lerobot
-

lekiwi录制训练推理流程实践
录制 设备端 先确定一下相机编号 cd ~/lerobot/ lerobot-find-cameras 生成路径:outputs/captured_images 然后修改uart的权限 sudo chmod 666 /dev/ttyACM0 启动等待连接 python -m lerobot.robots.lekiwi.lekiwi_host \ --robot.id=R1225280 \ --robot.cameras='{ "front": {"type":"opencv","index_or_path":"/dev/video2","width":640,"height":480,"fps":30}, "wrist": {"type":"opencv","index_or_path":"/dev/video0","width":480,"height":640,"fps":30,"rotation":"ROTATE_90"} }' \ --host.connection_time_s=300 如果分辨率跑不上去,就让相机用motion-JPEG传输帧,很多UVC相机默认YUYV在640x480只能到25fps。 python -m lerobot.robots.lekiwi.lekiwi_host \ --robot.id=R1225280 \ --robot.cameras='{ "front": {"type":"opencv","index_or_path":"/dev/video2","width":640,"height":480,"fps":30,"fourcc":"MJPG"}, "wrist": {"type":"opencv","index_or_path":"/dev/video0","width":480,"height":640,"fps":30,"rotation":"ROTATE_90","fourcc":"MJPG"} }' \ --host.connection_time_s=300 遥控端 启动前,需要配置一下,主要修改lekiwi/record.py。 主臂型号SO101:将SO100修改为SO101型号。 网络配置remote_ip:配置连接设备的ip地址,remote_ip:LeKiwi机器人主机的IP地址。id:机器人实例标识符。 机械臂配置port:配置领航臂的串口和标定参数文件,port="/dev/ttyACM0", id="R07252801"。 数据集路径HF_REPO_ID:配置录制数据集上传到的Hugging Face仓库,格式为用户名/仓库名,会存储到~/.cache/xxx路径下。 任务配置:配置采集回合数NUM_EPISODES,每个回合的时间EPISODE_TIME_SEC(单位秒),重置环境时间RESET_TIME_SEC(秒),任务描述信息TASK_DESCRIPTION。录制帧率FPS。 diff --git a/examples/lekiwi/record.py b/examples/lekiwi/record.py --- a/examples/lekiwi/record.py +++ b/examples/lekiwi/record.py -from lerobot.teleoperators.so100_leader import SO100Leader, SO100LeaderConfig +from lerobot.teleoperators.so101_leader import SO101Leader, SO101LeaderConfig EPISODE_TIME_SEC = 30 RESET_TIME_SEC = 10 TASK_DESCRIPTION = "My task description" -HF_REPO_ID = "<hf_username>/<dataset_repo_id>" +HF_REPO_ID = "laumy/lekiwi" -robot_config = LeKiwiClientConfig(remote_ip="172.18.134.136", id="lekiwi") -leader_arm_config = SO100LeaderConfig(port="/dev/tty.usbmodem585A0077581", id="my_awesome_leader_arm") +robot_config = LeKiwiClientConfig(remote_ip="10.0.90.31", id="lekiwi") +leader_arm_config = SO101LeaderConfig(port="/dev/ttyACM0", id="R07252801") keyboard_config = KeyboardTeleopConfig() -leader_arm = SO100Leader(leader_arm_config) +leader_arm = SO101Leader(leader_arm_config) 配置好后启动脚本进行采集数据,采集完成后数据存储在~/.cache/huggingface/lerobot/laumy/lekiwi/ python examples/lekiwi/record.py 训练 lerobot-train \ --dataset.repo_id=laumy/lekiwi \ --policy.type=act \ --output_dir=outputs/train/act_lekiwi_test \ --job_name=act_lekiwi_test \ --policy.device=cpu \ --policy.push_to_hub=false \ --wandb.enable=false \ --batch_size=8 --steps=10000 --policy.push_to_hub=false:训练的模型是否上传hugging face。 --policy.repo_id=your_username/your_model_name:指定推送的路径名称。 --wandb.enable=false:是否启用Weights & Biases (W&B) 实验跟踪。 推理 设备端 python -m lerobot.robots.lekiwi.lekiwi_host \ --robot.id=R1225280 \ --robot.cameras='{ "front": {"type":"opencv","index_or_path":"/dev/video2","width":640,"height":480,"fps":30,"fourcc":"MJPG"}, "wrist": {"type":"opencv","index_or_path":"/dev/video0","width":480,"height":640,"fps":30,"rotation":"ROTATE_90","fourcc":"MJPG"} }' \ --host.connection_time_s=300 PC端 启动前先修改配置,这里跟record.py修改差不多。 模型路径HF_MODEL_ID:如果不是本地目录则尝试从hugging face上下载。 数据集路径HF_DATASET_ID:推理还需要数据集主要是用于输入数据的归一化和策略输出反归一化。 设备remote_ip:配置设备端的ip地址。 index 4501008d..f508d448 100644 --- a/examples/lekiwi/evaluate.py +++ b/examples/lekiwi/evaluate.py @@ -29,12 +29,12 @@ from lerobot.utils.visualization_utils import init_rerun NUM_EPISODES = 2 FPS = 30 EPISODE_TIME_SEC = 60 -TASK_DESCRIPTION = "My task description" -HF_MODEL_ID = "<hf_username>/<model_repo_id>" -HF_DATASET_ID = "<hf_username>/<eval_dataset_repo_id>" +TASK_DESCRIPTION = "Move to grab block" +HF_MODEL_ID = "output/act" +HF_DATASET_ID = "laumy/lekiwi" # Create the robot configuration & robot -robot_config = LeKiwiClientConfig(remote_ip="172.18.134.136", id="lekiwi") +robot_config = LeKiwiClientConfig(remote_ip="10.0.90.31", id="lekiwi") 改完之后启动运行 python examples/lekiwi/evaluate.py -

Lekiwi驱动链路分析
系统架构 硬件组成 Lekiwi是一个底盘+机械臂的结构。 机械臂: 6个自由度(shoulder_pan, shoulder_lift, elbow_flex, wrist_flex, wrist_roll, gripper) 移动底盘:3个全向轮,三轮全向移动(left_wheel, back_wheel, right_wheel) github官网Lekiwi使用 Koch v1.1 机械臂、U2D2 电机控制器和 Dynamixel XL430 电机作为移动基座。我这里买到的使用的是feetech电机,机械臂和底盘一共9个motor接入到一个串口总线上,对于机械臂和底盘移动只需要通过一个串口总线进行。 软件架构 我这里将软件架构分为3层。 应用层:对设备的操作,实例化设备一个设备后,对设备进行连接,移动控制,观测数据获取。 总线层:实现一个MotorBus基类,对设备的一些操作进行统一定义、约束。实现操作的逻辑,具体的实现由继承设备来实现。 设备层:具体设备的实现,继承与MotorBus,实现对电机底层通信接口。 感觉这个框架不是很合理,主要的框架设计是设备层继承总线层的基类,继承相当于是扩展,应用层没有起到屏蔽设备的作用。在应用层要创建一个设备实例如self.bus = FeetechMotorsBus(),而FeetechMotorsBus继承MotorsBus,应用层直接操作FeetechMotorsBus实例,没有达到屏蔽底层的效果。可以完全借鉴Linux设备驱动模型,分为设备、总线、驱动(应用),设备注册后,总线负责匹配设备和驱动,完全隔离,不用关系底层的设备是什么。 驱动链路 初始化 class LeKiwi(Robot): config_class = LeKiwiConfig name = "lekiwi" def __init__(self, config: LeKiwiConfig): super().__init__(config) self.config = config norm_mode_body = MotorNormMode.DEGREES if config.use_degrees else MotorNormMode.RANGE_M100_100 self.bus = FeetechMotorsBus( port=self.config.port, motors={ # arm "arm_shoulder_pan": Motor(1, "sts3215", norm_mode_body), "arm_shoulder_lift": Motor(2, "sts3215", norm_mode_body), "arm_elbow_flex": Motor(3, "sts3215", norm_mode_body), "arm_wrist_flex": Motor(4, "sts3215", norm_mode_body), "arm_wrist_roll": Motor(5, "sts3215", norm_mode_body), "arm_gripper": Motor(6, "sts3215", MotorNormMode.RANGE_0_100), # base "base_left_wheel": Motor(7, "sts3215", MotorNormMode.RANGE_M100_100), "base_back_wheel": Motor(8, "sts3215", MotorNormMode.RANGE_M100_100), "base_right_wheel": Motor(9, "sts3215", MotorNormMode.RANGE_M100_100), }, calibration=self.calibration, ) self.arm_motors = [motor for motor in self.bus.motors if motor.startswith("arm")] self.base_motors = [motor for motor in self.bus.motors if motor.startswith("base")] self.cameras = make_cameras_from_configs(config.cameras) 继承Robot,指定了配置类为LeKiwiConfig其定义了uart的端口、相机的编号等信息。将角度统一归一化到[-100,100],创建Feetech电机总线实例,创建Feetech电机型号sts3215,配置了机械臂电机ID为1至6,底盘编号为7至9编号。同时对相机也进行了初始化,用于后续的视觉观测。 连接 robot.connect()————> def connect(self, calibrate: bool = True) -> None: if self.is_connected: raise DeviceAlreadyConnectedError(f"{self} already connected") self.bus.connect() if not self.is_calibrated and calibrate: logger.info( "Mismatch between calibration values in the motor and the calibration file or no calibration file found" ) self.calibrate() for cam in self.cameras.values(): cam.connect() self.configure() logger.info(f"{self} connected.") 初始化完成之后即可进行发起连接,连接主要是根据指定的串口好进行打开,然后进行握手验证,ping所有配置的电机,检查校准文件与电机的状态,并设置PID、加速度等参数。 校准 def calibrate(self) -> None: if self.calibration: # Calibration file exists, ask user whether to use it or run new calibration user_input = input( f"Press ENTER to use provided calibration file associated with the id {self.id}, or type 'c' and press ENTER to run calibration: " ) if user_input.strip().lower() != "c": logger.info(f"Writing calibration file associated with the id {self.id} to the motors") self.bus.write_calibration(self.calibration) return logger.info(f"\nRunning calibration of {self}") motors = self.arm_motors + self.base_motors self.bus.disable_torque(self.arm_motors) for name in self.arm_motors: self.bus.write("Operating_Mode", name, OperatingMode.POSITION.value) input("Move robot to the middle of its range of motion and press ENTER....") homing_offsets = self.bus.set_half_turn_homings(self.arm_motors) homing_offsets.update(dict.fromkeys(self.base_motors, 0)) full_turn_motor = [ motor for motor in motors if any(keyword in motor for keyword in ["wheel", "wrist_roll"]) ] unknown_range_motors = [motor for motor in motors if motor not in full_turn_motor] print( f"Move all arm joints except '{full_turn_motor}' sequentially through their " "entire ranges of motion.\nRecording positions. Press ENTER to stop..." ) range_mins, range_maxes = self.bus.record_ranges_of_motion(unknown_range_motors) for name in full_turn_motor: range_mins[name] = 0 range_maxes[name] = 4095 self.calibration = {} for name, motor in self.bus.motors.items(): self.calibration[name] = MotorCalibration( id=motor.id, drive_mode=0, homing_offset=homing_offsets[name], range_min=range_mins[name], range_max=range_maxes[name], ) self.bus.write_calibration(self.calibration) self._save_calibration() print("Calibration saved to", self.calibration_fpath) 首次校准,从归零到测量范围,生成并保存文件流程,后续使用按回车复用已有校准;输入 'c' 重新校准。可以总结为如下: LeKiwi.calibrate() → 用户选择(使用已有/重新校准) → 归零设置 → 运动范围测量 → 校准参数构建 → FeetechMotorsBus.write_calibration() → MotorsBus.write_calibration() → 逐个写入电机寄存器 校准主要是限定几个参数,如归零偏移、运动范围、驱动模式。校准的流程是由用户选择使用已经有的校准文件直接写入校准还是进行重新启动校准流程校准。 动作执行 def send_action(self, action: dict[str, Any]) -> dict[str, Any]: if not self.is_connected: raise DeviceNotConnectedError(f"{self} is not connected.") arm_goal_pos = {k: v for k, v in action.items() if k.endswith(".pos")} base_goal_vel = {k: v for k, v in action.items() if k.endswith(".vel")} base_wheel_goal_vel = self._body_to_wheel_raw( base_goal_vel["x.vel"], base_goal_vel["y.vel"], base_goal_vel["theta.vel"] ) # Cap goal position when too far away from present position. # /!\ Slower fps expected due to reading from the follower. if self.config.max_relative_target is not None: present_pos = self.bus.sync_read("Present_Position", self.arm_motors) goal_present_pos = {key: (g_pos, present_pos[key]) for key, g_pos in arm_goal_pos.items()} arm_safe_goal_pos = ensure_safe_goal_position(goal_present_pos, self.config.max_relative_target) arm_goal_pos = arm_safe_goal_pos # Send goal position to the actuators arm_goal_pos_raw = {k.replace(".pos", ""): v for k, v in arm_goal_pos.items()} self.bus.sync_write("Goal_Position", arm_goal_pos_raw) self.bus.sync_write("Goal_Velocity", base_wheel_goal_vel) return {**arm_goal_pos, **base_goal_vel} 输入为动作的序列,输出为实际发送的动作。首先将机械臂(后缀.pos)目标位置和底盘目标速度(后缀.vel)进行分离,如下: # 分离前 action = { "arm_shoulder_pan.pos": 45.0, # 机械臂位置 "arm_elbow_flex.pos": -30.0, "x.vel": 0.1, # 底盘速度 "y.vel": 0.0, "theta.vel": 0.05 } # 分离后 arm_goal_pos = { "arm_shoulder_pan.pos": 45.0, "arm_elbow_flex.pos": -30.0 } base_goal_vel = { "x.vel": 0.1, "y.vel": 0.0, "theta.vel": 0.05 } 然后调用_body_to_wheel_raw进行底盘运动学转换,输入为底盘坐标系速度 (x, y, θ),输出为三轮电机速度指令。转换的时候需要进行安全限制,实际获取机械臂的关节位置,然后计算步幅(目标位置-当前位置),超过max_relative_target 则裁剪使用安全的目标位置。 最后就是调用sync_write分别写入控制机械臂和底盘。下面总结一下流程: LeKiwi.send_action(action) → 动作分离(机械臂位置 + 底盘速度) → 底盘运动学转换 → 安全限制检查 → FeetechMotorsBus.sync_write() → MotorsBus._sync_write() → 批量写入电机寄存器 对Lekiwi的控制,由于底盘是3个万向轮,所以需要进行运动学转换,现将机械臂和底盘进行分离,计算之处底盘坐标系转换的3轮速度,在确保安全限制的条件下,调用sync_write进行写入,sync_write是同时写入多个电机。 状态读取 def get_observation(self) -> dict[str, Any]: if not self.is_connected: raise DeviceNotConnectedError(f"{self} is not connected.") # Read actuators position for arm and vel for base start = time.perf_counter() arm_pos = self.bus.sync_read("Present_Position", self.arm_motors) base_wheel_vel = self.bus.sync_read("Present_Velocity", self.base_motors) base_vel = self._wheel_raw_to_body( base_wheel_vel["base_left_wheel"], base_wheel_vel["base_back_wheel"], base_wheel_vel["base_right_wheel"], ) arm_state = {f"{k}.pos": v for k, v in arm_pos.items()} obs_dict = {**arm_state, **base_vel} dt_ms = (time.perf_counter() - start) * 1e3 logger.debug(f"{self} read state: {dt_ms:.1f}ms") # Capture images from cameras for cam_key, cam in self.cameras.items(): start = time.perf_counter() obs_dict[cam_key] = cam.async_read() dt_ms = (time.perf_counter() - start) * 1e3 logger.debug(f"{self} read {cam_key}: {dt_ms:.1f}ms") return obs_dict 首先调用sync_read分别读取机械臂位置和底盘的当前速度,然后调用底盘速度逆运动学转换(三轮电机->底盘坐标系速度(x, y, θ)),接着将机械臂位置和底盘转换的坐标系速度整合,再次就是对相机图像的待机,先遍历所有配置相机,将图像的数据添加到观测字段,最终再进行整合得到观测字典。 obs_dict = { # 机械臂位置 "arm_shoulder_pan.pos": 45.2, "arm_shoulder_lift.pos": -12.8, # ... 其他关节 # 底盘速度 "x.vel": 0.15, "y.vel": -0.08, "theta.vel": 0.12, # 相机图像 "camera_1": numpy_array, # (H, W, 3) "camera_2": numpy_array, # (H, W, 3) } 下面是总结流程 LeKiwi.get_observation() → FeetechMotorsBus.sync_read() → MotorsBus._sync_read() → 批量读取电机状态 → 底盘速度逆运动学 → 相机图像采集 获取状态与动作执行相反,首先读取到电机的状态,然后通过逆运动学,将底盘的速度转换为坐标系。 -
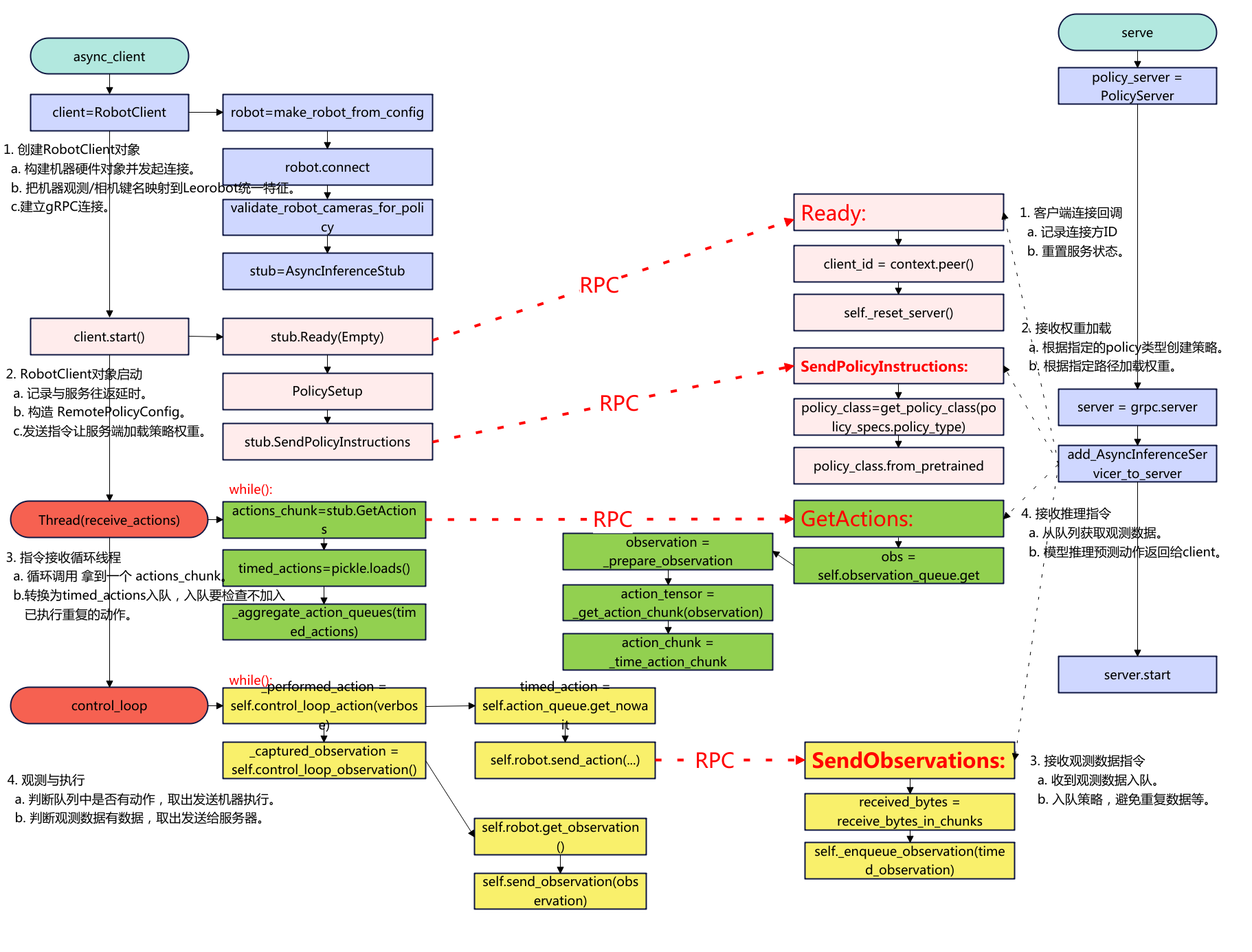
SmolVLA 异步推理:远程 Policy Server 与本地 Client 实操
概述 本文记录lerobot smolvla异步推理实践,将SmolVLA的策略server部署到AutoDL上,真机client在本地笔记本上运行。 下面是代码的流程图: 环境准备 先登录AutoDL事先搭建好lerobot的环境,这里就不再重复了,参考往期文章。lerobot环境搭建好后,需要先安装smolvla和gRPC。 # 建议先升级打包工具 python -m pip install -U pip setuptools wheel pip install -e ".[smolvla]" # 安装 gRPC 及相关 python -m pip install grpcio grpcio-tools protobuf 服务器 python src/lerobot/scripts/server/policy_server.py --host=127.0.0.1 --port=8080 --fps=30 --inference_latency=0.033 --obs_queue_timeout=2 启动成功后的日志如下: python src/lerobot/scripts/server/policy_server.py --host=127.0.0.1 --port=8080 --fps=30 --inference_latency=0 --obs_queue_timeout=2 INFO 2025-08-28 10:33:07 y_server.py:384 {'fps': 30, 'host': '127.0.0.1', 'inference_latency': 0.0, 'obs_queue_timeout': 2.0, 'port': 8080} INFO 2025-08-28 10:33:07 y_server.py:394 PolicyServer started on 127.0.0.1:8080 被客户端连接后的日志: INFO 2025-08-28 10:40:42 y_server.py:104 Client ipv4:127.0.0.1:45038 connected and ready INFO 2025-08-28 10:40:42 y_server.py:130 Receiving policy instructions from ipv4:127.0.0.1:45038 | Policy type: smolvla | Pretrained name or path: outputs/smolvla_weigh_08181710/pretrained_model | Actions per chunk: 50 | Device: cuda Loading HuggingFaceTB/SmolVLM2-500M-Video-Instruct weights ... INFO 2025-08-28 10:40:54 odeling.py:1004 We will use 90% of the memory on device 0 for storing the model, and 10% for the buffer to avoid OOM. You can set `max_memory` in to a higher value to use more memory (at your own risk). Reducing the number of VLM layers to 16 ... Loading weights from local directory INFO 2025-08-28 10:41:14 y_server.py:150 Time taken to put policy on cuda: 32.3950 seconds INFO 2025-08-28 10:41:14 ort/utils.py:74 <Logger policy_server (NOTSET)> Starting receiver INFO 2025-08-28 10:41:14 y_server.py:175 Received observation #0 | Avg FPS: 3.45 | Target: 30.00 | One-way latency: -9.22ms INFO 2025-08-28 10:41:14 y_server.py:205 Running inference for observation #0 (must_go: True) INFO 2025-08-28 10:41:15 ort/utils.py:74 <Logger policy_server (NOTSET)> Starting receiver INFO 2025-08-28 10:41:15 y_server.py:175 Received observation #0 | Avg FPS: 3.45 | Target: 30.00 | One-way latency: -9.58ms 服务器仅本地监听(12.0.0.1),这样不暴露公网,客户端通过SSH隧道安全转发。 nohup python src/lerobot/scripts/server/policy_server.py --host=127.0.0.1 --port=8080 --fps=30 --inference_latency=0.033 --obs_queue_timeout=2 >/tmp/policy_server.log 2>&1 & 也可以选择后台运行。 客户端 建立SSH转发 在本地客户端线建立SSH本地端口转发(隧道) ssh -p <服务器ssh的port> -fN -L 8080:127.0.0.1:8080 <用户名@服务器ssh的ip或域名> 如:ssh -p 20567 -fN -L 8080:127.0.0.1:8080 root@connect.xx.xxx.com 如果不想后台运行,运行在前台(Crtl+C结束) ssh -p 20567 -N -L 8080:127.0.0.1:8080 root@connect.xx.xxx.com 本地运行 python src/lerobot/scripts/server/robot_client.py \ --robot.type=so101_follower --robot.port=/dev/ttyACM0 --robot.id=R12252801 \ --robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}}" \ --policy_type=smolvla \ --pretrained_name_or_path=outputs/smolvla_weigh_08181710/pretrained_model \ --policy_device=cuda \ --actions_per_chunk=50 \ --fps=30 \ --server_address=localhost:8080 \ --chunk_size_threshold=0.8 \ --debug_visualize_queue_size=True 其他参数 --debug_visualize_queue_size=True: 执行结束后可视化队列情况。 需要安装 pip install matplotlib。 --aggregate_fn_name=conservative:当新动作到达时,如果队列中已经存在相同时间步的动作,系统会使用聚合函数来合并它们。如果为latest_only(默认),只用最新动作,这样可能会抖动剧烈。 --pretrained_name_or_path 会在“服务器上”加载。需要确保服务器上outputs/smolvla_weigh_08181710路径有权重文件。 连接执行的日志如下: python src/lerobot/scripts/server/robot_client.py --robot.type=so101_follower --robot.port=/dev/ttyACM0 --robot.id=R12252801 --robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 320, height: 240, fps: 25}, fixed: {type: opencv, index_or_path: 0, width: 320, height: 240, fps: 25}}" --policy_type=smolvla --pretrained_name_or_path=outputs/smolvla_weigh_08181710/pretrained_model --policy_device=cuda --actions_per_chunk=50 --chunk_size_threshold=0.8 --fps=30 --server_address=localhost:8080 --aggregate_fn_name=average INFO 2025-08-28 10:40:38 t_client.py:478 {'actions_per_chunk': 50, 'aggregate_fn_name': 'average', 'chunk_size_threshold': 0.8, 'debug_visualize_queue_size': False, 'fps': 30, 'policy_device': 'cuda', 'policy_type': 'smolvla', 'pretrained_name_or_path': 'outputs/smolvla_weigh_08181710/pretrained_model', 'robot': {'calibration_dir': None, 'cameras': {'fixed': {'color_mode': <ColorMode.RGB: 'rgb'>, 'fps': 25, 'height': 240, 'index_or_path': 0, 'rotation': <Cv2Rotation.NO_ROTATION: 0>, 'warmup_s': 1, 'width': 320}, 'handeye': {'color_mode': <ColorMode.RGB: 'rgb'>, 'fps': 25, 'height': 240, 'index_or_path': 6, 'rotation': <Cv2Rotation.NO_ROTATION: 0>, 'warmup_s': 1, 'width': 320}}, 'disable_torque_on_disconnect': True, 'id': 'R12252801', 'max_relative_target': None, 'port': '/dev/ttyACM0', 'use_degrees': False}, 'server_address': 'localhost:8080', 'task': '', 'verify_robot_cameras': True} INFO 2025-08-28 10:40:40 a_opencv.py:179 OpenCVCamera(6) connected. INFO 2025-08-28 10:40:41 a_opencv.py:179 OpenCVCamera(0) connected. INFO 2025-08-28 10:40:41 follower.py:104 R12252801 SO101Follower connected. WARNING 2025-08-28 10:40:42 ils/utils.py:54 No accelerated backend detected. Using default cpu, this will be slow. WARNING 2025-08-28 10:40:42 /policies.py:80 Device 'cuda' is not available. Switching to 'cpu'. WARNING 2025-08-28 10:40:42 ils/utils.py:54 No accelerated backend detected. Using default cpu, this will be slow. WARNING 2025-08-28 10:40:42 /policies.py:80 Device 'cuda' is not available. Switching to 'cpu'. INFO 2025-08-28 10:40:42 t_client.py:121 Initializing client to connect to server at localhost:8080 INFO 2025-08-28 10:40:42 t_client.py:140 Robot connected and ready INFO 2025-08-28 10:40:42 t_client.py:163 Sending policy instructions to policy server INFO 2025-08-28 10:41:14 t_client.py:486 Starting action receiver thread... INFO 2025-08-28 10:41:14 t_client.py:454 Control loop thread starting INFO 2025-08-28 10:41:14 t_client.py:280 Action receiving thread starting INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 | INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 288.72 INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 | INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 132.22 INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 | INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 127.84 INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 | INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 123.95 INFO 2025-08-28 10:41:15 t_client.py:216 Sent observation #0 | INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 140.21 INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 0.54 INFO 2025-08-28 10:41:15 t_client.py:469 Control loop (ms): 0.42 如果使用ACT策略,对于ACT来说chunk_size_threshold不要设置太大,实测发现不然一个chunk到下一个chunk抖动比较严重 python src/lerobot/scripts/server/robot_client.py \ --robot.type=so101_follower \ --robot.port=/dev/ttyACM0 \ --robot.id=R12252801 \ --robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}}" \ --policy_type=act \ --pretrained_name_or_path=outputs/act_weigh_07271539/pretrained_model \ --policy_device=cuda \ --actions_per_chunk=100 \ --fps=30 \ --server_address=localhost:8080 \ --chunk_size_threshold=0.1 以上就是用SSH隧道的方式实现异步推理的过程。 参考:https://hugging-face.cn/docs/lerobot/async 常见问题 (0)服务器监控日志分析 Received observation #136:服务器接收到第136个观察数据 Avg FPS: 11.52:实际观测数据帧率,根据客户端每秒采样时间计算,跟服务端没有关系。 Target:目标设置的观测数据帧率,如15帧/s。 One-way latency: 客户端到服务器的单向网络延迟为1.71ms。 inference time: 模型推理耗时时长为1667ms。 action chunk #136:生成了第136个动作块。 Total time: 推理+序列化总处理时长。 (1)服务端实际的观测帧率低 INFO 2025-08-29 09:47:05 y_server.py:175 Received observation #573 | Avg FPS: 1.20 | Target: 30.00 | One-way latency: 35.78ms 可以看到上面的收到的观测帧率平均只有1.2,看看服务端计算FPS的逻辑。 # 每次接收观测时调用 self.total_obs_count += 1 # 包括所有接收的观测(包括被过滤的) total_duration = current_timestamp - self.first_timestamp avg_fps = (self.total_obs_count - 1) / total_duration 影响服务端的接受观测帧帧率的有客户端观测发送频率低,服务端观测被过滤,推理时间长间接影响 关于客户端观测数据的发送限制如下: # 只有当队列大小/动作块大小 <= 阈值时才发送观测 if queue_size / action_chunk_size <= chunk_size_threshold: send_observation() 可以看到只有满足上面的小于动作阈值才会发送,所以要加大发送的帧率需要改大阈值chunk_size_threshold,减少actions_per_chunk,减少queue_size。 对于ACT策略的FPS 低可能不是问题,这是观察发送频率,不是控制频率,因为ACT 策略就是低频观察,高频执行,主要看机器是不是以30FPS动作执行就好。smolvla也是同样的。因此有时候不要过于误解这个观测帧率,太高的观测帧率也不一定是好事。 (2)观测数据被过滤 y_server.py:191 Observation #510 has been filtered out 服务端会根据这次和上次的关节角度计算欧拉来判断相似性,默认的阈值参数是1,可以改小一点,对相似性的判断严苛一下。 def observations_similar( obs1: TimedObservation, obs2: TimedObservation, lerobot_features: dict[str, dict], atol: float = 1 ) -> bool: ...... return bool(torch.linalg.norm(obs1_state - obs2_state) < atol) 如上修改atol的值,可以改小为如0.5。 总结一下: 对于分布式推理不要过于去纠结实际的观测帧率,而是应该看控制的实际帧率,只要控制动作的帧率(如下的延时,大概就是30fps)是满足的就是可以的,也就是说动作队列中动作不要去获取的时候是空。 对于参数优化重点看服务端的推理延时和客户端的队列管理。 服务端是可以设置推理延时的 # 推理延迟控制 --inference_latency=0.033 # 模型推理延迟(秒) # 观察队列管理 --obs_queue_timeout=2 # 获取观测队列超时时间(秒) 客户端动作管理 --actions_per_chunk=100 # 一个动作块的序列大小,越大推理负载就重 --chunk_size_threshold=0.5 # 队列阈值,越大缓存的动作序列越多,越小实时性越好。 --fps=30 # 控制频率 如果要低延时那么就需要把fps提高,也就是服务端的推理时间设置小,客户端的chunk、threshold要小,fps要高。 -
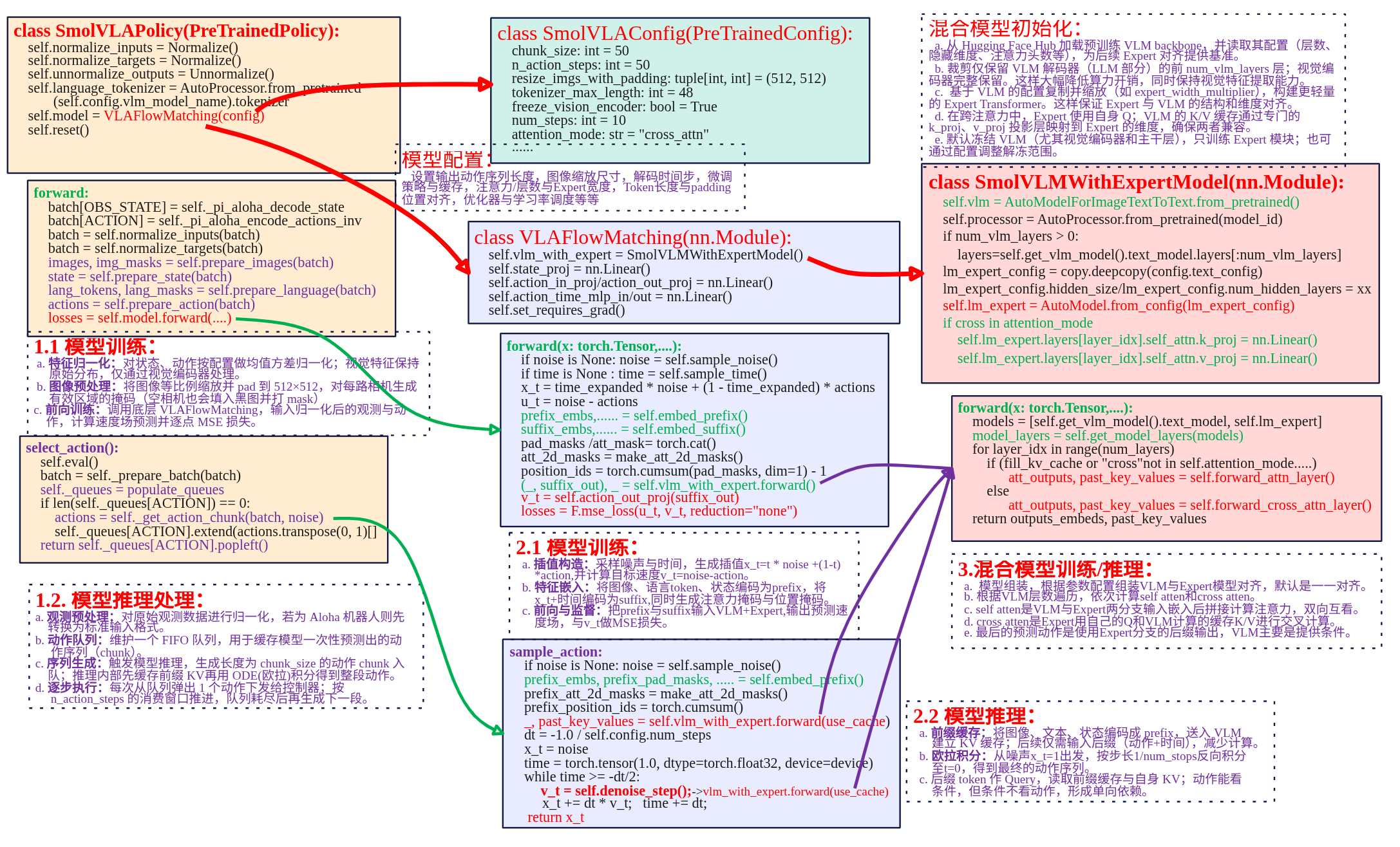
LeRobot SmolVLA:从训练到推理链路剖析
框架 本文主要对lerobot SmolVLA策略代码进行分析,下面是策略实现关键部分框图。 SmolVLAPolicay类封装向上提供策略的调用。SmolVLAConfig是对SmolVLA策略的配置,用于配置输出动作序列长度、观测图像输入后到模型的缩放尺寸以及微调策略等等。SmolVLAPolicay类中关键的成员是VLAFlowMatching类,是实现SmolVLA模型flow matching机制训练、推理的核心。在VLAFlowMatching类中关系成员是SmolVLMWithExpertModel类,其定义了VLM+Expert模型具体实现。 SmolVLA策略实现主要涉及SmolVLAPolicy、VLAFlowMatching 、SmolVLMWithExperModel三个类来实现。就以模型训练、模型推理两条主线来进行总结。 训练 训练过程可以分为一下几个核心部分: 数据输入处理:图像、文本和状态通过各自处理方法嵌入并标准化,合并成统一的输入,供后续层次处理。 VLM与专家模型交互前向传播:图像、文本和状态数据通过VLM和专家模型进行多层次的自注意力和交叉注意力计算,得到联合特征表示。 损失计算与优化:通过计算预测动作和目标动作之间的损失,具体是速度场的损失,使用反向传播更新参数。 模型参数冻结与训练策略:通过冻结不必要的模型部分(VLM),专注优化重要部分,减少计算的开销。 输入处理 SmolVLA模型分为前缀prefix、后缀suffix输入。前缀主要是观测端数据由图像、文本和机器的状态嵌入构成,提供给VLM处理,目的是为模型提供上下文信息,理解任务的背景。后缀是用于生成过程中,输入的是噪声动作+时间步,经过Expert模型处理输出具体的预测动作。 (1)前缀prefix嵌入 def embed_prefix(self, images, img_masks, lang_tokens, lang_masks, state: torch.Tensor = None): embs = [] pad_masks = [] att_masks = [] # 处理图像 for _img_idx, (img, img_mask) in enumerate(zip(images, img_masks)): img_emb = self.vlm_with_expert.embed_image(img) embs.append(img_emb) pad_masks.append(img_mask) # 处理语言 lang_emb = self.vlm_with_expert.embed_language_tokens(lang_tokens) embs.append(lang_emb) pad_masks.append(lang_masks) # 处理状态 state_emb = self.state_proj(state) embs.append(state_emb) state_mask = torch.ones_like(state_emb) pad_masks.append(state_mask) # 合并所有嵌入 embs = torch.cat(embs, dim=1) pad_masks = torch.cat(pad_masks, dim=1) att_masks = torch.cat(att_masks, dim=1) return embs, pad_masks, att_masks 代码的流程是依次对输入图像、语言、机器状态进行分别做embedding,然后进行按列合并为一个前缀输入。 图像嵌入:通过embed_image方法转换为嵌入表示,每个图像的嵌入被添加到embs列表中,img_mask则记录图像的有效区域。 文本嵌入:通过embed_language_tokens() 被转换为嵌入表示,lang_emb 是语言的嵌入,包含了语言的语法和语义信息。 状态嵌入:状态信息通过 state_proj() 映射到与图像和文本相同维度的空间,得到 state_emb。 最终图像嵌入、文本嵌入和状态嵌入通过 torch.cat() 方法按列合并成一个大的 前缀输入(Prefix)。pad_masks 和 att_masks 也被合并成一个统一的输入,确保每个模态的信息能够与其他模态的输入一起传递。 图像和文本嵌入调用已经隐式包含了位置编码,状态信息state_proj 转换为嵌入,尽管没有显式的位置信息,但会在模型中通过与其他模态嵌入的融合获取上下文信息。 (2)后缀Suffix嵌入 def embed_suffix(self, noisy_actions, timestep): embs = [] pad_masks = [] att_masks = [] # 使用 MLP 融合时间步长和动作信息 action_emb = self.action_in_proj(noisy_actions) device = action_emb.device bsize = action_emb.shape[0] dtype = action_emb.dtype # 使用正弦-余弦位置编码生成时间嵌入 time_emb = create_sinusoidal_pos_embedding( timestep, self.vlm_with_expert.expert_hidden_size, self.config.min_period, self.config.max_period, device=device, ) time_emb = time_emb.type(dtype=dtype) # 将时间嵌入和动作嵌入结合 time_emb = time_emb[:, None, :].expand_as(action_emb) action_time_emb = torch.cat([action_emb, time_emb], dim=2) action_time_emb = self.action_time_mlp_in(action_time_emb) action_time_emb = F.silu(action_time_emb) # swish == silu action_time_emb = self.action_time_mlp_out(action_time_emb) # 将生成的动作嵌入加入到输入中 embs.append(action_time_emb) bsize, action_time_dim = action_time_emb.shape[:2] action_time_mask = torch.ones(bsize, action_time_dim, dtype=torch.bool, device=device) pad_masks.append(action_time_mask) # 设置注意力掩码,防止图像、语言和状态的输入与动作输入相互影响 att_masks += [1] * self.config.chunk_size embs = torch.cat(embs, dim=1) pad_masks = torch.cat(pad_masks, dim=1) att_masks = torch.tensor(att_masks, dtype=embs.dtype, device=embs.device) att_masks = att_masks[None, :].expand(bsize, len(att_masks)) return embs, pad_masks, att_masks 后缀的输入主要是提供给Expert专家模型用于flow matching预测出输出,输入是噪声动作(noisy actions)+时间步长(timestep)。上述代码可以分为以下几个部分: 时间步长嵌入:时间步长(timestep)用于表示当前的生成步骤,生成一个正弦-余弦位置编码(Sine-Cosine Positional Embedding)。create_sinusoidal_pos_embedding() 使用正弦和余弦函数生成时间嵌入,增强模型对时序的理解。 动作嵌入:动作通过 action_in_proj 进行嵌入,得到 action_emb。这一步是将生成的动作(采样的噪声动作)转化为嵌入表示。 融合时间和动作:动作嵌入与时间嵌入(time_emb)通过 torch.cat() 进行拼接,形成一个新的包含时间信息的动作嵌入。这样,生成的动作不仅包含来自环境的信息,还加入了时间步长的变化。 MLP处理:合并后的动作嵌入通过 action_time_mlp_in 和 action_time_mlp_out 层进行处理。这个过程是对动作嵌入进行进一步的处理,确保其能够适应后续的生成任务。 最终,生成的动作嵌入被加入到 embs 列表中,并通过 torch.cat() 合并为一个统一的后缀输入。这个后缀输入将与前缀输入一起通过 Transformer 层进行处理。 前向传播 forward是整个前向传播的核心,将将输入组合后通过模型计算输出。 def forward( self, images, img_masks, lang_tokens, lang_masks, state, actions, noise=None, time=None ): # 1. 前缀输入的生成 prefix_embs, prefix_pad_masks, prefix_att_masks = self.embed_prefix( images, img_masks, lang_tokens, lang_masks, state ) # 2. 后缀输入的生成 suffix_embs, suffix_pad_masks, suffix_att_masks = self.embed_suffix(actions, time) # 3. 拼接前缀和后缀的嵌入 pad_masks = torch.cat([prefix_pad_masks, suffix_pad_masks], dim=1) att_masks = torch.cat([prefix_att_masks, suffix_att_masks], dim=1) # 4. 计算注意力掩码 att_2d_masks = make_att_2d_masks(pad_masks, att_masks) position_ids = torch.cumsum(pad_masks, dim=1) - 1 # 5. 前向计算 (_, suffix_out), _ = self.vlm_with_expert.forward( attention_mask=att_2d_masks, position_ids=position_ids, past_key_values=None, inputs_embeds=[prefix_embs, suffix_embs], use_cache=False, fill_kv_cache=False, ) # 6. 速度场预测计算损失 suffix_out = suffix_out[:, -self.config.chunk_size :] suffix_out = suffix_out.to(dtype=torch.float32) v_t = self.action_out_proj(suffix_out) losses = F.mse_loss(v_t, actions, reduction="none") return losses 代码调用前缀、后缀输入然后进行拼接得到inputs_embeds,然后再计算注意力的掩码就可以调用VLM+Expert模型进行前向计算。