负载均衡之负载跟踪
各任务负载、各cpu的算力(频率+架构)、任务迁移开销(调度域,调度组)。
root@Linux:/# cat /proc/loadavg
3.49 3.43 3.54 4/131 3065
cat /proc/loadavg可以获取CPU全局平均负载,前面的三个值分别表示为1分钟、5分钟、15分钟系统平均负载,第四个字段正在运行的进程数量/总进程数量,第五个字段最后一个运行的进程ID。
公式①:CPU负载=就绪队列总权重
早期系统计算系统负载是所有CPU上就绪队列的总权重,但是使用权重来计算是比较局限的,因为负载考虑的是对CPU资源占用情况,而权重高的进程可能并不一定会一直运行,或许运行一会就一直睡眠,因此使用就绪队列的总权重并不合理。
在权重的基础上进行演化,从全局考虑整体就绪队列到追踪每一个调度实体对CPU资源的占用,从而调度器有更精细的控制。在一段时间内,将每个任务可运行时间考虑进去(可运行表示处于就绪队列中,但并不是在执行),这样就能够代表任务对CPU的资源占用情况。
公式②:load = weight * t /T
采样一段时间T,任务处于运行状态时间为t,该任务对CPU的负载可运行时间与采样时间的比值再与权重相乘。
公式②看起来是比较合理,但是仍然存在问题,考虑一些场景,假设相同优先级A任务和B任务在某天同一时刻启动,A任务运行了半天就一直睡眠,而B任务一启动就睡眠半天,然后一直运行。按照公式②的计算A和B的负载是一样的,显然不合理,在最近的这段时间内任务B的负载要高于A,因此基于公式再进行了演化,加入历史运行情况的参数。
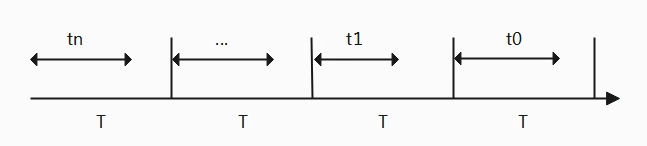
公式③:load = weight * (t0*y^0+ t1*y^1 + t2*y^2+...+tn*y^n)/T
负载计算将历史运行因素考虑进去,但是历史因素的因素有一个衰减(decay)过程,也就是说离当前最近的影响最大,离当前时间越远影响程度越小,所以衰减因子y^32=0.5。为了便于系统计算对公式在进行了量化,采样周期为1ms,所以公式为
公式④L = L0 + L1*y^1 + L2*y^2 + L3* y^3 +.... Ln*y^n。
下面是描述调度实体或就绪队列的负载信息。
struct sched_avg {
u64 last_update_time;
u64 load_sum;
u64 runnable_sum;
u32 util_sum;
u32 period_contrib;
unsigned long load_avg;
unsigned long runnable_avg;
unsigned long util_avg;
struct util_est util_est;
} ____cacheline_aligned;
- last_update_time: 上次更新负载信息的时间点,可用于计算差值。
- load_sum:调度实体来说是任务累计历史衰减总时间,包括running+runnable+blocked,对于调度队列来说是其所有任务累计工作总负载,前者统计的仅仅是时间,后者是工作负载即时间乘权重。
- runnable_sum: 调度实体来说是running+runnable累计历史衰减总时间,
- util_sum:调度实体来说正在运行状态下的累计衰减总时间,调度队列来说其所有正在运行任务的总时间。
- period_contrib: 存放着上一次时间采样时,不能凑成一个周期的剩余时间。
- _avg/util_avg:根据_sum计算得到的负载均值。
- util_est:辅助计算阻塞之前load avg信息。
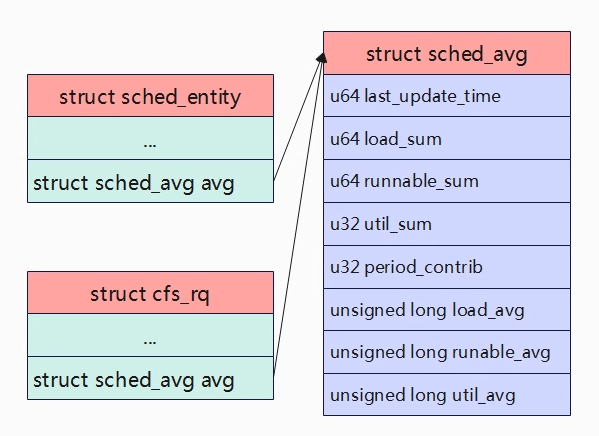
上面是struct cfs_rq/struct sched_entity 与struct sched_avg之间的关系,也就是说在计算负载时有调度实体的负载和就绪队列的负载。
/*
* sched_entity:
*
* task:
* se_weight() = se->load.weight
* se_runnable() = !!on_rq
*
* group: [ see update_cfs_group() ]
* se_weight() = tg->weight * grq->load_avg / tg->load_avg
* se_runnable() = grq->h_nr_running
*
* runnable_sum = se_runnable() * runnable = grq->runnable_sum
* runnable_avg = runnable_sum
*
* load_sum := runnable
* load_avg = se_weight(se) * load_sum
*
* cfq_rq:
*
* runnable_sum = \\Sum se->avg.runnable_sum
* runnable_avg = \\Sum se->avg.runnable_avg
*
* load_sum = \\Sum se_weight(se) * se->avg.load_sum
* load_avg = \\Sum se->avg.load_avg
*/
PELT基本原理
公式④L = L0 + L1*y^1 + L2*y^2 + L3* y^3 +.... Ln*y^n。


在计算负载时,计算时刻并不能这么精确,这次计算的时间距离上一次计算负载的时间跨越了多个周期,如上图所示,last_update_time时刻表示上一次计算负载,而这次计算的负载为now时刻。时间可以分为3段d1、d2、d3,之所以这样划分当前计算时刻与上一次计算负载的时刻并不一定落在周期点。假设last_update_time时刻的计算出来的负载为,根据划分的3段,因此系统的负载计算为:Llast,先不考虑权重,那么当前时刻负载为:
