最新文章
-

ROS2常用开发工具:launch、TF、Gazebo、rosbag、rqt
launch 在ROS2中,lauch是一个程序启动器,它的作用是一条命令可以启动多个节点,加载参数文件(YAML),重映射话题/服务/动作名称,条件启动(仿真/真机切换),嵌套调用其他launch文件。 lauch文件支持3种格式 格式 后缀 特点 推荐度 Python .launch.py 功能最强,可写逻辑、条件,官方推荐 ⭐⭐⭐⭐⭐ XML .launch.xml 类似 ROS1,结构清晰,但灵活性差 ⭐⭐ YAML .launch.yaml 简洁配置,功能最弱 ⭐ 但在ROS2中目前更多的使用.launch.py。这里我们重点介绍此种方式。 launch文件结构 最小的结构示例 from launch import LaunchDescription from launch_ros.actions import Node def generate_launch_description(): return LaunchDescription([ Node(package='pkg_name', executable='exe_name', name='node_name') ]) 创建launch文件需要导入launch和launch_ros模块,入口函数为generate_launch_description(),该函数中定义了要启动的节点,通过LaunchDescription来描述节点如包、执行程序、名称。 使用步骤 (1)创建一个包 cd ~/dev_ws/src ros2 pkg create --build-type ament_python launch_demo (2)新建launch目录 一般launch文件都会有个单独的目录,因此新建目录用于存放launch文件。 cd launch_demo mkdir launch (3)编写lauch文件 demo.launch.py from launch import LaunchDescription from launch_ros.actions import Node def generate_launch_description(): return LaunchDescription([ Node(package='learn_topic_cpp', executable='topic_helloworld_pub', name='pub', output='screen'), Node(package='learn_topic_cpp', executable='topic_helloworld_sub', name='sub', output='screen') ]) (4)修改setup.py 注册launch文件,主要是将.launch文件要拷贝到install/share/xxx/launch目录下。 from setuptools import find_packages, setup import os from glob import glob ...... data_files=[ (os.path.join('share', package_name, 'launch'), glob('launch/*.launch.py')), ] ..... 需要导入setuptools、os、glob这几个模块。 (5)编译&环境刷新 cd ~/dev_ws colcon build source install/setup.bash (6)运行测试 ros2 launch launch_demo demo.launch.py 进阶功能 (1)加载参数 config/params.yaml my_node: ros__parameters: use_sim_time: true max_speed: 2.0 launch 文件: Node( package='my_pkg', executable='my_node', parameters=['config/params.yaml'] ) (2)命令行参数 from launch.actions import DeclareLaunchArgument from launch.substitutions import LaunchConfiguration DeclareLaunchArgument('use_sim_time', default_value='false') Node( package='my_pkg', executable='my_node', parameters=[{'use_sim_time': LaunchConfiguration('use_sim_time')}] ) 在运行的时候可以传递参数 ros2 launch my_pkg demo.launch.py use_sim_time:=true (3)条件启动 from launch.conditions import IfCondition Node( package='gazebo_ros', executable='gzserver', condition=IfCondition(LaunchConfiguration('use_gazebo')) ) 只有当条件use_gazebo满足时才会启动,如运行。 ros2 launch my_pkg demo.launch.py use_gazebo:=true (4)话题重映射 Node( package='my_pkg', executable='controller', remappings=[('/cmd_vel', '/robot1/cmd_vel')] ) 可以将节点中的话题进行重映射,如把节点内部用到的 /cmd_vel 改名为 /robot1/cmd_vel,在实际场景中多机器人系统可以避免冲突。 TF TF是transform的缩写,其作用主要是维护并查询机器人系统中各个坐标系之间的关系(包括位置+姿态)。其主要的核心功能如下: 管理多个坐标系的父子关系(各个坐标系之间形成一颗TF树) 提供任意两个坐标系之间的变换(平移+旋转) 试试广播、查询坐标关系。 可以理解为TF就像是一个全局的时空字典,每个坐标系(Frame)都是字典里的key,而变化关系是key之间的link。 常见的坐标系有 map:世界地图坐标系,一般是静态的,当机器人定位完成后,map是全局的参考。 odom:里程计坐标系(相对),会随着时间推移会漂移。 base_link:机器人本地中心,是所有传感器和控制指令的基准。 camera_link:摄像头坐标系。 laser_link:雷达坐标系。 典型的TF树 map → odom → base_link → camera_link → laser_link 每个坐标都有一个父坐标系(除了根map),变换是单项定义的。孙子的坐标系的位姿等于“父坐标系的位姿+子坐标系的相对位姿”。如上要知道map与camera_link的关系。则T_map_camera = T_map_odom × T_odom_base × T_base_camera 运行命令,查询 turtle2 坐标系相对于 turtle1 坐标系的变换关系。 ros2 run tf2_ros tf2_echo turtle2 turtle1 打印数据如下: At time 1758102120.301409314 - Translation: [3.679, -0.208, 0.000] - Rotation: in Quaternion [0.000, 0.000, 0.003, 1.000] - Rotation: in RPY (radian) [0.000, -0.000, 0.006] - Rotation: in RPY (degree) [0.000, -0.000, 0.364] - Matrix: 1.000 -0.006 0.000 3.679 0.006 1.000 0.000 -0.208 0.000 0.000 1.000 0.000 0.000 0.000 0.000 1.000 Translation:平移,子坐标系的原点,相对于父坐标系的位置是x = 3.679 m,y = -0.208 m,z = 0 m。 Quaternion:旋转,单位四元数。 RPY :欧拉角。 Matrix:变换矩阵。 也可以使用rviz2来直观感受一下 广播与查询 举例一个场景机器人本体 base_link → 传感器 camera_link。 (1)广播父子坐标 import rclpy from rclpy.node import Node from geometry_msgs.msg import TransformStamped from tf2_ros import TransformBroadcaster import tf_transformations # 四元数工具 class FrameBroadcaster(Node): def __init__(self): super().__init__('frame_broadcaster') self.broadcaster = TransformBroadcaster(self) self.timer = self.create_timer(0.1, self.broadcast_tf) # 10Hz 发布 def broadcast_tf(self): t = TransformStamped() t.header.stamp = self.get_clock().now().to_msg() t.header.frame_id = 'base_link' # 父坐标系 t.child_frame_id = 'camera_link' # 子坐标系 # 平移: 相机在机器人前方 0.2m,高 0.5m t.transform.translation.x = 0.2 t.transform.translation.y = 0.0 t.transform.translation.z = 0.5 # 旋转: 无旋转 q = tf_transformations.quaternion_from_euler(0, 0, 0) t.transform.rotation.x = q[0] t.transform.rotation.y = q[1] t.transform.rotation.z = q[2] t.transform.rotation.w = q[3] self.broadcaster.sendTransform(t) def main(): rclpy.init() node = FrameBroadcaster() rclpy.spin(node) if __name__ == '__main__': main() 调用TransformBroadcaster用于广播坐标变换父->子。 (2)查询坐标 import rclpy from rclpy.node import Node from tf2_ros import Buffer, TransformListener class FrameListener(Node): def __init__(self): super().__init__('frame_listener') self.tf_buffer = Buffer() self.listener = TransformListener(self.tf_buffer, self) self.timer = self.create_timer(1.0, self.lookup_tf) def lookup_tf(self): try: # 查询 base_link 在 map 下的变换 trans = self.tf_buffer.lookup_transform( 'map', # 父坐标系 'base_link', # 子坐标系 rclpy.time.Time()) t = trans.transform.translation r = trans.transform.rotation self.get_logger().info( f"位置: x={t.x:.2f}, y={t.y:.2f}, z={t.z:.2f}; " f"四元数: [{r.x:.3f}, {r.y:.3f}, {r.z:.3f}, {r.w:.3f}]" ) except Exception as e: self.get_logger().warn(f"查询失败: {e}") def main(): rclpy.init() node = FrameListener() rclpy.spin(node) if __name__ == '__main__': main() 调用TransformListener + Buffer查询坐标,打印如下: 位置: x=3.68, y=-0.21, z=0.00; 四元数: [0.000, 0.000, 0.003, 1.000] 也可以用命令行: ros2 run tf2_ros tf2_echo base_link camera_link Gazebo 安装 sudo apt-get update sudo apt-get install lsb-release gnupg sudo curl https://packages.osrfoundation.org/gazebo.gpg --output /usr/share/keyrings/pkgs-osrf-archive-keyring.gpg echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/pkgs-osrf-archive-keyring.gpg] https://packages.osrfoundation.org/gazebo/ubuntu-stable $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/gazebo-stable.list > /dev/null sudo apt-get update sudo apt install gz-harmonic sudo apt install ros-jazzy-ros-gz 详情参考Binary Installation on Ubuntu。 安装完成后,启动下面命令正常启动就说明安装好了。 gz sim 机器仿真示例 启动一个机器仿真环境 ros2 launch ros_gz_sim_demos diff_drive.launch.py 启动一个键盘控制节点 ros2 run teleop_twist_keyboard teleop_twist_keyboard --ros-args -r cmd_vel:=model/vehicle_blue/cmd_vel 使用i/j/,/l四个按键可以控制机器人前后左右动作。 传感器示例 ros2 launch ros_gz_sim_demos rgbd_camera_bridge.launch.py 仿真摄像头,运行上面命令后会打开Gazebo仿真界面和RViz上位机。可以在Gazebo中直接看到RGBD相机仿真后发布的图像数据。 RViz RViz 全称 ROS Visualization,是 ROS(Robot Operating System)里一个非常重要的三维可视化工具。它的作用主要是帮助开发者 直观地查看机器人系统中的数据和状态。 RViz的作用主要有坐标系可视化、传感器数据展示、机器人模型显示、路径与轨迹可视化、调试与验证等等。 RViz的核心功能模块主要有Displays、Views、Tools、Topics订阅。 RViz只负责可视化(接受数据显示)不会进行物理仿真,而Gazebo是物理仿真器,可以模拟机器人运动、环境交互。常用的做法是Gazebo负责仿真将数据发布到ROS 然后通过RViz显示数据。 RViz已经集成到完整版的ROS中,一般不需要额外单独安装。 ros2 run rviz2 rviz2 示例:tf数据可视化 分别启动两个终端,运行海龟跟随运动。 ros2 launch learning_tf turtle_following_demo.launch.py ros2 run turtlesim turtle_teleop_key 接着运行rviz2 ros2 run rviz2 rviz2 添加TF 坐标系显示 示例:图像数据可视化 ros2 run usb_cam usb_cam_node_exe 执行启动相机驱动,如果找不到命令就先安装sudo apt install ros-jazzy-usb-cam 按照上面的方式添加image,如果报错 需要把topic订阅改为/image_raw rosbag rosbag 是 ROS(Robot Operating System)中的一种数据记录与回放工具,用来保存和重放机器人运行时产生的各种消息数据。简单来说,它就像“黑匣子”,能把机器人运行时的传感器、话题消息、控制指令等全部记录下来,方便后期调试和复现实验。 记录数据 先启动"老演员" ros2 run turtlesim turtlesim_node ros2 run turtlesim turtle_teleop_key 然后创建一个文件夹用于存放录制数据 mkdir ~/bagfiles cd ~/bagfiles/ 列出当前有哪些话题 ros2 topic list -v Published topics: * /parameter_events [rcl_interfaces/msg/ParameterEvent] 3 publishers * /rosout [rcl_interfaces/msg/Log] 3 publishers * /turtle1/cmd_vel [geometry_msgs/msg/Twist] 1 publisher * /turtle1/color_sensor [turtlesim/msg/Color] 1 publisher * /turtle1/pose [turtlesim/msg/Pose] 1 publisher Subscribed topics: * /parameter_events [rcl_interfaces/msg/ParameterEvent] 3 subscribers * /turtle1/cmd_vel [geometry_msgs/msg/Twist] 1 subscriber 接下来就记录/turtle1/cmd_vel话题。 ros2 bag record /turtle1/cmd_vel 这样只要在键盘终端控制海龟不断移动,就可以记录下数据了。停止记录Ctrl+C。 laumy@ThinkBook-14-G7-IAH:~/bagfiles$ tree . └── rosbag2_2025_09_18-12_52_52 ├── metadata.yaml └── rosbag2_2025_09_18-12_52_52_0.mcap 2 directories, 2 files 回放数据 可以使用下面命令查看数据文件信息。 laumy@ThinkBook-14-G7-IAH:~/bagfiles$ ros2 bag info rosbag2_2025_09_18-13_01_53/ Files: rosbag2_2025_09_18-13_01_53_0.mcap Bag size: 29.8 KiB Storage id: mcap ROS Distro: jazzy Duration: 26.796084773s Start: Sep 18 2025 13:01:58.126984611 (1758171718.126984611) End: Sep 18 2025 13:02:24.923069384 (1758171744.923069384) Messages: 251 Topic information: Topic: /turtle1/cmd_vel | Type: geometry_msgs/msg/Twist | Count: 251 | Serialization Format: cdr Service: 0 Service information: 回放命令: ros2 bag play rosbag2_2025_09_18-13_01_53/ 这样海龟就会复制刚才键盘执行的运动路径。 rqt rqt 是 ROS 官方提供的一个基于 Qt 的 GUI 框架,本质上是一个 插件管理和可视化平台。 它的设计理念是:ROS 系统是分布式的,节点、话题、服务、参数等很多,调试和监控光靠命令行不直观,因此需要一个统一的 图形化工具箱 来观察和操作。 使用如下命令来安装 sudo apt install ros-jazzy-rqt 安装完成之后,执行 rqt rqt默认是没有选择任何插件。要添加插件,需要从插件菜单中选择项目。 日志显示 日志显示有两种打开方式一种是执行rqt后,在Plugins->Logging->Console-打开,另外一种是执行下面命令 ros2 run rqt_console rqt_console 图像显示 在启动之前先运行usb ros2 run usb_cam usb_cam_node_exe UI界面启动"Plugins->Visualization>Image View"或者通过命令的方式: ros2 run rqt_image_view rqt_image_view 接着添加订阅的话题 发布话题/服务数据 不仅可以在命令行中发布话题或服务,也可以通过rqt工具发布。 先启动turtlesim ros2 run turtlesim turtlesim_node 然后使用rqt的"Plugin->Topics->MessagePublish"。 绘制数据曲线 rqt还可以绘制数据曲线,将需要显示的xy坐标使用曲线描述出来,便于体现机器人的速度、位置等信息随时间变化的趋势。 "Plugins->Visualization>plot" 然后依次添加topic,就可以记录轨迹了。 节点可视化 打开“introspection->Node Graph”可以看到系统中所有的节点关系。 附录:本文来自《ROS2智能机器人开发实践》笔记 -
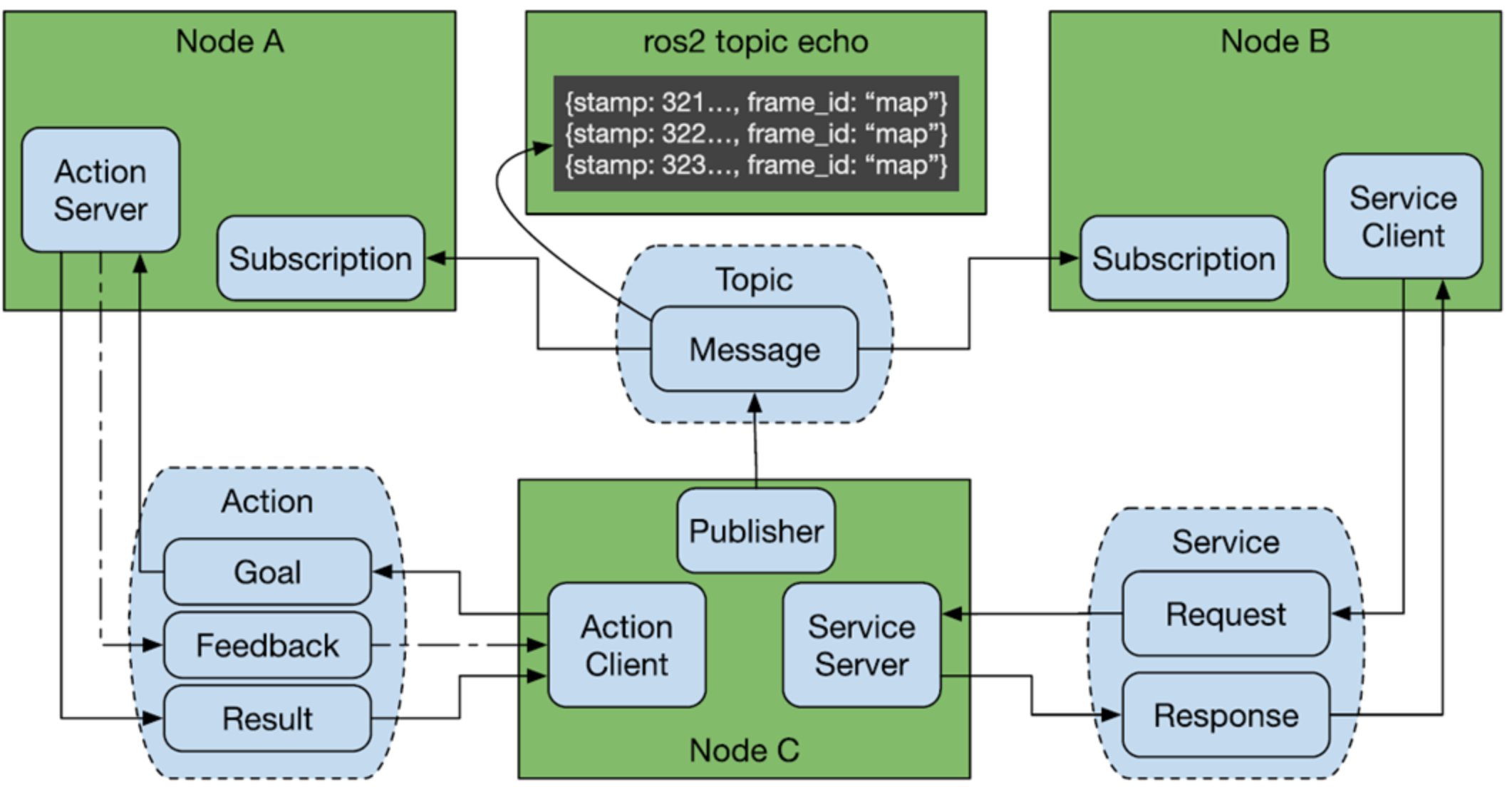
ROS2节点通信:话题、服务、动作三剑客+参数
