Pipecat MCP 实战流程分析:从 Client 到 Server
简介
本文主要基于Pipecat实现一个MCP stdio传输方式调用的示例。基于智谱Web-Search-Pro实现一个MCP Server,然后在Pipecat应用基础上实现MCP Client,实现可以实时查询天气等功能。通过这个示例来理解pipecat的mcp调用流程。
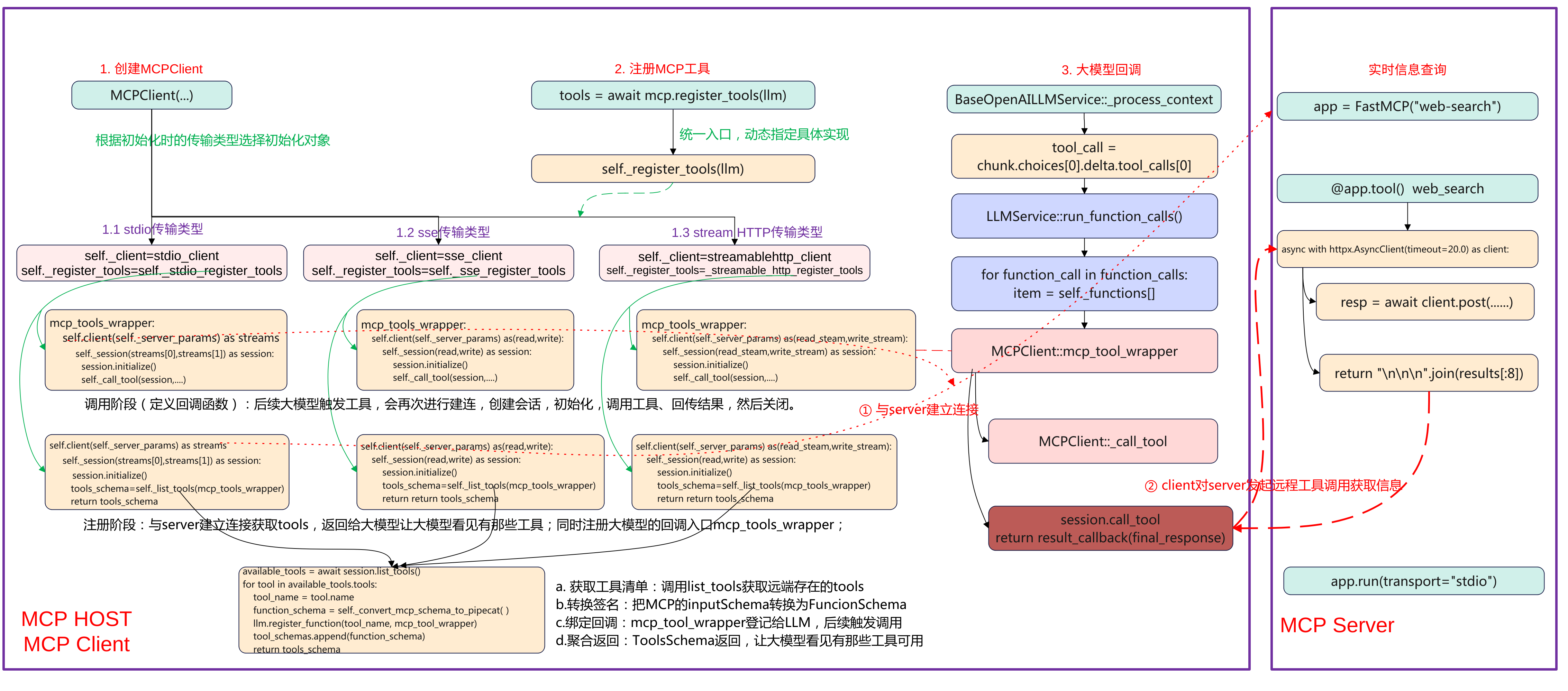
先上一张完整流程图,本文将重点围绕MCP Host、MCP Client端的创建MCP Client、注册MCP工具、以及大模型回调来展开说明pipecat上MCP的调用流程。
Pipecat MCP client端
下面pipecat应用MCP Host的关键代码:
# STT: DashScope FunASR (realtime)
stt = DashscopeFunASRSTTService(api_key=os.getenv("DASHSCOPE_API_KEY"))
# TTS: DashScope CosyVoice v2 (streaming)
tts = DashscopeCosyVoiceTTSService(
api_key=os.getenv("DASHSCOPE_API_KEY"),
voice="longxiaochun_v2",
)
# LLM: Qwen (DashScope OpenAI compatible)
llm = QwenLLMService(
api_key=os.getenv("DASHSCOPE_API_KEY"),
# Mainland China endpoint for OpenAI-compatible API:
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus",
)
server_script = os.path.join(os.path.dirname(__file__), "mcp", "web_search_mcp.py")
mcp = MCPClient(
server_params=StdioServerParameters(
command=sys.executable,
args=[server_script],
env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")},
)
)
tools = await mcp.register_tools(llm)
system = f"""
你是一个在 WebRTC 通话里的中文助手。
- 回答尽量简洁,必要时可调用 MCP 工具完成查询/检索/图片等任务。
- 输出会被转换为语音,避免使用过多特殊字符。
- 工具调用时少解释过程,直接给出关键结论。
"""
messages = [{"role": "system", "content": system}]
context = LLMContext(messages, tools) if tools else LLMContext(messages)
context_aggregator = LLMContextAggregatorPair(context)
pipeline = Pipeline(
[
transport.input(), # Transport user input
stt,
context_aggregator.user(), # User spoken responses
llm, # LLM
tts, # TTS
transport.output(), # Transport bot output
context_aggregator.assistant(), # Assistant spoken responses and tool context
]
)
task = PipelineTask(
pipeline,
params=PipelineParams(
enable_metrics=True,
enable_usage_metrics=True,
),
idle_timeout_secs=runner_args.pipeline_idle_timeout_secs,
)
(1)语音识别
stt = DashscopeFunASRSTTService(api_key=os.getenv("DASHSCOPE_API_KEY"))
使用了DashScope提供的FunASR实时语音识别服务,输入音频流来自WebRTC,输出为识别的文字,这这是整个pipeline的第一个处理单元。
(2)语音合成
tts = DashscopeCosyVoiceTTSService(
api_key=os.getenv("DASHSCOPE_API_KEY"),
voice="longxiaochun_v2",
)
