workqueue
API接口
初始化
| 函数 | 说明 |
|---|---|
| DECLARE_WORK(n, f) | 静态定义一个work,实际就是定义一个struct work_struct的全局变量。 |
| DECLARE_DELAYED_WORK(_work, _func) | 静态定义一个work,与上面的区别就是work可以在指定时间之后再由线程来执行。 |
| INIT_WORK(_work, _func) | 可以动态的分配一个struct work_struct,但是调用该函数进行初始化。 |
| INIT_DELAYED_WORK(_work, _func) | 动态分配,延迟work执行。 |
触发执行
| 函数 | 说明 |
|---|---|
| schedule_work(struct work_struct *work) | 调度一个work运行,会将work挂入到默认workqueue(system_wq)中运行。 |
| queue_work(struct workqueue_struct *wq,struct work_struct *work) | 调度一个work在指定的workqueue上运行。 |
| queue_delayed_work(struct workqueue_struct*wq,struct delayed_work *dwork,unsigned long delay) | 延迟一段时间调度一个work在指定的workqueue上运行。 |
schedule_work实际上也是调用queue_work,将其wq指定为system_wq,在workqueue_init_early进行初始化工作队列时会默认创建几个workqueue。
创建workqueue
| create_workqueue(name) | 创建一个普通的workqueue,该workqueue将在每个cpu上都创建一个worker thread,后文会描述。 |
| create_freezable_workqueue(name) | 在suspend的时候不冻结内核线程的worker thread |
| create_singlethread_workqueue(name) | 只有一个thread,所有的work在thread中排队运行。 |
| cstruct workqueue_struct *alloc_workqueue(const char *fmt,unsigned int flags,int max_active, …) | 最原始的分配函数,上面三个函数都会调用到该函数,其中第三个参数是工作队列中当前能够运行的最大work数量,当大于该值其work将会被添加到未激活的链表中等待运行的work完成后才能运行。上面三个函数的max_active都是1,因此work都是排队运行的,因此要并行work使用alloc_workqueue来创建。 |
除了系统定义的几个默认workqueue,用户可以调用上面的函数自己创建workqueue,对于queue_work来说一般用就可以指定使用自己创建的workqueue。
数据结构

workqueue涉及到几个重要的数据结构,可以结合下面的图来进行理解。
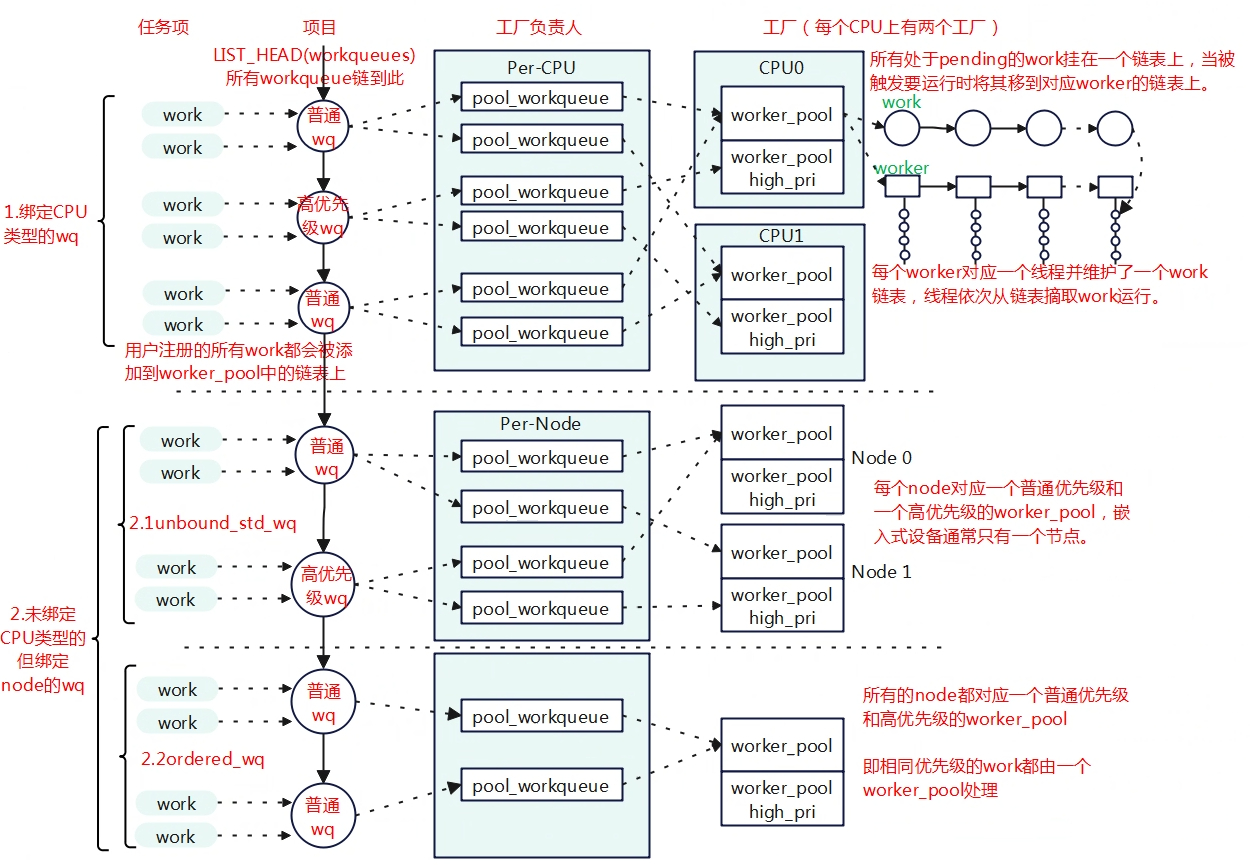
- work_struct: “任务项”,也可以称为工作,填充了用户实际要处理函数任务。初始化后的work将会被添加到worker_pool中链表上。
- workqueue_struct:“项目”;任务由那个工作队列负责运行,即可理解为任务所属“项目”,“项目”是多个任务的集合。一个工作队列可以处理多个任务。系统在初始化时默认创建了一些工作队列如system_wq,system_highpri_wq等,用户也可以调用alloc_workqueue来创建一个工作队列。系统定义了一个全局的链表workqueues,所有的工作队列都连接到该链表上。
- worker:“工人”;每一个worker对应一个task,该worker上可能挂接着多个等待处理的任务。
- worker_pool:“工厂”;一个“工厂”里面多个“工人”,工厂还没被触发的任务都挂在worklist链表上。
- pool_workqueue:“厂长”;建立workqueue_struct和pool_workqueue的联系。
workqueue是把work推迟到一个内核线程中去执行,结合上面的数据结构关系具体描述就是:一个项目(workqueue)上可以处理很多个工作(work),这些项目(workqueue)的工作(work)交给工厂负责人(pool_wokerqueue)协调到一个工厂(woker_pool)去生产,工厂(worker_pool)中当收到要启动处理工作(work)时,就安排一个工人(worker)去执行工作(work)。
worker_pool是管理了多个worker,每个worker对应一个task。因此我们也称worker_pool为线程池。线程池的线程数量是可以动态分配或移除。线程池可以分为与特定CPU绑定的线程池和没有绑定的线程池两类。
