最新文章
-
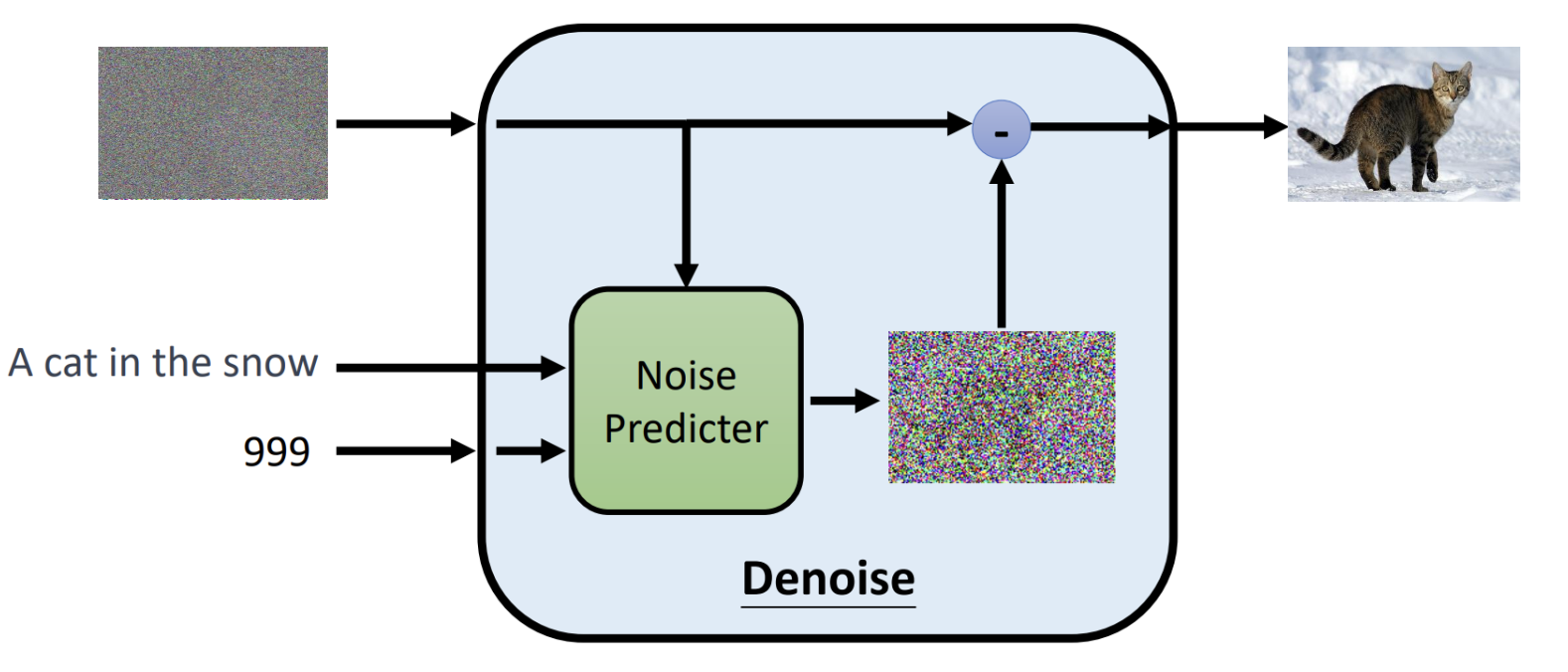
Diffusion:如何从噪声中生成清晰图像
概述 图像生成是当下研究的热点,diffusion是一种人工智能领域图像生成的基础模型,当下Stable diffusion、DALL·E、MidJourney文生图模型的基座都使用了diffusion。 diffusion扩散模型属于生成式模型,生成图像不是正向从0到1构成图像而是反向的预先生成一个随机的噪声图中然后根据文本提示词逐渐的去噪"扣"出图像。主要思想是先训练一个权重模型,把一张清晰照片弄得越来越模糊(加入噪声),然后把模糊的图片融合文本提示词作为输入去训练一个模型学会“擦亮它”,反向恢复成清晰图像。训练完成后,就得到了模型的权重,那么使用这个权重模型只要给一副完全随机的“噪点图”和要生成图片的提示词,它就能一步步去掉噪声,变出一幅崭新、逼真的图片。 借用米开朗基罗雕刻"大卫像"时说的"我在大理石中看见天使,于是我不停地雕刻,直至使他自由”。而diffusion也是这样的原理,通过随机生成的一个噪声图片,结合输入的文字去掉噪音恢复到你想象的照片样子。 工作原理 推理 (1)输入阶段 输入阶段有3个输入信息,分别是随机噪声图像、文本提示、时间步。 随机噪声图像:最开始随机生成一个高斯噪声的图片。 文本提示:告诉模型,想要生成的内容是什么。 时间步:指明当前是去噪第几步,模型是一个多步迭代去噪的过程。按照数字依次递减进行迭代,数值越小去噪强度越弱。 (2)模型处理 核心组件是Noise Predictor(一般是一个U-Net结构神经网络),输入的带噪图像$X_{t}$、时间步$t$、以及提示文本通过Noise Predictor预测出这张图里有多少噪声,生成一张噪声图片$\epsilon^\theta(x_t, t, c)$。 (3)输出阶段 将输入-减去预测出的噪声图片就得到最后的去噪图片了,$x_{t-1} = x_t - \epsilon^\theta(x_t, t, c)$。 (4)迭代 迭代一轮得到一个降噪图片之后,接着将输出的降噪图片作为输入的带噪图片按照之前的步骤进行重复,直至$t$=$T$(比如$1000$)一直迭代到$t$=$0$得到最终的图像。当所有步骤完成后,随机噪声逐渐被“洗掉”,生成的就是一张符合条件描述的清晰图像。 下面是推理过程的算法伪代码 初始化:$x_T \sim \mathcal{N}(0, I)$从标准高斯分布中采样一个随机噪声向量(或噪声图像),作为生成过程的起点。 迭代循环:从$t$=$T$到$t$=$1$逐步迭代,每次去掉一部分噪声。如果$t$>$1$,额外采样一个噪声向量$z\sim \mathcal{N}(0, I)$。如果$t$=$1$,则$z$=$0$,即最后一步不加噪声。 核心公式:先去掉预测的噪声(括号里面的部分)得到更接近干净数据的样子,接着在进行缩放调整(除以$\sqrt{\alpha_t}$),最后加一点随机噪声$\sigma_t z$来保持生成的多样性。 输出:当循环结束时,最终的$x_0$就是最终生成的清晰图像了。 对于核心公式的参数这里稍微补充一下 参数 $\epsilon_\theta(x_t, t)$是预测的噪声; 参数$\alpha_t$取值范围是$0$~$1$,控制在第$t$步中保留多少原始图像信息加入多少噪声,当$\alpha_t$接近$1$时几乎保留全部信息,噪声小;当值趋于0时,原始信号衰减就大,噪声比例高; 参数$\bar{\alpha}_t$累积乘积参数,表示从第$1$步到$t$步累积保留原始信息的比例。 参数$\sigma_t z$随机扰动项,保持采样的多样性。 训练 训练模型我们需要把模型的输出结果和真实值进行比较才能进行梯度下降找到网络权重,那该如何设计准备训练结果和真实值的数据? diffusion模型的核心是要预测出图片的噪声分布然后减去预测的噪声得到真实的输出照片。以上图第一步进行说明,使用原始的图片,通过随机生成一个噪声图($x_{1}$)迭加作用到原始图片上这样就得到了模型的带噪声的输入图像,然后融合文本、时间步模型前向计算得到噪声图($x_2$)。已经知道了真实的噪声图是$x_{1}$,那么计算$x_{1}$和$x_{2}$的相似性就可以计算出损失了。 训练过程中关于图片-文本可以从Lion平台上获取,通过上面步骤取样照片然后不断加强噪声得到越来越模糊的图片送入模型预测进行计算迭代权重,让模型学会真正准确预测每一步中"加进去的噪声",训练完成之后,模型学会了如何"识别噪声",在推理时就从纯随机噪声$x_T$出发,通过文本提示词反向迭代去噪得到最终的想要的照片。 论文中的伪代码如下: repeat:表示循环执行训练过程。 采样数据:$x_0 \sim q(x_0)$从真实数据分布$q(x_0)$中采样一个训练样本比如一张猫。 随机采样时间步:$t \sim \text{Uniform}({1, \dots, T})$随机挑选一个扩散的时间步$t$,确保模型能在不同噪声水平都学会去噪。 采样噪声:$\epsilon \sim \mathcal{N}(0, I)$从标准的高斯分布中采样一份噪声,用于后续得到到原始图片上。 梯度下降更新参数:计算预测噪声和真实噪声$\epsilon$的均方误差。 模型 本章节简要说一下业界文生图模型,其结构可以总结为以上3个部分,文本编码器、生成式模型、解码器。 文本编码器:将用户输入的文本提示通过预训练的文本编码器如CLIP Text Encoder将自然语言转化为向量表示。 生成式模型:将编码的文本向量和噪声图像noisy latent作为输入,然后逐步迭代去噪。这里的模型如有diffusion、autoregressive等。输出是压缩到更低维的"潜在空间"。 解码器:将生成式模型的输入Latten Representation通过解码器还原最终生成清晰图像。生成式模型一般输出的是压缩的低维潜在空间,这样可以降低每一步迭代的计算量,最终加一个解码器来将其还原。 下面是stable diffusion、DALL-E、Imagen的模型结构图,核心组成都是上面3个部分,这里就不过多阐述了。 stable diffusion DALL-E Imagen 本文主要来自李宏毅Diffusion Model原理解析的笔记。 -
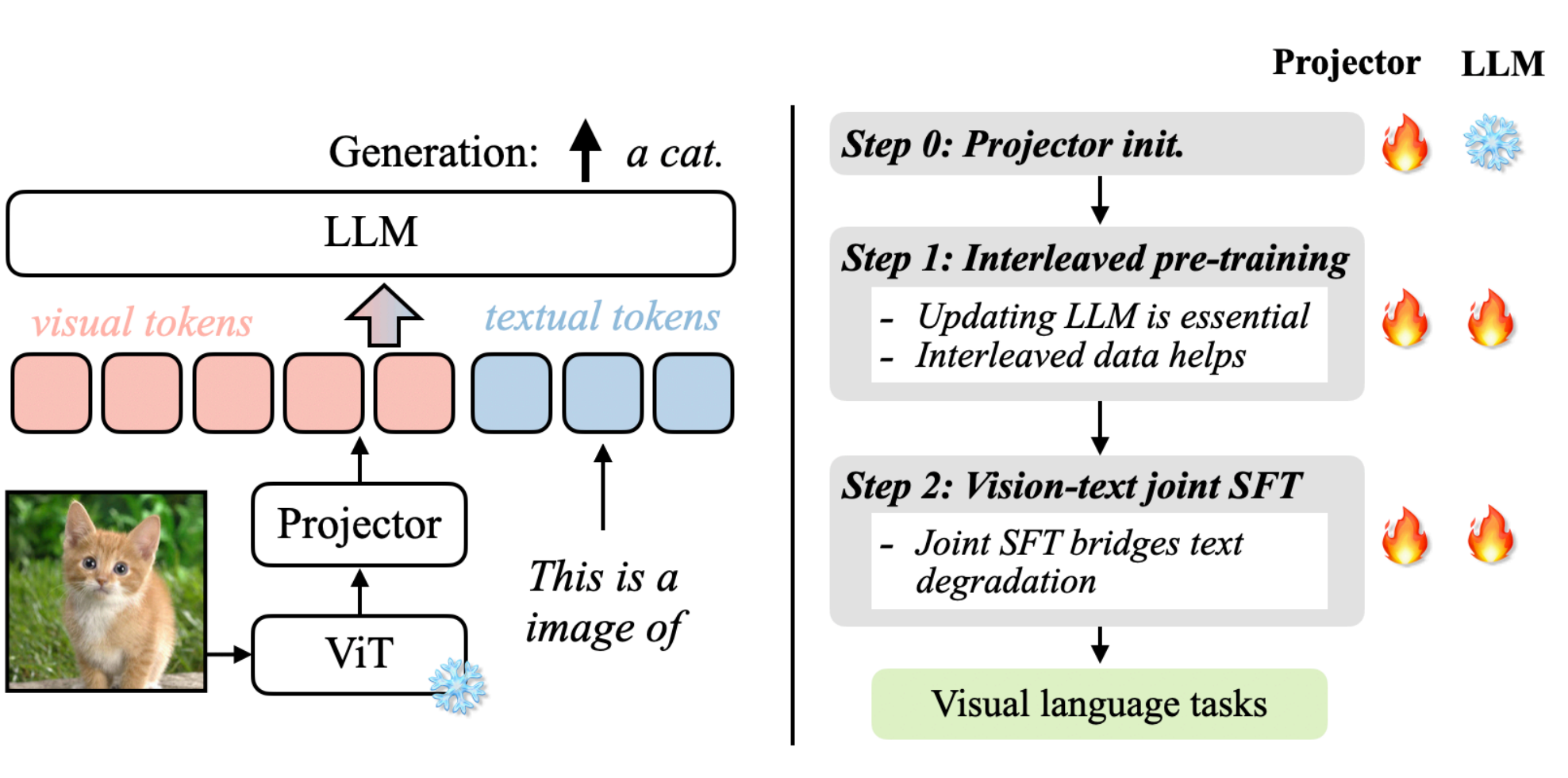
视觉 Token 如何注入语言模型?VLM拆解
VLM与LLM 如果说我们有一张图片、一个图表想让大模型来帮忙理解那应该要怎么实现了? 标准的LLM语言大模型只能处理文本序列,是不能够读取图像的,如果没有办法将视觉的数据转换为LLM能够理解的形式,那么LLM是无法处理的。需要注意的是我们这里说的LLM并不是transformer,LLM指的是大语言模型如DeepSeek,GPT,Qwen,其是使用了transformer架构应用,而transformer是一种神经网络架构。LLM的token专门指的是文本token来自Tokennizer其输入是字节流,而transformer不一定是文本单位,可以是任何序列元素如词、图像(上节说的ViT)等。 要解决语言大模型理解图片,那么这就是视觉-语言大模派上用场了。回顾一下我们此前说的ViT视觉大模型,是不是就是用提取图像特征的,因此本章节我们要介绍的正是视觉大模型与语言大模型的融合:vision language model,即视觉-语言大模型。 视觉-语言大模型是视觉大模型+语言大模型的结合,其主要有哪些用途?核心用处是让 AI 能够“读图如读文”,在多模态场景下实现理解、生成和交互,如下示例: 内容理解:多模态的问答VQA,比如给一张图让大模型理解图片里面描述了什么,让其识别图片里物体、动作、关系,自动生成图片说明(Image Captioning)等等。 信息获取与搜索:给一张图找对应的描述,或给一句话找到相关图片(比如电商商品搜索)以及搜索引擎文字搜图或图搜文字等。 模型结构 发展到今天有很多的视觉-语言大模型,各自都有自己的架构实现。我们先以VILA为例来说明一下视觉-语言大模型的关键组件,上图来自论文:VILA: On Pre-training for Visual Language Models。 上图我们先来分析一下其运作流程,可以分为左右两部分:左图可以看成是怎么跑起来的(数据流推理/前向),右图是如何训练的步骤。 数据流 左图:数据流推理 ViT: 首先将图像送入ViT视觉编码器,提取出视觉特征。 Projector:因为ViT输出的特征维度可能与LLM词嵌入维度不一致,所以这里也需要通过一个线性层/小MLP做映射,把视觉特征空间转换为LLM的嵌入空间为,为上图的visual tokens。 token融合:文本提示经过tokenizer转换为text tual tokens与visu tokens在同一序列中进行拼接或交错输入到LLM。 LLM生成:进入LLM后,视觉与文本已在同一token流中就可以共同参与计算注意力,最后输出最后的结果a cat。 训练策略 右图:训练策略 训练主要分为3个阶段,projector初始化,交错式预训练、监督微调,主要涉及projector和LLM模型参数更新,火焰代表参数会被更新,雪花代表冻结不更新。 Step 0 Projector初始化:只训Projector,LLM冻结,通常ViT也冻结,目的是先把视觉特征大致对齐到LLM词向量空间,避免一上来就动LLM破坏语言能力。 Step 1 交错式预训练:同时更新Projector与LLM,在包含图像-文本交错(图像token混在文本序列里)的数据上做自回归训练。更新LLM才参数才能让LLM学会"在文本上下文中使用视觉特征";图像和文本的输入进行交错能够教会模型跨模态对齐与引用。 Step2 监督微调:联合微调projector与LLM,输入数据是指令时的多模态问答/对话。这样可以把能力对齐到agent任务上,同时避免LLM文本能力退化。 小结 通过VILA架构为例,我们大概了解了VLM视觉-语言大模型的架构,我们总结下VLM模型架构主要可以分为三大部分: 视觉编码器:将视觉输入转换为结构化的数值表示,提取语义信息。如基于transformer架构的ViT,将图像分割成小块,通过transformer编码全局和局部特征;如传统基于CNN卷积神经网络ResNet,擅长提取局部纹理特征。 投影器:视觉和文本嵌入必须对齐到一个共享的多模态嵌入空间。通常由一个较小的模块完成,称为投影层或融合层:常见的实现方式有MLP通过全连接层转化维度(如DeepSeek-VL);交叉注意力机制通过动态关联图像区域与文本token(如llama 3.2 vision),增强空间理解。 LLM:接收图像+文本融合后的多模态输入,生成自然语言响应(如描述、答案、推理)。 QA1:这里的投影器projector与此前我们分析ViT中的projection线性投影有什么不一样? ViT中的projection作用是将图像分割后的每个小块线性映射为固定维度向量(token)作为transformer编码器的输入;而VLM的projector是将视觉编码器(如ViT)输出特征映射到语言大模型(LLM)的文本嵌入空间,解决跨模态语义鸿沟。一个是作用在ViT的输入映射为transformer的标准输入另外是一个作用再ViT的输出映射为LLM的标准输入。 QA2:为什么要将图像和文本进行融合多模态嵌入空间? 多模态嵌入空间是VLM具备推理能力的关键,通过在同一潜在空间表示视觉和文本信息,主要有以下优势: 上下文感知:使不同模态之间能够进行丰富的交互,这意味着模型能够将文本概念(例如,“公交车”、“十字路口”)准确地与视觉特征信息(公交车位置、颜色、十字路口)连续起来。 语义连接:将抽象的文本概念与具体的视觉示例进行对齐。例如模型不仅将“行人”理解为单词,还将其视为图像中可视觉识别的实体。 跨模态推理:允许模型在不同模态之间进行推理,回答复杂的视觉问题,进行逻辑推断,或检测微妙的视觉-文本差异。 模型预训练 训练史 先来看看视觉识别训练的发展,可以划分为5个阶段:传统机器学习与预测,深度学习从零训练与预测,监督式预训练、微调与预测,无监督预训练、微调与预测,视觉语言模型预训练与零样本预测。稍微总结一下各自特点。 传统机器学习与预测:需要人工设计学习特征。 深度学习从零训练与预测:从零自己标注大量数据(因为没法迁移),从零训练。 监督式预训练、微调与预测:预训练复用公开标注好的海量数据(可以迁移,所以可用公开别人标注好的海量数据),从零标注一些少量数进行微调。 无监督预训练、微调与预测:预训练数据集再扩大了,可以直接爬取互联网的数据进行训练,但还是需要从零标注一些少量数据进行微调。 视觉语言模型预训练与零样本预测:不需要进行微调了,那么也不需要标注的数据集了,做到零样本。 VLM的预训练与零样本预测方式与过往的相比,对下游视觉识别任务上实现零样本,去掉了微调的过程,那么这种方式就可以有效利用大规模的网络数据。 预训练架构 因为VLM有很多种模型架构,因此预训练的架构也有区别,下面列出常见的几种。 双塔式架构:视觉和文本模态分别通过独立的编码器处理(如ViT处理图像、BERT处理文本),模态交互仅发生在编码后的特征层面,在最后进行融合,典型的模型有CLIP、ALIGN等。 双分支架构:在独立编码器基础上引入动态交互模块,支持灵活切换双塔或单塔模式,实现任务自适应融合如VLMo、Mini-Gemini等。 单塔式架构:像和文本输入共享同一Transformer编码器,通过交叉注意力机制实现早期深度融合,典型的模型如ViLT,FLAVA等。 预训练目标 前面阐述了当前视觉-语言大模型通常采用预训练与零样本预测的方式。那么在视觉语言大模型(Vision-Language Models, VLM)中我们的预训练目标是什么了?所谓预训练目标(Pre-training Objectives)是让模型从海量无标注图文对中自动学习跨模态关联的核心机制。这些目标的目的建立视觉与语言模态的语义对齐,为下游任务(如视觉问答、图像描述)提供通用表征基础。而当前的训练目标大致可以分为3类:对比目标、生成目标、对齐目标。 对比目标:让模型学会"配对"正确的图文,并区分错误的组合,比如正样本匹配的图文对(如猫图 + “一只猫”),模型需让它们的特征向量高度相似;负样本不匹配的图文对(如猫图 + “一辆汽车”),模型需让它们的特征向量差异巨大。计算的损失函数为所有配对的相似度误差(如 InfoNCE损失),指导模型调整参数,代表模型有CLIP、ALIGN等,该方式一般适用于零样本分类、图文检索的模型。 生成目标:让模型“填空”或“创作”,通过预测缺失内容学习深层语义。具体输入通过mask遮住文本或图像,训练模型让其复原得到网络权重。该方式一般应用与图像描述、视觉问答(VQA)的模型。 对齐目标:让模型能够把句子的词精准对应到图中位置,要求最高。比如用目标检测框出识别图中的物体(如汽车),与文本中的词精确关联。该方式一般用于目标检测、语义分割等场景。 VLM模型 当前已经出现了很多视觉语言模型,各自的模型都具有独特的功能,在视觉语言研究领域和实际应用上扮演着重要的贡献,除了在第2章节我们介绍的VILA外,这里我们在本章节再补充举例几个进行简要说明一下。 CLIP 上图是CLIP模型,是一个典型的双塔式视觉-语言模型,由视觉编码器(ViT)和文本编码器(Transformer)等核心组件构成。通过预训练对比目标的方式学习实现图像与文本的跨膜态对齐,其核心创新点在于无需任务特定训练,直接利用自然语言提示(Pormt)完成零样本预测,支持识别训练数据中为出现的新类别。 从图中我们可以看成可以分为3个阶段,对比预训练、创建零样本分类器、零样本预测。 (1)对比预训练阶段 输入是海量的图文对,如图片输入狗+文本输入"pepper the aussie pup"。 编码:文本编码器(如transformer)将文本嵌入向量,图像编码器(如ViT/ResNet)将图像嵌入向量。 目标:图文预文本嵌入向量的点积度量图文相似性。通过对比损失(infoNCE)计算图文相似度矩阵。拉近匹配对(如对角线深蓝块,如狗图与"狗"文本),推远不匹配对(非对角线浅色块,如狗图与“汽车”文本)。 (2)创建零样本分类器 输入:新任务的类别标签(如 "dog", "bird", "car")。 处理:将标签转化为提示文本(如 "a photo of a {label}"),文本编码器生成所有标签的文本嵌入向量。 输出:得到一组文本嵌入,构成无需训练的分类器权重(传统模型需图像数据训练分类头) (3)零样本预测 输入:一张新图像(如鸟的图片)。 处理:图像编码器生成图像嵌入向量(左侧绿色向量),计算该向量与所有类别文本嵌入相似度。 输出:选择相似度最高的文本标签作为预测结果(如输出 "a photo of a bird")。 总结一下就是,通过上面的预训练,将配对的图文靠近,非配对的原理,学到语义对齐的公共空间,这样在在推理时把“类别标签”也写成一句话,当作“文本查询”;用这句“查询”去和图像向量比相似度,谁最像选谁。 LLaVA LLaVA是把视觉模型提取的图像特征通过一个映射层转成语言模型能理解的 token,然后和用户的语言指令一起输入到大语言模型(LLM),从而实现图像理解与多模态对话。其架构主要由Vision Encoder(视觉编码器)、Projector(视觉特征投影)、Language Instruction(语言指令输入)、LLM大模型几个组件构成,跟我们前面第2章节总结的结构类似,这里就不过多阐述了。下面简要说一下流程: 输入图像:输入的图像通过Vision Encoder提取特征$Z_{v}$。具体来说,预训练用的是CLIP模型的视觉编码器ViT-L/14。 特征投影:通过projector W提取的图像特征$Z_{v}$转换成LLM能够处理的token表示$H_{v}$。 输入指令:用户文本$X_{q}$转换为token表示$H_{q}$。 拼接输入:将[$H_{v}$,$H_{q}$]拼接一起送入LLM。 语言生成:LLM输出语言响应$X_{a}$,完成图像理解+问答。 LLaVA 是一个用于对齐视觉和语言数据以处理复杂多模态任务的复杂模型。它采用独特的方法,将图像处理与大型语言模型融合,以增强其解释和响应图像相关查询的能力。通过利用文本和视觉表示,LLaVA 在视觉问答、交互式图像生成以及涉及图像的基于对话的任务中表现出色。其与强大语言模型的集成使其能够生成详细描述,并协助实时视觉语言交互。 参考: 1. An Introduction to Vision-Language Modeling 2. Vision Language Transformers: A Survey 3. Understanding Vision-Language Models (VLMs): A Practical Guide 4. Guide to Vision-Language Models (VLMs) -
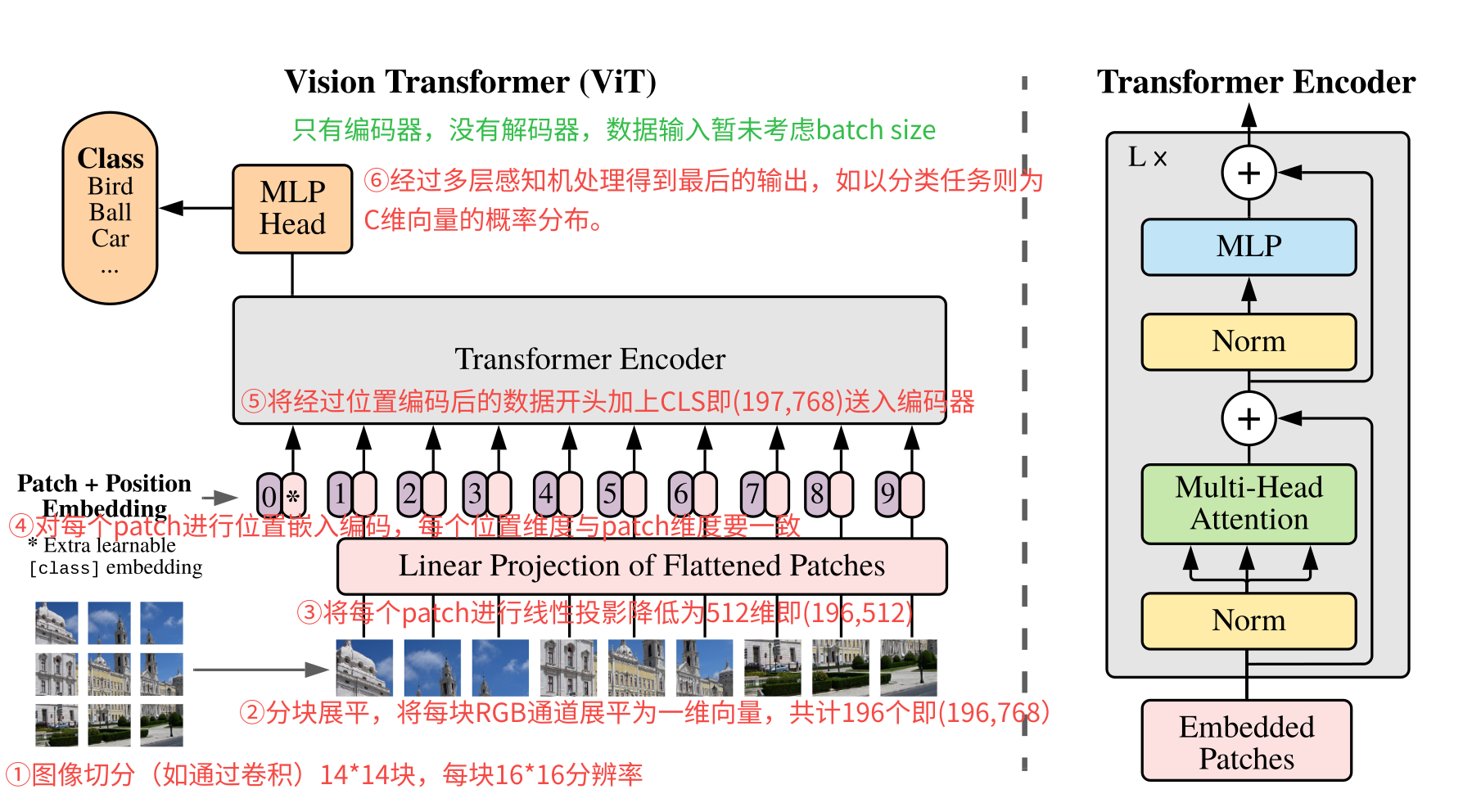
解读ViT:Transformer 在视觉领域如何落地
背景 计算机视觉领域,一直都是卷积天下。传统的卷积神经网络(CNN)依赖于卷积核提取局部特征,效果很好,但是也有一些不足,如需要人工设计卷积结构包括卷积核大小和层数,另外就是难以捕捉全局的依赖关系。 transformer最早更多的是应用在NLP领域的架构,用注意力机制来捕捉长距离的依赖。那把transformer应用在视觉领域了,会有什么效果吗?而在2021年发表的https://arxiv.org/abs/2010.11929这篇论文就是使用transformer应用在图像识别的领域。 论文中提到基于transformer使用监督学习方式训练模型进行图像分类时,在中等规模数据集(如ImageNet)上如果没有使用强正则化其准确率略低于同等规模的ResNet。但是当加大数据集(1400W至3亿张图像)训练时,发现其识别水平超越了现有技术。 模型概览 上图就是整个ViT模型结构了,对transformer比较熟悉的,整个结构就很简单了。可以发现只有transformer encoder没有transformer decoder。 这里先整体看看其流程步骤: 图像切块:原图输入为224x224分辨率的图像,将其切分为14x14共196块的(如使用卷积),每块大小的分辨率为16x16。 分块展平:将每块为16x16分辨率的patch展平为一维向量,共计有196个这样的向量。由于每块是RGB 3通道图像,因此向量维度为16x16x3= 768,按照RGB排布进行展开为一维向量。因此最后的数据形状为(196,768)。 线性投影:对每个patch的向量乘以一个权重矩阵,映射到D维的embedding空间,这个D维跟transformer输入维度一致(默认是512)。因此经过转换后的数据就变成了(196,768)->(196,512)。 位置编码:对经过线性映射的patch加上位置编码,每个patch一个位置向量,其向量的维度与patch维度一致,总的位置编码矩阵为(196,512)。将这个位置编码与经过线性映射的进行相加得到输入。 编码输入:经过位置编码后的输入然后在最开始加上了[CLS]向量送入编码器。因此输入的数据为(197,512)。如果算上批量数据最后就是(B,197,768)。B为batch size,197为patch数,512为embedding维度。 编码输出:最后经过多层感知机MLP得到最后的输出,如果是分类任务的话,就是(B,C)结果,B为batch size,C为类别数。也就是结果每行就是一个概率分布。 常见问题 (1)图像是如何切分展平的? 以输入尺寸3x224x224的RGB图像为例,块大小为16x16,因此块的数量为14x14=196个块。每个块3x16x16被拉成一维向量长度为16x16x3=768,也就是每个块被展平为768维向量,一共有196个块,也就是说转换为(196,768)的矩阵。 (2)每个patch为什么要展平? 主要是transformer的输入要求,因为transformer是序列处理器,其输入必现是一维的向量序列,而图像分块后得到的每个块是二维矩阵。还记得在transformer实现文章中吗?输入的是(seq,d_model),seq为token的数量,而d_model为每个token嵌入的向量。当然这里的图像最后还需要经过映射降维跟这里的d_model保持一致,这样才能输入到transformer的编码器中。 (3)线性投影有什么作用? 主要有两个作用,其一是图像分块展平后得到的是高维稀疏向量(如16163=768),包含了大量冗余信息如局部宽高、噪声等,缺乏高层语义表达,数据量大,计算量也大,线性投影是一个可训练全连接权重矩阵,可以提取保留关键局部特征;其二是为了适配transformer输入结构,Transformer要求输入为固定维度向量序列(如 D=512)。线性投影统一所有图像块的输出维度,确保自注意力机制可计算。 (4)这里的位置编码与transformer的有什么不同吗? ViT中的位置编码使用的是自适应位置编码,transformer中用的是正余弦固定公式,因为ViT中的输入序列位置一般都有限,因此用1D的可学习的位置编码即可,这个位置编码是一个可学习的参数矩阵,初始化为全0,在训练过程中通过反向传播自动优化。 (5)输出的MLP与transformer FFN有什么不同吗? 基本一样的,FFN是前馈神经网络的统称,MLP是具体的前馈神经网络具体实现特指全连接网络。 (6)最后的输出是什么样的? ViT最后的输出结构根据实际任务需求有关,如果是图像分类任务,在最终输出是[CLS] token向量经 MLP Head映射后的logits(未归一化的类别分数),形状为 [B, K](K为类别数); (7)整个处理流程数据变化是怎么样的? 处理阶段 输入形状 操作 输出形状 示例值(B=64) 原始输入 [B, C, H, W] — [64, 3, 224, 224] Patch分块 + 展平 [B, C, H, W] 卷积核尺寸=步长=P(如 16×16) [B, N, P²·C] [64, 196, 768] 线性投影(Patch Embedding) [B, N, P²·C] 全连接层映射至目标维度 D=512 [B, N, D] [64, 196, 512] 添加 Class Token [B, N, D] 序列前拼接可学习的 [CLS] 向量 [B, N+1, D] [64, 197, 512] 位置编码叠加 [B, N+1, D] 加可学习位置编码 E_{pos} ∈ ℝ^{1×(N+1)×D} [B, N+1, D] [64, 197, 512] Transformer 编码器 [B, N+1, D] 多头自注意力(MSA) + MLP 前馈网络 [B, N+1, D] [64, 197, 512] 分类头输出 [B, D](仅取 [CLS]) 全连接层映射至类别数 K [B, K] [64, 1000] -

lerobot之smolvla体验
环境安装 pip install -e ".[smolvla]" 在原来lerobot的环境基础上。 启动训练 本文主要是记录复现lerobot smolvla策略的效果,为了快速看到效果,这里不进行采集数据了,直接用此前ACT采集的数据,将数据打包放到autodl云服务器上进行训练。 python src/lerobot/scripts/train.py \ --dataset.root=/root/autodl-tmp/lerobot/data/record-07271539 \ --dataset.repo_id=laumy/record-07271539 \ --policy.push_to_hub=false \ --policy.path=lerobot/smolvla_base \ --policy.device=cuda \ --output_dir=outputs/train/smolvla_test \ --job_name=smolvla_test --batch_size=64 \ --steps=20000 --wandb.enable=false 或者 python -m lerobot.scripts.train \ --policy.type=smolvla \ --policy.vlm_model_name=HuggingFaceTB/SmolVLM2-500M-Video-Instruct \ --policy.load_vlm_weights=true \ --policy.num_vlm_layers=16 \ --policy.num_expert_layers=8 \ --dataset.repo_id=laumy/record-07271539 \ --output_dir=outputs/train/smolvla_test2 \ --job_name=smolvla_test \ --batch_size=64 --steps=20000 --wandb.enable=false 如果数据集在huggingface上面,则需要先登陆hugging face huggingface-cli login 填写token. python src/lerobot/scripts/train.py \ --dataset.repo_id=laumy0929/grab_candy_or_lemon \ --policy.path=lerobot/smolvla_base \ --policy.device=cuda \ --policy.repo_id=laumy0929/smolvla_test \ --output_dir=outputs/train/smolvla_test \ --job_name=smolvla_test --batch_size=64 \ --steps=20000 --wandb.enable=false 关于数据集的获取取决于两个参数,一个是repo_id另外一个是dataset.root。 repo_id: 必填字段,是在 Hugging Face Hub 上的数据集标识(datasets 仓库名)。 dataset.root :选填字段,是本地数据集所在目录。 训练首先从 dataset.root 读取本地数据;如果本地缺失需要的文件,才会用 repo_id 到 Hub 拉取缺的内容到这个 root 目录里。 下面有几个场景。 如果同时给定了dataset.root和dataset.repo_id 如果 root 目录已经是规范的 LeRobot v2 数据集结构(有 meta/info.json、data/.parquet、可选 videos/.mp4),会直接用本地文件,不会下载。 如果本地缺少 meta(或部分 data 文件),代码会用 repo_id 从 Hub 把缺的部分同步到你指定的 root 目录后再加载。 如果只传dataset.repo_id 会把本地根目录设为默认缓存:~/.cache/huggingface/lerobot/{repo_id}(若设置了环境变量 LEROBOT_HOME,则用 $LEROBOT_HOME/{repo_id}),如果本地缓存里已经有完整数据,则直接用本地文件,不再下载。如果本地没有缓存,远端也没有数据,就会报错。 推理验证 python -m lerobot.record \ --robot.type=so101_follower \ --robot.disable_torque_on_disconnect=true \ --robot.port=/dev/ttyACM0 --robot.cameras="{ handeye: {type: opencv, index_or_path: 4, width: 640, height: 480, fps: 30}, fixed: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}}" \ --robot.id=R12252801 \ --display_data=false \ --dataset.single_task="Grab the cube" \ --policy.path=outputs/smolvla_weigh_08181710/pretrained_model \ --dataset.episode_time_s=240 \ --dataset.repo_id=laumy/eval_smolvla_08181710 常见问题 训练报错如下: Traceback (most recent call last): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connection.py", line 198, in _new_conn sock = connection.create_connection( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/util/connection.py", line 85, in create_connection raise err File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/util/connection.py", line 73, in create_connection sock.connect(sa) TimeoutError: [Errno 110] Connection timed out The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 787, in urlopen response = self._make_request( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 488, in _make_request raise new_e File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 464, in _make_request self._validate_conn(conn) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 1093, in _validate_conn conn.connect() File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connection.py", line 753, in connect self.sock = sock = self._new_conn() File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connection.py", line 207, in _new_conn raise ConnectTimeoutError( urllib3.exceptions.ConnectTimeoutError: (<urllib3.connection.HTTPSConnection object at 0x7fe651566380>, 'Connection to huggingface.co timed out. (connect timeout=None)') The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/adapters.py", line 667, in send resp = conn.urlopen( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/connectionpool.py", line 841, in urlopen retries = retries.increment( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/urllib3/util/retry.py", line 519, in increment raise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type] urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/HuggingFaceTB/SmolVLM2-500M-Video-Instruct/tree/main/additional_chat_templates?recursive=False&expand=False (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7fe651566380>, 'Connection to huggingface.co timed out. (connect timeout=None)')) During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/root/autodl-tmp/lerobot/src/lerobot/scripts/train.py", line 291, in <module> train() File "/root/autodl-tmp/lerobot/src/lerobot/configs/parser.py", line 226, in wrapper_inner response = fn(cfg, *args, **kwargs) File "/root/autodl-tmp/lerobot/src/lerobot/scripts/train.py", line 139, in train policy = make_policy( File "/root/autodl-tmp/lerobot/src/lerobot/policies/factory.py", line 168, in make_policy policy = policy_cls.from_pretrained(**kwargs) File "/root/autodl-tmp/lerobot/src/lerobot/policies/pretrained.py", line 101, in from_pretrained instance = cls(config, **kwargs) File "/root/autodl-tmp/lerobot/src/lerobot/policies/smolvla/modeling_smolvla.py", line 356, in __init__ self.language_tokenizer = AutoProcessor.from_pretrained(self.config.vlm_model_name).tokenizer File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/models/auto/processing_auto.py", line 288, in from_pretrained config_dict, _ = ProcessorMixin.get_processor_dict(pretrained_model_name_or_path, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/processing_utils.py", line 873, in get_processor_dict for template in list_repo_templates( File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/utils/hub.py", line 161, in list_repo_templates return [ File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/transformers/utils/hub.py", line 161, in <listcomp> return [ File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 3168, in list_repo_tree for path_info in paginate(path=tree_url, headers=headers, params={"recursive": recursive, "expand": expand}): File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/huggingface_hub/utils/_pagination.py", line 36, in paginate r = session.get(path, params=params, headers=headers) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/sessions.py", line 602, in get return self.request("GET", url, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/sessions.py", line 589, in request resp = self.send(prep, **send_kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/sessions.py", line 703, in send r = adapter.send(request, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/huggingface_hub/utils/_http.py", line 96, in send return super().send(request, *args, **kwargs) File "/root/miniconda3/envs/lerobot/lib/python3.10/site-packages/requests/adapters.py", line 688, in send raise ConnectTimeout(e, request=request) requests.exceptions.ConnectTimeout: (MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/HuggingFaceTB/SmolVLM2-500M-Video-Instruct/tree/main/additional_chat_templates?recursive=False&expand=False (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7fe651566380>, 'Connection to huggingface.co timed out. (connect timeout=None)'))"), '(Request ID: 7f4d5747-ec95-47cc-a55f-cb3e230c52e2)') 原因是训练在初始化 SmolVLA 的 VLM 时需要从 Hugging Face Hub 拉取资源(AutoProcessor.from_pretrained 默认用 vlm_model_name=HuggingFaceTB/SmolVLM2-500M-Video-Instruct)。你的机器连到 huggingface.co 超时,导致下载失败并报 ConnectTimeout。 解决办法:export HF_ENDPOINT=https://hf-mirror.com 把原本指向 https://huggingface.co 的所有 Hub 请求(模型/数据集下载、API 调用)改走 https://hf-mirror.com。作用范围仅当前这个终端会话。关闭终端或开新终端就失效。 训练过程过程中警告 huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) TOKENIZERS_PARALLELISM是分词器在一次调用会开多线程并行处理文本。分词器库是hugging Face的分词器库,负责把文本指令变成模型可用的token id序列,也能把id还原会文本,跟我们此前在一步步实现transformer 的词表类型。出现这样的警告是tokenizers它开了多线程并发,而 DataLoader 再 fork 出子进程并发(本身DataLoader是可以并发),这样容易有死锁风险,为安全起见,库检测到这种顺序就自动把自己的多线程并行关掉,并给出提示。如果要关掉tokenizers的多线程并发,export TOKENIZERS_PARALLELISM=false。 -