使用DataScope的CosyVoice2模型,将LLM输出的文本转为语音,参数Voice为”龙小纯”音色,支持流式输出,边生成边播放。
(3)大语言模型
llm = QwenLLMService(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus",
)
使用DashSCcope的Qwen plus模型,其兼容OpenAI接口模式,通过统一的LLMService封装,可以插拔替换,接收来自STT的文字输入,并可调用MCP工具。
(4)MCP工具客户端
mcp = MCPClient(
server_params=StdioServerParameters(
command=sys.executable,
args=[server_script],
env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")},
)
)
tools = await mcp.register_tools(llm)
MCPClient启动一个外部MCP工具进程web_search_mcp.py,MCP是一个工具协议层,让LLM可以调用外部函数。register_tools会把MCP提供的工具注册进LLM,使其可以向OpenAI Function Call一样调用。例如查询天气、搜索网页、生成图片等。
(5)系统提示词system prompt
system = """
你是一个在 WebRTC 通话里的中文助手。
- 回答尽量简洁,必要时可调用 MCP 工具完成查询/检索/图片等任务。
- 输出会被转换为语音,避免使用过多特殊字符。
- 工具调用时少解释过程,直接给出关键结论。
"""
LLMContex保持当前对话上下文、系统提示与工具注册,LLMContextAggregatorPair维护用户与助手的历史消息流(多轮对话记忆),这让语音交互能记住上下文内容,而非每轮都从0开始。
(6)pipeline定义语言交互主流程
pipeline = Pipeline([
transport.input(), # 用户语音输入流
stt, # 语音转文字
context_aggregator.user(),# 更新用户对话上下文
llm, # 调用大模型
tts, # 文本转语音
transport.output(), # 输出音频到客户端
context_aggregator.assistant(), # 保存助手回答上下文
])
| 顺序 | 模块 | 输入 | 输出 |
|---|---|---|---|
| 1 | transport.input() |
麦克风语音 | 音频流 |
| 2 | stt |
音频流 | 用户文字 |
| 3 | context_aggregator.user() |
用户文字 | 更新上下文 |
| 4 | llm |
上下文 | 模型回答文本 |
| 5 | tts |
回答文本 | 音频流 |
| 6 | transport.output() |
音频流 | 扬声器播放 |
| 7 | context_aggregator.assistant() |
模型回答 | 保存为记忆 |
(7)pipeline任务封装
task = PipelineTask(
pipeline,
params=PipelineParams(
enable_metrics=True,
enable_usage_metrics=True,
),
idle_timeout_secs=runner_args.pipeline_idle_timeout_secs,
)
封装为可执行任务,支持性能监控与使用统计,可设置空闲超时自动关闭。
MCP Server工具端
(1)导入依赖与初始化
import os, asyncio, sys
import httpx
from mcp.server import FastMCP
app = FastMCP("web-search")
FastMCP(“web-search”) 表示这是一个名为 “web-search” 的 MCP 工具服务,CP 协议使用 JSON-RPC over stdio。httpx是异步HTTP客户端,用于调用外部搜索接口,如果httpx缺失,本地按照pip install httpx。
@app.tool()
async def web_search(query: str) -> str:
"""
搜索互联网内容
Args:
query: 要搜索的内容
Returns:
搜索结果的简要总结
"""
_log(f"tool called: web_search(query={repr(query)[:120]})")
api_key = os.getenv("BIGMODEL_API_KEY")
if not api_key:
_log("Missing BIGMODEL_API_KEY")
return "Missing BIGMODEL_API_KEY"
