Diffusion:如何从噪声中生成清晰图像
概述
图像生成是当下研究的热点,diffusion是一种人工智能领域图像生成的基础模型,当下Stable diffusion、DALL·E、MidJourney文生图模型的基座都使用了diffusion。
diffusion扩散模型属于生成式模型,生成图像不是正向从0到1构成图像而是反向的预先生成一个随机的噪声图中然后根据文本提示词逐渐的去噪”扣”出图像。主要思想是先训练一个权重模型,把一张清晰照片弄得越来越模糊(加入噪声),然后把模糊的图片融合文本提示词作为输入去训练一个模型学会“擦亮它”,反向恢复成清晰图像。训练完成后,就得到了模型的权重,那么使用这个权重模型只要给一副完全随机的“噪点图”和要生成图片的提示词,它就能一步步去掉噪声,变出一幅崭新、逼真的图片。
借用米开朗基罗雕刻”大卫像”时说的”我在大理石中看见天使,于是我不停地雕刻,直至使他自由”。而diffusion也是这样的原理,通过随机生成的一个噪声图片,结合输入的文字去掉噪音恢复到你想象的照片样子。
工作原理
推理
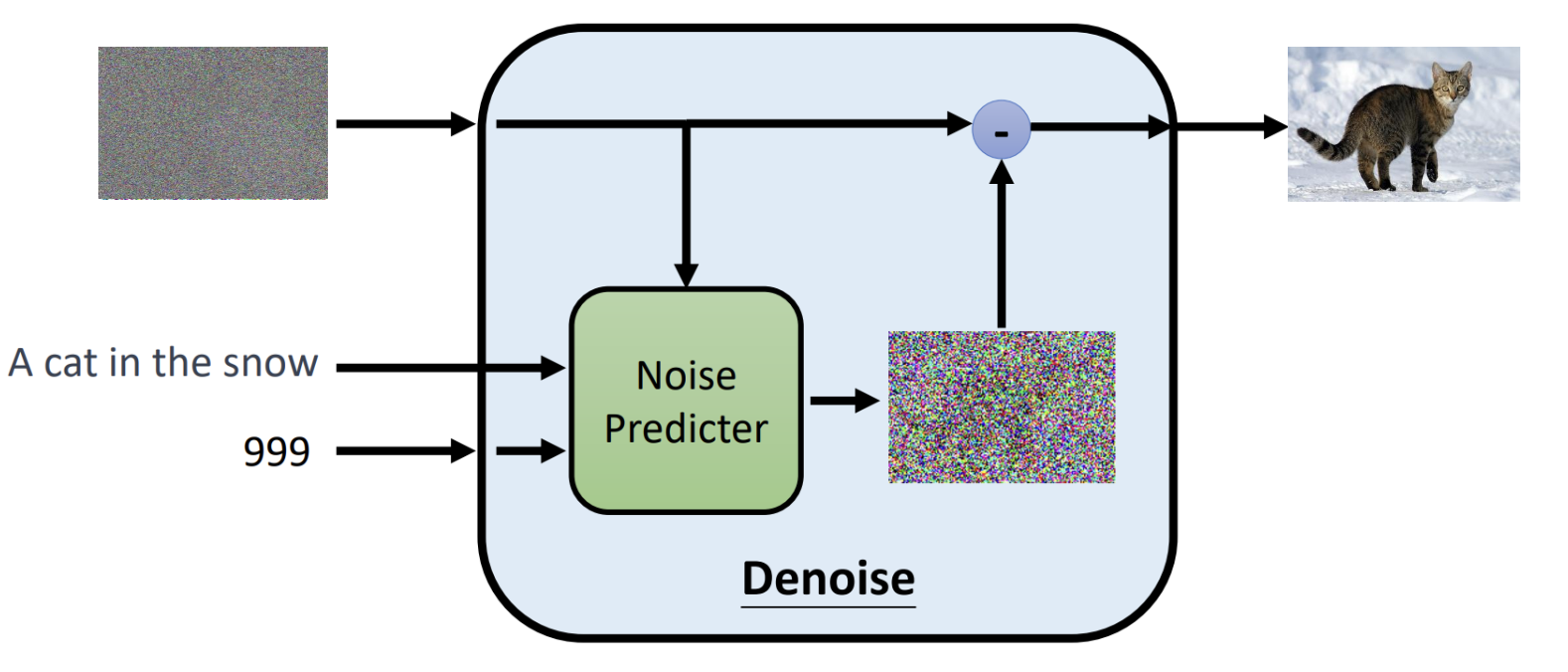
(1)输入阶段
输入阶段有3个输入信息,分别是随机噪声图像、文本提示、时间步。
- 随机噪声图像:最开始随机生成一个高斯噪声的图片。
- 文本提示:告诉模型,想要生成的内容是什么。
- 时间步:指明当前是去噪第几步,模型是一个多步迭代去噪的过程。按照数字依次递减进行迭代,数值越小去噪强度越弱。
(2)模型处理
核心组件是Noise Predictor(一般是一个U-Net结构神经网络),输入的带噪图像X_{t}、时间步t、以及提示文本通过Noise Predictor预测出这张图里有多少噪声,生成一张噪声图片\epsilon^\theta(x_t, t, c)。
(3)输出阶段
将输入-减去预测出的噪声图片就得到最后的去噪图片了,x_{t-1} = x_t – \epsilon^\theta(x_t, t, c)。