在前向计算中有两个参数use_cache 和 fill_kv_cache 参数,这两个参数的设置控制 key-value 缓存 的使用。 (1)模型组合 models = [self.get_vlm_model().text_model, self.lm_expert] model_layers = self.get_model_layers(models) def get_model_layers(self, models: list) -> list: vlm_layers = [] expert_layers = [] multiple_of = self.num_vlm_layers // self.num_expert_layers for i in range(self.num_vlm_layers): if multiple_of > 0 and i > 0 and i % multiple_of != 0: expert_layer = None else: expert_layer_index = i // multiple_of if multiple_of > 0 else i expert_layer = models[1].layers[expert_layer_index] vlm_layers.append(models[0].layers[i]) expert_layers.append(expert_layer) return [vlm_layers, expert_layers] 模型混合主要是生成一个混合的模型层列表,通过get_model_layers函数计算并返回 VLM 层和 Expert 层的对齐关系,VLM层和Expert层对齐是基于multiple_of来进行层级分配的。如果某些 VLM 层 没有对应的 Expert 层,则设置为 None,仅由 VLM 层处理。默认情况下VLM和Expert的层数一样都为16,下图看看VLM=8,Expert=4的示例。 因此最终对于SmolVLA来说,模型是一个混合的模型层列表model_layers。可以通过model_layers[i][layer_idx]来访问具体的模型,model_layers[0][x]为VLM模型,model_layers[1][x]为Expert模型。如model_layers[0][2]为第二层的VLM,model_layers[1][2]为第二层的Expert,model_layers[1][1]为None。 (2)处理输入嵌入 for hidden_states in inputs_embeds: if hidden_states is None: continue batch_size = hidden_states.shape[0] 遍历输入嵌入(inputs_embeds),检查是否有无效的输入(即 None),并获取当前批次的大小batch_size。 inputs_embeds:模型的输入嵌入数据,可能包含多种模态的输入(例如,图像嵌入、文本嵌入等)。 hidden_states.shape[0]:获取当前输入数据的批次大小。 (3)自注意力与交叉注意力 num_layers = self.num_vlm_layers head_dim = self.vlm.config.text_config.head_dim for layer_idx in range(num_layers): if ( fill_kv_cache or "cross" not in self.attention_mode or (self.self_attn_every_n_layers > 0 and layer_idx % self.self_attn_every_n_layers == 0) ): att_outputs, past_key_values = self.forward_attn_layer() else: att_outputs, past_key_values = self.forward_cross_attn_layer() 使用VLM层数来进行遍历,因为VLM侧的层数是Expert的一倍。进行如循环根据条件来判断是进行自注意力计算还是交叉注意力计算。 判断使用自注意力的条件是有3种情况(其中一种满足即可): fill_kv_cache:如果需要填充 键值缓存(key-value cache),则使用自注意力计算。 "cross" not in self.attention_mode:如果当前没有启用交叉注意力模式,则使用自注意力。 self_attn_every_n_layers:在每隔 n 层计算自注意力时,执行该条件。通常用于启用跨层的自注意力机制。 具体关于自注意力与交叉注意力计算的细节见后续章节。 (4)残差连接与前馈网络 out_emb += hidden_states after_first_residual = out_emb.clone() out_emb = layer.post_attention_layernorm(out_emb) out_emb = layer.mlp(out_emb) out_emb += after_first_residual 残差连接:每一层都使用残差连接,将当前层的输出与原始输入相加,防止深层网络的梯度消失问题。 前馈网络(MLP):通过前馈神经网络(通常包括一个隐藏层和激活函数)进行处理,进一步捕捉输入的非线性关系。 (5)输出处理 outputs_embeds = [] for i, hidden_states in enumerate(inputs_embeds): if hidden_states is not None: out_emb = models[i].norm(hidden_states) outputs_embeds.append(out_emb) else: outputs_embeds.append(None) return outputs_embeds, past_key_values 遍历输入嵌入(inputs_embeds),对每个有效的 hidden_states 进行 归一化处理(models[i].norm())。如果嵌入无效(即 None),则直接将 None 放入输出列表中,以保持输入结构的对齐。最终返回 处理后的嵌入 和 past_key_values(如果有的话)。 归一化(通常是层归一化)确保嵌入在后续计算中具有更好的数值稳定性,帮助模型学习。对缺失的嵌入(None)进行特殊处理,主要是VLM+Expert对齐时,Expert通常为VLM的一半,而模型遍历是时按照VLM层次来遍历的,所以有一半的Expert是None,但是这部的None不能在处理VLM层的时候断掉Expert的输入,否则Expert模型梯度链就断了。 损失计算 SmolVLAPolicy.forward(...) ...... 调 VLAFlowMatching 计算逐样本/逐步/逐维损失(不聚合) losses = self.model.forward(images, img_masks, lang_tokens, lang_masks, state, actions, noise, time) if actions_is_pad is not None: in_episode_bound = ~actions_is_pad losses = losses * in_episode_bound.unsqueeze(-1) # 去掉为对齐而pad出的 action 维度 losses = losses[:, :, : self.config.max_action_dim] # 聚合为标量 loss(反向传播用) loss = losses.mean() return loss, {"loss": loss.item()} 在SmolVLAPolicy.forward(...)调用VLAFlowMatching.forward计算返回损失,下面直接来看VLAFlowMatching.forward。 def forward(self, images, img_masks, lang_tokens, lang_masks, state, actions, noise=None, time=None) -> Tensor: # ① 采样噪声与时间 if noise is None: noise = self.sample_noise(actions.shape, actions.device) # ~N(0,1) if time is None: time = self.sample_time(actions.shape[0], actions.device) # Beta(1.5,1.0)→偏向 t≈1 # ② 合成中间点 x_t 与“真向量场” u_t time_expanded = time[:, None, None] # [B,1,1] x_t = time_expanded * noise + (1 - time_expanded) * actions # convex组合 u_t = noise - actions # ③ 前缀/后缀嵌入(图像+文本+状态 | 动作+时间),拼注意力mask/位置id prefix_embs, prefix_pad_masks, prefix_att_masks = self.embed_prefix(images, img_masks, lang_tokens, lang_masks, state) suffix_embs, suffix_pad_masks, suffix_att_masks = self.embed_suffix(x_t, time) pad_masks = torch.cat([prefix_pad_masks, suffix_pad_masks], dim=1) att_masks = torch.cat([prefix_att_masks, suffix_att_masks], dim=1) att_2d_masks = make_att_2d_masks(pad_masks, att_masks) position_ids = torch.cumsum(pad_masks, dim=1) - 1 # ④ 走双塔文本Transformer:prefix + suffix(训练时不建缓存) (_, suffix_out), _ = self.vlm_with_expert.forward( attention_mask=att_2d_masks, position_ids=position_ids, past_key_values=None, inputs_embeds=[prefix_embs, suffix_embs], use_cache=False, fill_kv_cache=False, ) suffix_out = suffix_out[:, -self.config.chunk_size :] # 取后缀对应的输出token # ⑤ Expert头→动作向量场 v_t,并与 u_t 做逐元素 MSE suffix_out = suffix_out.to(dtype=torch.float32) # 数值稳定 v_t = self.action_out_proj(suffix_out) losses = F.mse_loss(u_t, v_t, reduction="none") # [B, T, A] 不聚合 return losses 核心思想还是学习一个向量场 $v_{\theta}(x_t,t)$ 去逼近真实向量场 $u_t = \epsilon - a$,其中 $$ x_t = t \cdot \epsilon + (1 - t) \cdot a, \quad \epsilon \sim \mathcal{N}(0,I) $$ $a$ 是机器真实的动作如舵机的角度,对应上述代码的action;$\epsilon$是noisy action,最开始随机生成采样而来,对应上述的noise。 模型参数 模型参数冻结主要是以下两个方法决定 SmolVLMWithExpertModel.set_requires_grad(管 VLM/Expert的大部分参数); VLAFlowMatching.set_requires_grad(只管 state 的投影头)。 (1)VLM/Expert大部分参数 def set_requires_grad(self): # 1) 冻结视觉编码器(可选) if self.freeze_vision_encoder: self.get_vlm_model().vision_model.eval() for p in self.get_vlm_model().vision_model.parameters(): p.requires_grad = False # 2) 只训练 Expert(常见默认) if self.train_expert_only: self.vlm.eval() for p in self.vlm.parameters(): p.requires_grad = False else: # 3) 非“只训 Expert”时,VLM 只冻结一小部分层,避免 DDP unused params last_layers = [self.num_vlm_layers - 1] if (self.num_vlm_layers != self.num_expert_layers and self.num_vlm_layers % self.num_expert_layers == 0): last_layers.append(self.num_vlm_layers - 2) frozen = ["lm_head", "text_model.model.norm.weight"] for L in last_layers: frozen.append(f"text_model.model.layers.{L}.") for name, p in self.vlm.named_parameters(): if any(k in name for k in frozen): p.requires_grad = False # 4) Expert 侧不训练 lm_head(没用到 LM 头) for name, p in self.lm_expert.named_parameters(): if "lm_head" in name: p.requires_grad = False 冻结视觉编码器:把 VLM 的 vision encoder 切到 eval(),并把其所有参数 requires_grad=False。对于VLM视觉部分已经比较稳定了,若下游数据量不大,继续训练易带来不稳定与显存开销;冻结能省资源并保持视觉表征稳定。 只训练 Expert:把VLM的(视觉编码+LLM)都起到eval且全部冻结。这是一种轻量微调策略——只训练 Expert+ 动作/时间/状态投影头,能在小数据上快速稳定收敛,避免对大模型语义分布造成破坏。 非“只训 Expert”时,VLM 只冻结一小部分层:永远冻结 VLM 的 lm_head(语言模型头,动作任务用不到),冻结text_model.model.norm.weight,降低训练不稳定,冻结最后 1 层; 总结一下: 目标 典型设置 实际可训练部分 轻量微调(默认/推荐起步) freeze_vision_encoder=True + train_expert_only=True Expert 全部层(除 lm_head) + 动作/时间/状态头(VLAFlowMatching 里的 action_in/out_proj、action_time_mlp_、state_proj) 加强表达(部分放开 VLM) freeze_vision_encoder=True/False + train_expert_only=False Expert 全部层 + 大多数 VLM 文本层(但冻结 lm_head、末尾 norm、最后 1–2 层) + 动作/时间/状态头 除了上面的参数之外在 SmolVLMWithExpertModel.train 中又做了一层保险: def train(self, mode=True): super().train(mode) if self.freeze_vision_encoder: self.get_vlm_model().vision_model.eval() if self.train_expert_only: self.vlm.eval() 即使外部调用了 model.train(),被冻的模块仍保持 eval(),避免 Dropout/BN 等训练态行为干扰。是否参与反向仍由 requires_grad 决定;两者配合保证“真冻结”。 (2)state 的投影头 class VLAFlowMatching(nn.Module): def __init__(self, config): super().__init__() self.config = config self.vlm_with_expert = SmolVLMWithExpertModel( ... ) # —— 与动作/状态/时间相关的投影头 —— self.state_proj = nn.Linear( self.config.max_state_dim, self.vlm_with_expert.config.text_config.hidden_size ) self.action_in_proj = nn.Linear(self.config.max_action_dim, self.vlm_with_expert.expert_hidden_size) self.action_out_proj = nn.Linear(self.vlm_with_expert.expert_hidden_size, self.config.max_action_dim) self.action_time_mlp_in = nn.Linear(self.vlm_with_expert.expert_hidden_size * 2, self.vlm_with_expert.expert_hidden_size) self.action_time_mlp_out = nn.Linear(self.vlm_with_expert.expert_hidden_size, self.vlm_with_expert.expert_hidden_size) self.set_requires_grad() # ← 这里调用 ... def set_requires_grad(self): for params in self.state_proj.parameters(): params.requires_grad = self.config.train_state_proj 根据 config.train_state_proj(布尔值)开/关状态投影层 state_proj 的可训练性。这里只对state_proj做控制,这个是把机器人状态(关节角、抓取开合等)映射到 VLM 文本编码器的隐藏维度。不同机器人/任务,状态分布差异很大(量纲、范围、相关性);是否需要学习这个映射,取决于你的数据规模与分布,所以可以根据train_state_proj=True/False来决定是否要训练或冻结。其它头(action_in/out_proj、action_time_mlp_*)对动作/时间更直接,通常都需要学习,因此默认不在这里冻结。 推理 推理的入口函数入口:SmolVLAPolicy.predict_action_chunk ->select_action-> VLAFlowMatching.sample_actions(...),推理跟训练流程大致相同,这里只简单总结一下不同点。 前缀缓存 prefix_embs, prefix_pad_masks, prefix_att_masks = self.embed_prefix(...) prefix_att_2d_masks = make_att_2d_masks(prefix_pad_masks, prefix_att_masks) prefix_position_ids = torch.cumsum(prefix_pad_masks, dim=1) - 1 # 只喂前缀,构建 KV cache _, past_key_values = self.vlm_with_expert.forward( attention_mask=prefix_att_2d_masks, position_ids=prefix_position_ids, past_key_values=None, inputs_embeds=[prefix_embs, None], # ★ 只有前缀 use_cache=self.config.use_cache, # 通常 True fill_kv_cache=True, # ★ 建缓存 ) 与训练的差别是训练不建缓存,推理先把 VLM 的 Q/K/V(更准确:K/V)算出来并存起来(past_key_values),这步只走 self-attn 分支(因为 fill_kv_cache=True),Expert 不参与。另外需要注意的时传递的输入只有prefix_embs而训练是inputs_embeds=[prefix_embs, suffix_embs]既要传递prefix_embs也有传递suffix_embs,这里的后缀编码为插值点的嵌入,即x_t = time_expanded * noise + (1 - time_expanded) * actions。因为没有Expert的输入,所以自注意力算的也只有VLM的输入。 后缀循环 dt = -1.0 / self.config.num_steps x_t = noise # 初始噪声 time = torch.tensor(1.0, ...) while time >= -dt/2: v_t = self.denoise_step(prefix_pad_masks, past_key_values, x_t, time) x_t += dt * v_t # Euler 更新 time += dt return x_t # 作为动作 做 ODE 去噪循环(Euler),每一步只算后缀。与训练的差别是“采一个随机 t 直接监督向量场”,推理是“从 t=1 积分到 t=0”(ODE 解)。这里的 num_steps 控制积分步数(精度/速度权衡)。 denoise_step(...)----> suffix_embs, suffix_pad_masks, suffix_att_masks = self.embed_suffix(x_t, timestep) # 组装 prefix/suffix 的联合注意力掩码(prefix 只提供 pad_2d 以允许被看) full_att_2d_masks = torch.cat([prefix_pad_2d_masks, suffix_att_2d_masks], dim=2) position_ids = prefix_offsets + torch.cumsum(suffix_pad_masks, dim=1) - 1 outputs_embeds, _ = self.vlm_with_expert.forward( attention_mask=full_att_2d_masks, position_ids=position_ids, past_key_values=past_key_values, # ★ 复用 prefix KV inputs_embeds=[None, suffix_embs],# ★ 只有后缀 use_cache=self.config.use_cache, # True fill_kv_cache=False, # ★ 不再建缓存 ) suffix_out = outputs_embeds[1][:, -chunk_size:] v_t = self.action_out_proj(suffix_out) denoise_step(...)拿缓存 + 只喂后缀(前缀为None),分层走 cross/self。VLM 不再重算 Q/K/V,层内 cross-attn 时,Expert 的 Query 去看 prefix 的 K/V 缓存;若该层被 self_attn_every_n_layers 强制 self,则只做 Expert 自注意(VLM 旁路,因为没有输入前缀)。与训练的差别是训练时两侧一起算(inputs_embeds=[prefix, suffix]),且无缓存。 训练 vs 推理 维度 训练(VLAFlowMatching.forward) 推理(sample_actions + denoise_step) 是否用真动作 用,参与构造 x_t,t 与 u_t=noise-actions,形成监督 不用(没有 label),从噪声解 ODE 得动作 时间使用 随机采样 t~Beta(1.5,1.0),单步监督 从 t=1 到 t=0 迭代(步长 dt=-1/num_steps) 是否建 KV Cache 否(use_cache=False, fill_kv_cache=False) 是:先prefix-only 建缓存;循环中 suffix-only 复用缓存 两塔前向喂法 一次性 inputs_embeds=[prefix, suffix] 两段:① [prefix, None](建缓存);② [None, suffix](复用缓存) 层内注意力路由 由 attention_mode / self_attn_every_n_layers 决定,但无缓存上下文 相同路由;cross 时 Expert-Q × cached VLM-KV;self 时只 Expert 自注意 位置编码(RoPE) 每层对参与计算的 Q/K 应用 同上;prefix 的位置在建缓存时用过;suffix 在每步都重算 损失/梯度 MSE(u_t, v_t) → 反向 无损失、无反向 输出后处理 返回标量 loss(policy 中聚合/掩码后) x_t 作为动作 → unnormalize →(可选)Aloha 映射;支持 n-step 队列 注意力 注意力的计算是模型训练和推理的核心,主要涉及自注意力和交叉注意力,这里单独总结一章节进行梳理分析。 自注意力 自注意力的代码注意在forward_attn_layer函数中,接下来根据代码来进行分析。 (1)自注意力QKV计算 query_states = [] key_states = [] value_states = [] 首先定义了Self-Attention 中的 Query、Key 和 Value。这些将用于计算注意力权重。 for i, hidden_states in enumerate(inputs_embeds): layer = model_layers[i][layer_idx] if hidden_states is None or layer is None: continue hidden_states = layer.input_layernorm(hidden_states) inputs_embeds 是一个包含不同模态输入的列表或张量。例如,它可能包含 VLM 的前缀输入(图像、文本、状态)和 Expert 的后缀输入(动作、时间)。enumerate(inputs_embeds) 会遍历 inputs_embeds 中的每个元素,并返回 i(当前元素的索引)和 hidden_states(对应的输入嵌入)。通过 enumerate 我们可以分别处理每个输入模态,i 用来区分是处理 VLM 还是 Expert。i=0 对应 VLM 的输入,i=1 对应 Expert 的输入。 因此model_layers[i][layer_idx]根据 i 来选择当前是处理 VLM 层还是 Expert 层。如果 i=0,则选择 VLM 的层;如果 i=1,则选择 Expert 的层。layer_idx是当前处理的层的索引,指定当前模型中的哪一层进行处理。 当判断hidden_states is None或layer is None是则跳过不处理,对于Expert侧来说会为空,因为外层是按照VLM层数来遍历的,Expert只有VLM的一半,因此每隔VLM一层就会有一个Expert为空。 先使用input_layernorm对当前输入hidden_states进行归一化。然后就各自进行Q/K/V计算。 hidden_states = hidden_states.to(dtype=layer.self_attn.q_proj.weight.dtype) query_state = layer.self_attn.q_proj(hidden_states).view(hidden_shape) key_state = layer.self_attn.k_proj(hidden_states).view(hidden_shape) value_state = layer.self_attn.v_proj(hidden_states).view(hidden_shape) query_states.append(query_state) key_states.append(key_state) value_states.append(value_state) 在for循环中,遍历VLM和Expert各自计算Q/K/V,然后把VLM和Expert计算的Q/K/V都分类各自加入到相同的列表中,如VLM和Expert的Q加入列表query_states.append。 (2)拼接QKV query_states = torch.cat(query_states, dim=1) key_states = torch.cat(key_states, dim=1) value_states = torch.cat(value_states, dim=1) 将VLM和Expert计算出来的Query、Key、Value各自拼接成一个大的张量,用于后续的注意力计算,从这里可以看出。VLM和Expert的注意力计算是使用一个transformer同时对VLM+Expert的输入拼接输入计算的。相当于VLM和Expert的输入可以双向注意力。 (3)EoPE编码 seq_len = query_states.shape[1] if seq_len < position_ids.shape[1]: _position_ids = position_ids[:, :seq_len] _attention_mask = attention_mask[:, :seq_len, :seq_len] else: _position_ids = position_ids _attention_mask = attention_mask attention_mask_ = _attention_mask position_ids_ = _position_ids query_states = apply_rope(query_states, position_ids_) key_states = apply_rope(key_states, position_ids_) 这段代码主要处理的是位置编码和注意力掩码,这里主要是引入了RoPE编码,计算两个位置之间的相对距离来构造编码,而不是仅仅依赖于绝对位置,提高增强模型的泛化能力。 (4)缓存机制 if use_cache: if fill_kv_cache: past_key_values[layer_idx] = { "key_states": key_states, "value_states": value_states, } else: # TODO here, some optimization can be done - similar to a `StaticCache` we can declare the `max_len` before. # so we create an empty cache, with just one cuda malloc, and if (in autoregressive case) we reach # the max len, then we (for instance) double the cache size. This implementation already exists # in `transformers`. (molbap) key_states = torch.cat([past_key_values[layer_idx]["key_states"], key_states], dim=1) value_states = torch.cat([past_key_values[layer_idx]["value_states"], value_states], dim=1) 将每一层的Key和Value缓存到past_key_values[layer_idx]中,模型训练时这里的use_cache设置为0,当模型是推理时use_cache设置为1,fill_kv_cache设置为1。主要是在推理阶段,会先调用VLM+Expert模型推理一次将Key、Value进行缓存保存起来,后续就只是推理Expert了,VLM将不再计算了,通过这样的方式以提高计算效率。 (5)注意力输出 att_output = attention_interface( attention_mask_, batch_size, head_dim, query_states, key_states, value_states ) return [att_output], past_key_values 注意力计算时会把可用来源(VLM 前缀、Expert 后缀)各自算出的 Q/K/V在序列维度拼接后统一做一次注意力,但掩码保证了“单向可见”,即VLM 与 Expert 的 Q/K/V都参与拼接,但二维掩码使 VLM 基本不看 Expert,Expert 能看 VLM。 交叉注意力 交叉注意力在forward_cross_attn_layer中实现。下面来进行分析。 (1)前缀自注意力 if len(inputs_embeds) == 2 and not past_key_values: seq_len = inputs_embeds[0].shape[1] position_id, expert_position_id = position_ids[:, :seq_len], position_ids[:, seq_len:] prefix_attention_mask = attention_mask[:, :seq_len, :seq_len] layer = model_layers[0][layer_idx] # 选 VLM 的第 layer_idx 层 hidden_states = layer.input_layernorm(inputs_embeds[0]) # 投影出 VLM 的 Q/K/V query_state = layer.self_attn.q_proj(hidden_states).view(B, Lp, H, Dh) key_state = layer.self_attn.k_proj(hidden_states).view(B, Lp, H, Dh) value_state = layer.self_attn.v_proj(hidden_states).view(B, Lp, H, Dh) # 对 Q/K 施加 RoPE(相对位置编码) query_states = apply_rope(query_state, position_id) key_states = apply_rope(key_state, position_id) # 只在 prefix 上自注意力(用 prefix 的方阵 mask) att_output = attention_interface(prefix_attention_mask, batch_size, head_dim, query_states, key_states, value_state) att_outputs.append(att_output) else: expert_position_id = position_ids 当满足inputs_embeds有前缀+后缀的数据且没有缓存的时,只取VLM的输入prefix用于计算自注意力,输出结果为att_outputs。同时如果这层是Expert的交叉注意力,那么VLM计算出来的K/V后面要给到后面Expert用作cross的K/V。 上面前缀自注意力只有只有训练的模型的时候进入交叉注意力每次都会跑,在推理阶段时每次推理只会跑一次。 (2)K/V cache缓存处理 if use_cache and past_key_values is None: past_key_values = {} if use_cache: if fill_kv_cache: past_key_values[layer_idx] = {"key_states": key_states, "value_states": value_states} else: key_states = past_key_values[layer_idx]["key_states"] value_states = past_key_values[layer_idx]["value_states"] 推理的时候会用到缓存,在推理时会调用两次forward。 建缓存阶段(prefix-only):外层会先单独跑一遍,只给 inputs_embeds=[prefix_embs, None],fill_kv_cache=True,把 VLM prefix 的 K/V 存到 past_key_values[layer_idx]。 后缀阶段(真正 cross):用 inputs_embeds=[prefix_embs, suffix_embs] 或者只给 suffix,fill_kv_cache=False,此时直接复用缓存里的 prefix K/V,不用再算。 (3)Expert的交叉注意力 expert_layer = model_layers[1][layer_idx] # 取 Expert 的第 layer_idx 层(可能是 None) if expert_layer is not None: expert_hidden_states = expert_layer.input_layernorm(inputs_embeds[1]) expert_layer is None 的出现是由 get_model_layers 对齐规则决定的,multiple_of = num_vlm_layers // num_expert_layers。Expert要能够计算交叉注意力也要满足当前层是否有Expert层。因为VLM和Expert是对齐的,不一定每一层都有Expert,而当self_attn_every_n_layers设置为2时,相当于是奇数层才会自注意力,而当VLM为16,Expert为8,那么正好Expert都在偶数层基数层没有,所以整个模型都没有注意力机制计算。 expert_query_state = expert_layer.self_attn.q_proj(expert_hidden_states) \ .view(B, Ls, He, Dhe) # 先把 VLM 的 K/V 合并 head 维,变为 [B, Lp, H*Dh] _key_states = key_states.to(dtype=expert_layer.self_attn.k_proj.weight.dtype).view(*key_states.shape[:2], -1) _value_states = value_states.to(dtype=expert_layer.self_attn.v_proj.weight.dtype).view(*value_states.shape[:2], -1) # 再喂给 Expert 自己的 k_proj/v_proj,把维度映射到 Expert 的头数与 head_dim expert_key_states = expert_layer.self_attn.k_proj(_key_states) \ .view(*_key_states.shape[:-1], -1, expert_layer.self_attn.head_dim) # [B, Lp, He, Dhe] expert_value_states = expert_layer.self_attn.v_proj(_value_states) \ .view(*_value_states.shape[:-1], -1, expert_layer.self_attn.head_dim) Expert的expert_query_state来自自己的输入,而expert_key_states、expert_value_states来之与key_states、value_states即为VLM计算过来的缓存K/V。也就是Expert计算注意力是Q使用自己的,而K/V使用的是VLM的。但是需要注意的是可能两边的模型VLM和Expert的hidden宽度、KV头数/维度不一样,先把 VLM K/V 的多头维合并(view(*, H*Dh)),再用 Expert 自己的 k_proj/v_proj 做一次线性变换,映射到 Expert 的多头维度。这就是代码里 “cross K/V 适配层” 的作用;对应到 init,当 attention_mode 包含 "cross" 时,会把 Expert 的 k_proj/v_proj 重定义成输入维=VLM 的 kv_heads x head_dim,输出维=Expert 的。 # 让 Expert 的 token 位置从 0 开始(RoPE 需要相对位置) expert_position_id = expert_position_id - torch.min(expert_position_id, dim=1, keepdim=True).values # 行选择 Expert 的 queries(后缀那段),列只到 prefix 的 K/V 长度(严格 cross,不看自己) expert_attention_mask = attention_mask[:, -inputs_embeds[1].shape[1]:, : expert_key_states.shape[1] ] # 对 Expert 的 Query 施加 RoPE expert_query_states = apply_rope(expert_query_state, expert_position_id) att_output = attention_interface(expert_attention_mask, batch_size, head_dim, expert_query_states, expert_key_states, expert_value_states) att_outputs.append(att_output) 接下来就是计算mask,确保Expert计算cross时只看到前缀(纯cross-attn),不能自回看(不看后缀自身)。再计算RoPE的位置编码,最后调用attention_interface计算交叉注意力得到结果输出。 return att_outputs, past_key_values 最终返回的是两个流对应的自注意力输出,att_outputs 的 长度与 inputs_embeds 对齐,索引0代表VLM 流的输出(前面 prefix 自注意力的结果);索引 1 代表Expert 流的输出(本层 cross 的结果;没有 Expert 就是 None)。外层主循环会据此对两个流分别过 o_proj + 残差 + MLP 等,继续下一层。 总结一下:cross-attn 分支“不拼接 Expert 的 K/V”:Expert 的 Q 只对 VLM 的 K/V(经投影到 Expert 维度)做注意。训练时VLM K/V现场算出并可选择写入缓存;Expert Q 只看这份 VLM K/V。推理时先用前缀阶段填好 VLM KV 缓存;去噪时 Expert Q 直接用缓存的 VLM K/V。VLM 不产生 Q,不会“看”Expert。 Expert要计算交叉注意力需要满足什么条件? 主要看3个参数 L = num_vlm_layers:VLM 总层数 E = num_expert_layers:Expert 总层数(必须 > 0 且能整除 L) S = self_attn_every_n_layers:每隔 S 层强制走一次自注意力(=这层不做 cross) 某层做 cross 的条件 : i % M 0 且(S = 0 或 i % S != 0) 举例1:L=16, E=8;有Expert的层是{0,2,4,6,8,10,12,14},若S=2这些层全是S的倍数,那么没有一层做cross。若S=3,做cross的为{2,4,8,10,14}。 总结一下就是能做cross的,先看每隔几层做cross(间接有self_attn_every_n_layers决定)同时要满足能做cross的这几层有没有Expert。一般情况下,当VLM和Expert具有相同层数是,奇数层做Cross,如果Expert为VLM的一半是需要设置self_attn_every_n_layers设置大于2以上的奇数才能做cross。 层类型 训练时 推理时 Self-Attn VLM & Expert 各自算 QKV → 拼接 → 双向注意 → 切分结果 同训练,但 prefix KV 在首轮缓存,后续复用;双向依旧存在,但 VLM 冻结 Cross-Attn VLM 自注意更新自身 KV;Expert 只算 Q,从 VLM KV(线性投影后)读条件 prefix KV 已缓存;Expert 只算 Q,直接读缓存的 VLM KV;无需重复计算 模型配置 SmolVLAConfig 模型配置主要是SmolVLAConfig类,其决定了训练/推理是模型结构、预处理、优化器/调度器、以及VLM骨干选择与冻结策略。 class SmolVLAConfig(PreTrainedConfig): # Input / output structure. n_obs_steps: int = 1 chunk_size: int = 50 n_action_steps: int = 50 normalization_mapping: dict[str, NormalizationMode] = field( default_factory=lambda: { "VISUAL": NormalizationMode.IDENTITY, "STATE": NormalizationMode.MEAN_STD, "ACTION": NormalizationMode.MEAN_STD, } ) # Shorter state and action vectors will be padded max_state_dim: int = 32 max_action_dim: int = 32 # Image preprocessing resize_imgs_with_padding: tuple[int, int] = (512, 512) # Add empty images. Used by smolvla_aloha_sim which adds the empty # left and right wrist cameras in addition to the top camera. empty_cameras: int = 0 # Converts the joint and gripper values from the standard Aloha space to # the space used by the pi internal runtime which was used to train the base model. adapt_to_pi_aloha: bool = False # Converts joint dimensions to deltas with respect to the current state before passing to the model. # Gripper dimensions will remain in absolute values. use_delta_joint_actions_aloha: bool = False # Tokenizer tokenizer_max_length: int = 48 # Decoding num_steps: int = 10 # Attention utils use_cache: bool = True # Finetuning settings freeze_vision_encoder: bool = True train_expert_only: bool = True train_state_proj: bool = True # Training presets optimizer_lr: float = 1e-4 optimizer_betas: tuple[float, float] = (0.9, 0.95) optimizer_eps: float = 1e-8 optimizer_weight_decay: float = 1e-10 optimizer_grad_clip_norm: float = 10 scheduler_warmup_steps: int = 1_000 scheduler_decay_steps: int = 30_000 scheduler_decay_lr: float = 2.5e-6 vlm_model_name: str = "HuggingFaceTB/SmolVLM2-500M-Video-Instruct" # Select the VLM backbone. load_vlm_weights: bool = False # Set to True in case of training the expert from scratch. True when init from pretrained SmolVLA weights add_image_special_tokens: bool = False # Whether to use special image tokens around image features. attention_mode: str = "cross_attn" prefix_length: int = -1 pad_language_to: str = "longest" # "max_length" num_expert_layers: int = 8 # Less or equal to 0 is the default where the action expert has the same number of layers of VLM. Otherwise the expert have less layers. num_vlm_layers: int = 16 # Number of layers used in the VLM (first num_vlm_layers layers) self_attn_every_n_layers: int = 2 # Interleave SA layers each self_attn_every_n_layers expert_width_multiplier: float = 0.75 # The action expert hidden size (wrt to the VLM) min_period: float = 4e-3 # sensitivity range for the timestep used in sine-cosine positional encoding max_period: float = 4.0 可以分为几个部分 (1)输入输出与时序 n_obs_steps: 输入观测的历史步数,默认为1。 chunk_size:每次模型生成的动作序列长度(后缀序列长度)。 n_action_steps:外部消费的动作步数,需要满足n_action_steps <= chunk_size(代码中已校验)。 采样与训练的后缀长度在 VLAFlowMatching.sample_actions/forward 中使用,动作队列在 SmolVLAPolicy 中按 n_action_steps 出队。 (2)归一化与特征维度 normalization_mapping:各模态的标准化策略,视觉默认 Identity,状态与动作 MeanStd。 max_state_dim/max_action_dim:状态、动作向量的固定上限维度;短向量会 pad 到该维度(pad_vector)。 Normalize/Unnormalize 与 state_proj/action_ x _proj 的投影维度。 (3)图像预处理与空相机 resize_imgs_with_padding=(512,512):视觉输入 pad-resize 到固定分辨率,然后再做 [-1,1] 归一化(SigLIP 习惯)。 empty_cameras:允许在 batch 缺少图像时补空相机占位(用于多摄像头但部分缺失的场景)。 (4)Aloha 相关开关 adapt_to_pi_aloha:状态/动作与 Aloha 空间的双向转换(关节翻转、夹爪角度/线性空间互转)。 use_delta_joint_actions_aloha:将关节维度转为相对量(目前未在 LeRobot 中实现,置 True 会报错)。 (5)文本与采样步数 tokenizer_max_length=48:语言 token 最大长度。 num_steps=10:Flow Matching 反推理的 Euler 步数(越大越精细,越慢)。 prepare_language、sample_actions 的迭代去噪循环。 (6)缓存与注意力 use_cache=True:是否使用 KV-Cache(前缀只算一次,后续重复用)。 attention_mode="cross_attn":与 SmolVLMWithExpertModel 的交叉注意力对齐策略。 prefix_length=-1/pad_language_to="longest":前缀长度/语言 padding 策略;用于构造 attention_mask 与 position_ids。 (7)微调的策略 freeze_vision_encoder=True:冻结 VLM 视觉编码器。 train_expert_only=True:只训练动作 expert(VLM 其它部分冻结)。 train_state_proj=True:是否训练状态投影层。 影响SmolVLMWithExpertModel.set_requires_grad 以及 VLM 参数的 requires_grad 设置。 (8)优化器与调度器 optimizer_* 与 scheduler_*:在训练入口 TrainPipelineConfig.validate() 使用,生成默认的 AdamW + 余弦退火带预热调度。 可被 CLI 覆写(如 --optimizer.lr 等)。 (9)VLM骨干与权重加载 vlm_model_name="HuggingFaceTB/SmolVLM2-500M-Video-Instruct":指定用哪个 VLM 仓库(用于取 tokenizer/processor,和构建骨干结构)。 load_vlm_weights=False:是否直接从该 VLM 仓库下载骨干权重。为 False时只拿 AutoConfig 构结构,权重随机初始化,随后通常被策略检查点覆盖。为 True时用 AutoModelForImageTextToText.from_pretrained 加载骨干权重(仅在 --policy.type=smolvla 路线下常用)。 与 --policy.path 的关系为用 --policy.path=lerobot/smolvla_base 时,实际权重来自本地/Hub 的策略检查点(包含 VLM+expert),不会使用骨干权重,但仍会用 vlm_model_name 主要是加载 tokenizer/processor。用 --policy.type=smolvla 时,vlm_model_name 决定骨干结构,load_vlm_weights 决定是否拉骨干权重,expert 按本地配置新建训练。 (10)层数与宽度对齐 num_vlm_layers:把 VLM 的文本层裁剪为前 N 层再用。裁剪层数后设为 self.num_vlm_layers。 num_expert_layers:专家 expert 模型的层数;若 ≤0 则默认与 VLM 层数相同。决定 expert 与 VLM 的层对齐步长 multiple_of = num_vlm_layers // num_expert_layers。只有在 i % multiple_of = 0 的 VLM 层位点才映射到一个 expert 层用于交叉注意力;其他层的 expert_layer 为空。 self_attn_every_n_layers:每隔 n 层强制走“仅自注意力”而不是交叉注意力。当 attention_mode 含 “cross” 且 fill_kv_cache=False 时,如果 layer_idx % n = 0 则走 self-attn 分支,否则走 cross-attn 分支。例如n=2 → 偶数层自注意、奇数层尝试交叉注意,但还需该层“有映射到的 expert 层”(见 multiple_of)才真正执行 cross-attn。 expert_width_multiplier:expert 的隐藏维度 = VLM 隐藏维度 × multiplier(同时重设 FFN 的 intermediate_size)。expert 更窄以降算力;但会改动线性层形状,需与加载的检查点一致,否则会维度不匹配。为实现 cross-attn,代码会按 VLM hidden 尺寸重建部分 q/k/v 投影,使其能接收来自 VLM 的输入(跳过“只自注意”层)。 在SmolVLAConfig配置集中定义了 SmolVLA 的“结构与训练/推理开关”。训练微调常用 --policy.path=lerobot/smolvla_base,此时多数结构参数不宜修改,微调时从smolvla_base中加载config.json配置;而从骨干自建训练时才需要精细调 num_expert_layers/num_vlm_layers/expert_width_multiplier/load_vlm_weights 等,并确保与骨干 hidden_size/层数一致。 加载流程 策略的加载主要分为两条入口路径,两者互斥,通过启动时参数指定。 (1)--policy.path=....方式 用 --policy.path=.....:指定一个已存在的策略checkpoint(Hub 上或本地目录)。如训练时微调可以指定lerobot/smolvla_base,推理时指定output/train/pretrained_model。会从 path/config.json 里反序列化成 SmolVLAConfig;会加载同目录下的 model.safetensors(整个策略权重:VLM骨干 + 动作专家 + 投影层等);训练开始时,模型已经有了一套完整的初始化参数(通常是预训练好的)。 python -m lerobot.scripts.train \ --policy.path=lerobot/smolvla_base \ --dataset.repo_id=xxx \ --batch_size=64 --steps=200000 这里会拿 Hugging Face Hub 上的 lerobot/smolvla_base(含 config.json + model.safetensors,整个策略权重:VLM骨干 + 动作专家 + 投影层等)来初始化。 (2)--policy.type=smolvla方式 指定一个 策略类别(由 @PreTrainedConfig.register_subclass("smolvla") 注册)。会创建一个全新的 SmolVLAConfig 对象(带默认超参),而不是加载 checkpoint。没有预训练权重,除非配合 load_vlm_weights=True,这时只会拉取纯VLM背骨的预训练权重(而动作专家层仍然是随机初始化)。可以用命令行参数覆盖任意超参(比如 --policy.num_expert_layers=4)。 python -m lerobot.scripts.train \ --policy.type=smolvla \ --dataset.repo_id=xxx \ --batch_size=64 --steps=200000 \ --policy.load_vlm_weights=True 从零(或仅用 VLM 预训练骨干)开始训练一个新策略。 下面以推理和训练举例说明其调用流程。 (1)训练使用policy.path方式 在 validate() 中读取 path,并把所有 --policy.xxx 作为“同层覆写”传入配置加载。 policy_path = parser.get_path_arg("policy") self.policy = PreTrainedConfig.from_pretrained(policy_path, cli_overrides=cli_overrides) self.policy.pretrained_path = policy_path 判断是从本地目录还是Hub下载获取配置文件,然后应用得到 SmolVLAConfig。只加载“配置”(config.json),不加载模型权重。权重加载发生在后续 policy_cls.from_pretrained(...)(另一个类,见 policies/pretrained.py)。 @classmethod def from_pretrained(cls, pretrained_name_or_path, *, ..., **policy_kwargs) -> T: model_id = str(pretrained_name_or_path) # 1) 决定从本地目录还是Hub取配置文件(只取config,不取权重) if Path(model_id).is_dir(): if CONFIG_NAME in os.listdir(model_id): config_file = os.path.join(model_id, CONFIG_NAME) else: print(f"{CONFIG_NAME} not found in {Path(model_id).resolve()}") else: try: config_file = hf_hub_download(repo_id=model_id, filename=CONFIG_NAME, ...) except HfHubHTTPError as e: raise FileNotFoundError(...) from e # 2) 应用CLI覆写(如 --policy.xxx=...) cli_overrides = policy_kwargs.pop("cli_overrides", []) with draccus.config_type("json"): return draccus.parse(cls, config_file, args=cli_overrides) 构建策略,注入数据集特征与统计,若存在 pretrained_path 则连同权重加载。 cfg.input_features/output_features = ... if cfg.pretrained_path: policy = policy_cls.from_pretrained(**kwargs) else: policy = policy_cls(**kwargs) 加载权重(目录或 Hub 的 model.safetensors),随后迁移到 device、设 eval()(训练循环里会再切回 train())。 if os.path.isdir(model_id): policy = cls._load_as_safetensor(...) policy.to(config.device); policy.eval() SmolVLA 特定初始化,即使走 path,仍按 vlm_model_name 加载 tokenizer/processor(非权重),并实例化骨干+expert。 self.language_tokenizer = AutoProcessor.from_pretrained(self.config.vlm_model_name).tokenizer self.model = VLAFlowMatching(config) (2)训练使用policy.type方式 draccus 按类型直接实例化 SmolVLAConfig(该类已注册)并解析 --policy.xxx。 @PreTrainedConfig.register_subclass("smolvla") class SmolVLAConfig(PreTrainedConfig): make_policy 同上;因无 pretrained_path,默认从零构建。若配置 load_vlm_weights=true,才会把骨干权重从 vlm_model_name 拉下来(expert 仍需训练)。 if load_vlm_weights: self.vlm = AutoModelForImageTextToText.from_pretrained(model_id, ...) else: config = AutoConfig.from_pretrained(model_id) self.vlm = SmolVLMForConditionalGeneration(config=config) (3)推理模式只能使用policy.path方式 policy_path = parser.get_path_arg("policy") self.policy = PreTrainedConfig.from_pretrained(policy_path, cli_overrides=cli_overrides) self.policy.pretrained_path = policy_path record 的配置按policy.path加载训练的模型,随后通过 predict_action/select_action 使用策略进行推理。 policy.path 对比 policy.type 维度 policy.path=... policy.type=smolvla 配置来源 从 checkpoint 目录/Hub 仓库里的 config.json 反序列化成 SmolVLAConfig 通过 @PreTrainedConfig.register_subclass("smolvla") 新建一个默认 SmolVLAConfig,命令行可覆写 权重来源 从 checkpoint 里的 model.safetensors 加载完整策略权重(VLM骨干 + 动作专家 + 投影层) 默认全随机;若 load_vlm_weights=True,则只加载 VLM骨干权重(SmolVLM2),动作专家仍随机 归一化统计 不从 checkpoint 恢复,而是来自数据集 dataset_stats(normalize_inputs/targets在加载时被忽略) 同左 Tokenizer/Processor 仍然会用 config.vlm_model_name(默认 HuggingFaceTB/SmolVLM2)加载 tokenizer/processor 同左 常见场景 - 直接推理- 微调已有策略 - 从零开始训练新策略- 换结构做实验(改 num_expert_layers、expert_width_multiplier等) 推理可用性 一键可用(权重完整) 不可直接用(专家没训练,输出无意义),除非后续手动加载你自己训练好的权重 是否需要 HuggingFaceTB/SmolVLM2 权重 不需要(只用到它的 processor/tokenizer) 如果 load_vlm_weights=True → 需要拉骨干权重;否则全随机 -