# Some endpoints accept raw key; others require Bearer. Try raw first to match user sample.
headers = {"Authorization": api_key}
payload = {
"tool": "web-search-pro",
"messages": [{"role": "user", "content": query}],
"stream": False,
}
async with httpx.AsyncClient(timeout=20.0) as client:
try:
_log("sending request to BigModel web-search-pro")
resp = await client.post(
"https://open.bigmodel.cn/api/paas/v4/tools", headers=headers, json=payload
)
_log(f"received response status={resp.status_code}")
resp.raise_for_status()
data = resp.json()
except Exception as e:
_log(f"request error: {e}")
return f"Web search error: {e}"
results = []
try:
for choice in data.get("choices", []):
message = choice.get("message", {})
for tool_call in message.get("tool_calls", []):
for item in tool_call.get("search_result", []) or []:
content = item.get("content")
if content:
results.append(content)
except Exception:
# Fallback to raw body
_log("unexpected response structure; returning raw JSON snippet")
return str(data)[:2000]
if not results:
_log("no results")
return "No results."
_log(f"returning {len(results)} result chunks")
return "\n\n\n".join(results[:8])
使用@app.tool定义工具的接口,其会注册一个工具到MCP Server,工具名称默认为函数名web_search。最终这个工具会暴露给MCP Client,LLM调用时就像function call一样。
函数中具体的实现是构造一个请求体并调用BigModel API。输入为query表示要查询的内容,最终返回查询到的JSON格式结果,将结果进行解析返回结构类似OpenAI格式。
MCP Client初始化
创建MCPClient类
if StdioServerParameters is None:
raise ImportError(
"StdioServerParameters not available in your MCP package. "
"Upgrade MCP: `pip install -U mcp`."
)
server_script = os.path.join(os.path.dirname(__file__), "mcp", "web_search_mcp.py")
mcp = MCPClient(
server_params=StdioServerParameters(
command=sys.executable,
args=[server_script],
env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")},
)
)
首先检查StdioServerParameters是否可用,不可用的haul则升级mcp包。接着计算server_script路径,指向FastMCP服务脚本(实现@app.tool)的web_search,构造MCPClient,传入stdio参数,参数如下:
- command=sys.executable 确保用当前虚拟环境的 Python 启动子进程(依赖一致)。
- args=[server_script] 启动该脚本。
- env={“BIGMODEL_API_KEY”: …} 把 BigModel 的 API Key 传给子进程(工具内部要用)。
server_script 指向真正提供工具的 MCP 服务器(定义了 @app.tool() 的 web_search)。
MCPClient构造
class MCPClient(BaseObject):
def __init__(
self,
server_params: ServerParameters,
**kwargs,
):
"""Initialize the MCP client with server parameters.
Args:
server_params: Server connection parameters (stdio or SSE).
**kwargs: Additional arguments passed to the parent BaseObject.
"""
super().__init__(**kwargs)
self._server_params = server_params
self._session = ClientSession
self._needs_alternate_schema = False
if isinstance(server_params, StdioServerParameters):
self._client = stdio_client
self._register_tools = self._stdio_register_tools
elif isinstance(server_params, SseServerParameters):
self._client = sse_client
self._register_tools = self._sse_register_tools
elif isinstance(server_params, StreamableHttpParameters):
self._client = streamablehttp_client
self._register_tools = self._streamable_http_register_tools
else:
raise TypeError(
f"{self} invalid argument type: `server_params` must be either StdioServerParameters, SseServerParameters, or StreamableHttpParameters."
