内存初始化基本概念
三级结构Node、Zone、Page
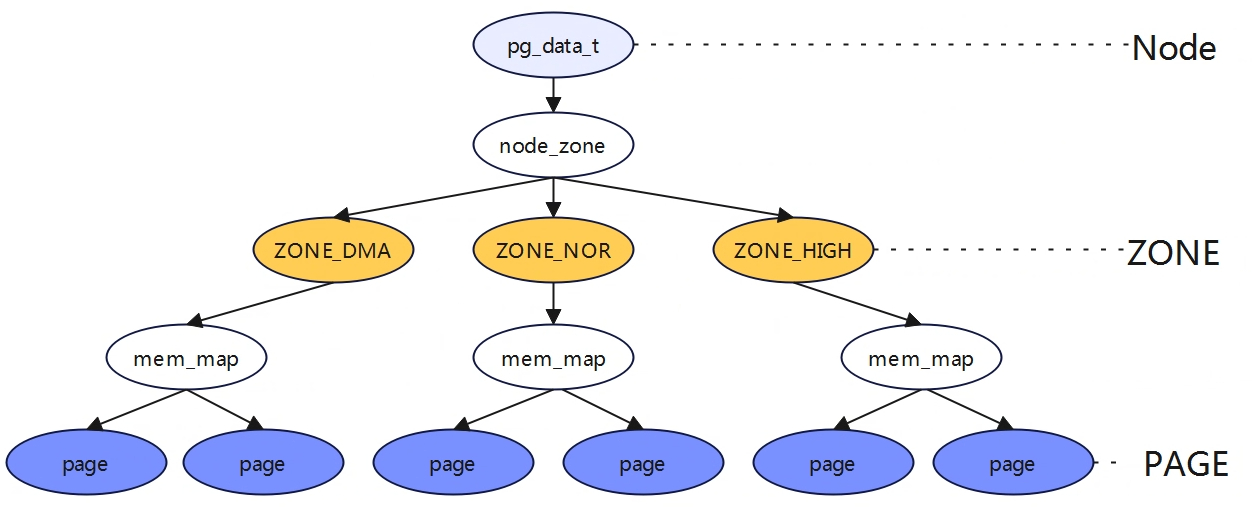
Node与内存架构UMA、NUMA
UMA架构(uniform memory acces)
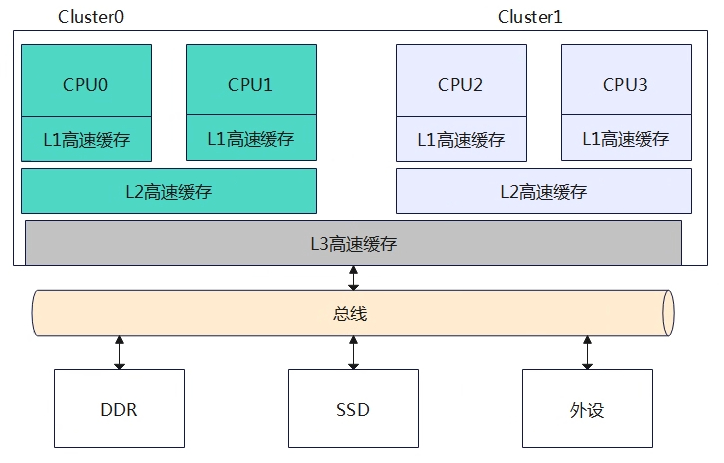
一致内存访问,所有CPU访问内存都需要过总线,距离都是一样的,所以每个处理器访问各个内存块都是同样快。如上图4个CPU都通过系统总线来访问物理内存DDR。目前大部分嵌入式系统或台式机系统采用UMA架构。
NUMA架构(Non-uniform memory acces)

非统一内存访问,系统中有多个内存节点和多个CPU簇,CPU访问本地内存节点的速度最快,访问远端的内存节点速度要慢一点。如上图该系统使用NUMA架构,有两个内存节点,其中CPU0和CPU1组成一个节点(Node0),他们可以通过系统总线访问本地DDR物理内存,同理CPU2和CPU3组成另外一个节点(Node1),他们也可以通过系统总线访问本地DDR物理内存。两个节点通过超路径互联总线连接,那么CPU0可以通过这个内部总线访问远端内存节点的物理内存,但是访问速度要比访问本地物理内存慢很多。
<include/linux/mmzone.h>
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; //节点中物理内存区域
struct zonelist node_zonelists[MAX_ZONELISTS]; //节点备用列表
int nr_zones; //节点内存区域个数
struct page *node_mem_map; /*NUMA节点内管理所有物理页page的数组*/
unsigned long node_start_pfn; /*NUMA节点第一个物理页的pfn*/
unsigned long node_present_pages; /* 物理内存页的总数 */
unsigned long node_spanned_pages; /* 物理内存页的总长度,包含洞在内 */
int node_id; //NUMA节点id
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
int kswapd_max_order;
......
