推理框架
-

llama.cpp 模型加载机制深度解析
概述 llama.cpp 的模型加载系统是一个高度优化的、支持多后端、多设备的模型权重加载框架。它通过精心设计的数据结构和加载流程,实现了: 零拷贝加载:通过内存映射(mmap)实现模型文件的零拷贝加载 多设备支持:自动发现和分配GPU、CPU等设备,支持模型分层加载到不同设备 架构无关:通过统一的抽象支持Llama、Qwen、DeepSeek、Mamba、RWKV等多种架构 高性能I/O:支持直接I/O、异步上传、预取等优化策略 本文将从数据结构、加载流程、I/O机制、设备管理等多个维度深入解析模型加载的实现细节。 关键数据结构 llama_model - 核心模型容器 llama_model 是模型加载后的核心容器,它持有模型的所有权重指针、元数据和设备信息。 结构定义 struct llama_model { llm_type type = LLM_TYPE_UNKNOWN; // 模型规模(如3B、7B) llm_arch arch = LLM_ARCH_UNKNOWN; // 模型架构(如Llama、Qwen) std::string name = "n/a"; // 模型名称 llama_hparams hparams = {}; // 超参数 llama_vocab vocab; // 词表 // 全局权重张量 struct ggml_tensor * tok_embd = nullptr; // Token Embeddings struct ggml_tensor * output = nullptr; // Output weights struct ggml_tensor * output_norm = nullptr; // Output normalization // 分类器相关(用于分类模型) struct ggml_tensor * cls = nullptr; // 层权重数组 std::vector<llama_layer> layers; // GGUF元数据 std::unordered_map<std::string, std::string> gguf_kv; // 设备列表 std::vector<ggml_backend_dev_t> devices; // LoRA适配器 std::unordered_set<llama_adapter_lora *> loras; // 性能统计 int64_t t_load_us = 0; int64_t t_start_us = 0; // Pimpl模式隐藏实现细节 private: struct impl; std::unique_ptr<impl> pimpl; }; 核心设计点 结构化抽象 - layers数组 std::vector layers 是核心设计 将重复的层权重封装到 llama_layer 中 支持动态层数,无需修改结构体定义 设备管理 devices 向量记录所有使用的后端设备 dev_layer(int il) 返回第 il 层所在的设备 dev_output() 返回输出层所在的设备 支持多GPU分层加载 Pimpl模式 隐藏底层实现细节(mmap管理、内存映射句柄等) 保持API稳定性,修改实现不影响头文件 权重指针而非数据 llama_model 不存储实际权重数据 只存储指向权重数据的指针(ggml_tensor *) 实际数据通过mmap映射或buffer管理 关键方法 load_arch(): 从loader加载架构信息 load_hparams(): 加载超参数 load_vocab(): 加载词表 load_tensors(): 创建张量并分配设备 build_graph(): 构建计算图 create_memory(): 创建KV Cache内存 llama_layer - 单层权重抽象 llama_layer 封装了Transformer单层的所有权重张量,支持多种架构变体。 结构定义(部分) struct llama_layer { // 归一化层 struct ggml_tensor * attn_norm = nullptr; struct ggml_tensor * attn_norm_b = nullptr; struct ggml_tensor * attn_q_norm = nullptr; // Gemma 2 struct ggml_tensor * attn_k_norm = nullptr; struct ggml_tensor * ssm_norm = nullptr; // Mamba // 注意力机制 struct ggml_tensor * wq = nullptr; // Query投影 struct ggml_tensor * wk = nullptr; // Key投影 struct ggml_tensor * wv = nullptr; // Value投影 struct ggml_tensor * wo = nullptr; // Output投影 struct ggml_tensor * wqkv = nullptr; // 合并QKV(某些架构) // 注意力偏置 struct ggml_tensor * bq = nullptr; struct ggml_tensor * bk = nullptr; struct ggml_tensor * bv = nullptr; struct ggml_tensor * bo = nullptr; // Feed-Forward网络 struct ggml_tensor * ffn_norm = nullptr; struct ggml_tensor * ffn_gate = nullptr; struct ggml_tensor * ffn_up = nullptr; struct ggml_tensor * ffn_down = nullptr; // 混合专家系统(MoE) struct ggml_tensor * ffn_gate_inp = nullptr; // 门控输入 struct ggml_tensor * ffn_gate_exps = nullptr; // 专家门控权重 struct ggml_tensor * ffn_up_exps = nullptr; // 专家上投影 struct ggml_tensor * ffn_down_exps = nullptr; // 专家下投影 // RoPE相关 struct ggml_tensor * rope_freqs = nullptr; struct ggml_tensor * rope_long = nullptr; // LongRoPE struct ggml_tensor * rope_short = nullptr; // ... 更多架构特定张量 }; 设计特点 通用层抽象 合并了对Gemma、Mixtral、Mamba、RWKV、DeepSeek等模型的支持 通过指针是否为nullptr判断架构是否使用该张量 架构变体支持 归一化变体:支持RMSNorm、LayerNorm、Gemma 2的特殊归一化 注意力变体:标准QKV、合并QKV、分组查询注意力(GQA) MoE支持:专家门控、共享专家(Shared Experts) 非Transformer:Mamba的SSM层、RWKV的循环层 加载流程 预分配:model.layers.resize(n_layer) 创建N个空层 点对点赋值:loader解析GGUF,将张量地址赋给对应层的指针 后端绑定:根据设备分配策略,将指针指向CPU或GPU内存 llama_model_loader - 权重加载器 llama_model_loader 是模型加载的"施工队",负责GGUF文件解析、权重索引、内存映射和数据搬运。 核心成员 struct llama_model_loader { // GGUF元数据 gguf_context_ptr meta; // GGUF解析器上下文 // 文件管理 llama_files files; // 主文件+分片文件句柄 llama_mmaps mappings; // 内存映射句柄 // 权重索引表(核心数据结构) std::map<std::string, llama_tensor_weight, weight_name_comparer> weights_map; // KV覆盖 std::unordered_map<std::string, llama_model_kv_override> kv_overrides; // 张量Buffer类型覆盖 const llama_model_tensor_buft_override * tensor_buft_overrides; // I/O配置 bool use_mmap; bool use_direct_io; bool check_tensors; }; 权重索引表:weights_map 这是loader最核心的数据结构,充当"权重目录": // Key: tensor名称,如 "tok_embeddings.weight", "blk.0.attn_q.weight" // Value: llama_tensor_weight(定位信息) struct llama_tensor_weight { uint16_t idx; // 文件分片索引(主文件=0,split可能是1、2...) size_t offs; // 在文件中的字节偏移 ggml_tensor * tensor; // 张量元数据(shape/type/name) }; weight_name_comparer:自定义排序规则 解析层索引(如 blk.5 → 5) 按层号排序,而非纯字符串排序 优化磁盘读取顺序,利用预读缓存 关键流程 构造函数:初始化GGUF解析 llama_model_loader::llama_model_loader(...) { // 1. 调用gguf_init_from_file解析文件头 meta.reset(gguf_init_from_file(fname.c_str(), params)); // 2. 识别架构 get_key(LLM_KV_GENERAL_ARCHITECTURE, arch_name, false); llm_kv = LLM_KV(llm_arch_from_string(arch_name)); // 3. 打开文件句柄 files.emplace_back(new llama_file(fname.c_str(), "rb", use_direct_io)); // 4. 构建weights_map索引表 for (ggml_tensor * cur = ggml_get_first_tensor(ctx); cur; ...) { weights_map.emplace(tensor_name, llama_tensor_weight(...)); } // 5. 处理分片文件(如果有) // ... } init_mappings:初始化内存映射 void llama_model_loader::init_mappings(bool prefetch, llama_mlocks * mlock_mmaps) { if (use_mmap) { for (const auto & file : files) { // 创建mmap映射 std::unique_ptr<llama_mmap> mapping = std::make_unique<llama_mmap>(file.get(), prefetch ? -1 : 0, is_numa); mappings.emplace_back(std::move(mapping)); // 可选:内存锁定 if (mlock_mmaps) { std::unique_ptr<llama_mlock> mlock_mmap(new llama_mlock()); mlock_mmap->init(mapping->addr()); mlock_mmaps->emplace_back(std::move(mlock_mmap)); } } } } create_tensor:创建张量对象(空壳) 从weights_map查找元数据 在指定的ggml_context中创建tensor对象 此时tensor->data仍为nullptr load_all_data:加载实际数据 遍历所有tensor 根据use_mmap选择路径: mmap路径:ggml_backend_tensor_alloc(buf_mmap, cur, data) 绑定mmap地址 文件读取路径:file->read_raw(cur->data, n_size) 读取到内存 GPU异步上传:分块读取+异步上传到GPU llama_hparams - 超参数蓝图 llama_hparams 存储模型的数学参数,决定计算图的形状和逻辑。 核心参数分类 基础架构参数 n_embd: 隐藏层维度(如4096) n_layer: 总层数 n_ctx_train: 训练时上下文长度 n_head_arr[]: 每层注意力头数(数组支持每层不同) n_head_kv_arr[]: 每层KV头数(GQA支持) 注意力机制变体 n_embd_head_k_mla: MLA压缩后的KV维度(DeepSeek-V2/V3) n_swa: 滑动窗口大小(Mistral) swa_layers[]: 哪些层启用滑动窗口 位置编码(RoPE & YaRN) rope_freq_base_train: RoPE基础频率 rope_freq_scale_train: RoPE缩放因子 rope_scaling_type_train: 缩放类型(linear/yarn/longrope) yarn_ext_factor: YaRN扩展因子 rope_sections[]: 部分维度旋转(Partial RoPE) 混合专家模型(MoE) n_expert: 总专家数 n_expert_used: 每个token激活的专家数(如8选2) n_ff_exp: 专家FFN维度 n_ff_shexp: 共享专家维度(DeepSeek) expert_gating_func: 门控函数类型 状态空间模型(SSM/Mamba) ssm_d_conv: 卷积维度 ssm_d_inner: 内部维度 ssm_d_state: 状态维度 recurrent_layer_arr[]: 哪些层是循环层(混合架构) 归一化与数值稳定性 f_norm_rms_eps: RMSNorm的epsilon f_attn_logit_softcapping: Gemma 2的注意力分数软上限 f_residual_scale: 残差连接缩放(Granite) 加载流程 void llama_model::load_hparams(llama_model_loader & ml) { const gguf_context * ctx = ml.meta.get(); // 1. 保存所有KV对到gguf_kv(用于元数据查询) for (int i = 0; i < gguf_get_n_kv(ctx); i++) { const char * name = gguf_get_key(ctx, i); const std::string value = gguf_kv_to_str(ctx, i); gguf_kv.emplace(name, value); } // 2. 读取基础参数 ml.get_key(LLM_KV_CONTEXT_LENGTH, hparams.n_ctx_train); ml.get_key(LLM_KV_EMBEDDING_LENGTH, hparams.n_embd); ml.get_key(LLM_KV_BLOCK_COUNT, hparams.n_layer); // 3. 读取数组参数(支持每层不同) ml.get_key_or_arr(LLM_KV_FEED_FORWARD_LENGTH, hparams.n_ff_arr, hparams.n_layer, false); ml.get_key_or_arr(LLM_KV_ATTENTION_HEAD_COUNT, hparams.n_head_arr, hparams.n_layer, false); // 4. 架构特定参数(根据arch分支) switch (arch) { case LLM_ARCH_LLAMA: /* ... */ break; case LLM_ARCH_DEEPSEEK: /* ... */ break; // ... } // 5. 参数校验与推导 // 如果某些参数缺失,根据架构进行推导 } 为什么hparams要独立出来? 多版本适配:不同架构可能完全没有某些参数(如Mamba没有n_head),但都有n_embd KV Cache管理:hparams决定KV Cache的内存布局和大小 计算图构建:推理时算子需要从hparams读取数学常数 GGML相关结构 gguf_context GGUF文件的内存映射索引,存储所有KV对和张量元信息。 struct gguf_context { uint32_t version; // GGUF协议版本 // KV键值对存储 std::vector<gguf_kv> kv; // 所有元数据KV对 // 张量信息 std::vector<gguf_tensor_info> info; // 所有权重的"档案" // 物理布局 size_t alignment; size_t offset; // 数据区偏移 void * data; // 数据区指针(如果已映射) }; ggml_backend_buffer 张量真实的"物理房产",解决跨设备内存管理问题。 struct ggml_backend_buffer { struct ggml_backend_buffer_i iface; // 函数指针接口 ggml_backend_buffer_type_t buft; // Buffer类型(CPU/CUDA/Metal等) void * context; // 后端内部状态 size_t size; // 大小 enum ggml_backend_buffer_usage usage; // 用途 }; 关键设计: iface 定义了如何操作这块内存(分配、释放、拷贝等) buft 标识内存由哪个后端分配 支持CPU、CUDA、Metal、Vulkan等多种后端 模型加载完整流程 入口函数:llama_model_load_from_file_impl 这是模型加载的入口点,负责设备发现、模型对象创建和错误处理。 static struct llama_model * llama_model_load_from_file_impl( const std::string & path_model, std::vector<std::string> & splits, struct llama_model_params params) { // 1. 初始化时间统计 ggml_time_init(); // 2. 检查后端是否已加载 if (!params.vocab_only && ggml_backend_reg_count() == 0) { LLAMA_LOG_ERROR("no backends are loaded\n"); return nullptr; } // 3. 设置默认进度回调(如果未提供) if (params.progress_callback == NULL) { params.progress_callback = [](float progress, void * ctx) { // 打印进度点 return true; }; } // 4. 创建模型对象 llama_model * model = new llama_model(params); // 5. 设备发现与选择(详见"设备管理"章节) if (params.devices) { // 使用用户指定的设备 for (ggml_backend_dev_t * dev = params.devices; *dev; ++dev) { model->devices.push_back(*dev); } } else { // 自动发现设备 // - 收集所有GPU设备 // - 收集集成GPU(iGPU) // - 收集RPC服务器 // - 按优先级排序 } // 6. 单GPU模式处理 if (params.split_mode == LLAMA_SPLIT_MODE_NONE) { if (params.main_gpu < 0) { model->devices.clear(); // 只用CPU } else { // 只保留指定的GPU model->devices = {model->devices[params.main_gpu]}; } } // 7. 打印设备信息 for (auto * dev : model->devices) { ggml_backend_dev_props props; ggml_backend_dev_get_props(dev, &props); LLAMA_LOG_INFO("using device %s - %zu MiB free\n", ggml_backend_dev_name(dev), props.memory_free/1024/1024); } // 8. 调用核心加载函数 const int status = llama_model_load(path_model, splits, *model, params); // 9. 错误处理 if (status < 0) { if (status == -1) { LLAMA_LOG_ERROR("failed to load model\n"); } else if (status == -2) { LLAMA_LOG_INFO("cancelled model load\n"); } llama_model_free(model); return nullptr; } return model; } 核心加载函数:llama_model_load 这是模型加载的核心流程,按顺序执行各个加载阶段。 static int llama_model_load( const std::string & fname, std::vector<std::string> & splits, llama_model & model, llama_model_params & params) { // 初始化时间统计 model.t_load_us = 0; time_meas tm(model.t_load_us); model.t_start_us = tm.t_start_us; try { // ========== 阶段0:创建Loader ========== llama_model_loader ml(fname, splits, params.use_mmap, params.use_direct_io, params.check_tensors, params.no_alloc, params.kv_overrides, params.tensor_buft_overrides); ml.print_info(); // 打印模型基本信息 model.hparams.vocab_only = params.vocab_only; model.hparams.no_alloc = params.no_alloc; // ========== 阶段1:架构识别 ========== try { model.load_arch(ml); } catch(const std::exception & e) { throw std::runtime_error("error loading model architecture: " + std::string(e.what())); } // ========== 阶段2:超参数加载 ========== try { model.load_hparams(ml); } catch(const std::exception & e) { throw std::runtime_error("error loading model hyperparameters: " + std::string(e.what())); } // CLIP模型特殊处理 if (model.arch == LLM_ARCH_CLIP) { throw std::runtime_error("CLIP cannot be used as main model"); } // ========== 阶段3:词表加载 ========== try { model.load_vocab(ml); } catch(const std::exception & e) { throw std::runtime_error("error loading model vocabulary: " + std::string(e.what())); } // ========== 阶段4:统计信息 ========== model.load_stats(ml); model.print_info(); // 打印完整模型信息 // ========== 早期退出:仅词表模式 ========== if (params.vocab_only) { LLAMA_LOG_INFO("vocab only - skipping tensors\n"); return 0; } // ========== 阶段5:张量创建与加载 ========== if (!model.load_tensors(ml)) { return -2; // 被进度回调取消 } } catch (const std::exception & err) { LLAMA_LOG_ERROR("error loading model: %s\n", err.what()); return -1; } return 0; } 阶段一:架构识别与元数据解析 load_arch实现 void llama_model::load_arch(llama_model_loader & ml) { arch = ml.get_arch(); // 从loader获取架构枚举 if (arch == LLM_ARCH_UNKNOWN) { throw std::runtime_error("unknown model architecture: '" + ml.get_arch_name() + "'"); } } loader中的架构识别 // llama_model_loader构造函数中 llama_model_loader::llama_model_loader(...) { // 1. 解析GGUF文件头 meta.reset(gguf_init_from_file(fname.c_str(), params)); // 2. 读取架构名称 std::string arch_name; get_key(llm_kv(LLM_KV_GENERAL_ARCHITECTURE), arch_name, false); // 3. 转换为枚举 llm_kv = LLM_KV(llm_arch_from_string(arch_name)); // llm_arch_from_string("llama") -> LLM_ARCH_LLAMA } 架构识别流程: GGUF文件头包含 general.architecture KV对 读取字符串值(如"llama"、"qwen"、"deepseek") 通过 llm_arch_from_string() 转换为枚举 如果无法识别,抛出异常 阶段二:超参数加载 详见 llama_hparams - 超参数蓝图 章节。 关键点: 从GGUF的KV对中读取所有超参数 支持数组参数(每层不同) 架构特定参数根据arch分支处理 参数校验与默认值推导 阶段三:词表加载 void llama_model::load_vocab(llama_model_loader & ml) { const auto kv = LLM_KV(arch); // 获取架构特定的KV键前缀 vocab.load(ml, kv); // 加载词表 } 词表加载包括: Token ID到字符串的映射 Token类型(普通/BOS/EOS/等) 特殊Token(如<|im_start|>) 子词合并规则(BPE/SPM等) 阶段四:张量创建与设备分配 这是最复杂的阶段,涉及张量创建、设备分配、Buffer类型选择等。 