最新文章
-
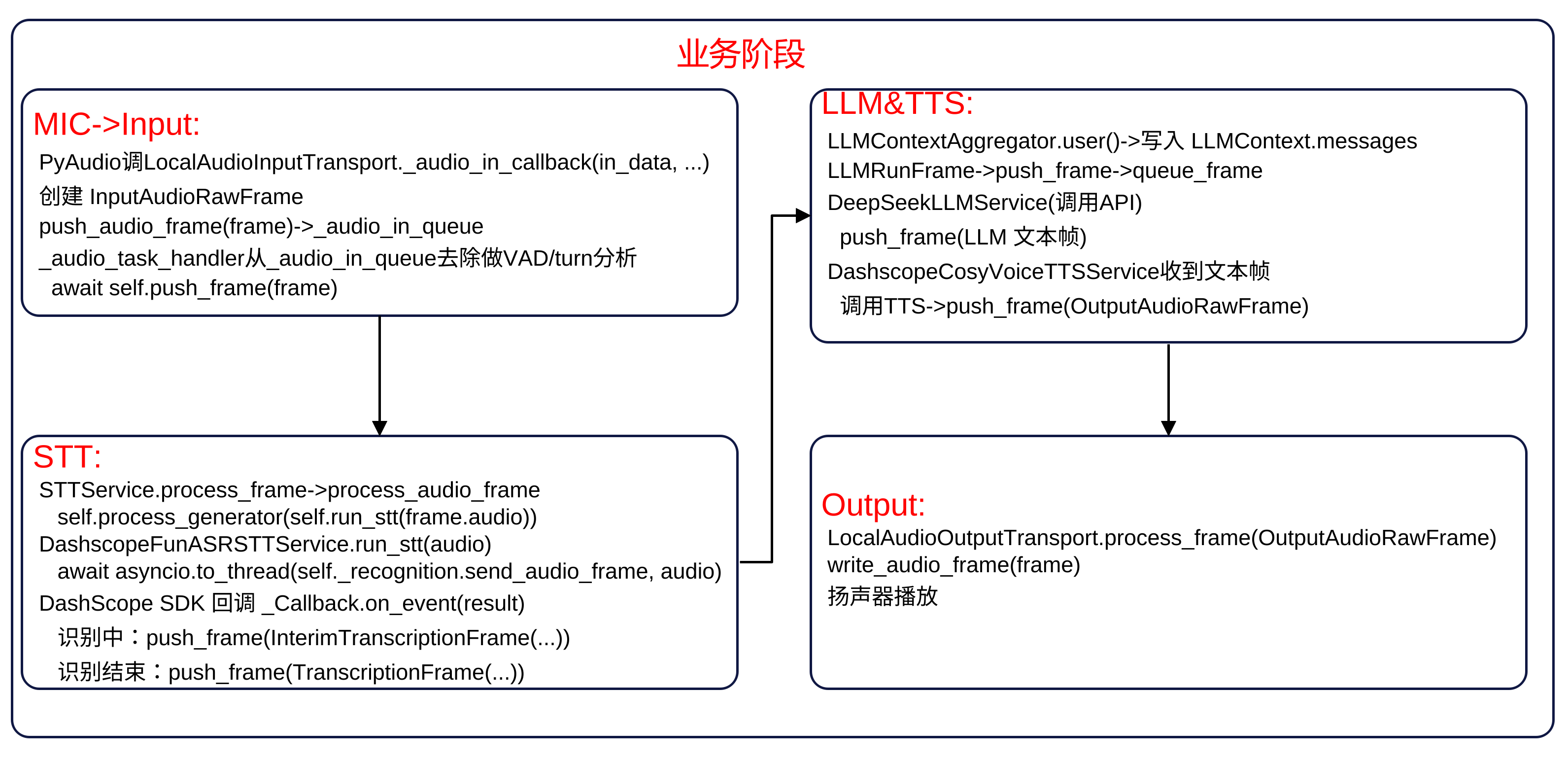
pipecat关键调用流程
业务流 启动阶段 帧处理 -
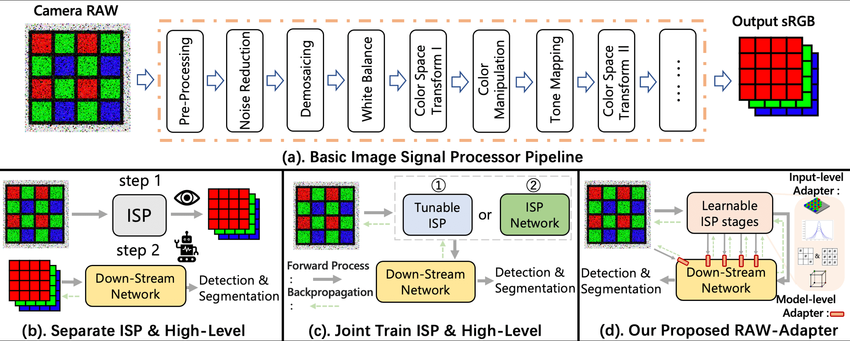
ISP(Image Signal Processor)关键技术指标
什么是ISP 一句话定义ISP:ISP就是把传感器吐出来的RAW电信号处理成可用于人眼、算法的图像数据的一整套“信号处理流水线”。 上面这张图是传统ISP流水线到AI ISP的演变。 (1)传统的ISP 传统的ISP,把传感器的RAW变成“人眼看起来好看”的sRGB图像,设计目标是给显示、编码、存储。核心指标是好看、稳定、符合显示标准。 名字 是什么(一句话) 在干嘛(直观理解) 不做会怎样 背后的直观原理 RAW 相机刚拍出来的“底片” 又暗又花,还是马赛克 人和算法几乎都用不了 传感器每个像素只看到一种颜色 Pre-Processing 修相机自己的毛病 修坏点、去黑边、补暗角 图像天生就歪、不均匀 把硬件缺陷在最早阶段修掉 Noise Reduction 去“雪花噪点” 把随机的脏点抹掉 图像像下雪,细节被噪声淹没 噪声是乱的,真实图像是连续的 Demosaicing 把马赛克变成彩色图 给每个像素补齐 RGB 画面全是格子,看不清 用邻居像素“猜”缺失颜色 White Balance 修正灯光颜色 让白的东西真的是白的 一会儿偏黄一会儿偏蓝 给 R/G/B 不同放大倍数 Color Space Transform 换颜色表达方式 从“相机语言”换成“通用语言” 不同设备颜色对不上 颜色坐标系的数学转换 Color Mapping 调色 / 美颜 让颜色更鲜艳、舒服 颜色发灰、发闷 用查表/曲线改颜色分布 Tone Mapping 调明暗 亮的压暗,暗的提亮 不是过曝就是全黑 用非线性曲线压亮度范围 Color Space Transform 输出前再转一次格式 变成显示/编码能用的格式 没法显示、没法存 适配显示/视频标准 sRGB 最终给人看的照片 手机上/屏幕看到的图 —— 人眼友好的标准颜色空间 3A是什么? 名字 全称 一句话白话 AE Auto Exposure 自动调亮度 AWB Auto White Balance 自动调颜色 AF Auto Focus 自动对焦 (2)Separate ISP & High-Level Vision 工业界的常见做法,特点仍然是为“人民服务”,被迫适应ISP输出。 RAW → ISP → RGB → Downstream Network step 1:摄像头通过ISP把RAW变成漂亮的sRGB图片,让人看起来舒服。 step 2:Down-Stream Network(下游网络,即 AI) 接收这张 sRGB 图片,进行 Detection(检测)或 Segmentation(分割)。 问题就是,ISP 为了让人眼舒服,可能会做“有损处理”。例如,为了降噪,把远处的纹理抹平了;或者为了 HDR,把原本线性的光照关系破坏了;AI 实际上是在“吃”人眼剩下的残羹冷炙。这就是为什么很多时候,人眼看着清楚,但 AI 识别率却上不去的原因。 (3)AI驱动的ISP 这是高端 AI 芯片(如自动驾驶芯片)正在探索的方向。原理: 不再使用固定的 ISP 参数。而是把 ISP 看作是一个可学习的网络 (ISP Network) 或者 可调参数的模块 (Tunable ISP)。 Backpropagation(反向传播): 注意那条虚线箭头。这意味着,如果 AI 识别错了,误差会反向传导回 ISP,告诉 ISP:“你刚才处理得不对,下次参数改一下。” 结果: ISP 不再为了“好看”而工作,而是专门为了“AI 识别率高”而工作。输出的图像可能人眼看着很怪(比如颜色发紫、对比度极高),但 AI 能够看清每一个细节。 (4)真正的端到端训练ISP 保留传统的ISP框架,在关键点引入可学习模块,输入/模型级的适配。旨在解决 (c) 方案太复杂、太难训练的问题。原理: 不完全抛弃传统 ISP,也不完全重写 ISP。而是在 RAW 数据和下游 AI 网络之间,插入一个轻量级的 Adapter(适配器)。 Learnable ISP stages: 让一小部分 ISP 功能变得“可学习”,专门把 RAW 数据转换成 AI 最喜欢的格式。 优势: 既利用了 RAW 数据的丰富信息,又不需要重新设计整个复杂的 ISP 硬件。 ISP的关键指标 图像质量(Image Quality, IQ) 这部分是最传统、也是厂商最爱卷的部分,关键的子指标如下: 指标 它解决什么问题 原理直觉 去噪 NR 低照、夜景噪声 空域/时域滤波 HDR / WDR 逆光、强对比 多曝光合成 / 曲线压缩 去马赛克 Demosaic RAW → RGB 插值 + 边缘保护 色彩还原 偏色、发灰 CCM / 3D LUT 锐化 发虚 高频增强 去雾 雾霾 对比度恢复模型 对于机器人来说,不是“越强越好”,主要关心的是能不能关掉、能不能锁参数、会不会引入时间的不稳定。 动态范围(Dynamic Range) 指标怎么看?把“亮的别爆,暗的别死” dB:60dB / 90dB / 120dB HDR:多帧 HDR(Multi-exposure),数字 WDR(Tone mapping) 对于机器人来说重要,尤其是户外、逆光、进出隧道,必须要。 时延(Latency)与确定性(Determinism) 这是机器人 vs消费电子的分水岭。 指标 含义 Line-based latency 不等一整帧 Frame-based latency 缓存整帧 Pipeline 深度 模块越多延迟越大 抖动(jitter) 帧到帧延迟是否稳定 延迟 ≠ 可怕,延迟不稳定 ≫ 可怕 同步与时间戳(Sync & Timestamp) 这是几乎所有 ISP 宣传页都会回避,但机器人最关键的点。关键问题。 多相机是否支持 硬同步 是否有 硬件时间戳 时间戳在哪一层打?曝光开始?帧结束?DMA 完成? 原理一句话,视觉 + IMU + 轮速 ≠ 同一个时间轴,SLAM就会崩。没有时间戳体系 = 再强 ISP 也不适合机器人。 几何一致性 项 用途 LDC 畸变校正 广角 / 鱼眼 标定模型 相机内参 双目 rectification 深度/SLAM 深度-RGB 对齐 传感器融合 ISP 不只是“修图”,它在 改变像素在空间中的几何含义。 可控性 AE/AWB/AF:是否可锁定、半自动、外部算法接管。 每个模块是否:可旁路、可独立配置、有确定顺序。 -

基于ubuntu系统安装使用Fast DDS
什么是Fast DDS Fast DDS是一个高性能的"分布式通信中间库",用来在不同进程、不同设备之间传输数据的。Fast DDS是用C++写的一个DDS实现,在同一台机器的多个进程、或者多态机器之间进行通信。可以类似于ROS2的发布和订阅主题,可以自动发现对端(不用手写IP列表),支持可靠/不可靠、实时性、历史缓存、持久化等各种Qos。 FastDDS与Socket、gRPC有什么区别? socket:自己管连接、重连、协议、序列化、发现等。 gRPC:偏请求、响应,RPC的风格。 FastDDS:原生支持多对多发布订阅,内置自动发现(谁上来就能发现谁),有非常丰富的Qos做实时系统的调优。 安装FastDDS 基于ubuntu 系统源码式编译安装FastDDS环境。 ~/FastDDS_ws/src$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 24.04.3 LTS Release: 24.04 Codename: noble 为了保持系统的干净,我们统一将fastdds相关的库和依赖安装到指定的目录。 export FAST_DDS_INSTALL_DIR=$HOME/fastdds_install # 创建安装目录和源码构建目录 mkdir -p $FAST_DDS_INSTALL_DIR 安装基础工具 sudo apt update sudo apt install -y \ build-essential \ cmake \ git \ libssl-dev \ libasio-dev \ libtinyxml2-dev \ wget \ zip FastDDS依赖C++编译环境、Cmake以及网络和XML解析库,因此需要安装以上的工具。 安装核心依赖 FastDDS主要依赖Foonathan memory和Fast CDR,前面是因为FastDDS使用foonathan_memory进行高效的内存管理(这对于实时性至关重要)。后者是FastDDS会把结构体编程二进制流,用于处理数据的序列化。 (1)安装Foonathan Memory # 创建一个工作目录 mkdir -p ~/FastDDS_ws/src cd ~/FastDDS_ws/src # 克隆仓库 git clone https://github.com/eProsima/foonathan_memory_vendor.git # 编译并安装 cd foonathan_memory_vendor mkdir build && cd build # 关键参数:-DCMAKE_INSTALL_PREFIX 指定安装位置 cmake .. -DCMAKE_INSTALL_PREFIX=$FAST_DDS_INSTALL_DIR -DBUILD_SHARED_LIBS=ON cmake --build . -j$(nproc) cmake --build . --target install (2)安装Fast CDR(序列化) cd ~/FastDDS_ws/src git clone https://github.com/eProsima/Fast-CDR.git cd Fast-CDR mkdir build && cd build # 关键参数:除了安装路径,还需要通过 -DCMAKE_PREFIX_PATH 告诉它去哪找 foonathan_memory (如果有依赖) cmake .. -DCMAKE_INSTALL_PREFIX=$FAST_DDS_INSTALL_DIR \ -DCMAKE_PREFIX_PATH=$FAST_DDS_INSTALL_DIR cmake --build . -j$(nproc) cmake --build . --target install 编译安装Fast DDS核心库 FastDDS需要依赖上面两个库。 cd ~/FastDDS_ws/src git clone https://github.com/eProsima/Fast-DDS.git cd Fast-DDS mkdir build && cd build # 关键参数解释: # -DCMAKE_INSTALL_PREFIX: 安装到我们自定义目录 # -DCMAKE_PREFIX_PATH: 告诉 CMake 去自定义目录里找 FastCDR 和 Foonathan cmake .. -DCMAKE_INSTALL_PREFIX=$FAST_DDS_INSTALL_DIR \ -DCMAKE_PREFIX_PATH=$FAST_DDS_INSTALL_DIR \ -DSECURITY=ON \ -DCOMPILE_EXAMPLES=ON cmake --build . -j$(nproc) cmake --build . --target install 配置代码生成器Fast-DDS-Gen 这个工具是永远将 # 1. 回到源码目录 cd ~/FastDDS_ws/src # 2. 克隆仓库 (获取最新版,通常是 v4.x) git clone --recursive https://github.com/eProsima/Fast-DDS-Gen.git fastddsgen # 3. 进入目录 cd Fast-DDS-Gen # 4. 编译 (会自动下载 Gradle 并构建,需要保持网络畅通) ./gradlew assemble 环境加载 因为我们没有安装到系统默认路径,需要设置一下环境变量。 vim $FAST_DDS_INSTALL_DIR/setup.bash #!/bin/bash # 获取脚本所在的目录 (即 ~/fastdds_install) INSTALL_ROOT=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd) # 1. 告诉系统去哪里找 .so 动态库 (运行时必须) export LD_LIBRARY_PATH=$INSTALL_ROOT/lib:$LD_LIBRARY_PATH # 2. 告诉 CMake 去哪里找 find_package(FastDDS) (编译时必须) export CMAKE_PREFIX_PATH=$INSTALL_ROOT:$CMAKE_PREFIX_PATH # 3. 将 bin 加入 PATH,这样你可以直接输 fastddsgen (工具使用) export PATH=$INSTALL_ROOT/bin:$PATH echo "Fast DDS environment sourced from: $INSTALL_ROOT" 验证与使用 source ~/fastdds_install/setup.bash mkdir -p ~/FastDDS_ws/src/SimpleChat cd ~/FastDDS_ws/src/SimpleChat (1)定义数据结构 // Chat.idl struct ChatMessage { unsigned long user_id; string message; }; (2)生成胶水代码 fastddsgen Chat.idl (3)编写发布者 创建 ChatPublisher.cpp。这个程序负责发送消息。 // ChatPublisher.cpp #include "ChatPubSubTypes.hpp" #include <fastdds/dds/domain/DomainParticipantFactory.hpp> #include <fastdds/dds/domain/DomainParticipant.hpp> #include <fastdds/dds/topic/TypeSupport.hpp> #include <fastdds/dds/publisher/Publisher.hpp> #include <fastdds/dds/publisher/DataWriter.hpp> #include <thread> #include <iostream> using namespace eprosima::fastdds::dds; int main() { // 1. 创建 Participant (参与者) DomainParticipantQos participant_qos = PARTICIPANT_QOS_DEFAULT; DomainParticipant* participant = DomainParticipantFactory::get_instance()->create_participant(0, participant_qos); if (!participant) return 1; // 2. 注册数据类型 TypeSupport type(new ChatMessagePubSubType()); type.register_type(participant); // 3. 创建 Topic Topic* topic = participant->create_topic("ChatTopic", type.get_type_name(), TOPIC_QOS_DEFAULT); // 4. 创建 Publisher Publisher* publisher = participant->create_publisher(PUBLISHER_QOS_DEFAULT); // 5. 创建 DataWriter DataWriter* writer = publisher->create_datawriter(topic, DATAWRITER_QOS_DEFAULT); // 6. 循环发送数据 ChatMessage data; data.user_id(101); // 假设我是用户 101 int count = 0; while (true) { data.message("Hello FastDDS " + std::to_string(count++)); writer->write(&data); std::cout << "[Sent] " << data.message() << std::endl; std::this_thread::sleep_for(std::chrono::seconds(1)); } // 清理资源 (实际代码中通常在析构或信号处理中做) // participant->delete_contained_entities(); // DomainParticipantFactory::get_instance()->delete_participant(participant); return 0; } (4)编写订阅者 创建 ChatSubscriber.cpp。这个程序负责监听并打印消息。 // ChatSubscriber.cpp #include "ChatPubSubTypes.hpp" #include <fastdds/dds/domain/DomainParticipantFactory.hpp> #include <fastdds/dds/domain/DomainParticipant.hpp> #include <fastdds/dds/topic/TypeSupport.hpp> #include <fastdds/dds/subscriber/Subscriber.hpp> #include <fastdds/dds/subscriber/DataReader.hpp> #include <fastdds/dds/subscriber/DataReaderListener.hpp> #include <fastdds/dds/subscriber/SampleInfo.hpp> #include <fastdds/dds/core/ReturnCode.hpp> #include <thread> #include <chrono> #include <iostream> using namespace eprosima::fastdds::dds; // 监听器类:回调函数在这里触发 class MyListener : public DataReaderListener { public: void on_data_available(DataReader* reader) override { ChatMessage data; SampleInfo info; // 取出数据 while (reader->take_next_sample(&data, &info) == eprosima::fastdds::dds::RETCODE_OK) { if (info.valid_data) { std::cout << "[Received] User " << data.user_id() << ": " << data.message() << std::endl; } } } void on_subscription_matched(DataReader* reader, const SubscriptionMatchedStatus& info) override { if (info.current_count_change == 1) { std::cout << ">> Match Found: Publisher connected!" << std::endl; } else if (info.current_count_change == -1) { std::cout << ">> Match Lost: Publisher disconnected." << std::endl; } } }; int main() { // 1. 