最新文章
-

Jetson Orin Nano环境搭建
安装浏览器 sudo apt update sudo apt install chromium-browser -y 安装后发现点击浏览器会没反应。按照下面方法配置。 snap download snapd --revision=24724 sudo snap ack snapd_24724.assert sudo snap install snapd_24724.snap sudo sudo snap refresh --hold snapd 配置VNC sudo apt update sudo apt install vino 然后配置 步骤1: 设置开机自启 对于 LXDE 桌面(例如 2 GB 版本的 Jetson Nano) mkdir -p ~/.config/autostart cp /usr/share/applications/vino-server.desktop ~/.config/autostart/. 对于 GNOME 桌面: cd /usr/lib/systemd/user/graphical-session.target.wants sudo ln -s ../vino-server.service ./. 步骤2:调整共享/认证设置 gsettings set org.gnome.Vino prompt-enabled false gsettings set org.gnome.Vino require-encryption false 步骤3:然后设置密码 # Replace thepassword with your desired password gsettings set org.gnome.Vino authentication-methods "['vnc']" gsettings set org.gnome.Vino vnc-password $(echo -n 'thepassword'|base64) 上面登录密码设置的是thepassword 步骤4: Reboot the system so that the settings take effect sudo reboot SSH ssh user@ip 输入密码就可以登录进去了。 conda环境 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh sh Miniconda3-latest-Linux-x86_64.sh source ~/.bashrc 注意这里是aarch64 -

为什么AlphaGo能自学围棋?强化学习基本概念
强化学习简介 什么是强化学习 以直升机控制飞行的程序来举例。 自动驾驶的直升机配备了机载计算机、GPS、加速度计、陀螺仪和磁罗盘,我们可以实时确定的知道直升机的位置。如何使用强化学习来让直升机飞行了? 在强化学习中,将直升机的位置、方向和速度等称为状态s,因此我们的目标或任务就是从直升机的状态映射到动作a的函数,意思是将两根控制杆推多远才能保持直升机在空中平衡、飞行而不坠毁。 要获取到动作a可以使用监督学习来训练神经网络,直接学习从x(状态a)到y(动作a)的映射,但事实证明直升机在控制移动时实际上时摸棱两可的,不好判断正确的行动是什么?是向做倾斜一点还是倾斜很多,还是稍微增加直升机的压力?要获得x的数据集和理想的动作y实际上是很困难的。因此对于控制直升机和其他机器人的许多任务,监督学习方法效果不佳,我们改用强化学习。 强化学习的关键输入称为reward(奖励),它告诉直升机何时表现良好,何时表现不佳。强化学习就像是在训练狗,你不知道狗会做出什么行为?但是我们可以判断狗行为的好坏,如果狗的行为是好的我们就就认为他是一个好狗给予奖励,如果它做出的行为不达我们的预期我们认为就是一个坏狗给予惩罚。我们期望它能自己学会如何做出好的动作行为而少做坏的动作行为。 火星探测器 火星探测器从初始状态运动到最终状态(terminal state),最终会得到一个累计的分数(return),每运动一次都会有相应的奖励reward。 当前火星探测器的初始位置在state 4,它可以向左也可以向右。 场景1:state 4(初始)(获得0)->state 3(获得0)->state 2(获得0)->state 1(获得100);最终得100。 场景2:state 4(初始)(获得0)->state 5(获得0)->state 6(获得40);最终得40。 场景3:state 4(初始)(获得0)->state 4(获得0)->state 4(获得0)->state 3(获得0)->state 2(获得0)->state 1(获得100);最终得100。 在每个时间步长上,机器人处于某种状态,我们称为S,它开始选择一个动作a,然后就获得一些奖励(reward),奖励值它从该状态获取,同时了它会切换为一个新的状态S’。公示表示为$(s,a,R(s),s')$,举个具体的例子,机器人处于状态4并采取行动时往左边走没有获得奖励(4,<-,0,3)。核心点就是状态(state)、动作(action)、奖励(reward)、下一个状态(next state),基本上就是每采取新动时都会发生情况,这就是强化学习算法要决定如何采取行动考虑的核心要素。 回报return 采取的行动会经历不同的状态以及如何享受不同的奖励,但是怎么去衡量一组特定的奖励比另外一组奖励好还是差了? 打个比方炒股方案1是你今天买入一支股票A然后后天就卖出了赚了1000块,而方案2你今天买入一支股票但是后天你亏了500,但是到第三天你赚了6000,那你更愿意追求那种方案了?虽然是第三天才显示有收益,但是第三天收益很高,显然会选择方案2。 为了计算这个回报分数,我们对动作后的奖励进行累加,但是了随着越往后的动作,我们需要添加一个折扣因子,也就是说越往前的比例系数越高,但是越往后所占的比例折扣就越大。如上图假设折扣因子(discount factor)为0.9,那么R1的折扣因子是1,R2的折扣因子就是0.9,R3的折扣因子就是0.9的平方依此类推。 最终获得的回报(return)取决于奖励(reward),而奖励取决于你采取的行动,因此回报取决于你采取的行动。 如折扣因子是0.5,如果从状态5向左走回报是6.25,如果是状态4向左走回报是12.5,而如果你状态就在6那么回报就是60。 总结一下强化学习的回报是系统获得的奖励总和,但需要加上折扣系数,每一个时间步的权重不一样,时间步越大奖励的系数结果就越小。 Policy 在强化学习中,可以通过很多不同的方式采取行动,比如我们可以决定始终选择更接近的奖励,如果最左边的奖励更接近则向左走,如果最右边的奖励更接近则向右走。当然我们也可以换种策略,始终追求更大的奖励等等。 策略Pi就是希望我们在那种状态下采取什么样的行动。state———>action。强化学习的目标就是要找到一个策略Pi,告诉在什么状态应该采取什么行动,执行每个状态以最大化回报。 小结 上面涉及到的概念,状态、动作、奖励、折扣因子、回报、策略。强化学习的目标就是让策略选择一个好的行动以获取最大的回报,这个决策过程被称为马尔可夫决策过程(MDP)。MDP指的是未来仅取决于当前的状态,而不取决于进入当前状态之前可能发生的任何事情,换句话说在马尔可夫决策过程中,未来取决于你现在所处的位置,而不取决于你是如何达到这里的;再换一种就是MDP是我们有一个机器人,我们要做的是选择动作a,根据这些动作、环境中发生的事情执行科学的任务。 State-action value funciton 状态动作函数Q 表示在状态s下,执行 动作a后,智能体所能获得的期望累计回报(Expected Return)。换句话说Q值衡量的是:"如果我在当前状态下做这个动作,长期来看能赚多少奖励?"。 计算$Q(s,a)$是强化学习算法的重要组成部分。也就是i说有办法计算s的Q,a,对于每个状态和每个动作,那么当你处于某个状态时,你所要做的就是看看不同的动作A,然后选择动作A,那就最大化s的Q,a。求Q的最大值。 贝尔曼方程 如何计算状态动作价值函数Q of S,A了? 在强化学习中有一个名为贝尔曼方程帮助我们解决计算状态动作值函数。下面来看看示例。 上图中有两个示例当在状态2,向右移动时,那么Q(2,->)=R(2)+0.5 max Q(3,a'0)=0+(0.5)25=12.5。当在状态4,向左移动时,那么Q(4,<-)=R(4)+0.5max Q(3,a')=0+(0.5)25=12.5。 贝尔曼方程体现的核心思想是:"一个状态的价值 = 即时奖励 + 后续状态的折扣价值"。也就是说,当前决策的好坏取决于当下奖励 + 未来的期望收益。 Continuous State Space continuous state space示例 对于火星车可能只有一个单一的状态1~6,对于下面的卡车来说有很多个状态,比如x,y,角度等等。而对于直升机来说又有更多参数集合的状态。 因此状态不仅仅是少数可能离散值的一个,它可以是一个数字向量。 月球着陆器 月球着陆车有很多状态变量,如上图所示。奖励函数我们可以设计成下面这样。 对于月球着陆器要学习的策略pi就是输入s,通过策略得到a,然后计算出最大的return。 学习Q 在状态s处,使用神经网络来计算4个动作中,那个动作的Q(s,nothing),Q(s,left),Q(s,main),Q(s,right)最大,然后选择那个最大值的动作。 那如何获得一个包含X和Y值的训练集,可以进行训练神经网络了?这就需要用到贝尔曼方程如上图,我们可以把贝尔曼方程的左边命名为X,右边命名为Y,神经网络的输入是一个状态和动作对。而输出Y就是就是Q。神经网络学习的就是X到Y的映射。 改进的神经网络架构 对于火星车前面的神经网络对应需要推理4次,即Q(s,nothing),Q(s,left),Q(s,main),Q(s,right),这样效率比较低,那么可以对算法进行改进推理一次直接输出4个动作的对应的Q。下面就是修改后的神经网络架构。 算法改进:ϵ贪婪策略 总结 学习流程 智能体观察当前状态 $s_t$ 根据策略 $\pi(a|s_t)$ 选择动作 $a_t$ 环境返回奖励 $r_t$ 和下一状态 $s_{t+1}$ 智能体根据反馈更新策略或价值函数 这一过程可用 马尔可夫决策过程(MDP) 表示: $$ [ \text{MDP} = (S, A, P, R, \gamma) ] $$ 其中: - 参数$S$:状态集合 - 参数$A$:动作集合 - 参数$P(s'|s,a)$:状态转移概率 - 参数$R(s,a)$:奖励函数 - 参数$\gamma$:折扣因子(0~1) 算法 (1)算法分类 类别 特征 代表算法 基于价值(Value-based) 学习 Q 值,间接得到策略 Q-learning、DQN 基于策略(Policy-based) 直接优化策略函数 REINFORCE、PPO Actor-Critic 混合 同时学习策略(Actor)和值函数(Critic) A2C、A3C、DDPG、SAC 基于模型(Model-based) 显式学习环境动态模型 Dyna-Q、Dreamer、MuZero (2)算法演进 阶段 特征 代表算法 传统表格法(Tabular RL) 离散状态空间,值表更新 Q-Learning, SARSA 深度强化学习(Deep RL) 神经网络逼近 Q 函数 DQN, Double DQN, Dueling DQN 连续动作控制(Continuous Control) 针对机械臂、无人车等连续控制问题 DDPG, TD3, SAC 策略梯度类(Policy Gradient) 直接优化策略参数 REINFORCE, PPO, TRPO 基于模型的RL(Model-based RL) 同时学习环境模型 + 策略 MuZero, DreamerV3 模仿学习 / 具身智能结合 利用演示或视觉模仿学习 GAIL, BC, VLA, RT系列 参考:本文主要来之吴恩达强化学习笔记 -
机器人全身控制浅谈:理解 WBC 的原理
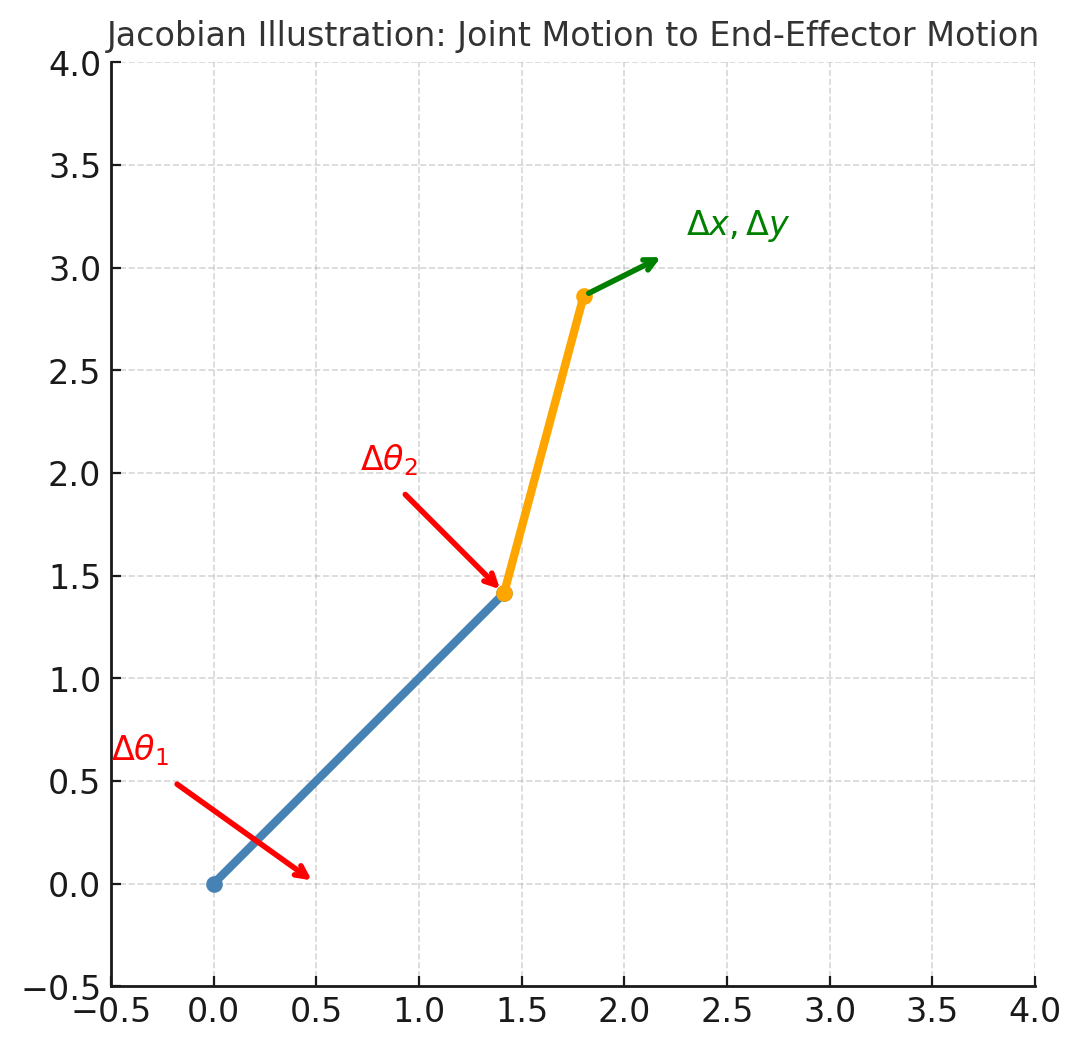