lerobot之smolvla体验
环境安装 pip install -e ".[smolvla]" 在原来lerobot的环境基础上。 启动训练 本文主要是记录复现lerobot smolvla策略的效果,为了快速看到效果,这里不进行采集数据了,直接用此前ACT采集的数据,将数据打包放到autodl云服务器上进行训练。 python src/lerobot/scripts/train.py \ --dataset.root=/root/autodl-tmp/lerobot/data/record-07271539 \ --dataset.repo_id=laumy/record-07271539 \ --policy.push_to_hub=false \ --policy.path=lerobot/smolvla_base \ --policy.device=cuda \ --output_dir=outputs/train/smolvla_test \ --job_name=smolvla_test --batch_size=64 \ --steps=20000 --wandb.enable=false 或者 python -m lerobot.scripts.train \ --policy.type=smolvla \ --policy.vlm_model_name=HuggingFaceTB/SmolVLM2-500M-Video-Instruct \ --policy.load_vlm_weights=true \ --policy.num_vlm_layers=16 \ --policy.num_expert_layers=8 \ --dataset.repo_id=laumy/record-07271539 \ --output_dir=outputs/train/smolvla_test2 \ --job_name=smolvla_test \ --batch_size=64 --steps=20000 --wandb.enable=false 如果数据集在huggingface上面,则需要先登陆hugging face huggingface-cli login 填写token. python src/lerobot/scripts/train.py \ --dataset.repo_id=laumy0929/grab_candy_or_lemon \ --policy.path=lerobot/smolvla_base \ --policy.device=cuda \ --policy.repo_id=laumy0929/smolvla_test \ --output_dir=outputs/train/smolvla_test \ --job_name=smolvla_test --batch_size=64 \ --steps=20000 --wandb.enable=false 关于数据集的获取取决于两个参数,一个是repo_id另外一个是dataset.root。 repo_id: 必填字段,是在 Hugging Face Hub 上的数据集标识(datasets 仓库名)。 dataset.root :选填字段,是本地数据集所在目录。 训练首先从 dataset.root 读取本地数据;如果本地缺失需要的文件,才会用 repo_id 到 Hub 拉取缺的内容到这个 root 目录里。 下面有几个场景。 如果同时给定了dataset.root和dataset.repo_id 如果 root 目录已经是规范的 LeRobot v2 数据集结构(有 meta/info.json、data/.parquet、可选 videos/.mp4),会直接用本地文件,不会下载。 如果本地缺少 meta(或部分 data 文件),代码会用 repo_id 从 Hub 把缺的部分同步到你指定的 root 目录后再加载。 如果只传dataset.repo_id 会把本地根目录设为默认缓存:~/.cache/huggingface/lerobot/{repo_id}(若设置了环境变量 LEROBOT_HOME,则用 $LEROBOT_HOME/{repo_id}),如果本地缓存里已经有完整数据,则直接用本地文件,不再下载。如果本地没有缓存,远端也没有数据,就会报错。 推理验证 python -m lerobot.record \ --robot.type=so101_follower \ --robot.disable_torque_on_disconnect=true \ --robot.port=/dev/ttyACM0 --robot.cameras="{ handeye: {type: opencv, index_or_path: 4, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}}" \ --robot.id=R12252801 \ --display_data=false \ --dataset.single_task="Grab the cube" \ --policy.path=outputs/smolvla_weigh_08181710/pretrained_model \ --dataset.episode_time_s=240 \ --dataset.repo_id=laumy/eval_smolvla_08181710 常见问题 训练报错如下: Traceback (most recent call last): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connection.py", line 198, in _new_conn sock = connection.create_connection( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/util/connection.py", line 85, in create_connection raise err File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/util/connection.py", line 73, in create_connection sock.connect(sa) TimeoutError: [Errno 110] Connection timed out The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 787, in urlopen response = self._make_request( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 488, in _make_request raise new_e File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 464, in _make_request self._validate_conn(conn) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 1093, in _validate_conn conn.connect() File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connection.py", line 753, in connect self.sock = sock = self._new_conn() File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connection.py", line 207, in _new_conn raise ConnectTimeoutError( urllib3.exceptions.ConnectTimeoutError: (<urllib3.connection.HTTPSConnection object at 0x7fe651566380>, 'Connection to huggingface.co timed out. (connect timeout=None)') The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/adapters.py", line 667, in send resp = conn.urlopen( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 841, in urlopen retries = retries.increment( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/util/retry.py", line 519, in increment raise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type] urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/HuggingFaceTB/SmolVLM2-500M-Video-Instruct/tree/main/additional_chat_templates?recursive=False&expand=False (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7fe651566380>, 'Connection to huggingface.co timed out. (connect timeout=None)')) During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/root/autodl-tmp/lerobot/src/lerobot/scripts/train.py", line 291, in <module> train() File "/root/autodl-tmp/lerobot/src/lerobot/configs/parser.py", line 226, in wrapper_inner response = fn(cfg, *args, **kwargs) File "/root/autodl-tmp/lerobot/src/lerobot/scripts/train.py", line 139, in train policy = make_policy( File "/root/autodl-tmp/lerobot/src/lerobot/policies/factory.py", line 168, in make_policy policy = policy_cls.from_pretrained(**kwargs) File "/root/autodl-tmp/lerobot/src/lerobot/policies/pretrained.py", line 101, in from_pretrained instance = cls(config, **kwargs) File "/root/autodl-tmp/lerobot/src/lerobot/policies/smolvla/modeling_smolvla.py", line 356, in __init__ self.language_tokenizer = AutoProcessor.from_pretrained(self.config.vlm_model_name).tokenizer File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/models/auto/processing_auto.py", line 288, in from_pretrained config_dict, _ = ProcessorMixin.get_processor_dict(pretrained_model_name_or_path, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/processing_utils.py", line 873, in get_processor_dict for template in list_repo_templates( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/utils/hub.py", line 161, in list_repo_templates return [ File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/utils/hub.py", line 161, in <listcomp> return [ File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 3168, in list_repo_tree for path_info in paginate(path=tree_url, headers=headers, params={"recursive": recursive, "expand": expand}): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/huggingface_hub/utils/_pagination.py", line 36, in paginate r = session.get(path, params=params, headers=headers) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/sessions.py", line 602, in get return self.request("GET", url, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/sessions.py", line 589, in request resp = self.send(prep, **send_kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/sessions.py", line 703, in send r = adapter.send(request, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/huggingface_hub/utils/_http.py", line 96, in send return super().send(request, *args, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/adapters.py", line 688, in send raise ConnectTimeout(e, request=request) requests.exceptions.ConnectTimeout: (MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/HuggingFaceTB/SmolVLM2-500M-Video-Instruct/tree/main/additional_chat_templates?recursive=False&expand=False (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7fe651566380>, 'Connection to huggingface.co timed out. (connect timeout=None)'))"), '(Request ID: 7f4d5747-ec95-47cc-a55f-cb3e230c52e2)') 原因是训练在初始化 SmolVLA 的 VLM 时需要从 Hugging Face Hub 拉取资源(AutoProcessor.from_pretrained 默认用 vlm_model_name=HuggingFaceTB/SmolVLM2-500M-Video-Instruct)。你的机器连到 huggingface.co 超时,导致下载失败并报 ConnectTimeout。 解决办法:export HF_ENDPOINT=https://hf-mirror.com 把原本指向 https://huggingface.co 的所有 Hub 请求(模型/数据集下载、API 调用)改走 https://hf-mirror.com。作用范围仅当前这个终端会话。关闭终端或开新终端就失效。 训练过程过程中警告 huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) TOKENIZERS_PARALLELISM是分词器在一次调用会开多线程并行处理文本。分词器库是hugging Face的分词器库,负责把文本指令变成模型可用的token id序列,也能把id还原会文本,跟我们此前在一步步实现transformer 的词表类型。出现这样的警告是tokenizers它开了多线程并发,而 DataLoader 再 fork 出子进程并发(本身DataLoader是可以并发),这样容易有死锁风险,为安全起见,库检测到这种顺序就自动把自己的多线程并行关掉,并给出提示。如果要关掉tokenizers的多线程并发,export TOKENIZERS_PARALLELISM=false。 -
lerobot ACT实现分析
配置类ACTConfig @PreTrainedConfig.register_subclass("act") @dataclass class ACTConfig(PreTrainedConfig): # 输入/输出结构 chunk_size: int = 100 # 动作块长度(每次预测的动作序列长度) n_action_steps: int = 100 # 每次策略调用执行的动作步数(≤ chunk_size) temporal_ensemble_coeff: float | None = None # 时序集成系数(None表示禁用) # VAE配置 use_vae: bool = True # 是否启用VAE(增强动作多样性) latent_dim: int = 32 # 潜在空间维度 kl_weight: float = 10.0 # KL散度损失权重 # Transformer配置 dim_model: int = 512 # Transformer隐藏维度 n_heads: int = 8 # 注意力头数 n_encoder_layers: int = 4 # 编码器层数 n_decoder_layers: int = 1 # 解码器层数(原始实现bug,仅用第1层) # 视觉Backbone vision_backbone: str = "resnet18" # 图像特征提取网络 ...... ACTConfig是ACT算法核心配置类,主要定义了模型结构、输入输出格式、训练参数和推理逻辑等。 输入/输出结构 参数主要配置模型输入观测、输出动作的基本格式,是连接环境与模型的桥梁。 # Input / output structure. n_obs_steps: int = 1 # 输入观测的时间步数(当前仅支持1步观测,即当前时刻观测) chunk_size: int = 100 # 动作块长度:每次预测的连续动作序列长度(核心参数,决定分块粒度) n_action_steps: int = 100 # 每次策略调用执行的动作步数(≤ chunk_size,默认与chunk_size一致,即一次执行整段动作块) normalization_mapping: dict[str, NormalizationMode] = field( default_factory=lambda: { "VISUAL": NormalizationMode.MEAN_STD, # 图像特征归一化:减均值除标准差 "STATE": NormalizationMode.MEAN_STD, # 状态特征(如机器人关节角)归一化:同上 "ACTION": NormalizationMode.MEAN_STD, # 动作归一化:同上(确保训练时输入分布稳定) } ) chunk_size 是 ACT 算法的核心设计:将长时序动作生成分解为固定长度的“动作块”(如100步),避免一次性规划整个任务序列,降低计算复杂度。 n_action_steps 控制每次策略调用后实际执行的动作步数。例如,若 chunk_size=100 且 n_action_steps=50,则模型预测100步动作,执行前50步,丢弃后50步(适用于需要频繁重新规划的场景)。 架构配置 从此前的具身智能ACT算法我们知道ACT模型算法主要是基于transformer结构,从实现上模型的核心组件可以分为视觉backbone、transformer、VAE结构。 (1)视觉backbone配置 # Vision backbone. vision_backbone: str = "resnet18" # 视觉特征提取网络:使用ResNet18(轻量级,适合实时控制) pretrained_backbone_weights: str | None = "ResNet18_Weights.IMAGENET1K_V1" # 预训练权重:使用ImageNet-1K预训练参数初始化,提升特征提取能力 replace_final_stride_with_dilation: int = False # 是否用空洞卷积替换ResNet的最终2x2 stride(默认关闭,保持特征图分辨率) 上面的参数是ACT算法中用于图像特征提取模块的核心配置,影响模型对视觉输入的理解能力和计算效率。 首先指定了图像特征提取的骨干网络为resnet18,其仅有18层网络,参数量约1100万,常用于实时机器人控制场景,ResNet是通过残差连接缓解深层网络梯度消失问题,能有效提取多尺度图像特征包括边缘纹理到语义信息。视觉 Backbone 的输出(如 ResNet-18 的 layer4 特征图)会被展平为序列,与机器人状态、潜在向量等多模态特征拼接后输入 Transformer 编码器。 其次指定了resnet18预训练权重的来源,默认使用使用 ImageNet-1K 数据集预训练的权重。 最后的replace_final_stride_with_dilation默认关闭,主要是控制是否用“空洞卷积”替换resnet最后一层的2*2步幅卷积。关闭空洞卷积适合对实时性要求高、特征分辨率要求低的场景,如粗粒度抓取任务。如果打开可保留更多的空洞细节(如物体边缘、纹理),适合精细操作如螺丝拧入、零件对齐、但是需要权衡计算量增加和内存的占用。 (2)transformer配置 # Transformer layers. pre_norm: bool = False # Transformer块归一化位置:False=后归一化(原始ACT实现),True=前归一化(更稳定但需调参) dim_model: int = 512 # Transformer隐藏层维度(特征维度) n_heads: int = 8 # 多头注意力头数(8头,总注意力维度=512/8=64/头) dim_feedforward: int = 3200 # 前馈网络中间维度(通常为dim_model的4-6倍,此处3200=512*6.25) feedforward_activation: str = "relu" # 前馈网络激活函数(ReLU,原始ACT实现) n_encoder_layers: int = 4 # Transformer编码器层数(4层,用于融合多模态输入特征) # 注:原始ACT实现中n_decoder_layers=7,但因代码bug仅使用第1层,此处对齐原始实现设为1 n_decoder_layers: int = 1 # Transformer解码器层数(1层,用于生成动作块序列) 上面参数定义了ACT算法中Transformer 编码器/解码器的核心结构参数,直接决定模型的序列建模能力、计算效率和特征融合效果。 pre_norm: 归一化位置 ,False=原始行为,True=训练更稳定(需重新调参),若训练发散,可尝试设为 True。 dim_model:特征维度(模型容量),增大→更强表达能力,但计算/内存成本平方级增长,机器人实时场景建议 ≤ 1024。 n_heads:注意力并行头数,增多更细粒度关注,但通信开销增大 ,保持 dim_model/n_heads = 64(如 512/8=64)。 n_encoder_layers: 特征融合深度,增多融合更充分,但推理延迟增加,机械臂操作建议 4-6 层。 n_decoder_layers: 动作生成深度,受原始 bug 限制,固定为 1 以对齐行为,若修复原始 bug,可尝试增至 3-4 层。 (3)VAE变分自编码配置 # VAE. use_vae: bool = True # 是否启用VAE(默认启用,通过潜在空间建模动作分布) latent_dim: int = 32 # VAE潜在空间维度(32维,压缩动作序列信息) n_vae_encoder_layers: int = 4 # VAE编码器层数(4层Transformer,用于将动作块编码为潜在分布) (4)推理配置 # Inference. # Note: ACT原论文中启用时序集成时默认值为0.01 temporal_ensemble_coeff: float | None = None # 时序集成系数:None=禁用,>0=启用(指数加权平均平滑动作) 该参数就是是否启动ACT的Temporal Ensembling机制,时序集成(Temporal Ensembling) 功能的启用与权重计算方式,用于在推理时平滑动作序列,避免机器人执行突变动作(尤其适用于精细操作如机械臂抓取、插入等任务)。 要启动Temporal Ensembling机制需显式设置该参数为非 None 的浮点值(如 0.01),且需满足n_action_steps 必须设为 1(每次策略调用仅执行 1 步动作,确保每步都通过集成优化)。 当 temporal_ensemble_coeff = α(如 0.01)时,ACTTemporalEnsembler 会对连续多轮预测的动作块(chunk_size 长度)进行 指数加权平均。 (5)训练损失配置 # Training and loss computation. dropout: float = 0.1 kl_weight: float = 10.0 dropout控制 Transformer 层的 随机失活概率,用于正则化,防止模型过拟合训练数据。在训练过程中,以 dropout 概率(此处 10%)随机将 Transformer 层(如多头注意力输出、前馈网络输出)的部分神经元激活值设为 0,强制模型学习更鲁棒的特征(不依赖特定神经元组合) kl_weight控制 KL 散度损失(KL-divergence Loss) 的权重,仅在启用 VAE(use_vae=True,默认启用)时生效。10.0 是一个较大的权重,表明原始 ACT 实现中更注重约束潜在分布的“规范性”(接近标准正态),以确保 VAE 能生成多样化的动作序列,避免模型仅记忆训练数据中的动作模式。 (6)训练优化 # Training preset optimizer_lr: float = 1e-5 optimizer_weight_decay: float = 1e-4 optimizer_lr_backbone: float = 1e-5 optimizer_lr控制除视觉Backbone外所有参数(如Transformer编码器/解码器、VAE层等)的梯度更新步长。学习率过大会导致训练不稳定(Loss震荡),过小则收敛缓慢。1e-5(0.00001)是训练Transformer类模型的经典学习率(如BERT、GPT等),尤其适用于。 optimizer_weight_decay权重衰减(L2正则化)系数,用于抑制过拟合。过小(如1e-5):正则化不足,易过拟合训练数据。过大(如1e-3):过度抑制参数更新,导致模型欠拟合。适用于机器人操作任务,训练数据通常包含噪声(如传感器误差、动作抖动),权重衰减可提升模型对噪声的鲁棒性。 optimizer_lr_backbone视觉Backbone(如ResNet18)参数的专用学习率。ACT原论文中Backbone与主模型联合训练,未使用更小的Backbone学习率。 在实际的工程中,可在get_optim_params 中显式区分Backbone与非Backbone参数,应用不同学习率: def get_optim_params(self) -> dict: return [ { "params": [p for n, p in self.named_parameters() if not n.startswith("model.backbone") and p.requires_grad], "lr": self.config.optimizer_lr, # 主参数学习率 }, { "params": [p for n, p in self.named_parameters() if n.startswith("model.backbone") and p.requires_grad], "lr": self.config.optimizer_lr_backbone, # Backbone专用学习率 }, ] 策略入口类ACTPolicy 初始化逻辑 class ACTPolicy(PreTrainedPolicy): def __init__(self, config: ACTConfig, dataset_stats=None): super().__init__(config) # 输入/输出归一化(标准化数据分布) self.normalize_inputs = Normalize(config.input_features, config.normalization_mapping, dataset_stats) self.unnormalize_outputs = Unnormalize(config.output_features, config.normalization_mapping, dataset_stats) self.model = ACT(config) # 加载ACT神经网络 # 初始化时序集成器(若启用) if config.temporal_ensemble_coeff is not None: self.temporal_ensembler = ACTTemporalEnsembler(config.temporal_ensemble_coeff, config.chunk_size) self.reset() # 重置动作队列/集成器 这段代码定义了一个基于Action Chunking Transformer (ACT)的策略类,主要用于机器人操作任务的动作生成。 self.normalize_inputs、self.normalize_targets、self.unnormalize_outputs。这3个参数用于数据预处理和后处理的关键组件,负责输入特征的归一化、目标动作的归一化以及模型输出动作的反归一化。 根据config.temporal_ensemble_coeff条件来判断是否初始化temporal ensembler,用于联系预测的动作块进行加权平均,提升动作输出的稳定性。ACTTemporalEnsembler通过指数权重(exp(-temporal_ensemble_coeff * i))对历史动作进行加权, older动作权重更高(原论文默认系数0.01)。 推理逻辑 select_action是ACTPolicy类的核心方法,主要的目的就是根据环境观测(batch)然后预测输出机器人要执行的动作。生成预测的动作有两种模式,一个是启用temporal ensemble方式另外一种不启用。 在进入预测生成动作之前先调用self.eval()强制策略进入评估模式(推理),因为策略处于训练模式(启用dropout等)。 (1)时间集成模式 def select_action(self, batch: dict[str, Tensor]) -> Tensor: if self.config.temporal_ensemble_coeff is not None: actions = self.predict_action_chunk(batch) # 生成动作块 action = self.temporal_ensembler.update(actions) # 时序集成平滑 return action 开启temporal ensemble:根据配置中temporal_ensemble_coeff条件优先走temporal ensemble模式。该模式先调用self.predict_action_chunk(batch)调用模型预测一个动作块((batch_size, chunk_size, action_dim)),即一次性预测多个连续动作。然后调用self.temporal_ensembler.update(actions)通过时间集成器对动作块进行加权平滑( older 动作权重更高,原论文默认系数 0.01),输出单个稳定动作。主要的目的就是论文中的减少动作抖动,提升机器人控制平滑性。需要注意的是如果开启了该模式,n_action_steps 必须为 1,否则会破坏集成器的时序加权逻辑。 时间集成核心实现 class ACTTemporalEnsembler: def __init__(self, temporal_ensemble_coeff: float, chunk_size: int): # 指数权重:w_i = exp(-coeff * i),i为动作索引(0为最旧动作) self.ensemble_weights = torch.exp(-temporal_ensemble_coeff * torch.arange(chunk_size)) self.ensemble_weights_cumsum = torch.cumsum(self.ensemble_weights, dim=0) # 权重累加和(用于归一化) def update(self, actions: Tensor) -> Tensor: # actions: (batch_size, chunk_size, action_dim) if self.ensembled_actions is None: self.ensembled_actions = actions.clone() # 初始化集成动作 else: # 在线加权更新:历史动作 * 累计权重 + 新动作 * 当前权重,再归一化 self.ensembled_actions *= self.ensemble_weights_cumsum[self.ensembled_actions_count - 1] self.ensembled_actions += actions[:, :-1] * self.ensemble_weights[self.ensembled_actions_count] self.ensembled_actions /= self.ensemble_weights_cumsum[self.ensembled_actions_count] return self.ensembled_actions[:, 0] # 返回集成后的首步动作 (2)动作队列模式 def select_action(self, batch: dict[str, Tensor]) -> Tensor: if len(self._action_queue) == 0: # 生成动作块(chunk_size步),取前n_action_steps步存入队列 actions = self.predict_action_chunk(batch)[:, :self.config.n_action_steps] # 队列形状:(n_action_steps, batch_size, action_dim),故转置后入队 self._action_queue.extend(actions.transpose(0, 1)) return self._action_queue.popleft() # 每次弹出队列首步动作 关闭temporal ensemble:未启用时间集成器是,使用简单的动作队列缓存动作块并逐步输出。首先调用调用 predict_action_chunk 获取动作块,这里将会输出一个chunk的动作。但是并不是把这个chunk的集合全都送入队列,而是截取前 n_action_steps 个动作(n_action_steps 为每次预测的动作步数,通常 ≤ chunk_size)。举个例子如果chunk_size是100,但是n_action_steps是50,那么策略一次预测出100个序列动作,但是只取前面的50个。最后把这动作块进行转置后加入队列,之所以转置是因为模型输出动作块形状为 (batch_size, n_action_steps, action_dim),而队列需要按时间步顺序存储(即 (n_action_steps, batch_size, action_dim)),因此通过 transpose(0, 1) 交换前两维。 为什么预测了chunk块,要用n_action_steps做限制了? 可能是因为利用了批量推理的效率,避免因动作块过长导致环境状态变化(如物体移动、机器人位姿偏移)时动作失效。同时限制单次执行的动作步数,强制模型在 n_action_steps 步后重新推理(基于最新观测),确保动作与环境状态同步。 训练损失计算 def forward(self, batch: dict[str, Tensor]) -> tuple[Tensor, dict]: batch = self.normalize_inputs(batch) # 输入归一化 batch = self.normalize_targets(batch) # 目标动作归一化 actions_hat, (mu, log_sigma_x2) = self.model(batch) # 模型输出:预测动作、VAE分布参数 # L1损失(忽略填充动作) l1_loss = (F.l1_loss(batch[ACTION], actions_hat, reduction="none") * ~batch["action_is_pad"].unsqueeze(-1)).mean() loss_dict = {"l1_loss": l1_loss.item()} # VAE KL散度损失(若启用) if self.config.use_vae: mean_kld = (-0.5 * (1 + log_sigma_x2 - mu.pow(2) - log_sigma_x2.exp())).sum(-1).mean() loss_dict["kld_loss"] = mean_kld.item() loss = l1_loss + mean_kld * self.config.kl_weight # 总损失 = 重构损失 + KL权重 * KL损失 else: loss = l1_loss return loss, loss_dict 这是ACTPolicy类训练模型的接口,负责接收输入数据、通过模推理生成动作预测、计算损失并返回总损失及损失组件字典。 首先对输入的观测数据进行归一化处理,normalize_inputs 基于数据集统计信息(均值、标准差)将输入特征缩放到标准分布(通常均值为0、方差为1),确保模型训练时输入数据分布稳定。 接着将图像特征统一整理到到 batch[OBS_IMAGES] 列表中,便于模型后续提取图像特征。 其次调用self.model(batch)进行模型推理返回模型预测的归一化动作序列,已经如果启用了VAE返回latent分布的均值和对数方差。 计算预测动作(actions_hat)与真实动作(batch[ACTION])的 L1 损失(平均绝对误差)。KL散度的理论意义在于度量两个概率分布之间的差异程度,当KL散度越大的时候,说明两者的差异程度越大;而当KL散度小的时候,则说明两者的差异程度小。如果两者相同的话,则该KL散度应该为0。如果启动了VAE,需要再计算KL散度,总的损失为L1损失与加权KL损失知乎,其中kl_weight是控制损失权重的超参数。如果没有启动VAE直接返回L1损失。 核心算法ACT 整体结构 class ACT(nn.Module): def __init__(self, config: ACTConfig): super().__init__() self.config = config # VAE编码器(可选):将动作序列编码为潜在分布 if config.use_vae: self.vae_encoder = ACTEncoder(config, is_vae_encoder=True) self.vae_encoder_latent_output_proj = nn.Linear(config.dim_model, config.latent_dim * 2) # 输出mu和log(sigma²) # 视觉Backbone:ResNet提取图像特征 if config.image_features: backbone_model = getattr(torchvision.models, config.vision_backbone)(weights=config.pretrained_backbone_weights) self.backbone = IntermediateLayerGetter(backbone_model, return_layers={"layer4": "feature_map"}) # 取layer4特征图 # Transformer编码器-解码器 self.encoder = ACTEncoder(config) # 处理多模态输入(图像、状态、潜在向量) self.decoder = ACTDecoder(config) # 生成动作块 self.action_head = nn.Linear(config.dim_model, config.action_feature.shape[0]) # 动作输出头 这段代码是ACT类的构造函数,主要是负责初始化模型的核心组件,包括VAE编码器、视觉backbone、transformer编码器/解码器、输入投影层、位置嵌入和动作预测头等。 (1)VAE编码器初始化 if self.config.use_vae: self.vae_encoder = ACTEncoder(config, is_vae_encoder=True) # VAE 编码器(Transformer 架构) self.vae_encoder_cls_embed = nn.Embedding(1, config.dim_model) # CLS 标记嵌入(用于 latent 分布参数) # 机器人状态投影层:将关节状态特征映射到模型隐藏维度 if self.config.robot_state_feature: self.vae_encoder_robot_state_input_proj = nn.Linear( self.config.robot_state_feature.shape[0], config.dim_model ) # 动作投影层:将动作特征映射到模型隐藏维度 self.vae_encoder_action_input_proj = nn.Linear( self.config.action_feature.shape[0], config.dim_model ) # Latent 分布投影层:将 VAE 编码器输出映射为 latent 均值和方差(维度=2*latent_dim) self.vae_encoder_latent_output_proj = nn.Linear(config.dim_model, config.latent_dim * 2) # 固定正弦位置嵌入:为 VAE 编码器输入序列添加位置信息(CLS + 机器人状态 + 动作序列) num_input_token_encoder = 1 + config.chunk_size # 1(CLS) + chunk_size(动作序列长度) if self.config.robot_state_feature: num_input_token_encoder += 1 # 若包含机器人状态,增加 1 个 token self.register_buffer( "vae_encoder_pos_enc", # 注册为缓冲区(不参与梯度更新) create_sinusoidal_pos_embedding(num_input_token_encoder, config.dim_model).unsqueeze(0), ) 调用ACTEncoder初始化一个VAE编码器,本质是一个transformer编码器,其参数is_vae_encoder=True 标志用于区分该编码器为 VAE 专用(影响层数、注意力机制等配置,具体见 ACTEncoder 实现)。 定义一个可学习的CLS标记,类似BERT中的[CLS],用于聚合VAE编码器输入序列的全局信息,最终生成latent分布参数(均值和方差),nn.Embedding(1, config.dim_model) 创建一个单元素嵌入表,输出维度为模型隐藏维度 dim_model。 当输入包含机器人状态特征(如关节角度、速度)时启用。通过线性层将机器人状态特征(原始维度)映射到模型隐藏维度 dim_model,确保与其他输入 token(如动作序列)维度一致,可拼接为序列输入。 同理将动作序列中的每个动作(原始维度,如机器人关节控制维度)通过线性层映射到 dim_model,转换为 Transformer 可处理的 token 序列。 将 VAE 编码器输出的 CLS 标记特征(维度 dim_model)映射到 latent 分布的参数空间。 最后的固定正弦位置嵌入,其作用是为 VAE 编码器的输入序列添加固定位置信息,帮助 Transformer 区分不同位置的 token(CLS、机器人状态、动作序列中的不同时间步)。 (2)视觉backbone初始化 if self.config.image_features: backbone_model = getattr(torchvision.models, config.vision_backbone)( replace_stride_with_dilation=[False, False, config.replace_final_stride_with_dilation], # 控制最后一层是否使用空洞卷积 weights=config.pretrained_backbone_weights, # 预训练权重(如 ImageNet) norm_layer=FrozenBatchNorm2d, # 冻结 BatchNorm 层(避免微调时破坏预训练分布) ) # 提取 ResNet 的 layer4 输出作为图像特征图(高层语义特征) self.backbone = IntermediateLayerGetter(backbone_model, return_layers={"layer4": "feature_map"}) 当ACT类中配置包含图像特征,初始化图像特征提取骨干网络,并通过 IntermediateLayerGetter 提取高层视觉特征供后续 Transformer 处理。 首先调用getattr动态加载 torchvision.models 中的 ResNet 模型(如 resnet18、resnet50),具体型号由配置 config.vision_backbone 指定。 然后使用 torchvision.ops.misc.IntermediateLayerGetter 从 ResNet 中提取指定层的输出,作为图像的高层特征。return_layers={"layer4": "feature_map"}指定提取 ResNet 的 layer4(最后一个残差块)输出,并将其重命名为 feature_map。ResNet 的 layer4 输出包含最抽象的视觉语义信息(如物体轮廓、纹理),是下游任务(如 Transformer 编码)的关键输入。self.backbone 调用时返回字典 {"feature_map": tensor},其中 tensor 为形状 (B, C, H, W) 的特征图(B 为 batch 大小,C 为通道数,H/W 为特征图高/宽)。 (3)transformer编码器/解码器初始化 # Transformer 编码器:处理输入特征(latent、机器人状态、环境状态、图像特征) self.encoder = ACTEncoder(config) # Transformer 解码器:生成动作序列(作为 VAE 解码器时,输入为 latent;否则直接处理编码器输出) self.decoder = ACTDecoder(config) 这两行代码是初始化ACT核心组件transformer编码器和解码器。 (4)输入投影层 # 机器人状态投影:将机器人关节状态特征(如关节角度、速度)映射到 dim_model if self.config.robot_state_feature: self.encoder_robot_state_input_proj = nn.Linear( self.config.robot_state_feature.shape[0], config.dim_model ) # 环境状态投影:将环境状态特征(如物体位置)映射到 dim_model if self.config.env_state_feature: self.encoder_env_state_input_proj = nn.Linear( self.config.env_state_feature.shape[0], config.dim_model ) # Latent 投影:将 VAE 输出的 latent 向量映射到 dim_model self.encoder_latent_input_proj = nn.Linear(config.latent_dim, config.dim_model) # 图像特征投影:通过 1x1 卷积将 Backbone 输出的特征图(C×H×W)映射到 dim_model if self.config.image_features: self.encoder_img_feat_input_proj = nn.Conv2d( backbone_model.fc.in_features, # Backbone 输出通道数(如 ResNet18 的 layer4 输出为 512) config.dim_model, kernel_size=1 # 1x1 卷积不改变空间维度,仅调整通道数 ) 在 Transformer 编码器中,要求所有输入 token 具有相同的维度(dim_model),而不同输入特征(状态、图像、latent 等)的原始维度各异,投影层通过线性/卷积变换实现维度对齐。 