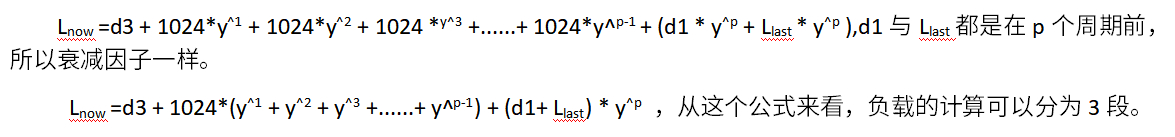
从这个公式来看,负载的计算可以分为3段。
val*y^p计算
先来看(d1+ Llast) * y^p 中代码的实现,由于y^p 的值是浮点,为了避免浮点运算可以转化为y^p = y^p * 2^32 >> 32,相当于先乘以2^32 再右移32(右移就是除),而y^p * 2^32 再系统中提前计算好了存放再数组runable_avg_yN_inv中,如下:
static const u32 runnable_avg_yN_inv[] __maybe_unused = {
0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6,
0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85,
0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581,
0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9,
0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80,
0x85aac367, 0x82cd8698,
};

//计算val * y^n,y^32 = 0.5。
static u64 decay_load(u64 val, u64 n)
{
unsigned int local_n;
//经过LOAD_AVG_PERIOD * 63周期后,就衰减为0了
if (unlikely(n > LOAD_AVG_PERIOD * 63))
return 0;
/* after bounds checking we can collapse to 32-bit */
local_n = n;
//如果衰减周期大于32,则计算方式有调整如下,反之直接查表,
//val * y^p =val * (y^32)^(p/32) * y^(p%32) * 2^32 >>32, p=p/32 + p%32,
//而y^32=1/2,所以val * (y^32)^(p/32) =val >> (p/32),
//y^(p%32) * 2^32 就先计算p%32,然后从runnable_avg_yN_inv表中查询。
if (unlikely(local_n >= LOAD_AVG_PERIOD)) {
val >>= local_n / LOAD_AVG_PERIOD; //val * (y^32)^(p/32) =val >> (p/32)
local_n %= LOAD_AVG_PERIOD; //p%32,便于从runnable_avg_yN_inv查询
}
val = mul_u64_u32_shr(val, runnable_avg_yN_inv[local_n], 32);
//val * runnable_avg_yN_inv[local_n] >> 32
return val;
}
1024*(y^1 + y^2 +……+ y^p-1)计算
由等比求和公式
y^p + y^p+1 + y^P+2 +......+ y^p+n=(y^p-y^p+n+1)/(1-y),
得
y^1 + y^2 + y^3 +......+ y^p-1 =( y^1-y^p) / (1-y) =( 1-y^p) / (1-y) - (1-y)/(1-y)=( 1-y^p) / (1-y)-1
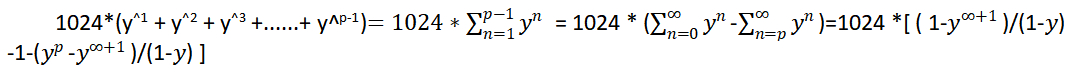
因为0<y<1,所以当趋于0(体验下什么叫做0.99^n和1.11^n),所以上面的公式再次简化为如下:

代码实现
Lnow =d3 + 1024*(y^1 + y^2 + y^3 +......+ y^p-1) + (d1+ Llast) * y^p
= Llast * y^p(step1)+ [d1 * y^p + LOAD_AVG_MAX - *LOAD_AVG_MAX - 1024 + d3](step2)
accumulate_sum是计算负载的核心函数,计算的负载结果并不是会增加而有可能是减少,负载的变化都在这个函数中实现,当调度实体没有在就绪队列时,随着时间的增加其对CPU的负载会逐渐减弱,而如果调度实体在就绪队列时,对CPU的负载就会逐渐增加。
static __always_inline u32
accumulate_sum(u64 delta, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u32 contrib = (u32)delta; /* p == 0 -> delta < 1024 */
u64 periods;
// sa->period_contrib是上次更新负载不足1024us周期的时间,delta是上次更新负载到现在要计算负载经过的时间,要计算有多少个周期需要加上period_contrib,见4.1.1的图。
delta += sa->period_contrib;
periods = delta / 1024; /* A period is 1024us (~1ms) */
/*
* Step 1: decay old *_sum if we crossed period boundaries.
