim_flag; (1)设置回收策略 struct scan_control sc = { .nr_to_reclaim = max(nr_pages, SWAP_CLUSTER_MAX),回收页面数量,一般是32。 .gfp_mask = current_gfp_context(gfp_mask), .order = order, .priority = NODE_RECLAIM_PRIORITY, .may_writepage = !!(node_reclaim_mode & RECLAIM_WRITE), 如果没有使用NUMA架构,node_reclaim_mode=0,所以不允许使用写回磁盘方式回收页面。 .may_unmap = !!(node_reclaim_mode & RECLAIM_UNMAP), 不允许使用取消清除页表的方式回收页面。 .may_swap = 1, .reclaim_idx = gfp_zone(gfp_mask), 指定zone进行页面回收 }; unsigned long pflags; trace_mm_vmscan_node_reclaim_begin(pgdat->node_id, order, sc.gfp_mask); cond_resched(); psi_memstall_enter(&pflags); fs_reclaim_acquire(sc.gfp_mask); /* * We need to be able to allocate from the reserves for RECLAIM_UNMAP * and we also need to be able to write out pages for RECLAIM_WRITE * and RECLAIM_UNMAP. */ noreclaim_flag = memalloc_noreclaim_save(); p->flags |= PF_SWAPWRITE; set_task_reclaim_state(p, &sc.reclaim_state); if (node_pagecache_reclaimable(pgdat) > pgdat->min_unmapped_pages) { /* * Free memory by calling shrink node with increasing * priorities until we have enough memory freed. */ do { shrink_node(pgdat, &sc); (2)通过sc控制该节点进行内存回收。 } while (sc.nr_reclaimed < nr_pages && --sc.priority >= 0); (3)回收的页框数大于本次分配任务的页框数或者sc.priority优先级降为0即完成页面回收。 } set_task_reclaim_state(p, NULL); current->flags &= ~PF_SWAPWRITE; memalloc_noreclaim_restore(noreclaim_flag); fs_reclaim_release(sc.gfp_mask); psi_memstall_leave(&pflags); trace_mm_vmscan_node_reclaim_end(sc.nr_reclaimed); return sc.nr_reclaimed >= nr_pages; } 快速内存回收需要根据node_reclaim_mode来决定unmap、writeback操作,arm64架构上通常是单节点所以该值为0,因此不能unmap就相当于不能释放页表,不能writeback相当于不能释放脏页和匿名页,那实际上就只能回收干净的文件页了,同时快速内存回收指定了zone区进行回收。 kswpad回收 待补充 直接页面回收 待补充 shrink_node 待补充 -

内存初始化之物理内存初始化
恒等映射与内核镜像映射__create_page_tables preserve_boot_args:保持启动参数到boot_args[]数组 set_cpu_boot_maode_flag:设置关于cpu boot相关的全局变量 __create_page_tables:创建恒等映射页表,内核映像映射页表 __cpu_setup:为打开mmu做一些cpu相关的初始化 __primary_switch:启动mmu,并跳转start_kernel()函数 恒等映射 (text:__idmap_text_start~__idmap_text_end/data:idmap_pg_dir~idmap_pg_end) 一旦启动MMU就需要使用虚拟地址,现代处理器大多数是多级流水线,处理器会提前预取多条指令到流水线中,打开MMU时,这些指令都是物理地址预取的;在MMU开启后,将以虚拟地址访问,这样就会出错,所以引入了“恒等映射”,即在过渡阶段的代码,虚拟地址和物理地址相等。恒等映射完成后,就启动MMU,进入虚拟地址访问阶段。恒等映射的代码在 __idmap_text_start~__idmap_text_end,可以从System.map文件中查询到。 kernel/build/System.map ffffffc00899b000 T __idmap_text_start ffffffc00899b000 T init_kernel_el ffffffc00899b00c t init_el1 ffffffc00899b034 t init_el2 ffffffc00899b1e8 t __cpu_stick_to_vhe ffffffc00899b1f8 t set_cpu_boot_mode_flag ffffffc00899b21c T secondary_holding_pen ffffffc00899b240 t pen ffffffc00899b254 T secondary_entry ffffffc00899b260 t secondary_startup ffffffc00899b27c t __secondary_switched ffffffc00899b310 t __secondary_too_slow ffffffc00899b31c T __enable_mmu ffffffc00899b37c T __cpu_secondary_check52bitva ffffffc00899b380 t __no_granule_support ffffffc00899b3a4 t __relocate_kernel ffffffc00899b3ec t __primary_switch ffffffc00899b428 t enter_vhe ffffffc00899b460 T cpu_resume ffffffc00899b488 T cpu_do_resume ffffffc00899b52c T idmap_cpu_replace_ttbr1 ffffffc00899b560 t __idmap_kpti_flag ffffffc00899b564 T idmap_kpti_install_ng_mappings ffffffc00899b5a0 t do_pgd ffffffc00899b5b8 t next_pgd ffffffc00899b5c8 t skip_pgd ffffffc00899b608 t walk_puds ffffffc00899b610 t next_pud ffffffc00899b614 t walk_pmds ffffffc00899b61c t do_pmd ffffffc00899b634 t next_pmd ffffffc00899b644 t skip_pmd ffffffc00899b654 t walk_ptes ffffffc00899b65c t do_pte ffffffc00899b680 t skip_pte ffffffc00899b690 t __idmap_kpti_secondary ffffffc00899b6d8 T __cpu_setup ffffffc00899b7dc T __idmap_text_end 恒等映射目的就是为__idmap_text_start~__idmap_text_end这段代码创建一个映射页表,使其虚拟地址和物理地址是相等的。在vmlinux.lds.S中,事先已经分配了IDMAP_DIR_SIZE的空间用于存储页表,通常器页表为3个连续的4KB页面,分别对于PGD,PUD,PMD页表,这里没有使用PTE,所以粒度是2MB的大小。 arch/arm64/kernel/vmlinux.lds.S idmap_pg_dir = .; . += IDMAP_DIR_SIZE; idmap_pg_end = .; 粗粒度的内核映像映射 (text: kernel_text / data:init_pg_dir~init_pg_end) 之所以要创建第二个页表,是因为cpu刚启动时,物理内存一般都在低地址(不过超过256TB),恒等映射的地址实际也在用户空间,即MMU启用后idmap_pg_dir会填入TTBR0,而内核空间链接地址(虚拟地址)都是在高地址,需要填入TTBR1,因此需要再创建一张表,映射整个内核镜像,且虚拟地址空间是再高地址0xffff xxxx xxxx xxxx arch/arm64/kernel/head.S /* * Map the kernel image (starting with PHYS_OFFSET). */ ///调用map_memory宏建立整个内核镜像代码段 的映射页表; /************************************************************************** * 为什么要建第二张表? * CPU刚启动时,物理内存一般都在低地址(不会超过256T大小),恒等映射的地址实际在用户空间了, * 即MMU启用后idmap_pg_dir会填入TTBR0; * 而内核空间的链接地址都是在高地址(内核空间在高地址),需要填入TTBR1; * 因此,这里再建一张表,映射整个内核镜像,且虚拟地址空间是在高地址区0xffffxxxx xxxx xxxx * 注:init_pg_dir和idmap_pg_dir两个页表映射区别: * (1)init_pg_dir映射的虚拟地址在高位0xffff xxxx xxxx xxxx; * idmap_pg_dir映射的虚拟地址在低位0x0000 xxxx xxxx xxxx; * MMU启用后,init_pg_dir填入TTBR1,idmap_pg_dir填入TTBR0; * (2)init_pg_dir映射大小是整个内核镜像,idmap_pg_dir映射2M, 只是内存访问过渡,成功开启MMU即可; ***************************************************************************/ adrp x0, init_pg_dir mov_q x5, KIMAGE_VADDR // compile time __va(_text) add x5, x5, x23 // add KASLR displacement mov x4, PTRS_PER_PGD adrp x6, _end // runtime __pa(_end) adrp x3, _text // runtime __pa(_text) sub x6, x6, x3 // _end - _text add x6, x6, x5 // runtime __va(_end) map_memory x0, x1, x5, x6, x7, x3, x4, x10, x11, x12, x13, x14 fixmap映射 先创建好页表,建立好虚拟地址到物理地址的映射关系。 Linux内核要访问物理内存,一旦开启MMU后,就只能通过虚拟地址查询页表找到物理地址进行访问,上一章节中建立恒等映射和粗粒度内核映像映射的页表,因此只能保证内核镜像正常访问。如果要解析DTB,访问设备IO等依然是无法访问的,因为查询不到对应的页表。因此内核引入了fixmap机制,就是事先分配一段虚拟地址空间,然后给定其虚拟地址创建好页表,页表中的表项最后一级指向的物理页帧号先不填充,等到实际要访问那段物理内存后再将其填充,内后通过fixmap这段虚拟地址范围就可以通过查询页表访问到物理内存。 Fixmap最关键要实现的目的就是将一段空间的虚拟地址与物理地址对应上,linux内核通过虚拟地址访问到物理空间,那既然是通过虚拟地址访问到物理地址,那必须构建填充这段虚拟地址到物理地址的页表,这样Linux内核经过MMU利用查找页表找到对应的物理地址进行访问。 fixmap空间分类 Fixmap是一段固定范围的虚拟地址,在其在编译的时候就确定好了。下面是添加一段打印可以查看FIXMAP区域的各小段的地址范围。 void __init early_fixmap_init(void) { pgd_t *pgdp; p4d_t *p4dp, p4d; pud_t *pudp; pmd_t *pmdp; unsigned long addr = FIXADDR_START; pgdp = pgd_offset_k(addr); p4dp = p4d_offset(pgdp, addr); printk(\"FIX_HOLE :0x%lx\\n\",__fix_to_virt(FIX_HOLE)); printk(\"FIX_FDT_END :0x%lx\\n\",__fix_to_virt(FIX_FDT_END)); printk(\"FIX_FDT :0x%lx\\n\",__fix_to_virt(FIX_FDT)); printk(\"FIX_EARLYCON_MEM_BASE:0x%lx\\n\",__fix_to_virt(FIX_EARLYCON_MEM_BASE)); printk(\"FIX_BTMAP_END :0x%lx\\n\",__fix_to_virt(FIX_BTMAP_END)); printk(\"FIX_BTMAP_BEGIN :0x%lx\\n\",__fix_to_virt(FIX_BTMAP_BEGIN)); printk(\"FIX_PTE :0x%lx\\n\",__fix_to_virt(FIX_PTE)); printk(\"FIX_PMD :0x%lx\\n\",__fix_to_virt(FIX_PMD)); printk(\"FIX_PUD :0x%lx\\n\",__fix_to_virt(FIX_PUD)); printk(\"FIX_PGD :0x%lx\\n\",__fix_to_virt(FIX_PGD)); printk(\"FIXADDR_START~TOP :0x%lx - 0x%lx (%6ld KB)\\n\", FIXADDR_START,FIXADDR_TOP,(FIXADDR_TOP-FIXADDR_START) >> 10); ....... } [ 0.000000] FIX_HOLE :0xfffffffdfe000000 //0x000007FFFFFFEFF0 [ 0.000000] FIX_FDT_END :0xfffffffdfdfff000 [ 0.000000] FIX_FDT :0xfffffffdfdc00000 //0x000007FFFFFFEFEE [ 0.000000] FIX_EARLYCON_MEM_BASE:0xfffffffdfdbff000 [ 0.000000] FIX_BTMAP_END :0xfffffffdfdbf9000 [ 0.000000] FIX_BTMAP_BEGIN :0xfffffffdfda3a000 [ 0.000000] FIX_PTE :0xfffffffdfda39000 [ 0.000000] FIX_PMD :0xfffffffdfda38000 [ 0.000000] FIX_PUD :0xfffffffdfda37000 [ 0.000000] FIX_PGD :0xfffffffdfda36000 //0x000007FFFFFFEFED [ 0.000000] FIXADDR_START~TOP :0xfffffffdfdbf9000 - 0xfffffffdfe000000 ( 4124 KB) 上面0xfffffffdfdbf9000 - 0xfffffffdfe000000这段虚拟地址范围就是fixed map区域,这段区域可以通过FIXADDR_START和FIXADDR_TOP来确定。Fixmap虚拟地址平均分成两个部分,两个部分permanent fixed addresses和temporary fixed addresses。permanent fixed addresses是永久映射,temporary fixed addresses是临时映射。永久映射是指在建立的映射关系在kernel阶段不会改变,仅供特定模块一直使用。临时映射就是模块使用前创建映射,使用后解除映射。fixmap区域又被继续细分,分配给不同模块使用。kernel中定义枚举类型作为index,根据index可以计算在fixmap区域的虚拟地址。 arch/arm64/include/asm/fixmap.h enum fixed_addresses { FIX_HOLE, /* * Reserve a virtual window for the FDT that is 2 MB larger than the * maximum supported size, and put it at the top of the fixmap region. * The additional space ensures that any FDT that does not exceed * MAX_FDT_SIZE can be mapped regardless of whether it crosses any * 2 MB alignment boundaries. * * Keep this at the top so it remains 2 MB aligned. */ #define FIX_FDT_SIZE (MAX_FDT_SIZE + SZ_2M) FIX_FDT_END, FIX_FDT = FIX_FDT_END + FIX_FDT_SIZE / PAGE_SIZE - 1, FIX_EARLYCON_MEM_BASE, FIX_TEXT_POKE0, #ifdef CONFIG_ACPI_APEI_GHES /* Used for GHES mapping from assorted contexts */ FIX_APEI_GHES_IRQ, FIX_APEI_GHES_SEA, #ifdef CONFIG_ARM_SDE_INTERFACE FIX_APEI_GHES_SDEI_NORMAL, FIX_APEI_GHES_SDEI_CRITICAL, #endif #endif /* CONFIG_ACPI_APEI_GHES */ #ifdef CONFIG_UNMAP_KERNEL_AT_EL0 FIX_ENTRY_TRAMP_TEXT3, FIX_ENTRY_TRAMP_TEXT2, FIX_ENTRY_TRAMP_TEXT1, FIX_ENTRY_TRAMP_DATA, #define TRAMP_VALIAS (__fix_to_virt(FIX_ENTRY_TRAMP_TEXT1)) #endif /* CONFIG_UNMAP_KERNEL_AT_EL0 */ __end_of_permanent_fixed_addresses, /* * Temporary boot-time mappings, used by early_ioremap(), * before ioremap() is functional. */ #define NR_FIX_BTMAPS (SZ_256K / PAGE_SIZE) #define FIX_BTMAPS_SLOTS 7 #define TOTAL_FIX_BTMAPS (NR_FIX_BTMAPS * FIX_BTMAPS_SLOTS) FIX_BTMAP_END = __end_of_permanent_fixed_addresses, FIX_BTMAP_BEGIN = FIX_BTMAP_END + TOTAL_FIX_BTMAPS - 1, /* * Used for kernel page table creation, so unmapped memory may be used * for tables. */ FIX_PTE, FIX_PMD, FIX_PUD, FIX_PGD, __end_of_fixed_addresses }; #define FIXADDR_SIZE (__end_of_permanent_fixed_addresses << PAGE_SHIFT) #define FIXADDR_START (FIXADDR_TOP - FIXADDR_SIZE) fixmap初始化 前面描述了,fixmap就是让一段固定的虚拟地址空间与一段物理空间建立映射,以便linux内核通过虚拟地址才能访问到对应物理地址的空间数据,虚拟地址到物理地址的转换是通过mmu查询页表得来的,因此需要构建填充虚拟地址到物理地址转换的页表。