计算机视觉
- Ai
- 2025-05-11
- 178热度
- 0评论
图像增广
什么是图像增广?图像增广(Image Augmentation)是通过对原始图像进行一系列随机变换(如旋转、裁剪、颜色调整等)生成多样化样本的数据增强技术,旨在扩充训练数据集、提升模型泛化能力。其核心逻辑是模拟真实场景中可能存在的多样性,使模型学习到更鲁棒的特征。
深度学习中泛化能力是模型对未见过的新数据的适应能力,其核心体现在从训练数据中学习通用规律而非简单记忆特例。应用图像增广可以随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。
d2l.set_figsize()
img = d2l.Image.open('../img/cat1.jpg')
d2l.plt.imshow(img);

常用的图像增广方法有翻转和裁剪、改变颜色等,大多数图像增广都是随机性,下面定义一个函数应用图像增广后显示的效果。
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_rows * num_cols)]
#for循环随机增强输出num_rows * num_cols个图像
#创建了一个列表Y,包含了num_rows * num_cols个增强后的图像
#aug(img)是对img应用增强操作。
d2l.show_images(Y, num_rows, num_cols, scale=scale)
- img:输入原始的图像
- aug:输入的增强函数
- num_rws: 显示增广后图像的行数。
- num_cols: 显示增广后图像的列数。
- scale:调整显示图像的缩放比例。
翻转和裁剪
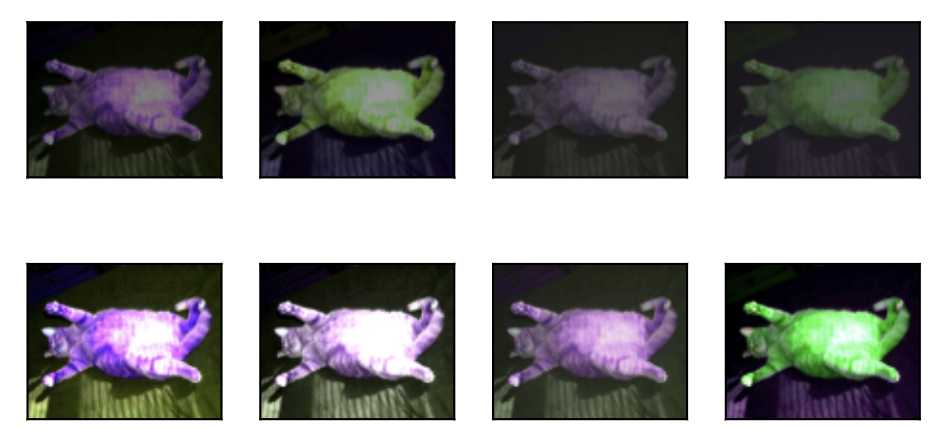
翻转有左右翻转、上下翻转,翻转该不会改变对象的类别,下面看看效果。
apply(img, torchvision.transforms.RandomHorizontalFlip())

