YOLOv2和YOLOv3
- Ai
- 2025-06-04
- 218热度
- 0评论
YOLOv2
回顾一下YOLOv1有哪些缺陷?
- 边界框训练时回归不稳定,导致定位误差大。
- 每个网格只能预测两个边界框且只能识别一类目标。
- 小目标检测效果差。
针对以上的问题,YOLOv2进行了改进,下面从检测机制优化、网络结构优化、训练策略优化3个维度进行。
检测机制优化
锚框(Anchor Box)机制
YOLOv1每个网格只会预测一个目标,因为每个网格预测的B个边界框的类别概率都是共享的,要是有多2个目标的中心都落在了一个网格中,那么有一个目标就没法预测了。怎么解决了? 让每个边界框都对应一个类别概率,这样就能做到每个网格可以预测多个目标了。
每个边界框训练是没有基准的,这样训练的时候就很不稳定。如果预先定义边界框,使训练的时候按照这些预定义的边界框作为基准进行训练调整。这里做个类比来理解,假设我们的目标坐标是(8,8),那么如果没有设置基准,从坐标(0,0)找到(8,8)就相对比较远,那假设我们从(6,6)这个基准开始找,那找到(8,8)的概率就大了。
上面预先定义的边界框就称为先验框(anchor Box),那么新的问题来了,这个anchor Box我们每个网格设置多少个?设置什么样的形状了?实际的数据集中Ground Truth(真实标签)边界框有些是长方形、有些是正方形。
YOLOv2使用了K均值聚类算法用于生成先验框(Anchor Boxes),其核心目标是从训练数据中自动学习边界框的尺寸和比例,替代人工预设的锚框,从而提升检测召回率与定位精度。YOLOv2通过聚类COCO数据集,得到5个先验框尺寸(如(0.25,0.33), (0.5,0.75)...),覆盖常见物体形状。
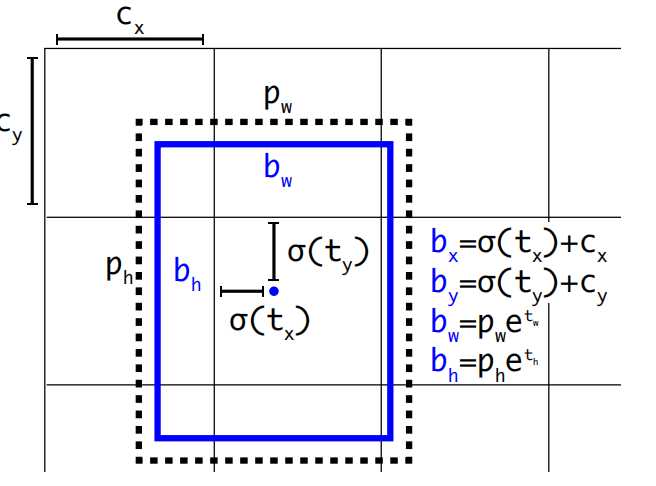
