负载均衡之调度组和调度域
概述
从上一章节大概应该能够理解负载和利用率的区别了,当一个进程正在运行或者即使没有在cpu上运行,而在就绪队列中等待运行,那么他依旧消耗cpu的负载。这是合理的,因为cpu的就绪队列有10个任务等待着运行与5个任务等待运行,明显是10个任务的负载重。而利用率只是关注正在运行的任务而不包含在就绪队列的任务,在某个时间段内可能某个任务的cpu利用率很高,但是占用完之后一直睡眠,那么其队系统的负载贡献还是较小。
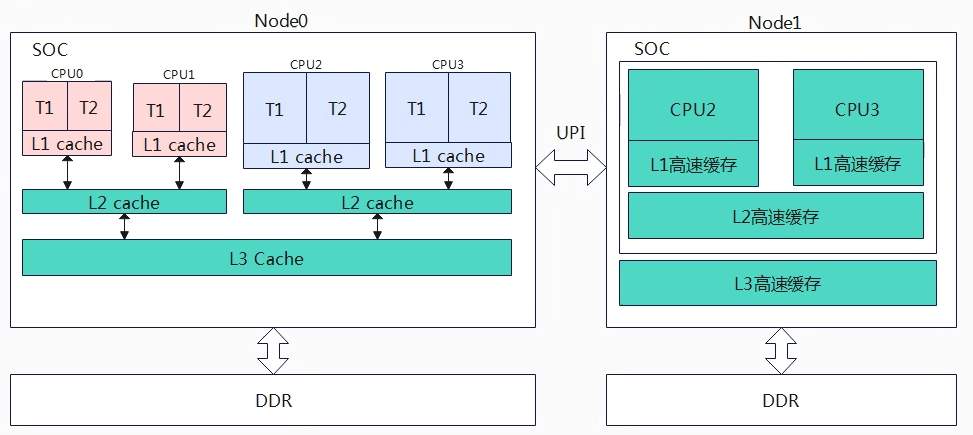
从CPU的层次划分,从大到小分为:
- NUMA: 多个SOC组成,通过UPI可以共享多块物理内存,常用于服务器。
- SOC: system-on-a-chip,集成了多个系统组件或功能的芯片,对应DIE。
- MC:multi-core,多核处理器,一个SOC集成多个核心,每个核心用于自己的缓存或寄存器资源,可以并行处理多个程序。
- SMT:Simultaneous Multi-Threading,超线程,单个核心处理器同时执行多个线程,在单个核心处理器引入多个逻辑执行单元和资源共享极致,实现更好的指令集并发性。
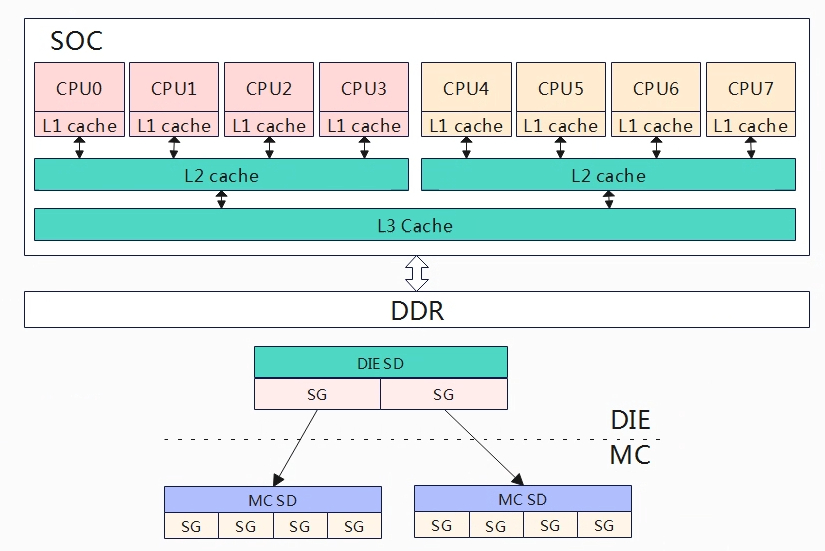
现在的嵌入式处理器通常包含SOC+MC技术,也就是在一个SOC上集成了多核处理器,目前遇到的SMT和NUMA的还比较少,因此本章节先讨论一个SOC上集成MC的情况。
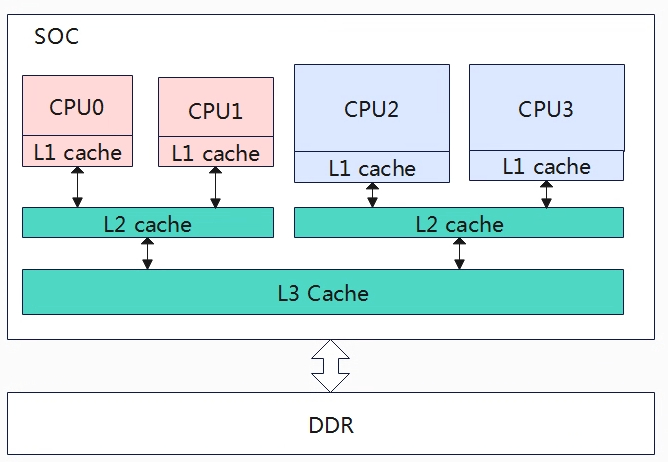
因为多核的出现,我们需要引入负载均衡,我们需要解决将SOC运行的任务均衡的分配到各个核上处理,但是并不能简单的平均分配任务到各个CPU上,从上图的架构来看,一个SOC上存在大小核的情况2个小核+2个大核,那自然大核的算力要高于小核的算力,同时我们还需要考虑CPU的频率,同样的架构核心高频的算力自然要高于低频的算力。除了配合各CPU的算力来均衡负载外,还需要考虑任务迁移的开销,上图CPU0上的任务迁移到CPU1上的开销会少于迁移到CPU2上,因为CPU0和CPU1共享L2 cache,如果迁移到L2上的话,cache就会失效,性能或许会减弱。基于上述这些因素,linux构建了相关的数据结构来处理这些问题,称为调度域和调度组。
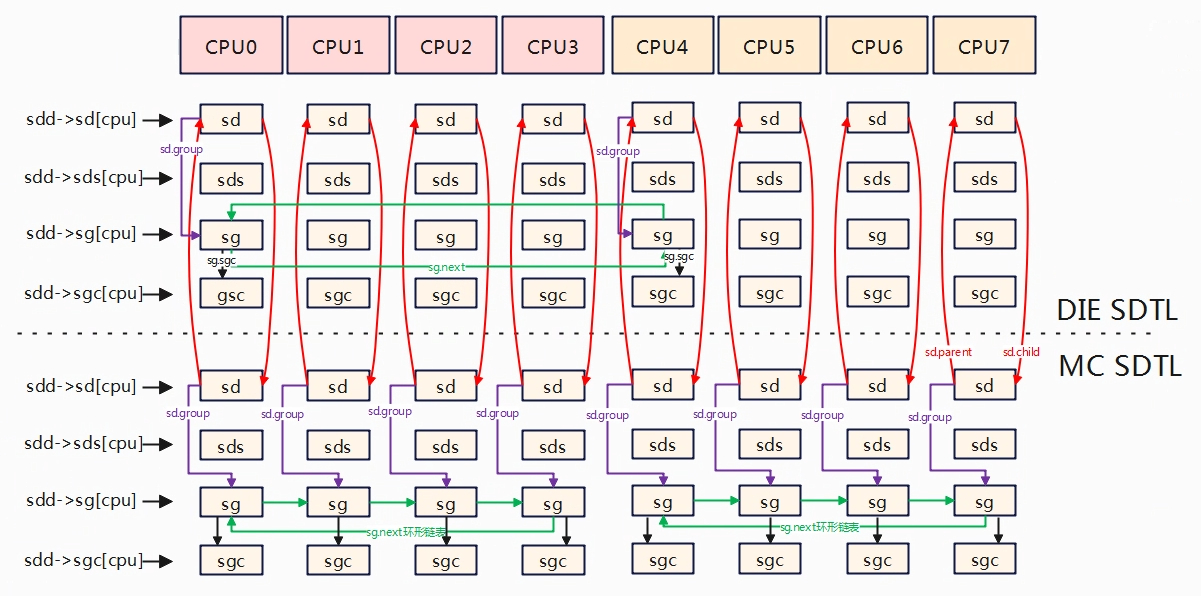
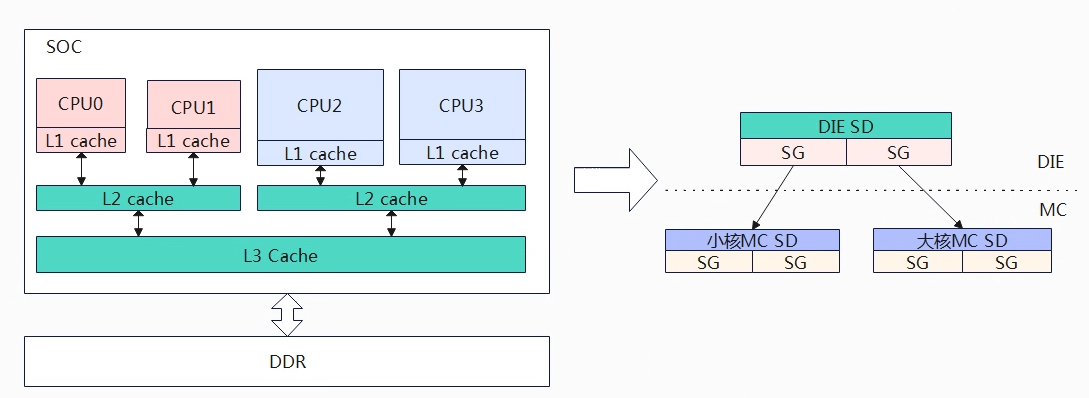
系统为了便于负载均衡,构建调度域(sched domain,简记sd)和调度组(sched group,简记sg)。按照架构层级可以依次划分为不同的SOC、相同SOC不同的核心、相同的核心不同的超线程。我们把相同层级称为调度域,越往下层的调度域共用的缓存越多,因此在任务做迁移时,优先选择从底层的调度域中进行。先不考虑SMT,上图的调度域可以分为两级从下往上MC domain(multi core domain),DIE domain。
- DIE domain:处于顶层,覆盖系统所有的CPU(CPU0~CPU3)。
- MC domain:处于底层,也称为base domain,分为小核MC domain(cpu0~cpu1)和大核MC domain(CPU2~CPU3),小核MC domain是一个cluster,大核MC domain是一个cluster。
负载均衡调度的最小单元是调度组,每个调度域进行分组。对于MC域,基本可以按照一个cpu是一组,所以小核MC domain可以分为两组(一个CPU对应一组),大核MC domain也是分为两组。对于DIE域,每个分组要覆盖到其child domain,DIE 域有两个子domain,分别是小核MC domain,大核MC domain,因此DIE domain分为两个组对于小核group和大核group。
数据结构
Linux内核使用struct sched_domain_topology_level,简称SDTL来描述CPU的层次关系。
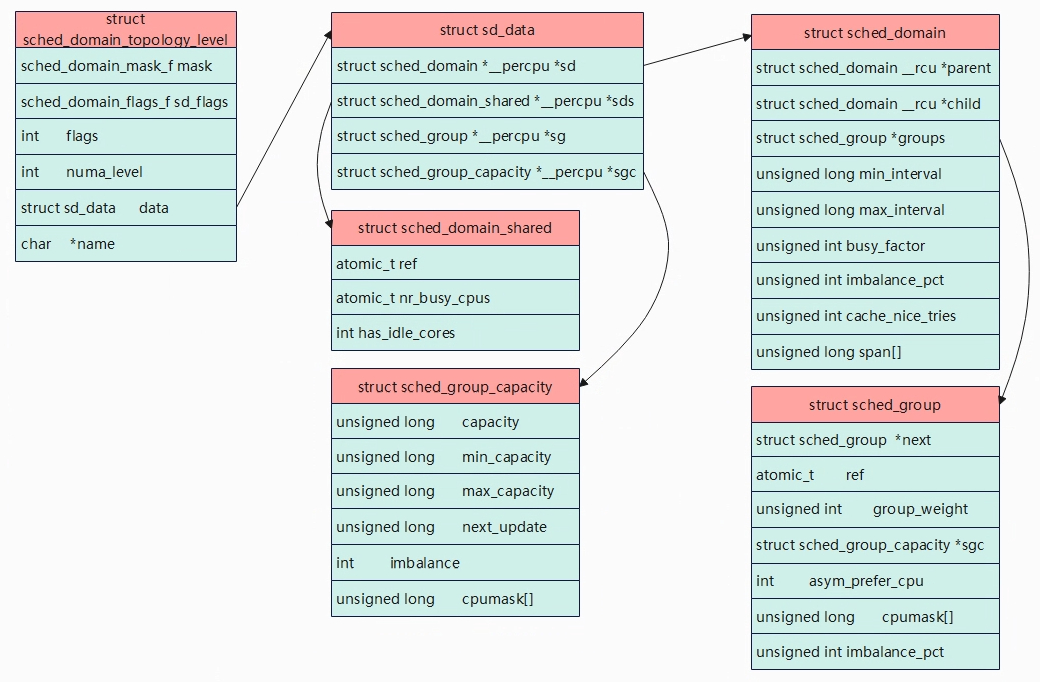
struct sched_domain_topology_level
- mask:函数指针,指定cpumask位图
- sd_flags:函数指针,指定标志位
- flags:进一步描述和设置调度域
- numa_level:NUMA层级,确定该层级为NUMA的那一层
- data:调度域数据结构,存储关于调度域的统计信息
- name:调度域名称
以下是内核默认定义了一个层次结构,DIE是默认打开,MC和SMT是可选的。
static struct sched_domain_topology_level default_topology[] = {
#ifdef CONFIG_SCHED_SMT
{ cpu_smt_mask, cpu_smt_flags, SD_INIT_NAME(SMT) },
#endif
#ifdef CONFIG_SCHED_MC
{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
#endif
{ cpu_cpu_mask, SD_INIT_NAME(DIE) },
{ NULL, },
};
static struct sched_domain_topology_level *sched_domain_topology =
default_topology;
struct sd_data,该结构体中成员都使用percpu来修饰,用于指示该指针是一个per-CPU变量,告诉编译器将变量的内存分配为每个CPU分别保留的独立内存块,如struct sched *__percpu *sd是指向struct sched_domain类型的per-CPU变量,也就是其指向的是一个数组(有cpu个数元素),数组的每个元素是指向一个struct sched_domain类型的指针,每个指针与一个特定的CPU相关联,分配数组是使用alloc_percpu来实现,该函数会分配一个具有相同大小的块,并为每个cpu都分配一个指针。
