GGML 入门:搞懂张量、内存池与计算图
ggml是什么
ggml是用于transformer架构推理的机器学习库,类似于pytorch、TensorFlow等机器学习库。ggml不需要第三方库的依赖,目前兼容X86、ARM、Apple Silicon、CUDA等。
小demo开始
int main(void)
{
#define rows_A 4
#define cols_A 2
float matrix_A[rows_A * cols_A] = {
2, 8,
5, 1,
4, 2,
8, 6
};
#define rows_B 3
#define cols_B 2
float matrix_B[rows_B * cols_B] = {
10, 5,
9, 9,
5, 4
};
size_t ctx_size = 0;
ctx_size += rows_A * cols_A * ggml_type_size(GGML_TYPE_F32);
ctx_size += rows_B * cols_B * ggml_type_size(GGML_TYPE_F32);
ctx_size += 2 * ggml_tensor_overhead();
ctx_size += ggml_graph_overhead();
ctx_size += 1024;
struct ggml_init_params params = {
.mem_size = ctx_size,
.mem_buffer = NULL,
.no_alloc = false,
};
struct ggml_context * ctx = ggml_init(params);
struct ggml_tensor * tensor_a = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_A, rows_A);
struct ggml_tensor * tensor_b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_B, rows_B);
memcpy(tensor_a->data, matrix_A, ggml_nbytes(tensor_a));
memcpy(tensor_b->data, matrix_B, ggml_nbytes(tensor_b));
struct ggml_cgraph * gf = ggml_new_graph(ctx);
struct ggml_tensor *result = ggml_mul_mat(ctx, tensor_a, tensor_b);
ggml_build_forward_expand(gf, result);
int n_threads = 1;
ggml_graph_compute_with_ctx(ctx, gf, n_threads);
float *result_data = (float *)result->data;
printf("mul mat (%d x %d) (transposed result):\n[", (int) result->ne[0], (int) result->ne[1]);
for (int j = 0; j < result->ne[1]; j++) {
if (j > 0) {
printf("\n");
}
for (int i = 0; i < result->ne[0]; i++) {
printf(" %.2f", result_data[j * result->ne[0] + i]);
}
}
printf(" ]\n");
ggml_free(ctx);
return 0;
}
下面以一个最小demo开始串起全流程,顺序是:
- 估算内存池需要的大小ctx_size。
- ggml_init创建context内存池。
- ggml_new_tensor_2d创建tensor,并把原始数组memcpy到tensor->data。
- ggml_new_graph创建graph。
- ggml_mul_mat创建一个“矩阵乘”节点(这里只是描述,还没算)
- ggml_build_forward_expand从result往回收集依赖,填充graph。
- ggml_graph_compute_with_ctx执行graph,结果写到result->data。
关键数据结构
本章节中涉及到一些关键的数据结构,理解这些数据结构对于整个架构至关重要。主要的ggml_context、ggml_tensor、ggml_cgraph。
- ggml_context:内存池管理器,用于存储张量、计算图等信息。
- ggml_tensor:计算的元数据,但不仅仅是存储tensor,还存储的tensor操作。
- ggml_cgraph:计算图的表示,用于传给后端的“计算执行顺序”。
内存池ggml_context
struct ggml_context {
size_t mem_size;
void * mem_buffer;
bool mem_buffer_owned;
bool no_alloc;
int n_objects;
struct ggml_object * objects_begin;
struct ggml_object * objects_end;
};
ggml_context从命名看是上下文,从编码上来看是用于存储的全局信息,一个装载各类对象 (如张量、计算图、其他数据) 的“容器”。