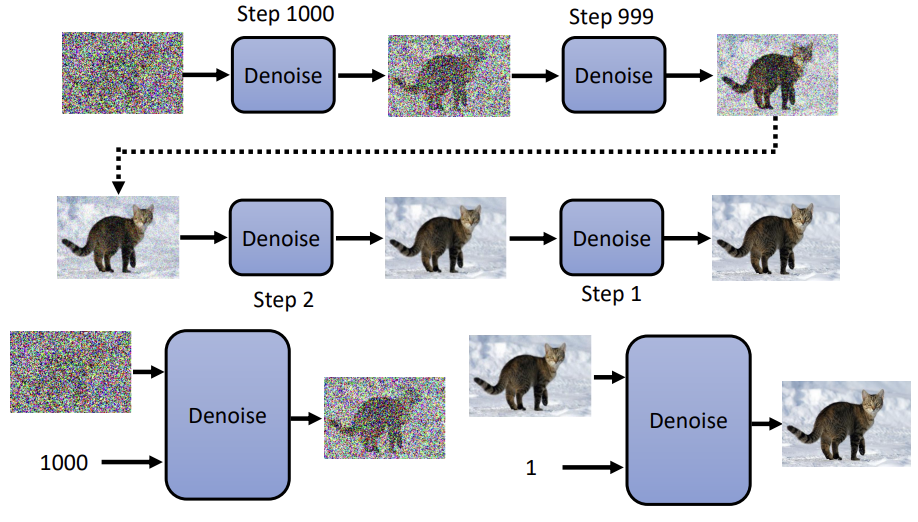
(4)迭代
迭代一轮得到一个降噪图片之后,接着将输出的降噪图片作为输入的带噪图片按照之前的步骤进行重复,直至t=T(比如1000)一直迭代到t=0得到最终的图像。当所有步骤完成后,随机噪声逐渐被“洗掉”,生成的就是一张符合条件描述的清晰图像。
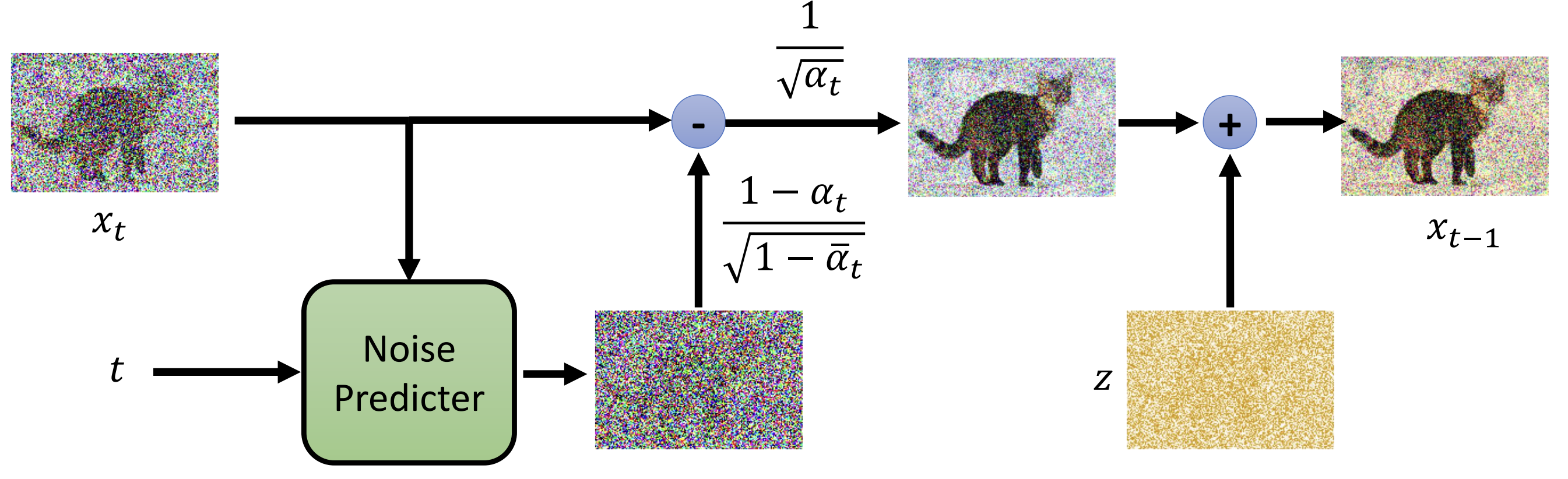
下面是推理过程的算法伪代码

- 初始化:x_T \sim \mathcal{N}(0, I)从标准高斯分布中采样一个随机噪声向量(或噪声图像),作为生成过程的起点。
- 迭代循环:从t=T到t=1逐步迭代,每次去掉一部分噪声。如果t>1,额外采样一个噪声向量z\sim \mathcal{N}(0, I)。如果t=1,则z=0,即最后一步不加噪声。
