自注意力机制
- Ai
- 2025-06-13
- 108热度
- 0评论
运作原理
自注意力机制要解决的是让机器根据输入序列能根据上下文来理解。举个例子,输入句子为"我有一个苹果手机",对于机器来说这里的"苹果"应该是指水果还是手机品牌了?所以要解决这个问题,就需要在上下文中去理解,那怎么在上下文中去理解了?那就是由句子中的其他词对于施加权重,让"苹果"更靠近"手机"。具体怎么做了?来看看下面的图。
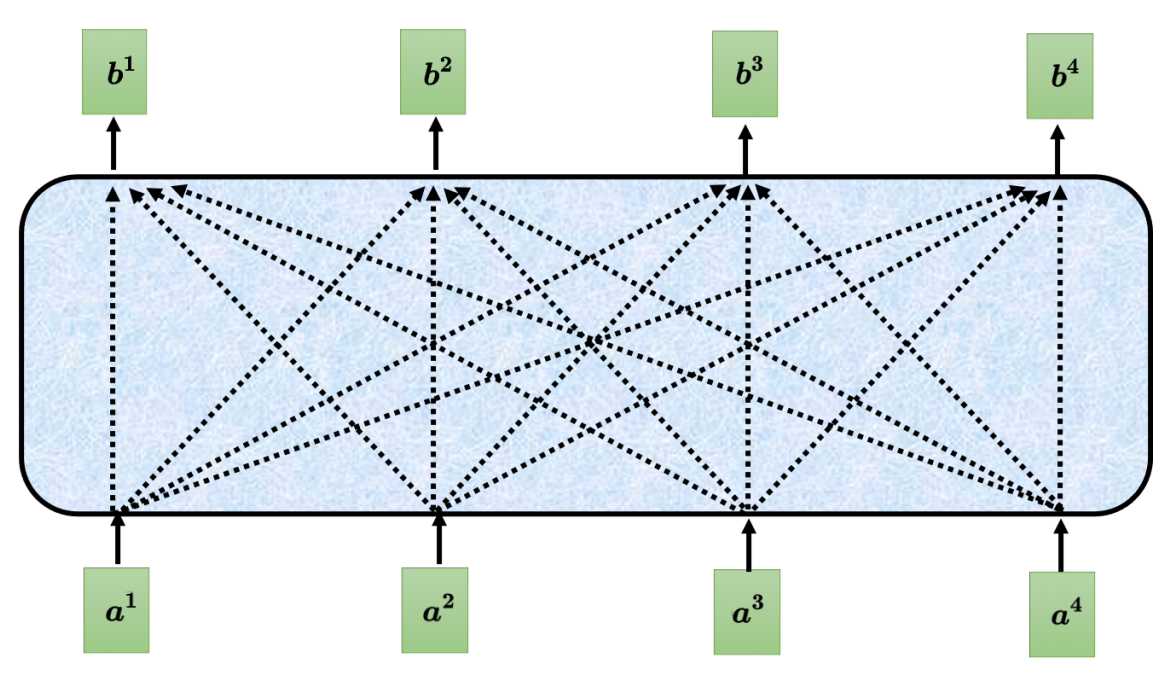
上图中的a1~a4是输入的词,每个输入的词都需要跟句子中的其他词做运算得到一个输出b1~b4。如a1要得到b1,那么a1需要与a2、a3、a4输入的词进行相关运算得到b1,同理其他a2、a3、a4对应输出b2、b3、b4。注意这里a1到b1的输出并不是a1与其他a2~a4的简单相乘或相加,那具体是怎么个相关运算了?