内存池布局
ggml_context就是ggml的内存池管理器,它管理一块连续的大内存mem_buffer,并在其中按顺序分配”对象”(tensor、graph、work_buffer),最后用ggml_free(ctx)一次性释放。
- mem_size:内存池的总大小。
- mem_buffer:内存池的基址地址,一整块连续内存的起点。
- mem_buffer_owned:这块mem_buffer由ggml拥有(负责释放)。
- no_alloc:是否禁止ggml自动为tensor分配tensor->data。
- n_objects:已经在ctx内存池里分配了多少个对象块(tensor/graph/work_buffer等)。
- objects_begin/end:ctx内存池里对象链表的头/尾。
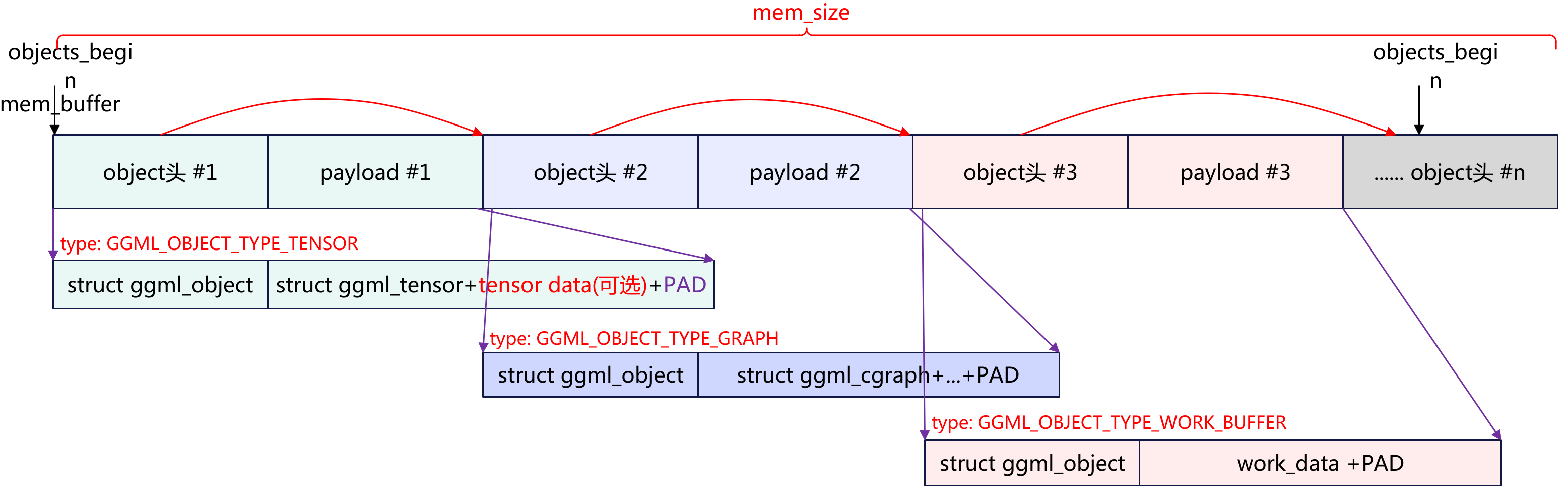
内存池中可以存储不同的对象,对象的类型主要分为3种。
- GGML_OBJECT_TYPE_TENSOR:存储张量+计算的节点。
- GGML_OBJECT_TYPE_GRAPH:一次执行要跑那些节点
- GGML_OBJECT_TYPE_WORK_BUFFER:执行过程中临时scratch内存。
每一类的存储类型内存布局都是先以struct ggml_object开头,然后是对应的类型数据。而具体的类型数据前面又存储个其内存数据的描述结构。(这种类型结构很经典,跟蓝牙的广播AD type一样,也跟之前设计的眼镜方案消息传输方案一样)。
struct ggml_object {
size_t offs;
size_t size;
struct ggml_object * next;
enum ggml_object_type type;
char padding[4];
};
ggml_object可以理解为header,其描述了存储数据的类型type,实际数据起始偏移(相对ctx->mem_buffer),实际的数据长度size,以及指向下一个类型的指针next。而padding是用于填充,保持对齐要求。
在ggml_object后面就是实际类型的数据,以tensor类型为例,同样开始存储的是struct ggml_tensor结构体,后面是实际的tensor数据以及padding,这里需要注意的是tensor的数据并不一定会存储在内存池中,主要根据struct ggml_context中的no_alloc来判断是否要为tensor分配空间,如果不需要那么这里只会存储的是描述tensor的数据结构即struct ggml_tensor+padding,在ggml_tensor中data指向的实际的tensor存储位置起始地址。
ctx->mem_buffer + (某个位置)
┌───────────────┬───────────────────┬──────────────────────┬──────┐
│ ggml_object头 │ ggml_tensor结构体 │ tensor data (bytes) │ PAD │
└───────────────┴───────────────────┴──────────────────────┴──────┘
↑ tensor 指针(result) ↑ tensor->data 指针
内存池是先预分配,后续实际需要多少就从内存池中获取多少。这就LwIP网络协议栈中的实现原理是一样的,类似先分配一块内存池MEM_POOL,这样的话就不用反复的申请提高计算效率。
关键API
这里总结一下跟ggml_context相关的关键API。
- 创建: ggml_init(params),创建一份ggml_context。
- 释放:ggml_free。
- 查询:
-
- ggml_used_mem(ctx):当前已用到的内存池在哪里。
-
- ggml_get_mem_size(ctx)/ggml_get_mem_buffer(ctx)
-
- ggml_get_no_alloc(ctx) / ggml_set_no_alloc(ctx)
下面我们重点分析一下ggml_init的实现。
分配内存池
ggml_init的实现其实非常简单,就是先使用malloc分配struct ggml_context数据结构,其次就是分配一块虚拟地址连续的mem_buffer。这里需要注意的是ggml_context和mem_buffer不要搞混了,ggml_context可不再内存池中,ggml_contexth是单独的一块数据结构用来管理内存池的,内存池的虚拟地址的连续的。
struct ggml_context * ggml_init(struct ggml_init_params params) {
static bool is_first_call = true;
ggml_critical_section_start();
if (is_first_call) {
// initialize time system (required on Windows)
ggml_time_init();
is_first_call = false;
}
ggml_critical_section_end();
struct ggml_context * ctx = GGML_MALLOC(sizeof(struct ggml_context));
// allow to call ggml_init with 0 size
if (params.mem_size == 0) {