} pg_data_t;
物理内存分区(zone)

物理内存是以页(4KB)来进行管理的,理想状态任何种类的数据都可以存放在页框中,但实际上受计算机体现结构硬件方面的制约,限制了页框的使用方式,如在X86体系结构下,ISA总线的DMA控制器,只能对内存前16MB进行寻址,所以导致ISA设备不能在整个32位地址空间指向DMA,只能使用物理内存的前16MB进行DMA操作,因此物理内存前16MB专门留给内核用于DMA分配,称之DMA ZONE。
32位的处理器只支持4G的虚拟地址,其中1G的地址空间给内核,如果物理内存实际有4G,那么1G的内核空间地址无法一一映射,Linux内核提出的解决方案将物理内存分成2部分,一部分直接做线性映射,另一部分采用动态映射,称为高端内存。如果是64位的处理器一般不会有高端内存,应该地址空间足够大。
16~896MB的物理空间区域被直接映射到内核态虚拟地址空间3G+16M~3G+896M这个范围。
剩余的128M,显然剩余的3200M的ZONE HIGH区域是无法通过直接映射的方式进行映射的,因此物理内存中的ZONE_HIGHMEM区域就只能采用动态映射的方式映射128M大小内核虚拟内存空间。
注意DMA_ZONE不是说只给DMA用,DMA要是不用还是可以继续给其他用,只要设置分配内存为GFP_DMA。
– ZONE_DMA(24): isa设备的DMA操作,寻址范围0~16M。
– ZONE_DMA32: 对于64位系统中,16M的空间不够用,于是定义可以寻址到4G,满足32位的DMA寻址。
– ZONE_NORMAL: 线性映射物理内存
– ZONE_HIGHMEM:高端内存,标记超出内核虚拟地址空间的物理内存段。64位架构没有该ZONE
– ZONE_MOVABLE:虚拟内存域,防止内存碎片的机制中会使用到该内存区域。(从逻辑上划分)
ZONE_DEVICE:为支持热插拔而分配的非易失性内存。(从逻辑上划分)
<include/linux/mmzone.h>
enum zone_type {
ZONE_DMA,
ZONE_DMA32,
ZONE_NORMAL,
ZONE_HIGHMEM,
ZONE_MOVABLE,
ZONE_DEVICE,
} ;
struct zone {
...