概念 WBC(Whole-Body Control,全身控制)是什么?机器人是由“各关节”组成的,其不是“各关节各玩各的”而是一个耦合的整体。在某个时刻可能要做很多事情,比如保持平衡(重心别出圈)、手/脚要动作到目标位置、躯干姿态不能乱、关节不能超限、脚下不能打滑。这些都是一系列任务的组合。 WBC的核心就是把这些任务(目标)和约束(物理/安全)写进一个小型优化问题,在每个控制周期(几百hz~1Khz)求解,得到“当下这毫秒,各关节应该怎么动/用多大力”。 一句话总结就是WBC就是用优化的方法求解出要给“关节多少力“”以便让机器的各个关节一起配合完成多个目标,且不违反物理与安全约束。 原理 动力学方程 要解释WBC的原理,那必须绕不开动力学方程,这里就先对动力学方程做个简单介绍。 $$ M(q)\dot{v} + h(q,v) = S^T \tau + J_c^T \lambda $$ 配合接触约束: $$ J_c v = 0,\quad \lambda \in \text{摩擦锥} $$ 通俗理解公式就是:“惯性 × 加速度 + 自然出现的力 = 电机能给的力 + 地面/物体的反力” 公式左边:机器人自身的自然物理 变量$M(q)\dot{v}$:惯性项。$M(q)$是质量矩阵,描述机器人在不同姿态下的惯性特性。$\dot{v} $是广义加速度(关节加速度或身体的加速度);其意义就像$F=ma$里面的$ma$,表示加速一个有惯性的物体需要的力 变量$h(q,v)$:重力+速度相关项(科氏力、离心力)。如果机器人静止,这里主要就是重力。如果在运动,这里就会出现"速度带来的额外力",类似开车转弯时身体被甩出去的感觉。 公式右边:外界能提供的“驱动力” 变量$S^T \tau$:电机能施加的关节力矩。$\tau$电机产生的力矩(控制器的输出),$S^T$选择矩阵,把电机力矩映射到广义坐标系中。 变量$J_c^T \lambda$:接触点反力。$\lambda$来自地面或物体的力(约束反作用力),$J_c$接触点的雅可比,把关节速度映射到接触点速度。$J_c^T \lambda$把“地面推脚的力”转换回“关节的力”。 直观记忆就是类比现实生活中的推车子: 你推车:电机力矩$\tau$。 地面支撑车子:接触反力$\lambda$。 车子有质量,要加速就得克服惯性:$M(q)\dot{v}$。 重力和转弯的惯性: $h(q,v)$。 接触力约束 还要满足接触力约束$J_c v = 0,\quad \lambda \in \text{摩擦锥}$,其中$J_c v = 0$意义是接触点速度为0,比如机器人脚贴在地上不滑、不穿透;$\quad \lambda \in \text{摩擦锥}$意义是接触力必须满足摩擦模型,脚不会不穷大摩擦,力要在摩擦椎范围内。 公式中涉及到一个雅可比,什么是雅可比$Jc$? 假设有一个机械臂: 关节角度:就像是控制的"按钮"。 手末端的位置:就是最终关心的"结果"。 那么问题就是关节角度动一动,末端的位置会怎么动了?这个"关节空间的微小变化"影响到“末端空间的微小变化”。这样一个映射关系,就是雅可比矩阵$J$。 图中红色箭头表示关节角度的小变化$\Delta \theta_1 , \Delta \theta_2$。红色箭头的变换导致绿色箭头末端位置的变化:$ \Delta x , \Delta y$。雅可比矩阵 $J$ 就是把 $$ \begin{bmatrix}\Delta \theta_1 \ \Delta \theta_2\end{bmatrix} \longrightarrow \begin{bmatrix}\Delta x \ \Delta y\end{bmatrix} $$ 因此如果想要末端动多少就用$J$,想算末端力传回关节多少就用$J^T$。 总结一下雅可比$J$就是关节空间和任务空间的桥梁,作用就是我们关节动多少,末端/接触点动多少。 动力学方程在WBC中的用处? 动力学方程是机器人身体运动的"牛顿定律",我们来看看WBC的目标是什么?WBC不只是让机器人"走"或"站",而是要全身协调,比如要去抓杯子,脚要保持不滑,躯干要保持平衡,关节力矩不能超过电机限制。所以WBC的本质是解一个优化问题,找出一组关节力矩$\tau$,既能完成任务目标,又满足动力学方程和约束。 优化问题 WBC的核心思路是把机器人全身的目标任务转化为优化问题,在满足物理规律和约束条件的前提下,求出最合适的一组关节力矩$\tau$。 具体一点在WBC中求解的决策变量通常是如下三个: 最优的关节力矩$\tau$。 接触点反力$\lambda$。 机器人下一步的加速度$\dot{v} $。 优化问题转换为数学的目标函数如下: $$ \min_{x} | J_{\text{task}} \dot{v} - \dot{v}_{\text{des}} |^2 + | \tau |^2 + | \lambda |^2 $$ 公式中$J_{\text{task}}\dot{v} - \dot{v}{\text{des}}$表示实际加速度与期望加速度的误差,$J{\text{task}} \dot{v}$是在当前关节加速度下,末端/任务空的实际加速度,而$\dot{v}_{\text{des}}$是我们期望任务空间实现的期望加速度(比如手往前加速 0.5 m/s²,质心保持 0 加速度)。 同时优化问题还要满足以下约束条件: 动力学约束:$M(q)\dot{v} + h(q,v) = S^T \tau + J_c^T \lambda$。这是硬约束,控制器必须遵守。 接触约束:$J_c v = 0$,接触点不能乱动(不滑、不穿透)。 摩擦约束:$\lambda \in \mathcal{K}_{\text{fric}}$,接触力必须符合摩擦模型(不能无限大)。 力矩限制:$\tau_{\min} \leq \tau \leq \tau_{\max}$。 总结一下优化问题的目标函数意思就是要满足任务误差最小化(手/身体/质心的加速度跟踪目标),同时要满足能量或力矩最小化(不能浪费力),同时满足接触力正则化(力要稳定不能乱跳)。 方程有了,怎么求解了? 这个目标函数是一个二次型,符合QP,所以可以用现成的QP求解器来解,例如:OSQP、qpOASES、Gurobi(商业求解器)、CPLEX(商业求解器)、CVXPy(Python 封装,常用于原型),这里就不过多阐述了。 总结一下WBC核心就是要解决一个优化问题:二次目标(误差最小 + 力矩正则) + 动力学/接触/摩擦/限幅约束。其求解的方式通常使用QP 求解器(实时、高效、全局最优)。求解的结果是关节力矩$\tau$(给电机执行),同时还得到加速度$\dot{v}$和接触力$\lambda$。 示例 接下来我们调用cvxpy库看看示例,直观体验一下。 import cvxpy as cp import numpy as np # ---- 机械臂参数 ---- l1, l2 = 1.0, 1.0 m1, m2 = 1.0, 1.0 theta1, theta2 = np.deg2rad(45), np.deg2rad(30) # ---- 雅可比(末端位置对关节的导数)---- J_task = np.array([ [-l1*np.sin(theta1) - l2*np.sin(theta1+theta2), -l2*np.sin(theta1+theta2)], [ l1*np.cos(theta1) + l2*np.cos(theta1+theta2), l2*np.cos(theta1+theta2)] ]) # ---- 动力学质量矩阵 M(简化版)---- M = np.array([ [m1*l1**2 + m2*(l1**2 + l2**2 + 2*l1*l2*np.cos(theta2)), m2*(l2**2 + l1*l2*np.cos(theta2))], [m2*(l2**2 + l1*l2*np.cos(theta2)), m2*l2**2] ]) h = np.zeros(2) # 忽略重力/科氏项 # ---- 接触约束:假设末端y方向不能动(竖直方向约束)---- Jc = np.array([[0, 1]]) @ J_task # 取末端y方向的行 # ---- 变量 ---- ddq = cp.Variable(2) # 关节加速度 tau = cp.Variable(2) # 力矩 lam = cp.Variable(1) # 接触力 (竖直反作用力) # ---- 期望任务加速度(末端x方向=1.0, y方向=0.0)---- xddot_des = np.array([1.0, 0.0]) # ---- 目标函数:末端任务 + 力矩/接触力正则 ---- objective = cp.Minimize( cp.sum_squares(J_task @ ddq - xddot_des) + 0.01*cp.sum_squares(tau) + 0.01*cp.sum_squares(lam) ) # ---- 约束 ---- constraints = [ M @ ddq + h == tau + Jc.T @ lam, # 动力学方程 Jc @ ddq == 0, # 接触点不加速 tau >= -10, tau <= 10, lam >= 0 # 接触力必须向上推 ] # ---- 求解 ---- prob = cp.Problem(objective, constraints) prob.solve() print("Optimal joint accelerations:", ddq.value) print("Optimal torques:", tau.value) print("Optimal contact force λ:", lam.value) print("End-effector acc achieved:", J_task @ ddq.value) print("Desired end-effector acc :", xddot_des) 上面的示例中可以分为几部分: (1)任务 末端(手)在水平 $x$ 方向产生 $1.0 \text{m/s}^2$ 的加速度。在垂直 $y$ 方向不要加速(因为手撑在桌子上,不应该离开桌面)。 数学写法: $$ \ddot{x}_{des} = [1.0,0.0]^T $$ (2)决策变量 优化器要决定的量是 $$ \ddot{q} = [\ddot{\theta}_1,\ddot{\theta}_2]^T, \quad \tau = [\tau_1,\tau_2]^T, \quad \lambda $$ (3)要优化的目标函数 最小化 $$ \min_{\ddot{q},\;\tau,\;\lambda}| J_{\text{task}} \ddot{q} - \ddot{x}_{des} |^2+ 0.01 |\tau|^2+ 0.01 |\lambda|^2 $$ (4)约束条件 动力学约束:$M(q)\ddot{q} + h(q,\dot{q}) = \tau + J_c^T \lambda$ 接触约束:$J_c \ddot{q} = 0$ 力矩范围:$-10 \leq \tau_i \leq 10$ 接触力非负:$\lambda \geq 0$ (5)输出结果 最后调用 prob = cp.Problem(objective, constraints) prob.solve() 求解得出结果: Optimal joint accelerations: [ 0.50615867 -1.88900987] Optimal torques: [-1.12977187 -0.94450493] Optimal contact force λ: [1.29515155e-23] End-effector acc achieved: [ 9.77823461e-01 -5.00938335e-17] Desired end-effector acc : [1. 0.] QP 解出来的就是 最优关节加速度:$\ddot{q}$ 最优关节力矩:$\tau$ 接触反力:$\lambda$ 实际末端加速度:$\ddot{x} = J_{\text{task}} \ddot{q}$ 并与期望值 $\ddot{x}_{des}$ 对比。 上面的代码中只截取了关键部分,下面是绘制图像的效果如下,可以直观体会看看: WBC与MPC 上一篇文章我们分析了MPC,那么MPC与WBC什么关系了? MPC在WBC之上,MPC作为决策层做"未来几步的规划",比如预测未来1S内,质心应该怎么移动,脚该放哪里,其输出的是期望的任务轨迹。WBC是在下层,拿到MPC给的任务(目标加速度/姿态/接触序列)在动力学和接触约束下,求解QP得到当下这一瞬间的关节力矩$\tau$。简而言之MPC决定“机器人未来要往哪走”,WBC决定“当前每个关节该怎么出力”。 举个例子:双足机器人走路 MPC:优化未来 1 秒的 质心轨迹、摆腿位置、支撑相切换。输出:期望的 $\ddot{x}_{des}$(质心加速度)、脚的落点计划。 WBC:把这些期望当作任务输入,解 QP ,输出关节力矩 $\tau$,同时计算接触力 $\lambda$,保证机器人在每一步不摔倒。 -
机器人控制利器:MPC入门与实践解析
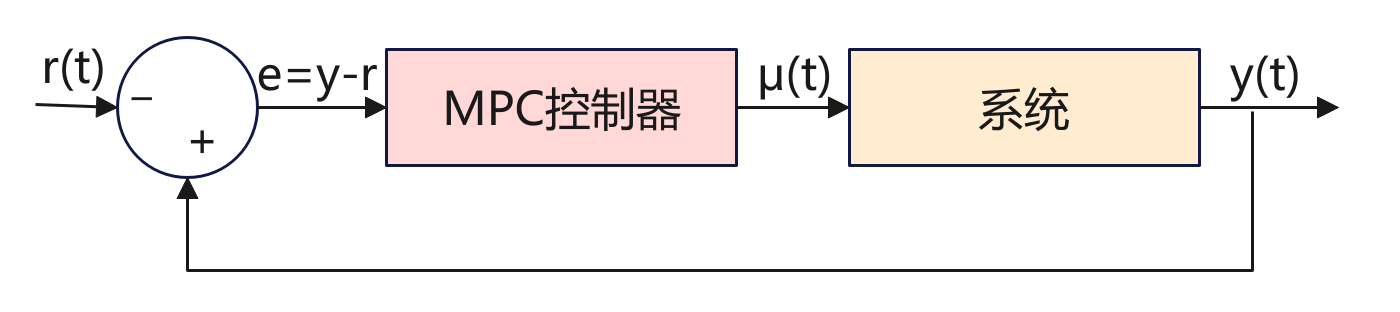
背景 MPC(Model Predictive Control)模型预测控制,是一种控制方法,广泛应用在机器人、无人驾驶、过程控制、能源系统等领域。它的核心思想用一句话来总结:利用系统模型预测未来,并通过优化选择当前最优的控制输入。 如上图是一个MPC应用框图,先来看看框图中的各个变量。 r(t):参考输入,系统希望达到的目标(设定值/reference signal),例如机器人要达到的位置、温度控制的目标值、车辆期望的速度等等。 e:误差e(t) = y(t) – r(t),用来计算实际的输出期望值的差距。 μ(t):控制输入,由MPC控制器计算出来,施加在系统上的控制量。 y(t):系统实际输出,比如位置、速度、温度等。 系统的目标是由MPC控制器计算输出一个μ(t)控制量,然后作用到系统,让系统的输出能够达到期望值。其中有一个反馈回路,形成一个闭环系统,实际的输出y(t)会反馈给比较器,与目标值对比,当未达到目标时,系统自动修正直到达到目标。 原理 系统模型 为了简单,我们先令系统的实际输出$y=x$,下面用数学建模来描述系统状态模型是 $$ x_{k+1} = A x_k + B u_k $$ 参数$x_k$:系统在时刻$k$的状态,比如汽车的位置和速度[p,v]。 参数$u_k$:系统在时刻$k$的控制输入,比如油门大小、方向盘角度、电机电压等。 A:状态的转移矩阵,决定了系统状态的演化方式。 B:输入矩阵,描述了控制输入如何影响状态的变换。 参数$x_{k+1}$:系统在下一时刻$k+1$的状态。 A和B是两个矩阵,A决定系统 在没有控制输入时,状态如何随时间演化。B决定控制输入$u_k$如何影响的状态。 上面的模型是线性模型,本文以此来进行分析。但是在实际场景中根据实际问题进行建模,模型可能是非线性的如下,这里就过多解释。 $$ x_{k+1} = f(x_k,u_k) $$ 预测未来 MPC原理就是从当前状态$x+k$出发,用模型递推,预测出未来的N步(如果看过之前关于ACT原理,其实MPC有很多类似之处): $$ x_{k+1},x_{k+2},x_{k+3},......,x_{k+N} $$ 目标函数 工程中我们最主要的目标是要求出控制量$u_t$以便让系统最终调整到我们预期的状态。 那如何来设计这个系统了? 前面我们建模了$k$时刻的状态$x_t$,那么这个状态+动作需要满足什么样的数学关系了? 与深度学习类似,我们要对状态+动作的数学关系求一个最小值的表达式。看公式: $$ J = \sum_{i=0}^{N-1} \Big[ (x_{k+i} - x_{k+i}^{\text{ref}})^T Q (x_{k+i} - x_{k+i}^{\text{ref}}) + u_{k+i}^T R u_{k+i} \Big] $$ 上面的公式可以分为两部分,前面部分代表的是k时刻输出状态与目标状态误差值,后面部分是控制的动作。