- Bound 线程池:这种线程池根据优先级分为高低两类,分别用来处理高优先级和低优先级的任务。绑定的线程池在系统中使用全局数组定义好了,DEFINE_PER_CPU_SHARED_ALIGNED(struct worker_pool [NR_STD_WORKER_POOLS], cpu_worker_pools), 取决于cpu的数量,根据高低优先级那么如果有n个cpu,那么就对应有2n个worker_pool。
- Unbound线程池:这类线程池可以运行在任意cpu上,其worker_pool是动态创建的,创建worker_pool时会判断其线程池熟悉,如线程优先级nice,如果属性一样就再重复创建,共有一个线程池。
worker_pool线程池与workqueue是没有直接联系的,当用户创建一个workqueue只是选择一个或多个线程池而已,对于bound类型的线程池,每个cpu有两个线程池对于高低优先级;对应unbound类型线程池,根据属性动态创建线程池。创建线程池后,默认情况下线程池会创建一个worker 线程来处理work,随着work数量的提交,woker_pool动态的调整worker来应对work数量。
后续约定workqueue简写wq;worker_pool简写pool,也称为线程池;pool_workqueue简写pwq;
初始化
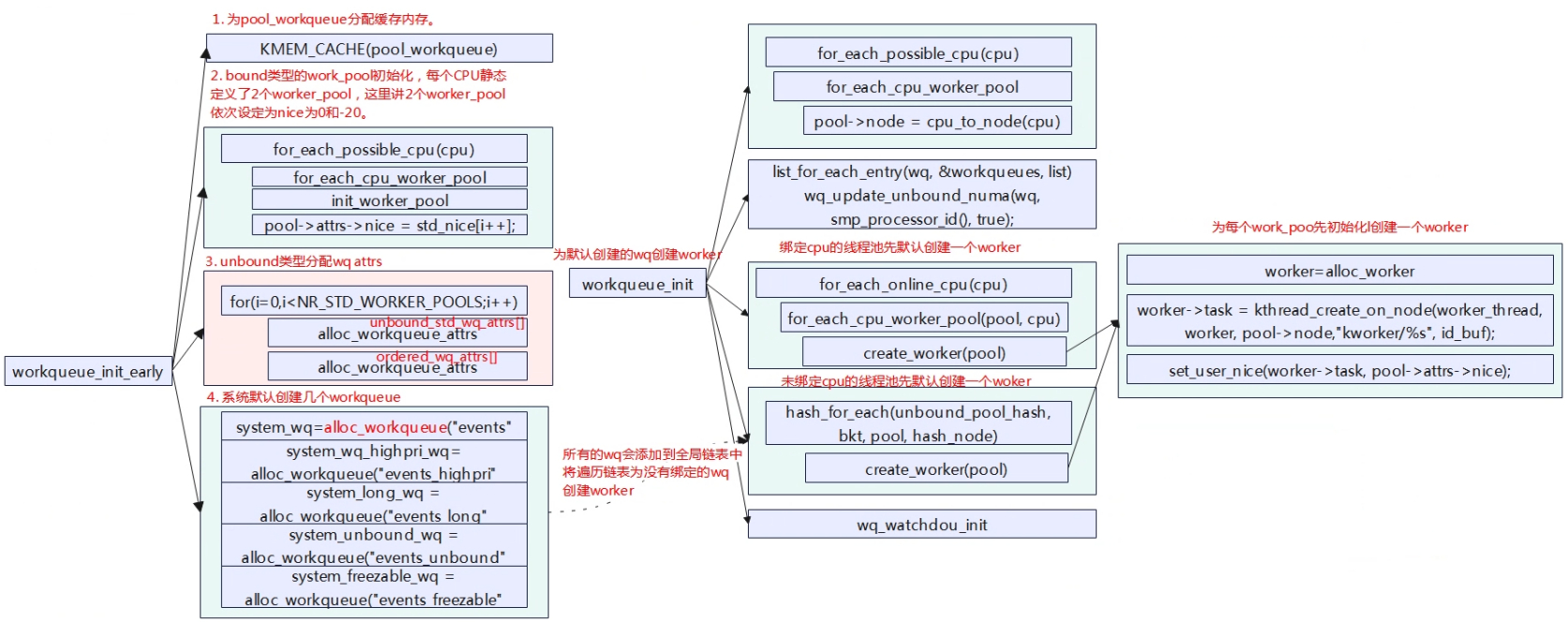
workqueue初始化分为两个阶段,分别为早期workqueue_init_early和workqueue_init。
workqueue early init
void __init workqueue_init_early(void)
{
int std_nice[NR_STD_WORKER_POOLS] = { 0, -20 };
pwq_cache = KMEM_CACHE(pool_workqueue, SLAB_PANIC);
BUG_ON(!alloc_cpumask_var(&wq_unbound_cpumask, GFP_KERNEL));
cpumask_copy(wq_unbound_cpumask, housekeeping_cpumask(hk_flags));
//静态为每个cpu创建两个线程池,用于处理高优先级和普通优先级的work。
for_each_possible_cpu(cpu) {
struct worker_pool *pool;
i = 0;
//为每个cpu定义了一个静态的worker_pool[2],这里遍历数组进行初始化,设定线程池运行的cpu、nice值以及所属node节点。其中nice值会有差别,依次为0和-20,这就决定了,这两个线程池的优先级运行优先级是不同的。
for_each_cpu_worker_pool(pool, cpu) {
BUG_ON(init_worker_pool(pool));
//初始化worker_pool,分配struct workqueue_attrs
pool->cpu = cpu;
cpumask_copy(pool->attrs->cpumask, cpumask_of(cpu));
//设置要运行的cpu,线程池是绑定在cpu上的。
pool->attrs->nice = std_nice[i++]; //设置线程的优先级
pool->node = cpu_to_node(cpu); //设置所属node节点
//分配worker pool id
mutex_lock(&wq_pool_mutex);
BUG_ON(worker_pool_assign_id(pool));
mutex_unlock(&wq_pool_mutex);
}
}
//除了静态为每个cpu创建两个线程池外,还可以创建跟cpu不绑定的线程池,线程池将会//动态的创建,这里先分配线程池的属性。
//动态创建的线程池又分为两类,分别是跟node节点绑定的线程池和跟node节点不绑定
//且线程池中任务运行按顺序执行的工作队列。
for (i = 0; i < NR_STD_WORKER_POOLS; i++) {
struct workqueue_attrs *attrs;
//用于Per-node 线程池的属性创建
BUG_ON(!(attrs = alloc_workqueue_attrs())); //分配一个workqueue_attrs。
attrs->nice = std_nice[i]; //也有两个优先级,因此每个节点至少也会创建两个线程池
unbound_std_wq_attrs[i] = attrs;//属性赋值到全局变量中保存。
/*
* An ordered wq should have only one pwq as ordering is
* guaranteed by max_active which is enforced by pwqs.
