一切皆文件之块设备驱动(四)
- 文件系统
- 2023-06-03
- 706热度
- 0评论
实验环境
kernel version: linux 5.15
kernel module: simpleblk.ko 参考上一章节
application:app_test 参考上一章节
块设备无文件系统方式读写
写数据
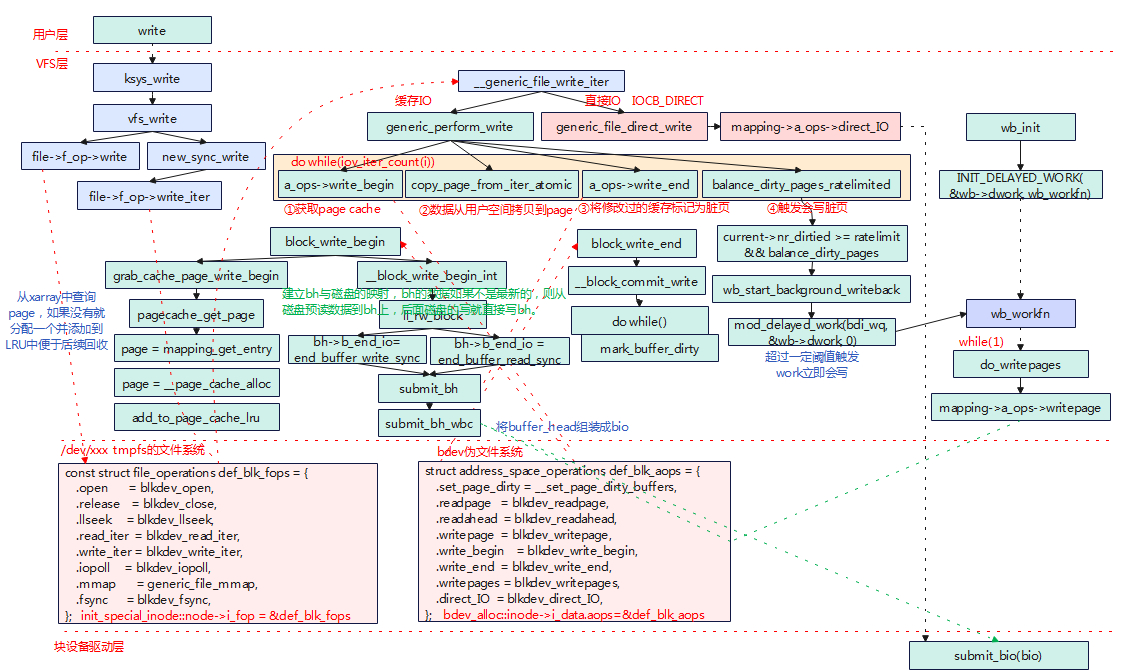
存储设备没有格式化挂载文件系统,那么对磁盘设备的操作会经过/dev/xxx tmpfs文件系统和bdev伪文件系统组合的方式读写磁盘。
- Write系统调用经过VFS调用到def_blk_fops中的blkdev_write_iter,该函数中继续调用到__generic_file_write_iter。
- 如果是缓冲I/O的方式,将经过4个步骤,分别为获取page cache、从用户空间拷贝数据到page、修改的缓存标记为脏页、根据阈值是否要写回脏页。
- 在write_begin中会查询是否有磁盘对应的page cache,如果没有就申请一个page用于磁盘的缓冲;对于新申请的page cache,会调用ll_rw_block进行预读,将磁盘数据读取到page中,后面的操作就直接对page 操作即可。
数据写到缓存页page中(文件系统层)
ksys_write
-->vfs_write
-->new_sync_write
-->blkdev_write_iter
-->blk_start_plug(&plug)
-->__generic_file_write_iter
-->blk_finish_plug(&plug)
generic_perform_write
-->a_ops->write_begin -->blkdev_write_begin
-->block_write_begin
--> grab_cache_page_write_begin 获取page缓存
--> __block_write_begin_int 写数据开始初始化
-->head = create_page_buffers 分配一个buffer_head
-->if (!buffer_mapped(bh)) err = get_block(inode, block, bh, 1);
-->blkdev_get_block 将块与buffer_head映射(把bh->b_bdev设置为inode对应的i_bdev并设置block号)
-->copy_page_from_iter_atomic 用户拷贝数据到page中
-->a_ops->write_end -->blkdev_write_end 写数据结束,设置page为脏页
-->balance_dirty_pages_ratelimited(mapping) 脏页太多触发回写到磁盘
打包数据成bio递交到块设备层
直接写磁盘一般有几种方式,在建立bh和磁盘映射时,如果数据不是最新的则调用ll_rw_block进行写;另外情况就是当脏页超过一定阈值、用户关闭文件等操作触发worker回写,本小节以触发worker方式回写为例。
wb_workfn
->wb_writeback
->__writeback_inodes_wb
->writeback_sb_inodes
->__writeback_single_inode
->do_writepages
->if(mapping->a_ops->writepages)
ret = mapping->a_ops->writepages(mapping, wbc)
->blkdev_writepages 调用bdev文件系统注册的写page函数
->else
ret = generic_writepages(mapping, wbc);
blkdev_writepages
->generic_writepages
->blk_start_plug(&plug)
->write_cache_pages
->__writepage
->blk_finish_plug(&plug);
__writepage
->mapping->a_ops->writepage(page, wbc);
->blkdev_writepage 注意与blkdev_writepages的区别(多了个s)
