一步步实现transformer
- Ai应用
- 21小时前
- 46热度
- 0评论
概述
在https://www.laumy.tech/2458.html#h37章节中,介绍了transformer的原理,本章用pytorch来实现一个将"我有一个苹果"翻译为英文"I have an apple"的模型,直观体会transformer原理实现。
接下来先上图看看整体的代码流程。
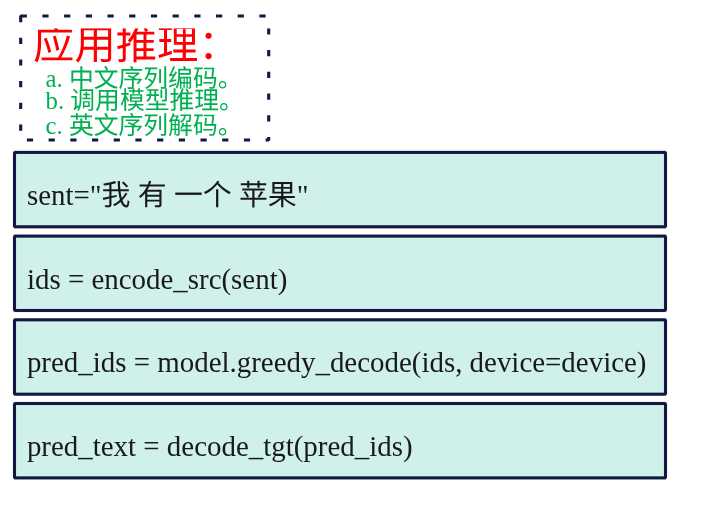
推理
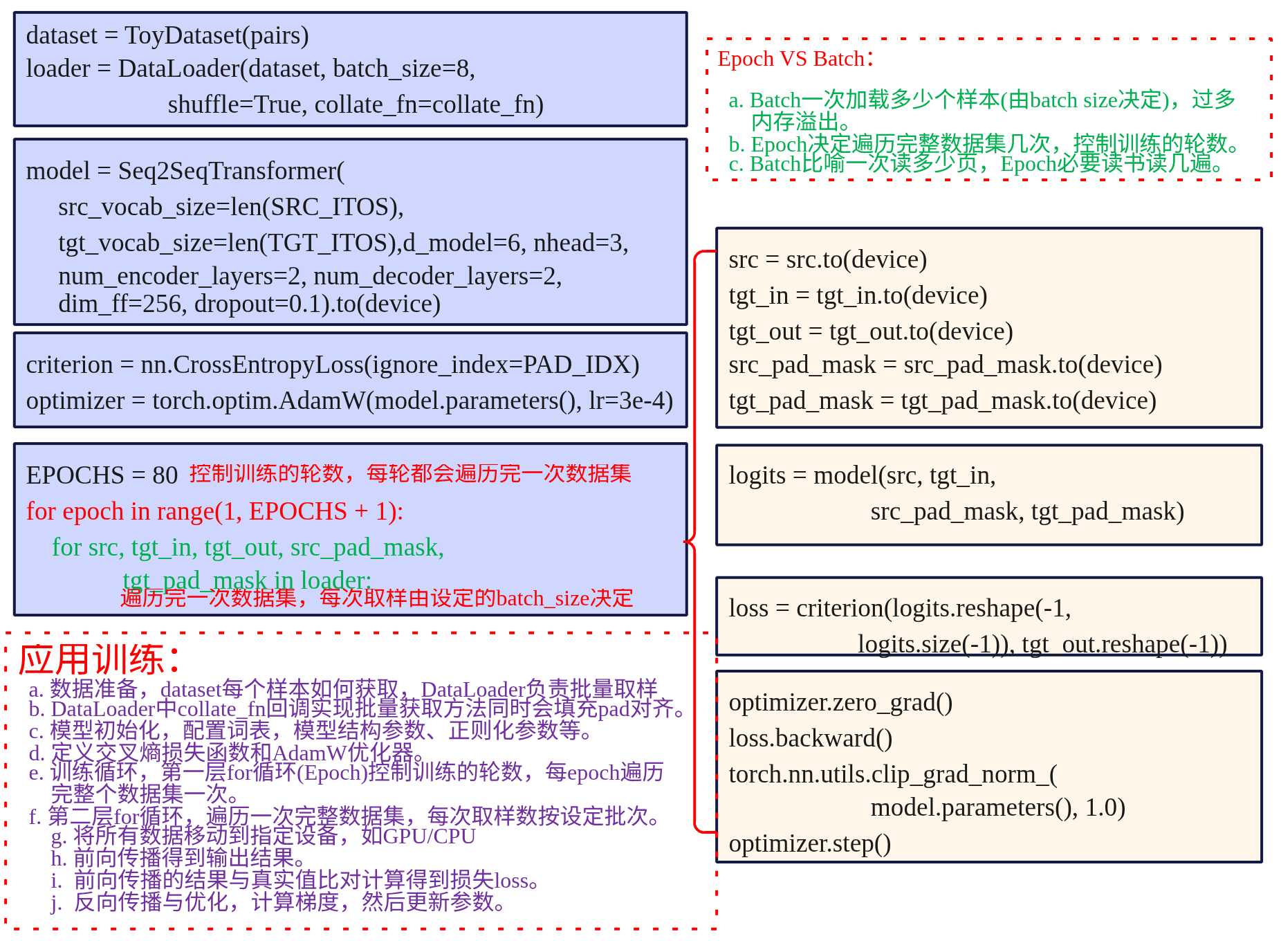
训练
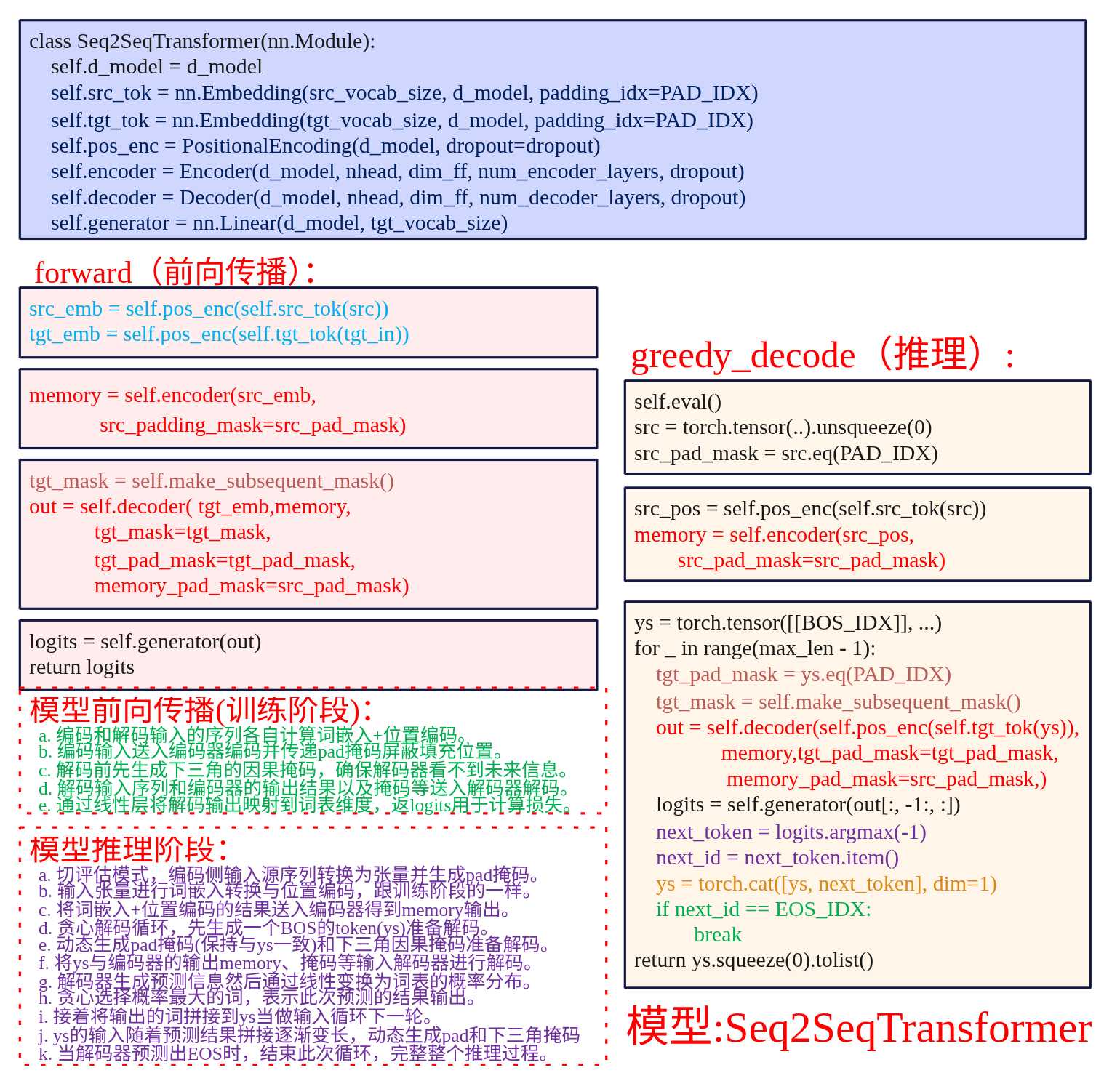
模型
编解码器
到这里就涵盖了整个transformer模型翻译的例子了,下面的章节只是对图中的代码进行展开说明,如果不想陷入细节,可以直接跳转到最后一节获取源码运行实验一下。
数据预处理
数据准备
(1) 准备原始文本对
既然要做翻译那得先有数据用于模型训练,因此需要先准备原始的中文->英文的文本对,下面是使用python列表(List)准备中英匹配语料,List中包含的是元组(Tuple)。
pairs = [
("我 有 一个 苹果", "i have an apple"),
("我 有 一本 书", "i have a book"),
("你 有 一个 苹果", "you have an apple"),
("他 有 一个 苹果", "he has an apple"),
("她 有 一个 苹果", "she has an apple"),
("我们 有 一个 苹果", "we have an apple"),
("我 喜欢 苹果", "i like apples"),
("我 吃 苹果", "i eat apples"),
("你 喜欢 书", "you like books"),
("我 喜欢 书", "i like books"),
("我 有 两个 苹果", "i have two apples"),
("我 有 红色 苹果", "i have red apples"),
]
为了方便,在构建原始文本对时,中英文的分词就以空格划分,这样接下来就可以根据空格来进行构建词表。
(2)构建词表
因为神经网络不能直接处理文本,模型只能处理数字,比如不能直接处理"我"、"有","I"等中英文词,对于计算机来讲都是数字,所以需要把文字转换为对应的映射表。
所以词表就是一个"字典",把每个词映射到一个唯一的数字ID上,所有的文本都需要转换为数字序列。
如下示例,中英文的编号。
# 中文词表示例
SRC_STOI = {
"我": 1,
"有": 2,
"一个": 3,
"苹果": 4,
"书": 5,
"喜欢": 6,
# ... 更多词
}
# 英文词表示例
TGT_STOI = {
"i": 1,
"have": 2,
"an": 3,
"apple": 4,
"a": 5,
"book": 6,
# ... 更多词
}
如何构建词表了。既然中文、英文都需要各自编号,那么得先把此前准备的原始文本队中文、英文各自拆出来,然后我们使用python的set集合,将中文、英文分别添加到set集合中,使用set集合的好处是可以自动去重,添加了重复元素,set就不会添加,这样就得到了各自的中文、英文词表。最后再对这些词表进行依次编号即可。
下面就看看使用python代码怎么实现,首先是将原始文本对拆解,把中文放一起,英文放一起。
src_texts = [p[0] for p in pairs]
tgt_texts = [p[1] for p in pairs]
print(src_texts)
print(tgt_texts)
src_texts ['我 有 一个 苹果', '我 有 一本 书', '你 有 一个 苹果', '他 有 一个 苹果', '她 有 一个 苹果', '我们 有 一个 苹果', '我 喜欢 苹果', '我 吃 苹果', '你 喜欢 书', '我 喜欢 书', '我 有 两个 苹果', '我 有 红色 苹果']
tgt_texts ['i have an apple', 'i have a book', 'you have an apple', 'he has an apple', 'she has an apple', 'we have an apple', 'i like apples', 'i eat apples', 'you like books', 'i like books', 'i have two apples', 'i have red apples']
接下来实现一个build_vocab函数,主要的思路就是句子先按照空格进行分好词,接着将所有词添加到set集合中,set集合会自动去重,这里需要注意的时,需要再加上3个特殊的词,分别是pad、bos、eos分别表示填充、开始、结束。填充是因为输入句子是不定长的,但是对于transformer来说所有的输入矩阵处理都是固定长度,所以不够的需要补齐,而bos和eos是用于transformer解码的,便于开始和结束翻译过程,最后构建好词表后就按照词表中进行变化,3个特殊词分为为1、2、3其他的词依次编号。
def build_vocab(examples: List[str]):
"""构建词表(字符串→索引 与 索引→字符串)
- 输入示例为用空格分词后的句子列表
- 加入特殊符号 `<pad>`, `<bos>`, `<eos>` 并将其它 token 排序,保证可复现
返回:
stoi: dict[token->id]
itos: List[id->token]
"""
tokens = set() # 建立一个集合,用于存储所有的词表(不重复的词)
for s in examples: # 依次遍历获得每个句子
for t in s.split(): # 通过空格划分,依次遍历句子中的每个词,
tokens.add(t.lower()) # 将词添加到set中,这里为了方便统一转换小写
itos = ["<pad>", "<bos>", "<eos>"] + sorted(tokens) # 加入3个特殊的词,同时对set中的词进行排序。
stoi = {t: i for i, t in enumerate(itos)} # 对词表中的词按照顺序依次编号
return stoi, itos
SRC_STOI, SRC_ITOS = build_vocab(src_texts)
TGT_STOI, TGT_ITOS = build_vocab(tgt_texts)
build_vocab最终返回是一个字典和列表,字典是词:编号的映射,列表是存放的是词表。列表是按照编号顺序依次排布,这样我们可以通过编号定位到时那个词。
为什么要一个字典和列表了?因为transformer输入是词->编号(转换为编码数字给计算机处理),输出是编号->词过程(转化为句子给人看)。通过字典我们可以查询词对应的编号[key:value],而通过列表的索引(编号)我们可以查询到对应的词。
中文和英文分别各自对应一个字典和词表。
SRC_STOI {'<pad>': 0, '<bos>': 1, '<eos>': 2, '一个': 3, '一本': 4, '两个': 5, '书': 6, '他': 7, '你': 8, '吃': 9, '喜欢': 10, '她': 11, '我': 12, '我们': 13, '有': 14, '红色': 15, '苹果': 16}
SRC_ITOS ['<pad>', '<bos>', '<eos>', '一个', '一本', '两个', '书', '他', '你', '吃', '喜欢', '她', '我', '我们', '有', '红色', '苹果']
TGT_STOI {'<pad>': 0, '<bos>': 1, '<eos>': 2, 'a': 3, 'an': 4, 'apple': 5, 'apples': 6, 'book': 7, 'books': 8, 'eat': 9, 'has': 10, 'have': 11, 'he': 12, 'i': 13, 'like': 14, 'red': 15, 'she': 16, 'two': 17, 'we': 18, 'you': 19}
TGT_ITOS ['<pad>', '<bos>', '<eos>', 'a', 'an', 'apple', 'apples', 'book', 'books', 'eat', 'has', 'have', 'he', 'i', 'like', 'red', 'she', 'two', 'we', 'you']
这样我们就给中文和英文的所有词都编好号了,同时通过列表也可以通过编号查询到词。
数据加载器
在pytorch中模型训练那必然少不了DataLoader和Dataset,关于这两个类的介绍在https://www.laumy.tech/2491.html#h23中有简要说明,这里就不阐述了。注意本小节说明的数据的批量处理都适用于训练准备,主要是实现Dataset和Dataloader用于pytorch模型的训练,如果只是推理则是不需要的。