*/
if (periods) {
//step1: 分别计算 Llast * y^p,历史负载的衰减
sa->load_sum = decay_load(sa->load_sum, periods);
sa->runnable_sum =
decay_load(sa->runnable_sum, periods);
sa->util_sum = decay_load((u64)(sa->util_sum), periods);
/*
* Step 2
*/
delta %= 1024;
//当load=0时,说明当前的调度实体不处于running或runnable,因此不需要计算新增负载负载贡献,而只计算负载衰减,过了一段时间周期,一直没得到运行,累计的负载衰减step1的操作就是衰减。
//step2: 计算[d1 * y^p + LOAD_AVG_MAX - *LOAD_AVG_MAX - 1024 +d3],period即P。
//当load !=0,说明调度实体处于running或runnable,就需要计算增加的负载贡献。
if (load) {
//d1= 1024 - sa->period_contrib, d3=delta % 1024。
contrib = __accumulate_pelt_segments(periods,
1024 - sa->period_contrib, delta);
}
}
//更新不足一个周期贡献值
sa->period_contrib = delta;
if (load)
sa->load_sum += load * contrib;
if (runnable)
sa->runnable_sum += runnable * contrib << SCHED_CAPACITY_SHIFT;
if (running)
sa->util_sum += contrib << SCHED_CAPACITY_SHIFT;
return periods;
}

static u32 __accumulate_pelt_segments(u64 periods, u32 d1, u32 d3)
{
u32 c1, c2, c3 = d3; /* y^0 == 1 */
c1 = decay_load((u64)d1, periods); //计算d1 * y^p
c2 = LOAD_AVG_MAX - decay_load(LOAD_AVG_MAX, periods) - 1024;
//计算LOAD_AVG_MAX - *LOAD_AVG_MAX - 1024
return c1 + c2 + c3;
}
负载更新
负载使用的是struct sched结构体来进行描述,负载的描述对象分为调度实体se负载(包含group se和task se)和调度实体所在的就绪队列cfs_rq负载。cfs_rq的负载可以先简单的理解为是其队列中所有调度实体se的贡献,当然不能简单是相加关系,需要考虑权重、cpu算力等因素,顶层的cfs_rq负载实际就等于CPU的负载。
追踪调度实体se的负载是基础,当调度实体se的负载变化时进而也会影响到其所在cfs_rq队列的负载变化,cfs_rq.load = f(se.load),负载更新的核心函数使用update_load_avg来实现,因此本小结主要就是围绕该函数进行解读。
负载的更新实际是基于某个时间刻进行计算,对于一个调度实体来说其有不同的运行状态,每个状态对CPU的负载计算是不相同的。
– 当一个任务处于running(正在运行)或runnable(就绪队列中)时,那么对系统的负载计算是贡献的,因此负载需要在原来的基础上(上一个时刻的负载衰减值)加上当前新增的贡献负载,也就是说任务处于就绪队列或者正在运行对于CPU来说就是有负荷的。