)
构造时“按参数类型选策略”。把同一套“注册逻辑”与不同“传输后端”(stdio/SSE/HTTP)解耦,延后到运行时绑定。具体的关键步骤如下:
- 保存参数与会话类:self._server_params = server_params:记录连接配置(命令/URL/headers/env 等)。self._session = ClientSession:后续用读写流构建 MCP 会话(initialize/list_tools/call_tool)。self._needs_alternate_schema = False:是否需要“严格 schema 清洗”留给后续判定。
- 选择传输实现与注册函数:根据传参来选择实际的client和注册函数,选择的类型为MCP的传输类型stdio类型、sse类型、streamhttp类型。
self._client 是“连接工厂”(异步上下文管理器),进入后产出读/写流(stdio 为子进程 stdin/stdout,SSE/HTTP 为对应流)。self._register_tools 是对应后端的“注册流程实现”,register_tools(llm) 会调用它去建连→初始化→列工具→注册“工具名→回调”。
这个设计要点是典型的Strategy + Factory:构造时完成“策略绑定”,后续使用统一入口(register_tools)。
MCP工具注册
mcp = MCPClient(
server_params=StdioServerParameters(
command=sys.executable,
args=[server_script],
env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")},
)
)
tools = await mcp.register_tools(llm)
创建完MCPClient对象后,就进行注册tools,调用到MCPClient::register_tools函数。
async def register_tools(self, llm) -> ToolsSchema:
"""Register all available MCP tools with an LLM service.
Connects to the MCP server, discovers available tools, converts their
schemas to Pipecat format, and registers them with the LLM service.
Args:
llm: The Pipecat LLM service to register tools with.
Returns:
A ToolsSchema containing all successfully registered tools.
"""
# Check once if the LLM needs alternate strict schema
self._needs_alternate_schema = llm and llm.needs_mcp_alternate_schema()
tools_schema = await self._register_tools(llm)
return tools_schema
统一入口,完成连接MCP——>获取工具列表——>转换schema——>注册到LLM并返回ToolsSchema的过程。
- self._needs_alternate_schema:询问当前 LLM 是否需要“严格 schema”兼容(有些 LLM 对 JSON Schema 更严格)。若为 True,后续在 schema 转换时会移除/调整如 additionalProperties 等字段。
- tools_schema = await self._register_tools(llm):这里的 _register_tools 是构造函数里根据 server_params 绑定的具体实现(stdio/SSE/HTTP 之一)。内部会实际建连、session.initialize()、session.list_tools()、把每个工具注册为 “工具名 → 回调(mcp_tool_wrapper)”,并组装 ToolsSchema。
ToolsSchema(standard_tools=[FunctionSchema…]),供上层塞进 LLMContext(messages, tools),让大模型“看见”可用工具,同时建立调用时的回调映射。
xxx_register_tools
根据参数传入的类型stdio、sse、streamable_http选择注册的工具,分别会调用如下:
- stdio类型:调用_stdio_register_tools
- sse类型:调用_sse_register_tools
- streamable类型:调用_streamable_http_register_tools
这里以stdio类型为例分析,
async def _stdio_register_tools(self, llm) -> ToolsSchema:
"""Register all available mcp tools with the LLM service.
Args:
llm: The Pipecat LLM service to register tools with
Returns:
A ToolsSchema containing all registered tools
"""
async def mcp_tool_wrapper(params: FunctionCallParams) -> None:
"""Wrapper for mcp tool calls to match Pipecat's function call interface."""
