DMA与cache一致性
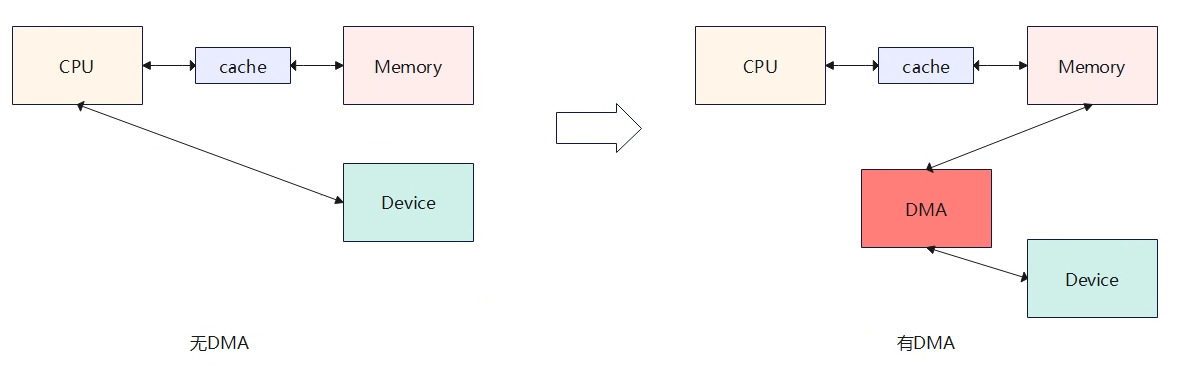
- 无DMA时:设备与内存之间数据搬运需要依靠CPU来完成。
- 有DMA时:DMA可以直接完成设备与内存直接的数据搬运,不需要cpu介入。
DMA的引入,优点是数据在内存和设备之间的搬运不需要CPU参与,这极大降低了CPU的负荷。但是也引入了新的问题,即cpu读取到的数据不一定是最新的,是因为中间cache的存在(如上图有DMA的情况),具体表现为当DMA修改从Device读取数据写入到memory后,即这块memory就被更新了,而此时cpu想要读取内存数据时,会先判断对应内存是否被cache命中,如果命中将直接读取cache中的数据内容不会经过内存,但是了cache中的数据并不是最新内存的数据,最新内存的数据已经被dma修改了。
为了解决上述DMA与Cache不一致的问题,引入了两种dma机制来处理:一致性DMA(Consistent mapping)和流式DMA(Stream mapping)。
(1)一致性DMA:可以认为是同步的(数据在搬运的时候就已经同步好了,没什么延时),也就是DMA和CPU之间看到的物理内存是一样的。DMA操作和CPU之间的主要隔阂主要是CPU会先访问cache,而DMA只操作物理内存,不会动cache。早期一致性DMA的实现主要就是让DMA处理的这段内存uncache,这样cpu和dma对内存的操作就是一致的,cpu每次访问都不会经过cache了,直接访问内存,这样导致的问题就是降低效率(相当于没有cache了),以至后来随着SOC的发展,SOC可以用硬件来做到CPU和外设的cache一致,简单来说就是DMA在处理设备和物理内存的搬运是,硬件会同时把cache也更新了。一致性DMA通常在驱动初始化的时候进行mapping一块内存,在驱动卸载时再进行unmapping掉。

(2)流式DMA:可以认为是异步的(数据搬运完成,需要进行刷一下cache相关的操作)。流式DMA没做一次DMA传输就需要mapping一次操作的内存,传输结束后进行unmapping。流式DMA之所以是异步,是因为等DMA搬运设备和内存的数据后,需要进行刷cache,刷cache需要根据方向来判断是clean cache还是invaild cache,当DMA将内存数据搬运到设备,则需要clean cache(清除cache数据,防止写回到内存);当DMA将设备数据搬运到内存,则需要invalid cache(使cpu获取的cache数据无效)。
与DMA相关的概念
DMA mapping
在早期,linux内核使用DMA操作的直接是物理地址,即利用phys_to_virt/virt_to_phys在CPU/memory/device直接处理DMA传输,这种代码不具备较好的移植性,随着硬件的发展,DMA地址和物理地址空间发生了变化,DMA地址空间已经不在等同于物理地址空间了,DMA地址空间到物理地址也需要转化,设备不能直接通过物理地址的方式访问物理内存,而需要通过IOMMU进行转化才能访问物理内存(Z->Y的变化,类似与虚拟地址到物理地址的变化)。

