
Agent的下一轮门槛是托管工作面
核心观点 Agent 基础设施正在从“能调用工具”转向“能托管工作”。GitHub、AWS、Microsoft、阿里云、Cloudflare 和 LangChain 的近期动作都指向同一件事:生产化 Agent 需要可见的工作
核心观点 Agent 基础设施正在从“能调用工具”转向“能托管工作”。GitHub、AWS、Microsoft、阿里云、Cloudflare 和 LangChain 的近期动作都指向同一件事:生产化 Agent 需要可见的工作
这篇文章把 ISP Pipeline 中常见缩写按数据流阶段串起来。看 ISP 文档时,不建议孤立记缩写,而是先判断它处在输入接收、RAW 前处理、HDR/3A、RGB/YUV 后处理、几何校正、输出,还是 AI/CV 支路。 完
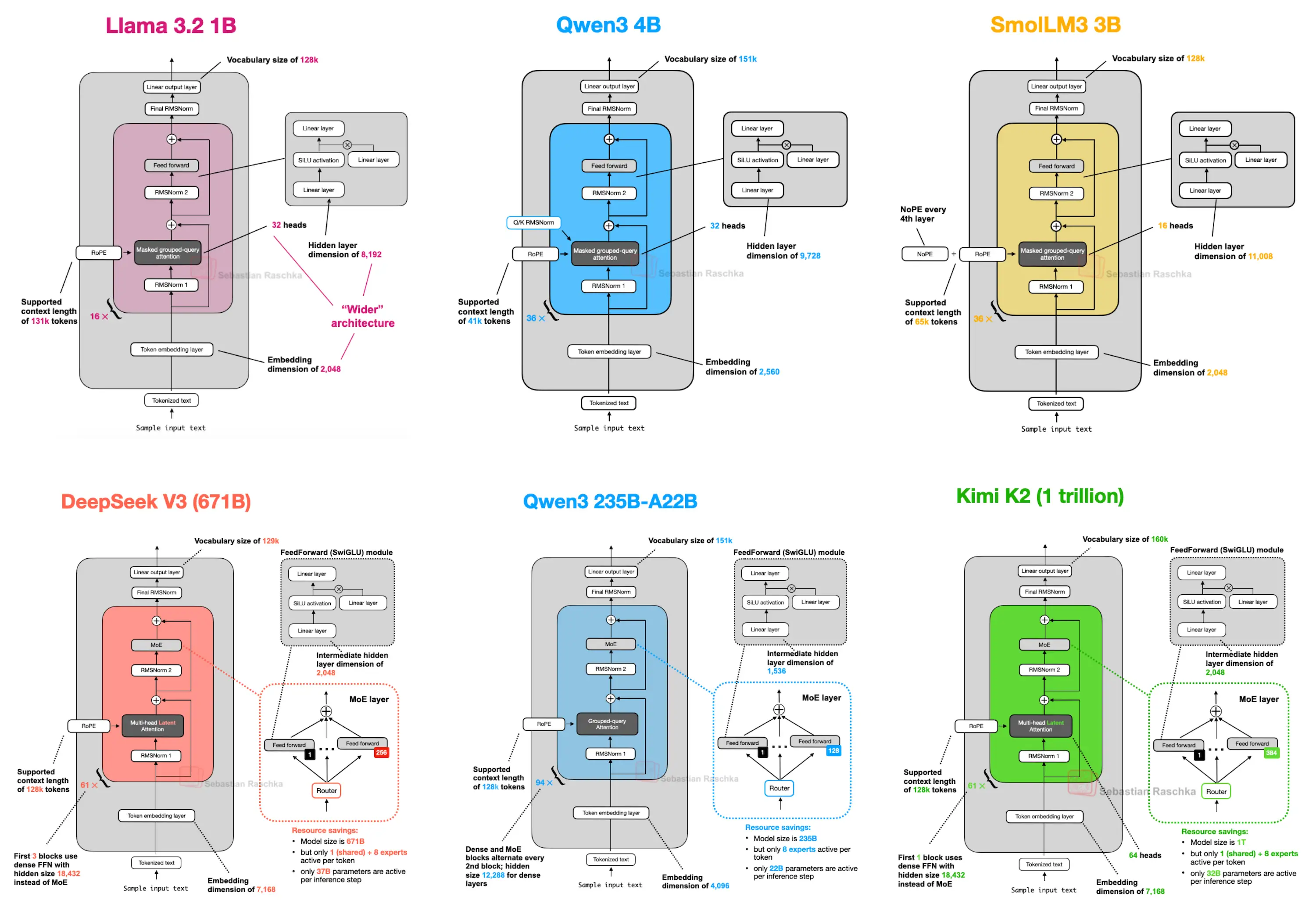
