文件系统
-

文件系统缓存
#To free pagecache echo 1 > /proc/sys/vm/drop_caches #To free dentry and inode cache echo 2 > /proc/sys/vm/drop_caches #To free pagecache,dentry cache,inode cache echo 3 > /proc/sys/vm/drop_caches dentry cache struct dentry反映的是文件系统对象(包括目录、文件)在内核中所在文件系统树的位置,在文件系统对文件的操作中inode是对应文件处理的核心对象,而要找到inode就需要先找到dentry,dentry对象内容指向了inode。因此在文件系统做dentry的搜索效率也一定程度上决定着文件系统操作效率,在linux系统中为了提高dentry的处理效率,实现了dentry高速缓存,dentry cache简称dcache。 在3.1.3章节中我们列出了dentry的数据结构组成,其中对于搜索的提升有两个关键数据结构。 struct dentry { struct hlist_bl_node d_hash; strcut list_head d_lru; } 在文件系统初始化时,调用vfs_caches_init->dcache_init为对dcache进行初始化,先创建一个dentry的slab,用于后续dentry对象的分配,同时还分配了一个dentry_hashtable用于管理dentry的全局hash表。 static void __init dcache_init(void) { /* * A constructor could be added for stable state like the lists, * but it is probably not worth it because of the cache nature * of the dcache. */ dentry_cache = KMEM_CACHE_USERCOPY(dentry, SLAB_RECLAIM_ACCOUNT|SLAB_PANIC|SLAB_MEM_SPREAD|SLAB_ACCOUNT, d_iname); /* Hash may have been set up in dcache_init_early */ if (!hashdist) return; dentry_hashtable = alloc_large_system_hash("Dentry cache", sizeof(struct hlist_bl_head), dhash_entries, 13, HASH_ZERO, &d_hash_shift, NULL, 0, 0); d_hash_shift = 32 - d_hash_shift; } 可以cat /proc/slabinfo | grep dentry查看dentry的情况。 dcache在kmem_cache_alloc的基础上定义了两个高层分配接口:d_alloc和d_alloc_root函数,用来从dentry_cache slab中分配dentry对象。d_alloc_root时用来为文件系统跟目录分配dentry对象的。 dentry释放后并不会马上清除掉,而是不缓存起来,所以通常有3种状态,而其中unused和negative是可以在主动触发释放是可以进行回收的。 inuse:正在被使用,引用技术d_lockref>0。 unused:未被内核使用,引用技术d_lockref为0,d_inode为空。 negative:相应的磁盘inode已经被删除,d_inode为空。 dentry结构通常在路径查找被创建,常用的有以下2种管理方式 哈希链表:static struct hlist_bl_head *dentry_hashtable __read_mostly,以dentry->name作为索引在dentry全局hash表中管理,用于提高路径查找效率。 LRU链表:处于unused和negative状态不再使用的dentry都通过其dentry->d_lru指针链接到super_block->s_dentry_lru中,当需要内存回收时,由prune_dcache_sb回收使用较少的dentry。 在linux系统中定义了dentry_stat_t数据结构来统计dcache信息。 struct dentry_stat_t { int nr_dentry; dentry的数量 int nr_unused; dentry为使用的数量 int age_limit;/* age in seconds */ int want_pages;/* pages requested by system */ int dummy[2]; }; extern struct dentry_stat_t dentry_stat; 可以通过节点/proc/sys/fs/dentry-state来获取,可以发现dentry-state的nr_dentry:15227与slab info中已经分配出去的对象15229差不多,16957表示当前dentry cache中一共还有多少个对象包括使用和为使用的,528表示每个对象的大小,单位是字节,可以看出一个对象是528字节,对应struct dentry数据结构的大小。 当系统使用echo 2 > /proc/sys/vm/drop_caches可以释放dentry和inode的缓存。 #To free dentry and inode cache echo 2 > /proc/sys/vm/drop_caches 执行上面的命令后,可以查看节点/proc/sys/fs/dentry-state或cat /proc/slabinfo | grep dentry可以看出dentry的数量变少了,系统回收了。 inode cache Inode是用于描述一个文件的,通常有一个或多个dentry与之对应,dentry已经描述了系统的目录树,提供了路径查找的方法,所以inode就不需要在搜索查询上处理复杂关系,管理方式也相对简单不少。 struct inode { ... /* Stat data, not accessed from path walking */ unsigned long i_ino; //与其i_sb一起计算hash作为在inode_hashtable中的索引 struct hlist_node i_hash; //inode_hashtable全局hash表中的节点 struct list_head i_lru; /* inode LRU list */ //其i_sb->s_inode_lru中的节点 ... } 与dentry类似,在内核初始化阶段,会调用inode_init初始化一个inode_cache的slab对象,用于inode的分配。同时还创建了一个用于管理inode的全局哈希表inode_hashtable。 void __init inode_init(void) { /* inode slab cache */ inode_cachep = kmem_cache_create("inode_cache", sizeof(struct inode), 0, (SLAB_RECLAIM_ACCOUNT|SLAB_PANIC| SLAB_MEM_SPREAD|SLAB_ACCOUNT), init_once); /* Hash may have been set up in inode_init_early */ if (!hashdist) return; inode_hashtable = alloc_large_system_hash("Inode-cache", sizeof(struct hlist_head), ihash_entries, 14, HASH_ZERO, &i_hash_shift, &i_hash_mask, 0, 0); } Inode结构主要涉及两种管理方式 inode哈希表:inode_hashtable, super_block和i_ino作为索引在inode在全局inode_hashtable中管理,主要通过i_ino查找到inode。 LRU链表:通过inode->i_lru链接到super_block->s_inode_lru上,表示不再使用的空闲inode,当需要内存回收是,从中选取最少使用的inode进行回收。 struct inodes_stat_t { long nr_inodes; long nr_unused; long dummy[5]; /* padding for sysctl ABI compatibility */ }; struct inodes_stat_t inodes_stat; 与dentry类似,inode也定义了一个inodes_stat用于统计inode信息,可以通过cat /proc/sys/fs/inode-state来查询。 page cache free显示中的buff和cache怎么理解,使用free -w会将buff和cache分开,字面上buffer缓冲,而cache是缓存。 free的数据来源与/proc/meminfo之间的关系。 buffers:内核缓冲区的内存,对应的是/proc/meminfo中的Buffers cache:是内核页缓存和slab用到的内存,对应的是/proc/meminfo中cached+SReclainmable之和。 buff/cache:则是buffers和cache之和。 所以要理解free中buff/cache的关键是要理解buffers、cached、SReclaimable三个的概念,下面是man proc的意思。 Buffers %lu Relatively temporary storage for raw disk blocks that shouldn't get tremendously large (20MB or so). Cached %lu In-memory cache for files read from the disk (the page cache). Doesn't include SwapCached. SReclaimable %lu (since Linux 2.6.19) Part of Slab, that might be reclaimed, such as caches. Buffers:是对原始磁盘块的零时存储,用于缓存磁盘的数据,通常不会特别大(20MB左右),因为对应用户来说读写数据可能是几个字节,但是对应磁盘来说是按block来操作的,这样内核就可以把分散写集中起来,如把多次小的写集合并成单次大的写。 Cached:是磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据,这样下次访问这些文件数据时,旧可以直接从内存快速获取,而不需要再次访问缓慢的磁盘,但是不包括交互到swap分区的。 SReclaimable:是slab的一部分。Slab包含可回收和不可回收两部分,可回收的用SReclaimable记录(dentry cache、inode cache属于slab的一部分),不可回收的用SUnrecalaim记录。 从上面buffers和cached的来看,buffer是对磁盘的,而cache是针对文件页缓存读的,看起来是分开的,但实际上buffers和cached并没有分开,都是page cache,下面将来进行阐述。 CPU的读写速度与磁盘的读写速度是有很大差距的,因此文件系统在访问磁盘时,并不会直接与磁盘进行交互,而是在具体的文件系统与磁盘之间申请一段缓冲buffer,这段缓冲buffer实际就是申请了一块内存,将磁盘的数据缓存到这块内存中,具体的文件系统对磁盘的读写就转换为对缓冲buffer的读写这样就可以提高处理的速度,系统负责定期的将缓冲buff与磁盘进行数据同步,当然也可以手动sync的方式进行同步。 早期linux0.11阶段,buffer cache在linux中对应的数据结构是struct buffer_head,简称bh,顾名思义,表示缓冲区头部,这个缓冲区缓冲的是磁盘块设备数据,早期阶段为了提高磁盘的读写消息,在磁盘之上增加了一个缓冲,磁盘的读写单位是block,一般block的大小是1KB,每个block就对应一个bh,而bh的内存申请是以原始的内存分配方式,还没有基于page来分配内存。 strcut buffer_head { char *b_data; /* pointer to data block (1024 bytes) *///指针。 unsigned long b_blocknr; /* block number */// 块号。 unsigned short b_dev; /* device (0 = free) */// 数据源的设备号。 unsigned char b_uptodate; // 更新标志:表示数据是否已更新。 unsigned char b_dirt; /* 0-clean,1-dirty *///修改标志:0 未修改,1 已修改. unsigned char b_count; /* users using this block */// 使用的用户数。 unsigned char b_lock; /* 0 - ok, 1 -locked */// 缓冲区是否被锁定。 struct task_struct *b_wait; // 指向等待该缓冲区解锁的任务。 struct buffer_head *b_prev; // hash 队列上前一块(这四个指针用于缓冲区的管理)。 struct buffer_head *b_next; // hash 队列上下一块。 struct buffer_head *b_prev_free; // 空闲表上前一块。 struct buffer_head *b_next_free; // 空闲表上下一块。 }; 发展到中间阶段时linux2.2版本,buffer 就基于page来分配内存,但是page cache和buffer没有什么直接连续,是各自独立的作用,page cache只用于负责mmap的部分处理,buffer 依旧负责对磁盘IO的访问缓冲,如下图。但这样就会出现一个问题,由于read/write是绕过了page cache,就会导致mmap和read/write操作同步问题,磁盘的同一份数据在page cache中有一份,在buffer中也有一份,这样分离的设计还会导致浪费内存。 struct buffer_head { /* First cache line: */ struct buffer_head * b_next; /* Hash queue list */ unsigned long b_blocknr; /* block number */ unsigned long b_size; /* block size */ kdev_t b_dev; /* device (B_FREE = free) */ kdev_t b_rdev; /* Real device */ unsigned long b_rsector; /* Real buffer location on disk */ struct buffer_head * b_this_page; /* circular list of buffers in one page */ unsigned long b_state; /* buffer state bitmap (see above) */ struct buffer_head * b_next_free; unsigned int b_count; /* users using this block */ /* Non-performance-critical data follows. */ char * b_data; /* pointer to data block (1024 bytes) */ unsigned int b_list; /* List that this buffer appears */ unsigned long b_flushtime; /* Time when this (dirty) buffer * should be written */ struct wait_queue * b_wait; struct buffer_head ** b_pprev; /* doubly linked list of hash-queue */ struct buffer_head * b_prev_free; /* doubly linked list of buffers */ struct buffer_head * b_reqnext; /* request queue */ /* * I/O completion */ void (*b_end_io)(struct buffer_head *bh, int uptodate); void *b_dev_id; }; 发展到第三阶段linux 2.4版本,对cache和buffer进行了融合,因为buffer的申请也是基于page的,那这两个为什么不融合在一起了,融合后buffer cache就直接存储在page cache中,但是依旧保留了buffer cache的描述。 struct buffer_head { unsigned long b_state; /* buffer state bitmap (see above) */ struct buffer_head *b_this_page;/* circular list of page's buffers */ struct page *b_page; /* the page this bh is mapped to */ sector_t b_blocknr; /* start block number */ size_t b_size; /* size of mapping */ char *b_data; /* pointer to data within the page */ struct block_device *b_bdev; bh_end_io_t *b_end_io; /* I/O completion */ void *b_private; /* reserved for b_end_io */ struct list_head b_assoc_buffers; /* associated with another mapping */ struct address_space *b_assoc_map; /* mapping this buffer is associated with */ atomic_t b_count; /* users using this buffer_head */ spinlock_t b_uptodate_lock; /* Used by the first bh in a page, to * serialise IO completion of other * buffers in the page */ }; 至此page cache和buffer 两者的关系融合了。磁盘的读写是按block为单位操作,一个block对应一个buffer_head缓冲,如块单位是1KB,那么1个page cache就有4个buffer_head。 对于文件系统的操作来说,buffer和cache都是page cache,对应的是进程打开文件内存的缓存,缓存在address_space::i_pages的xarray上,缓存的数量为address_space::nrpages。 Buffer_head的原义是与block对应,按照磁盘的布局分为元数据区和数据区域,元数据是用于管理磁盘的如supper_block、inode等,数据区域才是正在的对应文件系统操作的数据。所以的对于cache和buffer的区别,buffer还存储了对磁盘管理的元数据缓存,这部分 再后来在linux2.4版本之后,新的文件系统开始引入了bio结构来替换buffer_head,但是原有的一些文件系统并没有完全替换使用bio,所以了就需要做bio兼容buffer_head,在磁盘操作前会调用到submit_bh_wbc函数,该函数会将buffer_head组装成bio,因此最终对磁盘的操作都会转为bio的方式,新的文件系统就直接使用bio。 static int submit_bh_wbc(int op, int op_flags, struct buffer_head *bh, enum rw_hint write_hint, struct writeback_control *wbc) { struct bio *bio; BUG_ON(!buffer_locked(bh)); BUG_ON(!buffer_mapped(bh)); BUG_ON(!bh->b_end_io); BUG_ON(buffer_delay(bh)); BUG_ON(buffer_unwritten(bh)); /* * Only clear out a write error when rewriting */ if (test_set_buffer_req(bh) && (op == REQ_OP_WRITE)) clear_buffer_write_io_error(bh); bio = bio_alloc(GFP_NOIO, 1); fscrypt_set_bio_crypt_ctx_bh(bio, bh, GFP_NOIO); bio->bi_iter.bi_sector = bh->b_blocknr * (bh->b_size >> 9); bio_set_dev(bio, bh->b_bdev); bio->bi_write_hint = write_hint; bio_add_page(bio, bh->b_page, bh->b_size, bh_offset(bh)); BUG_ON(bio->bi_iter.bi_size != bh->b_size); bio->bi_end_io = end_bio_bh_io_sync; bio->bi_private = bh; if (buffer_meta(bh)) op_flags |= REQ_META; if (buffer_prio(bh)) op_flags |= REQ_PRIO; bio_set_op_attrs(bio, op, op_flags); /* Take care of bh's that straddle the end of the device */ guard_bio_eod(bio); if (wbc) { wbc_init_bio(wbc, bio); wbc_account_cgroup_owner(wbc, bh->b_page, bh->b_size); } submit_bio(bio); return 0; } 以上的page cache和buffer cache的融合是针对使用文件系统的方式访问块设备的场景。但是如果以下的两个方式访问磁盘①使用文件②使用块设备节点,这两种方式对应的page cache是不同的,文件的方式是buff/cache,而块设备节点是buff(实际也是page cache分配),这种情况下一个物理磁盘的block数据仍然对应linux内核的两份page,一个是通过通用文件层访问的文件page cache(page cache),另一个是通过块设备节点访问的page cache(buffer cache)。另外需要注意的是,如果通过块设备节点访问声明了O_DIRECT,将会直接访问磁盘不会经过buff。 上图如果分别使用文件系统方式/mnt/test的方式或者裸设备/dev/sda的方式去写磁盘,即使是一个位置,但是将会有两份page cache,前者的page cache对应的就是free中的cache,而后边的page cache对应的是free中的buff。 可以从/proc/meminfo的实现来研究一下buff和cache的区别。 static int meminfo_proc_show(struct seq_file *m, void *v) { struct sysinfo i; unsigned long committed; long cached; long available; unsigned long pages[NR_LRU_LISTS]; unsigned long sreclaimable, sunreclaim; int lru; si_meminfo(&i); si_swapinfo(&i); committed = vm_memory_committed(); cached = global_node_page_state(NR_FILE_PAGES) - total_swapcache_pages() - i.bufferram; if (cached < 0) cached = 0; for (lru = LRU_BASE; lru < NR_LRU_LISTS; lru++) pages[lru] = global_node_page_state(NR_LRU_BASE + lru); available = si_mem_available(); sreclaimable = global_node_page_state_pages(NR_SLAB_RECLAIMABLE_B); sunreclaim = global_node_page_state_pages(NR_SLAB_UNRECLAIMABLE_B); show_val_kb(m, "MemTotal: ", i.totalram); show_val_kb(m, "MemFree: ", i.freeram); show_val_kb(m, "MemAvailable: ", available); show_val_kb(m, "Buffers: ", i.bufferram); //show_val_kb会将page数量转化为kb。 