投影层(Projection Layer) 是一类用于将不同类型的输入特征(如机器人状态、环境状态、 latent 向量、图像特征等)映射到统一维度的神经网络层。其核心作用是将原始输入特征的维度转换为 Transformer 编码器能够处理的隐藏维度(即代码中的 config.dim_model),确保多模态输入(如状态、图像)能被编码器统一处理。 在ACT类中定义了多个投影层 self.config.robot_state_feature:输入为机器人状态特征(如关节角度、速度),原始维度为 self.config.robot_state_feature.shape[0],通过线性层(nn.Linear)将机器人状态的原始维度映射到 dim_model,使其成为 Transformer 编码器可接收的 token。 self.config.env_state_feature:环境状态特征(如物体位置、场景参数),原始维度为 self.config.env_state_feature.shape[0],与机器人状态投影层类似,通过线性层将环境状态映射到 dim_model,实现多模态特征的维度统一。 self.encoder_latent_input_proj:输入是Latent 向量(来自 VAE 采样或零向量),维度为 config.latent_dim,将 latent 向量从 latent 空间维度映射到 dim_model,作为 Transformer 编码器的核心输入 token 之一。 self.encoder_img_feat_input_proj:输入是图像特征图(来自 ResNet 骨干网络的 layer4 输出),通道数为 backbone_model.fc.in_features(如 ResNet18 为 512),通过 1x1 卷积层(nn.Conv2d)将图像特征图的通道数调整为 dim_model,同时保持空间维度(H×W)不变,以便展平为序列 token 输入 Transformer。 (5)位置嵌入 # 1D 位置嵌入:用于 latent、机器人状态、环境状态等非图像特征(共 n_1d_tokens 个 token) n_1d_tokens = 1 # latent 占 1 个 token if self.config.robot_state_feature: n_1d_tokens += 1 # 机器人状态占 1 个 token if self.config.env_state_feature: n_1d_tokens += 1 # 环境状态占 1 个 token self.encoder_1d_feature_pos_embed = nn.Embedding(n_1d_tokens, config.dim_model) # 可学习的 1D 位置嵌入 # 2D 位置嵌入:用于图像特征图(H×W 空间位置) if self.config.image_features: self.encoder_cam_feat_pos_embed = ACTSinusoidalPositionEmbedding2d(config.dim_model // 2) # 正弦 2D 位置嵌入 位置嵌入是 Transformer 的关键组件,用于解决自注意力机制 对输入序列顺序不敏感 的问题。本代码中有一个1D特征位置嵌入层和图像特征位置嵌入式层。 1D 特征位置嵌入式层:为 1D 特征 token 提供 可学习的位置嵌入,帮助 Transformer 区分不同类型 token 的位置(如 latent 是第 1 个 token,机器人状态是第 2 个等)。 2D 图像特征位置嵌入层:为图像特征图的 2D 空间像素 提供 正弦位置嵌入,编码像素在特征图中的 (高度, 宽度) 空间位置信息。 (6)解码器位置嵌入与动作预测头 self.decoder_pos_embed = nn.Embedding(config.chunk_size, config.dim_model) # chunk_size 为动作序列长度 self.action_head = nn.Linear(config.dim_model, self.config.action_feature.shape[0]) self.decoder_pos_embed:为解码器生成的动作序列(action chunk)提供 可学习的位置嵌入,帮助 Transformer 解码器区分动作序列中不同时间步的位置信息(如第 1 个动作、第 2 个动作等)。 self.action_head:将解码器输出的高维特征(config.dim_model 维度)投影到实际动作空间维度,生成最终可执行的动作序列。 forward方法 forward负责执行 Action Chunking Transformer 的完整前向传播流程,涵盖 VAE 编码(可选)、多模态输入处理、Transformer 编码器-解码器计算,最终输出动作序列及潜在变量分布参数(若启用 VAE)。以下是分步骤解析。 (1)输入验证与 batch_size 确定 if self.config.use_vae and self.training: assert "action" in batch, "actions must be provided when using the variational objective in training mode." if "observation.images" in batch: batch_size = batch["observation.images"][0].shape[0] else: batch_size = batch["observation.environment_state"].shape[0] 若启用变分目标(VAE)且处于训练模式,需确保输入包含动作序列("action"),因为 VAE 编码器需以动作序列为目标数据。确定batch_size,根据输入模态(图像或环境状态)确定批次大小,确保后续张量操作维度对齐。 (2) Latent 向量生成(VAE 编码逻辑) # 构建 VAE 编码器输入:[cls_token, 机器人状态(可选), 动作序列] cls_embed = einops.repeat(self.vae_encoder_cls_embed.weight, "1 d -> b 1 d", b=batch_size) # (B, 1, D) if self.config.robot_state_feature: robot_state_embed = self.vae_encoder_robot_state_input_proj(batch["observation.state"]).unsqueeze(1) # (B, 1, D) action_embed = self.vae_encoder_action_input_proj(batch["action"]) # (B, S, D) vae_encoder_input = torch.cat([cls_embed, robot_state_embed, action_embed] if self.config.robot_state_feature else [cls_embed, action_embed], axis=1) # (B, S+2, D) 或 (B, S+1, D) # 添加固定正弦位置嵌入 pos_embed = self.vae_encoder_pos_enc.clone().detach().permute(1, 0, 2) # (S+2, 1, D) # 构建注意力掩码(忽略填充 token) cls_joint_is_pad = torch.full((batch_size, 2 if self.config.robot_state_feature else 1), False, device=batch["observation.state"].device) key_padding_mask = torch.cat([cls_joint_is_pad, batch["action_is_pad"]], axis=1) # (B, S+2) 或 (B, S+1) # VAE 编码器前向传播,提取 cls token 输出 cls_token_out = self.vae_encoder(vae_encoder_input.permute(1, 0, 2), pos_embed=pos_embed, key_padding_mask=key_padding_mask)[0] # (B, D) latent_pdf_params = self.vae_encoder_latent_output_proj(cls_token_out) # (B, 2*latent_dim) mu = latent_pdf_params[:, :self.config.latent_dim] # 均值 (B, latent_dim) log_sigma_x2 = latent_pdf_params[:, self.config.latent_dim:] # 2*log(标准差) (B, latent_dim) # 重参数化采样 latent 向量 latent_sample = mu + log_sigma_x2.div(2).exp() * torch.randn_like(mu) # (B, latent_dim) 将动作序列编码为 latent 分布(均值 mu、方差相关参数 log_sigma_x2),并通过重参数化技巧采样得到 latent 向量,作为 Transformer 编码器的核心输入。 (3)无VAE时的latent向量初始化 mu = log_sigma_x2 = None latent_sample = torch.zeros([batch_size, self.config.latent_dim], dtype=torch.float32).to(batch["observation.state"].device) 如果不启用VAE或非训练模式,直接使用零向量作为latent输入。 (4)transformer编码器输入构建 encoder_in_tokens = [self.encoder_latent_input_proj(latent_sample)] # latent 投影:(B, latent_dim) → (B, dim_model) encoder_in_pos_embed = list(self.encoder_1d_feature_pos_embed.weight.unsqueeze(1)) # 1D token 位置嵌入:(n_1d_tokens, 1, dim_model) # 添加机器人状态 token(若启用) if self.config.robot_state_feature: encoder_in_tokens.append(self.encoder_robot_state_input_proj(batch["observation.state"])) # (B, dim_model) # 添加环境状态 token(若启用) if self.config.env_state_feature: encoder_in_tokens.append(self.encoder_env_state_input_proj(batch["observation.environment_state"])) # (B, dim_model) 1D特征token处理,通过线性层(nn.Linear)将 latent 向量、机器人/环境状态的原始维度映射到模型隐藏维度 dim_model,确保各 token 维度一致。为每个 1D token(latent、状态)分配可学习的位置嵌入,编码其在序列中的位置信息。 if self.config.image_features: all_cam_features = [] all_cam_pos_embeds = [] for img in batch["observation.images"]: # 遍历多相机图像 # 骨干网络提取特征图(如 ResNet layer4 输出) cam_features = self.backbone(img)["feature_map"] # (B, C_backbone, H, W) # 图像位置嵌入(2D 正弦位置编码) cam_pos_embed = self.encoder_cam_feat_pos_embed(cam_features).to(dtype=cam_features.dtype) # (1, dim_model, H, W) # 特征投影:调整通道数至 dim_model cam_features = self.encoder_img_feat_input_proj(cam_features) # (B, dim_model, H, W) # 展平为序列:(H*W, B, dim_model) cam_features = einops.rearrange(cam_features, "b c h w -> (h w) b c") cam_pos_embed = einops.rearrange(cam_pos_embed, "b c h w -> (h w) b c") all_cam_features.append(cam_features) all_cam_pos_embeds.append(cam_pos_embed) # 拼接多相机特征 encoder_in_tokens.extend(torch.cat(all_cam_features, axis=0)) encoder_in_pos_embed.extend(torch.cat(all_cam_pos_embeds, axis=0)) 对于图像的特征输入,启用图像输入,通过视觉骨干网络提取特征并转换为序列 token。通过 1x1 卷积(encoder_img_feat_input_proj)将特征图通道数调整为 dim_model,再展平为序列 token(H*W 个像素 token)。通过 ACTSinusoidalPositionEmbedding2d 为像素 token 添加空间位置信息,编码其在特征图中的 (H, W) 坐标。 (5)transformer编码器-解码器前向传播 # 堆叠所有输入 token 和位置嵌入 encoder_in_tokens = torch.stack(encoder_in_tokens, axis=0) # (seq_len, B, dim_model) encoder_in_pos_embed = torch.stack(encoder_in_pos_embed, axis=0) # (seq_len, 1, dim_model) # 编码器前向传播 encoder_out = self.encoder(encoder_in_tokens, pos_embed=encoder_in_pos_embed) # (seq_len, B, dim_model) 上面为编码器输出,输入序列为包含 1D 特征 token(latent、状态)和图像像素 token,总长度为 seq_len = n_1d_tokens + sum(H*W for 各相机)。通过自注意力机制融合多模态输入,输出包含全局上下文的特征序列 encoder_out。 # 解码器输入初始化为零向量(类似 DETR 的目标查询) decoder_in = torch.zeros((self.config.chunk_size, batch_size, self.config.dim_model), dtype=encoder_in_pos_embed.dtype, device=encoder_in_pos_embed.device) # (chunk_size, B, dim_model) # 解码器前向传播(交叉注意力融合编码器输出) decoder_out = self.decoder( decoder_in, encoder_out, encoder_pos_embed=encoder_in_pos_embed, # 编码器位置嵌入 decoder_pos_embed=self.decoder_pos_embed.weight.unsqueeze(1), # 解码器动作序列位置嵌入 ) # (chunk_size, B, dim_model) # 转换维度并投影到动作空间 decoder_out = decoder_out.transpose(0, 1) # (B, chunk_size, dim_model) actions = self.action_head(decoder_out) # (B, chunk_size, action_dim) return actions, (mu, log_sigma_x2) 解码器部分,初始化为零向量序列(长度 chunk_size,即一次预测的动作数量),类似 DETR 的“目标查询”。解码器通过交叉注意力机制关注编码器输出的上下文特征,生成动作序列特征。通过 action_head(线性层)将解码器输出的高维特征投影到机器人动作空间维度(action_dim),得到最终动作序列。 最终返回actions和(mu, log_sigma_x2)。前者是形状 (B, chunk_size, action_dim),预测的动作序列;后者是若启用 VAE,返回 latent 分布的均值和方差参数(log_sigma_x2 = 2*log(σ)),否则为 (None, None)。 ACT编码器 ACTEncoder ACTEncoder 是 Transformer 编码器的顶层容器,负责堆叠多个 ACTEncoderLayer(编码器层)并执行最终归一化,支持 VAE 编码器 和 主 Transformer 编码器 两种角色。 class ACTEncoder(nn.Module): def __init__(self, config: ACTConfig, is_vae_encoder: bool = False): super().__init__() self.is_vae_encoder = is_vae_encoder # 根据角色选择编码器层数(VAE 编码器 vs 主编码器) num_layers = config.n_vae_encoder_layers if self.is_vae_encoder else config.n_encoder_layers # 堆叠 num_layers 个编码器层 self.layers = nn.ModuleList([ACTEncoderLayer(config) for _ in range(num_layers)]) # 最终归一化(预归一化模式下启用) self.norm = nn.LayerNorm(config.dim_model) if config.pre_norm else nn.Identity() 通过 is_vae_encoder 区分角色,分别使用 n_vae_encoder_layers(VAE 专用层数)或 n_encoder_layers(主编码器层数)。通过 nn.ModuleList 管理多个 ACTEncoderLayer,形成深度编码器结构。若 config.pre_norm=True(预归一化),对所有层输出做最终归一化;否则使用 nn.Identity(无操作),此时归一化在每层内部完成(后归一化)。 def forward( self, x: Tensor, pos_embed: Tensor | None = None, key_padding_mask: Tensor | None = None ) -> Tensor: for layer in self.layers: x = layer(x, pos_embed=pos_embed, key_padding_mask=key_padding_mask) x = self.norm(x) return x 逐层特征提取:输入张量 x(形状通常为 (seq_len, batch_size, dim_model))依次通过所有 ACTEncoderLayer,每层融合自注意力和前馈网络特征。 位置嵌入与掩码:pos_embed 提供序列位置信息,key_padding_mask 标记需忽略的填充位置,两者均传递给每层。 最终归一化:所有层处理完毕后,通过 self.norm 输出最终特征。 ACTEncoderLayer 下面是单个编码器层的实现 class ACTEncoderLayer(nn.Module): def __init__(self, config: ACTConfig): super().__init__() # 自注意力模块 self.self_attn = nn.MultiheadAttention(config.dim_model, config.n_heads, dropout=config.dropout) # 前馈网络(Linear -> Activation -> Dropout -> Linear) self.linear1 = nn.Linear(config.dim_model, config.dim_feedforward) self.dropout = nn.Dropout(config.dropout) self.linear2 = nn.Linear(config.dim_feedforward, config.dim_model) # 归一化与 dropout 层 self.norm1, self.norm2 = nn.LayerNorm(config.dim_model), nn.LayerNorm(config.dim_model) self.dropout1, self.dropout2 = nn.Dropout(config.dropout), nn.Dropout(config.dropout) # 激活函数与归一化模式标记 self.activation = get_activation_fn(config.feedforward_activation) self.pre_norm = config.pre_norm ACTEncoderLayer 是编码器的核心计算单元,包含 自注意力机制、前馈网络 和 残差连接,支持预归一化(PreNorm)或后归一化(PostNorm)模式。 自注意力:nn.MultiheadAttention 实现多头注意力,输入维度 dim_model,头数 n_heads。 前馈网络:将特征从 dim_model 映射到 dim_feedforward(扩展维度),经激活和 dropout 后映射回 dim_model。 归一化与 dropout:每层包含两个归一化层(norm1 用于注意力,norm2 用于前馈网络)和两个 dropout 层,增强训练稳定性。 def forward(self, x, pos_embed: Tensor | None = None, key_padding_mask: Tensor | None = None) -> Tensor: # 自注意力模块 + 残差连接 skip = x if self.pre_norm: # 预归一化:先归一化再计算注意力 x = self.norm1(x) q = k = x if pos_embed is None else x + pos_embed # query 和 key 融合位置嵌入 x = self.self_attn(q, k, value=x, key_padding_mask=key_padding_mask)[0] # 取注意力输出(忽略权重) x = skip + self.dropout1(x) # 残差连接 + dropout # 前馈网络模块 + 残差连接 if self.pre_norm: # 预归一化:先归一化再计算前馈 skip = x x = self.norm2(x) else: # 后归一化:先计算注意力再归一化 x = self.norm1(x) skip = x x = self.linear2(self.dropout(self.activation(self.linear1(x)))) # 前馈网络 x = skip + self.dropout2(x) # 残差连接 + dropout if not self.pre_norm: # 后归一化:最后归一化输出 x = self.norm2(x) return x 上面是forward方法,可以分为自注意力阶段和前馈网络阶段。 自注意力阶段:残差连接,skip 保存输入,注意力输出经 dropout1 后与 skip 相加。位置嵌入,q 和 k 若有 pos_embed 则叠加位置信息,帮助模型捕捉序列顺序。归一化时机,pre_norm=True 时,先对 x 归一化(norm1)再计算注意力;否则后归一化(注意力后通过 norm1 归一化)。 前馈网络阶段:前馈计算,x 经线性层扩展维度、激活(如 ReLU/GELU)、dropout、线性层压缩维度。残差与归一化,类似注意力阶段,pre_norm 决定归一化时机,最终输出融合残差的特征。 总结一下,ACTEncoder,通过堆叠多个 ACTEncoderLayer 实现深度编码,动态适配 VAE 或主编码器角色,输出融合全局依赖的序列特征。ACTEncoderLayer,单个编码器层核心,通过“自注意力+前馈网络+残差连接”提取局部与全局特征,支持预/后归一化模式,是 Transformer 编码器的基础组件。两者协同构成 ACT 模型的编码器部分,负责将多模态输入(如图像、状态)编码为上下文特征,供解码器生成动作序列。 ACT解码器 ACTDecoder ACTDecoder 是 Transformer 解码器的顶层模块,负责堆叠多个 ACTDecoderLayer(解码器子层)并对最终输出进行归一化,实现从编码器上下文特征到动作序列的映射。 class ACTDecoder(nn.Module): def __init__(self, config: ACTConfig): super().__init__() self.layers = nn.ModuleList([ACTDecoderLayer(config) for _ in range(config.n_decoder_layers)]) self.norm = nn.LayerNorm(config.dim_model) 通过 nn.ModuleList 创建 config.n_decoder_layers 个 ACTDecoderLayer 实例,构成深度解码器(每层包含自注意力、交叉注意力和前馈网络)。使用 nn.LayerNorm 对所有解码器层的输出进行归一化,稳定训练过程。 def forward( self, x: Tensor, encoder_out: Tensor, decoder_pos_embed: Tensor | None = None, encoder_pos_embed: Tensor | None = None, ) -> Tensor: for layer in self.layers: x = layer( x, encoder_out, decoder_pos_embed=decoder_pos_embed, encoder_pos_embed=encoder_pos_embed ) if self.norm is not None: x = self.norm(x) return x 输入参数如下: x:解码器输入序列(初始为零向量,形状 (chunk_size, batch_size, dim_model),chunk_size 为动作序列长度); encoder_out:编码器输出特征(形状 (encoder_seq_len, batch_size, dim_model)); decoder_pos_embed:解码器位置嵌入(为动作序列提供时序位置信息); encoder_pos_embed:编码器位置嵌入(为编码器特征提供位置信息,辅助交叉注意力)。 将输入 x、编码器输出 encoder_out 及位置嵌入依次传入每个 ACTDecoderLayer,更新 x 为每层输出。所有层处理完毕后,通过 self.norm 对输出进行归一化,返回形状为 (chunk_size, batch_size, dim_model) 的特征张量(后续将映射为动作序列)。 ACTDecoderLayer 下面再介绍下ACTDecoderLayer。 ACTDecoderLayer 是解码器的基础单元,包含 自注意力(捕捉动作序列内部依赖)、交叉注意力(融合编码器上下文特征)和 前馈网络(增强特征表达能力)三大模块,支持预归一化(PreNorm)或后归一化(PostNorm)模式。 class ACTDecoderLayer(nn.Module): def __init__(self, config: ACTConfig): super().__init__() # 自注意力(解码器内部时序依赖建模) self.self_attn = nn.MultiheadAttention(config.dim_model, config.n_heads, dropout=config.dropout) # 交叉注意力(融合编码器输出特征) self.multihead_attn = nn.MultiheadAttention(config.dim_model, config.n_heads, dropout=config.dropout) # 前馈网络(特征变换与增强) self.linear1 = nn.Linear(config.dim_model, config.dim_feedforward) # 升维 self.dropout = nn.Dropout(config.dropout) self.linear2 = nn.Linear(config.dim_feedforward, config.dim_model) # 降维 # 归一化层(3个,分别对应自注意力、交叉注意力、前馈网络) self.norm1, self.norm2, self.norm3 = [nn.LayerNorm(config.dim_model) for _ in range(3)] # Dropout层(3个,增强正则化) self.dropout1, self.dropout2, self.dropout3 = [nn.Dropout(config.dropout) for _ in range(3)] # 激活函数(如ReLU/GELU) self.activation = get_activation_fn(config.feedforward_activation) # 归一化模式标记(PreNorm/PostNorm) self.pre_norm = config.pre_norm 前向传播forward可以分为3个阶段,分为自注意力->交叉注意力->前馈网络,每个阶段都包含归一化->计算->dropout->残差连接的逻辑。 (1)自注意力阶段 skip = x # 残差连接的输入 if self.pre_norm: # 预归一化:先归一化,再计算注意力 x = self.norm1(x) # Query和Key融合位置嵌入(Value不融合,保持原始特征) q = k = self.maybe_add_pos_embed(x, decoder_pos_embed) x = self.self_attn(q, k, value=x)[0] # 自注意力输出(忽略注意力权重) x = skip + self.dropout1(x) # 残差连接 + Dropout (2)交叉注意力阶段 if self.pre_norm: # 预归一化:更新残差输入,归一化当前特征 skip = x x = self.norm2(x) else: # 后归一化:先归一化自注意力输出,再更新残差输入 x = self.norm1(x) skip = x # Query(解码器特征)融合解码器位置嵌入,Key(编码器特征)融合编码器位置嵌入 x = self.multihead_attn( query=self.maybe_add_pos_embed(x, decoder_pos_embed), key=self.maybe_add_pos_embed(encoder_out, encoder_pos_embed), value=encoder_out, )[0] # 交叉注意力输出(忽略权重) x = skip + self.dropout2(x) # 残差连接 + Dropout (3)前馈网络 if self.pre_norm: # 预归一化:更新残差输入,归一化当前特征 skip = x x = self.norm3(x) else: # 后归一化:先归一化交叉注意力输出,再更新残差输入 x = self.norm2(x) skip = x # 前馈网络:升维→激活→Dropout→降维 x = self.linear2(self.dropout(self.activation(self.linear1(x)))) x = skip + self.dropout3(x) # 残差连接 + Dropout if not self.pre_norm: # 后归一化:最后归一化前馈网络输出 x = self.norm3(x) -
lerobot学习率调度器
学习率调度器简介 是什么 学习率调度器(Learning Rate Scheduler)是深度学习训练中动态调整优化器学习率的工具(注意是在优化器的基础上动态调整学习率),通过优化收敛过程提升模型性能。 学习率(η)控制梯度更新步长,参数更新量 = -η × 梯度。过大步长导致震荡,过小则陷入局部最优或训练缓慢,固定学习率易导致训练初期震荡或后期收敛缓慢,调度器在训练期间自适应调整初期较高学习率加速收敛,中期稳定探索最优解,后期精细调优避免震荡。 以下是常见的学习率调度器 StepLR:每隔固定epoch将学习率乘以衰减因子(如step_size=10, gamma=0.5)。 ExponentialLR:每epoch按指数衰减(lr = lr × gamma)。 CosineAnnealingLR:按余弦曲线周期下降:η = η_min + 0.5×(η_max - η_min)×(1 + cos(π×t/T_max))。 OneCycleLR:分两阶段:线性升温至峰值,再退火至极小值。 PowerLR:基于幂律关系调整,与批次大小和token数量无关。 怎么用 import torch.optim as optim from torch.optim.lr_scheduler import StepLR # 1. 定义模型和优化器 model = ... # 神经网络模型 optimizer = optim.SGD(model.parameters(), lr=0.1) # 初始学习率0.1 # 2. 创建调度器(绑定优化器) scheduler = StepLR(optimizer, step_size=30, gamma=0.5) # 每30epoch衰减50% # 3. 训练循环 for epoch in range(100): # 前向传播 + 反向传播 train(...) optimizer.zero_grad() loss.backward() optimizer.step() # 4. 更新学习率(通常在epoch结束时) scheduler.step() # 查看当前学习率 print(f"Epoch {epoch}: LR={scheduler.get_last_lr()[0]:.6f}") 上面代码演示了基础的学习率调度使用示例,创建一个学习率调度器,传入的参数有优化器,主要的目的是让学习率调度器和优化器绑定,因为相当于是在优化器的基础上改进学习率调度。接下来就是在前向、反向传播更新完参数后调用scheduler.step()更新学习率,以便下一次计算使用。 from torch.optim.lr_scheduler import CosineAnnealingLR optimizer = SGD(model.parameters(), lr=0.01) # 基础学习率 total_epochs = 100 warmup_epochs = 10 # 预热epoch数 for epoch in range(total_epochs): # 1. 预热阶段:前10epoch线性增长 if epoch < warmup_epochs: lr = 0.01 * (epoch / warmup_epochs) for param_group in optimizer.param_groups: param_group['lr'] = lr # 2. 余弦退火阶段 else: scheduler = CosineAnnealingLR(optimizer, T_max=total_epochs-warmup_epochs, eta_min=1e-5) scheduler.step() # 训练代码同上... print(f"Epoch {epoch}: LR={optimizer.param_groups[0]['lr']:.6f}") 上面使用的是余弦退火+预热的方式。 lerobot调度器 抽象基类 @dataclass class LRSchedulerConfig(draccus.ChoiceRegistry, abc.ABC): num_warmup_steps: int # 预热步数(所有调度器的公共参数) @property def type(self) -> str: return self.get_choice_name(self.__class__) # 获取子类注册名称(如 "diffuser") @abc.abstractmethod def build(self, optimizer: Optimizer, num_training_steps: int) -> LRScheduler | None: """创建学习率调度器实例""" raise NotImplementedError LRSchedulerConfig是学习率调度器配置的核心抽象,通过抽象接口定义+配置注册机制,实现了学习率调度策略的统一管理与灵活扩展。 其同样继承了abc.ABC标记为抽象基类,强制子类事项build抽象方法,同时继承draccus.ChoiceRegistry提供子类注册机制,通过 @LRSchedulerConfig.register_subclass("名称") 将子类与调度器类型绑定(如 "diffuser" → DiffuserSchedulerConfig),支持配置驱动的动态实例化。同时使用了@dataclass 装饰器自动生成构造函数、repr 等方法,简化调度器超参数的定义与管理。 其核心属性只有一个num_warmup_steps表示学习率预热步数。预热是深度学习训练的常见技巧(尤其在 Transformer 等模型中),将其作为基类字段可避免子类重复定义。也是几乎所有学习率调度器的基础参数,用于控制“预热阶段”(学习率从低到高线性增长的步数),避免训练初期因高学习率导致的不稳定。 其只有两个方法type和build,type是用于获取子类注册调度器类型名称进而匹配到对应子类,而build的方法是强制子类实现。 实例化子类 lerobot的学习率调度实现了3个DiffuserSchedulerConfig、VQBeTSchedulerConfig、CosineDecayWithWarmupSchedulerConfig子类,这里以DiffuserSchedulerConfig简单说明。 @LRSchedulerConfig.register_subclass("diffuser") @dataclass class DiffuserSchedulerConfig(LRSchedulerConfig): name: str = "cosine" # 调度器类型(如 "cosine"、"linear",来自 diffusers) num_warmup_steps: int | None = None # 预热步数(可选,未指定则不预热) def build(self, optimizer: Optimizer, num_training_steps: int) -> LambdaLR: from diffusers.optimization import get_scheduler # 复用 Diffusers 的调度器实现 kwargs = {**asdict(self), "num_training_steps": num_training_steps, "optimizer": optimizer} # 构造调度器参数:类字段 + 训练相关参数 return get_scheduler(**kwargs) # 调用 diffusers API 创建调度器 diffusers.optimization.get_scheduler 是 Diffusers 库提供的调度器工厂函数,支持多种预定义策略(如 "cosine"、"linear"、"constant" 等)。 asdict(self)将 DiffuserSchedulerConfig 实例的字段(如 name="cosine"、num_warmup_steps=1000)转换为字典;而num_training_steps:总训练步数(调度器需基于此计算衰减周期);最后的optimizer就是待绑定的优化器实例(调度器需调整其参数组的学习率)。 状态管理 (1)存储 def save_scheduler_state(scheduler: LRScheduler, save_dir: Path) -> None: state_dict = scheduler.state_dict() # 获取调度器状态(如当前 step、预热步数等) write_json(state_dict, save_dir / SCHEDULER_STATE) # 保存为 JSON 文件(如 "scheduler_state.json") 该函数主要是将学习率调度器的状态写入到磁盘,为后续断点续训提供支持。state_dict = scheduler.state_dict()获取调度器的当前状态字典,包含调度器运行所需的所有动态信息。接着调用write_json写入到到文件中,文件名默认scheduler_state.json。 (2)加载 def load_scheduler_state(scheduler: LRScheduler, save_dir: Path) -> LRScheduler: # 从 JSON 加载状态,并按当前调度器结构适配(确保兼容性) state_dict = deserialize_json_into_object(save_dir / SCHEDULER_STATE, scheduler.state_dict()) scheduler.load_state_dict(state_dict) # 恢复状态 return scheduler 该函数也比较简单,主要负责从磁盘加载之前保存的调度器状态(如当前训练步数、学习率调整进度等),使训练能够从断点处继续,确保学习率调整策略的连续性。 工程调用 命令参数 在lerobot中,启动训练是可以通过参数来实例化使用哪些调度器,如下。 --scheduler.type=diffuser指定使用diffuser调度类。 --scheduler.num_warmup_steps=1000指定预热步数。 --scheduler.num_warmup_steps=0.5指定余弦衰减周期。 创建 工程中通过 optim/factory.py 中的 make_optimizer_and_scheduler 函数统一创建优化器和调度器,并完成两者的绑定。 def make_optimizer_and_scheduler( cfg: TrainPipelineConfig, policy: PreTrainedPolicy ) -> tuple[Optimizer, LRScheduler | None]: # 1. 创建优化器(基于优化器配置,如 AdamConfig、MultiAdamConfig) optimizer = cfg.optimizer.build(policy.parameters()) # policy.parameters() 为模型参数 # 2. 创建调度器(基于调度器配置,如 DiffuserSchedulerConfig、VQBeTSchedulerConfig) # 关键:通过调度器配置的 `build` 方法,将优化器作为参数传入,完成绑定。 lr_scheduler = cfg.scheduler.build(optimizer, cfg.steps) if cfg.scheduler is not None else None return optimizer, lr_scheduler 优化器创建:cfg.optimizer.build(...) 根据配置生成优化器实例(如 Adam、AdamW),并关联模型参数(policy.parameters())。 调度器绑定:cfg.scheduler.build(optimizer, cfg.steps) 调用调度器配置类(如 DiffuserSchedulerConfig)的 build 方法,将优化器实例作为参数传入,生成与该优化器绑定的调度器实例(如 LambdaLR) 更新 在训练过程中,如工程 scripts/train.py 中,调度器被集成到训练循环,通过 scheduler.step() 更新学习率通过调用scheduler.step() 更新学习率。 def train(): # ... 初始化优化器、调度器 ... optimizer, lr_scheduler = make_optimizer_and_scheduler(cfg, policy) for step in range(start_step, cfg.steps): # ... 前向传播、损失计算、反向传播 ... optimizer.step() if lr_scheduler is not None: lr_scheduler.step() # 调用调度器更新学习率 续训恢复 在断点续训是,通过 utils/train_utils.py 中的 save_training_state 和 load_training_state 函数处理断点续训,其中调用了 schedulers.py 的状态管理函数: def save_training_state(step: int, optimizer: Optimizer, lr_scheduler: LRScheduler | None, save_dir: Path): # ... 保存优化器状态 ... if lr_scheduler is not None: save_scheduler_state(lr_scheduler, save_dir) # 调用 schedulers.py 中的保存函数 def load_training_state(checkpoint_path: Path, optimizer: Optimizer, lr_scheduler: LRScheduler | None): # ... 加载优化器状态 ... if lr_scheduler is not None: lr_scheduler = load_scheduler_state(lr_scheduler, checkpoint_path) # 调用 schedulers.py 中的加载函数 return step, optimizer, lr_scheduler -
lerobot策略优化器
torch.optim简介 在学校lerobot的策略优化器前,我们先再复习一下什么是优化器。 什么优化器 优化器官方解释就是在深度学习中让损失函数通过梯度下降思想逐步调整参数以达到最小损失。 简单理解优化器的就是更新计算参数的,根据损失函数的梯度方向调整模型权重和偏置值,公式为:新参数 = 旧参数 - 学习率 × 梯度。通过迭代逐步逼近最优解。在文章http://www.laumy.tech/2050.html我们已经探讨过常用的优化算法。 接下来我们再来从PyTorch使用的角度复习一下。torch.optim 是 PyTorch 官方优化器模块,提供了 SGD、Adam、AdamW 等主流优化算法的实现,所有的优化器都继承自基类 torch.optim.Optimizer。其核心作用是如下: 自动化参数更新:根据反向传播计算的梯度,按特定优化策略(如 Adam 的自适应学习率)更新模型参数。 统一接口抽象:通过 Optimizer 基类封装不同算法,提供一致的使用流程(zero_grad() 清空梯度 → step() 更新参数)。 在Pytorch中优化器统一封装成torch.optim接口调用,可以有以下优势。 避免重复实现复杂算法:无需手动编写 Adam 的动量、二阶矩估计等逻辑,直接调用成熟接口。 灵活支持训练需求:支持单/多参数组优化(如不同模块用不同学习率)、学习率调度、梯度清零等核心训练逻辑。 工程化与可维护性:通过统一接口管理超参数(lr、weight_decay),便于实验对比与代码复用。 torch.optim怎么用 Step 1:定义模型与优化器 import torch from torch import nn, optim # 1. 定义模型(示例:简单线性层) model = nn.Linear(in_features=10, out_features=2) # 2. 初始化优化器:传入模型参数 + 超参数 optimizer = optim.Adam( params=model.parameters(), # 待优化参数(PyTorch 参数迭代器) lr=1e-3, # 学习率(核心超参数) betas=(0.9, 0.999), # Adam 动量参数(控制历史梯度影响) weight_decay=0.01 # 权重衰减(L2 正则化,可选) ) 定义了一个optimizer使用的是Adam优化器,该优化器学习率设置为1e-3,权重衰减为0.01。 Step 2:训练循环 # 模拟输入数据(batch_size=32,特征维度=10) inputs = torch.randn(32, 10) targets = torch.randn(32, 2) # 模拟目标值 # 训练循环 for epoch in range(10): # ① 清空过往梯度(必须!否则梯度累积导致更新异常) optimizer.zero_grad() # ② 前向传播 + 计算损失 outputs = model(inputs) loss = nn.MSELoss()(outputs, targets) # 均方误差损失 # ③ 反向传播计算梯度 + 优化器更新参数 loss.backward() # 自动计算所有可训练参数的梯度 optimizer.step() # 根据梯度更新参数 print(f"Epoch {epoch}, Loss: {loss.item():.4f}") loss是损失,通过调用loss.backward()进行反向传播Pytorch就自动把梯度计算好保存了,然后调用关键的一部optimizer.step()就可以执行参数更新了(即新参数=旧参数-学习率*梯度),需要注意的是,在调用loss.backward()进行反向传播计算梯度时,要先调用optimizer.zero_grad()把之前的梯度值情况,因此每计算一次梯度都是被保存,不情况会导致梯度累积。 Step 3:差异化优化参数分组 # 定义参数组(不同模块用不同学习率) optimizer = optim.Adam([ { "params": model.backbone.parameters(), # backbone 参数 "lr": 1e-5 # 小学习率微调 }, { "params": model.head.parameters(), # 任务头参数 "lr": 1e-3 # 大学习率更新 } ], betas=(0.9, 0.999)) # 公共超参数(所有组共享) 上面是针对同一个模型内不同模块使用不同的超参数lr。 抽象基类OptimizerConfig OptimizerConfig 是所有优化器配置的抽象基类,通过 draccus.ChoiceRegistry 实现子类注册机制(类似插件系统),为新增优化器类型提供统一接口。 @dataclass class OptimizerConfig(draccus.ChoiceRegistry, abc.ABC): lr: float weight_decay: float grad_clip_norm: float @property def type(self) -> str: return self.get_choice_name(self.__class__) @classmethod def default_choice_name(cls) -> str | None: return "adam" @abc.abstractmethod def build(self) -> torch.optim.Optimizer | dict[str, torch.optim.Optimizer]: raise NotImplementedError 继承关系 class OptimizerConfig(draccus.ChoiceRegistry, abc.ABC): OptimizerConfig 继承abc.ABC和draccus.ChoiceRegistry,前者标记为抽象基类,强制子类实现build的抽象方法,确保接口的一致性。后者提供子类注册机制,通过@OptimizerConfig.register_subclass("名称") 将子类与优化器类型绑定(如 "adam" → AdamConfig),支持配置驱动的动态实例化。 核心属性 lr: float # 学习率(核心超参数) weight_decay: float # 权重衰减(L2正则化系数) grad_clip_norm: float # 梯度裁剪阈值(防止梯度爆炸) 上面3个参数都是优化器的基础配置,避免子类重复定义。 lr/weight_decay:直接传递给 torch.optim 优化器(如 Adam 的 lr 参数) grad_clip_norm:不参与优化器创建,而是在训练流程中用于梯度裁剪(如 train.py 中 torch.nn.utils.clip_grad_norm_) 核心方法 (1)type属性用于表示优化器类型 @property def type(self) -> str: return self.get_choice_name(self.__class__) 通过 draccus.ChoiceRegistry 的 get_choice_name 方法,获取子类注册的优化器类型名称(如 AdamConfig 的 type 为 "adam")。 在实际应用中,在配置解析时,通过 type 字段(如 {"type": "adam"})即可匹配到对应子类(AdamConfig),实现“配置→实例”的自动映射。 (2)default_choice_name默认优化器类型 @classmethod def default_choice_name(cls) -> str | None: return "adam" 当配置中为显式指定type时,默认是用adam类型即AdamConfig,旨在简化用户配置,无需手动指定常见优化器类型。 (3)build抽象接口,优化器创建接口 @abc.abstractmethod def build(self) -> torch.optim.Optimizer | dict[str, torch.optim.Optimizer]: """Build the optimizer. It can be a single optimizer or a dictionary of optimizers.""" raise NotImplementedError 强制子类实现build的方法。 实例化子类 optimizers.py中一共定义了4种优化器配置子类,adam,adamw,sgd, multi_adam,其中前3个是单参数优化器,最后一个是多参数优化器,最终均通过build方法创建torch.optim实例 单参数优化器 @OptimizerConfig.register_subclass("adam") @dataclass class AdamConfig(OptimizerConfig): lr: float = 1e-3 betas: tuple[float, float] = (0.9, 0.999) eps: float = 1e-8 weight_decay: float = 0.0 grad_clip_norm: float = 10.0 def build(self, params: dict) -> torch.optim.Optimizer: kwargs = asdict(self) # 将 dataclass 字段转为字典 kwargs.pop("grad_clip_norm") # 移除梯度裁剪阈值(非优化器参数) return torch.optim.Adam(params, **kwargs) # 创建 PyTorch Adam 实例 AdamConfig 是 OptimizerConfig 的核心子类,封装了 Adam 优化器的配置与实例化逻辑,通过 draccus 注册机制与工程训练流程深度集成。 @OptimizerConfig.register_subclass("adam")将 AdamConfig 类与字符串 "adam" 绑定,实现 配置驱动的动态实例化,当配置文件中 optimizer.type: "adam" 时,draccus 会自动解析并实例化 AdamConfig。继承自 OptimizerConfig 的 ChoiceRegistry 机制,确保子类可通过 type 字段被唯一标识。 @dataclass自动生成 init、repr 等方法,简化超参数管理,无需手动编写构造函数,直接通过类字段定义超参数(如 lr=1e-3)。 在AdamConfig中默认初始化了一些参数值,其中lr、betas、eps、weight_decay直接对应 torch.optim.Adam 的参数,通过 build 方法传递给 PyTorch 优化器,而grad_clip_norm不参与优化器创建,而是用于训练时的梯度裁剪(如 train.py 中 torch.nn.utils.clip_grad_norm_),实现“优化器参数”与“训练流程参数”的职责分离。 在最后的build方法中,调用torch.optim.Adam(params, **kwargs) 实例化优化器。在此之前,先调用asdict(self)将 AdamConfig 实例的字段(如 lr、betas)转换为字典 {"lr": 1e-3, "betas": (0.9, 0.999), ...},再调用kwargs.pop("grad_clip_norm")剔除 grad_clip_norm(梯度裁剪阈值),因其不属于torch.optim.Adam 的参数(优化器仅负责参数更新,梯度裁剪是训练流程的独立步骤)。 