在linux内核中,页表存储通过定义了3个全局数组bm_pud,bm_pmd,bt_pte来存储。因此early_fixmap_init的目的来填充这几个数组(页表)。 static pte_t bm_pte[PTRS_PER_PTE] __page_aligned_bss; static pmd_t bm_pmd[PTRS_PER_PMD] __page_aligned_bss __maybe_unused; static pud_t bm_pud[PTRS_PER_PUD] __page_aligned_bss __maybe_unused; 没有建立PGD,PGD在swapper_pg_dir中,在内核镜像的数据段 PTRS_PER_PTE/PMD/PUD为页表entry的数目 #define PTRS_PER_PTE (1 << (PAGE_SHIFT - 3)) arch/arm64/mm/mmu.c void __init early_fixmap_init(void) { pgd_t *pgd; p4d_t *p4dp, p4d; pud_t *pud; pmd_t *pmd; unsigned long addr = FIXADDR_START; (1)FIXADDR_START定义了fixedmap区域的起始地址。 pgdp = pgd_offset_k(addr); p4dp = p4d_offset(pgdp, addr);//3级页表中p4dp=pgd p4d = READ_ONCE(*p4dp);//读表项中的内容 (2)获取addr对应的pgd全局页表表项地址,页表是swapper_pg_dir的空间 if (CONFIG_PGTABLE_LEVELS > 3 && !(pgd_none(*pgd) || pgd_page_paddr(*pgd) == __pa_symbol(bm_pud))) { pud = pud_offset_kimg(pgd, addr); } else { (3)因为是3级页表p4d_node=0,因此不会进入这里,也就是不会使用bm_pud if (p4d_none(p4d)) __p4d_populate(p4dp, __pa_symbol(bm_pud), P4D_TYPE_TABLE); pud = fixmap_pud(addr); (4)获取addr在PUD页表项中的偏移地址,这里是3级页表,所以pud=pgdp } if (pud_none(*pud)) __pud_populate(pud, __pa_symbol(bm_pmd), PMD_TYPE_TABLE); (5)将bm_pmd的物理地址写到pgd页表对应表项中 pmd = fixmap_pmd(addr); (6)获取addr在对应页表中表项的地址(虚拟地址)。 __pmd_populate(pmd, __pa_symbol(bm_pte), PMD_TYPE_TABLE); (7)将bm_pte的物理地址写到pmd页表中。 } TIPS:当使用3级页表时,内核如何判断是否需要创建PUD页表? arch/arm64/include/asm/pgtable-types.h #if CONFIG_PGTABLE_LEVELS == 2 #include <asm-generic/pgtable-nopmd.h> #elif CONFIG_PGTABLE_LEVELS == 3 #include <asm-generic/pgtable-nopud.h> #elif CONFIG_PGTABLE_LEVELS == 4 #include <asm-generic/pgtable-nop4d.h> #endif 从上可知,页表是3级页表时,包含的pud相关的头文件时#include <asm-generic/pgtable-nopud.h> include/asm-generic/pgtable-nopud.h static inline int p4d_none(p4d_t p4d) { return 0; } //直接返回0 static inline int p4d_bad(p4d_t p4d) { return 0; } static inline int p4d_present(p4d_t p4d) { return 1; } static inline void p4d_clear(p4d_t *p4d) { } #define p4d_populate(mm, p4d, pud) do { } while (0) #define p4d_populate_safe(mm, p4d, pud) do { } while (0) #define set_p4d(p4dptr, p4dval) set_pud((pud_t *)(p4dptr), (pud_t) { p4dval }) static inline pud_t *pud_offset(p4d_t *p4d, unsigned long address) { return (pud_t *)p4d; } #define pud_offset pud_offset #define pud_val(x) (p4d_val((x).p4d)) #define __pud(x) ((pud_t) { __p4d(x) }) #define p4d_page(p4d) (pud_page((pud_t){ p4d })) #define p4d_pgtable(p4d) ((pud_t *)(pud_pgtable((pud_t){ p4d }))) #define pud_alloc_one(mm, address) NULL #define pud_free(mm, x) do { } while (0) #define pud_free_tlb(tlb, x, a) do { } while (0) #undef pud_addr_end #define pud_addr_end(addr, end) (end) 实际上,early_fixmap_init只是建立了一个映射的框架,实际的物理地址和虚拟地址的映射关系是没有填充的,这个需要实际使用的时候再去填充对应的pte entry。 bm_pud/bm_pmd/bm_pte是全局数组(全局数据段),该阶段访问这几个全局数组的虚拟地址能够可以通过mmu转化为物理地址,因为这几个变量是属于内核映像中,在上一章节中内核镜像中的所有包括数据段、代码段等都可以进行访问了,因此这几个全局数组的虚拟地址是不需要映射的。 fixmap相关函数 #define pte_offset_phys(dir,addr) (pmd_page_paddr(READ_ONCE(*(dir))) + pte_index(addr) * sizeof(pte_t)) //查找虚拟地址对应PTE的物理地址(基地址),也就是对应PMD条目中的值。 #define pte_set_fixmap(addr) ((pte_t *)set_fixmap_offset(FIX_PTE, addr)) //获取addr(物理地址)对应的虚拟地址,其虚拟地址在FIX_PTE这个范围(建立映射)。 #define pte_set_fixmap_offset(pmd, addr) pte_set_fixmap(pte_offset_phys(pmd, addr)) //获取addr在PTE页表项的虚拟地址,其虚拟地址范围在FIX_PTE这个范围(建立映射)。 #define pte_clear_fixmap() clear_fixmap(FIX_PTE) //清除FIX_PTE虚拟地址的映射 #define pmd_set_fixmap(addr) ((pmd_t *)set_fixmap_offset(FIX_PMD, addr)) #define pmd_set_fixmap_offset(pud, addr) pmd_set_fixmap(pmd_offset_phys(pud, addr)) #define pmd_clear_fixmap() clear_fixmap(FIX_PMD) #define pud_set_fixmap(addr) ((pud_t *)set_fixmap_offset(FIX_PUD, addr)) #define pud_set_fixmap_offset(p4d, addr) pud_set_fixmap(pud_offset_phys(p4d, addr)) #define pud_clear_fixmap() clear_fixmap(FIX_PUD) #define pgd_set_fixmap(addr) ((pgd_t *)set_fixmap_offset(FIX_PGD, addr)) #define pgd_clear_fixmap() clear_fixmap(FIX_PGD) fixmap io映射 static void __iomem *prev_map[FIX_BTMAPS_SLOTS] __initdata; static unsigned long prev_size[FIX_BTMAPS_SLOTS] __initdata; static unsigned long slot_virt[FIX_BTMAPS_SLOTS] __initdata; void __init early_ioremap_setup(void) { int i; for (i = 0; i < FIX_BTMAPS_SLOTS; i++) if (WARN_ON(prev_map[i])) break; for (i = 0; i < FIX_BTMAPS_SLOTS; i++) slot_virt[i] = __fix_to_virt(FIX_BTMAP_BEGIN - NR_FIX_BTMAPS*i); } Ioremap的空间存放再slot_vir数组中,其虚拟地址空间每一个跨度为NR_FIX_BITMAPS。 实际进行IO映射的时候,会调用到__early_ioremap函数,在该函数中回去填充pte entry,这样虚拟地址和io设备的物理地址就匹配上了。 fixmap DTB映射 arch/arm64/kernel/setup.c setup_machine_fdt-> void *__init fixmap_remap_fdt(phys_addr_t dt_phys, int *size, pgprot_t prot) { const u64 dt_virt_base = __fix_to_virt(FIX_FDT); //从FIXMAP中获取设备树的虚拟地址 int offset; void *dt_virt; /* * Check whether the physical FDT address is set and meets the minimum * alignment requirement. Since we are relying on MIN_FDT_ALIGN to be * at least 8 bytes so that we can always access the magic and size * fields of the FDT header after mapping the first chunk, double check * here if that is indeed the case. */ BUILD_BUG_ON(MIN_FDT_ALIGN < 8); if (!dt_phys || dt_phys % MIN_FDT_ALIGN) return NULL; /* * Make sure that the FDT region can be mapped without the need to * allocate additional translation table pages, so that it is safe * to call create_mapping_noalloc() this early. * * On 64k pages, the FDT will be mapped using PTEs, so we need to * be in the same PMD as the rest of the fixmap. * On 4k pages, we\'ll use section mappings for the FDT so we only * have to be in the same PUD. */ BUILD_BUG_ON(dt_virt_base % SZ_2M); BUILD_BUG_ON(__fix_to_virt(FIX_FDT_END) >> SWAPPER_TABLE_SHIFT != __fix_to_virt(FIX_BTMAP_BEGIN) >> SWAPPER_TABLE_SHIFT); offset = dt_phys % SWAPPER_BLOCK_SIZE; dt_virt = (void *)dt_virt_base + offset; /* map the first chunk so we can read the size from the header */ create_mapping_noalloc(round_down(dt_phys, SWAPPER_BLOCK_SIZE), dt_virt_base, SWAPPER_BLOCK_SIZE, prot); //根据提供的物理地址和虚拟地址设置页表entry,建立dbt物理地址到fixmap中虚拟地址的映射 if (fdt_magic(dt_virt) != FDT_MAGIC) return NULL; //获取dtb文件大小 *size = fdt_totalsize(dt_virt); //DTB的大小不能超过2M if (*size > MAX_FDT_SIZE) return NULL; //如果DTB文件结尾的地址空间超过了上面建立的2M地址范围,需要紧接这再映射2M地址空间。 if (offset + *size > SWAPPER_BLOCK_SIZE) create_mapping_noalloc(round_down(dt_phys, SWAPPER_BLOCK_SIZE), dt_virt_base, round_up(offset + *size, SWAPPER_BLOCK_SIZE), prot); return dt_virt; } TIPS:如何打开linux内核pr_debug相关的打印 打开pr_debug的打印 (1)将Default console loglevel 设置到8 Kernel hacking > printk and dmesg options (8)Default console loglevel (1-15) (2)在对应的模块上编译添加-DDEBUG宏 diff --git a/drivers/of/Makefile b/drivers/of/Makefile index e0360a44306e..25bc584536b3 100644 --- a/drivers/of/Makefile +++ b/drivers/of/Makefile +ccflags-y :=-DDEBUG Memblock Linux内核使用伙伴系统管理内存,在伙伴系统之前,内核通过memblock来管理。在系统启动阶段,使用memblock记录理内存的使用情况,可以分成好几块。 - 永久分配给系统内核:内核镜像占用的部分,如代码、数据段等;设备树DTB等 - 预留给外设的连续内存:如GPU/Camera/多核共享等需要预留大量连续内存。 - 其他部分:以上的剩余部分内存,需要进行内存管理。 Memblock将以上内存按功能划分为若干内存区,使用不同的类型存放在memory和reserved两个集合中,memory即动态内存,reserved即静态分配的内存。 获取物理内存大小 在设备树中,使用节点名称为memory来描述内存信息,如果系统中有多个内存范围,那么device tree中可能会创建多个内存节点,或者一个单独的内存节点通过reg属性指定内存的访问。 假设一个64位系统具有以下的物理内存块: - RAM:起始地址0x0,长度0x80000000(2GB) - RAM:起始地址0x100000000,长度0x100000000(4GB) 方法一 memory@0 { device_type = \"memory\"; reg = < 0x000000000 0x00000000 0x00000000 0x80000000 0x000000001 0x00000000 0x00000001 0x00000000>; }; 第一个整数(0x00000000):表示物理地址的高32位。 第二个整数(0x00000000):表示物理地址的低32位。在这个例子中,物理地址为0x00000000。 第三个整数(0x00000000):表示大小的高32位。 第四个整数(0x80000000):表示大小的低32位。在这个例子中,大小为0x80000000,即2GB。 第五个整数(0x00000001):表示物理地址的高32位。 第六个整数(0x00000000):表示物理地址的低32位。在这个例子中,物理地址为0x100000000。 第七个整数(0x00000001):表示大小的高32位。 第八个整数(0x00000000):表示大小的低32位。在这个例子中,大小为0x100000000,即4GB。 方法二 memory@0 { device_type = \"memory\"; reg = < 0x000000000 0x00000000 0x00000000 0x80000000>; }; memory@100000000 { device_type = \"memory\"; reg = < 0x000000001 0x00000000 0x00000001 0x00000000>; }; 有些平台中在设备树中有时并没有去描述该节点,那是因为在uboot启动的时候会创建或改写该节点,实际的物理内存大小可能在boot0阶段就探测到了。 int fdt_fixup_memory_banks(void *blob, u64 start[], u64 size[], int banks) { int err, nodeoffset; int len, i; u8 tmp[MEMORY_BANKS_MAX * 16]; /* Up to 64-bit address + 64-bit size */ if (banks > MEMORY_BANKS_MAX) { printf(\"%s: num banks %d exceeds hardcoded limit %d.\" \" Recompile with higher MEMORY_BANKS_MAX?\\n\", __FUNCTION__, banks, MEMORY_BANKS_MAX); return -1; } err = fdt_check_header(blob); if (err < 0) { printf(\"%s: %s\\n\", __FUNCTION__, fdt_strerror(err)); return err; } /* find or create \"/memory\" node. */ nodeoffset = fdt_find_or_add_subnode(blob, 0, \"memory\"); if (nodeoffset < 0) return nodeoffset; err = fdt_setprop(blob, nodeoffset, \"device_type\", \"memory\", sizeof(\"memory\")); if (err < 0) { printf(\"WARNING: could not set %s %s.\\n\", \"device_type\", fdt_strerror(err)); return err; } for (i = 0; i < banks; i++) { if (start[i] == 0 && size[i] == 0) break; } banks = i; if (!banks) return 0; for (i = 0; i < banks; i++) if (start[i] == 0 && size[i] == 0) break; banks = i; len = fdt_pack_reg(blob, tmp, start, size, banks); err = fdt_setprop(blob, nodeoffset, \"reg\", tmp, len); if (err < 0) { printf(\"WARNING: could not set %s %s.