解读ViT:Transformer 在视觉领域如何落地
背景
计算机视觉领域,一直都是卷积天下。传统的卷积神经网络(CNN)依赖于卷积核提取局部特征,效果很好,但是也有一些不足,如需要人工设计卷积结构包括卷积核大小和层数,另外就是难以捕捉全局的依赖关系。
transformer最早更多的是应用在NLP领域的架构,用注意力机制来捕捉长距离的依赖。那把transformer应用在视觉领域了,会有什么效果吗?而在2021年发表的https://arxiv.org/abs/2010.11929这篇论文就是使用transformer应用在图像识别的领域。
论文中提到基于transformer使用监督学习方式训练模型进行图像分类时,在中等规模数据集(如ImageNet)上如果没有使用强正则化其准确率略低于同等规模的ResNet。但是当加大数据集(1400W至3亿张图像)训练时,发现其识别水平超越了现有技术。
模型概览
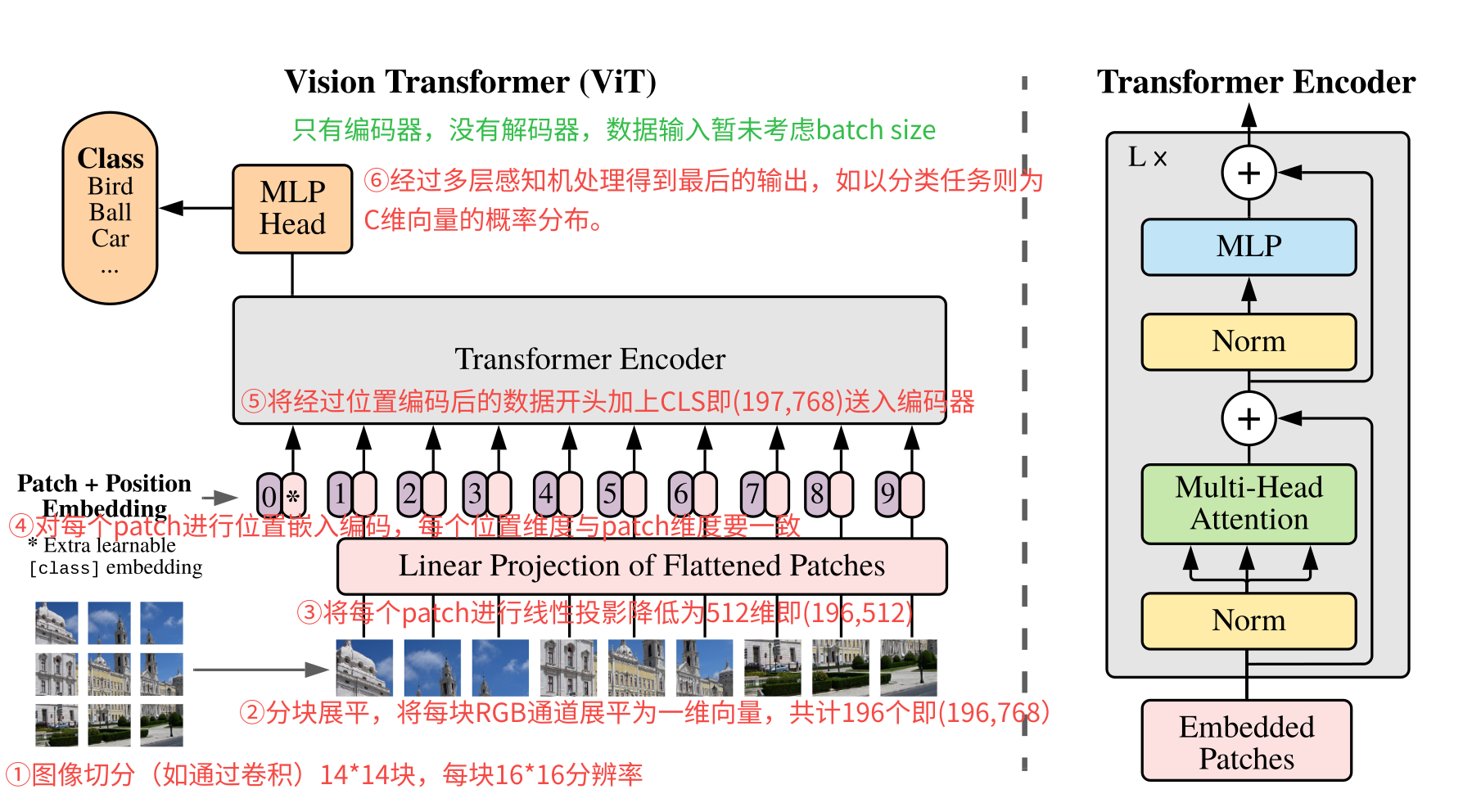
上图就是整个ViT模型结构了,对transformer比较熟悉的,整个结构就很简单了。可以发现只有transformer encoder没有transformer decoder。
这里先整体看看其流程步骤:
- 图像切块:原图输入为224×224分辨率的图像,将其切分为14×14共196块的(如使用卷积),每块大小的分辨率为16×16。
- 分块展平:将每块为16×16分辨率的patch展平为一维向量,共计有196个这样的向量。由于每块是RGB 3通道图像,因此向量维度为16x16x3= 768,按照RGB排布进行展开为一维向量。因此最后的数据形状为(196,768)。
- 线性投影:对每个patch的向量乘以一个权重矩阵,映射到D维的embedding空间,这个D维跟transformer输入维度一致(默认是512)。因此经过转换后的数据就变成了(196,768)->(196,512)。
- 位置编码:对经过线性映射的patch加上位置编码,每个patch一个位置向量,其向量的维度与patch维度一致,总的位置编码矩阵为(196,512)。将这个位置编码与经过线性映射的进行相加得到输入。