也就是说我们最核心的是要误差越小越好,同时控制的动作不要太大。误差小好理解,动作变化不要太大是因为要保证控制动作要平滑。两部分都是求平方$e^2$和$u^2$放大比例(跟深度学习中的损失差不多),同时各自有一个权重Q和R,这两个参数是权重参数可调,Q用来平衡快速到目标,R用来调节平衡动作要平稳。 公式中$x$和$J$可以说是已知的,那么就可以求出$u$控制量了。 对于求解$u$,需要根据实际的模型,如果模型是线性模型+二次目标函数这样就比较简单使用二次规划QP可以快速解析或数值求解。如果是非线性模型,那么就变成非线性规划NLP,需要迭代求解器(如SQP、IPOPT)。当然如果是简单还可以使用穷举控制序列$U$,直接算$J$取最小。 约束条件 约束条件是在求解代价函数最小值过程中,显示的对控制量$u$、$x_k$做约束。这样的目的是比如对于车来说油门不能超过100%,速度不能超速,机械臂必能超过关节限位等。 因此在求救$J$时,可以添加约束条件,如下: $$ u_{\min} \leq u_k \leq u_{\max};x_{\min} \leq x_k \leq x_{\max} $$ 第一个是 控制输入约束(油门、方向盘角度不能无限大)。第二个是 状态约束(位置、速度等不能超过物理限制)。 工作流程 MPC控制系统中,其工作流程最核心的滚动时域控制,其核心点是每次预测出N步,但是并不是一下就全部执行完N步,因为预测也是有偏差同时在执行过程中会有变化。而是每次预测N步,但是只取第一步进行执行,然后根据新的输出结果重新预测下一个N步。这个其实跟ACT的时间集成有点类似,也就是在每个时间刻都会预测N步,而MPC是取第一步执行,而ACT是取k时刻和此前时刻的加权平均。 下面来看看具体的执行流程: 当前时刻$K$:系统处于某个状态如蓝线上面的红点,控制器采集到当前状态作为优化的起点。 预测未来N步:橙色窗口覆盖未来N步的时间区;红色虚线显示预测的未来轨迹,如果采用这一串控制动作$U=[u_k,u_{k+1}...]$系统怎么走。 优化并得到最优控制序列:在预测窗口里,MPC通过解$J$(误差+控制代价)最小值得到结果一整串最优控制动作序列$U$。 只执行一步:红色箭头指向当前窗口里的第一个控制输入$u_k$,下方蓝色阶梯控制曲线更新,系统真是状态推进到下一个时刻;上方状态曲线的红点更新到新的位置。 丢弃其余动作:窗口里的控制动作$(u_{k+1},u_{k+2}...)$丢弃,因为下一时刻会重新优化得到新的控制动作。 窗口前移,重复循环:橙色预测窗口右移一格$(k->k+1->k+2)$,控制器基于新状态重新预测、重新优化,再次执行第一步,丢弃其余周而复始直到达到目标。 因此整个过程核心就是MPC的滚动时域机制:预测未来——>优化整串动作——>执行第一步——>丢弃其余——>窗口前移——>重新计算。 示例程序 下面是一个简单的示例加深对MPC的认识。场景是一个一维的小车: 状态$x=[位置,速度]$,控制输入$u=加速度$。 小车从0开始,目标位置在10米,并希望最后速度接近0. 用MPC做控制,预测N步,计算代价,找到最优控制序列,但只执行第一个动作然后滚动。 求解$u$这里直接使用的是穷举法。 import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation # --- 系统模型 (离散时间) --- dt = 0.2 # 状态空间模型: x_{k+1} = A x_k + B u_k # x = [位置, 速度],u = 加速度 A = np.array([[1, dt], [0, 1]]) B = np.array([[0.5*dt**2], [dt]]) # 初始状态: 位置=0, 速度=0 x = np.array([0.0, 0.0]) # 目标状态: 位置=10, 速度=0 (停在10米处) target = np.array([10.0, 0.0]) # --- MPC 参数 --- N = 5 # 预测时域长度 (未来看5步) U_candidates = [-1, 0, 1] # 控制输入候选集合 (加速度: -1=刹车, 0=不动, 1=加速) def simulate(x0, u_seq): """ 给定初始状态 x0 和一段控制序列 u_seq, 用系统模型递推未来轨迹,并计算代价 J """ x = x0.copy() cost = 0.0 traj = [x.copy()] # 保存预测轨迹 (用于可视化) for u in u_seq: # 状态更新 (预测未来) x = A @ x + B.flatten()*u traj.append(x.copy()) # 代价函数 J = 误差项 + 控制代价 err = x - target cost += err[0]**2 + 0.3*err[1]**2 + 0.1*(u**2) # 位置误差^2 + 速度误差^2(权重0.3) + 控制输入^2(权重0.1) return cost, np.array(traj) # --- MPC 主循环 (滚动时域控制) --- history_x = [] # 真实执行的状态轨迹 history_u = [] # 实际执行的控制输入 (只取最优序列的第一步) pred_trajs = [] # 每次优化得到的预测轨迹 (整串) for step in range(60): best_cost = 1e9 best_seq = None best_traj = None # 穷举所有可能的控制序列 U = [u_k, u_{k+1}, ..., u_{k+N-1}] for U in np.array(np.meshgrid(*[U_candidates]*N)).T.reshape(-1,N): cost, traj = simulate(x, U) if cost < best_cost: best_cost = cost best_seq = U # 当前最优控制序列 best_traj = traj # 当前最优预测轨迹 # 保存数据 (真实轨迹、控制输入、预测轨迹) history_x.append(x.copy()) history_u.append(best_seq[0]) # 只执行第一步 u_k* pred_trajs.append(best_traj) # 保存整条预测轨迹用于画红虚线 # 执行第一步 (滚动时域控制的核心:只执行u_k) u = best_seq[0] x = A @ x + B.flatten()*u # 收敛条件 (位置接近10, 速度≈0) if abs(x[0]-target[0]) < 0.1 and abs(x[1]-target[1]) < 0.1: history_x.append(x.copy()) history_u.append(0) # 终端时控制输入设为0 break history_x = np.array(history_x) # --- 动态可视化 --- fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(8, 6)) # 上图:位置随时间 ax1.axhline(target[0], color="green", linestyle="--", label="Target position") (line_real,) = ax1.plot([], [], "bo-", label="Real trajectory") # 蓝点=真实轨迹 (line_pred,) = ax1.plot([], [], "r--", label="Predicted trajectory") # 红虚线=预测轨迹 (point_exec,) = ax1.plot([], [], "ro", markersize=8, label="Execute point") # 红点=执行点 ax1.set_xlim(0, len(history_x)+N) ax1.set_ylim(0, target[0]+5) ax1.set_ylabel("Position") ax1.legend() # 下图:控制输入 (line_u,) = ax2.step([], [], where="post", label="Control input u") ax2.set_xlim(0, len(history_u)) ax2.set_ylim(min(U_candidates)-0.5, max(U_candidates)+0.5) ax2.set_xlabel("Time step") ax2.set_ylabel("u") ax2.legend() # --- 动画更新函数 --- def update(frame): # 蓝线:实际轨迹 line_real.set_data(np.arange(frame+1), history_x[:frame+1,0]) # 红虚线:预测轨迹 (窗口内) pred = pred_trajs[frame] line_pred.set_data(np.arange(frame, frame+len(pred)), pred[:,0]) # 红点:当前执行点 point_exec.set_data([frame], [history_x[frame,0]]) # 阶梯:控制输入 line_u.set_data(np.arange(frame+1), history_u[:frame+1]) return line_real, line_pred, point_exec, line_u # 动画循环:frames=len(pred_trajs),表示每个MPC优化时刻 ani = animation.FuncAnimation(fig, update, frames=len(pred_trajs), interval=800, blit=True, repeat=False) plt.show() -
语音生成模型:CosyVoice入门实践
是什么 CosyVoice是阿里开源的一款文字转语音的开源模型,可以支持音色复刻。 怎么用 环境安装 (1)代码下载 git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git cd CosyVoice git submodule update --init --recursive 因为CosyVoice仓库中还依赖了第三方的Matcha-TTS,所以克隆本地仓库后,还需要下载第三方的。 (2)创建conda环境 conda create -n cosyvoice -y python=3.10 conda activate cosyvoice pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com 创建conda环境并安装依赖。如果没有安装cuda工具的话,还需要执行下面命令安装。 sudo apt install nvidia-cuda-toolkit (3)下载预训练模型 sudo apt update && sudo apt install git-lfs -y mkdir -p pretrained_models git clone https://www.modelscope.cn/iic/CosyVoice2-0.5B.git pretrained_models/CosyVoice2-0.5B git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct git clone https://www.modelscope.cn/iic/CosyVoice-ttsfrd.git pretrained_models/CosyVoice-ttsfrd 上面的模型文件选择一个即可,需要注意的是因为模型比较大,所以要在本地安装git-lfs才能下载大文件。 测试 python3 webui.py --port 50000 --model_dir pretrained_models/CosyVoice-300M 执行上面命令后,就可以登录网页输入http://127.0.0.1:50000/进行测试了。 -
语音识别模型:SenseVoice入门实践
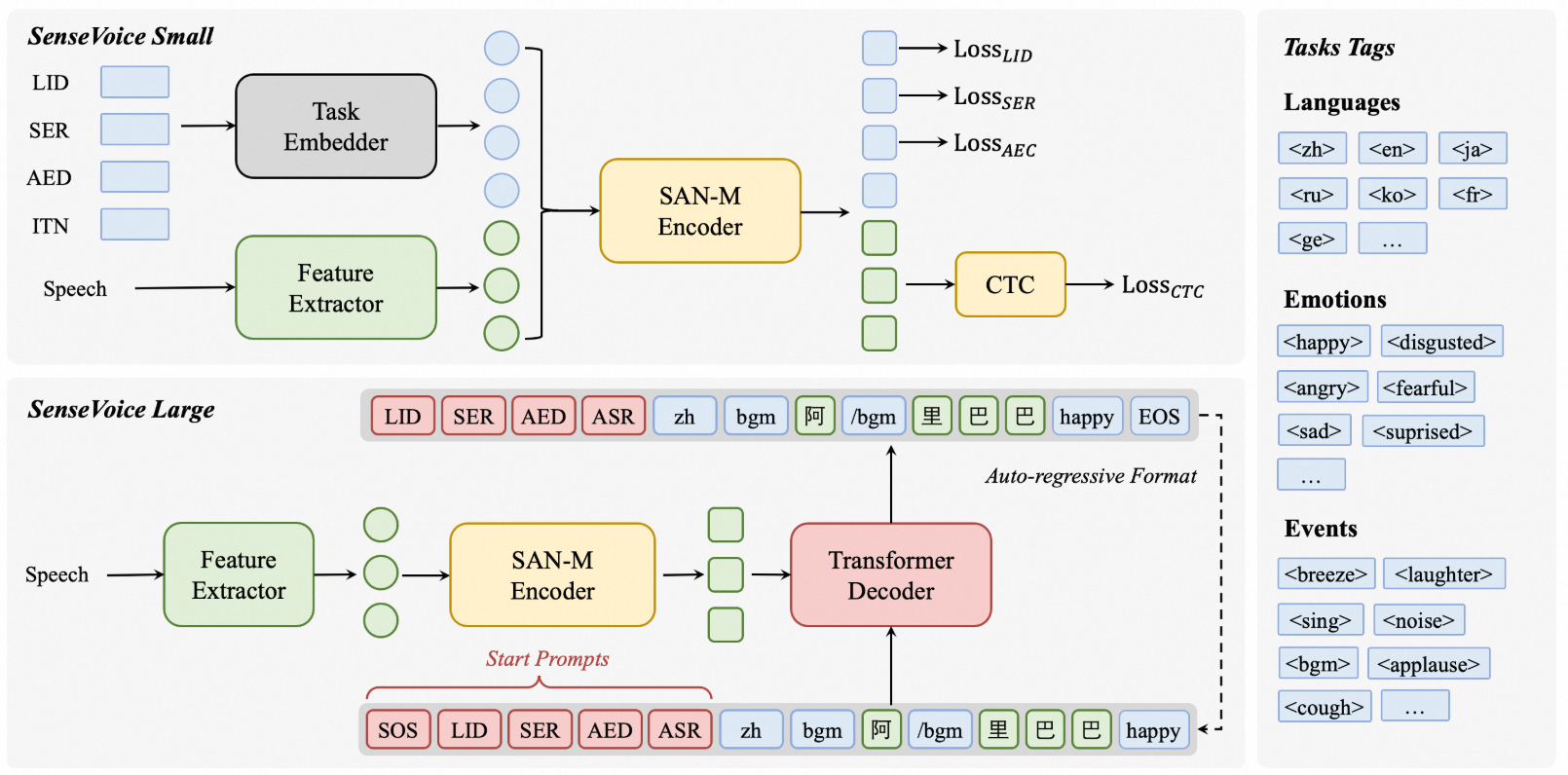