pw,ph是先验框anchor的宽高(根据K类均值聚类得来),tx,ty,tw,th模型预测的偏移量(训练得到)。所以通过pw,ph,tx,ty,tw,th就可以计算出实际要预测的框bx,by,bw,bh。模型最终预测出tx,ty,tw,th这四个值就可以计算出bx,by,bw,bh。
这里需要注意
- YOLOv2中对tx,ty进行了sigmod归一化,防止训练初期,中心点数值极大训练不稳定。
- YOLOv2预测边界框的宽和高初始值是基于先验框而来,是模型对每个锚框输出宽高缩放因子(t_w, t_h),通过聚类生成的先验框指数变换得到最终宽高。而YOLOv1是根据图像实际宽高缩放而来。
全卷积网络与先验框
YOLOv1最后阶段使用的是全连接层,使用全连接层不仅仅参数量大,同时会将先前的特征图包含的空间信息破坏,在YOLOv2中改成了全卷积结构。
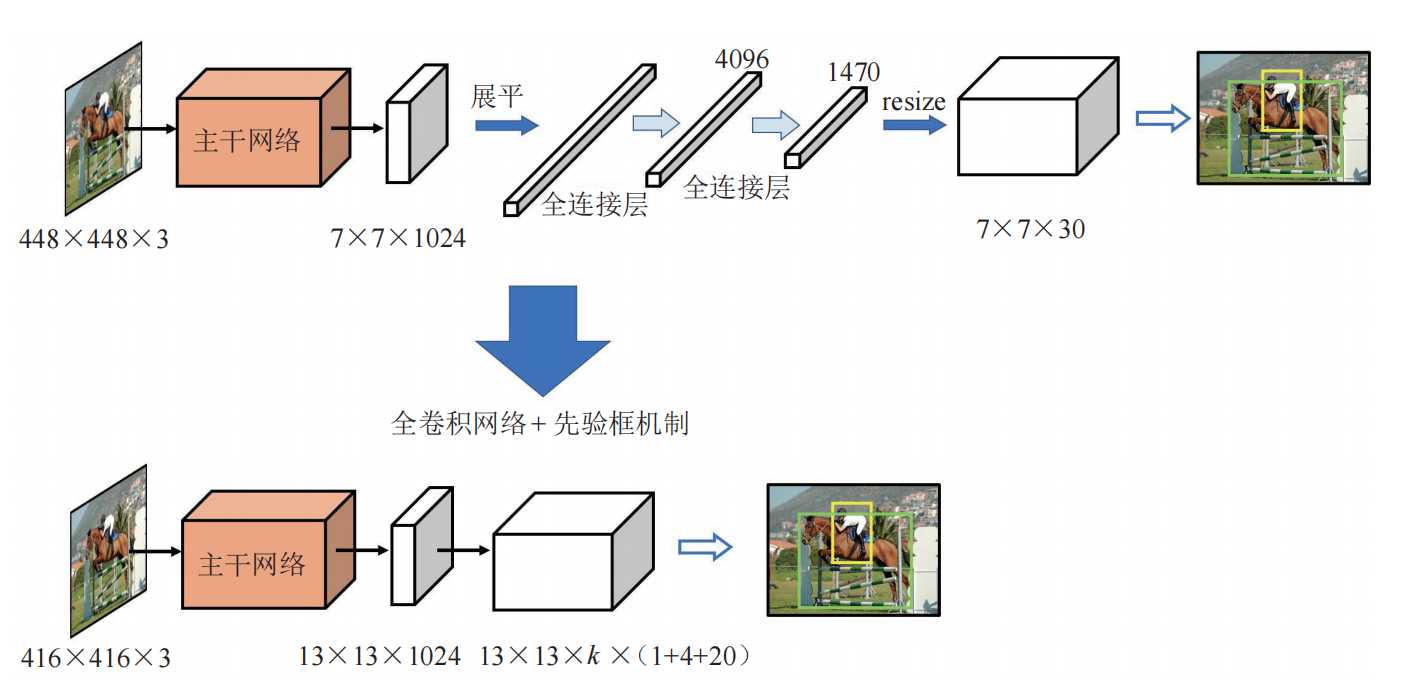
可以看到输出也发生了变化YOLOv1的输出是7 x 7 x (1+4+1+4+20),而YOLOv2输出是13 x 13 x k x (1 + 4 + 20),这里的k是每个网格的先验框数量,一般为5。(1+4+20)分别是锚框的置信度、边界框坐标、类别概率,每个anchor先验框都对应一个(1+4+20),也就是说每个先验框可以检测一个目标,这样就解决了YOLOv1中每个网格只能检测一个目标的问题,YOLOv2中每个网格有5个先验框,就可以检测最多5个类别。
网络结构优化

- 加入批量归一化: YOLOv1中每层卷积都是由线性卷积+非线性激活函数组成,由于批量归一化得到越来越普遍的应用,并且效果较好,因此在YOLOv2每层卷积层都加入了批量归一化。所以卷积层就变成了线性卷积+归一化+非线性激活函数组成。
