连续内存分配器CMA
CMA,contiguous memory allocator是内存管理子系统的一个模块,其主要为了解决分配连续的物理内存。尽管有了伙伴系统、slab分配器以及相关的内存回收机制,但是对于一些驱动如camera、display等模块一下需要分配比较大的一块连续物理内存,随着系统运行久之后,碎片化严重,分配较大的连续内存会变得困难,而同时又不能直接预留一块大的连续内存只用于连续物理内存分配,因为当模块不使用这些内存时,内存就浪费掉了。因此为解决这个问题,提出了CMA机制,先预留一部分内存出来专门用于CMA内存,当驱动没有分配使用的时候,这些memory可以给伙伴系统供其他模块正常使用,当需要分配连续的大内存时,就回收回来形成物理地址连续的大块内存。
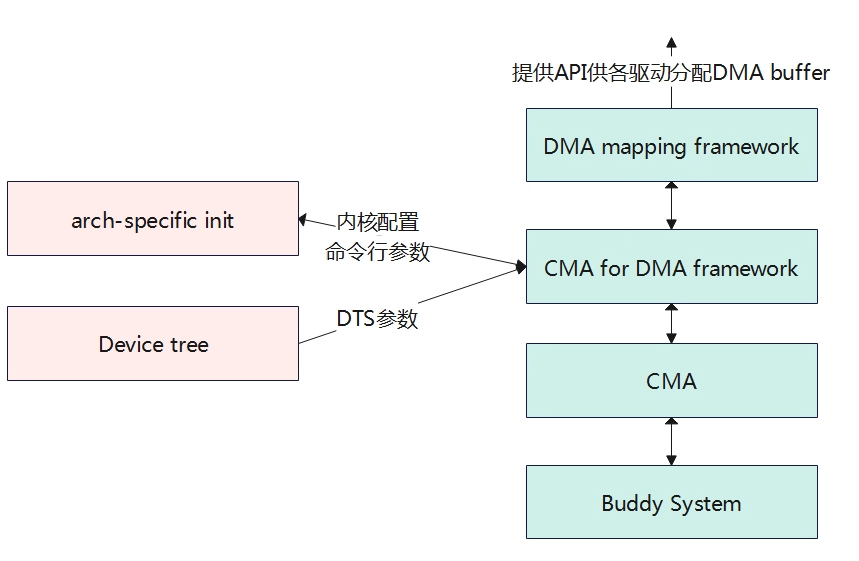
上图可以看出CMA所处的位置,CMA向下是基于伙伴系统,向上是提供给DMA的封装接口,最终用户通过操作DMA buffer来分配和释放内存。CMA的区域有两种方式可以进行配置,分别是内核命令行参数配置和DTS设备树的方式配置。
struct cma {
unsigned long base_pfn; 物理地址起始页帧号
unsigned long count; 区域的总页数
unsigned long *bitmap; 页的分配情况0表示free,1表示已分配。
unsigned int order_per_bit; 每次分配/释放对应的2^order 页,与bitmap的bit对应
struct mutex lock;
#ifdef CONFIG_CMA_DEBUGFS
struct hlist_head mem_head;
spinlock_t mem_head_lock;
#endif
const char *name;
};
extern struct cma cma_areas[MAX_CMA_AREAS];
extern unsigned cma_area_count;
内核使用struct cma结构体来描述cma区域,系统中可能有多个cma区域,使用一个全局的数组来描述所有的cma区域struct cma cma_areas[MAX_CMA_AREAS];
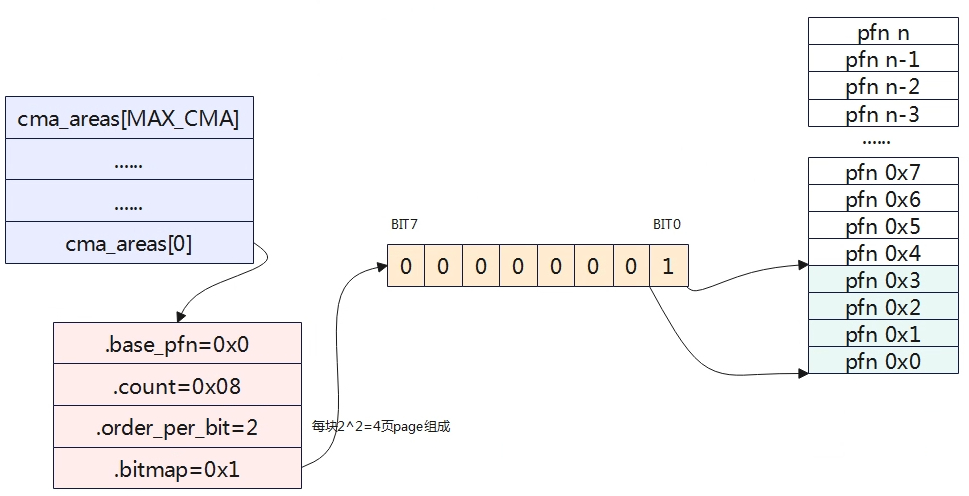
如上图,cma_areas 0号区域,物理页号从0开始,每块内存由4页物理帧组成,目前只分配了第0块。
CMA区域创建
创建CMA区域有两种方式:第一种方式是通过设备树DTS的配置方式,另一种是根据命令行或宏配置方式。
设备数的方式创建
/* global autoconfigured region for contiguous allocations */
linux,cma {
compatible = "shared-dma-pool";
reusable;
size = <0x4000000>;
alignment = <0x2000>;
linux,cma-default;
};
CMA的内存区域通过以上设备树信息来进行描述,对节点的解析在rmem_cma_setup函数中进行。
static int __init rmem_cma_setup(struct reserved_mem *rmem)
{
phys_addr_t align = PAGE_SIZE << max(MAX_ORDER - 1, pageblock_order);
phys_addr_t mask = align - 1;
unsigned long node = rmem->fdt_node;
bool default_cma = of_get_flat_dt_prop(node, "linux,cma-default", NULL);
(1)解析linux,cma-default节点。
struct cma *cma;
int err;
if (size_cmdline != -1 && default_cma) {
pr_info("Reserved memory: bypass %s node, using cmdline CMA params instead\\n",
rmem->name);
return -EBUSY;
}