简介 在ROS系统每个节点可以理解为一个进程,更准确的说法它是一个包含了特定功能的独立执行单元。节点在ROS2中通常是一个可执行文件,负责执行特定的任务,如控制机器人、传感器数据处理等。每个节点可以通过ROS2的通信机制与其他节点进行数据交换。 在具体的工程应用中,需要多个节点进行配合完成一个具体的产品。那么多个节点直接如何进行通信了,ROS系统提供了话题、服务、动作这几种方式,当然除了上面3中之外还有一种参数的方式,这种方式是一种共享的全局变量,让各个节点可以进行查询/设置参数以达到信息传输的目的。 话题 搞过网络MQTT的对ROS2中的话题通信理解就简单了,可以说ROS2中的话题通信与MQTT是一模一样的。话题通信分为发布者和订阅者。发布者通过话题(topic)发布消息,订阅者通过订阅该话题后可接受到该消息。话题的通信是异步通信的方式,结构上是多对多的关系。 python示例 先创建一个包 cd ~/dev_ws/src/ ros2 pkg create --build-type ament_python learning_topic_python 创建一个发布者节点程序topic_hello_pub.py import rclpy from rclpy.node import Node from std_msgs.msg import String class PublisherNode(Node): def __init__(self, name): super().__init__(name) self.pub = self.create_publisher(String, "hello", 10) self.timer = self.create_timer(1.0, self.publish_message) def publish_message(self): msg = String() msg.data = "Hello, ROS2!" self.pub.publish(msg) self.get_logger().info("Published: %s" % msg.data) def main(args=None): rclpy.init(args=args) node = PublisherNode("publisher_node") rclpy.spin(node) node.destroy_node() rclpy.shutdown() 创建订阅者节点程序topic_hello_sub.py import rclpy from rclpy.node import Node from std_msgs.msg import String class SubscriberNode(Node): def __init__(self, name): super().__init__(name) self.sub = self.create_subscription(String, "hello", self.callback, 10) def callback(self, msg): self.get_logger().info("Received: %s" % msg.data) def main(args=None): rclpy.init(args=args) node = SubscriberNode("subscriber_node") rclpy.spin(node) node.destroy_node() rclpy.shutdown() 程序运行发布者 ros2 run learning_topic_python topic_hello_pub 程序运行订阅者 ros2 run learning_topic_python topic_hello_sub 核心点就是发布调用self.create_publisher,订阅调用self.create_subscription。 C++示例 创建一个包 ros2 pkg create --build-type ament_cmake learn_topic_cpp 编写发布者节点 #include <chrono> #include <functional> #include <memory> #include <string> #include "rclcpp/rclcpp.hpp" #include "std_msgs/msg/string.hpp" using namespace std::chrono_literals; class PublisherNode : public rclcpp::Node { public: PublisherNode() : Node("topic_hello") { publisher_ = this->create_publisher<std_msgs::msg::String>("hello", 10); timer_ = this->create_wall_timer(1s, std::bind(&PublisherNode::timer_callback, this)); } private: void timer_callback() { auto msg = std_msgs::msg::String(); msg.data = "Hello, ROS2!"; publisher_->publish(msg); RCLCPP_INFO(this->get_logger(), "Published: %s", msg.data.c_str()); } rclcpp::TimerBase::SharedPtr timer_; rclcpp::Publisher<std_msgs::msg::String>::SharedPtr publisher_; }; int main(int argc, char * argv[]) { rclcpp::init(argc, argv); rclcpp::spin(std::make_shared<PublisherNode>()); rclcpp::shutdown(); return 0; } 编写订阅者节点 #include <memory> #include "rclcpp/rclcpp.hpp" #include "std_msgs/msg/string.hpp" using namespace std::chrono_literals; using std::placeholders::_1; class SubscriberNode : public rclcpp::Node { public: SubscriberNode() : Node("topic_hello") { subscription_ = this->create_subscription<std_msgs::msg::String>("hello", 10, std::bind(&SubscriberNode::topic_callback, this, _1)); RCLCPP_INFO(this->get_logger(), "SubscriberNode initialized"); } private: void topic_callback(const std_msgs::msg::String::SharedPtr msg) const { RCLCPP_INFO(this->get_logger(), "I heard: '%s'", msg->data.c_str()); } rclcpp::Subscription<std_msgs::msg::String>::SharedPtr subscription_; }; int main(int argc, char * argv[]) { rclcpp::init(argc, argv); rclcpp::spin(std::make_shared<SubscriberNode>()); rclcpp::shutdown(); return 0; } 运行测试 到这里话题的python和cpp示例都实践了,话题主要使用的是异步的方式。 服务 在 ROS 2 中,服务(Service)通信是一种 请求-响应模式,允许客户端发送请求到服务端,服务端处理请求并返回响应。这种方式通常用于需要同步交互的情况,如远程调用、控制请求或计算任务等。这种通信方式与HTTP的通信方式类似,只有一个服务器,由客户端发起get,然后服务端响应数据。 python示例 创建一个包 ros2 pkg create --build-type ament_python learn_srv_python 创建一个add_server.py节点 import sys import rclpy from rclpy.node import Node from learning_interface.srv import AddTwoInts class adderServer(Node): def __init__(self, name): super().__init__(name) self.srv = self.create_service(AddTwoInts, 'add_two_int', self.adder_callback) def adder_callback(self, request, response): response.sum = request.a + request.b self.get_logger().info('Incoming request\na: %d b: %d' % (request.a, request.b)) return response def main(args=None): rclpy.init(args=args) node = adderServer("Service_adder_server") rclpy.spin(node) rclpy.shutdown() 再创建一个add_client.py节点 from socket import timeout import sys import rclpy from rclpy.node import Node from learning_interface.srv import AddTwoInts class adderClient(Node): def __init__(self, name): super().__init__(name) self.client = self.create_client(AddTwoInts, 'add_two_int') while not self.client.wait_for_service(timeout_sec=1.0): self.get_logger().info('server not available, waiting again...') self.request = AddTwoInts.Request() def send_request(self): self.request.a = int(sys.argv[1]) self.request.b = int(sys.argv[2]) self.future = self.client.call_async(self.request) def main(args=None): rclpy.init(args=args) node = adderClient("Service_adder_client") node.send_request() while rclpy.ok(): rclpy.spin_once(node) if node.future.done(): try: response = node.future.result() except Exception as e: node.get_logger().info( 'Service call failed %r' %(e,)) else: node.get_logger().info( 'Result of add_two_ints: for %d + %d = %d' % (node.request.a, node.request.b, response.sum)) break node.destroy_node() rclpy.shutdown() 运行结果如下 示例演示了客户端请求两个数给服务器计算求和,服务器收到客户端的数据后,计算后返回结果。 在创建client和server的时候,要能够匹配上需要有共同的地址如create_service参数为"add_two_int"和create_client的参数地址一样。在服务端需要注册一个回调函数adder_callback,当收到客户端的数据时调用回调函数返回结果。 C++示例 创建一个C++的包 ros2 pkg create --build-type ament_cmake learn_srv_cpp 创建add_server.cpp节点代码 #include "rclcpp/rclcpp.hpp" #include "learning_interface/srv/add_two_ints.hpp" #include <memory> void adderServer(const std::shared_ptr<learning_interface::srv::AddTwoInts::Request> request, std::shared_ptr<learning_interface::srv::AddTwoInts::Response> response) { response->sum = request->a + request->b; RCLCPP_INFO(rclcpp::get_logger("rclcpp"), "Incoming request\na: %ld b: %ld", request->a, request->b); RCLCPP_INFO(rclcpp::get_logger("rclcpp"), "sending back response: [%ld]", response->sum); } int main(int argc, char **argv) { rclcpp::init(argc, argv); std::shared_ptr<rclcpp::Node> node = rclcpp::Node::make_shared("service_adder_server"); rclcpp::Service<learning_interface::srv::AddTwoInts>::SharedPtr service = node->create_service<learning_interface::srv::AddTwoInts>("add_two_int", &adderServer); RCLCPP_INFO(rclcpp::get_logger("rclcpp"), "Ready to add two ints."); rclcpp::spin(node); rclcpp::shutdown(); } 创建一个add_client.cpp节点代码 #include "rclcpp/rclcpp.hpp" #include "learning_interface/srv/add_two_ints.hpp" #include <memory> #include <chrono> #include <cstdlib> using namespace std::chrono_literals; int main(int argc, char **argv) { rclcpp::init(argc, argv); if (argc != 3) { RCLCPP_INFO(rclcpp::get_logger("rclcpp"), "usage: service_adder_client X Y"); return 1; } std::shared_ptr<rclcpp::Node> node = rclcpp::Node::make_shared("service_adder_client"); rclcpp::Client<learning_interface::srv::AddTwoInts>::SharedPtr client = node->create_client<learning_interface::srv::AddTwoInts>("add_two_int"); auto request = std::make_shared<learning_interface::srv::AddTwoInts::Request>(); request->a = atoll(argv[1]); request->b = atoll(argv[2]); while (!client->wait_for_service(1s)) { if (!rclcpp::ok()) { RCLCPP_ERROR(rclcpp::get_logger("rclcpp"), "Interrupted while waiting for the service. Exiting."); return 0; } RCLCPP_INFO(rclcpp::get_logger("rclcpp"), "service not available, waiting again..."); } auto result = client->async_send_request(request); // Wait for the result if (rclcpp::spin_until_future_complete(node, result) == rclcpp::FutureReturnCode::SUCCESS) { RCLCPP_INFO(rclcpp::get_logger("rclcpp"), "Result of add_two_ints: for %ld + %ld = %ld", request->a, request->b, result.get()->sum); } else { RCLCPP_ERROR(rclcpp::get_logger("rclcpp"), "Failed to call service add_two_ints"); } rclcpp::shutdown(); return 0; } 结果运行如下: 总结一下服务的通信方式可以理解为跟http的类似,基于请求和响应的方式进行,只有一个服务器,但是可以有多个客户端是一个一对多的通信结构。数据的通信跟话题相比其是同步传输,而话题是异步传输。 动作 ROS 2 的 Action 是一种用于实现异步、长时间运行的任务的通信机制,常用于那些需要反馈或结果的任务。相比 ROS 2 的 Service(同步请求-响应模式),Action 允许客户端请求任务并在任务执行过程中接收反馈,最终获取任务的结果。它通常适用于需要较长时间处理的任务,如机器人运动控制、路径规划、抓取任务等。 具体的通信流程如下: 可以分为3个阶段 阶段1:客户端异步的方式发送目标。 阶段2:服务端定期反馈实时结果。 阶段3:服务端反馈最终的结果。 python示例 创建一个包 ros2 pkg create --build-type ament_python learn_action_python 创建一个服务端节点程序action_server.py import time import rclpy # ROS2 Python接口库 from rclpy.node import Node # ROS2 节点类 from rclpy.action import ActionServer # ROS2 动作服务器类 from learning_interface.action import MoveCircle # 自定义的圆周运动接口 class MoveCircleActionServer(Node): def __init__(self, name): super().__init__(name) # ROS2节点父类初始化 self._action_server = ActionServer( # 创建动作服务器(接口类型、动作名、回调函数) self, MoveCircle, 'move_circle', self.execute_callback) def execute_callback(self, goal_handle): # 执行收到动作目标之后的处理函数 self.get_logger().info('Moving circle...') feedback_msg = MoveCircle.Feedback() # 创建一个动作反馈信息的消息 for i in range(0, 360, 30): # 从0到360度,执行圆周运动,并周期反馈信息 feedback_msg.state = i # 创建反馈信息,表示当前执行到的角度 self.get_logger().info('Publishing feedback: %d' % feedback_msg.state) goal_handle.publish_feedback(feedback_msg) # 发布反馈信息 time.sleep(0.5) self.get_logger().info('Goal succeeded') goal_handle.succeed() # 动作执行成功 result = MoveCircle.Result() # 创建结果消息 result.finish = True return result # 反馈最终动作执行的结果 def main(args=None): # ROS2节点主入口main函数 rclpy.init(args=args) # ROS2 Python接口初始化 node = MoveCircleActionServer("action_move_server") # 创建ROS2节点对象并进行初始化 rclpy.spin(node) # 循环等待ROS2退出 node.destroy_node() # 销毁节点对象 rclpy.shutdown() # 关闭ROS2 Python接口 创建一个客户端阶段程序action_client.py import rclpy # ROS2 Python接口库 from rclpy.node import Node # ROS2 节点类 from rclpy.action import ActionClient # ROS2 动作客户端类 from learning_interface.action import MoveCircle # 自定义的圆周运动接口 class MoveCircleActionClient(Node): def __init__(self, name): super().