->block_write_full_page
->__block_write_full_page
->submit_bh_wbc
submit_bh_wbc(REQ_OP_WRITE, write_flags, bh,inode->i_write_hint, wbc);
将bh转化为bio
->bio = bio_alloc(GFP_NOIO, 1); 分配一个bio
->bio->bi_iter.bi_sector = bh->b_blocknr * (bh->b_size >> 9);
->bio_set_dev(bio, bh->b_bdev);
->bio->bi_write_hint = write_hint;
->bio_add_page(bio, bh->b_page, bh->b_size, bh_offset(bh));
->bio->bi_end_io = end_bio_bh_io_sync;
->bio->bi_private = bh;
递交bio
->submit_bio(bio);
submit_bio
->submit_bio_noacct
->__submit_bio_noacct
->__submit_bio
->if (disk->fops->submit_bio)
->ret = disk->fops->submit_bio(bio); 如果块设备注册了submit_bio直接调用(一般是ramdisk使用这种方式)
->else
->blk_mq_submit_bio(bio) 如果没有注册则进入mq
创建和发送request
blk_qc_t blk_mq_submit_bio(struct bio *bio)
{
获取存储设备的request queue(包含blk_mq_ctx和blk_mq_hw_ctx)
struct request_queue *q = bio->bi_disk->queue;
如果内存区处于高位区,则重新映射到低位区
blk_queue_bounce(q, &bio);
如果bio块太大,则对bio进行分割
__blk_queue_split(&bio, &nr_segs);
if (!bio)
goto queue_exit;
如果队列中没有禁用合并则尝试在task的current->plug上合并
if (!is_flush_fua && !blk_queue_nomerges(q) &&
blk_attempt_plug_merge(q, bio, nr_segs, &same_queue_rq))
goto queue_exit; //合并成功后直接退出
为了管理request,早期内核为每个task都定义了一个struct blk_plug,同task的request暂时都
会挂载到blk_plug.mg_list中,新增的bio到来时,会遍历blk_plug.mq_list,如果存在合适的
request直接添加,如果不存在就申请一个新的request添加。
尝试在IO调度器或软队列ctx中合并,合并成功则返回
if (blk_mq_sched_bio_merge(q, bio, nr_segs))
goto queue_exit;
rq_qos_throttle(q, bio);
hipri = bio->bi_opf & REQ_HIPRI;
data.cmd_flags = bio->bi_opf;
如果bio没法合并到原有的request中去,则重新申请一个新的request。
rq = __blk_mq_alloc_request(&data);
rq_qos_track(q, rq, bio);
cookie = request_to_qc_t(data.hctx, rq);
将bio中的数据添加到新申请的request中
blk_mq_bio_to_request(rq, bio, nr_segs);
获取plug
plug = blk_mq_plug(q, bio);
1. 如果是刷新flush/fua请求,则绕过调度器直接插入请求
if (unlikely(is_flush_fua)) {
/* Bypass scheduler for flush requests */