创建 Participant DomainParticipant* participant = DomainParticipantFactory::get_instance()->create_participant(0, PARTICIPANT_QOS_DEFAULT); // 2. 注册类型 TypeSupport type(new ChatMessagePubSubType()); type.register_type(participant); // 3. 创建 Topic Topic* topic = participant->create_topic("ChatTopic", type.get_type_name(), TOPIC_QOS_DEFAULT); // 4. 创建 Subscriber Subscriber* subscriber = participant->create_subscriber(SUBSCRIBER_QOS_DEFAULT); // 5. 创建 DataReader 并绑定 Listener MyListener listener; // 注意:这里需要传入 Listener 指针,并掩码设置我们要监听所有状态 DataReader* reader = subscriber->create_datareader(topic, DATAREADER_QOS_DEFAULT, &listener); std::cout << "Waiting for messages... (Press Ctrl+C to stop)" << std::endl; // 阻塞主线程,否则 main 结束程序就退出了 while(true) { std::this_thread::sleep_for(std::chrono::milliseconds(100)); } return 0; } (5)编写CmakeList cmake_minimum_required(VERSION 3.10) project(SimpleChat) set(CMAKE_CXX_STANDARD 11) find_package(FastDDS REQUIRED) # --- 关键修改:匹配你 tree 里的文件 --- # Chat.hpp 是头文件,不需要加入 source list # 加入 ChatPubSubTypes.cxx 和 ChatTypeObjectSupport.cxx set(GENERATED_SOURCES ChatPubSubTypes.cxx ChatTypeObjectSupport.cxx ) add_executable(ChatPublisher ChatPublisher.cpp ${GENERATED_SOURCES}) target_link_libraries(ChatPublisher fastdds) add_executable(ChatSubscriber ChatSubscriber.cpp ${GENERATED_SOURCES}) target_link_libraries(ChatSubscriber fastdds) (6)编译运行 cd build cmake .. make -j4 ./ChatSubscriber & ./ChatPublisher -
JSON-RPC 2.0 规范解读
概述 JSON-RPC是一种无状态、轻量的远程调用(RPC)协议,其有一套规范,定义了若干数据结构及其处理规则。它对传输层是无关的,可以在同一进程中传递使用,也可以跨进程、跨环境如socket、http等传递环境使用。 官方对JSON-RPC 2.0的规范定义其实也非常简单,主要请求对象、响应对象。 请求对象 一个RPC调用是通过向服务器发送一个Request对象来表示。 { "jsonrpc": "2.0", "method": "xxx", "params": ..., "id": ... } Rrequest对象具体有以下成员: jsonrpc:一个指定JSON-RPC协议版本的字符串,必须正好是"2.0"。该成员必须。 method:一个包含要调用的方法名称字符串,用于区分要调用的是那个方法。该成员必须。 params:一个结构化智,用于存储方法调用期间要使用的参数值。该成员可省略。 id:由客户端建立的标识符,如果包含必须是一个字符串、数字或NULL值。 可以理解为method就是函数名,params就是函数的参数。 params是可以省略的,id的如果请求需要回复是不必须要的,如果请求不需要回复就不需要带,这种一般是通知。 通知 request对象可以分为带回复的请求,和不需要回复的请求,后者成为notification,跟BLE的传输协议是不是有点像?(没错就是notify和indicate的区别)。 (1)请求需要回复的示例 { "jsonrpc": "2.0", "id": 1, "method": "get_temp", "params": {} } (2)通知(请求不需要回复) { "jsonrpc": "2.0", "method": "robot.chassis.forward", "params": { "speed": 0.5 } } 通知是一个不需要id成员的请求对象,一个作为通知的请求对象表示客户端对相应的响应对象都不感兴趣,因此不需要向客户端返回响应对象。服务器必须不回复通知,包括哪些在批量请求中的通知。 根据定义,通知是不可确认的,因为它们没有要返回的响应对象。因此,客户端不会知道任何错误(例如无效的参数、内部错误)。 参数结构 参数是可选的,如果存在参数,rpc调用的参数必须以结构化值的形式提供。可以通过array数组按位置提供或通过object对象按名称提供。 按数组位置提供: params必须是一个数组,其中包含服务器期望的顺序值。 按对象名称提供:params必须是一个对象,其成员名称必须与服务器期望的参数名称匹配。缺少预期名称可能会导致生成错误。名称必须完全匹配,包括大小写,以匹配方法期望的参数。 (1)按数组位置 "params": [value1, value2, value3] 参数顺序必须完全匹配,客户端与服务器双方必须清楚位置含义,如果顺序错了就调用失败(服务器无法解析),参数数目要匹配缺少或多给都会报错。如下: { "jsonrpc": "2.0", "method": "add", "params": [3, 5], "id": 1 } 这种一般适用于资源小,带宽紧张的事实控制,参数稍而且固定的场景。 (2)按对象名称 "params": { "x": 1, "y": 2, "speed": 0.5 } 按对象名称提供的最灵活,最容易读,这是一个键-值对的方式,但是参数的名称必须要完全匹配(包括大小写),参数的顺序没有要求。如下示例: { "jsonrpc": "2.0", "method": "robot.arm.move", "params": { "joint1": 10, "joint2": -5 }, "id": 1 } 按数组的方式可以理解为只有原始数据,没有对应数据的标签。而按照对象的方式有数据和对应的标签。 响应对象 当发起一个rpc调用时,除了通知外,服务器都需要进行响应回复。响应分为正常的响应和错误的响应。 成功的响应,格式如下: { "jsonrpc": "2.0", "result": ..., "id": ... } 错误的响应: { "jsonrpc": "2.0", "error": { "code": ..., "message": .... }, "id": ... } 响应表示为一个JSON对象,包含一下成员: jsonrpc:一个指定JSON-RPC协议版本的字符串,必须正好是2.0。 result:成功的响应必须包含。 error:错误的响应必须包含。 id: 该成员必须,必须与请求对象的id成员值相同,表示一一对应。 成功响应 成功响应回复的是result的成员,示例如下: { "id": 2, "jsonrpc": "2.0", "result": { "temperature": 3, "desc": "Sunny" } } 错误响应 { "jsonrpc": "2.0", "id": 1, "error": { "code": -32602, "message": "Invalid params", "data": "speed must be 0~1" } } 错误的响应官方提供了标准的错误码含义。 code 含义 -32700 Parse error 解析错误 -32600 Invalid Request 无效请求 -32601 Method not found 找不到方法 -32602 Invalid params 参数错误 -32603 Internal error 内部错误 -32000 to -32099 保留用于实现定义的服务器错误。 批量调用 同时发送多个 Request 对象时,客户端可以发送一个包含 Request 对象的数组。服务器在处理完所有批量的request对象后,应返回一个包含相应response对象的数组。每个request对象都应该有一个对象的response对象,但通知不应有任何response对象。服务器可以将批量rpc调用作为一组并发处理,以任意顺序和任意并行度进行处理。 从批量调用返回的response对象可以在数组中按任意顺序返回。客户端应根据每个对象的id成员,在request对象集和结果response对象集之间匹配上下文。 如果批量rpc调用本身无法被识别为有效的JSON或至少包含一个值的数组,服务器的响应必须是一个单独的response对象。如果发送给客户端response数组中不包含任何response对象,服务器不得返回空数组,而应什么也不返回。 以下是示例一次发多个请求: [ { "jsonrpc": "2.0", "id": 1, "method": "get_temp" }, { "jsonrpc": "2.0", "id": 2, "method": "get_humidity" } ] 响应: [ { "jsonrpc": "2.0", "id": 1, "result": 25 }, { "jsonrpc": "2.0", "id": 2, "result": 60 } ] 这种批量的调用一般在多传感器融合的时候非常好用。 -
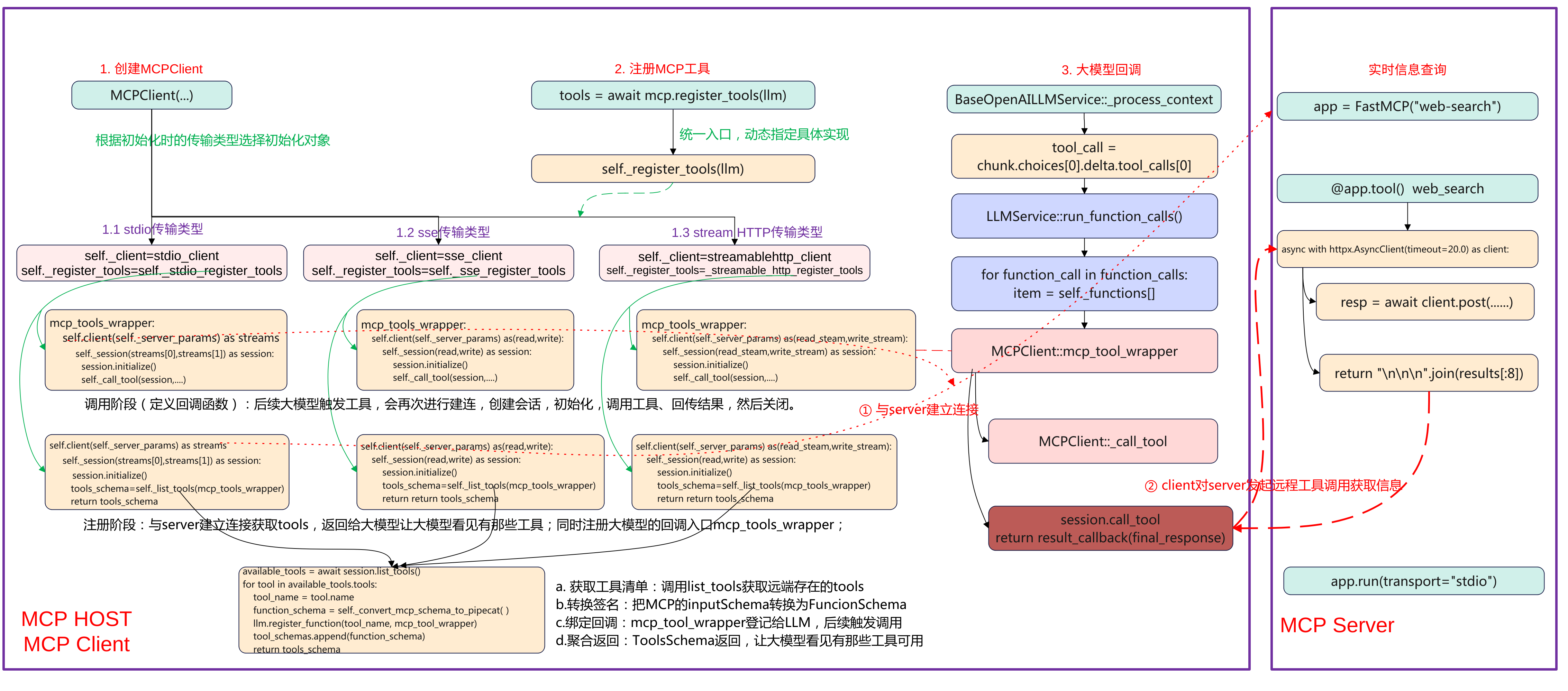
Pipecat MCP 实战流程分析:从 Client 到 Server
简介 本文主要基于Pipecat实现一个MCP stdio传输方式调用的示例。基于智谱Web-Search-Pro实现一个MCP Server,然后在Pipecat应用基础上实现MCP Client,实现可以实时查询天气等功能。通过这个示例来理解pipecat的mcp调用流程。 先上一张完整流程图,本文将重点围绕MCP Host、MCP Client端的创建MCP Client、注册MCP工具、以及大模型回调来展开说明pipecat上MCP的调用流程。 Pipecat MCP client端 下面pipecat应用MCP Host的关键代码: # STT: DashScope FunASR (realtime) stt = DashscopeFunASRSTTService(api_key=os.getenv("DASHSCOPE_API_KEY")) # TTS: DashScope CosyVoice v2 (streaming) tts = DashscopeCosyVoiceTTSService( api_key=os.getenv("DASHSCOPE_API_KEY"), voice="longxiaochun_v2", ) # LLM: Qwen (DashScope OpenAI compatible) llm = QwenLLMService( api_key=os.getenv("DASHSCOPE_API_KEY"), # Mainland China endpoint for OpenAI-compatible API: base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-plus", ) server_script = os.path.join(os.path.dirname(__file__), "mcp", "web_search_mcp.py") mcp = MCPClient( server_params=StdioServerParameters( command=sys.executable, args=[server_script], env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")}, ) ) tools = await mcp.register_tools(llm) system = f""" 你是一个在 WebRTC 通话里的中文助手。 - 回答尽量简洁,必要时可调用 MCP 工具完成查询/检索/图片等任务。 - 输出会被转换为语音,避免使用过多特殊字符。 - 工具调用时少解释过程,直接给出关键结论。 """ messages = [{"role": "system", "content": system}] context = LLMContext(messages, tools) if tools else LLMContext(messages) context_aggregator = LLMContextAggregatorPair(context) pipeline = Pipeline( [ transport.input(), # Transport user input stt, context_aggregator.user(), # User spoken responses llm, # LLM tts, # TTS transport.output(), # Transport bot output context_aggregator.assistant(), # Assistant spoken responses and tool context ] ) task = PipelineTask( pipeline, params=PipelineParams( enable_metrics=True, enable_usage_metrics=True, ), idle_timeout_secs=runner_args.pipeline_idle_timeout_secs, ) (1)语音识别 stt = DashscopeFunASRSTTService(api_key=os.getenv("DASHSCOPE_API_KEY")) 使用了DashScope提供的FunASR实时语音识别服务,输入音频流来自WebRTC,输出为识别的文字,这这是整个pipeline的第一个处理单元。 (2)语音合成 tts = DashscopeCosyVoiceTTSService( api_key=os.getenv("DASHSCOPE_API_KEY"), voice="longxiaochun_v2", ) 使用DataScope的CosyVoice2模型,将LLM输出的文本转为语音,参数Voice为"龙小纯"音色,支持流式输出,边生成边播放。 (3)大语言模型 llm = QwenLLMService( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-plus", ) 使用DashSCcope的Qwen plus模型,其兼容OpenAI接口模式,通过统一的LLMService封装,可以插拔替换,接收来自STT的文字输入,并可调用MCP工具。 (4)MCP工具客户端 mcp = MCPClient( server_params=StdioServerParameters( command=sys.executable, args=[server_script], env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")}, ) ) tools = await mcp.register_tools(llm) MCPClient启动一个外部MCP工具进程web_search_mcp.py,MCP是一个工具协议层,让LLM可以调用外部函数。register_tools会把MCP提供的工具注册进LLM,使其可以向OpenAI Function Call一样调用。例如查询天气、搜索网页、生成图片等。 (5)系统提示词system prompt system = """ 你是一个在 WebRTC 通话里的中文助手。 - 回答尽量简洁,必要时可调用 MCP 工具完成查询/检索/图片等任务。 - 输出会被转换为语音,避免使用过多特殊字符。 - 工具调用时少解释过程,直接给出关键结论。 """ LLMContex保持当前对话上下文、系统提示与工具注册,LLMContextAggregatorPair维护用户与助手的历史消息流(多轮对话记忆),这让语音交互能记住上下文内容,而非每轮都从0开始。 (6)pipeline定义语言交互主流程 pipeline = Pipeline([ transport.input(), # 用户语音输入流 stt, # 语音转文字 context_aggregator.user(),# 更新用户对话上下文 llm, # 调用大模型 tts, # 文本转语音 transport.output(), # 输出音频到客户端 context_aggregator.assistant(), # 保存助手回答上下文 ]) 顺序 模块 输入 输出 1 transport.input() 麦克风语音 音频流 2 stt 音频流 用户文字 3 context_aggregator.user() 用户文字 更新上下文 4 llm 上下文 模型回答文本 5 tts 回答文本 音频流 6 transport.output() 音频流 扬声器播放 7 context_aggregator.assistant() 模型回答 保存为记忆 (7)pipeline任务封装 task = PipelineTask( pipeline, params=PipelineParams( enable_metrics=True, enable_usage_metrics=True, ), idle_timeout_secs=runner_args.pipeline_idle_timeout_secs, ) 封装为可执行任务,支持性能监控与使用统计,可设置空闲超时自动关闭。 MCP Server工具端 (1)导入依赖与初始化 import os, asyncio, sys import httpx from mcp.server import FastMCP app = FastMCP("web-search") FastMCP("web-search") 表示这是一个名为 "web-search" 的 MCP 工具服务,CP 协议使用 JSON-RPC over stdio。