(1)Dataset继承类实现
首先要实现DataLoader中关键的输入类Dataset继承类,用于产出“单个样本”,怎么按索引取到一个样本,以及总共有多少个样本。每个样本是中文句子->英文句子。样本集为此前定义pairs,但是要把pairs中句子转换为编号,词表在前面我们已经构建好了,直接查询就行,那这里我们定义一个Example用于定义样本,src是中文句子的编号列表,tgt是对于英文句子的编号列表。
@dataclass
class Example:
"""单条并行样本
- src: 源语言索引序列(不含 BOS/EOS)
- tgt: 目标语言索引序列(含 BOS/EOS)
"""
src: List[int]
tgt: List[int]
接下来就是实现Dataset的继承类ToyDataset,返回有多少个样本,以及通过编号获取指定的样本。
class ToyDataset(Dataset):
"""语料数据集,用于快速过拟合演示。"""
def __init__(self, pairs: List[Tuple[str, str]]):
self.data = [Example(encode_src(s), encode_tgt(t)) for s, t in pairs]
def __len__(self): return len(self.data)
def __getitem__(self, idx): return self.data[idx]
需要把pairs句子中词列表编码为数字列表,这里实现encode_src用于将输入(即pairs中的中文)编号为列表,再实现encode_tgt将输出(即pairs中的英文)编号为列表。使用for列表推导式从pairs列表中获取到s(中文句子)和t(英文句子)然后传入encode_src和encoder_tgt进而构建一个新的列表元素Example。这样就组建样本的self.data的样本列表,元素为Example类型,可以通过idx获取到指定的样本。
def encode_src(s: str) -> List[int]:
"""将原语句(已空格分词)编码为索引序列(不含 BOS/EOS)。"""
return [SRC_STOI[w.lower()] for w in s.split()]
def encode_tgt(s: str) -> List[int]:
"""将目标语句编码为索引序列,并在首尾添加 BOS/EOS。"""
return [BOS_IDX] + [TGT_STOI[w.lower()] for w in s.split()] + [EOS_IDX]
上面就是输入句子编码为编号向量的实现了,也很简单,通过此前构建的词表字典,通过词就可以搜索到对应编号了。这里需要注意的是编码的源句子(输入)是没有包含BOS和EOS的,因为transformer的编码器不需要BOS和EOS,而编码的目标句子(输出)需要在句子前加上BOS,句子结尾加上EOS,因为transformer的解码器输入需要通过BOS来翻译第一个词,通过EOS来结束一个句子的翻译,要是不明白为什么了可以看看前面transformer原理的文章。
(2)Dataload
DataLoader 负责“成批取样”,模型训练输入数据不是一个样本一个样本的送入训练,而是按照批次(多个样本合成一个批次)进行训练,这样训练效率才高。DataLoader决定批大小、是否打乱、多进程加载,返回的是一个可迭代的对象。
DataLoader重点是要实现 collate_fn回调,也就是怎么把一个批里的样本“拼起来”。
loader = DataLoader(dataset, batch_size=8, shuffle=True, collate_fn=collate_fn)
训练transformer,准备数据。我们的目的是要能够返回批量数据,批量数据也有好几个类型。
- 输入给encoder批量数据:输入矩阵类型(B,S),包含补齐的padding。
- 输入给decoder的批量数据:输入给decoder的矩阵类型(B,T),包含BOS以及右对齐的padding。不能加EOS,因为EOS是预测的结果,防止模型训练作弊。
- decoder输出的批量数据:解码器的监督目标,主要用于预测数据与实际的结果比较计算损失,矩阵类型(B,T),不含BOS但是包含EOS。
- encoder输入的pad掩码数据:因为输入给encoder的数据有padding,所以要告诉transformer哪些做了补齐,后续计算的时候要处理。
- decoder输入的pad掩码数据:同上。
def collate_fn(batch: List[Example]):
"""将一个 batch 的样本对齐为等长张量,并构造 teacher forcing 所需的输入/输出。
返回:
- src: (B,S) 源序列,已 padding
- tgt_in: (B,T) 解码器输入(含 BOS,右对齐 padding)
- tgt_out: (B,T) 解码器监督目标(对 tgt_in 右移一位,含 EOS)
- src_pad_mask: (B,S) 源端 padding 掩码,True 表示 padding 位置
- tgt_pad_mask: (B,T) 目标端 padding 掩码(针对输入序列)
"""
# padding to max length in batch
src_max = max(len(b.src) for b in batch)
tgt_max = max(len(b.tgt) for b in batch)
src_batch = []
tgt_in_batch = []
tgt_out_batch = []
for ex in batch:
src = ex.src + [PAD_IDX] * (src_max - len(ex.src))
# Teacher forcing: shift-in, shift-out
tgt_in = ex.tgt[:-1] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[:-1]))
tgt_out = ex.tgt[1:] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[1:]))
src_batch.append(src)
tgt_in_batch.append(tgt_in)
tgt_out_batch.append(tgt_out)
src = torch.tensor(src_batch, dtype=torch.long) # (B, S)
tgt_in = torch.tensor(tgt_in_batch, dtype=torch.long) # (B, T_in)
tgt_out = torch.tensor(tgt_out_batch, dtype=torch.long) # (B, T_out)
src_pad_mask = src.eq(PAD_IDX) # (B, S)
tgt_pad_mask = tgt_in.eq(PAD_IDX) # (B, T)
return src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask
上面就是Dataloader回调函数如何获取批量数据的实现了,输入为一个列表(包含所有样本的列表)。输出为5个2维向量,分别对应的就是上面说的5个批量数据。
首先计算样本列表中最长的源序列长度src_max和目标序列长度tgt_max,为后续的不足长度的句子进行padding操作,提供基准的长度。
其次使用for循环遍历每个样本(Example),将源序列src(encoder的输入)使用PAD_IDX填充到相同长度,保持做对齐;将目标序列输入(tgt_in)去掉最后一个token(EOS)作为decoder的输入,目标序列输出比对样本tgb_out去掉第一个tokenBOS作为监督目标,使用的teacher Forcing机制,这样就是实现了输入预测下一个的训练模式数据准备。
最后就是准备src和tgt_in的mask矩阵,形状跟src和tgt_in一样,使用python的eq比对如果对应的位置是padding就是true,不是就是false。
模型架构
数据准备好了,接下来就是设计我们的模型了。我们的模型是一个翻译模型可以分为两个路径,一个是编码路径和解码路径。
- 编码路径:词嵌入->位置编码->编码器。
- 解码路径:词嵌入->位置编码->解码器->生成器。
Class Seq2SeqTransformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=128, nhead=4,
num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1):
super().__init__()
self.d_model = d_model
# 编码路径
# 1.词嵌入层,将tokenID转换为密集向量
self.src_tok = nn.Embedding(src_vocab_size, d_model, padding_idx=PAD_IDX)
