ONNX Runtime Python端侧模型部署YOLOv5
- Ai应用
- 2025-06-18
- 276热度
- 0评论
ONNX Runtime介绍
ONNX Runtime不依赖于Pytorch、tensorflow等机器学习训练模型框架。他提供了一种简单的方法,可以在CPU、GPU、NPU上运行模型。通常ONNX Runtime用于端侧设备模型的运行推理。要使用ONNX Runtime运行模型,一般的步骤如下:
- 用你最喜欢的框架(如pytorch、tensorflow、paddle等)训练一个模型。
- 将模型转换或导出为ONNX格式。
- 在端侧使用ONNX Runtime加载并运行模型。
模型的训练和导出为ONNX格式这里就不再阐述了。下面基于python在端侧运行模型的示例:
import numpy
# 导入numpy模块
import onnxruntime as rt
# 导入onnxruntime模块
sess = rt.InferenceSession(
"logreg_iris.onnx", providers=rt.get_available_providers())
# 加载模型logreg_iris.onnx
input_name = sess.get_inputs()[0].name
# 获取模型的输入名称,对应的是使用https://netron.app/中intput name。
pred_onx = sess.run(None, {input_name: X_test.astype(numpy.float32)})[0]
# 运行模型推理,返回结果到pred_onx中
print(pred_onx)
上面给出的python示例中,端侧运行模型可以总结为2个步骤。加载模型,模型推理。
加载模型
class onnxruntime.InferenceSession(
path_or_bytes: str | bytes | os.PathLike,
sess_options: onnxruntime.SessionOptions | None = None,
providers: Sequence[str | tuple[str, dict[Any, Any]]] | None = None,
provider_options: Sequence[dict[Any, Any]] | None = None, **kwargs)
- path_or_bytes: 模型文件名或者ONNX、ORT格式二进制。
- sess_options: 会话选项,比如配置线程数、优先级。
- providers: 指定执行提供者优先级(['CUDAExecutionProvider','CPUExecutionProvider'])
- provider_options: 字典序列,为每个提供者配置专属参数(如CUDA设备ID)
options = onnxruntime.SessionOptions()
options.SetIntraOpNumThreads(4)
# 多设备优先级配置
session = InferenceSession(
"model.onnx",
sess_options=options,
providers=[
('CUDAExecutionProvider', {'device_id': 0}),
'CPUExecutionProvider'
]
)
模型推理
outputs = senssion.run(output_names, input_feed, run_options=None)
- output_names:输出节点名称,字符串列表,指定需要获取的输出节点名称,若为None则返回所有输出
- input_feed:输入数据,字典类型,结构为{"输入节点名": numpy数组/ORTValue},建议使用ORTValue封装输入数据以减少CPU-GPU拷贝开销。
- run_options:运行参数,如日志级别。
import numpy as np
import onnxruntime as ort
# 创建示例数据
cpu_data = np.random.rand(1, 3, 224, 224).astype(np.float32)
# 转换为GPU上的ORTValue
gpu_ort_value = ort.OrtValue.ortvalue_from_numpy(
cpu_data,
device_type='cuda', # 关键参数:指定GPU设备
device_id=0 # GPU设备ID(多卡时指定)
)
print(gpu_ort_value.device_name()) # 输出: 'Cuda'
results = session.run(
["output_name"],
{"input_name": gpu_ort_value} # 避免CPU->GPU拷贝
)
在运行模型是,需要获取模型的输入和输出名称,可以通过调用对应的函数session.get_inputs(),session.get_outputs()来获取。inputs和outputs函数返回的是onnxruntime.NodeArg类,该类是ONNX Runtime中表示计算图节点输入/输出参数的核心类,该类有3个成员变量,如下:
- property name: 参数唯一标识符,对应计算图中的节点名称。
- property shape: 张量形状。
- property type:数据类型(如tensor(float32)/tensor(int64))
以下是获取输入名称和输出名称的示例。
input_name = session.get_inputs()[0].name
output_names = [output.name for output in session.get_outputs()]
详细请参考:https://onnxruntime.ai/docs/api/python/api_summary.html
YOLOv5运行示例
加载模型
session_options = ort.SessionOptions()
session_options.intra_op_num_threads = 1