httpx是异步HTTP客户端,用于调用外部搜索接口,如果httpx缺失,本地按照pip install httpx。 @app.tool() async def web_search(query: str) -> str: """ 搜索互联网内容 Args: query: 要搜索的内容 Returns: 搜索结果的简要总结 """ _log(f"tool called: web_search(query={repr(query)[:120]})") api_key = os.getenv("BIGMODEL_API_KEY") if not api_key: _log("Missing BIGMODEL_API_KEY") return "Missing BIGMODEL_API_KEY" # Some endpoints accept raw key; others require Bearer. Try raw first to match user sample. headers = {"Authorization": api_key} payload = { "tool": "web-search-pro", "messages": [{"role": "user", "content": query}], "stream": False, } async with httpx.AsyncClient(timeout=20.0) as client: try: _log("sending request to BigModel web-search-pro") resp = await client.post( "https://open.bigmodel.cn/api/paas/v4/tools", headers=headers, json=payload ) _log(f"received response status={resp.status_code}") resp.raise_for_status() data = resp.json() except Exception as e: _log(f"request error: {e}") return f"Web search error: {e}" results = [] try: for choice in data.get("choices", []): message = choice.get("message", {}) for tool_call in message.get("tool_calls", []): for item in tool_call.get("search_result", []) or []: content = item.get("content") if content: results.append(content) except Exception: # Fallback to raw body _log("unexpected response structure; returning raw JSON snippet") return str(data)[:2000] if not results: _log("no results") return "No results." _log(f"returning {len(results)} result chunks") return "\n\n\n".join(results[:8]) 使用@app.tool定义工具的接口,其会注册一个工具到MCP Server,工具名称默认为函数名web_search。最终这个工具会暴露给MCP Client,LLM调用时就像function call一样。 函数中具体的实现是构造一个请求体并调用BigModel API。输入为query表示要查询的内容,最终返回查询到的JSON格式结果,将结果进行解析返回结构类似OpenAI格式。 MCP Client初始化 创建MCPClient类 if StdioServerParameters is None: raise ImportError( "StdioServerParameters not available in your MCP package. " "Upgrade MCP: `pip install -U mcp`." ) server_script = os.path.join(os.path.dirname(__file__), "mcp", "web_search_mcp.py") mcp = MCPClient( server_params=StdioServerParameters( command=sys.executable, args=[server_script], env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")}, ) ) 首先检查StdioServerParameters是否可用,不可用的haul则升级mcp包。接着计算server_script路径,指向FastMCP服务脚本(实现@app.tool)的web_search,构造MCPClient,传入stdio参数,参数如下: command=sys.executable 确保用当前虚拟环境的 Python 启动子进程(依赖一致)。 args=[server_script] 启动该脚本。 env={"BIGMODEL_API_KEY": ...} 把 BigModel 的 API Key 传给子进程(工具内部要用)。 server_script 指向真正提供工具的 MCP 服务器(定义了 @app.tool() 的 web_search)。 MCPClient构造 class MCPClient(BaseObject): def __init__( self, server_params: ServerParameters, **kwargs, ): """Initialize the MCP client with server parameters. Args: server_params: Server connection parameters (stdio or SSE). **kwargs: Additional arguments passed to the parent BaseObject. """ super().__init__(**kwargs) self._server_params = server_params self._session = ClientSession self._needs_alternate_schema = False if isinstance(server_params, StdioServerParameters): self._client = stdio_client self._register_tools = self._stdio_register_tools elif isinstance(server_params, SseServerParameters): self._client = sse_client self._register_tools = self._sse_register_tools elif isinstance(server_params, StreamableHttpParameters): self._client = streamablehttp_client self._register_tools = self._streamable_http_register_tools else: raise TypeError( f"{self} invalid argument type: `server_params` must be either StdioServerParameters, SseServerParameters, or StreamableHttpParameters." ) 构造时“按参数类型选策略”。把同一套“注册逻辑”与不同“传输后端”(stdio/SSE/HTTP)解耦,延后到运行时绑定。具体的关键步骤如下: 保存参数与会话类:self._server_params = server_params:记录连接配置(命令/URL/headers/env 等)。self._session = ClientSession:后续用读写流构建 MCP 会话(initialize/list_tools/call_tool)。self._needs_alternate_schema = False:是否需要“严格 schema 清洗”留给后续判定。 选择传输实现与注册函数:根据传参来选择实际的client和注册函数,选择的类型为MCP的传输类型stdio类型、sse类型、streamhttp类型。 self._client 是“连接工厂”(异步上下文管理器),进入后产出读/写流(stdio 为子进程 stdin/stdout,SSE/HTTP 为对应流)。self._register_tools 是对应后端的“注册流程实现”,register_tools(llm) 会调用它去建连→初始化→列工具→注册“工具名→回调”。 这个设计要点是典型的Strategy + Factory:构造时完成“策略绑定”,后续使用统一入口(register_tools)。 MCP工具注册 mcp = MCPClient( server_params=StdioServerParameters( command=sys.executable, args=[server_script], env={"BIGMODEL_API_KEY": os.getenv("BIGMODEL_API_KEY", "")}, ) ) tools = await mcp.register_tools(llm) 创建完MCPClient对象后,就进行注册tools,调用到MCPClient::register_tools函数。 async def register_tools(self, llm) -> ToolsSchema: """Register all available MCP tools with an LLM service. Connects to the MCP server, discovers available tools, converts their schemas to Pipecat format, and registers them with the LLM service. Args: llm: The Pipecat LLM service to register tools with. Returns: A ToolsSchema containing all successfully registered tools. """ # Check once if the LLM needs alternate strict schema self._needs_alternate_schema = llm and llm.needs_mcp_alternate_schema() tools_schema = await self._register_tools(llm) return tools_schema 统一入口,完成连接MCP——>获取工具列表——>转换schema——>注册到LLM并返回ToolsSchema的过程。 self._needs_alternate_schema:询问当前 LLM 是否需要“严格 schema”兼容(有些 LLM 对 JSON Schema 更严格)。若为 True,后续在 schema 转换时会移除/调整如 additionalProperties 等字段。 tools_schema = await self._register_tools(llm):这里的 _register_tools 是构造函数里根据 server_params 绑定的具体实现(stdio/SSE/HTTP 之一)。内部会实际建连、session.initialize()、session.list_tools()、把每个工具注册为 “工具名 → 回调(mcp_tool_wrapper)”,并组装 ToolsSchema。 ToolsSchema(standard_tools=[FunctionSchema...]),供上层塞进 LLMContext(messages, tools),让大模型“看见”可用工具,同时建立调用时的回调映射。 xxx_register_tools 根据参数传入的类型stdio、sse、streamable_http选择注册的工具,分别会调用如下: stdio类型:调用_stdio_register_tools sse类型:调用_sse_register_tools streamable类型:调用_streamable_http_register_tools 这里以stdio类型为例分析, async def _stdio_register_tools(self, llm) -> ToolsSchema: """Register all available mcp tools with the LLM service. Args: llm: The Pipecat LLM service to register tools with Returns: A ToolsSchema containing all registered tools """ async def mcp_tool_wrapper(params: FunctionCallParams) -> None: """Wrapper for mcp tool calls to match Pipecat's function call interface.""" logger.debug( f"Executing tool '{params.function_name}' with call ID: {params.tool_call_id}" ) logger.trace(f"Tool arguments: {json.dumps(params.arguments, indent=2)}") try: async with self._client(self._server_params) as streams: async with self._session(streams[0], streams[1]) as session: await session.initialize() await self._call_tool( session, params.function_name, params.arguments, params.result_callback ) except Exception as e: error_msg = f"Error calling mcp tool {params.function_name}: {str(e)}" logger.error(error_msg) logger.exception("Full exception details:") await params.result_callback(error_msg) logger.debug("Starting registration of mcp tools") async with self._client(self._server_params) as streams: async with self._session(streams[0], streams[1]) as session: await session.initialize() tools_schema = await self._list_tools(session, mcp_tool_wrapper, llm) return tools_schema (1)定义回调mcp_tool_wrapper(未来执行) 定义回调 mcp_tool_wrapper(未来每次工具调用时执行),这个是要注册进llm大模型的,用于后续大模型触发的回调。具体的步骤如下: 记录日志 → 建立到 MCP 的 stdio 连接:self._client(self._server_params)。 取到读写流 streams[0]/streams[1] → 构建 ClientSession → initialize()。 调用 _call_tool(session, name, args, result_callback) 执行工具;异常则通过 result_callback 把错误文本回传。 (2)注册阶段(当前执行) 再开一次短连接并 initialize() 调用 _list_tools(session, mcp_tool_wrapper, llm),获取远端工具清单,转为 FunctionSchema 并用 llm.register_function(tool_name, mcp_tool_wrapper) 将“工具名→回调”登记到 LLM;聚合为 ToolsSchema 返回。 _list_tools async def _list_tools(self, session, mcp_tool_wrapper, llm): available_tools = await session.list_tools() tool_schemas: List[FunctionSchema] = [] try: logger.debug(f"Found {len(available_tools)} available tools") except: pass for tool in available_tools.tools: tool_name = tool.name logger.debug(f"Processing tool: {tool_name}") logger.debug(f"Tool description: {tool.description}") try: # Convert the schema function_schema = self._convert_mcp_schema_to_pipecat( tool_name, {"description": tool.description, "input_schema": tool.inputSchema}, ) # Register the wrapped function logger.debug(f"Registering function handler for '{tool_name}'") llm.register_function(tool_name, mcp_tool_wrapper) # Add to list of schemas tool_schemas.append(function_schema) logger.debug(f"Successfully registered tool '{tool_name}'") except Exception as e: logger.error(f"Failed to register tool '{tool_name}': {str(e)}") logger.exception("Full exception details:") continue logger.debug(f"Completed registration of {len(tool_schemas)} tools") tools_schema = ToolsSchema(standard_tools=tool_schemas) return tools_schema _list_tools是用当前MCP会话把远端工具同步到LLM,具体的步骤如下: list_tools() 获取远端工具清单。 