YOLOv1目标检测原理
- 深度学习
- 2025-06-03
- 254热度
- 0评论
介绍
YOLO在目标视觉检测应用广泛,You Only Look Once的简称。作者期望YOLO能像人一样只需要看一眼就能够立即识别其中的物体、位置及交互关系。能够达到快速、实时检测的效果。
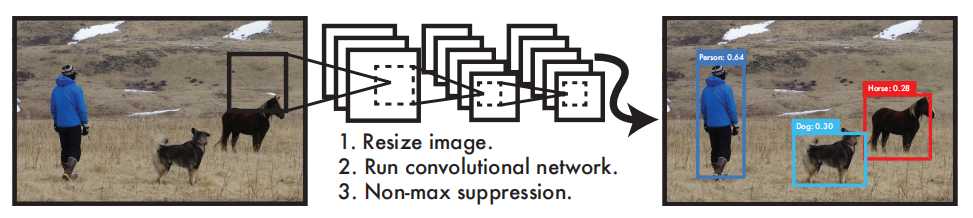
YOLO检测系统可以简要分为3个步骤:
- Resize image:调整输入图像的大小为448 x 448。
- Run Convolutional network:CNN卷积网络处理。
- Non-max suppression:使用非极大值抑制。
YOLO与其他目标检测系统有什么不同或优势?
YOLO 非常简单,如上图。单个卷积网络可以同时预测多个边界框及其类别概率。YOLO 使用完整图像进行训练,并直接优化检测性能。与传统的目标检测方法相比,这种统一的模型具有诸多优势。
首先,YOLO速度极快。由于YOLO将检测视为一个回归问题,因此无需复杂的流程。只需在测试时对一张新图像运行神经网络即可预测检测结果。