load_tensors流程概览 bool llama_model::load_tensors(llama_model_loader & ml) { const int n_layer = hparams.n_layer; const int n_gpu_layers = this->n_gpu_layers(); // ========== 步骤1:构建Buffer类型列表 ========== pimpl->cpu_buft_list = make_cpu_buft_list(devices, ...); for (auto * dev : devices) { buft_list_t buft_list = make_gpu_buft_list(dev, split_mode, tensor_split); buft_list.insert(buft_list.end(), pimpl->cpu_buft_list.begin(), pimpl->cpu_buft_list.end()); pimpl->gpu_buft_list.emplace(dev, std::move(buft_list)); } // ========== 步骤2:计算设备分割点 ========== std::vector<float> splits(n_devices()); // 根据tensor_split参数或默认策略(按显存)分配 // ========== 步骤3:分配层到设备 ========== auto get_layer_buft_list = [&](int il) -> layer_dev { if (il < i_gpu_start || (il - i_gpu_start) >= act_gpu_layers) { return {cpu_dev, &pimpl->cpu_buft_list}; } const int layer_gpu = /* 根据splits计算 */; return {devices.at(layer_gpu), &pimpl->gpu_buft_list.at(devices.at(layer_gpu))}; }; pimpl->dev_input = {cpu_dev, &pimpl->cpu_buft_list}; pimpl->dev_layer.resize(n_layer); for (int il = 0; il < n_layer; ++il) { pimpl->dev_layer[il] = get_layer_buft_list(il); } pimpl->dev_output = get_layer_buft_list(n_layer); // ========== 步骤4:创建GGML Context ========== // 为每个Buffer类型创建独立的context std::map<ggml_backend_buffer_type_t, ggml_context_ptr> ctx_map; auto ctx_for_buft = [&](ggml_backend_buffer_type_t buft) -> ggml_context * { // 查找或创建context }; // ========== 步骤5:创建张量对象(架构特定) ========== layers.resize(n_layer); auto create_tensor = [&](const LLM_TN_IMPL & tn, const std::initializer_list<int64_t> & ne, int flags) -> ggml_tensor * { // 1. 从weights_map查找元数据 ggml_tensor * t_meta = ml.get_tensor_meta(tn.str().c_str()); // 2. 选择Buffer类型 buft_list_t * buft_list = /* 根据tensor层级选择 */; ggml_backend_buffer_type_t buft = select_weight_buft(hparams, t_meta, op, *buft_list); // 3. 检查覆盖规则 if (ml.tensor_buft_overrides) { // 应用用户指定的覆盖 } // 4. 获取或创建context ggml_context * ctx = ctx_for_buft(buft); // 5. 创建tensor对象(此时data仍为nullptr) return ml.create_tensor(ctx, tn, ne, flags); }; // 架构特定的张量创建 switch (arch) { case LLM_ARCH_LLAMA: tok_embd = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, 0); output_norm = create_tensor(tn(LLM_TENSOR_OUTPUT_NORM, "weight"), {n_embd}, 0); output = create_tensor(tn(LLM_TENSOR_OUTPUT, "weight"), {n_embd, n_vocab}, TENSOR_NOT_REQUIRED); for (int i = 0; i < n_layer; ++i) { auto & layer = layers[i]; layer.attn_norm = create_tensor(tn(LLM_TENSOR_ATTN_NORM, "weight", i), {n_embd}, 0); layer.wq = create_tensor(tn(LLM_TENSOR_ATTN_Q, "weight", i), {n_embd, n_embd_head_k * n_head}, 0); // ... 更多张量 } break; // ... 其他架构 } // ========== 步骤6:初始化内存映射 ========== ml.init_mappings(params.prefetch, &pimpl->mlock_mmaps); // ========== 步骤7:加载实际数据 ========== if (!ml.load_all_data(ctxs_bufs, params.progress_callback, params.progress_callback_user_data)) { return false; // 被取消 } // ========== 步骤8:保存Context和Buffer ========== for (auto & [buft, ctx] : ctx_map) { std::vector<ggml_backend_buffer_ptr> bufs; // 收集该context下的所有buffer pimpl->ctxs_bufs.emplace_back(ctx, std::move(bufs)); } return true; } 设备分配策略 输入层:始终在CPU(dev_input = cpu_dev) 中间层:根据n_gpu_layers和tensor_split分配 输出层:与最后一层相同设备 分割计算: // 默认分割:按显存比例 if (all_zero) { for (size_t i = 0; i < n_devices(); ++i) { ggml_backend_dev_props props; ggml_backend_dev_get_props(devices[i], &props); total_free += props.memory_free; } float acc = 0.0f; for (size_t i = 0; i < n_devices(); ++i) { ggml_backend_dev_props props; ggml_backend_dev_get_props(devices[i], &props); acc += props.memory_free / total_free; splits[i] = acc; } } 阶段五:权重数据加载 load_all_data实现 bool llama_model_loader::load_all_data( std::vector<std::pair<ggml_context_ptr, std::vector<ggml_backend_buffer_ptr>>> & ctxs_bufs, llama_progress_callback progress_callback, void * progress_callback_user_data) { // ========== 准备异步上传(如果支持) ========== ggml_backend_t upload_backend = /* 检查是否支持异步上传 */; std::vector<ggml_backend_buffer_ptr> host_buffers; std::vector<void *> host_ptrs; std::vector<ggml_backend_event_ptr> events; // ========== 遍历所有tensor ========== for (struct ggml_tensor * cur = ggml_get_first_tensor(ctx); cur != NULL; cur = ggml_get_next_tensor(ctx, cur)) { const auto * weight = get_weight(ggml_get_name(cur)); if (weight == nullptr) continue; // 进度回调 if (progress_callback) { if (!progress_callback((float) size_done / size_data, progress_callback_user_data)) { return false; // 用户取消 } } size_t n_size = ggml_nbytes(cur); // ========== 路径A:mmap模式(零拷贝) ========== if (use_mmap) { const auto & mapping = mappings.at(weight->idx); uint8_t * data = (uint8_t *) mapping->addr() + weight->offs; // 验证数据(如果启用) if (check_tensors) { validation_result.emplace_back(std::async(std::launch::async, [cur, data, n_size] { return std::make_pair(cur, ggml_validate_row_data(cur->type, data, n_size)); })); } // 绑定到mmap内存 ggml_backend_buffer_t buf_mmap = bufs.at(weight->idx); if (buf_mmap && cur->data == nullptr) { ggml_backend_tensor_alloc(buf_mmap, cur, data); // tensor->buffer = buf_mmap // tensor->data = data (指向mmap地址) } else { // 拷贝数据(如果tensor已有buffer) ggml_backend_tensor_set(cur, data, 0, n_size); } } // ========== 路径B:文件读取模式 ========== else { const auto & file = files.at(weight->idx); // CPU buffer:直接读取 if (ggml_backend_buffer_is_host(cur->buffer)) { file->seek(weight->offs, SEEK_SET); file->read_raw(cur->data, n_size); if (check_tensors) { validation_result.emplace_back(std::async(std::launch::async, [cur, n_size] { return std::make_pair(cur, ggml_validate_row_data(cur->type, cur->data, n_size)); })); } } // GPU buffer:异步上传 else { if (upload_backend) { // 分块读取+异步上传 size_t offset = weight->offs; size_t aligned_offset = offset & ~(alignment - 1); // ... 对齐读取边界 while (bytes_read < read_end - read_start) { // 等待上一个上传完成 ggml_backend_event_synchronize(events[buffer_idx]); // 读取对齐块 file->read_raw_unsafe(host_ptrs[buffer_idx], read_size); // 异步上传到GPU ggml_backend_tensor_set_async(upload_backend, cur, host_ptrs[buffer_idx], data_read, data_to_copy); ggml_backend_event_record(events[buffer_idx], upload_backend); buffer_idx = (buffer_idx + 1) % n_buffers; // 轮转缓冲区 } } else { // 同步上传 read_buf.resize(n_size); file->seek(weight->offs, SEEK_SET); file->read_raw(read_buf.data(), n_size); ggml_backend_tensor_set(cur, read_buf.data(), 0, n_size); } } } size_done += n_size; } // ========== 验证结果 ========== if (check_tensors) { for (auto & future : validation_result) { auto [tensor, valid] = future.get(); if (!valid) { throw std::runtime_error(format("tensor '%s' has invalid data", ggml_get_name(tensor))); } } } return true; } 三种数据加载路径对比 路径 适用场景 性能 内存占用 mmap绑定 CPU推理,mmap可用 最快(零拷贝) 最小(共享文件页) 文件读取+CPU CPU推理,mmap不可用 中等 中等(需要内存拷贝) 异步上传 GPU推理,支持异步 快(重叠I/O和计算) 中等(需要pinned memory) 同步上传 GPU推理,不支持异步 慢 中等 GGUF协议与I/O抽象 GGUF文件格式解析 GGUF(GPT-Generated Unified Format)是llama.cpp使用的二进制模型格式。 文件结构 ┌─────────────────────────────────────┐ │ Magic Number (4 bytes) │ "GGUF" ├─────────────────────────────────────┤ │ Version (4 bytes) │ 协议版本 ├─────────────────────────────────────┤ │ n_kv (8 bytes) │ KV对数量 ├─────────────────────────────────────┤ │ KV Pairs (变长) │ │ - Key: 字符串长度 + 字符串 │ │ - Type: 类型枚举 │ │ - Value: 根据类型存储 │ ├─────────────────────────────────────┤ │ n_tensors (8 bytes) │ 张量数量 ├─────────────────────────────────────┤ │ Tensor Info Array (变长) │ │ - Name: 字符串长度 + 字符串 │ │ - n_dims: 维度数 │ │ - dims[]: 各维度大小 │ │ - type: 数据类型 │ │ - offset: 数据偏移(相对数据区) │ ├─────────────────────────────────────┤ │ Alignment Padding │ 对齐到16字节 ├─────────────────────────────────────┤ │ Tensor Data (变长) │ 实际权重数据 └─────────────────────────────────────┘ 解析流程 struct gguf_context * gguf_init_from_file_impl(FILE * file, ...) { const struct gguf_reader gr(file); struct gguf_context * ctx = new gguf_context; // 1. 校验Magic Number uint32_t magic = gr.read_u32(); if (magic != GGUF_MAGIC) { throw std::runtime_error("invalid GGUF magic"); } // 2. 读取版本 ctx->version = gr.read_u32(); // 3. 读取KV对数量 int64_t n_kv = gr.read_u64(); // 4. 循环读取所有KV对 for (int64_t i = 0; i < n_kv; ++i) { std::string key = gr.read_string(); gguf_type type = (gguf_type)gr.read_u32(); switch (type) { case GGUF_TYPE_UINT8: ctx->kv.emplace_back(key, gr.read_u8()); break; case GGUF_TYPE_INT32: ctx->kv.emplace_back(key, gr.read_i32()); break; case GGUF_TYPE_FLOAT32: ctx->kv.emplace_back(key, gr.read_f32()); break; case GGUF_TYPE_STRING: ctx->kv.emplace_back(key, gr.read_string()); break; // ... 更多类型 } } // 5. 读取张量数量 int64_t n_tensors = gr.read_u64(); // 6. 循环读取所有张量信息 for (int64_t i = 0; i < n_tensors; ++i) { struct gguf_tensor_info info; info.name = gr.read_string(); info.n_dims = gr.read_u32(); for (uint32_t j = 0; j < info.n_dims; ++j) { info.dims[j] = gr.read_u64(); } info.type = (ggml_type)gr.read_u32(); info.offset = gr.read_u64(); // 相对数据区的偏移 ctx->info.push_back(info); } // 7. 计算数据区偏移 ctx->offset = gr.tell(); // 当前位置就是数据区开始 return ctx; } 内存映射(mmap)机制 mmap是llama.cpp实现零拷贝加载的核心技术。 mmap初始化 llama_mmap::llama_mmap(struct llama_file * file, size_t prefetch, bool numa) { size = file->size(); int fd = file->file_id(); #ifdef _POSIX_MAPPED_FILES int flags = MAP_SHARED; // Linux优化:预读建议 if (posix_fadvise(fd, 0, 0, POSIX_FADV_SEQUENTIAL)) { LLAMA_LOG_WARN("posix_fadvise failed\n"); } // 预填充页面(如果启用) if (prefetch) { flags |= MAP_POPULATE; } // 执行mmap addr = mmap(NULL, file->size(), PROT_READ, flags, fd, 0); if (addr == MAP_FAILED) { throw std::runtime_error(format("mmap failed: %s", strerror(errno))); } // 预取建议(如果启用) if (prefetch > 0) { posix_madvise(addr, std::min(file->size(), prefetch), POSIX_MADV_WILLNEED); } // NUMA优化 if (numa) { posix_madvise(addr, file->size(), POSIX_MADV_RANDOM); } #endif } mmap优势 零拷贝:文件数据直接映射到虚拟地址空间,无需拷贝 延迟加载:页面在首次访问时才从磁盘读取(按需分页) 内存共享:多个进程可以共享同一份映射,节省内存 操作系统优化:OS可以预读、缓存页面 mmap绑定tensor // 在load_all_data中 if (use_mmap) { const auto & mapping = mappings.at(weight->idx); uint8_t * data = (uint8_t *) mapping->addr() + weight->offs; // 关键:将tensor的data指针直接指向mmap地址 ggml_backend_tensor_alloc(buf_mmap, cur, data); // 执行后: // cur->buffer = buf_mmap // cur->data = data (指向mmap虚拟地址) } 注意:mmap地址是虚拟地址,实际数据仍在文件页中,由OS管理。 权重索引表构建 weights_map构建流程 llama_model_loader::llama_model_loader(...) { // 1. 解析GGUF元数据 meta.reset(gguf_init_from_file(fname.c_str(), params)); ggml_context * ctx = contexts[0]; // 2. 遍历GGML context中的所有tensor元数据 for (ggml_tensor * cur = ggml_get_first_tensor(ctx); cur; cur = ggml_get_next_tensor(ctx, cur)) { std::string tensor_name = std::string(cur->name); // 3. 计算文件偏移 size_t offs = gguf_get_data_offset(gguf_ctx) + gguf_get_tensor_offset(gguf_ctx, tensor_idx); // 4. 插入索引表(使用自定义排序) weights_map.emplace(tensor_name, llama_tensor_weight(files[0].get(), 0, meta.get(), cur)); } // 5. 处理分片文件(如果有) for (const auto & split : splits) { // 解析分片GGUF // 合并tensor到weights_map(idx递增) } } weight_name_comparer排序规则 struct weight_name_comparer { bool operator()(const std::string & a, const std::string & b) const { int bid_a = -1, bid_b = -1; // 解析层号(如 "blk.5.attn_q.weight" -> 5) sscanf(a.c_str(), "blk.%d.", &bid_a); sscanf(b.c_str(), "blk.%d.", &bid_b); // 按层号排序 if (bid_a != bid_b) { return bid_a < bid_b; } // 同层按名称排序 return a < b; } }; 排序目的:优化磁盘读取顺序,利用OS预读缓存。 数据加载路径 详见 阶段五:权重数据加载 章节。 设备管理与多GPU支持 设备发现与选择 自动设备发现 // 在llama_model_load_from_file_impl中 std::vector<ggml_backend_dev_t> gpus; std::vector<ggml_backend_dev_t> igpus; // 集成GPU std::vector<ggml_backend_dev_t> rpc_servers; // RPC服务器 for (size_t i = 0; i < ggml_backend_dev_count(); ++i) { ggml_backend_dev_t dev = ggml_backend_dev_get(i); switch (ggml_backend_dev_type(dev)) { case GGML_BACKEND_DEVICE_TYPE_GPU: { // 检查设备ID是否重复 ggml_backend_dev_props props; ggml_backend_dev_get_props(dev, &props); auto it = std::find_if(gpus.begin(), gpus.end(), [&props](ggml_backend_dev_t d) { // 比较device_id return /* 相同ID */; }); if (it == gpus.end()) { gpus.push_back(dev); } break; } case GGML_BACKEND_DEVICE_TYPE_IGPU: igpus.push_back(dev); break; } } // 优先级:RPC服务器 > 独立GPU > 集成GPU(仅当无其他设备时) model->devices.insert(model->devices.begin(), rpc_servers.begin(), rpc_servers.end()); model->devices.insert(model->devices.end(), gpus.begin(), gpus.end()); if (model->devices.empty()) { model->devices.insert(model->devices.end(), igpus.begin(), igpus.end()); } 单GPU模式 if (params.split_mode == LLAMA_SPLIT_MODE_NONE) { if (params.main_gpu < 0) { model->devices.clear(); // 只用CPU } else { // 只保留指定的GPU ggml_backend_dev_t main_gpu = model->devices[params.main_gpu]; model->devices.clear(); model->devices.push_back(main_gpu); } } 层到设备的映射策略 分割点计算 // 默认:按显存比例 std::vector<float> splits(n_devices()); if (all_zero) { // tensor_split全为0 size_t total_free = 0; for (size_t i = 0; i < n_devices(); ++i) { ggml_backend_dev_props props; ggml_backend_dev_get_props(devices[i], &props); total_free += props.memory_free; } float acc = 0.0f; for (size_t i = 0; i < n_devices(); ++i) { ggml_backend_dev_props props; ggml_backend_dev_get_props(devices[i], &props); acc += props.memory_free / total_free; splits[i] = acc; // 累积比例 } } else { // 使用用户指定的tensor_split float acc = 0.0f; for (size_t i = 0; i < n_devices(); ++i) { acc += tensor_split[i]; splits[i] = acc; } } 层分配函数 auto get_layer_buft_list = [&](int il) -> layer_dev { const bool is_swa = il < int(hparams.n_layer) && hparams.is_swa(il); // CPU层 if (il < i_gpu_start || (il - i_gpu_start) >= act_gpu_layers) { return {cpu_dev, &pimpl->cpu_buft_list}; } // GPU层:根据splits查找 float layer_ratio = float(il - i_gpu_start) / act_gpu_layers; const int layer_gpu = std::upper_bound(splits.begin(), splits.begin() + n_devices(), layer_ratio) - splits.begin(); auto * dev = devices.at(layer_gpu); return {dev, &pimpl->gpu_buft_list.at(dev)}; }; 示例:3个GPU,splits = [0.33, 0.67, 1.0] 层0-10 → GPU 0 层11-21 → GPU 1 层22-32 → GPU 2 Buffer类型选择 Buffer类型列表构建 // CPU Buffer类型列表 buft_list_t make_cpu_buft_list(...) { buft_list_t buft_list; // 1. Split buffer(如果启用) if (tensor_split && n_devices() > 1) { // 添加split buffer类型 } // 2. 