sd = alloc_percpu(struct sched_domain *),则sd分配了per-CPU变量的内存空间,这意味着每个CPU都有自己独立的struct sched_domain指针变量,当给其每个CPU的指针变量赋值后,后续可以通过sd[cpu]来cpu上的struct sched_domain变量。
- sd[]: 描述CPU的调度域,实际是一个指针数组,每个数组元素指针指向cpu所属的调度域,下同。
- sds[]:存储调度域共享数据,用于描述多个CPU共享的调度域。
- sg[]:每个cpu都有一个指向调度组的指针,用于描述CPU所属的调度组
- sgc[]:调度组的容量信息,用于描述调度组的资源容量。
在系统中,为了避免多核之间的互斥访问影响性能,调度域sched_domain数据结构采用Per-CPU的变量来构建,每个CPU都维护一个调度域数据结构。
struct sched_domain_shared,为了降低锁竞争,sd是per-cpu的,但是有一些信息需要在per-cpu上的sd之间共享,不能在每个sd上构建,这些共享的信息就存储在sds上。
- nr_busy_cpus:该sd中忙的cpu个数。
- has_idle_cores:该sd中是否有idle cpu。
struct sched_group_capacity
- capacity:
- min/max_capacity:
- next_update:
- imbalance:
- cpumask[]
struct sched_domain
- parent和child:调度域会形成层次结构,parent和child建立了不同层级的父子关系。对于base domain而言,其child=NULL,对于顶层domain而言,parent=NULL。
- groups:一个调度域中有若干调度组,这些调到组形成一个环形的链表,groups成员就是链表头。
- flags:调度域的标志,SD_BALANCE_NEWIDLE是否支持newidle balance,SD_SHARE_PKG_RESOURCES是否共享cache等资源。
- span[]:调度域中cpu 核形成的cpu mask,即调度域覆盖的cpu核范围,当前调度域可使用那几个cpu核。
struct sched_group
- next: 调度域中的所有group都会形成一个链表,next指向下一个group。
- ref:该调度组被应用的次数。
- group_weight:调度组中有多少个cpu。
- sgc:调度组的算力信息。
- cpumask:调度组包括那些cpu。
include/linux/cpumask.h
struct cpumask {
DECLARE_BITMAP(bits, NR_CPUS);
//unsigned long bits[1];
}
//NR_CPUS为核心数,以8核,64位系统计算为例。
#define DECLARE_BITMAP(name,bits) \\
unsigned long name[BITS_TO_LONGS(bits)]
#define BITS_TO_LONGS(nr) __KERNEL_DIV_ROUND_UP(nr, BITS_PER_TYPE(long))
#define __KERNEL_DIV_ROUND_UP(n, d) (((n) + (d) - 1) / (d))
#define BITS_PER_TYPE(type) (sizeof(type) * BITS_PER_BYTE)
#define BITS_PER_BYTE 8
(((n) + (d) - 1) / (d)) = (((8) + (64) - 1) / (64)) = 1
struct s_data {
struct sched_domain * __percpu *sd;
struct root_domain *rd;
};
CPU拓扑结构
Linux内核中,通过读取dts文件,建立Topology。
cpus {
#address-cells = <0x02>;
#size-cells = <0x00>;
cpu@0 {
device_type = "cpu";
compatible = "arm,cortex-a55";
reg = <0x00 0x00>;
enable-method = "psci";
cpu-idle-states = <0x02 0x03>;
capacity-dmips-mhz = <0x39a>;
clocks = <0x04 0x01>;
operating-points-v2 = <0x05>;
#cooling-cells = <0x02>;
dynamic-power-coefficient = <0x11e>;
cpu-supply = <0x06>;
phandle = <0x09>;
};
cpu@100 {
device_type = "cpu";
compatible = "arm,cortex-a55";
reg = <0x00 0x100>;
enable-method = "psci";
cpu-idle-states = <0x02 0x03>;
capacity-dmips-mhz = <0x39a>;
clocks = <0x04 0x01>;
operating-points-v2 = <0x05>;
#cooling-cells = <0x02>;
phandle = <0x0a>;
};
cpu@200 {
device_type = "cpu";
compatible = "arm,cortex-a55";
reg = <0x00 0x200>;
enable-method = "psci";
cpu-idle-states = <0x02 0x03>;
capacity-dmips-mhz = <0x39a>;
clocks = <0x04 0x01>;
operating-points-v2 = <0x05>;
#cooling-cells = <0x02>;
