transformer
- Ai
- 2025-06-13
- 139热度
- 0评论
模型结构
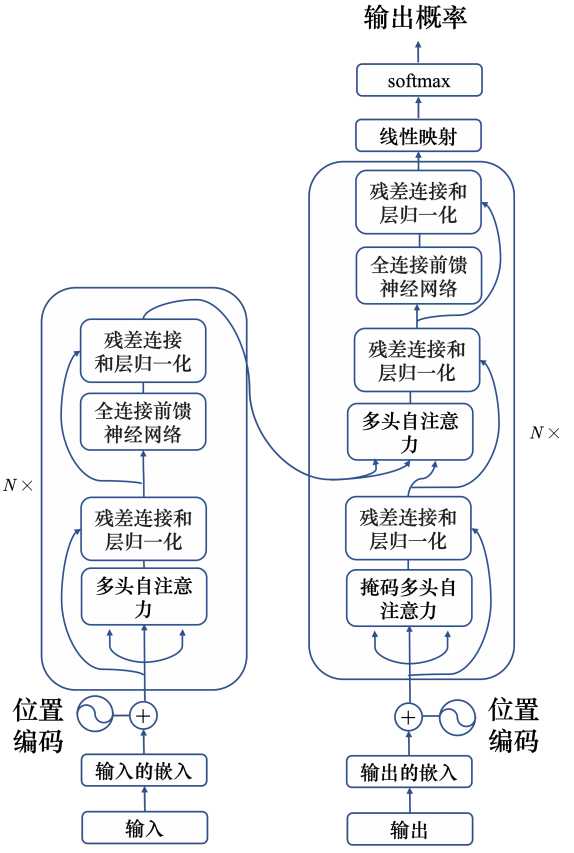
transform使用了自注意力机制,由编码器和解码器组成。
编码器
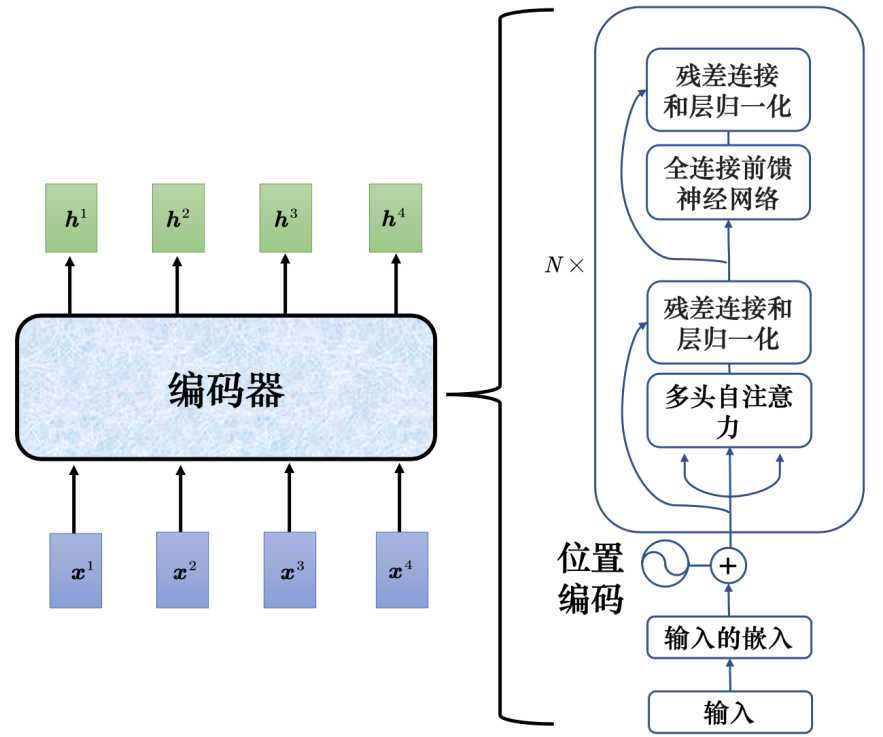
transformer的编码器输入一排向量,输出另外一排同样长度的向量。transformer的编码中加入了残差连接和层归一化,其中N X表示重复N此。首先在输入的地方需要加上位置编码,经过自注意力处理后,再嘉盛残差连接和层归一化。接下来经过全连接的前馈神经网络,再做一次残差连接和层归一化,这就是一个完整的块输出,而这个块重复N此。
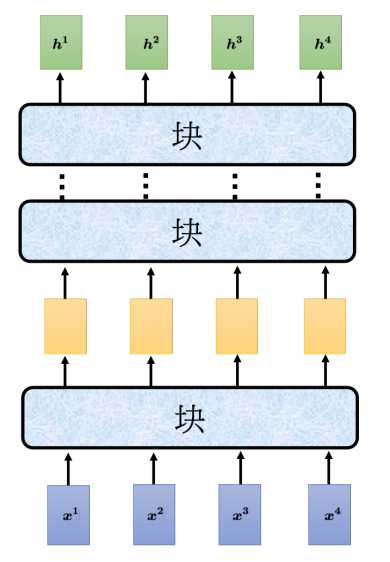
上图中的块就是前面说的多头注意力+残差连接和层归一化+全连接前馈神经网络等组成。编码器可以理解为就是对输入进行编码处理。