– 当一个任务没有正运行或没有处于就绪队列中如处于睡眠态,那么也要考虑其任务的历史负载,睡眠的任务必然是此前运行过因为得不到某个资源而从就绪队列中移除,而该任务此前的任务负载也需要考虑进去,只不过会随着时间的增加,任务的负载会不断的衰减,最终趋于0(要是中间没有再次运行)。
如下图负载更新可以分为四部分,触发负载更新,更新task和所属cfs_rq平均负载,负载、运行负载、利用率计算,group se负载传播,本章节会按这四个部分依次展开。
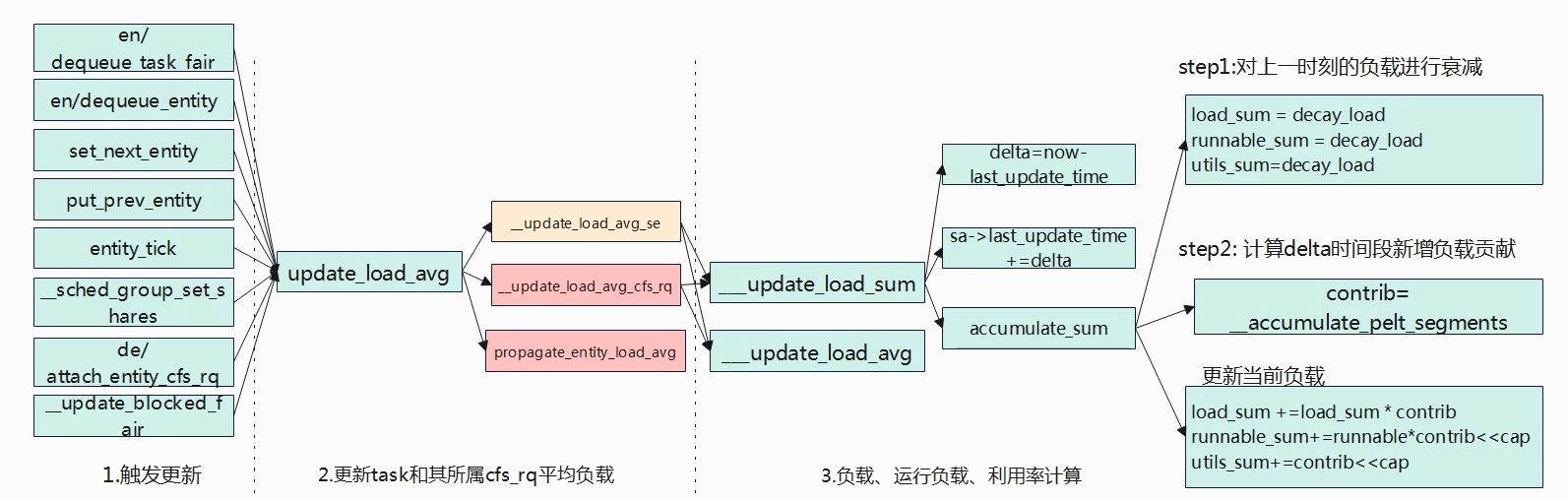
触发负载更新
- en/dequeue_task_fair:任务被唤醒/睡眠、CPU/Cgroup迁移、任务调度参数变化等会导致任务出入队变化就会触发负载更新。
- set_next_entity:进程切换设置下一个要运行的任务。
- put_prev_entity:进程切换将被抢占的任务重新放入队列。
- entity_tick:周期性的tick触发。
- __sched_group_set_shares:修改task group的调度参数。
- de/attach_entity_cfs_rq:唤醒新创建任务、非CFS调度类切换CFS调度类等,cfs_rq在cgroup的迁移等等。
上面列出了一部分场景会触发负载更新,如任务的出入队列、设置下一个要运行的任务、被抢占的任务重新入队、周期性调度更新等,下面以几个场景来进行说明。
(1)任务入队enqueue_task_fair->enqueue_entity。
static void
enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
......
for_each_sched_entity(se) {
...
if (se->on_rq) break;
enqueue_entity(cfs_rq, se, flags);
...
}
//se入队所属cfs_rq,并向上遍历直到对应的组调度实体被加入到cfs_rq为止(se要调度,//其父实体也必须入队),enqueue_entity中会更新一次负载,见下,此次的负载更新主要//负责从下到上对应的父调度实体加入到就绪队列为止,再往上就调用下面的code来进行//更新了,如下图示例只更新到cfs_rq2层级权重。
for_each_sched_entity(se) {
update_load_avg(cfs_rq, se, UPDATE_TG);
se_update_runnable(se); //更新se所属cfs_rq上的任务数量,负载跟该值也有关系。
update_cfs_group(se);
}
//这里就是补全了再往上层级剩余部分se和cfs_rq负载信息,如下如更新cfs_rq1+cfs_rq0
//权重
....
}
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
......
update_load_avg(cfs_rq, se, UPDATE_TG | DO_ATTACH);
//更新load avg多传递了一个DO_ATTACH的flag,当一个任务从一个队列迁移到一个新队
//列,那么PELT的层级结构发生了变化,这时候需要负载的传播过程。
se_update_runnable(se);
update_cfs_group(se);
account_entity_enqueue(cfs_rq, se);
....