phandle = <0x0b>;
};
cpu@300 {
device_type = "cpu";
compatible = "arm,cortex-a55";
reg = <0x00 0x300>;
enable-method = "psci";
cpu-idle-states = <0x02 0x03>;
capacity-dmips-mhz = <0x39a>;
clocks = <0x04 0x01>;
operating-points-v2 = <0x05>;
#cooling-cells = <0x02>;
phandle = <0x0c>;
};
cpu@400 {
device_type = "cpu";
compatible = "arm,cortex-a55";
reg = <0x00 0x400>;
enable-method = "psci";
cpu-idle-states = <0x02 0x03>;
capacity-dmips-mhz = <0x400>;
clocks = <0x04 0x03>;
operating-points-v2 = <0x07>;
#cooling-cells = <0x02>;
dynamic-power-coefficient = <0x162>;
cpu-supply = <0x08>;
phandle = <0x0d>;
};
cpu@500 {
device_type = "cpu";
compatible = "arm,cortex-a55";
reg = <0x00 0x500>;
enable-method = "psci";
cpu-idle-states = <0x02 0x03>;
capacity-dmips-mhz = <0x400>;
clocks = <0x04 0x03>;
operating-points-v2 = <0x07>;
#cooling-cells = <0x02>;
phandle = <0x0e>;
};
cpu@600 {
device_type = "cpu";
compatible = "arm,cortex-a55";
reg = <0x00 0x600>;
enable-method = "psci";
cpu-idle-states = <0x02 0x03>;
capacity-dmips-mhz = <0x400>;
clocks = <0x04 0x03>;
operating-points-v2 = <0x07>;
#cooling-cells = <0x02>;
phandle = <0x0f>;
};
cpu@700 {
device_type = "cpu";
compatible = "arm,cortex-a55";
reg = <0x00 0x700>;
enable-method = "psci";
cpu-idle-states = <0x02 0x03>;
capacity-dmips-mhz = <0x400>;
clocks = <0x04 0x03>;
operating-points-v2 = <0x07>;
#cooling-cells = <0x02>;
phandle = <0x10>;
};
cpu-map {
cluster0 {
core0 {
cpu = <0x09>;
};
core1 {
cpu = <0x0a>;
};
core2 {
cpu = <0x0b>;
};
core3 {
cpu = <0x0c>;
};
};
cluster1 {
core0 {
cpu = <0x0d>;
};
core1 {
cpu = <0x0e>;
};
core2 {
cpu = <0x0f>;
};
core3 {
cpu = <0x10>;
};
};
};
}
上面的dts描述,soc中有8个核心,分为两个cluster,cpu0~cpu3,cpu4~cpu7,因此调度域可以这样划分。
- DIE: cpu 0~7
- MC: cpu 0~3一组,cpu4~7一组。
可以通过 /sys/devices/system/cpu/cpuX/topology节点来获取topology相关信息。
root@TinaLinux:/sys/devices/system/cpu/cpu0/topology# cat *
01 //core_cpus
0 //core_cpus_list
0 //core_id
0f //core_siblings
0-3 //core_siblings_list
01 //die_cpus
0 //die_cpus_list
-1 //die_id
0f //package_cpus
0-3 //package_cpus_list
0 //physical_package_id
01 //thread_siblings
0 //thread_siblings_list
root@TinaLinux:/sys/devices/system/cpu/cpu6/topology# cat *
40 //core_cpus
6 //core_cpus_list
2 //core_id
f0 //core_siblings
4-7 //core_siblings_list
40 //die_cpus
6 //die_cpus_list
-1 //die_id
f0 //package_cpus
4-7 //package_cpus_list
1 //physical_package_id
40 //thread_siblings
7 //thread_siblings_list
在后续章节中,我们都以当前的拓扑结构举例来说明。
创建sd和sg
CPU MASK
#define cpu_possible_mask ((const struct cpumask *)&__cpu_possible_mask)
//系统中有多少个CPU核可以运行
#define cpu_online_mask ((const struct cpumask *)&__cpu_online_mask)