\\n\", \"reg\", fdt_strerror(err)); return err; } return 0; 所以,在设备树中找不到描述,可以在系统启动阶段在uboot阶段查看内存节点。 => fdt list /memory memory { reg = <0x00000000 0x40000000 0x00000000 0x80000000>; device_type = \"memory\"; }; 物理地址起始:0x40000000 物理内存大小:0x80000000(2GB) 内核调用early_init_dt_scan_nodes扫描DTB,然后将物理内存同故宫memblock_add添加到memblock中进行管理。 drivers/os/fdt.c void __init early_init_dt_scan_nodes(void) { int rc = 0; /* Initialize {size,address}-cells info */ of_scan_flat_dt(early_init_dt_scan_root, NULL); /* Retrieve various information from the /chosen node */ rc = of_scan_flat_dt(early_init_dt_scan_chosen, boot_command_line); if (!rc) pr_warn(\"No chosen node found, continuing without\\n\"); /* Setup memory, calling early_init_dt_add_memory_arch */ of_scan_flat_dt(early_init_dt_scan_memory, NULL); early_init_dt_add_memory_arch(base, size); memblock_add(base, size); //从设备树中读取到物理内存的地址和大小,添加到memblock中 /* Handle linux,usable-memory-range property */ early_init_dt_check_for_usable_mem_range(); } 管理结构体 第一层:struct memblock,定义一个全局变量,用来维护所有的物理内存; 第二层:struct memblock_type,系统中内存类型,包括可分配使用的内存和保留的内存; 第三层:struct memblock_region,描述具体内存区域,包含在struct memblock_type中的regions数组中,最多存放128个。 mm/memblock.c static struct memblock_region memblock_memory_init_regions[INIT_MEMBLOCK_REGIONS] __initdata_memblock; static struct memblock_region memblock_reserved_init_regions[INIT_MEMBLOCK_RESERVED_REGIONS] __initdata_memblock; struct memblock memblock __initdata_memblock = { .memory.regions = memblock_memory_init_regions, .memory.cnt = 1, /* empty dummy entry */ .memory.max = INIT_MEMBLOCK_REGIONS, .memory.name = \"memory\", .reserved.regions = memblock_reserved_init_regions, .reserved.cnt = 1, /* empty dummy entry */ .reserved.max = INIT_MEMBLOCK_RESERVED_REGIONS, .reserved.name = \"reserved\", .bottom_up = false, .current_limit = MEMBLOCK_ALLOC_ANYWHERE, }; 定义了memblock全局变量,因此是不需要初始化的,在定义的时候就进行了初始化。regions指向的也是静态全局的数组,数组的大小为INIT_MEMBLOCK_REGIONS(128),在实际代码中,可以看到,当超过这个数组时,这个数组将会进行动态扩大。 memblock主要接口函数 Memblock系统提供一些列接口供内核模块使用,包括内存区块的添加、预留、内存申请等功能。 - memblock_add:将内存块添加到可用内存集合,添加新的内存块区域到memblock.memory中。 - memblock_reserve:将内存块添加到预留内存集合 - memblock_phys_alloc:用于申请memblock中的物理内存 - memblock_remove:删除内存块区域 - memblock_alloc:分配内存 - memblock_free:释放内存 memblock_add memblock_add函数将物理内存区块添加到可用内存集合中,结构管理图如下 memblock_reserve 与memblock_add类似 memblock_alloc void *memblock_alloc(phys_addr_t size, phys_addr_t align) memblock_alloc_try_nid memblock_alloc_internal memblock_alloc_range_nid memblock_find_in_range_node phys_to_virt(alloc) 最终调用memblock_find_in_range_node实现物理内存的分配。memblock_phys_alloc函数与该函数类似,区别是memblock_alloc在分配后会会调用phys_to_virt将物理地址转化为虚拟地址,而memblock_phys_alloc不会。 Arm64 memblock init 物理内存都添加到系统之后,会调用arm64_memblock_init对整个物理内存进行整理,主要的工作就是remove掉一些no-map区域(不归内核管理),同时保留一些关键区域,如内核镜像区,dtb中reserved的内存节点。 上图中,浅绿色的就是reserved部分,不能被分配使用,而剩下的部分就可以通过调用上小章节中的函数去使用内存了。 小结: (1)系统通过memblock以数组memory type的方式记录物理内存空间,数组中每一个内存区域描述了一段内存信息,包括base,size,node id等。 (2)在memblock信息中,已经被使用或者被内核定义需要保留的区域,会存储在reserved 数组中。 (3)memory type数组中并不是代表整个内核系统的内存空间,因为股份驱动会保留一段内存区域供自己单独使用,其在dts中具有no-map熟悉的reserved-memory节点,不会由内核创建地址映射。 (4)可以通过内核调试节点/sys/kernel/debug/memblockk进行查询相关信息 paging_init 上一章节中,物理内存通过该memblock模块添加进了系统,但是此时仍然只有DTB和image所在的两端物理内存可以访问,其他物理内存还访问不了,因为其还没有建立其页表。即使可以通过memblock_alloc分配物理内存,但是也不能访问,因为其虚拟地址对应的页表没有生成,只有是创建了页表才能通过虚拟地址转化访问物理地址。 void __init paging_init(void) { pgd_t *pgdp = pgd_set_fixmap(__pa_symbol(swapper_pg_dir)); //(1)获取一页内存用于构建PGD映射表,返回的是虚拟地址。 map_kernel(pgdp); //(2)完成内核的映射,包括text,data,bss段等。 map_mem(pgdp); //(3)将memblock子系统添加到物理内存进行映射 pgd_clear_fixmap(); cpu_replace_ttbr1(lm_alias(swapper_pg_dir)); //(4)切换页表,新建立页表内容替换swapper_pg_dir init_mm.pgd = swapper_pg_dir; memblock_free(__pa_symbol(init_pg_dir), __pa_symbol(init_pg_end) - __pa_symbol(init_pg_dir)); //(5)新的映射更新完成,释放掉临时空间 memblock_allow_resize(); } 构建PGD映射表 页目录直接使用的是swapper_pg_dir,一个条目映射的空间本身就很大,一个entry对应范围有512GB。 arch/arm64/include/asm/fixmap.h enum fixed_addresses { ...... /* * Used for kernel page table creation, so unmapped memory may be used * for tables. */ FIX_PTE, FIX_PMD, FIX_PUD, FIX_PGD, ...... }; pgd_t *pgdp = pgd_set_fixmap(__pa_symbol(swapper_pg_dir)); #define pgd_set_fixmap(addr) ((pgd_t *)set_fixmap_offset(FIX_PGD, addr)) #define set_fixmap_offset(idx, phys) \\ __set_fixmap_offset(idx, phys, FIXMAP_PAGE_NORMAL) #define __set_fixmap_offset(idx, phys, flags) \\ ({ \\ unsigned long ________addr; \\ __set_fixmap(idx, phys, flags); \\ ________addr = fix_to_virt(idx) + ((phys) & (PAGE_SIZE - 1)); \\ ________addr; \\ }) arch/arm64/kernel/vmlinux.lds.S swapper_pg_dir = .; . += PAGE_SIZE; swapper_pg_dir是实现分配的一段空间,处于内核镜像的data段。 通过__pa_symbol先将swapper_pg_dir转化为物理地址,然后与FIX_PGD地址范围进行映射,后续就可以通过虚拟地址FIX_PGD这段访问访问到swapper_pg_dir这块物理空间。 early_pgtable_alloc 对内核各个段、以及memblock管理的物理内存建立映射,在上一章节中已经获取到了PGD全局目录页表,但是接下来的PUD,PMD,PTE对应的页表是需要进行动态分配的,空间的分配可以使用memblock提供的函数进行分配,但是如何进行访问填充页表了?memblock分配空间内核是没法直接访问的,因为没有创建页表,没法通过查表的方式进行查找到物理地址。这个时候前面fixmap就发挥作用了,在fixmap章节中,已经创建了虚拟地址到物理地址的页表,有一段实际的虚拟地址对应的物理地址是待填充的,那就是FIX_PTE~FIX_PGD,所以就可以利用这段空间将memblock分配到的物理地址与FIX_PTE~FIX_PGD对应上,这样内核就可以通过虚拟地址进行访问了,就可以填充页表内容。 内核访问物理内存使用的都是虚拟地址,而硬件模块比如MMU等访问内存使用的是物理地址,不需要从虚拟地址到物理地址转换(否则就陷入循环了)。虚拟地址转为物理地址需要查找页表找到对应的物理地址,而这个页表需要进行填充(建立映射关系),因此内核在填充页表的时候,也是使用的虚拟地址访问。只要把各级页表填充好之后就可以了,最终MMU在翻译的时候就访问的是物理地址。 static phys_addr_t __init early_pgtable_alloc(int shift) { phys_addr_t phys; void *ptr; phys = memblock_phys_alloc_range(PAGE_SIZE, PAGE_SIZE, 0, MEMBLOCK_ALLOC_NOLEAKTRACE); //(1)先分配一块物理内存 ptr = pte_set_fixmap(phys); //(2)将当前的物理内存与fixmap的虚拟地址进行映射,映射完成后,内核即可访问这段内存,用的是PTE这段,PGD,PUD,PMD用在哪里? memset(ptr, 0, PAGE_SIZE); pte_clear_fixmap(); return phys; } 从上可以看出分配一个页表需要PAGE_SIZE的大小,也就等于一个物理页帧大小4KB。页表有512个条目,每个条目占用8字节。 内核镜像细粒度映射-map_kernel Map_kernel主要完成内核中各个段的映射,包括text、rodata、init、data、bss等各个段。 static void __init map_kernel(pgd_t *pgdp) map_kernel_segment(pgdp, _stext, _etext, text_prot, &vmlinux_text, 0, VM_NO_GUARD); map_kernel_segment(pgdp, __start_rodata, __inittext_begin, PAGE_KERNEL, &vmlinux_rodata, NO_CONT_MAPPINGS, VM_NO_GUARD); map_kernel_segment(pgdp, __inittext_begin, __inittext_end, text_prot, &vmlinux_inittext, 0, VM_NO_GUARD); //.init map_kernel_segment(pgdp, __initdata_begin, __initdata_end, PAGE_KERNEL, &vmlinux_initdata, 0, VM_NO_GUARD);//.data map_kernel_segment(pgdp, _data, _end, PAGE_KERNEL, &vmlinux_data, 0, 0); //.bss 启动日志 [ 0.000000] Virtual kernel memory layout: [ 0.000000] modules : 0xffffffc000000000 - 0xffffffc008000000 ( 128 MB) [ 0.000000] vmalloc : 0xffffffc008000000 - 0xfffffffdf0000000 ( 247 GB) [ 0.000000] .text : 0xffffffc008080000 - 0xffffffc008a30000 ( 9920 KB) [ 0.000000] .rodata : 0xffffffc008a30000 - 0xffffffc008d70000 ( 3328 KB) [ 0.000000] .init : 0xffffffc008d70000 - 0xffffffc008ef0000 ( 1536 KB) [ 0.000000] .data : 0xffffffc008ef0000 - 0xffffffc00900f008 ( 1149 KB) [ 0.000000] .bss : 0xffffffc00900f008 - 0xffffffc009069920 ( 363 KB) [ 0.000000] fixed : 0xfffffffdfdbf9000 - 0xfffffffdfe000000 ( 4124 KB) [ 0.000000] PCI I/O : 0xfffffffdfe800000 - 0xfffffffdff800000 ( 16 MB) [ 0.000000] vmemmap : 0xfffffffe00000000 - 0xffffffff00000000 ( 4 GB maximum) [ 0.000000] 0xfffffffe00000000 - 0xfffffffe02000000 ( 32 MB actual) [ 0.000000] memory : 0xffffff8000000000 - 0xffffff8080000000 ( 2048 MB) [ 0.000000] PAGE_OFFSET : 0xffffff8000000000 [ 0.000000] PHYS_OFFSET : 0x 40000000 [ 0.000000] KIMAGE_VADDR : 0xffffffc008000000 static void __init map_kernel_segment(pgd_t *pgdp, void *va_start, void *va_end, pgprot_t prot, struct vm_struct *vma, int flags, unsigned long vm_flags) { phys_addr_t pa_start = __pa_symbol(va_start); //将虚拟地址转为物理地址 unsigned long size = va_end - va_start; BUG_ON(!PAGE_ALIGNED(pa_start)); BUG_ON(!PAGE_ALIGNED(size)); __create_pgd_mapping(pgdp, pa_start, (unsigned long)va_start, size, prot, early_pgtable_alloc, flags); if (!(vm_flags & VM_NO_GUARD)) size += PAGE_SIZE; vma->addr = va_start; vma->phys_addr = pa_start; vma->size = size; vma->flags = VM_MAP | vm_flags; vma->caller = __builtin_return_address(0); vm_area_add_early(vma); } 线性映射-map_mem 完成对物理内存的映射,这部分的物理内存是同故宫memblock_add添加系统中的,函数中将会遍历memblock中的各个块,然后调用__map_memblock来完成实际的映射操作。 static void __init map_mem(pgd_t *pgdp) { ...... memblock_mark_nomap(kernel_start, kernel_end - kernel_start); //(1)不对设置了MEMBLOCK_NOMAP的标志映射 /* map all the memory banks */ for_each_mem_range(i, &start, &end) { if (start >= end) break; /* * The linear map must allow allocation tags reading/writing * if MTE is present. Otherwise, it has the same attributes as * PAGE_KERNEL. */ __map_memblock(pgdp, start, end, pgprot_tagged(PAGE_KERNEL), flags); } //(2)遍历memblock中的各个块并完成内存的映射 } 遍历memblock.memory进行逐一映射。 