Ai应用
-

密码保护:端侧vscode AI开发环境搭建
此内容受密码保护。如需查看请在下方输入访问密码: 密码: -
llama.cpp部署大模型
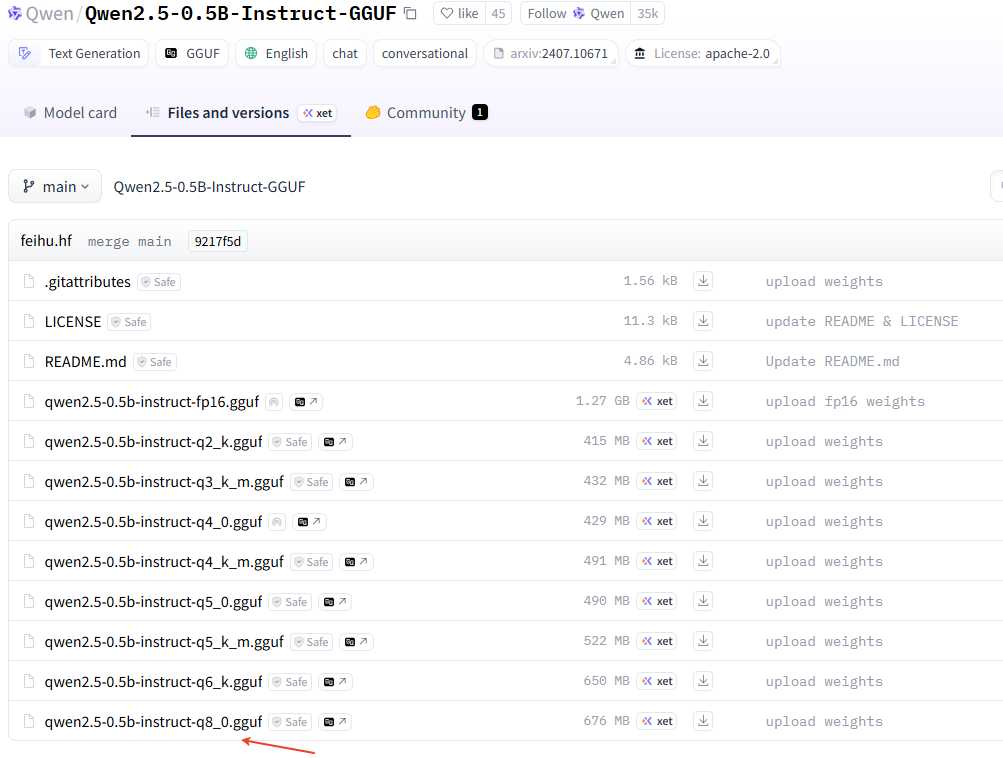
安装llama.cpp 从GitHub上下载官方的源码。 git clone https://github.com/ggml-org/llama.cpp.git cd llama.cpp 使用camke进行编译,先创建build环境 cmake -B build 发现有报错curl没有安装。 -- The C compiler identification is GNU 11.3.0 -- The CXX compiler identification is GNU 11.3.0 -- Detecting C compiler ABI info -- Detecting C compiler ABI info - done -- Check for working C compiler: /usr/bin/cc - skipped -- Detecting C compile features -- Detecting C compile features - done -- Detecting CXX compiler ABI info -- Detecting CXX compiler ABI info - done -- Check for working CXX compiler: /usr/bin/c++ - skipped -- Detecting CXX compile features -- Detecting CXX compile features - done -- Found Git: /usr/bin/git (found version "2.34.1") -- Looking for pthread.h -- Looking for pthread.h - found -- Performing Test CMAKE_HAVE_LIBC_PTHREAD -- Performing Test CMAKE_HAVE_LIBC_PTHREAD - Success -- Found Threads: TRUE -- Warning: ccache not found - consider installing it for faster compilation or disable this warning with GGML_CCACHE=OFF -- CMAKE_SYSTEM_PROCESSOR: x86_64 -- GGML_SYSTEM_ARCH: x86 -- Including CPU backend -- Found OpenMP_C: -fopenmp (found version "4.5") -- Found OpenMP_CXX: -fopenmp (found version "4.5") -- Found OpenMP: TRUE (found version "4.5") -- x86 detected -- Adding CPU backend variant ggml-cpu: -march=native -- Could NOT find CURL (missing: CURL_LIBRARY CURL_INCLUDE_DIR) CMake Error at common/CMakeLists.txt:85 (message): Could NOT find CURL. Hint: to disable this feature, set -DLLAMA_CURL=OFF 使用apt-get安装libcur14,如下。 sudo apt-get update sudo apt-get install libcurl4-openssl-dev 安装curl成功后,解决了,继续执行cmake -B build,会生成build目录。 cmake -B build -- Warning: ccache not found - consider installing it for faster compilation or disable this warning with GGML_CCACHE=OFF -- CMAKE_SYSTEM_PROCESSOR: x86_64 -- GGML_SYSTEM_ARCH: x86 -- Including CPU backend -- x86 detected -- Adding CPU backend variant ggml-cpu: -march=native -- Found CURL: /usr/lib/x86_64-linux-gnu/libcurl.so (found version "7.81.0") -- Configuring done -- Generating done -- Build files have been written to: /root/autodl-tmp/llama.cpp/build 接着llama.cpp的源码。 cmake --build build --config Release 编译完成之后,生成的二进制都在llama.cpp/build/bin目录下。 模型下载 使用wget下载模型。 wget https://huggingface.co/bartowski/Llama-3.2-3B-Instruct-GGUF/resolve/main/Llama-3.2-3B-Instruct-Q8_0.gguf llamap.cpp只能使用GGUF格式的大模型,使用的模型可以在Hugging Face获取https://huggingface.co/。也可以在modelscope上获取https://modelscope.cn/models。 这里有个技巧,可能仓库里面有很多量化参数的模型,如果使用git全部clone下来会比较久,这里可以只下载指定的GGUF模型,点击要使用的模型,如下: 然后,获取到下面的下载链接。 如果是modelsscope,找到下载,然后鼠标长按左键不松手拖到上面的输入网址框获取到下载链接。 这样就可以使用wget进行下载了。 wget https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct-GGUF/resolve/main/qwen2.5-0.5b-instruct-q8_0.gguf wget https://modelscope.cn/models/Qwen/Qwen2.5-3B-Instruct-GGUF/resolve/master/qwen2.5-3b-instruct-q8_0.gguf 模型测试 运行大模型 ./llama.cpp/build/bin/llama-cli -m model/Llama-3.2-3B-Instruct-Q8_0.gguf --perf --show-timings -lv 3 运行日志如下,可以看到使用的是CPU,没有使用GPU,因为前面编译的时候没有使能CUDA。 llama_perf_sampler_print: sampling time = 8.06 ms / 80 runs ( 0.10 ms per token, 9920.63 tokens per second) llama_perf_context_print: load time = 1070.39 ms llama_perf_context_print: prompt eval time = 859.42 ms / 15 tokens ( 57.29 ms per token, 17.45 tokens per second) llama_perf_context_print: eval time = 20880.31 ms / 65 runs ( 321.24 ms per token, 3.11 tokens per second) llama_perf_context_print: total time = 37979.41 ms / 80 tokens load time: 模型加载时间,耗时1070.39ms,属于一次性开销,与模型大小和硬件I/O性能相关。 prompt eaval time: 有些也称为prefill(TPS),表示提示词处理时间,处理15个输入Token耗时859.42ms,平均57.29ms/Token,速度17.45 Token/s。 eval time:有些也称为decode (TPS), 表示生成推理时间,生成65个Token耗时20880.31ms,平均321.24ms/Token,速度仅3.11 Token/s,显著低于采样阶段的9920.63 Token/s,说明生成阶段存在计算瓶颈。 sampling time: 采样80次仅8.06ms,速度高达9920.63 Token/s,表明采样算法本身效率极高,非性能瓶颈。 total time: 输入到输出的总耗时,包括模型加载时间、提示词处理时间、生成推理时间,其他时间(可能含内存交换或调度延迟) 可以使用vscode的打开多个终端,一个执行大模型交互,一个使用htop看看CPU和内存使用情况。 如果要配偶llama-server就执行下面的方式。 # 1. 启动服务器 ./build/bin/llama-server \ -m ../model/qwen2.5-0.5b-instruct-q8_0.gguf \ --port 8080 \ --host 0.0.0.0 # 2. 测试:在另一个终端测试 curl http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "qwen2.5", "messages": [{"role": "user", "content": "你好"}] }' 从上面看输入是17.45 token/s,输出是3.11 token/s,速度还是比较慢。 没有使用GPU,都是用cpu在推理。那么怎么使能使用gpu了?使用下面的方式,构建编译的时候打开CUDA,然后重新编译试一下。要用多线程编译,否则编译贼慢。 cd llama.cpp cmake -B build -DGGML_CUDA=ON cmake --build build --config Release -j16 重新运行模型后,看到硬件信息用了GPU了。 llama_perf_sampler_print: sampling time = 10.88 ms / 105 runs ( 0.10 ms per token, 9649.85 tokens per second) llama_perf_context_print: load time = 959.88 ms llama_perf_context_print: prompt eval time = 573.18 ms / 14 tokens ( 40.94 ms per token, 24.43 tokens per second) llama_perf_context_print: eval time = 17212.83 ms / 91 runs ( 189.15 ms per token, 5.29 tokens per second) llama_perf_context_print: total time = 34584.56 ms / 105 tokens 输出token有提升,但是看起来不明显,为啥了? -

密码保护:YOLOv5端侧部署代码分析
此内容受密码保护。如需查看请在下方输入访问密码: 密码: -

端侧部署YOLOv5模型