默认CPU buffer buft_list.emplace_back(cpu_dev, ggml_backend_dev_buffer_type(cpu_dev)); // 3. Extra buffer类型(如果启用) if (use_extra_bufts) { auto * extra_bufts = ggml_backend_dev_get_extra_bufts(cpu_dev); // 添加extra buffer } return buft_list; } // GPU Buffer类型列表 buft_list_t make_gpu_buft_list(ggml_backend_dev_t dev, ...) { buft_list_t buft_list; // 1. Split buffer(如果启用) if (split_mode == LLAMA_SPLIT_MODE_LAYER) { // 添加split buffer } // 2. 默认GPU buffer buft_list.emplace_back(dev, ggml_backend_dev_buffer_type(dev)); // 3. Host buffer(用于CPU-GPU传输) auto * host_buft = ggml_backend_dev_host_buffer_type(dev); if (host_buft) { buft_list.emplace_back(dev, host_buft); } // 4. CPU buffer作为fallback buft_list.insert(buft_list.end(), cpu_buft_list.begin(), cpu_buft_list.end()); return buft_list; } 权重Buffer类型选择 ggml_backend_buffer_type_t select_weight_buft( const llama_hparams & hparams, ggml_tensor * w, ggml_op op, const buft_list_t & buft_list) { // 1. 检查权重是否支持该buffer类型 for (const auto & [dev, buft] : buft_list) { if (weight_buft_supported(hparams, w, op, buft, dev)) { return buft; } } // 2. 回退到CPU return ggml_backend_cpu_buffer_type(); } 选择策略: 优先选择GPU buffer(如果支持该操作) 回退到Host buffer(用于传输) 最后回退到CPU buffer 异步上传机制 异步上传初始化 ggml_backend_t upload_backend = [&]() -> ggml_backend_t { if (use_mmap || check_tensors) { return nullptr; // mmap或验证模式下不使用异步上传 } // 检查backend是否支持异步上传 auto * buf = bufs.count(0) ? bufs.at(0) : nullptr; if (!buf) return nullptr; auto * buft = ggml_backend_buffer_get_type(buf); auto * dev = ggml_backend_buft_get_device(buft); if (!dev) return nullptr; // 检查能力 ggml_backend_dev_props props; ggml_backend_dev_get_props(dev, &props); if (!props.caps.async || !props.caps.host_buffer || !props.caps.events) { return nullptr; } // 创建pinned memory buffers auto * host_buft = ggml_backend_dev_host_buffer_type(dev); for (size_t idx = 0; idx < n_buffers; ++idx) { auto * buf = ggml_backend_buft_alloc_buffer(host_buft, buffer_size); host_buffers.emplace_back(buf); host_ptrs.emplace_back(ggml_backend_buffer_get_base(buf)); auto * event = ggml_backend_event_new(dev); events.emplace_back(event); } return ggml_backend_dev_init(dev, nullptr); }(); 异步上传流程 // 在load_all_data中 if (upload_backend) { size_t offset = weight->offs; size_t aligned_offset = offset & ~(alignment - 1); size_t offset_from_alignment = offset - aligned_offset; file->seek(aligned_offset, SEEK_SET); size_t bytes_read = 0; size_t data_read = 0; while (bytes_read < read_end - read_start) { size_t read_size = std::min<size_t>(buffer_size, read_end - read_start - bytes_read); // 等待上一个上传完成(避免覆盖) ggml_backend_event_synchronize(events[buffer_idx]); // 读取对齐块到pinned memory file->read_raw_unsafe(host_ptrs[buffer_idx], read_size); // 计算实际数据部分(排除对齐填充) uintptr_t ptr_data = /* 对齐后的指针 */; size_t data_to_copy = read_size; if (bytes_read == 0) { ptr_data += offset_from_alignment; data_to_copy -= offset_from_alignment; } // 异步上传到GPU(不阻塞) ggml_backend_tensor_set_async(upload_backend, cur, reinterpret_cast<void *>(ptr_data), data_read, data_to_copy); // 记录事件(用于后续同步) ggml_backend_event_record(events[buffer_idx], upload_backend); data_read += data_to_copy; bytes_read += read_size; buffer_idx = (buffer_idx + 1) % n_buffers; // 轮转缓冲区 } } 优势: 重叠I/O和计算:读取下一块数据时,上一块正在上传 多缓冲区轮转:避免等待上传完成 对齐读取:提高I/O效率 内存管理优化 内存映射(mmap)优化 详见 内存映射(mmap)机制 章节。 补充优化点: 预填充页面:MAP_POPULATE标志立即读取所有页面(适用于小模型) 预读建议:POSIX_MADV_WILLNEED告诉OS预读页面 NUMA感知:POSIX_MADV_RANDOM优化NUMA系统访问模式 内存锁定(mlock)机制 mlock将内存页面锁定在RAM中,防止被swap到磁盘。 struct llama_mlock { void init(void * ptr) { // 初始化mlock } void grow_to(size_t target_size) { // 扩展锁定区域 #ifdef _POSIX_MEMLOCK_RANGE if (mlock(ptr, target_size) != 0) { // 处理错误(可能需要root权限) } #endif } }; 使用场景: 实时推理系统(避免swap延迟) 需要root权限或CAP_IPC_LOCK能力 NUMA感知 NUMA(Non-Uniform Memory Access)系统需要优化内存访问模式。 // 在init_mappings中 bool is_numa = false; auto * dev = ggml_backend_dev_by_type(GGML_BACKEND_DEVICE_TYPE_CPU); if (dev) { auto * reg = ggml_backend_dev_backend_reg(dev); auto * is_numa_fn = (decltype(ggml_is_numa) *) ggml_backend_reg_get_proc_address(reg, "ggml_backend_cpu_is_numa"); if (is_numa_fn) { is_numa = is_numa_fn(); } } // 创建mmap时传递NUMA标志 std::unique_ptr<llama_mmap> mapping = std::make_unique<llama_mmap>(file.get(), prefetch ? -1 : 0, is_numa); NUMA优化: 使用POSIX_MADV_RANDOM提示OS随机访问模式 避免跨NUMA节点访问(如果可能) 内存碎片管理 llama.cpp通过以下策略减少内存碎片: 按Buffer类型分组:相同类型的tensor使用同一个context 对齐分配:tensor数据按16字节对齐 mmap零拷贝:避免额外分配 架构特定加载逻辑 架构识别流程 // 1. 从GGUF读取架构名称 std::string arch_name; ml.get_key(LLM_KV_GENERAL_ARCHITECTURE, arch_name, false); // 2. 转换为枚举 llm_arch arch = llm_arch_from_string(arch_name); // "llama" -> LLM_ARCH_LLAMA // "qwen" -> LLM_ARCH_QWEN // ... // 3. 设置模型架构 model.arch = arch; 张量命名约定 llama.cpp使用统一的张量命名约定: {prefix}.{layer_idx}.{tensor_name}.{suffix} 示例: - tok_embeddings.weight (输入层) - blk.0.attn_norm.weight (第0层,注意力归一化) - blk.0.attn_q.weight (第0层,Query投影) - blk.0.ffn_gate.weight (第0层,FFN门控) - output_norm.weight (输出层) - output.weight (输出权重) 架构特定前缀: Llama: blk.{i} Qwen: blk.{i} DeepSeek: blk.{i} Mamba: blk.{i} (但使用SSM层) 特殊架构处理 MoE架构(Mixtral/DeepSeek) if (n_expert > 0) { // 门控输入 layer.ffn_gate_inp = create_tensor( tn(LLM_TENSOR_FFN_GATE_INP, "weight", i), {n_embd, n_expert}, 0); // 专家权重(3D张量:n_embd x n_ff x n_expert) layer.ffn_gate_exps = create_tensor( tn(LLM_TENSOR_FFN_GATE_EXPS, "weight", i), {n_embd, n_ff, n_expert}, TENSOR_NOT_REQUIRED); layer.ffn_up_exps = create_tensor( tn(LLM_TENSOR_FFN_UP_EXPS, "weight", i), {n_embd, n_ff, n_expert}, 0); layer.ffn_down_exps = create_tensor( tn(LLM_TENSOR_FFN_DOWN_EXPS, "weight", i), {n_ff, n_embd, n_expert}, 0); // 共享专家(DeepSeek) if (hparams.n_ff_shexp > 0) { layer.ffn_gate_shexp = create_tensor(...); layer.ffn_up_shexp = create_tensor(...); layer.ffn_down_shexp = create_tensor(...); } } Mamba架构 case LLM_ARCH_MAMBA: case LLM_ARCH_MAMBA2: // SSM归一化 layer.ssm_norm = create_tensor( tn(LLM_TENSOR_SSM_NORM, "weight", i), {n_embd}, 0); // SSM参数 layer.ssm_dt_rank = create_tensor(...); layer.ssm_in = create_tensor(...); layer.ssm_out = create_tensor(...); // ... break; RWKV架构 case LLM_ARCH_RWKV6: case LLM_ARCH_RWKV7: // RWKV使用循环层,不使用标准注意力 // 特殊的time_mix参数 layer.time_mix_k = create_tensor(...); layer.time_mix_v = create_tensor(...); // ... break; 错误处理与进度跟踪 异常处理机制 try { llama_model_loader ml(...); model.load_arch(ml); model.load_hparams(ml); model.load_vocab(ml); model.load_tensors(ml); } catch (const std::exception & err) { LLAMA_LOG_ERROR("error loading model: %s\n", err.what()); return -1; } 常见错误: 文件不存在或格式错误 架构不支持 超参数缺失或无效 张量缺失或形状不匹配 内存不足 进度回调系统 typedef bool (*llama_progress_callback)(float progress, void * ctx); // 在load_all_data中 if (progress_callback) { float progress = (float) size_done / size_data; if (!progress_callback(progress, progress_callback_user_data)) { return false; // 用户取消 } } 使用示例: bool my_progress(float progress, void * ctx) { printf("Loading: %.1f%%\r", progress * 100); fflush(stdout); return true; // 返回false可取消加载 } llama_model_params params = llama_model_default_params(); params.progress_callback = my_progress; params.progress_callback_user_data = nullptr; 取消加载机制 进度回调返回false时,加载会立即停止: // 在load_all_data中 if (progress_callback) { if (!progress_callback((float) size_done / size_data, progress_callback_user_data)) { return false; // 取消加载 } } // 在llama_model_load中 if (!model.load_tensors(ml)) { return -2; // 返回-2表示取消 } 数据结构关联关系总结 加载链路关联 ┌─────────────────────────────────────────────────────────────┐ │ 阶段 1: GGUF 读取 │ │ │ │ gguf_init_from_file() │ │ ↓ │ │ 解析所有 KV 对 → 存储在 gguf_context->kv 中 │ │ - "general.architecture" = "llama" │ │ - "llama.context_length" = 4096 │ │ - "llama.embedding_length" = 4096 │ │ - "llama.block_count" = 32 │ │ │ │ 结果:ml.meta (gguf_context_ptr) 持有所有 KV 对 │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 阶段 2: 架构识别 │ │ │ │ model.load_arch(ml) │ │ ↓ │ │ ml.get_arch() → 从gguf_context读取架构名称 │ │ ↓ │ │ model.arch = LLM_ARCH_LLAMA │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 阶段 3: 超参数加载 │ │ │ │ model.load_hparams(ml) │ │ ↓ │ │ ml.get_key(LLM_KV_CONTEXT_LENGTH, hparams.n_ctx_train) │ │ ↓ │ │ 从gguf_context->kv查找并填充hparams │ │ │ │ 结果:model.hparams 包含所有数学参数 │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 阶段 4: 张量创建 │ │ │ │ model.load_tensors(ml) │ │ ↓ │ │ 1. 根据hparams.n_layer创建layers数组 │ │ layers.resize(n_layer) │ │ │ │ 2. 从weights_map查找张量元数据 │ │ weight = ml.get_weight("blk.0.attn_q.weight") │ │ │ │ 3. 创建tensor对象(空壳) │ │ layer.wq = ml.create_tensor(ctx, tn, {n_embd, ...}, 0) │ │ │ │ 4. 分配设备 │ │ pimpl->dev_layer[0] = get_layer_buft_list(0) │ │ │ │ 结果:所有tensor对象已创建,但data仍为nullptr │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 阶段 5: 数据加载 │ │ │ │ ml.load_all_data() │ │ ↓ │ │ 遍历所有tensor: │ │ for (tensor in ctx) { │ │ weight = get_weight(tensor->name) │ │ if (use_mmap) { │ │ data = mapping->addr() + weight->offs │ │ ggml_backend_tensor_alloc(buf, tensor, data) │ │ // tensor->data = data (指向mmap地址) │ │ } else { │ │ file->read_raw(tensor->data, n_size) │ │ } │ │ } │ │ │ │ 结果:tensor->data指向实际权重数据 │ └─────────────────────────────────────────────────────────────┘ 数据结构职责划分 数据结构 职责 生命周期 gguf_context GGUF文件元数据存储 加载期间 llama_model_loader 权重索引、文件管理、数据加载 加载期间 llama_hparams 数学参数存储 模型生命周期 llama_model 权重指针、设备管理、元数据 模型生命周期 llama_layer 单层权重指针 模型生命周期 ggml_tensor 张量元数据+数据指针 模型生命周期 ggml_backend_buffer 物理内存管理 模型生命周期 关键设计模式 Pimpl模式:隐藏实现细节,保持API稳定 索引表模式:weights_map作为"目录",快速定位权重 策略模式:设备分配、Buffer选择通过策略函数实现 工厂模式:create_tensor根据架构创建不同张量 总结 GGUF读取的调用链 GGUF文件的读取在llama.cpp中遵循以下调用链: llama_model_load_from_file_impl() ↓ llama_model_load() ↓ llama_model_loader::llama_model_loader() // 构造函数 ↓ gguf_init_from_file() // 打开文件并调用解析函数 ↓ gguf_init_from_file_impl() // 实际解析函数 ↓ gguf_reader // 文件读取器 关键调用点: // 在 llama_model_loader 构造函数中(llama-model-loader.cpp:531) struct gguf_init_params params = { /*.no_alloc = */ true, // 只读取元数据,不分配tensor数据 /*.ctx = */ &ctx, // 返回ggml_context用于存储tensor元数据 }; meta.reset(gguf_init_from_file(fname.c_str(), params)); // meta 是 gguf_context_ptr,持有解析后的GGUF元数据 GGUF解析的详细流程 gguf_init_from_file_impl 按以下顺序解析文件: 步骤1:校验Magic Number std::vector<char> magic; gr.read(magic, 4); // 读取4字节 // 验证是否为 "GGUF" 步骤2:读取文件头 gr.read(ctx->version); // 读取版本号(4字节) gr.read(n_kv); // 读取KV对数量(8字节) gr.read(n_tensors); // 读取张量数量(8字节) 步骤3:解析所有KV对 for (int64_t i = 0; i < n_kv; ++i) { std::string key = gr.read_string(); // 读取键名 gguf_type type = (gguf_type)gr.read_u32(); // 读取类型 // 根据类型读取值 switch (type) { case GGUF_TYPE_UINT8: ctx->kv.emplace_back(key, gr.read_u8()); break; case GGUF_TYPE_INT32: ctx->kv.emplace_back(key, gr.read_i32()); break; case GGUF_TYPE_FLOAT32: ctx->kv.emplace_back(key, gr.read_f32()); break; case GGUF_TYPE_STRING: ctx->kv.emplace_back(key, gr.read_string()); break; // ... 更多类型 } } // 结果:所有KV对存储在 ctx->kv 向量中 步骤4:解析所有张量信息 for (int64_t i = 0; i < n_tensors; ++i) { struct gguf_tensor_info info; info.name = gr.read_string(); // 张量名称 info.n_dims = gr.read_u32(); // 维度数 for (uint32_t j = 0; j < info.n_dims; ++j) { info.dims[j] = gr.read_u64(); // 各维度大小 } info.type = (ggml_type)gr.read_u32(); // 数据类型 info.offset = gr.read_u64(); // 数据偏移(相对数据区) ctx->info.push_back(info); } // 结果:所有张量信息存储在 ctx->info 向量中 步骤5:计算数据区偏移 ctx->offset = gr.tell(); // 当前位置就是数据区开始位置 // 此时文件指针已跳过所有元数据,指向实际权重数据 步骤6:创建GGML Context和Tensor元数据(如果no_alloc=false) if (params.ctx && !params.no_alloc) { // 创建ggml_context ggml_context * ctx_data = ggml_init({...