多参数优化器 @OptimizerConfig.register_subclass("multi_adam") @dataclass class MultiAdamConfig(OptimizerConfig): optimizer_groups: dict[str, dict[str, Any]] = field(default_factory=dict) # 组内超参数 def build(self, params_dict: dict[str, list]) -> dict[str, torch.optim.Optimizer]: optimizers = {} for name, params in params_dict.items(): # 合并默认超参数与组内超参数(组内参数优先) group_config = self.optimizer_groups.get(name, {}) optimizer_kwargs = { "lr": group_config.get("lr", self.lr), # 组内 lr 或默认 lr "betas": group_config.get("betas", (0.9, 0.999)), "weight_decay": group_config.get("weight_decay", self.weight_decay), } optimizers[name] = torch.optim.Adam(params, **optimizer_kwargs) # 为每组创建独立优化器 return optimizers # 返回优化器字典:{"backbone": optimizer1, "head": optimizer2, ...} MultiAdamConfig 是 OptimizerConfig 的关键子类,专为多参数组优化场景设计,支持为模型不同模块(如 backbone 与 head)创建独立的 Adam 优化器,实现差异化超参数配置。 首先跟前面单参数的属性不同点是多了一个optimizer_groups,这是一个超参数字典,存储多组不同的超参数,示例如下。 optimizer_groups={ "backbone": {"lr": 1e-5, "weight_decay": 1e-4}, # 低学习率微调 backbone "head": {"lr": 1e-3, "betas": (0.95, 0.999)} # 高学习率更新 head,自定义动量参数 } build的方法主要逻辑如下: def build(self, params_dict: dict[str, list]) -> dict[str, torch.optim.Optimizer]: optimizers = {} for name, params in params_dict.items(): # 1. 获取组内超参数(无则使用默认) group_config = self.optimizer_groups.get(name, {}) # 2. 合并默认与组内超参数 optimizer_kwargs = { "lr": group_config.get("lr", self.lr), "betas": group_config.get("betas", (0.9, 0.999)), "eps": group_config.get("eps", 1e-5), "weight_decay": group_config.get("weight_decay", self.weight_decay), } # 3. 为该组创建 Adam 优化器 optimizers[name] = torch.optim.Adam(params, **optimizer_kwargs) return optimizers # 返回:{组名: 优化器实例} 其中params_dict是超参数组的来源,是字典类型,键为参数组名称(需与 optimizer_groups 键匹配),值为该组参数列表(如模型某模块的 parameters())。通常是策略类的get_optim_params方法提供,如下: # 策略类中拆分参数组(示例逻辑) def get_optim_params(self): return { "backbone": self.backbone.parameters(), "head": self.head.parameters() } 主要的核心逻辑是对于每个参数组,优先使用 optimizer_groups 中的超参数(如 group_config.get("lr")),无则回退到默认值(如 self.lr),然后为每个参数组创建独立的 torch.optim.Adam 实例,确保参数更新互不干扰。 优化器状态管理 状态保存 将优化器的某一个时刻参数进行存储,方便过程查看以及重新加载模型训练等等。 def save_optimizer_state( optimizer: torch.optim.Optimizer | dict[str, torch.optim.Optimizer], # 优化器实例或字典 save_dir: Path # 根保存目录 ) -> None: if isinstance(optimizer, dict): # 1. 处理多参数优化器字典(如 MultiAdamConfig 创建的优化器) for name, opt in optimizer.items(): # 遍历优化器名称与实例(如 "backbone": opt1) optimizer_dir = save_dir / name # 创建子目录:根目录/优化器名称(如 save_dir/backbone) optimizer_dir.mkdir(exist_ok=True, parents=True) # 确保目录存在(含父目录创建) _save_single_optimizer_state(opt, optimizer_dir) # 委托单优化器保存逻辑 else: # 2. 处理单参数优化器(如 AdamConfig 创建的优化器) _save_single_optimizer_state(optimizer, save_dir) # 直接使用根目录保存 区分单参数和多参数优化器,对应多参数优化器为每个优化器创建独立子目录(如 save_dir/backbone、save_dir/head),避免不同优化器的状态文件冲突。如果是单优化器,则直接调用 _save_single_optimizer_state,状态文件保存于 save_dir 根目录,结构简洁。 def _save_single_optimizer_state(optimizer: torch.optim.Optimizer, save_dir: Path) -> None: """Save a single optimizer's state to disk.""" # 1. 获取优化器完整状态字典(含参数组和内部状态) state = optimizer.state_dict() # 2. 分离参数组(超参数配置)与剩余状态(张量数据) param_groups = state.pop("param_groups") # 参数组:学习率、权重衰减等超参数(非张量) flat_state = flatten_dict(state) # 剩余状态:动量、二阶矩等张量(展平嵌套字典,便于序列化) # 3. 保存张量状态(safetensors)与参数组(JSON) save_file(flat_state, save_dir / OPTIMIZER_STATE) # 张量数据:高效二进制存储(如 "optimizer_state.safetensors") write_json(param_groups, save_dir / OPTIMIZER_PARAM_GROUPS) # 参数组:JSON 格式(如 "optimizer_param_groups.json"方便可视化查看) 存储张量和非张量的格式 param_groups:包含优化器的超参数配置(如 lr、weight_decay、betas),是列表嵌套字典的结构,存储为JSON格式,JSON 序列化后可直接查看超参数,便于训练过程追溯。其文件名为optimizer_param_groups.json。 state:包含优化器的内部状态张量(如 Adam 的 exp_avg、exp_avg_sq 动量缓冲区),是嵌套字典结构,通过 flatten_dict 展平后用 safetensors 保存,safetensors专为张量设计的存储格式,支持高效读写、内存映射,避免 PyTorch torch.save 的 pickle 兼容性问题。其文件名为optimizer_state.safetensors。 状态加载 def load_optimizer_state( optimizer: torch.optim.Optimizer | dict[str, torch.optim.Optimizer], # 待恢复的优化器(单实例或字典) save_dir: Path # 状态文件根目录 ) -> torch.optim.Optimizer | dict[str, torch.optim.Optimizer]: if isinstance(optimizer, dict): # 1. 处理多优化器字典(如 MultiAdamConfig 创建的优化器) loaded_optimizers = {} for name, opt in optimizer.items(): # 遍历优化器名称与实例(如 "backbone": opt1) optimizer_dir = save_dir / name # 子目录路径:根目录/优化器名称(如 save_dir/backbone) if optimizer_dir.exists(): # 仅当目录存在时加载(避免新增优化器时出错) loaded_optimizers[name] = _load_single_optimizer_state(opt, optimizer_dir) else: loaded_optimizers[name] = opt # 目录不存在时返回原优化器 return loaded_optimizers else: # 2. 处理单优化器(如 AdamConfig 创建的优化器) return _load_single_optimizer_state(optimizer, save_dir) # 直接从根目录加载 同样是区分单参数和多参数,对于多参数组根据save_dir / name 定位每个优化器的独立子目录(与 save_optimizer_state 的保存结构对应),如果是单参数优化器直接调用 _load_single_optimizer_state,从 save_dir 根目录加载状态文件。 def _load_single_optimizer_state(optimizer: torch.optim.Optimizer, save_dir: Path) -> torch.optim.Optimizer: """Load a single optimizer's state from disk.""" # 1. 获取当前优化器的状态字典结构(用于校验与适配) current_state_dict = optimizer.state_dict() # 2. 加载并恢复张量状态(safetensors → 嵌套字典) flat_state = load_file(save_dir / OPTIMIZER_STATE) # 加载展平的张量状态(如 "optimizer_state.safetensors") state = unflatten_dict(flat_state) # 恢复为嵌套字典(与保存时的 flatten_dict 对应) # 3. 处理优化器内部状态(如动量缓冲区) if "state" in state: # 将字符串键转为整数(safetensors 保存时键为字符串,PyTorch 期望参数索引为整数) loaded_state_dict = {"state": {int(k): v for k, v in state["state"].items()}} else: loaded_state_dict = {"state": {}} # 新创建的优化器可能无状态,初始化为空 # 4. 处理参数组(超参数配置,如学习率、权重衰减) if "param_groups" in current_state_dict: # 从 JSON 反序列化参数组,并确保结构与当前优化器匹配 param_groups = deserialize_json_into_object( save_dir / OPTIMIZER_PARAM_GROUPS, # 加载参数组 JSON 文件(如 "optimizer_param_groups.json") current_state_dict["param_groups"] # 以当前参数组结构为模板,确保兼容性 ) loaded_state_dict["param_groups"] = param_groups # 5. 将恢复的状态字典加载到优化器 optimizer.load_state_dict(loaded_state_dict) return optimizer 张量的状态恢复部分,通过 unflatten_dict 将保存时展平的状态(flatten_dict)恢复为嵌套字典,匹配 PyTorch 优化器状态的原始结构。接着通过state["state"] 的键在保存时被序列化为字符串(如 "0"),加载时需转回整数(如 0),以匹配 PyTorch 参数索引的整数类型。 对于参数组恢复先通过JSON 反序列化,deserialize_json_into_object 将 JSON 文件中的参数组配置(如 [{"lr": 1e-3, ...}, ...])反序列化为 Python 对象。再以当前优化器的 current_state_dict["param_groups"] 为模板,确保加载的参数组与当前优化器的参数结构兼容(如参数组数量、超参数字段匹配),避免因配置变更导致的加载失败。 最后合并 state(张量数据)和 param_groups(超参数配置)为完整状态字典,通过 optimizer.load_state_dict 完成优化器状态恢复。 工程调用 创建流程 # 1. 策略提供参数(如多参数组) params = policy.get_optim_params() # 例如:{"backbone": [params1...], "head": [params2...]} # 2. 配置解析:根据 config.optimizer.type 实例化对应子类(如 MultiAdamConfig) cfg.optimizer = MultiAdamConfig( lr=1e-3, optimizer_groups={"backbone": {"lr": 1e-5}, "head": {"lr": 1e-3}} ) # 3. 创建优化器实例 optimizer = cfg.optimizer.build(params) # 返回:{"backbone": Adam, "head": Adam} 训练流程 def update_policy(...): # 前向传播计算损失 loss, output_dict = policy.forward(batch) # 反向传播与梯度裁剪 grad_scaler.scale(loss).backward() grad_scaler.unscale_(optimizer) torch.nn.utils.clip_grad_norm_(policy.parameters(), grad_clip_norm) # 参数更新 grad_scaler.step(optimizer) optimizer.zero_grad() # 清空梯度 -

lerobot训练
初始化 @parser.wrap() def train(cfg: TrainPipelineConfig): cfg.validate() # 验证配置合法性(如路径、超参数范围) init_logging() # 初始化日志系统(本地文件+控制台输出) if cfg.seed is not None: set_seed(cfg.seed) # 固定随机种子(确保训练可复现) device = get_safe_torch_device(cfg.policy.device, log=True) # 自动选择训练设备(GPU/CPU) torch.backends.cudnn.benchmark = True # 启用CuDNN自动优化(加速卷积运算) torch.backends.cuda.matmul.allow_tf32 = True # 启用TF32精度(加速矩阵乘法) 初始化阶段主要是解析参数,初始化日志,确定训练的设备。 参数解析依旧是使用了装饰器parser.wrap,通过命令后参数构建生成TrainPipelineConfig类,该类是LeRobot 框架中训练流程的核心配置类,继承自 HubMixin(支持 Hugging Face Hub 交互),通过 dataclass 定义训练全流程的参数(如数据集路径、模型超参、训练步数等)。其核心作用是: 参数聚合:统一管理数据集、策略模型、优化器、评估等模块的配置,避免参数分散。 合法性校验:通过 validate 方法确保配置参数有效(如路径存在、超参数范围合理)。 可复现性支持:固定随机种子、保存/加载配置,确保训练过程可复现。 Hub 集成:支持从 Hub 加载预训练配置或推送配置至 Hub,便于共享和断点续训。 (1)核心属性 dataset:DatasetConfig, 数据集配置(如 repo_id="laumy/record-07271539"、图像预处理参数) env: envs.EnvConfig,评估环境配置(如仿真环境类型、任务名称,仅用于训练中评估) policy: PreTrainedConfig,策略模型配置(如 ACT 的 Transformer 层数、视觉编码器类型)。 output_dir: Path,训练输出目录(保存 checkpoint、日志、评估视频)。 resume,是否从 checkpoint 续训(需指定 checkpoint_path) seed,随机种子(控制模型初始化、数据 shuffle、评估环境随机性,确保复现)。 num_workers,数据加载线程数,用于加速数据预处理。 batch_size,训练批次大小,即单步输入样本数。 steps,总训练步数,每次参数更新计为1步。 log_freq,日志记录频率,每 200 步打印一次训练指标,如 loss、梯度范数。 eval_freq,评估频率(每 20,000 步在环境中测试策略性能,计算成功率、平均奖励) save_checkpoint,是否保存 checkpoint(模型权重、优化器状态),用于续训。 wandb,Weights & Biases 日志配置(控制是否上传指标、视频至 WandB) use_policy_training_preset,是否使用策略内置的训练预设(如 ACT 策略默认 AdamW 优化器、学习率)。 optimizer,优化器配置(如学习率、权重衰减,仅当 use_policy_training_preset=False 时需手动设置)。 scheduler,学习率调度器配置(如余弦退火,同上)。 (2)核心方法 post_init:初始化实例后设置 checkpoint_path(断点续训时的路径),为后续配置校验做准备。 validate:确保所有配置参数合法且一致,例如续训时校验 checkpoint 路径存在,自动生成唯一输出目录(避免覆盖),强制要求非预设模式下手动指定优化器。 _save_pretrained:将配置保存为 JSON 文件(train_config.json),用于 Hub 共享或本地存储。 from_pretrained::从 Hub 或本地路径加载配置(支持断点续训或复用已有配置)。 数据与模型准备 # 1. 加载离线数据集(如机器人操作轨迹数据) logging.info("Creating dataset") dataset = make_dataset(cfg) # 从HuggingFace Hub或本地路径加载数据集 # 2. 初始化策略模型(如ACT、Diffusion Policy) logging.info("Creating policy") policy = make_policy( cfg=cfg.policy, # 策略配置(如ACT的transformer层数、视觉编码器类型) ds_meta=dataset.meta, # 数据集元信息(输入/输出维度、特征类型) ) # 3. 创建优化器和学习率调度器 logging.info("Creating optimizer and scheduler") optimizer, lr_scheduler = make_optimizer_and_scheduler(cfg, policy) # 默认AdamW优化器 grad_scaler = GradScaler(device.type, enabled=cfg.policy.use_amp) # 混合精度训练梯度缩放器 make_dataset(cfg):根据配置加载数据集(如 laumy/record-07271539),返回 LeRobotDataset 对象,包含观测(图像、关节状态)和动作序列。 make_policy(...):根据 policy.type(如 act)和数据集元信息初始化模型,自动适配输入维度(如图像分辨率、状态维度)和输出维度(如动作空间大小)。 make_optimizer_and_scheduler(cfg, policy):创建优化器(默认AdamW,学习率 1e-5)和调度器(默认无,可配置余弦退火等),支持对不同参数组设置不同学习率(如视觉 backbone 微调)。 数据加载 数据加载调用的是make_dataset函数,其是LeRobot 框架中数据集创建的核心工厂函数,负责根据训练配置(TrainPipelineConfig)初始化离线机器人数据集。它整合了图像预处理、时序特征处理(delta timestamps)和数据集元信息加载,最终返回可直接用于训练的 LeRobotDataset 对象。 根据数据集配置初始化图像预处理管道(如Resize、Normalize、RandomCrop等)。若 cfg.dataset.image_transforms.enable=True(通过命令行或配置文件设置),则创建 ImageTransforms 实例,加载预设的图像变换参数(如分辨率、是否翻转等),否则不进行图像预处理。 image_transforms = ( ImageTransforms(cfg.dataset.image_transforms) if cfg.dataset.image_transforms.enable else None ) (1)单数据集加载 if isinstance(cfg.dataset.repo_id, str): # 加载数据集元信息(特征定义、统计数据、帧率等) ds_meta = LeRobotDatasetMetadata( cfg.dataset.repo_id, root=cfg.dataset.root, revision=cfg.dataset.revision ) # 计算时序偏移(delta timestamps) delta_timestamps = resolve_delta_timestamps(cfg.policy, ds_meta) # 创建 LeRobotDataset 实例 dataset = LeRobotDataset( cfg.dataset.repo_id, # 数据集标识(HuggingFace Hub repo_id 或本地路径) root=cfg.dataset.root, # 本地缓存根目录 episodes=cfg.dataset.episodes, # 指定加载的轨迹片段(如 ["ep001", "ep002"]) delta_timestamps=delta_timestamps, # 时序特征偏移(见下文详解) image_transforms=image_transforms, # 图像预处理管道 revision=cfg.dataset.revision, # 数据集版本(如 Git commit hash) video_backend=cfg.dataset.video_backend, # 视频解码后端(如 "pyav") ) 首先实例化LeRobotDatasetMetadata,加载数据集的信息,包括特征定义如observation.images.laptop 的形状、action的维度等,以及统计信息如图像均值/方差、动作范围,还有帧率fps以便时序偏移计算。 其次调用resolve_delta_timestamps根据模型计算时序特征偏移,例如如果策略需要当前帧及前2帧的观测,则生成[-0.04, -0.02, 0](单位:秒),用于从数据中提取多时序特征。 接着实例化LeRobotDataset,其实现数据加载、时序特征拼接、图像预处理等功能,为悬链提供批次化数据,具体见http://www.laumy.tech/2332.html#h37 (2)多数据集支持 else: raise NotImplementedError("The MultiLeRobotDataset isn't supported for now.") # 以下为预留的多数据集加载代码(暂未实现) dataset = MultiLeRobotDataset( cfg.dataset.repo_id, # 多数据集标识列表(如 ["repo1", "repo2"]) image_transforms=image_transforms, video_backend=cfg.dataset.video_backend, ) logging.info(f"多数据集索引映射: {pformat(dataset.repo_id_to_index)}") 预留多数据集合并功能(如融合不同场景的机器人轨迹数据),目前未实现,直接抛出 NotImplementedError。 (3)imsageNet统计量替换 if cfg.dataset.use_imagenet_stats: for key in dataset.meta.camera_keys: # 遍历所有相机图像特征(如 "observation.images.laptop") for stats_type, stats in IMAGENET_STATS.items(): # IMAGENET_STATS = {"mean": [...], "std": [...]} dataset.meta.stats[key][stats_type] = torch.tensor(stats, dtype=torch.float32) 其目的主要将数据集图像的归一化统计量(均值/方差)替换为 ImageNet 预训练模型的统计量。当使用预训练视觉编码器(如 ResNet)时,用 ImageNet 统计量归一化图像,可提升模型迁移学习效果(避免因数据集自身统计量导致的分布偏移)。 模型加载 # 初始化策略模型(如ACT、Diffusion Policy) logging.info("Creating policy") policy = make_policy( cfg=cfg.policy, # 策略配置(如ACT的transformer层数、视觉编码器类型) ds_meta=dataset.meta, # 数据集元信息(输入/输出维度、特征类型) ) make_policy 是 LeRobot 框架中策略模型实例化的核心工厂函数,负责根据配置(PreTrainedConfig)、数据集元信息(ds_meta)或环境配置(env_cfg),动态创建并初始化策略模型(如 ACT、Diffusion、TDMPC 等)。其核心作用是自动适配策略输入/输出维度(基于数据或环境特征),并支持加载预训练权重或初始化新模型。 在函数中,根据策略类型cfg.type,如 "act"、"diffusion")动态获取对应的策略类,如若 cfg.type = "act",get_policy_class 返回 ACTPolicy 类(ACT 策略的实现)。如果模型需要明确输入特征(如图像、状态)和输出特征(如动作)的维度,需进一步通过数据集或环境解析。 if ds_meta is not None: features = dataset_to_policy_features(ds_meta.features) # 从数据集元信息提取特征 kwargs["dataset_stats"] = ds_meta.stats # 数据集统计量(用于输入归一化,如图像均值/方差) else: if not cfg.pretrained_path: logging.warning("无数据集统计量,归一化模块可能初始化异常") # 无预训练时,缺少数据统计量会导致归一化参数异常 features = env_to_policy_features(env_cfg) # 从环境配置提取特征(如 Gym 环境的观测/动作空间) 如果定义了离线数据进行解析特征,否则基于环境解析特征。 获取到特征后进行配置输入/输出特征。 cfg.output_features = {key: ft for key, ft in features.items() if ft.type is FeatureType.ACTION} cfg.input_features = {key: ft for key, ft in features.items() if key not in cfg.output_features} 将解析后的特征划分为输入特征(如图像、状态)和输出特征(仅动作,FeatureType.ACTION),并更新到策略配置 cfg 中。例如若 features 包含 "observation.images.laptop"(图像)和 "action"(动作),则:input_features = {"observation.images.laptop": ...},output_features = {"action": ...}。 接着对模型进行实例化,也就是预训练模型的加载或新模型的初始化。 if cfg.pretrained_path: # 加载预训练策略(如从 HuggingFace Hub 或本地路径) kwargs["pretrained_name_or_path"] = cfg.pretrained_path policy = policy_cls.from_pretrained(**kwargs) # 调用策略类的 from_pretrained 方法加载权重 else: # 初始化新模型(随机权重) policy = policy_cls(** kwargs) # 传入配置和特征信息初始化模型结构 最后将模型迁移到目标设备,如cuda:0或cpu。 policy.to(cfg.device) # 将模型移至目标设备(如 "cuda:0"、"cpu") assert isinstance(policy, nn.Module) # 确保返回的是 PyTorch 模型 return policy 创建优化器 # 创建优化器和学习率调度器 logging.info("Creating optimizer and scheduler") optimizer, lr_scheduler = make_optimizer_and_scheduler(cfg, policy) # 默认AdamW优化器 grad_scaler = GradScaler(device.type, enabled=cfg.policy.use_amp) # 混合精度训练梯度缩放器 负责初始化训练核心组件:优化器(更新模型参数)、学习率调度器(动态调整学习率)和梯度缩放器(混合精度训练支持)。三者共同构成策略模型的“参数更新引擎”,直接影响训练效率和收敛稳定性。 (1)优化器与调度器创建 通过工厂函数 make_optimizer_and_scheduler 动态创建优化器和学习率调度器,参数来源于配置 cfg 和策略模型 policy。该函数根据 TrainPipelineConfig 中的 optimizer 和 scheduler 配置,或策略预设(use_policy_training_preset=True),生成优化器和调度器。其中优化器默认使用 AdamW(带权重衰减的 Adam),参数包括学习率(cfg.optimizer.lr)、权重衰减系数(cfg.optimizer.weight_decay)等,优化对象为 policy.parameters()(策略模型的可学习参数);而调度器如果配置了 scheduler.type(如 "cosine"),则创建对应学习率调度器(如余弦退火调度器),否则返回 None。 若 cfg.use_policy_training_preset=True(默认),则直接使用策略内置的优化器参数(如 ACT 策略默认 lr=3e-4,weight_decay=1e-4),无需手动配置 optimizer 和 scheduler。 (2)梯度缩放器初始化 GradScaler用于解决低精度(如 float16)训练中的梯度下溢问题。device.type参数模型所在设备类型("cuda"/"mps"/"cpu"),确保缩放器与设备匹配。参数enabled=cfg.policy.use_amp确定是否启用混合精度训练(由策略配置 use_amp 控制)。若为 False,缩放器将禁用(梯度不缩放)。 本质原理是混合精度训练时,前向传播使用低精度(加速计算),但梯度可能因数值过小而下溢(变为 0)。GradScaler 通过梯度缩放(放大损失值 → 梯度按比例放大 → 更新时反缩放)避免下溢,同时保证参数更新精度。 数据加载器配置 # 创建时序感知采样器(针对机器人轨迹数据) if hasattr(cfg.policy, "drop_n_last_frames"): # 如ACT策略需丢弃轨迹末尾帧 sampler = EpisodeAwareSampler( dataset.episode_data_index, # 轨迹索引信息 drop_n_last_frames=cfg.policy.drop_n_last_frames, # 丢弃每段轨迹末尾N帧 shuffle=True, # 轨迹内随机打乱 ) else: sampler = None # 普通随机采样 # 构建DataLoader(多线程加载+内存锁定) dataloader = torch.utils.data.DataLoader( dataset, num_workers=cfg.num_workers, # 数据加载线程数(加速IO) batch_size=cfg.batch_size, # 批次大小 sampler=sampler, pin_memory=device.type != "cpu", # 内存锁定(加速CPU→GPU数据传输) ) dl_iter = cycle(dataloader) # 循环迭代器(数据集遍历完后自动重启) EpisodeAwareSampler:确保采样的batch包含完整轨迹片段(避免时序断裂),适配机器人操作等时序依赖任务。 cycle(dataloader):将DataLoader转换为无限迭代器,支持训练步数(cfg.steps)远大于数据集长度的场景。 采样器选择 hasattr(cfg.policy, "drop_n_last_frames")用于检查模型中是否支持drop_n_last_frames 属性(如 ACT 策略需丢弃每段轨迹的最后 N 帧,避免无效数据)。如果支持,则启用时序感知采样EpisodeAwareSampler。器策略依赖时序连续的轨迹数据(如机器人操作的连贯动作序列)。核心参数如下: dataset.episode_data_index:数据集轨迹索引(记录每段轨迹的起始/结束位置),确保采样时不跨轨迹断裂时序。 drop_n_last_frames=cfg.policy.drop_n_last_frames:丢弃每段轨迹的最后 N 帧(如因传感器延迟导致的无效帧)。 shuffle=True:轨迹内部随机打乱(但保持轨迹内时序连续性),平衡随机性与时序完整性。 若模型策略中不支持时序感知采样,那么则采用普通的随机采样,使用默认随机采样(shuffle=True,sampler=None),DataLoader 直接对数据集全局打乱。 数据加载管道 dataloader = torch.utils.data.DataLoader基于采样器配置,创建 PyTorch DataLoader,实现多线程并行数据加载,为训练循环提供高效的批次数据。 num_workers=cfg.num_workers:使用配置的线程数并行加载数据(如 8 线程),避免数据加载成为训练瓶颈。 pin_memory=True(当使用 GPU 时):将数据加载到固定内存页,加速数据从 CPU 异步传输到 GPU,减少等待时间。 drop_last=False:保留最后一个可能不完整的批次(尤其在小数据集场景,避免数据浪费)。 batch_size:控制每个批次的样本数量。batch_size=8 时,所有张量第一维度为 8。 sampler:控制采样顺序(时序连续/随机)。EpisodeAwareSampler 确保动作序列来自同一段轨迹。 num_workers:控制并行加载的子进程数,影响数据加载速度(非数据结构)。num_workers=8 比单线程加载快 5-10 倍(取决于硬件)。注意其并行只会影响数据加载速度,不会影响训练速度,当前数据加载是持续循环进行,而非一次性完成,但是这个相对训练时间。通过控制并行数据加载进程数,减少 GPU 等待时间,提升整体效率。 dataloader 是 torch.utils.data.DataLoader 类的实例,本质是一个可迭代对象(iterable),用于按批次加载数据。其核心作用是将原始数据集(LeRobotDataset)转换为训练可用的批次化数据,支持多线程并行加载、自定义采样顺序等功能。 DataLoader 通过以下步骤将原始数据集(LeRobotDataset)转换为批次化数据 数据集索引采样:原始数据集 dataset(LeRobotDataset 实例),包含所有机器人轨迹数据。通过 sampler 参数(如 EpisodeAwareSampler 或默认随机采样)生成样本索引序列,决定数据加载顺序。 多线程并行加载:num_workers=cfg.num_workers:启动 num_workers 个子进程并行执行 dataset.getitem(index),从磁盘/内存中加载单个样本数据(如读取图像、解析状态)。 样本拼接:默认行为:DataLoader 使用 torch.utils.data.default_collate 函数,将多个单样本字典(来自不同子进程)拼接为批次字典,对每个特征键(如 "observation.images.laptop"),将所有单样本张量(shape=[C, H, W])堆叠为批次张量(shape=[B, C, H, W]);非张量数据(如列表)会被转换为张量或保留为列表(取决于数据类型)。 内存优化:pin_memory=device.type != "cpu":当使用 GPU 时,启用内存锁定(pin memory),将加载的张量数据存入 CPU 的固定内存页,加速后续异步传输到 GPU 的过程(batch[key].to(device, non_blocking=True)) 循环迭代器 dl_iter = cycle(dataloader) 将 DataLoader 转换为无限迭代器,支持按“训练步数”(cfg.steps)而非“ epochs” 训练。离线训练通常以固定步数(如 100,000 步)为目标,而非遍历数据集次数(epochs)。当数据集较小时,cycle(dataloader) 可在数据集遍历结束后自动重启,确保训练步数达标。 那dataloader输出的批次数据结构长什么样的? 当通过 next(dl_iter) 获取批次数据时(如代码中 first_batch = next(dl_iter)),返回的是一个字典类型的批次数据,结构如下: dl_iter = cycle(dataloader) first_batch = next(dl_iter) for key, value in first_batch.items(): if isinstance(value, torch.Tensor): print(f"{key}: shape={value.shape}, dtype={value.dtype}") else: print(f"{key}: type={type(value)}") 打印如下: observation.images.handeye: shape=torch.Size([8, 3, 480, 640]), dtype=torch.float32 observation.images.fixed: shape=torch.Size([8, 3, 480, 640]), dtype=torch.float32 action: shape=torch.Size([8, 100, 6]), dtype=torch.float32 observation.state: shape=torch.Size([8, 6]), dtype=torch.float32 timestamp: shape=torch.Size([8]), dtype=torch.float32 frame_index: shape=torch.Size([8]), dtype=torch.int64 episode_index: shape=torch.Size([8]), dtype=torch.int64 index: shape=torch.Size([8]), dtype=torch.int64 task_index: shape=torch.Size([8]), dtype=torch.int64 action_is_pad: shape=torch.Size([8, 100]), dtype=torch.bool task: type=<class 'list'> 可以看到一个batch有8组数据,因为TrainPipelineConfig::batch_size设置的8,控制每个批次的样本数量,batch_size定义了每次参数更新是输入模型的样本数量,如这里的8,就是表示输入8个样本更新一次参数。batch_size的设定要根据模型大小、GPU内存、数据特征综合确定。 如果batch_size过小,批次(如 batch_size=1)的梯度受单个样本噪声影响大,导致参数更新方向不稳定,Loss 曲线剧烈震荡(如下图示例),难以收敛到稳定最小值,如果模型使用了BN层,过小的批次会导致BN统计量(均值/方差)估计不准,影响特征表达。同时GPU利用率低,训练速度会变慢; 如果batch_size过大最直接的影响就是GPU内存会溢出,同时会导致收敛速度变慢或陷入次优解。 一般情况下,若数据集样本量少(如仅 1k 样本),可设 batch_size=32(全量数据集的 3%),避免批次占比过大导致过拟合;若模型中含有BN层,batch_size 建议 ≥ 16,确保 BN 统计量稳定。 batch_size 状态 典型问题 解决方案 过大(OOM) GPU 内存溢出,收敛慢 减小批次/降低图像分辨率/梯度累积 过小(<4) Loss 波动大,GPU 利用率低 增大批次至 8-32(需满足内存) 合理(8-32) 梯度稳定,GPU 利用率高(80%-90%) 维持默认或根据模型/数据微调 batch_size 的核心是平衡内存、速度与收敛性,建议从默认值开始,结合硬件条件和训练监控动态调整。 开始训练 训练模式设置 policy.train() 将策略模型切换为训练模式,确保所有层(如 Dropout、BatchNorm)按训练逻辑运行。PyTorch模型模式有差异,分为训练模式和评估模式。 训练模式:启用 Dropout(随机丢弃神经元防止过拟合)、BatchNorm 更新运行时统计量(均值/方差)。 评估模式(policy.eval()):关闭 Dropout、BatchNorm 使用训练阶段累积的统计量。 在训练循环前显式调用,避免因模型残留评估模式导致训练效果异常(如 Dropout 未激活导致过拟合)。 指标跟踪初始化 train_metrics = { "loss": AverageMeter("loss", ":.3f"), # 训练损失(格式:保留3位小数) "grad_norm": AverageMeter("grdn", ":.3f"), # 梯度范数(格式:缩写"grdn",保留3位小数) "lr": AverageMeter("lr", ":0.1e"), # 学习率(格式:科学计数法,保留1位小数) "update_s": AverageMeter("updt_s", ":.3f"), # 单步更新耗时(格式:缩写"updt_s",保留3位小数) "dataloading_s": AverageMeter("data_s", ":.3f"),# 数据加载耗时(格式:缩写"data_s",保留3位小数) } 通过 AverageMeter 类(来自 lerobot.utils.logging_utils)定义需跟踪的核心训练指标,支持实时平均计算和格式化输出训练信息,这个类实例最终通过参数传递给MetricsTracker。AverageMeter 功能为内部维护 sum(累积和)、count(样本数)、avg(平均值),通过 update 方法更新指标,并按指定格式(如 ":.3f")输出。例:每步训练后调用 train_metrics["loss"].update(loss.item()),自动累积并计算平均 loss。 train_tracker = MetricsTracker( cfg.batch_size, # 批次大小(用于计算每样本指标) dataset.num_frames, # 数据集总帧数(用于进度比例计算) dataset.num_episodes, # 数据集总轨迹数(辅助日志上下文) train_metrics, # 上述定义的指标跟踪器字典 initial_step=step # 初始步数(支持断点续训时从上次步数开始跟踪) ) 创建 MetricsTracker 实例(来自 lerobot.utils.logging_utils),用于聚合、格式化和记录所有训练指标,主要的作用如下: 指标更新:训练循环中通过 train_tracker.loss = loss.item() 便捷更新单个指标。 平均计算:自动对 AverageMeter 指标进行滑动平均(如每 log_freq 步输出平均 loss)。 日志输出:调用 logging.info(train_tracker) 时,按统一格式打印所有指标(如 loss: 0.523 | grdn: 1.234 | lr: 3.0e-4)。 断点续训支持:通过 initial_step=step 确保从断点恢复训练时,指标统计不重复计算。 总结下该代码段是训练前的关键初始化步骤,通过 AverageMeter 和 MetricsTracker 构建训练全流程的指标监控框架,为后续训练循环中的指标更新、日志记录和性能调优提供参考。 启动循环训练 logging.info("Start offline training on a fixed dataset") # 启动训练循环,从当前 step(初始为 0 或断点续训的步数)迭代至 cfg.steps(配置文件中定义的总训练步数,如 100,000 步)。 for _ in range(step, cfg.steps): # 1. 加载数据batch batch = next(dl_iter) # 从循环迭代器获取batch batch = {k: v.to(device, non_blocking=True) for k, v in batch.items() if isinstance(v, torch.Tensor)} # 数据移至设备 # 2. 单步训练(前向传播→损失计算→反向传播→参数更新) train_tracker, output_dict = update_policy( train_tracker, policy, batch, optimizer, cfg.optimizer.grad_clip_norm, # 梯度裁剪阈值(默认1.0) grad_scaler=grad_scaler, use_amp=cfg.policy.use_amp, # 启用混合精度训练 ) # 3. 训练状态更新与记录 step += 1 if is_log_step: # 按log_freq记录训练指标(loss、梯度范数等) logging.info(train_tracker) if is_saving_step: # 按save_freq保存模型checkpoint save_checkpoint(checkpoint_dir, step, cfg, policy, optimizer, lr_scheduler) if is_eval_step: # 按eval_freq在环境中评估策略性能 eval_info = eval_policy(eval_env, policy, cfg.eval.n_episodes) # 执行评估 update_policy(...):核心训练函数,实现: -- 前向传播:policy.forward(batch) 计算损失(如动作预测MSE损失+VAE KL散度)。 -- 反向传播:grad_scaler.scale(loss).backward() 缩放损失梯度(混合精度训练)。 -- 梯度裁剪:torch.nn.utils.clip_grad_norm_ 限制梯度范数(防止梯度爆炸)。 -- 参数更新:grad_scaler.step(optimizer) 更新模型参数,optimizer.zero_grad() 清空梯度缓存。 save_checkpoint(...):保存模型权重、优化器状态、学习率调度器状态和当前步数,支持断点续训。 eval_policy(...):在仿真环境中测试策略性能,计算平均奖励、成功率等指标,并保存评估视频。 上面代码是train 函数的核心训练循环,负责执行离线训练的完整流程:从数据加载、模型参数更新,到指标记录、模型保存与策略评估。循环以“训练步数”(step)为驱动,从初始步数(0 或断点续训的步数)运行至目标步数(cfg.steps),确保模型充分训练并实时监控性能。 (1)循环初始化,按步数迭代 for _ in range(step, cfg.steps): 启动训练循环,从当前 step(初始为 0 或断点续训的步数)迭代至 cfg.steps(配置文件中定义的总训练步数,如 100,000 步)。 (2)数据加载与耗时记录 start_time = time.perf_counter() batch = next(dl_iter) # 从无限迭代器获取批次数据 train_tracker.dataloading_s = time.perf_counter() - start_time # 记录数据加载耗时 dl_iter = cycle(dataloader):cycle 将 DataLoader 转换为无限迭代器,数据集遍历完毕后自动重启,确保训练步数达标(而非受限于数据集大小)。 dataloading_s 指标:通过 train_tracker 记录单批次加载时间,用于监控数据加载是否成为训练瓶颈(若该值接近模型更新时间 update_s,需优化数据加载)。 (3)批次数据设备迁移 for key in batch: if isinstance(batch[key], torch.Tensor): batch[key] = batch[key].to(device, non_blocking=True) 将批次中的张量数据(如图像、动作)异步传输到目标设备(GPU/CPU)。其中non_blocking=True:启用异步数据传输,允许 CPU 在数据传输至 GPU 的同时执行后续计算(如模型前向传播准备),提升硬件利用率。 (4)模型参数更新 train_tracker, output_dict = update_policy( train_tracker, policy, batch, optimizer, cfg.optimizer.grad_clip_norm, grad_scaler=grad_scaler, lr_scheduler=lr_scheduler, use_amp=cfg.policy.use_amp, ) 调用 update_policy 函数执行单次参数更新,流程包括: 前向传播:计算模型输出和损失(loss = policy.forward(batch))。 混合精度训练:通过 torch.autocast 启用低精度计算(若 use_amp=True),加速训练并节省显存。 反向传播:梯度缩放(grad_scaler.scale(loss).backward())避免数值下溢,梯度裁剪(clip_grad_norm_)防止梯度爆炸。 参数更新:优化器.step() 更新参数,学习率调度器.step() 动态调整学习率。 指标记录:返回更新后的训练指标(loss、梯度范数、学习率等)。 (5)步数递增与状态跟踪 step += 1 # 步数递增(在更新后,确保日志/评估对应已完成的更新) train_tracker.step() # 更新指标跟踪器的当前步数 step用于更新当前系统的训练步数,是整个训练过程的基础计算器。train_tracker.step()通知训练指标跟踪器进入新阶段。 is_log_step = cfg.log_freq > 0 and step % cfg.log_freq == 0 is_saving_step = step % cfg.save_freq == 0 or step == cfg.steps is_eval_step = cfg.eval_freq > 0 and step % cfg.eval_freq == 0 通过计算这些标志,用于后续的逻辑控制。 is_log_step:日志打印标志位,当配置的日志频率(cfg.log_freq)大于0且当前步数是cfg.log_freq 倍数时激活日志的打印。cfg.log_freq是来自用户的命令行参数的配置。默认是200步打印一次。 is_saving_step:保存标志位,当配置的保存频率相等或是其倍数时激活保存。默认是20000步保存一次。 is_eval_step:模型评估标志为。默认是20000评估一次。 标志通过模块化设计实现了训练过程的精细化控制,参数均来自TrainConfig配置类。 (6)训练指标日志(按频率触发) is_log_step = cfg.log_freq > 0 and step % cfg.log_freq == 0 if is_log_step: logging.info(train_tracker) # 控制台打印平均指标(如 loss: 0.523 | grdn: 1.234) if wandb_logger: wandb_log_dict = train_tracker.to_dict() if output_dict: wandb_log_dict.update(output_dict) # 合并模型输出指标(如策略特定的辅助损失) wandb_logger.log_dict(wandb_log_dict, step) # 上传至 WandB train_tracker.reset_averages() # 重置平均计数器,准备下一轮统计 根据前面计算的is_log_step满足时,默认是200步,则调用logging.info()输出训练的指标,如损失、准确率。如果启动了wandb,则将跟踪器数据转换为字典,合并额外输出(output_dict)后记录到WandB,关联当前步数。最后调用train_tracker.reset_averages() 清除跟踪累计值,为下一周期计数做准备。 (7)模型 checkpoint 保存(按频率触发) if cfg.save_checkpoint and is_saving_step: logging.info(f"Checkpoint policy after step {step}") checkpoint_dir = get_step_checkpoint_dir(cfg.output_dir, cfg.steps, step) save_checkpoint(checkpoint_dir, step, cfg, policy, optimizer, lr_scheduler) # 保存模型、优化器、调度器状态 update_last_checkpoint(checkpoint_dir) # 更新 "last" 软链接指向最新 checkpoint if wandb_logger: wandb_logger.log_policy(checkpoint_dir) # 上传 checkpoint 至 WandB artifacts 默认是启动了save_checkpoint, 每20000步将训练结束的状态进行保存一次,便于支持断点续训和模型版本管理。其中save_checkpoint函数和输出目录结构如下: 005000/ # training step at checkpoint ├── pretrained_model/ │ ├── config.json # 存储模型架构定义,包括网络层数、隐藏维度、激活函数类型等拓扑结构信息 │ ├── model.safetensors # 采用SafeTensors格式存储模型权重,包含所有可学习参数的张量数据,具有内存安全和高效加载特性 │ └── train_config.json # 序列化的训练配置对象,包含超参数(学习率、批大小)、数据路径、预处理策略等完整训练上下文 └── training_state/ ├── optimizer_param_groups.json # 记录参数分组信息,包括不同层的学习率、权重衰减等差异化配置 ├── optimizer_state.safetensors # 保存优化器动态状态,如Adam的一阶矩(momentum)和二阶矩(variance)估计,SGD的动量缓冲区等 ├── rng_state.safetensors # 捕获PyTorch全局RNG和CUDA(如使用)的随机数状态,确保恢复训练时数据采样和权重初始化的一致性 ├── scheduler_state.json #学习率调度器的内部状态,包括当前调度阶段、预热状态、周期信息等 └── training_step.json #当前训练迭代次数,用于精确定位训练数据读取位置 pretrained_dir = checkpoint_dir / PRETRAINED_MODEL_DIR policy.save_pretrained(pretrained_dir) # 保存模型架构和权重 cfg.save_pretrained(pretrained_dir) # 保存训练配置 save_training_state(checkpoint_dir, step, optimizer, scheduler) # 保存训练动态状态 update_last_checkpoint用于维护一个指向最新检查点目录的符号链接(symlink),在训练过程中跟踪和管理最新的模型检查点。 def update_last_checkpoint(checkpoint_dir: Path) -> Path: # 1. 构建符号链接路径:在检查点父目录下创建名为 LAST_CHECKPOINT_LINK 的链接 last_checkpoint_dir = checkpoint_dir.parent / LAST_CHECKPOINT_LINK # 2. 如果符号链接已存在,则先删除旧链接 if last_checkpoint_dir.is_symlink(): last_checkpoint_dir.unlink() # 3. 