* Turn off NUMA so that dfl_pwq is used for all nodes.
*/
//用于工作队列中任务顺序执行线程池属性创建
BUG_ON(!(attrs = alloc_workqueue_attrs()));
attrs->nice = std_nice[i]; //高低优先级的线程池
attrs->no_numa = true; //与节点无关
ordered_wq_attrs[i] = attrs;
}
//系统将默认创建几个工作队列。
system_wq = alloc_workqueue("events", 0, 0);
system_highpri_wq = alloc_workqueue("events_highpri", WQ_HIGHPRI, 0);
system_long_wq = alloc_workqueue("events_long", 0, 0);
system_unbound_wq = alloc_workqueue("events_unbound", WQ_UNBOUND,
WQ_UNBOUND_MAX_ACTIVE);
system_freezable_wq = alloc_workqueue("events_freezable",
WQ_FREEZABLE, 0);
system_power_efficient_wq = alloc_workqueue("events_power_efficient",
WQ_POWER_EFFICIENT, 0);
system_freezable_power_efficient_wq = alloc_workqueue("events_freezable_power_efficient",
WQ_FREEZABLE | WQ_POWER_EFFICIENT,
0);
BUG_ON(!system_wq || !system_highpri_wq || !system_long_wq ||
!system_unbound_wq || !system_freezable_wq ||
!system_power_efficient_wq ||
!system_freezable_power_efficient_wq);
}
在workqueue_init_early的初始化过程中,先初始化每个cpu上的线程池,在系统中为每个cpu上静态定义每个cpu上定义了一个struct worker_pool cpu_worker_pools[2]的数组(DEFINE_PER_CPU_SHARED_ALIGNED(struct worker_pool [NR_STD_WORKER_POOLS], cpu_worker_pools)),即每个cpu上有两个线程池,分别用于高优先级和低优先级。
除了为每个CPU绑定两个高低优先级的线程池外,还可以动态的创建线程池,动态创建的线程池可分为跟内存node绑定和跟node节点不绑定且工作队列中的任务顺序执行,所以系统先为没有绑定cpu类型的线程池先分配好属性,存储在unbound_std_wq_attrs[2]和ordered_wq_attrs[2]中,从属性的数组定义也可以看出,每一类也有两个线程池对应的是高优先级和普通优先级。
workqueue init
void __init workqueue_init(void)
{
struct workqueue_struct *wq;
struct worker_pool *pool;
int cpu, bkt;
/*
* It\'d be simpler to initialize NUMA in workqueue_init_early() but
* CPU to node mapping may not be available that early on some
* archs such as power and arm64. As per-cpu pools created
* previously could be missing node hint and unbound pools NUMA
* affinity, fix them up.
*
* Also, while iterating workqueues, create rescuers if requested.
*/
//对numa的wq初始化,嵌入式设备一般只有一个node,所以对于numa的我们暂不深入
wq_numa_init();
mutex_lock(&wq_pool_mutex);
for_each_possible_cpu(cpu) {
for_each_cpu_worker_pool(pool, cpu) {
pool->node = cpu_to_node(cpu);
}
}
list_for_each_entry(wq, &workqueues, list) {
wq_update_unbound_numa(wq, smp_processor_id(), true);
WARN(init_rescuer(wq),
\"workqueue: failed to create early rescuer for %s\",
wq->name);
}
mutex_unlock(&wq_pool_mutex);
遍历CPU,为每个绑定cpu的线程池创建一个worker
/* create the initial workers */
for_each_online_cpu(cpu) {
for_each_cpu_worker_pool(pool, cpu) {
pool->flags &= ~POOL_DISASSOCIATED;
BUG_ON(!create_worker(pool));
}
}
//为unbound类型的创建一个线程池?