apply(img, torchvision.transforms.RandomVerticalFlip())

除了翻转还可以随机裁剪。
shape_aug = torchvision.transforms.RandomResizedCrop(
(200, 200), scale=(0.1, 1), ratio=(0.5, 2))
apply(img, shape_aug)

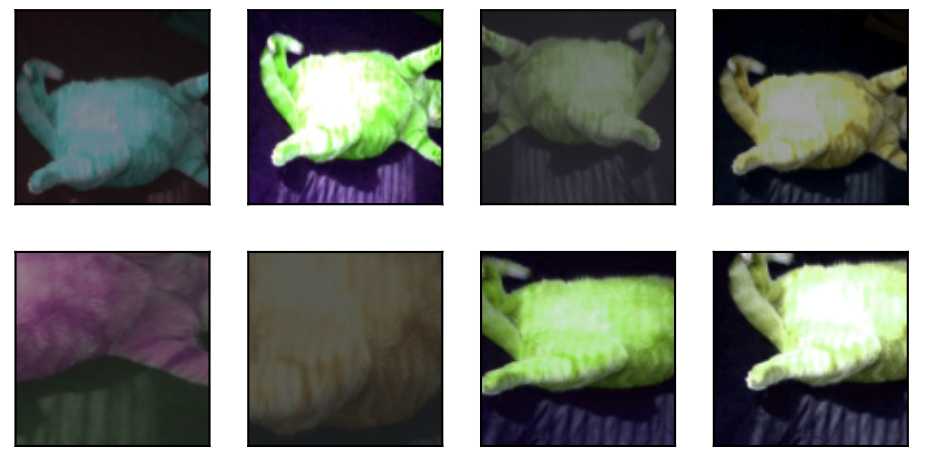
改变颜色
改变颜色可包括几个方面包括亮度、对比度、饱和度和色调。
color_aug = torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
apply(img, color_aug)
混合增强
在实际项目中,可以将多种图像增广方面混合起来,可以调用Compose来实现。
augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), color_aug, shape_aug])
apply(img, augs)
微调(fine-tuning)
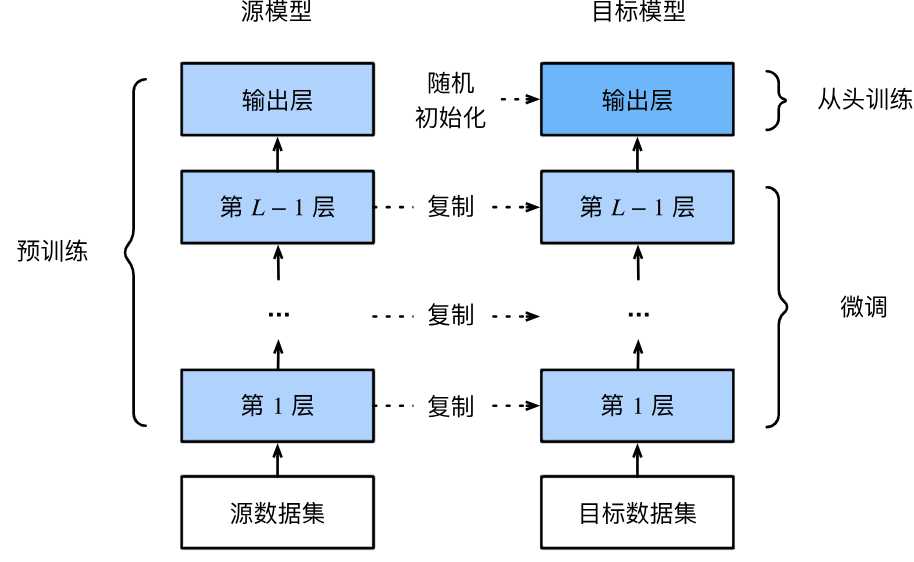
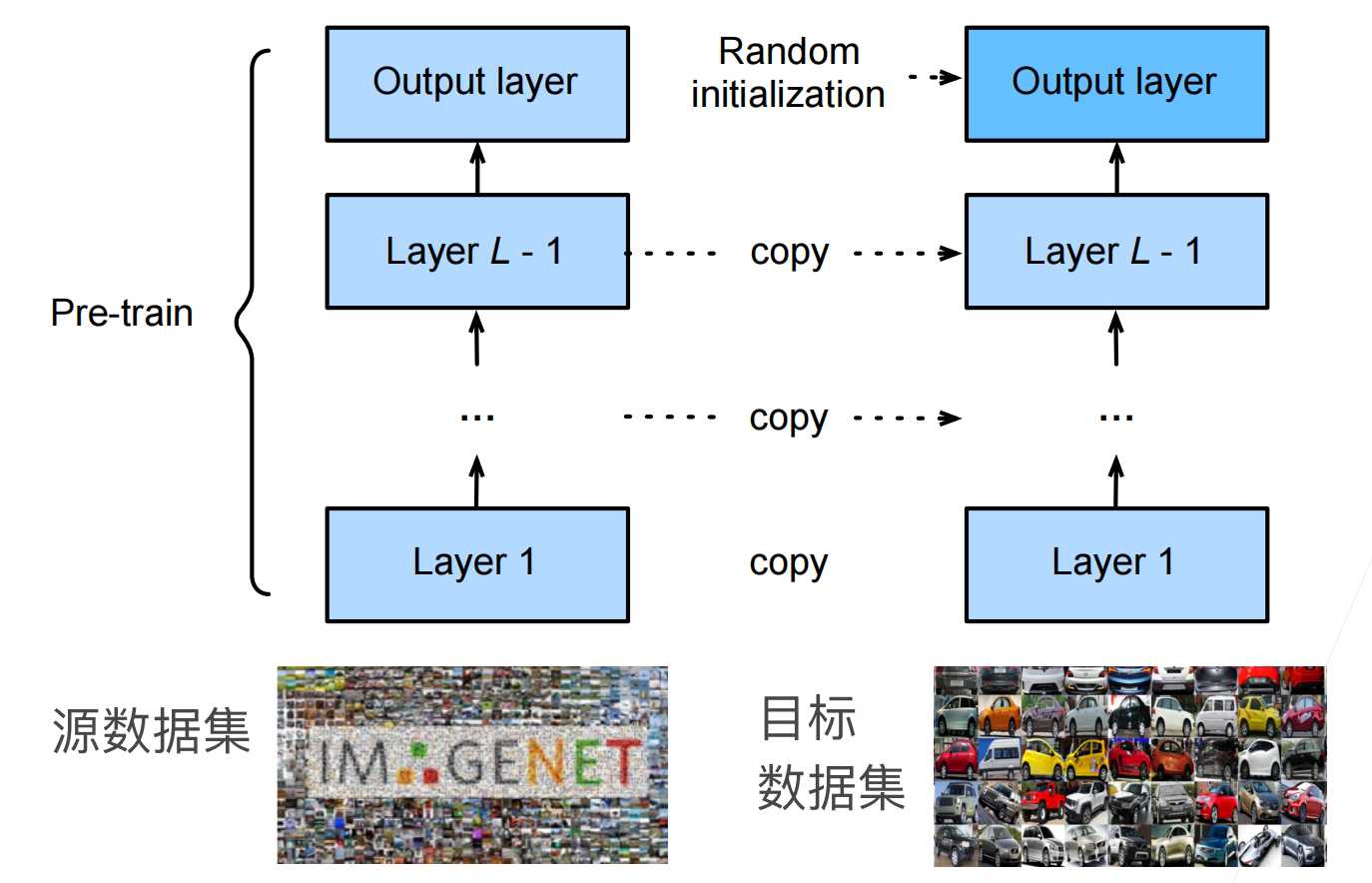
微调是在一个预训练模型的基础上,针对特定任务或数据集进行进一步训练,以便使模型能够更好的使用新的数据和任务。微调的步骤如下:
- 在源数据上预训练源模型。
- 创建一个新的目标模型,将源模型上的所有设计及参数(除输出层外)复制到目标模型。
- 新的目标模型添加输出层,输出数是目标数据集中类别数,只随机初始化该输出的参数。
- 新的目标集上训练目标模型。输出层是从头训练,而其他层是根据源模型参数进行微调。
为什么要微调?因为一个新的模型训练很贵,不但需要重新标注数据集、训练,那既然已经有训练好的模型,我们为何不根据训练好的模型稍加调整,站在巨人的肩膀上了?