是什么 SenseVoice是多语言识别的模型,支持语音转文字(ASR, Automatic Speech Recognition,自动语音识别),语种识别(LID, Language Identification),语音情感识别(SER, Speech Emotion Recognition),音频事件检测 / 声学事件分类(AED/AEC, Audio Event Detection / Classification),逆文本正则化 / 标点 / 富文本转写等。 怎么用 配置环境 配置一个conda sensevoice环境并且激活。 conda create -n sensevoice python=3.10 conda activate sensevoice 拉取代码,安装依赖 git clone https://github.com/FunAudioLLM/SenseVoice.git cd SenseVoice/ pip install -r requirements.txt 示例测试 代码中有两个示例分别是demo1.py和demo2.py,执行后可以看看效果。 python demo1.py 执行后会自动从modelscope上下载模型和相关配置到本地。 下载到本地后有模型和相关的配置文件以及示例音频。 (sensevoice) laumy@ThinkBook-14-G7-IAH:~/.cache/modelscope/hub/models/iic$ tree . ├── SenseVoiceSmall │ ├── am.mvn │ ├── chn_jpn_yue_eng_ko_spectok.bpe.model │ ├── configuration.json │ ├── config.yaml │ ├── example │ │ ├── en.mp3 │ │ ├── ja.mp3 │ │ ├── ko.mp3 │ │ ├── yue.mp3 │ │ └── zh.mp3 │ ├── fig │ │ ├── aed_figure.png │ │ ├── asr_results.png │ │ ├── inference.png │ │ ├── sensevoice.png │ │ ├── ser_figure.png │ │ └── ser_table.png │ ├── model.pt │ ├── README.md │ └── tokens.json └── speech_fsmn_vad_zh-cn-16k-common-pytorch ├── am.mvn ├── configuration.json ├── config.yaml ├── example │ └── vad_example.wav ├── fig │ └── struct.png ├── model.pt └── README.md 7 directories, 25 files 最后的识别效果为 还可以测试webui版本 python webui.py 然后网址输入:http://127.0.0.1:7860, 注意不能开代理否则会启动失败。 接口调用 主要简要分析一下使用funASR调用示例。 (1)模型加载 model = AutoModel(model=[str], device=[str], ncpu=[int], output_dir=[str], batch_size=[int], hub=[str], **kwargs) model:模型仓库中的名称 device:推理的设备,如gpu ncpu:cpu并行线程。 output_dir:输出结果的输出路径 batch_size:解码时的批处理,样本个数 hub:从modelscope下载模型。如果为hf,从huggingface下载模型。 (2)推理 res = model.generate(input=[str], output_dir=[str]) input:要解码的输入可以是wav文件路径, 例如: asr_example.wav。 output_dir: 输出结果的输出路径。 实时识别 编写一个示例实时识别 #!/usr/bin/env python3 # -*- encoding: utf-8 -*- # Real-time microphone transcription (pure memory) using ALSA (pyalsaaudio) + numpy import argparse import os import signal import sys import time from pathlib import Path from typing import Optional import numpy as np def _safe_imports() -> None: try: import alsaaudio # noqa: F401 except Exception: print( "缺少 pyalsaaudio,请先安装:\n pip install pyalsaaudio\nUbuntu 可能需要:sudo apt-get install -y python3-alsaaudio 或 alsa-utils", file=sys.stderr, ) raise def _safe_import_model(): try: from funasr import AutoModel from funasr.utils.postprocess_utils import rich_transcription_postprocess except Exception: print( "导入 funasr 失败。如果仓库根目录存在本地 'funasr.py',请重命名(如 'funasr_demo.py')以避免遮蔽外部库。", file=sys.stderr, ) raise return AutoModel, rich_transcription_postprocess def int16_to_float32(audio_int16: np.ndarray) -> np.ndarray: if audio_int16.dtype != np.int16: audio_int16 = audio_int16.astype(np.int16, copy=False) return (audio_int16.astype(np.float32) / 32768.0).clip(-1.0, 1.0) def resample_to_16k(audio_f32: np.ndarray, orig_sr: int) -> tuple[np.ndarray, int]: if orig_sr == 16000: return audio_f32, 16000 backend = os.environ.get("SV_RESAMPLE", "poly").lower() # poly|librosa|linear # 优先使用更快的 poly(scipy),其次 librosa,最后线性插值兜底 if backend in ("poly", "auto"): try: from scipy.signal import resample_poly # type: ignore y = resample_poly(audio_f32, 16000, orig_sr) return y.astype(np.float32, copy=False), 16000 except Exception: pass if backend in ("librosa", "auto"): try: import librosa # type: ignore y = librosa.resample(audio_f32, orig_sr=orig_sr, target_sr=16000) return y.astype(np.float32, copy=False), 16000 except Exception: pass # 线性插值兜底(最慢但零依赖) x = np.arange(audio_f32.size, dtype=np.float32) new_n = int(round(audio_f32.size * 16000.0 / float(orig_sr))) if new_n <= 1: return audio_f32, orig_sr new_x = np.linspace(0.0, x[-1] if x.size > 0 else 0.0, new_n, dtype=np.float32) y = np.interp(new_x, x, audio_f32).astype(np.float32) return y, 16000 def _build_cfg_from_env() -> dict: cfg = {} # runtime knobs try: cfg["min_rms"] = float(os.environ.get("SV_MIN_RMS", "0.003")) except Exception: cfg["min_rms"] = 0.003 try: cfg["overlap_sec"] = float(os.environ.get("SV_OVERLAP_SEC", "0.3")) except Exception: cfg["overlap_sec"] = 0.3 cfg["merge_vad"] = os.environ.get("SV_MERGE_VAD", "0") == "1" try: cfg["merge_len"] = float(os.environ.get("SV_MERGE_LEN", "2.0")) except Exception: cfg["merge_len"] = 2.0 cfg["debug"] = os.environ.get("SV_DEBUG") == "1" cfg["resample_backend"] = os.environ.get("SV_RESAMPLE", "poly").lower() cfg["dump_wav_path"] = os.environ.get("SV_DUMP_WAV") return cfg def _select_strong_channel(frame_any: np.ndarray, channels: int, debug: bool) -> np.ndarray: if channels <= 1: return frame_any frame_mat = frame_any.reshape(-1, channels) ch_rms = np.sqrt(np.mean(frame_mat.astype(np.float32) ** 2, axis=0)) sel = int(np.argmax(ch_rms)) if debug: print(f"[debug] multi-channel rms={ch_rms.tolist()}, select ch={sel}", flush=True) return frame_mat[:, sel] def _ensure_pcm_open(alsa_audio, device: str | None, samplerate: int, channels: int, period_frames: int) -> tuple[object, int, str, str]: tried: list[tuple[str, str, str]] = [] for dev in [device or "default", f"plughw:{(device or 'default').split(':')[-1]}" if (device and not device.startswith('plughw')) else None]: if not dev: continue for fmt in (alsa_audio.PCM_FORMAT_S16_LE, alsa_audio.PCM_FORMAT_S32_LE): try: p = alsa_audio.PCM(type=alsa_audio.PCM_CAPTURE, mode=alsa_audio.PCM_NORMAL, device=dev) p.setchannels(channels) p.setrate(samplerate) p.setformat(fmt) p.setperiodsize(period_frames) dtype = np.int16 if fmt == alsa_audio.PCM_FORMAT_S16_LE else np.int32 sample_bytes = 2 if dtype == np.int16 else 4 fmt_name = "S16_LE" if dtype == np.int16 else "S32_LE" return p, sample_bytes, fmt_name, dev except Exception as e: # noqa: BLE001 tried.append((dev, "S16_LE" if fmt == alsa_audio.PCM_FORMAT_S16_LE else "S32_LE", str(e))) continue raise RuntimeError(f"打开 ALSA 设备失败,尝试: {tried}") def _to_int16_mono(raw_bytes: bytes, sample_bytes: int, channels: int, debug: bool) -> np.ndarray: if sample_bytes == 2: frame_any = np.frombuffer(raw_bytes, dtype=np.int16) else: frame_any = np.frombuffer(raw_bytes, dtype=np.int32) frame_any = (frame_any.astype(np.int32) >> 16).astype(np.int16) if channels > 1: frame_any = _select_strong_channel(frame_any, channels, debug) return frame_any.astype(np.int16, copy=False) def _should_infer(audio_f32: np.ndarray, min_rms: float, debug: bool, frames_count: int) -> bool: if audio_f32.size == 0: return False rms = float(np.sqrt(np.mean(np.square(audio_f32)))) if rms < min_rms: if debug: print(f"[debug] frames={frames_count}, rms={rms:.4f} < min_rms={min_rms:.4f}, skip", flush=True) return False return True def _infer_block(model, arr: np.ndarray, sr: int, cfg: dict, language: str, running_cache: dict) -> str: prefer = os.environ.get("SV_INPUT_FORMAT", "f32") # candidate arrays f32 = arr.astype(np.float32, copy=False) i16 = (np.clip(f32, -1.0, 1.0) * 32767.0).astype(np.int16) candidates: list[tuple[np.ndarray, bool]] if prefer == "i16": candidates = [(i16, False), (f32, False), (i16[None, :], True), (f32[None, :], True)] elif prefer == "f32_2d": candidates = [(f32[None, :], True), (f32, False), (i16[None, :], True), (i16, False)] elif prefer == "i16_2d": candidates = [(i16[None, :], True), (i16, False), (f32[None, :], True), (f32, False)] else: candidates = [(f32, False), (i16, False), (f32[None, :], True), (i16[None, :], True)] res = None for cand, _is2d in candidates: try: try: res = model.generate( input=cand, input_fs=sr, cache=running_cache, language=language, use_itn=True, batch_size_s=60, merge_vad=cfg["merge_vad"], merge_length_s=cfg["merge_len"], ) except TypeError: res = model.generate( input=cand, fs=sr, cache=running_cache, language=language, use_itn=True, batch_size_s=60, merge_vad=cfg["merge_vad"], merge_length_s=cfg["merge_len"], ) break except Exception: continue if not res: return "" out = res[0].get("text", "") return out def run_in_memory( model_dir: str, device: str, language: str, samplerate: int, channels: int, block_seconds: float, alsa_device: Optional[str], ) -> None: _safe_imports() AutoModel, rich_post = _safe_import_model() # 关闭底层 tqdm 进度条等多余输出 os.environ.setdefault("TQDM_DISABLE", "1") print("加载模型...", flush=True) model = AutoModel( model=model_dir, trust_remote_code=True, remote_code="./model.py", vad_model="fsmn-vad", vad_kwargs={"max_single_segment_time": 30000}, device=device, disable_update=True, ) import alsaaudio # 更小的 periodsize,降低 I/O 错误概率;推理聚合由 block_seconds 控制 period_frames = max(256, int(0.1 * samplerate)) cfg = _build_cfg_from_env() # 打开设备,尝试 S16 -> S32;必要时切换 plughw 以启用自动重采样/重格式化 pcm, sample_bytes, fmt_name, open_dev = _ensure_pcm_open(alsaaudio, alsa_device, samplerate, channels, period_frames) if cfg["debug"]: print(f"[debug] opened ALSA device {open_dev} fmt={fmt_name} period={period_frames}", flush=True) print( f"开始录音(纯内存采集),设备={alsa_device or 'default'}, sr={samplerate}, ch={channels}, period={period_frames},按 Ctrl+C 停止。\n", flush=True, ) running_cache: dict = {} printed_text = "" # 聚合到这一帧阈值后才调用一次模型,降低调用频率与输出 min_frames = max(1, int(block_seconds * samplerate)) # 重叠帧数,减少句首/句尾丢失 overlap_frames = int(max(0, cfg["overlap_sec"]) * samplerate) block_buf: list[np.ndarray] = [] buf_frames = 0 stop_flag = False def handle_sigint(signum, frame): # noqa: ANN001 nonlocal stop_flag stop_flag = True signal.signal(signal.SIGINT, handle_sigint) # 连续读取 PCM,并聚合达到阈值后执行一次增量推理 while not stop_flag: try: length, data = pcm.read() except Exception as e: # noqa: BLE001 # 读失败时尝试重建(常见于某些 DMIC Raw) if cfg["debug"]: print(f"[debug] pcm.read error: {e}, reopen stream", flush=True) # 尝试使用 plughw 以获得自动格式/采样率适配 dev = alsa_device or "default" if not dev.startswith("plughw") and dev != "default": dev = f"plughw:{dev.split(':')[-1]}" pcm, sample_bytes, fmt_name, open_dev = _ensure_pcm_open(alsaaudio, dev, samplerate, channels, period_frames) length, data = pcm.read() if length <= 0: time.sleep(0.005) continue # 根据实际格式解析 bytes pcm_int16 = _to_int16_mono(data, sample_bytes, channels, cfg["debug"]) block_buf.append(pcm_int16) buf_frames += pcm_int16.size if buf_frames < min_frames: continue # 达到阈值,拼接并转换为 float32 [-1, 1] joined = np.concatenate(block_buf, axis=0) # 为下一个块保留尾部重叠 if overlap_frames > 0 and joined.size > overlap_frames: tail = joined[-overlap_frames:] block_buf = [tail.astype(np.int16, copy=False)] buf_frames = tail.size else: block_buf.clear() buf_frames = 0 audio_block_f32 = int16_to_float32(joined) # 若采样率不是 16k,重采样到 16k audio_block_f32, eff_sr = resample_to_16k(audio_block_f32, samplerate) if not _should_infer(audio_block_f32, cfg["min_rms"], cfg["debug"], joined.size): continue if cfg["debug"]: rms = float(np.sqrt(np.mean(np.square(audio_block_f32)))) print(f"[debug] frames={joined.size}, eff_sr={eff_sr}, rms={rms:.4f}, infer", flush=True) # 可选:调试时将当前块写到一个覆盖的临时 WAV(重采样后,单声道16k),方便用 aplay 检查采音 if cfg["dump_wav_path"]: import wave, tempfile dump_path = cfg["dump_wav_path"] or str( Path(tempfile.gettempdir()) / "sv_debug_block.wav" ) with wave.open(dump_path, "wb") as wf: wf.setnchannels(1) wf.setsampwidth(2) wf.setframerate(eff_sr) dump_i16 = (np.clip(audio_block_f32, -1.0, 1.0) * 32767.0).astype(np.int16) wf.writeframes(dump_i16.tobytes()) # 执行推理 res_text = _infer_block(model, audio_block_f32, eff_sr, cfg, language, running_cache) if not res_text: continue text = rich_post(res_text) if text.startswith(printed_text): new_part = text[len(printed_text) :] else: new_part = text if new_part: print(new_part, end="", flush=True) printed_text += new_part # 停止前做一次 flush:如果还有残留缓冲,强制推理,避免句尾丢失 if block_buf: try: joined = np.concatenate(block_buf, axis=0) audio_block_f32 = int16_to_float32(joined) audio_block_f32, eff_sr = resample_to_16k(audio_block_f32, samplerate) text = _infer_block(model, audio_block_f32, eff_sr, cfg, language, running_cache) text = rich_post(text) if text: print(text[len(printed_text):], end="", flush=True) except Exception: pass print("\n已停止。") def main() -> None: parser = argparse.ArgumentParser(description="Real-time mic transcription (in-memory ALSA)") parser.add_argument("--model", default="iic/SenseVoiceSmall", help="模型仓库或本地路径") parser.add_argument("--device", default="cuda:0", help="设备,如 cuda:0 或 cpu") parser.add_argument("--language", default="auto", help="语言代码或 'auto'") parser.add_argument("--samplerate", type=int, default=16000, help="采样率") parser.add_argument("--channels", type=int, default=1, help="通道数") parser.add_argument("--block-seconds", type=float, default=1.0, help="每次推理块时长(秒)") parser.add_argument("--min-rms", type=float, default=0.003, help="触发推理的最小能量阈值(0-1)") parser.add_argument("--overlap-seconds", type=float, default=0.3, help="块间重叠时长(秒),减少句首/句尾丢失") parser.add_argument("--merge-vad", action="store_true", help="启用 VAD 合并(默认关闭以获得更快输出)") parser.add_argument("--merge-length", type=float, default=2.0, help="VAD 合并的最大分段时长(秒)") parser.add_argument("--debug", action="store_true", help="打印调试信息(RMS、帧数等)") parser.add_argument("--alsa-device", default=None, help="ALSA 设备名(如 hw:0,0 或 default)") args = parser.parse_args() # 将 CLI 设置传入环境变量,供运行体内读取 if args.debug: os.environ["SV_DEBUG"] = "1" os.environ["SV_MIN_RMS"] = str(args.min_rms) os.environ["SV_MERGE_VAD"] = "1" if args.merge_vad else "0" os.environ["SV_MERGE_LEN"] = str(args.merge_length) os.environ["SV_OVERLAP_SEC"] = str(args.overlap_seconds) run_in_memory( model_dir=args.model, device=args.device, language=args.language, samplerate=args.samplerate, channels=args.channels, block_seconds=args.block_seconds, alsa_device=args.alsa_device, ) if __name__ == "__main__": main() 执行前先安装一下模块组件 pip install pyalsaaudio 接着运行,就可以实时说话转换为文字了。 python demo_realtime_memory.py --alsa-device plughw:0,6 --samplerate 48000 --channels 2 --block-seconds 1.0 --language zh --device cuda:0 参考:https://github.com/FunAudioLLM/SenseVoice -