struct pglist_data *zone_pgdat;
unsigned long zone_start_pfn;
unsigned long spanned_pages;
unsigned long present_pages;
struct free_area free_area[MAX_ORDER];
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
}
page
page(页)是linux内核管理物理内存的最小单元,内核将整个物理内存按照页对齐方式划分成成千上万个页进行管理,内核为了管理这些页将每个页抽象成struct page结构管理每个页状态及属性。struct page结构本身就占有一定内存,所以struct page不能过大。

PFN(page frame number):PFN与struct page一一对应,内核提供两个宏来完成PFN与物理页结构struct page之间相互转换,分别是page_to_pfn与pfn_to_page。
在Linux内核中,struct page数据结构通常与实际的物理内存页帧是一一对应的。Linux内核使用一个双向链表来跟踪所有可用和不可用的物理页面。
在初始化期间,内核通过调用\”memblock_init()\”等函数将系统中所有的物理内存区域划分为相同大小的页面,并为每个页面分配一个struct page数据结构。这些页面的struct page结构体被组织成一个双向链表,并存储在pgdat_list全局变量中。
当需要分配物理页面时,内核会从pgdat_list中选择一个合适的节点,并在该节点的伙伴系统上查找一个可用的物理页面。如果找到了一个可用页面,则将该页面的struct page结构体标记为已占用,并返回一个指向该页面的指针。反之,则会尝试从其他NUMA节点或者交换空间中获取可用页面。
因此,无论是通过伙伴系统获取物理页面,还是直接访问某个物理地址,都可以通过struct page数据结构来跟踪和管理实际的物理内存页面。
<include/linux/mm_types.h>
struct page {
1.标志位
unsigned long flags; /* Atomic flags, some possibly
2.5个字的联合体(32位20字节,64位40字节),分别有8个部分。用于匿名页面、文件映射、slab分配器等描述。
union {
2.1 管理匿名/文件页面
struct { /* Page cache and anonymous pages */
struct list_head lru;
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
unsigned long private;
};
2.2.管理网络协议栈
struct { /* page_pool used by netstack */
unsigned long pp_magic;
struct page_pool *pp;
unsigned long _pp_mapping_pad;
unsigned long dma_addr;
union {
unsigned long dma_addr_upper;
atomic_long_t pp_frag_count;
};
};
2.3. slab相关描述
struct { /* slab, slob and slub */
union {
struct list_head slab_list;
struct { /* Partial pages */
struct page *next;
#ifdef CONFIG_64BIT
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
#else
short int pages;
short int pobjects;
#endif
};
};
struct kmem_cache *slab_cache; /* not slob */
void *freelist; /* first free object */
union {
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};
2.4 用于复合页尾页描述
struct { /* Tail pages of compound page */
unsigned long compound_head; /* Bit zero is set */
/* First tail page only */
unsigned char compound_dtor;
unsigned char compound_order;
atomic_t compound_mapcount;
unsigned int compound_nr; /* 1 << compound_order */
};
2.5 复合页的第二个尾页描述
struct { /* Second tail page of compound page */
unsigned long _compound_pad_1; /* compound_head */
atomic_t hpage_pinned_refcount;
struct list_head deferred_list;
};
2.6 页表页面描述
struct { /* Page table pages */
unsigned long _pt_pad_1; /* compound_head */
pgtable_t pmd_huge_pte; /* protected by page->ptl */
unsigned long _pt_pad_2; /* mapping */
union {
struct mm_struct *pt_mm; /* x86 pgds only */
atomic_t pt_frag_refcount; /* powerpc */
};
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
};
2.7 ZONE_DEVICE页面描述
struct { /* ZONE_DEVICE pages */
struct dev_pagemap *pgmap;
void *zone_device_data;