计算当前检查点目录相对于父目录的相对路径 relative_target = checkpoint_dir.relative_to(checkpoint_dir.parent) # 4. 创建新的符号链接,指向当前检查点目录 last_checkpoint_dir.symlink_to(relative_target) (8)策略评估(按频率触发) is_eval_step = cfg.eval_freq > 0 and step % cfg.eval_freq == 0 if cfg.env and is_eval_step: step_id = get_step_identifier(step, cfg.steps) logging.info(f"Eval policy at step {step}") with torch.no_grad(), torch.autocast(...) if use_amp else nullcontext(): eval_info = eval_policy(eval_env, policy, cfg.eval.n_episodes, ...) # 在环境中执行策略评估 # 记录评估指标(平均奖励、成功率、耗时)并上传至 WandB eval_tracker = MetricsTracker(...) eval_tracker.avg_sum_reward = eval_info["aggregated"]["avg_sum_reward"] ... logging.info(eval_tracker) if wandb_logger: wandb_logger.log_dict(...) wandb_logger.log_video(...) # 上传评估视频 在强化学习和机器人控制领域,策略评估(Policy Evaluation) 是指在特定环境中系统性测试智能体策略(Policy)性能的过程。它通过执行预设数量的评估回合,收集关键指标(如奖励、成功率、执行时间等),客观衡量策略的实际效果。总结一下就是有以下4个核心作用。 性能监控:跟踪训练过程中策略性能的变化趋势,判断模型是否收敛或退化 过拟合检测:通过独立评估集验证策略泛化能力,避免在训练数据上过拟合 决策依据:基于评估指标决定是否保存模型、调整超参数或终止训练 行为分析:通过可视化记录(如代码中的评估视频)观察策略执行细节,发现异常行为 负责在指定训练步骤对策略进行系统性评估,并记录关键指标与可视化结果。代码块实现了周期性策略评估机制,当满足环境配置(cfg.env)和评估步骤标志(is_eval_step)时才会触发。 按 cfg.eval_freq(这里默认是20000步)在环境中评估策略性能,核心功能: 无梯度推理:torch.no_grad() 禁用梯度计算,节省显存并加速评估。 指标计算:通过 eval_policy 获取平均奖励(avg_sum_reward)、成功率(pc_success)等关键指标。 可视化:保存评估视频(如机器人执行任务的轨迹)并上传至 WandB,直观观察策略行为。 训练更新 训练环境准备 device = get_device_from_parameters(policy) policy.train() with torch.autocast(device_type=device.type) if use_amp else nullcontext(): loss, output_dict = policy.forward(batch) 先调用get_device_from_parameters从模型参数自动推断当前计算设备,确保后续张量操作与模型参数在同医社保上,避免跨设备数据传输错误。 接着调用policy.train()将模型切换为训练模式,主要是启动dropout层随机失活功能,激活BatchNormalization层的移动平均统计更新等,与评估模式区别推理时需要调用policy.eval()。 最后使用了with预计用于创建一个上下文管理器,在进入代码块是调用管理器enter()方法,退出时调用exit()方法,这种机制确保资源被正确获取和释放或在特定上下文中执行代码,其代码等价于如下。 if use_amp: context_manager = torch.autocast(device_type=device.type) else: context_manager = nullcontext() with context_manager: loss, output_dict = policy.forward(batch) 也就是当条件激活use_amp启用混合精度训练,否则使用空上下文,torch.autocast会动态选择最优精度,对数值稳定性要求高的操作保留FP32。 最后就是调用loss, output_dict = policy.forward(batch)这是模型前向计算的核心函数,返回的是损失值和输出字典。 batch包含的是训练数据(图像、关节动作等),policy.forward()处理输入并生成预测值并计算与真实值的差距loss,然后loss将用于后续梯队的计算。 这里在总结一下什么是混合精度训练? 混合精度训练(Mixed Precision Training)主要指 FP16(半精度浮点数)与 FP32(单精度浮点数)的混合使用。 FP16:用于模型前向/反向传播的计算(如矩阵乘法、激活函数等),占用内存少(仅为 FP32 的一半),且支持 GPU 硬件加速(如 NVIDIA Tensor Cores)。 FP32:用于存储模型参数、梯度和优化器状态,避免低精度导致的数值精度损失(如梯度下溢、参数更新不稳定)。 默认是使用F32精度进行,因为使用低精度FP16可以加速训练速度(计算量小,可以并发更多数据)、降低内存(仅占用FP32一半的内存)等好处,所以代码中如果use_amp=True,将启动混合精度训练。但是低精度也有个坏处就是数值精度会损失导致梯度为0参数不稳定,但是可以通过GradScaler进行放大loss进而放大梯度,反向传播计算完了之后再反缩放回来,确保梯度进行不丢失。 梯队计算 grad_scaler.scale(loss).backward() grad_scaler.unscale_(optimizer) grad_norm = torch.nn.utils.clip_grad_norm_( policy.parameters(), grad_clip_norm, error_if_nonfinite=False, ) 这段代码是训练处理计算梯队的核心流程,主要就是用于计算梯队。 首先grad_scaler.scale(loss).backward()是将损失放大然后间接放大梯队,grad_scaler 是 PyTorch 的 GradScaler 实例,用于自动混合精度训练中管理梯度缩放,scale(loss)将损失值放大scaler倍(通常是2^n),避免梯度在反向传播中因数值过小而下溢为0。在混合精度训练(如使用 FP16)时,小梯度可能因数值精度不足而“下溢”(变为 0)。通过 scale(loss) 将损失值放大(例如放大 2^k 倍),反向传播时梯度也会同步放大,避免梯度下溢。最后backward()触发反向传播,计算所有可训练参数的梯度(此时梯度已被放大)。 其次再调用grad_scaler.unscale_(optimizer)将放大的梯度恢复到原始尺寸,由于损失被放大,方向传播的梯队也被同等放大,使用unscale_对所有参数梯度执行反缩放,相当于处于scaler。 最后是调用 torch.nn.utils.clip_grad_norm_执行梯度裁剪(Gradient Clipping),限制梯度的 L2 范数,防止梯度爆炸。其返回结果grad_norm是一个标量float,表示 梯度裁剪后所有参数梯度的总 L2 范数。 总结一下,段代码是混合精度训练中梯度处理的标准流程,解决了两个核心问题。 数值精度问题:通过 scale(loss) 和 unscale_(optimizer) 确保小梯度在低精度(如 FP16)下不丢失,同时恢复梯度原始范围用于后续优化。 梯度爆炸问题:通过 clip_grad_norm_ 限制梯度大小,避免过大梯度导致参数更新不稳定(例如权重跳变、Loss 震荡)。 但需要注意的是,如果没有启动混合精度grad_scaler.scale(loss)和grad_scaler.unscale_(optimizer)没有缩放和反缩放作用,但梯队采集逻辑正常运作。为启动混合精度时整个流程与标准 FP32 训练完全一致,grad_scaler 相关操作因「禁用状态」而自动失效,不会引入额外计算开销。 参数优化与更新 with lock if lock is not None else nullcontext(): grad_scaler.step(optimizer) grad_scaler.update() optimizer.zero_grad() if lr_scheduler is not None: lr_scheduler.step() 先试用with lock条件性启动线程锁,确保参数更新的线程安全。 grad_scaler.step(optimizer)执行参数更新,为了下一次重新计算损失。 接着调用grad_scaler.update()动态调整梯度的缩放因子,主要是自动平衡FP16的数值范围限制,在避免梯度下溢和溢出之间找到最优缩放比例。 最后就是调用optimizer.zero_grad()清除优化器中所有参数梯度缓存,因为Pytorch梯队计算默认都是累积模式(param.grad会累加),需要手动清零与loss.backward()配对,形成成"清零→前向→反向→更新→清零"的完整循环。 lr_scheduler.step()是按照批次更新学习率,可以使用循环学习率、余弦退化调度以及梯队的自适应调度等策略。 对于训练的闭环可以看成:scale(loss)→backward()→unscale_()→clip_grad_norm_()→step()→update()形成完整的混合精度训练流程,解决FP16数值范围限制问题。 最后update_policy返回的是train_metrics和output_dict。前者是传递给日志系统(如TensorBoard/WandB)进行可视化,后者是包含模型前向传播的详细输出(如预测值、中间特征),可用于后续分析 训练状态维护 if has_method(policy, "update"): policy.update() train_metrics.loss = loss.item() train_metrics.grad_norm = grad_norm.item() train_metrics.lr = optimizer.param_groups[0]["lr"] return train_metrics, output_dict 如果policy有update的方法,则调用进行更新,这里主要是做兼容性设计。 最后train_metrics主要是记录量化训练过程中的关键特征,为监控、调试和优化提供数据支撑。 训练收尾 # 训练结束后清理 if eval_env: eval_env.close() # 关闭评估环境(释放资源) logging.info("End of training") # 推送模型至HuggingFace Hub(若启用) if cfg.policy.push_to_hub: policy.push_model_to_hub(cfg) # 保存模型配置、权重至Hub,支持后续部署 eval_env.close():关闭仿真环境(如Gym/DM Control),释放显存和CPU资源。 policy.push_model_to_hub(cfg):将训练好的模型(权重+配置)推送至HuggingFace Hub,支持跨设备共享和部署。 总结 -
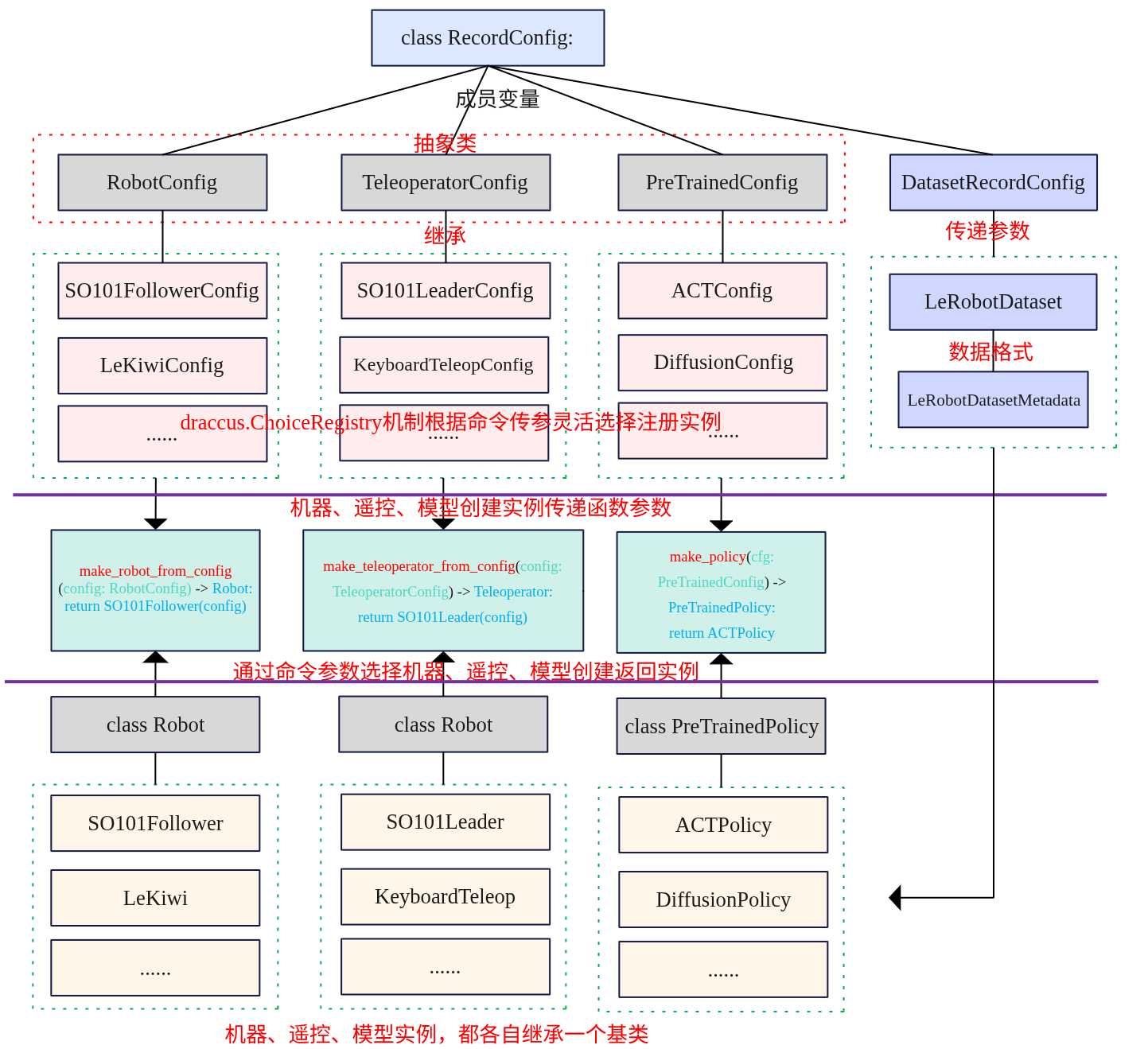
lerobot录制
简介 lerobot record是关键核心流程,其包括了数据的采集和模型推理两部分。 如果是数据采集模式,命令启动如下 python -m lerobot.record \ --robot.disable_torque_on_disconnect=true \ --robot.type=so101_follower \ --robot.port=/dev/ttyACM0 \ --robot.id=R12252801 \ --robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}}" \ --teleop.type=so101_leader \ --teleop.port=/dev/ttyACM1 \ --teleop.id=R07252608 \ --dataset.repo_id=${HF_USER}/record-07271148\ --dataset.num_episodes=10 \ --dataset.reset_time_s=5 \ --dataset.push_to_hub=false \ --dataset.single_task="Grab the cube" \ --display_data=true 如果是模型推理模式,则命令如下: python -m lerobot.record \ --robot.type=so101_follower \ --robot.disable_torque_on_disconnect=true \ --robot.port=/dev/ttyACM0 \ --robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}}" \ --robot.id=R12252801 \ --display_data=false \ --dataset.single_task="Put brick into the box" \ --policy.path=outputs/weigh_07280842/pretrained_model \ --dataset.episode_time_s=240 \ --dataset.repo_id=${HF_USER}/eval_so101_07271148 默认录制时长是60s,60S后会停止,如果要改长加上--dataset.episode_time_s=640 主要的区别是如果是采集模式需要使用--teleop参数启动遥控机器,如果是模型推理模式则不需要启动遥控机器,但是需要指定模型路径--policy.path,本质上就是机器人的动作指令来源于哪里,要么来之遥控器的,要么来自模型推理出来的。 在阅读本文前,这里先做一个总结: 从上图可以看出整个录制流程主要围绕机器设备、遥控设备、模型、数据集四个要素进行展开。 机器:有SO101Follower、LeKiwi等机器,都继承Robot类。通过命令行参数robot.type调用make_robot_from_config函数选择创建具体的实例设备,函数返回的还是Robot但是指向的是具体的机器实例如SO101Follower,利用了多态的特性做到了解耦,如果要新添机器时,只需要参考SO101Follower添加一个新的设备即可。在创建机器实例时传递RobotConfig参数,这个参数依旧是抽象基类,其继承了draccus.ChoiceRregistry,通过命令行参数robot.type选择注册具体的配置如SO101FollowerConfig。 遥控:用于控制机器,常用于数据的采集。这里同样通过命令行参数teleop.type调用make_teleoperator_from_config函数选择创建具体的设备实例,创建实例时需要传递TeleoperatorConfig参数,其也是一个抽象基类,基于命令选择注册实例化的配置类参数,如SO101LeaderConfig。 模型:模型用于决策推理动作,其和遥控二选一,如果指定了遥控了,模型就不需要指定了。通用使用了机器、遥控的解耦机制,具体的实例化为ACT或DiffusionPolicy等。 数据:通过参数dataset.xxx将参数构建为DataRecordConfig类,然后将其中的信息传递给LeRobotDataset。 lerobot的整个代码框架将具体的设备、配置、模型等做到了解耦,方便拓展新的设备,其设计思想值得借鉴。下面本文将先按照执行命令启动流程可以分为参数解析、硬件设备初始化与连接、数据集初始化、采集循环、数据保存等几个阶段,接下来将按照这几个阶段进行介绍。 关键配置类 在介绍关键流程时,先来总结一下关键record流程需要的配置类数据结构,这些Config类主要用于机器、遥控、模型实例化传递的参数。 RecordConfig RecordConfig是整个record入口函数的传递参数,其通过命令行的参数构建形成RecordConfig对象传递给函数。 class RecordConfig: # 1. 核心以来配置 # 机器人硬件配置如型号、端口、相机参数等,有RobotConfig类定义 # 如s101_folloer的通信端口、关节限制等,必现通过命令行或代码显式传入。 robot: RobotConfig #数据集录制配置,如repo_id,num_episodes、fpsdeng,必现显式传入。 dataset: DatasetRecordConfig # 2.控制方式配置(可选) # 遥控操作器配置,如So100_leader,可选。 teleop: TeleoperatorConfig | None = None # 预训练策略配置,如模型路径、推理设备等。 policy: PreTrainedConfig | None = None #3. UI与反馈配置(可选) # 是否实时显示相机画面,通过rerun可视化工具 display_data: bool = False # 是否启用语音合成反馈,人机的提示声,默认开启。 play_sounds: bool = True # 是否从现有数据集续录 resume: bool = False def __post_init__(self): # 如果指定了policy,则进行加载模型 policy_path = parser.get_path_arg("policy") if policy_path: cli_overrides = parser.get_cli_overrides("policy") self.policy = PreTrainedConfig.from_pretrained(policy_path, cli_overrides=cli_overrides) self.policy.pretrained_path = policy_path # teleop和policy必须要指定一个 if self.teleop is None and self.policy is None: raise ValueError("Choose a policy, a teleoperator or both to control the robot") @classmethod def __get_path_fields__(cls) -> list[str]: """This enables the parser to load config from the policy using `--policy.path=local/dir`""" return ["policy"] RecordConfig中有几个关键的成员,分别是RobotConfig,DatasetRrcordConfig、TeleoperatorConfig、PreTrainedConfig。其中除了DatasetRrcordConfig外的其他几个都是继承draccus.ChoiceRegistry 和 abc.ABC,是一个抽象基类,需通过注册的子类(如特定机器人型号的配置类)实例化,种设计既保证了配置的结构化(继承 abc.ABC),又支持灵活的子类选择(通过 draccus.ChoiceRegistry 实现配置注册与解析)。 RobotConfig 控制硬件接口,确保机器人正确连接和数据采集; DatasetRecordConfig 控制数据存储,定义数据集格式和元信息; TeleoperatorConfig 和 PreTrainedConfig 控制机器人行为,分别对应手动和自动控制模式。 RobotConfig #标记为数据类,所有字段必现通过关键参数传入,自动生成__init__等方法 @dataclass(kw_only=True) #继承draccus框架选择注册机制,允许子类如SO100FollowerConfig、KochFollowerConfig #作为可选机器人型号注册,支持通过配置文件或命令行参数 #动态选择例如--robot.type=s101_follower #abc.ABC抽象基类,不可直接实例化,必现通过子类具体机器人型号配置使用。 class RobotConfig(draccus.ChoiceRegistry, abc.ABC): # 机器的唯一标识实例 id: str | None = None # 标定文件存储目录 calibration_dir: Path | None = None #是 dataclass 的初始化后钩子,用于补充参数校验逻辑,确保机器人配置的合法性。 #主要是检查cameras中的宽高、帧率等。 def __post_init__(self): if hasattr(self, "cameras") and self.cameras: for _, config in self.cameras.items(): for attr in ["width", "height", "fps"]: if getattr(config, attr) is None: raise ValueError( f"Specifying '{attr}' is required for the camera to be used in a robot" ) #通过 draccus.ChoiceRegistry 的 get_choice_name 方法,动态返回子类的注册名称(即机器人型号)。 @property def type(self) -> str: return self.get_choice_name(self.__class__) RobotConfig 是抽象基类(ABC),仅定义所有机器共有的通用配置字段,如id、calibration_dir。其继承了draccus.ChoiceRegistry实现了不同机器人型号的动态注册与选择。 下面以一个继承实例说明 @RobotConfig.register_subclass("so101_follower") @dataclass class SO101FollowerConfig(RobotConfig): # 机器的通信端口,如/dev/ttyACM0,通过--robot.port命令传入 port: str # 断开连接时是否关闭电机扭矩,通过命令--robot.disable_torque_on_disconnect disable_torque_on_disconnect: bool = True # 电机相对位置目标安全上限,防止运动幅度过大。 max_relative_target: int | None = None # 相机的配置通过字典的方式。 cameras: dict[str, CameraConfig] = field(default_factory=dict) #--robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}} # 是否使用角度制而非弧度制 use_degrees: bool = False 这是框架自定义的子类注册装饰器,作用是将 SO101FollowerConfig 类与字符串 so101_follower 绑定,使其成为 RobotConfig 的可选型号。装饰器内部会将 SO101FollowerConfig 类添加到 RobotConfig 的“子类注册表”中,键为 so101_follower,值为类本身。当用户通过命令行传入 --robot.type=so101_follower 时,框架会从注册表中查找并实例化该类。 总结一下,RobotConfig是机器的硬件配置,但是其是一个虚拟基类,其具体实例的机器型号通过子类继承RobotConfig,有很多型号的子类,其巧妙的使用了draccus.ChoiceRegistry注册机制(RobotConfig继承),通过参数--robot.type来指定具体实例化的设备。同时这里也使用了多态的特性,通过统一的RobotConfig接口操作不同实例的具体实现,如通过 robot.type 属性(基类定义),可以动态判断具体子类类型,并执行对应逻辑。 if cfg.robot.type == "so101_follower": # 通过基类接口获取子类类型 print(f"SO101 特有端口: {cfg.robot.port}") # 访问子类特有属性 elif cfg.robot.type == "so100_follower": print(f"SO100 特有IP: {cfg.robot.ip_address}") # 另一子类的特有属性 DatasetRecordConfig class DatasetRecordConfig: #1. 数据集标识与存储 #数据集唯一标识符,格式为 '{hf_username}/{dataset_name}' (e.g. `lerobot/test`),用于定位hugging Face Hub仓库或本地路径 repo_id: str #录制任务的文字描述,用于标注数据用途。 single_task: str # 数据集本地存储根目录,如果未指定使用~/.cache/huggingface/datasets root: str | Path | None = None # 2.录制控制参数 # 录制的帧率,控制数据采集帧率。 fps: int = 30 # 单段录制时长,默认60S episode_time_s: int | float = 60 # 重置环境时长,两端录制之间预留环境重置时间。 reset_time_s: int | float = 60 # 总录制段数,控制数据集包含样本数量(如50段*60S=3000S总数据) num_episodes: int = 50 #3. 数据处理与上传 # 是否将录制图像帧编码为视频文件,默认开启 video: bool = True # 是否上传数据集到hugging Face Hub,默认自动上传。 push_to_hub: bool = True # Hub仓库是否设置为私有,默认是公开 private: bool = False # 上传到hub上的数据集标签 tags: list[str] | None = None #4. 图像存储性能参数 #图像写入的线程数 num_image_writer_processes: int = 0 #每个相机图像写入的线程数 num_image_writer_threads_per_camera: int = 4 def __post_init__(self): if self.single_task is None: raise ValueError("You need to provide a task as argument in `single_task`.") #__post_init__ 是 dataclass 的初始化后钩子方法,在 __init__ 初始化所有字段后自动执行, # 用于补充校验逻辑。 # 确保 single_task 字段不为空。因为 single_task 是描述录制任务的核心元数据(无默认值且必选), # 若未提供则直接抛出错误,避免后续数据标注缺失关键信息。 DatasetRecordConfig 是数据集录制任务的参数容器,被嵌套在 RecordConfig 中(作为 RecordConfig.dataset 字段),最终通过 parser.wrap() 装饰器从命令行参数解析生成实例。 例如,用户通过命令行指定: --dataset.repo_id=aliberts/record-test --dataset.num_episodes=2 --dataset.single_task="Grab the cube" 这些参数会被解析为 DatasetRecordConfig 实例,其字段值(如 num_episodes=2)直接控制录制逻辑(如 record_loop 函数的循环次数)。 TeleoperatorConfig @dataclass(kw_only=True) class TeleoperatorConfig(draccus.ChoiceRegistry, abc.ABC): # Allows to distinguish between different teleoperators of the same type id: str | None = None # Directory to store calibration file calibration_dir: Path | None = None @property def type(self) -> str: return self.get_choice_name(self.__class__) TeleoperatorConfig 是远程遥控操作器(如手柄、键盘、 leader 机器人)的抽象配置基类,用于定义所有遥操作器共有的通用配置字段和动态选择机制。它与RobotConfig类似,同样继承了draccus.ChoiceRegistry 实现了注册机制,其具体的子类又继承TeleoperatorConfig。 @TeleoperatorConfig.register_subclass("so101_leader") @dataclass class SO101LeaderConfig(TeleoperatorConfig): # Port to connect to the arm port: str use_degrees: bool = False 用户通过-teleop.type指定来实例化具体的操作设备,如--teleop.type=so101_leader时,具体的流程如下。 框架通过 draccus.ChoiceRegistry 查找注册名称为 so101_leader 的子类(如 SO101LeaderConfig); 实例化该子类,接收命令行参数(如 --teleop.port=/dev/ttyACM0)并初始化特有字段(如 port); 最终通过 TeleoperatorConfig 基类引用(如 cfg.teleop)传入 make_teleoperator_from_config 函数,创建具体遥操作器实例。 PreTrainedConfig @dataclass class PreTrainedConfig(draccus.ChoiceRegistry, HubMixin, abc.ABC): #1. 观测与特征配置 # 策略输入的观测部署,如=2表示输入当前+前1步观测 n_obs_steps: int = 1 #特征归一化模式映射{"image":"mead_std"} normalization_mapping: dict[str, NormalizationMode] = field(default_factory=dict) #输入特征的规范{"image": PolicyFeature(type=VISUAL, shape=(3, 224, 224))}) input_features: dict[str, PolicyFeature] = field(default_factory=dict) #输出特征规范输出特征规范(定义策略输出的特征类型,如 {"action": PolicyFeature(type=ACTION, shape=(6,))}) output_features: dict[str, PolicyFeature] = field(default_factory=dict) #2. 设备与性能配置 # 策略运行设备如是否使用cuda或cpu device: str | None = None # cuda | cpu | mp #是否启用自动混合精度训练 use_amp: bool = False #3. hugging face Hub继承 #是否将配置上传到Hub push_to_hub: bool = False #Hub的id repo_id: str | None = None # 仓库是否私有 private: bool | None = None # 仓库的标签 tags: list[str] | None = None # Add tags to your policy on the hub. license: str | None = None #方法在__init__后执行,处理运行设备选择和AMP的可用性 def __post_init__(self): self.pretrained_path = None #自动选择可用设备,如果用户指定的设备不可用。 if not self.device or not is_torch_device_available(self.device): auto_device = auto_select_torch_device() logging.warning(f"Device '{self.device}' is not available. Switching to '{auto_device}'.") self.device = auto_device.type #自动禁用不支持AMP if self.use_amp and not is_amp_available(self.device): logging.warning( f"Automatic Mixed Precision (amp) is not available on device '{self.device}'. Deactivating AMP." ) self.use_amp = False #通过 draccus.ChoiceRegistry 的 get_choice_name 方法,返回子类注册的策略型号名称(如 sac、tdmpc),用于日志打印和策略选择逻辑 @property def type(self) -> str: return self.get_choice_name(self.__class__) #抽象方法 observation_delta_indices:返回观测特征的差分索引 action_delta_indices : 返回动作特征的差分索引 reward_delta_indices : 返回奖励特征的差分索引 et_optimizer_preset() : 返回优化器配置 get_scheduler_preset() : 返回学习率调度器配置(如 CosineAnnealing)。 validate_features() :校验 input_features 和 output_features 的合法性(如形状匹配) #将策略配置实例(含超参数、特征规范、设备设置等)序列化 #为标准 JSON 文件 config.json,存储到指定目录。这是策略配 #置上传到 Hugging Face Hub 的前置步骤——Hub 要求模型/配 #置必须包含 config.json 以描述其参数,而 _save_pretrained 正 #是生成该文件的标准化实现。例如,当调用 #config.push_to_hub() 时,框架会先调用 _save_pretrained 将 #配置保存到临时目录,再将该目录上传到 Hub,最终用户可通 #过 PreTrainedConfig.from_pretrained("repo_id") 加载此 JSON #配置。 def _save_pretrained(self, save_directory: Path) -> None: with open(save_directory / CONFIG_NAME, "w") as f, draccus.config_type("json"): draccus.dump(self, f, indent=4) #from_pretrained 是 PreTrainedConfig 的 核心类方法,用于从 #本地目录 或 Hugging Face Hub 加载预训练策略的配置文件 #(config.json),并实例化为具体的配置对象(如 SACConfig、 #TDMPCConfig)。它是策略配置“复用与共享”的入口,支持通过 #命令行参数覆盖配置,实现灵活的参数调整。 @classmethod def from_pretrained( cls: Type[T], pretrained_name_or_path: str | Path, *, force_download: bool = False, resume_download: bool = None, proxies: dict | None = None, token: str | bool | None = None, cache_dir: str | Path | None = None, local_files_only: bool = False, revision: str | None = None, **policy_kwargs, ) -> T: model_id = str(pretrained_name_or_path) config_file: str | None = None #从本地目录加载 if Path(model_id).is_dir(): if CONFIG_NAME in os.listdir(model_id): config_file = os.path.join(model_id, CONFIG_NAME) else: print(f"{CONFIG_NAME} not found in {Path(model_id).resolve()}") #从hugging face hub下载 else: try: config_file = hf_hub_download( repo_id=model_id, filename=CONFIG_NAME, revision=revision, cache_dir=cache_dir, force_download=force_download, proxies=proxies, resume_download=resume_download, token=token, local_files_only=local_files_only, ) except HfHubHTTPError as e: raise FileNotFoundError( f"{CONFIG_NAME} not found on the HuggingFace Hub in {model_id}" ) from e # HACK: this is very ugly, ideally we'd like to be able to do that natively with draccus # something like --policy.path (in addition to --policy.type) cli_overrides = policy_kwargs.pop("cli_overrides", []) with draccus.config_type("json"): return draccus.parse(cls, config_file, args=cli_overrides) PreTrainedConfig是所有策略模型如ACT,TDMPC的抽象配置类,定义了策略训练/推理所需的通用参数,特征规范、设备配置及Hugging Face Hub交互机制。它通过 dataclass、draccus.ChoiceRegistry 和 abc.ABC 实现“配置标准化”“多策略兼容”和“Hub 集成”,是策略初始化的核心参数载体。 draccus.ChoiceRegistry:通用跟前面的RobotConfig类似,支持动态子类注册,允许子类(如 SACConfig、TDMPCConfig)作为“策略选项”注册,支持通过 --policy.type=sac 动态选择。 HubMixin:Hugging Face Hub 交互混入类,提供 from_pretrained(从 Hub/本地加载配置)和 _save_pretrained(保存配置到 Hub/本地)方法,实现策略配置的共享与复用。 abc.ABC:抽象基类,包含未实现的抽象方法(如 get_optimizer_preset),强制子类必须实现核心逻辑,确保策略配置的完整性。 参数解析 输入的参数会draccus 解析器读取所有 --xxx 参数,映射到 RecordConfig 类(定义在 record.py 中),生成结构化配置对象 RecordConfig类型的cfg实例,关键的配置项如下: robot.type=so101_follower:指定机器人类型为 so101_follower(从动机器人)。 teleop.type=so101_leader:指定遥操作器类型为 so101_leader(主动遥操作器)。 dataset.num_episodes=10:采集10个回合数据。 display_data=true:启用 Rerun 可视化工具显示摄像头画面和机器人状态。 RecordConfig的cfg实例构造是,会调用RecordConfig.post_init 检查如single_task,--teleop.type以及-policy.type必现要选择一个。因为录制要么就是验证模式,要么就是数据采集模式。验证模式就是通过大模型推理得到的动作数据,而采集模式通过遥控臂得到的数据控制设备。 硬件初始化与连接 机器人的初始化so101_follower robot = make_robot_from_config(cfg.robot) robot.connect() 传入的参数是cfg.robot,cfg.robot是一个基类,实际实例化为so101_follower的实例,这里使用了多态的特性。根据传入的参数--robot.port=/dev/ttyACM0 连接到机器人串口,初始化通信协议(如 ROS 或自定义串口协议)。根据 --robot.cameras 配置两个 OpenCV 摄像头。--robot.disable_torque_on_disconnect=true 确保程序退出时机器人断电,避免碰撞风险。 遥控机器初始化so101_leader teleop = make_teleoperator_from_config(cfg.teleop) if cfg.teleop is not None else None teleop.connect() 遥控机器初始化是可选的,如果指定了模型即是验证的方式,那么就不用启动遥控机器了,只有采集数据的时候才需要遥控机器。 总结一下,通过make_robot_from_config根据传入的robot.type创建一个机器实例,这里是class SO101Follower(Robot)。如果是采集模式还会创建一个遥控机器人实例,通过make_teleoperator_from_config生成实例class SO101Leader(Teleoperator)。 数据集创建 数据特征定义 # 动作特征->数据集动作特征 action_features = hw_to_dataset_features(robot.action_features, "action", cfg.dataset.video) # 观测特征->数据集观测特征 obs_features = hw_to_dataset_features(robot.observation_features, "observation", cfg.dataset.video) # 整个动作特征、观测特征 dataset_features = {**action_features, **obs_features} from pprint import pprint print("Action Features:") pprint(action_features) print("Observation Features:") pprint(obs_features) print("Dataset Features:") pprint(dataset_features) 数据应该长什么样? 这总的要格式要求吧? hw_to_dataset_features就是将机器硬件特征(电机位置、摄像头图像)转换为数据集特征描述,也就是说数据要按照这个格式来。格式包含数据类型dtype、形状shape等。下面根据直接打印action_features、obs_features、dataset_features的打印的结果来分别分析。 Action Features: { 'action': { 'dtype': 'float32', 'shape': (6,), 'names': ['shoulder_pan.pos', 'shoulder_lift.pos', 'elbow_flex.pos', 'wrist_flex.pos', 'wrist_roll.pos', 'gripper.pos'] } } Observation Features: { 'observation.state': { # 机器人关节状态 'dtype': 'float32', 'shape': (6,), 'names': ['shoulder_pan.pos', ..., 'gripper.pos'] # 与动作特征电机名称一致 }, 'observation.images.handeye': { # 手眼相机图像 'dtype': 'video', 'shape': (480, 640, 3), 'names': ['height', 'width', 'channels'] }, 'observation.images.fixed': { # 固定视角相机图像 'dtype': 'video', 'shape': (480, 640, 3), 'names': ['height', 'width', 'channels'] } } 动作与观测特征 生成action_features、obs_features都是调用hw_to_dataset_features函数,下面来看看这个函数的实现。 # 函数入参为3个 # -hw_features: dict[str, type | tuple] 机器硬件特征字典,键为特征名称如关节名、摄像头名,值为特征的类型如float或图像尺寸元组(height,width,channels),注意这里的type是类型不是实际的数值 # -prefix: str 特征前缀,用于区分数据集不同的部分 # -use_video: bool 是否将摄像头图像编码为视频 def hw_to_dataset_features( hw_features: dict[str, type | tuple], prefix: str, use_video: bool = True ) -> dict[str, dict]: features = {} # 1.硬件特征分类,将关节特征和图像特征分出来 # jointfs是关键特征,通过for循环遍历hw_features.items()满足ftype为float。然后将key和ftype通过新的键值对存储到joint_fs中。 #示例输出:{"shoulder_pan.pos": float, "shoulder_lift.pos": float, ..., "gripper.pos": float}(共6个关节)。 joint_fts = {key: ftype for key, ftype in hw_features.items() if ftype is float} #cam_fs是摄像头的图像特征,值为(height, width, channels)元组。 #示例输出:{"handeye": (480, 640, 3), "fixed": (480, 640, 3)}(两个摄像头,分辨率480×640,RGB三通道)。 cam_fts = {key: shape for key, shape in hw_features.items() if isinstance(shape, tuple)} #2. 关节特征转换数值型 #根据传入的action动作指令,构建一个新的键值对,键为action。 if joint_fts and prefix == "action": features[prefix] = { "dtype": "float32", #统一数值类型为float32,适合模型训练 "shape": (len(joint_fts),),#形状关键数量,如6个关键,(6,) "names": list(joint_fts),#关节名称列表,与机人电机意义对应 } #3. 观测装特特征,与前面action结构类似,只是键值为observation.state if joint_fts and prefix == "observation": features[f"{prefix}.state"] = { "dtype": "float32", "shape": (len(joint_fts),), "names": list(joint_fts), } #4. 摄像头特征转换,为每个摄像头生成图像/视频存储特征 for key, shape in cam_fts.items(): features[f"{prefix}.images.{key}"] = { "dtype": "video" if use_video else "image", #存储类型:视频或图像 "shape": shape, #图像尺寸(height, width, channels) "names": ["height", "width", "channels"],#形状维度名称 } _validate_feature_names(features) return features 数据集的创建关键来源hw_features: dict[str, type | tuple]参数,该值来源于robot.action_features、robot.observation_features,根据参数的实例化以SO101Follower实例为例。 @property def _motors_ft(self) -> dict[str, type]: return {f"{motor}.pos": float for motor in self.bus.motors} @property def _cameras_ft(self) -> dict[str, tuple]: return { cam: (self.config.cameras[cam].height, self.config.cameras[cam].width, 3) for cam in self.cameras } @cached_property def observation_features(self) -> dict[str, type | tuple]: return {**self._motors_ft, **self._cameras_ft} @cached_property def action_features(self) -> dict[str, type]: return self._motors_ft 电机位置特征结构_motors_ft定义了电机位置特征结构,描述关节运动的状态,其来源于self.bus.motors管理的电机列表,在Init中初始化,包含6个关节电机: motors={ "shoulder_pan": Motor(1, "sts3215", ...), # 肩转 "shoulder_lift": Motor(2, "sts3215", ...), # 肩抬 "elbow_flex": Motor(3, "sts3215", ...), # 肘弯 "wrist_flex": Motor(4, "sts3215", ...), # 腕弯 "wrist_roll": Motor(5, "sts3215", ...), # 腕转 "gripper": Motor(6, "sts3215", ...), # 夹爪 } 其输出格式返回字典 {电机名.pos: 数据类型},例如: { "shoulder_pan.pos": float, "shoulder_lift.pos": float, ..., "gripper.pos": float } float表示电机位置是浮点数值。 摄像头图像特征定义机器人摄像头图像特征的结构,用于描述视觉传感器数据格式。来源self.cameras 是由 make_cameras_from_configs 创建的摄像头实例(如 handeye、fixed 摄像头),配置来自 self.config.cameras(包含分辨率等参数)。其输出格式为返回字典 {摄像头名: (高度, 宽度, 通道数)},例如: { "handeye": (480, 640, 3), # 480px高、640px宽、RGB三通道 "fixed": (480, 640, 3) } 观测特征observation_features整合了电机位置和摄像头图像特征,定义机器人完整可观测装特,提供数据集录制和策略决策。通过字典解包(**)合并 _motors_ft(电机位置)和 _cameras_ft(摄像头图像),输出示例: { # 电机位置特征(来自 _motors_ft) "shoulder_pan.pos": float, "shoulder_lift.pos": float, ..., "gripper.pos": float, # 摄像头图像特征(来自 _cameras_ft) "handeye": (480, 640, 3), "fixed": (480, 640, 3) } 动作特征action_features定义机器人的动作指令格式,即遥控机器人。其直接服用_motors_ft,说明动作指令就是电机目标位置。 数据集特征合并 dataset_features = {**action_features, **obs_features} 合并动作特征与观测特征,形成数据集完整存储结构,用于初始化 LeRobotDataset。确保每个时间步的记录包含「观测→动作」的完整配对,满足训练需求(如模仿学习中,观测为输入,动作为标签)。 Dataset Features: { 'action': { 'dtype': 'float32', 'shape': (6,), 'names': [ 'shoulder_pan.pos', 'shoulder_lift.pos', 'elbow_flex.pos', 'wrist_flex.pos', 'wrist_roll.pos', 'gripper.pos' ] }, 'observation.state': { 'dtype': 'float32', 'shape': (6,), 'names': [ 'shoulder_pan.pos', 'shoulder_lift.pos', 'elbow_flex.pos', 'wrist_flex.pos', 'wrist_roll.pos', 'gripper.pos' ] }, 'observation.images.handeye': { 'dtype': 'video', 'shape': (480, 640, 3), 'names': ['height', 'width', 'channels'] }, 'observation.images.fixed': { 'dtype': 'video', 'shape': (480, 640, 3), 'names': ['height', 'width', 'channels'] } } action:是遥控操作机器(如SO101Leader)的关节位置数据 observation.state:机器人(如S0101Follower)实时采集的关节位置数据。 observation.images.xx:机器人实时采集的图像数据,可有多个。 创建数据集 创建数据集,是创建一个空的数据集。 传入的参数有repo_id标识了数据集的目录,root为数据集的根目录等等,具体如下阐述。 dataset = LeRobotDataset.create( cfg.dataset.repo_id, cfg.dataset.fps, root=cfg.dataset.root, robot_type=robot.name, features=dataset_features, use_videos=cfg.dataset.video, image_writer_processes=cfg.dataset.num_image_writer_processes, image_writer_threads=cfg.dataset.num_image_writer_threads_per_camera * len(robot.cameras), ) cfg.dataset.repo_id: 数据集的唯一标识,用于本地粗才能路径标识和上传hugging Face Hub上传的仓库名称 cfg.dataset.fps:录制帧率。 root=cfg.dataset.root:本地存储的路径,可以通过--dataset.root指定,如果没有提供,则默认使用缓存目录~/.cache/huggingface/ robot_type=robot.name:机器的唯一标识,会写入到meta.json中。 features=dataset_features:核心参数,数据集特征定义,由上一章节合并特征。 use_videos=cfg.dataset.video: 图像的存储格式,true表示使用mpr格式。False保留为PNG格式,占用空间大。内部在录制结束后,通过encode_episode_videos 调用 ffmpeg 将 PNG 序列转为视频(定义于 lerobot_dataset.py). image_writer_processes: 图像写入的进程数量,默认0,仅使用线程即一个进程。 image_writer_threads:图像写入的线程数,默认4线程/摄像头 × N摄像头。 LeRobotDataset.create LeRobotDataset.create返回的是一个LeRobotDataset对象实例。 典型的LeRobotDataset本地存储为: . ├── data │ ├── chunk-000 │ │ ├── episode_000000.parquet │ │ ├── episode_000001.parquet │ │ ├── episode_000002.parquet │ │ └── ... │ ├── chunk-001 │ │ ├── episode_001000.parquet │ │ ├── episode_001001.parquet │ │ ├── episode_001002.parquet │ │ └── ... │ └── ... ├── meta │ ├── episodes.jsonl │ ├── info.json │ ├── stats.json │ └── tasks.jsonl └── videos ├── chunk-000 │ ├── observation.images.laptop │ │ ├── episode_000000.mp4 │ │ ├── episode_000001.mp4 │ │ ├── episode_000002.mp4 │ │ └── ... │ ├── observation.images.phone │ │ ├── episode_000000.mp4 │ │ ├── episode_000001.mp4 │ │ ├── episode_000002.mp4 │ │ └── ... ├── chunk-001 └── ... 