windows访问Linux搭建的samba服务
Linux 服务 安装 Samba 是Linux上实现SMB/CIFS 协议的服务,可以让 Windows、Linux、macOS 之间互相访问文件夹。 安装samba sudo apt update sudo apt install samba -y 配置 (1)配置文件 sudo vim /etc/samba/smb.conf [share] path = /home/bianbu browseable = yes writable = yes valid users = bianbu read only = no [share] 是共享名称,如window访问可以"\服务器IP\share",如下图。 path 访问的共享目录路径 valid users 表示允许访问的用户,这里一般要与系统的用户一致。 (2)设置用户名 设置Samba用户,注意用户名要是系统中存在的用户名。 sudo smbpasswd -a bianbu 启动 启动服务器并设置开机自启动 sudo systemctl restart smbd sudo systemctl enable smbd 检查状态 systemctl status smbd bianbu@bianbu:~$ sudo systemctl restart smbd sudo systemctl enable smbd Synchronizing state of smbd.service with SysV service script with /usr/lib/systemd/systemd-sysv-install. Executing: /usr/lib/systemd/systemd-sysv-install enable smbd bianbu@bianbu:~$ systemctl status smbd ● smbd.service - Samba SMB Daemon Loaded: loaded (/usr/lib/systemd/system/smbd.service; enabled; preset: enabled) Active: active (running) since Tue 2025-09-23 15:41:53 CST; 8s ago Docs: man:smbd(8) man:samba(7) man:smb.conf(5) Main PID: 22211 (smbd) Status: "smbd: ready to serve connections..." Tasks: 3 (limit: 4089) Memory: 7.1M (peak: 7.6M) CPU: 435ms CGroup: /system.slice/smbd.service ├─22211 /usr/sbin/smbd --foreground --no-process-group ├─22220 "smbd: notifyd" . └─22221 "smbd: cleanupd " 9月 23 15:41:53 bianbu systemd[1]: Starting smbd.service - Samba SMB Daemon... 9月 23 15:41:53 bianbu (smbd)[22211]: smbd.service: Referenced but unset environment variable evaluates to an empty string: SMBDOPTIONS 9月 23 15:41:53 bianbu systemd[1]: Started smbd.service - Samba SMB Daemon. windows连接 ip就是服务器地址,share就是smb.conf。注意如果连接不上,就把"使用其他凭据连接勾选上"。 接着输入用户命令和密码,这里的用户名和密码就是使用sudo smbpasswd -a bianbu命令配置的。 排查 (1)测试linux段samba服务是否正常 测试本地samba服务运行情况。 sudo apt update sudo apt install smbclient -y 然后运行 smbclient -L localhost -U bianbu smbclient是samba提供的客户端工具,用来测试samba服务器是否能正常工作。 ** 在window上命令测试是否联通** 在window上试试命令: net use * \\192.168.0.34\Shared /user:192.168.0.34\bianbu 密码 -
ROS2 建图与导航:Slam_toolbox、Nav2实践
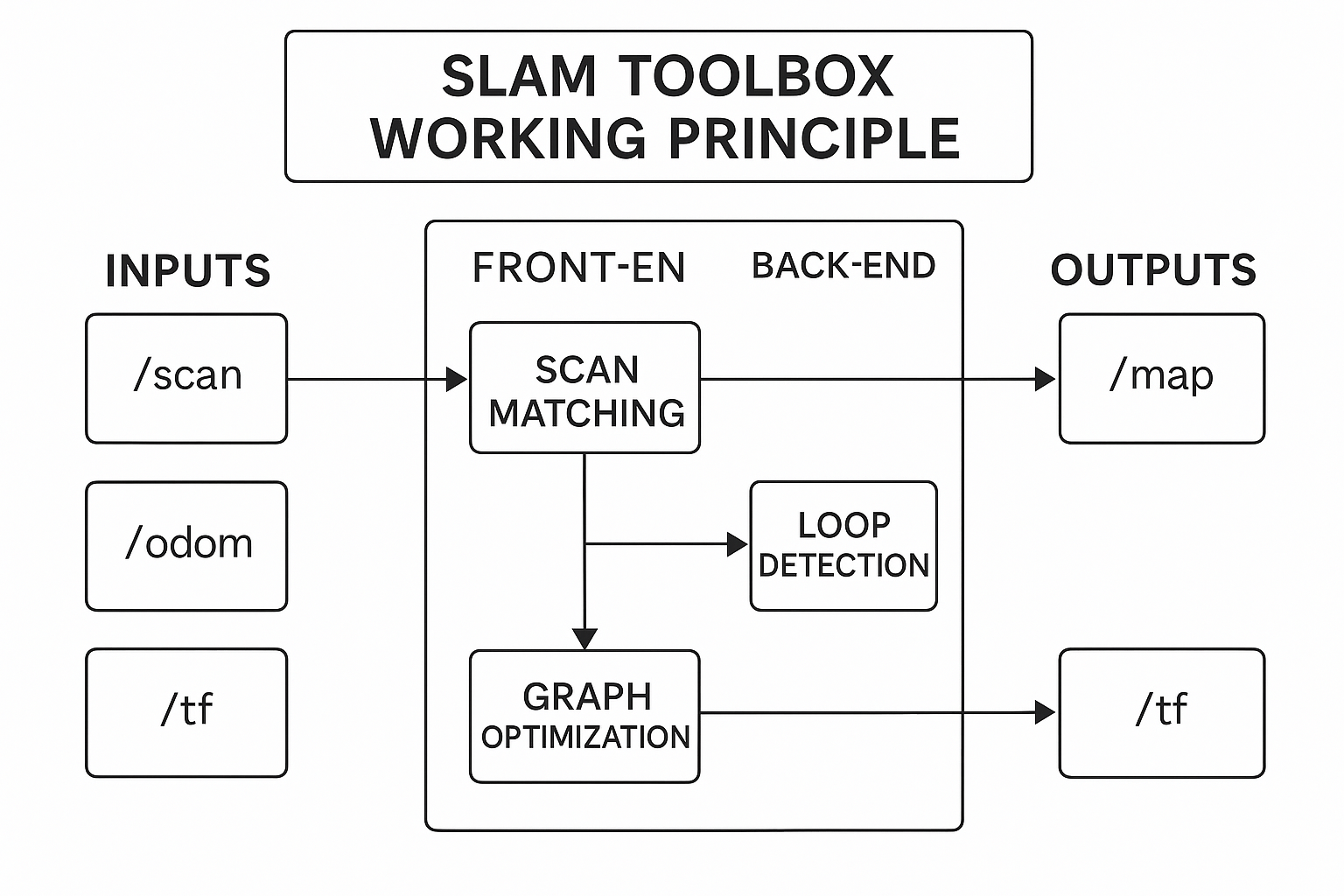
地图构建 在 ROS2 中,地图构建常用 SLAM(Simultaneous Localization and Mapping) 技术。其大概流程是: 传感器采集数据:可使用激光雷达(2D/3D LiDAR)或相机(VSLAM) 里程计信息:来自机器人轮式里程计/IMU SLAM算法处理:融合传感器数据+里程计,估计机器人位姿同时构建环境栅格地图。 地图表示:最终生成map.pgm(图像)+map.yaml(参数配置) SLAM简单理解就是让机器人在一个陌生的环境能够自主定位和地图构建,常用的ROS2建图工具有: slam_toolbox:ROS2官方推荐,支持在线建图(机器人移动时建图)、离线建图(先存bag后生成地图)、增量式建图(可保存后编辑地图)。 cartographer_ros:google出品,实时性能好,但配置较复杂。 RTAB-Map:可用于视觉/激光SLAM,支持3D。 slam_toolbox 先来简单看看slam_toolbox的流程,其输入为/scan(激光雷达点云)、/odom(里程计)、/tf(坐标变换)三个话题;经过处理后输出/map(占据栅格地图nav_msgs/OccupancyGrid格式)、/tf(发布map->odom的变换用于定位)。 (1)安装依赖包 sudo apt install ros-${ROS_DISTRO}-slam-toolbox sudo apt install ros-${ROS_DISTRO}-turtlebot3* 上面的命令第一条命令安装slam_toolbox算法库,其支持在线建图/离线建图/增量式建图,包含的内容有online_async_launch.py(在线异步建图)、online_sync_launch.py(在线同步建图)、offline_launch.py(离线建图),提供的节点有async_slam_toolbox_node、sync_slam_toolbox_node。 第二条命令是安装TurtleBot3 全套支持包,主要是提供机器人模型+仿真环境+驱动+可视化,主要包含的子包有turtlebot3_description(URDF机器人模型)、turtlebot3_gazebo(Gazebo 仿真环境)、turtlebot3_bringup(真机启动配置)、turtlebot3_teleop(键盘遥控程序)、turtlebot3_cartographer(Cartographer 建图的配置)、turtlebot3_navigation2(Nav2 配置文件) 使用turtlebot3要添加环境变量。 echo "export TURTLEBOT3_MODEL=burger" >> ~/.bashrc source ~/.bashrc (2)启动Gazebo仿真环境 ros2 launch turtlebot3_gazebo turtlebot3_house.launch.py 启动之后就看到上图的环境了。启动后创建了以下节点 laumy@ThinkBook-14-G7-IAH:~$ ros2 node list /robot_state_publisher /ros_gz_bridge /robot_state_publisher:根据 URDF 模型发布机器人各个 link 的 TF 变换。输入为/joint_states,输出为/tf, /tf_static。 /ros_gz_bridge:桥接 Gazebo (Ignition/Harmonic) 与 ROS2。将 Gazebo 插件产生的数据转成 ROS2 话题,比如 /odom、/scan、/imu。也把 ROS2 的 /cmd_vel 控制命令转发到 Gazebo 控制插件。 以下话题 laumy@ThinkBook-14-G7-IAH:~$ ros2 topic list /clock /cmd_vel /imu /joint_states /odom /parameter_events /robot_description /rosout /scan /tf /tf_static /clock:仿真时间(来自 Gazebo) /cmd_vel : 速度控制输入(你发指令控制机器人时用) /imu : IMU 传感器数据(加速度、角速度) /joint_states : 关节状态(机器人轮子转角/速度) /odom : 里程计数据(机器人相对位姿估计) /scan : 激光雷达数据(2D 激光点云) /tf, /tf_static : 坐标变换(map/odom/base_link/laser 等) /robot_description : 机器人模型(URDF 内容) /rosout, /parameter_events : 系统日志和参数事件(ROS2 通用) 总体的数据流如下图 (3)运行slam_toolbox建图 ros2 launch slam_toolbox online_async_launch.py use_sim_time:=True online_async_launch.py 表示使用异步建图(适合实时建图),use_sim_time:=True 使用 Gazebo 的仿真时间。 运行上面命令已经开始在建图了。 (4)RViz可视化 ros2 run rviz2 rviz2 在RViz中进行设置 Fixed Frame:设置为map 添加插件:Map(话题/map)、LaserScan(话题/scan) (5)控制机器人移动 ros2 run turtlebot3_teleop teleop_keyboard 用键盘方向键让机器人在环境里转一圈,地图会逐渐补全。 Control Your TurtleBot3! --------------------------- Moving around: w a s d x 这个节点会根据键盘的输入发布消息到 /cmd_vel [geometry_msgs/msg/Twist] (6)地图保存 ros2 run nav2_map_server map_saver_cli 会把内存中的/map话题保存生成map.pgm和map.yaml两个文件,以便后续的导航Nav2使用。生成在当前执行命令的目录下。 laumy@ThinkBook-14-G7-IAH:~/map$ tree . ├── map_1758272082.pgm └── map_1758272082.yaml 1 directory, 2 files Cartographer 待补充 RTAB 待补充 自主导航 目前导航使用比较多的是Nav2,框架如下。 其主要流程可以分为4大部分 感知输入:输入激光雷达/scan、里程计/odom、TF(map->odom->base_link)、地图/map。 定位:使用AMCL(Adaptive Monte Carlo Localization),在已有的地图中定位机器人位置,发布map->odom的TF。 规划:全局规划器 (planner_server)从当前位置到目标点,规划一条全局路径(比如 A*、Dijkstra、NavFn)。局部规划器 (controller_server):根据实时传感器数据,计算机器人下一步的速度指令 /cmd_vel(如 DWB controller)。 执行调度:行为树 (bt_navigator)管理整个任务流程定位 → 规划 → 控制 → 到达目标。恢复器 (recoveries_server)遇到障碍或失败时执行恢复动作(原地旋转、清理代价地图)。 安装 sudo apt update sudo apt install ros-${ROS_DISTRO}-navigation2 sudo apt install ros-${ROS_DISTRO}-nav2-bringup 启动导航 先启动仿真环境,这里使用world地图不用house了。 ros2 launch turtlebot3_gazebo turtlebot3_world.launch.py 再启动导航,需要指定地图。 ros2 launch turtlebot3_navigation2 navigation2.launch.py use_sim_time:=True map:=/home/laumy/map/map_1758275883.yaml 设定导航 (1)设定机器人位置 在 RViz 工具栏选择 2D Pose Estimate 工具。在地图上点击机器人所在位置,拖动鼠标设定朝向。RViz 会往 /initialpose 话题发布一条消息,AMCL 接收到后,就会生成 map → odom 的 TF。 (2)设定目标位置 这样机器人就会自动移动到目标点。 -