__init__(name) # ROS2节点父类初始化 self._action_client = ActionClient( # 创建动作客户端(接口类型、动作名) self, MoveCircle, 'move_circle') def send_goal(self, enable): # 创建一个发送动作目标的函数 self.get_logger().info('Waiting for action server...') self._action_client.wait_for_server() # 等待动作的服务器端启动 goal_msg = MoveCircle.Goal() # 创建一个动作目标的消息 goal_msg.enable = enable # 设置动作目标为使能,希望机器人开始运动 self.get_logger().info('Sending goal request...') self._send_goal_future = self._action_client.send_goal_async( # 异步方式发送动作的目标 goal_msg, # 动作目标 feedback_callback=self.feedback_callback) # 处理周期反馈消息的回调函数 self._send_goal_future.add_done_callback(self.goal_response_callback) # 设置一个服务器收到目标之后反馈时的回调函数 def goal_response_callback(self, future): # 创建一个服务器收到目标之后反馈时的回调函数 goal_handle = future.result() # 接收动作的结果 if not goal_handle.accepted: # 如果动作被拒绝执行 self.get_logger().info('Goal rejected :(') return self.get_logger().info('Goal accepted :)') # 动作被顺利执行 self._get_result_future = goal_handle.get_result_async() # 异步获取动作最终执行的结果反馈 self._get_result_future.add_done_callback(self.get_result_callback) # 设置一个收到最终结果的回调函数 def get_result_callback(self, future): # 创建一个收到最终结果的回调函数 result = future.result().result # 读取动作执行的结果 self.get_logger().info('Result: {%d}' % result.finish) # 日志输出执行结果 def feedback_callback(self, feedback_msg): # 创建处理周期反馈消息的回调函数 feedback = feedback_msg.feedback # 读取反馈的数据 self.get_logger().info('Received feedback: {%d}' % feedback.state) def main(args=None): # ROS2节点主入口main函数 rclpy.init(args=args) # ROS2 Python接口初始化 node = MoveCircleActionClient("action_move_client") # 创建ROS2节点对象并进行初始化 node.send_goal(True) # 发送动作目标 rclpy.spin(node) # 循环等待ROS2退出 node.destroy_node() # 销毁节点对象 rclpy.shutdown() # 关闭ROS2 Python接口 运行 总结一下流程: 客户端 服务端 | | |-- 发送目标 ----------->| | |-- execute_callback() 被调用 | | (开始执行动作) | | |<-- 目标接受/拒绝 ------|-- 立即响应目标请求 | | |-- goal_response_callback 被调用 | | | |-- 开始循环执行 | | (0°, 30°, 60°...) | | |<-- 反馈消息 ----------|-- publish_feedback(0°) | | |-- feedback_callback 被调用 | | |<-- 反馈消息 ----------|-- publish_feedback(30°) | | |-- feedback_callback 被调用 | | |<-- 反馈消息 ----------|-- publish_feedback(60°) | | |-- feedback_callback 被调用 | | | ... (继续循环) ... | | | |<-- 反馈消息 ----------|-- publish_feedback(330°) | | |-- feedback_callback 被调用 | | | |-- 动作执行完成 | |-- goal_handle.succeed() | |-- 返回结果 | | |<-- 最终结果 ----------|-- 发送结果消息 | | |-- get_result_callback 被调用 | | |-- 动作完成 -----------| 客户端一共注册了3个回调: goal_response_callback:服务器第一次接收到目标请求后的回调函数,调用self._send_goal_future.add_done_callback设置。 feedback_callback:调用send_goal_async时注册,这个回调是服务器实时反馈的回调函数。 get_result_callback:服务器最后返回的结果回调。调用self._get_result_future.add_done_callback注册。 服务端就仅仅只有execute_callback一个回调,即对应客户端的feedback回调,另外两个都是隐式的。 C++示例 创建一个包 ros2 pkg create --build-type ament_cmake learn_action_cpp 创建客户端节点程序action_client.cpp #include <iostream> #include "rclcpp/rclcpp.hpp" // ROS2 C++接口库 #include "rclcpp_action/rclcpp_action.hpp" // ROS2 动作类 #include "learning_interface/action/move_circle.hpp" // 自定义的圆周运动接口 using namespace std; class MoveCircleActionClient : public rclcpp::Node { public: // 定义一个自定义的动作接口类,便于后续使用 using CustomAction = learning_interface::action::MoveCircle; // 定义一个处理动作请求、取消、执行的客户端类 using GoalHandle = rclcpp_action::ClientGoalHandle<CustomAction>; explicit MoveCircleActionClient(const rclcpp::NodeOptions & node_options = rclcpp::NodeOptions()) : Node("action_move_client", node_options) // ROS2节点父类初始化 { this->client_ptr_ = rclcpp_action::create_client<CustomAction>( // 创建动作客户端(接口类型、动作名) this->get_node_base_interface(), this->get_node_graph_interface(), this->get_node_logging_interface(), this->get_node_waitables_interface(), "move_circle"); } // 创建一个发送动作目标的函数 void send_goal(bool enable) { // 检查动作服务器是否可以使用 if (!this->client_ptr_->wait_for_action_server(std::chrono::seconds(10))) { RCLCPP_ERROR(this->get_logger(), "Client: Action server not available after waiting"); rclcpp::shutdown(); return; } // 绑定动作请求、取消、执行的回调函数 auto send_goal_options = rclcpp_action::Client<CustomAction>::SendGoalOptions(); using namespace std::placeholders; send_goal_options.goal_response_callback = std::bind(&MoveCircleActionClient::goal_response_callback, this, _1); send_goal_options.feedback_callback = std::bind(&MoveCircleActionClient::feedback_callback, this, _1, _2); send_goal_options.result_callback = std::bind(&MoveCircleActionClient::result_callback, this, _1); // 创建一个动作目标的消息 auto goal_msg = CustomAction::Goal(); goal_msg.enable = enable; // 异步方式发送动作的目标 RCLCPP_INFO(this->get_logger(), "Client: Sending goal"); this->client_ptr_->async_send_goal(goal_msg, send_goal_options); } private: rclcpp_action::Client<CustomAction>::SharedPtr client_ptr_; // 创建一个服务器收到目标之后反馈时的回调函数 void goal_response_callback(GoalHandle::SharedPtr goal_message) { if (!goal_message) { RCLCPP_ERROR(this->get_logger(), "Client: Goal was rejected by server"); rclcpp::shutdown(); // Shut down client node } else { RCLCPP_INFO(this->get_logger(), "Client: Goal accepted by server, waiting for result"); } } // 创建处理周期反馈消息的回调函数 void feedback_callback( GoalHandle::SharedPtr, const std::shared_ptr<const CustomAction::Feedback> feedback_message) { std::stringstream ss; ss << "Client: Received feedback: "<< feedback_message->state; RCLCPP_INFO(this->get_logger(), "%s", ss.str().c_str()); } // 创建一个收到最终结果的回调函数 void result_callback(const GoalHandle::WrappedResult & result_message) { switch (result_message.code) { case rclcpp_action::ResultCode::SUCCEEDED: break; case rclcpp_action::ResultCode::ABORTED: RCLCPP_ERROR(this->get_logger(), "Client: Goal was aborted"); rclcpp::shutdown(); // 关闭客户端节点 return; case rclcpp_action::ResultCode::CANCELED: RCLCPP_ERROR(this->get_logger(), "Client: Goal was canceled"); rclcpp::shutdown(); // 关闭客户端节点 return; default: RCLCPP_ERROR(this->get_logger(), "Client: Unknown result code"); rclcpp::shutdown(); // 关闭客户端节点 return; } RCLCPP_INFO(this->get_logger(), "Client: Result received: %s", (result_message.result->finish ? "true" : "false")); rclcpp::shutdown(); // 关闭客户端节点 } }; // ROS2节点主入口main函数 int main(int argc, char * argv[]) { // ROS2 C++接口初始化 rclcpp::init(argc, argv); // 创建一个客户端指针 auto action_client = std::make_shared<MoveCircleActionClient>(); // 发送动作目标 action_client->send_goal(true); // 创建ROS2节点对象并进行初始化 rclcpp::spin(action_client); // 关闭ROS2 C++接口 rclcpp::shutdown(); return 0; } 创建服务端节点程序action_server.cpp #include <iostream> #include "rclcpp/rclcpp.hpp" // ROS2 C++接口库 #include "rclcpp_action/rclcpp_action.hpp" // ROS2 动作类 #include "learning_interface/action/move_circle.hpp" // 自定义的圆周运动接口 using namespace std; class MoveCircleActionServer : public rclcpp::Node { public: // 定义一个自定义的动作接口类,便于后续使用 using CustomAction = learning_interface::action::MoveCircle; // 定义一个处理动作请求、取消、执行的服务器端 using GoalHandle = rclcpp_action::ServerGoalHandle<CustomAction>; explicit MoveCircleActionServer(const rclcpp::NodeOptions & action_server_options = rclcpp::NodeOptions()) : Node("action_move_server", action_server_options) // ROS2节点父类初始化 { using namespace std::placeholders; this->action_server_ = rclcpp_action::create_server<CustomAction>( // 创建动作服务器(接口类型、动作名、回调函数) this->get_node_base_interface(), this->get_node_clock_interface(), this->get_node_logging_interface(), this->get_node_waitables_interface(), "move_circle", std::bind(&MoveCircleActionServer::handle_goal, this, _1, _2), std::bind(&MoveCircleActionServer::handle_cancel, this, _1), std::bind(&MoveCircleActionServer::handle_accepted, this, _1)); } private: rclcpp_action::Server<CustomAction>::SharedPtr action_server_; // 动作服务器 // 响应动作目标的请求 rclcpp_action::GoalResponse handle_goal( const rclcpp_action::GoalUUID & uuid, std::shared_ptr<const CustomAction::Goal> goal_request) { RCLCPP_INFO(this->get_logger(), "Server: Received goal request: %d", goal_request->enable); (void)uuid; // 如请求为enable则接受运动请求,否则就拒绝 if (goal_request->enable) { return rclcpp_action::GoalResponse::ACCEPT_AND_EXECUTE; } else { return rclcpp_action::GoalResponse::REJECT; } } // 响应动作取消的请求 rclcpp_action::CancelResponse handle_cancel( const std::shared_ptr<GoalHandle> goal_handle_canceled_) { RCLCPP_INFO(this->get_logger(), "Server: Received request to cancel action"); (void) goal_handle_canceled_; return rclcpp_action::CancelResponse::ACCEPT; } // 处理动作接受后具体执行的过程 void handle_accepted(const std::shared_ptr<GoalHandle> goal_handle_accepted_) { using namespace std::placeholders; // 在线程中执行动作过程 std::thread{std::bind(&MoveCircleActionServer::execute, this, _1), goal_handle_accepted_}.detach(); } void execute(const std::shared_ptr<GoalHandle> goal_handle_) { const auto requested_goal = goal_handle_->get_goal(); // 动作目标 auto feedback = std::make_shared<CustomAction::Feedback>(); // 动作反馈 auto result = std::make_shared<CustomAction::Result>(); // 动作结果 RCLCPP_INFO(this->get_logger(), "Server: Executing goal"); rclcpp::Rate loop_rate(1); // 动作执行的过程 for (int i = 0; (i < 361) && rclcpp::ok(); i=i+30) { // 检查是否取消动作 if (goal_handle_->is_canceling()) { result->finish = false; goal_handle_->canceled(result); RCLCPP_INFO(this->get_logger(), "Server: Goal canceled"); return; } // 更新反馈状态 feedback->state = i; // 发布反馈状态 goal_handle_->publish_feedback(feedback); RCLCPP_INFO(this->get_logger(), "Server: Publish feedback"); loop_rate.sleep(); } // 动作执行完成 if (rclcpp::ok()) { result->finish = true; goal_handle_->succeed(result); RCLCPP_INFO(this->get_logger(), "Server: Goal succeeded"); } } }; // ROS2节点主入口main函数 int main(int argc, char * argv[]) { // ROS2 C++接口初始化 rclcpp::init(argc, argv); // 创建ROS2节点对象并进行初始化 rclcpp::spin(std::make_shared<MoveCircleActionServer>()); // 关闭ROS2 C++接口 rclcpp::shutdown(); return 0; } 客户端同样也是注册了3个回调: 目标的回调:goal_response_callback 反馈的回调:feedback_callback 结果的回调:result_callback 运行代码 通信接口 在 ROS 2 中,通信接口(Communication Interface)是指节点之间用于交换信息的机制和定义。这些接口可以通过不同的通信方式(如发布/订阅、服务、动作等)实现,且每种方式都有其特定的通信协议和数据结构。 在ROS 2系统中提供了多种通信接口,每种接口都有不同的用途和行为。常见的通信接口类型包括: 话题(Topic):使用.msg文件格式定义消息类型。 