- 融合高分辨率特征图:YOLOv1输出的特征图是13 x 13 x 1024,分辨率越低丢失的特征就越多。为了解决这个问题,YOLOv2在第17层单独抽出一层26 x 26 x 512的特征图,然后通过特殊的降采样得到13 x 13 x 256的特征图,最后将这个13 x 13 x 256的特征图与前面13 x 13 x 1024的相加,这样达到提高特征信息保留。
多尺度训练

YOLOv2在训练上也做了进一步的优化,因为同一张图像,缩放到不同尺寸,不同尺寸包含的图像信息也不同。因此为了提高精度,引入了多尺度训练训练机制。
具体就是在训练网络时,对图像按照320、352、384、416、448、480、512、544、576、608等不同输入尺寸进行训练。
总结一下,YOLOv2针对YOLOv1的改进点有以下。
- 增加先验框机制:每个网格使用K类均值聚类预设K个先验框作为基准训练。每个先验框负责预测一个目标。
- 加入批量归一化:每个卷积层对训练数据做批量归一化处理。
- 高分辨率特征图:网格划分13 x 13,主干网络中抽离一路高分辨率特征图进行特殊处理然后再加回去。
- 对尺度训练:训练阶段使用不同尺度的图像数据进行训练。
YOLOv3

对应目标检测网络可以由主干网络、颈部网络、检测头。
- 主干网络:提取多尺度特征。通过卷积层、池化层等操作,将输入图像逐层抽象化,生成不同层级的特征图。有浅层特征和深层特征。浅层特征是保留细节(如边缘、纹理),适合小目标检测;深层特征是蕴含语义信息(如物体整体结构),适合大目标识别。
- 颈部网络:融合与优化特征。连接主干网络与检测头,整合不同层级的特征图,增强模型对不同尺度目标的感知能力。
- 检测头:执行具体检测任务。基于融合后的特征,输出目标的位置、类别及置信度。