self.tgt_tok = nn.Embedding(tgt_vocab_size, d_model, padding_idx=PAD_IDX)
# 2. 对输入添加位置信息
self.pos_enc = PositionalEncoding(d_model, dropout=dropout)
# 3. 源序列的编码
self.encoder = Encoder(d_model, nhead, dim_ff, num_encoder_layers, dropout)
# 解码路径
# 1. 解码生成目标序列
self.decoder = Decoder(d_model, nhead, dim_ff, num_decoder_layers, dropout)
# 2. 将解码器输出转换为词表概率
self.generator = nn.Linear(d_model, tgt_vocab_size)
词嵌入直接调用的是神经网络的库nn.Embedding,其他部分都要自己实现,接下来我们会一一展开。下面我们需要先实现模型Seq2SeqTransformer的方法,主要包括如下:
- make_subsequent_mask:解码器因果掩码,不允许解码器看到未来。
- forward: 模型前向传播的方法,pytorch训练的时候自动调用。
- greedy_decode:模型推理方法,用于推理的应用。
因果掩码
为什么需要掩码了?主要是让模型不能看到未来的词。
推理阶段虽然是自回归一个一个输入然后一个一个迭代输出,但是在训练阶段,我们解码器的样本是全部一次性输入的。如下的步骤,我们虽然给到模型输入为:"BOS i have an apple ",但是每个步骤给到模型看到的不能是全部,否则给模型都看到输入结果了,那还谈啥预测,模型会偷懒直接就照搬就是一个映射过程了。如当输入BOS i 期望预测输出i have,如果没有掩码模型都看到全部的"BOS i have an apple ",就不是预测了,模型的参数也没法迭代了。
# 步骤1: 输入BOS → 期望输出i
# 步骤2: 输入BOS i → 期望输出i have
# 步骤3: 输入BOS i have → 期望输出i have an
# 步骤4: 输入BOS i have an → 期望输出 i have an apple
# 步骤5: 输入BOS i have an apple → 期望输出i have an apple EOS
哪有个问题,为什么我们输入的时候不按照要多少输入多少,为啥要全部一下给到输入?输入倒是可以要多少输入多少,但是要要考虑模型的并行训练,实际上上面的5个步骤在模型训练时是并行进行的,模型训练要的是训练参数,在某个阶段看到什么输入遇到什么输出,都分好类了自然可以并行的,所以这就需要结合掩码了,告诉模型那个步骤你能看到哪些?
总结一下mask的作用就是让模型不能看到未来的词,同时也是让模型不要对padding位进行误预测。
def make_subsequent_mask(self, sz: int) -> torch.Tensor:
"""构造大小为 (sz, sz) 的下三角因果掩码;True 为屏蔽(不允许看未来)。"""
return torch.triu(torch.ones(sz, sz, dtype=torch.bool), diagonal=1)
mask是要生成一个下三角形状,示例如下:
# 对于序列长度4
mask = make_subsequent_mask(4)
# 结果:
# [[False, True, True, True], # 位置0: 只能看位置0
# [False, False, True, True], # 位置1: 能看位置0,1
# [False, False, False, True], # 位置2: 能看位置0,1,2
# [False, False, False, False]] # 位置3: 能看所有位置
前向传播
def forward(self, src, tgt_in, src_pad_mask, tgt_pad_mask):
"""训练/教师强制阶段的前向。
参数:
- src: (B, S) 源 token id
- tgt_in: (B, T) 目标端输入(以 BOS 开头)
- src_pad_mask: (B, S) True 为 padding
- tgt_pad_mask: (B, T) True 为 padding(针对 tgt_in)
返回:
- logits: (B, T, V) 词表维度的分类分布
"""
# 1) 词嵌入 + 位置编码
src_emb = self.pos_enc(self.src_tok(src)) # (B,S,C)
tgt_emb = self.pos_enc(self.tgt_tok(tgt_in)) # (B,T,C)
# 2) 编码:仅使用 key_padding_mask 屏蔽 padding
memory = self.encoder(src_emb, src_key_padding_mask=src_pad_mask) # (B,S,C)
# 3) 解码:自注意力需要因果掩码 + padding 掩码;交叉注意力需要 memory 的 padding 掩码
tgt_mask = self.make_subsequent_mask(tgt_in.size(1)).to(src.device) # (T,T)
out = self.decoder(
tgt_emb,
memory,
tgt_mask=tgt_mask,
tgt_key_padding_mask=tgt_pad_mask,
memory_key_padding_mask=src_pad_mask,
) # (B,T,C)
logits = self.generator(out)
return logits
上面就是模型的训练了,也比较简单,就是对输入词进行词嵌入+位置编码计算,然后送入编码器得到输出特征矩阵memory;给编码器输入的只是padding的掩码,因为不要提取padding的词;
其次生成因果掩码,将编码器的的特征矩阵输出结果memory以及解码器侧自身的输入给到解码器最终得到(B,T,C)的输出矩阵,其包含了最终输出结果词位置的隐藏信息;
最后调用self.generator(out)即线性变化得到输出目标词表的概率分布(B,T,V);后面就可以用其使用交叉熵跟目标结果进行比对计算损失了。
解码推理
@torch.no_grad()
def greedy_decode(self, src_ids: List[int], max_len=20, device="cpu"):
"""在推理阶段进行贪心解码。
参数:
- src_ids: 源端 token id 序列(不含 BOS/EOS)
- max_len: 最大生成长度(含 BOS/EOS)
- device: 运行设备
返回:
- 生成的目标端 id 序列(含 BOS/EOS)
"""
#切换为评估模式,关闭dropout/batchnorm等随机性
self.eval()
# 将源端token id序列转换为张量,并添加一个维度,如[1, 2, 3, 4] -> [[1, 2, 3, 4]]
# 变为批维度的 (1, S);dtype 为 long 主要是以适配 nn.Embedding的输入格式。
src = torch.tensor(src_ids, dtype=torch.long, device=device).unsqueeze(0)
# 生成一个跟src相同形状的mask矩阵,让编码器不要计算提取pandding的位置信息。
#按元素判断 src 是否等于 PAD_IDX,等于的位置为 True,不等的位置为 False。
src_pad_mask = src.eq(PAD_IDX)
# 计算src_tok= src 经过词嵌入+位置编码后的结果
src_tok = self.src_tok(src)
src_pos = self.pos_enc(src_tok)
# 将该结果送入编码器,返回的memory就是编码器提取的特征向量。
# 输入编码器,即使没有填充(pandding)的token,也需要传入src_key_padding_mask。
memory = self.encoder(src_pos, src_key_padding_mask=src_pad_mask)
# 初始化目标端token id序列,维度为(1,1),初始值为BOS_IDX
# 表示目标端序列的开始,BOS_IDX=1
# 推理时输入是没有PAD,但是仍然需要tgt_pad_mask.
ys = torch.tensor([[BOS_IDX]], dtype=torch.long, device=device)
for _ in range(max_len - 1):
#计算本次解码的Mask,跟ys形状一样。
tgt_pad_mask = ys.eq(PAD_IDX)
# 计算本次因果掩码,把未来看到的token都屏蔽。
tgt_mask = self.make_subsequent_mask(ys.size(1)).to(device)