- 核心公式:先去掉预测的噪声(括号里面的部分)得到更接近干净数据的样子,接着在进行缩放调整(除以\sqrt{\alpha_t}),最后加一点随机噪声\sigma_t z来保持生成的多样性。
- 输出:当循环结束时,最终的x_0就是最终生成的清晰图像了。
对于核心公式的参数这里稍微补充一下
- 参数 \epsilon_\theta(x_t, t)是预测的噪声;
- 参数\alpha_t取值范围是0~1,控制在第t步中保留多少原始图像信息加入多少噪声,当\alpha_t接近1时几乎保留全部信息,噪声小;当值趋于0时,原始信号衰减就大,噪声比例高;
- 参数\bar{\alpha}_t累积乘积参数,表示从第1步到t步累积保留原始信息的比例。
- 参数\sigma_t z随机扰动项,保持采样的多样性。
训练
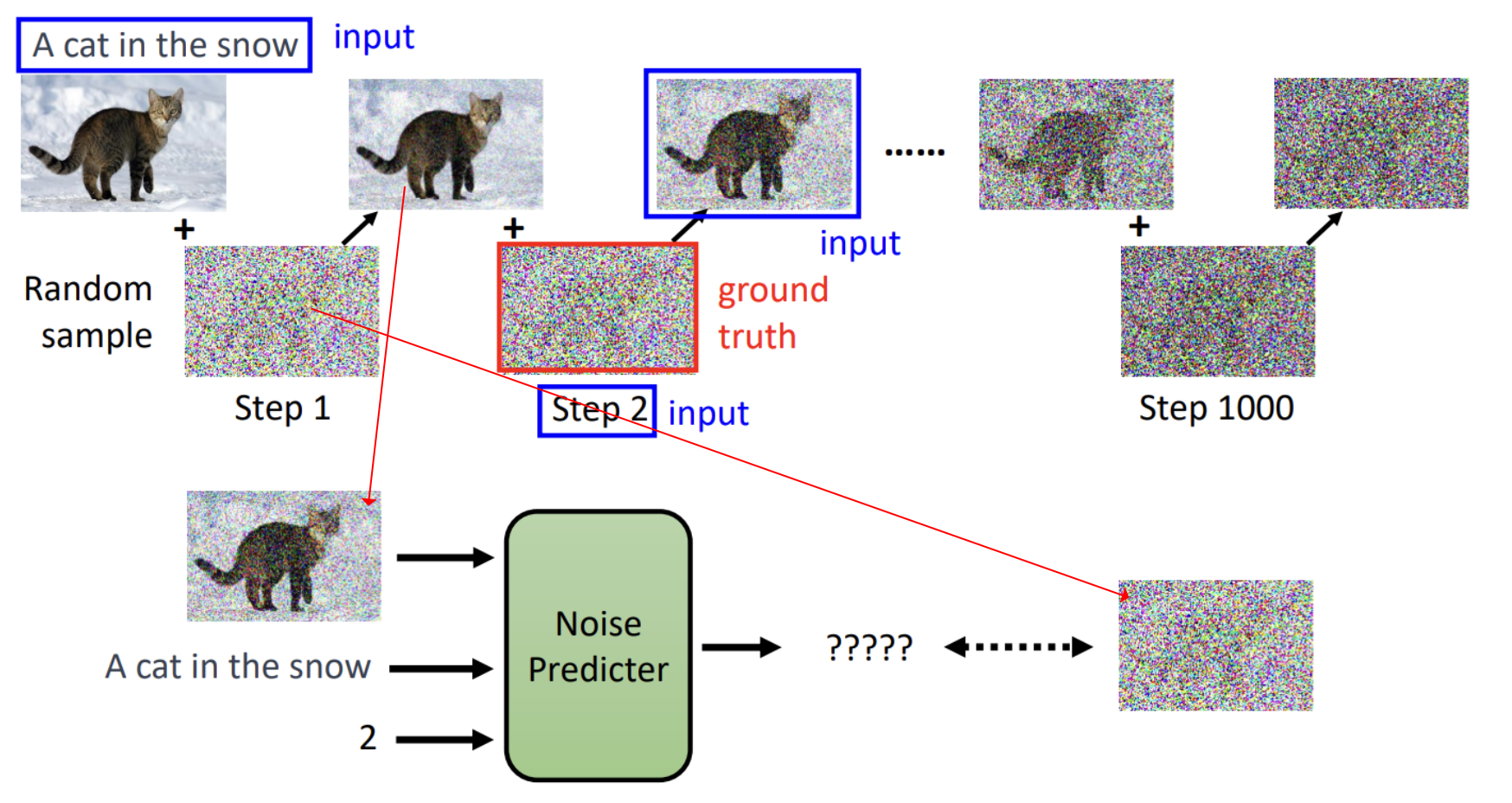
训练模型我们需要把模型的输出结果和真实值进行比较才能进行梯度下降找到网络权重,那该如何设计准备训练结果和真实值的数据?
