llama.cpp部署大模型
- Ai
- 2025-06-16
- 168热度
- 0评论
安装llama.cpp
从GitHub上下载官方的源码。
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
使用camke进行编译,先创建build环境
cmake -B build
发现有报错curl没有安装。
-- The C compiler identification is GNU 11.3.0
-- The CXX compiler identification is GNU 11.3.0
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/cc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Found Git: /usr/bin/git (found version "2.34.1")
-- Looking for pthread.h
-- Looking for pthread.h - found
-- Performing Test CMAKE_HAVE_LIBC_PTHREAD
-- Performing Test CMAKE_HAVE_LIBC_PTHREAD - Success
-- Found Threads: TRUE
-- Warning: ccache not found - consider installing it for faster compilation or disable this warning with GGML_CCACHE=OFF
-- CMAKE_SYSTEM_PROCESSOR: x86_64
-- GGML_SYSTEM_ARCH: x86
-- Including CPU backend
-- Found OpenMP_C: -fopenmp (found version "4.5")
-- Found OpenMP_CXX: -fopenmp (found version "4.5")
-- Found OpenMP: TRUE (found version "4.5")
-- x86 detected
-- Adding CPU backend variant ggml-cpu: -march=native
-- Could NOT find CURL (missing: CURL_LIBRARY CURL_INCLUDE_DIR)
CMake Error at common/CMakeLists.txt:85 (message):
Could NOT find CURL. Hint: to disable this feature, set -DLLAMA_CURL=OFF
使用apt-get安装libcur14,如下。
sudo apt-get update
sudo apt-get install libcurl4-openssl-dev
安装curl成功后,解决了,继续执行cmake -B build,会生成build目录。
cmake -B build
-- Warning: ccache not found - consider installing it for faster compilation or disable this warning with GGML_CCACHE=OFF
-- CMAKE_SYSTEM_PROCESSOR: x86_64
-- GGML_SYSTEM_ARCH: x86
-- Including CPU backend
-- x86 detected
-- Adding CPU backend variant ggml-cpu: -march=native
-- Found CURL: /usr/lib/x86_64-linux-gnu/libcurl.so (found version "7.81.0")
-- Configuring done
-- Generating done
-- Build files have been written to: /root/autodl-tmp/llama.cpp/build