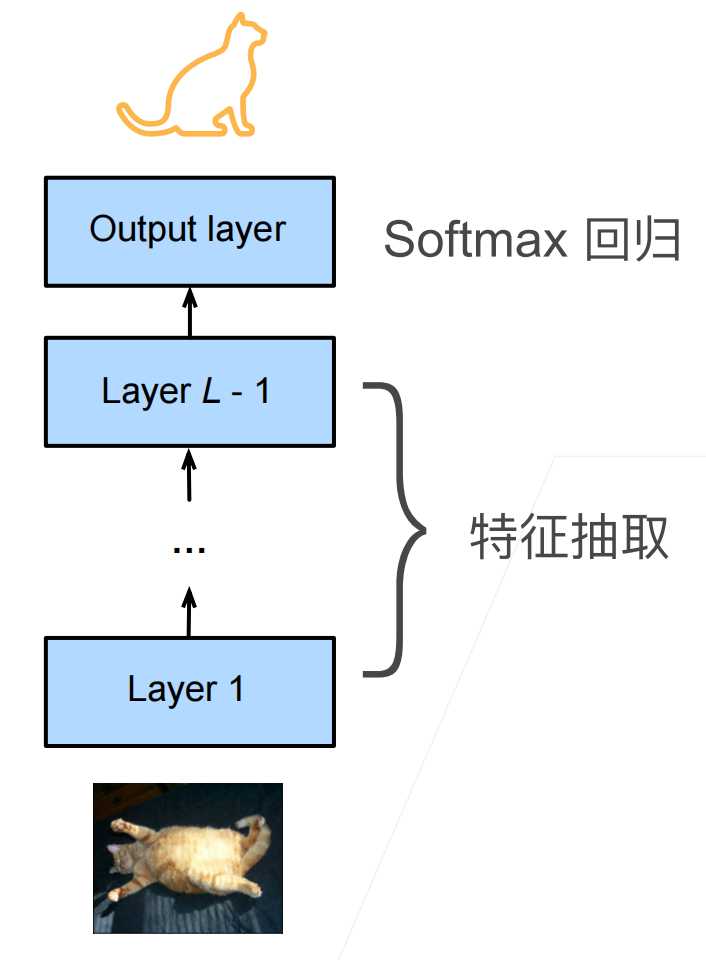
为什么可以微调了? 一般神经网络可以分成两块
- 特征提取: 将原始的像素变成容易线性分割的特征。
- softmax回归:线性分类器做分类。
因此特征提取部分一般是通用做法,所以容易复用,我们只需要替换到softmax输出层重新训练即可。
微调中权重参数是怎么初始化的?对于特征提取部分直接复制原来预训练的模型,输出层因为是修改替换的,所以需要重新随机初始化进行训练。微调训练是一个目标数据集上的正常训练任务,但是使用更强的正则化,具体体现在使用更小的学习率和使用更少的数据迭代。预训练模型源数据集若远远复杂于新目标数据集,通常微调效果更好。
下面是使用ResNet-18作为源模型来进行微调概要示例。
pretrained_net = torchvision.models.resnet18(pretrained=True)
#定义和初始化预训练模型,指定pretrained=True,表示自动下载预训练的模型参数。
pretrained_net.fc
#.fc表示最后输出层即全连接层,先打印看看效果
# 打印结果:Linear(in_features=512, out_features=1000, bias=True)
# 可以看到最后输出层是输入512,输出1000的全连接层
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
#我们将最后的全连接层修改为输入不变,但是输出为2的全连接层,表示只分类2个目标。
nn.init.xavier_uniform_(finetune_net.fc.weight);
#对新定义的全连接层fc进行权重初始化,采用的是xavier均分布方法
train_fine_tuning(finetune_net, 5e-5)
#使用新的模型进行训练。
微调是通过使用大数据上得到预训练好的模型来初始化模型权重来完成提升精度,使用微调通常速度更快、精度更高。
目标检测
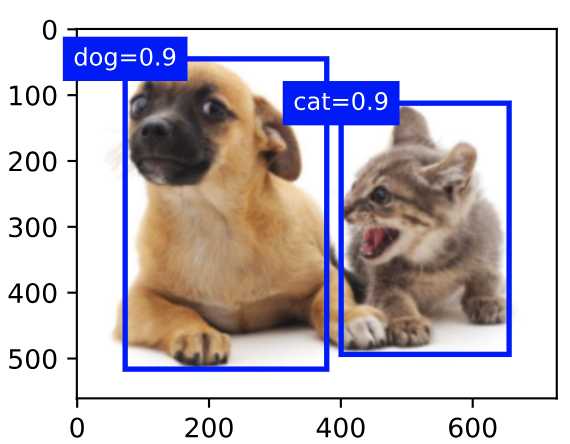
目标检测或目标识别是用于识别图像中多个感兴趣的目标,不仅知道他们的类别,还需要知道他们在图像中的具体位置。
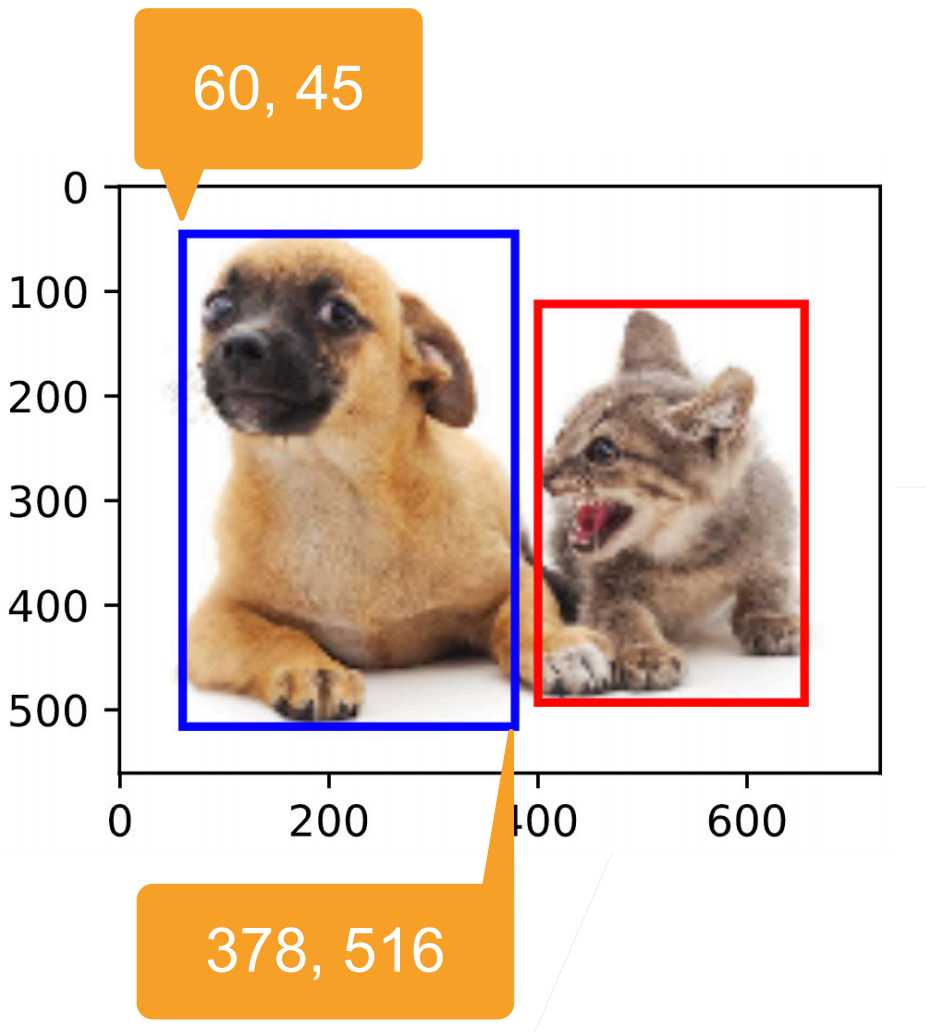
如上图,图中有个狗和猫,通过一个边缘框框起来,边缘框左上角坐标+右下角坐标即可定位。
锚框(anchor box)
目标检测既然要在图像中检测出感兴趣目标的位置(坐标),那么就需要遍历框住不同的区域来进行识别。目标检测算法会在输入图像中抽样大量区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘,从而更准确的预测目标的真实边界框。不同的模型抽样的方法不同,这里主要介绍的是以每个像素为中心,生成多个缩放比和宽高比不同的边界框,这些边界就称为锚框。
如何生成锚框了?