YOLOv2对于小目标的检测还是不够精确,这一缺陷的主要原因是YOLOv2只使用了32倍的降采样率。
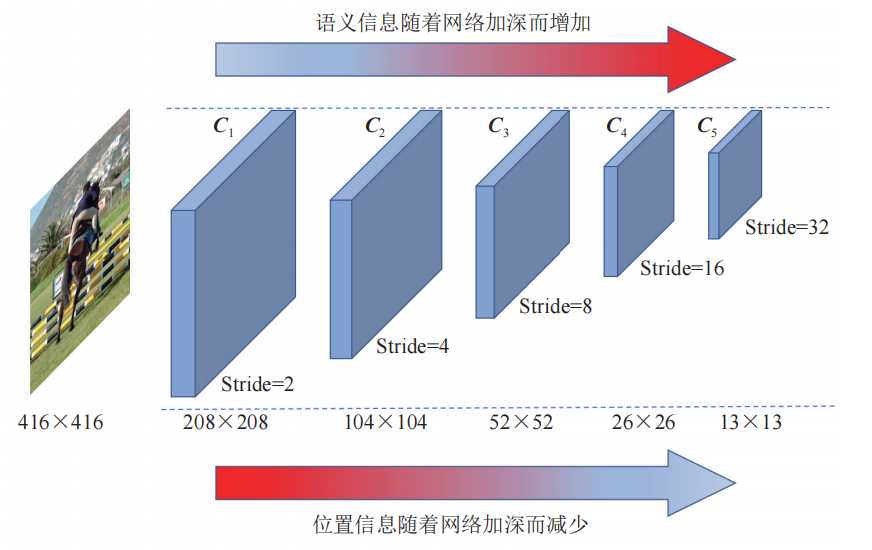
- 浅层卷积层:没有经过更多的卷积层处理,提出的语义信息较少,具有较浅的语义信息;但对应没有过多的降采样因此具备较多的位置信息。
- 深层卷积层:经过更多的卷积层处理,提取更多的语义信息;但是位置信息经过了太多的降采样,丢失了位置信息。
语义信息可以理解为是什么类别的物品,位置信息是这个物品在图中的什么坐标位置。浅层卷积层更适合检测小目标(语义信息不需要这么多),深层卷积层适合检测大目标(需要更多的语义信息)。根据这个认知,YOLOv3主干网络就使用了3个不同尺寸的特征图,分布对应的降采样是32、16、8倍。对于小尺度目标使用的是8倍将采样并在浅层网络进行先提出输出针对性处理。而大尺度目标使用32倍降采样在最深层的网络中进行输出。
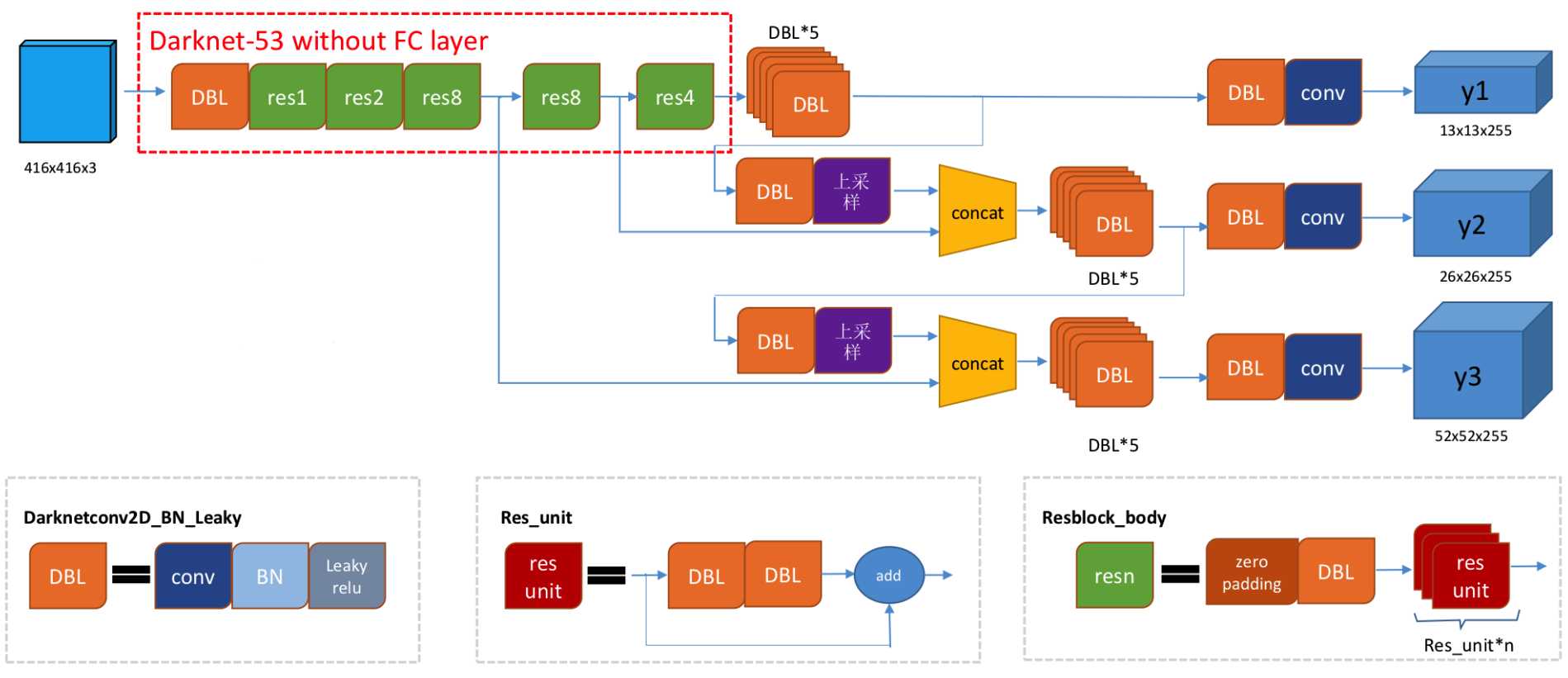
输入是416 x 416的图像,输出的是3个特征图,分布是C1=B X 256 X 52 X 52;C2=B x 512 x 26 x 26;C3=B x 1024 x 13 x 13,这里的B是先验框,一般为3。针对输入图像做了52x52、26x26、13x13三种不同疏密度的网格。
3个特征图根据多级检测结构推理后,得到最终预测的3个结果。y1= B x (4 + 1 + Nc) x 13 x 13;y2= B x (4 + 1 + Nc) x26 x 26;y3= B x (4 + 1 + Nc) x 52 x 52; 其中B为先验框数量,一般是3。Nc是类别个数,根据实际数据集,YOLOv3使用的是COCO数据集,有80个类别。
参考:
- 书籍《YOLO目标检测》