};
2.8 rcu描述
struct rcu_head rcu_head;
};
3.4个字节的联合体,用于管理_mapcount等使用计数
union { /* This union is 4 bytes in size. */
atomic_t _mapcount;
unsigned int page_type;
unsigned int active; /* SLAB */
int units; /* SLOB */
};
4.用于管理引用计数
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */
atomic_t _refcount;
} _struct_page_alignment;
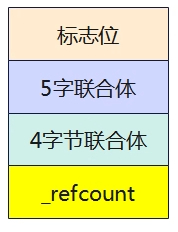
struct page数据结构可以分为4个部分:
– 标志位:页面的标志位。
– 5字联合体:用于匿名/文件页面描述,slab分配器描述等8个部分。
– 4字节联合体:用于管理页面使用的情况。
– 4字节引用:用于管理页面引用情况。
标志位
<include/linux/page-flags.h>
enum pageflags {
PG_locked, /* Page is locked. Don't touch. */
PG_referenced,
PG_uptodate, 表示页面的数据已经从块设备成功读取
PG_dirty, 表示页面内容发生改变,为脏页。没有跟外部存储器同步。
PG_lru, 页面在LRU链表中
PG_active,
PG_workingset,
PG_waiters, /* Page has waiters, check its waitqueue. Must be bit #7 and in the same byte as "PG_locked" */
PG_error,
PG_slab,
PG_owner_priv_1, /* Owner use. If pagecache, fs may use*/
PG_arch_1,
PG_reserved,
PG_private, /* If pagecache, has fs-private data */
PG_private_2, /* If pagecache, has fs aux data */
PG_writeback, /* Page is under writeback */
PG_head, /* A head page */
PG_mappedtodisk, /* Has blocks allocated on-disk */
PG_reclaim, /* To be reclaimed asap */
PG_swapbacked, /* Page is backed by RAM/swap */
PG_unevictable, /* Page is "unevictable" */
#ifdef CONFIG_MMU
PG_mlocked, /* Page is vma mlocked */
#endif
#ifdef CONFIG_ARCH_USES_PG_UNCACHED
PG_uncached, /* Page has been mapped as uncached */
#endif
#ifdef CONFIG_MEMORY_FAILURE
PG_hwpoison, /* hardware poisoned page. Don't touch */
#endif
#if defined(CONFIG_PAGE_IDLE_FLAG) && defined(CONFIG_64BIT)
PG_young,
PG_idle,
#endif
#ifdef CONFIG_64BIT
PG_arch_2,
#endif
#ifdef CONFIG_KASAN_HW_TAGS
PG_skip_kasan_poison,
#endif
#ifdef CONFIG_64BIT
PG_oem_reserved,
#endif
__NR_PAGEFLAGS,
/* Filesystems */
PG_checked = PG_owner_priv_1,
/* SwapBacked */
PG_swapcache = PG_owner_priv_1, /* Swap page: swp_entry_t in private */
/* Two page bits are conscripted by FS-Cache to maintain local caching
* state. These bits are set on pages belonging to the netfs's inodes
* when those inodes are being locally cached.
*/
PG_fscache = PG_private_2, /* page backed by cache */
/* XEN */
/* Pinned in Xen as a read-only pagetable page. */
PG_pinned = PG_owner_priv_1,
/* Pinned as part of domain save (see xen_mm_pin_all()). */
PG_savepinned = PG_dirty,
/* Has a grant mapping of another (foreign) domain's page. */
PG_foreign = PG_owner_priv_1,
/* Remapped by swiotlb-xen. */
PG_xen_remapped = PG_owner_priv_1,
/* SLOB */
PG_slob_free = PG_private,
/* Compound pages. Stored in first tail page's flags */
PG_double_map = PG_workingset,
#ifdef CONFIG_MEMORY_FAILURE
/*
* Compound pages. Stored in first tail page's flags.
* Indicates that at least one subpage is hwpoisoned in the
* THP.
