jetson orin nano使用llamap.cpp跑大模型
安装
确认一下是否有/usr/local/cuda/bin/nvcc,有就配置一下环境。
# 临时在当前终端生效
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
# 验证 nvcc 是否能找到
nvcc --version
如果没有就安装
sudo -E apt install cuda-toolkit
下载代码
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
安装魔塔下载工具
pip install modelscope -i https://mirrors.aliyun.com/pypi/simple/
编译
mkdir build
cmake .. -DGGML_CUDA=ON
cmake --build . --config Release -j $(nproc)
跑模型
低功耗模式
下载模型
mkdir model_zoo
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct-GGUF qwen2.5-1.5b-instruct-q4_0.gguf --local_dir ./model_zoo
测试模型
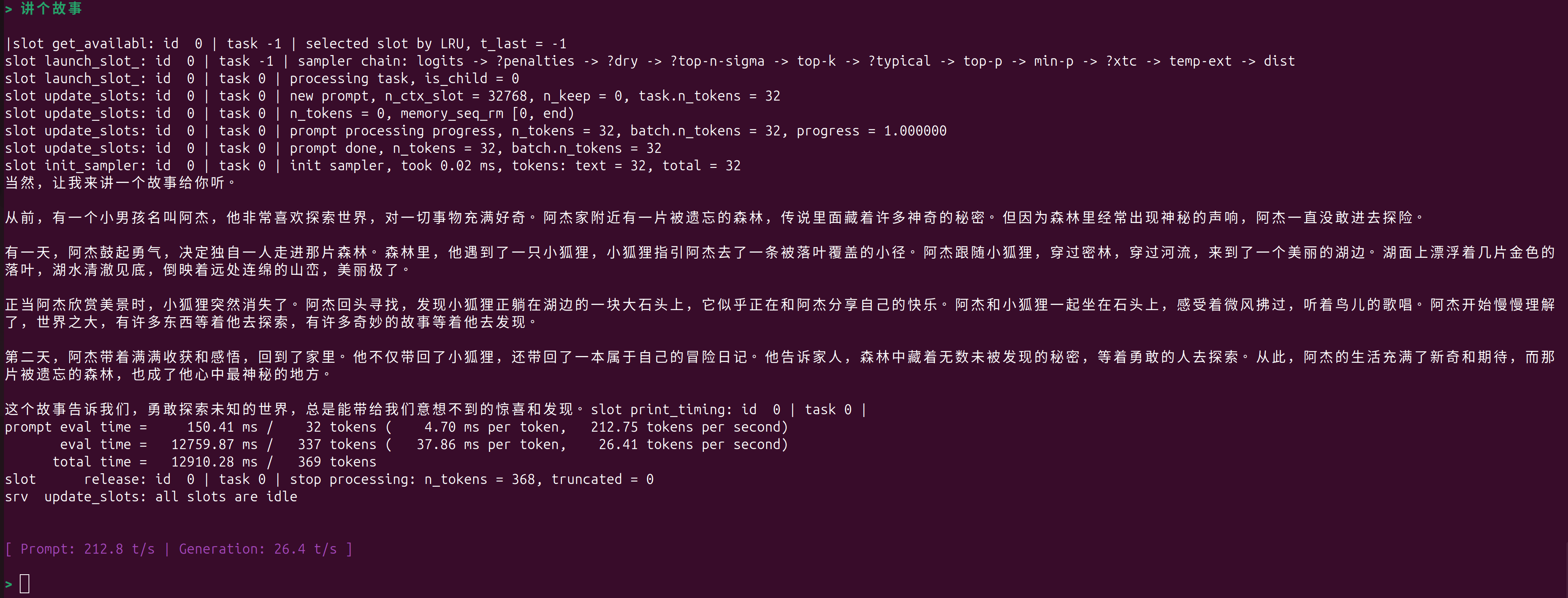
./build/bin/llama-cli -m ../model_zoo/qwen2.5-1.5b-instruct-q4_0.gguf --perf --show-timings -lv 3
换个笑话
|slot get_availabl: id 0 | task -1 | selected slot by LCP similarity, sim_best = 0.952 (> 0.100 thold), f_keep = 1.000
slot launch_slot_: id 0 | task -1 | sampler chain: logits -> ?penalties -> ?dry -> ?top-n-sigma -> top-k -> ?typical -> top-p -> min-p -> ?xtc -> temp-ext -> dist
slot launch_slot_: id 0 | task 184 | processing task, is_child = 0
slot update_slots: id 0 | task 184 | new prompt, n_ctx_slot = 4096, n_keep = 0, task.n_tokens = 248
slot update_slots: id 0 | task 184 | n_tokens = 236, memory_seq_rm [236, end)
slot update_slots: id 0 | task 184 | prompt processing progress, n_tokens = 248, batch.n_tokens = 12, progress = 1.000000
slot update_slots: id 0 | task 184 | prompt done, n_tokens = 248, batch.n_tokens = 12
slot init_sampler: id 0 | task 184 | init sampler, took 0.11 ms, tokens: text = 248, total = 248
好的,以下是一个不同的笑话:
为什么电脑没有呼吸?