服务(Service):使用.srv文件格式定义消息类型 动作(Action):使用.action文件格式定义消息类型。 对于通信接口有一些查明命令 查询通信接口:ros2 interface list 查询某个通信接口定义:ros2 interface show <接口名> 查询某个功能包中的通信接口定义:ros2 interface package <包名> 如下示例 laumy@ThinkBook-14-G7-IAH:~/dev_ws$ ros2 interface package learn_action_cpp laumy@ThinkBook-14-G7-IAH:~/dev_ws$ ros2 interface show learning_interface/srv/AddTwoInts int64 a # 第一个加数 int64 b # 第二个加数 --- int64 sum # 求和结果 下面举例创建通信接口的示例,为了方便我们直接在一个包里面创建3个不同类型的通信接口,分别对应.msg,.action,.srv。步骤如下: (1)创建一个包 ros2 pkg create my_interfaces --build-type ament_cmake (2)创建文件下存放.msg、.srv、.action文件 mkdir msg srv action (3)定义.msg文件 在 msg 文件夹中创建一个 .msg 文件。比如创建一个 MyMessage.msg 文件,定义消息格式: int32 id string name float64 value (4)定义.srv文件 在 srv 文件夹中创建一个 .srv 文件。比如创建一个 AddTwoInts.srv 文件,定义服务请求和响应格式: int64 a int64 b --- int64 sum (5)定义.action文件 在 action 文件夹中创建一个 .action 文件。比如创建一个 MoveTo.action 文件,定义动作的目标、结果和反馈格式: # Goal float64 x float64 y --- # Result bool success string message --- # Feedback float64 distance_remaining (6)修改CMakeList.txt 添加依赖:在 find_package 部分,添加对 ROS 2 生成接口工具的依赖 find_package(rosidl_default_generators REQUIRED) 添加接口文件的生成:使用 rosidl_generate_interfaces 命令生成消息、服务和动作的代码。 rosidl_generate_interfaces(${PROJECT_NAME} "msg/MyMessage.msg" "srv/AddTwoInts.srv" "action/MoveTo.action" ) 安装生成的接口文件: install(DIRECTORY msg srv action DESTINATION share/${PROJECT_NAME} ) (7)修改packge.xml文件 在 package.xml 中,添加对 rosidl_default_runtime 和 rclpy 等依赖的声明,确保能够生成并使用这些接口。 <depend>rosidl_default_runtime</depend> <depend>rclpy</depend> <depend>example_interfaces</depend> (8)编译 colcon build (9)使用定义的接口 话题通信 from my_interfaces.msg import MyMessage 服务通信 from my_interfaces.srv import AddTwoInts 动作通信 from my_interfaces.action import MoveTo 参数 在ROS2系统中,想要获取一些硬件设备如摄像头的分辨率等怎么表示了,这就用到了ROS系统中的参数。在 ROS 2 中,系统参数(System Parameters)用于存储和配置节点的运行时设置。通过参数,用户可以灵活地调整节点的行为,而无需修改源代码。ROS 2 的参数机制非常强大,支持动态更改参数值,并且能够在节点启动时通过命令行或 YAML 配置文件进行预设。 参数可以认为是多个节点可以互相访问的全局变量。 定义参数 (1)创建一个ROS2 包 参数的定义可以包含在其他功能的包中,也可以单独的定义一个包。 ros2 pkg create my_param_pkg --build-type ament_python cd my_param_pkg (2)声明参数 在 ROS 2 中,节点需要在初始化时声明参数。你可以为每个参数指定一个默认值和类型。 import rclpy from rclpy.node import Node class ParamExampleNode(Node): def __init__(self): super().__init__('param_example_node') # 声明参数,并为其设定默认值 self.declare_parameter('param_name', 'default_value') self.declare_parameter('param_int', 10) self.declare_parameter('param_bool', True) def main(args=None): rclpy.init(args=args) node = ParamExampleNode() rclpy.spin(node) rclpy.shutdown() if __name__ == '__main__': main() 使用 declare_parameter() 方法声明一个参数。 查询与设置 代码的方式查询与设置,调用get_parameter和set_parameters进行获取和设置参数 获取参数 param_value = self.get_parameter('param_name').get_parameter_value().string_value param_int_value = self.get_parameter('param_int').get_parameter_value().integer_value param_bool_value = self.get_parameter('param_bool').get_parameter_value().bool_value 设置参数 self.set_parameters([Parameter('param_name', value='new_value')]) 也可以通过YAML文件的方式设置 param_example_node: ros__parameters: param_name: "new_value" param_int: 20 param_bool: false 通过 YAML 文件来为节点提供参数配置,这对于启动时设置多个参数非常有用。使用 --params-file 参数启动节点并加载该配置文件: ros2 run my_param_pkg my_node --params-file params.yaml 还可以通过命令行的方式设置和查询。 列出节点参数 ros2 param list /param_example_node 获取参数的值 ros2 param get /param_example_node param_name 设置参数的值 ros2 param set /param_example_node param_name "new_value" 还可以通过注册参数回调来处理参数的动态更新。当参数值发生变化时,回调函数会被调用。可以通过 add_on_set_parameters_callback() 注册这个回调。 def parameter_callback(params): for param in params: self.get_logger().info(f"Parameter '{param.name}' has been updated to {param.value}") return rclpy.parameter.SetParametersResult(successful=True) self.add_on_set_parameters_callback(parameter_callback) DDS DDS(Data Distribution Service)是 ROS 2 的核心通信协议,话题、服务和动作都是基于底层的DDS实现。DDS 是一个中间件标准,它定义了数据交换、通信模式和可靠性保证的方式。ROS 2 采用 DDS 来实现节点之间的通信,提供了高效、灵活的实时数据传输机制。 DDS 提供了一些强大的特性,包括高可用性、灵活的 QoS(Quality of Service)配置、低延迟和高吞吐量。它是面向数据的,适合用于需要数据流的场景,如机器人、物联网、自动驾驶等领域。 ROS2系统中对DDS实现做了解耦,可以有不同的 DDS 实现(例如,Fast DDS、Cyclone DDS、RTI Connext DDS)提供了不同的功能和特性,但它们遵循相同的 DDS 标准。 DDS通信结构中,只有在一个domain域中才能通信,可以理解在一个网段中,所以了要能够使应用互相通信,需要将各个应用绑定到一个domain中。 DDS中还有另外一个特性就是服务特性QoS,可以设置通信的传输质量,优先级等。 在 ROS 2 中,可以通过 rclcpp 或 rclpy 中的接口来设置 QoS,下面简单举例。例如,设置话题的 QoS: from rclpy.qos import QoSProfile, QoSReliabilityPolicy, QoSHistoryPolicy from std_msgs.msg import String qos_profile = QoSProfile( reliability=QoSReliabilityPolicy.RELIABLE, history=QoSHistoryPolicy.KEEP_LAST, depth=10 ) publisher = node.create_publisher(String, 'topic_name', qos_profile) 本文关于ROS2的通信记录到此,具体在根据实践中查询吧。 附录:本文来自《ROS2智能机器人开发实践》笔记 -
ubuntu系统异常:无法进入登录桌面
概述 最近发现ubuntu系统24.04.2的版本用着用着休眠熄屏后,突然登录不了,然后重启也进入不了桌面,显示如下: 按Ctrl + Alt + F3也进入不了tty控制台。 解决办法 重启系统进入Advanced options for Ubuntu(recovery mode)模式,进去后选择进去后选 root shell。然后强制进入命令行启动。 systemctl set-default multi-user.target reboot 重启后重装 GNOME 相关包。 sudo apt install --reinstall ubuntu-desktop gdm3 gnome-shell 然后 sudo systemctl restart gdm3 如果能够进入桌面那就说明成功了,此前的问题是GNOME 桌面核心包不完整/损坏,重装后依赖被补齐所以恢复了。 因为刚才设置了每次启动都进入命令行,所以恢复默认启动进入桌面。 sudo systemctl set-default graphical.target sudo reboot 常见问题 (1)发现外接的显示器,鼠标显示老是跳动? 把内置显示器和外接的显示器缩放都改到一样200%,看起来有效果。 -

ROS2实践:创建一个包和节点
准备 在ROS2中什么是包,什么是节点? 包(Package) 是 ROS 2 的基本构建单元,包含了代码、资源、配置和依赖,组织着机器人的各个功能模块。这个packge可以理解为openwrt的package,主要用于怎么构建、编译代码,存放程序的配置等等。 节点(Node) 是 ROS 2 中执行的具体单元,它是一个程序,可以完成传感器读取、控制计算、数据处理等任务,并通过话题、服务或动作与其他节点进行通信。可以理解为openwrt中package中实际的程序,一个节点是一个进程。 一个包中可以有多个节点,节点与包是包含的关系。 安装前面的文章安装好ROS2的开发环境。 安装colcon编译工具、rosdep工具。 sudo apt install python3-colcon-ros 创建一个工作空间 mkdir -p ~/dev_ws/src python的方式 创建一个包 cd ~/dev_ws/src/ ros2 pkg create --build-type ament_cmake learning_pkg_python 创建完成后,会产生如下文件 . ├── learning_pkg_python │ ├── learning_pkg_python │ │ └── __init__.py │ ├── package.xml │ ├── resource │ │ └── learning_pkg_python │ ├── setup.cfg │ ├── setup.py │ └── test │ ├── test_copyright.py │ ├── test_flake8.py │ └── test_pep257.py 创建节点程序 在~/dev_ws/src/learning_pkg_python/learning_pkg_python目录下创建一个node_helloworld_class.py文件,实现代码如下: #! /usr/bin/env python3 # -*- coding: utf-8 -*- import rclpy from rclpy.node import Node import time class HelloworldNode(Node): def __init__(self, name): super().__init__(name) while rclpy.ok(): self.get_logger().info("Hello World") time.sleep(0.5) def main(args=None): rclpy.init(args=args) node = HelloworldNode("node_helloworld_class") rclpy.spin(node) node.destroy_node() rclpy.shutdown() 注意node_helloworld_class.py文件要和默认的init.py在一个目录下,保持同级。 设置程序入口 entry_points={ 'console_scripts': [ 'node_helloworld_class = learning_pkg_python.node_helloworld_class:main', ], }, 设置python的程序入口,让ROS2系统知道python程序的入口。 console_scripts::这告诉Python包管理器(如pip)要创建哪些命令行可执行脚本。 node_helloworld_class:这是终端中ros2 run后面直接运行的命令名称。 learning_pkg_python.node_helloworld_class:main:这是Python模块的路径(包名.模块名) 编译 cd ~/dev_ws/ colcon build 编译的时候,要切换到工程的根目录下进行编译。因为编译会在当前的根目录下生成build、install、log,而工程下会有很多包,因此建议都切换到工程的根目录下进行编译。 执行 ros2 run learning_pkg_python node_helloworld_class CPP方式 创建一个包 执行创建包的命令 ros2 pkg create --build-type ament_cmake learning_pkg_cpp 下面是生成的包的目录结构 . ├── learning_pkg_cpp │ ├── CMakeLists.txt │ ├── include │ │ └── learning_pkg_cpp │ ├── package.xml │ └── src 创建节点程序 在learning_pkg_cpp/src目录下创建一个node_helloworld_class.cpp文件,编写代码。 #include "rclcpp/rclcpp.hpp" #include "std_msgs/msg/string.hpp" class HelloWorldClass : public rclcpp::Node { public: HelloWorldClass():Node("hello_world_class") { while(rclcpp::ok()) { RCLCPP_INFO(this->get_logger(), "Hello World"); sleep(1); } } }; int main(int argc, char *argv[]) { rclcpp::init(argc, argv); rclcpp::spin(std::make_shared<HelloWorldClass>()); rclcpp::shutdown(); return 0; } 设置编译选项 python是不用编译的,但是C++程序需要编译因此需要更新CmakeLists.txt。在文件中添加一下内容。 find_package(rclcpp REQUIRED) # 查找依赖的功能包rclcpp,提供ROS2 C++的基础接口 add_executable(node_helloworld_class src/node_helloworld_class.cpp) # 添加一个可执行文件名称为node_helloworld_class,源码路径为src/node_helloworld_class.cpp ament_target_dependencies(node_helloworld_class rclcpp) #编译时链接rclcpp的依赖库 install(TARGETS node_helloworld_class DESTINATION lib/${PROJECT_NAME} ) #将可执行文件拷贝到install目录下。 编译执行 # 编译 cd ~/dev_ws/ colcon build # 运行 source install/setup.bash #先执行一下环境变量,可以补全新的命令。 常用命令 创建包 创建一个功能包的命令 ros2 pkg create --build-type <build-type> <packge_name> pkg:调用功能包相关功能的子命令。 create:创建功能包的子命令。 build-type:表示新创建的功能包是C++还是Python,如果使用C++或者C,这里是"ament_cmake";如果使用python,这里就是"ament_python"。 packege_name:新建功能包的名字。 示例 cd ~/dev_ws/src ros2 pkg create --build-type ament_cmake learning_pkg_cpp ros2 pkg create --build-type ament_python learning_pkg_python 注意执行上面命令时,就会在当前目录下进行创建包,因此为了工程目录的结构,要切换到指定的目录进行创建。 运行 ros2 run <package_name> <executable_name> [arguments] -

ROS2安装:ubuntu 24.04.2上实践