static void __init map_mem(pgd_t *pgdp) { ...... memblock_mark_nomap(kernel_start, kernel_end - kernel_start); //(1)不对设置了MEMBLOCK_NOMAP的标志映射 /* map all the memory banks */ for_each_mem_range(i, &start, &end) { if (start >= end) break; /* * The linear map must allow allocation tags reading/writing * if MTE is present. Otherwise, it has the same attributes as * PAGE_KERNEL. */ __map_memblock(pgdp, start, end, pgprot_tagged(PAGE_KERNEL), flags); } //(2)遍历memblock中的各个块并完成内存的映射 } static void __init __map_memblock(pgd_t *pgdp, phys_addr_t start, phys_addr_t end, pgprot_t prot, int flags) { __create_pgd_mapping(pgdp, start, __phys_to_virt(start), end - start, prot, early_pgtable_alloc, flags); } Start是要映射的物理地址,__phys_to_virt(start)是要映射的虚拟地址,由此可见,这段空间是进行的线性映射。 __create_pgd_mapping map_kernel与map_mem最终都会调用__create_pgd_mapping进行映射。 static void __create_pgd_mapping(pgd_t *pgdir, phys_addr_t phys, unsigned long virt, phys_addr_t size, pgprot_t prot, phys_addr_t (*pgtable_alloc)(int), int flags) { unsigned long addr, end, next; pgd_t *pgdp = pgd_offset_pgd(pgdir, virt); //获取要映射地址virt在PGD页表目录的表项对应的地址(虚拟地址),接下来将会进行填充内容(下一级页表的物理地址)。 /* * If the virtual and physical address don\'t have the same offset * within a page, we cannot map the region as the caller expects. */ if (WARN_ON((phys ^ virt) & ~PAGE_MASK)) return; //让物理内存由原理的按字节计算位置改为按页计算位置 phys &= PAGE_MASK; addr = virt & PAGE_MASK; end = PAGE_ALIGN(virt + size);//按PAGE对齐的方式算,结束地址多少。 do { next = pgd_addr_end(addr, end); //找到当前PGD的结束地址,一般来说PGD entry只有一个,所以这里的循环只会有依次。原因是一个PGD有512个条目,每个条目表示512GB(2^39)的虚拟地址空间。 alloc_init_pud(pgdp, addr, next, phys, prot, pgtable_alloc, flags); //初始化该PGD条目对应的PUD phys += next - addr; } while (pgdp++, addr = next, addr != end); } alloc_init_pud static void alloc_init_pud(pgd_t *pgdp, unsigned long addr, unsigned long end, phys_addr_t phys, pgprot_t prot, phys_addr_t (*pgtable_alloc)(int), int flags) { unsigned long next; pud_t *pudp; p4d_t *p4dp = p4d_offset(pgdp, addr); //获取第四级页表中页表项的地址,MR527是三级页表,所以p4dp=pgdp。 p4d_t p4d = READ_ONCE(*p4dp); //读取表项中的内容,实际读的就是PGD目录(3级) //判断表项内容是否为空,如果为空需要进行PUD,这里表项不为空,因为是3级页表,所以不需要创建PUD if (p4d_none(p4d)) { p4dval_t p4dval = P4D_TYPE_TABLE | P4D_TABLE_UXN; phys_addr_t pud_phys; if (flags & NO_EXEC_MAPPINGS) p4dval |= P4D_TABLE_PXN; BUG_ON(!pgtable_alloc); pud_phys = pgtable_alloc(PUD_SHIFT); __p4d_populate(p4dp, pud_phys, p4dval); p4d = READ_ONCE(*p4dp); } BUG_ON(p4d_bad(p4d)); /* * No need for locking during early boot. And it doesn\'t work as * expected with KASLR enabled. */ if (system_state != SYSTEM_BOOTING) mutex_lock(&fixmap_lock); pudp = pud_set_fixmap_offset(p4dp, addr); //计算所在PUD(PGD)偏移表项的地址(虚拟地址),其地址(虚拟)空间在fixmap范围内FIX_PUD(FIX_PGD)范围内,因为要访问其物理空间,需要查询页表,所以使用之前创建好的页表,填充映射好后,可以直接访问。 do { pud_t old_pud = READ_ONCE(*pudp); next = pud_addr_end(addr, end); //PUD起始和结束位置,大小是1GB。空间比较大,只循环一次。 /* * For 4K granule only, attempt to put down a 1GB block */ if (use_1G_block(addr, next, phys) && (flags & NO_BLOCK_MAPPINGS) == 0) { pud_set_huge(pudp, phys, prot); /* * After the PUD entry has been populated once, we * only allow updates to the permission attributes. */ BUG_ON(!pgattr_change_is_safe(pud_val(old_pud), READ_ONCE(pud_val(*pudp)))); } else { alloc_init_cont_pmd(pudp, addr, next, phys, prot, pgtable_alloc, flags);//循环在各个PUD映射表现建立对应PMD页表 BUG_ON(pud_val(old_pud) != 0 && pud_val(old_pud) != READ_ONCE(pud_val(*pudp))); } phys += next - addr; } while (pudp++, addr = next, addr != end); pud_clear_fixmap(); if (system_state != SYSTEM_BOOTING) mutex_unlock(&fixmap_lock); } alloc_init_cont_pmd static void alloc_init_cont_pmd(pud_t *pudp, unsigned long addr, unsigned long end, phys_addr_t phys, pgprot_t prot, phys_addr_t (*pgtable_alloc)(int), int flags) { unsigned long next; pud_t pud = READ_ONCE(*pudp);//获取PUD页表中addr对应的表项内容,也就是PMD页表地址 /* * Check for initial section mappings in the pgd/pud. */ BUG_ON(pud_sect(pud)); //如果PUD页表为空,则分配一个页表,页表中的表项为创建512个。页表大小一个为4K,每个表项占8字节。 if (pud_none(pud)) { pudval_t pudval = PUD_TYPE_TABLE | PUD_TABLE_UXN; phys_addr_t pmd_phys; if (flags & NO_EXEC_MAPPINGS) pudval |= PUD_TABLE_PXN; BUG_ON(!pgtable_alloc); pmd_phys = pgtable_alloc(PMD_SHIFT); __pud_populate(pudp, pmd_phys, pudval);//将PMD页表的物理地址填充到映射地址对应的PUD(实际上是PGD,3级页表)表项中 pud = READ_ONCE(*pudp); } BUG_ON(pud_bad(pud)); do { pgprot_t __prot = prot; next = pmd_cont_addr_end(addr, end); //一个PMD entry映射范围是2M,所以计算需要多少个entry。但是如果是连续的物理内存,init_pmd不是只初始化一个entry,而是一下初始化多个entry,多少个entry由CONT_PMDS。所以这里的地址范围next的距离将是CONT_PMDS*PMD_SIZE。 /* use a contiguous mapping if the range is suitably aligned */ if ((((addr | next | phys) & ~CONT_PMD_MASK) == 0) && (flags & NO_CONT_MAPPINGS) == 0) __prot = __pgprot(pgprot_val(prot) | PTE_CONT); init_pmd(pudp, addr, next, phys, __prot, pgtable_alloc, flags); //初始化PMD页表,创建下一级页表,同时将其物理地址填充到表项中。 phys += next - addr; } while (addr = next, addr != end); } init_pmd static void init_pmd(pud_t *pudp, unsigned long addr, unsigned long end, phys_addr_t phys, pgprot_t prot, phys_addr_t (*pgtable_alloc)(int), int flags) { unsigned long next; pmd_t *pmdp; pmdp = pmd_set_fixmap_offset(pudp, addr); //获取映射地址addr对应PMD页表项的地址(虚拟地址),其地址范围在FIX_PMD中,因为访问物理内存也需要查询页表,那就将其物理地址映射到FIXMAP范围,就可以进行直接访问虚拟地址了。 do { pmd_t old_pmd = READ_ONCE(*pmdp);//遍历PMD表项, next = pmd_addr_end(addr, end); //每个PMD的映射范围是2M,遍历需要多少个PTE。 /* try section mapping first */ if (((addr | next | phys) & ~PMD_MASK) == 0 && (flags & NO_BLOCK_MAPPINGS) == 0) { pmd_set_huge(pmdp, phys, prot); /* * After the PMD entry has been populated once, we * only allow updates to the permission attributes. */ BUG_ON(!pgattr_change_is_safe(pmd_val(old_pmd), READ_ONCE(pmd_val(*pmdp)))); } else { alloc_init_cont_pte(pmdp, addr, next, phys, prot, pgtable_alloc, flags); BUG_ON(pmd_val(old_pmd) != 0 && pmd_val(old_pmd) != READ_ONCE(pmd_val(*pmdp))); } phys += next - addr; } while (pmdp++, addr = next, addr != end); pmd_clear_fixmap(); } static void alloc_init_cont_pte(pmd_t *pmdp, unsigned long addr, unsigned long end, phys_addr_t phys, pgprot_t prot, phys_addr_t (*pgtable_alloc)(int), int flags) { unsigned long next; pmd_t pmd = READ_ONCE(*pmdp);//获得PTE映射表的头地址 BUG_ON(pmd_sect(pmd)); if (pmd_none(pmd)) {//如果没有该表则创建一个 pmdval_t pmdval = PMD_TYPE_TABLE | PMD_TABLE_UXN; phys_addr_t pte_phys; if (flags & NO_EXEC_MAPPINGS) pmdval |= PMD_TABLE_PXN; pte_phys = pgtable_alloc(PAGE_SHIFT); __pmd_populate(pmdp, pte_phys, pmdval); pmd = READ_ONCE(*pmdp); } do { pgprot_t __prot = prot; next = pte_cont_addr_end(addr, end); //一个PTE entry映射范围是4K,所以计算需要多少个entry。但是如果是连续的物理内存,init_pmd不是只初始化一个entry,而是一下初始化多个entry,多少个entry由CONT_PTES。所以这里的地址范围next的距离将是CONT_PTES*PTE_SIZE。 /* use a contiguous mapping if the range is suitably aligned */ if ((((addr | next | phys) & ~CONT_PTE_MASK) == 0) && (flags & NO_CONT_MAPPINGS) == 0) __prot = __pgprot(pgprot_val(prot) | PTE_CONT); init_pte(pmdp, addr, next, phys, __prot);//初始化每一个PTE的表项记录,对应物理页帧 phys += next - addr; } while (addr = next, addr != end); } init_pte static void init_pte(pmd_t *pmdp, unsigned long addr, unsigned long end, phys_addr_t phys, pgprot_t prot) { pte_t *ptep; ptep = pte_set_fixmap_offset(pmdp, addr);//根据addr找到对应的PTE Entry位置 do { pte_t old_pte = READ_ONCE(*ptep); //读这个entry的值,一般来说新建的entry是没有valid的值的 set_pte(ptep, pfn_pte(__phys_to_pfn(phys), prot)); //将物理地址转换为页帧,然后写入PTE /* * After the PTE entry has been populated once, we * only allow updates to the permission attributes. */ BUG_ON(!pgattr_change_is_safe(pte_val(old_pte), READ_ONCE(pte_val(*ptep)))); phys += PAGE_SIZE; } while (ptep++, addr += PAGE_SIZE, addr != end); pte_clear_fixmap(); } 内核debug日志 内核debug日志 map_kernel_segment:pgdp:fffffffdfda36000,[va_start:ffffffc008a30000,va_end:ffffffc008d70000] paging_init+0x14c/0x524 __create_pgd_mapping:pgdp:0xfffffffdfda36800, size pgd_t:8, map_kernel_segment+0xf4/0x160 alloc_init_pud,333: pgdp:0xfffffffdfda36800, map_kernel_segment+0xf4/0x160 alloc_init_cont_pmd,274: pudp:0xfffffffdfda36800, size pud_t:8,map_kernel_segment+0xf4/0x160 init_pmd,235: pmdp:0xfffffffdfda38228, size pmd_t:8, addr:0xffffffc008a30000,end:0xffffffc008d70000 map_kernel_segment+0xf4/0x160 alloc_init_cont_pte,193: pmdp:0xfffffffdfda38228,addr:0xffffffc008a30000,end:0xffffffc008c00000 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39200,size pte_t:8, end:0xffffffc008a40000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39280,size pte_t:8, end:0xffffffc008a50000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39300,size pte_t:8, end:0xffffffc008a60000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39380,size pte_t:8, end:0xffffffc008a70000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39400,size pte_t:8, end:0xffffffc008a80000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39480,size pte_t:8, end:0xffffffc008a90000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39500,size pte_t:8, end:0xffffffc008aa0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39580,size pte_t:8, end:0xffffffc008ab0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39600,size pte_t:8, end:0xffffffc008ac0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39680,size pte_t:8, end:0xffffffc008ad0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39700,size pte_t:8, end:0xffffffc008ae0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39780,size pte_t:8, end:0xffffffc008af0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39800,size pte_t:8, end:0xffffffc008b00000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39880,size