文件系统常见系统调用
- 文件系统
- 2023-05-27
- 166热度
- 0评论
上一章节中,我们编写了没有带磁盘设备的文件系统,了解了文件系统操作的大致流程,本章节我们继续在上一章节的基础上完善文件系统,并梳理从用户空间到内核空间大致的调用流程。实验的代码我们使用开源的示例https://github.com/sysprog21/simplefs/tree/master,在启动本章节之前建议先搭建好试验环境,将simplefs挂载起来,当然有余力的也可以在上一节示例代码的基础上借鉴开源的示例补全。
mount

挂载文件系统有两个关键点
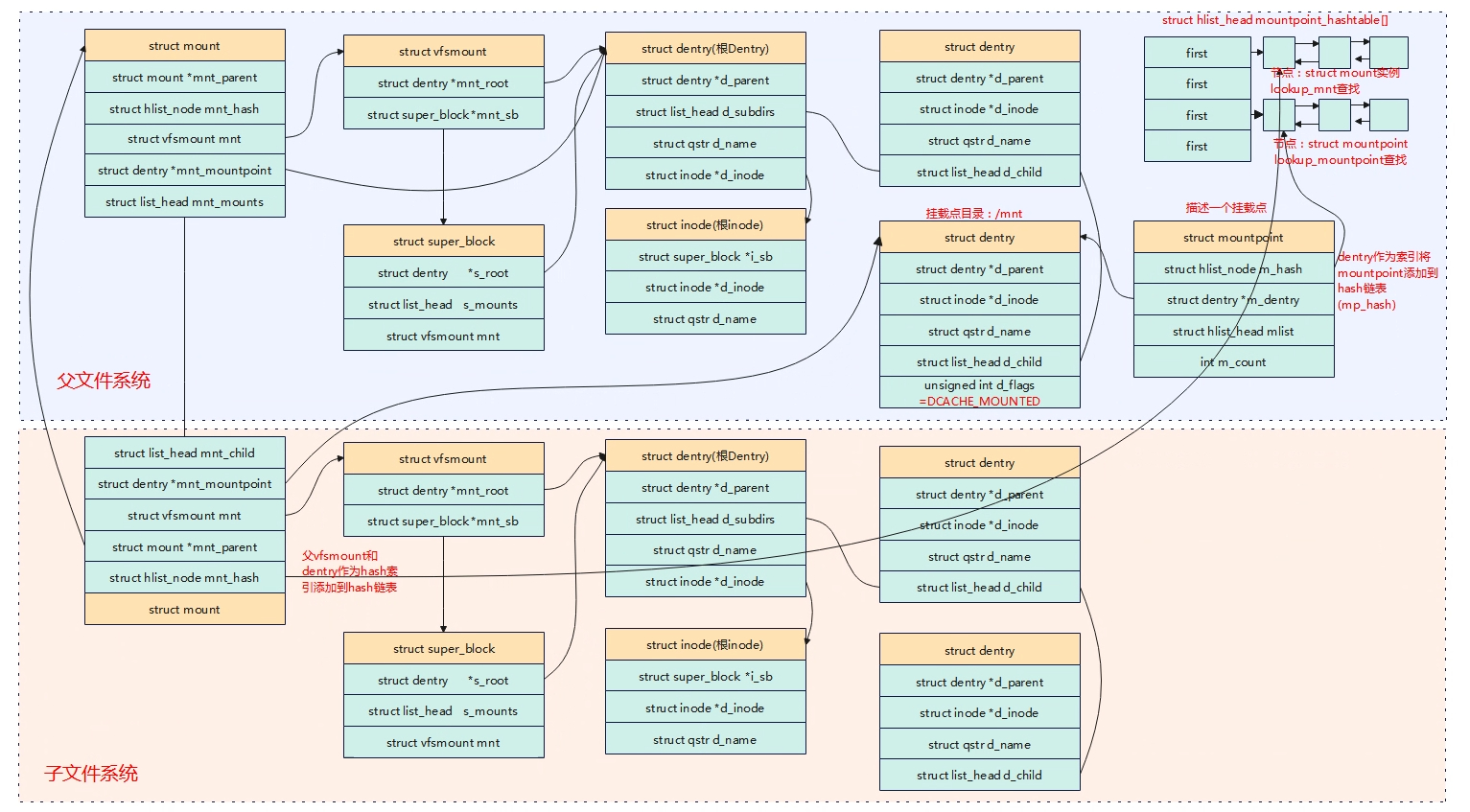
- 创建一个VFS struct super_block的实例,并从磁盘中读取磁盘super_block信息填充,同时分配一个根inode从磁盘中读取信息填充,并创建根inode对应的根dentry。
- 创建一个struct mount实例(包含了struct vfsmount)以及挂载点struct mountpoint实例,并添加到全局文件系统的hash表中,建立起文件系统树的联系。
下面是第一个关键点的流程和数据结构直接的关系。

mount_bdev主要做了3件事情,第一调用blkdev_get_by_path根据/dev/xxx名字找到相应的设备并打开它,第二调用sget根据打开的设备,查询是否有对应磁盘的supper_block,如果没有就分配一个。第三调用fill_super回调函数填充super_block。文件系统建立起来之后,对文件的读写就通过文件系统来进行。
以下是第二个关键点数据结构实例直接的联系
跨文件系统路径解析
path_lookupat
link_path_walk
walk_component
step_into
handle_mounts
traverse_mounts