- 编码输入:经过位置编码后的输入然后在最开始加上了[CLS]向量送入编码器。因此输入的数据为(197,512)。如果算上批量数据最后就是(B,197,768)。B为batch size,197为patch数,512为embedding维度。
- 编码输出:最后经过多层感知机MLP得到最后的输出,如果是分类任务的话,就是(B,C)结果,B为batch size,C为类别数。也就是结果每行就是一个概率分布。
常见问题
(1)图像是如何切分展平的?
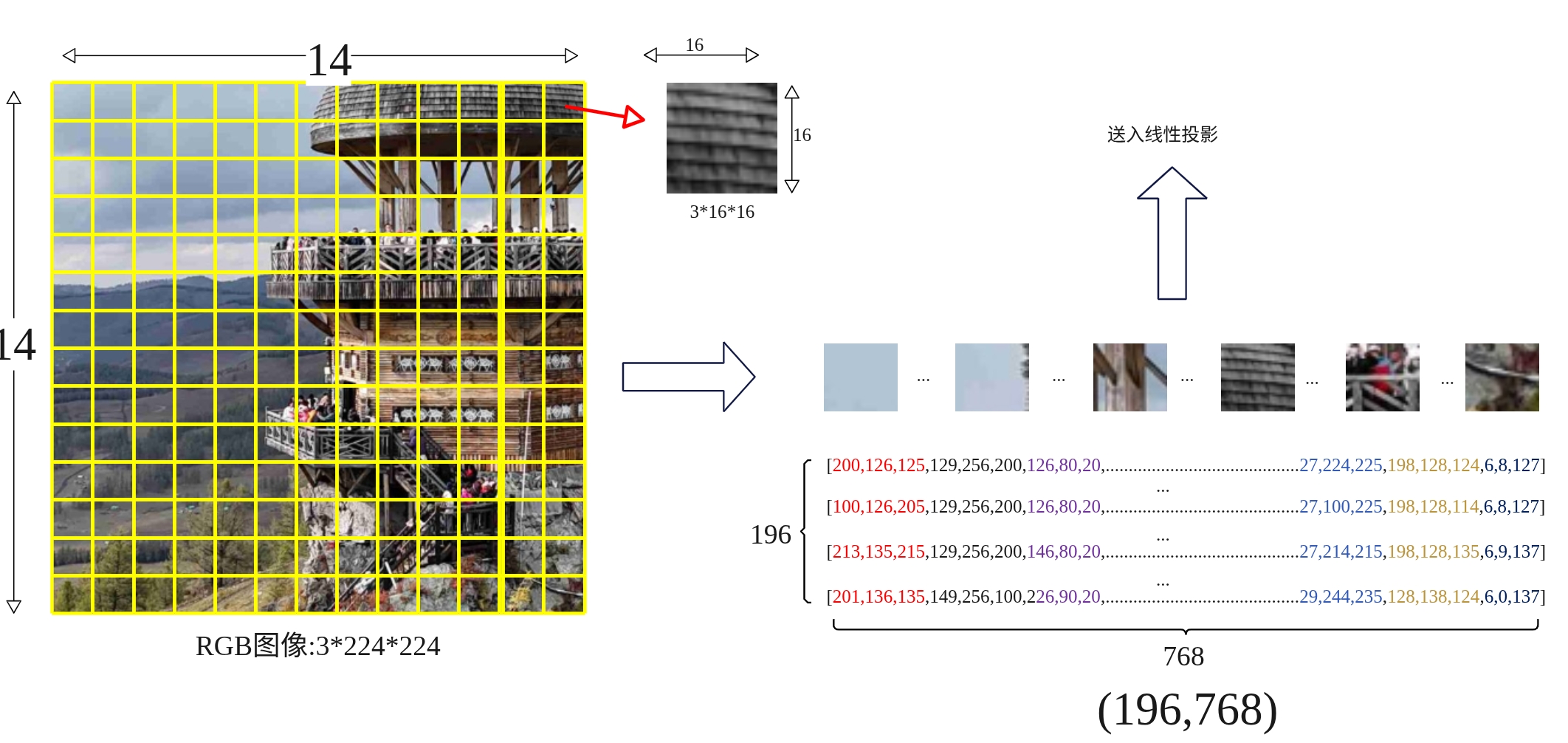
以输入尺寸3x224x224的RGB图像为例,块大小为16×16,因此块的数量为14×14=196个块。每个块3x16x16被拉成一维向量长度为16x16x3=768,也就是每个块被展平为768维向量,一共有196个块,也就是说转换为(196,768)的矩阵。
(2)每个patch为什么要展平?
主要是transformer的输入要求,因为transformer是序列处理器,其输入必现是一维的向量序列,而图像分块后得到的每个块是二维矩阵。还记得在transformer实现文章中吗?输入的是(seq,d_model),seq为token的数量,而d_model为每个token嵌入的向量。当然这里的图像最后还需要经过映射降维跟这里的d_model保持一致,这样才能输入到transformer的编码器中。
(3)线性投影有什么作用?
主要有两个作用,其一是图像分块展平后得到的是高维稀疏向量(如16163=768),包含了大量冗余信息如局部宽高、噪声等,缺乏高层语义表达,数据量大,计算量也大,线性投影是一个可训练全连接权重矩阵,可以提取保留关键局部特征;其二是为了适配transformer输入结构,Transformer要求输入为固定维度向量序列(如 D=512)。线性投影统一所有图像块的输出维度,确保自注意力机制可计算。
(4)这里的位置编码与transformer的有什么不同吗?