核心属性 meta: LeRobotDatasetMetadata类,元数据管理器,存储数据集“说明书”:特征定义(动作/观测维度)、帧率、机器人类型、任务描述等。 repo_id: str类型,数据集唯一标识(如 lerobot/pick_cube),用于 Hugging Face Hub 定位和本地路径标识。 root:Path,本地存储根路径(默认:~/.cache/huggingface/lerobot/{repo_id}),包含 data/(Parquet)、meta/(元数据)、videos/(视频)。 revision: str类型,表示数据集的版本,默认代码库版本为v2.1。 tolerance_s:float类型,时间戳校验容差,确保录制视频帧率稳定性。 hf_dataset: Hugging Face Dataset 对象,存储非图像数据(关节位置、时间戳等),以 Parquet 格式。 episode_data_index: dirc类型,episode 索引映射表,记录每个 episode 的起始/结束帧位置(如 {"from": [0, 300], "to": [299, 599]}),加速帧检索。 delta_indices: dict类型,时间戳偏移索引(如 {"past": [-2, -1], "future": [1, 2]}),用于多模态数据同步(如动作与图像对齐)。 episode_buffer: dict类型,内存缓冲区,临时存储当前录制的帧数据(如 {"action": [], "observation.images.handeye": [], "timestamp": []})。 image_writer:AsyncImageWriter,异步图像写入器(多线程/多进程),避免图像存储阻塞主控制循环(确保录制帧率稳定)。 image_transforms:图像预处理函数(如 torchvision.transforms.Resize、Normalize),训练时动态应用于摄像头图像。 video_backend: str类型,视频解码后端(默认 torchcodec 或 pyav),支持从 MP4 中精准提取指定时间戳的帧。 核心方法 init: 数据集加载的入口,根据本地缓存状态完成元数据校验、数据下载(若缺失) 和时间戳同步检查,确保数据集可用。 add_frame:逐帧添加数据到缓冲区,录制时将单帧数据(动作、观测、图像)添加到 episode_buffer,并异步写入图像(避免阻塞控制循环)。 save_episode:写入到磁盘,录制完成一个 episode 后,将 episode_buffer 中的数据写入磁盘。包括非图像数据转换为Parquet文件存储到xxx.parquet,图像数据编码为MP4存储,元数据更新info.json,episodes.jsonl,episodes_stats.jsonl。 getiterm:数据的加载与训练适配,实现 torch.utils.data.Dataset 接口,支持通过 DataLoader 加载数据用于训练。 push_to_hub:将数据集(元数据、Parquet、视频)上传至 Hugging Face Hub,自动生成数据集卡片(README.md),包含特征说明、硬件兼容性和统计信息 pull_from_repo:从 Hub 拉取指定版本的数据集,支持按 allow_patterns 筛选文件(如仅拉取元数据 meta/ 或特定 episode)。 start_image_writer/stop_image_writer:为避免图像存储阻塞录制主循环(导致帧率波动),通过 AsyncImageWriter 启动多线程/多进程写入器。 create:数据的新建或加载,是初始化的类方法。 @classmethod def create( cls, repo_id: str, # 数据集标识(用户指定) fps: int, # 帧率(默认 30 FPS) features: dict, # 特征定义(动作+观测,来自机器人硬件) root: ..., # 本地路径 robot_type: str, # 机器人类型(如 "so101_follower") use_videos: bool = True, # 是否编码视频(默认 True) image_writer_processes: int = 0, # 图像写入进程数 image_writer_threads: int = 4 * len(robot.cameras), # 图像写入线程数 ) -> "LeRobotDataset": # 1. 初始化元数据(调用 LeRobotDatasetMetadata.create) obj.meta = LeRobotDatasetMetadata.create( repo_id=repo_id, fps=fps, features=features, robot_type=robot_type, use_videos=use_videos ) # 2. 启动图像写入器(异步写入) if image_writer_processes or image_writer_threads: obj.start_image_writer(image_writer_processes, image_writer_threads) # 3. 初始化 episode 缓冲区(内存临时存储) obj.episode_buffer = obj.create_episode_buffer() # 4. 创建空 HF Dataset(存储非图像数据) obj.hf_dataset = obj.create_hf_dataset() return obj 元数据驱动:通过 LeRobotDatasetMetadata.create 确保数据集特征与机器人硬件严格对齐,避免录制后因特征不匹配导致训练错误。 性能优化:异步图像写入器(多线程/多进程)解决了录制时 I/O 阻塞问题,保障实时控制循环的稳定性。 标准化存储:统一 Parquet+MP4 格式,兼容 Hugging Face Hub 生态和 PyTorch DataLoader,简化“录制-训练”流程。 LeRobotDataset.create 是一个类方法,通过 @classmethod 装饰,其核心特性是无需先实例化LeRobotDataset 类即可调用,直接通过类名 LeRobotDataset.create(...) 触发,并返回一个初始化完成的 LeRobotDataset 实例,通常用于工厂模式或单例模式的场景。 类方法(@classmethod)的第一个参数是 cls(代表类本身),因此可以直接通过类名触发,而非实例。LeRobotDataset.create 的作用正是绕开普通构造函数 init,为新建数据集执行特殊初始化逻辑(如元数据创建、目录结构搭建、异步写入器启动等),最终返回一个完整的 LeRobotDataset 实例。 LeRobotDatasetMetadata.create 在LeRobotDataset中会调用到obj.meta = LeRobotDatasetMetadata.create创建一个LeRobotDatasetMetadata对象,其核心功能是为全新数据集初始化元数据结构,包括目录创建、特征定义合并、元数据文件生成(如 meta/info.json)和硬件兼容性校验,确保后续机器人数据录制(关节状态、摄像头图像等)与存储格式严格对齐。 @classmethod def create( cls, repo_id: str, fps: int, features: dict, robot_type: str | None = None, root: str | Path | None = None, use_videos: bool = True, ) -> "LeRobotDatasetMetadata": """Creates metadata for a LeRobotDataset.""" obj = cls.__new__(cls) #创建空的 LeRobotDatasetMetadata 实例(不触发 __init__,避免加载现有元数据) obj.repo_id = repo_id # 数据集标识(如 "username/pick_cube") obj.root = Path(root) if root is not None else HF_LEROBOT_HOME / repo_id # 本地路径(默认缓存目录) obj.root.mkdir(parents=True, exist_ok=False) # TODO(aliberts, rcadene): implement sanity check for features # 合并用户提供的特征与默认特征(补充必选字段) features = {**features, **DEFAULT_FEATURES} _validate_feature_names(features) # 校验特征名称合法性(如禁止含空格、特殊字符,确保与硬件接口一致) obj.tasks, obj.task_to_task_index = {}, {} # 任务列表(如 {"pick": 0, "place": 1})及索引映射 obj.episodes_stats, obj.stats, obj.episodes = {}, {}, {} # 初始化 episode 统计信息、全局统计、episode 列表 obj.info = create_empty_dataset_info(CODEBASE_VERSION, fps, features, use_videos, robot_type) #生成数据集的“总说明书”(meta/info.json),包含以下关键信息 if len(obj.video_keys) > 0 and not use_videos: raise ValueError() write_json(obj.info, obj.root / INFO_PATH) obj.revision = None return obj LeRobotDatasetMetadata.create 是新建数据集的“元数据基石”,通过标准化目录结构、特征定义和兼容性校验,确保机器人录制数据(动作、图像、状态)的存储格式与硬件特征严格对齐。其输出的 LeRobotDatasetMetadata 实例是连接机器人硬件与数据集文件系统的核心桥梁,为后续数据录制、编码和训练加载提供统一的元信息描述。 加载数据集 加载数据集是加载已经存在的数据集,针对的场景是针对此前的录制场景接着录制,与创建数据集不同,创建数据集是从头开始,创建一个空的数据集。那么lerobot怎么进行恢复了? 前面章节无论是LeRobotDataset.create 还是LeRobotDatasetMetadata.create都会绕过类的构造函数xxx.init的运行,那么xxx.init在哪里运行了? LeRobotDataset.init 是类的默认构造函数,仅在直接实例化 LeRobotDataset 时调用,核心场景是 恢复已有数据集的录制或加载。而 LeRobotDataset.create 是类方法,用于创建全新数据集,二者分工明确,对应不同的用户需求。接下来针对恢复的场景来说明。 当输入参数--resume=true,即在原来的数据集基础上进行。 if cfg.resume: #走恢复模式 dataset = LeRobotDataset( cfg.dataset.repo_id,# 数据集标识(如 "lerobot/pick_cube") root=cfg.dataset.root,# 本地存储路径(默认:~/.cache/huggingface/lerobot/{repo_id}) ) ) if hasattr(robot, "cameras") and len(robot.cameras) > 0: dataset.start_image_writer( num_processes=cfg.dataset.num_image_writer_processes, num_threads=cfg.dataset.num_image_writer_threads_per_camera * len(robot.cameras), ) sanity_check_dataset_robot_compatibility(dataset, robot, cfg.dataset.fps, dataset_features) else: dataset = LeRobotDataset.create(......) 关键流程是实例化LeRobotDataset,触发LeRobotDataset.init 方法,LeRobotDataset类的初始化代码如下。 LeRobotDataset.init LeRobotDataset: def __init__( self, repo_id: str, # 数据集标识(如 "lerobot/pick_cube") root: ..., # 本地存储路径(默认:~/.cache/huggingface/lerobot/{repo_id}) episodes: list[int] | None = None, # 指定加载的 episode 索引(如 [0, 2, 5]) image_transforms: Callable | None = None, # 图像预处理(如 Resize、Normalize) delta_timestamps: ..., # 时间戳偏移(用于多模态数据同步) tolerance_s: float = 1e-4, # 时间戳校验容差(确保帧率稳定性) revision: ..., # 数据集版本(默认代码库版本 v2.1) force_cache_sync: bool = False, # 强制同步缓存(忽略本地文件,重新拉取) download_videos: bool = True, # 是否下载视频文件 video_backend: str | None = None, # 视频解码后端(如 "pyav"、"torchcodec") ): # 1. 初始化基础路径与配置 self.repo_id = repo_id self.root = Path(root) or HF_LEROBOT_HOME / repo_id # 本地路径 #没有创建的话默认就是~/.cache/huggingface/lerobot self.root.mkdir(exist_ok=True, parents=True) # 创建目录(若不存在) # 2. 加载元数据(通过 LeRobotDatasetMetadata) self.meta = LeRobotDatasetMetadata( self.repo_id, self.root, self.revision, force_cache_sync=force_cache_sync ) # 3. 加载实际数据(优先本地缓存,缺失则从 Hub 下载) try: if force_cache_sync: raise FileNotFoundError # 强制同步时跳过本地缓存 # 验证本地数据文件完整性 assert all((self.root / fpath).is_file() for fpath in self.get_episodes_file_paths()) self.hf_dataset = self.load_hf_dataset() # 加载 Parquet 格式数据(非图像) except (AssertionError, FileNotFoundError): # 从 Hub 下载数据(含 Parquet 和视频文件) self.revision = get_safe_version(self.repo_id, self.revision) # 校验版本合法性 self.download_episodes(download_videos) # 下载指定 episode 数据 self.hf_dataset = self.load_hf_dataset() # 重新加载数据 # 4. 数据校验(确保时间戳与帧率匹配) timestamps = torch.stack(tuple(self.hf_dataset["timestamp"])).numpy() episode_indices = torch.stack(tuple(self.hf_dataset["episode_index"])).numpy() check_timestamps_sync( # 校验每帧时间间隔是否为 1/fps ± tolerance_s timestamps, episode_indices, self.episode_data_index, self.fps, self.tolerance_s ) LeRobotDataset 类的构造函数(init 方法),其核心作用是加载已存在的机器人数据集(本地或 Hugging Face Hub),并完成元数据校验、数据完整性检查、时间戳同步等关键步骤,为后续数据访问(如训练、可视化)提供统一接口。该方法是 LeRobotDataset 类的“入口”,仅在恢复已有数据集或加载数据集用于训练时调用。 LeRobotDataset 是基于 PyTorch Dataset 的子类,专为机器人数据设计,支持两种场景: 加载本地已有数据集:从指定路径(root)直接读取元数据和数据文件。 从 Hugging Face Hub 下载数据集:若本地数据缺失,自动从 Hub 拉取并加载。 无论哪种场景,init 均确保数据集的元数据一致性(如机器人类型、帧率)、数据完整性(文件不缺失)和时间戳有效性(符合录制帧率),为下游任务(如策略训练)提供可靠数据。 LeRobotDatasetMetadata.init 在LeRobotDataset.init中实例化了self.meta = LeRobotDatasetMetadata,该类创建时会调用构造函数LeRobotDatasetMetadata.init。 lass LeRobotDatasetMetadata: def __init__( self, repo_id: str, root: str | Path | None = None, revision: str | None = None, force_cache_sync: bool = False, ): self.repo_id = repo_id # 数据集唯一标识 self.revision = revision if revision else CODEBASE_VERSION # 版本(默认代码库版本) self.root = Path(root) if root is not None else HF_LEROBOT_HOME / repo_id #本地路径(默认缓存目录) try: if force_cache_sync: raise FileNotFoundError self.load_metadata() except (FileNotFoundError, NotADirectoryError): if is_valid_version(self.revision): self.revision = get_safe_version(self.repo_id, self.revision) (self.root / "meta").mkdir(exist_ok=True, parents=True) self.pull_from_repo(allow_patterns="meta/") # 加载本地元数据 self.load_metadata() def load_metadata(self): self.info = load_info(self.root) check_version_compatibility(self.repo_id, self._version, CODEBASE_VERSION) self.tasks, self.task_to_task_index = load_tasks(self.root) self.episodes = load_episodes(self.root) if self._version < packaging.version.parse("v2.1"): self.stats = load_stats(self.root) self.episodes_stats = backward_compatible_episodes_stats(self.stats, self.episodes) else: self.episodes_stats = load_episodes_stats(self.root) self.stats = aggregate_stats(list(self.episodes_stats.values())) def load_metadata(self): self.info = load_info(self.root) check_version_compatibility(self.repo_id, self._version, CODEBASE_VERSION) self.tasks, self.task_to_task_index = load_tasks(self.root) self.episodes = load_episodes(self.root) if self._version < packaging.version.parse("v2.1"): self.stats = load_stats(self.root) self.episodes_stats = backward_compatible_episodes_stats(self.stats, self.episodes) else: self.episodes_stats = load_episodes_stats(self.root) self.stats = aggregate_stats(list(self.episodes_stats.values())) 从 self.root/meta 目录加载核心元数据文件(info.json、tasks.jsonl、episodes.jsonl 等),并校验元数据版本与当前代码库兼容性(check_version_compatibility) 录制流程 policy = None if cfg.policy is None else make_policy(cfg.policy, ds_meta=dataset.meta) #如果是能了策略模型,进行实例创建 listener, events = init_keyboard_listener() #初始化监听键盘事件 先判断是否指定了策略模型,如果指定了进行创建实例。同时初始化键盘监听器 recorded_episodes = 0 while recorded_episodes < cfg.dataset.num_episodes and not events["stop_recording"]: # 录制当前回合数据 log_say(f"Recording episode {dataset.num_episodes}", cfg.play_sounds) # 语音提示开始录制 record_loop( # 核心数据采集函数 robot=robot, teleop=teleop, # 遥操作器输入(或策略生成动作) policy=policy, dataset=dataset, # 数据写入目标 control_time_s=cfg.dataset.episode_time_s, # 单回合录制时长(默认60秒) display_data=cfg.display_data, # 实时可视化 ) # 回合间环境重置(给用户调整物体位置的时间) # 该阶段不写入数据,用于用户重置环境。 if not events["stop_recording"] and (...): log_say("Reset the environment", cfg.play_sounds) record_loop( # 重置阶段不记录数据(dataset=None) robot=robot, teleop=teleop, control_time_s=cfg.dataset.reset_time_s, # 重置时长(用户指定5秒) dataset=None, # 禁用数据写入 ) # 处理重录事件(用户按 'r' 触发) if events["rerecord_episode"]: log_say("Re-record episode", cfg.play_sounds) dataset.clear_episode_buffer() # 清空当前回合无效数据 continue # 重新录制当前回合 dataset.save_episode() # 保存当前回合数据到磁盘(图像、状态、动作) recorded_episodes += 1 # 回合计数+1 核心是调用record_loop进行采集录制,过程中监听用户输入的键盘值处理相关逻辑如右键结束单次录制,左键重复录制,ESC退出流程。 当前回合录制结束后,继续调用record_loop只是传递的参数不一样,等待环境复位。录制完当前回合后,调用dataset.save_episode()将数据写入到磁盘中。 录制循环 record_loop函数在两种场景下被调用,主要的作用是协调机器人控制(遥操作/策略)、数据采集与存储,确保数据帧率稳定且格式符合数据集要求。 正常录制:按配置时长(control_time_s)录制 episode 数据,保存到数据集。 环境重置:录制结束后,执行一段无数据保存的控制(让用户手动重置环境)。 初始化与参数校验 # 校验数据集帧率与录制帧率一致性 if dataset is not None and dataset.fps != fps: raise ValueError(f"The dataset fps should be equal to requested fps ({dataset.fps} != {fps}).") # 多遥操作器处理(如机械臂遥操作 + 键盘底盘控制) teleop_arm = teleop_keyboard = None if isinstance(teleop, list): # 分离键盘遥操作器和机械臂遥操作器 teleop_keyboard = next((t for t in teleop if isinstance(t, KeyboardTeleop)), None) teleop_arm = next((t for t in teleop if isinstance(t, (SO100Leader, ...))), None) # 校验:仅支持 LeKiwi 机器人,且必须包含 1 个键盘遥操作器 + 1 个机械臂遥操作器 if not (teleop_arm and teleop_keyboard and len(teleop) == 2 and robot.name == "lekiwi_client"): raise ValueError(...) # 策略重置(若使用策略控制,确保初始状态一致) if policy is not None: policy.reset() 首先校验一下数据集的帧率与录制帧率是否一致,如果遥控机器人有多个实例,比如主臂+键盘,一般这种组合用于lekiwi,包含一个键盘遥控操作器和1个机械臂遥控操作器。最后判断是否使用模型推理控制,如果是使用了先进行复位。 主循环控制与数据采集 timestamp = 0 # episode 已录制时长(秒) start_episode_t = time.perf_counter() # 起始时间戳 while timestamp < control_time_s: start_loop_t = time.perf_counter() # 本轮循环起始时间 # 检查是否提前退出(如用户按特定按键) if events["exit_early"]: events["exit_early"] = False break # 1. 获取机器人观测(传感器数据:摄像头图像、关节角度等) observation = robot.get_observation() # 2. 构建观测帧(符合数据集格式) if policy is not None or dataset is not None: observation_frame = build_dataset_frame(dataset.features, observation, prefix="observation") # 3. 生成动作(策略/遥操作器二选一) if policy is not None: # 策略生成动作:输入观测帧,输出动作值 action_values = predict_action( observation_frame, policy, device=get_safe_torch_device(...), ... ) # 格式化动作:按机器人动作特征(如关节名称)构建字典 action = {key: action_values[i].item() for i, key in enumerate(robot.action_features)} elif policy is None and isinstance(teleop, Teleoperator): # 单遥操作器:直接获取动作 action = teleop.get_action() elif policy is None and isinstance(teleop, list): # 多遥操作器:合并机械臂动作和底盘动作 arm_action = teleop_arm.get_action() # 机械臂动作 base_action = robot._from_keyboard_to_base_action(teleop_keyboard.get_action()) # 底盘动作 action = {**arm_action, **base_action} # 合并动作 # 4. 执行动作并记录实际发送的动作(可能因安全限制被裁剪) sent_action = robot.send_action(action) # 5. 保存数据到数据集(若启用) if dataset is not None: action_frame = build_dataset_frame(dataset.features, sent_action, prefix="action") # 动作帧 frame = {**observation_frame, **action_frame} # 合并观测与动作 dataset.add_frame(frame, task=single_task) # 添加到数据集 # 6. 可视化数据(若启用) if display_data: log_rerun_data(observation, action) # 记录数据用于 Rerun 可视化 # 7. 维持帧率:等待剩余时间以确保循环周期为 1/FPS 秒 dt_s = time.perf_counter() - start_loop_t # 本轮循环耗时 busy_wait(1 / fps - dt_s) # busy 等待以补足时间 # 更新 episode 已录制时长 timestamp = time.perf_counter() - start_episode_t 这里分为两种模式,一个是模型推理模式和遥控操作模式,前者是使用大模型进行预测产生动作处理,后者是用于大模型训练采集数据。 对于采集数据模式流程如下: 获取观测原始数据:调用robot.get_observation()获取观测数据,包括机器关节的数据、摄像头数据等。用于后续的数据存储。 获取遥控机器人的动作数据:调用action = teleop.get_action()获取到动作数据。如果是多遥控操作器,需要将其合并动作。 发送机器人执行动作:调用sent_action = robot.send_action(action)执行动作。 保存数据集:先调用build_dataset_frame构建遥控臂的数据action,然后将action与从臂机器的观测数据action_values进行合并frame,最后调用dataset.add_frame添加到数据集中。 可视化数据:如果启动了可视化数据,调用log_rerun_data记录数据用于rerun可视化。 时长更新:录制一轮有一个默认的等待时长,调用busy_wait进行等待。 对于模型推理模式流程如下: 获取观测原始数据:调用robot.get_observation()获取观测数据,包括机器关节的数据、摄像头数据等。 构建模型输入数据:要能够喂给模型做预测动作,需要将数据转换为模型可接收的格式,调用build_dataset_frame将观测原始数据进行转换。 模型生成预测动作:调用predict_action得到预测动作action_values,接着将action_values转换为机器的动作特征action。 发送预测动作:调用robot.send_action(action)将预测动作发送给机器进行执行。 下面是observation = robot.get_observation()返回的数据格式,主要包括的是6个舵机关节位置信息+两个相机的图像信息,一共8个键值对。 observation: {'elbow_flex.pos': 99.54710144927537, 'fixed': array([[[ 58, 48, 39], [ 56, 46, 37], [ 49, 39, 29], ..., ..., [ 45, 81, 69], [ 54, 87, 76], [ 55, 88, 77]]], shape=(480, 640, 3), dtype=uint8), 'gripper.pos': 2.666666666666667, 'handeye': array([[[76, 71, 75], [75, 70, 74], [69, 67, 70], ..., ..., [38, 73, 31], [31, 68, 25], [26, 63, 20]]], shape=(480, 640, 3), dtype=uint8), 'shoulder_lift.pos': -98.65771812080537, 'shoulder_pan.pos': -10.490956072351423, 'wrist_flex.pos': 54.17743324720067, 'wrist_roll.pos': -3.5714285714285694} 原始的观测数据,要经过处理,以便喂给模型或者存储到本地,输出的数据如下,一共有3个键值对,包括2个摄像头的键值对和一个舵机关节位置的,可以看到将前面6个舵机的合并为一个键值对了。 observation_frame: {'observation.images.fixed': array([[[ 80, 55, 61], [ 73, 48, 54], [ 68, 48, 49], ..., ..., [ 62, 82, 73], [ 69, 89, 80], [ 73, 90, 82]]], shape=(480, 640, 3), dtype=uint8), 'observation.images.handeye': array([[[67, 78, 72], [72, 83, 77], [69, 85, 75], ..., ..., [51, 71, 20], [39, 59, 6], [42, 63, 7]]], shape=(480, 640, 3), dtype=uint8), 'observation.state': array([-10.490956 , -98.657715 , 99.547104 , 54.177433 , -3.5714285, 2.6666667], dtype=float32)} 发送给机器人的动作数据,比较简单如下,也就是6个舵机的关节位置信息。 sent_action: {'elbow_flex.pos': 99.63685882886972, 'gripper.pos': 0.6509357200976403, 'shoulder_lift.pos': -99.36102236421725, 'shoulder_pan.pos': -10.0, 'wrist_flex.pos': 53.53886235345203, 'wrist_roll.pos': -3.598634095087988} 存储录制数据时,需要遥控机器action_frame、观测机器abservation_frame(前面已经列出了),下面看看相关数据的格式。 action_frame是遥控机器的sent_action转换而来,调用action_frame = build_dataset_frame(dataset.features, sent_action, prefix="action"),实际上就是将sent_action数据6个键值对改为1个键值对。 action_frame: {'action': array([-10. , -99.36102 , 99.636856 , 53.538864 , -3.598634 , 0.6509357], dtype=float32)} 最后将经过处理的一个遥控机器数据和经过处理的观测数据进行合并,最终得到如下4个键值对的数据。 frame: {'action': array([-10. , -99.36102 , 99.636856 , 53.538864 , -3.598634 , 0.6509357], dtype=float32), 'observation.images.fixed': array([[[ 70, 62, 51], [ 63, 55, 44], [ 61, 54, 44], ..., ..., [ 53, 95, 83], [ 47, 90, 80], [ 58, 104, 93]]], shape=(480, 640, 3), dtype=uint8), 'observation.images.handeye': array([[[76, 80, 55], [78, 82, 59], [77, 79, 57], ..., ..., [52, 64, 18], [47, 61, 12], [50, 66, 17]]], shape=(480, 640, 3), dtype=uint8), 'observation.state': array([-10.490956 , -98.657715 , 99.547104 , 54.177433 , -3.5714285, 2.6666667], dtype=float32)} 可视化显示 # 6. 可视化数据(若启用) if display_data: log_rerun_data(observation, action) # 记录数据用于 Rerun 可视化 可以看到界面显示的observation.xxx和action.xxx就是调用的这里log_rerun_data函数,理论上来说observation和action要越吻合越好,因为action是模型推理或主臂的动作,observation是实际的动作。 数据存储 在上一节中,循序录制过程中,将经过处理的遥控机器数据action_frame和经过处理后的机器观测数据observation_frame合并得到的数据frame,然后先调用dataset.add_frame(frame, task=single_task)写入,最后调用save_episode方法将缓存数据写入磁盘。 写入缓存 add_frame 是 LeRobotDataset 类的核心方法之一,负责将单帧机器人数据暂存到内存缓冲区(episode_buffer),并对图像数据进行预处理(如格式转换、临时存储)。该方法是数据录制流程中的关键环节,确保每帧数据符合数据集格式要求,并为后续的 save_episode 方法(将缓冲区数据写入磁盘)做准备。 def add_frame(self, frame: dict, task: str, timestamp: float | None = None) -> None: # 1. 数据格式转换PyTorch Tensor → NumPy 数组 # 目的是统一数据格式为 NumPy 数组(数据集底层存储格式),避免因混合 Tensor/NumPy 类型导致后续处理异常。 for name in frame: if isinstance(frame[name], torch.Tensor): frame[name] = frame[name].numpy() #2. 数据校验,确保帧格式符合数据集定义 #检查 frame 中的所有特征(如 observation.state、action) #是否与 self.features 中定义的 dtype(数据类型)、shape #(维度)一致。例如,若 self.features 定义 action 为 #float32 且形状为 (6,),则校验 frame["action"] 是否满足这些 #条件,确保数据规范性。 validate_frame(frame, self.features) #3. 如果没有初始化 episode 缓冲区,则初始化创建 # 内存缓冲区,用于累积当前 episode 的所有帧数据。结构 #与 self.features 对应,例如包含 observation.state、 #action、timestamp 等键,每个键的值为列表(按帧顺序存 #储数据) if self.episode_buffer is None: self.episode_buffer = self.create_episode_buffer() # 4. 记录帧索引与时间戳 # 未提供 timestamp,默认按帧率(self.fps)计算相对时间 #(如 30 FPS 时,第 0 帧为 0s,第 1 帧为 1/30 ≈0.033s),确保时间序列连续性 frame_index = self.episode_buffer["size"] if timestamp is None: timestamp = frame_index / self.fps # 记录存储frame_index,timestamp,task self.episode_buffer["frame_index"].append(frame_index) self.episode_buffer["timestamp"].append(timestamp) self.episode_buffer["task"].append(task) # 5. 添加一帧数据到episode_buffer for key in frame: if key not in self.features: raise ValueError( f"An element of the frame is not in the features. '{key}' not in '{self.features.keys()}'." ) # 如果是图像,处理追加到数据缓冲区 if self.features[key]["dtype"] in ["image", "video"]: img_path = self._get_image_file_path( episode_index=self.episode_buffer["episode_index"], image_key=key, frame_index=frame_index ) if frame_index == 0: img_path.parent.mkdir(parents=True, exist_ok=True) #通过 _get_image_file_path 生成标准化路径,调用存储图片,可同步可异步。 self._save_image(frame[key], img_path) self.episode_buffer[key].append(str(img_path)) else: # 如果是动作特征数据直接追加到原始数据缓冲区 self.episode_buffer[key].append(frame[key]) #6. 最后更新缓冲区大小 self.episode_buffer["size"] += 1 add_frame 是机器人数据录制的“数据暂存中枢”,通过内存缓冲区累积帧数据、预处理图像并校验数据格式,为后续持久化存储奠定基础。其设计兼顾了录制效率(异步图像写入)和数据可靠性(格式校验),是构建标准化机器人数据集的核心环节,其设计,总结有以下优点: 数据暂存与累积:通过 episode_buffer 在内存中临时存储一整段 episode 的数据,避免频繁磁盘 I/O 影响录制帧率。 图像预处理解耦:将图像保存与数据记录分离,支持异步图像写入(AsyncImageWriter),确保主录制循环(record_loop)不受图像存储速度影响,维持稳定帧率。 数据一致性校验:通过 validate_frame 提前过滤无效数据,避免错误数据进入后续流程(如 save_episode 写入磁盘) 写入磁盘 录制完一轮,会调用dataset.save_episode()进行存储写入磁盘。 def save_episode(self, episode_data: dict | None = None) -> None: #1. 输入处理与数据校验 if not episode_data: episode_buffer = self.episode_buffer #使用内存缓冲区数据(默认流程) #校验缓冲区数据的完整性,确保所有特征(如 #observation.state、action)的长度一致(与 episode 总帧 #数匹配),且 episode_index 未超出当前数据集范围 validate_episode_buffer(episode_buffer, self.meta.total_episodes, self.features) # 2.从缓冲区中提取非特征数据(这些键不直接存储到 Parquet) episode_length = episode_buffer.pop("size")# 当前 episode 的总帧数 tasks = episode_buffer.pop("task")# 每帧的任务标签列表(可能重复) episode_tasks = list(set(tasks))# 当前 episode 涉及的唯一任务列表 episode_index = episode_buffer["episode_index"] # 当前 episode 的索引 #3. 构建全局索引与episode标识,确保每帧在整个数据集中有唯一标识,便于后续数据加载时定位。 # 生成全局帧索引(从数据集总帧数开始累加) episode_buffer["index"] = np.arange(self.meta.total_frames, self.meta.total_frames + episode_length) #生成 episode_index 数组(所有帧均属于当前 episode) episode_buffer["episode_index"] = np.full((episode_length,), episode_index) # 4. 任务标签处理与元数据更新 # 添加新任务到元数据(若任务不存在) for task in episode_tasks: task_index = self.meta.get_task_index(task) if task_index is None: self.meta.add_task(task)# 新增任务并更新 tasks.jsonl # 生成 task_index 数组(将每帧的任务标签映射为整数索引) episode_buffer["task_index"] = np.array([self.meta.get_task_index(task) for task in tasks]) # 5.数值特征数据格式化 for key, ft in self.features.items(): # 跳过索引类特征、图像和视频(这些由其他逻辑处理) if key in ["index", "episode_index", "task_index"] or ft["dtype"] in ["image", "video"]: continue # 将列表形式的帧数据堆叠为二维数组(shape: [episode_length, feature_dim]) episode_buffer[key] = np.stack(episode_buffer[key]) #若 action 特征为长度 6 的向量,episode_buffer["action"] # 会从 [ [a0], [a1], ..., [aN] ] 堆叠为 [ [a0_0, ..., a0_5], ..., [aN_0, ..., aN_5] ],符合 Parquet 存储格式。 #6. 等待异步图像写入完成 self._wait_image_writer()# 确保所有临时图像文件已写入磁盘 # 保存数值到Parquet文件 self._save_episode_table(episode_buffer, episode_index) ep_stats = compute_episode_stats(episode_buffer, self.features) # _save_episode_table 行为 # 从缓冲区提取特征数据,构造 datasets.Dataset 对象。 # 将数据写入 Parquet 文件(路径由元数据的 get_data_file_path 生成,如 data/chunk-000/episode_000000.parquet)。 # 更新内存中的 hf_dataset(拼接新 episode 数据)。 #8. 若启用视频模式,将图像编码存储为视频文件 if len(self.meta.video_keys) > 0: video_paths = self.encode_episode_videos(episode_index) # 将临时图像编码为 MP4 #调用 ffmpeg 将临时目录下的图像帧(如 images/observation.images.laptop/episode_000000/frame_*.png) #编码为 MP4 视频,存储路径由元数据的 get_video_file_path 定义 for key in self.meta.video_keys: episode_buffer[key] = video_paths[key] # 记录视频文件路径 # `meta.save_episode` be executed after encoding the videos #9. 更新元数据与校验时间戳 # 更新元数据(总 episodes、总 frames、chunks 等) self.meta.save_episode(episode_index, episode_length, episode_tasks, ep_stats) # 校验时间戳连续性(确保帧间隔符合帧率 1/fps ± tolerance_s) ep_data_index = get_episode_data_index(self.meta.episodes, [episode_index]) ep_data_index_np = {k: t.numpy() for k, t in ep_data_index.items()} check_timestamps_sync( episode_buffer["timestamp"],# 帧时间戳数组 episode_buffer["episode_index"],# episode 索引数组 ep_data_index_np,# episode 帧范围 self.fps,# 帧率 self.tolerance_s,# 时间容差 ) #10. 文件完整性校验与资源清理 # 验证视频文件数量(每个 episode × 每个视频 key 应对应一个 MP4) video_files = list(self.root.rglob("*.mp4")) assert len(video_files) == self.num_episodes * len(self.meta.video_keys) # 验证 Parquet 文件数量(每个 episode 对应一个 Parquet) parquet_files = list(self.root.rglob("*.parquet")) assert len(parquet_files) == self.num_episodes # 删除临时图像目录(已编码为视频,无需保留) img_dir = self.root / "images" if img_dir.is_dir(): shutil.rmtree(self.root / "images") # 重置缓冲区,准备下一段 episode 录制 if not episode_data: # Reset the buffer self.episode_buffer = self.create_episode_buffer() save_episode 是 LeRobotDataset 类的核心方法,负责将内存缓冲区(episode_buffer)中累积的单段 episode 数据持久化到磁盘,同时更新元数据、生成视频文件、校验数据完整性,并重置缓冲区以准备下一段录制。该方法是数据录制流程的“收尾环节”,确保每段 episode 数据符合 LeRobot 数据集格式规范。主要功能如下: 数据持久化:将内存中的帧数据(数值特征、图像路径)写入 Parquet 文件(结构化数据)和 MP4 文件(视频数据)。 元数据更新:更新数据集元信息(如总 episode 数、总帧数、任务标签),确保元数据与实际数据一致。 数据校验:验证时间戳连续性、文件完整性(如视频/Parquet 文件数量匹配预期),避免无效数据入库。 资源清理:删除临时图像文件(已编码为视频),释放内存缓冲区。 save_episode 是 LeRobot 数据集录制的“最终执行者”,通过系统化的数据格式化、编码、校验和清理,将内存中的临时帧数据转化为符合规范的磁盘存储,同时维护元数据一致性和数据完整性。其设计确保了录制数据的可靠性、存储效率和下游可用性,是连接实时录制与离线数据使用的关键桥梁。 结束采集 log_say("Stop recording", cfg.play_sounds, blocking=True) # 语音提示结束录制 robot.disconnect() # 断开机器人连接(禁用扭矩,确保安全) if teleop is not None: teleop.disconnect() # 断开遥操作器连接 if not is_headless() and listener is not None: listener.stop() # 停止键盘监听器 断开设备,停止键盘监听。 if cfg.dataset.push_to_hub: dataset.push_to_hub(tags=cfg.dataset.tags, private=cfg.dataset.private) # 上传数据集到 Hugging Face Hub 将数据上传到hugging Face Hub上。 -
lerobot示教