//系统中有多少个CPU核正在运行
#define cpu_present_mask ((const struct cpumask *)&__cpu_present_mask)
//系统中有多少个正处于运行状态的CPU核。
#define cpu_active_mask ((const struct cpumask *)&__cpu_active_mask)
//系统中有多少个活跃的CPU核
#define cpu_dying_mask ((const struct cpumask *)&__cpu_dying_mask)
//系统中有多少个将死的cpu核
如果没有CONFIG_HOTPULG_CPU,那么present=possible,active = online。
int sched_init_domains(const struct cpumask *cpu_map)
{
int err;
zalloc_cpumask_var(&sched_domains_tmpmask, GFP_KERNEL);
zalloc_cpumask_var(&sched_domains_tmpmask2, GFP_KERNEL);
zalloc_cpumask_var(&fallback_doms, GFP_KERNEL);
arch_update_cpu_topology();
asym_cpu_capacity_scan();
ndoms_cur = 1;
doms_cur = alloc_sched_domains(ndoms_cur);
//创建cpumask_var_t类型,存储用于当前调度域的可用的cpu。
if (!doms_cur)
doms_cur = &fallback_doms;
cpumask_and(doms_cur[0], cpu_map, housekeeping_cpumask(HK_FLAG_DOMAIN));
//cpu_map为cpu_active_mask,在active中排除掉不能用于调度域的cpu,isolcpus对某些//cpu进行的隔离,不参与调度域中,doms_cur最终保存的排除之后可用调度域的cpu。
err = build_sched_domains(doms_cur[0], NULL);
//调度域建立。
return err;
}
为DIE和MC分配每CPU的sd/sdc/sg/sgc空间
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
enum s_alloc alloc_state = sa_none;
struct sched_domain *sd;
struct s_data d;
......
//分配DIE,MC SDTL拓扑相关数据结构,初始化一个struct s_data;
alloc_state = __visit_domain_allocation_hell(&d, cpu_map);
......
}
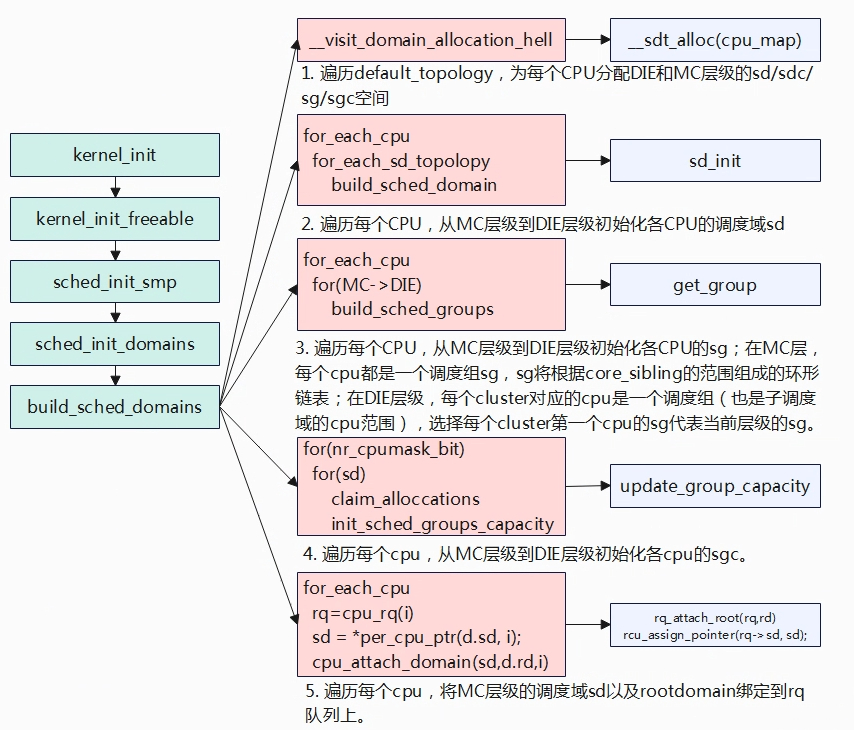
build_shed_domains函数中首先调用__visit_domain_allocation_hell为每个cpu分配各个调度域层级(DIE/MC)分配sd/sdc/sg/sgc。
struct sched_domain_topology_level {
sched_domain_mask_f mask;
sched_domain_flags_f sd_flags;
int flags;
int numa_level;
struct sd_data data;
#ifdef CONFIG_SCHED_DEBUG
char *name;
#endif
};
//定义了一个static struct sched_domain_topology_level default_topology[]全局变量。
static struct sched_domain_topology_level default_topology[] = {
#ifdef CONFIG_SCHED_SMT
{ cpu_smt_mask, cpu_smt_flags, SD_INIT_NAME(SMT) },
#endif
#ifdef CONFIG_SCHED_MC
{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
#endif
{ cpu_cpu_mask, SD_INIT_NAME(DIE) },
{ NULL, },
};
内核定义了一个全局变量static struct sched_domain_topology_level default_topology[],该变量根据宏配置调度域的层次,DIE调度域是默认开启的,往下是MC调度域,再到SMT调度域,由于ARM架构SMT调度目前见得还比较少,所以再不考虑,build_shed_domains得核心就是各层级得SDTL。
static enum s_alloc
__visit_domain_allocation_hell(struct s_data *d, const struct cpumask *cpu_map)
{
memset(d, 0, sizeof(*d));
//为全局struct sched_domain_topology_level default_topology[]的DIE和MC分配对应的
//per-CPU sd/sds/sg/sgc
if (__sdt_alloc(cpu_map))
return sa_sd_storage;
//为每个CPU分配了一个调度域,作用是用户存储最底层(MC)的sd,也就是每个CPU 的
//d->sd指向MC的sd,这只是临时分配,用于在建立sg的时候辅助使用,后续会销毁。
d->sd = alloc_percpu(struct sched_domain *);
if (!d->sd)
return sa_sd_storage;
//分配一个rootdomain并进行初始化,主要用于rt的?