(2)CMA对应的reserved memory节点必须有reusable属性,不能有no-map属性。
reusable属性才能被伙伴系统回收使用。
if (!of_get_flat_dt_prop(node, "reusable", NULL) ||
of_get_flat_dt_prop(node, "no-map", NULL))
return -EINVAL;
if ((rmem->base & mask) || (rmem->size & mask)) {
pr_err("Reserved memory: incorrect alignment of CMA region\\n");
return -EINVAL;
}
(3)解析出来的参数进行初始化CMA区域
err = cma_init_reserved_mem(rmem->base, rmem->size, 0, rmem->name, &cma);
if (err) {
pr_err("Reserved memory: unable to setup CMA region\\n");
return err;
}
/* Architecture specific contiguous memory fixup. */
dma_contiguous_early_fixup(rmem->base, rmem->size);
if (default_cma)
dma_contiguous_default_area = cma;
rmem->ops = &rmem_cma_ops;
rmem->priv = cma;
pr_info("Reserved memory: created CMA memory pool at %pa, size %ld MiB\\n",
&rmem->base, (unsigned long)rmem->size / SZ_1M);
return 0;
}
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
rmem_cma_setup函数主要解析设备树,获取cma区域的地址及大小,然后调用cma_init_reserved_mem函数从全局数组struct cma cma_areas[MAX_CMA_AREAS]获取一个cma进行初始化设置。
int __init cma_init_reserved_mem(phys_addr_t base, phys_addr_t size,
unsigned int order_per_bit,
const char *name,
struct cma **res_cma)
{
struct cma *cma;
phys_addr_t alignment;
/* Sanity checks */
if (cma_area_count == ARRAY_SIZE(cma_areas)) {
pr_err("Not enough slots for CMA reserved regions!\\n");
return -ENOSPC;
}
if (!size || !memblock_is_region_reserved(base, size))
return -EINVAL;
/* ensure minimal alignment required by mm core */
alignment = PAGE_SIZE <<
max_t(unsigned long, MAX_ORDER - 1, pageblock_order);
/* alignment should be aligned with order_per_bit */
if (!IS_ALIGNED(alignment >> PAGE_SHIFT, 1 << order_per_bit))
return -EINVAL;
if (ALIGN(base, alignment) != base || ALIGN(size, alignment) != size)
return -EINVAL;
/*
* Each reserved area must be initialised later, when more kernel
* subsystems (like slab allocator) are available.