show_val_kb(m, "Cached: ", cached); show_val_kb(m, "SwapCached: ", total_swapcache_pages()); ...... } 先来看看buff,buffers为i.bufferram,而该值在si_meminfo(&i)中计算而来,在该函数中调用nr_blockdev_pages计算而来。 void si_meminfo(struct sysinfo *val) { val->totalram = totalram_pages(); val->sharedram = global_node_page_state(NR_SHMEM); val->freeram = global_zone_page_state(NR_FREE_PAGES); val->bufferram = nr_blockdev_pages(); val->totalhigh = totalhigh_pages(); val->freehigh = nr_free_highpages(); val->mem_unit = PAGE_SIZE; } 再看看下面的函数调用,buffers是遍历所有的块设备,累加address->i_mapping上nrpages值,该值就是xarray树上对应的page数量,对应上图中直接操作磁盘节点读写的方式 “open /dev/sda”。 long nr_blockdev_pages(void) { struct inode *inode; long ret = 0; spin_lock(&blockdev_superblock->s_inode_list_lock); list_for_each_entry(inode, &blockdev_superblock->s_inodes, i_sb_list) ret += inode->i_mapping->nrpages; spin_unlock(&blockdev_superblock->s_inode_list_lock); return ret; } 再来看看cached的计算cached = global_node_page_state(NR_FILE_PAGES) -total_swapcache_pages() - i.bufferram,其中 global_node_page_state(NR_FILE_PAGES) 为vm_node_stat[NR_FILE_PAGES]的值。内核中定义了一个全局变量atomic_long_t vm_node_stat[],用于统计全局内存的信息,搜索内核中关于NR_FILE_PAGES的标志,主要有以下三个函数修改。 __mod_lruvec_page_state(item,val) //对全局变量vm_node_stat[item]增加val __dec_lruvec_page_state()//对全局变量vm_node_stat[item]减1 __inc_lruvec_page_state()//对全局变量vm_node_stat[item]加1 示例 __mod_lruvec_page_state(page, NR_FILE_PAGES, -nr) __mod_node_page_state(page_pgdat(page), idx, val) node_page_state_add(delta, pgdat, item) //delta=-nr atomic_long_add(x, &pgdat->vm_stat[item]); atomic_long_add(x, &vm_node_stat[item]); 从上面的函数调用,__mod_lruvec_page_state(struct page *page,enum node_stat_item idx, int val)的作用就是根据item类型(这里是NR_FILE_PAGES)对全局变量vm_node_stat[item]增加val。 从上的函数调用流程可知,无论是文件系统的写还是读,当分配新的page时,会调用add_to_page_cache_lru将page添加到xarray树上,并调用__inc_lruvec_page_state增加page计数,同时会添加到LRU链表用于后续回收。除了调用generic_file_read/write读写文件系统会修改vm_node_stat[NR_FILE_PAGES]外,还有不少操作也会让vm_node_stat[NR_FILE_PAGES]会增加,如通过dev节点直接对磁盘的操作(buffers),以及匿名页交换到swap分区的也会修改。因此vm_node_stat[NR_FILE_PAGES]是一个总的值,实际在计算cached的时候会把交换到swap分区、以及buffers的值减去。cached = global_node_page_state(NR_FILE_PAGES) -total_swapcache_pages() - i.bufferram。 总结下: 对于文件系统的操作方式来说(如/mnt/UDISK/test),大部分是cached(buffers和cached以及合并了),会占用少部分的buffer,主要是存储一些元数据的存储是划到buffer中。 对于磁盘的操作方式来说(如/dev/sda),只有buffers。 可以使用测试使用vmstat观察buff和cache的变化情况。 通过文件系统的方式 写入到文件系统中 echo 3 > /proc/sys/vm/drop_caches dd if=/dev/urandom of=/mnt/UDISK/test bs=1M count=5 从文件系统中读 echo 3 > /proc/sys/vm/drop_caches dd if=/mnt/UDISK/test4 of=/tmp/test bs=1M count=10 通过vmstat统计来看,写入到文件系统ext4上或从文件系统读,基本都是cache在变化。 通过磁盘的方式操作 echo 3 > /proc/sys/vm/drop_caches dd if=/dev/urandom of=/dev/mmcblk0p9 bs=1M count=8 echo 3 > /proc/sys/vm/drop_caches dd if=/dev/mmcblk0p9 of=/dev/null bs=1M count=8 通过磁盘的方式操作,可以发现buff和cache都有变化(这里的cache还包括了slab可以回收部分,如果查询/proc/meminfo下的cached变化会更少些),但是buff变化更大些,然后突然又降回去了(被系统回收了)读磁盘数据会缓存到buffer中。 Direct IO写 dd if=/dev/urandom of=/dev/mmcblk0p9 bs=1M count=10 oflag=direct 可以发现buff,cache基本没变化。 -

一切皆文件之块设备驱动(五)
实验环境 准备 kernel version: linux 5.15 kernel module: 块设备:simpleblk.ko 文件系统:simplefs.ko application: 制作文件系统:mkfs.simplefs 步骤 1.加载块设备驱动:insmod simpleblk.ko 2.加载文件系统:insmod simplefs.ko 3.查看文件系统类型:cat /proc/filesystems | grep simplefs 4.格式化块设备为simplefs:./mkfs.simplefs /dev/sblkdev1 5.挂载文件系统: 5.1创建挂载目录:mkdir simplefs 5.2格式化为simplefs:mount -t simplefs /dev/sblkdev1 /simplefs 块设备带文件系统方式读写 写数据 有具体文件系统的写与上一章节无文件系统的写主要的区别是,def_blk_fops和def_blk_aops依次替换为simplefs_file_ops和simplefs_aops。前者直接裸写方式使用了系统注册实现的bdev文件系统,而后者主要使用的是自定义注册的文件系统,在流程上没有太大的差异。数据打包成bio递交到块设备层后就一样的实现了,这里就不再赘述了。 读数据 读数据也是类似,def_blk_fops和def_blk_aops依次替换为simplefs_file_ops和simplefs_aops。主要流程上与上一章节无太大差异。 -
一切皆文件之块设备驱动(四)
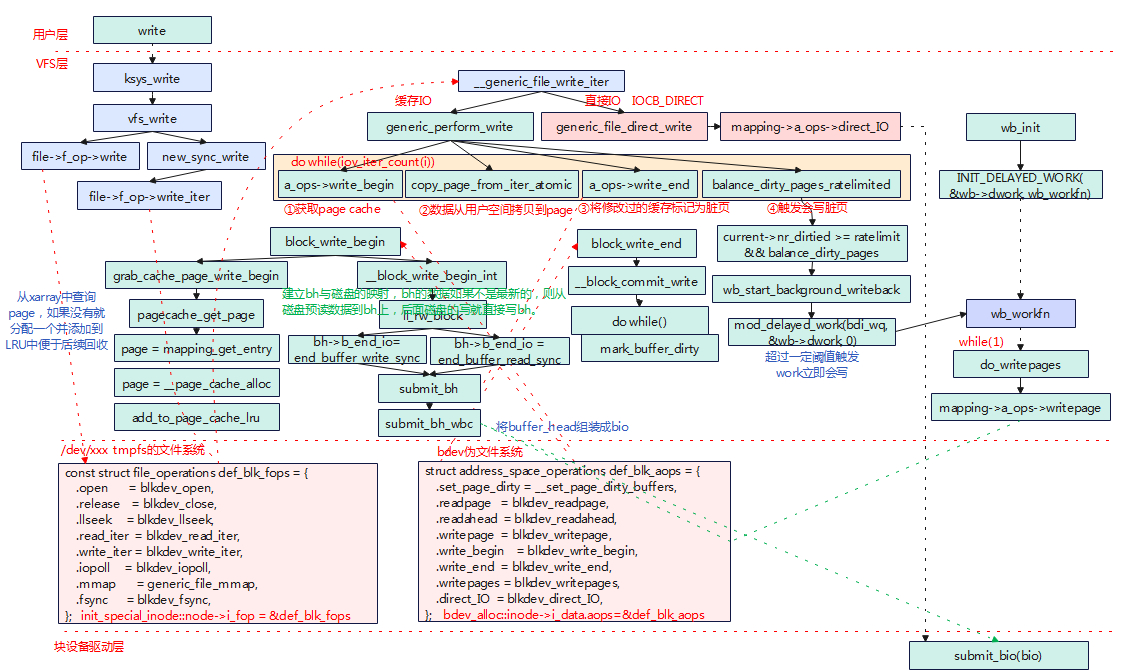
实验环境 kernel version: linux 5.15 kernel module: simpleblk.ko 参考上一章节 application:app_test 参考上一章节 块设备无文件系统方式读写 写数据 存储设备没有格式化挂载文件系统,那么对磁盘设备的操作会经过/dev/xxx tmpfs文件系统和bdev伪文件系统组合的方式读写磁盘。 Write系统调用经过VFS调用到def_blk_fops中的blkdev_write_iter,该函数中继续调用到__generic_file_write_iter。 如果是缓冲I/O的方式,将经过4个步骤,分别为获取page cache、从用户空间拷贝数据到page、修改的缓存标记为脏页、根据阈值是否要写回脏页。 在write_begin中会查询是否有磁盘对应的page cache,如果没有就申请一个page用于磁盘的缓冲;对于新申请的page cache,会调用ll_rw_block进行预读,将磁盘数据读取到page中,后面的操作就直接对page 操作即可。 数据写到缓存页page中(文件系统层) ksys_write -->vfs_write -->new_sync_write -->blkdev_write_iter -->blk_start_plug(&plug) -->__generic_file_write_iter -->blk_finish_plug(&plug) generic_perform_write -->a_ops->write_begin -->blkdev_write_begin -->block_write_begin --> grab_cache_page_write_begin 获取page缓存 --> __block_write_begin_int 写数据开始初始化 -->head = create_page_buffers 分配一个buffer_head -->if (!buffer_mapped(bh)) err = get_block(inode, block, bh, 1); -->blkdev_get_block 将块与buffer_head映射(把bh->b_bdev设置为inode对应的i_bdev并设置block号) -->copy_page_from_iter_atomic 用户拷贝数据到page中 -->a_ops->write_end -->blkdev_write_end 写数据结束,设置page为脏页 -->balance_dirty_pages_ratelimited(mapping) 脏页太多触发回写到磁盘 打包数据成bio递交到块设备层 直接写磁盘一般有几种方式,在建立bh和磁盘映射时,如果数据不是最新的则调用ll_rw_block进行写;另外情况就是当脏页超过一定阈值、用户关闭文件等操作触发worker回写,本小节以触发worker方式回写为例。 wb_workfn ->wb_writeback ->__writeback_inodes_wb ->writeback_sb_inodes ->__writeback_single_inode ->do_writepages ->if(mapping->a_ops->writepages) ret = mapping->a_ops->writepages(mapping, wbc) ->blkdev_writepages 调用bdev文件系统注册的写page函数 ->else ret = generic_writepages(mapping, wbc); blkdev_writepages ->generic_writepages ->blk_start_plug(&plug) ->write_cache_pages ->__writepage ->blk_finish_plug(&plug); __writepage ->mapping->a_ops->writepage(page, wbc); ->blkdev_writepage 注意与blkdev_writepages的区别(多了个s) ->block_write_full_page ->__block_write_full_page ->submit_bh_wbc submit_bh_wbc(REQ_OP_WRITE, write_flags, bh,inode->i_write_hint, wbc); 将bh转化为bio ->bio = bio_alloc(GFP_NOIO, 1); 分配一个bio ->bio->bi_iter.bi_sector = bh->b_blocknr * (bh->b_size >> 9); ->bio_set_dev(bio, bh->b_bdev); ->bio->bi_write_hint = write_hint; ->bio_add_page(bio, bh->b_page, bh->b_size, bh_offset(bh)); ->bio->bi_end_io = end_bio_bh_io_sync; ->bio->bi_private = bh; 递交bio ->submit_bio(bio); submit_bio ->submit_bio_noacct ->__submit_bio_noacct ->__submit_bio ->if (disk->fops->submit_bio) ->ret = disk->fops->submit_bio(bio); 如果块设备注册了submit_bio直接调用(一般是ramdisk使用这种方式) ->else ->blk_mq_submit_bio(bio) 如果没有注册则进入mq 创建和发送request blk_qc_t blk_mq_submit_bio(struct bio *bio) { 获取存储设备的request queue(包含blk_mq_ctx和blk_mq_hw_ctx) struct request_queue *q = bio->bi_disk->queue; 如果内存区处于高位区,则重新映射到低位区 blk_queue_bounce(q, &bio); 如果bio块太大,则对bio进行分割 __blk_queue_split(&bio, &nr_segs); if (!bio) goto queue_exit; 如果队列中没有禁用合并则尝试在task的current->plug上合并 if (!is_flush_fua && !blk_queue_nomerges(q) && blk_attempt_plug_merge(q, bio, nr_segs, &same_queue_rq)) goto queue_exit; //合并成功后直接退出 为了管理request,早期内核为每个task都定义了一个struct blk_plug,同task的request暂时都 会挂载到blk_plug.mg_list中,新增的bio到来时,会遍历blk_plug.mq_list,如果存在合适的 request直接添加,如果不存在就申请一个新的request添加。 尝试在IO调度器或软队列ctx中合并,合并成功则返回 if (blk_mq_sched_bio_merge(q, bio, nr_segs)) goto queue_exit; rq_qos_throttle(q, bio); hipri = bio->bi_opf & REQ_HIPRI; data.cmd_flags = bio->bi_opf; 如果bio没法合并到原有的request中去,则重新申请一个新的request。 rq = __blk_mq_alloc_request(&data); rq_qos_track(q, rq, bio); cookie = request_to_qc_t(data.hctx, rq); 将bio中的数据添加到新申请的request中 blk_mq_bio_to_request(rq, bio, nr_segs); 获取plug plug = blk_mq_plug(q, bio); 1. 如果是刷新flush/fua请求,则绕过调度器直接插入请求 if (unlikely(is_flush_fua)) { /* Bypass scheduler for flush requests */ blk_insert_flush(rq); blk_mq_run_hw_queue(data.hctx, true);启动请求派发 2. 当前任务正在做IO Plug && 设备硬件队列只有一个(hw_ctx?),将request插入到当前任务的plug list } else if (plug && (q->nr_hw_queues == 1 || blk_mq_is_sbitmap_shared(rq->mq_hctx->flags) || q->mq_ops->commit_rqs || !blk_queue_nonrot(q))) { unsigned int request_count = plug->rq_count; struct request *last = NULL; if (!request_count) trace_block_plug(q); else last = list_entry_rq(plug->mq_list.prev); if (request_count >= blk_plug_max_rq_count(plug) || (last && blk_rq_bytes(last) >= BLK_PLUG_FLUSH_SIZE)) { blk_flush_plug_list(plug, false); trace_block_plug(q); } blk_add_rq_to_plug(plug, rq); 3. 如果request queue配置了调度器 } else if (q->elevator) { /* Insert the request at the IO scheduler queue */ blk_mq_sched_insert_request(rq, false, true, true); 将请求插入到调度器队列 4. 有plug && request queue没有禁止合并 走这个分支说明不是刷新请求、没有IO调度器。 } else if (plug && !blk_queue_nomerges(q)) { if (list_empty(&plug->mq_list)) same_queue_rq = NULL; if (same_queue_rq) { list_del_init(&same_queue_rq->queuelist); plug->rq_count--; } blk_add_rq_to_plug(plug, rq); trace_block_plug(q); if (same_queue_rq) { data.hctx = same_queue_rq->mq_hctx; trace_block_unplug(q, 1, true); blk_mq_try_issue_directly(data.hctx, same_queue_rq, &cookie); } 5. 设备硬件队列有多个(hw_ctx?) } else if ((q->nr_hw_queues > 1 && is_sync) || !data.hctx->dispatch_busy) { /* * There is no scheduler and we can try to send directly * to the hardware. */ blk_mq_try_issue_directly(data.hctx, rq, &cookie); } else { /* Default case. */ blk_mq_sched_insert_request(rq, false, true, true); } if (!hipri) return BLK_QC_T_NONE; return cookie; queue_exit: blk_queue_exit(q); return BLK_QC_T_NONE; } IO派发blk_mq_run_hw_queue 在mutilate queue中很多点都会触发IO请求到块设备驱动中 blk_mq_run_hw_queue ->__blk_mq_delay_run_hw_queue ->blk_mq_sched_dispatch_requests ->__blk_mq_sched_dispatch_requests ->blk_mq_do_dispatch_sched ->blk_mq_dispatch_rq_list ->ret = q->mq_ops->queue_rq(hctx, &bd); ->用户注册的回调函数.queue_rq 示例dump_stack [ 917.615686] _queue_rq+0x74/0x210 [simplefs] [ 917.620462] blk_mq_dispatch_rq_list+0x130/0x8cc [ 917.625633] blk_mq_do_dispatch_sched+0x2a8/0x32c [ 917.630902] __blk_mq_sched_dispatch_requests+0x14c/0x1b0 [ 917.636948] blk_mq_sched_dispatch_requests+0x40/0x80 [ 917.642609] __blk_mq_run_hw_queue+0x58/0x90 [ 917.647389] __blk_mq_delay_run_hw_queue+0x1d4/0x200 [ 917.652951] blk_mq_run_hw_queue+0x98/0x100 [ 917.657634] blk_mq_sched_insert_requests+0x90/0x170 [ 917.663193] blk_mq_flush_plug_list+0x130/0x1ec [ 917.668267] blk_flush_plug_list+0xec/0x120 [ 917.672950] blk_finish_plug+0x40/0xe0 [ 917.677149] wb_writeback+0x1e8/0x3b0 [ 917.681246] wb_workfn+0x39c/0x584 [ 917.685043] process_one_work+0x204/0x420 [ 917.689535] worker_thread+0x74/0x4dc [ 917.693634] kthread+0x128/0x134 [ 917.697247] ret_from_fork+0x10/0x20 读数据 预读 ksys_read ->vfs_read ->new_sync_read ->file->f_op->read_iter ->blkdev_read_iter blkdev_read_iter ->generic_file_read_iter ->filemap_read ->filemap_get_pages 获取page缓存 ->filemap_get_read_batch(mapping, index, last_index, pvec); 获取缓存页面 ->for(head = xas_load(&xas); head; head = xas_next(&xas)) 遍历xarray树,查询是否有缓存页 ->pagevec_add(pvec, head) ->if (!pagevec_count(pvec)) 如果没有获取到缓存页面,则进行页面预读 ->page_cache_sync_readahead 文件预读(文件预读会在重新自己分配page) ->page_cache_sync_ra ->ondemand_readahead ->if (!pagevec_count(pvec)) err = filemap_create_page(filp, mapping... 