接着llama.cpp的源码。
cmake --build build --config Release
编译完成之后,生成的二进制都在llama.cpp/build/bin目录下。
模型下载
使用wget下载模型。
wget https://huggingface.co/bartowski/Llama-3.2-3B-Instruct-GGUF/resolve/main/Llama-3.2-3B-Instruct-Q8_0.gguf
llamap.cpp只能使用GGUF格式的大模型,使用的模型可以在Hugging Face获取https://huggingface.co/。也可以在modelscope上获取https://modelscope.cn/models。
这里有个技巧,可能仓库里面有很多量化参数的模型,如果使用git全部clone下来会比较久,这里可以只下载指定的GGUF模型,点击要使用的模型,如下:
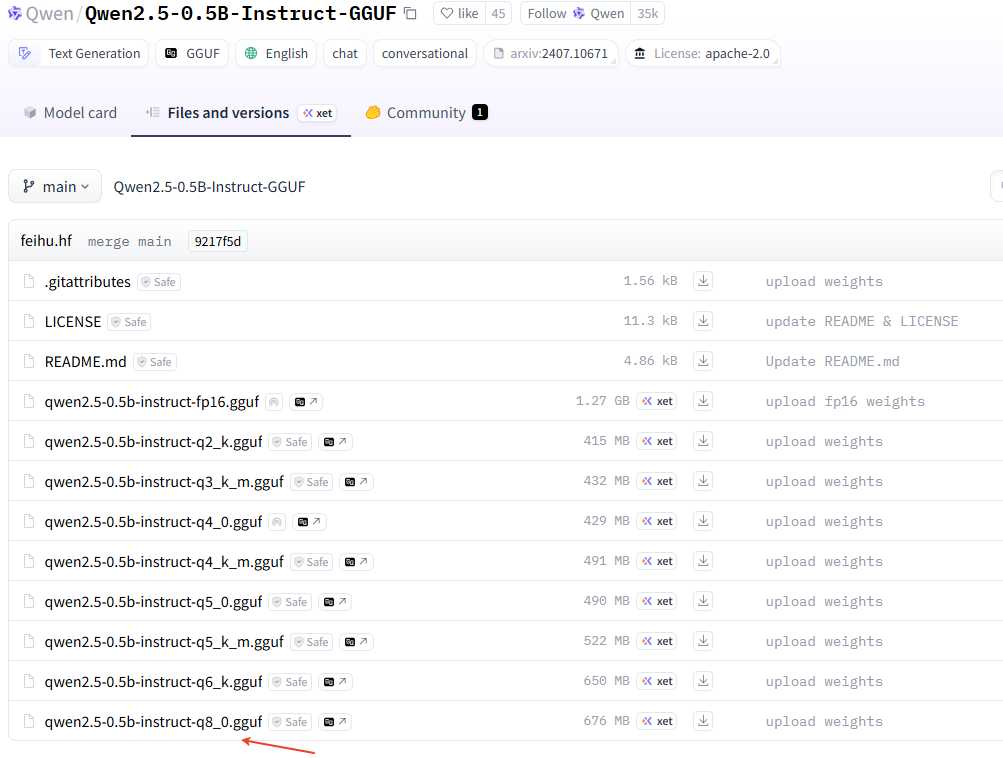
然后,获取到下面的下载链接。
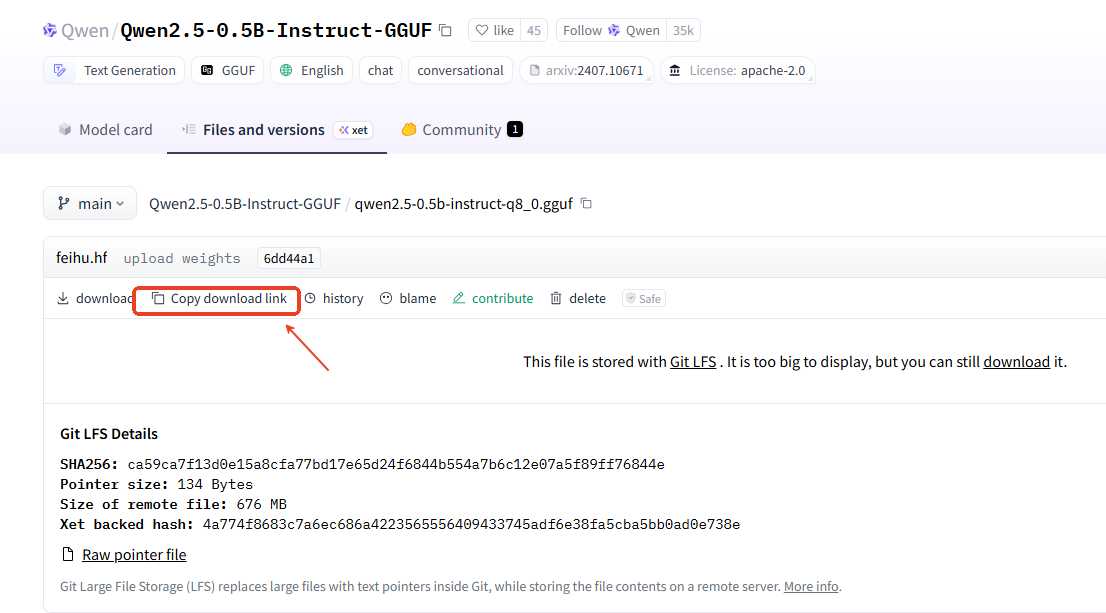
如果是modelsscope,找到下载,然后鼠标长按左键不松手拖到上面的输入网址框获取到下载链接。
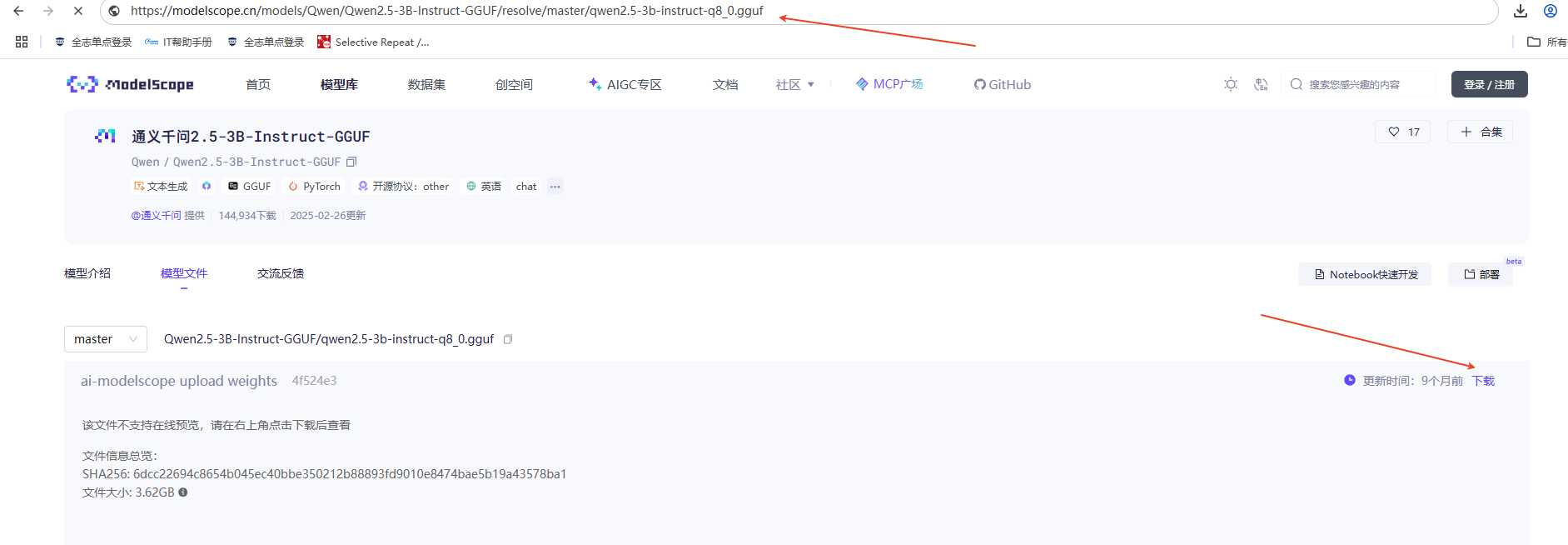
这样就可以使用wget进行下载了。
wget https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct-GGUF/resolve/main/qwen2.5-0.5b-instruct-q8_0.gguf
wget https://modelscope.cn/models/Qwen/Qwen2.5-3B-Instruct-GGUF/resolve/master/qwen2.5-3b-instruct-q8_0.gguf
模型测试
运行大模型