__traverse_mounts(struct path *path, ......)
{
while (flags & DCACHE_MANAGED_DENTRY) {
......
if (flags & DCACHE_MOUNTED) { // 目录是挂载点?
struct vfsmount *mounted = lookup_mnt(path); //获取vfsmount
if (mounted) { // ... in our namespace
dput(path->dentry);
if (need_mntput)
mntput(path->mnt);
path->mnt = mounted; //填充新的vfsmount
path->dentry = dget(mounted->mnt_root);//新文件系统的根目录
// here we know it's positive
flags = path->dentry->d_flags;
need_mntput = true;
continue;
}
}
......
}
}
- 文件系统挂载后创建super_block、mount、mountpoint、根inode、根dentry对象。
- 一个目录可以被多个文件系统挂载,新挂载的文件系统会导致之前的挂载被隐藏。
- 一个目录被文件系统挂载后,原来目录的其他子目录和文件会被隐藏。
- 每次挂载都会有一个mount实例描述本次挂载。
open
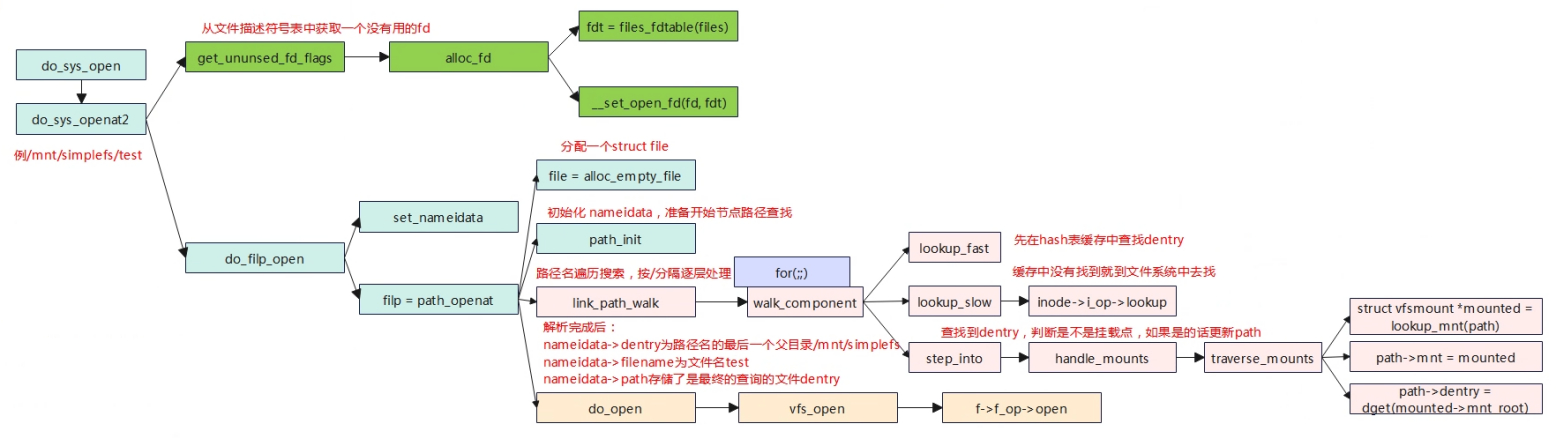
先调用get_ununsed_fd_flags获取一个空闲的fd。