如果还是没有获取到缓存页面,则创建一个新的页面 ->add_to_page_cache_lru 添加页面到LRU中,便于回收 ->error = filemap_read_page(file, mapping, page); 读取数据到页面 ->page = pvec->pages[pagevec_count(pvec) - 1]; 获取批量缓存的最后一页 ->if (PageReadahead(page)) 判断最后一个页面是否需要预读 ->filemap_readahead 文件预读 ->page_cache_async_readahead ->for(i = 0; i < pagevec_count(&pvec); i++) 拷贝数据给应用 copied = copy_page_to_iter(page, offset, bytes, iter); 文件缓存页预读取 page_cache_sync_ra ->ondemand_readahead ->do_page_cache_ra ->page_cache_ra_unbounded 根据请求预读的数量遍历xarray树,如果page不存在就重新申请添加page并读取数据添加到LRU上。 ->for (i = 0; i < nr_to_read; i++) ->struct page *page = xa_load(&mapping->i_pages, index + i); ->if (page && !xa_is_value(page)) ->read_pages(ractl, &page_pool, true); ->page = __page_cache_alloc(gfp_mask); ->read_pages ->read_pages read_pages ->blk_start_plug(&plug) 在task_struct上安装一个list,用于合并多个request请求 ->if (aops->readahead) ->aops->readahead(rac) ->blkdev_readahead 1. block层预读 ------> ->else if(aops->readpages) ->aops->readpages(rac->file, rac->mapping, pages,readahead_count(rac)); ->else ->while ((page = readahead_page(rac))) ->blk_finish_plug(&plug); 2.将task_struct上合并request请求flush到存储设备队列 ->blk_flush_plug_list ->blk_mq_flush_plug_list 1.block层预读 ------>blkdev_readahead ->mpage_readahead ->mpage_bio_submit ->submit_bio(bio) submit_bio(bio) ->submit_bio_noacct ->__submit_bio ->blk_mq_submit_bio ->plug & hwqueue == 1 2.blk_mq_flush_plug_list ->blk_mq_sched_insert_requests ->blk_mq_run_hw_queue blk_mq_run_hw_queue ->__blk_mq_delay_run_hw_queue ->__blk_mq_run_hw_queue ->blk_mq_sched_dispatch_requests ->blk_mq_do_dispatch_sched ->blk_mq_dispatch_rq_list ->用户注册的回调函数.queue_rq -->read 从缓存中读取 ksys_read ->vfs_read ->new_sync_read ->file->f_op->read_iter ->blkdev_read_iter blkdev_read_iter ->generic_file_read_iter ->filemap_read ->filemap_get_pages 获取page缓存 ->filemap_get_read_batch(mapping, index, last_index, pvec); 获取缓存页面 ->for(head = xas_load(&xas); head; head = xas_next(&xas)) 遍历xarray树,查询有缓存页 ->pagevec_add(pvec, head) ->for(i = 0; i < pagevec_count(&pvec); i++) 拷贝数据给应用 copied = copy_page_to_iter(page, offset, bytes, iter); 与预读相比,如果在缓存中命中后,将直接从缓存中获取返回,在filemap_get_pages函数中获取缓存页,如果已经存在缓存页则不需要进行预读操作,接下来从缓存中拷贝数据给应用空间即可。 -

一切皆文件之块设备驱动(三)
块设备驱动示例 #include <linux/blk_types.h> #include <linux/blkdev.h> #include <linux/device.h> #include <linux/blk-mq.h> #include <linux/list.h> #include <linux/module.h> #include <linux/hdreg.h> /* for HDIO_GETGEO */ #include <linux/cdrom.h> /* for CDROM_GET_CAPABILITY */ #define CONFIG_SBLKDEV_REQUESTS_BASED struct sblkdev_device { struct list_head link; sector_t capacity; /* Device size in sectors */ u8 *data; /* The data in virtual memory */ #ifdef CONFIG_SBLKDEV_REQUESTS_BASED struct blk_mq_tag_set tag_set; #endif struct gendisk *disk; }; struct sblkdev_device *sblkdev_add(int major, int minor, char *name, sector_t capacity); void sblkdev_remove(struct sblkdev_device *dev); extern int dump_flag; #ifdef CONFIG_SBLKDEV_REQUESTS_BASED static inline int process_request(struct request *rq, unsigned int *nr_bytes) { int ret = 0; struct bio_vec bvec; struct req_iterator iter; struct sblkdev_device *dev = rq->q->queuedata; loff_t pos = blk_rq_pos(rq) << SECTOR_SHIFT; loff_t dev_size = (dev->capacity << SECTOR_SHIFT); dump_stack(); printk("%s,%d\\n",__func__,__LINE__); rq_for_each_segment(bvec, rq, iter) { unsigned long len = bvec.bv_len; void *buf = page_address(bvec.bv_page) + bvec.bv_offset; if ((pos + len) > dev_size) len = (unsigned long)(dev_size - pos); if (rq_data_dir(rq)) { printk("%s, %d write:",__func__,__LINE__); memcpy(dev->data + pos, buf, len); /* WRITE */ } else { printk("%s, %d read:",__func__,__LINE__); memcpy(buf, dev->data + pos, len); /* READ */ } pos += len; *nr_bytes += len; } return ret; } static blk_status_t _queue_rq(struct blk_mq_hw_ctx *hctx, const struct blk_mq_queue_data *bd) { unsigned int nr_bytes = 0; blk_status_t status = BLK_STS_OK; struct request *rq = bd->rq; dump_stack(); printk("%s,%d\\n",__func__,__LINE__); //might_sleep(); cant_sleep(); /* cannot use any locks that make the thread sleep */ blk_mq_start_request(rq); if (process_request(rq, &nr_bytes)) status = BLK_STS_IOERR; pr_debug("request %llu:%d processed\\n", blk_rq_pos(rq), nr_bytes); blk_mq_end_request(rq, status); return status; } static struct blk_mq_ops mq_ops = { .queue_rq = _queue_rq, }; #else /* CONFIG_SBLKDEV_REQUESTS_BASED */ static inline void process_bio(struct sblkdev_device *dev, struct bio *bio) { struct bio_vec bvec; struct bvec_iter iter; loff_t pos = bio->bi_iter.bi_sector << SECTOR_SHIFT; loff_t dev_size = (dev->capacity << SECTOR_SHIFT); unsigned long start_time; dump_stack(); printk("%s,%d\\n",__func__,__LINE__); start_time = bio_start_io_acct(bio); bio_for_each_segment(bvec, bio, iter) { unsigned int len = bvec.bv_len; void *buf = page_address(bvec.bv_page) + bvec.bv_offset; if ((pos + len) > dev_size) { /* len = (unsigned long)(dev_size - pos);*/ bio->bi_status = BLK_STS_IOERR; break; } if (bio_data_dir(bio)) { printk("process_bio write\\n"); memcpy(dev->data + pos, buf, len); /* WRITE */ } else { printk("process_bio read\\n"); memcpy(buf, dev->data + pos, len); /* READ */ } pos += len; } bio_end_io_acct(bio, start_time); bio_endio(bio); } blk_qc_t _submit_bio(struct bio *bio) { blk_qc_t ret = BLK_QC_T_NONE; struct sblkdev_device *dev = bio->bi_bdev->bd_disk->private_data; printk("%s,%d\\n",__func__,__LINE__); might_sleep(); //cant_sleep(); /* cannot use any locks that make the thread sleep */ process_bio(dev, bio); return ret; } #endif /* CONFIG_SBLKDEV_REQUESTS_BASED */ static int _open(struct block_device *bdev, fmode_t mode) { struct sblkdev_device *dev = bdev->bd_disk->private_data; dump_flag = 1; printk("%s,%d\\n",__func__,__LINE__); if (!dev) { pr_err("Invalid disk private_data\\n"); return -ENXIO; } pr_debug("Device was opened\\n"); return 0; } static void _release(struct gendisk *disk, fmode_t mode) { struct sblkdev_device *dev = disk->private_data; printk("%s,%d\\n",__func__,__LINE__); if (!dev) { pr_err("Invalid disk private_data\\n"); return; } pr_debug("Device was closed\\n"); } static inline int ioctl_hdio_getgeo(struct sblkdev_device *dev, unsigned long arg) { struct hd_geometry geo = {0}; printk("%s,%d\\n",__func__,__LINE__); geo.start = 0; if (dev->capacity > 63) { sector_t quotient; geo.sectors = 63; quotient = (dev->capacity + (63 - 1)) / 63; if (quotient > 255) { geo.heads = 255; geo.cylinders = (unsigned short) ((quotient + (255 - 1)) / 255); } else { geo.heads = (unsigned char)quotient; geo.cylinders = 1; } } else { geo.sectors = (unsigned char)dev->capacity; geo.cylinders = 1; geo.heads = 1; } if (copy_to_user((void *)arg, &geo, sizeof(geo))) return -EINVAL; return 0; } static int _ioctl(struct block_device *bdev, fmode_t mode, unsigned int cmd, unsigned long arg) { struct sblkdev_device *dev = bdev->bd_disk->private_data; pr_debug("contol command [0x%x] received\\n", cmd); printk("%s,%d\\n",__func__,__LINE__); switch (cmd) { case HDIO_GETGEO: return ioctl_hdio_getgeo(dev, arg); case CDROM_GET_CAPABILITY: return -EINVAL; default: return -ENOTTY; } } #ifdef CONFIG_COMPAT static int _compat_ioctl(struct block_device *bdev, fmode_t mode, unsigned int cmd, unsigned long arg) { printk("%s,%d\\n",__func__,__LINE__); // CONFIG_COMPAT is to allow running 32-bit userspace code on a 64-bit kernel return -ENOTTY; // not supported } #endif static const struct block_device_operations fops = { .owner = THIS_MODULE, .open = _open, .release = _release, .ioctl = _ioctl, #ifdef CONFIG_COMPAT .compat_ioctl = _compat_ioctl, #endif #ifndef CONFIG_SBLKDEV_REQUESTS_BASED .submit_bio = _submit_bio, #endif }; /* * sblkdev_remove() - Remove simple block device */ void sblkdev_remove(struct sblkdev_device *dev) { printk("%s,%d\\n",__func__,__LINE__); del_gendisk(dev->disk); #ifdef HAVE_BLK_MQ_ALLOC_DISK #ifdef HAVE_BLK_CLEANUP_DISK blk_cleanup_disk(dev->disk); #else put_disk(dev->disk); #endif #else blk_cleanup_queue(dev->disk->queue); put_disk(dev->disk); #endif #ifdef CONFIG_SBLKDEV_REQUESTS_BASED blk_mq_free_tag_set(&dev->tag_set); #endif vfree(dev->data); kfree(dev); pr_info("simple block device was removed\\n"); } #ifdef CONFIG_SBLKDEV_REQUESTS_BASED static inline int init_tag_set(struct blk_mq_tag_set *set, void *data) { printk("%s,%d\\n",__func__,__LINE__); //设置blk_mq_ops set->ops = &mq_ops; //设置硬件队列个数 set->nr_hw_queues = 1; set->nr_maps = 1; //设置队列深度 set->queue_depth = 128; set->numa_node = NUMA_NO_NODE; set->flags = BLK_MQ_F_SHOULD_MERGE | BLK_MQ_F_STACKING; set->cmd_size = 0; set->driver_data = data; return blk_mq_alloc_tag_set(set); } #endif /* * sblkdev_add() - Add simple block device */ struct sblkdev_device *sblkdev_add(int major, int minor, char *name, sector_t capacity) { struct sblkdev_device *dev = NULL; int ret = 0; struct gendisk *disk; pr_info("add device '%s' capacity %llu sectors\\n", name, capacity); dev = kzalloc(sizeof(struct sblkdev_device), GFP_KERNEL); if (!dev) { ret = -ENOMEM; goto fail; } INIT_LIST_HEAD(&dev->link); dev->capacity = capacity; dev->data = __vmalloc(capacity << SECTOR_SHIFT, GFP_NOIO | __GFP_ZERO); if (!dev->data) { ret = -ENOMEM; goto fail_kfree; } #ifdef CONFIG_SBLKDEV_REQUESTS_BASED ret = init_tag_set(&dev->tag_set, dev); if (ret) { pr_err("Failed to allocate tag set\\n"); goto fail_vfree; } disk = blk_mq_alloc_disk(&dev->tag_set, dev); if (unlikely(!disk)) { ret = -ENOMEM; pr_err("Failed to allocate disk\\n"); goto fail_free_tag_set; } if (IS_ERR(disk)) { ret = PTR_ERR(disk); pr_err("Failed to allocate disk\\n"); goto fail_free_tag_set; } #else disk = blk_alloc_disk(NUMA_NO_NODE); if (!disk) { pr_err("Failed to allocate disk\\n"); ret = -ENOMEM; goto fail_vfree; } #endif dev->disk = disk; /* only one partition */ #ifdef GENHD_FL_NO_PART_SCAN disk->flags |= GENHD_FL_NO_PART_SCAN; #else disk->flags |= GENHD_FL_NO_PART; #endif /* removable device */ /* disk->flags |= GENHD_FL_REMOVABLE; */ disk->major = major; disk->first_minor = minor; disk->minors = 1; disk->fops = &fops; disk->private_data = dev; sprintf(disk->disk_name, name); set_capacity(disk, dev->capacity); #ifdef CONFIG_SBLKDEV_BLOCK_SIZE blk_queue_physical_block_size(disk->queue, CONFIG_SBLKDEV_BLOCK_SIZE); blk_queue_logical_block_size(disk->queue, CONFIG_SBLKDEV_BLOCK_SIZE); blk_queue_io_min(disk->queue, CONFIG_SBLKDEV_BLOCK_SIZE); blk_queue_io_opt(disk->queue, CONFIG_SBLKDEV_BLOCK_SIZE); #else blk_queue_physical_block_size(disk->queue, SECTOR_SIZE); blk_queue_logical_block_size(disk->queue, SECTOR_SIZE); #endif blk_queue_max_hw_sectors(disk->queue, BLK_DEF_MAX_SECTORS); blk_queue_flag_set(QUEUE_FLAG_NOMERGES, disk->queue); #ifdef HAVE_ADD_DISK_RESULT ret = add_disk(disk); if (ret) { pr_err("Failed to add disk '%s'\\n", disk->disk_name); goto fail_put_disk; } #else add_disk(disk); #endif pr_info("Simple block device [%d:%d] was added\\n", major, minor); return dev; #ifdef HAVE_ADD_DISK_RESULT fail_put_disk: #ifdef HAVE_BLK_MQ_ALLOC_DISK #ifdef