导出 ONNX模型 python export.py --weights runs/train/exp2/weights/ NPU不支持动态输入,使用onnxim工具进行转换为固定输入,先安装onnxsim工具。 pip install onnxsim -i https://pypi.doubanio.com/simple/ 接着进行转换 python -m onnxsim runs/train/exp2/weights/best.onnx yolov5s-sim.onnx --input-shape 1,3,640,640 模型裁剪 在实际端侧中,NPU端量化的后处理运算不适合使用uint8量化,一般使用float的混合量化,但这样相对麻烦,本文示例将后处理放在CPU测进行,所以我们需要把下图中的后处理部分裁剪掉。 import onnx onnx.utils.extract_model('./yolov5s-mask.onnx', './yolov5s-mask-rt.onnx', ['images'], ['/model.24/Reshape_output_0','/model.24/Reshape_8_output_0','/model.24/Reshape_16_output_0']) 使用上面的python可以进行裁剪,输入为[images],输出为3个节点,下面是最后一个节点的示例截图。实际要根据模型文件进行调整。 python extrat-mask.py 接着使用上面的命令,就输出了裁剪后的模型yolov5s-mask-rt.onnx。 如果原生的模型没有将后处理裁剪,输入输出如下: 输出的tensor[1,25200,85],其中25200=3x(20x20+40x40+80x80),即3个特征图一共25200个先验框。 原生模型使用裁剪后使用netron.app打开得到输入输出如下: YOLOv5模型参数含义详细解释如下: 模型名称: 表示模型或图结构的名称,此处为从主图结构中提取的名称。 输入参数:float32[1,3,640,640],表示输入张量的数据类型和维度。1表示一次处理的样本,3为通道数,输入的高宽均为640,此前YOLOv3是416。 输出参数:有3个输出张量。 -- /model.24/Reshape_output_0:表示8倍降采样率,输出为float32[1,3,85,80,80],网格划分为80x80,每个网格有3给先验框,每个先验框预测包含85个元素(坐标4、置信度1、类别80)。 -- /model.24/Reshape_8_output_0:float32[1,3,85,40,40],网格尺寸为40x40。 -- /model.24/Reshape_16_output_0:float32[1,3,85,20,20],网格尺寸为20x20。 模型参数数量:parameter参数为7225908,表示模型中参数的总数,这是模型复杂度和计算资源需求的重要指标。 再来看看此次针对口罩微调后裁剪后的模型输入输出,使用netron.app打开得到输入输出如下: 上图可以看到,网格划分、先验框数量是一样的,不一样的是预测的元素为8(坐标4,置信度1,类别3)。 创建端侧转换环境 sudo docker images sudo docker run --ipc=host -itd -v /home/xxx/ai/docker_data:/workspace --name laumy_npu_v1.8.x ubuntu-npu:v1.8.11 /bin/bash sudo docker ps -a sudo docker exec -it 55f9cd9eb15e /bin/bash 在进行端侧部署前,需要准备量化环境,这里直接使用的是docker环境。 模型转换 创建目录 |-- data | |-- maksssksksss0.png | |-- maksssksksss1.png | |-- maksssksksss10.png | |-- maksssksksss11.png | |-- maksssksksss12.png | |-- maksssksksss13.png | |-- maksssksksss14.png | |-- maksssksksss15.png | |-- maksssksksss16.png | |-- maksssksksss17.png | |-- maksssksksss18.png | |-- maksssksksss19.png | |-- maksssksksss2.png | |-- maksssksksss3.png | |-- maksssksksss4.png | |-- maksssksksss5.png | |-- maksssksksss6.png | |-- maksssksksss7.png | |-- maksssksksss8.png | `-- maksssksksss9.png |-- dataset.txt `-- yolov5s-mask-rt.onnx 准备数据量化的数据data、数据配置dataset.txt(内容如下)、裁剪的模型yolov5s-mask-rt.onnx。 ./data/maksssksksss0.png ./data/maksssksksss1.png ./data/maksssksksss2.png ./data/maksssksksss3.png ./data/maksssksksss4.png ./data/maksssksksss5.png ./data/maksssksksss6.png ./data/maksssksksss7.png ./data/maksssksksss8.png ./data/maksssksksss9.png ./data/maksssksksss10.png ./data/maksssksksss11.png ./data/maksssksksss12.png ./data/maksssksksss13.png ./data/maksssksksss14.png ./data/maksssksksss15.png ./data/maksssksksss16.png ./data/maksssksksss17.png ./data/maksssksksss18.png ./data/maksssksksss19.png 模型导入 pegasus import onnx --model yolov5s-mask-rt.onnx --output-data yolov5s-mask-rt.data --output-model yolov5s-mask-rt.json 模型导入将输出yolov5s-mask-rt.json和yolov5s-mask-rt.data文件。前者为后期量化需要的网络结构文件,后者为模型网络权重文件。 前后处理配置文件yml 生成前处理配置文件 pegasus generate inputmeta --model yolov5s-mask-rt.json --input-meta-output yolov5s-mask-rt_inputmeta.yml 生成后处理配置文件,因为后处理是在cpu上处理并且我们已经裁剪掉了onn模型的后处理,可以不生成。 pegasus generate postprocess-file --model yolov5s-mask-rt.json --postprocess-file-output yolov5s-mask-rt_postprocess_file.yml 上面根据模型网络结构文件yolov5s-mask-rt.json转化生成后续量化需要的前处理和后处理描述文件,格式为yml格式。 input_meta: databases: - path: dataset.txt #表示模型量化需要的数据描述文件 type: TEXT ports: - lid: images_205 #表示输入节点名称。 category: image dtype: float32 sparse: false tensor_name: layout: nchw #输入数据的排列格式,n表示batch,c表示channel,h表示高,w表示宽 shape: #模型输入的形状 - 1 #输入数据的batch,如果后面量化的batch参数不为1,需要改这里。 - 3 - 640 - 640 fitting: scale preprocess: reverse_channel: true mean: - 0 - 0 - 0 scale: #3通道的缩放值,yolov5s需要改为0.00392157 - 1.0 - 1.0 - 1.0 preproc_node_params: add_preproc_node: false #是否添加预处理节点,用于格式转化和裁剪,这里要改为true preproc_type: IMAGE_RGB #预处理输入的格式 preproc_image_size: - 640 - 640 preproc_crop: enable_preproc_crop: false crop_rect: - 0 - 0 - 640 - 640 preproc_perm: - 0 - 1 - 2 - 3 redirect_to_output: false 对于模型的输入yml,需要将scale修改为0.00392157,同时默认使用cpu预处理图像,所以add_preproc_node设置为true。 量化 pegasus quantize --model yolov5s-mask-rt.json --model-data yolov5s-mask-rt.data --device CPU --iterations=12 --with-input-meta yolov5s-mask-rt_inputmeta.yml --rebuild --model-quantize yolov5s-mask-rt.quantize --quantizer asymmetric_affine --qtype uint8 下面是量化模型的参数解析: model: 模型的网络结构文件 model-data:模型需要的权重文件 with-input-meta:模型需要前处理配置文件 model-quantize: 输出的模型文件 iterations: 模型量化使用的数据量,设置1(默认)使用dataset第一条数据。若设置20,会先遍历dataset.txt中的20行数据。 qtype:量化数据类型,有int8,uint8,int16等。 batch_size: 量化多少轮,如果不为1,需要改输入的yml文件shape,先用默认。 量化后,会生成量化文件yolov5s-mask-rt.quantize。 推理 pegasus inference --model yolov5s-mask-rt.json --model-data yolov5s-mask-rt.data --dtype quantized --model-quantize yolov5s-mask-rt.quantize --device CPU --with-input-meta yolov5s-mask-rt_inputmeta.yml --postprocess-file yolov5s-mask-rt_postprocess_file.yml 模型推理是为了验证量化后的模型效果,这步可省略。 导出模型 pegasus export ovxlib --model yolov5s-mask-rt.json --model-data yolov5s-mask-rt.data --dtype quantized --model-quantize yolov5s-mask-rt.quantize --save-fused-graph --target-ide-project 'linux64' --with-input-meta yolov5s-mask-rt_inputmeta.yml --output-path ovxilb/yolov5s-mask-rt/yolov5s-simprj --pack-nbg-unify --postprocess-file yolov5s-mask-rt_postprocess_file.yml --optimize "VIP9000PICO_PID0XEE" --viv-sdk ${VIV_SDK} 模型导出,最终会生成ovxilb/yolov5s-mask-rt_nbg_unify/network_binary.nb 端侧部署 修改端侧后处理的分类名和数量配置文件。 改完之后,执行./build_linux.sh -t \编译生成端侧的应用,将可执行应用推到设备端。 ./yolov5 -b network_binary.nb -i mask-test.jpeg model_file=network_binary.nb, input=mask-test.jpeg, loop_count=1, malloc_mbyte=10 input 0 dim 3 640 640 1, data_format=2, quant_format=0, name=input[0], none-quant output 0 dim 80 80 8 3, data_format=0, name=uid_20000_sub_uid_1_out_0, none-quant output 1 dim 40 40 8 3, data_format=0, name=uid_20001_sub_uid_1_out_0, none-quant output 2 dim 20 20 8 3, data_format=0, name=uid_20002_sub_uid_1_out_0, none-quant nbg name=network_binary.nb, size: 7196096. create network 0: 35626 us. prepare network: 38972 us. buffer ptr: 0xb6996000, buffer size: 1228800 feed input cost: 94526 us. network: 0, loop count: 1 run time for this network 0: 119081 us. detection num: 1 1: 94%, [ 316, 228, 541, 460], 1 draw objects time : 154 ms destory npu finished. ~NpuUint. 参考: https://v853.docs.aw-ol.com/en/npu/dev_npu/ https://blog.csdn.net/weixin_42904656/article/details/127768309 -