解码器
解码器分为自回归解码和非自回归解码。
自回归解码(Autoregressive,AT)
以语言识别为例,输入一段声音,输出一串文字。
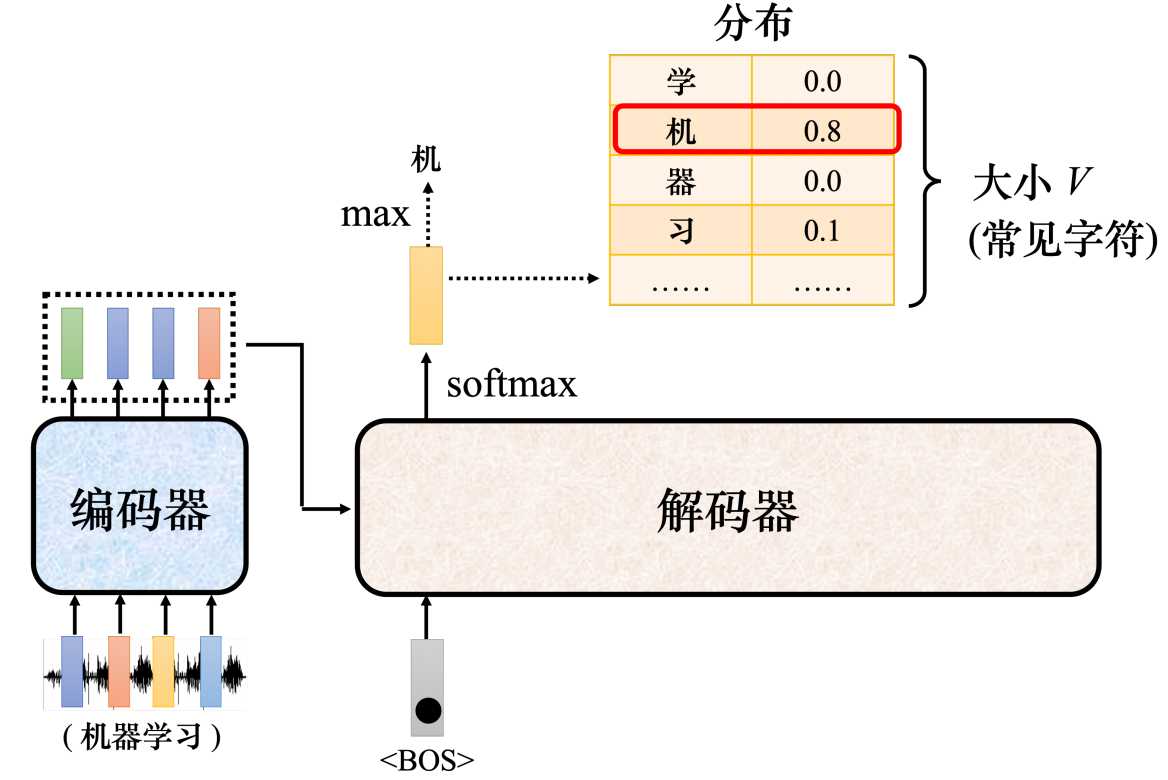
- 首先,将一段"机器学习"的音频输入给编码器,编码器会输出一排向量。然后将这一排向量送入到编码器中。
- 其次,解码器输入一个代表开始的特殊符号BOS(Begin of Sequence),这是一个特殊的词元(token),代表开始。编码器读入BOS后,就会输出一个向量。这个向量代表了词表中每个词的概率,跟分类一样,经过了softmax操作,总和为1。向量的长度和词表一样大,每个中文一对应一个分值。
- 接着,在向量中挑选分数最高的作为解码器的第一个输出。这里应该就是"机"。
- 最后,把编码器的输出"机"当成解码器新的输入,输入为特殊符号"BOS"和"机",解码器同样输出一个向量,这个向量里面给出了每一个中文字的分数,这里应该是"器"分数最高,这个过程反复持续下去。