假设输入图像的高度是h,宽度是w。那么就以每个像素按照缩放比(scale)和宽高(aspect ratio)比,为中心生成不同形状的锚框,那么锚框的宽度和高度分别为[锚框的宽度和高度分别是hs\sqrt{r}和hs/\sqrt{r}。]。在实践中,如果按照缩放比和宽高比组合时,每个输入图像共有whnm个锚框,这样数量太庞大,计算复杂度会很高,因此只考虑包含s和r的组合。(s_1, r_1), (s_1, r_2), \ldots, (s_1, r_m), (s_2, r_1), (s_3, r_1), \ldots, (s_n, r_1).,这样对于整个输入图像,将生成wh(n+m-1)个锚框。
img = d2l.plt.imread('../img/catdog.jpg')
h, w = img.shape[:2]
print(h, w)
X = torch.rand(size=(1, 3, h, w))
Y = multibox_prior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
# multibox_prior返回的形状是(批量大小,锚框的数量,4)
Y.shape
输处:
561 728
torch.Size([1, 2042040, 4])
可以看到运行后,锚框的数量是2042040。
d2l.set_figsize()
bbox_scale = torch.tensor((w, h, w, h))
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, boxes[250, 250, :, :] * bbox_scale,
['s=0.75, r=1', 's=0.5, r=1', 's=0.25, r=1', 's=0.75, r=2',
's=0.75, r=0.5'])
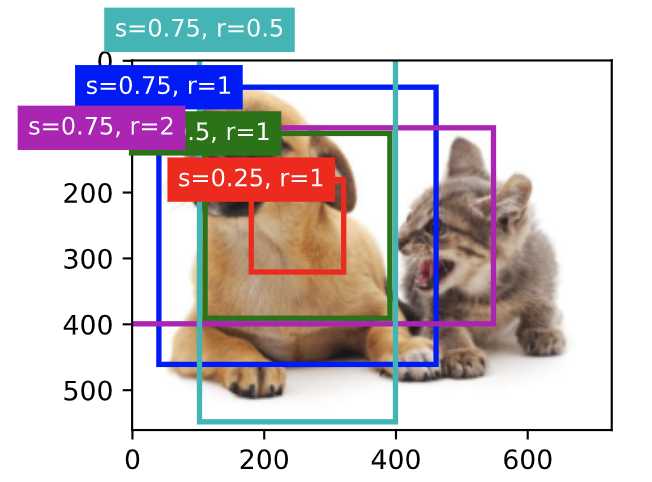
上面是画出坐标[250,250]像素点,取一些s/r值的锚框效果。
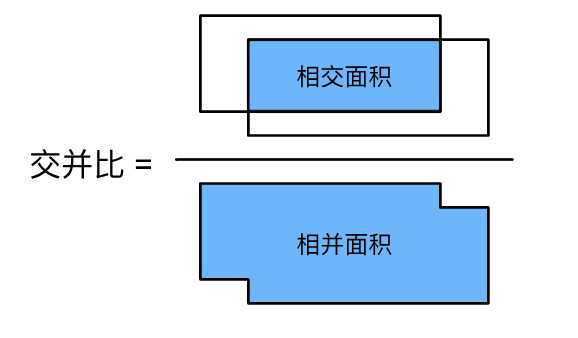
如何衡量锚框和真实目标边界框的相似性了,使用交并比IoU,即两个边界框相交面积与相并面积的比。给定集合\mathcal{A}和\mathcal{B},他们的杰卡德系数是他们交集的大小除以他们并集的大小:
J(\mathcal{A},\mathcal{B}) = \frac{\left|\mathcal{A} \cap \mathcal{B}\right|}{\left| \mathcal{A} \cup \mathcal{B}\right|}.
交并比的取值范围是0~1:0表示两个边界无重合像素,1表示两个边界完成重合。
在实际训练中如何标注锚框了?