因为它只有一个输入口,一个输出口。slot print_timing: id 0 | task 184 |
prompt eval time = 214.26 ms / 12 tokens ( 17.85 ms per token, 56.01 tokens per second)
eval time = 1691.48 ms / 22 tokens ( 76.89 ms per token, 13.01 tokens per second)
total time = 1905.74 ms / 34 tokens
slot release: id 0 | task 184 | stop processing: n_tokens = 269, truncated = 0
srv update_slots: all slots are idle
[ Prompt: 56.0 t/s | Generation: 13.0 t/s ]
看起来速度不是很快。
再跑一个3B的试试看。
./build/bin/llama-cli -m ../model_zoo/qwen2.5-3b-instruct-q4_0.gguf --perf --show-timings -lv 3
prompt eval time = 1412.32 ms / 15 tokens ( 94.15 ms per token, 10.62 tokens per second)
eval time = 48064.10 ms / 244 tokens ( 196.98 ms per token, 5.08 tokens per second)
total time = 49476.41 ms / 259 tokens
slot release: id 0 | task 148 | stop processing: n_tokens = 469, truncated = 0
srv update_slots: all slots are idle
[ Prompt: 10.6 t/s | Generation: 5.1 t/s ]
看起来不太行。
加上个参数重新编译试试,针对CUDA的能力计算数值,加这个参数,llama.cpp 的 cmake 默认可能不会启用针对特定 GPU 架构的深度优化
rm -rf build && mkdir build && cd build
cmake .. -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=87
#或者cmake .. -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=native