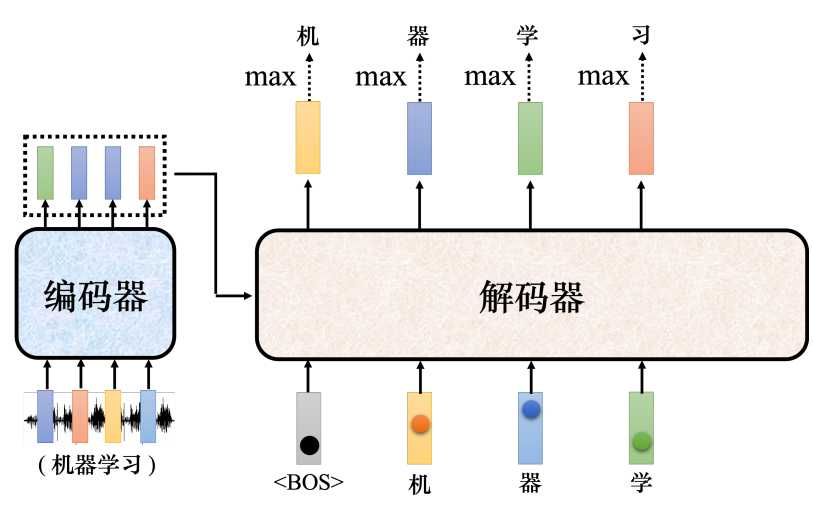
上面的运作过程中,解码器把上次的输出当做输入反复下去,那么如何让解码器停止了?要让解码器停止,也需要准备一个特别的结束符号"EOS",当产生完"习"之后,再把"习"当做编码器输入以后,解码器要能够输出"EOS",这个EOS的概率必须最大,输出了EOS,整个解码产生的序列就结束了。
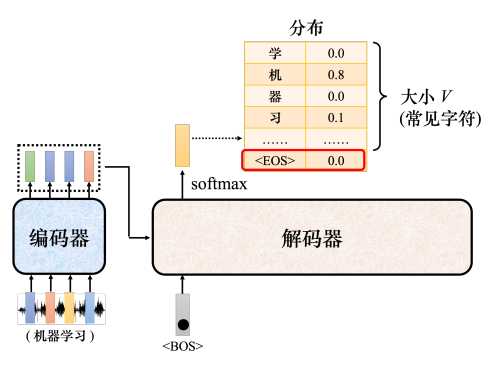
总结一下,自回归模型就是,解码器先读入编码的输入,然后输入BOS,输出W1,再把W1当做输入,再输出W2,直到输出EOS为止。
非回归解码(NAT)
自回归编码是根据上次解码器的输入一个字一个字的输出,假设要输入长度一百个字的句子,就需要做一百次的解码。那能不能一次性全部输出了?这就是非自回归解码器,假设产生的是中文的句子,非自回归不是一次产生一个字,而是一次把整个具体都产生出来。那要怎么做了,有两个做法。