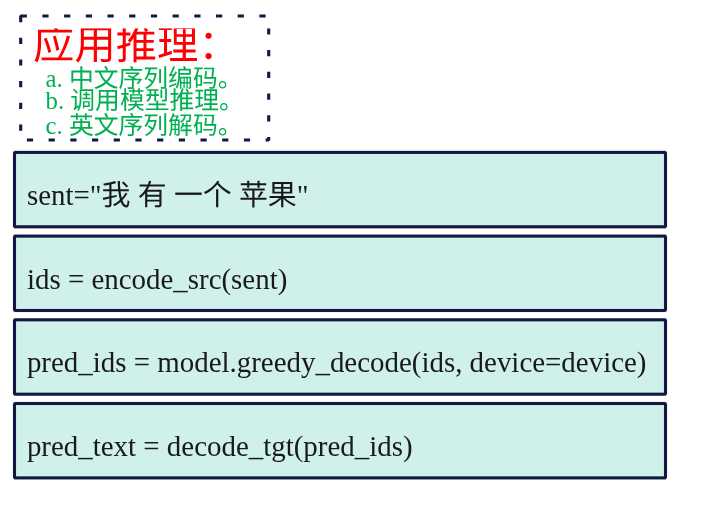
从零实现 Transformer:中英文翻译实例
概述 在http://www.laumy.tech/2458.html#h37章节中,介绍了transformer的原理,本章用pytorch来实现一个将"我有一个苹果"翻译为英文"I have an apple"的模型,直观体会transformer原理实现。 接下来先上图看看整体的代码流程。 推理 训练 模型 编解码器 到这里就涵盖了整个transformer模型翻译的例子了,下面的章节只是对图中的代码进行展开说明,如果不想陷入细节,可以直接跳转到最后一节获取源码运行实验一下。 数据预处理 数据准备 (1) 准备原始文本对 既然要做翻译那得先有数据用于模型训练,因此需要先准备原始的中文->英文的文本对,下面是使用python列表(List)准备中英匹配语料,List中包含的是元组(Tuple)。 pairs = [ ("我 有 一个 苹果", "i have an apple"), ("我 有 一本 书", "i have a book"), ("你 有 一个 苹果", "you have an apple"), ("他 有 一个 苹果", "he has an apple"), ("她 有 一个 苹果", "she has an apple"), ("我们 有 一个 苹果", "we have an apple"), ("我 喜欢 苹果", "i like apples"), ("我 吃 苹果", "i eat apples"), ("你 喜欢 书", "you like books"), ("我 喜欢 书", "i like books"), ("我 有 两个 苹果", "i have two apples"), ("我 有 红色 苹果", "i have red apples"), ] 为了方便,在构建原始文本对时,中英文的分词就以空格划分,这样接下来就可以根据空格来进行构建词表。 (2)构建词表 因为神经网络不能直接处理文本,模型只能处理数字,比如不能直接处理"我"、"有","I"等中英文词,对于计算机来讲都是数字,所以需要把文字转换为对应的映射表。 所以词表就是一个"字典",把每个词映射到一个唯一的数字ID上,所有的文本都需要转换为数字序列。 如下示例,中英文的编号。 # 中文词表示例 SRC_STOI = { "我": 1, "有": 2, "一个": 3, "苹果": 4, "书": 5, "喜欢": 6, # ... 更多词 } # 英文词表示例 TGT_STOI = { "i": 1, "have": 2, "an": 3, "apple": 4, "a": 5, "book": 6, # ... 更多词 } 如何构建词表了。既然中文、英文都需要各自编号,那么得先把此前准备的原始文本队中文、英文各自拆出来,然后我们使用python的set集合,将中文、英文分别添加到set集合中,使用set集合的好处是可以自动去重,添加了重复元素,set就不会添加,这样就得到了各自的中文、英文词表。最后再对这些词表进行依次编号即可。 下面就看看使用python代码怎么实现,首先是将原始文本对拆解,把中文放一起,英文放一起。 src_texts = [p[0] for p in pairs] tgt_texts = [p[1] for p in pairs] print(src_texts) print(tgt_texts) src_texts ['我 有 一个 苹果', '我 有 一本 书', '你 有 一个 苹果', '他 有 一个 苹果', '她 有 一个 苹果', '我们 有 一个 苹果', '我 喜欢 苹果', '我 吃 苹果', '你 喜欢 书', '我 喜欢 书', '我 有 两个 苹果', '我 有 红色 苹果'] tgt_texts ['i have an apple', 'i have a book', 'you have an apple', 'he has an apple', 'she has an apple', 'we have an apple', 'i like apples', 'i eat apples', 'you like books', 'i like books', 'i have two apples', 'i have red apples'] 接下来实现一个build_vocab函数,主要的思路就是句子先按照空格进行分好词,接着将所有词添加到set集合中,set集合会自动去重,这里需要注意的时,需要再加上3个特殊的词,分别是pad、bos、eos分别表示填充、开始、结束。填充是因为输入句子是不定长的,但是对于transformer来说所有的输入矩阵处理都是固定长度,所以不够的需要补齐,而bos和eos是用于transformer解码的,便于开始和结束翻译过程,最后构建好词表后就按照词表中进行变化,3个特殊词分为为1、2、3其他的词依次编号。 def build_vocab(examples: List[str]): """构建词表(字符串→索引 与 索引→字符串) - 输入示例为用空格分词后的句子列表 - 加入特殊符号 `<pad>`, `<bos>`, `<eos>` 并将其它 token 排序,保证可复现 返回: stoi: dict[token->id] itos: List[id->token] """ tokens = set() # 建立一个集合,用于存储所有的词表(不重复的词) for s in examples: # 依次遍历获得每个句子 for t in s.split(): # 通过空格划分,依次遍历句子中的每个词, tokens.add(t.lower()) # 将词添加到set中,这里为了方便统一转换小写 itos = ["<pad>", "<bos>", "<eos>"] + sorted(tokens) # 加入3个特殊的词,同时对set中的词进行排序。 stoi = {t: i for i, t in enumerate(itos)} # 对词表中的词按照顺序依次编号 return stoi, itos SRC_STOI, SRC_ITOS = build_vocab(src_texts) TGT_STOI, TGT_ITOS = build_vocab(tgt_texts) build_vocab最终返回是一个字典和列表,字典是词:编号的映射,列表是存放的是词表。列表是按照编号顺序依次排布,这样我们可以通过编号定位到时那个词。 为什么要一个字典和列表了?因为transformer输入是词->编号(转换为编码数字给计算机处理),输出是编号->词过程(转化为句子给人看)。通过字典我们可以查询词对应的编号[key:value],而通过列表的索引(编号)我们可以查询到对应的词。 中文和英文分别各自对应一个字典和词表。 SRC_STOI {'<pad>': 0, '<bos>': 1, '<eos>': 2, '一个': 3, '一本': 4, '两个': 5, '书': 6, '他': 7, '你': 8, '吃': 9, '喜欢': 10, '她': 11, '我': 12, '我们': 13, '有': 14, '红色': 15, '苹果': 16} SRC_ITOS ['<pad>', '<bos>', '<eos>', '一个', '一本', '两个', '书', '他', '你', '吃', '喜欢', '她', '我', '我们', '有', '红色', '苹果'] TGT_STOI {'<pad>': 0, '<bos>': 1, '<eos>': 2, 'a': 3, 'an': 4, 'apple': 5, 'apples': 6, 'book': 7, 'books': 8, 'eat': 9, 'has': 10, 'have': 11, 'he': 12, 'i': 13, 'like': 14, 'red': 15, 'she': 16, 'two': 17, 'we': 18, 'you': 19} TGT_ITOS ['<pad>', '<bos>', '<eos>', 'a', 'an', 'apple', 'apples', 'book', 'books', 'eat', 'has', 'have', 'he', 'i', 'like', 'red', 'she', 'two', 'we', 'you'] 这样我们就给中文和英文的所有词都编好号了,同时通过列表也可以通过编号查询到词。 数据加载器 在pytorch中模型训练那必然少不了DataLoader和Dataset,关于这两个类的介绍在http://www.laumy.tech/2491.html#h23中有简要说明,这里就不阐述了。注意本小节说明的数据的批量处理都适用于训练准备,主要是实现Dataset和Dataloader用于pytorch模型的训练,如果只是推理则是不需要的。 (1)Dataset继承类实现 首先要实现DataLoader中关键的输入类Dataset继承类,用于产出“单个样本”,怎么按索引取到一个样本,以及总共有多少个样本。每个样本是中文句子->英文句子。样本集为此前定义pairs,但是要把pairs中句子转换为编号,词表在前面我们已经构建好了,直接查询就行,那这里我们定义一个Example用于定义样本,src是中文句子的编号列表,tgt是对于英文句子的编号列表。 @dataclass class Example: """单条并行样本 - src: 源语言索引序列(不含 BOS/EOS) - tgt: 目标语言索引序列(含 BOS/EOS) """ src: List[int] tgt: List[int] 接下来就是实现Dataset的继承类ToyDataset,返回有多少个样本,以及通过编号获取指定的样本。 class ToyDataset(Dataset): """语料数据集,用于快速过拟合演示。""" def __init__(self, pairs: List[Tuple[str, str]]): self.data = [Example(encode_src(s), encode_tgt(t)) for s, t in pairs] def __len__(self): return len(self.data) def __getitem__(self, idx): return self.data[idx] 需要把pairs句子中词列表编码为数字列表,这里实现encode_src用于将输入(即pairs中的中文)编号为列表,再实现encode_tgt将输出(即pairs中的英文)编号为列表。使用for列表推导式从pairs列表中获取到s(中文句子)和t(英文句子)然后传入encode_src和encoder_tgt进而构建一个新的列表元素Example。这样就组建样本的self.data的样本列表,元素为Example类型,可以通过idx获取到指定的样本。 def encode_src(s: str) -> List[int]: """将原语句(已空格分词)编码为索引序列(不含 BOS/EOS)。""" return [SRC_STOI[w.lower()] for w in s.split()] def encode_tgt(s: str) -> List[int]: """将目标语句编码为索引序列,并在首尾添加 BOS/EOS。""" return [BOS_IDX] + [TGT_STOI[w.lower()] for w in s.split()] + [EOS_IDX] 上面就是输入句子编码为编号向量的实现了,也很简单,通过此前构建的词表字典,通过词就可以搜索到对应编号了。这里需要注意的是编码的源句子(输入)是没有包含BOS和EOS的,因为transformer的编码器不需要BOS和EOS,而编码的目标句子(输出)需要在句子前加上BOS,句子结尾加上EOS,因为transformer的解码器输入需要通过BOS来翻译第一个词,通过EOS来结束一个句子的翻译,要是不明白为什么了可以看看前面transformer原理的文章。 (2)Dataload DataLoader 负责“成批取样”,模型训练输入数据不是一个样本一个样本的送入训练,而是按照批次(多个样本合成一个批次)进行训练,这样训练效率才高。DataLoader决定批大小、是否打乱、多进程加载,返回的是一个可迭代的对象。 DataLoader重点是要实现 collate_fn回调,也就是怎么把一个批里的样本“拼起来”。 loader = DataLoader(dataset, batch_size=8, shuffle=True, collate_fn=collate_fn) 训练transformer,准备数据。我们的目的是要能够返回批量数据,批量数据也有好几个类型。 输入给encoder批量数据:输入矩阵类型(B,S),包含补齐的padding。 输入给decoder的批量数据:输入给decoder的矩阵类型(B,T),包含BOS以及右对齐的padding。不能加EOS,因为EOS是预测的结果,防止模型训练作弊。 decoder输出的批量数据:解码器的监督目标,主要用于预测数据与实际的结果比较计算损失,矩阵类型(B,T),不含BOS但是包含EOS。 encoder输入的pad掩码数据:因为输入给encoder的数据有padding,所以要告诉transformer哪些做了补齐,后续计算的时候要处理。 decoder输入的pad掩码数据:同上。 def collate_fn(batch: List[Example]): """将一个 batch 的样本对齐为等长张量,并构造 teacher forcing 所需的输入/输出。 返回: - src: (B,S) 源序列,已 padding - tgt_in: (B,T) 解码器输入(含 BOS,右对齐 padding) - tgt_out: (B,T) 解码器监督目标(对 tgt_in 右移一位,含 EOS) - src_pad_mask: (B,S) 源端 padding 掩码,True 表示 padding 位置 - tgt_pad_mask: (B,T) 目标端 padding 掩码(针对输入序列) """ # padding to max length in batch src_max = max(len(b.src) for b in batch) tgt_max = max(len(b.tgt) for b in batch) src_batch = [] tgt_in_batch = [] tgt_out_batch = [] for ex in batch: src = ex.src + [PAD_IDX] * (src_max - len(ex.src)) # Teacher forcing: shift-in, shift-out tgt_in = ex.tgt[:-1] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[:-1])) tgt_out = ex.tgt[1:] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[1:])) src_batch.append(src) tgt_in_batch.append(tgt_in) tgt_out_batch.append(tgt_out) src = torch.tensor(src_batch, dtype=torch.long) # (B, S) tgt_in = torch.tensor(tgt_in_batch, dtype=torch.long) # (B, T_in) tgt_out = torch.tensor(tgt_out_batch, dtype=torch.long) # (B, T_out) src_pad_mask = src.eq(PAD_IDX) # (B, S) tgt_pad_mask = tgt_in.eq(PAD_IDX) # (B, T) return src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask 上面就是Dataloader回调函数如何获取批量数据的实现了,输入为一个列表(包含所有样本的列表)。输出为5个2维向量,分别对应的就是上面说的5个批量数据。 首先计算样本列表中最长的源序列长度src_max和目标序列长度tgt_max,为后续的不足长度的句子进行padding操作,提供基准的长度。 其次使用for循环遍历每个样本(Example),将源序列src(encoder的输入)使用PAD_IDX填充到相同长度,保持做对齐;将目标序列输入(tgt_in)去掉最后一个token(EOS)作为decoder的输入,目标序列输出比对样本tgb_out去掉第一个tokenBOS作为监督目标,使用的teacher Forcing机制,这样就是实现了输入预测下一个的训练模式数据准备。 最后就是准备src和tgt_in的mask矩阵,形状跟src和tgt_in一样,使用python的eq比对如果对应的位置是padding就是true,不是就是false。 模型架构 数据准备好了,接下来就是设计我们的模型了。我们的模型是一个翻译模型可以分为两个路径,一个是编码路径和解码路径。 编码路径:词嵌入->位置编码->编码器。 解码路径:词嵌入->位置编码->解码器->生成器。 Class Seq2SeqTransformer(nn.Module): def __init__(self, src_vocab_size, tgt_vocab_size, d_model=128, nhead=4, num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1): super().__init__() self.d_model = d_model # 编码路径 # 1.词嵌入层,将tokenID转换为密集向量 self.src_tok = nn.Embedding(src_vocab_size, d_model, padding_idx=PAD_IDX) self.tgt_tok = nn.Embedding(tgt_vocab_size, d_model, padding_idx=PAD_IDX) # 2. 对输入添加位置信息 self.pos_enc = PositionalEncoding(d_model, dropout=dropout) # 3. 源序列的编码 self.encoder = Encoder(d_model, nhead, dim_ff, num_encoder_layers, dropout) # 解码路径 # 1. 解码生成目标序列 self.decoder = Decoder(d_model, nhead, dim_ff, num_decoder_layers, dropout) # 2. 将解码器输出转换为词表概率 self.generator = nn.Linear(d_model, tgt_vocab_size) 词嵌入直接调用的是神经网络的库nn.Embedding,其他部分都要自己实现,接下来我们会一一展开。下面我们需要先实现模型Seq2SeqTransformer的方法,主要包括如下: make_subsequent_mask:解码器因果掩码,不允许解码器看到未来。 forward: 模型前向传播的方法,pytorch训练的时候自动调用。 greedy_decode:模型推理方法,用于推理的应用。 因果掩码 为什么需要掩码了?主要是让模型不能看到未来的词。 推理阶段虽然是自回归一个一个输入然后一个一个迭代输出,但是在训练阶段,我们解码器的样本是全部一次性输入的。如下的步骤,我们虽然给到模型输入为:"BOS i have an apple ",但是每个步骤给到模型看到的不能是全部,否则给模型都看到输入结果了,那还谈啥预测,模型会偷懒直接就照搬就是一个映射过程了。如当输入BOS i 期望预测输出i have,如果没有掩码模型都看到全部的"BOS i have an apple ",就不是预测了,模型的参数也没法迭代了。 # 步骤1: 输入BOS → 期望输出i # 步骤2: 输入BOS i → 期望输出i have # 步骤3: 输入BOS i have → 期望输出i have an # 步骤4: 输入BOS i have an → 期望输出 i have an apple # 步骤5: 输入BOS i have an apple → 期望输出i have an apple EOS 哪有个问题,为什么我们输入的时候不按照要多少输入多少,为啥要全部一下给到输入?输入倒是可以要多少输入多少,但是要要考虑模型的并行训练,实际上上面的5个步骤在模型训练时是并行进行的,模型训练要的是训练参数,在某个阶段看到什么输入遇到什么输出,都分好类了自然可以并行的,所以这就需要结合掩码了,告诉模型那个步骤你能看到哪些? 总结一下mask的作用就是让模型不能看到未来的词,同时也是让模型不要对padding位进行误预测。 def make_subsequent_mask(self, sz: int) -> torch.Tensor: """构造大小为 (sz, sz) 的下三角因果掩码;True 为屏蔽(不允许看未来)。""" return torch.triu(torch.ones(sz, sz, dtype=torch.bool), diagonal=1) mask是要生成一个下三角形状,示例如下: # 对于序列长度4 mask = make_subsequent_mask(4) # 结果: # [[False, True, True, True], # 位置0: 只能看位置0 # [False, False, True, True], # 位置1: 能看位置0,1 # [False, False, False, True], # 位置2: 能看位置0,1,2 # [False, False, False, False]] # 位置3: 能看所有位置 前向传播 def forward(self, src, tgt_in, src_pad_mask, tgt_pad_mask): """训练/教师强制阶段的前向。 参数: - src: (B, S) 源 token id - tgt_in: (B, T) 目标端输入(以 BOS 开头) - src_pad_mask: (B, S) True 为 padding - tgt_pad_mask: (B, T) True 为 padding(针对 tgt_in) 返回: - logits: (B, T, V) 词表维度的分类分布 """ # 1) 词嵌入 + 位置编码 src_emb = self.pos_enc(self.src_tok(src)) # (B,S,C) tgt_emb = self.pos_enc(self.tgt_tok(tgt_in)) # (B,T,C) # 2) 编码:仅使用 key_padding_mask 屏蔽 padding memory = self.encoder(src_emb, src_key_padding_mask=src_pad_mask) # (B,S,C) # 3) 解码:自注意力需要因果掩码 + padding 掩码;交叉注意力需要 memory 的 padding 掩码 tgt_mask = self.make_subsequent_mask(tgt_in.size(1)).to(src.device) # (T,T) out = self.decoder( tgt_emb, memory, tgt_mask=tgt_mask, tgt_key_padding_mask=tgt_pad_mask, memory_key_padding_mask=src_pad_mask, ) # (B,T,C) logits = self.generator(out) return logits 上面就是模型的训练了,也比较简单,就是对输入词进行词嵌入+位置编码计算,然后送入编码器得到输出特征矩阵memory;给编码器输入的只是padding的掩码,因为不要提取padding的词; 其次生成因果掩码,将编码器的的特征矩阵输出结果memory以及解码器侧自身的输入给到解码器最终得到(B,T,C)的输出矩阵,其包含了最终输出结果词位置的隐藏信息; 最后调用self.generator(out)即线性变化得到输出目标词表的概率分布(B,T,V);后面就可以用其使用交叉熵跟目标结果进行比对计算损失了。 解码推理 @torch.no_grad() def greedy_decode(self, src_ids: List[int], max_len=20, device="cpu"): """在推理阶段进行贪心解码。 参数: - src_ids: 源端 token id 序列(不含 BOS/EOS) - max_len: 最大生成长度(含 BOS/EOS) - device: 运行设备 返回: - 生成的目标端 id 序列(含 BOS/EOS) """ #切换为评估模式,关闭dropout/batchnorm等随机性 self.eval() # 将源端token id序列转换为张量,并添加一个维度,如[1, 2, 3, 4] -> [[1, 2, 3, 4]] # 变为批维度的 (1, S);dtype 为 long 主要是以适配 nn.Embedding的输入格式。 src = torch.tensor(src_ids, dtype=torch.long, device=device).unsqueeze(0) # 生成一个跟src相同形状的mask矩阵,让编码器不要计算提取pandding的位置信息。 #按元素判断 src 是否等于 PAD_IDX,等于的位置为 True,不等的位置为 False。 src_pad_mask = src.eq(PAD_IDX) # 计算src_tok= src 经过词嵌入+位置编码后的结果 src_tok = self.src_tok(src) src_pos = self.pos_enc(src_tok) # 将该结果送入编码器,返回的memory就是编码器提取的特征向量。 # 输入编码器,即使没有填充(pandding)的token,也需要传入src_key_padding_mask。 memory = self.encoder(src_pos, src_key_padding_mask=src_pad_mask) # 初始化目标端token id序列,维度为(1,1),初始值为BOS_IDX # 表示目标端序列的开始,BOS_IDX=1 # 推理时输入是没有PAD,但是仍然需要tgt_pad_mask. ys = torch.tensor([[BOS_IDX]], dtype=torch.long, device=device) for _ in range(max_len - 1): #计算本次解码的Mask,跟ys形状一样。 tgt_pad_mask = ys.eq(PAD_IDX) # 计算本次因果掩码,把未来看到的token都屏蔽。 tgt_mask = self.make_subsequent_mask(ys.size(1)).to(device) # 可以看到当推理模式时,解码器输入token数量依次是1,2,3,4..... out = self.decoder( self.pos_enc(self.tgt_tok(ys)), memory, tgt_key_padding_mask=tgt_pad_mask, memory_key_padding_mask=src_pad_mask, ) # 转化为预测词的概率分布 logits = self.generator(out[:, -1:, :]) # 使用贪心选择概率最大的作为本次预测的目标 next_token = logits.argmax(-1) next_id = next_token.item() # 显示选择的token token_text = TGT_ITOS[next_id] if next_id < len(TGT_ITOS) else f"ID_{next_id}" print(f"选择: {token_text}({next_id})") ys = torch.cat([ys, next_token], dim=1) # 当下一个输出为EOS时表示结束,则退出。 if next_id == EOS_IDX: break return ys.squeeze(0).tolist() 上面代码的设计要点主要为几个部分: 编码信息提取:将要翻译的句子进行词嵌入,位置编码,然后送入编码器计算提出特征信息memory,最终给到解码器作为输入。 自回归生成:最开始使用BOS一个token+编码器此前计算的输出memory、掩码等信息输入给解码器,解码器预测得到一个输出,然后将输出拼接会此前BOS的后面形成解码器新的输入,以此循环进行预测,直至遇到EOS结束。解侧输入序列长度逐步增长:1 → 2 → 3 → 4 → ...,最开始的序列为BOS表示开始。 掩码生成:使用了因果掩码和padding掩码;虽然推理阶段没有对输入数据进行padding操作,但是依旧需要这两个掩码,主要的考量是保持接口的一致性(原来的接口需要传递这个参数)。 贪心策略:解码器的输出进行线性变化得到词表的概率分布后,然后挑选概率最高的token。 结束循环:当判断到模型预测出EOS时,模式则结束,整个预测完成。 位置编码 class PositionalEncoding(nn.Module): """经典正弦/余弦位置编码。 给定嵌入 `x (B,L,C)`,按长度切片并与位置编码相加,再做 dropout。 """ def __init__(self, d_model: int, max_len: int = 5000, dropout: float = 0.1): super().__init__() self.dropout = nn.Dropout(dropout) # 创建一个形状为 (max_len, d_model) 的零张量,用于存储位置编码 pe = torch.zeros(max_len, d_model) # (L, C) # 创建一个形状为 (max_len, 1) 的张量,用于存储位置索引 position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (L, 1) # 创建一个形状为 (d_model//2,) 的张量,用于存储位置编码的缩放因子 div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # sin, cos 交错 pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0) # (1, L, C) self.register_buffer("pe", pe) def forward(self, x: torch.Tensor): # (B, L, C) """为输入嵌入添加位置编码并做 dropout。 参数: - x: (B, L, C) 返回: - (B, L, C) """ x = x + self.pe[:, : x.size(1)] return self.dropout(x) # 对于位置 pos 和维度 i: # 偶数维度: PE(pos, 2i) = sin(pos / 10000^(2i/d_model)) # 奇数维度: PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model)) # pe[:, 0::2]: 选择所有行的偶数列 (0, 2, 4, ...) # pe[:, 1::2]: 选择所有行的奇数列 (1, 3, 5, ...) # 计算过程: # 位置0: sin(0 * div_term), cos(0 * div_term), sin(0 * div_term), ... # 位置1: sin(1 * div_term), cos(1 * div_term), sin(1 * div_term), ... # 位置2: sin(2 * div_term), cos(2 * div_term), sin(2 * div_term), ... 位置编码比较简单,就是按照sin和cos按公式计算生成向量,最终返回词嵌入向量+位置编码向量。 编码器 class Encoder(nn.Module): def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1): super().__init__() self.layers = nn.ModuleList([ EncoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers) ]) def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor: """堆叠若干编码层。 参数: - x: (B, S, C) - src_key_padding_mask: (B, S) True 为 padding 返回: - (B, S, C) """ for layer in self.layers: x = layer(x, src_key_padding_mask=src_key_padding_mask) return x 编码器框架就是若干个编码层堆叠起来,但是每层的都有自己的参数,主要调用的是nn.ModuleList进行注册子模块,确保参数都能够被优化器找到,num_layers控制了编码器的深度。 前向传播函数也很简单,输入一次通过每一个编码层,得到的输出结果给到下一个编码层,以此循环最终经过最后一层编码器得得到的特征信息,给后续解码器使用。 class EncoderLayer(nn.Module): """Transformer 编码层(后归一化 post-norm 版本) 子层:自注意力 + 前馈;均带残差连接与 LayerNorm。 """ def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.self_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm1 = nn.LayerNorm(d_model) self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout) self.norm2 = nn.LayerNorm(d_model) def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor: """单层编码层前向。 参数: - x: (B, S, C) - src_key_padding_mask: (B, S) True 为 padding 返回: - (B, S, C) """ # 自注意力子层 attn_out = self.self_attn(x, x, x, attn_mask=None, key_padding_mask=src_key_padding_mask) x = self.norm1(x + attn_out) # 前馈子层 ff_out = self.ff(x) x = self.norm2(x + ff_out) return x 编码层的组件为MultiHeadAttention、LayerNorm、PositionwiseFeedForward这与我们此前介绍的transformer原理一致。 其前向传播过程,首先输入X(查询),X(键),X(值),qkv都是一样的;注意力计算时,把attn_mask=None,因为编码器不需要因果掩码,但是需要padding mask。其次进行残差连接计算x+attn_out,再调用norml进行层归一化,最后是计算前馈网络,再进行归一化就得到一层的输出结果了。 class PositionwiseFeedForward(nn.Module): """前馈网络:逐位置的两层 MLP(含激活与 dropout)""" def __init__(self, d_model: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.fc1 = nn.Linear(d_model, dim_ff) self.fc2 = nn.Linear(dim_ff, d_model) self.act = nn.ReLU() self.dropout = nn.Dropout(dropout) def forward(self, x: torch.Tensor) -> torch.Tensor: """两层逐位置前馈网络。 参数: - x: (B, L, C) 返回: - (B, L, C) """ x = self.fc2(self.dropout(self.act(self.fc1(x)))) x = self.dropout(x) return x 前馈网络主要两层: 第一层:d_model → dim_ff (通常 dim_ff = 4 * d_model) 激活函数:ReLU。 第二层:dim_ff → d_model 就是对输入进行升维然后非线性变化再降维,提取更多的信息。两层都使用了dropout,展开就是如下。 # 1. 第一层线性变换 x = self.fc1(x) # (B, L, C) → (B, L, dim_ff) # 2. 激活函数 x = self.act(x) # 应用ReLU # 3. 第一个dropout x = self.dropout(x) # 随机置零部分神经元 # 4. 第二层线性变换 x = self.fc2(x) # (B, L, dim_ff) → (B, L, C) # 5. 第二个dropout x = self.dropout(x) # 最终dropout 解码器 class Decoder(nn.Module): def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1): super().__init__() self.layers = nn.ModuleList([ DecoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers) ]) def forward( self, x: torch.Tensor, memory: torch.Tensor, tgt_mask: torch.Tensor | None = None, tgt_key_padding_mask: torch.Tensor | None = None, memory_key_padding_mask: torch.Tensor | None = None, ) -> torch.Tensor: """堆叠若干解码层。 参数: - x: (B, T, C) 目标端嵌入 - memory: (B, S, C) 编码器输出 - tgt_mask: (T, T) 因果掩码,True 为屏蔽 - tgt_key_padding_mask: (B, T) 目标端 padding 掩码 - memory_key_padding_mask: (B, S) 源端 padding 掩码 返回: - (B, T, C) """ for layer in self.layers: x = layer( x, memory, tgt_mask=tgt_mask, tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=memory_key_padding_mask, ) return x 与编码器类似,使用nn.ModuleList创建多个解码层,每个解码层都是独立的DecoderLayer实例;解码器的输入数据有两个,一个是解码器侧自己的输入序列,另外一个是编码器计算得到的特征信息。解码器的每一层都需要输入编码器给的特征序列,但是都是一样的;解码器层计算得到的输出将传递给下一层解码器层,循环得到最后的输出。 Decoder (解码器) ├── DecoderLayer 1 (解码层1) │ ├── MultiHeadAttention (自注意力) │ ├── LayerNorm1 + 残差连接 │ ├── MultiHeadAttention (交叉注意力) │ ├── LayerNorm2 + 残差连接 │ ├── PositionwiseFeedForward (前馈网络) │ └── LayerNorm3 + 残差连接 ├── DecoderLayer 2 (解码层2) │ └── ... (同上结构) └── ... (重复 num_layers 次) 输入: x (B, T, C) + memory (B, S, C) → DecoderLayer 1 → DecoderLayer 2 → ... → DecoderLayer N → 输出: (B, T, C) 其前向传播也大同小异,与编码器不同的是需要传递因果掩码,tgt_mask,防止看到未来信息,同时还传入了源序列的pandding掩码,跟输入给编码器的mask是一样的。 class DecoderLayer(nn.Module): """Transformer 解码层(自注意力 + 交叉注意力 + 前馈)""" def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.self_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm1 = nn.LayerNorm(d_model) self.cross_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm2 = nn.LayerNorm(d_model) self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout) self.norm3 = nn.LayerNorm(d_model) def forward( self, x: torch.Tensor, memory: torch.Tensor, tgt_mask: torch.Tensor | None = None, tgt_key_padding_mask: torch.Tensor | None = None, memory_key_padding_mask: torch.Tensor | None = None, ) -> torch.Tensor: """单层解码层前向。 参数: - x: (B, T, C) 解码器输入 - memory: (B, S, C) 编码器输出 - tgt_mask: (T, T) 因果掩码,true为屏蔽 - tgt_key_padding_mask: (B, T) - memory_key_padding_mask: (B, S) 返回: - (B, T, C) """ # 1) 解码器自注意力(带因果掩码 tgt_mask) sa = self.self_attn(x, x, x, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask) x = self.norm1(x + sa) # 2) 交叉注意力:Q 来自解码器,K/V 来自编码器 memory ca = self.cross_attn(x, memory, memory, attn_mask=None, key_padding_mask=memory_key_padding_mask) x = self.norm2(x + ca) # 3) 前馈 ff = self.ff(x) x = self.norm3(x + ff) return x 解码器层比编码器层多了一个cross_attn交叉注意力。除了输入数据有些不同,其他都基本类似,下面按前向传播的流程来分析一下。 首先是第一个子层自注意力的计算,输入X(q),X(k),X(v)来自解码器侧路径的输入,推理模式则是由自己预测自回归的输入,训练模式是给定的。自注意力传入了因果掩码attn_mask和屏蔽pandding mask。 其次就是计算残差和层归一化,与编码器类似。 接着就是计算交叉注意力了,核心的注意力类还是MultiHeadAttention,跟编码器和解码器的都来自一个。唯一的区别就是传入的参数不一样,其中查询Q来自于解码器当前的状态X即解码器上一个自注意力的的输出,特征路径是解码器给的信息。而键值K,V则使用的是编码器的输出memory,不使用因果掩码,因为因果掩码前面已经处理了。 最后就是前馈网络的升维和降维处理等了,跟编码器就一样了,就不阐述了。 三个子层的不同作用: 自注意力层:处理目标序列内部的关系,生成"i have an apple"时,"have"应该关注"i","an"应该关注"i have",通过因果掩码确保只能看到历史信息。 交叉注意力层:让解码器"看到"编码器的信息,翻译成英文时,需要参考中文源序列,通过交叉注意力,解码器可以访问编码器的完整表示。 前馈网络则层:增加非线性表达能力,每个位置独立计算,不涉及位置间的关系。 注意力 接下来就是核心MultiHeadAttention。 MultiHeadAttention class MultiHeadAttention(nn.Module): """多头注意力(Batch-first) - 输入输出为 (B, L, C) - 内部将通道 C 切分到 H 个头,每头维度 Dh=C/H - 支持两类掩码: 1) attn_mask: (Lq, Lk) 下三角等自回归掩码 2) key_padding_mask: (B, Lk) 序列 padding 掩码 两者会在内部合并为可广播到 (B,H,Lq,Lk) 的布尔张量。 """ def __init__(self, d_model: int, nhead: int, dropout: float = 0.1): super().__init__() assert d_model % nhead == 0, "d_model 必须能被 nhead 整除" self.d_model = d_model self.nhead = nhead self.d_head = d_model // nhead self.w_q = nn.Linear(d_model, d_model) self.w_k = nn.Linear(d_model, d_model) self.w_v = nn.Linear(d_model, d_model) self.attn = ScaledDotProductAttention(dropout) self.proj = nn.Linear(d_model, d_model) self.dropout = nn.Dropout(dropout) # 将 (B, L, C) 重塑为 (B, L, H, Dh),原来的数据都不会变化,只是形状改变了 # 加了一个维,然后交换了张量维度顺序。 def _shape(self, x: torch.Tensor) -> torch.Tensor: """(B, L, C) 切分重排为 (B, H, L, Dh)。""" B, L, C = x.shape # 第一步:将 (B, L, C) 重塑为 (B, L, H, Dh) x_reshaped = x.view(B, L, self.nhead, self.d_head) #x.view不复制数据,只是改变数据的"视角",数据在内存中存储顺序不变 # 第二步:交换维度 1 和 2,从 (B, L, H, Dh) 变为 (B, H, L, Dh) x_transposed = x_reshaped.transpose(1, 2) return x_transposed def _merge(self, x: torch.Tensor) -> torch.Tensor: """(B, H, L, Dh) 合并重排回 (B, L, C)。""" B, H, L, Dh = x.shape # 第一步:交换维度 1 和 2,从 (B, H, L, Dh) 变为 (B, L, H, Dh) x_transposed = x.transpose(1, 2) # 第二步:确保内存连续,然后重塑为 (B, L, H*Dh) x_contiguous = x_transposed.contiguous() # 第三步:重塑为 (B, L, C) 其中 C = H * Dh x_reshaped = x_contiguous.view(B, L, H * Dh) return x_reshaped # 因为QKV算的是矩阵,在transformer中涉及到两个mask # 一个是attn_mask控制哪些位置可以相互关注,如因果掩码防止看未来 # 一个是key_padding_mask控制哪些位置是有效的,如填充token不应该被关注 # 因为都要计算所以把这两个使用|合并起来,一起跟QKV计算即可,否则得计算两次。 # 对于encode来说传参只会穿key_pandding_mask,另外一个没有 # 对于decoder来说,两个都会传递。 def _build_attn_mask( self, Lq: int, Lk: int, attn_mask: torch.Tensor | None, key_padding_mask: torch.Tensor | None, device: torch.device, ) -> torch.Tensor | None: """将两类掩码合并成 (1/ B, 1/ H, Lq, Lk) 可广播布尔张量。True 表示屏蔽。""" mask = None if attn_mask is not None: # (Lq, Lk) -> (1,1,Lq,Lk) m1 = attn_mask.to(device).unsqueeze(0).unsqueeze(0) mask = m1 if mask is None else (mask | m1) if key_padding_mask is not None: # (B, Lk) -> (B,1,1,Lk) m2 = key_padding_mask.to(device).unsqueeze(1).unsqueeze(1) mask = m2 if mask is None else (mask | m2) return mask (0)网络层定义 self.w_q = nn.Linear(d_model, d_model) # 查询线性变换 self.w_k = nn.Linear(d_model, d_model) # 键线性变换 self.w_v = nn.Linear(d_model, d_model) # 值线性变换 self.attn = ScaledDotProductAttention(dropout) # 缩放点积注意力 self.proj = nn.Linear(d_model, d_model) # 输出投影 self.dropout = nn.Dropout(dropout) # 输出dropout w_q, w_k, w_v: 将输入转换为查询、键、值表示,attn为计算注意力权重和加权求和,proj将多头结果投影会原始维度,dropout是防止过拟合。 (1)将输入分成多个头 对输入按照head划分为多份,所以这里需要注意的是d_model必现要能被nhead整除,确保每个头有相同的维度。如原来的输入为(B,L,C)切分后变成(B, H, L, Dh),Dh=d_model/nhead。 第一步先使用view重塑为(B, H, L, Dh),然后第二步进行重排。举个例子输入为(B, L, C) = (1, 4, 6)重塑为(B, L, H, Dh) = (1, 4, 2, 3),重塑后的内存布局,[word1_head1_3, word1_head2_3, word2_head1_3, word2_head2_3, ...]每个词的头是交错存储的,为了适应多头注意力的并行计算还要重排一下,让每个头的数据连续存储。 (2)掩码合并 将key_padding_mask和attn_mask(因果)进行合并,这样后续计算就不用计算两次了。 # 使用逻辑或运算 | 合并 # True | True = True (屏蔽) # True | False = True (屏蔽) # False | False = False (不屏蔽) # 最终掩码形状: (B, H, Lq, Lk) 或 (1, H, Lq, Lk) # 可以广播到注意力计算的形状 (3)每个头计算注意力 Q = self._shape(self.w_q(query)) # (B,H,Lq,Dh) K = self._shape(self.w_k(key)) # (B,H,Lk,Dh) V = self._shape(self.w_v(value)) # (B,H,Lk,Dh) mask = self._build_attn_mask(Lq, Lk, attn_mask, key_padding_mask, device) out = self.attn(Q, K, V, mask) # (B,H,Lq,Dh) 计算注意力时,首先对输入分别进行计算线性变换(如QxWq,这样就有参数了)然后重排分别得到QKV,对于编码器来说输入的query、key、value都是一样的,计算QKV的方式也是一样的,都是进行线性nn.Linear层然后再进行重排,但是各自有各自参数,这就是要训练的参数。经过线性层的结果后都需要调用_shape进行重排划分为多个头的数据,便于输入给多头注意力;构建好合并后的掩码之后,就传递到attn中计算注意力。计算出的多头的注意力,需要合并为原来的形状,最后再通过一个线性变化得到最后的结果输出。 完整的数据流示例: # 输入: query (1, 4, 6), key (1, 4, 6), value (1, 4, 6) # 参数: d_model=6, nhead=2, d_head=3 # 步骤1: 线性变换 (保持形状) # w_q(query): (1, 4, 6) -> (1, 4, 6) # w_k(key): (1, 4, 6) -> (1, 4, 6) # w_v(value): (1, 4, 6) -> (1, 4, 6) # 每个词从6维变换到6维 # 学习查询、键、值的表示 # 步骤2: 分头 # _shape(w_q(query)): (1, 4, 6) -> (1, 2, 4, 3) # _shape(w_k(key)): (1, 4, 6) -> (1, 2, 4, 3) # _shape(w_v(value)): (1, 4, 6) -> (1, 2, 4, 3) # 将6维分成2个头,每个头3维 # 头1: 3维表示 # 头2: 3维表示 # 步骤3: 注意力计算 # attn(Q, K, V, mask): (1, 2, 4, 3) -> (1, 2, 4, 3) # 每个头独立计算注意力: # 头1: 计算4个位置之间的注意力,每个位置3维 # 头2: 计算4个位置之间的注意力,每个位置3维 # 步骤4: 合并头 # _merge(out): (1, 2, 4, 3) -> (1, 4, 6) # 将2个头的3维表示合并回6维 # 每个位置现在包含所有头的信息 # 步骤5: 输出变换 # proj(out): (1, 4, 6) -> (1, 4, 6) # dropout(out): (1, 4, 6) -> (1, 4, 6) # 最终输出: (1, 4, 6) ScaledDotProductAttention class ScaledDotProductAttention(nn.Module): """缩放点积注意力(单头) 给定 Q(查询)、K(键)、V(值) 与掩码,计算注意力加权输出。 形状约定: - Q: (B, H, Lq, Dh) - K: (B, H, Lk, Dh) - V: (B, H, Lk, Dh) - mask: 可广播到 (B, H, Lq, Lk),True 表示屏蔽。 """ def __init__(self, dropout: float = 0.1): super().__init__() self.dropout = nn.Dropout(dropout) def forward(self, Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor, mask: torch.Tensor | None = None): """计算缩放点积注意力。 参数: - Q: (B, H, Lq, Dh) - K: (B, H, Lk, Dh) - V: (B, H, Lk, Dh) - mask: 可广播到 (B, H, Lq, Lk) 的布尔掩码,True 表示屏蔽 返回: - (B, H, Lq, Dh) """ d_k = Q.size(-1) # 注意力分数 = QK^T / sqrt(dk) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # (B,H,Lq,Lk) if mask is not None: # 对被屏蔽位置填充一个极小值,softmax 后 ~0 scores = scores.masked_fill(mask, float("-inf")) attn = torch.softmax(scores, dim=-1) # (B,H,Lq,Lk) attn = self.dropout(attn) out = torch.matmul(attn, V) # (B,H,Lq,Dh) return out 这里就是实现缩放点积注意力机制了,Q.transpose(-2, -1)将K的最后两个维度转置,torch.matmul(Q, K^T): 计算Q和K的点积,再math.sqrt(d_k): 缩放因子,防止分数过大。 可以看到会根据传入的mask进行处理,让mask=True的位置会被填充为-inf,这样经过softmax之后,这些位置就接近0,从而实现了屏蔽某位位置的效果。 softmax是将分数转换为概率分布,所有位置的权重和为1,分数越高的位置,权重越大,也就是跟词相关性越大提取的值越丰富,如果是0那基本不相关,掩码为true的位置就是0,也就是基本不提取信息。 总结一下,核心就是公式Attention(Q,K,V) = softmax(QK^T/√d_k)V计算。 应用 接下来就是调用应用了 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") dataset = ToyDataset(pairs) loader = DataLoader(dataset, batch_size=8, shuffle=True, collate_fn=collate_fn) model = Seq2SeqTransformer( src_vocab_size=len(SRC_ITOS), tgt_vocab_size=len(TGT_ITOS), d_model=6, nhead=3, num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1 ).to(device) criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX) optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4) 定义dataset、loader准备数据,然后定义模型model,损失函数定义以及优化方法。 def evaluate_sample(sent="我 有 一个 苹果"): """辅助函数:对输入中文句子进行编码→推理→解码并打印结果。""" ids = encode_src(sent) print("ids",ids) pred_ids = model.greedy_decode(ids, device=device) pred_text = decode_tgt(pred_ids) print(f'INPUT : {sent}') print(f'OUTPUT: {pred_text}\n') print("Before training:") evaluate_sample("我 有 一个 苹果") 上面是整个应用翻译应用,在没有训练出参数,自然预测出的结果是不对的。 EPOCHS = 800 # 小步数即可过拟合玩具数据 for epoch in range(1, EPOCHS + 1): model.train() total_loss = 0.0 for src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask in loader: src = src.to(device) tgt_in = tgt_in.to(device) tgt_out = tgt_out.to(device) src_pad_mask = src_pad_mask.to(device) tgt_pad_mask = tgt_pad_mask.to(device) logits = model(src, tgt_in, src_pad_mask, tgt_pad_mask) # (B, T, V) loss = criterion(logits.reshape(-1, logits.size(-1)), tgt_out.reshape(-1)) optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() total_loss += loss.item() if epoch % 5 == 0 or epoch == 1: print(f"Epoch {epoch:02d} | loss={total_loss/len(loader):.4f}") evaluate_sample("我 有 一个 苹果") 上面是训练过程。 常见问题 (1) 解码器训练时的输入和推理时的输入有什么不同? 训练模式是固定长度输入,例如(2,5),所有样本都padding到相同长度,批次内所有样本的长度一致。 # 使用教师强制,目标序列已知 tgt_in = [BOS, i, have, an, apple,PAD] # 完整的输入序列 tgt_out = [i, have, an, apple, EOS] # 完整的监督目标 而推理模式序列长度随着时间步逐步增长,例如# 例如: (1, 1) → (1, 2) → (1, 3) → ...,每次生成后长度+1。 # 逐步生成,每次只预测下一个token ys = [[BOS_ID]] # 第1步 ys = [[BOS_ID, i]] # 第2步 ys = [[BOS_ID, i, have]] # 第3步 ys = [[BOS_ID, i, have, an]] # 第4步 ys = [[BOS_ID, i, have, an,apple]] # 第5步 之所以有这样的差异是训练时用的是Teacher Forcing优势,使用了并行计算让所有位置可以同时计算预测,提高效率快速收敛。而推理时是自回归模式,每个token的生成只能基于之前输出的信息。 (2)什么情况下输入数据需要PAD? 通常无论是编码器的输入还是解码器的输入如果不是批量并行计算都可以不用PAD,但如果是批量并行都需要PAD MASK。 在训练模式下,为了提高效率需要批量并行计算,所以无论编码器还是解码器的输入都是需要PAD,在本文中要不要PAD动作是在DataLoader的回调函数中collate_fn进行的,会对编码器和解码器的输入都会pad对齐到一样的长度。 因此最主要的考量是否要批量并行计算,因为并行计算如果长度不同,无法并行处理,无论是自注意力分数、前馈网络、还是残差连接,只有长度一致,才能并行一下处理多个样本。而往往训练模型基本都是批量处理。 总之只处理一个样本时可以不需要PAD,如果要批量都一定需要PAD。而只处理一个样本,往往是推理模式场景。 (3)既然推理模式的编码器和解码器输入没有进行PAD到一定长度,那为什么无论编码器和解码器都依旧还需要传入PAD mask? 需要PAD mask我认为本质上有两点原因:其一用于告知模型输入序列的长度,其二为了接口的一致性,因为transformer最核心的是无论编码器还是解码器最终的核心是Scaled Dot-Product Attetion,可以理解为这是一个共有底层函数,都要调用,做兼容了所以一定要传这个参数。 (3)推理模式的解码器既然是一个一个token往后生成的然后依次拼接回给到输入,未来的词其实根本就没有输入,为什么还需要下三角度的因果mask? 本质上还是保证接口的兼容性,这块都无论是推理还是训练模式都需要传入这个因果mask。 首先在实现层面让训练模式和推理模式代码能够兼容,训练模式使用的是teacher forcing把整个目标序列一次性喂进去,那自然不能让模型看到未来token。推理模式严格上如果一次一个token,每次只输入已经生成的部分,在这种最简单的视线下,确实不需要再加下三角mask,因为未来token不存在,自然无法attend到。但是大多数框架都选择统一接口,无论训练还是推理都传causal mask,避免在不同模式下切换逻辑。 其次从推理模式的多样性考虑,即使是推理阶段,也有可能遇到这种情况,也就是批量生成,一次生成多个序列,每个序列长度不同。 下三角是一个通用的"未来屏蔽"机制,不只是为了防止模型看见未来token,也是为了让实现和训练推理保持一致,并支持批量/并行推理优化。 附:完整源码 # toy_transformer_translation.py # A tiny, runnable Transformer seq2seq example to translate Chinese->English on a toy dataset. # PyTorch >= 2.0 recommended. import math import random from dataclasses import dataclass from typing import List, Tuple import torch import torch.nn as nn from torch.utils.data import DataLoader, Dataset random.seed(0) torch.manual_seed(0) # -------------------------- # 1) Toy parallel corpus # -------------------------- pairs = [ # 基本陈述 ("我 有 一个 苹果", "i have an apple"), ("我 有 一本 书", "i have a book"), ("你 有 一个 苹果", "you have an apple"), ("他 有 一个 苹果", "he has an apple"), ("她 有 一个 苹果", "she has an apple"), ("我们 有 一个 苹果", "we have an apple"), ("我 喜欢 苹果", "i like apples"), ("我 吃 苹果", "i eat apples"), ("你 喜欢 书", "you like books"), ("我 喜欢 书", "i like books"), # 稍作扩展 ("我 有 两个 苹果", "i have two apples"), ("我 有 红色 苹果", "i have red apples"), ] # 中文使用"空格分词(简化)",英文用空格分词 def build_vocab(examples: List[str]): """构建词表(字符串→索引 与 索引→字符串) - 输入示例为用空格分词后的句子列表 - 加入特殊符号 `<pad>`, `<bos>`, `<eos>` 并将其它 token 排序,保证可复现 返回: stoi: dict[token->id] itos: List[id->token] """ tokens = set() # 建立一个集合,用于存储所有不同的token for s in examples: # 遍历所有句子,s是句子,如我 有 一个 苹果 for t in s.split(): # 遍历句子中的每个token,t是token,如我 tokens.add(t.lower()) # 将token添加到集合中,并转换为小写,如我 # 特殊符号 itos = ["<pad>", "<bos>", "<eos>"] + sorted(tokens) # 将特殊符号和所有不同的token排序 # print(itos) stoi = {t: i for i, t in enumerate(itos)} # 将token和索引建立映射关系 # print(stoi) return stoi, itos src_texts = [p[0] for p in pairs] tgt_texts = [p[1] for p in pairs] print("src_texts",src_texts) print("tgt_texts",tgt_texts) SRC_STOI, SRC_ITOS = build_vocab(src_texts) print("SRC_STOI",SRC_STOI) print("SRC_ITOS",SRC_ITOS) TGT_STOI, TGT_ITOS = build_vocab(tgt_texts) print("TGT_STOI",TGT_STOI) print("TGT_ITOS",TGT_ITOS) PAD_IDX, BOS_IDX, EOS_IDX = 0, 1, 2 #将源语句编码为索引序列(不含 BOS/EOS),如我 有 一个 苹果 -> [1, 2, 3, 4] def encode_src(s: str) -> List[int]: """将原语句(已空格分词)编码为索引序列(不含 BOS/EOS)。""" return [SRC_STOI[w.lower()] for w in s.split()] def encode_tgt(s: str) -> List[int]: """将目标语句编码为索引序列,并在首尾添加 BOS/EOS。""" return [BOS_IDX] + [TGT_STOI[w.lower()] for w in s.split()] + [EOS_IDX] def decode_tgt(ids: List[int]) -> str: """将目标端索引序列解码回字符串(忽略 PAD/BOS,遇到 EOS 停止)。""" words = [] for i in ids: if i == EOS_IDX: break if i in (PAD_IDX, BOS_IDX): continue words.append(TGT_ITOS[i]) return " ".join(words) @dataclass class Example: """单条并行样本 - src: 源语言索引序列(不含 BOS/EOS) - tgt: 目标语言索引序列(含 BOS/EOS) """ src: List[int] tgt: List[int] class ToyDataset(Dataset): """极小玩具平行语料数据集,用于快速过拟合演示。""" def __init__(self, pairs: List[Tuple[str, str]]): self.data = [Example(encode_src(s), encode_tgt(t)) for s, t in pairs] def __len__(self): return len(self.data) def __getitem__(self, idx): return self.data[idx] def collate_fn(batch: List[Example]): """将一个 batch 的样本对齐为等长张量,并构造 teacher forcing 所需的输入/输出。 