HAVE_BLK_CLEANUP_DISK blk_cleanup_disk(dev->disk); #else put_disk(dev->disk); #endif #else blk_cleanup_queue(dev->queue); put_disk(dev->disk); #endif #endif /* HAVE_ADD_DISK_RESULT */ #ifdef CONFIG_SBLKDEV_REQUESTS_BASED fail_free_tag_set: blk_mq_free_tag_set(&dev->tag_set); #endif fail_vfree: vfree(dev->data); fail_kfree: kfree(dev); fail: pr_err("Failed to add block device\\n"); return ERR_PTR(ret); } /* * A module can create more than one block device. * The configuration of block devices is implemented in the simplest way: * using the module parameter, which is passed when the module is loaded. * Example: * modprobe sblkdev catalog="sblkdev1,2048;sblkdev2,4096" */ static int sblkdev_major; static LIST_HEAD(sblkdev_device_list); static char *sblkdev_catalog = "sblkdev1,2048;sblkdev2,4096"; /* * sblkdev_init() - Entry point 'init'. * * Executed when the module is loaded. Parses the catalog parameter and * creates block devices. */ static int __init sblkdev_init(void) { int ret = 0; int inx = 0; char *catalog; char *next_token; char *token; size_t length; sblkdev_major = register_blkdev(sblkdev_major, KBUILD_MODNAME); if (sblkdev_major <= 0) { pr_info("Unable to get major number\\n"); return -EBUSY; } length = strlen(sblkdev_catalog); if ((length < 1) || (length > PAGE_SIZE)) { pr_info("Invalid module parameter 'catalog'\\n"); ret = -EINVAL; goto fail_unregister; } catalog = kzalloc(length + 1, GFP_KERNEL); if (!catalog) { ret = -ENOMEM; goto fail_unregister; } strcpy(catalog, sblkdev_catalog); next_token = catalog; while ((token = strsep(&next_token, ";"))) { struct sblkdev_device *dev; char *name; char *capacity; sector_t capacity_value; name = strsep(&token, ","); if (!name) continue; capacity = strsep(&token, ","); if (!capacity) continue; ret = kstrtoull(capacity, 10, &capacity_value); if (ret) break; dev = sblkdev_add(sblkdev_major, inx, name, capacity_value); if (IS_ERR(dev)) { ret = PTR_ERR(dev); break; } list_add(&dev->link, &sblkdev_device_list); inx++; } kfree(catalog); if (ret == 0) return 0; fail_unregister: unregister_blkdev(sblkdev_major, KBUILD_MODNAME); return ret; } /* * sblkdev_exit() - Entry point 'exit'. * * Executed when the module is unloaded. Remove all block devices and cleanup * all resources. */ static void __exit sblkdev_exit(void) { struct sblkdev_device *dev; while ((dev = list_first_entry_or_null(&sblkdev_device_list, struct sblkdev_device, link))) { list_del(&dev->link); sblkdev_remove(dev); } if (sblkdev_major > 0) unregister_blkdev(sblkdev_major, KBUILD_MODNAME); } module_init(sblkdev_init); module_exit(sblkdev_exit); module_param_named(catalog, sblkdev_catalog, charp, 0644); MODULE_PARM_DESC(catalog, "New block devices catalog in format '<name>,<capacity sectors>;...'"); MODULE_LICENSE("GPL"); MODULE_AUTHOR("Sergei Shtepa"); 应用程序示例 #include <stdio.h> #include <unistd.h> #include <fcntl.h> void dump_f(char *buff, int len) { int i; for(i= 0; i < len ; i ++) { if(i % 21 == 0) printf("\\n"); printf("%x ", buff[i]); } printf("\\n"); } int main(int argc, char *argv[]) { int fd; char buf[4096]; int i; sleep(3); //run ./funtion.sh to trace vfs_read of this process fd = open("/dev/sblkdev1", O_RDWR); printf("fd ====:%d\\n",fd); int ch = 0; for (;;) { ch = getopt(argc, argv, "rw"); if (ch < 0) { printf("not param.\\n"); break; } switch (ch) { case 'r': printf("test read 1...............\\n"); read(fd, buf, 4096); dump_f(buf,42); sleep(2); printf("test read 2...............\\n"); read(fd, buf, 4096); dump_f(buf,42); sleep(2); printf("test read 3...............\\n"); read(fd, buf, 4096); dump_f(buf,42); sleep(2); printf("test read 4...............\\n"); read(fd, buf, 4096); dump_f(buf,42); sleep(2); printf("test read 5...............\\n"); read(fd, buf, 4096); dump_f(buf,42); while(1) sleep(4); break; case 'w': for(i=0;i<4096;i++) buf[i] = i; printf("test write 1............\\n"); write(fd, buf, 4096); sleep(3); printf("test write 2............\\n"); write(fd, buf, 4096); sleep(3); printf("test write 3............\\n"); write(fd, buf, 4096); sleep(3); printf("test write 4............\\n"); write(fd, buf, 4096); sleep(3); printf("test write 5............\\n"); write(fd, buf, 4096); sleep(3); while(1) sleep(4); break; default: printf("Not support\\n"); break; } } while(1) sleep(4); return 0; } trace脚本 debugfs=/sys/kernel/debug echo nop > $debugfs/tracing/current_tracer echo 0 > $debugfs/tracing/tracing_on echo `pidof appxxx` > $debugfs/tracing/set_ftrace_pid echo function_graph > $debugfs/tracing/current_tracer echo vfs_read > $debugfs/tracing/set_graph_function echo 1 > $debugfs/tracing/tracing_on 实验 insmod simpleblk.ko app -w & app -r & 代码分析 初始化请求队列 初始化请求队列在init_tag_set中实现,在init_tag_set函数中填充了struct blk_mq_tag_set *set数据结构,blk_mq_tag_set用于描述与存储设备相关的集合,对存储器IO特征进行的抽象。 struct blk_mq_tag_set { struct blk_mq_queue_map map[HCTX_MAX_TYPES]; 软件队列CTX到硬件队列hctx的映射表 unsigned int nr_maps; 映射表的数量 const struct blk_mq_ops *ops; 块设备驱动的mq函数操作集合 unsigned int nr_hw_queues; 块设备的硬件队列hctx数量,大多情况是1 unsigned int queue_depth; 块设备硬件队列深度 unsigned int reserved_tags; unsigned int cmd_size; 块设备驱动为每个request分配的额外空间大小 ...... }; init_tag_set中调用blk_mq_alloc_tag_set为一个或者多个请求队列分配tag和request集合。 int blk_mq_alloc_tag_set(struct blk_mq_tag_set *set) 设置硬件队列数量、映射表数量(nr_maps) ->set->nr_maps = xxx ->set->nr_hw_queues = xxx ->set->queue_depth = xxx 根据硬件队列数量拓展tags数组 ->blk_mq_alloc_tag_set_tags 更新映射表(cpu id-> hw queue id) ->ret = blk_mq_update_queue_map(set); 分配request和tag ->ret = blk_mq_alloc_map_and_requests(set); 数据处理 数据处理有两种方式,主要区别于block_device_operations中有没有实现submit_bio,如果实现了该函数文件系统下来的数据打包成bio后就直接回调该函数;如果没有实现该函数,文件系统下来的数据打包成bio后需要经过request queue进行处理,然后再派发回调到struct blk_mq_ops 注册的.queue_rq进行处理。 请求队列(request queue)里面包含一系列(request),在reqeust里面包含bio,真正的数据就存储在bio里面,因此对数据的处理就是从request_queue中取出一个一个的reqeust,然后再从reqeust里面取出bio,在处理请求时通过blk_mq_start_request和blk_mq_end_request来开始请求和结束请求。 -

一切皆文件之块设备驱动(二)
打开块设备 mknod 块设备同样要使用mknod创建设备节点,这与字符设备一样。会调用到init_special_inode填充inode的file_operations,只不过块设备注册的是def_blk_fops。 void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev) { inode->i_mode = mode; if (S_ISCHR(mode)) { inode->i_fop = &def_chr_fops; inode->i_rdev = rdev; } else if (S_ISBLK(mode)) { inode->i_fop = &def_blk_fops; inode->i_rdev = rdev; } else if (S_ISFIFO(mode)) inode->i_fop = &pipefifo_fops; else if (S_ISSOCK(mode)) ; /* leave it no_open_fops */ else printk(KERN_DEBUG "init_special_inode: bogus i_mode (%o) for" " inode %s:%lu\\n", mode, inode->i_sb->s_id, inode->i_ino); } def_blk_fops如下,与字符设备一样,当打开块设备时,就会调用到blk_dev_open。 const struct file_operations def_blk_fops = { .open = blkdev_open, .release = blkdev_close, .llseek = blkdev_llseek, .read_iter = blkdev_read_iter, .write_iter = blkdev_write_iter, .iopoll = blkdev_iopoll, .mmap = generic_file_mmap, .fsync = blkdev_fsync, .unlocked_ioctl = block_ioctl, #ifdef CONFIG_COMPAT .compat_ioctl = compat_blkdev_ioctl, #endif .splice_read = generic_file_splice_read, .splice_write = iter_file_splice_write, .fallocate = blkdev_fallocate, } blk_dev_open blk_dev_open里面关键的操作时调用blkdev_get获取到块设备,并赋值file中f_mapping。 static int blkdev_open(struct inode *inode, struct file *filp) { struct block_device *bdev; ...... bdev = blkdev_get_by_dev(inode->i_rdev, filp->f_mode, filp); if (IS_ERR(bdev)) return PTR_ERR(bdev); filp->f_mapping = bdev->bd_inode->i_mapping; filp->f_wb_err = filemap_sample_wb_err(filp->f_mapping); return 0; } bdev文件系统 blk_dev_open调用blkdev_get_by_dev获取到块设备得bdev,获取块设备是通过bdev文件系统来查询获取,下面先来了解下bdev文件系统的注册过程。 bdev是系统注册是在系统启动初始化阶段调用bdev_cache_init注册的,每个块设备在bdev文件系统中都有一个inode,linux利用block_inode数据结构将inode和block_device进行关联起来,对设备block_device的查找转化为在bdev文件系统中对inode的查找。 -

一切皆文件之块设备驱动(一)
块设备驱动简介 在linux系统中,有3大驱动类型,分别是:字符设备驱动、块设备驱动、网络设备驱动。块设备驱动与文件系统有着密不可分的关系,块设备是文件系统实际的数据传输单位,通常存储设备有eMMC,Nand/Nor flash,机械硬盘,固态硬盘等,这里所说的块设备驱动,实际就是这些存储设备驱动。块设备驱动与字符设备驱动有较大差异,块设备驱动是以块位单位进行读写,而字符设备驱动以字节为单位进行传输。块设备驱动可以进行随机访问,块设备驱动一般都有缓冲区来暂存数据,当对块设备进行写入时会先将数据写到缓冲区中,累计到一定数据量后才一次性刷到设备中,这样既可以提高读写的速度也可以提高快设备驱动的寿命;相对字符设备数据的操作都是字节流的方式,字符设备没有缓冲区。 关键数据结构 block_device linux系统中使用strcut block_device来表示块设备,可以表示磁盘或一个特定的分区。下面我们看一下strcut block_device数据结构,该数据结构表示块设备。 struct block_device { sector_t bd_start_sect; struct disk_stats __percpu *bd_stats; unsigned long bd_stamp; bool bd_read_only; /* read-only policy */ dev_t bd_dev; int bd_openers; struct inode * bd_inode; /* will die */ struct super_block * bd_super; void * bd_claiming; struct device bd_device; void * bd_holder; int bd_holders; bool bd_write_holder; struct kobject *bd_holder_dir; u8 bd_partno; spinlock_t bd_size_lock; /* for bd_inode->i_size updates */ struct gendisk * bd_disk; /* The counter of freeze processes */ int bd_fsfreeze_count; /* Mutex for freeze */ struct mutex bd_fsfreeze_mutex; struct super_block *bd_fsfreeze_sb; struct partition_meta_info *bd_meta_info; #ifdef CONFIG_FAIL_MAKE_REQUEST bool bd_make_it_fail; #endif } __randomize_layout; bd_dev: 该块设备(分区)的设备号 bd_inode: 设备的文件inode,bdev文件系统将通过该inode来标识块设备。 bd_disk: 指向描述整个设备的gendisk。 block_device是bdevfs伪文件系统对块设备或设备分区的抽象,它与设备号唯一对应。 gendisk linux系统中,struct gendisk是通用存储设备描述,跟具体的硬件设备关联,一个具体的硬件存储设备可以分为多个分区,而每个分区的对应用block_device描述。 struct gendisk { /* major, first_minor and minors are input parameters only, * don't use directly. Use disk_devt() and disk_max_parts(). */ int major; /* major number of driver */磁盘主设备号 int first_minor; 磁盘第一个次设备 int minors; /* maximum number of minors, =1 for 次设备的数量,也是分区数量 * disks that can't be partitioned. */ char disk_name[DISK_NAME_LEN]; /* name of major driver */ unsigned short events; /* supported events */ unsigned short event_flags; /* flags related to event processing */ struct xarray part_tbl; 对应分区表,每一项对应要给分区信息 struct block_device *part0; const struct block_device_operations *fops;磁盘操作函数集 struct request_queue *queue; 磁盘对应的请求队列,对磁盘操作的请求都放在这个队列中 void *private_data; int flags; unsigned long state; #define GD_NEED_PART_SCAN 0 #define GD_READ_ONLY 1 #define GD_DEAD 2 struct mutex open_mutex; /* open/close mutex */ unsigned open_partitions; /* number of open partitions */ struct backing_dev_info *bdi; struct kobject *slave_dir; #ifdef CONFIG_BLOCK_HOLDER_DEPRECATED struct list_head slave_bdevs; #endif struct timer_rand_state *random; atomic_t sync_io; /* RAID */ struct disk_events *ev; #ifdef CONFIG_BLK_DEV_INTEGRITY struct kobject integrity_kobj; #endif /* CONFIG_BLK_DEV_INTEGRITY */ #if IS_ENABLED(CONFIG_CDROM) struct cdrom_device_info *cdi; #endif int node_id; struct badblocks *bb; struct lockdep_map lockdep_map; u64 diskseq; } major: 存储设备的主设备号 first_minor: 存储设备的第一个次设备号 minors:存储设备的次设备号数量,也对应存储设备的分区数量。 part_tbl:存储设备对应的分区表 fops:存储设备块操作集合,与字符设备的file_operations一样。 queue:存储设备对应的请求队列,对磁盘的请求都会放到该队列中。 下面是磁盘的操作函数集合block_device_operations,与字符设备驱动file_operations类似。 