云服务器搭建YOLOv5训练环境
介绍 本文使用AutoDL云服务搭建YOLOv5的运行环境。 获取云服务器 在这个链接上https://www.autodl.com/home订阅服务,这里选择的是按量计费。 镜像选择基础镜像Mniconda最新ubuntu环境。 交钱订阅完成后就可以获取到登录的信息了。 这里使用的是ssh工具根据获取到的登录名和密码进行登录,需要注意的是端口可能不是默认的22,按照实际的端口进行。 配置conda环境 由于autoDL的服务器可能并不能访问外网,这里先将conda的源更换为清华的源。 conda config --remove-key channels conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ conda config --set show_channel_urls yes pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 接下来创建和激活虚拟环境 conda create -n yolov5 python==3.8.5 # 创建虚拟环境名称为yolov5, python版本为3.8.5 conda activate yolov5 # 激活yolov5环境 conda init # 如果提示没有初始化conda环境的话,执行conda init后退出控制台重新登录,再次激活。 conda env list # 通过上面的命令可以查看当前创建的conda虚拟环境 拉取YOLOv5代码环境 通过官网链接获取YOLOv5的代码。 cd autodl-tmp/ #这里先切换到audodl-tmp目录,这个空间比较大,读写也比较快。 git clone https://github.com/ultralytics/yolov5 # 在github上拉取代码 如果要在本地使用vscode查看代码的话,可以参考:https://www.autodl.com/docs/vscode/ 这里需要注意的是,audoDL可能没有访问GitHub,处理的办法就是参考这个方法在服务器上面做一个代理,https://github.com/VocabVictor/clash-for-AutoDL 或者https://gitee.com/laumy0929/clash-for-AutoDL 获取到CLASH_URL如下示例: 截屏2025-07-17 12.34.36 截屏2025-07-17 12.39.15 按照yolov5的代码环境需要的包 pip install -r requirements.txt 安装完成后,进行推理测试,看看环境是否安装正常,执行detect.py 指定模型文件和输入图片进行测试。 python detect.py --weights yolov5s.pt --source data/images/bus.jpg 执行上面脚本是,会自动拉取预训练的模型yolov5s.pt,最终将推理结果存储到runs/detect/exp2目录下。 训练自定义数据集 这里从GitHub上抓了一个口罩的书籍集,https://github.com/iAmEthanMai/mask-detection-dataset.git,使用git clone拉取到本地。 git clone https://github.com/iAmEthanMai/mask-detection-dataset.git 查看mask的数据集配置,有3个分类。这里使用yolov5s进行微调,复制一份yolov5的模型配置文件,并修改分类为3,需要根据实际的数据集存放的位置调整一下路径。 cp models/yolov5s.yaml models/mask_yolov5s.yaml 配置完成后就可以进行训练了。 python train.py --data mask-detection-dataset/data/data.yaml --cfg models/mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 4 模型文件将输出到:runs/train/exp5/weights/ python detect.py --weights runs/train/exp5/weights/best.pt --source mask-detection-dataset/data/images/maksssksksss1.png 上面执行命令使用训练的模型文件测试看看效果。 -

Windows Ai开发环境安装
annaconda可以理解为ai环境可以创建很多个房间,比如允许多个不同版本的python。每个房间可以保存不同的环境变量。 步骤1:下载安装包,安装anaconda,https://www.anaconda.com/ 步骤2:设置环境变量 设置环境变量需要根据软件实际的安装位置,这里的软件是安装的D盘的。在cmd命令中,执行conda info表示设置环境变量成功。 步骤3: 创建环境 打开Anaconda Prompt终端界面,创建开发环境前,先更新清华的源。 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/linux-64/ conda config --set show_channel_urls yes 然后进行安装: conda create -n py39_test python=3.9 -y 其中-n指定环境的名称, python=3.9表示安装python3.9的版本,-y表示同意所有安装过程中的所有确认。 步骤4: 激活环境 conda activate py39_test 步骤4:安装基础环境 pip install -r requirements.txt 使用pip install 进行安装,requirements.txt内容如下。 contourpy==1.3.0 cycler==0.12.1 filelock==3.16.1 fonttools==4.55.3 fsspec==2024.12.0 importlib_resources==6.5.2 Jinja2==3.1.5 kiwisolver==1.4.7 MarkupSafe==3.0.2 matplotlib==3.9.4 mpmath==1.3.0 networkx==3.2.1 numpy==2.0.2 packaging==24.2 pandas==2.2.3 pillow==11.1.0 pyparsing==3.2.1 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.17.0 sympy==1.13.1 torch==2.5.1 torchaudio==2.5.1 torchvision==0.20.1 typing_extensions==4.12.2 tzdata==2024.2 zipp==3.21.0 使用pip list可以查看安装的包。 步骤5:安装pycharm,下载链接 https://www.jetbrains.com/pycharm/download/?section=windows -

小智Ai语音交互简要分析
app start 主要是初始化板级、显示、WiFi连接、音频codec、编解码、协议、音效、唤醒几个环节。 auto& board = Board::GetInstance(); //获取板级实例 SetDeviceState(kDeviceStateStarting);//设置出事状态为kDeviceStateStarting /* Setup the display */ auto display = board.GetDisplay(); //获取显示实例 /* Setup the audio codec */ auto codec = board.GetAudioCodec();//获取codec实例 opus_decode_sample_rate_ = codec->output_sample_rate();//获取当前codec的采样率 opus_decoder_ = std::make_unique<OpusDecoderWrapper>(opus_decode_sample_rate_, 1);//初始化opus解码,设置解码采样率 opus_encoder_ = std::make_unique<OpusEncoderWrapper>(16000, 1, OPUS_FRAME_DURATION_MS);//初始化opus编码,设置采样率16Khz // For ML307 boards, we use complexity 5 to save bandwidth // For other boards, we use complexity 3 to save CPU //根据板级来设置opus编码的复杂度 if (board.GetBoardType() == "ml307") { ESP_LOGI(TAG, "ML307 board detected, setting opus encoder complexity to 5"); opus_encoder_->SetComplexity(5); } else { ESP_LOGI(TAG, "WiFi board detected, setting opus encoder complexity to 3"); opus_encoder_->SetComplexity(3); } //如果codec的采样率不是16Khz,需要进行重采样,下面是重采样初始化。 if (codec->input_sample_rate() != 16000) { input_resampler_.Configure(codec->input_sample_rate(), 16000); reference_resampler_.Configure(codec->input_sample_rate(), 16000); } //注册codec输入音频的回调,表示有录音的pcm,触发mainloop处理。 codec->OnInputReady([this, codec]() { BaseType_t higher_priority_task_woken = pdFALSE; xEventGroupSetBitsFromISR(event_group_, AUDIO_INPUT_READY_EVENT, &higher_priority_task_woken); return higher_priority_task_woken == pdTRUE; }); //注册codec输出音频的回调,表示有录音的pcm,触发mainloop处理。 codec->OnOutputReady([this]() { BaseType_t higher_priority_task_woken = pdFALSE; xEventGroupSetBitsFromISR(event_group_, AUDIO_OUTPUT_READY_EVENT, &higher_priority_task_woken); return higher_priority_task_woken == pdTRUE; }); //启动硬件codec,使能录音和播放。 