params.mem_size = GGML_MEM_ALIGN;
}
const size_t mem_size = params.mem_buffer ? params.mem_size : GGML_PAD(params.mem_size, GGML_MEM_ALIGN);
*ctx = (struct ggml_context) {
/*.mem_size =*/ mem_size,
/*.mem_buffer =*/ params.mem_buffer ? params.mem_buffer : ggml_aligned_malloc(mem_size),
/*.mem_buffer_owned =*/ params.mem_buffer ? false : true,
/*.no_alloc =*/ params.no_alloc,
/*.n_objects =*/ 0,
/*.objects_begin =*/ NULL,
/*.objects_end =*/ NULL,
};
GGML_ASSERT(ctx->mem_buffer != NULL);
GGML_ASSERT_ALIGNED(ctx->mem_buffer);
GGML_PRINT_DEBUG("%s: context initialized\n", __func__);
return ctx;
}
从上面的代码可以看出主要是调用GGML_MALLOC分配struct ggml_context本体,接着判断用户是否传入mem_buffer,如果没有传递同时mem_size有设置就会在内部分配一块。
张量ggml_tensor
数据结构
struct ggml_tensor {
enum ggml_type type;
struct ggml_backend_buffer * buffer;
int64_t ne[GGML_MAX_DIMS]; // number of elements
size_t nb[GGML_MAX_DIMS]; // stride in bytes:
// nb[0] = ggml_type_size(type)
// nb[1] = nb[0] * (ne[0] / ggml_blck_size(type)) + padding
// nb[i] = nb[i-1] * ne[i-1]
// compute data
enum ggml_op op;
// op params - allocated as int32_t for alignment
int32_t op_params[GGML_MAX_OP_PARAMS / sizeof(int32_t)];
int32_t flags;
struct ggml_tensor * src[GGML_MAX_SRC];
// source tensor and offset for views
struct ggml_tensor * view_src;
size_t view_offs;
void * data;
char name[GGML_MAX_NAME];
void * extra; // extra things e.g. for ggml-cuda.cu
char padding[8];
};
上面是ggml_tensor的结构体,ggml_tensor是ggml的核心对象,既是一个多维数组的描述符(type/shape/stride/data),也是计算图里的一个节点(op/src/params/flags)。
ggml_tensor代表了两种类型,理解这两类类型十分关键:
- 数据张量:张量持有实际的数据,包含一个多维数组的数组。
- 运算张量:这个张量表示的是有多个输入张量的运算结果,只有实际运算时才会有数据。
主要是通过数据结构中的op来判断,如果op为GGML_OP_NONE则表示的是张量数据,如果op为操作符如GGML_OP_MUL_MAT则表示张量不含数据,而是表示两个张量矩阵乘法的结果。
(1)作为数组的字段
- type:元素的类型(F32/F16/量化类型),决定元素/块大小,行大小。
- ne[]:每维有多少个元素,ggml默认最多4维。
- nb[]:描述每个维度步长。
(2)作为计算节点的字段
- op: 这个tensor通过那个算子得到。如果维GGML_OP_NONE表示不是算子输出而是输入张量。
- src[]: 算子节点输入张量的指针数组,如对于mul_mat来说src[0]=a,src[1]=b。这决定后续计算graph的根本。
- op_prarams:算子的额外参数。
(3)View/切片/共享数据
view_src+view_offs表示这个tensor是另一个tensor的视图(共享data,不重新分配),data通常等于view_src->data+view_offs。
(4)与后端/设备相关字段
- buffer:指向ggml_backend_buffer(后端的内存抽象),CPU简单路径下很多时候是NULL或默认。
- extra:给特定后端/实现放额外信息的扩展指针。
总结一下ggml_tensor承担的两件事情,一是存储张量/数组的描述,而是用于计算计算节点。
分配张量
分配张量就是调用ggml_new_tensor_xx,如下:
- struct ggml_tensor * ggml_new_tensor_1d:分配1维的张量。
- struct ggml_tensor * ggml_new_tensor_2d: 分配2维的张量。