调用link_path_walk对路径名进行查找,里面是个循环会使用”/”分隔逐层处理,如果依次解析发现子目录是新的文件系统(相当于从A文件系统跨到B文件系统)则进行更新path,path中存储了vfsmount和dentry。文件/mnt/simplefs/test,link_path_walk会解析前面得路径部分/mnt/simplefs,解析完毕得时候nameidata的dentry为路径名的最后一部分的父目录/mnt/simplefs,而nameidata->filename为路径名的最后一部分”test”。再查找文件路径最后一部分对应的dentry,linux为了提高目录项目对象的处理效率,实现了一个目录项的高速换成dentry cache,查询的时候先从缓存中查找,调用的是lookup_fast,如果缓存没有找到就调用到对应的文件系统中去照,对应的是上一级目录inode的inode_operations->lookup函数,最终将找到后的新生成的dentry赋值到path中。
最后调用do_open下陷到f->f_op->open调用到具体的文件系统中,在vfs_open中也会将文件相关的信息填充到struct file中,如f->f_inode,f->f_mapping等。
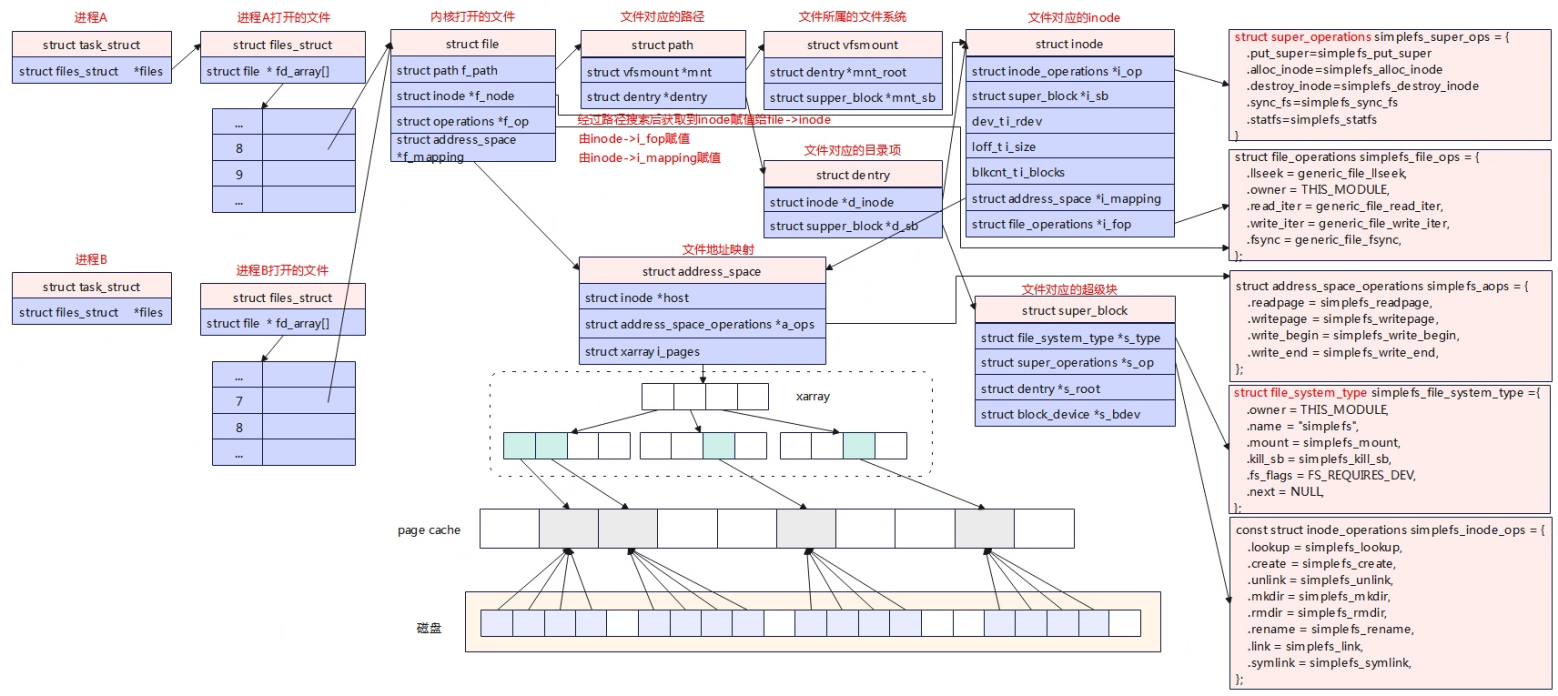
write

用户空间write通过系统调用进入到内核层vfs_write,在vfs_write中判断是struct file_operations填充的是write还是write_iter,这里选择的是write_iter,在simplefs文件系统中write_iter注册的是通用写generic_file_write_iter,在这个函数中会根据标志IOCB_DIRECT判断写如是否要经过缓存。
缓存是内存中的一块内存,Linux为了进一步改进性能,默认情况下不会直接操作硬盘,而是读写都在内存中,待一定时机后在一并批量写入磁盘,以提高读写效率。根据是否使用内存作为缓存,可以把文件的I/O操作分为缓存I/O和直接I/O,直接I/O的方式是不经过缓存。