cmake --build . --config Release -j$(nproc)
再测试执行:
./build/bin/llama-cli -m ../model_zoo/qwen2.5-3b-instruct-q4_0.gguf --perf --show-timings -lv 3 -ngl 99
prompt eval time = 201.92 ms / 13 tokens ( 15.53 ms per token, 64.38 tokens per second)
eval time = 39903.36 ms / 386 tokens ( 103.38 ms per token, 9.67 tokens per second)
total time = 40105.28 ms / 399 tokens
slot release: id 0 | task 159 | stop processing: n_tokens = 598, truncated = 0
srv update_slots: all slots are idle
[ Prompt: 64.4 t/s | Generation: 9.7 t/s ]
推理速度上来了,稳定在10 token/s。
再跑跑bench
./build/bin/llama-bench -m ../model_zoo/qwen2.5-3b-instruct-q4_0.gguf -ngl 99
ggml_cuda_init: found 1 CUDA devices:
Device 0: Orin, compute capability 8.7, VMM: yes
| model | size | params | backend | ngl | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: |
| qwen2 3B Q4_0 | 1.86 GiB | 3.40 B | CUDA | 99 | pp512 | 259.35 ± 0.46 |
| qwen2 3B Q4_0 | 1.86 GiB | 3.40 B | CUDA | 99 | tg128 | 8.98 ± 0.03 |
build: 37c35f0e1 (7787)
(base) bianbu@ubuntu:~/llama.cpp$
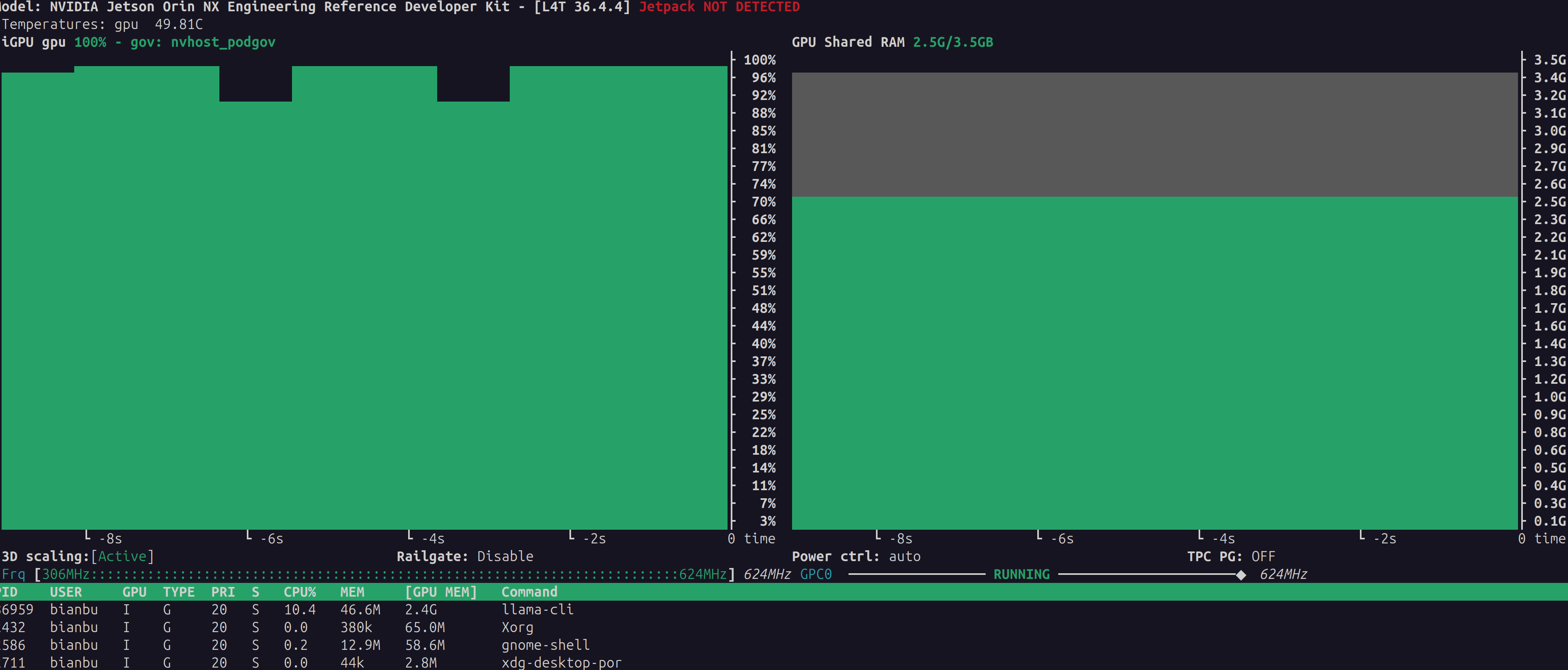
sudo nvpmodel -m 0 # 开启最大功率模式
sudo jetson_clocks # 锁定 CPU/GPU/内存频率到最高