ViT中的位置编码使用的是自适应位置编码,transformer中用的是正余弦固定公式,因为ViT中的输入序列位置一般都有限,因此用1D的可学习的位置编码即可,这个位置编码是一个可学习的参数矩阵,初始化为全0,在训练过程中通过反向传播自动优化。
(5)输出的MLP与transformer FFN有什么不同吗?
基本一样的,FFN是前馈神经网络的统称,MLP是具体的前馈神经网络具体实现特指全连接网络。
(6)最后的输出是什么样的?
ViT最后的输出结构根据实际任务需求有关,如果是图像分类任务,在最终输出是[CLS] token向量经 MLP Head映射后的logits(未归一化的类别分数),形状为 [B, K](K为类别数);
(7)整个处理流程数据变化是怎么样的?
| 处理阶段 | 输入形状 | 操作 | 输出形状 | 示例值(B=64) |
|---|---|---|---|---|
| 原始输入 | [B, C, H, W] |
— | [64, 3, 224, 224] |
|
| Patch分块 + 展平 | [B, C, H, W] |
卷积核尺寸=步长=P(如 16×16) | [B, N, P²·C] |
[64, 196, 768] |
| 线性投影 (Patch Embedding) |
[B, N, P²·C] |
全连接层映射至目标维度 D=512 |
[B, N, D] |
[64, 196, 512] |
| 添加 Class Token | [B, N, D] |
序列前拼接可学习的 [CLS] 向量 |
[B, N+1, D] |
[64, 197, 512] |
| 位置编码叠加 | [B, N+1, D] |
加可学习位置编码 E_{pos} ∈ ℝ^{1×(N+1)×D} |
[B, N+1, D] |
[64, 197, 512] |
| Transformer 编码器 | [B, N+1, D] |
多头自注意力(MSA) + MLP 前馈网络 | [B, N+1, D] |
[64, 197, 512] |
| 分类头输出 | [B, D](仅取 [CLS]) |
全连接层映射至类别数 K |
[B, K] |
[64, 1000] |