# 可以看到当推理模式时,解码器输入token数量依次是1,2,3,4.....
out = self.decoder(
self.pos_enc(self.tgt_tok(ys)),
memory,
tgt_key_padding_mask=tgt_pad_mask,
memory_key_padding_mask=src_pad_mask,
)
# 转化为预测词的概率分布
logits = self.generator(out[:, -1:, :])
# 使用贪心选择概率最大的作为本次预测的目标
next_token = logits.argmax(-1)
next_id = next_token.item()
# 显示选择的token
token_text = TGT_ITOS[next_id] if next_id < len(TGT_ITOS) else f"ID_{next_id}"
print(f"选择: {token_text}({next_id})")
ys = torch.cat([ys, next_token], dim=1)
# 当下一个输出为EOS时表示结束,则退出。
if next_id == EOS_IDX:
break
return ys.squeeze(0).tolist()
上面代码的设计要点主要为几个部分:
- 编码信息提取:将要翻译的句子进行词嵌入,位置编码,然后送入编码器计算提出特征信息memory,最终给到解码器作为输入。
- 自回归生成:最开始使用BOS一个token+编码器此前计算的输出memory、掩码等信息输入给解码器,解码器预测得到一个输出,然后将输出拼接会此前BOS的后面形成解码器新的输入,以此循环进行预测,直至遇到EOS结束。解侧输入序列长度逐步增长:1 → 2 → 3 → 4 → ...,最开始的序列为BOS表示开始。
- 掩码生成:使用了因果掩码和padding掩码;虽然推理阶段没有对输入数据进行padding操作,但是依旧需要这两个掩码,主要的考量是保持接口的一致性(原来的接口需要传递这个参数)。
- 贪心策略:解码器的输出进行线性变化得到词表的概率分布后,然后挑选概率最高的token。
- 结束循环:当判断到模型预测出EOS时,模式则结束,整个预测完成。
位置编码
class PositionalEncoding(nn.Module):
"""经典正弦/余弦位置编码。
给定嵌入 `x (B,L,C)`,按长度切片并与位置编码相加,再做 dropout。
"""
def __init__(self, d_model: int, max_len: int = 5000, dropout: float = 0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个形状为 (max_len, d_model) 的零张量,用于存储位置编码
pe = torch.zeros(max_len, d_model) # (L, C)
# 创建一个形状为 (max_len, 1) 的张量,用于存储位置索引
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (L, 1)
# 创建一个形状为 (d_model//2,) 的张量,用于存储位置编码的缩放因子
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# sin, cos 交错
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # (1, L, C)
self.register_buffer("pe", pe)
def forward(self, x: torch.Tensor): # (B, L, C)
"""为输入嵌入添加位置编码并做 dropout。
参数:
- x: (B, L, C)
返回:
- (B, L, C)
"""
x = x + self.pe[:, : x.size(1)]
return self.dropout(x)
# 对于位置 pos 和维度 i:
# 偶数维度: PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
# 奇数维度: PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
# pe[:, 0::2]: 选择所有行的偶数列 (0, 2, 4, ...)
# pe[:, 1::2]: 选择所有行的奇数列 (1, 3, 5, ...)
# 计算过程:
# 位置0: sin(0 * div_term), cos(0 * div_term), sin(0 * div_term), ...
# 位置1: sin(1 * div_term), cos(1 * div_term), sin(1 * div_term), ...
# 位置2: sin(2 * div_term), cos(2 * div_term), sin(2 * div_term), ...
位置编码比较简单,就是按照sin和cos按公式计算生成向量,最终返回词嵌入向量+位置编码向量。
编码器
class Encoder(nn.Module):
def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1):
super().__init__()
self.layers = nn.ModuleList([
EncoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers)
])
def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor:
"""堆叠若干编码层。
参数:
- x: (B, S, C)
- src_key_padding_mask: (B, S) True 为 padding
返回:
- (B, S, C)
"""
for layer in self.layers:
x = layer(x, src_key_padding_mask=src_key_padding_mask)
return x
编码器框架就是若干个编码层堆叠起来,但是每层的都有自己的参数,主要调用的是nn.ModuleList进行注册子模块,确保参数都能够被优化器找到,num_layers控制了编码器的深度。
前向传播函数也很简单,输入一次通过每一个编码层,得到的输出结果给到下一个编码层,以此循环最终经过最后一层编码器得得到的特征信息,给后续解码器使用。
class EncoderLayer(nn.Module):
"""Transformer 编码层(后归一化 post-norm 版本)
子层:自注意力 + 前馈;均带残差连接与 LayerNorm。
"""
def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, nhead, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor:
"""单层编码层前向。
参数:
- x: (B, S, C)
- src_key_padding_mask: (B, S) True 为 padding
返回:
- (B, S, C)
"""
# 自注意力子层
attn_out = self.self_attn(x, x, x, attn_mask=None, key_padding_mask=src_key_padding_mask)
x = self.norm1(x + attn_out)
# 前馈子层
ff_out = self.ff(x)
x = self.norm2(x + ff_out)
return x
编码层的组件为MultiHeadAttention、LayerNorm、PositionwiseFeedForward这与我们此前介绍的transformer原理一致。
其前向传播过程,首先输入X(查询),X(键),X(值),qkv都是一样的;注意力计算时,把attn_mask=None,因为编码器不需要因果掩码,但是需要padding mask。其次进行残差连接计算x+attn_out,再调用norml进行层归一化,最后是计算前馈网络,再进行归一化就得到一层的输出结果了。
class PositionwiseFeedForward(nn.Module):
"""前馈网络:逐位置的两层 MLP(含激活与 dropout)"""
def __init__(self, d_model: int, dim_ff: int, dropout: float = 0.1):
super().__init__()
self.fc1 = nn.Linear(d_model, dim_ff)
self.fc2 = nn.Linear(dim_ff, d_model)
self.act = nn.ReLU()
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""两层逐位置前馈网络。
参数:
- x: (B, L, C)
返回:
- (B, L, C)
"""
x = self.fc2(self.dropout(self.act(self.fc1(x))))
x = self.dropout(x)
return x
前馈网络主要两层:
- 第一层:d_model → dim_ff (通常 dim_ff = 4 * d_model)
- 激活函数:ReLU。
- 第二层:dim_ff → d_model
就是对输入进行升维然后非线性变化再降维,提取更多的信息。两层都使用了dropout,展开就是如下。
# 1. 第一层线性变换
x = self.fc1(x) # (B, L, C) → (B, L, dim_ff)
# 2. 激活函数
x = self.act(x) # 应用ReLU
# 3. 第一个dropout
x = self.dropout(x) # 随机置零部分神经元
# 4. 第二层线性变换
x = self.fc2(x) # (B, L, dim_ff) → (B, L, C)
# 5. 第二个dropout
x = self.dropout(x) # 最终dropout
解码器
class Decoder(nn.Module):
def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1):
super().__init__()
self.layers = nn.ModuleList([
DecoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers)
])
def forward(
self,
x: torch.Tensor,
memory: torch.Tensor,
tgt_mask: torch.Tensor | None = None,
tgt_key_padding_mask: torch.Tensor | None = None,
memory_key_padding_mask: torch.Tensor | None = None,
) -> torch.Tensor:
"""堆叠若干解码层。
参数:
- x: (B, T, C) 目标端嵌入
- memory: (B, S, C) 编码器输出
- tgt_mask: (T, T) 因果掩码,True 为屏蔽
- tgt_key_padding_mask: (B, T) 目标端 padding 掩码
- memory_key_padding_mask: (B, S) 源端 padding 掩码
返回:
- (B, T, C)
"""
for layer in self.layers:
x = layer(
x,
memory,
tgt_mask=tgt_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
)
return x
与编码器类似,使用nn.ModuleList创建多个解码层,每个解码层都是独立的DecoderLayer实例;解码器的输入数据有两个,一个是解码器侧自己的输入序列,另外一个是编码器计算得到的特征信息。解码器的每一层都需要输入编码器给的特征序列,但是都是一样的;解码器层计算得到的输出将传递给下一层解码器层,循环得到最后的输出。
Decoder (解码器)
├── DecoderLayer 1 (解码层1)
│ ├── MultiHeadAttention (自注意力)
│ ├── LayerNorm1 + 残差连接
│ ├── MultiHeadAttention (交叉注意力)
│ ├── LayerNorm2 + 残差连接
│ ├── PositionwiseFeedForward (前馈网络)
│ └── LayerNorm3 + 残差连接
├── DecoderLayer 2 (解码层2)
│ └── ... (同上结构)
└── ... (重复 num_layers 次)
输入: x (B, T, C) + memory (B, S, C) → DecoderLayer 1 → DecoderLayer 2 → ... → DecoderLayer N → 输出: (B, T, C)
其前向传播也大同小异,与编码器不同的是需要传递因果掩码,tgt_mask,防止看到未来信息,同时还传入了源序列的pandding掩码,跟输入给编码器的mask是一样的。
class DecoderLayer(nn.Module):
"""Transformer 解码层(自注意力 + 交叉注意力 + 前馈)"""
def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, nhead, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.cross_attn = MultiHeadAttention(d_model, nhead, dropout)
self.norm2 = nn.LayerNorm(d_model)
self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout)
self.norm3 = nn.LayerNorm(d_model)
def forward(
self,
x: torch.Tensor,
memory: torch.Tensor,
tgt_mask: torch.Tensor | None = None,
tgt_key_padding_mask: torch.Tensor | None = None,
memory_key_padding_mask: torch.Tensor | None = None,
) -> torch.Tensor:
"""单层解码层前向。
参数:
- x: (B, T, C) 解码器输入
- memory: (B, S, C) 编码器输出
- tgt_mask: (T, T) 因果掩码,true为屏蔽
- tgt_key_padding_mask: (B, T)
- memory_key_padding_mask: (B, S)
返回:
- (B, T, C)
"""