ROS2机器感知:相机、雷达、IMU
相机 相机安装 sudo apt install ros-jazzy-usb-cam 可视化 run usb_cam usb_cam_node_exe --ros-args -p video_device:=/dev/video2 ros2 run rqt_image_vew rqt_image_view 上面的-p指定具体的摄像头,可以用v4l2-ctl --list-devices列出。 参数 查看当前相机的发布话题 laumy@ThinkBook-14-G7-IAH:~/dev_ws$ ros2 topic info -v /image_raw Type: sensor_msgs/msg/Image Publisher count: 1 Node name: usb_cam Node namespace: / Topic type: sensor_msgs/msg/Image Topic type hash: RIHS01_d31d41a9a4c4bc8eae9be757b0beed306564f7526c88ea6a4588fb9582527d47 Endpoint type: PUBLISHER GID: 01.0f.e7.13.47.a9.02.80.00.00.00.00.00.00.18.03 QoS profile: Reliability: RELIABLE History (Depth): UNKNOWN Durability: VOLATILE Lifespan: Infinite Deadline: Infinite Liveliness: AUTOMATIC Liveliness lease duration: Infinite Subscription count: 1 Node name: rqt_gui_cpp_node_43605 Node namespace: / Topic type: sensor_msgs/msg/Image Topic type hash: RIHS01_d31d41a9a4c4bc8eae9be757b0beed306564f7526c88ea6a4588fb9582527d47 Endpoint type: SUBSCRIPTION GID: 01.0f.e7.13.55.aa.5f.b0.00.00.00.00.00.00.14.04 QoS profile: Reliability: BEST_EFFORT History (Depth): UNKNOWN Durability: VOLATILE Lifespan: Infinite Deadline: Infinite Liveliness: AUTOMATIC Liveliness lease duration: Infinite 查看话题下的消息类型 laumy@ThinkBook-14-G7-IAH:~/dev_ws$ ros2 interface show sensor_msgs/msg/Image # This message contains an uncompressed image # (0, 0) is at top-left corner of image std_msgs/Header header # Header timestamp should be acquisition time of image builtin_interfaces/Time stamp int32 sec uint32 nanosec string frame_id # Header frame_id should be optical frame of camera # origin of frame should be optical center of cameara # +x should point to the right in the image # +y should point down in the image # +z should point into to plane of the image # If the frame_id here and the frame_id of the CameraInfo # message associated with the image conflict # the behavior is undefined uint32 height # image height, that is, number of rows uint32 width # image width, that is, number of columns # The legal values for encoding are in file include/sensor_msgs/image_encodings.hpp # If you want to standardize a new string format, join # ros-users@lists.ros.org and send an email proposing a new encoding. string encoding # Encoding of pixels -- channel meaning, ordering, size # taken from the list of strings in include/sensor_msgs/image_encodings.hpp uint8 is_bigendian # is this data bigendian? uint32 step # Full row length in bytes uint8[] data # actual matrix data, size is (step * rows) 三维相机 略 雷达 常见的雷达类型,单线激光雷达、多线激光雷达。 消息格式 可用下面命令查看雷达的消息类型 ros2 interface show sensor_msgs/msg/LaserScan 打印如下: # Single scan from a planar laser range-finder # # If you have another ranging device with different behavior (e.g. a sonar # array), please find or create a different message, since applications # will make fairly laser-specific assumptions about this data std_msgs/Header header # timestamp in the header is the acquisition time of builtin_interfaces/Time stamp int32 sec uint32 nanosec string frame_id # the first ray in the scan. # # in frame frame_id, angles are measured around # the positive Z axis (counterclockwise, if Z is up) # with zero angle being forward along the x axis float32 angle_min # start angle of the scan [rad] float32 angle_max # end angle of the scan [rad] float32 angle_increment # angular distance between measurements [rad] float32 time_increment # time between measurements [seconds] - if your scanner # is moving, this will be used in interpolating position # of 3d points float32 scan_time # time between scans [seconds] float32 range_min # minimum range value [m] float32 range_max # maximum range value [m] float32[] ranges # range data [m] # (Note: values < range_min or > range_max should be discarded) float32[] intensities # intensity data [device-specific units]. If your # device does not provide intensities, please leave # the array empty. 开箱示例 开箱即用的示例 #安装 sudo apt install ros-jazzy-turtlebot3* -y #启动Gazebo仿真 export TURTLEBOT3_MODEL=burger ros2 launch turtlebot3_gazebo turtlebot3_world.launch.py #打开RViz2 ros2 launch turtlebot3_bringup rviz2.launch.py 如果要让车动起来的话 export TURTLEBOT3_MODEL=burger ros2 run turtlebot3_teleop teleop_keyboard 键盘的 W A S D 控制机器人移动,RViz2 里 /scan 会随着车动而更新。 IMU 在 ROS2 里,IMU 指的是 惯性测量单元(Inertial Measurement Unit),是一类传感器的统称。它在机器人系统中非常常见,比如无人车、无人机、移动机器人几乎都需要 IMU。 IMU包含加速度计、陀螺仪、磁力计(可选)。 消息格式 IMU的数据格式如下: laumy@ThinkBook-14-G7-IAH:~/dev_ws$ ros2 interface show sensor_msgs/msg/Imu # This is a message to hold data from an IMU (Inertial Measurement Unit) # # Accelerations should be in m/s^2 (not in g's), and rotational velocity should be in rad/sec # # If the covariance of the measurement is known, it should be filled in (if all you know is the # variance of each measurement, e.g. from the datasheet, just put those along the diagonal) # A covariance matrix of all zeros will be interpreted as "covariance unknown", and to use the # data a covariance will have to be assumed or gotten from some other source # # If you have no estimate for one of the data elements (e.g. your IMU doesn't produce an # orientation estimate), please set element 0 of the associated covariance matrix to -1 # If you are interpreting this message, please check for a value of -1 in the first element of each # covariance matrix, and disregard the associated estimate. std_msgs/Header header builtin_interfaces/Time stamp int32 sec uint32 nanosec string frame_id geometry_msgs/Quaternion orientation #姿态,x,y,z的角度,用 四元数 表示姿态(避免欧拉角万向节锁)。一般看这个就行了。 float64 x 0 float64 y 0 float64 z 0 float64 w 1 float64[9] orientation_covariance # Row major about x, y, z axes geometry_msgs/Vector3 angular_velocity #角速度,绕 x/y/z 轴的角速度 float64 x float64 y float64 z float64[9] angular_velocity_covariance # Row major about x, y, z axes geometry_msgs/Vector3 linear_acceleration #线性加速度,三个分量:沿 x/y/z 轴的加速度 float64 x float64 y float64 z float64[9] linear_acceleration_covariance # Row major x, y z 开箱示例 下面是一个开箱即用的示例。Gazebo 里已经有 IMU 传感器插件,可以直接加载。运行下面命令: ros2 launch ros_gz_sim_demos imu.launch.py 如果要用rviz2来显示的话,需要安装imu插件 sudo apt install ros-jazzy-rviz-imu-plugin 可以在仿真器中选择工具Translate(十字箭头图标)、Rotate(圆弧箭头图标)调整位置和角度,可以看到右边RViz中的也会跟着变化。 也可以使用下面命令来实时打印 ros2 topic echo /imu -