struct block_device_operations { blk_qc_t (*submit_bio) (struct bio *bio); int (*open) (struct block_device *, fmode_t); void (*release) (struct gendisk *, fmode_t); int (*rw_page)(struct block_device *, sector_t, struct page *, unsigned int); int (*ioctl) (struct block_device *, fmode_t, unsigned, unsigned long); int (*compat_ioctl) (struct block_device *, fmode_t, unsigned, unsigned long); unsigned int (*check_events) (struct gendisk *disk, unsigned int clearing); void (*unlock_native_capacity) (struct gendisk *); int (*getgeo)(struct block_device *, struct hd_geometry *); int (*set_read_only)(struct block_device *bdev, bool ro); /* this callback is with swap_lock and sometimes page table lock held */ void (*swap_slot_free_notify) (struct block_device *, unsigned long); int (*report_zones)(struct gendisk *, sector_t sector, unsigned int nr_zones, report_zones_cb cb, void *data); char *(*devnode)(struct gendisk *disk, umode_t *mode); struct module *owner; const struct pr_ops *pr_ops; /* * Special callback for probing GPT entry at a given sector. * Needed by Android devices, used by GPT scanner and MMC blk * driver. */ int (*alternative_gpt_sector)(struct gendisk *disk, sector_t *sector); }; submit_bio: 对存储设备读写操作,但不一定会使用submit_bio来传输,而是通过请求队列来完成。 open: 打开指定的块设备 rw_page:读写指定的页 ioctl:块设备的I/O控制 在block_device_operations结构中不像字符设备驱动有对应的read和write函数,有些内核版本甚至没有submit_bio,对于块设备的读写操作,主要是通过request_queue,request和bio来实现的。 request_queue:内核对存储设备的读写操作会先发送到request_queue中,该队列中包含有一系列的request,在request中具体的基本单元是bio,bio保存了对存储设备读写的实际数据,包括从存储设备的那个地址读写,具体的长度等信息。 request: 存储设备的请求队列中,包含多个内核对存储设备的多个request,每个请求包含多个bio。 bio:内核对存储设备读写会构造一个或者多个的bio,bio数据结构包含了对存储设备具体的读写位置和长度等信息。 接下来将单独对三者关系进行深入描述。 bio,request,request_queue Generic Block layer 文件系统向下就是Generic Block Layer,文件系统请求读写的文件位置需要被转换到对应的存储介质的位置(如磁盘的扇区号)。如下是文件系统写过程,将写请求根据文件的pos位转化为bio。 int __block_write_begin(struct page *page, loff_t pos, unsigned len, get_block_t *get_block) -->return __block_write_begin_int(page, pos, len, get_block, NULL); -->ll_rw_block(int op, int op_flags, int nr, struct buffer_head *bhs[]) -->int submit_bh(int op, int op_flags, struct buffer_head *bh) -->submit_bio(bio) bio是块设备数据传输最小单元,下面是struct bio的数据结构。 bio_vec:标识存储设备中数据缓存在page的位置,描述IO请求在内存段的数据位置属性(page地址,页内偏移,长度)。 bvec_iter:标识操作数据在存储设备的位置,描述IO请求在存储器段的数据位置属性(起始sector,长度)。 I/O Scheduler Layer 从submit_bio调用开始,bio被block层抽象为request进行管理,request会被组织到request queue中。IO调度器的目的是在现有请求下,让尽可能少操作存储设备,提高存储设备的读写效率。在IO调度器中,从文件系统提交下来的bio被构造成request结构,一个request结构包含了多个bio,而物理存储设备都会有对应的request queue,里面存放着相关的request,新的bio可能被合并到request queue现有的request结构中,也有可能生成新的request,如何合并、插入等取决于设备驱动选择的IO调度算法。 I/O请求 早期阶段,只有一个单队列single-queue,随着多核体系结构的发展,单队列的暴露了较多劣势,如多核请求队列时,需要使用spinlock来做同步,锁的竞争带来比较高的额外开销,因此后来引入了multi-queue,将单个队列请求锁的竞争分散到多个队列中,这样就极大提高了并发IO的处理能力。 multi-queue结构分为两层队列设计,分别是Per-CPU级别的软件暂存队列(Software staging queue,Per CPU)和存储设备硬件派发队列(Hardware Dispatch queue,Per Disk Per channel); 软件暂存队列(ctx):对应的数据结构blk_mq_ctx,为每个cpu分配一个软件队列,将bio生成一个新的request或合并到已有的request中。bio的提交/完成处理、IO请求合并/排序/标记、调度记账等block layer操作都在该队列中进行。队列是Per CPU,所以每个CPU io请求并发的时候不存在锁竞争问题。 硬件派发队列(hctx):对应的数据结构blk_mq_hw_ctx,每个存储设备的每个硬件队列(通常为一个)分配一个硬件派发队列,用于处理上层软件暂存队列下发的io请求。在存储设备驱动初始化时,blk-mq会将一个或多个软件暂存队列固定映射到一个硬件派发队列,后续软件队列上的io请求就会直接往映射的硬件派发队列下发,最终下发到硬件存储设备。 https://blog.csdn.net/morecrazylove/article/details/128712522 https://blog.csdn.net/juS3Ve/article/details/79890688 -

一切皆文件之字符设备
#include <linux/module.h> #include <linux/fs.h> #include <linux/uaccess.h> #define DEVICE_NAME "mychardev" #define BUFFER_SIZE 1024 static char device_buffer[BUFFER_SIZE]; static int open_count = 0; static int device_open(struct inode *inode, struct file *file) { if (open_count > 0) return -EBUSY; open_count++; return 0; } static int device_release(struct inode *inode, struct file *file) { open_count--; return 0; } static ssize_t device_read(struct file *file, char __user *buffer, size_t length, loff_t *offset) { int bytes_to_read; if (*offset >= BUFFER_SIZE) return 0; bytes_to_read = min(length, (size_t)(BUFFER_SIZE - *offset)); if (copy_to_user(buffer, device_buffer + *offset, bytes_to_read)) return -EFAULT; *offset += bytes_to_read; return bytes_to_read; } static ssize_t device_write(struct file *file, const char __user *buffer, size_t length, loff_t *offset) { int bytes_to_write; if (*offset >= BUFFER_SIZE) return 0; bytes_to_write = min(length, (size_t)(BUFFER_SIZE - *offset)); if (copy_from_user(device_buffer + *offset, buffer, bytes_to_write)) return -EFAULT; *offset += bytes_to_write; return bytes_to_write; } static struct file_operations fops = { .open = device_open, .release = device_release, .read = device_read, .write = device_write, }; static int __init chardev_init(void) { int ret = register_chrdev(0, DEVICE_NAME, &fops); if (ret < 0) { printk(KERN_ALERT "Failed to register char device\\n"); return ret; } printk(KERN_INFO "Char device driver registered,major:%d\\n",ret); return 0; } static void __exit chardev_exit(void) { unregister_chrdev(0, DEVICE_NAME); printk(KERN_INFO "Char device driver unregistered\\n"); } module_init(chardev_init); module_exit(chardev_exit); MODULE_LICENSE("GPL"); MODULE_AUTHOR("Your Name"); MODULE_DESCRIPTION("A simple character device driver"); 下面是一个加载字符设备驱动后的测试示例。 mknod /dev/mychardev c MAJOR_NUMBER 0 #MAJOR_NUMER为注册字符设备时获得的主设备号 echo "Hello, world!" > /dev/mychardev # 写入数据到设备 cat /dev/mychardev # 从设备读取数据 注册字符设备驱动 (1)先调用__register_chrdev_region分配一个strcut char_device_strcut的实例,这个实例表示一个字符设备驱动,在函数中会填充cd数据结构。系统为了管理设备,为每个设备编了号,每个设备又分为主设备号和次设备号,主设备号用来区分不同类似的设备,而次设备号用来区分同一类型的多个设备,如IIC驱动的主设备号是100,IIC有3个设备IIC-0,IIC-1,IIC-2,这3个设备共用一套驱动。可以通过cat /proc/devices 查看已加载的驱动设备主设备号。 static struct char_device_struct { struct char_device_struct *next; //指向下一个字符设备 unsigned int major; //主设备号 unsigned int baseminor; //次设备起始值 int minorct; //次设备数量 char name[64]; //设备或驱动的名称 struct cdev *cdev; /* will die */ } *chrdevs[CHRDEV_MAJOR_HASH_SIZE]; (2)调用cdev_alloc分配设备一个cdev实例,cdev描述了一个字符设备。 struct cdev { struct kobject kobj; //内核对象,通过他将设备统一加到设备驱动模型中管理 struct module *owner; const struct file_operations *ops; //文件系统与设备直接的操作函数集合 struct list_head list;//所有的字符设备驱动形成链表 dev_t dev; //字符设备的设备号,由主设备和次设备构成 unsigned int count; } __randomize_layout; (3)填充用户注册的驱动函数操作集合,用户注册的open/read/write等函数,这是文件系统与设备的沟通桥梁。 (4)将cdev添加到strutct kobj_map *cdev_map全局列表中,kobj_map中有255个probe,每个probe对应一个主设备,相当于字符设备的数量不能超过255。每个主设备下可以由多个次设备。 创建设备节点 insmod加载完成驱动后,通常需要使用mknod创建一个设备节点,这样用户就可以通过文件系统节点的方式访问设备,下面是mknod的使用示例。 mknod /dev/xxx 设备类型 主设备号 从设备号 从上图的流程图可知,/dev是挂载了tmpfs类型的文件系统。在系统启动初始化的时候会调用shmem_init注册一个tmpfs类型的文件系统。 在使用mknode在/dev下创建设备驱动节点,与前面文件系统创建一个新文件类似,关键点就是为文件创建一个dentry和inode,然后填充inode对应的数据,我们需要重点关注的是inode填充的i_fop的操作函数集合是def_chr_fops,这个file_operations对应的open是chardev_open,因此后续在用户打开文件时将会调用到该函数。 驱动系统调用 上一小节中,使用mknod创建设备节点时,inode->i_fop填充的是def_char_fops,在文件系统打开时就会调用到chrdev_open函数,打开的流程与前面分析的流程一致,这里就不再分析了,我们这里重点关注跟设备驱动相关的差异。chrdev_open函数如下: static int chrdev_open(struct inode *inode, struct file *filp) { const struct file_operations *fops; struct cdev *p; struct cdev *new = NULL; int ret = 0; spin_lock(&cdev_lock); p = inode->i_cdev; //获取文件对应的cdev,如果为空则需要进行查找。 if (!p) { struct kobject *kobj; int idx; spin_unlock(&cdev_lock); kobj = kobj_lookup(cdev_map, inode->i_rdev, &idx); //从cdev_map中查找kobj if (!kobj) return -ENXIO; new = container_of(kobj, struct cdev, kobj);//获取到cdev spin_lock(&cdev_lock); /* Check i_cdev again in case somebody beat us to it while we dropped the lock. */ p = inode->i_cdev; if (!p) { inode->i_cdev = p = new; //将cdev赋值给inode list_add(&inode->i_devices, &p->list);//将inode添加到设备列表中 new = NULL; } else if (!cdev_get(p)) ret = -ENXIO; } else if (!cdev_get(p)) ret = -ENXIO; spin_unlock(&cdev_lock); cdev_put(new); if (ret) return ret; ret = -ENXIO; fops = fops_get(p->ops); //获取驱动注册的file_operations if (!fops) goto out_cdev_put; replace_fops(filp, fops); //将struct file中的f_op更新跟驱动的注册的file_operations if (filp->f_op->open) { ret = filp->f_op->open(inode, filp); //调用驱动注册的open函数 if (ret) goto out_cdev_put; } return 0; out_cdev_put: cdev_put(p); return ret; } chrdev_open函数关键的作用先从cdev_map中找到设备的cdev,然后填充到inode中,这样下次操作设备文件节点时就不用再查找了,接下来非常关键的作用是将strcut file中的f_op由原来inode->i_fop指向的file_operations(def_chr_fops)替换为驱动注册的file_operations,这样后续用户在进程中再操作该文件节点时,对文件的open/read/write等操作经过VFS后就直接调用到驱动注册的file_opearations操作集合了,不会再经过def_chr_fops。 -

文件系统常见系统调用
上一章节中,我们编写了没有带磁盘设备的文件系统,了解了文件系统操作的大致流程,本章节我们继续在上一章节的基础上完善文件系统,并梳理从用户空间到内核空间大致的调用流程。实验的代码我们使用开源的示例https://github.com/sysprog21/simplefs/tree/master,在启动本章节之前建议先搭建好试验环境,将simplefs挂载起来,当然有余力的也可以在上一节示例代码的基础上借鉴开源的示例补全。 mount 挂载文件系统有两个关键点 创建一个VFS struct super_block的实例,并从磁盘中读取磁盘super_block信息填充,同时分配一个根inode从磁盘中读取信息填充,并创建根inode对应的根dentry。 创建一个struct mount实例(包含了struct vfsmount)以及挂载点struct mountpoint实例,并添加到全局文件系统的hash表中,建立起文件系统树的联系。 下面是第一个关键点的流程和数据结构直接的关系。 mount_bdev主要做了3件事情,第一调用blkdev_get_by_path根据/dev/xxx名字找到相应的设备并打开它,第二调用sget根据打开的设备,查询是否有对应磁盘的supper_block,如果没有就分配一个。第三调用fill_super回调函数填充super_block。文件系统建立起来之后,对文件的读写就通过文件系统来进行。 以下是第二个关键点数据结构实例直接的联系 跨文件系统路径解析 path_lookupat link_path_walk walk_component step_into handle_mounts traverse_mounts __traverse_mounts(struct path *path, ......) { while (flags & DCACHE_MANAGED_DENTRY) { ...... if (flags & DCACHE_MOUNTED) { // 目录是挂载点? struct vfsmount *mounted = lookup_mnt(path); //获取vfsmount if (mounted) { // ... in our namespace dput(path->dentry); if (need_mntput) mntput(path->mnt); path->mnt = mounted; //填充新的vfsmount path->dentry = dget(mounted->mnt_root);//新文件系统的根目录 // here we know it's positive flags = path->dentry->d_flags; need_mntput = true; continue; } } ...... } } 文件系统挂载后创建super_block、mount、mountpoint、根inode、根dentry对象。 一个目录可以被多个文件系统挂载,新挂载的文件系统会导致之前的挂载被隐藏。 一个目录被文件系统挂载后,原来目录的其他子目录和文件会被隐藏。 每次挂载都会有一个mount实例描述本次挂载。 open 先调用get_ununsed_fd_flags获取一个空闲的fd。 调用link_path_walk对路径名进行查找,里面是个循环会使用”/”分隔逐层处理,如果依次解析发现子目录是新的文件系统(相当于从A文件系统跨到B文件系统)则进行更新path,path中存储了vfsmount和dentry。文件/mnt/simplefs/test,link_path_walk会解析前面得路径部分/mnt/simplefs,解析完毕得时候nameidata的dentry为路径名的最后一部分的父目录/mnt/simplefs,而nameidata->filename为路径名的最后一部分”test”。再查找文件路径最后一部分对应的dentry,linux为了提高目录项目对象的处理效率,实现了一个目录项的高速换成dentry cache,查询的时候先从缓存中查找,调用的是lookup_fast,如果缓存没有找到就调用到对应的文件系统中去照,对应的是上一级目录inode的inode_operations->lookup函数,最终将找到后的新生成的dentry赋值到path中。 最后调用do_open下陷到f->f_op->open调用到具体的文件系统中,在vfs_open中也会将文件相关的信息填充到struct file中,如f->f_inode,f->f_mapping等。 write 用户空间write通过系统调用进入到内核层vfs_write,在vfs_write中判断是struct file_operations填充的是write还是write_iter,这里选择的是write_iter,在simplefs文件系统中write_iter注册的是通用写generic_file_write_iter,在这个函数中会根据标志IOCB_DIRECT判断写如是否要经过缓存。 缓存是内存中的一块内存,Linux为了进一步改进性能,默认情况下不会直接操作硬盘,而是读写都在内存中,待一定时机后在一并批量写入磁盘,以提高读写效率。根据是否使用内存作为缓存,可以把文件的I/O操作分为缓存I/O和直接I/O,直接I/O的方式是不经过缓存。 默认情况为了提高写效率都会调用generic_perform_write使用缓存I/O的方式写入,在generic_perform_write中分为四个步骤: 调用具体文件系统注册的write_begin,在该函数中,如果是日志式的文件系统会先记录相关日志,这里的simplefs文件系统不带日志系统。另外重要的事情就是获取page页,在struct file中有一个成员struct address_space,struct address_space->i_pages是一个xarray树,磁盘的内容映射到这颗树上。在准备写入数据时,会从树中查询是否有对应个page,如果有则获取到该page,如果没有则重新分配一个page,添加到树上。 获得page后,调用copy_page_from_iter_atomic将用户空间数据写到page中。 数据写到page后,将对用的page设置为脏页,脏页的数据是需要定期同步到磁盘的。 最后在balance_dirty_pages_ratelimited会检查是否要进行缓存数据的刷写,可以看出在每次写缓存时,都会调用该函数来检查一下页缓存的总容量,如果超过设定的阈值就会立即触发wb_workfn进行写入到磁盘。平时用的sync也是,将缓存与磁盘进行同步。 论O_DIRECT和O_SYNC? read 大体流程跟write的类似,我们重点看唤醒I/O读的方式,通过filemap_get_pages获取page,如果没有找到不但读取一页,还有进行预读,调用page_cache_sync_readahead函数发起预读操作,这次预读的操作应该是在原来的page缓存基础上发起预读补充,预读后再进行判断是否找到要读数据对应的page,如果还是没有则直接分配一个page添加到树上,然后从磁盘中读取数据填充,接着判断一下page的数据是否填满需要预读,如果需要则发起一次异步预读操作。最后找到要读数据对应的page后,调用copy_page_to_iter将数据拷贝到用户空间。 -