d->rd = alloc_rootdomain();
if (!d->rd)
return sa_sd;
return sa_rootdomain;
}
__visist_domain_allocation_hell调用__sdt_alloc,分配SDTL中的struct sd_data data并进行初始化。
struct sd_data {
struct sched_domain *__percpu *sd;
struct sched_domain_shared *__percpu *sds;
struct sched_group *__percpu *sg;
struct sched_group_capacity *__percpu *sgc;
};
sd_data的成员都是__percpu类型,需要先调用alloc_percpu分配相同大小的cpu个数区域,这些区域存储的是指针,指向每个cpu对应的sd/sds/sg/sgc,以struct sched_domain *__percpu *sd为例,sdd->sd = alloc_percpu(struct sched_domain *)分配一块指针数组,数组元素的个数为cpu核个数,sd指向这个指针数组,数组中的指针用于后续每个CPU指向分配的sd空间。
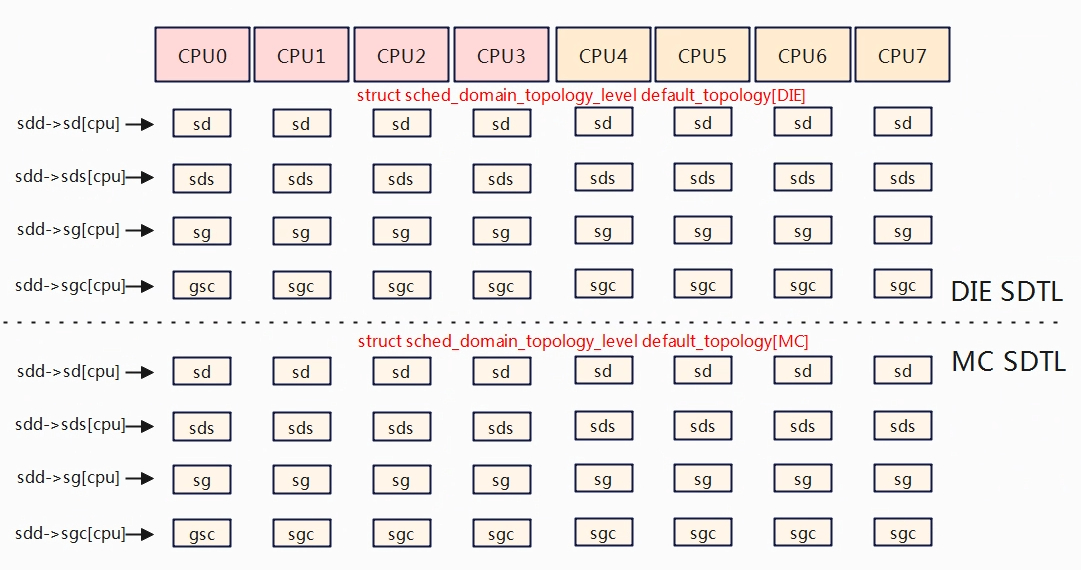
static int __sdt_alloc(const struct cpumask *cpu_map)
{
struct sched_domain_topology_level *tl;
int j;
//遍历SDTL,这里有MC和DIE。
for_each_sd_topology(tl) {
struct sd_data *sdd = &tl->data;
//分配当前层级调度域sd Per-CPU变量(指针数组,数组元素为cpu个数指针,下同)
sdd->sd = alloc_percpu(struct sched_domain *);
if (!sdd->sd)
return -ENOMEM;
//分配当前层级sdc Per-CPU变量
sdd->sds = alloc_percpu(struct sched_domain_shared *);
if (!sdd->sds)
return -ENOMEM;
//分配当前层级sg Per-CPU变量
sdd->sg = alloc_percpu(struct sched_group *);
if (!sdd->sg)
return -ENOMEM;
//分配当前层级sgc Per-CPU变量
sdd->sgc = alloc_percpu(struct sched_group_capacity *);
if (!sdd->sgc)
return -ENOMEM;
//上面已经完成当前层级Per-CPU变量,下面就遍历每个cpu分配sd/sds/sg/sgc,Per-CPU
//遍历将一一对应指向。
for_each_cpu(j, cpu_map) {
struct sched_domain *sd;
struct sched_domain_shared *sds;
struct sched_group *sg;
struct sched_group_capacity *sgc;
sd = kzalloc_node(sizeof(struct sched_domain) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
if (!sd)
return -ENOMEM;
*per_cpu_ptr(sdd->sd, j) = sd;
//如对应cpu0来说,sdd-sd[0] = sd,sdd-sd[0]是一个指针,指向当前分配的sd空间。
sds = kzalloc_node(sizeof(struct sched_domain_shared),
GFP_KERNEL, cpu_to_node(j));
if (!sds)
return -ENOMEM;
*per_cpu_ptr(sdd->sds, j) = sds;
sg = kzalloc_node(sizeof(struct sched_group) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
if (!sg)
return -ENOMEM;
sg->next = sg;
*per_cpu_ptr(sdd->sg, j) = sg;