在实际训练中,我们将每个锚框视为一个训练样本,为了训练目标检测模型,我们为每个锚框的类别和偏移进行标签,类别是与锚框相关的目标类别,偏移是真实边界框相对锚框的偏移量。在预测的时候,首先每张图片生成多个锚框,预测所有锚框的类别和偏移量,根据预测的偏移量调整他们的位置以获得预测的边界框,最后输出符合条件的预测边界框。
在预测时,可能输出许多相似的具有明显重叠的预测边界框,他们都围绕同一个目标。为了简化输出,使用非极大值抑制合并属于同一目标的相似的预测边界框。非极大值抑制的主要原理时,进行比较每个预测边界框的置信度,具体使用IoU来比较选取最大值。
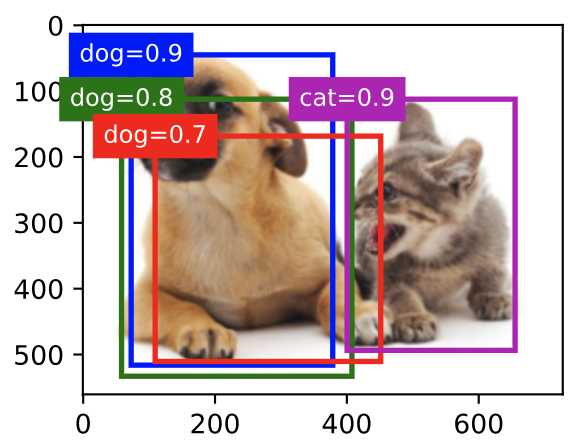
通过非极大抑制预测处理后的结果。
区域卷积神经网络
R-CNN
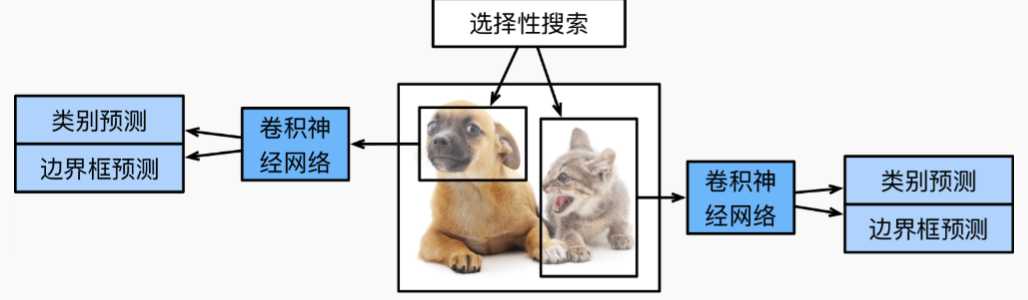
R-CNN从图像中选取若干(如2000)提议区域(如锚框是一种选取方法),预测标注他们的类别和边界框(如偏移量),然后使用卷积神经网络对每个提议区域进行前向传播已抽取特征,根据特征来预测类别和边界框。
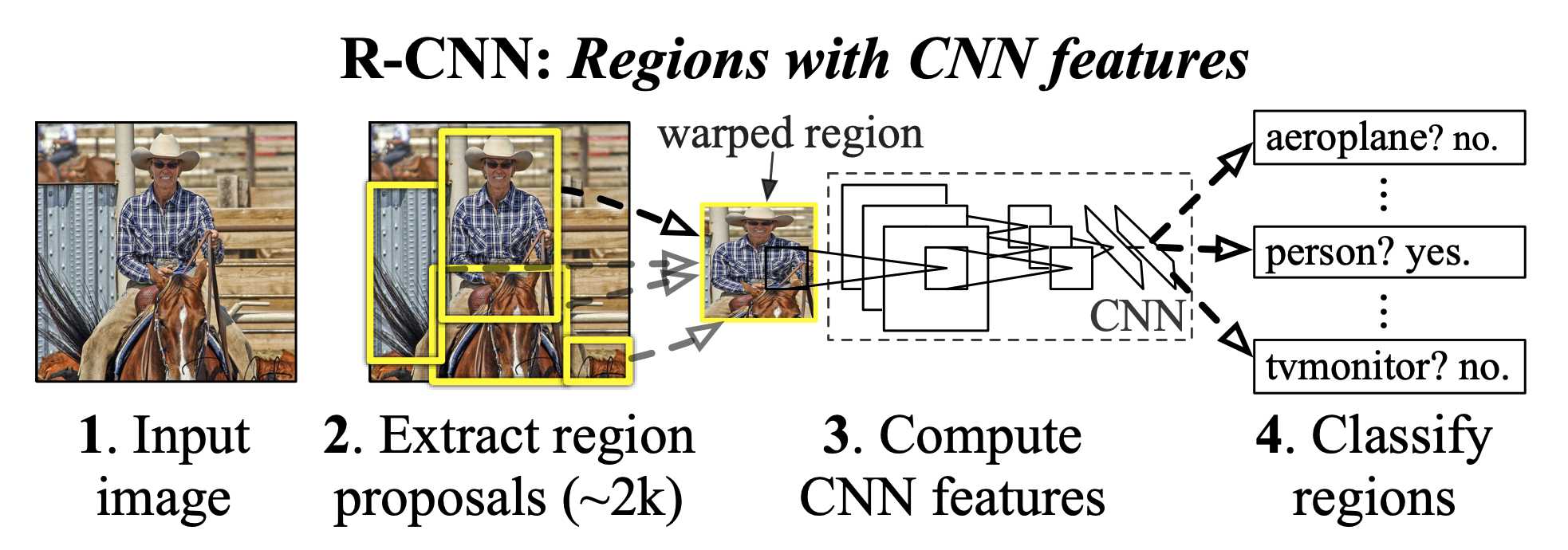
使用R-CNN一般使用的是预训练来的卷积网络来抽取图像特征,但是每个图像会选出上千个提议区域,每个提议区域都需要经过卷积计算,这样也要上千次的卷积神经网络前向传播来执行目标检测,因此这样速度会很慢。
Fast R-CNN