实现简单文件系统
文件系统注册与挂载 static struct file_system_type simplefs_fs_type = { .owner = THIS_MODULE, .name = "simplefs", .mount = simplefs_mount, .kill_sb = simplefs_kill_sb, }; static int __init init_simplefs(void) { return register_filesystem(&simplefs_fs_type); } 调用register_filesystem注册一个文件系统,传入参数为file_system_type结构体,用于描述文件系统类型,其中name为文件系统的名称,在使用mount -t xxx指定文件系统类型是即为该名称,使用cat /proc/filesystems可以查询linux系统中所有注册的文件系统类型。file_system_type中mount和kill_sb分别对应mount和umount的操作。 static struct dentry *simplefs_mount(struct file_system_type *fs_type, int flags, const char *dev_name, void *data) { return mount_nodev(fs_type, flags, data, simplefs_fill_super); } 在执行mount是会触发simplefs_mount调用,该函数中调用mount_nodev来mount一个文件系统,mount_nodev表示该文件系统没有对应的磁盘,对应mount -t xxx none /xxx的命令,通常情况下对应直接使用内存作为存储空间的使用该函数来进行,类似的还有如tmpfs,devfs等。而如果挂载的文件系统存储介质对应磁盘需调用mount_bdev,对应具体的磁盘设备,对应的命令mount -t ext4 /dev/xxx /xxx命令。 上面示例中,mount_nodev中其中重要的参数simplefs_fill_super,在执行mount_nodev会回调该函数,原义为用于填充超级块对象,同时创建根目录的inode信息,完成inode和dentry的初始化关联。在挂载文件系统时,在fill_super中完成了根目录inode的初始化,填充inode的函数操作集合,后续访问数据时就可以通过该inode函数操作集合来对文件访问。 static int simplefs_fill_super(struct super_block *sb, void *data, int silent) { struct inode *root; struct dentry *root_dentry; sb->s_magic = SIMPLEFS_MAGIC_NUMBER; root = simplefs_get_inode(sb, NULL, S_IFDIR | 0755); if (!root) { printk("get inode failed\\n"); return -ENOMEM; } root_dentry = d_make_root(root); if (!root_dentry) { iput(root); printk("make root failed\\n"); return -ENOMEM; } sb->s_root = root_dentry; return 0; } 调用simplefs_get_inode获取一个新的inode节点,然后调用用d_make_root生成inode对应的dentry,再将dentry赋值给sb->s_root即可完成根目录的挂载,后续切到当前的目录,相应的操作就转为当前文件系统类型的操作。 static struct inode *simplefs_get_inode(struct super_block *sb, const struct inode *dir, umode_t mode) { struct inode *inode; inode = new_inode(sb); if (inode) { inode->i_ino = get_next_ino(); inode->i_sb = sb; inode_init_owner(&init_user_ns, inode, dir, mode); inode->i_op = &simplefs_dir_inode_ops; inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode); switch (mode & S_IFMT) { case S_IFDIR: inode->i_fop = &simplefs_dir_ops; break; case S_IFREG: inode->i_fop = &simplefs_file_ops; default: break; } } return inode; } 上面是创建一个新的inode示例,inode用于描述一个文件或目录。调用new_node来分配一个新的inode,接着对inode进行基本的初始化,其中最重要的是填充inode->i_op和inode->i_fop。 static struct inode_operations simplefs_dir_inode_ops = { .lookup = simplefs_lookup, .create = simplefs_create, .unlink = simplefs_unlink, }; inode->i_op是inode的函数操作方法,上面示例lookup用于查找dentry是否存在,dentry是关于文件路径的描述,包括文件和目录,通过指定的文件路径名进行搜索是否存在找到对应dentry,dentry中的数据结构关联了inode,进而实现通过dentry找到对应的inode。create对应的是文件或目录的创建,unlink是文件的删除。 static struct file_operations simplefs_dir_ops = { .owner = THIS_MODULE, .iterate = simplefs_iterate, }; static struct file_operations simplefs_file_ops = { .read = simplefs_read_file, .write = simplefs_write_file, }; inode->i_fop就是实际对文件的操作,与struc file->f_op相关联。这里区分目录和文件,如果inode是目录的话,那么目录存储的是目录下各个文件或目录的信息,所以重点的操作函数是遍历目录对应上面的simplefs_iterate。而inode是文件的话,主要的操作就是对文件具体的读或者写。 文件创建与删除 在文件系统注册章节,执行mount文件系统操作后,回调了填充super函数,在该函数中创建了一个根目录,后续对应文件或目录的创建就可以基于这个根目录进行拓展。根目录对应一个inode,inode填充了i_fop操作函数,因此当我们创建文件时,就会调用对应的操作函数create。 static int simplefs_create (struct user_namespace *ns, struct inode *dir,struct dentry *dentry, umode_t mode, bool excl) { struct inode *inode; struct simplefs_file *s_file; int block = -1; if (strlen(dentry->d_name.name) > SIMPLEFS_FILENAME_LEN) return -ENAMETOOLONG; //分配一个新的inode inode = simplefs_get_inode(dir->i_sb, dir, mode); if (!inode) { printk("get new inode faild\\n"); return -ENOSPC; } block = simplefs_get_block(i_block); if (block < 0) return -ENOSPC; s_file = kmalloc(sizeof(struct simplefs_file), GFP_KERNEL); s_file->inode = inode->i_ino; s_file->mode = mode; strcpy(s_file->filename, dentry->d_name.name); i_block[block].data = s_file; dir->i_mtime = dir->i_ctime = current_time(dir); //将新分配的inode填充到当前目录项 d_instantiate(dentry, inode); return 0; } crate入参函数中,dir为父目录的inode,dentry为新创建的dentry,没有关联inode,需要在该函数中新创建一个inode,最后调用d_instantiate与新创建的inode进行关联。因此在create操作中,主要的工作就是创建一个新的inode,然后调用d_instantiate将这个inode与dentry进行关联。dentry应该是在上级调用的时候就创建了。 目录遍历 当我们在执行ll或ls命令的时候,会列出当前目录下有那些文件或目录,这个操作就会调用file_operations中iterate成员函数。 static int simplefs_iterate (struct file *dir, struct dir_context *ctx) { struct simplefs_file *f = NULL; int i; if (ctx->pos >= SIMPLEFS_BLOCK_SIZE +2) return 0; if (!dir_emit_dots(dir, ctx)) // . .. return 0; for (i = 0; i < SIMPLEFS_BLOCK_SIZE; i++) { ctx->pos ++; if (!i_block[i].use) continue; f = (struct simplefs_file *)i_block[i].data; if (f && !dir_emit(ctx, f->filename, SIMPLEFS_FILENAME_LEN, f->inode, DT_UNKNOWN)) break; } return 0; } 上面示例中,关于iterate的实现最关键的是调用dir_emit将文件名或文件列到屏幕上显示。 文件读写 文件的读写调用的是file_operations中read和write函数。 static ssize_t simplefs_write_file(struct file *f, const char __user *buf, size_t len, loff_t *ppos) { struct inode *inode = file_inode(f); struct blks_desc *blk_desc = (struct blks_desc *)inode->i_private; int newdatalen = *ppos + len; char *newdata; int i; if (!buf || len == 0) { return -EINVAL; } if (!blk_desc) { i = simplefs_get_block(d_block); if (i < 0) return -ENOSPC; else { blk_desc = inode->i_private = &d_block[i]; d_block[i].use = 1; } } newdata = krealloc(blk_desc->data, newdatalen, GFP_KERNEL); if (!newdata) return -ENOMEM; if (copy_from_user(newdata + *ppos, buf, len)) return -EFAULT; blk_desc->data = newdata; *ppos += len; blk_desc->size = *ppos; return len; } static ssize_t simplefs_read_file(struct file *f, char __user *buf, size_t len, loff_t *ppos) { struct inode *inode = file_inode(f); struct blks_desc *blk_desc = (struct blks_desc *)inode->i_private; ssize_t ret = 0; if (!blk_desc) { ret = -EINVAL; goto out; } printk("%s,%d\\n",__func__,__LINE__); if (*ppos >= blk_desc->size) return 0; len = min((size_t) blk_desc->size, len); if (copy_to_user(buf, blk_desc->data + *ppos, len)) { ret = -EFAULT; goto out; } *ppos += len; ret = len; out: return ret; } 读写函数就比较简单了,因为没有操作具体的磁盘文件,所以直接调用copy_to/from_user从用户空间到内核空间的数据搬运,实际的文件操作系统中尤其涉及磁盘的操作会复杂不少,会涉及到page cache相关的操作,本章节只是简单介绍下概念有个整体的认识,后续章节我们会具体再介绍。 小结 最后编译生成ko文件加载到内核中,就可以测试了,下面是测试命令。 insmod simplefs.ko mkdir -p /mnt/simplefs mount -t simplefs none /mnt/simplefs cd /mnt/simplefs touch a echo 11111 > a cat a ll 以下是基于linux5.15完整的测试代码: #include <linux/module.h> #include <linux/fs.h> #include <linux/pagemap.h> #include <linux/slab.h> #include <linux/init.h> #include <linux/namei.h> #define SIMPLEFS_FILENAME_LEN 255 #define SIMPLEFS_BLOCK_SIZE 255 struct simplefs_file { unsigned long inode; umode_t mode; char filename[SIMPLEFS_FILENAME_LEN]; }; struct blks_desc { void *data; uint32_t size; uint8_t use; }; static struct blks_desc i_block[SIMPLEFS_BLOCK_SIZE]; static struct blks_desc d_block[SIMPLEFS_BLOCK_SIZE]; #define SIMPLEFS_MAGIC_NUMBER 0x13131313 MODULE_IMPORT_NS(VFS_internal_I_am_really_a_filesystem_and_am_NOT_a_driver); static struct file_operations simplefs_dir_ops; static struct file_operations simplefs_file_ops; static struct inode_operations simplefs_dir_inode_ops; static int simplefs_get_block(struct blks_desc *blks) { int i; for (i = 0; i < SIMPLEFS_BLOCK_SIZE; i++) { if (!blks[i].use) { blks[i].use = 1; return i; } } return -1; } static struct inode *simplefs_get_inode(struct super_block *sb, const struct inode *dir, umode_t mode) { struct inode *inode; inode = new_inode(sb); if (inode) { inode->i_ino = get_next_ino(); inode->i_sb = sb; inode_init_owner(&init_user_ns, inode, dir, mode); inode->i_op = &simplefs_dir_inode_ops; inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode); switch (mode & S_IFMT) { case S_IFDIR: inode->i_fop = &simplefs_dir_ops; break; case S_IFREG: inode->i_fop = &simplefs_file_ops; default: break; } } return inode; } static int simplefs_create (struct user_namespace *ns, struct inode *dir,struct dentry *dentry, umode_t mode, bool excl) { struct inode *inode; struct simplefs_file *s_file; int block = -1; if (strlen(dentry->d_name.name) > SIMPLEFS_FILENAME_LEN) return -ENAMETOOLONG; inode = simplefs_get_inode(dir->i_sb, dir, mode); if (!inode) { printk("get new inode faild\\n"); return -ENOSPC; } block = simplefs_get_block(i_block); if (block < 0) return -ENOSPC; s_file = kmalloc(sizeof(struct simplefs_file), GFP_KERNEL); s_file->inode = inode->i_ino; s_file->mode = mode; strcpy(s_file->filename, dentry->d_name.name); i_block[block].data = s_file; dir->i_mtime = dir->i_ctime = current_time(dir); d_instantiate(dentry, inode); return 0; } static int simplefs_unlink (struct inode *dir,struct dentry *dentry) { int i; struct simplefs_file *s_file; struct inode *inode = dentry->d_inode; struct blks_desc *blk_desc = (struct blks_desc *)inode->i_private; if (blk_desc && blk_desc->data) { kfree(blk_desc->data); blk_desc->use = 0; } for (i = 0; i < SIMPLEFS_BLOCK_SIZE; i++) { if (i_block[i].use) { s_file = (struct simplefs_file *) i_block[i].data; if (!strcmp(s_file->filename, dentry->d_name.name)) { kfree(s_file); i_block[i].data = NULL; i_block[i].use = 0; drop_nlink(inode); } } } return 0; } static struct dentry *simplefs_lookup (struct inode *parent_inode, struct dentry *child_dentry, unsigned int flags) { int i; for (i = 0 ; i < SIMPLEFS_BLOCK_SIZE; i ++) { struct simplefs_file *f = (struct simplefs_file *)i_block[i].data; if (f && !strcmp(f->filename, child_dentry->d_name.name)) { struct inode *inode = simplefs_get_inode(parent_inode->i_sb, parent_inode, f->mode); d_add(child_dentry, inode); return NULL; } } return NULL; } static ssize_t simplefs_read_file(struct file *f, char __user *buf, size_t len, loff_t *ppos) { struct inode *inode = file_inode(f); struct blks_desc *blk_desc = (struct blks_desc *)inode->i_private; ssize_t ret = 0; if (!blk_desc) { ret = -EINVAL; goto out; } if (*ppos >= blk_desc->size) return 0; len = min((size_t) blk_desc->size, len); if (copy_to_user(buf, blk_desc->data + *ppos, len)) { ret = -EFAULT; goto out; } *ppos += len; ret = len; out: return ret; } static ssize_t simplefs_write_file(struct file *f, const char __user *buf, size_t len, loff_t *ppos) { struct inode *inode = file_inode(f); struct blks_desc *blk_desc = (struct blks_desc *)inode->i_private; int newdatalen = *ppos + len; char *newdata; int i; if (!buf || len == 0) { return -EINVAL; } if (!blk_desc) { i = simplefs_get_block(d_block); if (i < 0) return -ENOSPC; else { blk_desc = inode->i_private = &d_block[i]; d_block[i].use = 1; } } newdata = krealloc(blk_desc->data, newdatalen, GFP_KERNEL); if (!newdata) return -ENOMEM; if (copy_from_user(newdata + *ppos, buf, len)) return -EFAULT; blk_desc->data = newdata; *ppos += len; blk_desc->size = *ppos; return len; } static int simplefs_iterate (struct file *dir, struct dir_context *ctx) { struct simplefs_file *f = NULL; int i; if (ctx->pos >= SIMPLEFS_BLOCK_SIZE +2) return 0; if (!dir_emit_dots(dir, ctx)) // . .. return 0; for (i = 0; i < SIMPLEFS_BLOCK_SIZE; i++) { ctx->pos ++; if (!i_block[i].use) continue; f = (struct simplefs_file *)i_block[i].data; if (f && !dir_emit(ctx, f->filename, SIMPLEFS_FILENAME_LEN, f->inode, DT_UNKNOWN)) break; } return 0; } static int simplefs_fill_super(struct super_block *sb, void *data, int silent) { struct inode *root; struct dentry *root_dentry; sb->s_magic = SIMPLEFS_MAGIC_NUMBER; root = simplefs_get_inode(sb, NULL, S_IFDIR | 0755); if (!root) { printk("get inode failed\\n"); return -ENOMEM; } root_dentry = d_make_root(root); if (!root_dentry) { iput(root); printk("make root failed\\n"); return -ENOMEM; } sb->s_root = root_dentry; return 0; } static struct dentry *simplefs_mount(struct file_system_type *fs_type, int flags, const char *dev_name, void *data) { return mount_nodev(fs_type, flags, data, simplefs_fill_super); } static void simplefs_kill_sb(struct super_block *sb) { kill_anon_super(sb); } static struct file_operations simplefs_dir_ops = { .owner = THIS_MODULE, .iterate = simplefs_iterate, }; static struct file_operations simplefs_file_ops = { .read = simplefs_read_file, .write = simplefs_write_file, }; static struct file_system_type simplefs_fs_type = { .owner = THIS_MODULE, .name = "simplefs", .mount = simplefs_mount, .kill_sb = simplefs_kill_sb, }; static int __init init_simplefs(void) { return register_filesystem(&simplefs_fs_type); } static void __exit exit_simplefs(void) { unregister_filesystem(&simplefs_fs_type); } module_init(init_simplefs); module_exit(exit_simplefs); MODULE_LICENSE("Dual BSD/GPL"); MODULE_AUTHOR("Laumy"); MODULE_DESCRIPTION("a simple file system"); 更完善的文件系统示例:https://github.com/sysprog21/simplefs/tree/master,一个简单的文件系统主要就是围绕四大对象进行填充描述,而超级块和inode是基础。 分配超级块结构,填充超级块信息。 定义具体文件系统inode,如struct ext4_inode。其中每个具体的文件系统inode会内嵌一个VFS inode,具体文件系统的inode在.alloc_inode中分配。 实现类型文件系统inode的操作函数集合,包括创建目录/文件。 实现file操作函数集合,包括目录遍历,文件的读写操作等。 实现文件与磁盘的映射address space操作集合。 -

虚拟文件系统
Linux系统中支持多种不同的文件系统,为了是用户可以通过一个文件系统操作界面,对各种不同的文件系统进行操作,在具体的文件系统(ext2/ext4等)之上增加了一层抽象一个统一的虚拟文件系统界面,向上提供归一化的文件操作,这个抽象层就称为虚拟文件系统。 为了实现抽象层,Linux内核定义了4个重要的数据结构对象。 supper block: 管理文件系统的相关描述信息。 Inode:一个文件对应一个inode,包含文件的相关信息,包括文件大小、创建时间、块大小等。 Dentry:表示一个目录项。 File:进程打开的文件。 上面4个对象都有对应的函数操作方法 supper_operations:文件系统的操作方法,如read_inode inode_operations:文件的操作方法,如create、link。 dentry_operations:目录项的操作方法,如d_compare、d_delete。 file:进程打开文件后的操作方法,如read、write。 四大对象数据结构 超级块对象 超级块,用于描述设备上的文件系统的总体信息如块大小、文件大小上限、文件系统类型、挂载点信息等。在构建一个文件系统时,内核会从存储设备特定位置获取相关的控制信息来填充内存中的超级块对象,当构建完成一个文件系统时就会对应一个超级块对象。 struct super_block include/linux/fs.h struct super_block { struct list_head s_list; /* Keep this first */ dev_t s_dev; /* search index; _not_ kdev_t */ unsigned char s_blocksize_bits; unsigned long s_blocksize; loff_t s_maxbytes; //文件大小上限 struct file_system_type *s_type; //文件系统类型 const struct super_operations *s_op; //超级块的方法 const struct dquot_operations *dq_op;//磁盘限额的方法 const struct quotactl_ops *s_qcop; const struct export_operations *s_export_op; unsigned long s_flags; unsigned long s_iflags; /* internal SB_I_* flags */ unsigned long s_magic; struct dentry *s_root; //文件系统目录挂载点 struct rw_semaphore s_umount; const struct dentry_operations *s_d_op; /* default d_op for dentries */ struct block_device *s_bdev; //对应的块设备,在文件系统mount调用mount_bdev时会根据设备的 名称找到对应的bdev填充,得到块设备描述后后续就可以调用s_read/s_write等操作块设备。 ...... } struct super_operations include/linux/fs.h struct super_operations { struct inode *(*alloc_inode)(struct super_block *sb); //在给定超级块下创建并初始化一个inode,inode即对应一个目录或文件的实例。 void (*destroy_inode)(struct inode *); void (*free_inode)(struct inode *); void (*dirty_inode) (struct inode *, int flags); int (*write_inode) (struct inode *, struct writeback_control *wbc); //指定索引点写磁盘 int (*drop_inode) (struct inode *); void (*evict_inode) (struct inode *); void (*put_super) (struct super_block *); int (*sync_fs)(struct super_block *sb, int wait); //文件系统与磁盘上的数据同步 int (*freeze_super) (struct super_block *); int (*freeze_fs) (struct super_block *); int (*thaw_super) (struct super_block *); int (*unfreeze_fs) (struct super_block *); int (*statfs) (struct dentry *, struct kstatfs *); int (*remount_fs) (struct super_block *, int *, char *); void (*umount_begin) (struct super_block *); int (*show_options)(struct seq_file *, struct dentry *); int (*show_devname)(struct seq_file *, struct dentry *); int (*show_path)(struct seq_file *, struct dentry *); int (*show_stats)(struct seq_file *, struct dentry *); #ifdef CONFIG_QUOTA ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t); ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t); struct dquot **(*get_dquots)(struct inode *); #endif long (*nr_cached_objects)(struct super_block *, struct shrink_control *); long (*free_cached_objects)(struct super_block *, struct shrink_control *); }; 索引节点对象 Inode对象代表了一个实际的文件,当文件被访问前需要先获取到该文件的inode,struct inode结构体包含了通用的属性和方法,如文件类型,文件大小,权限,创建时间等信息。 struct inode include/linux/fs.h struct inode { umode_t i_mode;//访问权限 unsigned short i_opflags; kuid_t i_uid; kgid_t i_gid; unsigned int i_flags; //文件系统标志 #ifdef CONFIG_FS_POSIX_ACL struct posix_acl *i_acl; struct posix_acl *i_default_acl; #endif const struct inode_operations *i_op; //索引节点的操作方法 struct super_block *i_sb; //所属超级块 struct address_space *i_mapping; //文件缓存 ...... union { const struct file_operations *i_fop; /* former ->i_op->default_file_ops */ void (*free_inode)(struct inode *); }; struct file_lock_context *i_flctx; struct address_space i_data; struct list_head i_devices; ...... } struct inode_operations include/linux/fs.h struct inode_operations { struct dentry * (*lookup) (struct inode *,struct dentry *, unsigned int); //在指定目录下搜索目录项,要获取inode,需要先获取dentry const char * (*get_link) (struct dentry *, struct inode *, struct delayed_call *); int (*permission) (struct user_namespace *, struct inode *, int); struct posix_acl * (*get_acl)(struct inode *, int, bool); int (*readlink) (struct dentry *, char __user *,int); int (*create) (struct user_namespace *, struct inode *,struct dentry *, umode_t, bool); //create或open系统调用创建或打开文件 int (*link) (struct dentry *,struct inode *,struct dentry *); int (*unlink) (struct inode *,struct dentry *); int (*symlink) (struct user_namespace *, struct inode *,struct dentry *, const char *); int (*mkdir) (struct user_namespace *, struct inode *,struct dentry *, umode_t);//创建目录 int (*rmdir) (struct inode *,struct dentry *);//删除目录 int (*mknod) (struct user_namespace *, struct inode *,struct dentry *, umode_t,dev_t);//创建管道、设备等特殊文件 int (*rename) (struct user_namespace *, struct inode *, struct dentry *, struct inode *, struct dentry *, unsigned int); int (*setattr) (struct user_namespace *, struct dentry *, struct iattr *); int (*getattr) (struct user_namespace *, const struct path *, struct kstat *, u32, unsigned int); ssize_t (*listxattr) (struct dentry *, char *, size_t); int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start, u64 len); int (*update_time)(struct inode *, struct timespec64 *, int); int (*atomic_open)(struct inode *, struct dentry *, struct file *, unsigned open_flag, umode_t create_mode); int (*tmpfile) (struct user_namespace *, struct inode *, struct dentry *, umode_t); int (*set_acl)(struct user_namespace *, struct inode *, struct posix_acl *, int); int (*fileattr_set)(struct user_namespace *mnt_userns, struct dentry *dentry, struct fileattr *fa); int (*fileattr_get)(struct dentry *dentry, struct fileattr *fa); } ____cacheline_aligned; 在VFS层定义了通用的struct inode,在具体的文件系统中可能还会定义属于具体文件系统的inode,如struct ext2_inode、struct ext4_inode,这些xxx_inode是对具体文件的描述如元数据相关信息即具体文件系统磁盘信息的描述,在分配struct inode时,会将xxx_inode的值赋值到struct inode中。其他像超级块,目录等对象也类似。 目录项对象 dentry虽翻译为目录项,但和文件系统中的目录并不是同一个概念,dentry属于文件系统的对象,包括目录、文件等,反映的是文件系统对象在内核中所在文件系统树的位置。每个文件除了有inode,同时也会有一个dentry结构,记录了文件的名称,父目录,子目录等信息,形成我们看到的层级树状结构。与inode不同时,dentry只存在于内存,磁盘上并没有对应的实体文件,因此目录项目不会涉及回写磁盘的操作。 dentry其中重要的是对文件搜索找出对应的文件的inode。遍历目录时比较耗时的,为了加快遍历和查找,内核中使用hash表来缓存dentry。 一个路径的各个组成部分,不管目录还是普通的文件,都是一个dentry对象,如/home/test.c,/,home,test.c都是一个目录项。为了增加搜索效率,这些目录项目缓存到hash表中。 struct dentry include/linux/dcache.h struct dentry { /* RCU lookup touched fields */ unsigned int d_flags; /* protected by d_lock */ seqcount_spinlock_t d_seq; /* per dentry seqlock */ struct hlist_bl_node d_hash; //用于目录项目查找的hash表 struct dentry *d_parent; //父目录项 struct qstr d_name; //目录项目名称 struct inode *d_inode; //目录项关联的索引节点 unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */ /* Ref lookup also touches following */ struct lockref d_lockref; /* per-dentry lock and refcount */ const struct dentry_operations *d_op; struct super_block *d_sb; /* The root of the dentry tree */ unsigned long d_time; /* used by d_revalidate */ void *d_fsdata; /* fs-specific data */ 具体文件系统中内存目录项目。 union { struct list_head d_lru; /* LRU list */ wait_queue_head_t *d_wait; /* in-lookup ones only */ }; struct list_head d_child; /* child of parent list */ struct list_head d_subdirs; /* our children */ /* * d_alias and d_rcu can share memory */ union { struct hlist_node d_alias; /* inode alias list */ struct hlist_bl_node d_in_lookup_hash; /* only for in-lookup ones */ struct rcu_head d_rcu; } d_u; ANDROID_KABI_RESERVE(1); ANDROID_KABI_RESERVE(2); } __randomize_layout; struct dentry include/linux/dcache.h struct dentry_operations { int (*d_revalidate)(struct dentry *, unsigned int); int (*d_weak_revalidate)(struct dentry *, unsigned int); int (*d_hash)(const struct dentry *, struct qstr *); //为目录项目生成hash表 int (*d_compare)(const struct dentry *, unsigned int, const char *, const struct qstr *); //比较两个文件 int (*d_delete)(const struct dentry *); int (*d_init)(struct dentry *); void (*d_release)(struct dentry *); void (*d_prune)(struct dentry *); void (*d_iput)(struct dentry *, struct inode *); char *(*d_dname)(struct dentry *, char *, int); struct vfsmount *(*d_automount)(struct path *); int (*d_manage)(const struct path *, bool); struct dentry *(*d_real)(struct dentry *, const struct inode *); void (*d_canonical_path)(const struct path *, struct path *); ANDROID_KABI_RESERVE(1); ANDROID_KABI_RESERVE(2); ANDROID_KABI_RESERVE(3); ANDROID_KABI_RESERVE(4); } ____cacheline_aligned; 文件对象 文件对象描述的是进程和文件直接的关系,对文件的操作都是由进程发起的,进程每打开一个文件,内核就创建一个文件对象,同一个文件可以被不同的进程打开,创建不同的文件对象。 