其次,YOLO在进行预测时会全局推理图像。与滑动窗口和基于区域提议的技术不同,YOLO在训练和测试期间会查看整幅图像,因此它隐式地编码了关于类别及其外观的上下文信息。Fast R-CNN 是一种领先的检测方法,由于无法看到更大的背景,它会将图像中的背景块误认为是物体。与 Fast R-CNN相比,YOLO 的背景错误率不到一半。
最后,YOLO学习的是可泛化的对象表征。在使用自然图像进行训练并在艺术作品上进行测试时,YOLO 的表现远超DPM和R-CNN 等领先的检测方法。由于 YOLO 具有高度的泛化能力,因此在应用于新领域或意外输入时,它不太可能崩溃。
更为详细的结构如下:
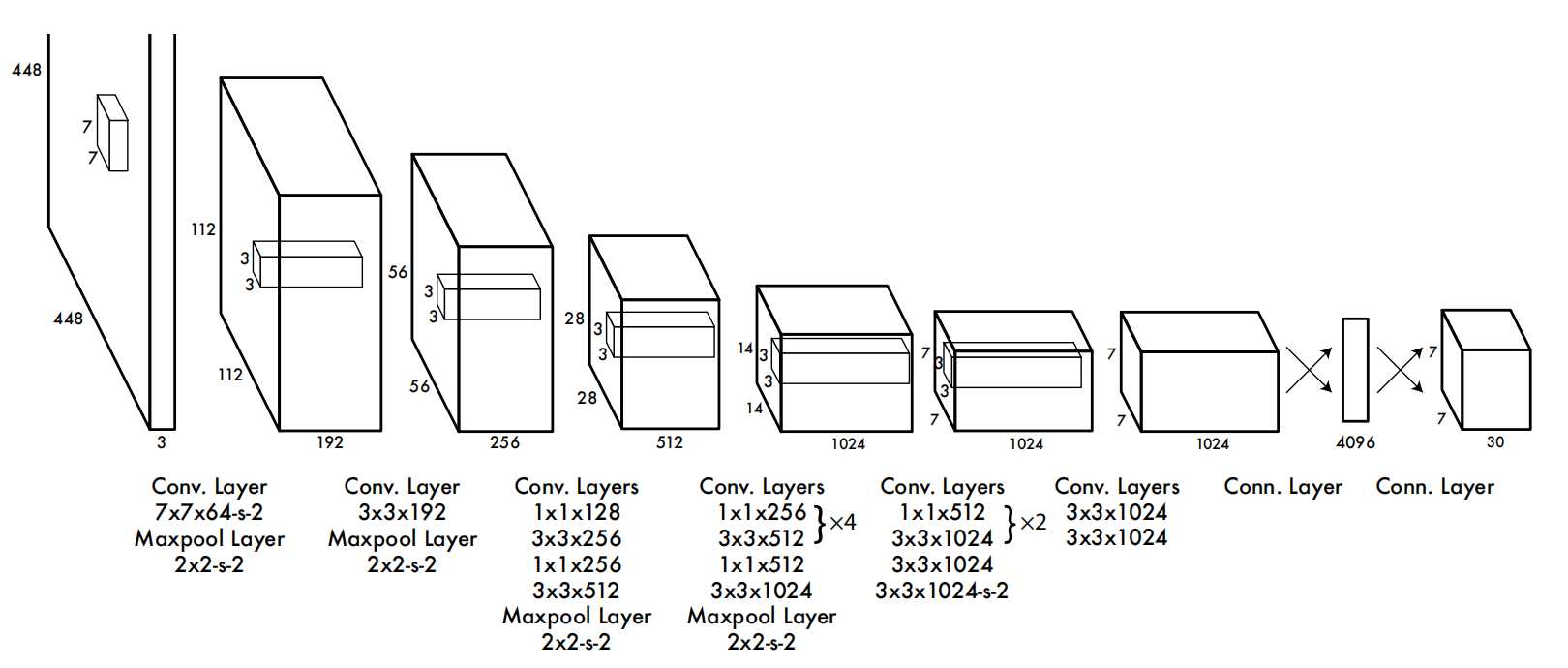
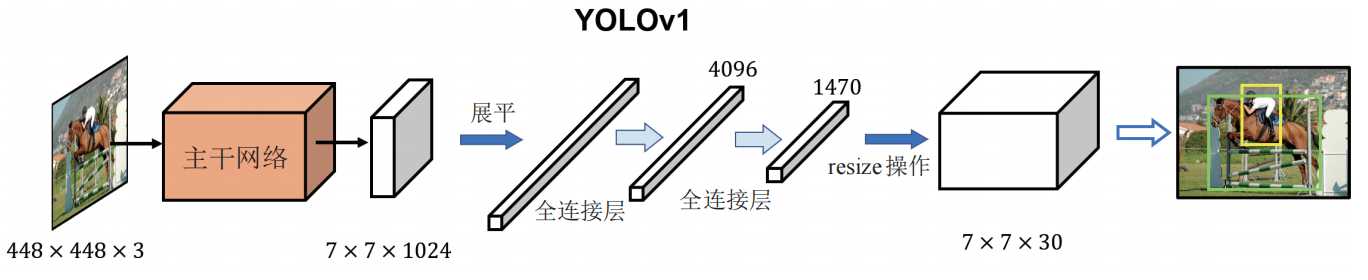
该网络包含24个卷积层和2个全连接层。不同于GoogLeNet使用的Inception模块,我们采用1×1降维层接3×3卷积层的简单设计。输入是448 x 448 x 3张量,最终输出是7×7×30的预测张量。
检测原理