前言 本文在unbuntu 24.04.2系统上搭建ROS2系统。 No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 24.04.2 LTS Release: 24.04 Codename: noble 设置编码格式 locale # check for UTF-8 sudo apt update && sudo apt install locales sudo locale-gen en_US en_US.UTF-8 sudo update-locale LC_ALL=en_US.UTF-8 LANG=en_US.UTF-8 export LANG=en_US.UTF-8 locale # verify settings 添加ROS apt仓库 启用 universe 仓库 sudo apt install software-properties-common sudo add-apt-repository universe 添加 ROS 的 GPG key 和 repository sudo apt update && sudo apt install curl gnupg2 lsb-release sudo curl -sSL https://raw.githubusercontent.com/ros/rosdistro/master/ros.key -o /usr/share/keyrings/ros-archive-keyring.gpg 将仓库添加到列表中 如果是ros2 jazzy版本使用下面的源。 echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/ros-archive-keyring.gpg] http://packages.ros.org/ros2/ubuntu $(source /etc/os-release && echo $UBUNTU_CODENAME) main" | sudo tee /etc/apt/sources.list.d/ros2.list > /dev/null 如果是ros2 humble使用下面的源 echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/ros-archive-keyring.gpg] https://mirrors.tuna.tsinghua.edu.cn/ros2/ubuntu $(source /etc/os-release && echo $UBUNTU_CODENAME) main" | sudo tee /etc/apt/sources.list.d/ros2.list > /dev/null 安装ROS 2 下载安装ROS2-jazzy桌面版软件。 sudo apt update sudo apt upgrade sudo apt install ros-jazzy-desktop 如果是ros2-humble sudo apt update sudo apt upgrade # 安装桌面完整版(包含 RViz 等工具) sudo apt install ros-humble-desktop 设置环境变量 执行上面的安装命令,没有报错就已经成功安装好ROS2了,默认在/opt路径下。因为要常用到ROS2相关的命令,因此可以添加一下环境变量。 echo "source /opt/ros/jazzy/setup.bash" >> ~/.bashrc source ~/.bashrc 如果是ros2-humble echo "source /opt/ros/humble/setup.bash" >> ~/.bashrc source ~/.bashrc 运行测试用例 在一个终端启动如下命令,表示一个数据的发布者节点发送消息。 ros2 run demo_nodes_cpp talker [INFO] [1757919638.619982839] [talker]: Publishing: 'Hello World: 1' [INFO] [1757919639.619919625] [talker]: Publishing: 'Hello World: 2' [INFO] [1757919640.619874774] [talker]: Publishing: 'Hello World: 3' [INFO] [1757919641.619899411] [talker]: Publishing: 'Hello World: 4' [INFO] [1757919642.619969273] [talker]: Publishing: 'Hello World: 5' [INFO] [1757919643.619894999] [talker]: Publishing: 'Hello World: 6' [INFO] [1757919644.619798092] [talker]: Publishing: 'Hello World: 7' [INFO] [1757919645.619868044] [talker]: Publishing: 'Hello World: 8' [INFO] [1757919646.619927174] [talker]: Publishing: 'Hello World: 9' 在另外一个终端执行一下命令,可以订阅此消息 ros2 run demo_nodes_py listener [INFO] [1757919722.633895350] [listener]: I heard: [Hello World: 85] [INFO] [1757919723.620902142] [listener]: I heard: [Hello World: 86] [INFO] [1757919724.621171224] [listener]: I heard: [Hello World: 87] [INFO] [1757919725.621231371] [listener]: I heard: [Hello World: 88] [INFO] [1757919726.620940203] [listener]: I heard: [Hello World: 89] 如果listener能够正确接收到消息,那么ROS2就已经在系统中安装好了。 -
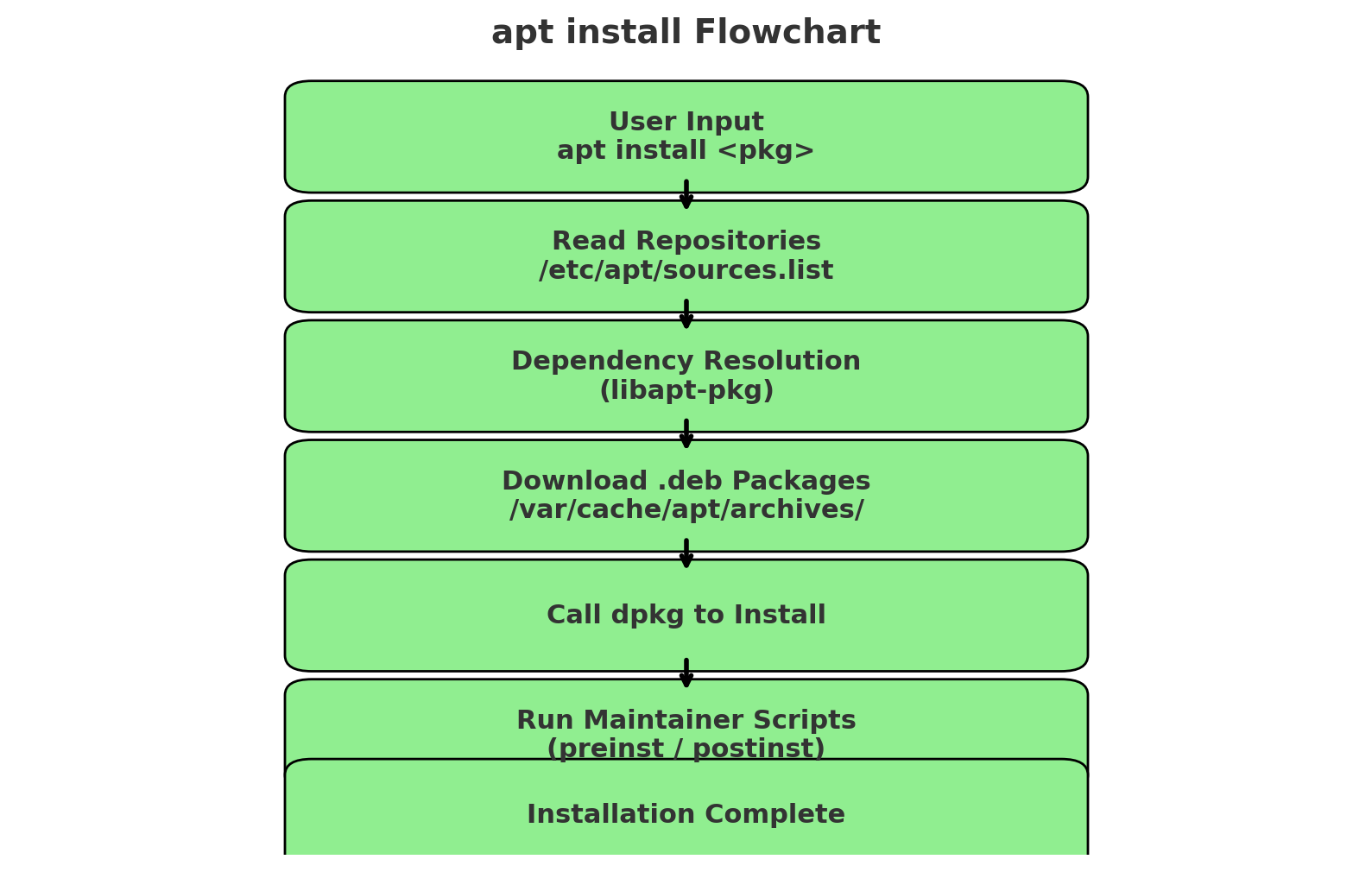
ubuntu apt 命令
介绍 apt是ubuntu/debian的包管理工具,主要用于安装、更新、卸载和管理系统软件,他是对apt-get和apt-cache的简化整合,输出更直观。 常用的apt命令 sudo apt update:从 /etc/apt/sources.list 和 /etc/apt/sources.list.d/ 指定的镜像源获取最新软件包列表。只更新索引信息,不会更新软件。 sudo apt upgrade:升级所有已安装软件到新版本,但不会移除/替换已有包。 sudo apt full-upgrade:更彻底,会移除或替换包以完成升级(系统大版本升级时常用) sudo apt install 包名:安装软件包 sudo apt remove 包名:卸载软件包但保留配置文件。 sudo apt purge 包名:卸载软件并删除配置文件。 apt search 关键字:搜索关键字的软件包。 apt show 包名:显示软件包的版本、依赖、来源等详细信息。 sudo apt autoremove:自动卸载系统中不再需要的依赖包。 sudo apt clean:清空 /var/cache/apt/archives/ 下的缓存 .deb 文件。 sudo apt autoclean:只删除无效的缓存文件(已经在源里不存在的旧版本)。 apt安装执行流程 以安装vim为例 sudo apt install vim (1)解析请求 apt 会先确认你输入的命令(如 install),以及指定的软件包名称。它会调用 libapt-pkg 库 来处理包依赖关系和软件源信息。 (2)查询软件源信息 apt读取本地缓存文件,/var/lib/apt/lists/ 下的索引文件(来自 /etc/apt/sources.list 和 /etc/apt/sources.list.d/)。如果缓存过期或你执行了 apt update,apt 会先通过 HTTP/HTTPS 向镜像源服务器拉取最新的软件包索引。 (3)依赖解析 apt 会分析你要安装的软件包需要哪些依赖(Dependencies)。依赖可能有必须依赖(必装),推荐依赖(默认安装),建议依赖(不自动安装,只提示)。apt通过SAT求解器选择最佳依赖组合。 (4)下载软件包 apt 确定要安装的 .deb 包后,从配置的镜像源下载对应的文件。下载位置:/var/cache/apt/archives/。apt 内部通过 Acquire 系统(支持 HTTP、HTTPS、FTP 等协议)拉取数据,并验证 GPG 签名 确保包没有被篡改。 (5)安装与配置 apt 把下载好的 .deb 包调用dpkg(Debian package manager) 处理。 dpkg -i xxx.deb dpkg 负责解压 .deb,把文件放到系统目录里(如 /usr/bin、/etc/ 等),并运行包的安装脚本(preinst、postinst、prerm、postrm)。apt 会在这个过程中自动处理依赖包的安装顺序。 (6)触发系统更新 完成安装后,apt 可能会调用:ldconfig 更新共享库缓存、update-initramfs 更新内核启动镜像、systemctl daemon-reload 重载 systemd 服务。 软件源 软件源是apt update/install时定义系统如何找到、解析和使用软件仓库的。 旧版 软件源的配置在如下地址。 /etc/apt/sources.list /etc/apt/sources.list.d/*.list 一条软件源的格式大致如下: deb http://mirrors.aliyun.com/ubuntu jammy main restricted universe multiverse deb:二进制包仓库(还有 deb-src 表示源码包)。 http://mirrors.aliyun.com/ubuntu:镜像源地址。 jammy:发行版代号(Ubuntu 22.04 LTS = jammy)。 main restricted universe multiverse:启用的组件。 新版 从 Ubuntu 22.04 LTS(部分更新后)和 23.04 起,apt 引入了一个新的配置格式,新格式(.sources YAML 格式): Types: deb URIs: http://archive.ubuntu.com/ubuntu Suites: jammy Components: main restricted universe multiverse 新格式的文件存放路径在 /etc/apt/sources.list.d/ubuntu.sources 内容如下: Types: deb URIs: http://cn.archive.ubuntu.com/ubuntu/ Suites: oracular oracular-updates oracular-backports Components: main restricted universe multiverse Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg Types: deb URIs: http://security.ubuntu.com/ubuntu/ Suites: oracular-security Components: main restricted universe multiverse Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg 第一段为主源+更新+回溯、第二段为安全更新源。 add-apt-repository add-apt-repository是用于添加/删除 APT 软件源(包括 PPA 和官方仓库组件)。这个命令由 software-properties-common 包提供。其目的简化对软件包源 /etc/apt/sources.list 和 /etc/apt/sources.list.d/x.list 文件的修改。 要使用add-apt-repository命令,需要安装software-properties-common工具,该工具包含了add-apt-repository命令。 sudo apt install software-properties-common add-apt-repository的语法为: sudo add-apt-repository [选项] <repository> 常见 repository类型: - PPA(个人/团队维护):ppa:用户名/仓库名。 - 官方仓库组件:universe、multiverse、restricted - 完整仓库地址:deb http://url distro component PPA PPA (Personal Package Archive)是个人/团队维护的软件,作用是提供官方仓库里没有的软件,或者比官方更快更新的版本。命名规则:ppa:用户名/仓库名。如下: sudo add-apt-repository ppa:deadsnakes/ppa deadsnakes → 维护者的用户名 ppa → 这个维护者创建的一个仓库,里面放了多个 Python 新版本 功能:能让你在 Ubuntu 上安装 Python 3.12、3.13 等官方仓库还没有的版本。 PPA 就像是别人开的小摊位,卖的是他们自己编译打包的软件。你可以信任并从那买,而不必等官方超市上架。 使用步骤: 添加PPA:sudo add-apt-repository ppa:<用户名>/<仓库名>;sudo apt update 安装软件:sudo apt install <软件包名> 删除PPA:sudo add-apt-repository -r ppa:<用户名>/<仓库名>;sudo apt update 示例 1:安装新版 Python,Ubuntu 自带的 Python 可能偏旧,如果想安装较新的 Python(比如 Python 3.12) sudo add-apt-repository ppa:deadsnakes/ppa sudo apt update sudo apt install python3.12 示例 2:安装新版 FFmpeg,官方仓库里的 FFmpeg 版本可能很老,如果你需要更新: sudo add-apt-repository ppa:savoury1/ffmpeg4 sudo apt update sudo apt install ffmpeg 示例 3:移除 PPA 安装的软件并恢复官方版本,假如你安装了 PPA 版本的 VLC,后来想回退到 Ubuntu 官方版本: sudo add-apt-repository -r ppa:videolan/stable-daily sudo apt update sudo apt install ppa-purge sudo ppa-purge ppa:videolan/stable-daily 官方仓库 组件 维护者 软件许可 举例 默认启用? main Ubuntu 官方团队 100% 开源、免费 bash、apt、systemd ✅ 默认启用 universe 社区志愿者维护 开源,但官方不保证支持 vim、ffmpeg ❌ 默认关 restricted 官方维护,但包含闭源驱动 通常是硬件驱动 NVIDIA/AMD 驱动 ❌ 默认关 multiverse 可能受限(版权/专利) 不完全自由,可能有法律限制 MP3 解码器、某些编解码器 ❌ 默认关 sudo add-apt-repository universe sudo add-apt-repository restricted sudo add-apt-repository multiverse sudo apt update 这几条命令分别启用: universe → 更多社区软件(开源,但官方不负责) restricted → 闭源驱动(主要是显卡、WiFi 驱动) multiverse → 可能有版权问题的软件(比如 DVD 解码器、某些编解码器) 总结 apt update → 更新索引 apt upgrade/full-upgrade → 升级系统 apt install/remove/purge → 安装和卸载软件 apt search/show → 查询软件 apt autoremove/clean/autoclean → 清理 -
Isaac Sim 快速入门:三种工作流程示例
简介 如果是NVIDIA Isaac Sim的新用户,可以按照本文的两个示例来体验Isaac Sim。本文主要提供Isaac Sim基础使用教程、机器人基础教程。 在快速入门教程中,所有可通过 GUI 执行的操作同样也能用 Python 实现。您可以在 GUI 操作与 Python 脚本之间自由切换。您在 GUI 中创建的所有内容都能保存为 USD 文件的一部分。 例如,您可以通过图形界面创建世界,并为机器人添加所需动作。随后将整个 USD 文件导入独立的 Python 脚本中,根据需求系统性地修改属性。 基础使用教程 本教程涵盖 Isaac Sim 的基础操作,包括界面导航、场景对象添加、查看对象基本属性以及运行模拟等内容。 通过本教程,您将从空白场景开始,根据三种不同工作流程的选择,最终实现机器人运动控制。提供三种不同工作流程的目的是展示 Isaac Sim 可根据需求以多种方式灵活使用。 可以查看两种工作流中的脚本以了解它们的差异。通过对比分析,有助于掌握如何执行完全相同的任务: 扩展脚本可在Window > Examples > Robotics Examples中找到,然后单击浏览器右上角的**Open Script **按钮。 独立脚本位于 \<isaac-sim-root-dir>/standalone_examples/tutorials/ 文件夹内。 可以通过编辑扩展示例中的任意脚本来体验"hot-reloading"功能。保存文件后,无需关闭模拟器即可立即看到变更生效。 在官方教程中有3个标签页,三个标签页执行相同操作并达成相同结果。 GUI: 图形用户界面 Extensions:扩展功能 Standalone Python:独立Python环境 GUI方式 步骤1:启动Isaac Sim linux:cd ~/isaacsim && ./isaac-sim.selector.sh windows:双击isaac-sim.selector.bat 模拟器完全加载后,创建新场景: 从顶部菜单栏点击File > New。首次启动 Isaac Sim 时,可能需要 5-10 分钟完成初始化。 步骤2: 添加地平面 为场景添加地平面:从顶部菜单栏点击Create > Physics > Ground Plane。 步骤3:添加光源 可以为场景添加光源以照亮其中的物体。如果场景中有光源但没有物体反射光线,场景仍会显得昏暗。 在顶部菜单栏中,点击Create > Lights > Distant Light。 步骤4:添加视觉立方体 "视觉"立方体是指没有附加物理属性的立方体,例如没有质量、没有碰撞体积。这种立方体不会受重力影响下落,也不会与其他物体发生碰撞。 从顶部菜单栏中,依次点击Create > Shape > Cube. 在用户界面最左侧找到箭头图标并点击Play。运行模拟时立方体不会有任何动作。 步骤5:移动、旋转与缩放立方体 使用左侧工具栏上的各种操控工具来操作立方体。 按下"W"键或点击移动工具即可拖拽移动立方体。通过点击箭头并拖拽可单轴移动,点击彩色方块并拖拽可双轴移动,点击工具中心的圆点并拖拽则可三轴自由移动。 按下“E”键或点击旋转控制器来旋转立方体。 按下“R”键或点击缩放控制器来调整立方体大小。点击箭头并拖动可单维度缩放,点击彩色方块并拖动可双维度缩放,点击控制器中心的圆圈并拖动则可实现三维同步缩放。 按下“esc”键取消选中立方体。 对于“移动”和“旋转”操作,可选择基于局部坐标系或世界坐标系进行操作。长按控制器即可查看选项。 可以通过立方体的Property属性面板进行更精确的修改,只需在对应输入框中输入具体数值即可。点击输入框旁的蓝色方块可将数值重置为默认值。 步骤6:添加物理与碰撞属性 常见的物理属性包括质量和惯性矩阵,这些属性使物体能够在重力作用下下落。碰撞属性则决定了物体能否与其他物体发生碰撞。 物理和碰撞属性可以分别添加,因此你可以创建一个能与其他物体碰撞但不受重力影响的物体,或是受重力影响但不会与其他物体碰撞的物体。但在多数情况下,这两个属性会同时添加。 为立方体添加物理和碰撞属性: 在场景树中找到对象("/World/Cube")并高亮显示它。 从工作区右下角的Property属性面板中,点击"Add"按钮并在下拉菜单中选择Physics。这将显示可添加到对象的一系列属性选项。 选择Rigid Body with Colliders Preset“带碰撞器的刚体预设”可为对象同时添加物理和碰撞网格。 按下播放Play按钮,观察立方体在重力作用下坠落并与地平面发生碰撞。 教程结束,记得保存你的工作。 扩展功能方式 通过一个名为"脚本编辑器"的现有扩展模块来演示扩展工作流的特性。脚本编辑器允许用户通过 Python 与场景进行交互。主要使用与独立 Python 工作流相同的 Python API。当我们开始与模拟时间轴交互时,特别是下一个教程中,这两种工作流的区别将变得清晰。 步骤1:启动 启动一个新的 Isaac Sim 实例,转到顶部菜单栏并点击Window > Script Editor。 步骤2:添加地平面 要通过交互式 Python 添加地平面,请将以下代码片段复制粘贴到脚本编辑器中,然后点击底部的运行Run按钮执行。 from isaacsim.core.api.objects.ground_plane import GroundPlane GroundPlane(prim_path="/World/GroundPlane", z_position=0) 步骤3:添加光源 可以为场景添加光源以照亮其中的物体。如果场景中有光源但没有物体反射光线,场景仍会显得昏暗。 在脚本编辑器中新建一个标签页(Tab > Add Tab)。 在脚本编辑器中复制粘贴以下代码片段并运行,即可添加光源。 import omni.usd from pxr import Sdf, UsdLux stage = omni.usd.get_context().get_stage() distantLight = UsdLux.DistantLight.Define(stage, Sdf.Path("/DistantLight")) distantLight.CreateIntensityAttr(300) 步骤4:添加视觉立方体 在脚本编辑器中新建一个标签页 (Tab > Add Tab)。 在脚本编辑器中复制粘贴以下代码片段并运行,即可添加两个立方体。我们将保留其中一个作为纯视觉对象,同时为另一个添加物理和碰撞属性以便对比。 import numpy as np from isaacsim.core.api.objects import VisualCuboid VisualCuboid( prim_path="/visual_cube", name="visual_cube", position=np.array([0, 0.5, 0.5]), size=0.3, color=np.array([255, 255, 0]), ) VisualCuboid( prim_path="/test_cube", name="test_cube", position=np.array([0, -0.5, 0.5]), size=0.3, color=np.array([0, 255, 255]), ) Isaac Sim 核心 API 是对原生 USD 和物理引擎 API 的封装。您可以使用原生 USD API 添加一个视觉立方体(不含物理和颜色属性)。请注意原生 USD API 更为冗长,但能提供对每个属性的更精细控制。 from pxr import UsdPhysics, PhysxSchema, Gf, PhysicsSchemaTools, UsdGeom import omni # USD api for getting the stage stage = omni.usd.get_context().get_stage() # Adding a Cube path = "/visual_cube_usd" cubeGeom = UsdGeom.Cube.Define(stage, path) cubePrim = stage.GetPrimAtPath(path) size = 0.5 offset = Gf.Vec3f(1.5,-0.2,1.0) cubeGeom.CreateSizeAttr(size) if not cubePrim.HasAttribute("xformOp:translate"): UsdGeom.Xformable(cubePrim).AddTranslateOp().Set(offset) else: cubePrim.GetAttribute("xformOp:translate").Set(offset) 步骤5:添加物理与碰撞属性 在 Isaac Sim 核心 API 中,我们为常用对象编写了封装器,这些封装器附带所有物理和碰撞属性。