struct file include/linux/fs.h struct file { union { struct llist_node fu_llist; struct rcu_head fu_rcuhead; } f_u; struct path f_path; struct inode *f_inode; /* cached value */ const struct file_operations *f_op; //文件的操作方法 /* * Protects f_ep, f_flags. * Must not be taken from IRQ context. */ spinlock_t f_lock; enum rw_hint f_write_hint; atomic_long_t f_count; unsigned int f_flags; fmode_t f_mode; struct mutex f_pos_lock; loff_t f_pos; struct fown_struct f_owner; const struct cred *f_cred; struct file_ra_state f_ra; u64 f_version; #ifdef CONFIG_SECURITY void *f_security; #endif /* needed for tty driver, and maybe others */ void *private_data; #ifdef CONFIG_EPOLL /* Used by fs/eventpoll.c to link all the hooks to this file */ struct hlist_head *f_ep; #endif /* #ifdef CONFIG_EPOLL */ struct address_space *f_mapping; errseq_t f_wb_err; errseq_t f_sb_err; /* for syncfs */ ANDROID_KABI_RESERVE(1); ANDROID_KABI_RESERVE(2); } __randomize_layout struct file_operations include/linux/fs.h struct file_operations { struct module *owner; loff_t (*llseek) (struct file *, loff_t, int); ssize_t (*read) (struct file *, char __user *, size_t, loff_t *); ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *); ssize_t (*read_iter) (struct kiocb *, struct iov_iter *); ssize_t (*write_iter) (struct kiocb *, struct iov_iter *); int (*iopoll)(struct kiocb *kiocb, bool spin); int (*iterate) (struct file *, struct dir_context *); //目录读取 int (*iterate_shared) (struct file *, struct dir_context *); __poll_t (*poll) (struct file *, struct poll_table_struct *); long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long); long (*compat_ioctl) (struct file *, unsigned int, unsigned long); int (*mmap) (struct file *, struct vm_area_struct *); unsigned long mmap_supported_flags; int (*open) (struct inode *, struct file *); int (*flush) (struct file *, fl_owner_t id); int (*release) (struct inode *, struct file *); int (*fsync) (struct file *, loff_t, loff_t, int datasync); int (*fasync) (int, struct file *, int); int (*lock) (struct file *, int, struct file_lock *); ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int); unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long); int (*check_flags)(int); int (*flock) (struct file *, int, struct file_lock *); ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int); ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int); int (*setlease)(struct file *, long, struct file_lock **, void **); long (*fallocate)(struct file *file, int mode, loff_t offset, loff_t len); void (*show_fdinfo)(struct seq_file *m, struct file *f); #ifndef CONFIG_MMU unsigned (*mmap_capabilities)(struct file *); #endif ssize_t (*copy_file_range)(struct file *, loff_t, struct file *, loff_t, size_t, unsigned int); loff_t (*remap_file_range)(struct file *file_in, loff_t pos_in, struct file *file_out, loff_t pos_out, loff_t len, unsigned int remap_flags); int (*fadvise)(struct file *, loff_t, loff_t, int); ANDROID_KABI_RESERVE(1); ANDROID_KABI_RESERVE(2); ANDROID_KABI_RESERVE(3); ANDROID_KABI_RESERVE(4); } __randomize_layout; 下面描述进程与文件操作联系 每个进程打开一个文件后,都有一个文件描述符fd。struct file *fd_array存储的就是这个进程打开的所有文件,称为文件描述符表,文件描述表的每一项都是一个指针,指向一个用于描述打开的struct file对象,struct file对象描述了文件的打开模式,当进程打开一个文件是,内核就会创建一个file对象,但是需要注意的是file对象不是专属某个进程,fd才是专属于某个进程,不同的文件描述符指针可以指向相同的file对象,表示共享打开的文件,struct file中有一个引用计数,描述了被多个进程引用的次数,只有引入计数为0时,内核才会销毁file对象。 其他数据结构 文件系统类型 Linux支持多种文件系统,内部用一个特殊的数据结构来描述每种文件系统的功能和行为。 include/linux/fs.h struct file_system_type { const char *name; //文件系统名称 int fs_flags; #define FS_REQUIRES_DEV 1 #define FS_BINARY_MOUNTDATA 2 #define FS_HAS_SUBTYPE 4 #define FS_USERNS_MOUNT 8 /* Can be mounted by userns root */ #define FS_DISALLOW_NOTIFY_PERM 16 /* Disable fanotify permission events */ #define FS_ALLOW_IDMAP 32 /* FS has been updated to handle vfs idmappings. */ #define FS_THP_SUPPORT 8192 /* Remove once all fs converted */ #define FS_RENAME_DOES_D_MOVE 32768 /* FS will handle d_move() during rename() internally. */ int (*init_fs_context)(struct fs_context *); const struct fs_parameter_spec *parameters; struct dentry *(*mount) (struct file_system_type *, int, const char *, void *);//挂载文件系统 void (*kill_sb) (struct super_block *); struct module *owner; struct file_system_type * next; struct hlist_head fs_supers; struct lock_class_key s_lock_key; struct lock_class_key s_umount_key; struct lock_class_key s_vfs_rename_key; struct lock_class_key s_writers_key[SB_FREEZE_LEVELS]; struct lock_class_key i_lock_key; struct lock_class_key i_mutex_key; struct lock_class_key invalidate_lock_key; struct lock_class_key i_mutex_dir_key; }; 文件系统挂载 Linux文件系统只有被挂载上,才能进行访问,使用一个vfsmount来描述一个挂载点。 include/linux/fs.h struct vfsmount { struct dentry *mnt_root; /* root of the mounted tree */ struct super_block *mnt_sb; /* pointer to superblock */ int mnt_flags; struct user_namespace *mnt_userns; ANDROID_KABI_RESERVE(1); ANDROID_KABI_RESERVE(2); ANDROID_KABI_RESERVE(3); ANDROID_KABI_RESERVE(4); } __randomize_layout; -

文件系统磁盘管理
磁盘空间布局 Extx将磁盘划分为等份的若干区域(最后一个区域可能会小一些),这些区域称为块组(block group)。磁盘以块组为单位进行管理。每个块组再划分为相同大小的block,这些block按功能分为原数据区和数据区。原数据区域也是占用block空间,但是是用于描述管理磁盘的信息,其中块0的原数据区域是相对比较复杂的,其包含了引导块、超级块、块组描述符、GDT、数据块位图、inode位图、inode表。出块组0外的其他块组就稍微简单些只有数据位图、inode位图、inode表。 Boot block:引导块,引导操作系统启动的区域,其并非文件系统的一部分,而是预留给操作系统使用的。 super block:超级块,文件系统的入口,记录了整个文件系统的描述信息,如格式化时指定的文件系统逻辑块大小、逻辑块的数量、inode的数量、根节点的ID和文件系统的特性相关信息。文件系统挂载时会从这里读取获取信息,可以通过dumpe2fs命令查看文件系统的超级块信息。 GDT:group descriptor table,块组描述表,紧跟在超级块之后,对块组信息的描述。块组描述符信息时以列表的形式组织,每个列表包括对应块组中数据位图的位置、inode位图的位置、inode表的位置信息。 Reserved GDT:预留块组描述表,为块组描述符预留的空间。 Block bitmap:数据块位图,标识当前块组中那些数据块被使用了,1个bit对应一个data block。 Inode bitmap:inode位图,与block bitmap类似,标识inode table中inode的使用情况。 Inode table:inode 表,inode是文件系统非常重要的概念,每个文件或目录对应一个inode来描述,inode 表中存储了inode的数据结构实体,即文件系统中有多少个文件+目录就有多少个inode的实体。 Data block:数据块,实际文件的内容,块组中出勤原数据剩余的就是数据块了,这些数据块也分为等分的大小,一般数据块的大小为1KB或2KB或4KB,由系统进行设置。 可以使用dumpe2fs来查看磁盘块信息,可以看到Group0有super block,gdt,reserved GDT。其他组没有superblock,但是可能会有backup superrblock,主要用于备份使用。大部分group只有block bitmap、inode bitmap、inode table。 文件数据管理 间接块的文件数据管理(ext2) 文件占用了磁盘中的那些空间是通过inode来进行标识,一个文件对应一个inode,在struct ext2_inode结构体有一个成员i_block[EXT2_N_BLOCKS],该成员的作用就是标识了当前文件占用的是磁盘中那些数据块。 struct ext2_inode { __le16 i_mode; /* File mode */ __le16 i_uid; /* Low 16 bits of Owner Uid */ __le32 i_size; /* Size in bytes */ __le32 i_atime; /* Access time */ __le32 i_ctime; /* Creation time */ __le32 i_mtime; /* Modification time */ __le32 i_dtime; /* Deletion Time */ ...... __le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */ EXT2_N_BLOCKS=15 __le32 i_generation; /* File version (for NFS) */ __le32 i_file_acl; /* File ACL */ __le32 i_dir_acl; /* Directory ACL */ ...... } #define EXT2_NDIR_BLOCKS 12 #define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS #define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) #define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1) #define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1) 直接索引:数组的前12个索引项一一对应磁盘的某一个数据块,假设磁盘的数据块大小是4K,那么前12个索引项可支持的文件大小为12*4KB=48KB,这种索引的方式速度是最快的,但是也不能无限制的增加数组的大小来一一对应数据块,这样耗费的内存空间将是很大的。为了解决这个问题,当文件大小超过一定大小将使用间接索引的方式。 间接索引:间接索引有2级、3级间接索引,以2级间接索引为例i_block[12]指向磁盘不是实际的数据块,而是指向下一级的地址,下一级地址中的数据块内容指向的数据块才是实际的内容。相当于使用磁盘的空间来存储数据块的索引,类似于虚拟内存的多级页表。 小结:在ext2的inode节点中有i_blocks[15]元素的数组,其中前12个元素存储的是文件数据的磁盘地址,第13个元素存储的地址所指向的磁盘数据存储的不是文件内容数据而是指向下一级的地址,也就是说该数组的元素和实际存储文件数据的磁盘块多出一个磁盘块用于存储磁盘的地址,这个磁盘块称为间接块。由于文件系统中块的大小是确定的,而地址长度和数组元素也是确定的,因此可以确定文件的最大大小。同时,每个地址指向的就是一个块,这种方式的特点就是磁盘的块大小是等分的,缺点就是如果用户写入远大于文件系统块的数据,还是要切分为指定大小的块,同时文件越大需要的元数据越多,寻址的级数也会变多,效率就会变差。 基于Extent的文件数据管理(ext4) Ext2的缺点所有的数据块大小是等分的,数据块的索引也是固定大小的,每个索引只能索引一个数据块,那么对于大文件来说,比如一个电影大小几个G,那么就需要很多的索引和很多的数据块组组合存储,这样的效率是及低的,在ext4中则进行了改进,主要的核心原理就是一个索引对应的块大小是不定的,比如一个3GB的电影文件,用一个索引就解决,只要在索引中给定磁盘块地址和长度就可以检索到,如下图各索引只要给定磁盘地址加上长度就可以索引到具体的文件所划分的磁盘块。 当然实际在实现时没这么简单,上面只是一个简化版本模型便于理解,但是核心原理就是上面的方式。在ext4文件系统上引入了extent机制,extent的数据存储方式,使用B+树的方式,而inode中的i_blocks[15]就变成了B+树的树根。使用extents,用一个struct ext4_extent结构就可以映射多个数据块,减少原数据块的使用。 Extent树的每个节点可以分为内部节点和叶子节点,每个节点的构成为ext4_extent_header+内容,内容根据内部节点和叶子节点有所不同,①如果节点是内部节点(ext4_extent_header.eh_depth>0),ext4_extent_header后面紧跟的是extent_header.eh_entries个struct ext4_extent_idx,也称为索引节点。②如果节点是叶子节点(ext4_extent_header.eh_depth=0),ext4_extent_header后面紧跟的是extent_header.eh_entries个Extent项struct ext4_extent数据结构。 原inode.iblocks[15]则存储的是Extent树的根节点,一共是60字节前12字节用于存储struct ext4_extent_header,后48字节用于存储4个struct ext4_extent_idx(每个12字节)。 struct ext4_inode: struct ext4_inode { __le16 i_mode; /* File mode */ __le16 i_uid; /* Low 16 bits of Owner Uid */ __le32 i_size_lo; /* Size in bytes */ __le32 i_atime; /* Access time */ __le32 i_ctime; /* Inode Change time */ __le32 i_mtime; /* Modification time */ __le32 i_dtime; /* Deletion Time */ __le16 i_gid; /* Low 16 bits of Group Id */ __le16 i_links_count; /* Links count */ __le32 i_blocks_lo; /* Blocks count */ __le32 i_flags; /* File flags */ ...... __le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */ EXT4_N_BLOCKS=15 ...... } #define EXT4_NDIR_BLOCKS 12 #define EXT4_IND_BLOCK EXT4_NDIR_BLOCKS #define EXT4_DIND_BLOCK (EXT4_IND_BLOCK + 1) #define EXT4_TIND_BLOCK (EXT4_DIND_BLOCK + 1) #define EXT4_N_BLOCKS (EXT4_TIND_BLOCK + 1) struct ext4_inode: ext4_extents.h struct ext4_extent_header { __le16 eh_magic; /* 支持不同的格式 */ __le16 eh_entries; /* 跟在头部后面的项目个数 */ __le16 eh_max; /* 项目中的存储容量 */ __le16 eh_depth; /* 树的深度 */ __le32 eh_generation; /* generation of the tree */ }; struct ext4_extent_idx,extent树的内部节点,也称为索引节点。 ext4_extents.h struct ext4_extent_idx { __le32 ei_block; /* index covers logical blocks from 'block' */ __le32 ei_leaf_lo; /*指向下一级的物理数据块,可以是索引节点或叶子节点 */ __le16 ei_leaf_hi; /* 物理数据块的高16位 */ __u16 ei_unused; }; -

文件系统基本概念
mount的机制是如何实现的? inode是如何分配的。磁盘inode和内存inode有什么区别? dentry缓存是怎么回事?如何管理? free命令中Cache和buff有什么区别?Page cache了?如何管理文件数据缓存? 扇区与簇 物理块和扇区,逻辑块和簇是相同概念。扇区(物理块)是磁盘最小的存储单元,磁头从磁盘读取数据的最小单元,一般是512B,即磁头每次从磁盘读取数据,都是一个扇区一个扇区读写。但对于操作系统来说无法对数目众多的扇区进行寻址,所以操作系统对磁盘的操作是以多个扇区组成形成一个簇为单位。 物理块/扇区是对磁盘操作而言的;逻辑块/簇是对软件操作系统(或文件系统)而言的,在linux中称为块,在windows中称为簇,操作系统从磁盘中拿一块数据,即完成一次磁盘IO。 块的大小在磁盘格式化时被指定,一般有1K/2K/4K,如果块的大小设置为4K,那么磁盘要读取8个扇区之后才将数据给操作系统。如果一个文件的大小是1K,而块的大小是4K,那么文件也会占用一个块的大小,剩余3K将会被空闲处理。 什么是文件系统 文件系统是一个控制数据存取的软件系统,实现文件的增、删、查、改等操作。文件系统是可以构建在磁盘(flash、SD卡、SSD等),也可以构建在网络或内存上,甚至可以构建在一个文件上。文件系统更重要的功能是抽象了一个更加容易访问的存储空间接口,这些接口包括对于程序开发的API和用户的操作等。 底层是具体的硬件设备,硬件设备是具备存储功能的介质包括磁盘、内存、网络、甚至文件。中间层是操作系统将存储介质抽象为一个连续的线性空间,线性空间可分为大小相同的块(1KB、2KB、4KB等),抽象为连续的线性空间主要是便于顶层的文件系统管理。顶层就是文件系统,文件系统对线性空间进行管理和抽象,便于用户进行操作,文件系统一般呈现为目录树,这里的层级结构就是平常的目录、子目录和文件等元素的集合。 目录:是一种容器,可以容纳子目录和普通文件,通过目录来对文件进行分类,便于用户访问,在linux中目录也是文件。 文件:是文件系统中存储数据的实体,文件有文件名,用于标识一个文件,文件的种类很多如txt、mp3、doc等,不同的文件类型需要对应于的应用来打开。具体文件可以分为普通文件、字符设备文件、块设备文件、套接字文件。 链接:分为软链接和硬链接;软链接是文件的另一种形态,其内容指向另外一个文件的路径,软链接也称为符号链接。硬链接则不同,是一个已存在文件的附加名称,在目录中增加了一项,但是其内容与源文件内容完全相同。 在linux系统中一切都是文件,可以使用ls -l通过显示结果查看文件类型。 常见的文件系统 本地文件系统:实现对磁盘的管理,常用的用EXT4、FAT、XFS、ZFS等 伪文件系统:不是持久化的数据,对应内存的文件系统,便于用于以文件的形式与内核数据交互,如proc、sysfs、configfs、debugfs等。 网络文件系统:基于tcp/ip协议的文件系统,运行具有网络的计算机访问另外一具有网络的计算机像访问本地文件系统一样。 文件系统使用 文件内容的访问 对于普通用户来说,通过命令或鼠标就能对文件进行操作,对于程序员来说可以通过API接口来进行完成,下面是举例常用接口。 API 描述 open 打开文件 read 从文件读数据 write 从文件写数据 close 关闭文件 lseek 移动文件指针位置 lseek 删除文件 格式化文件系统与挂载 格式化文件系统是在一个存储设备上构建一个文件系统,而挂载则是将文件系统激活在文件系统的目录树中可以进行访问。 (1)文件系统的构建命令 mkfs.xxx /dev/xxx 如mkfs.ext4 /dev/sdb, 将块设备格式化为ext4文件系统 (2)文件系统挂载 文件系统只有挂载到系统中,才可以进行访问。 mount -t [fs type] -o [opt] device dir 如mount -t ext4 /dev/sdb /mnt/ext4 除了手动挂载文件系统,linux还支持自动挂载,通过配置fstab配置文件即可进行挂载对应的设备。 proc /proc proc defaults 0 0 sysfs /sys sysfs defaults 0 0 devtmpfs /dev devtmpfs defaults 0 0 tmpfs /tmp tmpfs defaults 0 0 tmpfs /var tmpfs defaults 0 0 还可以基于文件来构建文件系统,下面是示例: # 1生成一个全0的二进制文件 dd if=/dev/zero of=ext4.bin bs=1M count=100 #2 格式化为EXT4文件系统 mkfs.ext4 ext4.bin #3 使用loop设备,访问块设备,需要在内核把CONFIG_BLK_DEV_LOOP打开。 losetup /dev/loop0 ./ext4.bin #4 挂载文件系统 mkdir ext4 mount /dev/loop10 ext4 文件系统的目录下可以挂载其他文件系统。