YOLO是做统一检测,其网络使用整幅图像的特征来预测每个边界框。它还能同时预测图像所有类别的所有边界框。这意味着YOLO网络对整幅图像及其中的所有物体进行全局推理。
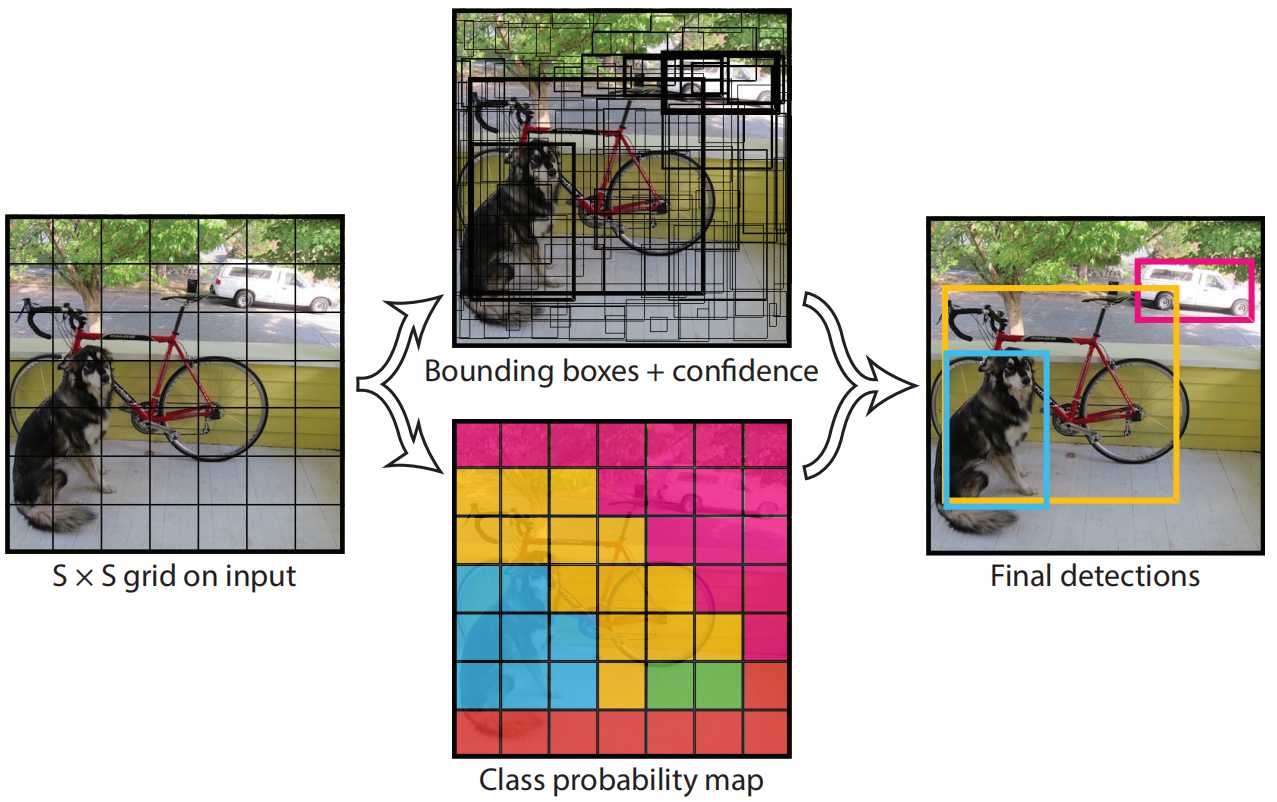
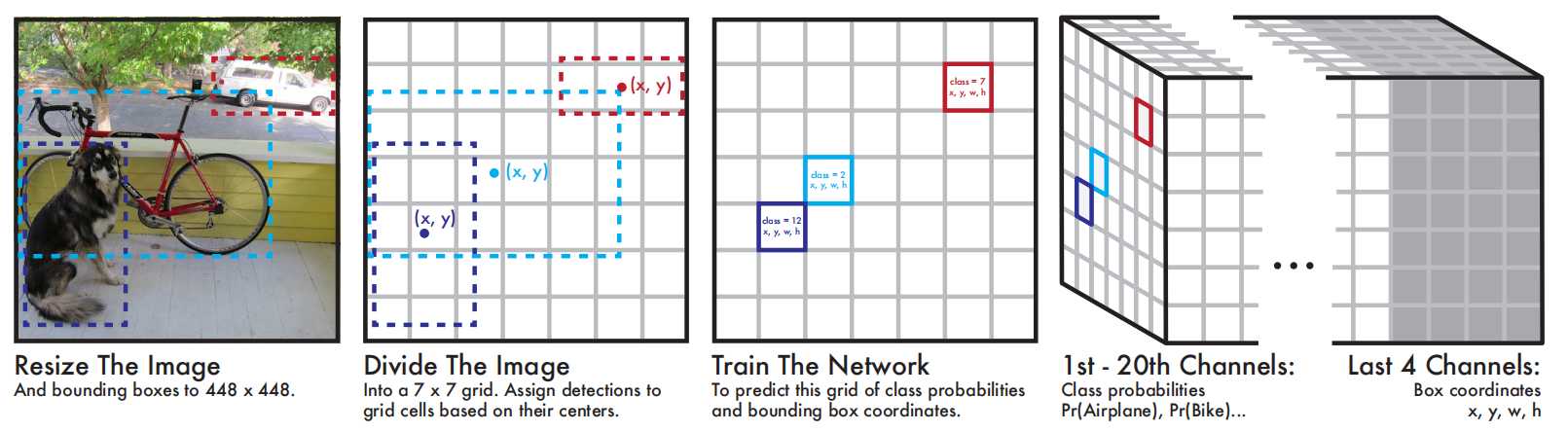
- 划分网格: 将输入图像划分为S X S个网格(grid)。
- 预测边界框:每个网格预测B个边界框(包含4个预测值x、y、w、h)并计算这些边界框的置信度分数以及C个条件类别概率。
置信度分数计算方式为:当网格中不存在任何物体,则为0,如果存在则等于预测框与真实框的交并比IOU。
C个条件类别概率:是C个预测类别,每个类别的概率值。因此总结一下,预测值为S X S X (B X 5 + C)个tensor。这里要注意的是,边界框的中心点并不是网格中心点,但中心点落在的这个网格负责这B个边界框的预测。
上面的图出之YOLOv1论文中的第5版本,如果不是很直观可以看看第1个版本,只不过第一个版本每个网格只预测一个边界框并且没有包含置信度。
为什么YOLOv1改进加了一个置信度?