# 1) 解码器自注意力(带因果掩码 tgt_mask)
sa = self.self_attn(x, x, x, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)
x = self.norm1(x + sa)
# 2) 交叉注意力:Q 来自解码器,K/V 来自编码器 memory
ca = self.cross_attn(x, memory, memory, attn_mask=None, key_padding_mask=memory_key_padding_mask)
x = self.norm2(x + ca)
# 3) 前馈
ff = self.ff(x)
x = self.norm3(x + ff)
return x
解码器层比编码器层多了一个cross_attn交叉注意力。除了输入数据有些不同,其他都基本类似,下面按前向传播的流程来分析一下。
首先是第一个子层自注意力的计算,输入X(q),X(k),X(v)来自解码器侧路径的输入,推理模式则是由自己预测自回归的输入,训练模式是给定的。自注意力传入了因果掩码attn_mask和屏蔽pandding mask。
其次就是计算残差和层归一化,与编码器类似。
接着就是计算交叉注意力了,核心的注意力类还是MultiHeadAttention,跟编码器和解码器的都来自一个。唯一的区别就是传入的参数不一样,其中查询Q来自于解码器当前的状态X即解码器上一个自注意力的的输出,特征路径是解码器给的信息。而键值K,V则使用的是编码器的输出memory,不使用因果掩码,因为因果掩码前面已经处理了。
最后就是前馈网络的升维和降维处理等了,跟编码器就一样了,就不阐述了。
三个子层的不同作用:
- 自注意力层:处理目标序列内部的关系,生成"i have an apple"时,"have"应该关注"i","an"应该关注"i have",通过因果掩码确保只能看到历史信息。
- 交叉注意力层:让解码器"看到"编码器的信息,翻译成英文时,需要参考中文源序列,通过交叉注意力,解码器可以访问编码器的完整表示。
- 前馈网络则层:增加非线性表达能力,每个位置独立计算,不涉及位置间的关系。
注意力
接下来就是核心MultiHeadAttention。
MultiHeadAttention
class MultiHeadAttention(nn.Module):
"""多头注意力(Batch-first)
- 输入输出为 (B, L, C)
- 内部将通道 C 切分到 H 个头,每头维度 Dh=C/H
- 支持两类掩码:
1) attn_mask: (Lq, Lk) 下三角等自回归掩码
2) key_padding_mask: (B, Lk) 序列 padding 掩码
两者会在内部合并为可广播到 (B,H,Lq,Lk) 的布尔张量。
"""
def __init__(self, d_model: int, nhead: int, dropout: float = 0.1):
super().__init__()
assert d_model
self.d_model = d_model
self.nhead = nhead
self.d_head = d_model // nhead
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.attn = ScaledDotProductAttention(dropout)
self.proj = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
# 将 (B, L, C) 重塑为 (B, L, H, Dh),原来的数据都不会变化,只是形状改变了
# 加了一个维,然后交换了张量维度顺序。
def _shape(self, x: torch.Tensor) -> torch.Tensor:
"""(B, L, C) 切分重排为 (B, H, L, Dh)。"""
B, L, C = x.shape
# 第一步:将 (B, L, C) 重塑为 (B, L, H, Dh)
x_reshaped = x.view(B, L, self.nhead, self.d_head)
#x.view不复制数据,只是改变数据的"视角",数据在内存中存储顺序不变
# 第二步:交换维度 1 和 2,从 (B, L, H, Dh) 变为 (B, H, L, Dh)
x_transposed = x_reshaped.transpose(1, 2)
return x_transposed
def _merge(self, x: torch.Tensor) -> torch.Tensor:
"""(B, H, L, Dh) 合并重排回 (B, L, C)。"""
B, H, L, Dh = x.shape
# 第一步:交换维度 1 和 2,从 (B, H, L, Dh) 变为 (B, L, H, Dh)
x_transposed = x.transpose(1, 2)
# 第二步:确保内存连续,然后重塑为 (B, L, H*Dh)
x_contiguous = x_transposed.contiguous()
# 第三步:重塑为 (B, L, C) 其中 C = H * Dh
x_reshaped = x_contiguous.view(B, L, H * Dh)
return x_reshaped
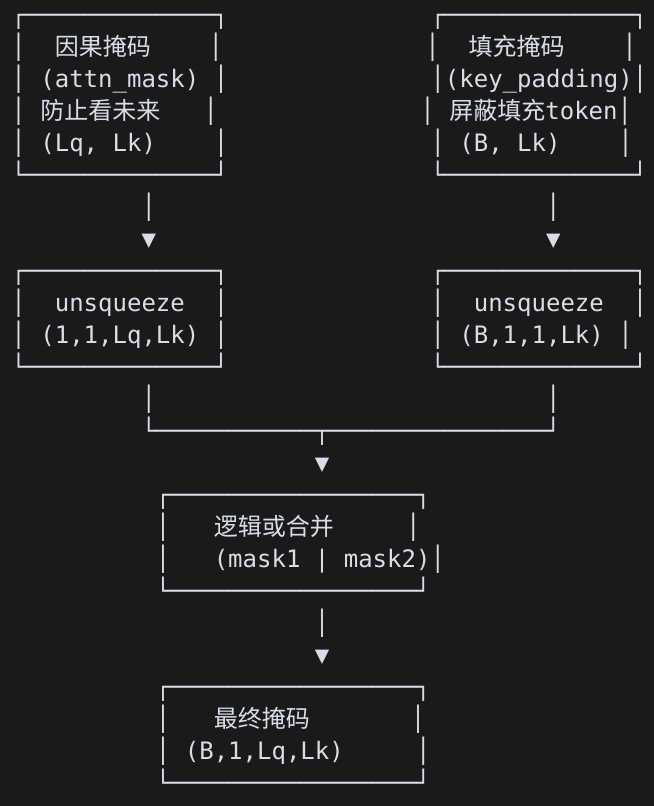
# 因为QKV算的是矩阵,在transformer中涉及到两个mask
# 一个是attn_mask控制哪些位置可以相互关注,如因果掩码防止看未来
# 一个是key_padding_mask控制哪些位置是有效的,如填充token不应该被关注
# 因为都要计算所以把这两个使用|合并起来,一起跟QKV计算即可,否则得计算两次。
# 对于encode来说传参只会穿key_pandding_mask,另外一个没有
# 对于decoder来说,两个都会传递。
def _build_attn_mask(
self,
Lq: int,
Lk: int,
attn_mask: torch.Tensor | None,
key_padding_mask: torch.Tensor | None,
device: torch.device,
) -> torch.Tensor | None:
"""将两类掩码合并成 (1/ B, 1/ H, Lq, Lk) 可广播布尔张量。True 表示屏蔽。"""
mask = None
if attn_mask is not None:
# (Lq, Lk) -> (1,1,Lq,Lk)
m1 = attn_mask.to(device).unsqueeze(0).unsqueeze(0)
mask = m1 if mask is None else (mask | m1)
if key_padding_mask is not None:
# (B, Lk) -> (B,1,1,Lk)
m2 = key_padding_mask.to(device).unsqueeze(1).unsqueeze(1)
mask = m2 if mask is None else (mask | m2)
return mask
(0)网络层定义
self.w_q = nn.Linear(d_model, d_model) # 查询线性变换
self.w_k = nn.Linear(d_model, d_model) # 键线性变换
self.w_v = nn.Linear(d_model, d_model) # 值线性变换
self.attn = ScaledDotProductAttention(dropout) # 缩放点积注意力
self.proj = nn.Linear(d_model, d_model) # 输出投影
self.dropout = nn.Dropout(dropout) # 输出dropout
w_q, w_k, w_v: 将输入转换为查询、键、值表示,attn为计算注意力权重和加权求和,proj将多头结果投影会原始维度,dropout是防止过拟合。
(1)将输入分成多个头
对输入按照head划分为多份,所以这里需要注意的是d_model必现要能被nhead整除,确保每个头有相同的维度。如原来的输入为(B,L,C)切分后变成(B, H, L, Dh),Dh=d_model/nhead。
第一步先使用view重塑为(B, H, L, Dh),然后第二步进行重排。举个例子输入为(B, L, C) = (1, 4, 6)重塑为(B, L, H, Dh) = (1, 4, 2, 3),重塑后的内存布局,[word1_head1_3, word1_head2_3, word2_head1_3, word2_head2_3, ...]每个词的头是交错存储的,为了适应多头注意力的并行计算还要重排一下,让每个头的数据连续存储。
(2)掩码合并
将key_padding_mask和attn_mask(因果)进行合并,这样后续计算就不用计算两次了。
# 使用逻辑或运算 | 合并
# True | True = True (屏蔽)
# True | False = True (屏蔽)
# False | False = False (不屏蔽)
# 最终掩码形状: (B, H, Lq, Lk) 或 (1, H, Lq, Lk)
# 可以广播到注意力计算的形状
(3)每个头计算注意力
Q = self._shape(self.w_q(query)) # (B,H,Lq,Dh)
K = self._shape(self.w_k(key)) # (B,H,Lk,Dh)
V = self._shape(self.w_v(value)) # (B,H,Lk,Dh)
mask = self._build_attn_mask(Lq, Lk, attn_mask, key_padding_mask, device)
out = self.attn(Q, K, V, mask) # (B,H,Lq,Dh)
计算注意力时,首先对输入分别进行计算线性变换(如QxWq,这样就有参数了)然后重排分别得到QKV,对于编码器来说输入的query、key、value都是一样的,计算QKV的方式也是一样的,都是进行线性nn.Linear层然后再进行重排,但是各自有各自参数,这就是要训练的参数。经过线性层的结果后都需要调用_shape进行重排划分为多个头的数据,便于输入给多头注意力;构建好合并后的掩码之后,就传递到attn中计算注意力。计算出的多头的注意力,需要合并为原来的形状,最后再通过一个线性变化得到最后的结果输出。
完整的数据流示例:
# 输入: query (1, 4, 6), key (1, 4, 6), value (1, 4, 6)
# 参数: d_model=6, nhead=2, d_head=3
# 步骤1: 线性变换 (保持形状)
# w_q(query): (1, 4, 6) -> (1, 4, 6)
# w_k(key): (1, 4, 6) -> (1, 4, 6)
# w_v(value): (1, 4, 6) -> (1, 4, 6)
# 每个词从6维变换到6维
# 学习查询、键、值的表示
# 步骤2: 分头
# _shape(w_q(query)): (1, 4, 6) -> (1, 2, 4, 3)
# _shape(w_k(key)): (1, 4, 6) -> (1, 2, 4, 3)
# _shape(w_v(value)): (1, 4, 6) -> (1, 2, 4, 3)
# 将6维分成2个头,每个头3维
# 头1: 3维表示
# 头2: 3维表示
# 步骤3: 注意力计算
# attn(Q, K, V, mask): (1, 2, 4, 3) -> (1, 2, 4, 3)
# 每个头独立计算注意力:
# 头1: 计算4个位置之间的注意力,每个位置3维
# 头2: 计算4个位置之间的注意力,每个位置3维
# 步骤4: 合并头
# _merge(out): (1, 2, 4, 3) -> (1, 4, 6)
# 将2个头的3维表示合并回6维
# 每个位置现在包含所有头的信息
# 步骤5: 输出变换
# proj(out): (1, 4, 6) -> (1, 4, 6)
# dropout(out): (1, 4, 6) -> (1, 4, 6)
# 最终输出: (1, 4, 6)
ScaledDotProductAttention
class ScaledDotProductAttention(nn.Module):
"""缩放点积注意力(单头)
给定 Q(查询)、K(键)、V(值) 与掩码,计算注意力加权输出。
形状约定:
- Q: (B, H, Lq, Dh)
- K: (B, H, Lk, Dh)
- V: (B, H, Lk, Dh)
- mask: 可广播到 (B, H, Lq, Lk),True 表示屏蔽。
"""
def __init__(self, dropout: float = 0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
def forward(self, Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor, mask: torch.Tensor | None = None):
"""计算缩放点积注意力。
参数:
- Q: (B, H, Lq, Dh)
- K: (B, H, Lk, Dh)
- V: (B, H, Lk, Dh)
- mask: 可广播到 (B, H, Lq, Lk) 的布尔掩码,True 表示屏蔽
返回:
- (B, H, Lq, Dh)
"""
d_k = Q.size(-1)
# 注意力分数 = QK^T / sqrt(dk)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # (B,H,Lq,Lk)
if mask is not None:
# 对被屏蔽位置填充一个极小值,softmax 后 ~0
scores = scores.masked_fill(mask, float("-inf"))
attn = torch.softmax(scores, dim=-1) # (B,H,Lq,Lk)
attn = self.dropout(attn)
out = torch.matmul(attn, V) # (B,H,Lq,Dh)
return out
这里就是实现缩放点积注意力机制了,Q.transpose(-2, -1)将K的最后两个维度转置,torch.matmul(Q, K^T): 计算Q和K的点积,再math.sqrt(d_k): 缩放因子,防止分数过大。
可以看到会根据传入的mask进行处理,让mask=True的位置会被填充为-inf,这样经过softmax之后,这些位置就接近0,从而实现了屏蔽某位位置的效果。
softmax是将分数转换为概率分布,所有位置的权重和为1,分数越高的位置,权重越大,也就是跟词相关性越大提取的值越丰富,如果是0那基本不相关,掩码为true的位置就是0,也就是基本不提取信息。
总结一下,核心就是公式Attention(Q,K,V) = softmax(QK^T/√d_k)V计算。
应用
接下来就是调用应用了