ROS2机器人仿真:urdf模型、gaezbo仿真
机器URDF模型 URDF 的全称是 Unified Robot Description Format(统一机器人描述格式)。它是 ROS / ROS2 系统里专门用来描述机器人结构和属性的一种 XML 格式文件。简单来说,URDF 就是“机器人说明书”,告诉 ROS:这个机器人长什么样、由哪些零件组成、它们之间怎么连接。 URDF核心作用是建模机器人、仿真可视化、运动学与动力学计算。一个带轮式的机器人URDF示例: <robot name="simple_bot"> <!-- 车体 --> <link name="base_link"> <visual> <geometry> <box size="0.5 0.3 0.1"/> </geometry> </visual> </link> <!-- 左轮 --> <link name="left_wheel"/> <joint name="left_wheel_joint" type="continuous"> <parent link="base_link"/> <child link="left_wheel"/> <origin xyz="0.2 0.15 0"/> <axis xyz="0 1 0"/> </joint> <!-- 右轮 --> <link name="right_wheel"/> <joint name="right_wheel_joint" type="continuous"> <parent link="base_link"/> <child link="right_wheel"/> <origin xyz="0.2 -0.15 0"/> <axis xyz="0 1 0"/> </joint> </robot> 创建一个URDF (1)创建一个包 ros2 pkg create --build-type ament_python learn_urdf --dependencies rclpy robot_state_publisher joint_state_publisher_gui rviz2 (2)新建urdf和launch目录 主要用于存放URDF和launch文件。 cd learn_urdf mkdir urdf launch (3)编写urdf文件 进入urdf目录,创建simple_bot.urdf模型文件。 <?xml version="1.0"?> <robot name="simple_bot"> <!-- 车体 --> <link name="base_link"> <visual> <geometry> <box size="0.5 0.3 0.1"/> <!-- 长0.5m 宽0.3m 高0.1m --> </geometry> <material name="gray"> <color rgba="0.7 0.7 0.7 1.0"/> </material> </visual> </link> <!-- 左轮 --> <link name="left_wheel"> <visual> <geometry> <cylinder radius="0.05" length="0.02"/> <!-- 半径0.05m 厚度0.02m --> </geometry> <!-- 旋转90度,让圆柱变成“轮子”横放 --> <origin xyz="0 0 0" rpy="1.5708 0 0"/> <material name="black"> <color rgba="0 0 0 1.0"/> </material> </visual> </link> <joint name="left_wheel_joint" type="continuous"> <parent link="base_link"/> <child link="left_wheel"/> <origin xyz="0.2 0.15 0"/> <!-- 相对于车体的位置 --> <axis xyz="0 0 1"/> <!-- 绕Z轴旋转 --> </joint> <!-- 右轮 --> <link name="right_wheel"> <visual> <geometry> <cylinder radius="0.05" length="0.02"/> </geometry> <origin xyz="0 0 0" rpy="1.5708 0 0"/> <material name="black"> <color rgba="0 0 0 1.0"/> </material> </visual> </link> <joint name="right_wheel_joint" type="continuous"> <parent link="base_link"/> <child link="right_wheel"/> <origin xyz="0.2 -0.15 0"/> <axis xyz="0 0 1"/> <!-- 改成绕 Z 轴旋转 --> </joint> </robot> (4)创建launch文件 进入launch目录,编写display.launch.py文件 from launch import LaunchDescription from launch_ros.actions import Node from ament_index_python.packages import get_package_share_directory import os def generate_launch_description(): # 找到 URDF 文件路径 urdf_file = os.path.join( get_package_share_directory('learn_urdf'), 'urdf', 'simple_bot.urdf' ) # 读取 URDF 文件 with open(urdf_file, 'r') as infp: robot_desc = infp.read() # robot_state_publisher 节点 rsp_node = Node( package='robot_state_publisher', executable='robot_state_publisher', output='screen', parameters=[{'robot_description': robot_desc}] ) # joint_state_publisher_gui 节点(带GUI,可以动关节) jsp_node = Node( package='joint_state_publisher_gui', executable='joint_state_publisher_gui', name='joint_state_publisher_gui', output='screen' ) # rviz2 节点 rviz_node = Node( package='rviz2', executable='rviz2', name='rviz2', output='screen' ) return LaunchDescription([rsp_node, jsp_node, rviz_node]) (5)配置setup.py from setuptools import setup import os from glob import glob ...... data_files=[ # 让 ROS2 知道这个包的安装位置 ('share/ament_index/resource_index/packages', ['resource/' + package_name]), ('share/' + package_name, ['package.xml']), # 安装 launch 文件 (os.path.join('share', package_name, 'launch'), glob('launch/*.launch.py')), # 安装 urdf 文件 (os.path.join('share', package_name, 'urdf'), glob('urdf/*.urdf')), ], ...... 找到 setup.py,把里面的 data_files 部分改成上面那样,主要加入导入的模块。 (6)编译运行 cd ~/dev_ws colcon build source install/setup.bash ros2 launch learn_urdf display.launch.py 执行上面命令后,就可以看到运行了rviz2,然后配置一下rviz2即可显示模型。 最后的效果就是这样,可以通过joint state publish调整轮子方向。 XACRO模型优化 XACRO是XML Macros,它是ROS 中对 URDF 的扩展,可以理解为 “带变量和函数的 URDF”。普通 URDF 是纯 XML,很死板,写起来很长;XACRO 在 URDF 的基础上加了变量、宏、表达式计算、条件/循环。 如下示例一个普通的URDF <link name="leg1"> <visual><geometry><cylinder radius="0.05" length="0.3"/></geometry></visual> </link> <link name="leg2"> <visual><geometry><cylinder radius="0.05" length="0.3"/></geometry></visual> </link> 有很多重复,如果用XACRO <xacro:macro name="leg" params="name"> <link name="${name}"> <visual> <geometry> <cylinder radius="0.05" length="0.3"/> </geometry> </visual> </link> </xacro:macro> <xacro:leg name="leg1"/> <xacro:leg name="leg2"/> 机器模型动起来 如果要让创建的模型能够动起来,那就要在Gazebo加载模型,然后通过/cmd_vel控制就可以让机器动起来了。 Gazebo是如何加载机器的模型了? 首先在xxx.launch.py中将机器的描述文件.xacro展开为标准的.urdf XML内容。然后会通过 robot_state_publisher 节点把这个 URDF 存到 ROS 参数服务器里/robot_description。 import xacro robot_desc = xacro.process_file('simple_bot.urdf.xacro').toxml() 其次,Gazebo并不能直接解析 URDF,它使用的是 SDF (Simulation Description Format)。需要通过spawn_entity.py 读取 URDF → 转成 SDF。因此在launch文件中有看到spawn_entity.py。 ros2 run gazebo_ros spawn_entity.py -topic robot_description -entity simple_bot 最后Gazebo 根据 SDF 构建物理模型,比如SDF的link、joint等等。 运动控制 这里直接就不在演示完整创建过程了,直接使用示例程序。 ros2 launch learning_gazebo_harmonic load_urdf_into_gazebo_harmonic.launch.py ros2 run teleop_twist_keyboard teleop_twist_keyboard 执行上面两个命令,就可以在控制终端i/j/k/l在仿真环境中控制机器人移动了。 相机仿真 可以给机器装上相机 ros2 launch learning_gazebo_harmonic load_mbot_camera_into_gazebo_harmonic.launch.py ros2 run rviz2 rviz2 雷达仿真 ros2 launch learning_gazebo_harmonic load_mbot_lidar_into_gazebo_harmonic.launch.py ros2 run rviz2 rviz2 附录:本文主要来自《ROS2智能机器人开发实践》笔记