codec->Start(); //开启一个mainloop线程,处理主要逻辑 /* Start the main loop */ xTaskCreate([](void* arg) { Application* app = (Application*)arg; app->MainLoop(); vTaskDelete(NULL); }, "main_loop", 4096 * 2, this, 4, nullptr); //等待WiFi连接好 /* Wait for the network to be ready */ board.StartNetwork(); // Initialize the protocol display->SetStatus(Lang::Strings::LOADING_PROTOCOL);//显示正在加载协议 根据使用MQTT还是Websocet来选择通信协议 #ifdef CONFIG_CONNECTION_TYPE_WEBSOCKET protocol_ = std::make_unique<WebsocketProtocol>(); #else protocol_ = std::make_unique<MqttProtocol>(); #endif //注册网络接收异常回调函数 protocol_->OnNetworkError([this](const std::string& message) { SetDeviceState(kDeviceStateIdle); Alert(Lang::Strings::ERROR, message.c_str(), "sad", Lang::Sounds::P3_EXCLAMATION); }); //注册接收音频的回调函数,接收到音频后,往加入解码队列 protocol_->OnIncomingAudio([this](std::vector<uint8_t>&& data) { std::lock_guard<std::mutex> lock(mutex_); if (device_state_ == kDeviceStateSpeaking) { audio_decode_queue_.emplace_back(std::move(data)); } }); //注册接收协议打开音频的回调,主要是下发解码的的属性信息,包括采样率等。 protocol_->OnAudioChannelOpened([this, codec, &board]() { board.SetPowerSaveMode(false); if (protocol_->server_sample_rate() != codec->output_sample_rate()) { ESP_LOGW(TAG, "Server sample rate %d does not match device output sample rate %d, resampling may cause distortion", protocol_->server_sample_rate(), codec->output_sample_rate()); } SetDecodeSampleRate(protocol_->server_sample_rate()); auto& thing_manager = iot::ThingManager::GetInstance(); protocol_->SendIotDescriptors(thing_manager.GetDescriptorsJson()); std::string states; if (thing_manager.GetStatesJson(states, false)) { protocol_->SendIotStates(states); } }); //注册音频的关闭回调 protocol_->OnAudioChannelClosed([this, &board]() { board.SetPowerSaveMode(true); Schedule([this]() { auto display = Board::GetInstance().GetDisplay(); display->SetChatMessage("system", ""); SetDeviceState(kDeviceStateIdle); }); }); //注册json解析回调,通知文本,状态等信息 protocol_->OnIncomingJson([this, display](const cJSON* root) { // Parse JSON data auto type = cJSON_GetObjectItem(root, "type"); //文字转语音的状态,包括start,stop,sentence_start/stop(句子开始结束), if (strcmp(type->valuestring, "tts") == 0) { auto state = cJSON_GetObjectItem(root, "state"); if (strcmp(state->valuestring, "start") == 0) { Schedule([this]() { aborted_ = false; if (device_state_ == kDeviceStateIdle || device_state_ == kDeviceStateListening) { SetDeviceState(kDeviceStateSpeaking); } }); } else if (strcmp(state->valuestring, "stop") == 0) { Schedule([this]() { if (device_state_ == kDeviceStateSpeaking) { background_task_->WaitForCompletion(); if (keep_listening_) { protocol_->SendStartListening(kListeningModeAutoStop); SetDeviceState(kDeviceStateListening); } else { SetDeviceState(kDeviceStateIdle); } } }); //句子开始 } else if (strcmp(state->valuestring, "sentence_start") == 0) { auto text = cJSON_GetObjectItem(root, "text"); if (text != NULL) { ESP_LOGI(TAG, "<< %s", text->valuestring); Schedule([this, display, message = std::string(text->valuestring)]() { display->SetChatMessage("assistant", message.c_str()); }); } } =//stt:语音转文字信息 } else if (strcmp(type->valuestring, "stt") == 0) { auto text = cJSON_GetObjectItem(root, "text"); if (text != NULL) { ESP_LOGI(TAG, ">> %s", text->valuestring); Schedule([this, display, message = std::string(text->valuestring)]() { display->SetChatMessage("user", message.c_str()); }); } } else if (strcmp(type->valuestring, "llm") == 0) { auto emotion = cJSON_GetObjectItem(root, "emotion"); if (emotion != NULL) { Schedule([this, display, emotion_str = std::string(emotion->valuestring)]() { display->SetEmotion(emotion_str.c_str()); }); } } else if (strcmp(type->valuestring, "iot") == 0) { auto commands = cJSON_GetObjectItem(root, "commands"); if (commands != NULL) { auto& thing_manager = iot::ThingManager::GetInstance(); for (int i = 0; i < cJSON_GetArraySize(commands); ++i) { auto command = cJSON_GetArrayItem(commands, i); thing_manager.Invoke(command); } } } }); //启动协议 protocol_->Start(); //检测OTA的版本,如果版本比较低则进行升级 // Check for new firmware version or get the MQTT broker address ota_.SetCheckVersionUrl(CONFIG_OTA_VERSION_URL); ota_.SetHeader("Device-Id", SystemInfo::GetMacAddress().c_str()); ota_.SetHeader("Client-Id", board.GetUuid()); ota_.SetHeader("Accept-Language", Lang::CODE); auto app_desc = esp_app_get_description(); ota_.SetHeader("User-Agent", std::string(BOARD_NAME "/") + app_desc->version); xTaskCreate([](void* arg) { Application* app = (Application*)arg; app->CheckNewVersion(); vTaskDelete(NULL); }, "check_new_version", 4096 * 2, this, 2, nullptr); #if CONFIG_USE_AUDIO_PROCESSOR //初始化音频处理,主要是降噪,回声消除,VAD检测等。 audio_processor_.Initialize(codec->input_channels(), codec->input_reference()); audio_processor_.OnOutput([this](std::vector<int16_t>&& data) { background_task_->Schedule([this, data = std::move(data)]() mutable { opus_encoder_->Encode(std::move(data), [this](std::vector<uint8_t>&& opus) { //如果启动了音效处理,注册ouput的输出回调。 Schedule([this, opus = std::move(opus)]() { protocol_->SendAudio(opus); }); }); }); }); //注册VAD状态变化 audio_processor_.OnVadStateChange([this](bool speaking) { if (device_state_ == kDeviceStateListening) { Schedule([this, speaking]() { if (speaking) { voice_detected_ = true; } else { voice_detected_ = false; } auto led = Board::GetInstance().GetLed(); led->OnStateChanged();//只点个灯?? }); } }); #endif #if CONFIG_USE_WAKE_WORD_DETECT //启动唤醒检测,初始化唤醒 wake_word_detect_.Initialize(codec->input_channels(), codec->input_reference()); //唤醒词处理回调函数,其中获取到的唤醒词是字符串,还包括获取处理唤醒词的音频编解码 //唤醒词音频部分是否仅仅是唤醒词部分,还包含其他内容数据?需要确认 wake_word_detect_.OnWakeWordDetected([this](const std::string& wake_word) { Schedule([this, &wake_word]() { //如果是idle状态,主要逻辑是,处理业务为连接网络,编码唤醒词,重开唤醒检测 //推送唤醒的音频数据和预料字符串到云端服务器。 if (device_state_ == kDeviceStateIdle) { SetDeviceState(kDeviceStateConnecting); //将唤醒音频内容进行编码 wake_word_detect_.EncodeWakeWordData(); if (!protocol_->OpenAudioChannel()) { //重新再次打开唤醒检测, wake_word_detect_.StartDetection(); return; } //哪些情况会停止唤醒检测:1 检测到唤醒词后会停止。2.处于listening的时候会停止。