遍历每个工具,inputSchema 转为 Pipecat 的 FunctionSchema(name/description/properties/required)。 调用 llm.register_function(tool_name, mcp_tool_wrapper) 把“工具名→回调”登记到 LLM(回调负责后续真实调用)。 把 FunctionSchema 累加到列表。 组装 ToolsSchema(standard_tools=...) 返回。 其目的是让大模型“看见”有哪些工具(用于决策),建立从“工具名”到“实际执行逻辑(mcp_tool_wrapper)”的映射,确保 tool_call 能打到 MCP。 大模型工具调用 触发tool_call @traced_llm async def _process_context(self, context: OpenAILLMContext | LLMContext): if chunk.choices[0].delta.tool_calls: tool_call = chunk.choices[0].delta.tool_calls[0] ... if tool_call.function and tool_call.function.name: function_name += tool_call.function.name tool_call_id = tool_call.id if tool_call.function and tool_call.function.arguments: arguments += tool_call.function.arguments 在_process_context中解析,大模型产生tool_call,接着组装函数调用并交给执行器。 function_calls.append( FunctionCallFromLLM(context=context, tool_call_id=tool_id, function_name=function_name, arguments=json.loads(arguments)) ) await self.run_function_calls(function_calls) 查表命中回调 async def run_function_calls(self, function_calls: Sequence[FunctionCallFromLLM]): if function_call.function_name in self._functions.keys(): item = self._functions[function_call.function_name] elif None in self._functions.keys(): item = self._functions[None] 在类LLMService中,LLM层查表命中"工具名-回调"。接着下发"调用进行时"帧并准备结果回调。 progress_frame = FunctionCallInProgressFrame(...) await self.push_frame(progress_frame, FrameDirection.DOWNSTREAM) await self.push_frame(progress_frame, FrameDirection.UPSTREAM) ..... async def function_call_result_callback(result: Any, *, properties: ...): result_frame = FunctionCallResultFrame(..., result=result, ...) await self.push_frame(result_frame, FrameDirection.DOWNSTREAM) await self.push_frame(result_frame, FrameDirection.UPSTREAM) MCP调用 以stdio为例最后触发已注册的回调。 async def _stdio_register_tools(self, llm) -> ToolsSchema: async with self._client(self._server_params) as streams: async with self._session(streams[0], streams[1]) as session: await session.initialize() await self._call_tool(session, params.function_name, params.arguments, params.result_callback) 真正调用MCP工具并聚合结果。 results = await session.call_tool(function_name, arguments=arguments) response = "" if results and hasattr(results, "content"): for i, content in enumerate(results.content): if hasattr(content, "text") and content.text: response += content.text await result_callback(response if response else "Sorry, could not call the mcp tool") -
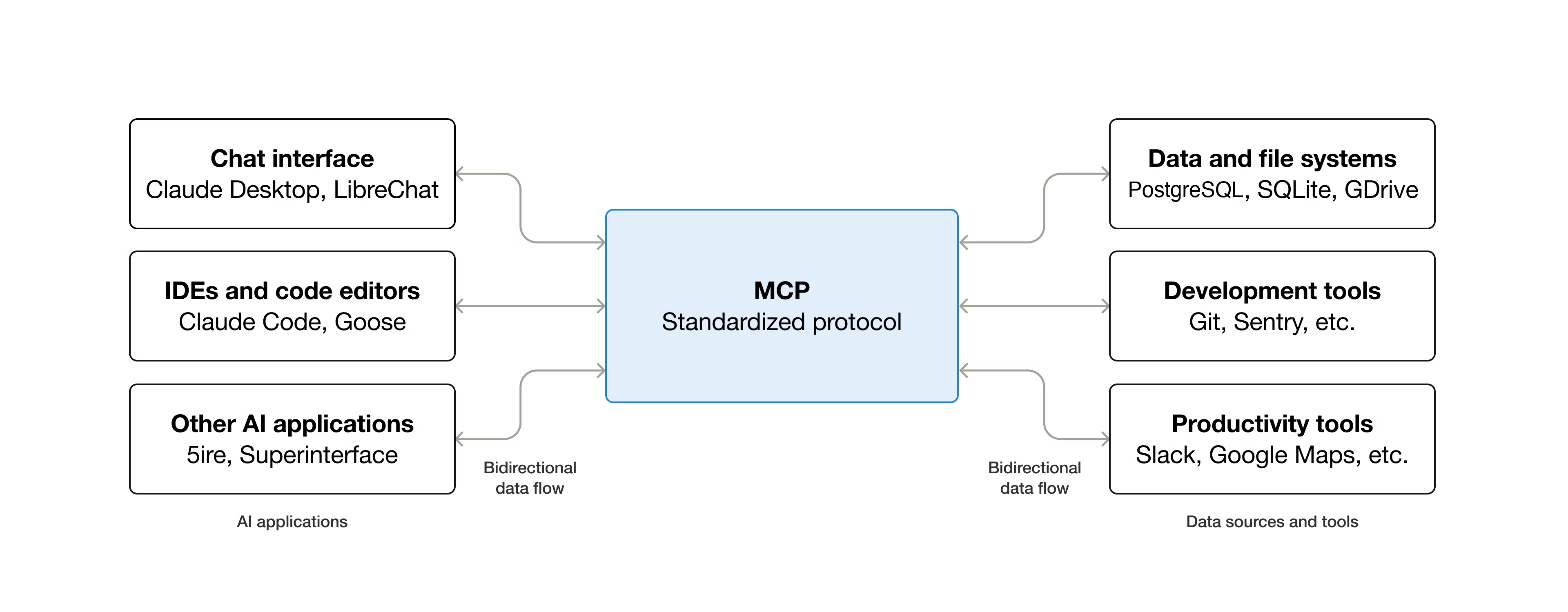
MCP 协议:AI 应用连接外部系统的标准化接口
简介 什么是MCP MCP是Model Context Protocol模型上下文的一个开源标准,用于连接人工智能应用程序到外部系统。使用MCP,让Claude、ChatGPT这样的AI application可以连接到数据源(例如本地文件、数据库)、工具(例如搜索引擎、计算器)和工作流(例如专业提示),从而能够访问关键信息并执行任务。 可以把MCP类比是AI application的USB-C接口,USB-C为电子设备提供了一种标准化的连接方式,MCP也为Ai application连接到外部系统提供了一种标准化的方式。 具体MCP能够实现什么了? Agents可以访问Google日历和Notion,充当更个性化的AI助手。 Claude code可以使用Figma设计生成整个网络应用程序。 企业聊天机器人可以连接到组织内部的多个数据库,使用户能够通过聊天分析数据。 AI模型可以在Blendoer中创建3D设计,并使用3D打印机将其打印出来。 MCP为什么重要? 根据生态系统的位置不同,MCP可以带来一些列的好处。 开发者:MCP在构建或集成AI应用程序或代理是,可以减少开发时间和复杂性。 AI应用或智能体:MCP提供对数据源、工具和应用程序系统的访问,这将增强能力并改善最终用户体验。 最终用户:MCP导致更强大的AI应用或智能体,它们可以访问您的数据并在必要时代表您采取行动。 MCP架构 模型上下文包括以下项目: MCP 规范:概述客户端和服务器实现要求的MCP规范。 MCP SDKs:实现MCP不同的编程语言SDK。 MCP开发工具:用于开发MCP服务器和客户端的工具。 MCP参考服务器实现:MCP服务端的参考代码。 MCP的概念 Participants参与者 MCP遵循客户端-服务端架构,其中MCP Host(如Claude Code或Claude Desktop等AI应用)建立与一个或多个MCP服务器的链接。MCP Host通过为每个MCP server创建一个MCP Client来实现这一点。每个MCP Client与其对一个的MCP Server保持一对一的专用连接。 在MCP架构中,关键参与者可以分为如下: MCP Host:协调和管理一个或多个MCP Client的AI应用。 MCP Client:一个维护与MCP Server连接的组件,并从MCP 服务器获取上下文供MCP主机使用。 MCP Server:一个想MCP 客户端提供上下文的程序。 下面来举个例子,Visual studio Code作为MCP Host。当Visual Studio Code与MCP Server建立连接时,Visual Studio Code运行时会实例化一个MCP Client对象,该对象维护与Sentry MCP服务的连接。当Visual Studio Code随后连接到另一个MCP Server时,Visual Studio Code运行时会实例化另一个MCP Client对象以维护此连接,从而保持MCP客户端与MCP服务器的一对一关系。 需要注意的是,MCP server指的是提供上下文数据的程序,无论他运行在哪里。MCP服务器可以子啊本地或远程运行。例如,当Claude桌面启动文件系统服务器时,服务器在同一个机器上本地运行,因为他使用STDIO传输。这通常被成为本地MCP server,而官方Sentry MCP服务器在Sentry平台运行,并使用Streamable HTTP传输,这通常被称为远程MCP服务器。 MCP的层次 MCP有两层组成: data layer:定义JSION-RPC的客户端-服务端通信协议,包括生命周期管理,以及核心原语,如工具、资源、提示和通知。 transport layer:定义使客户端和服务器之间能够进行数据交换的通信机制和通道,包括特定于传输的连接建立、信息帧和授权。 从概念上将,数据层是内层,而传输层是外层。 Data layer 数据层实现了一个基于JSON-RPC 2.0的交互协议,该协议定义了消息结构和语义。该层包括。 Lifecycle management:处理客户端和服务器之间的连接初始化、能力协商和连接终止。 Server features:使服务器能够提供核心功能,包括用于AI操作的工具、用于上下文数据的资源以及从客户端接收和发送交互。 Client features:使服务器能够请求客户端从主机LLM采样、从用户获取输入以及向客户端记录消息。 Utility features:支持实时更新通知和长时间运行操作的进度跟踪等附加功能。 Transport layer 传输层管理客户端和服务器之间的通信通道和身份验证,它处理连接建立、消息帧处理以及MCP参与之间的安全通信。 MCP 支持两种传输机制: stdio transport:使用标准输入/输出流,在本地同一台机器上的进程之间进行直接进程通信,提供最佳性能且无网络开销。 Streamable HTTP transport: 使用HTTP POST传输客户端到服务器的消息,并可选的使用服务器发送事件(Server-Sent Events)实现流式传输功能。这种传输方式支持远程服务器通信,并支持标准HTTP认证方法,包括令牌、API密钥和自定义头信息。 传输层将通信细节抽象化,与协议层分离,使得 JSON-RPC 2.0 消息格式在所有传输机制中保持一致。 Data Layer Protocol MCP的核心部分之一是定义MCP client与MCP server之间的模式和语义。开发者可以会发现数据层特别是基本数据类型集合,这是MCP中最有趣的部分。他是定义开发者如何从MCP服务器共享上下文到MCP客户端的部分。 MCP 使用JSION-RPC 2.0作为其底层的RPC协议,客户端和服务器相互发送请求并做出相应的会议,当无需响应时,可以使用通知。 MCP定义了服务器可以公开的3个核心基本概念: Tools:AI应用程序可以调用执行操作的可执行函数(例如,文件操作、API调用、数据库查询) Rresources:为AI应用程序提供上下文信息的数据源(例如,文件内容、数据库记录、API响应) Prompts:可重复使用的模版,有助于构建与语言模型交互(例如系统提示、少量样本示例) 每种原始类型都有与之关联的发现方法(/list)、检索方法(/get),在某些情况下还有执行方法(tools/call)。在MCP客户端将使用*/list方法发现可用的原始类型。例如,客户端可以先列出所有可用的工具(tools/list),然后执行他们。 MCP还定义了客户端可以公开的原语,这些原语允许MCP服务器构建更丰富的交互。 Sampling:采样,允许server从client的ai应用程序请求语音模型补全,当server希望访问语言模型,但希望保持模型独立且不在其MCP server中包含语音模型SDK时,这很有用。他们可以使用sampling/comlete方法从客户端的AI应用程序请求语音模型补全。 Elicitation:提取,允许server从用户哪里请求额外信息,当server希望从用户获取更多信息,或请求确认某个操作时,这很有用,使用elicitation/request方法从用户哪里请求额外信息。 logging:日志记录,允许server向client发送日志信息,用于调试和监控目的。 Notifications该协议支持实时通知,以实现server与client之间的动态更新,例如,当server可用工具发生变化是,比如新功能可用或现有工具被修改,服务器可以向连接的客户端发送工具更新通知,告知这些变化,通知以JSON-RPC 2.0通知消息的形式发送,并使用MCP server能够向连接的client提供实时更新。 协议交互Example 初始化(生命周期管理) MCP通过能力协商握手开始生命周期管理,如生命周期管理部分所述,客户端发送initialize请求以建立连接并协商支持的功能。 initialize request { "jsonrpc": "2.0", "id": 1, "method": "initialize", "params": { "protocolVersion": "2025-06-18", "capabilities": { "elicitation": {} }, "clientInfo": { "name": "example-client", "version": "1.0.0" } } } initialize response { "jsonrpc": "2.0", "id": 1, "result": { "protocolVersion": "2025-06-18", "capabilities": { "tools": { "listChanged": true }, "resources": {} }, "serverInfo": { "name": "example-server", "version": "1.0.0" } } } 这段是典型的JSON-RPC协议交互过程,用于客户端和服务端建立连接时的初始化握手。客户端发送initialize方法,服务端results回复确定版本和返回支持的功能。初始化过程是MCP生命周期管理的关键部分,其服务有几个目的: 协议版本协商:protocolVersion字段确保客户端和服务端使用兼容的协议版本,可以防止不同版本尝试交互是可能发生通信错误,如果未能协商出相互兼容的版本,则应该终止连接。 能力发现:capabilities对象允许每一方声明他们支持的功能,包括他们可以处理的基元(工具、资源、提示)以及是否支持通知等特性。通过避免不支持的操作来实现高效通信。 身份交换:clientInfo和serverInfo对象提供用于调试和兼容性目的的识别和版本信息。 上面的示例中能力协商展示了如何声明MCP原语: 客户端的功能 "elicitation": {} - 客户端声明可以处理用户交互请求(可以接收 elicitation/create 方法调用) 服务端的功能: "tools": {"listChanged": true} - 服务器支持工具原语,并且在其工具列表发生变化时可以发送 tools/list_changed 通知 "resources": {} - 服务器也支持资源原语(可以处理 resources/list 和 resources/read 方法) 最后初始化成功后,客户端再发送同志表示已准备就绪 { "jsonrpc": "2.0", "method": "notifications/initialized" } 在初始化过程中,AI application的MCP client管理器连接到server后,并将它们的能力存储起来以供后续使用。应用程序使用这些信息来确定那些server可以提供特定类型的功能(tools、resource、prompts),以及它们是否支持实时更新。下面是AI application初始化伪代码。 # Pseudo Code async with stdio_client(server_config) as (read, write): async with ClientSession(read, write) as session: init_response = await session.initialize() if init_response.capabilities.tools: app.register_mcp_server(session, supports_tools=True) app.set_server_ready(session) 工具发现 连接建立成功后,client可以通过发送tools/list请求发现可用的工具。这个请求是MCP工具发现机制的基础,他允许client在尝试使用工具之前了解server有那些可用的工具。 工具列表请求: { "jsonrpc": "2.0", "id": 2, "method": "tools/list" } 工具列表请求很简单,tools/list的方法,不包含任何参数。 工具列表回复 { "jsonrpc": "2.0", "id": 2, "result": { "tools": [ { "name": "calculator_arithmetic", "title": "Calculator", "description": "Perform mathematical calculations including basic arithmetic, trigonometric functions, and algebraic operations", "inputSchema": { "type": "object", "properties": { "expression": { "type": "string", "description": "Mathematical expression to evaluate (e.g., '2 + 3 * 4', 'sin(30)', 'sqrt(16)')" } }, "required": ["expression"] } }, { "name": "weather_current", "title": "Weather Information", "description": "Get current weather information for any location worldwide", "inputSchema": { "type": "object", "properties": { "location": { "type": "string", "description": "City name, address, or coordinates (latitude,longitude)" }, "units": { "type": "string", "enum": ["metric", "imperial", "kelvin"], "description": "Temperature units to use in response", "default": "metric" } }, "required": ["location"] } } ] } } 响应包含一个tools数组,该数组提供了关于每个可用的工具全面元数据。