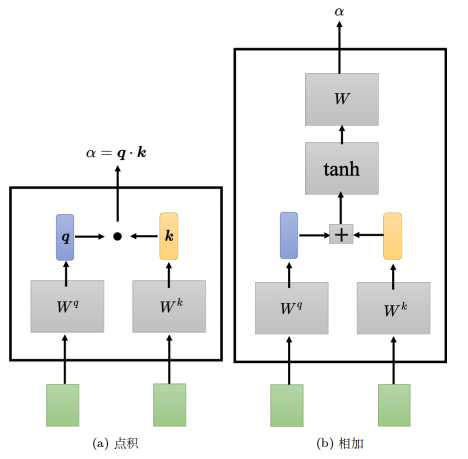
计算向量关联程度的方法有点积和相加,目前比较常用的是点积。下面以点积来进行说明。在自注意力模型中,采样查询-键-值(Query-Key-Value)的模式。主要分为3个步骤,分别是计算QK内积、再计算V向量、最后加权得到b。
QK内积
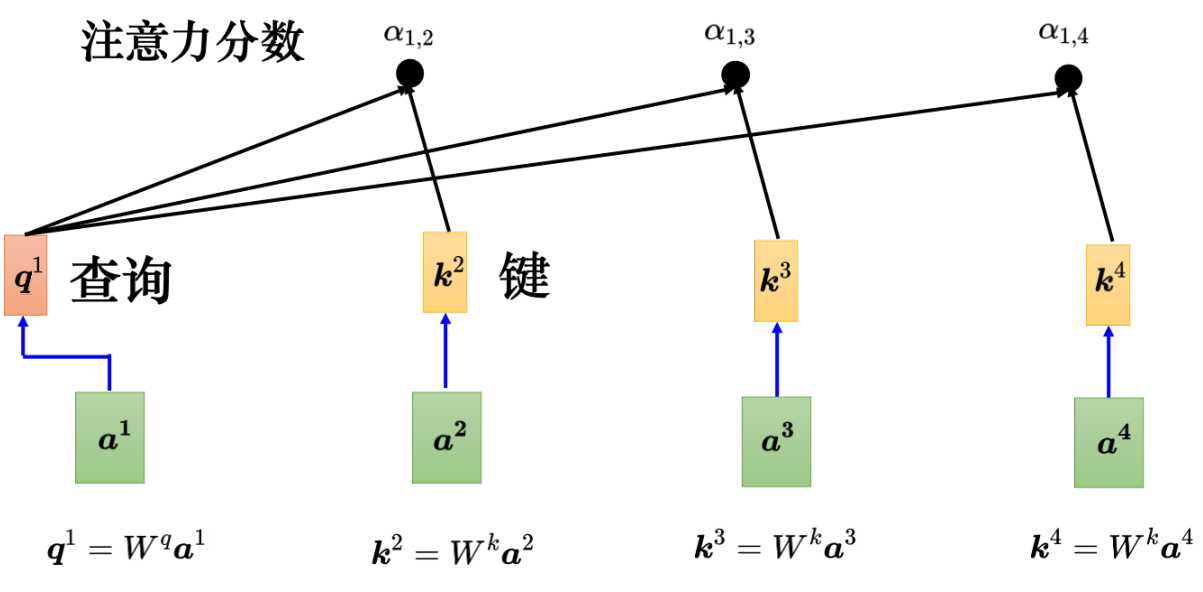
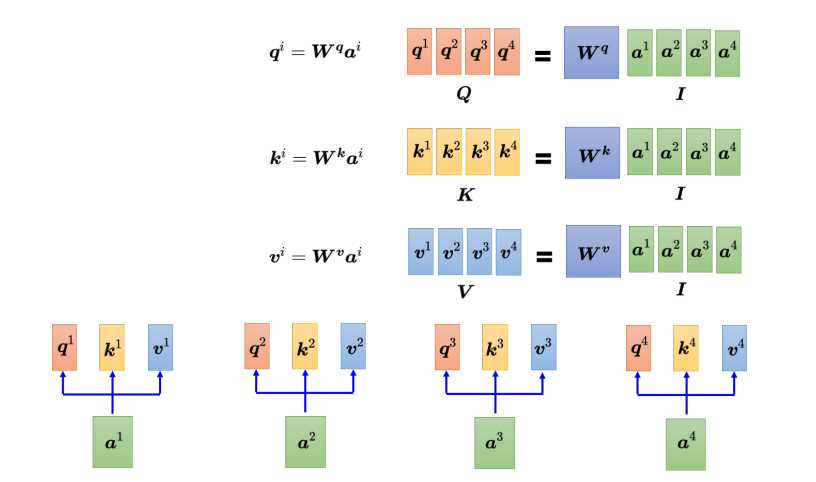
- q: q称为查询,就是使用搜索引擎查找相关文章的关键字。q的计算方式为输入乘上Wq矩阵得到,如把a1乘上Wq得到q1。
- k: k称为键值,输入乘上Wk得到向量k。如a2,a3,a4乘以Wk得到k2,k3,k4。
- qk:把q和k做点积就得到a12,a13,a14,即表征a1与a2,a3,a4之间的关联性了。