}
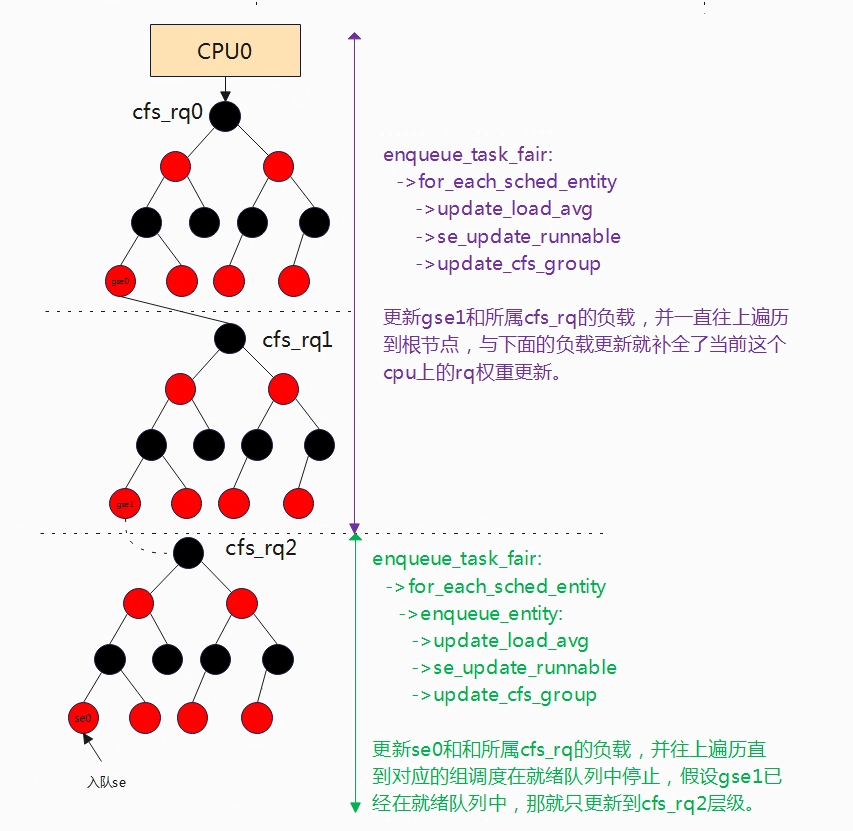
当调度实体se入队时,自然调度实体se的负载是要更新的,又因为se所属的cfs_rq是其下所有se的负载和,所以当其他se变化时,那么cfs_rq的负载也需要做对应的更新,所以可以在update_load_avg函数中可以看到会先更新se再更新se所属的cfs_rq。而在一个cpu的调度队列中,由于组调度的引入,会有多个层级的情况,因此当最底层的se变化时,对应的cfs_rq变化继而在影响上一层级gse变化,再影响ges所属cfs_rq的变化直到最顶层。简而言之,最底层的se和cfs_rq负载变化会导致上一层的se(gse)和cfs_rq负载也随之变化,直至顶层的cfs_rq。
(2)任务出队dequeue_task_fair->dequeue_entity。
这是入队的逆过程,
static void
dequeue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
......
for_each_sched_entity(se) {
...
dequeue_entity(cfs_rq, se, flags);
...
}
for_each_sched_entity(se) {
update_load_avg(cfs_rq, se, UPDATE_TG);
se_update_runnable(se);
update_cfs_group(se);
}
....
}
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
......
update_load_avg(cfs_rq, se, UPDATE_TG);
//更新调度实体及所属cfs_rq的负载
se_update_runnable(se);
//如果是group se,任务已经出队(如进入阻塞状态),那么其runnable_weight需要更新。
//因为对于group se,只有在计算runnable_sum才会考虑任务数量,但是任务已经出队了
//就不再是runnable状态了,是block或者dead状态了。
//这里并没有更新,那么任务阻塞出队cfs rq的负载没有变化,只不
account_entity_enqueue(cfs_rq, se);
//将调度实体的load weight从cfs rq中加上。
update_cfs_group(se);
....
}
从上述队列出队来看,并没有将load_avg负载减去,而是变化了runnable相关的负载计算,所以即使任务出队进入阻塞状态,其负载依旧在load_avg中,只不过随着时间的增长而衰减。
task与cfs_rq平均负载
这一小节我们主要来分析一下update_load_avg函数主要的作用,直接上代码吧。
static inline void update_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
u64 now = cfs_rq_clock_pelt(cfs_rq)
//获取当前的时刻,减去了空闲时间,也就是该调度实体时间运行的时刻。
int decayed;
/*
* Track task load average for carrying it to new CPU after migrated, and
* track group sched_entity load average for task_h_load calc in migration
*/
//先计算调度实体的调度负载。
if (se->avg.last_update_time && !(flags & SKIP_AGE_LOAD))
__update_load_avg_se(now, cfs_rq, se);
//计算调度实体所属cfs_rq的负载。
decayed = update_cfs_rq_load_avg(now, cfs_rq);
//group se负载传播:如果调度实体是group se,其下任务有新增或移除等变化,则需要重//新更新group se所在层次的负载,group se下的cfs rq,负载变化要传播到上一层级(group se所在层级)。
decayed |= propagate_entity_load_avg(se);
//se->avg.last_update_time为0且DO_ATTACH,表示任务从其他队列迁移过来新入队的。
if (!se->avg.last_update_time && (flags & DO_ATTACH)) {
/*
* DO_ATTACH means we\'re here from enqueue_entity().