- struct ggml_tensor * ggml_new_tensor_3d:分配3维的张量。
- struct ggml_tensor * ggml_new_tensor_4d:分配4维的张量。
最终张量的分配都会调用ggml_new_tensor来实现。下面以ggml_new_tensor_2d为例。
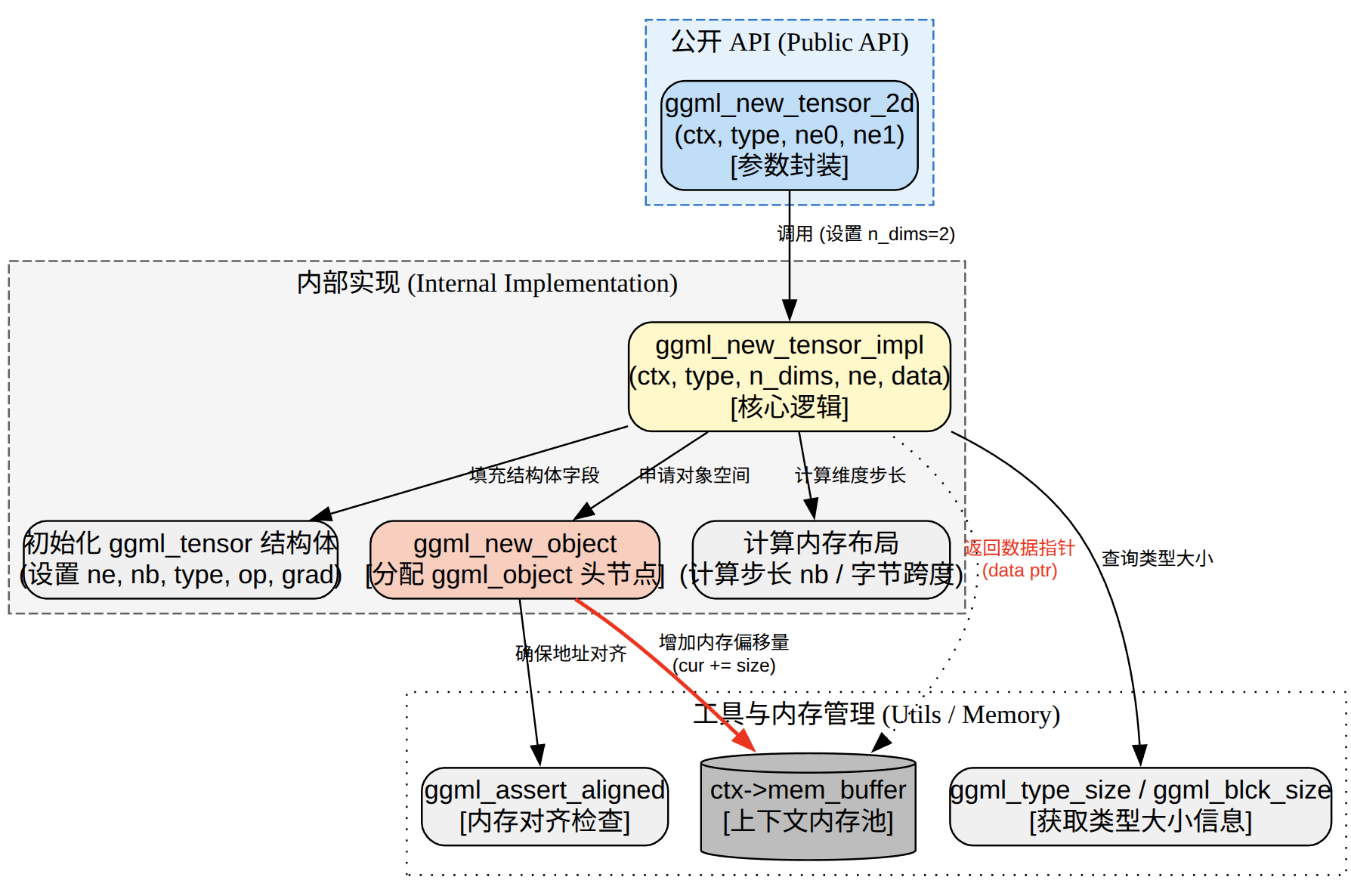
ggml_new_tensor_2d最终会调用内部的ggml_new_tensor_impl来实现,主要的流程就是先试用ggml_new_object从内存池中分配一个头节点,然后在分配payload也就是再从内存池分配ensor的结构体,接着根据no_alloc来判断是否要为tensor的data从内存池分配空间,最后就是填充好ggml_object和ggml_tensor。
创建的tensor主要有两部分组成
- tensor结构体本身:shape、stride、op、src等信息。
- 可选的数据区:紧跟在结构体后面((result + 1)),只有在 view_src NULL && ctx->no_alloc false 时才会在 ctx 内存池里实际分配。
这是ggml核心设计之一,ctx是一个arean/内存池,所有对象顺序追加,没有逐个free;ggml_free一次性释放整个池。
计算图ggml_cgraph
关键数据结构
struct ggml_cgraph {
int size; // maximum number of nodes/leafs/grads/grad_accs
int n_nodes; // number of nodes currently in use
int n_leafs; // number of leafs currently in use
struct ggml_tensor ** nodes; // tensors with data that can change if the graph is evaluated
struct ggml_tensor ** grads; // the outputs of these tensors are the gradients of the nodes
struct ggml_tensor ** grad_accs; // accumulators for node gradients
struct ggml_tensor ** leafs; // tensors with constant data
int32_t * use_counts;// number of uses of each tensor, indexed by hash table slot
struct ggml_hash_set visited_hash_set;
enum ggml_cgraph_eval_order order;
};
- nodes[]:真正要执行的算子节点(有op,或是参数param)。
- leafs[]:常量/叶子(op=NONE且不是param),例如常量张量。
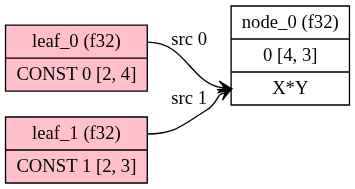
在ggml中理解叶子(leaf)和节点(node)十分关键。
这两个都是用struct ggml_tensor来表示的,leaf是没有算子的(op=NONE),leaf可以理解为是输入/常量,他不需要通过执行算子来产生数据,数据已经在tensor->data中了,通过前面的memcpy进来或者后端的buffer提供,也不会前向执行中被计算出来;而node是需要再图执行是被处理的,包括两类
- 真正的算子输出:它的值来之执行的op,由tensor->src[]通过tensor->op计算而来。
- 参数:这个 tensor 是训练里要被当作变量去优化更新的参数(比如权重参数),既是op=NONE,但是也会放进node。
针对我们的demo,tensor_a、tensor_b是由ggml_new_tensor_2d创建的默认op=NONE,也不是PARAM这个就是leaf。而result=ggml_mul_mat(ctx, tensor_a, tensor_b)会设置result->op=GGML_OP_MUL_MAT且src[0]=tensor_a,src[1]=tensor_b,这个就是node。
再总结一下leafs就是图的“外部给定值”(常量/输入),不由 op 产生;nodes是图的“计算产生值”(算子输出)+ “训练参数(PARAM)”。
分配计算图
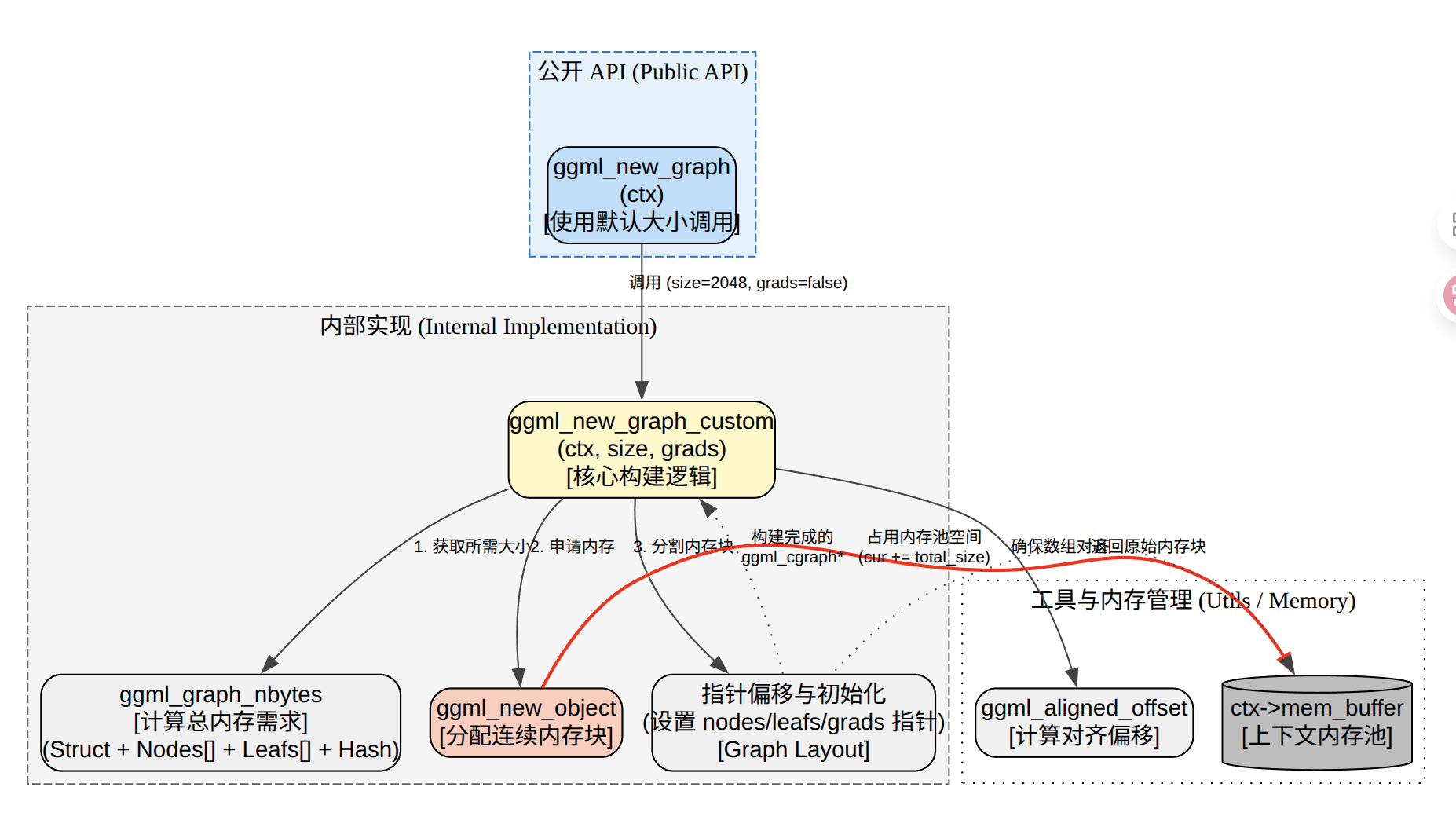
分配计算图是在ctx的内存池里一次性分配并初始化一张计算图ggml_cgraph,同时把图需要的数组nodes/leafs/use_counts/hash_keys/(可选)grads/grad_accs/hash_used)都放在同一个对象内存块里,并把这些指针指向那块内存。
struct ggml_cgraph * ggml_new_graph_custom(struct ggml_context * ctx, size_t size, bool grads) {
const size_t obj_size = ggml_graph_nbytes(size, grads);
struct ggml_object * obj = ggml_new_object(ctx, GGML_OBJECT_TYPE_GRAPH, obj_size);