您可以通过以下代码片段添加一个具有物理和碰撞属性的立方体。 import numpy as np from isaacsim.core.api.objects import DynamicCuboid DynamicCuboid( prim_path="/dynamic_cube", name="dynamic_cube", position=np.array([0, -1.0, 1.0]), scale=np.array([0.6, 0.5, 0.2]), size=1.0, color=np.array([255, 0, 0]), ) 另外,如果想修改现有对象使其具备物理和碰撞属性,可以使用以下代码片段。 from isaacsim.core.prims import RigidPrim RigidPrim("/test_cube") from isaacsim.core.prims import GeometryPrim prim = GeometryPrim("/test_cube") prim.apply_collision_apis() 点击播放Play按钮,观察立方体在重力作用下坠落并与地平面碰撞。 步骤6: 移动、旋转与缩放立方体 使用核心 API 移动物体: import numpy as np from isaacsim.core.prims import XFormPrim translate_offset = np.array([[1.5,1.2,1.0]]) orientation_offset = np.array([[0.7,0.7,0,1]]) # note this is in radians scale = np.array([[1,1.5,0.2]]) stage = omni.usd.get_context().get_stage() cube_in_coreapi = XFormPrim(prim_paths_expr="/test_cube") cube_in_coreapi.set_world_poses(translate_offset, orientation_offset) cube_in_coreapi.set_local_scales(scale) 使用原始 USD API 移动物体: from pxr import UsdGeom, Gf import omni.usd stage = omni.usd.get_context().get_stage() cube_prim = stage.GetPrimAtPath("/visual_cube_usd") translate_offset = Gf.Vec3f(1.5,-0.2,1.0) rotate_offset = Gf.Vec3f(90,-90,180) # note this is in degrees scale = Gf.Vec3f(1,1.5,0.2) # translation if not cube_prim.HasAttribute("xformOp:translate"): UsdGeom.Xformable(cube_prim).AddTranslateOp().Set(translate_offset) else: cube_prim.GetAttribute("xformOp:translate").Set(translate_offset) # rotation if not cube_prim.HasAttribute("xformOp:rotateXYZ"): # there are also "xformOp:orient" for quaternion rotation, as well as "xformOp:rotateX", "xformOp:rotateY", "xformOp:rotateZ" for individual axis rotation UsdGeom.Xformable(cube_prim).AddRotateXYZOp().Set(rotate_offset) else: cube_prim.GetAttribute("xformOp:rotateXYZ").Set(rotate_offset) # scale if not cube_prim.HasAttribute("xformOp:scale"): UsdGeom.Xformable(cube_prim).AddScaleOp().Set(scale) else: cube_prim.GetAttribute("xformOp:scale").Set(scale) 独立python环境方式 脚本位于standalone_examples/tutorials/getting_started.py,要运行该脚本,请打开终端,导航至 Isaac Sim 安装根目录,并执行以下命令: ./python.sh standalone_examples/tutorials/getting_started.py 机器人基础教程 本小节介绍如何将机器人添加到场景中、移动机器人以及检查机器人状态。在开始教程前,请确保已经完成了上一章节isaac sim基础使用教程。 GUI方式 步骤1:向场景中添加机器人 新建场景:通过File > New Stage.。 添加机器人:向场景添加机器人,从顶部菜单栏点击Create > Robots > Franka Emika Panda Arm。 步骤2:检查机器人 使用物理检查器查看机器人关节属性。 前往Tools > Physics > Physics Inspector.。右侧将打开一个窗口。 选择 Franka 进行检查。窗口默认会显示关节信息,例如上下限位及默认位置。 点击右上角的三横线图标可查看更多选项,例如关节刚度和阻尼系数。 可选)修改这些数值,观察舞台上机器人随参数变化的运动。修改成功后会出现绿色对勾标记。 点击绿色对勾按钮,将当前参数设为机器人新的默认值。 步骤3:控制机器人 基于图形界面的机器人控制器位于 Omniverse 可视化编程工具 OmniGraphs 中。OmniGraph 相关章节提供了更深入的教程指导。本教程将通过快捷工具生成控制图,然后在 OmniGraph 编辑器中查看该控制图。 通过菜单栏选择 Tools > Robotics > Omnigraph Controllers > Joint Position.来打开控制图生成器。。 在新弹出的关节位置控制器**Articulation Position Controller Inputs **输入窗口中,点击 Robot Prim 字段旁的添加"Add"按钮。 选择 Franka 作为目标对象。 点击确定生成图表。 要移动机器人的话按照下面步骤 在右上角的“舞台”选项卡中,选择Graph > Position_Controller.。 选择 JointCommandArray 节点。您可以通过在舞台树中选择该节点,或在图表编辑器中选择该节点来完成此操作。 在右下角的Property选项卡中,可以看到关节命令值。构造数组节点Construct Array Node下的输入Inputs项对应机器人上的关节,从基座关节开始。 点击+按住+拖动不同的数值字段,或输入不同的值,可以看到机械臂位置发生变化。 点击Play开始模拟。 要生成可视化的图标 打开图表编辑器窗口:**Window > Graph Editors > Action Graph. **。该编辑器窗口会在包含机器人的视口选项卡下方以新选项卡形式打开。 调出新打开的浏览器标签页。 点击位于图形编辑器窗口中央的Edit Action Graph选项。 从列表中选择唯一存在的图形。 选择一个数组并查看Stage和Property选项卡,以了解每个数组节点关联的值。 在图形中选择"关节控制器"Articulation Controller对象以查看其属性。 Extension方式 步骤1:向场景添加机器人 新建一个场景(File > New)。要将机器人添加到场景中,请将以下代码片段复制粘贴到脚本编辑器中并运行。 import carb from isaacsim.core.prims import Articulation from isaacsim.core.utils.stage import add_reference_to_stage from isaacsim.storage.native import get_assets_root_path import numpy as np assets_root_path = get_assets_root_path() if assets_root_path is None: carb.log_error("Could not find Isaac Sim assets folder") usd_path = assets_root_path + "/Isaac/Robots/FrankaRobotics/FrankaPanda/franka.usd" prim_path = "/World/Arm" add_reference_to_stage(usd_path=usd_path, prim_path=prim_path) arm_handle = Articulation(prim_paths_expr=prim_path, name="Arm") arm_handle.set_world_poses(positions=np.array([[0, -1, 0]])) 步骤2:检查机器人 Isaac Sim 核心 API 提供了许多函数调用来获取机器人相关信息。以下是查询关节数量与名称、各类关节属性以及关节状态的示例代码。 在脚本编辑器中新建标签页,复制粘贴以下代码片段。该操作需在上一步添加机器人完成后执行(此时 arm_handle 已创建)。运行代码前需先点击播放Play按钮,这些命令需在物理引擎运行状态下才能生效。 # Get the number of joints num_joints = arm_handle.num_joints print("Number of joints: ", num_joints) # Get joint names joint_names = arm_handle.joint_names print("Joint names: ", joint_names) # Get joint limits joint_limits = arm_handle.get_dof_limits() print("Joint limits: ", joint_limits) # Get joint positions joint_positions = arm_handle.get_joint_positions() print("Joint positions: ", joint_positions) 请注意,点击"运行"时仅会打印一次状态信息,即使模拟正在持续运行。如需查看最新状态,需反复点击"运行"按钮。若希望在每个物理步长都打印信息,需要将这些命令插入到每个物理步长都会执行的回调函数中。在章节"工作流程"中详细讲解时间步进机制。 要将命令插入物理回调中,请在脚本编辑器的单独标签页中运行以下代码片段。 import asyncio from isaacsim.core.api.simulation_context import SimulationContext async def test(): def print_state(dt): joint_positions = arm_handle.get_joint_positions() print("Joint positions: ", joint_positions) simulation_context = SimulationContext() await simulation_context.initialize_simulation_context_async() await simulation_context.reset_async() simulation_context.add_physics_callback("printing_state", print_state) asyncio.ensure_future(test()) 按下播放键启动模拟,然后运行该代码片段。您将看到终端在每个物理步骤打印出的信息。 如果不再需要每个物理步骤都打印信息,可以通过运行以下代码片段来移除物理回调。 simulation_context = SimulationContext() simulation_context.remove_physics_callback("printing_state") 步骤3:控制机器人 在 Isaac Sim 中有多种控制机器人的方式。最底层是直接发送关节指令来设置位置、速度和力矩。以下是通过关节层级的 Articulation API 控制机器人的示例。 在脚本编辑器中新建一个标签页,复制粘贴以下代码片段。该代码需在前述添加机器人步骤完成后运行(此时 arm_handle 已建立)。运行代码片段前请先点击播放键Play。这些指令需在物理引擎运行状态下生效。我们将提供两个位置供您切换。若您已将上述打印状态代码片段添加至每个物理步骤,当机器人移动时您应能看到打印的关节编号发生变化。 # Set joint position randomly arm_handle.set_joint_positions([[-1.5, 0.0, 0.0, -1.5, 0.0, 1.5, 0.5, 0.04, 0.04]]) # Set all joints to 0 arm_handle.set_joint_positions([[0.0, 0.0, 0.0 , 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]]) 与前述 get_joint_positions 功能类似,此处的 set_joint_positions 仅在您点击"运行"时执行一次。若您希望在每个物理步骤发送指令,则需将这些命令插入到每个物理步骤都会执行的物理回调函数中。 独立Python方式 脚本位于 standalone_examples/tutorials/getting_started_robot.py 。要运行该脚本,请打开终端,导航至 Isaac Sim 安装的根目录,并执行以下命令: ./python.sh standalone_examples/tutorials/getting_started_robot.py 到此就完成了基本的操作了,接下来就是一系列的教程可以参考:《机器人设置教程系列》。 -
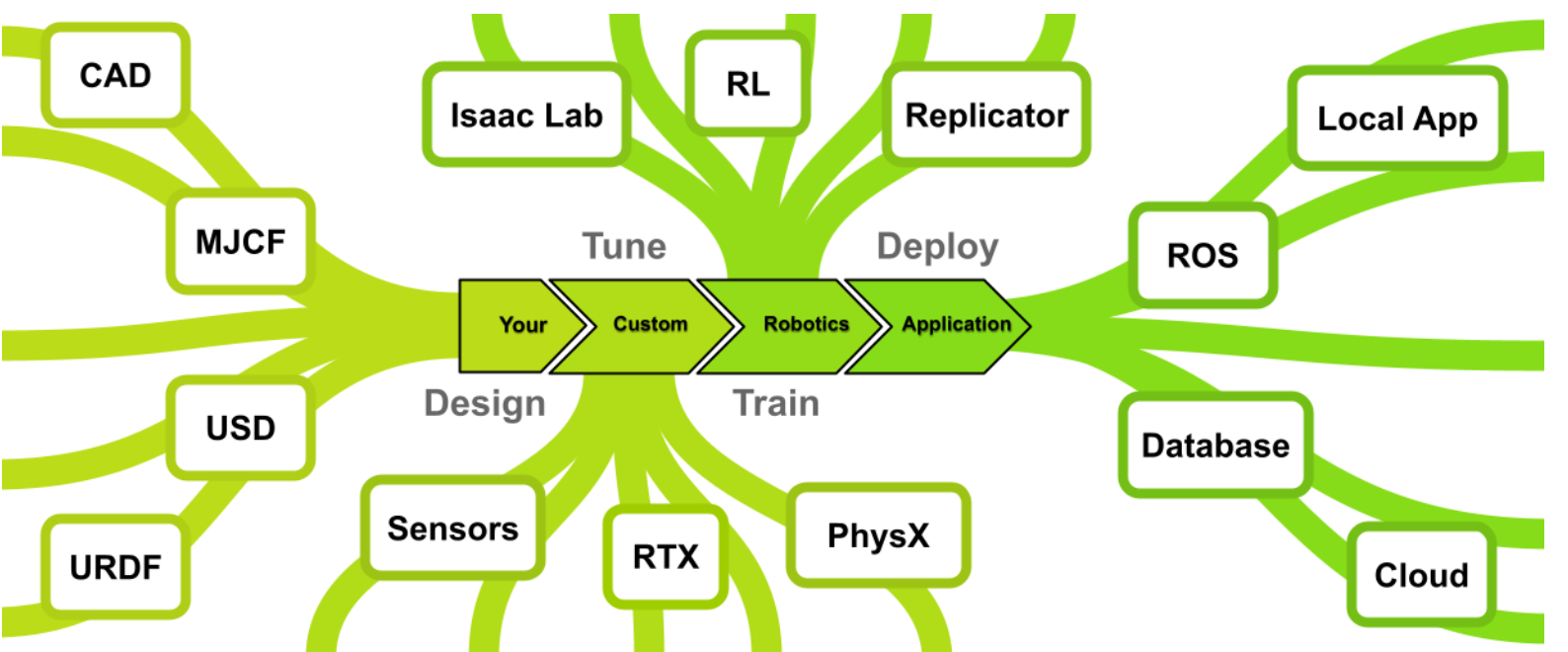
Isaac Sim v5.0.0:探索AI 机器人仿真平台
什么是isaac sim NVIDIA Issac Sim是一款基于NVIDIA omniverse构建的参考应用应用程序,使开发人员能够在基于物理的虚拟环境开发、模拟和测试AI机器人。 设计 Isaac Sim提供了一系列工作流程,用于导入和调整最常见格式(包括Onshape、统一机器人描述格式URDF和MuJoco XML格式MJCF)设计的机械系统。这通过使用通用常见描述USD实现,该开源3D常见描述API具有高度可扩展性,是Isaac Sim核心的统一数据交换格式。 微调与训练 Isaac Sim的核心功能在与其仿真能力本身:这是一个基于GPU的高保真physX物理引擎,能够支持工业规模的传感器PTX渲染。该平台通过直接调用GPU,实现了对各类传感器(包括摄像头、激光雷达和接触式传感器)的仿真模拟。这种能力进而支持数字孪生技术的实现,让您的端到端流程在真实机器人启动前就能完成测试运行。Isaac Sim提供了一整套工具链:通过Replicator生成合成数据,利用Omnigraph编程仿真环境,调整PhysX参数以匹配实现物理特性,最终通过强化学习RL等多样化方法训练控制智能体。 部署 Isaac Sim预先配备了所有必要组建,不仅能将智能体部署到真实机器人,还能构建与这类系统完全集成的应用程序。Omniverse提供了应用基础设施API,包括图形界面和文件管理功能。该平台还提供了与ROS 2桥接API,实现真实机器人与仿真的直接通信,同时搭建NVIDIA Isaac ROS:一套高性能硬件加速的ROS 2工具包,专为打造自主机器人而设计。 快速入门 快速安装:一小时内完成安装并开始使用。 Isaac Sim基础教程:助您快速上手 NVIDIA Isaac 仿真平台 工作站安装:本地工作站安装指南。 容器安装:远程桌面服务器安装指南。 开发工具:用于调试和开发的工具与环境。 python脚本与教程:使用 NVIDIA Isaac Sim 核心 Python API 构建环境、机器人和任务的工具与教程。 图形用户界面参考:通过图形用户界面了解 NVIDIA Isaac Sim 中的机器人基础概念。 导入与导出功能:支持多种文件格式的机器人及资产导入导出功能。 机器人设置:Isaac Sim 提供的机器人修改工具集。 机器人设置教程系列:关于机器人配置工具及工作流程的系列教学。 机器人仿真:用于模拟机器人的控制器与运动生成工具。 ROS2:ROS2桥接与接口。 Isaac Lab:强化学习框架与克隆器API。 合成数据生成:用于生成合成书记的工具集与工作流程。 数字孪生::用于构建和操作数字孪生的工具,如仓库物流、Cortex 和地图绘制。 系统架构 Isaac Sim旨在支持新型机器人工具的创建,并增强现有工具的功能。该平台为为C++和Python提供了灵活的API,可根据需求以不同深度集成到项目中。平台目标并非与现有软件竞争,而是与之协调并提升其能力。为此,Isaac Sim的许多组建都是开源的,可自由独立使用。可以在Onshape中设计机器人,用Isaac Sim模拟传感器,并通过ROS或其他消息系统控制场景。同样,也可以完全基于isaac sim提供的ingt构建完整的独立应用程序。 Omniverse Kit Isaac Sim基于Omniverse Kit构建,这是一个用于开发原生Omniverse应用和微服务的工具包。Omniverse Kit通过一系列轻量级插件提供多样化功能。这些插件采样C语言接口开发以确保API持久兼容性,同时提供python解释器以便进行便捷的脚本编写和定制。 通过 Python API 可以为 Omniverse Kit 编写新扩展,或为 Omniverse 创建新体验。 开发工作流 Isaac Sim基于C++和Python构建,通常分别通过编译插件和绑定进行操作。这意味着该平台能够支持多种工作流程,拥有构建和交互利用Isaac Sim项目。Isaac Sim提供完整的OMniverse应用程序,拥有与机器人交互和仿真,虽然这是用户与平台互动的最常见方式,但绝非唯一途径。Isaac Sim还以VS code和Jupyter Notebook扩展形式提供直接python开发支持。此外Isaac Sim不仅限与同步操作,还能通过ROS2实现硬件在环运行,从而促进仿真到现实的迁移以及数字孪生应用。 USD格式 NVIDIA Isaac Sim采用USD通过常见描述文件格式呈现常见。Universal Scene Description(USD)是由皮克斯开发的一种易于扩展的开源 3D 场景描述文件格式,专为内容创作和不同工具间的交互而设计。凭借其强大功能和通用性,USD 不仅被视觉特效领域广泛采用,还应用于建筑、设计、机器人、制造等多个学科领域。 安装指南 Isaac Sim支持windows和Linux系统安装。可通过容器( container)、工作站(workstation)、云端(in the cloud)、直播流(livestream)或者python环境进行部署,根据使用场景,还可以自定义硬件配置。 快速安装 快速安装适用于演示场景,可让您了解完整产品的功能概览。完成快速安装后,您能创建包含机器人的虚拟房间,这将更全面的展示产品能力。该只能面向具备基础计算机知识的安装人员。 windows或linux系统快速安装步骤: (1)下载以下任意安装包 windows: windows系统兼容性检查工具 linux:linux系统兼容性检查工具 (2)将安装包解压至制定文件夹 (3)运行脚本检查 window:请双击 omni.isaac.sim.compatibility_check.bat。 linux:./omni.isaac.sim.compatibility_check.sh 更多信息参阅:Isaac Sim兼容性检查 (4)下载任意一个安装包 window:https://download.isaacsim.omniverse.nvidia.com/isaac-sim-standalone-5.0.0-windows-x86_64.zip linux:https://download.isaacsim.omniverse.nvidia.com/isaac-sim-standalone-5.0.0-linux-x86_64.zip (5)创建一个isaac-sim的文件夹 在windows的C:/或linux根目录下直接创建一个名为isaac-sim的文件夹。然后将下载的文件解压到文件夹中去。 (6)在isaac-sim文件夹中,执行操作 window:请双击 isaac-sim.selector.bat linux:命令窗口中运行 ./post_install.sh ,然后运行 ./isaac-sim.selector.sh。 (7)在issac应用选择起窗口,选择"start" 有关应用选择器的详细信息,请参阅《Isaac Sim 应用选择器》。随后将打开另一个命令窗口并运行脚本,此过程可能比预期耗时更长。在此期间由于会出现空白窗口,可能看似安装失败。请继续等待。 (8)issac启动成功 (9)选择 选择创建一个房间 Create > Environment > Simple Room. (10)选择创建一个机械臂 Create > Robots > Franka Emika Panda Arm. (11)点击运行模拟 在屏幕最左侧寻找箭头按钮,点击它来运行一段简短模拟。 