预测框与真实框的交并比(定位质量),这样可以预测质量。YOLO将图像划分为网格,每个网格仅预测一组类别概率(与预测框数量无关),若直接用类别概率判断物体存在性,会忽略定位质量。例如一个网格预测出“狗”的概率为90
为什么YOLOv1最开始每个网格是一个边界框后面变成了多个?
- 单框局限:每个网格仅预测一个边界框时,模型难以适应不同长宽比的物体(如瘦高的行人和扁平的汽车)。
- 多框设计:通过预测两个不同长宽比的边界框(如一个方形、一个长方形),模型可灵活匹配不同形状的目标,提高定位精度。
- 训练机制:训练时,选择与真实框IoU更高的预测框负责该物体,另一个框则被抑制(不参与损失计算),从而驱动网络学习多样化的边界框表达。
- 单框瓶颈:网格内若存在多个重叠目标(如密集人群),单框设计只能检测其中一个物体,导致漏检49。
- 冗余预测:两个边界框提供双重检测机会,即使一个框被错误抑制,另一框仍可能捕获未被覆盖的目标811。
但是这里需要注意的是,在YOLOv1中,同一个网格内的两个边界框(边界框1和边界框2)预测的类别结果是同一个类,因为类别的预测是共享的,也就是说预测的类别概率是共享的,每个网格只能预测一个类别目标。这也是YOLOv1的缺陷,如果有2个不同类别的物体中心都落在了同一个网格中,这样就没有同时预测两个物体。
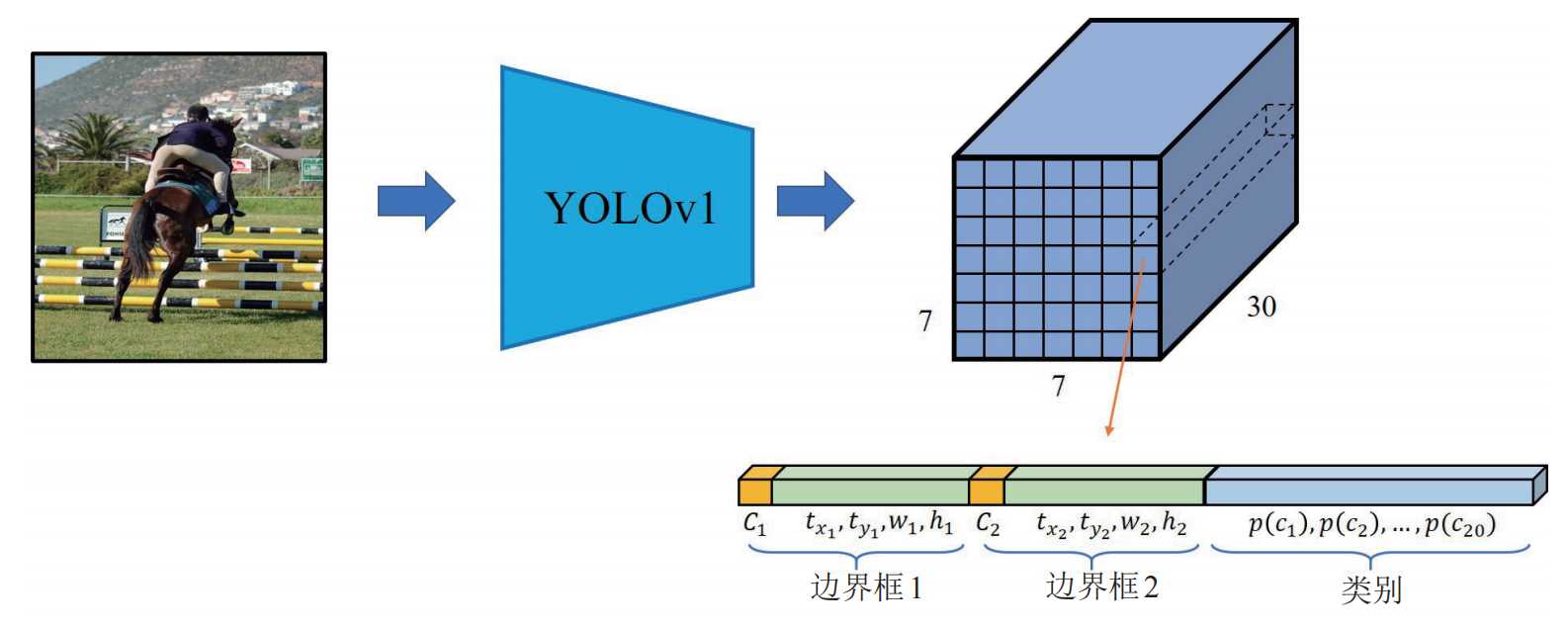
总结:YOLO系统将检测建模为回归问题,它将图像划分为 S × S 的网格,并为每个网格单元预测 B 个边界框、这些框的置信度以及 C 个类别概率。这些预测被编码为S × S × (B ∗ 5 + C) 张量。为了在 PASCAL VOC 上评估 YOLO,作者使用 S = 7,B = 2。PASCAL VOC 有 20 个标记类别,因此 C = 20,最终预测是一个结果是7 × 7 × 30的张量。