这种基于数组的结构允许服务端同时暴露多个工具,同时保持不同功能之间的清晰界限。 响应中给每个工具对象包含几个关键字段: name: 服务器命名空间内工具的唯一标识符。这作为工具执行的主键,应遵循清晰的命名模式(例如, calculator_arithmetic 而不是仅仅 calculate )。 title : 客户端可以向用户展示的工具的可读显示名称。 description : 该工具的作用是什么以及何时使用它的详细说明。 inputSchema : 一个 JSON Schema,定义了预期的输入参数,支持类型验证并提供关于必需和可选参数的清晰文档。 inputSchema是描述tool需要的输入参数的规范,告诉LLM参数叫什么、类型是什么,有那些枚举、那些字段是必填,是否有默认值。结构如下: inputSchema └── type: object ← 输入是一个对象 └── properties ← 参数的列表(有那些参数) ├── expression ← 参数1,不要被expression迷惑只是一个参数的命名。 └── location ← 参数2 └── units ← 参数3 └── required ← 哪些字段必须提供 AI application从所有连接的MCP server获取可用的tools,并将它们组合成一个语言模型可以访问的统一工具注册表。这使得LLM能够了解他可以执行那些操作,并在对话期间自动生成相应的工具调用。下面是python tools发现的伪代码。 # Pseudo-code using MCP Python SDK patterns available_tools = [] for session in app.mcp_server_sessions(): tools_response = await session.list_tools() available_tools.extend(tools_response.tools) conversation.register_available_tools(available_tools) 工具执行 客户端现在可以使用tools/call的方法执行一个tool,这展示了MCP 原语在实际中的使用方式:在发现可用工具后,客户端可以用适当的参数调用它们。 理解工具执行的请求 tools/call请求遵循结构化格式,确保客户端和服务端之间的类型安全和清晰通信,请注意,我们使用的是发现响应中的正确工具名称,而不是简化名称。 工具调用请求: { "jsonrpc": "2.0", "id": 3, "method": "tools/call", "params": { "name": "weather_current", "arguments": { "location": "San Francisco", "units": "imperial" } } } 请求结构包含几个重要的组件: name:必须与发现响应中的工具名称( weather_current )完全匹配。这确保服务器能够正确识别要执行哪个工具。 arguments : 包含工具的 inputSchema 定义的输入参数。 JSON-RPC 结构:使用标准的 JSON-RPC 2.0 格式,并使用独特的 id 进行请求-响应关联。 工具调用响应: { "jsonrpc": "2.0", "id": 3, "result": { "content": [ { "type": "text", "text": "Current weather in San Francisco: 68°F, partly cloudy with light winds from the west at 8 mph. Humidity: 65%" } ] } } content 数组:工具响应返回一个内容对象数组,允许进行丰富、多格式的响应(文本、图像、资源等)。 Content Types:每个内容对象都有一个 type 字段。在这个例子中, "type": "text" 表示纯文本内容,但 MCP 支持多种内容类型以适应不同的使用场景。 Structured Output:结构化输出,该响应提供可操作的资讯,供 AI 应用作为语言模型交互的上下文使用。 当语言模型在对话中决定使用工具时,AI application会拦截工具调用,将其路由到适当的MCP服务器执行该调用,并将结果作为对话流程的一部分返回给LLM。这使LLM能够访问实时数据并在外部世界执行操作。下面是工具调用的是示例操作: # Pseudo-code for AI application tool execution async def handle_tool_call(conversation, tool_name, arguments): session = app.find_mcp_session_for_tool(tool_name) result = await session.call_tool(tool_name, arguments) conversation.add_tool_result(result.content) 实时更新 MCP支持实时通知,使server能够在未被明确请求的情况下通知客户端有关变更,这展示了通知系统,这是一个关键特性,它使MCP连接保持同步和响应。 当服务器的可用tool发生变化时,例如新功能可用、现有工具被修改或工具暂时不可用,服务端可以主动通知连接的客户端。 { "jsonrpc": "2.0", "method": "notifications/tools/list_changed" } notifications有关键的特性 No Response Required: 请注意通知中没有 id 字段。这遵循 JSON-RPC 2.0 通知的语义,即不期望或发送响应。 Capability-Based:此通知仅由在初始化期间(如步骤 1 所示)在其工具能力中声明了 "listChanged": true 的服务器发送。 Event-Driven:服务器根据内部状态变化决定何时发送通知,使 MCP 连接动态且响应迅速。 客户端收到notification后,客户端通常会通过请求更新的工具列表做出反应,这会形成一个刷新周期,使客户端对可用工具的理解保持最新: { "jsonrpc": "2.0", "id": 4, "method": "tools/list" } 当ai application收到关于tools变更的通知时,它会理解刷新其工具注册表并更新LLM的可用功能。这确保了正在进行的对话始终能够访问最新的一套工具,并LLM可以随着新功能的可用而动态适应。 # Pseudo-code for AI application notification handling async def handle_tools_changed_notification(session): tools_response = await session.list_tools() app.update_available_tools(session, tools_response.tools) if app.conversation.is_active(): app.conversation.notify_llm_of_new_capabilities() MCP Server MCP Server是通过标准协议接口向AI applicant提供功能的应用程序,常见例子包括文档访问的文件系统服务器、用于数据查询的数据库服务器、用于代码管理的Github服务器、用于团队沟通的slack服务器以及用于日程安排的日历服务器。 服务器通过3个构建模块提供功能: tools:LLM可以主动调用的功能,并根据用户请求决定何时使用它们。工具可以写入数据库、调用外部API、修改文件或触发其他逻辑。比如搜索航班、发送消息、创建日历事件。由模型来控制。 resources:提供只读访问权限以获取上下文信息的被动数据源,例如文件内容、数据库模式或API文档。比如检索文档、访问知识库、读取日历等。由application来控制。 prompts:预构建的指令模版,告诉模型如何使用特定的工具和资源。比如计划假期、总结我的会议、起草一封电子邮件等。由用户来控制。 下面假设一个场景来展示每个工具的作用,并介绍如何协同工作。 tools 工具使AI模型能够执行操作,每个tool定义了具有类型输入和输出的特定操作,模型根据上下文请求工具执行。 (1)tools如何工作的 具体的工作原理是LLMs可以调用的模式定义接口,MCP使用JSON Schema进行验证。每个工具执行一个具有明确定义的输入和输出的单一操作。tools在执行前可能需要用户同意,这有助于确保用户对模型采取的操作保持控制。 协议的操作: tools/list: 目的是发现可用工具,返回的是包含模式定义的工具数组。 tools/call:目的是执行特定的工具,返回的是工具执行的结果。 下面是示例工具的定义: { name: "searchFlights", description: "Search for available flights", inputSchema: { type: "object", properties: { origin: { type: "string", description: "Departure city" }, destination: { type: "string", description: "Arrival city" }, date: { type: "string", format: "date", description: "Travel date" } }, required: ["origin", "destination", "date"] } } (2)示例:旅行预定 tools使ai applicantion能够udaibiao用户执行操作,在旅行规划场景中,AI应用程序可能会使用多个工具来帮助预定假期。 航班的搜索:查询多个航班公司并返回结构化的航班选型。 searchFlights(origin: "NYC", destination: "Barcelona", date: "2024-06-15") 日历的阻止:在用户的日历中标记旅行日期。 createCalendarEvent(title: "Barcelona Trip", startDate: "2024-06-15", endDate: "2024-06-22") 邮件的通知:向同事发送自动的离境邮件。 sendEmail(to: "team@work.com", subject: "Out of Office", body: "...") (3)用户交互模型 工具由模型控制,这意味着AI模型可以自动的发型和调用它们。然而,MCP通过多种机制强调人工监督。 为了信任和安全,应用程序可以通过各种机制实现用户控制,例如: 在 UI 中显示可用工具,使用户能够定义工具是否应在特定交互中可用 单个工具执行的审批对话框 预先批准某些安全操作的权限设置 显示所有工具执行及其结果的活动日志 resources 资源为AI应用程序提供结构化访问信息,这些信息可以被应用程序检索并提供给模型作为上下文。 (1)resources如何工作的 资源从文件、API、数据库或其他AI需要理解上下文的任何来源中暴露数据。应用程序可以直接访问这些信息并决定如何使用它,无论是选择相关的部分、使用嵌入进行搜索,还是将所有信息传递给模型。 每个资源都有一个唯一的URI(例如, file:///path/to/document.md),并声明其MIME类型以进行适当的内容处理。 resources支持两种发现模式: Direct Resources: 指向特定数据的固定 URI。示例: calendar://events/2024 - 返回 2024 年的日历可用性。 Resource Templates:带参数的动态 URI,用于灵活查询。 资源模板包含标题、描述和预期 MIME 类型等元数据,使其可发现且自描述。下面是协议操作: resources/list:目的是列出可用的直接资源,返回的是资源描述符数组。 resources/templates/list:目的是发现资源的模版,返回的是资源模版定义数组。 resources/read:目的是获取资源内容,返回的是带元数据的资源数据。 resources/subscribe:目的是监控资源变化,返回的是订阅确认。 (2)示例:获取旅行规划上下文 继续以旅行规划为例,resources为AI application提供访问相关信息的方式: Calendar data:calendar://events/2024,日历数据,检查用户可用性。 Travel documents :file:///Documents/Travel/passport.pdf,访问重要文件。 Previous itineraries:trips://history/barcelona-2023,参考过去的旅行和偏好。 AI应用检索这些资源,并决定如何处理它们,无论是使用嵌入或关键词搜索选择数据子集,还是将原始数据直接传递给模型。在这种情况下,它向模型提供日历数据、天气信息和旅行偏好,使模型能够检查可用性、查询天气模式并参考过去的旅行偏好。 下面是resource模版示例: { "uriTemplate": "weather://forecast/{city}/{date}", "name": "weather-forecast", "title": "Weather Forecast", "description": "Get weather forecast for any city and date", "mimeType": "application/json" } { "uriTemplate": "travel://flights/{origin}/{destination}", "name": "flight-search", "title": "Flight Search", "description": "Search available flights between cities", "mimeType": "application/json" } 这些模版支持灵活的查询,对于天气数据,用户可以访问任何城市/日期组合的预报。对于航班,它们可以搜索任意两个机场之间的航线。当用户输入NYC作为origin机场,并开始输入Bar作为destination机场时,系统可以建议BCN或BGI。 (3)用户交互模型 resources有营养程序驱动,使其在获取、处理和呈现可用上下文方面具有灵活性,常见的交互模式包括: 用于在熟悉的类似文件夹的结构中浏览资源的树形或列表视图。 用于查找特定资源的搜索和筛选界面 基于启发式或 AI 选择的自动上下文包含或智能建议 用于包含单个或多个资源的手动或批量选择界面 Prompts 提示提供可重用的模版,它们允许MCP服务器为特定领域提供参数化提示,或展示如何最佳使用MCP服务器。 (1)Prompts如何工作的 提示是定义预期输入和交互模式的结构化模版。它们由用户控制,需要显示调用而非自动触发。提示可以感知上下文,引用可用的资源和工具来创建全面的流程。下面是协议的操作: prompts/list:目的是发现可用提示,返回的是提示描述符数组。 prompts/get:目的是检索提示详情,返回的是带参数的完整提示定义。 (2)示例 提示为场景任务提供结构化的模版。 { "name": "plan-vacation", "title": "Plan a vacation", "description": "Guide through vacation planning process", "arguments": [ { "name": "destination", "type": "string", "required": true }, { "name": "duration", "type": "number", "description": "days" }, { "name": "budget", "type": "number", "required": false }, { "name": "interests", "type": "array", "items": { "type": "string" } } ] } MCP Client MCP client由主机应用程序实例化,用于与特定的MCP server进行通信。主机应用程序,如claude.ai或集成开发环境IDE,管理整体用户体验并协调多个客户端。每个客户端负责与一个server进行直接通信。host是用户交互的应用程序,而client是使能server连接的协议级组件。 除了利用server提供上下文外,client还可以向server提供多种功能。这些client功能使server开发能够构建更丰富的交互。 sampling:采样允许server通过client请求LLM补全,从实现代理式工作流程。这种方法将用户权限和安全措施完全至于客户端的控制之下。比如一个用于预定旅行的服务器可以向LLM发送航班列表,并请求LLM为用户挑选最佳航班。 Roots:Roots允许客户端指定服务器应关注的目录,通过协调机制传达预期的范围。比如一个用于预定旅行的服务器可能会被授予特定目录的权限,从中可以读取用户的日历。 Elicitaion:交互式信息提取使服务器能够在交互过程中请求的特定信息,为服务器按需收集信息提供了一种结构化的方式。比如预定旅行的服务器可能会询问用户对飞机座位、房间类型或联系方式的偏好。 Elicitaion 交互式信息提取使server能够在交互过程中请求特定信息,创建更动态和响应迅速的工作流程。 (1)概述 Elicitaion提供了一种结构化的方式,让server按需收集必要信息。server不再需要一开始就获取所有信息或在数据缺失时失败,而是可以暂停操作,向用户请求特定的输入。者创造了更灵活的交互方式,server能够根据用户需求进行调整,而不是遵循僵化的模式。下面提取的流程: 该流程支持动态信息收集,server在需要时可以请求特定的数据,用户通过合适的界面提供信息,server则继续使用新获取的上下文进行后续处理。 (2)示例 提取组件的示例如下: { method: "elicitation/requestInput", params: { message: "Please confirm your Barcelona vacation booking details:", schema: { type: "object", properties: { confirmBooking: { type: "boolean", description: "Confirm the booking (Flights + Hotel = $3,000)" }, seatPreference: { type: "string", enum: ["window", "aisle", "no preference"], description: "Preferred seat type for flights" }, roomType: { type: "string", enum: ["sea view", "city view", "garden view"], description: "Preferred room type at hotel" }, travelInsurance: { type: "boolean", default: false, description: "Add travel insurance ($150)" } }, required: ["confirmBooking"] } } } Roots roots定义服务器操作的文件系统边界,允许客户端指定服务器应关注的目录。 roots是client向server传到文件系统访问边界的机制,它们由指示服务器可以操作的目录文件URI组成,帮助server理解可用文件和文件夹的范围。虽然roots传到了预期的边界,但他们并不强制执行安全显示。实际的安全必须在操作系统级别通过文件权限或沙盒机制来强制执行。 下面是roots结构 { "uri": "file:///Users/agent/travel-planning", "name": "Travel Planning Workspace" } roots是专有的文件系统路径,始终使用file:// 的URL方案,它们帮助server理解项目边界、工作空间组织和可访问的目录。根列表可以根据用户在不同项目或文件夹中工作动态更新,当边界发生变化时,服务器通过roots/list_changed接收通知。 sampling 采样允许server通过client请求语言模型补全,在保持安全性和用户控制的同时,实现代理行为。 采样使server能够在不直接继承或支付AI模型费用的情况下执行依赖AI的任务。相反,服务器可以请求已经具有AI模型访问权限的客户代表它们处理这些任务。这种方法将用户权限和安全措施完全置于客户控制之下。由于采样请求发生在其他操作的上下文中,并且作为单独的模型调用进行处理,它们在不同上下文之间保持清晰的界限,从而能够更有效地使用上下文窗口。 该流程通过多个人工审核环境确保安全性。用户可以在响应返回server之前,审查并修改初始请求和生成的响应。 { messages: [ { role: "user", content: "Analyze these flight options and recommend the best choice:\n" + "[47 flights with prices, times, airlines, and layovers]\n" + "User preferences: morning departure, max 1 layover" } ], modelPreferences: { hints: [{ name: "claude-sonnet-4-20250514" // Suggested model }], costPriority: 0.3, // Less concerned about API cost speedPriority: 0.2, // Can wait for thorough analysis intelligencePriority: 0.9 // Need complex trade-off evaluation }, systemPrompt: "You are a travel expert helping users find the best flights based on their preferences", maxTokens: 1500 } 本文主要来自官方文档的翻译:https://modelcontextprotocol.io/docs/getting-started/intro -
lekiwi录制训练推理流程实践
录制 设备端 先确定一下相机编号 cd ~/lerobot/ lerobot-find-cameras 生成路径:outputs/captured_images 然后修改uart的权限 sudo chmod 666 /dev/ttyACM0 启动等待连接 python -m lerobot.robots.lekiwi.lekiwi_host \ --robot.id=R1225280 \ --robot.cameras='{ "front": {"type":"opencv","index_or_path":"/dev/video2","width":640,"height":480,"fps":30}, "wrist": {"type":"opencv","index_or_path":"/dev/video0","width":480,"height":640,"fps":30,"rotation":"ROTATE_90"} }' \ --host.connection_time_s=300 如果分辨率跑不上去,就让相机用motion-JPEG传输帧,很多UVC相机默认YUYV在640x480只能到25fps。 python -m lerobot.robots.lekiwi.lekiwi_host \ --robot.id=R1225280 \ --robot.cameras='{ "front": {"type":"opencv","index_or_path":"/dev/video2","width":640,"height":480,"fps":30,"fourcc":"MJPG"}, "wrist": {"type":"opencv","index_or_path":"/dev/video0","width":480,"height":640,"fps":30,"rotation":"ROTATE_90","fourcc":"MJPG"} }' \ --host.connection_time_s=300 遥控端 启动前,需要配置一下,主要修改lekiwi/record.py。 主臂型号SO101:将SO100修改为SO101型号。 网络配置remote_ip:配置连接设备的ip地址,remote_ip:LeKiwi机器人主机的IP地址。id:机器人实例标识符。 机械臂配置port:配置领航臂的串口和标定参数文件,port="/dev/ttyACM0", id="R07252801"。 数据集路径HF_REPO_ID:配置录制数据集上传到的Hugging Face仓库,格式为用户名/仓库名,会存储到~/.cache/xxx路径下。 任务配置:配置采集回合数NUM_EPISODES,每个回合的时间EPISODE_TIME_SEC(单位秒),重置环境时间RESET_TIME_SEC(秒),任务描述信息TASK_DESCRIPTION。录制帧率FPS。 diff --git a/examples/lekiwi/record.py b/examples/lekiwi/record.py --- a/examples/lekiwi/record.py +++ b/examples/lekiwi/record.py -from lerobot.teleoperators.so100_leader import SO100Leader, SO100LeaderConfig +from lerobot.teleoperators.so101_leader import SO101Leader, SO101LeaderConfig EPISODE_TIME_SEC = 30 RESET_TIME_SEC = 10 TASK_DESCRIPTION = "My task description" -HF_REPO_ID = "<hf_username>/<dataset_repo_id>" +HF_REPO_ID = "laumy/lekiwi" -robot_config = LeKiwiClientConfig(remote_ip="172.18.134.136", id="lekiwi") -leader_arm_config = SO100LeaderConfig(port="/dev/tty.usbmodem585A0077581", id="my_awesome_leader_arm") +robot_config = LeKiwiClientConfig(remote_ip="10.0.90.31", id="lekiwi") +leader_arm_config = SO101LeaderConfig(port="/dev/ttyACM0", id="R07252801") keyboard_config = KeyboardTeleopConfig() -leader_arm = SO100Leader(leader_arm_config) +leader_arm = SO101Leader(leader_arm_config) 配置好后启动脚本进行采集数据,采集完成后数据存储在~/.cache/huggingface/lerobot/laumy/lekiwi/ python examples/lekiwi/record.py 训练 lerobot-train \ --dataset.repo_id=laumy/lekiwi \ --policy.type=act \ --output_dir=outputs/train/act_lekiwi_test \ --job_name=act_lekiwi_test \ --policy.device=cpu \ --policy.push_to_hub=false \ --wandb.enable=false \ --batch_size=8 --steps=10000 --policy.push_to_hub=false:训练的模型是否上传hugging face。 --policy.repo_id=your_username/your_model_name:指定推送的路径名称。 --wandb.enable=false:是否启用Weights & Biases (W&B) 实验跟踪。 推理 设备端 python -m lerobot.robots.lekiwi.lekiwi_host \ --robot.id=R1225280 \ --robot.cameras='{ "front": {"type":"opencv","index_or_path":"/dev/video2","width":640,"height":480,"fps":30,"fourcc":"MJPG"}, "wrist": {"type":"opencv","index_or_path":"/dev/video0","width":480,"height":640,"fps":30,"rotation":"ROTATE_90","fourcc":"MJPG"} }' \ --host.connection_time_s=300 PC端 启动前先修改配置,这里跟record.py修改差不多。 模型路径HF_MODEL_ID:如果不是本地目录则尝试从hugging face上下载。 数据集路径HF_DATASET_ID:推理还需要数据集主要是用于输入数据的归一化和策略输出反归一化。 设备remote_ip:配置设备端的ip地址。 index 4501008d..f508d448 100644 --- a/examples/lekiwi/evaluate.py +++ b/examples/lekiwi/evaluate.py @@ -29,12 +29,12 @@ from lerobot.utils.visualization_utils import init_rerun NUM_EPISODES = 2 FPS = 30 EPISODE_TIME_SEC = 60 -TASK_DESCRIPTION = "My task description" -HF_MODEL_ID = "<hf_username>/<model_repo_id>" -HF_DATASET_ID = "<hf_username>/<eval_dataset_repo_id>" +TASK_DESCRIPTION = "Move to grab block" +HF_MODEL_ID = "output/act" +HF_DATASET_ID = "laumy/lekiwi" # Create the robot configuration & robot -robot_config = LeKiwiClientConfig(remote_ip="172.18.134.136", id="lekiwi") +robot_config = LeKiwiClientConfig(remote_ip="10.0.90.31", id="lekiwi") 改完之后启动运行 python examples/lekiwi/evaluate.py -
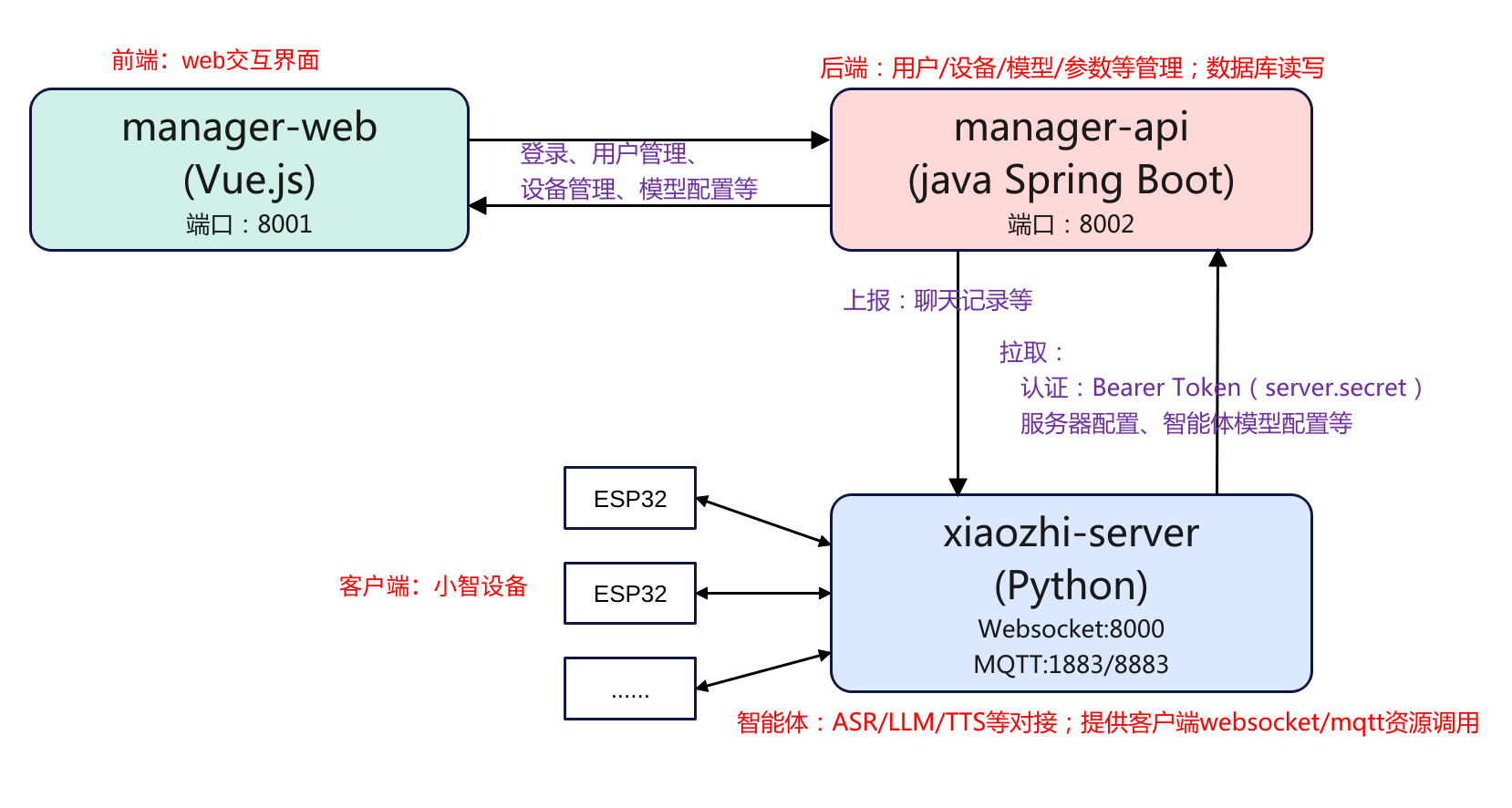
ubuntu系统xiaozhi server本地部署
简介 本文主要是记录在ubuntu系统从零源码的方式本地部署小智Ai服务端的过程,项目的地址为:xiaozhi-server。在部署之前简单了解一下其项目框架,这里总结可以分为3部分:manager-web、manager-api、xiaozhi-server,这3部分的运行是互相独立的,相互之间通过http rest api的方式进行访问,如下图: manager-web: 前端控制台(Vue)。管理员用浏览器操作;调用后端接口,不直接连设备。 manager-api: 后端管理服务(Java Spring Boot)。负责用户/设备/模型/参数/OTA/激活等业务,对外提供 REST API;对数据库(MySQL)与缓存(Redis)读写。 xiaozhi-server: 实时语音与智能体服务(Python)。负责 WebSocket 连接、ASR/LLM/TTS、工具/视觉接口;启动时向 manager-api 拉取配置、运行时上报对话。 3个组件分别使用了不用的语言环境,其中manager-web使用的是Vue.js,而manager-api使用的是java spring boot,xiaozhi-server使用的是python。因此需要装3个不同的语言环境。同时对于后端manager-api需要对数据进行存储,因此还需要安装mysql、redis。下面就围绕这3部分进行展开。 先在本地拉取一份代码: git clone https://github.com/xinnan-tech/xiaozhi-esp32-server.git 值得注意的时,xiaozhi server最简化版本安装,只需要安装xiaozhi-server即可,简化版部署见后续章节。 manager-api安装 数据库安装 由于后端的数据管理需要用到数据库,因此需要安装mysql、redis。 (1)mysql安装 # 安装MySQL sudo apt update sudo apt install -y mysql-server # 启动MySQL服务 sudo systemctl start mysql sudo systemctl enable mysql # 创建数据库 sudo mysql -e "CREATE DATABASE xiaozhi_esp32_server CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;" # 创建用户并指定认证方式(关键改动) sudo mysql -e "CREATE USER 'xiaozhi'@'localhost' IDENTIFIED WITH mysql_native_password BY 'xiaozhi123';" # 授权 sudo mysql -e "GRANT ALL PRIVILEGES ON xiaozhi_esp32_server.* TO 'xiaozhi'@'localhost';" sudo mysql -e "FLUSH PRIVILEGES;" mysql数据库安装后,同时也创建了用户和密码,分别是xiaozhi和xiaozhi123,这个后续需要填充到manaer-api的配置文件中,以便manager-api可以访问。 (2)安装Redis # 安装Redis sudo apt install -y redis-server # 启动Redis服务 sudo systemctl start redis-server sudo systemctl enable redis-server # 检查Redis状态 redis-cli ping Spring boot环境安装 因为后端程序manager-api使用的是java spring boot,因此需要安装java的运行环境。官方提示安装JDK21和Maven,前者是java的运行环境,后者是java项目管理工具。 # 安装JDK 21 sudo apt install -y openjdk-21-jdk # 设置JAVA_HOME环境变量 echo 'export JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64' >> ~/.bashrc echo 'export PATH=$JAVA_HOME/bin:$PATH' >> ~/.bashrc source ~/.bashrc # 验证Java安装 java -version # 安装Maven sudo apt install -y maven # 验证Maven安装 mvn -version 配置数据库 数据库和java环境安装好后,就可以配置java spring boot与数据库的连接了。 在xiaozhi-esp32-server/main/manager-api/src/main/resources/application-dev.yml中配置数据库连接信息 @@ -13,8 +13,8 @@ spring: #MySQL driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/xiaozhi_esp32_server?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true - username: root - password: 123456 + username: xiaozhi + password: xiaozhi123 initial-size: 10 max-active: 100 min-idle: 10 在xiaozhi-esp32-server/main/src/main/resources/application-dev.yml中配置Redis连接信息(redis默认配置好了,不用改) spring: data: redis: host: localhost port: 6379 password: database: 0 编译运行 配置好对数据库的连接后,就可以进行编译了。 # 进入manager-api目录 cd xiaozhi-esp32-server/main/manager-api # 编译项目 mvn clean package -DskipTests # 编译完成后的jar包位置 ls -lh target/*.jar 编译完成之后,就可以运行项目了。 