pte_t:8, end:0xffffffc008b10000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39900,size pte_t:8, end:0xffffffc008b20000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39980,size pte_t:8, end:0xffffffc008b30000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39a00,size pte_t:8, end:0xffffffc008b40000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39a80,size pte_t:8, end:0xffffffc008b50000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39b00,size pte_t:8, end:0xffffffc008b60000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39b80,size pte_t:8, end:0xffffffc008b70000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39c00,size pte_t:8, end:0xffffffc008b80000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39c80,size pte_t:8, end:0xffffffc008b90000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39d00,size pte_t:8, end:0xffffffc008ba0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39d80,size pte_t:8, end:0xffffffc008bb0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39e00,size pte_t:8, end:0xffffffc008bc0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39e80,size pte_t:8, end:0xffffffc008bd0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39f00,size pte_t:8, end:0xffffffc008be0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39f80,size pte_t:8, end:0xffffffc008bf0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda3a000,size pte_t:8, end:0xffffffc008c00000,number:16 map_kernel_segment+0xf4/0x160 alloc_init_cont_pte,193: pmdp:0xfffffffdfda38230,addr:0xffffffc008c00000,end:0xffffffc008d70000 map_kernel_segment+0xf4/0x160 memblock_reserve: [0x00000000bfffc000-0x00000000bfffcfff] memblock_alloc_range_nid+0xec/0x154 memblock_add_range: [0x00000000bfffc000] memblock_reserve+0xac/0x160 memblock_insert_region:name:reserved [0x00000000bfffc000] size:1000,memblock_add_range.constprop.0.isra.0+0x19c/0x214 alloc_init_cont_pte,204: pte_phys:0xbfffc000, map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39080,size pte_t:8, end:0xffffffc008c10000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39100,size pte_t:8, end:0xffffffc008c20000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39180,size pte_t:8, end:0xffffffc008c30000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39200,size pte_t:8, end:0xffffffc008c40000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39280,size pte_t:8, end:0xffffffc008c50000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39300,size pte_t:8, end:0xffffffc008c60000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39380,size pte_t:8, end:0xffffffc008c70000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39400,size pte_t:8, end:0xffffffc008c80000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39480,size pte_t:8, end:0xffffffc008c90000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39500,size pte_t:8, end:0xffffffc008ca0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39580,size pte_t:8, end:0xffffffc008cb0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39600,size pte_t:8, end:0xffffffc008cc0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39680,size pte_t:8, end:0xffffffc008cd0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39700,size pte_t:8, end:0xffffffc008ce0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39780,size pte_t:8, end:0xffffffc008cf0000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39800,size pte_t:8, end:0xffffffc008d00000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39880,size pte_t:8, end:0xffffffc008d10000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39900,size pte_t:8, end:0xffffffc008d20000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39980,size pte_t:8, end:0xffffffc008d30000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39a00,size pte_t:8, end:0xffffffc008d40000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39a80,size pte_t:8, end:0xffffffc008d50000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39b00,size pte_t:8, end:0xffffffc008d60000,number:16 map_kernel_segment+0xf4/0x160 init_pte,179: ptep:0xfffffffdfda39b80,size pte_t:8, end:0xffffffc008d70000,number:16 map_kernel_segment+0xf4/0x160 number表示在函数中调用一次init_pte调用set_pte的此次,为16次。 bootmem_init 完成了linux物理内存框架的初始化,包括Node, Zone, Page Frame以及对应的数据结构等。 void __init bootmem_init(void) { unsigned long min, max; min = PFN_UP(memblock_start_of_DRAM()); max = PFN_DOWN(memblock_end_of_DRAM()); early_memtest(min << PAGE_SHIFT, max << PAGE_SHIFT); max_pfn = max_low_pfn = max; min_low_pfn = min; arch_numa_init(); /* * must be done after arch_numa_init() which calls numa_init() to * initialize node_online_map that gets used in hugetlb_cma_reserve() * while allocating required CMA size across online nodes. */ #if defined(CONFIG_HUGETLB_PAGE) && defined(CONFIG_CMA) arm64_hugetlb_cma_reserve(); #endif dma_pernuma_cma_reserve(); kvm_hyp_reserve(); /* * sparse_init() tries to allocate memory from memblock, so must be * done after the fixed reservations */ sparse_init(); zone_sizes_init(min, max); /* * Reserve the CMA area after arm64_dma_phys_limit was initialised. */ dma_contiguous_reserve(arm64_dma_phys_limit); /* * request_standard_resources() depends on crashkernel\'s memory being * reserved, so do it here. */ if (IS_ENABLED(CONFIG_ZONE_DMA) || IS_ENABLED(CONFIG_ZONE_DMA32)) reserve_crashkernel(); memblock_dump_all(); sparse_init Linux内核使用通常有三种内存模型,前面两种基本不再使用,目前常用的就是Sparse memory model,sparse init就是对该模型的初始化,主要的目的就是将memblock.memory添加到struct mem_section进行管理。 memory_present static void __init memblocks_present(void) { unsigned long start, end; int i, nid; for_each_mem_pfn_range(i, MAX_NUMNODES, &start, &end, &nid) memory_present(nid, start, end); //从memblock.memory进行遍历可用内存,每块memory返回的是PFN的范围start~end,每个PFN大小4KB。 } /* Record a memory area against a node. */ static void __init memory_present(int nid, unsigned long start, unsigned long end) { unsigned long pfn; #ifdef CONFIG_SPARSEMEM_EXTREME if (unlikely(!mem_section)) { unsigned long size, align; size = sizeof(struct mem_section *) * NR_SECTION_ROOTS; align = 1 << (INTERNODE_CACHE_SHIFT); mem_section = memblock_alloc(size, align); //分配NR_SECTION_ROOTS个数组指针,用于指向struct mem_section的实例。 if (!mem_section) panic(\"%s: Failed to allocate %lu bytes align=0x%lx\\n\", __func__, size, align); } #endif start &= PAGE_SECTION_MASK; mminit_validate_memmodel_limits(&start, &end); for (pfn = start; pfn < end; pfn += PAGES_PER_SECTION) { unsigned long section = pfn_to_section_nr(pfn); struct mem_section *ms; sparse_index_init(section, nid); ->section = sparse_index_alloc(nid); //为存在的mem_section分配一个实例,并添加到mem_sction中。 set_section_nid(section, nid); ms = __nr_to_section(section); //获取该section的指针 if (!ms->section_mem_map) { ms->section_mem_map = sparse_encode_early_nid(nid) | SECTION_IS_ONLINE; __section_mark_present(ms, section); } //设置该section的online标志和node id值 } } 物理内存空间按照seciton来组织的,每个section内部其memory是连续的。一个section包含多个page,在内核中由PAGES_PER_SECTION来决定,linux 5.15内核3级页表中为32768,因此内存的范围是32768*4KB=128MB,也就是说一个section最大的内存范围是128MB。 PFN找到对应的page,可以通过PFN->section->page。 page找到PFN,page->section index->memory_section->section_mem_map->PFN sparse_init_nid 内存添加到mem_section后,就进行遍历present的section,然后为其分配对应的section结构以及对应的struct page结构体。 for_each_present_section_nr(pnum_begin + 1, pnum_end) { int nid = sparse_early_nid(__nr_to_section(pnum_end)); if (nid == nid_begin) { map_count++; continue; } /* Init node with sections in range [pnum_begin, pnum_end) */ sparse_init_nid(nid_begin, pnum_begin, pnum_end, map_count); nid_begin = nid; pnum_begin = pnum_end; map_count = 1; } static void __init sparse_init_nid(int nid, unsigned long pnum_begin, unsigned long pnum_end, unsigned long map_count) { struct mem_section_usage *usage; unsigned long pnum; struct page *map; //(1)为mem_section中的mem_section_usage分配内存,用于存储内存段的使用情况 usage = sparse_early_usemaps_alloc_pgdat_section(NODE_DATA(nid), mem_section_usage_size() * map_count); if (!usage) { pr_err(\"%s: node[%d] usemap allocation failed\", __func__, nid); goto failed; } //(2)为struct page结构体分配内存,一个section最大指向128MB的空间,将分配128*1024/4个数量。 sparse_buffer_init(map_count * section_map_size(), nid); for_each_present_section_nr(pnum_begin, pnum) { unsigned long pfn = section_nr_to_pfn(pnum); if (pnum >= pnum_end) break; map = __populate_section_memmap(pfn, PAGES_PER_SECTION, nid, NULL); //获取该section对应的page 结构体地址,如果使能了vmemmap模型,则地址范围在vmememap区域中,需要建立vmmemap到page frame的页表。 if (!map) { pr_err(\"%s: node[%d] memory map backing failed. Some memory will not be available.\", __func__, nid); pnum_begin = pnum; sparse_buffer_fini(); goto failed; } check_usemap_section_nr(nid, usage); sparse_init_one_section(__nr_to_section(pnum), pnum, map, usage, SECTION_IS_EARLY); //设置section对应的page结构体指针及其标志 usage = (void *) usage + mem_section_usage_size(); } sparse_buffer_fini(); return; failed: /* We failed to allocate, mark all the following pnums as not present */ for_each_present_section_nr(pnum_begin, pnum) { struct mem_section *ms; if (pnum >= pnum_end) break; ms = __nr_to_section(pnum); ms->section_mem_map = 0; } } 虚拟地址空间vmmepmap区域,是内核中page数据的虚拟地址,针对sparse内存模型,内核申请的page返回的地址在该区域。 