diffusion模型的核心是要预测出图片的噪声分布然后减去预测的噪声得到真实的输出照片。以上图第一步进行说明,使用原始的图片,通过随机生成一个噪声图(x_{1})迭加作用到原始图片上这样就得到了模型的带噪声的输入图像,然后融合文本、时间步模型前向计算得到噪声图(x_2)。已经知道了真实的噪声图是x_{1},那么计算x_{1}和x_{2}的相似性就可以计算出损失了。
训练过程中关于图片-文本可以从Lion平台上获取,通过上面步骤取样照片然后不断加强噪声得到越来越模糊的图片送入模型预测进行计算迭代权重,让模型学会真正准确预测每一步中”加进去的噪声”,训练完成之后,模型学会了如何”识别噪声”,在推理时就从纯随机噪声x_T出发,通过文本提示词反向迭代去噪得到最终的想要的照片。
论文中的伪代码如下:

- repeat:表示循环执行训练过程。
- 采样数据:x_0 \sim q(x_0)从真实数据分布q(x_0)中采样一个训练样本比如一张猫。
- 随机采样时间步:t \sim \text{Uniform}({1, \dots, T})随机挑选一个扩散的时间步t,确保模型能在不同噪声水平都学会去噪。
- 采样噪声:\epsilon \sim \mathcal{N}(0, I)从标准的高斯分布中采样一份噪声,用于后续得到到原始图片上。
- 梯度下降更新参数:计算预测噪声和真实噪声\epsilon的均方误差。