# 加载 ONNX 模型
session = ort.InferenceSession(
"yolov5_n.q.onnx",
sess_options=session_options,
providers=["XXXExecutionProvider"])
创建SessionOptions对象用于定制化会话行为,限制算子内部并行线程数为1,加载名为yolov5_n.q.onnx的量化版YOLOv5模型,指定自定义执行提供者XXXExecutionProvider。
图像预处理
image = cv2.imread(args.image)
#image shape (375, 500, 3)
image_shape = image.shape[:2]
#image_shape的值(375, 500),取前面2个值为图像的宽高
# 获取图像的尺寸大小高和宽。
input_tensor = preprocess(image)
# 图像预处理函数
def preprocess(image, input_size=(640, 640)):
# 调整图像大小为640*640,
image = cv2.resize(image, input_size)
# 转换颜色空间RGB
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 归一化处理
#astype(np.float32)将图像像素值从整数类型(如uint8)转换为32位浮点数,
#避免后续除法运算的精度损失,/ 255.0将像素值从[0,255]的原始范围线性映射到[0,1]区间,
#符合神经网络输入的典型数值范围要求
image = image.astype(np.float32) / 255.0
# 转置模型为CHW格式,原输入是HWC格式。
# 输入的数据是(640,640,3),需要调整为NCHW模型格式 [batch, channel, height, width]
# 使用np.transpose进行转置,变换成(3,640,640)
image = np.transpose(image, (2, 0, 1))
image = np.expand_dims(image, axis=0)
# 接着再加上一个轴变化成(1,3,640,640)tensor。
return image
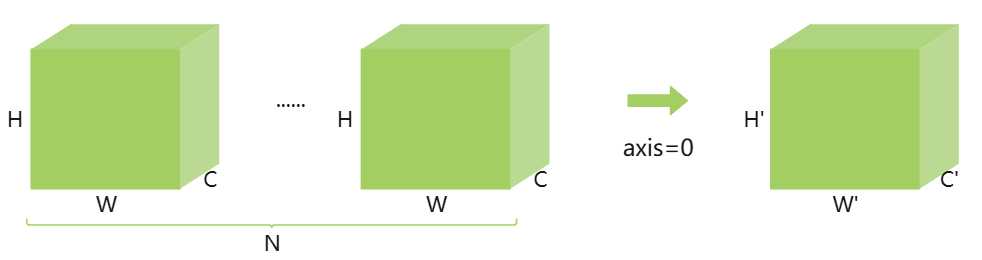
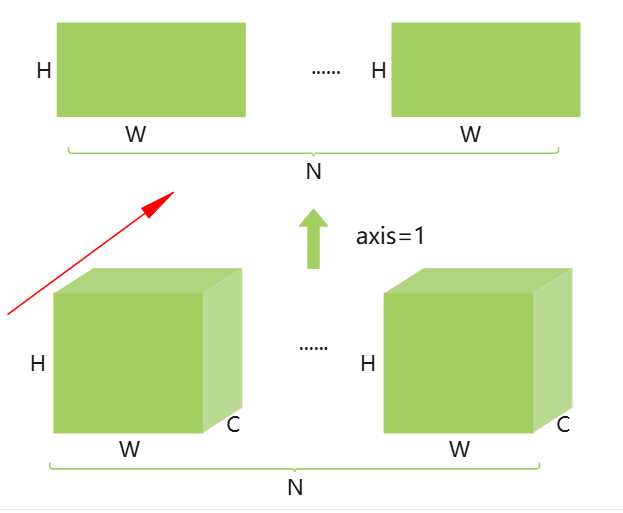
如何理解深度学习中的轴了? 在深度学习中,轴可以理解为维度。如上图是一个NCHW排布的格式,把N当成第一个维度即位轴0,C第二维度即为轴1,H第三维度即为轴2,W为第四维度即为轴3。np.expand_dims(image, axis=0)即拓展了轴0,原来只有3个维度现在变成4个维度了,N为1。还可以按照指定的轴进行求和,即做压缩。执行np.sum(data, axis=0)时,也就是沿着N的维度就行压缩求和,就变成如上图。由原来的(N,C,W,H)变成了(C',W',H'),即N个CWH中的各自相加。如果是np.sum(data,axis=1),那就是按照C维度方向进行相加,结果就是(N,W,H),即如RGB格式就是每个图像RGB 3通道的像素相加,如下图所示。
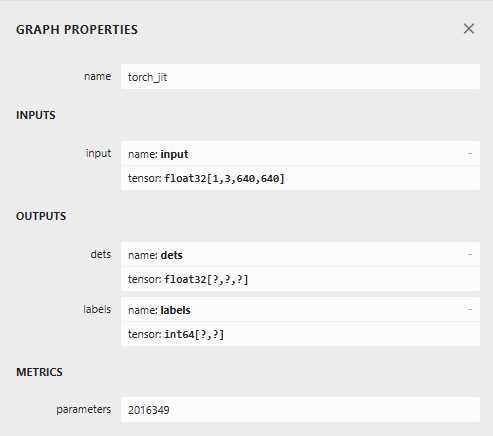
模型推理
模型推理前,需要获取计算图输入和输入的名称
input_name = session.get_inputs()[0].name
output_names = [output.name for output in session.get_outputs()]
print('input name', input_name)
print('output name', output_names)
输出结果与下图对应。
input name input
output name ['dets', 'labels']
获取到intput_name和ouput_names后,即可调用运行推理。
outputs = session.run(output_names, {input_name: input_tensor})
模型后处理
# 把batch这个维度去掉
dets = outputs[0].squeeze()
labels_pred = outputs[1].squeeze()
#将坐标进行缩放以适应实际图片的大小。
input_size = (640, 640)
scale_x = image_shape[1] / input_size[0]
scale_y = image_shape[0] / input_size[1]
dets[:, 0] *= scale_x
dets[:, 1] *= scale_y
dets[:, 2] *= scale_x
dets[:, 3] *= scale_y
模型outputs有两个输出,一个是dets,这是一个二位数组dets[n][5],其中det[5]包含了坐标x1, y1, x2, y2,score,前面4个预选框的坐标,后面一个为预选框的分数。
def visualize_results(image, dets, labels_pred, labels, conf_threshold):
for i in range(len(dets)):
det = dets[i]
score = det[4] #每个框的分数
if score > conf_threshold: #小于分数的剔除
class_id = int(labels_pred[i])
x1, y1, x2, y2 = map(int, det[:4])
label = labels[class_id]
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(image, f'{label}: {score:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
return image
根据阈值分数进行画框,最终完成结果的后处理,注意上面并没有进行极大值抑制。