zone_sizes_init static void __init zone_sizes_init(unsigned long min, unsigned long max) { unsigned long max_zone_pfns[MAX_NR_ZONES] = {0}; unsigned int __maybe_unused acpi_zone_dma_bits; unsigned int __maybe_unused dt_zone_dma_bits; phys_addr_t __maybe_unused dma32_phys_limit = max_zone_phys(32); #ifdef CONFIG_ZONE_DMA acpi_zone_dma_bits = fls64(acpi_iort_dma_get_max_cpu_address()); dt_zone_dma_bits = fls64(of_dma_get_max_cpu_address(NULL)); zone_dma_bits = min3(32U, dt_zone_dma_bits, acpi_zone_dma_bits); arm64_dma_phys_limit = max_zone_phys(zone_dma_bits); max_zone_pfns[ZONE_DMA] = PFN_DOWN(arm64_dma_phys_limit); //跟进实际物理内存计算ZONE_DMA区的最大PFN数量 #endif #ifdef CONFIG_ZONE_DMA32 max_zone_pfns[ZONE_DMA32] = disable_dma32 ? 0 : PFN_DOWN(dma32_phys_limit); //计算ZONE_DMA_32区的最大PFN数量 if (!arm64_dma_phys_limit) arm64_dma_phys_limit = dma32_phys_limit; #endif max_zone_pfns[ZONE_NORMAL] = max; //计算ZONE_NORMAL区的最大PFN数量 printk(\"%s,%d:dma:%lu, dma32:%lu, Normal:%lu %pS\\n\", __func__,__LINE__, max_zone_pfns[ZONE_DMA], max_zone_pfns[ZONE_DMA32], max_zone_pfns[ZONE_NORMAL],(void *)_RET_IP_); free_area_init(max_zone_pfns); //初始化node和zone信息,以及page结构体。 } free_area_init void __init free_area_init(unsigned long *max_zone_pfn) { unsigned long start_pfn, end_pfn; int i, nid, zone; bool descending; /* Record where the zone boundaries are */ memset(arch_zone_lowest_possible_pfn, 0, sizeof(arch_zone_lowest_possible_pfn)); memset(arch_zone_highest_possible_pfn, 0, sizeof(arch_zone_highest_possible_pfn)); start_pfn = find_min_pfn_with_active_regions(); descending = arch_has_descending_max_zone_pfns(); for (i = 0; i < MAX_NR_ZONES; i++) { if (descending) zone = MAX_NR_ZONES - i - 1; else zone = i; if (zone == ZONE_MOVABLE) continue; //ZONE_MOVABLE是一个虚拟ZONE,实际内存空间不是独立的,因此不需要初始化 end_pfn = max(max_zone_pfn[zone], start_pfn); arch_zone_lowest_possible_pfn[zone] = start_pfn; arch_zone_highest_possible_pfn[zone] = end_pfn; //填充每个zone的地址范围 start_pfn = end_pfn; } /* Find the PFNs that ZONE_MOVABLE begins at in each node */ memset(zone_movable_pfn, 0, sizeof(zone_movable_pfn)); find_zone_movable_pfns_for_nodes(); //获取每个节点中ZONE_MOVABLE PFNs /* Print out the zone ranges */ pr_info(\"Zone ranges:\\n\"); for (i = 0; i < MAX_NR_ZONES; i++) { if (i == ZONE_MOVABLE) continue; pr_info(\" %-8s \", zone_names[i]); if (arch_zone_lowest_possible_pfn[i] == arch_zone_highest_possible_pfn[i]) pr_cont(\"empty\\n\"); else pr_cont(\"[mem %#018Lx-%#018Lx]\\n\", (u64)arch_zone_lowest_possible_pfn[i] << PAGE_SHIFT, ((u64)arch_zone_highest_possible_pfn[i] << PAGE_SHIFT) - 1); } //打印每个Zone区域的地址范围。 /* Print out the PFNs ZONE_MOVABLE begins at in each node */ pr_info(\"Movable zone start for each node\\n\"); for (i = 0; i < MAX_NUMNODES; i++) { if (zone_movable_pfn[i]) pr_info(\" Node %d: %#018Lx\\n\", i, (u64)zone_movable_pfn[i] << PAGE_SHIFT); } //打印每个节点中ZONE_MOVABLE地址范围 /* * Print out the early node map, and initialize the * subsection-map relative to active online memory ranges to * enable future \"sub-section\" extensions of the memory map. */ pr_info(\"Early memory node ranges\\n\"); for_each_mem_pfn_range(i, MAX_NUMNODES, &start_pfn, &end_pfn, &nid) { pr_info(\" node %3d: [mem %#018Lx-%#018Lx]\\n\", nid, (u64)start_pfn << PAGE_SHIFT, ((u64)end_pfn << PAGE_SHIFT) - 1); subsection_map_init(start_pfn, end_pfn - start_pfn); } //初始化每个node,实际上ARM64上通常只有一个 /* Initialise every node */ mminit_verify_pageflags_layout(); setup_nr_node_ids(); for_each_online_node(nid) { pg_data_t *pgdat = NODE_DATA(nid); free_area_init_node(nid); //初始化node相关结构体中pgdat内容,包括各个ZONE区域的spanned_pages,present_pages,memap_pages,nr_kernel_pages,nr_all_pages等等 /* Any memory on that node */ if (pgdat->node_present_pages) node_set_state(nid, N_MEMORY); //将node状态从N_ONLINE切换到N_MEMORY状态 check_for_memory(pgdat, nid); } memmap_init(); //遍历memblock的region,跟进PFN找到对应的struct page,对该结构体进行初始化,设置MIFRATE_MOVABLE标志等等。 } free_area_init_node static void __init free_area_init_node(int nid) { pg_data_t *pgdat = NODE_DATA(nid); unsigned long start_pfn = 0; unsigned long end_pfn = 0; /* pg_data_t should be reset to zero when it\'s allocated */ WARN_ON(pgdat->nr_zones || pgdat->kswapd_highest_zoneidx); //获取该节点中PFN的起始号和结束号 get_pfn_range_for_nid(nid, &start_pfn, &end_pfn); pgdat->node_id = nid; pgdat->node_start_pfn = start_pfn; //设置该节点的起始PFN pgdat->per_cpu_nodestats = NULL; pr_info(\"Initmem setup node %d [mem %#018Lx-%#018Lx]\\n\", nid, (u64)start_pfn << PAGE_SHIFT, end_pfn ? ((u64)end_pfn << PAGE_SHIFT) - 1 : 0); calculate_node_totalpages(pgdat, start_pfn, end_pfn); //计算pgdat中struct zone成员中的spanned_pages,present_pages等变量内容 alloc_node_mem_map(pgdat); pgdat_set_deferred_range(pgdat); free_area_init_core(pgdat); // 设置 zone data结构体,包括设置其所有的pages reserved,所有memory queues是空,清空memory bitmaps等等 } free_area_init_core static void __init free_area_init_core(struct pglist_data *pgdat) { enum zone_type j; int nid = pgdat->node_id; pgdat_init_internals(pgdat); pgdat->per_cpu_nodestats = &boot_nodestats; for (j = 0; j < MAX_NR_ZONES; j++) { struct zone *zone = pgdat->node_zones + j; unsigned long size, freesize, memmap_pages; size = zone->spanned_pages; freesize = zone->present_pages; /* * Adjust freesize so that it accounts for how much memory * is used by this zone for memmap. This affects the watermark * and per-cpu initialisations */ memmap_pages = calc_memmap_size(size, freesize); if (!is_highmem_idx(j)) { if (freesize >= memmap_pages) { freesize -= memmap_pages; if (memmap_pages) pr_debug(\" %s zone: %lu pages used for memmap\\n\", zone_names[j], memmap_pages); } else pr_warn(\" %s zone: %lu memmap pages exceeds freesize %lu\\n\", zone_names[j], memmap_pages, freesize); } /* Account for reserved pages */ if (j == 0 && freesize > dma_reserve) { freesize -= dma_reserve; pr_debug(\" %s zone: %lu pages reserved\\n\", zone_names[0], dma_reserve); } if (!is_highmem_idx(j)) nr_kernel_pages += freesize; /* Charge for highmem memmap if there are enough kernel pages */ else if (nr_kernel_pages > memmap_pages * 2) nr_kernel_pages -= memmap_pages; nr_all_pages += freesize; /* * Set an approximate value for lowmem here, it will be adjusted * when the bootmem allocator frees pages into the buddy system. * And all highmem pages will be managed by the buddy system. */ zone_init_internals(zone, j, nid, freesize); if (!size) continue; set_pageblock_order(); setup_usemap(zone); init_currently_empty_zone(zone, zone->zone_start_pfn, size); //初始化伙伴系统中使用的free_area[] } } zone_init_free_lists static void __meminit zone_init_free_lists(struct zone *zone) { unsigned int order, t; for_each_migratetype_order(order, t) { INIT_LIST_HEAD(&zone->free_area[order].free_list[t]); zone->free_area[order].nr_free = 0; } //初始化free_area[]对应的链表。 //for_each_migratetype_order可用于迭代指定迁移类型的所有分配阶,先遍历free_area[],再遍历free_list[] } 启动打印信息 启动打印信息。 [ 0.000000] Zone ranges: [ 0.000000] DMA [mem 0x0000000040000000-0x00000000bfffffff] [ 0.000000] DMA32 empty [ 0.000000] Normal empty [ 0.000000] Movable zone start for each node [ 0.000000] Early memory node ranges [ 0.000000] node 0: [mem 0x0000000040000000-0x0000000041ffffff] [ 0.000000] node 0: [mem 0x0000000042000000-0x000000004210ffff] [ 0.000000] node 0: [mem 0x0000000042110000-0x00000000421fffff] [ 0.000000] node 0: [mem 0x0000000042200000-0x0000000042243fff] [ 0.000000] node 0: [mem 0x0000000042244000-0x00000000423fffff] [ 0.000000] node 0: [mem 0x0000000042400000-0x0000000042443fff] [ 0.000000] node 0: [mem 0x0000000042444000-0x00000000bfffffff] 内核如何直到给定的分配内存属于何种迁移类型? 内核提供两个标志,分别用于分配内存是可移动的(__GFP_MOVABLE)或可回收的(__GFP_RECATMABLE),如果这些标志都没有设置,则分配的内存假定为不可移动。 如何初始化可移动性的分组? build_all_zonelists 主要是为node创建一个内存分配时优先级的顺序。将系统中各个节点的各个zone,按照备选节点的优先级顺序依次填写到对应结构体描述符的struct zonelist node_zonelist[]数组中。某node的zonelist可以按下面的优先级进行赋值: (1)对于不同节点,本地node内存放在zonelist的最前面,其他node的内存根据其与本节点的distance值从小到大依次排列。 (2)对于node内部不同的zone也存在优先级关系,normal zone排在dma zone的前面。 -

内存初始化之页表基本操作