sgc = kzalloc_node(sizeof(struct sched_group_capacity) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
if (!sgc)
return -ENOMEM;
*per_cpu_ptr(sdd->sgc, j) = sgc;
}
}
return 0;
}
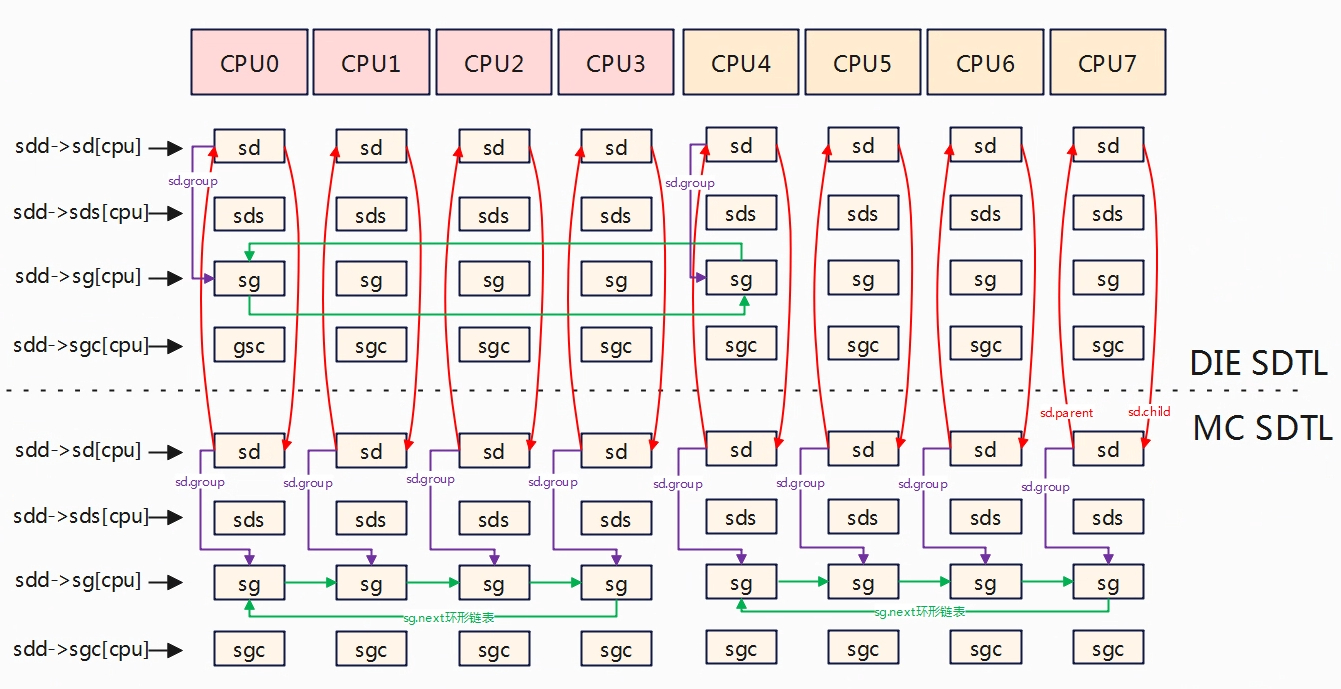
执行完__sdt_alloc,层次结构就如下所示,如对应DIE层次,sdd-sd[0~7]分别指向各自cpu分配的sd区域。
初始化调度域sd
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
enum s_alloc alloc_state = sa_none;
struct sched_domain *sd;
struct s_data d;
struct rq *rq = NULL;
int i, ret = -ENOMEM;
bool has_asym = false;
........
//遍历每个CPU,从下往上初始化SDTL的sd,先初始化MC再初始化DIE。
// DIE的sd 其child指向MC的sd,MC的sd 其parent指向DIE的sd。
for_each_cpu(i, cpu_map) {
struct sched_domain_topology_level *tl;
sd = NULL;
for_each_sd_topology(tl) {
if (WARN_ON(!topology_span_sane(tl, cpu_map, i)))
goto error;
//初始化调度域
sd = build_sched_domain(tl, cpu_map, attr, sd, i);
has_asym |= sd->flags & SD_ASYM_CPUCAPACITY;
if (tl == sched_domain_topology)
*per_cpu_ptr(d.sd, i) = sd;
//将最低层级的sd保存到s_data.sd的per_cpu变量中,最底层为MC level的sd
//为下一步建立sg做准备。
if (tl->flags & SDTL_OVERLAP)
sd->flags |= SD_OVERLAP;
if (cpumask_equal(cpu_map, sched_domain_span(sd)))
break;
//sched_domain_span(sd)用于获取给定调度域sd的范围cpu,也就是说当前调度域
//中覆盖的cpu是那几个。
//调度域都有一个范围,表示该调度域可以管理的CPU范围,这个范围通常有一
//个cpumask表示,其中每个位都对应一个cpu,调度域的范围定义了该调度域影//响的cpu集合。
}
}
........
}
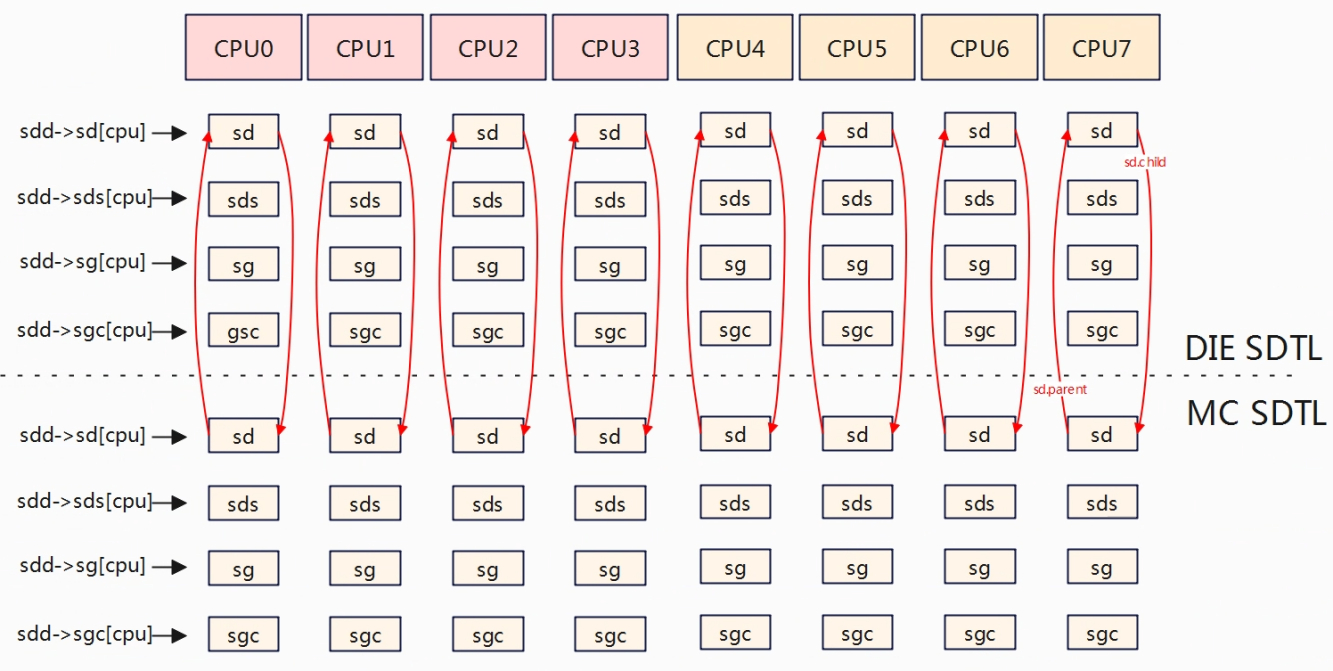
for_each_cpu遍历每一个cpu,接着for_each_sd_topology(tl)对每个cpu从最底层依次往上构建调度域,先构建MC再DIE。build_sched_domain中会调用sd_init对调度域进行初始化,主要是struct sched_domain结构体成员赋值,同时建立起MC与DIE层级sd的父子联系,如下对于DIE层级,每cpu的sd.child指向MC层级的sd,而MC层级sd.parent指向DIE层级的sd。在初始化调度域是会设置其span,span为调度域作用的cpu范围,实际是根据span的作用范围来对当前调度域层级进行分组。如MC层级,按照4.2.1.2的拓扑结构,有两个MC调度域名,CPU0~CPU3是一组,所以CPU0~CPU3的sd->span是相同的,CPU4~CPU7是一组,所以CPU4~CPU7的sd->span相同的。sd->span非常重要,在后续章节中也会使用该信息来建立sg之间的联系。
初始化调度组sg
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
enum s_alloc alloc_state = sa_none;
struct sched_domain *sd;
struct s_data d;
struct rq *rq = NULL;
int i, ret = -ENOMEM;
bool has_asym = false;
........