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dataset = ToyDataset(pairs)
loader = DataLoader(dataset, batch_size=8, shuffle=True, collate_fn=collate_fn)
model = Seq2SeqTransformer(
src_vocab_size=len(SRC_ITOS),
tgt_vocab_size=len(TGT_ITOS),
d_model=6, nhead=3, num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1
).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
定义dataset、loader准备数据,然后定义模型model,损失函数定义以及优化方法。
def evaluate_sample(sent="我 有 一个 苹果"):
"""辅助函数:对输入中文句子进行编码→推理→解码并打印结果。"""
ids = encode_src(sent)
print("ids",ids)
pred_ids = model.greedy_decode(ids, device=device)
pred_text = decode_tgt(pred_ids)
print(f'INPUT : {sent}')
print(f'OUTPUT: {pred_text}\n')
print("Before training:")
evaluate_sample("我 有 一个 苹果")
上面是整个应用翻译应用,在没有训练出参数,自然预测出的结果是不对的。
EPOCHS = 800 # 小步数即可过拟合玩具数据
for epoch in range(1, EPOCHS + 1):
model.train()
total_loss = 0.0
for src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask in loader:
src = src.to(device)
tgt_in = tgt_in.to(device)
tgt_out = tgt_out.to(device)
src_pad_mask = src_pad_mask.to(device)
tgt_pad_mask = tgt_pad_mask.to(device)
logits = model(src, tgt_in, src_pad_mask, tgt_pad_mask) # (B, T, V)
loss = criterion(logits.reshape(-1, logits.size(-1)), tgt_out.reshape(-1))
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
total_loss += loss.item()
if epoch
print(f"Epoch {epoch:02d} | loss={total_loss/len(loader):.4f}")
evaluate_sample("我 有 一个 苹果")
上面是训练过程。
常见问题
(1) 解码器训练时的输入和推理时的输入有什么不同?
训练模式是固定长度输入,例如(2,5),所有样本都padding到相同长度,批次内所有样本的长度一致。
# 使用教师强制,目标序列已知
tgt_in = [BOS, i, have, an, apple,PAD] # 完整的输入序列
tgt_out = [i, have, an, apple, EOS] # 完整的监督目标
而推理模式序列长度随着时间步逐步增长,例如# 例如: (1, 1) → (1, 2) → (1, 3) → ...,每次生成后长度+1。
# 逐步生成,每次只预测下一个token
ys = [[BOS_ID]] # 第1步
ys = [[BOS_ID, i]] # 第2步
ys = [[BOS_ID, i, have]] # 第3步
ys = [[BOS_ID, i, have, an]] # 第4步
ys = [[BOS_ID, i, have, an,apple]] # 第5步
之所以有这样的差异是训练时用的是Teacher Forcing优势,使用了并行计算让所有位置可以同时计算预测,提高效率快速收敛。而推理时是自回归模式,每个token的生成只能基于之前输出的信息。
(2)什么情况下输入数据需要PAD?
通常无论是编码器的输入还是解码器的输入如果不是批量并行计算都可以不用PAD,但如果是批量并行都需要PAD MASK。
在训练模式下,为了提高效率需要批量并行计算,所以无论编码器还是解码器的输入都是需要PAD,在本文中要不要PAD动作是在DataLoader的回调函数中collate_fn进行的,会对编码器和解码器的输入都会pad对齐到一样的长度。
因此最主要的考量是否要批量并行计算,因为并行计算如果长度不同,无法并行处理,无论是自注意力分数、前馈网络、还是残差连接,只有长度一致,才能并行一下处理多个样本。而往往训练模型基本都是批量处理。
总之只处理一个样本时可以不需要PAD,如果要批量都一定需要PAD。而只处理一个样本,往往是推理模式场景。
(3)既然推理模式的编码器和解码器输入没有进行PAD到一定长度,那为什么无论编码器和解码器都依旧还需要传入PAD mask?
需要PAD mask我认为本质上有两点原因:其一用于告知模型输入序列的长度,其二为了接口的一致性,因为transformer最核心的是无论编码器还是解码器最终的核心是Scaled Dot-Product Attetion,可以理解为这是一个共有底层函数,都要调用,做兼容了所以一定要传这个参数。
(3)推理模式的解码器既然是一个一个token往后生成的然后依次拼接回给到输入,未来的词其实根本就没有输入,为什么还需要下三角度的因果mask?
本质上还是保证接口的兼容性,这块都无论是推理还是训练模式都需要传入这个因果mask。
首先在实现层面让训练模式和推理模式代码能够兼容,训练模式使用的是teacher forcing把整个目标序列一次性喂进去,那自然不能让模型看到未来token。推理模式严格上如果一次一个token,每次只输入已经生成的部分,在这种最简单的视线下,确实不需要再加下三角mask,因为未来token不存在,自然无法attend到。但是大多数框架都选择统一接口,无论训练还是推理都传causal mask,避免在不同模式下切换逻辑。
其次从推理模式的多样性考虑,即使是推理阶段,也有可能遇到这种情况,也就是批量生成,一次生成多个序列,每个序列长度不同。
下三角是一个通用的"未来屏蔽"机制,不只是为了防止模型看见未来token,也是为了让实现和训练推理保持一致,并支持批量/并行推理优化。
附:完整源码
# toy_transformer_translation.py
# A tiny, runnable Transformer seq2seq example to translate Chinese->English on a toy dataset.
# PyTorch >= 2.0 recommended.
import math
import random
from dataclasses import dataclass
from typing import List, Tuple
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
random.seed(0)
torch.manual_seed(0)
# --------------------------
# 1) Toy parallel corpus
# --------------------------
pairs = [
# 基本陈述
("我 有 一个 苹果", "i have an apple"),
("我 有 一本 书", "i have a book"),
("你 有 一个 苹果", "you have an apple"),
("他 有 一个 苹果", "he has an apple"),
("她 有 一个 苹果", "she has an apple"),
("我们 有 一个 苹果", "we have an apple"),
("我 喜欢 苹果", "i like apples"),
("我 吃 苹果", "i eat apples"),
("你 喜欢 书", "you like books"),
("我 喜欢 书", "i like books"),
# 稍作扩展
("我 有 两个 苹果", "i have two apples"),
("我 有 红色 苹果", "i have red apples"),
]
# 中文使用"空格分词(简化)",英文用空格分词
def build_vocab(examples: List[str]):
"""构建词表(字符串→索引 与 索引→字符串)
- 输入示例为用空格分词后的句子列表
- 加入特殊符号 `<pad>`, `<bos>`, `<eos>` 并将其它 token 排序,保证可复现
返回:
stoi: dict[token->id]
itos: List[id->token]
"""
tokens = set()
# 建立一个集合,用于存储所有不同的token
for s in examples: # 遍历所有句子,s是句子,如我 有 一个 苹果
for t in s.split(): # 遍历句子中的每个token,t是token,如我
tokens.add(t.lower()) # 将token添加到集合中,并转换为小写,如我
# 特殊符号
itos = ["<pad>", "<bos>", "<eos>"] + sorted(tokens) # 将特殊符号和所有不同的token排序
# print(itos)
stoi = {t: i for i, t in enumerate(itos)} # 将token和索引建立映射关系
# print(stoi)
return stoi, itos
src_texts = [p[0] for p in pairs]
tgt_texts = [p[1] for p in pairs]
print("src_texts",src_texts)
print("tgt_texts",tgt_texts)
SRC_STOI, SRC_ITOS = build_vocab(src_texts)
print("SRC_STOI",SRC_STOI)
print("SRC_ITOS",SRC_ITOS)
TGT_STOI, TGT_ITOS = build_vocab(tgt_texts)
print("TGT_STOI",TGT_STOI)
print("TGT_ITOS",TGT_ITOS)
PAD_IDX, BOS_IDX, EOS_IDX = 0, 1, 2
#将源语句编码为索引序列(不含 BOS/EOS),如我 有 一个 苹果 -> [1, 2, 3, 4]
def encode_src(s: str) -> List[int]:
"""将原语句(已空格分词)编码为索引序列(不含 BOS/EOS)。"""
return [SRC_STOI[w.lower()] for w in s.split()]
def encode_tgt(s: str) -> List[int]:
"""将目标语句编码为索引序列,并在首尾添加 BOS/EOS。"""
return [BOS_IDX] + [TGT_STOI[w.lower()] for w in s.split()] + [EOS_IDX]
def decode_tgt(ids: List[int]) -> str:
"""将目标端索引序列解码回字符串(忽略 PAD/BOS,遇到 EOS 停止)。"""
words = []
for i in ids:
if i == EOS_IDX:
break
if i in (PAD_IDX, BOS_IDX):
continue
words.append(TGT_ITOS[i])
return " ".join(words)
@dataclass
class Example:
"""单条并行样本
- src: 源语言索引序列(不含 BOS/EOS)
- tgt: 目标语言索引序列(含 BOS/EOS)
"""
src: List[int]
tgt: List[int]
class ToyDataset(Dataset):
"""极小玩具平行语料数据集,用于快速过拟合演示。"""
def __init__(self, pairs: List[Tuple[str, str]]):
self.data = [Example(encode_src(s), encode_tgt(t)) for s, t in pairs]
def __len__(self): return len(self.data)
def __getitem__(self, idx): return self.data[idx]
def collate_fn(batch: List[Example]):
"""将一个 batch 的样本对齐为等长张量,并构造 teacher forcing 所需的输入/输出。
返回:
- src: (B,S) 源序列,已 padding
- tgt_in: (B,T) 解码器输入(含 BOS,右对齐 padding)
- tgt_out: (B,T) 解码器监督目标(对 tgt_in 右移一位,含 EOS)
- src_pad_mask: (B,S) 源端 padding 掩码,True 表示 padding 位置
- tgt_pad_mask: (B,T) 目标端 padding 掩码(针对输入序列)
"""
# padding to max length in batch
src_max = max(len(b.src) for b in batch)
tgt_max = max(len(b.tgt) for b in batch)
src_batch = []
tgt_in_batch = []
tgt_out_batch = []
for ex in batch:
src = ex.src + [PAD_IDX] * (src_max - len(ex.src))
# Teacher forcing: shift-in, shift-out
tgt_in = ex.tgt[:-1] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[:-1]))
tgt_out = ex.tgt[1:] + [PAD_IDX] * (tgt_max - 1 - len(ex.tgt[1:]))
src_batch.append(src)
tgt_in_batch.append(tgt_in)
tgt_out_batch.append(tgt_out)
src = torch.tensor(src_batch, dtype=torch.long) # (B, S)
tgt_in = torch.tensor(tgt_in_batch, dtype=torch.long) # (B, T_in)
