模型训练GPU跑飞
- Ai
- 7天前
- 33热度
- 0评论
问题
当前使用的是魔改版的NVIDIA 2080 Ti 22G显卡,发现在模型训练过程中,跑着跑着就报错了,具体如下:
raceback (most recent call last):
File "/home/laumy/lerobot/./src/lerobot/scripts/train.py", line 291, in <module>
train()
File "/home/laumy/lerobot/src/lerobot/configs/parser.py", line 226, in wrapper_inner
response = fn(cfg, *args, **kwargs)
File "/home/laumy/lerobot/./src/lerobot/scripts/train.py", line 212, in train
train_tracker, output_dict = update_policy(
File "/home/laumy/lerobot/./src/lerobot/scripts/train.py", line 101, in update_policy
train_metrics.loss = loss.item()
RuntimeError: CUDA error: unspecified launch failure
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
然后使用nvidia-smi发现显卡都找不到了。
nvidia-smi
No devices were found
排查
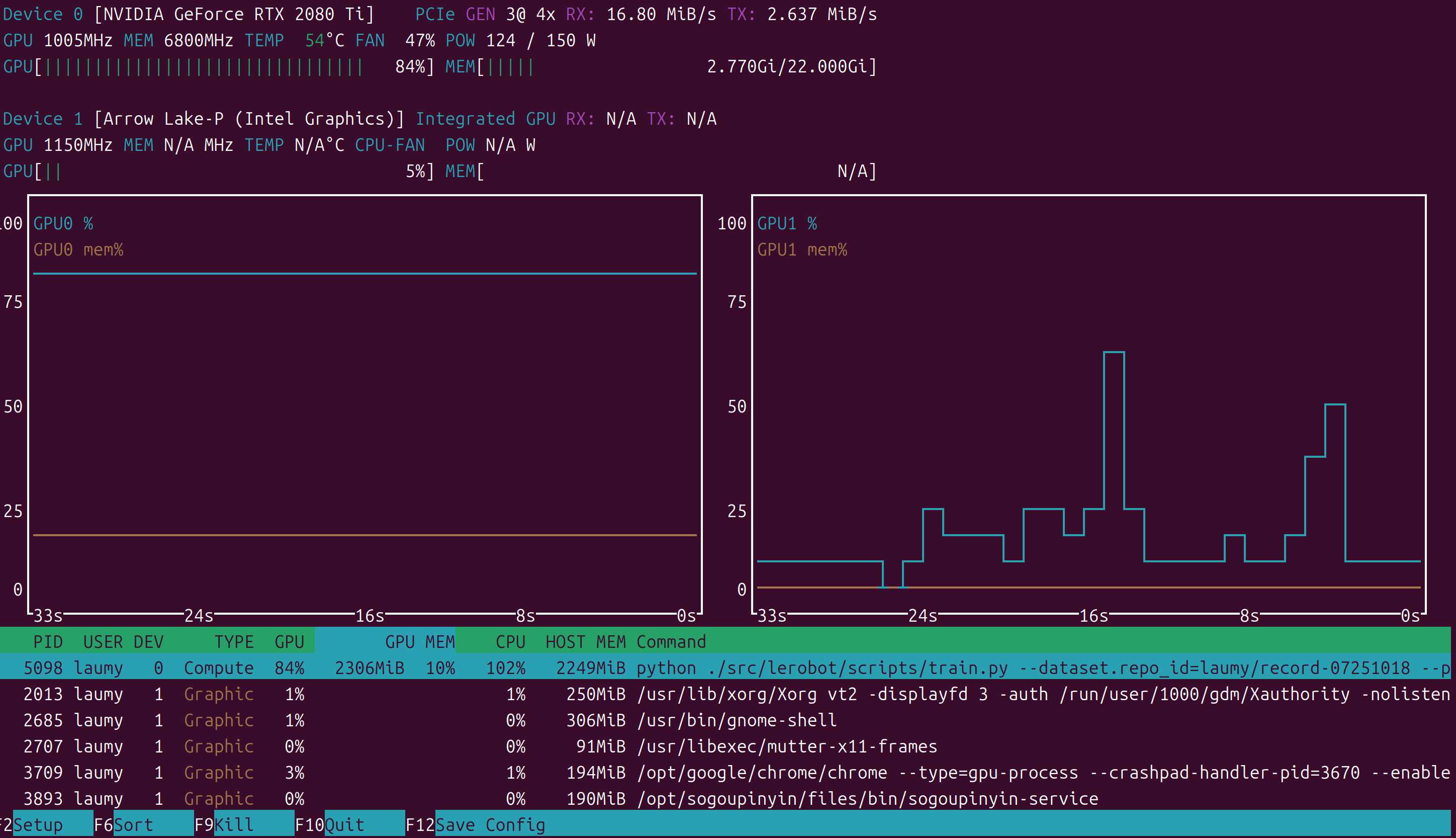
重启电脑,重新训练模型,同时执行以下命令查看显卡情况。
watch -n nvidia-smi
发现训练过程中,温度飙升非常快,初步怀疑是性能跑太满,导致温度过高保护了。
解决
限制GPU的功率和核心频率
sudo nvidia-smi -pl 150 # 将功率限制设置为150W
sudo nvidia-smi -lgc 1000,1000 # 限制核心频率为1000MHz
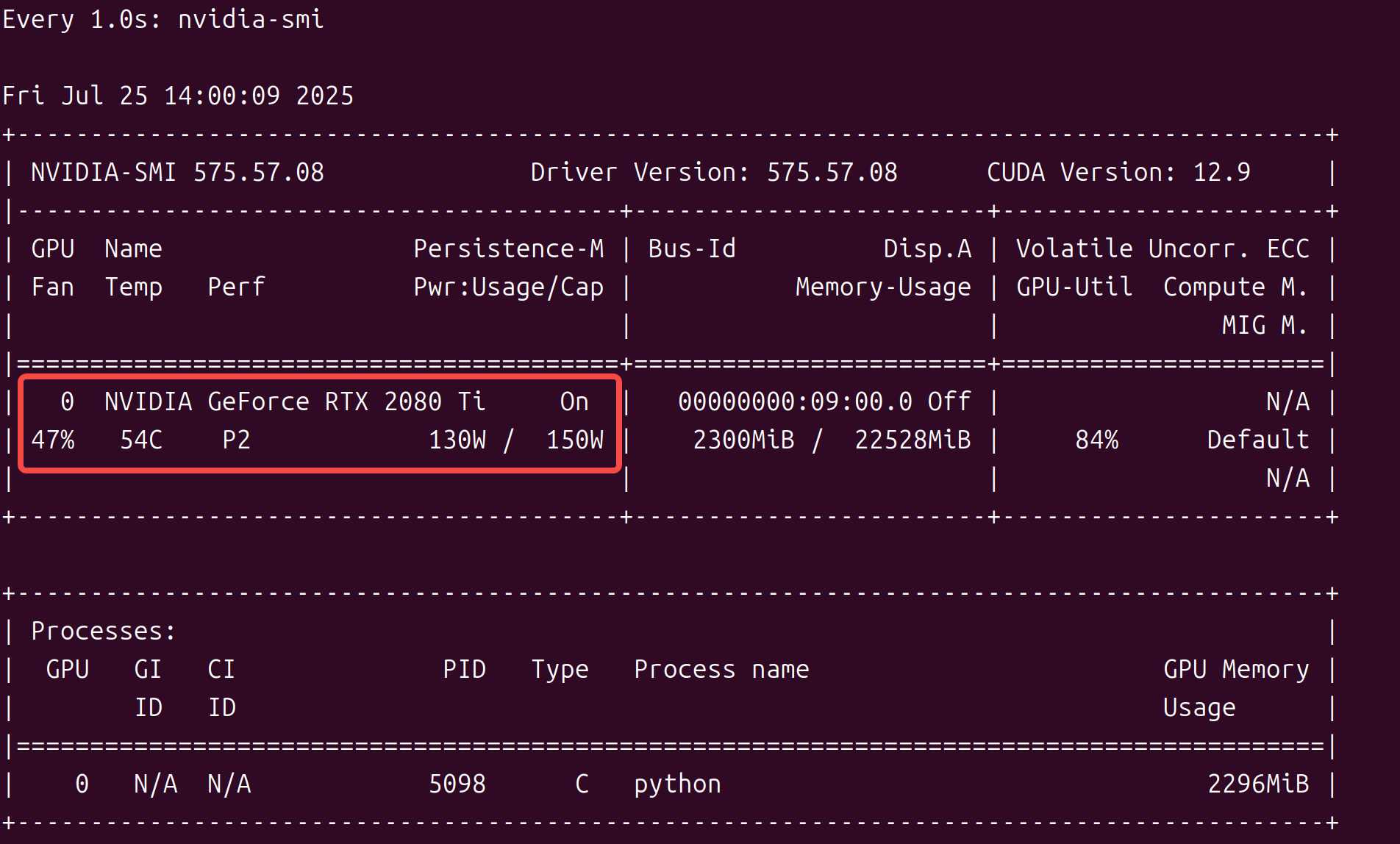
限制后继续跑,发现没有问题了。也可以使用nvidia-smi -a来详细查看参数。
另外如果想实时查看GPU监控,可以使用
nvtop