*/
PG_has_hwpoisoned = PG_mappedtodisk,
#endif
/* non-lru isolated movable page */
PG_isolated = PG_reclaim,
/* Only valid for buddy pages. Used to track pages that are reported */
PG_reported = PG_uptodate,
};
有相关函数用于操作这些标志,如下:
– Pagexxx():用于检查页面是否设置了PG_xxx标志位,如PageDirty检查是否PG_dirty被置位。
– SetPagexxx():设置页面的PG_xxx标志位,如SetPageDirty用于设置PG_dirty标志位
– ClearPagexxx():清楚PG_xxx标志位
mapping
在struct page中mapping成员表示当前页面的数据来源,主要分为3种情况:
– 匿名页面:mapping指向VMA的anon_vma数据结构,数据原始来源于用户空间。
– 文件页面:mapping指向文件所属的address_space数据结构,包含文件所属的存储介质信息,如inode。
– swap页面(文件页面):指向交换分区的swapper_spaces。
<include/linux/fs.h>
struct address_space {
struct inode *host;
struct xarray i_pages;
struct rw_semaphore invalidate_lock;
gfp_t gfp_mask;
atomic_t i_mmap_writable;
#ifdef CONFIG_READ_ONLY_THP_FOR_FS
/* number of thp, only for non-shmem files */
atomic_t nr_thps;
#endif
struct rb_root_cached i_mmap;
struct rw_semaphore i_mmap_rwsem;
unsigned long nrpages;
pgoff_t writeback_index;
const struct address_space_operations *a_ops;
unsigned long flags;
errseq_t wb_err;
spinlock_t private_lock;
struct list_head private_list;
void *private_data;
ANDROID_KABI_RESERVE(1);
ANDROID_KABI_RESERVE(2);
ANDROID_KABI_RESERVE(3);
ANDROID_KABI_RESERVE(4);
} __attribute__((aligned(sizeof(long)))) __randomize_layout;
mapping指向数据的低2位可以用于判断当前页面的类型:
– bit[0]:用于判断是否为匿名页。PageAnon()函数
– bit[0]:用于判断是否为非LRU页面。_PageMovable()函数
– Bit[0:1]:若都为11,则表示KSM页面。PageKsm()函数
page_mapping()返回page数据结构种mapping成员指向的地址空间,即address_space。
_refcount
表示内核引用页面的次数
– _refcount=0:页面为空闲页面或即将要被释放的页面
– _refcount>0:页面已经被分配且内核正在使用,暂时不会被释放。get_page()会让其+1,put_page()让其-1。
在使用alloc_pages分配页面时,_refcount会变成1。当页面加入LRU时,页面被kswpad内核线程使用会+1。在页面被映射到其他用户进程的PTE时,_refcount会+1。
_mapcount
表示这个页面被进程映射的个数,即映射了多少个用户PTE。page_mapped()函数用于判断该页面是否映射到用户PTE
– _mapcount=-1:没有PTE映射到页面
– _mapcount=0:只有一个进程映射到页面
– _mapcount>0:有多个进程映射到这个页面
三种内存模型
物理内存被划分为多个相同长度的页,如何组织管理这些页的方式称为物理内存模型,不同的物理内存模型,对应的page_to_pfn和pfn_to_page计算逻辑不一样。
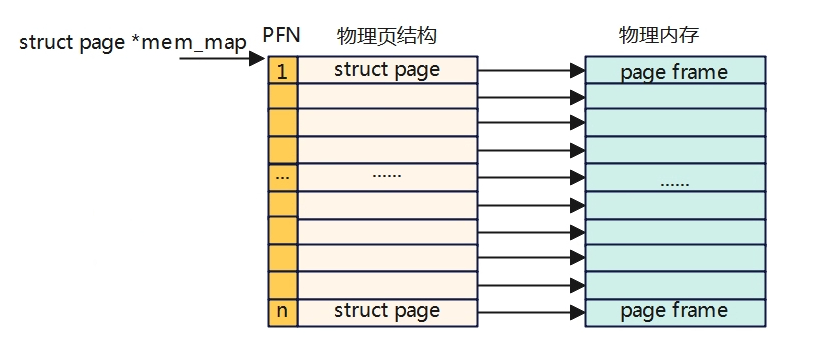
FLAT memory model
所有的物理内存是连续的,中间内存没有空洞,划分出来的一页一页的物理页必然也是连续的,并且每页的大小是固定的,Linux早期使用的就是这种内存模型。
<include/asm-generic/memory_model.h>
#if defined(CONFIG_FLATMEM)
#ifndef ARCH_PFN_OFFSET
#define ARCH_PFN_OFFSET (0UL)
#endif
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \\
ARCH_PFN_OFFSET)