损失函数
YOLOv1的损失函数使用的是边界框坐标(x,y,w,h)、置信度、类别概率计算而来,公式如下图。

- 边界框坐标损失:第一第二行公式,计算的是边界框坐标的损失。
- 置信度损失:分为有目标和无目标,无目标学习标签就是0,有目标学习标签是1.
- 类别损失:每个类别的损失,针对的是每个网格单元的损失,不是预测框的。
关于边界框的位置参数是怎么样的?下面总结一下:
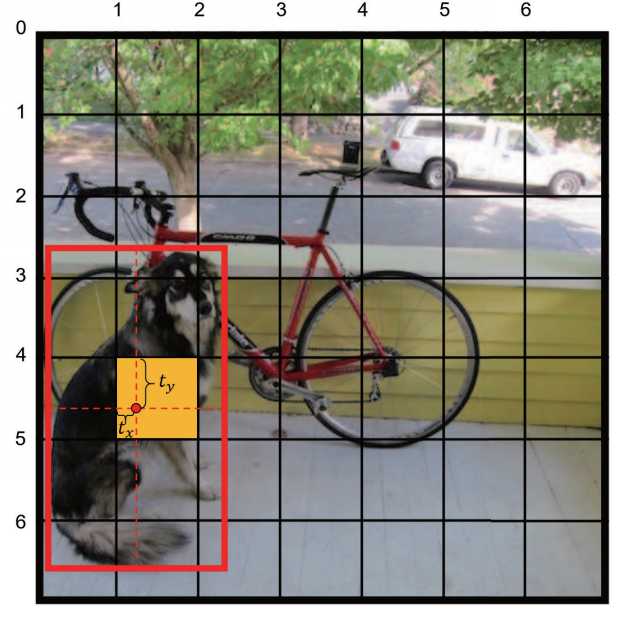
- tx, ty: 是边界框中心坐标相对于当前网格(第5行第二列)左上角的偏移量(归一化到 [0,1] 区间)。
- w, h: 是边界框的实际宽度和高度归一化到 [0,1],相对于整张图像的尺寸宽和高进行进行缩小比例。
详细的计算公式:
- 中心点坐标:x = (C_x + tx) / S, y = (C_y + ty) / S,(C_x, C_y为网格左上角坐标,S为网格划分数量)
- 宽高:w = 框宽 / 图宽, h = 框高 / 图高
YOLOv1的边界框参数优点是直接预测实际位置,无需先验框(Anchor Box),模型结构简单。缺点就宽高直接回归导致训练不稳定,定位精度较低;
模型后处理
YOLOv1模型训练完成后,给定一个448 x 448 x 3的tensor,模型输出是一个7 x 7 x 30的 tensor,也就是每个网格位置包含2个边界框的置信度输出C1和C2,两个边界框的位置参数(tx1,ty1,w1,h1)和(tx2,ty2,w2,h2)以及20个类别的概率p1~p20。