hash_for_each(unbound_pool_hash, bkt, pool, hash_node)
BUG_ON(!create_worker(pool));
wq_online = true;
wq_watchdog_init();
}
创建工作队列
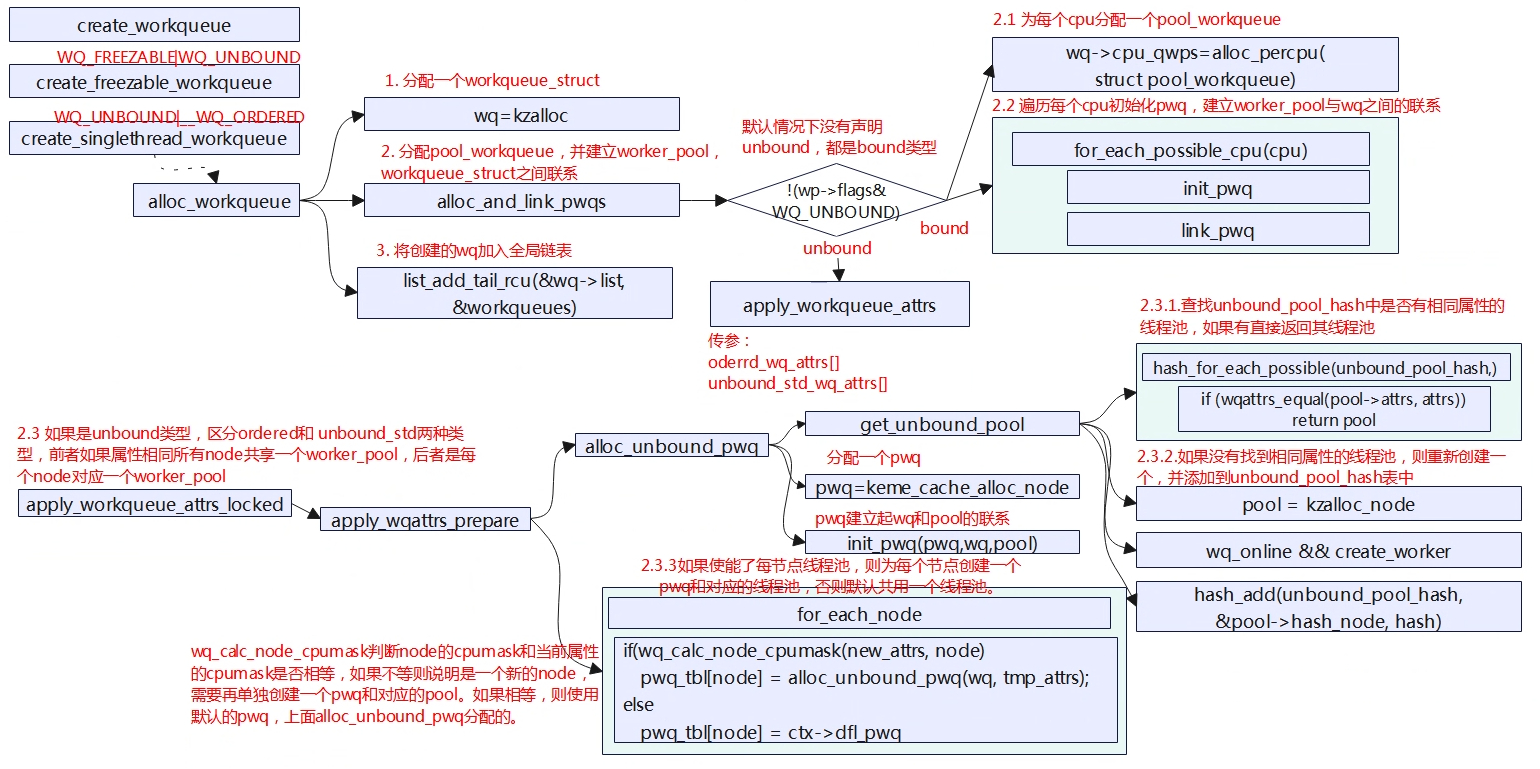
创建工作队列主要的工作就是确定好工作队列使用的线程池(worker_pool),工作队列分为BOUND CPU类型和UNBOUND CPU类型。用户可以调用create_workqueue、create_freezable_workqueue以及create_singlethread_workqueue等API接口来创建队列,这些API接口最终都会调用alloc_workqueue来实现,只不过每个函数传入的参数是不一样的,对于后两个函数就是UNBOUND类型,同时create_singlethread_workqueue还是ORDERED类型,该类型的工作队列表示其所处理的工作都是按顺序排队运行的。
在解释创建工作队列的流程前我们再来说明下workqueue、pool_workqueue、worker_pool之间的关系。worker_pool是线程的集合,可以实际处理任务的,挂在workqueue上的工作最终都会交由worker_pool来处理,但是workqueue和worker_pool并没有直接一对一的关系,而是多对多的关系,可以理解要生产的产品和工厂是解耦的,工厂是一个共享的池子,因此要做一个产品(workqueue)和工厂产线生产(worker_pool)之间的联系需要个中间人来张罗,所以pool_workqueue就是这中间人,用于确定制作这个产品选择那个工厂。
Workqueue如何获取到worker_pool?
(1)对于bound workqueue,是每个cpu都绑定了两个高优先级和普通优先级的线程池,这些cpu上的线程池都是共享的,因此对于workqueue需要为每个cpu的每个线程池分配一个pool_workqueue来对应到线程池,即该workqueue需要分配2*cpu个数的pool_workqueue,pool_workqueue与worker_pool是一一对应的关系。在alloc_workqueue调用alloc_percpu来分配pwq,然后遍历每个cpu获取到worker_pool,建立器pwq,wq,pool之间的联系。
(2)对于unbound workqueue,就稍微复杂些因为workqueue要找的线程池没有与cpu进行绑定,不像bound workqueue定义好了worker_pool,所以了workqueue需要动态的分配创建pwq,pool。而unbound workqueue又分为两种类型排队运行的工作队列和标准的工作队列,排队运行的工作队列所有的工作将排队依次运行而标准的工作队列意味这可并发。两种类型的队列属性分别存储在ordered_wq_attrs[]和unbound_std_wq_attrs[]两个数组中。当检查到workqueue是unbound类型后,就调用apply_workqueue_attrs分别传入不同的属性创建线程池。
A.unbound std类型:与内存节点node有关联,将会为每个node节点创建高优先级和普通优先级的线程池,之所以这么做是因为不同的node节点之间切会带来性能损耗,因此每个node都创建2个线程池。
B.unbound ordered类型:与内存节点node没有关联了,多个同一优先级的workqueue共享一个worker_pool。

调度工作运行
触发调度
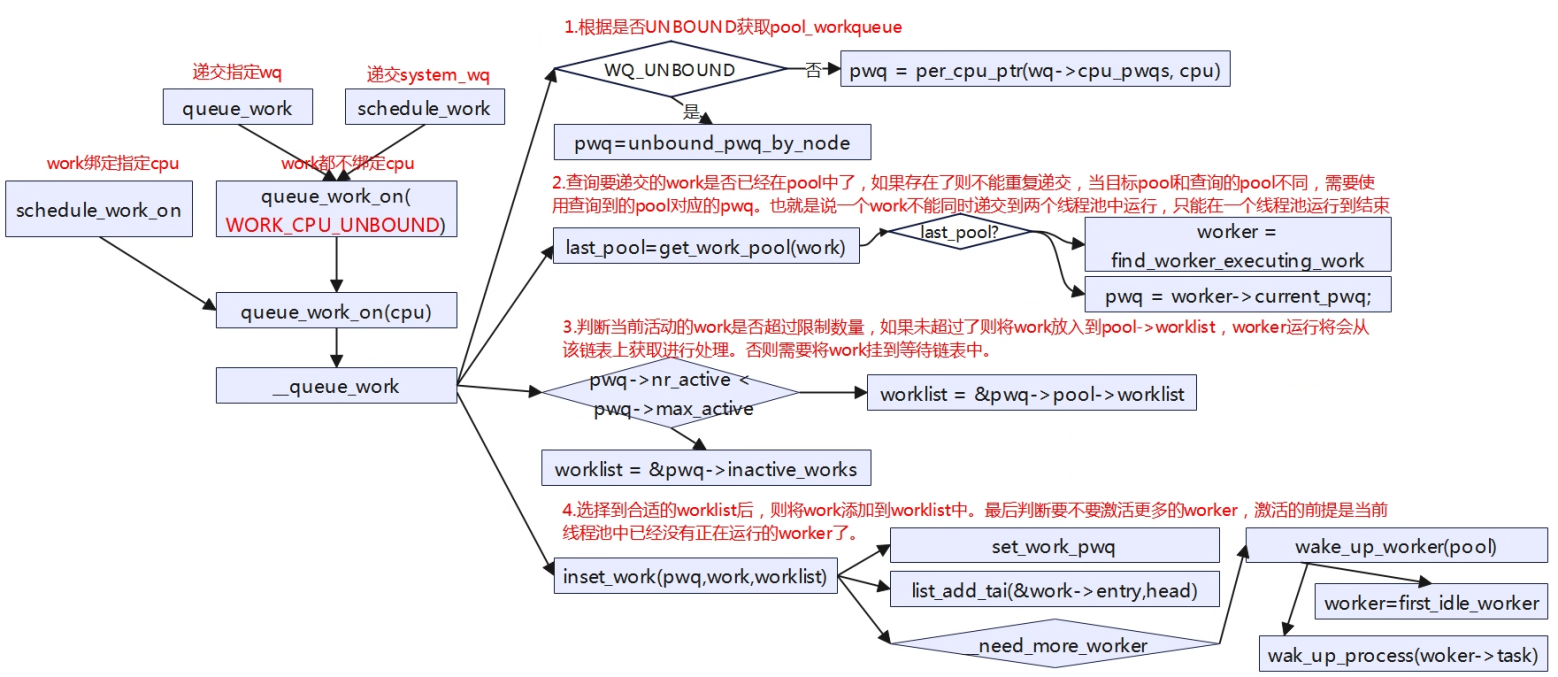
触发调度最后都会调用到_queue_work来执行,只是根据不同的场景有不同的参数可选择配置。对于常用的queue_work(struct workqueue_struct *wq,struct work_struct *work)来说是将work递交到指定的wq来运行,一般用户自己创建的wq,而schedule_work(struct work_struct *work)只有一个参数,将work递交到默认的system_wq来运行,queue_work和schedule_work递交的work在wq中处理,都不绑定cpu,这里的绑定不是WQ_UNBOUND,WQ_UNBOUND和WORK_CPU_UNBOUND是有区别的,WQ_UNBOUND确定WQ的类型是normal Per-CPU worker_pool还是unbound worker_pool,确定了WQ的类型才使用WORK_CPU_UNBOUND进一部分确定work是否要绑定cpu运行。
static void __queue_work(int cpu, struct workqueue_struct *wq,
struct work_struct *work)
{
struct pool_workqueue *pwq;
struct worker_pool *last_pool;
struct list_head *worklist;
unsigned int work_flags;