/* Build the groups for the domains */
for_each_cpu(i, cpu_map) {
//d.sd是最底层得调度域,这里是MC,即每cpu的sd
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
sd->span_weight = cpumask_weight(sched_domain_span(sd));
if (sd->flags & SD_OVERLAP) {
if (build_overlap_sched_groups(sd, i))
goto error;
} else {
if (build_sched_groups(sd, i))
goto error;
}
}
}
........
}
for_each_cpu遍历每个cpu,for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent)遍历当前cpu的调度域,从MC调度域往上开始,调用build_sched_groups构建当前调度域的调度组。
static int
build_sched_groups(struct sched_domain *sd, int cpu)
{
struct sched_group *first = NULL, *last = NULL;
struct sd_data *sdd = sd->private;
const struct cpumask *span = sched_domain_span(sd);
//获取当前调度域的cpu作用范围,对于DIE层级,span是cpu0~cpu7而对于MC层级
//span是core_siblings,即cpu0~cpu3或cpu4~cpu7。
struct cpumask *covered;
int i;
lockdep_assert_held(&sched_domains_mutex);
covered = sched_domains_tmpmask;
cpumask_clear(covered);
//从当前cpu开始遍历整个sd span。
for_each_cpu_wrap(i, span, cpu) {
struct sched_group *sg;
if (cpumask_test_cpu(i, covered))
//已经在coverd msk中的cpu,继续执行,与下面的cpumask_or配合,避免重复指向。
continue;
//获取cpu i的调度组sg
sg = get_group(i, sdd);
cpumask_or(covered, covered, sched_group_span(sg));
//coverd = coverd | sched_group_span(sg)
if (!first)
first = sg;//每个cpu进来的第一个sg
if (last)
last->next = sg;//每个sg的下一个sg
last = sg;
}
last->next = first; //最后一个sg再指向第一个sg,就形成环形链表了。
sd->groups = first; //sd->groups指向第一个sg,对于MC是自己的sg
return 0;
}
在MC调度域层级,根据调度域sd->span定义的cpu范围内的sg形成环形链表,下面就是两个环形链表,对应的就是MC调度域层级的两个调度域实体。
在DIE区域,sg取的是子调度域所在的第一个cpu,即cpu0所在的sg和cpu4所在的sg。
static struct sched_group *get_group(int cpu, struct sd_data *sdd)
{
struct sched_domain *sd = *per_cpu_ptr(sdd->sd, cpu);
struct sched_domain *child = sd->child;
struct sched_group *sg;
bool already_visited;
if (child)
cpu = cpumask_first(sched_domain_span(child));
//如果调度域存在子调度域,则cpu获取子调度域的第一个cpu,只有DIE层级才有子调度//域,所以这里是cpu0或cpu4
sg = *per_cpu_ptr(sdd->sg, cpu); //获取当前层级cpu上的sg
sg->sgc = *per_cpu_ptr(sdd->sgc, cpu);//获取当前层级cpu上的sgc,将sg->sgc指向sgc
/* Increase refcounts for claim_allocations: */
already_visited = atomic_inc_return(&sg->ref) > 1;
/* sgc visits should follow a similar trend as sg */
WARN_ON(already_visited != (atomic_inc_return(&sg->sgc->ref) > 1));
/* If we have already visited that group, it\'s already initialized. */
if (already_visited)
return sg;
//如果是DIE层级
if (child) {
cpumask_copy(sched_group_span(sg), sched_domain_span(child));
//将子调度域的cpu范围赋值到调度组sg的cpu范围,子sd->span = 父sg->cpumask
cpumask_copy(group_balance_mask(sg), sched_group_span(sg));
//将调度组sg的cpu范围赋值到sg的平衡掩码balance mask
} else {
cpumask_set_cpu(cpu, sched_group_span(sg));
//将cpu添加到调度组sg的cpu范围中
cpumask_set_cpu(cpu, group_balance_mask(sg));
//将cpu添加到调度组sg平衡掩码中
}
sg->sgc->capacity = SCHED_CAPACITY_SCALE * cpumask_weight(sched_group_span(sg));
//计算调度组能力。
sg->sgc->min_capacity = SCHED_CAPACITY_SCALE;
sg->sgc->max_capacity = SCHED_CAPACITY_SCALE;
return sg;
}
MC层级基本是一个cpu对应一个调度组sg,而对于DIE层级一个cluster对应一个调度组,调度组表示一般选择每个cluster的第一个cpu,该sg代表的不是一个cpu,而是整个cluster上的cpu,所以cpu上的sg->cpumask为子调度域的sd->span。
构建调度组能力sgc
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
......
/* Calculate CPU capacity for physical packages and nodes */
//遍历每个CPU,从大到小开始遍历,然后依次遍历MC到DIE,初始化sg的cpu_capacity
for (i = nr_cpumask_bits-1; i >= 0; i--) {
if (!cpumask_test_cpu(i, cpu_map))
continue;
//还是从底层MC开始往上遍历,初始化sgc
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
claim_allocations(i, sd);
init_sched_groups_capacity(i, sd);
}
}
......