页表级数 如何确定page table level?确定了VABITS和PAGES size之后,页表级数也可确定,根据内核的配置如下: config PGTABLE_LEVELS int default 2 if ARM64_16K_PAGES && ARM64_VA_BITS_36 default 2 if ARM64_64K_PAGES && ARM64_VA_BITS_42 default 3 if ARM64_64K_PAGES && (ARM64_VA_BITS_48 || ARM64_VA_BITS_52) default 3 if ARM64_4K_PAGES && ARM64_VA_BITS_39 default 3 if ARM64_16K_PAGES && ARM64_VA_BITS_47 default 4 if !ARM64_64K_PAGES && ARM64_VA_BITS_48 另外在代码头文件中还有宏定义确定 arch/arm64/include/asm/pgtable-hwdef.h #define ARM64_HW_PGTABLE_LEVELS(va_bits) (((va_bits) - 4) / (PAGE_SHIFT - 3)) Va_bits虚拟地址位宽,PAGE_SHIFT就是page size。 页表表项大小 #define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) ((PAGE_SHIFT - 3) * (4 - (n)) + 3) #if CONFIG_PGTABLE_LEVELS > 2 #define PMD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(2) #define PMD_SIZE (_AC(1, UL) << PMD_SHIFT) #define PMD_MASK (~(PMD_SIZE-1)) #define PTRS_PER_PMD PTRS_PER_PTE #endif #if CONFIG_PGTABLE_LEVELS > 3 #define PUD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(1) #define PUD_SIZE (_AC(1, UL) << PUD_SHIFT) #define PUD_MASK (~(PUD_SIZE-1)) #define PTRS_PER_PUD PTRS_PER_PTE #endif #define PGDIR_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(4 - CONFIG_PGTABLE_LEVELS) #define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT) #define PGDIR_MASK (~(PGDIR_SIZE-1)) #define PTRS_PER_PGD (1 << (VA_BITS - PGDIR_SHIFT)) XXX_SHIFT:各级页表索引在虚拟地址中的偏移,如下图。 XXX_SIZE:各级页表表项描述的地址空间大小(一个条目),如arm64 PMD_SIZE 为2MB(2^21)。 XXX_MASK:各级页表屏蔽位掩码。 PTRS_PER_XXX:各级页表存放的表项个数 一般2^8=512。 CONFIG_ARM64_VA_BITS_39=y CONFIG_ARM64_VA_BITS=39 CONFIG_ARM64_PA_BITS_48=y CONFIG_ARM64_PA_BITS=48 CONFIG_ARM64_PAGE_SHIFT=12 PMD_SHIFT=21 //虚拟地址右移21位得到PMD表项entry地址,指向PTE表的。 PUD_SHIFT=30 //虚拟地址右移30位得到PUD表项entry地址,指向PMD表。 PGDIR_SHIFT=30 //PUD=PGD PTRS_PER_PGD=512 PTRS_PER_PTE=512 PTRS_PER_PMD=512 PTRS_PER_PUM=512 /* PAGE_SHIFT determines the page size */ #define PAGE_SHIFT CONFIG_ARM64_PAGE_SHIFT #define PAGE_SIZE (_AC(1, UL) << PAGE_SHIFT) #define PAGE_MASK (~(PAGE_SIZE-1)) CONFIG_ARM64_CONT_PTE_SHIFT=4 //一个PTE(Page Table Entry)可以表示2^4=16个连续的物理页面,如果page size = 4K,那么一个PTE表示连续物理空间大小微16*4KB=64KB。 #define CONT_PTE_SHIFT (CONFIG_ARM64_CONT_PTE_SHIFT + PAGE_SHIFT) //=16 //PTE映射的连续物理页面大小,2^16=64KB。 #define CONT_PTES (1 << (CONT_PTE_SHIFT - PAGE_SHIFT)) //一个连续物理页面需要PTE的数量,如上面64KB,需要16个PTE,实际也是64KB/4KB=16,每个PTE映射4KB大小。相当于给PTE再分个组,16个PTE组成一组,对应一段映射范围。 #define CONT_PTE_SIZE (CONT_PTES * PAGE_SIZE) //连续物理页面需要PTE映射的空间大小,4KB*16=64KB #define CONT_PTE_MASK (~(CONT_PTE_SIZE - 1)) #define CONT_PMD_SHIFT (CONFIG_ARM64_CONT_PMD_SHIFT + PMD_SHIFT) //4+21=25 #define CONT_PMDS (1 << (CONT_PMD_SHIFT - PMD_SHIFT)) //2^4=16 #define CONT_PMD_SIZE (CONT_PMDS * PMD_SIZE) #define CONT_PMD_MASK (~(CONT_PMD_SIZE - 1)) 其他页表相关定义 表项数据类型定义 typedef u64 pteval_t; typedef u64 pmdval_t; typedef u64 pudval_t; typedef u64 p4dval_t; typedef u64 pgdval_t; typedef struct { pteval_t pte; } pte_t; typedef struct { pmdval_t pmd; } pmd_t; typedef struct { pudval_t pud; } pud_t; typedef struct { pgdval_t pgd; } pgd_t; ypedef struct { pteval_t pgprot; } pgprot_t; 获取表项索引值 #define pgd_index(addr) (((addr) >> PGDIR_SHIFT) & (PTRS_PER_PGD - 1)) #define pud_index(addr) (((addr) >> PUD_SHIFT) & (PTRS_PER_PUD - 1)) #define pmd_index(addr) (((addr) >> PMD_SHIFT) & (PTRS_PER_PMD - 1)) #define pte_index(addr) (((addr) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1)) 获取表项地址 #define pgd_offset(mm, addr) (pgd_offset_raw((mm)->pgd, (addr))) #define pgd_offset_k(addr) pgd_offset(&init_mm, addr) #define pud_offset_phys(dir, addr) (pgd_page_paddr(*(dir)) + pud_index(addr) * sizeof(pud_t)) #define pud_offset(dir, addr) ((pud_t *)__va(pud_offset_phys((dir), (addr)))) #define pmd_offset_phys(dir, addr) (pud_page_paddr(*(dir)) + pmd_index(addr) * sizeof(pmd_t)) #define pmd_offset(dir, addr) ((pmd_t *)__va(pmd_offset_phys((dir), (addr)))) #define pte_offset_phys(dir,addr) (pmd_page_paddr(READ_ONCE(*(dir))) + pte_index(addr) * sizeof(pte_t)) #define pte_offset_kernel(dir,addr) ((pte_t *)__va(pte_offset_phys((dir), (addr)))) 通过虚拟地址,获取表项的地址(虚拟地址),用这些函数拿到表项中具体的地址用于填充等操作。 表项状态判断 #define xxx_none(pud) (!pud_val(pud)) //判断是否为空表项,指向的下一级页表没分配 #define xxx_bad(pud) (!pud_table(pud)) //判断是否为坏表项 #define xxx_present(pud) pte_present(pud_pte(pud))//判断表项是否存在 表项设置 pte_wrprotect 设置为写保护 pte_mkwrite 设置为可写 pte_mkclean 清除脏标志 pte_mkdirty 设置脏标志 pte_mkyoung 设置为访问标志 pte_mkold 清除访问标志 set_pte 设置pte到ptep pte_pfn 页表项目中取出页帧号 pfn_pte 页帧号和标志组合成页表项 页目录/页表分配和释放 Xxx_alloc 页表分配,如分配页全局目录 Eg: pte_alloc Xxx_free 页表释放, Eg: pte_free -
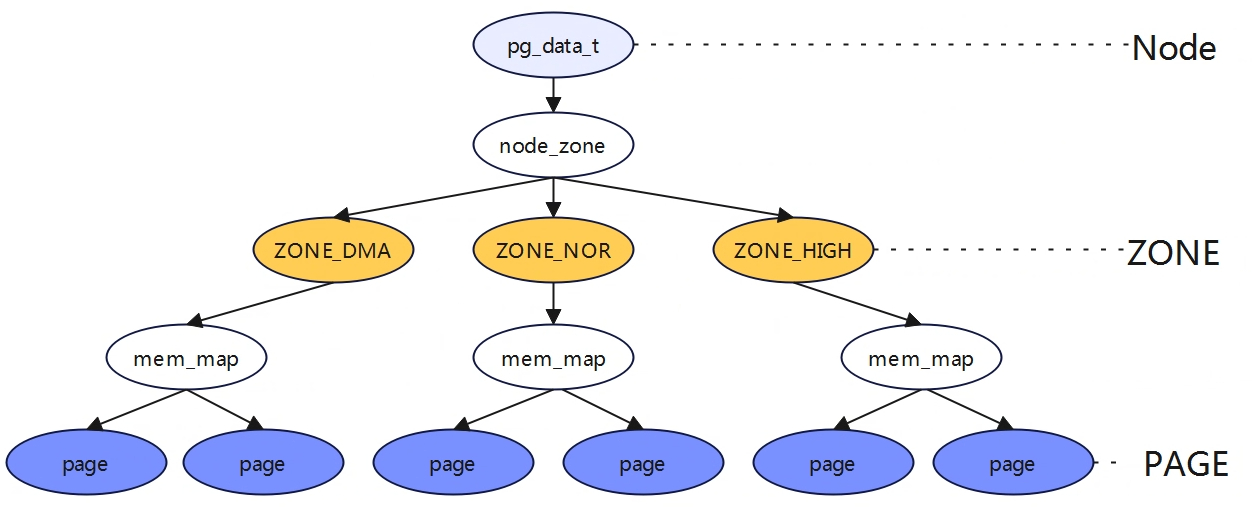
内存初始化基本概念
三级结构Node、Zone、Page Node与内存架构UMA、NUMA UMA架构(uniform memory acces) 一致内存访问,所有CPU访问内存都需要过总线,距离都是一样的,所以每个处理器访问各个内存块都是同样快。如上图4个CPU都通过系统总线来访问物理内存DDR。目前大部分嵌入式系统或台式机系统采用UMA架构。 NUMA架构(Non-uniform memory acces) 非统一内存访问,系统中有多个内存节点和多个CPU簇,CPU访问本地内存节点的速度最快,访问远端的内存节点速度要慢一点。如上图该系统使用NUMA架构,有两个内存节点,其中CPU0和CPU1组成一个节点(Node0),他们可以通过系统总线访问本地DDR物理内存,同理CPU2和CPU3组成另外一个节点(Node1),他们也可以通过系统总线访问本地DDR物理内存。两个节点通过超路径互联总线连接,那么CPU0可以通过这个内部总线访问远端内存节点的物理内存,但是访问速度要比访问本地物理内存慢很多。 <include/linux/mmzone.h> typedef struct pglist_data { struct zone node_zones[MAX_NR_ZONES]; //节点中物理内存区域 struct zonelist node_zonelists[MAX_ZONELISTS]; //节点备用列表 int nr_zones; //节点内存区域个数 struct page *node_mem_map; /*NUMA节点内管理所有物理页page的数组*/ unsigned long node_start_pfn; /*NUMA节点第一个物理页的pfn*/ unsigned long node_present_pages; /* 物理内存页的总数 */ unsigned long node_spanned_pages; /* 物理内存页的总长度,包含洞在内 */ int node_id; //NUMA节点id wait_queue_head_t kswapd_wait; struct task_struct *kswapd; int kswapd_max_order; ...... } pg_data_t; 物理内存分区(zone) 物理内存是以页(4KB)来进行管理的,理想状态任何种类的数据都可以存放在页框中,但实际上受计算机体现结构硬件方面的制约,限制了页框的使用方式,如在X86体系结构下,ISA总线的DMA控制器,只能对内存前16MB进行寻址,所以导致ISA设备不能在整个32位地址空间指向DMA,只能使用物理内存的前16MB进行DMA操作,因此物理内存前16MB专门留给内核用于DMA分配,称之DMA ZONE。 32位的处理器只支持4G的虚拟地址,其中1G的地址空间给内核,如果物理内存实际有4G,那么1G的内核空间地址无法一一映射,Linux内核提出的解决方案将物理内存分成2部分,一部分直接做线性映射,另一部分采用动态映射,称为高端内存。如果是64位的处理器一般不会有高端内存,应该地址空间足够大。 16~896MB的物理空间区域被直接映射到内核态虚拟地址空间3G+16M~3G+896M这个范围。 剩余的128M,显然剩余的3200M的ZONE HIGH区域是无法通过直接映射的方式进行映射的,因此物理内存中的ZONE_HIGHMEM区域就只能采用动态映射的方式映射128M大小内核虚拟内存空间。 注意DMA_ZONE不是说只给DMA用,DMA要是不用还是可以继续给其他用,只要设置分配内存为GFP_DMA。 - ZONE_DMA(24): isa设备的DMA操作,寻址范围0~16M。 - ZONE_DMA32: 对于64位系统中,16M的空间不够用,于是定义可以寻址到4G,满足32位的DMA寻址。 - ZONE_NORMAL: 线性映射物理内存 - ZONE_HIGHMEM:高端内存,标记超出内核虚拟地址空间的物理内存段。64位架构没有该ZONE - ZONE_MOVABLE:虚拟内存域,防止内存碎片的机制中会使用到该内存区域。(从逻辑上划分) ZONE_DEVICE:为支持热插拔而分配的非易失性内存。(从逻辑上划分) <include/linux/mmzone.h> enum zone_type { ZONE_DMA, ZONE_DMA32, ZONE_NORMAL, ZONE_HIGHMEM, ZONE_MOVABLE, ZONE_DEVICE, } ; struct zone { ... struct pglist_data *zone_pgdat; unsigned long zone_start_pfn; unsigned long spanned_pages; unsigned long present_pages; struct free_area free_area[MAX_ORDER]; atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS]; } page page(页)是linux内核管理物理内存的最小单元,内核将整个物理内存按照页对齐方式划分成成千上万个页进行管理,内核为了管理这些页将每个页抽象成struct page结构管理每个页状态及属性。struct page结构本身就占有一定内存,所以struct page不能过大。 PFN(page frame number):PFN与struct page一一对应,内核提供两个宏来完成PFN与物理页结构struct page之间相互转换,分别是page_to_pfn与pfn_to_page。 在Linux内核中,struct page数据结构通常与实际的物理内存页帧是一一对应的。Linux内核使用一个双向链表来跟踪所有可用和不可用的物理页面。 在初始化期间,内核通过调用\"memblock_init()\"等函数将系统中所有的物理内存区域划分为相同大小的页面,并为每个页面分配一个struct page数据结构。这些页面的struct page结构体被组织成一个双向链表,并存储在pgdat_list全局变量中。 当需要分配物理页面时,内核会从pgdat_list中选择一个合适的节点,并在该节点的伙伴系统上查找一个可用的物理页面。如果找到了一个可用页面,则将该页面的struct page结构体标记为已占用,并返回一个指向该页面的指针。反之,则会尝试从其他NUMA节点或者交换空间中获取可用页面。 因此,无论是通过伙伴系统获取物理页面,还是直接访问某个物理地址,都可以通过struct page数据结构来跟踪和管理实际的物理内存页面。 <include/linux/mm_types.h> struct page { 1.标志位 unsigned long flags; /* Atomic flags, some possibly 2.5个字的联合体(32位20字节,64位40字节),分别有8个部分。用于匿名页面、文件映射、slab分配器等描述。 union { 2.1 管理匿名/文件页面 struct { /* Page cache and anonymous pages */ struct list_head lru; struct address_space *mapping; pgoff_t index; /* Our offset within mapping. */ unsigned long private; }; 2.2.管理网络协议栈 struct { /* page_pool used by netstack */ unsigned long pp_magic; struct page_pool *pp; unsigned long _pp_mapping_pad; unsigned long dma_addr; union { unsigned long dma_addr_upper; atomic_long_t pp_frag_count; }; }; 2.3. slab相关描述 struct { /* slab, slob and slub */ union { struct list_head slab_list; struct { /* Partial pages */ struct page *next; #ifdef CONFIG_64BIT int pages; /* Nr of pages left */ int pobjects; /* Approximate count */ #else short int pages; short int pobjects; #endif }; }; struct kmem_cache *slab_cache; /* not slob */ void *freelist; /* first free object */ union { void *s_mem; /* slab: first object */ unsigned long counters; /* SLUB */ struct { /* SLUB */ unsigned inuse:16; unsigned objects:15; unsigned frozen:1; }; }; }; 2.4 用于复合页尾页描述 struct { /* Tail pages of compound page */ unsigned long compound_head; /* Bit zero is set */ /* First tail page only */ unsigned char compound_dtor; unsigned char compound_order; atomic_t compound_mapcount; unsigned int compound_nr; /* 1 << compound_order */ }; 2.5 复合页的第二个尾页描述 struct { /* Second tail page of compound page */ unsigned long _compound_pad_1; /* compound_head */ atomic_t hpage_pinned_refcount; struct list_head deferred_list; }; 2.6 页表页面描述 struct { /* Page table pages */ unsigned long _pt_pad_1; /* compound_head */ pgtable_t pmd_huge_pte; /* protected by page->ptl */ unsigned long _pt_pad_2; /* mapping */ union { struct mm_struct *pt_mm; /* x86 pgds only */ atomic_t pt_frag_refcount; /* powerpc */ }; #if ALLOC_SPLIT_PTLOCKS spinlock_t *ptl; #else spinlock_t ptl; #endif }; 2.7 ZONE_DEVICE页面描述 struct { /* ZONE_DEVICE pages */ struct dev_pagemap *pgmap; void *zone_device_data; }; 2.8 rcu描述 struct rcu_head rcu_head; }; 3.4个字节的联合体,用于管理_mapcount等使用计数 union { /* This union is 4 bytes in size. */ atomic_t _mapcount; unsigned int page_type; unsigned int active; /* SLAB */ int units; /* SLOB */ }; 4.用于管理引用计数 /* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */ atomic_t _refcount; } _struct_page_alignment; struct page数据结构可以分为4个部分: - 标志位:页面的标志位。 - 5字联合体:用于匿名/文件页面描述,slab分配器描述等8个部分。 - 4字节联合体:用于管理页面使用的情况。 - 4字节引用:用于管理页面引用情况。 标志位 <include/linux/page-flags.h> enum pageflags { PG_locked, /* Page is locked. Don't touch. */ PG_referenced, PG_uptodate, 表示页面的数据已经从块设备成功读取 PG_dirty, 表示页面内容发生改变,为脏页。没有跟外部存储器同步。 