unsigned int req_cpu = cpu;
/*
* While a work item is PENDING && off queue, a task trying to
* steal the PENDING will busy-loop waiting for it to either get
* queued or lose PENDING. Grabbing PENDING and queueing should
* happen with IRQ disabled.
*/
lockdep_assert_irqs_disabled();
/* if draining, only works from the same workqueue are allowed */
if (unlikely(wq->flags & __WQ_DRAINING) &&
WARN_ON_ONCE(!is_chained_work(wq)))
return;
rcu_read_lock();
retry:
/* pwq which will be used unless @work is executing elsewhere */
//先判断wq unbound还是bound,如果是unbound,那么cpu选择的范围需要根据node
//节点来限制,如果是bound那么cpu就限定了。
//WQ_UNBOUND用于区分是wq是bound类型还是未bound类型,WORK_CPU_UNBOUND
//用于进一步限定woker_pool线程池是否指定选择那一个cpu。
if (wq->flags & WQ_UNBOUND) {
if (req_cpu == WORK_CPU_UNBOUND)
cpu = wq_select_unbound_cpu(raw_smp_processor_id());
//unbound类型,cpu也没有绑定,则选择一个cpu,优先选择本地cpu。
pwq = unbound_pwq_by_node(wq, cpu_to_node(cpu));
} else {
if (req_cpu == WORK_CPU_UNBOUND)
cpu = raw_smp_processor_id();
//如果req_cpu类型是WORK_CPU_UNBOUND,那么也是选择当前代码运行的cpu
pwq = per_cpu_ptr(wq->cpu_pwqs, cpu);
}
/*
* If @work was previously on a different pool, it might still be
* running there, in which case the work needs to be queued on that
* pool to guarantee non-reentrancy.
*/
//查询work是否已经在线程池内了
last_pool = get_work_pool(work);
//如果work已经在线程池中,且当前所在的worker_pool与获取的worker_pool不是同一个
if (last_pool && last_pool != pwq->pool) {
struct worker *worker;
raw_spin_lock(&last_pool->lock);
//查询work对应的挂到那个worker上
worker = find_worker_executing_work(last_pool, work);
//如果当前的worker所在的wq和请求的wq相同,则获取当前运行worker的pwq,//相当于前面获取的pwq被覆盖更新了,这样做的目的是防止work被重复放到不同的
//线程池中处理,也就是说当一个work被某一个线程池中接受处理后,一直需要等待//其处理完毕,不能更换另外另外一个线程池worker_pool。
if (worker && worker->current_pwq->wq == wq) {
pwq = worker->current_pwq;
} else {
/* meh... not running there, queue here */
raw_spin_unlock(&last_pool->lock);
raw_spin_lock(&pwq->pool->lock);
}
} else {
raw_spin_lock(&pwq->pool->lock);
}
/*
* pwq is determined and locked. For unbound pools, we could have
* raced with pwq release and it could already be dead. If its
* refcnt is zero, repeat pwq selection. Note that pwqs never die
* without another pwq replacing it in the numa_pwq_tbl or while
* work items are executing on it, so the retrying is guaranteed to
* make forward-progress.