返回: - src: (B,S) 源序列,已 padding - tgt_in: (B,T) 解码器输入(含 BOS,右对齐 padding) - tgt_out: (B,T) 解码器监督目标(对 tgt_in 右移一位,含 EOS) - src_pad_mask: (B,S) 源端 padding 掩码,True 表示 padding 位置 - tgt_pad_mask: (B,T) 目标端 padding 掩码(针对输入序列) """ # padding to max length in batch src_max = max(len(b.src) for b in batch) tgt_max = max(len(b.tgt) for b in batch) src_batch = [] tgt_in_batch = [] tgt_out_batch = [] for ex in batch: src = ex.src + [PAD_IDX] * (src_max - len(ex.src)) # Teacher forcing: shift-in, shift-out tgt_in = ex.tgt[:-1] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[:-1])) tgt_out = ex.tgt[1:] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[1:])) src_batch.append(src) tgt_in_batch.append(tgt_in) tgt_out_batch.append(tgt_out) src = torch.tensor(src_batch, dtype=torch.long) # (B, S) tgt_in = torch.tensor(tgt_in_batch, dtype=torch.long) # (B, T_in) tgt_out = torch.tensor(tgt_out_batch, dtype=torch.long) # (B, T_out) src_pad_mask = src.eq(PAD_IDX) # (B, S) tgt_pad_mask = tgt_in.eq(PAD_IDX) # (B, T) return src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask # -------------------------- # 2) Positional encoding # -------------------------- class PositionalEncoding(nn.Module): """经典正弦/余弦位置编码。 给定嵌入 `x (B,L,C)`,按长度切片并与位置编码相加,再做 dropout。 """ def __init__(self, d_model: int, max_len: int = 5000, dropout: float = 0.1): super().__init__() self.dropout = nn.Dropout(dropout) # 创建一个形状为 (max_len, d_model) 的零张量,用于存储位置编码 pe = torch.zeros(max_len, d_model) # (L, C) # 创建一个形状为 (max_len, 1) 的张量,用于存储位置索引 position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (L, 1) # 创建一个形状为 (d_model//2,) 的张量,用于存储位置编码的缩放因子 div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # sin, cos 交错 pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0) # (1, L, C) self.register_buffer("pe", pe) def forward(self, x: torch.Tensor): # (B, L, C) """为输入嵌入添加位置编码并做 dropout。 参数: - x: (B, L, C) 返回: - (B, L, C) """ x = x + self.pe[:, : x.size(1)] return self.dropout(x) # -------------------------- # 3) 手写 Transformer 编码/解码层(含详细注释) # -------------------------- class ScaledDotProductAttention(nn.Module): """缩放点积注意力(单头) 给定 Q(查询)、K(键)、V(值) 与掩码,计算注意力加权输出。 形状约定: - Q: (B, H, Lq, Dh) - K: (B, H, Lk, Dh) - V: (B, H, Lk, Dh) - mask: 可广播到 (B, H, Lq, Lk),True 表示屏蔽。 """ def __init__(self, dropout: float = 0.1): super().__init__() self.dropout = nn.Dropout(dropout) def forward(self, Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor, mask: torch.Tensor | None = None): """计算缩放点积注意力。 参数: - Q: (B, H, Lq, Dh) - K: (B, H, Lk, Dh) - V: (B, H, Lk, Dh) - mask: 可广播到 (B, H, Lq, Lk) 的布尔掩码,True 表示屏蔽 返回: - (B, H, Lq, Dh) """ d_k = Q.size(-1) # 注意力分数 = QK^T / sqrt(dk) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # (B,H,Lq,Lk) if mask is not None: # 对被屏蔽位置填充一个极小值,softmax 后 ~0 scores = scores.masked_fill(mask, float("-inf")) attn = torch.softmax(scores, dim=-1) # (B,H,Lq,Lk) attn = self.dropout(attn) out = torch.matmul(attn, V) # (B,H,Lq,Dh) return out class MultiHeadAttention(nn.Module): """多头注意力(Batch-first) - 输入输出为 (B, L, C) - 内部将通道 C 切分到 H 个头,每头维度 Dh=C/H - 支持两类掩码: 1) attn_mask: (Lq, Lk) 下三角等自回归掩码 2) key_padding_mask: (B, Lk) 序列 padding 掩码 两者会在内部合并为可广播到 (B,H,Lq,Lk) 的布尔张量。 """ def __init__(self, d_model: int, nhead: int, dropout: float = 0.1): super().__init__() assert d_model % nhead == 0, "d_model 必须能被 nhead 整除" self.d_model = d_model self.nhead = nhead self.d_head = d_model // nhead self.w_q = nn.Linear(d_model, d_model) self.w_k = nn.Linear(d_model, d_model) self.w_v = nn.Linear(d_model, d_model) self.attn = ScaledDotProductAttention(dropout) self.proj = nn.Linear(d_model, d_model) self.dropout = nn.Dropout(dropout) # 将 (B, L, C) 重塑为 (B, L, H, Dh),原来的数据都不会变化,只是形状改变了 # 加了一个维,然后交换了张量维度顺序。 def _shape(self, x: torch.Tensor) -> torch.Tensor: """(B, L, C) 切分重排为 (B, H, L, Dh)。""" B, L, C = x.shape # 第一步:将 (B, L, C) 重塑为 (B, L, H, Dh) x_reshaped = x.view(B, L, self.nhead, self.d_head) #x.view不复制数据,只是改变数据的"视角",数据在内存中存储顺序不变 # 第二步:交换维度 1 和 2,从 (B, L, H, Dh) 变为 (B, H, L, Dh) x_transposed = x_reshaped.transpose(1, 2) return x_transposed def _merge(self, x: torch.Tensor) -> torch.Tensor: """(B, H, L, Dh) 合并重排回 (B, L, C)。""" B, H, L, Dh = x.shape # 第一步:交换维度 1 和 2,从 (B, H, L, Dh) 变为 (B, L, H, Dh) x_transposed = x.transpose(1, 2) # 第二步:确保内存连续,然后重塑为 (B, L, H*Dh) x_contiguous = x_transposed.contiguous() # 第三步:重塑为 (B, L, C) 其中 C = H * Dh x_reshaped = x_contiguous.view(B, L, H * Dh) return x_reshaped # 因为QKV算的是矩阵,在transformer中涉及到两个mask # 一个是attn_mask控制哪些位置可以相互关注,如因果掩码防止看未来 # 一个是key_padding_mask控制哪些位置是有效的,如填充token不应该被关注 # 因为都要计算所以把这两个使用|合并起来,一起跟QKV计算即可,否则得计算两次。 # 对于encode来说传参只会穿key_pandding_mask,另外一个没有 # 对于decoder来说,两个都会传递。 def _build_attn_mask( self, Lq: int, Lk: int, attn_mask: torch.Tensor | None, key_padding_mask: torch.Tensor | None, device: torch.device, ) -> torch.Tensor | None: """将两类掩码合并成 (1/ B, 1/ H, Lq, Lk) 可广播布尔张量。True 表示屏蔽。""" mask = None if attn_mask is not None: # (Lq, Lk) -> (1,1,Lq,Lk) m1 = attn_mask.to(device).unsqueeze(0).unsqueeze(0) mask = m1 if mask is None else (mask | m1) if key_padding_mask is not None: # (B, Lk) -> (B,1,1,Lk) m2 = key_padding_mask.to(device).unsqueeze(1).unsqueeze(1) mask = m2 if mask is None else (mask | m2) return mask def forward( self, query: torch.Tensor, key: torch.Tensor, value: torch.Tensor, attn_mask: torch.Tensor | None = None, key_padding_mask: torch.Tensor | None = None, ) -> torch.Tensor: """多头注意力前向。 参数: - query, key, value: (B, L, C) - attn_mask: (Lq, Lk) 因果/结构掩码,True 为屏蔽 - key_padding_mask: (B, Lk) padding 掩码,True 为 padding 返回: - (B, Lq, C) """ # 输入均为 (B, L, C) B, Lq, _ = query.shape _, Lk, _ = key.shape device = query.device Q = self._shape(self.w_q(query)) # (B,H,Lq,Dh) K = self._shape(self.w_k(key)) # (B,H,Lk,Dh) V = self._shape(self.w_v(value)) # (B,H,Lk,Dh) mask = self._build_attn_mask(Lq, Lk, attn_mask, key_padding_mask, device) out = self.attn(Q, K, V, mask) # (B,H,Lq,Dh) out = self._merge(out) # (B,Lq,C) out = self.proj(out) out = self.dropout(out) return out class PositionwiseFeedForward(nn.Module): """前馈网络:逐位置的两层 MLP(含激活与 dropout)""" def __init__(self, d_model: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.fc1 = nn.Linear(d_model, dim_ff) self.fc2 = nn.Linear(dim_ff, d_model) self.act = nn.ReLU() self.dropout = nn.Dropout(dropout) def forward(self, x: torch.Tensor) -> torch.Tensor: """两层逐位置前馈网络。 参数: - x: (B, L, C) 返回: - (B, L, C) """ x = self.fc2(self.dropout(self.act(self.fc1(x)))) x = self.dropout(x) return x class EncoderLayer(nn.Module): """Transformer 编码层(后归一化 post-norm 版本) 子层:自注意力 + 前馈;均带残差连接与 LayerNorm。 """ def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.self_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm1 = nn.LayerNorm(d_model) self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout) self.norm2 = nn.LayerNorm(d_model) def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor: """单层编码层前向。 参数: - x: (B, S, C) - src_key_padding_mask: (B, S) True 为 padding 返回: - (B, S, C) """ # 自注意力子层 attn_out = self.self_attn(x, x, x, attn_mask=None, key_padding_mask=src_key_padding_mask) x = self.norm1(x + attn_out) # 前馈子层 ff_out = self.ff(x) x = self.norm2(x + ff_out) return x class DecoderLayer(nn.Module): """Transformer 解码层(自注意力 + 交叉注意力 + 前馈)""" def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1): super().__init__() self.self_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm1 = nn.LayerNorm(d_model) self.cross_attn = MultiHeadAttention(d_model, nhead, dropout) self.norm2 = nn.LayerNorm(d_model) self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout) self.norm3 = nn.LayerNorm(d_model) def forward( self, x: torch.Tensor, memory: torch.Tensor, tgt_mask: torch.Tensor | None = None, tgt_key_padding_mask: torch.Tensor | None = None, memory_key_padding_mask: torch.Tensor | None = None, ) -> torch.Tensor: """单层解码层前向。 参数: - x: (B, T, C) 解码器输入 - memory: (B, S, C) 编码器输出 - tgt_mask: (T, T) 因果掩码,true为屏蔽 - tgt_key_padding_mask: (B, T) - memory_key_padding_mask: (B, S) 返回: - (B, T, C) """ # 1) 解码器自注意力(带因果掩码 tgt_mask) sa = self.self_attn(x, x, x, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask) x = self.norm1(x + sa) # 2) 交叉注意力:Q 来自解码器,K/V 来自编码器 memory ca = self.cross_attn(x, memory, memory, attn_mask=None, key_padding_mask=memory_key_padding_mask) x = self.norm2(x + ca) # 3) 前馈 ff = self.ff(x) x = self.norm3(x + ff) return x class Encoder(nn.Module): def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1): super().__init__() self.layers = nn.ModuleList([ EncoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers) ]) def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor: """堆叠若干编码层。 参数: - x: (B, S, C) - src_key_padding_mask: (B, S) True 为 padding 返回: - (B, S, C) """ for layer in self.layers: x = layer(x, src_key_padding_mask=src_key_padding_mask) return x class Decoder(nn.Module): def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1): super().__init__() self.layers = nn.ModuleList([ DecoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers) ]) def forward( self, x: torch.Tensor, memory: torch.Tensor, tgt_mask: torch.Tensor | None = None, tgt_key_padding_mask: torch.Tensor | None = None, memory_key_padding_mask: torch.Tensor | None = None, ) -> torch.Tensor: """堆叠若干解码层。 参数: - x: (B, T, C) 目标端嵌入 - memory: (B, S, C) 编码器输出 - tgt_mask: (T, T) 因果掩码,True 为屏蔽 - tgt_key_padding_mask: (B, T) 目标端 padding 掩码 - memory_key_padding_mask: (B, S) 源端 padding 掩码 返回: - (B, T, C) """ for layer in self.layers: x = layer( x, memory, tgt_mask=tgt_mask, tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=memory_key_padding_mask, ) return x class Seq2SeqTransformer(nn.Module): """最小可运行的手写 Transformer 序列到序列模型 - 使用我们实现的 Encoder/Decoder/MHA/FFN - 仍保持与上文训练/解码接口一致 """ def __init__(self, src_vocab_size, tgt_vocab_size, d_model=128, nhead=4, num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1): super().__init__() self.d_model = d_model self.src_tok = nn.Embedding(src_vocab_size, d_model, padding_idx=PAD_IDX) self.tgt_tok = nn.Embedding(tgt_vocab_size, d_model, padding_idx=PAD_IDX) self.pos_enc = PositionalEncoding(d_model, dropout=dropout) self.encoder = Encoder(d_model, nhead, dim_ff, num_encoder_layers, dropout) self.decoder = Decoder(d_model, nhead, dim_ff, num_decoder_layers, dropout) self.generator = nn.Linear(d_model, tgt_vocab_size) def make_subsequent_mask(self, sz: int) -> torch.Tensor: """构造大小为 (sz, sz) 的下三角因果掩码;True 为屏蔽(不允许看未来)。""" return torch.triu(torch.ones(sz, sz, dtype=torch.bool), diagonal=1) def forward(self, src, tgt_in, src_pad_mask, tgt_pad_mask): """训练/教师强制阶段的前向。 参数: - src: (B, S) 源 token id - tgt_in: (B, T) 目标端输入(以 BOS 开头) - src_pad_mask: (B, S) True 为 padding - tgt_pad_mask: (B, T) True 为 padding(针对 tgt_in) 返回: - logits: (B, T, V) 词表维度的分类分布 """ # 1) 词嵌入 + 位置编码 src_emb = self.pos_enc(self.src_tok(src)) # (B,S,C) tgt_emb = self.pos_enc(self.tgt_tok(tgt_in)) # (B,T,C) # 2) 编码:仅使用 key_padding_mask 屏蔽 padding memory = self.encoder(src_emb, src_key_padding_mask=src_pad_mask) # (B,S,C) # 3) 解码:自注意力需要因果掩码 + padding 掩码;交叉注意力需要 memory 的 padding 掩码 tgt_mask = self.make_subsequent_mask(tgt_in.size(1)).to(src.device) # (T,T) out = self.decoder( tgt_emb, memory, tgt_mask=tgt_mask, tgt_key_padding_mask=tgt_pad_mask, memory_key_padding_mask=src_pad_mask, ) # (B,T,C) logits = self.generator(out) return logits @torch.no_grad() def greedy_decode(self, src_ids: List[int], max_len=20, device="cpu"): """在推理阶段进行贪心解码。 参数: - src_ids: 源端 token id 序列(不含 BOS/EOS) - max_len: 最大生成长度(含 BOS/EOS) - device: 运行设备 返回: - 生成的目标端 id 序列(含 BOS/EOS) """ #切换为评估模式,关闭dropout/batchnorm等随机性 self.eval() # 将源端token id序列转换为张量,并添加一个维度,如[1, 2, 3, 4] -> [[1, 2, 3, 4]] # 变为批维度的 (1, S);dtype 为 long 主要是以适配 nn.Embedding的输入格式。 src = torch.tensor(src_ids, dtype=torch.long, device=device).unsqueeze(0) # 生成一个跟src相同形状的mask矩阵,让编码器不要计算提取pandding的位置信息。 #按元素判断 src 是否等于 PAD_IDX,等于的位置为 True,不等的位置为 False。 src_pad_mask = src.eq(PAD_IDX) # 计算src_tok= src 经过词嵌入+位置编码后的结果 src_tok = self.src_tok(src) src_pos = self.pos_enc(src_tok) # 将该结果送入编码器,返回的memory就是编码器提取的特征向量。 # 输入编码器,即使没有填充(pandding)的token,也需要传入src_key_padding_mask。 memory = self.encoder(src_pos, src_key_padding_mask=src_pad_mask) # 初始化目标端token id序列,维度为(1,1),初始值为BOS_IDX # 表示目标端序列的开始,BOS_IDX=1 # 推理时输入是没有PAD,但是仍然需要tgt_pad_mask. ys = torch.tensor([[BOS_IDX]], dtype=torch.long, device=device) for _ in range(max_len - 1): #计算本次解码的Mask,跟ys形状一样。 tgt_pad_mask = ys.eq(PAD_IDX) # 计算本次因果掩码,把未来看到的token都屏蔽。 tgt_mask = self.make_subsequent_mask(ys.size(1)).to(device) # 可以看到当推理模式时,解码器输入token数量依次是1,2,3,4..... out = self.decoder( self.pos_enc(self.tgt_tok(ys)), memory, tgt_key_padding_mask=tgt_pad_mask, memory_key_padding_mask=src_pad_mask, ) # 转化为预测词的概率分布 logits = self.generator(out[:, -1:, :]) # 使用贪心选择概率最大的作为本次预测的目标 next_token = logits.argmax(-1) next_id = next_token.item() # 显示选择的token token_text = TGT_ITOS[next_id] if next_id < len(TGT_ITOS) else f"ID_{next_id}" print(f"选择: {token_text}({next_id})") ys = torch.cat([ys, next_token], dim=1) if next_id == EOS_IDX: break return ys.squeeze(0).tolist() # -------------------------- # 4) Train # -------------------------- device = torch.device("cuda" if torch.cuda.is_available() else "cpu") dataset = ToyDataset(pairs) loader = DataLoader(dataset, batch_size=8, shuffle=True, collate_fn=collate_fn) model = Seq2SeqTransformer( src_vocab_size=len(SRC_ITOS), tgt_vocab_size=len(TGT_ITOS), d_model=6, nhead=3, num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1 ).to(device) criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX) optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4) def evaluate_sample(sent="我 有 一个 苹果"): """辅助函数:对输入中文句子进行编码→推理→解码并打印结果。""" ids = encode_src(sent) print("ids",ids) pred_ids = model.greedy_decode(ids, device=device) pred_text = decode_tgt(pred_ids) print(f'INPUT : {sent}') print(f'OUTPUT: {pred_text}\n') print("Before training:") evaluate_sample("我 有 一个 苹果") EPOCHS = 80 # 小步数即可过拟合玩具数据 for epoch in range(1, EPOCHS + 1): model.train() total_loss = 0.0 for src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask in loader: src = src.to(device) tgt_in = tgt_in.to(device) tgt_out = tgt_out.to(device) src_pad_mask = src_pad_mask.to(device) tgt_pad_mask = tgt_pad_mask.to(device) logits = model(src, tgt_in, src_pad_mask, tgt_pad_mask) # (B, T, V) loss = criterion(logits.reshape(-1, logits.size(-1)), tgt_out.reshape(-1)) optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() total_loss += loss.item() if epoch % 5 == 0 or epoch == 1: print(f"Epoch {epoch:02d} | loss={total_loss/len(loader):.4f}") evaluate_sample("我 有 一个 苹果") print("After training:") evaluate_sample("我 有 一个 苹果") evaluate_sample("我 有 一本 书") evaluate_sample("你 有 一个 苹果") -
dataset和DataLoader