}); // 为每个tensor创建ggml_tensor对象 for (size_t i = 0; i < ctx->info.size(); ++i) { struct ggml_tensor * cur = ggml_new_tensor(ctx_data, ...); ggml_set_name(cur, info.t.name); // 如果no_alloc=false,将data指针指向文件中的数据位置 cur->data = (char *) data->data + info.offset; } } 读取后存储的数据结构 GGUF解析后的数据存储在以下结构中: gguf_context(核心存储结构) struct gguf_context { uint32_t version; // GGUF版本 std::vector<gguf_kv> kv; // 所有KV对 // 例如: // kv[0] = {"general.architecture", "llama"} // kv[1] = {"llama.context_length", 4096} // kv[2] = {"llama.embedding_length", 4096} // ... std::vector<gguf_tensor_info> info; // 所有张量信息 // 例如: // info[0] = {name: "tok_embeddings.weight", dims: [4096, 32000], type: F16, offset: 0} // info[1] = {name: "blk.0.attn_q.weight", dims: [4096, 4096], type: F16, offset: 131072000} // ... size_t alignment; // 对齐字节数(通常16或32) size_t offset; // 数据区在文件中的偏移 void * data; // 数据区指针(如果已映射) }; llama_model_loader中的存储 struct llama_model_loader { gguf_context_ptr meta; // 持有gguf_context // meta.get() 返回 gguf_context*,包含所有KV对和张量信息 llama_files files; // 文件句柄列表 // files[0] = 主文件 // files[1..n] = 分片文件(如果有) std::map<std::string, llama_tensor_weight> weights_map; // 权重索引表,Key是tensor名称,Value包含: // - idx: 文件索引(0=主文件,1..n=分片) // - offs: 在文件中的字节偏移 // - tensor: 指向ggml_tensor元数据 }; 在llama.cpp中的调用流程 完整调用链: // 1. 用户调用入口 llama_model * model = llama_model_load_from_file("model.gguf", params); // 2. 内部调用链 llama_model_load_from_file_impl() → llama_model_load() → llama_model_loader ml(fname, ...) // 构造函数开始解析GGUF → gguf_init_from_file(fname, params) → gguf_init_from_file_impl(file, params) // 解析文件头、KV对、张量信息 // 返回 gguf_context* → meta.reset(gguf_context*) // 保存到loader中 → 遍历ctx中的tensor,构建weights_map → 处理分片文件(如果有) // 3. 后续使用 model.load_arch(ml) // 从meta读取架构名称 model.load_hparams(ml) // 从meta读取超参数 model.load_vocab(ml) // 从meta读取词表 model.load_tensors(ml) // 从weights_map定位权重,从文件读取数据 关键访问接口: // 在 llama_model_loader 中访问KV对 ml.get_key(LLM_KV_CONTEXT_LENGTH, hparams.n_ctx_train); // 内部调用: // gguf_find_key(meta.get(), "llama.context_length") // gguf_get_val_u32(meta.get(), key_id) // 访问张量元数据 ggml_tensor * t_meta = ml.get_tensor_meta("blk.0.attn_q.weight"); // 内部从weights_map查找,返回ggml_tensor*(只有元数据,data为nullptr) // 访问权重位置 const auto * weight = ml.get_weight("blk.0.attn_q.weight"); // 返回 llama_tensor_weight,包含: // weight->idx = 0(主文件) // weight->offs = 131072000(文件偏移) // weight->tensor = ggml_tensor*(元数据) 数据流转图 ┌───────────────────────────────────────────────┐ │ GGUF文件(磁盘) │ │ ┌─────────┬─────────┬─────────┬─────────┐ │ │ │ Magic │ Version │ n_kv │ KV Pairs │ │ │ └─────────┴─────────┴─────────┴─────────┘ │ │ ┌─────────┬─────────────────────────────┐ │ │ │n_tensors │ Tensor Info Array │ │ │ └─────────┴─────────────────────────────┘ │ │ ┌───────────────────────────────────────┐ │ │ │ Tensor Data (实际权重) │ │ │ └───────────────────────────────────────┘ │ └──────────────────────────────────────────────┘ ↓ gguf_init_from_file() ┌────────────────────────────────────────────┐ │ gguf_context(内存) │ │ │ │ ctx->kv[]: │ │ [0] = {"general.architecture", "llama"} │ │ [1] = {"llama.context_length", 4096} │ │ [2] = {"llama.embedding_length", 4096} │ │ ... │ │ │ │ ctx->info[]: │ │ [0] = {name: "tok_embeddings.weight", offset: 0, ...} │ │ [1] = {name: "blk.0.attn_q.weight", offset: 131072000,...} │ │ ... │ │ │ │ ctx->offset = 数据区偏移 │ └────────────────────────────────────────────┘ ↓ 存储到 llama_model_loader ┌────────────────────────────────────────────┐ │ llama_model_loader │ │ │ │ meta: gguf_context_ptr → 持有所有KV和tensor信息 │ │ │ │ weights_map: │ │ "tok_embeddings.weight" → {idx:0, offs:0, tensor:...} │ │ "blk.0.attn_q.weight" → {idx:0, offs:131072000, tensor:...} │ │ ... │ │ │ │ files: [主文件句柄, 分片1句柄, ...] │ └────────────────────────── ─────────────────┘ ↓ 使用 ┌───────────────────────────────────────────┐ │ 模型加载各阶段 │ │ │ │ load_arch(): 从 meta->kv 读取架构名称 │ │ load_hparams(): 从 meta->kv 读取超参数 │ │ load_vocab(): 从 meta->kv 读取词表 │ │ load_tensors(): 从 weights_map 定位权重,从文件读取数据 │ └───────────────────────────────────────────┘ -
ggml后端架构简要分析
后端系统概述 GGML后端系统主要提供如下功能: 统一接口: 不同硬件平台使用相关的API。 自动选择:根据硬件自动选择最优后端。 灵活切换:可以在运行时切换后端。 扩展性:易于添加的新后端。 后端主要涉及如下概念: Backend:执行计算的抽象层(CPU,CUDA, Metal等) Buffer:后端管理的内存缓冲区。 Buffer Type:缓冲区的类型(主机内存、GPU内存等) Graph Plan:计算图的执行。 Devcice:物理设备(CPU,GPU等) 后端接口 核心类型 typedef struct ggml_backend * ggml_backend_t; // 后端句柄 typedef struct ggml_backend_buffer * ggml_backend_buffer_t; // 缓冲区句柄 typedef struct ggml_backend_buffer_type * ggml_backend_buffer_type_t; // 缓冲区类型 主要的API (1)后端管理 // 获取后端名称 const char * ggml_backend_name(ggml_backend_t backend); // 释放后端 void ggml_backend_free(ggml_backend_t backend); // 获取默认缓冲区类型 ggml_backend_buffer_type_t ggml_backend_get_default_buffer_type(ggml_backend_t backend); (2)缓冲区的操作 // 分配缓冲区 ggml_backend_buffer_t ggml_backend_alloc_buffer(ggml_backend_t backend, size_t size); // 释放缓冲区 void ggml_backend_buffer_free(ggml_backend_buffer_t buffer); // 获取缓冲区基址 void * ggml_backend_buffer_get_base(ggml_backend_buffer_t buffer); (3)Tensor操作 // 设置 tensor 数据 void ggml_backend_tensor_set(struct ggml_tensor * tensor, const void * data, size_t offset, size_t size); // 获取 tensor 数据 void ggml_backend_tensor_get(const struct ggml_tensor * tensor, void * data, size_t offset, size_t size); (4)计算图执行 // 同步执行 enum ggml_status ggml_backend_graph_compute(ggml_backend_t backend, struct ggml_cgraph * cgraph); // 异步执行 enum ggml_status ggml_backend_graph_compute_async(ggml_backend_t backend, struct ggml_cgraph * cgraph); 后端注册机制 注册流程 位置: src/ggml-backend-reg.cpp 初始化时注册: struct ggml_backend_registry { std::vector<ggml_backend_reg_entry> backends; ggml_backend_registry() { #ifdef GGML_USE_CUDA register_backend(ggml_backend_cuda_reg()); #endif #ifdef GGML_USE_METAL register_backend(ggml_backend_metal_reg()); #endif #ifdef GGML_USE_CPU register_backend(ggml_backend_cpu_reg()); #endif // ... 其他后端 } }; 后端注册结构 struct ggml_backend_reg { const char * name; // 后端名称 ggml_backend_t (*init_fn)(void); // 初始化函数 size_t (*dev_count_fn)(void); // 设备数量 // ... 其他函数指针 }; 动态加载 支持从动态库加载后端 ggml_backend_reg_t ggml_backend_load(const char * path); 4. demo.c vs demo_backend.c 对比 demo.c (传统模式) (1)特点 使用 ggml_init()直接分配内存 所有 tensor 从 context 分配 使用 ggml_graph_compute_with_ctx()执行 简单直接,适合 CPU 计算 (2)代码流程 // 1. 初始化 context ctx = ggml_init(params); // 2. 创建 tensor (从 context 分配) tensor = ggml_new_tensor_2d(ctx, ...); // 3. 构建计算图 gf = ggml_new_graph(ctx); ggml_build_forward_expand(gf, result); // 4. 执行 (使用 context 的工作内存) ggml_graph_compute_with_ctx(ctx, gf, n_threads); (3)内存管理 Context 管理所有内存 预分配内存池 运行时不再分配 demo_backend.c (后端模式) (1)特点 使用后端系统管理内存 支持 GPU 等后端 使用 ggml_gallocr 分配内存 更灵活,适合生产环境 (2)代码流程 // 1. 初始化后端 backend = ggml_backend_cpu_init(); // 或 CUDA, Metal 等 // 2. 初始化 context (no_alloc = true) ctx = ggml_init(params_no_alloc); // 3. 创建 tensor (不分配内存) tensor = ggml_new_tensor_2d(ctx, ...); // 4. 后端分配内存 buffer = ggml_backend_alloc_ctx_tensors(ctx, backend); // 5. 设置数据 ggml_backend_tensor_set(tensor, data, ...); // 6. 构建计算图 gf = ggml_new_graph(ctx_cgraph); ggml_build_forward_expand(gf, result); // 7. 分配计算图内存 allocr = ggml_gallocr_new(...); ggml_gallocr_alloc_graph(allocr, gf); // 8. 后端执行 ggml_backend_graph_compute(backend, gf); (3)内存管理 后端管理内存分配 支持不同内存类型 (主机内存、GPU 内存) 使用 ggml_gallocr优化分配 关键差异 特性 demo.c demo_backend.c 内存管理 Context 直接管理 后端系统管理 GPU 支持 否 是 内存类型 仅主机内存 支持多种类型 5. 内存分配器 ggml_gallocr (Graph Allocator) 用于 优化计算图的内存分配 减少内存碎片 支持内存复用 Tensor分配 适用场景:你希望某些 tensor 放到特定的内存/设备(比如 Spacemit/特殊 CPU buffer),而另一些 tensor 仍放在默认 CPU buffer。核心 API 是: ggml_backend_buft_get_alloc_size():算出某个 buft 下该 tensor 需要的实际分配大小 ggml_backend_buft_alloc_buffer():分配一块后端 buffer ggml_backend_buffer_get_base():拿到 buffer 的 base 地址 ggml_backend_tensor_alloc(buffer, tensor, base + offset):把 tensor “绑定”到这块 buffer 的地址上 典型流程(精简版): // 0) 构建 tensor 时建议 ctx.no_alloc = true(只建元数据,不在 ctx 内部分配) struct ggml_tensor * a = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_A, rows_A); struct ggml_tensor * b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_B, rows_B); // 1) 为 a 选择特殊 buft(如 Spacemit),为 b 选择默认 CPU buft ggml_backend_buffer_type_t a_buft = ggml_backend_cpu_riscv64_spacemit_buffer_type(); ggml_backend_buffer_type_t cpu_buft = ggml_backend_get_default_buffer_type(backend); // 2) 分配 buffer 并把 tensor 绑定进去 size_t a_size = ggml_backend_buft_get_alloc_size(a_buft, a); ggml_backend_buffer_t a_buf = ggml_backend_buft_alloc_buffer(a_buft, a_size); ggml_backend_tensor_alloc(a_buf, a, ggml_backend_buffer_get_base(a_buf)); size_t b_size = ggml_backend_buft_get_alloc_size(cpu_buft, b); ggml_backend_buffer_t b_buf = ggml_backend_buft_alloc_buffer(cpu_buft, b_size); ggml_backend_tensor_alloc(b_buf, b, ggml_backend_buffer_get_base(b_buf)); // 3) 写入/读取 tensor 数据(后端负责必要的数据搬运) ggml_backend_tensor_set(a, host_ptr_A, 0, ggml_nbytes(a)); ggml_backend_tensor_set(b, host_ptr_B, 0, ggml_nbytes(b)); // ... graph compute ... ggml_backend_tensor_get(out, host_ptr_out, 0, ggml_nbytes(out)); 要点: buffer 的生命周期必须覆盖计算阶段(结束后再 ggml_backend_buffer_free())。 这种方式本质上是“你负责 placement”,适合做 demo/异构内存验证/特殊平台适配。 Graph分配 适用场景:你希望把“中间 tensor + 输出 tensor”的内存分配交给 allocator 统一规划,减少碎片、提升复用率。前提通常是: 用于建图的 ctx 设置.no_alloc = true(tensor 先不分配) 图 gf 已经 ggml_build_forward_expand()完整展开 典型流程: // 1) 创建分配器:通常用 backend 的默认 buffer type ggml_gallocr_t allocr = ggml_gallocr_new( ggml_backend_get_default_buffer_type(backend) ); // 2) 为计算图分配内存(会给图里需要的 tensor 规划并分配后端 buffer) ggml_gallocr_alloc_graph(allocr, gf); // 3) 执行计算图 ggml_backend_graph_compute(backend, gf); // 4) 释放分配器(以及其内部持有的资源) ggml_gallocr_free(allocr); 可选优化(大模型/多次重复执行同结构图时更常见): ggml_gallocr_reserve(allocr, gf):先“规划/预留”一次,再根据 ggml_gallocr_get_buffer_size()观察峰值需求(见一些大 example 的用法)。 Workflow分配 适用场景:你有多个后端(例如主后端 + CPU fallback),希望由 scheduler/allocator 完成: 图的 tensor 分配 跨后端的 placement/拷贝(如果需要) simple/simple-backend.cpp 的核心思路是: 建图时 .no_alloc = true 每次计算前调用 ggml_backend_sched_alloc_graph()触发分配 用 ggml_backend_tensor_set/get在 host 与后端 tensor 之间传数据 典型流程(精简版): // 1) 初始化多个 backend,并创建 sched ggml_backend_t backend = ggml_backend_init_best(); ggml_backend_t cpu_backend = ggml_backend_init_by_type(GGML_BACKEND_DEVICE_TYPE_CPU, NULL); ggml_backend_t backends[] = { backend, cpu_backend }; ggml_backend_sched_t sched = ggml_backend_sched_new(backends, NULL, 2, GGML_DEFAULT_GRAPH_SIZE, /*pipeline_parallel=*/false, /*graph_copy=*/true); // 2) 建图(ctx.no_alloc=true;图结构固定后可重复执行) struct ggml_cgraph * gf = ...; // ggml_new_graph + ggml_build_forward_expand // 3) 分配 + 执行 ggml_backend_sched_reset(sched); ggml_backend_sched_alloc_graph(sched, gf); ggml_backend_tensor_set(a, host_ptr_A, 0, ggml_nbytes(a)); ggml_backend_tensor_set(b, host_ptr_B, 0, ggml_nbytes(b)); ggml_backend_sched_graph_compute(sched, gf); struct ggml_tensor * out = ggml_graph_node(gf, -1); ggml_backend_tensor_get(out, host_ptr_out, 0, ggml_nbytes(out)); 要点: 这条路线更接近“生产用法”:分配/拷贝/执行由 backend 系统统一处理,你只维护图和输入输出。 如果你需要“像 demo_spacemit.c 那样手动把某个输入 tensor 固定到特定 buft”,就不要完全依赖 scheduler 的自动分配;通常应采用tensor 级手动分配或者在更高层做 placement 策略(取决于后端能力)。 -

llama.cpp初探:simple示例代码简要分析
加载后端 void ggml_backend_load_all() { ggml_backend_load_all_from_path(nullptr); } void ggml_backend_load_all_from_path(const char * dir_path) { #ifdef NDEBUG bool silent = true; #else bool silent = false; #endif ggml_backend_load_best("blas", silent, dir_path); ggml_backend_load_best("zendnn", silent, dir_path); ggml_backend_load_best("cann", silent, dir_path); ggml_backend_load_best("cuda", silent, dir_path); ggml_backend_load_best("hip", silent, dir_path); ggml_backend_load_best("metal", silent, dir_path); ggml_backend_load_best("rpc", silent, dir_path); ggml_backend_load_best("sycl", silent, dir_path); ggml_backend_load_best("vulkan", silent, dir_path); ggml_backend_load_best("opencl", silent, dir_path); ggml_backend_load_best("hexagon", silent, dir_path); ggml_backend_load_best("musa", silent, dir_path); ggml_backend_load_best("cpu", silent, dir_path); // check the environment variable GGML_BACKEND_PATH to load an out-of-tree backend const char * backend_path = std::getenv("GGML_BACKEND_PATH"); if (backend_path) { ggml_backend_load(backend_path); } } 动态加载所有可用的计算后端(CPU、CUDA、Metal 等),让 llama.cpp 能在不同硬件上运行。通过评分机制选择最适合的后端进行注册。每个后端会提供一个获取评分的函数,使用该函数进行计算得到分值,比如使用位运算累加看看性能。注册后端注释是加载其对应后端的动态库,将后端添加到backends向量。 加载模型 先看看看GGUF的模型文件。 (1)文件头: 位于文件的最开始位置,用于快速校验文件是否合法。 Magic Number (4 bytes): 0x47 0x47 0x55 0x46,对应的 ASCII 码就是 "GGUF"。加载器首先读取这4个字节,如果不对,直接报错。 Version (4 bytes): 版本号(图中是 3)。这允许加载器处理不同版本的格式变化(向后兼容)。 Tensor Count (8 bytes, UINT64): 模型中包含的张量(权重矩阵)总数。比如一个 7B 模型可能有几百个 Tensor。 Metadata KV Count (8 bytes, UINT64): 元数据键值对的数量。这是 GGUF 最核心的改进点。 (2)元数据键值对:接在头部之后,这部分定义了模型的所有非权重信息 以前的格式(如 GGML)通常把超参数(层数、维度等)写死在代码或特定的结构体里。GGUF 改用 Key-Value 映射。 架构信息: general.architecture = "llama"(告诉加载器用哪套逻辑加载)。 模型参数: llama.context_length = 4096, llama.embedding_length = 4096 等。 Tokenizer (词表): 这一点非常重要。GGUF 将词表(tokenizer.ggml.tokens)直接打包在文件里,不再需要额外的 tokenizer.json 或 vocab.model 文件。这实现了真正的“单文件发布”。 其他: 作者信息、量化方法描述等。 (3)张量信息表:索引目录 在读取完所有元数据后,就是 Tensor 的索引列表。这里不包含实际的权重数据,只是数据的“描述”和“指针”。对于每一个 Tensor(共 tensor_count 个),包含以下字段: Name: 字符串,例如 blk.0.ffn_gate.weight。这对应了模型层中的具体权重名称。 n_dimensions: 维度数量(例如 2 表示矩阵,1 表示向量)。 