大模型推理的"第一性原理" 从Deepseek V3到Kimi K2 无论模型如何变化,当前主流大模型的核心架构都是基于transformer。其本质是一个由多层相同结构
概述 llama.cpp 的模型加载系统是一个高度优化的、支持多后端、多设备的模型权重加载框架。它通过精心设计的数据结构和加载流程,实现了: 零拷贝加载:通过内存映射(mmap)实现模型文件的零拷贝加载
后端系统概述 GGML后端系统主要提供如下功能: 统一接口: 不同硬件平台使用相关的API。 自动选择:根据硬件自动选择最优后端。 灵活切换:可以在运行时切换后端。 扩展性:易于添加的新后端。

加载后端 void ggml_backend_load_all() { ggml_backend_load_all_from_path(nullptr); } void ggml_backend_load_all_from_path(const char * dir_path) { #ifdef NDEBUG bool silent = true; …
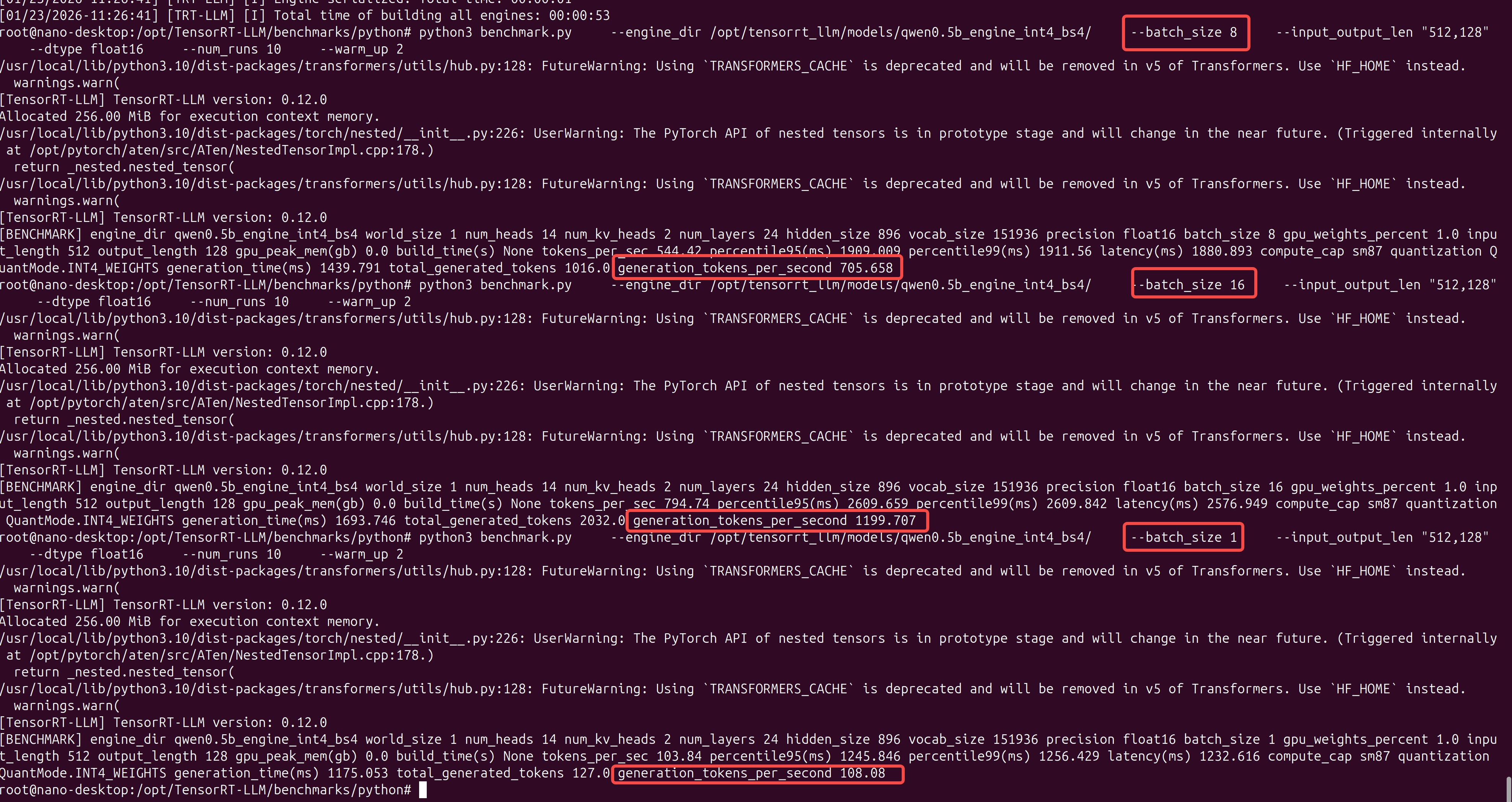
准备 硬件信息 硬件信息如下: sudo cat /proc/device-tree/model NVIDIA Jetson Orin NX Enginejetson_releasee Developer Kit(base) nano@nano-desktop:~$ jetson_release Software part of jetson-stats …
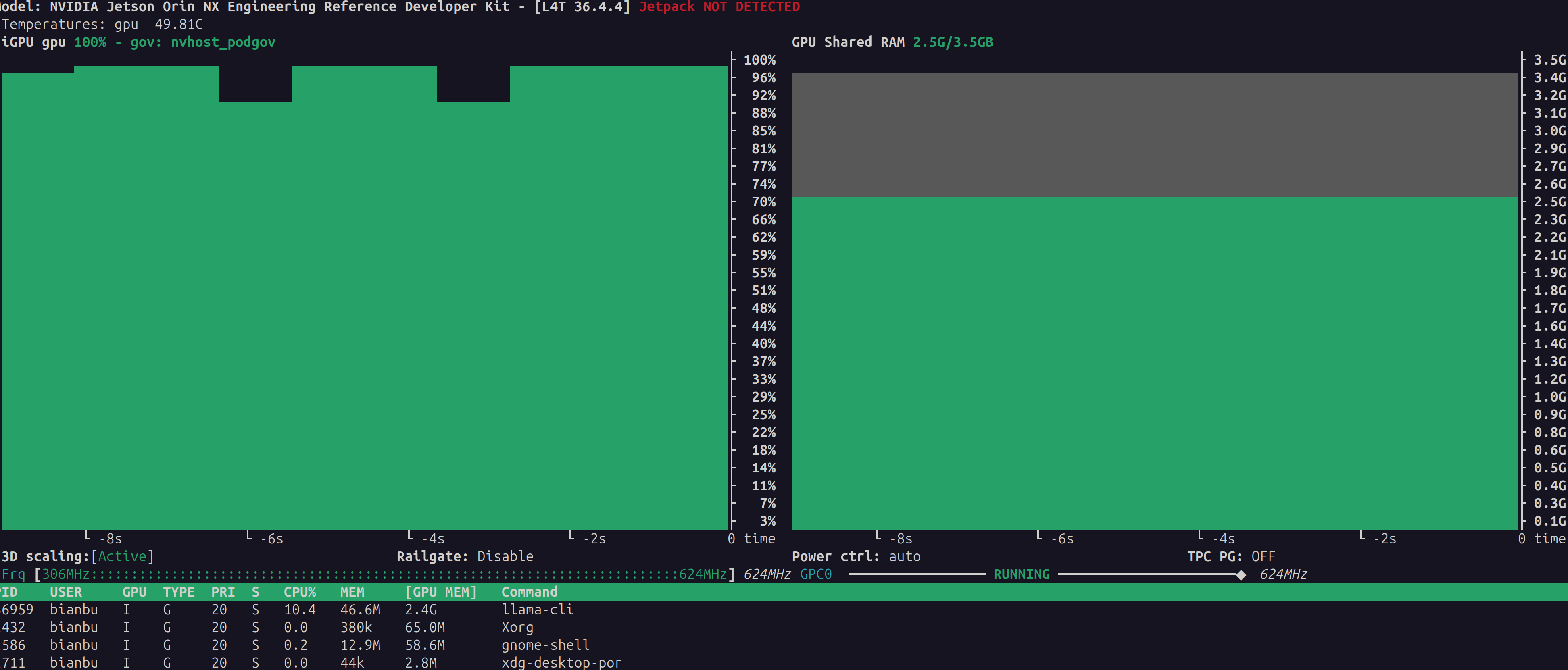
安全说明:本文是本地 AI 推理开发笔记,只记录 Jetson Orin Nano 上的 CUDA 环境检查、llama.cpp 官方源码编译、开源 GGUF 模型测试和性能观察。页面不提供可执行安装包,不要求输入账号、密码、支付信息或任
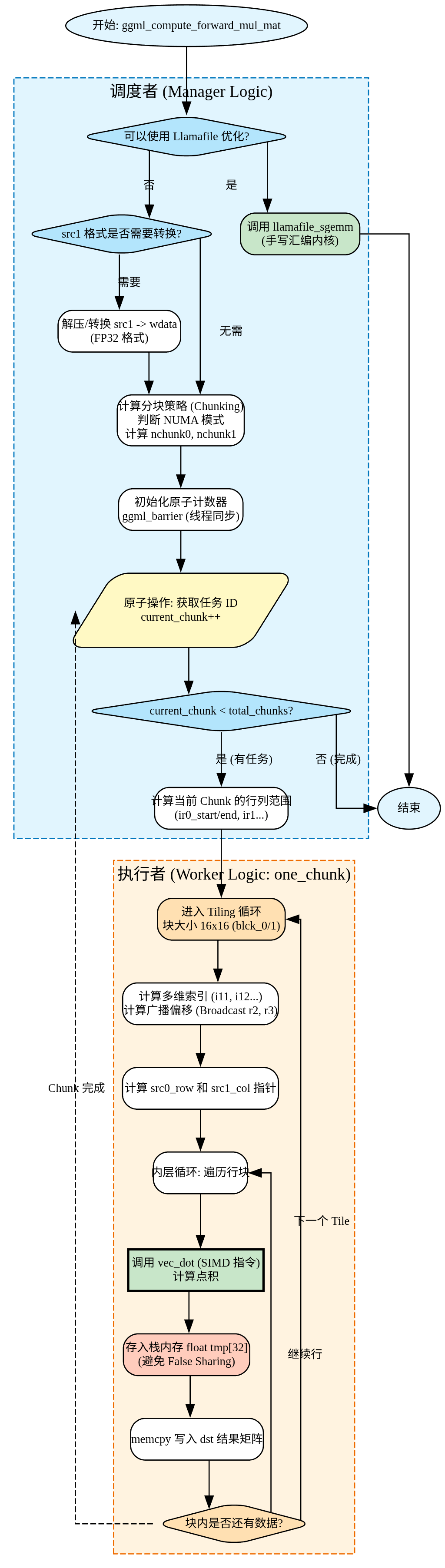
算子实现 调用流程 主要是ggml_compute_forward_mul_mat函数,该函数把任务拆分,最终计算执行调用ggml_compute_forward_mul_mat_on
使能方法 在linux 6.12版本之后原生SDK就支持了PREEMPT_RT,使能方式如下: make kernel_menuconfig General setup ---> <*> Fully Preemptible Kernel (Real-Time) 或者直接搜索CONFIG_PREEMPT_RT=y 确认是否已经打开 zcat …
矩阵相乘 是神经网络中算力消耗最大的部分,通常占据 LLM 推理计算量的 95% 以上。 矩阵乘法 (Matrix Multiplication / GEMM) 这是最通用的矩阵运算形式,也是 AI 芯片中 Tensor Core 或 MAC 阵列的主要工作内容。 定义: 设矩阵 $A$ 的形状为 $(M \times K