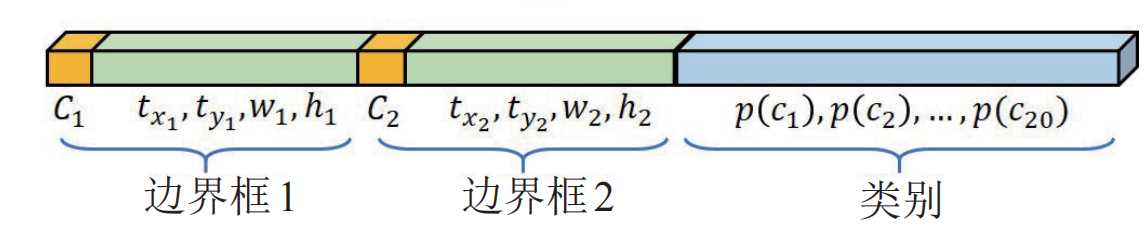
显然上面的输出结果不是我们想要的,我们要进行处理,筛选出最优的值,具体的处理步骤如下:
- 计算所有边界框得分:每个网格预测的边界框进行计算得分,计算公式分数=置信度值 x 类别概率中最大的值。
- 阈值剔除: 根据上一个步骤计算的得分,设定一个阈值比如0.3, 剔除小于阈值分数的边界框。
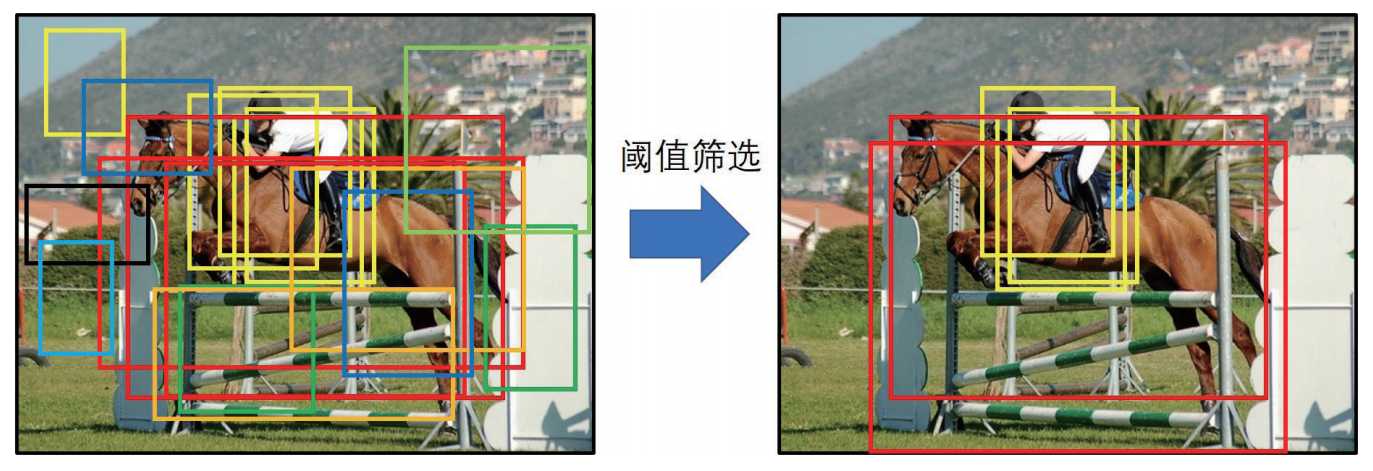
- 计算边界框位置:剔除一部分阈值后,计算编辑框的参数位置包括x,y,w,h。
- 非极大值抑制:经过前面的步骤后,同一个目标可能还是有多个预测边界框,最后试用非极大值抑制将重复检查的框去掉。最后就得到下面的示例结果。

总结一下YOLOv1的优缺点:
优点:
- 速度快,实时性强:首次实现端到端训练,推理速度达 45 FPS,简化了检测流程。
- 结构简单: 统一为单一回归问题,避免了区域提议(Region Proposal)的复杂步骤。
- 计算效率高:全卷积网络设计,适合资源受限的嵌入式设备。
缺点:
- 检测精度低:每个网格仅预测2个边界框且只能识别单一物体,同时对密集小目标检测效果差网络划分7x7精度不够。
- 定位不准确:边界框回归不稳定,导致定位误差大,与边界框的宽高定义为实际宽高缩放有关。
- 灵活性差:输入分辨率固定(448×448),不支持多尺度训练,网格划分(如 7×7)限制检测数量上限(最多 49 个物体)。
- 泛化能力弱:对非常规长宽比或重叠物体处理效果差。
参考:
1. 论文:https://arxiv.org/pdf/1506.02640v5
2. 书籍《YOLO目标检测》