启动 示教的功能主要是主臂控制,从臂跟随,在数据采集是非常的一环。下面是模块启动的执行命令: python -m lerobot.teleoperate \ --robot.type=so101_follower \ --robot.port=/dev/ttyACM0 \ --robot.id=R12252801 \ --teleop.type=so101_leader \ --teleop.port=/dev/ttyACM1 \ --teleop.id=R07252608 python解释器回安装sys.path查找lerobot.teleoperate模块,找到执行lerobot/src/lerobot/teleoperate.py文件,调用teleoperate函数。 ## 配置解析 @draccus.wrap() def teleoperate(cfg: TeleoperateConfig): init_logging() logging.info(pformat(asdict(cfg))) ## 初始化可视化工具 if cfg.display_data: _init_rerun(session_name="teleoperation") ##创建操作设备和机器人实例 teleop = make_teleoperator_from_config(cfg.teleop) robot = make_robot_from_config(cfg.robot) ## 连接设备 teleop.connect() robot.connect() ##示教循环 try: teleop_loop(teleop, robot, cfg.fps, display_data=cfg.display_data, duration=cfg.teleop_time_s) except KeyboardInterrupt: pass finally: if cfg.display_data: rr.rerun_shutdown() ## 断开连接 teleop.disconnect() robot.disconnect() if __name__ == "__main__": teleoperate() 下面展开来说明一下。 配置解析 @draccus.wrap() def teleoperate(cfg: TeleoperateConfig): # 初始化日志记录 init_logging() # 打印配置信息 logging.info(pformat(draccus.asdict(cfg))) 在teleoperate.py中teleoperate函数使用@draccus.wrap()装饰器解析命令行参数,将参数转换为TeleoperateConfig类型的配置对象。dracus是用于配置解析的库,类型与argparse。 这里的TeleoperateConfig是一个自定义的配置类,定义如下: from dataclasses import dataclass @dataclass class RobotConfig: type: str port: str id: str @dataclass class TeleopConfig: type: str port: str id: str @dataclass class TeleoperateConfig: teleop: TeleoperatorConfig robot: RobotConfig # Limit the maximum frames per second. fps: int = 60 teleop_time_s: float | None = None # Display all cameras on screen display_data: bool = False 可以看到TeleoperateConfig类中属性定义了robot,teleop两个对象,命令行的参数将会映射到,如: --robot.type=so101_follower:对应cfg.robot.type --teleop.port=/dev/ttyACM1:对应cfg.teleop.port 初始化可视化工具 if cfg.display_data: _init_rerun(session_name="teleoperation") 当参数--display_data=true,即cfg.display_data 为 True,则调用 _init_rerun 函数初始化 rerun 可视化工具。rerun 是一个用于记录和可视化科学数据的工具。 def _init_rerun(session_name: str = "lerobot_control_loop") -> None: """Initializes the Rerun SDK for visualizing the control loop.""" batch_size = os.getenv("RERUN_FLUSH_NUM_BYTES", "8000") os.environ["RERUN_FLUSH_NUM_BYTES"] = batch_size rr.init(session_name) memory_limit = os.getenv("LEROBOT_RERUN_MEMORY_LIMIT", "10%") rr.spawn(memory_limit=memory_limit) _init_rerun函数的主要功能是初始化Rerun SDK,设置数据刷新的字节数和内存使用限制,然后启动Rerun会话,为后续的控制循环可视化工作做准备。 其中有两个参数是从环境变量中获取,分别是RERUN_FLUSH_NUM_BYTES和LEROBOT_RERUN_MEMORY_LIMIT,用于控制每次刷新是处理数据的字节数和限制使用的内存量。 创建主从臂实例 teleop = make_teleoperator_from_config(cfg.teleop) robot = make_robot_from_config(cfg.robot) 调用调用 make_teleoperator_from_config 和make_robot_from_config 函数,根据配置对象创建 SO101Leader遥操作设备实例和 SO101Follower 机器人实例。 def make_teleoperator_from_config(config: TeleoperatorConfig) -> Teleoperator: if config.type == "keyboard": from .keyboard import KeyboardTeleop return KeyboardTeleop(config) elif config.type == "koch_leader": from .koch_leader import KochLeader return KochLeader(config) elif config.type == "so100_leader": from .so100_leader import SO100Leader return SO100Leader(config) elif config.type == "so101_leader": from .so101_leader import SO101Leader return SO101Leader(config) ...... 以leader为例,最终调用SO101Leader对象实例。 class SO101Leader(Teleoperator): """ SO-101 Leader Arm designed by TheRobotStudio and Hugging Face. """ config_class = SO101LeaderConfig name = "so101_leader" def __init__(self, config: SO101LeaderConfig): super().__init__(config) #调用父类Teleoperator够着函数初始化属性,包括 #self.id:设备的唯一标识符,从配置对象中获取。 #self.calibration_dir:校准文件的存储目录。 #self.calibration_fpath:校准文件的完整路径。 #self.calibration:存储电机校准信息的字典。 self.config = config #类型为 SO101LeaderConfig,存储传入的配置对象,方便在类的其他方法中访问配置信息。 norm_mode_body = MotorNormMode.DEGREES if config.use_degrees else MotorNormMode.RANGE_M100_100 self.bus = FeetechMotorsBus( port=self.config.port, motors={ "shoulder_pan": Motor(1, "sts3215", norm_mode_body), "shoulder_lift": Motor(2, "sts3215", norm_mode_body), "elbow_flex": Motor(3, "sts3215", norm_mode_body), "wrist_flex": Motor(4, "sts3215", norm_mode_body), "wrist_roll": Motor(5, "sts3215", norm_mode_body), "gripper": Motor(6, "sts3215", MotorNormMode.RANGE_0_100), }, calibration=self.calibration, ) #类型为 FeetechMotorsBus,用于与 Feetech 电机进行通信,初始化时传入端口、电机信息和校准信息。 SO101Leader类继承了Teleoperator,super().init(config) 调用父类 Teleoperator 的构造函数初始化的属性。 class Teleoperator(abc.ABC): def __init__(self, config: TeleoperatorConfig): self.id = config.id #设备的id self.calibration_dir = ( config.calibration_dir if config.calibration_dir else HF_LEROBOT_CALIBRATION / TELEOPERATORS / self.name ) #校准文件的存储目录 self.calibration_dir.mkdir(parents=True, exist_ok=True) #创建校准目录 self.calibration_fpath = self.calibration_dir / f"{self.id}.json" self.calibration: dict[str, MotorCalibration] = {} # 初始化一个字典,键为字符串,值为MotorCalibration if self.calibration_fpath.is_file(): self._load_calibration() #检查校准文件是否存在,存在调用加载校准信息的方法。 Teleoperator定义了一个遥控的基类,其构造函数中接受一个TeleoperatorConfig类型的参数config,主要有以下属性。 self.id:设备的唯一标识符,从传入的配置对象 config 里获取,用于在系统中唯一标识该 SO101Leader 设备实例。 self.calibration_dir:校准文件的存储目录。若 config.calibration_dir 有值则使用该值,否则使用默认路径。此目录用于存放设备的校准文件。 self.calibration_fpath:校准文件的完整路径,由 self.calibration_dir 和设备 id 组合而成,文件格式为 JSON。 self.calibration:存储电机校准信息的字典,键为电机名称,值为 MotorCalibration 类型的对象,用于保存电机的校准参数。 而SO101Leader类中自己定义的实力属性有 - self.config:类型为 SO101LeaderConfig,存储传入的配置对象。借助这个属性,类的其他方法可以访问配置信息,如端口号、是否使用角度单位等。 - self.bus:类型为 FeetechMotorsBus,用于和 Feetech 电机进行通信。初始化时传入端口、电机信息和校准信息,后续可以通过该对象实现电机的读写操作、校准等功能。 总结下就是SO101Leader 类包含 2 个类属性和多个实例属性,这些属性从不同层面描述了 SO101 领导者手臂设备的类型、配置、校准信息以及与电机的通信对象等。而SO101Follower也是同理这里就不过多阐述。 连接设备 teleop.connect() robot.connect() 连接设备就是各自调用此前创建实例的connect方法,建立与硬件设备的连接。以teleop为例,最总调用到self.bus.connect发起连接并进行配置。 def connect(self, calibrate: bool = True) -> None: if self.is_connected: raise DeviceAlreadyConnectedError(f"{self} already connected") self.bus.connect() if not self.is_calibrated and calibrate: self.calibrate() self.configure() logger.info(f"{self} connected.") 跟随控制 def teleop_loop( teleop: Teleoperator, robot: Robot, fps: int, display_data: bool = False, duration: float | None = None ): display_len = max(len(key) for key in robot.action_features) start = time.perf_counter() while True: loop_start = time.perf_counter() #从主臂获取动作位置数据 action = teleop.get_action() #如果启动了实时显示,进行显示 if display_data: observation = robot.get_observation() log_rerun_data(observation, action) #将主臂的动作位置数据发送给从臂 robot.send_action(action) #计算循环执行时间 dt_s = time.perf_counter() - loop_start busy_wait(1 / fps - dt_s) loop_s = time.perf_counter() - loop_start #打印动作的信息,每个舵机的位置。 print("\n" + "-" * (display_len + 10)) print(f"{'NAME':<{display_len}} | {'NORM':>7}") for motor, value in action.items(): print(f"{motor:<{display_len}} | {value:>7.2f}") print(f"\ntime: {loop_s * 1e3:.2f}ms ({1 / loop_s:.0f} Hz)") if duration is not None and time.perf_counter() - start >= duration: return # 将终端的文本光标向上移动一定的行数,以此实现覆盖上一次输出内容的效果,从而在终端里模拟实时更新的显示 move_cursor_up(len(action) + 5) -
lerobot设备标定
why calibrate 先来看看标定后的数据 { "shoulder_pan": { #肩部旋转关节 "id": 1, "drive_mode": 0, "homing_offset": -1620, "range_min": 1142, "range_max": 2931 }, "shoulder_lift": { #肩部升降关节 "id": 2, "drive_mode": 0, "homing_offset": 2025, "range_min": 844, "range_max": 3053 }, "elbow_flex": { #肘部弯曲关节 "id": 3, "drive_mode": 0, "homing_offset": -1208, "range_min": 963, "range_max": 3078 }, "wrist_flex": { #腕部弯曲关节 "id": 4, "drive_mode": 0, "homing_offset": 2021, "range_min": 884, "range_max": 3222 }, "wrist_roll": { #腕部旋转关节 "id": 5, "drive_mode": 0, "homing_offset": -777, "range_min": 142, "range_max": 3961 }, "gripper": { #夹爪关节 "id": 6, "drive_mode": 0, "homing_offset": 909, "range_min": 1978, "range_max": 3522 } } 上面数据是每个舵机的相关参数,一共有6个舵机,每个舵机都有一个id来标识,可以对应实物来看实际是从下到上。 id: 电机的唯一标识符,用于在总线通信时精准定位和控制特定电机。 drive_mode: 电机的驱动模式,取值为 0 表示特定的驱动模式,不同驱动模式会影响电机的运动特性与控制方式。 homing_offset:归位偏移量,指电机从物理零点位置到校准零点位置的偏移量。此参数能保证电机在每次启动时都能回到准确的零点位置,从而提升运动精度。 range_min 和 range_max:电机运动范围的最小值和最大值,以数值形式呈现。这两个参数限定了电机的运动边界,避免因超出范围而导致硬件损坏或者运动异常。range_min 和 range_max:电机运动范围的最小值和最大值,以数值形式呈现。这两个参数限定了电机的运动边界,避免因超出范围而导致硬件损坏或者运动异常。 上面的参数信息在代码中lerobot/src/lerobot/robots/koch_follower/koch_follower.py 中回进行配置。 从上面的配置信息可知,之所以要标定,就是要获取电机的一些物理特性,主要是几个方面:明确电机物理运动范围、归一化电机位置、确保机器人运行精度等。 明确电机范围 机器的电机要有特定的物理运动范围,因为发送要是超过这个范围,回造成硬件损坏。使用calibrate操作可以记录每个电机的最小和最大位置限制,保证后续发送的指令都在安全范围内。 lerobot/src/lerobot/robots/so101_follower/so101_follower.py def calibrate(self) -> None: # ...已有代码... print( "Move all joints sequentially through their entire ranges " "of motion.\nRecording positions. Press ENTER to stop..." ) range_mins, range_maxes = self.bus.record_ranges_of_motion() self.calibration = {} for motor, m in self.bus.motors.items(): self.calibration[motor] = MotorCalibration( id=m.id, drive_mode=0, homing_offset=homing_offsets[motor], range_min=range_mins[motor], range_max=range_maxes[motor], ) # ...已有代码... 归一化电机位置 不同电机的原始位置值可能都离散的任意值,这些依赖于具体的电机型号,不具备通用性。calibrate 操作能将这些原始位置值归一化为有意义的连续值,像百分比、角度等,方便后续处理和控制。 lerobot/src/lerobot/motors/motors_bus.py def _normalize(self, id_, val, min_, max_, drive_mode): motor = self._id_to_name(id_) if self.motors[motor].norm_mode is MotorNormMode.RANGE_M100_100: norm = (((val - min_) / (max_ - min_)) * 200) - 100 normalized_values[id_] = -norm if drive_mode else norm # ...已有代码... 确保机器运行精度 lerobot/src/lerobot/robots/so100_leader/so100_leader.py 中的 calibrate def calibrate(self) -> None: # ...已有代码... input(f"Move {self} to the middle of its range of motion and press ENTER....") homing_offsets = self.bus.set_half_turn_homings() # ...已有代码... 通过校准,可以确定电机的归位偏移量(homing offset),这有助于提高机器人运动的精度和重复性。在实际应用中,准确的位置控制对机器人完成任务至关重要。 最后经过校准后的数据,后续无需在重复校准,校准保存的路径一般在~/.cache/huggingface/lerobot/calibration,实际运行过程中,回进行加载。 保存 def _save_calibration(self, fpath: Path | None = None) -> None: draccus.dump(self.calibration, f, indent=4) 加载 def _load_calibration(self, fpath: Path | None = None) -> None: self.calibration = draccus.load(dict[str, MotorCalibration], f) 校准流程 python -m lerobot.calibrate \ --robot.type=so101_follower \ --robot.port=/dev/ttyACM0 \ --robot.id=R12252801 上面是执行命令示例,接下来个跟踪一下流程。Python 解释器接收到 python -m lerobot.calibrate 命令后,会将 lerobot.calibrate 当作一个可执行模块来处理。按照 Python 模块查找机制,会在 sys.path 所包含的路径里寻找 lerobot/calibrate.py 文件,对应的文件路径为lerobot/src/lerobot/calibrate.py。 @draccus.wrap() def calibrate(cfg: CalibrateConfig): init_logging() logging.info(pformat(asdict(cfg))) if isinstance(cfg.device, RobotConfig): device = make_robot_from_config(cfg.device) elif isinstance(cfg.device, TeleoperatorConfig): device = make_teleoperator_from_config(cfg.device) device.connect(calibrate=False) device.calibrate() device.disconnect() if __name__ == "__main__": calibrate() 调用calibrate含税,从calibrate可以看到主要的步骤为: 参数解析与配置初始化 创建设备实例 连接设备 设备校准 设备断开连接 参数解析与配置初始化 calibrate函数被@draccus.wrap()装饰,draccus是一个用于解析命令行参数并创建配置对象的库。 @dataclass class CalibrateConfig: teleop: TeleoperatorConfig | None = None robot: RobotConfig | None = None def __post_init__(self): if bool(self.teleop) == bool(self.robot): raise ValueError("Choose either a teleop or a robot.") self.device = self.robot if self.robot else self.teleop draccus会把命令行参数--robot.type=so101_follower --robot.port=/dev/ttyACM0 --robot.id=R12252801解析成CalibrateConfig类的实例。robot属性会被初始化为RobotConfig类型的对象,如果是--teleop.type=so101_leader 将会初始化为TeleoperatorConfig类型的对象。RobotConfig对象在config.py中定义的。 @dataclass(kw_only=True) class RobotConfig(draccus.ChoiceRegistry, abc.ABC): # Allows to distinguish between different robots of the same type id: str | None = None # Directory to store calibration file calibration_dir: Path | None = None def __post_init__(self): if hasattr(self, "cameras") and self.cameras: for _, config in self.cameras.items(): for attr in ["width", "height", "fps"]: if getattr(config, attr) is None: raise ValueError( f"Specifying '{attr}' is required for the camera to be used in a robot" ) @property def type(self) -> str: return self.get_choice_name(self.__class__) 其会根据命令行参数或配置文件中的类型字段,动态选择并创建对应的配置子类实例。 如当前的参数有type,port,id分别设置为so101_follower、/dev/ttyACM0 和 R12252801。 创建设备实例 根据cfg.device类型,调用对应工厂含税创建设备实例。 if isinstance(cfg.device, RobotConfig): device = make_robot_from_config(cfg.device) elif isinstance(cfg.device, TeleoperatorConfig): device = make_teleoperator_from_config(cfg.device) 由于 cfg.device 是 RobotConfig 类型,所以会调用 make_robot_from_config(cfg.device)。该函数可能定义在 /home/laumy/lerobot/src/lerobot/robots/init.py 或者相关的工厂模块中,依据 cfg.device.type 的值(即 so101_follower),会创建 SO101Follower 类的实例。 连接设备 调用 device.connect(calibrate=False) 方法连接设备,lerobot/src/lerobot/robots/so101_follower/so101_follower.py 文件中,其 connect 方法可能如下: def connect(self, calibrate: bool = True) -> None: if self.is_connected: raise DeviceAlreadyConnectedError(f"{self} already connected") # 连接串口总线 self.bus = DynamixelBus(port=self.config.port, baudrate=1000000) self.bus.connect() if not self.is_calibrated and calibrate: self.calibrate() # 连接摄像头 for cam in self.cameras.values(): cam.connect() self.configure() logger.info(f"{self} connected.") 因为传入的 calibrate=False,所以不会触发自动校准。在连接过程中,会先连接串口总线,再连接摄像头,最后进行设备配置。 标定动作 调用 device.calibrate() 方法对设备进行校准,SO101Follower 类的 calibrate 方法可能如下: def calibrate(self) -> None: logger.info(f"\nRunning calibration of {self}") # 禁用扭矩 self.bus.disable_torque() # 设置电机工作模式为位置模式 for motor in self.bus.motors: self.bus.write("Operating_Mode", motor, OperatingMode.POSITION.value) # 手动操作提示 input(f"Move {self} to the middle of its range of motion and press ENTER....") # 设置半圈归零偏移量 homing_offsets = self.bus.set_half_turn_homings() print( "Move all joints sequentially through their entire ranges " "of motion.\nRecording positions. Press ENTER to stop..." ) # 记录关节运动范围 range_mins, range_maxes = self.bus.record_ranges_of_motion() self.calibration = {} for motor, m in self.bus.motors.items(): self.calibration[motor] = MotorCalibration( id=m.id, drive_mode=0, homing_offset=homing_offsets[motor], range_min=range_mins[motor], range_max=range_maxes[motor], ) # 将校准数据写入电机 self.bus.write_calibration(self.calibration) # 保存校准数据 self._save_calibration() 校准过程包含禁用扭矩、设置电机工作模式、手动操作提示、记录关节运动范围、保存校准数据等步骤。 设备断开连接 调用 device.disconnect() 方法断开设备连接,SO101Follower 类的 disconnect 方法如下: def disconnect(self): if not self.is_connected: raise DeviceNotConnectedError(f"{self} is not connected.") # 断开串口总线连接 self.bus.disconnect(self.config.disable_torque_on_disconnect) # 断开摄像头连接 for cam in self.cameras.values(): cam.disconnect() logger.info(f"{self} disconnected.") -
模型训练GPU跑飞
问题 当前使用的是魔改版的NVIDIA 2080 Ti 22G显卡,发现在模型训练过程中,跑着跑着就报错了,具体如下: raceback (most recent call last): File "/home/laumy/lerobot/./src/lerobot/scripts/train.py", line 291, in <module> train() File "/home/laumy/lerobot/src/lerobot/configs/parser.py", line 226, in wrapper_inner response = fn(cfg, *args, **kwargs) File "/home/laumy/lerobot/./src/lerobot/scripts/train.py", line 212, in train train_tracker, output_dict = update_policy( File "/home/laumy/lerobot/./src/lerobot/scripts/train.py", line 101, in update_policy train_metrics.loss = loss.item() RuntimeError: CUDA error: unspecified launch failure CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1 Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions. 然后使用nvidia-smi发现显卡都找不到了。 nvidia-smi No devices were found 排查 重启电脑,重新训练模型,同时执行以下命令查看显卡情况。 watch -n nvidia-smi 发现训练过程中,温度飙升非常快,初步怀疑是性能跑太满,导致温度过高保护了。 解决 限制GPU的功率和核心频率 sudo nvidia-smi -pl 150 # 将功率限制设置为150W sudo nvidia-smi -lgc 1000,1000 # 限制核心频率为1000MHz 限制后继续跑,发现没有问题了。也可以使用nvidia-smi -a来详细查看参数。 另外如果想实时查看GPU监控,可以使用 nvtop 修改显卡为高性能模式 把GPU的runtime PM和PCIe ASPM关掉,下面是开机自启动配置脚本。 sudo vim /usr/local/sbin/fix-nvidia-runtime-pm.sh #!/bin/bash # 强制关闭 ASPM,避免因节能进入低功耗模式 echo performance | tee /sys/module/pcie_aspm/parameters/policy # 获取 NVIDIA GPU 的 PCIe 设备路径 GPU_DEV="0000:$(lspci | awk '/NVIDIA/{print $1; exit}')" if [ -z "$GPU_DEV" ]; then echo "NVIDIA GPU not found, exiting script." exit 1 fi # 设置 GPU 的 power/control 为 'on',确保设备不会休眠 CUR="/sys/bus/pci/devices/${GPU_DEV}" while [ -n "$CUR" ] && [ -e "$CUR" ]; do if [ -w "$CUR/power/control" ]; then echo on | sudo tee "$CUR/power/control" fi # 上一级桥 PARENT=$(readlink -f "$CUR/..") [[ "$PARENT" == "/sys/devices" ]] && break CUR="$PARENT" done # 启用 NVIDIA persistence 模式,避免 GPU 重置 nvidia-smi -pm 1 # 输出信息确认操作成功 echo "GPU power control set to 'on' and ASPM disabled." 配置可执行sudo chmod +x /usr/local/sbin/fix-nvidia-runtime-pm.sh 然后配置开机自启动 sudo vim /etc/systemd/system/fix-nvidia-runtime-pm.service [Unit] Description=Force NVIDIA GPU power control 'on' and disable ASPM After=multi-user.target Wants=multi-user.target [Service] Type=oneshot ExecStart=/usr/local/sbin/fix-nvidia-runtime-pm.sh RemainAfterExit=true [Install] WantedBy=multi-user.target 然后设置开机自启动 sudo systemctl daemon-reload sudo systemctl enable fix-nvidia-runtime-pm.service sudo systemctl start fix-nvidia-runtime-pm.service 重启后可以验证一下 cat /sys/bus/pci/devices/0000:$(lspci | awk '/NVIDIA/{print $1; exit}')/power/control 如果打开的是on成功 cat /sys/module/pcie_aspm/parameters/policy 输出应该是 [performance] -

lerobot搭建
设备查询 本文是记录ubuntu系统lerobot试验的快捷命令,方便开始负责执行设备,不会介绍为什么? python -m lerobot.find_port sudo chmod +666 /dev/ttyACM0 /dev/ttyACM1 python -m lerobot.find_cameras 机器标定 从臂标定 python -m lerobot.calibrate \ --robot.type=so101_follower \ --robot.port=/dev/ttyACM0 \ --robot.id=R12252801 主臂标定 python -m lerobot.calibrate \ --teleop.type=so101_leader \ --teleop.port=/dev/ttyACM1 \ --teleop.id=R07252608 标定的文件路径默认存储在/home/laumy/.cache/huggingface/lerobot/calibration。如果要更改路径。 --robot.calibration_dir=/home/laumy/lerobot/calibrations --teleop.calibration_dir=/home/laumy/lerobot/calibrations 如果指定了路径,后续的代码都需要指定。 示教 python -m lerobot.teleoperate \ --robot.type=so101_follower \ --robot.port=/dev/ttyACM0 \ --robot.id=R12252801 \ --teleop.type=so101_leader \ --teleop.port=/dev/ttyACM1 \ --teleop.id=R07252608 数据采集 python -m lerobot.record \ --robot.disable_torque_on_disconnect=true \ --robot.type=so101_follower \ --robot.port=/dev/ttyACM0 \ --robot.id=R12252801 \ --robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}}" \ --teleop.type=so101_leader \ --teleop.port=/dev/ttyACM1 \ --teleop.id=R07252608 \ --dataset.repo_id=laumy/record-07271148\ --dataset.num_episodes=10 \ --dataset.reset_time_s=5 \ --dataset.push_to_hub=false \ --dataset.single_task="Grab the cube" \ --display_data=true repo_id必现为"用户名/数据集名"格式,代码中会检测是否有"/"。 数据存储默认的路径为/home/laumy/.cache/huggingface/lerobot/laumy/record-07271148如果要修改路径的话,加上下面参数。 --dataset.root=/home/laumy/lerobot/data/record_07271148 如果要继续上一次的录制,可以添加在上面命令基础上加上: --resume=true 如果数据采集过程中,突然异常终止,无法恢复报错如下时。 Traceback (most recent call last): File "/home/laumy/lerobot/./src/lerobot/scripts/train.py", line 291, in <module> train() File "/home/laumy/lerobot/src/lerobot/configs/parser.py", line 226, in wrapper_inner response = fn(cfg, *args, **kwargs) File "/home/laumy/lerobot/./src/lerobot/scripts/train.py", line 128, in train dataset = make_dataset(cfg) File "/home/laumy/lerobot/src/lerobot/datasets/factory.py", line 90, in make_dataset dataset = LeRobotDataset( File "/home/laumy/lerobot/src/lerobot/datasets/lerobot_dataset.py", line 489, in __init__ check_timestamps_sync(timestamps, episode_indices, ep_data_index_np, self.fps, self.tolerance_s) File "/home/laumy/lerobot/src/lerobot/datasets/utils.py", line 585, in check_timestamps_sync raise ValueError( ValueError: One or several timestamps unexpectedly violate the tolerance inside episode range. This might be due to synchronization issues during data collection. [{'diff': np.float32(-15.966666), 'episode_index': 90, 'timestamps': [np.float32(15.966666), np.float32(0.0)]}] 解决办法就是到数据集路径下~/.cache/huggingface/lerobot/laumy/record-07261516/检查数据,一般就是数据集不匹配了,打开data和videos下面的数据,看看数量是否和meta里面的jsonl对齐了,因为程序采集过程中异常终止,可能只写了data目录或videos目录,但是meta目录下没来得及写就崩溃退出,把最新的一组数据删除了并把meta下面的所有文件数量对齐就可以了。 需要注意的时,info.json中的数据要特别进行修改,下面是需要修改info.json的地方。 { "codebase_version": "v2.1", "robot_type": "so101_follower", "total_episodes": 54, ------采集的周期 "total_frames": 21243, ------采集的总长度,是episodes.jsonl的总和,这个可以通过后面的脚步来计算确认 "total_tasks": 1, "total_videos": 108, -----总的视频数量,一般是episodes * 2 "total_chunks": 1, "chunks_size": 1000, "fps": 30, "splits": { "train": "0:54" -----用于划分给训练集的数据,后面的数据一般要和total_episodes一致。 }, 如果meta/info.json中total_frames是所有视频的总帧数,是从meta/episodes.jsonl中所有的length字段获取的总和,如果做了调整要重新计算更新一下这个total_frames。下面是重新计算的脚步。 import os import json import argparse from pathlib import Path def calibrate_total_frames(dataset_root): dataset_root = Path(dataset_root) # 手动指定 INFO_PATH 和 EPISODES_PATH info_path = dataset_root / "info.json" # 替换为实际的元数据文件路径 episodes_path = dataset_root / "episodes.jsonl" # 替换为实际的剧集信息文件路径 # 检查元数据文件是否存在 if not info_path.exists(): print(f"Metadata file {info_path} does not exist.") return # 检查剧集信息文件是否存在 if not episodes_path.exists(): print(f"Episodes file {episodes_path} does not exist.") return # 加载元数据python ./src/lerobot/scripts/train.py \ --dataset.repo_id=${HF_USER}/record-07271539 \ --policy.type=act \ --output_dir=outputs/train/weigh_07271539 \ --job_name=act_so101_test \ --policy.device=cuda \ --policy.push_to_hub=false \ --wandb.enable=false with open(info_path, 'r') as f: info = json.load(f) # 重新计算 total_frames total_frames = 0 with open(episodes_path, 'r') as f: for line in f: episode = json.loads(line) total_frames += episode.get('length', 0) # 更新元数据 # info["total_frames"] = total_frames # with open(info_path, 'w') as f: # json.dump(info, f, indent=4) print(f"Total frames calibrated to {total_frames}") if __name__ == "__main__": parser = argparse.ArgumentParser(description='Calibrate total frames in dataset metadata.') parser.add_argument('dataset_root', type=str, help='Root path of the dataset') args = parser.parse_args() calibrate_total_frames(args.dataset_root) 训练 python ./src/lerobot/scripts/train.py \ --dataset.repo_id=laumy/record-07271539 \ --policy.type=act \ --output_dir=outputs/train/weigh_07271539 \ --job_name=act_so101_test \ --policy.device=cuda \ --policy.push_to_hub=false \ --wandb.enable=false 训练过程如果不小心终止了,执行下面命令可以接着上次的训练。 python ./src/lerobot/scripts/train.py \ --config_path=outputs/train/weigh_07271539/checkpoints/last/pretrained_model/train_config.json \ --resume=true --steps=200000 --steps参数表示迭代次数,这里表示200K次。 测试 python -m lerobot.record \ --robot.type=so101_follower \ --robot.disable_torque_on_disconnect=true \ --robot.port=/dev/ttyACM0 \ --robot.cameras="{ handeye: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}}" \ --robot.id=R12252801 \ --display_data=false \ --dataset.single_task="Put brick into the box" \ --policy.path=outputs/weigh_07280842/pretrained_model \ --dataset.episode_time_s=240 \ --dataset.repo_id=laumy/eval_so101_07280842 默认录制时长是60s,60S后会停止,如果要改长加上--dataset.episode_time_s=640 class ACTConfig(PreTrainedConfig): n_obs_steps: int = 1 chunk_size: int = 100 n_action_steps: int = 1 n_obs_steps:传递给策略的观测时间窗口大小,具体是指包含当前步骤在内的连续观测步数。也就是说我要观测几步动作来预测接下来的动作。 chunk_size=100: 动作预测分块大小,为单次模型前向传播预测的动作序列总长度(以环境步数为单位),简单理解就是预测的动作步数,实际执行的动作会从这里面选择。 n_action_steps:从预测的动作分块中实际执行的步数,所以必须满足 n_action_steps ≤ chunk_size。 观测序列 → [O_t-n, ..., O_t] → 策略网络 → [A1...A100] → 执行[A1...A50] ↑ ↑ ↑ ↑ n_obs_steps=3 chunk_size=1 n_action_steps=50 一般来说如果是抓取固定的物体,n_obs_steps(3~5)设置可设较小值,chun_size设置大一点以减少策略调用频率,n_action_steps一般取chunk_size/2。如果是动态的环境(如装配、堆叠)n_obs_steps建议设置大一点10~20,chunk_size也缩减一点。 action.xxx: 代表的是要设定执行的动作,也就是主臂或者模型推理处理发送的指令。 observation.xxx:实际执行的动作。 一般情况下observation要跟action越吻合越好。 其他(废弃) 用于记录,可不用看 mac 找uart和摄像头 export HF_USER=laumy python -m lerobot.find_port python -m lerobot.find_cameras 从臂标定 python -m lerobot.calibrate \ --robot.type=so101_follower \ --robot.port=/dev/tty.usbmodem5A7A0576331 \ --robot.id=R12252801 主臂标定 python -m lerobot.calibrate \ --teleop.type=so101_leader \ --teleop.port=/dev/tty.usbmodem5A7A0582001 \ --teleop.id=R07252608 示教 python -m lerobot.teleoperate \ --robot.type=so101_follower \ --robot.port=/dev/ttyACM0 \ --robot.id=R12252801 \ --teleop.type=so101_leader \ --teleop.port=/dev/ttyACM1 \ --teleop.id=R07252608 采集数据 python -m lerobot.record \ --robot.disable_torque_on_disconnect=true \ --robot.type=so101_follower \ --robot.port=/dev/ttyACM0 \ --robot.id=R12252801 \ --robot.cameras="{ handeye: {type: opencv, index_or_path: 8, width: 640, height: 360, fps: 30}, fixed: {type: opencv, index_or_path: 10, width: 640, height: 360, fps: 30}}" \ --teleop.type=so101_leader \ --teleop.port=/dev/ttyACM1 \ --teleop.id=R07252608 \ --dataset.repo_id=${HF_USER}/record-test \ --dataset.num_episodes=10 \ --dataset.reset_time_s=5 \ --dataset.push_to_hub=false \ --dataset.single_task="Grab the cube" 训练 python ./src/lerobot/scripts/train.py \ --dataset.repo_id=${HF_USER}/data_07181406 \ --policy.type=act \ --output_dir=outputs/train/weigh_07181406 \ --job_name=act_so101_test \ --policy.device=cuda \ --policy.push_to_hub=false \ --wandb.enable=false 测试 python -m lerobot.record \ --robot.type=so101_follower \ --robot.disable_torque_on_disconnect=true \ --robot.port=/dev/ttyACM0 \ --robot.cameras="{ handeye: {type: opencv, index_or_path: 8, width: 640, height: 360, fps: 30}, fixed: {type: opencv, index_or_path: 10, width: 640, height: 360, fps: 30}}" \ --robot.id=R12252801 \ --display_data=false \ --dataset.single_task="Put lego brick into the transparent box" \ --policy.path=outputs/100000/pretrained_model \ --dataset.repo_id=${HF_USER}/eval_so101 windows 找uart和摄像头 set HF_USER=86152 python -m lerobot.find_port python -m lerobot.find_cameras 从臂标定 python -m lerobot.calibrate ` --robot.type=so101_follower ` --robot.port=COM5 ` --robot.id=R12252801 主臂标定 python -m lerobot.calibrate ` --teleop.type=so101_leader ` --teleop.port=COM6 ` --teleop.id=R07252608 示教 python -m lerobot.teleoperate ` --robot.type=so101_follower ` --robot.port=COM5 ` --robot.id=R12252801 ` --teleop.type=so101_leader ` --teleop.port=COM6 ` --teleop.id=R07252608 录制 t 训练 python src/lerobot/scripts/train.py ` --dataset.repo_id=86152/data_07181406 ` --policy.type=act ` --output_dir=outputs/train/weigh_07181406 ` --job_name=act_so101_test ` --policy.device=cuda ` --policy.push_to_hub=false ` --wandb.enable=false 测试 python -m lerobot.record ` --robot.type=so101_follower ` --robot.disable_torque_on_disconnect=true ` --robot.port=COM5 ` --robot.cameras="{ handeye: {type: opencv, index_or_path: 1, width: 640, height: 360, fps: 30}, fixed: {type: opencv, index_or_path: 2, width: 640, height: 360, fps: 30}}" ` --robot.id=R12252801 ` --display_data=false ` --dataset.single_task="Put lego brick into the transparent box" ` --dataset.repo_id=${HF_USER}/eval_so101 ` --policy.path=outputs/train/weigh_07172300/checkpoints/last/pretrained_model unbuntu export HF_USER=laumy python lerobot/scripts/find_motors_bus_port.py python lerobot/common/robot_devices/cameras/opencv.py python lerobot/scripts/control_robot.py \ --robot.type=so101 \ --control.type=record \ --control.fps=30 \ --control.single_task="Grasp a lego block and put it in the bin." \ --control.repo_id=${HF_USER}/so101_test \ --control.tags='["so101","tutorial"]' \ --control.warmup_time_s=5 \ --control.episode_time_s=30 \ --control.reset_time_s=5 \ --control.num_episodes=10 \ --control.push_to_hub=false 如果要继续上一次的录制,可以添加在上面命令基础上加上:--control.resume=true 可视化训练数据 python lerobot/scripts/visualize_dataset_html.py --repo-id ${HF_USER}/so101_test 拷贝数据到服务器 scp -P 18620 so101_test.tar.gz root@connect.bjb1.seetacloud.com:~/ python lerobot/scripts/train.py \ --dataset.repo_id=${HF_USER}/so101_test \ --policy.type=act \ --output_dir=outputs/train/act_so101_test0717 \ --job_name=act_so101_test \ --policy.device=cuda \ --wandb.enable=false python lerobot/scripts/control_robot.py \ --robot.type=so101 \ --control.type=record \ --control.fps=30 \ --control.single_task="Grasp a lego block and put it in the bin." \ --control.repo_id=${HF_USER}/eval_act_so101_test \ --control.tags='["tutorial"]' \ --control.warmup_time_s=5 \ --control.episode_time_s=30 \ --control.reset_time_s=30 \ --control.num_episodes=10 \ --control.push_to_hub=false \ --control.policy.path=outputs/train/act_so101_test/checkpoints/last/pretrained_model