blk_insert_flush(rq);
blk_mq_run_hw_queue(data.hctx, true);启动请求派发
2. 当前任务正在做IO Plug && 设备硬件队列只有一个(hw_ctx?),将request插入到当前任务的plug list
} else if (plug && (q->nr_hw_queues == 1 ||
blk_mq_is_sbitmap_shared(rq->mq_hctx->flags) ||
q->mq_ops->commit_rqs || !blk_queue_nonrot(q))) {
unsigned int request_count = plug->rq_count;
struct request *last = NULL;
if (!request_count)
trace_block_plug(q);
else
last = list_entry_rq(plug->mq_list.prev);
if (request_count >= blk_plug_max_rq_count(plug) || (last &&
blk_rq_bytes(last) >= BLK_PLUG_FLUSH_SIZE)) {
blk_flush_plug_list(plug, false);
trace_block_plug(q);
}
blk_add_rq_to_plug(plug, rq);
3. 如果request queue配置了调度器
} else if (q->elevator) {
/* Insert the request at the IO scheduler queue */
blk_mq_sched_insert_request(rq, false, true, true); 将请求插入到调度器队列
4. 有plug && request queue没有禁止合并
走这个分支说明不是刷新请求、没有IO调度器。
} else if (plug && !blk_queue_nomerges(q)) {
if (list_empty(&plug->mq_list))
same_queue_rq = NULL;
if (same_queue_rq) {
list_del_init(&same_queue_rq->queuelist);
plug->rq_count--;
}
blk_add_rq_to_plug(plug, rq);
trace_block_plug(q);
if (same_queue_rq) {
data.hctx = same_queue_rq->mq_hctx;
trace_block_unplug(q, 1, true);
blk_mq_try_issue_directly(data.hctx, same_queue_rq,
&cookie);
}
5. 设备硬件队列有多个(hw_ctx?)
} else if ((q->nr_hw_queues > 1 && is_sync) ||
!data.hctx->dispatch_busy) {
/*
* There is no scheduler and we can try to send directly
* to the hardware.
*/
blk_mq_try_issue_directly(data.hctx, rq, &cookie);
} else {
/* Default case. */
blk_mq_sched_insert_request(rq, false, true, true);
}
if (!hipri)
return BLK_QC_T_NONE;
return cookie;
queue_exit:
blk_queue_exit(q);
return BLK_QC_T_NONE;
}
IO派发blk_mq_run_hw_queue
在mutilate queue中很多点都会触发IO请求到块设备驱动中
blk_mq_run_hw_queue
->__blk_mq_delay_run_hw_queue
->blk_mq_sched_dispatch_requests
->__blk_mq_sched_dispatch_requests
->blk_mq_do_dispatch_sched