* !last_update_time means we\'ve passed through
* migrate_task_rq_fair() indicating we migrated.
*
* IOW we\'re enqueueing a task on a new CPU.
*/
//刚加入队列,计算se的负载主要是根据当前所属cfs_rq以及cpu算力等信息进行计//算,接着再将se的负载信息load、runnable、tutil传播到所属cfs_rq的负载。最后会//调用add_tg_cfs_propagate启动负载传播,只有调用了这个函数上面的//propagate_entity_load_avg才会具体执行传播动作。
attach_entity_load_avg(cfs_rq, se);
//更新group的平均负载。
update_tg_load_avg(cfs_rq);
} else if (decayed) { //负载有变化
cfs_rq_util_change(cfs_rq, 0); //触发是否需要调频
if (flags & UPDATE_TG)
update_tg_load_avg(cfs_rq);
}
}
负载、运行负载、利用率计算
负载计算可以分为两类,调度实体(task se、group se)和调度实体所属的cfs_rq;调度实体的计算是调用函数__update_load_avg_se实现,cfs_rq的计算是调用__update_load_avg_cfs_rq来实现,但是最终都会调用___update_load_sum来计算,只是传入的参数不一样。但两类都使用struct sched_avg结构体来进行描述,主要的核心就是需要先计算出{load|runnable|utils}_sum|avg,计算方法总结如下,后续的代码实际也是围绕这个计算公式来执行。

- {load|runnable|utils}_sum’:上一时刻计算的负载。
- contrib:上一个时刻到当前时刻负载贡献。
- SCHED_CAPACITY_SHIFT:归一化处理,一般是2^10=1024。
- divider:LOAD_AVG_MAX – (1024 – avg->period_contrib),最大负载。
无论load,runnable,running为任何值,只要更新负载上一时刻计算的{load|runnable|utils}_sum’都会衰减。
当load=0时,runable和running也都为0,因为load的取值为se->on_rq,该值为1就已经包含了runnable+running;若该值为0,那么就不是runnable或running,那自然runnable和running为0。
当load≠0,runnable≠0或running≠0,其对应的{load|runnable|utils}_sum会有新增负载贡献。
处于blocked状态的调度实体,不会带来新增负载贡献(load=runnable=running=0),但是会对历史负载进行衰减(step1计算的就是历史负载衰减)。
root@TinaLinux:/# cat /proc/1214/task/1214/sched
wifi_daemon (1214, #threads: 2)
-------------------------------------------------------------------
se.exec_start : 19745.413299
se.vruntime : 2705.836320
se.sum_exec_runtime : 0.599750
se.nr_migrations : 0
nr_switches : 1
nr_voluntary_switches : 1
nr_involuntary_switches : 0
se.load.weight : 1048576
se.avg.load_sum : 47234
se.avg.runnable_sum : 17325956
se.avg.util_sum : 17325956
se.avg.load_avg : 1024
se.avg.runnable_avg : 361
se.avg.util_avg : 361
se.avg.last_update_time : 19745214464
se.avg.util_est.ewma : 361
se.avg.util_est.enqueued : 361
policy : 0
prio : 120
clock-delta : 83
__update_load_avg_se
参数说明:
– load:为se->on_rq,表示当前任务是否处于可运行态,包括runnable + running,对于调度实体来说load要么为0,要么为1。
– runnable:为se_runnable(se),调度实体是task se则为se->on_rq,如果是group se,则为se->runnable_weight。对于group se来说只要其下有一个se是runnable或running,则group se为runnable或running。runnable_weigh等于处于runnable或running的任务数量。
– running:为cfs_rq->curr se,也就是说当前是否有任务正在运行。
对于task se来说load,runnable,running非0即1;对于group se来说,load,running非0即1,runnable为group se其下运行的任务数量。以下是传入的参数示例:
task se: load=runnable=1,running=1
group se: load = 1, runnable = se->runnable_weight, running =1

从上面看出,对于task se与group se的计算,区别主要是runnabe_sum的计算方式不同,group se新增负载贡献需要乘以runnable_weight(group se其下的任务数量)。
{load|runnable|utils}_sum计算的负载只是时间没有权重,但是load_avg需要考虑权重,是权重*时间。
int __update_load_avg_se(u64 now, struct cfs_rq *cfs_rq, struct sched_entity *se)
{
//计算{load|runnable|utils}_sum,这里传入三个参数load,runnable,running。
//load:为se->on_rq,se->on_rq=1表示running+runnable
//runnable:为se_runnable(se),这里要考虑当前的调度实体是group se还是task se,如果是task se那就等于se->on_rq,但是如果是group se则为se->runnable_weight,该值实际等于该任务组中running+runnable的任务数量,对于组调度实体来说组内即使有一个任务处于running或runnable那么group se就是running或runnable。
//running:代表当前正在运行的任务。
if (___update_load_sum(now, &se->avg, !!se->on_rq, se_runnable(se),