PG_lru, 页面在LRU链表中 PG_active, PG_workingset, PG_waiters, /* Page has waiters, check its waitqueue. Must be bit #7 and in the same byte as "PG_locked" */ PG_error, PG_slab, PG_owner_priv_1, /* Owner use. If pagecache, fs may use*/ PG_arch_1, PG_reserved, PG_private, /* If pagecache, has fs-private data */ PG_private_2, /* If pagecache, has fs aux data */ PG_writeback, /* Page is under writeback */ PG_head, /* A head page */ PG_mappedtodisk, /* Has blocks allocated on-disk */ PG_reclaim, /* To be reclaimed asap */ PG_swapbacked, /* Page is backed by RAM/swap */ PG_unevictable, /* Page is "unevictable" */ #ifdef CONFIG_MMU PG_mlocked, /* Page is vma mlocked */ #endif #ifdef CONFIG_ARCH_USES_PG_UNCACHED PG_uncached, /* Page has been mapped as uncached */ #endif #ifdef CONFIG_MEMORY_FAILURE PG_hwpoison, /* hardware poisoned page. Don't touch */ #endif #if defined(CONFIG_PAGE_IDLE_FLAG) && defined(CONFIG_64BIT) PG_young, PG_idle, #endif #ifdef CONFIG_64BIT PG_arch_2, #endif #ifdef CONFIG_KASAN_HW_TAGS PG_skip_kasan_poison, #endif #ifdef CONFIG_64BIT PG_oem_reserved, #endif __NR_PAGEFLAGS, /* Filesystems */ PG_checked = PG_owner_priv_1, /* SwapBacked */ PG_swapcache = PG_owner_priv_1, /* Swap page: swp_entry_t in private */ /* Two page bits are conscripted by FS-Cache to maintain local caching * state. These bits are set on pages belonging to the netfs's inodes * when those inodes are being locally cached. */ PG_fscache = PG_private_2, /* page backed by cache */ /* XEN */ /* Pinned in Xen as a read-only pagetable page. */ PG_pinned = PG_owner_priv_1, /* Pinned as part of domain save (see xen_mm_pin_all()). */ PG_savepinned = PG_dirty, /* Has a grant mapping of another (foreign) domain's page. */ PG_foreign = PG_owner_priv_1, /* Remapped by swiotlb-xen. */ PG_xen_remapped = PG_owner_priv_1, /* SLOB */ PG_slob_free = PG_private, /* Compound pages. Stored in first tail page's flags */ PG_double_map = PG_workingset, #ifdef CONFIG_MEMORY_FAILURE /* * Compound pages. Stored in first tail page's flags. * Indicates that at least one subpage is hwpoisoned in the * THP. */ PG_has_hwpoisoned = PG_mappedtodisk, #endif /* non-lru isolated movable page */ PG_isolated = PG_reclaim, /* Only valid for buddy pages. Used to track pages that are reported */ PG_reported = PG_uptodate, }; 有相关函数用于操作这些标志,如下: - Pagexxx():用于检查页面是否设置了PG_xxx标志位,如PageDirty检查是否PG_dirty被置位。 - SetPagexxx():设置页面的PG_xxx标志位,如SetPageDirty用于设置PG_dirty标志位 - ClearPagexxx():清楚PG_xxx标志位 mapping 在struct page中mapping成员表示当前页面的数据来源,主要分为3种情况: - 匿名页面:mapping指向VMA的anon_vma数据结构,数据原始来源于用户空间。 - 文件页面:mapping指向文件所属的address_space数据结构,包含文件所属的存储介质信息,如inode。 - swap页面(文件页面):指向交换分区的swapper_spaces。 <include/linux/fs.h> struct address_space { struct inode *host; struct xarray i_pages; struct rw_semaphore invalidate_lock; gfp_t gfp_mask; atomic_t i_mmap_writable; #ifdef CONFIG_READ_ONLY_THP_FOR_FS /* number of thp, only for non-shmem files */ atomic_t nr_thps; #endif struct rb_root_cached i_mmap; struct rw_semaphore i_mmap_rwsem; unsigned long nrpages; pgoff_t writeback_index; const struct address_space_operations *a_ops; unsigned long flags; errseq_t wb_err; spinlock_t private_lock; struct list_head private_list; void *private_data; ANDROID_KABI_RESERVE(1); ANDROID_KABI_RESERVE(2); ANDROID_KABI_RESERVE(3); ANDROID_KABI_RESERVE(4); } __attribute__((aligned(sizeof(long)))) __randomize_layout; mapping指向数据的低2位可以用于判断当前页面的类型: - bit[0]:用于判断是否为匿名页。PageAnon()函数 - bit[0]:用于判断是否为非LRU页面。_PageMovable()函数 - Bit[0:1]:若都为11,则表示KSM页面。PageKsm()函数 page_mapping()返回page数据结构种mapping成员指向的地址空间,即address_space。 _refcount 表示内核引用页面的次数 - _refcount=0:页面为空闲页面或即将要被释放的页面 - _refcount>0:页面已经被分配且内核正在使用,暂时不会被释放。get_page()会让其+1,put_page()让其-1。 在使用alloc_pages分配页面时,_refcount会变成1。当页面加入LRU时,页面被kswpad内核线程使用会+1。在页面被映射到其他用户进程的PTE时,_refcount会+1。 _mapcount 表示这个页面被进程映射的个数,即映射了多少个用户PTE。page_mapped()函数用于判断该页面是否映射到用户PTE - _mapcount=-1:没有PTE映射到页面 - _mapcount=0:只有一个进程映射到页面 - _mapcount>0:有多个进程映射到这个页面 三种内存模型 物理内存被划分为多个相同长度的页,如何组织管理这些页的方式称为物理内存模型,不同的物理内存模型,对应的page_to_pfn和pfn_to_page计算逻辑不一样。 FLAT memory model 所有的物理内存是连续的,中间内存没有空洞,划分出来的一页一页的物理页必然也是连续的,并且每页的大小是固定的,Linux早期使用的就是这种内存模型。 <include/asm-generic/memory_model.h> #if defined(CONFIG_FLATMEM) #ifndef ARCH_PFN_OFFSET #define ARCH_PFN_OFFSET (0UL) #endif #define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET)) #define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \\ ARCH_PFN_OFFSET) #endif 在平坦内存模型下,page_to_pfn与pfn_to_page计算逻辑基于mem_map数组进行偏移操作。 Discontiguous memory model 平坦度内存模型适用于一整块连续的物理内存,而对于多块非连续的物理内存使用平坦度内存模型会造成很大的空间浪费(平坦度模型使用数组mem_map[]来进行管理,而数组是连续的,从0开始递增的,而物理内存有空洞,那么中间就会出现mem_map一段指向空,但是还占用了内存空间),所以为了组织和管理不连续的物理内存,内核引入了DISCONTIGMEM非连续内存模型,用来消除这些不联系的内存地址空洞对mem_map的空间浪费。 <include/asm-generic/memory_model.h> #if defined(CONFIG_DISCONTIGMEM) #define __pfn_to_page(pfn) \\ ({ unsigned long __pfn = (pfn); \\ unsigned long __nid = arch_pfn_to_nid(__pfn); \\ NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\\ }) #define __page_to_pfn(pg) \\ ({ const struct page *__pg = (pg); \\ struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \\ (unsigned long)(__pg - __pgdat->node_mem_map) + \\ __pgdat->node_start_pfn; \\ }) #endif 5.15内核版本已经没有非连续性内存模型的,使用了Sparse memory model替换. 通过arch_pfn_to_nid根据物理页的PFN定位到物理页所在的node,再根据node中node_mem_map算偏移。 通过page_to_nid根据struct page定义page所在的node。 Sparse memory model 随着内存技术的发展,内核可以支持物理内存热插拔,这样node节点中的物理内存可能也不是连续的,为了解决这个问题,内核又引入了稀疏内存模型。 稀疏内存模型使用struct mem_section结构体来表示,用于管理连续内存块单元的被称为section,通常情况下物理页为4K,section大小为128M,物理页16K,section大小为512M。这些小的连续物理内存通过数组的方式被组织管理,每个struct mem_sction结构体中有一个指针指向section中管理连续内存的page数组。所有的mem_section被存放在一个全局数组中,每个mem_section都可以在系统运行时改变系统运行offline/online状态,以支持热插拔功能。 为了减少管理内存占用的数据结构空间,稀疏内存模型的思想与多级页表的思想类似,一级页表是必须要分配内存的,但是后面的几级进行按需分配,这里也类似,先定义一个静态的数组指针,每个数组指针管理一大块内存(4K物理页,就是128M),数组指向的实例根据实际进行动态分配空间。 <include/asm-generic/memory_model.h> struct mem_section mem_section[NR_SECTION_ROOTS][SECTIONS_PER_ROOT] <include/asm-generic/memory_model.h> #if defined(CONFIG_SPARSEMEM) /* * Note: section's mem_map is encoded to reflect its start_pfn. * section[i].section_mem_map == mem_map's address - start_pfn; */ #define __page_to_pfn(pg) \\ ({ const struct page *__pg = (pg); \\ int __sec = page_to_section(__pg); \\ (unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \\ }) #define __pfn_to_page(pfn) \\ ({ unsigned long __pfn = (pfn); \\ struct mem_section *__sec = __pfn_to_section(__pfn); \\ __section_mem_map_addr(__sec) + __pfn; \\ }) #endif /* CONFIG_FLATMEM/DISCONTIGMEM/SPARSEMEM */ 内核虚拟地址空间分布 上图表示的是整个虚拟地址空间,虚拟地址使用了48bit来寻址,因此寻址范围为2^48=256TB。在实际应用过程中,可以通过内核的配置选项来确定虚拟地址的位宽。 PABITS指的是物理地址的寻址范围,一般物理地址的寻址范围由硬件决定,内核只需要配置成与硬件一样即可,通常ARM64位的PABITS=48。 -

内存管理概述
地址空间 虚拟地址:程序使用的内存地址;物理地址:硬件的地址空间。虚拟地址通过MMU转化为物理地址,虚拟地址的长度与实际的物理内存容量没有关系,从系统中每个进程的角度看,地址空间的进程无法感知其他进程的存在。 32位cpu处理的地址空间为2^32=4G,所以虚拟地址空间为4G,分为用户空间和内核空间。用户空间的范围0~TASK_SIZE(可配置)通常为0x00000000~0xBFFFFFFF,内核空间的地址范围0xC0000000~0xFFFFFFF。由于地址空间虚拟化的结果,每个用户进程都认为自身有3G内存,而内核空间总是同样的,无论当前执行的是那个进程。 64位的cpu寻址空间为2^64,但实际只使用了47位,即寻址范围位2^48=256TB,多出的高16位就形成了地址空洞。内核空间的高16位全为1,用户空间的高16位全为0,可以直接方便判断是用户空间地址还是内核空间地址。 虚拟与物理地址 虚拟地址空间和物理内存被划分为很多等长的部分,称之为页,物理内存页被称为页帧。 进程1的页3和进程2的页1同时指向了物理页帧3,这种情况是可能的,因为两个虚拟地址空间的页可以映射到同一物理内存页,内核负责讲虚拟地址空间映射到物理地址空间,可以决定那些内存区域在进程之间共享,那些不共享。 进程的虚拟地址空间不是所有的页都映射到物理内存页帧上,因为没有这么大的一个物理内存供所有进程都一一映射完(一个进程3G,10个进程就是30G),因此只需要将当前使用的页进行映射(加载到内存中)。主要分为一些地址空间完全没有使用,另外就是有一些页被暂时换出到磁盘上,需要的时候再换回。当程序执行虚拟地址没有映射到物理地址,将运行缺页异常处理。 页表 将虚拟地址空间映射到物理地址空间的数据结构称为页表。实现两个地址空间的管理最容易的方法是使用数组,对虚拟地址空间的每一页,都分配一个数组项。该数组项指向与之关联的页帧。 二级页表 把虚拟地址分为3部分,PGD+PT+Offset组成。 为什么要使用多级页表? (1)一级页表 一个进程4GB的虚拟地址空间需要4GB/4KB=1MB个页表项,每个页表项占用4字节,每个一级页表需要4MB的存储空间,一个进程需要4MB的内存来存储页表,那100个进程需要400MB。 (2)二级页表 一级页表PGD:一共4096项,每个页表项4字节,一共16KB。 二级页表PTE:一共4096个PTE页表,每个二级页表包含256个页表项,大小为1KB(256 * 4字节),所有的二级页表大小一共是4K * 1KB=4MB。 一个进程需要4MB+16KB的内存来存储页表。 根据linux内核局部性原理,不是所有的地址空间都需要映射到物理内存,所以二级页表实际的页表占用内存大小为(16KB+1KB * n) * m,其中n表示PTE的个数,m表示进程的数目。 因此对比一级页表,一个进程最少需要4MB的空间,而二级页表最少需要17KB的空间。 多级页表 PGD: page global directory,页全局目录 PUD: page upper directory,页上级目录 PMD:page middle directory,页中间目录 PT:page table,直接页表 linux 4.11之后,页表拓展到5级,在页全局目录和页上级目录之间增加了页四级目录。各个处理器架构可以选择5级、4级、3级、2级,使用CONFIG_PGTABLE_LEVELS来配置页表级数。页表级数越多,存储空间越小,主要是利用了内存管理的局部性原理,但是相应的硬件结构越复杂,访问的速度也会降低。针对访问速度的问题,CPU试图通过以下两种方法加速其转换过程。 (1)CPU中有一个专门的部分MMU(Memory Management Unit,内存管理单元),该单元优化了内存访问的操作。(通过硬件来负责转化,所有的页表都是存储在物理内存中,由软件按照要求先填写好,然后给一级页表的起始地址给TTBRx,后续虚拟地址到物理地址的转换就由MMU自动完成) (2)地址转换中出现最频繁的那些地址,保存到地址转换缓冲器中(TLB,Translation Lookaside Buffer),下次访问直接从缓存器中获得地址数据,不在进行地址转换。 物理内存分配 物理内存被均匀的分配为多个相等长度的页(页帧),通常大小为4KB。内核在分配内存时,必须要记录页帧的状态(是否已分配),以免两个进程使用同样的内存区域。由于内存分配和释放非常的频繁,内核还必须保证相关的操作尽快完成。 伙伴系统 内核中很多时候要求分配连续的页,快速检测内存中连续区域,内核使用伙伴系统。 内核对所有大小相同的伙伴,都放置到同一个列表中管理。空闲内存块总是两两分组,每组中的两个内存块称为伙伴。 如果系统中需要8个页帧,则将16个页帧组成的块分成两个伙伴,其中一块用户满足应用程序使用,剩余的8个页帧则放置到对应8页大小内存块列表中。 如果两个伙伴都是空闲的,内核会可以将其合并为一个更大的内存块,作为下一层上某个内存块的伙伴。 slab缓存 物理页帧的大小为4KB,但是内核本身经常需要分配比4KB小的内存块。由于内核无法使用标准库的函数,因而在伙伴系统的基础上自行定义额外的内存管理层,将伙伴系统提供的页划分为更小的部分。该方法不仅可以分配内存,还为频繁使用的小对象实现一个一般性的缓存-slab缓存。可以通过两种方法分配内存: (1)频繁使用的对象,内存定义了只包含所需类型对象的示例缓存。每次需要某种对象时,可以从对应的缓存快速分配。Slab缓存自动维护与伙伴系统的交互,在缓存用完时会请求新的页帧。 (2)通常情况下小内存的分配,内核针对不同大小的对象定义了一组slab缓存,可以像用户空间编程一样,使用类似的函数获取,如kmalloc和kfree。 页面交换和页面回收 页面交换:通过利用磁盘空间作为扩展内存,从而增大可用的内存。在内核需要更多内存时,不经常使用的页可以写入到磁盘中,如果再访问相关数据时,内核再将相应的页切换会内存。 页面回收:内存映射被修改的内容与底层的块设备同步,此时也称为数据写回。数据刷出后,内核即可将页帧用于其他用途。