->blk_mq_dispatch_rq_list
->ret = q->mq_ops->queue_rq(hctx, &bd);
->用户注册的回调函数.queue_rq
示例dump_stack
[ 917.615686] _queue_rq+0x74/0x210 [simplefs]
[ 917.620462] blk_mq_dispatch_rq_list+0x130/0x8cc
[ 917.625633] blk_mq_do_dispatch_sched+0x2a8/0x32c
[ 917.630902] __blk_mq_sched_dispatch_requests+0x14c/0x1b0
[ 917.636948] blk_mq_sched_dispatch_requests+0x40/0x80
[ 917.642609] __blk_mq_run_hw_queue+0x58/0x90
[ 917.647389] __blk_mq_delay_run_hw_queue+0x1d4/0x200
[ 917.652951] blk_mq_run_hw_queue+0x98/0x100
[ 917.657634] blk_mq_sched_insert_requests+0x90/0x170
[ 917.663193] blk_mq_flush_plug_list+0x130/0x1ec
[ 917.668267] blk_flush_plug_list+0xec/0x120
[ 917.672950] blk_finish_plug+0x40/0xe0
[ 917.677149] wb_writeback+0x1e8/0x3b0
[ 917.681246] wb_workfn+0x39c/0x584
[ 917.685043] process_one_work+0x204/0x420
[ 917.689535] worker_thread+0x74/0x4dc
[ 917.693634] kthread+0x128/0x134
[ 917.697247] ret_from_fork+0x10/0x20
读数据
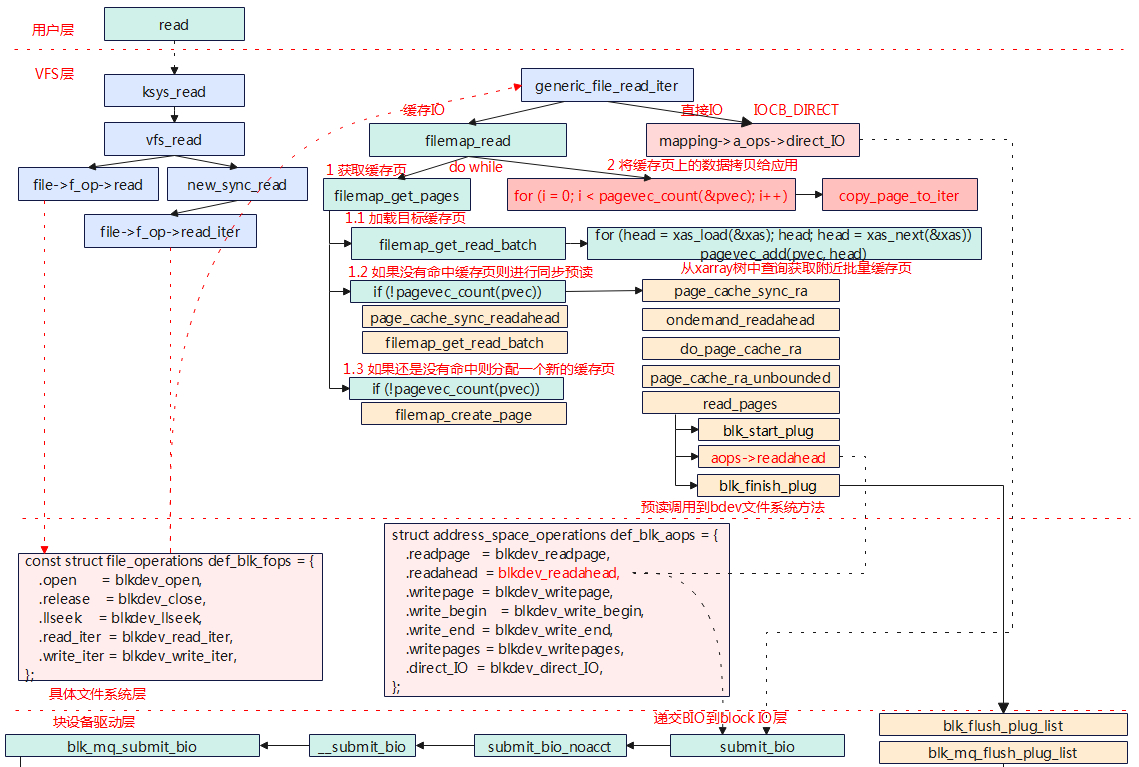

预读
ksys_read
->vfs_read
->new_sync_read
->file->f_op->read_iter
->blkdev_read_iter
blkdev_read_iter
->generic_file_read_iter
->filemap_read
->filemap_get_pages 获取page缓存
->filemap_get_read_batch(mapping, index, last_index, pvec); 获取缓存页面
->for(head = xas_load(&xas); head; head = xas_next(&xas)) 遍历xarray树,查询是否有缓存页
->pagevec_add(pvec, head)
->if (!pagevec_count(pvec)) 如果没有获取到缓存页面,则进行页面预读
->page_cache_sync_readahead 文件预读(文件预读会在重新自己分配page)
->page_cache_sync_ra
->ondemand_readahead
->if (!pagevec_count(pvec))
err = filemap_create_page(filp, mapping... 如果还是没有获取到缓存页面,则创建一个新的页面
->add_to_page_cache_lru 添加页面到LRU中,便于回收
->error = filemap_read_page(file, mapping, page); 读取数据到页面
->page = pvec->pages[pagevec_count(pvec) - 1]; 获取批量缓存的最后一页
->if (PageReadahead(page)) 判断最后一个页面是否需要预读
->filemap_readahead 文件预读
->page_cache_async_readahead
->for(i = 0; i < pagevec_count(&pvec); i++) 拷贝数据给应用