- 方法1:用分类器来解决,将编码器的的输出结果先给分类器,分类器得到一个数字,这个数字达标的是解码器要输出的长度,比如输入是5,非自回归的解码器就是吃5个BOS,这样就产生了5个中文的子。
- 方法2:给编码器一堆的BOS词元,因为输出的句子有上限,假设不超过300个字,那就输入300个BOS,解码器就输出300个字,输出句子中EOS右边的输出就裁掉。
简单来说,非自回归解码是一次性输出句子,与自回归解码不同的是,非字回归解码输入的全是BOS,而自回归解码输入的是上一轮的输出。

transform的训练
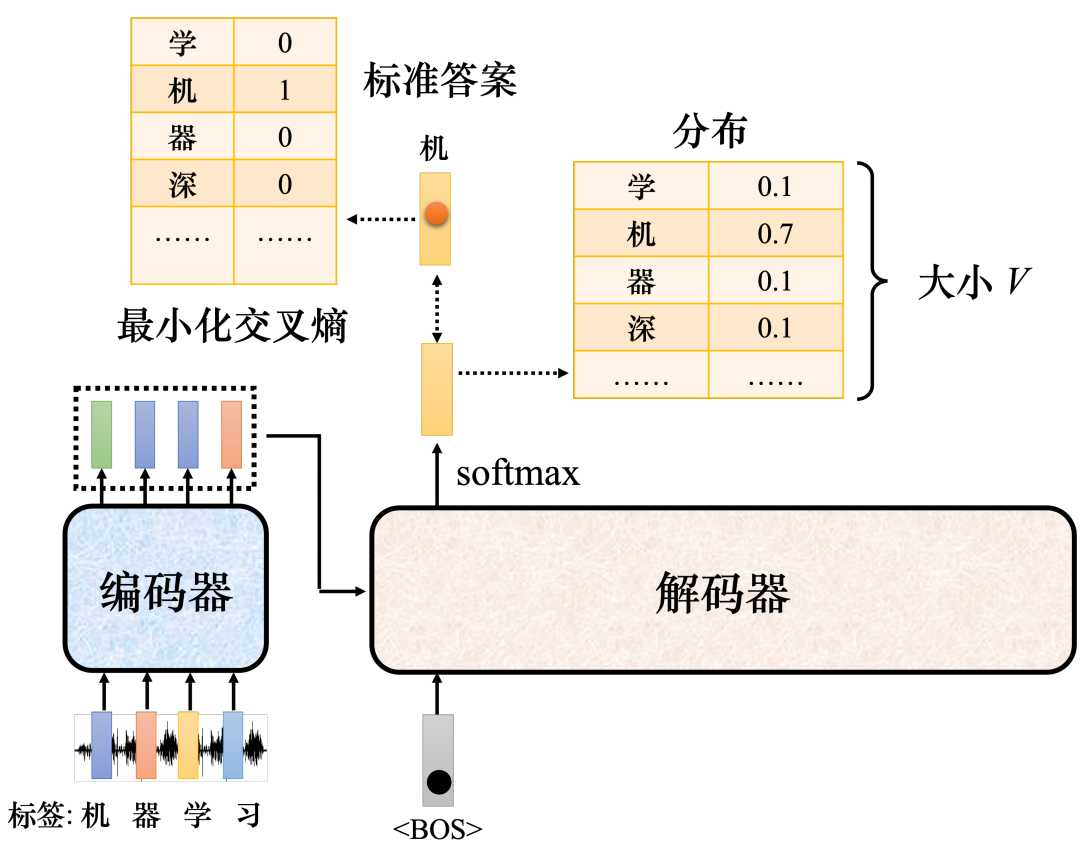
既然要训练,就要去衡量误差,这个误差怎么衡量了? 解码器的输出一个是概率分布,以输出的"机"为例,当输入"BOS"的时候,输出的答案应该要跟"机"这个向量越接近越好。
参考书籍:《深度学习详解》