3.OTA升级过程会停止 std::vector<uint8_t> opus; //编码并将唤醒数据推送到服务器(除了唤醒词可能还包括说话数据?) // Encode and send the wake word data to the server while (wake_word_detect_.GetWakeWordOpus(opus)) { protocol_->SendAudio(opus); } //发送唤醒词的字符串 // Set the chat state to wake word detected protocol_->SendWakeWordDetected(wake_word); ESP_LOGI(TAG, "Wake word detected: %s", wake_word.c_str()); keep_listening_ = true; SetDeviceState(kDeviceStateIdle); } else if (device_state_ == kDeviceStateSpeaking) { //如果说话状态,则将说话进行停止,设置一个停止标志位,并发送停止speak给服务不要再发opus了? AbortSpeaking(kAbortReasonWakeWordDetected); } else if (device_state_ == kDeviceStateActivating) { SetDeviceState(kDeviceStateIdle); } }); }); //启动唤醒检测 wake_word_detect_.StartDetection(); #endif //设置状态为IDLE状态 SetDeviceState(kDeviceStateIdle); esp_timer_start_periodic(clock_timer_handle_, 1000000); mainloop void Application::MainLoop() { while (true) { auto bits = xEventGroupWaitBits(event_group_, SCHEDULE_EVENT | AUDIO_INPUT_READY_EVENT | AUDIO_OUTPUT_READY_EVENT, pdTRUE, pdFALSE, portMAX_DELAY); //处理录音音频处理,将收到的音频做处理送到队列 if (bits & AUDIO_INPUT_READY_EVENT) { InputAudio(); } //处理云端音频处理,将编码的音频进行解码送播放器 if (bits & AUDIO_OUTPUT_READY_EVENT) { OutputAudio(); } //处理其他任务的队列 if (bits & SCHEDULE_EVENT) { std::unique_lock<std::mutex> lock(mutex_); std::list<std::function<void()>> tasks = std::move(main_tasks_); lock.unlock(); for (auto& task : tasks) { task(); } } } } 录音通路 录音处理 // I2S收到音频,触发app应用注册的回调函数通知函数codec->OnInputReady,如下 //通知有数据了,实际读数据通过Read去读。 IRAM_ATTR bool AudioCodec::on_recv(i2s_chan_handle_t handle, i2s_event_data_t *event, void *user_ctx) { auto audio_codec = (AudioCodec*)user_ctx; if (audio_codec->input_enabled_ && audio_codec->on_input_ready_) { return audio_codec->on_input_ready_(); } return false; } //通过eventsetbit触发通知mainloop线程处理音频 codec->OnInputReady([this, codec]() { BaseType_t higher_priority_task_woken = pdFALSE; xEventGroupSetBitsFromISR(event_group_, AUDIO_INPUT_READY_EVENT, &higher_priority_task_woken); return higher_priority_task_woken == pdTRUE; }); //在mainloop中触发Application::InputAudio() void Application::InputAudio() { //获取codec的实例 auto codec = Board::GetInstance().GetAudioCodec(); std::vector<int16_t> data; //获取codec的音频pcm数据存到data中。 if (!codec->InputData(data)) { return;//如果数据为空,直接返回 } //如果采样率不是16Khz,需要进行重采样 if (codec->input_sample_rate() != 16000) { if (codec->input_channels() == 2) { auto mic_channel = std::vector<int16_t>(data.size() / 2); auto reference_channel = std::vector<int16_t>(data.size() / 2); for (size_t i = 0, j = 0; i < mic_channel.size(); ++i, j += 2) { mic_channel[i] = data[j]; reference_channel[i] = data[j + 1]; } auto resampled_mic = std::vector<int16_t>(input_resampler_.GetOutputSamples(mic_channel.size())); auto resampled_reference = std::vector<int16_t>(reference_resampler_.GetOutputSamples(reference_channel.size())); input_resampler_.Process(mic_channel.data(), mic_channel.size(), resampled_mic.data()); reference_resampler_.Process(reference_channel.data(), reference_channel.size(), resampled_reference.data()); data.resize(resampled_mic.size() + resampled_reference.size()); for (size_t i = 0, j = 0; i < resampled_mic.size(); ++i, j += 2) { data[j] = resampled_mic[i]; data[j + 1] = resampled_reference[i]; } } else { auto resampled = std::vector<int16_t>(input_resampler_.GetOutputSamples(data.size())); input_resampler_.Process(data.data(), data.size(), resampled.data()); data = std::move(resampled); } } //如果启动了唤醒检测,判断唤醒检测是否还在运行,如果还在运行将当前的数据合并到唤醒 //检测的buffer中。 #if CONFIG_USE_WAKE_WORD_DETECT if (wake_word_detect_.IsDetectionRunning()) { wake_word_detect_.Feed(data); //会将当前的数据喂给AFE接口,用于做唤醒词 //唤醒词也直接送到云端了??? } #endif //如果打开了音效处理,将音频数据push到音效处理中,直接返回 #if CONFIG_USE_AUDIO_PROCESSOR if (audio_processor_.IsRunning()) { audio_processor_.Input(data); } #else //如果没有打开音效处理,判断当前的状态是否是监听状态,如果是将音频进行编码 //然后推送到远端服务中。 if (device_state_ == kDeviceStateListening) { background_task_->Schedule([this, data = std::move(data)]() mutable { opus_encoder_->Encode(std::move(data), [this](std::vector<uint8_t>&& opus) { Schedule([this, opus = std::move(opus)]() { protocol_->SendAudio(opus); }); }); }); } #endif } 音效处理 以下是音效处理过程 //将数据喂给AFE模块,当处理完了之后会触发回调? void AudioProcessor::Input(const std::vector<int16_t>& data) { input_buffer_.insert(input_buffer_.end(), data.begin(), data.end()); auto feed_size = afe_iface_->get_feed_chunksize(afe_data_) * channels_; while (input_buffer_.size() >= feed_size) { auto chunk = input_buffer_.data(); afe_iface_->feed(afe_data_, chunk); input_buffer_.erase(input_buffer_.begin(), input_buffer_.begin() + feed_size); } } void AudioProcessor::AudioProcessorTask() { auto fetch_size = afe_iface_->get_fetch_chunksize(afe_data_); auto feed_size = afe_iface_->get_feed_chunksize(afe_data_); ESP_LOGI(TAG, "Audio communication task started, feed size: %d fetch size: %d", feed_size, fetch_size); while (true) { //获取到PROCESSOR_RUNNING后,不会清除bit(第三个参数),也就说会再次得到运行。 //也就是说AudioProcessor::Start()后,这个会循环运行,直到调用Stop清除。 xEventGroupWaitBits(event_group_, PROCESSOR_RUNNING, pdFALSE, pdTRUE, portMAX_DELAY); //等待获取处理后的数据。 auto res = afe_iface_->fetch_with_delay(afe_data_, portMAX_DELAY); if ((xEventGroupGetBits(event_group_) & PROCESSOR_RUNNING) == 0) { continue; } if (res == nullptr || res->ret_value == ESP_FAIL) { if (res != nullptr) { ESP_LOGI(TAG, "Error code: %d", res->ret_value); } continue; } // VAD state change if (vad_state_change_callback_) { if (res->vad_state == VAD_SPEECH && !is_speaking_) { is_speaking_ = true; vad_state_change_callback_(true); } else if (res->vad_state == VAD_SILENCE && is_speaking_) { is_speaking_ = false; vad_state_change_callback_(false); } } //获取到数据,将数据回调给app->audio_processor_.OnOutput if (output_callback_) { output_callback_(std::vector<int16_t>(res->data, res->data + res->data_size / sizeof(int16_t))); } } } //处理的音效数据的回调,将数据进行编码,然后推送到云端服务器。 