*/
if (unlikely(!pwq->refcnt)) {
if (wq->flags & WQ_UNBOUND) {
raw_spin_unlock(&pwq->pool->lock);
cpu_relax();
goto retry;
}
/* oops */
WARN_ONCE(true, \"workqueue: per-cpu pwq for %s on cpu%d has 0 refcnt\",
wq->name, cpu);
}
/* pwq determined, queue */
trace_workqueue_queue_work(req_cpu, pwq, work);
if (WARN_ON(!list_empty(&work->entry)))
goto out;
pwq->nr_in_flight[pwq->work_color]++;
work_flags = work_color_to_flags(pwq->work_color);
//如果work运行的数量还没有超过限制,则获取pwq对应pool的worklist,也就是说后面
//会将work加入到该work中,如果数量超了则挂到临时pwq未激活的链表上。
if (likely(pwq->nr_active < pwq->max_active)) {
trace_workqueue_activate_work(work);
pwq->nr_active++;
worklist = &pwq->pool->worklist;
//获取到的worklist如果上面没有工作,则更新时间。
if (list_empty(worklist))
pwq->pool->watchdog_ts = jiffies;
} else {
work_flags |= WORK_STRUCT_INACTIVE;
worklist = &pwq->inactive_works;
}
debug_work_activate(work);
//将work插入到worklist上。
insert_work(pwq, work, worklist, work_flags);
out:
raw_spin_unlock(&pwq->pool->lock);
rcu_read_unlock();
}
static void insert_work(struct pool_workqueue *pwq, struct work_struct *work,
struct list_head *head, unsigned int extra_flags)
{
struct worker_pool *pool = pwq->pool;
/* record the work call stack in order to print it in KASAN reports */
kasan_record_aux_stack_noalloc(work);
//设置flag,并将work添加到worklist链表上
/* we own @work, set data and link */
set_work_pwq(work, pwq, extra_flags);
list_add_tail(&work->entry, head);
get_pwq(pwq);
/*
* Ensure either wq_worker_sleeping() sees the above
* list_add_tail() or we see zero nr_running to avoid workers lying
* around lazily while there are works to be processed.
*/
smp_mb();
//如果没有空闲的worker了,则唤醒一个新的worker运行。
if (__need_more_worker(pool))
wake_up_worker(pool);
}
static void wake_up_worker(struct worker_pool *pool)
{
//从pool的idle_list上获取一个worker,触发运行。
struct worker *worker = first_idle_worker(pool);
if (likely(worker))
wake_up_process(worker->task);
}
执行调度
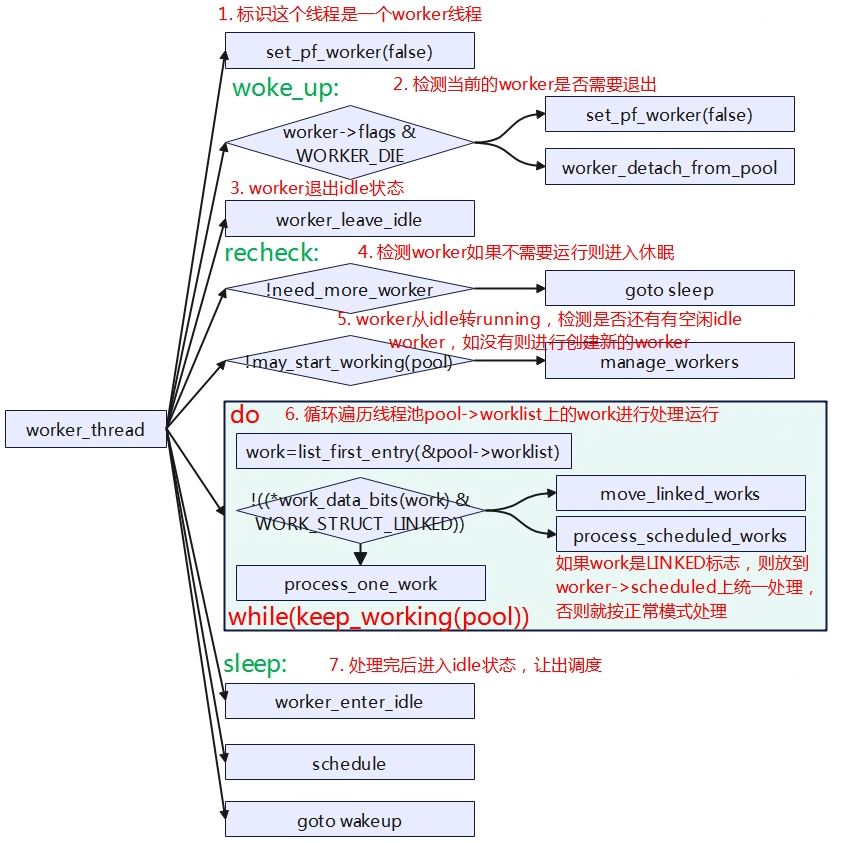
static int worker_thread(void *__worker)
{
struct worker *worker = __worker;
struct worker_pool *pool = worker->pool;
/* tell the scheduler that this is a workqueue worker */
//通知调度器,这是一个worker
set_pf_worker(true);
woke_up:
raw_spin_lock_irq(&pool->lock);
/* am I supposed to die? */
//判断该worker是否要退出?
if (unlikely(worker->flags & WORKER_DIE)) {
raw_spin_unlock_irq(&pool->lock);
WARN_ON_ONCE(!list_empty(&worker->entry));
set_pf_worker(false);
set_task_comm(worker->task, \"kworker/dying\");
ida_free(&pool->worker_ida, worker->id);
worker_detach_from_pool(worker);
kfree(worker);
return 0;
}
//离开idle状态,被唤醒之前都是idle状态
worker_leave_idle(worker);
recheck:
//检查线程池上是否有work要处理并且当前没有正在运行的worker了则进行处理,否则
//进入休眠状态。
/* no more worker necessary? */
if (!need_more_worker(pool))
goto sleep;
//如果pool上的idle worker数量为0,则创建一个worker备用
/* do we need to manage? */
if (unlikely(!may_start_working(pool)) && manage_workers(worker))
goto recheck;
/*
* ->scheduled list can only be filled while a worker is
* preparing to process a work or actually processing it.