struct ggml_cgraph * cgraph = (struct ggml_cgraph *) ((char *) ctx->mem_buffer + obj->offs);
// the size of the hash table is doubled since it needs to hold both nodes and leafs
size_t hash_size = ggml_hash_size(size * 2);
void * p = cgraph + 1;
struct ggml_tensor ** nodes_ptr = incr_ptr_aligned(&p, size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *));
struct ggml_tensor ** leafs_ptr = incr_ptr_aligned(&p, size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *));
int32_t * use_counts_ptr = incr_ptr_aligned(&p, hash_size * sizeof(int32_t), sizeof(int32_t));
struct ggml_tensor ** hash_keys_ptr = incr_ptr_aligned(&p, hash_size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *));
struct ggml_tensor ** grads_ptr = grads ? incr_ptr_aligned(&p, hash_size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)) : NULL;
struct ggml_tensor ** grad_accs_ptr = grads ? incr_ptr_aligned(&p, hash_size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)) : NULL;
ggml_bitset_t * hash_used = incr_ptr_aligned(&p, ggml_bitset_size(hash_size) * sizeof(ggml_bitset_t), sizeof(ggml_bitset_t));
// check that we allocated the correct amount of memory
assert(obj_size == (size_t)((char *)p - (char *)cgraph));
*cgraph = (struct ggml_cgraph) {
/*.size =*/ size,
/*.n_nodes =*/ 0,
/*.n_leafs =*/ 0,
/*.nodes =*/ nodes_ptr,
/*.grads =*/ grads_ptr,
/*.grad_accs =*/ grad_accs_ptr,
/*.leafs =*/ leafs_ptr,
/*.use_counts =*/ use_counts_ptr,
/*.hash_table =*/ { hash_size, hash_used, hash_keys_ptr },
/*.order =*/ GGML_CGRAPH_EVAL_ORDER_LEFT_TO_RIGHT,
};
ggml_hash_set_reset(&cgraph->visited_hash_set);
if (grads) {
memset(cgraph->grads, 0, hash_size*sizeof(struct ggml_tensor *));
memset(cgraph->grad_accs, 0, hash_size*sizeof(struct ggml_tensor *));
}
return cgraph;
}
如果grads=false,表示是这是推理/前向图,内存布局如下:
graph payload (obj->offs 指向起点)
+------------------------------+
| struct ggml_cgraph | <- cgraph 指向这里
| - nodes -> nodes_ptr |
| - leafs -> leafs_ptr |
| - visited_hash_set.size |
| - visited_hash_set.used -> hash_used
| - visited_hash_set.keys -> hash_keys_ptr
| - use_counts -> use_counts_ptr
| - grads/grad_accs == NULL |
+------------------------------+
| (对齐到 sizeof(ptr)) |
+------------------------------+
| nodes_ptr[size] | array of struct ggml_tensor*
+------------------------------+
| leafs_ptr[size] | array of struct ggml_tensor*
+------------------------------+