audio_processor_.OnOutput([this](std::vector<int16_t>&& data) { background_task_->Schedule([this, data = std::move(data)]() mutable { opus_encoder_->Encode(std::move(data), [this](std::vector<uint8_t>&& opus) { Schedule([this, opus = std::move(opus)]() { protocol_->SendAudio(opus); }); }); }); }); 播放通路 //1. 通过解析输入的json来启动状态的切换。 protocol_->OnIncomingJson([this, display](const cJSON* root) { // Parse JSON data auto type = cJSON_GetObjectItem(root, "type"); if (strcmp(type->valuestring, "tts") == 0) { auto state = cJSON_GetObjectItem(root, "state"); //收到云端音频,云端会发送start,需要切换到speaking状态。 if (strcmp(state->valuestring, "start") == 0) { Schedule([this]() { aborted_ = false; if (device_state_ == kDeviceStateIdle || device_state_ == kDeviceStateListening) { SetDeviceState(kDeviceStateSpeaking); } }); //本次话题结束后,云端会发送stop,可切换到idle。 } else if (strcmp(state->valuestring, "stop") == 0) { Schedule([this]() { if (device_state_ == kDeviceStateSpeaking) { background_task_->WaitForCompletion(); if (keep_listening_) { protocol_->SendStartListening(kListeningModeAutoStop); SetDeviceState(kDeviceStateListening); } else { SetDeviceState(kDeviceStateIdle); } } }); } else if (strcmp(state->valuestring, "sentence_start") == 0) { auto text = cJSON_GetObjectItem(root, "text"); if (text != NULL) { ESP_LOGI(TAG, "<< %s", text->valuestring); Schedule([this, display, message = std::string(text->valuestring)]() { display->SetChatMessage("assistant", message.c_str()); }); } } //2.解析到云端的json后,会发生状态的迁移 void Application::SetDeviceState(DeviceState state) { if (device_state_ == state) { return; } clock_ticks_ = 0; auto previous_state = device_state_; device_state_ = state; ESP_LOGI(TAG, "STATE: %s", STATE_STRINGS[device_state_]); // The state is changed, wait for all background tasks to finish background_task_->WaitForCompletion(); //如果后台有线程还在运行,等待运行结束 auto& board = Board::GetInstance(); auto codec = board.GetAudioCodec(); auto display = board.GetDisplay(); auto led = board.GetLed(); led->OnStateChanged(); switch (state) { case kDeviceStateUnknown: case kDeviceStateIdle: //idle状态,显示"待命" display->SetStatus(Lang::Strings::STANDBY); display->SetEmotion("neutral"); #if CONFIG_USE_AUDIO_PROCESSOR //关掉音效处理 audio_processor_.Stop(); #endif #if CONFIG_USE_WAKE_WORD_DETECT //开启语音唤醒检测 wake_word_detect_.StartDetection(); #endif break; case kDeviceStateConnecting: //连接状态,表示连接服务器 display->SetStatus(Lang::Strings::CONNECTING); display->SetEmotion("neutral"); display->SetChatMessage("system", ""); break; case kDeviceStateListening: //说话状态,显示说话中 display->SetStatus(Lang::Strings::LISTENING); display->SetEmotion("neutral"); //复位解码器,清除掉原来的 ResetDecoder(); //复位编码器的状态 opus_encoder_->ResetState(); #if CONFIG_USE_AUDIO_PROCESSOR //启动音效处理(回声消除?) audio_processor_.Start(); #endif #if CONFIG_USE_WAKE_WORD_DETECT //关闭唤醒检测 wake_word_detect_.StopDetection(); #endif //更新IOT状态 UpdateIotStates(); if (previous_state == kDeviceStateSpeaking) { // FIXME: Wait for the speaker to empty the buffer vTaskDelay(pdMS_TO_TICKS(120)); } break; case kDeviceStateSpeaking: display->SetStatus(Lang::Strings::SPEAKING); //复位解码器 ResetDecoder(); //使能codec输出 codec->EnableOutput(true); #if CONFIG_USE_AUDIO_PROCESSOR //音效处理停止 audio_processor_.Stop(); #endif #if CONFIG_USE_WAKE_WORD_DETECT //开启唤醒检测 wake_word_detect_.StartDetection(); #endif break; default: // Do nothing break; } } //3. 接收云端音频数据的回调,如果是speak状态,将数据入队到队列 protocol_->OnIncomingAudio([this](std::vector<uint8_t>&& data) { std::lock_guard<std::mutex> lock(mutex_); if (device_state_ == kDeviceStateSpeaking) { audio_decode_queue_.emplace_back(std::move(data)); } }); //4.当音频输出准备好后,不会不断的调用这个回调??触发mainloop调用OutputAudio codec->OnOutputReady([this]() { BaseType_t higher_priority_task_woken = pdFALSE; xEventGroupSetBitsFromISR(event_group_, AUDIO_OUTPUT_READY_EVENT, &higher_priority_task_woken); return higher_priority_task_woken == pdTRUE; }); //5. output处理 void Application::OutputAudio() { auto now = std::chrono::steady_clock::now(); auto codec = Board::GetInstance().GetAudioCodec(); const int max_silence_seconds = 10; std::unique_lock<std::mutex> lock(mutex_); //判断解码队列是否为空,如果为空,把codec输出关了,也就是不要再触发回调 if (audio_decode_queue_.empty()) { // Disable the output if there is no audio data for a long time if (device_state_ == kDeviceStateIdle) { auto duration = std::chrono::duration_cast<std::chrono::seconds>(now - last_output_time_).count(); if (duration > max_silence_seconds) { codec->EnableOutput(false); } } return; } //如果是在监听状态,清除掉解码队列,直接返回 if (device_state_ == kDeviceStateListening) { audio_decode_queue_.clear(); return; } //获取编码的数据 last_output_time_ = now; auto opus = std::move(audio_decode_queue_.front()); audio_decode_queue_.pop_front(); lock.unlock(); //将解码数据添加到调度中进行解码播放 background_task_->Schedule([this, codec, opus = std::move(opus)]() mutable { //如果禁止标志位置起,直接退出。在打断唤醒的时候回置起 if (aborted_) { return; } std::vector<int16_t> pcm; //解码为pcm if (!opus_decoder_->Decode(std::move(opus), pcm)) { return; } //如果云端的采样率和codec采样率不一样,进行重采样。 // Resample if the sample rate is different if (opus_decode_sample_rate_ != codec->output_sample_rate()) { int target_size = output_resampler_.GetOutputSamples(pcm.size()); std::vector<int16_t> resampled(target_size); output_resampler_.Process(pcm.data(), pcm.size(), resampled.data()); pcm = std::move(resampled); } //播放音频 codec->OutputData(pcm); }); } -
2条命令本地部署deepseek