通常情况下,得到最终的qk内积结果(记为axx)会进行一次归一化处理得到a',可以使用softmax也可以使用别的激活函数,如下图所示。
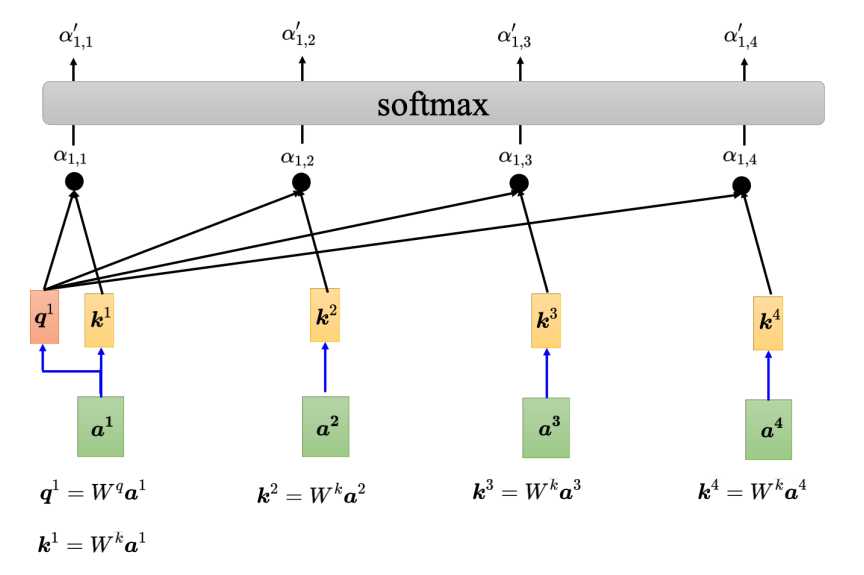
最终处理的结果a'表示的是输入a1与其他a2~a4存在的关联性分数,也称为注意力分数,也可以说是一个权重值,上下文中其他的词对a1最终词的解释权重。
V向量
qk内积计算了注意力分数,那接下来需要根据注意力的分数提取出信息得到最终的b。那么要进行提取,那必然需要先获取到其他词的特征信息,怎么获取了,获取的方式非常简单,就是让各自输入乘以Wv矩阵得到一个向量V。比如a1乘以Wv得到V1,a2乘以Wv得到V2。
加权和b
得到了各自的注意力分数qk,也获取到了各自输入的特征信息,最后就可以计算最终的输出b了。公式为: b^1 = \sum_{i} \alpha_{1,i}' v^i 。就是特征信息V和注意力分数进行相乘,然后把所有结果加起来。