(base) bianbu@ubuntu:~/llama.cpp$ ./build/bin/llama-bench -m ../model_zoo/qwen2.5-3b-instruct-q4_0.gguf -ngl 99
ggml_cuda_init: found 1 CUDA devices:
Device 0: Orin, compute capability 8.7, VMM: yes
| model | size | params | backend | ngl | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: |
| qwen2 3B Q4_0 | 1.86 GiB | 3.40 B | CUDA | 99 | pp512 | 264.42 ± 0.27 |
| qwen2 3B Q4_0 | 1.86 GiB | 3.40 B | CUDA | 99 | tg128 | 9.17 ± 0.01 |
build: 37c35f0e1 (7787)
超级性能模式
上面跑了一下看起来还是很慢,看了一下jetson官网,要跑性能,需要设置电源为超级性能模式,点击 Ubuntu 桌面顶部栏右侧的 NVIDIA 图标
Power mode
0: 15W
1: 25W
2: MAXN SUPER
如果没有MAXN SUPER,执行下面的命令安装。
sudo apt remove nvidia-l4t-bootloader
sudo apt install nvidia-l4t-bootloader
sudo reboot
如果还是无法配置的话,参考下:super mode
接下来,接着跑。
./build/bin/llama-cli -m ../model_zoo_gguf/model_zoo/qwen2.5-1.5b-instruct-q4_0.gguf --perf --show-timings -lv 3 -ngl 99
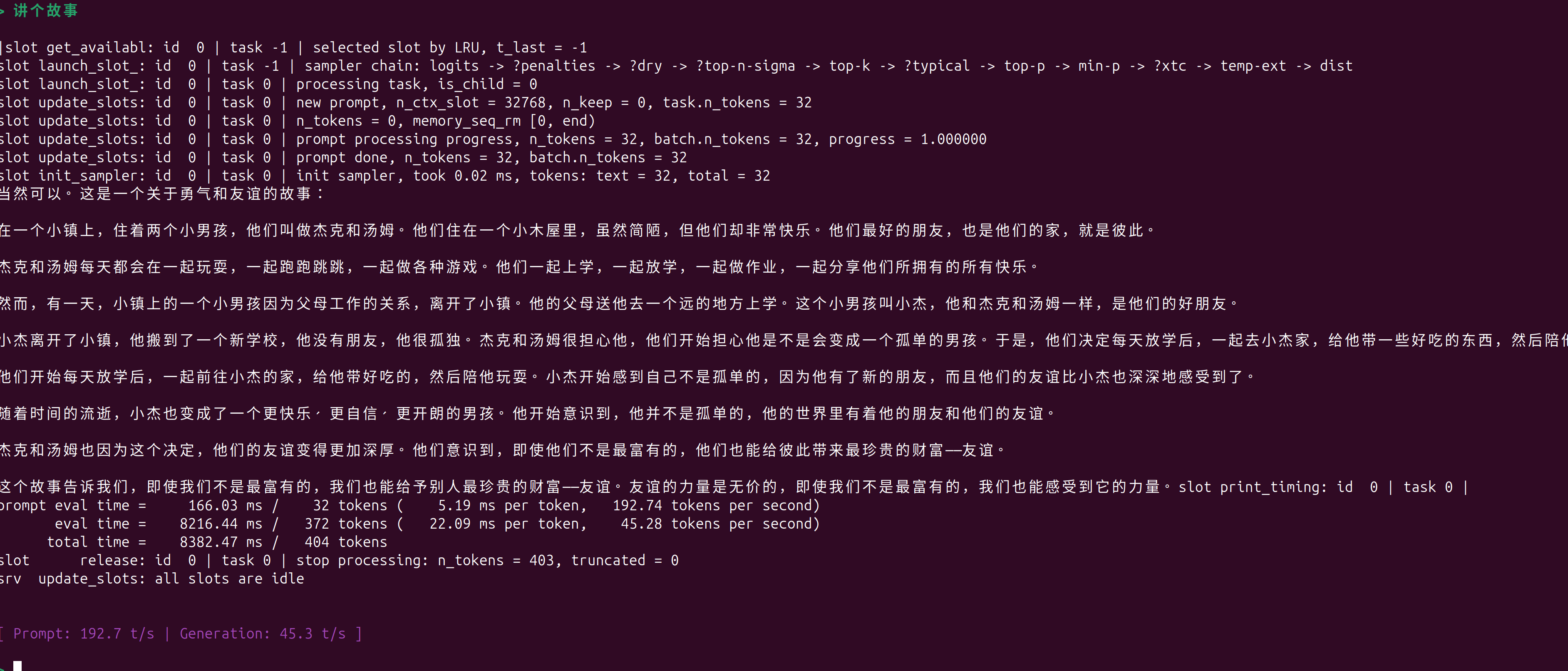
./build/bin/llama-bench -m ../model_zoo_gguf/model_zoo/qwen2.5-1.5b-instruct-q4_0.gguf -ngl 99

在跑个3B的
./build/bin/llama-bench -m ../model_zoo_gguf/model_zoo/qwen2.5-3b-instruct-q4_0.gguf -ngl 99

./build/bin/llama-cli -m ../model_zoo_gguf/model_zoo/qwen2.5-3b-instruct-q4_0.gguf -ngl 99 --perf -lv 3