| use_counts_ptr[hash_size] | array of int32_t (按 hash slot)
+------------------------------+
| hash_keys_ptr[hash_size] | array of struct ggml_tensor* (hash keys)
+------------------------------+
| hash_used bitset | ggml_bitset_t[bitset_size(hash_size)]
+------------------------------+
| (尾部 padding 到 GGML_MEM_ALIGN) |
+------------------------------+
如果grads=true,对应的就是训练图/反向图,在hash_keys_ptr后面多两段。
... hash_keys_ptr[hash_size]
+------------------------------+
| grads_ptr[hash_size] | struct ggml_tensor* (每个被访问 tensor 的 grad 输出)
+------------------------------+
| grad_accs_ptr[hash_size] | struct ggml_tensor* (grad accumulator)
+------------------------------+
| hash_used bitset
...
我们重点看推理这部分,在graph payload中,前面部门存储的是ggml_cgraph结构体,后面紧跟的就是ggml_cgraph结构的内容。其中就最关键的是nodes[]和leafs[],前者存储是指向node类型tensor的指针,后者存储的指向leafs类型tensor的指针。
计算图构建
计算节点
在ggml中创建一个算子节点,就是调用类似ggml_mul_mat的函数。
struct ggml_tensor * ggml_mul_mat(
struct ggml_context * ctx,
struct ggml_tensor * a,
struct ggml_tensor * b) {
GGML_ASSERT(ggml_can_mul_mat(a, b));
GGML_ASSERT(!ggml_is_transposed(a));
const int64_t ne[4] = { a->ne[1], b->ne[1], b->ne[2], b->ne[3] };
struct ggml_tensor * result = ggml_new_tensor(ctx, GGML_TYPE_F32, 4, ne);
result->op = GGML_OP_MUL_MAT;
result->src[0] = a;
result->src[1] = b;
return result;
}
上面的代码其实很简单,就是创建一个ggml_tensor,然后赋值op和要操作的src[0]和src[1],最后返回的也是ggml_tensor。
所以了ggml_mul_mat并不会立刻进行做矩阵乘法运算,它只是创建了一个”算子节点”,把算子类型和输入依赖挂上去,等后面ggml_build_forward_expand+ggml_graph_compute_with_ctx才正在执行。
计算图
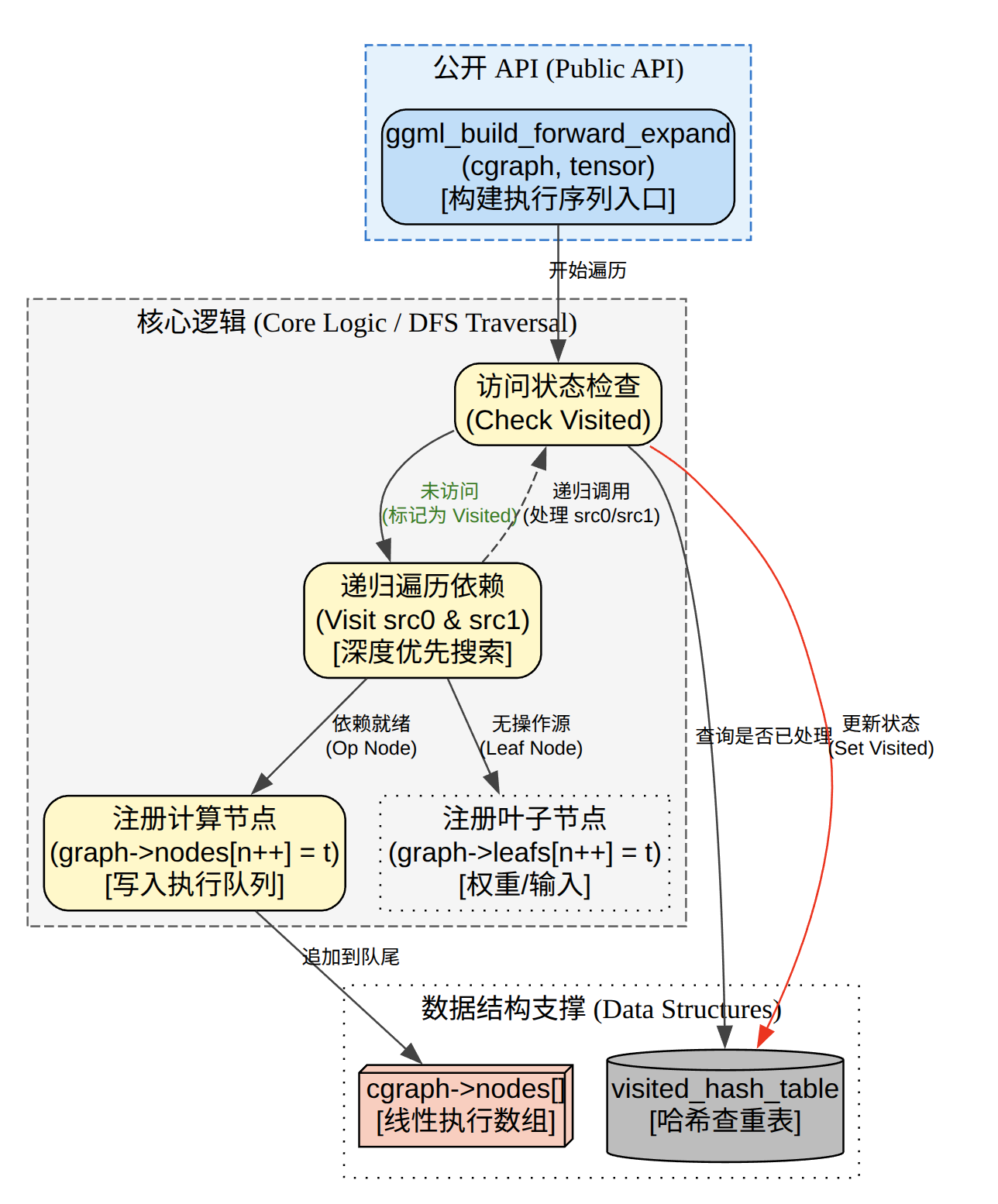
ggml_build_forward_expand是GGML计算图构建最关键的一部,核心任务是执行拓扑排序,从一个目标节点开始(通常是Loss或输出张量),递归的遍历所有依赖项(源张量src[0],src[1]),并将它们按照”先输入后输出”的顺序填入计算图的执行队列中nodes数组。
static size_t ggml_visit_parents(struct ggml_cgraph * cgraph, struct ggml_tensor * node) {
// 1) 用 visited_hash_set 去重:同一个 tensor 只处理一次
size_t node_hash_pos = ggml_hash_find(&cgraph->visited_hash_set, node);
if (!ggml_bitset_get(cgraph->visited_hash_set.used, node_hash_pos)) {
cgraph->visited_hash_set.keys[node_hash_pos] = node;
ggml_bitset_set(cgraph->visited_hash_set.used, node_hash_pos);
cgraph->use_counts[node_hash_pos] = 0;
} else {
return node_hash_pos;
}
// 2) 递归访问 node->src[k],同时对每个 src 做 use_counts++
for (int i = 0; i < GGML_MAX_SRC; ++i) {
struct ggml_tensor * src = node->src[k];
if (src) {
size_t src_hash_pos = ggml_visit_parents(cgraph, src);
cgraph->use_counts[src_hash_pos]++;