R-CNN的性能瓶颈主要在于对每个提议区域,卷积神经网络的前向传播都是独立的,没有共享计算。而这些提议区域往往会有重叠,这样会导致特征抽取重复计算。而使用Faster-CNN则进行了改进。
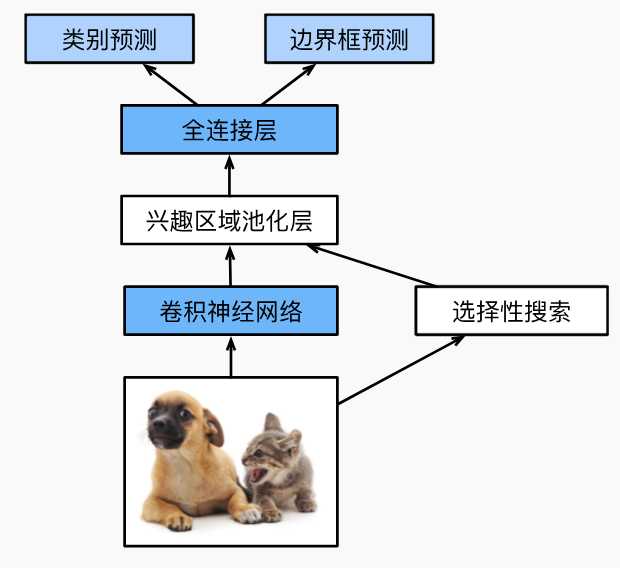
与R-CNN相比,Fast R-CNN用来提取特征的卷积神经网络输入的是整个图像,而不是各个提议区域,这样就不用像R-CNN对每个提议区域都进行卷积神经网络计算。
而选择性搜索生成的n个提议区域还是不变,不同的是Fast R-CNN引入了兴趣区域汇聚层,将卷积神经网络的输出和提议区域作为输入,输出连接后的各个提议区域抽取特征。而R-CNN对提议区域的处理是直接输入到分类器中,输出目标类别。
总结一下Fast R-CNN有主要有两点:
- 经过卷积神经网络数量不同:R-CNN所有提议区域都需要经过,而Fast R-CNN只需要输入完整的一张图片。
- 提议区域用处不用:R-CNN将提议区域最终到分类器中输出目标类别,而Fast R-CNN将提议区域和经过卷积神经网络输出的特征当做输入给到兴趣区域池化层。
Faster R-CNN
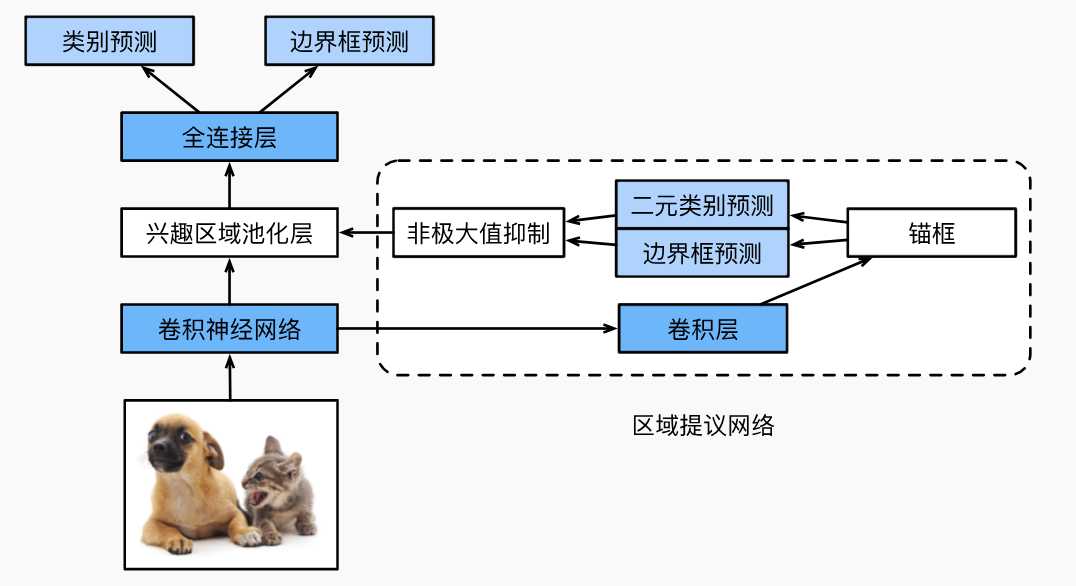
Fast R-CNN的缺点就是在选择性搜索中还是会生成大量的提议区域,为了优化这个提出了Faster R-CNN,提出将选择性搜索替换为区域提议网络,从而减少提议区域生成的数量。
如何减少提议区域生成的数量了? 主要使用了非极大值抑制,将提议区域中相似的或者说重叠比较多的剔除掉,这样输入到兴趣区域池化层就变少了。