dimensions: 具体的形状数组,例如 [4096, 32000]。 Type: 数据类型,例如 GGML_TYPE_Q2_K(2-bit 量化)、F16 等。 Offset (8 bytes, UINT64): 这是最关键的字段。它是一个指针(偏移量),告诉程序:“这个张量的实际二进制数据,位于文件数据区的第 X 个字节处”。 (4)数据区:图中右侧箭头指向的 10110... 部分。 这是文件体积最大的部分,包含所有权重矩阵的实际二进制数据。内存映射 (mmap) 的奥秘,因为有了上面的 Offset,llama_model_load_from_file 不需要把整个几 GB 的文件一次性读入 RAM。 它只需要调用系统级 API mmap,将文件映射到虚拟内存。当模型推理需要用到 blk.0 的权重时,CPU/GPU 根据 Offset 直接去磁盘(或文件系统缓存)里拿数据。这就是为什么 GGUF 模型启动速度极快且内存占用低的原因。 模型加载主要是将GGUF加载进来,主要的流程是先检查是否有注册后端,然后选择对应的设备,接着解析GGUF元信息包括KV/张量表,接着按照n_gpu_layers/tensor_split分配层与buffer,再者就是读取/映射/上传权重数据,返回llama_model对象指针。 其中最核心的函数就是llama_mode_load,这个函数主要的作用如下: load_arch:先知道是什么架构,后面的 KV key 解释/张量命名规则才对。 load_hparams:读 GGUF KV 填充超参。 load_vocab:构建 tokenizer/vocab。 load_tensors:决定设备/缓冲区并实际装载权重数据。 load_arch load_arch加载的是模型的架构类型,比如LLaMA、Falcon、Qwen、CLIP等大类,存储到llama_mode::arch字段里面,这个来源是GGUF的metadata key。 get_key(llm_kv(LLM_KV_GENERAL_ARCHITECTURE), arch_name, false); llm_kv = LLM_KV(llm_arch_from_string(arch_name)); load_arch本身只是把loader里解析好的枚举出来。 void llama_model::load_arch(llama_model_loader & ml) { arch = ml.get_arch(); if (arch == LLM_ARCH_UNKNOWN) { throw std::runtime_error("unknown model architecture: '" + ml.get_arch_name() + "'"); } } 之所以要解析加载arch是因为后面所以得操作都依赖着arch,比如怎么解释GGUF、怎么建张量的逻辑依赖arch。l oad_hparams 需要 arch 才知道该读哪些 KV、如何解释超参,而且它还用 arch 做特殊分支(例如 CLIP 直接跳过 hparams)。 load_vocab 会用 arch 构造 LLM_KV(arch),影响 vocab/tokenizer 的加载规则。 load_tensors 更是直接 switch (arch) 来决定要创建哪些权重张量、张量命名/shape/op 映射等。 load_hparams struct llama_hparams { bool vocab_only; bool no_alloc; bool rope_finetuned; bool use_par_res; bool swin_norm; uint32_t n_ctx_train; // context size the model was trained on uint32_t n_embd; uint32_t n_embd_features = 0; uint32_t n_layer; // ... uint32_t n_rot; uint32_t n_embd_head_k; uint32_t n_embd_head_v; uint32_t n_expert = 0; uint32_t n_expert_used = 0; // ... }; 这里的 hparams 指的是 llama_model 里的 模型超参数/结构参数(hyper-parameters):决定模型“长什么样”(层数、隐藏维度、头数、RoPE/ALiBi/SWA/MoE 等配置)。它对应的结构体是 struct llama_hparams llama_model::load_hparams(ml) 会从 GGUF 的 KV(metadata)里读取并填充 model.hparams(以及一些辅助状态,比如 gguf_kv 字符串表、type 等) 模型结构: 训练时的context长度、embedding/hidden size、transformer block 数、MoE等。 注意力/FFN:支持 KV 是标量或数组:有些模型每层不同。 RoPE相关:rope_finetuned / rope_freq_base_train / rope_freq_scale_train / rope_scaling_type_train / n_rot / n_embd_head_k/v 等 架构特化项:比如 LLM_ARCH_WAVTOKENIZER_DEC 会额外读 posnet/convnext 参数。 load_vocab load_vocab 加载的是 模型的词表/分词器(tokenizer + vocab):包括每个 token 的文本、score、属性(normal/control/user_defined/unknown/byte 等),以及各种 special token(BOS/EOS/EOT/PAD/…)和不同 tokenizer(SPM/BPE/WPM/UGM/RWKV/…)所需的附加数据(如 BPE merges、charsmap 等)。 struct llama_vocab { struct token_data { std::string text; float score; llama_token_attr attr; }; void load(llama_model_loader & ml, const LLM_KV & kv); std::string get_tokenizer_model() const; std::string get_tokenizer_pre() const; enum llama_vocab_type get_type() const; enum llama_vocab_pre_type get_pre_type() const; uint32_t n_tokens() const; uint32_t n_token_types() const; // ... }; 模型的推理需要做文本到token id的双向转换,输入的prompt必须先tokenize 才能喂给llama_decode,输出的token id必须detokenize 才能打印成字符串。不同模型(LLaMA / Falcon / ChatGLM / …)的 tokenizer 规则不同(SPM/BPE/WPM/UGM…,以及 pre-tokenization 规则),如果 vocab 没加载或加载错,模型就“无法正确理解输入/输出” load_tensor 这里的tensor是指模型推理所需的所有权重张量(weghts),比如: token embedding:tok_embd 每层 attention 的 Wq/Wk/Wv/Wo(以及可选 bias、norm 权重等) 每层 FFN 的 Wgate/Wup/Wdown(MoE 还会有专家张量、router 等) 输出层/输出 embedding(有些模型与 tok_embd 共享,需要 duplicated 处理) 在load tensors会按arch分支创建这些张量,比如已LLAMA类分支片段。 tok_embd = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, 0); // output output_norm = create_tensor(tn(LLM_TENSOR_OUTPUT_NORM, "weight"), {n_embd}, 0); output = create_tensor(tn(LLM_TENSOR_OUTPUT, "weight"), {n_embd, n_vocab}, TENSOR_NOT_REQUIRED); if (output == NULL) { output = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, TENSOR_DUPLICATED); } for (int i = 0; i < n_layer; ++i) { auto & layer = layers[i]; layer.attn_norm = create_tensor(tn(LLM_TENSOR_ATTN_NORM, "weight", i), {n_embd}, 0); layer.wq = create_tensor(tn(LLM_TENSOR_ATTN_Q, "weight", i), {n_embd, n_embd_head_k * n_head}, 0); layer.wk = create_tensor(tn(LLM_TENSOR_ATTN_K, "weight", i), {n_embd, n_embd_k_gqa}, 0); layer.wv = create_tensor(tn(LLM_TENSOR_ATTN_V, "weight", i), {n_embd, n_embd_v_gqa}, 0); layer.wo = create_tensor(tn(LLM_TENSOR_ATTN_OUT, "weight", i), {n_embd_head_k * n_head, n_embd}, 0); } (1)tensor对象(ggml_tensor *)存在哪里? 按语义分组存到 llama_model 的成员里:比如 tok_embd / output_norm / output,以及每层的 layers[i].wq/wk/wv/... 等(这些都是 ggml_tensor * 指针)。 struct llama_model { // ... struct ggml_tensor * tok_embd = nullptr; // ... struct ggml_tensor * output_norm = nullptr; struct ggml_tensor * output = nullptr; // ... std::vector<llama_layer> layers; // ... std::vector<std::pair<std::string, struct ggml_tensor *>> tensors_by_name; // ... }; 按名字查 tensor:load_tensors() 完成后会把每个 ggml_context 里的 tensor 都放进 tensors_by_name(主要用于内部/统计与 get_tensor(name) 这种按名访问)。 // populate tensors_by_name for (auto & [ctx, _] : pimpl->ctxs_bufs) { for (auto * cur = ggml_get_first_tensor(ctx.get()); cur != NULL; cur = ggml_get_next_tensor(ctx.get(), cur)) { tensors_by_name.emplace_back(ggml_get_name(cur), cur); } } 对应按名取 const ggml_tensor * llama_model::get_tensor(const char * name) const { auto it = std::find_if(tensors_by_name.begin(), tensors_by_name.end(), [name](const std::pair<std::string, ggml_tensor *> & it) { return it.first == name; }); if (it == tensors_by_name.end()) { return nullptr; } return it->second; } (2)tensor数据(权重内容)存在哪里? ggml_tensor 自身只是一个“描述 + 指针”,真正的权重数据会落在三类地方之一: CPU/GPU 后端 buffer 里:load_tensors() 会为不同 buffer type 创建对应的 backend buffer,并把它们与承载 tensor metadata 的 ggml_context 绑在一起。这些 buffer 句柄被保存在:pimpl->ctxs_bufs struct llama_model::impl { // contexts where the model tensors metadata is stored as well as the corresponding buffers: std::vector<std::pair<ggml_context_ptr, std::vector<ggml_backend_buffer_ptr>>> ctxs_bufs; // ... }; mmap 映射区域(文件映射内存):如果启用 mmap,loader 会把模型文件映射进内存,某些 tensor 的 data 会直接指向映射区域,或者后端 buffer 会通过 buffer_from_host_ptr 包装映射内存。映射对象被保存在loader侧:ml.mappings,model侧:pimpl->mappings。 no_alloc 模式:ml.no_alloc 时只是创建 tensor 元信息与“dummy buffer”,不装载数据,用于某些统计/规划场景。 (3)tensor是怎么分配到那个设备上的? 在GPU上还是CPU上,决策分为两层: 层级/设备选择(dev):决定每一层(input/repeating/output)用哪个 ggml_backend_dev_t(CPU / GPU / RPC / IGPU…)。 buffer type 选择(buft):在选定设备后,再决定该 tensor 用哪个 ggml_backend_buffer_type_t(同一设备也可能有多种 buffer type;并且还会把 CPU buffer type 作为 fallback)。 流程梳理(从“设备列表”到“权重进后端 buffer”)如下: ┌──────────────────────────────────────────────────────────────┐ │ llama_model_load_from_file_impl(path, params) │ │ - 选择/构建 model->devices (GPU/RPC/IGPU...) │ └───────────────┬──────────────────────────────────────────────┘ │ v ┌──────────────────────────────────────────────────────────────┐ │ llama_model_load(...) │ │ - llama_model_loader ml(...) 读取 GGUF 元信息、索引 tensors │ │ - model.load_arch/load_hparams/load_vocab │ │ - model.load_tensors(ml) ← 重点 │ └───────────────┬──────────────────────────────────────────────┘ │ v ┌──────────────────────────────────────────────────────────────┐ │ llama_model::load_tensors(ml) │ │ A) 构建候选 buft 列表 │ │ cpu_buft_list = make_cpu_buft_list(...) │ │ gpu_buft_list[dev] = make_gpu_buft_list(dev,...) + CPU fb │ │ │ │ B) 决定每层放哪台设备(层→dev) │ │ splits = tensor_split 或按 dev free-mem 默认计算 │ │ i_gpu_start = (n_layer+1 - n_gpu_layers) │ │ dev_input=CPU, dev_layer[il]=CPU/GPU..., dev_output=... │ │ │ │ C) 决定每个 tensor 用哪个 buft,并创建 ggml_tensor 元信息 │ │ 对每个权重 tensor: │ │ - 根据层(input/repeating/output)选 buft_list │ │ - buft = select_weight_buft(...) (考虑 op/type/override) │ │ - ctx = ctx_map[buft] (同 buft 归到同 ggml_context) │ │ - ml.create_tensor(ctx, ...) (创建 tensor meta) │ │ ml.done_getting_tensors() 校验数量 │ └───────────────┬──────────────────────────────────────────────┘ │ v ┌──────────────────────────────────────────────────────────────┐ │ D) 分配后端 buffer(真正“存储权重”的地方) │ │ ml.init_mappings(...) (mmap 时建立映射、算 size_data) │ │ 对每个 (buft -> ctx): │ │ - 若满足条件: ggml_backend_dev_buffer_from_host_ptr(...) │ │ (把 mmap 的区间包装成后端 buffer,少拷贝) │ │ - 否则: ggml_backend_alloc_ctx_tensors_from_buft(ctx,buft)│ │ - 结果保存到 model.pimpl->ctxs_bufs 维持生命周期 │ │ - 标记 buffer usage = WEIGHTS (帮助调度) │ └───────────────┬──────────────────────────────────────────────┘ │ v ┌──────────────────────────────────────────────────────────────┐ │ E) 装载权重数据到后端(mmap/读文件/异步上传) │ │ 对每个 ctx: ml.load_all_data(ctx, buf_map, progress_cb) │ │ - progress_cb 返回 false => 取消 => load_tensors 返回 false│ │ 若 use_mmap_buffer: model.pimpl->mappings 接管 ml.mappings │ │ 同时填充 model.tensors_by_name 供按名查询/统计 │ └──────────────────────────────────────────────────────────────┘ │ v ┌──────────────────────────────────────────────────────────────┐ │ 推理阶段 build_graph / llama_decode │ │ - 直接引用 model.tok_embd / model.layers[i].wq... 等 ggml_tensor│ │ - 后端根据 tensor 绑定的 buffer 决定在 CPU/GPU 执行与取数 │ └──────────────────────────────────────────────────────────────┘ buft 是什么? buft 是 ggml_backend_buffer_type_t(backend buffer type),可以理解为“某个后端设备上,用哪一种内存/分配方式来存放 tensor 数据”的类型句柄。 在 load_tensors() 里它的作用是:给每个权重 tensor 选择一个合适的 buffer type,并据此把 tensor 归到对应的 ggml_context,最终用该 buft 去创建真实的后端 buffer(CPU RAM / GPU VRAM / 远端 RPC buffer / host pinned buffer 等)。 load_tensors() 里按 tensor 所在层选一个 buft_list,再用 select_weight_buft(...) 选出最终 buft: if (!buft) { buft = select_weight_buft(hparams, t_meta, op, *buft_list); if (!buft) { throw std::runtime_error(format("failed to find a compatible buffer type for tensor %s", tn.str().c_str())); } } 随后用 buft 决定该 tensor 属于哪个 ggml_context(ctx_for_buft(buft)),并最终分配后端 buffer(例如 ggml_backend_alloc_ctx_tensors_from_buft(ctx, buft) 或 mmap 的 ggml_backend_dev_buffer_from_host_ptr(...))。 buft 和 dev(device)的区别 - dev(ggml_backend_dev_t):是哪块设备(CPU / 某张 GPU / RPC 设备…) - buft(ggml_backend_buffer_type_t):在这块设备上“用哪种 buffer 类型/内存形式”来存 tensor(默认 device buffer、host buffer、特殊优化 buffer 等) (4)推理阶段如何使用这些权重 后续推理构图时(model.build_graph(...) ——>各 src/models/xx.cpp),会直接用 llama_model 里的这些 ggml_tensor x 作为权重输入,和激活值做 ggml 运算(matmul/add/norm/rope…)。例如 src/models/stablelm.cpp 在构图时直接用: model.tok_embd 做输入 embedding - model.layers[il].wq/wk/wv 做 Q/K/V 投影 - model.layers[il].bq/bk/bv(可选)加 bias - ggml_rope_ext 用 rope 参数对 Q/K 做 RoPE Tokenization const llama_vocab * vocab = llama_model_get_vocab(model); // tokenize the prompt // find the number of tokens in the prompt const int n_prompt = -llama_tokenize(vocab, prompt.c_str(), prompt.size(), NULL, 0, true, true); // allocate space for the tokens and tokenize the prompt std::vector<llama_token> prompt_tokens(n_prompt); if (llama_tokenize(vocab, prompt.c_str(), prompt.size(), prompt_tokens.data(), prompt_tokens.size(), true, true) < 0) { fprintf(stderr, "%s: error: failed to tokenize the prompt\n", __func__); return 1; } 这段代码主要的作用是做文本->token ID的转换。整段的流程可以总结一下。 拿vocab:llama_model_get_vocab(model) 获取 tokenizer/词表句柄; 预估token数:第一次 llama_tokenize(..., NULL, 0, ...),只算需要多少 token,返回负数取反得到 n_prompt; 分配缓存:std::vector prompt_tokens(n_prompt); 为 prompt 分配精确长度的 token 缓冲区; 真正 tokenize:第二次 llama_tokenize 把 token id 写进 prompt_tokens,如果失败或容量不够返回 < 0 则报错退出。 llama_tokenize() tokenize 的对象是 一段输入文本(UTF-8 字符串),输出是 token id 序列(llama_token):也就是模型能直接消费的离散符号编号。它依赖 llama_vocab(模型绑定的 tokenizer + 词表 + special token 规则),把文本切分/编码成 token ids。 llama_tokenize会转发到vocab->tokenize,先做 special token 分段,再按 vocab type 分发到具体 tokenizer session。 std::vector<llama_token> llama_vocab::impl::tokenize(const std::string & raw_text, bool add_special, bool parse_special) const { // 1) special token partition(把 raw_text 切成「普通文本片段」和「已识别的特殊 token」) tokenizer_st_partition(fragment_buffer, parse_special); // 2) 按 vocab type 分发到具体 tokenizer session switch (get_type()) { case LLAMA_VOCAB_TYPE_SPM: llm_tokenizer_spm_session(...).tokenize(...); break; case LLAMA_VOCAB_TYPE_BPE: llm_tokenizer_bpe_session(...).tokenize(...); break; case LLAMA_VOCAB_TYPE_WPM: llm_tokenizer_wpm_session(...).tokenize(...); break; case LLAMA_VOCAB_TYPE_UGM: llm_tokenizer_ugm_session(...).tokenize(...); break; case LLAMA_VOCAB_TYPE_RWKV: llm_tokenizer_rwkv_session(...).tokenize(...); break; case LLAMA_VOCAB_TYPE_PLAMO2: llm_tokenizer_plamo2_session(...).tokenize(...); break; default: GGML_ABORT(...); } return output; } SPM SentencePiece BPE-ish 合并,项目里叫 SPM tokenizer,入口类是llm_tokenizer_spm_session,其核心思路是把文本先按 UTF-8 字符拆成链表 symbol,然后不断从优先队列取“得分最高”的可合并 bigram,做合并,最后把每个合并后的片段映射为 token。 