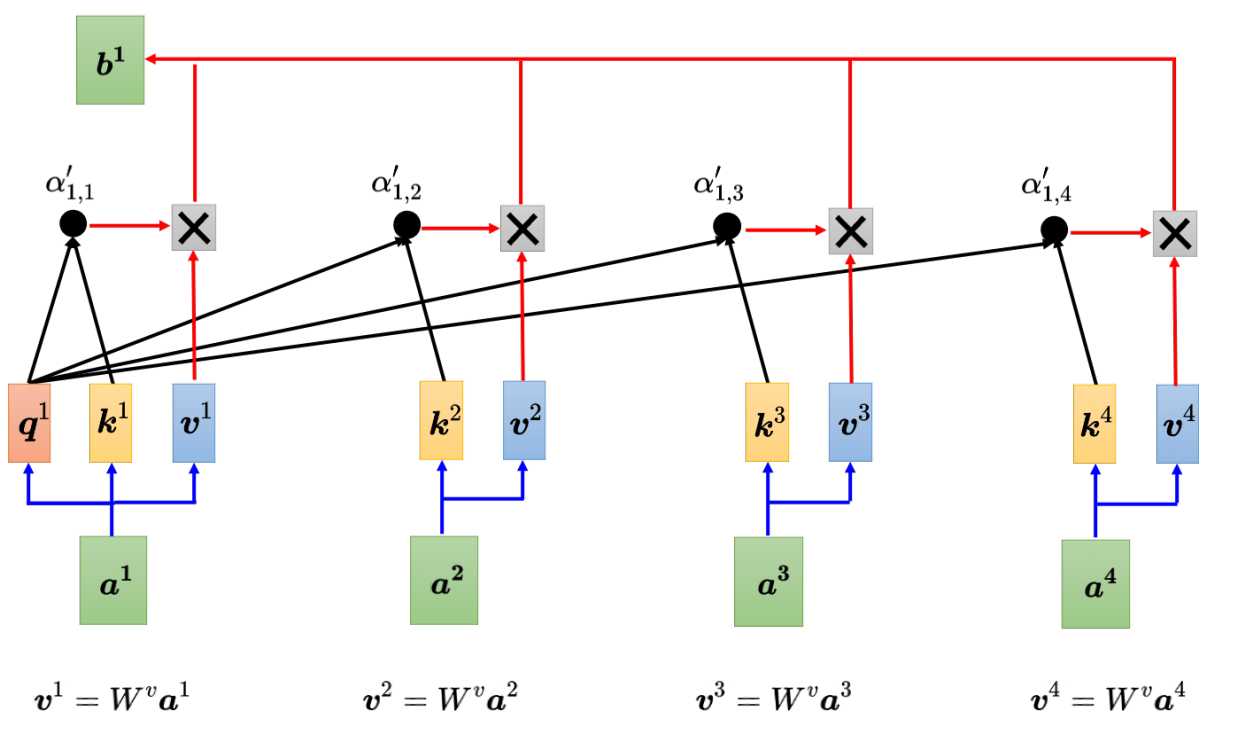
如果a1和a2的关联性很强,那么a12'的值就大,跟V2相乘值对应也就大,这样b1的值就可能比较接近V2。所以谁的注意力分数越大,谁的V就会主导抽出的结果。
小结
上面通过以a1进行相关运算后输出b1过程,a2、a3、a4计算过程同理,同时输入的各自计算是并行的,不需要各自依赖,这也是与RNN的本质区别。同时计算过程中出现的Wq、Wk、Wv都是要学习的参数。而在实际过程中,并行运算都是通过矩阵的方式进行的,这里就不再过多阐述了。
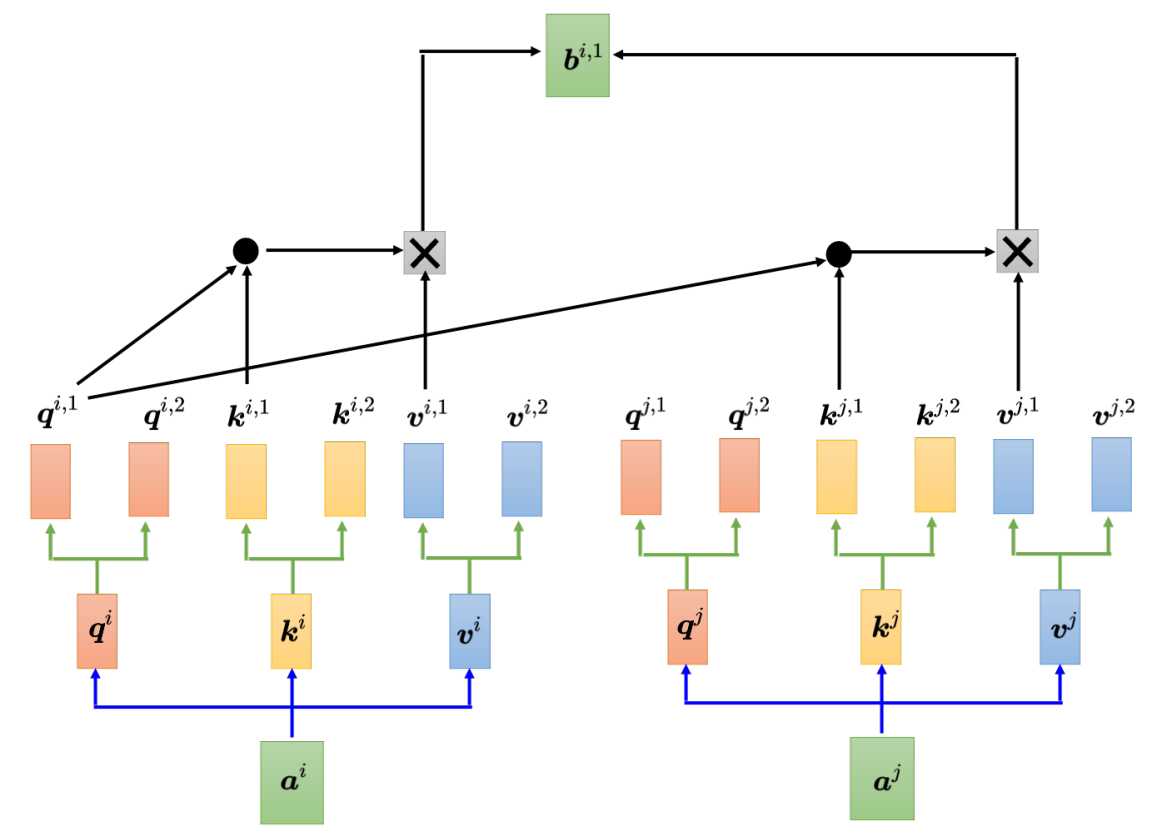
多头注意力,所谓多头注意力,就是对应的qk有多个,也就是说W参数也有多个。
位置编码,在计算QKV的时候,引入位置编码,让输入的位置也占一定的权重。

参考书籍:《深度学习详解》