* Make sure nobody diddled with it while I was sleeping.
*/
WARN_ON_ONCE(!list_empty(&worker->scheduled));
/*
* Finish PREP stage. We\'re guaranteed to have at least one idle
* worker or that someone else has already assumed the manager
* role. This is where @worker starts participating in concurrency
* management if applicable and concurrency management is restored
* after being rebound. See rebind_workers() for details.
*/
worker_clr_flags(worker, WORKER_PREP | WORKER_REBOUND);
do {
//从线程池pool->worklist上的获取一个work
struct work_struct *work =
list_first_entry(&pool->worklist,
struct work_struct, entry);
pool->watchdog_ts = jiffies;
//如果work不是linked,这里的link指的是有关联的work?
if (likely(!(*work_data_bits(work) & WORK_STRUCT_LINKED))) {
/* optimization path, not strictly necessary */
//处理work
process_one_work(worker, work);
if (unlikely(!list_empty(&worker->scheduled)))
process_scheduled_works(worker);
} else {
//特殊的work,先将其插入到worker->scheduled上,然后调度一起运行。
move_linked_works(work, &worker->scheduled, NULL);
process_scheduled_works(worker);
}
} while (keep_working(pool));
//一直循环,直到pool->worklist上链表的work处理完成。
worker_set_flags(worker, WORKER_PREP);
sleep:
/*
* pool->lock is held and there\'s no work to process and no need to
* manage, sleep. Workers are woken up only while holding
* pool->lock or from local cpu, so setting the current state
* before releasing pool->lock is enough to prevent losing any
* event.
*/
//处理完了,继续进入idle状态
worker_enter_idle(worker);
__set_current_state(TASK_IDLE);
raw_spin_unlock_irq(&pool->lock);
schedule();
goto woke_up;
}
static void process_one_work(struct worker *worker, struct work_struct *work)
__releases(&pool->lock)
__acquires(&pool->lock)
{
struct pool_workqueue *pwq = get_work_pwq(work);
struct worker_pool *pool = worker->pool;
bool cpu_intensive = pwq->wq->flags & WQ_CPU_INTENSIVE;
unsigned long work_data;
struct worker *collision;
#ifdef CONFIG_LOCKDEP
/*
* It is permissible to free the struct work_struct from
* inside the function that is called from it, this we need to
* take into account for lockdep too. To avoid bogus \"held
* lock freed\" warnings as well as problems when looking into
* work->lockdep_map, make a copy and use that here.
*/
struct lockdep_map lockdep_map;
lockdep_copy_map(&lockdep_map, &work->lockdep_map);
#endif
/* ensure we\'re on the correct CPU */
WARN_ON_ONCE(!(pool->flags & POOL_DISASSOCIATED) &&
raw_smp_processor_id() != pool->cpu);
/*
* A single work shouldn\'t be executed concurrently by
* multiple workers on a single cpu. Check whether anyone is
* already processing the work. If so, defer the work to the
* currently executing one.
*/
//检查work已经在其他worker上执行,则将work放入对应的worker->scheduled中延后执行
collision = find_worker_executing_work(pool, work);
if (unlikely(collision)) {
move_linked_works(work, &collision->scheduled, NULL);
return;
}
//将要执行的work更新为当前要运行的work
/* claim and dequeue */
debug_work_deactivate(work);
hash_add(pool->busy_hash, &worker->hentry, (unsigned long)work);
worker->current_work = work;
worker->current_func = work->func;
worker->current_pwq = pwq;
work_data = *work_data_bits(work);
worker->current_color = get_work_color(work_data);
/*
* Record wq name for cmdline and debug reporting, may get
* overridden through set_worker_desc().
*/
strscpy(worker->desc, pwq->wq->name, WORKER_DESC_LEN);
list_del_init(&work->entry);
/*
* CPU intensive works don\'t participate in concurrency management.
* They\'re the scheduler\'s responsibility. This takes @worker out
* of concurrency management and the next code block will chain
* execution of the pending work items.
*/
//如果当前cpu是密集型,则设置一个标志位
if (unlikely(cpu_intensive))
worker_set_flags(worker, WORKER_CPU_INTENSIVE);
/*
* Wake up another worker if necessary. The condition is always
* false for normal per-cpu workers since nr_running would always
* be >= 1 at this point. This is used to chain execution of the
* pending work items for WORKER_NOT_RUNNING workers such as the
* UNBOUND and CPU_INTENSIVE ones.
*/
//再次检查,是否需要wake up另外的worker,对于normal per-cpu worker总不会触发,
//主要针对unbound 和 cpu 密集型
if (need_more_worker(pool))
wake_up_worker(pool);
/*
* Record the last pool and clear PENDING which should be the last
* update to @work. Also, do this inside @pool->lock so that
* PENDING and queued state changes happen together while IRQ is
* disabled.
*/
set_work_pool_and_clear_pending(work, pool->id);
raw_spin_unlock_irq(&pool->lock);
lock_map_acquire(&pwq->wq->lockdep_map);
lock_map_acquire(&lockdep_map);
/*
* Strictly speaking we should mark the invariant state without holding
* any locks, that is, before these two lock_map_acquire()\'s.
*
* However, that would result in:
*
* A(W1)
* WFC(C)
* A(W1)
* C(C)
*
* Which would create W1->C->W1 dependencies, even though there is no
* actual deadlock possible. There are two solutions, using a
* read-recursive acquire on the work(queue) \'locks\', but this will then
* hit the lockdep limitation on recursive locks, or simply discard
* these locks.
*
* AFAICT there is no possible deadlock scenario between the
* flush_work() and complete() primitives (except for single-threaded
* workqueues), so hiding them isn\'t a problem.
*/
lockdep_invariant_state(true);
trace_workqueue_execute_start(work);
//执行work函数
worker->current_func(work);
/*
* While we must be careful to not use \"work\" after this, the trace
* point will only record its address.
*/
trace_workqueue_execute_end(work, worker->current_func);
lock_map_release(&lockdep_map);
lock_map_release(&pwq->wq->lockdep_map);
if (unlikely(in_atomic() || lockdep_depth(current) > 0)) {
pr_err(\"BUG: workqueue leaked lock or atomic: %s/0x%08x/%d\\n\"
\" last function: %ps\\n\",
current->comm, preempt_count(), task_pid_nr(current),
worker->current_func);
debug_show_held_locks(current);
dump_stack();
}
/*
* The following prevents a kworker from hogging CPU on !PREEMPTION
* kernels, where a requeueing work item waiting for something to
* happen could deadlock with stop_machine as such work item could
* indefinitely requeue itself while all other CPUs are trapped in
* stop_machine. At the same time, report a quiescent RCU state so
* the same condition doesn\'t freeze RCU.