struct llm_tokenizer_spm_session { void tokenize(const std::string & text, std::vector<llama_token> & output) { // split into utf8 chars -> symbols // seed work_queue with all 2-char tokens -> try_add_bigram // pop highest score, merge, and push new bigrams // resegment each final symbol into token ids / byte tokens } } 在 impl::tokenize 的 SPM 分支里,会先把空格转义成 “▁”(U+2581),并处理 add_space_prefix、BOS/EOS: if (add_space_prefix && is_prev_special) { text = ' '; } text += fragment... llama_escape_whitespace(text); // ' ' -> ▁ llm_tokenizer_spm_session session(vocab); session.tokenize(text, output); BEP Byte Pair Encoding,入口类:llm_tokenizer_bpe_session,其核心思路是 1) 用“pre-tokenizer regex”(不同模型 pre_type 不同)把文本切成词片段(word_collection)。 2) 每个词片段再按 UTF-8 拆成 symbols。 3) 用 vocab.find_bpe_rank(left,right) 查 merges rank(越小越优先),不断合并。 4) 合并结束后把每个最终 symbol 映射为 token(找不到就回退到逐字节 token)。 WPM WordPiece,入口类:llm_tokenizer_wpm_session,核心思路是: 先做 NFD 归一化 + 按 whitespace/标点切词(preprocess) 每个词前加 “▁” 对每个词做 最长匹配(从当前位置往后尽量取最长、且在 vocab 中存在的 token) 若某个词无法完全分解,回退整个词为unk UGM 入口类:llm_tokenizer_ugm_session,核心思路:典型 unigram LM 的 Viterbi 最优切分: 先 normalize 输入 每个位置沿 trie 找所有可能 token,做动态规划选择 “累计得分最大”的路径 走不通就用 unknown token + penalty 最后从末尾回溯得到 token 序列 初始化上下文 llama_context_params ctx_params = llama_context_default_params(); // n_ctx is the context size ctx_params.n_ctx = n_prompt + n_predict - 1; // n_batch is the maximum number of tokens that can be processed in a single call to llama_decode ctx_params.n_batch = n_prompt; // enable performance counters ctx_params.no_perf = false; llama_context * ctx = llama_init_from_model(model, ctx_params); if (ctx == NULL) { fprintf(stderr , "%s: error: failed to create the llama_context\n" , __func__); return 1; } 这段代码主要的作用是创建llama_context,用于管理推理的状态KV cache、batch 分配器、backend 调度器等)。 配置上下文参数、batch大小、性能统计。创建llama_context包括初始化计算后端,分配KV cache内存,创建batch分配器和调度器,预留计算图内存。llama_context是推理的核心对象,后续的llama_decode调用都会使用它来管理状态和执行计算。 初始化采样器 auto sparams = llama_sampler_chain_default_params(); sparams.no_perf = false; llama_sampler * smpl = llama_sampler_chain_init(sparams); llama_sampler_chain_add(smpl, llama_sampler_init_greedy()); 构造一个“采样器链”(sampler chain),并在其中添加一个贪心采样器(greedy sampler),后面主循环用它从 logits 里选下一个 token。下面按调用顺序拆开。采样器接收一个 llama_token_data_array(包含所有候选 token 的 id、logit、概率),经过处理(过滤、排序、选择等),最终确定一个 token。 处理提示词 // print the prompt token-by-token for (auto id : prompt_tokens) { char buf[128]; int n = llama_token_to_piece(vocab, id, buf, sizeof(buf), 0, true); if (n < 0) { fprintf(stderr, "%s: error: failed to convert token to piece\n", __func__); return 1; } std::string s(buf, n); printf("%s", s.c_str()); } // prepare a batch for the prompt llama_batch batch = llama_batch_get_one(prompt_tokens.data(), prompt_tokens.size()); if (llama_model_has_encoder(model)) { if (llama_encode(ctx, batch)) { fprintf(stderr, "%s : failed to eval\n", __func__); return 1; } llama_token decoder_start_token_id = llama_model_decoder_start_token(model); if (decoder_start_token_id == LLAMA_TOKEN_NULL) { decoder_start_token_id = llama_vocab_bos(vocab); } batch = llama_batch_get_one(&decoder_start_token_id, 1); } llama_token_to_piece是将token ID转换为文本并输出,llama_batch_get_one是为prompt创建batch结构。通过llama_model_has_encoder检查模型是不是编码-解码模型,如果是先进行prompt,在准备decoder的起始batch。 总结一下就是先调用llama_encode编码prompt的token,做完这一步,encoder部分就结束了,接着让decoder开始工作,我们知道大模型是一个自回归模型,需要有第一个token作为起点,类似机器翻译里的 BOS。 最后的llama_batch_get_one这里就是准备decoder起始batch。 llama_encode llama_decode 生成循环 for (int n_pos = 0; n_pos + batch.n_tokens < n_prompt + n_predict; ) { // evaluate the current batch with the transformer model if (llama_decode(ctx, batch)) { fprintf(stderr, "%s : failed to eval, return code %d\n", __func__, 1); return 1; } n_pos += batch.n_tokens; // sample the next token { new_token_id = llama_sampler_sample(smpl, ctx, -1); // is it an end of generation? if (llama_vocab_is_eog(vocab, new_token_id)) { break; } char buf[128]; int n = llama_token_to_piece(vocab, new_token_id, buf, sizeof(buf), 0, true); if (n < 0) { fprintf(stderr, "%s: error: failed to convert token to piece\n", __func__); return 1; } std::string s(buf, n); printf("%s", s.c_str()); fflush(stdout); // prepare the next batch with the sampled token batch = llama_batch_get_one(&new_token_id, 1); n_decode += 1; } } 这段代码是自回归文本生成的核心循环,实现decoder->sample->print的循环。llama_decode进行decoder,然后调用llamap_sampler_sample采样下一个token,获取对应的token ID,通过调用llama_vocab_is_eog来检查结束条件,判断采样到的token是否为结束token,是则退出循环。最后调用llama_token_to_piece将token ID转换为文本并打印。 核心的思想其实跟之前写的:从零实现 Transformer:中英文翻译实例文章是一样的。 -
GGML的CPU算子解读:矩阵乘法
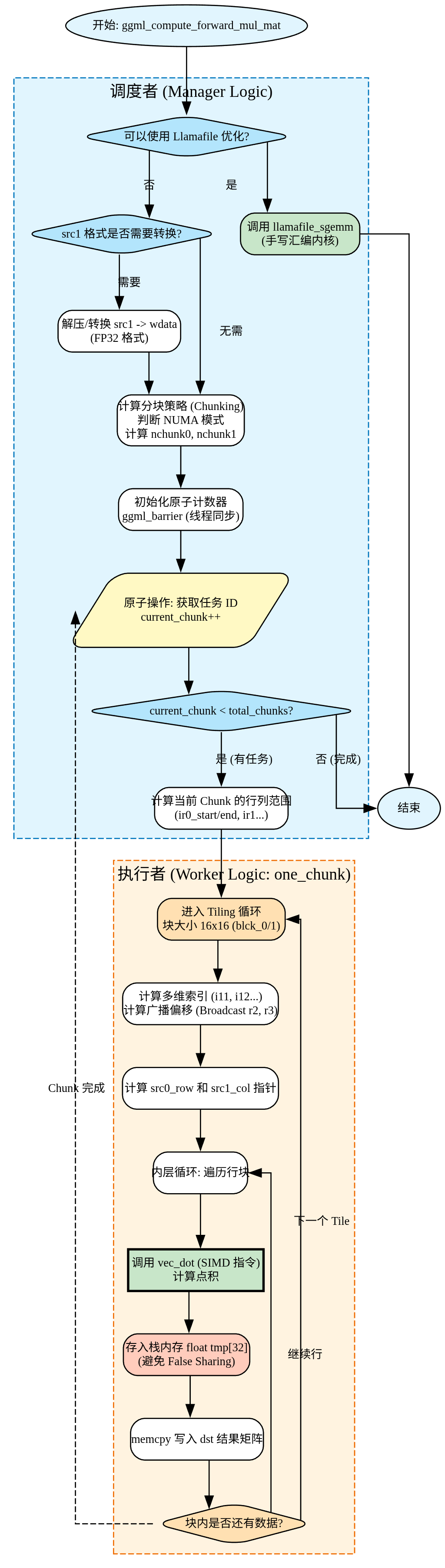
算子实现 调用流程 主要是ggml_compute_forward_mul_mat函数,该函数把任务拆分,最终计算执行调用ggml_compute_forward_mul_mat_one_chunk实现。 任务拆分 void ggml_compute_forward_mul_mat( const struct ggml_compute_params * params, struct ggml_tensor * dst) { // 1. 获取输入和输出张量的指针 const struct ggml_tensor * src0 = dst->src[0]; const struct ggml_tensor * src1 = dst->src[1]; // 2. 初始化一堆本地变量 (ne0, nb0 等),方便后面写公式 GGML_TENSOR_BINARY_OP_LOCALS // 3. 获取当前线程的信息 const int ith = params->ith; // 我是第几个线程? const int nth = params->nth; // 总共有几个线程? // 4. 获取src0(权重)的数据类型,用于后续查询src1(输入/激活值)必须转换为什么类型才能进行计算。 //在大语言模型中,为了省内存,src0(权重矩阵)通常是经过量化的比如Q4_0,Q5_1,Q8_0等格式。 enum ggml_type const vec_dot_type = type_traits_cpu[src0->type].vec_dot_type; // ... (省略一堆 GGML_ASSERT 检查,确保维度合法,比如 src0 和 src1 能不能相乘) ... #if GGML_USE_LLAMAFILE // 5. 【极速通道】如果系统支持 llamafile 的手写汇编优化,直接丢给它算,算完直接返回。 // 这比下面的 C 代码快得多。 if (src1_cont) { // ... 尝试调用 llamafile_sgemm ... if (!llamafile_sgemm(...)) goto UseGgmlGemm1; // 如果失败,就跳回下面的普通通道 return; } UseGgmlGemm1:; #endif // 6. 如果src1的类型与src0的类型不匹配,需要将src1转换成vec_dot_type类型。 if (src1->type != vec_dot_type) { char * wdata = params->wdata; // ... (循环遍历 src1,把数据解压并复制到 wdata) ... // 这里用了 from_float 函数进行转换 } // 7. 【同步】确保所有线程都知道数据准备好了 //只让线程0做一次初始化,把 current_chunk 设为 nth:因为每个线程先从 current_chunk = ith //开始领一个“私有起始 chunk”,所以下一个“公共可抢”的 chunk 从 nth 开始。 if (ith == 0) { atomic_store_explicit(¶ms->threadpool->current_chunk, nth, memory_order_relaxed); } ggml_barrier(params->threadpool); // barrier 等待:确保所有线程都完成了“src1 预处理/计数器初始化”,再进入真正的 chunk 计算阶段。 // ... (再次尝试 llamafile 优化,省略) ... // 8. 【切蛋糕】决定每个任务块 (chunk) 有多大 // nr0 是结果矩阵的行数,nr1 是其余维度的大小 const int64_t nr0 = ne0; //nr0 代表结果矩阵在“第一维”的长度(可以理解为输出的行数/一个主维度)。 const int64_t nr1 = ne1 * ne2 * ne3; //nr1 把其余维度展平成第二维(把 ne1*ne2*ne3 看成“列块/批次展平后的列方向”)。 int chunk_size = 16; // 默认每块按 16 规模做分块(和 one_chunk 内的 16×16 tiling 呼应)。 if (nr0 == 1 || nr1 == 1) { chunk_size = 64; } // 如果矩阵很细长,就切大一点 // 算出总共有多少块蛋糕 (nchunk0 * nchunk1) int64_t nchunk0 = (nr0 + chunk_size - 1) / chunk_size; int64_t nchunk1 = (nr1 + chunk_size - 1) / chunk_size; // 9. 【NUMA 优化】如果是多路 CPU 服务器,或者切得太碎了,就改用保守策略 if (nchunk0 * nchunk1 < nth * 4 || ggml_is_numa()) { nchunk0 = nr0 > nr1 ? nth : 1; nchunk1 = nr0 > nr1 ? 1 : nth; } // 计算每个块实际包含多少行/列 (dr0, dr1) //把 nr0/nr1 平均分给 nchunk0/nchunk1,得到每块在两维上的跨度 dr0/dr1。 const int64_t dr0 = (nr0 + nchunk0 - 1) / nchunk0; const int64_t dr1 = (nr1 + nchunk1 - 1) / nchunk1; // 10. 【开始干活】线程开始领任务 // 一开始,第 ith 个线程领第 ith 块蛋糕 //每个线程先从 current_chunk = ith 开始,保证一开始每个线程都有活(减少原子争用)。 int current_chunk = ith; while (current_chunk < nchunk0 * nchunk1) { // 算出当前蛋糕块在矩阵的哪个位置 (start 到 end) const int64_t ith0 = current_chunk % nchunk0; const int64_t ith1 = current_chunk / nchunk0; const int64_t ir0_start = dr0 * ith0; const int64_t ir0_end = MIN(ir0_start + dr0, nr0); // ... (同理算出 ir1 的范围) ... // 11. 【核心调用】把这一小块任务交给工人去算 // num_rows_per_vec_dot 是看 CPU 是否支持一次算两行 (MMLA 指令) ggml_compute_forward_mul_mat_one_chunk(..., ir0_start, ir0_end, ir1_start, ir1_end); // 如果线程数比蛋糕块还多,干完这一块就可以下班了 if (nth >= nchunk0 * nchunk1) { break; } // 12. 【抢任务】否则,去原子计数器里“取号”,领下一块没人干的蛋糕 current_chunk = atomic_fetch_add_explicit(¶ms->threadpool->current_chunk, 1, memory_order_relaxed); } } 计算执行 static void ggml_compute_forward_mul_mat_one_chunk( // ... 参数省略,主要是范围 ir0_start 等 ... ) { // 1. 获取数据指针 const struct ggml_tensor * src0 = dst->src[0]; const struct ggml_tensor * src1 = dst->src[1]; // ... 初始化本地变量 ... // 2. 准备点积函数 (vec_dot) // type_traits_cpu 是一张表,根据数据类型查到最优的计算函数 ggml_vec_dot_t const vec_dot = type_traits_cpu[type].vec_dot; // 3. 【广播因子】计算 src1 比 src0 大多少倍 // 比如 src1 有 2 个头,src0 只有 1 个头,那 r2 就是 2。计算时 src0 要重复用。 const int64_t r2 = ne12 / ne02; const int64_t r3 = ne13 / ne03; // 如果任务范围是空的,直接返回 if (ir0_start >= ir0_end || ir1_start >= ir1_end) { return; } // 4. 【Tiling 分块参数】 // 即使是这一小块任务,也要再切碎,为了放进 CPU 缓存 (L1 Cache) const int64_t blck_0 = 16; const int64_t blck_1 = 16; // 5. 定义临时缓冲区,防止多个线程写内存冲突 (False Sharing) float tmp[32]; // 6. 【双重 Tiling 循环】开始遍历任务块 // iir1 每次跳 16 行 for (int64_t iir1 = ir1_start; iir1 < ir1_end; iir1 += blck_1) { // iir0 每次跳 16 列 for (int64_t iir0 = ir0_start; iir0 < ir0_end; iir0 += blck_0) { // 7. 【处理块内的每一行】 for (int64_t ir1 = iir1; ir1 < iir1 + blck_1 && ir1 < ir1_end; ir1 += num_rows_per_vec_dot) { // 8. 【计算索引】这部分数学很绕,简单说就是: // 根据当前的行号 ir1,反推出它在 src1 的第几层、第几页 (i13, i12, i11) const int64_t i13 = (ir1 / (ne12 * ne1)); const int64_t i12 = (ir1 - i13 * ne12 * ne1) / ne1; const int64_t i11 = (ir1 - i13 * ne12 * ne1 - i12 * ne1); // 9. 【应用广播】算出对应的 src0 的位置 // 如果 src0 比较小,就除以倍率 r2, r3 来复用数据 const int64_t i03 = i13 / r3; const int64_t i02 = i12 / r2; // 拿到 src0 这一行的内存地址 const char * src0_row = (const char*)src0->data + (0 + i02 * nb02 + i03 * nb03); // 拿到 src1 这一列的内存地址 (wdata 是之前解压好的数据) const char * src1_col = (const char*)wdata + ...; // (省略复杂的偏移量计算) // 拿到 结果 dst 的写入地址 float * dst_col = (float*)((char*)dst->data + ...); // 10. 【核心计算循环】 // 遍历 src0 的行 (分块内),调用 SIMD 指令进行计算 for (int64_t ir0 = iir0; ir0 < iir0 + blck_0 && ir0 < ir0_end; ir0 += num_rows_per_vec_dot) { // vec_dot:一次性计算 ne00 个元素的点积 // 结果先存在 tmp 数组里,而不是直接写回 dst vec_dot(ne00, &tmp[ir0 - iir0], ..., src0_row + ir0 * nb01, ..., src1_col, ...); } // 11. 【写回结果】 // 把算好的 tmp 里的数据,一次性拷贝 (memcpy) 到最终的目标 dst_col for (int cn = 0; cn < num_rows_per_vec_dot; ++cn) { memcpy(&dst_col[iir0 + ...], tmp + ..., ...); } } } } } 以一个例子来总结一下。 void ggml_compute_forward_mul_mat( const struct ggml_compute_params * params, // 计算参数(包含线程信息) struct ggml_tensor * dst // 结果矩阵 C = A × B ) 功能是矩阵乘法:结果矩阵C=矩阵A x 矩阵B。其并行的策略如下: 切分对象: 结果矩阵C(不是A和B) 并行方式:2D切分+work_stealing(工作窃取) 写入方式:每个线程直接写入结果矩阵的不同位置。 矩阵A (m×k) × 矩阵B (k×n) = 结果矩阵C (m×n) ↑ ↑ ↑ 只读 只读 切分这个! 如上,矩阵A和B是只读的,所有线程都需要读取完整的A和B,结果矩阵C需要写入,每个线程写入不同的位置,切分C可以让多个线程并行计算不同的部分,互不干扰。 示例演示 输入数据 矩阵A (4行×3列): ┌─────────┐ │ 1 2 3 │ │ 4 5 6 │ │ 7 8 9 │ │ 10 11 12│ └─────────┘ 矩阵B (3行×4列): ┌─────────────┐ │ 1 2 3 4 │ │ 5 6 7 8 │ │ 9 10 11 12 │ └─────────────┘ 要计算:结果矩阵C = A × B (4行×4列) 分配结果矩阵 结果矩阵C(内存已分配,4×4 = 16个float): ┌─────────────────────┐ │ ? ? ? ? │ ← 行0 │ ? ? ? ? │ ← 行1 │ ? ? ? ? │ ← 行2 │ ? ? ? ? │ ← 行3 └─────────────────────┘ 列0 列1 列2 列3 计算切分参数 假设:2个线程,chunk_size = 2 nr0 = 4, nr1 = 4 nchunk0 = (4 + 2 - 1) / 2 = 3 nchunk1 = (4 + 2 - 1) / 2 = 3 总块数 = 3 × 3 = 9 检查:9 < 2 * 4 = 8? 不,9 >= 8 -> 不触发优化,保持3×3切分 dr0 = (4 + 3 - 1) / 3 = 2 // 每个块2行 dr1 = (4 + 3 - 1) / 3 = 2 // 每个块2列 切分结果矩阵 结果矩阵C (4×4) 被切分成9个块: ┌──────┬──────┬──────┐ │ 块0 │ 块1 │ 块2 │ ← 行块0(行0-1) │[0,0] │[0,1] │[0,2] │ │[1,0] │[1,1] │[1,2] │ ├──────┼──────┼──────┤ │ 块3 │ 块4 │ 块5 │ ← 行块1(行2-3) │[2,0] │[2,1] │[2,2] │ │[3,0] │[3,1] │[3,2] │ ├──────┼──────┼──────┤ │ 块6 │ 块7 │ 块8 │ ← 行块2(超出边界) │[0,3] │[1,3] │[2,3] │ │[1,3] │[2,3] │[3,3] │ └──────┴──────┴──────┘ 映射表 列0 列1 列2 列3 ┌────┬────┬────┬────┐ │块0 │块0 │块3 │块3 │ ← 行0 │ │ │ │ │ ├────┼────┼────┼────┤ │块0 │块0 │块3 │块3 │ ← 行1 │ │ │ │ │ ├────┼────┼────┼────┤ │块1 │块1 │块4 │块4 │ ← 行2 │ │ │ │ │ ├────┼────┼────┼────┤ │块1 │块1 │块4 │块4 │ ← 行3 └────┴────┴────┴────┘ 块0: ith0=0, ith1=0 → C[0:2, 0:2] → 左上角 2×2 块1: ith0=1, ith1=0 → C[2:4, 0:2] → 左下角 2×2 块3: ith0=0, ith1=1 → C[0:2, 2:4] → 右上角 2×2 块4: ith0=1, ith1=1 → C[2:4, 2:4] → 右下角 2×2 转换的过程 // 步骤1:块编号 → 块坐标 current_chunk = 3 ith0 = 3 % 3 = 0 // 块在第0行(行方向的第0个块) ith1 = 3 / 3 = 1 // 块在第1列(列方向的第1个块) // 步骤2:块坐标 → 实际位置 ir0_start = dr0 * ith0 = 2 * 0 = 0 // 从第0行开始 ir0_end = MIN(0 + 2, 4) = 2 // 到第2行结束(不包括2,实际是0-1行) ir1_start = dr1 * ith1 = 2 * 1 = 2 // 从第2列开始 ir1_end = MIN(2 + 2, 4) = 4 // 到第4列结束(不包括4,实际是2-3列) // 步骤3:实际位置 → 结果矩阵元素 块3 = C[0:2, 2:4] = { C[0][2], C[0][3], C[1][2], C[1][3] } 之所以要做一个映射,是因为work-stealing需要一维的变化,原子操作只能操作一个整数,线程并发是以块为最小运算单位。也是为了方便后面做负载均衡。 并行运算 (1)线程0的工作 current_chunk = 0 // 从块0开始 // 处理块0 ith0 = 0 % 3 = 0, ith1 = 0 / 3 = 0 ir0_start = 0, ir0_end = 2 // 行0-1 ir1_start = 0, ir1_end = 2 // 列0-1 计算: C[0][0] = A[0行] · B[第0列] = [1,2,3]·[1,5,9] = 38 C[0][1] = A[0行] · B[第1列] = [1,2,3]·[2,6,10] = 44 C[1][0] = A[1行] · B[第0列] = [4,5,6]·[1,5,9] = 83 C[1][1] = A[1行] · B[第1列] = [4,5,6]·[2,6,10] = 98 直接写入结果矩阵: dst->data[0*4 + 0] = 38 // C[0][0] dst->data[0*4 + 1] = 44 // C[0][1] dst->data[1*4 + 0] = 83 // C[1][0] dst->data[1*4 + 1] = 98 // C[1][1] // 完成后,抢下一个块 current_chunk = atomic_fetch_add(¤t_chunk, 1) = 2 // 处理块2(无效,会被跳过) ir0_start = 4, ir0_end = 4 // 空 → 跳过 // 继续抢下一个块 current_chunk = atomic_fetch_add(¤t_chunk, 1) = 3 // 处理块3 (2)线程1的工作 current_chunk = 1 // 从块1开始 // 处理块1 ith0 = 1 % 3 = 1, ith1 = 1 / 3 = 0 ir0_start = 2, ir0_end = 4 // 行2-3 ir1_start = 0, ir1_end = 2 // 列0-1 计算并写入 C[2:4, 0:2]... // 完成后,抢下一个块 current_chunk = atomic_fetch_add(¤t_chunk, 1) = 4 // 处理块4 (3)最终的结果 所有线程完成后,结果矩阵C: ┌─────────────────────┐ │ 38 44 50 56 │ ← 所有元素都已计算并写入 │ 83 98 113 128 │ │ 128 152 176 200 │ │ 173 206 239 272 │ └─────────────────────┘ -