}
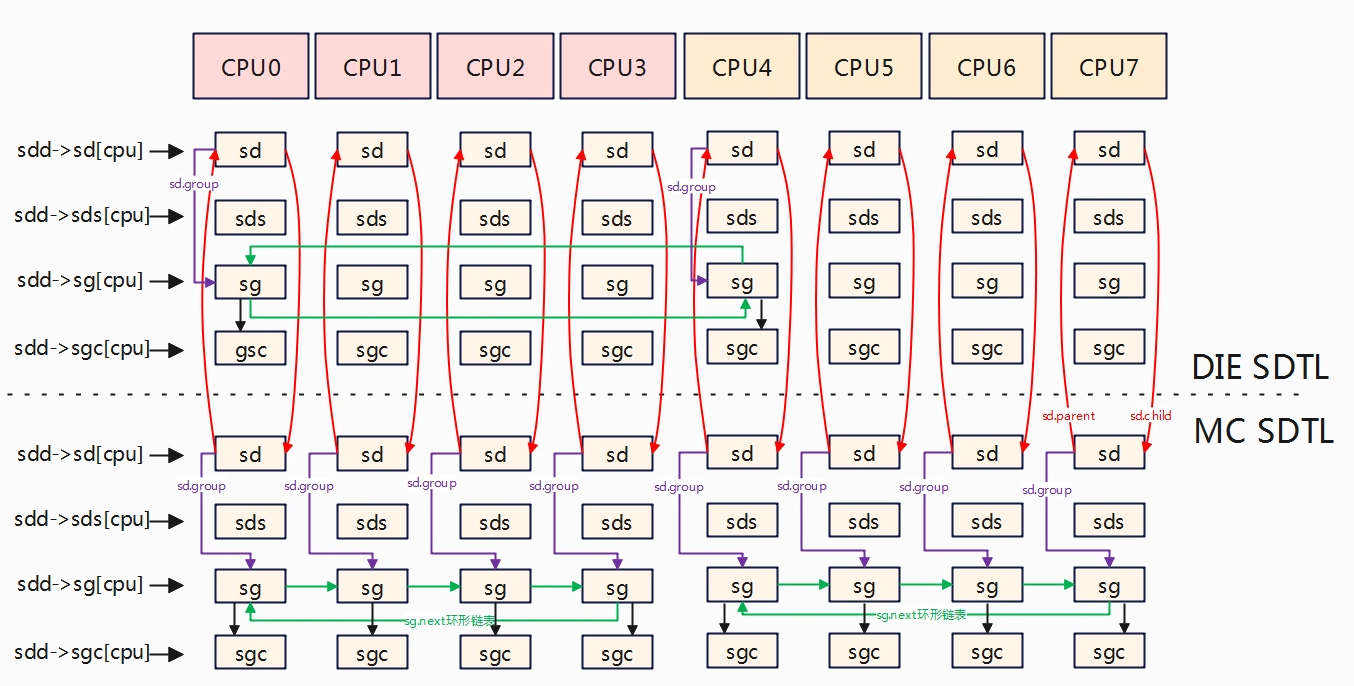
遍历每个cpu,然后从MC层级往上到DIE层级,初始化每cpu各层级的sgc。
static void init_sched_groups_capacity(int cpu, struct sched_domain *sd)
{
struct sched_group *sg = sd->groups;
WARN_ON(!sg);
//循环,对sg环形链表中所有的sg->group_weight进行初始化。
do {
int cpu, max_cpu = -1;
sg->group_weight = cpumask_weight(sched_group_span(sg));
if (!(sd->flags & SD_ASYM_PACKING))
goto next;
for_each_cpu(cpu, sched_group_span(sg)) {
if (max_cpu < 0)
max_cpu = cpu;
else if (sched_asym_prefer(cpu, max_cpu))
max_cpu = cpu;
}
sg->asym_prefer_cpu = max_cpu;
next:
sg = sg->next;
} while (sg != sd->groups);
if (cpu != group_balance_cpu(sg))
return;
update_group_capacity(sd, cpu); //更新group 的capacity。
}
将每cpu的MC层级sd、rootdomain与cpu rq绑定
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
......
//遍历每个cpu,获取最底层的调度域MC,将其与d.rd以及cpu rq绑定起来
for_each_cpu(i, cpu_map) {
rq = cpu_rq(i);
sd = *per_cpu_ptr(d.sd, i);
/* Use READ_ONCE()/WRITE_ONCE() to avoid load/store tearing: */
if (rq->cpu_capacity_orig > READ_ONCE(d.rd->max_cpu_capacity))
WRITE_ONCE(d.rd->max_cpu_capacity, rq->cpu_capacity_orig);
cpu_attach_domain(sd, d.rd, i);
}
......
}
for_each_cpu遍历所有cpu,sd = *per_cpu_ptr(d.sd, i)获取的是MC层级的调度域,最后调用cpu_attach_domain进行绑定。
static void
cpu_attach_domain(struct sched_domain *sd, struct root_domain *rd, int cpu)
{
......
sched_domain_debug(sd, cpu);
rq_attach_root(rq, rd); // 将新的root domain与cpu rq绑定,rd->rd = rd。
tmp = rq->sd;
rcu_assign_pointer(rq->sd, sd); //将新的sd与rd->sd 绑定
dirty_sched_domain_sysctl(cpu);
destroy_sched_domains(tmp);
update_top_cache_domain(cpu);
}
将每个cpu的MC层级的调度域sd赋值给当前cpu调度队列的rq->sd,将root domain 赋值为当前cpu调度队列的rq->rd。
总结:
- 根据CPU架构的层次,从下到上,分为MC层级->DIE层级,每个层级使用struct sched_domain_topology_levels(SDTL)数据结构描述。
- 考虑多核的锁竞争访问,每层级SDTL为每个cpu定义了sd/sds/sg/sgc数据结构。
- 在同一层级(如MC层级)由SOC架构(DTS描述)来确定那些是兄弟关系(core_siblings),兄弟关系在调度域sd中使用sd->span来描述,在调度组中sg中使用sg->cpumask来描述,属于兄弟关系的cpu核属于一个调度域。DIE层级的sg->cpumask = MC层级sd->span。
- 对于MC层级来说每个cpu就是一个调度组sg,兄弟关系的sg归属为一个调度域,该调度域的sg形成一个环形链表,但不同cpu指向的环形链表首元素是不同的,首元素指向的都是自己cpu所在的sg,如cpu0的链表顺序是(0,1,2,3),cpu1的链表顺序是(1,2,3,0)。
- 对于DIE层级来说每个cluster是一个调度组,每个调度组有多个cpu,调度组覆盖的cpu范围子调度域的cpu覆盖范围,也可以认为是每个cluster的cpu范围。同时调度组选取的是子调度域cpu范围的第一顺序cpu作为调度组,也可以认为是每个cluster的第一个cpu。
- 对于DIE层其每cpu的调度域sd.child指向下一级MC层每cpu调度域sd,而MC层其每cpu调度域sd.parent指向上一级DIE层每cpu调度域sd。
- 负载均衡时会优先从最底层级进行均衡,从下往上意味着可选择的cpu会越来越多,但是均衡的代价也会越来越大。