tgt_out = torch.tensor(tgt_out_batch, dtype=torch.long) # (B, T_out)
src_pad_mask = src.eq(PAD_IDX) # (B, S)
tgt_pad_mask = tgt_in.eq(PAD_IDX) # (B, T)
return src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask
# --------------------------
# 2) Positional encoding
# --------------------------
class PositionalEncoding(nn.Module):
"""经典正弦/余弦位置编码。
给定嵌入 `x (B,L,C)`,按长度切片并与位置编码相加,再做 dropout。
"""
def __init__(self, d_model: int, max_len: int = 5000, dropout: float = 0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个形状为 (max_len, d_model) 的零张量,用于存储位置编码
pe = torch.zeros(max_len, d_model) # (L, C)
# 创建一个形状为 (max_len, 1) 的张量,用于存储位置索引
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (L, 1)
# 创建一个形状为 (d_model//2,) 的张量,用于存储位置编码的缩放因子
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# sin, cos 交错
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # (1, L, C)
self.register_buffer("pe", pe)
def forward(self, x: torch.Tensor): # (B, L, C)
"""为输入嵌入添加位置编码并做 dropout。
参数:
- x: (B, L, C)
返回:
- (B, L, C)
"""
x = x + self.pe[:, : x.size(1)]
return self.dropout(x)
# --------------------------
# 3) 手写 Transformer 编码/解码层(含详细注释)
# --------------------------
class ScaledDotProductAttention(nn.Module):
"""缩放点积注意力(单头)
给定 Q(查询)、K(键)、V(值) 与掩码,计算注意力加权输出。
形状约定:
- Q: (B, H, Lq, Dh)
- K: (B, H, Lk, Dh)
- V: (B, H, Lk, Dh)
- mask: 可广播到 (B, H, Lq, Lk),True 表示屏蔽。
"""
def __init__(self, dropout: float = 0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
def forward(self, Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor, mask: torch.Tensor | None = None):
"""计算缩放点积注意力。
参数:
- Q: (B, H, Lq, Dh)
- K: (B, H, Lk, Dh)
- V: (B, H, Lk, Dh)
- mask: 可广播到 (B, H, Lq, Lk) 的布尔掩码,True 表示屏蔽
返回:
- (B, H, Lq, Dh)
"""
d_k = Q.size(-1)
# 注意力分数 = QK^T / sqrt(dk)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # (B,H,Lq,Lk)
if mask is not None:
# 对被屏蔽位置填充一个极小值,softmax 后 ~0
scores = scores.masked_fill(mask, float("-inf"))
attn = torch.softmax(scores, dim=-1) # (B,H,Lq,Lk)
attn = self.dropout(attn)
out = torch.matmul(attn, V) # (B,H,Lq,Dh)
return out
class MultiHeadAttention(nn.Module):
"""多头注意力(Batch-first)
- 输入输出为 (B, L, C)
- 内部将通道 C 切分到 H 个头,每头维度 Dh=C/H
- 支持两类掩码:
1) attn_mask: (Lq, Lk) 下三角等自回归掩码
2) key_padding_mask: (B, Lk) 序列 padding 掩码
两者会在内部合并为可广播到 (B,H,Lq,Lk) 的布尔张量。
"""
def __init__(self, d_model: int, nhead: int, dropout: float = 0.1):
super().__init__()
assert d_model
self.d_model = d_model
self.nhead = nhead
self.d_head = d_model // nhead
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.attn = ScaledDotProductAttention(dropout)
self.proj = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
# 将 (B, L, C) 重塑为 (B, L, H, Dh),原来的数据都不会变化,只是形状改变了
# 加了一个维,然后交换了张量维度顺序。
def _shape(self, x: torch.Tensor) -> torch.Tensor:
"""(B, L, C) 切分重排为 (B, H, L, Dh)。"""
B, L, C = x.shape
# 第一步:将 (B, L, C) 重塑为 (B, L, H, Dh)
x_reshaped = x.view(B, L, self.nhead, self.d_head)
#x.view不复制数据,只是改变数据的"视角",数据在内存中存储顺序不变
# 第二步:交换维度 1 和 2,从 (B, L, H, Dh) 变为 (B, H, L, Dh)
x_transposed = x_reshaped.transpose(1, 2)
return x_transposed
def _merge(self, x: torch.Tensor) -> torch.Tensor:
"""(B, H, L, Dh) 合并重排回 (B, L, C)。"""
B, H, L, Dh = x.shape
# 第一步:交换维度 1 和 2,从 (B, H, L, Dh) 变为 (B, L, H, Dh)
x_transposed = x.transpose(1, 2)
# 第二步:确保内存连续,然后重塑为 (B, L, H*Dh)
x_contiguous = x_transposed.contiguous()
# 第三步:重塑为 (B, L, C) 其中 C = H * Dh
x_reshaped = x_contiguous.view(B, L, H * Dh)
return x_reshaped
# 因为QKV算的是矩阵,在transformer中涉及到两个mask
# 一个是attn_mask控制哪些位置可以相互关注,如因果掩码防止看未来
# 一个是key_padding_mask控制哪些位置是有效的,如填充token不应该被关注
# 因为都要计算所以把这两个使用|合并起来,一起跟QKV计算即可,否则得计算两次。
# 对于encode来说传参只会穿key_pandding_mask,另外一个没有
# 对于decoder来说,两个都会传递。
def _build_attn_mask(
self,
Lq: int,
Lk: int,
attn_mask: torch.Tensor | None,
key_padding_mask: torch.Tensor | None,
device: torch.device,
) -> torch.Tensor | None:
"""将两类掩码合并成 (1/ B, 1/ H, Lq, Lk) 可广播布尔张量。True 表示屏蔽。"""
mask = None
if attn_mask is not None:
# (Lq, Lk) -> (1,1,Lq,Lk)
m1 = attn_mask.to(device).unsqueeze(0).unsqueeze(0)
mask = m1 if mask is None else (mask | m1)
if key_padding_mask is not None:
# (B, Lk) -> (B,1,1,Lk)
m2 = key_padding_mask.to(device).unsqueeze(1).unsqueeze(1)
mask = m2 if mask is None else (mask | m2)
return mask
def forward(
self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
attn_mask: torch.Tensor | None = None,
key_padding_mask: torch.Tensor | None = None,
) -> torch.Tensor:
"""多头注意力前向。
参数:
- query, key, value: (B, L, C)
- attn_mask: (Lq, Lk) 因果/结构掩码,True 为屏蔽
- key_padding_mask: (B, Lk) padding 掩码,True 为 padding
返回:
- (B, Lq, C)
"""
# 输入均为 (B, L, C)
B, Lq, _ = query.shape
_, Lk, _ = key.shape
device = query.device
Q = self._shape(self.w_q(query)) # (B,H,Lq,Dh)
K = self._shape(self.w_k(key)) # (B,H,Lk,Dh)
V = self._shape(self.w_v(value)) # (B,H,Lk,Dh)
mask = self._build_attn_mask(Lq, Lk, attn_mask, key_padding_mask, device)
out = self.attn(Q, K, V, mask) # (B,H,Lq,Dh)
out = self._merge(out) # (B,Lq,C)
out = self.proj(out)
out = self.dropout(out)
return out
class PositionwiseFeedForward(nn.Module):
"""前馈网络:逐位置的两层 MLP(含激活与 dropout)"""
def __init__(self, d_model: int, dim_ff: int, dropout: float = 0.1):
super().__init__()
self.fc1 = nn.Linear(d_model, dim_ff)
self.fc2 = nn.Linear(dim_ff, d_model)
self.act = nn.ReLU()
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""两层逐位置前馈网络。
参数:
- x: (B, L, C)
返回:
- (B, L, C)
"""
x = self.fc2(self.dropout(self.act(self.fc1(x))))
x = self.dropout(x)
return x
class EncoderLayer(nn.Module):
"""Transformer 编码层(后归一化 post-norm 版本)
子层:自注意力 + 前馈;均带残差连接与 LayerNorm。
"""
def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, nhead, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor:
"""单层编码层前向。
参数:
- x: (B, S, C)
- src_key_padding_mask: (B, S) True 为 padding
返回:
- (B, S, C)
"""
# 自注意力子层
attn_out = self.self_attn(x, x, x, attn_mask=None, key_padding_mask=src_key_padding_mask)
x = self.norm1(x + attn_out)
# 前馈子层
ff_out = self.ff(x)
x = self.norm2(x + ff_out)
return x
class DecoderLayer(nn.Module):
"""Transformer 解码层(自注意力 + 交叉注意力 + 前馈)"""
def __init__(self, d_model: int, nhead: int, dim_ff: int, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, nhead, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.cross_attn = MultiHeadAttention(d_model, nhead, dropout)
self.norm2 = nn.LayerNorm(d_model)
self.ff = PositionwiseFeedForward(d_model, dim_ff, dropout)
self.norm3 = nn.LayerNorm(d_model)
def forward(
self,
x: torch.Tensor,
memory: torch.Tensor,
tgt_mask: torch.Tensor | None = None,
tgt_key_padding_mask: torch.Tensor | None = None,
memory_key_padding_mask: torch.Tensor | None = None,
) -> torch.Tensor:
"""单层解码层前向。
参数:
- x: (B, T, C) 解码器输入
- memory: (B, S, C) 编码器输出
- tgt_mask: (T, T) 因果掩码,true为屏蔽