从CPU角度看到的地址是虚拟地址,要访问对应的物理地址需要页表将虚拟地址与物理地址映射起来。
从DMA角度看到的地址是总线地址,DMA的主要工作是负责设备与物理内存数据的搬运。当数据需要从物理内存搬运到设备时,物理地址B会通过host brigde转化为总线地址A,即可访问到设备。当数据从设备到物理内存搬运,总线地址Z会通过IOMMU转为为物理地址Y,即可访问物理内存。当CPU要访问设备时,虚拟地址与物理地址B通过ioremap进行映射,再通过host bridge访问到总线地址A,这样就建立起C->B->A的访问。
IOMMU
通过MMU的引入,Linux内存管理子系统解决了CPU内存离散的访问问题,对应用户空间,虚拟地址是连续的,但是对应的物理地址页帧确实可以离散的,对用户是屏蔽的,毫无感知的。但是在内核空间如外设(类DMA设备,不具MMU功能)想要访问内存,一般需要连续的物理内存地址,而连续的大块内存对长期允许的系统来说是奢侈的存在,因此引入了IOMMU,专门用于解决外设(DMA)无法访问连续物理内存的问题,对应外设角色来看,相当于也引入了虚拟地址的概念,IOMMU的用途就是将外设角度访问的虚拟地址转化为物理地址,这样即便物理内存不是连续的也没关系,虚拟地址连续就行,IOMMU会负责将外设访问的虚拟地址转化成物理地址,这样就解决了外设需要分配大块连续内存的问题,分配离散的物理内存也能满足要求了。
DMA传输方向
- DMA_TO_DEVICE: 从内存到设备。
- DMA_FROM_DEVICE:从设备到内存。
- DMA_BIDIRECTIONAL:双向传输。
流式DMA需要指定方向,一致性DMA具有隐式的方向属性为双向(DMA_BIDIRECTIONAL),在方向属性性,如果不明确方向,可以使用DMA_BIDIRECTIONAL,由平台来保证,但这样会引入性能的额外开销。
cache的工作模式
Write-back:回写模式,cache内容更改不需要每次写回内存,直到新的cache要刷新或软件要求刷新才会写回
Write-through:写直通,每次强制将内容写回内存主要时为了内存与cache相一致。
Prefectching:一些cache允许处理器对cache line进行预取,以响应读请求,读取的相邻内容同时被读处理。
DMA 访问系统内存的限制
DMA负责设备与物理内存的数据搬运,那么DMA是否对系统内存访问无限制?DMA访问的内存还是有一些特点和要求的。
– 伙伴系统分配的内存:如kmalloc、kmem_cache_alloc分配的接口可以直接用于DMA mapping接口的API。
– vmalloc/kmap: 由于分配的内存是不联系的,对于DMA来使用比较麻烦。
– 全局变量(数组):一般可以用于DMA操作,但需要注意cacheline对齐,避免chache coherence问题。
DMA寻址范围限制
不同的硬件平台,器DMA的寻址范围可能会有限制,如系统总线寻址是64bit,但是设备的DMA驱动访问的只有24bit,也就只能访问16M以下的系统内存,因此系统提供了接口,用于确定设备DMA寻址访问声明。
int dma_set_mask_and_coherent(struct device *dev, u64 mask);
上面的接口同时设置一致性和流式DMA寻址范围。如果一致性和流式DMA的地址掩码不同,还可以分别设定,如下:
int dma_set_mask(struct device *dev, u64 mask); //用于流式DMA地址掩码
int dma_set_coherent_mask(struct device *dev, u64 mask); //用于一致性DMA地址掩码
一致性DMA映射
一致性DMA映射,也称为静态映射,与dma_map_xxx函数的差异就是会分配好物理内存并建立好映射,内存是长期存在。