环境是centos,下面是部署步骤。 命令1: 安装ollama 安装命令:curl -fsSL https://ollama.com/install.sh | sh 安装日志: >>> Cleaning up old version at /usr/local/lib/ollama >>> Installing ollama to /usr/local >>> Downloading Linux amd64 bundle ######################################################################## 100.0% >>> Creating ollama user... >>> Adding ollama user to video group... >>> Adding current user to ollama group... >>> Creating ollama systemd service... >>> Enabling and starting ollama service... Created symlink from /etc/systemd/system/default.target.wants/ollama.service to /etc/systemd/system/ollama.service. >>> The Ollama API is now available at 127.0.0.1:11434. >>> Install complete. Run "ollama" from the command line. 命令2:下载deepseek模型 安装命令:ollama run deepseek-r1:7b 安装完成后,会直接进入交互控制台: pulling manifest pulling 96c415656d37... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.7 GB pulling 369ca498f347... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 387 B pulling 6e4c38e1172f... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.1 KB pulling f4d24e9138dd... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 148 B pulling 40fb844194b2... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 487 B verifying sha256 digest writing manifest success >>> hello <think> </think> Hello! How can I assist you today? 😊 >>> 你好 <think> </think> 你好!有什么我可以帮助你的吗?😊 >>> 你是什么模型 <think> </think> 您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。 运行时,如果加上--verbose可以查看运行性能参数,如下: total duration: 379.511567ms load duration: 14.749448ms prompt eval count: 60 token(s) prompt eval duration: 15.863495ms prompt eval rate: 3782.27 tokens/s eval count: 64 token(s) eval duration: 322.980292ms eval rate: 198.15 tokens/s total duration:总耗时379.51ms,表示从请求开始到响应完成的整体处理时间 load duration: 模型加载耗时14.75ms,可能涉及模型初始化或数据加载阶段的时间消耗 prompt eval count:输入提示词(prompt)解析的token数量为60个 prompt eval duration:提示词解析耗时15.86ms,反映模型对输入文本的预处理效率 prompt eval rate: 提示词解析速率3782.27 tokens/s,属于高性能表现(通常千级tokens/s为优秀) eval count: 生成输出的token数量为64个 eval duration: 生成耗时322.98ms,占整体耗时的主要部分。 eval rate: 生成速率198.15 tokens/s,属于典型的大模型推理速度(百级tokens/s为常见范围) GGUF导入部署 这种方式可以通过导入GUFF格式的大模型,GUFF格式大模型可以从Hugging Face获取https://huggingface.co/。也可以在modelscope上获取https://modelscope.cn/models。 首先从Hugging Face或者modelscope下载GGUF格式的模型,然后部署主要分为两个步骤 创建模型 通过create指定模型modelfile。 ollama create qwen2.5:7b -f qwen2.5-7b.modelfile modelfile内容如下,指定了模型的路径,模型配置文件描述了模型的参数,更多信息这里不做阐述。 FROM "./qwen2.5-7b-instruct-q4_0.gguf" 运行模型 列出模型 ollama list 运行模型 verbose参数可以打印性能。 ollama run qwen2.5:7b --verbose 也可以使用ollama pull从ollama官方下载,https://ollama.com/search 支持API访问 修改ollama的本地端口 /etc/systemd/system/ollama.service [Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/local/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin" Environment="OLLAMA_HOST=0.0.0.0" [Install] WantedBy=default.target 然后重新启动 systemctl daemon-reload systemctl restart ollama 确认是否启动成功: sudo netstat -tulpn | grep 11434 # 确认监听0.0.0.0:11434:cite[3]:cite[6] 远程API调用示例 # 查询API版本(验证连通性) curl http://<服务器公网IP>:11434/api/version # 发送生成请求 curl http://localhost:11434/api/generate -d "{\\\\\\\\\\\\\\\\"model\\\\\\\\\\\\\\\\": \\\\\\\\\\\\\\\\"deepseek-r1:7b\\\\\\\\\\\\\\\\", \\\\\\\\\\\\\\\\"prompt\\\\\\\\\\\\\\\\": \\\\\\\\\\\\\\\\"为什么草是绿的\\\\\\\\\\\\\\\\"}" 参考:https://github.com/datawhalechina/handy-ollama/blob/main/docs/C4/1.%20Ollama%20API%20%E4%BD%BF%E7%94%A8%E6%8C%87%E5%8D%97.md 支持web聊天 安装docker 如果要按照网页版的聊天需要安装open ui,先安装docker。 (1)更新系统 sudo yum update -y (2)Docker 需要一些依赖包,你可以通过运行以下命令来安装: sudo yum install -y yum-utils device-mapper-persistent-data lvm2 (3)更新本地镜像源 sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo sed -i 's/download.docker.com/mirrors.aliyun.com\\\\\\\\\\\\\\\\/docker-ce/g' /etc/yum.repos.d/docker-ce.repo yum makecache fast (4)安装docker sudo yum install -y docker-ce (5)设置开机自启动 sudo systemctl start docker sudo systemctl enable docker (6)验证 sudo docker --version systemctl status docker docker安装open webui 拉取并运行 Open WebUI 容器,将容器端口 8080 映射到主机 3000 端口 docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main 如果3000端口被占用了,会报错,重新启动也会提示错误如下。 报错解决: docker run -d -p 6664:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main docker: Error response from daemon: Conflict. The container name "/open-webui" is already in use by container "88f6e12e8e3814038911c30d788cb222d0792a9fc0af45f41140e07186e62a16". You have to remove (or rename) that container to be able to reuse that name. 你遇到的问题是 Docker 容器名称冲突。错误消息表明,容器名称 /open-webui 已经被另一个正在运行的容器占用,因此你无法启动新的容器。 (1)查看当前运行的容器: docker ps -a 88f6e12e8e38 ghcr.io/open-webui/open-webui:main "bash start.sh" 3 minutes ago Created open-webui (2)停止并删除已有的容器 docker stop open-webui docker rm open-webui 登录网址https://xxx:6664 配置即可访问。 -

豆包大模型接入体验
前置条件 需要先创建获得API key和创建推理接入点。 API key获取 https://www.volcengine.com/docs/82379/1361424#f79da451 创建推理接入点 https://www.volcengine.com/docs/82379/1099522 安装python环境 python版本需要安装到Python 2.7或以上版本。执行python --version可以检查当前Python的版本信息。