./llama.cpp/build/bin/llama-cli -m model/Llama-3.2-3B-Instruct-Q8_0.gguf
运行日志如下,可以看到使用的是CPU,没有使用GPU,因为前面编译的时候没有使能CUDA。
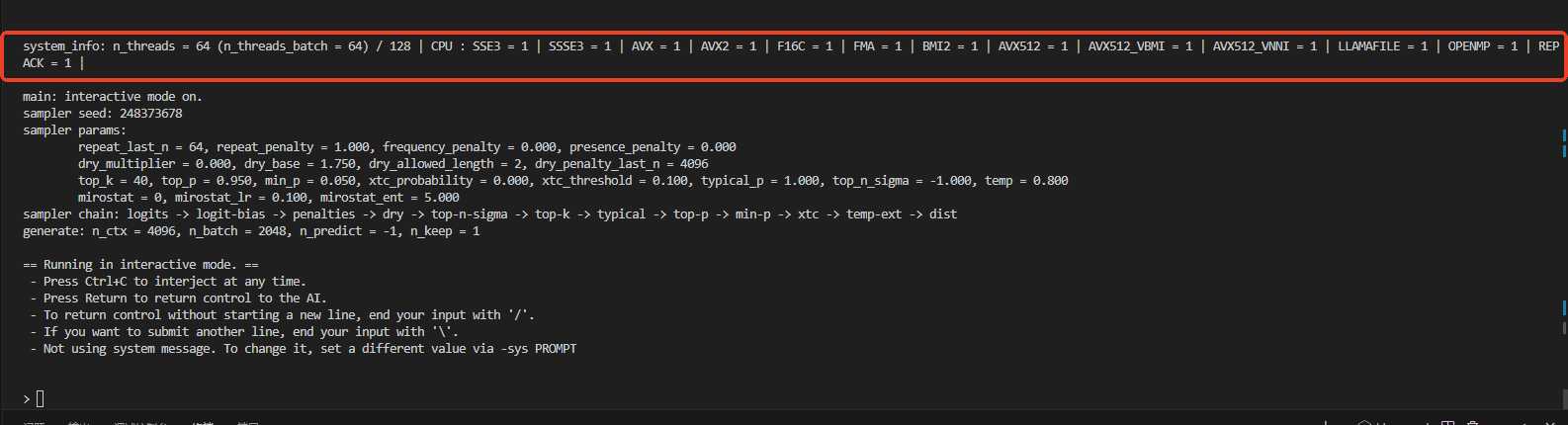
llama_perf_sampler_print: sampling time = 8.06 ms / 80 runs ( 0.10 ms per token, 9920.63 tokens per second)
llama_perf_context_print: load time = 1070.39 ms
llama_perf_context_print: prompt eval time = 859.42 ms / 15 tokens ( 57.29 ms per token, 17.45 tokens per second)
llama_perf_context_print: eval time = 20880.31 ms / 65 runs ( 321.24 ms per token, 3.11 tokens per second)
llama_perf_context_print: total time = 37979.41 ms / 80 tokens
- load time: 模型加载时间,耗时1070.39ms,属于一次性开销,与模型大小和硬件I/O性能相关。
- prompt eaval time: 有些也称为prefill(TPS),表示提示词处理时间,处理15个输入Token耗时859.42ms,平均57.29ms/Token,速度17.45 Token/s。
- eval time:有些也称为decode (TPS), 表示生成推理时间,生成65个Token耗时20880.31ms,平均321.24ms/Token,速度仅3.11 Token/s,显著低于采样阶段的9920.63 Token/s,说明生成阶段存在计算瓶颈。
- sampling time: 采样80次仅8.06ms,速度高达9920.63 Token/s,表明采样算法本身效率极高,非性能瓶颈。