}
}
// 3) 分类:leaf vs node(leaf 是 op==NONE 且不是 PARAM)
if (node->op == GGML_OP_NONE && !(node->flags & GGML_TENSOR_FLAG_PARAM)) {
cgraph->leafs[cgraph->n_leafs++] = node;
} else {
cgraph->nodes[cgraph->n_nodes++] = node;
}
return node_hash_pos;
}
核心在这个ggml_visit_parents函数中,核心原理是从results开始往上遍历,把tensor为leafs类型的添加到leafs[]中,把tensor为node类型的添加到nodes[]中。
(1)去重
在ggml_visit_parents中会去重,同一个tensor可能会被多个算子引用,但是只希望他在图中出现一次,通过使用 visited_hash_set(key 是 tensor 指针地址)记录“见没见过”。见过就直接返回,不再 DFS,不再追加 nodes/leafs。
(2)递归遍历DFS
先递归访问 node->src[],再把 node 自己追加到 nodes/leafs。这天然形成一种顺序:后序遍历(post-order),直觉上就是:先把依赖(输入、上游算子)放进图,再放当前算子输出,这就是为什么 build 结束后,nodes[] 基本满足“依赖在前,使用在后”,便于执行。
(3)use_count使用次数统计
cgraph->use_counts[src_hash_pos]++ 表示:这个 src tensor 被作为某个 node 的输入用了一次。
它按 “hash slot” 存(不是按 nodes[] 下标),原因是:去重后每个 tensor 都能在 hash 表里找到一个稳定位置,方便后续用同一套索引关联其它数组(例如 grads/grad_accs 在训练图里也是按 hash slot 对齐)。
if (node->op == GGML_OP_NONE && !(node->flags & GGML_TENSOR_FLAG_PARAM)) {
cgraph->leafs[cgraph->n_leafs] = node;
cgraph->n_leafs++;
} else {
cgraph->nodes[cgraph->n_nodes] = node;
cgraph->n_nodes++;
}
从这个代码中也可以看到对于ggml_tensor,是怎么区分leaf和node的。
- leaf:op为NONE 且不是 PARAM ->通常代表“常量/输入常量”(不需要通过执行算子得到)
- node:其它情况 ->需要在图执行时被处理的东西(算子输出 or 训练参数)
下面以简单的图来说明一下,我们的示例小demo的表达式如下:
result (MUL_MAT)
/ \
tensor_a tensor_b
(op NONE) (op NONE)
调用 ggml_build_forward_expand(gf, result) 的 DFS(后序)大致是:
visit(result)
visit(tensor_a) -> leafs += tensor_a
visit(tensor_b) -> leafs += tensor_b
nodes += result
得到的结构就是
cgraph->leafs: [ tensor_a, tensor_b ]
如果图更复杂,有共享子图(DAG),去重就很关键:
z = add(x, x) // x 被用两次
/ \
x x
visit(z):
visit(x): 第一次见到 -> leafs += x
visit(x): 第二次见到 -> 直接 return(不重复加入)
use_counts[x] 会被 ++ 两次
nodes += z
计算结果就是
leafs: [x]
nodes: [z]
use_counts[x] == 2
执行计算
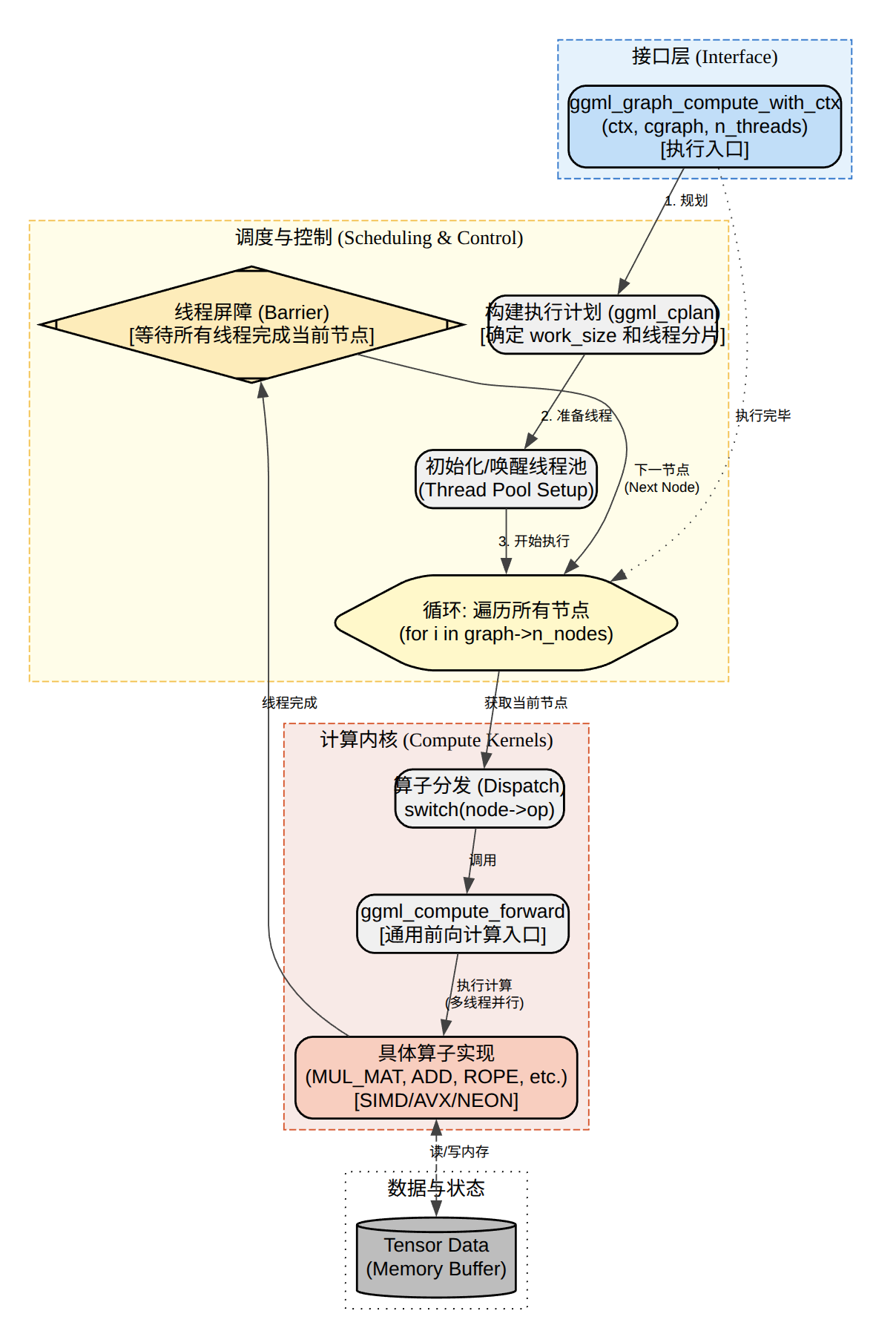
ggml_graph_cmpute会先调用ggml_graph_plan算出需要多大的临时buffer,然后把这个work buffer直接从ctx的内存池分配出来,最后在启动图的计算。
图规划
ggml_graph_plan(cgraph, n_threads, NULL)的目标是决定实际用多少线程+估算整张图执行所需的最大临时内存work_size。plan会编译cgraph->nodes[],对每个node
- 计算 n_tasks = ggml_get_n_tasks(node, n_threads)(这个 op 适合拆多少任务)
- 估算该 op 需要的额外临时空间 cur
- 全图取 work_size = max(work_size, cur)(注意是 max,不是 sum,因为 work buffer 复用)
for (int i = 0; i < cgraph->n_nodes; i++) {
struct ggml_tensor * node = cgraph->nodes[i];
const int n_tasks = ggml_get_n_tasks(node, n_threads);
max_tasks = MAX(max_tasks, n_tasks);
size_t cur = 0;
// ... switch(node->op) 估算 cur ...