- tgt_key_padding_mask: (B, T)
- memory_key_padding_mask: (B, S)
返回:
- (B, T, C)
"""
# 1) 解码器自注意力(带因果掩码 tgt_mask)
sa = self.self_attn(x, x, x, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)
x = self.norm1(x + sa)
# 2) 交叉注意力:Q 来自解码器,K/V 来自编码器 memory
ca = self.cross_attn(x, memory, memory, attn_mask=None, key_padding_mask=memory_key_padding_mask)
x = self.norm2(x + ca)
# 3) 前馈
ff = self.ff(x)
x = self.norm3(x + ff)
return x
class Encoder(nn.Module):
def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1):
super().__init__()
self.layers = nn.ModuleList([
EncoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers)
])
def forward(self, x: torch.Tensor, src_key_padding_mask: torch.Tensor | None = None) -> torch.Tensor:
"""堆叠若干编码层。
参数:
- x: (B, S, C)
- src_key_padding_mask: (B, S) True 为 padding
返回:
- (B, S, C)
"""
for layer in self.layers:
x = layer(x, src_key_padding_mask=src_key_padding_mask)
return x
class Decoder(nn.Module):
def __init__(self, d_model: int, nhead: int, dim_ff: int, num_layers: int, dropout: float = 0.1):
super().__init__()
self.layers = nn.ModuleList([
DecoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers)
])
def forward(
self,
x: torch.Tensor,
memory: torch.Tensor,
tgt_mask: torch.Tensor | None = None,
tgt_key_padding_mask: torch.Tensor | None = None,
memory_key_padding_mask: torch.Tensor | None = None,
) -> torch.Tensor:
"""堆叠若干解码层。
参数:
- x: (B, T, C) 目标端嵌入
- memory: (B, S, C) 编码器输出
- tgt_mask: (T, T) 因果掩码,True 为屏蔽
- tgt_key_padding_mask: (B, T) 目标端 padding 掩码
- memory_key_padding_mask: (B, S) 源端 padding 掩码
返回:
- (B, T, C)
"""
for layer in self.layers:
x = layer(
x,
memory,
tgt_mask=tgt_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
)
return x
class Seq2SeqTransformer(nn.Module):
"""最小可运行的手写 Transformer 序列到序列模型
- 使用我们实现的 Encoder/Decoder/MHA/FFN
- 仍保持与上文训练/解码接口一致
"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=128, nhead=4,
num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1):
super().__init__()
self.d_model = d_model
self.src_tok = nn.Embedding(src_vocab_size, d_model, padding_idx=PAD_IDX)
self.tgt_tok = nn.Embedding(tgt_vocab_size, d_model, padding_idx=PAD_IDX)
self.pos_enc = PositionalEncoding(d_model, dropout=dropout)
self.encoder = Encoder(d_model, nhead, dim_ff, num_encoder_layers, dropout)
self.decoder = Decoder(d_model, nhead, dim_ff, num_decoder_layers, dropout)
self.generator = nn.Linear(d_model, tgt_vocab_size)
def make_subsequent_mask(self, sz: int) -> torch.Tensor:
"""构造大小为 (sz, sz) 的下三角因果掩码;True 为屏蔽(不允许看未来)。"""
return torch.triu(torch.ones(sz, sz, dtype=torch.bool), diagonal=1)
def forward(self, src, tgt_in, src_pad_mask, tgt_pad_mask):
"""训练/教师强制阶段的前向。
参数:
- src: (B, S) 源 token id
- tgt_in: (B, T) 目标端输入(以 BOS 开头)
- src_pad_mask: (B, S) True 为 padding
- tgt_pad_mask: (B, T) True 为 padding(针对 tgt_in)
返回:
- logits: (B, T, V) 词表维度的分类分布
"""
# 1) 词嵌入 + 位置编码
src_emb = self.pos_enc(self.src_tok(src)) # (B,S,C)
tgt_emb = self.pos_enc(self.tgt_tok(tgt_in)) # (B,T,C)
# 2) 编码:仅使用 key_padding_mask 屏蔽 padding
memory = self.encoder(src_emb, src_key_padding_mask=src_pad_mask) # (B,S,C)
# 3) 解码:自注意力需要因果掩码 + padding 掩码;交叉注意力需要 memory 的 padding 掩码
tgt_mask = self.make_subsequent_mask(tgt_in.size(1)).to(src.device) # (T,T)
out = self.decoder(
tgt_emb,
memory,
tgt_mask=tgt_mask,
tgt_key_padding_mask=tgt_pad_mask,
memory_key_padding_mask=src_pad_mask,
) # (B,T,C)
logits = self.generator(out)
return logits
@torch.no_grad()
def greedy_decode(self, src_ids: List[int], max_len=20, device="cpu"):
"""在推理阶段进行贪心解码。
参数:
- src_ids: 源端 token id 序列(不含 BOS/EOS)
- max_len: 最大生成长度(含 BOS/EOS)
- device: 运行设备
返回:
- 生成的目标端 id 序列(含 BOS/EOS)
"""
#切换为评估模式,关闭dropout/batchnorm等随机性
self.eval()
# 将源端token id序列转换为张量,并添加一个维度,如[1, 2, 3, 4] -> [[1, 2, 3, 4]]
# 变为批维度的 (1, S);dtype 为 long 主要是以适配 nn.Embedding的输入格式。
src = torch.tensor(src_ids, dtype=torch.long, device=device).unsqueeze(0)
# 生成一个跟src相同形状的mask矩阵,让编码器不要计算提取pandding的位置信息。
#按元素判断 src 是否等于 PAD_IDX,等于的位置为 True,不等的位置为 False。
src_pad_mask = src.eq(PAD_IDX)
# 计算src_tok= src 经过词嵌入+位置编码后的结果
src_tok = self.src_tok(src)
src_pos = self.pos_enc(src_tok)
# 将该结果送入编码器,返回的memory就是编码器提取的特征向量。
# 输入编码器,即使没有填充(pandding)的token,也需要传入src_key_padding_mask。
memory = self.encoder(src_pos, src_key_padding_mask=src_pad_mask)
# 初始化目标端token id序列,维度为(1,1),初始值为BOS_IDX
# 表示目标端序列的开始,BOS_IDX=1
# 推理时输入是没有PAD,但是仍然需要tgt_pad_mask.
ys = torch.tensor([[BOS_IDX]], dtype=torch.long, device=device)
for _ in range(max_len - 1):
#计算本次解码的Mask,跟ys形状一样。
tgt_pad_mask = ys.eq(PAD_IDX)
# 计算本次因果掩码,把未来看到的token都屏蔽。
tgt_mask = self.make_subsequent_mask(ys.size(1)).to(device)
# 可以看到当推理模式时,解码器输入token数量依次是1,2,3,4.....
out = self.decoder(
self.pos_enc(self.tgt_tok(ys)),
memory,
tgt_key_padding_mask=tgt_pad_mask,
memory_key_padding_mask=src_pad_mask,
)
# 转化为预测词的概率分布
logits = self.generator(out[:, -1:, :])
# 使用贪心选择概率最大的作为本次预测的目标
next_token = logits.argmax(-1)
next_id = next_token.item()
# 显示选择的token
token_text = TGT_ITOS[next_id] if next_id < len(TGT_ITOS) else f"ID_{next_id}"
print(f"选择: {token_text}({next_id})")
ys = torch.cat([ys, next_token], dim=1)
if next_id == EOS_IDX:
break
return ys.squeeze(0).tolist()
# --------------------------
# 4) Train
# --------------------------
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dataset = ToyDataset(pairs)
loader = DataLoader(dataset, batch_size=8, shuffle=True, collate_fn=collate_fn)
model = Seq2SeqTransformer(
src_vocab_size=len(SRC_ITOS),
tgt_vocab_size=len(TGT_ITOS),
d_model=6, nhead=3, num_encoder_layers=2, num_decoder_layers=2, dim_ff=256, dropout=0.1
).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
def evaluate_sample(sent="我 有 一个 苹果"):
"""辅助函数:对输入中文句子进行编码→推理→解码并打印结果。"""
ids = encode_src(sent)
print("ids",ids)
pred_ids = model.greedy_decode(ids, device=device)
pred_text = decode_tgt(pred_ids)
print(f'INPUT : {sent}')
print(f'OUTPUT: {pred_text}\n')
print("Before training:")
evaluate_sample("我 有 一个 苹果")
EPOCHS = 80 # 小步数即可过拟合玩具数据
for epoch in range(1, EPOCHS + 1):
model.train()
total_loss = 0.0
for src, tgt_in, tgt_out, src_pad_mask, tgt_pad_mask in loader:
src = src.to(device)
tgt_in = tgt_in.to(device)
tgt_out = tgt_out.to(device)
src_pad_mask = src_pad_mask.to(device)
tgt_pad_mask = tgt_pad_mask.to(device)
logits = model(src, tgt_in, src_pad_mask, tgt_pad_mask) # (B, T, V)
loss = criterion(logits.reshape(-1, logits.size(-1)), tgt_out.reshape(-1))
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
total_loss += loss.item()
if epoch
print(f"Epoch {epoch:02d} | loss={total_loss/len(loader):.4f}")
evaluate_sample("我 有 一个 苹果")
print("After training:")
evaluate_sample("我 有 一个 苹果")
evaluate_sample("我 有 一本 书")
evaluate_sample("你 有 一个 苹果")