copied = copy_page_to_iter(page, offset, bytes, iter);
文件缓存页预读取
page_cache_sync_ra
->ondemand_readahead
->do_page_cache_ra
->page_cache_ra_unbounded
根据请求预读的数量遍历xarray树,如果page不存在就重新申请添加page并读取数据添加到LRU上。
->for (i = 0; i < nr_to_read; i++)
->struct page *page = xa_load(&mapping->i_pages, index + i);
->if (page && !xa_is_value(page))
->read_pages(ractl, &page_pool, true);
->page = __page_cache_alloc(gfp_mask);
->read_pages
->read_pages
read_pages
->blk_start_plug(&plug) 在task_struct上安装一个list,用于合并多个request请求
->if (aops->readahead)
->aops->readahead(rac)
->blkdev_readahead 1. block层预读 ------>
->else if(aops->readpages)
->aops->readpages(rac->file, rac->mapping, pages,readahead_count(rac));
->else
->while ((page = readahead_page(rac)))
->blk_finish_plug(&plug); 2.将task_struct上合并request请求flush到存储设备队列
->blk_flush_plug_list
->blk_mq_flush_plug_list
1.block层预读 ------>blkdev_readahead
->mpage_readahead
->mpage_bio_submit
->submit_bio(bio)
submit_bio(bio)
->submit_bio_noacct
->__submit_bio
->blk_mq_submit_bio
->plug & hwqueue == 1
2.blk_mq_flush_plug_list
->blk_mq_sched_insert_requests
->blk_mq_run_hw_queue
blk_mq_run_hw_queue
->__blk_mq_delay_run_hw_queue
->__blk_mq_run_hw_queue
->blk_mq_sched_dispatch_requests
->blk_mq_do_dispatch_sched
->blk_mq_dispatch_rq_list
->用户注册的回调函数.queue_rq -->read
从缓存中读取
ksys_read
->vfs_read
->new_sync_read
->file->f_op->read_iter
->blkdev_read_iter
blkdev_read_iter
->generic_file_read_iter
->filemap_read
->filemap_get_pages 获取page缓存
->filemap_get_read_batch(mapping, index, last_index, pvec); 获取缓存页面
->for(head = xas_load(&xas); head; head = xas_next(&xas)) 遍历xarray树,查询有缓存页
->pagevec_add(pvec, head)
->for(i = 0; i < pagevec_count(&pvec); i++) 拷贝数据给应用
copied = copy_page_to_iter(page, offset, bytes, iter);
与预读相比,如果在缓存中命中后,将直接从缓存中获取返回,在filemap_get_pages函数中获取缓存页,如果已经存在缓存页则不需要进行预读操作,接下来从缓存中拷贝数据给应用空间即可。