isaac 系统需求 对操作系统需求如下 对驱动的要求如下 工作站安装 工作站安装方式是在本地允许模拟器,需要对本地电脑有较高的要求,官方要求最低的配置要为RTX4080的显卡。因此若本地配置了GPU的windows或linux系统上以GUI应用程序允许isaac sim,推荐采用工作站安装方式。下面是安装步骤 (1)isaac Sim兼容性检查工具 Isaac 兼容性检查工具是一款轻量级应用程序,可通过编程方式检查本地的软硬件要求,会给出运行NVIDIA isaac sim时那些要求满足或不满足。 下载工具:Latest Release兼容性工具 解压:将压缩包解压到指定文件夹。 运行:在Linux系统上云霄omni.isaac.sim.compatibility_check.sh脚本,在windows系统上运行omni.isaac.sim.compatibility_check.bat文件。 点击工具的"Test Kit"按钮就会显示测试结果。 应用程序会以不同颜色高亮显示以下状态: 绿色:表示优秀 浅绿色:表示良好 橙色:表示基本满足,建议更高配置 红色:不足/不支持 应用程序检查维度为: NVIDIA GPU:驱动程序版本、支持RTX功能的GPU、显存容量。 CPU、内存和存储:CPU处理器、CPU核心数量、运行内存、可用存储空间。 others:操作系统、显示设备。 对于操作系统如果ubuntu大于版本号也会变成红色,可先测试是否可运行,实测是可以,但不排除有兼容性问题。 (2)下载软件包 下载链接:Latest Release,根据自己的系统选择软件包下载的本地。 在本地创建一个isaacsim文件夹,然后将压缩包解压到文件夹。 (3)运行启动 先创建extension_examples 的符号链接,请运行 post_install 脚本。 linux:./post_install.sh windows:双击 post_install.bat 文件 然后就可以启动应用程序 linux: 执行 ./isaac-sim.selector.sh windows:双击isaac-sim.selector.bat 文件 启动后会弹出以下界面 在弹出的窗口中选择isaac Sim Full,然后点击START就可以运行。启动过程中可能要一点时间,如果期间弹出“程序无法响应”,可以选择等待,以免被误杀。 启动后就可以开始第一个基础教程了:基础教程。 总结一下命令执行的实例: linux系统 mkdir ~/isaacsim cd ~/Downloads unzip "isaac-sim-standalone-5.0.0-linux-x86_64.zip" -d ~/isaacsim cd ~/isaacsim ./post_install.sh ./isaac-sim.selector.sh window系统 mkdir C:\isaacsim cd %USERPROFILE%/Downloads tar -xvzf "isaac-sim-standalone-5.0.0-windows-x86_64.zip" -C C:\isaacsim cd C:\isaacsim post_install.bat isaac-sim.selector.bat Docker容器安装 在远程服务器或者云端部署isaac sim建议使用docker容器的方式。 (1)检查系统是否满足需求 首先先确保系统满足运行NVIDIA isaac Sim所需的系统要求和驱动程序要求。 (2)安装docker Docker installation using the convenience script curl -fsSL https://get.docker.com -o get-docker.sh sudo sh get-docker.sh Post-install steps for Docker sudo groupadd docker sudo usermod -aG docker $USER newgrp docker Verify Docker docker run hello-world 详细的docker安装步骤见docker安装,安装后的配置步骤见配置步骤。 (3)安装NVIDIA容器工具包 Configure the repository curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list \ && \ sudo apt-get update Install the NVIDIA Container Toolkit packages sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker Configure the container runtime sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker Verify NVIDIA Container Toolkit docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi 安装最新版本的 NVIDIA 容器工具包以获取安全补丁。 (4)容器部署 docker pull nvcr.io/nvidia/isaac-sim:5.0.0 拉取isaac sim容器。 然后以交互式bash会话运行isaac sim容器。 docker run --name isaac-sim --entrypoint bash -it --runtime=nvidia --gpus all -e "ACCEPT_EULA=Y" --rm --network=host \ -e "PRIVACY_CONSENT=Y" \ -v ~/docker/isaac-sim/cache/kit:/isaac-sim/kit/cache:rw \ -v ~/docker/isaac-sim/cache/ov:/root/.cache/ov:rw \ -v ~/docker/isaac-sim/cache/pip:/root/.cache/pip:rw \ -v ~/docker/isaac-sim/cache/glcache:/root/.cache/nvidia/GLCache:rw \ -v ~/docker/isaac-sim/cache/computecache:/root/.nv/ComputeCache:rw \ -v ~/docker/isaac-sim/logs:/root/.nvidia-omniverse/logs:rw \ -v ~/docker/isaac-sim/data:/root/.local/share/ov/data:rw \ -v ~/docker/isaac-sim/documents:/root/Documents:rw \ nvcr.io/nvidia/isaac-sim:5.0.0 使用 -e "ACCEPT_EULA=Y" 标志即表示您接受 NVIDIA Omniverse 许可协议中规定的镜像许可协议。 使用 -e "PRIVACY_CONSENT=Y" 标志即表示您同意数据收集与使用协议中的条款。不设置此标志即可选择退出数据收集。 使用-e "PRIVACY_USERID=\<emai\l>" 标志可选择性地设置用于标记会话日志。 最后以原生直播模式启动 isaac sim ./runheadless.sh -v 运行直播客户端前,必须确保 Isaac Sim 应用已加载就绪。Isaac Sim 可能需要几分钟才能完全加载。-v 标志用于在着色器缓存预热时显示额外日志。要确认这一点,请留意控制台或日志中的这一行:Isaac Sim Full Streaming App is loaded。 首次加载 Isaac Sim 时,着色器缓存需要较长时间。后续运行 Isaac Sim 会更快,因为着色器已被缓存,且容器运行时缓存会被挂载。 (5)安装isaac sim WebRTC流媒体客户端 见后续章节。输入运行 Isaac Sim 容器的机器或实例的 IP 地址,点击连接按钮开始实时流传输。 云部署 Isaac Sim以容器形式提供,可在本地运行,也可在配备NVIDIA RTX的亚马逊云服务、微软、谷歌云平台、腾讯云或阿里云上运行,并支持将应用程序直接流式传输到您的桌面。这种基于云的交付方式能为任何桌面系统提供最新的RTX图像处理能力与性能,无需本地配置NVIDIA RTX GPU。 根据选择的云服务提供商,提供以下可选方案。 NVIDIA Brev:NVIDIA Brev Instructions AWS:Amazon Web Instructions Azure:Microsoft Cloud Instructions GCP:Google Cloud Instructions Tencent:Tencent Cloud Instructions Alibaba:Alibaba Cloud Instructions Volcano Engine:Volcano Engine Instructions Remote:Remote Workstation Instructions 上述链接提供了云端部署指南,包含通过 SSIsaac Automator 是一款高级工具,可帮助将自定义 Isaac Sim 部署自动化至公有云平台。该工具支持通过 SSH、基于网页的 VNC 客户端以及远程桌面客户端访问 Isaac Sim 实例,兼容 AWS、Azure、GCP 和阿里云等主流云服务商。H 和远程桌面客户端访问实例的操作说明。 直播客户端 本节将介绍如何以无界面模式直播运行 Isaac Sim 实例。需要注意的是每个 Isaac Sim 实例同一时间只能采用一种直播方式。同一时间仅允许一个客户端访问单个 Isaac Sim 实例。要远程退出 Isaac Sim 应用程序:点击文件菜单,然后在流式传输的 Isaac Sim 应用中选择退出。接着关闭 Isaac Sim WebRTC 流媒体客户端应用。当 Isaac Sim 运行在 A100 GPU 上时不支持直播功能。直播需要 NVENC(NVIDIA 编码器)支持,而 A100 GPU 不包含该编码器。 Isaac Sim WebRTC流媒体客户端是推荐的远程查看工具,可让您在桌面或工作站以无需配置高性能GPU可以查看Isaac Sim画面。 (1)服务端的启动 要使用Isaac Sim WebRTC流媒体客户端,需要先在远程运行isaac Sim。 linux:cd ~/isaacsim && ./isaac-sim.streaming.sh windows:双击isaac-sim.streaming.bat Docker:./runheadless.sh PIP:isaacsim isaacsim.exp.full.streaming --no-window Python sample:./python.sh standalone_examples/api/isaacsim.simulation_app/livestream.py 要可以通过互联网连接远程实例运行isaac sim,需要添加以下标志:--/app/livestream/publicEndpointAddress= --/app/livestream/port=49100。如在docker容器示例中: PUBLIC_IP=$(curl -s ifconfig.me) && ./runheadless.sh --/app/livestream/publicEndpointAddress=$PUBLIC_IP --/app/livestream/port=49100 然后在 Isaac Sim WebRTC 流媒体客户端应用中使用相同的公共 IP。运行 Isaac Sim 的主机必须开放UDP port 47998和TCP port 49100。 确保 Isaac Sim 应用已加载就绪。首次启动时,Isaac Sim 可能需要数分钟才能完全加载完成。 为确认加载状态,请在终端/控制台输出或应用日志中查找以下信息。使用 PIP 或 Python Sample 运行时可能不会显示该行信息。Isaac Sim Full Streaming App is loaded. (2)客户端的启动 请根据您的平台,从最新发布版块下载 Isaac Sim WebRTC 流媒体客户端。 运行 Isaac Sim WebRTC 流媒体客户端应用程序。 使用默认的 127.0.0.1 IP 地址作为服务器,连接到本地 Isaac Sim 实例。点击"连接"。连接过程可能需要一些时间。连接成功后,您将在客户端窗口中看到 Isaac Sim 界面。 需要注意的是建议在与 Isaac Sim 无头实例相同的网络中使用 WebRTC 流媒体客户端。连接到同一网络中无头模式的 Isaac Sim 实例时,请将 127.0.0.1 替换为运行 Isaac Sim 的计算机 IP 地址。 linux系统:在终端中运行 chmod +x xx.AppImage 命令,使应用程序获得可执行权限。双击 AppImage 文件即可运行 Isaac Sim WebRTC 流媒体客户端。重要提示:在 Ubuntu 22.04 或更高版本上运行需安装 libfuse2。具体安装方法请参阅《安装 FUSE 2》指南。 windows:若在连接本地或远程 Isaac Sim 实例时遇到问题,请确保 Windows 防火墙允许列表中已添加/kit/kit.exe 及 Isaac Sim WebRTC 流媒体客户端应用。 macbook:打开 DMG 文件后,点击并拖拽 Isaac Sim WebRTC 流媒体客户端应用程序至"应用程序"文件夹图标完成安装。 要重新加载连接,请在视图菜单中点击“重新加载”。如果一段时间后出现空白屏幕,此操作可能会有所帮助。 Python环境安装 主要是在python虚拟环境中通过PIP安装Isaac Sim和使用isaac Sim默认python环境。这里就不展开了,具体参考链接:python环境安装 Isaac Sim 资源库 isaac Sim提供多种资源与机器人模型,助您构建虚拟世界。部分资源专为isaac Sim及机器人应用打造,另一些则适用于其他基于NVIDIA Omniverse的应用程序。默认提供的资源均可在Window > Browsers选项卡中找到。 内容浏览器集中管理所有isaac Sim资源与文件,包含下来全部资源清单,以及URDF文件、配置文件、策略二进制等。Window > Browsers > Content。 isaac Sim最新版本提供示例资源包可供下载。使用这些资源时,需将文件下载至本地磁盘或Nucleus服务器。下文中所有资源路径均默认相对于 persistent.isaac.asset_root.default 设置中的默认资源根目录。详见本地资源包章节。 首次加载资源时耗时较长:机器人模型可能需要数分钟加载,大型环境场景的加载时间可能长达十分钟以上 资源分类如下: 机器人资产 相机与深度传感器 非视觉传感器 道具 环境 精选资源 Neural Volume渲染 机器人 NVIDIA Isaac Sim 支持多种具有不同底盘、外形和功能的机器人。这些机器人可分为轮式机器人、全向移动机器人、四足机器人、机械臂和空中机器人(无人机),它们位于内容浏览器的 Isaac Sim/Robots 文件夹中。 (1)轮式机器人 Limo是NVIDIA Isaac Sim 支持集成 ROS 系统的 AgileX Limo 差速驱动底盘机器人。Robots/AgilexRobotics/Limo/limo.usd NVIDIA 卡特机器人专为导航相关应用提供差速移动底盘。新一代 Nova 卡特机器人基于 Nova Orin 计算与传感器平台打造。 NVIDIA Isaac Sim 支持 Clearpath 移动机器人,包括 Dingo 和 Jackal。Clearpath 机器人位于 Robots/Clearpath 中。 Evobot 是一款采用两轮驱动的自平衡机器人,专为抓取和运输物体设计。该机器人由德国多特蒙德弗劳恩霍夫研究所开发。 Forklift 叉车模型采用单枢轴轮和滚轮设计,通过连接至关节动作的棱柱关节来控制升降操作。 JetBot是开源 NVIDIA JetBot 人工智能机器人平台为创客、学生和爱好者提供了构建创意趣味 AI 应用所需的一切。 Idealworks iw.hub 是一款配备激光雷达和摄像头的移动底盘,搭载 NVIDIA AGX GPU 实现自主导航。该平台负载能力达 1000 公斤,最高行驶速度 2.2 米/秒。 iRobot 公司推出的 Create3 机器人是一款先进的差速驱动机器人,专为多种教育应用场景设计。其圆形底盘集成了多种传感器和先进控制功能,特别适合室内导航、环境建图等任务。NVIDIA Isaac Sim 中的 Create3 机器人配备了差速驱动系统和各类传感器,可实现高度逼真的仿真效果。Create 3 机器人可在 Robots/iRobot/Create3/create_3.usd - 基础版本中找到。已配置移动底盘物理系统。更多信息参阅 iRobot Create 3 。 Leatherback 是 NVIDIA 用于自动驾驶的研究平台。皮背甲机器人位于 Robots/NVIDIA/Leatherback/leatherback.usd (2)全向移动机器人 Kaya机器人是一个展示 Isaac 机器人引擎在 NVIDIA Jetson Nano™平台上运行能力与灵活性的演示平台。该平台采用 3D 打印部件和爱好者级组件设计,力求实现最大程度的可及性,并配备三轮全向驱动系统,使其能够朝任意方向移动。 Robots/NVIDIA/Kaya/kaya.usd :基础版本 Robots/NVIDIA/Kaya/kaya_ogn_gamepad.usd:基础版本,外加使用全向控制器实现的游戏手柄操控功能。 O3dyn 是由多特蒙德弗劳恩霍夫研究所开发的自主全向运输机器人。凭借其全向轮,该机器人可实现任意方向移动,并通过四个杠杆抓取托盘,进而抬升托盘进行运输。 Robots/Fraunhofer/O3dyn/o3dyn.usd: 基础版本。包含移动底盘、夹具与升降机构的物理绑定,以及传感器定位功能。 Robots/Fraunhofer/O3dyn/o3dyn_controller.usd :基础版本,外加使用全向控制器实现的游戏手柄操控功能。 (3)四足机器人 Ant蚂蚁是一种基础四足机器人,腿部采用旋转关节设计,其原型源自 OpenAI Gym 中的 Ant 机器人。 Robots/IsaacSim/Ant/ant.usd :基础版本。可通过菜单栏中 Create>Robots>Ant 选项创建。 Robots/IsaacSim/Ant/ant_instanceable.usd :可实例化版本,专为强化学习场景配置以创建多个高效克隆体。 ANYmal 机器人是由 ANYbotics 开发的自主四足机器人。Isaac Sim 支持 B、C、D 三种型号。 Boston Dynamics Spot 波士顿动力 Spot 机器人位于 Robots/BostonDynamics/spot Unitree Quadruped Robots 宇树四足机器人A1、B2、Go1 和 Go2 是 Unitree Robotics 研发的四足机器人,在 Isaac Sim 中进行仿真。四足示例中使用的是 A1 型号。 关于四组机器人控制示例,请参阅:Isaac Sim 中的强化学习策略示例 (4)机械臂机器人 Denso Cobotta 包含以下 Denso 型号:Cobotta Pro 900、Cobotta Pro 1300。位于 Robots/Denso/Cobotta。 Fanuc CRX10iA/L 是一款 6 轴机器人,有效载荷为 10 公斤。 Festo费斯托协作机器人是一款六轴气动机械臂。 Flexiv Rizon 4 是一款 7 轴自适应机械臂。 RobotStudio是lerobot机械臂,包含以下 RobotStudio 模型:SO-100、SO-101。RobotStudio 机器人位于 Robots/RobotStudio。 太多了,只列出部分。 (5)空中机器人 Crazyflie 2.X 微型四轴飞行器机器人 Ingenuity火星直升机"机智号" (6)人形机器人 Fourier Intelligence GR1 傅里叶智能 GR1 Unitree Humanoids 宇树人形机器人,位于 Robots/Unitree Xiao Peng PX5 小鹏 PX5机器人位于 Robots/XiaoPeng/PX5 (7)移动式机械臂 Clearpath Ridgeback提供两种 Clearpath Ridgeback 型号配置:一种配备 Emika Franka Panda 机械臂,另一种配备 Universal Robots UR5 机械臂。位于 Robots>Clearpath 目录下。 Boston Dynamics Spot 波士顿动力 Spot 机器人,带机械臂的 Spot 机器人位于 Robots>BostonDynamics>spot 路径下 相机与深度传感器 Isaac Sim 支持相机和深度传感器,其数字孪生体可在内容浏览器中找到,位于 Isaac Sim/Sensors 目录下,并按制造商分类存放于子文件夹中。这里就不过多阐述。 非视觉传感器 Isaac Sim 模拟了多种类型的非视觉传感器模型,其数字孪生体可在内容浏览器的 Isaac Sim/Sensors 路径下找到,并按制造商分类存放于子文件夹中。 部分非视觉传感器类型尚未提供数字孪生体。有关这些传感器的详细信息(包括如何通过图形界面创建它们),请点击下方链接: 接触传感器 惯性测量单元传感器 光束传感器 激光雷达 雷达 道具 道具主要是一些角色人物如警察、医生、工人,以及杂项资产。 环境资产 环境资产提供如网格、房间、仓库、医院、办公室、赛道、小型仓库数字孪生 (1)简单网格 这个简易环境包含一块带有网格纹理的平坦地面和围边。系统提供了三种配置:前两种为直角转角,第三种则为圆角设计。 (2)简单房间 包含一张桌子的简易房间 在内容浏览器中搜索 simple_room.usd 或通过创建菜单:Create>Environments>Simple Room (3)仓库 一个包含货架及可放置物品的仓库环境。提供四种配置方案: (4)医院 医院环境,包含多个房间和空间。 (5)办公室 一个办公环境,包含多个房间和开放式平面布局。 (6)赛道 地面上勾勒出的 Jetracer 赛道轮廓。 (7)小型仓库数字孪生 一个小型仓库的数字孪生,可以使用。 精选资产 Nova Carter 搭载 Nova Orin™传感器与计算架构,是一套完整的机器人开发平台,可加速新一代自主移动机器人(AMR)的开发和部署。 