我这里的版本已经到3.8.10 python3 --version Python 3.8.10 接着安装豆包sdk pip install volcengine-python-sdk Collecting volcengine-python-sdk Downloading volcengine-python-sdk-1.0.118.tar.gz (3.1 MB) |████████████████████████████████| 3.1 MB 9.7 kB/s Requirement already satisfied: certifi>=2017.4.17 in /usr/lib/python3/dist-packages (from volcengine-python-sdk) (2019.11.28) Requirement already satisfied: python-dateutil>=2.1 in /usr/lib/python3/dist-packages (from volcengine-python-sdk) (2.7.3) Requirement already satisfied: six>=1.10 in /usr/lib/python3/dist-packages (from volcengine-python-sdk) (1.14.0) Requirement already satisfied: urllib3>=1.23 in /usr/lib/python3/dist-packages (from volcengine-python-sdk) (1.25.8) Building wheels for collected packages: volcengine-python-sdk Building wheel for volcengine-python-sdk (setup.py) ... done Created wheel for volcengine-python-sdk: filename=volcengine_python_sdk-1.0.118-py3-none-any.whl size=10397043 sha256=c4546246eb0ef4e1c68e8047c6f2773d601821bd1acb7bc3a6162919f161423b Stored in directory: /home/apple/.cache/pip/wheels/d2/dc/23/70fa1060e1a527a290fc87a35469401b7588cdb51a2b75797d Successfully built volcengine-python-sdk Installing collected packages: volcengine-python-sdk Successfully installed volcengine-python-sdk-1.0.118 需要更新 pip install --upgrade 'volcengine-python-sdk[ark]' Requirement already up-to-date: volcengine-python-sdk[ark] in /home/apple/.local/lib/python3.8/site-packages (1.0.118) Requirement already satisfied, skipping upgrade: urllib3>=1.23 in /usr/lib/python3/dist-packages (from volcengine-python-sdk[ark]) (1.25.8) Requirement already satisfied, skipping upgrade: six>=1.10 in /usr/lib/python3/dist-packages (from volcengine-python-sdk[ark]) (1.14.0) Requirement already satisfied, skipping upgrade: python-dateutil>=2.1 in /usr/lib/python3/dist-packages (from volcengine-python-sdk[ark]) (2.7.3) Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/lib/python3/dist-packages (from volcengine-python-sdk[ark]) (2019.11.28) Collecting cryptography<43.0.4,>=43.0.3; extra == "ark" Downloading cryptography-43.0.3-cp37-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (4.0 MB) |████████████████████████████████| 4.0 MB 1.7 MB/s Collecting httpx<1,>=0.23.0; extra == "ark" Downloading httpx-0.28.1-py3-none-any.whl (73 kB) |████████████████████████████████| 73 kB 1.0 MB/s Collecting pydantic<3,>=1.9.0; extra == "ark" Downloading pydantic-2.10.4-py3-none-any.whl (431 kB) |████████████████████████████████| 431 kB 1.6 MB/s Collecting anyio<5,>=3.5.0; extra == "ark" Downloading anyio-4.5.2-py3-none-any.whl (89 kB) |████████████████████████████████| 89 kB 1.8 MB/s Collecting cffi>=1.12; platform_python_implementation != "PyPy" Downloading cffi-1.17.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (446 kB) |████████████████████████████████| 446 kB 1.2 MB/s Collecting httpcore==1.* Downloading httpcore-1.0.7-py3-none-any.whl (78 kB) |████████████████████████████████| 78 kB 1.8 MB/s Requirement already satisfied, skipping upgrade: idna in /usr/lib/python3/dist-packages (from httpx<1,>=0.23.0; extra == "ark"->volcengine-python-sdk[ark]) (2.8) Collecting pydantic-core==2.27.2 Downloading pydantic_core-2.27.2-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (2.0 MB) |████████████████████████████████| 2.0 MB 1.0 MB/s Collecting typing-extensions>=4.12.2 Downloading typing_extensions-4.12.2-py3-none-any.whl (37 kB) Collecting annotated-types>=0.6.0 Downloading annotated_types-0.7.0-py3-none-any.whl (13 kB) Collecting exceptiongroup>=1.0.2; python_version < "3.11" Downloading exceptiongroup-1.2.2-py3-none-any.whl (16 kB) Collecting sniffio>=1.1 Downloading sniffio-1.3.1-py3-none-any.whl (10 kB) Collecting pycparser Downloading pycparser-2.22-py3-none-any.whl (117 kB) |████████████████████████████████| 117 kB 2.9 MB/s Collecting h11<0.15,>=0.13 Downloading h11-0.14.0-py3-none-any.whl (58 kB) |████████████████████████████████| 58 kB 3.3 MB/s Installing collected packages: pycparser, cffi, cryptography, h11, httpcore, exceptiongroup, typing-extensions, sniffio, anyio, httpx, pydantic-core, annotated-types, pydantic WARNING: The script httpx is installed in '/home/apple/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. Successfully installed annotated-types-0.7.0 anyio-4.5.2 cffi-1.17.1 cryptography-43.0.3 exceptiongroup-1.2.2 h11-0.14.0 httpcore-1.0.7 httpx-0.28.1 pycparser-2.22 pydantic-2.10.4 pydantic-core-2.27.2 sniffio-1.3.1 typing-extensions-4.12.2 测试 单张图片测试 vim test.py import os # 通过 pip install volcengine-python-sdk[ark] 安装方舟SDK from volcenginesdkarkruntime import Ark # 替换为您的模型推理接入点 model="ep-20250101121404-stw4s" # 初始化Ark客户端,从环境变量中读取您的API Key client = Ark( api_key=os.getenv('ARK_API_KEY'), ) # 创建一个对话请求 response = client.chat.completions.create( # 指定您部署了视觉理解大模型的推理接入点ID model = model, messages = [ { "role": "user", # 指定消息的角色为用户 "content": [ # 消息内容列表 {"type": "text", "text":"这张图片讲了什么?"}, # 文本消息 { "type": "image_url", # 图片消息 # 图片的URL,需要大模型进行理解的图片链接 "image_url": {"url": "http://www.laumy.tech/wp-content/uploads/2024/12/wp_editor_md_7a3e5882d13fb51eecfaaf7fc8c53b59.jpg"} }, ], } ], ) print(response.choices[0]) 执行返回结果 python3 test.py Choice( finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage( content='这张图片展示了一个WebRTC(Web实时通信)的流程示意图,涉及到PC(个人计算机)、MQTT代理(mqtt broker)和CEMARA设备。以下是流程图的主要步骤: \n\n1. **PC端操作**: \n - **连接和订阅**:PC端首先进行连接(connect),然后订阅相关主题("webrtc/id/jsonrpc"和"webrtc/id/jsonrpc-replay")。 \n - **发布消息**:PC端发布消息(pub),发送"offer"请求(offer (req))。 \n - **接收消息**:PC端接收来自MQTT代理的消息,包括"message"事件和相关的应答(res)。 \n - **创建应答**:PC端创建应答(pc.createAnswer),并设置远程描述(pc.setRemoteDescription)。 \n\n2. **STUN/TURN服务器交互**: \n - **STUN/TURN绑定请求和应答**:在STUN/TURN服务器上,PC端发起绑定请求(binding req)和应答(binding res),获取SDP(Session Description Protocol)信息。 \n - **ANSWER请求和应答**:PC端发送ANSWER请求(anser (req)),并接收ANSWER应答(anser (res))。 \n\n3. **检查和连接过程**: \n - **检查连接**:PC端按照优先级顺序检查连接的顺畅性(host、srflx、relay)。 \n - **连接完成**:经过一系列的检查和交互,PC端与CEMARA设备成功连接(CONNECTED)。\n\n4. **数据交互和完成**: \n - **数据交互**:PC端和CEMARA设备开始进行数据交互(agent_send和agent_recv)。 \n - **完成状态**:数据交互完成后,流程进入“COMPLETED”状态,表示整个WebRTC通信过程结束。 \n\n整个流程图清晰地展示了WebRTC通信过程中PC端与MQTT代理以及STUN/TURN服务器之间的交互过程,包括连接、消息发布、应答接收、绑定请求、检查连接等步骤,最终实现了PC端与CEMARA设备的数据通信。', role='assistant', function_call=None, tool_calls=None, audio=None ) )