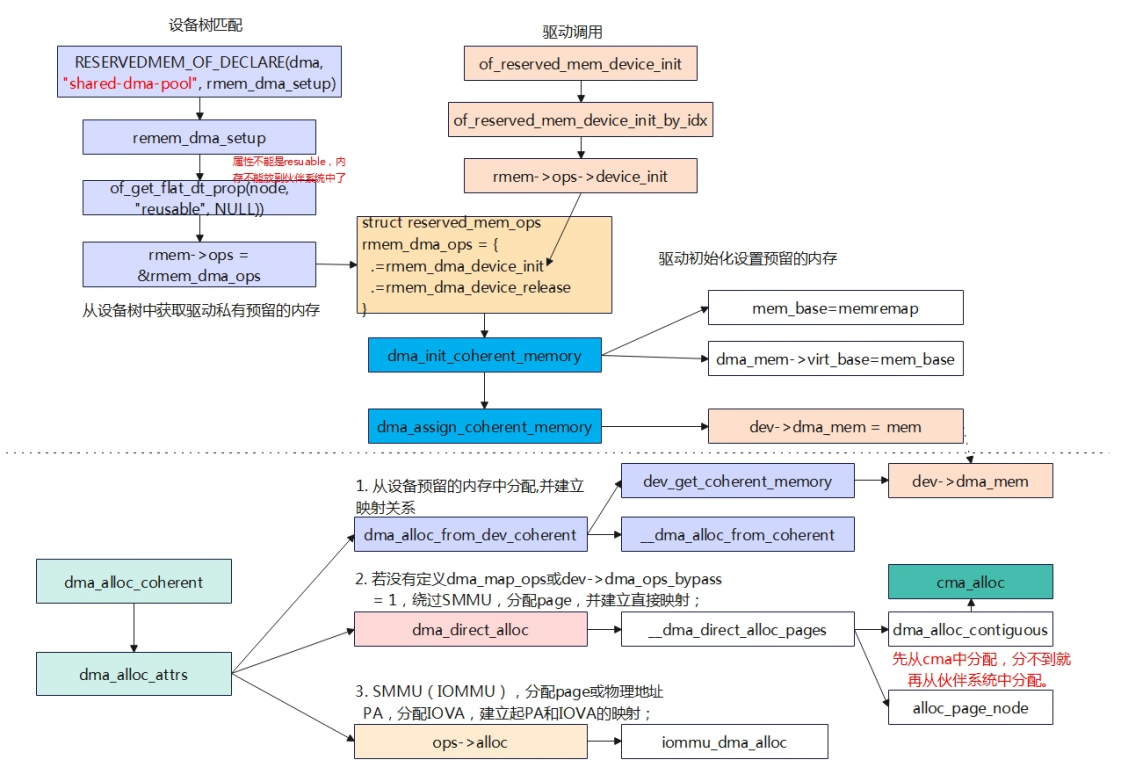
使用dma_alloc_coherent分配内存,一共有3种方式,①依次为先从设备驱动预留的内存进行分配,驱动预留的内存为在设备树中事先从物理内存预留了一块内存,该内存看起来不会加入到伙伴系统,专门留给驱动的dma分配。②如果驱动预留内存分配失败,则系统管理的物理内存中分配,这里会先从CMA中申请,CMA申请不到再从伙伴系统中获取。③最后从IOMMU的方式中分配内存。
流式DMA映射
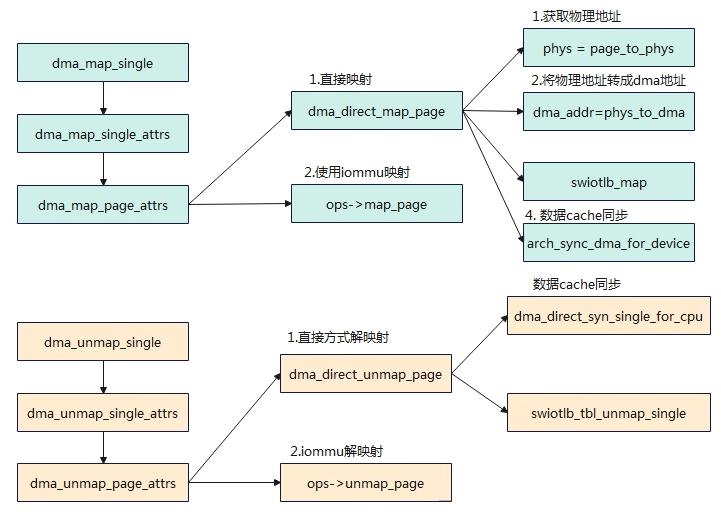
与dma_alloc_coherent相比,dma_map_xxx该函数不会分配内存,只是建立好虚拟地址到DMA的映射关系(将分配好的内存转化成设备/DMA可访问的地址)。调用者必须保证虚地址的物理内存时连续的,且物理地址范围必须满足device中的dma_mask限制,dma_map_xxx调用等dma传输完成后,需要马上调用dma_unmap_xxx。dma_map_xxx有三个函数,区别主要表现在物理内存组织上,dma_map_sg将多个物理内存进行映射成一块连续内存,dma_map_single将一块连续物理内存进行映射;dma_map_page将一个物理页进行映射。
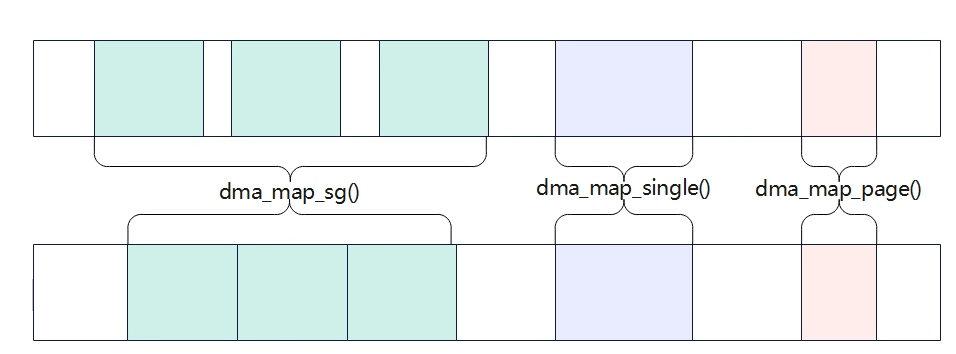
一块联系内存映射dma_map_single


多个连续物理内存映射dma_ma_sg

一个物理页映射dma_map_page