cfs_rq->curr == se)) {
//计算{load|runnable|utils}_avg,其中对于load_sum需要乘以权重se_weight(se)。
___update_load_avg(&se->avg, se_weight(se));
cfs_se_util_change(&se->avg);
trace_pelt_se_tp(se);
return 1;
}
return 0;
}
update_cfs_rq_load_avg
- load:为scale_load_down(cfs_rq->load.weight),可以先简单理解为cfs_rq上所有任务的权重和。
- runnable:为h_nr_running,表示当前在就绪队列中的任务数量,包含正在运行的任务。
- running:为cfs_rq->curr != NULL,cfs_rq队列有任务运行。
下面示例对比task se与cfs_rq。
Task se: load=runnable=1,running=1
group se:load = cfs_rq->load.weight,runnable = cfs_rq->h_nr_running, running =1

从上面公式可以看出,task se和cfs-rq的差别
① task (group)se的load_sum不考虑权重只考虑时间,而cfs_rq需要考虑整个队列的权重。
② task se是一个任务,所以 runnable_sum新增负载贡献乘1,而task group 、cfs_rq 计算的runnable_sum需要乘以任务数量。
③ load_avg对于cfs_rq是不需要乘以权重的,而task se需要相乘权重。
int __update_load_avg_cfs_rq(u64 now, struct cfs_rq *cfs_rq)
{
//计算cfs_rq的{load|runnable|utils}_sum,
//load = cfs_rq->load.weight为当前cfs_rq队列上的权重和,对于64为系统做了缩放。
//runnable = cfs_rq->h_nr_running,当前队列上的任务数量。
//running = cfs_rq->curr != NULL
if (___update_load_sum(now, &cfs_rq->avg,
scale_load_down(cfs_rq->load.weight),
cfs_rq->h_nr_running,
cfs_rq->curr != NULL)) {
___update_load_avg(&cfs_rq->avg, 1);
trace_pelt_cfs_tp(cfs_rq);
return 1;
}
return 0;
}
实际上cfs_rq的负载初值,就是其下task (group)的和,得到初值后,如果没有任务出入队列的情况下,就按照上面的公式进行更新负载,如果说有任务出入队列那么就需要重新更新初值,这个过程叫负载传播。
static void
enqueue_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
cfs_rq->avg.load_avg += se->avg.load_avg;
cfs_rq->avg.load_sum += se_weight(se) * se->avg.load_sum;
}
cfs_rq->avg.util_avg += se->avg.util_avg;
cfs_rq->avg.util_sum += se->avg.util_sum;
cfs_rq->avg.runnable_avg += se->avg.runnable_avg;
cfs_rq->avg.runnable_sum += se->avg.runnable_sum;
___update_load_sum
__update_load_avg_se和__update_load_avg_cfs_rq最终都要调用___update_load_sum来计算调度实体负载。
int ___update_load_sum(u64 now, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u64 delta;
//delta为当前时刻与上一次计算负载的时间差
delta = now - sa->last_update_time;
/*
* This should only happen when time goes backwards, which it
* unfortunately does during sched clock init when we swap over to TSC.
*/
if ((s64)delta < 0) {
sa->last_update_time = now;
return 0;
}
/*
* Use 1024ns as the unit of measurement since it\'s a reasonable
* approximation of 1us and fast to compute.
*/
delta >>= 10;
if (!delta)
return 0;
sa->last_update_time += delta << 10;
/*
* running is a subset of runnable (weight) so running can\'t be set if
* runnable is clear. But there are some corner cases where the current
* se has been already dequeued but cfs_rq->curr still points to it.
* This means that weight will be 0 but not running for a sched_entity
* but also for a cfs_rq if the latter becomes idle. As an example,
* this happens during idle_balance() which calls
* update_blocked_averages().
*
* Also see the comment in accumulate_sum().
*/
if (!load)
runnable = running = 0;
//如果load=0,即cfs_rq->0为0,那么任务不会处于running、runnable,因此也不需要计
//算runnable、running的新增负载贡献。正在运行的任务即使出队了,但是cfs_rq=1。
/*
* Now we know we crossed measurement unit boundaries. The *_avg
* accrues by two steps:
*
* Step 1: accumulate *_sum since last_update_time. If we haven\'t
* crossed period boundaries, finish.