简介 Dataset和DataLoader在pytorch中主要用于数据的组织。这两个类通常一起搭配处理深度学习中的数据流。 Dataset 用于产出“单个样本”:定义怎么按索引取到一个样本,以及总共有多少个样本。 DataLoader 负责“成批取样”:决定批大小、是否打乱、多进程加载、并用 collate_fn 把一个批里的样本“拼起来”(对齐、padding、mask、teacher forcing 等)。 一句话记忆:Dataset 只管“单条样本”;DataLoader 负责“多条怎么一起、怎么并行、怎么对齐”。变长就写 collate_fn,性能就调 workers/pin_memory/分桶。 Dataset Dataset类作用:定义数据集的统一接口,支持自定义数据加载逻辑。 关键方法: init:初始化数据路径、预处理函数等。 len:返回数据集样本总数。 getitem:根据索引返回单个样本(数据+标签)。 通常情况下用户都会有自己的数据集,所以定义的数据集类继承dataset。 #准备一个数据集 pairs: List[Tuple[str, str]] = [ ("我 有 一个 苹果", "i have an apple"), ("我 有 一本 书", "i have a book"), ("你 喜欢 书", "you like books"), ("我 吃 苹果", "i eat apples"), ] def build_vocab(texts: List[str]): tokens = set() for s in texts: tokens.update([w.lower() for w in s.split()]) itos = ["<pad>", "<bos>", "<eos>"] + sorted(tokens) stoi = {t: i for i, t in enumerate(itos)} return stoi, itos src_texts = [s for s, _ in pairs] tgt_texts = [t for _, t in pairs] SRC_STOI, SRC_ITOS = build_vocab(src_texts) TGT_STOI, TGT_ITOS = build_vocab(tgt_texts) PAD_IDX, BOS_IDX, EOS_IDX = 0, 1, 2 def encode_src(s: str) -> List[int]: return [SRC_STOI[w.lower()] for w in s.split()] def encode_tgt(s: str) -> List[int]: return [BOS_IDX] + [TGT_STOI[w.lower()] for w in s.split()] + [EOS_IDX] # Dataset:定义“单样本怎么取” @dataclass class Example: src: List[int] tgt: List[int] class ToyDataset(Dataset): def __init__(self, pairs: List[Tuple[str, str]]): for s, t in pairs: print("encode_src(s)",encode_src(s)) print("encode_tgt(t)",encode_tgt(t)) self.data = [Example(encode_src(s), encode_tgt(t)) for s, t in pairs] def __len__(self) -> int: return len(self.data) def __getitem__(self, idx: int) -> Example: return self.data[idx] 样本结构:用 Example(src: List[int], tgt: List[int]) 表示一条样本的源序列与目标序列(都是 token id 列表)。 词表与编码:源序列仅分词并映射到 id。目标序列前加 bos、后加 eos,便于自回归训练。 协议:实现 len 和 getitem 两个方法即可被 DataLoader 使用。 DataLoader class torch.utils.data.DataLoader(Data[T_co]): def __init__( self, dataset, batch_size: int = 1, shuffle: bool | None = None, sampler = None, batch_sampler = None, num_workers: int = 0, collate_fn = None, pin_memory: bool = False, drop_last: bool = False, timeout: float = 0, worker_init_fn = None, multiprocessing_context = None, generator = None, prefetch_factor: int = 2, persistent_workers: bool = False, pin_memory_device: str = "" ): ... dataset: Dataset 或 IterableDataset 实例。 batch_size: 每批样本数。 shuffle: 是否在每个 epoch 打乱索引(Map-style 且未显式传 sampler 时有效)。 sampler: 自定义样本采样器(与 shuffle 互斥;指定它就不要再用 shuffle)。 batch_sampler: 一次直接产出“一个 batch 的索引列表”(与 batch_size、shuffle、sampler 互斥)。 num_workers: 进程数(0 为主进程;>0 开多进程并行加载)。 collate_fn(samples_list) -> batch: 批内拼接函数;变长序列需要自定义(默认会尝试堆叠等长 tensor)。 pin_memory: 将 batch 固定到页锁内存,配合 CUDA 加速 H2D 拷贝。 drop_last: 数据量不是 batch_size 整数倍时,是否丢弃最后不满的一批。 timeout: 从 worker 等待数据的秒数(>0 时生效)。 worker_init_fn(worker_id): 每个 worker 的初始化回调(设随机种子、打开文件等)。 multiprocessing_context: 指定多进程上下文(spawn/forkserver 等)。 generator: 控制随机性(打乱、采样)用的随机数生成器。 prefetch_factor: 每个 worker 预取多少个 batch(num_workers > 0 时有效)。 persistent_workers: True 时 DataLoader 第一次迭代后保持 worker 不销毁,提高多轮迭代性能。 pin_memory_device: 当 pin_memory=True 时,指定固定内存的设备标签(一般留空即可)。 DataLoader返回是一个可迭代的对象,每次迭代产出一个批次的样本。一个批次的内容就是把当批样本列表交给 collate_fn 的返回值(若未自定义,则用 PyTorch 的默认 default_collate)。而类型取决于两点Dataset.getitem 返回什么(tensor/数值/dict/tuple…)和collate_fn 如何把一批“样本列表”拼成“批次”。 这里重点阐述一下collate_fn是一个用户需要注册的回调函数,目的是要把一个批的样本拼接起来。同时对于输入样本如果张量的形状不一致如变长序列,进行padding、对齐、mask等动作。 def collate_fn(batch: List[Example]): src_max = max(len(b.src) for b in batch) tgt_max = max(len(b.tgt) for b in batch) src_batch: List[List[int]] = [] tgt_in_batch: List[List[int]] = [] tgt_out_batch: List[List[int]] = [] for ex in batch: src = ex.src + [PAD_IDX] * (src_max - len(ex.src)) # teacher forcing:输入去掉最后一个、输出去掉第一个 tgt_in = ex.tgt[:-1] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[:-1])) tgt_out = ex.tgt[1:] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[1:])) src_batch.append(src) tgt_in_batch.append(tgt_in) tgt_out_batch.append(tgt_out) src = torch.tensor(src_batch, dtype=torch.long) # (B,S) tgt_in = torch.tensor(tgt_in_batch, dtype=torch.long) # (B,T) tgt_out = torch.tensor(tgt_out_batch, dtype=torch.long) # (B,T) src_pad_mask = src.eq(PAD_IDX) # (B,S) True=PAD tgt_pad_mask = tgt_in.eq(PAD_IDX) # (B,T) True=PAD return src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask 输入:batch 是若干个 Example,每个包含 src: List[int] 与 tgt: List[int](目标序列已含 bos/eos)。 核心:对齐变长序列(右侧 padding),构造 teacher forcing 的 (tgt_in, tgt_out),并生成 padding 掩码。 输出: src: (B, S) tgt_in: (B, T) tgt_out: (B, T) src_pad_mask: (B, S);True=PAD tgt_pad_mask: (B, T);True=PAD 首先使用src_max/tgt_max计算批内最长长度,这样能够将所有样本右侧补到同一长度,方便堆叠为矩阵。 接着定义批内累积的容器src_batch,tgt_in_batch,tgt_out_batch。 src_batch: 编码器输入样本的批次。 tgt_in_batch:解码器输入样本的批次。 tgt_out_batch:解码器输出样本的批次。 其次使用for循环对每个样本进行补齐,使其跟src_max、tgt_max长度一致,[PAD_IDX] * (src_max - len(ex.src))的意思是将[PAD_IDX]的单元素列表重复src_max - len(ex.src)用于拼接追加到ex.src后,使其对齐。tgt_in和tgt_out同理。 在对tgt_in和tgt_out做样本补齐时,因为输入ex.tgt是包含了bos和eos目标序列,对于tgt_in输入需要去掉最后一个token bos,tgt_out输出需要去掉第一个token eos。 然后就是将补齐的序列依次添加到src_batch,tgt_in_batch,tgt_out_batch。这样就对输入的数据进行了分类,把编码器的输入整合了在一起,解码器的输入和输出整合了一起。 最后就是将批内对齐后的源序列列表转换为张量,同时计算src和tag_in的mask,也就是说对数据哪些位置添加了pad。 下面是collate_fn相关的打印数据,便于理解。 batch [Example(src=[9, 10, 3, 11], tgt=[1, 11, 10, 4, 5, 2]), Example(src=[6, 8, 5], tgt=[1, 13, 12, 8, 2])] src [9, 10, 3, 11] tgt_in [1, 11, 10, 4, 5] tgt_out [11, 10, 4, 5, 2] src [6, 8, 5, 0] tgt_in [1, 13, 12, 8, 0] tgt_out [13, 12, 8, 2, 0] src_batch [[9, 10, 3, 11], [6, 8, 5, 0]] tgt_in_batch [[1, 11, 10, 4, 5], [1, 13, 12, 8, 0]] tgt_out_batch [[11, 10, 4, 5, 2], [13, 12, 8, 2, 0]] src tensor([[ 9, 10, 3, 11], [ 6, 8, 5, 0]]) tgt_in tensor([[ 1, 11, 10, 4, 5], [ 1, 13, 12, 8, 0]]) tgt_out tensor([[11, 10, 4, 5, 2], [13, 12, 8, 2, 0]]) src_pad_mask tensor([[False, False, False, False], [False, False, False, True]]) tgt_pad_mask tensor([[False, False, False, False, False], [False, False, False, False, True]]) src tensor([[ 9, 10, 3, 11], [ 6, 8, 5, 0]]) tgt_in tensor([[ 1, 11, 10, 4, 5], [ 1, 13, 12, 8, 0]]) tgt_out tensor([[11, 10, 4, 5, 2], [13, 12, 8, 2, 0]]) src_mask tensor([[False, False, False, False], [False, False, False, True]]) tgt_mask tensor([[False, False, False, False, False], [False, False, False, False, True]]) 最后完整的示例代码 #!/usr/bin/env python3 """ 最小可运行示例:用 Dataset + DataLoader(含 collate_fn)演示变长序列如何拼批并生成 padding 掩码。 运行: python3 dataloader_demo.py """ from dataclasses import dataclass from typing import List, Tuple import torch from torch.utils.data import Dataset, DataLoader # -------------------------- # 1) 准备一点语料(空格分词) # -------------------------- pairs: List[Tuple[str, str]] = [ ("我 有 一个 苹果", "i have an apple"), ("我 有 一本 书", "i have a book"), ("你 喜欢 书", "you like books"), ("我 吃 苹果", "i eat apples"), ] def build_vocab(texts: List[str]): tokens = set() for s in texts: tokens.update([w.lower() for w in s.split()]) itos = ["<pad>", "<bos>", "<eos>"] + sorted(tokens) stoi = {t: i for i, t in enumerate(itos)} return stoi, itos src_texts = [s for s, _ in pairs] tgt_texts = [t for _, t in pairs] SRC_STOI, SRC_ITOS = build_vocab(src_texts) TGT_STOI, TGT_ITOS = build_vocab(tgt_texts) PAD_IDX, BOS_IDX, EOS_IDX = 0, 1, 2 def encode_src(s: str) -> List[int]: return [SRC_STOI[w.lower()] for w in s.split()] def encode_tgt(s: str) -> List[int]: return [BOS_IDX] + [TGT_STOI[w.lower()] for w in s.split()] + [EOS_IDX] # -------------------------- # 2) Dataset:定义“单样本怎么取” # -------------------------- @dataclass class Example: src: List[int] tgt: List[int] class ToyDataset(Dataset): def __init__(self, pairs: List[Tuple[str, str]]): for s, t in pairs: print("encode_src(s)",encode_src(s)) print("encode_tgt(t)",encode_tgt(t)) self.data = [Example(encode_src(s), encode_tgt(t)) for s, t in pairs] def __len__(self) -> int: return len(self.data) def __getitem__(self, idx: int) -> Example: return self.data[idx] # -------------------------- # 3) collate_fn:把“样本列表”拼成一批(对齐 padding + 生成 mask + teacher forcing) # -------------------------- def collate_fn(batch: List[Example]): src_max = max(len(b.src) for b in batch) #计算批次内最长长度,这样能将样本右侧补齐到同一长度,方便堆叠矩阵 tgt_max = max(len(b.tgt) for b in batch) src_batch: List[List[int]] = [] tgt_in_batch: List[List[int]] = [] tgt_out_batch: List[List[int]] = [] print("batch",batch) for ex in batch: src = ex.src + [PAD_IDX] * (src_max - len(ex.src)) # teacher forcing:输入去掉最后一个、输出去掉第一个 tgt_in = ex.tgt[:-1] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[:-1])) tgt_out = ex.tgt[1:] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[1:])) print("src",src) print("tgt_in",tgt_in) print("tgt_out",tgt_out) src_batch.append(src) tgt_in_batch.append(tgt_in) tgt_out_batch.append(tgt_out) print("src_batch",src_batch) print("tgt_in_batch",tgt_in_batch) print("tgt_out_batch",tgt_out_batch) src = torch.tensor(src_batch, dtype=torch.long) # (B,S) tgt_in = torch.tensor(tgt_in_batch, dtype=torch.long) # (B,T) tgt_out = torch.tensor(tgt_out_batch, dtype=torch.long) # (B,T) src_pad_mask = src.eq(PAD_IDX) # (B,S) True=PAD tgt_pad_mask = tgt_in.eq(PAD_IDX) # (B,T) True=PAD print("src",src) print("tgt_in",tgt_in) print("tgt_out",tgt_out) print("src_pad_mask",src_pad_mask) print("tgt_pad_mask",tgt_pad_mask) return src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask # -------------------------- # 4) DataLoader:定义“如何按批取样本”并演示输出 # -------------------------- def main(): dataset = ToyDataset(pairs) for i in range(len(dataset)): print("dataset",dataset.__getitem__(i)) loader = DataLoader( dataset, batch_size=2, shuffle=True, num_workers=0, # 跨平台演示,用 0;Linux 可调大 collate_fn=collate_fn, pin_memory=False, ) # EPOCH=40 # for epoch in range(EPOCH): # for src, tgt_in, tgt_out, src_mask, tgt_mask in loader: # 前向、loss、反传、优化 total_steps = 1000 data_iter = iter(loader) for step in range(total_steps): try: src, tgt_in, tgt_out, src_mask, tgt_mask = next(data_iter) except StopIteration: # 当前迭代器用尽,重建一个新的(相当于进入新一轮) data_iter = iter(loader) src, tgt_in, tgt_out, src_mask, tgt_mask = next(data_iter) print("src",src) print("tgt_in",tgt_in) print("tgt_out",tgt_out) print("src_mask",src_mask) print("tgt_mask",tgt_mask) if __name__ == "__main__": main() iter(loader): 把可迭代的 DataLoader 变成“批次迭代器”。 next(iterator): 从该迭代器中取“下一个批次”。第一次调用就是“第一个 batch”。 it = iter(loader) batch1 = next(it) batch2 = next(it) 在 shuffle=True 时,每次 iter(loader) 相当于开始“新的一轮遍历”,顺序会重新洗牌;drop_last、num_workers、pin_memory 等参数会影响批次数量、并行加载与传输性能。 当然除了用next迭代,还是用for循环的方式,如下: for epoch in range(EPOCH): for src, tgt_in, tgt_out, src_mask, tgt_mask in loader: print("src", src) print("tgt_in", tgt_in) print("tgt_out", tgt_out) print("src_mask", src_mask) print("tgt_mask", tgt_mask) -

数据维度
维度是什么 维度=数据需要“几个”索引才能定位到一个元素,也叫做轴数(axis)或阶(rank)。 可以看成"套盒子"的层数,盒子里面装盒子,再装数字。每多一层外括号/分类,就多一维。 0维=一个数;1维=一排数;2维=表格;3维=一摞表格;更高维=外面再套一层一层分类; 判断有几个维度的方法: 获取一个元素需要几个索引才能定位到。 多一层外括号=多一维;形状从外到内写“有多少个”。(外层是更粗粒度的分类,写在前面,如小批量彩色图像 (B, C, H, W);批次B、通道C、高H、宽W) 1D: ──●──●──●── 一条线 2D: 行×列 一张表 ┌───────┐ │● ● ● │ │● ● ● │ └───────┘ 3D: 多张2D表叠成“砖块” 从0到多维的例子 0维(标量):单个数 42 标量 shape:(), 只要“指它自己”就能找到,例:体温36.5。 1维(向量):一排数 [3, 5, 8] 向量shape:(N),需要1个索引(第几个)才能定位。 2维(矩阵/表格):多排多列 [ [1, 2, 3], [4, 5, 6] [7, 8, 9]] 矩阵shape:(R,C),需要2个索引(第几行,第几列)才能定位到。 3维度(立体):多张矩阵堆叠 [ [[1,2,3], [4,5,6]], [[7,8,9], [11,12,13]] ] 或 层0: [ [...], [...], ... ] 层1: [ [...], [...], ... ] ... 立体shape:(D,R,C),需要3个索引(第几层、第几行、第几列)才能定位到。 n维(张量):继续外面套一层索引 如4维度,小批量彩色图像 (B, C, H, W);批次B、通道C、高H、宽W 深度学习场景维度含义 图像/CNN:(B,C,H,W),B为batch个数,C为图像通道,H为图像高度,W为图像宽度。 文本/transformer:(B,S,C),Batch size,批大小。一次前向里同时处理的样本数。S有时也写作L,Sequence length,序列长度/时间步数(NLP 的 token 数、语音/时序的帧数)。在图像等场景里,若把二维特征展平成序列,也可表示展平后的步数。Channels/Features,特征维度。NLP 里常指 embedding 或 d_model;CV 里指通道数;时序里指每步的特征维度。[B, S, C] 通常表示“B 个样本,每个样本有 S 个时间步/位置,每个时间步有 C 维特征”。 怎么理解C(特征维/通道数)? 在一个张量形状 [B, S, C] 中,C 表示“每个位置(序列中的每个 token/时间步)所携带的特征向量维度”。也就是“描述一个位置所需的数值属性个数”。 表达能力上限: C 越大,单个位置能承载的信息越丰富(更“宽”的向量空间),可拟合更复杂的模式。 稳定性与信息瓶颈: 太小的 C 可能造成信息瓶颈,难以表达远距离依赖或复杂结构。 计算与显存代价: 层内线性/注意力的主计算大多与 C^2 成正比,激活占用与 BLC 成正比。增大 C 会显著提高计算/显存成本。 x.dim() # 轴数,也就是多少个维度。 x.shape # 形状,如 (B,L,C) x.size(-1) # 最后一维长度 -

Transformer 原理解析:从注意力机制到自回归生成
概述 框架 以翻译作为例子,从宏观角度理解大模型,可以把大模型视为一个黑匣子,它可以输入一种语言然后输出另外一种翻译语言,如下图所示。 如果将模型稍微展开一下,模型分为encoders和decoders两部分。为什么要分为编码器和解码器了?主要是从以下动机考量。 条件生成需求:在机器翻译、摘要、对话等条件文本生成任务重,需要读懂输入再逐步输出目标序列这两个事情的约束不同。读懂输入需要双上下文(每个词即要看到左也要右),也就是说要在上下文中去理解,没有因果约束。而生成输出需要的是自回归,因为是预测,只需要看历史不能偷看未来,这就需要因果掩码的自注意力。 结构解耦:把理解和生成拆开,分别最优各自的注意力、掩码和结构,这样更清晰也更高效。 encoders是有多个相同的encoder堆叠在一起形成,decoders也是一样。 encoder和decoder在结构上都是相同的,但是他们不共享权重。下图是encoder和decoder微观结构。 编码器将输入的序列X=(x1,......,xn)映射到连续表示序列Z=(z1,.....zn),然后将Z给到解码器。解码器每次生成一个元素的符号输出序列(y1,......yn)。解码器在每一步都是自回归的,在生成下一步时将先前生成的符号作为额外输入。 编码器:编码器由N=6个相同层堆叠组成。每层都有两个子层,第一个子层是多头注意力(Multi-Head Attention),第二个是简单的按位置完全连接的前馈网络(Feed Forward)。在两个子层的周围分别采用残差连接(Add),然后再进行层正则化(Norm)。每个子层的输出是LayerNorm(X+Sublayer(X)),其中Sublayer(X)是由子层本身实现的函数。为了促进这些残差连接,模型中所有子层以及嵌入层都产生维度为$d_{model}$=512的输出。 解码器:解码器也是由N=6个相同层堆栈组成,除了每个解码器层中的两个子层之外,解码器还插入了第三个子层Masked Multi-Head Attention,该子层对编码堆栈的输出执行多头注意。与编码器类似,在每个子层周围采用残差连接然后正则化。与编码器不同的是,这里增加了Masked Multi-Head Attention修改于Multi-Head Attention,防止当前的输入元素关注到后续的位置元素,这种掩码加上输出嵌入偏移一个位置,确保位置i的预测只能依赖小于i的位置的已知输出。 流程 下面以一个中文句子翻译为英文为例,简要说明步骤。 word embedding: 输入的句子分词得到["我", "有", "一个", "苹果"],然后将每个词进行词嵌入(算法这里不阐述)转换为6维的向量。 positional encoding:每个词进行位置编码,生成相关的位置信息。每个词的向量维度与词embedding维度一致。 transformer输入X: X=embedding + positional embedding,shape形状为(seq_len,d_model),其中seq_len为输入token数量,这里为4,d_model为词embedding向量维度。 编码输出矩阵E:输入X经过编码器后,经过自注意力分数等计算最后输出矩阵E将作为解码器的输入。矩阵E与输入的X形状一致。 解码输出:解码器的输出根据输入一个一个产生的,最开始的时候输入"BOS"代表开始将输出"I",输入"BOS I"输出I have,输入"BOS I have"输出"I have an".......。 mask:在解码器内部有一个mask,其主要的作用是让生成步骤仅以来历史信息,不能访问未来的词。因为decoder是一个一个词生成的,自注意力层天然会计算序列中所有位置间的关联,若不施加约束,模型可能尝试为当前未生成的空白位置分配权重,生成第3个词时,模型默认会为第4、5等未来位置计算注意力权重(尽管这些位置尚无实际内容)。 输入 transformer的输入是一个多阶段的过程,核心的目标是将原始序列的数据转换为包含语义和位置信息的向量表示,这里重点分为word embedding和positional encoding。 word embedding 在进行word embedding之前,需要先把输入句子进行分词,得到离散的序列。如"我有一个苹果" → ["我", "有", "一个", "苹果"]。 所谓word embedding词嵌入,就是将句子拆分的每个词映射到固定维度的向量,transformer论文中默认的向量维度为512,本文的示例是6维。如下: 我:[0.2, -0.3, 0.7, 0.1, -0.5, 0.4] 有:[0.6, 0.2, -0.8, 0.3, 0.1, -0.4] 一个:[-0.4, 0.9, 0.2, -0.1, 0.3, 0.6] 苹果:[0.5, -0.7, 0.4, 0.8, -0.2, 1.1] 关于转换映射的有很多方式,如随机初始化+训练学习的方式,或者word2vec,Glove等外部嵌入算法,这里就先不研究了。 positional encoding 自注意力机制本身不具备序列顺序的感知能力,而自然语言的语义高度以来次序,比如"猫爪老鼠"和"老鼠抓猫"含义就完全相反。因此需要显性的为每个词助于顺序信息,通过给每个位置进行编号,让模型感知词序。 而在transformer中,使用是的正弦函数和余弦函数给每个词生成唯一向量,其中偶数的向量维度使用正弦函数计算得到,基数使用余弦函数计算得到。其公式如下: 变量说明 变量$pos$:词在序列中的位置(从0或1开始,示例中为1~4,如"我"是1,"有"是2,“一个”是3,"苹果"是4) 变量$i$:向量维度索引(从0开始,文档示例中$d_{\text{model}}=6$,故$i=0,1,2$) 变量$d_{\text{model}}$:模型隐藏层维度,也是word embedding向量维度(示例中为6,原始论文中为512) 下面基于d_mode=6说明计算过程,以第一个词"我"为例,计算其过程。 已知条件 变量$pos=1$(第1个词的位置) 变量$d_{\text{model}}=6$(向量维度为6) 变量$i=0,1,2$(对应3对奇偶维度) 维度0(偶数位,$2i=0$):$PE_{(1,0)} = \sin\left(\frac{1}{10000^{2×0/6}}\right) \approx 0.8 \quad $ 维度1(奇数位,$2i+1=1$):$PE_{(1,1)} = \cos\left(\frac{1}{10000^{2×0/6}}\right) \approx 0.5 \quad $ 维度2(偶数位,$2i=2$):$PE_{(1,2)} = \sin\left(\frac{1}{10000^{2×1/6}}\right) \approx 0.1 \quad$ 维度3(奇数位,$2i+1=3$):$PE_{(1,3)} = \cos\left(\frac{1}{10000^{2×1/6}}\right) \approx 1.0 \quad $ 维度4(偶数位,$2i=4$):$PE_{(1,4)} = \sin\left(\frac{1}{10000^{2×2/6}}\right) = \approx 0.0 \quad$ 维度5(奇数位,$2i+1=5$):$PE_{(1,5)} = \cos\left(\frac{1}{10000^{2×2/6}}\right) \quad 1.0 $ 最后得到"我"的positional encoding为[0.8,0.5,0.1,1.0.0.0,1.0]。 使用正弦函数、余弦函数进行编码有以下好处。 相对位置可学习:对于任意位置偏移$k$,$PE_{pos+k}$可表示为$PE_{pos}$的线性组合(利用三角函数的和角公式),使模型能轻松学习相对位置关系。 无界序列适应:公式基于指数函数衰减,对任意长度的序列(远超训练时的最大长度)均能生成有效编码,避免了学习型位置编码的泛化性问题。 数值稳定性:正弦/余弦函数的值域固定在$[-1,1]$,与词嵌入向量相加后不会导致数值范围剧烈波动,有利于模型训练稳定。 注意力机制 在transformer中最关键的就是Multi-Head Attention,本小节先来重点分析其实现原理。Multi-Head Attention由多个Scaled Dot-Product Attention组成。 注意力函数可以描述为将查询(Query)和一组键值对(Key-Value)映射到输出,其中查询、键、值和输出都是向量,输出计算为加权和。 Scaled Dot-Product Attetion 其核心的公式就是如下: $$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$ 对于Scaled Dot-Product Attention自下而上计算的流程如下: MatMul:输入查询矩阵 Q(目标序列)与键矩阵 K(源序列)进行矩阵乘法,主要用于计算原始相关性的分数。$\text{Scores} = QK^T$ Scale:缩放的目的是防止计算的分数导致softmax梯度消失,因此对结果进行缩放。$\text{Scaled Scores} = \frac{\text{Scores}}{\sqrt{d_k}}$。 Optional Mask:mask用于遮挡无效位置(如未来词或填充符),训练是设置-inf,只有在解码器的时候用。 SoftMax:对计算分数进行归一化,输出注意力权重权重概率分布。$\text{Weights} = \text{softmax}(\text{Masked Scores})$ MatMul:前面的QK计算得出了目标词在句子中的哪些词相关性比较大,也就是得到一个注意力分数,最后根据注意力分数做加权求和到最后的目标词上下文信息向量。$ \text{Output} = \text{Weights} \cdot V$ 接下来我们展开按照流程来分析一下。 计算QKV Transformer中引入Q(Query)、K(Key)、V(Value)三元组的设计是注意力机制的核心创新,使用QKV本质是实现动态语义的聚集。传统的传统RNN/CNN在长距离建模时存在固有缺陷,CNN依赖局部卷积核,RNN受制于顺序编码,无法动态关注全局关键信息。而使用QKV三元组模拟"信息检索系统" Query(查询):表示当前需要关注的内容,需要“寻找什么信息”(如翻译中"apple"要找出"苹果"的语义需求)。 Key(键):描述源信息的特征标签(如中文词"苹果"的语义属性)。 Value(值):存储实际待提取的信息本体(如"苹果"的词嵌入向量)。 自注意力机制就是用q去找相关的k,得到注意力分数,然后通过注意力分数去从v中提取信息。 如翻译“I have an apple”时,生成“apple”的Query会去找跟(“苹果”)相关的key计算高相似度,然后用得到的K取提取Value(“苹果”的语义向量),实现精准跨语言对齐。 使用Q MatMul K的方式可以量化查询的需求与源特征的匹配程度,最后在MatMul上V是因为做最终的提取。 既然Q MatMul K是量化查询需求与源特征的匹配程度,那么每个词一般都是在句子中去理解的,所以每个词都需要去计算在句子中其他词的关联。 每个都需要与句子中的其他进行相关性计算,各自得到一个输出。如a1最终计算出得到b1,a2计算得到b2......。 (1)以单个词为例说明运作流程 下面以a1为例: 首先a1先自己计算出q1,q1=Wq a1,其中Wq为权重参数。 其次句子中所有词a1,a2,a3,a4分别乘Wk计算各自得到k1,k2,k3,k4。 接着q1分别与k1,k2,k3,k4分别做点积计算得到a11,a12,a13,a14。 最后在对a11,a12,a13,a14做softmax得到最终的结果。a'11,a'12,a'13,a'14。 为什么要做softmax了? 归一化概率:将原始分数(可能为任意实数)转换为概率分布,使得所有权重和为1,便于后续的加权求和操作(即用这些权重来加权值向量)。 增强区分度:softmax 的指数运算会放大高分数的影响,同时抑制低分数。这样,模型可以更加关注最相关的键,而忽略不相关的键。在图中,如果某个 α{1,i} 较大,经过 softmax 后其对应的 α'{1,i} 会远大于其他较小的分数对应的权重,从而实现选择性聚焦。 在对softmax之前还要进行一次scale这里就不周赘述了。 a'11,a'12,a'13,a'14即为a1对句子中每个词的注意力分数,计算出值后就可以根据其值从序列里面抽取出了重要的信息,根据a'11,a'12,a'13,a'14可知输入的词向量哪些跟与a1相关性大,接下来即可根据关联性(即注意力分数)抽取重要的信息。 将向量a1~a4分别乘以Wv权重得到新的向量v1,v2,v3,v4,将其中的每一个向量分别乘以注意力分数a'xx,再把结果加起来。 $$ b_1 = \sum_{i} \alpha'_{1,i} v_i $$ 如果a1和a2关联性强,即a'12的值就很大,那么在做加权和以后,得到的b1就越接近与v2,所以谁的注意力分数越大,谁的v就会主导抽取结果。同理可以计算出b2,b3,b4。 (2)以矩阵乘法角度说明运作流程 上面的过程是单个词的计算过程,但是实际在自注意力模型的运作过程中,是通过矩阵乘法的方式计算的,这样效率才高,接下来看看从矩阵乘法的角度理解运行过程。 因为每个词都要产生qkv,即每个ai都要乘以权重参数Wq得到qi,那么可以把这些ai合并起来当做一个矩阵,即把a1到a4拼接起来,看成一个矩阵I,矩阵I有4列,其中每一列都是自注意力模型的输入。把矩阵I乘以矩阵Wq,就可以得到Q。其中Wq则是权重参数,Q则可以看成q1~q4的拼接。 同理产生k和v的操作跟q一模一样,计算得到K,V矩阵。 通过两个Q与K转置相乘就可以得到注意力分数的矩阵A,然后将A经过softmax得到A'。 最后使用注意力分数A'提出V,得到最终的输出矩阵O,即b1~b4的拼接。 最后总结下,自注意力模型输入是一组向量,将这些向量拼接起来得到I,让后将I分别乘以三个矩阵Wq,Wk,Wq,得到另外三个矩阵QKV,将Q乘以K的转置得到A,然后对A在做一些处理得到A',A'为注意力分数矩阵,将A'乘以V提取出特征,最后得到自注意力的输出O。 Multi-Head Attention 论文中阐述,与其使用一套维度为$d_{model}$的单头注意力,还不如把输入的Query、Key、Value各自用不同的、可学习的线性投影经过注意力机制映射出$h$份版本,每份的维度更小,计为$d_{k}$和$d_{v}$。 在每一份(也就是每个头)上各自并行计算注意力,得到$d_{v}-$维的输出,然后再把所有头的输出沿特征维度拼接,再做一次线性投影到得到最终的输出。 为什么要做多头?多头可以“同时在不同表示子空间里看信息”。一个头往往只能聚焦一种关系(比如短距依赖),多个头能并行关注不同关系(长距、句法、语义等)。如果只有单头,容易把多种关系“平均混在一起”,表达力受限。 多头注意力会把输入进行降维值C/h,这样每个头的输入维度就为C/h。为什么使用"多头+降维"而不是"多头不降维",主要会是考虑如果每个头都保持默认的输入C维,h个头拼接后会是[B, L, h·C],参数量与计算复杂度都膨胀 h 倍,不经济。标准做法让每头维度变为 C/h,拼接回到 C,因此总计算/参数量与单头同量级,但表达力更强(多视角、子空间解耦)。 下面是来说明一下多头注意力机制是如何计算的,下面省略了输入降维的过程。 如上图,先把a乘以一个矩阵得到q,然后再把q乘以另外两个矩阵得到q1,q2。qi1和qi2代表的有两个头,表示要查询两种不同的相关性,那么既然有两个q,k,v也得需要两个,同理得到各自的两个k,v。 关于多头注意力机制的计算跟上一节的计算类似,各自的头计算各自的,如上图是计算头1,下图是计算头2。 通过各自头的计算,那么将会得到各自头的一个输出bi1,bi2,最后需要将bi1和bi2拼起来,先乘以一个矩阵进行变换得到bi,再送到下下一层。 encoder 编码器有多个相同的子编码器叠加而成,最小单元的子编码器由Multil-Head Aattention、Add & Norm、Feed Forward这几个组件构成,Multil-head Attention前面已经解释了,接下来重点分析剩余模块的流程。为表述方便后面的编码器都默认指最小单元的编码器。 