#endif
在平坦内存模型下,page_to_pfn与pfn_to_page计算逻辑基于mem_map数组进行偏移操作。
Discontiguous memory model

平坦度内存模型适用于一整块连续的物理内存,而对于多块非连续的物理内存使用平坦度内存模型会造成很大的空间浪费(平坦度模型使用数组mem_map[]来进行管理,而数组是连续的,从0开始递增的,而物理内存有空洞,那么中间就会出现mem_map一段指向空,但是还占用了内存空间),所以为了组织和管理不连续的物理内存,内核引入了DISCONTIGMEM非连续内存模型,用来消除这些不联系的内存地址空洞对mem_map的空间浪费。
<include/asm-generic/memory_model.h>
#if defined(CONFIG_DISCONTIGMEM)
#define __pfn_to_page(pfn) \\
({ unsigned long __pfn = (pfn); \\
unsigned long __nid = arch_pfn_to_nid(__pfn); \\
NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\\
})
#define __page_to_pfn(pg) \\
({ const struct page *__pg = (pg); \\
struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \\
(unsigned long)(__pg - __pgdat->node_mem_map) + \\
__pgdat->node_start_pfn; \\
})
#endif
5.15内核版本已经没有非连续性内存模型的,使用了Sparse memory model替换.
通过arch_pfn_to_nid根据物理页的PFN定位到物理页所在的node,再根据node中node_mem_map算偏移。
通过page_to_nid根据struct page定义page所在的node。
Sparse memory model

随着内存技术的发展,内核可以支持物理内存热插拔,这样node节点中的物理内存可能也不是连续的,为了解决这个问题,内核又引入了稀疏内存模型。

稀疏内存模型使用struct mem_section结构体来表示,用于管理连续内存块单元的被称为section,通常情况下物理页为4K,section大小为128M,物理页16K,section大小为512M。这些小的连续物理内存通过数组的方式被组织管理,每个struct mem_sction结构体中有一个指针指向section中管理连续内存的page数组。所有的mem_section被存放在一个全局数组中,每个mem_section都可以在系统运行时改变系统运行offline/online状态,以支持热插拔功能。
为了减少管理内存占用的数据结构空间,稀疏内存模型的思想与多级页表的思想类似,一级页表是必须要分配内存的,但是后面的几级进行按需分配,这里也类似,先定义一个静态的数组指针,每个数组指针管理一大块内存(4K物理页,就是128M),数组指向的实例根据实际进行动态分配空间。
<include/asm-generic/memory_model.h>
struct mem_section mem_section[NR_SECTION_ROOTS][SECTIONS_PER_ROOT]
<include/asm-generic/memory_model.h>
#if defined(CONFIG_SPARSEMEM)
/*
* Note: section's mem_map is encoded to reflect its start_pfn.
* section[i].section_mem_map == mem_map's address - start_pfn;
*/
#define __page_to_pfn(pg) \\
({ const struct page *__pg = (pg); \\
int __sec = page_to_section(__pg); \\
(unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \\
})
#define __pfn_to_page(pfn) \\
({ unsigned long __pfn = (pfn); \\
struct mem_section *__sec = __pfn_to_section(__pfn); \\
__section_mem_map_addr(__sec) + __pfn; \\
})
#endif /* CONFIG_FLATMEM/DISCONTIGMEM/SPARSEMEM */
内核虚拟地址空间分布

上图表示的是整个虚拟地址空间,虚拟地址使用了48bit来寻址,因此寻址范围为2^48=256TB。在实际应用过程中,可以通过内核的配置选项来确定虚拟地址的位宽。

PABITS指的是物理地址的寻址范围,一般物理地址的寻址范围由硬件决定,内核只需要配置成与硬件一样即可,通常ARM64位的PABITS=48。