*/
cma = &cma_areas[cma_area_count];
(1)从全局数组中获取一个cma
if (name)
snprintf(cma->name, CMA_MAX_NAME, name);
else
snprintf(cma->name, CMA_MAX_NAME, "cma%d\\n", cma_area_count);
(2)设置cma相关的参数
cma->base_pfn = PFN_DOWN(base);
cma->count = size >> PAGE_SHIFT;
cma->order_per_bit = order_per_bit;
*res_cma = cma;
cma_area_count++;
totalcma_pages += (size / PAGE_SIZE);
return 0;
}
命令行或宏方式创建
内核还提供通过内核启动参数或宏的方式来进行配置,本章节重点描述内核启动参数的方式,这里的启动参数一般是uboot传递过来的参数。
env.cfg
earlycon=uart8250,mmio32,0x02500000
initcall_debug=0
console=ttyAS0,115200
nand_root=/dev/nand0p4
mmc_root=/dev/mmcblk0p4
nor_root=/dev/mtdblock4
init=/init
loglevel=8
selinux=0
cma=64M
mac=
wifi_mac=
bt_mac=
specialstr=
keybox_list=hdcpkey,widevine
笔者系统中内核的启动参数配置在env.cfg中,如下cma的大小配置为64M。内核代码中通过函数dma_contiguous_reserve进行获取cmdline或宏配置的cma大小。
void __init dma_contiguous_reserve(phys_addr_t limit)
{
phys_addr_t selected_size = 0;
phys_addr_t selected_base = 0;
phys_addr_t selected_limit = limit;
bool fixed = false;
pr_debug("%s(limit %08lx)\\n", __func__, (unsigned long)limit);
(1)获取cmdline中传入的cma size大小和地址。
if (size_cmdline != -1) {
selected_size = size_cmdline;
selected_base = base_cmdline;
selected_limit = min_not_zero(limit_cmdline, limit);
if (base_cmdline + size_cmdline == limit_cmdline)
fixed = true;
} else { 这里是宏定义的方式
#ifdef CONFIG_CMA_SIZE_SEL_MBYTES
selected_size = size_bytes;
#elif defined(CONFIG_CMA_SIZE_SEL_PERCENTAGE)
selected_size = cma_early_percent_memory();
#elif defined(CONFIG_CMA_SIZE_SEL_MIN)
selected_size = min(size_bytes, cma_early_percent_memory());
#elif defined(CONFIG_CMA_SIZE_SEL_MAX)
selected_size = max(size_bytes, cma_early_percent_memory());
#endif
}
if (selected_size && !dma_contiguous_default_area) {
pr_debug("%s: reserving %ld MiB for global area\\n", __func__,
(unsigned long)selected_size / SZ_1M);
(2)获取到cma区域后,进行初始化
dma_contiguous_reserve_area(selected_size, selected_base,
selected_limit,
&dma_contiguous_default_area,
fixed);
}
}
dma_contiguous_reserve_area函数最终还是会调用到cma_init_reserved_mem,进而获取一个cma实例,然后进行初始化cma结构体。
CMA初始化
static int __init cma_init_reserved_areas(void)
{
int i;
遍历CMA数组,进行初始化
for (i = 0; i < cma_area_count; i++)
cma_activate_area(&cma_areas[i]);
return 0;
}
core_initcall(cma_init_reserved_areas);
主要是遍历cma_areas数组,进行初始化。
static void __init cma_activate_area(struct cma *cma)
{
unsigned long base_pfn = cma->base_pfn, pfn;
struct zone *zone;
(1)计算需要的bitmap大小,然后进行分配。主要受count和bit的影响。
cma->bitmap = bitmap_zalloc(cma_bitmap_maxno(cma), GFP_KERNEL);
if (!cma->bitmap)
goto out_error;
/*
* alloc_contig_range() requires the pfn range specified to be in the
* same zone. Simplify by forcing the entire CMA resv range to be in the
* same zone.
*/
WARN_ON_ONCE(!pfn_valid(base_pfn));
(2)判断物理页是否都在一个zone区,需要在同一个zone区。
zone = page_zone(pfn_to_page(base_pfn));
for (pfn = base_pfn + 1; pfn < base_pfn + cma->count; pfn++) {
WARN_ON_ONCE(!pfn_valid(pfn));
if (page_zone(pfn_to_page(pfn)) != zone)
goto not_in_zone;
}
(3)将物理页释放到伙伴系统中去。
for (pfn = base_pfn; pfn < base_pfn + cma->count;
pfn += pageblock_nr_pages)
init_cma_reserved_pageblock(pfn_to_page(pfn));
spin_lock_init(&cma->lock);
#ifdef CONFIG_CMA_DEBUGFS
INIT_HLIST_HEAD(&cma->mem_head);
spin_lock_init(&cma->mem_head_lock);
#endif
return;
not_in_zone:
bitmap_free(cma->bitmap);
out_error:
/* Expose all pages to the buddy, they are useless for CMA. */
for (pfn = base_pfn; pfn < base_pfn + cma->count; pfn++)
free_reserved_page(pfn_to_page(pfn));
totalcma_pages -= cma->count;
cma->count = 0;
pr_err("CMA area %s could not be activated\\n", cma->name);
return;
}
CMA应用
DMA的申请
struct page *dma_alloc_from_contiguous(struct device *dev, size_t count,
unsigned int align, bool no_warn)
{
if (align > CONFIG_CMA_ALIGNMENT)
align = CONFIG_CMA_ALIGNMENT;
return cma_alloc(dev_get_cma_area(dev), count, align, no_warn);
}
DMA的释放
bool dma_release_from_contiguous(struct device *dev, struct page *pages,
int count)
{
return cma_release(dev_get_cma_area(dev), pages, count);
}
对内核的申请和释放提供给用户使用的分配是dma_alloc_from_contiguous和dma_release_from_contiguous,其调用的是cma_alloc和cma_release来实现的。
cma_alloc指定CMA areas上分配count个连续的page frame,具体就是遍历bitmap看是否有可用内存,如果有就向伙伴系统申请内存,如果伙伴系统将对应的内存挪给其他应用了,那么需要进行页面迁移、页面回收等操作回收回来。
ION
待补充