Mask R-CNN
如果训练集标注了每个目标图像的像素级位置,那么可以使用Mask R-CNN。
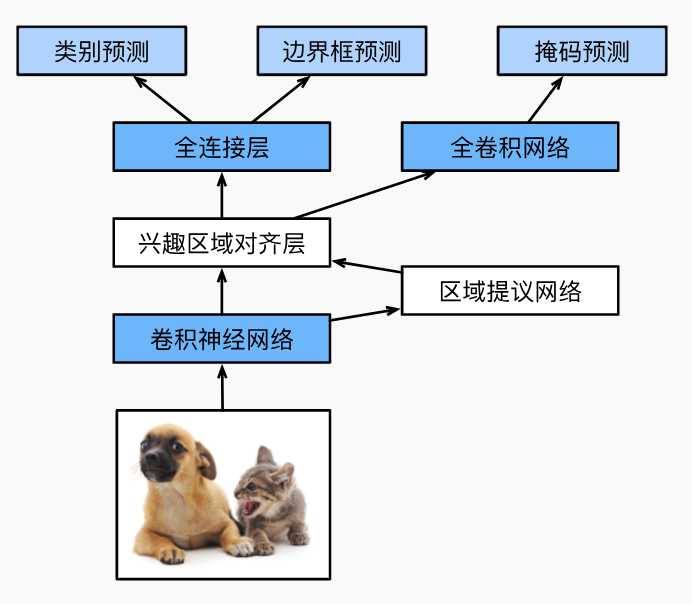
从上图可以看出 Mask R-CNN相对Faster R-CNN变换点在后面部分,Mask R-CNN将兴趣区域汇聚层替换为兴趣区域对齐层。这里的对齐层就是通过在训练集上实现标注目标的具体位置通过双线性超值来的,这样就可以更精准保留特征图的信息,实现像素级的预测。可以理解为Faster R-CNN兴趣区域层还需要调参经过一堆网络计算预测,而这里通过实现标注的区域进一步确定了位置。
SSD
待补充
YOLO
Faster R-CNN的检测分为两个阶段,首先区域提议网络(RPN)生成候选区域,接着在使用卷积神经网络对这些候选区域进行分类和边界框回归。 而yolo是单阶段检测,他将图像分成一个S*S的网格,每个网络预测多个边界框和相应类别的概率。YOLO一次性处理整个图像,直接进行目标分类和定位回归,速度相对较快。Faster R-CNN精度会更高一些,在复杂场景和多目标检测比较优越。而YOLO实时性、低延迟,但是精度偏低,但是随着YOLO的进化精度逐渐在提升。

语义分割
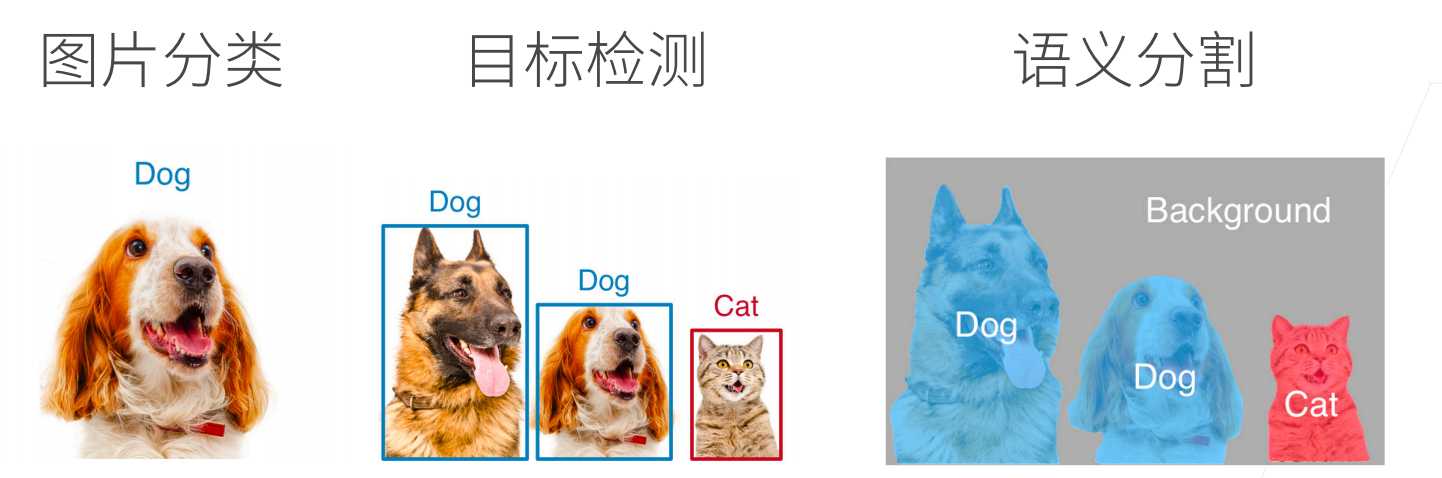
语义分割是对图像中的每个像素进行分类到特定类别中。与目标检测不同的是,目标检测是识别图像中的物体并定位其边界框,而语义分割是则对图像的每个像素进行标注,赋予每个像素一个表情。语义分割是像素级别的分类。语义分割的应用如图像处理背景虚化、智能驾驶路面分割。