Add & Norm Add & Norm在编码器一个block中出现了两次,首次出现是位于 Multi-Head Attention(橙色模块)的输出端,再次出现是位于 Feed Forward(蓝色模块)的输出端。如下图: (1)残差连接 残差连接的作用是在深层网络中,梯度在反向传播时可能会消失或爆炸。残差连接通过将输入直接加到函数输出上(即 F(x) + x),提供了一个恒等映射的路径。这使得梯度在反向传播时可以直接流过,从而缓解了梯度消失的问题,使深层网络训练成为可能。 Add操作是残差连接(Resudual Connection),其公式 $$ \mathbf{y} = \mathcal{F}(\mathbf{x}, {\mathbf{W}_i}) + \mathbf{x} $$ (2)层归一化 层归一化的作用是在残差连接之后,数据的分布可能会发生变化,可能会导致后续层的学习变得困难,使用层归一化能够重新调整数据分布(如将每一层的输出归一化为均值为0,方差为1),从而加速训练并提高模型的泛化能力。 层归一化计算公式步骤如下: 这里使用的是层归一化而非批归一化,主要是可以独立处理每个样本,应对变长序列输入,同时对小批量训练不依赖批量统计量。 为什么Add&Norm要成对使用? 每个主要计算层后面都有Add & Norm,形成了一种模式:计算层 -> Add & Norm。这样,每个计算层的输出在传递给下一层之前都会被重新调整,使得模型在训练过程中保持稳定。如果只有残差连接而没有归一化,那么随着层数的增加,输出的尺度可能会不断增长,导致训练不稳定;如果只有归一化而没有残差连接,则可能无法解决深层网络中的梯度消失问题。 Feed Forward 先来看看什么是Feed Forward,前馈神经有两层全连接神经网络组成,中间使用非线性激活函数(通常是ReLU),数学表达式如下: $$ FFN(x) = \text{ReLU}(xW_1 + b_1)W_2 + b_2 $$ (1)特征扩展,将特征维度从512扩展至2048 $$ \boxed{ h_i = \text{ReLU}( \underbrace{x_i}{1 \times 512} \underbrace{W_1}{512 \times 2048} + b_1 )} $$ $x_i$:位置$i$的输入向量($1 \times 512$) $W_1$:扩展层权重矩阵($512 \times 2048$) 前面输入attention结果本质上计算是加权平均,都是线性操作,这里引入ReLu非线性变化,使模型能学习更复杂的函数映射。同时升维可以在高维空间捕捉更细微模式。 (2)进行特征压缩,将特征从2048压缩回512 $$ \boxed{ y_i = \underbrace{h_i}{1 \times 2048} \underbrace{W_2}{2048 \times 512} + b_2 } $$ $h_i$:ReLU激活后的特征向量($1 \times 2048$) $W_2$:压缩层权重矩阵($2048 \times 512$) 最后再从高维进行降维,保持与后续模块的兼容性。 总结一下FFN的作用有如下: 高纬投影:将输入映射到高维空间(如512→2048),捕获更复杂的特征组合。 非线性激活:引入非线性(如ReLU),打破线性变换限制,增强模型表达能力。 低维还原:将特征压缩回原始维度,保持与后续模块兼容性。 encoder block Multi-Head Attention、Add & Norm、Feed Ward构成了一个encoder block。 每个encoder block接入输入矩阵Xnd,并输出一个矩阵Ond,再把输出的O当做输入传递给下一个encoder,通过多个encoder的叠加,最后一个encoder block输出的就是编码信息矩阵E,用于送入到解码器中,就完成transformer的Encoder。 decoder decoder与encoder大致的结构类似,但是也有差别主要由Masked Multi-head Attention、Multi-head Attention、Add & Norm、Feed Forward组成,这里唯一不一样的是Masked Multi-head Attention,接下来分模块介绍一下关键流程。 Masked Multi-head Attention Masked Multi-head Attention通过一个掩码来阻止每个位置选择器后面的输入信息。 Multi-head Attention自注意力输入一排向量,自己输出另一排向量,这一排向量中的每个项链都要看过完整的输入后才能决定。如上图必现根据a1,a2,a3,a4的所有信息来输出b1。 而掩码多头注意力则不再看右边的部分,如下图。 在产生b1的时候,只考虑a1的信息,不再考虑a2,a3,a4的信息。在产生b2的时候,只考虑a1,a2的信息,不再考虑a3,a4的信息,在产生b3的时候,只考虑a1,a2,a3的信息,不再考虑a4的信息,只有在阐述b4的时候,才考虑整个输入序列的信息。 下面是Multi-head Attention产生b2的过程,b2需要和a1,a2,a2,a3的qkv信息计算得到b2。 而如果是Masked Multi-head Attention,b2只需要拿q2和k1、k2计算注意力,最后只计算v1和v2的加权和,不管a2右边的部分,则计算过下。 为什么在注意力机制中加上掩码了? 因为解码器的输出是一个一个产生的,只能考虑左边已经生成的部分,而没有办法考虑未生成的右边部分。举个例子,先有得a1,再有a2,接下来是a3,然后是a4。这个跟编码器中的self-attention不一样,编码器中的是a1,a2,a3,a4一次性输入模型,编码器一次性处理输出。正因为解码器这个特性,现有a1,才能预测输出a2,再有后面的a3,a4,所以当我们在计算b2时,a3,a4实际是还没输出的,所以没有办法考虑a3,a4。 Multi-head Attention 第二个Mult-head Attention也称为交叉注意力,结构组成与编码器没什么差别。主要的差异点计算输入,解码器的第二个Multi-head Attention(交叉注意力)输入,这个注意力层的Query来自解码器前一层(通常是解码器的第一个Masked Self-Attention层)的输出,而Key和Value则来自编码器的最终输出(即最后一个编码器层的输出)。因此,该注意力层的目的是让解码器在生成当前输出时能够关注到输入序列的相关部分。 输出 transformer最后的输出层是linear层和softmax层。 linear层:将解码器输出的高维语义向量映射到词汇表空间,输入为(batch_size, seq_len, d_model),输出为(batch_size, seq_len, vocab_size),主要的作用是将抽象语义转换为具体词汇的匹配分数(Logits)。 softmax层:将Logits转换为概率分布,输入为Logits矩阵,输出为(batch_size, seq_len, vocab_size)的概率张量,满足概率约束(和为1),支持损失计算与生成任务。 Linear层 Linear层主要作用是计算解码器向量与每个词嵌入的点积,得到词汇表中每个词的原始匹配分数,计算公式为。 $$Logits = X \cdot W^{T} + b$$ X:解码器最后一层输出(形状 [batch_size, seq_len, d_model],例:[1, 4, 6]) W:权重矩阵(形状 [vocab_size, d_model],例:50000×6) b:偏置项(可选) 最终的输出是词汇表中每个词的概率(形状 [batch_size, seq_len, vocab_size],例:[1, 5, 10000]),假设这里的词库为10000个。 如下: logits = [ "I": 8.76, "have": 7.23, "a": 5.89, "an": 6.54, "apple": 7.91, ... # 其他99995个词 ] softmax层 $$P(\text{word}i) = \frac{e^{\text{logits}_i}}{\sum{j=1}^{V} e^{\text{logits}_j}}$$ V: 词汇表的大小 指数运算:放大高分优势。 如下 "I": 0.38, "have": 0.22, "an": 0.18, "apple": 0.15, "a": 0.04, ... # 其他词概率极小 总结一下: 时间步 解码器输入 Linear层Logits示例 Softmax后概率 选定词 1 <bos> I=9.8, He=1.2,... I=0.99,He=0.03,... I 2 <bos> I have=8.5, has=0.5,... have=0.97,has=0.02,.... have 3 <bos> I have an=7.9, a=2.1,... an=0.95,a=0.04 an 4 <bos> I have an apple=9.5, app=3.2,... apple=0.99,app=0.03,.... apple 到这里,transformer的原理就分析完了。 参考如下: 书籍:深度学习详解 https://arxiv.org/abs/1706.03762 https://jalammar.github.io/illustrated-transformer/ https://zhuanlan.zhihu.com/p/338817680 -
建图导航ROS2包输入和输出节点
SLAM 2D 激光:slam_toolbox (1)安装启动 sudo apt update sudo apt install ros-jazzy-slam-toolbox ros2 launch slam_toolbox online_async_launch.py (2)输入输出 ros2 node info /slam_toolbox /slam_toolbox Subscribers: /clock: rosgraph_msgs/msg/Clock /map: nav_msgs/msg/OccupancyGrid /parameter_events: rcl_interfaces/msg/ParameterEvent /scan: sensor_msgs/msg/LaserScan /slam_toolbox/feedback: visualization_msgs/msg/InteractiveMarkerFeedback Publishers: /map: nav_msgs/msg/OccupancyGrid /map_metadata: nav_msgs/msg/MapMetaData /parameter_events: rcl_interfaces/msg/ParameterEvent /pose: geometry_msgs/msg/PoseWithCovarianceStamped /rosout: rcl_interfaces/msg/Log /slam_toolbox/graph_visualization: visualization_msgs/msg/MarkerArray /slam_toolbox/scan_visualization: sensor_msgs/msg/LaserScan /slam_toolbox/transition_event: lifecycle_msgs/msg/TransitionEvent /slam_toolbox/update: visualization_msgs/msg/InteractiveMarkerUpdate /tf: tf2_msgs/msg/TFMessage Service Servers: /slam_toolbox/change_state: lifecycle_msgs/srv/ChangeState /slam_toolbox/clear_changes: slam_toolbox/srv/Clear /slam_toolbox/describe_parameters: rcl_interfaces/srv/DescribeParameters /slam_toolbox/deserialize_map: slam_toolbox/srv/DeserializePoseGraph /slam_toolbox/dynamic_map: nav_msgs/srv/GetMap /slam_toolbox/get_available_states: lifecycle_msgs/srv/GetAvailableStates /slam_toolbox/get_available_transitions: lifecycle_msgs/srv/GetAvailableTransitions /slam_toolbox/get_interactive_markers: visualization_msgs/srv/GetInteractiveMarkers /slam_toolbox/get_parameter_types: rcl_interfaces/srv/GetParameterTypes /slam_toolbox/get_parameters: rcl_interfaces/srv/GetParameters /slam_toolbox/get_state: lifecycle_msgs/srv/GetState /slam_toolbox/get_transition_graph: lifecycle_msgs/srv/GetAvailableTransitions /slam_toolbox/get_type_description: type_description_interfaces/srv/GetTypeDescription /slam_toolbox/list_parameters: rcl_interfaces/srv/ListParameters /slam_toolbox/manual_loop_closure: slam_toolbox/srv/LoopClosure /slam_toolbox/pause_new_measurements: slam_toolbox/srv/Pause /slam_toolbox/reset: slam_toolbox/srv/Reset /slam_toolbox/save_map: slam_toolbox/srv/SaveMap /slam_toolbox/serialize_map: slam_toolbox/srv/SerializePoseGraph /slam_toolbox/set_parameters: rcl_interfaces/srv/SetParameters /slam_toolbox/set_parameters_atomically: rcl_interfaces/srv/SetParametersAtomically /slam_toolbox/toggle_interactive_mode: slam_toolbox/srv/ToggleInteractive Service Clients: Action Servers: Action Clients: 2D/3D 激光 SLAM:Cartographer (1)安装启动 sudo apt install ros-jazzy-cartographer-ros sudo apt install ros-jazzy-turtlebot3-cartographer # 这里的 cartographer.launch.py 是真实存在的! ros2 launch turtlebot3_cartographer cartographer.launch.py \ use_sim_time:=false \ is_turtlebot3:=false (2)查看输入输出 2D ros2 node info /cartographer_node /cartographer_node Subscribers: /odom: nav_msgs/msg/Odometry /parameter_events: rcl_interfaces/msg/ParameterEvent /scan: sensor_msgs/msg/LaserScan Publishers: /constraint_list: visualization_msgs/msg/MarkerArray /landmark_poses_list: visualization_msgs/msg/MarkerArray /parameter_events: rcl_interfaces/msg/ParameterEvent /rosout: rcl_interfaces/msg/Log /scan_matched_points2: sensor_msgs/msg/PointCloud2 /submap_list: cartographer_ros_msgs/msg/SubmapList /tf: tf2_msgs/msg/TFMessage /trajectory_node_list: visualization_msgs/msg/MarkerArray Service Servers: /cartographer_node/describe_parameters: rcl_interfaces/srv/DescribeParameters /cartographer_node/get_parameter_types: rcl_interfaces/srv/GetParameterTypes /cartographer_node/get_parameters: rcl_interfaces/srv/GetParameters /cartographer_node/get_type_description: type_description_interfaces/srv/GetTypeDescription /cartographer_node/list_parameters: rcl_interfaces/srv/ListParameters /cartographer_node/set_parameters: rcl_interfaces/srv/SetParameters /cartographer_node/set_parameters_atomically: rcl_interfaces/srv/SetParametersAtomically /finish_trajectory: cartographer_ros_msgs/srv/FinishTrajectory /get_trajectory_states: cartographer_ros_msgs/srv/GetTrajectoryStates /read_metrics: cartographer_ros_msgs/srv/ReadMetrics /start_trajectory: cartographer_ros_msgs/srv/StartTrajectory /submap_query: cartographer_ros_msgs/srv/SubmapQuery /tf2_frames: tf2_msgs/srv/FrameGraph /trajectory_query: cartographer_ros_msgs/srv/TrajectoryQuery /write_state: cartographer_ros_msgs/srv/WriteState Service Clients: Action Servers: Action Clients: 3D ros2 node info /cartographer_node /cartographer_node Subscribers: /imu/data: sensor_msgs/msg/Imu /odometry: nav_msgs/msg/Odometry /parameter_events: rcl_interfaces/msg/ParameterEvent /velodyne_points: sensor_msgs/msg/PointCloud2 Publishers: /constraint_list: visualization_msgs/msg/MarkerArray /landmark_poses_list: visualization_msgs/msg/MarkerArray /parameter_events: rcl_interfaces/msg/ParameterEvent /rosout: rcl_interfaces/msg/Log /scan_matched_points2: sensor_msgs/msg/PointCloud2 /submap_list: cartographer_ros_msgs/msg/SubmapList /tf: tf2_msgs/msg/TFMessage /trajectory_node_list: visualization_msgs/msg/MarkerArray Service Servers: /cartographer_node/describe_parameters: rcl_interfaces/srv/DescribeParameters /cartographer_node/get_parameter_types: rcl_interfaces/srv/GetParameterTypes /cartographer_node/get_parameters: rcl_interfaces/srv/GetParameters /cartographer_node/get_type_description: type_description_interfaces/srv/GetTypeDescription /cartographer_node/list_parameters: rcl_interfaces/srv/ListParameters /cartographer_node/set_parameters: rcl_interfaces/srv/SetParameters /cartographer_node/set_parameters_atomically: rcl_interfaces/srv/SetParametersAtomically /finish_trajectory: cartographer_ros_msgs/srv/FinishTrajectory /get_trajectory_states: cartographer_ros_msgs/srv/GetTrajectoryStates /read_metrics: cartographer_ros_msgs/srv/ReadMetrics /start_trajectory: cartographer_ros_msgs/srv/StartTrajectory /submap_query: cartographer_ros_msgs/srv/SubmapQuery /tf2_frames: tf2_msgs/srv/FrameGraph /trajectory_query: cartographer_ros_msgs/srv/TrajectoryQuery /write_state: cartographer_ros_msgs/srv/WriteState Service Clients: Action Servers: Action Clients: 视觉/激光 SLAM: RTAB-Map (1)安装启动 sudo apt update sudo apt install ros-jazzy-rtabmap-ros # 启动 RTAB-Map (无界面模式 + 订阅激光雷达) ros2 launch rtabmap_launch rtabmap.launch.py \ rtabmap_viz:=false \ use_sim_time:=false \ subscribe_scan:=true \ frame_id:=base_link \ approx_sync:=true (2)查看输入输出 ros2 node info /rtabmap/rtabmap /rtabmap/rtabmap Subscribers: /camera/depth_registered/image_raw: sensor_msgs/msg/Image /camera/rgb/camera_info: sensor_msgs/msg/CameraInfo /camera/rgb/image_rect_color: sensor_msgs/msg/Image /detections: apriltag_msgs/msg/AprilTagDetectionArray /gps/fix: sensor_msgs/msg/NavSatFix /imu/data: sensor_msgs/msg/Imu /parameter_events: rcl_interfaces/msg/ParameterEvent /rtabmap/apriltag/detections: apriltag_msgs/msg/AprilTagDetectionArray /rtabmap/aruco/detections: aruco_msgs/msg/MarkerArray /rtabmap/aruco_opencv/detections: aruco_opencv_msgs/msg/ArucoDetection /rtabmap/global_pose: geometry_msgs/msg/PoseWithCovarianceStamped /rtabmap/goal: geometry_msgs/msg/PoseStamped /rtabmap/goal_node: rtabmap_msgs/msg/Goal /rtabmap/initialpose: geometry_msgs/msg/PoseWithCovarianceStamped /rtabmap/landmark_detection: rtabmap_msgs/msg/LandmarkDetection /rtabmap/landmark_detections: rtabmap_msgs/msg/LandmarkDetections /rtabmap/odom: nav_msgs/msg/Odometry /rtabmap/odom_info: rtabmap_msgs/msg/OdomInfo /rtabmap/rtabmap/republish_node_data: std_msgs/msg/Int32MultiArray /scan: sensor_msgs/msg/LaserScan /user_data_async: rtabmap_msgs/msg/UserData Publishers: /diagnostics: diagnostic_msgs/msg/DiagnosticArray /goal_pose: geometry_msgs/msg/PoseStamped /parameter_events: rcl_interfaces/msg/ParameterEvent /rosout: rcl_interfaces/msg/Log /rtabmap/cloud_ground: sensor_msgs/msg/PointCloud2 /rtabmap/cloud_map: sensor_msgs/msg/PointCloud2 /rtabmap/cloud_obstacles: sensor_msgs/msg/PointCloud2 /rtabmap/global_path: nav_msgs/msg/Path /rtabmap/global_path_nodes: rtabmap_msgs/msg/Path /rtabmap/goal_reached: std_msgs/msg/Bool /rtabmap/grid_prob_map: nav_msgs/msg/OccupancyGrid /rtabmap/info: rtabmap_msgs/msg/Info /rtabmap/labels: visualization_msgs/msg/MarkerArray /rtabmap/landmarks: geometry_msgs/msg/PoseArray /rtabmap/local_grid_empty: sensor_msgs/msg/PointCloud2 /rtabmap/local_grid_ground: sensor_msgs/msg/PointCloud2 /rtabmap/local_grid_obstacle: sensor_msgs/msg/PointCloud2 /rtabmap/local_path: nav_msgs/msg/Path /rtabmap/local_path_nodes: rtabmap_msgs/msg/Path /rtabmap/localization_pose: geometry_msgs/msg/PoseWithCovarianceStamped /rtabmap/map: nav_msgs/msg/OccupancyGrid /rtabmap/mapData: rtabmap_msgs/msg/MapData /rtabmap/mapGraph: rtabmap_msgs/msg/MapGraph /rtabmap/mapOdomCache: rtabmap_msgs/msg/MapGraph /rtabmap/mapPath: nav_msgs/msg/Path /rtabmap/octomap_binary: octomap_msgs/msg/Octomap /rtabmap/octomap_empty_space: sensor_msgs/msg/PointCloud2 /rtabmap/octomap_full: octomap_msgs/msg/Octomap /rtabmap/octomap_global_frontier_space: sensor_msgs/msg/PointCloud2 /rtabmap/octomap_grid: nav_msgs/msg/OccupancyGrid /rtabmap/octomap_ground: sensor_msgs/msg/PointCloud2 /rtabmap/octomap_obstacles: sensor_msgs/msg/PointCloud2 /rtabmap/octomap_occupied_space: sensor_msgs/msg/PointCloud2 /tf: tf2_msgs/msg/TFMessage Service Servers: /rtabmap/rtabmap/add_link: rtabmap_msgs/srv/AddLink /rtabmap/rtabmap/backup: std_srvs/srv/Empty /rtabmap/rtabmap/cancel_goal: std_srvs/srv/Empty /rtabmap/rtabmap/cleanup_local_grids: rtabmap_msgs/srv/CleanupLocalGrids /rtabmap/rtabmap/describe_parameters: rcl_interfaces/srv/DescribeParameters /rtabmap/rtabmap/detect_more_loop_closures: rtabmap_msgs/srv/DetectMoreLoopClosures /rtabmap/rtabmap/get_map: nav_msgs/srv/GetMap /rtabmap/rtabmap/get_map_data: rtabmap_msgs/srv/GetMap /rtabmap/rtabmap/get_map_data2: rtabmap_msgs/srv/GetMap2 /rtabmap/rtabmap/get_node_data: rtabmap_msgs/srv/GetNodeData /rtabmap/rtabmap/get_nodes_in_radius: rtabmap_msgs/srv/GetNodesInRadius /rtabmap/rtabmap/get_parameter_types: rcl_interfaces/srv/GetParameterTypes /rtabmap/rtabmap/get_parameters: rcl_interfaces/srv/GetParameters /rtabmap/rtabmap/get_plan: nav_msgs/srv/GetPlan /rtabmap/rtabmap/get_plan_nodes: rtabmap_msgs/srv/GetPlan /rtabmap/rtabmap/get_prob_map: nav_msgs/srv/GetMap /rtabmap/rtabmap/get_type_description: type_description_interfaces/srv/GetTypeDescription /rtabmap/rtabmap/global_bundle_adjustment: rtabmap_msgs/srv/GlobalBundleAdjustment /rtabmap/rtabmap/list_labels: rtabmap_msgs/srv/ListLabels /rtabmap/rtabmap/list_parameters: rcl_interfaces/srv/ListParameters /rtabmap/rtabmap/load_database: rtabmap_msgs/srv/LoadDatabase /rtabmap/rtabmap/log_debug: std_srvs/srv/Empty /rtabmap/rtabmap/log_error: std_srvs/srv/Empty /rtabmap/rtabmap/log_info: std_srvs/srv/Empty /rtabmap/rtabmap/log_warning: std_srvs/srv/Empty /rtabmap/rtabmap/octomap_binary: octomap_msgs/srv/GetOctomap /rtabmap/rtabmap/octomap_full: octomap_msgs/srv/GetOctomap /rtabmap/rtabmap/pause: std_srvs/srv/Empty /rtabmap/rtabmap/publish_map: rtabmap_msgs/srv/PublishMap /rtabmap/rtabmap/remove_label: rtabmap_msgs/srv/RemoveLabel /rtabmap/rtabmap/reset: std_srvs/srv/Empty /rtabmap/rtabmap/resume: std_srvs/srv/Empty /rtabmap/rtabmap/set_goal: rtabmap_msgs/srv/SetGoal /rtabmap/rtabmap/set_label: rtabmap_msgs/srv/SetLabel /rtabmap/rtabmap/set_mode_localization: std_srvs/srv/Empty /rtabmap/rtabmap/set_mode_mapping: std_srvs/srv/Empty /rtabmap/rtabmap/set_parameters: rcl_interfaces/srv/SetParameters /rtabmap/rtabmap/set_parameters_atomically: rcl_interfaces/srv/SetParametersAtomically /rtabmap/rtabmap/trigger_new_map: std_srvs/srv/Empty /rtabmap/rtabmap/update_parameters: std_srvs/srv/Empty Service Clients: /rtabmap/rtabmap/describe_parameters: rcl_interfaces/srv/DescribeParameters /rtabmap/rtabmap/get_parameter_types: rcl_interfaces/srv/GetParameterTypes /rtabmap/rtabmap/get_parameters: rcl_interfaces/srv/GetParameters /rtabmap/rtabmap/list_parameters: rcl_interfaces/srv/ListParameters /rtabmap/rtabmap/set_parameters: rcl_interfaces/srv/SetParameters /rtabmap/rtabmap/set_parameters_atomically: rcl_interfaces/srv/SetParametersAtomically Action Servers: Action Clients: 导航 NAV2 (1)安装启动 # 安装 Nav2 的核心带起动包 sudo apt install ros-jazzy-nav2-bringup # 这是一个“模拟启动”,虽然没有地图,但会把所有节点拉起来 ros2 launch nav2_bringup bringup_launch.py \ use_sim_time:=false \ map:=/dev/null \ autostart:=true (2)查看输入输出 查看输入 ros2 node list | grep nav2 # 随便挑一个核心节点查,比如 bt_navigator ros2 node info /bt_navigator ros2 node info /bt_navigator /bt_navigator Subscribers: /goal_pose: geometry_msgs/msg/PoseStamped /odom: nav_msgs/msg/Odometry /parameter_events: rcl_interfaces/msg/ParameterEvent /tf: tf2_msgs/msg/TFMessage /tf_static: tf2_msgs/msg/TFMessage Publishers: /bt_navigator/transition_event: lifecycle_msgs/msg/TransitionEvent /parameter_events: rcl_interfaces/msg/ParameterEvent /rosout: rcl_interfaces/msg/Log Service Servers: /bt_navigator/change_state: lifecycle_msgs/srv/ChangeState /bt_navigator/describe_parameters: rcl_interfaces/srv/DescribeParameters /bt_navigator/get_available_states: lifecycle_msgs/srv/GetAvailableStates /bt_navigator/get_available_transitions: lifecycle_msgs/srv/GetAvailableTransitions /bt_navigator/get_parameter_types: rcl_interfaces/srv/GetParameterTypes /bt_navigator/get_parameters: rcl_interfaces/srv/GetParameters /bt_navigator/get_state: lifecycle_msgs/srv/GetState /bt_navigator/get_transition_graph: lifecycle_msgs/srv/GetAvailableTransitions /bt_navigator/get_type_description: type_description_interfaces/srv/GetTypeDescription /bt_navigator/list_parameters: rcl_interfaces/srv/ListParameters /bt_navigator/set_parameters: rcl_interfaces/srv/SetParameters /bt_navigator/set_parameters_atomically: rcl_interfaces/srv/SetParametersAtomically Service Clients: Action Servers: /navigate_through_poses: nav2_msgs/action/NavigateThroughPoses /navigate_to_pose: nav2_msgs/action/NavigateToPose Action Clients: /navigate_to_pose: nav2_msgs/action/NavigateToPose 查看输出 ros2 node info /controller_server ros2 node info /controller_server /controller_server Subscribers: /odom: nav_msgs/msg/Odometry /parameter_events: rcl_interfaces/msg/ParameterEvent /speed_limit: nav2_msgs/msg/SpeedLimit Publishers: /cmd_vel_nav: geometry_msgs/msg/Twist /controller_server/transition_event: lifecycle_msgs/msg/TransitionEvent /optimal_trajectory: nav_msgs/msg/Path /parameter_events: rcl_interfaces/msg/ParameterEvent /rosout: rcl_interfaces/msg/Log /trajectories: visualization_msgs/msg/MarkerArray /transformed_global_plan: nav_msgs/msg/Path Service Servers: /controller_server/change_state: lifecycle_msgs/srv/ChangeState /controller_server/describe_parameters: rcl_interfaces/srv/DescribeParameters /controller_server/get_available_states: lifecycle_msgs/srv/GetAvailableStates /controller_server/get_available_transitions: lifecycle_msgs/srv/GetAvailableTransitions /controller_server/get_parameter_types: rcl_interfaces/srv/GetParameterTypes /controller_server/get_parameters: rcl_interfaces/srv/GetParameters /controller_server/get_state: lifecycle_msgs/srv/GetState /controller_server/get_transition_graph: lifecycle_msgs/srv/GetAvailableTransitions /controller_server/get_type_description: type_description_interfaces/srv/GetTypeDescription /controller_server/list_parameters: rcl_interfaces/srv/ListParameters /controller_server/set_parameters: rcl_interfaces/srv/SetParameters /controller_server/set_parameters_atomically: rcl_interfaces/srv/SetParametersAtomically Service Clients: Action Servers: /follow_path: nav2_msgs/action/FollowPath Action Clients: 传感器融合:EKF (1)安装启动 sudo apt install ros-jazzy-robot-localization ros2 launch robot_localization ekf.launch.py (2)查看输入输出 ros2 node info /ekf_filter_node ros2 node info /ekf_filter_node /ekf_filter_node Subscribers: /cmd_vel: geometry_msgs/msg/Twist /example/imu: sensor_msgs/msg/Imu /example/odom: nav_msgs/msg/Odometry /example/odom2: nav_msgs/msg/Odometry /example/pose: geometry_msgs/msg/PoseWithCovarianceStamped /example/twist: geometry_msgs/msg/TwistWithCovarianceStamped /parameter_events: rcl_interfaces/msg/ParameterEvent /set_pose: geometry_msgs/msg/PoseWithCovarianceStamped Publishers: /diagnostics: diagnostic_msgs/msg/DiagnosticArray /odometry/filtered: nav_msgs/msg/Odometry /parameter_events: rcl_interfaces/msg/ParameterEvent /rosout: rcl_interfaces/msg/Log /tf: tf2_msgs/msg/TFMessage Service Servers: /ekf_filter_node/describe_parameters: rcl_interfaces/srv/DescribeParameters /ekf_filter_node/get_parameter_types: rcl_interfaces/srv/GetParameterTypes /ekf_filter_node/get_parameters: rcl_interfaces/srv/GetParameters /ekf_filter_node/get_type_description: type_description_interfaces/srv/GetTypeDescription /ekf_filter_node/list_parameters: rcl_interfaces/srv/ListParameters /ekf_filter_node/set_parameters: rcl_interfaces/srv/SetParameters /ekf_filter_node/set_parameters_atomically: rcl_interfaces/srv/SetParametersAtomically /enable: std_srvs/srv/Empty /reset: std_srvs/srv/Empty /set_pose: robot_localization/srv/SetPose /toggle: robot_localization/srv/ToggleFilterProcessing Service Clients: Action Servers: Action Clients: -
lerobot ACT实现分析
配置类ACTConfig @PreTrainedConfig.register_subclass("act") @dataclass class ACTConfig(PreTrainedConfig): # 输入/输出结构 chunk_size: int = 100 # 动作块长度(每次预测的动作序列长度) n_action_steps: int = 100 # 每次策略调用执行的动作步数(≤ chunk_size) temporal_ensemble_coeff: float | None = None # 时序集成系数(None表示禁用) # VAE配置 use_vae: bool = True # 是否启用VAE(增强动作多样性) latent_dim: int = 32 # 潜在空间维度 kl_weight: float = 10.0 # KL散度损失权重 # Transformer配置 dim_model: int = 512 # Transformer隐藏维度 n_heads: int = 8 # 注意力头数 n_encoder_layers: int = 4 # 编码器层数 n_decoder_layers: int = 1 # 解码器层数(原始实现bug,仅用第1层) # 视觉Backbone vision_backbone: str = "resnet18" # 图像特征提取网络 ...... ACTConfig是ACT算法核心配置类,主要定义了模型结构、输入输出格式、训练参数和推理逻辑等。 输入/输出结构 参数主要配置模型输入观测、输出动作的基本格式,是连接环境与模型的桥梁。 # Input / output structure. n_obs_steps: int = 1 # 输入观测的时间步数(当前仅支持1步观测,即当前时刻观测) chunk_size: int = 100 # 动作块长度:每次预测的连续动作序列长度(核心参数,决定分块粒度) n_action_steps: int = 100 # 每次策略调用执行的动作步数(≤ chunk_size,默认与chunk_size一致,即一次执行整段动作块) normalization_mapping: dict[str, NormalizationMode] = field( default_factory=lambda: { "VISUAL": NormalizationMode.MEAN_STD, # 图像特征归一化:减均值除标准差 "STATE": NormalizationMode.MEAN_STD, # 状态特征(如机器人关节角)归一化:同上 "ACTION": NormalizationMode.MEAN_STD, # 动作归一化:同上(确保训练时输入分布稳定) } ) chunk_size 是 ACT 算法的核心设计:将长时序动作生成分解为固定长度的“动作块”(如100步),避免一次性规划整个任务序列,降低计算复杂度。 n_action_steps 控制每次策略调用后实际执行的动作步数。例如,若 chunk_size=100 且 n_action_steps=50,则模型预测100步动作,执行前50步,丢弃后50步(适用于需要频繁重新规划的场景)。 架构配置 从此前的具身智能ACT算法我们知道ACT模型算法主要是基于transformer结构,从实现上模型的核心组件可以分为视觉backbone、transformer、VAE结构。 (1)视觉backbone配置 # Vision backbone. vision_backbone: str = "resnet18" # 视觉特征提取网络:使用ResNet18(轻量级,适合实时控制) pretrained_backbone_weights: str | None = "ResNet18_Weights.IMAGENET1K_V1" # 预训练权重:使用ImageNet-1K预训练参数初始化,提升特征提取能力 replace_final_stride_with_dilation: int = False # 是否用空洞卷积替换ResNet的最终2x2 stride(默认关闭,保持特征图分辨率) 上面的参数是ACT算法中用于图像特征提取模块的核心配置,影响模型对视觉输入的理解能力和计算效率。 首先指定了图像特征提取的骨干网络为resnet18,其仅有18层网络,参数量约1100万,常用于实时机器人控制场景,ResNet是通过残差连接缓解深层网络梯度消失问题,能有效提取多尺度图像特征包括边缘纹理到语义信息。视觉 Backbone 的输出(如 ResNet-18 的 layer4 特征图)会被展平为序列,与机器人状态、潜在向量等多模态特征拼接后输入 Transformer 编码器。 其次指定了resnet18预训练权重的来源,默认使用使用 ImageNet-1K 数据集预训练的权重。 最后的replace_final_stride_with_dilation默认关闭,主要是控制是否用“空洞卷积”替换resnet最后一层的2*2步幅卷积。关闭空洞卷积适合对实时性要求高、特征分辨率要求低的场景,如粗粒度抓取任务。如果打开可保留更多的空洞细节(如物体边缘、纹理),适合精细操作如螺丝拧入、零件对齐、但是需要权衡计算量增加和内存的占用。 (2)transformer配置 # Transformer layers. pre_norm: bool = False # Transformer块归一化位置:False=后归一化(原始ACT实现),True=前归一化(更稳定但需调参) dim_model: int = 512 # Transformer隐藏层维度(特征维度) n_heads: int = 8 # 多头注意力头数(8头,总注意力维度=512/8=64/头) dim_feedforward: int = 3200 # 前馈网络中间维度(通常为dim_model的4-6倍,此处3200=512*6.25) feedforward_activation: str = "relu" # 前馈网络激活函数(ReLU,原始ACT实现) n_encoder_layers: int = 4 # Transformer编码器层数(4层,用于融合多模态输入特征) # 注:原始ACT实现中n_decoder_layers=7,但因代码bug仅使用第1层,此处对齐原始实现设为1 n_decoder_layers: int = 1 # Transformer解码器层数(1层,用于生成动作块序列) 上面参数定义了ACT算法中Transformer 编码器/解码器的核心结构参数,直接决定模型的序列建模能力、计算效率和特征融合效果。 pre_norm: 归一化位置 ,False=原始行为,True=训练更稳定(需重新调参),若训练发散,可尝试设为 True。 dim_model:特征维度(模型容量),增大→更强表达能力,但计算/内存成本平方级增长,机器人实时场景建议 ≤ 1024。 n_heads:注意力并行头数,增多更细粒度关注,但通信开销增大 ,保持 dim_model/n_heads = 64(如 512/8=64)。 n_encoder_layers: 特征融合深度,增多融合更充分,但推理延迟增加,机械臂操作建议 4-6 层。 n_decoder_layers: 动作生成深度,受原始 bug 限制,固定为 1 以对齐行为,若修复原始 bug,可尝试增至 3-4 层。 (3)VAE变分自编码配置 # VAE. use_vae: bool = True # 是否启用VAE(默认启用,通过潜在空间建模动作分布) latent_dim: int = 32 # VAE潜在空间维度(32维,压缩动作序列信息) n_vae_encoder_layers: int = 4 # VAE编码器层数(4层Transformer,用于将动作块编码为潜在分布) (4)推理配置 # Inference. # Note: ACT原论文中启用时序集成时默认值为0.01 temporal_ensemble_coeff: float | None = None # 时序集成系数:None=禁用,>0=启用(指数加权平均平滑动作) 该参数就是是否启动ACT的Temporal Ensembling机制,时序集成(Temporal Ensembling) 功能的启用与权重计算方式,用于在推理时平滑动作序列,避免机器人执行突变动作(尤其适用于精细操作如机械臂抓取、插入等任务)。 要启动Temporal Ensembling机制需显式设置该参数为非 None 的浮点值(如 0.01),且需满足n_action_steps 必须设为 1(每次策略调用仅执行 1 步动作,确保每步都通过集成优化)。 当 temporal_ensemble_coeff = α(如 0.01)时,ACTTemporalEnsembler 会对连续多轮预测的动作块(chunk_size 长度)进行 指数加权平均。 (5)训练损失配置 # Training and loss computation. dropout: float = 0.1 kl_weight: float = 10.0 dropout控制 Transformer 层的 随机失活概率,用于正则化,防止模型过拟合训练数据。在训练过程中,以 dropout 概率(此处 10%)随机将 Transformer 层(如多头注意力输出、前馈网络输出)的部分神经元激活值设为 0,强制模型学习更鲁棒的特征(不依赖特定神经元组合) kl_weight控制 KL 散度损失(KL-divergence Loss) 的权重,仅在启用 VAE(use_vae=True,默认启用)时生效。10.0 是一个较大的权重,表明原始 ACT 实现中更注重约束潜在分布的“规范性”(接近标准正态),以确保 VAE 能生成多样化的动作序列,避免模型仅记忆训练数据中的动作模式。 (6)训练优化 # Training preset optimizer_lr: float = 1e-5 optimizer_weight_decay: float = 1e-4 optimizer_lr_backbone: float = 1e-5 optimizer_lr控制除视觉Backbone外所有参数(如Transformer编码器/解码器、VAE层等)的梯度更新步长。学习率过大会导致训练不稳定(Loss震荡),过小则收敛缓慢。1e-5(0.00001)是训练Transformer类模型的经典学习率(如BERT、GPT等),尤其适用于。 optimizer_weight_decay权重衰减(L2正则化)系数,用于抑制过拟合。过小(如1e-5):正则化不足,易过拟合训练数据。过大(如1e-3):过度抑制参数更新,导致模型欠拟合。适用于机器人操作任务,训练数据通常包含噪声(如传感器误差、动作抖动),权重衰减可提升模型对噪声的鲁棒性。 optimizer_lr_backbone视觉Backbone(如ResNet18)参数的专用学习率。ACT原论文中Backbone与主模型联合训练,未使用更小的Backbone学习率。 在实际的工程中,可在get_optim_params 中显式区分Backbone与非Backbone参数,应用不同学习率: def get_optim_params(self) -> dict: return [ { "params": [p for n, p in self.named_parameters() if not n.startswith("model.backbone") and p.requires_grad], "lr": self.config.optimizer_lr, # 主参数学习率 }, { "params": [p for n, p in self.named_parameters() if n.startswith("model.backbone") and p.requires_grad], "lr": self.config.optimizer_lr_backbone, # Backbone专用学习率 }, ] 策略入口类ACTPolicy 初始化逻辑 class ACTPolicy(PreTrainedPolicy): def __init__(self, config: ACTConfig, dataset_stats=None): super().__init__(config) # 输入/输出归一化(标准化数据分布) self.normalize_inputs = Normalize(config.input_features, config.normalization_mapping, dataset_stats) self.unnormalize_outputs = Unnormalize(config.output_features, config.normalization_mapping, dataset_stats) self.model = ACT(config) # 加载ACT神经网络 # 初始化时序集成器(若启用) if config.temporal_ensemble_coeff is not None: self.temporal_ensembler = ACTTemporalEnsembler(config.temporal_ensemble_coeff, config.chunk_size) self.reset() # 重置动作队列/集成器 这段代码定义了一个基于Action Chunking Transformer (ACT)的策略类,主要用于机器人操作任务的动作生成。 self.normalize_inputs、self.normalize_targets、self.unnormalize_outputs。这3个参数用于数据预处理和后处理的关键组件,负责输入特征的归一化、目标动作的归一化以及模型输出动作的反归一化。 根据config.temporal_ensemble_coeff条件来判断是否初始化temporal ensembler,用于联系预测的动作块进行加权平均,提升动作输出的稳定性。ACTTemporalEnsembler通过指数权重(exp(-temporal_ensemble_coeff * i))对历史动作进行加权, older动作权重更高(原论文默认系数0.01)。 推理逻辑 select_action是ACTPolicy类的核心方法,主要的目的就是根据环境观测(batch)然后预测输出机器人要执行的动作。生成预测的动作有两种模式,一个是启用temporal ensemble方式另外一种不启用。 在进入预测生成动作之前先调用self.eval()强制策略进入评估模式(推理),因为策略处于训练模式(启用dropout等)。 (1)时间集成模式 def select_action(self, batch: dict[str, Tensor]) -> Tensor: if self.config.temporal_ensemble_coeff is not None: actions = self.predict_action_chunk(batch) # 生成动作块 action = self.temporal_ensembler.update(actions) # 时序集成平滑 return action 开启temporal ensemble:根据配置中temporal_ensemble_coeff条件优先走temporal ensemble模式。该模式先调用self.predict_action_chunk(batch)调用模型预测一个动作块((batch_size, chunk_size, action_dim)),即一次性预测多个连续动作。然后调用self.temporal_ensembler.update(actions)通过时间集成器对动作块进行加权平滑( older 动作权重更高,原论文默认系数 0.01),输出单个稳定动作。主要的目的就是论文中的减少动作抖动,提升机器人控制平滑性。需要注意的是如果开启了该模式,n_action_steps 必须为 1,否则会破坏集成器的时序加权逻辑。 时间集成核心实现 class ACTTemporalEnsembler: def __init__(self, temporal_ensemble_coeff: float, chunk_size: int): # 指数权重:w_i = exp(-coeff * i),i为动作索引(0为最旧动作) self.ensemble_weights = torch.exp(-temporal_ensemble_coeff * torch.arange(chunk_size)) self.ensemble_weights_cumsum = torch.cumsum(self.ensemble_weights, dim=0) # 权重累加和(用于归一化) def update(self, actions: Tensor) -> Tensor: # actions: (batch_size, chunk_size, action_dim) if self.ensembled_actions is None: self.ensembled_actions = actions.clone() # 初始化集成动作 else: # 在线加权更新:历史动作 * 累计权重 + 新动作 * 当前权重,再归一化 self.ensembled_actions *= self.ensemble_weights_cumsum[self.ensembled_actions_count - 1] self.ensembled_actions += actions[:, :-1] * self.ensemble_weights[self.ensembled_actions_count] self.ensembled_actions /= self.ensemble_weights_cumsum[self.ensembled_actions_count] return self.ensembled_actions[:, 0] # 返回集成后的首步动作 (2)动作队列模式 def select_action(self, batch: dict[str, Tensor]) -> Tensor: if len(self._action_queue) == 0: # 生成动作块(chunk_size步),取前n_action_steps步存入队列 actions = self.predict_action_chunk(batch)[:, :self.config.n_action_steps] # 队列形状:(n_action_steps, batch_size, action_dim),故转置后入队 self._action_queue.extend(actions.transpose(0, 1)) return self._action_queue.popleft() # 每次弹出队列首步动作 关闭temporal ensemble:未启用时间集成器是,使用简单的动作队列缓存动作块并逐步输出。首先调用调用 predict_action_chunk 获取动作块,这里将会输出一个chunk的动作。但是并不是把这个chunk的集合全都送入队列,而是截取前 n_action_steps 个动作(n_action_steps 为每次预测的动作步数,通常 ≤ chunk_size)。举个例子如果chunk_size是100,但是n_action_steps是50,那么策略一次预测出100个序列动作,但是只取前面的50个。最后把这动作块进行转置后加入队列,之所以转置是因为模型输出动作块形状为 (batch_size, n_action_steps, action_dim),而队列需要按时间步顺序存储(即 (n_action_steps, batch_size, action_dim)),因此通过 transpose(0, 1) 交换前两维。 为什么预测了chunk块,要用n_action_steps做限制了? 可能是因为利用了批量推理的效率,避免因动作块过长导致环境状态变化(如物体移动、机器人位姿偏移)时动作失效。同时限制单次执行的动作步数,强制模型在 n_action_steps 步后重新推理(基于最新观测),确保动作与环境状态同步。 训练损失计算 def forward(self, batch: dict[str, Tensor]) -> tuple[Tensor, dict]: batch = self.normalize_inputs(batch) # 输入归一化 batch = self.normalize_targets(batch) # 目标动作归一化 actions_hat, (mu, log_sigma_x2) = self.model(batch) # 模型输出:预测动作、VAE分布参数 # L1损失(忽略填充动作) l1_loss = (F.l1_loss(batch[ACTION], actions_hat, reduction="none") * ~batch["action_is_pad"].unsqueeze(-1)).mean() loss_dict = {"l1_loss": l1_loss.item()} # VAE KL散度损失(若启用) if self.config.use_vae: mean_kld = (-0.5 * (1 + log_sigma_x2 - mu.pow(2) - log_sigma_x2.exp())).sum(-1).mean() loss_dict["kld_loss"] = mean_kld.item() loss = l1_loss + mean_kld * self.config.kl_weight # 总损失 = 重构损失 + KL权重 * KL损失 else: loss = l1_loss return loss, loss_dict 这是ACTPolicy类训练模型的接口,负责接收输入数据、通过模推理生成动作预测、计算损失并返回总损失及损失组件字典。 首先对输入的观测数据进行归一化处理,normalize_inputs 基于数据集统计信息(均值、标准差)将输入特征缩放到标准分布(通常均值为0、方差为1),确保模型训练时输入数据分布稳定。 接着将图像特征统一整理到到 batch[OBS_IMAGES] 列表中,便于模型后续提取图像特征。 其次调用self.model(batch)进行模型推理返回模型预测的归一化动作序列,已经如果启用了VAE返回latent分布的均值和对数方差。 计算预测动作(actions_hat)与真实动作(batch[ACTION])的 L1 损失(平均绝对误差)。KL散度的理论意义在于度量两个概率分布之间的差异程度,当KL散度越大的时候,说明两者的差异程度越大;而当KL散度小的时候,则说明两者的差异程度小。如果两者相同的话,则该KL散度应该为0。如果启动了VAE,需要再计算KL散度,总的损失为L1损失与加权KL损失知乎,其中kl_weight是控制损失权重的超参数。如果没有启动VAE直接返回L1损失。 核心算法ACT 整体结构 class ACT(nn.Module): def __init__(self, config: ACTConfig): super().__init__() self.config = config # VAE编码器(可选):将动作序列编码为潜在分布 if config.use_vae: self.vae_encoder = ACTEncoder(config, is_vae_encoder=True) self.vae_encoder_latent_output_proj = nn.Linear(config.dim_model, config.latent_dim * 2) # 输出mu和log(sigma²) # 视觉Backbone:ResNet提取图像特征 if config.image_features: backbone_model = getattr(torchvision.models, config.vision_backbone)(weights=config.pretrained_backbone_weights) self.backbone = IntermediateLayerGetter(backbone_model, return_layers={"layer4": "feature_map"}) # 取layer4特征图 # Transformer编码器-解码器 self.encoder = ACTEncoder(config) # 处理多模态输入(图像、状态、潜在向量) self.decoder = ACTDecoder(config) # 生成动作块 self.action_head = nn.Linear(config.dim_model, config.action_feature.shape[0]) # 动作输出头 这段代码是ACT类的构造函数,主要是负责初始化模型的核心组件,包括VAE编码器、视觉backbone、transformer编码器/解码器、输入投影层、位置嵌入和动作预测头等。 (1)VAE编码器初始化 if self.config.use_vae: self.vae_encoder = ACTEncoder(config, is_vae_encoder=True) # VAE 编码器(Transformer 架构) self.vae_encoder_cls_embed = nn.Embedding(1, config.dim_model) # CLS 标记嵌入(用于 latent 分布参数) # 机器人状态投影层:将关节状态特征映射到模型隐藏维度 if self.config.robot_state_feature: self.vae_encoder_robot_state_input_proj = nn.Linear( self.config.robot_state_feature.shape[0], config.dim_model ) # 动作投影层:将动作特征映射到模型隐藏维度 self.vae_encoder_action_input_proj = nn.Linear( self.config.action_feature.shape[0], config.dim_model ) # Latent 分布投影层:将 VAE 编码器输出映射为 latent 均值和方差(维度=2*latent_dim) self.vae_encoder_latent_output_proj = nn.Linear(config.dim_model, config.latent_dim * 2) # 固定正弦位置嵌入:为 VAE 编码器输入序列添加位置信息(CLS + 机器人状态 + 动作序列) num_input_token_encoder = 1 + config.chunk_size # 1(CLS) + chunk_size(动作序列长度) if self.config.robot_state_feature: num_input_token_encoder += 1 # 若包含机器人状态,增加 1 个 token self.register_buffer( "vae_encoder_pos_enc", # 注册为缓冲区(不参与梯度更新) create_sinusoidal_pos_embedding(num_input_token_encoder, config.dim_model).unsqueeze(0), ) 调用ACTEncoder初始化一个VAE编码器,本质是一个transformer编码器,其参数is_vae_encoder=True 标志用于区分该编码器为 VAE 专用(影响层数、注意力机制等配置,具体见 ACTEncoder 实现)。 定义一个可学习的CLS标记,类似BERT中的[CLS],用于聚合VAE编码器输入序列的全局信息,最终生成latent分布参数(均值和方差),nn.Embedding(1, config.dim_model) 创建一个单元素嵌入表,输出维度为模型隐藏维度 dim_model。 当输入包含机器人状态特征(如关节角度、速度)时启用。通过线性层将机器人状态特征(原始维度)映射到模型隐藏维度 dim_model,确保与其他输入 token(如动作序列)维度一致,可拼接为序列输入。 同理将动作序列中的每个动作(原始维度,如机器人关节控制维度)通过线性层映射到 dim_model,转换为 Transformer 可处理的 token 序列。 