java -jar target/xiaozhi-esp32-api.jar --spring.profiles.active=dev 运行如果没有什么报错就说明启动成功了。 manager-web安装 安装node.js 由于前端使用的的是vue.js,所以需要安装node.js环境。 # 安装Node.js 20 curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash - sudo apt install -y nodejs # 验证Node.js安装 node -v npm -v 安装依赖 node.js环境安装好后,就可以安装manager-web的依赖了。 # 进入manager-web目录 cd xiaozhi-esp32-server/main/manager-web # 安装依赖 npm install 启动 切换到manager-web路径下,就可以运行服务程序了。 cd xiaozhi-esp32-server/main/manager-web npm run serve 启动成功之后,就可以访问后台了。登陆地址:http://127.0.0.1:8001,登陆后进行注册一个用户就可以进入到后台进行配置了。 配置模型api key 要让设备能够访问,需要配置模型的api key,登陆到智普的后台,注册获取一个api key。 这里使用的是智谱ai,注册一个账户,然后申请一个api key 然后登陆智控台配置密钥。 xiaozhi-server安装 conda python环境 # 下载并安装miniconda wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh bash Miniconda3-latest-Linux-x86_64.sh -b -p $HOME/miniconda3 # 初始化conda $HOME/miniconda3/bin/conda init bash source ~/.bashrc # 创建Python环境 conda remove -n xiaozhi-esp32-server --all -y conda create -n xiaozhi-esp32-server python=3.10 -y # 激活环境 conda activate xiaozhi-esp32-server # 添加清华源 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge # 安装必要的系统库 conda install -y libopus ffmpeg libiconv python依赖包 # 进入xiaozhi-server目录 cd xiaozhi-esp32-server/main/xiaozhi-server # 设置pip镜像源 pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ # 安装Python依赖 pip install -r requirements.txt 下载语音模型 # 进入models目录 cd xiaozhi-esp32-server/main/xiaozhi-server/models # 下载模型文件(推荐阿里云镜像) cd SenseVoiceSmall wget https://modelscope.cn/models/iic/SenseVoiceSmall/resolve/master/model.pt # 验证文件 ls -lh model.pt 配置密钥 配置密钥主要是xiaozhi-server与manager-api交互时需要进行认证,因此需要先获取密钥。 (1)先在本地创建配置文件 # 创建data目录 cd xiaozhi-esp32-server/main/xiaozhi-server mkdir -p data # 复制配置文件 cp config_from_api.yaml data/.config.yaml # 编辑配置文件 vim data/.config.yaml 配置.config.yaml: manager-api: url: http://127.0.0.1:8002/xiaozhi secret: 待会从智控台获取 server: websocket: ws://你的IP:8000/xiaozhi/v1/ (2)然后登陆智控台获取密钥 访问智控台:http://127.0.0.1:8001 注册账号(第一个为超级管理员) 登录 → 参数管理 → 找到 server.secret 并复制 回到xiaozhi-server配置: vim xiaozhi-esp32-server/main/xiaozhi-server/data/.config.yaml 设置为 manager-api: url: http://127.0.0.1:8002/xiaozhi secret: 你刚才复制的server.secret值 启动服务 cd xiaozhi-esp32-server/main/xiaozhi-server conda activate xiaozhi-esp32-server python app.py 执行成功的话应该是下面这样 (xiaozhi-esp32-server) liumingyuan@HP-ProBook:~/xiaozhi-esp32-server/main/xiaozhi-server$ python app.py 从API读取配置 251029 20:47:34[0.8.5-00000000000000][core.providers.vad.silero]-INFO-SileroVAD 251029 20:47:34[0.8.5-00000000000000][core.utils.modules_initialize]-INFO-初始化组件: vad成功 VAD_SileroVAD 251029 20:47:38[0.8.5-00000000000000][core.providers.asr.fun_local]-INFO-funasr version: 1.2.3. 251029 20:47:38[0.8.5-00000000000000][core.utils.modules_initialize]-INFO-ASR模块初始化完成 251029 20:47:38[0.8.5-00000000000000][core.utils.modules_initialize]-INFO-初始化组件: asr成功 ASR_FunASR 251029 20:47:38[0.8.5-00000000000000][__main__]-INFO-视觉分析接口是 http://10.0.90.104:8003/mcp/vision/explain 251029 20:47:38[0.8.5-00000000000000][__main__]-INFO-Websocket地址是 ws://10.0.90.104:8000/xiaozhi/v1/ 251029 20:47:38[0.8.5-00000000000000][__main__]-INFO-=======上面的地址是websocket协议地址,请勿用浏览器访问======= 251029 20:47:38[0.8.5-00000000000000][__main__]-INFO-如想测试websocket请用谷歌浏览器打开test目录下的test_page.html 251029 20:47:38[0.8.5-00000000000000][__main__]-INFO-============================================================= 服务访问地址: 智控台:http://127.0.0.1:8001 API文档:http://127.0.0.1:8002/xiaozhi/doc.html WebSocket:ws://127.0.0.1:8000/xiaozhi/v1/ OTA接口:http://127.0.0.1:8002/xiaozhi/ota/ 配置websocket和OTA 由于是全模块部署,所以需要登陆智能控台,设置ota和websocket的接口,需要注意的是weboscket的启动必须是要等xiaozhi-server app启动才能设置。 OTA接口:http://你电脑局域网的ip:8002/xiaozhi/ota/ Websocket接口:ws://你电脑局域网的ip:8000/xiaozhi/v1/ 请你务必把以上两个接口地址写入到智控台中:他们将会影响websocket地址发放和自动升级功能。 1、使用超级管理员账号,登录智控台,在顶部菜单找到参数管理,找到参数编码是server.websocket,输入你的Websocket接口。 2、使用超级管理员账号,登录智控台,在顶部菜单找到参数管理,找到数编码是server.ota,输入你的OTA接口。 简化部署 所谓简化部署就是只跑xiaozhi-server,前后端都不跑。简化部署先参考"xiaozhi-server安装"章节,然后再次基础上进行配置文件即可。与完整部署xiaozhi-server部分唯一的区别就是配置文件不一样。如果要对接前后端使用的默认文件是config_from_api.yaml而如果是简化部署使用的默认文件是config.yaml。 下面是配置步骤。 cd xiaozhi-esp32-server/main/xiaozhi-server/data cp .config.yaml .config.yaml_back #对云端的配置作个备份 cp ../config.yaml .config.yaml #拷贝默认的配置 设置API key 测试 本地服务搭建好好后可以进行测试验证,可以使用xiaozhi-server自带的test程序,也可以使用开源的客户端py-xiaozhi,或者直接搭建esp32的设备接入。这里先用前面两者方式。 xiaozhi-server test cd xiaozhi-esp32-server/main/xiaozhi-server/test python -m http.server 8006 然后网页登陆:http://localhost:8006/test_page.html py-xiaozhi git clone https://github.com/huangjunsen0406/py-xiaozhi.git sudo apt-get update && sudo apt-get install -y portaudio19-dev libportaudio2 conda create -n py-xiaozhi-client python=3.10 conda activate py-xiaozhi-client 配置完成之后就可以执行应用获取到设备验证码之后,登陆绑定即可进行对话。 python main.py --protocol websocket -

Lekiwi驱动链路分析
系统架构 硬件组成 Lekiwi是一个底盘+机械臂的结构。 机械臂: 6个自由度(shoulder_pan, shoulder_lift, elbow_flex, wrist_flex, wrist_roll, gripper) 移动底盘:3个全向轮,三轮全向移动(left_wheel, back_wheel, right_wheel) github官网Lekiwi使用 Koch v1.1 机械臂、U2D2 电机控制器和 Dynamixel XL430 电机作为移动基座。我这里买到的使用的是feetech电机,机械臂和底盘一共9个motor接入到一个串口总线上,对于机械臂和底盘移动只需要通过一个串口总线进行。 软件架构 我这里将软件架构分为3层。 应用层:对设备的操作,实例化设备一个设备后,对设备进行连接,移动控制,观测数据获取。 总线层:实现一个MotorBus基类,对设备的一些操作进行统一定义、约束。实现操作的逻辑,具体的实现由继承设备来实现。 设备层:具体设备的实现,继承与MotorBus,实现对电机底层通信接口。 感觉这个框架不是很合理,主要的框架设计是设备层继承总线层的基类,继承相当于是扩展,应用层没有起到屏蔽设备的作用。在应用层要创建一个设备实例如self.bus = FeetechMotorsBus(),而FeetechMotorsBus继承MotorsBus,应用层直接操作FeetechMotorsBus实例,没有达到屏蔽底层的效果。可以完全借鉴Linux设备驱动模型,分为设备、总线、驱动(应用),设备注册后,总线负责匹配设备和驱动,完全隔离,不用关系底层的设备是什么。 驱动链路 初始化 class LeKiwi(Robot): config_class = LeKiwiConfig name = "lekiwi" def __init__(self, config: LeKiwiConfig): super().__init__(config) self.config = config norm_mode_body = MotorNormMode.DEGREES if config.use_degrees else MotorNormMode.RANGE_M100_100 self.bus = FeetechMotorsBus( port=self.config.port, motors={ # arm "arm_shoulder_pan": Motor(1, "sts3215", norm_mode_body), "arm_shoulder_lift": Motor(2, "sts3215", norm_mode_body), "arm_elbow_flex": Motor(3, "sts3215", norm_mode_body), "arm_wrist_flex": Motor(4, "sts3215", norm_mode_body), "arm_wrist_roll": Motor(5, "sts3215", norm_mode_body), "arm_gripper": Motor(6, "sts3215", MotorNormMode.RANGE_0_100), # base "base_left_wheel": Motor(7, "sts3215", MotorNormMode.RANGE_M100_100), "base_back_wheel": Motor(8, "sts3215", MotorNormMode.RANGE_M100_100), "base_right_wheel": Motor(9, "sts3215", MotorNormMode.RANGE_M100_100), }, calibration=self.calibration, ) self.arm_motors = [motor for motor in self.bus.motors if motor.startswith("arm")] self.base_motors = [motor for motor in self.bus.motors if motor.startswith("base")] self.cameras = make_cameras_from_configs(config.cameras) 继承Robot,指定了配置类为LeKiwiConfig其定义了uart的端口、相机的编号等信息。将角度统一归一化到[-100,100],创建Feetech电机总线实例,创建Feetech电机型号sts3215,配置了机械臂电机ID为1至6,底盘编号为7至9编号。同时对相机也进行了初始化,用于后续的视觉观测。 连接 robot.connect()————> def connect(self, calibrate: bool = True) -> None: if self.is_connected: raise DeviceAlreadyConnectedError(f"{self} already connected") self.bus.connect() if not self.is_calibrated and calibrate: logger.info( "Mismatch between calibration values in the motor and the calibration file or no calibration file found" ) self.calibrate() for cam in self.cameras.values(): cam.connect() self.configure() logger.info(f"{self} connected.") 初始化完成之后即可进行发起连接,连接主要是根据指定的串口好进行打开,然后进行握手验证,ping所有配置的电机,检查校准文件与电机的状态,并设置PID、加速度等参数。 校准 def calibrate(self) -> None: if self.calibration: # Calibration file exists, ask user whether to use it or run new calibration user_input = input( f"Press ENTER to use provided calibration file associated with the id {self.id}, or type 'c' and press ENTER to run calibration: " ) if user_input.strip().lower() != "c": logger.info(f"Writing calibration file associated with the id {self.id} to the motors") self.bus.write_calibration(self.calibration) return logger.info(f"\nRunning calibration of {self}") motors = self.arm_motors + self.base_motors self.bus.disable_torque(self.arm_motors) for name in self.arm_motors: self.bus.write("Operating_Mode", name, OperatingMode.POSITION.value) input("Move robot to the middle of its range of motion and press ENTER....") homing_offsets = self.bus.set_half_turn_homings(self.arm_motors) homing_offsets.update(dict.fromkeys(self.base_motors, 0)) full_turn_motor = [ motor for motor in motors if any(keyword in motor for keyword in ["wheel", "wrist_roll"]) ] unknown_range_motors = [motor for motor in motors if motor not in full_turn_motor] print( f"Move all arm joints except '{full_turn_motor}' sequentially through their " "entire ranges of motion.