work_size = MAX(work_size, cur);
}
if (work_size > 0) {
work_size += CACHE_LINE_SIZE*(n_threads);
}
cplan.threadpool = threadpool;
cplan.n_threads = MIN(max_tasks, n_threads);
cplan.work_size = work_size;
cplan.work_data = NULL;
return cplan;
很多 op 需要一块临时空间(例如把 src1 转换/pack 成适合 vec-dot 的布局),但这些临时空间可以在不同节点之间复用,所以用 “最大需求” 的单一 work buffer 就够。struct ggml_cplan 如下
struct ggml_cplan {
size_t work_size;
uint8_t * work_data;
int n_threads;
struct ggml_threadpool * threadpool;
ggml_abort_callback abort_callback;
void * abort_callback_data;
};
- work_size:执行改图所需的临时工作区大小。
- work_data:指向调用方分配的临时工作区内存。
- n_threads:希望永远执行图的线程数(影响并行度、某些kernel的分块方式等)。
- threadpool:可选的线程池句柄。
分配work buffer
主要的目的就是在ctx的内存池里分配一块连续的内存作为work buffer,并把指针协会cplan.work_data。
cplan.work_data = (uint8_t *)ggml_new_buffer(ctx, cplan.work_size);
return ggml_graph_compute(cgraph, &cplan);
为什么放 ctx 里,主要是避免每次 compute 时 malloc/free,并且生命周期跟 ctx 同步;缺点是 ctx 必须预留足够大(demo 里看到加了 ggml_graph_overhead() 和额外 1024,就是类似目的)。
执行
ggml_graph_compute就是执行了
(1)首先是先启动线程池
- 初始化计算后端如 cpu backend。
- 根据 cplan->threadpool 是否为空,创建一个临时 threadpool 或复用传入的 threadpool。
- 并行运行 ggml_graph_compute_thread
enum ggml_status ggml_graph_compute(struct ggml_cgraph * cgraph, struct ggml_cplan * cplan) {
ggml_cpu_init();
GGML_ASSERT(cplan);
GGML_ASSERT(cplan->n_threads > 0);
GGML_ASSERT(cplan->work_size == 0 || cplan->work_data != NULL);
int n_threads = cplan->n_threads;
struct ggml_threadpool * threadpool = cplan->threadpool;
if (threadpool == NULL) {
disposable_threadpool = true;
// 创建 threadpool
threadpool = ggml_threadpool_new_impl(&ttp, cgraph, cplan);
} else {
// 复用 threadpool:设置当前要跑的 cgraph/cplan 等
threadpool->cgraph = cgraph;
threadpool->cplan = cplan;
// ...
}
// 然后让各线程进入 ggml_graph_compute_thread(...)
}
启动线程池后每个线程跑 ggml_graph_compute_thread,按 node 顺序执行 op,每个线程会构造一个ggml_compute_params,里面包含线程编号和线程数,全局work buffer,同步/屏障等信息。
struct ggml_compute_params {
int ith, nth;
size_t wsize;
void * wdata;
struct ggml_threadpool * threadpool;
};
(2)线程执行的主流程
static thread_ret_t ggml_graph_compute_thread(void * data) {
const struct ggml_cgraph * cgraph = tp->cgraph;
const struct ggml_cplan * cplan = tp->cplan;
struct ggml_compute_params params = {
.ith = state->ith,
.nth = ...,
.wsize = cplan->work_size,
.wdata = cplan->work_data,
.threadpool= tp,
};
for (int node_n = 0; node_n < cgraph->n_nodes && ...; node_n++) {
struct ggml_tensor * node = cgraph->nodes[node_n];
if (ggml_op_is_empty(node->op)) {
continue;
}
ggml_compute_forward(¶ms, node);
if (node_n + 1 < cgraph->n_nodes) {
ggml_barrier(state->threadpool); // 每个 node 结束后做一次全线程同步
}
}
ggml_barrier(state->threadpool);
return 0;
}
上面的ggml_graph_compute_thread是OpenMP模式。有有个多个线程同时执行ggml_graph_compute_thread。
#pragma omp parallel num_threads(n_threads) // 8 个线程
{
int ith = omp_get_thread_num(); // 0, 1, 2, ..., 7
ggml_graph_compute_thread(&threadpool->workers[ith]); // 8 个线程都调用
}
执行模式是,节点内并行,节点间串行。
所有线程都执行相同的循环:
for (int node_n = 0; node_n < cgraph->n_nodes; node_n++) {
ggml_compute_forward(¶ms, node); // ← 这里并行!
ggml_barrier(...); // ← 这里同步!
}
每个线程遍历相同的节点序列,但是调用ggml_compute_forward内部不同线程处理不同的数据部分。但是需要注意的是并行的是在节点内部,不是节点之间。
计算图:节点0 → 节点1 → 节点2
线程执行流程:
┌─────────────────────────────────────────┐
│ 线程 0: for (node_n=0; node_n<3; node_n++) │
│ 线程 1: for (node_n=0; node_n<3; node_n++) │
│ 线程 2: for (node_n=0; node_n<3; node_n++) │
│ ... │
│ 线程 7: for (node_n=0; node_n<3; node_n++) │
└─────────────────────────────────────────┘
所有线程都遍历所有节点,但在每个节点内部,它们处理不同的数据部分。节点内部的数据会切分,以矩阵加法为例。
// 节点 0: A + B → C (假设 C 是 1024x1024 的矩阵)
// 线程 0: 计算 C[0:128, :] ← 只处理这部分
// 线程 1: 计算 C[128:256, :] ← 只处理这部分
// 线程 2: 计算 C[256:384, :] ← 只处理这部分
// ...
// 线程 7: 计算 C[896:1024, :] ← 只处理这部分
// 所有线程同时计算,没有重复!
ggml_compute_forward 里会根据 node->op 分发到具体 kernel。比如 MUL_MAT:
case GGML_OP_MUL_MAT:
{
ggml_compute_forward_mul_mat(params, tensor);
} break;
(3)以一个例子来理解哪里串行,哪里并行
W (leaf) x (leaf)
\ /
\ /
y = MUL_MAT b (leaf)
| |
+-----> y2 = ADD
|
v
o = RELU
经过DFS后续遍历后,结果是:
cgraph->nodes[0] = y (MUL_MAT)
cgraph->nodes[1] = y2 (ADD)
cgraph->nodes[2] = o (RELU)
因为各个node的计算是有前后依赖的,因此不行并行,也就是说node0 -> node1 -> node2 是串行推进,不能乱序并发(因为 node1 依赖 node0 输出,node2 依赖 node1 输出)。
for node_n in [0..n_nodes):
所有线程一起执行 nodes[node_n]
barrier 等齐
而并行多线程计算你的是单个node的内部,每个node内部数据量很大,通常会拆快让多个线程并行计算。
时间 →
thread0: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B|
thread1: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B|
thread2: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B|
thread3: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B|
其中竖线|B|就是ggml_barrier,所有线程必须等到这一个node全部完成,才能进入到下一个node,而有4个线程同时干一个算子的事情。在一个node算子内,数据量通常是一个多维的矩阵,那么对数据可以做拆分tile分发到多个线程并发执行,这样就可以提高速度。