默认情况为了提高写效率都会调用generic_perform_write使用缓存I/O的方式写入,在generic_perform_write中分为四个步骤:
- 调用具体文件系统注册的write_begin,在该函数中,如果是日志式的文件系统会先记录相关日志,这里的simplefs文件系统不带日志系统。另外重要的事情就是获取page页,在struct file中有一个成员struct address_space,struct address_space->i_pages是一个xarray树,磁盘的内容映射到这颗树上。在准备写入数据时,会从树中查询是否有对应个page,如果有则获取到该page,如果没有则重新分配一个page,添加到树上。
- 获得page后,调用copy_page_from_iter_atomic将用户空间数据写到page中。
- 数据写到page后,将对用的page设置为脏页,脏页的数据是需要定期同步到磁盘的。
- 最后在balance_dirty_pages_ratelimited会检查是否要进行缓存数据的刷写,可以看出在每次写缓存时,都会调用该函数来检查一下页缓存的总容量,如果超过设定的阈值就会立即触发wb_workfn进行写入到磁盘。平时用的sync也是,将缓存与磁盘进行同步。
论O_DIRECT和O_SYNC?

read

大体流程跟write的类似,我们重点看唤醒I/O读的方式,通过filemap_get_pages获取page,如果没有找到不但读取一页,还有进行预读,调用page_cache_sync_readahead函数发起预读操作,这次预读的操作应该是在原来的page缓存基础上发起预读补充,预读后再进行判断是否找到要读数据对应的page,如果还是没有则直接分配一个page添加到树上,然后从磁盘中读取数据填充,接着判断一下page的数据是否填满需要预读,如果需要则发起一次异步预读操作。最后找到要读数据对应的page后,调用copy_page_to_iter将数据拷贝到用户空间。