GGML计算基础:矩阵的基本运算
矩阵相乘 是神经网络中算力消耗最大的部分,通常占据 LLM 推理计算量的 95% 以上。 矩阵乘法 (Matrix Multiplication / GEMM) 这是最通用的矩阵运算形式,也是 AI 芯片中 Tensor Core 或 MAC 阵列的主要工作内容。 定义: 设矩阵 $A$ 的形状为 $(M \times K)$,矩阵 $B$ 的形状为 $(K \times N)$,则它们的乘积 $C = A \times B$ 的形状为 $(M \times N)$。 计算公式: 目标矩阵中第 $i$ 行第 $j$ 列的元素,等于 $A$ 的第 $i$ 行与 $B$ 的第 $j$ 列的对应元素乘积之和: $$ C_{ij} = \sum_{k=1}^{K} A_{ik} \cdot B_{kj} $$ 工程视角: 维度约束:左矩阵的列数 ($K$) 必须等于右矩阵的行数 ($K$)。这个 $K$ 维度在运算中会被“消掉”(Reduction)。 LLM 应用:全连接层 (Linear Layers)、注意力机制中的 $Q/K/V$ 投影。 硬件特性:典型的计算密集型算子。优化的核心在于提高数据复用率(Data Reuse),减少从 HBM/DRAM 读取数据的次数。 向量点积 (Vector Dot Product) 在数学上,点积是矩阵乘法的一种特例;在物理意义上,它是衡量相似度的工具。 定义:两个同维度向量 $\vec{a}$ 和 $\vec{b}$ 的运算。 计算公式: $$ \vec{a} \cdot \vec{b} = \sum_{i=1}^{n} a_i b_i $$ 结果:结果是一个标量 (Scalar),即一个单纯的数值。 工程视角: 几何意义:反映两个向量方向的一致性。方向越接近,点积越大。 LLM 应用:Self-Attention 的核心逻辑。虽然代码实现通常是批量矩阵乘法 ($Q \times K^T$),但其数学本质是计算 Query 向量与 Key 向量的点积来获得注意力分数。 逐元素运算 (Element-wise Operations) 这类运算的特点是不改变矩阵形状,且计算之间互不依赖。它们通常对算力要求不高,但对显存带宽极其敏感。 逐元累积 (Hadamard Product) 常被称为 "Element-wise Product"。 定义: 两个形状完全相同的矩阵 $A$ 和 $B$ 进行运算。 计算公式: $$ (A \odot B){ij} = A{ij} \times B_{ij} $$ 工程视角: LLM 应用: 门控 (Gating):如 LLaMA 使用的 SwiGLU 激活函数,通过逐元素相乘来控制信息通过量。 掩码 (Masking):在 Attention 矩阵中,将不需要关注的位置乘以 0(或加负无穷)。 加法与减法 定义: 两个形状相同的矩阵对应位置相加或相减。 计算公式: $$(A \pm B){ij} = A{ij} \pm B_{ij}$$ 工程视角: LLM 应用: 残差连接 (Residual Connection):$X + \text{Layer}(X)$。这是深层网络能够训练的关键。 偏置 (Bias):$Y = XW + b$。 硬件特性:典型的 Memory Bound 操作。因为每个数据读进来只做一次简单的加法就写回去了,算术强度(Arithmetic Intensity)极低。 标量乘法 (Scalar Multiplication) 定义: 一个单独的数值 $\lambda$ 乘以矩阵中的每一个元素。 计算公式: $$ (\lambda A){ij} = \lambda \cdot A{ij} $$ 工程视角: LLM 应用: 缩放 (Scaling):Attention 中的 $\frac{QK^T}{\sqrt{d_k}}$,防止点积数值过大导致 Softmax 梯度消失。 归一化 (Normalization):LayerNorm 中的 $\gamma$ 参数本质上也是一种特定维度的缩放。 结构变换 (Structural Transformations) 这类操作通常不涉及数值的改变,而是改变数据的排列方式或索引方式。 转置 (Transpose) 定义: 将矩阵的行和列互换。 公式: $$(A^T){ij} = A{ji}$$ 工程视角: LLM 应用:多头注意力机制 (Multi-Head Attention) 中,为了并行计算多个头,需要频繁进行 (Batch, Seq, Head, Dim) 到(Batch, Head, Seq, Dim) 的维度置换(Permute,广义的转置)。 硬件挑战:转置意味着非连续的内存访问。在硬件设计中,通常需要专门的 Transpose Engine 或者利用 SRAM/寄存器文件进行巧妙的数据混洗,否则会严重导致 Cache Miss。 广播 (Broadcasting) 这是工程实现中极为重要的机制,允许不同形状的张量进行算术运算。 定义: 当两个矩阵形状不匹配时,自动将较小的矩阵在特定维度上进行逻辑上的复制,使其与大矩阵形状一致,再进行运算。 规则: 从最后面的维度开始对齐。 如果某个维度大小为 1,则可以扩展到任意大小。 工程视角: 例子:矩阵 $A(100 \times 256)$ 加上向量 $b(1 \times 256)$。系统会将 $b$ 在第 0 维复制 100 次。 硬件优势:优秀的 SDK 或 NPU 设计支持“隐式广播”,即不需要真的在内存中复制数据,只需利用 Stride(步长)为 0 的寻址方式重复读取同一个数据,从而节省大量的显存带宽。 -
GGML多线程计算:OpenMP简介
OpenMP是什么 OpenMP是一套用于共享内存并行系统的多线程程序设计标准。通俗的将,它允许通过简单的编译器指令(#pragma)将原本串行执行的C/C++ for循环瞬间变成多线程并发执行,而不需要手动的调用pthread_create的创建、销毁和同步。 核心模型:Fork-Join模型是理解OpenMP的关键。 Fork:主线程运行到并行区,Fork出一组线程。 Join:任务完成后,线程组同步并合并,只剩下主线程继续执行。 核心语法:从串行到并行 并行循环 这是最常用的指令。它告诉编译器:“把下面这个 for 循环的迭代次数拆分,分配给不同的线程同时跑”。 void add_arrays(float* a, float* b, float* c, int n) { for (int i = 0; i < n; i++) { c[i] = a[i] + b[i]; } } 要让他在多核CPU上并行,只需要加上一行: void add_arrays(float* a, float* b, float* c, int n) { // 自动将 n 次循环拆分给当前可用的线程 #pragma omp parallel for for (int i = 0; i < n; i++) { c[i] = a[i] + b[i]; // 每个线程处理一部分 i } } 数据作用域 写并发最怕数据竞争(Data Race)。OpenMP 必须明确变量是“大家共用”还是“每人一份”。 shared(x): 默认属性。所有线程读写同一个内存地址 x。比如输入的大矩阵。 private(i): 每个线程都有自己独立的变量 i 副本,互不干扰。比如循环计数器。 #pragma omp parallel for private(i, j) shared(A, B, C) for (int i = 0; i < rows; i++) { // ... } 规约 是计算“点积”(Dot Product)或“求和”时的神器。如果多个线程同时往同一个变量 sum 里加值,会冲突。 解决:使用 reduction(+:sum)。每个线程并在本地算自己的小 sum,最后 OpenMP 自动把所有线程的小 sum 加在一起。 float dot_product(float* a, float* b, int n) { float sum = 0.0; // 告诉编译器:sum 是归约变量,操作是加法 #pragma omp parallel for reduction(+:sum) for (int i = 0; i < n; i++) { sum += a[i] * b[i]; } return sum; } 循环是如何被切分的? 初学者最大的疑问通常是:多线程并发执行循环时,i 变量不会冲突吗?大家都执行 i++ 岂不是乱套了?答案是:不会。OpenMP 做的是“分地盘”,而不是“抢地盘”。 (1)空间划分 当编译器看到 #pragma omp parallel for 时,它并没有让多个线程去争夺同一个全局 i。相反,它把 0 到 n 这个迭代范围(Iteration Space)切成了若干块(Chunks),分给了不同的线程。 假设 n = 100,且有 4 个线程,默认调度下: 线程 0 负责 i 属于 [0, 24] 线程 1 负责 i 属于 [25, 49] 线程 2 负责 i 属于 [50, 74] 线程 3 负责 i 属于 [75, 99] (2)变量私有化 在生成的底层代码中,循环变量 i 被自动标记为线程私有(Private)。 线程 1 里的 i 实际上是一个局部变量,它从 25 开始,自己累加到 49。 它完全看不到线程 0 的 i 是多少。 结论:所谓的并发,是大家在各自划定的跑道上同时跑,互不干扰。 -
GGML 入门:搞懂张量、内存池与计算图
ggml是什么 ggml是用于transformer架构推理的机器学习库,类似于pytorch、TensorFlow等机器学习库。ggml不需要第三方库的依赖,目前兼容X86、ARM、Apple Silicon、CUDA等。 小demo开始 int main(void) { #define rows_A 4 #define cols_A 2 float matrix_A[rows_A * cols_A] = { 2, 8, 5, 1, 4, 2, 8, 6 }; #define rows_B 3 #define cols_B 2 float matrix_B[rows_B * cols_B] = { 10, 5, 9, 9, 5, 4 }; size_t ctx_size = 0; ctx_size += rows_A * cols_A * ggml_type_size(GGML_TYPE_F32); ctx_size += rows_B * cols_B * ggml_type_size(GGML_TYPE_F32); ctx_size += 2 * ggml_tensor_overhead(); ctx_size += ggml_graph_overhead(); ctx_size += 1024; struct ggml_init_params params = { .mem_size = ctx_size, .mem_buffer = NULL, .no_alloc = false, }; struct ggml_context * ctx = ggml_init(params); struct ggml_tensor * tensor_a = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_A, rows_A); struct ggml_tensor * tensor_b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_B, rows_B); memcpy(tensor_a->data, matrix_A, ggml_nbytes(tensor_a)); memcpy(tensor_b->data, matrix_B, ggml_nbytes(tensor_b)); struct ggml_cgraph * gf = ggml_new_graph(ctx); struct ggml_tensor *result = ggml_mul_mat(ctx, tensor_a, tensor_b); ggml_build_forward_expand(gf, result); int n_threads = 1; ggml_graph_compute_with_ctx(ctx, gf, n_threads); float *result_data = (float *)result->data; printf("mul mat (%d x %d) (transposed result):\n[", (int) result->ne[0], (int) result->ne[1]); for (int j = 0; j < result->ne[1]; j++) { if (j > 0) { printf("\n"); } for (int i = 0; i < result->ne[0]; i++) { printf(" %.2f", result_data[j * result->ne[0] + i]); } } printf(" ]\n"); ggml_free(ctx); return 0; } 下面以一个最小demo开始串起全流程,顺序是: 估算内存池需要的大小ctx_size。 ggml_init创建context内存池。 ggml_new_tensor_2d创建tensor,并把原始数组memcpy到tensor->data。 ggml_new_graph创建graph。 ggml_mul_mat创建一个“矩阵乘”节点(这里只是描述,还没算) ggml_build_forward_expand从result往回收集依赖,填充graph。 ggml_graph_compute_with_ctx执行graph,结果写到result->data。 关键数据结构 本章节中涉及到一些关键的数据结构,理解这些数据结构对于整个架构至关重要。主要的ggml_context、ggml_tensor、ggml_cgraph。 ggml_context:内存池管理器,用于存储张量、计算图等信息。 ggml_tensor:计算的元数据,但不仅仅是存储tensor,还存储的tensor操作。 ggml_cgraph:计算图的表示,用于传给后端的“计算执行顺序”。 内存池ggml_context struct ggml_context { size_t mem_size; void * mem_buffer; bool mem_buffer_owned; bool no_alloc; int n_objects; struct ggml_object * objects_begin; struct ggml_object * objects_end; }; ggml_context从命名看是上下文,从编码上来看是用于存储的全局信息,一个装载各类对象 (如张量、计算图、其他数据) 的“容器”。 内存池布局 ggml_context就是ggml的内存池管理器,它管理一块连续的大内存mem_buffer,并在其中按顺序分配"对象"(tensor、graph、work_buffer),最后用ggml_free(ctx)一次性释放。 mem_size:内存池的总大小。 mem_buffer:内存池的基址地址,一整块连续内存的起点。 mem_buffer_owned:这块mem_buffer由ggml拥有(负责释放)。 no_alloc:是否禁止ggml自动为tensor分配tensor->data。 n_objects:已经在ctx内存池里分配了多少个对象块(tensor/graph/work_buffer等)。 objects_begin/end:ctx内存池里对象链表的头/尾。 内存池中可以存储不同的对象,对象的类型主要分为3种。 GGML_OBJECT_TYPE_TENSOR:存储张量+计算的节点。 GGML_OBJECT_TYPE_GRAPH:一次执行要跑那些节点 GGML_OBJECT_TYPE_WORK_BUFFER:执行过程中临时scratch内存。 每一类的存储类型内存布局都是先以struct ggml_object开头,然后是对应的类型数据。而具体的类型数据前面又存储个其内存数据的描述结构。(这种类型结构很经典,跟蓝牙的广播AD type一样,也跟之前设计的眼镜方案消息传输方案一样)。 struct ggml_object { size_t offs; size_t size; struct ggml_object * next; enum ggml_object_type type; char padding[4]; }; ggml_object可以理解为header,其描述了存储数据的类型type,实际数据起始偏移(相对ctx->mem_buffer),实际的数据长度size,以及指向下一个类型的指针next。而padding是用于填充,保持对齐要求。 在ggml_object后面就是实际类型的数据,以tensor类型为例,同样开始存储的是struct ggml_tensor结构体,后面是实际的tensor数据以及padding,这里需要注意的是tensor的数据并不一定会存储在内存池中,主要根据struct ggml_context中的no_alloc来判断是否要为tensor分配空间,如果不需要那么这里只会存储的是描述tensor的数据结构即struct ggml_tensor+padding,在ggml_tensor中data指向的实际的tensor存储位置起始地址。 ctx->mem_buffer + (某个位置) ┌───────────────┬───────────────────┬──────────────────────┬──────┐ │ ggml_object头 │ ggml_tensor结构体 │ tensor data (bytes) │ PAD │ └───────────────┴───────────────────┴──────────────────────┴──────┘ ↑ tensor 指针(result) ↑ tensor->data 指针 内存池是先预分配,后续实际需要多少就从内存池中获取多少。这就LwIP网络协议栈中的实现原理是一样的,类似先分配一块内存池MEM_POOL,这样的话就不用反复的申请提高计算效率。 关键API 这里总结一下跟ggml_context相关的关键API。 创建: ggml_init(params),创建一份ggml_context。 释放:ggml_free。 查询: ggml_used_mem(ctx):当前已用到的内存池在哪里。 ggml_get_mem_size(ctx)/ggml_get_mem_buffer(ctx) ggml_get_no_alloc(ctx) / ggml_set_no_alloc(ctx) 下面我们重点分析一下ggml_init的实现。 分配内存池 ggml_init的实现其实非常简单,就是先使用malloc分配struct ggml_context数据结构,其次就是分配一块虚拟地址连续的mem_buffer。这里需要注意的是ggml_context和mem_buffer不要搞混了,ggml_context可不再内存池中,ggml_contexth是单独的一块数据结构用来管理内存池的,内存池的虚拟地址的连续的。 struct ggml_context * ggml_init(struct ggml_init_params params) { static bool is_first_call = true; ggml_critical_section_start(); if (is_first_call) { // initialize time system (required on Windows) ggml_time_init(); is_first_call = false; } ggml_critical_section_end(); struct ggml_context * ctx = GGML_MALLOC(sizeof(struct ggml_context)); // allow to call ggml_init with 0 size if (params.mem_size == 0) { params.mem_size = GGML_MEM_ALIGN; } const size_t mem_size = params.mem_buffer ? params.mem_size : GGML_PAD(params.mem_size, GGML_MEM_ALIGN); *ctx = (struct ggml_context) { /*.mem_size =*/ mem_size, /*.mem_buffer =*/ params.mem_buffer ? params.mem_buffer : ggml_aligned_malloc(mem_size), /*.mem_buffer_owned =*/ params.mem_buffer ? false : true, /*.no_alloc =*/ params.no_alloc, /*.n_objects =*/ 0, /*.objects_begin =*/ NULL, /*.objects_end =*/ NULL, }; GGML_ASSERT(ctx->mem_buffer != NULL); GGML_ASSERT_ALIGNED(ctx->mem_buffer); GGML_PRINT_DEBUG("%s: context initialized\n", __func__); return ctx; } 从上面的代码可以看出主要是调用GGML_MALLOC分配struct ggml_context本体,接着判断用户是否传入mem_buffer,如果没有传递同时mem_size有设置就会在内部分配一块。 张量ggml_tensor 数据结构 struct ggml_tensor { enum ggml_type type; struct ggml_backend_buffer * buffer; int64_t ne[GGML_MAX_DIMS]; // number of elements size_t nb[GGML_MAX_DIMS]; // stride in bytes: // nb[0] = ggml_type_size(type) // nb[1] = nb[0] * (ne[0] / ggml_blck_size(type)) + padding // nb[i] = nb[i-1] * ne[i-1] // compute data enum ggml_op op; // op params - allocated as int32_t for alignment int32_t op_params[GGML_MAX_OP_PARAMS / sizeof(int32_t)]; int32_t flags; struct ggml_tensor * src[GGML_MAX_SRC]; // source tensor and offset for views struct ggml_tensor * view_src; size_t view_offs; void * data; char name[GGML_MAX_NAME]; void * extra; // extra things e.g. for ggml-cuda.cu char padding[8]; }; 上面是ggml_tensor的结构体,ggml_tensor是ggml的核心对象,既是一个多维数组的描述符(type/shape/stride/data),也是计算图里的一个节点(op/src/params/flags)。 ggml_tensor代表了两种类型,理解这两类类型十分关键: 数据张量:张量持有实际的数据,包含一个多维数组的数组。 运算张量:这个张量表示的是有多个输入张量的运算结果,只有实际运算时才会有数据。 主要是通过数据结构中的op来判断,如果op为GGML_OP_NONE则表示的是张量数据,如果op为操作符如GGML_OP_MUL_MAT则表示张量不含数据,而是表示两个张量矩阵乘法的结果。 (1)作为数组的字段 type:元素的类型(F32/F16/量化类型),决定元素/块大小,行大小。 ne[]:每维有多少个元素,ggml默认最多4维。 nb[]:描述每个维度步长。 (2)作为计算节点的字段 op: 这个tensor通过那个算子得到。如果维GGML_OP_NONE表示不是算子输出而是输入张量。 src[]: 算子节点输入张量的指针数组,如对于mul_mat来说src[0]=a,src[1]=b。这决定后续计算graph的根本。 op_prarams:算子的额外参数。 (3)View/切片/共享数据 view_src+view_offs表示这个tensor是另一个tensor的视图(共享data,不重新分配),data通常等于view_src->data+view_offs。 (4)与后端/设备相关字段 buffer:指向ggml_backend_buffer(后端的内存抽象),CPU简单路径下很多时候是NULL或默认。 extra:给特定后端/实现放额外信息的扩展指针。 总结一下ggml_tensor承担的两件事情,一是存储张量/数组的描述,而是用于计算计算节点。 分配张量 分配张量就是调用ggml_new_tensor_xx,如下: struct ggml_tensor * ggml_new_tensor_1d:分配1维的张量。 struct ggml_tensor * ggml_new_tensor_2d: 分配2维的张量。 struct ggml_tensor * ggml_new_tensor_3d:分配3维的张量。 struct ggml_tensor * ggml_new_tensor_4d:分配4维的张量。 最终张量的分配都会调用ggml_new_tensor来实现。下面以ggml_new_tensor_2d为例。 ggml_new_tensor_2d最终会调用内部的ggml_new_tensor_impl来实现,主要的流程就是先试用ggml_new_object从内存池中分配一个头节点,然后在分配payload也就是再从内存池分配ensor的结构体,接着根据no_alloc来判断是否要为tensor的data从内存池分配空间,最后就是填充好ggml_object和ggml_tensor。 创建的tensor主要有两部分组成 tensor结构体本身:shape、stride、op、src等信息。 可选的数据区:紧跟在结构体后面((result + 1)),只有在 view_src NULL && ctx->no_alloc false 时才会在 ctx 内存池里实际分配。 这是ggml核心设计之一,ctx是一个arean/内存池,所有对象顺序追加,没有逐个free;ggml_free一次性释放整个池。 计算图ggml_cgraph 关键数据结构 struct ggml_cgraph { int size; // maximum number of nodes/leafs/grads/grad_accs int n_nodes; // number of nodes currently in use int n_leafs; // number of leafs currently in use struct ggml_tensor ** nodes; // tensors with data that can change if the graph is evaluated struct ggml_tensor ** grads; // the outputs of these tensors are the gradients of the nodes struct ggml_tensor ** grad_accs; // accumulators for node gradients struct ggml_tensor ** leafs; // tensors with constant data int32_t * use_counts;// number of uses of each tensor, indexed by hash table slot struct ggml_hash_set visited_hash_set; enum ggml_cgraph_eval_order order; }; nodes[]:真正要执行的算子节点(有op,或是参数param)。 leafs[]:常量/叶子(op=NONE且不是param),例如常量张量。 在ggml中理解叶子(leaf)和节点(node)十分关键。 