模型
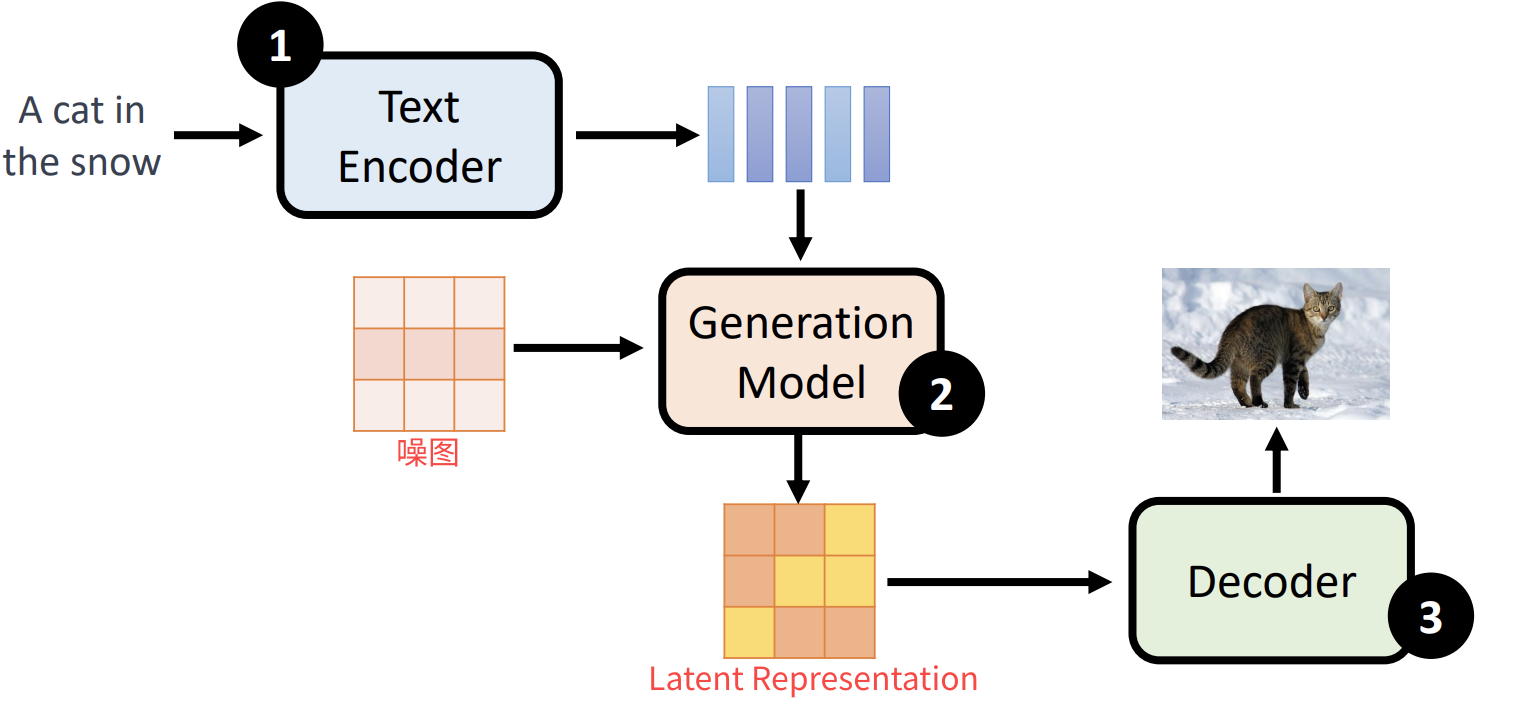
本章节简要说一下业界文生图模型,其结构可以总结为以上3个部分,文本编码器、生成式模型、解码器。
- 文本编码器:将用户输入的文本提示通过预训练的文本编码器如CLIP Text Encoder将自然语言转化为向量表示。
- 生成式模型:将编码的文本向量和噪声图像noisy latent作为输入,然后逐步迭代去噪。这里的模型如有diffusion、autoregressive等。输出是压缩到更低维的”潜在空间”。
- 解码器:将生成式模型的输入Latten Representation通过解码器还原最终生成清晰图像。