- total time: 输入到输出的总耗时,包括模型加载时间、提示词处理时间、生成推理时间,其他时间(可能含内存交换或调度延迟)
可以使用vscode的打开多个终端,一个执行大模型交互,一个使用htop看看CPU和内存使用情况。
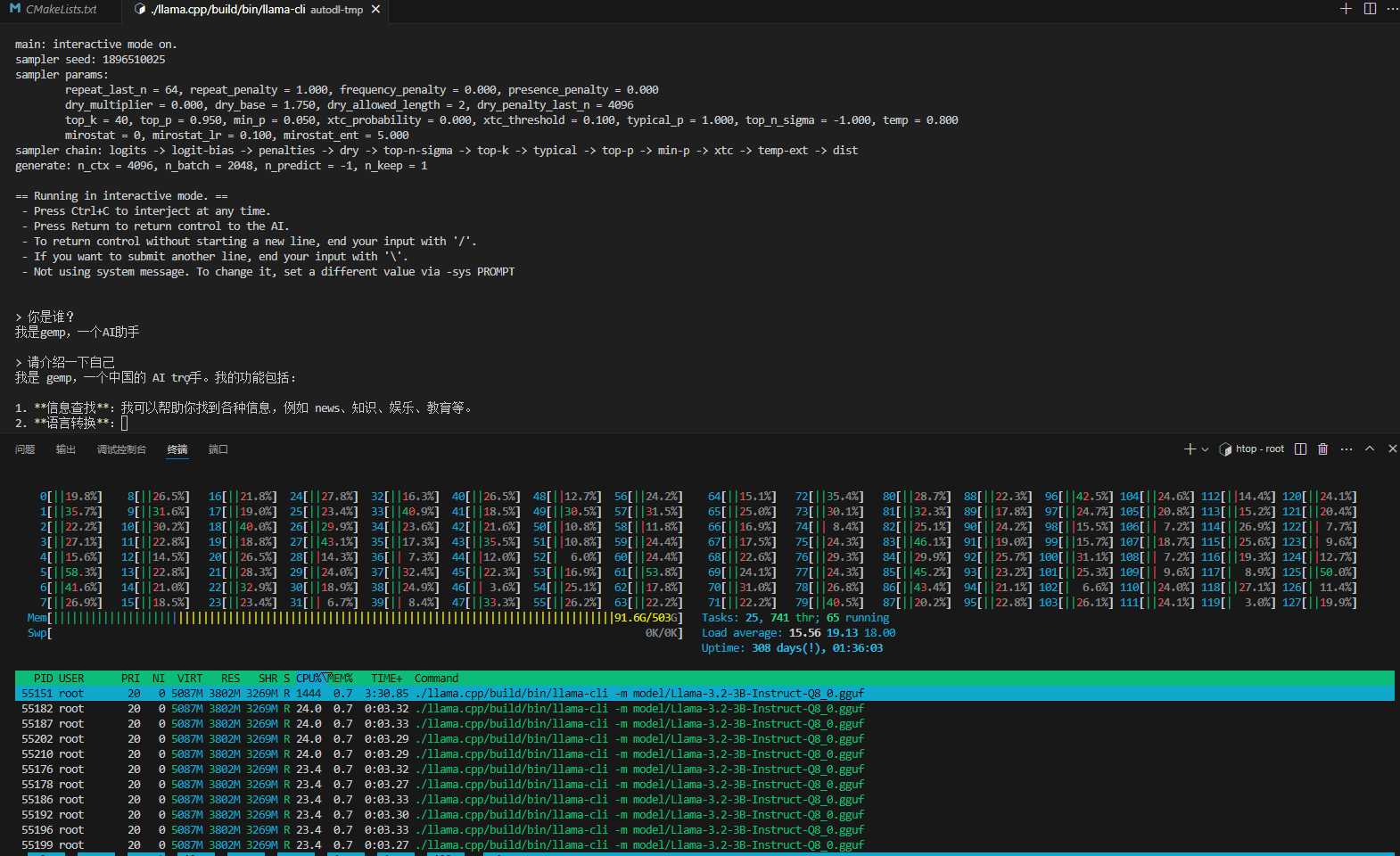
从上面看输入是17.45 token/s,输出是3.11 token/s,速度还是比较慢。
没有使用GPU,都是用cpu在推理。那么怎么使能使用gpu了?使用下面的方式,构建编译的时候打开CUDA,然后重新编译试一下。要用多线程编译,否则编译贼慢。
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release -j16
重新运行模型后,看到硬件信息用了GPU了。
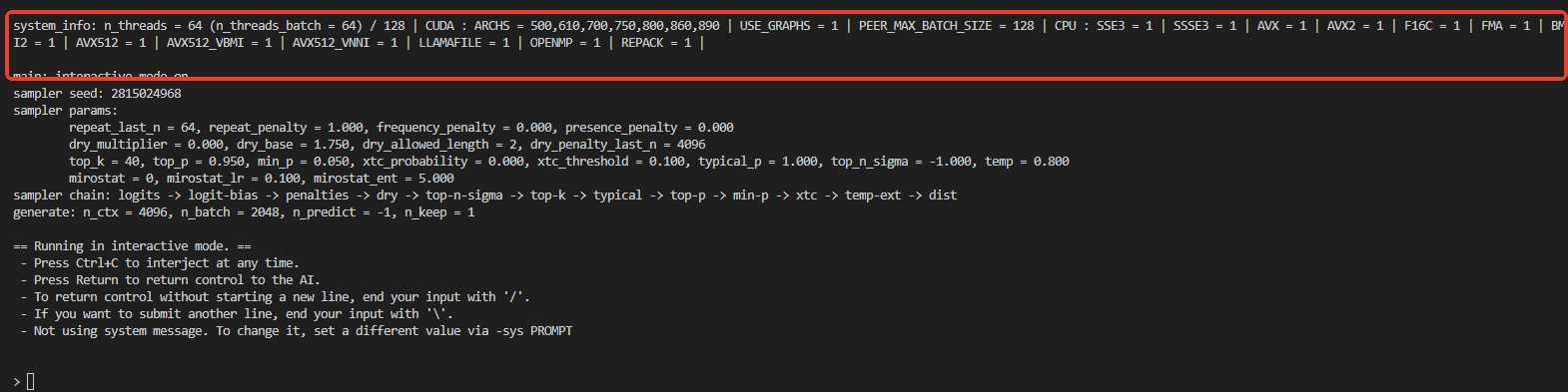
llama_perf_sampler_print: sampling time = 10.88 ms / 105 runs ( 0.10 ms per token, 9649.85 tokens per second)
llama_perf_context_print: load time = 959.88 ms
llama_perf_context_print: prompt eval time = 573.18 ms / 14 tokens ( 40.94 ms per token, 24.43 tokens per second)
llama_perf_context_print: eval time = 17212.83 ms / 91 runs ( 189.15 ms per token, 5.29 tokens per second)
llama_perf_context_print: total time = 34584.56 ms / 105 tokens
输出token有提升,但是看起来不明显,为啥了?