这两个都是用struct ggml_tensor来表示的,leaf是没有算子的(op=NONE),leaf可以理解为是输入/常量,他不需要通过执行算子来产生数据,数据已经在tensor->data中了,通过前面的memcpy进来或者后端的buffer提供,也不会前向执行中被计算出来;而node是需要再图执行是被处理的,包括两类 真正的算子输出:它的值来之执行的op,由tensor->src[]通过tensor->op计算而来。 参数:这个 tensor 是训练里要被当作变量去优化更新的参数(比如权重参数),既是op=NONE,但是也会放进node。 针对我们的demo,tensor_a、tensor_b是由ggml_new_tensor_2d创建的默认op=NONE,也不是PARAM这个就是leaf。而result=ggml_mul_mat(ctx, tensor_a, tensor_b)会设置result->op=GGML_OP_MUL_MAT且src[0]=tensor_a,src[1]=tensor_b,这个就是node。 再总结一下leafs就是图的“外部给定值”(常量/输入),不由 op 产生;nodes是图的“计算产生值”(算子输出)+ “训练参数(PARAM)”。 分配计算图 分配计算图是在ctx的内存池里一次性分配并初始化一张计算图ggml_cgraph,同时把图需要的数组nodes/leafs/use_counts/hash_keys/(可选)grads/grad_accs/hash_used)都放在同一个对象内存块里,并把这些指针指向那块内存。 struct ggml_cgraph * ggml_new_graph_custom(struct ggml_context * ctx, size_t size, bool grads) { const size_t obj_size = ggml_graph_nbytes(size, grads); struct ggml_object * obj = ggml_new_object(ctx, GGML_OBJECT_TYPE_GRAPH, obj_size); struct ggml_cgraph * cgraph = (struct ggml_cgraph *) ((char *) ctx->mem_buffer + obj->offs); // the size of the hash table is doubled since it needs to hold both nodes and leafs size_t hash_size = ggml_hash_size(size * 2); void * p = cgraph + 1; struct ggml_tensor ** nodes_ptr = incr_ptr_aligned(&p, size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)); struct ggml_tensor ** leafs_ptr = incr_ptr_aligned(&p, size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)); int32_t * use_counts_ptr = incr_ptr_aligned(&p, hash_size * sizeof(int32_t), sizeof(int32_t)); struct ggml_tensor ** hash_keys_ptr = incr_ptr_aligned(&p, hash_size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)); struct ggml_tensor ** grads_ptr = grads ? incr_ptr_aligned(&p, hash_size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)) : NULL; struct ggml_tensor ** grad_accs_ptr = grads ? incr_ptr_aligned(&p, hash_size * sizeof(struct ggml_tensor *), sizeof(struct ggml_tensor *)) : NULL; ggml_bitset_t * hash_used = incr_ptr_aligned(&p, ggml_bitset_size(hash_size) * sizeof(ggml_bitset_t), sizeof(ggml_bitset_t)); // check that we allocated the correct amount of memory assert(obj_size == (size_t)((char *)p - (char *)cgraph)); *cgraph = (struct ggml_cgraph) { /*.size =*/ size, /*.n_nodes =*/ 0, /*.n_leafs =*/ 0, /*.nodes =*/ nodes_ptr, /*.grads =*/ grads_ptr, /*.grad_accs =*/ grad_accs_ptr, /*.leafs =*/ leafs_ptr, /*.use_counts =*/ use_counts_ptr, /*.hash_table =*/ { hash_size, hash_used, hash_keys_ptr }, /*.order =*/ GGML_CGRAPH_EVAL_ORDER_LEFT_TO_RIGHT, }; ggml_hash_set_reset(&cgraph->visited_hash_set); if (grads) { memset(cgraph->grads, 0, hash_size*sizeof(struct ggml_tensor *)); memset(cgraph->grad_accs, 0, hash_size*sizeof(struct ggml_tensor *)); } return cgraph; } 如果grads=false,表示是这是推理/前向图,内存布局如下: graph payload (obj->offs 指向起点) +------------------------------+ | struct ggml_cgraph | <- cgraph 指向这里 | - nodes -> nodes_ptr | | - leafs -> leafs_ptr | | - visited_hash_set.size | | - visited_hash_set.used -> hash_used | - visited_hash_set.keys -> hash_keys_ptr | - use_counts -> use_counts_ptr | - grads/grad_accs == NULL | +------------------------------+ | (对齐到 sizeof(ptr)) | +------------------------------+ | nodes_ptr[size] | array of struct ggml_tensor* +------------------------------+ | leafs_ptr[size] | array of struct ggml_tensor* +------------------------------+ | use_counts_ptr[hash_size] | array of int32_t (按 hash slot) +------------------------------+ | hash_keys_ptr[hash_size] | array of struct ggml_tensor* (hash keys) +------------------------------+ | hash_used bitset | ggml_bitset_t[bitset_size(hash_size)] +------------------------------+ | (尾部 padding 到 GGML_MEM_ALIGN) | +------------------------------+ 如果grads=true,对应的就是训练图/反向图,在hash_keys_ptr后面多两段。 ... hash_keys_ptr[hash_size] +------------------------------+ | grads_ptr[hash_size] | struct ggml_tensor* (每个被访问 tensor 的 grad 输出) +------------------------------+ | grad_accs_ptr[hash_size] | struct ggml_tensor* (grad accumulator) +------------------------------+ | hash_used bitset ... 我们重点看推理这部分,在graph payload中,前面部门存储的是ggml_cgraph结构体,后面紧跟的就是ggml_cgraph结构的内容。其中就最关键的是nodes[]和leafs[],前者存储是指向node类型tensor的指针,后者存储的指向leafs类型tensor的指针。 计算图构建 计算节点 在ggml中创建一个算子节点,就是调用类似ggml_mul_mat的函数。 struct ggml_tensor * ggml_mul_mat( struct ggml_context * ctx, struct ggml_tensor * a, struct ggml_tensor * b) { GGML_ASSERT(ggml_can_mul_mat(a, b)); GGML_ASSERT(!ggml_is_transposed(a)); const int64_t ne[4] = { a->ne[1], b->ne[1], b->ne[2], b->ne[3] }; struct ggml_tensor * result = ggml_new_tensor(ctx, GGML_TYPE_F32, 4, ne); result->op = GGML_OP_MUL_MAT; result->src[0] = a; result->src[1] = b; return result; } 上面的代码其实很简单,就是创建一个ggml_tensor,然后赋值op和要操作的src[0]和src[1],最后返回的也是ggml_tensor。 所以了ggml_mul_mat并不会立刻进行做矩阵乘法运算,它只是创建了一个"算子节点",把算子类型和输入依赖挂上去,等后面ggml_build_forward_expand+ggml_graph_compute_with_ctx才正在执行。 计算图 ggml_build_forward_expand是GGML计算图构建最关键的一部,核心任务是执行拓扑排序,从一个目标节点开始(通常是Loss或输出张量),递归的遍历所有依赖项(源张量src[0],src[1]),并将它们按照"先输入后输出"的顺序填入计算图的执行队列中nodes数组。 static size_t ggml_visit_parents(struct ggml_cgraph * cgraph, struct ggml_tensor * node) { // 1) 用 visited_hash_set 去重:同一个 tensor 只处理一次 size_t node_hash_pos = ggml_hash_find(&cgraph->visited_hash_set, node); if (!ggml_bitset_get(cgraph->visited_hash_set.used, node_hash_pos)) { cgraph->visited_hash_set.keys[node_hash_pos] = node; ggml_bitset_set(cgraph->visited_hash_set.used, node_hash_pos); cgraph->use_counts[node_hash_pos] = 0; } else { return node_hash_pos; } // 2) 递归访问 node->src[k],同时对每个 src 做 use_counts++ for (int i = 0; i < GGML_MAX_SRC; ++i) { struct ggml_tensor * src = node->src[k]; if (src) { size_t src_hash_pos = ggml_visit_parents(cgraph, src); cgraph->use_counts[src_hash_pos]++; } } // 3) 分类:leaf vs node(leaf 是 op==NONE 且不是 PARAM) if (node->op == GGML_OP_NONE && !(node->flags & GGML_TENSOR_FLAG_PARAM)) { cgraph->leafs[cgraph->n_leafs++] = node; } else { cgraph->nodes[cgraph->n_nodes++] = node; } return node_hash_pos; } 核心在这个ggml_visit_parents函数中,核心原理是从results开始往上遍历,把tensor为leafs类型的添加到leafs[]中,把tensor为node类型的添加到nodes[]中。 (1)去重 在ggml_visit_parents中会去重,同一个tensor可能会被多个算子引用,但是只希望他在图中出现一次,通过使用 visited_hash_set(key 是 tensor 指针地址)记录“见没见过”。见过就直接返回,不再 DFS,不再追加 nodes/leafs。 (2)递归遍历DFS 先递归访问 node->src[],再把 node 自己追加到 nodes/leafs。这天然形成一种顺序:后序遍历(post-order),直觉上就是:先把依赖(输入、上游算子)放进图,再放当前算子输出,这就是为什么 build 结束后,nodes[] 基本满足“依赖在前,使用在后”,便于执行。 (3)use_count使用次数统计 cgraph->use_counts[src_hash_pos]++ 表示:这个 src tensor 被作为某个 node 的输入用了一次。 它按 “hash slot” 存(不是按 nodes[] 下标),原因是:去重后每个 tensor 都能在 hash 表里找到一个稳定位置,方便后续用同一套索引关联其它数组(例如 grads/grad_accs 在训练图里也是按 hash slot 对齐)。 if (node->op == GGML_OP_NONE && !(node->flags & GGML_TENSOR_FLAG_PARAM)) { cgraph->leafs[cgraph->n_leafs] = node; cgraph->n_leafs++; } else { cgraph->nodes[cgraph->n_nodes] = node; cgraph->n_nodes++; } 从这个代码中也可以看到对于ggml_tensor,是怎么区分leaf和node的。 leaf:op为NONE 且不是 PARAM ->通常代表“常量/输入常量”(不需要通过执行算子得到) node:其它情况 ->需要在图执行时被处理的东西(算子输出 or 训练参数) 下面以简单的图来说明一下,我们的示例小demo的表达式如下: result (MUL_MAT) / \ tensor_a tensor_b (op NONE) (op NONE) 调用 ggml_build_forward_expand(gf, result) 的 DFS(后序)大致是: visit(result) visit(tensor_a) -> leafs += tensor_a visit(tensor_b) -> leafs += tensor_b nodes += result 得到的结构就是 cgraph->leafs: [ tensor_a, tensor_b ] 如果图更复杂,有共享子图(DAG),去重就很关键: z = add(x, x) // x 被用两次 / \ x x visit(z): visit(x): 第一次见到 -> leafs += x visit(x): 第二次见到 -> 直接 return(不重复加入) use_counts[x] 会被 ++ 两次 nodes += z 计算结果就是 leafs: [x] nodes: [z] use_counts[x] == 2 执行计算 ggml_graph_cmpute会先调用ggml_graph_plan算出需要多大的临时buffer,然后把这个work buffer直接从ctx的内存池分配出来,最后在启动图的计算。 图规划 ggml_graph_plan(cgraph, n_threads, NULL)的目标是决定实际用多少线程+估算整张图执行所需的最大临时内存work_size。plan会编译cgraph->nodes[],对每个node 计算 n_tasks = ggml_get_n_tasks(node, n_threads)(这个 op 适合拆多少任务) 估算该 op 需要的额外临时空间 cur 全图取 work_size = max(work_size, cur)(注意是 max,不是 sum,因为 work buffer 复用) for (int i = 0; i < cgraph->n_nodes; i++) { struct ggml_tensor * node = cgraph->nodes[i]; const int n_tasks = ggml_get_n_tasks(node, n_threads); max_tasks = MAX(max_tasks, n_tasks); size_t cur = 0; // ... switch(node->op) 估算 cur ... work_size = MAX(work_size, cur); } if (work_size > 0) { work_size += CACHE_LINE_SIZE*(n_threads); } cplan.threadpool = threadpool; cplan.n_threads = MIN(max_tasks, n_threads); cplan.work_size = work_size; cplan.work_data = NULL; return cplan; 很多 op 需要一块临时空间(例如把 src1 转换/pack 成适合 vec-dot 的布局),但这些临时空间可以在不同节点之间复用,所以用 “最大需求” 的单一 work buffer 就够。struct ggml_cplan 如下 struct ggml_cplan { size_t work_size; uint8_t * work_data; int n_threads; struct ggml_threadpool * threadpool; ggml_abort_callback abort_callback; void * abort_callback_data; }; work_size:执行改图所需的临时工作区大小。 work_data:指向调用方分配的临时工作区内存。 n_threads:希望永远执行图的线程数(影响并行度、某些kernel的分块方式等)。 threadpool:可选的线程池句柄。 分配work buffer 主要的目的就是在ctx的内存池里分配一块连续的内存作为work buffer,并把指针协会cplan.work_data。 cplan.work_data = (uint8_t *)ggml_new_buffer(ctx, cplan.work_size); return ggml_graph_compute(cgraph, &cplan); 为什么放 ctx 里,主要是避免每次 compute 时 malloc/free,并且生命周期跟 ctx 同步;缺点是 ctx 必须预留足够大(demo 里看到加了 ggml_graph_overhead() 和额外 1024,就是类似目的)。 执行 ggml_graph_compute就是执行了 (1)首先是先启动线程池 初始化计算后端如 cpu backend。 根据 cplan->threadpool 是否为空,创建一个临时 threadpool 或复用传入的 threadpool。 并行运行 ggml_graph_compute_thread enum ggml_status ggml_graph_compute(struct ggml_cgraph * cgraph, struct ggml_cplan * cplan) { ggml_cpu_init(); GGML_ASSERT(cplan); GGML_ASSERT(cplan->n_threads > 0); GGML_ASSERT(cplan->work_size == 0 || cplan->work_data != NULL); int n_threads = cplan->n_threads; struct ggml_threadpool * threadpool = cplan->threadpool; if (threadpool == NULL) { disposable_threadpool = true; // 创建 threadpool threadpool = ggml_threadpool_new_impl(&ttp, cgraph, cplan); } else { // 复用 threadpool:设置当前要跑的 cgraph/cplan 等 threadpool->cgraph = cgraph; threadpool->cplan = cplan; // ... } // 然后让各线程进入 ggml_graph_compute_thread(...) } 启动线程池后每个线程跑 ggml_graph_compute_thread,按 node 顺序执行 op,每个线程会构造一个ggml_compute_params,里面包含线程编号和线程数,全局work buffer,同步/屏障等信息。 struct ggml_compute_params { int ith, nth; size_t wsize; void * wdata; struct ggml_threadpool * threadpool; }; (2)线程执行的主流程 static thread_ret_t ggml_graph_compute_thread(void * data) { const struct ggml_cgraph * cgraph = tp->cgraph; const struct ggml_cplan * cplan = tp->cplan; struct ggml_compute_params params = { .ith = state->ith, .nth = ..., .wsize = cplan->work_size, .wdata = cplan->work_data, .threadpool= tp, }; for (int node_n = 0; node_n < cgraph->n_nodes && ...; node_n++) { struct ggml_tensor * node = cgraph->nodes[node_n]; if (ggml_op_is_empty(node->op)) { continue; } ggml_compute_forward(¶ms, node); if (node_n + 1 < cgraph->n_nodes) { ggml_barrier(state->threadpool); // 每个 node 结束后做一次全线程同步 } } ggml_barrier(state->threadpool); return 0; } 上面的ggml_graph_compute_thread是OpenMP模式。有有个多个线程同时执行ggml_graph_compute_thread。 #pragma omp parallel num_threads(n_threads) // 8 个线程 { int ith = omp_get_thread_num(); // 0, 1, 2, ..., 7 ggml_graph_compute_thread(&threadpool->workers[ith]); // 8 个线程都调用 } 执行模式是,节点内并行,节点间串行。 所有线程都执行相同的循环: for (int node_n = 0; node_n < cgraph->n_nodes; node_n++) { ggml_compute_forward(¶ms, node); // ← 这里并行! ggml_barrier(...); // ← 这里同步! } 每个线程遍历相同的节点序列,但是调用ggml_compute_forward内部不同线程处理不同的数据部分。但是需要注意的是并行的是在节点内部,不是节点之间。 计算图:节点0 → 节点1 → 节点2 线程执行流程: ┌─────────────────────────────────────────┐ │ 线程 0: for (node_n=0; node_n<3; node_n++) │ │ 线程 1: for (node_n=0; node_n<3; node_n++) │ │ 线程 2: for (node_n=0; node_n<3; node_n++) │ │ ... │ │ 线程 7: for (node_n=0; node_n<3; node_n++) │ └─────────────────────────────────────────┘ 所有线程都遍历所有节点,但在每个节点内部,它们处理不同的数据部分。节点内部的数据会切分,以矩阵加法为例。 // 节点 0: A + B → C (假设 C 是 1024x1024 的矩阵) // 线程 0: 计算 C[0:128, :] ← 只处理这部分 // 线程 1: 计算 C[128:256, :] ← 只处理这部分 // 线程 2: 计算 C[256:384, :] ← 只处理这部分 // ... // 线程 7: 计算 C[896:1024, :] ← 只处理这部分 // 所有线程同时计算,没有重复! ggml_compute_forward 里会根据 node->op 分发到具体 kernel。比如 MUL_MAT: case GGML_OP_MUL_MAT: { ggml_compute_forward_mul_mat(params, tensor); } break; (3)以一个例子来理解哪里串行,哪里并行 W (leaf) x (leaf) \ / \ / y = MUL_MAT b (leaf) | | +-----> y2 = ADD | v o = RELU 经过DFS后续遍历后,结果是: cgraph->nodes[0] = y (MUL_MAT) cgraph->nodes[1] = y2 (ADD) cgraph->nodes[2] = o (RELU) 因为各个node的计算是有前后依赖的,因此不行并行,也就是说node0 -> node1 -> node2 是串行推进,不能乱序并发(因为 node1 依赖 node0 输出,node2 依赖 node1 输出)。 for node_n in [0..n_nodes): 所有线程一起执行 nodes[node_n] barrier 等齐 而并行多线程计算你的是单个node的内部,每个node内部数据量很大,通常会拆快让多个线程并行计算。 时间 → thread0: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B| thread1: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B| thread2: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B| thread3: [ node0: MUL_MAT 计算一部分tile ] |B| [ node1: ADD 处理一部分元素 ] |B| [ node2: RELU 处理一部分元素 ] |B| 其中竖线|B|就是ggml_barrier,所有线程必须等到这一个node全部完成,才能进入到下一个node,而有4个线程同时干一个算子的事情。在一个node算子内,数据量通常是一个多维的矩阵,那么对数据可以做拆分tile分发到多个线程并发执行,这样就可以提高速度。