将 VAE 编码器输出的 CLS 标记特征(维度 dim_model)映射到 latent 分布的参数空间。 最后的固定正弦位置嵌入,其作用是为 VAE 编码器的输入序列添加固定位置信息,帮助 Transformer 区分不同位置的 token(CLS、机器人状态、动作序列中的不同时间步)。 (2)视觉backbone初始化 if self.config.image_features: backbone_model = getattr(torchvision.models, config.vision_backbone)( replace_stride_with_dilation=[False, False, config.replace_final_stride_with_dilation], # 控制最后一层是否使用空洞卷积 weights=config.pretrained_backbone_weights, # 预训练权重(如 ImageNet) norm_layer=FrozenBatchNorm2d, # 冻结 BatchNorm 层(避免微调时破坏预训练分布) ) # 提取 ResNet 的 layer4 输出作为图像特征图(高层语义特征) self.backbone = IntermediateLayerGetter(backbone_model, return_layers={"layer4": "feature_map"}) 当ACT类中配置包含图像特征,初始化图像特征提取骨干网络,并通过 IntermediateLayerGetter 提取高层视觉特征供后续 Transformer 处理。 首先调用getattr动态加载 torchvision.models 中的 ResNet 模型(如 resnet18、resnet50),具体型号由配置 config.vision_backbone 指定。 然后使用 torchvision.ops.misc.IntermediateLayerGetter 从 ResNet 中提取指定层的输出,作为图像的高层特征。return_layers={"layer4": "feature_map"}指定提取 ResNet 的 layer4(最后一个残差块)输出,并将其重命名为 feature_map。ResNet 的 layer4 输出包含最抽象的视觉语义信息(如物体轮廓、纹理),是下游任务(如 Transformer 编码)的关键输入。self.backbone 调用时返回字典 {"feature_map": tensor},其中 tensor 为形状 (B, C, H, W) 的特征图(B 为 batch 大小,C 为通道数,H/W 为特征图高/宽)。 (3)transformer编码器/解码器初始化 # Transformer 编码器:处理输入特征(latent、机器人状态、环境状态、图像特征) self.encoder = ACTEncoder(config) # Transformer 解码器:生成动作序列(作为 VAE 解码器时,输入为 latent;否则直接处理编码器输出) self.decoder = ACTDecoder(config) 这两行代码是初始化ACT核心组件transformer编码器和解码器。 (4)输入投影层 # 机器人状态投影:将机器人关节状态特征(如关节角度、速度)映射到 dim_model if self.config.robot_state_feature: self.encoder_robot_state_input_proj = nn.Linear( self.config.robot_state_feature.shape[0], config.dim_model ) # 环境状态投影:将环境状态特征(如物体位置)映射到 dim_model if self.config.env_state_feature: self.encoder_env_state_input_proj = nn.Linear( self.config.env_state_feature.shape[0], config.dim_model ) # Latent 投影:将 VAE 输出的 latent 向量映射到 dim_model self.encoder_latent_input_proj = nn.Linear(config.latent_dim, config.dim_model) # 图像特征投影:通过 1x1 卷积将 Backbone 输出的特征图(C×H×W)映射到 dim_model if self.config.image_features: self.encoder_img_feat_input_proj = nn.Conv2d( backbone_model.fc.in_features, # Backbone 输出通道数(如 ResNet18 的 layer4 输出为 512) config.dim_model, kernel_size=1 # 1x1 卷积不改变空间维度,仅调整通道数 ) 在 Transformer 编码器中,要求所有输入 token 具有相同的维度(dim_model),而不同输入特征(状态、图像、latent 等)的原始维度各异,投影层通过线性/卷积变换实现维度对齐。 投影层(Projection Layer) 是一类用于将不同类型的输入特征(如机器人状态、环境状态、 latent 向量、图像特征等)映射到统一维度的神经网络层。其核心作用是将原始输入特征的维度转换为 Transformer 编码器能够处理的隐藏维度(即代码中的 config.dim_model),确保多模态输入(如状态、图像)能被编码器统一处理。 在ACT类中定义了多个投影层 self.config.robot_state_feature:输入为机器人状态特征(如关节角度、速度),原始维度为 self.config.robot_state_feature.shape[0],通过线性层(nn.Linear)将机器人状态的原始维度映射到 dim_model,使其成为 Transformer 编码器可接收的 token。 self.config.env_state_feature:环境状态特征(如物体位置、场景参数),原始维度为 self.config.env_state_feature.shape[0],与机器人状态投影层类似,通过线性层将环境状态映射到 dim_model,实现多模态特征的维度统一。 self.encoder_latent_input_proj:输入是Latent 向量(来自 VAE 采样或零向量),维度为 config.latent_dim,将 latent 向量从 latent 空间维度映射到 dim_model,作为 Transformer 编码器的核心输入 token 之一。 self.encoder_img_feat_input_proj:输入是图像特征图(来自 ResNet 骨干网络的 layer4 输出),通道数为 backbone_model.fc.in_features(如 ResNet18 为 512),通过 1x1 卷积层(nn.Conv2d)将图像特征图的通道数调整为 dim_model,同时保持空间维度(H×W)不变,以便展平为序列 token 输入 Transformer。 (5)位置嵌入 # 1D 位置嵌入:用于 latent、机器人状态、环境状态等非图像特征(共 n_1d_tokens 个 token) n_1d_tokens = 1 # latent 占 1 个 token if self.config.robot_state_feature: n_1d_tokens += 1 # 机器人状态占 1 个 token if self.config.env_state_feature: n_1d_tokens += 1 # 环境状态占 1 个 token self.encoder_1d_feature_pos_embed = nn.Embedding(n_1d_tokens, config.dim_model) # 可学习的 1D 位置嵌入 # 2D 位置嵌入:用于图像特征图(H×W 空间位置) if self.config.image_features: self.encoder_cam_feat_pos_embed = ACTSinusoidalPositionEmbedding2d(config.dim_model // 2) # 正弦 2D 位置嵌入 位置嵌入是 Transformer 的关键组件,用于解决自注意力机制 对输入序列顺序不敏感 的问题。本代码中有一个1D特征位置嵌入层和图像特征位置嵌入式层。 1D 特征位置嵌入式层:为 1D 特征 token 提供 可学习的位置嵌入,帮助 Transformer 区分不同类型 token 的位置(如 latent 是第 1 个 token,机器人状态是第 2 个等)。 2D 图像特征位置嵌入层:为图像特征图的 2D 空间像素 提供 正弦位置嵌入,编码像素在特征图中的 (高度, 宽度) 空间位置信息。 (6)解码器位置嵌入与动作预测头 self.decoder_pos_embed = nn.Embedding(config.chunk_size, config.dim_model) # chunk_size 为动作序列长度 self.action_head = nn.Linear(config.dim_model, self.config.action_feature.shape[0]) self.decoder_pos_embed:为解码器生成的动作序列(action chunk)提供 可学习的位置嵌入,帮助 Transformer 解码器区分动作序列中不同时间步的位置信息(如第 1 个动作、第 2 个动作等)。 self.action_head:将解码器输出的高维特征(config.dim_model 维度)投影到实际动作空间维度,生成最终可执行的动作序列。 forward方法 forward负责执行 Action Chunking Transformer 的完整前向传播流程,涵盖 VAE 编码(可选)、多模态输入处理、Transformer 编码器-解码器计算,最终输出动作序列及潜在变量分布参数(若启用 VAE)。以下是分步骤解析。 (1)输入验证与 batch_size 确定 if self.config.use_vae and self.training: assert "action" in batch, "actions must be provided when using the variational objective in training mode." if "observation.images" in batch: batch_size = batch["observation.images"][0].shape[0] else: batch_size = batch["observation.environment_state"].shape[0] 若启用变分目标(VAE)且处于训练模式,需确保输入包含动作序列("action"),因为 VAE 编码器需以动作序列为目标数据。确定batch_size,根据输入模态(图像或环境状态)确定批次大小,确保后续张量操作维度对齐。 (2) Latent 向量生成(VAE 编码逻辑) # 构建 VAE 编码器输入:[cls_token, 机器人状态(可选), 动作序列] cls_embed = einops.repeat(self.vae_encoder_cls_embed.weight, "1 d -> b 1 d", b=batch_size) # (B, 1, D) if self.config.robot_state_feature: robot_state_embed = self.vae_encoder_robot_state_input_proj(batch["observation.state"]).unsqueeze(1) # (B, 1, D) action_embed = self.vae_encoder_action_input_proj(batch["action"]) # (B, S, D) vae_encoder_input = torch.cat([cls_embed, robot_state_embed, action_embed] if self.config.robot_state_feature else [cls_embed, action_embed], axis=1) # (B, S+2, D) 或 (B, S+1, D) # 添加固定正弦位置嵌入 pos_embed = self.vae_encoder_pos_enc.clone().detach().permute(1, 0, 2) # (S+2, 1, D) # 构建注意力掩码(忽略填充 token) cls_joint_is_pad = torch.full((batch_size, 2 if self.config.robot_state_feature else 1), False, device=batch["observation.state"].device) key_padding_mask = torch.cat([cls_joint_is_pad, batch["action_is_pad"]], axis=1) # (B, S+2) 或 (B, S+1) # VAE 编码器前向传播,提取 cls token 输出 cls_token_out = self.vae_encoder(vae_encoder_input.permute(1, 0, 2), pos_embed=pos_embed, key_padding_mask=key_padding_mask)[0] # (B, D) latent_pdf_params = self.vae_encoder_latent_output_proj(cls_token_out) # (B, 2*latent_dim) mu = latent_pdf_params[:, :self.config.latent_dim] # 均值 (B, latent_dim) log_sigma_x2 = latent_pdf_params[:, self.config.latent_dim:] # 2*log(标准差) (B, latent_dim) # 重参数化采样 latent 向量 latent_sample = mu + log_sigma_x2.div(2).exp() * torch.randn_like(mu) # (B, latent_dim) 将动作序列编码为 latent 分布(均值 mu、方差相关参数 log_sigma_x2),并通过重参数化技巧采样得到 latent 向量,作为 Transformer 编码器的核心输入。 (3)无VAE时的latent向量初始化 mu = log_sigma_x2 = None latent_sample = torch.zeros([batch_size, self.config.latent_dim], dtype=torch.float32).to(batch["observation.state"].device) 如果不启用VAE或非训练模式,直接使用零向量作为latent输入。 (4)transformer编码器输入构建 encoder_in_tokens = [self.encoder_latent_input_proj(latent_sample)] # latent 投影:(B, latent_dim) → (B, dim_model) encoder_in_pos_embed = list(self.encoder_1d_feature_pos_embed.weight.unsqueeze(1)) # 1D token 位置嵌入:(n_1d_tokens, 1, dim_model) # 添加机器人状态 token(若启用) if self.config.robot_state_feature: encoder_in_tokens.append(self.encoder_robot_state_input_proj(batch["observation.state"])) # (B, dim_model) # 添加环境状态 token(若启用) if self.config.env_state_feature: encoder_in_tokens.append(self.encoder_env_state_input_proj(batch["observation.environment_state"])) # (B, dim_model) 1D特征token处理,通过线性层(nn.Linear)将 latent 向量、机器人/环境状态的原始维度映射到模型隐藏维度 dim_model,确保各 token 维度一致。为每个 1D token(latent、状态)分配可学习的位置嵌入,编码其在序列中的位置信息。 if self.config.image_features: all_cam_features = [] all_cam_pos_embeds = [] for img in batch["observation.images"]: # 遍历多相机图像 # 骨干网络提取特征图(如 ResNet layer4 输出) cam_features = self.backbone(img)["feature_map"] # (B, C_backbone, H, W) # 图像位置嵌入(2D 正弦位置编码) cam_pos_embed = self.encoder_cam_feat_pos_embed(cam_features).to(dtype=cam_features.dtype) # (1, dim_model, H, W) # 特征投影:调整通道数至 dim_model cam_features = self.encoder_img_feat_input_proj(cam_features) # (B, dim_model, H, W) # 展平为序列:(H*W, B, dim_model) cam_features = einops.rearrange(cam_features, "b c h w -> (h w) b c") cam_pos_embed = einops.rearrange(cam_pos_embed, "b c h w -> (h w) b c") all_cam_features.append(cam_features) all_cam_pos_embeds.append(cam_pos_embed) # 拼接多相机特征 encoder_in_tokens.extend(torch.cat(all_cam_features, axis=0)) encoder_in_pos_embed.extend(torch.cat(all_cam_pos_embeds, axis=0)) 对于图像的特征输入,启用图像输入,通过视觉骨干网络提取特征并转换为序列 token。通过 1x1 卷积(encoder_img_feat_input_proj)将特征图通道数调整为 dim_model,再展平为序列 token(H*W 个像素 token)。通过 ACTSinusoidalPositionEmbedding2d 为像素 token 添加空间位置信息,编码其在特征图中的 (H, W) 坐标。 (5)transformer编码器-解码器前向传播 # 堆叠所有输入 token 和位置嵌入 encoder_in_tokens = torch.stack(encoder_in_tokens, axis=0) # (seq_len, B, dim_model) encoder_in_pos_embed = torch.stack(encoder_in_pos_embed, axis=0) # (seq_len, 1, dim_model) # 编码器前向传播 encoder_out = self.encoder(encoder_in_tokens, pos_embed=encoder_in_pos_embed) # (seq_len, B, dim_model) 上面为编码器输出,输入序列为包含 1D 特征 token(latent、状态)和图像像素 token,总长度为 seq_len = n_1d_tokens + sum(H*W for 各相机)。通过自注意力机制融合多模态输入,输出包含全局上下文的特征序列 encoder_out。 # 解码器输入初始化为零向量(类似 DETR 的目标查询) decoder_in = torch.zeros((self.config.chunk_size, batch_size, self.config.dim_model), dtype=encoder_in_pos_embed.dtype, device=encoder_in_pos_embed.device) # (chunk_size, B, dim_model) # 解码器前向传播(交叉注意力融合编码器输出) decoder_out = self.decoder( decoder_in, encoder_out, encoder_pos_embed=encoder_in_pos_embed, # 编码器位置嵌入 decoder_pos_embed=self.decoder_pos_embed.weight.unsqueeze(1), # 解码器动作序列位置嵌入 ) # (chunk_size, B, dim_model) # 转换维度并投影到动作空间 decoder_out = decoder_out.transpose(0, 1) # (B, chunk_size, dim_model) actions = self.action_head(decoder_out) # (B, chunk_size, action_dim) return actions, (mu, log_sigma_x2) 解码器部分,初始化为零向量序列(长度 chunk_size,即一次预测的动作数量),类似 DETR 的“目标查询”。解码器通过交叉注意力机制关注编码器输出的上下文特征,生成动作序列特征。通过 action_head(线性层)将解码器输出的高维特征投影到机器人动作空间维度(action_dim),得到最终动作序列。 最终返回actions和(mu, log_sigma_x2)。前者是形状 (B, chunk_size, action_dim),预测的动作序列;后者是若启用 VAE,返回 latent 分布的均值和方差参数(log_sigma_x2 = 2*log(σ)),否则为 (None, None)。 ACT编码器 ACTEncoder ACTEncoder 是 Transformer 编码器的顶层容器,负责堆叠多个 ACTEncoderLayer(编码器层)并执行最终归一化,支持 VAE 编码器 和 主 Transformer 编码器 两种角色。 class ACTEncoder(nn.Module): def __init__(self, config: ACTConfig, is_vae_encoder: bool = False): super().__init__() self.is_vae_encoder = is_vae_encoder # 根据角色选择编码器层数(VAE 编码器 vs 主编码器) num_layers = config.n_vae_encoder_layers if self.is_vae_encoder else config.n_encoder_layers # 堆叠 num_layers 个编码器层 self.layers = nn.ModuleList([ACTEncoderLayer(config) for _ in range(num_layers)]) # 最终归一化(预归一化模式下启用) self.norm = nn.LayerNorm(config.dim_model) if config.pre_norm else nn.Identity() 通过 is_vae_encoder 区分角色,分别使用 n_vae_encoder_layers(VAE 专用层数)或 n_encoder_layers(主编码器层数)。通过 nn.ModuleList 管理多个 ACTEncoderLayer,形成深度编码器结构。若 config.pre_norm=True(预归一化),对所有层输出做最终归一化;否则使用 nn.Identity(无操作),此时归一化在每层内部完成(后归一化)。 def forward( self, x: Tensor, pos_embed: Tensor | None = None, key_padding_mask: Tensor | None = None ) -> Tensor: for layer in self.layers: x = layer(x, pos_embed=pos_embed, key_padding_mask=key_padding_mask) x = self.norm(x) return x 逐层特征提取:输入张量 x(形状通常为 (seq_len, batch_size, dim_model))依次通过所有 ACTEncoderLayer,每层融合自注意力和前馈网络特征。 位置嵌入与掩码:pos_embed 提供序列位置信息,key_padding_mask 标记需忽略的填充位置,两者均传递给每层。 最终归一化:所有层处理完毕后,通过 self.norm 输出最终特征。 ACTEncoderLayer 下面是单个编码器层的实现 class ACTEncoderLayer(nn.Module): def __init__(self, config: ACTConfig): super().__init__() # 自注意力模块 self.self_attn = nn.MultiheadAttention(config.dim_model, config.n_heads, dropout=config.dropout) # 前馈网络(Linear -> Activation -> Dropout -> Linear) self.linear1 = nn.Linear(config.dim_model, config.dim_feedforward) self.dropout = nn.Dropout(config.dropout) self.linear2 = nn.Linear(config.dim_feedforward, config.dim_model) # 归一化与 dropout 层 self.norm1, self.norm2 = nn.LayerNorm(config.dim_model), nn.LayerNorm(config.dim_model) self.dropout1, self.dropout2 = nn.Dropout(config.dropout), nn.Dropout(config.dropout) # 激活函数与归一化模式标记 self.activation = get_activation_fn(config.feedforward_activation) self.pre_norm = config.pre_norm ACTEncoderLayer 是编码器的核心计算单元,包含 自注意力机制、前馈网络 和 残差连接,支持预归一化(PreNorm)或后归一化(PostNorm)模式。 自注意力:nn.MultiheadAttention 实现多头注意力,输入维度 dim_model,头数 n_heads。 前馈网络:将特征从 dim_model 映射到 dim_feedforward(扩展维度),经激活和 dropout 后映射回 dim_model。 归一化与 dropout:每层包含两个归一化层(norm1 用于注意力,norm2 用于前馈网络)和两个 dropout 层,增强训练稳定性。 def forward(self, x, pos_embed: Tensor | None = None, key_padding_mask: Tensor | None = None) -> Tensor: # 自注意力模块 + 残差连接 skip = x if self.pre_norm: # 预归一化:先归一化再计算注意力 x = self.norm1(x) q = k = x if pos_embed is None else x + pos_embed # query 和 key 融合位置嵌入 x = self.self_attn(q, k, value=x, key_padding_mask=key_padding_mask)[0] # 取注意力输出(忽略权重) x = skip + self.dropout1(x) # 残差连接 + dropout # 前馈网络模块 + 残差连接 if self.pre_norm: # 预归一化:先归一化再计算前馈 skip = x x = self.norm2(x) else: # 后归一化:先计算注意力再归一化 x = self.norm1(x) skip = x x = self.linear2(self.dropout(self.activation(self.linear1(x)))) # 前馈网络 x = skip + self.dropout2(x) # 残差连接 + dropout if not self.pre_norm: # 后归一化:最后归一化输出 x = self.norm2(x) return x 上面是forward方法,可以分为自注意力阶段和前馈网络阶段。 自注意力阶段:残差连接,skip 保存输入,注意力输出经 dropout1 后与 skip 相加。位置嵌入,q 和 k 若有 pos_embed 则叠加位置信息,帮助模型捕捉序列顺序。归一化时机,pre_norm=True 时,先对 x 归一化(norm1)再计算注意力;否则后归一化(注意力后通过 norm1 归一化)。 前馈网络阶段:前馈计算,x 经线性层扩展维度、激活(如 ReLU/GELU)、dropout、线性层压缩维度。残差与归一化,类似注意力阶段,pre_norm 决定归一化时机,最终输出融合残差的特征。 总结一下,ACTEncoder,通过堆叠多个 ACTEncoderLayer 实现深度编码,动态适配 VAE 或主编码器角色,输出融合全局依赖的序列特征。ACTEncoderLayer,单个编码器层核心,通过“自注意力+前馈网络+残差连接”提取局部与全局特征,支持预/后归一化模式,是 Transformer 编码器的基础组件。两者协同构成 ACT 模型的编码器部分,负责将多模态输入(如图像、状态)编码为上下文特征,供解码器生成动作序列。 ACT解码器 ACTDecoder ACTDecoder 是 Transformer 解码器的顶层模块,负责堆叠多个 ACTDecoderLayer(解码器子层)并对最终输出进行归一化,实现从编码器上下文特征到动作序列的映射。 class ACTDecoder(nn.Module): def __init__(self, config: ACTConfig): super().__init__() self.layers = nn.ModuleList([ACTDecoderLayer(config) for _ in range(config.n_decoder_layers)]) self.norm = nn.LayerNorm(config.dim_model) 通过 nn.ModuleList 创建 config.n_decoder_layers 个 ACTDecoderLayer 实例,构成深度解码器(每层包含自注意力、交叉注意力和前馈网络)。使用 nn.LayerNorm 对所有解码器层的输出进行归一化,稳定训练过程。 def forward( self, x: Tensor, encoder_out: Tensor, decoder_pos_embed: Tensor | None = None, encoder_pos_embed: Tensor | None = None, ) -> Tensor: for layer in self.layers: x = layer( x, encoder_out, decoder_pos_embed=decoder_pos_embed, encoder_pos_embed=encoder_pos_embed ) if self.norm is not None: x = self.norm(x) return x 输入参数如下: x:解码器输入序列(初始为零向量,形状 (chunk_size, batch_size, dim_model),chunk_size 为动作序列长度); encoder_out:编码器输出特征(形状 (encoder_seq_len, batch_size, dim_model)); decoder_pos_embed:解码器位置嵌入(为动作序列提供时序位置信息); encoder_pos_embed:编码器位置嵌入(为编码器特征提供位置信息,辅助交叉注意力)。 将输入 x、编码器输出 encoder_out 及位置嵌入依次传入每个 ACTDecoderLayer,更新 x 为每层输出。所有层处理完毕后,通过 self.norm 对输出进行归一化,返回形状为 (chunk_size, batch_size, dim_model) 的特征张量(后续将映射为动作序列)。 ACTDecoderLayer 下面再介绍下ACTDecoderLayer。 ACTDecoderLayer 是解码器的基础单元,包含 自注意力(捕捉动作序列内部依赖)、交叉注意力(融合编码器上下文特征)和 前馈网络(增强特征表达能力)三大模块,支持预归一化(PreNorm)或后归一化(PostNorm)模式。 class ACTDecoderLayer(nn.Module): def __init__(self, config: ACTConfig): super().__init__() # 自注意力(解码器内部时序依赖建模) self.self_attn = nn.MultiheadAttention(config.dim_model, config.n_heads, dropout=config.dropout) # 交叉注意力(融合编码器输出特征) self.multihead_attn = nn.MultiheadAttention(config.dim_model, config.n_heads, dropout=config.dropout) # 前馈网络(特征变换与增强) self.linear1 = nn.Linear(config.dim_model, config.dim_feedforward) # 升维 self.dropout = nn.Dropout(config.dropout) self.linear2 = nn.Linear(config.dim_feedforward, config.dim_model) # 降维 # 归一化层(3个,分别对应自注意力、交叉注意力、前馈网络) self.norm1, self.norm2, self.norm3 = [nn.LayerNorm(config.dim_model) for _ in range(3)] # Dropout层(3个,增强正则化) self.dropout1, self.dropout2, self.dropout3 = [nn.Dropout(config.dropout) for _ in range(3)] # 激活函数(如ReLU/GELU) self.activation = get_activation_fn(config.feedforward_activation) # 归一化模式标记(PreNorm/PostNorm) self.pre_norm = config.pre_norm 前向传播forward可以分为3个阶段,分为自注意力->交叉注意力->前馈网络,每个阶段都包含归一化->计算->dropout->残差连接的逻辑。 (1)自注意力阶段 skip = x # 残差连接的输入 if self.pre_norm: # 预归一化:先归一化,再计算注意力 x = self.norm1(x) # Query和Key融合位置嵌入(Value不融合,保持原始特征) q = k = self.maybe_add_pos_embed(x, decoder_pos_embed) x = self.self_attn(q, k, value=x)[0] # 自注意力输出(忽略注意力权重) x = skip + self.dropout1(x) # 残差连接 + Dropout (2)交叉注意力阶段 if self.pre_norm: # 预归一化:更新残差输入,归一化当前特征 skip = x x = self.norm2(x) else: # 后归一化:先归一化自注意力输出,再更新残差输入 x = self.norm1(x) skip = x # Query(解码器特征)融合解码器位置嵌入,Key(编码器特征)融合编码器位置嵌入 x = self.multihead_attn( query=self.maybe_add_pos_embed(x, decoder_pos_embed), key=self.maybe_add_pos_embed(encoder_out, encoder_pos_embed), value=encoder_out, )[0] # 交叉注意力输出(忽略权重) x = skip + self.dropout2(x) # 残差连接 + Dropout (3)前馈网络 if self.pre_norm: # 预归一化:更新残差输入,归一化当前特征 skip = x x = self.norm3(x) else: # 后归一化:先归一化交叉注意力输出,再更新残差输入 x = self.norm2(x) skip = x # 前馈网络:升维→激活→Dropout→降维 x = self.linear2(self.dropout(self.activation(self.linear1(x)))) x = skip + self.dropout3(x) # 残差连接 + Dropout if not self.pre_norm: # 后归一化:最后归一化前馈网络输出 x = self.norm3(x)