*/
cond_resched();
raw_spin_lock_irq(&pool->lock);
/* clear cpu intensive status */
if (unlikely(cpu_intensive))
worker_clr_flags(worker, WORKER_CPU_INTENSIVE);
/* tag the worker for identification in schedule() */
worker->last_func = worker->current_func;
/* we\'re done with it, release */
hash_del(&worker->hentry);
worker->current_work = NULL;
worker->current_func = NULL;
worker->current_pwq = NULL;
worker->current_color = INT_MAX;
pwq_dec_nr_in_flight(pwq, work_data);
//pwq->nr_active--,判断是否要处理延时队列,
//将此前pwq->inactive_works添加到pool->worklist
}
总结:工作队列可以分为3种,Per CPU,Unbound,Ordered(属于unbound的一种)
– Per CPU: create_workequeue(name),创建的WQ使用的线程池是使用Per – CPU静态定义的线程池,每个CPU有两个线程池,分别对于高优先级和低优先级。当触发queue_work时,如果没有指定cpu,则将work递交给当前运行cpu的线程池。该类型的wq,同一个work不能同时递交到多个线程池上运行,同时在一个线程池中也不能同时有多个worker来运行,work一旦选定worker将需要在该worker上运行结束;不同的work可以递交到不同的线程池,这样会在不同的cpu上并发执行。
– Unbound:create_freezable_workqueue(name),创建的WQ使用的线程池动态创建的,会优先选择当前代码运行的cpu,获取到对应的node节点,然后查询当前node节点上是否有线程池,如果有则递交到该线程池处理,如果没有则新建一个线程池。对应这种类型的wq是需要考虑功耗的,在选择cpu时会尽可能的选择当前运行的cpu,让已经休眠的cpu尽可能的保持休眠,毕竟cpu从休眠到唤醒会有更大功耗消耗。如果没有NUMA的架构,那么就只有一个dfl默认的线程池。
– Ordered:create_singlethread_workqueue(name),该类型的wq也是unbound的一种,只不过该工作队列只有一个线程池,这样可以保证工作队列的工作可以顺序运行,也就是说在该wq上的work是没法并发运行的,只能排队运行。
线程池动态管理
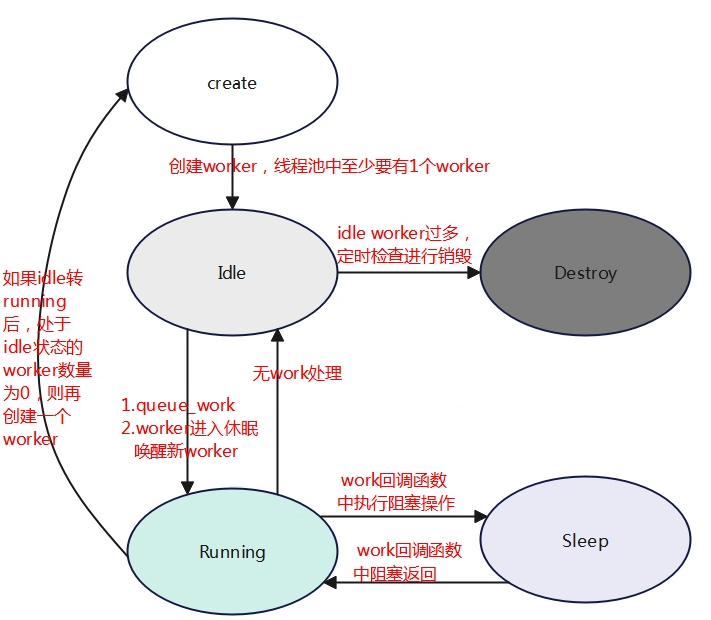
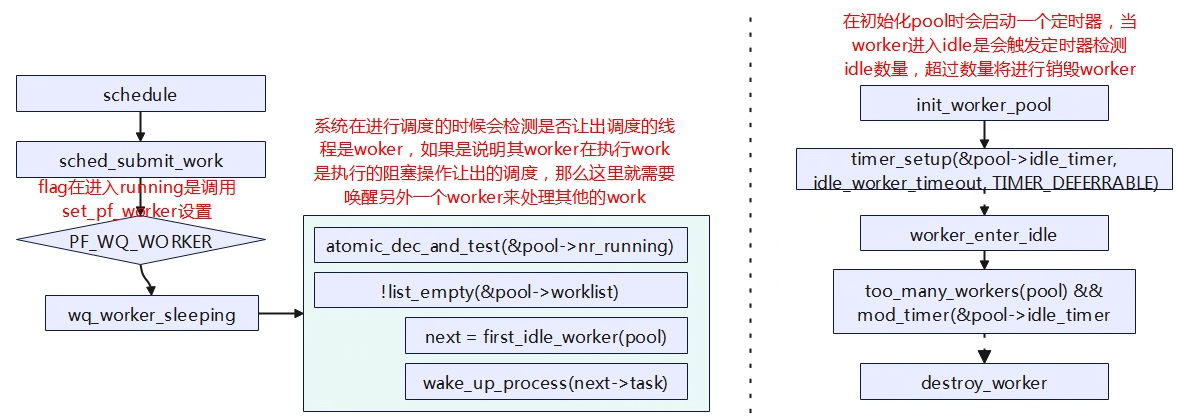
线程池将进行动态的增减管理worker,当创一个新的wq后,线程池至少会创建一个worker,该worker会挂到pool->idle_list链表上,当用户调用queue_work或者有另外一个worker处理work导致进入休眠将会触发worker从idle转到running状态进行处理work,当worker从idle进入running中状态时检查是否还有剩余的worker,如果没有了需要动态再创建要给worker,以备后续其他work的运行。处于running状态的worker如果在执行work回调函数时遇到阻塞该worker将进入到休眠状态,唤醒后再次返回到运行状态。当worker处理完线程池pool->worklist上的所有work时将会进入到idle状态,后台会有一个定时器检查处于idle状态的worker,如果大于1个就进行销毁。
下面是running->sleep触发另外一个worker运行和worker销毁的流程。