*/
//计算*_sum负载。
if (!accumulate_sum(delta, sa, load, runnable, running))
return 0;
return 1;
}
delta为计算当前与上一次更新负载权重的差值,用于后续计算调度负载信息。该函数中会判断load是否等于0,如果为0,说明当前调度实体没有处于running或runnable状态,没有在就绪队列中就不需要计算新增调度负载贡献(注意是贡献,表增量),同时调度实体应该要进行调度负载衰减(没得运行,那么自然对CPU的消耗要降低),因此会调用decay_load对load_sum、runnable_sum、util_sum进行衰减;反之如果load不为0,那么说明调度实体处于running或runnable,那么就需要计算调度负载贡献,最后调度负载等于衰减的负载+新增贡献负载。
负载传播
当一个新创建或从其他cpu迁移的task se加入到一个新的cfs_rq队列时,会导致整个层级的cfs_rq负载发生变化。任务的休眠导致出队的不算?
会调用attach_entity_load_avg/detach_entity_load_avg来更新cfs_rq load_avg。本章节我们以task se从一个cpu迁移到另外一个cpu的cfs_rq为例说明,update_load_avg->attach_entity_load_avg。
static void attach_entity_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
/*
* cfs_rq->avg.period_contrib can be used for both cfs_rq and se.
* See ___update_load_avg() for details.
*/
u32 divider = get_pelt_divider(&cfs_rq->avg);
//
/*
* When we attach the @se to the @cfs_rq, we must align the decay
* window because without that, really weird and wonderful things can
* happen.
*
* XXX illustrate
*/
//当前调度实体的参数从所属cfs_rq中更新
se->avg.last_update_time = cfs_rq->avg.last_update_time;
se->avg.period_contrib = cfs_rq->avg.period_contrib;
/*
* Hell(o) Nasty stuff.. we need to recompute _sum based on the new
* period_contrib. This isn\'t strictly correct, but since we\'re
* entirely outside of the PELT hierarchy, nobody cares if we truncate
* _sum a little.
*/
//重新计算utils_sum、runnable_sum、load_sum。
se->avg.util_sum = se->avg.util_avg * divider;
se->avg.runnable_sum = se->avg.runnable_avg * divider;
se->avg.load_sum = se->avg.load_avg * divider;
if (se_weight(se) < se->avg.load_sum)
se->avg.load_sum = div_u64(se->avg.load_sum, se_weight(se));
else
se->avg.load_sum = 1;
//将负载信息{load|runnable|util}_更新累加到cfs_rq中。
enqueue_load_avg(cfs_rq, se);
cfs_rq->avg.util_avg += se->avg.util_avg;
cfs_rq->avg.util_sum += se->avg.util_sum;
cfs_rq->avg.runnable_avg += se->avg.runnable_avg;
cfs_rq->avg.runnable_sum += se->avg.runnable_sum;
//启动负载传播,使能了这个标志,对于gse类型的调度实体才能调用
//propagate_entity_load_avg进行负载传播。
add_tg_cfs_propagate(cfs_rq, se->avg.load_sum);
//触发调频
cfs_rq_util_change(cfs_rq, 0);
trace_pelt_cfs_tp(cfs_rq);
}
对于组任务调度实体,还需要调用propagate_entity_load_avg函数更新当前层级的负载信息。
static inline int propagate_entity_load_avg(struct sched_entity *se)
{
struct cfs_rq *cfs_rq, *gcfs_rq;
//如果时task直接返回,只有gse才需要传播和更新负载。
if (entity_is_task(se))
return 0;
//获取gse其下的cfs_rq
gcfs_rq = group_cfs_rq(se);
//如果没有启动传播,直接返回,有变化才需要更新,没有就直接返回。
if (!gcfs_rq->propagate)
return 0;
gcfs_rq->propagate = 0;
//获取gse所属的cfs_rq
cfs_rq = cfs_rq_of(se);
//将gcfs_rq上的runnable_sum传递到其所属的cfs_rq上,后续会不断的往上循环更新。
add_tg_cfs_propagate(cfs_rq, gcfs_rq->prop_runnable_sum);
//更新gse的utis_avg/sum,所属cfs的utis_avg/sum
update_tg_cfs_util(cfs_rq, se, gcfs_rq);
//更新gse的runnable_avg/sum,所属cfs的runnable_avg/sum
update_tg_cfs_runnable(cfs_rq, se, gcfs_rq);
//更新gse的laod_avg/sum,所属cfs的load_avg/sum
update_tg_cfs_load(cfs_rq, se, gcfs_rq);
trace_pelt_cfs_tp(cfs_rq);
trace_pelt_se_tp(se);
return 1;
}
在更新{utils|runnable|load}_sum|avg的时候,更新gse和所属的cfs_rq,这里的更新与__update_load_avg_se和__update_load_avg_cfs_rq的调用计算是不是重复了?毕竟调用关系是update_load_avg中先调用__update_load_avg_se和__update_load_avg_cfs_rq分别计算se和cfs_rq,然后再调用propagate_entity_load_avg进行更新。答案显然不是,这里的更新可以认为是设置初始值,因为并不是每次都会调用且必须是group se类型才会调用propagate_entity_load_avg计算。__update_load_avg_se和__update_load_avg_cfs_rq是在其初始值的基础上进行更新负载。