语义分割和实例分割的区别是语音分割只对像素类别进行分类,而示例分割是在像素类别中对实例在区分,如下图所示。
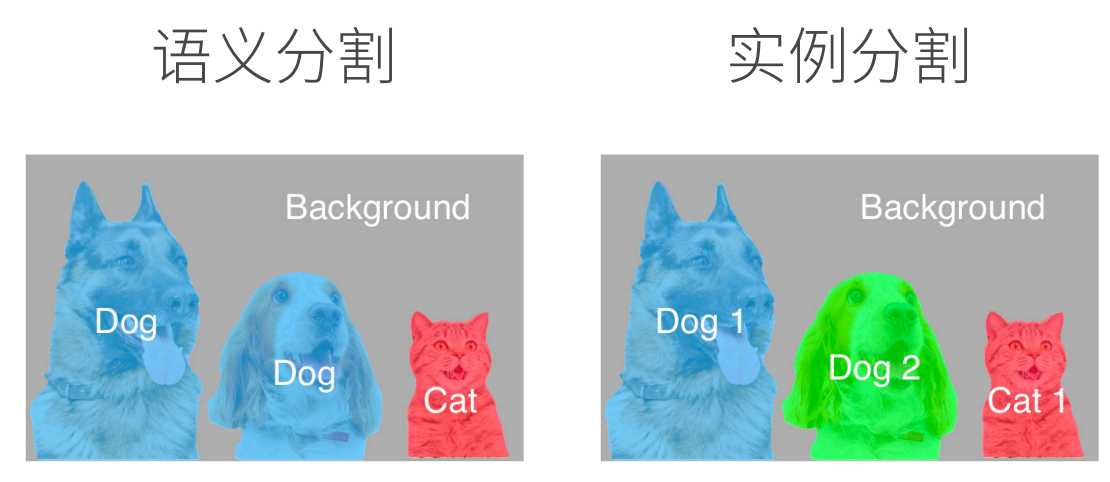
最重要的语义分割数据集是Pascal VOC2012。
转置卷积
卷积不会增大原来的输入高宽,要么维持不变、要么减小。而转置卷积则可以用来增大输入高宽。
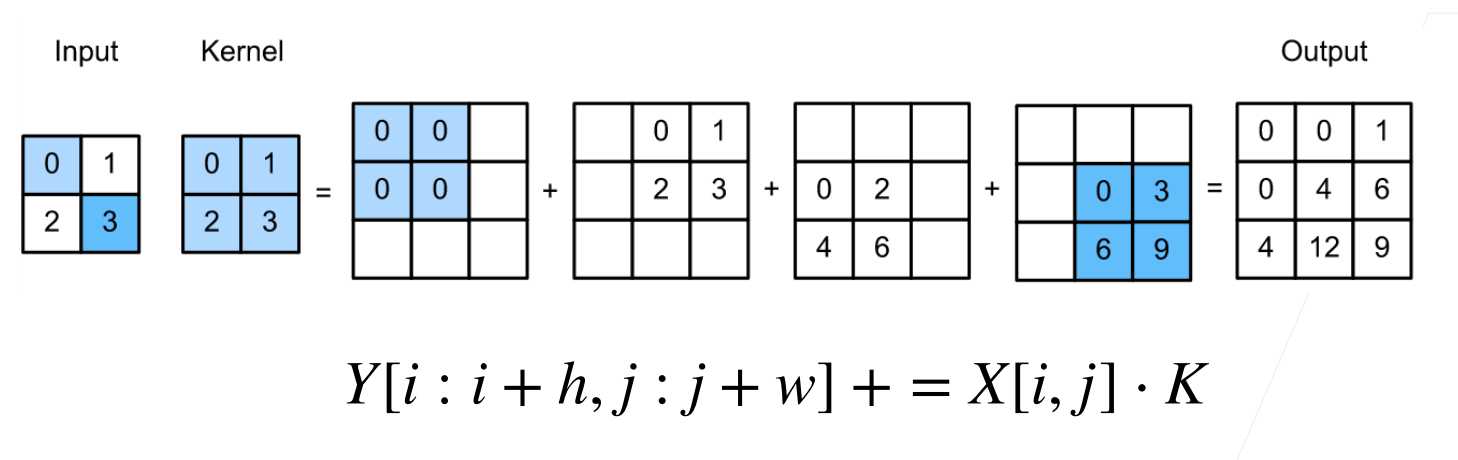
转置卷积可以认为是卷积的逆过程。
全卷积网络FCN
语义分割是对图像中的每个像素分类,通常输入的图像大小和输出图像的大小要一样,也就是说输出类别的预测与输入图像在像素级上是具有一一对应关系。
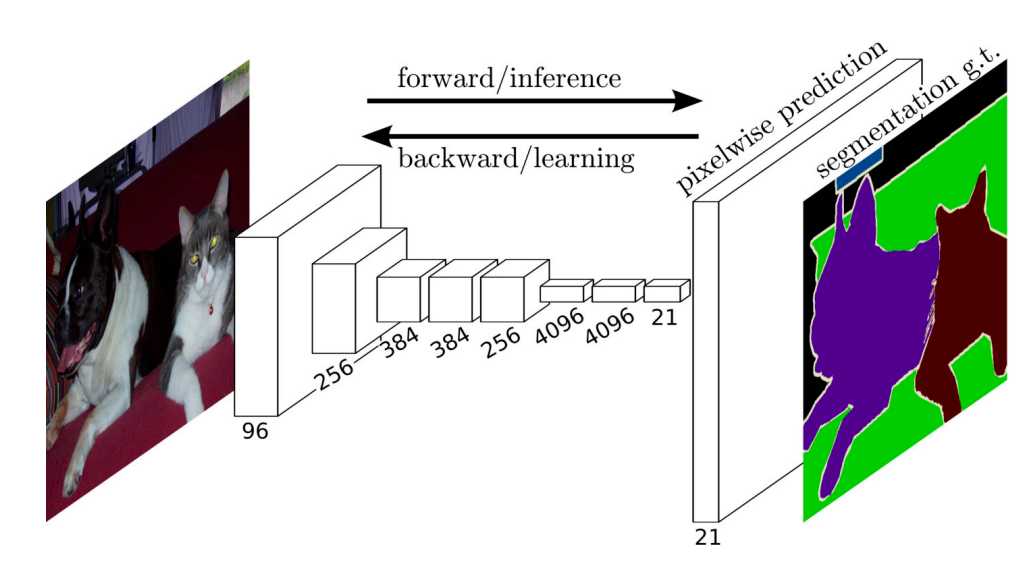
FCN是用来做语义分割最早的深度卷积神经网络之一,他使用转置卷积层来替换CNN最后的全连接层。
样式迁移
图像处理经常会遇到滤镜,而使用卷积神经网络,自动将一张图像的风格应用在另外一张图像上,即称为样式迁移。

如上图,将style image中的样式迁移到content image上,就得到一张合成图片。
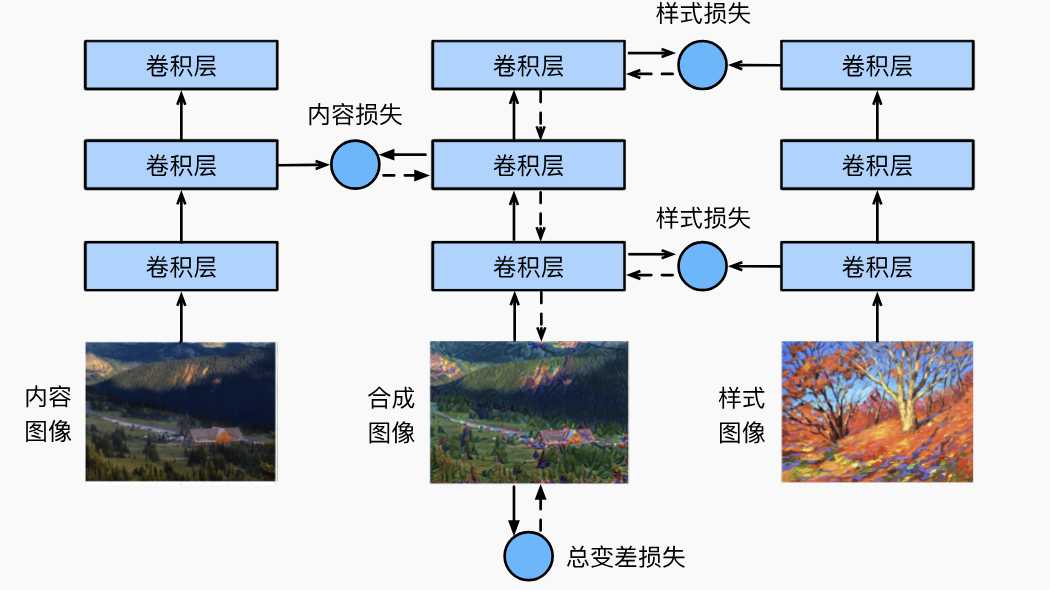
最终的损失内容损失+样式损失,即总变成损失。也就是说训练的时候输出图像的内容要跟源图像的内容接近,而样式跟样式图片接近。
本文来自: <动手学深度学习 V2> 的学习笔记