Nova Carter 目前作为 Isaac AMR 和 Isaac ROS 软件的双重参考平台,支持真实场景与仿真环境下的开发工作。用户可通过赛格威机器人公司购买 Nova Carter 机器人。 关于功能完整的 Nova Carter Isaac Sim 资产详情,请参阅Nova Carter 文档页面。 注意Nova Carter 机器人在首次加载时可能需要数分钟时间。 Neural Volume渲染 NuRec(神经重建)技术能够利用源自真实世界图像的神经体积数据,在 Omniverse 中进行场景渲染。这些基于 3D 高斯模型的场景可作为标准 USD 资产加载至 Isaac Sim,用于可视化与仿真。 有关 NuRec 在 Omniverse 中的详细工作原理(包括数据准备、渲染设置及已知限制),请参阅NuRec 文档。要生成兼容场景,可使用开源项目3DGruT——该项目提供从图像集合训练 3D 高斯模型的工具,并能导出适用于 Omniverse 应用的 USDZ 格式数据。 示例展示了如何将 NuRec 场景加载到 Isaac Sim 中并运行模拟。该代码片段遍历提供的示例,首先加载指定的舞台,随后加载 carter 导航资源并设置起始位置。接着检查是否需要在生成位置创建碰撞地平面,若需要,则创建一个应用了碰撞 API 的平面基元。然后设置 carter 导航目标基元位置,并运行指定步数的模拟。在模拟过程中,轮式机器人将朝目标位置行进。 import asyncio import os import omni.kit.commands import omni.kit.app import omni.usd import omni.timeline from isaacsim.storage.native import get_assets_root_path_async from isaacsim.core.utils.stage import add_reference_to_stage from pxr import PhysxSchema, UsdGeom, UsdPhysics # User path of the HF NuRec dataset USER_PATH = "/home/user/PhysicalAI-Robotics-NuRec" # Paths for loading and placing the Nova Carter navigation asset and its target. NOVA_CARTER_NAV_URL = "/Isaac/Samples/Replicator/OmniGraph/nova_carter_nav_only.usd" NOVA_CARTER_NAV_USD_PATH = "/World/NovaCarterNav" NOVA_CARTER_NAV_TARGET_PATH = f"{NOVA_CARTER_NAV_USD_PATH}/targetXform" # Scenarios for testing navigation in the environments EXAMPLE_CONFIGS = [ { "name": "Voyager Cafe", "stage_url": f"{USER_PATH}/nova_carter-cafe/stage.usdz", "nav_start_loc": (0, 0, 0), "nav_relative_target_loc": (-3, -1.5, 0), "create_collision_ground_plane": False, "num_simulation_steps": 500, }, { "name": "Galileo Lab", "stage_url": f"{USER_PATH}/nova_carter-galileo/stage.usdz", "nav_start_loc": (3.5, 2.5, 0), "nav_relative_target_loc": (4, 0, 0), "create_collision_ground_plane": False, "num_simulation_steps": 500, }, { "name": "Wormhole", "stage_url": f"{USER_PATH}/nova_carter-wormhole/stage.usdz", "nav_start_loc": (0, 0, 0), "nav_relative_target_loc": (5, 0, 0), "create_collision_ground_plane": False, "num_simulation_steps": 500, }, { "name": "ZH Lounge", "stage_url": f"{USER_PATH}/zh_lounge/usd/zh_lounge.usda", "nav_start_loc": (-1.5, -3, -1.6), "nav_relative_target_loc": (-0.5, 5, -1.6), "create_collision_ground_plane": True, "num_simulation_steps": 500, }, ] async def run_example_async(example_config): example_name = example_config.get("name") print(f"Running example: '{example_name}'") # Open the stage stage_url = example_config.get("stage_url") if not stage_url: print(f"Stage URL not provided, exiting") return if not os.path.exists(stage_url): print(f"Stage URL does not exist: '{stage_url}', exiting") return print(f"Opening stage: '{stage_url}'") await omni.usd.get_context().open_stage_async(stage_url) stage = omni.usd.get_context().get_stage() # Make sure the physics scene is set to synchronous for the navigation to work for prim in stage.Traverse(): if prim.IsA(UsdPhysics.Scene): physx_scene = PhysxSchema.PhysxSceneAPI.Apply(prim) physx_scene.GetUpdateTypeAttr().Set("Synchronous") break # Load the carter navigation asset assets_root_path = await get_assets_root_path_async() carter_nav_path = assets_root_path + NOVA_CARTER_NAV_URL print(f"Loading carter nova asset: '{carter_nav_path}'") carter_nav_prim = add_reference_to_stage(usd_path=carter_nav_path, prim_path=NOVA_CARTER_NAV_USD_PATH) # Set the carter navigation start location nav_start_loc = example_config.get("nav_start_loc") if not nav_start_loc: print(f"Navigation start location not provided, exiting") return print(f"Setting carter navigation start location to: {nav_start_loc}") if not carter_nav_prim.GetAttribute("xformOp:translate"): UsdGeom.Xformable(carter_nav_prim).AddTranslateOp() carter_nav_prim.GetAttribute("xformOp:translate").Set(nav_start_loc) # Check if a collision ground plane needs to be created at the spawn location if example_config.get("create_collision_ground_plane"): plane_path = "/World/CollisionPlane" print(f"Creating collision ground plane {plane_path} at {nav_start_loc}") omni.kit.commands.execute("CreateMeshPrimWithDefaultXform", prim_path=plane_path, prim_type="Plane") plane_prim = stage.GetPrimAtPath(plane_path) plane_prim.GetAttribute("xformOp:scale").Set((10, 10, 1)) plane_prim.GetAttribute("xformOp:translate").Set(nav_start_loc) if not plane_prim.HasAPI(UsdPhysics.CollisionAPI): collision_api = UsdPhysics.CollisionAPI.Apply(plane_prim) else: collision_api = UsdPhysics.CollisionAPI(plane_prim) collision_api.CreateCollisionEnabledAttr(True) plane_prim.GetAttribute("visibility").Set("invisible") # Set the carter navigation target prim location nav_relative_target_loc = example_config.get("nav_relative_target_loc") if not nav_relative_target_loc: print(f"Navigation relative target location not provided, exiting") return print(f"Setting carter navigation target location to: {nav_relative_target_loc}") carter_navigation_target_prim = stage.GetPrimAtPath(NOVA_CARTER_NAV_TARGET_PATH) if not carter_navigation_target_prim.IsValid(): print(f"Carter navigation target prim not found at path: '{NOVA_CARTER_NAV_TARGET_PATH}', exiting") return if not carter_navigation_target_prim.GetAttribute("xformOp:translate"): UsdGeom.Xformable(carter_navigation_target_prim).AddTranslateOp() carter_navigation_target_prim.GetAttribute("xformOp:translate").Set(nav_relative_target_loc) # Run the simulation for the given number of steps num_simulation_steps = example_config.get("num_simulation_steps") if not num_simulation_steps: print(f"Number of simulation steps not provided, exiting") return print(f"Running {num_simulation_steps} simulation steps") timeline = omni.timeline.get_timeline_interface() timeline.play() for i in range(num_simulation_steps): if i % 10 == 0: print(f"Step {i}, time: {timeline.get_current_time():.4f}") await omni.kit.app.get_app().next_update_async() print(f"Simulation complete, pausing timeline") timeline.pause() async def run_examples_async(): for example_config in EXAMPLE_CONFIGS: await run_example_async(example_config) asyncio.ensure_future(run_examples_async()) 从 Hugging Face 下载 NVIDIA NuRec 数据集。更新脚本中的 USER_PATH 变量: USER_PATH = "/home/user/PhysicalAI-Robotics-NuRec"。 本文主要来自Isaac Sim Documentation V5.0.0的翻译。 -
解决ubuntu安装搜狗输入闪烁
切换使用Xorg显示 之所以要切换Xorg显示是因为搜狗输入如果使用wayland显示,切到中文会一直闪烁,因此需要使用Xorg显示。 echo $XDG_SESSION_TYPE 先检查当前是那种图像绘画,如果打印是x11则是Xorg,如果是wayland则是wayland。 全局修改为Xorg显示。 sudo vim /etc/gdm3/custom.conf 将下面这行去掉# #WaylandEnable=false 然后 sudo systemctl restart gdm3 重启 卸载fcitx5安装fcitx 需要把fcitx5卸载了,安装fcitx4。 sudo apt remove --purge fcitx5 fcitx5-* -y sudo apt autoremove 然后安装 sudo apt install fcitx 安装搜狗 安装官方的进行安装即可 https://shurufa.sogou.com/linux/guide -
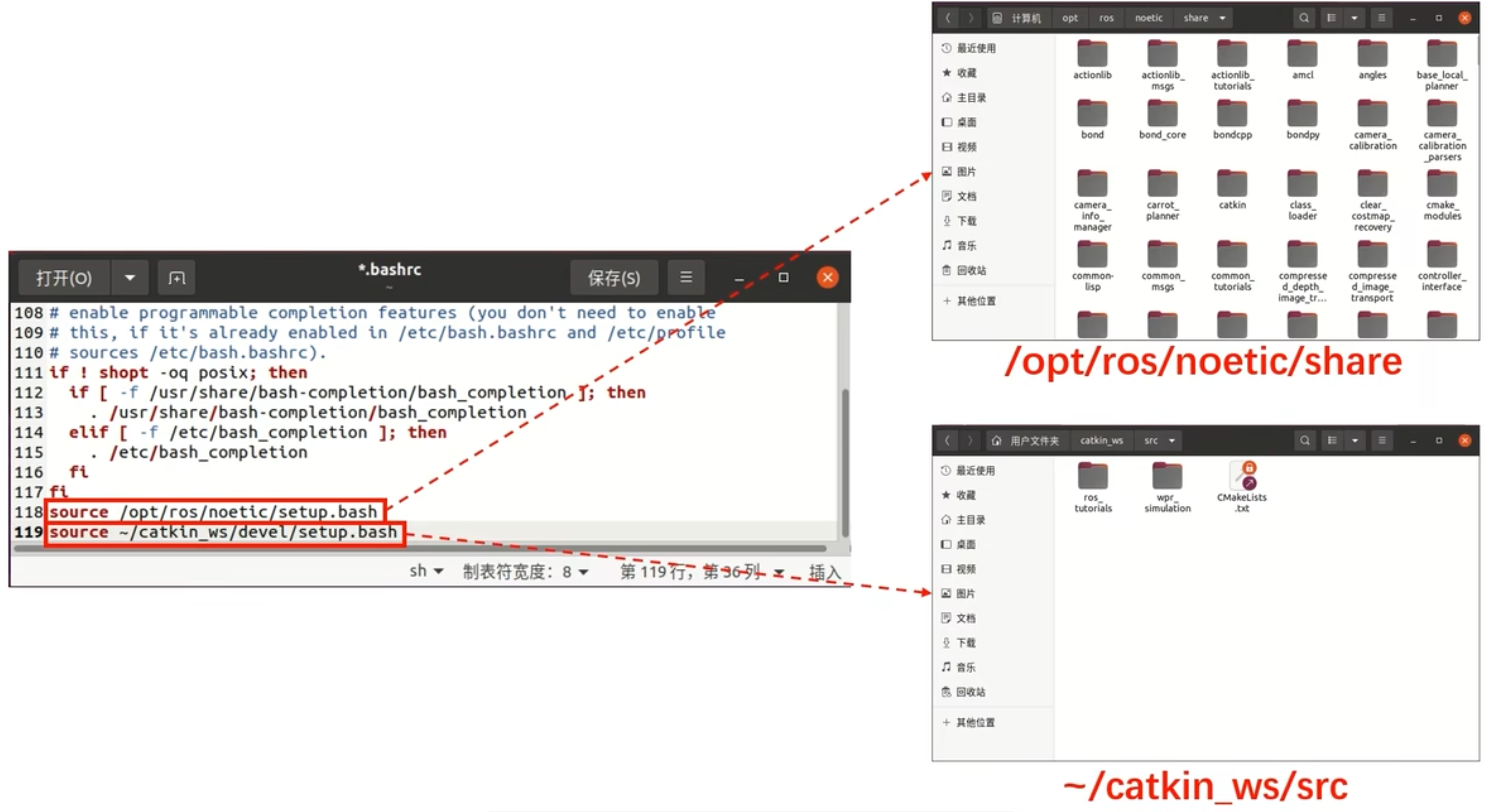
什么是ROS:机器人操作系统快览随记
ROS的秘诀 梳理出有什么节点,每个节点的输入和输出是什么? 环境搭建 catkin vscode ROS插件、bracket pair colorizer 2 terminator sudo apt install terminator CRTL+ALT+T启动 CRTL+SHIFT+E左右分屏 CRTL+SHIFT+O上下分屏 CRTL+SHIFT+W关闭窗口 程序 基础单元node 节点的容器packege,以packege安装节点,packege里面有多个节点。节点不能脱离packege存在。 编写节点步骤 订阅与发布 多个节点直接的信息交互 跟MQTT机制类似。 消息类型,bool、byte、float.......可上官网查看https://index.ros.org 发布者 步骤: 1. 确定话题名称和消息类型 2. 包含消息类型的头文件。 3. 通过NodeHandler大管家发布一个话题获得消息发送对象。 4. 生成要发送的消息包并进行发送数据复制。 5. 调用消息发送对象publish函数发布消息。 常用工具: rostopic list 列出当前系统所有活跃的话题 rostopic echo <主题名称> 显示话题中发送的消息包内容 rostopic hz 查看话题发布频率 订阅者 步骤: 1. 确定话题名称和消息类型。 2. 包含ros.h和消息类型对应头文件。 3. 通过NodeHandler订阅一个话题并设置一个消息接收回调。 4. 定义一个回调函数。 5. main函数中执行ros::spinOnce(),在while循环中可以响应接收消息。 常用工具:rqt_graph 查看ROS中节点,通讯关系。 launch 可以支持一下启动多个节点,使用xml来描述。 使用launch文件,可以通过roslaunch指令一次启动多个节点。 在lauch文件中,为节点添加output="screen"属性,可以让节点信息输出终端。 在launch文件中,为节点添加launch-prefix="gnome-terminal -e"属性,可以让节点单独运行在一个独立终端中。 可以通过launch文件来分析工程代码。 python方式 使用python的方式,只需要开始的时候编译一次,同步一下环境就行,后续就不用编译了,因为python是脚本,不需要编译。 机器的运动控制 线性方向:X,Y,Z坐标值。 角度控制:X,Y,Z方向旋转角度。 使用wbr_simulation,要控制机器人就发送消息就行了,消息类型就是线性方向+角度 要控制对主题/cmd_vel发布指令即可。 RViz 激光雷达原理,发射红外,接收红外,通过光速与时间计算障碍物距离,360°旋转。 Rviz是观测传感器数据,显示到仿真界面中。 激光雷达 激光雷达的数据包格式 float32[] ranges #一个数组,每个角度对应的测试距离。共360 float32[] ranges # 每个角度的信号强度,强度越高对上上面的测试距离越可信 如何获取到雷达测距数据? 使用wbr_simulation,订阅/scan话题即可获取到雷达数据。激光雷达每扫描一圈,就会调用一次注册订阅的话题回调函数。 如何实现运动避障的效果? 订阅/scan获取雷达测试数据,对/cmd_vel主题进行发布控制。当发现测距比较近的时候,就发布控制指令进行调整。 IMU 用于测量空间姿态,也就是陀螺仪。 消息包格式 imu/data_raw( sensor_msgs/Imu):加速度输出的矢量加速度、陀螺仪输出的旋转角速度 imu/data(sensor_msgs/imu):对矢量加速度和旋转角速度融合后的4元素姿态描述。最后可以通过这4元素计算出欧拉角度。 imu/mag(sensor_msgs/MagneticField):磁强计输出数据。 ros中怎么获取数据?订阅/imu/data主题得到4元素,然后通过FT计算欧拉角,得到相对X,Y,Z的旋转角度。 航向锁定的实验 获取到朝向角后,然后通过/cmd_vel发布主题进行控制。 ROS消息包 标准消息包:std_msgs,包含数值类型、数组类型、结构体类型。 常规消息包:common_msgs,包括(sensor_msgs)传感器消息包、(geometry_msgs)几何消息包、(nav_msgs)导航消息包等等。 自定义消息包:根据基本的消息包类型来构建消息。需要按照ros规则来创建一个.msg的文件, rosmsg show xxx显示。 栅格地图:map_server 获取/map主题,获取栅格坐标格式为nav_msgs/OccupancyGird,可以和RVIZ进行联动显示。 SLAM simultaneous localization and mapping 同时定位与地图构建 如何建图原理? 先确定一个参考位置,然后进行移动,每移动一个位置获得一个图,这个图可以是用视觉识别的物体、雷达探测障碍物等方式,然后通过每个位置获得的图进行拼接合并,以此获取到全局的地图。 在ros系统中如何获取地图 激光雷电 发布/scan-> Slam节点获取处理 发布/map->RViz显示 hector_mapping开源的slam算法 TF TransForm描述两个坐标系的空间关系,坐标变化关系。简单理解就是机器人相对参考坐标的位置关系 由TF发布节点,通过/tf主题来发布。 结合里程计的 gmaping建图算法。 导航 详细的官方图 规划器 先使用目标点生成一个导航路线,然后按照导航路线走,在过程中遇到障碍物则进行避障。在move_base中提供了不同风格的规划器拥有规划路线如Dijkstra算法、A*算法。 定位算法 接着需要知道机器人的具体位置,知道具体的位置才能跟着导航路线走,这就需要定位节点如AMCL算法。 代价地图 代价地图,因为导航路线规划有时候的最短路径没有考虑机器人的尺寸,可能会导致机器人沿着墙边走而导致卡住,代价地图就是把障碍物线设置一个虚拟的安全距离(也可以说是把障碍物膨胀变大些)。全局代价地图和全局代价地图。 恢复行为 机器在运动过程中遇到了障碍物导致不能行动,会进入应急机制重新进行规划路线。 局部规划器 DWA、TEB、WpbhLocalPlanner等等。 ACTION action是节点通信的另外一种方式,与订阅/发布不同而是可以双向传输,传输的双方分别是client和Server。client向server发送信息后,server可以持续不断的通知返回信息。 如:可以通过action接口来调用move_base设置导航的功能。client发送导航的目的地,然后server按照目的地运动,client阻塞等待server的回复,当server到达目的时返回结果。 航点的目的地,不用口算、目测;具体的导航目的地可以用插件获取,如waterplus_map_tools。可以将导航插件写到launch。 ROS相机 /image_raw主题:相机原始数据 /image_color:相机的彩色图像 /image_color_rect:畸变校正后的彩色图像。 /camera_info:相机相关的参数。 获取到图像后可以调用opencv处理图像,如果要做目标跟随,可以找出目标的坐标,然后跟随运动。