\nRecording positions. Press ENTER to stop..." ) range_mins, range_maxes = self.bus.record_ranges_of_motion(unknown_range_motors) for name in full_turn_motor: range_mins[name] = 0 range_maxes[name] = 4095 self.calibration = {} for name, motor in self.bus.motors.items(): self.calibration[name] = MotorCalibration( id=motor.id, drive_mode=0, homing_offset=homing_offsets[name], range_min=range_mins[name], range_max=range_maxes[name], ) self.bus.write_calibration(self.calibration) self._save_calibration() print("Calibration saved to", self.calibration_fpath) 首次校准,从归零到测量范围,生成并保存文件流程,后续使用按回车复用已有校准;输入 'c' 重新校准。可以总结为如下: LeKiwi.calibrate() → 用户选择(使用已有/重新校准) → 归零设置 → 运动范围测量 → 校准参数构建 → FeetechMotorsBus.write_calibration() → MotorsBus.write_calibration() → 逐个写入电机寄存器 校准主要是限定几个参数,如归零偏移、运动范围、驱动模式。校准的流程是由用户选择使用已经有的校准文件直接写入校准还是进行重新启动校准流程校准。 动作执行 def send_action(self, action: dict[str, Any]) -> dict[str, Any]: if not self.is_connected: raise DeviceNotConnectedError(f"{self} is not connected.") arm_goal_pos = {k: v for k, v in action.items() if k.endswith(".pos")} base_goal_vel = {k: v for k, v in action.items() if k.endswith(".vel")} base_wheel_goal_vel = self._body_to_wheel_raw( base_goal_vel["x.vel"], base_goal_vel["y.vel"], base_goal_vel["theta.vel"] ) # Cap goal position when too far away from present position. # /!\ Slower fps expected due to reading from the follower. if self.config.max_relative_target is not None: present_pos = self.bus.sync_read("Present_Position", self.arm_motors) goal_present_pos = {key: (g_pos, present_pos[key]) for key, g_pos in arm_goal_pos.items()} arm_safe_goal_pos = ensure_safe_goal_position(goal_present_pos, self.config.max_relative_target) arm_goal_pos = arm_safe_goal_pos # Send goal position to the actuators arm_goal_pos_raw = {k.replace(".pos", ""): v for k, v in arm_goal_pos.items()} self.bus.sync_write("Goal_Position", arm_goal_pos_raw) self.bus.sync_write("Goal_Velocity", base_wheel_goal_vel) return {**arm_goal_pos, **base_goal_vel} 输入为动作的序列,输出为实际发送的动作。首先将机械臂(后缀.pos)目标位置和底盘目标速度(后缀.vel)进行分离,如下: # 分离前 action = { "arm_shoulder_pan.pos": 45.0, # 机械臂位置 "arm_elbow_flex.pos": -30.0, "x.vel": 0.1, # 底盘速度 "y.vel": 0.0, "theta.vel": 0.05 } # 分离后 arm_goal_pos = { "arm_shoulder_pan.pos": 45.0, "arm_elbow_flex.pos": -30.0 } base_goal_vel = { "x.vel": 0.1, "y.vel": 0.0, "theta.vel": 0.05 } 然后调用_body_to_wheel_raw进行底盘运动学转换,输入为底盘坐标系速度 (x, y, θ),输出为三轮电机速度指令。转换的时候需要进行安全限制,实际获取机械臂的关节位置,然后计算步幅(目标位置-当前位置),超过max_relative_target 则裁剪使用安全的目标位置。 最后就是调用sync_write分别写入控制机械臂和底盘。下面总结一下流程: LeKiwi.send_action(action) → 动作分离(机械臂位置 + 底盘速度) → 底盘运动学转换 → 安全限制检查 → FeetechMotorsBus.sync_write() → MotorsBus._sync_write() → 批量写入电机寄存器 对Lekiwi的控制,由于底盘是3个万向轮,所以需要进行运动学转换,现将机械臂和底盘进行分离,计算之处底盘坐标系转换的3轮速度,在确保安全限制的条件下,调用sync_write进行写入,sync_write是同时写入多个电机。 状态读取 def get_observation(self) -> dict[str, Any]: if not self.is_connected: raise DeviceNotConnectedError(f"{self} is not connected.") # Read actuators position for arm and vel for base start = time.perf_counter() arm_pos = self.bus.sync_read("Present_Position", self.arm_motors) base_wheel_vel = self.bus.sync_read("Present_Velocity", self.base_motors) base_vel = self._wheel_raw_to_body( base_wheel_vel["base_left_wheel"], base_wheel_vel["base_back_wheel"], base_wheel_vel["base_right_wheel"], ) arm_state = {f"{k}.pos": v for k, v in arm_pos.items()} obs_dict = {**arm_state, **base_vel} dt_ms = (time.perf_counter() - start) * 1e3 logger.debug(f"{self} read state: {dt_ms:.1f}ms") # Capture images from cameras for cam_key, cam in self.cameras.items(): start = time.perf_counter() obs_dict[cam_key] = cam.async_read() dt_ms = (time.perf_counter() - start) * 1e3 logger.debug(f"{self} read {cam_key}: {dt_ms:.1f}ms") return obs_dict 首先调用sync_read分别读取机械臂位置和底盘的当前速度,然后调用底盘速度逆运动学转换(三轮电机->底盘坐标系速度(x, y, θ)),接着将机械臂位置和底盘转换的坐标系速度整合,再次就是对相机图像的待机,先遍历所有配置相机,将图像的数据添加到观测字段,最终再进行整合得到观测字典。 obs_dict = { # 机械臂位置 "arm_shoulder_pan.pos": 45.2, "arm_shoulder_lift.pos": -12.8, # ... 其他关节 # 底盘速度 "x.vel": 0.15, "y.vel": -0.08, "theta.vel": 0.12, # 相机图像 "camera_1": numpy_array, # (H, W, 3) "camera_2": numpy_array, # (H, W, 3) } 下面是总结流程 LeKiwi.get_observation() → FeetechMotorsBus.sync_read() → MotorsBus._sync_read() → 批量读取电机状态 → 底盘速度逆运动学 → 相机图像采集 获取状态与动作执行相反,首先读取到电机的状态,然后通过逆运动学,将底盘的速度转换为坐标系。 -

lekiwi+Orin Nano环境搭建
环境准备 简要记录在Orin nano平台搭建lekiwi环境,可以远程遥控底盘移动和机械臂示教的过程,需要的硬件如下: - NVIDIA Jetson Orin Nano开发板 - Lekiwi套件(底盘、主从机械臂) - PC,预装好Ubuntu系统 组装硬件 将底盘、主从机械臂、Orin nano组装好,需要注意的是由于官方默认使用的计算平台是树莓派,所以默认提供的供电接口是USB 5V。我们这里使用的Orin Nano平台,使用的是DC5525电源接口,因此需要提前购买准备DC5521 to DC5525的转接线。 详细组装可以参考 (1)https://github.com/SIGRobotics-UIUC/LeKiwi/blob/main/Assembly.md (2)https://huggingface.co/docs/lerobot/so101#step-by-step-assembly-instructions Orin nano 首先,首次启动先接上键盘、鼠标、显示器登录配置好网络和VNC。 sudo apt update sudo apt install vino # 设置vino开机自启 mkdir -p ~/.config/autostart cp /usr/share/applications/vino-server.desktop ~/.config/autostart/. cd /usr/lib/systemd/user/graphical-session.target.wants sudo ln -s ../vino-server.service ./. # 调整共享/认证设置 gsettings set org.gnome.Vino prompt-enabled false gsettings set org.gnome.Vino require-encryption false # 设置密码,默认thepassword gsettings set org.gnome.Vino authentication-methods "['vnc']" gsettings set org.gnome.Vino vnc-password $(echo -n 'thepassword'|base64) # 然后重启就可以使用VNC viewer访问了 sudo reboot 其次,安装conda 环境,由于Jetson架构是aarch64,所以下载miniconda aarch64的版本。 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh sh Miniconda3-latest-Linux-x86_64.sh source ~/.bashrc PC ubunut 同理安装conda环境,与jetson不一样的是,PC是X86架构。 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh sh Miniconda3-latest-Linux-x86_64.sh source ~/.bashrc 软件安装 代码下载 在Orin nano和PC ubuntu上各自从github上克隆开源代码。 git clone https://github.com/huggingface/lerobot.git 配置安装 首先,在Orin nano和PC ubuntu上各自创建lekiwi的环境。 conda create -n lekiwi python=3.10 conda activate lekiwi 其次,切到lerobot环境下进行安装 cd lerobot pip install -e ".[feetech]" conda install -c conda-forge ffmpeg=7.1.1 遥操作 标定 需要给主臂、从臂进行标定,以限制关节的最大运动范围。在标定前,可以先看看视频怎么操作机械臂https://huggingface.co/docs/lerobot/so101#calibrate (1)从臂的运行命令如下 lerobot-calibrate \ --robot.type=lekiwi \ --robot.id=R1225280 \ --robot.cameras='{handeye: {type: opencv, index_or_path: 0, width: 640, height: 360, fps: 30}}' 标定的文件 (2)主臂的运行命令如下: lerobot-calibrate \ --teleop.type=so101_leader \ --teleop.port=/dev/ttyACM0 \ --teleop.id=R07252801 (3)标定好后会在下面路径存储标定的参数 # orin nano平台 ~/.cache/huggingface/lerobot/calibration/robots/lekiwi/R1225280.json # ubuntu平台 ~/.cache/huggingface/lerobot/calibration/teleoperators/so101_leader/R07252801.json 遥控 (1)由于PC和lekiwi之前的遥控使用的是gRPC,所以需要先安装zmq,否则会报错。 pip install zmq (2)orin nano启动命令,host.connection_time_s设置的是时间(单位是秒),超过这个时间会自动断开。 python -m lerobot.robots.lekiwi.lekiwi_host \ --robot.id=R1225280 \ --robot.cameras='{handeye: {type: opencv, index_or_path: 0, width: 640, height: 360, fps: 30}}' \ --host.connection_time_s=300 (3)PC ubuntu需要修改示例代码,修改点如下: diff --git a/examples/lekiwi/teleoperate.py b/examples/lekiwi/teleoperate.py index 6b430df4..cb4ad415 100644 --- a/examples/lekiwi/teleoperate.py +++ b/examples/lekiwi/teleoperate.py @@ -18,20 +18,20 @@ import time from lerobot.robots.lekiwi import LeKiwiClient, LeKiwiClientConfig from lerobot.teleoperators.keyboard.teleop_keyboard import KeyboardTeleop, KeyboardTeleopConfig -from lerobot.teleoperators.so100_leader import SO100Leader, SO100LeaderConfig +from lerobot.teleoperators.so101_leader import SO101Leader, SO101LeaderConfig from lerobot.utils.robot_utils import busy_wait from lerobot.utils.visualization_utils import init_rerun, log_rerun_data FPS = 30 # Create the robot and teleoperator configurations -robot_config = LeKiwiClientConfig(remote_ip="172.18.134.136", id="my_lekiwi") -teleop_arm_config = SO100LeaderConfig(port="/dev/tty.usbmodem585A0077581", id="my_awesome_leader_arm") +robot_config = LeKiwiClientConfig(remote_ip="192.168.0.33", id="my_lekiwi") +teleop_arm_config = SO101LeaderConfig(port="/dev/ttyACM0", id="R07252801") keyboard_config = KeyboardTeleopConfig(id="my_laptop_keyboard") # Initialize the robot and teleoperator robot = LeKiwiClient(robot_config) -leader_arm = SO100Leader(teleop_arm_config) +leader_arm = SO101Leader(teleop_arm_config) keyboard = KeyboardTeleop(keyboard_config) 将SO100改成SO101,因为我们的主臂使用的是SO101 将remote_ip改成jetson nano的ip 配置好SO101的uart端口和标定的文件 (4)PC ubunut执行命令 python examples/lekiwi/teleoperate.py 之后就可以使用键盘和主臂进行遥控操作了。 Key Action W 前进 S 后退 A 左移 D 右移 Z 左转(逆时针) X 右转(顺时针) R 加速一档 F 减速一档