生成式模型一般输出的是压缩的低维潜在空间,这样可以降低每一步迭代的计算量,最终加一个解码器来将其还原。
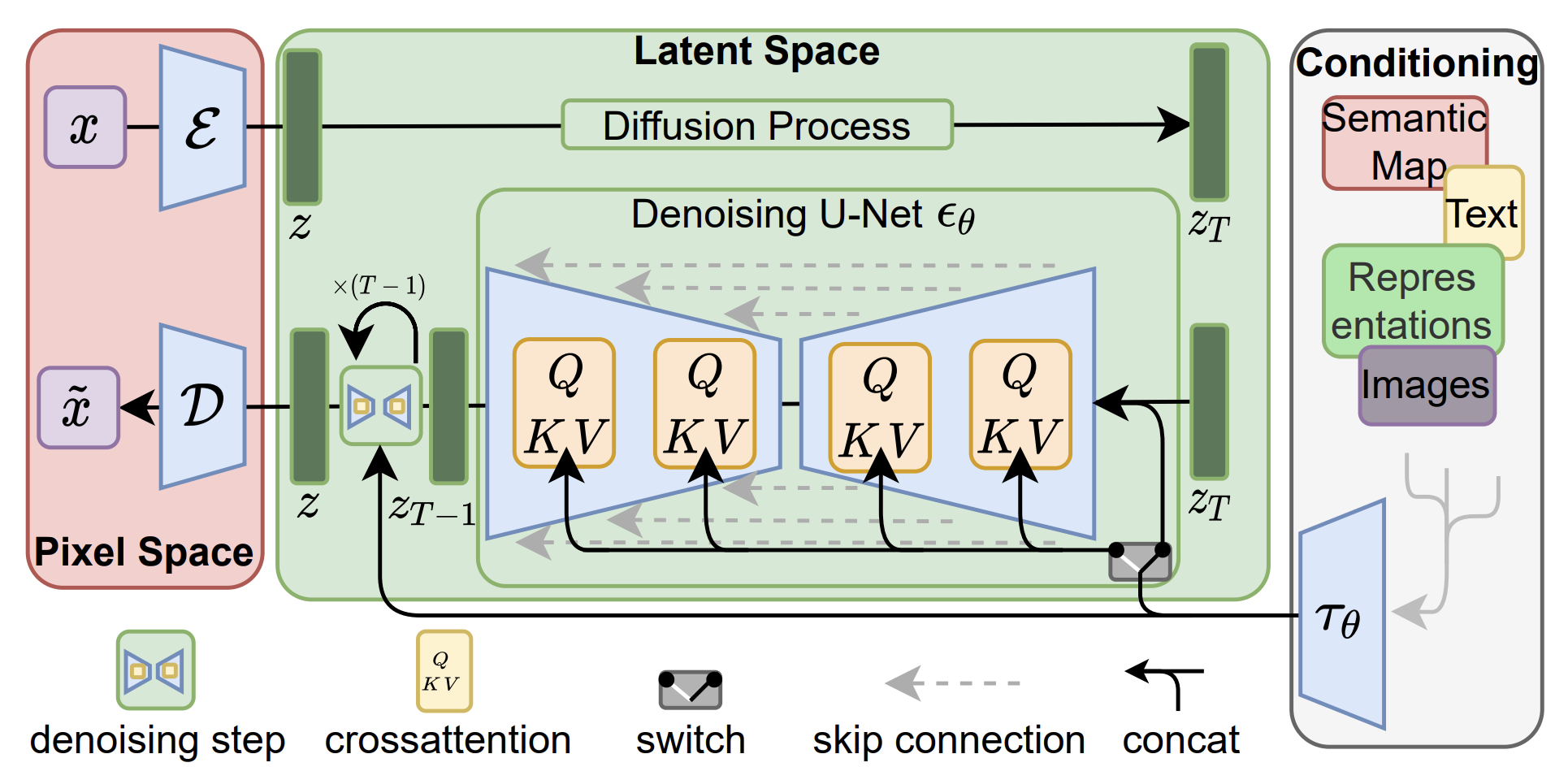
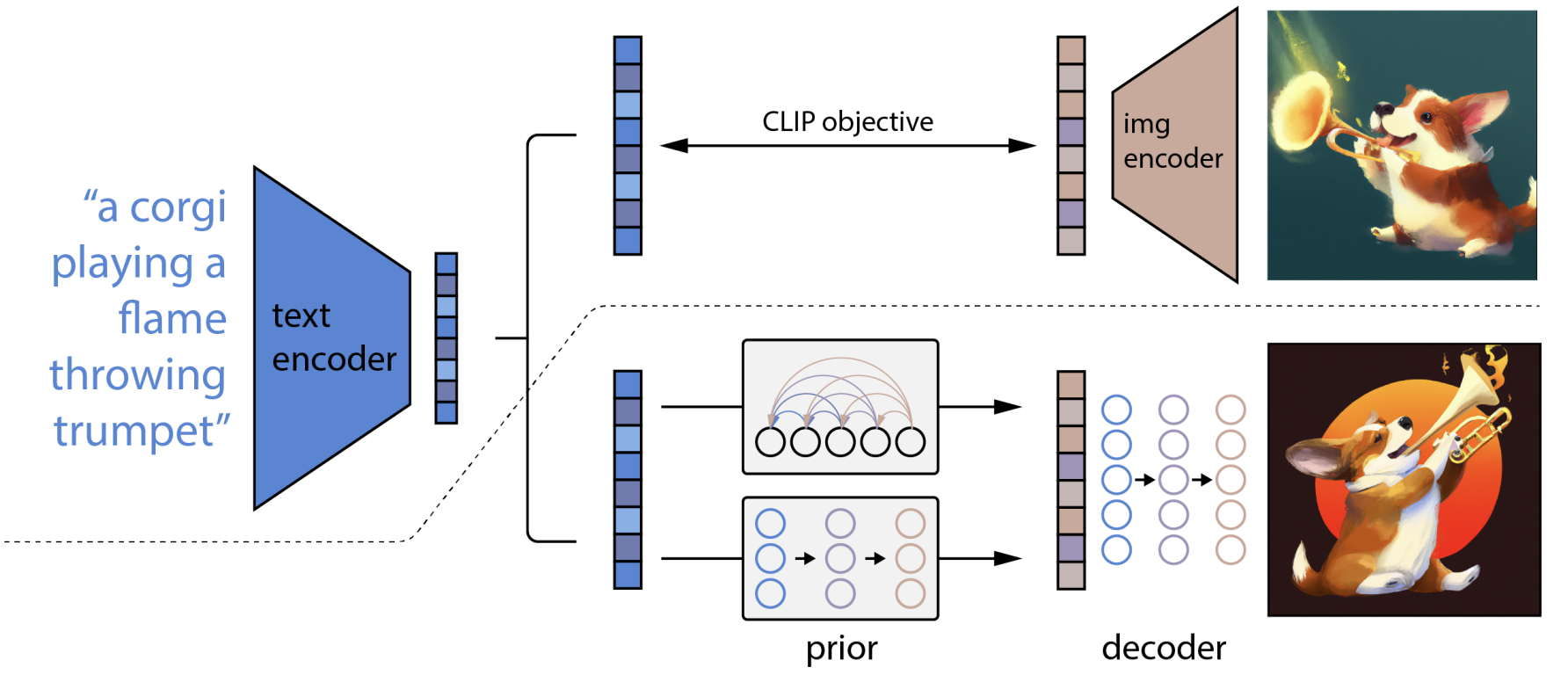
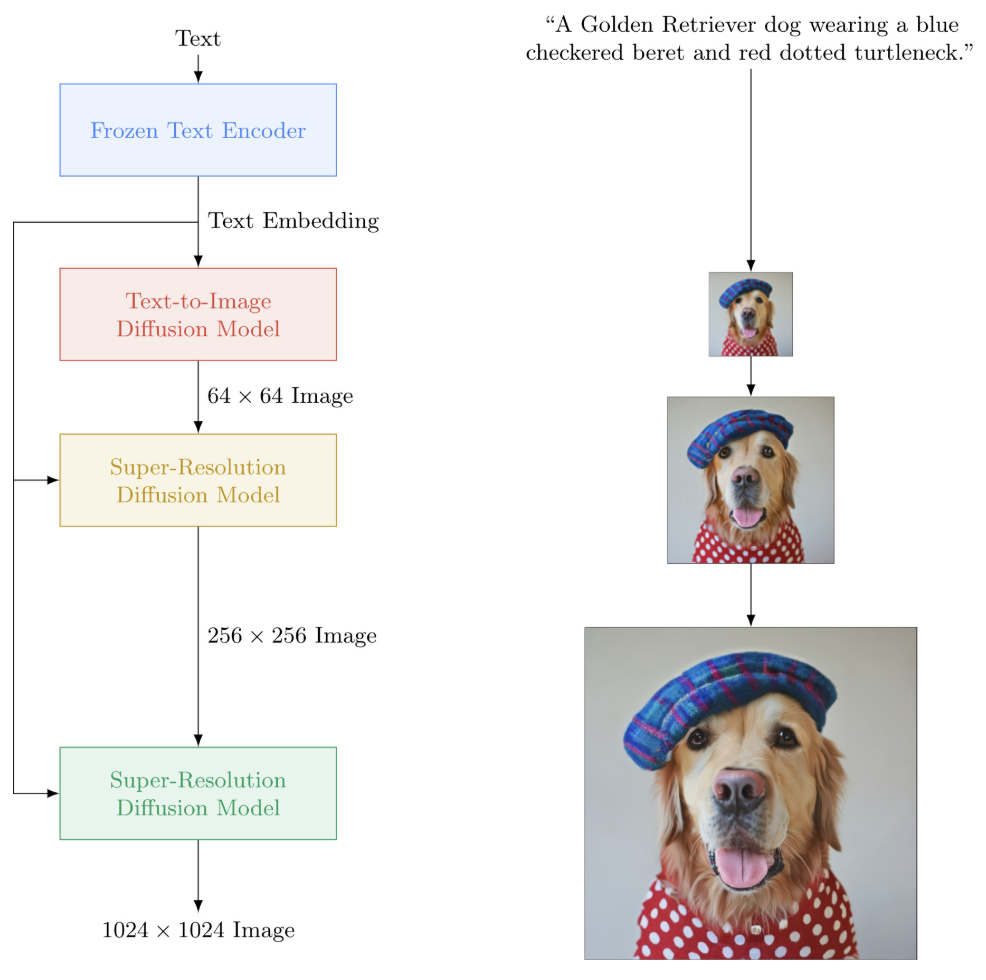
下面是stable diffusion、DALL-E、Imagen的模型结构图,核心组成都是上面3个部分,这里就不过多阐述了。
stable diffusion
DALL-E
Imagen
本文主要来自李宏毅Diffusion Model原理解析的笔记。