logger.debug(
f"Executing tool '{params.function_name}' with call ID: {params.tool_call_id}"
)
logger.trace(f"Tool arguments: {json.dumps(params.arguments, indent=2)}")
try:
async with self._client(self._server_params) as streams:
async with self._session(streams[0], streams[1]) as session:
await session.initialize()
await self._call_tool(
session, params.function_name, params.arguments, params.result_callback
)
except Exception as e:
error_msg = f"Error calling mcp tool {params.function_name}: {str(e)}"
logger.error(error_msg)
logger.exception("Full exception details:")
await params.result_callback(error_msg)
logger.debug("Starting registration of mcp tools")
async with self._client(self._server_params) as streams:
async with self._session(streams[0], streams[1]) as session:
await session.initialize()
tools_schema = await self._list_tools(session, mcp_tool_wrapper, llm)
return tools_schema
(1)定义回调mcp_tool_wrapper(未来执行)
定义回调 mcp_tool_wrapper(未来每次工具调用时执行),这个是要注册进llm大模型的,用于后续大模型触发的回调。具体的步骤如下:
- 记录日志 → 建立到 MCP 的 stdio 连接:self._client(self._server_params)。
- 取到读写流 streams[0]/streams[1] → 构建 ClientSession → initialize()。
- 调用 _call_tool(session, name, args, result_callback) 执行工具;异常则通过 result_callback 把错误文本回传。
(2)注册阶段(当前执行)
- 再开一次短连接并 initialize()
- 调用 _list_tools(session, mcp_tool_wrapper, llm),获取远端工具清单,转为 FunctionSchema 并用 llm.register_function(tool_name, mcp_tool_wrapper) 将“工具名→回调”登记到 LLM;聚合为 ToolsSchema 返回。
_list_tools
async def _list_tools(self, session, mcp_tool_wrapper, llm):
available_tools = await session.list_tools()
tool_schemas: List[FunctionSchema] = []
try:
logger.debug(f"Found {len(available_tools)} available tools")
except:
pass
for tool in available_tools.tools:
tool_name = tool.name
logger.debug(f"Processing tool: {tool_name}")
logger.debug(f"Tool description: {tool.description}")
try:
# Convert the schema
function_schema = self._convert_mcp_schema_to_pipecat(
tool_name,
{"description": tool.description, "input_schema": tool.inputSchema},
)
# Register the wrapped function
logger.debug(f"Registering function handler for '{tool_name}'")
llm.register_function(tool_name, mcp_tool_wrapper)
# Add to list of schemas
tool_schemas.append(function_schema)
logger.debug(f"Successfully registered tool '{tool_name}'")
except Exception as e:
logger.error(f"Failed to register tool '{tool_name}': {str(e)}")
logger.exception("Full exception details:")
continue
logger.debug(f"Completed registration of {len(tool_schemas)} tools")
tools_schema = ToolsSchema(standard_tools=tool_schemas)
return tools_schema
_list_tools是用当前MCP会话把远端工具同步到LLM,具体的步骤如下:
- list_tools() 获取远端工具清单。
- 遍历每个工具,inputSchema 转为 Pipecat 的 FunctionSchema(name/description/properties/required)。
- 调用 llm.register_function(tool_name, mcp_tool_wrapper) 把“工具名→回调”登记到 LLM(回调负责后续真实调用)。
- 把 FunctionSchema 累加到列表。
- 组装 ToolsSchema(standard_tools=…) 返回。
其目的是让大模型“看见”有哪些工具(用于决策),建立从“工具名”到“实际执行逻辑(mcp_tool_wrapper)”的映射,确保 tool_call 能打到 MCP。
大模型工具调用
触发tool_call
@traced_llm
async def _process_context(self, context: OpenAILLMContext | LLMContext):
if chunk.choices[0].delta.tool_calls:
tool_call = chunk.choices[0].delta.tool_calls[0]
...
if tool_call.function and tool_call.function.name:
function_name += tool_call.function.name
tool_call_id = tool_call.id
if tool_call.function and tool_call.function.arguments:
arguments += tool_call.function.arguments
在_process_context中解析,大模型产生tool_call,接着组装函数调用并交给执行器。
function_calls.append(
FunctionCallFromLLM(context=context, tool_call_id=tool_id,
function_name=function_name, arguments=json.loads(arguments))
)
await self.run_function_calls(function_calls)
查表命中回调
async def run_function_calls(self, function_calls: Sequence[FunctionCallFromLLM]):
if function_call.function_name in self._functions.keys():
item = self._functions[function_call.function_name]
elif None in self._functions.keys():
item = self._functions[None]
在类LLMService中,LLM层查表命中”工具名-回调”。接着下发”调用进行时”帧并准备结果回调。
progress_frame = FunctionCallInProgressFrame(...)
await self.push_frame(progress_frame, FrameDirection.DOWNSTREAM)
await self.push_frame(progress_frame, FrameDirection.UPSTREAM)
.....
async def function_call_result_callback(result: Any, *, properties: ...):
result_frame = FunctionCallResultFrame(..., result=result, ...)
await self.push_frame(result_frame, FrameDirection.DOWNSTREAM)
await self.push_frame(result_frame, FrameDirection.UPSTREAM)
MCP调用
以stdio为例最后触发已注册的回调。
async def _stdio_register_tools(self, llm) -> ToolsSchema:
async with self._client(self._server_params) as streams:
async with self._session(streams[0], streams[1]) as session:
await session.initialize()
await self._call_tool(session, params.function_name, params.arguments, params.result_callback)
真正调用MCP工具并聚合结果。
results = await session.call_tool(function_name, arguments=arguments)
response = ""
if results and hasattr(results, "content"):
for i, content in enumerate(results.content):
if hasattr(content, "text") and content.text:
response += content.text
await result_callback(response if response else "Sorry, could not call the mcp tool")